
サンプリング装置、サンプリングプログラム、およびその方法
【課題】探索のために最適化されていないデータソースに対して、全体の傾向を適切に取得することができるサンプリング装置を提供することを目的とする。
【解決手段】記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置であって、記録位置に対応する乱数を生成する乱数生成手段と、前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するレコード選択手段と、前記選択されたレコードのレコード長を取得するレコード長取得手段と、前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するサンプル決定手段と、を有することを特徴とする。
【解決手段】記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置であって、記録位置に対応する乱数を生成する乱数生成手段と、前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するレコード選択手段と、前記選択されたレコードのレコード長を取得するレコード長取得手段と、前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するサンプル決定手段と、を有することを特徴とする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、サンプリング装置、サンプリングプログラム、およびその方法に関する。
【背景技術】
【0002】
データベースや分散ファイルといった大規模なデータソースから処理対象のデータを取得し、複数の処理ノードによって分散処理を行う技術が知られている。また、分散処理のためのデータをどのようにデータソースから取得し、処理ノードに割り振れば効率がよいかといった研究が従来から行われている。
【0003】
分散処理システムにおいては、生成するタスクの大きさに偏りが生じると、大きなタスクを割り当てられたノードに負荷が集中し、全体のスループット(処理性能)が下がるという性質がある。そのため、処理ノードの単位性能あたりのタスクを均等に割り当てる必要があり、そのための方法として、Skewed Joinと呼ばれるアルゴリズムが用いられる。
【0004】
非特許文献1には、Skewed Joinを実現するために、データソースから値をサンプリン
グして、データソース中のデータの値の出現頻度を表すヒストグラムを作成し、そのヒストグラムに応じて分散処理の割り当てを決める手法が記載されている。Skewed Joinには
、作成されたヒストグラムがデータソース全体の傾向を代表していれば、取得されるデータのサイズを均等にできるという利点がある。
【0005】
データソースからデータのサンプリングを行い、ヒストグラムを作成したうえで、分散処理のタスクを決定する場合、そのサンプリング結果はできるだけ公平であること、つまりデータソース全体の傾向を表していることが求められる。ヒストグラムに現れたレコードの分布が、実際の件数と乖離したものである場合、処理能力を超えたレコード件数が処理ノードに割り当たり、全体のスループットを低下させる原因となるためである。
【0006】
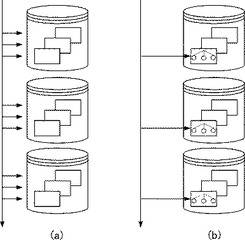
サンプリングを行う方法には、図1に示すように、データソース全体にアクセスをする方法と、一部だけを読み込む方法がある。図1(a)は、データソースである記憶装置内の全てのファイルにアクセスを行い、全レコードを読み込む様子を示した図である。非特許文献2には、このようにファイル全体を読み込んでサンプリングを行う方法が開示されている。
【0007】
また、図1(b)は、記憶装置内の一部のファイルに記録されている参照用データを参照し、サンプリングを行う様子を示した図である。参照用データとは、一般的にデータベース索引などの探索用に用意されたデータを指す。参照用データには、例えば、ハッシュやツリーなどの種類があり、これらを参照することにより、特定のキーを持つレコードがデータソース内のどの位置に存在するかを知ることができる。すなわち、サンプリング手段はデータソースの一部のみを参照することで、データソース全体のデータ分布を把握することができる。
【0008】
特許文献1には、参照用データとして近似問合せエンジンを用意し、データベースに対する近似回答を提供する技術が記載されている。特許文献1に記載の発明は、データベースに対応した参照用データである近似問合せエンジンを用意し、データベースの更新に対応して、所定の確率で近似問合せエンジン内の複数のデータサンプルを更新することを特徴とする。近似問合せエンジン内のデータは、データベースをサンプリングしたものと同等であるため、データベースエンジンは、近似問合せエンジンにアクセスすることで、データベース全体にアクセスすることなくデータの分布を取得することができる。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特開平11−353331号公報
【非特許文献】
【0010】
【非特許文献1】”Skewed Join”、[online]、Apache Pig Wiki、[平成23年9月16日検索]、インターネット<URL:http://wiki.apache.org/pig/PigSkewedJoinSpec>
【非特許文献2】Jefferey Scott Vitter,“Random Sampling with a Reservoir”,ACM Transactions on Mathematical Software,Vol.11,pp.37-57,Mar.1985
【発明の概要】
【発明が解決しようとする課題】
【0011】
データソースからデータのサンプリングを行う際、ファイル全体を読み込む方式である、非特許文献2に記載された技術によると、確実にデータソース内のデータ分布を取得できる一方、データソースが大きくなるほど読み込みに時間がかかるという欠点がある。たとえば、読み込み性能が毎秒100MBであって記憶容量が100GBである記憶装置を10台並列にしたデータソースがあった場合、全データの読み込みに約17分かかる。この方法では、データソースが大規模になると、実用的な速度を得ることが難しくなる。
【0012】
一方、データソースの一部だけを読み込んでヒストグラムを作成する手法を用いる場合、効率的に処理を行うため、データソース内にあらかじめハッシュやツリーなどの探索コストが低いデータ構造を用意しておく必要がある。
【0013】
しかし、データソースが、書き込み当初より探索のために構造化されていないケースも考えられる。例えば、車両の走行ログや、Webのアクセスログのように、書込みのスループットが要求されるデータは、構造化して格納されていることが仮定しにくい。これらのデータを構造化するためには、データソース全体を読み込み、構造化した状態で再度格納し直す必要があるため、結局、データソースの全体を読み込む手法となってしまう。
【0014】
このように、従来技術においては、探索のために最適化されていないデータソースからサンプリングを行う場合において性能上の問題が存在していた。
【0015】
この問題を解消するために、従来技術の他にもいくつかのサンプリング方法が考えられる。たとえば、データソースの先頭から特定個数のレコードをサンプリングする方法である。しかし、この方法によると、記録されているデータが、時系列データのようにその分布に局所性を持っている場合、ヒストグラムがデータソース全体の傾向と異なってしまうという別の問題がある。たとえば、記録されているデータのうち、特定の傾向を持ったデータがデータソースの後方に集中している場合、先頭のデータをサンプリングすると、実際のデータと異なったサンプル結果となってしまい、公平なサンプリングが実現できなくなる。
【0016】
また、別の方法として、データソース中の位置をランダムに特定し、その位置に存在するレコードをサンプリング対象として取り出す、ランダムサンプリングと呼ばれる手法がある。しかし、この方法を用いた場合、サイズの大きいレコードが選択されやすいため、レコードのサイズにばらつきがある場合、不公平な選択がなされる。不公平な選択がなされると、取得されたヒストグラムは、やはりデータソース全体の傾向と異なってしまう。
【0017】
このように、データソースに格納されているデータが、探索のために最適化されておら
ず、かつ局所的な傾向がある場合、データソース内のデータの分散を示すヒストグラムを取得するための公平なサンプリングができない、すなわちサンプリング結果の信頼性が低くなるという問題がある。
【0018】
本発明は上記の問題点を考慮してなされたものであり、探索のために最適化されていないデータソースに対して、全体の傾向を適切に取得することができるサンプリング装置を提供することを目的とする。
【課題を解決するための手段】
【0019】
上記目的を達成するために、本発明に係るサンプリング装置では、以下の手段によりデータソースに対するサンプリングを行う。
【0020】
本発明に係るサンプリング装置は、記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置であって、記録位置に対応する乱数を生成する乱数生成手段と、前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するレコード選択手段と、前記選択されたレコードのレコード長を取得するレコード長取得手段と、前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するサンプル決定手段と、を有することを特徴とする。
【0021】
すなわち、データソースの中から、乱数によって特定された位置に存在するレコードの長さを取得し、当該長さに応じた確率で、選択されたレコードをサンプルとして採用する。データソース中の記録位置をランダムに指定して読み込むランダムサンプリングでは、レコードの長さによって選択される確率が変化する。これに対し、選択後に採用確率を乗じることで、各レコードが選ばれる確率を調整することができる。この手法によって、信頼性の高いサンプリングが可能となる。
【0022】
また、前記サンプル決定手段は、前記取得されたレコードのレコード長と反比例するように前記確率を算出することを特徴とすることが好ましい。
【0023】
すなわち、選択されたレコードのレコード長が長いほど、サンプルとして採用する確率を低くする。これにより、全てのレコードが同じ確率でサンプリングされるようになる。
【0024】
また、本発明に係るサンプリング装置は、前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得する最小レコード長取得手段をさらに有し、前記
サンプル決定手段は、前記選択されたレコードのレコード長をSkとし、Smin/Skの式
によって前記確率を算出することを特徴とすることが好ましい。
【0025】
すなわち、基本とするレコード長をSminとし、Sminを、選択されたレコードの長さで除することにより、当該レコードを採用する確率を決定する。このように構成することにより、ランダムサンプリングの効率を最大限とすることができる。
【0026】
また、本発明に係るサンプリング装置は、前記サンプルとして採用されたレコードから、前記記憶装置に記録されたデータの度数分布を示すヒストグラムを生成するヒストグラム生成手段をさらに有することを特徴としてもよい。
【0027】
ヒストグラムを生成することにより、記録されたデータの度数分布を集計することができるため、分散処理システムにおける本発明の適用が容易になる。
【0028】
また、前記記憶装置は、分散ファイルシステムであり、前記ヒストグラムを用いて、外
部の分散処理ノードに実行すべき処理を割り当てることを特徴としてもよい。
【0029】
このように構成することにより、分散処理システムにおいて、割り当てるタスクのサイズを平均化することが可能になるため、システム全体の処理スループットを向上させることが可能になる。
【発明の効果】
【0030】
本発明によれば、探索のために最適化されていないデータソースに対して、全体の傾向を適切に取得することができるサンプリング装置を提供することができる。
【図面の簡単な説明】
【0031】
【図1】既存のデータサンプリング手法を説明する図である。
【図2】第一の実施形態に係るシステムの構成を表した図である。
【図3】第一の実施形態に係るヒストグラムの例を表した図である。
【図4】第一の実施形態に係るデータソースの内容例を表した図である。
【図5】第一の実施形態に係るシステムの処理フローチャートである。
【図6】第二の実施形態に係るシステムの構成図である。
【図7】第二の実施形態に係るシステムの概要図である。
【発明を実施するための形態】
【0032】
(第一の実施形態)
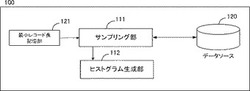
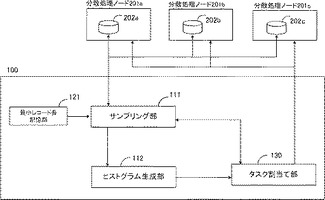
第一の実施形態に係るサンプリング装置について、図2を用いて詳細な説明をする。図2は、第一の実施形態に係るサンプリング装置のシステム構成を表す図である。
【0033】
本実施形態に係るサンプリング装置100は、データソースにアクセスし、ランダムに既定数のレコードを選択するサンプリング部111と、サンプリング結果に基づいてデータソース内のデータ分布であるヒストグラムを生成するヒストグラム生成部112、および、データソースに記録されているレコードのうち、最小レコードのサイズを記録した最小レコード長記憶部121から構成される。
【0034】
以上の構成は、不図示の中央演算処理装置(CPU)および主記憶装置(RAM)、補助記憶装置(記憶媒体)によって実行される。本実施形態で説明する処理を実行するプログラムコードが補助記憶装置に格納され、当該プログラムコードをCPUが読み出して実行することにより、前述した実施形態の機能が実現される。
【0035】
データソース120は、サンプリング対象となるデータが格納されている手段であり、関係データベースやデータファイル、ディスク装置などに相当する。本実施形態においては、一つのデータファイルを想定して説明するが、複数のレコードを記録できる手段であれば、どのようなものが用いられてもよい。また、これらのデータ格納手段は一つの装置に限定されるものではない。たとえばディスクアレイや分散ファイルシステムなど、仮想的な記憶手段を一つのデータソースとしてもよい。
【0036】
データソースには、改行コードやカンマ等のセパレータ(デリミタ)で区切られた1件分のレコードが複数個格納されている。これらのレコードは、それぞれ長さが異なっており、レコードの記録位置はメモリアドレスによって特定することができる。メモリアドレスとは、レコードが記録されている物理的もしくは論理的な場所を特定するための情報であり、例えばデータソースがファイルであれば先頭からのバイト数、分散ファイルシステムであればファイルの記録位置を示す仮想アドレス等が該当する。
【0037】
最小レコード長記憶部121は、データソース120が有しているレコードのうち、最
小となるレコード長を記録した手段である。例えば、レコードの最小値が512バイトである場合、最小レコード長記憶部121は、512バイトという数値を保持する。最小レコード長記憶部121は、装置として必ずしも独立している必要はなく、例えばデータソース120に、サンプリング対象のデータと一緒に記録されていてもよい。レコードが追加される際に、追加されたレコードの長さが最小レコード長を下回る場合は、最小レコード長は最新の値で更新される。
【0038】
サンプリング部111は、データソース120から、ランダムに既定個数のレコードを取得する動作を行う手段である。実施形態の説明では、データソースから既定個数のレコードをランダムに取得する動作をサンプリングと称する。詳細な動作については後述する。
【0039】
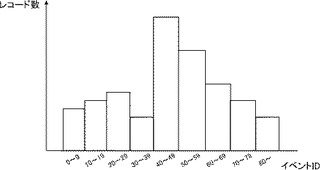
ヒストグラム生成部112は、サンプリング部111がサンプリングを行ったデータに基づいて、データソース内のレコードの度数分布を表すヒストグラムを生成する手段である。ヒストグラムは、サンプリングされたデータのキーを基に度数分布を作成する。図3は、作成されたヒストグラムの例である。本例は、車両走行ログをイベントIDで分類し、それぞれのIDに対応するレコードの数を表している。
【0040】
次に、サンプリング部111がサンプリングを行う方法について説明する。図4は、データソースに格納されたレコード全体を表した図である。ここでは便宜的に、レコード長の最小値をSmin、データソースの全体長をSmin×10として説明を行う。サンプリング部111は、データソースが有しているメモリアドレスに対応する一様乱数を生成し、サンプル対象のメモリアドレスを決定する。仮に、図4に示したデータソースに対して処理を行う場合、0≦N≦10×Sminの範囲をとる乱数Nを決定し、決定したメモリアドレ
スに存在するレコードを取得する。この処理により、対象のデータソースの中の単一のレコードが特定される。例えば、Smin=1、N=3であった場合、図4(a)の場合はレ
コード4、図4(b)の場合はレコード3が選択される。
【0041】
図4(a)は、全て同じ長さのレコードが一様に記録されている場合を表した図である。この場合、ランダムにサンプリングを行うと、レコードAからレコードJの10個が等しい確率で取得される。つまり、各レコードは理論上同じ数がサンプリングされるため、ヒストグラムに偏りは発生せず、前述したような問題は発生しない。
【0042】
図4(b)は、それぞれのレコード長が異なる場合を表した図である。例えば、レコード3およびレコード6は、レコード1の2倍の長さを持っており、レコード5は3倍の長さを持っている。このような場合、データソース上の記録位置であるメモリアドレスをランダムに決定し、対応する箇所にあるレコードを取得しようとすると、サイズが最少であるレコード1,2,4に対して、レコード3と6は2倍、レコード5は3倍それぞれ選択されやすくなる。
【0043】
つまり、各レコードが均等に選択されなくなるため、実際のレコード数は等しいにもかかわらず、作成されるヒストグラムに現れる分布には偏りが発生する。
【0044】
そこで、本実施形態では、サンプリング手段がレコードを選択する際に、当該レコードをサンプルとして採用するか否かの判定を、以下の式(1)によって行う。Sminは、デ
ータソースに記録されているレコードのうち最小となるレコード長であり、Skは、選択
されたレコードの長さを表す。
採用確率p=Smin/Sk … 式(1)
サンプリング部111は、式(1)によって計算された採用確率pに従って、選択したレコードをサンプルとして採用するか否かを決定する。例えば、採用確率pが0.1であ
った場合、10%の確率で、選択したレコードを採用し、90%の確率で選択を破棄する。確率の計算は、たとえば0〜1の範囲の実数をとる乱数を新たに生成し、結果が採用確率以下であった場合にのみ選択したレコードを採用する等の方法によって行うことができる。
【0045】
この方法によると、レコードの長さと、ランダムに選択されたレコードを採用する確率を反比例させることができる。つまり、レコードの長さに反比例した採用確率pを式(1)に乗ずることで、全てのレコードに対して、サンプリングされる確率を同一にすることができる。
【0046】
データソース全体の長さをLとすると、Skのレコード長を持つレコードが選択される
確率は、Sk/Lとなる。これに、式(1)を乗ずると、
Sk/L×Smin/Sk=Smin/L … 式(2)
となり、全てのレコードのサンプリングされる確率が同一となることが確認できる。
【0047】
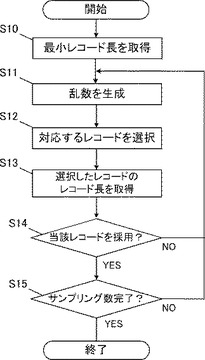
次に、サンプリング部111の動作フローチャートである図5を参照しながら、サンプリング動作を説明する。本実施形態に係るサンプリング装置が動作を開始すると、サンプリング部111は、最小レコード長記憶部121から最小レコード長を取得する(S10)。最小レコードは、前述したように、可変レコード長のうち最小の値である。
【0048】
次に、データソース中の特定の位置を決定するための乱数を生成する(S11)。生成する乱数は一様乱数であって、データソースに記録されているレコードの記録位置を特定できるものであればどのように生成しても構わない。生成する乱数の範囲は、たとえばディスク装置であれば、データが格納されているセクタ番号の最小値から最大値までとすることが考えられる。
【0049】
次に、決定した乱数に対応するレコードを選択する(S12)。つまり、データソースから、乱数によって特定した記録位置に属しているレコードが選択される。なお、本実施形態では、追記のみを行うデータソースを想定しているため、特定した位置にレコードが存在しない場合の処理は行っていないが、フラグメント等によってデータが存在しない場合を考慮してもよい。その場合、ステップS11へ戻り再度処理を行ってもよいし、前後の直近に存在するレコードを選択してもよい。
【0050】
次に、選択したレコードの長さを取得し(S13)、取得されたレコード長と、最小レコード長を用いて、式(1)による計算を行い、計算された採用確率に従って、当該レコードを採用するか否かを決定する(S14)。決定方法は、前述したように、新たに乱数を生成して判断してもよいし、他の方法を用いてもよい。選択したレコードを採用しないと判断した場合、処理はステップS11へ戻り、乱数の生成を再度行う。
【0051】
次に、サンプリングの回数が規定回数に達したかを判定する(S15)。サンプリングの回数は、装置によって固有なものであってもよいし、データソースの規模に応じて自動で決定されてもよい。規定回数のサンプリングが終了した場合、処理は終了し、規定回数に達していなかった場合は再度レコードの選択が行われる。
【0052】
以上の処理により、サンプリング部111は、既定サンプル数分のレコードを取得することができる。取得されたレコードは、そのレコード長に関係なくランダムに選択されたものとなる。
【0053】
サンプリング部111がサンプルの収集を完了させると、ヒストグラム生成部生成部112が、収集したサンプルを用いてヒストグラムの生成を行う。ヒストグラムは、取得し
たサンプルデータが有するキーごとに、レコードの件数を加算することで生成される。
【0054】
本実施形態によれば、レコード長がそれぞれ異なるデータソースからサンプリングを行うサンプリング装置において、レコード長に反比例するように採用確率を設定することで、レコード長にかかわらず均等にレコードをサンプリングすることができる。すなわち、生成されたヒストグラムはデータソース全体の傾向を代表するものとなるため、巨大なデータソースであっても、短時間でデータ分布の傾向を得ることができる。
【0055】
なお、第一の実施形態においては、ヒストグラム生成部を用いてヒストグラムの生成を行ったが、ヒストグラムを他の手段で生成できる場合や、ヒストグラム以外のデータ集計手段が利用できる場合は、ヒストグラム生成部は必須構成ではない。
【0056】
(第二の実施形態)
第二の実施形態は、第一の実施形態におけるサンプリング装置100を、分散処理フレームワークであるHadoopを利用した分散処理システムに組み込んだ形態である。図6は、第二の実施形態に係るシステム構成図であり、図7は、第二の実施形態に係るシステムの概念図である。なお、第二の実施形態に係るサンプリング装置が収集を行うデータソースおよびレコードの構成は、第一の実施形態で説明したものと同一である。
【0057】
第二の実施形態では、分散処理ノードが持っている分散ファイルをデータソースとして利用する。分散ファイル202a,b,cは、それぞれ分散処理ノードであるコンピュータ201a,b,c上に配置され、サンプリング部111からシームレスにアクセスすることができる。すなわち、サンプリング部111からは、一つのデータソースがあるように見えるため、第一の実施形態と同様の方法によってデータのサンプリングを行うことができる。
【0058】
また、ヒストグラム生成部112が生成したヒストグラムは、タスク割り当て部130へ送信される。タスク割り当て部130は、生成されたヒストグラムをもとに、分散ファイル202a,b,cより処理すべきタスクを取得し、分散処理ノード201a,b,cに対して処理を割り当てる。
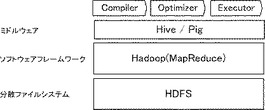
【0059】
本実施形態は、分散処理フレームワークであるHadoop上で動作するHiveに本発明を適用したものである。図7に示した通り、Hiveには、Compiler、Optimizer、Executorの三つのフェーズがある。このうち、Optimizerフェーズにてサンプリングを行い、得られたヒストグラムから、分散処理ノードの単位性能あたりのタスクサイズが均等になるように、Executorフェーズでタスクの割り当て、すなわちスケジューリングを行う。
【0060】
このように構成することにより、分散処理におけるノード間の負荷の偏りが減り、システム全体のスループットを向上させることができる。なお、本例ではHiveへの適用例を挙げたが、Pigなど、Hadoopで動作する他のミドルウェアを適用してもよい。
【0061】
(変形例)
上記の実施形態はあくまでも一例であって、本発明はその要旨を逸脱しない範囲内で適宜変更して実施しうるものである。たとえば、実施形態の説明においては、処理を行うプログラムを補助記憶装置に記録し、CPUによって処理を行う例を挙げたが、処理はFPGAによって行われてもよいし、ハードウェアとして設計され実行されてもよい。
【0062】
また、実施形態の説明においては、選択されたレコードをサンプルとして採用する確率pをSmin/Skの式によって計算したが、採用確率pをa×Smin/Sk(ただし0<a<1)としても、各レコードがサンプリングされる確率を同一にすることができる。ただし
、係数aを乗じた場合、一回の実行でレコードがサンプリングされない確率が上昇するため、採用確率pはSmin/Skとした場合が最も効率がよい。
【0063】
また、発明の効果を得るためには、選択されたレコードのサイズに応じて、当該レコードを採用する確率を調整する、すなわち選択されたレコードが長いほど採用確率を下げる必要があるが、採用確率はレコード長に反比例していなくともよい。
【0064】
たとえば、採用確率pをn/Sk(nは任意の定数)とし、pが1を超えた場合は1と
して扱ってもよい。この場合、各レコードが選択される確率は同一とはならないが、均一の値に近づけることはできる。このように、各レコードがサンプリングされる確率を均一の値に近づけるためには、選択されたレコードが長くなるに従って採用確率を下げることができればよい。
【0065】
また、レコードのサイズが極端にばらついている際、何度も選択を繰り返さないと必要な個数のレコードをサンプリングできないケースが考えられる。例えば、レコードの平均サイズをSavgとすると、一回の実行でレコードが選択される確率はSmin/Savgである
ため、n回のサンプリングに必要なループ数は、(n×Savg)/Sminとなる。この値が全体のレコード件数を超える場合は、データソース全体を読み込んだほうが効率が良くなる。
【0066】
例えば図4(b)の例では、Savg=1.66…×Sminとなるため、n≧4である場合、ループ数が総レコード数以上となる。そのため、前記条件に当てはまるほどレコードのサイズにばらつきがある場合、アルゴリズムから確率的な要素を減らすようにしてもよい。
【0067】
例えば、ランダムに選択したレコードから、m番目、m×2番目・・・のレコードを選ぶことにより、一回のループで一つ以上のレコードを確実にサンプリングできるようになる。これにより、レコードの傾向の局所性がヒストグラムに反映されてしまうという副作用が生じるが、ランダムに選んだレコードから離れたレコードを選択することで、その影響を緩和できる可能性がある。
【符号の説明】
【0068】
100 サンプリング装置
111 サンプリング部
112 ヒストグラム生成部
120 データソース
121 最小レコード長記憶部
130 タスク割当て部
201a,b,c 分散処理ノード
202a,b,c 分散ファイルノード
【技術分野】
【0001】
本発明は、サンプリング装置、サンプリングプログラム、およびその方法に関する。
【背景技術】
【0002】
データベースや分散ファイルといった大規模なデータソースから処理対象のデータを取得し、複数の処理ノードによって分散処理を行う技術が知られている。また、分散処理のためのデータをどのようにデータソースから取得し、処理ノードに割り振れば効率がよいかといった研究が従来から行われている。
【0003】
分散処理システムにおいては、生成するタスクの大きさに偏りが生じると、大きなタスクを割り当てられたノードに負荷が集中し、全体のスループット(処理性能)が下がるという性質がある。そのため、処理ノードの単位性能あたりのタスクを均等に割り当てる必要があり、そのための方法として、Skewed Joinと呼ばれるアルゴリズムが用いられる。
【0004】
非特許文献1には、Skewed Joinを実現するために、データソースから値をサンプリン
グして、データソース中のデータの値の出現頻度を表すヒストグラムを作成し、そのヒストグラムに応じて分散処理の割り当てを決める手法が記載されている。Skewed Joinには
、作成されたヒストグラムがデータソース全体の傾向を代表していれば、取得されるデータのサイズを均等にできるという利点がある。
【0005】
データソースからデータのサンプリングを行い、ヒストグラムを作成したうえで、分散処理のタスクを決定する場合、そのサンプリング結果はできるだけ公平であること、つまりデータソース全体の傾向を表していることが求められる。ヒストグラムに現れたレコードの分布が、実際の件数と乖離したものである場合、処理能力を超えたレコード件数が処理ノードに割り当たり、全体のスループットを低下させる原因となるためである。
【0006】
サンプリングを行う方法には、図1に示すように、データソース全体にアクセスをする方法と、一部だけを読み込む方法がある。図1(a)は、データソースである記憶装置内の全てのファイルにアクセスを行い、全レコードを読み込む様子を示した図である。非特許文献2には、このようにファイル全体を読み込んでサンプリングを行う方法が開示されている。
【0007】
また、図1(b)は、記憶装置内の一部のファイルに記録されている参照用データを参照し、サンプリングを行う様子を示した図である。参照用データとは、一般的にデータベース索引などの探索用に用意されたデータを指す。参照用データには、例えば、ハッシュやツリーなどの種類があり、これらを参照することにより、特定のキーを持つレコードがデータソース内のどの位置に存在するかを知ることができる。すなわち、サンプリング手段はデータソースの一部のみを参照することで、データソース全体のデータ分布を把握することができる。
【0008】
特許文献1には、参照用データとして近似問合せエンジンを用意し、データベースに対する近似回答を提供する技術が記載されている。特許文献1に記載の発明は、データベースに対応した参照用データである近似問合せエンジンを用意し、データベースの更新に対応して、所定の確率で近似問合せエンジン内の複数のデータサンプルを更新することを特徴とする。近似問合せエンジン内のデータは、データベースをサンプリングしたものと同等であるため、データベースエンジンは、近似問合せエンジンにアクセスすることで、データベース全体にアクセスすることなくデータの分布を取得することができる。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特開平11−353331号公報
【非特許文献】
【0010】
【非特許文献1】”Skewed Join”、[online]、Apache Pig Wiki、[平成23年9月16日検索]、インターネット<URL:http://wiki.apache.org/pig/PigSkewedJoinSpec>
【非特許文献2】Jefferey Scott Vitter,“Random Sampling with a Reservoir”,ACM Transactions on Mathematical Software,Vol.11,pp.37-57,Mar.1985
【発明の概要】
【発明が解決しようとする課題】
【0011】
データソースからデータのサンプリングを行う際、ファイル全体を読み込む方式である、非特許文献2に記載された技術によると、確実にデータソース内のデータ分布を取得できる一方、データソースが大きくなるほど読み込みに時間がかかるという欠点がある。たとえば、読み込み性能が毎秒100MBであって記憶容量が100GBである記憶装置を10台並列にしたデータソースがあった場合、全データの読み込みに約17分かかる。この方法では、データソースが大規模になると、実用的な速度を得ることが難しくなる。
【0012】
一方、データソースの一部だけを読み込んでヒストグラムを作成する手法を用いる場合、効率的に処理を行うため、データソース内にあらかじめハッシュやツリーなどの探索コストが低いデータ構造を用意しておく必要がある。
【0013】
しかし、データソースが、書き込み当初より探索のために構造化されていないケースも考えられる。例えば、車両の走行ログや、Webのアクセスログのように、書込みのスループットが要求されるデータは、構造化して格納されていることが仮定しにくい。これらのデータを構造化するためには、データソース全体を読み込み、構造化した状態で再度格納し直す必要があるため、結局、データソースの全体を読み込む手法となってしまう。
【0014】
このように、従来技術においては、探索のために最適化されていないデータソースからサンプリングを行う場合において性能上の問題が存在していた。
【0015】
この問題を解消するために、従来技術の他にもいくつかのサンプリング方法が考えられる。たとえば、データソースの先頭から特定個数のレコードをサンプリングする方法である。しかし、この方法によると、記録されているデータが、時系列データのようにその分布に局所性を持っている場合、ヒストグラムがデータソース全体の傾向と異なってしまうという別の問題がある。たとえば、記録されているデータのうち、特定の傾向を持ったデータがデータソースの後方に集中している場合、先頭のデータをサンプリングすると、実際のデータと異なったサンプル結果となってしまい、公平なサンプリングが実現できなくなる。
【0016】
また、別の方法として、データソース中の位置をランダムに特定し、その位置に存在するレコードをサンプリング対象として取り出す、ランダムサンプリングと呼ばれる手法がある。しかし、この方法を用いた場合、サイズの大きいレコードが選択されやすいため、レコードのサイズにばらつきがある場合、不公平な選択がなされる。不公平な選択がなされると、取得されたヒストグラムは、やはりデータソース全体の傾向と異なってしまう。
【0017】
このように、データソースに格納されているデータが、探索のために最適化されておら
ず、かつ局所的な傾向がある場合、データソース内のデータの分散を示すヒストグラムを取得するための公平なサンプリングができない、すなわちサンプリング結果の信頼性が低くなるという問題がある。
【0018】
本発明は上記の問題点を考慮してなされたものであり、探索のために最適化されていないデータソースに対して、全体の傾向を適切に取得することができるサンプリング装置を提供することを目的とする。
【課題を解決するための手段】
【0019】
上記目的を達成するために、本発明に係るサンプリング装置では、以下の手段によりデータソースに対するサンプリングを行う。
【0020】
本発明に係るサンプリング装置は、記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置であって、記録位置に対応する乱数を生成する乱数生成手段と、前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するレコード選択手段と、前記選択されたレコードのレコード長を取得するレコード長取得手段と、前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するサンプル決定手段と、を有することを特徴とする。
【0021】
すなわち、データソースの中から、乱数によって特定された位置に存在するレコードの長さを取得し、当該長さに応じた確率で、選択されたレコードをサンプルとして採用する。データソース中の記録位置をランダムに指定して読み込むランダムサンプリングでは、レコードの長さによって選択される確率が変化する。これに対し、選択後に採用確率を乗じることで、各レコードが選ばれる確率を調整することができる。この手法によって、信頼性の高いサンプリングが可能となる。
【0022】
また、前記サンプル決定手段は、前記取得されたレコードのレコード長と反比例するように前記確率を算出することを特徴とすることが好ましい。
【0023】
すなわち、選択されたレコードのレコード長が長いほど、サンプルとして採用する確率を低くする。これにより、全てのレコードが同じ確率でサンプリングされるようになる。
【0024】
また、本発明に係るサンプリング装置は、前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得する最小レコード長取得手段をさらに有し、前記
サンプル決定手段は、前記選択されたレコードのレコード長をSkとし、Smin/Skの式
によって前記確率を算出することを特徴とすることが好ましい。
【0025】
すなわち、基本とするレコード長をSminとし、Sminを、選択されたレコードの長さで除することにより、当該レコードを採用する確率を決定する。このように構成することにより、ランダムサンプリングの効率を最大限とすることができる。
【0026】
また、本発明に係るサンプリング装置は、前記サンプルとして採用されたレコードから、前記記憶装置に記録されたデータの度数分布を示すヒストグラムを生成するヒストグラム生成手段をさらに有することを特徴としてもよい。
【0027】
ヒストグラムを生成することにより、記録されたデータの度数分布を集計することができるため、分散処理システムにおける本発明の適用が容易になる。
【0028】
また、前記記憶装置は、分散ファイルシステムであり、前記ヒストグラムを用いて、外
部の分散処理ノードに実行すべき処理を割り当てることを特徴としてもよい。
【0029】
このように構成することにより、分散処理システムにおいて、割り当てるタスクのサイズを平均化することが可能になるため、システム全体の処理スループットを向上させることが可能になる。
【発明の効果】
【0030】
本発明によれば、探索のために最適化されていないデータソースに対して、全体の傾向を適切に取得することができるサンプリング装置を提供することができる。
【図面の簡単な説明】
【0031】
【図1】既存のデータサンプリング手法を説明する図である。
【図2】第一の実施形態に係るシステムの構成を表した図である。
【図3】第一の実施形態に係るヒストグラムの例を表した図である。
【図4】第一の実施形態に係るデータソースの内容例を表した図である。
【図5】第一の実施形態に係るシステムの処理フローチャートである。
【図6】第二の実施形態に係るシステムの構成図である。
【図7】第二の実施形態に係るシステムの概要図である。
【発明を実施するための形態】
【0032】
(第一の実施形態)
第一の実施形態に係るサンプリング装置について、図2を用いて詳細な説明をする。図2は、第一の実施形態に係るサンプリング装置のシステム構成を表す図である。
【0033】
本実施形態に係るサンプリング装置100は、データソースにアクセスし、ランダムに既定数のレコードを選択するサンプリング部111と、サンプリング結果に基づいてデータソース内のデータ分布であるヒストグラムを生成するヒストグラム生成部112、および、データソースに記録されているレコードのうち、最小レコードのサイズを記録した最小レコード長記憶部121から構成される。
【0034】
以上の構成は、不図示の中央演算処理装置(CPU)および主記憶装置(RAM)、補助記憶装置(記憶媒体)によって実行される。本実施形態で説明する処理を実行するプログラムコードが補助記憶装置に格納され、当該プログラムコードをCPUが読み出して実行することにより、前述した実施形態の機能が実現される。
【0035】
データソース120は、サンプリング対象となるデータが格納されている手段であり、関係データベースやデータファイル、ディスク装置などに相当する。本実施形態においては、一つのデータファイルを想定して説明するが、複数のレコードを記録できる手段であれば、どのようなものが用いられてもよい。また、これらのデータ格納手段は一つの装置に限定されるものではない。たとえばディスクアレイや分散ファイルシステムなど、仮想的な記憶手段を一つのデータソースとしてもよい。
【0036】
データソースには、改行コードやカンマ等のセパレータ(デリミタ)で区切られた1件分のレコードが複数個格納されている。これらのレコードは、それぞれ長さが異なっており、レコードの記録位置はメモリアドレスによって特定することができる。メモリアドレスとは、レコードが記録されている物理的もしくは論理的な場所を特定するための情報であり、例えばデータソースがファイルであれば先頭からのバイト数、分散ファイルシステムであればファイルの記録位置を示す仮想アドレス等が該当する。
【0037】
最小レコード長記憶部121は、データソース120が有しているレコードのうち、最
小となるレコード長を記録した手段である。例えば、レコードの最小値が512バイトである場合、最小レコード長記憶部121は、512バイトという数値を保持する。最小レコード長記憶部121は、装置として必ずしも独立している必要はなく、例えばデータソース120に、サンプリング対象のデータと一緒に記録されていてもよい。レコードが追加される際に、追加されたレコードの長さが最小レコード長を下回る場合は、最小レコード長は最新の値で更新される。
【0038】
サンプリング部111は、データソース120から、ランダムに既定個数のレコードを取得する動作を行う手段である。実施形態の説明では、データソースから既定個数のレコードをランダムに取得する動作をサンプリングと称する。詳細な動作については後述する。
【0039】
ヒストグラム生成部112は、サンプリング部111がサンプリングを行ったデータに基づいて、データソース内のレコードの度数分布を表すヒストグラムを生成する手段である。ヒストグラムは、サンプリングされたデータのキーを基に度数分布を作成する。図3は、作成されたヒストグラムの例である。本例は、車両走行ログをイベントIDで分類し、それぞれのIDに対応するレコードの数を表している。
【0040】
次に、サンプリング部111がサンプリングを行う方法について説明する。図4は、データソースに格納されたレコード全体を表した図である。ここでは便宜的に、レコード長の最小値をSmin、データソースの全体長をSmin×10として説明を行う。サンプリング部111は、データソースが有しているメモリアドレスに対応する一様乱数を生成し、サンプル対象のメモリアドレスを決定する。仮に、図4に示したデータソースに対して処理を行う場合、0≦N≦10×Sminの範囲をとる乱数Nを決定し、決定したメモリアドレ
スに存在するレコードを取得する。この処理により、対象のデータソースの中の単一のレコードが特定される。例えば、Smin=1、N=3であった場合、図4(a)の場合はレ
コード4、図4(b)の場合はレコード3が選択される。
【0041】
図4(a)は、全て同じ長さのレコードが一様に記録されている場合を表した図である。この場合、ランダムにサンプリングを行うと、レコードAからレコードJの10個が等しい確率で取得される。つまり、各レコードは理論上同じ数がサンプリングされるため、ヒストグラムに偏りは発生せず、前述したような問題は発生しない。
【0042】
図4(b)は、それぞれのレコード長が異なる場合を表した図である。例えば、レコード3およびレコード6は、レコード1の2倍の長さを持っており、レコード5は3倍の長さを持っている。このような場合、データソース上の記録位置であるメモリアドレスをランダムに決定し、対応する箇所にあるレコードを取得しようとすると、サイズが最少であるレコード1,2,4に対して、レコード3と6は2倍、レコード5は3倍それぞれ選択されやすくなる。
【0043】
つまり、各レコードが均等に選択されなくなるため、実際のレコード数は等しいにもかかわらず、作成されるヒストグラムに現れる分布には偏りが発生する。
【0044】
そこで、本実施形態では、サンプリング手段がレコードを選択する際に、当該レコードをサンプルとして採用するか否かの判定を、以下の式(1)によって行う。Sminは、デ
ータソースに記録されているレコードのうち最小となるレコード長であり、Skは、選択
されたレコードの長さを表す。
採用確率p=Smin/Sk … 式(1)
サンプリング部111は、式(1)によって計算された採用確率pに従って、選択したレコードをサンプルとして採用するか否かを決定する。例えば、採用確率pが0.1であ
った場合、10%の確率で、選択したレコードを採用し、90%の確率で選択を破棄する。確率の計算は、たとえば0〜1の範囲の実数をとる乱数を新たに生成し、結果が採用確率以下であった場合にのみ選択したレコードを採用する等の方法によって行うことができる。
【0045】
この方法によると、レコードの長さと、ランダムに選択されたレコードを採用する確率を反比例させることができる。つまり、レコードの長さに反比例した採用確率pを式(1)に乗ずることで、全てのレコードに対して、サンプリングされる確率を同一にすることができる。
【0046】
データソース全体の長さをLとすると、Skのレコード長を持つレコードが選択される
確率は、Sk/Lとなる。これに、式(1)を乗ずると、
Sk/L×Smin/Sk=Smin/L … 式(2)
となり、全てのレコードのサンプリングされる確率が同一となることが確認できる。
【0047】
次に、サンプリング部111の動作フローチャートである図5を参照しながら、サンプリング動作を説明する。本実施形態に係るサンプリング装置が動作を開始すると、サンプリング部111は、最小レコード長記憶部121から最小レコード長を取得する(S10)。最小レコードは、前述したように、可変レコード長のうち最小の値である。
【0048】
次に、データソース中の特定の位置を決定するための乱数を生成する(S11)。生成する乱数は一様乱数であって、データソースに記録されているレコードの記録位置を特定できるものであればどのように生成しても構わない。生成する乱数の範囲は、たとえばディスク装置であれば、データが格納されているセクタ番号の最小値から最大値までとすることが考えられる。
【0049】
次に、決定した乱数に対応するレコードを選択する(S12)。つまり、データソースから、乱数によって特定した記録位置に属しているレコードが選択される。なお、本実施形態では、追記のみを行うデータソースを想定しているため、特定した位置にレコードが存在しない場合の処理は行っていないが、フラグメント等によってデータが存在しない場合を考慮してもよい。その場合、ステップS11へ戻り再度処理を行ってもよいし、前後の直近に存在するレコードを選択してもよい。
【0050】
次に、選択したレコードの長さを取得し(S13)、取得されたレコード長と、最小レコード長を用いて、式(1)による計算を行い、計算された採用確率に従って、当該レコードを採用するか否かを決定する(S14)。決定方法は、前述したように、新たに乱数を生成して判断してもよいし、他の方法を用いてもよい。選択したレコードを採用しないと判断した場合、処理はステップS11へ戻り、乱数の生成を再度行う。
【0051】
次に、サンプリングの回数が規定回数に達したかを判定する(S15)。サンプリングの回数は、装置によって固有なものであってもよいし、データソースの規模に応じて自動で決定されてもよい。規定回数のサンプリングが終了した場合、処理は終了し、規定回数に達していなかった場合は再度レコードの選択が行われる。
【0052】
以上の処理により、サンプリング部111は、既定サンプル数分のレコードを取得することができる。取得されたレコードは、そのレコード長に関係なくランダムに選択されたものとなる。
【0053】
サンプリング部111がサンプルの収集を完了させると、ヒストグラム生成部生成部112が、収集したサンプルを用いてヒストグラムの生成を行う。ヒストグラムは、取得し
たサンプルデータが有するキーごとに、レコードの件数を加算することで生成される。
【0054】
本実施形態によれば、レコード長がそれぞれ異なるデータソースからサンプリングを行うサンプリング装置において、レコード長に反比例するように採用確率を設定することで、レコード長にかかわらず均等にレコードをサンプリングすることができる。すなわち、生成されたヒストグラムはデータソース全体の傾向を代表するものとなるため、巨大なデータソースであっても、短時間でデータ分布の傾向を得ることができる。
【0055】
なお、第一の実施形態においては、ヒストグラム生成部を用いてヒストグラムの生成を行ったが、ヒストグラムを他の手段で生成できる場合や、ヒストグラム以外のデータ集計手段が利用できる場合は、ヒストグラム生成部は必須構成ではない。
【0056】
(第二の実施形態)
第二の実施形態は、第一の実施形態におけるサンプリング装置100を、分散処理フレームワークであるHadoopを利用した分散処理システムに組み込んだ形態である。図6は、第二の実施形態に係るシステム構成図であり、図7は、第二の実施形態に係るシステムの概念図である。なお、第二の実施形態に係るサンプリング装置が収集を行うデータソースおよびレコードの構成は、第一の実施形態で説明したものと同一である。
【0057】
第二の実施形態では、分散処理ノードが持っている分散ファイルをデータソースとして利用する。分散ファイル202a,b,cは、それぞれ分散処理ノードであるコンピュータ201a,b,c上に配置され、サンプリング部111からシームレスにアクセスすることができる。すなわち、サンプリング部111からは、一つのデータソースがあるように見えるため、第一の実施形態と同様の方法によってデータのサンプリングを行うことができる。
【0058】
また、ヒストグラム生成部112が生成したヒストグラムは、タスク割り当て部130へ送信される。タスク割り当て部130は、生成されたヒストグラムをもとに、分散ファイル202a,b,cより処理すべきタスクを取得し、分散処理ノード201a,b,cに対して処理を割り当てる。
【0059】
本実施形態は、分散処理フレームワークであるHadoop上で動作するHiveに本発明を適用したものである。図7に示した通り、Hiveには、Compiler、Optimizer、Executorの三つのフェーズがある。このうち、Optimizerフェーズにてサンプリングを行い、得られたヒストグラムから、分散処理ノードの単位性能あたりのタスクサイズが均等になるように、Executorフェーズでタスクの割り当て、すなわちスケジューリングを行う。
【0060】
このように構成することにより、分散処理におけるノード間の負荷の偏りが減り、システム全体のスループットを向上させることができる。なお、本例ではHiveへの適用例を挙げたが、Pigなど、Hadoopで動作する他のミドルウェアを適用してもよい。
【0061】
(変形例)
上記の実施形態はあくまでも一例であって、本発明はその要旨を逸脱しない範囲内で適宜変更して実施しうるものである。たとえば、実施形態の説明においては、処理を行うプログラムを補助記憶装置に記録し、CPUによって処理を行う例を挙げたが、処理はFPGAによって行われてもよいし、ハードウェアとして設計され実行されてもよい。
【0062】
また、実施形態の説明においては、選択されたレコードをサンプルとして採用する確率pをSmin/Skの式によって計算したが、採用確率pをa×Smin/Sk(ただし0<a<1)としても、各レコードがサンプリングされる確率を同一にすることができる。ただし
、係数aを乗じた場合、一回の実行でレコードがサンプリングされない確率が上昇するため、採用確率pはSmin/Skとした場合が最も効率がよい。
【0063】
また、発明の効果を得るためには、選択されたレコードのサイズに応じて、当該レコードを採用する確率を調整する、すなわち選択されたレコードが長いほど採用確率を下げる必要があるが、採用確率はレコード長に反比例していなくともよい。
【0064】
たとえば、採用確率pをn/Sk(nは任意の定数)とし、pが1を超えた場合は1と
して扱ってもよい。この場合、各レコードが選択される確率は同一とはならないが、均一の値に近づけることはできる。このように、各レコードがサンプリングされる確率を均一の値に近づけるためには、選択されたレコードが長くなるに従って採用確率を下げることができればよい。
【0065】
また、レコードのサイズが極端にばらついている際、何度も選択を繰り返さないと必要な個数のレコードをサンプリングできないケースが考えられる。例えば、レコードの平均サイズをSavgとすると、一回の実行でレコードが選択される確率はSmin/Savgである
ため、n回のサンプリングに必要なループ数は、(n×Savg)/Sminとなる。この値が全体のレコード件数を超える場合は、データソース全体を読み込んだほうが効率が良くなる。
【0066】
例えば図4(b)の例では、Savg=1.66…×Sminとなるため、n≧4である場合、ループ数が総レコード数以上となる。そのため、前記条件に当てはまるほどレコードのサイズにばらつきがある場合、アルゴリズムから確率的な要素を減らすようにしてもよい。
【0067】
例えば、ランダムに選択したレコードから、m番目、m×2番目・・・のレコードを選ぶことにより、一回のループで一つ以上のレコードを確実にサンプリングできるようになる。これにより、レコードの傾向の局所性がヒストグラムに反映されてしまうという副作用が生じるが、ランダムに選んだレコードから離れたレコードを選択することで、その影響を緩和できる可能性がある。
【符号の説明】
【0068】
100 サンプリング装置
111 サンプリング部
112 ヒストグラム生成部
120 データソース
121 最小レコード長記憶部
130 タスク割当て部
201a,b,c 分散処理ノード
202a,b,c 分散ファイルノード
【特許請求の範囲】
【請求項1】
記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置であって、
記録位置に対応する乱数を生成する乱数生成手段と、
前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するレコード選択手段と、
前記選択されたレコードのレコード長を取得するレコード長取得手段と、
前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するサンプル決定手段と、
を有する
ことを特徴とするサンプリング装置。
【請求項2】
前記サンプル決定手段は、前記取得されたレコードのレコード長と反比例するように前記確率を算出する
ことを特徴とする、請求項1に記載のサンプリング装置。
【請求項3】
前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得す
る最小レコード長取得手段をさらに有し、
前記サンプル決定手段は、前記選択されたレコードのレコード長をSkとし、Smin/Skの式によって前記確率を算出する
ことを特徴とする、請求項2に記載のサンプリング装置。
【請求項4】
前記サンプルとして採用されたレコードから、前記記憶装置に記録されたデータの度数分布を示すヒストグラムを生成するヒストグラム生成手段をさらに有する
ことを特徴とする、請求項3に記載のサンプリング装置。
【請求項5】
前記記憶装置は、分散ファイルシステムであり、前記ヒストグラムを用いて、外部の分散処理ノードに実行すべき処理を割り当てる
ことを特徴とする、請求項4に記載のサンプリング装置。
【請求項6】
記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置が行うサンプリング方法であって、
記録位置に対応する乱数を発生させるステップと、
前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するステップと、
前記選択されたレコードのレコード長を取得するステップと、
前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するステップと、
を含む
ことを特徴とするサンプリング方法。
【請求項7】
前記取得されたレコードのレコード長と反比例するように前記確率を算出する
ことを特徴とする、請求項6に記載のサンプリング方法。
【請求項8】
前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得す
るステップをさらに備え、
前記選択されたレコードのレコード長をSkとし、Smin/Skの式によって前記確率を
算出する
ことを特徴とする、請求項7に記載のサンプリング方法。
【請求項9】
コンピュータに、
記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングさせるプログラムであって、
記録位置に対応する乱数を発生させる処理と、
前記複数のレコードから、前記生成した乱数に対応する記録位置に記録されたレコードを選択する処理と、
前記選択されたレコードのレコード長を取得する処理と、
前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用する処理と、
を実行させる
ことを特徴とするプログラム。
【請求項10】
前記コンピュータに、
前記取得されたレコードのレコード長と反比例するように前記確率を算出させる
ことを特徴とする、請求項9に記載のプログラム。
【請求項11】
前記コンピュータに、
前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得す
る処理をさらに実行させ、
前記選択されたレコードのレコード長をSkとし、Smin/Skの式によって前記確率を
算出させる
ことを特徴とする、請求項10に記載のプログラム。
【請求項1】
記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置であって、
記録位置に対応する乱数を生成する乱数生成手段と、
前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するレコード選択手段と、
前記選択されたレコードのレコード長を取得するレコード長取得手段と、
前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するサンプル決定手段と、
を有する
ことを特徴とするサンプリング装置。
【請求項2】
前記サンプル決定手段は、前記取得されたレコードのレコード長と反比例するように前記確率を算出する
ことを特徴とする、請求項1に記載のサンプリング装置。
【請求項3】
前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得す
る最小レコード長取得手段をさらに有し、
前記サンプル決定手段は、前記選択されたレコードのレコード長をSkとし、Smin/Skの式によって前記確率を算出する
ことを特徴とする、請求項2に記載のサンプリング装置。
【請求項4】
前記サンプルとして採用されたレコードから、前記記憶装置に記録されたデータの度数分布を示すヒストグラムを生成するヒストグラム生成手段をさらに有する
ことを特徴とする、請求項3に記載のサンプリング装置。
【請求項5】
前記記憶装置は、分散ファイルシステムであり、前記ヒストグラムを用いて、外部の分散処理ノードに実行すべき処理を割り当てる
ことを特徴とする、請求項4に記載のサンプリング装置。
【請求項6】
記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングするサンプリング装置が行うサンプリング方法であって、
記録位置に対応する乱数を発生させるステップと、
前記複数のレコードから、前記生成した乱数に対応する記録位置にデータを有するレコードを選択するステップと、
前記選択されたレコードのレコード長を取得するステップと、
前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用するステップと、
を含む
ことを特徴とするサンプリング方法。
【請求項7】
前記取得されたレコードのレコード長と反比例するように前記確率を算出する
ことを特徴とする、請求項6に記載のサンプリング方法。
【請求項8】
前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得す
るステップをさらに備え、
前記選択されたレコードのレコード長をSkとし、Smin/Skの式によって前記確率を
算出する
ことを特徴とする、請求項7に記載のサンプリング方法。
【請求項9】
コンピュータに、
記憶装置に記録された複数のレコードの中から、ランダムにレコードをサンプリングさせるプログラムであって、
記録位置に対応する乱数を発生させる処理と、
前記複数のレコードから、前記生成した乱数に対応する記録位置に記録されたレコードを選択する処理と、
前記選択されたレコードのレコード長を取得する処理と、
前記取得されたレコード長に基づいて算出した確率で、前記選択されたレコードをサンプルとして採用する処理と、
を実行させる
ことを特徴とするプログラム。
【請求項10】
前記コンピュータに、
前記取得されたレコードのレコード長と反比例するように前記確率を算出させる
ことを特徴とする、請求項9に記載のプログラム。
【請求項11】
前記コンピュータに、
前記複数のレコードのうち、サイズが最小であるレコードのレコード長Sminを取得す
る処理をさらに実行させ、
前記選択されたレコードのレコード長をSkとし、Smin/Skの式によって前記確率を
算出させる
ことを特徴とする、請求項10に記載のプログラム。
【図1】


【図2】

【図3】
【図4】

【図5】
【図6】
【図7】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2013−101539(P2013−101539A)
【公開日】平成25年5月23日(2013.5.23)
【国際特許分類】
【出願番号】特願2011−245492(P2011−245492)
【出願日】平成23年11月9日(2011.11.9)
【出願人】(502087460)株式会社トヨタIT開発センター (232)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
【公開日】平成25年5月23日(2013.5.23)
【国際特許分類】
【出願日】平成23年11月9日(2011.11.9)
【出願人】(502087460)株式会社トヨタIT開発センター (232)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
[ Back to top ]