
未知の顔の入力画像を既知の顔の基準画像と比較する方法

【課題】方法は、既知の顔の基準画像を使用して入力画像内の未知の顔を識別する。
【解決手段】各画像からHaar−like特徴ベクトルを抽出する。このベクトルを圧縮する。入力画像の圧縮特徴ベクトルと、基準画像のセットからの各圧縮特徴ベクトルとの間のL1ノルムを求めて、最も類似している基準画像を求める。最も類似している基準画像に関連付けられる顔のアイデンティティが、入力画像内の未知の顔のアイデンティティとして指定される。
【解決手段】各画像からHaar−like特徴ベクトルを抽出する。このベクトルを圧縮する。入力画像の圧縮特徴ベクトルと、基準画像のセットからの各圧縮特徴ベクトルとの間のL1ノルムを求めて、最も類似している基準画像を求める。最も類似している基準画像に関連付けられる顔のアイデンティティが、入力画像内の未知の顔のアイデンティティとして指定される。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、包括的にはパターン及び物体の認識に関し、より詳細には、圧縮特徴ベクトルを使用して静止画像及び動画像内で人の顔を識別することに関する。
【背景技術】
【0002】
人を識別する際に、顔の画像が使用されることが多い。本発明において使用される場合、混乱を招かないように、検出とは、画像内にあるのが何であるか、すなわち、画像内に顔があるか否かを意味している。また、識別とは、画像内にいるのが誰であるか、すなわち、画像内の顔のアイデンティティ(identity:識別性)を判断することを意味している。
【0003】
顔識別では、未知の顔を特徴のベクトルによって表すことができる。2つの顔画像を比較するために、特徴ベクトルを使用して類似度スコアが計算される。類似度スコアが高いほど、それらの顔は、類似している。一例の顔識別用途では、特徴値は、32ビットで記憶される浮動小数点数である。単一の顔の特徴ベクトルは、1000個程度の特徴、すなわち、32000ビットを有する。明らかに、このような大きな特徴ベクトルは、メモリを消費し、処理のために相当量の資源を必要とする。これは、既知の基準画像の基礎的データベースが数百万の画像を含む可能性がある場合に、特に当てはまる。
【0004】
自明の解決策は、特徴ベクトルを圧縮することである。しかしながら、データを圧縮することは、データを廃棄することになり、圧縮されたデータに対する操作によって、結果の精度が低下することがよく知られている。
【0005】
顔識別
人の最も視覚的に区別可能な特徴の1つが、顔である。したがって、静止画像及び動画像(ビデオ)内の顔の検出及び識別は、画像から人を識別することが望ましい多くの用途にとって重要な技術である。顔識別は、コンピュータビジョン技術に対して極度に困難な課題を提示する。
【0006】
たとえば、監視カメラが必要とする顔画像では、シーンの照明が粗末であり、制御されていないことが多く、該カメラは、一般的に品質が低く、通常、シーンの重要である可能性がある部分から離れている。シーン内の顔のロケーション及び向きは、通常、制御することができない。髪の生え際、まつ毛、及び顎のようないくつかの顔特徴は、変化しやすい。口のような他の特徴は、特にビデオ内では非常に変化しやすい。
【0007】
顔識別システムの中核は、2つの画像を入力として取り込んで類似度スコアを出力する類似度関数である。顔類似度関数を使用して未知の顔の画像(入力画像)を、既知の顔の画像(基準画像)のセットと比較することができる。基準画像のセットは、同じ顔の複数の画像を含むことができる。各画像は、関連付けられる識別情報を有する。未知の入力顔は、最大類似度スコアが閾値を上回っている限り、入力顔と比較したときに最大の類似度スコアを有する基準画像のアイデンティティとして識別される。そうでなければ入力顔は、未知のままである。
【0008】
2つの顔の間の類似度スコアを計算する多くの方法が存在する。ほとんどすべての方法が、最初に2つの顔のそれぞれの特徴ベクトルを計算すること、そして、次に特徴ベクトルを比較することを含む。既知の方法は、主成分分析(固有顔)、線形判別分析(フィッシャー顔)、及び弾性バンチグラフを使用する。
【発明の概要】
【発明が解決しようとする課題】
【0009】
問題点として、特徴のサイズが非常に大きくなり、記憶するのに大量のコンピュータメモリを必要とする可能性がある。
【課題を解決するための手段】
【0010】
方法は、2つの顔画像を比較して類似度スコアをもたらす。各画像から特徴ベクトルを抽出する。特徴ベクトルを圧縮して、該圧縮特徴ベクトルを比較して類似度スコアをもたらす。
【図面の簡単な説明】
【0011】
【図1】本発明の実施の形態による顔認識方法のブロック図である。
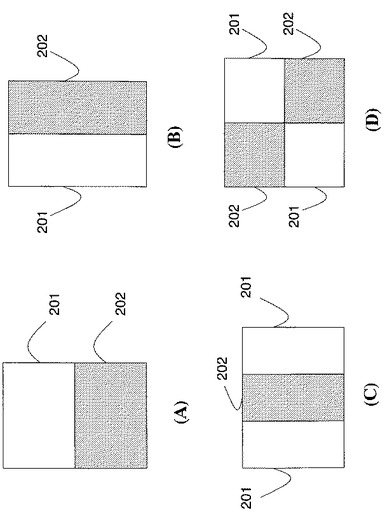
【図2】本発明の実施の形態によるテンプレートフィルタである((A)〜(D))。
【図3】本発明の実施の形態による矩形領域内の画素強度の総和である。
【発明を実施するための形態】
【0012】
図1は、本発明の実施の形態による2つの顔画像を比較する方法を示す。未知の顔から取得された画像101から特徴ベクトル111を抽出する(110)。別の顔の画像102から異なる特徴ベクトル112も抽出する。特徴ベクトル111を圧縮特徴ベクトル121に量子化し、特徴ベクトル112を圧縮特徴ベクトル122に量子化する。圧縮特徴ベクトルを比較して(130)、類似度スコア140を求める。類似度スコアは、2つの画像101及び102内の顔が同じであるか否かを指示する。
【0013】
前処理:顔検出
本発明では、顔の画像がどのように取得されるかは重要ではない。従来の顔検出を使用することができる。本明細書において使用される場合、混乱を招かないように、検出とは、画像内にあるのが何であるか、すなわち、画像内に顔があるか否かを意味している。また、識別とは、画像内にいるのが誰であるか、すなわち、画像内の顔のアイデンティティが何であるかを意味している。
【0014】
後処理:正規化
選択肢として、計算される画像対内の顔を、サイズ、向き、及び照明に関して正規化することができる。たとえば、顔は、ほぼ画像全体を占めることができ、垂直方向及び水平方向に位置調整することができる。
【0015】
特徴抽出
特徴抽出中、複数のフィルタを、入力画像及び基準画像内の画素の矩形パッチに適用する。フィルタは、パッチと同じサイズ及びロケーションのテンプレートフィルタとすることができる。たとえば、図2(A)〜(D)に示すように、Haar−like特徴を抽出することができる。単純な矩形Haar−like特徴は、画像内の2つ以上の矩形パッチ201及び202内の画素値の加重和、又は総和の差と定義することができる。矩形パッチは、連続的であり、画像内で任意の位置及びスケールにあることができる。Haar−like特徴は、エッジ若しくはテクスチャ変化のような、画像内の特定の特性の存否を指示する、又はパッチが暗い領域と明るい領域との間の境界上にわたって位置しているか否かを指示することができる。特徴ベクトルの形成に使用される数百又は数千の特徴は、通常、トレーニング段階において、数百又は数千の可能な特徴からなるはるかに大きいセットから学習される。
【0016】
Haar−like特徴は、積分画像を使用して迅速に計算することができる。積分画像は、画像と同じサイズを有する行列の形態の2次元ルックアップテーブルとして定義される。積分画像の各要素は、該要素の位置に関して、原画像の左上領域に位置するすべての画素の総和を含む。これによって、非常に少数、たとえば、4つのルックアップを使用して、任意の位置又はスケールにおいて画像内の矩形パッチの総和、すなわち総和=pt4−pt3−pt2+pt1を計算することができる。ここで、要素点ptnは、Haar−like特徴における矩形の角を形成する積分画像の要素である。
【0017】
図3に示すように、矩形ABCD310の角A311、角B312、角C313及び角D314において積分画像値を有する積分画像200の矩形領域310内の画素強度の総和を、
エリア(ABCD)=A+D−B−C
として求めることができる。
【0018】
特徴圧縮
特徴のすべての可能な値を0〜2b−1の整数にマッピングすることによって、実数値特徴ベクトル内の特徴をbビットに圧縮する。これは、最初に(たとえば、トレーニング段階において)顔の大きなセットにわたって各特徴の平均(μ)及び標準偏差(σ)を計算することによって行われる。次いで、(たとえば)平均の1標準偏差内に入る特徴の値を、単純な線形マッピングを使用して0〜2b−1の実数にマッピングする。平均−1標準偏差よりも小さい任意の特徴値を0にマッピングする。平均+1標準偏差よりも大きい任意の特徴値を2b−1にマッピングする。次いで、マッピングした特徴値を切り捨てて(量子化して)整数値をもたらす。標準偏差をsσに一般化することができることに留意されたい。ここで、変数sは、実数、たとえば、1.0、1.1、2.0、3.0、3.5等である。スカラーsは、平均μの周囲の切り捨て領域の幅を制御する。
【0019】
この特徴圧縮方法は、下式として等式で表すことができる。
【0020】
【数1】

【0021】
ここで、fiは、入力特徴の値であり、μiは、特徴の平均であり、sσiは、特徴のスケーリングされた標準偏差(複数可)であり、bは、圧縮特徴における所望のビット数であり、Fiは、0〜2b−1の整数値を有することができる最終的な圧縮特徴値である。
【0022】
驚くべきことに、また、予測とは対照的に、本発明の方法は、非常に少数の特徴ビットで良好に機能する。通常、特徴値を表すのに使用するビット数を低減すると、精度も減少すると予測するであろう。しかしながら、本発明における圧縮方法に関しては、これは当てはまらない。本発明では、0〜255、すなわちb=8の範囲内の値を有する正確な結果を得ることができる。したがって、本発明の圧縮係数は、4倍である。さらに、より驚くべきことに、また、すべての予測及び常識に反して、本発明者らは、本発明の方法が、たった1ビット(b=1)でも機能すること、及び8ビットから1ビットにしても、本発明の結果の精度がほとんど減少しないことを発見した。
【0023】
平均及び標準偏差
各特徴の平均(μ)及び標準偏差(複数可)(σ)を画像のトレーニングセットから計算することができる。トレーニング画像の総数がrであり、nが各特徴ベクトル内の特徴の総数である。x番目のトレーニング画像から抽出される特徴ベクトルは、vx=[f1、f2、・・・、fn]であり、ここで1≦x≦rである。vxのi番目の特徴値がfiであり、ここで1≦i≦nである。平均のベクトルμ=[μ1、μ2、・・・、μn]は、下式によって求められる。
【0024】
【数2】
【0025】
標準偏差のベクトルσ=[σ1、σ2、・・・、σn]は、下式によって求められる。
【0026】
【数3】
【0027】
特徴比較
2つの圧縮特徴ベクトル、FとGとの間の距離(類似度)を計算するさまざまな方法が存在する。単純な方法は、2つの特徴ベクトルの間のL1ノルムを求める。これは、数学的に、下式として表すことができる。
【0028】
【数4】
【0029】
ここで、Fiは、Fの特徴ベクトルのi番目の特徴であり、Giは、特徴ベクトルGのi番目の特徴であり、dは、特徴ベクトルFと特徴ベクトルGとの間の結果として求められるL1距離である。
【0030】
次いで、類似度スコアSを、
S=M−d
として計算することができる。ここで、Mは、2つの特徴ベクトル間のL1ノルムの可能な最大スコアである。bビットでの2つの圧縮ベクトルの場合、L1ノルムの最大スコアは(2b−1)*nである。
【技術分野】
【0001】
本発明は、包括的にはパターン及び物体の認識に関し、より詳細には、圧縮特徴ベクトルを使用して静止画像及び動画像内で人の顔を識別することに関する。
【背景技術】
【0002】
人を識別する際に、顔の画像が使用されることが多い。本発明において使用される場合、混乱を招かないように、検出とは、画像内にあるのが何であるか、すなわち、画像内に顔があるか否かを意味している。また、識別とは、画像内にいるのが誰であるか、すなわち、画像内の顔のアイデンティティ(identity:識別性)を判断することを意味している。
【0003】
顔識別では、未知の顔を特徴のベクトルによって表すことができる。2つの顔画像を比較するために、特徴ベクトルを使用して類似度スコアが計算される。類似度スコアが高いほど、それらの顔は、類似している。一例の顔識別用途では、特徴値は、32ビットで記憶される浮動小数点数である。単一の顔の特徴ベクトルは、1000個程度の特徴、すなわち、32000ビットを有する。明らかに、このような大きな特徴ベクトルは、メモリを消費し、処理のために相当量の資源を必要とする。これは、既知の基準画像の基礎的データベースが数百万の画像を含む可能性がある場合に、特に当てはまる。
【0004】
自明の解決策は、特徴ベクトルを圧縮することである。しかしながら、データを圧縮することは、データを廃棄することになり、圧縮されたデータに対する操作によって、結果の精度が低下することがよく知られている。
【0005】
顔識別
人の最も視覚的に区別可能な特徴の1つが、顔である。したがって、静止画像及び動画像(ビデオ)内の顔の検出及び識別は、画像から人を識別することが望ましい多くの用途にとって重要な技術である。顔識別は、コンピュータビジョン技術に対して極度に困難な課題を提示する。
【0006】
たとえば、監視カメラが必要とする顔画像では、シーンの照明が粗末であり、制御されていないことが多く、該カメラは、一般的に品質が低く、通常、シーンの重要である可能性がある部分から離れている。シーン内の顔のロケーション及び向きは、通常、制御することができない。髪の生え際、まつ毛、及び顎のようないくつかの顔特徴は、変化しやすい。口のような他の特徴は、特にビデオ内では非常に変化しやすい。
【0007】
顔識別システムの中核は、2つの画像を入力として取り込んで類似度スコアを出力する類似度関数である。顔類似度関数を使用して未知の顔の画像(入力画像)を、既知の顔の画像(基準画像)のセットと比較することができる。基準画像のセットは、同じ顔の複数の画像を含むことができる。各画像は、関連付けられる識別情報を有する。未知の入力顔は、最大類似度スコアが閾値を上回っている限り、入力顔と比較したときに最大の類似度スコアを有する基準画像のアイデンティティとして識別される。そうでなければ入力顔は、未知のままである。
【0008】
2つの顔の間の類似度スコアを計算する多くの方法が存在する。ほとんどすべての方法が、最初に2つの顔のそれぞれの特徴ベクトルを計算すること、そして、次に特徴ベクトルを比較することを含む。既知の方法は、主成分分析(固有顔)、線形判別分析(フィッシャー顔)、及び弾性バンチグラフを使用する。
【発明の概要】
【発明が解決しようとする課題】
【0009】
問題点として、特徴のサイズが非常に大きくなり、記憶するのに大量のコンピュータメモリを必要とする可能性がある。
【課題を解決するための手段】
【0010】
方法は、2つの顔画像を比較して類似度スコアをもたらす。各画像から特徴ベクトルを抽出する。特徴ベクトルを圧縮して、該圧縮特徴ベクトルを比較して類似度スコアをもたらす。
【図面の簡単な説明】
【0011】
【図1】本発明の実施の形態による顔認識方法のブロック図である。
【図2】本発明の実施の形態によるテンプレートフィルタである((A)〜(D))。
【図3】本発明の実施の形態による矩形領域内の画素強度の総和である。
【発明を実施するための形態】
【0012】
図1は、本発明の実施の形態による2つの顔画像を比較する方法を示す。未知の顔から取得された画像101から特徴ベクトル111を抽出する(110)。別の顔の画像102から異なる特徴ベクトル112も抽出する。特徴ベクトル111を圧縮特徴ベクトル121に量子化し、特徴ベクトル112を圧縮特徴ベクトル122に量子化する。圧縮特徴ベクトルを比較して(130)、類似度スコア140を求める。類似度スコアは、2つの画像101及び102内の顔が同じであるか否かを指示する。
【0013】
前処理:顔検出
本発明では、顔の画像がどのように取得されるかは重要ではない。従来の顔検出を使用することができる。本明細書において使用される場合、混乱を招かないように、検出とは、画像内にあるのが何であるか、すなわち、画像内に顔があるか否かを意味している。また、識別とは、画像内にいるのが誰であるか、すなわち、画像内の顔のアイデンティティが何であるかを意味している。
【0014】
後処理:正規化
選択肢として、計算される画像対内の顔を、サイズ、向き、及び照明に関して正規化することができる。たとえば、顔は、ほぼ画像全体を占めることができ、垂直方向及び水平方向に位置調整することができる。
【0015】
特徴抽出
特徴抽出中、複数のフィルタを、入力画像及び基準画像内の画素の矩形パッチに適用する。フィルタは、パッチと同じサイズ及びロケーションのテンプレートフィルタとすることができる。たとえば、図2(A)〜(D)に示すように、Haar−like特徴を抽出することができる。単純な矩形Haar−like特徴は、画像内の2つ以上の矩形パッチ201及び202内の画素値の加重和、又は総和の差と定義することができる。矩形パッチは、連続的であり、画像内で任意の位置及びスケールにあることができる。Haar−like特徴は、エッジ若しくはテクスチャ変化のような、画像内の特定の特性の存否を指示する、又はパッチが暗い領域と明るい領域との間の境界上にわたって位置しているか否かを指示することができる。特徴ベクトルの形成に使用される数百又は数千の特徴は、通常、トレーニング段階において、数百又は数千の可能な特徴からなるはるかに大きいセットから学習される。
【0016】
Haar−like特徴は、積分画像を使用して迅速に計算することができる。積分画像は、画像と同じサイズを有する行列の形態の2次元ルックアップテーブルとして定義される。積分画像の各要素は、該要素の位置に関して、原画像の左上領域に位置するすべての画素の総和を含む。これによって、非常に少数、たとえば、4つのルックアップを使用して、任意の位置又はスケールにおいて画像内の矩形パッチの総和、すなわち総和=pt4−pt3−pt2+pt1を計算することができる。ここで、要素点ptnは、Haar−like特徴における矩形の角を形成する積分画像の要素である。
【0017】
図3に示すように、矩形ABCD310の角A311、角B312、角C313及び角D314において積分画像値を有する積分画像200の矩形領域310内の画素強度の総和を、
エリア(ABCD)=A+D−B−C
として求めることができる。
【0018】
特徴圧縮
特徴のすべての可能な値を0〜2b−1の整数にマッピングすることによって、実数値特徴ベクトル内の特徴をbビットに圧縮する。これは、最初に(たとえば、トレーニング段階において)顔の大きなセットにわたって各特徴の平均(μ)及び標準偏差(σ)を計算することによって行われる。次いで、(たとえば)平均の1標準偏差内に入る特徴の値を、単純な線形マッピングを使用して0〜2b−1の実数にマッピングする。平均−1標準偏差よりも小さい任意の特徴値を0にマッピングする。平均+1標準偏差よりも大きい任意の特徴値を2b−1にマッピングする。次いで、マッピングした特徴値を切り捨てて(量子化して)整数値をもたらす。標準偏差をsσに一般化することができることに留意されたい。ここで、変数sは、実数、たとえば、1.0、1.1、2.0、3.0、3.5等である。スカラーsは、平均μの周囲の切り捨て領域の幅を制御する。
【0019】
この特徴圧縮方法は、下式として等式で表すことができる。
【0020】
【数1】
【0021】
ここで、fiは、入力特徴の値であり、μiは、特徴の平均であり、sσiは、特徴のスケーリングされた標準偏差(複数可)であり、bは、圧縮特徴における所望のビット数であり、Fiは、0〜2b−1の整数値を有することができる最終的な圧縮特徴値である。
【0022】
驚くべきことに、また、予測とは対照的に、本発明の方法は、非常に少数の特徴ビットで良好に機能する。通常、特徴値を表すのに使用するビット数を低減すると、精度も減少すると予測するであろう。しかしながら、本発明における圧縮方法に関しては、これは当てはまらない。本発明では、0〜255、すなわちb=8の範囲内の値を有する正確な結果を得ることができる。したがって、本発明の圧縮係数は、4倍である。さらに、より驚くべきことに、また、すべての予測及び常識に反して、本発明者らは、本発明の方法が、たった1ビット(b=1)でも機能すること、及び8ビットから1ビットにしても、本発明の結果の精度がほとんど減少しないことを発見した。
【0023】
平均及び標準偏差
各特徴の平均(μ)及び標準偏差(複数可)(σ)を画像のトレーニングセットから計算することができる。トレーニング画像の総数がrであり、nが各特徴ベクトル内の特徴の総数である。x番目のトレーニング画像から抽出される特徴ベクトルは、vx=[f1、f2、・・・、fn]であり、ここで1≦x≦rである。vxのi番目の特徴値がfiであり、ここで1≦i≦nである。平均のベクトルμ=[μ1、μ2、・・・、μn]は、下式によって求められる。
【0024】
【数2】
【0025】
標準偏差のベクトルσ=[σ1、σ2、・・・、σn]は、下式によって求められる。
【0026】
【数3】
【0027】
特徴比較
2つの圧縮特徴ベクトル、FとGとの間の距離(類似度)を計算するさまざまな方法が存在する。単純な方法は、2つの特徴ベクトルの間のL1ノルムを求める。これは、数学的に、下式として表すことができる。
【0028】
【数4】
【0029】
ここで、Fiは、Fの特徴ベクトルのi番目の特徴であり、Giは、特徴ベクトルGのi番目の特徴であり、dは、特徴ベクトルFと特徴ベクトルGとの間の結果として求められるL1距離である。
【0030】
次いで、類似度スコアSを、
S=M−d
として計算することができる。ここで、Mは、2つの特徴ベクトル間のL1ノルムの可能な最大スコアである。bビットでの2つの圧縮ベクトルの場合、L1ノルムの最大スコアは(2b−1)*nである。
【特許請求の範囲】
【請求項1】
未知の顔の入力画像を既知の顔の基準画像と比較する方法であって、
各前記画像から特徴ベクトルを抽出するステップと、
前記特徴ベクトルを圧縮特徴ベクトルに圧縮するステップと、
2つの前記顔の類似度スコアを求めるために、前記圧縮特徴ベクトルを比較するステップステップと
を含む方法。
【請求項2】
前記特徴は、前記画像内の画素の2つ以上の矩形パッチ内の画素値の加重和、又は総和の差として定義される矩形Haar−like特徴であり、前記矩形パッチは、前記画像内で任意の位置及びスケールにおいて連続している請求項1に記載の方法。
【請求項3】
前記Haar−like特徴は、積分画像から求められる請求項2に記載の方法。
【請求項4】
前記特徴ベクトルは、対応する既知の顔のセットの基準画像のセットのそれぞれから抽出及び圧縮され、前記入力画像の前記圧縮特徴ベクトルは、前記基準画像のセットの各前記特徴ベクトルと比較されて、前記未知の顔の各前記既知の顔との類似度スコアが求められる請求項1に記載の方法。
【請求項5】
nは、各前記特徴ベクトル内の特徴の数であり、v=[f1、f2、・・・、fn]は、各前記画像から抽出される前記特徴ベクトルであり、fiは、前記特徴ベクトルvxのi番目の特徴であり、ここで1≦i≦nであり、μ=[μ1、μ2、・・・、μn]は、前記特徴の平均のベクトルであり、σ=[σ1、σ2、・・・、σn]は、前記特徴の標準偏差のベクトルであり、sは、μの周囲の切り捨て領域の幅を制御するスカラー定数であり、前記圧縮するステップは、
抽出された各特徴値fiに関して
【数1】
に従って値Fiを求めることをさらに含み、ここで、bは、前記値Fiを記憶するのに使用されるビット数である、請求項1に記載の方法。
【請求項6】
前記平均及び前記標準偏差は、トレーニング画像のセットから求められ、該トレーニング画像の総数は、rであり、nは、各前記特徴ベクトル内の特徴の総数であり、x番目のトレーニング画像から抽出される特徴ベクトルは、vx=[f1、f2、・・・、fn]であり、ここで1≦x≦rであり、vxのi番目の特徴値は、fiであり、ここで1≦i≦nであり、平均のベクトルμ=[μ1、μ2、・・・、μn]は、
【数2】
に従って求められ、標準偏差のベクトルσ=[σ1、σ2、・・・、σn]は、
【数3】
に従って求められる請求項5に記載の方法。
【請求項7】
F=[F1、F2、・・・、Fn]は、前記入力画像の前記圧縮特徴ベクトルであり、G=[G1、G2、・・・、Gn]は、前記基準画像の前記圧縮特徴ベクトルであり、Mは、前記圧縮特徴ベクトルF及び前記圧縮特徴ベクトルGのL1ノルムの最大値であり、前記類似度スコアは
【数4】
に従って求められる請求項1に記載の方法。
【請求項8】
正規化特徴ベクトルを生成するために、前記特徴ベクトルを正規化するステップと、
量子化特徴ベクトルを生成するために、前記正規化特徴ベクトルを量子化するステップと
をさらに含み、
前記比較するステップは、前記量子化特徴ベクトルを使用する請求項1に記載の方法。
【請求項9】
各前記基準画像は、関連付けられるアイデンティティを有し、該基準画像の該関連付けられるアイデンティティは、最大類似度スコアが所定の閾値を上回っている限り、前記入力画像の顔と比較したときに前記最大類似度スコアを有する請求項4に記載の方法。
【請求項10】
bは、8である請求項5に記載の方法。
【請求項11】
bは、1である請求項5に記載の方法。
【請求項12】
前記標準偏差は、sσの形態にあり、sは実数である請求項5に記載の方法。
【請求項1】
未知の顔の入力画像を既知の顔の基準画像と比較する方法であって、
各前記画像から特徴ベクトルを抽出するステップと、
前記特徴ベクトルを圧縮特徴ベクトルに圧縮するステップと、
2つの前記顔の類似度スコアを求めるために、前記圧縮特徴ベクトルを比較するステップステップと
を含む方法。
【請求項2】
前記特徴は、前記画像内の画素の2つ以上の矩形パッチ内の画素値の加重和、又は総和の差として定義される矩形Haar−like特徴であり、前記矩形パッチは、前記画像内で任意の位置及びスケールにおいて連続している請求項1に記載の方法。
【請求項3】
前記Haar−like特徴は、積分画像から求められる請求項2に記載の方法。
【請求項4】
前記特徴ベクトルは、対応する既知の顔のセットの基準画像のセットのそれぞれから抽出及び圧縮され、前記入力画像の前記圧縮特徴ベクトルは、前記基準画像のセットの各前記特徴ベクトルと比較されて、前記未知の顔の各前記既知の顔との類似度スコアが求められる請求項1に記載の方法。
【請求項5】
nは、各前記特徴ベクトル内の特徴の数であり、v=[f1、f2、・・・、fn]は、各前記画像から抽出される前記特徴ベクトルであり、fiは、前記特徴ベクトルvxのi番目の特徴であり、ここで1≦i≦nであり、μ=[μ1、μ2、・・・、μn]は、前記特徴の平均のベクトルであり、σ=[σ1、σ2、・・・、σn]は、前記特徴の標準偏差のベクトルであり、sは、μの周囲の切り捨て領域の幅を制御するスカラー定数であり、前記圧縮するステップは、
抽出された各特徴値fiに関して
【数1】
に従って値Fiを求めることをさらに含み、ここで、bは、前記値Fiを記憶するのに使用されるビット数である、請求項1に記載の方法。
【請求項6】
前記平均及び前記標準偏差は、トレーニング画像のセットから求められ、該トレーニング画像の総数は、rであり、nは、各前記特徴ベクトル内の特徴の総数であり、x番目のトレーニング画像から抽出される特徴ベクトルは、vx=[f1、f2、・・・、fn]であり、ここで1≦x≦rであり、vxのi番目の特徴値は、fiであり、ここで1≦i≦nであり、平均のベクトルμ=[μ1、μ2、・・・、μn]は、
【数2】
に従って求められ、標準偏差のベクトルσ=[σ1、σ2、・・・、σn]は、
【数3】
に従って求められる請求項5に記載の方法。
【請求項7】
F=[F1、F2、・・・、Fn]は、前記入力画像の前記圧縮特徴ベクトルであり、G=[G1、G2、・・・、Gn]は、前記基準画像の前記圧縮特徴ベクトルであり、Mは、前記圧縮特徴ベクトルF及び前記圧縮特徴ベクトルGのL1ノルムの最大値であり、前記類似度スコアは
【数4】
に従って求められる請求項1に記載の方法。
【請求項8】
正規化特徴ベクトルを生成するために、前記特徴ベクトルを正規化するステップと、
量子化特徴ベクトルを生成するために、前記正規化特徴ベクトルを量子化するステップと
をさらに含み、
前記比較するステップは、前記量子化特徴ベクトルを使用する請求項1に記載の方法。
【請求項9】
各前記基準画像は、関連付けられるアイデンティティを有し、該基準画像の該関連付けられるアイデンティティは、最大類似度スコアが所定の閾値を上回っている限り、前記入力画像の顔と比較したときに前記最大類似度スコアを有する請求項4に記載の方法。
【請求項10】
bは、8である請求項5に記載の方法。
【請求項11】
bは、1である請求項5に記載の方法。
【請求項12】
前記標準偏差は、sσの形態にあり、sは実数である請求項5に記載の方法。
【図1】


【図2】
【図3】

【図2】
【図3】
【公開番号】特開2010−157212(P2010−157212A)
【公開日】平成22年7月15日(2010.7.15)
【国際特許分類】
【外国語出願】
【出願番号】特願2009−246478(P2009−246478)
【出願日】平成21年10月27日(2009.10.27)
【出願人】(597067574)ミツビシ・エレクトリック・リサーチ・ラボラトリーズ・インコーポレイテッド (484)
【住所又は居所原語表記】201 BROADWAY, CAMBRIDGE, MASSACHUSETTS 02139, U.S.A.
【Fターム(参考)】
【公開日】平成22年7月15日(2010.7.15)
【国際特許分類】
【出願番号】特願2009−246478(P2009−246478)
【出願日】平成21年10月27日(2009.10.27)
【出願人】(597067574)ミツビシ・エレクトリック・リサーチ・ラボラトリーズ・インコーポレイテッド (484)
【住所又は居所原語表記】201 BROADWAY, CAMBRIDGE, MASSACHUSETTS 02139, U.S.A.
【Fターム(参考)】
[ Back to top ]