
音声認識装置、音声認識方法、及び音声認識プログラム
【課題】 音声を取得する情報処理端末と音声認識を行う装置とをネットワークを介して接続して音声認識処理を行う場合に、ネットワークの通信状態を考慮した技術を提供する。
【解決手段】 ユーザが発した音声を取得し、音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成する、音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバ200に、当該音声特徴情報を送信し、サーバ200から音声認識結果を受信し、音声認識結果が所定時間受信できない場合に、音声特徴情報を再送信し、再送信を所定回数実行し、かつサーバ200から音声認識結果が受信できない場合に、音声認識処理を行う。
【解決手段】 ユーザが発した音声を取得し、音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成する、音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバ200に、当該音声特徴情報を送信し、サーバ200から音声認識結果を受信し、音声認識結果が所定時間受信できない場合に、音声特徴情報を再送信し、再送信を所定回数実行し、かつサーバ200から音声認識結果が受信できない場合に、音声認識処理を行う。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、音声認識技術に関する。
【背景技術】
【0002】
従来から、ユーザが発した音声を解析して言語情報を抽出する、いわゆる音声認識技術が多用されている。このような音声認識技術は、一般に音声認識に用いる言語辞書の語彙量、あるいは音声から抽出した音声特徴情報から言語を認識する認識エンジンの性能などによって、音声認識結果の精度が左右されていた。そして、十分な語彙量の言語辞書を備えた高性能な認識エンジンは、一般に高性能なコンピュータと大容量の記憶手段とを用いることで実現していた。
【0003】
そこで、上述のような音声認識技術を車載用や携帯用の情報処理端末で実現するには、従来からユーザが用いる情報処理端末と、音声認識処理を行うサーバとを分散して、小型の端末において高性能な音声認識技術を提供することが鑑みられていた。また、音声認識処理を情報処理端末側とサーバ側とで実行可能にして、ユーザの指示に応じてどちらで音声認識処理を行うかを切り替える技術もあった。
【0004】
なお、本発明に関連する、音声認識に関連する技術(例えば、特許文献1から3参照。)が開示されている。
【特許文献1】特開2002−182896号公報
【特許文献2】特開2002−318132号公報
【特許文献3】特開2003−44091号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
しかしながら、上述のような情報処理端末とサーバによる分散型の音声認識処理は、例えば以下のような問題があった。
すなわち、従来の分散型の音声認識処理では、情報処理端末とサーバとを接続するネットワークの通信状態を考慮しているものはなかった。このため、サーバ側で音声認識処理を行う場合に、ネットワークの通信状態が悪化して音声認識に必要な情報の通信が困難になると、正確な音声認識処理を迅速に行うことが困難であった。
【0006】
本発明は上記事項に鑑みて為されたものである。すなわち、本発明は、音声を取得する情報処理端末と音声認識を行う装置とをネットワークを介して接続して音声認識処理を行う場合に、ネットワークの通信状態を考慮した技術を提供することを解決すべき課題とする。
【課題を解決するための手段】
【0007】
本発明は前記課題を解決するために、以下の手段を採用した。
すなわち、本発明は、ユーザが発した音声を取得し、音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成し、音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音声特徴情報を送信し、サーバから音声認識結果を受信し、音声認識結果が所定時間受信できない場合に、音声特徴情報を再送信し、再送信を所定回数実行し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行うことを特徴とする。
【0008】
本発明では、音声認識処理をサーバ側で行う場合に、その音声認識結果の受信状況に応
じて音声認識に用いる特徴情報を再送信する。また、本発明では、サーバ側の応答がない場合には、サーバ側ではなく装置自身で音声認識処理を行う。
【0009】
従って、本発明によれば、音声を取得する情報処理端末と音声認識を行う装置とをネットワークを介して接続して音声認識処理を行う場合に、ネットワークの通信状態を考慮した技術を提供することができる。
【0010】
また、本発明は、音声認識結果に対応するユーザからのコンテンツに対する処理の要求を、アクション要求情報としてサーバに送信し、アクション要求情報に対するサーバの応答が所定時間受信できない場合に、当該アクション要求情報を再送信することを特徴とする。
【0011】
本発明では、サーバ側が音声認識結果に基づく処理を行う場合に、その処理の要求をサーバからの応答があるまで再送信する。
従って、本発明によれば、ユーザの操作なしに、迅速に処理の要求をサーバに送信することができる。
【0012】
また、本発明は、音声特徴情報を所定回数送信しサーバから音声認識結果が受信できない場合、及びアクション要求情報を所定回数送信し応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促すことを特徴とする。
【0013】
本発明では、音声特徴情報あるいはアクション要求情報を再送信したにもかかわらず、サーバ側の応答がない場合には、音声の取得処理から再度行うために、ユーザに音声
を発するように要求する。
従って、本発明によれば、ネットワークを介した音声認識処理において、正確な音声認識処理を実行することができる。
【0014】
なお、本発明は、以上の何れかの機能を実現させるプログラムであってもよい。また、本発明は、そのようなプログラムをコンピュータが読み取り可能な記憶媒体に記録してもよい。また、本発明は、以上の何れかの機能を実現する装置であってもよい。さらに、本発明は、以上の何れかの機能を実現する通信端末であってもよい。
【発明の効果】
【0015】
本発明によれば、音声を取得する情報処理端末と音声認識を行う装置とをネットワークを介して接続して音声認識処理を行う場合に、ネットワークの通信状態を考慮した技術を提供することができる。
【発明を実施するための最良の形態】
【0016】
以下、図面を参照して、本発明の好適な実施の形態に係る音声認識装置の機能を備えた情報処理端末の一例(以下、情報処理端末100という)を、図面に基づいて説明する。本実施の形態において、情報処理端末100は、コンピュータにプログラムを実行させることによって、本発明に係る音声認識方法を実行する。
【0017】
〈装置構成〉
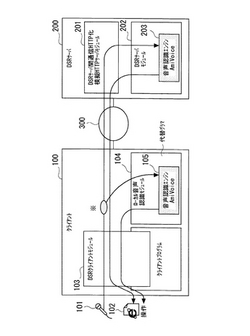
図1は、情報処理端末100、及び情報処理端末100の要求に基づいて音声認識処理を行うサーバ(以下DSRサーバ200という)とからなるシステムの構成図である。本シ
ステムは、クライアントの情報処理端末100とDSRサーバ200とがネットワーク30
0を介して接続している。
【0018】
情報処理端末100は、音声入力手段101,出力手段102,DSRクライアントモジ
ュール103,ローカル音声認識モジュール104,音声認識エンジン105を備える。
音声入力手段101は、一般のマイクなどの音声入力装置が考えられる。出力手段102は、例えば液晶式ディスプレイなどの画像出力装置が考えられる。
DSRクライアントモジュール103は、情報処理端末100の処理能力にとらわれるこ
となく音声認識処理を行うために、サーバ側で音声認識処理を行う、いわゆる分散型音声認識(Distributed Speech Recognition:以下DSRとする)の端末側(クライアント)の
機能構成を実現する。DSRクライアントモジュール103は、本発明の音声認識装置10
0の音声取得手段,特徴情報抽出手段,送信手段,受信手段,再送指示手段に相当する機能を備える。
【0019】
すなわち、DSRクライアントモジュール103は、音声取得手段の機能として、音声入
力手段101を介してユーザが発した音声を取得する。また、DSRクライアントモジュー
ル103は、特徴情報抽出手段の機能として、音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成する。本実施の形態において、音声特徴情報とは、人間の発した言語の音声情報から、その言語の内容を特定することができる音声情報のみを抽出して圧縮したものである。
【0020】
また、DSRクライアントモジュール103は、送信手段の機能として、音声特徴情報に
基づいて言語情報を認識する音声認識処理を行うDSRサーバ200に、音声特徴情報を送
信する。DSRクライアントモジュール103は、受信手段の機能として、DSRサーバ200から音声認識結果を受信する。
【0021】
また、DSRクライアントモジュール103は、再送指示手段の機能として、音声認識結
果が所定時間受信できない場合に、音声特徴情報を再送信する。また、DSRクライアント
モジュール103は、アクション要求情報に対するDSRサーバ200の応答が所定時間受
信できない場合に、アクション要求情報を再送信する。
【0022】
また、DSRクライアントモジュール103は、アクション要求手段の機能として、音声
認識結果に対応したユーザからのコンテンツに対する処理の要求(例えば、カラオケコンテンツに対する楽曲の配信要求など)を、アクション要求情報としてDSRサーバ200に
送信する。
【0023】
そして、DSRクライアントモジュール103は、音声再取得指示手段の機能として、音
声特徴情報を所定回数送信したときに、DSRサーバ200から音声認識結果が受信できな
い場合には、ユーザの音声を再度取得するように促す。また、DSRクライアントモジュー
ル103は、アクション要求情報を所定回数送信したときに、DSRサーバ200から応答
が受信できない場合には、ユーザの音声を再度取得するように促す。
【0024】
ローカル音声認識モジュール104は、音声認識エンジン105を有する。音声認識エンジン105は、DSRサーバ200による音声認識処理がネットワーク300の通信状態
によって困難であると判断した場合に音声認識処理を行う。音声認識エンジン105が音声認識処理を行う場合とは、例えば音声特徴情報の再送信を所定回数指示し、かつDSRサ
ーバ200から音声認識結果が受信できない場合が考えられる。
【0025】
DSRサーバ200は、サーバモジュール201,DSRサーバモジュール202,音声認識エンジン203を備える。
【0026】
サーバモジュール201は、ネットワーク300を介して情報処理端末100とHTTP(HyperText Transfer Protocol)ベースの1回の要求に対して1回の応答を行う、いわゆ
るセッションレス型の通信方式を行い、DSRサーバモジュール202とはTCP/IP(Transmission Control Protocol/Internet Protocol)ソケット利用のWebへの要求に対して1回
のセッションを維持する、いわゆるセッション持続型の通信を行うための処理を行う。
【0027】
DSRサーバモジュール202は、音声認識エンジン203を有する。この音声認識エン
ジン203は、情報処理端末100から送信された音声特徴情報に基づいて音声認識処理を行う。
【0028】
〈音声認識処理の概要〉
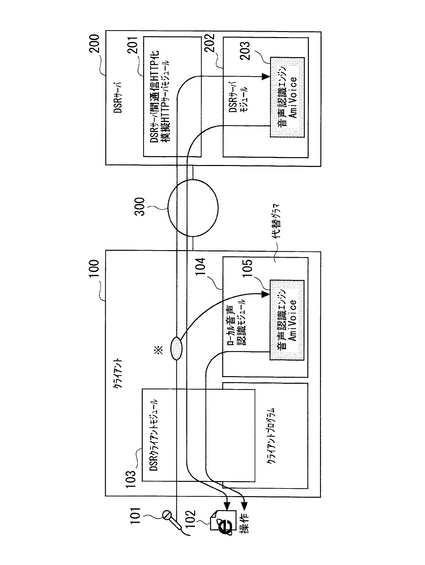
次に、本実施の形態に係るシステムによる、分散型音声認識処理について説明する。
図2は、本システムによる、DSRサーバ200側による音声認識処理(センタ音声認識
)と情報処理端末100側による音声認識処理(ローカル音声認識)との区分を説明する図である。本システムは、カラオケコンテンツなどのネットワーク型コンテンツに対する情報の要求を情報処理端末100で実行する場合には、基本的にはセンタ音声認識によって処理を行う。そして、この場合には、本システムは、通信状況が不良のときに自動的にローカル音声認識に切り替える。
【0029】
また、本システムは、ユーザの音声を認識し、その認識した音声の指示に従いオーディオ操作やエアコン操作する場合などのように車内で完結する純粋制御系ローカルコンテンツを情報処理端末100が実行する場合には、情報処理端末100内の音声認識エンジン105によって音声認識処理を行い、必要に応じてネットワーク型コンテンツに移行したときには、センタ音声認識によって処理する。
【0030】
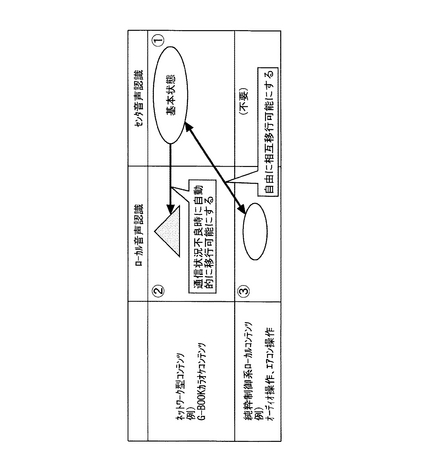
〈音声認識処理の説明〉
図3は、情報処理端末100とDSRサーバ200とによるシステムによる、音声認識処
理を説明するフローチャートである。
【0031】
情報処理端末100は、ユーザが音声を発する(発話)すると、音声を取得する(S101)。このとき、情報処理端末100は、この音声に対する音声認識処理をクライアント側とセンタ側とのどちらで行うかを判断する。
【0032】
ローカル音声認識モジュール104が音声認識処理を行う場合には、DSRクライアント
モジュール103は、取得した音声から言語を認識可能な音声情報を抽出して圧縮した音声特徴情報を抽出する。そして、DSRクライアントモジュール103は、ローカル音声認
識モジュール104に音声特徴情報を送信する(S102)。音声特徴情報を受信したローカル音声認識モジュール104は、この音声特徴情報から言語情報を抽出する音声認識処理(例えば、「カラオケ配信」という音声情報から、「からおけはいしん」という音声の内容を特定可能な特徴情報を抽出する処理)を行う(S103)。音声認識処理後、ローカル音声認識モジュール104は、S111の処理を行う。
【0033】
DSRサーバ200のDSRサーバモジュール202が有する音声認識エンジン203が音声認識処理を行う場合には、DSRクライアントモジュール103は、取得した音声から音声
特徴情報を抽出する。
【0034】
DSRクライアントモジュール103は、ネットワーク300を介して音声特徴情報をDSRサーバ200に送信する。そして、DSRクライアントモジュール103は、DSRサーバ200への音声特徴情報の送信が成功したか否かを判断する(S104)。このとき、DSRク
ライアントモジュール103は、音声特徴情報の送信が成功したか否かの判断を、送信された音声特徴情報に対する応答がDSRサーバ200からあるか否かに基づいて判断する。
【0035】
音声特徴情報の送信が成功した場合には、DSRサーバ200は、音声認識エンジン20
3によって音声認識処理を行う(S105)。S105の処理後、DSRクライアントモジ
ュール103は、S111の処理に移行する。
【0036】
音声特徴情報の送信が失敗した場合には、DSRクライアントモジュール103は、音声
認識モジュール104に音声認識エンジン203(代替グラマ)があるか否かを判断する(S106)。代替グラマがある場合には、DSRクライアントモジュール103は、代替
グラマをセット(音声認識モジュール104を使用可能状態にする)する(S107)。
【0037】
DSRクライアントモジュール103は、DSRサーバ200から応答がない場合には、一定の回数送信に失敗したか否かを判断する(S108)。そして、一定の失敗回数に達していない場合は、DSRクライアントモジュール103は、音声特徴情報の送信(自動再送信
)を繰り返す(S109)。
【0038】
そして、DSRクライアントモジュール103は、所定の回数音声特徴情報の送信を繰り
返しても応答がない場合には、音声特徴情報の送信が失敗したものと判断して、ユーザに音声の再送信を要求する再送信ボタンを表示する(S110)。再送信ボタンの表示後、DSRクライアントモジュール103は、S104の処理に戻る。
【0039】
DSRクライアントモジュール103は、図3に示す表に従って、ローカルとサーバとに
おける音声認識の良否を判断する(S111)。この表によれば、ローカルとサーバとの双方で音声認識が成功した場合には、DSRクライアントモジュール103は、その応答に
信頼度を示す情報が付されていれば、信頼度の高い方の結果を用いる。信頼度とは、例えば、サーバから情報処理端末へ10段階の評価値を引き渡せばよい。また、ローカルで音声認識が成功してサーバで音声認識が失敗した場合には、DSRクライアントモジュール1
03は、ローカルでの音声認識結果を用いる。また、サーバで音声認識が成功し、ローカルでの音声認識が失敗した場合には、DSRクライアントモジュール103は、サーバの音
声認識結果を用いる。そして、ローカルとサーバとの双方で音声認識が失敗した場合には、DSRクライアントモジュール103は、音声認識失敗と判断する。
【0040】
DSRクライアントモジュール103は、S111の処理後、音声認識結果がオーディオ
やエアコンの操作などのローカルコンテンツに対する指示である場合には、ローカルコンテンツの表示を行う(S112)。
【0041】
DSRクライアントモジュール103は、S111の処理後、音声認識結果がカラオケコ
ンテンツなどのネットワーク型コンテンツへの指示である場合には、その認識結果に対するネットワーク型コンテンツへの動作(アクション)を要求する情報(例えば、カラオケコンテンツに対する楽曲の配信要求など)を取得に成功したか否かを判断する(S113)。
【0042】
アクション情報の取得に成功した場合には、DSRクライアントモジュール103は、ネ
ットワーク型コンテンツのページを受信して出力手段102に表示が成功したか否かを判断する(S114)。ページの表示に失敗した場合には、DSRクライアントモジュール1
03は、出力手段102に再取得ボタンを表示して、ユーザにページの再取得を要求する(S115)。そして、ユーザが再取得ボタンを不図示のポインティングデバイスで押下した場合に、DSRクライアントモジュール103は、制御をS114に戻す。また、ペー
ジの表示に成功した場合には、DSRクライアントモジュール103は、ネットワーク型コ
ンテンツのWebページが表示完了であるとして、本システムの処理を終了する(S116)。
【0043】
S113において、アクション情報の取得に失敗した場合には、DSRクライアントモジ
ュール103は、そのアクション情報の取得を所定回数繰り返す。そして、DSRクライア
ントモジュール103は、一定回数のアクション情報の取得の失敗を繰り返したか否かを判断する(S117)。失敗した場合には、DSRクライアントモジュール103は、アク
ション情報の取得要求を自動的に再送信する(S118)。
【0044】
一定回数の再送信後も、Webページの取得(アクション)に失敗した場合には、DSR
クライアントモジュール103は、出力手段102に再取得ボタンを表示して、ユーザにページの再取得を促す(S119)。
【0045】
〈システムの処理例1〉
次に、本システムによる、音声認識処理の流れを場合分けした上で例示して説明する。第1の処理例は、情報処理端末100とDSRサーバ200との通信状態が良好な場合の流
れを説明する。
【0046】
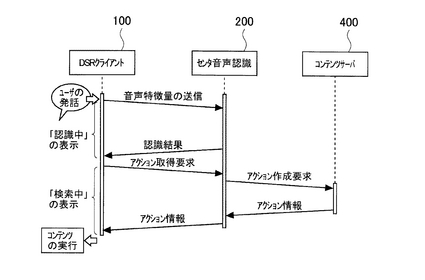
図4は、本システムによる、第1の処理例を説明する流れ図である。
情報処理端末100(以下、DSRクライアント100)は、ユーザの発話(音声)を受
け付ける。DSRクライアント100は、音声から音声特徴情報を抽出する。そして、DSRクライアント100は、音声特徴情報をDSRサーバ200(センタ音声認識)に送信する。
この間、DSRクライアント100のディスプレイ(不図示)には、音声認識中であること
を示す「認識中」などの文字が表示される。
【0047】
DSRサーバ200は、音声特徴情報から音声認識処理を行って音声認識結果を出力する
。DSRサーバ200は、音声認識結果をDSRクライアント100に送信する。
音声認識結果を受信したDSRクライアント100は、その音声認識結果に基づいたネッ
トワーク型コンテンツのページに対するアクション情報の取得要求を、DSRサーバ200
を介してコンテンツサーバ400に送信する。この間DSRクライアント100のディスプ
レイには、アクション情報に基づいたコンテンツ取得処理中であることを示す「検索中」などの文字が表示される。
【0048】
コンテンツサーバ400は、アクション情報の取得要求に対応するアクション情報をDSRクライアント100に送信する。
このようにすると、本システムの第1の処理例では、DSRクライアント100が音声認
識処理に基づいたコンテンツの利用が可能になる。
【0049】
〈システムの処理例2〉
第2の処理例は、本システムの音声認識処理において、DSRクライアント100とDSRサーバ200との通信状態が不良であるために、センタ音声認識ができない場合の処理を説明する。
【0050】
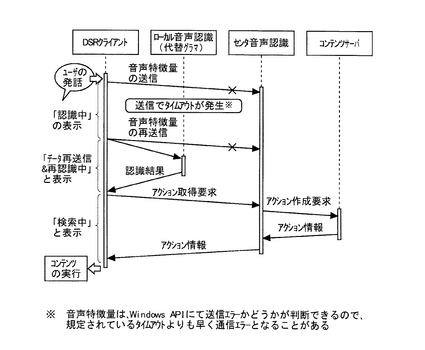
図5は、本システムによる、第2の処理例を説明する流れ図である。
DSRクライアント100は、ユーザの音声から抽出した音声特徴情報をDSRサーバ200に送信したものの、送信時の応答にタイムアウトが発生した場合に、再送信を行う。再送信後、さらにタイムアウトがある場合には、DSRクライアント100は、ローカルの音声
認識エンジン105(代替グラマ)を用いて音声認識を行う。この間、DSRクライアント
100のディスプレイ(不図示)には、音声認識中であることを示す「認識中」などの文字が表示されたのち、代替グラマによる音声認識を行っていることを示す、「データ再送信&再認識中」の文字が表示される。
【0051】
音声認識エンジン105による音声認識処理終了後、DSRクライアント100は、音声
認識結果に基づいたアクション情報の取得要求をコンテンツサーバ400に送信して、コンテンツサーバ400からアクション情報を取得する。この間DSRクライアント100の
ディスプレイには、アクション情報に基づいたコンテンツ取得処理中であることを示す「検索中」などの文字が表示される。
【0052】
このようにすると、本システムの第2の処理例では、DSRクライアント100とDSRサーバ200との通信状態が不良であるためにセンタ音声認識が不可能であっても、ローカルの音声認識エンジン105によって音声認識処理が可能になる。従って、本システムの第2の処理例によれば、分散型音声認識処理において、通信状態に左右されることなく音声認識処理を行うことができる。
【0053】
〈システムの処理例3〉
第3の処理例は、第2の処理例と比較して、音声特徴情報送信時の通信状態が不良であり、かつアクション情報の取得要求時の通信状態も不良であるためにセンタ音声認識を用いた処理が不可能な場合の処理例を示す。
【0054】
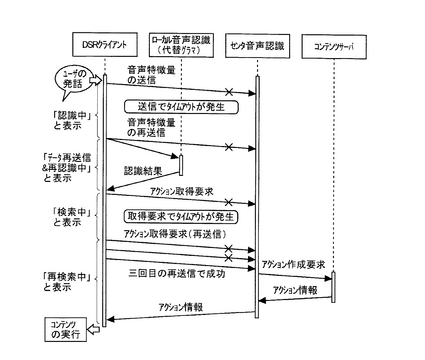
図6は、本システムの第3の処理例を説明する流れ図である。
DSRクライアント100は、音声特徴情報の送信時にタイムアウトが発生して、ローカ
ルの音声認識エンジン105によって音声認識処理を行う。この間、DSRクライアント1
00のディスプレイ(不図示)には、音声認識中であることを示す「認識中」などの文字が表示されたのち、代替グラマによる音声認識を行っていることを示す、「データ再送信&再認識中」の文字が表示される。その後、DSRクライアント100は、ローカルの音声認識エンジン105の音声認識結果に基づいたアクション情報の取得要求をコンテンツサーバ400に送信するものの、タイムアウトが発生した場合には、一定の回数再送信を行う。第3の処理例では、三回目の再送信でコンテンツサーバ400に送信が完了している。この間DSRクライアント100のディスプレイには、アクション情報に基づいたコンテン
ツ取得処理中であることを示す「検索中」や再送時を示す「再検索中」などの文字が表示される。
【0055】
このようにすると、第3の処理例では、コンテンツサーバ400へのアクション情報の取得要求時に通信状態が悪化した場合であっても、DSRクライアント100が再送信を行
うため、ユーザに負担をかけることなくコンテンツの利用が可能になる。
【0056】
〈システムの処理例4〉
第4の処理例では、第3の処理例と比較して、アクション情報の取得要求時の再送信を一定回数繰り返したものの、タイムアウトが発生した場合を示す。
【0057】
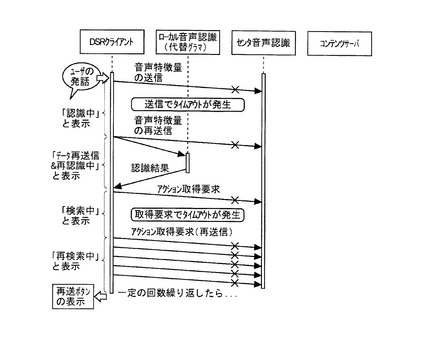
図7は、本システムの第4の処理例を説明する流れ図である。
第4の処理例では、アクション情報の取得要求にタイムアウトが発生して、DSRクライ
アント100が5回再送信を繰り返したものの、コンテンツサーバ400側からの応答がない場合には、再送ボタンを生成してユーザに再送信を促す。
【0058】
〈システムの処理例5〉
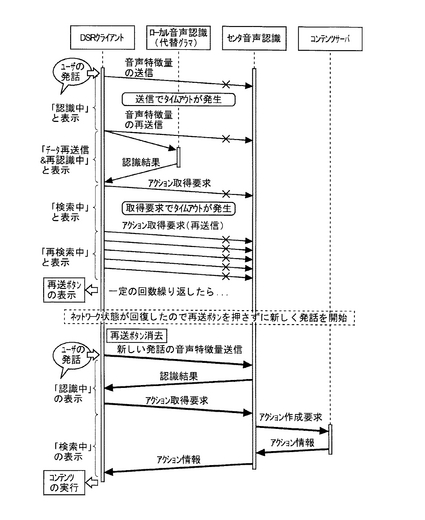
第5の処理例では、アクション情報の取得要求時に一定の回数再送信を繰り返した後で、再送ボタンによって新たなセンタ音声認識とアクション情報の取得要求とを行う場合を示す。
【0059】
図8は、本システムの第5の処理例を説明する流れ図である。
第5の処理例では、DSRクライアント100最初の発話から抽出した音声特徴情報をDSRサーバ200に送信するものの、DSRサーバ200との通信がタイムアウトとなる。その
ため、DSRクライアント100は、ローカルの音声認識エンジン105によって音声認識
処理を行う。この間、DSRクライアント100のディスプレイ(不図示)には、音声認識
中であることを示す「認識中」などの文字が表示されたのち、代替グラマによる音声認識を行っていることを示す、「データ再送信&再認識中」の文字が表示される。その後、DSRクライアント100は、ローカルの音声認識エンジン105の音声認識結果に基づいたアクション情報の取得要求を送信するものの、DSRサーバ200との通信がタイムアウトと
なる。この間DSRクライアント100のディスプレイには、アクション情報に基づいたコ
ンテンツ取得処理中であることを示す「検索中」や再送時を示す「再検索中」などの文字が表示される。DSRクライアント100は、アクション情報の取得要求の再送信を一定回
数繰り返した後、ユーザの音声の再送信を促す再送ボタンを表示して、音声特徴情報の再送信を促す。
【0060】
その後、DSRクライアント100は、DSRサーバ200との通信をするためのネットワークの状態が回復した場合には、再送ボタンを消去して、ユーザに新しい発話による音声認識処理を行うことを促す。ユーザは、再送ボタンが消去されたことで、新しい発話を行う。
【0061】
このようにすると、第5の処理例では、ネットワークの状態によって、音声特徴情報及びアクション情報の取得要求の送信が不可能な場合であっても、ネットワークの状態が回復したことに合わせて、新たな音声認識処理を実行する。従って、第5の処理例によれば、ネットワークの状態に合わせて、即座に音声認識処理を実行することができる。また、上記第1から第5の処理例において、処理の経過を示す「認識中」「再認識中」「検索中」「再検索中」の文字をディスプレイに表示することにより、DSRクライアント100が
どのような処理を行っているかをユーザに対して通知することができる。従って、DSRク
ライアント100は、ユーザに対して安心感をもたらすことができる。
【図面の簡単な説明】
【0062】
【図1】情報処理端末、及びDSRサーバとからなるシステムの構成図である。
【図2】本システムによる、DSRサーバ側による音声認識処理と情報処理端末側による音声認識処理との区分を説明する図である。
【図3】情報処理端末とDSRサーバとによるシステムによる、音声認識処理を説明するフローチャートである。
【図4】本システムによる、第1の処理例を説明する流れ図である。
【図5】本システムによる、第2の処理例を説明する流れ図である。
【図6】本システムの第3の処理例を説明する流れ図である。
【図7】本システムの第4の処理例を説明する流れ図である。
【図8】本システムの第5の処理例を説明する流れ図である。
【符号の説明】
【0063】
100 DSRクライアント(情報処理端末)
101 音声入力手段
102 出力手段
103 DSRクライアントモジュール
104 ローカル音声認識モジュール
105 音声認識エンジン
200 DSRサーバ
201 サーバモジュール
202 DSRサーバモジュール
203 音声認識エンジン
300 ネットワーク
400 コンテンツサーバ
【技術分野】
【0001】
本発明は、音声認識技術に関する。
【背景技術】
【0002】
従来から、ユーザが発した音声を解析して言語情報を抽出する、いわゆる音声認識技術が多用されている。このような音声認識技術は、一般に音声認識に用いる言語辞書の語彙量、あるいは音声から抽出した音声特徴情報から言語を認識する認識エンジンの性能などによって、音声認識結果の精度が左右されていた。そして、十分な語彙量の言語辞書を備えた高性能な認識エンジンは、一般に高性能なコンピュータと大容量の記憶手段とを用いることで実現していた。
【0003】
そこで、上述のような音声認識技術を車載用や携帯用の情報処理端末で実現するには、従来からユーザが用いる情報処理端末と、音声認識処理を行うサーバとを分散して、小型の端末において高性能な音声認識技術を提供することが鑑みられていた。また、音声認識処理を情報処理端末側とサーバ側とで実行可能にして、ユーザの指示に応じてどちらで音声認識処理を行うかを切り替える技術もあった。
【0004】
なお、本発明に関連する、音声認識に関連する技術(例えば、特許文献1から3参照。)が開示されている。
【特許文献1】特開2002−182896号公報
【特許文献2】特開2002−318132号公報
【特許文献3】特開2003−44091号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
しかしながら、上述のような情報処理端末とサーバによる分散型の音声認識処理は、例えば以下のような問題があった。
すなわち、従来の分散型の音声認識処理では、情報処理端末とサーバとを接続するネットワークの通信状態を考慮しているものはなかった。このため、サーバ側で音声認識処理を行う場合に、ネットワークの通信状態が悪化して音声認識に必要な情報の通信が困難になると、正確な音声認識処理を迅速に行うことが困難であった。
【0006】
本発明は上記事項に鑑みて為されたものである。すなわち、本発明は、音声を取得する情報処理端末と音声認識を行う装置とをネットワークを介して接続して音声認識処理を行う場合に、ネットワークの通信状態を考慮した技術を提供することを解決すべき課題とする。
【課題を解決するための手段】
【0007】
本発明は前記課題を解決するために、以下の手段を採用した。
すなわち、本発明は、ユーザが発した音声を取得し、音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成し、音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音声特徴情報を送信し、サーバから音声認識結果を受信し、音声認識結果が所定時間受信できない場合に、音声特徴情報を再送信し、再送信を所定回数実行し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行うことを特徴とする。
【0008】
本発明では、音声認識処理をサーバ側で行う場合に、その音声認識結果の受信状況に応
じて音声認識に用いる特徴情報を再送信する。また、本発明では、サーバ側の応答がない場合には、サーバ側ではなく装置自身で音声認識処理を行う。
【0009】
従って、本発明によれば、音声を取得する情報処理端末と音声認識を行う装置とをネットワークを介して接続して音声認識処理を行う場合に、ネットワークの通信状態を考慮した技術を提供することができる。
【0010】
また、本発明は、音声認識結果に対応するユーザからのコンテンツに対する処理の要求を、アクション要求情報としてサーバに送信し、アクション要求情報に対するサーバの応答が所定時間受信できない場合に、当該アクション要求情報を再送信することを特徴とする。
【0011】
本発明では、サーバ側が音声認識結果に基づく処理を行う場合に、その処理の要求をサーバからの応答があるまで再送信する。
従って、本発明によれば、ユーザの操作なしに、迅速に処理の要求をサーバに送信することができる。
【0012】
また、本発明は、音声特徴情報を所定回数送信しサーバから音声認識結果が受信できない場合、及びアクション要求情報を所定回数送信し応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促すことを特徴とする。
【0013】
本発明では、音声特徴情報あるいはアクション要求情報を再送信したにもかかわらず、サーバ側の応答がない場合には、音声の取得処理から再度行うために、ユーザに音声
を発するように要求する。
従って、本発明によれば、ネットワークを介した音声認識処理において、正確な音声認識処理を実行することができる。
【0014】
なお、本発明は、以上の何れかの機能を実現させるプログラムであってもよい。また、本発明は、そのようなプログラムをコンピュータが読み取り可能な記憶媒体に記録してもよい。また、本発明は、以上の何れかの機能を実現する装置であってもよい。さらに、本発明は、以上の何れかの機能を実現する通信端末であってもよい。
【発明の効果】
【0015】
本発明によれば、音声を取得する情報処理端末と音声認識を行う装置とをネットワークを介して接続して音声認識処理を行う場合に、ネットワークの通信状態を考慮した技術を提供することができる。
【発明を実施するための最良の形態】
【0016】
以下、図面を参照して、本発明の好適な実施の形態に係る音声認識装置の機能を備えた情報処理端末の一例(以下、情報処理端末100という)を、図面に基づいて説明する。本実施の形態において、情報処理端末100は、コンピュータにプログラムを実行させることによって、本発明に係る音声認識方法を実行する。
【0017】
〈装置構成〉
図1は、情報処理端末100、及び情報処理端末100の要求に基づいて音声認識処理を行うサーバ(以下DSRサーバ200という)とからなるシステムの構成図である。本シ
ステムは、クライアントの情報処理端末100とDSRサーバ200とがネットワーク30
0を介して接続している。
【0018】
情報処理端末100は、音声入力手段101,出力手段102,DSRクライアントモジ
ュール103,ローカル音声認識モジュール104,音声認識エンジン105を備える。
音声入力手段101は、一般のマイクなどの音声入力装置が考えられる。出力手段102は、例えば液晶式ディスプレイなどの画像出力装置が考えられる。
DSRクライアントモジュール103は、情報処理端末100の処理能力にとらわれるこ
となく音声認識処理を行うために、サーバ側で音声認識処理を行う、いわゆる分散型音声認識(Distributed Speech Recognition:以下DSRとする)の端末側(クライアント)の
機能構成を実現する。DSRクライアントモジュール103は、本発明の音声認識装置10
0の音声取得手段,特徴情報抽出手段,送信手段,受信手段,再送指示手段に相当する機能を備える。
【0019】
すなわち、DSRクライアントモジュール103は、音声取得手段の機能として、音声入
力手段101を介してユーザが発した音声を取得する。また、DSRクライアントモジュー
ル103は、特徴情報抽出手段の機能として、音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成する。本実施の形態において、音声特徴情報とは、人間の発した言語の音声情報から、その言語の内容を特定することができる音声情報のみを抽出して圧縮したものである。
【0020】
また、DSRクライアントモジュール103は、送信手段の機能として、音声特徴情報に
基づいて言語情報を認識する音声認識処理を行うDSRサーバ200に、音声特徴情報を送
信する。DSRクライアントモジュール103は、受信手段の機能として、DSRサーバ200から音声認識結果を受信する。
【0021】
また、DSRクライアントモジュール103は、再送指示手段の機能として、音声認識結
果が所定時間受信できない場合に、音声特徴情報を再送信する。また、DSRクライアント
モジュール103は、アクション要求情報に対するDSRサーバ200の応答が所定時間受
信できない場合に、アクション要求情報を再送信する。
【0022】
また、DSRクライアントモジュール103は、アクション要求手段の機能として、音声
認識結果に対応したユーザからのコンテンツに対する処理の要求(例えば、カラオケコンテンツに対する楽曲の配信要求など)を、アクション要求情報としてDSRサーバ200に
送信する。
【0023】
そして、DSRクライアントモジュール103は、音声再取得指示手段の機能として、音
声特徴情報を所定回数送信したときに、DSRサーバ200から音声認識結果が受信できな
い場合には、ユーザの音声を再度取得するように促す。また、DSRクライアントモジュー
ル103は、アクション要求情報を所定回数送信したときに、DSRサーバ200から応答
が受信できない場合には、ユーザの音声を再度取得するように促す。
【0024】
ローカル音声認識モジュール104は、音声認識エンジン105を有する。音声認識エンジン105は、DSRサーバ200による音声認識処理がネットワーク300の通信状態
によって困難であると判断した場合に音声認識処理を行う。音声認識エンジン105が音声認識処理を行う場合とは、例えば音声特徴情報の再送信を所定回数指示し、かつDSRサ
ーバ200から音声認識結果が受信できない場合が考えられる。
【0025】
DSRサーバ200は、サーバモジュール201,DSRサーバモジュール202,音声認識エンジン203を備える。
【0026】
サーバモジュール201は、ネットワーク300を介して情報処理端末100とHTTP(HyperText Transfer Protocol)ベースの1回の要求に対して1回の応答を行う、いわゆ
るセッションレス型の通信方式を行い、DSRサーバモジュール202とはTCP/IP(Transmission Control Protocol/Internet Protocol)ソケット利用のWebへの要求に対して1回
のセッションを維持する、いわゆるセッション持続型の通信を行うための処理を行う。
【0027】
DSRサーバモジュール202は、音声認識エンジン203を有する。この音声認識エン
ジン203は、情報処理端末100から送信された音声特徴情報に基づいて音声認識処理を行う。
【0028】
〈音声認識処理の概要〉
次に、本実施の形態に係るシステムによる、分散型音声認識処理について説明する。
図2は、本システムによる、DSRサーバ200側による音声認識処理(センタ音声認識
)と情報処理端末100側による音声認識処理(ローカル音声認識)との区分を説明する図である。本システムは、カラオケコンテンツなどのネットワーク型コンテンツに対する情報の要求を情報処理端末100で実行する場合には、基本的にはセンタ音声認識によって処理を行う。そして、この場合には、本システムは、通信状況が不良のときに自動的にローカル音声認識に切り替える。
【0029】
また、本システムは、ユーザの音声を認識し、その認識した音声の指示に従いオーディオ操作やエアコン操作する場合などのように車内で完結する純粋制御系ローカルコンテンツを情報処理端末100が実行する場合には、情報処理端末100内の音声認識エンジン105によって音声認識処理を行い、必要に応じてネットワーク型コンテンツに移行したときには、センタ音声認識によって処理する。
【0030】
〈音声認識処理の説明〉
図3は、情報処理端末100とDSRサーバ200とによるシステムによる、音声認識処
理を説明するフローチャートである。
【0031】
情報処理端末100は、ユーザが音声を発する(発話)すると、音声を取得する(S101)。このとき、情報処理端末100は、この音声に対する音声認識処理をクライアント側とセンタ側とのどちらで行うかを判断する。
【0032】
ローカル音声認識モジュール104が音声認識処理を行う場合には、DSRクライアント
モジュール103は、取得した音声から言語を認識可能な音声情報を抽出して圧縮した音声特徴情報を抽出する。そして、DSRクライアントモジュール103は、ローカル音声認
識モジュール104に音声特徴情報を送信する(S102)。音声特徴情報を受信したローカル音声認識モジュール104は、この音声特徴情報から言語情報を抽出する音声認識処理(例えば、「カラオケ配信」という音声情報から、「からおけはいしん」という音声の内容を特定可能な特徴情報を抽出する処理)を行う(S103)。音声認識処理後、ローカル音声認識モジュール104は、S111の処理を行う。
【0033】
DSRサーバ200のDSRサーバモジュール202が有する音声認識エンジン203が音声認識処理を行う場合には、DSRクライアントモジュール103は、取得した音声から音声
特徴情報を抽出する。
【0034】
DSRクライアントモジュール103は、ネットワーク300を介して音声特徴情報をDSRサーバ200に送信する。そして、DSRクライアントモジュール103は、DSRサーバ200への音声特徴情報の送信が成功したか否かを判断する(S104)。このとき、DSRク
ライアントモジュール103は、音声特徴情報の送信が成功したか否かの判断を、送信された音声特徴情報に対する応答がDSRサーバ200からあるか否かに基づいて判断する。
【0035】
音声特徴情報の送信が成功した場合には、DSRサーバ200は、音声認識エンジン20
3によって音声認識処理を行う(S105)。S105の処理後、DSRクライアントモジ
ュール103は、S111の処理に移行する。
【0036】
音声特徴情報の送信が失敗した場合には、DSRクライアントモジュール103は、音声
認識モジュール104に音声認識エンジン203(代替グラマ)があるか否かを判断する(S106)。代替グラマがある場合には、DSRクライアントモジュール103は、代替
グラマをセット(音声認識モジュール104を使用可能状態にする)する(S107)。
【0037】
DSRクライアントモジュール103は、DSRサーバ200から応答がない場合には、一定の回数送信に失敗したか否かを判断する(S108)。そして、一定の失敗回数に達していない場合は、DSRクライアントモジュール103は、音声特徴情報の送信(自動再送信
)を繰り返す(S109)。
【0038】
そして、DSRクライアントモジュール103は、所定の回数音声特徴情報の送信を繰り
返しても応答がない場合には、音声特徴情報の送信が失敗したものと判断して、ユーザに音声の再送信を要求する再送信ボタンを表示する(S110)。再送信ボタンの表示後、DSRクライアントモジュール103は、S104の処理に戻る。
【0039】
DSRクライアントモジュール103は、図3に示す表に従って、ローカルとサーバとに
おける音声認識の良否を判断する(S111)。この表によれば、ローカルとサーバとの双方で音声認識が成功した場合には、DSRクライアントモジュール103は、その応答に
信頼度を示す情報が付されていれば、信頼度の高い方の結果を用いる。信頼度とは、例えば、サーバから情報処理端末へ10段階の評価値を引き渡せばよい。また、ローカルで音声認識が成功してサーバで音声認識が失敗した場合には、DSRクライアントモジュール1
03は、ローカルでの音声認識結果を用いる。また、サーバで音声認識が成功し、ローカルでの音声認識が失敗した場合には、DSRクライアントモジュール103は、サーバの音
声認識結果を用いる。そして、ローカルとサーバとの双方で音声認識が失敗した場合には、DSRクライアントモジュール103は、音声認識失敗と判断する。
【0040】
DSRクライアントモジュール103は、S111の処理後、音声認識結果がオーディオ
やエアコンの操作などのローカルコンテンツに対する指示である場合には、ローカルコンテンツの表示を行う(S112)。
【0041】
DSRクライアントモジュール103は、S111の処理後、音声認識結果がカラオケコ
ンテンツなどのネットワーク型コンテンツへの指示である場合には、その認識結果に対するネットワーク型コンテンツへの動作(アクション)を要求する情報(例えば、カラオケコンテンツに対する楽曲の配信要求など)を取得に成功したか否かを判断する(S113)。
【0042】
アクション情報の取得に成功した場合には、DSRクライアントモジュール103は、ネ
ットワーク型コンテンツのページを受信して出力手段102に表示が成功したか否かを判断する(S114)。ページの表示に失敗した場合には、DSRクライアントモジュール1
03は、出力手段102に再取得ボタンを表示して、ユーザにページの再取得を要求する(S115)。そして、ユーザが再取得ボタンを不図示のポインティングデバイスで押下した場合に、DSRクライアントモジュール103は、制御をS114に戻す。また、ペー
ジの表示に成功した場合には、DSRクライアントモジュール103は、ネットワーク型コ
ンテンツのWebページが表示完了であるとして、本システムの処理を終了する(S116)。
【0043】
S113において、アクション情報の取得に失敗した場合には、DSRクライアントモジ
ュール103は、そのアクション情報の取得を所定回数繰り返す。そして、DSRクライア
ントモジュール103は、一定回数のアクション情報の取得の失敗を繰り返したか否かを判断する(S117)。失敗した場合には、DSRクライアントモジュール103は、アク
ション情報の取得要求を自動的に再送信する(S118)。
【0044】
一定回数の再送信後も、Webページの取得(アクション)に失敗した場合には、DSR
クライアントモジュール103は、出力手段102に再取得ボタンを表示して、ユーザにページの再取得を促す(S119)。
【0045】
〈システムの処理例1〉
次に、本システムによる、音声認識処理の流れを場合分けした上で例示して説明する。第1の処理例は、情報処理端末100とDSRサーバ200との通信状態が良好な場合の流
れを説明する。
【0046】
図4は、本システムによる、第1の処理例を説明する流れ図である。
情報処理端末100(以下、DSRクライアント100)は、ユーザの発話(音声)を受
け付ける。DSRクライアント100は、音声から音声特徴情報を抽出する。そして、DSRクライアント100は、音声特徴情報をDSRサーバ200(センタ音声認識)に送信する。
この間、DSRクライアント100のディスプレイ(不図示)には、音声認識中であること
を示す「認識中」などの文字が表示される。
【0047】
DSRサーバ200は、音声特徴情報から音声認識処理を行って音声認識結果を出力する
。DSRサーバ200は、音声認識結果をDSRクライアント100に送信する。
音声認識結果を受信したDSRクライアント100は、その音声認識結果に基づいたネッ
トワーク型コンテンツのページに対するアクション情報の取得要求を、DSRサーバ200
を介してコンテンツサーバ400に送信する。この間DSRクライアント100のディスプ
レイには、アクション情報に基づいたコンテンツ取得処理中であることを示す「検索中」などの文字が表示される。
【0048】
コンテンツサーバ400は、アクション情報の取得要求に対応するアクション情報をDSRクライアント100に送信する。
このようにすると、本システムの第1の処理例では、DSRクライアント100が音声認
識処理に基づいたコンテンツの利用が可能になる。
【0049】
〈システムの処理例2〉
第2の処理例は、本システムの音声認識処理において、DSRクライアント100とDSRサーバ200との通信状態が不良であるために、センタ音声認識ができない場合の処理を説明する。
【0050】
図5は、本システムによる、第2の処理例を説明する流れ図である。
DSRクライアント100は、ユーザの音声から抽出した音声特徴情報をDSRサーバ200に送信したものの、送信時の応答にタイムアウトが発生した場合に、再送信を行う。再送信後、さらにタイムアウトがある場合には、DSRクライアント100は、ローカルの音声
認識エンジン105(代替グラマ)を用いて音声認識を行う。この間、DSRクライアント
100のディスプレイ(不図示)には、音声認識中であることを示す「認識中」などの文字が表示されたのち、代替グラマによる音声認識を行っていることを示す、「データ再送信&再認識中」の文字が表示される。
【0051】
音声認識エンジン105による音声認識処理終了後、DSRクライアント100は、音声
認識結果に基づいたアクション情報の取得要求をコンテンツサーバ400に送信して、コンテンツサーバ400からアクション情報を取得する。この間DSRクライアント100の
ディスプレイには、アクション情報に基づいたコンテンツ取得処理中であることを示す「検索中」などの文字が表示される。
【0052】
このようにすると、本システムの第2の処理例では、DSRクライアント100とDSRサーバ200との通信状態が不良であるためにセンタ音声認識が不可能であっても、ローカルの音声認識エンジン105によって音声認識処理が可能になる。従って、本システムの第2の処理例によれば、分散型音声認識処理において、通信状態に左右されることなく音声認識処理を行うことができる。
【0053】
〈システムの処理例3〉
第3の処理例は、第2の処理例と比較して、音声特徴情報送信時の通信状態が不良であり、かつアクション情報の取得要求時の通信状態も不良であるためにセンタ音声認識を用いた処理が不可能な場合の処理例を示す。
【0054】
図6は、本システムの第3の処理例を説明する流れ図である。
DSRクライアント100は、音声特徴情報の送信時にタイムアウトが発生して、ローカ
ルの音声認識エンジン105によって音声認識処理を行う。この間、DSRクライアント1
00のディスプレイ(不図示)には、音声認識中であることを示す「認識中」などの文字が表示されたのち、代替グラマによる音声認識を行っていることを示す、「データ再送信&再認識中」の文字が表示される。その後、DSRクライアント100は、ローカルの音声認識エンジン105の音声認識結果に基づいたアクション情報の取得要求をコンテンツサーバ400に送信するものの、タイムアウトが発生した場合には、一定の回数再送信を行う。第3の処理例では、三回目の再送信でコンテンツサーバ400に送信が完了している。この間DSRクライアント100のディスプレイには、アクション情報に基づいたコンテン
ツ取得処理中であることを示す「検索中」や再送時を示す「再検索中」などの文字が表示される。
【0055】
このようにすると、第3の処理例では、コンテンツサーバ400へのアクション情報の取得要求時に通信状態が悪化した場合であっても、DSRクライアント100が再送信を行
うため、ユーザに負担をかけることなくコンテンツの利用が可能になる。
【0056】
〈システムの処理例4〉
第4の処理例では、第3の処理例と比較して、アクション情報の取得要求時の再送信を一定回数繰り返したものの、タイムアウトが発生した場合を示す。
【0057】
図7は、本システムの第4の処理例を説明する流れ図である。
第4の処理例では、アクション情報の取得要求にタイムアウトが発生して、DSRクライ
アント100が5回再送信を繰り返したものの、コンテンツサーバ400側からの応答がない場合には、再送ボタンを生成してユーザに再送信を促す。
【0058】
〈システムの処理例5〉
第5の処理例では、アクション情報の取得要求時に一定の回数再送信を繰り返した後で、再送ボタンによって新たなセンタ音声認識とアクション情報の取得要求とを行う場合を示す。
【0059】
図8は、本システムの第5の処理例を説明する流れ図である。
第5の処理例では、DSRクライアント100最初の発話から抽出した音声特徴情報をDSRサーバ200に送信するものの、DSRサーバ200との通信がタイムアウトとなる。その
ため、DSRクライアント100は、ローカルの音声認識エンジン105によって音声認識
処理を行う。この間、DSRクライアント100のディスプレイ(不図示)には、音声認識
中であることを示す「認識中」などの文字が表示されたのち、代替グラマによる音声認識を行っていることを示す、「データ再送信&再認識中」の文字が表示される。その後、DSRクライアント100は、ローカルの音声認識エンジン105の音声認識結果に基づいたアクション情報の取得要求を送信するものの、DSRサーバ200との通信がタイムアウトと
なる。この間DSRクライアント100のディスプレイには、アクション情報に基づいたコ
ンテンツ取得処理中であることを示す「検索中」や再送時を示す「再検索中」などの文字が表示される。DSRクライアント100は、アクション情報の取得要求の再送信を一定回
数繰り返した後、ユーザの音声の再送信を促す再送ボタンを表示して、音声特徴情報の再送信を促す。
【0060】
その後、DSRクライアント100は、DSRサーバ200との通信をするためのネットワークの状態が回復した場合には、再送ボタンを消去して、ユーザに新しい発話による音声認識処理を行うことを促す。ユーザは、再送ボタンが消去されたことで、新しい発話を行う。
【0061】
このようにすると、第5の処理例では、ネットワークの状態によって、音声特徴情報及びアクション情報の取得要求の送信が不可能な場合であっても、ネットワークの状態が回復したことに合わせて、新たな音声認識処理を実行する。従って、第5の処理例によれば、ネットワークの状態に合わせて、即座に音声認識処理を実行することができる。また、上記第1から第5の処理例において、処理の経過を示す「認識中」「再認識中」「検索中」「再検索中」の文字をディスプレイに表示することにより、DSRクライアント100が
どのような処理を行っているかをユーザに対して通知することができる。従って、DSRク
ライアント100は、ユーザに対して安心感をもたらすことができる。
【図面の簡単な説明】
【0062】
【図1】情報処理端末、及びDSRサーバとからなるシステムの構成図である。
【図2】本システムによる、DSRサーバ側による音声認識処理と情報処理端末側による音声認識処理との区分を説明する図である。
【図3】情報処理端末とDSRサーバとによるシステムによる、音声認識処理を説明するフローチャートである。
【図4】本システムによる、第1の処理例を説明する流れ図である。
【図5】本システムによる、第2の処理例を説明する流れ図である。
【図6】本システムの第3の処理例を説明する流れ図である。
【図7】本システムの第4の処理例を説明する流れ図である。
【図8】本システムの第5の処理例を説明する流れ図である。
【符号の説明】
【0063】
100 DSRクライアント(情報処理端末)
101 音声入力手段
102 出力手段
103 DSRクライアントモジュール
104 ローカル音声認識モジュール
105 音声認識エンジン
200 DSRサーバ
201 サーバモジュール
202 DSRサーバモジュール
203 音声認識エンジン
300 ネットワーク
400 コンテンツサーバ
【特許請求の範囲】
【請求項1】
ユーザが発した音声を取得する音声取得手段と、
前記音声から、当該音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成する特徴情報抽出手段と、
前記音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音声特徴情報を送信する送信手段と、
前記サーバから音声認識結果を受信する受信手段と、
前記音声認識結果が所定時間受信できない場合に、前記音声特徴情報の再送信を前記送信手段に指示する再送指示手段と、
前記再送指示手段による再送信を所定回数指示し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行う音声認識手段と、を備える音声認識装置。
【請求項2】
前記音声認識結果に対応するユーザからの処理の要求を、アクション要求情報として前記送信手段を介して前記サーバに送信するアクション要求手段をさらに備え、
前記再送指示手段が、前記アクション要求情報に対する前記サーバの応答が所定時間受信できない場合に、当該アクション要求情報の再送信を前記送信手段に指示する、請求項1に記載の音声認識装置。
【請求項3】
前記音声特徴情報を所定回数送信しサーバから前記音声認識結果が受信できない場合、及び前記アクション要求情報を所定回数送信し前記応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促す指示を行う音声再取得指示手段をさらに備える、請求項1または2に記載の音声認識装置。
【請求項4】
ユーザが発した音声を取得するステップと、
前記音声から、当該音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成するステップと、
前記音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音声特徴情報を送信するステップと、
前記サーバから音声認識結果を受信するステップと、
前記音声認識結果が所定時間受信できない場合に、前記音声特徴情報を再送信するステップと、
前記再送信を所定回数実行し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行うステップと、をコンピュータが実行する音声認識方法。
【請求項5】
前記音声認識結果に対応するユーザからの処理の要求を、アクション要求情報として前記サーバに送信するステップと、
前記アクション要求情報に対する前記サーバの応答が所定時間受信できない場合に、当該アクション要求情報を再送信するステップと、をさらにコンピュータが実行する請求項4に記載の音声認識方法。
【請求項6】
前記音声特徴情報を所定回数送信しサーバから前記音声認識結果が受信できない場合、及び前記アクション要求情報を所定回数送信し前記応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促すステップをさらにコンピュータが実行する、請求項4または5に記載の音声認識方法。
【請求項7】
ユーザが発した音声を取得するステップと、
前記音声から、当該音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成するステップと、
前記音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音
声特徴情報を送信するステップと、
前記サーバから音声認識結果を受信するステップと、
前記音声認識結果が所定時間受信できない場合に、前記音声特徴情報を再送信するステップと、
前記再送信を所定回数実行し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行うステップと、をコンピュータに実行させる音声認識プログラム。
【請求項8】
前記音声認識結果に対応するユーザからの処理の要求を、アクション要求情報として前記サーバに送信するステップと、
前記アクション要求情報に対する前記サーバの応答が所定時間受信できない場合に、当該アクション要求情報を再送信するステップと、をさらにコンピュータに実行させる請求項7に記載の音声認識プログラム。
【請求項9】
前記音声特徴情報を所定回数送信しサーバから前記音声認識結果が受信できない場合、及び前記アクション要求情報を所定回数送信し前記応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促すステップをさらにコンピュータに実行させる、請求項7または8に記載の音声認識プログラム。
【請求項1】
ユーザが発した音声を取得する音声取得手段と、
前記音声から、当該音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成する特徴情報抽出手段と、
前記音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音声特徴情報を送信する送信手段と、
前記サーバから音声認識結果を受信する受信手段と、
前記音声認識結果が所定時間受信できない場合に、前記音声特徴情報の再送信を前記送信手段に指示する再送指示手段と、
前記再送指示手段による再送信を所定回数指示し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行う音声認識手段と、を備える音声認識装置。
【請求項2】
前記音声認識結果に対応するユーザからの処理の要求を、アクション要求情報として前記送信手段を介して前記サーバに送信するアクション要求手段をさらに備え、
前記再送指示手段が、前記アクション要求情報に対する前記サーバの応答が所定時間受信できない場合に、当該アクション要求情報の再送信を前記送信手段に指示する、請求項1に記載の音声認識装置。
【請求項3】
前記音声特徴情報を所定回数送信しサーバから前記音声認識結果が受信できない場合、及び前記アクション要求情報を所定回数送信し前記応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促す指示を行う音声再取得指示手段をさらに備える、請求項1または2に記載の音声認識装置。
【請求項4】
ユーザが発した音声を取得するステップと、
前記音声から、当該音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成するステップと、
前記音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音声特徴情報を送信するステップと、
前記サーバから音声認識結果を受信するステップと、
前記音声認識結果が所定時間受信できない場合に、前記音声特徴情報を再送信するステップと、
前記再送信を所定回数実行し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行うステップと、をコンピュータが実行する音声認識方法。
【請求項5】
前記音声認識結果に対応するユーザからの処理の要求を、アクション要求情報として前記サーバに送信するステップと、
前記アクション要求情報に対する前記サーバの応答が所定時間受信できない場合に、当該アクション要求情報を再送信するステップと、をさらにコンピュータが実行する請求項4に記載の音声認識方法。
【請求項6】
前記音声特徴情報を所定回数送信しサーバから前記音声認識結果が受信できない場合、及び前記アクション要求情報を所定回数送信し前記応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促すステップをさらにコンピュータが実行する、請求項4または5に記載の音声認識方法。
【請求項7】
ユーザが発した音声を取得するステップと、
前記音声から、当該音声を言語情報として認識するために必要な音声情報を抽出し圧縮した音声特徴情報を生成するステップと、
前記音声特徴情報に基づいて言語情報を認識する音声認識処理を行うサーバに、当該音
声特徴情報を送信するステップと、
前記サーバから音声認識結果を受信するステップと、
前記音声認識結果が所定時間受信できない場合に、前記音声特徴情報を再送信するステップと、
前記再送信を所定回数実行し、かつサーバから音声認識結果が受信できない場合に、音声認識処理を行うステップと、をコンピュータに実行させる音声認識プログラム。
【請求項8】
前記音声認識結果に対応するユーザからの処理の要求を、アクション要求情報として前記サーバに送信するステップと、
前記アクション要求情報に対する前記サーバの応答が所定時間受信できない場合に、当該アクション要求情報を再送信するステップと、をさらにコンピュータに実行させる請求項7に記載の音声認識プログラム。
【請求項9】
前記音声特徴情報を所定回数送信しサーバから前記音声認識結果が受信できない場合、及び前記アクション要求情報を所定回数送信し前記応答が受信できない場合の少なくともいずれかの場合には、再度音声取得手段にユーザの音声を取得するように促すステップをさらにコンピュータに実行させる、請求項7または8に記載の音声認識プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2006−3696(P2006−3696A)
【公開日】平成18年1月5日(2006.1.5)
【国際特許分類】
【出願番号】特願2004−180837(P2004−180837)
【出願日】平成16年6月18日(2004.6.18)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
【出願人】(502087460)株式会社トヨタIT開発センター (232)
【Fターム(参考)】
【公開日】平成18年1月5日(2006.1.5)
【国際特許分類】
【出願日】平成16年6月18日(2004.6.18)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
【出願人】(502087460)株式会社トヨタIT開発センター (232)
【Fターム(参考)】
[ Back to top ]