
アセンブリング前処理装置、該プログラム、及びコンピュータクラスタシステムの該制御方法
【課題】生物配列断片のインデックス作成処理の高速化を図るアセンブリング前処理装置を提供する。
【解決手段】生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得する取得部と、アセンブリング前処理を実行するプロセスが部分配列情報に関するアセンブリング前処理を担当するか否かを判定する担当判定部と、プロセスが部分配列情報に関するアセンブリング前処理を担当すると判定された場合、生物配列情報における部分配列情報の位置を示す位置情報を配列位置格納部に登録する登録部と、を備えるアセンブリング前処理装置により、上記課題の解決を図る。
【解決手段】生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得する取得部と、アセンブリング前処理を実行するプロセスが部分配列情報に関するアセンブリング前処理を担当するか否かを判定する担当判定部と、プロセスが部分配列情報に関するアセンブリング前処理を担当すると判定された場合、生物配列情報における部分配列情報の位置を示す位置情報を配列位置格納部に登録する登録部と、を備えるアセンブリング前処理装置により、上記課題の解決を図る。
【発明の詳細な説明】
【技術分野】
【0001】
本実施形態の一側面は、配列アセンブリングの前処理技術に関する。
【背景技術】
【0002】
配列アセンブリングとは、バイオインフォマティクスにおいて短い塩基配列の断片から元の長い塩基配列を再構築することをいう。配列アセンブリングの1つに、De novo アセンブル(assemble)がある。De novo アセンブリとは、シーケンサ装置が出力したDNA(デオキシリボ核酸)、RNA(リボ核酸)等の生物配列(以下、「Read配列」と称する)を繋ぎ合わせて(assemble)、元の生物配列を再構築することをいう。ここで、シーケンサ装置とは、DNA/ RNA等の塩基配列を自動的に読み取る装置である。
【0003】
アセンブル手法として、例えば、De Bruijn Graphによるアセンブルがある。De Bruijn Graphによるアセンブルでは、まず、Read配列をある長さの断片に細切れにした配列(生物配列断片)を生成する。以下では、生物配列断片を、「K-mer」と称する。次に、K-merからDe Bruijn Graphを作成する。そして、このDe Bruijn Graphについて、オイラーパス問題を解く(すなわち、De Bruijn Graphの全辺を通るパスを求める)。
【0004】
De Bruijn Graphを作成する前処理として、K-merがRead配列のどこに存在するのかを管理するK-merインデックステーブルが作成されるが、正確なアセンブル処理を行うには、大量のRead配列を用いる。したがって、コンピュータを用いて、De Bruijn Graphを作成する場合、その前処理に用いるK-merインデックステーブルの作成に、大量のメモリ容量が消費される。
【0005】
ところで、大量のデータを複数のサーバを用いて処理する技術の1つに、分散KVS(キーバリュー型データストア : Key-Value Store)がある。分散KVSとは、キーと値からなる比較的単純な構造の連想配列を、多数のサーバで高速に処理するデータストアを示す。分散KVSでは、KVSクライアント装置が、キーの値に応じて、保存先のサーバ装置(KVSサーバ)を変えることで、複数のサーバに分散してデータを保存する。これにより、分散KVSでは、大量のデータをスケールアウト型で扱うことができる。
【先行技術文献】
【非特許文献】
【0006】
【非特許文献1】Daniel R. Zerbino and Ewan Birney “Velvet: Algorithms for de novo short read assembly using de Bruijn graph”, Genome Res., 2008 18: 821-829
【非特許文献2】“MEMCACHED”、[online] 、[平成23年11月15日検索]、インターネット、<http://memcached.org/>
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述したように、コンピュータを用いて、De Bruijn Graphを作成する場合、その前処理に用いるK-merインデックステーブルの作成に際して、例えば、数十〜数百ギガバイトのオーダで大量のメモリ容量が消費される。したがって、そのような膨大なデータを処理するために、処理時間が長くなる。
【0008】
また、分散KVSを用いて、複数のKVSサーバにK-merインデックステーブルの作成を実行させる場合でも、KVSクライアントにそれらのKVSサーバに処理を分散させる処理が集中する。そのため、KVSクライアントでの分散処理がボトルネックとなり、処理の高速化を図ることができない可能性がある。
【0009】
そこで、本実施形態の一側面によれば、生物配列断片のインデックス作成処理の高速化を図る情報処理装置を提供する。
【課題を解決するための手段】
【0010】
本実施形態の一側面にかかるアセンブリング前処理装置は、取得部、担当判定部、登録部を含む。取得部は、生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得する。担当判定部は、アセンブリング前処理を実行するプロセスが部分配列情報に関するアセンブリング前処理を担当するか否かを判定する。登録部は、プロセスが部分配列情報に関するアセンブリング前処理を担当すると判定された場合、生物配列情報における部分配列情報の位置を示す位置情報を配列位置格納部に登録する。
【発明の効果】
【0011】
本実施形態の一側面によれば、生物配列断片のインデックス作成処理の高速化を図ることができる。
【図面の簡単な説明】
【0012】
【図1】K-merインデックステーブルを説明するための図である。
【図2】K-merインデックステーブルの作成を説明するための図(その1)である。
【図3】K-merインデックステーブルの作成を説明するための図(その2)である。
【図4】本実施形態におけるアセンブリング前処理装置の構造の一例を示す。
【図5】本実施形態における複数のプロセスによる並列処理を実現する方法の一例を示す。
【図6】本実施形態におけるK-merインデックス作成処理の全体のフローを示す。
【図7】本実施形態の一実施例におけるアセンブリング前処理システムの一例を示す。
【図8】本実施形態の一実施例におけるK-merインデックス部分テーブル及びK-merインデックステーブルのデータ構造を示す。
【図9】本実施形態の一実施例における並列化された各プロセス(各計算機)が行うK-merインデックス部分テーブル作成処理フローを示す。
【図10】本実施形態を適用したコンピュータのハードウェア環境の構成ブロック図である。
【発明を実施するための形態】
【0013】
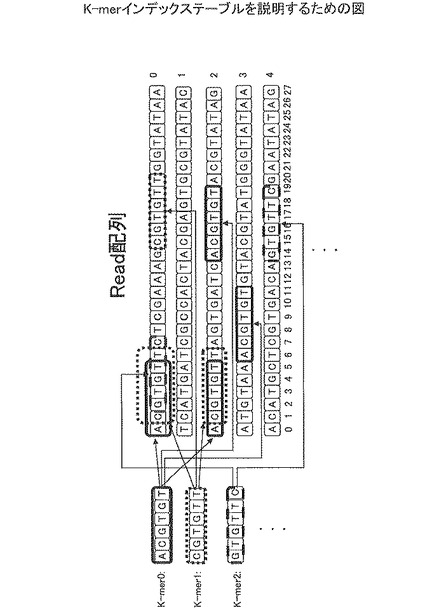
図1は、K-merインデックステーブルを説明するための図である。図1の例では、Read配列は、上段より、Read配列0、Read配列1、Read配列3、Read配列4、・・・で示される。Read配列は、位置0〜位置27までの28個の塩基配列で表される。ここで、「A」はアデニンを示す。「G」はグアニンを示す。「T」は、チミンを示す。「C」は、シトシンを示す。
【0014】
K-mer n(n=0,1,2,・・・)は、Read配列を1文字ずらしで長さKの文字列に区切った部分配列である。例えば、K-mer0は、Read配列0の位置0から6文字切り取った部分配列である。K-mer1は、Read配列0の位置1から6文字切り取った部分配列である。K-mer2は、Read配列0の位置2から6文字切り取った部分配列である。
【0015】
このように、i番目のRead配列およびそのRead配列のj番目の位置によって、K-merがどのRead配列のどの場所に存在するかを特定することができる。このように、各K-merがどのRead配列のどの場所に存在するかの情報を保持するテーブルが、K-merインデックステーブルである。
【0016】
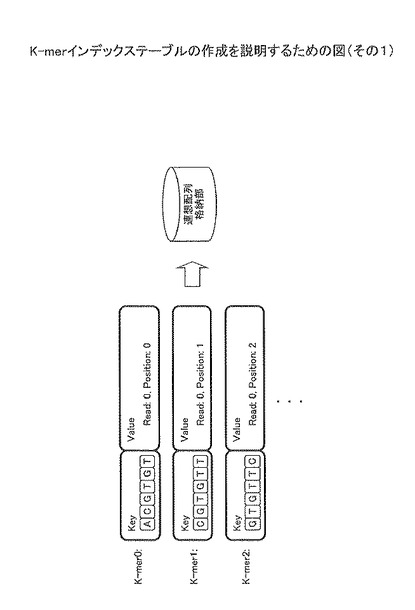
図2及び図3は、K-merインデックステーブルの作成を説明するための図である。コンピュータを用いて、K-merインデックステーブルを作成する場合について考える。この場合、CPU(Central Processing Unit)は、Read配列を読み込むと、図2に示すように、Read配列の先頭から順次K-merを取得する。CPUは、順次取得したK-merをキーとし、K-merの位置情報(Read:i、Position:j)を値として、連想配列格納部に格納していく。ここで、位置情報(Read:i、Position:j)は、i番目のRead配列、およびそのRead配列のj番目の位置を示す。また、連想配列格納部はコンピュータ上のメモリに配置される。
【0017】
例えば、K-mer0の場合、キーとして「ACGTGT」が格納され、値として「Read:0、Position:0」が格納される。例えば、K-mer1の場合、キーとして「CGTGTT」が格納され、値として「Read:0、Position:1」が格納される。例えば、K-mer2の場合、キーとして「GTGTTC」が格納され、値として「Read:0、Position:2」が格納される。
【0018】
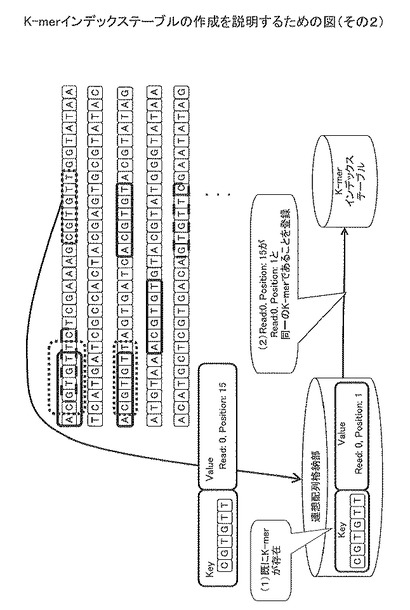
図3に示すように、Read配列から取得したK-mer(対象K-mer)と同一のK-mer(基準K-mer)が連想配列格納部に既に存在していた場合、CPUはK-merインデックステーブルに、基準K-merの位置情報と対象K-merの位置情報を関係付けて登録する。
【0019】
例えば、「Read:0、Position:15」にあるK-mer「CGTGTT」を連想配列格納部に格納する場合について考える。この場合、K-mer「CGTGTT」は既に連想配列格納部に登録されているので、「Read:0, Position: 15」のK-merが「Read:0, Position: 1」のK-merと同一であることを示す情報をK-merインデックステーブルに登録する。
【0020】
このようにして、連想配列格納部及びK-merインデックステーブルが作成される。
ところが、Read配列が大量に存在する場合、K-merも大量になり、大量のK-merを処理することになる。その結果、連想配列格納部が肥大化し、コンピュータ上のメモリを大量に消費することになる。また、コンピュータの処理量も増加するので、処理時間が長くなる可能性もある。
【0021】
そこで、処理時間を短縮させるために、CPUの処理効率を向上させることが考えられる。例えば、複数のスレッドが同時に動作するマルチスレッド方式を用いた場合には、各スレッドが、自身が担当するRead配列について処理を行う。
【0022】
しかしながら、マルチスレッド方式の場合、各スレッドは、同一プロセス内で動作しているため、メモリ空間を共有している。したがって、複数のスレッドは、共有メモリ上にある同一の連想配列格納部を更新することになる。そのため、例えば、連想配列格納部において、同じキーを有するエントリを更新する場合にはスレッド間の競合が生じるので、排他制御を行う。排他制御とは、あるスレッドに資源を独占的に利用させている間は、他のスレッドが利用できないようにする事で整合性を保つ処理をいう。
【0023】
排他制御の結果、あるスレッドが資源を利用している間は、競合する他のスレッドはその利用が終了するまで待つことになり、待ち時間が発生する。そのため、処理時間が遅延する。
【0024】
また、複数のスレッドを用いて処理をしても、各スレッドはプロセスメモリ空間を共有するため、プロセスメモリ空間を分離できない。したがって、プロセス当たりのメモリ使用量は変わらない。
【0025】
そこで、プロセス当たりの処理量を軽減させる方法の1つとして、分散KVSを利用することが考えられる。しかしながら、分散KVSを用いて、複数のKVSサーバにK-merインデックステーブルの作成を実行させる場合でも、KVSクライアントにそれらのKVSサーバに処理を分散させる処理が集中する。そのため、KVSクライアントがボトルネックとなり、処理の高速化を図ることができない可能性がある。
【0026】
そこで、本実施形態では、以下に説明するように、生物配列断片のインデックス作成処理の高速化を図る情報処理装置を提供する。
【0027】
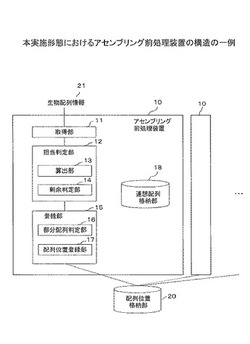
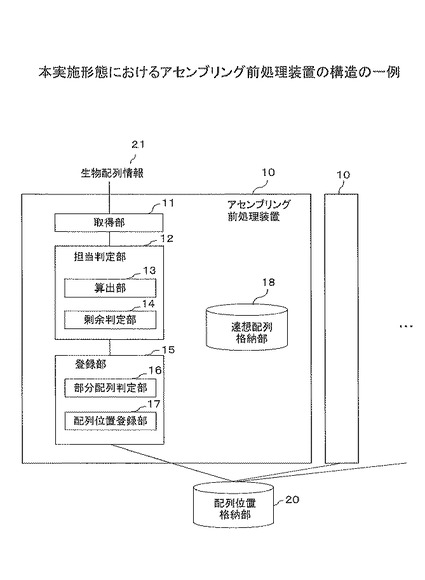
図4は、本実施形態におけるアセンブリング前処理装置の構造の一例を示す。アセンブリング前処理装置10は、複数存在する。アセンブリング前処理装置10は、取得部11、担当判定部12、登録部15を含む。
【0028】
取得部11は、生物配列情報21の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報(K-mer)を1文字ずつずらして取得する。取得部11の一例として、図9のS13、S14の処理がある。生物配列情報21は、シーケンサ装置が出力したDNA/ RNA等の生物配列(Read配列)である。
【0029】
担当判定部12は、アセンブリング前処理を実行するプロセスが部分配列情報に関するアセンブリング前処理を担当するか否かを判定する。担当判定部12の一例として、図9のS15〜S17の処理がある。
【0030】
登録部15は、プロセスが部分配列情報に関するアセンブリング前処理を担当すると判定された場合、生物配列情報21における部分配列情報の位置を示す位置情報を配列位置格納部20に登録する。登録部15の一例として、図9のS18、S20の処理がある。
【0031】
このように構成することにより、各プロセスは、自身の担当するK-merを対象にしてK-merインデックステーブルを作成することができるので、プロセス当たりの処理量が減少すると共に、処理の並列化を図ることができる。したがって、生物配列断片のインデックス作成処理の高速化を図ることができる。
【0032】
担当判定部12は、算出部13、剰余判定部14を含む。
算出部13は、部分配列情報のハッシュ値を算出し、ハッシュ値を第1の値で割ったときの剰余値を算出する。第1の値は、アセンブリング前処理装置の数、またはプロセス数を示す。ここでのプロセスとは、取得部11、算出部12、剰余判定部13、部分配列判定部14、及び登録部15により実行される一連の処理を実行するプロセスを示す。算出部13の一例として、図9のS15、S16の処理がある。
【0033】
剰余判定部14は、算出した剰余値が、第2の値であるか否かを判定する。剰余判定部14の一例として、図9のS17の処理がある。
【0034】
このように構成することにより、K-merにより一意に処理を担当するプロセスが決定され、同一のK-merは、同一のプロセスにより処理することができる。
【0035】
登録部15は、部分配列判定部16を含む。部分配列判定部16は、算出した剰余値が第2の値であると判定された場合、取得した部分配列情報が、部分配列をキーとする連想配列を格納する連想配列格納部18に登録されているか否かを判定する。部分配列判定部16の一例として、図9のS18の処理がある。連想配列格納部18の一例として、連想配列格納部43がある。
【0036】
このように構成することにより、K-merインデックステーブル作成のために用いる連想配列を作成することができる。また、プロセス単位で連想配列格納部へK-merを登録することができるので、マルチスレッド方式を採用した場合の競合の問題も生じない。
【0037】
登録部15は、配列位置登録部17を含む。配列位置登録部17は、部分配列情報が連想配列格納部18に登録されている場合、生物配列情報における部分配列情報の位置情報と、連想配列格納部に登録されている部分配列情報の生物配列情報21における位置情報とを関係付けて配列位置格納部20に登録する。配列位置登録部17の一例として、S19の処理がある。配列位置格納部20の一例として、例えば、K-merインデックステーブル56がある。
【0038】
このように構成することにより、K-merインデックステーブルを作成することができる。
【0039】
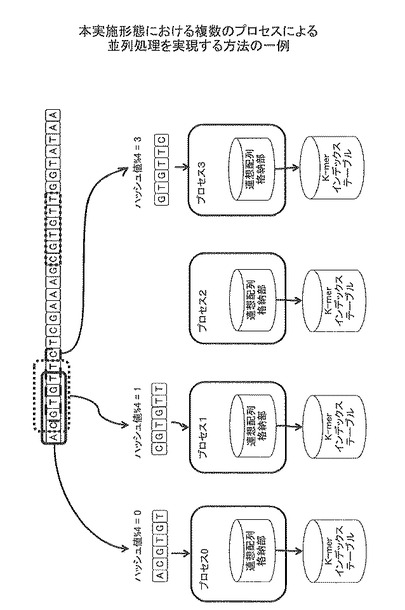
図5は、本実施形態における複数のプロセスによる並列処理を実現する方法の一例を示す。各プロセスは、ハッシュ関数を用いて、生体配列から読み出したK-merのハッシュ値を算出する。各プロセスは、そのハッシュ値をプロセス数で割った剰余に応じて、自身がそのK-merについてのK-merインデックステーブル作成処理を担当するか否かを判定する。そのプロセスがそのK-merについてのK-merインデックステーブル作成処理を担当すると判定した場合、そのプロセスは、そのK-merについてのK-merインデックステーブル作成処理を行う。これにより、K-merのハッシュ値をプロセス数で割った剰余に応じて、K-merについてのK-merインデックステーブル作成処理を担当するプロセスを動作させることができる。
【0040】
例えば、図5に示すように、K-merインデックステーブル作成処理を4つのプロセスで行うとする。K-merインデックステーブル作成処理では、各プロセスは、自身が担当するK-merであると判定した場合、そのK-merが連想配列格納部に登録されていなければ、そのK-merを連想配列格納部に登録する。
【0041】
各プロセスは、自身が担当するK-merであると判定した場合、そのK-merが連想配列格納部に登録されていれば、次の処理を行う。すなわち、そのプロセスは、K-merインデックステーブルにK-merの位置情報と、連想配列格納部21に登録されているK-merの位置情報を関係付けて登録する。
【0042】
なお、各プロセスは、自身の担当するK-merを判別するために、予め固有の値(担当No.)を保持している。例えば、図5の場合、プロセス0は、値0を有している。プロセス1は、値1を有している。プロセス2は、値2を有している。プロセス3は、値3を有している。K-merのハッシュ値をプロセス数で割った剰余が、各プロセスが予め有している値と同じであれば、そのプロセスがそのK-merについてのK-merインデックステーブル作成処理を担当する。
【0043】
例えば、図5において、各プロセスは、Read配列からK-mer nを読み出し、ハッシュ関数を用いてK-mer nのハッシュ値を計算し、計算したハッシュ値を4で割った場合の剰余を計算する。剰余が0である場合、プロセス0がそのK-mer nについてのK-merインデックステーブル作成を担当する。
【0044】
担当プロセスを決定するときの指標は、K-merのハッシュ値をプロセス数で割って得られる剰余以外でも、次の条件を満たせばよい。その条件とは、(1)K-merにより一意の値が決まる、(2)担当プロセスが少なくとも1つ存在する、(3)K-merがノード毎に十分に分散(一様分布に近ければ近いほどよい)である。
【0045】
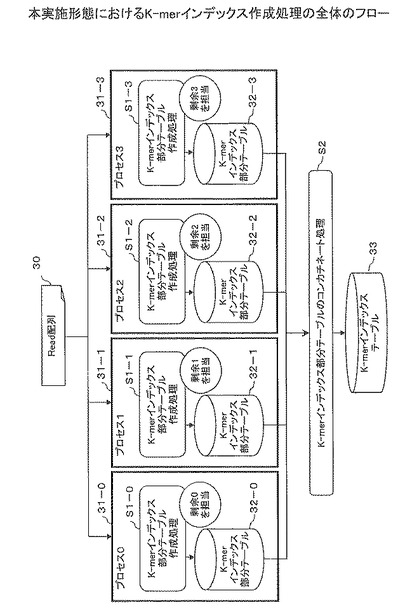
図6は、本実施形態におけるK-merインデックス作成処理の全体のフローを示す。上述の通り、各プロセスは、予め担当No.を有している。例えば、図6の場合、プロセス0(31−0)は、担当No.として値0を有している。プロセス1(31−1)は、担当No.として値1を有している。プロセス2(31−2)は、担当No.として値2を有している。プロセス3(31−3)は、担当No.として値3を有している。
【0046】
各プロセス0〜3(31−0〜31−3)は、Read配列30を読み込み、K-merインデックス部分テーブル作成処理S1(S1−0〜S1−3)を行う。ここで、K-merインデックス部分テーブル作成処理S1とは、次の処理をいう。すなわち、各プロセスは、Read配列30から読み出したK-merのハッシュ値をハッシュ関数を用いて算出する。そのハッシュ値をプロセス数で割った剰余に応じて、そのプロセスが、自身が担当するK-merについての処理であるかを判定する。そのプロセスが担当するK-merについての処理であると判定した場合、そのプロセスは、そのK-merが連想配列格納部に登録されていなければ、そのK-merを連想配列格納部に登録する。そのK-merが連想配列格納部に登録されていなければ、そのプロセスは、次の処理を行う。すなわち、そのプロセスは、K-merインデックス部分テーブル32(32−0〜32−3)にK-merの位置情報と、連想配列格納部に登録されているK-merの位置情報を関係付けて登録する。
【0047】
各プロセス0〜3において、K-merインデックス部分テーブル作成処理S1(S1−0〜S1−3)の終了後、特定のプロセスは、次の処理を行う。すなわち、特定のプロセスは、各プロセスで作成されたK-merインデックス部分テーブルを連結して、K-merインデックステーブル33を作成する(コンカーチネート処理S2)。なお、特定のプロセスは、プロセス0〜3のいずれかでもよいし、プロセス0〜3とは別のプロセスでもよい。
【0048】
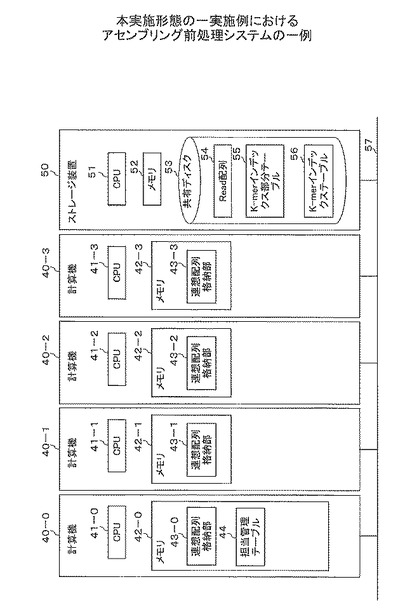
図7は、本実施形態の一実施例におけるアセンブリング前処理システムの一例を示す。アセンブリング前処理システムは、計算機40(40−0〜40−3)及びストレージ装置50を含む。計算機40(40−0〜40−3)及びストレージ装置50は、ネットワーク57で接続されている。
【0049】
計算機40は、CPU41(41−0〜41−3)、メモリ42(42−0〜42−3)を含む。CPU41は、計算機全体の動作を制御する。メモリ42は、データを格納する記憶装置である。メモリ42(42−0〜42−3)は、連想配列格納部43(43−0〜43−3)を保持する。
【0050】
計算機40−0のメモリ42−0は、さらに、担当管理テーブル44を保持する。担当管理テーブル44は、担当No.と、各計算機40−0を識別する計算機識別情報とが関係付けられて格納されている。なお、担当管理テーブル44のエントリをカウントすれば、プロセス数を得ることができる。
【0051】
ストレージ装置50は、CPU51、メモリ52、共有ディスク53を含む。CPU51は、ストレージ装置50全体の動作を制御する。メモリ52は、データを格納する記憶装置である。共有ディスク53は、ネットワーク57を介して、計算機40−0〜40−3が共有で利用する大容量記憶装置である。共有ディスク53は、Read配列54、K-merインデックス部分テーブル55、K-merインデックステーブル56を格納する。
【0052】
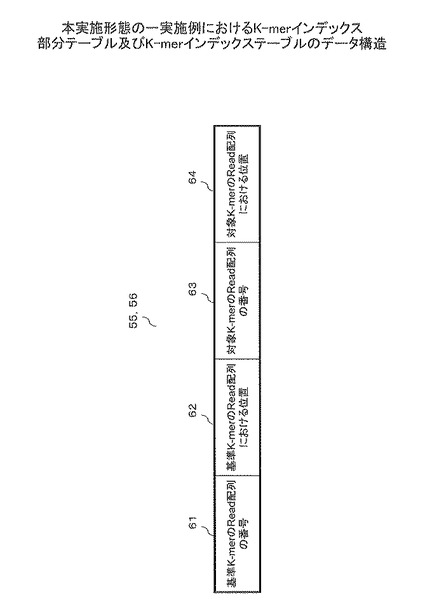
図8は、本実施形態の一実施例におけるK-merインデックス部分テーブル及びK-merインデックステーブルのデータ構造を示す。K-merインデックス部分テーブル55及びK-merインデックステーブル56のデータ構造は同一であるので、以下では、K-merインデックス部分テーブル55について説明する。
【0053】
K-merインデックス部分テーブル55は、「基準K-merのRead配列の番号」61、「基準K-merのRead配列における位置」62、「対象K-merのRead配列の番号」63、「対象K-merのRead配列における位置」64を含む。
【0054】
ここで、基準K-merとは、連想配列格納部43(43−0〜43−3)に格納されているK-merをいう。具体的には、基準K-merは、各プロセス(計算機40)において処理を実行する場合に、各プロセス(計算機40)でRead配列から1文字ずつずらして読み出して得られた同一のK-merのうち、最初に検出されたK-merのことである。
【0055】
対象K-merとは、各プロセス(計算機40)でRead配列から1文字ずつずらして読み出して得られた同一のK-merのうち、2番目以降に検出されたK-merのことである。
【0056】
「基準K-merのRead配列の番号」61及び「基準K-merのRead配列における位置」62には、連想配列格納部43(43−0〜43−3)に格納されているK-mer(基準K-mer)のRead配列の番号、及びそのRead配列における位置が格納される。
【0057】
「対象K-merのRead配列の番号」63、及び「対象K-merのRead配列における位置」64は、基準K-merの検出後に検出された、基準K-merと同一のK-mer(対象K-mer)のRead配列の番号、及びそのRead配列における位置が格納される。
【0058】
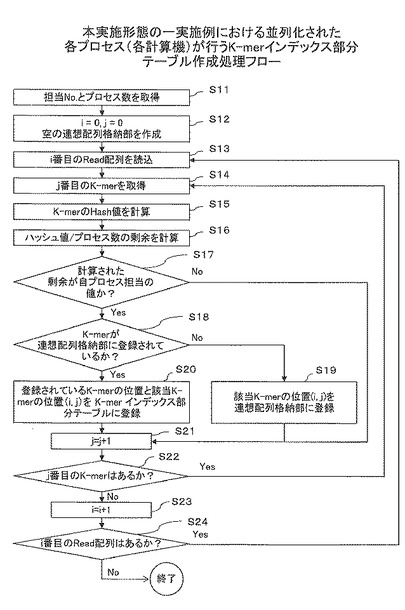
図9は、本実施形態の一実施例における並列化された各プロセス(各計算機)が行うK-merインデックス部分テーブル作成処理フローを示す。CPU41は、担当No.とプロセス数Pを取得する(S11)。本実施形態では、CPU41−1〜41−3は、計算機40−0にアクセスして、自身の計算機識別番号をキーとして担当管理テーブル44から自身の担当No.を取得し、担当管理テーブル44のエントリをカウントしてプロセス数Pを取得する。計算機40−0については、CPU41−0は、メモリ42−0にアクセスし、自身の計算機識別番号をキーとして担当管理テーブル44から自身の担当No.を取得し、担当管理テーブル44のエントリをカウントしてプロセス数Pを取得する。CPU41−0は、担当No.として値0を取得する。CPU41−1は、担当No.として値1を取得する。CPU41−2は、担当No.として値2を取得する。CPU41−3は、担当No.として値3を取得する。なお、担当No.とプロセス数Pは、各計算機40に予め設定しておいてもよい。なお、プロセス数Pは、本実施例では、4である。
【0059】
CPU41は、初期化処理を行う(S12)。すなわち、CPU41は、変数i=0、j=0を設定すると共に、空の連想配列格納部43を作成する。
【0060】
CPU41は、ストレージ装置50の共有ディスク53にアクセスし、i番目のRead配列54を読み込む(S13)。それから、CPU41は、そのi番目のRead配列におけるj番目のK-merを取得する(S14)。
【0061】
CPU41は、予めメモリ42に展開したハッシュ関数を用いて、取得したK-merのハッシュ値Hを算出する(S15)。CPU41は、算出したハッシュ値Hをプロセス数Pで割って得られる剰余を算出する(S16)。
【0062】
CPU41は、得られた剰余が、担当No.と等しいか否かを判定する(S17)。得られた剰余が担当No.と等しくない場合(S17で「No」)、S21の処理に進む。得られた剰余が担当No.と等しい場合(S17で「Yes」)、CPU41は、その取得したK-merが連想配列格納部43に登録されているか否かを判定する(S18)。
【0063】
その取得したK-merが連想配列格納部43に登録されていない場合(S18で「No」)、CPU41は、その取得したK-mer(基準K-mer)の位置(i,j)を、連想配列格納部43に登録する(S19)。
【0064】
その取得したK-merが連想配列格納部43に登録されている場合(S18で「Yes」)、CPU41は、次の処理を行う。CPU41は、取得したK-mer(対象K-mer)の位置(i,j)と、連想配列格納部43に登録されているK-mer(基準K-mer)の位置とを関係付けて、ストレージ装置50の共有ディスク53内のK-merインデックス部分テーブル55に登録する(S20)。K-merインデックス部分テーブル55は、ストレージ装置50の共有ディスク53内に計算機40毎に構築される。
【0065】
S17で「No」の場合、またはS20もしくはS21の終了後、CPU41は、変数jをインクリメントする(S21)。CPU41は、そのi番目のRead配列におけるj番目のK-merが存在するか否かを判定する(S22)。
【0066】
そのi番目のRead配列におけるj番目のK-merが存在する場合(S22で「Yes」)、S14の処理へ戻る。そのi番目のRead配列におけるj番目のK-merが存在しない場合(S22で「No」)、CPU41は、変数iをインクリメントする(S23)。
【0067】
CPU41は、i番目のRead配列が存在するか否かを判定する(S24)。i番目のRead配列が存在する場合(S24で「Yes」)、S14の処理へ戻る。i番目のRead配列が存在しない場合(S24で「No」)、本フローは終了する。
【0068】
これにより、各プロセス(各計算機40)で作成されたK-merインデックス部分テーブル55が、ストレージ装置50の共有ディスク53内に格納される。
【0069】
計算機40−0は、ストレージ装置50の共有ディスク53内にある各プロセス(各計算機40)で作成されたK-merインデックス部分テーブル55を連結して、K-merインデックステーブル56を作成し、共有ディスク53に格納する。
【0070】
なお、S20において、CPU41は、対象K-merの位置と、基準K-merの位置とを関係付けて、ストレージ装置50の共有ディスク53内の、対応するK-merインデックス部分テーブル55に登録したが、これに限定されない。例えば、各CPU41は、対象K-merの位置と、基準K-merの位置とを関係付けて、ストレージ装置50の共有ディスク53内の、共有のK-merインデックステーブル55に登録するようにしてもよい。この場合、K-merインデックステーブル55を管理するDBMS(DataBase Management System)によって、K-merインデックステーブル55に対する各計算機40からのエントリの追加処理が制御される。
【0071】
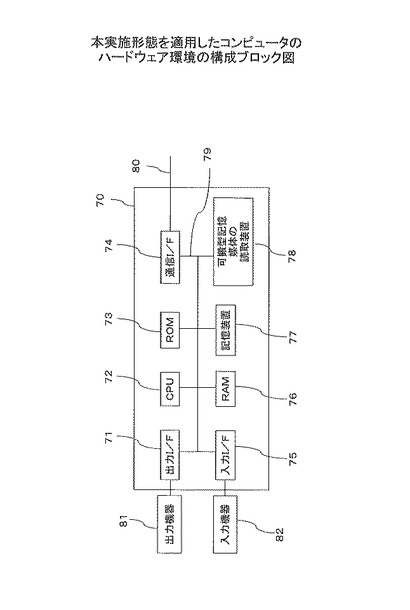
図10は、本実施形態を適用したコンピュータのハードウェア環境の構成ブロック図である。コンピュータ70は、本実施形態の処理を行うプログラムを読み込むことにより、アセンブリング前処理装置10、または計算機40として機能する。
【0072】
コンピュータ70は、出力I/F71、CPU72、ROM73、通信I/F74、入力I/F75、RAM76、記憶装置77、読み取り装置78、バス79を含む。コンピュータ70は、出力機器81、及び入力機器82と接続可能である。
【0073】
ここで、CPUは、中央演算装置を示す。ROMは、リードオンリメモリを示す。RAMは、ランダムアクセスメモリを示す。I/Fは、インターフェースを示す。バス79には、出力I/F71、CPU72、ROM73、通信I/F74、入力I/F75、RAM76、記憶装置77、読み取り装置78が接続されている。読み取り装置78は、可搬型記録媒体を読み出す装置である。出力機器81は、出力I/F71に接続されている。入力機器82は、入力I/F75に接続されている。
【0074】
記憶装置77としては、ハードディスクドライブ、フラッシュメモリ装置、磁気ディスク装置など様々な形式の記憶装置を使用することができる。
【0075】
記憶装置77またはROM73には、例えば、本実施形態で説明した処理を実現するアセンブリング前処理プログラム、連想配列格納部43が格納されている。また、記憶装置77またはROM73は、担当管理テーブル、Read配列、K-merインデックス部分テーブル55、K-merインデックステーブル56等を記憶することもできる。
【0076】
CPU72は、記憶装置77等に格納した本実施形態で説明した処理を実現するプログラムを読み出し、当該プログラムを実行する。具体的には、CPU72は、当該プログラムを実行することにより、取得部11、担当判定部12、登録部15として機能する。
【0077】
本実施形態で説明した処理を実現するプログラムは、プログラム提供者側から通信ネットワーク80、および通信I/F74を介して、例えば記憶装置77に格納してもよい。また、本実施形態で説明した処理を実現するプログラムは、市販され、流通している可搬型記憶媒体に格納されていてもよい。この場合、この可搬型記憶媒体は読み取り装置78にセットされて、CPU72によってそのプログラムが読み出されて、実行されてもよい。可搬型記憶媒体としてはCD−ROM、フレキシブルディスク、光ディスク、光磁気ディスク、IC(integrated circuit)カード、USB(Universal Serial Bus)メモリ装置など様々な形式の記憶媒体を使用することができる。このような記憶媒体に格納されたプログラムが読み取り装置78によって読み取られる。
【0078】
また、入力機器82には、キーボード、マウス、電子カメラ、ウェブカメラ、マイク、スキャナ、センサ、タブレット、タッチパネルなどを用いることが可能である。また、出力機器81には、ディスプレイ、プリンタ、スピーカなどを用いることが可能である。また、ネットワーク80は、インターネット、LAN、WAN、専用線、有線、無線等の通信網であってよい。
【0079】
なお、本実施形例では、シングルプロセッサを有する計算機を用いて、アセンブリング前処理を行ったが、マルチプロセッサを有する計算機を用いてアセンブリング前処理を行ってもよい。
【0080】
本実施形態によれば、コンピュータクラスタ等の分散メモリ型のコンピュータシステムを用いて、K-merインデックステーブル作成のプロセスを並列化することができる。これにより、CPU当たりのメモリ消費量を削減することができる。また、CPU当たりの処理するK-merの数が削減される。ハッシュ値が完全に分散していることを条件に、プロセス数に比例して実行時間の短縮を図ることができる。また、各プロセスが完全に独立しているので、プロセス間においてリソースの競合の発生を回避することができる。これにより、処理速度の低下を防止することができる。また、あるコンピュータから複数のコンピュータに対して、各コンピュータが担当するK-merを振り分ける処理がないので、当該振分処理によるボトルネックの問題も生じない。
【0081】
なお、本実施形態は、以上に述べた実施の形態に限定されるものではなく、本実施形態の要旨を逸脱しない範囲内で種々の構成または実施形態を取ることができる。
【符号の説明】
【0082】
10 アセンブリング前処理装置
11 取得部
12 担当判定部
13 算出部
14 剰余判定部
15 登録部
16 部分配列判定部
17 配列位置登録部
18 連想配列格納部
20 配列位置格納部
21 生体配列情報
40(40−0〜40−3) 計算機
41(41−0〜41−3) CPU
42(42−0〜42−3) メモリ
43(43−0〜43−3) 連想配列格納部
44 担当管理テーブル
50 ストレージ装置
51 CPU
52 メモリ
53 共有ディスク
54 Read配列
55 K-merインデックス部分テーブル
56 K-merインデックステーブル
57 ネットワーク
【技術分野】
【0001】
本実施形態の一側面は、配列アセンブリングの前処理技術に関する。
【背景技術】
【0002】
配列アセンブリングとは、バイオインフォマティクスにおいて短い塩基配列の断片から元の長い塩基配列を再構築することをいう。配列アセンブリングの1つに、De novo アセンブル(assemble)がある。De novo アセンブリとは、シーケンサ装置が出力したDNA(デオキシリボ核酸)、RNA(リボ核酸)等の生物配列(以下、「Read配列」と称する)を繋ぎ合わせて(assemble)、元の生物配列を再構築することをいう。ここで、シーケンサ装置とは、DNA/ RNA等の塩基配列を自動的に読み取る装置である。
【0003】
アセンブル手法として、例えば、De Bruijn Graphによるアセンブルがある。De Bruijn Graphによるアセンブルでは、まず、Read配列をある長さの断片に細切れにした配列(生物配列断片)を生成する。以下では、生物配列断片を、「K-mer」と称する。次に、K-merからDe Bruijn Graphを作成する。そして、このDe Bruijn Graphについて、オイラーパス問題を解く(すなわち、De Bruijn Graphの全辺を通るパスを求める)。
【0004】
De Bruijn Graphを作成する前処理として、K-merがRead配列のどこに存在するのかを管理するK-merインデックステーブルが作成されるが、正確なアセンブル処理を行うには、大量のRead配列を用いる。したがって、コンピュータを用いて、De Bruijn Graphを作成する場合、その前処理に用いるK-merインデックステーブルの作成に、大量のメモリ容量が消費される。
【0005】
ところで、大量のデータを複数のサーバを用いて処理する技術の1つに、分散KVS(キーバリュー型データストア : Key-Value Store)がある。分散KVSとは、キーと値からなる比較的単純な構造の連想配列を、多数のサーバで高速に処理するデータストアを示す。分散KVSでは、KVSクライアント装置が、キーの値に応じて、保存先のサーバ装置(KVSサーバ)を変えることで、複数のサーバに分散してデータを保存する。これにより、分散KVSでは、大量のデータをスケールアウト型で扱うことができる。
【先行技術文献】
【非特許文献】
【0006】
【非特許文献1】Daniel R. Zerbino and Ewan Birney “Velvet: Algorithms for de novo short read assembly using de Bruijn graph”, Genome Res., 2008 18: 821-829
【非特許文献2】“MEMCACHED”、[online] 、[平成23年11月15日検索]、インターネット、<http://memcached.org/>
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述したように、コンピュータを用いて、De Bruijn Graphを作成する場合、その前処理に用いるK-merインデックステーブルの作成に際して、例えば、数十〜数百ギガバイトのオーダで大量のメモリ容量が消費される。したがって、そのような膨大なデータを処理するために、処理時間が長くなる。
【0008】
また、分散KVSを用いて、複数のKVSサーバにK-merインデックステーブルの作成を実行させる場合でも、KVSクライアントにそれらのKVSサーバに処理を分散させる処理が集中する。そのため、KVSクライアントでの分散処理がボトルネックとなり、処理の高速化を図ることができない可能性がある。
【0009】
そこで、本実施形態の一側面によれば、生物配列断片のインデックス作成処理の高速化を図る情報処理装置を提供する。
【課題を解決するための手段】
【0010】
本実施形態の一側面にかかるアセンブリング前処理装置は、取得部、担当判定部、登録部を含む。取得部は、生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得する。担当判定部は、アセンブリング前処理を実行するプロセスが部分配列情報に関するアセンブリング前処理を担当するか否かを判定する。登録部は、プロセスが部分配列情報に関するアセンブリング前処理を担当すると判定された場合、生物配列情報における部分配列情報の位置を示す位置情報を配列位置格納部に登録する。
【発明の効果】
【0011】
本実施形態の一側面によれば、生物配列断片のインデックス作成処理の高速化を図ることができる。
【図面の簡単な説明】
【0012】
【図1】K-merインデックステーブルを説明するための図である。
【図2】K-merインデックステーブルの作成を説明するための図(その1)である。
【図3】K-merインデックステーブルの作成を説明するための図(その2)である。
【図4】本実施形態におけるアセンブリング前処理装置の構造の一例を示す。
【図5】本実施形態における複数のプロセスによる並列処理を実現する方法の一例を示す。
【図6】本実施形態におけるK-merインデックス作成処理の全体のフローを示す。
【図7】本実施形態の一実施例におけるアセンブリング前処理システムの一例を示す。
【図8】本実施形態の一実施例におけるK-merインデックス部分テーブル及びK-merインデックステーブルのデータ構造を示す。
【図9】本実施形態の一実施例における並列化された各プロセス(各計算機)が行うK-merインデックス部分テーブル作成処理フローを示す。
【図10】本実施形態を適用したコンピュータのハードウェア環境の構成ブロック図である。
【発明を実施するための形態】
【0013】
図1は、K-merインデックステーブルを説明するための図である。図1の例では、Read配列は、上段より、Read配列0、Read配列1、Read配列3、Read配列4、・・・で示される。Read配列は、位置0〜位置27までの28個の塩基配列で表される。ここで、「A」はアデニンを示す。「G」はグアニンを示す。「T」は、チミンを示す。「C」は、シトシンを示す。
【0014】
K-mer n(n=0,1,2,・・・)は、Read配列を1文字ずらしで長さKの文字列に区切った部分配列である。例えば、K-mer0は、Read配列0の位置0から6文字切り取った部分配列である。K-mer1は、Read配列0の位置1から6文字切り取った部分配列である。K-mer2は、Read配列0の位置2から6文字切り取った部分配列である。
【0015】
このように、i番目のRead配列およびそのRead配列のj番目の位置によって、K-merがどのRead配列のどの場所に存在するかを特定することができる。このように、各K-merがどのRead配列のどの場所に存在するかの情報を保持するテーブルが、K-merインデックステーブルである。
【0016】
図2及び図3は、K-merインデックステーブルの作成を説明するための図である。コンピュータを用いて、K-merインデックステーブルを作成する場合について考える。この場合、CPU(Central Processing Unit)は、Read配列を読み込むと、図2に示すように、Read配列の先頭から順次K-merを取得する。CPUは、順次取得したK-merをキーとし、K-merの位置情報(Read:i、Position:j)を値として、連想配列格納部に格納していく。ここで、位置情報(Read:i、Position:j)は、i番目のRead配列、およびそのRead配列のj番目の位置を示す。また、連想配列格納部はコンピュータ上のメモリに配置される。
【0017】
例えば、K-mer0の場合、キーとして「ACGTGT」が格納され、値として「Read:0、Position:0」が格納される。例えば、K-mer1の場合、キーとして「CGTGTT」が格納され、値として「Read:0、Position:1」が格納される。例えば、K-mer2の場合、キーとして「GTGTTC」が格納され、値として「Read:0、Position:2」が格納される。
【0018】
図3に示すように、Read配列から取得したK-mer(対象K-mer)と同一のK-mer(基準K-mer)が連想配列格納部に既に存在していた場合、CPUはK-merインデックステーブルに、基準K-merの位置情報と対象K-merの位置情報を関係付けて登録する。
【0019】
例えば、「Read:0、Position:15」にあるK-mer「CGTGTT」を連想配列格納部に格納する場合について考える。この場合、K-mer「CGTGTT」は既に連想配列格納部に登録されているので、「Read:0, Position: 15」のK-merが「Read:0, Position: 1」のK-merと同一であることを示す情報をK-merインデックステーブルに登録する。
【0020】
このようにして、連想配列格納部及びK-merインデックステーブルが作成される。
ところが、Read配列が大量に存在する場合、K-merも大量になり、大量のK-merを処理することになる。その結果、連想配列格納部が肥大化し、コンピュータ上のメモリを大量に消費することになる。また、コンピュータの処理量も増加するので、処理時間が長くなる可能性もある。
【0021】
そこで、処理時間を短縮させるために、CPUの処理効率を向上させることが考えられる。例えば、複数のスレッドが同時に動作するマルチスレッド方式を用いた場合には、各スレッドが、自身が担当するRead配列について処理を行う。
【0022】
しかしながら、マルチスレッド方式の場合、各スレッドは、同一プロセス内で動作しているため、メモリ空間を共有している。したがって、複数のスレッドは、共有メモリ上にある同一の連想配列格納部を更新することになる。そのため、例えば、連想配列格納部において、同じキーを有するエントリを更新する場合にはスレッド間の競合が生じるので、排他制御を行う。排他制御とは、あるスレッドに資源を独占的に利用させている間は、他のスレッドが利用できないようにする事で整合性を保つ処理をいう。
【0023】
排他制御の結果、あるスレッドが資源を利用している間は、競合する他のスレッドはその利用が終了するまで待つことになり、待ち時間が発生する。そのため、処理時間が遅延する。
【0024】
また、複数のスレッドを用いて処理をしても、各スレッドはプロセスメモリ空間を共有するため、プロセスメモリ空間を分離できない。したがって、プロセス当たりのメモリ使用量は変わらない。
【0025】
そこで、プロセス当たりの処理量を軽減させる方法の1つとして、分散KVSを利用することが考えられる。しかしながら、分散KVSを用いて、複数のKVSサーバにK-merインデックステーブルの作成を実行させる場合でも、KVSクライアントにそれらのKVSサーバに処理を分散させる処理が集中する。そのため、KVSクライアントがボトルネックとなり、処理の高速化を図ることができない可能性がある。
【0026】
そこで、本実施形態では、以下に説明するように、生物配列断片のインデックス作成処理の高速化を図る情報処理装置を提供する。
【0027】
図4は、本実施形態におけるアセンブリング前処理装置の構造の一例を示す。アセンブリング前処理装置10は、複数存在する。アセンブリング前処理装置10は、取得部11、担当判定部12、登録部15を含む。
【0028】
取得部11は、生物配列情報21の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報(K-mer)を1文字ずつずらして取得する。取得部11の一例として、図9のS13、S14の処理がある。生物配列情報21は、シーケンサ装置が出力したDNA/ RNA等の生物配列(Read配列)である。
【0029】
担当判定部12は、アセンブリング前処理を実行するプロセスが部分配列情報に関するアセンブリング前処理を担当するか否かを判定する。担当判定部12の一例として、図9のS15〜S17の処理がある。
【0030】
登録部15は、プロセスが部分配列情報に関するアセンブリング前処理を担当すると判定された場合、生物配列情報21における部分配列情報の位置を示す位置情報を配列位置格納部20に登録する。登録部15の一例として、図9のS18、S20の処理がある。
【0031】
このように構成することにより、各プロセスは、自身の担当するK-merを対象にしてK-merインデックステーブルを作成することができるので、プロセス当たりの処理量が減少すると共に、処理の並列化を図ることができる。したがって、生物配列断片のインデックス作成処理の高速化を図ることができる。
【0032】
担当判定部12は、算出部13、剰余判定部14を含む。
算出部13は、部分配列情報のハッシュ値を算出し、ハッシュ値を第1の値で割ったときの剰余値を算出する。第1の値は、アセンブリング前処理装置の数、またはプロセス数を示す。ここでのプロセスとは、取得部11、算出部12、剰余判定部13、部分配列判定部14、及び登録部15により実行される一連の処理を実行するプロセスを示す。算出部13の一例として、図9のS15、S16の処理がある。
【0033】
剰余判定部14は、算出した剰余値が、第2の値であるか否かを判定する。剰余判定部14の一例として、図9のS17の処理がある。
【0034】
このように構成することにより、K-merにより一意に処理を担当するプロセスが決定され、同一のK-merは、同一のプロセスにより処理することができる。
【0035】
登録部15は、部分配列判定部16を含む。部分配列判定部16は、算出した剰余値が第2の値であると判定された場合、取得した部分配列情報が、部分配列をキーとする連想配列を格納する連想配列格納部18に登録されているか否かを判定する。部分配列判定部16の一例として、図9のS18の処理がある。連想配列格納部18の一例として、連想配列格納部43がある。
【0036】
このように構成することにより、K-merインデックステーブル作成のために用いる連想配列を作成することができる。また、プロセス単位で連想配列格納部へK-merを登録することができるので、マルチスレッド方式を採用した場合の競合の問題も生じない。
【0037】
登録部15は、配列位置登録部17を含む。配列位置登録部17は、部分配列情報が連想配列格納部18に登録されている場合、生物配列情報における部分配列情報の位置情報と、連想配列格納部に登録されている部分配列情報の生物配列情報21における位置情報とを関係付けて配列位置格納部20に登録する。配列位置登録部17の一例として、S19の処理がある。配列位置格納部20の一例として、例えば、K-merインデックステーブル56がある。
【0038】
このように構成することにより、K-merインデックステーブルを作成することができる。
【0039】
図5は、本実施形態における複数のプロセスによる並列処理を実現する方法の一例を示す。各プロセスは、ハッシュ関数を用いて、生体配列から読み出したK-merのハッシュ値を算出する。各プロセスは、そのハッシュ値をプロセス数で割った剰余に応じて、自身がそのK-merについてのK-merインデックステーブル作成処理を担当するか否かを判定する。そのプロセスがそのK-merについてのK-merインデックステーブル作成処理を担当すると判定した場合、そのプロセスは、そのK-merについてのK-merインデックステーブル作成処理を行う。これにより、K-merのハッシュ値をプロセス数で割った剰余に応じて、K-merについてのK-merインデックステーブル作成処理を担当するプロセスを動作させることができる。
【0040】
例えば、図5に示すように、K-merインデックステーブル作成処理を4つのプロセスで行うとする。K-merインデックステーブル作成処理では、各プロセスは、自身が担当するK-merであると判定した場合、そのK-merが連想配列格納部に登録されていなければ、そのK-merを連想配列格納部に登録する。
【0041】
各プロセスは、自身が担当するK-merであると判定した場合、そのK-merが連想配列格納部に登録されていれば、次の処理を行う。すなわち、そのプロセスは、K-merインデックステーブルにK-merの位置情報と、連想配列格納部21に登録されているK-merの位置情報を関係付けて登録する。
【0042】
なお、各プロセスは、自身の担当するK-merを判別するために、予め固有の値(担当No.)を保持している。例えば、図5の場合、プロセス0は、値0を有している。プロセス1は、値1を有している。プロセス2は、値2を有している。プロセス3は、値3を有している。K-merのハッシュ値をプロセス数で割った剰余が、各プロセスが予め有している値と同じであれば、そのプロセスがそのK-merについてのK-merインデックステーブル作成処理を担当する。
【0043】
例えば、図5において、各プロセスは、Read配列からK-mer nを読み出し、ハッシュ関数を用いてK-mer nのハッシュ値を計算し、計算したハッシュ値を4で割った場合の剰余を計算する。剰余が0である場合、プロセス0がそのK-mer nについてのK-merインデックステーブル作成を担当する。
【0044】
担当プロセスを決定するときの指標は、K-merのハッシュ値をプロセス数で割って得られる剰余以外でも、次の条件を満たせばよい。その条件とは、(1)K-merにより一意の値が決まる、(2)担当プロセスが少なくとも1つ存在する、(3)K-merがノード毎に十分に分散(一様分布に近ければ近いほどよい)である。
【0045】
図6は、本実施形態におけるK-merインデックス作成処理の全体のフローを示す。上述の通り、各プロセスは、予め担当No.を有している。例えば、図6の場合、プロセス0(31−0)は、担当No.として値0を有している。プロセス1(31−1)は、担当No.として値1を有している。プロセス2(31−2)は、担当No.として値2を有している。プロセス3(31−3)は、担当No.として値3を有している。
【0046】
各プロセス0〜3(31−0〜31−3)は、Read配列30を読み込み、K-merインデックス部分テーブル作成処理S1(S1−0〜S1−3)を行う。ここで、K-merインデックス部分テーブル作成処理S1とは、次の処理をいう。すなわち、各プロセスは、Read配列30から読み出したK-merのハッシュ値をハッシュ関数を用いて算出する。そのハッシュ値をプロセス数で割った剰余に応じて、そのプロセスが、自身が担当するK-merについての処理であるかを判定する。そのプロセスが担当するK-merについての処理であると判定した場合、そのプロセスは、そのK-merが連想配列格納部に登録されていなければ、そのK-merを連想配列格納部に登録する。そのK-merが連想配列格納部に登録されていなければ、そのプロセスは、次の処理を行う。すなわち、そのプロセスは、K-merインデックス部分テーブル32(32−0〜32−3)にK-merの位置情報と、連想配列格納部に登録されているK-merの位置情報を関係付けて登録する。
【0047】
各プロセス0〜3において、K-merインデックス部分テーブル作成処理S1(S1−0〜S1−3)の終了後、特定のプロセスは、次の処理を行う。すなわち、特定のプロセスは、各プロセスで作成されたK-merインデックス部分テーブルを連結して、K-merインデックステーブル33を作成する(コンカーチネート処理S2)。なお、特定のプロセスは、プロセス0〜3のいずれかでもよいし、プロセス0〜3とは別のプロセスでもよい。
【0048】
図7は、本実施形態の一実施例におけるアセンブリング前処理システムの一例を示す。アセンブリング前処理システムは、計算機40(40−0〜40−3)及びストレージ装置50を含む。計算機40(40−0〜40−3)及びストレージ装置50は、ネットワーク57で接続されている。
【0049】
計算機40は、CPU41(41−0〜41−3)、メモリ42(42−0〜42−3)を含む。CPU41は、計算機全体の動作を制御する。メモリ42は、データを格納する記憶装置である。メモリ42(42−0〜42−3)は、連想配列格納部43(43−0〜43−3)を保持する。
【0050】
計算機40−0のメモリ42−0は、さらに、担当管理テーブル44を保持する。担当管理テーブル44は、担当No.と、各計算機40−0を識別する計算機識別情報とが関係付けられて格納されている。なお、担当管理テーブル44のエントリをカウントすれば、プロセス数を得ることができる。
【0051】
ストレージ装置50は、CPU51、メモリ52、共有ディスク53を含む。CPU51は、ストレージ装置50全体の動作を制御する。メモリ52は、データを格納する記憶装置である。共有ディスク53は、ネットワーク57を介して、計算機40−0〜40−3が共有で利用する大容量記憶装置である。共有ディスク53は、Read配列54、K-merインデックス部分テーブル55、K-merインデックステーブル56を格納する。
【0052】
図8は、本実施形態の一実施例におけるK-merインデックス部分テーブル及びK-merインデックステーブルのデータ構造を示す。K-merインデックス部分テーブル55及びK-merインデックステーブル56のデータ構造は同一であるので、以下では、K-merインデックス部分テーブル55について説明する。
【0053】
K-merインデックス部分テーブル55は、「基準K-merのRead配列の番号」61、「基準K-merのRead配列における位置」62、「対象K-merのRead配列の番号」63、「対象K-merのRead配列における位置」64を含む。
【0054】
ここで、基準K-merとは、連想配列格納部43(43−0〜43−3)に格納されているK-merをいう。具体的には、基準K-merは、各プロセス(計算機40)において処理を実行する場合に、各プロセス(計算機40)でRead配列から1文字ずつずらして読み出して得られた同一のK-merのうち、最初に検出されたK-merのことである。
【0055】
対象K-merとは、各プロセス(計算機40)でRead配列から1文字ずつずらして読み出して得られた同一のK-merのうち、2番目以降に検出されたK-merのことである。
【0056】
「基準K-merのRead配列の番号」61及び「基準K-merのRead配列における位置」62には、連想配列格納部43(43−0〜43−3)に格納されているK-mer(基準K-mer)のRead配列の番号、及びそのRead配列における位置が格納される。
【0057】
「対象K-merのRead配列の番号」63、及び「対象K-merのRead配列における位置」64は、基準K-merの検出後に検出された、基準K-merと同一のK-mer(対象K-mer)のRead配列の番号、及びそのRead配列における位置が格納される。
【0058】
図9は、本実施形態の一実施例における並列化された各プロセス(各計算機)が行うK-merインデックス部分テーブル作成処理フローを示す。CPU41は、担当No.とプロセス数Pを取得する(S11)。本実施形態では、CPU41−1〜41−3は、計算機40−0にアクセスして、自身の計算機識別番号をキーとして担当管理テーブル44から自身の担当No.を取得し、担当管理テーブル44のエントリをカウントしてプロセス数Pを取得する。計算機40−0については、CPU41−0は、メモリ42−0にアクセスし、自身の計算機識別番号をキーとして担当管理テーブル44から自身の担当No.を取得し、担当管理テーブル44のエントリをカウントしてプロセス数Pを取得する。CPU41−0は、担当No.として値0を取得する。CPU41−1は、担当No.として値1を取得する。CPU41−2は、担当No.として値2を取得する。CPU41−3は、担当No.として値3を取得する。なお、担当No.とプロセス数Pは、各計算機40に予め設定しておいてもよい。なお、プロセス数Pは、本実施例では、4である。
【0059】
CPU41は、初期化処理を行う(S12)。すなわち、CPU41は、変数i=0、j=0を設定すると共に、空の連想配列格納部43を作成する。
【0060】
CPU41は、ストレージ装置50の共有ディスク53にアクセスし、i番目のRead配列54を読み込む(S13)。それから、CPU41は、そのi番目のRead配列におけるj番目のK-merを取得する(S14)。
【0061】
CPU41は、予めメモリ42に展開したハッシュ関数を用いて、取得したK-merのハッシュ値Hを算出する(S15)。CPU41は、算出したハッシュ値Hをプロセス数Pで割って得られる剰余を算出する(S16)。
【0062】
CPU41は、得られた剰余が、担当No.と等しいか否かを判定する(S17)。得られた剰余が担当No.と等しくない場合(S17で「No」)、S21の処理に進む。得られた剰余が担当No.と等しい場合(S17で「Yes」)、CPU41は、その取得したK-merが連想配列格納部43に登録されているか否かを判定する(S18)。
【0063】
その取得したK-merが連想配列格納部43に登録されていない場合(S18で「No」)、CPU41は、その取得したK-mer(基準K-mer)の位置(i,j)を、連想配列格納部43に登録する(S19)。
【0064】
その取得したK-merが連想配列格納部43に登録されている場合(S18で「Yes」)、CPU41は、次の処理を行う。CPU41は、取得したK-mer(対象K-mer)の位置(i,j)と、連想配列格納部43に登録されているK-mer(基準K-mer)の位置とを関係付けて、ストレージ装置50の共有ディスク53内のK-merインデックス部分テーブル55に登録する(S20)。K-merインデックス部分テーブル55は、ストレージ装置50の共有ディスク53内に計算機40毎に構築される。
【0065】
S17で「No」の場合、またはS20もしくはS21の終了後、CPU41は、変数jをインクリメントする(S21)。CPU41は、そのi番目のRead配列におけるj番目のK-merが存在するか否かを判定する(S22)。
【0066】
そのi番目のRead配列におけるj番目のK-merが存在する場合(S22で「Yes」)、S14の処理へ戻る。そのi番目のRead配列におけるj番目のK-merが存在しない場合(S22で「No」)、CPU41は、変数iをインクリメントする(S23)。
【0067】
CPU41は、i番目のRead配列が存在するか否かを判定する(S24)。i番目のRead配列が存在する場合(S24で「Yes」)、S14の処理へ戻る。i番目のRead配列が存在しない場合(S24で「No」)、本フローは終了する。
【0068】
これにより、各プロセス(各計算機40)で作成されたK-merインデックス部分テーブル55が、ストレージ装置50の共有ディスク53内に格納される。
【0069】
計算機40−0は、ストレージ装置50の共有ディスク53内にある各プロセス(各計算機40)で作成されたK-merインデックス部分テーブル55を連結して、K-merインデックステーブル56を作成し、共有ディスク53に格納する。
【0070】
なお、S20において、CPU41は、対象K-merの位置と、基準K-merの位置とを関係付けて、ストレージ装置50の共有ディスク53内の、対応するK-merインデックス部分テーブル55に登録したが、これに限定されない。例えば、各CPU41は、対象K-merの位置と、基準K-merの位置とを関係付けて、ストレージ装置50の共有ディスク53内の、共有のK-merインデックステーブル55に登録するようにしてもよい。この場合、K-merインデックステーブル55を管理するDBMS(DataBase Management System)によって、K-merインデックステーブル55に対する各計算機40からのエントリの追加処理が制御される。
【0071】
図10は、本実施形態を適用したコンピュータのハードウェア環境の構成ブロック図である。コンピュータ70は、本実施形態の処理を行うプログラムを読み込むことにより、アセンブリング前処理装置10、または計算機40として機能する。
【0072】
コンピュータ70は、出力I/F71、CPU72、ROM73、通信I/F74、入力I/F75、RAM76、記憶装置77、読み取り装置78、バス79を含む。コンピュータ70は、出力機器81、及び入力機器82と接続可能である。
【0073】
ここで、CPUは、中央演算装置を示す。ROMは、リードオンリメモリを示す。RAMは、ランダムアクセスメモリを示す。I/Fは、インターフェースを示す。バス79には、出力I/F71、CPU72、ROM73、通信I/F74、入力I/F75、RAM76、記憶装置77、読み取り装置78が接続されている。読み取り装置78は、可搬型記録媒体を読み出す装置である。出力機器81は、出力I/F71に接続されている。入力機器82は、入力I/F75に接続されている。
【0074】
記憶装置77としては、ハードディスクドライブ、フラッシュメモリ装置、磁気ディスク装置など様々な形式の記憶装置を使用することができる。
【0075】
記憶装置77またはROM73には、例えば、本実施形態で説明した処理を実現するアセンブリング前処理プログラム、連想配列格納部43が格納されている。また、記憶装置77またはROM73は、担当管理テーブル、Read配列、K-merインデックス部分テーブル55、K-merインデックステーブル56等を記憶することもできる。
【0076】
CPU72は、記憶装置77等に格納した本実施形態で説明した処理を実現するプログラムを読み出し、当該プログラムを実行する。具体的には、CPU72は、当該プログラムを実行することにより、取得部11、担当判定部12、登録部15として機能する。
【0077】
本実施形態で説明した処理を実現するプログラムは、プログラム提供者側から通信ネットワーク80、および通信I/F74を介して、例えば記憶装置77に格納してもよい。また、本実施形態で説明した処理を実現するプログラムは、市販され、流通している可搬型記憶媒体に格納されていてもよい。この場合、この可搬型記憶媒体は読み取り装置78にセットされて、CPU72によってそのプログラムが読み出されて、実行されてもよい。可搬型記憶媒体としてはCD−ROM、フレキシブルディスク、光ディスク、光磁気ディスク、IC(integrated circuit)カード、USB(Universal Serial Bus)メモリ装置など様々な形式の記憶媒体を使用することができる。このような記憶媒体に格納されたプログラムが読み取り装置78によって読み取られる。
【0078】
また、入力機器82には、キーボード、マウス、電子カメラ、ウェブカメラ、マイク、スキャナ、センサ、タブレット、タッチパネルなどを用いることが可能である。また、出力機器81には、ディスプレイ、プリンタ、スピーカなどを用いることが可能である。また、ネットワーク80は、インターネット、LAN、WAN、専用線、有線、無線等の通信網であってよい。
【0079】
なお、本実施形例では、シングルプロセッサを有する計算機を用いて、アセンブリング前処理を行ったが、マルチプロセッサを有する計算機を用いてアセンブリング前処理を行ってもよい。
【0080】
本実施形態によれば、コンピュータクラスタ等の分散メモリ型のコンピュータシステムを用いて、K-merインデックステーブル作成のプロセスを並列化することができる。これにより、CPU当たりのメモリ消費量を削減することができる。また、CPU当たりの処理するK-merの数が削減される。ハッシュ値が完全に分散していることを条件に、プロセス数に比例して実行時間の短縮を図ることができる。また、各プロセスが完全に独立しているので、プロセス間においてリソースの競合の発生を回避することができる。これにより、処理速度の低下を防止することができる。また、あるコンピュータから複数のコンピュータに対して、各コンピュータが担当するK-merを振り分ける処理がないので、当該振分処理によるボトルネックの問題も生じない。
【0081】
なお、本実施形態は、以上に述べた実施の形態に限定されるものではなく、本実施形態の要旨を逸脱しない範囲内で種々の構成または実施形態を取ることができる。
【符号の説明】
【0082】
10 アセンブリング前処理装置
11 取得部
12 担当判定部
13 算出部
14 剰余判定部
15 登録部
16 部分配列判定部
17 配列位置登録部
18 連想配列格納部
20 配列位置格納部
21 生体配列情報
40(40−0〜40−3) 計算機
41(41−0〜41−3) CPU
42(42−0〜42−3) メモリ
43(43−0〜43−3) 連想配列格納部
44 担当管理テーブル
50 ストレージ装置
51 CPU
52 メモリ
53 共有ディスク
54 Read配列
55 K-merインデックス部分テーブル
56 K-merインデックステーブル
57 ネットワーク
【特許請求の範囲】
【請求項1】
生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得する取得部と、
アセンブリング前処理を実行するプロセスが前記部分配列情報に関するアセンブリング前処理を担当するか否かを判定する担当判定部と、
前記プロセスが前記部分配列情報に関するアセンブリング前処理を担当すると判定された場合、前記生物配列情報における前記部分配列情報の位置を示す位置情報を配列位置格納部に登録する登録部と、
を備えることを特徴とするアセンブリング前処理装置。
【請求項2】
前記担当判定部は、
前記部分配列情報のハッシュ値を算出し、前記ハッシュ値を第1の値で割ったときの剰余値を算出する算出部と、
算出した前記剰余値が、第2の値であるか否かを判定する剰余判定部と、
を備えることを特徴とする請求項1に記載のアセンブリング前処理装置。
【請求項3】
前記登録部は、
前記算出した前記剰余値が前記第2の値であると判定された場合、前記取得した部分配列情報が、該部分配列をキーとする連想配列を格納する連想配列格納部に登録されているか否かを判定する部分配列判定部と、
を備えることを特徴とする請求項2に記載のアセンブリング前処理装置。
【請求項4】
前記登録部は、さらに、
前記部分配列情報が前記連想配列格納部に登録されている場合、前記生物配列情報における該部分配列情報の位置情報と、該連想配列格納部に登録されている部分配列情報の前記生物配列情報における位置情報と、を関係付けて前記配列位置格納部に登録する配列位置登録部
を備えることを特徴とする請求項3に記載のアセンブリング前処理装置。
【請求項5】
コンピュータに、
生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得し、
アセンブリング前処理を実行するプロセスが前記部分配列情報に関するアセンブリング前処理を担当するか否かを判定し、
前記プロセスが前記部分配列情報に関するアセンブリング前処理を担当すると判定された場合、前記生物配列情報における前記部分配列情報の位置を示す位置情報を配列位置格納部に登録する、
処理を実行させるアセンブリング前処理プログラム。
【請求項6】
アセンブリング前処理を担当するか否かの判定において、前記コンピュータは、
前記部分配列情報のハッシュ値を算出し、前記ハッシュ値を第1の値で割ったときの剰余値を算出し、
算出した前記剰余値が、第2の値であるか否かを判定する
処理を実行させる請求項5に記載のアセンブリング前処理プログラム。
【請求項7】
前記登録する処理において、前記コンピュータは、
前記算出した前記剰余値が前記第2の値であると判定された場合、前記取得した部分配列情報が、該部分配列をキーとする連想配列を格納する連想配列格納部に登録されているか否かを判定する
処理を実行させる請求項6に記載のアセンブリング前処理プログラム。
【請求項8】
前記登録する処理において、前記コンピュータは、
前記部分配列情報が前記連想配列格納部に登録されている場合、前記生物配列情報における該部分配列情報の位置情報と、該連想配列格納部に登録されている部分配列情報の前記生物配列情報における位置情報と、を関係付けて前記配列位置格納部に登録する
処理を実行させる請求項6に記載のアセンブリング前処理プログラム。
【請求項9】
アセンブリングの前処理を複数のコンピュータで実行するコンピュータクラスタシステムの制御方法であって、
前記複数のコンピュータのそれぞれは、
生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得し、
アセンブリング前処理を実行するプロセスが前記部分配列情報に関するアセンブリング前処理を担当するか否かを判定し、
前記プロセスが前記部分配列情報に関するアセンブリング前処理を担当すると判定された場合、前記生物配列情報における前記部分配列情報の位置を示す位置情報を配列位置格納部に登録する
ことを特徴とするコンピュータクラスタシステムの制御方法。
【請求項1】
生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得する取得部と、
アセンブリング前処理を実行するプロセスが前記部分配列情報に関するアセンブリング前処理を担当するか否かを判定する担当判定部と、
前記プロセスが前記部分配列情報に関するアセンブリング前処理を担当すると判定された場合、前記生物配列情報における前記部分配列情報の位置を示す位置情報を配列位置格納部に登録する登録部と、
を備えることを特徴とするアセンブリング前処理装置。
【請求項2】
前記担当判定部は、
前記部分配列情報のハッシュ値を算出し、前記ハッシュ値を第1の値で割ったときの剰余値を算出する算出部と、
算出した前記剰余値が、第2の値であるか否かを判定する剰余判定部と、
を備えることを特徴とする請求項1に記載のアセンブリング前処理装置。
【請求項3】
前記登録部は、
前記算出した前記剰余値が前記第2の値であると判定された場合、前記取得した部分配列情報が、該部分配列をキーとする連想配列を格納する連想配列格納部に登録されているか否かを判定する部分配列判定部と、
を備えることを特徴とする請求項2に記載のアセンブリング前処理装置。
【請求項4】
前記登録部は、さらに、
前記部分配列情報が前記連想配列格納部に登録されている場合、前記生物配列情報における該部分配列情報の位置情報と、該連想配列格納部に登録されている部分配列情報の前記生物配列情報における位置情報と、を関係付けて前記配列位置格納部に登録する配列位置登録部
を備えることを特徴とする請求項3に記載のアセンブリング前処理装置。
【請求項5】
コンピュータに、
生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得し、
アセンブリング前処理を実行するプロセスが前記部分配列情報に関するアセンブリング前処理を担当するか否かを判定し、
前記プロセスが前記部分配列情報に関するアセンブリング前処理を担当すると判定された場合、前記生物配列情報における前記部分配列情報の位置を示す位置情報を配列位置格納部に登録する、
処理を実行させるアセンブリング前処理プログラム。
【請求項6】
アセンブリング前処理を担当するか否かの判定において、前記コンピュータは、
前記部分配列情報のハッシュ値を算出し、前記ハッシュ値を第1の値で割ったときの剰余値を算出し、
算出した前記剰余値が、第2の値であるか否かを判定する
処理を実行させる請求項5に記載のアセンブリング前処理プログラム。
【請求項7】
前記登録する処理において、前記コンピュータは、
前記算出した前記剰余値が前記第2の値であると判定された場合、前記取得した部分配列情報が、該部分配列をキーとする連想配列を格納する連想配列格納部に登録されているか否かを判定する
処理を実行させる請求項6に記載のアセンブリング前処理プログラム。
【請求項8】
前記登録する処理において、前記コンピュータは、
前記部分配列情報が前記連想配列格納部に登録されている場合、前記生物配列情報における該部分配列情報の位置情報と、該連想配列格納部に登録されている部分配列情報の前記生物配列情報における位置情報と、を関係付けて前記配列位置格納部に登録する
処理を実行させる請求項6に記載のアセンブリング前処理プログラム。
【請求項9】
アセンブリングの前処理を複数のコンピュータで実行するコンピュータクラスタシステムの制御方法であって、
前記複数のコンピュータのそれぞれは、
生物配列情報の先頭から、K(Kは任意の整数)文字の文字列である部分配列情報を1文字ずつずらして取得し、
アセンブリング前処理を実行するプロセスが前記部分配列情報に関するアセンブリング前処理を担当するか否かを判定し、
前記プロセスが前記部分配列情報に関するアセンブリング前処理を担当すると判定された場合、前記生物配列情報における前記部分配列情報の位置を示す位置情報を配列位置格納部に登録する
ことを特徴とするコンピュータクラスタシステムの制御方法。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2013−106567(P2013−106567A)
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願番号】特願2011−254762(P2011−254762)
【出願日】平成23年11月22日(2011.11.22)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願日】平成23年11月22日(2011.11.22)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
[ Back to top ]