
イオン検出およびN次元データのパラメータ推定
LC/IMS/MS分析のための方法および装置は、試料からノイズの多い生データを取得することと、データをアーチファクト低減フィルタに畳み込むことと、保持時間次元、イオン移動度次元、および質量対電荷比次元において、畳み込まれたデータの1つまたは複数のイオンピークを特定することとを伴う。

【発明の詳細な説明】
【技術分野】
【0001】
本出願は、参照によりその全文を本明細書に組み込まれている、2006年5月26日に出願された米国仮特許出願第60/808,901号の利益および優先権を主張するものである。
【0002】
本発明は、一般に、化合物の分析に関するものであり、より具体的には、液体クロマトグラフィ、イオン移動度分光分析、および質量分析により捕集されたイオンの検出および定量化に関するものである。
【背景技術】
【0003】
質量分析計(MS)は、試料中の分子種の同定および定量化に広く使用されている。分析時に、試料中の分子がイオン化され、分析のため質量分析計内に導入されるイオンが形成される。質量分析計は、導入されるイオンの質量対電荷比(m/z)および強度を測定する。
【0004】
質量分析計は、単一の試料スペクトル内で確実に検出され、定量化される異なるイオンの数について制限がある。その結果、多数の分子種を含む試料が発生しうるスペクトルは複雑すぎて、従来の質量分析計を使用したのでは解釈または分析を行えない。
【0005】
それに加えて、分子種の濃度は、広い範囲にわたって変化することが多い。例えば、生体試料は、典型的には、高い濃度のときよりも低い濃度のときのほうが多くの分子種を有する。したがって、イオンのかなりの画分が低濃度で出現する。この低濃度は、普通の質量分析計の検出限界に近いことが多い。さらに、低濃度では、イオン検出は、背景ノイズおよび/または干渉背景分子の影響を受ける。したがって、このような少量の化学種の検出は、背景ノイズをできる限り取り除き、スペクトル中に存在する干渉種の数を減らすことにより改善されうる。
【0006】
試料を質量分析計に注入するのに先立って、このようなスペクトルの複雑度を低減するために、クロマトグラフ分離が普通に使用される。例えば、ペプチドまたはタンパク質は、普通のクロマトグラフ保持時間で溶出するイオンのクラスタを生成し、スペクトル内で重なるピークを発生することが多い。時間内にさまざまな分子からクラスタを分離することで、このようなクラスタにより発生するスペクトルの解釈が簡単になる。
【0007】
普通のクロマトグラフ分離装置は、ガスクロマトグラフ(GC)および液体クロマトグラフ(LC)を含む。質量分析計に結合された場合、その結果できあがるシステムは、GC/MSまたはLC/MSシステムと呼ばれる。GC/MSまたはLC/MSシステムは、典型的には、GCまたはLCの出力がMSに直接結合されるオンラインシステムである。
【0008】
LC/MS併用システムは、分析者にとって、さまざまな試料中の分子種を同定し、定量化する強力な手段となっている。普通の試料は、数個または数千個の分子種の混合物を含む。分子は、広範な特性および特徴を示すことが多く、それぞれの分子種は、複数のイオンを発生しうる。例えば、ペプチドの質量は、その核の同位体型に依存し、エレクトロスプレーインターフェースが、ペプチドおよびタンパク質を複数の荷電状態群にイオン化することができる。
【0009】
LC/MSシステムでは、試料は、特定の時間に液体クロマトグラフ内に注入される。液体クロマトグラフは、時間の経過とともに試料を溶出させ、その結果、液体クロマトグラフから溶離液が出る。液体クロマトグラフから出る溶離液は、質量分析計のイオン源内に連続的に導入される。分離が進むにつれ、MSにより生じる質量スペクトルの組成が現れ、溶離液の変化する組成を反映する。
【0010】
典型的には、コンピュータベースのシステムが、規則的時間間隔でスペクトルをサンプリングし、記録する。従来のシステムでは、収集されたスペクトルは、LC分離が完了してから分析される。
【0011】
収集した後、従来のLC/MSシステムは、一次元スペクトルおよびクロマトグラムを生成する。イオンの応答(または強度)は、スペクトルまたはクロマトグラムのいずれかに見られるようなピークの高さまたは面積である。従来のLC/MSシステムにより生成されるスペクトルまたはクロマトグラムを分析するためには、イオンに対応するこのようなスペクトルまたはクロマトグラムのピークが、特定されるか、または検出されなければならない。検出されたピークを分析し、それらのピークを引き起こすイオンの特性を決定する。これらの特性は、保持時間、質量対電荷比、および強度を含む。
【0012】
1個のイオンに対する質量または質量対電荷比(m/z)推定値は、そのイオンを含むスペクトルを調べることにより導き出される。1個のイオンに対する保持時間推定値は、そのイオンを含むクロマトグラムを調べることにより導き出される。単一の質量チャネルクロマトグラムのピーク頂点の時間的位置から、イオンの保持時間が得られる。1回のスペクトル走査のピーク頂点のm/z位置から、イオンのm/z値が得られる。
【0013】
LC/MSシステムを使用してイオンを検出する従来の技術では、全イオンクロマトグラム(TIC)を形成する。典型的には、この技術は、検出を必要とする比較的少ないイオンがある場合に適用される。TICは、それぞれのスペクトル走査内で、すべてのm/z値にわたって収集されたすべての応答を総和し、その総和を走査時間についてプロットすることにより生成される。理想的には、TIC内のそれぞれのピークは、単一イオンに対応する。
【発明の概要】
【発明が解決しようとする課題】
【0014】
複数の分子からのピークの共溶出は、TICにおけるピークを検出するこの方法の考えられる問題の1つである。共溶出の結果、TIC内に見られるそれぞれの孤立ピークは、固有のイオンに対応しえない。このような共溶出ピークを分離する従来の方法では、TICから1つのピークの頂点を選択し、その選択されたピークの頂点に対応する時間に対するスペクトルを収集する。その結果得られるスペクトルのプロットは、一連の質量ピークであり、それぞれ共通保持時間に溶出する単一イオンに対応すると思われる。
【0015】
また、複雑な混合物の場合、共溶出は、典型的には、スペクトル応答の総和を、例えば制限された範囲のm/zチャネルにわたる総和により、収集されたチャネルの部分集合のみについての総和に制限する。総和されたクロマトグラムから、制限されているm/z範囲内で検出されたイオンに関する情報が得られる。それに加えて、クロマトグラフピーク頂点毎にスペクトルを収集できる。この方法ですべてのイオンを同定するためには、複数の総和されたクロマトグラムが一般に必要である。
【0016】
ピーク検出で出会う他の問題としては、検出器ノイズがある。検出器ノイズ効果を軽減する一般的な技術は、スペクトルまたはクロマトグラムをシグナル平均化することである。例えば、特定のクロマトグラフのピークに対応するスペクトルを共付加して、ノイズ効果を低減することができる。質量対電荷比値とともにピーク面積および高さは、平均されたスペクトル内のピークを分析することで求められる。同様に、スペクトルピークの頂点を中心とするクロマトグラムを共付加することで、クロマトグラム中のノイズ効果を緩和し、保持時間だけでなくクロマトグラフのピーク面積および高さの推定もより正確にできる。
【0017】
これらの問題とは別に、従来のピーク検出ルーチンを使用してクロマトグラフまたはスペクトルのピークを検出する場合にさらに問題が生じる。手動で実行された場合、このような従来の方法は、主観的であるとともに退屈なものでもある。自動的に実行される場合でも、このような方法は、ピークを同定するために閾値を主観的に選択するので主観的であるといえる。さらに、これらの従来の方法は、単一の抽出されたスペクトルまたはクロマトグラムのみを使用してデータを分析するため不正確になる傾向があり、また最高の統計的精度または最低の統計的分散を有するイオンパラメータの推定量をもたらさない。最後に、従来のピーク検出技術では、低濃度におけるイオン、または複雑なクロマトグラムに対し一様な再現性のある結果が必ずしも得られるわけではなく、共溶出およびイオン干渉はよくある問題になりがちである。
【課題を解決するための手段】
【0018】
本発明のいくつかの実施形態は、3つまたはそれ以上の次元のデータを必要とする分析計装および方法を伴う。例えば、本発明のいくつかの好ましい実施形態は、LC、イオン移動度分光分析(IMS)、およびMSを含む装置を伴う。本発明のいくつかの態様は、LC/IMS/MSおよび他の高次元のデータ生成技術が、畳み込みフィルタを使用してノイズおよび/またはピーク干渉により引き起こされるアーチファクトを低減することで、効率的なデータ評価の恩恵を受けるという理解に起因するものである。さらに、データをイオン移動度の次元などの比較的低い、または最低の次元に一時的に縮退すると、分析が高速化され、また質量分析次元などのより高い、または最高の分離能次元で、データ分析時に無視される可能性のある収集データの大部分を識別することができる。さらに、例えばイオン移動度次元では、保持時間および/または質量次元などの他の次元において他の何らかの形で重なるイオンピークの区別が可能になる。
【0019】
例えば、いくつかのLC/IMS/MSベースの実施形態では、より速く、より効率的であるデータの特徴により、イオン移動度次元において縮退され、高速線形二次元有限インパルス応答(FIR)フィルタとの畳み込みがなされたデータのデータ行列を作成して出力畳み込み行列を生成することにより正確に、また最適な形で推定される、イオン移動度、質量対電荷比(m/z)、保持時間、およびイオン強度などのイオンパラメータが得られる。ピーク検出ルーチンは、出力畳み込み行列に適用され、これにより試料中のイオンに対応するピークを同定する。
【0020】
同定されたピークは、適宜、元のデータのどの部分がピークを含むかを示すために使用される。これらの示されている部分が、適宜、三次元フィルタに畳み込まれ、次いで、イオンピークが、すべての次元において特定される。低分離能次元の評価により、例えば、他の次元において重なるイオンピークの解明が可能になる。
【0021】
したがって、例示的な一実施形態では、本発明は、LC/IMS/MS分析の方法を特徴とする。この方法は、試料からノイズの多い生データを取得することを含む。データは、三次元データ要素の集合を含み、それぞれの要素はイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付けるが、ただしノイズはイオンピークアーチファクトに関連付けられる。この方法は、さらに、イオン移動度次元において、そのデータ要素の集合を縮退して、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成することと、その縮退データ要素の集合を、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたピークアーチファクトを有するデータ要素の畳み込まれた集合を形成することと、保持時間次元および質量対電荷比次元において、畳み込まれた縮退データ要素の集合のイオンピークを特定することと、データ要素の畳み込まれた集合のイオンピークの配置に応じて、さらなる分析対象となる生データの1つまたは複数の部分を選択することと、少なくともイオン移動度次元において、生データのそれらの部分のそれぞれについて1つまたは複数のイオンピークを特定することとを含む。
【0022】
第2の例示的な一実施形態では、本発明は、N次元分析の方法を特徴とする。この方法は、それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、ノイズの多いデータを試料から取り出すことと、そのデータ要素の集合をアーチファクト低減フィルタに畳み込み、データ要素の畳み込まれた集合を生成することと、データ要素の畳み込まれた集合内の1つまたは複数のイオンピークを特定することとを含む。
【0023】
他の態様では、本発明は、化学処理装置を伴う。装置は、例えば、上述の方法の1つを実装するように構成された制御ユニットを備える。
【図面の簡単な説明】
【0024】
【図1】本発明の一実施形態による例示的なLC/MSシステムの略図である。
【図2】例示的なクロマトグラフまたはスペクトルピークの図である。
【図3A】例示的なLC/MS実験で生成された3つのイオンに対する例示的なスペクトルを示す図である。
【図3B】例示的なLC/MS実験で生成された3つのイオンに対する例示的なスペクトルを示す図である。
【図3C】例示的なLC/MS実験で生成された3つのイオンに対する例示的なスペクトルを示す図である。
【図4A】図3A〜図3Cの例示的なイオンに対応するクロマトグラムを示す図である。
【図4B】図3A〜図3Cの例示的なイオンに対応するクロマトグラムを示す図である。
【図4C】図3A〜図3Cの例示的なイオンに対応するクロマトグラムを示す図である。
【図5】本発明の一実施形態によりデータを処理する方法の流れ図である。
【図6】本発明の一実施形態によりデータを処理する方法の、図解による流れ図である。
【図7】本発明の一実施形態によりイオンを検出する際に使用する閾値を決定する方法の、図解による流れ図である。
【図8】本発明の一実施形態による例示的なデータ行列を示す図である。
【図9】本発明の一実施形態による図3A〜図3Cおよび図4A〜図4Cのデータから作成された例示的なデータ行列の等高線図である。
【図10】本発明の一実施形態によりノイズの存在しないデータを処理する簡略化された方法の流れ図である。
【図11】図9の例示的なデータ行列に対する共溶出イオンの効果を示す図である。
【図12A】図3A〜図3Cに示されている例示的なデータに対する共溶出イオンの「段状」効果を示す図である。
【図12B】図3A〜図3Cに示されている例示的なデータに対する共溶出イオンの「段状」効果を示す図である。
【図12C】図3A〜図3Cに示されている例示的なデータに対する共溶出イオンの「段状」効果を示す図である。
【図13】本発明の実施形態により作成されたデータ行列中の例示的なデータにノイズがどのような影響を及ぼすかを示す図である。
【図14A】図13に示されているデータ行列に例示されている例示的なデータに対応する3つのイオンに対するスペクトルを示す図である。
【図14B】図13に示されているデータ行列に例示されている例示的なデータに対応する3つのイオンに対するスペクトルを示す図である。
【図14C】図13に示されているデータ行列に例示されている例示的なデータに対応する3つのイオンに対するスペクトルを示す図である。
【図14D】図13に示されているデータ行列に例示されている例示的なデータに対応するイオンに対するクロマトグラムを示す図である。
【図14E】図13に示されているデータ行列に例示されている例示的なデータに対応するイオンに対するクロマトグラムを示す図である。
【図14F】図13に示されているデータ行列に例示されている例示的なデータに対応するイオンに対するクロマトグラムを示す図である。
【図15】本発明の一実施形態による例示的な一次元アポダイズサビツキー−ゴーレイ2階微分フィルタを示す図である。
【図16A】本発明の一実施形態によるスペクトル(m/z)方向の例示的な一次元フィルタの断面を示す図である。
【図16B】本発明の一実施形態によるクロマトグラフ(時間)方向の例示的な一次元フィルタの断面を示す図である。
【図16C】本発明の一実施形態によるスペクトル(m/z)方向の例示的な一次元平滑化フィルタf1の断面を示す図である。
【図16D】本発明の一実施形態によるクロマトグラフ方向の例示的な一次元2階微分フィルタg1の断面を示す図である。
【図16E】本発明の一実施形態によるクロマトグラフ方向の例示的な一次元平滑化フィルタg2の断面を示す図である。
【図16F】本発明の一実施形態によるスペクトル(m/z)方向の例示的な一次元2階微分フィルタf2の断面を示す図である。
【図17A】本発明の実施形態によるデータ行列に格納されるようなLC/MSデータにより生成されうる例示的なピークを示す図である。
【図17B】本発明の一実施形態による例示的な階数2のフィルタの点源応答(有限インパルス応答)を示す図である。
【図17C】質量が等しく、ほぼ同時であるが、まったく同時というわけではない2つのLC/MSピークのシミュレーションを示す図である。
【図17D】図17Cの2ピークシミュレーションの質量におけるピーク断面を示す図である。
【図17E】図17Cの2ピークシミュレーションの時間におけるピーク断面を示す図である。
【図17F】図17Cの2ピークシミュレーションに計数(ショット)ノイズを加える効果を示す図である。
【図17G】図17Fの付加ノイズ2ピークシミュレーションの質量におけるピーク断面を示す図である。
【図17H】図17Fの付加ノイズ2ピークシミュレーションの時間におけるピーク断面を示す図である。
【図17I】階数2のフィルタを図17Fのシミュレートされたデータに畳み込んだ結果を例示する図である。
【図17J】図17Iに例示されている結果の質量におけるピーク断面を示す図である。
【図17K】図17Iに例示されている結果の時間におけるピーク断面を示す図である。
【図18】本発明の一実施形態によりデータのリアルタイム処理を実行する流れ図である。
【図19A】図18の流れ図の方法によりデータのリアルタイム処理を実行する方法を示す図解である。
【図19B】図18の流れ図の方法によりデータのリアルタイム処理を実行する方法を示す図解である。
【図20】本発明の一実施形態により適切な閾値を決定する方法の流れ図である。
【図21】本発明の一実施形態によりピーク純度計量を決定する方法の流れ図である。
【図22A】2つの親分子とその結果の非常に多数の分子から結果として得られる例示的なLC/MSデータ行列を示す図である。
【図22B】時間t1における図22Aのデータに対応する例示的な複雑なスペクトルを示す図である。
【図22C】時間t2における図22Aのデータに対応する例示的な複雑なスペクトルを示す図である。
【図23A】本発明の一実施形態により生成される未修正および修正イオンリスト中で関係するイオンをどのように同定できるかを示す図解である。
【図23B】本発明の一実施形態により生成される未修正および修正イオンリスト中で関係するイオンをどのように同定できるかを示す図解である。
【図24】本発明の一実施形態による、分析の方法の流れ図である。
【発明を実施するための形態】
【0025】
「クロマトグラフィ」−化合物の分離で使用される装置および/または方法のことである。クロマトグラフ装置は、典型的には、圧力および/または電気力および/または磁力の下で流体および/またはイオンを移動する。「クロマトグラム」という用語は、文脈にもよるが、本明細書では、クロマトグラフ手段により導き出されるデータまたはデータの表現を指す。クロマトグラムは、データ点の集合を含むことができ、それぞれのデータ点は、2つまたはそれ以上の値からなり、これらの値の1つは、多くの場合、クロマトグラフ保持時間値であり、残りの(複数の)値は、典型的には、強度または大きさの値に関連し、さらに、これらは試料の成分の量または濃度に対応する。
【0026】
本発明は、クロマトグラフデータの生成および分析をサポートするものである。本発明のいくつかの実施形態は、試料成分を分離する単一のモジュールを備える装置を伴うが、他の実施形態は、複数のモジュールを伴う。例えば、本発明の原理は、液体クロマトグラフィ装置だけでなく、例えば、液体クロマトグラフィモジュール、イオン移動度分光分析モジュール、および質量分析モジュールを備える装置にも適用可能である。いくつかのマルチモジュールベースの実施形態では、クロマトグラフィモジュールは、適切なインターフェースを通じてイオン移動度分光分析モジュールと流体連通し、次いで、IMSモジュールが、エレクトロスプレーイオン化インターフェースなどの適切なインターフェースを使用することで、質量分析モジュールにインターフェースされる。いくつかの適切なインターフェースは、ときどき、分離された物質をイオン形態で生成するか、またはイオン形態に保持する。試料流体の流れは、典型的には、蒸発し、イオン化され、質量分析モジュールの入口オリフィスに送られる。
【0027】
そのため、いくつかの実施形態は、データ要素の集合からなる多次元データを生成し、それぞれの実施形態は、保持時間(クロマトグラフィモジュールから導かれる)、イオン移動度、および質量対電荷比などの測定次元に関連付けられた弁を有する。次元に関する弁の固有の集合は、実験的に、例えば、質量分析モジュールで測定されるようなイオン強度の弁にリンクされる。
【0028】
タンパク質−本明細書では、単一のポリペプチドとして組み立てられたアミノ酸の特定一次配列を指す。
【0029】
ペプチド−本明細書では、タンパク質の一次配列内に含まれる単一のポリペプチドとして組み立てられたアミノ酸の特定配列を指す。
【0030】
前駆ペプチド−タンパク質切断プロトコールを使用して生成されるトリプシンペプチド(または他のタンパク質切断生成物)。これらの前駆体は、適宜クロマトグラフィにより分離され、質量分析計に渡される。イオン源は、これらの前駆ペプチドをイオン化して、典型的には、前駆体のプラスに帯電したタンパク質化形態を生成する。このようなプラスに帯電したタンパク質化前駆体イオンの質量は、本明細書では、前駆体の「mwHPlus」または「MH+」と呼ぶ。以下では、「前駆体質量」という用語は、一般にイオン化されたペプチド前駆体のタンパク質化されたmwHPlusまたはMH+を指す。
【0031】
フラグメント−LC/MS分析では、複数の種類のフラグメントが発生しうる。トリプシンペプチド前駆体の場合、フラグメントは、無傷のペプチド前駆体の衝突フラグメンテーションから生成され、一次アミノ酸配列が始めの前駆ペプチド内に含まれるポリペプチドイオンを含むことができる。YイオンおよびBイオンは、このようなペプチドフラグメントの例である。トリプシンペプチドのフラグメントは、さらに、インモニウムイオン、リン酸イオン(PO3)などの官能基、特定の分子または特定の種類の分子から切断された質量タグ、あるいは前駆体からの水(H2O)またはアンモニア(NH3)分子の「ニュートラルロス」を含むこともできる。
【0032】
YイオンおよびBイオン−ペプチドがペプチド結合部位で分断する場合、また電荷がN末端フラグメント上に保持される場合、そのフラグメントイオンはBイオンと呼ばれる。電荷が、C末端フラグメント上に保持される場合、フラグメントイオンは、Yイオンと呼ばれる。考えられるフラグメントおよびその名称のより包括的なリストは、Roepstorff、Fohlman「Biomed Mass Spectrom」1984;11(11):601およびJohnsonらのAnal.Chem 1987,59(21):2621:2625に記載されている。
【0033】
保持時間−文脈上、典型的には、要素がその最大強度に達するクロマトグラフィプロファイル内の点を意味する。
【0034】
イオン−例えば、ペプチドは、典型的には、構成要素である元素の同位体が天然依存度によるイオンの集合体としてLC/MS分析中に現れる。イオンは、例えば、保持時間とm/z値を有する。質量分析計(MS)はイオンのみを検出する。LC/MS技術では、検出されたすべてのイオンについてさまざまな観察された測定結果が得られる。これは、質量対電荷比(m/z)、質量(m)、保持時間、および計数されたイオンの個数などのイオンのシグナル強度を含む。
【0035】
ノイズ−本明細書では、計数統計およびガウス分布に起因するポアソンノイズ、熱効果に起因するジョンソンノイズ、および実イオンピークを隠すか、または偽イオンピークを発生する傾向のある他のノイズ源を含む、検出器ノイズなどの発生源から生じる生データ成分を指し示す。
【0036】
アーチファクト−本明細書では、例えば、ノイズ、ピーク干渉、およびピーク重なりから生じるような、生データ中の偽ピークを指す。
【0037】
一般に、LC/IMS/MS分析では、適宜、例えば、質量、電荷、保持時間、移動度、および全強度に関してペプチドを経験的に記述する。ペプチドは、クロマトグラフィカラムから溶出するときに、特定の保持期間にわたって溶出し、単一の保持時間に最大シグナルに到達する。イオン化および(場合によっては)フラグメンテーションの後、ペプチドは、関連するイオンの集合体として現れる。この集合体内の異なるイオンは、共通ペプチドの異なる同位体組成および電荷に対応する。関連するイオンの集合体内のそれぞれのイオンは、単一のピーク保持時間およびピーク形状をもたらす。これらのイオンは、共通のペプチドに由来しているため、それぞれのイオンのピーク保持時間およびピーク形状は、多少の測定許容誤差範囲内で、同一である。それぞれのペプチドをMSで収集することにより、すべての同位体および荷電状態について複数のイオン検出が行われ、すべて多少の測定許容誤差内で同じピーク保持時間およびピーク形状を共有する。
【0038】
LC/MS分離では、単一のペプチド(前駆体またはフラグメント)から、複数の荷電状態を有する、イオンのクラスタとして出現する、多数のイオン検出が得られる。このようなクラスタから得られるこれらのイオン検出結果の逆畳み込みは、荷電状態にある、測定されたシグナル強度の、特定の保持時間における、固有のモノアイソトピック質量の単一の実体の存在を示している。
【0039】
本発明の実施形態は、溶媒中に溶解されうる大分子不揮発性検体を含むさまざまなアプリケーションに適用できる。本発明の実施形態は、これ以降、LC、LC/MS、またはLC/IMS/MSシステムに関して説明されているけれども、本発明の実施形態は、GC、GC/MS、およびGC/IMS/MSシステムを含む、他の分析技術と併用して動作するように構成されうる。文脈上、LC/MSデータの分析に一次元および二次元行列を使用する実施形態が、図1〜図23を参照しつつ最初に説明される。その後、LC/IMS/MSおよび高次元の技術に関係する、本発明のいくつかの好ましい実施形態が、図24を参照しつつ説明される。
【0040】
図1は、本発明の一実施形態による例示的なLC/MSシステム101の略図である。LC/MS分析は、試料102を液体クロマトグラフ104内に自動的に、または手動で注入することにより実行される。ポンプ103およびインジェクタ105によりクロマトグラフィ溶媒の高圧流を送り、試料102を液体クロマトグラフ104内のクロマトグラフィカラム106に強制的に通して移動させる。カラム106は、典型的には、結合された分子を表面に含むシリカビーズの充填カラムを含む。試料、溶媒、およびビーズ中の分子種間の競合的相互作用が、それぞれの分子種の移動速度を決定する。
【0041】
分子種はカラム106内を通って移動し、特徴的な時間においてカラム106から現れる、つまり溶出する。この特徴的な時間は、一般に、分子の保持時間と呼ばれる。分子は、カラム106から溶出すると、質量分析計108などの検出器に運ばれうる。
【0042】
保持時間は、特徴的な時間である。つまり、保持時間tにカラムから溶出する分子は、実際に、本質的には時間tを中心とするある期間にわたって溶出する。この期間にわたる溶出プロフィルは、クロマトグラフピークと呼ばれる。クロマトグラフピークの溶出プロフィルは、釣鐘形曲線により記述することができる。ピークの釣鐘形は、典型的には半分の高さで全幅、つまり半値全幅(FWHM)により記述される。分子の保持時間は、ピークの溶出プロフィルの頂点の時間である。質量分析計により生成されるスペクトル中に出現するスペクトルピークは、類似の形状を有し、類似の方法で特徴付けることができる。図2は、ピーク頂点204を有する例示的なクロマトグラフピークまたはスペクトルピーク202を示している。FWHMおよび高さまたはピーク202も、図2に例示されている。
【0043】
その後の説明のために、ピークは、図2に示されているようにガウス分布を有するものと仮定される。ガウス分布では、FWHMは、ガウス分布の標準偏差σの約2.35倍である。
【0044】
クロマトグラフピーク幅は、ピーク高さと無関係であり、実質的に、与えられた分離方法に対する分子の定数特性である。理想的な場合では、所定のクロマトグラフ法について、すべての分子種は、同じピーク幅で溶出する。しかし、典型的には、ピーク幅は、保持時間の関数として変化する。例えば、分離の終わりに溶出する分子は、分離で早い段階に溶出する分子に関連するピーク幅に比べて数倍広いピーク幅を示すことがある。
【0045】
その幅に加えて、クロマトグラフピークまたはスペクトルピークは、ある高さまたは面積を有する。一般に、ピークの高さおよび面積は、液体クロマトグラフに注入される化学種の量または質量に比例する。強度という用語は、一般に、クロマトグラフピークまたはスペクトルピークの高さまたは面積のいずれかを指す。
【0046】
クロマトグラフ分離は、実質的に連続的なプロセスであるけれども、溶離液を分析する検出器は、典型的には、その溶離液を規則正しい間隔でサンプリングする。検出器が溶離液をサンプリングする速度は、サンプリングレートまたはサンプリング頻度と呼ばれる。それとは別に、検出器が溶離液をサンプリングする間隔は、サンプリング間隔またはサンプリング周期と呼ばれる。サンプリング周期は、システムがそれぞれのピークのプロファイルを適切にサンプリングできる十分な長さでなければならないため、最小サンプリング周期は、クロマトグラフピークの幅により制限される。例えば、サンプリング周期は、クロマトグラフピークのFWHMにおいて5回程度測定が実行されるように設定されうる。
【0047】
LC/MSシステムでは、クロマトグラフ溶離液は、図1に示されているように分析のため質量分析計(MS)108内に導入される。MS 108は、脱溶媒和システム110、イオン化装置112、質量分析器114、検出器116、およびコンピュータ118を備える。試料がMS 108内に導入されると、脱溶媒和システム110が、溶媒を取り除き、イオン化源112が、検体分子をイオン化する。LC 104から展開する分子をイオン化するイオン化法は、電子衝撃(EI)、エレクトロスプレー(ES)、および大気化学イオン化(APCI)を含む。APCIでは、イオン化および脱溶媒和の順序は逆にされることに留意されたい。
【0048】
次いで、イオン化された分子は、質量分析器114に運ばれる。質量分析器114は、分子をその質量対電荷比によりソートするか、またはフィルタリングする。MS 108内のイオン化された分子を分析するために使用される質量分析器114などの質量分析器は、四重極質量分析器(Q)、飛行時間型(TOF)質量分析器、およびフーリエ変換ベースの質量分析計(FTMS)を含む。
【0049】
質量分析器は、例えば、四重極飛行時間型(Q−TOF)質量分析器を備えるさまざまな構成においてタンデム型にすることができる。タンデム構成では、すでに質量分析済みの分子のオンライン衝突修正および分析が可能である。例えば、トリプル四重極ベースの質量分析器(Q1−Q2−Q3またはQ1−Q2−TOF質量分析器など)では、第2の四重極(Q2)は、加速電圧を第1の四重極(Q1)により分離されるイオンにインポートする。これらのイオンは、Q2にあからさまに導入されるガスと衝突する。これらのイオンは、このような衝突の結果、砕けてフラグメントになる。これらのフラグメントは、さらに、第3の四重極(Q3)またはTOFにより分析される。本発明の実施形態は、上述のような任意のモードの質量分析から得られたスペクトルおよびクロマトグラムに適用可能である。
【0050】
次いで、m/zに対するそれぞれの値における分子は、検出デバイス116で検出される。例示的なイオン検出デバイスは、電流測定電位計および単一イオン計数マルチチャネルプレート(MCP)を備える。MCPからのシグナルは、ディスクリミネータとその後に続く時間領域コンバータ(TDC)またはアナログ−デジタル(ATD)コンバータにより分析されうる。本発明の説明のために、MCP検出ベースのシステムが仮定される。その結果、検出器応答は、特定のカウント数で表される。この検出器応答(つまり、カウント数)は、質量対電荷比のそれぞれの間隔で検出されたイオンの強度に比例する。
【0051】
LC/MSシステムは、時間をかけて集めた一連のスペクトルまたは走査を出力する。質量対電荷スペクトルは、m/zの関数としてプロットされる強度である。スペクトルのそれぞれの要素、つまり単一の質量対電荷比は、チャネルと呼ばれる。時間を追って単一チャネルを見ると、対応する質量対電荷比に対するクロマトグラムが得られる。生成された質量対電荷スペクトルまたは走査は、コンピュータ118により取得されて記録され、コンピュータ118からアクセス可能なハードディスクドライブなどの記録媒体に格納されうる。典型的には、スペクトルまたはクロマトグラムは、値の配列として記録され、コンピュータシステム118により格納される。この配列は、表示され、数学的に分析されうる。
【0052】
MS 108などのMSシステムを構成する特定の機能要素は、LC/MSシステム毎に異なることがある。本発明の実施形態は、MSシステムを構成しうるさまざまコンポーネントと併用するように構成されうる。
【0053】
クロマトグラフ分離およびイオンの検出と記録の後、分離後データ分析システム(DAS)を使用して、データが分析される。本発明の代替え実施形態では、DASは、リアルタイムまたはほぼリアルタイムで分析を実行する。DASは、一般的に、図1に示されているコンピュータ118などのコンピュータ上で実行されるコンピュータソフトウェアにより実装される。本明細書で説明されているようにDASを実行するように構成されうるコンピュータは、当業者によく知られているものである。DASは、スペクトルおよび/またはクロマトグラムの視覚的表示を行うだけでなく、データに対する数学的分析を実行するためのツールも備えることを含む、多数のタスクを実行するように構成される。DASにより得られる分析結果は、検討され、さらに分析されるべき、1回の注入から得られる結果および/または一組の数回の注入操作から得られる結果を分析することを含む。試料集合に適用される分析の実施例は、注目する検体に対する較正曲線の作成、および未知のものには存在するが、コントロールには存在しない新しい種類の化合物の検出を含む。本発明の実施形態によるDASは、ここで説明される。
【0054】
図3A〜図3Cは、例示的なLC/MS実験で生成された3つのイオン(イオン1、イオン2、およびイオン3)に対する例示的なスペクトルを示す図である。イオン1、イオン2、およびイオン3に関連付けられているピークは、保持時間およびm/zの限られた範囲内に出現する。本発明の実施例では、イオン1、イオン2、イオン3の質量対電荷比は異なること、またイオンの親分子は、ほぼ同じだが、正確には同じでない保持時間に溶出されることが仮定される。その結果、それぞれの分子の溶出プロフィルは、重なるか、または共溶出となる。これらの仮定の下で、3つの分子すべてが、MSのイオン化源内に存在する時間がある。例えば、図3A〜図3Cに示されている例示的なスペクトルは、3つのイオンすべてが、MSイオン化源内に存在していたときに収集された。これは、それぞれのスペクトルが、イオン1、2、および3のそれぞれに関連付けられているピークを示すため明白である。図3A〜図3Cに示されている例示的なスペクトルからわかるように、スペクトルピークの重なりはない。重なりがないことは、この質量分析計はこれらのスペクトルピークを分離して検出したことを示している。イオン1、2、および3に対応するピークの頂点の配置は、その質量対電荷比を表している。
【0055】
スペクトル中のイオンが単一のスペクトルのみを使用して溶出する正確な保持時間、あるいは相対的保持時間すら決定することは可能でない。例えば、スペクトルBに対するデータが収集されたときに、イオン1、2、および3に関連付けられている3つの分子すべてがカラムから溶出していたことがわかる。しかし、スペクトルBのみを分析したのでは、イオン1、2、および3の溶出時間の間の関係を決定することは可能でない。そのため、スペクトルBは、分子がカラムから溶出し始めたときには、クロマトグラフピークの先頭に対応する時間に、または分子がほぼ溶出を終了したときには、クロマトグラフピークの終わりから、またはその間のある時点において、収集されている可能性がある。
【0056】
保持時間に関係するより正確な情報は、連続するスペクトルを調べることにより得られる。この付加情報は、溶出分子の保持時間または少なくとも溶出順序を含むことができる。例えば、図3A〜図3Cに示されているスペクトルA、B、およびCは、時間tAにスペクトルAが収集され、後の時間tBにスペクトルBが収集され、時間tBよりも後の時間である、時間tCにスペクトルCが収集されるように連続的に収集されたと仮定する。次いで、それぞれの分子の溶出順序は、tAからtCまで時間が進むときに連続的に収集されたスペクトル中に出現するピークの相対的高さを調べることにより決定されうる。このように調べることで、時間が進むにつれ、イオン2がイオン1に関して強度を減じること、またイオン3がイオン1に関して強度を増やすことがわかる。したがって、イオン2は、イオン1の前に溶出し、イオン3は、イオン1の後に溶出する。
【0057】
この溶出順序は、スペクトル中に見つかるそれぞれのピークに対応するクロマトグラムを生成することにより検証できる。これは、イオン1、2、および3に対応するピークのそれぞれの頂点でm/z値を得ることにより達成されうる。これら3つのm/z値が与えられると、DASは、それぞれの走査に対しそのm/zで得られた強度をそれぞれのスペクトルから抽出する。次いで、抽出された強度は、溶出時間に関してプロットされる。このようなプロットは、図4A〜図4Cに例示されている。図4A〜図4Cのプロットは、図3A〜図3Cのピークを調べることにより得られるm/z値におけるイオン1、2、および3に対するクロマトグラムを表していることがわかる。それぞれのクロマトグラムは、単一のピークを含む。図4A〜図4Cに例示されているようなイオン1、2、および3に対するクロマトグラムを調べることで、イオン2が最も早い時期に溶出し、イオン3が最も遅い時期に溶出することを確認する。図4A〜図4Cに示されているクロマトグラムのそれぞれにおける頂点配置は、それぞれのイオンに対応する分子の溶出時間を表す。
【0058】
この導入を念頭に置いて、本発明の実施形態は、スペクトルおよびクロマトグラムなどの実験分析出力を分析して、イオンを最適な形で検出し、検出されたイオンに関係するパラメータを定量化することに関係する。さらに、本発明の実施形態は、著しく簡素化されたスペクトルおよびクロマトグラムをもたらすことができる。
【0059】
図5は、スペクトルおよびクロマトグラムなどの実験分析出力を処理する流れ図500である。流れ図500は、上述のDASを含むさまざまな方法で具現化することができる。図5に例示されている本発明の実施形態では、分析は以下のように進行する。
ステップ502:クロマトグラフデータおよびスペクトルデータを有する二次元データ行列を作成する。
ステップ504:このデータ行列に適用する二次元畳み込みフィルタを指定する。
ステップ506:二次元畳み込みフィルタをデータ行列に適用する。例えば、データ行列は、二次元フィルタに畳み込むことができる。
ステップ508:二次元フィルタをデータ行列に適用した出力のピークを検出する。それぞれの検出されたピークは、イオンに対応するとみなされる。ピーク検出を最適化するために閾値化が使用できる。
ステップ510:それぞれの検出されたピークについてイオンパラメータを抽出する。パラメータは、保持時間、質量対電荷比、強度、スペクトル方向のピーク幅、および/またはクロマトグラフ方向のピーク幅などのイオン特性を含む。
ステップ512:抽出されたイオンに関連付けられているイオンパラメータをリストまたはテーブルに格納する。格納操作は、ピークが検出される毎に、または複数のもしくはすべてのピークが検出された後に実行できる。
ステップ514:抽出されたイオンパラメータを使用して、データの後処理を行う。例えば、データを簡約するためにイオンパラメータテーブルが使用可能である。このような簡約は、例えば、スペクトルまたはクロマトグラフィの複雑さを低減するようにウィンドウ操作を行うことにより実行できる。分子の特性は、この簡約されたデータから推論されうる。
【0060】
図6および図7は、流れ図500の前述のステップを記述する図解による流れ図である。図6は、本発明の一実施形態によりLC/MSデータを処理する方法の、図解による流れ図602である。より具体的には、図解による流れ図602のそれぞれの要素は、本発明の一実施形態によるステップの結果を示す。要素604は、本発明の一実施形態により作成された例示的なLC/MSデータ行列である。後述のように、LC/MSデータ行列は、連続する時間において収集されたLC/MSスペクトルをデータ行列の連続する列内に入れることにより作成されうる。要素606は、所望のフィルタ処理特性により指定されうる例示的な二次元畳み込みフィルタである。二次元フィルタを指定する際の考慮事項の詳細を以下で説明する。要素608は、本発明の一実施形態により、要素606の二次元フィルタを要素604のLC/MSデータ行列に適用することを表している。LC/MSデータ行列への二次元フィルタのそのような例示的な適用は、LC/MSデータ行列が二次元畳み込みフィルタに畳み込まれる二次元畳み込みである。フィルタ処理ステップの出力は、出力されたデータ行列であり、その実施例は、要素610として例示されている。データ行列へのフィルタの適用が、畳み込みを含む場合、出力は、出力される畳み込み行列である。
【0061】
要素612は、出力データ行列に対しピーク検出を実行してイオンに関連付けられているピークを同定または検出した結果を例示している。ピーク検出を最適化するために閾値化が使用できる。この時点で、イオンは、検出されたと考えられる。要素614は、検出されたイオンを使用して作成されるイオン特性の例示的なリストまたはテーブルである。
【0062】
図7は、本発明の一実施形態によるイオンパラメータテーブルをさらに集約するために検出閾値およびその適用を決定する結果を示す図解による流れ図702である。要素706は、イオンパラメータリストである要素704からアクセスされる例示的なピークデータを表す。要素706は、アクセスされたデータを使用して検出閾値を決定する結果を例示する。決定された閾値は、ステップ704のように生成されたイオンパラメータリストに適用され、編集済みのイオンパラメータリストを生成するが、この実施例はステップ708として例示されている。前述のステップは、ここで、さらに詳しく説明される。
【0063】
ステップ1:データ行列を作成する
LC/MS分析の出力を異なる一連のスペクトルおよびクロマトグラムと見るのではなく、LC/MS出力を強度のデータ行列として構成するのが有益である。本発明の一実施形態では、データ行列は、時間の経過とともに収集されたそれぞれの連続するスペクトルに関連付けられているデータをデータ行列の連続する列内に入れて、強度の二次元データ行列を形成することにより作成される。図8は、時間的に連続して収集された5つのスペクトルがデータ行列800の連続する列801−805内に格納されている例示的なそのようなデータ行列800を示している。スペクトルが、このようにして格納された場合、データ行列800の行は、格納されているスペクトル中の対応するm/z値におけるクロマトグラムを表す。これらのクロマトグラムは、データ行列800内の行811−815により示される。したがって、行列形式では、データ行列のそれぞれの列は、特定の時間に収集されたスペクトルを表し、それぞれの行は、固定されたm/zにおいて収集されたクロマトグラムを表す。データ行列のそれぞれの要素は、特定のm/z(対応するスペクトル中の)に対する特定の時間(対応するクロマトグラム中の)において収集された強度値である。本開示では、カラム指向のスペクトルデータと行指向のクロマトグラフデータを仮定しているけれども、本発明の代替え実施形態では、データ行列は、行がスペクトルを表し、列がクロマトグラムを表すように方向付けられる。
【0064】
図9は、スペクトルデータをデータ行列の連続する列内に格納することにより上述のように生成されたデータ行列の例示的な図解による表現(特に等高線図)である。図9に示されている等高線図では、イオン1、2、および3はそれぞれ、強度の島として表示されている。等高線図は、3つのイオンの存在を示すだけでなく、溶出順序がイオン2、続いてイオン1、続いてイオン3であることも明確に示している。図9は、さらに、3つの頂点902a、902b、および902cも示している。頂点902aは、イオン1に対応し、頂点902bは、イオン2に対応し、頂点902cは、イオン3に対応している。頂点902a、902b、および902cの配置は、それぞれイオン1、2、および3に対するm/zおよび保持時間に対応する。等高線図のゼロ値面よりも高い頂点の高さは、イオンの強度の尺度となる。単一のイオンに関連付けられているカウントまたは強度は、楕円領域つまり島の中に含まれる。m/z(列)方向のこの領域のFWHMは、スペクトル(質量)ピークのFWHMである。行(時間)方向のこの領域のFWHMは、クロマトグラフピークのFWHMである。
【0065】
島を形成する同心円状の等高線の一番内側は、最高の強度を有する要素を示す。この極大または最大要素は、最も近い隣接要素よりも大きな強度を有する。例えば、二次元データ等高線では、極大または頂点は、振幅が最も近い隣接要素よりも大きい任意の点である。本発明の一実施形態では、極大または頂点は、8個の最も近い隣接要素よりも大きくなければならない。例えば、表1では、中心要素は、極大であるが、それは8個の隣接する要素のそれぞれが10よりも小さな値を有するからである。
【表1】
【0066】
図9の等高線図に引かれた直線が6本ある。イオン1、イオン2、およびイオン3と標識が付けられた、3本の水平線は、図4A〜図4Cに示されているようにそれぞれイオン1、2、および3に対するクロマトグラムに対応する断面を識別する。A、B、およびCと標識が付けられた、3本の垂直線は、図3A〜図3Cに例示されているようにそれぞれ質量スペクトル3A、3B、および3Cに対応する断面を識別する。
【0067】
データ行列が作成された後、イオンが検出される。検出されたイオン毎に、保持時間、m/z、および強度などのイオンパラメータが得られる。データ行列にノイズが含まれず、イオンが互いに干渉し合わない(例えば、クロマトグラフ共溶出およびスペクトル干渉による)場合、それぞれのイオンは、図9の等高線図に例示されているように、強度の固有の孤立した島を形成する。
【0068】
図9に示されているように、それぞれの島は、単一の最大要素を含む。ノイズがない場合、本発明の一実施形態による共溶出または干渉、イオン検出、およびパラメータ定量化は、図10の流れ図1000に示されているように、以下の通りに進行する:
ステップ1001:データ行列を形成する
ステップ1002:データ行列内のそれぞれの要素の問い合わせを行う
ステップ1004:強度の極大であり、正値を有するすべての要素を識別する
ステップ1006:それぞれのそのような極大にイオンとして標識付けする
ステップ1008:イオンパラメータを抽出する
ステップ1010:イオンパラメータをテーブル形式にする
ステップ1012:イオンパラメータを後処理して、分子特性を得る。
【0069】
ステップ1008では、それぞれのイオンのパラメータは、最大要素を調べることにより得られる。イオンの保持時間は、最大要素を含む走査の時間である。イオンのm/zは、最大要素を含むチャネルに対するm/zである。イオンの強度は、最大要素それ自体の強度であるか、そうでなければ、強度は、最大要素の周囲にある要素の強度の総和とすることもできる。これらのパラメータの推定精度を高めるために、後述の補間技術が使用されうる。例えば、クロマトグラフおよびスペクトル方向のピークの幅を含む、二次的な観測可能パラメータも、決定されうる。
【0070】
ステップ2および3:フィルタの指定および適用
フィルタの必要性
LC/MS実験には、共溶出、干渉、またはノイズは、あるとしても、めったに存在しない。共溶出、干渉、またはノイズの存在は、イオンを正確に、また確実に検出する能力をひどく低下させる可能性がある。したがって、流れ図1000に例示されている単純な検出および定量化手順は、すべての状況において適しているわけではない。
【0071】
共溶出
図11は、ピーク幅が有限であることによる共溶出および干渉の効果を示す例示的な等高線図である。図11に示されている実施例において、他のイオン、つまりイオン4は、イオン1のと比べていくぶん大きいm/z値および保持時間値を有するとともに、イオン1の頂点のFWHM内にあるスペクトル方向とクロマトグラフ方向の両方で頂点を有すると仮定される。その結果、イオン4は、クロマトグラフ方向でイオン1と共溶出し、スペクトル方向でイオン1と干渉する。
【0072】
図12A〜図12Cは、図11の直線A、B、およびCにより示される時間におけるイオン4の共溶出によるスペクトル効果を示す。図12A〜図12Cに示されているそれぞれのスペクトルにおいて、イオン4は、イオン1に対する段部として現れる。これは、さらに、イオン4に関連付けられた明確に異なる頂点がないため、図11に示されている等高線図からも明らかである。
【0073】
そのため、LC/MSシステムにおける検出の問題の1つは、イオンの対が時間に関して共溶出し、スペクトルに関して干渉して、イオンの対が単一の極大値のみを形成し、2つの極大値を形成しないという点である。共溶出または干渉は、データ行列内で有意な強度を有する真のイオンが見逃される、つまり検出されないという状況を引き起こす可能性がある。イオンとしての真のピークのこのような見逃された検出は、偽陰性と呼ばれる。
【0074】
ノイズ
LC/MSシステムで発生するノイズは、典型的には、検出ノイズと化学的ノイズの2つのカテゴリに分けられる。検出器ノイズと化学的ノイズとが合わさって、イオンの検出および定量化が行われる際のベースラインとなる背景ノイズを定める。
【0075】
検出ノイズは、ショットノイズまたは熱雑音とも呼ばれ、すべての検出プロセスに固有のものである。例えば、MCPなどの計数検出器は、ショットノイズを付加し、電位計などの増幅器は、熱雑音またはジョンソンノイズを付加する。ショットノイズの統計量は、一般的に、ポアソン分布により記述される。ジョンソンノイズの統計量は、一般的に、ガウス分布により記述される。このような検出ノイズは、システムに固有のものであり、なくすことはできない。
【0076】
LC/MSシステムに生じる第2の種類のノイズは、化学的ノイズである。化学的ノイズは、複数の発生源から生じる。例えば、分離とイオン化のプロセスでうっかり捕捉してしまった小さな分子は、化学的ノイズを引き起こす可能性がある。このような分子は、一定量存在しうるものであり、それぞれ本質的に一定の背景強度を所定の質量対電荷比で発生するか、またはそれぞれのそのような分子は分離され、それにより特徴的な保持時間にクロマトグラフィプロファイルを形成することができる。化学的ノイズの他の発生源は、複合試料中に見られ、これは、濃度が広いダイナミックレンジで変化する分子と濃度が低いほど効果が著しく現れる干渉元素の両方を含みうる。
【0077】
図13は、ノイズの効果を示す例示的な等高線図である。図13では、化学的ノイズおよび検出器ノイズの効果をシミュレートするため、数値生成ノイズがイオンピーク等高線図に加えられている。図14Aは、図13の直線A、B、およびCにそれぞれ対応している質量スペクトル(スペクトルA、B、およびC)を例示しており、図14Bは、図13でイオン1、イオン2、およびイオン3とそれぞれ標識付けされている直線に対応するイオン1、2、3に対するクロマトグラムを例示している。図13からわかるように、追加ノイズの有害な効果の1つは、イオン1および2に関連付けられている公称頂点配置のFWHMの範囲内を含む、プロット全体にわたって頂点を出現させることである。これらのノイズに由来する頂点は、イオンに対応するピークとして誤って識別される可能性があり、したがってイオン検出が偽陽性となる。
【0078】
そのため、極大は、イオンではなくむしろノイズによるものと考えられる。その結果、偽ピーク、つまり、イオンに関連付けられていないピークが、1つのイオンとして数えられる可能性がある。さらに、ノイズは、1つのイオンに対し複数の多重極大値を発生する可能性もある。このような多重最大値があると、真のイオンを代表しないピークが検出される可能性がある。したがって、実際に複数のピークが単一のイオンにのみ起因する場合に、単一のイオンから得られるピークは、別々のイオンとして重複計数される可能性がある。このように偽ピークをイオンとして検出することは、偽陽性と呼ばれる。
【0079】
ノイズ効果を無視することに加えて、図10で説明されている単純なイオン検出アルゴリズムは、一般に統計的に最適ではない。これは、保持時間、m/z、および強度の推定値の分散が、単一の最大要素のノイズ特性により決定されるためである。簡素化されたアルゴリズムでは、最大要素の周囲にある強度の島の中の他の要素を使用しない。以下でさらに詳しく説明されるように、このような隣接要素は、推定値の分散を低減するために使用されうる。
【0080】
畳み込みの役割
本発明のいくつかの実施形態によれば、LC/MSデータ行列は、二次元配列である。このようなデータ行列は、これをフィルタ係数の二次元配列に畳み込むことにより処理されうる。
【0081】
本発明のいくつかの実施形態で使用される畳み込み演算は、従来のシステムで使用されている単純なシグナル加算平均方式に比べてピーク検出に対するより一般的で強力なアプローチであるといえる。本発明のいくつかの実施形態で使用される畳み込み演算は、図10で説明されている方法の制限を解消する。
【0082】
フィルタ係数は、複数の単一チャネルまたは走査を分析することで得られるものと比べて優れたシグナル対ノイズ比を有するイオンパラメータの推定値が得られるように選択できる。
【0083】
畳み込みフィルタ係数は、特定のデータ集合に対し最大の精度または最小の統計的分散を有するイオンパラメータの推定値を形成するように選択することができる。本発明のいくつかの実施形態のこれらの利点は、従来のシステムによるものと比べて、低濃度でイオンに対する再現性の高い結果をもたらすものである。
【0084】
本発明のいくつかの実施形態の他の利点は、共溶出され、干渉するイオンを分離して検出できるようにフィルタ係数が選択されうることである。例えば、質量スペクトル中で他のイオンに対する段部として出現するイオンの頂点は、本発明のいくつかの実施形態における適宜指定されたフィルタ係数を使用して検出できる。このような検出は、共溶出およびイオン干渉が共通の問題となっている、複合クロマトグラムを分析する際の従来の技術に付随する制限を解消する。
【0085】
本発明のいくつかの実施形態の他の利点は、ベースラインシグナルを差し引くようにフィルタ係数が選択され、これによりイオン強度のより正確な推定を行えるという点である。
【0086】
本発明のいくつかの実施形態の他の利点は、畳み込みの計算負荷を最小限に抑えるようにフィルタ係数が選択され、その結果ピーク検出およびイオンパラメータの推定を高速実行できるという点である。
【0087】
一般に、例えば、サビツキー−ゴーレイ(SG)平滑化および微分フィルタを含む、多数のフィルタ形状が、畳み込みにおいて使用できる。フィルタ形状は、平滑化、ピーク同定、ノイズ低減、およびベースライン低減を含む、多数の機能を実行するように選択されうる。本発明の好ましい実施形態で使用されるフィルタ形状は、以下で説明される。
【0088】
本発明における畳み込みの実装
本発明のいくつかの実施形態による畳み込み演算は、線形、非反復性で、データ行列内のデータの値に依存しない。本発明の一実施形態では、畳み込み演算は、コンピュータ118などの汎用コンピュータを使用し汎用プログラミング言語を用いて実装される。本発明の代替え実施形態では、畳み込み演算は、デジタルシグナルプロセッサ(DSP)と呼ばれる専用プロセッサで実装される。典型的には、DSPベースのフィルタリングでは、汎用コンピュータベースのフィルタリングに比べて処理速度が向上する。
【0089】
一般に、畳み込みは、2つの入力を組み合わせて、1つの出力を形成する。本発明のいくつかの実施形態では、二次元畳み込みを用いる。二次元畳み込み演算への入力の1つは、LC/MS実験のスペクトル出力から形成される強度のデータ行列である。二次元畳み込み演算への第2の入力は、フィルタ係数の行列である。畳み込み演算は、出力畳み込み行列を出力する。一般に、出力畳み込み行列は、入力されたLC/MS行列と同じ数の行および列の要素を有する。
【0090】
本発明の説明を簡単にするため、LC/MSデータ行列は、矩形であり、フィルタ係数の行列のサイズは、ピークのサイズに相当すると仮定する。この場合、フィルタ係数行列のサイズは、入力データ行列または出力畳み込み行列のサイズよりも小さい。
【0091】
出力行列の要素は、まずフィルタ行列が入力データ行列内の一要素を中心とするように構成され、次いで入力データ行列要素が、対応するフィルタ行列要素を乗算され、それらの積が総和され、出力畳み込みデータ行列の要素が形成されるというようにして入力LC/MSデータ行列から得られる。隣接要素を組み合わせることにより、畳み込みフィルタは、イオンの保持時間、質量対電荷比、および強度の推定値の分散を低減する。
【0092】
出力畳み込み行列のエッジ値は、出力畳み込み行列のエッジからフィルタ幅の半分までの範囲内にある要素である。一般に、これらの要素は、本発明のいくつかの実施形態における無効な値に設定され、無効なフィルタリング値であることを示しうる。一般に、これらのエッジ値を無視することは、本発明のいくつかの実施形態については有意な制限ではなく、これらの無効値は、その後の処理において無視できる。
【0093】
一次元畳み込み
一次元の場合の畳み込みは、詳細に明確に説明される。この説明の後に、畳み込みを二次元の場合に一般化する。本発明の好ましい実施形態で使用される二次元の畳み込み演算は、一連の一次元畳み込みをデータ行列に適用することにより実装されるため、まず一次元の場合を説明するのが得策である。
【0094】
一次元では、畳み込み演算は、以下のように定義される。強度diの一次元のN要素の入力配列と畳み込みフィルタ係数fjの一次元のM要素の配列が与えられた場合、畳み込み演算は
【数1】
で定義されるが、ただし、ciは、出力畳み込み配列であり、i=1,...,Nである。便宜上、Mは、奇数となるように選択される。インデックスjは、j=−h,...,0,...hであり、hは、h≡(M−1)/2で定義される。
【0095】
そのため、ciの値は、diの周囲のh個の要素の重み付き総和に対応する。スペクトルおよびクロマトグラムは、ピークを含む一次元入力配列の実施例である。畳み込みフィルタfjの幅は、ほぼピークの幅となるように設定される。したがって、Mは、ピークの幅をスパンとする配列要素の個数のオーダーである。ピークは、典型的には、入力配列の長さNよりもかなり小さい幅を有し、したがって一般には、M□Nである。
【0096】
diに対するインデックスiは、1からNまでの値をとるけれども、本発明のいくつかの実施形態では、ciは、エッジ効果に対応できるようにi>hまたはi≦(N−h)についてのみ定義される。配列境界付近にある、つまり、i≦hまたはi>(N−h)である場合のciに対する値は、総和については定義されない。そのようなエッジ効果は、ciに対する値を、i>hまたはi≦(N−h)となるように制限し、総和が定義されるようにすることにより取り扱うことができる。この場合、総和は、配列エッジから十分に遠いところにあるピークにのみ適用され、フィルタfjは、そのピークの近傍内にあるすべての点に適用できる。つまり、フィルタリングは、データ配列diのエッジでは実行されないということである。一般に、エッジ効果を無視することは、本発明の実施形態については有意な制限とならない。
【0097】
フィルタリングされた値が1<i<hまたはN≧i>(N−h)に対するエッジの付近で必要な場合、それらのエッジ要素についてデータ配列および/またはフィルタ係数のいずれかが修正されうる。データ行列は、h個の要素を配列のそれぞれの末尾に付加することにより修正することができ、またM個係数フィルタを、N+2h個の要素を含む配列に適用するとよい。
【0098】
それとは別に、エッジ効果は、エッジの付近のフィルタリングに対しM個未満の点があることに対応できるようにフィルタリング機能の限度を適宜修正することにより考慮されうる。
【0099】
二次元畳み込み
上述の一次元畳み込み演算は、本発明の実施形態で使用する二次元データの場合に一般化できる。二次元の場合、畳み込み演算への入力の1つは、i=1,...,Mおよびj=1,...,Nである2つのインデックス(i,j)を添え字とするデータ行列di,jである。入力データ行列のデータ値は、実験毎に異なることがある。畳み込みへの他の入力は、これもまた2つのインデックスを添え字とする固定フィルタ係数fp,qの集合である。フィルタ係数行列fp,qは、P×Q個の係数を有する行列である。変数hおよびlは、h≡(P−1)/2およびl≡(Q−1)/2と定義される。したがって、p=−h,...,hおよびq=−l,...,lである。
【0100】
di,jをfp,qに畳み込むと、出力畳み込み行列ci,j
【数2】
が得られる。
【0101】
一般に、フィルタのサイズは、データ行列のサイズに比べてかなり小さく、P<<MおよびQ<<Nとなる。上記の式は、ci,jが、fp,qの中心をdi,jの(i,j)番目の要素とし、次いでフィルタ係数fp,qを使用して周囲の強度の重み付き総和を求めることにより計算されることを示している。したがって、出力行列ci,jのそれぞれの要素は、di,jの要素の重み付き総和に対応し、それぞれの要素di,jは、i,j番目の要素を中心とする領域から得られる。
【0102】
di,jに対するインデックスiおよびjは、iは1からNまで、jは1からMまでの値をとるけれども、本発明のいくつかの実施形態では、ci,jは、エッジ効果に対応できるようにi≧hまたはi≦(N−h)およびj≧lまたはj≦(M−l)についてのみ定義される。配列境界付近にある、つまり、i<hまたはi>(N−h)および/またはj≧lまたはj≦(M−l)である場合のciに対する値は、総和については定義されない。そのようなエッジ効果は、ci,jに対する値を、総和が定義される値に制限することにより取り扱うことができる。この場合、総和は、配列エッジから十分に遠いところにあるピークにのみ適用され、フィルタfp,qは、そのピークの近傍内にあるすべての点に適用できる。つまり、フィルタリングは、データ配列di,jのエッジでは実行されないということである、一般に、エッジ効果を無視することは、本発明の実施形態については有意な制限とならない。
【0103】
フィルタリングされた値が1≦i<hおよびN≧i>(N−h)に対するエッジの付近で必要な場合、それらのエッジ要素についてデータ行列および/またはフィルタ係数行列のいずれかが修正されうる。アプローチの1つは、それぞれの行の末尾にh個の要素を付加し、それぞれの列の末尾にl個の要素を付加する。次いで、二次元畳み込みフィルタが、(N+2h)×(M+2l)個の要素を含むデータ行列に適用される。
【0104】
それとは別に、エッジ効果は、行エッジの付近のフィルタリングに対しP個未満の点があり、列エッジ付近のフィルタリングに対しQ個の点があることに対応できるようにフィルタリング機能の限度を適宜修正することにより考慮されうる。
【0105】
式(2)の実装に対する計算負荷は以下のように計算することができる。fp,qがP×Q個の係数を含んでいる場合、ci,jに対する値を計算するのに必要な乗算の回数は、P×Qである。例えば、P=20およびQ=20の場合、出力畳み込み行列中のそれぞれの出力点ci,jを決定するのに400回の乗算が必要であるという結果になる。これは、二次元畳み込みに対する他のアプローチで緩和できる高い計算負荷である。
【0106】
階数1のフィルタによる二次元畳み込み
式(2)で記述される二次元畳み込みフィルタは、P×Q個の独立に指定された係数を含むフィルタ行列を適用する。フィルタ係数を指定する他の方法がある。結果として得られる畳み込み係数は、自由に指定されるようなものではないけれども、計算負荷は緩和される。
【0107】
フィルタ係数を指定するそのような代替えの一方法は、階数1のフィルタとしてのものである。階数1の畳み込みフィルタを記述するには、LC/MSデータ行列に対する二次元畳み込みが、2つの一次元畳み込みを連続して適用することにより実現されうることを考慮する。例えば、参照により本明細書に組み込まれているJOHN H.KARL「INTRODUCTION TO DIGITAL SIGNAL PROCESSING」PG.320(ACADEMIC PRESS 1989)(“KARL”)を参照のこと。例えば、一次元フィルタgqは、LC/MSデータ行列のそれぞれの行に適用され、中間畳み込み行列を形成する。この中間畳み込み行列に対し、第2の一次元フィルタfpがそれぞれの列に適用される。それぞれの一次元フィルタは、異なるフィルタ係数の集合で指定できる。式(3)は、階数1の畳み込みフィルタを含むフィルタが連続してどのように適用されるかを示しており、そこでは、中間行列は括弧で囲まれている。
【数3】
【0108】
式(3)の実装に対する計算負荷は以下のように計算することができる。fpがP個の係数を含み、gqがQ個の係数を含んでいる場合、ci,jに対する値を計算するのに必要な乗算の回数は、P+Qである。例えば、P=20およびQ=20の場合、出力畳み込み行列中のそれぞれの出力点ci,jを決定するのに乗算は40回あればよい。これからわかるように、これは、それぞれのci,jを決定するのに20×20=400が必要である式(2)で記述される二次元畳み込みの一般的な場合よりも計算効率が高い。
【0109】
式(4)は、連続する演算が、要素が一次元フィルタの対毎の積である単一係数行列にデータ行列を畳み込むことと等価であることを例示する式(3)を整理し直したものである。式(4)を調べると、階数1の式を使用した場合、有効な二次元畳み込み行列は、2つの一次元畳み込みベクトルの外積により形成された階数1の行列であることがわかる。そこで、式(4)は、
【数4】
のように書き直すことができる。二次元係数行列Fpqは、畳み込み演算から得られる。Fpqは、階数1の行列の形式をとり、階数1の行列は、列ベクトル(ここではfp)と行ベクトル(ここではgq)の外積として定義される。例えば、参照により本明細書に組み込まれている、GILBERT STRANG「INTRODUCTION TO APPLIED MATHEMATICS」68FF(WELLESLEY−CAMBRIDGE PRESS 1986)(「STRANG」)を参照のこと。
【0110】
階数1のフィルタ実装を使用する本発明の実施形態では、階数1のフィルタは、フィルタ毎に1つずつ、2つの直交する断面により特徴付けられる。それぞれの直交する断面に対するフィルタは、一次元フィルタ配列により指定される。
【0111】
階数2のフィルタによる二次元畳み込み
二次元畳み込み演算は、階数2のフィルタにより実行されうる。階数2のフィルタによる二次元畳み込みは、2つの階数1のフィルタを計算し、その結果を足し合わせることにより実行される。したがって、本発明の実施形態で実行される二次元畳み込みに対する階数2のフィルタを実装するのに、4つのフィルタ
【数5】
および
【数6】
が必要である。
【0112】
2つのフィルタ、
【数7】
および
【数8】
は、第1の階数1のフィルタに関連付けられており、2つのフィルタ、
【数9】
および
【数10】
は、第2の階数1のフィルタに関連付けられている。これら4つのフィルタ
【数11】
および
【数12】
は、
【数13】
のように実装される。
【0113】
フィルタ
【数14】
および
【数15】
は、スペクトル方向(列にそって)で適用され、フィルタ
【数16】
および
【数17】
は、クロマトグラフ方向(行にそって)で適用される。式(7)は、中間行列が括弧で囲まれており、それぞれのフィルタ対がどのようにして連続的に適用されうるか、また2つの階数1のフィルタから得られる結果がどのように総和されるかを例示している。式(7)は、本発明の実施形態により階数2のフィルタを実装する好ましい方法を示している。
【0114】
式(8)は、階数2のフィルタ構成における連続する演算が、要素が2つの一次元フィルタ対の対毎の積の総和である単一係数行列にデータ行列を畳み込むことと等価であることを示すように式(7)を整理し直したものである。
【0115】
階数2のフィルタの計算要件を分析するために、
【数18】
と
【数19】
が両方ともP個の係数を含み、
【数20】
と
【数21】
が両方ともQ個の係数を含む場合に、出力畳み込み行列ci,jの要素に対する値を計算するために必要な乗算回数が2(P+Q)であることを考慮する。したがって、P=20およびQ=20の場合、出力畳み込み行列のそれぞれの要素を計算するのに乗算を80回行うだけでよいが、式(2)に示されているような一般の場合には、それぞれのci,jを計算するのに20×20=400回の乗算が必要になる。
【0116】
そこで、階数2のフィルタを使用する本発明の一実施形態では、有効な二次元畳み込み行列は、一次元ベクトルの2つの対の外積の総和から形成される。式(8)は、
【数22】
のように書き直すことができる。
【0117】
二次元係数行列Fpqは、畳み込み演算から得られる。二次元係数行列Fpqは、階数2の行列の形式をとり、階数2の行列は、STRANGで説明されているように2つの一次独立の階数1の行列の和として定義される。ここで、
【数23】
および
【数24】
は、それぞれ階数1の行列である。
【0118】
フィルタ指定
式(2)、(3)、および(7)は、すべて本発明の二次元畳み込みフィルタの実施形態である。式(2)では、フィルタ係数を行列fp,qとして指定し、式(3)では、フィルタ係数を2つの一次元フィルタfpおよびgqの集合として指定し、式(7)では、これらのフィルタを4つの一次元フィルタ
【数25】
および
【数26】
の集合として指定する。
【0119】
式(2)、(3)、および(7)は、これらの係数の好ましい値を指定しない。本発明に対するフィルタ係数の値は、図10の方法の制限を解消するように選択される。これらのフィルタ係数は、検出器および化学的ノイズの効果の低減、共溶出および干渉ピークの部分的分離検出、ベースラインノイズの差し引き、ならびに計算効率および高速演算の実現を含む複数の目標を達成するように選択される。
【0120】
整合フィルタ定理(MFT)は、式(2)を使用して実装することができるフィルタ係数を求めるための、従来技術において知られている規範的方法である。例えば、217のKARL、参照により本明細書に組み込まれているBRIAN D.O.ANDERSON & JOHN B.MOORE「OPTIMAL FILTERING」223ff (PRENTICE−HALL INC.1979)(「ANDERSON」)の223ffを参照のこと。MFTから得られたフィルタは、シグナルの存在を検出し、検出器ノイズの効果を低減するように設計されている。次いで、このようなフィルタは、LC/MSデータ行列でイオンを検出するために使用され、またイオンの保持時間、質量対電荷比、および強度を測定するために使用されうる。MFTから得られたフィルタは、図10の方法に勝る改善となっている。特に、このようなフィルタは、ピーク頂点の近傍内にあるピークの範囲内の要素から得られるデータを組み合わせることにより分散を低減し、精度を向上させる。しかし、このようなフィルタは、ベースラインノイズを差し引くか、または共溶出および干渉ピークを分離し検出するようには設計されていない。MFTから得られるフィルタは、高速演算を可能にするようには設計されていない。
【0121】
MFTおよびMFTから得られるフィルタ係数の集合は、図10の方法に対する改善となっていることが説明されており、次いでベースラインを差し引く修正済みフィルタは、共溶出および干渉の効果を低減するが、それでも検出器および化学的ノイズの効果を低減することが説明される。このようなフィルタは、平滑化フィルタと2階微分フィルタの組み合わせを使用しており、また式(3)および(7)を使用して実装される。好ましい実施形態では、式(7)を、ともにノイズを低減し、干渉ピークを分離検出し、ベースラインを差し引き、計算負荷を低減して高速演算に対応できるようにする平滑化フィルタと2階微分フィルタの組み合わせとともに使用する。
【0122】
一次元畳み込み用の整合フィルタ定理
一次元畳み込みについて最初にMFTが説明される。次いで、二次元畳み込みに一般化する。
【0123】
検出機能を実行するようにfjに対する係数が選択される。例えば、整合フィルタ定理(MFT)では、検出機能を実行するために使用されうる整合フィルタと呼ばれるフィルタ係数の集合を形成する。
【0124】
MFTでは、データ配列diが、シグナルr0siと追加ノイズniとの和
【数27】
としてモデル化されうると仮定する。シグナルの形状は、固定されており、係数siの集合として記述される。スケール係数r0が、シグナルの振幅を決定する。MFTは、さらに、このシグナルが有界であると仮定する。つまり、シグナルは、ある領域の外でゼロである(または無視できるくらい小さい)。シグナルは、M個の要素上に広がると仮定される。便宜上、Mは、典型的には、奇数になるように選択され、シグナルの中心は、s0に置かれる。hがh≡(M−1)/2と定義された場合、i<−hおよびi>hについてsi=0である。上記の式の中で、シグナルの中心は、i=i0のところに現れる。
【0125】
この記述を簡素化するために、ノイズ要素niは、平均値0、標準偏差σ0の無相関のガウス偏差であると仮定される。MFTに対するより一般的な定式化は、相関または有色雑音に適応している。例えば、ANDERSONの288−304を参照のこと。
【0126】
これらの仮定の下で、それぞれの要素のシグナル対ノイズ比(SNR)はr0si/σ0である。シグナルsiを含むデータの重み付き総和のSNRは、シグナルと一致するように中心を揃えた、重みwiのM要素集合を考えることにより決定されうるが、ただし、h≡(M−1)/2、およびi=−h,...,0,...hである。これらの重みはシグナルと一致するように中心を揃えられていると仮定すると、重み付き総和Sは、
【数28】
と定義される。
【0127】
集合平均におけるノイズ項の平均値は、ゼロである。したがって、それぞれの配列内のシグナルが同じであるが、ノイズは異なる配列の集合に対するSの平均値は、
【数29】
である。
【0128】
ノイズの寄与率を決定するために、ノイズのみを含む領域に重みが適用される。総和の集合平均は、ゼロである。集合平均に関する重み付き総和の標準偏差は、
【数30】
である。
【0129】
最後に、SNRは、
【数31】
と決定される。この結果は、重み付け係数wiの一般的な集合に対するものである。
【0130】
MFTは、SNRを最大化するwiに対する値を指定する。重み付け係数wiが、単位長のM次元ベクトルwの要素としてみなされる場合、つまり、重み付け係数が
【数32】
になるように正規化された場合、SNRは、ベクトルwがベクトルsと同じ方向を指している場合に最大化される。これらのベクトルは、それぞれの要素が互いに比例する場合、つまり、wi∝siの場合に同じ方向を指す。したがって、MFTは、重み付け関数がシグナルそれ自体の形状である場合に、重み付き総和が最高のシグナル対ノイズ比を有することを意味する。
【0131】
wiが、wi=siとなるように選択される場合、単位標準偏差を有するノイズに関して、SNRは、
【数33】
に低減される。SNRのこの定式化は、フィルタ係数がそのシグナルを中心とするときの重み付き総和のシグナル特性およびフィルタがノイズのみの領域内にあるときのノイズ特性に対応する。
【0132】
二次元畳み込み用の整合フィルタ定理
一次元の場合について上で説明されているMFTは、さらに、データの二次元配列内に埋め込まれた有界二次元シグナルの二次元の場合に一般化されうる。前述のように、データは、シグナルとノイズの和
【数34】
としてモデル化されると仮定されるが、ただし、シグナルSi,jは、範囲が制限され、またその中心は、振幅r0を持つ(i0,j0)に置かれる。それぞれのノイズ要素ni,jは、平均値0および標準偏差σ0の独立ガウス偏差である。
【0133】
シグナルSi,jを含むデータの重み付き総和のSNRを決定するために、重みwi,jのP×Q要素の集合を考えるが、ただし、i=−h,...,hおよびj=−l,...,lとなるようなh=(P−1)/2およびl=(Q−1)/2である。重みは、シグナルと一致するように中心を揃えられる。重み付き総和Sは
【数35】
である。
【0134】
この集合上のSの平均値は
【数36】
である。ノイズの標準偏差は
【数37】
であり、シグナル対ノイズ比は
【数38】
である。
【0135】
上述の一次元の場合のように、SNRは、重み付け関数の形状は、シグナルに比例するときに、つまり、wi,j∝si,jのときに最大化される。重み付き総和のシグナル特性は、フィルタ係数がそのシグナルを中心とする場合に対応し、重み付き総和のノイズ特性は、フィルタがノイズのみの領域内にある場合に対応する。
【0136】
整合フィルタは、隣接要素を最適な形で組み合わせることにより最大のシグナル対ノイズ比を得る。整合フィルタ係数を使用する畳み込みフィルタは、イオンの保持時間、質量対電荷比、および強度の推定値の分散を最小にする。
【0137】
一意的な最大値が得られることが保証される整合フィルタ
一般に、畳み込みを使用するシグナル検出は、データ配列にそってフィルタ係数を移動し、それぞれの点で重み付き総和を求めることにより進む。例えば、フィルタ係数が、MFTを満たす、つまりwi=siである場合(フィルタがシグナルに整合している)、データのノイズのみの領域において、出力の振幅は、ノイズによって決まる。フィルタがシグナルに重なると、振幅は増大し、フィルタがシグナルと時間的に揃ったときに一意的な最大値に達しなければならない。
【0138】
一次元ガウス整合フィルタ
一次元畳み込みに対する前述の技術の一実施例として、シグナルが単一イオンからの結果として得られる単一ピークである場合を考察する。ピーク(スペクトルまたはクロマトグラフ)は、幅が標準偏差σpで与えられるガウス分布としてモデル化されうるが、ただし、幅は試料要素の単位で測定される。次いで、シグナルは
【数39】
である。
【0139】
フィルタ境界は、±4σpに設定されると仮定する。整合フィルタ定理によれば、フィルタは、0を中心とし、±4σpを境界とするシグナル形状それ自体、つまり、ガウス型である。このような整合フィルタの係数は、
【数40】
により与えられる。
【0140】
さらに、システムが、標準偏差に従って4点をサンプリングすると仮定する。その結果、σp=4となり、したがって、i=−16,...,16であり、フィルタは、本発明の実施例では幅が33点となる。一次元のガウス整合フィルタ(GMF)では、畳み込み出力配列の最大シグナルは7.09r0であり、ノイズ振幅は2.66σ0である。整合フィルタを使用することに関連するSNRは、2.66(r0/σ0)である。
【0141】
一次元のボックスカーフィルタと対比されるガウス整合フィルタ
一次元についてGMFと単純ボックスカーフィルタとを対比する。ここでもまた、シグナルは、上述のガウス形状でモデル化されるピークであると仮定される。ボックスカーに対するフィルタ境界も、±4σpに設定されると仮定する。ボックスカーフィルタの係数は、
【数41】
により与えられる。ボックスカーフィルタの出力は、M個の点にわたる入力シグナルの平均値である(M=8σp+1)。
【0142】
ここでもまた、さらに、システムが標準偏差に従って4点をサンプリングし、したがって、ボックスカーフィルタの幅が33点であると仮定する。単位高さのガウスピークについては、ボックスカーフィルタを使用するピーク上の平均シグナルは、0.304r0であり、ノイズの標準偏差は
【数42】
である。ボックスカーフィルタを使用するSNRは、1.75(r0/σ0)である。
【0143】
したがって、ボックスカーに関するガウス整合フィルタのSNRは、2.66/1.75=1.52、またはボックスカーフィルタにより得られる値の50%以上高い。
【0144】
整合フィルタおよびボックスカーフィルタは両方とも線形である。これらのフィルタのいずれかをガウスピーク形状に畳み込むことで、固有の最大値を有する出力がもたらされる。したがって、本発明の実施形態の畳み込みにおいて、これらのフィルタのいずれかを使用できる。しかし、ガウスノイズの場合、極大値ではSNRが高いので、整合フィルタが好ましい。
【0145】
ガウスノイズおよびポアソンノイズ
ガウス整合フィルタは、ノイズがガウス分布に従う場合に最適なフィルタである。計数検出器では、ボックスカーフィルタは、ピークに関連付けられているすべてのカウントの単なる総和であるため最適なものとなる。ピークに関連付けられているすべてのカウントを総和するために、ボックスカーフィルタの幅は、そのピークの幅に関係していなければならない。典型的には、ボックスカーフィルタの幅は、ピークのFWHMの2から3倍である。
【0146】
二次元ガウス整合フィルタ
二次元畳み込みに対する整合フィルタ技術の一実施例として、シグナルが単一イオンからの結果として得られる単一ピークである場合を考察する。このピークは、スペクトル方向とクロマトグラフ方向の両方においてガウス分布としてモデル化されうる。スペクトル幅は、標準偏差σpにより与えられ、その幅は、試料要素の単位で測定され、クロマトグラフ幅は、標準偏差σqにより与えられ、その幅は、試料要素の単位で測定される。次いで、データ行列要素i0,j0を中心とするシグナルは、
【数43】
となる。
【0147】
フィルタ境界は、±4σpおよび±4σqに設定されると仮定する。整合フィルタ定理によれば、フィルタは、0を中心とし、±4σpおよび±4σqを境界とするシグナル形状それ自体、つまり、ガウス型である。このような整合フィルタの係数は、
【数44】
により与えられる。
【0148】
さらに、システムが、スペクトル方向とクロマトグラフ方向の両方について標準偏差に従って4点をサンプリングすると仮定する。その結果、σp=4およびσq=4となり、したがって、p=−16,...,16およびq=−16,...,16であり、フィルタは、本発明の実施例では33×33点である。二次元のガウス整合フィルタ(GMF)では、畳み込み出力行列の最大シグナルは50.3r0であり、ノイズ振幅は7.09σ0である。整合フィルタを使用することに関連するSNRは、7.09(r0/σ0)である。
【0149】
二次元畳み込みフィルタは、クロマトグラフ方向と質量分析方向の両方でLC/MSデータ行列に対しフィルタ演算を実行する。畳み込み演算の結果、出力畳み込み行列は、形状が一般に入力LC/MSデータ行列に関して広げられるか、または他の何らかの形で歪まされているピークを含む。特に、ガウス整合フィルタは、常に、入力ピークに関するクロマトグラフ方向とスペクトル方向の両方の方向に
【数45】
倍に広げられた出力畳み込み行列中にピークを生成する。
【0150】
一見すると、GMFにより行われる拡大は、保持時間、質量対電荷比、または強度のクリティカルパラメータの正確な推定にとって有害な場合があるように思われる。しかし、整合フィルタ定理は、二次元畳み込みが、結果として得られる頂点関連値がそのピークの保持時間、m/z、および強度の統計上最適な推定値をもたらすようにそのピークに関連付けられているすべてのスペクトル要素およびクロマトグラフ要素の有効な組み合わせを形成する保持時間、質量対電荷比、および強度結果を有する頂点値を生成することを示している。
【0151】
二次元のボックスカーフィルタと対比されるガウス整合フィルタ
二次元についてGMFと単純ボックスカーフィルタとを対比する。ここでもまた、シグナルは、上述のガウス形状でモデル化されるピークであると仮定される。ボックスカーに対するフィルタ境界も、±4σpに設定されると仮定する。ボックスカーフィルタの係数は、
【数46】
により与えられる。ボックスカーフィルタの出力は、M×N個の点にわたる入力シグナルの平均値である。
【0152】
ここでもまた、さらに、システムが標準偏差に従って4点をサンプリングし、したがって、ボックスカーフィルタの幅が33×33点であると仮定する。単位高さのガウスピークについては、ボックスカーフィルタを使用するピーク上の平均シグナルは、0.092r0であり、ノイズの標準偏差は0.303σ0である。ボックスカーフィルタを使用するSNRは、3.04(r0/σ0)である。
【0153】
したがって、ボックスカーに関するガウス整合フィルタのSNRは、7/3=2.3、またはボックスカーフィルタにより得られる値の2倍以上である。
【0154】
整合フィルタおよびボックスカーフィルタは両方とも線形である。これらのフィルタのいずれかをガウスピーク形状に畳み込むことで、固有の最大値を有する出力がもたらされる。したがって、本発明の実施形態の畳み込みにおいて、これらのフィルタのいずれかを使用できる。しかし、ガウスノイズの場合、極大値ではSNRが高いので、整合フィルタが好ましい。
【0155】
ガウスノイズおよびポアソンノイズ
二次元のガウス整合フィルタは、ノイズがガウス分布に従う場合に最適なフィルタである。計数検出器では、ボックスカーフィルタは、ピークに関連付けられているすべてのカウントの単なる総和であるため最適なものとなる。ピークに関連付けられているすべてのカウントを総和するために、ボックスカーフィルタの幅は、スペクトル方向およびクロマトグラフ方向でそのピークの幅に関係していなければならない。典型的には、ボックスカーフィルタの幅は、スペクトル方向およびクロマトグラフ方向の両方の方向でピークのそれぞれのFWHMの2から3倍である。
【0156】
LC/MSデータ行列におけるイオンの検出用のガウス整合フィルタ
ガウス整合フィルタについては、二次元畳み込みフィルタの指定(ステップ2)は、上述のようにガウスフィルタ係数fp,qである係数であり、次いで、これらのフィルタ係数を使用してフィルタの適用(ステップ3)が式(2)に従って行われる。ステップ2およびステップ3のこの実施形態では、イオンを検出し、保持時間、質量対電荷比、および強度を決定する方法を実現する。このような方法からの結果は、検出器ノイズの効果を低減し、また図10の方法に勝る改善となっている。
【0157】
整合フィルタでないフィルタ係数
シグナル形状に従うもの以外の線形重み付け係数も使用できる。このような係数から、可能な最高のSNRが得られない場合もあるが、他の釣り合いの取れる利点を有する場合がある。これらの利点は、共溶出および干渉ピークを部分的に分離する能力、ベースラインノイズの差し引き、および高速演算を可能にする計算効率を含む。ここでは、ガウス整合フィルタの制限を分析し、これらの制限を解消する線形フィルタ係数を説明する。
【0158】
ガウス整合フィルタの課題
ガウスピークについては、整合フィルタ定理(MFT)では、ガウス整合フィルタ(GMF)を他の畳み込みフィルタと比較したように最高のシグナル対ノイズ比を有する応答を持つフィルタとして指定する。しかし、ガウス整合フィルタ(GMF)は、すべての場合において最適であるわけではない。
【0159】
GMFの欠点の1つは、それぞれのイオンに対し幅広にされた、または拡大された出力ピークを生成することである。ピークの広がりを説明しやすくするために、正の値および標準の幅σsを有するシグナルが、正の値および標準の幅σfを有するフィルタに畳み込まれる場合、畳み込まれた出力の標準の幅が増大することはよく知られていることである。シグナルとフィルタ幅が直交する形で組み合わさり、
【数47】
の出力幅を形成する。GMFの場合、シグナルおよびフィルタの幅が等しいと、出力ピークは、入力ピークよりも約
【数48】
倍、つまり40%広い。
【0160】
ピークの広がりにより、小さなピークの頂点が大きなピークで隠蔽される可能性がある。このような隠蔽は、例えば、小さなピークが、時間的にほぼ共溶出され、質量対電荷比に関して大きなピークとほぼ同時に生じる場合に発生する可能性がある。このような共溶出を補正する一方法は、畳み込みフィルタの幅を低減することである。例えば、ガウス畳み込みフィルタの幅を半分にしても、生成する出力ピークは入力ピークよりも12%しか広くならない。しかし、ピーク幅は、整合していないため、SNRは、GMFを使用して得られるものに関して低減される。低減されたSNRの欠点は、ほぼ同時に生じるピークの対を検出する能力が高まるという利点で相殺される。
【0161】
GMFの他の欠点は、正の係数しか持たない点である。したがって、GMFは、それぞれのイオンの基礎をなすベースライン応答を保存する。正係数フィルタは、常に、頂点振幅が実際のピーク振幅と基礎をなすベースライン応答の和であるピークを生成する。このような背景ベースライン強度は、検出器ノイズとさらに他の低レベルのピーク、ときには化学的ノイズと呼ばれるピークと組み合わさることによるものである場合がある。
【0162】
振幅のより正確な尺度を得るために、ベースライン差し引き演算が典型的には使用される。このような演算は、典型的には、そのピークの周囲のベースライン応答を検出し、それらの応答をピーク中心に対し補間し、その応答をピーク値から差し引いてピーク強度の最適な推定値を得るために別のアルゴリズムを必要とする。
【0163】
それとは別に、ベースライン差し引きは、負の係数だけでなく正の係数も有するフィルタを指定することにより実行されうる。このようなフィルタは、逆畳み込みフィルタとも呼ばれ、データの2階微分を抽出するフィルタに形状が似ているフィルタ係数により実装される。このようなフィルタは、それぞれの検出されたイオンに対する単一の極大応答を生成するように構成できる。このようなフィルタの他の利点は、逆畳み込みの尺度を与える、つまり分離能向上をもたらすことである。したがって、このようなフィルタが元のデータ行列中に現れるピークの頂点を保存するだけでなく、元のデータの中では、独立した頂点としてではなく、段部としてしか見えないピークに対する頂点を形成することもできる。したがって、逆畳み込みフィルタは、共溶出および干渉にかかわる問題を解決することができる。
【0164】
GMFの第3の欠点は、これが、一般的に、出力畳み込み行列中のそれぞれのデータ点を計算するのに多数の乗算を必要とすることである。したがって、GMFを使用する畳み込みは、典型的には、他のフィルタを使用する畳み込みに比べて計算コストが高く、また長い計算時間を要する。後述のように、GMF以外のフィルタ指定は、本発明のいくつかの実施形態で使用されうる。
【0165】
2階微分フィルタの利点
シグナルの2階微分を抽出するフィルタは、本発明のいくつかの実施形態によりイオンを検出する際に特に有用である。これは、シグナルの2階微分が、シグナルの曲率の尺度だからであり、それはピークの最も顕著な特性である。一次元で考察されようと、二次元で考察されようと、それ以上の次元で考察されようと、ピークの頂点は、一般的に、最高の曲率の大きさを有するピークの点である。段付きのピークは、さらに、高い曲率の領域でも表される。その結果、曲率に対する応答性があるので、ピーク検出を高めるとともに、より大きな干渉ピークの背景に対し段付きピークの存在を検出する能力を向上させるために2階微分フィルタが使用されうる。
【0166】
ピークの頂点における2階微分は、負の値を有するが、それは、頂点におけるピークの曲率が最大限負だからである。本発明のいくつかの例示的な、制限のない実施形態では、逆2階微分フィルタを使用する。逆2階微分フィルタは、係数のすべてが−1を掛けられた2階微分フィルタである。逆2階微分フィルタの出力は、ピーク頂点において正である。断りのない限り、本発明のいくつかの実施例で参照されているすべての2階微分フィルタは、逆2階微分フィルタとみなされる。2階微分フィルタのすべてのプロットは、逆2階微分フィルタである。
【0167】
2階微分フィルタの定数または直線(0の曲率を有する)に対する応答は、ゼロである。したがって、2階微分フィルタは、ピークの基礎をなすベースライン応答に対しゼロの応答を有する。2階微分フィルタは、ピークの頂点における曲率に応答し、基礎となるベースラインには応答しない。そのため、2階微分フィルタは、実際に、ベースライン差し引きを実行する。図15は、クロマトグラフ方向とスペクトル方向のいずれかまたは両方において適用されうる例示的な2階微分フィルタの断面を示している。
【0168】
一次元の2階微分フィルタ
一次元の場合、2階微分フィルタは、平滑化フィルタよりも有利であるが、それは、頂点における2階微分フィルタの振幅が、基礎となるピークの振幅に比例するからである。さらに、ピークの2階微分は、ベースラインに応答しない。そこで、実質的に、2階微分フィルタは、ベースライン差し引きおよび補正の演算を自動的に実行する。
【0169】
2階微分フィルタの欠点は、ピーク頂点に関してノイズを増大させるという望ましくない効果を持つことがある点である。このノイズ増大効果は、データを事前平滑化するか、または2階微分フィルタの幅を増やすことにより緩和されうる。例えば、本発明の一実施形態では、2階微分畳み込みフィルタの幅が増大される。2階微分畳み込みフィルタの幅を増大すると、畳み込み時に入力データ行列内のデータを平滑化する能力が高まる。
【0170】
平滑化して2階微分を求めるためのサビツキー−ゴーレイフィルタ
データの単一チャネル(スペクトルまたはクロマトグラム)に対し、データを平滑化する(つまり、ノイズの効果を低減する)、またはデータを微分する従来の方法は、フィルタの適用によるものである。本発明の一実施形態では、平滑化または微分は、単一のスペクトルまたはクロマトグラムに対応するそのデータ配列を固定値フィルタ係数の集合に畳み込むことにより一次元データ配列に対し実行される。
例えば、よく知られている有限インパルス応答(FIR)フィルタは、平滑化および微分の演算を含むさまざまな演算を実行するように、適切な係数で指定されうる。例えば、KARLを参照のこと。好適な平滑化フィルタは、一般的に、対称的な釣鐘曲線を示し、すべて正値をとり、単一の最大値を有する。使用されうる例示的な平滑化フィルタは、ガウス形状、三角形状、放物形状、台形状、余弦波形状を有するフィルタを含み、それぞれ単一の最大値を有する形状として特徴付けられる。非対称の裾引き形状の曲線を有する平滑化フィルタも、本発明のいくつかの実施形態において使用できる。
【0171】
データの一次元配列を平滑化または微分するように指定されうるFIRフィルタのファミリは、よく知られているサビツキー−ゴーレイフィルタである。例えば、参照により本明細書に組み込まれているA.SAVITZKY & M.J.E.GOLAY「ANALYTICAL CHEMISTRY」VOL.36,PP.1627−1639を参照のこと。サビツキー−ゴーレイ(SG)多項式フィルタは、重み付き多項式形状の総和により指定される平滑化および微分フィルタの好適なファミリを形成する。このフィルタファミリ内の0次平滑化フィルタは、上部が平たい(ボックスカー)フィルタである。このフィルタファミリ内の2次平滑化フィルタは、単一の正の最大値を有する放物形である。このフィルタファミリ内で2階微分を得る2次フィルタは、単一の負の最大値を有し、平均値が0である放物形である。対応する逆2階微分SGフィルタは正の最大値を有する。
【0172】
アポダイズサビツキー−ゴーレイフィルタ
SGフィルタの修正により、本発明においてうまく動作する一群の平滑化および2階微分フィルタが得られる。これらの修正SGフィルタは、アポダイズサビツキー−ゴーレイ(ASG)フィルタと呼ばれる。アポダイゼーションという用語は、重み係数の配列をSGフィルタ係数の最小二乗微分に適用することにより得られるフィルタ係数を指す。重み係数は、アポダイゼーション関数である。本発明のいくつかの実施形態で使用されるASGフィルタでは、アポダイゼーション関数は、以下のソフトウェアコードによるコサインウィンドウ(COSINEWINDOWにより定められる)である。このアポダイゼーション関数は、ASG平滑化フィルタを構成するために重み付き最小二乗を介してボックスカーフィルタに適用され、またASG2階微分フィルタを構成するために2階微分SG二次多項式に適用される。ボックスカーフィルタおよび2階微分二次式は、それ自体、サビツキー−ゴーレイ多項式フィルタの実施例となっている。
【0173】
すべてのSGフィルタは、対応するアポダイズサビツキー−ゴーレイ(ASG)フィルタを持つ。ASGフィルタは、対応するSGフィルタと同じ基本フィルタ関数を構成するが、不要な高周波ノイズ成分が多く減衰される。アポダイゼーションは、SGフィルタの平滑化および微分特性を保存するが、その一方で高周波遮断特性を大いに改善している。特に、アポダイゼーションは、フィルタ境界においてSGフィルタ係数の鋭い遷移を除去し、それらを0への滑らかな遷移で置き換える。(これは、0への滑らかな遷移を強制するコサインアポダイゼーション関数である)。上述の高周波ノイズのせいで二重に数える危険性が減じるため、滑らかな裾は有利である。このようなASGフィルタの実施例は、コサイン平滑化フィルタおよびコサインアポダイズ二次多項式サビツキー−ゴーレイ2階微分フィルタを含む。
【0174】
本発明の好ましい実施形態では、これらの平滑化および2階微分ASGフィルタは、LC/MSデータ行列の列および行に適用されるように指定される。
【0175】
二次元畳み込みに対する階数1のフィルタの実施例
二次元畳み込みに対する階数1の定式化の適用例として、ガウス分布となるように式(3)の中のfpおよびgqを選択することが可能である。その結果として得られるFpqは、それぞれの行および列内においてガウス分布を有する。Fpqに対する値は、近いが、二次元GMFに対するfp,qとは同一でない。したがって、この特定の階数1の定式化では、GMFと同様に実行されるが、計算時間が短縮される。例えば、上記の実施例では、例えば、PおよびQが20に等しかった場合、階数1のフィルタの計算要件を使用することで計算負荷は、400/40=10分の1低減される。
【0176】
ガウス分布を持つようにfpおよびgqを選択することと、式(3)に従ってこれらのフィルタを適用することで、本発明によるステップ2およびステップ3の一実施形態が構成される。
【0177】
しかし、本発明の他の実施形態では、階数1のフィルタの次元毎に別々のフィルタを適用することができる。本発明の一実施形態では、例えば、fp(スペクトル方向で適用されるフィルタ)は、平滑化フィルタであり、gq(クロマトグラフ方向で適用されるフィルタ)は、2階微分フィルタである。このようなフィルタの組み合わせを用いることで、フィルタリングに典型的に関連する問題を克服する異なる階数1のフィルタ実装が指定されうる。例えば、階数1のフィルタを含むフィルタは、GMFに関連する前述の問題を解消するように指定できる。
【0178】
式3により実装される、前述の階数1のフィルタは、式2により実装されるGMFに比べて計算効率が高く、したがって高速である。さらに、指定されたフィルタの組み合わせにより、定量的作業に使用されうる線形のベースライン補正応答が得られる。
【0179】
さらに、このフィルタの組み合わせは、クロマトグラフ方向で融合したピークを鋭くするか、または部分的に逆畳み込みする。
【0180】
前述の利点を有する本発明のいくつかの実施形態で使用する例示的な階数1のフィルタは、対応する質量ピークのFWHMの約70%であるFWHMを有する余弦ASG平滑化フィルタである第1のフィルタfpおよび対応するクロマトグラフピークのFWHMの約70%であるゼロ交差幅を有するASG2階微分フィルタである第2のフィルタgqを含む。他のフィルタおよびフィルタの組み合わせは、本発明の他の実施形態における階数1のフィルタとして使用できる。
【0181】
図16Aは、LC/MSデータ行列の列に適用して中間行列を形成するために階数1のフィルタで使用する例示的な余弦ASG平滑化フィルタのスペクトル方向の断面を示している。図16Bは、生成された中間行列の行に適用される例示的なASG2階微分フィルタのクロマトグラフ方向の断面を示している。
【0182】
fpおよびgqのフィルタ関数は、逆にすることができる。つまり、fpを2階微分フィルタとし、gqを平滑化フィルタとすることができる。このような階数1のフィルタは、スペクトル方向で段付きピークの逆畳み込みを行い、クロマトグラフ方向で平滑化する。
【0183】
fpおよびgqは両方とも2階微分フィルタであってはならないことに留意されたい。fpとgqの両方が2階微分フィルタである場合に結果として得られる階数1の積行列は、イオンピークに畳み込まれたときに正の極大値を1個ではなく、全部で5個含む。4つの追加の正の頂点は、これらのフィルタに関連付けられている負のローブの積から生じるサイドローブである。したがって、フィルタのこの特定の組み合わせにより、提案されている方法に適ささない階数1のフィルタができあがる。
【0184】
後述の階数2の定式化では、スペクトル方向とクロマトグラフ方向の両方向で平滑化フィルタおよび2階微分フィルタの特性を有するフィルタを実装する。
【0185】
階数1の畳み込みフィルタを使用する本発明の実施形態のいくつかのフィルタ組み合わせが表2に説明されている。
【表2】
それぞれのフィルタ組み合わせは、ステップ2の一実施形態であり、それぞれ、階数1のフィルタとなって、式(3)を使用して適用され、それによりステップ3を使用する。他のフィルタおよびフィルタの組み合わせは、本発明の他の実施形態における階数1のフィルタとして使用できる。
【0186】
好ましい実施形態である二次元畳み込みに対する階数2のフィルタの実施例
階数2のフィルタは、2つの次元のそれぞれについて2つのフィルタの指定を必要とする。本発明の好ましい一実施形態では、計算効率のよい方法で上述のようにGMFに関連する問題を解消するために4つのフィルタが指定される。
【0187】
例えば、本発明の一実施形態では、第1の階数1のフィルタは、
【数49】
のようなスペクトル平滑化フィルタおよび
【数50】
のようなクロマトグラフ2階微分フィルタを含む。例示的なこのような平滑化フィルタは、余弦フィルタであり、そのFWHMは、対応する質量ピークのFWHMの約70%である。例示的なこのような2階微分フィルタは、ASG2階微分フィルタであり、そのゼロ交差幅は、対応するクロマトグラフピークのFWHMの約70%である。第2の階数1のフィルタは、
【数51】
のようなスペクトル2階微分フィルタおよび
【数52】
のようなクロマトグラフ平滑化フィルタを含む。例示的なこのような2階微分フィルタは、ASG2階微分フィルタであり、そのゼロ交差幅は、対応する質量ピークのFWHMの約70%である。例示的なこのような平滑化フィルタは、余弦フィルタであり、そのFWHMは、対応するクロマトグラフピークのFWHMの約70%である。他のフィルタおよびフィルタの組み合わせも、本発明のいくつかの実施形態において使用できる。このようなフィルタの断面は、それぞれ、図16C、図16D、図16E、および図16Fに例示されている。
【0188】
上述の階数2のフィルタは、GMFに勝るいくつかの利点を有する。これは、階数2のフィルタであるため、GMFよりも計算効率が高く、したがって、実行速度も速い。さらに、それぞれの断面は、係数の総和が0になる2階微分フィルタであるため、定量的作業に使用されうる線形のベースライン補正応答を構成し、またクロマトグラフ方向とスペクトル方向において融合するピークを鋭くするか、または部分的に逆畳み込みする。
【0189】
本発明の好ましい階数2のフィルタ実施形態では、列フィルタのそれぞれのフィルタ幅(係数の数に関する)は、スペクトルピーク幅に比例して設定され、複数の行フィルタのうちのそれぞれのフィルタのフィルタ幅(係数の数に関する)は、クロマトグラフピーク幅に比例して設定される。本発明の好ましい実施形態では、列フィルタの幅は、互いに等しくなるように、またスペクトルピークのFWHMに比例するように設定される。例えば、5つのチャネルのスペクトルピーク幅FWHMについて、フィルタ幅は、11点に設定されうるため、平滑化と2階微分の両方のスペクトルフィルタのフィルタ幅は、11点の同じ値に設定されることになる。同様に、好ましい実施形態では、行フィルタの幅は、互いに等しくなるように、またクロマトグラフピークのFWHMに比例するように設定される。例えば、5つのチャネルのクロマトグラフピーク幅FWHMについて、フィルタ幅は、11点に設定されうるため、平滑化と2階微分の両方のスペクトルフィルタのフィルタ幅は、11点の同じ値に設定されることになる。このようにしてフィルタ幅を選択することで、階数1のフィルタは、等しい次元を有する階数2のフィルタを含む。つまり、第1の階数1のフィルタが、次元M×Nを有する場合、第2の階数1のフィルタの次元も、次元M×Nを有する。階数2のフィルタは、等しい次元を有する階数1のフィルタで構成される必要はないこと、また好適な階数1のフィルタが加算され、これにより階数2のフィルタを形成することができることに留意されたい。
【0190】
階数1のフィルタが加算されることで、階数2のフィルタが構成され、したがって、フィルタは、総和の前に相対的な意味で正規化されなければならない。好ましい実施形態では、第1の階数1のフィルタは、スペクトル方向において平滑化フィルタであり、クロマトグラフ方向で2階微分フィルタである。このフィルタが、第2の階数1のフィルタよりも大きな重みを付けられた場合、組み合わせたフィルタは、スペクトル方向の平滑化ならびにクロマトグラフ方向のピークのベースライン差し引きおよび逆畳み込みをより重要視したものとなる。そのため、2つの階数1のフィルタの相対的正規化が、クロマトグラフ方向およびスペクトル方向の平滑化および微分の相対的重要視を決定する。
【0191】
例えば、2つの階数1のフィルタ
【数53】
を考察するが、ただし、式(11)は、第1の階数1のフィルタであり、式(12)は、第2の階数1のフィルタである。本発明の好ましい一実施形態では、それぞれの階数1のフィルタは、その係数の二乗の総和が1に等しくなるように正規化される。この正規化では、平滑化および微分に対する等しい重みをスペクトル方向およびクロマトグラフ方向に与える。つまり、それぞれM×Nの次元を有する階数1のフィルタに対し、
【数54】
となる。
【0192】
好ましい実施形態の平滑化フィルタおよび2階微分フィルタは、適切なスケーリング係数をそれぞれの階数1の行列の係数に適用することによりこの基準を満たすように正規化されうる。
【0193】
さらに、好ましい実施形態では、それぞれの階数1のフィルタの行次元は、同じであり、それぞれの階数1のフィルタの列次元は、同じである。その結果、
【数55】
のように階数2の畳み込みフィルタの点源を得るために、これらの係数が加算されうる。式(13)から、二次元畳み込みフィルタFp,qを決定するためには、2つの階数1のフィルタの相対的正規化が必要であることがわかる。
【0194】
二次元畳み込みフィルタの好ましい実施形態に対するフィルタ係数
例示的な階数2のフィルタが、図17A〜図17Kに関して説明されている。このフィルタは、イオンを検出し、ベースライン応答を差し引き、融合したピークを部分的に分離し、高い計算効率で実行するために使用されうるステップ2およびステップ3の一実施形態である。
【0195】
特に、この階数2のフィルタは、段付きピークを検出するために有用である。本発明のいくつかの実施形態による階数2のフィルタは、クロマトグラフ方向およびスペクトル方向の両方の2階微分フィルタを含むことができる。曲率に対する2階微分フィルタの応答性から、このような階数2のフィルタは、段付きピークの頂点がデータ中で明らかでない場合のある段付きピークを検出することができる。階数2のフィルタが曲率を測定する2階微分フィルタを含むとした場合、データ中には直接的には見られない第2のピークの頂点が、出力畳み込み行列内の別の頂点として検出されうる。
【0196】
図17Aは、LC/MSデータ中に生成されうるシミュレートされたピークのグラフ表現であり、水平軸は、図に示されているように走査時間およびm/zチャネルを表し、垂直軸は、強度を表す。図17Bは、本発明の好ましい実施形態により、階数2のフィルタに対応する畳み込みフィルタ行列を示している。
【0197】
このシミュレーションでは、すべてのイオンのスペクトルピーク幅およびクロマトグラフピーク幅は、8点、FWHMである。4つすべてのフィルタに対するフィルタ係数の数は、15点である。
【0198】
図17Cは、同じ質量を有し、ほぼ同時であるが、まったく同時というわけではない2つのLC/MSピークのシミュレーションを示している。図17Dは、ピーク断面が質量の純粋なピークであることを例示しており、図17Eは、ピーク断面が時間的な段部1704を示すことを例示している。図17F〜図17Hは、図17D〜図17Eに例示されている段付きピークを含むそれぞれのサンプリングされた要素に対するシミュレートされた計数(ショットノイズ)の効果を例示している。図17Gおよび図17Hは、計数ノイズが加えられたことで生じる断面を例示している。図17Gと図17Hの両方からわかるように、計数ノイズの結果として多数の極大値が発生する。したがって、2個のイオンのみが存在するとしても、計数ノイズは、偽陽性イオン検出を引き起こす可能性のある多数のスプリアス極大値を発生しうることがわかる。
【0199】
図17I〜図17Kは、階数2のフィルタをシミュレートされたデータに畳み込んだ結果を例示している。結果として得られる出力畳み込み行列(図17Iの等高線図により表される)は、2つの異なるピーク1702および1706を含む。ピーク1702は、2個のイオンのうち強度の高いほうに関連付けられたピークであり、ピーク1706は、強度の低い段付きイオンのピークである。図17Jは、スペクトル(質量対電荷比)方向の出力畳み込み行列の断面である。図17Kは、クロマトグラフ(時間)方向の出力畳み込み行列の断面である。
【0200】
図17I〜図17Kを検討することにより観察されることは、本発明の階数2のフィルタベースの実施形態が、計数ノイズの効果を低減し、段付きピークを逆畳み込みして、複数の極大値を形成することである。それぞれの極大値は、1つのイオンに関連付けられる。その結果、本発明のこの実施形態は、さらに偽陽性率を下げる。イオンパラメータ、m/z、保持時間、および強度は、上述のように検出された極大値を分析することにより得られる。
【0201】
単一の極大値を生成する場合にフィルタが使用可能
上述のフィルタおよび畳み込み方法は、LC/MSデータ行列内のイオンを検出するために使用できる。フィルタ係数の他の集合も、ステップ2の実施形態として選択されうる。
【0202】
入力シグナルは、一意の最大値を有するLC/MSデータ行列内のピークであり、したがって、ステップ2の畳み込みフィルタは、畳み込みプロセスを通してその一意の正の最大値を忠実に維持しなければならない。ステップ2の実施形態であるために畳み込みフィルタが満たさなければならない一般的な要件は、一意の最大値を有する入力に畳み込んだときに一意の最大値を生成する出力を畳み込みフィルタが有していなければならないということである。
【0203】
釣鐘型応答を有するイオンの場合、この条件は、単一の正の最大値を有し、すべて釣鐘形である断面を持つ畳み込みフィルタにより満たされる。このようなフィルタの実施例は、逆放物形状フィルタ、三角形状フィルタ、および余弦フィルタを含む。特に、一意の正値頂点を有するという特性を持つ畳み込みフィルタでは、そのフィルタが本発明のいくつかの実施形態で使用するのに適した候補フィルタとなる。フィルタ係数の等高線図を使用することで、極大値の個数と配置を調べることができる。フィルタを通る行、列、および対角線上のすべての断面は、単一の正の極大値を有していなければならない。多くのフィルタ形状が、この条件を満たしており、したがって、本発明のいくつかの実施形態で使用できる。
【0204】
単一の極大値を生成するのでボックスカーが使用可能
許容可能な他のフィルタ形状は、定数値を有するフィルタ(つまり、ボックスカーフィルタ)である。これは、ピークをボックスカーフィルタに畳み込む演算が、単一の最大値を有する出力を生成するからである。本発明のいくつかの実施形態において有利なボックスカーフィルタのよく知られている特性は、そのような形状が、与えられた数のフィルタ点について最小の分散を生じることである。ボックスカーフィルタの他の利点は、一般にガウスまたは余弦フィルタなどの他の形状を有するフィルタに比べて少ない乗算回数で実装できる点である。
【0205】
ボックスカーの次元は、スペクトル方向およびクロマトグラフ方向の両方のピークの広がりと一致すべきである。ボックスカーが小さすぎると、ピークに関連するすべてのカウントが総和されることがない。ボックスカーが大きすぎると、他の隣接するピークからのカウントが含まれることがある。
【0206】
しかし、ボックスカーフィルタは、さらに、本発明が適用されうるいくつかの用途に対しては際だった不利点を有する。例えば、ボックスカーフィルタの伝達関数は、それらのフィルタが高周波ノイズを通過させることを示している。このようなノイズは、本発明のいくつかの用途では望ましくないと思われる、低振幅シグナル(低SNR)に対するピークを二重に数える危険性を増大する可能性がある。したがって、ボックスカー形状以外のフィルタ形状は、本発明の用途では一般的に好ましい。
【0207】
2階微分フィルタは単一の極大値を生成することができる
一意の最大値を有する入力に畳み込んだときに一意の最大値を生成する出力を有する他の好適な畳み込みフィルタ群は、単一の正の極大値を有し、負のサイドローブを持つフィルタである。このようなフィルタの実施例は、曲率に対し応答性のある2階微分フィルタを含む。平滑化フィルタから平均値を差し引くことにより、好適な2階微分フィルタが指定されうる。このようなフィルタは、ボックスカー、三角形状、および台形状の組み合わせから組み立てることが可能であるが、データを微分するフィルタの最も一般的な指定は、サビツキー−ゴーレイ多項式フィルタである。
【0208】
ガウスノイズおよびポアソンノイズ
ガウス整合フィルタは、ノイズがガウス分布に従う場合に最適なフィルタである。計数検出器からのノイズは、ポアソン分布を有する。ポアソンノイズの場合、ボックスカーがピークに関連付けられているすべてのカウントを単純に総和するだけなので、ボックスカーフィルタは検出で使用するのに最適なフィルタと言ってよい。しかし、GMFについて説明されている制限の多くは、ポアソンノイズの場合であってもボックスカーフィルタにそのまま適用される。ボックスカーフィルタは、ベースラインノイズを差し引くことができず、また干渉および共溶出ピークを分離し検出することができない。それに加えて、ボックスカーフィルタの伝達関数では、ピーク頂点について二重に数える可能性がある。
【0209】
好ましい実施形態の階数2のフィルタは、ガウスノイズおよびポアソンノイズの両方の場合についてSNRの妥協の産物である。この階数2のフィルタは、重なり合うピークのベースライン差し引きと部分的分離の利点を有する。
【0210】
フィルタ係数を決定する際のピーク幅の役割
本発明の実施形態では、入力行列Dに畳み込まれる畳み込みフィルタFの係数は、1つのイオンに対応するピークの典型的な形状および幅に対応するように選択される。例えば、フィルタFの中心の行の断面は、クロマトグラフピーク形状と一致し、フィルタFの中心の列の断面は、スペクトルピーク形状と一致する。畳み込みフィルタの幅は、ピークのFWHMに一致させることができるけれども(時間と質量対電荷比)、このような幅の一致は必要ないことに留意されたい。
【0211】
イオン強度の解釈とフィルタ係数のスケーリング
本発明では、強度測定推定値は、極大値におけるフィルタ出力の応答である。LC/MSデータ行列が畳み込まれるフィルタ係数の集合は、強度のスケーリングを決定する。フィルタ係数の集合が異なれば、強度スケーリングも異なり、本発明の強度のこの推定値は、必ずしもピーク面積またはピーク高さに正確に対応しない。
【0212】
しかし、強度測定値は、畳み込み演算が強度測定値の一次結合であるため、ピーク面積またはピーク高さに比例する。したがって、極大値におけるフィルタ出力の応答は、そのイオンを生じさせる試料中の分子の濃度に比例する。次いで、極大値におけるフィルタ出力の応答は、イオンの応答のピークの面積または高さと同じようにして試料中の分子の定量的測定のために使用されうる。
【0213】
フィルタの矛盾のない集合が、標準、キャリブレータ、および試料の強度を決定するために使用されると仮定すると、結果として得られる強度測定値は、強度スケーリングに関係なく正確で定量可能な結果をもたらす。例えば、本発明の実施形態により生成される強度は、検体の濃度を決定するためにその後使用されうる濃度較正曲線を定めるのに使用できる。
【0214】
非対称ピーク形状
上記の実施例は、スペクトル方向とクロマトグラフ方向のイオンのピーク形状がガウス型であり、したがって対称的であると仮定している。一般に、ピーク形状は、対称的ではない。非対称ピーク形状のよくある実施例は、裾を引いたガウス分布であり、階段指数型に畳み込まれたガウス型である。ここで説明されている方法は、非対称であるピーク形状にそのまま適用される。対称フィルタが非対称ピークに適用される場合、出力畳み込み行列中の頂点の配置は、一般的に、非対称ピークの頂点配置に正確に対応するわけではない。しかし、ピーク非対称(クロマトグラフ方向またはスペクトル方向のいずれか)に由来するオフセットは、実質的に、定数オフセットとなる。このようなオフセットは、従来の質量分析較正により、また内部標準を使用する保持時間較正により容易に補正される。
【0215】
整合フィルタ定理によれば、非対称ピークの検出に対する最適な形状は、非対称ピーク形状それ自体である。しかし、対称フィルタの幅が、非対称ピークの幅と一致すると仮定すると、対称フィルタと整合非対称フィルタとの間の検出効率の差は、本発明の目的に関しては最小となる。
【0216】
データを補間し、オフセットするようにフィルタ係数を変更する
係数修正の他の使い途は、質量分析計の較正による小さな変化に対応するように補間することである。このような係数修正は、スペクトル毎に発生しうる。例えば、質量較正の変化が、チャネルの一部を0.3だけオフセットする場合、そのような質量オフセットがない場合に出力がどうなるかを推定する列フィルタ(平滑化および2階微分の両方)が導出されうる。このようにして、リアルタイムの質量補正を行うことができる。典型的には、結果として得られるフィルタはわずかに非対称である。
【0217】
動的フィルタリング
フィルタ幅スケーリングなどのフィルタ特性は、LC分離またはMS走査の知られている変化特性に応じて変化しうる。例えば、TOF質量分析計では、ピーク幅(FWHM)は、それぞれの走査の過程で低い値(0.010amuなど)から広い値(0.130amuなど)まで変化することが知られている。本発明の好ましい一実施形態では、平滑化フィルタおよび微分フィルタの係数の個数は、スペクトルピークのFWHMの約2倍に等しくなるように設定される。MS走査が、例えば、低質量から高質量まで進行するにつれ、好ましい実施形態により使用される平滑化および2階微分の両方の列フィルタのフィルタ幅は、フィルタ幅とピーク幅との関係を保存するようにしかるべく拡大されうる。同様に、クロマトグラフピークの幅が、分離時に変化することが知られている場合、行フィルタの幅は、フィルタ幅とピーク幅との関係を保存するように拡大または縮小されうる。
【0218】
階数1および階数2のフィルタのリアルタイムの実施形態
従来のLC/MSシステムでは、分離が進むとともにスペクトルが収集される。典型的には、スペクトルは、一定のサンプリングレート(例えば、1秒に1回の割合)でコンピュータのメモリ内に書き込まれる。1つまたは複数の完全なスペクトルが収集された後、これらは、ハードディスクメモリなどのより永続的な記憶装置に書き込まれる。このような後収集処理も、本発明の実施形態において実行できる。したがって、本発明の一実施形態では、畳み込み行列は、収集が完了した後にしか生成されない。本発明のこのような一実施形態では、オリジナルのデータと畳み込み行列それ自体は、検出された極大値の分析から得られたイオンパラメータリストのように格納される。
【0219】
それに加えて、階数1および階数2のフィルタを使用する本発明の実施形態は、リアルタイムで動作するように構成されうる。本発明のリアルタイムの実施形態では、畳み込み行列の列は、データの収集中に形成される。そのため、初期列(スペクトルに対応する)は、すべてのスペクトルの収集が完了する前に、形成され、分析され、そのイオンパラメータをディスクに書き込むようにできる。
【0220】
本発明のこのリアルタイムの実施形態では、本質的に、コンピュータのメモリ内にあるデータを分析し、イオンパラメータリストのみを永続的なハードディスクドライブに書き込む。この文脈において、リアルタイムとは、階数1および階数2のフィルタリングが、データが収集されるのと同時にコンピュータメモリ内のスペクトルに対し実行されることである。したがって、分離の始めにLC/MSにより検出されたイオンは、ディスクに書き込まれたスペクトル内で検出され、それらのイオンに関連付けられたパラメータを含むイオンパラメータリストの部分も、分離の進行とともにディスクに書き込まれる。
【0221】
典型的には、リアルタイム処理を開始することに関連する時間の遅延が生じる。時間t、および幅Δtにおけるクロマトグラフピークで溶出するイオンを含むスペクトルは、収集されるとすぐに処理されうる。典型的には、リアルタイム処理は、時間t+3Δtにおいて、つまり、3つのスペクトルが最初に収集された後に開始する。次いで、クロマトグラフピークの分析により決定されたイオンパラメータが、コンピュータのディスクなどの永続的記憶装置内に作成され、格納されているイオンパラメータリストに追記される。リアルタイム処理は、上述の技術により進行する。
【0222】
リアルタイム処理の利点としては、(1)イオンパラメータリストを素早く取得できること、(2)イオンパラメータリスト内の情報に基づきリアルタイムプロセスをトリガすることが挙げられる。このようなリアルタイムプロセスは、分析のため溶離液を貯蔵するための分別捕集および停流技術を含む。例示的なこのような停流技術では、溶離液を核磁気共鳴(NMR)スペクトル検出器において捕捉する。
【0223】
図18は、本発明の好ましい一実施形態によるリアルタイム処理の方法を例示する流れ図1800である。この方法は、例えば、DSPベースの設計におけるハードウェア、または上述のDASなどにおけるソフトウェアで実行できる。以下の説明に基づきこのようなハードウェアまたはソフトウェアを構成する方法は、当業者にとっては明らかなものであろう。説明を簡単にするため、この方法は、DAS実行ソフトウェアにより実行される場合として説明される。図19A〜図19Bは、スペクトルバッファ1902、クロマトグラフバッファ1906、および頂点バッファ1910、さらに流れ図1800に例示されている方法を実行する際にどのように操作されるかも示している。
【0224】
DASは、次のスペクトル要素を受け取ることでステップ1802の方法を開始する。図19A〜図19Bにおいて、これらのスペクトル要素は、S1、S2、S3、S4、およびS5として示され、それぞれ、時間T1、T2、T3、T4、およびT5で受け取るスペクトル要素に対応する。ステップ1804で、DASは、受け取ったスペクトル要素が0であるかそうでないかを判定する。受け取ったスペクトル要素が0であれば、DASは、次のスペクトル要素を受け取ることでステップ1802の方法を続行する。スペクトル要素が0でなければ、スペクトルフィルタ1904の係数をスケーリングするために、その強度が使用される。図19A〜図19Bに示されている実施例では、スペクトルフィルタ1904は、フィルタ係数F1、F2、およびF3を有する3要素フィルタである。スケーリングは、それぞれのフィルタ係数に受け取ったスペクトル要素の強度を乗算することによりなされる。
【0225】
ステップ1808で、スケーリングされたスペクトルフィルタ係数が、スペクトルバッファに追加される。スペクトルバッファは、1つの配列である。スペクトルバッファ内の要素の個数は、それぞれのスペクトル内の要素の個数に等しい。
【0226】
総和を実行するために、フィルタ1904は、受け取ったスペクトル要素に対応するスペクトルバッファの要素が、フィルタ1904の中心に揃うように位置を揃えられる。したがって、時間T1において、スペクトル要素S1が受け取られると、フィルタ1904の中心F2は、スペクトルバッファの要素1902aに揃えられ、時間T2において、スペクトル要素S2が受け取られると、フィルタ1904の中心F2は、スペクトルバッファ要素1902bに揃えられ、というように続く。これらのステップは、図19A〜図19Bに例示されており、そこでは、フィルタ係数F1、F2、およびF3のスケーリング、およびスペクトルバッファ1902への追加が、時間T1、T2、T3、T4、およびT5に対して例示されており、これは、本発明の実施例では、スペクトルバッファ1902を埋めるのに十分なスペクトル要素を受け取るのに要する時間である。その結果得られるスケーリングされた総和も、図19A〜図19Bのスペクトルバッファ要素において示されている。
【0227】
ステップ1810で、DASは、スペクトルバッファがいっぱいになっているかどうか、つまり、受け取って処理されたスペクトル要素の個数が、スペクトルフィルタ内の要素の個数と同じであるかどうかを判定する。同じでなければ、DASは、次のスペクトル要素を待つことでステップ1802の方法を続行する。スペクトルバッファがいっぱいである場合、DASは、ステップ1812の方法を続行する。
【0228】
ステップ1812で、DASは、新しいスペクトルをクロマトグラフバッファ1906に移動する。クロマトグラフバッファ1906は、Nスペクトルを含むが、ただし、Nは、クロマトグラフバッファ内の係数の個数である。本発明の実施例では、Nは3である。クロマトグラフバッファ1906は、先入れ後出し(FILO)バッファとして構成される。したがって、新しいスペクトルが追加されると、最も古いスペクトルが削除される。ステップ1812で新しいスペクトルが追加されると、最も古いスペクトルが破棄される。ステップ1814で、DASは、クロマトグラフフィルタ1907をクロマトグラフバッファ1906のそれぞれの行に適用する。フィルタを適用した後、中央の列1908は、出力畳み込み行列の単一列畳み込みスペクトルに対応する。ステップ1816で、DASは、畳み込みスペクトルを頂点バッファ1910に移動する。
【0229】
本発明の一実施形態では、頂点バッファ1910は、幅が3スペクトル分ある、つまり、頂点バッファ1910は、3つの列スペクトルを含む。スペクトル列のそれぞれが、好ましくは、完全なスペクトルの長さを有する。頂点バッファ1910は、FILOバッファである。したがって、ステップ1816で、クロマトグラフバッファ1906からの新しい列が頂点バッファ1910に追記されると、最も古い列スペクトルが破棄される。
【0230】
後述のようなピーク検出アルゴリズムは、頂点バッファ1910の中央の列1912に対し実行されうる。最も近い隣接要素の値を使用することによりピークおよびイオンパラメータの分析をより正確に行うために、中央の列1912が使用される。これらのピークを分析することにより、DASは、ステップ1820でイオンパラメータ(保持時間、m/z、および強度など)を抽出してイオンパラメータリストに格納することができる。さらに、スペクトルピーク幅情報も、列にそって極大値に隣接する点を調べることにより得られる。
【0231】
頂点バッファ1910は、さらに、3スペクトルを超える幅に拡大できる。例えば、クロマトグラフピーク幅を測定するには、頂点バッファを、クロマトグラフピークのFWHMに少なくとも等しい数のスペクトルを含むように、例えば、クロマトグラフピークのFWHMの2倍に拡大する必要がある。
【0232】
本発明のリアルタイムの実施形態では、オリジナルのスペクトルを記録する必要はない。フィルタリングされたスペクトルのみが記録される。したがって、本発明のリアルタイムの実施形態の大容量記憶装置の必要性は減じられる。しかし、一般的に、本発明のリアルタイムの実施形態には、記憶メモリ、例えば、RAMを追加する必要がある。本発明の階数1のフィルタに基づくリアルタイムの実施形態に対しては、単一のスペクトルバッファのみあればよい。本発明の階数2のフィルタに基づくリアルタイムの実施形態については、2つのスペクトルバッファが必要であり、1つは平滑化スペクトルフィルタ用、もう1つは2階微分スペクトルフィルタ用である。
【0233】
ステップ4:ピーク検出
イオンが1つ存在すると、出力畳み込み行列内に強度の極大値を有するピークを1つ発生する。本発明の実施形態の検出プロセスは、このようなピークを検出する。本発明の一実施形態では、検出プロセスは、検出閾値条件を満たす最大強度を有するピークを複数のイオンに対応するピークとして識別する。本明細書で使用されているように、検出閾値条件を満たすことは、検出閾値を超える基準を満たすこととして定義される。例えば、この基準は、検出閾値条件を満たすか、または検出閾値条件を満たすか、またはそれを超える可能性がある。それに加えて、本発明のいくつかの実施形態では、この基準は、検出閾値条件を下回るか、または検出閾値条件を満たすかまたはそれを下回る可能性がある。
【0234】
出力畳み込み行列内の強度のそれぞれの極大値は、1つのイオンに対応する1つのピークに対する1つの候補である。上述のように、検出器ノイズが存在しない場合、すべての極大値は、1つのイオンに対応するとみなされる。しかし、ノイズが存在する場合、いくつかの極大値(特に低振幅極大値)は、ノイズのみによるものであり、検出されたイオンに対応する真のピークを表さない。したがって、検出閾値条件を満たす極大値がノイズによるものである可能性がほぼなくなるように検出閾値を設定することが重要である。
【0235】
それぞれのイオンは、出力畳み込み行列内に強度の一意の頂点または最大値を形成する。出力畳み込み行列内のこれらの一意の最大値の特性から、試料中に存在するイオンの個数および特性に関する情報が得られる。これらの特性は、ピークの配置、幅、および他の特性を含む。本発明の一実施形態では、出力畳み込み行列内のすべての極大値が識別される。その後の処理により、イオンに関連しないと判定されるものが排除される。
【0236】
本発明のいくつかの実施形態によれば、強度の極大値は、その極大値が検出閾値条件を満たす場合のみ検出されたイオンに対応するとみなされる。検出閾値それ自体は、強度の極大値の比較の基準となる強度である。検出閾値は、主観的または客観的手段により求められる。実質的に、検出閾値は、真のピークの分布を、検出閾値条件を満たすものと、検出閾値条件を満たさないものの2つのクラスに分ける。検出閾値条件を満たさないピークは、無視される。したがって、検出閾値条件を満たさない真のピークは、無視される。このような無視される真のピークは、偽陰性と呼ばれる。
【0237】
この閾値は、ノイズピークの分布も、検出閾値条件を満たすものと、検出閾値条件を満たさないものの2つのクラスに分ける。検出閾値条件を満たすノイズピークは、イオンであるとみなされる。イオンとみなされるノイズピークは、偽陽性と呼ばれる。
【0238】
本発明のいくつかの実施形態では、検出閾値は、典型的には、通常は低い、所望の偽陽性率が得られるように設定される。つまり、検出閾値は、ノイズピークが所定の実験で検出閾値条件を満たす確率がゼロであるように設定される。
【0239】
低い偽陽性率を得るには、検出閾値はより高い値に設定される。検出閾値をより高い値に設定して偽陽性率を下げると、偽陰性率が上昇する、つまりイオンに対応する低振幅の真のピークが検出されない確率が高くなるという望ましくない効果を生じる。したがって、検出閾値は、これらの競合する因子を念頭に置いて設定される。
【0240】
検出閾値は、主観的または客観的に決定できる。閾値化の方法の目標は、主観的であろうと客観的であろうと、イオンリストを編集するために使用する検出閾値を決定することである。検出閾値条件を満たさない強度を有するすべてのピークは、ノイズであると考えられる。これらの「ノイズ」ピークは、除去され、それ以降の分析に含まれない。
【0241】
検出閾値を設定する主観的方法は、観測されたノイズの最大値に近い直線を引くことである。検出閾値条件を満たす極大値はどれも、イオンに対応するピークであると考えられる。検出閾値条件を満たさない極大値はどれも、ノイズであると考えられる。閾値を決定するための主観的方法が使用されうるが、客観的な方法が好ましい。
【0242】
本発明のいくつかの実施形態により検出閾値を選択する客観的方法の1つは、出力畳み込み行列データのヒストグラムを使用する。図20は、本発明の一実施形態により検出閾値を客観的に決定する方法の流れ図である。この方法は、図7に図解として示されている。この方法は、以下のステップに従って進行する。
ステップ2002:出力畳み込み行列内に見つかるすべての正の極大値の強度を昇順に並べ替える。
ステップ2004:出力畳み込みデータ行列内の強度データの標準偏差をリスト内の35.1パーセンタイルにある強度として決定する。
ステップ2006:標準偏差の倍数に基づき検出閾値を決定する。
ステップ2008:検出閾値条件を満たすピークを使用して編集済みイオンリストまたはイオンパラメータリストを生成する。
【0243】
上記の方法は、極大値の大半がガウスノイズによるものである場合に適用可能である。例えば、1000個の強度がある場合、ステップ2004で、351番目の強度がガウス標準偏差を表すと判定する。最大強度の分布が、ガウスノイズプロセスのみによるものであった場合、値が351番目の強度を超えた極大値は、ガウスノイズ分布により予測される頻度で出現する。
【0244】
そこで、検出閾値は、351番目の強度の倍数である。例えば、2つの検出閾値を考える。検出閾値の1つは、2つの標準偏差に対応する。検出閾値の1つは、4つの標準偏差に対応する。2偏差閾値から生じる偽陰性は少ないが、偽陽性は多い。ガウスノイズ分布の特性から、2標準偏差閾値は、ピークの約5%が誤ってイオンとして識別されることを意味している。4偏差閾値から生じる偽陰性は多く、偽陽性は著しく少ない。ガウスノイズ分布の特性から、4標準偏差閾値は、ピークの約0.01%が誤ってイオンとして識別されることを意味している。
【0245】
すべての極大値の強度のリストを並べ替えるのではなく、強度の間隔について強度の個数が記録されるヒストグラム表示が使用されうる。ヒストグラムは、一連の一様な間隔で並ぶ強度値を選択することにより得られ、値のそれぞれの対は間隔を定め、それぞれのビン内に入る最大強度の個数を計数するものである。ヒストグラムは、1ビン当たりの強度の個数とそれぞれのビンを定める平均強度値との対比である。ヒストグラムは、強度の分布の標準偏差を決定する図式解法をなす。
【0246】
経験的方法の一変種では、畳み込み出力ノイズの標準偏差σと入力ノイズの標準偏差σ0との間の関係を使用して、検出閾値を設定する。上記のフィルタ分析から、この関係は、入力ノイズが無相関ガウス偏差であると仮定して
【数56】
として与えられる。入力ノイズσ0は、入力LCL/MSデータ行列から背景ノイズの標準偏差として測定されうる。背景ノイズのみを含むLC/MSの一領域は、ブランク注入から得られる、つまり、LC/MSデータは、試料が注入されずに分離から得られるということである。
【0247】
そのため、出力の標準偏差は、フィルタ係数Fi,jと測定された背景ノイズσ0の値のみを使用して推論されうる。次いで、検出閾値は、導出された出力ノイズ標準偏差σに基づき設定されうる。
【0248】
ステップ5:ピークパラメータ抽出
イオンに対応するピークである極大値を識別した後、それぞれのピークに対するパラメータが推定される。本発明の一実施形態では、推定されるパラメータは、保持時間、質量対電荷比、および強度である。クロマトグラフピーク幅(FWHM)および質量対電荷ピーク幅(FWHM)などの追加のパラメータも推定できる。
【0249】
それぞれの識別されたイオンのパラメータは、出力畳み込みデータ行列内の検出されたピークの極大値の特性から得られる。本発明の一実施形態では、これらのパラメータは、(1)イオンの保持時間は、(フィルタリングされた)最大要素を含む(フィルタリングされた)走査の時間であり、(2)イオンのm/zは、(フィルタリングされた)最大要素を含む(フィルタリングされた)チャネルのm/zであり、(3)イオンの強度は、(フィルタリングされた)最大要素それ自体の強度であるというようにして、決定される。
【0250】
スペクトル方向またはクロマトグラフ方向のピークの幅は、そのピークをまたぐ最近ゼロ交差点の配置の間の距離を測定するか、またはピークをまたぐ最近最小値間の距離を測定することにより決定されうる。このようなピーク幅は、ピークがその隣接要素から分離されることを確認するために使用できる。他の情報は、ピーク幅を考慮して集めることができる。例えば、ピーク幅に対し予想外に大きい値である場合は、同時に生じているピークであることを示している可能性がある。したがって、ゼロ交差または極大値の配置は、干渉する同時発生の効果を推定するか、またはイオンパラメータリスト内に格納されているパラメータ値を修正するための入力として使用できる。
【0251】
ピークを分析することにより決定されたパラメータは、さらに、隣接要素を考慮することにより最適化されうる。畳み込み行列の要素は、データのデジタル試料を表しているため、クロマトグラフ(時間)次元のピークの真の頂点は、試料時間と正確には一致しない場合があり、またスペクトル(質量対電荷比)次元のピークの真の頂点は、質量対電荷比チャネルと正確には一致しない場合がある。その結果、典型的には、時間次元および質量対電荷比次元におけるシグナルの実際の最大値は、サンプリング周期または質量対電荷比チャネル間隔の数分の1だけ利用可能なサンプリング値からオフセットされる。これらの分数オフセットは、曲線適合法などの補間を使用してピークに対応する極大値を有する要素の周囲にある行列要素の値から推定できる。
【0252】
例えば、二次元の文脈において、1つのイオンに対応する極大値を含む出力畳み込み行列の要素から真の頂点の分数オフセットを推定する技術は、二次元形状を、極大値およびその最近隣接要素を含むデータ行列の要素に適合させるものである。本発明のいくつかの実施形態では、二次元放物形は、その頂点に近い畳み込みピークの形状に対するよい近似となるため使用される。例えば、放物形は、ピークとその8個の最近隣接要素を含む9要素行列に適合させることができる。他の適合法も、本発明の範囲と精神から逸脱することなくこの補間に使用できる。
【0253】
放物線適合法を使用する場合、イオンパラメータを決定するピーク頂点の補間値が計算される。補間値を使用すると、走査時間およびスペクトルチャネルの値を読み取ることにより得られるものと比べて、保持時間、m/z、および強度の推定をより正確に行える。最大値における放物線の値とその最大値に対応するその補間された時間およびm/z値は、イオン強度、保持時間、およびm/zの推定値である。
【0254】
二次元放物線適合の最大値の行方向における補間された配置は、保持時間の最適な推定となっている。二次元放物線適合の最大値の列方向における補間された配置は、質量対電荷比の最適な推定値を与える。ベースラインよりも上の頂点の補間された高さは、イオン強度または濃度の最適な推定値(フィルタ係数でスケーリングされる)となる。
【0255】
本発明の実施形態は、さらに、中間畳み込み行列の結果からピークパラメータを抽出するように構成することができる。例えば、検出されたイオンに対応する単一ピークを特定する上述の方法は、行列のそれぞれの行または列内のピークを特定するためにも使用されうる。これらのピークは、知られている時間または質量値におけるスペクトルまたはクロマトグラムを格納するのに有用な場合がある。
【0256】
例えば、2階微分フィルタから得られたるスペクトルまたはクロマトグラムは、上述の中間畳み込み行列からのそれぞれの行および列について求めることができる。これらの中間結果は、極大値についても調べることができる。これらの最大値は、実質的にクロマトグラムおよびスペクトルの平滑化バージョンである。極大値は、抽出されて保存され、特定の時間または時間範囲における試料のスペクトル成分に関する追加の詳細、または典型的な質量または質量範囲におけるクロマトグラフ成分に関する追加の詳細を得ることができる。
【0257】
測定誤差
本発明の実施形態により生成されるそれぞれのイオンパラメータ測定結果は、1つの推定であるため、それぞれのそのような測定には測定誤差が関連する。これらの関連する測定誤差は、統計的に推定されうる。
【0258】
2つの異なる因子が、測定誤差に関わる。因子の1つは、系統誤差または較正誤差である。例えば、質量分析計のm/z軸が完全には較正されていない場合、与えられたm/z値はオフセットを含む。系統誤差は、典型的には、一定のままである。例えば、較正誤差は、m/z範囲全体にわたって本質的に一定である。このような誤差は、特定のイオンのシグナル対ノイズまたは振幅と無関係である。同様に、質量対電荷比の場合、誤差は、スペクトル方向のピーク幅とは無関係である。
【0259】
測定誤差に関わる第2の因子は、それぞれの測定に関連するそれ以上減らせない統計誤差である。この誤差は、熱またはショットノイズ関係の効果により生じる。与えられたイオンに対するこの誤差の大きさまたは分散は、イオンのピーク幅および強度に依存する。統計誤差は、再現性を測定するものであり、したがって、較正誤差とは無関係である。統計誤差に対するもう1つの言いまわしは、精度である。
【0260】
それぞれの測定に関連する統計誤差は、原理上、測定が行われる装置の基本動作パラメータから推定されうる。例えば、質量分析計では、これらの動作パラメータは、典型的には、マイクロチャネル計数プレート(MCP)の効率に結びついた装置のイオン化および移動効率を含む。それとともに、これらの動作パラメータは、イオンに関連付けられているカウントを決定する。これらのカウントは、質量分析計を使用する測定に関連する統計誤差を決定する。例えば、上述の測定に関連する統計誤差は、典型的には、ポアソン分布に従う。それぞれの誤差に対する数値は、誤差伝搬の理論に従って計数統計から求めることができる。例えば、P.R.BEVINGTON「DATA REDUCTION AND ERROR ANALYSIS FOR THE PHYSICAL SCIENCES」58−64 (MCGRAW−HILL 1969)を参照のこと。
【0261】
一般に、統計誤差は、データから直接推論することもできる。データから統計誤差を直接推論する方法の1つでは、測定の再現性を調べる。例えば、同じ混合物の反復注入により、同じ分子に対するm/z値の統計的再現性を確定することができる。注入によるm/z値の差は、統計誤差によるものである可能性が高い。
【0262】
保持時間測定に関連する誤差の場合、統計的再現性を実現することが難しいが、それは、反復注入から生じる系統誤差が、統計誤差を隠蔽する傾向があるからである。この問題を解消する技術は、共通の親分子から得られた異なるm/z値においてイオンを調べるというものである。共通の分子に由来するイオンは、同一の固有保持時間を有すると予想される。その結果、共通の親に由来する分子の保持時間の測定結果の差は、ピーク特性の測定に関連する基本検出器ノイズに関連する統計誤差による可能性が高い。
【0263】
本発明の一実施形態を使用して実行され、格納されているそれぞれの測定は、関連する統計誤差および系統誤差の推定に伴うことができる。これらの誤差は、それぞれの検出されたイオンに対するパラメータ推定にも当てはまるけれども、それらの値は、一般的にイオンの集合を分析することにより推論することができる。好適な誤差分析を行った後、検出されたイオンに対するそれぞれの測定に関連する誤差は、検出されたイオン測定に対応するテーブルのそれぞれの行内に含めることができる。本発明のこのような一実施形態では、テーブルのそれぞれの行には、それぞれのイオンに関連する15個の測定結果を入れることができる。これらの測定結果は、行ならびにその関連する統計誤差および系統誤差に対応する検出されたイオンに対する5つの測定結果、つまり、保持時間、質量対電荷比、強度、スペクトルFWHM、およびクロマトグラフFWHMである。
【0264】
上述のように、保持時間およびm/zの測定誤差の統計成分、つまり精度は、それぞれのピーク幅および強度に依存する。高いSNRを有するピークについては、精度は、それぞれのピーク幅のFWHMよりも実質的に小さい場合がある。例えば、20ミリamuのFWHMおよび高いSNRを有するピークについては、精度は1ミリamu未満となる可能性がある。ノイズよりも高いところでほとんど検出可能でないピークについては、精度は20ミリamuとすることができる。統計誤差のここでの説明のために、FWHMは、畳み込みの前のLC/MSクロマトグラムにおけるピークのFWHMであると考えられる。
【0265】
精度は、ピーク幅に比例し、ピーク振幅に逆比例する。一般的に、精度、ピーク幅、およびピーク振幅の間の関係は、
【数57】
で表すことができる。
【0266】
この関係において、σmは、m/zの測定の精度であり(標準誤差として表される)、wmは、ピークの幅であり(FWHMのミリamuで表される)、hpは、ピークの強度であり(ポストフィルタリングされたシグナル対ノイズ比として表される)、およびkは、1のオーダーの無次元定数である。kの正確な値は、使用されるフィルタ法によって決まる。この式は、σmがwm未満であることを示している。したがって、本発明では、検出されたイオンに対するm/zの推定をオリジナルのLC/MSデータで測定されたm/zピーク幅のFWHMよりも小さい精度で実行できる。
【0267】
保持時間の測定に関しても、類似の考察が当てはまる。ピークの保持時間を測定できる精度は、ピーク幅とシグナル強度の組み合わせに依存する。ピークのFWHM maxが0.5分である場合、保持時間は、0.05分(3秒)の、標準誤差で記述される、精度に合わせて測定されうる。本発明を使用することで、検出されたイオンに対する保持時間の推定をオリジナルのLC/MSデータで測定された保持時間ピーク幅のFWHMよりも小さい精度で実行できる。
【0268】
ステップ6:抽出されたパラメータを格納する
上述のように、本発明のいくつかの実施形態の1つの出力は、検出されたイオンに対応するパラメータのテーブルまたはリストである。このイオンパラメータテーブル、またはリストは、それぞれの検出されたイオンに対応する行を有し、それぞれの行は1つまたは複数のイオンパラメータを含み、必要ならば、その関連する誤差パラメータを含む。本発明の一実施形態では、イオンパラメータテーブル内のそれぞれの行は、保持時間、質量対電荷比、および強度の3つのパラメータを有する。追加のイオンパラメータおよび関連する誤差は、リスト内に表されているそれぞれの検出されたイオンについて格納されうる。例えば、FWHMにより測定されたような検出イオンのピーク幅またはクロマトグラフ方向および/またはスペクトル方向のそのゼロ交差幅が決定され、格納されうる。
【0269】
ゼロ交差幅は、2階微分フィルタでフィルタリングが実行される場合に適用可能である。2階微分のゼロ値は、ピークの上り勾配側と下り勾配側の両方におけるピークの変曲点で出現する。ガウスピークプロファイルについては、変曲点は、ピーク頂点から+/1標準偏差の距離のところに出現する。したがって、変曲点により測定された幅は、ピークの2標準偏差幅に対応する。そのため、ゼロ交差幅は、ほぼ2つの標準偏差に対応するピーク幅の高さ独立の尺度となる。本発明の一実施形態では、テーブル内の行の個数は、検出されたイオンの個数に対応する。
【0270】
本発明は、さらに、データ圧縮の利点も有する。これは、イオンパラメータテーブル内に収められている情報を格納するのに必要なコンピュータメモリが、最初に生成されたオリジナルのLC/MSデータを格納するのに必要なメモリ量に比べて著しく少ないためである。例えば、3600個のスペクトル(例えば、1時間の間1秒に1回の割合で収集されたスペクトル)を含む典型的な注入では、それぞれのスペクトル中に400,000個の分離能要素(例えば、50から2,000amuまでの20,000:1のMS分離能)があるとして、強度のLC/MSデータ行列を格納するのに数ギガバイトを超えるメモリを必要とする。
【0271】
複雑な試料では、本発明のいくつかの実施形態を使用することで、100,000のオーダーでイオンが検出されうる。これらの検出されたイオンは、100,000個の行を有するテーブルにより表され、それぞれの行は検出された1個のイオンに対応するイオンパラメータを含む。それぞれの検出されたイオンに対する所望のパラメータを格納するのに必要なコンピュータ記憶装置の容量は、典型的には、100メガバイト未満である。この記憶装置の容量は、最初に生成されたデータを格納するのに必要なメモリのうちのごくわずかに相当する。イオンパラメータテーブルに格納されているイオンパラメータデータにアクセスし、抽出して、さらに処理を進めることができる。データを格納その他の方法も、本発明のいくつかの実施形態において使用できる。
【0272】
必要な記憶容量が著しく低減されるだけでなく、LC/MSデータの後処理の計算効率も、最初に生成されたLC/MSデータではなくイオンパラメータリストを使用してこのような分析が実行されれば著しく改善される。これは、処理される必要のあるデータ点の数が著しく低減されることによるものである。
【0273】
ステップ7:スペクトルおよびクロマトグラムを簡素化する
結果として得られるイオンリストまたはテーブルを参照して、新規の有用なスペクトルを形成することができる。例えば、上述のように、保持時間の向上した推定に基づきテーブルからイオンを選択することで、複雑度が大幅に低減されたスペクトルが生成される。それとは別に、m/z値の向上した推定に基づきテーブルからイオンを選択することで、複雑度が大幅に低減されたクロマトグラムが生成される。以下でさらに詳しく説明されるように、例えば、保持時間ウィンドウは、注目する化学種に無関係のイオンを除外するために使用されうる。保持時間選択スペクトルは、スペクトル中に複数のイオンを誘発する、タンパク質、ペプチド、およびそのフラグメンテーション生成物などの分子種の質量スペクトルの解釈を簡素化する。同様に、m/zウィンドウは、同じであるか、または類似しているm/z値を有するイオンを区別するように定義されうる。
【0274】
保持ウィンドウという概念を使用することで、LC/MSクロマトグラムから簡素化されたスペクトルが得られる。ウィンドウの幅は、クロマトグラフピークのFWHM以下となるように選択できる。いくつかの場合において、ピークのFWHMの1/10などのより小さなウィンドウが選択される。保持時間ウィンドウは、注目するピークの頂点に一般に関連付けられている特定の保持時間を選択し、次いで、選択された特定の保持時間を中心とする一定範囲の値を選択することにより定義される。
【0275】
例えば、最高の強度値を有するイオンが選択され、保持時間が記録されるようにできる。保持時間ウィンドウは、記録された保持時間を中心として選択される。次いで、イオンパラメータテーブル内に格納された保持時間が調べられる。保持時間ウィンドウ内に収まる保持時間を有するイオンのみが、スペクトルに含めるものとして選択される。30秒のFWHMを有するピークについては、保持時間ウィンドウの有用な値は、±15秒と大きいか、または±1.5秒と小さい場合がある。
【0276】
保持時間ウィンドウは、ほぼ同時に溶出するイオンを選択するように指定することができ、また関係付けの対象となる候補でもある。このような保持時間ウィンドウは、無関係の分子を除外する。したがって、保持ウィンドウを使用してピークリストから得られるスペクトルは、注目する化学種に対応するイオンのみを含み、そのため、生成されるスペクトルが著しく簡素化される。これは、典型的には注目する化学種に無関係のイオンを含む従来の技術により生成されるスペクトルに勝る大きな改善点である。
【0277】
また、イオンパラメータテーブルを使用する方法は、クロマトグラフピーク純度を分析する手段ともなる。ピーク純度は、ピークが単一イオンによるものであるか、またはイオンの共溶出の結果によるものであるかを示す。例えば、本発明の実施形態により生成されたイオンパラメータリストを参照することにより、分析者は、注目する主ピークの時間内に化合物またはイオンがいくつ溶出するかを判定することができる。ピーク純度の尺度または計量を設定する方法は、図21に関して説明されている。
【0278】
ステップ2102で、保持時間ウィンドウが選択される。保持時間ウィンドウは、注目するイオンに対応するピークのリフトオフとタッチダウンに対応する。ステップ2104で、イオンパラメータテーブルが参照され、これにより、選択された保持時間ウィンドウ内で溶出するすべてのイオンを同定する。ステップ2106で、識別されたイオン(注目するイオンを含む)の強度の総和が求められる。ステップ2108で、ピーク純度計量が計算される。ピーク純度計量は、数多くの方法で定義されうる。本発明の一実施形態では、ピーク純度計量は、
純度=100*(注目するピークの強度)/(保持ウィンドウ内のすべてのピークの強度の総和)
で定義される。
それとは別に、本発明の他の実施形態では、ピーク純度は、
純度=100*(最も強い強度)/(保持ウィンドウ内のすべてのピークの強度の総和)
で定義される。
ピーク純度の両方の定義において、ピーク純度は、パーセント値で表されている。
【0279】
本発明のスペクトル簡素化特性は、さらに、生体試料をより簡単に研究する場合にも使用できる。生体試料は、LC/MS法を使用して一般に分析される混合物の重要なクラスである。生体試料は、一般に、複合分子を含む。そのような複合分子の特徴は、特異分子種が、複数のイオンを生成しうるという点にある。ペプチドは、さまざまな同位体状態で天然に存在する。したがって、与えられた電荷で出現するペプチドは、m/zの複数の値で出現し、それぞれそのペプチドの異なる同位体状態に対応する。十分な分離能があれば、ペプチドの質量スペクトルは、特性イオン群を示す。
【0280】
典型的には高い質量を有するタンパク質は、異なる荷電状態にイオン化される。タンパク質中の同位体変化は、質量分析計の分離能では検出できないけれども、異なる荷電状態で出現するイオンは、一般に、分離され検出されうる。このようなイオンは、タンパク質を同定するのを補助するために使用できる特徴的パターンを形成する。そこで、本発明の方法であれば、共通の保持時間を有するため共通のタンパク質からのそれらのイオンを関連付けることができるであろう。そこで、これらのイオンは、例えば、Fennらの米国特許第5,130,538号で開示されている方法により分析されうる簡素化されたスペクトルを形成する。
【0281】
質量分析計は、質量それ自体ではなく、質量対電荷比のみを測定する。しかし、生成するイオンのパターンからペプチドおよびタンパク質などの分子の荷電状態を推論することは可能である。この推論された荷電状態を使用して、分子の質量が推定されうる。例えば、タンパク質が複数の荷電状態にある場合、m/z値の間隔から、電荷を推論し、電荷を知ってそれぞれのイオンの質量を計算し、最終的に、荷電されていない親の質量を推定することが可能である。同様に、ペプチドについても、m/zの電荷が特定の質量mに対する同位体の値における電荷によるものである場合、隣接するイオンの間隔から電荷を推論することが可能である。
【0282】
イオンからのm/z値を使用して電荷と親質量を推論するよく知られている技術が多数ある。このような例示的な技術は、参照により本明細書に組み込まれている、米国特許第5,130,538号で説明されている。これらの技術のそれぞれに対する必要条件は、正しいイオンの選択とm/zに対する正確な値の使用である。検出されたイオンパラメータテーブル内に表されているイオンは、これらの技術への入力として使用されうる高精度の値をもたらし、精度の高い結果を生み出す。
【0283】
それに加えて、引用されている方法のいくつかでは、スペクトル内に出現する可能性のある複数のイオンを区別することによりスペクトルの複雑度を低減しようと試みている。一般に、これらの技術は、突出したピークを中心とするスペクトルを選択するか、または単一のピークに関連付けられるスペクトルを組み合わせて、単一の抽出MSスペクトルを得る。そのピークが複数の同時発生イオンを生成した分子からのピークであった場合、スペクトルは、無関係の化学種からのイオンを含むすべてのイオンを含むことになるであろう。
【0284】
これらの無関係の化学種は、注目する化学種とまったく同じ保持時間で溶出するイオンからのものとすることができるか、またはより一般に、無関係の化学種は、異なる保持時間で溶出するイオンからのものである。しかし、これらの異なる保持時間が、クロマトグラフピーク幅のほぼFWHMのウィンドウ内にある場合、それらのピークの前部または尾部からのイオンが、スペクトル中に出現する可能性が高い。無関係の化学種に関連するピークが出現する場合は、それらの化学種を検出して取り除くようにその後処理する必要がある。同時発生するいくつかの場合において、これらは測定結果を偏らせている可能性がある。
【0285】
図22Aは、2つの親分子と結果として得られる多数のイオンから結果として得られる例示的なLC/MSデータ行列を示している。この実施例では、LC/MSデータ行列において、化学種は時間t1に溶出して4個のイオンを生成し、他の化学種は時間t2に溶出して5個のイオンを生成する。2つの異なる化学種があるとしても、スペクトルが時間t1または時間t2に抽出されるならば、結果のスペクトルは、9個のイオンのそれぞれから1つずつ、9個のピークを含むであろう。しかし、本発明では、これらの9個のイオンのそれぞれについて9つの正確な保持時間(m/zおよび強度とともに)を得る。次いでスペクトルが、t1に実質的に等しい保持時間を有しているイオンのみから形成された場合、4個のイオンのみが存在することになる。この簡素化されたスペクトルは、図22Bに示されている。同様に、次いでスペクトルが、t2に実質的に等しい保持時間を有しているイオンのみから形成された場合、5個のイオンのみが存在することになる。この簡素化されたスペクトルは、図22Cに示されている。
【0286】
応用例
LC/MSシステムで試料が収集されるとともに、複数のスペクトルが典型的にはクロマトグラフピーク上で収集され、保持時間が正確に推論される。例えば、本発明のいくつかの実施形態では、FWHM毎に5つのスペクトルが収集される。
【0287】
LC/MSシステムの構成をスペクトル毎に交互配置することが可能である。例えば、すべての偶数番のスペクトルが、1つのモードで収集され、すべての奇数番のインターリーブするスペクトルが、別のモードで動作するように構成されているMSにより収集されうる。例示的な二重モード収集動作は、LC/MSEと交互に並ぶLC/MSにおいて使用することができ、一方のモード(LC/MS)では、非フラグメントイオンが収集され、第2のモード(LC/MSE)では、第1のモードで収集された非フラグメントイオンのフラグメントが収集される。これらのモードは、衝突セルを横断するときにイオンに印加される電圧のレベルにより区別される。第1のモードでは、電圧は低く、第2のモードでは、電圧は高い(Batemanら)。
【0288】
このようなシステムでは、1つのモードにおいてシステムにより収集されたフラグメントまたはイオンは、未修正イオンと同じ保持時間を保有するクロマトグラフプロファイルで出現する。これは、非フラグメントおよびフラグメントイオンが、同じ分子種に共通のものであるからであり、分子の溶出プロフィルは、その分子に由来するすべての非フラグメントおよびフラグメントイオン上にインプリントされる。これらの溶出プロフィルは、実質的に時間的整合性を有しているが、それは、オンラインのMSでモードを切り換えるのに要する余分な時間は、クロマトグラフピークのピーク幅またはFWHMと比較して短いからである。例えば、MS内の分子の移動時間は、典型的には、ミリ秒またはマイクロ秒のオーダーであるが、クロマトグラフピークの幅は、典型的には数秒または数分のオーダーである。したがって、特に、非フラグメントおよびフラグメントイオンの保持時間は、実質的に同一である。さらに、それぞれのピークのFWHMも同じになり、さらに、それぞれのピークのクロマトグラフプロファイルは、実質的に同じになる。
【0289】
2つの動作モードで収集されたスペクトルは、2つの独立のデータ行列に分けられる。上述の畳み込み、頂点検出、パラメータ推定、および閾値化の演算は、両方に独立に適用されうる。このような分析の結果、イオンの2つのリストが得られるけれども、これらのリスト内に出現するイオンは互いに関係を有する。例えば、1つの動作モードに対応するイオンのリスト内に現れる高強度を有する強いイオンは、他の動作モードにより収集された修正イオンのリスト内に対の一方を持つことができる。このような場合、イオンは、典型的には、共通の保持時間を有する。このような関係するイオンを分析のため互いに関連付けるには、上述のように保持時間を制約するウィンドウが、両方のデータ行列内に見つかるイオンに適用されうる。このようなウィンドウを適用した結果は、共通の保持時間を有する、したがって関係付けられる可能性の高い2つのリスト内でイオンを識別することである。
【0290】
これらの関係するイオンの保持時間が同一であっても、検出器ノイズの効果が現れる結果として、これらのイオンの保持時間の測定された値はいくぶん異なることになる。この差は、統計誤差の顕現であり、イオンの保持時間の測定の精度を測定するものである。本発明では、イオンの推定保持時間の差は、クロマトグラフピーク幅のFWHMよりも小さい。例えば、ピークのFWHMが30秒である場合、イオン同士の保持時間のバラツキは、低強度ピークでは15秒未満であり、高強度ピークでは1.5秒未満である。同じ分子のイオンを収集する(および無関係のイオンを除去する)ために使用されるウィンドウ幅は、この実施例では、±15秒と大きいか、または±1.5秒と小さい場合がある。
【0291】
図23A〜図23Bは、本発明の一実施形態により生成される未修正および修正イオンリスト中で関係するイオンをどのように同定できるかを示す図解である。データ行列2302は、未修正MS実験からの結果として得られるスペクトル中に検出された3つの前駆体イオン2304、2306、および2308を示す。データ行列2310は、例えば上述のようにフラグメンテーションを引き起こすようにMSが修正された後に実験の結果として得られる8個のイオンを示す。データ行列2310内のイオンに関係するデータ行列2302内のイオンが、t0、t1、およびt2と標識されている3本の垂直線により示されているように、同じ保持時間に現れる。例えば、データ行列2310内のイオン2308aおよび2308bは、データ行列2302内のイオン2308に関係する。データ行列2310内のイオン2306a、2306b、および2306cは、データ行列2302内のイオン2306に関係する。データ行列2310内のイオン2304a、2304b、および2304cは、データ行列2302内のイオン2304に関係する。これらの関係は、それぞれ時間t0、t1、およびt2を中心とする適切な幅を有する保持時間ウィンドウにより識別できる。
【0292】
イオンパラメータリストは、さまざまな分析に使用できる。このような1つの分析は、フィンガープリンティングまたはマッピングを伴う。全体としてよく特徴付けられている、本質的に同じ組成を有し、成分が同じ相対量で存在する混合物の多数の実施例がある。生物学的実施例は、尿、脳脊髄液、および涙液などの代謝の最終生成物を含む。他の実施例は、組織および血液に見られる細胞集団のタンパク質成分である。他の実施例は、組織および血液に見られる細胞集団のタンパク質成分の酵素消化物である。これらの消化物は、二重モードLC/MSおよびLC/MSEにより分析可能なペプチド混合物を含む。工業における実施例は、香水、香料、フレイバー、ガソリンもしくはオイルの燃料分析を含む。環境面での実施例は、農薬、燃料および除草剤、および水と土壌の汚染を含む。
【0293】
これらの液体中で観察されることが予想されるものからの異常は、薬物もしくは製剤原料の摂取または注射の結果生じる代謝産物の場合の生体異物、代謝液中の薬物不正使用の証拠、ジュース、フレイバー、および香料などの製品中の混ぜ物、または燃料分析を含む。本発明の実施形態により生成されるイオンパラメータリストは、フィンガープリントまたは多変量解析の技術で知られている方法への入力として使用されうる。SIMCA(Umetrics社、スウェーデン所在)、またはPirouette(lnfometrix社、米国ワシントン州ウッデンビル所在)などのソフトウェア分析パッケージは、試料集団間のイオンの変化を識別することにより、フィンガープリントまたは多変量解析技術を使用してそのような異常を検出するように構成できる。これらの分析では、混合物中の実体の正規分布を判定し、次いで、基準からずれている試料を識別することができる。
【0294】
化合物の合成により、付加的分子的実体とともに所望の化合物を生成することができる。これらの付加的分子的実体は、合成経路を特徴付ける。イオンパラメータリストは、実際、化合物を合成する合成経路を特徴付けるために使用されうるフィンガープリントとなる。
【0295】
本発明が適用可能な他の重要な応用例に、バイオマーカー発見がある。濃度の変化が病状と一意に、または薬物の作用と相関する分子の発見は、疾病の検出または薬物発見のプロセスの基本である。バイオマーカー分子は、細胞集団または代謝産物または血液および血清などの流体中に出現しうる。よく知られている方法を使用して対照および疾病または投薬状態について生成されるイオンパラメータリストの比較結果を用いて、疾病または薬物の作用に対するマーカーである分子を同定することができる。
【0296】
N次元データとLC/IMS/MS
本発明のいくつかの実施形態は、LC/MS装置から得られるものよりも高い次元のデータを伴う。これらの実施形態のうちいくつかは、LC/IMS/MS装置を伴う。以下の説明は、主にLC/IMS/MSデータを対象としているが、当業者であれば、本明細書で説明されている原理は、3次元およびそれ以上の次元のデータを出力するさまざまな装置にも広範に適用可能であることを理解するであろう。
【0297】
これらのいくつかの実施形態は、LCモジュール、IMSモジュール、およびTOF−MSモジュールを備える。本発明のいくつかの実施例が適宜実装されるこのような装置の一実施例は、2003年1月2日に公開されたBatemanらの米国特許公開第2003/01084号で説明されている。
【0298】
第1に、本発明のいくつかの態様の広い文脈に関して、異なる数の次元のデータの収集が説明される。例えば、LCのみ、またはMSのみの装置で見られるような単一チャネル検出器では、一次元データは、典型的には、二次元プロットで表示される。次いで、そのプロットの中ですべてのピークを特定しなければならない。
【0299】
LCの場合、典型的な検出器は、紫外線/可視光線(UV/Vis)光吸収検出を実行する。ピークパラメータは、カラムから溶出するときのピークの保持時間および吸収度である。
【0300】
MSの場合、例えば、四重極またはTOFベースのMSで実行されるときに、電磁力が、異なるm/z比のイオンを分離するために使用され、検出器は、m/z比の関数としてイオン強度の値を出力する。強度対m/zデータの二次元プロット中のピークを特定するためのルーチンが必要である。組み合わせLC/MSでは、ピークは、特定されなければならない、つまり3つの次元(イオン強度対保持時間およびm/z)でプロットされたデータ中のアーチファクトから区別されなければならない。
【0301】
後述のいくつかのLC/IMS/MS関係の実施形態では、3つの分離関係の次元が、イオン強度値に関連付けられる。分離の3つの次元−液体クロマトグラフィ、続いてイオン移動度、続いて質量分析−が、イオンの対応する3つの特性、保持時間、イオン移動度、および質量対電荷比の尺度となる。MSモジュールは、イオンのピークとの関連でm/z値においてイオンを特定する。ピークは、例えば、マイクロチャネルプレートにより測定されるような、イオンのピークの積分されたイオンカウント数に関連付けられる。
【0302】
表3は、本発明のいくつかの実施形態により得られるデータのさまざまな数の次元をまとめたものである。第1の列は、いくつかの特定の分析技術と、N回の分離に関連するデータのN個の次元を有する技術に対するより一般的な参照のリストである。Nは、適宜3つまたはそれ以上の大きさに等しい。第2の列は、本発明のいくつかの実施形態により、アーチファクトを低減し、重なるピークを区別しやすくするために使用される畳み込みフィルタの次元の数のリストである。いくつかの好ましい実装では、畳み込みフィルタの次元の数は、分離の数と一致する。
【0303】
定義することを目的として、分離の次元に加えて、イオン強度をデータの次元として処理することを選択した場合、データは、分離次元の数よりも1だけ大きい次元を有するものとして適宜参照される。
【0304】
畳み込みの後、極大値に関連するピークは、畳み込みデータ内で特定される。例えば、三次元空間内の極大値は、隣接要素のすべてよりも大きい値を有するデータ点(本明細書ではデータ要素と呼ばれる)として適宜定義される。例えば、三次元分離空間内の要素は、3×3×3−1=26個の隣接要素を有する。したがって、極大は、一般に、中央の要素と26個の隣接要素との比較を必要とする。
【0305】
表3の第3の列は、1つの点が1つの極大値であると確定するために実行される比較の回数のリストである。残りの列は、分離次元のリストである。極大値は、ピークの頂点を識別する。それぞれの頂点は1つのイオンに対応する。この「発明実施するための形態」の残り部分では、LC/IMS/MSおよび、より大きいな分離の次元を重点的に取りあげる。
【表3】
【0306】
図24は、本発明の例示的な一実施形態による、LC/IMS/MS分析の方法2400の流れ図である。方法2400は、試料からノイズの多い生データを取得すること2410を含む。データは、三次元データ要素の集合を含み、それぞれの要素はイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付ける。方法2400は、さらに、イオン移動度次元において、そのデータ要素の集合を縮退して、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成すること2420と、縮退データ要素の集合を、例えば、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込むこと2430とを含む。方法2400は、さらに、保持時間次元および質量対電荷比次元において、データ要素の畳み込まれた集合のイオンピークを特定すること2440と、特定されたイオンピークに応答して、ノイズを含む生データの1つまたは複数の部分をさらなる分析のため選択すること2450とを含む。方法2400は、さらに、ノイズを含む生データの選択された部分を、例えば、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込み込むこと2460と、保持時間次元、イオン移動度次元、および質量対電荷比次元において、畳み込まれた生データ中のイオンピークを特定すること2470とを含む。
【0307】
畳み込まれた縮退データ要素の集合の特定2440されたイオンピークに応じて、さらなる分析対象として選択2450された生データの1つまたは複数の部分が選択される。保持時間次元および質量対電荷比次元において、畳み込まれた縮退データ要素集合のイオンピークの配置は、生データ中の注目する、保持時間次元および質量対電荷比次元における配置を示す。
【0308】
そこで、適宜、さらなる分析のため選択された部分は、生データの完全イオン移動度次元を含むが、生データの保持時間次元および質量対電荷比次元の制限された領域のみを含む。これらの制限された領域は、データ要素の畳み込まれた縮退集合により示される配置を含む。次いで、生データの部分が、例えば、特定されたイオンピークを実質的に中心とするように選択される。したがって、意味のあるデータまたは注目するデータを含まないデータ空間の部分の不効率な分析を行わなくて済む。さらに、選択された部分のサイズは、観察されているように、または所定のように、ピーク幅に応じて適宜選択される。好ましくは、選択された部分のサイズは、それぞれの次元において、その次元におけるピーク幅よりも大きい。
【0309】
上述のように、畳み込み2460は、生データの三次元畳み込みを必要とする。ピーク情報判定のため、極大値が、適宜3つの次元(保持時間、イオン移動度、およびイオンm/z)における探索により特定され2440、極大値の特定により、3つの分離関係のイオン特性−保持時間、移動度、およびm/z−がイオンの強度に関連付けられる(MSを介して検出された多数のイオンに対応する)。ピークの頂点の値は、畳み込みフィルタが適宜正規化されている場合に、イオンピーク全体にわたって積分されたイオン強度をもたらす。
【0310】
次に表4を参照すると、方法2400は、3つの異なる次元において生データの異なる分離能レベルを利用する(m/z次元では比較的高い分離能、イオン移動度次元では比較的低い分離能、保持時間次元では中程度の分離能)。表4は、分離能のこれらの違いを示している。3つの次元について、表4は、典型的な測定範囲、サンプリング周期、要素数(つまり、範囲をサンプリング周期で除算したもの)、ピーク半値全幅(時間に関して)、ピーク半値全幅(データ点要素に関して)、および分離能(分離可能なピークの数に関して)のリストである。
【表4】
【0311】
18,000のMS分離能は、強度の150,000個のチャネルに対応し、8チャネルのピーク幅(FWHM)を有する。2番目に高い分離能は、クロマトグラフ次元であり、100分の分離および30秒のピーク幅を持つ(7.5回の走査に対応する)。最低の分離能は、イオン移動度によって与えられる。7個の要素のFWHMの示されている実施例を仮定すると、IMS分離能は200チャネルスペクトルに対しピーク30個である。この理想化された実施例では、質量および移動度を持つピーク幅の典型的なバラツキを無視する。
【0312】
さらに詳しく述べると、方法2400は、以下のように適宜実装される。さまざまな走査から得られる生データは、三次元データ配列に組み立てられるが、ただし、第1の軸は、クロマトグラフ保持時間に対応する走査集合の時間であり、第2の軸は、移動度ドリフト時間に対応する走査集合内の走査番号に対応し、第3の軸は、質量対電荷比に対応するチャネル番号である。三次元畳み込みは、三次元データ配列に適用される。三次元における極大値により、イオンピークが特定される。ピークの頂点の値は、畳み込みフィルタがこの目的のために正規化されている場合に、第4のイオン特性である、ピークの全体にわたって積分された強度を示す。
【0313】
三次元畳み込みでは、例えば、平滑化または2階微分フィルタ、またはそのようなフィルタの組み合わせを使用する。畳み込みフィルタの係数は、信号対ノイズ比を最大にし、統計誤差特性を最小にし、ベースライン背景を取り除き、および/またはイオン干渉の効果を緩和するように適宜選択される。より効率的に計算するために、方法2400の上記の説明に示されているように、三次元畳み込みが、生データのサブボリュームに適宜適用される。これらのサブボリュームは、LC/MSデータに応じて選択される。縮退2420データは、すべての移動度スペクトルを組み合わせること(加算することなど)により得られる。適宜、それぞれの次元に対する自動ピーク幅計算のように、不感時間補正およびロック質量補正が方法2400に組み込まれる。
【0314】
方法2400は、分離関係のデータのN個の次元を形成するN回の逐次分離に拡張可能である。そのようなデータは、N次元超立方体として適宜組み立てられ、N次元畳み込みは、超立方体内のすべての点に適用される。極大値は、例えば、1つの点の強度をN次元空間内のそれぞれの要素を中心とする3N個の隣接要素と比較することにより見つけられる。補間式により、それぞれのピークのN次元パラメータを特定し、N次元ピーク頂点の値が、N次元分離の後にピークに関連付けられているすべてのカウントまたはシグナルの原因となるピークの強度である。
【0315】
方法2400は、適宜重心データに適用される。重心アプローチでは、走査集合において、1回の走査に対し記録された情報のみが、ピーク情報であり、それぞれのピークは、質量と強度とで記述される。それぞれの質量−強度対は、質量分析法の分離能に対応する幅を有するガウスピークで置き換えられ、例えば、それぞれのスペクトルの連続体表現は、ピークリストから再構成される。再構成された連続体スペクトルは、立方体に組み立てられ、分析される。
【0316】
上述のように、効率上の理由から、三次元畳み込みフィルタを生データのボリューム全体に適用しないように適宜選択し、データを操作するのに必要な演算回数は、次元の数の累乗で増大する。現在利用可能な処理装置を使用しても、LC/IMS/MSベースのシステムの1回の注入で得られるデータすべてに適用される一般的な三次元畳み込みは、例えば、計算に数日を要する。方法2400は、完全な三次元畳み込みから得られるものに匹敵する結果を出しながら、計算時間を、例えば、1時間未満に短縮できる可能性を有している。適宜、二次元および三次元の畳み込みフィルタをデータから抽出された線形配列に逐次的に適用される一次元フィルタで近似することにより計算効率をさらに高められる。
【0317】
以下は、LC/IMS/MSベースのシステムに対するデータ計算の一実施例である。イオン強度は、三次元のボリュームにまとめられ、それぞれのデータ要素は、カウント(C)として測定される、強度であり、それぞれの要素は、保持時間(T)、移動度(D)、および質量対電荷比μに対応する3つの変数を添え字とする。数学的には、この三次元データのそれぞれの要素は、3つのインデックスが付けられる。化学者は、一般に、このようなデータを「四次元」データと呼び、強度をデータの付加的次元とみなす。この実施例でそれぞれのデータ要素に使用される表記は、Ci,j,kであり、Cは整数インデックスi,j,kにより指定されたデータ要素において測定されたカウントである。これらのインデックスは、走査番号(保持時間、Ti)、走査集合番号(移動度、Di)、およびチャネル番号(質量対電荷比、μk)に対応する。そこで、
Ci,j,k=C(Ti,Dj,μk)
となる。
【0318】
この実施例では、LC/IMS/MSシステムにおけるイオンの応答は、三次元のガウスピークとして近似され、それぞれのイオンは特性ピーク幅にわたって広がるカウントを生成する。
【0319】
3つの方向のそれぞれにおけるピークの幅は、分離モードの一特性である。標準偏差ピーク幅は、クロマトグラフ方向、移動度方向、および質量スペクトル方向に対しσT、σD、およびσμである。カウントは、データ要素上に
【数58】
のように分布するが、ただし、Cvは、積分されたボリュームカウントであり、インデックスi、j、kは、それぞれクロマトグラフ走査時間、移動度走査時間、および質量対電荷チャネルに対応する。ガウスピークは、i0、j0、およびk0を中心とする(小数値をとる)。頂点計数率と積分ボリューム計数率との関係は、
【数59】
で表される。
【0320】
このようなデータでイオンを検出し、この実施例では配列Ci,j,kからその特性を測定する、つまり、i0、j0、k0、およびCvを推論するために、畳み込みフィルタを使用してこれらのパラメータを推定する。畳み込みデータの極大値により、イオンを特定し、その強度を推定する。
【0321】
フィルタ係数Fl,m,nの集合が与えられると、三次元畳み込みの出力は、
【数60】
により与えられる三次元ボリュームであり、Ri,j,kは、畳み込み要素である。
【0322】
フィルタ係数Fl,m,nは、三次元ボリュームを範囲としており、それぞれの次元の幅は、それぞれの次元におけるピークの幅に関連付けられている。Fのインデックスは、0を中心として対称的であり、それぞれの次元内の要素の個数は、(2L+1)、(2M+1)、および(2N+1)である。
【0323】
この実施例では、Fl,m,nの幅は、MSおよびIMSの次元上で変化するピーク幅と一致するように調節される。それぞれの出力値Ri,j,kの計算は、存在するフィルタ係数の数だけ乗算を必要とする。
【0324】
畳み込みの式により示されているように、Ri,j,kの値は、計数Fl,m,nの中心を要素Ci,j,kに置き、指示された乗算および加算を実行することにより得られる。一般に、入力値Ci,j,kの数だけ出力値Ri,j,kがある。
【0325】
三次元の応用事例では、Ri,j,kは、その値が隣接要素のすべての要素の値を超える場合に極大値である。つまり、Ri,j,kが、(3×3×3=27)要素の立方体の中心にある場合、Ri,j,kの値は、そのイオンピーク強度値が、その26個の最近隣接要素の値を超える場合に最大値となる。正規化係数は、非正規化フィルタをモデルガウスピークに畳み込むことにより得られ、モデルガウスピークのピーク幅は、物理的に予想されるピーク幅に対応する。イオンは、畳み込みの最大値が適宜選択された閾値を超える場合に検出される。閾値検出に対する値は、例えば、100カウント以下に設定される。
【0326】
ピーク検出が与えられた場合、三次元におけるその頂点の配置は、例えば、三次元二次曲線を最大値の付近の27個の要素に当てはめることにより得られる。最大値の補間されたインデックス値から、ピークの特性が得られ、イオンの保持時間、移動度、および質量対電荷比に対応する分数インデックスが得られる。一般に、スペクトルは未較正であり、したがって、質量対電荷比は未較正である。
【0327】
畳み込みの演算回数は、得られた強度の数とフィルタ係数の数の積に比例する。この演算回数は、データの次元の累乗で増大する。そこで、LC/IMS/MSベースのシステムに対する畳み込みアプローチでは、適宜、増大する可能性のある演算回数の問題に取り組まなければならない。
【0328】
上述のように、計算の演算回数を減らす一方法は、三次元畳み込みフィルタを一連の一次元畳み込みフィルタ群として実装することである。図1〜図23Bを参照しつつ上で説明されているように、一次元フィルタの複数回適用は、近似として、二次元または三次元フィルタ行列を実装する。例えば、21×21要素の二次元畳み込み行列は、スペクトル方向に2つ、保持時間次元に2つとする4つの一次元畳み込みで置き換えられる。三次元畳み込みの場合、21×21×21三次元畳み込みフィルタは、それぞれの次元に3つの一次元畳み込みを使用する、9つの一次元畳み込みで置き換えられる。このアプローチは、例えば、二次元の場合には1/6、三次元の場合には1/48に、計算時間を短縮する。
【0329】
上述のように、イオン検出を行うためにすべての生データ点に対する畳み込み要素を計算する必要はない。好ましくは、それぞれのイオンの極大値を特定するのに十分なRi,j,kに対する値を計算するだけである。最小数は、例えば、それぞれのイオンについてRi,j,kの3×3×3の値の立方体である。極大値は、その立方体の中心のRi,j,kの値が周囲にある26個すべての値よりも大きい場合に見つかる。したがって、原理上、100,000個のイオンが見つかる場合、例示的な一実施例では、約3,000,000個の要素のみ、または潜在的畳み込み要素の総数4.5×1010の0.01%未満があればよい。これらの臨界畳み込み値の計算は、状況にもよるが数秒を要する。実際には、この最小値よりも多くの要素が計算される。したがって、本発明では、いくつかの実施形態において、IMSモジュールをLC/MSシステムに加えると、その大半が必要な情報をもたらさない測定されるデータ点の数が適宜大幅に増大するという考えを利用している。
【0330】
この実施例では、生データは、三次元LC/IMS/MSデータから二次元LC/MSデータ行列を構成することによりイオン移動度次元において縮退される。二次元LC/MS行列の要素
【数61】
は、
【数62】
のようにして、同じクロマトグラフ走査時間および質量スペクトルチャネルで測定されたすべての移動度からの強度を総和することにより得られる。
【0331】
上述のように、この次元は最低の分離能またはピーク容量を有するため、好ましくは移動度次元に対する総和を行い、次いで、その結果得られるT×μ二次元配列は、次元の他の2つの可能な対よりも多くの分離能要素を有する。
【0332】
二次元畳み込みがこの縮退配列に適用され、畳み込み要素
【数63】
の配列を決定するが、ただし、
【数64】
である。
【0333】
ここで、
【数65】
は、二次元畳み込みフィルタであり、
【数66】
は、二次元畳み込み要素である。要素
【数67】
の極大値により、二次元行列内に見つかるそれぞれの二次元イオンの保持時間およびm/zが特定される。
【0334】
本発明の実施例では、すべてのイオンがこれら二次元イオンピーク(類似のイオン運動性による複数のイオンから生じる可能性がある)によって説明が付くという仮定を利用する。したがって、二次元畳み込みの結果は、三次元畳み込みをどこに適用するかを示しており、それぞれの二次元イオンピークは、1つまたは複数の三次元イオンに対応する。特定の二次元イオンピークに対するイオン干渉がない場合、対応する三次元ボリュームにより、イオン移動度次元にその配置を有する単一イオン検出が行われる。
【0335】
二次元イオンピーク配置の判定毎に、三次元畳み込み要素の集合が計算される。本発明の実施例では、特定されたそれぞれのピークについて、これらの要素は、二次元ピーク配置の保持時間およびm/zを中心とし、200個すべての移動度スペクトルを範囲とする三次元ボリュームを対象範囲とする。
【0336】
したがって、三次元データから、イオンの移動度特性が得られるが、保持時間、m/z、および/または強度情報は、すでに、畳み込み二次元データにより与えられているか、または好ましくは、より正確に、オリジナルの三次元データによっても与えられている。そのため、三次元畳み込み要素の制限付きの選択を計算するだけで十分である。
【0337】
特定されたピークの幅上に分布する頂点を有する複数のイオンを含むことができる、畳み込み二次元データ内で特定された、ピークに対応するために、以下のスキームが適宜使用される。畳み込み要素は、それぞれの二次元イオン検出結果を中心とする11個の保持時間要素×11個の質量対電荷比要素×200個のイオン移動度要素のボリューム上で計算される。この実施例では、毎秒2億回の演算で計算を行うと仮定すると、約38分の処理時間で、LC/IMS/MSシステムに試料注入を1回行ったときのすべてのイオンに対する保持時間、イオン移動度、質量対電荷比、およびイオン強度が得られる。三次元畳み込み要素が計算されるボリュームを減らして、さらに、計算時間を(例えば、さらに1/20に短縮し)管理可能なレベルに下げる。
【0338】
本発明の好ましい実施形態の前記開示は、例示および説明を目的として提示されている。網羅的であることも発明を開示されている正確な形態に制限することも意図されていない。本明細書で説明されている実施形態のさまざまな変更形態および修正形態は、上記の開示に照らして当業者には明白なことであろう。本発明の範囲は、付属の請求項だけでなく、その等価の事項によっても定められるものとする。
【0339】
さらに、本発明の代表的な実施形態を説明する際に、明細書において、本発明の方法および/またはプロセスをステップの特定の並びとして提示していることがある。しかし、方法またはプロセスが、本明細書で説明されているステップの特定の順序に依存しない限り、その方法またはプロセスは、説明されているステップの特定の並びに限定されるべきではない。当業者であれば理解するように、ステップの他の並びも可能である場合がある。したがって、本明細書で説明されているステップの特定の順序は、請求項に対する制限と解釈されるべきではない。それに加えて、本発明の方法および/またはプロセスを対象とする請求項は、それらのステップを書かれている順序で実行することに限定されるべきではなく、また当業者は、それらのステップの並びは変えられてもよいが、それでも本発明の精神および範囲に従っていることを容易に理解できる。
【技術分野】
【0001】
本出願は、参照によりその全文を本明細書に組み込まれている、2006年5月26日に出願された米国仮特許出願第60/808,901号の利益および優先権を主張するものである。
【0002】
本発明は、一般に、化合物の分析に関するものであり、より具体的には、液体クロマトグラフィ、イオン移動度分光分析、および質量分析により捕集されたイオンの検出および定量化に関するものである。
【背景技術】
【0003】
質量分析計(MS)は、試料中の分子種の同定および定量化に広く使用されている。分析時に、試料中の分子がイオン化され、分析のため質量分析計内に導入されるイオンが形成される。質量分析計は、導入されるイオンの質量対電荷比(m/z)および強度を測定する。
【0004】
質量分析計は、単一の試料スペクトル内で確実に検出され、定量化される異なるイオンの数について制限がある。その結果、多数の分子種を含む試料が発生しうるスペクトルは複雑すぎて、従来の質量分析計を使用したのでは解釈または分析を行えない。
【0005】
それに加えて、分子種の濃度は、広い範囲にわたって変化することが多い。例えば、生体試料は、典型的には、高い濃度のときよりも低い濃度のときのほうが多くの分子種を有する。したがって、イオンのかなりの画分が低濃度で出現する。この低濃度は、普通の質量分析計の検出限界に近いことが多い。さらに、低濃度では、イオン検出は、背景ノイズおよび/または干渉背景分子の影響を受ける。したがって、このような少量の化学種の検出は、背景ノイズをできる限り取り除き、スペクトル中に存在する干渉種の数を減らすことにより改善されうる。
【0006】
試料を質量分析計に注入するのに先立って、このようなスペクトルの複雑度を低減するために、クロマトグラフ分離が普通に使用される。例えば、ペプチドまたはタンパク質は、普通のクロマトグラフ保持時間で溶出するイオンのクラスタを生成し、スペクトル内で重なるピークを発生することが多い。時間内にさまざまな分子からクラスタを分離することで、このようなクラスタにより発生するスペクトルの解釈が簡単になる。
【0007】
普通のクロマトグラフ分離装置は、ガスクロマトグラフ(GC)および液体クロマトグラフ(LC)を含む。質量分析計に結合された場合、その結果できあがるシステムは、GC/MSまたはLC/MSシステムと呼ばれる。GC/MSまたはLC/MSシステムは、典型的には、GCまたはLCの出力がMSに直接結合されるオンラインシステムである。
【0008】
LC/MS併用システムは、分析者にとって、さまざまな試料中の分子種を同定し、定量化する強力な手段となっている。普通の試料は、数個または数千個の分子種の混合物を含む。分子は、広範な特性および特徴を示すことが多く、それぞれの分子種は、複数のイオンを発生しうる。例えば、ペプチドの質量は、その核の同位体型に依存し、エレクトロスプレーインターフェースが、ペプチドおよびタンパク質を複数の荷電状態群にイオン化することができる。
【0009】
LC/MSシステムでは、試料は、特定の時間に液体クロマトグラフ内に注入される。液体クロマトグラフは、時間の経過とともに試料を溶出させ、その結果、液体クロマトグラフから溶離液が出る。液体クロマトグラフから出る溶離液は、質量分析計のイオン源内に連続的に導入される。分離が進むにつれ、MSにより生じる質量スペクトルの組成が現れ、溶離液の変化する組成を反映する。
【0010】
典型的には、コンピュータベースのシステムが、規則的時間間隔でスペクトルをサンプリングし、記録する。従来のシステムでは、収集されたスペクトルは、LC分離が完了してから分析される。
【0011】
収集した後、従来のLC/MSシステムは、一次元スペクトルおよびクロマトグラムを生成する。イオンの応答(または強度)は、スペクトルまたはクロマトグラムのいずれかに見られるようなピークの高さまたは面積である。従来のLC/MSシステムにより生成されるスペクトルまたはクロマトグラムを分析するためには、イオンに対応するこのようなスペクトルまたはクロマトグラムのピークが、特定されるか、または検出されなければならない。検出されたピークを分析し、それらのピークを引き起こすイオンの特性を決定する。これらの特性は、保持時間、質量対電荷比、および強度を含む。
【0012】
1個のイオンに対する質量または質量対電荷比(m/z)推定値は、そのイオンを含むスペクトルを調べることにより導き出される。1個のイオンに対する保持時間推定値は、そのイオンを含むクロマトグラムを調べることにより導き出される。単一の質量チャネルクロマトグラムのピーク頂点の時間的位置から、イオンの保持時間が得られる。1回のスペクトル走査のピーク頂点のm/z位置から、イオンのm/z値が得られる。
【0013】
LC/MSシステムを使用してイオンを検出する従来の技術では、全イオンクロマトグラム(TIC)を形成する。典型的には、この技術は、検出を必要とする比較的少ないイオンがある場合に適用される。TICは、それぞれのスペクトル走査内で、すべてのm/z値にわたって収集されたすべての応答を総和し、その総和を走査時間についてプロットすることにより生成される。理想的には、TIC内のそれぞれのピークは、単一イオンに対応する。
【発明の概要】
【発明が解決しようとする課題】
【0014】
複数の分子からのピークの共溶出は、TICにおけるピークを検出するこの方法の考えられる問題の1つである。共溶出の結果、TIC内に見られるそれぞれの孤立ピークは、固有のイオンに対応しえない。このような共溶出ピークを分離する従来の方法では、TICから1つのピークの頂点を選択し、その選択されたピークの頂点に対応する時間に対するスペクトルを収集する。その結果得られるスペクトルのプロットは、一連の質量ピークであり、それぞれ共通保持時間に溶出する単一イオンに対応すると思われる。
【0015】
また、複雑な混合物の場合、共溶出は、典型的には、スペクトル応答の総和を、例えば制限された範囲のm/zチャネルにわたる総和により、収集されたチャネルの部分集合のみについての総和に制限する。総和されたクロマトグラムから、制限されているm/z範囲内で検出されたイオンに関する情報が得られる。それに加えて、クロマトグラフピーク頂点毎にスペクトルを収集できる。この方法ですべてのイオンを同定するためには、複数の総和されたクロマトグラムが一般に必要である。
【0016】
ピーク検出で出会う他の問題としては、検出器ノイズがある。検出器ノイズ効果を軽減する一般的な技術は、スペクトルまたはクロマトグラムをシグナル平均化することである。例えば、特定のクロマトグラフのピークに対応するスペクトルを共付加して、ノイズ効果を低減することができる。質量対電荷比値とともにピーク面積および高さは、平均されたスペクトル内のピークを分析することで求められる。同様に、スペクトルピークの頂点を中心とするクロマトグラムを共付加することで、クロマトグラム中のノイズ効果を緩和し、保持時間だけでなくクロマトグラフのピーク面積および高さの推定もより正確にできる。
【0017】
これらの問題とは別に、従来のピーク検出ルーチンを使用してクロマトグラフまたはスペクトルのピークを検出する場合にさらに問題が生じる。手動で実行された場合、このような従来の方法は、主観的であるとともに退屈なものでもある。自動的に実行される場合でも、このような方法は、ピークを同定するために閾値を主観的に選択するので主観的であるといえる。さらに、これらの従来の方法は、単一の抽出されたスペクトルまたはクロマトグラムのみを使用してデータを分析するため不正確になる傾向があり、また最高の統計的精度または最低の統計的分散を有するイオンパラメータの推定量をもたらさない。最後に、従来のピーク検出技術では、低濃度におけるイオン、または複雑なクロマトグラムに対し一様な再現性のある結果が必ずしも得られるわけではなく、共溶出およびイオン干渉はよくある問題になりがちである。
【課題を解決するための手段】
【0018】
本発明のいくつかの実施形態は、3つまたはそれ以上の次元のデータを必要とする分析計装および方法を伴う。例えば、本発明のいくつかの好ましい実施形態は、LC、イオン移動度分光分析(IMS)、およびMSを含む装置を伴う。本発明のいくつかの態様は、LC/IMS/MSおよび他の高次元のデータ生成技術が、畳み込みフィルタを使用してノイズおよび/またはピーク干渉により引き起こされるアーチファクトを低減することで、効率的なデータ評価の恩恵を受けるという理解に起因するものである。さらに、データをイオン移動度の次元などの比較的低い、または最低の次元に一時的に縮退すると、分析が高速化され、また質量分析次元などのより高い、または最高の分離能次元で、データ分析時に無視される可能性のある収集データの大部分を識別することができる。さらに、例えばイオン移動度次元では、保持時間および/または質量次元などの他の次元において他の何らかの形で重なるイオンピークの区別が可能になる。
【0019】
例えば、いくつかのLC/IMS/MSベースの実施形態では、より速く、より効率的であるデータの特徴により、イオン移動度次元において縮退され、高速線形二次元有限インパルス応答(FIR)フィルタとの畳み込みがなされたデータのデータ行列を作成して出力畳み込み行列を生成することにより正確に、また最適な形で推定される、イオン移動度、質量対電荷比(m/z)、保持時間、およびイオン強度などのイオンパラメータが得られる。ピーク検出ルーチンは、出力畳み込み行列に適用され、これにより試料中のイオンに対応するピークを同定する。
【0020】
同定されたピークは、適宜、元のデータのどの部分がピークを含むかを示すために使用される。これらの示されている部分が、適宜、三次元フィルタに畳み込まれ、次いで、イオンピークが、すべての次元において特定される。低分離能次元の評価により、例えば、他の次元において重なるイオンピークの解明が可能になる。
【0021】
したがって、例示的な一実施形態では、本発明は、LC/IMS/MS分析の方法を特徴とする。この方法は、試料からノイズの多い生データを取得することを含む。データは、三次元データ要素の集合を含み、それぞれの要素はイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付けるが、ただしノイズはイオンピークアーチファクトに関連付けられる。この方法は、さらに、イオン移動度次元において、そのデータ要素の集合を縮退して、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成することと、その縮退データ要素の集合を、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたピークアーチファクトを有するデータ要素の畳み込まれた集合を形成することと、保持時間次元および質量対電荷比次元において、畳み込まれた縮退データ要素の集合のイオンピークを特定することと、データ要素の畳み込まれた集合のイオンピークの配置に応じて、さらなる分析対象となる生データの1つまたは複数の部分を選択することと、少なくともイオン移動度次元において、生データのそれらの部分のそれぞれについて1つまたは複数のイオンピークを特定することとを含む。
【0022】
第2の例示的な一実施形態では、本発明は、N次元分析の方法を特徴とする。この方法は、それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、ノイズの多いデータを試料から取り出すことと、そのデータ要素の集合をアーチファクト低減フィルタに畳み込み、データ要素の畳み込まれた集合を生成することと、データ要素の畳み込まれた集合内の1つまたは複数のイオンピークを特定することとを含む。
【0023】
他の態様では、本発明は、化学処理装置を伴う。装置は、例えば、上述の方法の1つを実装するように構成された制御ユニットを備える。
【図面の簡単な説明】
【0024】
【図1】本発明の一実施形態による例示的なLC/MSシステムの略図である。
【図2】例示的なクロマトグラフまたはスペクトルピークの図である。
【図3A】例示的なLC/MS実験で生成された3つのイオンに対する例示的なスペクトルを示す図である。
【図3B】例示的なLC/MS実験で生成された3つのイオンに対する例示的なスペクトルを示す図である。
【図3C】例示的なLC/MS実験で生成された3つのイオンに対する例示的なスペクトルを示す図である。
【図4A】図3A〜図3Cの例示的なイオンに対応するクロマトグラムを示す図である。
【図4B】図3A〜図3Cの例示的なイオンに対応するクロマトグラムを示す図である。
【図4C】図3A〜図3Cの例示的なイオンに対応するクロマトグラムを示す図である。
【図5】本発明の一実施形態によりデータを処理する方法の流れ図である。
【図6】本発明の一実施形態によりデータを処理する方法の、図解による流れ図である。
【図7】本発明の一実施形態によりイオンを検出する際に使用する閾値を決定する方法の、図解による流れ図である。
【図8】本発明の一実施形態による例示的なデータ行列を示す図である。
【図9】本発明の一実施形態による図3A〜図3Cおよび図4A〜図4Cのデータから作成された例示的なデータ行列の等高線図である。
【図10】本発明の一実施形態によりノイズの存在しないデータを処理する簡略化された方法の流れ図である。
【図11】図9の例示的なデータ行列に対する共溶出イオンの効果を示す図である。
【図12A】図3A〜図3Cに示されている例示的なデータに対する共溶出イオンの「段状」効果を示す図である。
【図12B】図3A〜図3Cに示されている例示的なデータに対する共溶出イオンの「段状」効果を示す図である。
【図12C】図3A〜図3Cに示されている例示的なデータに対する共溶出イオンの「段状」効果を示す図である。
【図13】本発明の実施形態により作成されたデータ行列中の例示的なデータにノイズがどのような影響を及ぼすかを示す図である。
【図14A】図13に示されているデータ行列に例示されている例示的なデータに対応する3つのイオンに対するスペクトルを示す図である。
【図14B】図13に示されているデータ行列に例示されている例示的なデータに対応する3つのイオンに対するスペクトルを示す図である。
【図14C】図13に示されているデータ行列に例示されている例示的なデータに対応する3つのイオンに対するスペクトルを示す図である。
【図14D】図13に示されているデータ行列に例示されている例示的なデータに対応するイオンに対するクロマトグラムを示す図である。
【図14E】図13に示されているデータ行列に例示されている例示的なデータに対応するイオンに対するクロマトグラムを示す図である。
【図14F】図13に示されているデータ行列に例示されている例示的なデータに対応するイオンに対するクロマトグラムを示す図である。
【図15】本発明の一実施形態による例示的な一次元アポダイズサビツキー−ゴーレイ2階微分フィルタを示す図である。
【図16A】本発明の一実施形態によるスペクトル(m/z)方向の例示的な一次元フィルタの断面を示す図である。
【図16B】本発明の一実施形態によるクロマトグラフ(時間)方向の例示的な一次元フィルタの断面を示す図である。
【図16C】本発明の一実施形態によるスペクトル(m/z)方向の例示的な一次元平滑化フィルタf1の断面を示す図である。
【図16D】本発明の一実施形態によるクロマトグラフ方向の例示的な一次元2階微分フィルタg1の断面を示す図である。
【図16E】本発明の一実施形態によるクロマトグラフ方向の例示的な一次元平滑化フィルタg2の断面を示す図である。
【図16F】本発明の一実施形態によるスペクトル(m/z)方向の例示的な一次元2階微分フィルタf2の断面を示す図である。
【図17A】本発明の実施形態によるデータ行列に格納されるようなLC/MSデータにより生成されうる例示的なピークを示す図である。
【図17B】本発明の一実施形態による例示的な階数2のフィルタの点源応答(有限インパルス応答)を示す図である。
【図17C】質量が等しく、ほぼ同時であるが、まったく同時というわけではない2つのLC/MSピークのシミュレーションを示す図である。
【図17D】図17Cの2ピークシミュレーションの質量におけるピーク断面を示す図である。
【図17E】図17Cの2ピークシミュレーションの時間におけるピーク断面を示す図である。
【図17F】図17Cの2ピークシミュレーションに計数(ショット)ノイズを加える効果を示す図である。
【図17G】図17Fの付加ノイズ2ピークシミュレーションの質量におけるピーク断面を示す図である。
【図17H】図17Fの付加ノイズ2ピークシミュレーションの時間におけるピーク断面を示す図である。
【図17I】階数2のフィルタを図17Fのシミュレートされたデータに畳み込んだ結果を例示する図である。
【図17J】図17Iに例示されている結果の質量におけるピーク断面を示す図である。
【図17K】図17Iに例示されている結果の時間におけるピーク断面を示す図である。
【図18】本発明の一実施形態によりデータのリアルタイム処理を実行する流れ図である。
【図19A】図18の流れ図の方法によりデータのリアルタイム処理を実行する方法を示す図解である。
【図19B】図18の流れ図の方法によりデータのリアルタイム処理を実行する方法を示す図解である。
【図20】本発明の一実施形態により適切な閾値を決定する方法の流れ図である。
【図21】本発明の一実施形態によりピーク純度計量を決定する方法の流れ図である。
【図22A】2つの親分子とその結果の非常に多数の分子から結果として得られる例示的なLC/MSデータ行列を示す図である。
【図22B】時間t1における図22Aのデータに対応する例示的な複雑なスペクトルを示す図である。
【図22C】時間t2における図22Aのデータに対応する例示的な複雑なスペクトルを示す図である。
【図23A】本発明の一実施形態により生成される未修正および修正イオンリスト中で関係するイオンをどのように同定できるかを示す図解である。
【図23B】本発明の一実施形態により生成される未修正および修正イオンリスト中で関係するイオンをどのように同定できるかを示す図解である。
【図24】本発明の一実施形態による、分析の方法の流れ図である。
【発明を実施するための形態】
【0025】
「クロマトグラフィ」−化合物の分離で使用される装置および/または方法のことである。クロマトグラフ装置は、典型的には、圧力および/または電気力および/または磁力の下で流体および/またはイオンを移動する。「クロマトグラム」という用語は、文脈にもよるが、本明細書では、クロマトグラフ手段により導き出されるデータまたはデータの表現を指す。クロマトグラムは、データ点の集合を含むことができ、それぞれのデータ点は、2つまたはそれ以上の値からなり、これらの値の1つは、多くの場合、クロマトグラフ保持時間値であり、残りの(複数の)値は、典型的には、強度または大きさの値に関連し、さらに、これらは試料の成分の量または濃度に対応する。
【0026】
本発明は、クロマトグラフデータの生成および分析をサポートするものである。本発明のいくつかの実施形態は、試料成分を分離する単一のモジュールを備える装置を伴うが、他の実施形態は、複数のモジュールを伴う。例えば、本発明の原理は、液体クロマトグラフィ装置だけでなく、例えば、液体クロマトグラフィモジュール、イオン移動度分光分析モジュール、および質量分析モジュールを備える装置にも適用可能である。いくつかのマルチモジュールベースの実施形態では、クロマトグラフィモジュールは、適切なインターフェースを通じてイオン移動度分光分析モジュールと流体連通し、次いで、IMSモジュールが、エレクトロスプレーイオン化インターフェースなどの適切なインターフェースを使用することで、質量分析モジュールにインターフェースされる。いくつかの適切なインターフェースは、ときどき、分離された物質をイオン形態で生成するか、またはイオン形態に保持する。試料流体の流れは、典型的には、蒸発し、イオン化され、質量分析モジュールの入口オリフィスに送られる。
【0027】
そのため、いくつかの実施形態は、データ要素の集合からなる多次元データを生成し、それぞれの実施形態は、保持時間(クロマトグラフィモジュールから導かれる)、イオン移動度、および質量対電荷比などの測定次元に関連付けられた弁を有する。次元に関する弁の固有の集合は、実験的に、例えば、質量分析モジュールで測定されるようなイオン強度の弁にリンクされる。
【0028】
タンパク質−本明細書では、単一のポリペプチドとして組み立てられたアミノ酸の特定一次配列を指す。
【0029】
ペプチド−本明細書では、タンパク質の一次配列内に含まれる単一のポリペプチドとして組み立てられたアミノ酸の特定配列を指す。
【0030】
前駆ペプチド−タンパク質切断プロトコールを使用して生成されるトリプシンペプチド(または他のタンパク質切断生成物)。これらの前駆体は、適宜クロマトグラフィにより分離され、質量分析計に渡される。イオン源は、これらの前駆ペプチドをイオン化して、典型的には、前駆体のプラスに帯電したタンパク質化形態を生成する。このようなプラスに帯電したタンパク質化前駆体イオンの質量は、本明細書では、前駆体の「mwHPlus」または「MH+」と呼ぶ。以下では、「前駆体質量」という用語は、一般にイオン化されたペプチド前駆体のタンパク質化されたmwHPlusまたはMH+を指す。
【0031】
フラグメント−LC/MS分析では、複数の種類のフラグメントが発生しうる。トリプシンペプチド前駆体の場合、フラグメントは、無傷のペプチド前駆体の衝突フラグメンテーションから生成され、一次アミノ酸配列が始めの前駆ペプチド内に含まれるポリペプチドイオンを含むことができる。YイオンおよびBイオンは、このようなペプチドフラグメントの例である。トリプシンペプチドのフラグメントは、さらに、インモニウムイオン、リン酸イオン(PO3)などの官能基、特定の分子または特定の種類の分子から切断された質量タグ、あるいは前駆体からの水(H2O)またはアンモニア(NH3)分子の「ニュートラルロス」を含むこともできる。
【0032】
YイオンおよびBイオン−ペプチドがペプチド結合部位で分断する場合、また電荷がN末端フラグメント上に保持される場合、そのフラグメントイオンはBイオンと呼ばれる。電荷が、C末端フラグメント上に保持される場合、フラグメントイオンは、Yイオンと呼ばれる。考えられるフラグメントおよびその名称のより包括的なリストは、Roepstorff、Fohlman「Biomed Mass Spectrom」1984;11(11):601およびJohnsonらのAnal.Chem 1987,59(21):2621:2625に記載されている。
【0033】
保持時間−文脈上、典型的には、要素がその最大強度に達するクロマトグラフィプロファイル内の点を意味する。
【0034】
イオン−例えば、ペプチドは、典型的には、構成要素である元素の同位体が天然依存度によるイオンの集合体としてLC/MS分析中に現れる。イオンは、例えば、保持時間とm/z値を有する。質量分析計(MS)はイオンのみを検出する。LC/MS技術では、検出されたすべてのイオンについてさまざまな観察された測定結果が得られる。これは、質量対電荷比(m/z)、質量(m)、保持時間、および計数されたイオンの個数などのイオンのシグナル強度を含む。
【0035】
ノイズ−本明細書では、計数統計およびガウス分布に起因するポアソンノイズ、熱効果に起因するジョンソンノイズ、および実イオンピークを隠すか、または偽イオンピークを発生する傾向のある他のノイズ源を含む、検出器ノイズなどの発生源から生じる生データ成分を指し示す。
【0036】
アーチファクト−本明細書では、例えば、ノイズ、ピーク干渉、およびピーク重なりから生じるような、生データ中の偽ピークを指す。
【0037】
一般に、LC/IMS/MS分析では、適宜、例えば、質量、電荷、保持時間、移動度、および全強度に関してペプチドを経験的に記述する。ペプチドは、クロマトグラフィカラムから溶出するときに、特定の保持期間にわたって溶出し、単一の保持時間に最大シグナルに到達する。イオン化および(場合によっては)フラグメンテーションの後、ペプチドは、関連するイオンの集合体として現れる。この集合体内の異なるイオンは、共通ペプチドの異なる同位体組成および電荷に対応する。関連するイオンの集合体内のそれぞれのイオンは、単一のピーク保持時間およびピーク形状をもたらす。これらのイオンは、共通のペプチドに由来しているため、それぞれのイオンのピーク保持時間およびピーク形状は、多少の測定許容誤差範囲内で、同一である。それぞれのペプチドをMSで収集することにより、すべての同位体および荷電状態について複数のイオン検出が行われ、すべて多少の測定許容誤差内で同じピーク保持時間およびピーク形状を共有する。
【0038】
LC/MS分離では、単一のペプチド(前駆体またはフラグメント)から、複数の荷電状態を有する、イオンのクラスタとして出現する、多数のイオン検出が得られる。このようなクラスタから得られるこれらのイオン検出結果の逆畳み込みは、荷電状態にある、測定されたシグナル強度の、特定の保持時間における、固有のモノアイソトピック質量の単一の実体の存在を示している。
【0039】
本発明の実施形態は、溶媒中に溶解されうる大分子不揮発性検体を含むさまざまなアプリケーションに適用できる。本発明の実施形態は、これ以降、LC、LC/MS、またはLC/IMS/MSシステムに関して説明されているけれども、本発明の実施形態は、GC、GC/MS、およびGC/IMS/MSシステムを含む、他の分析技術と併用して動作するように構成されうる。文脈上、LC/MSデータの分析に一次元および二次元行列を使用する実施形態が、図1〜図23を参照しつつ最初に説明される。その後、LC/IMS/MSおよび高次元の技術に関係する、本発明のいくつかの好ましい実施形態が、図24を参照しつつ説明される。
【0040】
図1は、本発明の一実施形態による例示的なLC/MSシステム101の略図である。LC/MS分析は、試料102を液体クロマトグラフ104内に自動的に、または手動で注入することにより実行される。ポンプ103およびインジェクタ105によりクロマトグラフィ溶媒の高圧流を送り、試料102を液体クロマトグラフ104内のクロマトグラフィカラム106に強制的に通して移動させる。カラム106は、典型的には、結合された分子を表面に含むシリカビーズの充填カラムを含む。試料、溶媒、およびビーズ中の分子種間の競合的相互作用が、それぞれの分子種の移動速度を決定する。
【0041】
分子種はカラム106内を通って移動し、特徴的な時間においてカラム106から現れる、つまり溶出する。この特徴的な時間は、一般に、分子の保持時間と呼ばれる。分子は、カラム106から溶出すると、質量分析計108などの検出器に運ばれうる。
【0042】
保持時間は、特徴的な時間である。つまり、保持時間tにカラムから溶出する分子は、実際に、本質的には時間tを中心とするある期間にわたって溶出する。この期間にわたる溶出プロフィルは、クロマトグラフピークと呼ばれる。クロマトグラフピークの溶出プロフィルは、釣鐘形曲線により記述することができる。ピークの釣鐘形は、典型的には半分の高さで全幅、つまり半値全幅(FWHM)により記述される。分子の保持時間は、ピークの溶出プロフィルの頂点の時間である。質量分析計により生成されるスペクトル中に出現するスペクトルピークは、類似の形状を有し、類似の方法で特徴付けることができる。図2は、ピーク頂点204を有する例示的なクロマトグラフピークまたはスペクトルピーク202を示している。FWHMおよび高さまたはピーク202も、図2に例示されている。
【0043】
その後の説明のために、ピークは、図2に示されているようにガウス分布を有するものと仮定される。ガウス分布では、FWHMは、ガウス分布の標準偏差σの約2.35倍である。
【0044】
クロマトグラフピーク幅は、ピーク高さと無関係であり、実質的に、与えられた分離方法に対する分子の定数特性である。理想的な場合では、所定のクロマトグラフ法について、すべての分子種は、同じピーク幅で溶出する。しかし、典型的には、ピーク幅は、保持時間の関数として変化する。例えば、分離の終わりに溶出する分子は、分離で早い段階に溶出する分子に関連するピーク幅に比べて数倍広いピーク幅を示すことがある。
【0045】
その幅に加えて、クロマトグラフピークまたはスペクトルピークは、ある高さまたは面積を有する。一般に、ピークの高さおよび面積は、液体クロマトグラフに注入される化学種の量または質量に比例する。強度という用語は、一般に、クロマトグラフピークまたはスペクトルピークの高さまたは面積のいずれかを指す。
【0046】
クロマトグラフ分離は、実質的に連続的なプロセスであるけれども、溶離液を分析する検出器は、典型的には、その溶離液を規則正しい間隔でサンプリングする。検出器が溶離液をサンプリングする速度は、サンプリングレートまたはサンプリング頻度と呼ばれる。それとは別に、検出器が溶離液をサンプリングする間隔は、サンプリング間隔またはサンプリング周期と呼ばれる。サンプリング周期は、システムがそれぞれのピークのプロファイルを適切にサンプリングできる十分な長さでなければならないため、最小サンプリング周期は、クロマトグラフピークの幅により制限される。例えば、サンプリング周期は、クロマトグラフピークのFWHMにおいて5回程度測定が実行されるように設定されうる。
【0047】
LC/MSシステムでは、クロマトグラフ溶離液は、図1に示されているように分析のため質量分析計(MS)108内に導入される。MS 108は、脱溶媒和システム110、イオン化装置112、質量分析器114、検出器116、およびコンピュータ118を備える。試料がMS 108内に導入されると、脱溶媒和システム110が、溶媒を取り除き、イオン化源112が、検体分子をイオン化する。LC 104から展開する分子をイオン化するイオン化法は、電子衝撃(EI)、エレクトロスプレー(ES)、および大気化学イオン化(APCI)を含む。APCIでは、イオン化および脱溶媒和の順序は逆にされることに留意されたい。
【0048】
次いで、イオン化された分子は、質量分析器114に運ばれる。質量分析器114は、分子をその質量対電荷比によりソートするか、またはフィルタリングする。MS 108内のイオン化された分子を分析するために使用される質量分析器114などの質量分析器は、四重極質量分析器(Q)、飛行時間型(TOF)質量分析器、およびフーリエ変換ベースの質量分析計(FTMS)を含む。
【0049】
質量分析器は、例えば、四重極飛行時間型(Q−TOF)質量分析器を備えるさまざまな構成においてタンデム型にすることができる。タンデム構成では、すでに質量分析済みの分子のオンライン衝突修正および分析が可能である。例えば、トリプル四重極ベースの質量分析器(Q1−Q2−Q3またはQ1−Q2−TOF質量分析器など)では、第2の四重極(Q2)は、加速電圧を第1の四重極(Q1)により分離されるイオンにインポートする。これらのイオンは、Q2にあからさまに導入されるガスと衝突する。これらのイオンは、このような衝突の結果、砕けてフラグメントになる。これらのフラグメントは、さらに、第3の四重極(Q3)またはTOFにより分析される。本発明の実施形態は、上述のような任意のモードの質量分析から得られたスペクトルおよびクロマトグラムに適用可能である。
【0050】
次いで、m/zに対するそれぞれの値における分子は、検出デバイス116で検出される。例示的なイオン検出デバイスは、電流測定電位計および単一イオン計数マルチチャネルプレート(MCP)を備える。MCPからのシグナルは、ディスクリミネータとその後に続く時間領域コンバータ(TDC)またはアナログ−デジタル(ATD)コンバータにより分析されうる。本発明の説明のために、MCP検出ベースのシステムが仮定される。その結果、検出器応答は、特定のカウント数で表される。この検出器応答(つまり、カウント数)は、質量対電荷比のそれぞれの間隔で検出されたイオンの強度に比例する。
【0051】
LC/MSシステムは、時間をかけて集めた一連のスペクトルまたは走査を出力する。質量対電荷スペクトルは、m/zの関数としてプロットされる強度である。スペクトルのそれぞれの要素、つまり単一の質量対電荷比は、チャネルと呼ばれる。時間を追って単一チャネルを見ると、対応する質量対電荷比に対するクロマトグラムが得られる。生成された質量対電荷スペクトルまたは走査は、コンピュータ118により取得されて記録され、コンピュータ118からアクセス可能なハードディスクドライブなどの記録媒体に格納されうる。典型的には、スペクトルまたはクロマトグラムは、値の配列として記録され、コンピュータシステム118により格納される。この配列は、表示され、数学的に分析されうる。
【0052】
MS 108などのMSシステムを構成する特定の機能要素は、LC/MSシステム毎に異なることがある。本発明の実施形態は、MSシステムを構成しうるさまざまコンポーネントと併用するように構成されうる。
【0053】
クロマトグラフ分離およびイオンの検出と記録の後、分離後データ分析システム(DAS)を使用して、データが分析される。本発明の代替え実施形態では、DASは、リアルタイムまたはほぼリアルタイムで分析を実行する。DASは、一般的に、図1に示されているコンピュータ118などのコンピュータ上で実行されるコンピュータソフトウェアにより実装される。本明細書で説明されているようにDASを実行するように構成されうるコンピュータは、当業者によく知られているものである。DASは、スペクトルおよび/またはクロマトグラムの視覚的表示を行うだけでなく、データに対する数学的分析を実行するためのツールも備えることを含む、多数のタスクを実行するように構成される。DASにより得られる分析結果は、検討され、さらに分析されるべき、1回の注入から得られる結果および/または一組の数回の注入操作から得られる結果を分析することを含む。試料集合に適用される分析の実施例は、注目する検体に対する較正曲線の作成、および未知のものには存在するが、コントロールには存在しない新しい種類の化合物の検出を含む。本発明の実施形態によるDASは、ここで説明される。
【0054】
図3A〜図3Cは、例示的なLC/MS実験で生成された3つのイオン(イオン1、イオン2、およびイオン3)に対する例示的なスペクトルを示す図である。イオン1、イオン2、およびイオン3に関連付けられているピークは、保持時間およびm/zの限られた範囲内に出現する。本発明の実施例では、イオン1、イオン2、イオン3の質量対電荷比は異なること、またイオンの親分子は、ほぼ同じだが、正確には同じでない保持時間に溶出されることが仮定される。その結果、それぞれの分子の溶出プロフィルは、重なるか、または共溶出となる。これらの仮定の下で、3つの分子すべてが、MSのイオン化源内に存在する時間がある。例えば、図3A〜図3Cに示されている例示的なスペクトルは、3つのイオンすべてが、MSイオン化源内に存在していたときに収集された。これは、それぞれのスペクトルが、イオン1、2、および3のそれぞれに関連付けられているピークを示すため明白である。図3A〜図3Cに示されている例示的なスペクトルからわかるように、スペクトルピークの重なりはない。重なりがないことは、この質量分析計はこれらのスペクトルピークを分離して検出したことを示している。イオン1、2、および3に対応するピークの頂点の配置は、その質量対電荷比を表している。
【0055】
スペクトル中のイオンが単一のスペクトルのみを使用して溶出する正確な保持時間、あるいは相対的保持時間すら決定することは可能でない。例えば、スペクトルBに対するデータが収集されたときに、イオン1、2、および3に関連付けられている3つの分子すべてがカラムから溶出していたことがわかる。しかし、スペクトルBのみを分析したのでは、イオン1、2、および3の溶出時間の間の関係を決定することは可能でない。そのため、スペクトルBは、分子がカラムから溶出し始めたときには、クロマトグラフピークの先頭に対応する時間に、または分子がほぼ溶出を終了したときには、クロマトグラフピークの終わりから、またはその間のある時点において、収集されている可能性がある。
【0056】
保持時間に関係するより正確な情報は、連続するスペクトルを調べることにより得られる。この付加情報は、溶出分子の保持時間または少なくとも溶出順序を含むことができる。例えば、図3A〜図3Cに示されているスペクトルA、B、およびCは、時間tAにスペクトルAが収集され、後の時間tBにスペクトルBが収集され、時間tBよりも後の時間である、時間tCにスペクトルCが収集されるように連続的に収集されたと仮定する。次いで、それぞれの分子の溶出順序は、tAからtCまで時間が進むときに連続的に収集されたスペクトル中に出現するピークの相対的高さを調べることにより決定されうる。このように調べることで、時間が進むにつれ、イオン2がイオン1に関して強度を減じること、またイオン3がイオン1に関して強度を増やすことがわかる。したがって、イオン2は、イオン1の前に溶出し、イオン3は、イオン1の後に溶出する。
【0057】
この溶出順序は、スペクトル中に見つかるそれぞれのピークに対応するクロマトグラムを生成することにより検証できる。これは、イオン1、2、および3に対応するピークのそれぞれの頂点でm/z値を得ることにより達成されうる。これら3つのm/z値が与えられると、DASは、それぞれの走査に対しそのm/zで得られた強度をそれぞれのスペクトルから抽出する。次いで、抽出された強度は、溶出時間に関してプロットされる。このようなプロットは、図4A〜図4Cに例示されている。図4A〜図4Cのプロットは、図3A〜図3Cのピークを調べることにより得られるm/z値におけるイオン1、2、および3に対するクロマトグラムを表していることがわかる。それぞれのクロマトグラムは、単一のピークを含む。図4A〜図4Cに例示されているようなイオン1、2、および3に対するクロマトグラムを調べることで、イオン2が最も早い時期に溶出し、イオン3が最も遅い時期に溶出することを確認する。図4A〜図4Cに示されているクロマトグラムのそれぞれにおける頂点配置は、それぞれのイオンに対応する分子の溶出時間を表す。
【0058】
この導入を念頭に置いて、本発明の実施形態は、スペクトルおよびクロマトグラムなどの実験分析出力を分析して、イオンを最適な形で検出し、検出されたイオンに関係するパラメータを定量化することに関係する。さらに、本発明の実施形態は、著しく簡素化されたスペクトルおよびクロマトグラムをもたらすことができる。
【0059】
図5は、スペクトルおよびクロマトグラムなどの実験分析出力を処理する流れ図500である。流れ図500は、上述のDASを含むさまざまな方法で具現化することができる。図5に例示されている本発明の実施形態では、分析は以下のように進行する。
ステップ502:クロマトグラフデータおよびスペクトルデータを有する二次元データ行列を作成する。
ステップ504:このデータ行列に適用する二次元畳み込みフィルタを指定する。
ステップ506:二次元畳み込みフィルタをデータ行列に適用する。例えば、データ行列は、二次元フィルタに畳み込むことができる。
ステップ508:二次元フィルタをデータ行列に適用した出力のピークを検出する。それぞれの検出されたピークは、イオンに対応するとみなされる。ピーク検出を最適化するために閾値化が使用できる。
ステップ510:それぞれの検出されたピークについてイオンパラメータを抽出する。パラメータは、保持時間、質量対電荷比、強度、スペクトル方向のピーク幅、および/またはクロマトグラフ方向のピーク幅などのイオン特性を含む。
ステップ512:抽出されたイオンに関連付けられているイオンパラメータをリストまたはテーブルに格納する。格納操作は、ピークが検出される毎に、または複数のもしくはすべてのピークが検出された後に実行できる。
ステップ514:抽出されたイオンパラメータを使用して、データの後処理を行う。例えば、データを簡約するためにイオンパラメータテーブルが使用可能である。このような簡約は、例えば、スペクトルまたはクロマトグラフィの複雑さを低減するようにウィンドウ操作を行うことにより実行できる。分子の特性は、この簡約されたデータから推論されうる。
【0060】
図6および図7は、流れ図500の前述のステップを記述する図解による流れ図である。図6は、本発明の一実施形態によりLC/MSデータを処理する方法の、図解による流れ図602である。より具体的には、図解による流れ図602のそれぞれの要素は、本発明の一実施形態によるステップの結果を示す。要素604は、本発明の一実施形態により作成された例示的なLC/MSデータ行列である。後述のように、LC/MSデータ行列は、連続する時間において収集されたLC/MSスペクトルをデータ行列の連続する列内に入れることにより作成されうる。要素606は、所望のフィルタ処理特性により指定されうる例示的な二次元畳み込みフィルタである。二次元フィルタを指定する際の考慮事項の詳細を以下で説明する。要素608は、本発明の一実施形態により、要素606の二次元フィルタを要素604のLC/MSデータ行列に適用することを表している。LC/MSデータ行列への二次元フィルタのそのような例示的な適用は、LC/MSデータ行列が二次元畳み込みフィルタに畳み込まれる二次元畳み込みである。フィルタ処理ステップの出力は、出力されたデータ行列であり、その実施例は、要素610として例示されている。データ行列へのフィルタの適用が、畳み込みを含む場合、出力は、出力される畳み込み行列である。
【0061】
要素612は、出力データ行列に対しピーク検出を実行してイオンに関連付けられているピークを同定または検出した結果を例示している。ピーク検出を最適化するために閾値化が使用できる。この時点で、イオンは、検出されたと考えられる。要素614は、検出されたイオンを使用して作成されるイオン特性の例示的なリストまたはテーブルである。
【0062】
図7は、本発明の一実施形態によるイオンパラメータテーブルをさらに集約するために検出閾値およびその適用を決定する結果を示す図解による流れ図702である。要素706は、イオンパラメータリストである要素704からアクセスされる例示的なピークデータを表す。要素706は、アクセスされたデータを使用して検出閾値を決定する結果を例示する。決定された閾値は、ステップ704のように生成されたイオンパラメータリストに適用され、編集済みのイオンパラメータリストを生成するが、この実施例はステップ708として例示されている。前述のステップは、ここで、さらに詳しく説明される。
【0063】
ステップ1:データ行列を作成する
LC/MS分析の出力を異なる一連のスペクトルおよびクロマトグラムと見るのではなく、LC/MS出力を強度のデータ行列として構成するのが有益である。本発明の一実施形態では、データ行列は、時間の経過とともに収集されたそれぞれの連続するスペクトルに関連付けられているデータをデータ行列の連続する列内に入れて、強度の二次元データ行列を形成することにより作成される。図8は、時間的に連続して収集された5つのスペクトルがデータ行列800の連続する列801−805内に格納されている例示的なそのようなデータ行列800を示している。スペクトルが、このようにして格納された場合、データ行列800の行は、格納されているスペクトル中の対応するm/z値におけるクロマトグラムを表す。これらのクロマトグラムは、データ行列800内の行811−815により示される。したがって、行列形式では、データ行列のそれぞれの列は、特定の時間に収集されたスペクトルを表し、それぞれの行は、固定されたm/zにおいて収集されたクロマトグラムを表す。データ行列のそれぞれの要素は、特定のm/z(対応するスペクトル中の)に対する特定の時間(対応するクロマトグラム中の)において収集された強度値である。本開示では、カラム指向のスペクトルデータと行指向のクロマトグラフデータを仮定しているけれども、本発明の代替え実施形態では、データ行列は、行がスペクトルを表し、列がクロマトグラムを表すように方向付けられる。
【0064】
図9は、スペクトルデータをデータ行列の連続する列内に格納することにより上述のように生成されたデータ行列の例示的な図解による表現(特に等高線図)である。図9に示されている等高線図では、イオン1、2、および3はそれぞれ、強度の島として表示されている。等高線図は、3つのイオンの存在を示すだけでなく、溶出順序がイオン2、続いてイオン1、続いてイオン3であることも明確に示している。図9は、さらに、3つの頂点902a、902b、および902cも示している。頂点902aは、イオン1に対応し、頂点902bは、イオン2に対応し、頂点902cは、イオン3に対応している。頂点902a、902b、および902cの配置は、それぞれイオン1、2、および3に対するm/zおよび保持時間に対応する。等高線図のゼロ値面よりも高い頂点の高さは、イオンの強度の尺度となる。単一のイオンに関連付けられているカウントまたは強度は、楕円領域つまり島の中に含まれる。m/z(列)方向のこの領域のFWHMは、スペクトル(質量)ピークのFWHMである。行(時間)方向のこの領域のFWHMは、クロマトグラフピークのFWHMである。
【0065】
島を形成する同心円状の等高線の一番内側は、最高の強度を有する要素を示す。この極大または最大要素は、最も近い隣接要素よりも大きな強度を有する。例えば、二次元データ等高線では、極大または頂点は、振幅が最も近い隣接要素よりも大きい任意の点である。本発明の一実施形態では、極大または頂点は、8個の最も近い隣接要素よりも大きくなければならない。例えば、表1では、中心要素は、極大であるが、それは8個の隣接する要素のそれぞれが10よりも小さな値を有するからである。
【表1】
【0066】
図9の等高線図に引かれた直線が6本ある。イオン1、イオン2、およびイオン3と標識が付けられた、3本の水平線は、図4A〜図4Cに示されているようにそれぞれイオン1、2、および3に対するクロマトグラムに対応する断面を識別する。A、B、およびCと標識が付けられた、3本の垂直線は、図3A〜図3Cに例示されているようにそれぞれ質量スペクトル3A、3B、および3Cに対応する断面を識別する。
【0067】
データ行列が作成された後、イオンが検出される。検出されたイオン毎に、保持時間、m/z、および強度などのイオンパラメータが得られる。データ行列にノイズが含まれず、イオンが互いに干渉し合わない(例えば、クロマトグラフ共溶出およびスペクトル干渉による)場合、それぞれのイオンは、図9の等高線図に例示されているように、強度の固有の孤立した島を形成する。
【0068】
図9に示されているように、それぞれの島は、単一の最大要素を含む。ノイズがない場合、本発明の一実施形態による共溶出または干渉、イオン検出、およびパラメータ定量化は、図10の流れ図1000に示されているように、以下の通りに進行する:
ステップ1001:データ行列を形成する
ステップ1002:データ行列内のそれぞれの要素の問い合わせを行う
ステップ1004:強度の極大であり、正値を有するすべての要素を識別する
ステップ1006:それぞれのそのような極大にイオンとして標識付けする
ステップ1008:イオンパラメータを抽出する
ステップ1010:イオンパラメータをテーブル形式にする
ステップ1012:イオンパラメータを後処理して、分子特性を得る。
【0069】
ステップ1008では、それぞれのイオンのパラメータは、最大要素を調べることにより得られる。イオンの保持時間は、最大要素を含む走査の時間である。イオンのm/zは、最大要素を含むチャネルに対するm/zである。イオンの強度は、最大要素それ自体の強度であるか、そうでなければ、強度は、最大要素の周囲にある要素の強度の総和とすることもできる。これらのパラメータの推定精度を高めるために、後述の補間技術が使用されうる。例えば、クロマトグラフおよびスペクトル方向のピークの幅を含む、二次的な観測可能パラメータも、決定されうる。
【0070】
ステップ2および3:フィルタの指定および適用
フィルタの必要性
LC/MS実験には、共溶出、干渉、またはノイズは、あるとしても、めったに存在しない。共溶出、干渉、またはノイズの存在は、イオンを正確に、また確実に検出する能力をひどく低下させる可能性がある。したがって、流れ図1000に例示されている単純な検出および定量化手順は、すべての状況において適しているわけではない。
【0071】
共溶出
図11は、ピーク幅が有限であることによる共溶出および干渉の効果を示す例示的な等高線図である。図11に示されている実施例において、他のイオン、つまりイオン4は、イオン1のと比べていくぶん大きいm/z値および保持時間値を有するとともに、イオン1の頂点のFWHM内にあるスペクトル方向とクロマトグラフ方向の両方で頂点を有すると仮定される。その結果、イオン4は、クロマトグラフ方向でイオン1と共溶出し、スペクトル方向でイオン1と干渉する。
【0072】
図12A〜図12Cは、図11の直線A、B、およびCにより示される時間におけるイオン4の共溶出によるスペクトル効果を示す。図12A〜図12Cに示されているそれぞれのスペクトルにおいて、イオン4は、イオン1に対する段部として現れる。これは、さらに、イオン4に関連付けられた明確に異なる頂点がないため、図11に示されている等高線図からも明らかである。
【0073】
そのため、LC/MSシステムにおける検出の問題の1つは、イオンの対が時間に関して共溶出し、スペクトルに関して干渉して、イオンの対が単一の極大値のみを形成し、2つの極大値を形成しないという点である。共溶出または干渉は、データ行列内で有意な強度を有する真のイオンが見逃される、つまり検出されないという状況を引き起こす可能性がある。イオンとしての真のピークのこのような見逃された検出は、偽陰性と呼ばれる。
【0074】
ノイズ
LC/MSシステムで発生するノイズは、典型的には、検出ノイズと化学的ノイズの2つのカテゴリに分けられる。検出器ノイズと化学的ノイズとが合わさって、イオンの検出および定量化が行われる際のベースラインとなる背景ノイズを定める。
【0075】
検出ノイズは、ショットノイズまたは熱雑音とも呼ばれ、すべての検出プロセスに固有のものである。例えば、MCPなどの計数検出器は、ショットノイズを付加し、電位計などの増幅器は、熱雑音またはジョンソンノイズを付加する。ショットノイズの統計量は、一般的に、ポアソン分布により記述される。ジョンソンノイズの統計量は、一般的に、ガウス分布により記述される。このような検出ノイズは、システムに固有のものであり、なくすことはできない。
【0076】
LC/MSシステムに生じる第2の種類のノイズは、化学的ノイズである。化学的ノイズは、複数の発生源から生じる。例えば、分離とイオン化のプロセスでうっかり捕捉してしまった小さな分子は、化学的ノイズを引き起こす可能性がある。このような分子は、一定量存在しうるものであり、それぞれ本質的に一定の背景強度を所定の質量対電荷比で発生するか、またはそれぞれのそのような分子は分離され、それにより特徴的な保持時間にクロマトグラフィプロファイルを形成することができる。化学的ノイズの他の発生源は、複合試料中に見られ、これは、濃度が広いダイナミックレンジで変化する分子と濃度が低いほど効果が著しく現れる干渉元素の両方を含みうる。
【0077】
図13は、ノイズの効果を示す例示的な等高線図である。図13では、化学的ノイズおよび検出器ノイズの効果をシミュレートするため、数値生成ノイズがイオンピーク等高線図に加えられている。図14Aは、図13の直線A、B、およびCにそれぞれ対応している質量スペクトル(スペクトルA、B、およびC)を例示しており、図14Bは、図13でイオン1、イオン2、およびイオン3とそれぞれ標識付けされている直線に対応するイオン1、2、3に対するクロマトグラムを例示している。図13からわかるように、追加ノイズの有害な効果の1つは、イオン1および2に関連付けられている公称頂点配置のFWHMの範囲内を含む、プロット全体にわたって頂点を出現させることである。これらのノイズに由来する頂点は、イオンに対応するピークとして誤って識別される可能性があり、したがってイオン検出が偽陽性となる。
【0078】
そのため、極大は、イオンではなくむしろノイズによるものと考えられる。その結果、偽ピーク、つまり、イオンに関連付けられていないピークが、1つのイオンとして数えられる可能性がある。さらに、ノイズは、1つのイオンに対し複数の多重極大値を発生する可能性もある。このような多重最大値があると、真のイオンを代表しないピークが検出される可能性がある。したがって、実際に複数のピークが単一のイオンにのみ起因する場合に、単一のイオンから得られるピークは、別々のイオンとして重複計数される可能性がある。このように偽ピークをイオンとして検出することは、偽陽性と呼ばれる。
【0079】
ノイズ効果を無視することに加えて、図10で説明されている単純なイオン検出アルゴリズムは、一般に統計的に最適ではない。これは、保持時間、m/z、および強度の推定値の分散が、単一の最大要素のノイズ特性により決定されるためである。簡素化されたアルゴリズムでは、最大要素の周囲にある強度の島の中の他の要素を使用しない。以下でさらに詳しく説明されるように、このような隣接要素は、推定値の分散を低減するために使用されうる。
【0080】
畳み込みの役割
本発明のいくつかの実施形態によれば、LC/MSデータ行列は、二次元配列である。このようなデータ行列は、これをフィルタ係数の二次元配列に畳み込むことにより処理されうる。
【0081】
本発明のいくつかの実施形態で使用される畳み込み演算は、従来のシステムで使用されている単純なシグナル加算平均方式に比べてピーク検出に対するより一般的で強力なアプローチであるといえる。本発明のいくつかの実施形態で使用される畳み込み演算は、図10で説明されている方法の制限を解消する。
【0082】
フィルタ係数は、複数の単一チャネルまたは走査を分析することで得られるものと比べて優れたシグナル対ノイズ比を有するイオンパラメータの推定値が得られるように選択できる。
【0083】
畳み込みフィルタ係数は、特定のデータ集合に対し最大の精度または最小の統計的分散を有するイオンパラメータの推定値を形成するように選択することができる。本発明のいくつかの実施形態のこれらの利点は、従来のシステムによるものと比べて、低濃度でイオンに対する再現性の高い結果をもたらすものである。
【0084】
本発明のいくつかの実施形態の他の利点は、共溶出され、干渉するイオンを分離して検出できるようにフィルタ係数が選択されうることである。例えば、質量スペクトル中で他のイオンに対する段部として出現するイオンの頂点は、本発明のいくつかの実施形態における適宜指定されたフィルタ係数を使用して検出できる。このような検出は、共溶出およびイオン干渉が共通の問題となっている、複合クロマトグラムを分析する際の従来の技術に付随する制限を解消する。
【0085】
本発明のいくつかの実施形態の他の利点は、ベースラインシグナルを差し引くようにフィルタ係数が選択され、これによりイオン強度のより正確な推定を行えるという点である。
【0086】
本発明のいくつかの実施形態の他の利点は、畳み込みの計算負荷を最小限に抑えるようにフィルタ係数が選択され、その結果ピーク検出およびイオンパラメータの推定を高速実行できるという点である。
【0087】
一般に、例えば、サビツキー−ゴーレイ(SG)平滑化および微分フィルタを含む、多数のフィルタ形状が、畳み込みにおいて使用できる。フィルタ形状は、平滑化、ピーク同定、ノイズ低減、およびベースライン低減を含む、多数の機能を実行するように選択されうる。本発明の好ましい実施形態で使用されるフィルタ形状は、以下で説明される。
【0088】
本発明における畳み込みの実装
本発明のいくつかの実施形態による畳み込み演算は、線形、非反復性で、データ行列内のデータの値に依存しない。本発明の一実施形態では、畳み込み演算は、コンピュータ118などの汎用コンピュータを使用し汎用プログラミング言語を用いて実装される。本発明の代替え実施形態では、畳み込み演算は、デジタルシグナルプロセッサ(DSP)と呼ばれる専用プロセッサで実装される。典型的には、DSPベースのフィルタリングでは、汎用コンピュータベースのフィルタリングに比べて処理速度が向上する。
【0089】
一般に、畳み込みは、2つの入力を組み合わせて、1つの出力を形成する。本発明のいくつかの実施形態では、二次元畳み込みを用いる。二次元畳み込み演算への入力の1つは、LC/MS実験のスペクトル出力から形成される強度のデータ行列である。二次元畳み込み演算への第2の入力は、フィルタ係数の行列である。畳み込み演算は、出力畳み込み行列を出力する。一般に、出力畳み込み行列は、入力されたLC/MS行列と同じ数の行および列の要素を有する。
【0090】
本発明の説明を簡単にするため、LC/MSデータ行列は、矩形であり、フィルタ係数の行列のサイズは、ピークのサイズに相当すると仮定する。この場合、フィルタ係数行列のサイズは、入力データ行列または出力畳み込み行列のサイズよりも小さい。
【0091】
出力行列の要素は、まずフィルタ行列が入力データ行列内の一要素を中心とするように構成され、次いで入力データ行列要素が、対応するフィルタ行列要素を乗算され、それらの積が総和され、出力畳み込みデータ行列の要素が形成されるというようにして入力LC/MSデータ行列から得られる。隣接要素を組み合わせることにより、畳み込みフィルタは、イオンの保持時間、質量対電荷比、および強度の推定値の分散を低減する。
【0092】
出力畳み込み行列のエッジ値は、出力畳み込み行列のエッジからフィルタ幅の半分までの範囲内にある要素である。一般に、これらの要素は、本発明のいくつかの実施形態における無効な値に設定され、無効なフィルタリング値であることを示しうる。一般に、これらのエッジ値を無視することは、本発明のいくつかの実施形態については有意な制限ではなく、これらの無効値は、その後の処理において無視できる。
【0093】
一次元畳み込み
一次元の場合の畳み込みは、詳細に明確に説明される。この説明の後に、畳み込みを二次元の場合に一般化する。本発明の好ましい実施形態で使用される二次元の畳み込み演算は、一連の一次元畳み込みをデータ行列に適用することにより実装されるため、まず一次元の場合を説明するのが得策である。
【0094】
一次元では、畳み込み演算は、以下のように定義される。強度diの一次元のN要素の入力配列と畳み込みフィルタ係数fjの一次元のM要素の配列が与えられた場合、畳み込み演算は
【数1】
で定義されるが、ただし、ciは、出力畳み込み配列であり、i=1,...,Nである。便宜上、Mは、奇数となるように選択される。インデックスjは、j=−h,...,0,...hであり、hは、h≡(M−1)/2で定義される。
【0095】
そのため、ciの値は、diの周囲のh個の要素の重み付き総和に対応する。スペクトルおよびクロマトグラムは、ピークを含む一次元入力配列の実施例である。畳み込みフィルタfjの幅は、ほぼピークの幅となるように設定される。したがって、Mは、ピークの幅をスパンとする配列要素の個数のオーダーである。ピークは、典型的には、入力配列の長さNよりもかなり小さい幅を有し、したがって一般には、M□Nである。
【0096】
diに対するインデックスiは、1からNまでの値をとるけれども、本発明のいくつかの実施形態では、ciは、エッジ効果に対応できるようにi>hまたはi≦(N−h)についてのみ定義される。配列境界付近にある、つまり、i≦hまたはi>(N−h)である場合のciに対する値は、総和については定義されない。そのようなエッジ効果は、ciに対する値を、i>hまたはi≦(N−h)となるように制限し、総和が定義されるようにすることにより取り扱うことができる。この場合、総和は、配列エッジから十分に遠いところにあるピークにのみ適用され、フィルタfjは、そのピークの近傍内にあるすべての点に適用できる。つまり、フィルタリングは、データ配列diのエッジでは実行されないということである。一般に、エッジ効果を無視することは、本発明の実施形態については有意な制限とならない。
【0097】
フィルタリングされた値が1<i<hまたはN≧i>(N−h)に対するエッジの付近で必要な場合、それらのエッジ要素についてデータ配列および/またはフィルタ係数のいずれかが修正されうる。データ行列は、h個の要素を配列のそれぞれの末尾に付加することにより修正することができ、またM個係数フィルタを、N+2h個の要素を含む配列に適用するとよい。
【0098】
それとは別に、エッジ効果は、エッジの付近のフィルタリングに対しM個未満の点があることに対応できるようにフィルタリング機能の限度を適宜修正することにより考慮されうる。
【0099】
二次元畳み込み
上述の一次元畳み込み演算は、本発明の実施形態で使用する二次元データの場合に一般化できる。二次元の場合、畳み込み演算への入力の1つは、i=1,...,Mおよびj=1,...,Nである2つのインデックス(i,j)を添え字とするデータ行列di,jである。入力データ行列のデータ値は、実験毎に異なることがある。畳み込みへの他の入力は、これもまた2つのインデックスを添え字とする固定フィルタ係数fp,qの集合である。フィルタ係数行列fp,qは、P×Q個の係数を有する行列である。変数hおよびlは、h≡(P−1)/2およびl≡(Q−1)/2と定義される。したがって、p=−h,...,hおよびq=−l,...,lである。
【0100】
di,jをfp,qに畳み込むと、出力畳み込み行列ci,j
【数2】
が得られる。
【0101】
一般に、フィルタのサイズは、データ行列のサイズに比べてかなり小さく、P<<MおよびQ<<Nとなる。上記の式は、ci,jが、fp,qの中心をdi,jの(i,j)番目の要素とし、次いでフィルタ係数fp,qを使用して周囲の強度の重み付き総和を求めることにより計算されることを示している。したがって、出力行列ci,jのそれぞれの要素は、di,jの要素の重み付き総和に対応し、それぞれの要素di,jは、i,j番目の要素を中心とする領域から得られる。
【0102】
di,jに対するインデックスiおよびjは、iは1からNまで、jは1からMまでの値をとるけれども、本発明のいくつかの実施形態では、ci,jは、エッジ効果に対応できるようにi≧hまたはi≦(N−h)およびj≧lまたはj≦(M−l)についてのみ定義される。配列境界付近にある、つまり、i<hまたはi>(N−h)および/またはj≧lまたはj≦(M−l)である場合のciに対する値は、総和については定義されない。そのようなエッジ効果は、ci,jに対する値を、総和が定義される値に制限することにより取り扱うことができる。この場合、総和は、配列エッジから十分に遠いところにあるピークにのみ適用され、フィルタfp,qは、そのピークの近傍内にあるすべての点に適用できる。つまり、フィルタリングは、データ配列di,jのエッジでは実行されないということである、一般に、エッジ効果を無視することは、本発明の実施形態については有意な制限とならない。
【0103】
フィルタリングされた値が1≦i<hおよびN≧i>(N−h)に対するエッジの付近で必要な場合、それらのエッジ要素についてデータ行列および/またはフィルタ係数行列のいずれかが修正されうる。アプローチの1つは、それぞれの行の末尾にh個の要素を付加し、それぞれの列の末尾にl個の要素を付加する。次いで、二次元畳み込みフィルタが、(N+2h)×(M+2l)個の要素を含むデータ行列に適用される。
【0104】
それとは別に、エッジ効果は、行エッジの付近のフィルタリングに対しP個未満の点があり、列エッジ付近のフィルタリングに対しQ個の点があることに対応できるようにフィルタリング機能の限度を適宜修正することにより考慮されうる。
【0105】
式(2)の実装に対する計算負荷は以下のように計算することができる。fp,qがP×Q個の係数を含んでいる場合、ci,jに対する値を計算するのに必要な乗算の回数は、P×Qである。例えば、P=20およびQ=20の場合、出力畳み込み行列中のそれぞれの出力点ci,jを決定するのに400回の乗算が必要であるという結果になる。これは、二次元畳み込みに対する他のアプローチで緩和できる高い計算負荷である。
【0106】
階数1のフィルタによる二次元畳み込み
式(2)で記述される二次元畳み込みフィルタは、P×Q個の独立に指定された係数を含むフィルタ行列を適用する。フィルタ係数を指定する他の方法がある。結果として得られる畳み込み係数は、自由に指定されるようなものではないけれども、計算負荷は緩和される。
【0107】
フィルタ係数を指定するそのような代替えの一方法は、階数1のフィルタとしてのものである。階数1の畳み込みフィルタを記述するには、LC/MSデータ行列に対する二次元畳み込みが、2つの一次元畳み込みを連続して適用することにより実現されうることを考慮する。例えば、参照により本明細書に組み込まれているJOHN H.KARL「INTRODUCTION TO DIGITAL SIGNAL PROCESSING」PG.320(ACADEMIC PRESS 1989)(“KARL”)を参照のこと。例えば、一次元フィルタgqは、LC/MSデータ行列のそれぞれの行に適用され、中間畳み込み行列を形成する。この中間畳み込み行列に対し、第2の一次元フィルタfpがそれぞれの列に適用される。それぞれの一次元フィルタは、異なるフィルタ係数の集合で指定できる。式(3)は、階数1の畳み込みフィルタを含むフィルタが連続してどのように適用されるかを示しており、そこでは、中間行列は括弧で囲まれている。
【数3】
【0108】
式(3)の実装に対する計算負荷は以下のように計算することができる。fpがP個の係数を含み、gqがQ個の係数を含んでいる場合、ci,jに対する値を計算するのに必要な乗算の回数は、P+Qである。例えば、P=20およびQ=20の場合、出力畳み込み行列中のそれぞれの出力点ci,jを決定するのに乗算は40回あればよい。これからわかるように、これは、それぞれのci,jを決定するのに20×20=400が必要である式(2)で記述される二次元畳み込みの一般的な場合よりも計算効率が高い。
【0109】
式(4)は、連続する演算が、要素が一次元フィルタの対毎の積である単一係数行列にデータ行列を畳み込むことと等価であることを例示する式(3)を整理し直したものである。式(4)を調べると、階数1の式を使用した場合、有効な二次元畳み込み行列は、2つの一次元畳み込みベクトルの外積により形成された階数1の行列であることがわかる。そこで、式(4)は、
【数4】
のように書き直すことができる。二次元係数行列Fpqは、畳み込み演算から得られる。Fpqは、階数1の行列の形式をとり、階数1の行列は、列ベクトル(ここではfp)と行ベクトル(ここではgq)の外積として定義される。例えば、参照により本明細書に組み込まれている、GILBERT STRANG「INTRODUCTION TO APPLIED MATHEMATICS」68FF(WELLESLEY−CAMBRIDGE PRESS 1986)(「STRANG」)を参照のこと。
【0110】
階数1のフィルタ実装を使用する本発明の実施形態では、階数1のフィルタは、フィルタ毎に1つずつ、2つの直交する断面により特徴付けられる。それぞれの直交する断面に対するフィルタは、一次元フィルタ配列により指定される。
【0111】
階数2のフィルタによる二次元畳み込み
二次元畳み込み演算は、階数2のフィルタにより実行されうる。階数2のフィルタによる二次元畳み込みは、2つの階数1のフィルタを計算し、その結果を足し合わせることにより実行される。したがって、本発明の実施形態で実行される二次元畳み込みに対する階数2のフィルタを実装するのに、4つのフィルタ
【数5】
および
【数6】
が必要である。
【0112】
2つのフィルタ、
【数7】
および
【数8】
は、第1の階数1のフィルタに関連付けられており、2つのフィルタ、
【数9】
および
【数10】
は、第2の階数1のフィルタに関連付けられている。これら4つのフィルタ
【数11】
および
【数12】
は、
【数13】
のように実装される。
【0113】
フィルタ
【数14】
および
【数15】
は、スペクトル方向(列にそって)で適用され、フィルタ
【数16】
および
【数17】
は、クロマトグラフ方向(行にそって)で適用される。式(7)は、中間行列が括弧で囲まれており、それぞれのフィルタ対がどのようにして連続的に適用されうるか、また2つの階数1のフィルタから得られる結果がどのように総和されるかを例示している。式(7)は、本発明の実施形態により階数2のフィルタを実装する好ましい方法を示している。
【0114】
式(8)は、階数2のフィルタ構成における連続する演算が、要素が2つの一次元フィルタ対の対毎の積の総和である単一係数行列にデータ行列を畳み込むことと等価であることを示すように式(7)を整理し直したものである。
【0115】
階数2のフィルタの計算要件を分析するために、
【数18】
と
【数19】
が両方ともP個の係数を含み、
【数20】
と
【数21】
が両方ともQ個の係数を含む場合に、出力畳み込み行列ci,jの要素に対する値を計算するために必要な乗算回数が2(P+Q)であることを考慮する。したがって、P=20およびQ=20の場合、出力畳み込み行列のそれぞれの要素を計算するのに乗算を80回行うだけでよいが、式(2)に示されているような一般の場合には、それぞれのci,jを計算するのに20×20=400回の乗算が必要になる。
【0116】
そこで、階数2のフィルタを使用する本発明の一実施形態では、有効な二次元畳み込み行列は、一次元ベクトルの2つの対の外積の総和から形成される。式(8)は、
【数22】
のように書き直すことができる。
【0117】
二次元係数行列Fpqは、畳み込み演算から得られる。二次元係数行列Fpqは、階数2の行列の形式をとり、階数2の行列は、STRANGで説明されているように2つの一次独立の階数1の行列の和として定義される。ここで、
【数23】
および
【数24】
は、それぞれ階数1の行列である。
【0118】
フィルタ指定
式(2)、(3)、および(7)は、すべて本発明の二次元畳み込みフィルタの実施形態である。式(2)では、フィルタ係数を行列fp,qとして指定し、式(3)では、フィルタ係数を2つの一次元フィルタfpおよびgqの集合として指定し、式(7)では、これらのフィルタを4つの一次元フィルタ
【数25】
および
【数26】
の集合として指定する。
【0119】
式(2)、(3)、および(7)は、これらの係数の好ましい値を指定しない。本発明に対するフィルタ係数の値は、図10の方法の制限を解消するように選択される。これらのフィルタ係数は、検出器および化学的ノイズの効果の低減、共溶出および干渉ピークの部分的分離検出、ベースラインノイズの差し引き、ならびに計算効率および高速演算の実現を含む複数の目標を達成するように選択される。
【0120】
整合フィルタ定理(MFT)は、式(2)を使用して実装することができるフィルタ係数を求めるための、従来技術において知られている規範的方法である。例えば、217のKARL、参照により本明細書に組み込まれているBRIAN D.O.ANDERSON & JOHN B.MOORE「OPTIMAL FILTERING」223ff (PRENTICE−HALL INC.1979)(「ANDERSON」)の223ffを参照のこと。MFTから得られたフィルタは、シグナルの存在を検出し、検出器ノイズの効果を低減するように設計されている。次いで、このようなフィルタは、LC/MSデータ行列でイオンを検出するために使用され、またイオンの保持時間、質量対電荷比、および強度を測定するために使用されうる。MFTから得られたフィルタは、図10の方法に勝る改善となっている。特に、このようなフィルタは、ピーク頂点の近傍内にあるピークの範囲内の要素から得られるデータを組み合わせることにより分散を低減し、精度を向上させる。しかし、このようなフィルタは、ベースラインノイズを差し引くか、または共溶出および干渉ピークを分離し検出するようには設計されていない。MFTから得られるフィルタは、高速演算を可能にするようには設計されていない。
【0121】
MFTおよびMFTから得られるフィルタ係数の集合は、図10の方法に対する改善となっていることが説明されており、次いでベースラインを差し引く修正済みフィルタは、共溶出および干渉の効果を低減するが、それでも検出器および化学的ノイズの効果を低減することが説明される。このようなフィルタは、平滑化フィルタと2階微分フィルタの組み合わせを使用しており、また式(3)および(7)を使用して実装される。好ましい実施形態では、式(7)を、ともにノイズを低減し、干渉ピークを分離検出し、ベースラインを差し引き、計算負荷を低減して高速演算に対応できるようにする平滑化フィルタと2階微分フィルタの組み合わせとともに使用する。
【0122】
一次元畳み込み用の整合フィルタ定理
一次元畳み込みについて最初にMFTが説明される。次いで、二次元畳み込みに一般化する。
【0123】
検出機能を実行するようにfjに対する係数が選択される。例えば、整合フィルタ定理(MFT)では、検出機能を実行するために使用されうる整合フィルタと呼ばれるフィルタ係数の集合を形成する。
【0124】
MFTでは、データ配列diが、シグナルr0siと追加ノイズniとの和
【数27】
としてモデル化されうると仮定する。シグナルの形状は、固定されており、係数siの集合として記述される。スケール係数r0が、シグナルの振幅を決定する。MFTは、さらに、このシグナルが有界であると仮定する。つまり、シグナルは、ある領域の外でゼロである(または無視できるくらい小さい)。シグナルは、M個の要素上に広がると仮定される。便宜上、Mは、典型的には、奇数になるように選択され、シグナルの中心は、s0に置かれる。hがh≡(M−1)/2と定義された場合、i<−hおよびi>hについてsi=0である。上記の式の中で、シグナルの中心は、i=i0のところに現れる。
【0125】
この記述を簡素化するために、ノイズ要素niは、平均値0、標準偏差σ0の無相関のガウス偏差であると仮定される。MFTに対するより一般的な定式化は、相関または有色雑音に適応している。例えば、ANDERSONの288−304を参照のこと。
【0126】
これらの仮定の下で、それぞれの要素のシグナル対ノイズ比(SNR)はr0si/σ0である。シグナルsiを含むデータの重み付き総和のSNRは、シグナルと一致するように中心を揃えた、重みwiのM要素集合を考えることにより決定されうるが、ただし、h≡(M−1)/2、およびi=−h,...,0,...hである。これらの重みはシグナルと一致するように中心を揃えられていると仮定すると、重み付き総和Sは、
【数28】
と定義される。
【0127】
集合平均におけるノイズ項の平均値は、ゼロである。したがって、それぞれの配列内のシグナルが同じであるが、ノイズは異なる配列の集合に対するSの平均値は、
【数29】
である。
【0128】
ノイズの寄与率を決定するために、ノイズのみを含む領域に重みが適用される。総和の集合平均は、ゼロである。集合平均に関する重み付き総和の標準偏差は、
【数30】
である。
【0129】
最後に、SNRは、
【数31】
と決定される。この結果は、重み付け係数wiの一般的な集合に対するものである。
【0130】
MFTは、SNRを最大化するwiに対する値を指定する。重み付け係数wiが、単位長のM次元ベクトルwの要素としてみなされる場合、つまり、重み付け係数が
【数32】
になるように正規化された場合、SNRは、ベクトルwがベクトルsと同じ方向を指している場合に最大化される。これらのベクトルは、それぞれの要素が互いに比例する場合、つまり、wi∝siの場合に同じ方向を指す。したがって、MFTは、重み付け関数がシグナルそれ自体の形状である場合に、重み付き総和が最高のシグナル対ノイズ比を有することを意味する。
【0131】
wiが、wi=siとなるように選択される場合、単位標準偏差を有するノイズに関して、SNRは、
【数33】
に低減される。SNRのこの定式化は、フィルタ係数がそのシグナルを中心とするときの重み付き総和のシグナル特性およびフィルタがノイズのみの領域内にあるときのノイズ特性に対応する。
【0132】
二次元畳み込み用の整合フィルタ定理
一次元の場合について上で説明されているMFTは、さらに、データの二次元配列内に埋め込まれた有界二次元シグナルの二次元の場合に一般化されうる。前述のように、データは、シグナルとノイズの和
【数34】
としてモデル化されると仮定されるが、ただし、シグナルSi,jは、範囲が制限され、またその中心は、振幅r0を持つ(i0,j0)に置かれる。それぞれのノイズ要素ni,jは、平均値0および標準偏差σ0の独立ガウス偏差である。
【0133】
シグナルSi,jを含むデータの重み付き総和のSNRを決定するために、重みwi,jのP×Q要素の集合を考えるが、ただし、i=−h,...,hおよびj=−l,...,lとなるようなh=(P−1)/2およびl=(Q−1)/2である。重みは、シグナルと一致するように中心を揃えられる。重み付き総和Sは
【数35】
である。
【0134】
この集合上のSの平均値は
【数36】
である。ノイズの標準偏差は
【数37】
であり、シグナル対ノイズ比は
【数38】
である。
【0135】
上述の一次元の場合のように、SNRは、重み付け関数の形状は、シグナルに比例するときに、つまり、wi,j∝si,jのときに最大化される。重み付き総和のシグナル特性は、フィルタ係数がそのシグナルを中心とする場合に対応し、重み付き総和のノイズ特性は、フィルタがノイズのみの領域内にある場合に対応する。
【0136】
整合フィルタは、隣接要素を最適な形で組み合わせることにより最大のシグナル対ノイズ比を得る。整合フィルタ係数を使用する畳み込みフィルタは、イオンの保持時間、質量対電荷比、および強度の推定値の分散を最小にする。
【0137】
一意的な最大値が得られることが保証される整合フィルタ
一般に、畳み込みを使用するシグナル検出は、データ配列にそってフィルタ係数を移動し、それぞれの点で重み付き総和を求めることにより進む。例えば、フィルタ係数が、MFTを満たす、つまりwi=siである場合(フィルタがシグナルに整合している)、データのノイズのみの領域において、出力の振幅は、ノイズによって決まる。フィルタがシグナルに重なると、振幅は増大し、フィルタがシグナルと時間的に揃ったときに一意的な最大値に達しなければならない。
【0138】
一次元ガウス整合フィルタ
一次元畳み込みに対する前述の技術の一実施例として、シグナルが単一イオンからの結果として得られる単一ピークである場合を考察する。ピーク(スペクトルまたはクロマトグラフ)は、幅が標準偏差σpで与えられるガウス分布としてモデル化されうるが、ただし、幅は試料要素の単位で測定される。次いで、シグナルは
【数39】
である。
【0139】
フィルタ境界は、±4σpに設定されると仮定する。整合フィルタ定理によれば、フィルタは、0を中心とし、±4σpを境界とするシグナル形状それ自体、つまり、ガウス型である。このような整合フィルタの係数は、
【数40】
により与えられる。
【0140】
さらに、システムが、標準偏差に従って4点をサンプリングすると仮定する。その結果、σp=4となり、したがって、i=−16,...,16であり、フィルタは、本発明の実施例では幅が33点となる。一次元のガウス整合フィルタ(GMF)では、畳み込み出力配列の最大シグナルは7.09r0であり、ノイズ振幅は2.66σ0である。整合フィルタを使用することに関連するSNRは、2.66(r0/σ0)である。
【0141】
一次元のボックスカーフィルタと対比されるガウス整合フィルタ
一次元についてGMFと単純ボックスカーフィルタとを対比する。ここでもまた、シグナルは、上述のガウス形状でモデル化されるピークであると仮定される。ボックスカーに対するフィルタ境界も、±4σpに設定されると仮定する。ボックスカーフィルタの係数は、
【数41】
により与えられる。ボックスカーフィルタの出力は、M個の点にわたる入力シグナルの平均値である(M=8σp+1)。
【0142】
ここでもまた、さらに、システムが標準偏差に従って4点をサンプリングし、したがって、ボックスカーフィルタの幅が33点であると仮定する。単位高さのガウスピークについては、ボックスカーフィルタを使用するピーク上の平均シグナルは、0.304r0であり、ノイズの標準偏差は
【数42】
である。ボックスカーフィルタを使用するSNRは、1.75(r0/σ0)である。
【0143】
したがって、ボックスカーに関するガウス整合フィルタのSNRは、2.66/1.75=1.52、またはボックスカーフィルタにより得られる値の50%以上高い。
【0144】
整合フィルタおよびボックスカーフィルタは両方とも線形である。これらのフィルタのいずれかをガウスピーク形状に畳み込むことで、固有の最大値を有する出力がもたらされる。したがって、本発明の実施形態の畳み込みにおいて、これらのフィルタのいずれかを使用できる。しかし、ガウスノイズの場合、極大値ではSNRが高いので、整合フィルタが好ましい。
【0145】
ガウスノイズおよびポアソンノイズ
ガウス整合フィルタは、ノイズがガウス分布に従う場合に最適なフィルタである。計数検出器では、ボックスカーフィルタは、ピークに関連付けられているすべてのカウントの単なる総和であるため最適なものとなる。ピークに関連付けられているすべてのカウントを総和するために、ボックスカーフィルタの幅は、そのピークの幅に関係していなければならない。典型的には、ボックスカーフィルタの幅は、ピークのFWHMの2から3倍である。
【0146】
二次元ガウス整合フィルタ
二次元畳み込みに対する整合フィルタ技術の一実施例として、シグナルが単一イオンからの結果として得られる単一ピークである場合を考察する。このピークは、スペクトル方向とクロマトグラフ方向の両方においてガウス分布としてモデル化されうる。スペクトル幅は、標準偏差σpにより与えられ、その幅は、試料要素の単位で測定され、クロマトグラフ幅は、標準偏差σqにより与えられ、その幅は、試料要素の単位で測定される。次いで、データ行列要素i0,j0を中心とするシグナルは、
【数43】
となる。
【0147】
フィルタ境界は、±4σpおよび±4σqに設定されると仮定する。整合フィルタ定理によれば、フィルタは、0を中心とし、±4σpおよび±4σqを境界とするシグナル形状それ自体、つまり、ガウス型である。このような整合フィルタの係数は、
【数44】
により与えられる。
【0148】
さらに、システムが、スペクトル方向とクロマトグラフ方向の両方について標準偏差に従って4点をサンプリングすると仮定する。その結果、σp=4およびσq=4となり、したがって、p=−16,...,16およびq=−16,...,16であり、フィルタは、本発明の実施例では33×33点である。二次元のガウス整合フィルタ(GMF)では、畳み込み出力行列の最大シグナルは50.3r0であり、ノイズ振幅は7.09σ0である。整合フィルタを使用することに関連するSNRは、7.09(r0/σ0)である。
【0149】
二次元畳み込みフィルタは、クロマトグラフ方向と質量分析方向の両方でLC/MSデータ行列に対しフィルタ演算を実行する。畳み込み演算の結果、出力畳み込み行列は、形状が一般に入力LC/MSデータ行列に関して広げられるか、または他の何らかの形で歪まされているピークを含む。特に、ガウス整合フィルタは、常に、入力ピークに関するクロマトグラフ方向とスペクトル方向の両方の方向に
【数45】
倍に広げられた出力畳み込み行列中にピークを生成する。
【0150】
一見すると、GMFにより行われる拡大は、保持時間、質量対電荷比、または強度のクリティカルパラメータの正確な推定にとって有害な場合があるように思われる。しかし、整合フィルタ定理は、二次元畳み込みが、結果として得られる頂点関連値がそのピークの保持時間、m/z、および強度の統計上最適な推定値をもたらすようにそのピークに関連付けられているすべてのスペクトル要素およびクロマトグラフ要素の有効な組み合わせを形成する保持時間、質量対電荷比、および強度結果を有する頂点値を生成することを示している。
【0151】
二次元のボックスカーフィルタと対比されるガウス整合フィルタ
二次元についてGMFと単純ボックスカーフィルタとを対比する。ここでもまた、シグナルは、上述のガウス形状でモデル化されるピークであると仮定される。ボックスカーに対するフィルタ境界も、±4σpに設定されると仮定する。ボックスカーフィルタの係数は、
【数46】
により与えられる。ボックスカーフィルタの出力は、M×N個の点にわたる入力シグナルの平均値である。
【0152】
ここでもまた、さらに、システムが標準偏差に従って4点をサンプリングし、したがって、ボックスカーフィルタの幅が33×33点であると仮定する。単位高さのガウスピークについては、ボックスカーフィルタを使用するピーク上の平均シグナルは、0.092r0であり、ノイズの標準偏差は0.303σ0である。ボックスカーフィルタを使用するSNRは、3.04(r0/σ0)である。
【0153】
したがって、ボックスカーに関するガウス整合フィルタのSNRは、7/3=2.3、またはボックスカーフィルタにより得られる値の2倍以上である。
【0154】
整合フィルタおよびボックスカーフィルタは両方とも線形である。これらのフィルタのいずれかをガウスピーク形状に畳み込むことで、固有の最大値を有する出力がもたらされる。したがって、本発明の実施形態の畳み込みにおいて、これらのフィルタのいずれかを使用できる。しかし、ガウスノイズの場合、極大値ではSNRが高いので、整合フィルタが好ましい。
【0155】
ガウスノイズおよびポアソンノイズ
二次元のガウス整合フィルタは、ノイズがガウス分布に従う場合に最適なフィルタである。計数検出器では、ボックスカーフィルタは、ピークに関連付けられているすべてのカウントの単なる総和であるため最適なものとなる。ピークに関連付けられているすべてのカウントを総和するために、ボックスカーフィルタの幅は、スペクトル方向およびクロマトグラフ方向でそのピークの幅に関係していなければならない。典型的には、ボックスカーフィルタの幅は、スペクトル方向およびクロマトグラフ方向の両方の方向でピークのそれぞれのFWHMの2から3倍である。
【0156】
LC/MSデータ行列におけるイオンの検出用のガウス整合フィルタ
ガウス整合フィルタについては、二次元畳み込みフィルタの指定(ステップ2)は、上述のようにガウスフィルタ係数fp,qである係数であり、次いで、これらのフィルタ係数を使用してフィルタの適用(ステップ3)が式(2)に従って行われる。ステップ2およびステップ3のこの実施形態では、イオンを検出し、保持時間、質量対電荷比、および強度を決定する方法を実現する。このような方法からの結果は、検出器ノイズの効果を低減し、また図10の方法に勝る改善となっている。
【0157】
整合フィルタでないフィルタ係数
シグナル形状に従うもの以外の線形重み付け係数も使用できる。このような係数から、可能な最高のSNRが得られない場合もあるが、他の釣り合いの取れる利点を有する場合がある。これらの利点は、共溶出および干渉ピークを部分的に分離する能力、ベースラインノイズの差し引き、および高速演算を可能にする計算効率を含む。ここでは、ガウス整合フィルタの制限を分析し、これらの制限を解消する線形フィルタ係数を説明する。
【0158】
ガウス整合フィルタの課題
ガウスピークについては、整合フィルタ定理(MFT)では、ガウス整合フィルタ(GMF)を他の畳み込みフィルタと比較したように最高のシグナル対ノイズ比を有する応答を持つフィルタとして指定する。しかし、ガウス整合フィルタ(GMF)は、すべての場合において最適であるわけではない。
【0159】
GMFの欠点の1つは、それぞれのイオンに対し幅広にされた、または拡大された出力ピークを生成することである。ピークの広がりを説明しやすくするために、正の値および標準の幅σsを有するシグナルが、正の値および標準の幅σfを有するフィルタに畳み込まれる場合、畳み込まれた出力の標準の幅が増大することはよく知られていることである。シグナルとフィルタ幅が直交する形で組み合わさり、
【数47】
の出力幅を形成する。GMFの場合、シグナルおよびフィルタの幅が等しいと、出力ピークは、入力ピークよりも約
【数48】
倍、つまり40%広い。
【0160】
ピークの広がりにより、小さなピークの頂点が大きなピークで隠蔽される可能性がある。このような隠蔽は、例えば、小さなピークが、時間的にほぼ共溶出され、質量対電荷比に関して大きなピークとほぼ同時に生じる場合に発生する可能性がある。このような共溶出を補正する一方法は、畳み込みフィルタの幅を低減することである。例えば、ガウス畳み込みフィルタの幅を半分にしても、生成する出力ピークは入力ピークよりも12%しか広くならない。しかし、ピーク幅は、整合していないため、SNRは、GMFを使用して得られるものに関して低減される。低減されたSNRの欠点は、ほぼ同時に生じるピークの対を検出する能力が高まるという利点で相殺される。
【0161】
GMFの他の欠点は、正の係数しか持たない点である。したがって、GMFは、それぞれのイオンの基礎をなすベースライン応答を保存する。正係数フィルタは、常に、頂点振幅が実際のピーク振幅と基礎をなすベースライン応答の和であるピークを生成する。このような背景ベースライン強度は、検出器ノイズとさらに他の低レベルのピーク、ときには化学的ノイズと呼ばれるピークと組み合わさることによるものである場合がある。
【0162】
振幅のより正確な尺度を得るために、ベースライン差し引き演算が典型的には使用される。このような演算は、典型的には、そのピークの周囲のベースライン応答を検出し、それらの応答をピーク中心に対し補間し、その応答をピーク値から差し引いてピーク強度の最適な推定値を得るために別のアルゴリズムを必要とする。
【0163】
それとは別に、ベースライン差し引きは、負の係数だけでなく正の係数も有するフィルタを指定することにより実行されうる。このようなフィルタは、逆畳み込みフィルタとも呼ばれ、データの2階微分を抽出するフィルタに形状が似ているフィルタ係数により実装される。このようなフィルタは、それぞれの検出されたイオンに対する単一の極大応答を生成するように構成できる。このようなフィルタの他の利点は、逆畳み込みの尺度を与える、つまり分離能向上をもたらすことである。したがって、このようなフィルタが元のデータ行列中に現れるピークの頂点を保存するだけでなく、元のデータの中では、独立した頂点としてではなく、段部としてしか見えないピークに対する頂点を形成することもできる。したがって、逆畳み込みフィルタは、共溶出および干渉にかかわる問題を解決することができる。
【0164】
GMFの第3の欠点は、これが、一般的に、出力畳み込み行列中のそれぞれのデータ点を計算するのに多数の乗算を必要とすることである。したがって、GMFを使用する畳み込みは、典型的には、他のフィルタを使用する畳み込みに比べて計算コストが高く、また長い計算時間を要する。後述のように、GMF以外のフィルタ指定は、本発明のいくつかの実施形態で使用されうる。
【0165】
2階微分フィルタの利点
シグナルの2階微分を抽出するフィルタは、本発明のいくつかの実施形態によりイオンを検出する際に特に有用である。これは、シグナルの2階微分が、シグナルの曲率の尺度だからであり、それはピークの最も顕著な特性である。一次元で考察されようと、二次元で考察されようと、それ以上の次元で考察されようと、ピークの頂点は、一般的に、最高の曲率の大きさを有するピークの点である。段付きのピークは、さらに、高い曲率の領域でも表される。その結果、曲率に対する応答性があるので、ピーク検出を高めるとともに、より大きな干渉ピークの背景に対し段付きピークの存在を検出する能力を向上させるために2階微分フィルタが使用されうる。
【0166】
ピークの頂点における2階微分は、負の値を有するが、それは、頂点におけるピークの曲率が最大限負だからである。本発明のいくつかの例示的な、制限のない実施形態では、逆2階微分フィルタを使用する。逆2階微分フィルタは、係数のすべてが−1を掛けられた2階微分フィルタである。逆2階微分フィルタの出力は、ピーク頂点において正である。断りのない限り、本発明のいくつかの実施例で参照されているすべての2階微分フィルタは、逆2階微分フィルタとみなされる。2階微分フィルタのすべてのプロットは、逆2階微分フィルタである。
【0167】
2階微分フィルタの定数または直線(0の曲率を有する)に対する応答は、ゼロである。したがって、2階微分フィルタは、ピークの基礎をなすベースライン応答に対しゼロの応答を有する。2階微分フィルタは、ピークの頂点における曲率に応答し、基礎となるベースラインには応答しない。そのため、2階微分フィルタは、実際に、ベースライン差し引きを実行する。図15は、クロマトグラフ方向とスペクトル方向のいずれかまたは両方において適用されうる例示的な2階微分フィルタの断面を示している。
【0168】
一次元の2階微分フィルタ
一次元の場合、2階微分フィルタは、平滑化フィルタよりも有利であるが、それは、頂点における2階微分フィルタの振幅が、基礎となるピークの振幅に比例するからである。さらに、ピークの2階微分は、ベースラインに応答しない。そこで、実質的に、2階微分フィルタは、ベースライン差し引きおよび補正の演算を自動的に実行する。
【0169】
2階微分フィルタの欠点は、ピーク頂点に関してノイズを増大させるという望ましくない効果を持つことがある点である。このノイズ増大効果は、データを事前平滑化するか、または2階微分フィルタの幅を増やすことにより緩和されうる。例えば、本発明の一実施形態では、2階微分畳み込みフィルタの幅が増大される。2階微分畳み込みフィルタの幅を増大すると、畳み込み時に入力データ行列内のデータを平滑化する能力が高まる。
【0170】
平滑化して2階微分を求めるためのサビツキー−ゴーレイフィルタ
データの単一チャネル(スペクトルまたはクロマトグラム)に対し、データを平滑化する(つまり、ノイズの効果を低減する)、またはデータを微分する従来の方法は、フィルタの適用によるものである。本発明の一実施形態では、平滑化または微分は、単一のスペクトルまたはクロマトグラムに対応するそのデータ配列を固定値フィルタ係数の集合に畳み込むことにより一次元データ配列に対し実行される。
例えば、よく知られている有限インパルス応答(FIR)フィルタは、平滑化および微分の演算を含むさまざまな演算を実行するように、適切な係数で指定されうる。例えば、KARLを参照のこと。好適な平滑化フィルタは、一般的に、対称的な釣鐘曲線を示し、すべて正値をとり、単一の最大値を有する。使用されうる例示的な平滑化フィルタは、ガウス形状、三角形状、放物形状、台形状、余弦波形状を有するフィルタを含み、それぞれ単一の最大値を有する形状として特徴付けられる。非対称の裾引き形状の曲線を有する平滑化フィルタも、本発明のいくつかの実施形態において使用できる。
【0171】
データの一次元配列を平滑化または微分するように指定されうるFIRフィルタのファミリは、よく知られているサビツキー−ゴーレイフィルタである。例えば、参照により本明細書に組み込まれているA.SAVITZKY & M.J.E.GOLAY「ANALYTICAL CHEMISTRY」VOL.36,PP.1627−1639を参照のこと。サビツキー−ゴーレイ(SG)多項式フィルタは、重み付き多項式形状の総和により指定される平滑化および微分フィルタの好適なファミリを形成する。このフィルタファミリ内の0次平滑化フィルタは、上部が平たい(ボックスカー)フィルタである。このフィルタファミリ内の2次平滑化フィルタは、単一の正の最大値を有する放物形である。このフィルタファミリ内で2階微分を得る2次フィルタは、単一の負の最大値を有し、平均値が0である放物形である。対応する逆2階微分SGフィルタは正の最大値を有する。
【0172】
アポダイズサビツキー−ゴーレイフィルタ
SGフィルタの修正により、本発明においてうまく動作する一群の平滑化および2階微分フィルタが得られる。これらの修正SGフィルタは、アポダイズサビツキー−ゴーレイ(ASG)フィルタと呼ばれる。アポダイゼーションという用語は、重み係数の配列をSGフィルタ係数の最小二乗微分に適用することにより得られるフィルタ係数を指す。重み係数は、アポダイゼーション関数である。本発明のいくつかの実施形態で使用されるASGフィルタでは、アポダイゼーション関数は、以下のソフトウェアコードによるコサインウィンドウ(COSINEWINDOWにより定められる)である。このアポダイゼーション関数は、ASG平滑化フィルタを構成するために重み付き最小二乗を介してボックスカーフィルタに適用され、またASG2階微分フィルタを構成するために2階微分SG二次多項式に適用される。ボックスカーフィルタおよび2階微分二次式は、それ自体、サビツキー−ゴーレイ多項式フィルタの実施例となっている。
【0173】
すべてのSGフィルタは、対応するアポダイズサビツキー−ゴーレイ(ASG)フィルタを持つ。ASGフィルタは、対応するSGフィルタと同じ基本フィルタ関数を構成するが、不要な高周波ノイズ成分が多く減衰される。アポダイゼーションは、SGフィルタの平滑化および微分特性を保存するが、その一方で高周波遮断特性を大いに改善している。特に、アポダイゼーションは、フィルタ境界においてSGフィルタ係数の鋭い遷移を除去し、それらを0への滑らかな遷移で置き換える。(これは、0への滑らかな遷移を強制するコサインアポダイゼーション関数である)。上述の高周波ノイズのせいで二重に数える危険性が減じるため、滑らかな裾は有利である。このようなASGフィルタの実施例は、コサイン平滑化フィルタおよびコサインアポダイズ二次多項式サビツキー−ゴーレイ2階微分フィルタを含む。
【0174】
本発明の好ましい実施形態では、これらの平滑化および2階微分ASGフィルタは、LC/MSデータ行列の列および行に適用されるように指定される。
【0175】
二次元畳み込みに対する階数1のフィルタの実施例
二次元畳み込みに対する階数1の定式化の適用例として、ガウス分布となるように式(3)の中のfpおよびgqを選択することが可能である。その結果として得られるFpqは、それぞれの行および列内においてガウス分布を有する。Fpqに対する値は、近いが、二次元GMFに対するfp,qとは同一でない。したがって、この特定の階数1の定式化では、GMFと同様に実行されるが、計算時間が短縮される。例えば、上記の実施例では、例えば、PおよびQが20に等しかった場合、階数1のフィルタの計算要件を使用することで計算負荷は、400/40=10分の1低減される。
【0176】
ガウス分布を持つようにfpおよびgqを選択することと、式(3)に従ってこれらのフィルタを適用することで、本発明によるステップ2およびステップ3の一実施形態が構成される。
【0177】
しかし、本発明の他の実施形態では、階数1のフィルタの次元毎に別々のフィルタを適用することができる。本発明の一実施形態では、例えば、fp(スペクトル方向で適用されるフィルタ)は、平滑化フィルタであり、gq(クロマトグラフ方向で適用されるフィルタ)は、2階微分フィルタである。このようなフィルタの組み合わせを用いることで、フィルタリングに典型的に関連する問題を克服する異なる階数1のフィルタ実装が指定されうる。例えば、階数1のフィルタを含むフィルタは、GMFに関連する前述の問題を解消するように指定できる。
【0178】
式3により実装される、前述の階数1のフィルタは、式2により実装されるGMFに比べて計算効率が高く、したがって高速である。さらに、指定されたフィルタの組み合わせにより、定量的作業に使用されうる線形のベースライン補正応答が得られる。
【0179】
さらに、このフィルタの組み合わせは、クロマトグラフ方向で融合したピークを鋭くするか、または部分的に逆畳み込みする。
【0180】
前述の利点を有する本発明のいくつかの実施形態で使用する例示的な階数1のフィルタは、対応する質量ピークのFWHMの約70%であるFWHMを有する余弦ASG平滑化フィルタである第1のフィルタfpおよび対応するクロマトグラフピークのFWHMの約70%であるゼロ交差幅を有するASG2階微分フィルタである第2のフィルタgqを含む。他のフィルタおよびフィルタの組み合わせは、本発明の他の実施形態における階数1のフィルタとして使用できる。
【0181】
図16Aは、LC/MSデータ行列の列に適用して中間行列を形成するために階数1のフィルタで使用する例示的な余弦ASG平滑化フィルタのスペクトル方向の断面を示している。図16Bは、生成された中間行列の行に適用される例示的なASG2階微分フィルタのクロマトグラフ方向の断面を示している。
【0182】
fpおよびgqのフィルタ関数は、逆にすることができる。つまり、fpを2階微分フィルタとし、gqを平滑化フィルタとすることができる。このような階数1のフィルタは、スペクトル方向で段付きピークの逆畳み込みを行い、クロマトグラフ方向で平滑化する。
【0183】
fpおよびgqは両方とも2階微分フィルタであってはならないことに留意されたい。fpとgqの両方が2階微分フィルタである場合に結果として得られる階数1の積行列は、イオンピークに畳み込まれたときに正の極大値を1個ではなく、全部で5個含む。4つの追加の正の頂点は、これらのフィルタに関連付けられている負のローブの積から生じるサイドローブである。したがって、フィルタのこの特定の組み合わせにより、提案されている方法に適ささない階数1のフィルタができあがる。
【0184】
後述の階数2の定式化では、スペクトル方向とクロマトグラフ方向の両方向で平滑化フィルタおよび2階微分フィルタの特性を有するフィルタを実装する。
【0185】
階数1の畳み込みフィルタを使用する本発明の実施形態のいくつかのフィルタ組み合わせが表2に説明されている。
【表2】
それぞれのフィルタ組み合わせは、ステップ2の一実施形態であり、それぞれ、階数1のフィルタとなって、式(3)を使用して適用され、それによりステップ3を使用する。他のフィルタおよびフィルタの組み合わせは、本発明の他の実施形態における階数1のフィルタとして使用できる。
【0186】
好ましい実施形態である二次元畳み込みに対する階数2のフィルタの実施例
階数2のフィルタは、2つの次元のそれぞれについて2つのフィルタの指定を必要とする。本発明の好ましい一実施形態では、計算効率のよい方法で上述のようにGMFに関連する問題を解消するために4つのフィルタが指定される。
【0187】
例えば、本発明の一実施形態では、第1の階数1のフィルタは、
【数49】
のようなスペクトル平滑化フィルタおよび
【数50】
のようなクロマトグラフ2階微分フィルタを含む。例示的なこのような平滑化フィルタは、余弦フィルタであり、そのFWHMは、対応する質量ピークのFWHMの約70%である。例示的なこのような2階微分フィルタは、ASG2階微分フィルタであり、そのゼロ交差幅は、対応するクロマトグラフピークのFWHMの約70%である。第2の階数1のフィルタは、
【数51】
のようなスペクトル2階微分フィルタおよび
【数52】
のようなクロマトグラフ平滑化フィルタを含む。例示的なこのような2階微分フィルタは、ASG2階微分フィルタであり、そのゼロ交差幅は、対応する質量ピークのFWHMの約70%である。例示的なこのような平滑化フィルタは、余弦フィルタであり、そのFWHMは、対応するクロマトグラフピークのFWHMの約70%である。他のフィルタおよびフィルタの組み合わせも、本発明のいくつかの実施形態において使用できる。このようなフィルタの断面は、それぞれ、図16C、図16D、図16E、および図16Fに例示されている。
【0188】
上述の階数2のフィルタは、GMFに勝るいくつかの利点を有する。これは、階数2のフィルタであるため、GMFよりも計算効率が高く、したがって、実行速度も速い。さらに、それぞれの断面は、係数の総和が0になる2階微分フィルタであるため、定量的作業に使用されうる線形のベースライン補正応答を構成し、またクロマトグラフ方向とスペクトル方向において融合するピークを鋭くするか、または部分的に逆畳み込みする。
【0189】
本発明の好ましい階数2のフィルタ実施形態では、列フィルタのそれぞれのフィルタ幅(係数の数に関する)は、スペクトルピーク幅に比例して設定され、複数の行フィルタのうちのそれぞれのフィルタのフィルタ幅(係数の数に関する)は、クロマトグラフピーク幅に比例して設定される。本発明の好ましい実施形態では、列フィルタの幅は、互いに等しくなるように、またスペクトルピークのFWHMに比例するように設定される。例えば、5つのチャネルのスペクトルピーク幅FWHMについて、フィルタ幅は、11点に設定されうるため、平滑化と2階微分の両方のスペクトルフィルタのフィルタ幅は、11点の同じ値に設定されることになる。同様に、好ましい実施形態では、行フィルタの幅は、互いに等しくなるように、またクロマトグラフピークのFWHMに比例するように設定される。例えば、5つのチャネルのクロマトグラフピーク幅FWHMについて、フィルタ幅は、11点に設定されうるため、平滑化と2階微分の両方のスペクトルフィルタのフィルタ幅は、11点の同じ値に設定されることになる。このようにしてフィルタ幅を選択することで、階数1のフィルタは、等しい次元を有する階数2のフィルタを含む。つまり、第1の階数1のフィルタが、次元M×Nを有する場合、第2の階数1のフィルタの次元も、次元M×Nを有する。階数2のフィルタは、等しい次元を有する階数1のフィルタで構成される必要はないこと、また好適な階数1のフィルタが加算され、これにより階数2のフィルタを形成することができることに留意されたい。
【0190】
階数1のフィルタが加算されることで、階数2のフィルタが構成され、したがって、フィルタは、総和の前に相対的な意味で正規化されなければならない。好ましい実施形態では、第1の階数1のフィルタは、スペクトル方向において平滑化フィルタであり、クロマトグラフ方向で2階微分フィルタである。このフィルタが、第2の階数1のフィルタよりも大きな重みを付けられた場合、組み合わせたフィルタは、スペクトル方向の平滑化ならびにクロマトグラフ方向のピークのベースライン差し引きおよび逆畳み込みをより重要視したものとなる。そのため、2つの階数1のフィルタの相対的正規化が、クロマトグラフ方向およびスペクトル方向の平滑化および微分の相対的重要視を決定する。
【0191】
例えば、2つの階数1のフィルタ
【数53】
を考察するが、ただし、式(11)は、第1の階数1のフィルタであり、式(12)は、第2の階数1のフィルタである。本発明の好ましい一実施形態では、それぞれの階数1のフィルタは、その係数の二乗の総和が1に等しくなるように正規化される。この正規化では、平滑化および微分に対する等しい重みをスペクトル方向およびクロマトグラフ方向に与える。つまり、それぞれM×Nの次元を有する階数1のフィルタに対し、
【数54】
となる。
【0192】
好ましい実施形態の平滑化フィルタおよび2階微分フィルタは、適切なスケーリング係数をそれぞれの階数1の行列の係数に適用することによりこの基準を満たすように正規化されうる。
【0193】
さらに、好ましい実施形態では、それぞれの階数1のフィルタの行次元は、同じであり、それぞれの階数1のフィルタの列次元は、同じである。その結果、
【数55】
のように階数2の畳み込みフィルタの点源を得るために、これらの係数が加算されうる。式(13)から、二次元畳み込みフィルタFp,qを決定するためには、2つの階数1のフィルタの相対的正規化が必要であることがわかる。
【0194】
二次元畳み込みフィルタの好ましい実施形態に対するフィルタ係数
例示的な階数2のフィルタが、図17A〜図17Kに関して説明されている。このフィルタは、イオンを検出し、ベースライン応答を差し引き、融合したピークを部分的に分離し、高い計算効率で実行するために使用されうるステップ2およびステップ3の一実施形態である。
【0195】
特に、この階数2のフィルタは、段付きピークを検出するために有用である。本発明のいくつかの実施形態による階数2のフィルタは、クロマトグラフ方向およびスペクトル方向の両方の2階微分フィルタを含むことができる。曲率に対する2階微分フィルタの応答性から、このような階数2のフィルタは、段付きピークの頂点がデータ中で明らかでない場合のある段付きピークを検出することができる。階数2のフィルタが曲率を測定する2階微分フィルタを含むとした場合、データ中には直接的には見られない第2のピークの頂点が、出力畳み込み行列内の別の頂点として検出されうる。
【0196】
図17Aは、LC/MSデータ中に生成されうるシミュレートされたピークのグラフ表現であり、水平軸は、図に示されているように走査時間およびm/zチャネルを表し、垂直軸は、強度を表す。図17Bは、本発明の好ましい実施形態により、階数2のフィルタに対応する畳み込みフィルタ行列を示している。
【0197】
このシミュレーションでは、すべてのイオンのスペクトルピーク幅およびクロマトグラフピーク幅は、8点、FWHMである。4つすべてのフィルタに対するフィルタ係数の数は、15点である。
【0198】
図17Cは、同じ質量を有し、ほぼ同時であるが、まったく同時というわけではない2つのLC/MSピークのシミュレーションを示している。図17Dは、ピーク断面が質量の純粋なピークであることを例示しており、図17Eは、ピーク断面が時間的な段部1704を示すことを例示している。図17F〜図17Hは、図17D〜図17Eに例示されている段付きピークを含むそれぞれのサンプリングされた要素に対するシミュレートされた計数(ショットノイズ)の効果を例示している。図17Gおよび図17Hは、計数ノイズが加えられたことで生じる断面を例示している。図17Gと図17Hの両方からわかるように、計数ノイズの結果として多数の極大値が発生する。したがって、2個のイオンのみが存在するとしても、計数ノイズは、偽陽性イオン検出を引き起こす可能性のある多数のスプリアス極大値を発生しうることがわかる。
【0199】
図17I〜図17Kは、階数2のフィルタをシミュレートされたデータに畳み込んだ結果を例示している。結果として得られる出力畳み込み行列(図17Iの等高線図により表される)は、2つの異なるピーク1702および1706を含む。ピーク1702は、2個のイオンのうち強度の高いほうに関連付けられたピークであり、ピーク1706は、強度の低い段付きイオンのピークである。図17Jは、スペクトル(質量対電荷比)方向の出力畳み込み行列の断面である。図17Kは、クロマトグラフ(時間)方向の出力畳み込み行列の断面である。
【0200】
図17I〜図17Kを検討することにより観察されることは、本発明の階数2のフィルタベースの実施形態が、計数ノイズの効果を低減し、段付きピークを逆畳み込みして、複数の極大値を形成することである。それぞれの極大値は、1つのイオンに関連付けられる。その結果、本発明のこの実施形態は、さらに偽陽性率を下げる。イオンパラメータ、m/z、保持時間、および強度は、上述のように検出された極大値を分析することにより得られる。
【0201】
単一の極大値を生成する場合にフィルタが使用可能
上述のフィルタおよび畳み込み方法は、LC/MSデータ行列内のイオンを検出するために使用できる。フィルタ係数の他の集合も、ステップ2の実施形態として選択されうる。
【0202】
入力シグナルは、一意の最大値を有するLC/MSデータ行列内のピークであり、したがって、ステップ2の畳み込みフィルタは、畳み込みプロセスを通してその一意の正の最大値を忠実に維持しなければならない。ステップ2の実施形態であるために畳み込みフィルタが満たさなければならない一般的な要件は、一意の最大値を有する入力に畳み込んだときに一意の最大値を生成する出力を畳み込みフィルタが有していなければならないということである。
【0203】
釣鐘型応答を有するイオンの場合、この条件は、単一の正の最大値を有し、すべて釣鐘形である断面を持つ畳み込みフィルタにより満たされる。このようなフィルタの実施例は、逆放物形状フィルタ、三角形状フィルタ、および余弦フィルタを含む。特に、一意の正値頂点を有するという特性を持つ畳み込みフィルタでは、そのフィルタが本発明のいくつかの実施形態で使用するのに適した候補フィルタとなる。フィルタ係数の等高線図を使用することで、極大値の個数と配置を調べることができる。フィルタを通る行、列、および対角線上のすべての断面は、単一の正の極大値を有していなければならない。多くのフィルタ形状が、この条件を満たしており、したがって、本発明のいくつかの実施形態で使用できる。
【0204】
単一の極大値を生成するのでボックスカーが使用可能
許容可能な他のフィルタ形状は、定数値を有するフィルタ(つまり、ボックスカーフィルタ)である。これは、ピークをボックスカーフィルタに畳み込む演算が、単一の最大値を有する出力を生成するからである。本発明のいくつかの実施形態において有利なボックスカーフィルタのよく知られている特性は、そのような形状が、与えられた数のフィルタ点について最小の分散を生じることである。ボックスカーフィルタの他の利点は、一般にガウスまたは余弦フィルタなどの他の形状を有するフィルタに比べて少ない乗算回数で実装できる点である。
【0205】
ボックスカーの次元は、スペクトル方向およびクロマトグラフ方向の両方のピークの広がりと一致すべきである。ボックスカーが小さすぎると、ピークに関連するすべてのカウントが総和されることがない。ボックスカーが大きすぎると、他の隣接するピークからのカウントが含まれることがある。
【0206】
しかし、ボックスカーフィルタは、さらに、本発明が適用されうるいくつかの用途に対しては際だった不利点を有する。例えば、ボックスカーフィルタの伝達関数は、それらのフィルタが高周波ノイズを通過させることを示している。このようなノイズは、本発明のいくつかの用途では望ましくないと思われる、低振幅シグナル(低SNR)に対するピークを二重に数える危険性を増大する可能性がある。したがって、ボックスカー形状以外のフィルタ形状は、本発明の用途では一般的に好ましい。
【0207】
2階微分フィルタは単一の極大値を生成することができる
一意の最大値を有する入力に畳み込んだときに一意の最大値を生成する出力を有する他の好適な畳み込みフィルタ群は、単一の正の極大値を有し、負のサイドローブを持つフィルタである。このようなフィルタの実施例は、曲率に対し応答性のある2階微分フィルタを含む。平滑化フィルタから平均値を差し引くことにより、好適な2階微分フィルタが指定されうる。このようなフィルタは、ボックスカー、三角形状、および台形状の組み合わせから組み立てることが可能であるが、データを微分するフィルタの最も一般的な指定は、サビツキー−ゴーレイ多項式フィルタである。
【0208】
ガウスノイズおよびポアソンノイズ
ガウス整合フィルタは、ノイズがガウス分布に従う場合に最適なフィルタである。計数検出器からのノイズは、ポアソン分布を有する。ポアソンノイズの場合、ボックスカーがピークに関連付けられているすべてのカウントを単純に総和するだけなので、ボックスカーフィルタは検出で使用するのに最適なフィルタと言ってよい。しかし、GMFについて説明されている制限の多くは、ポアソンノイズの場合であってもボックスカーフィルタにそのまま適用される。ボックスカーフィルタは、ベースラインノイズを差し引くことができず、また干渉および共溶出ピークを分離し検出することができない。それに加えて、ボックスカーフィルタの伝達関数では、ピーク頂点について二重に数える可能性がある。
【0209】
好ましい実施形態の階数2のフィルタは、ガウスノイズおよびポアソンノイズの両方の場合についてSNRの妥協の産物である。この階数2のフィルタは、重なり合うピークのベースライン差し引きと部分的分離の利点を有する。
【0210】
フィルタ係数を決定する際のピーク幅の役割
本発明の実施形態では、入力行列Dに畳み込まれる畳み込みフィルタFの係数は、1つのイオンに対応するピークの典型的な形状および幅に対応するように選択される。例えば、フィルタFの中心の行の断面は、クロマトグラフピーク形状と一致し、フィルタFの中心の列の断面は、スペクトルピーク形状と一致する。畳み込みフィルタの幅は、ピークのFWHMに一致させることができるけれども(時間と質量対電荷比)、このような幅の一致は必要ないことに留意されたい。
【0211】
イオン強度の解釈とフィルタ係数のスケーリング
本発明では、強度測定推定値は、極大値におけるフィルタ出力の応答である。LC/MSデータ行列が畳み込まれるフィルタ係数の集合は、強度のスケーリングを決定する。フィルタ係数の集合が異なれば、強度スケーリングも異なり、本発明の強度のこの推定値は、必ずしもピーク面積またはピーク高さに正確に対応しない。
【0212】
しかし、強度測定値は、畳み込み演算が強度測定値の一次結合であるため、ピーク面積またはピーク高さに比例する。したがって、極大値におけるフィルタ出力の応答は、そのイオンを生じさせる試料中の分子の濃度に比例する。次いで、極大値におけるフィルタ出力の応答は、イオンの応答のピークの面積または高さと同じようにして試料中の分子の定量的測定のために使用されうる。
【0213】
フィルタの矛盾のない集合が、標準、キャリブレータ、および試料の強度を決定するために使用されると仮定すると、結果として得られる強度測定値は、強度スケーリングに関係なく正確で定量可能な結果をもたらす。例えば、本発明の実施形態により生成される強度は、検体の濃度を決定するためにその後使用されうる濃度較正曲線を定めるのに使用できる。
【0214】
非対称ピーク形状
上記の実施例は、スペクトル方向とクロマトグラフ方向のイオンのピーク形状がガウス型であり、したがって対称的であると仮定している。一般に、ピーク形状は、対称的ではない。非対称ピーク形状のよくある実施例は、裾を引いたガウス分布であり、階段指数型に畳み込まれたガウス型である。ここで説明されている方法は、非対称であるピーク形状にそのまま適用される。対称フィルタが非対称ピークに適用される場合、出力畳み込み行列中の頂点の配置は、一般的に、非対称ピークの頂点配置に正確に対応するわけではない。しかし、ピーク非対称(クロマトグラフ方向またはスペクトル方向のいずれか)に由来するオフセットは、実質的に、定数オフセットとなる。このようなオフセットは、従来の質量分析較正により、また内部標準を使用する保持時間較正により容易に補正される。
【0215】
整合フィルタ定理によれば、非対称ピークの検出に対する最適な形状は、非対称ピーク形状それ自体である。しかし、対称フィルタの幅が、非対称ピークの幅と一致すると仮定すると、対称フィルタと整合非対称フィルタとの間の検出効率の差は、本発明の目的に関しては最小となる。
【0216】
データを補間し、オフセットするようにフィルタ係数を変更する
係数修正の他の使い途は、質量分析計の較正による小さな変化に対応するように補間することである。このような係数修正は、スペクトル毎に発生しうる。例えば、質量較正の変化が、チャネルの一部を0.3だけオフセットする場合、そのような質量オフセットがない場合に出力がどうなるかを推定する列フィルタ(平滑化および2階微分の両方)が導出されうる。このようにして、リアルタイムの質量補正を行うことができる。典型的には、結果として得られるフィルタはわずかに非対称である。
【0217】
動的フィルタリング
フィルタ幅スケーリングなどのフィルタ特性は、LC分離またはMS走査の知られている変化特性に応じて変化しうる。例えば、TOF質量分析計では、ピーク幅(FWHM)は、それぞれの走査の過程で低い値(0.010amuなど)から広い値(0.130amuなど)まで変化することが知られている。本発明の好ましい一実施形態では、平滑化フィルタおよび微分フィルタの係数の個数は、スペクトルピークのFWHMの約2倍に等しくなるように設定される。MS走査が、例えば、低質量から高質量まで進行するにつれ、好ましい実施形態により使用される平滑化および2階微分の両方の列フィルタのフィルタ幅は、フィルタ幅とピーク幅との関係を保存するようにしかるべく拡大されうる。同様に、クロマトグラフピークの幅が、分離時に変化することが知られている場合、行フィルタの幅は、フィルタ幅とピーク幅との関係を保存するように拡大または縮小されうる。
【0218】
階数1および階数2のフィルタのリアルタイムの実施形態
従来のLC/MSシステムでは、分離が進むとともにスペクトルが収集される。典型的には、スペクトルは、一定のサンプリングレート(例えば、1秒に1回の割合)でコンピュータのメモリ内に書き込まれる。1つまたは複数の完全なスペクトルが収集された後、これらは、ハードディスクメモリなどのより永続的な記憶装置に書き込まれる。このような後収集処理も、本発明の実施形態において実行できる。したがって、本発明の一実施形態では、畳み込み行列は、収集が完了した後にしか生成されない。本発明のこのような一実施形態では、オリジナルのデータと畳み込み行列それ自体は、検出された極大値の分析から得られたイオンパラメータリストのように格納される。
【0219】
それに加えて、階数1および階数2のフィルタを使用する本発明の実施形態は、リアルタイムで動作するように構成されうる。本発明のリアルタイムの実施形態では、畳み込み行列の列は、データの収集中に形成される。そのため、初期列(スペクトルに対応する)は、すべてのスペクトルの収集が完了する前に、形成され、分析され、そのイオンパラメータをディスクに書き込むようにできる。
【0220】
本発明のこのリアルタイムの実施形態では、本質的に、コンピュータのメモリ内にあるデータを分析し、イオンパラメータリストのみを永続的なハードディスクドライブに書き込む。この文脈において、リアルタイムとは、階数1および階数2のフィルタリングが、データが収集されるのと同時にコンピュータメモリ内のスペクトルに対し実行されることである。したがって、分離の始めにLC/MSにより検出されたイオンは、ディスクに書き込まれたスペクトル内で検出され、それらのイオンに関連付けられたパラメータを含むイオンパラメータリストの部分も、分離の進行とともにディスクに書き込まれる。
【0221】
典型的には、リアルタイム処理を開始することに関連する時間の遅延が生じる。時間t、および幅Δtにおけるクロマトグラフピークで溶出するイオンを含むスペクトルは、収集されるとすぐに処理されうる。典型的には、リアルタイム処理は、時間t+3Δtにおいて、つまり、3つのスペクトルが最初に収集された後に開始する。次いで、クロマトグラフピークの分析により決定されたイオンパラメータが、コンピュータのディスクなどの永続的記憶装置内に作成され、格納されているイオンパラメータリストに追記される。リアルタイム処理は、上述の技術により進行する。
【0222】
リアルタイム処理の利点としては、(1)イオンパラメータリストを素早く取得できること、(2)イオンパラメータリスト内の情報に基づきリアルタイムプロセスをトリガすることが挙げられる。このようなリアルタイムプロセスは、分析のため溶離液を貯蔵するための分別捕集および停流技術を含む。例示的なこのような停流技術では、溶離液を核磁気共鳴(NMR)スペクトル検出器において捕捉する。
【0223】
図18は、本発明の好ましい一実施形態によるリアルタイム処理の方法を例示する流れ図1800である。この方法は、例えば、DSPベースの設計におけるハードウェア、または上述のDASなどにおけるソフトウェアで実行できる。以下の説明に基づきこのようなハードウェアまたはソフトウェアを構成する方法は、当業者にとっては明らかなものであろう。説明を簡単にするため、この方法は、DAS実行ソフトウェアにより実行される場合として説明される。図19A〜図19Bは、スペクトルバッファ1902、クロマトグラフバッファ1906、および頂点バッファ1910、さらに流れ図1800に例示されている方法を実行する際にどのように操作されるかも示している。
【0224】
DASは、次のスペクトル要素を受け取ることでステップ1802の方法を開始する。図19A〜図19Bにおいて、これらのスペクトル要素は、S1、S2、S3、S4、およびS5として示され、それぞれ、時間T1、T2、T3、T4、およびT5で受け取るスペクトル要素に対応する。ステップ1804で、DASは、受け取ったスペクトル要素が0であるかそうでないかを判定する。受け取ったスペクトル要素が0であれば、DASは、次のスペクトル要素を受け取ることでステップ1802の方法を続行する。スペクトル要素が0でなければ、スペクトルフィルタ1904の係数をスケーリングするために、その強度が使用される。図19A〜図19Bに示されている実施例では、スペクトルフィルタ1904は、フィルタ係数F1、F2、およびF3を有する3要素フィルタである。スケーリングは、それぞれのフィルタ係数に受け取ったスペクトル要素の強度を乗算することによりなされる。
【0225】
ステップ1808で、スケーリングされたスペクトルフィルタ係数が、スペクトルバッファに追加される。スペクトルバッファは、1つの配列である。スペクトルバッファ内の要素の個数は、それぞれのスペクトル内の要素の個数に等しい。
【0226】
総和を実行するために、フィルタ1904は、受け取ったスペクトル要素に対応するスペクトルバッファの要素が、フィルタ1904の中心に揃うように位置を揃えられる。したがって、時間T1において、スペクトル要素S1が受け取られると、フィルタ1904の中心F2は、スペクトルバッファの要素1902aに揃えられ、時間T2において、スペクトル要素S2が受け取られると、フィルタ1904の中心F2は、スペクトルバッファ要素1902bに揃えられ、というように続く。これらのステップは、図19A〜図19Bに例示されており、そこでは、フィルタ係数F1、F2、およびF3のスケーリング、およびスペクトルバッファ1902への追加が、時間T1、T2、T3、T4、およびT5に対して例示されており、これは、本発明の実施例では、スペクトルバッファ1902を埋めるのに十分なスペクトル要素を受け取るのに要する時間である。その結果得られるスケーリングされた総和も、図19A〜図19Bのスペクトルバッファ要素において示されている。
【0227】
ステップ1810で、DASは、スペクトルバッファがいっぱいになっているかどうか、つまり、受け取って処理されたスペクトル要素の個数が、スペクトルフィルタ内の要素の個数と同じであるかどうかを判定する。同じでなければ、DASは、次のスペクトル要素を待つことでステップ1802の方法を続行する。スペクトルバッファがいっぱいである場合、DASは、ステップ1812の方法を続行する。
【0228】
ステップ1812で、DASは、新しいスペクトルをクロマトグラフバッファ1906に移動する。クロマトグラフバッファ1906は、Nスペクトルを含むが、ただし、Nは、クロマトグラフバッファ内の係数の個数である。本発明の実施例では、Nは3である。クロマトグラフバッファ1906は、先入れ後出し(FILO)バッファとして構成される。したがって、新しいスペクトルが追加されると、最も古いスペクトルが削除される。ステップ1812で新しいスペクトルが追加されると、最も古いスペクトルが破棄される。ステップ1814で、DASは、クロマトグラフフィルタ1907をクロマトグラフバッファ1906のそれぞれの行に適用する。フィルタを適用した後、中央の列1908は、出力畳み込み行列の単一列畳み込みスペクトルに対応する。ステップ1816で、DASは、畳み込みスペクトルを頂点バッファ1910に移動する。
【0229】
本発明の一実施形態では、頂点バッファ1910は、幅が3スペクトル分ある、つまり、頂点バッファ1910は、3つの列スペクトルを含む。スペクトル列のそれぞれが、好ましくは、完全なスペクトルの長さを有する。頂点バッファ1910は、FILOバッファである。したがって、ステップ1816で、クロマトグラフバッファ1906からの新しい列が頂点バッファ1910に追記されると、最も古い列スペクトルが破棄される。
【0230】
後述のようなピーク検出アルゴリズムは、頂点バッファ1910の中央の列1912に対し実行されうる。最も近い隣接要素の値を使用することによりピークおよびイオンパラメータの分析をより正確に行うために、中央の列1912が使用される。これらのピークを分析することにより、DASは、ステップ1820でイオンパラメータ(保持時間、m/z、および強度など)を抽出してイオンパラメータリストに格納することができる。さらに、スペクトルピーク幅情報も、列にそって極大値に隣接する点を調べることにより得られる。
【0231】
頂点バッファ1910は、さらに、3スペクトルを超える幅に拡大できる。例えば、クロマトグラフピーク幅を測定するには、頂点バッファを、クロマトグラフピークのFWHMに少なくとも等しい数のスペクトルを含むように、例えば、クロマトグラフピークのFWHMの2倍に拡大する必要がある。
【0232】
本発明のリアルタイムの実施形態では、オリジナルのスペクトルを記録する必要はない。フィルタリングされたスペクトルのみが記録される。したがって、本発明のリアルタイムの実施形態の大容量記憶装置の必要性は減じられる。しかし、一般的に、本発明のリアルタイムの実施形態には、記憶メモリ、例えば、RAMを追加する必要がある。本発明の階数1のフィルタに基づくリアルタイムの実施形態に対しては、単一のスペクトルバッファのみあればよい。本発明の階数2のフィルタに基づくリアルタイムの実施形態については、2つのスペクトルバッファが必要であり、1つは平滑化スペクトルフィルタ用、もう1つは2階微分スペクトルフィルタ用である。
【0233】
ステップ4:ピーク検出
イオンが1つ存在すると、出力畳み込み行列内に強度の極大値を有するピークを1つ発生する。本発明の実施形態の検出プロセスは、このようなピークを検出する。本発明の一実施形態では、検出プロセスは、検出閾値条件を満たす最大強度を有するピークを複数のイオンに対応するピークとして識別する。本明細書で使用されているように、検出閾値条件を満たすことは、検出閾値を超える基準を満たすこととして定義される。例えば、この基準は、検出閾値条件を満たすか、または検出閾値条件を満たすか、またはそれを超える可能性がある。それに加えて、本発明のいくつかの実施形態では、この基準は、検出閾値条件を下回るか、または検出閾値条件を満たすかまたはそれを下回る可能性がある。
【0234】
出力畳み込み行列内の強度のそれぞれの極大値は、1つのイオンに対応する1つのピークに対する1つの候補である。上述のように、検出器ノイズが存在しない場合、すべての極大値は、1つのイオンに対応するとみなされる。しかし、ノイズが存在する場合、いくつかの極大値(特に低振幅極大値)は、ノイズのみによるものであり、検出されたイオンに対応する真のピークを表さない。したがって、検出閾値条件を満たす極大値がノイズによるものである可能性がほぼなくなるように検出閾値を設定することが重要である。
【0235】
それぞれのイオンは、出力畳み込み行列内に強度の一意の頂点または最大値を形成する。出力畳み込み行列内のこれらの一意の最大値の特性から、試料中に存在するイオンの個数および特性に関する情報が得られる。これらの特性は、ピークの配置、幅、および他の特性を含む。本発明の一実施形態では、出力畳み込み行列内のすべての極大値が識別される。その後の処理により、イオンに関連しないと判定されるものが排除される。
【0236】
本発明のいくつかの実施形態によれば、強度の極大値は、その極大値が検出閾値条件を満たす場合のみ検出されたイオンに対応するとみなされる。検出閾値それ自体は、強度の極大値の比較の基準となる強度である。検出閾値は、主観的または客観的手段により求められる。実質的に、検出閾値は、真のピークの分布を、検出閾値条件を満たすものと、検出閾値条件を満たさないものの2つのクラスに分ける。検出閾値条件を満たさないピークは、無視される。したがって、検出閾値条件を満たさない真のピークは、無視される。このような無視される真のピークは、偽陰性と呼ばれる。
【0237】
この閾値は、ノイズピークの分布も、検出閾値条件を満たすものと、検出閾値条件を満たさないものの2つのクラスに分ける。検出閾値条件を満たすノイズピークは、イオンであるとみなされる。イオンとみなされるノイズピークは、偽陽性と呼ばれる。
【0238】
本発明のいくつかの実施形態では、検出閾値は、典型的には、通常は低い、所望の偽陽性率が得られるように設定される。つまり、検出閾値は、ノイズピークが所定の実験で検出閾値条件を満たす確率がゼロであるように設定される。
【0239】
低い偽陽性率を得るには、検出閾値はより高い値に設定される。検出閾値をより高い値に設定して偽陽性率を下げると、偽陰性率が上昇する、つまりイオンに対応する低振幅の真のピークが検出されない確率が高くなるという望ましくない効果を生じる。したがって、検出閾値は、これらの競合する因子を念頭に置いて設定される。
【0240】
検出閾値は、主観的または客観的に決定できる。閾値化の方法の目標は、主観的であろうと客観的であろうと、イオンリストを編集するために使用する検出閾値を決定することである。検出閾値条件を満たさない強度を有するすべてのピークは、ノイズであると考えられる。これらの「ノイズ」ピークは、除去され、それ以降の分析に含まれない。
【0241】
検出閾値を設定する主観的方法は、観測されたノイズの最大値に近い直線を引くことである。検出閾値条件を満たす極大値はどれも、イオンに対応するピークであると考えられる。検出閾値条件を満たさない極大値はどれも、ノイズであると考えられる。閾値を決定するための主観的方法が使用されうるが、客観的な方法が好ましい。
【0242】
本発明のいくつかの実施形態により検出閾値を選択する客観的方法の1つは、出力畳み込み行列データのヒストグラムを使用する。図20は、本発明の一実施形態により検出閾値を客観的に決定する方法の流れ図である。この方法は、図7に図解として示されている。この方法は、以下のステップに従って進行する。
ステップ2002:出力畳み込み行列内に見つかるすべての正の極大値の強度を昇順に並べ替える。
ステップ2004:出力畳み込みデータ行列内の強度データの標準偏差をリスト内の35.1パーセンタイルにある強度として決定する。
ステップ2006:標準偏差の倍数に基づき検出閾値を決定する。
ステップ2008:検出閾値条件を満たすピークを使用して編集済みイオンリストまたはイオンパラメータリストを生成する。
【0243】
上記の方法は、極大値の大半がガウスノイズによるものである場合に適用可能である。例えば、1000個の強度がある場合、ステップ2004で、351番目の強度がガウス標準偏差を表すと判定する。最大強度の分布が、ガウスノイズプロセスのみによるものであった場合、値が351番目の強度を超えた極大値は、ガウスノイズ分布により予測される頻度で出現する。
【0244】
そこで、検出閾値は、351番目の強度の倍数である。例えば、2つの検出閾値を考える。検出閾値の1つは、2つの標準偏差に対応する。検出閾値の1つは、4つの標準偏差に対応する。2偏差閾値から生じる偽陰性は少ないが、偽陽性は多い。ガウスノイズ分布の特性から、2標準偏差閾値は、ピークの約5%が誤ってイオンとして識別されることを意味している。4偏差閾値から生じる偽陰性は多く、偽陽性は著しく少ない。ガウスノイズ分布の特性から、4標準偏差閾値は、ピークの約0.01%が誤ってイオンとして識別されることを意味している。
【0245】
すべての極大値の強度のリストを並べ替えるのではなく、強度の間隔について強度の個数が記録されるヒストグラム表示が使用されうる。ヒストグラムは、一連の一様な間隔で並ぶ強度値を選択することにより得られ、値のそれぞれの対は間隔を定め、それぞれのビン内に入る最大強度の個数を計数するものである。ヒストグラムは、1ビン当たりの強度の個数とそれぞれのビンを定める平均強度値との対比である。ヒストグラムは、強度の分布の標準偏差を決定する図式解法をなす。
【0246】
経験的方法の一変種では、畳み込み出力ノイズの標準偏差σと入力ノイズの標準偏差σ0との間の関係を使用して、検出閾値を設定する。上記のフィルタ分析から、この関係は、入力ノイズが無相関ガウス偏差であると仮定して
【数56】
として与えられる。入力ノイズσ0は、入力LCL/MSデータ行列から背景ノイズの標準偏差として測定されうる。背景ノイズのみを含むLC/MSの一領域は、ブランク注入から得られる、つまり、LC/MSデータは、試料が注入されずに分離から得られるということである。
【0247】
そのため、出力の標準偏差は、フィルタ係数Fi,jと測定された背景ノイズσ0の値のみを使用して推論されうる。次いで、検出閾値は、導出された出力ノイズ標準偏差σに基づき設定されうる。
【0248】
ステップ5:ピークパラメータ抽出
イオンに対応するピークである極大値を識別した後、それぞれのピークに対するパラメータが推定される。本発明の一実施形態では、推定されるパラメータは、保持時間、質量対電荷比、および強度である。クロマトグラフピーク幅(FWHM)および質量対電荷ピーク幅(FWHM)などの追加のパラメータも推定できる。
【0249】
それぞれの識別されたイオンのパラメータは、出力畳み込みデータ行列内の検出されたピークの極大値の特性から得られる。本発明の一実施形態では、これらのパラメータは、(1)イオンの保持時間は、(フィルタリングされた)最大要素を含む(フィルタリングされた)走査の時間であり、(2)イオンのm/zは、(フィルタリングされた)最大要素を含む(フィルタリングされた)チャネルのm/zであり、(3)イオンの強度は、(フィルタリングされた)最大要素それ自体の強度であるというようにして、決定される。
【0250】
スペクトル方向またはクロマトグラフ方向のピークの幅は、そのピークをまたぐ最近ゼロ交差点の配置の間の距離を測定するか、またはピークをまたぐ最近最小値間の距離を測定することにより決定されうる。このようなピーク幅は、ピークがその隣接要素から分離されることを確認するために使用できる。他の情報は、ピーク幅を考慮して集めることができる。例えば、ピーク幅に対し予想外に大きい値である場合は、同時に生じているピークであることを示している可能性がある。したがって、ゼロ交差または極大値の配置は、干渉する同時発生の効果を推定するか、またはイオンパラメータリスト内に格納されているパラメータ値を修正するための入力として使用できる。
【0251】
ピークを分析することにより決定されたパラメータは、さらに、隣接要素を考慮することにより最適化されうる。畳み込み行列の要素は、データのデジタル試料を表しているため、クロマトグラフ(時間)次元のピークの真の頂点は、試料時間と正確には一致しない場合があり、またスペクトル(質量対電荷比)次元のピークの真の頂点は、質量対電荷比チャネルと正確には一致しない場合がある。その結果、典型的には、時間次元および質量対電荷比次元におけるシグナルの実際の最大値は、サンプリング周期または質量対電荷比チャネル間隔の数分の1だけ利用可能なサンプリング値からオフセットされる。これらの分数オフセットは、曲線適合法などの補間を使用してピークに対応する極大値を有する要素の周囲にある行列要素の値から推定できる。
【0252】
例えば、二次元の文脈において、1つのイオンに対応する極大値を含む出力畳み込み行列の要素から真の頂点の分数オフセットを推定する技術は、二次元形状を、極大値およびその最近隣接要素を含むデータ行列の要素に適合させるものである。本発明のいくつかの実施形態では、二次元放物形は、その頂点に近い畳み込みピークの形状に対するよい近似となるため使用される。例えば、放物形は、ピークとその8個の最近隣接要素を含む9要素行列に適合させることができる。他の適合法も、本発明の範囲と精神から逸脱することなくこの補間に使用できる。
【0253】
放物線適合法を使用する場合、イオンパラメータを決定するピーク頂点の補間値が計算される。補間値を使用すると、走査時間およびスペクトルチャネルの値を読み取ることにより得られるものと比べて、保持時間、m/z、および強度の推定をより正確に行える。最大値における放物線の値とその最大値に対応するその補間された時間およびm/z値は、イオン強度、保持時間、およびm/zの推定値である。
【0254】
二次元放物線適合の最大値の行方向における補間された配置は、保持時間の最適な推定となっている。二次元放物線適合の最大値の列方向における補間された配置は、質量対電荷比の最適な推定値を与える。ベースラインよりも上の頂点の補間された高さは、イオン強度または濃度の最適な推定値(フィルタ係数でスケーリングされる)となる。
【0255】
本発明の実施形態は、さらに、中間畳み込み行列の結果からピークパラメータを抽出するように構成することができる。例えば、検出されたイオンに対応する単一ピークを特定する上述の方法は、行列のそれぞれの行または列内のピークを特定するためにも使用されうる。これらのピークは、知られている時間または質量値におけるスペクトルまたはクロマトグラムを格納するのに有用な場合がある。
【0256】
例えば、2階微分フィルタから得られたるスペクトルまたはクロマトグラムは、上述の中間畳み込み行列からのそれぞれの行および列について求めることができる。これらの中間結果は、極大値についても調べることができる。これらの最大値は、実質的にクロマトグラムおよびスペクトルの平滑化バージョンである。極大値は、抽出されて保存され、特定の時間または時間範囲における試料のスペクトル成分に関する追加の詳細、または典型的な質量または質量範囲におけるクロマトグラフ成分に関する追加の詳細を得ることができる。
【0257】
測定誤差
本発明の実施形態により生成されるそれぞれのイオンパラメータ測定結果は、1つの推定であるため、それぞれのそのような測定には測定誤差が関連する。これらの関連する測定誤差は、統計的に推定されうる。
【0258】
2つの異なる因子が、測定誤差に関わる。因子の1つは、系統誤差または較正誤差である。例えば、質量分析計のm/z軸が完全には較正されていない場合、与えられたm/z値はオフセットを含む。系統誤差は、典型的には、一定のままである。例えば、較正誤差は、m/z範囲全体にわたって本質的に一定である。このような誤差は、特定のイオンのシグナル対ノイズまたは振幅と無関係である。同様に、質量対電荷比の場合、誤差は、スペクトル方向のピーク幅とは無関係である。
【0259】
測定誤差に関わる第2の因子は、それぞれの測定に関連するそれ以上減らせない統計誤差である。この誤差は、熱またはショットノイズ関係の効果により生じる。与えられたイオンに対するこの誤差の大きさまたは分散は、イオンのピーク幅および強度に依存する。統計誤差は、再現性を測定するものであり、したがって、較正誤差とは無関係である。統計誤差に対するもう1つの言いまわしは、精度である。
【0260】
それぞれの測定に関連する統計誤差は、原理上、測定が行われる装置の基本動作パラメータから推定されうる。例えば、質量分析計では、これらの動作パラメータは、典型的には、マイクロチャネル計数プレート(MCP)の効率に結びついた装置のイオン化および移動効率を含む。それとともに、これらの動作パラメータは、イオンに関連付けられているカウントを決定する。これらのカウントは、質量分析計を使用する測定に関連する統計誤差を決定する。例えば、上述の測定に関連する統計誤差は、典型的には、ポアソン分布に従う。それぞれの誤差に対する数値は、誤差伝搬の理論に従って計数統計から求めることができる。例えば、P.R.BEVINGTON「DATA REDUCTION AND ERROR ANALYSIS FOR THE PHYSICAL SCIENCES」58−64 (MCGRAW−HILL 1969)を参照のこと。
【0261】
一般に、統計誤差は、データから直接推論することもできる。データから統計誤差を直接推論する方法の1つでは、測定の再現性を調べる。例えば、同じ混合物の反復注入により、同じ分子に対するm/z値の統計的再現性を確定することができる。注入によるm/z値の差は、統計誤差によるものである可能性が高い。
【0262】
保持時間測定に関連する誤差の場合、統計的再現性を実現することが難しいが、それは、反復注入から生じる系統誤差が、統計誤差を隠蔽する傾向があるからである。この問題を解消する技術は、共通の親分子から得られた異なるm/z値においてイオンを調べるというものである。共通の分子に由来するイオンは、同一の固有保持時間を有すると予想される。その結果、共通の親に由来する分子の保持時間の測定結果の差は、ピーク特性の測定に関連する基本検出器ノイズに関連する統計誤差による可能性が高い。
【0263】
本発明の一実施形態を使用して実行され、格納されているそれぞれの測定は、関連する統計誤差および系統誤差の推定に伴うことができる。これらの誤差は、それぞれの検出されたイオンに対するパラメータ推定にも当てはまるけれども、それらの値は、一般的にイオンの集合を分析することにより推論することができる。好適な誤差分析を行った後、検出されたイオンに対するそれぞれの測定に関連する誤差は、検出されたイオン測定に対応するテーブルのそれぞれの行内に含めることができる。本発明のこのような一実施形態では、テーブルのそれぞれの行には、それぞれのイオンに関連する15個の測定結果を入れることができる。これらの測定結果は、行ならびにその関連する統計誤差および系統誤差に対応する検出されたイオンに対する5つの測定結果、つまり、保持時間、質量対電荷比、強度、スペクトルFWHM、およびクロマトグラフFWHMである。
【0264】
上述のように、保持時間およびm/zの測定誤差の統計成分、つまり精度は、それぞれのピーク幅および強度に依存する。高いSNRを有するピークについては、精度は、それぞれのピーク幅のFWHMよりも実質的に小さい場合がある。例えば、20ミリamuのFWHMおよび高いSNRを有するピークについては、精度は1ミリamu未満となる可能性がある。ノイズよりも高いところでほとんど検出可能でないピークについては、精度は20ミリamuとすることができる。統計誤差のここでの説明のために、FWHMは、畳み込みの前のLC/MSクロマトグラムにおけるピークのFWHMであると考えられる。
【0265】
精度は、ピーク幅に比例し、ピーク振幅に逆比例する。一般的に、精度、ピーク幅、およびピーク振幅の間の関係は、
【数57】
で表すことができる。
【0266】
この関係において、σmは、m/zの測定の精度であり(標準誤差として表される)、wmは、ピークの幅であり(FWHMのミリamuで表される)、hpは、ピークの強度であり(ポストフィルタリングされたシグナル対ノイズ比として表される)、およびkは、1のオーダーの無次元定数である。kの正確な値は、使用されるフィルタ法によって決まる。この式は、σmがwm未満であることを示している。したがって、本発明では、検出されたイオンに対するm/zの推定をオリジナルのLC/MSデータで測定されたm/zピーク幅のFWHMよりも小さい精度で実行できる。
【0267】
保持時間の測定に関しても、類似の考察が当てはまる。ピークの保持時間を測定できる精度は、ピーク幅とシグナル強度の組み合わせに依存する。ピークのFWHM maxが0.5分である場合、保持時間は、0.05分(3秒)の、標準誤差で記述される、精度に合わせて測定されうる。本発明を使用することで、検出されたイオンに対する保持時間の推定をオリジナルのLC/MSデータで測定された保持時間ピーク幅のFWHMよりも小さい精度で実行できる。
【0268】
ステップ6:抽出されたパラメータを格納する
上述のように、本発明のいくつかの実施形態の1つの出力は、検出されたイオンに対応するパラメータのテーブルまたはリストである。このイオンパラメータテーブル、またはリストは、それぞれの検出されたイオンに対応する行を有し、それぞれの行は1つまたは複数のイオンパラメータを含み、必要ならば、その関連する誤差パラメータを含む。本発明の一実施形態では、イオンパラメータテーブル内のそれぞれの行は、保持時間、質量対電荷比、および強度の3つのパラメータを有する。追加のイオンパラメータおよび関連する誤差は、リスト内に表されているそれぞれの検出されたイオンについて格納されうる。例えば、FWHMにより測定されたような検出イオンのピーク幅またはクロマトグラフ方向および/またはスペクトル方向のそのゼロ交差幅が決定され、格納されうる。
【0269】
ゼロ交差幅は、2階微分フィルタでフィルタリングが実行される場合に適用可能である。2階微分のゼロ値は、ピークの上り勾配側と下り勾配側の両方におけるピークの変曲点で出現する。ガウスピークプロファイルについては、変曲点は、ピーク頂点から+/1標準偏差の距離のところに出現する。したがって、変曲点により測定された幅は、ピークの2標準偏差幅に対応する。そのため、ゼロ交差幅は、ほぼ2つの標準偏差に対応するピーク幅の高さ独立の尺度となる。本発明の一実施形態では、テーブル内の行の個数は、検出されたイオンの個数に対応する。
【0270】
本発明は、さらに、データ圧縮の利点も有する。これは、イオンパラメータテーブル内に収められている情報を格納するのに必要なコンピュータメモリが、最初に生成されたオリジナルのLC/MSデータを格納するのに必要なメモリ量に比べて著しく少ないためである。例えば、3600個のスペクトル(例えば、1時間の間1秒に1回の割合で収集されたスペクトル)を含む典型的な注入では、それぞれのスペクトル中に400,000個の分離能要素(例えば、50から2,000amuまでの20,000:1のMS分離能)があるとして、強度のLC/MSデータ行列を格納するのに数ギガバイトを超えるメモリを必要とする。
【0271】
複雑な試料では、本発明のいくつかの実施形態を使用することで、100,000のオーダーでイオンが検出されうる。これらの検出されたイオンは、100,000個の行を有するテーブルにより表され、それぞれの行は検出された1個のイオンに対応するイオンパラメータを含む。それぞれの検出されたイオンに対する所望のパラメータを格納するのに必要なコンピュータ記憶装置の容量は、典型的には、100メガバイト未満である。この記憶装置の容量は、最初に生成されたデータを格納するのに必要なメモリのうちのごくわずかに相当する。イオンパラメータテーブルに格納されているイオンパラメータデータにアクセスし、抽出して、さらに処理を進めることができる。データを格納その他の方法も、本発明のいくつかの実施形態において使用できる。
【0272】
必要な記憶容量が著しく低減されるだけでなく、LC/MSデータの後処理の計算効率も、最初に生成されたLC/MSデータではなくイオンパラメータリストを使用してこのような分析が実行されれば著しく改善される。これは、処理される必要のあるデータ点の数が著しく低減されることによるものである。
【0273】
ステップ7:スペクトルおよびクロマトグラムを簡素化する
結果として得られるイオンリストまたはテーブルを参照して、新規の有用なスペクトルを形成することができる。例えば、上述のように、保持時間の向上した推定に基づきテーブルからイオンを選択することで、複雑度が大幅に低減されたスペクトルが生成される。それとは別に、m/z値の向上した推定に基づきテーブルからイオンを選択することで、複雑度が大幅に低減されたクロマトグラムが生成される。以下でさらに詳しく説明されるように、例えば、保持時間ウィンドウは、注目する化学種に無関係のイオンを除外するために使用されうる。保持時間選択スペクトルは、スペクトル中に複数のイオンを誘発する、タンパク質、ペプチド、およびそのフラグメンテーション生成物などの分子種の質量スペクトルの解釈を簡素化する。同様に、m/zウィンドウは、同じであるか、または類似しているm/z値を有するイオンを区別するように定義されうる。
【0274】
保持ウィンドウという概念を使用することで、LC/MSクロマトグラムから簡素化されたスペクトルが得られる。ウィンドウの幅は、クロマトグラフピークのFWHM以下となるように選択できる。いくつかの場合において、ピークのFWHMの1/10などのより小さなウィンドウが選択される。保持時間ウィンドウは、注目するピークの頂点に一般に関連付けられている特定の保持時間を選択し、次いで、選択された特定の保持時間を中心とする一定範囲の値を選択することにより定義される。
【0275】
例えば、最高の強度値を有するイオンが選択され、保持時間が記録されるようにできる。保持時間ウィンドウは、記録された保持時間を中心として選択される。次いで、イオンパラメータテーブル内に格納された保持時間が調べられる。保持時間ウィンドウ内に収まる保持時間を有するイオンのみが、スペクトルに含めるものとして選択される。30秒のFWHMを有するピークについては、保持時間ウィンドウの有用な値は、±15秒と大きいか、または±1.5秒と小さい場合がある。
【0276】
保持時間ウィンドウは、ほぼ同時に溶出するイオンを選択するように指定することができ、また関係付けの対象となる候補でもある。このような保持時間ウィンドウは、無関係の分子を除外する。したがって、保持ウィンドウを使用してピークリストから得られるスペクトルは、注目する化学種に対応するイオンのみを含み、そのため、生成されるスペクトルが著しく簡素化される。これは、典型的には注目する化学種に無関係のイオンを含む従来の技術により生成されるスペクトルに勝る大きな改善点である。
【0277】
また、イオンパラメータテーブルを使用する方法は、クロマトグラフピーク純度を分析する手段ともなる。ピーク純度は、ピークが単一イオンによるものであるか、またはイオンの共溶出の結果によるものであるかを示す。例えば、本発明の実施形態により生成されたイオンパラメータリストを参照することにより、分析者は、注目する主ピークの時間内に化合物またはイオンがいくつ溶出するかを判定することができる。ピーク純度の尺度または計量を設定する方法は、図21に関して説明されている。
【0278】
ステップ2102で、保持時間ウィンドウが選択される。保持時間ウィンドウは、注目するイオンに対応するピークのリフトオフとタッチダウンに対応する。ステップ2104で、イオンパラメータテーブルが参照され、これにより、選択された保持時間ウィンドウ内で溶出するすべてのイオンを同定する。ステップ2106で、識別されたイオン(注目するイオンを含む)の強度の総和が求められる。ステップ2108で、ピーク純度計量が計算される。ピーク純度計量は、数多くの方法で定義されうる。本発明の一実施形態では、ピーク純度計量は、
純度=100*(注目するピークの強度)/(保持ウィンドウ内のすべてのピークの強度の総和)
で定義される。
それとは別に、本発明の他の実施形態では、ピーク純度は、
純度=100*(最も強い強度)/(保持ウィンドウ内のすべてのピークの強度の総和)
で定義される。
ピーク純度の両方の定義において、ピーク純度は、パーセント値で表されている。
【0279】
本発明のスペクトル簡素化特性は、さらに、生体試料をより簡単に研究する場合にも使用できる。生体試料は、LC/MS法を使用して一般に分析される混合物の重要なクラスである。生体試料は、一般に、複合分子を含む。そのような複合分子の特徴は、特異分子種が、複数のイオンを生成しうるという点にある。ペプチドは、さまざまな同位体状態で天然に存在する。したがって、与えられた電荷で出現するペプチドは、m/zの複数の値で出現し、それぞれそのペプチドの異なる同位体状態に対応する。十分な分離能があれば、ペプチドの質量スペクトルは、特性イオン群を示す。
【0280】
典型的には高い質量を有するタンパク質は、異なる荷電状態にイオン化される。タンパク質中の同位体変化は、質量分析計の分離能では検出できないけれども、異なる荷電状態で出現するイオンは、一般に、分離され検出されうる。このようなイオンは、タンパク質を同定するのを補助するために使用できる特徴的パターンを形成する。そこで、本発明の方法であれば、共通の保持時間を有するため共通のタンパク質からのそれらのイオンを関連付けることができるであろう。そこで、これらのイオンは、例えば、Fennらの米国特許第5,130,538号で開示されている方法により分析されうる簡素化されたスペクトルを形成する。
【0281】
質量分析計は、質量それ自体ではなく、質量対電荷比のみを測定する。しかし、生成するイオンのパターンからペプチドおよびタンパク質などの分子の荷電状態を推論することは可能である。この推論された荷電状態を使用して、分子の質量が推定されうる。例えば、タンパク質が複数の荷電状態にある場合、m/z値の間隔から、電荷を推論し、電荷を知ってそれぞれのイオンの質量を計算し、最終的に、荷電されていない親の質量を推定することが可能である。同様に、ペプチドについても、m/zの電荷が特定の質量mに対する同位体の値における電荷によるものである場合、隣接するイオンの間隔から電荷を推論することが可能である。
【0282】
イオンからのm/z値を使用して電荷と親質量を推論するよく知られている技術が多数ある。このような例示的な技術は、参照により本明細書に組み込まれている、米国特許第5,130,538号で説明されている。これらの技術のそれぞれに対する必要条件は、正しいイオンの選択とm/zに対する正確な値の使用である。検出されたイオンパラメータテーブル内に表されているイオンは、これらの技術への入力として使用されうる高精度の値をもたらし、精度の高い結果を生み出す。
【0283】
それに加えて、引用されている方法のいくつかでは、スペクトル内に出現する可能性のある複数のイオンを区別することによりスペクトルの複雑度を低減しようと試みている。一般に、これらの技術は、突出したピークを中心とするスペクトルを選択するか、または単一のピークに関連付けられるスペクトルを組み合わせて、単一の抽出MSスペクトルを得る。そのピークが複数の同時発生イオンを生成した分子からのピークであった場合、スペクトルは、無関係の化学種からのイオンを含むすべてのイオンを含むことになるであろう。
【0284】
これらの無関係の化学種は、注目する化学種とまったく同じ保持時間で溶出するイオンからのものとすることができるか、またはより一般に、無関係の化学種は、異なる保持時間で溶出するイオンからのものである。しかし、これらの異なる保持時間が、クロマトグラフピーク幅のほぼFWHMのウィンドウ内にある場合、それらのピークの前部または尾部からのイオンが、スペクトル中に出現する可能性が高い。無関係の化学種に関連するピークが出現する場合は、それらの化学種を検出して取り除くようにその後処理する必要がある。同時発生するいくつかの場合において、これらは測定結果を偏らせている可能性がある。
【0285】
図22Aは、2つの親分子と結果として得られる多数のイオンから結果として得られる例示的なLC/MSデータ行列を示している。この実施例では、LC/MSデータ行列において、化学種は時間t1に溶出して4個のイオンを生成し、他の化学種は時間t2に溶出して5個のイオンを生成する。2つの異なる化学種があるとしても、スペクトルが時間t1または時間t2に抽出されるならば、結果のスペクトルは、9個のイオンのそれぞれから1つずつ、9個のピークを含むであろう。しかし、本発明では、これらの9個のイオンのそれぞれについて9つの正確な保持時間(m/zおよび強度とともに)を得る。次いでスペクトルが、t1に実質的に等しい保持時間を有しているイオンのみから形成された場合、4個のイオンのみが存在することになる。この簡素化されたスペクトルは、図22Bに示されている。同様に、次いでスペクトルが、t2に実質的に等しい保持時間を有しているイオンのみから形成された場合、5個のイオンのみが存在することになる。この簡素化されたスペクトルは、図22Cに示されている。
【0286】
応用例
LC/MSシステムで試料が収集されるとともに、複数のスペクトルが典型的にはクロマトグラフピーク上で収集され、保持時間が正確に推論される。例えば、本発明のいくつかの実施形態では、FWHM毎に5つのスペクトルが収集される。
【0287】
LC/MSシステムの構成をスペクトル毎に交互配置することが可能である。例えば、すべての偶数番のスペクトルが、1つのモードで収集され、すべての奇数番のインターリーブするスペクトルが、別のモードで動作するように構成されているMSにより収集されうる。例示的な二重モード収集動作は、LC/MSEと交互に並ぶLC/MSにおいて使用することができ、一方のモード(LC/MS)では、非フラグメントイオンが収集され、第2のモード(LC/MSE)では、第1のモードで収集された非フラグメントイオンのフラグメントが収集される。これらのモードは、衝突セルを横断するときにイオンに印加される電圧のレベルにより区別される。第1のモードでは、電圧は低く、第2のモードでは、電圧は高い(Batemanら)。
【0288】
このようなシステムでは、1つのモードにおいてシステムにより収集されたフラグメントまたはイオンは、未修正イオンと同じ保持時間を保有するクロマトグラフプロファイルで出現する。これは、非フラグメントおよびフラグメントイオンが、同じ分子種に共通のものであるからであり、分子の溶出プロフィルは、その分子に由来するすべての非フラグメントおよびフラグメントイオン上にインプリントされる。これらの溶出プロフィルは、実質的に時間的整合性を有しているが、それは、オンラインのMSでモードを切り換えるのに要する余分な時間は、クロマトグラフピークのピーク幅またはFWHMと比較して短いからである。例えば、MS内の分子の移動時間は、典型的には、ミリ秒またはマイクロ秒のオーダーであるが、クロマトグラフピークの幅は、典型的には数秒または数分のオーダーである。したがって、特に、非フラグメントおよびフラグメントイオンの保持時間は、実質的に同一である。さらに、それぞれのピークのFWHMも同じになり、さらに、それぞれのピークのクロマトグラフプロファイルは、実質的に同じになる。
【0289】
2つの動作モードで収集されたスペクトルは、2つの独立のデータ行列に分けられる。上述の畳み込み、頂点検出、パラメータ推定、および閾値化の演算は、両方に独立に適用されうる。このような分析の結果、イオンの2つのリストが得られるけれども、これらのリスト内に出現するイオンは互いに関係を有する。例えば、1つの動作モードに対応するイオンのリスト内に現れる高強度を有する強いイオンは、他の動作モードにより収集された修正イオンのリスト内に対の一方を持つことができる。このような場合、イオンは、典型的には、共通の保持時間を有する。このような関係するイオンを分析のため互いに関連付けるには、上述のように保持時間を制約するウィンドウが、両方のデータ行列内に見つかるイオンに適用されうる。このようなウィンドウを適用した結果は、共通の保持時間を有する、したがって関係付けられる可能性の高い2つのリスト内でイオンを識別することである。
【0290】
これらの関係するイオンの保持時間が同一であっても、検出器ノイズの効果が現れる結果として、これらのイオンの保持時間の測定された値はいくぶん異なることになる。この差は、統計誤差の顕現であり、イオンの保持時間の測定の精度を測定するものである。本発明では、イオンの推定保持時間の差は、クロマトグラフピーク幅のFWHMよりも小さい。例えば、ピークのFWHMが30秒である場合、イオン同士の保持時間のバラツキは、低強度ピークでは15秒未満であり、高強度ピークでは1.5秒未満である。同じ分子のイオンを収集する(および無関係のイオンを除去する)ために使用されるウィンドウ幅は、この実施例では、±15秒と大きいか、または±1.5秒と小さい場合がある。
【0291】
図23A〜図23Bは、本発明の一実施形態により生成される未修正および修正イオンリスト中で関係するイオンをどのように同定できるかを示す図解である。データ行列2302は、未修正MS実験からの結果として得られるスペクトル中に検出された3つの前駆体イオン2304、2306、および2308を示す。データ行列2310は、例えば上述のようにフラグメンテーションを引き起こすようにMSが修正された後に実験の結果として得られる8個のイオンを示す。データ行列2310内のイオンに関係するデータ行列2302内のイオンが、t0、t1、およびt2と標識されている3本の垂直線により示されているように、同じ保持時間に現れる。例えば、データ行列2310内のイオン2308aおよび2308bは、データ行列2302内のイオン2308に関係する。データ行列2310内のイオン2306a、2306b、および2306cは、データ行列2302内のイオン2306に関係する。データ行列2310内のイオン2304a、2304b、および2304cは、データ行列2302内のイオン2304に関係する。これらの関係は、それぞれ時間t0、t1、およびt2を中心とする適切な幅を有する保持時間ウィンドウにより識別できる。
【0292】
イオンパラメータリストは、さまざまな分析に使用できる。このような1つの分析は、フィンガープリンティングまたはマッピングを伴う。全体としてよく特徴付けられている、本質的に同じ組成を有し、成分が同じ相対量で存在する混合物の多数の実施例がある。生物学的実施例は、尿、脳脊髄液、および涙液などの代謝の最終生成物を含む。他の実施例は、組織および血液に見られる細胞集団のタンパク質成分である。他の実施例は、組織および血液に見られる細胞集団のタンパク質成分の酵素消化物である。これらの消化物は、二重モードLC/MSおよびLC/MSEにより分析可能なペプチド混合物を含む。工業における実施例は、香水、香料、フレイバー、ガソリンもしくはオイルの燃料分析を含む。環境面での実施例は、農薬、燃料および除草剤、および水と土壌の汚染を含む。
【0293】
これらの液体中で観察されることが予想されるものからの異常は、薬物もしくは製剤原料の摂取または注射の結果生じる代謝産物の場合の生体異物、代謝液中の薬物不正使用の証拠、ジュース、フレイバー、および香料などの製品中の混ぜ物、または燃料分析を含む。本発明の実施形態により生成されるイオンパラメータリストは、フィンガープリントまたは多変量解析の技術で知られている方法への入力として使用されうる。SIMCA(Umetrics社、スウェーデン所在)、またはPirouette(lnfometrix社、米国ワシントン州ウッデンビル所在)などのソフトウェア分析パッケージは、試料集団間のイオンの変化を識別することにより、フィンガープリントまたは多変量解析技術を使用してそのような異常を検出するように構成できる。これらの分析では、混合物中の実体の正規分布を判定し、次いで、基準からずれている試料を識別することができる。
【0294】
化合物の合成により、付加的分子的実体とともに所望の化合物を生成することができる。これらの付加的分子的実体は、合成経路を特徴付ける。イオンパラメータリストは、実際、化合物を合成する合成経路を特徴付けるために使用されうるフィンガープリントとなる。
【0295】
本発明が適用可能な他の重要な応用例に、バイオマーカー発見がある。濃度の変化が病状と一意に、または薬物の作用と相関する分子の発見は、疾病の検出または薬物発見のプロセスの基本である。バイオマーカー分子は、細胞集団または代謝産物または血液および血清などの流体中に出現しうる。よく知られている方法を使用して対照および疾病または投薬状態について生成されるイオンパラメータリストの比較結果を用いて、疾病または薬物の作用に対するマーカーである分子を同定することができる。
【0296】
N次元データとLC/IMS/MS
本発明のいくつかの実施形態は、LC/MS装置から得られるものよりも高い次元のデータを伴う。これらの実施形態のうちいくつかは、LC/IMS/MS装置を伴う。以下の説明は、主にLC/IMS/MSデータを対象としているが、当業者であれば、本明細書で説明されている原理は、3次元およびそれ以上の次元のデータを出力するさまざまな装置にも広範に適用可能であることを理解するであろう。
【0297】
これらのいくつかの実施形態は、LCモジュール、IMSモジュール、およびTOF−MSモジュールを備える。本発明のいくつかの実施例が適宜実装されるこのような装置の一実施例は、2003年1月2日に公開されたBatemanらの米国特許公開第2003/01084号で説明されている。
【0298】
第1に、本発明のいくつかの態様の広い文脈に関して、異なる数の次元のデータの収集が説明される。例えば、LCのみ、またはMSのみの装置で見られるような単一チャネル検出器では、一次元データは、典型的には、二次元プロットで表示される。次いで、そのプロットの中ですべてのピークを特定しなければならない。
【0299】
LCの場合、典型的な検出器は、紫外線/可視光線(UV/Vis)光吸収検出を実行する。ピークパラメータは、カラムから溶出するときのピークの保持時間および吸収度である。
【0300】
MSの場合、例えば、四重極またはTOFベースのMSで実行されるときに、電磁力が、異なるm/z比のイオンを分離するために使用され、検出器は、m/z比の関数としてイオン強度の値を出力する。強度対m/zデータの二次元プロット中のピークを特定するためのルーチンが必要である。組み合わせLC/MSでは、ピークは、特定されなければならない、つまり3つの次元(イオン強度対保持時間およびm/z)でプロットされたデータ中のアーチファクトから区別されなければならない。
【0301】
後述のいくつかのLC/IMS/MS関係の実施形態では、3つの分離関係の次元が、イオン強度値に関連付けられる。分離の3つの次元−液体クロマトグラフィ、続いてイオン移動度、続いて質量分析−が、イオンの対応する3つの特性、保持時間、イオン移動度、および質量対電荷比の尺度となる。MSモジュールは、イオンのピークとの関連でm/z値においてイオンを特定する。ピークは、例えば、マイクロチャネルプレートにより測定されるような、イオンのピークの積分されたイオンカウント数に関連付けられる。
【0302】
表3は、本発明のいくつかの実施形態により得られるデータのさまざまな数の次元をまとめたものである。第1の列は、いくつかの特定の分析技術と、N回の分離に関連するデータのN個の次元を有する技術に対するより一般的な参照のリストである。Nは、適宜3つまたはそれ以上の大きさに等しい。第2の列は、本発明のいくつかの実施形態により、アーチファクトを低減し、重なるピークを区別しやすくするために使用される畳み込みフィルタの次元の数のリストである。いくつかの好ましい実装では、畳み込みフィルタの次元の数は、分離の数と一致する。
【0303】
定義することを目的として、分離の次元に加えて、イオン強度をデータの次元として処理することを選択した場合、データは、分離次元の数よりも1だけ大きい次元を有するものとして適宜参照される。
【0304】
畳み込みの後、極大値に関連するピークは、畳み込みデータ内で特定される。例えば、三次元空間内の極大値は、隣接要素のすべてよりも大きい値を有するデータ点(本明細書ではデータ要素と呼ばれる)として適宜定義される。例えば、三次元分離空間内の要素は、3×3×3−1=26個の隣接要素を有する。したがって、極大は、一般に、中央の要素と26個の隣接要素との比較を必要とする。
【0305】
表3の第3の列は、1つの点が1つの極大値であると確定するために実行される比較の回数のリストである。残りの列は、分離次元のリストである。極大値は、ピークの頂点を識別する。それぞれの頂点は1つのイオンに対応する。この「発明実施するための形態」の残り部分では、LC/IMS/MSおよび、より大きいな分離の次元を重点的に取りあげる。
【表3】
【0306】
図24は、本発明の例示的な一実施形態による、LC/IMS/MS分析の方法2400の流れ図である。方法2400は、試料からノイズの多い生データを取得すること2410を含む。データは、三次元データ要素の集合を含み、それぞれの要素はイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付ける。方法2400は、さらに、イオン移動度次元において、そのデータ要素の集合を縮退して、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成すること2420と、縮退データ要素の集合を、例えば、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込むこと2430とを含む。方法2400は、さらに、保持時間次元および質量対電荷比次元において、データ要素の畳み込まれた集合のイオンピークを特定すること2440と、特定されたイオンピークに応答して、ノイズを含む生データの1つまたは複数の部分をさらなる分析のため選択すること2450とを含む。方法2400は、さらに、ノイズを含む生データの選択された部分を、例えば、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込み込むこと2460と、保持時間次元、イオン移動度次元、および質量対電荷比次元において、畳み込まれた生データ中のイオンピークを特定すること2470とを含む。
【0307】
畳み込まれた縮退データ要素の集合の特定2440されたイオンピークに応じて、さらなる分析対象として選択2450された生データの1つまたは複数の部分が選択される。保持時間次元および質量対電荷比次元において、畳み込まれた縮退データ要素集合のイオンピークの配置は、生データ中の注目する、保持時間次元および質量対電荷比次元における配置を示す。
【0308】
そこで、適宜、さらなる分析のため選択された部分は、生データの完全イオン移動度次元を含むが、生データの保持時間次元および質量対電荷比次元の制限された領域のみを含む。これらの制限された領域は、データ要素の畳み込まれた縮退集合により示される配置を含む。次いで、生データの部分が、例えば、特定されたイオンピークを実質的に中心とするように選択される。したがって、意味のあるデータまたは注目するデータを含まないデータ空間の部分の不効率な分析を行わなくて済む。さらに、選択された部分のサイズは、観察されているように、または所定のように、ピーク幅に応じて適宜選択される。好ましくは、選択された部分のサイズは、それぞれの次元において、その次元におけるピーク幅よりも大きい。
【0309】
上述のように、畳み込み2460は、生データの三次元畳み込みを必要とする。ピーク情報判定のため、極大値が、適宜3つの次元(保持時間、イオン移動度、およびイオンm/z)における探索により特定され2440、極大値の特定により、3つの分離関係のイオン特性−保持時間、移動度、およびm/z−がイオンの強度に関連付けられる(MSを介して検出された多数のイオンに対応する)。ピークの頂点の値は、畳み込みフィルタが適宜正規化されている場合に、イオンピーク全体にわたって積分されたイオン強度をもたらす。
【0310】
次に表4を参照すると、方法2400は、3つの異なる次元において生データの異なる分離能レベルを利用する(m/z次元では比較的高い分離能、イオン移動度次元では比較的低い分離能、保持時間次元では中程度の分離能)。表4は、分離能のこれらの違いを示している。3つの次元について、表4は、典型的な測定範囲、サンプリング周期、要素数(つまり、範囲をサンプリング周期で除算したもの)、ピーク半値全幅(時間に関して)、ピーク半値全幅(データ点要素に関して)、および分離能(分離可能なピークの数に関して)のリストである。
【表4】
【0311】
18,000のMS分離能は、強度の150,000個のチャネルに対応し、8チャネルのピーク幅(FWHM)を有する。2番目に高い分離能は、クロマトグラフ次元であり、100分の分離および30秒のピーク幅を持つ(7.5回の走査に対応する)。最低の分離能は、イオン移動度によって与えられる。7個の要素のFWHMの示されている実施例を仮定すると、IMS分離能は200チャネルスペクトルに対しピーク30個である。この理想化された実施例では、質量および移動度を持つピーク幅の典型的なバラツキを無視する。
【0312】
さらに詳しく述べると、方法2400は、以下のように適宜実装される。さまざまな走査から得られる生データは、三次元データ配列に組み立てられるが、ただし、第1の軸は、クロマトグラフ保持時間に対応する走査集合の時間であり、第2の軸は、移動度ドリフト時間に対応する走査集合内の走査番号に対応し、第3の軸は、質量対電荷比に対応するチャネル番号である。三次元畳み込みは、三次元データ配列に適用される。三次元における極大値により、イオンピークが特定される。ピークの頂点の値は、畳み込みフィルタがこの目的のために正規化されている場合に、第4のイオン特性である、ピークの全体にわたって積分された強度を示す。
【0313】
三次元畳み込みでは、例えば、平滑化または2階微分フィルタ、またはそのようなフィルタの組み合わせを使用する。畳み込みフィルタの係数は、信号対ノイズ比を最大にし、統計誤差特性を最小にし、ベースライン背景を取り除き、および/またはイオン干渉の効果を緩和するように適宜選択される。より効率的に計算するために、方法2400の上記の説明に示されているように、三次元畳み込みが、生データのサブボリュームに適宜適用される。これらのサブボリュームは、LC/MSデータに応じて選択される。縮退2420データは、すべての移動度スペクトルを組み合わせること(加算することなど)により得られる。適宜、それぞれの次元に対する自動ピーク幅計算のように、不感時間補正およびロック質量補正が方法2400に組み込まれる。
【0314】
方法2400は、分離関係のデータのN個の次元を形成するN回の逐次分離に拡張可能である。そのようなデータは、N次元超立方体として適宜組み立てられ、N次元畳み込みは、超立方体内のすべての点に適用される。極大値は、例えば、1つの点の強度をN次元空間内のそれぞれの要素を中心とする3N個の隣接要素と比較することにより見つけられる。補間式により、それぞれのピークのN次元パラメータを特定し、N次元ピーク頂点の値が、N次元分離の後にピークに関連付けられているすべてのカウントまたはシグナルの原因となるピークの強度である。
【0315】
方法2400は、適宜重心データに適用される。重心アプローチでは、走査集合において、1回の走査に対し記録された情報のみが、ピーク情報であり、それぞれのピークは、質量と強度とで記述される。それぞれの質量−強度対は、質量分析法の分離能に対応する幅を有するガウスピークで置き換えられ、例えば、それぞれのスペクトルの連続体表現は、ピークリストから再構成される。再構成された連続体スペクトルは、立方体に組み立てられ、分析される。
【0316】
上述のように、効率上の理由から、三次元畳み込みフィルタを生データのボリューム全体に適用しないように適宜選択し、データを操作するのに必要な演算回数は、次元の数の累乗で増大する。現在利用可能な処理装置を使用しても、LC/IMS/MSベースのシステムの1回の注入で得られるデータすべてに適用される一般的な三次元畳み込みは、例えば、計算に数日を要する。方法2400は、完全な三次元畳み込みから得られるものに匹敵する結果を出しながら、計算時間を、例えば、1時間未満に短縮できる可能性を有している。適宜、二次元および三次元の畳み込みフィルタをデータから抽出された線形配列に逐次的に適用される一次元フィルタで近似することにより計算効率をさらに高められる。
【0317】
以下は、LC/IMS/MSベースのシステムに対するデータ計算の一実施例である。イオン強度は、三次元のボリュームにまとめられ、それぞれのデータ要素は、カウント(C)として測定される、強度であり、それぞれの要素は、保持時間(T)、移動度(D)、および質量対電荷比μに対応する3つの変数を添え字とする。数学的には、この三次元データのそれぞれの要素は、3つのインデックスが付けられる。化学者は、一般に、このようなデータを「四次元」データと呼び、強度をデータの付加的次元とみなす。この実施例でそれぞれのデータ要素に使用される表記は、Ci,j,kであり、Cは整数インデックスi,j,kにより指定されたデータ要素において測定されたカウントである。これらのインデックスは、走査番号(保持時間、Ti)、走査集合番号(移動度、Di)、およびチャネル番号(質量対電荷比、μk)に対応する。そこで、
Ci,j,k=C(Ti,Dj,μk)
となる。
【0318】
この実施例では、LC/IMS/MSシステムにおけるイオンの応答は、三次元のガウスピークとして近似され、それぞれのイオンは特性ピーク幅にわたって広がるカウントを生成する。
【0319】
3つの方向のそれぞれにおけるピークの幅は、分離モードの一特性である。標準偏差ピーク幅は、クロマトグラフ方向、移動度方向、および質量スペクトル方向に対しσT、σD、およびσμである。カウントは、データ要素上に
【数58】
のように分布するが、ただし、Cvは、積分されたボリュームカウントであり、インデックスi、j、kは、それぞれクロマトグラフ走査時間、移動度走査時間、および質量対電荷チャネルに対応する。ガウスピークは、i0、j0、およびk0を中心とする(小数値をとる)。頂点計数率と積分ボリューム計数率との関係は、
【数59】
で表される。
【0320】
このようなデータでイオンを検出し、この実施例では配列Ci,j,kからその特性を測定する、つまり、i0、j0、k0、およびCvを推論するために、畳み込みフィルタを使用してこれらのパラメータを推定する。畳み込みデータの極大値により、イオンを特定し、その強度を推定する。
【0321】
フィルタ係数Fl,m,nの集合が与えられると、三次元畳み込みの出力は、
【数60】
により与えられる三次元ボリュームであり、Ri,j,kは、畳み込み要素である。
【0322】
フィルタ係数Fl,m,nは、三次元ボリュームを範囲としており、それぞれの次元の幅は、それぞれの次元におけるピークの幅に関連付けられている。Fのインデックスは、0を中心として対称的であり、それぞれの次元内の要素の個数は、(2L+1)、(2M+1)、および(2N+1)である。
【0323】
この実施例では、Fl,m,nの幅は、MSおよびIMSの次元上で変化するピーク幅と一致するように調節される。それぞれの出力値Ri,j,kの計算は、存在するフィルタ係数の数だけ乗算を必要とする。
【0324】
畳み込みの式により示されているように、Ri,j,kの値は、計数Fl,m,nの中心を要素Ci,j,kに置き、指示された乗算および加算を実行することにより得られる。一般に、入力値Ci,j,kの数だけ出力値Ri,j,kがある。
【0325】
三次元の応用事例では、Ri,j,kは、その値が隣接要素のすべての要素の値を超える場合に極大値である。つまり、Ri,j,kが、(3×3×3=27)要素の立方体の中心にある場合、Ri,j,kの値は、そのイオンピーク強度値が、その26個の最近隣接要素の値を超える場合に最大値となる。正規化係数は、非正規化フィルタをモデルガウスピークに畳み込むことにより得られ、モデルガウスピークのピーク幅は、物理的に予想されるピーク幅に対応する。イオンは、畳み込みの最大値が適宜選択された閾値を超える場合に検出される。閾値検出に対する値は、例えば、100カウント以下に設定される。
【0326】
ピーク検出が与えられた場合、三次元におけるその頂点の配置は、例えば、三次元二次曲線を最大値の付近の27個の要素に当てはめることにより得られる。最大値の補間されたインデックス値から、ピークの特性が得られ、イオンの保持時間、移動度、および質量対電荷比に対応する分数インデックスが得られる。一般に、スペクトルは未較正であり、したがって、質量対電荷比は未較正である。
【0327】
畳み込みの演算回数は、得られた強度の数とフィルタ係数の数の積に比例する。この演算回数は、データの次元の累乗で増大する。そこで、LC/IMS/MSベースのシステムに対する畳み込みアプローチでは、適宜、増大する可能性のある演算回数の問題に取り組まなければならない。
【0328】
上述のように、計算の演算回数を減らす一方法は、三次元畳み込みフィルタを一連の一次元畳み込みフィルタ群として実装することである。図1〜図23Bを参照しつつ上で説明されているように、一次元フィルタの複数回適用は、近似として、二次元または三次元フィルタ行列を実装する。例えば、21×21要素の二次元畳み込み行列は、スペクトル方向に2つ、保持時間次元に2つとする4つの一次元畳み込みで置き換えられる。三次元畳み込みの場合、21×21×21三次元畳み込みフィルタは、それぞれの次元に3つの一次元畳み込みを使用する、9つの一次元畳み込みで置き換えられる。このアプローチは、例えば、二次元の場合には1/6、三次元の場合には1/48に、計算時間を短縮する。
【0329】
上述のように、イオン検出を行うためにすべての生データ点に対する畳み込み要素を計算する必要はない。好ましくは、それぞれのイオンの極大値を特定するのに十分なRi,j,kに対する値を計算するだけである。最小数は、例えば、それぞれのイオンについてRi,j,kの3×3×3の値の立方体である。極大値は、その立方体の中心のRi,j,kの値が周囲にある26個すべての値よりも大きい場合に見つかる。したがって、原理上、100,000個のイオンが見つかる場合、例示的な一実施例では、約3,000,000個の要素のみ、または潜在的畳み込み要素の総数4.5×1010の0.01%未満があればよい。これらの臨界畳み込み値の計算は、状況にもよるが数秒を要する。実際には、この最小値よりも多くの要素が計算される。したがって、本発明では、いくつかの実施形態において、IMSモジュールをLC/MSシステムに加えると、その大半が必要な情報をもたらさない測定されるデータ点の数が適宜大幅に増大するという考えを利用している。
【0330】
この実施例では、生データは、三次元LC/IMS/MSデータから二次元LC/MSデータ行列を構成することによりイオン移動度次元において縮退される。二次元LC/MS行列の要素
【数61】
は、
【数62】
のようにして、同じクロマトグラフ走査時間および質量スペクトルチャネルで測定されたすべての移動度からの強度を総和することにより得られる。
【0331】
上述のように、この次元は最低の分離能またはピーク容量を有するため、好ましくは移動度次元に対する総和を行い、次いで、その結果得られるT×μ二次元配列は、次元の他の2つの可能な対よりも多くの分離能要素を有する。
【0332】
二次元畳み込みがこの縮退配列に適用され、畳み込み要素
【数63】
の配列を決定するが、ただし、
【数64】
である。
【0333】
ここで、
【数65】
は、二次元畳み込みフィルタであり、
【数66】
は、二次元畳み込み要素である。要素
【数67】
の極大値により、二次元行列内に見つかるそれぞれの二次元イオンの保持時間およびm/zが特定される。
【0334】
本発明の実施例では、すべてのイオンがこれら二次元イオンピーク(類似のイオン運動性による複数のイオンから生じる可能性がある)によって説明が付くという仮定を利用する。したがって、二次元畳み込みの結果は、三次元畳み込みをどこに適用するかを示しており、それぞれの二次元イオンピークは、1つまたは複数の三次元イオンに対応する。特定の二次元イオンピークに対するイオン干渉がない場合、対応する三次元ボリュームにより、イオン移動度次元にその配置を有する単一イオン検出が行われる。
【0335】
二次元イオンピーク配置の判定毎に、三次元畳み込み要素の集合が計算される。本発明の実施例では、特定されたそれぞれのピークについて、これらの要素は、二次元ピーク配置の保持時間およびm/zを中心とし、200個すべての移動度スペクトルを範囲とする三次元ボリュームを対象範囲とする。
【0336】
したがって、三次元データから、イオンの移動度特性が得られるが、保持時間、m/z、および/または強度情報は、すでに、畳み込み二次元データにより与えられているか、または好ましくは、より正確に、オリジナルの三次元データによっても与えられている。そのため、三次元畳み込み要素の制限付きの選択を計算するだけで十分である。
【0337】
特定されたピークの幅上に分布する頂点を有する複数のイオンを含むことができる、畳み込み二次元データ内で特定された、ピークに対応するために、以下のスキームが適宜使用される。畳み込み要素は、それぞれの二次元イオン検出結果を中心とする11個の保持時間要素×11個の質量対電荷比要素×200個のイオン移動度要素のボリューム上で計算される。この実施例では、毎秒2億回の演算で計算を行うと仮定すると、約38分の処理時間で、LC/IMS/MSシステムに試料注入を1回行ったときのすべてのイオンに対する保持時間、イオン移動度、質量対電荷比、およびイオン強度が得られる。三次元畳み込み要素が計算されるボリュームを減らして、さらに、計算時間を(例えば、さらに1/20に短縮し)管理可能なレベルに下げる。
【0338】
本発明の好ましい実施形態の前記開示は、例示および説明を目的として提示されている。網羅的であることも発明を開示されている正確な形態に制限することも意図されていない。本明細書で説明されている実施形態のさまざまな変更形態および修正形態は、上記の開示に照らして当業者には明白なことであろう。本発明の範囲は、付属の請求項だけでなく、その等価の事項によっても定められるものとする。
【0339】
さらに、本発明の代表的な実施形態を説明する際に、明細書において、本発明の方法および/またはプロセスをステップの特定の並びとして提示していることがある。しかし、方法またはプロセスが、本明細書で説明されているステップの特定の順序に依存しない限り、その方法またはプロセスは、説明されているステップの特定の並びに限定されるべきではない。当業者であれば理解するように、ステップの他の並びも可能である場合がある。したがって、本明細書で説明されているステップの特定の順序は、請求項に対する制限と解釈されるべきではない。それに加えて、本発明の方法および/またはプロセスを対象とする請求項は、それらのステップを書かれている順序で実行することに限定されるべきではなく、また当業者は、それらのステップの並びは変えられてもよいが、それでも本発明の精神および範囲に従っていることを容易に理解できる。
【特許請求の範囲】
【請求項1】
LC/IMS/MS分析の方法であって、
試料から、それぞれの要素がイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付け、ノイズはイオンピークアーチファクトに関連付けられている三次元データ要素の集合を含むノイズの多い生データを取得することと、
イオン移動度次元において、そのデータ要素の集合を縮退して、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成することと、
縮退データ要素の集合を、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成することと、
保持時間次元および質量対電荷比次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定することと、
縮退データ要素の畳み込まれた集合の特定されたイオンピークに応じて、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を選択することと、
ノイズの多い生データの選択された1つまたは複数の部分を、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込むことと、
イオン移動度次元において、生データのそれぞれの畳み込まれた部分について1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項2】
生データのそれぞれの畳み込まれた部分に対する1つまたは複数のイオンピークを特定することが、生データの畳み込み込まれた部分の保持時間次元および質量対電荷比次元における1つまたは複数のイオンピークを特定することをさらに含む、請求項1に記載の方法。
【請求項3】
さらに、特定されたイオンピークについて、生データの畳み込まれた部分の保持時間次元および質量対電荷比次元と、縮退データ要素の畳み込まれた集合の保持時間次元および質量対電荷比次元と比較することを含む、請求項2に記載の方法。
【請求項4】
生データのそれぞれの畳み込まれた部分に対する1つまたは複数のイオンピークを特定することが、保持時間次元および質量対電荷比次元で重なるイオン移動度次元における少なくとも2つのイオンピークを特定することを含む、請求項1に記載の方法。
【請求項5】
さらに、保持時間次元および質量対電荷比次元において、生データの畳み込まれた1つまたは複数の部分の重なるイオンピークを特定することを含む、請求項1に記載の方法。
【請求項6】
1つまたは複数の部分がそれぞれ、保持時間次元および質量対電荷比次元におけるノイズの多い生データの制限された範囲およびイオン移動度次元における制限されていない範囲からなる、請求項1に記載の方法。
【請求項7】
それぞれの部分の制限された範囲が、実質的に、関連する特定されたイオンピークを中心とする、請求項6に記載の方法。
【請求項8】
イオンピークを特定することが、畳み込まれた生データのイオン強度極大値を判定することを含む、請求項1に記載の方法。
【請求項9】
さらに、曲線を特定された1つまたは複数のイオンピークのうちの少なくとも1つのイオンピークに当てはめて、少なくとも1つのピークの少なくとも質量対電荷比次元における配置の精度を改善することを含む、請求項1に記載の方法。
【請求項10】
曲線を当てはめることが、曲線を極大値に関連付けられている3つの最大のイオン強度値に当てはめることを含む、請求項9に記載の方法。
【請求項11】
曲線が、二次式に基づいている、請求項10に記載の方法。
【請求項12】
さらに、曲線を特定された1つまたは複数のイオンピークのうちの少なくとも1つのイオンピークに当てはめて、少なくとも1つのピークの少なくともイオン移動度次元における配置の精度を改善することを含む、請求項1に記載の方法。
【請求項13】
さらに、曲線を特定された1つまたは複数のイオンピークのうちの少なくとも1つのイオンピークに当てはめて、少なくとも1つのピークの少なくとも保持時間次元における配置の精度を改善することを含む、請求項1に記載の方法。
【請求項14】
さらに、1つまたは複数の特定されたピークの高さがピークイオン総数に関連付けられるように三次元行列の要素を正規化することを含む、請求項1に記載の方法。
【請求項15】
試料を分析する方法であって、
それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、イオンピークアーチファクトに関連するノイズの多い生データを、試料から取得することと、
少なくとも最低の分離能を有する次元において、それぞれの要素が組み合わされたイオンカウント強度を少なくとも3つの次元のうちの残りの次元に関連付ける縮退データ要素の集合を形成するようにデータ要素の集合を縮退することと、
縮退データ要素の集合を、縮退データ要素と同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込み、それにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成することと、
少なくとも3つの次元のうちの残りの次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定することと、
縮退データ要素の畳み込まれた集合のイオンピークの配置に関連付けられている、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を、選択することと、
ノイズの多い生データの選択された1つまたは複数の部分を、ノイズの多い生データと同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込むことと、
最低分離能次元において、ノイズの多い生データの畳み込まれた、選択済みの1つまたは複数の部分のそれぞれについて1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項16】
複数の部分のそれぞれに対する1つまたは複数のイオンピークを特定することが、複数の部分のそれぞれの保持時間次元および質量対電荷比次元における1つまたは複数のイオンピークを特定することをさらに含む、請求項15に記載の方法。
【請求項17】
化学処理のための装置であって、
クロマトグラフィモジュールと、
イオン移動度モジュールと、
質量分析モジュールと、
少なくとも1つのプロセッサおよび複数の命令を格納するための少なくとも1つのメモリを備える、モジュールと通信する制御ユニットであって、これら複数の命令が、少なくとも1つのプロセッサにより実行されたときに、
試料から、それぞれの要素がイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付け、ノイズはイオンピークアーチファクトに関連付けられている三次元データ要素の集合を含むノイズの多い生データを取得するステップと、
イオン移動度次元において、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成するようにそのデータ要素の集合を縮退するステップと、
縮退データ要素の集合を、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成するステップと、
保持時間次元および質量対電荷比次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定するステップと、
縮退データ要素の畳み込まれた集合の特定されたイオンピークに応じて、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を選択するステップと、
ノイズの多い生データの選択された1つまたは複数の部分を、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込むステップと、
イオン移動度次元において、生データのそれぞれの畳み込まれた選択済みの1つまたは複数の部分について1つまたは複数のイオンピークを特定するステップとを実行させる、制御ユニットとを備える、装置。
【請求項18】
装置であって、
それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、イオンピークアーチファクトに関連するノイズの多い生データを、試料から取得するように構成された分析モジュールと、
少なくとも最低の分離能を有する次元において、データ要素の集合を縮退し、それぞれの要素が組み合わされたイオンカウント強度を少なくとも3つの次元のうちの残りの次元に関連付ける縮退データ要素の縮小集合を形成する手段と、
縮退データ要素の集合を、縮退データ要素と同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込み、それにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成する手段と、
少なくとも3つの次元のうちの残りの次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定する手段と、
縮退データ要素の畳み込まれた集合のイオンピークの配置に関連付けられている、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を、選択する手段と、
ノイズの多い生データの選択された1つまたは複数の部分を、ノイズの多い生データと同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込む手段と、
最低分離能次元において、ノイズの多い生データの畳み込まれた、選択済みの1つまたは複数の部分のそれぞれについて1つまたは複数のイオンピークを特定する手段とを備える、装置。
【請求項19】
LC/IMS/MS分析の方法であって、
試料から、それぞれの要素がイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付け、ノイズはイオンピークアーチファクトに関連付けられている三次元データ要素の集合を含むノイズの多い生データを取得することと、
三次元データ要素を、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたイオンピークアーチファクトを有するデータ要素の畳み込まれた集合を形成することと、
保持時間次元、イオン移動度次元、および質量対電荷比次元において、畳み込まれた三次元データ要素の1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項20】
特定することが、イオンピークを畳み込まれた三次元データ要素におけるイオン強度の極大値に関連付けることを含む、請求項19に記載の方法。
【請求項21】
少なくとも2つの特定されたピークが、保持時間次元または質量対電荷比次元において重なっている、請求項19に記載の方法。
【請求項22】
少なくとも2つの特定されたピークが、実質的に同じイオン移動度を有する、請求項19に記載の方法。
【請求項23】
試料を分析する方法であって、
それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、イオンピークアーチファクトに関連するノイズの多い生データを、試料から取得することと、
ノイズの多い生データを、ノイズの多い生データと同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込み、これによりデータ要素の少なくとも三次元の畳み込まれた集合を形成することと、
データ要素の少なくとも三次元の畳み込まれた集合において、1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項24】
特定することが、イオンピークを少なくとも三次元の畳み込まれたデータ要素におけるイオン強度の極大値に関連付けることを含む、請求項23に記載の方法。
【請求項1】
LC/IMS/MS分析の方法であって、
試料から、それぞれの要素がイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付け、ノイズはイオンピークアーチファクトに関連付けられている三次元データ要素の集合を含むノイズの多い生データを取得することと、
イオン移動度次元において、そのデータ要素の集合を縮退して、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成することと、
縮退データ要素の集合を、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成することと、
保持時間次元および質量対電荷比次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定することと、
縮退データ要素の畳み込まれた集合の特定されたイオンピークに応じて、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を選択することと、
ノイズの多い生データの選択された1つまたは複数の部分を、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込むことと、
イオン移動度次元において、生データのそれぞれの畳み込まれた部分について1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項2】
生データのそれぞれの畳み込まれた部分に対する1つまたは複数のイオンピークを特定することが、生データの畳み込み込まれた部分の保持時間次元および質量対電荷比次元における1つまたは複数のイオンピークを特定することをさらに含む、請求項1に記載の方法。
【請求項3】
さらに、特定されたイオンピークについて、生データの畳み込まれた部分の保持時間次元および質量対電荷比次元と、縮退データ要素の畳み込まれた集合の保持時間次元および質量対電荷比次元と比較することを含む、請求項2に記載の方法。
【請求項4】
生データのそれぞれの畳み込まれた部分に対する1つまたは複数のイオンピークを特定することが、保持時間次元および質量対電荷比次元で重なるイオン移動度次元における少なくとも2つのイオンピークを特定することを含む、請求項1に記載の方法。
【請求項5】
さらに、保持時間次元および質量対電荷比次元において、生データの畳み込まれた1つまたは複数の部分の重なるイオンピークを特定することを含む、請求項1に記載の方法。
【請求項6】
1つまたは複数の部分がそれぞれ、保持時間次元および質量対電荷比次元におけるノイズの多い生データの制限された範囲およびイオン移動度次元における制限されていない範囲からなる、請求項1に記載の方法。
【請求項7】
それぞれの部分の制限された範囲が、実質的に、関連する特定されたイオンピークを中心とする、請求項6に記載の方法。
【請求項8】
イオンピークを特定することが、畳み込まれた生データのイオン強度極大値を判定することを含む、請求項1に記載の方法。
【請求項9】
さらに、曲線を特定された1つまたは複数のイオンピークのうちの少なくとも1つのイオンピークに当てはめて、少なくとも1つのピークの少なくとも質量対電荷比次元における配置の精度を改善することを含む、請求項1に記載の方法。
【請求項10】
曲線を当てはめることが、曲線を極大値に関連付けられている3つの最大のイオン強度値に当てはめることを含む、請求項9に記載の方法。
【請求項11】
曲線が、二次式に基づいている、請求項10に記載の方法。
【請求項12】
さらに、曲線を特定された1つまたは複数のイオンピークのうちの少なくとも1つのイオンピークに当てはめて、少なくとも1つのピークの少なくともイオン移動度次元における配置の精度を改善することを含む、請求項1に記載の方法。
【請求項13】
さらに、曲線を特定された1つまたは複数のイオンピークのうちの少なくとも1つのイオンピークに当てはめて、少なくとも1つのピークの少なくとも保持時間次元における配置の精度を改善することを含む、請求項1に記載の方法。
【請求項14】
さらに、1つまたは複数の特定されたピークの高さがピークイオン総数に関連付けられるように三次元行列の要素を正規化することを含む、請求項1に記載の方法。
【請求項15】
試料を分析する方法であって、
それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、イオンピークアーチファクトに関連するノイズの多い生データを、試料から取得することと、
少なくとも最低の分離能を有する次元において、それぞれの要素が組み合わされたイオンカウント強度を少なくとも3つの次元のうちの残りの次元に関連付ける縮退データ要素の集合を形成するようにデータ要素の集合を縮退することと、
縮退データ要素の集合を、縮退データ要素と同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込み、それにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成することと、
少なくとも3つの次元のうちの残りの次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定することと、
縮退データ要素の畳み込まれた集合のイオンピークの配置に関連付けられている、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を、選択することと、
ノイズの多い生データの選択された1つまたは複数の部分を、ノイズの多い生データと同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込むことと、
最低分離能次元において、ノイズの多い生データの畳み込まれた、選択済みの1つまたは複数の部分のそれぞれについて1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項16】
複数の部分のそれぞれに対する1つまたは複数のイオンピークを特定することが、複数の部分のそれぞれの保持時間次元および質量対電荷比次元における1つまたは複数のイオンピークを特定することをさらに含む、請求項15に記載の方法。
【請求項17】
化学処理のための装置であって、
クロマトグラフィモジュールと、
イオン移動度モジュールと、
質量分析モジュールと、
少なくとも1つのプロセッサおよび複数の命令を格納するための少なくとも1つのメモリを備える、モジュールと通信する制御ユニットであって、これら複数の命令が、少なくとも1つのプロセッサにより実行されたときに、
試料から、それぞれの要素がイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付け、ノイズはイオンピークアーチファクトに関連付けられている三次元データ要素の集合を含むノイズの多い生データを取得するステップと、
イオン移動度次元において、それぞれの要素が組み合わされたイオンカウント強度を保持時間次元および質量対電荷比次元に関連付ける縮退データ要素の集合を形成するようにそのデータ要素の集合を縮退するステップと、
縮退データ要素の集合を、二次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成するステップと、
保持時間次元および質量対電荷比次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定するステップと、
縮退データ要素の畳み込まれた集合の特定されたイオンピークに応じて、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を選択するステップと、
ノイズの多い生データの選択された1つまたは複数の部分を、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込むステップと、
イオン移動度次元において、生データのそれぞれの畳み込まれた選択済みの1つまたは複数の部分について1つまたは複数のイオンピークを特定するステップとを実行させる、制御ユニットとを備える、装置。
【請求項18】
装置であって、
それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、イオンピークアーチファクトに関連するノイズの多い生データを、試料から取得するように構成された分析モジュールと、
少なくとも最低の分離能を有する次元において、データ要素の集合を縮退し、それぞれの要素が組み合わされたイオンカウント強度を少なくとも3つの次元のうちの残りの次元に関連付ける縮退データ要素の縮小集合を形成する手段と、
縮退データ要素の集合を、縮退データ要素と同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込み、それにより低減されたピークアーチファクトを有する縮退データ要素の畳み込まれた集合を形成する手段と、
少なくとも3つの次元のうちの残りの次元において、縮退データ要素の畳み込まれた集合のイオンピークを特定する手段と、
縮退データ要素の畳み込まれた集合のイオンピークの配置に関連付けられている、さらなる分析対象となるノイズの多い生データの1つまたは複数の部分を、選択する手段と、
ノイズの多い生データの選択された1つまたは複数の部分を、ノイズの多い生データと同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込む手段と、
最低分離能次元において、ノイズの多い生データの畳み込まれた、選択済みの1つまたは複数の部分のそれぞれについて1つまたは複数のイオンピークを特定する手段とを備える、装置。
【請求項19】
LC/IMS/MS分析の方法であって、
試料から、それぞれの要素がイオンカウント強度を保持時間次元、イオン移動度次元、および質量対電荷比次元に関連付け、ノイズはイオンピークアーチファクトに関連付けられている三次元データ要素の集合を含むノイズの多い生データを取得することと、
三次元データ要素を、三次元行列に関連付けられているアーチファクト低減フィルタに畳み込み、これにより低減されたイオンピークアーチファクトを有するデータ要素の畳み込まれた集合を形成することと、
保持時間次元、イオン移動度次元、および質量対電荷比次元において、畳み込まれた三次元データ要素の1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項20】
特定することが、イオンピークを畳み込まれた三次元データ要素におけるイオン強度の極大値に関連付けることを含む、請求項19に記載の方法。
【請求項21】
少なくとも2つの特定されたピークが、保持時間次元または質量対電荷比次元において重なっている、請求項19に記載の方法。
【請求項22】
少なくとも2つの特定されたピークが、実質的に同じイオン移動度を有する、請求項19に記載の方法。
【請求項23】
試料を分析する方法であって、
それぞれの要素がイオンカウント強度を異なる分離能の少なくとも3つの次元に関連付けるデータ要素の集合を含む、イオンピークアーチファクトに関連するノイズの多い生データを、試料から取得することと、
ノイズの多い生データを、ノイズの多い生データと同じ数の次元を有する行列に関連付けられているアーチファクト低減フィルタに畳み込み、これによりデータ要素の少なくとも三次元の畳み込まれた集合を形成することと、
データ要素の少なくとも三次元の畳み込まれた集合において、1つまたは複数のイオンピークを特定することとを含む、方法。
【請求項24】
特定することが、イオンピークを少なくとも三次元の畳み込まれたデータ要素におけるイオン強度の極大値に関連付けることを含む、請求項23に記載の方法。
【図1】

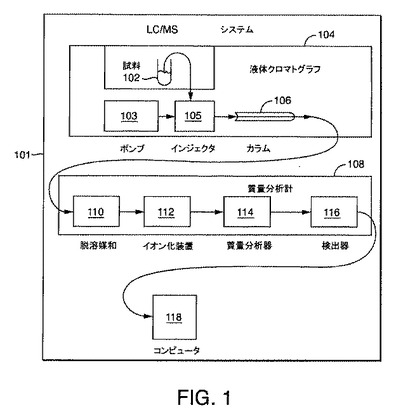
【図2】
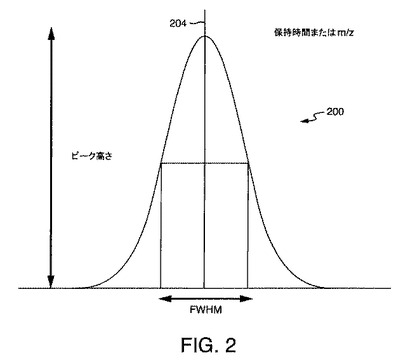
【図3A】
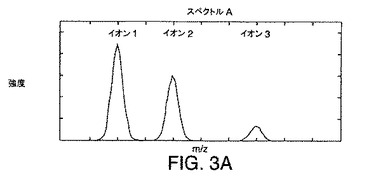
【図3B】
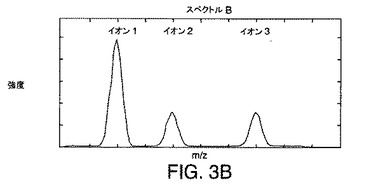
【図3C】
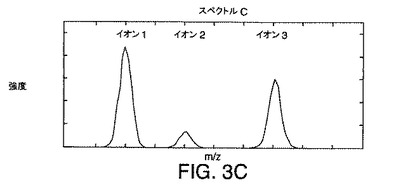
【図4A】
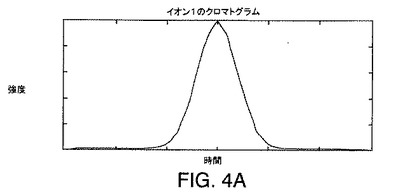
【図4B】
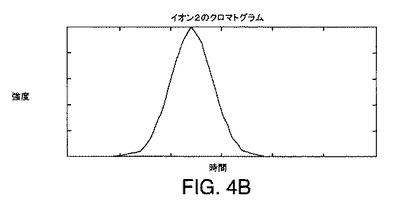
【図4C】
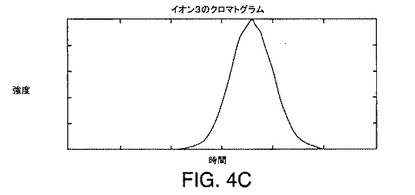
【図5】
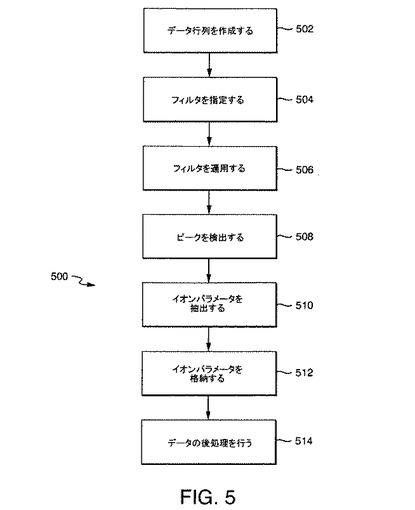
【図6】
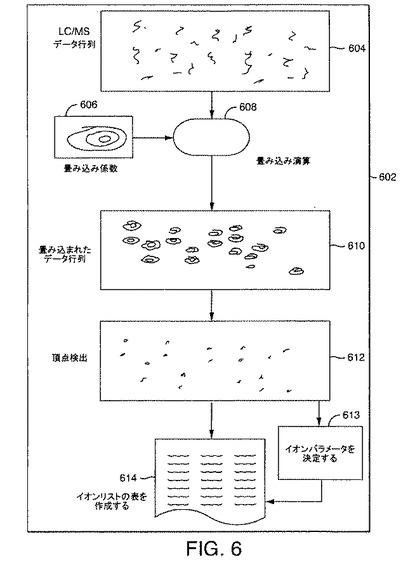
【図7】
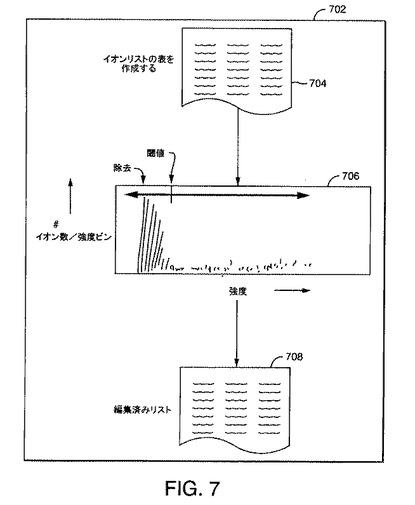
【図8】
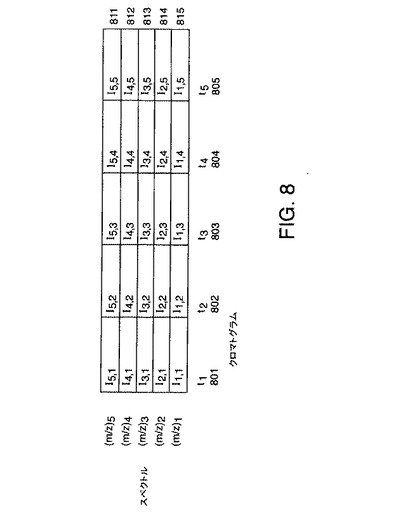
【図9】
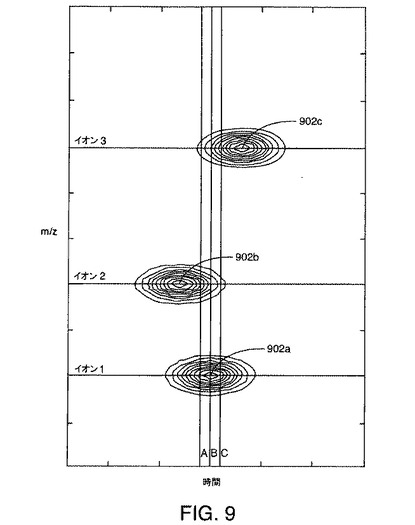
【図10】
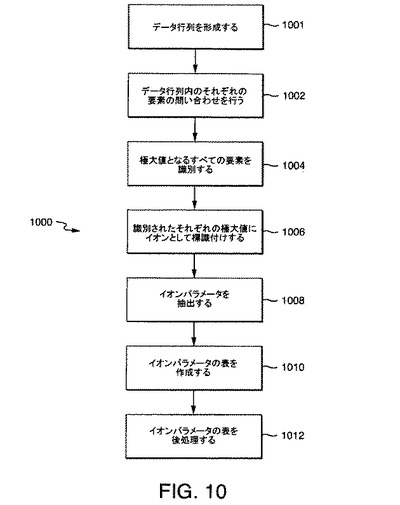
【図11】
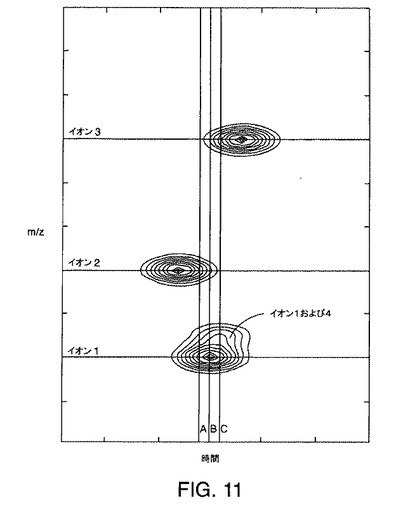
【図12A】
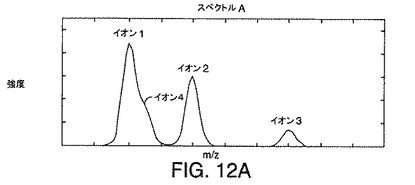
【図12B】
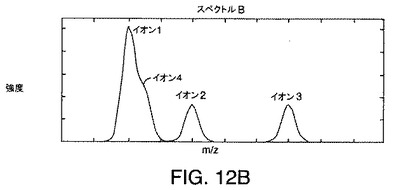
【図12C】
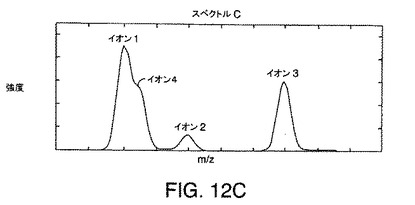
【図13】
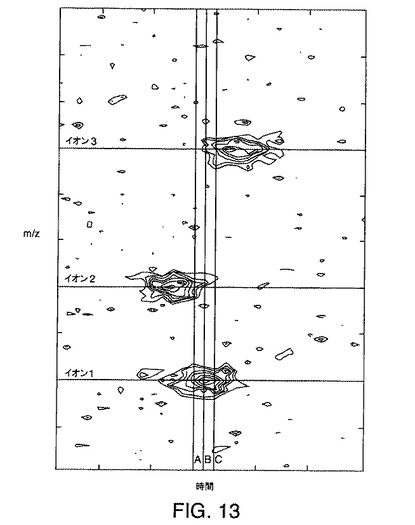
【図14A】
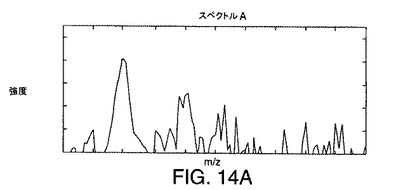
【図14B】
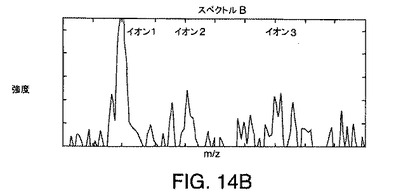
【図14C】
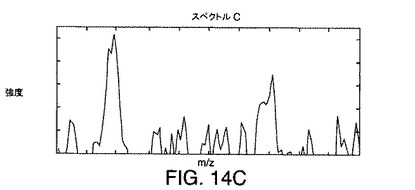
【図14D】
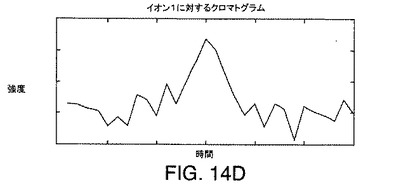
【図14E】
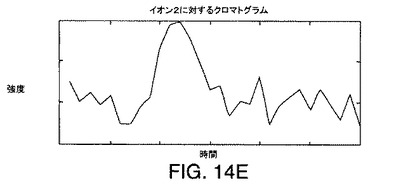
【図14F】
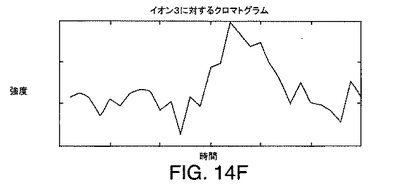
【図15】
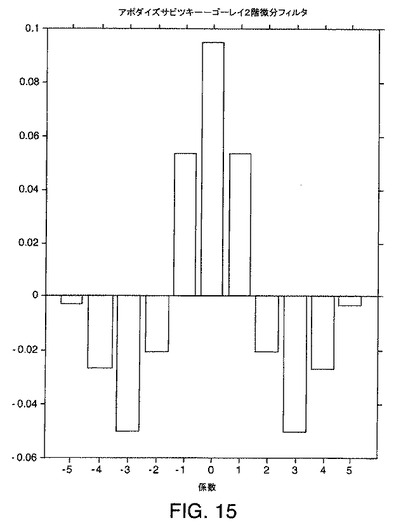
【図16A】
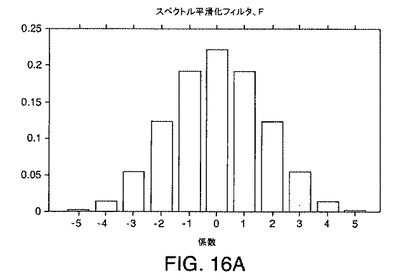
【図16B】
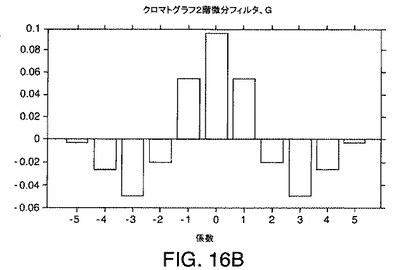
【図16C】
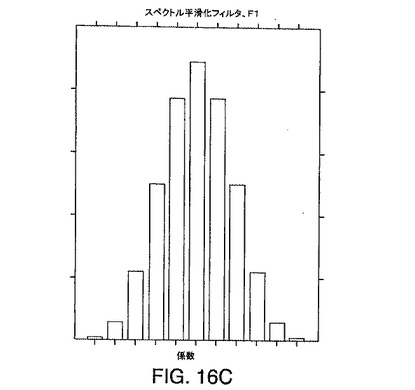
【図16D】
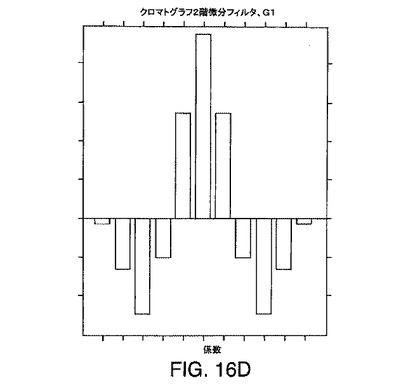
【図16E】
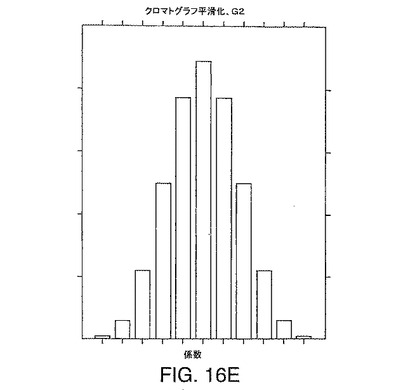
【図16F】
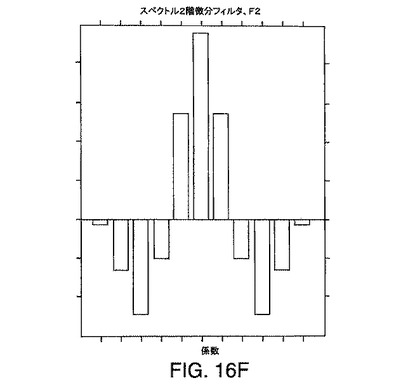
【図17A】
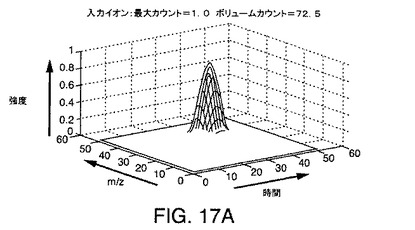
【図17B】
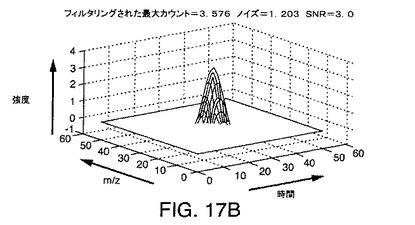
【図17C】
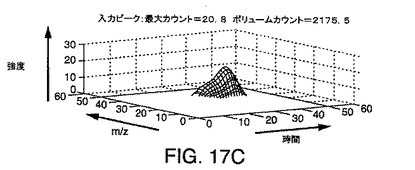
【図17D】
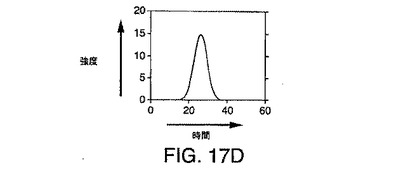
【図17E】
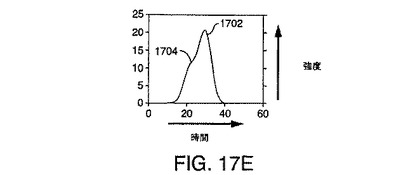
【図17F】
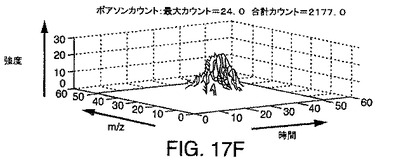
【図17G】
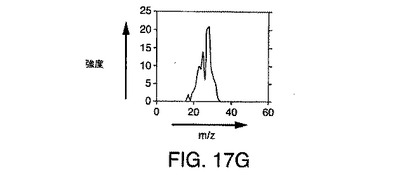
【図17H】
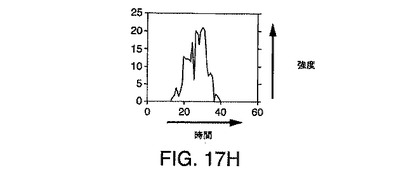
【図17I】
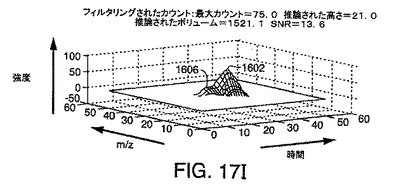
【図17J】
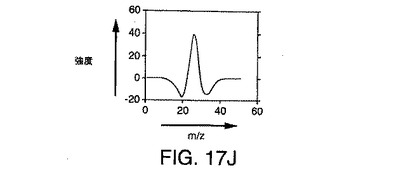
【図17K】
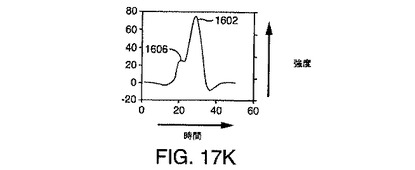
【図18】
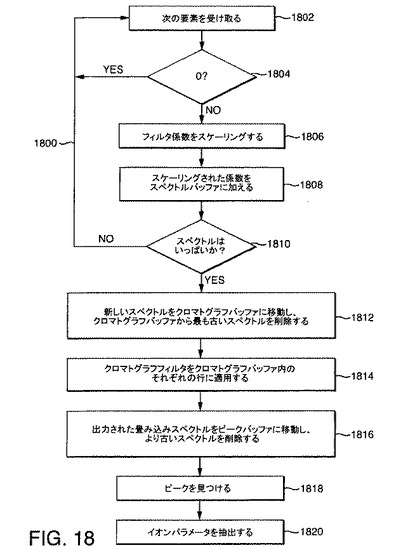
【図19A】
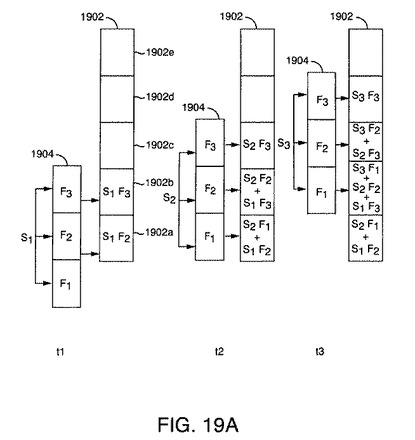
【図19B】
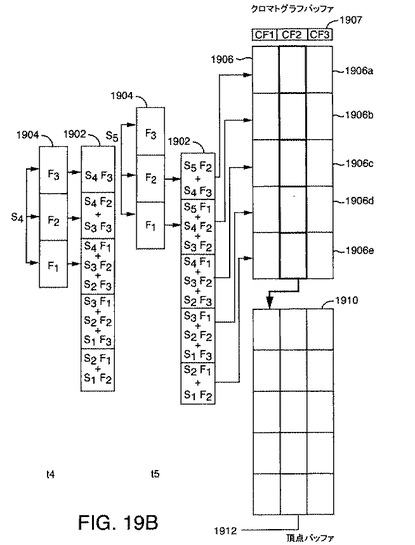
【図20】
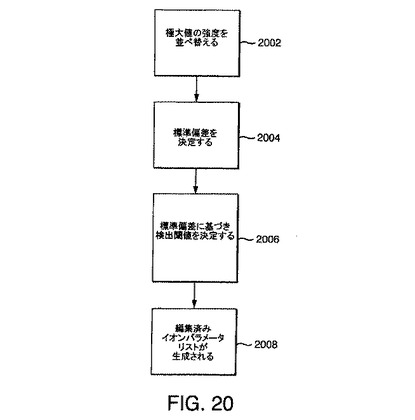
【図21】
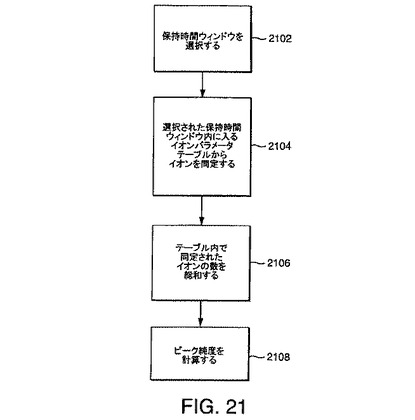
【図22A】
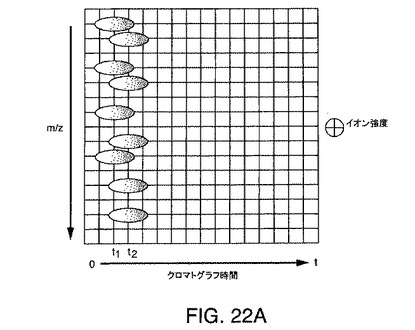
【図22B】
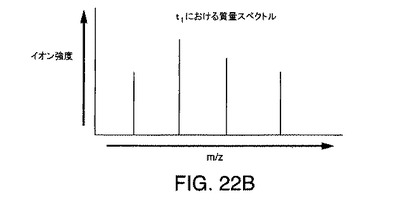
【図22C】
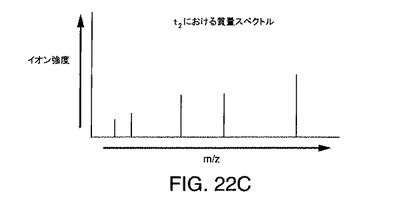
【図23A】
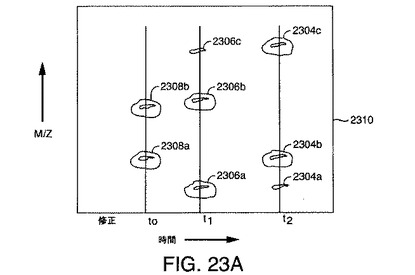
【図23B】
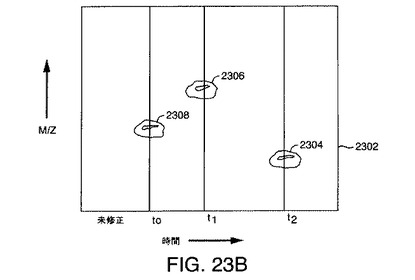
【図24】
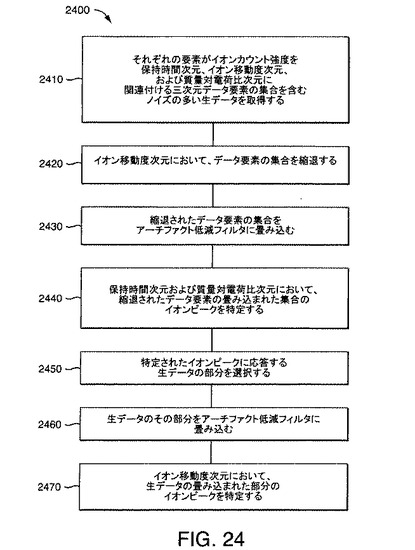
【図2】
【図3A】
【図3B】
【図3C】
【図4A】
【図4B】
【図4C】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12A】
【図12B】
【図12C】
【図13】
【図14A】
【図14B】
【図14C】
【図14D】
【図14E】
【図14F】
【図15】
【図16A】
【図16B】
【図16C】
【図16D】
【図16E】
【図16F】
【図17A】
【図17B】
【図17C】
【図17D】
【図17E】
【図17F】
【図17G】
【図17H】
【図17I】
【図17J】
【図17K】
【図18】
【図19A】
【図19B】
【図20】
【図21】
【図22A】
【図22B】
【図22C】
【図23A】
【図23B】
【図24】
【公表番号】特表2009−539067(P2009−539067A)
【公表日】平成21年11月12日(2009.11.12)
【国際特許分類】
【出願番号】特願2009−512324(P2009−512324)
【出願日】平成19年5月25日(2007.5.25)
【国際出願番号】PCT/US2007/069784
【国際公開番号】WO2007/140327
【国際公開日】平成19年12月6日(2007.12.6)
【出願人】(509131764)ウオーターズ・テクノロジーズ・コーポレイシヨン (46)
【Fターム(参考)】
【公表日】平成21年11月12日(2009.11.12)
【国際特許分類】
【出願日】平成19年5月25日(2007.5.25)
【国際出願番号】PCT/US2007/069784
【国際公開番号】WO2007/140327
【国際公開日】平成19年12月6日(2007.12.6)
【出願人】(509131764)ウオーターズ・テクノロジーズ・コーポレイシヨン (46)
【Fターム(参考)】
[ Back to top ]