
インテグリンヘテロ二量体およびそのサブユニット
【課題】新規サブユニットα10をサブユニットβと共に含む組換体または単離インテグリンヘテロ二量体を提供する。
【解決手段】α10インテグリンは、ウシ軟骨細胞から、コラーゲン−II型アフィニティカラム上で精製することができる。インテグリンまたはサブユニットα10はあらゆる型の細胞の、例えば軟骨細胞、骨芽細胞および線維芽細胞のマーカーまたは標的として使用することができる。インテグリンまたはそのサブユニットα10は、種々の生理学的または治療方法におけるマーカーまたは標的として使用することができる。それらは、医薬組成物およびワクチンにおける活性成分として使用することができる。
【解決手段】α10インテグリンは、ウシ軟骨細胞から、コラーゲン−II型アフィニティカラム上で精製することができる。インテグリンまたはサブユニットα10はあらゆる型の細胞の、例えば軟骨細胞、骨芽細胞および線維芽細胞のマーカーまたは標的として使用することができる。インテグリンまたはそのサブユニットα10は、種々の生理学的または治療方法におけるマーカーまたは標的として使用することができる。それらは、医薬組成物およびワクチンにおける活性成分として使用することができる。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、サブユニットα10およびサブユニットβを含む組み換え体または単離インテグリンヘテロ二量体、それのサブユニットα10、上記インテグリンの相同体およびフラグメントならびに類似の生物学的活性を有する上記サブユニットα10の相同体およびフラグメント、それの生産方法、それをコードするポリヌクレオチドおよびオリゴヌクレオチド、それを含むベクターおよび細胞、それに特異的に結合する結合実体、ならびにそれの使用に関するものである。
【背景技術】
【0002】
インテグリンは、細胞−細胞および細胞−マトリックス相互反応を仲介するトランスメンブラン糖タンパク質の大きなフアミリーである(1−5)。この超フアミリーの全ての既知メンバーは、α−およびβ−サブユニットからなる非共有結合的に会合したヘテロ二量体である。現在では、八つのβ−サブユニット(β1 −β8 )(6)および十六のα−サブユニット(α1 −α9 、αV 、αM 、αL 、αX 、αIIb 、αE およびαD )が特徴付けられており(6−21)、これらのサブユニットは会合して20を超す異種のインテグリンを生ずる。β1 サブユニットは10種の異なったα−サブユニットα1 −α9 およびαV と会合することが証明され、かつ、コラーゲン、ラミニンおよびフィブロネクチン等の細胞外マトリックスタンパク質との相互反応を仲介することが証明されている。主たるコラーゲン結合インテグリンはα1 β1 およびα2 β1 (22−25)である(22−25)。インテグリンα3 β1 およびα9 β1 もコラーゲンと相互反応すると報告されているが(26,27)、この相互反応については充分に理解されていない(28)。α−およびβーインテグリンサブユニットの細胞外N−末端領域はリガンドの結合に重要である(29,30)。このα−サブユニットの末端領域はFGおよびGAP共通配列を含む7回折畳み繰り返し配列(12,31)からなる。この繰り返しは、推定2価カチオン結合サイト含む最後の3回または4回繰り返し部分を伴ったβープロペラー領域(32)へと折り畳むことが予見される。α−インテグリンサブユニットα1 、α2 、αD 、αE 、αL 、αM 、αX は〜200アミノ酸挿入領域であるI−領域(A〜領域)を含み、このことは von Willebrand 因子、軟骨マトリックスタンパク質および補体因子C2 およびB(33,34)中の配列に対する類似性を示す。このI−領域は、第2および第3FG−GAP繰り返し体間に局在し、金属依存性付着サイト(MIDAS) を含み、かつ、このものはリガンドの結合に関与する(35−38)。
【0003】
軟骨中の唯一の細胞型である軟骨細胞は、α1 β1 、α2 β1 、α3 β1 、α5 β1 、α6 β1 、αV β3 およびαV β5 (39−41)を包含する多数の異なったインテグリンを発現する。α1 β1 およびα2 β1 は軟骨の主成分の一つであるII型コラーゲン(25)との軟骨細胞相互反応を仲介することが判明している。またα2 β1 は軟骨マトリックスタンパク質 コンドロアドヘリン(42)に対する受容体である。
【発明の開示】
【課題を解決するための手段】
【0004】
この発明はサブユニットα10を、サブユニットβ特にサブユニットβ1 と会合した形態で含む新規コラーゲン型II結合インテグリンに関するものであるが、他のβ−サブユニットも顧慮に値する。好ましい実施対様では、このインテグリンはヒトまたはウシの間接軟骨細胞ならびにヒト軟骨肉腫細胞から単離されている。
【0005】
またこの発明は、サブユニットβ好ましくはサブユニットβ1 と会合したサブユニットα10を含むウシインテグリンヘテロ二量体等の、他の種から単離した上記インテグリンのインテグリン相同体、ならびにヒト細胞の他の型からまたは他の種由来の細胞から単離した相同体も包含する。
【0006】
この発明は具体的には、SEQ ID No.1 または SEQ ID No.2 で示されるアミノ酸配列を含む組み換え体または単離インテグリンサブユニットα10に関し、かつ、同じ生物学的活性を示す、その相同体またはフラグメントに関する。
【0007】
この発明はさらに、SEQ ID No.1 または SEQ ID No.2 で示されるアミノ酸配列を含む組み換えインテグリンサブユニットα10、または類似の生物学的活性を示すその相同体もしはフラグメントの生産方法に関し、この方法は次の工程:
a)インテグリンサブユニットα10をコードするヌクレオチド配列を含むポリヌクレオチド、または類似の生物学的活性を示すその相同体もしはフラグメントを単離し;
b)単離したポリヌクレオチドを含む発現ベクターを構築し;
c)上記発現ベクターを用いて宿主細胞をトランスフオームし;
d)トランスフオームされた宿主細胞を、インテグリンサブユニットα10 の発現に適する条件下の培地中で、または類似の生物学的活性をトランフオームされた宿主細胞中で示すそれらの相同体もしくはフラグメントの発現に適する条件下の培地中で培養し;かつ任意に、
e)インテグリンサブユニットα10、または類似の生物学的活性を示すその相同体もしくはフラグメントを上記トランスフオームされ宿主主細胞または上記培地から単離する工程;
を包含する。
このインテグリンα10、または類似活性を示すそれらの相同体もしくはフラグメントも、それらが天然に存在する細胞からの単離により提供され得る。
【0008】
この発明はまた、インテグリンサブユニットα10、または類似の生物学的活性を示すそれらの相同体もしくはフラグメントをコードするヌクレオチドを含む単離ポリヌクレオチドにも関し、このポリヌクレオチドは SEQ ID No.1または SEQ ID No.2 で示されるポリヌクレオチド配列、またはその一部を含む。
【0009】
この発明はさらに、 SEQ ID No.1または SEQ ID No.2 で示されるアミノ酸配列を示すインテグリンサブユニットα10、またはそれらの相同体もしくはフラグメントをコードするDNAまたはRNAに交配する単離ポリヌクレオチドまたはオリゴヌクレオチドにも関し、この場合、上記ポリヌクレオチドまたはオリゴヌクレオチドはインテグリンサブユニットα1 をコードするDNAまたはRNAと交配する素質がない。
【0010】
さらなる観点において、この発明は上記ポリヌクレオチドを含むベクターに関し、かつ、上記ベクターを含む細胞および SEQ ID No.1または SEQ ID No.2 で示されるような、これらゲノム中に統合されたポリヌクレオチドまたはオリゴヌクレオチドを有する細胞に関する。
【0011】
この発明はまた、タンパク質、ペプチド、炭水化物、脂質、天然リガンド、ポリクローナル抗体またはモノクローナル抗体等の、インテグリンサブユニットα10またはそれらの相同体もしくはフラグメントへの特異的結合能力を有する結合実体にも関する。
【0012】
さらなる観点でこの発明は、サブユニットα10およびサブユニットβを含む組み換え体または単離インテグリンヘテロ二量体に関し、この場合、サブユニットα10は SEQ ID No.1または SEQ ID No.2 で示されるようなアミノ酸配列または類似の生物学的活性を示す相同体またはフラグメントを含む。好ましい実施態様では、このサブユニットβはβ1 である。
【0013】
またこの発明は、サブユニットα10およびサブユニットβを含む組み換え体インテグリンヘテロ二量体の生成方法にも関し、この場合、このサブユニットα10は SEQ ID No.1または SEQ ID No.2 で示されるようなアミノ酸配列を含み、この方法は次の工程:
a)インテグリンヘテロ二量体のサブユニットα10をコードするヌクレオチド配列を含む一つのポリヌクレオチド、および任意に、インテグリンヘテロ二量体のサブユニットβまたは類似の生物学的活性を示すその相同体またはフラグメントをコードするヌクレオチド配列を含む他のポリヌクレオチドを単離し;
b)上記サブユニットβをコードする上記単離ヌクレオチドを含む発現ベクターとの組み合わせで、上記サブユニットα10をコードする上記単離ポリヌクレオチドを含む発現ベクターを構築し;
c)上記発現ベクターを用いて宿主細胞をトランスフオームし;
d)トランスフオームされた上記宿主細胞を、サブユニットα10およびβを含むインテグリンヘテロ二量体の発現に適する条件下の培地中で、または類似の生物学的活性を上記トランスフオームされた宿主細胞中で示すその相同体またはフラグメントの発現に適する条件下の培地中で培養し;かつ任意に、
e)サブユニットα10 おょびβを含むインテグリンヘテロ二量体、または同じ生物学的活性を示すその相同体またはフラグメントを上記トランスフオームされた宿主細胞または上記培地から単離する工程;
を包含する。
【0014】
このインテグリンヘテロ二量体、または類似の生物学的活性を示す相同体もしくはフラグメントもまた、これらが天然に存在する細胞からの単離により提供され得る。
【0015】
さらにこの発明は、第1ベクターを含む細胞に関し、この第1ベクターは、インテグリンヘテロ二量体のサブユニットα10をコードする、または類似の生物学的活性を示すそれらの相同体もしは部分をコードするポリヌクレオチドを含み、このポリヌクレオチドは、 SEQ ID No.1または SEQ ID No.2 で示されるようなヌクレオチド配列もしくはそれらの部分、および、任意に第2ベクターを含み、上記第2ベクターは、インテグリンヘテロ二量体のサブユニットβまたはその相同体もしくはフラグメントをコードするポリヌクレオチドを含む。
【0016】
さらなる他の観点では、この発明はサブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体に特異結合し得る、または類似の生物学的活性を示す相同体もしくはフラグメントに特異結合する能力を有する結合実体に関し、この場合のサブユニットはβ1 である。好ましい結合実体はタンパク質、ペプチド、炭水化物、脂質、天然リガンド、ポリクロ−ナル抗体およびモノクローナル抗体である。
【0017】
さらなる観点で、この発明はインテグリンサブユニットα10のフラグメントに関し、この場合のフラグメントは細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドである。
【0018】
一つの実施態様では、上記フラグメントはアミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチドである。
【0019】
他の実施態様では、上記フラグメントは SEQ ID No.1 のアミノ酸約952からアミノ酸約986のアミノ酸配列を含む。
【0020】
さらなる実施態様では、上記フラグメントは SEQ ID No.1 のアミノ酸約140からアミノ酸約337のアミノ酸配列を含む。
【0021】
この発明の他の実施態様は、ヒトインテグリンサブユニットα10のフラグメントをコードするポリヌクレオチドまたはオリゴヌクレオチドに関する。一つの実施態様ではオリゴヌクレオチドのこのポリヌクレオチドは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドであるフラグメントをコードする。さらなる実施態様では、このポリヌクレオチドまたはオリゴヌクレオチドは上記定義のフラグメントをコードする。
【0022】
この発明はまた、上記定義のインテグリンサブユニットα10のフラグメントに特異的に結合し得る能力を有する結合性実体に関する。
【0023】
またこの発明は、 SEQ ID No.1 または SEQ ID No.2 で示されるアミノ酸配列を含むインテグリンサブユニットα10、または上記サブユニットα10 およびサブユニットβを含むインテグリンヘテロ二量体、または類似の生物学的活性を示す上記インテグリンの相同体もしくはフラグメントを、上記インテグリンサブユニットα10を発現する細胞もしくは組織のマーカーまたは標的分子として含むインテグリンサブユニットα10を使用する方法に関し、この場合の細胞もしくは組織はヒト由来のものを包含する動物細胞もしくは組織である。
【0024】
この方法の実施態様におけるフラグメントは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドである。
【0025】
この方法のさらなる実施態様では、このフラグメントはアミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチド、または SEQ ID No.1 のアミノ酸No.約952からアミノ酸No.約986のアミノ酸配列を含むフラグメント、またはSEQ ID No.1のアミノ酸No.約140からアミノ酸約337のアミノ酸配列を含むフラグメントを含むペプチドである。
【0026】
サブユニットβは好ましくはβ1 である。この細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞または繊維芽細胞からなる群から選択するのが好ましい。
【0027】
上記方法は、軟骨損傷、トラウマ、慢性間節リウマチおよび骨間節炎を包含する病理的症状等の、上記サブユニットα10が関与する病離的症状の間に使用できる。
【0028】
上記方法は、胎児性発生期間の軟骨の形成の検出または軟骨の生理学的もしくは治療的修復の検出に使用できる。上記方法はまた、軟骨細胞の選択および分析、または軟骨細胞の仕分け、単離もしくは精製のために使用できる。
【0029】
この方法のさらなる実施態様は、軟骨または軟骨細胞の移植期間中に軟骨または軟骨細胞の再生を検出する方法である。
【0030】
この方法のさらなる実施態様は、軟骨細胞の分化を in vitro で研究するための方法である。
【0031】
またこの発明は、SEQ ID No.1 または SEQ ID No.2に見られるアミノ酸配列を含むインテグリンサブユニットα10 に対する特異結合能力を有する結合実体、または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体に対する特異結合能力を有する結合実体、または、類似の生物学的活性を示すそれらの相同体もしくはフラグメントに対する特異結合能力を有する結合実体を、上記インテグリンサブユニットα10を発現する細胞もしくは組織のマーカまたは標的分子として使用する方法にも関し、この場合の細胞または組織はヒト由来を包含する動物からのものである。
【0032】
上記方法におけるフラグメントは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドであってもよい。好ましい実施態様における上記フラグメントはアミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ 、または SEQ No. 1 のアミノ酸配列 約No. 952 からアミノ酸配列 約No. 986 を含むフラグメント、または SEQ No. 1 のアミノ酸配列 約No. 140 からアミノ酸配列 約No. 337 を含むフラグメントを含むペプチドである。
【0033】
この方法は、SEQ ID No.1 または SEQ ID No.2に見られるアミノ酸配列を含むインテグリンサブユニットα10の存在、または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体の存在、または類似の生物学的活性を示すその相同体もしくはフラグメントの存在を検出する目的でも使用できる。
【0034】
この方法のさらなる実施態様では、上記方法は胚発生、血管形成、または癌の発生期間中に細胞の分化状態を決定するための方法である。
【0035】
さらなる実施態様におけるこの方法は、インテグリンサブユニットα10の細胞上での存在、または類似生物学的活性を示す上記インテグリンサブユニットの相同体もしくはフラグメントの細胞上での存在を検出する方法であり、この方法ではSEQ ID No.1 に見られるヌクレオチド配列から選択されたポリヌクレオチドもしくはオリゴポリヌクレオチドを含む群から選択されたポリヌクレオチドもしくはオリゴポリヌクレオチドが、交配条件下にマーカーとして使用され、この場合、上記ポリヌクレオチドもしくはオリゴポリヌクレオチドはインテグリンサブユニットα1をコードするDNAもしくはRNAと交配する素質がない。上記細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択されてもよい。上記インテグリンフラグメントは、細胞質領域、I−領域およびスプライスド領域から選択された、アミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチド等のペプチド、または SEQ ID No.1 のアミノ酸約 No.952からアミノ酸約 No.986、または SEQ ID No.1 のアミノ酸約 No.140からアミノ酸約 No.337を含むフラグメントを包含する群から選択されたペプチドでる。
【0036】
さらなる実施態様におけるこの方法は、病理学的症状における、組織再生における、または軟骨の治療もしくは病理学的修復における、発生期間中の細胞の分化状態を決定するための方法である。この病理学的症状は、間節リウマチ、骨間節炎または癌を包含する病理学的症状のいずれでもよい。この細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞を包含する群から選択できる。
【0037】
さらなる実施態様におけるこの方法は、病理学的症状における、組織再生における、および軟骨の治療もしくは病理学的修復における、発生期間中の細胞の分化状態を決定するための方法であり、この場合、 SEQ ID No.1に見られるポリヌクレオチド配列から選択されたポリヌクレオチドもしくはオリゴポリヌクレオチドが交配条件下のマーカーとして使用され、この場合の上記ポリヌクレオチドもしくはオリゴポリヌクレオチドはインテグリンサブユニットα1をコードするDNAもしくはRNAと交配する素質がない。この観点における実施態様は方法を含み、この場合、上記ポリヌクレオチドもしくはオリゴポリヌクレオチドは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドをコードするポリヌクレオチドもしくはオリゴポリヌクレオチドであり、例えば、アミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチドをコードするポリヌクレオチドまたはオリゴヌクレオチドまたは SEQ ID No.1 のアミノ酸約 No. 952 からアミノ酸約No. 986 から選択されたアミノ酸配列または SEQ ID No.1 のアミノ酸約 No. 140 からアミノ酸約No. 337 のアミノ酸配列を含むペプチドをコードするポリヌクレオチドもしくはオリゴポリヌクレオチドである。上記病理学的症状は、間節リウマチ、骨間節炎または癌を包含する病理学的症状のいずれでもよい。この細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞を包含する群から選択できる。
【0038】
さらなる観点でこの発明は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体;またはそのサブユニットα10;または類似の生物学的活性を示す上記インテグリンもしくはサブユニットα10の相同体もしくはフラグメント;を使用できる医薬的作因もしくは抗体を活性成分として含む医薬組成物に関する。上記医薬組成物の実施態様は、軟骨、骨もしくは血液導管の形成を刺激、阻害または阻止する目的における組成物の使用である。さらなる実施態様は、感染、炎症後および外科的介入後の腱/靭帯間および組織周辺間の癒着防止に使用する医薬組成物を包含する。
【0039】
この発明はまた、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または上記インテグリンもしくはサブユニットα10の相同体またはフラグメント、または上記インテグリンサブユニットα10をコードするDNAもしはRNAを活性成分として含むワクチンニ関する。
【0040】
この発明のさらなる観点は、軟骨または軟骨細胞の移植におけるマーカーまたは標的としての、上記定義のインテグリンサブユニットα10の使用に関する。
【0041】
この発明のさらなる観点は、オセオ組み込みを刺激するための移植組織片表面への軟骨細胞および/または骨芽細胞の付着促進目的の、SEQ ID No.1 または SEQ ID No.2 に見られるアミノ酸配列を含むインテグリンサブユニットα10に特異結合する能力を有する結合実体の使用方法、または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体に特異結合する能力を有する結合実体の使用方法、または類似生物学的活性を示すその相同体もしくはフラグメントに特異結合する能力を有する結合実体の使用方法に関する。
【0042】
この発明はまた、インテグリンサブユニットα10または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体を、癒着で組織機能を損なった腱、靭帯、骨格筋における抗癒着薬剤もしくは分子に対する標的として使用することに関する。
【0043】
この発明には、軟骨形成もしくは骨形成の刺激、阻害または阻止のための方法に関し、この方法は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または類似の生物学的活性を示す上記インテグリンまたはサブユニットα10の相同体もしくはフラグメントを標的分子として使用し得る医薬作因または抗体の適当量を、被験者に投与することが包含される。
【0044】
他の実施態様におるこの発明は、癒着が組織機能を損なった場合の感染後、炎症後、および外科的介入後の腱/靭帯間および周辺組織の癒着防止方法に関するものであり、この方法は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または類似の生物学的活性を示す上記インテグリンまたはサブユニットα10の相同体もしくはフラグメントを標的分子として使用し得る医薬作因または抗体の適当量を、被験者に投与することを包含する。
【0045】
この発明はまた、サブユニットα10よびサブユニットβを含むインテグリンヘテロ二量体、またはそれのサブユニットα10、または類似の生物学的活性を示す上記インテグリンの相同体またはフラグメントの活性化または遮断により、細胞外マトリックス合成および修復を刺激する方法に関するものである。
【0046】
さらなる観点でこの発明は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または上記インテグリンまたはサブユニットの相同体もしくはフラグメントの相互反応を包含する、インテグリン結合性実体の存在を in vitro で検出するための方法に関し、この方法では、上記インテグリン、サブユニットα10、または類似生物学的活性を示すその相同体もしはフラグメントをして、その天然リガンドへの結合性または試料中に存在する他のインテグリン結合性タンパク質への結合性を変調せしめるための試料を使用する。
【0047】
この発明はまた、サブユニットα10およびサブユニットβ、またはそのサブユニットα10、または上記インテグリンまたはサブユニットの相同体もしくはフラグメントを含むヒトヘテロ二量体インテグリンの相互反応の結果を in vitro で研究する方法に関し、この方法では、インテグリン結合性実体を用いて細胞性反応を開始させる。上記結果は細胞機能における改変として測定され得る。
【0048】
この発明のさらなる観点は、インテグリンサブユニットα10またはそれらの相同体もしくはフラグメントをコードするDNAもしくはRNAを標的分子として使用する方法に関する。この観点での実施態様では、ポリヌクレオチドもしくはオリゴポリヌクレオチドが、インテグリンサブユニットα10またはそれらの相同体もしくはフラグメントをコードするDNAもしくはRNAと交配し、それによって上記ポリヌクレオチドもしくはオリゴポリヌクレオチドはインテグリンサブユニットα1をコードするDNAもしくはRNAとの交配ができない。
【0049】
この発明はまた、サブユニットα10およびサブユニットβ、またはそのサブユニットα10、または上記インテグリンもしくはサブユニットの相同体もしくはフラグメント、またはインテグリンサブユニットα10またはその相同体もしくはフラグメントをコードするDNAもしくはRNAを含むヒトヘテロ二量体インテグリンを、脈管形成期間中のマーカーまたは標的分子として使用する方法にも関する。
【発明の具体的な説明】
【0050】
この発明は、ヒトおよびウシ軟骨細胞がβ1 フアミリーにおける新規II型コラーゲン結合性インテグリンを発現することを証明する。以前の研究では、ヒトの軟骨肉腫細胞もまたインテグリンを発現することに対するいくつかの証拠が提出された(25)。インテグリンサブユニットβ1 に対する抗体を用いた免疫沈殿実験では、この新規αインテグリンサブユニットは還元性条件下に約160kDaの見掛け分子量を示し、かつ、α 2インテグリンサブユニットよりも分子量が僅かに大きかったことを明らかにした。これを単離する目的で、αサブユニットII型コラーゲン結合性タンパク質をウシ軟骨細胞から親和精製した。先ずこの軟骨細胞リゼイトをフィブロネクチン−「Sepharpse 」プレカラムに塗布し、次で流動物をII型コラーゲン「Sepharose 」カラムに塗布した。約 160 kDのMr を示すタンパク質が、コラーゲンカラムからEDTAを用いて特異溶離されたが、フィブロネクチンカラムからは溶離されなかった。このMr は未確認β1 関連インテグリンサブユニットのMr と一致した。この 160 kDタンパク質バンドを SDS-PAGE ゲルから切除し、トリプシンで消化し、、単離ペプチドのアミノ酸配列を分析した。
【0051】
単離ペプチドに対応するプライマーがウシcDNAからの 900 bpPCRフラグメントを増幅し、このcDNAをクーロン化し、配列決定し、かつヒトインテグリンαサブユニット相同体を得る目的でヒト間節軟骨細胞λZapIIcDNAライブラリーのスクリーニング用に使用した。二つの重複クローン hcl および hc2 を単離し、サブクローン化し、配列決定した。これらのクローンは、cDNAの3’末端を包含するポリヌクレオチド配列の2/3を含んでいた。α10cDNAの5’末端を含む第3クローンを RACE 手法を用いて得た。160 kDタンパク質配列の配列分析によれば、このものはインテグリンαサブユニットフアミリーの1員であることを示し、かつ、このタンパク質は通称α10であることが判明した。
【0052】
α10の推定アミノ酸配列は、以前刊行された報告書(6−12)に記載のインテグリンαサブユニットの一般的構造を共有することが判明した。α10の大きな細胞外N末端部分は、βプロペラー領域(32)へと折り畳まれることが最近予見された7回折畳み繰り返し配列を含んでいる。このインテグリンサブユニットα10は、三つの推定2価のカチオン結合性サイト(DxD/NxD/NxxxD )(53)、単一スパントランスメンブラン領域および短い細胞質領域を含む。大半のαインテグリンサブユニットとは反対に、α10の細胞質領域は保守配列KxGFF (R/K) Rを含まない。α10中に予見されたアミノ酸配列は KLGFFAH である。いくつかの報告が、このインテグリン細胞質領域が信号トランスダクションに必須であり(54)、また、α−およびβ−インテグリン細胞質領域の膜−近位領域がインテグリンの立体構造および親和状態を変調するのに関与することを示す(55−57)。α鎖中の GFFKR モチーフはインテグリンサブユニットの会合に重要であり、また血漿膜へのインテグリンの輸送に対して重要であることが暗示される(58)。この KXGFFKR 領域は、細胞内タンパク質カルレチクリン(59)と相互反応し、興味あることには、カルレチクリンが存在しない胚幹細胞は、インテグリン仲介細胞付着性に欠けることが判った(60)。したがってα10の配列 KXGFFKR はα10β1 およびマトリックスタンパク質間の親和性を調節するための重要な因子を有する可能性がある。
【0053】
インテグリンαサブユニットは20〜40%の総体的同一性を共有することは既知である(61)。配列決定によれば、このα10サブユニットは、最高の同一性α1 (37%)およびα2 (35%)をもってαサブユニット含有I領域と最も密接に関連することを示す。インテグリンα1 β1 および α2 β1 はコラーゲンおよびラミニン両方に対する受容体であり(24;62;63)、また出願人らは最近、α2 β1 が軟骨マトリックスタンパク質コンドロアドヘリンと相互反応することも証明した(42)。II型コラゲーン−「Sepharoses」上でα10β1 が単離されたので、出願人らは、II型コラーゲンはα10β1 に対するリガンドであることを知った。同時に出願人らは親和精製実験により、α10β1 はI型コラーゲンとは相互反応するが、ラミニンまたはコンドロアドヘリンもまたこのインテグリンに対するリガンドであるか否かの問題解決はこれららである。
【0054】
還元型および非還元型の両条件下にα10会合β鎖は、β1 インテグリンサブユニットのように移動した。α10会合β鎖がβ1 であるか否かを証明する目的で、軟骨細胞リゼイトをα10またはβ1 に対する抗体を用いて免疫沈殿させ、次いでβ1 サブユニットに対する抗体を用いてウエスターンブロットに処した。これらの結果は、α10がβ1 インテグリンのフアミリーであることを明瞭に証明した。しかし、α10が同時に他のβ鎖と結合する可能性は排除できない。
【0055】
α10の細胞質領域に対して高めたポリクローナルペプチド抗体は二つのタンパク質バンドMr 約 160 kD(α10)および 125 kD(β1 )を還元型条件下に沈殿した。α10抗体を用いた免疫組織化学によれば、ヒト間節軟骨の組織部分中での軟骨細胞の染色を示した。この抗体染色は、α10ペプチドを用いた抗体の予備保温が染色を完全に廃止させたので、この抗体染色は明らかに特異的であった。胚組織からのマウス手足部分の免疫組織化学的染色は、間葉組織の縮合期間中にアップレギュレーションされることを証明した。このことは、このインテグリンサブユニットα10が軟骨形成期間中に重要であることを示す。生後3日のマウスでは、α10が圧倒的コラーゲン結合性インテグリンサブユニットであることが分かり、このことはα10が正常の軟骨機能の維持に重要な機能を有することを示す。
【0056】
タンパク質およびmRNAレベルでの発現研究によれば、α10の部分は寧ろ限定的であることを示す。免疫組織化学分析によれば、α10インテグリンサブユニットは軟骨中で主として発現されるが、このものは同時に軟骨膜、骨膜、Ranvier の骨化溝、間節周辺の筋膜おょび骨格筋ならびに心臓弁の間節様構造中にも見いだされる。この分布はα10インテグリンサブユニットが繊維芽細胞および骨芽細胞上にも存在することを指摘する。異なった細胞型からのcDNAのPCR増幅によれば、交互にスプライスされたα10インテグリンサブユニットの存在が明になった。このスプライスドα10は繊維芽細胞中に圧倒的であり、繊維芽細胞中のα10は軟骨細胞に存在するα10に比べて異なった機能を有する可能性があることを示唆する。
【0057】
インテグリンサブユニットα10の発現は、軟骨細胞を単層中で培養すると低減するように見られた。これとは対照的にα10の発現は、この細胞をアルギン酸塩ビーズ中で培養すると増加するのが見られた。後者の培養モデルは軟骨細胞の表現型を保持するすることが知られているので、上記結果はα10が分化軟骨細胞に対するマーカーとして機能できることを暗示している。
【0058】
腱/靭帯間および周辺組織の癒着は感染、傷害後、および外科的介入後の公知問題点である。間節および間節シート間の癒着は滑走機能を損ない、かつ、例えば手指の間節の治癒中に著しい問題点を引き起こし、その結果、機能不全に至る。間節および骨格筋の筋膜中へのα10インテグリンサブユニットの局在化は、α10をして、腱/靭帯の機能の損失を防止し得る抗癒着性を有する医薬物質または分子に対する可能性ある標的となさしめ得る。またインテグリンサブユニットα10は、癒着が問題になる他の組織における抗癒着性を有する医薬物質もしくは分子に対する標的ともなり得る。
【実施例】
【0059】
実施例1
II型コラーゲン−「Sepharose 」上でのα10インテグリンサブユニットの親和精製
材料および方法
ウシ軟骨細胞、ヒト軟骨細胞またはヒト軟骨腫瘍細胞を前記のように単離した[Holmval らの Exp Cell Res, 221, 496-503 (1995), Camper らの JBC, 273, 20383-20389 (1998) ]。ウシ軟骨細胞の「Triton X-100」リゼイトを、フイブロネクチン−「Sepharose 」プレカラム、次いでII型コラーゲン−「Sepharose 」上に施し、このインテグリンサブユニットα10をII型コラーゲンカラムから EDTA により溶離した(Camper らの JBC, 273, 20383-20389(1998)。溶離タンパク質をメタノール/クロロホルムで沈殿させ、還元型条件下に SDS-PAGE により分離し、クーマシーブルーで染色した(Camper らの JBC, 273, 20383-20389 (1998) 。α10 タンパク質バンドからのペプチドをトリプシンおよび相液クロマトグラフイーを用いた in-gel 消化により単離し、Edman 分解(Camper らの JBC, 273, 20383-20389 (1998)により配列決定した。
【0060】
結果
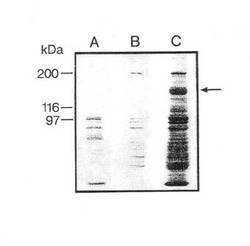
図1は、フイブロネクチン−「Sepharose 」からの EDTA 溶離タンパク質(A)、II型コラーゲン−「Sepharose 」カラムからの 流動物(B)およびII型コラーゲン−「Sepharose 」からの EDTA 溶離タンパク質(C)を示す。II型コラーゲン−「Sepharose 」カラムから特異的に溶離したα10インテグリンサブユニット(160 kDa) を矢印で示す。図2は、ウシインテグリンサブユニットα10から溶離した6種のペプチドのアミノ酸配列を示す。図3a、bおよびcは,α10インテグリンサブユニットがウシ軟骨細胞(3a)、ヒト軟骨細胞(3b)上に存在することを示す。
II型コラーゲンに対する親和性、β1 インテグリンサブユニットとの共沈殿および還元型条件下の分子量 160 kDaにより、異なった細胞上でのα10インテグリンサブユニットを確認する。これらの結果は、α10が軟骨細胞および軟骨肉腫細胞から単離され得ることを示す。
【0061】
実施例2
ウシα10インテグリンサブユニットに対応するPCRフラグメントの増幅
材料および方法
ウシペプチド1(図2)に対応するポリヌクレオチド配列を増幅するために、縮重プライマー GAY AAY ACI GCI CAR AC ( DNTAQT, forward ) および TIA TIS WRT GRT GIG GYT (EPHHSI, reverse) をPCRに用いた (Camper らの JBC, 273, 20383-20389 (1998) 。次いで ペプチド1のクローン化ヌクレオチド配列に対応する内部特異プライマー TCA GCC TAC ATT CAG TAT (SAYIQY, forward)をウシペプチド2(図2) に対応するICK RTC CC, RTG ICC IGG (PGHWDR, reverse) と共に用いて 900 bp PCRフラグメントをウシcDNAから増幅した。2倍縮重の位置には混合塩基を使用し、3または4倍縮重の位置にはイノシンを使用した。mRNA単離およびcDNA合成を文献記載(Camper らの
JBC, 273, 20383-20389 (1998) に準拠して実施した。精製フラグメントをクーローン化し、精製し、文献記載に従って配列決定した(Camper らの JBC, 273, 20383-20389 (1998) )。
結果
ペプチド1のヌクレオチド配列(図2)が、ウシcDNAのPCR増幅、クローン化および配列決定により得られた。このヌクレオチド配列から正確なプライマーを設計し、ペプチド2−6に対応する縮重プライマーを用いるPCR増幅に応用した。ペプチド1および2に対応するプライマーがウシcDNAからの 900 bp フラグメントを増幅した(図4)。
【0062】
実施例3
ヒトα10インテグリンサブユニットのクローン化および配列分析
材料および方法
ウシα10インテグリンに対応するクローン化 900 bp PCRフラグメントを、DIG DNA ラベル化キット(Boehringer Mannheim) に準拠してジゴキシゲニン−ラベル化し、ヒト間節軟骨細胞λ ZapII cDNAライブラリー(Michael Bayliss, TheRoyal Veterinary Basic Sciences, London, UK により提供)(52) のスクリーニング用のプローブとして用いた。cDNA挿入断片を伴う pBluescript SK + プラスミドを含むポジテイブクローンを、ZAP-cDNA R合成キット(Stratagene) 記載のように in vivo で切除することにより ZAP ベクターからレスキユーした。選択プラスミドを精製し、文献に準拠して、T3 、T7 および内部特異プライマーを用いて配列決定した(Camper らの JBC, 273, 20383-20389 (1998)。α10の5’末端をコードするcDNAを得る目的で、出願人らはプライマー AAC TCG TCT TCC AGT GCC ATT CGT GGG (reverse; α10 cDNAにおける残基 1254-1280)を設計し、これを 「MarathonTM」cDNA増幅キット(Clontech INC., Palo Alto, CA) の記載に準拠してcDNA5’末端(RACE) の急速増幅に用いた。
【0063】
結果
二つの重複クローン hc1 および hc2 (図5)を単離し、サブクローン化し、配列決定した。これらのクローンは、cDNAの3’末端を含むヌクレオチド配列の2/3を含んでいた。α10cDNAの5’末端を含む第3クローン(race1; 図5)が RACE 技法を用いて得られた。α10 cDNA、3884 ヌクレオチドの三つの重複クローンを配列決定した。このポリヌクレオチド配列および推定アミノ酸配列を図6に示す。この配列は、1167 アミノ酸成熟タンパク質をコードすると予測される 3504 ヌクレオチドオープンリーデイング枠を含む。シグナルペプチド開裂サイトは矢印で示し、ウシペプチド配列に対するヒト相同体は下線を施し、I領域は四角で囲んだ(boxed) 。金属イオン結合サイトは下波線で示し、潜在的N−グリコシル化サイトは星印で示し、推定トランスメンブラン領域は2重下線で示す。正常に保存された細胞質配列はドットおよびダッシュ下波線で示す。
【0064】
実施例4
α10のスプライス変種を含むクローンの確認
ヒト軟骨細胞ライブラリー(実施例3参照)から単離した一つのクローンは
nt 位置 2942 および 3055 間のヌクレオチドが削除さた以外は,α10インテグリンサブユニットの配列と同一の配列を含んでいた。α10のスプライス変種は、このスプライス領域をフランキングするプライマーを用いたPCR実験において証明された(図14参照)。
【0065】
実施例5
ノーザンブロットによるα10インテグリンサブユニットの同定
材料および方法
ウシ軟骨細胞 mRNAを 「QuickPrep R Micro 」mRNA精製キット(Pharmacia Biotech, Uppsala, Sweden )を用いて精製し、1%アガロース−ホルムアルデヒドゲル上で分離し、ナイロン膜に移し、IV架橋により固定化した。Random Primed DNAラベル化キット(Boehringer Mannheim) を用いてcDNAプローブを32Pラベル化した。フイルターを 5x SSE, 5X Denharts 溶液、0.1% SDS, 50μg/mlサケ精子DNAおよび50%ホルムアミド中、42℃で2〜4時間予備交配し、次いで特異プローブ(0.5〜1 × 106 cpm/ml)を含む同一溶液を用いて42℃で一昼夜交配した。特異的に結合したcDNAプローブをリン光イメージャー装置(Fuji)を用いて分析した。再プローブに先立ちフイルターを0.1% SDS 中、80℃で1間洗浄してストリップした。このα10インテグリンcDNAプローブを、制限酵素 BamHI (GIBCO BRL) および NcoI (Boehringer Mannheim) を用いて racel含有プラスミドから単離した。ラットβ1 インテグリンcDNAプローブは Staffan Johansson, Uppsala, Sweden から寄贈された。
【0066】
結果
ウシ軟骨細胞からのmRNAのノーザンブロット分析によれば、ヒトα10 cDNAプローブが約 5.4 kb (図7)の単一mRNAと交配した。比較として、インテグリンサブユニットα1に対応するcDNAプローブを用いた。このcDNAプローブは同一フイルター上の約 3.5 kb のmRNAバンドと交配した。これらの結果は、α10に対するcDNAプローブがmRNAレベルでα10インテグリンサブユニットを同定するのに使用できることを示す。
【0067】
実施例6
インテグリンサブユニットα10に対する抗体の調製
α10細胞質領域の一部 Ckkipeeekreekle に対応するペプチド(図6参照)を合成し、鍵穴カサガイヘモシアニン(KLH) に複合させた。ペプチド/KLH 複合体を用いてラビットを免疫化しインテグリンサブユニットα10に対する抗血清を生じさせた。α10を認識する抗体はペプチド結合カラム(Innovagen AB) 上で親和精製した。
【0068】
実施例7
軟骨細胞からのインテグリンサブユニットα10の免疫沈殿
材料および方法
ヒト軟骨細胞を 125 Iラベル化し「Triton X-100」 を用いて溶菌し、文献(Holmvall らの Exp. Cell Res, 221, 496-503 (1995) 、Camper らの JBC, 273, 20383-20389 (1998) )記載のように免疫沈殿した。125I ラベル化ヒト軟骨細胞の「Triton X-100」 リゼイトを、インテグリンサブユニットβ1 、α1 、α2 、α3 、α10に対するポリクローナル抗体を用いて免疫沈殿した。この免疫沈殿タンパク質を非還元型条件下に SDS-PAGE (4−12%)により分離し、リン光イメージャーにより肉視した。α10またはβ1 で免疫沈殿したヒト軟骨細胞の「Triton X-100」 リゼイトを非還元型条件下に SDS-PAGE (8%)により分離し、ポリクローナルβ1 抗体を使用するウエスターンブロットおよび Camper らによる JBC, 273, 20383-20389 (1998) 記載のように化学発光検出法を用いて分析した。
【0069】
結果
α10の細胞質領域に対して高めたポリクローナルペプチド抗体は、 Mr が約 160 kD (α10)および 125 kD (β1 )を有する二つのタンパク質バンドを非還元型条件下に沈殿した。α10会合β鎖はβ1 インテグリンサブユニットのように移動した(図8a)。軟骨細胞におけるα10会合β鎖が実際にβ1 であることを実証するために、軟骨細胞ライゼイトをα10 orb β1 に対する抗体を用いて免疫沈殿し、次いでβ1 サブユニットに対する抗体を用いたウエスターンブロットに処した(図8b)。これらの結果は、α10がβ1 インテグリンフアミリーの1員であることを明瞭に示した。しかし、これらの結果は、α10が他の状況下に他のβ鎖と会合できる可能性を排除はしない。
【0070】
実施例8
ヒトおよびマウス軟骨におけるインテグリンサブユニットα10の免疫組織化学的染色
手術期間に得られた成人軟骨(trochlear groove ) の凍結部分(Anders Lindahl, Salgrenska Hospital, Gothenburg, Sweden 提供)および生後3日のマウス手足からの凍結部分を固定し、文献記載(Camper らの JBC, 273, 20383-20389 (1998) のように免疫組織かがく用に調製した。α10インテグリンサブユニットの発現は一次抗体(実施例6参照)およびペルオキシダーゼに複合した二次 抗体として、細胞質領域に対するポリクローナル抗体を用いて分析した。
【0071】
結果
図9はヒト成人間節の軟骨の染色を示す。
α10の細胞質領域を認識するα10抗体は、ヒト間節軟骨の組織部分における軟骨細胞を染色した(A)。この染色は、α10ペプチドを用いて抗体を予備保温すると減少した(B)。α10インテグリンサブユニットを認識する対照抗体は軟骨細胞に結合しなかった(C)。
【0072】
図10は、α10抗体が、成長期の骨原基における軟骨細胞の大半を染色することを示す(aおよびb)。このα10抗体も Ranvierの骨化溝中の細胞を認識し、 metaphys における軟骨をライニングしている骨樹皮中の骨芽細胞はα10に対して特に高度にポジテイブである。Ranvier の骨化溝中の細胞は、骨の直径方向の成長に重要であると信じられる。このインテグリンサブユニットα10もまた軟骨膜および骨膜中に高度に発現される。これらの組織中の細胞は軟骨組織の修復に重要であるらしい。インテグリンサブユニットα10の上記局在化は、軟骨組織の機能に対して重要であることを暗示している。
【0073】
実施例9
マウスの発生期におけるインテグリンサブユニットα10の免疫組織化学的染色材料および方法
マウス胚(13.5日)からの凍結部分を、 Camper らの JBC, 273, 20383-20389 (1998) 記載に準拠して免疫組織化学によるα10発現用に研究した。α10インテグリンサブユニットの発現は、一次抗体(実施例6参照)およびペルオキシダーゼに複合した二次抗体としての細胞質領域に対するポリキローナル抗体を用いて分析した。この胚部分もインテグリンサブユニットα10(Pharmingen からのモノクローナル抗体)およびII型コラーゲン(モノクローナル抗体、Dr John Mo, Lund University, Sweden から寄贈)の発現のために研究した。
【0074】
図11は、α10インテグリンサブユニットが、間葉細胞が縮合を受て軟骨を形成する際には手足中で調節されないことを示す(a)。特に新規に形成された軟骨の端部はα10の高度発現を示す。軟骨形成は軟骨特異II型コラーゲンの高度発現により証明される(b)。α10インテグリンサブユニットに対する対照抗体は、軟骨上で弱い発現のみを示した(c)。他の実験では、α10の発現が、手足、肋骨、脊椎を包含する全ての軟骨含有組織中に見いだされた。軟骨形成期間中のα10のアップレギュレーションは、このインテグリンサブユニットが軟骨および骨の発生ならびに損傷軟骨の修復の両方に重要であることを暗示する。
【0075】
実施例10
間節軟骨以外の組織におけるα10のmRNA発現
材料および方法
α10インテグリンサブユニットの発現を、異なったヒト組織中でのmRNAレベルで試験した。図12に示した組織からの固定化mRNAを用いるノーザンドットブロットを、制限酵素 BamH1 およびNcol を用いて race 1-含有プラスミドから単離したα10インテグリンcDNAプローブを用いて交配した。交配の程度をリン発光イマージヤーを用いて分析した。次の記号は増加順序:−、+、++、+++、++++で表示するmRNAレベルを示す。
【0076】
結果
交配mRNAの分析によれば、α10は大動脈、気管、心臓、肺、および腎臓に発現された(図2)。他の全ての組織はα10発現に対しネガテイブのように見えた。これらの結果は、α10インテグリンサブユニットの制限的分布を暗示する。
【0077】
実施例11
腱および骨格筋周りの筋膜および心臓弁内の腱構築体におけるα10の免疫組織化学的染色
材料および方法
手術期中に得られた成人軟骨(trochlear groove )の凍結部分(Anders Lindahl, Salgrenska Hospital, Gothenburg, Sweden により提供)および生後3日マウス手足からの凍結部分を固定し、文献記載のように免疫組織化学用に調製した(Camper らの JBC, 273, 20383-20389 (1998)。α10インテグリンサブユニットの発現は、一次抗体(実施例6参照)およびペルオキシザーゼに複合した第二抗体としての細胞質領域に対するポリクローナル抗体を用いて分析した。
【0078】
結果
図13に見られるように、α10の発現は腱を取り巻く筋膜(a)および骨格筋(b)中および心臓弁の腱構造(c)に見いだされた。この局在化は、α10が軟骨特異的II型コラーゲン以外にも他のマトリックス分子にも結合し得ることを暗示する。腱表面上へのインテグリンα10の局在化は、α10が、感染、障害後または手術後の腱/靭帯間および組織周辺にしばしば起きる好ましからぬ癒着に関与し得ることを示す。
【0079】
実施例12
軟骨細胞、内皮細胞および繊維芽細胞におけるα10インテグリンサブユニットのmRNA発現
材料および方法
mRNAの単離、cDNAの合成およびPCR増幅は文献記載のように行った(Camper らの JBC, 273, 20383-20389 (1998) ) 。
結果
図14は、ヒト間節軟骨細胞(レーンA6 およびB1 )、ヒトへその緒静脈内皮細胞(レーンA2)、ヒト繊維芽細胞(レーンA4 )、およびラット腱(図14b、レーンB2 )からのα10cDNAのPCR増幅を示す。レーン1、3および5(図14A)は、内皮細胞、繊維芽細胞および軟骨細胞それぞれにおけるインテグリンサブユニットα10に対応する増幅フラグメントを示す。α10配列位置 nt 2919-2943 (forward) および nt 3554-3578 (reverse) (図6参照)の対応するcDNAプライマーは異なった細胞からのα10cDNAの増幅に使用された。この図は、α10が三種の全ての細胞型で増幅されたことを示す。α10の二つのフラグメントは増幅され、このものはα10の元来の形態で(一層大きなフラグメント)、かつスプライス変異(一層小さなフラグメント)の形態で存在した。この一層大きなフラグメントは軟骨細胞中で大勢を占め、一方、一層小さなフラグメントは腱中に一層顕著であった(B2 )。
【0080】
実施例13
α10哺乳類発現ベクターの構築
α10の等身大タンパク質コード配列(三つのクローンからの併合;図6参照)を哺乳類発現ベクターpcDNA3.1/Zeo (Invitrogen) 中に挿入た。このベクターは SV40 プロモーターおよび Zeosin 選択配列を含む。このα10含有発現ベクターを、β1 インテグリンサブユニットは発現するがα10サブユニットの発現に欠く細胞中にトランスフエクトした。細胞表面上のα10インテグリンサブユニットの発現は、免疫沈殿法および/またはα10に対して特異的な抗体を用いたフロー血球計算により分析できる。リガンド結合能力および挿入されたα10インテグリンサブユニットの機能は細胞付着実験およびシグナル化実験で実証できる。
【0081】
実施例14
α10のスプライス変種を含む哺乳類発現ベクターの構築
α10のスピライス変種の等身大タンパク質コード配列を哺乳類発現ベクター pc DNA3 (実施例13参照)中に挿入した。このスプライス変種の発現および機能は実施例13記載のように分析でき、かつ、無傷のα10インテグリンサブユニットと比較できる。
【0082】
実施例15
α10インテグリンゲノムDNAの部分単離および特性化
材料および方法
制限酵素 EamHI (GIBCO BRI) およびNcoI(Boehringer Mannheim ) を用いたracel 含有プラスミドから単離したヒトαcDNAを、32Pラベル化し、マウス 129 コスミドライブラリー(Reinhard Fassler, Lund University 提供)のスクリーニン用プローブとして用いた。ポジテイブクローンを単離し、サブクローンした。選択プラスミドを精製し、文献(Camper らの JBC,273, 20383-20389 (1998) に準拠してT3 、T7 および内部特異プライマーを用いて配列決定した。次いでマウスゲノムDNAに対応するプライマーを構築し、PCRに用いて増幅し、コスミドクローンからα10のゲノム配列を同定した。
【0083】
図15は、α10遺伝子の 7958 nt を示す。α10インテグリンの上記部分ゲノムDNA配列はエクソン8および Kozak 配列を含む。このマウスゲノムα10配列を用いてノックアウト実験用の標的ベクターを生じさせた。
【0084】
実施例16
アルギン酸塩(alginate)ビーズ中で培養したα10インテグリンサブユニットのアップレギュレーション(upregulation)
単層で2週間培養したヒト軟骨細胞をトリプシン−EDTAで脱離し、アルギン酸塩ビーズ中に導入した。アルギン酸塩ビーズ中で培養した軟骨細胞は、単層中で培養された軟骨細胞の脱分化間、それらの表現型を保存することは既知である。アルギン酸塩もしくは単層中いずれかで培養した軟骨細胞を11日後に単離し、125 Iで表面ラベル化した。このα10インテグリンサブユニットを次いで細胞質領域を認識するポリクローナル抗体を用いて免疫沈殿した(実施例6参照および Camper らの JBC, 273, 20383-20389 (1989) ) 。
【0085】
結果
図16に見られるように、アルギン酸塩ビーズ中で培養した軟骨細胞(レーン3および4)はα10 β1 のそれらのタンパク質発現を上方調節アップレギュレーションした。このことは、極めて低いα10β1 発現を示す、単層中で培養(レーン1および2)した軟骨細胞とは対照的であった。ab対照抗体を用いた免疫沈殿をレーン1および3に示す。軟骨細胞はアルギン酸塩中でそれらの軟骨特異的マトリクス生産を保持するが、単層中で培養したものは保持せず、この事実はアルギン酸塩が軟骨細胞の表現型を保持することを示す。これらの結果は、α10インテグリンサブユニットが分化軟骨細胞に対するマーカーとして使用できることを支持する。
【0086】
実施例17
ヒト平滑筋細胞からのα10インテグリンサブユニットの免疫沈殿
材料および方法
ヒト平滑筋細胞をヒト大動脈から単離した。培養1週間後、細胞を125 Iラベル化し、溶菌し、かつインテグリンサブユニットβ1 (レーン1)、α1 (レーン2)、α2 (レーン3)、α10(レーン4)、α 3(レーン5)、対照(レーン6)’図17)に対する抗体を用いて免疫沈殿させた。この実験は実施例7記載のように実施した。α10抗体は、α10およびβ1 インテグリンサブユニットに対応する平滑菌細胞から二つのバンドを沈殿した(図17)。
【0087】
実施例18
α10スライス領域に対する配列を含む細菌性発現ベクターの構築
交互スプライスド領域(アミノ酸 pos. 952-986, SEQ. ID 1) の E.coli 中での細胞内発現のためのプラスミドを文献記載のように構築した。この交互スプライスド領域をE. coli 高頻度コドンテーブルを用いてバック翻訳し、元の配列(SEQ. ID 1 ヌクレオチド pos. 2940-3044) と96%同一性のcDNA配列を創った。配列重複エクステンシン(Horon らの Biotechniques 8:528, 1990) を用いてプライマーα10pfor (表I)およびα10prev (表I)を、α10アミノ酸配列をコードする2重鎖フラグメントの創造に用いた。ブドウ状球菌タンパク質AのZ領域を含むPETベクター中でサブクローンするための制限酵素サイトを創る目的で、このフラグメントをプライマ−α10pfor2 (表I)およびα10prev2 (表I)を用いるPCR鋳型として用て、トロンビン開裂サイトを中間に有するZ領域のアミノ末端とα10スプライスド領域との融合体を創った。第2PCR反応で生じたフラグメントを示し(SEQ ID No. 3)、また発現ベクター中でのサブクローンに使用した新規制限酵素も示す。
【0088】
【表1】

【0089】
【表2】
【表3】
【表4】
【表5】
【0090】
[配列表]
SEQUENCE LISTING
(1) 一般的情報:
(i) 配列の総数: 2
(2) 配列番号1の情報:
(i) 配列特徴:
(A) 配列の長さ: 3884 塩基対
(B) 配列の型: 核酸およびアミノ酸
(C) 鎖の数: 二本鎖
(D) トポロジー: 直鎖状
(ii) 配列の種類: cDNA
(vi) 起源:
(E) 生物名: ヒト
(F) 細胞の種類: 軟骨細胞
(xi) 配列の記載: 配列番号1:
CAGGTCAGAAACCGATCAGGCATGGAACTCCCCTTCGTCACTCACCTGTTCTTGCCCCTG
1 ---------+---------+---------+---------+---------+---------+ 60
GTCCAGTCTTTGGCTAGTCCGTACCTTGAGGGGAAGCAGTGAGTGGACAAGAACGGGGAC
a M E L P F V T H L F L P L -
GTGTTCCTGACAGGTCTCTGCTCCCCCTTTAACCTGGATGAACATCACCCACGCCTATTC
61 ---------+---------+---------+---------+---------+---------+ 120
CACAAGGACTGTCCAGAGACGAGGGGGAAATTGGACCTACTTGTAGTGGGTGCGGATAAG
a V F L T G L C S P F N L D E H H P R L F -
CCAGGGCCACCAGAAGCTGAATTTGGATACAGTGTCTTACAACATGTTGGGGGTGGACAG
121 ---------+---------+---------+---------+---------+---------+ 180
GGTCCCGGTGGTCTTCGACTTAAACCTATGTCACAGAATGTTGTACAACCCCCACCTGTC
a P G P P E A E F G Y S V L Q H V G G G Q -
CGATGGATGCTGGTGGGCGCCCCCTGGGATGGGCCTTCAGGCGACCGGAGGGGGGACGTT
181 ---------+---------+---------+---------+---------+---------+ 240
GCTACCTACGACCACCCGCGGGGGACCCTACCCGGAAGTCCGCTGGCCTCCCCCCTGCAA
a R W M L V G A P W D G P S G D R R G D V -
TATCGCTGCCCTGTAGGGGGGGCCCACAATGCCCCATGTGCCAAGGGCCACTTAGGTGAC
241 ---------+---------+---------+---------+---------+---------+ 300
ATAGCGACGGGACATCCCCCCCGGGTGTTACGGGGTACACGGTTCCCGGTGAATCCACTG
a Y R C P V G G A H N A P C A K G H L G D -
TACCAACTGGGAAATTCATCTCATCCTGCTGTGAATATGCACCTGGGGATGTCTCTGTTA
301 ---------+---------+---------+---------+---------+---------+ 360
ATGGTTGACCCTTTAAGTAGAGTAGGACGACACTTATACGTGGACCCCTACAGAGACAAT
a Y Q L G N S S H P A V N M H L G M S L L -
GAGACAGATGGTGATGGGGGATTCATGGCCTGTGCCCCTCTCTGGTCTCGTGCTTGTGGC
361 ---------+---------+---------+---------+---------+---------+ 420
CTCTGTCTACCACTACCCCCTAAGTACCGGACACGGGGAGAGACCAGAGCACGAACACCG
a E T D G D G G F M A C A P L W S R A C G -
AGCTCTGTCTTCAGTTCTGGGATATGTGCCCGTGTGGATGCTTCATTCCAGCCTCAGGGA
421 ---------+---------+---------+---------+---------+---------+ 480
TCGAGACAGAAGTCAAGACCCTATACACGGGCACACCTACGAAGTAAGGTCGGAGTCCCT
a S S V F S S G I C A R V D A S F Q P Q G -
AGCCTGGCACCCACTGCCCAACGCTGCCCAACATACATGGATGTTGTCATTGTCTTGGAT
481 ---------+---------+---------+---------+---------+---------+ 540
TCGGACCGTGGGTGACGGGTTGCGACGGGTTGTATGTACCTACAACAGTAACAGAACCTA
a S L A P T A Q R C P T Y M D V V I V L D -
GGCTCCAACAGCATCTACCCCTGGTCTGAAGTTCAGACCTTCCTACGAAGACTGGTAGGG
541 ---------+---------+---------+---------+---------+---------+ 600
CCGAGGTTGTCGTAGATGGGGACCAGACTTCAAGTCTGGAAGGATGCTTCTGACCATCCC
a G S N S I Y P W S E V Q T F L R R L V G -
AAACTGTTTATTGACCCAGAACAGATACAGGTGGGACTGGTACAGTATGGGGAGAGCCCT
601 ---------+---------+---------+---------+---------+---------+ 660
TTTGACAAATAACTGGGTCTTGTCTATGTCCACCCTGACCATGTCATACCCCTCTCGGGA
a K L F I D P E Q I Q V G L V Q Y G E S P -
GTACATGAGTGGTCCCTGGGAGATTTCCGAACGAAGGAAGAAGTGGTGAGAGCAGCAAAG
661 ---------+---------+---------+---------+---------+---------+ 720
CATGTACTCACCAGGGACCCTCTAAAGGCTTGCTTCCTTCTTCACCACTCTCGTCGTTTC
a V H E W S L G D F R T K E E V V R A A K -
AACCTCAGTCGGCGGGAGGGACGAGAAACAAAGACTGCCCAAGCAATAATGGTGGCCTGC
721 ---------+---------+---------+---------+---------+---------+ 780
TTGGAGTCAGCCGCCCTCCCTGCTCTTTGTTTCTGACGGGTTCGTTATTACCACCGGACG
a N L S R R E G R E T K T A Q A I M V A C -
ACAGAAGGGTTCAGTCAGTCCCATGGGGGCCGACCCGAGGCTGCCAGGCTACTGGTGGTT
781 ---------+---------+---------+---------+---------+---------+ 840
TGTCTTCCCAAGTCAGTCAGGGTACCCCCGGCTGGGCTCCGACGGTCCGATGACCACCAA
a T E G F S Q S H G G R P E A A R L L V V -
GTCACTGATGGAGAGTCCCATGATGGAGAGGAGCTTCCTGCAGCACTAAAGGCCTGTGAG
841 ---------+---------+---------+---------+---------+---------+ 900
CAGTGACTACCTCTCAGGGTACTACCTCTCCTCGAAGGACGTCGTGATTTCCGGACACTC
a V T D G E S H D G E E L P A A L K A C E -
GCTGGAAGAGTGACACGCTATGGGATTGCAGTCCTTGGTCACTACCTCCGGCGGCAGCGA
901 ---------+---------+---------+---------+---------+---------+ 960
CGACCTTCTCACTGTGCGATACCCTAACGTCAGGAACCAGTGATGGAGGCCGCCGTCGCT
a A G R V T R Y G I A V L G H Y L R R Q R -
GATCCCAGCTCTTTCCTGAGAGAAATTAGAACTATTGCCAGTGATCCAGATGAGCGATTC
961 ---------+---------+---------+---------+---------+---------+ 1020
CTAGGGTCGAGAAAGGACTCTCTTTAATCTTGATAACGGTCACTAGGTCTACTCGCTAAG
a D P S S F L R E I R T I A S D P D E R F -
TTCTTCAATGTCACAGATGAGGCTGCTCTGACTGACATTGTGGATGCACTAGGAGATCGG
1021 ---------+---------+---------+---------+---------+---------+ 1080
AAGAAGTTACAGTGTCTACTCCGACGAGACTGACTGTAACACCTACGTGATCCTCTAGCC
a F F N V T D E A A L T D I V D A L G D R -
ATTTTTGGCCTTGAAGGGTCCCATGCAGAAAACGAAAGCTCCTTTGGGCTGGAAATGTCT
1081 ---------+---------+---------+---------+---------+---------+ 1140
TAAAAACCGGAACTTCCCAGGGTACGTCTTTTGCTTTCGAGGAAACCCGACCTTTACAGA
a I F G L E G S H A E N E S S F G L E M S -
CAGATTGGTTTCTCCACTCATCGGCTAAAGGATGGGATTCTTTTTGGGATGGTGGGGGCC
1141 ---------+---------+---------+---------+---------+---------+ 1200
GTCTAACCAAAGAGGTGAGTAGCCGATTTCCTACCCTAAGAAAAACCCTACCACCCCCGG
a Q I G F S T H R L K D G I L F G M V G A -
TATGACTGGGGAGGCTCTGTGCTATGGCTTGAAGGAGGCCACCGCCTTTTCCCCCCACGA
1201 ---------+---------+---------+---------+---------+---------+ 1260
ATACTGACCCCTCCGAGACACGATACCGAACTTCCTCCGGTGGCGGAAAAGGGGGGTGCT
a Y D W G G S V L W L E G G H R L F P P R -
ATGGCACTGGAAGACGAGTTCCCCCCTGCACTGCAGAACCATGCAGCCTACCTGGGTTAC
1261 ---------+---------+---------+---------+---------+---------+ 1320
TACCGTGACCTTCTGCTCAAGGGGGGACGTGACGTCTTGGTACGTCGGATGGACCCAATG
a M A L E D E F P P A L Q N H A A Y L G Y -
TCTGTTTCTTCCATGCTTTTGCGGGGTGGACGCCGCCTGTTTCTCTCTGGGGCTCCTCGA
1321 ---------+---------+---------+---------+---------+---------+ 1380
AGACAAAGAAGGTACGAAAACGCCCCACCTGCGGCGGACAAAGAGAGACCCCGAGGAGCT
a S V S S M L L R G G R R L F L S G A P R -
TTTAGACATCGAGGAAAAGTCATCGCCTTCCAGCTTAAGAAAGATGGGGCTGTGAGGGTT
1381 ---------+---------+---------+---------+---------+---------+ 1440
AAATCTGTAGCTCCTTTTCAGTAGCGGAAGGTCGAATTCTTTCTACCCCGACACTCCCAA
a F R H R G K V I A F Q L K K D G A V R V -
GCCCAGAGCCTCCAGGGGGAGCAGATTGGTTCATACTTTGGCAGTGAGCTCTGCCCATTG
1441 ---------+---------+---------+---------+---------+---------+ 1500
CGGGTCTCGGAGGTCCCCCTCGTCTAACCAAGTATGAAACCGTCACTCGAGACGGGTAAC
a A Q S L Q G E Q I G S Y F G S E L C P L -
GATACAGATAGGGATGGAACAACTGATGTCTTACTTGTGGCTGCCCCCATGTTCCTGGGA
1501 ---------+---------+---------+---------+---------+---------+ 1560
CTATGTCTATCCCTACCTTGTTGACTACAGAATGAACACCGACGGGGGTACAAGGACCCT
a D T D R D G T T D V L L V A A P M F L G -
CCCCAGAACAAGGAAACAGGACGTGTTTATGTGTATCTGGTAGGCCAGCAGTCCTTGCTG
1561 ---------+---------+---------+---------+---------+---------+ 1620
GGGGTCTTGTTCCTTTGTCCTGCACAAATACACATAGACCATCCGGTCGTCAGGAACGAC
a P Q N K E T G R V Y V Y L V G Q Q S L L -
ACCCTCCAAGGAACACTTCAGCCAGAACCCCCCCAGGATGCTCGGTTTGGCTTTGCCATG
1621 ---------+---------+---------+---------+---------+---------+ 1680
TGGGAGGTTCCTTGTGAAGTCGGTCTTGGGGGGGTCCTACGAGCCAAACCGAAACGGTAC
a T L Q G T L Q P E P P Q D A R F G F A M -
GGAGCTCTTCCTGATCTGAACCAAGATGGTTTTGCTGATGTGGCTGTGGGGGCGCCTCTG
1681 ---------+---------+---------+---------+---------+---------+ 1740
CCTCGAGAAGGACTAGACTTGGTTCTACCAAAACGACTACACCGACACCCCCGCGGAGAC
a G A L P D L N Q D G F A D V A V G A P L -
GAAGATGGGCACCAGGGAGCACTGTACCTGTACCATGGAACCCAGAGTGGAGTCAGGCCC
1741 ---------+---------+---------+---------+---------+---------+ 1800
CTTCTACCCGTGGTCCCTCGTGACATGGACATGGTACCTTGGGTCTCACCTCAGTCCGGG
a E D G H Q G A L Y L Y H G T Q S G V R P -
CATCCTGCCCAGAGGATTGCTGCTGCCTCCATGCCACATGCCCTCAGCTACTTTGGCCGA
1801 ---------+---------+---------+---------+---------+---------+ 1860
GTAGGACGGGTCTCCTAACGACGACGGAGGTACGGTGTACGGGAGTCGATGAAACCGGCT
a H P A Q R I A A A S M P H A L S Y F G R -
AGTGTGGATGGTCGGCTAGATCTGGATGGAGATGATCTGGTCGATGTGGCTGTGGGTGCC
1861 ---------+---------+---------+---------+---------+---------+ 1920
TCACACCTACCAGCCGATCTAGACCTACCTCTACTAGACCAGCTACACCGACACCCACGG
a S V D G R L D L D G D D L V D V A V G A -
CAGGGGGCAGCCATCCTGCTCAGCTCCCGGCCCATTGTCCATCTGACCCCATCACTGGAG
1921 ---------+---------+---------+---------+---------+---------+ 1980
GTCCCCCGTCGGTAGGACGAGTCGAGGGCCGGGTAACAGGTAGACTGGGGTAGTGACCTC
a Q G A A I L L S S R P I V H L T P S L E -
GTGACCCCACAGGCCATCAGTGTGGTTCAGAGGGACTGTAGGCGGCGAGGCCAAGAAGCA
1981 ---------+---------+---------+---------+---------+---------+ 2040
CACTGGGGTGTCCGGTAGTCACACCAAGTCTCCCTGACATCCGCCGCTCCGGTTCTTCGT
a V T P Q A I S V V Q R D C R R R G Q E A -
GTCTGTCTGACTGCAGCCCTTTGCTTCCAAGTGACCTCCCGTACTCCTGGTCGCTGGGAT
2041 ---------+---------+---------+---------+---------+---------+ 2100
CAGACAGACTGACGTCGGGAAACGAAGGTTCACTGGAGGGCATGAGGACCAGCGACCCTA
a V C L T A A L C F Q V T S R T P G R W D -
CACCAATTCTACATGAGGTTCACCGCATCACTGGATGAATGGACTGCTGGGGCACGTGCA
2101 ---------+---------+---------+---------+---------+---------+ 2160
GTGGTTAAGATGTACTCCAAGTGGCGTAGTGACCTACTTACCTGACGACCCCGTGCACGT
a H Q F Y M R F T A S L D E W T A G A R A -
GCATTTGATGGCTCTGGCCAGAGGTTGTCCCCTCGGAGGCTCCGGCTCAGTGTGGGGAAT
2161 ---------+---------+---------+---------+---------+---------+ 2220
CGTAAACTACCGAGACCGGTCTCCAACAGGGGAGCCTCCGAGGCCGAGTCACACCCCTTA
a A F D G S G Q R L S P R R L R L S V G N -
GTCACTTGTGAGCAGCTACACTTCCATGTGCTGGATACATCAGATTACCTCCGGCCAGTG
2221 ---------+---------+---------+---------+---------+---------+ 2280
CAGTGAACACTCGTCGATGTGAAGGTACACGACCTATGTAGTCTAATGGAGGCCGGTCAC
a V T C E Q L H F H V L D T S D Y L R P V -
GCCTTGACTGTGACCTTTGCCTTGGACAATACTACAAAGCCAGGGCCTGTGCTGAATGAG
2281 ---------+---------+---------+---------+---------+---------+ 2340
CGGAACTGACACTGGAAACGGAACCTGTTATGATGTTTCGGTCCCGGACACGACTTACTC
a A L T V T F A L D N T T K P G P V L N E -
GGCTCACCCACCTCTATACAAAAGCTGGTCCCCTTCTCAAAGGATTGTGGCCCTGACAAT
2341 ---------+---------+---------+---------+---------+---------+ 2400
CCGAGTGGGTGGAGATATGTTTTCGACCAGGGGAAGAGTTTCCTAACACCGGGACTGTTA
a G S P T S I Q K L V P F S K D C G P D N -
GAATGTGTCACAGACCTGGTGCTTCAAGTGAATATGGACATCAGAGGCTCCAGGAAGGCC
2401 ---------+---------+---------+---------+---------+---------+ 2460
CTTACACAGTGTCTGGACCACGAAGTTCACTTATACCTGTAGTCTCCGAGGTCCTTCCGG
a E C V T D L V L Q V N M D I R G S R K A -
CCATTTGTGGTTCGAGGTGGCCGGCGGAAAGTGCTGGTATCTACAACTCTGGAGAACAGA
2461 ---------+---------+---------+---------+---------+---------+ 2520
GGTAAACACCAAGCTCCACCGGCCGCCTTTCACGACCATAGATGTTGAGACCTCTTGTCT
a P F V V R G G R R K V L V S T T L E N R -
AAGGAAAATGCTTACAATACGAGCCTGAGTATCATCTTCTCTAGAAACCTCCACCTGGCC
2521 ---------+---------+---------+---------+---------+---------+ 2580
TTCCTTTTACGAATGTTATGCTCGGACTCATAGTAGAAGAGATCTTTGGAGGTGGACCGG
a K E N A Y N T S L S I I F S R N L H L A -
AGTCTCACTCCTCAGAGAGAGAGCCCAATAAAGGTGGAATGTGCCGCCCCTTCTGCTCAT
2581 ---------+---------+---------+---------+---------+---------+ 2640
TCAGAGTGAGGAGTCTCTCTCTCGGGTTATTTCCACCTTACACGGCGGGGAAGACGAGTA
a S L T P Q R E S P I K V E C A A P S A H -
GCCCGGCTCTGCAGTGTGGGGCATCCTGTCTTCCAGACTGGAGCCAAGGTGACCTTTCTG
2641 ---------+---------+---------+---------+---------+---------+ 2700
CGGGCCGAGACGTCACACCCCGTAGGACAGAAGGTCTGACCTCGGTTCCACTGGAAAGAC
a A R L C S V G H P V F Q T G A K V T F L -
CTAGAGTTTGAGTTTAGCTGCTCCTCTCTCCTGAGCCAGGTCTTTGGGAAGCTGACTGCC
2701 ---------+---------+---------+---------+---------+---------+ 2760
GATCTCAAACTCAAATCGACGAGGAGAGAGGACTCGGTCCAGAAACCCTTCGACTGACGG
a L E F E F S C S S L L S Q V F G K L T A -
AGCAGTGACAGCCTGGAGAGAAATGGCACCCTTCAAGAAAACACAGCCCAGACCTCAGCC
2761 ---------+---------+---------+---------+---------+---------+ 2820
TCGTCACTGTCGGACCTCTCTTTACCGTGGGAAGTTCTTTTGTGTCGGGTCTGGAGTCGG
a S S D S L E R N G T L Q E N T A Q T S A -
TACATCCAATATGAGCCCCACCTCCTGTTCTCTAGTGAGTCTACCCTGCACCGCTATGAG
2821 ---------+---------+---------+---------+---------+---------+ 2880
ATGTAGGTTATACTCGGGGTGGAGGACAAGAGATCACTCAGATGGGACGTGGCGATACTC
a Y I Q Y E P H L L F S S E S T L H R Y E -
GTTCACCCATATGGGACCCTCCCAGTGGGTCCTGGCCCAGAATTCAAAACCACTCTCAGG
2881 ---------+---------+---------+---------+---------+---------+ 2940
CAAGTGGGTATACCCTGGGAGGGTCACCCAGGACCGGGTCTTAAGTTTTGGTGAGAGTCC
a V H P Y G T L P V G P G P E F K T T L R -
GTTCAGAACCTAGGCTGCTATGTGGTCAGTGGCCTCATCATCTCAGCCCTCCTTCCAGCT
2941 ---------+---------+---------+---------+---------+---------+ 3000
CAAGTCTTGGATCCGACGATACACCAGTCACCGGAGTAGTAGAGTCGGGAGGAAGGTCGA
a V Q N L G C Y V V S G L I I S A L L P A -
GTGGCCCATGGGGGCAATTACTTCCTATCACTGTCTCAAGTCATCACTAACAATGCAAGC
3001 ---------+---------+---------+---------+---------+---------+ 3060
CACCGGGTACCCCCGTTAATGAAGGATAGTGACAGAGTTCAGTAGTGATTGTTACGTTCG
a V A H G G N Y F L S L S Q V I T N N A S -
TGCATAGTGCAGAACCTGACTGAACCCCCAGGCCCACCTGTGCATCCAGAGGAGCTTCAA
3061 ---------+---------+---------+---------+---------+---------+ 3120
ACGTATCACGTCTTGGACTGACTTGGGGGTCCGGGTGGACACGTAGGTCTCCTCGAAGTT
a C I V Q N L T E P P G P P V H P E E L Q -
CACACAAACAGACTGAATGGGAGCAATACTCAGTGTCAGGTGGTGAGGTGCCACCTTGGG
3121 ---------+---------+---------+---------+---------+---------+ 3180
GTGTGTTTGTCTGACTTACCCTCGTTATGAGTCACAGTCCACCACTCCACGGTGGAACCC
a H T N R L N G S N T Q C Q V V R C H L G -
CAGCTGGCAAAGGGGACTGAGGTCTCTGTTGGACTATTGAGGCTGGTTCACAATGAATTT
3181 ---------+---------+---------+---------+---------+---------+ 3240
GTCGACCGTTTCCCCTGACTCCAGAGACAACCTGATAACTCCGACCAAGTGTTACTTAAA
a Q L A K G T E V S V G L L R L V H N E F -
TTCCGAAGAGCCAAGTTCAAGTCCCTGACGGTGGTCAGCACCTTTGAGCTGGGAACCGAA
3241 ---------+---------+---------+---------+---------+---------+ 3300
AAGGCTTCTCGGTTCAAGTTCAGGGACTGCCACCAGTCGTGGAAACTCGACCCTTGGCTT
a F R R A K F K S L T V V S T F E L G T E -
GAGGGCAGTGTCCTACAGCTGACTGAAGCCTCCCGTTGGAGTGAGAGCCTCTTGGAGGTG
3301 ---------+---------+---------+---------+---------+---------+ 3360
CTCCCGTCACAGGATGTCGACTGACTTCGGAGGGCAACCTCACTCTCGGAGAACCTCCAC
a E G S V L Q L T E A S R W S E S L L E V -
GTTCAGACCCGGCCTATCCTCATCTCCCTGTGGATCCTCATAGGCAGTGTCCTGGGAGGG
3361 ---------+---------+---------+---------+---------+---------+ 3420
CAAGTCTGGGCCGGATAGGAGTAGAGGGACACCTAGGAGTATCCGTCACAGGACCCTCCC
a V Q T R P I L I S L W I L I G S V L G G -
TTGCTCCTGCTTGCTCTCCTTGTCTTCTGCCTGTGGAAGCTTGGCTTCTTTGCCCATAAG
3421 ---------+---------+---------+---------+---------+---------+ 3480
AACGAGGACGAACGAGAGGAACAGAAGACGGACACCTTCGAACCGAAGAAACGGGTATTC
a L L L L A L L V F C L W K L G F F A H K -
AAAATCCCTGAGGAAGAAAAAAGAGAAGAGAAGTTGGAGCAATGAATGTAGAATAAGGGT
3481 ---------+---------+---------+---------+---------+---------+ 3540
TTTTAGGGACTCCTTCTTTTTTCTCTTCTCTTCAACCTCGTTACTTACATCTTATTCCCA
a K I P E E E K R E E K L E Q
CTAGAAAGTCCTCCCTGGCAGCTTTCTTCAAGAGACTTGCATAAAAGCAGAGGTTTGGGG
3541 ---------+---------+---------+---------+---------+---------+ 3600
GATCTTTCAGGAGGGACCGTCGAAAGAAGTTCTCTGAACGTATTTTCGTCTCCAAACCCC
GCTCAGATGGGACAAGAAGCCGCCTCTGGACTATCTCCCCAGACCAGCAGCCTGACTTGA
3601 ---------+---------+---------+---------+---------+---------+ 3660
CGAGTCTACCCTGTTCTTCGGCGGAGACCTGATAGAGGGGTCTGGTCGTCGGACTGAACT
CTTTTGAGTCCTAGGGATGCTGCTGGCTAGAGATGAGGCTTTACCTCAGACAAGAAGAGC
3661 ---------+---------+---------+---------+---------+---------+ 3720
GAAAACTCAGGATCCCTACGACGACCGATCTCTACTCCGAAATGGAGTCTGTTCTTCTCG
TGGCACCAAAACTAGCCATGCTCCCACCCTCTGCTTCCCTCCTCCTCGTGATCCTGGTTC
3721 ---------+---------+---------+---------+---------+---------+ 3780
ACCGTGGTTTTGATCGGTACGAGGGTGGGAGACGAAGGGAGGAGGAGCACTAGGACCAAG
CATAGCCAACACTGGGGCTTTTGTTTGGGGTCCTTTTATCCCCAGGAATCAATAATTTTT
3781 ---------+---------+---------+---------+---------+---------+ 3840
GTATCGGTTGTGACCCCGAAAACAAACCCCAGGAAAATAGGGGTCCTTAGTTATTAAAAA
TTGCCTAGGAAAAAAAAAAGCGGCCGCGAATTCGATATCAAGCT
3841 ---------+---------+---------+---------+---- 3884
AACGGATCCTTTTTTTTTTCGCCGGCGCTTAAGCTATAGTTCGA
(2) 配列番号2の情報:
(i) 配列特徴:
(A) 配列の長さ: 3779 塩基対
(B) 配列の型: 核酸およびアミノ酸
(C) 鎖の数: 二本鎖
(D) トポロジー: 直鎖状
(E)
(i) 配列の種類: cDNA
(vi) 起源:
(A) 生物名: ヒト
(B) 細胞の種類: 軟骨細胞
(xi) 配列の記載: 配列番号2:
CAGGTCAGAAACCGATCAGGCATGGAACTCCCCTTCGTCACTCACCTGTTCTTGCCCCTG
1 ---------+---------+---------+---------+---------+---------+ 60
GTCCAGTCTTTGGCTAGTCCGTACCTTGAGGGGAAGCAGTGAGTGGACAAGAACGGGGAC
M E L P F V T H L F L P L -
GTGTTCCTGACAGGTCTCTGCTCCCCCTTTAACCTGGATGAACATCACCCACGCCTATTC
61 ---------+---------+---------+---------+---------+---------+ 120
CACAAGGACTGTCCAGAGACGAGGGGGAAATTGGACCTACTTGTAGTGGGTGCGGATAAG
a V F L T G L C S P F N L D E H H P R L F -
CCAGGGCCACCAGAAGCTGAATTTGGATACAGTGTCTTACAACATGTTGGGGGTGGACAG
121 ---------+---------+---------+---------+---------+---------+ 180
GGTCCCGGTGGTCTTCGACTTAAACCTATGTCACAGAATGTTGTACAACCCCCACCTGTC
a P G P P E A E F G Y S V L Q H V G G G Q -
CGATGGATGCTGGTGGGCGCCCCCTGGGATGGGCCTTCAGGCGACCGGAGGGGGGACGTT
181 ---------+---------+---------+---------+---------+---------+ 240
GCTACCTACGACCACCCGCGGGGGACCCTACCCGGAAGTCCGCTGGCCTCCCCCCTGCAA
a R W M L V G A P W D G P S G D R R G D V -
TATCGCTGCCCTGTAGGGGGGGCCCACAATGCCCCATGTGCCAAGGGCCACTTAGGTGAC
241 ---------+---------+---------+---------+---------+---------+ 300
ATAGCGACGGGACATCCCCCCCGGGTGTTACGGGGTACACGGTTCCCGGTGAATCCACTG
a Y R C P V G G A H N A P C A K G H L G D -
TACCAACTGGGAAATTCATCTCATCCTGCTGTGAATATGCACCTGGGGATGTCTCTGTTA
301 ---------+---------+---------+---------+---------+---------+ 360
ATGGTTGACCCTTTAAGTAGAGTAGGACGACACTTATACGTGGACCCCTACAGAGACAAT
a Y Q L G N S S H P A V N M H L G M S L L -
GAGACAGATGGTGATGGGGGATTCATGGCCTGTGCCCCTCTCTGGTCTCGTGCTTGTGGC
361 ---------+---------+---------+---------+---------+---------+ 420
CTCTGTCTACCACTACCCCCTAAGTACCGGACACGGGGAGAGACCAGAGCACGAACACCG
a E T D G D G G F M A C A P L W S R A C G -
AGCTCTGTCTTCAGTTCTGGGATATGTGCCCGTGTGGATGCTTCATTCCAGCCTCAGGGA
421 ---------+---------+---------+---------+---------+---------+ 480
TCGAGACAGAAGTCAAGACCCTATACACGGGCACACCTACGAAGTAAGGTCGGAGTCCCT
a S S V F S S G I C A R V D A S F Q P Q G -
AGCCTGGCACCCACTGCCCAACGCTGCCCAACATACATGGATGTTGTCATTGTCTTGGAT
481 ---------+---------+---------+---------+---------+---------+ 540
TCGGACCGTGGGTGACGGGTTGCGACGGGTTGTATGTACCTACAACAGTAACAGAACCTA
a S L A P T A Q R C P T Y M D V V I V L D -
GGCTCCAACAGCATCTACCCCTGGTCTGAAGTTCAGACCTTCCTACGAAGACTGGTAGGG
541 ---------+---------+---------+---------+---------+---------+ 600
CCGAGGTTGTCGTAGATGGGGACCAGACTTCAAGTCTGGAAGGATGCTTCTGACCATCCC
a G S N S I Y P W S E V Q T F L R R L V G -
AAACTGTTTATTGACCCAGAACAGATACAGGTGGGACTGGTACAGTATGGGGAGAGCCCT
601 ---------+---------+---------+---------+---------+---------+ 660
TTTGACAAATAACTGGGTCTTGTCTATGTCCACCCTGACCATGTCATACCCCTCTCGGGA
a K L F I D P E Q I Q V G L V Q Y G E S P -
GTACATGAGTGGTCCCTGGGAGATTTCCGAACGAAGGAAGAAGTGGTGAGAGCAGCAAAG
661 ---------+---------+---------+---------+---------+---------+ 720
CATGTACTCACCAGGGACCCTCTAAAGGCTTGCTTCCTTCTTCACCACTCTCGTCGTTTC
a V H E W S L G D F R T K E E V V R A A K -
AACCTCAGTCGGCGGGAGGGACGAGAAACAAAGACTGCCCAAGCAATAATGGTGGCCTGC
721 ---------+---------+---------+---------+---------+---------+ 780
TTGGAGTCAGCCGCCCTCCCTGCTCTTTGTTTCTGACGGGTTCGTTATTACCACCGGACG
a N L S R R E G R E T K T A Q A I M V A C -
ACAGAAGGGTTCAGTCAGTCCCATGGGGGCCGACCCGAGGCTGCCAGGCTACTGGTGGTT
781 ---------+---------+---------+---------+---------+---------+ 840
TGTCTTCCCAAGTCAGTCAGGGTACCCCCGGCTGGGCTCCGACGGTCCGATGACCACCAA
a T E G F S Q S H G G R P E A A R L L V V -
GTCACTGATGGAGAGTCCCATGATGGAGAGGAGCTTCCTGCAGCACTAAAGGCCTGTGAG
841 ---------+---------+---------+---------+---------+---------+ 900
CAGTGACTACCTCTCAGGGTACTACCTCTCCTCGAAGGACGTCGTGATTTCCGGACACTC
a V T D G E S H D G E E L P A A L K A C E -
GCTGGAAGAGTGACACGCTATGGGATTGCAGTCCTTGGTCACTACCTCCGGCGGCAGCGA
901 ---------+---------+---------+---------+---------+---------+ 960
CGACCTTCTCACTGTGCGATACCCTAACGTCAGGAACCAGTGATGGAGGCCGCCGTCGCT
a A G R V T R Y G I A V L G H Y L R R Q R -
GATCCCAGCTCTTTCCTGAGAGAAATTAGAACTATTGCCAGTGATCCAGATGAGCGATTC
961 ---------+---------+---------+---------+---------+---------+ 1020
CTAGGGTCGAGAAAGGACTCTCTTTAATCTTGATAACGGTCACTAGGTCTACTCGCTAAG
a D P S S F L R E I R T I A S D P D E R F -
TTCTTCAATGTCACAGATGAGGCTGCTCTGACTGACATTGTGGATGCACTAGGAGATCGG
1021 ---------+---------+---------+---------+---------+---------+ 1080
AAGAAGTTACAGTGTCTACTCCGACGAGACTGACTGTAACACCTACGTGATCCTCTAGCC
a F F N V T D E A A L T D I V D A L G D R -
ATTTTTGGCCTTGAAGGGTCCCATGCAGAAAACGAAAGCTCCTTTGGGCTGGAAATGTCT
1081 ---------+---------+---------+---------+---------+---------+ 1140
TAAAAACCGGAACTTCCCAGGGTACGTCTTTTGCTTTCGAGGAAACCCGACCTTTACAGA
a I F G L E G S H A E N E S S F G L E M S -
CAGATTGGTTTCTCCACTCATCGGCTAAAGGATGGGATTCTTTTTGGGATGGTGGGGGCC
1141 ---------+---------+---------+---------+---------+---------+ 1200
GTCTAACCAAAGAGGTGAGTAGCCGATTTCCTACCCTAAGAAAAACCCTACCACCCCCGG
a Q I G F S T H R L K D G I L F G M V G A -
TATGACTGGGGAGGCTCTGTGCTATGGCTTGAAGGAGGCCACCGCCTTTTCCCCCCACGA
1201 ---------+---------+---------+---------+---------+---------+ 1260
ATACTGACCCCTCCGAGACACGATACCGAACTTCCTCCGGTGGCGGAAAAGGGGGGTGCT
a Y D W G G S V L W L E G G H R L F P P R -
ATGGCACTGGAAGACGAGTTCCCCCCTGCACTGCAGAACCATGCAGCCTACCTGGGTTAC
1261 ---------+---------+---------+---------+---------+---------+ 1320
TACCGTGACCTTCTGCTCAAGGGGGGACGTGACGTCTTGGTACGTCGGATGGACCCAATG
a M A L E D E F P P A L Q N H A A Y L G Y -
TCTGTTTCTTCCATGCTTTTGCGGGGTGGACGCCGCCTGTTTCTCTCTGGGGCTCCTCGA
1321 ---------+---------+---------+---------+---------+---------+ 1380
AGACAAAGAAGGTACGAAAACGCCCCACCTGCGGCGGACAAAGAGAGACCCCGAGGAGCT
a S V S S M L L R G G R R L F L S G A P R -
TTTAGACATCGAGGAAAAGTCATCGCCTTCCAGCTTAAGAAAGATGGGGCTGTGAGGGTT
1381 ---------+---------+---------+---------+---------+---------+ 1440
AAATCTGTAGCTCCTTTTCAGTAGCGGAAGGTCGAATTCTTTCTACCCCGACACTCCCAA
a F R H R G K V I A F Q L K K D G A V R V -
GCCCAGAGCCTCCAGGGGGAGCAGATTGGTTCATACTTTGGCAGTGAGCTCTGCCCATTG
1441 ---------+---------+---------+---------+---------+---------+ 1500
CGGGTCTCGGAGGTCCCCCTCGTCTAACCAAGTATGAAACCGTCACTCGAGACGGGTAAC
a A Q S L Q G E Q I G S Y F G S E L C P L -
GATACAGATAGGGATGGAACAACTGATGTCTTACTTGTGGCTGCCCCCATGTTCCTGGGA
1501 ---------+---------+---------+---------+---------+---------+ 1560
CTATGTCTATCCCTACCTTGTTGACTACAGAATGAACACCGACGGGGGTACAAGGACCCT
a D T D R D G T T D V L L V A A P M F L G -
CCCCAGAACAAGGAAACAGGACGTGTTTATGTGTATCTGGTAGGCCAGCAGTCCTTGCTG
1561 ---------+---------+---------+---------+---------+---------+ 1620
GGGGTCTTGTTCCTTTGTCCTGCACAAATACACATAGACCATCCGGTCGTCAGGAACGAC
a P Q N K E T G R V Y V Y L V G Q Q S L L -
ACCCTCCAAGGAACACTTCAGCCAGAACCCCCCCAGGATGCTCGGTTTGGCTTTGCCATG
1621 ---------+---------+---------+---------+---------+---------+ 1680
TGGGAGGTTCCTTGTGAAGTCGGTCTTGGGGGGGTCCTACGAGCCAAACCGAAACGGTAC
a T L Q G T L Q P E P P Q D A R F G F A M -
GGAGCTCTTCCTGATCTGAACCAAGATGGTTTTGCTGATGTGGCTGTGGGGGCGCCTCTG
1681 ---------+---------+---------+---------+---------+---------+ 1740
CCTCGAGAAGGACTAGACTTGGTTCTACCAAAACGACTACACCGACACCCCCGCGGAGAC
a G A L P D L N Q D G F A D V A V G A P L -
GAAGATGGGCACCAGGGAGCACTGTACCTGTACCATGGAACCCAGAGTGGAGTCAGGCCC
1741 ---------+---------+---------+---------+---------+---------+ 1800
CTTCTACCCGTGGTCCCTCGTGACATGGACATGGTACCTTGGGTCTCACCTCAGTCCGGG
a E D G H Q G A L Y L Y H G T Q S G V R P -
CATCCTGCCCAGAGGATTGCTGCTGCCTCCATGCCACATGCCCTCAGCTACTTTGGCCGA
1801 ---------+---------+---------+---------+---------+---------+ 1860
GTAGGACGGGTCTCCTAACGACGACGGAGGTACGGTGTACGGGAGTCGATGAAACCGGCT
a H P A Q R I A A A S M P H A L S Y F G R -
AGTGTGGATGGTCGGCTAGATCTGGATGGAGATGATCTGGTCGATGTGGCTGTGGGTGCC
1861 ---------+---------+---------+---------+---------+---------+ 1920
TCACACCTACCAGCCGATCTAGACCTACCTCTACTAGACCAGCTACACCGACACCCACGG
a S V D G R L D L D G D D L V D V A V G A -
CAGGGGGCAGCCATCCTGCTCAGCTCCCGGCCCATTGTCCATCTGACCCCATCACTGGAG
1921 ---------+---------+---------+---------+---------+---------+ 1980
GTCCCCCGTCGGTAGGACGAGTCGAGGGCCGGGTAACAGGTAGACTGGGGTAGTGACCTC
a Q G A A I L L S S R P I V H L T P S L E -
GTGACCCCACAGGCCATCAGTGTGGTTCAGAGGGACTGTAGGCGGCGAGGCCAAGAAGCA
1981 ---------+---------+---------+---------+---------+---------+ 2040
CACTGGGGTGTCCGGTAGTCACACCAAGTCTCCCTGACATCCGCCGCTCCGGTTCTTCGT
a V T P Q A I S V V Q R D C R R R G Q E A -
GTCTGTCTGACTGCAGCCCTTTGCTTCCAAGTGACCTCCCGTACTCCTGGTCGCTGGGAT
2041 ---------+---------+---------+---------+---------+---------+ 2100
CAGACAGACTGACGTCGGGAAACGAAGGTTCACTGGAGGGCATGAGGACCAGCGACCCTA
a V C L T A A L C F Q V T S R T P G R W D -
CACCAATTCTACATGAGGTTCACCGCATCACTGGATGAATGGACTGCTGGGGCACGTGCA
2101 ---------+---------+---------+---------+---------+---------+ 2160
GTGGTTAAGATGTACTCCAAGTGGCGTAGTGACCTACTTACCTGACGACCCCGTGCACGT
a H Q F Y M R F T A S L D E W T A G A R A -
GCATTTGATGGCTCTGGCCAGAGGTTGTCCCCTCGGAGGCTCCGGCTCAGTGTGGGGAAT
2161 ---------+---------+---------+---------+---------+---------+ 2220
CGTAAACTACCGAGACCGGTCTCCAACAGGGGAGCCTCCGAGGCCGAGTCACACCCCTTA
a A F D G S G Q R L S P R R L R L S V G N -
GTCACTTGTGAGCAGCTACACTTCCATGTGCTGGATACATCAGATTACCTCCGGCCAGTG
2221 ---------+---------+---------+---------+---------+---------+ 2280
CAGTGAACACTCGTCGATGTGAAGGTACACGACCTATGTAGTCTAATGGAGGCCGGTCAC
a V T C E Q L H F H V L D T S D Y L R P V -
GCCTTGACTGTGACCTTTGCCTTGGACAATACTACAAAGCCAGGGCCTGTGCTGAATGAG
2281 ---------+---------+---------+---------+---------+---------+ 2340
CGGAACTGACACTGGAAACGGAACCTGTTATGATGTTTCGGTCCCGGACACGACTTACTC
a A L T V T F A L D N T T K P G P V L N E -
GGCTCACCCACCTCTATACAAAAGCTGGTCCCCTTCTCAAAGGATTGTGGCCCTGACAAT
2341 ---------+---------+---------+---------+---------+---------+ 2400
CCGAGTGGGTGGAGATATGTTTTCGACCAGGGGAAGAGTTTCCTAACACCGGGACTGTTA
a G S P T S I Q K L V P F S K D C G P D N -
GAATGTGTCACAGACCTGGTGCTTCAAGTGAATATGGACATCAGAGGCTCCAGGAAGGCC
2401 ---------+---------+---------+---------+---------+---------+ 2460
CTTACACAGTGTCTGGACCACGAAGTTCACTTATACCTGTAGTCTCCGAGGTCCTTCCGG
a E C V T D L V L Q V N M D I R G S R K A -
CCATTTGTGGTTCGAGGTGGCCGGCGGAAAGTGCTGGTATCTACAACTCTGGAGAACAGA
2461 ---------+---------+---------+---------+---------+---------+ 2520
GGTAAACACCAAGCTCCACCGGCCGCCTTTCACGACCATAGATGTTGAGACCTCTTGTCT
a P F V V R G G R R K V L V S T T L E N R -
AAGGAAAATGCTTACAATACGAGCCTGAGTATCATCTTCTCTAGAAACCTCCACCTGGCC
2521 ---------+---------+---------+---------+---------+---------+ 2580
TTCCTTTTACGAATGTTATGCTCGGACTCATAGTAGAAGAGATCTTTGGAGGTGGACCGG
a K E N A Y N T S L S I I F S R N L H L A -
AGTCTCACTCCTCAGAGAGAGAGCCCAATAAAGGTGGAATGTGCCGCCCCTTCTGCTCAT
2581 ---------+---------+---------+---------+---------+---------+ 2640
TCAGAGTGAGGAGTCTCTCTCTCGGGTTATTTCCACCTTACACGGCGGGGAAGACGAGTA
a S L T P Q R E S P I K V E C A A P S A H -
GCCCGGCTCTGCAGTGTGGGGCATCCTGTCTTCCAGACTGGAGCCAAGGTGACCTTTCTG
2641 ---------+---------+---------+---------+---------+---------+ 2700
CGGGCCGAGACGTCACACCCCGTAGGACAGAAGGTCTGACCTCGGTTCCACTGGAAAGAC
a A R L C S V G H P V F Q T G A K V T F L -
CTAGAGTTTGAGTTTAGCTGCTCCTCTCTCCTGAGCCAGGTCTTTGGGAAGCTGACTGCC
2701 ---------+---------+---------+---------+---------+---------+ 2760
GATCTCAAACTCAAATCGACGAGGAGAGAGGACTCGGTCCAGAAACCCTTCGACTGACGG
a L E F E F S C S S L L S Q V F G K L T A -
AGCAGTGACAGCCTGGAGAGAAATGGCACCCTTCAAGAAAACACAGCCCAGACCTCAGCC
2761 ---------+---------+---------+---------+---------+---------+ 2820
TCGTCACTGTCGGACCTCTCTTTACCGTGGGAAGTTCTTTTGTGTCGGGTCTGGAGTCGG
a S S D S L E R N G T L Q E N T A Q T S A -
TACATCCAATATGAGCCCCACCTCCTGTTCTCTAGTGAGTCTACCCTGCACCGCTATGAG
2821 ---------+---------+---------+---------+---------+---------+ 2880
ATGTAGGTTATACTCGGGGTGGAGGACAAGAGATCACTCAGATGGGACGTGGCGATACTC
a Y I Q Y E P H L L F S S E S T L H R Y E -
GTTCACCCATATGGGACCCTCCCAGTGGGTCCTGGCCCAGAATTCAAAACCACTCTCAGG
2881 ---------+---------+---------+---------+---------+---------+ 2940
CAAGTGGGTATACCCTGGGAGGGTCACCCAGGACCGGGTCTTAAGTTTTGGTGAGAGTCC
a V H P Y G T L P V G P G P E F K T T L R -
ACTAACAATGCAAGCTGCATAGTGCAGAACCTGACTGAACCCCCAGGCCCACCTGTGCAT
2941 ---------+---------+---------+---------+---------+---------+ 3000
TGATTGTTACGTTCGACGTATCACGTCTTGGACTGACTTGGGGGTCCGGGTGGACACGTA
a T N N A S C I V Q N L T E P P G P P V H -
CCAGAGGAGCTTCAACACACAAACAGACTGAATGGGAGCAATACTCAGTGTCAGGTGGTG
3001 ---------+---------+---------+---------+---------+---------+ 3060
GGTCTCCTCGAAGTTGTGTGTTTGTCTGACTTACCCTCGTTATGAGTCACAGTCCACCAC
a P E E L Q H T N R L N G S N T Q C Q V V -
AGGTGCCACCTTGGGCAGCTGGCAAAGGGGACTGAGGTCTCTGTTGGACTATTGAGGCTG
3061 ---------+---------+---------+---------+---------+---------+ 3120
TCCACGGTGGAACCCGTCGACCGTTTCCCCTGACTCCAGAGACAACCTGATAACTCCGAC
a R C H L G Q L A K G T E V S V G L L R L -
GTTCACAATGAATTTTTCCGAAGAGCCAAGTTCAAGTCCCTGACGGTGGTCAGCACCTTT
3121 ---------+---------+---------+---------+---------+---------+ 3180
CAAGTGTTACTTAAAAAGGCTTCTCGGTTCAAGTTCAGGGACTGCCACCAGTCGTGGAAA
a V H N E F F R R A K F K S L T V V S T F -
GAGCTGGGAACCGAAGAGGGCAGTGTCCTACAGCTGACTGAAGCCTCCCGTTGGAGTGAG
3181 ---------+---------+---------+---------+---------+---------+ 3240
CTCGACCCTTGGCTTCTCCCGTCACAGGATGTCGACTGACTTCGGAGGGCAACCTCACTC
a E L G T E E G S V L Q L T E A S R W S E -
AGCCTCTTGGAGGTGGTTCAGACCCGGCCTATCCTCATCTCCCTGTGGATCCTCATAGGC
3241 ---------+---------+---------+---------+---------+---------+ 3300
TCGGAGAACCTCCACCAAGTCTGGGCCGGATAGGAGTAGAGGGACACCTAGGAGTATCCG
a S L L E V V Q T R P I L I S L W I L I G -
AGTGTCCTGGGAGGGTTGCTCCTGCTTGCTCTCCTTGTCTTCTGCCTGTGGAAGCTTGGC
3301 ---------+---------+---------+---------+---------+---------+ 3360
TCACAGGACCCTCCCAACGAGGACGAACGAGAGGAACAGAAGACGGACACCTTCGAACCG
a S V L G G L L L L A L L V F C L W K L G -
TTCTTTGCCCATAAGAAAATCCCTGAGGAAGAAAAAAGAGAAGAGAAGTTGGAGCAATGA
3361 ---------+---------+---------+---------+---------+---------+ 3420
AAGAAACGGGTATTCTTTTAGGGACTCCTTCTTTTTTCTCTTCTCTTCAACCTCGTTACT
a F F A H K K I P E E E K R E E K L E Q
ATGTAGAATAAGGGTCTAGAAAGTCCTCCCTGGCAGCTTTCTTCAAGAGACTTGCATAAA
3421 ---------+---------+---------+---------+---------+---------+ 3480
TACATCTTATTCCCAGATCTTTCAGGAGGGACCGTCGAAAGAAGTTCTCTGAACGTATTT
AGCAGAGGTTTGGGGGCTCAGATGGGACAAGAAGCCGCCTCTGGACTATCTCCCCAGACC
3481 ---------+---------+---------+---------+---------+---------+ 3540
TCGTCTCCAAACCCCCGAGTCTACCCTGTTCTTCGGCGGAGACCTGATAGAGGGGTCTGG
AGCAGCCTGACTTGACTTTTGAGTCCTAGGGATGCTGCTGGCTAGAGATGAGGCTTTACC
3541 ---------+---------+---------+---------+---------+---------+ 3600
TCGTCGGACTGAACTGAAAACTCAGGATCCCTACGACGACCGATCTCTACTCCGAAATGG
TCAGACAAGAAGAGCTGGCACCAAAACTAGCCATGCTCCCACCCTCTGCTTCCCTCCTCC
3601 ---------+---------+---------+---------+---------+---------+ 3660
AGTCTGTTCTTCTCGACCGTGGTTTTGATCGGTACGAGGGTGGGAGACGAAGGGAGGAGG
TCGTGATCCTGGTTCCATAGCCAACACTGGGGCTTTTGTTTGGGGTCCTTTTATCCCCAG
3661 ---------+---------+---------+---------+---------+---------+ 3720
AGCACTAGGACCAAGGTATCGGTTGTGACCCCGAAAACAAACCCCAGGAAAATAGGGGTC
GAATCAATAATTTTTTTGCCTAGGAAAAAAAAAAGCGGCCGCGAATTCGATATCAAGCT
3721 ---------+---------+---------+---------+---------+--------- 3779
CTTAGTTATTAAAAAAACGGATCCTTTTTTTTTTCGCCGGCGCTTAAGCTATAGTTCGA
(2) 配列番号3の情報:
(i) 配列特徴:
(A) 配列の長さ: 143 塩基対
(B) 配列の型: 核酸およびアミノ酸
(C) 鎖の数: 二本鎖
(D) トポロジー: 直鎖状
(iii) 配列の種類: cDNA
(vi) 起源:
(A)生物名: ヒト
(B) 細胞の種類: 軟骨細胞
(xi) 配列の記載: 配列番号3:
NdeI
|
GGGGCATATGGTTCAGAACCTGGGTTGCTACGTTGTTTCCGGTCTGATCATCTCCGCTCT
1 ---------+---------+---------+---------+---------+---------+ 60
CCCCGTATACCAAGTCTTGGACCCAACGATGCAACAAAGGCCAGACTAGTAGAGGCGAGA
b G H M V Q N L G C Y V V S G L I I S A L -
GCTGCCGGCTGTTGCTCACGGTGGTAACTACTTCCTAAGCTTGTCCCAGGTTATCAGCGG
61 ---------+---------+---------+---------+---------+---------+ 120
CGACGGCCGACAACGAGTGCCACCATTGATGAAGGATTCGAACAGGGTCCAATAGTCGCC
b L P A V A H G G N Y F L S L S Q V I S G -
BamHI
|
CCTGGTGCCGCGCGGATCCCCCC
121 ---------+---------+--- 143
GGACCACGGCGCGCCTAGGGGGG
b L V P R G S P -
【図面の簡単な説明】
【0091】
【図1】II型コラーゲン−「Sepharose 」上でのα10インテグリンサブユニットの親和精製を示す。
【図2】ウシα10インテグリンサブユニットからのペプチドのアミノ酸配列を示す。
【図3】Aは、ウシ軟骨細胞からのインテグリンサブユニットα10の親和精製および免疫沈殿を示す。 Bは、ヒト軟骨細胞からのインテグリンサブユニットα10の親和精製および免疫沈殿を示す。 Cは、ヒト軟骨肉腫細胞からのインテグリンサブユニットα10の親和精製および免疫沈殿を示す。
【図4】ウシインテグリンサブユニットα10に対応する 900bpPCRフラグメントを示す。
【図5】3種の重複クローンの線図である。
【図6】ヒロα10インテグリンサブユニットのヌクレオチド配列および推定アミノ酸配列を示す。
【図7】インテグリンα10mRNAのノーザンブロットを示す。
【図8】α10の細胞質領域に対する抗体を用いたヒト軟骨細胞からのα10インテグリンサブユニットの免疫沈殿を示す(a)。α10 会合β鎖のウエスターンブロット(b)。
【図9】ヒト間節軟骨中のα10インテグリンの染色を示す。
【図10】生後3日マウスの手足軟骨におけるα10インテグリンの染色を示す。
【図11】生後13.5日マウスの胚におけるα10インテグリンの染色を示す。
【図12】各種ヒト組織中のα10mRNAの交配を示す。
【図13】生後3日マウスの手足における間節周りの靭帯(a)、骨格筋(b)および心臓弁(c)の染色をシスプラチン。
【図14】ヒト軟骨細胞、ヒト内皮細胞。ヒト繊維芽細胞およびラット間節からのα10インテグリンサブユニットに対応するPCRフラグメントを示す。
【図15】ヒトインテグリンサブユニットα10の部分ゲノムヌクレオチド配列を示す。
【図16】アルギン酸塩中で培養した軟骨細胞におけるα10インテグリンサブユニットのアップレギュレーションを示す。
【図17】ヒト平滑筋細胞からのα10インテグリンサブユニットの染色を示す。
【技術分野】
【0001】
この発明は、サブユニットα10およびサブユニットβを含む組み換え体または単離インテグリンヘテロ二量体、それのサブユニットα10、上記インテグリンの相同体およびフラグメントならびに類似の生物学的活性を有する上記サブユニットα10の相同体およびフラグメント、それの生産方法、それをコードするポリヌクレオチドおよびオリゴヌクレオチド、それを含むベクターおよび細胞、それに特異的に結合する結合実体、ならびにそれの使用に関するものである。
【背景技術】
【0002】
インテグリンは、細胞−細胞および細胞−マトリックス相互反応を仲介するトランスメンブラン糖タンパク質の大きなフアミリーである(1−5)。この超フアミリーの全ての既知メンバーは、α−およびβ−サブユニットからなる非共有結合的に会合したヘテロ二量体である。現在では、八つのβ−サブユニット(β1 −β8 )(6)および十六のα−サブユニット(α1 −α9 、αV 、αM 、αL 、αX 、αIIb 、αE およびαD )が特徴付けられており(6−21)、これらのサブユニットは会合して20を超す異種のインテグリンを生ずる。β1 サブユニットは10種の異なったα−サブユニットα1 −α9 およびαV と会合することが証明され、かつ、コラーゲン、ラミニンおよびフィブロネクチン等の細胞外マトリックスタンパク質との相互反応を仲介することが証明されている。主たるコラーゲン結合インテグリンはα1 β1 およびα2 β1 (22−25)である(22−25)。インテグリンα3 β1 およびα9 β1 もコラーゲンと相互反応すると報告されているが(26,27)、この相互反応については充分に理解されていない(28)。α−およびβーインテグリンサブユニットの細胞外N−末端領域はリガンドの結合に重要である(29,30)。このα−サブユニットの末端領域はFGおよびGAP共通配列を含む7回折畳み繰り返し配列(12,31)からなる。この繰り返しは、推定2価カチオン結合サイト含む最後の3回または4回繰り返し部分を伴ったβープロペラー領域(32)へと折り畳むことが予見される。α−インテグリンサブユニットα1 、α2 、αD 、αE 、αL 、αM 、αX は〜200アミノ酸挿入領域であるI−領域(A〜領域)を含み、このことは von Willebrand 因子、軟骨マトリックスタンパク質および補体因子C2 およびB(33,34)中の配列に対する類似性を示す。このI−領域は、第2および第3FG−GAP繰り返し体間に局在し、金属依存性付着サイト(MIDAS) を含み、かつ、このものはリガンドの結合に関与する(35−38)。
【0003】
軟骨中の唯一の細胞型である軟骨細胞は、α1 β1 、α2 β1 、α3 β1 、α5 β1 、α6 β1 、αV β3 およびαV β5 (39−41)を包含する多数の異なったインテグリンを発現する。α1 β1 およびα2 β1 は軟骨の主成分の一つであるII型コラーゲン(25)との軟骨細胞相互反応を仲介することが判明している。またα2 β1 は軟骨マトリックスタンパク質 コンドロアドヘリン(42)に対する受容体である。
【発明の開示】
【課題を解決するための手段】
【0004】
この発明はサブユニットα10を、サブユニットβ特にサブユニットβ1 と会合した形態で含む新規コラーゲン型II結合インテグリンに関するものであるが、他のβ−サブユニットも顧慮に値する。好ましい実施対様では、このインテグリンはヒトまたはウシの間接軟骨細胞ならびにヒト軟骨肉腫細胞から単離されている。
【0005】
またこの発明は、サブユニットβ好ましくはサブユニットβ1 と会合したサブユニットα10を含むウシインテグリンヘテロ二量体等の、他の種から単離した上記インテグリンのインテグリン相同体、ならびにヒト細胞の他の型からまたは他の種由来の細胞から単離した相同体も包含する。
【0006】
この発明は具体的には、SEQ ID No.1 または SEQ ID No.2 で示されるアミノ酸配列を含む組み換え体または単離インテグリンサブユニットα10に関し、かつ、同じ生物学的活性を示す、その相同体またはフラグメントに関する。
【0007】
この発明はさらに、SEQ ID No.1 または SEQ ID No.2 で示されるアミノ酸配列を含む組み換えインテグリンサブユニットα10、または類似の生物学的活性を示すその相同体もしはフラグメントの生産方法に関し、この方法は次の工程:
a)インテグリンサブユニットα10をコードするヌクレオチド配列を含むポリヌクレオチド、または類似の生物学的活性を示すその相同体もしはフラグメントを単離し;
b)単離したポリヌクレオチドを含む発現ベクターを構築し;
c)上記発現ベクターを用いて宿主細胞をトランスフオームし;
d)トランスフオームされた宿主細胞を、インテグリンサブユニットα10 の発現に適する条件下の培地中で、または類似の生物学的活性をトランフオームされた宿主細胞中で示すそれらの相同体もしくはフラグメントの発現に適する条件下の培地中で培養し;かつ任意に、
e)インテグリンサブユニットα10、または類似の生物学的活性を示すその相同体もしくはフラグメントを上記トランスフオームされ宿主主細胞または上記培地から単離する工程;
を包含する。
このインテグリンα10、または類似活性を示すそれらの相同体もしくはフラグメントも、それらが天然に存在する細胞からの単離により提供され得る。
【0008】
この発明はまた、インテグリンサブユニットα10、または類似の生物学的活性を示すそれらの相同体もしくはフラグメントをコードするヌクレオチドを含む単離ポリヌクレオチドにも関し、このポリヌクレオチドは SEQ ID No.1または SEQ ID No.2 で示されるポリヌクレオチド配列、またはその一部を含む。
【0009】
この発明はさらに、 SEQ ID No.1または SEQ ID No.2 で示されるアミノ酸配列を示すインテグリンサブユニットα10、またはそれらの相同体もしくはフラグメントをコードするDNAまたはRNAに交配する単離ポリヌクレオチドまたはオリゴヌクレオチドにも関し、この場合、上記ポリヌクレオチドまたはオリゴヌクレオチドはインテグリンサブユニットα1 をコードするDNAまたはRNAと交配する素質がない。
【0010】
さらなる観点において、この発明は上記ポリヌクレオチドを含むベクターに関し、かつ、上記ベクターを含む細胞および SEQ ID No.1または SEQ ID No.2 で示されるような、これらゲノム中に統合されたポリヌクレオチドまたはオリゴヌクレオチドを有する細胞に関する。
【0011】
この発明はまた、タンパク質、ペプチド、炭水化物、脂質、天然リガンド、ポリクローナル抗体またはモノクローナル抗体等の、インテグリンサブユニットα10またはそれらの相同体もしくはフラグメントへの特異的結合能力を有する結合実体にも関する。
【0012】
さらなる観点でこの発明は、サブユニットα10およびサブユニットβを含む組み換え体または単離インテグリンヘテロ二量体に関し、この場合、サブユニットα10は SEQ ID No.1または SEQ ID No.2 で示されるようなアミノ酸配列または類似の生物学的活性を示す相同体またはフラグメントを含む。好ましい実施態様では、このサブユニットβはβ1 である。
【0013】
またこの発明は、サブユニットα10およびサブユニットβを含む組み換え体インテグリンヘテロ二量体の生成方法にも関し、この場合、このサブユニットα10は SEQ ID No.1または SEQ ID No.2 で示されるようなアミノ酸配列を含み、この方法は次の工程:
a)インテグリンヘテロ二量体のサブユニットα10をコードするヌクレオチド配列を含む一つのポリヌクレオチド、および任意に、インテグリンヘテロ二量体のサブユニットβまたは類似の生物学的活性を示すその相同体またはフラグメントをコードするヌクレオチド配列を含む他のポリヌクレオチドを単離し;
b)上記サブユニットβをコードする上記単離ヌクレオチドを含む発現ベクターとの組み合わせで、上記サブユニットα10をコードする上記単離ポリヌクレオチドを含む発現ベクターを構築し;
c)上記発現ベクターを用いて宿主細胞をトランスフオームし;
d)トランスフオームされた上記宿主細胞を、サブユニットα10およびβを含むインテグリンヘテロ二量体の発現に適する条件下の培地中で、または類似の生物学的活性を上記トランスフオームされた宿主細胞中で示すその相同体またはフラグメントの発現に適する条件下の培地中で培養し;かつ任意に、
e)サブユニットα10 おょびβを含むインテグリンヘテロ二量体、または同じ生物学的活性を示すその相同体またはフラグメントを上記トランスフオームされた宿主細胞または上記培地から単離する工程;
を包含する。
【0014】
このインテグリンヘテロ二量体、または類似の生物学的活性を示す相同体もしくはフラグメントもまた、これらが天然に存在する細胞からの単離により提供され得る。
【0015】
さらにこの発明は、第1ベクターを含む細胞に関し、この第1ベクターは、インテグリンヘテロ二量体のサブユニットα10をコードする、または類似の生物学的活性を示すそれらの相同体もしは部分をコードするポリヌクレオチドを含み、このポリヌクレオチドは、 SEQ ID No.1または SEQ ID No.2 で示されるようなヌクレオチド配列もしくはそれらの部分、および、任意に第2ベクターを含み、上記第2ベクターは、インテグリンヘテロ二量体のサブユニットβまたはその相同体もしくはフラグメントをコードするポリヌクレオチドを含む。
【0016】
さらなる他の観点では、この発明はサブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体に特異結合し得る、または類似の生物学的活性を示す相同体もしくはフラグメントに特異結合する能力を有する結合実体に関し、この場合のサブユニットはβ1 である。好ましい結合実体はタンパク質、ペプチド、炭水化物、脂質、天然リガンド、ポリクロ−ナル抗体およびモノクローナル抗体である。
【0017】
さらなる観点で、この発明はインテグリンサブユニットα10のフラグメントに関し、この場合のフラグメントは細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドである。
【0018】
一つの実施態様では、上記フラグメントはアミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチドである。
【0019】
他の実施態様では、上記フラグメントは SEQ ID No.1 のアミノ酸約952からアミノ酸約986のアミノ酸配列を含む。
【0020】
さらなる実施態様では、上記フラグメントは SEQ ID No.1 のアミノ酸約140からアミノ酸約337のアミノ酸配列を含む。
【0021】
この発明の他の実施態様は、ヒトインテグリンサブユニットα10のフラグメントをコードするポリヌクレオチドまたはオリゴヌクレオチドに関する。一つの実施態様ではオリゴヌクレオチドのこのポリヌクレオチドは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドであるフラグメントをコードする。さらなる実施態様では、このポリヌクレオチドまたはオリゴヌクレオチドは上記定義のフラグメントをコードする。
【0022】
この発明はまた、上記定義のインテグリンサブユニットα10のフラグメントに特異的に結合し得る能力を有する結合性実体に関する。
【0023】
またこの発明は、 SEQ ID No.1 または SEQ ID No.2 で示されるアミノ酸配列を含むインテグリンサブユニットα10、または上記サブユニットα10 およびサブユニットβを含むインテグリンヘテロ二量体、または類似の生物学的活性を示す上記インテグリンの相同体もしくはフラグメントを、上記インテグリンサブユニットα10を発現する細胞もしくは組織のマーカーまたは標的分子として含むインテグリンサブユニットα10を使用する方法に関し、この場合の細胞もしくは組織はヒト由来のものを包含する動物細胞もしくは組織である。
【0024】
この方法の実施態様におけるフラグメントは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドである。
【0025】
この方法のさらなる実施態様では、このフラグメントはアミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチド、または SEQ ID No.1 のアミノ酸No.約952からアミノ酸No.約986のアミノ酸配列を含むフラグメント、またはSEQ ID No.1のアミノ酸No.約140からアミノ酸約337のアミノ酸配列を含むフラグメントを含むペプチドである。
【0026】
サブユニットβは好ましくはβ1 である。この細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞または繊維芽細胞からなる群から選択するのが好ましい。
【0027】
上記方法は、軟骨損傷、トラウマ、慢性間節リウマチおよび骨間節炎を包含する病理的症状等の、上記サブユニットα10が関与する病離的症状の間に使用できる。
【0028】
上記方法は、胎児性発生期間の軟骨の形成の検出または軟骨の生理学的もしくは治療的修復の検出に使用できる。上記方法はまた、軟骨細胞の選択および分析、または軟骨細胞の仕分け、単離もしくは精製のために使用できる。
【0029】
この方法のさらなる実施態様は、軟骨または軟骨細胞の移植期間中に軟骨または軟骨細胞の再生を検出する方法である。
【0030】
この方法のさらなる実施態様は、軟骨細胞の分化を in vitro で研究するための方法である。
【0031】
またこの発明は、SEQ ID No.1 または SEQ ID No.2に見られるアミノ酸配列を含むインテグリンサブユニットα10 に対する特異結合能力を有する結合実体、または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体に対する特異結合能力を有する結合実体、または、類似の生物学的活性を示すそれらの相同体もしくはフラグメントに対する特異結合能力を有する結合実体を、上記インテグリンサブユニットα10を発現する細胞もしくは組織のマーカまたは標的分子として使用する方法にも関し、この場合の細胞または組織はヒト由来を包含する動物からのものである。
【0032】
上記方法におけるフラグメントは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドであってもよい。好ましい実施態様における上記フラグメントはアミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ 、または SEQ No. 1 のアミノ酸配列 約No. 952 からアミノ酸配列 約No. 986 を含むフラグメント、または SEQ No. 1 のアミノ酸配列 約No. 140 からアミノ酸配列 約No. 337 を含むフラグメントを含むペプチドである。
【0033】
この方法は、SEQ ID No.1 または SEQ ID No.2に見られるアミノ酸配列を含むインテグリンサブユニットα10の存在、または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体の存在、または類似の生物学的活性を示すその相同体もしくはフラグメントの存在を検出する目的でも使用できる。
【0034】
この方法のさらなる実施態様では、上記方法は胚発生、血管形成、または癌の発生期間中に細胞の分化状態を決定するための方法である。
【0035】
さらなる実施態様におけるこの方法は、インテグリンサブユニットα10の細胞上での存在、または類似生物学的活性を示す上記インテグリンサブユニットの相同体もしくはフラグメントの細胞上での存在を検出する方法であり、この方法ではSEQ ID No.1 に見られるヌクレオチド配列から選択されたポリヌクレオチドもしくはオリゴポリヌクレオチドを含む群から選択されたポリヌクレオチドもしくはオリゴポリヌクレオチドが、交配条件下にマーカーとして使用され、この場合、上記ポリヌクレオチドもしくはオリゴポリヌクレオチドはインテグリンサブユニットα1をコードするDNAもしくはRNAと交配する素質がない。上記細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択されてもよい。上記インテグリンフラグメントは、細胞質領域、I−領域およびスプライスド領域から選択された、アミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチド等のペプチド、または SEQ ID No.1 のアミノ酸約 No.952からアミノ酸約 No.986、または SEQ ID No.1 のアミノ酸約 No.140からアミノ酸約 No.337を含むフラグメントを包含する群から選択されたペプチドでる。
【0036】
さらなる実施態様におけるこの方法は、病理学的症状における、組織再生における、または軟骨の治療もしくは病理学的修復における、発生期間中の細胞の分化状態を決定するための方法である。この病理学的症状は、間節リウマチ、骨間節炎または癌を包含する病理学的症状のいずれでもよい。この細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞を包含する群から選択できる。
【0037】
さらなる実施態様におけるこの方法は、病理学的症状における、組織再生における、および軟骨の治療もしくは病理学的修復における、発生期間中の細胞の分化状態を決定するための方法であり、この場合、 SEQ ID No.1に見られるポリヌクレオチド配列から選択されたポリヌクレオチドもしくはオリゴポリヌクレオチドが交配条件下のマーカーとして使用され、この場合の上記ポリヌクレオチドもしくはオリゴポリヌクレオチドはインテグリンサブユニットα1をコードするDNAもしくはRNAと交配する素質がない。この観点における実施態様は方法を含み、この場合、上記ポリヌクレオチドもしくはオリゴポリヌクレオチドは、細胞質領域、I−領域およびスプライスド領域のペプチドを含む群から選択されたペプチドをコードするポリヌクレオチドもしくはオリゴポリヌクレオチドであり、例えば、アミノ酸配列 KLGFFAHKKIPEEEKREEKLEQ を含むペプチドをコードするポリヌクレオチドまたはオリゴヌクレオチドまたは SEQ ID No.1 のアミノ酸約 No. 952 からアミノ酸約No. 986 から選択されたアミノ酸配列または SEQ ID No.1 のアミノ酸約 No. 140 からアミノ酸約No. 337 のアミノ酸配列を含むペプチドをコードするポリヌクレオチドもしくはオリゴポリヌクレオチドである。上記病理学的症状は、間節リウマチ、骨間節炎または癌を包含する病理学的症状のいずれでもよい。この細胞は、軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞を包含する群から選択できる。
【0038】
さらなる観点でこの発明は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体;またはそのサブユニットα10;または類似の生物学的活性を示す上記インテグリンもしくはサブユニットα10の相同体もしくはフラグメント;を使用できる医薬的作因もしくは抗体を活性成分として含む医薬組成物に関する。上記医薬組成物の実施態様は、軟骨、骨もしくは血液導管の形成を刺激、阻害または阻止する目的における組成物の使用である。さらなる実施態様は、感染、炎症後および外科的介入後の腱/靭帯間および組織周辺間の癒着防止に使用する医薬組成物を包含する。
【0039】
この発明はまた、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または上記インテグリンもしくはサブユニットα10の相同体またはフラグメント、または上記インテグリンサブユニットα10をコードするDNAもしはRNAを活性成分として含むワクチンニ関する。
【0040】
この発明のさらなる観点は、軟骨または軟骨細胞の移植におけるマーカーまたは標的としての、上記定義のインテグリンサブユニットα10の使用に関する。
【0041】
この発明のさらなる観点は、オセオ組み込みを刺激するための移植組織片表面への軟骨細胞および/または骨芽細胞の付着促進目的の、SEQ ID No.1 または SEQ ID No.2 に見られるアミノ酸配列を含むインテグリンサブユニットα10に特異結合する能力を有する結合実体の使用方法、または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体に特異結合する能力を有する結合実体の使用方法、または類似生物学的活性を示すその相同体もしくはフラグメントに特異結合する能力を有する結合実体の使用方法に関する。
【0042】
この発明はまた、インテグリンサブユニットα10または上記サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体を、癒着で組織機能を損なった腱、靭帯、骨格筋における抗癒着薬剤もしくは分子に対する標的として使用することに関する。
【0043】
この発明には、軟骨形成もしくは骨形成の刺激、阻害または阻止のための方法に関し、この方法は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または類似の生物学的活性を示す上記インテグリンまたはサブユニットα10の相同体もしくはフラグメントを標的分子として使用し得る医薬作因または抗体の適当量を、被験者に投与することが包含される。
【0044】
他の実施態様におるこの発明は、癒着が組織機能を損なった場合の感染後、炎症後、および外科的介入後の腱/靭帯間および周辺組織の癒着防止方法に関するものであり、この方法は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または類似の生物学的活性を示す上記インテグリンまたはサブユニットα10の相同体もしくはフラグメントを標的分子として使用し得る医薬作因または抗体の適当量を、被験者に投与することを包含する。
【0045】
この発明はまた、サブユニットα10よびサブユニットβを含むインテグリンヘテロ二量体、またはそれのサブユニットα10、または類似の生物学的活性を示す上記インテグリンの相同体またはフラグメントの活性化または遮断により、細胞外マトリックス合成および修復を刺激する方法に関するものである。
【0046】
さらなる観点でこの発明は、サブユニットα10およびサブユニットβを含むインテグリンヘテロ二量体、またはそのサブユニットα10、または上記インテグリンまたはサブユニットの相同体もしくはフラグメントの相互反応を包含する、インテグリン結合性実体の存在を in vitro で検出するための方法に関し、この方法では、上記インテグリン、サブユニットα10、または類似生物学的活性を示すその相同体もしはフラグメントをして、その天然リガンドへの結合性または試料中に存在する他のインテグリン結合性タンパク質への結合性を変調せしめるための試料を使用する。
【0047】
この発明はまた、サブユニットα10およびサブユニットβ、またはそのサブユニットα10、または上記インテグリンまたはサブユニットの相同体もしくはフラグメントを含むヒトヘテロ二量体インテグリンの相互反応の結果を in vitro で研究する方法に関し、この方法では、インテグリン結合性実体を用いて細胞性反応を開始させる。上記結果は細胞機能における改変として測定され得る。
【0048】
この発明のさらなる観点は、インテグリンサブユニットα10またはそれらの相同体もしくはフラグメントをコードするDNAもしくはRNAを標的分子として使用する方法に関する。この観点での実施態様では、ポリヌクレオチドもしくはオリゴポリヌクレオチドが、インテグリンサブユニットα10またはそれらの相同体もしくはフラグメントをコードするDNAもしくはRNAと交配し、それによって上記ポリヌクレオチドもしくはオリゴポリヌクレオチドはインテグリンサブユニットα1をコードするDNAもしくはRNAとの交配ができない。
【0049】
この発明はまた、サブユニットα10およびサブユニットβ、またはそのサブユニットα10、または上記インテグリンもしくはサブユニットの相同体もしくはフラグメント、またはインテグリンサブユニットα10またはその相同体もしくはフラグメントをコードするDNAもしくはRNAを含むヒトヘテロ二量体インテグリンを、脈管形成期間中のマーカーまたは標的分子として使用する方法にも関する。
【発明の具体的な説明】
【0050】
この発明は、ヒトおよびウシ軟骨細胞がβ1 フアミリーにおける新規II型コラーゲン結合性インテグリンを発現することを証明する。以前の研究では、ヒトの軟骨肉腫細胞もまたインテグリンを発現することに対するいくつかの証拠が提出された(25)。インテグリンサブユニットβ1 に対する抗体を用いた免疫沈殿実験では、この新規αインテグリンサブユニットは還元性条件下に約160kDaの見掛け分子量を示し、かつ、α 2インテグリンサブユニットよりも分子量が僅かに大きかったことを明らかにした。これを単離する目的で、αサブユニットII型コラーゲン結合性タンパク質をウシ軟骨細胞から親和精製した。先ずこの軟骨細胞リゼイトをフィブロネクチン−「Sepharpse 」プレカラムに塗布し、次で流動物をII型コラーゲン「Sepharose 」カラムに塗布した。約 160 kDのMr を示すタンパク質が、コラーゲンカラムからEDTAを用いて特異溶離されたが、フィブロネクチンカラムからは溶離されなかった。このMr は未確認β1 関連インテグリンサブユニットのMr と一致した。この 160 kDタンパク質バンドを SDS-PAGE ゲルから切除し、トリプシンで消化し、、単離ペプチドのアミノ酸配列を分析した。
【0051】
単離ペプチドに対応するプライマーがウシcDNAからの 900 bpPCRフラグメントを増幅し、このcDNAをクーロン化し、配列決定し、かつヒトインテグリンαサブユニット相同体を得る目的でヒト間節軟骨細胞λZapIIcDNAライブラリーのスクリーニング用に使用した。二つの重複クローン hcl および hc2 を単離し、サブクローン化し、配列決定した。これらのクローンは、cDNAの3’末端を包含するポリヌクレオチド配列の2/3を含んでいた。α10cDNAの5’末端を含む第3クローンを RACE 手法を用いて得た。160 kDタンパク質配列の配列分析によれば、このものはインテグリンαサブユニットフアミリーの1員であることを示し、かつ、このタンパク質は通称α10であることが判明した。
【0052】
α10の推定アミノ酸配列は、以前刊行された報告書(6−12)に記載のインテグリンαサブユニットの一般的構造を共有することが判明した。α10の大きな細胞外N末端部分は、βプロペラー領域(32)へと折り畳まれることが最近予見された7回折畳み繰り返し配列を含んでいる。このインテグリンサブユニットα10は、三つの推定2価のカチオン結合性サイト(DxD/NxD/NxxxD )(53)、単一スパントランスメンブラン領域および短い細胞質領域を含む。大半のαインテグリンサブユニットとは反対に、α10の細胞質領域は保守配列KxGFF (R/K) Rを含まない。α10中に予見されたアミノ酸配列は KLGFFAH である。いくつかの報告が、このインテグリン細胞質領域が信号トランスダクションに必須であり(54)、また、α−およびβ−インテグリン細胞質領域の膜−近位領域がインテグリンの立体構造および親和状態を変調するのに関与することを示す(55−57)。α鎖中の GFFKR モチーフはインテグリンサブユニットの会合に重要であり、また血漿膜へのインテグリンの輸送に対して重要であることが暗示される(58)。この KXGFFKR 領域は、細胞内タンパク質カルレチクリン(59)と相互反応し、興味あることには、カルレチクリンが存在しない胚幹細胞は、インテグリン仲介細胞付着性に欠けることが判った(60)。したがってα10の配列 KXGFFKR はα10β1 およびマトリックスタンパク質間の親和性を調節するための重要な因子を有する可能性がある。
【0053】
インテグリンαサブユニットは20〜40%の総体的同一性を共有することは既知である(61)。配列決定によれば、このα10サブユニットは、最高の同一性α1 (37%)およびα2 (35%)をもってαサブユニット含有I領域と最も密接に関連することを示す。インテグリンα1 β1 および α2 β1 はコラーゲンおよびラミニン両方に対する受容体であり(24;62;63)、また出願人らは最近、α2 β1 が軟骨マトリックスタンパク質コンドロアドヘリンと相互反応することも証明した(42)。II型コラゲーン−「Sepharoses」上でα10β1 が単離されたので、出願人らは、II型コラーゲンはα10β1 に対するリガンドであることを知った。同時に出願人らは親和精製実験により、α10β1 はI型コラーゲンとは相互反応するが、ラミニンまたはコンドロアドヘリンもまたこのインテグリンに対するリガンドであるか否かの問題解決はこれららである。
【0054】
還元型および非還元型の両条件下にα10会合β鎖は、β1 インテグリンサブユニットのように移動した。α10会合β鎖がβ1 であるか否かを証明する目的で、軟骨細胞リゼイトをα10またはβ1 に対する抗体を用いて免疫沈殿させ、次いでβ1 サブユニットに対する抗体を用いてウエスターンブロットに処した。これらの結果は、α10がβ1 インテグリンのフアミリーであることを明瞭に証明した。しかし、α10が同時に他のβ鎖と結合する可能性は排除できない。
【0055】
α10の細胞質領域に対して高めたポリクローナルペプチド抗体は二つのタンパク質バンドMr 約 160 kD(α10)および 125 kD(β1 )を還元型条件下に沈殿した。α10抗体を用いた免疫組織化学によれば、ヒト間節軟骨の組織部分中での軟骨細胞の染色を示した。この抗体染色は、α10ペプチドを用いた抗体の予備保温が染色を完全に廃止させたので、この抗体染色は明らかに特異的であった。胚組織からのマウス手足部分の免疫組織化学的染色は、間葉組織の縮合期間中にアップレギュレーションされることを証明した。このことは、このインテグリンサブユニットα10が軟骨形成期間中に重要であることを示す。生後3日のマウスでは、α10が圧倒的コラーゲン結合性インテグリンサブユニットであることが分かり、このことはα10が正常の軟骨機能の維持に重要な機能を有することを示す。
【0056】
タンパク質およびmRNAレベルでの発現研究によれば、α10の部分は寧ろ限定的であることを示す。免疫組織化学分析によれば、α10インテグリンサブユニットは軟骨中で主として発現されるが、このものは同時に軟骨膜、骨膜、Ranvier の骨化溝、間節周辺の筋膜おょび骨格筋ならびに心臓弁の間節様構造中にも見いだされる。この分布はα10インテグリンサブユニットが繊維芽細胞および骨芽細胞上にも存在することを指摘する。異なった細胞型からのcDNAのPCR増幅によれば、交互にスプライスされたα10インテグリンサブユニットの存在が明になった。このスプライスドα10は繊維芽細胞中に圧倒的であり、繊維芽細胞中のα10は軟骨細胞に存在するα10に比べて異なった機能を有する可能性があることを示唆する。
【0057】
インテグリンサブユニットα10の発現は、軟骨細胞を単層中で培養すると低減するように見られた。これとは対照的にα10の発現は、この細胞をアルギン酸塩ビーズ中で培養すると増加するのが見られた。後者の培養モデルは軟骨細胞の表現型を保持するすることが知られているので、上記結果はα10が分化軟骨細胞に対するマーカーとして機能できることを暗示している。
【0058】
腱/靭帯間および周辺組織の癒着は感染、傷害後、および外科的介入後の公知問題点である。間節および間節シート間の癒着は滑走機能を損ない、かつ、例えば手指の間節の治癒中に著しい問題点を引き起こし、その結果、機能不全に至る。間節および骨格筋の筋膜中へのα10インテグリンサブユニットの局在化は、α10をして、腱/靭帯の機能の損失を防止し得る抗癒着性を有する医薬物質または分子に対する可能性ある標的となさしめ得る。またインテグリンサブユニットα10は、癒着が問題になる他の組織における抗癒着性を有する医薬物質もしくは分子に対する標的ともなり得る。
【実施例】
【0059】
実施例1
II型コラーゲン−「Sepharose 」上でのα10インテグリンサブユニットの親和精製
材料および方法
ウシ軟骨細胞、ヒト軟骨細胞またはヒト軟骨腫瘍細胞を前記のように単離した[Holmval らの Exp Cell Res, 221, 496-503 (1995), Camper らの JBC, 273, 20383-20389 (1998) ]。ウシ軟骨細胞の「Triton X-100」リゼイトを、フイブロネクチン−「Sepharose 」プレカラム、次いでII型コラーゲン−「Sepharose 」上に施し、このインテグリンサブユニットα10をII型コラーゲンカラムから EDTA により溶離した(Camper らの JBC, 273, 20383-20389(1998)。溶離タンパク質をメタノール/クロロホルムで沈殿させ、還元型条件下に SDS-PAGE により分離し、クーマシーブルーで染色した(Camper らの JBC, 273, 20383-20389 (1998) 。α10 タンパク質バンドからのペプチドをトリプシンおよび相液クロマトグラフイーを用いた in-gel 消化により単離し、Edman 分解(Camper らの JBC, 273, 20383-20389 (1998)により配列決定した。
【0060】
結果
図1は、フイブロネクチン−「Sepharose 」からの EDTA 溶離タンパク質(A)、II型コラーゲン−「Sepharose 」カラムからの 流動物(B)およびII型コラーゲン−「Sepharose 」からの EDTA 溶離タンパク質(C)を示す。II型コラーゲン−「Sepharose 」カラムから特異的に溶離したα10インテグリンサブユニット(160 kDa) を矢印で示す。図2は、ウシインテグリンサブユニットα10から溶離した6種のペプチドのアミノ酸配列を示す。図3a、bおよびcは,α10インテグリンサブユニットがウシ軟骨細胞(3a)、ヒト軟骨細胞(3b)上に存在することを示す。
II型コラーゲンに対する親和性、β1 インテグリンサブユニットとの共沈殿および還元型条件下の分子量 160 kDaにより、異なった細胞上でのα10インテグリンサブユニットを確認する。これらの結果は、α10が軟骨細胞および軟骨肉腫細胞から単離され得ることを示す。
【0061】
実施例2
ウシα10インテグリンサブユニットに対応するPCRフラグメントの増幅
材料および方法
ウシペプチド1(図2)に対応するポリヌクレオチド配列を増幅するために、縮重プライマー GAY AAY ACI GCI CAR AC ( DNTAQT, forward ) および TIA TIS WRT GRT GIG GYT (EPHHSI, reverse) をPCRに用いた (Camper らの JBC, 273, 20383-20389 (1998) 。次いで ペプチド1のクローン化ヌクレオチド配列に対応する内部特異プライマー TCA GCC TAC ATT CAG TAT (SAYIQY, forward)をウシペプチド2(図2) に対応するICK RTC CC, RTG ICC IGG (PGHWDR, reverse) と共に用いて 900 bp PCRフラグメントをウシcDNAから増幅した。2倍縮重の位置には混合塩基を使用し、3または4倍縮重の位置にはイノシンを使用した。mRNA単離およびcDNA合成を文献記載(Camper らの
JBC, 273, 20383-20389 (1998) に準拠して実施した。精製フラグメントをクーローン化し、精製し、文献記載に従って配列決定した(Camper らの JBC, 273, 20383-20389 (1998) )。
結果
ペプチド1のヌクレオチド配列(図2)が、ウシcDNAのPCR増幅、クローン化および配列決定により得られた。このヌクレオチド配列から正確なプライマーを設計し、ペプチド2−6に対応する縮重プライマーを用いるPCR増幅に応用した。ペプチド1および2に対応するプライマーがウシcDNAからの 900 bp フラグメントを増幅した(図4)。
【0062】
実施例3
ヒトα10インテグリンサブユニットのクローン化および配列分析
材料および方法
ウシα10インテグリンに対応するクローン化 900 bp PCRフラグメントを、DIG DNA ラベル化キット(Boehringer Mannheim) に準拠してジゴキシゲニン−ラベル化し、ヒト間節軟骨細胞λ ZapII cDNAライブラリー(Michael Bayliss, TheRoyal Veterinary Basic Sciences, London, UK により提供)(52) のスクリーニング用のプローブとして用いた。cDNA挿入断片を伴う pBluescript SK + プラスミドを含むポジテイブクローンを、ZAP-cDNA R合成キット(Stratagene) 記載のように in vivo で切除することにより ZAP ベクターからレスキユーした。選択プラスミドを精製し、文献に準拠して、T3 、T7 および内部特異プライマーを用いて配列決定した(Camper らの JBC, 273, 20383-20389 (1998)。α10の5’末端をコードするcDNAを得る目的で、出願人らはプライマー AAC TCG TCT TCC AGT GCC ATT CGT GGG (reverse; α10 cDNAにおける残基 1254-1280)を設計し、これを 「MarathonTM」cDNA増幅キット(Clontech INC., Palo Alto, CA) の記載に準拠してcDNA5’末端(RACE) の急速増幅に用いた。
【0063】
結果
二つの重複クローン hc1 および hc2 (図5)を単離し、サブクローン化し、配列決定した。これらのクローンは、cDNAの3’末端を含むヌクレオチド配列の2/3を含んでいた。α10cDNAの5’末端を含む第3クローン(race1; 図5)が RACE 技法を用いて得られた。α10 cDNA、3884 ヌクレオチドの三つの重複クローンを配列決定した。このポリヌクレオチド配列および推定アミノ酸配列を図6に示す。この配列は、1167 アミノ酸成熟タンパク質をコードすると予測される 3504 ヌクレオチドオープンリーデイング枠を含む。シグナルペプチド開裂サイトは矢印で示し、ウシペプチド配列に対するヒト相同体は下線を施し、I領域は四角で囲んだ(boxed) 。金属イオン結合サイトは下波線で示し、潜在的N−グリコシル化サイトは星印で示し、推定トランスメンブラン領域は2重下線で示す。正常に保存された細胞質配列はドットおよびダッシュ下波線で示す。
【0064】
実施例4
α10のスプライス変種を含むクローンの確認
ヒト軟骨細胞ライブラリー(実施例3参照)から単離した一つのクローンは
nt 位置 2942 および 3055 間のヌクレオチドが削除さた以外は,α10インテグリンサブユニットの配列と同一の配列を含んでいた。α10のスプライス変種は、このスプライス領域をフランキングするプライマーを用いたPCR実験において証明された(図14参照)。
【0065】
実施例5
ノーザンブロットによるα10インテグリンサブユニットの同定
材料および方法
ウシ軟骨細胞 mRNAを 「QuickPrep R Micro 」mRNA精製キット(Pharmacia Biotech, Uppsala, Sweden )を用いて精製し、1%アガロース−ホルムアルデヒドゲル上で分離し、ナイロン膜に移し、IV架橋により固定化した。Random Primed DNAラベル化キット(Boehringer Mannheim) を用いてcDNAプローブを32Pラベル化した。フイルターを 5x SSE, 5X Denharts 溶液、0.1% SDS, 50μg/mlサケ精子DNAおよび50%ホルムアミド中、42℃で2〜4時間予備交配し、次いで特異プローブ(0.5〜1 × 106 cpm/ml)を含む同一溶液を用いて42℃で一昼夜交配した。特異的に結合したcDNAプローブをリン光イメージャー装置(Fuji)を用いて分析した。再プローブに先立ちフイルターを0.1% SDS 中、80℃で1間洗浄してストリップした。このα10インテグリンcDNAプローブを、制限酵素 BamHI (GIBCO BRL) および NcoI (Boehringer Mannheim) を用いて racel含有プラスミドから単離した。ラットβ1 インテグリンcDNAプローブは Staffan Johansson, Uppsala, Sweden から寄贈された。
【0066】
結果
ウシ軟骨細胞からのmRNAのノーザンブロット分析によれば、ヒトα10 cDNAプローブが約 5.4 kb (図7)の単一mRNAと交配した。比較として、インテグリンサブユニットα1に対応するcDNAプローブを用いた。このcDNAプローブは同一フイルター上の約 3.5 kb のmRNAバンドと交配した。これらの結果は、α10に対するcDNAプローブがmRNAレベルでα10インテグリンサブユニットを同定するのに使用できることを示す。
【0067】
実施例6
インテグリンサブユニットα10に対する抗体の調製
α10細胞質領域の一部 Ckkipeeekreekle に対応するペプチド(図6参照)を合成し、鍵穴カサガイヘモシアニン(KLH) に複合させた。ペプチド/KLH 複合体を用いてラビットを免疫化しインテグリンサブユニットα10に対する抗血清を生じさせた。α10を認識する抗体はペプチド結合カラム(Innovagen AB) 上で親和精製した。
【0068】
実施例7
軟骨細胞からのインテグリンサブユニットα10の免疫沈殿
材料および方法
ヒト軟骨細胞を 125 Iラベル化し「Triton X-100」 を用いて溶菌し、文献(Holmvall らの Exp. Cell Res, 221, 496-503 (1995) 、Camper らの JBC, 273, 20383-20389 (1998) )記載のように免疫沈殿した。125I ラベル化ヒト軟骨細胞の「Triton X-100」 リゼイトを、インテグリンサブユニットβ1 、α1 、α2 、α3 、α10に対するポリクローナル抗体を用いて免疫沈殿した。この免疫沈殿タンパク質を非還元型条件下に SDS-PAGE (4−12%)により分離し、リン光イメージャーにより肉視した。α10またはβ1 で免疫沈殿したヒト軟骨細胞の「Triton X-100」 リゼイトを非還元型条件下に SDS-PAGE (8%)により分離し、ポリクローナルβ1 抗体を使用するウエスターンブロットおよび Camper らによる JBC, 273, 20383-20389 (1998) 記載のように化学発光検出法を用いて分析した。
【0069】
結果
α10の細胞質領域に対して高めたポリクローナルペプチド抗体は、 Mr が約 160 kD (α10)および 125 kD (β1 )を有する二つのタンパク質バンドを非還元型条件下に沈殿した。α10会合β鎖はβ1 インテグリンサブユニットのように移動した(図8a)。軟骨細胞におけるα10会合β鎖が実際にβ1 であることを実証するために、軟骨細胞ライゼイトをα10 orb β1 に対する抗体を用いて免疫沈殿し、次いでβ1 サブユニットに対する抗体を用いたウエスターンブロットに処した(図8b)。これらの結果は、α10がβ1 インテグリンフアミリーの1員であることを明瞭に示した。しかし、これらの結果は、α10が他の状況下に他のβ鎖と会合できる可能性を排除はしない。
【0070】
実施例8
ヒトおよびマウス軟骨におけるインテグリンサブユニットα10の免疫組織化学的染色
手術期間に得られた成人軟骨(trochlear groove ) の凍結部分(Anders Lindahl, Salgrenska Hospital, Gothenburg, Sweden 提供)および生後3日のマウス手足からの凍結部分を固定し、文献記載(Camper らの JBC, 273, 20383-20389 (1998) のように免疫組織かがく用に調製した。α10インテグリンサブユニットの発現は一次抗体(実施例6参照)およびペルオキシダーゼに複合した二次 抗体として、細胞質領域に対するポリクローナル抗体を用いて分析した。
【0071】
結果
図9はヒト成人間節の軟骨の染色を示す。
α10の細胞質領域を認識するα10抗体は、ヒト間節軟骨の組織部分における軟骨細胞を染色した(A)。この染色は、α10ペプチドを用いて抗体を予備保温すると減少した(B)。α10インテグリンサブユニットを認識する対照抗体は軟骨細胞に結合しなかった(C)。
【0072】
図10は、α10抗体が、成長期の骨原基における軟骨細胞の大半を染色することを示す(aおよびb)。このα10抗体も Ranvierの骨化溝中の細胞を認識し、 metaphys における軟骨をライニングしている骨樹皮中の骨芽細胞はα10に対して特に高度にポジテイブである。Ranvier の骨化溝中の細胞は、骨の直径方向の成長に重要であると信じられる。このインテグリンサブユニットα10もまた軟骨膜および骨膜中に高度に発現される。これらの組織中の細胞は軟骨組織の修復に重要であるらしい。インテグリンサブユニットα10の上記局在化は、軟骨組織の機能に対して重要であることを暗示している。
【0073】
実施例9
マウスの発生期におけるインテグリンサブユニットα10の免疫組織化学的染色材料および方法
マウス胚(13.5日)からの凍結部分を、 Camper らの JBC, 273, 20383-20389 (1998) 記載に準拠して免疫組織化学によるα10発現用に研究した。α10インテグリンサブユニットの発現は、一次抗体(実施例6参照)およびペルオキシダーゼに複合した二次抗体としての細胞質領域に対するポリキローナル抗体を用いて分析した。この胚部分もインテグリンサブユニットα10(Pharmingen からのモノクローナル抗体)およびII型コラーゲン(モノクローナル抗体、Dr John Mo, Lund University, Sweden から寄贈)の発現のために研究した。
【0074】
図11は、α10インテグリンサブユニットが、間葉細胞が縮合を受て軟骨を形成する際には手足中で調節されないことを示す(a)。特に新規に形成された軟骨の端部はα10の高度発現を示す。軟骨形成は軟骨特異II型コラーゲンの高度発現により証明される(b)。α10インテグリンサブユニットに対する対照抗体は、軟骨上で弱い発現のみを示した(c)。他の実験では、α10の発現が、手足、肋骨、脊椎を包含する全ての軟骨含有組織中に見いだされた。軟骨形成期間中のα10のアップレギュレーションは、このインテグリンサブユニットが軟骨および骨の発生ならびに損傷軟骨の修復の両方に重要であることを暗示する。
【0075】
実施例10
間節軟骨以外の組織におけるα10のmRNA発現
材料および方法
α10インテグリンサブユニットの発現を、異なったヒト組織中でのmRNAレベルで試験した。図12に示した組織からの固定化mRNAを用いるノーザンドットブロットを、制限酵素 BamH1 およびNcol を用いて race 1-含有プラスミドから単離したα10インテグリンcDNAプローブを用いて交配した。交配の程度をリン発光イマージヤーを用いて分析した。次の記号は増加順序:−、+、++、+++、++++で表示するmRNAレベルを示す。
【0076】
結果
交配mRNAの分析によれば、α10は大動脈、気管、心臓、肺、および腎臓に発現された(図2)。他の全ての組織はα10発現に対しネガテイブのように見えた。これらの結果は、α10インテグリンサブユニットの制限的分布を暗示する。
【0077】
実施例11
腱および骨格筋周りの筋膜および心臓弁内の腱構築体におけるα10の免疫組織化学的染色
材料および方法
手術期中に得られた成人軟骨(trochlear groove )の凍結部分(Anders Lindahl, Salgrenska Hospital, Gothenburg, Sweden により提供)および生後3日マウス手足からの凍結部分を固定し、文献記載のように免疫組織化学用に調製した(Camper らの JBC, 273, 20383-20389 (1998)。α10インテグリンサブユニットの発現は、一次抗体(実施例6参照)およびペルオキシザーゼに複合した第二抗体としての細胞質領域に対するポリクローナル抗体を用いて分析した。
【0078】
結果
図13に見られるように、α10の発現は腱を取り巻く筋膜(a)および骨格筋(b)中および心臓弁の腱構造(c)に見いだされた。この局在化は、α10が軟骨特異的II型コラーゲン以外にも他のマトリックス分子にも結合し得ることを暗示する。腱表面上へのインテグリンα10の局在化は、α10が、感染、障害後または手術後の腱/靭帯間および組織周辺にしばしば起きる好ましからぬ癒着に関与し得ることを示す。
【0079】
実施例12
軟骨細胞、内皮細胞および繊維芽細胞におけるα10インテグリンサブユニットのmRNA発現
材料および方法
mRNAの単離、cDNAの合成およびPCR増幅は文献記載のように行った(Camper らの JBC, 273, 20383-20389 (1998) ) 。
結果
図14は、ヒト間節軟骨細胞(レーンA6 およびB1 )、ヒトへその緒静脈内皮細胞(レーンA2)、ヒト繊維芽細胞(レーンA4 )、およびラット腱(図14b、レーンB2 )からのα10cDNAのPCR増幅を示す。レーン1、3および5(図14A)は、内皮細胞、繊維芽細胞および軟骨細胞それぞれにおけるインテグリンサブユニットα10に対応する増幅フラグメントを示す。α10配列位置 nt 2919-2943 (forward) および nt 3554-3578 (reverse) (図6参照)の対応するcDNAプライマーは異なった細胞からのα10cDNAの増幅に使用された。この図は、α10が三種の全ての細胞型で増幅されたことを示す。α10の二つのフラグメントは増幅され、このものはα10の元来の形態で(一層大きなフラグメント)、かつスプライス変異(一層小さなフラグメント)の形態で存在した。この一層大きなフラグメントは軟骨細胞中で大勢を占め、一方、一層小さなフラグメントは腱中に一層顕著であった(B2 )。
【0080】
実施例13
α10哺乳類発現ベクターの構築
α10の等身大タンパク質コード配列(三つのクローンからの併合;図6参照)を哺乳類発現ベクターpcDNA3.1/Zeo (Invitrogen) 中に挿入た。このベクターは SV40 プロモーターおよび Zeosin 選択配列を含む。このα10含有発現ベクターを、β1 インテグリンサブユニットは発現するがα10サブユニットの発現に欠く細胞中にトランスフエクトした。細胞表面上のα10インテグリンサブユニットの発現は、免疫沈殿法および/またはα10に対して特異的な抗体を用いたフロー血球計算により分析できる。リガンド結合能力および挿入されたα10インテグリンサブユニットの機能は細胞付着実験およびシグナル化実験で実証できる。
【0081】
実施例14
α10のスプライス変種を含む哺乳類発現ベクターの構築
α10のスピライス変種の等身大タンパク質コード配列を哺乳類発現ベクター pc DNA3 (実施例13参照)中に挿入した。このスプライス変種の発現および機能は実施例13記載のように分析でき、かつ、無傷のα10インテグリンサブユニットと比較できる。
【0082】
実施例15
α10インテグリンゲノムDNAの部分単離および特性化
材料および方法
制限酵素 EamHI (GIBCO BRI) およびNcoI(Boehringer Mannheim ) を用いたracel 含有プラスミドから単離したヒトαcDNAを、32Pラベル化し、マウス 129 コスミドライブラリー(Reinhard Fassler, Lund University 提供)のスクリーニン用プローブとして用いた。ポジテイブクローンを単離し、サブクローンした。選択プラスミドを精製し、文献(Camper らの JBC,273, 20383-20389 (1998) に準拠してT3 、T7 および内部特異プライマーを用いて配列決定した。次いでマウスゲノムDNAに対応するプライマーを構築し、PCRに用いて増幅し、コスミドクローンからα10のゲノム配列を同定した。
【0083】
図15は、α10遺伝子の 7958 nt を示す。α10インテグリンの上記部分ゲノムDNA配列はエクソン8および Kozak 配列を含む。このマウスゲノムα10配列を用いてノックアウト実験用の標的ベクターを生じさせた。
【0084】
実施例16
アルギン酸塩(alginate)ビーズ中で培養したα10インテグリンサブユニットのアップレギュレーション(upregulation)
単層で2週間培養したヒト軟骨細胞をトリプシン−EDTAで脱離し、アルギン酸塩ビーズ中に導入した。アルギン酸塩ビーズ中で培養した軟骨細胞は、単層中で培養された軟骨細胞の脱分化間、それらの表現型を保存することは既知である。アルギン酸塩もしくは単層中いずれかで培養した軟骨細胞を11日後に単離し、125 Iで表面ラベル化した。このα10インテグリンサブユニットを次いで細胞質領域を認識するポリクローナル抗体を用いて免疫沈殿した(実施例6参照および Camper らの JBC, 273, 20383-20389 (1989) ) 。
【0085】
結果
図16に見られるように、アルギン酸塩ビーズ中で培養した軟骨細胞(レーン3および4)はα10 β1 のそれらのタンパク質発現を上方調節アップレギュレーションした。このことは、極めて低いα10β1 発現を示す、単層中で培養(レーン1および2)した軟骨細胞とは対照的であった。ab対照抗体を用いた免疫沈殿をレーン1および3に示す。軟骨細胞はアルギン酸塩中でそれらの軟骨特異的マトリクス生産を保持するが、単層中で培養したものは保持せず、この事実はアルギン酸塩が軟骨細胞の表現型を保持することを示す。これらの結果は、α10インテグリンサブユニットが分化軟骨細胞に対するマーカーとして使用できることを支持する。
【0086】
実施例17
ヒト平滑筋細胞からのα10インテグリンサブユニットの免疫沈殿
材料および方法
ヒト平滑筋細胞をヒト大動脈から単離した。培養1週間後、細胞を125 Iラベル化し、溶菌し、かつインテグリンサブユニットβ1 (レーン1)、α1 (レーン2)、α2 (レーン3)、α10(レーン4)、α 3(レーン5)、対照(レーン6)’図17)に対する抗体を用いて免疫沈殿させた。この実験は実施例7記載のように実施した。α10抗体は、α10およびβ1 インテグリンサブユニットに対応する平滑菌細胞から二つのバンドを沈殿した(図17)。
【0087】
実施例18
α10スライス領域に対する配列を含む細菌性発現ベクターの構築
交互スプライスド領域(アミノ酸 pos. 952-986, SEQ. ID 1) の E.coli 中での細胞内発現のためのプラスミドを文献記載のように構築した。この交互スプライスド領域をE. coli 高頻度コドンテーブルを用いてバック翻訳し、元の配列(SEQ. ID 1 ヌクレオチド pos. 2940-3044) と96%同一性のcDNA配列を創った。配列重複エクステンシン(Horon らの Biotechniques 8:528, 1990) を用いてプライマーα10pfor (表I)およびα10prev (表I)を、α10アミノ酸配列をコードする2重鎖フラグメントの創造に用いた。ブドウ状球菌タンパク質AのZ領域を含むPETベクター中でサブクローンするための制限酵素サイトを創る目的で、このフラグメントをプライマ−α10pfor2 (表I)およびα10prev2 (表I)を用いるPCR鋳型として用て、トロンビン開裂サイトを中間に有するZ領域のアミノ末端とα10スプライスド領域との融合体を創った。第2PCR反応で生じたフラグメントを示し(SEQ ID No. 3)、また発現ベクター中でのサブクローンに使用した新規制限酵素も示す。
【0088】
【表1】
【0089】
【表2】
【表3】
【表4】
【表5】
【0090】
[配列表]
SEQUENCE LISTING
(1) 一般的情報:
(i) 配列の総数: 2
(2) 配列番号1の情報:
(i) 配列特徴:
(A) 配列の長さ: 3884 塩基対
(B) 配列の型: 核酸およびアミノ酸
(C) 鎖の数: 二本鎖
(D) トポロジー: 直鎖状
(ii) 配列の種類: cDNA
(vi) 起源:
(E) 生物名: ヒト
(F) 細胞の種類: 軟骨細胞
(xi) 配列の記載: 配列番号1:
CAGGTCAGAAACCGATCAGGCATGGAACTCCCCTTCGTCACTCACCTGTTCTTGCCCCTG
1 ---------+---------+---------+---------+---------+---------+ 60
GTCCAGTCTTTGGCTAGTCCGTACCTTGAGGGGAAGCAGTGAGTGGACAAGAACGGGGAC
a M E L P F V T H L F L P L -
GTGTTCCTGACAGGTCTCTGCTCCCCCTTTAACCTGGATGAACATCACCCACGCCTATTC
61 ---------+---------+---------+---------+---------+---------+ 120
CACAAGGACTGTCCAGAGACGAGGGGGAAATTGGACCTACTTGTAGTGGGTGCGGATAAG
a V F L T G L C S P F N L D E H H P R L F -
CCAGGGCCACCAGAAGCTGAATTTGGATACAGTGTCTTACAACATGTTGGGGGTGGACAG
121 ---------+---------+---------+---------+---------+---------+ 180
GGTCCCGGTGGTCTTCGACTTAAACCTATGTCACAGAATGTTGTACAACCCCCACCTGTC
a P G P P E A E F G Y S V L Q H V G G G Q -
CGATGGATGCTGGTGGGCGCCCCCTGGGATGGGCCTTCAGGCGACCGGAGGGGGGACGTT
181 ---------+---------+---------+---------+---------+---------+ 240
GCTACCTACGACCACCCGCGGGGGACCCTACCCGGAAGTCCGCTGGCCTCCCCCCTGCAA
a R W M L V G A P W D G P S G D R R G D V -
TATCGCTGCCCTGTAGGGGGGGCCCACAATGCCCCATGTGCCAAGGGCCACTTAGGTGAC
241 ---------+---------+---------+---------+---------+---------+ 300
ATAGCGACGGGACATCCCCCCCGGGTGTTACGGGGTACACGGTTCCCGGTGAATCCACTG
a Y R C P V G G A H N A P C A K G H L G D -
TACCAACTGGGAAATTCATCTCATCCTGCTGTGAATATGCACCTGGGGATGTCTCTGTTA
301 ---------+---------+---------+---------+---------+---------+ 360
ATGGTTGACCCTTTAAGTAGAGTAGGACGACACTTATACGTGGACCCCTACAGAGACAAT
a Y Q L G N S S H P A V N M H L G M S L L -
GAGACAGATGGTGATGGGGGATTCATGGCCTGTGCCCCTCTCTGGTCTCGTGCTTGTGGC
361 ---------+---------+---------+---------+---------+---------+ 420
CTCTGTCTACCACTACCCCCTAAGTACCGGACACGGGGAGAGACCAGAGCACGAACACCG
a E T D G D G G F M A C A P L W S R A C G -
AGCTCTGTCTTCAGTTCTGGGATATGTGCCCGTGTGGATGCTTCATTCCAGCCTCAGGGA
421 ---------+---------+---------+---------+---------+---------+ 480
TCGAGACAGAAGTCAAGACCCTATACACGGGCACACCTACGAAGTAAGGTCGGAGTCCCT
a S S V F S S G I C A R V D A S F Q P Q G -
AGCCTGGCACCCACTGCCCAACGCTGCCCAACATACATGGATGTTGTCATTGTCTTGGAT
481 ---------+---------+---------+---------+---------+---------+ 540
TCGGACCGTGGGTGACGGGTTGCGACGGGTTGTATGTACCTACAACAGTAACAGAACCTA
a S L A P T A Q R C P T Y M D V V I V L D -
GGCTCCAACAGCATCTACCCCTGGTCTGAAGTTCAGACCTTCCTACGAAGACTGGTAGGG
541 ---------+---------+---------+---------+---------+---------+ 600
CCGAGGTTGTCGTAGATGGGGACCAGACTTCAAGTCTGGAAGGATGCTTCTGACCATCCC
a G S N S I Y P W S E V Q T F L R R L V G -
AAACTGTTTATTGACCCAGAACAGATACAGGTGGGACTGGTACAGTATGGGGAGAGCCCT
601 ---------+---------+---------+---------+---------+---------+ 660
TTTGACAAATAACTGGGTCTTGTCTATGTCCACCCTGACCATGTCATACCCCTCTCGGGA
a K L F I D P E Q I Q V G L V Q Y G E S P -
GTACATGAGTGGTCCCTGGGAGATTTCCGAACGAAGGAAGAAGTGGTGAGAGCAGCAAAG
661 ---------+---------+---------+---------+---------+---------+ 720
CATGTACTCACCAGGGACCCTCTAAAGGCTTGCTTCCTTCTTCACCACTCTCGTCGTTTC
a V H E W S L G D F R T K E E V V R A A K -
AACCTCAGTCGGCGGGAGGGACGAGAAACAAAGACTGCCCAAGCAATAATGGTGGCCTGC
721 ---------+---------+---------+---------+---------+---------+ 780
TTGGAGTCAGCCGCCCTCCCTGCTCTTTGTTTCTGACGGGTTCGTTATTACCACCGGACG
a N L S R R E G R E T K T A Q A I M V A C -
ACAGAAGGGTTCAGTCAGTCCCATGGGGGCCGACCCGAGGCTGCCAGGCTACTGGTGGTT
781 ---------+---------+---------+---------+---------+---------+ 840
TGTCTTCCCAAGTCAGTCAGGGTACCCCCGGCTGGGCTCCGACGGTCCGATGACCACCAA
a T E G F S Q S H G G R P E A A R L L V V -
GTCACTGATGGAGAGTCCCATGATGGAGAGGAGCTTCCTGCAGCACTAAAGGCCTGTGAG
841 ---------+---------+---------+---------+---------+---------+ 900
CAGTGACTACCTCTCAGGGTACTACCTCTCCTCGAAGGACGTCGTGATTTCCGGACACTC
a V T D G E S H D G E E L P A A L K A C E -
GCTGGAAGAGTGACACGCTATGGGATTGCAGTCCTTGGTCACTACCTCCGGCGGCAGCGA
901 ---------+---------+---------+---------+---------+---------+ 960
CGACCTTCTCACTGTGCGATACCCTAACGTCAGGAACCAGTGATGGAGGCCGCCGTCGCT
a A G R V T R Y G I A V L G H Y L R R Q R -
GATCCCAGCTCTTTCCTGAGAGAAATTAGAACTATTGCCAGTGATCCAGATGAGCGATTC
961 ---------+---------+---------+---------+---------+---------+ 1020
CTAGGGTCGAGAAAGGACTCTCTTTAATCTTGATAACGGTCACTAGGTCTACTCGCTAAG
a D P S S F L R E I R T I A S D P D E R F -
TTCTTCAATGTCACAGATGAGGCTGCTCTGACTGACATTGTGGATGCACTAGGAGATCGG
1021 ---------+---------+---------+---------+---------+---------+ 1080
AAGAAGTTACAGTGTCTACTCCGACGAGACTGACTGTAACACCTACGTGATCCTCTAGCC
a F F N V T D E A A L T D I V D A L G D R -
ATTTTTGGCCTTGAAGGGTCCCATGCAGAAAACGAAAGCTCCTTTGGGCTGGAAATGTCT
1081 ---------+---------+---------+---------+---------+---------+ 1140
TAAAAACCGGAACTTCCCAGGGTACGTCTTTTGCTTTCGAGGAAACCCGACCTTTACAGA
a I F G L E G S H A E N E S S F G L E M S -
CAGATTGGTTTCTCCACTCATCGGCTAAAGGATGGGATTCTTTTTGGGATGGTGGGGGCC
1141 ---------+---------+---------+---------+---------+---------+ 1200
GTCTAACCAAAGAGGTGAGTAGCCGATTTCCTACCCTAAGAAAAACCCTACCACCCCCGG
a Q I G F S T H R L K D G I L F G M V G A -
TATGACTGGGGAGGCTCTGTGCTATGGCTTGAAGGAGGCCACCGCCTTTTCCCCCCACGA
1201 ---------+---------+---------+---------+---------+---------+ 1260
ATACTGACCCCTCCGAGACACGATACCGAACTTCCTCCGGTGGCGGAAAAGGGGGGTGCT
a Y D W G G S V L W L E G G H R L F P P R -
ATGGCACTGGAAGACGAGTTCCCCCCTGCACTGCAGAACCATGCAGCCTACCTGGGTTAC
1261 ---------+---------+---------+---------+---------+---------+ 1320
TACCGTGACCTTCTGCTCAAGGGGGGACGTGACGTCTTGGTACGTCGGATGGACCCAATG
a M A L E D E F P P A L Q N H A A Y L G Y -
TCTGTTTCTTCCATGCTTTTGCGGGGTGGACGCCGCCTGTTTCTCTCTGGGGCTCCTCGA
1321 ---------+---------+---------+---------+---------+---------+ 1380
AGACAAAGAAGGTACGAAAACGCCCCACCTGCGGCGGACAAAGAGAGACCCCGAGGAGCT
a S V S S M L L R G G R R L F L S G A P R -
TTTAGACATCGAGGAAAAGTCATCGCCTTCCAGCTTAAGAAAGATGGGGCTGTGAGGGTT
1381 ---------+---------+---------+---------+---------+---------+ 1440
AAATCTGTAGCTCCTTTTCAGTAGCGGAAGGTCGAATTCTTTCTACCCCGACACTCCCAA
a F R H R G K V I A F Q L K K D G A V R V -
GCCCAGAGCCTCCAGGGGGAGCAGATTGGTTCATACTTTGGCAGTGAGCTCTGCCCATTG
1441 ---------+---------+---------+---------+---------+---------+ 1500
CGGGTCTCGGAGGTCCCCCTCGTCTAACCAAGTATGAAACCGTCACTCGAGACGGGTAAC
a A Q S L Q G E Q I G S Y F G S E L C P L -
GATACAGATAGGGATGGAACAACTGATGTCTTACTTGTGGCTGCCCCCATGTTCCTGGGA
1501 ---------+---------+---------+---------+---------+---------+ 1560
CTATGTCTATCCCTACCTTGTTGACTACAGAATGAACACCGACGGGGGTACAAGGACCCT
a D T D R D G T T D V L L V A A P M F L G -
CCCCAGAACAAGGAAACAGGACGTGTTTATGTGTATCTGGTAGGCCAGCAGTCCTTGCTG
1561 ---------+---------+---------+---------+---------+---------+ 1620
GGGGTCTTGTTCCTTTGTCCTGCACAAATACACATAGACCATCCGGTCGTCAGGAACGAC
a P Q N K E T G R V Y V Y L V G Q Q S L L -
ACCCTCCAAGGAACACTTCAGCCAGAACCCCCCCAGGATGCTCGGTTTGGCTTTGCCATG
1621 ---------+---------+---------+---------+---------+---------+ 1680
TGGGAGGTTCCTTGTGAAGTCGGTCTTGGGGGGGTCCTACGAGCCAAACCGAAACGGTAC
a T L Q G T L Q P E P P Q D A R F G F A M -
GGAGCTCTTCCTGATCTGAACCAAGATGGTTTTGCTGATGTGGCTGTGGGGGCGCCTCTG
1681 ---------+---------+---------+---------+---------+---------+ 1740
CCTCGAGAAGGACTAGACTTGGTTCTACCAAAACGACTACACCGACACCCCCGCGGAGAC
a G A L P D L N Q D G F A D V A V G A P L -
GAAGATGGGCACCAGGGAGCACTGTACCTGTACCATGGAACCCAGAGTGGAGTCAGGCCC
1741 ---------+---------+---------+---------+---------+---------+ 1800
CTTCTACCCGTGGTCCCTCGTGACATGGACATGGTACCTTGGGTCTCACCTCAGTCCGGG
a E D G H Q G A L Y L Y H G T Q S G V R P -
CATCCTGCCCAGAGGATTGCTGCTGCCTCCATGCCACATGCCCTCAGCTACTTTGGCCGA
1801 ---------+---------+---------+---------+---------+---------+ 1860
GTAGGACGGGTCTCCTAACGACGACGGAGGTACGGTGTACGGGAGTCGATGAAACCGGCT
a H P A Q R I A A A S M P H A L S Y F G R -
AGTGTGGATGGTCGGCTAGATCTGGATGGAGATGATCTGGTCGATGTGGCTGTGGGTGCC
1861 ---------+---------+---------+---------+---------+---------+ 1920
TCACACCTACCAGCCGATCTAGACCTACCTCTACTAGACCAGCTACACCGACACCCACGG
a S V D G R L D L D G D D L V D V A V G A -
CAGGGGGCAGCCATCCTGCTCAGCTCCCGGCCCATTGTCCATCTGACCCCATCACTGGAG
1921 ---------+---------+---------+---------+---------+---------+ 1980
GTCCCCCGTCGGTAGGACGAGTCGAGGGCCGGGTAACAGGTAGACTGGGGTAGTGACCTC
a Q G A A I L L S S R P I V H L T P S L E -
GTGACCCCACAGGCCATCAGTGTGGTTCAGAGGGACTGTAGGCGGCGAGGCCAAGAAGCA
1981 ---------+---------+---------+---------+---------+---------+ 2040
CACTGGGGTGTCCGGTAGTCACACCAAGTCTCCCTGACATCCGCCGCTCCGGTTCTTCGT
a V T P Q A I S V V Q R D C R R R G Q E A -
GTCTGTCTGACTGCAGCCCTTTGCTTCCAAGTGACCTCCCGTACTCCTGGTCGCTGGGAT
2041 ---------+---------+---------+---------+---------+---------+ 2100
CAGACAGACTGACGTCGGGAAACGAAGGTTCACTGGAGGGCATGAGGACCAGCGACCCTA
a V C L T A A L C F Q V T S R T P G R W D -
CACCAATTCTACATGAGGTTCACCGCATCACTGGATGAATGGACTGCTGGGGCACGTGCA
2101 ---------+---------+---------+---------+---------+---------+ 2160
GTGGTTAAGATGTACTCCAAGTGGCGTAGTGACCTACTTACCTGACGACCCCGTGCACGT
a H Q F Y M R F T A S L D E W T A G A R A -
GCATTTGATGGCTCTGGCCAGAGGTTGTCCCCTCGGAGGCTCCGGCTCAGTGTGGGGAAT
2161 ---------+---------+---------+---------+---------+---------+ 2220
CGTAAACTACCGAGACCGGTCTCCAACAGGGGAGCCTCCGAGGCCGAGTCACACCCCTTA
a A F D G S G Q R L S P R R L R L S V G N -
GTCACTTGTGAGCAGCTACACTTCCATGTGCTGGATACATCAGATTACCTCCGGCCAGTG
2221 ---------+---------+---------+---------+---------+---------+ 2280
CAGTGAACACTCGTCGATGTGAAGGTACACGACCTATGTAGTCTAATGGAGGCCGGTCAC
a V T C E Q L H F H V L D T S D Y L R P V -
GCCTTGACTGTGACCTTTGCCTTGGACAATACTACAAAGCCAGGGCCTGTGCTGAATGAG
2281 ---------+---------+---------+---------+---------+---------+ 2340
CGGAACTGACACTGGAAACGGAACCTGTTATGATGTTTCGGTCCCGGACACGACTTACTC
a A L T V T F A L D N T T K P G P V L N E -
GGCTCACCCACCTCTATACAAAAGCTGGTCCCCTTCTCAAAGGATTGTGGCCCTGACAAT
2341 ---------+---------+---------+---------+---------+---------+ 2400
CCGAGTGGGTGGAGATATGTTTTCGACCAGGGGAAGAGTTTCCTAACACCGGGACTGTTA
a G S P T S I Q K L V P F S K D C G P D N -
GAATGTGTCACAGACCTGGTGCTTCAAGTGAATATGGACATCAGAGGCTCCAGGAAGGCC
2401 ---------+---------+---------+---------+---------+---------+ 2460
CTTACACAGTGTCTGGACCACGAAGTTCACTTATACCTGTAGTCTCCGAGGTCCTTCCGG
a E C V T D L V L Q V N M D I R G S R K A -
CCATTTGTGGTTCGAGGTGGCCGGCGGAAAGTGCTGGTATCTACAACTCTGGAGAACAGA
2461 ---------+---------+---------+---------+---------+---------+ 2520
GGTAAACACCAAGCTCCACCGGCCGCCTTTCACGACCATAGATGTTGAGACCTCTTGTCT
a P F V V R G G R R K V L V S T T L E N R -
AAGGAAAATGCTTACAATACGAGCCTGAGTATCATCTTCTCTAGAAACCTCCACCTGGCC
2521 ---------+---------+---------+---------+---------+---------+ 2580
TTCCTTTTACGAATGTTATGCTCGGACTCATAGTAGAAGAGATCTTTGGAGGTGGACCGG
a K E N A Y N T S L S I I F S R N L H L A -
AGTCTCACTCCTCAGAGAGAGAGCCCAATAAAGGTGGAATGTGCCGCCCCTTCTGCTCAT
2581 ---------+---------+---------+---------+---------+---------+ 2640
TCAGAGTGAGGAGTCTCTCTCTCGGGTTATTTCCACCTTACACGGCGGGGAAGACGAGTA
a S L T P Q R E S P I K V E C A A P S A H -
GCCCGGCTCTGCAGTGTGGGGCATCCTGTCTTCCAGACTGGAGCCAAGGTGACCTTTCTG
2641 ---------+---------+---------+---------+---------+---------+ 2700
CGGGCCGAGACGTCACACCCCGTAGGACAGAAGGTCTGACCTCGGTTCCACTGGAAAGAC
a A R L C S V G H P V F Q T G A K V T F L -
CTAGAGTTTGAGTTTAGCTGCTCCTCTCTCCTGAGCCAGGTCTTTGGGAAGCTGACTGCC
2701 ---------+---------+---------+---------+---------+---------+ 2760
GATCTCAAACTCAAATCGACGAGGAGAGAGGACTCGGTCCAGAAACCCTTCGACTGACGG
a L E F E F S C S S L L S Q V F G K L T A -
AGCAGTGACAGCCTGGAGAGAAATGGCACCCTTCAAGAAAACACAGCCCAGACCTCAGCC
2761 ---------+---------+---------+---------+---------+---------+ 2820
TCGTCACTGTCGGACCTCTCTTTACCGTGGGAAGTTCTTTTGTGTCGGGTCTGGAGTCGG
a S S D S L E R N G T L Q E N T A Q T S A -
TACATCCAATATGAGCCCCACCTCCTGTTCTCTAGTGAGTCTACCCTGCACCGCTATGAG
2821 ---------+---------+---------+---------+---------+---------+ 2880
ATGTAGGTTATACTCGGGGTGGAGGACAAGAGATCACTCAGATGGGACGTGGCGATACTC
a Y I Q Y E P H L L F S S E S T L H R Y E -
GTTCACCCATATGGGACCCTCCCAGTGGGTCCTGGCCCAGAATTCAAAACCACTCTCAGG
2881 ---------+---------+---------+---------+---------+---------+ 2940
CAAGTGGGTATACCCTGGGAGGGTCACCCAGGACCGGGTCTTAAGTTTTGGTGAGAGTCC
a V H P Y G T L P V G P G P E F K T T L R -
GTTCAGAACCTAGGCTGCTATGTGGTCAGTGGCCTCATCATCTCAGCCCTCCTTCCAGCT
2941 ---------+---------+---------+---------+---------+---------+ 3000
CAAGTCTTGGATCCGACGATACACCAGTCACCGGAGTAGTAGAGTCGGGAGGAAGGTCGA
a V Q N L G C Y V V S G L I I S A L L P A -
GTGGCCCATGGGGGCAATTACTTCCTATCACTGTCTCAAGTCATCACTAACAATGCAAGC
3001 ---------+---------+---------+---------+---------+---------+ 3060
CACCGGGTACCCCCGTTAATGAAGGATAGTGACAGAGTTCAGTAGTGATTGTTACGTTCG
a V A H G G N Y F L S L S Q V I T N N A S -
TGCATAGTGCAGAACCTGACTGAACCCCCAGGCCCACCTGTGCATCCAGAGGAGCTTCAA
3061 ---------+---------+---------+---------+---------+---------+ 3120
ACGTATCACGTCTTGGACTGACTTGGGGGTCCGGGTGGACACGTAGGTCTCCTCGAAGTT
a C I V Q N L T E P P G P P V H P E E L Q -
CACACAAACAGACTGAATGGGAGCAATACTCAGTGTCAGGTGGTGAGGTGCCACCTTGGG
3121 ---------+---------+---------+---------+---------+---------+ 3180
GTGTGTTTGTCTGACTTACCCTCGTTATGAGTCACAGTCCACCACTCCACGGTGGAACCC
a H T N R L N G S N T Q C Q V V R C H L G -
CAGCTGGCAAAGGGGACTGAGGTCTCTGTTGGACTATTGAGGCTGGTTCACAATGAATTT
3181 ---------+---------+---------+---------+---------+---------+ 3240
GTCGACCGTTTCCCCTGACTCCAGAGACAACCTGATAACTCCGACCAAGTGTTACTTAAA
a Q L A K G T E V S V G L L R L V H N E F -
TTCCGAAGAGCCAAGTTCAAGTCCCTGACGGTGGTCAGCACCTTTGAGCTGGGAACCGAA
3241 ---------+---------+---------+---------+---------+---------+ 3300
AAGGCTTCTCGGTTCAAGTTCAGGGACTGCCACCAGTCGTGGAAACTCGACCCTTGGCTT
a F R R A K F K S L T V V S T F E L G T E -
GAGGGCAGTGTCCTACAGCTGACTGAAGCCTCCCGTTGGAGTGAGAGCCTCTTGGAGGTG
3301 ---------+---------+---------+---------+---------+---------+ 3360
CTCCCGTCACAGGATGTCGACTGACTTCGGAGGGCAACCTCACTCTCGGAGAACCTCCAC
a E G S V L Q L T E A S R W S E S L L E V -
GTTCAGACCCGGCCTATCCTCATCTCCCTGTGGATCCTCATAGGCAGTGTCCTGGGAGGG
3361 ---------+---------+---------+---------+---------+---------+ 3420
CAAGTCTGGGCCGGATAGGAGTAGAGGGACACCTAGGAGTATCCGTCACAGGACCCTCCC
a V Q T R P I L I S L W I L I G S V L G G -
TTGCTCCTGCTTGCTCTCCTTGTCTTCTGCCTGTGGAAGCTTGGCTTCTTTGCCCATAAG
3421 ---------+---------+---------+---------+---------+---------+ 3480
AACGAGGACGAACGAGAGGAACAGAAGACGGACACCTTCGAACCGAAGAAACGGGTATTC
a L L L L A L L V F C L W K L G F F A H K -
AAAATCCCTGAGGAAGAAAAAAGAGAAGAGAAGTTGGAGCAATGAATGTAGAATAAGGGT
3481 ---------+---------+---------+---------+---------+---------+ 3540
TTTTAGGGACTCCTTCTTTTTTCTCTTCTCTTCAACCTCGTTACTTACATCTTATTCCCA
a K I P E E E K R E E K L E Q
CTAGAAAGTCCTCCCTGGCAGCTTTCTTCAAGAGACTTGCATAAAAGCAGAGGTTTGGGG
3541 ---------+---------+---------+---------+---------+---------+ 3600
GATCTTTCAGGAGGGACCGTCGAAAGAAGTTCTCTGAACGTATTTTCGTCTCCAAACCCC
GCTCAGATGGGACAAGAAGCCGCCTCTGGACTATCTCCCCAGACCAGCAGCCTGACTTGA
3601 ---------+---------+---------+---------+---------+---------+ 3660
CGAGTCTACCCTGTTCTTCGGCGGAGACCTGATAGAGGGGTCTGGTCGTCGGACTGAACT
CTTTTGAGTCCTAGGGATGCTGCTGGCTAGAGATGAGGCTTTACCTCAGACAAGAAGAGC
3661 ---------+---------+---------+---------+---------+---------+ 3720
GAAAACTCAGGATCCCTACGACGACCGATCTCTACTCCGAAATGGAGTCTGTTCTTCTCG
TGGCACCAAAACTAGCCATGCTCCCACCCTCTGCTTCCCTCCTCCTCGTGATCCTGGTTC
3721 ---------+---------+---------+---------+---------+---------+ 3780
ACCGTGGTTTTGATCGGTACGAGGGTGGGAGACGAAGGGAGGAGGAGCACTAGGACCAAG
CATAGCCAACACTGGGGCTTTTGTTTGGGGTCCTTTTATCCCCAGGAATCAATAATTTTT
3781 ---------+---------+---------+---------+---------+---------+ 3840
GTATCGGTTGTGACCCCGAAAACAAACCCCAGGAAAATAGGGGTCCTTAGTTATTAAAAA
TTGCCTAGGAAAAAAAAAAGCGGCCGCGAATTCGATATCAAGCT
3841 ---------+---------+---------+---------+---- 3884
AACGGATCCTTTTTTTTTTCGCCGGCGCTTAAGCTATAGTTCGA
(2) 配列番号2の情報:
(i) 配列特徴:
(A) 配列の長さ: 3779 塩基対
(B) 配列の型: 核酸およびアミノ酸
(C) 鎖の数: 二本鎖
(D) トポロジー: 直鎖状
(E)
(i) 配列の種類: cDNA
(vi) 起源:
(A) 生物名: ヒト
(B) 細胞の種類: 軟骨細胞
(xi) 配列の記載: 配列番号2:
CAGGTCAGAAACCGATCAGGCATGGAACTCCCCTTCGTCACTCACCTGTTCTTGCCCCTG
1 ---------+---------+---------+---------+---------+---------+ 60
GTCCAGTCTTTGGCTAGTCCGTACCTTGAGGGGAAGCAGTGAGTGGACAAGAACGGGGAC
M E L P F V T H L F L P L -
GTGTTCCTGACAGGTCTCTGCTCCCCCTTTAACCTGGATGAACATCACCCACGCCTATTC
61 ---------+---------+---------+---------+---------+---------+ 120
CACAAGGACTGTCCAGAGACGAGGGGGAAATTGGACCTACTTGTAGTGGGTGCGGATAAG
a V F L T G L C S P F N L D E H H P R L F -
CCAGGGCCACCAGAAGCTGAATTTGGATACAGTGTCTTACAACATGTTGGGGGTGGACAG
121 ---------+---------+---------+---------+---------+---------+ 180
GGTCCCGGTGGTCTTCGACTTAAACCTATGTCACAGAATGTTGTACAACCCCCACCTGTC
a P G P P E A E F G Y S V L Q H V G G G Q -
CGATGGATGCTGGTGGGCGCCCCCTGGGATGGGCCTTCAGGCGACCGGAGGGGGGACGTT
181 ---------+---------+---------+---------+---------+---------+ 240
GCTACCTACGACCACCCGCGGGGGACCCTACCCGGAAGTCCGCTGGCCTCCCCCCTGCAA
a R W M L V G A P W D G P S G D R R G D V -
TATCGCTGCCCTGTAGGGGGGGCCCACAATGCCCCATGTGCCAAGGGCCACTTAGGTGAC
241 ---------+---------+---------+---------+---------+---------+ 300
ATAGCGACGGGACATCCCCCCCGGGTGTTACGGGGTACACGGTTCCCGGTGAATCCACTG
a Y R C P V G G A H N A P C A K G H L G D -
TACCAACTGGGAAATTCATCTCATCCTGCTGTGAATATGCACCTGGGGATGTCTCTGTTA
301 ---------+---------+---------+---------+---------+---------+ 360
ATGGTTGACCCTTTAAGTAGAGTAGGACGACACTTATACGTGGACCCCTACAGAGACAAT
a Y Q L G N S S H P A V N M H L G M S L L -
GAGACAGATGGTGATGGGGGATTCATGGCCTGTGCCCCTCTCTGGTCTCGTGCTTGTGGC
361 ---------+---------+---------+---------+---------+---------+ 420
CTCTGTCTACCACTACCCCCTAAGTACCGGACACGGGGAGAGACCAGAGCACGAACACCG
a E T D G D G G F M A C A P L W S R A C G -
AGCTCTGTCTTCAGTTCTGGGATATGTGCCCGTGTGGATGCTTCATTCCAGCCTCAGGGA
421 ---------+---------+---------+---------+---------+---------+ 480
TCGAGACAGAAGTCAAGACCCTATACACGGGCACACCTACGAAGTAAGGTCGGAGTCCCT
a S S V F S S G I C A R V D A S F Q P Q G -
AGCCTGGCACCCACTGCCCAACGCTGCCCAACATACATGGATGTTGTCATTGTCTTGGAT
481 ---------+---------+---------+---------+---------+---------+ 540
TCGGACCGTGGGTGACGGGTTGCGACGGGTTGTATGTACCTACAACAGTAACAGAACCTA
a S L A P T A Q R C P T Y M D V V I V L D -
GGCTCCAACAGCATCTACCCCTGGTCTGAAGTTCAGACCTTCCTACGAAGACTGGTAGGG
541 ---------+---------+---------+---------+---------+---------+ 600
CCGAGGTTGTCGTAGATGGGGACCAGACTTCAAGTCTGGAAGGATGCTTCTGACCATCCC
a G S N S I Y P W S E V Q T F L R R L V G -
AAACTGTTTATTGACCCAGAACAGATACAGGTGGGACTGGTACAGTATGGGGAGAGCCCT
601 ---------+---------+---------+---------+---------+---------+ 660
TTTGACAAATAACTGGGTCTTGTCTATGTCCACCCTGACCATGTCATACCCCTCTCGGGA
a K L F I D P E Q I Q V G L V Q Y G E S P -
GTACATGAGTGGTCCCTGGGAGATTTCCGAACGAAGGAAGAAGTGGTGAGAGCAGCAAAG
661 ---------+---------+---------+---------+---------+---------+ 720
CATGTACTCACCAGGGACCCTCTAAAGGCTTGCTTCCTTCTTCACCACTCTCGTCGTTTC
a V H E W S L G D F R T K E E V V R A A K -
AACCTCAGTCGGCGGGAGGGACGAGAAACAAAGACTGCCCAAGCAATAATGGTGGCCTGC
721 ---------+---------+---------+---------+---------+---------+ 780
TTGGAGTCAGCCGCCCTCCCTGCTCTTTGTTTCTGACGGGTTCGTTATTACCACCGGACG
a N L S R R E G R E T K T A Q A I M V A C -
ACAGAAGGGTTCAGTCAGTCCCATGGGGGCCGACCCGAGGCTGCCAGGCTACTGGTGGTT
781 ---------+---------+---------+---------+---------+---------+ 840
TGTCTTCCCAAGTCAGTCAGGGTACCCCCGGCTGGGCTCCGACGGTCCGATGACCACCAA
a T E G F S Q S H G G R P E A A R L L V V -
GTCACTGATGGAGAGTCCCATGATGGAGAGGAGCTTCCTGCAGCACTAAAGGCCTGTGAG
841 ---------+---------+---------+---------+---------+---------+ 900
CAGTGACTACCTCTCAGGGTACTACCTCTCCTCGAAGGACGTCGTGATTTCCGGACACTC
a V T D G E S H D G E E L P A A L K A C E -
GCTGGAAGAGTGACACGCTATGGGATTGCAGTCCTTGGTCACTACCTCCGGCGGCAGCGA
901 ---------+---------+---------+---------+---------+---------+ 960
CGACCTTCTCACTGTGCGATACCCTAACGTCAGGAACCAGTGATGGAGGCCGCCGTCGCT
a A G R V T R Y G I A V L G H Y L R R Q R -
GATCCCAGCTCTTTCCTGAGAGAAATTAGAACTATTGCCAGTGATCCAGATGAGCGATTC
961 ---------+---------+---------+---------+---------+---------+ 1020
CTAGGGTCGAGAAAGGACTCTCTTTAATCTTGATAACGGTCACTAGGTCTACTCGCTAAG
a D P S S F L R E I R T I A S D P D E R F -
TTCTTCAATGTCACAGATGAGGCTGCTCTGACTGACATTGTGGATGCACTAGGAGATCGG
1021 ---------+---------+---------+---------+---------+---------+ 1080
AAGAAGTTACAGTGTCTACTCCGACGAGACTGACTGTAACACCTACGTGATCCTCTAGCC
a F F N V T D E A A L T D I V D A L G D R -
ATTTTTGGCCTTGAAGGGTCCCATGCAGAAAACGAAAGCTCCTTTGGGCTGGAAATGTCT
1081 ---------+---------+---------+---------+---------+---------+ 1140
TAAAAACCGGAACTTCCCAGGGTACGTCTTTTGCTTTCGAGGAAACCCGACCTTTACAGA
a I F G L E G S H A E N E S S F G L E M S -
CAGATTGGTTTCTCCACTCATCGGCTAAAGGATGGGATTCTTTTTGGGATGGTGGGGGCC
1141 ---------+---------+---------+---------+---------+---------+ 1200
GTCTAACCAAAGAGGTGAGTAGCCGATTTCCTACCCTAAGAAAAACCCTACCACCCCCGG
a Q I G F S T H R L K D G I L F G M V G A -
TATGACTGGGGAGGCTCTGTGCTATGGCTTGAAGGAGGCCACCGCCTTTTCCCCCCACGA
1201 ---------+---------+---------+---------+---------+---------+ 1260
ATACTGACCCCTCCGAGACACGATACCGAACTTCCTCCGGTGGCGGAAAAGGGGGGTGCT
a Y D W G G S V L W L E G G H R L F P P R -
ATGGCACTGGAAGACGAGTTCCCCCCTGCACTGCAGAACCATGCAGCCTACCTGGGTTAC
1261 ---------+---------+---------+---------+---------+---------+ 1320
TACCGTGACCTTCTGCTCAAGGGGGGACGTGACGTCTTGGTACGTCGGATGGACCCAATG
a M A L E D E F P P A L Q N H A A Y L G Y -
TCTGTTTCTTCCATGCTTTTGCGGGGTGGACGCCGCCTGTTTCTCTCTGGGGCTCCTCGA
1321 ---------+---------+---------+---------+---------+---------+ 1380
AGACAAAGAAGGTACGAAAACGCCCCACCTGCGGCGGACAAAGAGAGACCCCGAGGAGCT
a S V S S M L L R G G R R L F L S G A P R -
TTTAGACATCGAGGAAAAGTCATCGCCTTCCAGCTTAAGAAAGATGGGGCTGTGAGGGTT
1381 ---------+---------+---------+---------+---------+---------+ 1440
AAATCTGTAGCTCCTTTTCAGTAGCGGAAGGTCGAATTCTTTCTACCCCGACACTCCCAA
a F R H R G K V I A F Q L K K D G A V R V -
GCCCAGAGCCTCCAGGGGGAGCAGATTGGTTCATACTTTGGCAGTGAGCTCTGCCCATTG
1441 ---------+---------+---------+---------+---------+---------+ 1500
CGGGTCTCGGAGGTCCCCCTCGTCTAACCAAGTATGAAACCGTCACTCGAGACGGGTAAC
a A Q S L Q G E Q I G S Y F G S E L C P L -
GATACAGATAGGGATGGAACAACTGATGTCTTACTTGTGGCTGCCCCCATGTTCCTGGGA
1501 ---------+---------+---------+---------+---------+---------+ 1560
CTATGTCTATCCCTACCTTGTTGACTACAGAATGAACACCGACGGGGGTACAAGGACCCT
a D T D R D G T T D V L L V A A P M F L G -
CCCCAGAACAAGGAAACAGGACGTGTTTATGTGTATCTGGTAGGCCAGCAGTCCTTGCTG
1561 ---------+---------+---------+---------+---------+---------+ 1620
GGGGTCTTGTTCCTTTGTCCTGCACAAATACACATAGACCATCCGGTCGTCAGGAACGAC
a P Q N K E T G R V Y V Y L V G Q Q S L L -
ACCCTCCAAGGAACACTTCAGCCAGAACCCCCCCAGGATGCTCGGTTTGGCTTTGCCATG
1621 ---------+---------+---------+---------+---------+---------+ 1680
TGGGAGGTTCCTTGTGAAGTCGGTCTTGGGGGGGTCCTACGAGCCAAACCGAAACGGTAC
a T L Q G T L Q P E P P Q D A R F G F A M -
GGAGCTCTTCCTGATCTGAACCAAGATGGTTTTGCTGATGTGGCTGTGGGGGCGCCTCTG
1681 ---------+---------+---------+---------+---------+---------+ 1740
CCTCGAGAAGGACTAGACTTGGTTCTACCAAAACGACTACACCGACACCCCCGCGGAGAC
a G A L P D L N Q D G F A D V A V G A P L -
GAAGATGGGCACCAGGGAGCACTGTACCTGTACCATGGAACCCAGAGTGGAGTCAGGCCC
1741 ---------+---------+---------+---------+---------+---------+ 1800
CTTCTACCCGTGGTCCCTCGTGACATGGACATGGTACCTTGGGTCTCACCTCAGTCCGGG
a E D G H Q G A L Y L Y H G T Q S G V R P -
CATCCTGCCCAGAGGATTGCTGCTGCCTCCATGCCACATGCCCTCAGCTACTTTGGCCGA
1801 ---------+---------+---------+---------+---------+---------+ 1860
GTAGGACGGGTCTCCTAACGACGACGGAGGTACGGTGTACGGGAGTCGATGAAACCGGCT
a H P A Q R I A A A S M P H A L S Y F G R -
AGTGTGGATGGTCGGCTAGATCTGGATGGAGATGATCTGGTCGATGTGGCTGTGGGTGCC
1861 ---------+---------+---------+---------+---------+---------+ 1920
TCACACCTACCAGCCGATCTAGACCTACCTCTACTAGACCAGCTACACCGACACCCACGG
a S V D G R L D L D G D D L V D V A V G A -
CAGGGGGCAGCCATCCTGCTCAGCTCCCGGCCCATTGTCCATCTGACCCCATCACTGGAG
1921 ---------+---------+---------+---------+---------+---------+ 1980
GTCCCCCGTCGGTAGGACGAGTCGAGGGCCGGGTAACAGGTAGACTGGGGTAGTGACCTC
a Q G A A I L L S S R P I V H L T P S L E -
GTGACCCCACAGGCCATCAGTGTGGTTCAGAGGGACTGTAGGCGGCGAGGCCAAGAAGCA
1981 ---------+---------+---------+---------+---------+---------+ 2040
CACTGGGGTGTCCGGTAGTCACACCAAGTCTCCCTGACATCCGCCGCTCCGGTTCTTCGT
a V T P Q A I S V V Q R D C R R R G Q E A -
GTCTGTCTGACTGCAGCCCTTTGCTTCCAAGTGACCTCCCGTACTCCTGGTCGCTGGGAT
2041 ---------+---------+---------+---------+---------+---------+ 2100
CAGACAGACTGACGTCGGGAAACGAAGGTTCACTGGAGGGCATGAGGACCAGCGACCCTA
a V C L T A A L C F Q V T S R T P G R W D -
CACCAATTCTACATGAGGTTCACCGCATCACTGGATGAATGGACTGCTGGGGCACGTGCA
2101 ---------+---------+---------+---------+---------+---------+ 2160
GTGGTTAAGATGTACTCCAAGTGGCGTAGTGACCTACTTACCTGACGACCCCGTGCACGT
a H Q F Y M R F T A S L D E W T A G A R A -
GCATTTGATGGCTCTGGCCAGAGGTTGTCCCCTCGGAGGCTCCGGCTCAGTGTGGGGAAT
2161 ---------+---------+---------+---------+---------+---------+ 2220
CGTAAACTACCGAGACCGGTCTCCAACAGGGGAGCCTCCGAGGCCGAGTCACACCCCTTA
a A F D G S G Q R L S P R R L R L S V G N -
GTCACTTGTGAGCAGCTACACTTCCATGTGCTGGATACATCAGATTACCTCCGGCCAGTG
2221 ---------+---------+---------+---------+---------+---------+ 2280
CAGTGAACACTCGTCGATGTGAAGGTACACGACCTATGTAGTCTAATGGAGGCCGGTCAC
a V T C E Q L H F H V L D T S D Y L R P V -
GCCTTGACTGTGACCTTTGCCTTGGACAATACTACAAAGCCAGGGCCTGTGCTGAATGAG
2281 ---------+---------+---------+---------+---------+---------+ 2340
CGGAACTGACACTGGAAACGGAACCTGTTATGATGTTTCGGTCCCGGACACGACTTACTC
a A L T V T F A L D N T T K P G P V L N E -
GGCTCACCCACCTCTATACAAAAGCTGGTCCCCTTCTCAAAGGATTGTGGCCCTGACAAT
2341 ---------+---------+---------+---------+---------+---------+ 2400
CCGAGTGGGTGGAGATATGTTTTCGACCAGGGGAAGAGTTTCCTAACACCGGGACTGTTA
a G S P T S I Q K L V P F S K D C G P D N -
GAATGTGTCACAGACCTGGTGCTTCAAGTGAATATGGACATCAGAGGCTCCAGGAAGGCC
2401 ---------+---------+---------+---------+---------+---------+ 2460
CTTACACAGTGTCTGGACCACGAAGTTCACTTATACCTGTAGTCTCCGAGGTCCTTCCGG
a E C V T D L V L Q V N M D I R G S R K A -
CCATTTGTGGTTCGAGGTGGCCGGCGGAAAGTGCTGGTATCTACAACTCTGGAGAACAGA
2461 ---------+---------+---------+---------+---------+---------+ 2520
GGTAAACACCAAGCTCCACCGGCCGCCTTTCACGACCATAGATGTTGAGACCTCTTGTCT
a P F V V R G G R R K V L V S T T L E N R -
AAGGAAAATGCTTACAATACGAGCCTGAGTATCATCTTCTCTAGAAACCTCCACCTGGCC
2521 ---------+---------+---------+---------+---------+---------+ 2580
TTCCTTTTACGAATGTTATGCTCGGACTCATAGTAGAAGAGATCTTTGGAGGTGGACCGG
a K E N A Y N T S L S I I F S R N L H L A -
AGTCTCACTCCTCAGAGAGAGAGCCCAATAAAGGTGGAATGTGCCGCCCCTTCTGCTCAT
2581 ---------+---------+---------+---------+---------+---------+ 2640
TCAGAGTGAGGAGTCTCTCTCTCGGGTTATTTCCACCTTACACGGCGGGGAAGACGAGTA
a S L T P Q R E S P I K V E C A A P S A H -
GCCCGGCTCTGCAGTGTGGGGCATCCTGTCTTCCAGACTGGAGCCAAGGTGACCTTTCTG
2641 ---------+---------+---------+---------+---------+---------+ 2700
CGGGCCGAGACGTCACACCCCGTAGGACAGAAGGTCTGACCTCGGTTCCACTGGAAAGAC
a A R L C S V G H P V F Q T G A K V T F L -
CTAGAGTTTGAGTTTAGCTGCTCCTCTCTCCTGAGCCAGGTCTTTGGGAAGCTGACTGCC
2701 ---------+---------+---------+---------+---------+---------+ 2760
GATCTCAAACTCAAATCGACGAGGAGAGAGGACTCGGTCCAGAAACCCTTCGACTGACGG
a L E F E F S C S S L L S Q V F G K L T A -
AGCAGTGACAGCCTGGAGAGAAATGGCACCCTTCAAGAAAACACAGCCCAGACCTCAGCC
2761 ---------+---------+---------+---------+---------+---------+ 2820
TCGTCACTGTCGGACCTCTCTTTACCGTGGGAAGTTCTTTTGTGTCGGGTCTGGAGTCGG
a S S D S L E R N G T L Q E N T A Q T S A -
TACATCCAATATGAGCCCCACCTCCTGTTCTCTAGTGAGTCTACCCTGCACCGCTATGAG
2821 ---------+---------+---------+---------+---------+---------+ 2880
ATGTAGGTTATACTCGGGGTGGAGGACAAGAGATCACTCAGATGGGACGTGGCGATACTC
a Y I Q Y E P H L L F S S E S T L H R Y E -
GTTCACCCATATGGGACCCTCCCAGTGGGTCCTGGCCCAGAATTCAAAACCACTCTCAGG
2881 ---------+---------+---------+---------+---------+---------+ 2940
CAAGTGGGTATACCCTGGGAGGGTCACCCAGGACCGGGTCTTAAGTTTTGGTGAGAGTCC
a V H P Y G T L P V G P G P E F K T T L R -
ACTAACAATGCAAGCTGCATAGTGCAGAACCTGACTGAACCCCCAGGCCCACCTGTGCAT
2941 ---------+---------+---------+---------+---------+---------+ 3000
TGATTGTTACGTTCGACGTATCACGTCTTGGACTGACTTGGGGGTCCGGGTGGACACGTA
a T N N A S C I V Q N L T E P P G P P V H -
CCAGAGGAGCTTCAACACACAAACAGACTGAATGGGAGCAATACTCAGTGTCAGGTGGTG
3001 ---------+---------+---------+---------+---------+---------+ 3060
GGTCTCCTCGAAGTTGTGTGTTTGTCTGACTTACCCTCGTTATGAGTCACAGTCCACCAC
a P E E L Q H T N R L N G S N T Q C Q V V -
AGGTGCCACCTTGGGCAGCTGGCAAAGGGGACTGAGGTCTCTGTTGGACTATTGAGGCTG
3061 ---------+---------+---------+---------+---------+---------+ 3120
TCCACGGTGGAACCCGTCGACCGTTTCCCCTGACTCCAGAGACAACCTGATAACTCCGAC
a R C H L G Q L A K G T E V S V G L L R L -
GTTCACAATGAATTTTTCCGAAGAGCCAAGTTCAAGTCCCTGACGGTGGTCAGCACCTTT
3121 ---------+---------+---------+---------+---------+---------+ 3180
CAAGTGTTACTTAAAAAGGCTTCTCGGTTCAAGTTCAGGGACTGCCACCAGTCGTGGAAA
a V H N E F F R R A K F K S L T V V S T F -
GAGCTGGGAACCGAAGAGGGCAGTGTCCTACAGCTGACTGAAGCCTCCCGTTGGAGTGAG
3181 ---------+---------+---------+---------+---------+---------+ 3240
CTCGACCCTTGGCTTCTCCCGTCACAGGATGTCGACTGACTTCGGAGGGCAACCTCACTC
a E L G T E E G S V L Q L T E A S R W S E -
AGCCTCTTGGAGGTGGTTCAGACCCGGCCTATCCTCATCTCCCTGTGGATCCTCATAGGC
3241 ---------+---------+---------+---------+---------+---------+ 3300
TCGGAGAACCTCCACCAAGTCTGGGCCGGATAGGAGTAGAGGGACACCTAGGAGTATCCG
a S L L E V V Q T R P I L I S L W I L I G -
AGTGTCCTGGGAGGGTTGCTCCTGCTTGCTCTCCTTGTCTTCTGCCTGTGGAAGCTTGGC
3301 ---------+---------+---------+---------+---------+---------+ 3360
TCACAGGACCCTCCCAACGAGGACGAACGAGAGGAACAGAAGACGGACACCTTCGAACCG
a S V L G G L L L L A L L V F C L W K L G -
TTCTTTGCCCATAAGAAAATCCCTGAGGAAGAAAAAAGAGAAGAGAAGTTGGAGCAATGA
3361 ---------+---------+---------+---------+---------+---------+ 3420
AAGAAACGGGTATTCTTTTAGGGACTCCTTCTTTTTTCTCTTCTCTTCAACCTCGTTACT
a F F A H K K I P E E E K R E E K L E Q
ATGTAGAATAAGGGTCTAGAAAGTCCTCCCTGGCAGCTTTCTTCAAGAGACTTGCATAAA
3421 ---------+---------+---------+---------+---------+---------+ 3480
TACATCTTATTCCCAGATCTTTCAGGAGGGACCGTCGAAAGAAGTTCTCTGAACGTATTT
AGCAGAGGTTTGGGGGCTCAGATGGGACAAGAAGCCGCCTCTGGACTATCTCCCCAGACC
3481 ---------+---------+---------+---------+---------+---------+ 3540
TCGTCTCCAAACCCCCGAGTCTACCCTGTTCTTCGGCGGAGACCTGATAGAGGGGTCTGG
AGCAGCCTGACTTGACTTTTGAGTCCTAGGGATGCTGCTGGCTAGAGATGAGGCTTTACC
3541 ---------+---------+---------+---------+---------+---------+ 3600
TCGTCGGACTGAACTGAAAACTCAGGATCCCTACGACGACCGATCTCTACTCCGAAATGG
TCAGACAAGAAGAGCTGGCACCAAAACTAGCCATGCTCCCACCCTCTGCTTCCCTCCTCC
3601 ---------+---------+---------+---------+---------+---------+ 3660
AGTCTGTTCTTCTCGACCGTGGTTTTGATCGGTACGAGGGTGGGAGACGAAGGGAGGAGG
TCGTGATCCTGGTTCCATAGCCAACACTGGGGCTTTTGTTTGGGGTCCTTTTATCCCCAG
3661 ---------+---------+---------+---------+---------+---------+ 3720
AGCACTAGGACCAAGGTATCGGTTGTGACCCCGAAAACAAACCCCAGGAAAATAGGGGTC
GAATCAATAATTTTTTTGCCTAGGAAAAAAAAAAGCGGCCGCGAATTCGATATCAAGCT
3721 ---------+---------+---------+---------+---------+--------- 3779
CTTAGTTATTAAAAAAACGGATCCTTTTTTTTTTCGCCGGCGCTTAAGCTATAGTTCGA
(2) 配列番号3の情報:
(i) 配列特徴:
(A) 配列の長さ: 143 塩基対
(B) 配列の型: 核酸およびアミノ酸
(C) 鎖の数: 二本鎖
(D) トポロジー: 直鎖状
(iii) 配列の種類: cDNA
(vi) 起源:
(A)生物名: ヒト
(B) 細胞の種類: 軟骨細胞
(xi) 配列の記載: 配列番号3:
NdeI
|
GGGGCATATGGTTCAGAACCTGGGTTGCTACGTTGTTTCCGGTCTGATCATCTCCGCTCT
1 ---------+---------+---------+---------+---------+---------+ 60
CCCCGTATACCAAGTCTTGGACCCAACGATGCAACAAAGGCCAGACTAGTAGAGGCGAGA
b G H M V Q N L G C Y V V S G L I I S A L -
GCTGCCGGCTGTTGCTCACGGTGGTAACTACTTCCTAAGCTTGTCCCAGGTTATCAGCGG
61 ---------+---------+---------+---------+---------+---------+ 120
CGACGGCCGACAACGAGTGCCACCATTGATGAAGGATTCGAACAGGGTCCAATAGTCGCC
b L P A V A H G G N Y F L S L S Q V I S G -
BamHI
|
CCTGGTGCCGCGCGGATCCCCCC
121 ---------+---------+--- 143
GGACCACGGCGCGCCTAGGGGGG
b L V P R G S P -
【図面の簡単な説明】
【0091】
【図1】II型コラーゲン−「Sepharose 」上でのα10インテグリンサブユニットの親和精製を示す。
【図2】ウシα10インテグリンサブユニットからのペプチドのアミノ酸配列を示す。
【図3】Aは、ウシ軟骨細胞からのインテグリンサブユニットα10の親和精製および免疫沈殿を示す。 Bは、ヒト軟骨細胞からのインテグリンサブユニットα10の親和精製および免疫沈殿を示す。 Cは、ヒト軟骨肉腫細胞からのインテグリンサブユニットα10の親和精製および免疫沈殿を示す。
【図4】ウシインテグリンサブユニットα10に対応する 900bpPCRフラグメントを示す。
【図5】3種の重複クローンの線図である。
【図6】ヒロα10インテグリンサブユニットのヌクレオチド配列および推定アミノ酸配列を示す。
【図7】インテグリンα10mRNAのノーザンブロットを示す。
【図8】α10の細胞質領域に対する抗体を用いたヒト軟骨細胞からのα10インテグリンサブユニットの免疫沈殿を示す(a)。α10 会合β鎖のウエスターンブロット(b)。
【図9】ヒト間節軟骨中のα10インテグリンの染色を示す。
【図10】生後3日マウスの手足軟骨におけるα10インテグリンの染色を示す。
【図11】生後13.5日マウスの胚におけるα10インテグリンの染色を示す。
【図12】各種ヒト組織中のα10mRNAの交配を示す。
【図13】生後3日マウスの手足における間節周りの靭帯(a)、骨格筋(b)および心臓弁(c)の染色をシスプラチン。
【図14】ヒト軟骨細胞、ヒト内皮細胞。ヒト繊維芽細胞およびラット間節からのα10インテグリンサブユニットに対応するPCRフラグメントを示す。
【図15】ヒトインテグリンサブユニットα10の部分ゲノムヌクレオチド配列を示す。
【図16】アルギン酸塩中で培養した軟骨細胞におけるα10インテグリンサブユニットのアップレギュレーションを示す。
【図17】ヒト平滑筋細胞からのα10インテグリンサブユニットの染色を示す。
【特許請求の範囲】
【請求項1】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなる組換え型または単離型インテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片。
【請求項2】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなる組換えインテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片の製造方法であって、
a)インテグリンサブユニットα10をコードするヌクレオチド配列を含んでなるポリヌクレオチド、または同等の生物学的活性を有するその相同体もしくは断片を単離し、
b)単離されたポリヌクレオチドを含んでなる発現ベクターを構築し、
c)宿主細胞をその発現ベクターで形質転換し、
d)形質転換宿主細胞においてインテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片を発現するに好適な条件下の培地で形質転換宿主細胞を培養し、さらに所望により、
e)形質転換宿主細胞または培養培地からインテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片を単離する工程を含んでなる方法。
【請求項3】
インテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片を製造し、それによりサブユニットがそれが天然に存在する細胞から単離される方法。
【請求項4】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードするヌクレオチド配列を含んでなり、ポリヌクレオチドが配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその好適な一部を含んでなる、単離ポリヌクレオチド。
【請求項5】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードするDNAまたはRNAとハイブリダイズするが、インテグリンサブユニットα1をコードするDNAまたはRNAとはハイブリダイズできない、単離ポリヌクレオチドまたはオリゴヌクレオチド。
【請求項6】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードし、配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその一部を含むポリヌクレオチドまたはオリゴヌクレオチドを含んでなるベクター。
【請求項7】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードするDNAまたはRNAとハイブリダイズするが、インテグリンサブユニットα1をコードするDNAまたはRNAとはハイブリダイズできない、ポリヌクレオチドまたはオリゴヌクレオチドを含んでなるベクター。
【請求項8】
請求項6および7のいずれか1項で定義されたベクターを含む細胞。
【請求項9】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードし、配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその一部を含んでなるポリヌクレオチドまたはオリゴヌクレオチドが細胞ゲノムに安定的に組み込まれている、請求項2の方法により作出される細胞。
【請求項10】
配列番号1もしくは配列番号2のアミノ酸配列を含んでなるインテグリンサブユニットアミノ酸10、またはその相同体もしくは断片に特異的に結合する能力を有する結合物。
【請求項11】
タンパク質、ペプチド、炭水化物、脂質、天然のインテグリン結合リガンド、ポリクローナルおよびモノクローナル抗体、ならびにその断片からなる群から選択される、請求項10記載の結合物。
【請求項12】
サブユニットα10およびサブユニットβを含んでなり、サブユニットα10が配列番号1または配列番号2で示されるアミノ酸配列、ならびに同等の生物学的活性を有するその相同体および断片を含んでなる、組換え型または単離型インテグリンヘテロ二量体。
【請求項13】
サブユニットβがβ1である、請求項12記載の組換え型または単離型インテグリンヘテロ二量体。
【請求項14】
サブユニットα10およびサブユニットβを含んでなり、サブユニットα10が配列番号1または配列番号2で示されるアミノ酸配列、およびその相同体および断片を含んでなる組換えインテグリンヘテロ二量体の製造方法であって、
a)インテグリンヘテロ二量体のサブユニットα10をコードするヌクレオチド配列と、所望によりインテグリンヘテロ二量体のサブユニットβをコードするヌクレオチド配列を含むもう1つのポリヌクレオチド、または同等の生物学的活性を有する相同体もしくは断片をコードするポリヌクレオチドもしくはオリゴヌクレオチドとを含んでなる1つのポリヌクレオチドを単離し、
b)サブユニットα10をコードする単離ポリヌクレオチドを含んでなる発現ベクターを、所望によりサブユニットβをコードする単離ヌクレオチドを含んでなる発現ベクターと組み合わせて構築し、
c)宿主細胞を発現ベクターで形質転換し、
d)形質転換宿主細胞においてサブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体を発現させるのに好適な条件下の培地で形質転換宿主細胞を培養し、さらに所望により、
e)形質転換宿主細胞または培地から、サブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体、あるいはそのα10サブユニットを単離する工程を含んでなる方法。
【請求項15】
サブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体を製造し、それによりインテグリンヘテロ二量体がそれが天然に存在する細胞から単離される方法。
【請求項16】
インテグリンヘテロ二量体のサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片をコードし、配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその一部を含むポリヌクレオチドもしくはオリゴヌクレオチドを含んでなる第1のベクターと、インテグリンヘテロ二量体のサブユニットβ、またはその相同体もしくは断片をコードするポリヌクレオチドもしくはオリゴヌクレオチドを含む第2のベクターとを含む細胞。
【請求項17】
サブユニットα10およびサブユニットβ、またはその相同体もしくは断片、または同等の生物学的活性を有するそのサブユニットα10を含んでなるインテグリンヘテロ二量体と特異的に結合する能力を有する結合物。
【請求項18】
サブユニットβがβ1である、請求項17記載の結合物。
【請求項19】
タンパク質、ペプチド、炭水化物、脂質、天然のインテグリン結合リガンド、およびその断片からなる群から選択される、請求項17または18記載の結合物。
【請求項20】
細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、インテグリンサブユニットα10の断片。
【請求項21】
アミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項20記載の断片。
【請求項22】
配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項20記載の断片。
【請求項23】
配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなるペプチドである、請求項20記載の断片。
【請求項24】
請求項20〜23のいずれか1項で定義されたインテグリンサブユニットα10の断片の製造方法であって、保護基を含むアミノ酸の一連の付加を含んでなる方法。
【請求項25】
請求項20〜23のいずれか1項で定義されたインテグリンサブユニットα10の断片をコードするポリヌクレオチドまたはオリゴヌクレオチド。
【請求項26】
請求項20〜23のいずれか1項で定義されたヒトインテグリンサブユニットα10の断片と特異的に結合する能力を有する結合物。
【請求項27】
タンパク質、ペプチド、炭水化物、脂質、天然のインテグリン結合リガンド、およびその断片からなる群から選択される、請求項26記載の結合物。
【請求項28】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβ、または同等の生物学的活性を有するそのインテグリンもしくはサブユニットの相同体もしくは断片を含んでなるインテグリンヘテロ二量体を、インテグリンサブユニットα10を発現する細胞または組織(この細胞またはヒトをはじめとする動物起源のものである)のマーカーもしくは標的分子として使用する方法。
【請求項29】
断片が細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、請求項28記載の方法。
【請求項30】
断片がアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項29記載の方法。
【請求項31】
断片が配列番号1のアミノ酸952番付近からアミノ酸986付近までのアミノ酸配列を含んでなる、請求項29記載の方法。
【請求項32】
断片が配列番号1のアミノ酸140番付近からアミノ酸337付近までのアミノ酸配列を含んでなる、請求項29記載の方法。
【請求項33】
サブユニットβがβ1である、請求項28記載の方法。
【請求項34】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項28記載の方法。
【請求項35】
サブユニットα10に関与する病状の際に使用される、請求項28〜34のいずれか1項に記載の方法。
【請求項36】
病状が軟骨の損傷を含む、請求項35記載の方法。
【請求項37】
病状が外傷、慢性関節リウマチおよび変形性関節症を含む、請求項36記載の方法。
【請求項38】
胚発達中の軟骨の形成を検出する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項39】
軟骨の生理学上または治療上の修復を検出する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項40】
軟骨細胞の選択および分析、または選別、単離もしくは精製する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項41】
軟骨または軟骨細胞の移植の際の軟骨または軟骨細胞の再生を検出する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項42】
軟骨細胞の分化のin vitro研究のための方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項43】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、または同等の生物学的活性を有するその相同体もしくは断片と特異的に結合する能力を有する結合物を、インテグリンサブユニットα10を発現する細胞または組織(この細胞またはヒトをはじめとする動物起源のものである)のマーカーもしくは標的として使用する方法。
【請求項44】
断片が細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、請求項43記載の方法。
【請求項45】
断片がアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項43記載の方法。
【請求項46】
断片が配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項43記載の方法。
【請求項47】
断片が配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなる、請求項43記載の方法。
【請求項48】
サブユニットβがβ1である、請求項43記載の方法。
【請求項49】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβ、もしくは同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体の存在を検出する方法である、請求項43〜48のいずれか1項に記載の方法。
【請求項50】
胚発達、血管形成または癌の発達中の細胞の分化段階を決定する方法である、請求項43〜48のいずれか1項に記載の方法。
【請求項51】
インテグリンサブユニットα10、または同等の生物学的活性を有するそのインテグリンサブユニットの相同体もしくは断片の存在を細胞において検出する方法であって、配列番号1で示されるポリヌクレオチドまたはオリゴヌクレオチドからなる群から選択されるポリヌクレオチドまたはオリゴヌクレオチドが、これらがインテグリンサブユニットα1をコードするDNAもしくはRNAとはハイブリダイズできないハイブリダイゼーション条件下でマーカーとして使用される方法。
【請求項52】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項51記載の方法。
【請求項53】
断片が細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、請求項51記載の方法。
【請求項54】
断片がアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項53記載の方法。
【請求項55】
断片が配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項53記載の方法。
【請求項56】
断片が配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなる、請求項53記載の方法。
【請求項57】
組織の再生または治療上の、また生理学上の軟骨の再生における病状において、発達中の細胞の分化段階を決定する方法である、請求項43〜48のいずれか1項に記載の方法。
【請求項58】
病状がインテグリンサブユニットα10に関与するいずれかの病状である、請求項57記載の方法。
【請求項59】
病状が慢性関節リウマチ、変形性関節炎および癌である、請求項58記載の方法。
【請求項60】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項57記載の方法。
【請求項61】
組織の再生および治療上の、また生理学上の軟骨の再生における病状において、発達中の細胞の分化段階を決定する方法であって、配列番号1で示されるヌクレオチド配列から選択されるポリヌクレオチドまたはオリゴヌクレオチドが、それらがインテグリンサブユニットα10をコードするDNAまたはRNAとはハイブリダイズできないハイブリダイゼーション条件下でマーカーとして使用される方法。
【請求項62】
ポリヌクレオチドまたはオリゴヌクレオチドが、細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドをコードするポリヌクレオチドまたはオリゴヌクレオチドである、請求項61記載の方法。
【請求項63】
ポリヌクレオチドまたはオリゴヌクレオチドがアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドをコードするポリヌクレオチドまたはオリゴヌクレオチドである、請求項62記載の方法。
【請求項64】
ペプチドが配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項62記載の方法。
【請求項65】
ペプチドが配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなる、請求項62記載の方法。
【請求項66】
病状がインテグリンサブユニットα10に関与するいずれかの病状である、請求項61記載の方法。
【請求項67】
病状が慢性関節リウマチ、変形性関節炎または癌である、請求項66記載の方法。
【請求項68】
病状がアテローム性動脈硬化症または炎症である、請求項66記載の方法。
【請求項69】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項61〜68のいずれか1項に記載の方法。
【請求項70】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンまたはサブユニットα10の相同体もしくは断片を標的分子として使用できる医薬剤または抗体を有効成分として含んでなる医薬組成物。
【請求項71】
軟骨、骨および血管の形成を刺激、阻害またはブロックするのに用いられる、請求項70記載の医薬組成物。
【請求項72】
癒着が組織の機能を損なう感染、炎症および外科手術的介入後の腱/靱帯と周辺組織との間の癒着を防ぐのに用いられる、請求項70記載の医薬組成物。
【請求項73】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、またはインテグリンもしくはサブユニットα10の相同体もしくは断片、またはインテグリンサブユニットα10をコードするDNAもしくはRNAを有効成分として含んでなるワクチン。
【請求項74】
軟骨または軟骨細胞の移植におけるインテグリンサブユニットα10の、マーカーまたは標的としての使用。
【請求項75】
軟骨細胞および/または骨芽細胞の、移植片の表面への接着を促進して骨の組み込みを刺激するために、配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体と特異的に結合する能力を有する結合物を使用する方法。
【請求項76】
腱、靱帯、骨格筋または癒着が組織の機能を損なうその他の組織における、インテグリンサブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片の、抗癒着薬または分子の標的としての使用。
【請求項77】
軟骨または骨の形成を刺激、阻害またはブロックする方法であって、サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片を標的分子として使用できる医薬または抗体の好適量を患者に投与することを含んでなる方法。
【請求項78】
癒着が組織の機能を損なう感染、炎症および外科手術的介入後の腱/靱帯および周辺組織間の癒着を防ぐ方法であって、サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片を標的分子として使用できる医薬または抗体の好適量を患者に投与することを含んでなる方法。
【請求項79】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片の活性化または阻害により細胞マトリックス合成および修復を刺激する方法。
【請求項80】
インテグリン結合物の存在をin vitroで検出する方法であって、サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、またはインテグリンもしくはサブユニットの相同体もしくは断片とサンプルとを相互作用させ、それによりインテグリン、サブユニットα10、または同等の生物学的活性を有する相同体もしくは断片を活性化させて、サンプル中に存在するその天然のリガンドまたはその他のインテグリン結合タンパク質への結合を変調することを含んでなる方法。
【請求項81】
サブユニットα10およびサブユニットβを含んでなるヒトヘテロ二量体インテグリン、またはそのサブユニットα10、またはインテグリンもしくはサブユニットの相同体もしくは断片とインテグリン結合物との相互作用の結果をin vitroで研究し、それにより細胞反応を誘導する方法。
【請求項82】
相互作用の結果が細胞機能の変化として測定される、請求項81記載の方法。
【請求項83】
インテグリンサブユニットα10またはその相同体もしくは断片をコードするDNAまたはRNAを標的分子として使用する方法。
【請求項84】
ポリヌクレオチドまたはオリゴヌクレオチドが、インテグリンサブユニットα10またはその相同体もしくは断片をコードするDNAまたはRNAとハイブリダイズするが、インテグリンサブユニットα1をコードするDNAまたはRNAとはハイブリダイズできない、請求項83記載の方法。
【請求項85】
サブユニットα10およびサブユニットβを含んでなるヒトヘテロ二量体インテグリン、またはそのサブユニットα10、またはインテグリンもしくはサブユニットの相同体もしくは断片、またはインテグリンサブユニットα10またはその相同体もしくは断片をコードするDNAもしくはRNAを血管形成の際の標的分子として使用する方法。
【請求項86】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片の細胞表面発現を刺激することができる医薬または抗体を有効成分として含んでなる医薬組成物。
【請求項1】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなる組換え型または単離型インテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片。
【請求項2】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなる組換えインテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片の製造方法であって、
a)インテグリンサブユニットα10をコードするヌクレオチド配列を含んでなるポリヌクレオチド、または同等の生物学的活性を有するその相同体もしくは断片を単離し、
b)単離されたポリヌクレオチドを含んでなる発現ベクターを構築し、
c)宿主細胞をその発現ベクターで形質転換し、
d)形質転換宿主細胞においてインテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片を発現するに好適な条件下の培地で形質転換宿主細胞を培養し、さらに所望により、
e)形質転換宿主細胞または培養培地からインテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片を単離する工程を含んでなる方法。
【請求項3】
インテグリンサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片を製造し、それによりサブユニットがそれが天然に存在する細胞から単離される方法。
【請求項4】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードするヌクレオチド配列を含んでなり、ポリヌクレオチドが配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその好適な一部を含んでなる、単離ポリヌクレオチド。
【請求項5】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードするDNAまたはRNAとハイブリダイズするが、インテグリンサブユニットα1をコードするDNAまたはRNAとはハイブリダイズできない、単離ポリヌクレオチドまたはオリゴヌクレオチド。
【請求項6】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードし、配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその一部を含むポリヌクレオチドまたはオリゴヌクレオチドを含んでなるベクター。
【請求項7】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードするDNAまたはRNAとハイブリダイズするが、インテグリンサブユニットα1をコードするDNAまたはRNAとはハイブリダイズできない、ポリヌクレオチドまたはオリゴヌクレオチドを含んでなるベクター。
【請求項8】
請求項6および7のいずれか1項で定義されたベクターを含む細胞。
【請求項9】
インテグリンサブユニットα10、またはその相同体もしくは断片をコードし、配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその一部を含んでなるポリヌクレオチドまたはオリゴヌクレオチドが細胞ゲノムに安定的に組み込まれている、請求項2の方法により作出される細胞。
【請求項10】
配列番号1もしくは配列番号2のアミノ酸配列を含んでなるインテグリンサブユニットアミノ酸10、またはその相同体もしくは断片に特異的に結合する能力を有する結合物。
【請求項11】
タンパク質、ペプチド、炭水化物、脂質、天然のインテグリン結合リガンド、ポリクローナルおよびモノクローナル抗体、ならびにその断片からなる群から選択される、請求項10記載の結合物。
【請求項12】
サブユニットα10およびサブユニットβを含んでなり、サブユニットα10が配列番号1または配列番号2で示されるアミノ酸配列、ならびに同等の生物学的活性を有するその相同体および断片を含んでなる、組換え型または単離型インテグリンヘテロ二量体。
【請求項13】
サブユニットβがβ1である、請求項12記載の組換え型または単離型インテグリンヘテロ二量体。
【請求項14】
サブユニットα10およびサブユニットβを含んでなり、サブユニットα10が配列番号1または配列番号2で示されるアミノ酸配列、およびその相同体および断片を含んでなる組換えインテグリンヘテロ二量体の製造方法であって、
a)インテグリンヘテロ二量体のサブユニットα10をコードするヌクレオチド配列と、所望によりインテグリンヘテロ二量体のサブユニットβをコードするヌクレオチド配列を含むもう1つのポリヌクレオチド、または同等の生物学的活性を有する相同体もしくは断片をコードするポリヌクレオチドもしくはオリゴヌクレオチドとを含んでなる1つのポリヌクレオチドを単離し、
b)サブユニットα10をコードする単離ポリヌクレオチドを含んでなる発現ベクターを、所望によりサブユニットβをコードする単離ヌクレオチドを含んでなる発現ベクターと組み合わせて構築し、
c)宿主細胞を発現ベクターで形質転換し、
d)形質転換宿主細胞においてサブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体を発現させるのに好適な条件下の培地で形質転換宿主細胞を培養し、さらに所望により、
e)形質転換宿主細胞または培地から、サブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体、あるいはそのα10サブユニットを単離する工程を含んでなる方法。
【請求項15】
サブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体を製造し、それによりインテグリンヘテロ二量体がそれが天然に存在する細胞から単離される方法。
【請求項16】
インテグリンヘテロ二量体のサブユニットα10、または同等の生物学的活性を有するその相同体もしくは断片をコードし、配列番号1もしくは配列番号2で示されるヌクレオチド配列またはその一部を含むポリヌクレオチドもしくはオリゴヌクレオチドを含んでなる第1のベクターと、インテグリンヘテロ二量体のサブユニットβ、またはその相同体もしくは断片をコードするポリヌクレオチドもしくはオリゴヌクレオチドを含む第2のベクターとを含む細胞。
【請求項17】
サブユニットα10およびサブユニットβ、またはその相同体もしくは断片、または同等の生物学的活性を有するそのサブユニットα10を含んでなるインテグリンヘテロ二量体と特異的に結合する能力を有する結合物。
【請求項18】
サブユニットβがβ1である、請求項17記載の結合物。
【請求項19】
タンパク質、ペプチド、炭水化物、脂質、天然のインテグリン結合リガンド、およびその断片からなる群から選択される、請求項17または18記載の結合物。
【請求項20】
細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、インテグリンサブユニットα10の断片。
【請求項21】
アミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項20記載の断片。
【請求項22】
配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項20記載の断片。
【請求項23】
配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなるペプチドである、請求項20記載の断片。
【請求項24】
請求項20〜23のいずれか1項で定義されたインテグリンサブユニットα10の断片の製造方法であって、保護基を含むアミノ酸の一連の付加を含んでなる方法。
【請求項25】
請求項20〜23のいずれか1項で定義されたインテグリンサブユニットα10の断片をコードするポリヌクレオチドまたはオリゴヌクレオチド。
【請求項26】
請求項20〜23のいずれか1項で定義されたヒトインテグリンサブユニットα10の断片と特異的に結合する能力を有する結合物。
【請求項27】
タンパク質、ペプチド、炭水化物、脂質、天然のインテグリン結合リガンド、およびその断片からなる群から選択される、請求項26記載の結合物。
【請求項28】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβ、または同等の生物学的活性を有するそのインテグリンもしくはサブユニットの相同体もしくは断片を含んでなるインテグリンヘテロ二量体を、インテグリンサブユニットα10を発現する細胞または組織(この細胞またはヒトをはじめとする動物起源のものである)のマーカーもしくは標的分子として使用する方法。
【請求項29】
断片が細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、請求項28記載の方法。
【請求項30】
断片がアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項29記載の方法。
【請求項31】
断片が配列番号1のアミノ酸952番付近からアミノ酸986付近までのアミノ酸配列を含んでなる、請求項29記載の方法。
【請求項32】
断片が配列番号1のアミノ酸140番付近からアミノ酸337付近までのアミノ酸配列を含んでなる、請求項29記載の方法。
【請求項33】
サブユニットβがβ1である、請求項28記載の方法。
【請求項34】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項28記載の方法。
【請求項35】
サブユニットα10に関与する病状の際に使用される、請求項28〜34のいずれか1項に記載の方法。
【請求項36】
病状が軟骨の損傷を含む、請求項35記載の方法。
【請求項37】
病状が外傷、慢性関節リウマチおよび変形性関節症を含む、請求項36記載の方法。
【請求項38】
胚発達中の軟骨の形成を検出する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項39】
軟骨の生理学上または治療上の修復を検出する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項40】
軟骨細胞の選択および分析、または選別、単離もしくは精製する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項41】
軟骨または軟骨細胞の移植の際の軟骨または軟骨細胞の再生を検出する方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項42】
軟骨細胞の分化のin vitro研究のための方法である、請求項28〜34のいずれか1項に記載の方法。
【請求項43】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、または同等の生物学的活性を有するその相同体もしくは断片と特異的に結合する能力を有する結合物を、インテグリンサブユニットα10を発現する細胞または組織(この細胞またはヒトをはじめとする動物起源のものである)のマーカーもしくは標的として使用する方法。
【請求項44】
断片が細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、請求項43記載の方法。
【請求項45】
断片がアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項43記載の方法。
【請求項46】
断片が配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項43記載の方法。
【請求項47】
断片が配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなる、請求項43記載の方法。
【請求項48】
サブユニットβがβ1である、請求項43記載の方法。
【請求項49】
配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβ、もしくは同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体の存在を検出する方法である、請求項43〜48のいずれか1項に記載の方法。
【請求項50】
胚発達、血管形成または癌の発達中の細胞の分化段階を決定する方法である、請求項43〜48のいずれか1項に記載の方法。
【請求項51】
インテグリンサブユニットα10、または同等の生物学的活性を有するそのインテグリンサブユニットの相同体もしくは断片の存在を細胞において検出する方法であって、配列番号1で示されるポリヌクレオチドまたはオリゴヌクレオチドからなる群から選択されるポリヌクレオチドまたはオリゴヌクレオチドが、これらがインテグリンサブユニットα1をコードするDNAもしくはRNAとはハイブリダイズできないハイブリダイゼーション条件下でマーカーとして使用される方法。
【請求項52】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項51記載の方法。
【請求項53】
断片が細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドである、請求項51記載の方法。
【請求項54】
断片がアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドである、請求項53記載の方法。
【請求項55】
断片が配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項53記載の方法。
【請求項56】
断片が配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなる、請求項53記載の方法。
【請求項57】
組織の再生または治療上の、また生理学上の軟骨の再生における病状において、発達中の細胞の分化段階を決定する方法である、請求項43〜48のいずれか1項に記載の方法。
【請求項58】
病状がインテグリンサブユニットα10に関与するいずれかの病状である、請求項57記載の方法。
【請求項59】
病状が慢性関節リウマチ、変形性関節炎および癌である、請求項58記載の方法。
【請求項60】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項57記載の方法。
【請求項61】
組織の再生および治療上の、また生理学上の軟骨の再生における病状において、発達中の細胞の分化段階を決定する方法であって、配列番号1で示されるヌクレオチド配列から選択されるポリヌクレオチドまたはオリゴヌクレオチドが、それらがインテグリンサブユニットα10をコードするDNAまたはRNAとはハイブリダイズできないハイブリダイゼーション条件下でマーカーとして使用される方法。
【請求項62】
ポリヌクレオチドまたはオリゴヌクレオチドが、細胞質ドメイン、Iドメインおよびスプライシングドメインのペプチドからなる群から選択されるペプチドをコードするポリヌクレオチドまたはオリゴヌクレオチドである、請求項61記載の方法。
【請求項63】
ポリヌクレオチドまたはオリゴヌクレオチドがアミノ酸配列KLGFFAHKKIPEEEKREEKLEQを含んでなるペプチドをコードするポリヌクレオチドまたはオリゴヌクレオチドである、請求項62記載の方法。
【請求項64】
ペプチドが配列番号1のアミノ酸952番付近からアミノ酸986番付近までのアミノ酸配列を含んでなる、請求項62記載の方法。
【請求項65】
ペプチドが配列番号1のアミノ酸140番付近からアミノ酸337番付近までのアミノ酸配列を含んでなる、請求項62記載の方法。
【請求項66】
病状がインテグリンサブユニットα10に関与するいずれかの病状である、請求項61記載の方法。
【請求項67】
病状が慢性関節リウマチ、変形性関節炎または癌である、請求項66記載の方法。
【請求項68】
病状がアテローム性動脈硬化症または炎症である、請求項66記載の方法。
【請求項69】
細胞が軟骨細胞、平滑筋細胞、内皮細胞、骨芽細胞および繊維芽細胞からなる群から選択される、請求項61〜68のいずれか1項に記載の方法。
【請求項70】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンまたはサブユニットα10の相同体もしくは断片を標的分子として使用できる医薬剤または抗体を有効成分として含んでなる医薬組成物。
【請求項71】
軟骨、骨および血管の形成を刺激、阻害またはブロックするのに用いられる、請求項70記載の医薬組成物。
【請求項72】
癒着が組織の機能を損なう感染、炎症および外科手術的介入後の腱/靱帯と周辺組織との間の癒着を防ぐのに用いられる、請求項70記載の医薬組成物。
【請求項73】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、またはインテグリンもしくはサブユニットα10の相同体もしくは断片、またはインテグリンサブユニットα10をコードするDNAもしくはRNAを有効成分として含んでなるワクチン。
【請求項74】
軟骨または軟骨細胞の移植におけるインテグリンサブユニットα10の、マーカーまたは標的としての使用。
【請求項75】
軟骨細胞および/または骨芽細胞の、移植片の表面への接着を促進して骨の組み込みを刺激するために、配列番号1もしくは配列番号2で示されるアミノ酸配列を含んでなるインテグリンサブユニットα10、またはサブユニットα10およびサブユニットβ、または同等の生物学的活性を有するその相同体もしくは断片を含んでなるインテグリンヘテロ二量体と特異的に結合する能力を有する結合物を使用する方法。
【請求項76】
腱、靱帯、骨格筋または癒着が組織の機能を損なうその他の組織における、インテグリンサブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片の、抗癒着薬または分子の標的としての使用。
【請求項77】
軟骨または骨の形成を刺激、阻害またはブロックする方法であって、サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片を標的分子として使用できる医薬または抗体の好適量を患者に投与することを含んでなる方法。
【請求項78】
癒着が組織の機能を損なう感染、炎症および外科手術的介入後の腱/靱帯および周辺組織間の癒着を防ぐ方法であって、サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片を標的分子として使用できる医薬または抗体の好適量を患者に投与することを含んでなる方法。
【請求項79】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片の活性化または阻害により細胞マトリックス合成および修復を刺激する方法。
【請求項80】
インテグリン結合物の存在をin vitroで検出する方法であって、サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、またはインテグリンもしくはサブユニットの相同体もしくは断片とサンプルとを相互作用させ、それによりインテグリン、サブユニットα10、または同等の生物学的活性を有する相同体もしくは断片を活性化させて、サンプル中に存在するその天然のリガンドまたはその他のインテグリン結合タンパク質への結合を変調することを含んでなる方法。
【請求項81】
サブユニットα10およびサブユニットβを含んでなるヒトヘテロ二量体インテグリン、またはそのサブユニットα10、またはインテグリンもしくはサブユニットの相同体もしくは断片とインテグリン結合物との相互作用の結果をin vitroで研究し、それにより細胞反応を誘導する方法。
【請求項82】
相互作用の結果が細胞機能の変化として測定される、請求項81記載の方法。
【請求項83】
インテグリンサブユニットα10またはその相同体もしくは断片をコードするDNAまたはRNAを標的分子として使用する方法。
【請求項84】
ポリヌクレオチドまたはオリゴヌクレオチドが、インテグリンサブユニットα10またはその相同体もしくは断片をコードするDNAまたはRNAとハイブリダイズするが、インテグリンサブユニットα1をコードするDNAまたはRNAとはハイブリダイズできない、請求項83記載の方法。
【請求項85】
サブユニットα10およびサブユニットβを含んでなるヒトヘテロ二量体インテグリン、またはそのサブユニットα10、またはインテグリンもしくはサブユニットの相同体もしくは断片、またはインテグリンサブユニットα10またはその相同体もしくは断片をコードするDNAもしくはRNAを血管形成の際の標的分子として使用する方法。
【請求項86】
サブユニットα10およびサブユニットβを含んでなるインテグリンヘテロ二量体、またはそのサブユニットα10、または同等の生物学的活性を有するインテグリンもしくはサブユニットα10の相同体もしくは断片の細胞表面発現を刺激することができる医薬または抗体を有効成分として含んでなる医薬組成物。
【図2】


【図12】

【図1】
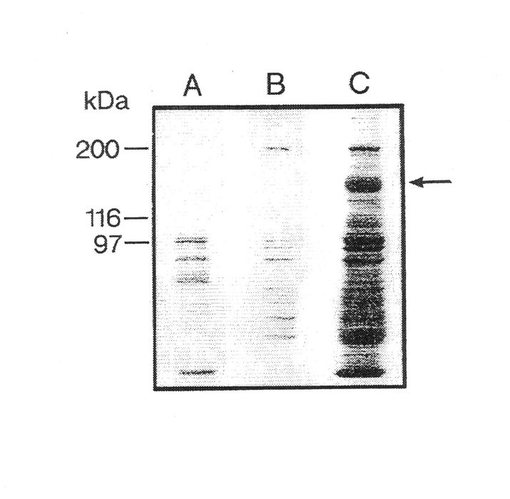
【図3】
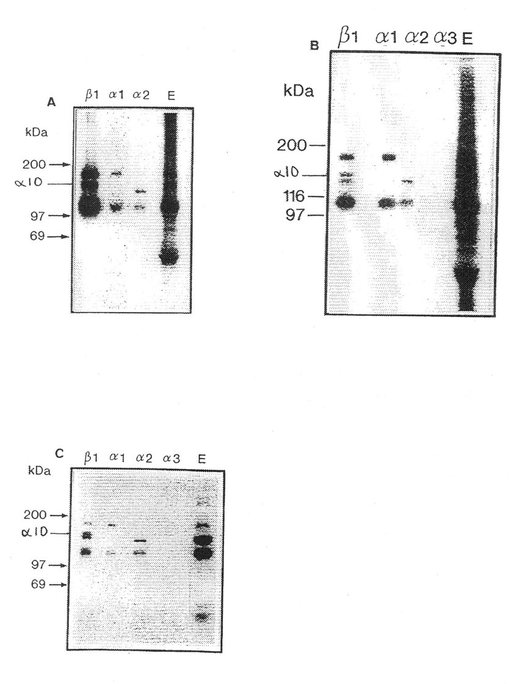
【図4】
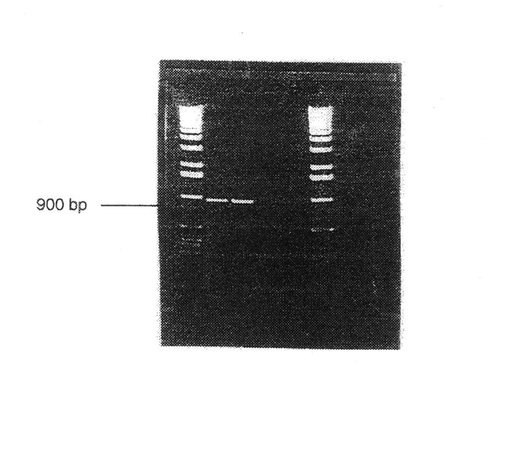
【図5】
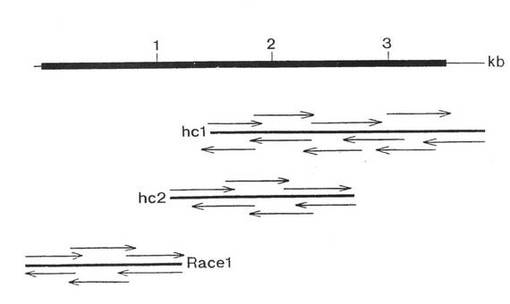
【図6】

【図7】
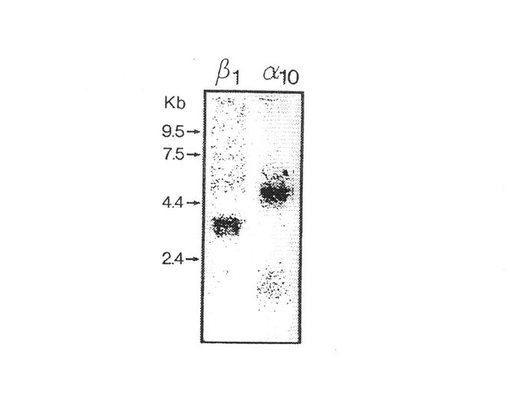
【図8】
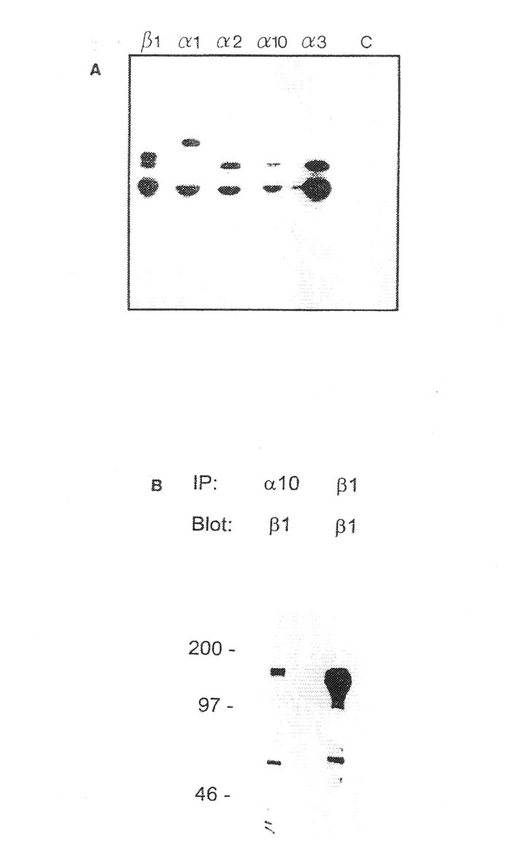
【図9】
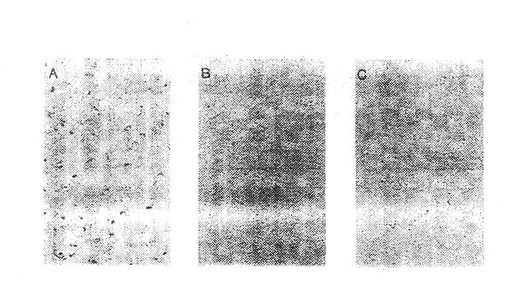
【図10】
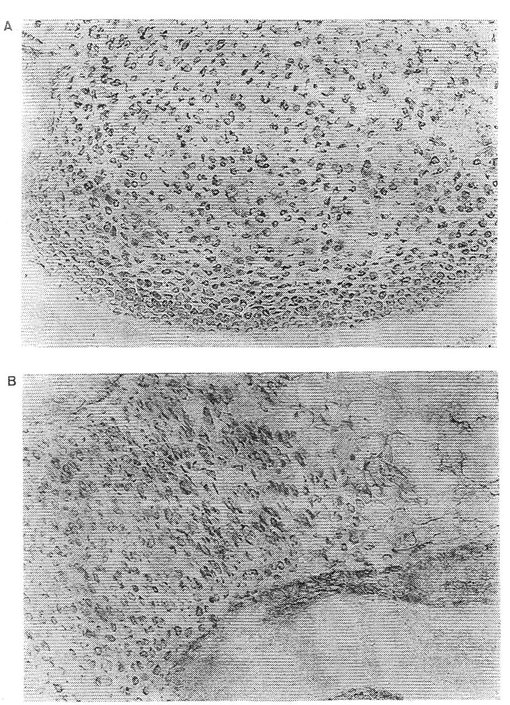
【図11】
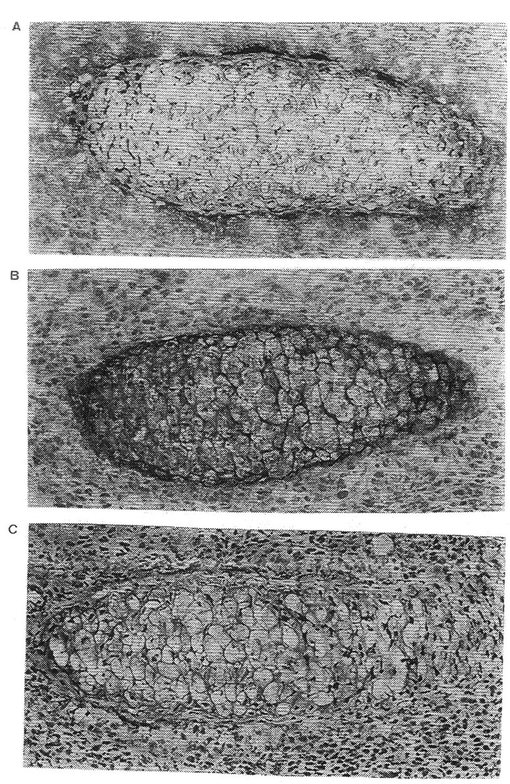
【図13】
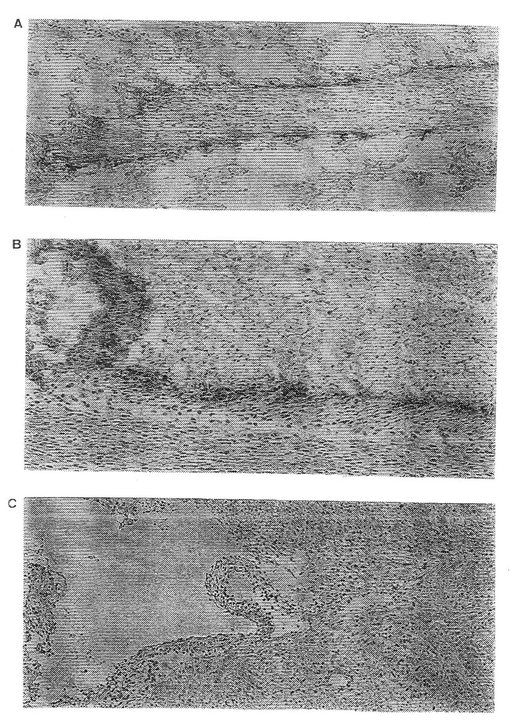
【図14】
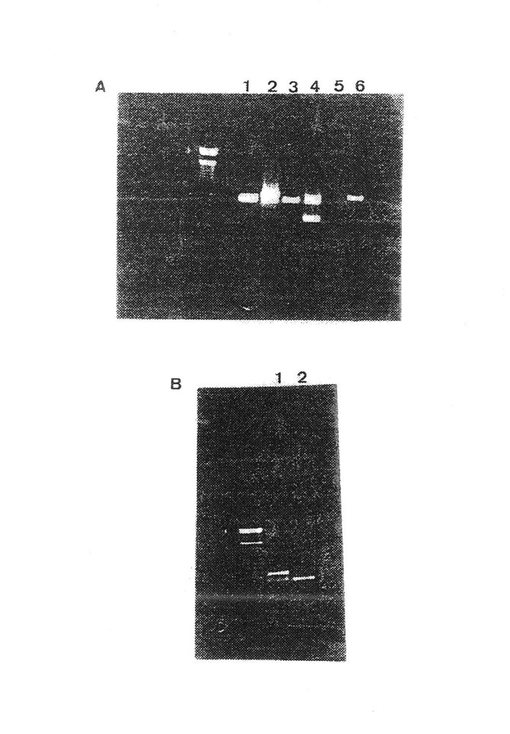
【図15a】

【図15b】

【図15c】

【図15d】

【図15e】

【図15f】

【図16】
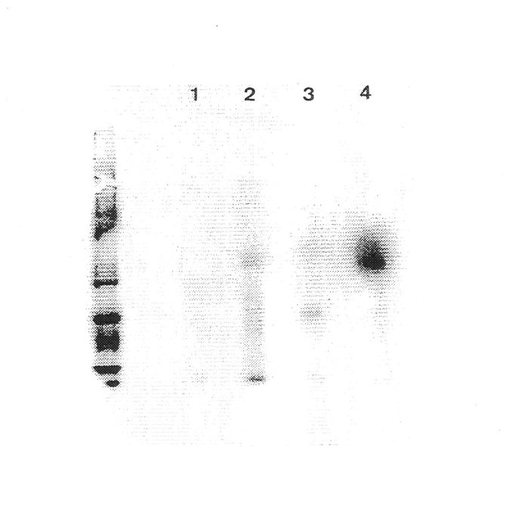
【図17】
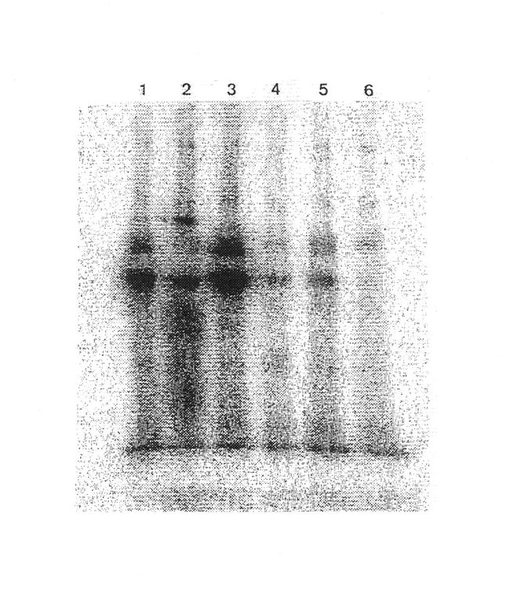
【図12】
【図1】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図13】
【図14】
【図15a】
【図15b】
【図15c】
【図15d】
【図15e】
【図15f】
【図16】
【図17】
【公開番号】特開2011−217745(P2011−217745A)
【公開日】平成23年11月4日(2011.11.4)
【国際特許分類】
【外国語出願】
【出願番号】特願2011−76144(P2011−76144)
【出願日】平成23年3月30日(2011.3.30)
【分割の表示】特願2000−542360(P2000−542360)の分割
【原出願日】平成11年3月31日(1999.3.31)
【出願人】(509254926)キシンテラ、アクチボラグ (1)
【氏名又は名称原語表記】XINTELA AB
【Fターム(参考)】
【公開日】平成23年11月4日(2011.11.4)
【国際特許分類】
【出願番号】特願2011−76144(P2011−76144)
【出願日】平成23年3月30日(2011.3.30)
【分割の表示】特願2000−542360(P2000−542360)の分割
【原出願日】平成11年3月31日(1999.3.31)
【出願人】(509254926)キシンテラ、アクチボラグ (1)
【氏名又は名称原語表記】XINTELA AB
【Fターム(参考)】
[ Back to top ]