
エージェント装置とこれを用いたエージェントシステム
【課題】 大規模検索システムを介して、インターネットに接続された各企業等が公開するサイトの情報が漏洩することを防止するシステムが存在しなかった。
【解決手段】 インターネットに接続された各企業等が公開する各サイト内又は当該サイトとインターネットとの間に配置され、大規模検索システムを介して、前記サイトの情報が漏洩する経路(covert channel)を推論し、事前にユーザに警告或いは情報フローを停止させるための情報フィルタを備えた。
【解決手段】 インターネットに接続された各企業等が公開する各サイト内又は当該サイトとインターネットとの間に配置され、大規模検索システムを介して、前記サイトの情報が漏洩する経路(covert channel)を推論し、事前にユーザに警告或いは情報フローを停止させるための情報フィルタを備えた。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、インターネットに接続されたサイトの情報が、大規模検索システムを介して漏洩することを防止するエージェント装置に関するものである。
【背景技術】
【0002】
インターネットに於けるクラウド,と言う概念を「検索システムと情報産出システムを基盤として,対象世界の関係を述語論理で記述しアドレス空間を関係付けた意味論」と定義する。この様な定義から始めて現状を観ると,ユーザのクラウド情報は一方的に検索インデックスサイトに流入するのみであり,ユーザがクラウドの情報フローを主体的に制約する機能が無い。これは社会システムの視点で観れば欠陥である。
【0003】
クラウド・コンピューティングは,SaaS(Soft−ware−as−a−Service),PaaS(Platform−as−a−Service),IaaS(Infrastructure−as−a−Service)を発展させたモデルである。或いは,クラウド・コンピューティングは,大規模検索システムとASPが一体化し,ネットの向こうにサービスだけが見えるシステムとも見做せる。本論文では,クラウド・コンピューティングの本質的概念をクラウドと記す事にする。クラウド内で企業体等のコミュニティは,互いに連携し,情報を交換・産出する。クラウドはグローバルな世界が前提であり,そこでは検索システムが重要な役割を持つ。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2008−165631号公報
【非特許文献】
【0005】
【非特許文献1】森住哲也,木下宏揚(神奈川大学):“インターネット社会の情報漏えい・情報改ざんを防止するセキュリティモデルの提案”,日本セキュリティ・マネジメント学会誌,1月(2007)
【非特許文献2】森住哲也,木下宏揚,辻井重男:“不確定な情報“covert channel”の直観主義論理による解釈と分析“,技術と社会・倫理研究会(SITE).(2007.7)
【非特許文献3】森住哲也,木下宏揚,辻井重男:“多元社会の意味ネットにおける存在論と認識論の役割(社会システムのためのアクセス制御agentの視点から)”,技術と社会・倫理研究会(SITE).(2008.7)
【非特許文献4】森住哲也,木下宏揚,辻井重男:“セマンティックWebのための統合セキュリティモデル”,css2008,(2008.10)
【発明の概要】
【発明が解決しようとする課題】
【0006】
クラウドは誰にとっても便利なサービスを実現可能な様に見えるが,実態は大規模検索システムを備えたサイトが情報フローを一極管理する仕組みになっている。しかし,各communityの持つ価値はそこに帰属する人間の心的価値が反映されるため,様々である。よって世界中に散在する価値をたった1つのcommunity(例えば大規模検索サイト)が一極集中管理する事は不自然であり危険である。
【0007】
この対応として,検索ロボットの巡回を阻止,或いは特定のIPアドレスのアクセスを拒否する方法がある。例えば,Webサーバのフォルダにアクセス制御機能を仕掛け(.htaccess),更にBasic認証によってアクセス制約する。この方法では大雑把なアクセス制御が可能である。
しかし,クラウドは多くの連携パートナーと行動を共にする場である。この場合,大雑把なアクセス制御では,情報漏えい・改ざんを引き起こす情報内容の伝播経路(covert channel)の生成を防止できない。更に,隠された情報が統計的手法によって推論され情報漏えいする脅威を防止できない。特に検索システムがクラウドで機能すると,covert channelと情報推論による脅威が増大する。しかし現状,対策されていない。
【0008】
本明細書では,クラウドと言う概念を「検索システムと情報産出システムを基盤として,対象世界の関係を述語論理で記述しアドレス空間を関係付けた意味論」と定義する。そして,クラウドの定義から,検索システム・意味産出行為・検索型とプッシュ型の情報伝達手段,の位置付けを明確化する。次に,クラウドと言う意味論のシステムに於いて,アクセス制御・情報フロー制御・推論制御と言う制約を課すシステムを提唱するその目的は,検索システムを伴った連携システムに於いて,自己のcommunityからの情報漏えいと情報改ざんを防止することを課題とする。
【0009】
クラウドへの制約は,個々のcommunity或いは個人のエージェントが実行する。エージェントは人間が持つ価値をcommunityに反映させる事を支援する道具として重要な位置付けにある。エージェントが引き受ける価値基準は,各community,或いは各個人が自己のクラウドに対して定めるセキュリティポリシーであり,その意味論はセキュリティモデルによって記述される。本明細書は,クラウド・検索・制約・エージェントと言うキーワードで示されるシステムを提案することを課題とする。
【課題を解決するための手段】
【0010】
本発明に係るエージェント装置は、インターネットに接続された各企業等(community)が公開する各サイト内又は当該サイトとインターネットとの間に配置され、前記各サイトの情報が、大規模検索システムを介して漏洩する経路(covert channel)を推論し、事前にユーザに警告或いは情報フローを停止させるための情報フィルタを備えたことを特徴とする。
【0011】
更に、本発明に係るエージェントシステムは、インターネットを介して前記各エージェント装置が互いに連携しあってcovert channelの情報フロー制御を行うことを特徴とする。
【発明の効果】
【0012】
本発明に係るエージェント装置とこれを用いたエージェントシステムは、検索システムを伴った連携システムに於いて,自己のcommunityからの情報漏えいと情報改ざんを防止するという利点がある。
【図面の簡単な説明】
【0013】
【図1】大規模検索システムを中心としたクラウドを示す概念図。
【図2】検索とcovert channelの関係を示す概念図
【図3】検索とコピー&ペーストによる情報拡散を示す模式図
【図4】本発明に係るエージェント装置を配置した概念図。(実施例1)
【発明を実施するための形態】
【0014】
本発明の説明に先立って、クラウドの現状(検索のためのクラウド)について説明する。
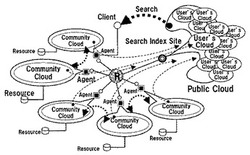
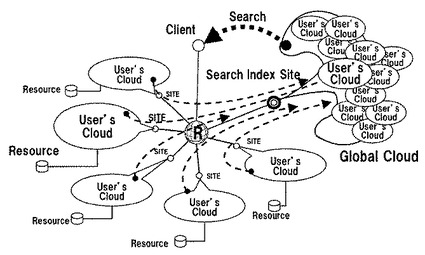
図1は現状の「大規模検索システムを中心としたクラウド」の概念図である。
【0015】
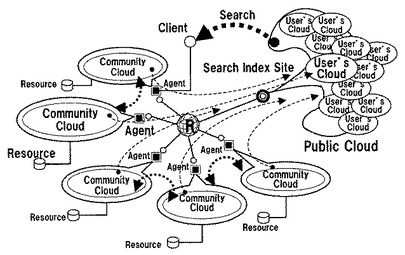
インターネットは中心の球体「R」,ルータ網を中心にサイトが接続される構造である。大規模検索システムはルータ網に接続されるサイトの1つ「検索サイト」である。クラウドは図1で模式的に大規模検索サイトにGlobal Cloudが在る様に表現している。
【0016】
しかし実際はGlobal Cloudに相当するインデックスがインターネットの中に分散配置されている。大規模検索システム以外のサイトでは,ホームページやBlogに,「ここではこんな内容のリソースが在る」と言う情報を公開している。これをUser’s Cloudと呼ぶ事にする。User’s CloudはResource Description Framework(RDF),或いはホームページに書かれているタグで記述される。これらは情報の内容を記述するメタ言語である,とも見做せる。
【0017】
大規模検索システムは,検索ロボットと呼ばれる機能によってUser’s Cloudを収集する。大規模検索システムは,User’s Cloudに於けるメタ言語間の関係を接続する。すると,それが「大規模検索システムの意味ネット」,Global Cloudになる。そしてそれこそがクラウドと呼ばれる本体である。
【0018】
Global Cloudのノードとは例えば「私の」,「ペットは」「その犬です」の中で「私の」と「その犬です」がノードに相当する,そして,「私の」と「その犬です」にはそれぞれアドレス(URL.URI)が割り当てられてインターネットからアクセス可能となる。大規模検索システムはそれらを検索のリソースとして無料で全世界から収集する。検索結果は世界のクライアントに応答される。
【0019】
言い換えれば,大規模検索システムのシステムは,図1に示す様に世界中のサイトが各々独立して持つ「情報と人間の関係地図(Global Cloud)」を大規模検索システムが一手に集める「人工知能的なシステム」である(5)。そして,情報と人間の関係が(公開されたものであるにせよ)大規模検索システムに集中し,大規模検索システムによって価値付けされるシステムである。
【0020】
次に、情報の格納場所とメタ的言語について説明する。
クラウドのシステムに於いて,情報,即ちファイルが格納される場所は,ファイルシステム,データベース(DB)である.一般にデータを複数のユーザが非同期に産出・参照・変更・削除する場合,データベースの原子性(Atomicity)、一貫性(Consistency)、独立性(Isolation)、永続性(Durability),(ACID特性)が満たされる様に設計される。
【0021】
しかし,インターネットの中に散在するデータベース(DB)は一極集中的なDBマネジメントシステムによって統括されているわけではない。クラウドの中で,集中管理のACID特性は,クリティカルな用途に限定される。クラウドではむしろ,従来のDBMS的な発想ではなく,
■世界のどこかでDBが変更されているかもしれない,と言う可能性
■世界の全てのDBの内容が既知であるとは限らない,と言う不確定性,
を許容し,データ同士の関係性に着目するシステムが必要になる。
【0022】
メタ的言語の関係としてのクラウドWebシステムはデータの格納場所としてPCのファイルシステムにただ置くだけ,と言うデータの格納形態を許容する。Webシステムは,ファイルシステムの中にあるファイル名,DBのファイル名前,DBのスキーマの名前,ハイパーテクスト内のタグの名前,をインデックスとし,メタ言語のレベルで関係付け,アドレスを割り振ってアクセス可能とする。クラウドはその関係の集まりである。
【0023】
更に、検索システムとクラウドについて説明する。
大規模検索システムは,クローラと呼ばれる検索ロボットによってインターネットサイトからWebページに掲載されている内容を収集する。次に,検索のためのインデックスが生成される。インデックスは検索を高速化するための原始的なデータベースであり,大規模検索システムの中核的機能である。クローラによって収集されたデータは,高速検索に適したキー値に変換(フィルタリング)され,キー値から1つの結果にアグリゲートされる。以上が大規模検索システムの機能である。
【0024】
インデックスは,キーワード,或いはタグを対象とする。タグの間の関係はRDF,OWLと言うオントロジーで記述される場合もある。本明細書では,インデックスの対象を「メタ的言語」と呼ぶことにする。
【0025】
クラウドの中で通信に使われるツールは,Web,e−メール,BLOG,チャット,SNS等である。それらのツールをクラウドで使う場合,即ち,グローバルなクラウドと言う特性を効果的にビジネスや情報発信の手段にする場合,検索システムはまず始めに操作されるツールとして位置づけられる。現状の検索システムは,オープンなメタ的言語を収集対象とする。検索するというsubject(主体)から観て,クラウドは次の様に位置付けられる。
(1)グローバルなクラウドの中には,自己にとって連携する価値を持つ,他者communityが散在する。
(2)或いは,クラウドの中にはマッシュアップされる事を期待して待機状態にあるサービスが散在する。
例えば,ガジェット(gadget),ウィジェット(Widget)がそれである。
(3)クラウドの中は自己から見れば全て分かるはずのない不確定な存在であり,もしかしたら見つけることができるかもしれない可能性としての存在である。つまり,クラウドは検索する自己の認識に先立つ実在ではない。
【0026】
クラウドの中で検索する主体から観た検索システムを次の様に定義する。
<定義1>検索システム: 検索システムは,クラウドと言うグローバルで不確定なsubjectとobjectの関係の中から,アクセスしたいsubject,或いはobjectを探し出し,アドレス解決して対象にアクセスするツールである。
言い換えれば,検索エンジンはクラウドの中で記述される言語が名指しする対象について,その存在条件の有様に基づいて探し出すツールである。
【0027】
クラウドを,コンピュータシステムのアーキテクチャの視点からではなく,テクストを通じた「コラボレーション」に主眼を置き人間が情報とその意味を産出する共同作業の場として捉える。類似の場としてグループウェアと言う概念があるが,クラウドとグループウェアの差異は,クラウドが「存在のための要素と関係」を意味論の構造と定義し,その下に「心的価値」を置くと言うシステムを前提すると言うところである。
「存在のための要素と関係」を意味論の構造と定義する,と言う部分が「クラウド」の工学的な構造に反映される。即ち「存在」を「行為」によって認知し,獲得した知識を蓄積する,と言う人間の本質的な行為の記述がクラウドである。
【0028】
<定義2>クラウド: クラウドとは,検索システムと情報産出システムを基盤として,対象世界の関係を述語論理で記述しアドレス空間を関係付けた意味論(セマンティック・クラウド)である。
【0029】
言い換えれば,クラウドの本質は「行為(認識)と存在を関連付けた地図(意味ネット)」である。具体的なクラウドは,主語と述語で記述される命題,及びそれらリソースへのアドレスの集まりである。セマンティックWebでリソースを記述するRDF,RDFスキーマは,この様な述語論理の世界を簡単化したもの,と見做せる。(簡単化とは普遍量化子,存在量化子が省略されていると言う事である)。
【0030】
ここで、クラウドのあるべき姿について考える。
クラウドの中で,意味産出活動は情報のCopy & Pasteという操作で実行される。
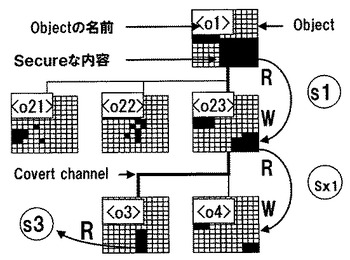
この様な操作に不可欠な制約機能は,アクセス制御・フロー制御(covert channel)・推論制御である。しかし,現状の大規模検索システムのクラウドはこれらの制約が全く考慮されていない。これは社会基盤のシステムとしての欠陥である。Covert channelは次に定義される情報フローである。
【0031】
<定義3>covert channel: 機密情報,個人情報を含むファイルの名前の内容が,細かく分断されて他のファイルにCopy & Pasteされ,情報漏えいする経路をcovert channelと言う。
【0032】
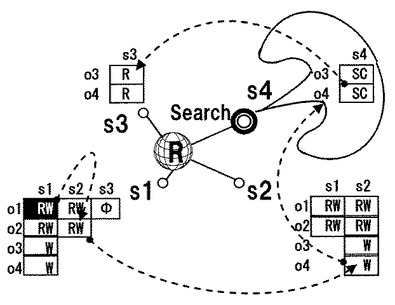
図2は検索とcovert channelの関係を示している。sはsubject,oはobject,RWはCopy & Paste可能,Φはアクセス禁止を表わす。s1はs3にo1へのアクセスを禁止している。s1とs2は連携しobject o1,o2,o3,o4を生成する。図2は,検索サイトs4によってs3がobject o3,o4を探し当てる事から,covert channelが生じる様子を示している。SCはサーチ可能を表す。
【0033】
クラウドの中のcovert channelの特徴は,
(1)各subjectは,他者のアクセス行列を最小限しか知らない事,
(2)検索のためにパミッションの一部を公開する事,
(3)検索サイトは,結果的にobjectにRead権を与える事,
である。クラウドと言うグローバルな意味論の中で,検索機能がobjectのメタ的な名前(インデックス)から情報(object)の内容を引いて来る。検索機能は世界中のユーザが利用するのであるから,パミッションの設定を誤り,covert channelが生じるままにしておけば,オリジナルの隠蔽したい情報の内容,或いはその一部分がCopy & Pasteによって他のobjectにフローし,更に「検索とCopy & Paste」によって世界中に拡散される事態になる(図3)。
【0034】
従って。意味を産出する社会システムとして機能する以上,情報フローに対する制約機能が不可欠である。
【0035】
知識に先立って〈〈物的な実在〉〉を認める事を拒否する事から始め,知覚の相対性を観念にまで拡張する論,流転性を観念にまで拡張する論,或いは,それらの論の知覚に関わる論の一部を許容し,しかしイデア的な形而上学的目標を定める論等,〈〈認識と存在〉〉に関する哲学は様々である。
【0036】
クラウドを社会のツールとして評価する場合,その様な哲学のどれに基づくかと言う偏りがあってはならない。クラウドのシステムは人それぞれ,社会それぞれの哲学やポリシーを各々が反映可能とするべきである。但し,人間が如何に「善く」あるべきか,と言うその点で社会システム全体が統制される必要がある。そのためには,ある一定の制約が必要となる,「善く」あるべき到達目標を各communityに帰属する人間が作成し,それに基づいて,情報フローを制御するツールとしてのシステムが必要である。しかし、現在の検索システムには,言語と論理を基調とする「知が集約するバブル構造」はあっても,「制約装置」が見当たらない。「制約装置」は道具であるから,即ち,現在の検索システムにはその道具を使う人間が不在である。
【0037】
更に,大規模検索システムが指向する社会システムは人工知能的な意味論が想定されている。しかし現システムデザインは,決して世界中の個々の企業,個々のcommunityや個人のためを考えていない。一極集中する組織だけが知識と金を獲得する仕組みになっている。しかもクラウドが言語と記号論理で処理される工学的世界であると言う制約が手伝って,工学的世界を支える人間の心的価値がすっかり排除されている。
【0038】
クラウドは本来,心的価値を反映する道具でなくてはならない。つまり,単なる大規模検索システムのためのクラウドシステムではなく,人間を支援する代理システム(エージェント)がクラウドに組み込まれなければならないのである。論理主義的な記号世界と社会は相容れない面を持つが,その差異を見据え,記号世界と心的価値世界を融合させる方向性を維持し続ける社会装置が必要なのである。エージェントはそのためのツールの1つとして位置付けられる。
【0039】
クラウドをベースとする社会は、オートポイエシス的な社会システムの集まりである事を想定する。
即ち,Community(企業等)の中から見れば境界が明確に定義されているが,communityの外部からは境界が曖昧である様な社会システムである。その様なcommunityの集合体がクラウドの中で機能する。この様な社会システムを実現するためには,個々のクラウド(Community Cloud)と検索システムが収集するPublic Cloudの情報フローを制御する装置,「エージェント」,が必要である(図4)。クラウド制御装置は各communityに置かれる。そしてcommunityの内部情報の漏えいを防止し,外部からの情報改竄を防止する,と言う制約機能によって,communityどうしの連携を維持・管理する。この形態こそが,ダイナミック・コラボレーションを提供する本質的な姿である。
【0040】
クラウドに制約エージェントを組込むために,検索行為と意味産出行為の位置付けをクラウドの枠組みの中で以下に記述する。
検索システムの位置付けとして、
■クラウドは,対象世界を述語論理によって記述した集まりであり,主語と目的語にはアドレス(URL,URI)が割り当てられる。
■インターネットに散在するサイトは,通信する情報に関するクラウドの部分集合を公開している。或いは,公開しないものについてもクラウドとして関係付けられている。
■サイトは,クラウドの一部分を交換する機能を持つ。
■サービスやガジェット等のアプリケーションは,objectとしてクラウドの一部を成す。
■検索システムはクラウドの情報を収集する。
この様なクラウドのシステムに於いて,企業,組織,個人は意味を産出し,社会システムに参加する。
意味産出行為の位置付け:
■クラウドに於いて意味を産出する行為,とは,ファイルの名前を参照し,内容を読み,新しい価値を記述,或いは他のファイルの内容をCopy & Pasteする事によって実行される。
即ち,クラウドは言語と言う記号と論理(意味論)によって意味産出の場をコーティングし,心的価値から引き離して人間に提供する道具である。
検索型とプッシュ型:
■クライアントがクラウドを介して情報,通信相手,或いはサービスを「知る」方法には次の3種類の場合がある。
・能動的に知る場合:検索して知る(ハイパーテクスト構造)。
・受動的に知る場合:プッシュ型Web,或いは,(Web)メールで必要情報を知らされる。
■一度,subject,objectを知る事ができれば,インタラクティブな意思通信が行われる。
クラウドに於けるobjectの分類:
■社会システム同士の関係,個人と社会システムの関係の中で,クラウドの中のobject(情報)をアクセス制御の対象として観ると,objectは次の3つに分類される。Open object,Close object,Federation object。
【0041】
Open,Close,Federationの区別の基準は何か,と言う問題は,communityとsubjectの関係,subjectとsubjectの関係,subjectとobjectの関係によって各communityのセキュリティポリシーによって定められる。この規則を一般化して記述した意味論がセキュリティモデルである。
【0042】
一般に,データベースやファイルシステムのセキュリティは,アクセス制御,情報フロー制御(covert channel制御),推論制御の3つがある。クラウドの制約はこれらを全て扱うセキュリティモデルとして記述される。
【0043】
クラウドにはsubject,object,属性,オペレーションが記述される。セキュリティモデルは,クラウドに於ける情報フロー経路の可能性を分析,或いは情報の推論の可能性を分析し制御する。
【0041】
セキュリティモデルはsubject,objectの持つ社会的属性,及び情報の分類属性(オントロジー等),アクセスのオペレーション(read,write等)との関係を記述するアクセス制御の意味論である。意味論に基づいて推論規則が作成される。
【0044】
セキュリティモデルの構造(要素と関係)は,主体(subject),客体(object),それらの集合体communityと言う要素,及びアクセス制御属性(競合・所有・プライバシー・役割・階層)と言う要素間の関係である。この構造に於いて,covert channelと言う情報フローから生じる情報漏えい・改ざん,及び情報推論による情報漏えいが直観主義論理で記述されるアクセス規則によって分析される。
【0045】
アクセス制御の意味論を記述する論理体系は直観主義論理である。
直観主義論理は可能性を記述する論理である。そのため,情報フローのプロセスを記述し,不確実を記述するアクセス規則として有効である。
直観主義論理の意味論によって情報フロー制御,情報推論制御のアクセス規則が記述される。
また,直観主義論理によってCopy & Paste,或いはデータの推論による不整合な情報フローの阻止とアクセシビリティを両立させる情報フィルタの規則が記述される。
【0046】
セキュリティモデルの意味論が対象とする分析・制御は,covert channelの情報フロー制御,及び情報推論制御である。
【0047】
(a)covert channel制御(情報フロー制御)
情報フロー制御の課題はcovert channelの分析・制御である。情報のCopy & Pasteによって引き起こされるcovert channelのプロセスを直観主義論理で記述する。そしてcovert channelの原因となるsubject,object,アクセス制御属性の組み合わせをアクセス規則で分析する。分析されたcovert channelのプロセスに情報フィルタ規則(直観主義論理)を適用し,情報漏えいを制御する。
【0048】
(b)情報推論制御
情報推論制御の課題は情報の意味の関連性を推論し分析・制御する事である。情報推論制御では,複数のデータによって機密情報が推論され,情報漏えいする可能性を分析する。そして情報推論による情報漏えいの原因となるsubject,object,アクセス制御属性の組み合わせを直観主義論理のアクセス規則で分析し,情報推論を引き起こす組み合わせに情報フィルタ規則を適用し,情報漏えいを制御する。
【0049】
エージェントシステムは,各エージェントが連携し,組織や個人のPCを介して流通する情報資産がCopy & Paste,或いはデータの推論によって情報漏えい・情報改ざんされる事を防止するシステムとする。エージェントは互いにcovert channel分析,或いは情報推論分析に必要最小限の情報をやり取りし,直観主義論理のアクセス制御によってcovert channel,及び情報推論の分析・制御を実行する。
【0050】
各エージェントは世界全体のCommunity Cloud,Public Cloudの部分,即ち情報の関係・ユーザの関係,及び,アクセス規則が関係付けられ情報・ユーザをメタ的言語のデータとして持つ。
エージェントは,クラウドの中のアクセス要求に対して,アクセス規則の制約の下で検索する。そして,相手の情報資産をread,或いはwriteするとどの様な脅威が生じるか,即ちcovert channel,情報推論による情報漏えい,情報改ざんの可能性を推論し,事前にユーザに警告,或いは情報フローをストップさせる情報フィルタを作動させる。
【符号の説明】
【0051】
S1,S2,S3,S4 subject(主体)
o1,o2,o3, object(客体)
【技術分野】
【0001】
本発明は、インターネットに接続されたサイトの情報が、大規模検索システムを介して漏洩することを防止するエージェント装置に関するものである。
【背景技術】
【0002】
インターネットに於けるクラウド,と言う概念を「検索システムと情報産出システムを基盤として,対象世界の関係を述語論理で記述しアドレス空間を関係付けた意味論」と定義する。この様な定義から始めて現状を観ると,ユーザのクラウド情報は一方的に検索インデックスサイトに流入するのみであり,ユーザがクラウドの情報フローを主体的に制約する機能が無い。これは社会システムの視点で観れば欠陥である。
【0003】
クラウド・コンピューティングは,SaaS(Soft−ware−as−a−Service),PaaS(Platform−as−a−Service),IaaS(Infrastructure−as−a−Service)を発展させたモデルである。或いは,クラウド・コンピューティングは,大規模検索システムとASPが一体化し,ネットの向こうにサービスだけが見えるシステムとも見做せる。本論文では,クラウド・コンピューティングの本質的概念をクラウドと記す事にする。クラウド内で企業体等のコミュニティは,互いに連携し,情報を交換・産出する。クラウドはグローバルな世界が前提であり,そこでは検索システムが重要な役割を持つ。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2008−165631号公報
【非特許文献】
【0005】
【非特許文献1】森住哲也,木下宏揚(神奈川大学):“インターネット社会の情報漏えい・情報改ざんを防止するセキュリティモデルの提案”,日本セキュリティ・マネジメント学会誌,1月(2007)
【非特許文献2】森住哲也,木下宏揚,辻井重男:“不確定な情報“covert channel”の直観主義論理による解釈と分析“,技術と社会・倫理研究会(SITE).(2007.7)
【非特許文献3】森住哲也,木下宏揚,辻井重男:“多元社会の意味ネットにおける存在論と認識論の役割(社会システムのためのアクセス制御agentの視点から)”,技術と社会・倫理研究会(SITE).(2008.7)
【非特許文献4】森住哲也,木下宏揚,辻井重男:“セマンティックWebのための統合セキュリティモデル”,css2008,(2008.10)
【発明の概要】
【発明が解決しようとする課題】
【0006】
クラウドは誰にとっても便利なサービスを実現可能な様に見えるが,実態は大規模検索システムを備えたサイトが情報フローを一極管理する仕組みになっている。しかし,各communityの持つ価値はそこに帰属する人間の心的価値が反映されるため,様々である。よって世界中に散在する価値をたった1つのcommunity(例えば大規模検索サイト)が一極集中管理する事は不自然であり危険である。
【0007】
この対応として,検索ロボットの巡回を阻止,或いは特定のIPアドレスのアクセスを拒否する方法がある。例えば,Webサーバのフォルダにアクセス制御機能を仕掛け(.htaccess),更にBasic認証によってアクセス制約する。この方法では大雑把なアクセス制御が可能である。
しかし,クラウドは多くの連携パートナーと行動を共にする場である。この場合,大雑把なアクセス制御では,情報漏えい・改ざんを引き起こす情報内容の伝播経路(covert channel)の生成を防止できない。更に,隠された情報が統計的手法によって推論され情報漏えいする脅威を防止できない。特に検索システムがクラウドで機能すると,covert channelと情報推論による脅威が増大する。しかし現状,対策されていない。
【0008】
本明細書では,クラウドと言う概念を「検索システムと情報産出システムを基盤として,対象世界の関係を述語論理で記述しアドレス空間を関係付けた意味論」と定義する。そして,クラウドの定義から,検索システム・意味産出行為・検索型とプッシュ型の情報伝達手段,の位置付けを明確化する。次に,クラウドと言う意味論のシステムに於いて,アクセス制御・情報フロー制御・推論制御と言う制約を課すシステムを提唱するその目的は,検索システムを伴った連携システムに於いて,自己のcommunityからの情報漏えいと情報改ざんを防止することを課題とする。
【0009】
クラウドへの制約は,個々のcommunity或いは個人のエージェントが実行する。エージェントは人間が持つ価値をcommunityに反映させる事を支援する道具として重要な位置付けにある。エージェントが引き受ける価値基準は,各community,或いは各個人が自己のクラウドに対して定めるセキュリティポリシーであり,その意味論はセキュリティモデルによって記述される。本明細書は,クラウド・検索・制約・エージェントと言うキーワードで示されるシステムを提案することを課題とする。
【課題を解決するための手段】
【0010】
本発明に係るエージェント装置は、インターネットに接続された各企業等(community)が公開する各サイト内又は当該サイトとインターネットとの間に配置され、前記各サイトの情報が、大規模検索システムを介して漏洩する経路(covert channel)を推論し、事前にユーザに警告或いは情報フローを停止させるための情報フィルタを備えたことを特徴とする。
【0011】
更に、本発明に係るエージェントシステムは、インターネットを介して前記各エージェント装置が互いに連携しあってcovert channelの情報フロー制御を行うことを特徴とする。
【発明の効果】
【0012】
本発明に係るエージェント装置とこれを用いたエージェントシステムは、検索システムを伴った連携システムに於いて,自己のcommunityからの情報漏えいと情報改ざんを防止するという利点がある。
【図面の簡単な説明】
【0013】
【図1】大規模検索システムを中心としたクラウドを示す概念図。
【図2】検索とcovert channelの関係を示す概念図
【図3】検索とコピー&ペーストによる情報拡散を示す模式図
【図4】本発明に係るエージェント装置を配置した概念図。(実施例1)
【発明を実施するための形態】
【0014】
本発明の説明に先立って、クラウドの現状(検索のためのクラウド)について説明する。
図1は現状の「大規模検索システムを中心としたクラウド」の概念図である。
【0015】
インターネットは中心の球体「R」,ルータ網を中心にサイトが接続される構造である。大規模検索システムはルータ網に接続されるサイトの1つ「検索サイト」である。クラウドは図1で模式的に大規模検索サイトにGlobal Cloudが在る様に表現している。
【0016】
しかし実際はGlobal Cloudに相当するインデックスがインターネットの中に分散配置されている。大規模検索システム以外のサイトでは,ホームページやBlogに,「ここではこんな内容のリソースが在る」と言う情報を公開している。これをUser’s Cloudと呼ぶ事にする。User’s CloudはResource Description Framework(RDF),或いはホームページに書かれているタグで記述される。これらは情報の内容を記述するメタ言語である,とも見做せる。
【0017】
大規模検索システムは,検索ロボットと呼ばれる機能によってUser’s Cloudを収集する。大規模検索システムは,User’s Cloudに於けるメタ言語間の関係を接続する。すると,それが「大規模検索システムの意味ネット」,Global Cloudになる。そしてそれこそがクラウドと呼ばれる本体である。
【0018】
Global Cloudのノードとは例えば「私の」,「ペットは」「その犬です」の中で「私の」と「その犬です」がノードに相当する,そして,「私の」と「その犬です」にはそれぞれアドレス(URL.URI)が割り当てられてインターネットからアクセス可能となる。大規模検索システムはそれらを検索のリソースとして無料で全世界から収集する。検索結果は世界のクライアントに応答される。
【0019】
言い換えれば,大規模検索システムのシステムは,図1に示す様に世界中のサイトが各々独立して持つ「情報と人間の関係地図(Global Cloud)」を大規模検索システムが一手に集める「人工知能的なシステム」である(5)。そして,情報と人間の関係が(公開されたものであるにせよ)大規模検索システムに集中し,大規模検索システムによって価値付けされるシステムである。
【0020】
次に、情報の格納場所とメタ的言語について説明する。
クラウドのシステムに於いて,情報,即ちファイルが格納される場所は,ファイルシステム,データベース(DB)である.一般にデータを複数のユーザが非同期に産出・参照・変更・削除する場合,データベースの原子性(Atomicity)、一貫性(Consistency)、独立性(Isolation)、永続性(Durability),(ACID特性)が満たされる様に設計される。
【0021】
しかし,インターネットの中に散在するデータベース(DB)は一極集中的なDBマネジメントシステムによって統括されているわけではない。クラウドの中で,集中管理のACID特性は,クリティカルな用途に限定される。クラウドではむしろ,従来のDBMS的な発想ではなく,
■世界のどこかでDBが変更されているかもしれない,と言う可能性
■世界の全てのDBの内容が既知であるとは限らない,と言う不確定性,
を許容し,データ同士の関係性に着目するシステムが必要になる。
【0022】
メタ的言語の関係としてのクラウドWebシステムはデータの格納場所としてPCのファイルシステムにただ置くだけ,と言うデータの格納形態を許容する。Webシステムは,ファイルシステムの中にあるファイル名,DBのファイル名前,DBのスキーマの名前,ハイパーテクスト内のタグの名前,をインデックスとし,メタ言語のレベルで関係付け,アドレスを割り振ってアクセス可能とする。クラウドはその関係の集まりである。
【0023】
更に、検索システムとクラウドについて説明する。
大規模検索システムは,クローラと呼ばれる検索ロボットによってインターネットサイトからWebページに掲載されている内容を収集する。次に,検索のためのインデックスが生成される。インデックスは検索を高速化するための原始的なデータベースであり,大規模検索システムの中核的機能である。クローラによって収集されたデータは,高速検索に適したキー値に変換(フィルタリング)され,キー値から1つの結果にアグリゲートされる。以上が大規模検索システムの機能である。
【0024】
インデックスは,キーワード,或いはタグを対象とする。タグの間の関係はRDF,OWLと言うオントロジーで記述される場合もある。本明細書では,インデックスの対象を「メタ的言語」と呼ぶことにする。
【0025】
クラウドの中で通信に使われるツールは,Web,e−メール,BLOG,チャット,SNS等である。それらのツールをクラウドで使う場合,即ち,グローバルなクラウドと言う特性を効果的にビジネスや情報発信の手段にする場合,検索システムはまず始めに操作されるツールとして位置づけられる。現状の検索システムは,オープンなメタ的言語を収集対象とする。検索するというsubject(主体)から観て,クラウドは次の様に位置付けられる。
(1)グローバルなクラウドの中には,自己にとって連携する価値を持つ,他者communityが散在する。
(2)或いは,クラウドの中にはマッシュアップされる事を期待して待機状態にあるサービスが散在する。
例えば,ガジェット(gadget),ウィジェット(Widget)がそれである。
(3)クラウドの中は自己から見れば全て分かるはずのない不確定な存在であり,もしかしたら見つけることができるかもしれない可能性としての存在である。つまり,クラウドは検索する自己の認識に先立つ実在ではない。
【0026】
クラウドの中で検索する主体から観た検索システムを次の様に定義する。
<定義1>検索システム: 検索システムは,クラウドと言うグローバルで不確定なsubjectとobjectの関係の中から,アクセスしたいsubject,或いはobjectを探し出し,アドレス解決して対象にアクセスするツールである。
言い換えれば,検索エンジンはクラウドの中で記述される言語が名指しする対象について,その存在条件の有様に基づいて探し出すツールである。
【0027】
クラウドを,コンピュータシステムのアーキテクチャの視点からではなく,テクストを通じた「コラボレーション」に主眼を置き人間が情報とその意味を産出する共同作業の場として捉える。類似の場としてグループウェアと言う概念があるが,クラウドとグループウェアの差異は,クラウドが「存在のための要素と関係」を意味論の構造と定義し,その下に「心的価値」を置くと言うシステムを前提すると言うところである。
「存在のための要素と関係」を意味論の構造と定義する,と言う部分が「クラウド」の工学的な構造に反映される。即ち「存在」を「行為」によって認知し,獲得した知識を蓄積する,と言う人間の本質的な行為の記述がクラウドである。
【0028】
<定義2>クラウド: クラウドとは,検索システムと情報産出システムを基盤として,対象世界の関係を述語論理で記述しアドレス空間を関係付けた意味論(セマンティック・クラウド)である。
【0029】
言い換えれば,クラウドの本質は「行為(認識)と存在を関連付けた地図(意味ネット)」である。具体的なクラウドは,主語と述語で記述される命題,及びそれらリソースへのアドレスの集まりである。セマンティックWebでリソースを記述するRDF,RDFスキーマは,この様な述語論理の世界を簡単化したもの,と見做せる。(簡単化とは普遍量化子,存在量化子が省略されていると言う事である)。
【0030】
ここで、クラウドのあるべき姿について考える。
クラウドの中で,意味産出活動は情報のCopy & Pasteという操作で実行される。
この様な操作に不可欠な制約機能は,アクセス制御・フロー制御(covert channel)・推論制御である。しかし,現状の大規模検索システムのクラウドはこれらの制約が全く考慮されていない。これは社会基盤のシステムとしての欠陥である。Covert channelは次に定義される情報フローである。
【0031】
<定義3>covert channel: 機密情報,個人情報を含むファイルの名前の内容が,細かく分断されて他のファイルにCopy & Pasteされ,情報漏えいする経路をcovert channelと言う。
【0032】
図2は検索とcovert channelの関係を示している。sはsubject,oはobject,RWはCopy & Paste可能,Φはアクセス禁止を表わす。s1はs3にo1へのアクセスを禁止している。s1とs2は連携しobject o1,o2,o3,o4を生成する。図2は,検索サイトs4によってs3がobject o3,o4を探し当てる事から,covert channelが生じる様子を示している。SCはサーチ可能を表す。
【0033】
クラウドの中のcovert channelの特徴は,
(1)各subjectは,他者のアクセス行列を最小限しか知らない事,
(2)検索のためにパミッションの一部を公開する事,
(3)検索サイトは,結果的にobjectにRead権を与える事,
である。クラウドと言うグローバルな意味論の中で,検索機能がobjectのメタ的な名前(インデックス)から情報(object)の内容を引いて来る。検索機能は世界中のユーザが利用するのであるから,パミッションの設定を誤り,covert channelが生じるままにしておけば,オリジナルの隠蔽したい情報の内容,或いはその一部分がCopy & Pasteによって他のobjectにフローし,更に「検索とCopy & Paste」によって世界中に拡散される事態になる(図3)。
【0034】
従って。意味を産出する社会システムとして機能する以上,情報フローに対する制約機能が不可欠である。
【0035】
知識に先立って〈〈物的な実在〉〉を認める事を拒否する事から始め,知覚の相対性を観念にまで拡張する論,流転性を観念にまで拡張する論,或いは,それらの論の知覚に関わる論の一部を許容し,しかしイデア的な形而上学的目標を定める論等,〈〈認識と存在〉〉に関する哲学は様々である。
【0036】
クラウドを社会のツールとして評価する場合,その様な哲学のどれに基づくかと言う偏りがあってはならない。クラウドのシステムは人それぞれ,社会それぞれの哲学やポリシーを各々が反映可能とするべきである。但し,人間が如何に「善く」あるべきか,と言うその点で社会システム全体が統制される必要がある。そのためには,ある一定の制約が必要となる,「善く」あるべき到達目標を各communityに帰属する人間が作成し,それに基づいて,情報フローを制御するツールとしてのシステムが必要である。しかし、現在の検索システムには,言語と論理を基調とする「知が集約するバブル構造」はあっても,「制約装置」が見当たらない。「制約装置」は道具であるから,即ち,現在の検索システムにはその道具を使う人間が不在である。
【0037】
更に,大規模検索システムが指向する社会システムは人工知能的な意味論が想定されている。しかし現システムデザインは,決して世界中の個々の企業,個々のcommunityや個人のためを考えていない。一極集中する組織だけが知識と金を獲得する仕組みになっている。しかもクラウドが言語と記号論理で処理される工学的世界であると言う制約が手伝って,工学的世界を支える人間の心的価値がすっかり排除されている。
【0038】
クラウドは本来,心的価値を反映する道具でなくてはならない。つまり,単なる大規模検索システムのためのクラウドシステムではなく,人間を支援する代理システム(エージェント)がクラウドに組み込まれなければならないのである。論理主義的な記号世界と社会は相容れない面を持つが,その差異を見据え,記号世界と心的価値世界を融合させる方向性を維持し続ける社会装置が必要なのである。エージェントはそのためのツールの1つとして位置付けられる。
【0039】
クラウドをベースとする社会は、オートポイエシス的な社会システムの集まりである事を想定する。
即ち,Community(企業等)の中から見れば境界が明確に定義されているが,communityの外部からは境界が曖昧である様な社会システムである。その様なcommunityの集合体がクラウドの中で機能する。この様な社会システムを実現するためには,個々のクラウド(Community Cloud)と検索システムが収集するPublic Cloudの情報フローを制御する装置,「エージェント」,が必要である(図4)。クラウド制御装置は各communityに置かれる。そしてcommunityの内部情報の漏えいを防止し,外部からの情報改竄を防止する,と言う制約機能によって,communityどうしの連携を維持・管理する。この形態こそが,ダイナミック・コラボレーションを提供する本質的な姿である。
【0040】
クラウドに制約エージェントを組込むために,検索行為と意味産出行為の位置付けをクラウドの枠組みの中で以下に記述する。
検索システムの位置付けとして、
■クラウドは,対象世界を述語論理によって記述した集まりであり,主語と目的語にはアドレス(URL,URI)が割り当てられる。
■インターネットに散在するサイトは,通信する情報に関するクラウドの部分集合を公開している。或いは,公開しないものについてもクラウドとして関係付けられている。
■サイトは,クラウドの一部分を交換する機能を持つ。
■サービスやガジェット等のアプリケーションは,objectとしてクラウドの一部を成す。
■検索システムはクラウドの情報を収集する。
この様なクラウドのシステムに於いて,企業,組織,個人は意味を産出し,社会システムに参加する。
意味産出行為の位置付け:
■クラウドに於いて意味を産出する行為,とは,ファイルの名前を参照し,内容を読み,新しい価値を記述,或いは他のファイルの内容をCopy & Pasteする事によって実行される。
即ち,クラウドは言語と言う記号と論理(意味論)によって意味産出の場をコーティングし,心的価値から引き離して人間に提供する道具である。
検索型とプッシュ型:
■クライアントがクラウドを介して情報,通信相手,或いはサービスを「知る」方法には次の3種類の場合がある。
・能動的に知る場合:検索して知る(ハイパーテクスト構造)。
・受動的に知る場合:プッシュ型Web,或いは,(Web)メールで必要情報を知らされる。
■一度,subject,objectを知る事ができれば,インタラクティブな意思通信が行われる。
クラウドに於けるobjectの分類:
■社会システム同士の関係,個人と社会システムの関係の中で,クラウドの中のobject(情報)をアクセス制御の対象として観ると,objectは次の3つに分類される。Open object,Close object,Federation object。
【0041】
Open,Close,Federationの区別の基準は何か,と言う問題は,communityとsubjectの関係,subjectとsubjectの関係,subjectとobjectの関係によって各communityのセキュリティポリシーによって定められる。この規則を一般化して記述した意味論がセキュリティモデルである。
【0042】
一般に,データベースやファイルシステムのセキュリティは,アクセス制御,情報フロー制御(covert channel制御),推論制御の3つがある。クラウドの制約はこれらを全て扱うセキュリティモデルとして記述される。
【0043】
クラウドにはsubject,object,属性,オペレーションが記述される。セキュリティモデルは,クラウドに於ける情報フロー経路の可能性を分析,或いは情報の推論の可能性を分析し制御する。
【0041】
セキュリティモデルはsubject,objectの持つ社会的属性,及び情報の分類属性(オントロジー等),アクセスのオペレーション(read,write等)との関係を記述するアクセス制御の意味論である。意味論に基づいて推論規則が作成される。
【0044】
セキュリティモデルの構造(要素と関係)は,主体(subject),客体(object),それらの集合体communityと言う要素,及びアクセス制御属性(競合・所有・プライバシー・役割・階層)と言う要素間の関係である。この構造に於いて,covert channelと言う情報フローから生じる情報漏えい・改ざん,及び情報推論による情報漏えいが直観主義論理で記述されるアクセス規則によって分析される。
【0045】
アクセス制御の意味論を記述する論理体系は直観主義論理である。
直観主義論理は可能性を記述する論理である。そのため,情報フローのプロセスを記述し,不確実を記述するアクセス規則として有効である。
直観主義論理の意味論によって情報フロー制御,情報推論制御のアクセス規則が記述される。
また,直観主義論理によってCopy & Paste,或いはデータの推論による不整合な情報フローの阻止とアクセシビリティを両立させる情報フィルタの規則が記述される。
【0046】
セキュリティモデルの意味論が対象とする分析・制御は,covert channelの情報フロー制御,及び情報推論制御である。
【0047】
(a)covert channel制御(情報フロー制御)
情報フロー制御の課題はcovert channelの分析・制御である。情報のCopy & Pasteによって引き起こされるcovert channelのプロセスを直観主義論理で記述する。そしてcovert channelの原因となるsubject,object,アクセス制御属性の組み合わせをアクセス規則で分析する。分析されたcovert channelのプロセスに情報フィルタ規則(直観主義論理)を適用し,情報漏えいを制御する。
【0048】
(b)情報推論制御
情報推論制御の課題は情報の意味の関連性を推論し分析・制御する事である。情報推論制御では,複数のデータによって機密情報が推論され,情報漏えいする可能性を分析する。そして情報推論による情報漏えいの原因となるsubject,object,アクセス制御属性の組み合わせを直観主義論理のアクセス規則で分析し,情報推論を引き起こす組み合わせに情報フィルタ規則を適用し,情報漏えいを制御する。
【0049】
エージェントシステムは,各エージェントが連携し,組織や個人のPCを介して流通する情報資産がCopy & Paste,或いはデータの推論によって情報漏えい・情報改ざんされる事を防止するシステムとする。エージェントは互いにcovert channel分析,或いは情報推論分析に必要最小限の情報をやり取りし,直観主義論理のアクセス制御によってcovert channel,及び情報推論の分析・制御を実行する。
【0050】
各エージェントは世界全体のCommunity Cloud,Public Cloudの部分,即ち情報の関係・ユーザの関係,及び,アクセス規則が関係付けられ情報・ユーザをメタ的言語のデータとして持つ。
エージェントは,クラウドの中のアクセス要求に対して,アクセス規則の制約の下で検索する。そして,相手の情報資産をread,或いはwriteするとどの様な脅威が生じるか,即ちcovert channel,情報推論による情報漏えい,情報改ざんの可能性を推論し,事前にユーザに警告,或いは情報フローをストップさせる情報フィルタを作動させる。
【符号の説明】
【0051】
S1,S2,S3,S4 subject(主体)
o1,o2,o3, object(客体)
【特許請求の範囲】
【請求項1】
各企業等(community)がインターネットに公開するサイト内又は当該サイトとインターネットとの間に配置され、前記サイトの情報が、大規模検索システムを介して漏洩する経路(covert channel)を推論し、事前にユーザに警告或いは情報フローを停止させるための情報フィルタを備えたことを特徴とするエージェント装置。
【請求項2】
請求項1に記載の各エージェント装置が、インターネットを介して互いに連携しあってcovert channelの情報フロー制御を行うことを特徴とするエージェントシステム。
【請求項1】
各企業等(community)がインターネットに公開するサイト内又は当該サイトとインターネットとの間に配置され、前記サイトの情報が、大規模検索システムを介して漏洩する経路(covert channel)を推論し、事前にユーザに警告或いは情報フローを停止させるための情報フィルタを備えたことを特徴とするエージェント装置。
【請求項2】
請求項1に記載の各エージェント装置が、インターネットを介して互いに連携しあってcovert channelの情報フロー制御を行うことを特徴とするエージェントシステム。
【図1】


【図2】
【図3】
【図4】
【図2】
【図3】
【図4】
【公開番号】特開2010−205239(P2010−205239A)
【公開日】平成22年9月16日(2010.9.16)
【国際特許分類】
【出願番号】特願2009−72768(P2009−72768)
【出願日】平成21年3月2日(2009.3.2)
【出願人】(305027456)ネッツエスアイ東洋株式会社 (200)
【Fターム(参考)】
【公開日】平成22年9月16日(2010.9.16)
【国際特許分類】
【出願日】平成21年3月2日(2009.3.2)
【出願人】(305027456)ネッツエスアイ東洋株式会社 (200)
【Fターム(参考)】
[ Back to top ]