
クリティカルパスに基づく解析のための性能モニタリングアーキテクチャ強化
【課題】マイクロアーキテクチャの性能をモニタリングし、そのモニタリングされた性能に基づいてマイクロアーキテクチャをチューニングする方法及び装置を提供する。
【解決手段】シミュレーション、解析上の推論、リタイアメントプッシュアウト測定、全体実行時間、およびインスタンス当たりのイベントコストを決定する他の方法によって性能がモニタリングされる。インスタンス当たりのイベントコストに基づき、マイクロアーキテクチャおよび/または実行ソフトウェアは、性能を強化すべくチューニングされる。
【解決手段】シミュレーション、解析上の推論、リタイアメントプッシュアウト測定、全体実行時間、およびインスタンス当たりのイベントコストを決定する他の方法によって性能がモニタリングされる。インスタンス当たりのイベントコストに基づき、マイクロアーキテクチャおよび/または実行ソフトウェアは、性能を強化すべくチューニングされる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、コンピュータシステムの分野に関し、詳しくはマイクロアーキテクチャの性能モニタリングおよびチューニングに関する。
【背景技術】
【0002】
性能解析は、マイクロアーキテクチャ設計を特徴づけ、デバッグし、およびチューニングしたり、ハードウェアおよびソフトウェアの性能上のボトルネックを発見および修復したり、回避可能な性能上の問題を突き止めるための基礎である。コンピュータ産業の発展に従い、マイクロアーキテクチャの性能を解析し、その解析に基づいてマイクロアーキテクチャを変更する能力はより複雑かつ重要になる。
【0003】
可能な限り最適のプラットフォームを与えることに加え、そのプラットフォームで最適に実行するべくアプリケーションをチューニングすることによって最適な性能が達成されることが多い。性能上のボトルネックを特定し、より適したコード生成を介してそれをいかに回避するかを解明すること、および、性能改善を確認すること、への投資には意味がある。その解析では、性能モニタが重要な要素となる。性能モニタリングは、プリシリコンシミュレーションよりも多くの量の性能データを与えるが、ストア・フォワーディングのような領域での性能を改善するべくマイクロアーキテクチャ設計を微調整するために使用されている。性能上の問題がどれくらいの頻度で生じるか、および、マイクロアーキテクチャのその部分を改善した場合にどの程度の利益が得られるかだけでも知ることは、シリコンチェンジ(silicon changes)を動機付ける上で必須である。
【0004】
過去においては、シリアル性能上のボトルネックを追跡することは、パラレルなアウトオブオーダ実行中のパフォーマンス制限を検出することよりもはるかに容易であったので、シリアル実行マシンの性能モニタリングは、比較的直接的であった。典型的な性能解析は、ワークロードのCPI(命令当たりのクロック数(clocks per instruction))を、以下のようにして個々のコンポーネントに分解する。1)ハードウェアの性能上のイベントをカウントし、2)プログラムのクリティカルパスへの各イベントの相対的寄与を評価し、3)ワークロードの性能上のボトルネックに寄与する個々のコンポーネントを結合して全体的な内訳(breakdown)にする。シングルマイクロアーキテクチャのためのインスタンス当たりのコストを評価することは、多くのストールコストのうち有意な部分をカバーするのに十分なスーパースカラーおよびパイプラインパラレリズムが存在する、アウトオブオーダで高度に投機的なマシンにとっては困難である。今日まで、その場しのぎの方法が使用されてインスタンス当たりのイベントのインパクトが評価されてきたが、その評価の正確さおよびバリエーションは未知なことが多かった。
【0005】
例えば、図1はシングルイシューマシンにおける、命令101−107のフェッチ、実行、およびリタイアメントの例を示す。命令102は、分岐予測ミス110を有する。分岐予測ミス110は、命令103のフェッチを遅延させて、命令102のかなり後に命令103のリタイアメントをプッシュアウトする(pushes out)。命令104は、第1レベルキャッシュミス120を有する。第1レベルキャッシュミス120は、命令105のリタイアメントをプッシュアウトする。しかし、命令104のリタイアメントプッシュアウト125は、命令105の第2レベルキャッシュミス130によって矮小化される。命令105の第2レベルキャッシュミス130は非常に長いレイテンシを有するので、命令106の分岐予測ミス135はそのリタイア面と時間になんらインパクトを与えることがない。図1に列挙されるように、リタイアメントプッシュアウトを測定することには、シングルイシューマシンにおいてさえ入り組んだ複雑性がある。ましてや、アウトオブオーダの高度に投機的なパラレル実行が可能なプロセッサにおける包括的な性能モニタリングであればなおさらである。
【発明の開示】
【0006】
以下の記載において、本発明の完全な理解を与えるべく具体的なアーキテクチャ、そのアーキテクチャ内のフィーチャ、チューニングメカニズム、およびシステム設定のような多数の具体的な詳細が述べられる。しかし、本発明を実施するべくこれらの具体的な詳細を採用しなければならないわけではないことは、当業者にとって明白であろう。他の例として、周知のロジック設計、ソフトウェアコンパイラ、ソフトウェア再設定技術、およびプロセッサをデフィーチャする技術(processor defeaturing techniques)のような周知のコンポーネントまたは方法は、本発明を不必要にあいまいにすることを回避すべく詳細には記載されない。
【0007】
本発明は例示として示され、添付図面の図によって限定されることを意図しない。
【発明を実施するための最良の形態】
【0008】
性能モニタリング
【0009】
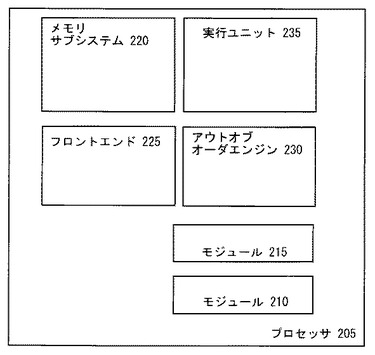
図2は、性能モニタリングモジュール210およびチューニングモジュール215を有するプロセッサ205の実施例を示す。プロセッサ205は、コードの実行および/またはデータのオペレーションのための任意の要素である。具体例として、プロセッサ205は、パラレル実行を行うことができる。他の実施例では、プロセッサ205は、アウトオブオーダ実行を行うことができる。プロセッサ205はまた、他の既知の処理ユニットおよび方法と同様に、分岐予測および投機的実行、を行うこともできる。
【0010】
プロセッサ250に示される他の処理ユニットは、メモリサブシステム220、フロントエンド225、アウトオブオーダエンジン230、および実行ユニット235を含む。これらのモジュール、ユニット、または機能ブロックの各々は、プロセッサ205のための前述の機能性を与える。実施例において、メモリサブシステムは、外部デバイスとインターフェイス接続される高レベルキャッシュおよびバスインターフェイスを含む。フロントエンド225は、予測ロジックおよびフェッチロジックを含む。アウトオブオーダエンジン230は、命令をリオーダするスケジューリングロジックを含む。実行ユニット235は、シリアルおよびパラレルで実行する浮動小数点および整数実行ユニットを含む。
【0011】
モジュール210およびモジュール215は、ハードウェア、ソフトウェア、ファームウェア、またはこれらの任意の組み合わせで実装される。一般には、モジュールの境界は様々であり、複数の機能は一緒に、および、異なる実施例では別々に実装される。一例では、性能モニタリングおよびチューニングは、シングルモジュールに実装される。図2に示す実施例では、モジュール210とモジュール215とは別々に示される。しかし、モジュール210とモジュール215とは、他の図示のユニット220−235によって実行されるソフトウェアである。
【0012】
モジュール210は、プロセッサ205の性能をモニタする。一実施例では、性能モニタリングは、クリティカルパスに対するインスタンス当たりのイベントコストを決定および/または導出することによって行われる。クリティカルパスは、任意の発生、タスクまたはイベントのレイテンシが増加すると仮定した場合に、オペレーション、命令、命令グループ、またはプログラムを完了するためにかかる時間に寄与するであろう発生、タスク、および/またはイベントのシーケンスの任意パスを含む。グラフでは、クリティカルパスは、所定マシン上で実行されるプログラム中のデータ、制御、およびリソースの依存性のグラフを通るパスとして言及されることがある。その所定マシンに対しては、その依存性のグラフにおける任意の円弧(arc)が長引いてそのプログラムの実行レイテンシ増加がもたらされる。
【0013】
したがって、換言すれば、イベント/フィーチャのクリティカルパスへのインスタンス当たりの寄与は、タスクまたはプログラムの完了に見られるレイテンシに対する第2レベルキャッシュミスのようなイベントの寄与、または、分岐予測ユニットのようなマイクロアーキテクチャフィーチャである。実際、イベントまたはフィーチャの寄与は、アプリケーションの領域にわたり著しく変化する。したがって、イベントまたはマイクロアーキテクチャフィーチャのコスト/寄与は、オペレーティングシステムのような所定のユーザレベルアプリケーションに対して決定される。モジュール215が、図3を参照して詳細に説明される。
【0014】
イベントは、レイテンシを導入するプロセッサの任意のオペレーション、発生、またはアクションを含む。マイクロプロセッサにおける一般的なイベントのいくつかの例は以下を含む。低レベルキャッシュミス、セカンダリキャッシュミス、高レベルキャッシュミス、キャッシュアクセス、キャッシュスヌープ、分岐予測ミス、メモリからのフェッチ、リタイアメントにおけるロック、ハードウェアプリフェッチ、フロントエンドストア、キャッシュスプリット、ストア・フォワーディング問題、リソースのストール、ライトバック、命令デコード、アドレス変換、変換バッファへのアクセス、整数演算実行、浮動小数点演算実行、レジスタのリネーミング、命令のスケジューリング、レジスタのリード、および、レジスタのライト。
【0015】
マイクロアーキテクチャフィーチャは、ロジック、機能ユニット、リソース、または前記イベントに関連するその他のフィーチャを含む。マイクロアーキテクチャフィーチャの例は以下を含む。キャッシュ、命令キャッシュ、データキャッシュ、分岐ターゲットアレイ、仮想メモリテーブル、レジスタファイル、変換テーブル、ルックアサイドバッファ、分岐予測ユニット、ハードウェアプリフェッチャ、実行ユニット、アウトオブオーダエンジン、アロケータユニット、レジスタリネーミングロジック、バスインターフェイスユニット、フェッチユニット、デコードユニット、アーキテクチャ状態レジスタ、実行ユニット、浮動小数点実行ユニット、整数実行ユニット、ALU、およびマイクロプロセッサの他の一般的なフィーチャ。
【0016】
命令当たりのクロック数
【0017】
性能の主要なインジケータの一つは、命令当たりのクロック数(clocks per instruction(CPI))である。CPIは、いくつかのコンポーネントにブレークダウンすることができる。これにより、いくつかのファクタ/イベントの各々に帰属するサイクルの一部(fraction)の指標が決定される。上述のように、これらのファクタは、キャッシュをミスしてDRAMに進むことにより導入されるレイテンシ、分岐予測ミスのペナルティ、リタイアメントメカニズムが招くパイプライン遅延、すなわちロック等に対するイベントを含む。ファクタの他の例は、ミスされたキャッシュ、分岐予測に使用される分岐ターゲットアレイにおけるミス、DRAMに進むためのバスインターフェイスの使用、および、ロックを実装するための状態マシンの使用のような、イベントに関連するマイクロアーキテクチャフィーチャを含む。
【0018】
典型的には、ファクタの発生数にサイクルにおけるその影響を乗じ、次にサイクルのトータル数で割ることによって、ファクタの相対的寄与が決定される。かかる内訳が、スカラーで非パイプラインの非投機的マシンに対してはプリサイスに提示される一方で、スーパースカラーでパイプラインのアウトオブオーダかつ高投機的マシンを説明するプリサイスサイクルを与えることは難しい。よくあることだが、かかるマシンによって利用されるワークロードには十分なパラレリズムが存在するので、そのマシンはストールの少なくとも一部を有用なワークを行うことによって隠すことができる。その結果、そのストールの局所的なインパクトは、プログラムのクリティカルパス全体にとっては、インスタンス当たりの理論的コストと比べてかなり小さな寄与となる。驚くべきことに、局所的なストールは、その局所的な遅延がより最適な全体的スケジュールをもたらす場合に、プログラムの全体実行時間に対してプラスの影響さえ有する。
【0019】
インスタンス当たりの寄与/コストの解析
【0020】
インスタンス当たりのイベントコスト、すなわちイベントのまたはマイクロアーキテクチャフィーチャのクリティカルパスへの寄与は、多くの異なる方法で決定できる。その方法は以下を含む。(1)解析上の評価、(2)性能モニタからのデュレーションカウント、(3)ハードウェア性能モニタによりおよびシミュレータにより測定されるようなリタイアメントプッシュアウト、ならびに(4)マイクロベンチマーク、シミュレーション、およびシリコンデフィーチャによって測定されるようなイベント数の変化に起因する全体実行時間の変化。
【0021】
解析上の評価
【0022】
第1実施例において、インスタンス当たりのコスト、すなわち、フィーチャの寄与は理論的に決定される。論理的な寄与は、アーキテクチャのシミュレーションと同様、イベントのフィーチャまたは発生のオペレーションについての実験に基づく知見も含む。これは、マイクロアーキテクチャの理解、およびリタイアメントへのというよりもむしろ実行段階へのフォーカスから導出されることが多い。解析上の評価の最も簡単な形態は、局所的なストールコストに特徴があり、他のオペレーション(実行または命令の段階)をパラレルで実行することから得られるパラレリズムによってそれらのストールがどれほどカバーされるかとは独立している。
【0023】
デュレーションカウント
【0024】
別の実施例において、性能モニタは、デュレーションカウントを介してフィーチャの寄与を決定する。いくつかの性能モニタイベントが定義されて注目事項が発生する各サイクルがカウントされる。これにより、インスタンスカウントの代わりにデュレーションカウントが得られる。かかる2つのカウントは、状態マシンがアクティブなサイクルである。例えばページウォークハンドラ、ロック状態マシン、および、1つ以上のエントリがキュー、例えば著しいキャッシュミスのあるバスのキュー、に存在するサイクルである。これらの例は、実行段階の時間を測定し、実行がロック状態マシンに対する場合となるリタイアメントにない限りは、必ずしもリタイアメントプッシュアウトを測定するわけではない。この特性形態は、ベンチマーク特有のコストを評価する分野において有用である。
【0025】
リタイアメントプッシュアウト
【0026】
リタイアメントプッシュアウトは、局所的なスケールでイベントおよびフィーチャの寄与を決定する上で、その測定をグローバルなスケールまで外挿することと同様に有用である。リタイアメントプッシュアウトは、一つのオペレーションが予測された時刻において、または予測されたサイクル中にリタイアしないときに生じる。例えば、命令(またはマイクロオペレーション)のシーケンシャルなペアに対して、第2命令が第1命令後(通常は同じサイクル内で、または、リタイアメントリソースが制約を受けている場合は次のサイクル内で)直ちにリタイアしない場合、リタイアメントはプッシュアウトされたとみなされる。リタイアメントプッシュアウトにより、後方「領域的」な(純粋に局所的というわけではない)、クリティカルパスへの寄与測定が与えられる。後方とは、リタイアメントプッシュアウトが、時間上の所定ポイントより前にリタイアした全てのオペレーションのオーバラップを認識しているというという意味である。50の局所的ストールコストを有する2つのオペレーションが別々に1サイクルを開始すると、2番目に対するリタイアメントプッシュアウトは、50ではなく、せいぜい1である。
【0027】
リタイアメントプッシュアウトの実測定は、プッシュアウトが測定され始める時に応じて様々である。一例では、その測定はイベントの発生による。別例では、プッシュアウトの測定は、命令またはオペレーションがリタイアしたはずの時からとなる。さらなる別例では、リタイアメントプッシュアウトは、リタイアメントプッシュアウトの発生数をカウンティングすることによってのみ測定される。これは、シーケンシャルなオペレーションのリタイアメントプッシュアウトを参照して以下に説明される。リタイアメントプッシュアウトによってインスタンス当たりの寄与を測定/導出するには様々な方法がある。例えば、リタイアメントプッシュアウトの2つの方法、すなわちシーケンシャルオペレーションとタギング、を説明する。
【0028】
両メカニズムは、ユーザが、異なるしきい値で繰り返し実行することによってリタイアメントプッシュアウト分布のヒストグラムを生成することを可能にする。シーケンシャルオペレーションのリタイアメントプッシュアウトは、プログラム内の全てのオペレーションに対するリタイアメント遅延のプロファイルを生成することができる。さらに、リタイアメントプッシュアウトのタギングは、分岐予測ミスの個別の寄与のような個々の/所定のイベントに対する遅延分布のプロファイルを生成することができる。
【0029】
シーケンシャルオペレーションのリタイアメントプッシュアウト、すなわちスローリタイアメント認定
【0030】
このメカニズムに対しては、シーケンシャルオペレーションのインスタンスは、リタイアしている連続オペレーション間、すなわちマイクロオペレーション間の遅延が、ユーザが特定したしきい値よりも大きい場合にカウントされる。その結果、連続オペレーションに対するプッシュアウトが測定され、所定のしきい値を越えるレイテンシを有するプッシュアウトの数が報告される。
【0031】
一実施例では、スローリタイアメント認定は、専用カウンタを使用して測定される。専用カウンタは、スレッドからの命令がリタイアしていないサイクルをカウントする。カウンタは、第1オペレーションがリタイアするとすぐにユーザ定義値に初期化される。設計に応じて、カウンタが所定の第2命令に対してアンダーフローまたはオーバフローする場合、その第2命令は、スローリタイアメント、すなわちリタイアメントプッシュアウトを有すると見なされる。
【0032】
ダウンカウンタを使用する設計の例として、25サイクルにわたりいくつの命令リタイアメントがプッシュアウトされたのかをユーザがカウントしたい場合、カウンタは所定値25に設定される。アンダーフローの場合、第2命令のリタイアメントはプッシュアウトとみなされる。アップカウンタの実施例では、ユーザ定義値は、0または負の数に初期化される。例えば、カウンタが0に初期化されて、しきい値25までカウントする。カウンタがオーバフローする場合は、リタイアメントプッシュアウトが存在する。別例では、アップカウンタが−25に初期化されて、0までカウントする。これは、カウンタのオーバフローを決定するときにロジック比較を単純化する。
【0033】
リタイアメントプッシュアウトタギング、すなわちリタイアメントプッシュアウトプロファイリング
【0034】
スローリタイアメント認定と非常に類似して、リタイアメントプッシュアウトタギングは、所定しきい値よりも上のリタイアメントプッシュアウトを有していた命令またはオペレーションを認定する。しかし、このメカニズムでは、スローリタイアメント認定は、注目する命令またはオペレーションについての多くの認定の一つに過ぎない。他の認定は、第2レベルキャッシュミスのような、その命令またはオペレーションに対して発生した所定イベントを含む。これらの認定は論理的に結合され、命令またはオペレーションが、特定の認定基準を満たす場合にカウントされる。なお、認定子/イベントは論理的にオペレートされるかまたは結合され、特定のマシン状態レジスタでユーザ定義が可能である。
【0035】
別の実施例では、オペレーションは、特定の単数または複数のイベントの実行に基づいてタギングされる。上述のように、パラレル実行は、所定イベントの実際の影響を隠す。具体例として、第3レベルキャッシュに対するミスは、第2レベルキャッシュに対するミスの影響を矮小化する。結果的に第2レベルキャッシュに対するミスとなるが第3レベルキャッシュをミスしない場合は、第2レベルキャッシュに対するミスの影響を隔離するべく所定のオペレーションがタギングされる。つまり、結果的に第3レベルキャッシュミスになるオペレーションの測定は、測定から除外される。したがって、そのタギングには、所定イベントの発生かつ少なくとも第2イベントの非発生時に、オペレーションを選択することが含まれる。
【0036】
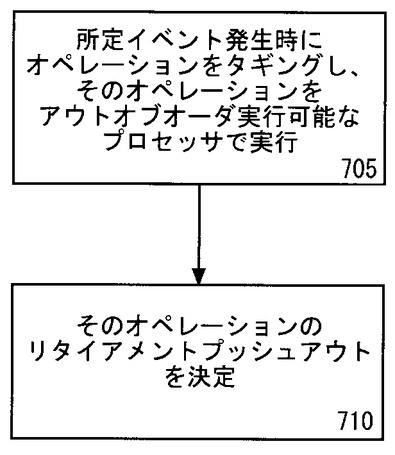
図7を手短に参照すると、タギングメカニズムを使用するリタイアメントプッシュアウトを測定するための実施例が示される。フロー705において、所定イベントの発生および/または所定イベントの実行に際してオペレーションがタギングされる。そのオペレーションは、パラレル実行ができるプロセッサにおいて実行される。しかし、プロセッサは、シリアル実行、投機的実行、およびアウトオブオーダ実行もできる。
【0037】
所定イベントは、上述のマイクロプロセッサにおける任意のイベントである。一実施例において、イベントは、リタイアメントイベントにおけるプリサイスイベントに基づくサンプリング(precise event based sampling(PEBS))である。PEBSにおいては、オペレーション(マイクロオペレーションまたは命令)は、キャッシュミスのような注目イベントを経験したものとしてマーキング(タギング)される。そのオペレーションがリタイアすると、リタイアメントロジックは、それがタギングされて特別のアクションを要するということに気付く。フラグおよびアーキテクチャレジスタのような命令およびアーキテクチャ状態のアドレスがメモリバッファ内に保存される。この場合、プッシュアウトレイテンシは、他の情報とともに記録される。プログラム実行は、かかる情報が記録されるメモリバッファが(ほぼ)満杯になるまでこうした特別のアクションをフォローし続ける。それが満杯(またはユーザが特定したウォーターマークよりも上)になると、性能モニタリング割り込みが起こり、ユーザがそのメモリバッファをリードすべきであるという信号が発生する。PEBSにおいて取られたアクションは、マイクロコードの命令を介して、ハードウェアにおける有限状態マシンかまたはその組み合わせのいずれかによって管理される。
【0038】
結果的にオペレーションのタギングとなるイベントのいくつかの具体例は以下を含む。キャッシュミス、キャッシュアクセス、キャッシュスヌープ、分岐予測ミス、リタイアメントのロック、ハードウェアプリフェッチ、ロード、ストア、ライトバック、および変換バッファへのアクセス。タギングは、測定のオペレーションを選択することを含む。なお、これらのイベントはまた、実行のターゲットともなる。これらのイベントの一つが上述の所定イベントとともに発生する場合にも、オペレーションはタギングされないからである。
【0039】
オペレーションのタギングまたは選択の後、フロー710において、そのオペレーションのリタイアメントプッシュアウトが決定される。上述のように、リタイアメントプッシュアウトを決定することは、所定イベントに起因する一の遅延したリタイアメントとしてオペレーションをカウンティングするだけではなく、リタイアメントの遅延を実測定することでもある。
【0040】
リタイアメントプッシュアウトの実測定が目的となる実施例においては、スローリタイアメント認定のために使用されるカウンタのようなカウンタ内のしきい係数(threshold modulus)は0に設定される。その結果、リタイアメントに係る最終値は、リタイアメントプッシュアウトに等しい正の数となる。一例では、第1カウンタが初期化されてリタイアメントプッシュアウトは、第1カウンタの初期化およびストレージレジスタの使用に基づいて決定される。この例では、第1カウンタの状態は、別のマシン状態レジスタにコピーされる。リタイアメントにおいて、ストレージレジスタはフリーズされ、更新されない。したがって、ストレージレジスタは、ソフトウェアがそれを読み出すまで安定である。
【0041】
なお、リタイアメント時の測定に関連してプッシュアウトの測定が参照されてきた。しかし、プッシュアウトは、フェッチ、デコード、イシュー、メモリーオペレーションのメモリーオーダリングバッファへの割り当て、およびメモリーオペレーションのグローバルな可視性のような、アウトオブオーダマシンにおける他のインオーダ渋滞ポイント(choke points)で測定されてよい。
【0042】
全体実行時間
【0043】
局所的なストールコストは、パラレルで行われる他のワークによって部分的にまたは完全にカバーできる。領域的な遅延を捕捉するリタイアメントプッシュアウトもまた、リタイアメントプッシュアウトが測定される時点でまだ進行中のワークまたは他のストールによって部分的にまたは完全にカバーできる。カバーされる一方向リタイアメントプッシュアウトは、上述のように図1に示す。所定オペレーションのストールがプログラムのクリティカルパスに与える寄与の究極の測定は、そのストール原因に起因して発生する実行レイテンシの変化である。
【0044】
グローバルなクリティカルパスに対する平均的な増分寄与の一つの指標は、プログラムの実行全体またはロングトレースを測定することすなわちロングトレース実行モニタリングである。このアプローチは、パイプラインのどこかで発生するクリティカルパスへの寄与をカバーし、他のパラレリズムが局所的な遅延をカバーするという事実を考慮に入れている。増分寄与は、実行時間を変化させるイベントのインスタンス数を変化させること、および、実行時間の変化をイベント数の変化で割って計算することによって導出される。例えば、キャッシュサイズの増加が、キャッシュミス数を100から90まで落ち、かつ、実行時間が2000から1600まで落ちると、増分寄与は、(2000−1600)/(100−90)=40サイクル/ミスとなる。
【0045】
この技術を実装するには複数の方法がある。第一に、マイクロベンチマークの2つのバージョンが形成される。一方はイベントを備え、他方は備えない。第二に、シミュレータ設定がイベントを導入または除去するように変更される。シミュレーションは、一つ以上のプログラムに対して両方の設定で実行される。イベント数と全実行時間との両方が各ケースに対して記録される。最後に、いくつかの製品は、分岐ターゲットアレイのサイズを縮小することまたはポリシーを変更することのような、シリコンデフィーチャをサポートする。これは、例えば、分岐予測速度に影響を与えるために使用される。
【0046】
上述のように、マイクロアーキテクチャフィーチャの寄与、すなわちイベントコストを決定することは、以下を介して行われる。(1)解析上の評価、(2)性能モニタからのデュレーションカウント、(3)ハードウェア性能モニタによりおよびシミュレータにより測定されるようなリタイアメントプッシュアウト、ならびに(4)マイクロベンチマーク、シミュレーション、およびシリコンデフィーチャによって測定されるような全体実行時間の変化。しかし、性能モニタリングおよびクリティカルパスへの寄与の決定は、上述の方法の一つの直接的な実施例に限られない。むしろ、任意の組み合わせが使用されてクリティカルパスへのシリコンフィーチャに係るイベントの寄与が解析される。
【0047】
所定イベントに対するインスタンス当たりのコストの例
【0048】
様々なイベントのインスタンス当たりのコストを評価するべく、インスタンス当たりの寄与の解析のセクションで説明した技術が使用される。もちろん、トレースの包括的なCPI内訳に対しては多数の寄与が存在する。4つの顕著な寄与が選択されて、説明された技術のそれぞれの効果が実証される。しかし、4つの各イベントに対しては、その技術の全てを使用することが必ずしも可能または好都合とは限らない。例えば、性能モニタリングのデュレーションカウントは、考慮中のイベントに対して利用可能ではない。同様に、シミュレータのサイズまたはポリシーを調整することによって実行をかく乱させることは、イベントの発生数に影響を与えること、または、所定トレースの実行時間を変化させることがない。表1は、これら4つの要因のそれぞれに対して、シミュレーションされた実行のかく乱に基づいて評価されたコストの概要を示す。全体的なシミュレーション結果に基づくインパクトの分散指標が与えられる。
【表1】

【0049】
分岐予測ミス
【0050】
分岐予測ミスは、アプリケーションがスローダウンする一般的な原因である。これにより、プロセッサパイプラインの再起動が強制され、投機的なワークが放棄される。分岐予測器は、時を経るにつれて段々正確になる。それにもかかわらず、深く広いパイプラインでは、予測ミスは、有用なワークを完了する機会を相当に喪失する原因となる。
【表2】
【0051】
分岐予測ミスコストの解析上の測定値は、遅延のサイクル数(31)である。分岐予測ミスは通常、実行時に遅延のサイクル数から検知される。通常、命令がトレースキャッシュからフェッチされて実行に戻る。解析上の視点は、マシンのフロントエンドで発生する実遅延を測定する。この遅延は、分岐条件を評価するときになんらかの遅延が存在する場合に、リソース障害または未解決のデータ依存に起因して、特にその依存がキャッシュミスを受けたロードに対する場合に、増加する。マイクロベンチマーク、HWリタイアメントプッシュアウト、およびシミュレーションされたリタイアメントプッシュアウトに見られるように、リタイアメントプッシュアウト遅延が30台半ばから40台になるのは、これらの理由による。表2において、HWリタイアメントプッシュアウトに対しては3つの値を示す。ここで使用されたマイクロベンチマークは、条件分岐を備えるがメモリ参照はしないループボディを有していた。35サイクルの場合と比べて28%多くの分岐が36の遅延を有し、27%多くの分岐が、30のサイクルに対して40の遅延を有し、および43%多くの分岐が40サイクルに対して41の遅延を有していた。マイクロベンチマークは、解析上のモデルに極めて近似する。これは、マイクロベンチマークはほとんどパラレルワークを含まず、複雑なクリーンアップが必要ないからである。
【0052】
しかし、図1に示すように、命令106が分岐予測ミスを有する場合、フロントエンドにおける遅延は、マシンのバックエンドに初期のリタイアメントプッシュアウトがあったとしても、なんらインパクトを与えない。また、後のキャッシュミスは、クリティカルパスへの分岐の寄与を著しく大きな遅延によって消し去る。これは、クリティカルパス全体への平均的な寄与がリタイアメントプッシュアウトよりも著しく低い一つの理由である。クリティカルパスへのシミュレーションされた全体的な寄与は、間接分岐予測器を無効にすることによって導出されるので、最後のターゲットを予測するのみである。さらに、実際のアプリケーションでは、オフパスコードが、有用なデータプリフェッチャおよび、予測ミスのインパクトを低減するDTLBルックアップの役割を果たす場合が多い。最後に、一つの予測ミスの処理を第2の予測ミスの処理に重複させることにより、クリティカルパス全体への平均的な寄与が減少する。
【0053】
この説明から、クリティカルパスへの実際の平均的な寄与がコンテキストに高度に依存し、リタイアメントプッシュアウトがインスタンス当たりのコストを過大評価することは明らかである。約70%のようなスケールファクタが、インスタンス当たりのコストの中央値を導出するべくHW測定リタイアメントプッシュアウトに適用される。なお、このイベントコストは、特定のマイクロアーキテクチャ、および、同一のマイクロアーキテクチャファミリ内の同等な実施例に高度に依存する。
【0054】
第1レベル(L1)キャッシュミス
【0055】
第1レベルキャッシュミスは一般的に発生する。アウトオブオーダプロセッサは、命令ストリームの独立したワークを見出して、そのミスを第2レベルキャッシュにサービスアウトする間プロセッサをビジーに維持すべく設計される。その結果、局所的なL1ミスコスト(例えばリタイアメントプッシュアウト)の小部分のみがクリティカルパス全体に寄与する。
【表3】
【0056】
ここでの解析上のモデルは、通常のロード対ユースコスト(normal load−to−use cost)のトップにおけるL1ミスのオーバヘッドを記述する。このイベントのためのマイクロベンチマークは、18サイクルオーバヘッドの一様分布に遭遇するポインタ追跡ループからなる。全てのL1ミスイベントに対するハードウェアリタイアメントプッシュアウトに−50%のスケールファクタが適用されて、インスタンス当たりのコストの中央値が定まる。
【0057】
第2レベル(L2)キャッシュミス
【0058】
第2レベルキャッシュミスは、より高レベルのキャッシュまたはメモリコントローラ/DRAMのいずれかに送り出される。アウトオブオーダプロセッサは、独立した複数のL2キャッシュミスを見つけ出して、これら長いトランザクションの処理をパイプライン化するように設計される。
【表4】
【0059】
キャッシュミスの解析上の測定値は、ストリーミングDRAMページヒットを伴う306クロックである。これは、3.4GHzプロセッサ上の800MHzのFSBを備える90nsのDRAMによって計算される。マイクロベンチマークは単純なポインタ追跡コードからなり、解析上のモデルと良好に相関する。このカーネルは、DTLBにおいてヒットするように設計されるが、ハードウェアプリフェッチャからの利益をなんらもたらさない。これは、所定のレイテンシを隠すパラレルワークを行う必要がほとんどなく、また、各ロードがDRAMに即座に送り出されるのを防止する独立したワークを行う必要がほとんどないからである。リタイアメントプッシュアウトおよびシミュレーションされた実行は全て結果的には、解析上の値よりも小さなインスタンス当たりのコストとなる。実際、シミュレーションされた実行については、インスタンス当たりのコストが、トレースにわたって広い分散を示し、解析上の値よりも短いのと長いのとの両方になる。明らかなことだが、スペクトルの短いレイテンシ側端部上には、オーバラップされたDRAMアクセスからの利益がある。インスタンス当たりのより長いレイテンシは、プロセッサメモリ要求のキュー深さ制限およびバス帯域幅不足を含むいくつかの態様で発生する。
【0060】
ハードウェアプリフェッチャは、このレイテンシにおいて非常に重要な役割を果たす。適切にスロットル制御されている間、これは多数の要求をメモリシステムに挿入する能力を有し、これによりその後のデマンドロードのレイテンシが増加する。スペクトルの他端において時々あるのは、プリフェッチャが、より若いロードのミスを回避できないほど遅いが、その若いロードの時刻においてデータをDRAMからの途中にしておくには十分早くプリフェッチを開始することである。この結果、インスタンス当たりの有効なミスのコストが減る。一般に、インスタンス当たりのコストの中央値は、HWリタイアメントプッシュアウト測定値に酷似する。
【0061】
上述で示唆したように、コストのバリエーションは、アプリケーションドメインにわたり著しく様々である。したがって、所定アプリケーションに対するコストを測定するためのインフィールドメカニズムを潜在的に有することは、特定のフィーチャの寄与を決定する上で極めて有用となる。このバリエーションに鑑み、マイクロアーキテクチャは、アプリケーション当たりの基準でチューニングされる。
【0062】
マイクロアーキテクチャのチューニング
【0063】
マイクロアーキテクチャは、例えばリタイアメントプッシュアウト測定、および、インスタンス当たりのイベントコストを決定するための全体実行時間測定の間にチューニングされる。しかし、マイクロアーキテクチャは、インスタンス当たりのイベントコストに応じてもチューニングされる。マイクロアーキテクチャフィーチャまたはマイクロアーキテクチャのチューニングは、マイクロアーキテクチャ内のポリシーの変更だけではなく、サイズ、ロジックの有効または無効、フィーチャ、および/またはマイクロアーキテクチャ内のユニットの変更も含む。
【0064】
一実施例において、チューニングは、マイクロアーキテクチャフィーチャの寄与すなわちインスタンス当たりの寄与に基づいて行われる。第一例では、どのアクションがクリティカルパスのレイテンシを低減するかに基づいて、フィーチャのサイズが変更され、フィーチャが有効にされ、フィーチャが無効にされ、または、フィーチャに関連するポリシーが変更される。別例では、電力のような他の考慮が使用されてマイクロアーキテクチャがチューニングされる。この例では、フィーチャを無効にすることは、レイテンシをわずかな量だけ増加させる。しかし、フィーチャの性能上の利益がわずかであること、および、フィーチャを無効にすることが著しく電力を節約することの決定に基づいて、フィーチャはチューニング、例えば無効化される。
【0065】
実験に基づく例では、以前のアーキテクチャについて注目されたのは、いくつかのマイクロワークロードにおいて著しい数のエイリアシングコンフリクトが認識されたということである。エイリアシングコンフリクトが発生した例の一つは、マルチスレッド間での同じキャッシュラインへのアクセスであった。
【0066】
ソフトウェアスレッドは、別のスレッドから独立して操作可能に実行されるプログラムの少なくとも一部である。ハードウェアでのマルチスレッド化までもサポートするマイクロプロセッサもあるが、この場合、プロセッサは、マルチソフトウェアスレッドの実行を独立してスケジュール化するべく、完全かつ独立のアーキテクチャ状態レジスタの少なくとも複数のセットを有する。しかし、これらのハードウェアスレッドは、キャッシュのようないくつかのリソースを共有する。以前は、マルチスレッドによってキャッシュ内の同じラインにアクセスすることは結果的に、キャッシュラインの置換および局所性の低減となった。したがって、スレッド用データメモリの開始アドレスは、スレッド間のキャッシュのライン置換を回避するべく異なる値に設定された。
【0067】
図3を参照すると、プロセッサ205内のモジュール215の所定実施例が示される。モジュール215は、クリティカルパスへのマイクロアーキテクチャフィーチャの寄与に少なくとも基づいて、ユーザレベルのアプリケーションのためのマイクロアーキテクチャフィーチャをチューニングする。
【0068】
このタイプのチューニングの特に具体的な例は以下を含む。アプリケーション実行中のハードウェアプリフェッチャの性能モニタリング、または、ガベージコレクションのようなアプリケーションのフェイズ。ガベージコレクションは、ハードウェアプリフェッチャが有効な状態で実行され、その後無効にされる。いくつかの例では、ガベージコレクションは、ハードウェアプリフェッチャなしでも良好に機能することがわかっている。したがって、ガベージコレクションアプリケーションの実行に際してマイクロアーキテクチャがチューニングされてハードウェアプリフェッチャが無効にされてもよい。
【0069】
性能解析に基づくポリシー変更のその他の例は以下を含む。プリフェッチのアグレッシブ性、同時スレディングマシンにおける異なるスレッドに対するリソースの相対的アロケーション、投機的ページウォーク、TLBに対する投機的更新、および、分岐とメモリ依存とに対する予測メカニズムの選択。
【0070】
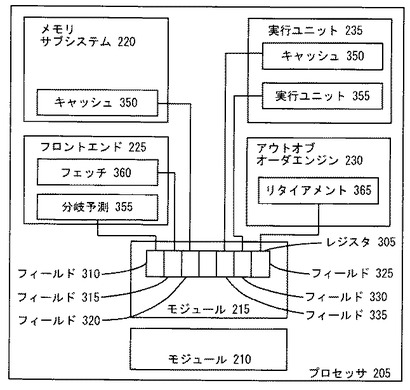
図3は、マイクロアーキテクチャフィーチャ、すなわち、メモリサブシステム220、キャッシュ350、フロントエンド225、分岐予測355、フェッチ360、実行ユニット235、キャッシュ350、実行ユニット355、アウトオブオーダエンジン230、および、リタイアメント365を示す。マイクロアーキテクチャフィーチャのその他の例は以下を含む。命令キャッシュ、データキャッシュ、分岐ターゲットアレイ、仮想メモリテーブル、レジスタファイル、変換テーブル、ルックアサイドバッファ、分岐予測ユニット、間接分岐予測器、ハードウェアプリフェッチャ、実行ユニット、アウトオブオーダエンジン、アロケータユニット、レジスタリネーミングロジック、バスインターフェイスユニット、フェッチユニット、デコードユニット、アーキテクチャ状態レジスタ、実行ユニット、浮動小数点実行ユニット、整数実行ユニット、ALU、および、その他の一般的なマイクロプロセッサフィーチャ。
【0071】
上述のように、マイクロアーキテクチャフィーチャをチューニングすることは、マイクロアーキテクチャフィーチャを有効または無効にすることを含む。上述からのハードウェアプリフェッチャに関する例と同様に、プリフェッチャは、寄与が強化されるすなわち良好になると決定されると無効にされる。このとき、そのフィーチャは、所定のソフトウェアプログラムの実行中に無効にされる。
【0072】
ユーザレベルアプリケーションに対するクリティカルパスへのマイクロアーキテクチャの寄与を決定する一つの方法は、ユーザレベルアプリケーションをマイクロアーキテクチャフィーチャを有効にしたままで実行することである。次に、マイクロアーキテクチャフィーチャを無効にしたままでユーザレベルアプリケーションを実行する。最後に、ユーザレベルアプリケーションに対するクリティカルパスへのマイクロアーキテクチャフィーチャの寄与が、フィーチャ有効のままのユーザレベルアプリケーションの実行と、フィーチャ無効のままのユーザレベルアプリケーションの実行との比較に基づいて決定される。単純には、ユーザレベルアプリケーションが実行されるたびに全体実行時間を測定することにより、どの全体実行時間が適しているか、有効または無効なフィーチャに関する全体時間が決定される。
【0073】
具体的な例として、モジュール215はデフィーチャレジスタ305を含む。デフィーチャレジスタ305は、フィールド310−335のような複数のフィールドを含む。フィールドは個別のビットでよく、または、各フィールドは複数のビットを有してよい。さらに、各フィールドは操作可能にマイクロアーキテクチャフィーチャをチューニングする。すなわち、フィールドは、フィールド310が分岐予測355に、フィールド315がフェッチ360に、フィールド320がキャッシュ350に、フィールド325がリタイアメントロジック365に、フィールド330が実行ユニット355に、および、フィールド335がキャッシュ350にというように、マイクロアーキテクチャフィーチャに関連する。フィールド310のようなフィールドの一つがセットされると分岐予測355は無効にされる。
【0074】
例えばソフトウェアプログラムのような、モジュール215に埋め込まれた、またはモジュール215の一部の、モジュール215に関連する別のモジュールは、無効時のクリティカルパスへのそのフィーチャの性能寄与が上述のように強化される場合、例えばフィールド310のようなフィールドをセットする。上述からわかるように、モジュール215はハードウェア、ソフトウェア、もしくはそれらの組み合わせでよく、またはモジュール210に関連するかもしくは部分的にオーバラップする。例えば、モジュール210の機能性の一部として、ユーザレベルプログラム実行中の分岐予測355の寄与を決定するべく、モジュール215に図示されるレジスタ305が使用されて例えば分岐予測355のようなプロセッサ205のフィーチャをチューニングするかまたは無効にする。
【0075】
別の実施例においては、デフィーチャすなわちチューニングは、フィーチャの物理的または仮想的なサイズ変更を含む。上述の例の別例として、ユーザレベルアプリケーションの実行を強化すべく分岐予測355の寄与が示される場合は、それに応じて分岐予測355のサイズがフィールド310を介して増加/減少される。以下の例は、プロセッサをチューニングする能力と、キャッシュミスのようなフィーチャまたはイベントの寄与をキャッシュのサイズをチューニングすることによって見出す能力との両方を示す。
【0076】
ソフトウェアのチューニング
【0077】
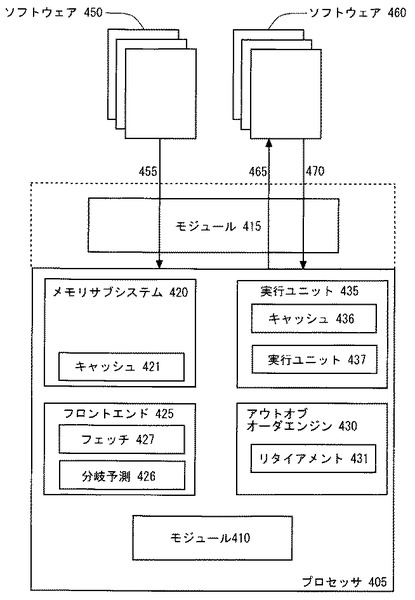
図4を参照して、プロセッサモニタリング性能およびソフトウェアのチューニングの実施例を示す。図2および図3に示すプロセッサ205に類似するプロセッサ405は、プロセッサに関連する任意の既知のロジックを有する。図示のように、プロセッサ405は以下のユニット/フィーチャを含む。メモリサブシステム420、フロントエンド425、アウトオブオーダエンジン430、および実行ユニット435。これら機能ブロックの各々の中には、その他多数のマイクロアーキテクチャフィーチャが存在する。例えば、第2レベルキャッシュ421、フェッチ/デコードユニット427、分岐予測426、リタイアメント431、第1レベルキャッシュ436、および実行ユニット437である。
【0078】
上述のように、モジュール410は、ソフトウェアプログラム実行に対するクリティカルパスにおけるインスタンス当たりのイベントコストを決定する。上述からインスタンス当たりのイベントコストを導出する例は、デュレーションカウント、リタイアメントプッシュアウト測定、およびロングトレース実行測定を含む。ここで繰り返すが、モジュール410およびモジュール415は、それらの機能性、ハードウェア、ソフトウェア、またはハードウェアとソフトウェアとの組み合わせがオーバラップするので、ぼやけた境界を有していてよい。
【0079】
モジュール415がフィーチャとのインターフェイスを有することによってマイクロアーキテクチャをチューニングした図3とは対照的に、モジュール415はクリティカルパスにおけるインスタンス当たりのイベントコストに基づいてソフトウェアプログラムをチューニングする。モジュール415は、プロセッサ405上で実行するコードをコンパイルおよび/またはインタプリトするための任意のハードウェア、ソフトウェア、またはそれらの組み合わせを含む。一実施例において、モジュール415は、プログラムのその後のラン(subsequent run)で実行されるコードを再コンパイルして上述のマイクロアーキテクチャフィーチャを利用するが、その頻度は、インスタンス当たりの決定されたイベントコストに基づいて最初にコンパイルされていたコードと比べて多いかまたは少ない。別の実施例において、モジュール415はプログラムの同じラン(same run)の残りに対して異なった態様でコードをコンパイルする。すなわち、動的なコンパイルまたは再コンパイルが使用されて所定のワークロードおよびプラットフォーム上の実行時間が改善される。
【0080】
マイクロアーキテクチャをチューニングすることができることに加え、上述のように、アプリケーションをチューニングしてそのプラットフォーム上でそれが最適に実行されるようにすることによって良好な性能が達成される。ソフトウェアのチューニングはコードを最適化することを含む。アプリケーションのチューニングの一例は、ソフトウェアプログラムの再コンパイルである。ソフトウェアのチューニングはまた以下を含む。キャッシュ内にフィットするブロックデータ構造にソフトウェア/コードを最適化すること、コードを再レイアウトして分岐予測器テーブルリソースの使用を必要としないデフォルト分岐予測条件を有効利用すること、異なる命令アドレスにおいてコードを放出して、分岐予測構造およびコードキャッシュ化構造の局所性管理の問題を引き起こしかねない所定のエイリアシング条件およびコンフリクト条件を回避すること、動的に割り当てられたメモリのまたはスタック(スタックアライメントを含む)のデータを再レイアウトして、キャッシュラインのスパニングが招くペナルティを回避すること、ならびに、アクセスの粒度およびアライメントを調整してストア・フォワーディング問題を回避すること。
【0081】
ソフトウェアのチューニングの具体例として、ソフトウェア450はプロセッサ405とともに/プロセッサ405上で実行される。モジュール410は、例えば分岐予測ロジック426内の分岐予測ミスのコストのような、インスタンス当たりのイベントコストを決定する。この解析に基づき、モジュール415は、ソフトウェア450をソフトウェア460に再レイアウトする。ソフトウェア460は同じユーザレベルアプリケーションであるが、再レイアウトされてプロセッサ405上で異なった態様で実行される。この例では、ソフトウェア460は再レイアウトされて、デフォルト分岐予測条件がより有効利用される。したがって、ソフトウェア460は再コンパイルされて、分岐予測426を異なった態様で利用する。他の例は以下を含む。コードで命令を実行して分岐予測ロジック426を無効にすること、および、分岐予測ロジック426によって使用されるソフトウェアヒントを変更すること。
【0082】
性能モニタリングのためのシステム
【0083】
次に図5を参照して、性能モニタリングを使用するシステムを示す。プロセッサ505はコントローラハブ550に接続され、コントローラハブ550はメモリ560に接続される。コントローラハブ550は、メモリコントローラハブまたはチップセットデバイスの他の部分であってよい。いくつかの例では、コントローラハブ550は、ビデオコントローラ555のような統合型ビデオコントローラを有する。しかし、ビデオコントローラ555はまた、コントローラハブ550に接続されたグラフィックスデバイス上にあってもよい。なお、示されるデバイスの各々の間には、その他のコンポーネント、インタコネクト、デバイス、および回路が存在する。
【0084】
プロセッサ505はモジュール510を含む。モジュール510は、ソフトウェアプログラム実行中のインスタンス当たりのイベント寄与を決定し、そのインスタンス当たりのイベント寄与に基づいてマイクロプロセッサ505のアーキテクチャ設定をチューニングし、そのアーキテクチャ設定をストアし、そのストアされたアーキテクチャ設定に基づきそのソフトウェアプログラムのその後の実行においてアーキテクチャ設定を再チューニングする。
【0085】
具体例として、モジュール510は、寄与モジュール511を利用し、オペレーティングシステムのようなソフトウェアプログラムの実行中のイベント寄与を決定する。ソフトウェアプログラムの他の例は以下を含む。ゲストアプリケーション、オペレーティングシステムアプリケーション、ベンチマーク、マイクロベンチマーク、ドライバ、および組み込みアプリケーション。この例に対しては、第1レベルキャッシュ536に対するミスのようなイベント寄与を仮定することは実行に著しい影響を与えるわけではなく、キャッシュ536はサイズが低減されて、クリティカルパスにおける実行時間に影響を与えることなく電力が節約される。したがって、チューニングモジュール512は、第1レベルキャッシュ536のサイズを低減することによってプロセッサ505のアーキテクチャをチューニングする。チューニングは、上述のようにして、プロセッサ505内の異なるフィーチャに関連するフィールドをレジスタが有したまま行われる。レジスタが使用される場合、アーキテクチャ設定をストアすることは、ストレージ513にレジスタ値をストアすることを含む。ストレージ513は、メモリ560のような単なる別のレジスタまたはメモリデバイスである。ソフトウェアプログラムのその後の実行において、性能モニタリングステップは繰り返す必要がなく、以前にストアされた設定がロードされる。したがって、アーキテクチャは、ストアされた設定に基づいてソフトウェアプログラム用に再チューニングされる。
【0086】
性能モニタリングの方法
【0087】
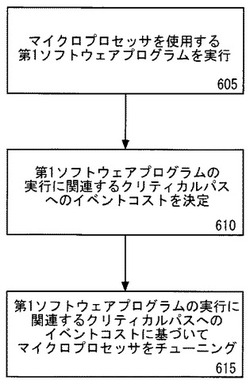
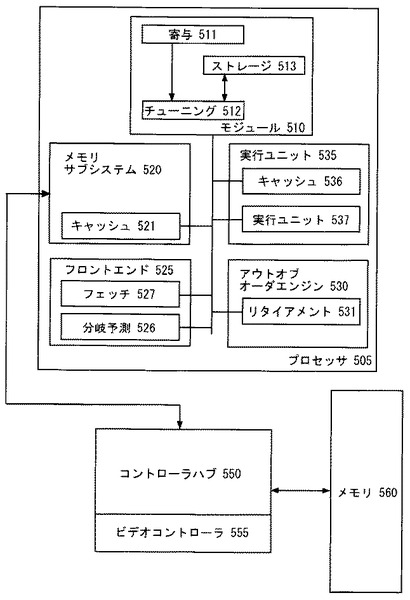
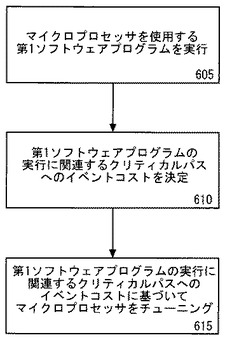
図6aは、性能をモニタリングしマイクロプロセッサをチューニングするためのフローチャートの実施例を示す。フロー605において、マイクロプロセッサを使用する第1ソフトウェアプログラムが実行される。一実施例において、マイクロプロセッサは、アウトオブオーダパラレル実行が可能である。次に、フロー610において、第1ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストが決定される。
【0088】
図6bを参照して、イベントコストを決定し、マイクロプロセッサをチューニングする例を示す。イベントコストは、フロー611に示すデュレーションカウント、フロー612に示すリタイアメントプッシュアウト、および/または、フロー613に示す全体実行時間を解析することによって決定される。なお、これらの方法の任意の組み合わせが使用されてイベントコストが決定される。
【0089】
マイクロプロセッサにおける一般的なイベントのいくつかの例は以下を含む。低レベルキャッシュミス、セカンダリキャッシュミス、高レベルキャッシュミス、キャッシュアクセス、キャッシュスヌープ、分岐予測ミス、メモリからのフェッチ、リタイアメントにおけるロック、ハードウェアプリフェッチ、ロード、ストア、ライトバック、命令デコード、アドレス変換、変換バッファへのアクセス、整数演算実行、浮動小数点演算実行、レジスタのリネーミング、命令のスケジューリング、レジスタのリード、および、レジスタのライト。
【0090】
図6aを参照すると、フロー615において、マイクロプロセッサは、第1ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストに基づいてチューニングされる。チューニングは、性能強化のためのマイクロアーキテクチャおよび/または実行時間に対する任意の変更を含む。図6bに戻り、チューニングの一例は、フロー617のようなマイクロアーキテクチャフィーチャの有効化または無効化を含む。フィーチャのいくつかの具体例は以下を含む。キャッシュ、変換テーブル、変換ルックアサイドバッファ(TLB)、分岐予測ユニット、ハードウェアプリフェッチャ、実行ユニット、および、アウトオブオーダエンジン。別例は、フロー616のようなマイクロアーキテクチャフィーチャのサイズまたは使用頻度の変更を含む。さらなる別例では、マイクロプロセッサのチューニングは、例えばハードウェアプリフェッチャを利用しないことのような、異なった態様でプロセッサを利用すべく実行されるソフトウェアプログラムのチューニング/コンパイルを含む。
【0091】
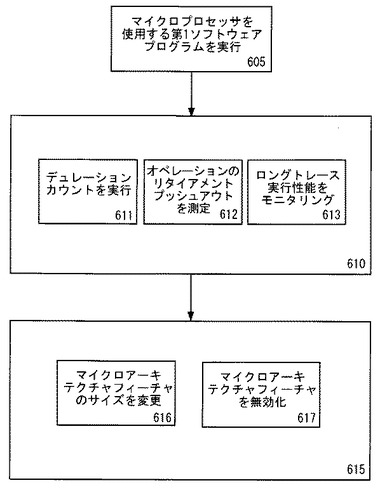
これまでのところ、性能モニタリングおよびチューニングが、性能モニタリングを記述するシングルソフトウェアプログラムを参照して説明されてきた。しかし、性能モニタリングおよびチューニングは、プロセッサ上で実行される任意数のアプリケーションによって実装できる。図6cは、第2プログラム用のアーキテクチャをプロファイリング/チューニングするためのフローチャートの実施例を示す。第1アプリケーションを再びロードするときにマイクロプロセッサは再チューニングされる。
【0092】
フロー605−615は、図6aに示すものと同じである。フロー620において、第1ソフトウェアプログラムに関連するマイクロプロセッサのチューニングを表す第1設定がストアされる。第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストがフロー625において決定される。フロー630において、第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストに基づいてマイクロプロセッサがチューニングされる。最後に、フロー635で、第1ソフトウェアプログラムのその後の実行のときに、ストアされた第1設定に基づいてマイクロプロセッサが再チューニングされる。
【0093】
上述からわかるように、個々のアプリケーションの性能に基づいてマイクロプロセッサが動的にチューニングされる。プロセッサの所定フィーチャは異なった態様で利用され、かつ、キャッシュミスのようなイベントのコストはアプリケーションごとに著しく様々であるが、マイクロアーキテクチャおよび/またはソフトウェアアプリケーション自体がより効率的かつ迅速に実行されるべくチューニングされる。フィーチャのイベントコストおよび寄与は、解析方法、シミュレーション、リタイアメントプッシュアウトの測定、および、特にパラレル実行マシンに対して正しい性能がモニタリングされていることを保証する全体実行時間の任意の組み合わせによって測定される。
【0094】
前述の明細書において、本発明がその所定実施例を参照して説明されてきた。しかし、それに対しては、添付の請求項に記載される本発明のより広い要旨および範囲から逸脱することなく、様々な修正および変更がなし得ることは明らかである。したがって、明細書および図面は、限定的な意味ではなく説明的な意味とみなすべきである。
【図面の簡単な説明】
【0095】
【図1】シングルイシューマシンにおける複数のオペレーションに対するフェッチ、実行、およびリタイアメントの実施例を示す。
【図2】第1性能モニタリングモジュールおよび第2マイクロアーキテクチャチューニングモジュールを含むプロセッサの実施例を示す。
【図3】図2の具体的な実施例を示す。
【図4】静的または動的にソフトウェアを再コンパイルするためのモジュールを含むプロセッサの実施例を示す。
【図5】性能をモニタリングし、かつ、プロセッサのマイクロアーキテクチャをチューニングするためのモジュールを有するプロセッサを含むシステムの実施例を示す。
【図6a】性能をモニタリングし、性能に基づいてマイクロプロセッサをチューニングするためのフローチャートの実施例を示す。
【図6b】図6aの具体的な実施例を示す。
【図6c】性能をモニタリングし、マイクロプロセッサをチューニングするための別の実施例を示す。
【図7】所定イベントの発生時にリタイアメントプッシュアウトを測定するための実施例を示す。
【技術分野】
【0001】
本発明は、コンピュータシステムの分野に関し、詳しくはマイクロアーキテクチャの性能モニタリングおよびチューニングに関する。
【背景技術】
【0002】
性能解析は、マイクロアーキテクチャ設計を特徴づけ、デバッグし、およびチューニングしたり、ハードウェアおよびソフトウェアの性能上のボトルネックを発見および修復したり、回避可能な性能上の問題を突き止めるための基礎である。コンピュータ産業の発展に従い、マイクロアーキテクチャの性能を解析し、その解析に基づいてマイクロアーキテクチャを変更する能力はより複雑かつ重要になる。
【0003】
可能な限り最適のプラットフォームを与えることに加え、そのプラットフォームで最適に実行するべくアプリケーションをチューニングすることによって最適な性能が達成されることが多い。性能上のボトルネックを特定し、より適したコード生成を介してそれをいかに回避するかを解明すること、および、性能改善を確認すること、への投資には意味がある。その解析では、性能モニタが重要な要素となる。性能モニタリングは、プリシリコンシミュレーションよりも多くの量の性能データを与えるが、ストア・フォワーディングのような領域での性能を改善するべくマイクロアーキテクチャ設計を微調整するために使用されている。性能上の問題がどれくらいの頻度で生じるか、および、マイクロアーキテクチャのその部分を改善した場合にどの程度の利益が得られるかだけでも知ることは、シリコンチェンジ(silicon changes)を動機付ける上で必須である。
【0004】
過去においては、シリアル性能上のボトルネックを追跡することは、パラレルなアウトオブオーダ実行中のパフォーマンス制限を検出することよりもはるかに容易であったので、シリアル実行マシンの性能モニタリングは、比較的直接的であった。典型的な性能解析は、ワークロードのCPI(命令当たりのクロック数(clocks per instruction))を、以下のようにして個々のコンポーネントに分解する。1)ハードウェアの性能上のイベントをカウントし、2)プログラムのクリティカルパスへの各イベントの相対的寄与を評価し、3)ワークロードの性能上のボトルネックに寄与する個々のコンポーネントを結合して全体的な内訳(breakdown)にする。シングルマイクロアーキテクチャのためのインスタンス当たりのコストを評価することは、多くのストールコストのうち有意な部分をカバーするのに十分なスーパースカラーおよびパイプラインパラレリズムが存在する、アウトオブオーダで高度に投機的なマシンにとっては困難である。今日まで、その場しのぎの方法が使用されてインスタンス当たりのイベントのインパクトが評価されてきたが、その評価の正確さおよびバリエーションは未知なことが多かった。
【0005】
例えば、図1はシングルイシューマシンにおける、命令101−107のフェッチ、実行、およびリタイアメントの例を示す。命令102は、分岐予測ミス110を有する。分岐予測ミス110は、命令103のフェッチを遅延させて、命令102のかなり後に命令103のリタイアメントをプッシュアウトする(pushes out)。命令104は、第1レベルキャッシュミス120を有する。第1レベルキャッシュミス120は、命令105のリタイアメントをプッシュアウトする。しかし、命令104のリタイアメントプッシュアウト125は、命令105の第2レベルキャッシュミス130によって矮小化される。命令105の第2レベルキャッシュミス130は非常に長いレイテンシを有するので、命令106の分岐予測ミス135はそのリタイア面と時間になんらインパクトを与えることがない。図1に列挙されるように、リタイアメントプッシュアウトを測定することには、シングルイシューマシンにおいてさえ入り組んだ複雑性がある。ましてや、アウトオブオーダの高度に投機的なパラレル実行が可能なプロセッサにおける包括的な性能モニタリングであればなおさらである。
【発明の開示】
【0006】
以下の記載において、本発明の完全な理解を与えるべく具体的なアーキテクチャ、そのアーキテクチャ内のフィーチャ、チューニングメカニズム、およびシステム設定のような多数の具体的な詳細が述べられる。しかし、本発明を実施するべくこれらの具体的な詳細を採用しなければならないわけではないことは、当業者にとって明白であろう。他の例として、周知のロジック設計、ソフトウェアコンパイラ、ソフトウェア再設定技術、およびプロセッサをデフィーチャする技術(processor defeaturing techniques)のような周知のコンポーネントまたは方法は、本発明を不必要にあいまいにすることを回避すべく詳細には記載されない。
【0007】
本発明は例示として示され、添付図面の図によって限定されることを意図しない。
【発明を実施するための最良の形態】
【0008】
性能モニタリング
【0009】
図2は、性能モニタリングモジュール210およびチューニングモジュール215を有するプロセッサ205の実施例を示す。プロセッサ205は、コードの実行および/またはデータのオペレーションのための任意の要素である。具体例として、プロセッサ205は、パラレル実行を行うことができる。他の実施例では、プロセッサ205は、アウトオブオーダ実行を行うことができる。プロセッサ205はまた、他の既知の処理ユニットおよび方法と同様に、分岐予測および投機的実行、を行うこともできる。
【0010】
プロセッサ250に示される他の処理ユニットは、メモリサブシステム220、フロントエンド225、アウトオブオーダエンジン230、および実行ユニット235を含む。これらのモジュール、ユニット、または機能ブロックの各々は、プロセッサ205のための前述の機能性を与える。実施例において、メモリサブシステムは、外部デバイスとインターフェイス接続される高レベルキャッシュおよびバスインターフェイスを含む。フロントエンド225は、予測ロジックおよびフェッチロジックを含む。アウトオブオーダエンジン230は、命令をリオーダするスケジューリングロジックを含む。実行ユニット235は、シリアルおよびパラレルで実行する浮動小数点および整数実行ユニットを含む。
【0011】
モジュール210およびモジュール215は、ハードウェア、ソフトウェア、ファームウェア、またはこれらの任意の組み合わせで実装される。一般には、モジュールの境界は様々であり、複数の機能は一緒に、および、異なる実施例では別々に実装される。一例では、性能モニタリングおよびチューニングは、シングルモジュールに実装される。図2に示す実施例では、モジュール210とモジュール215とは別々に示される。しかし、モジュール210とモジュール215とは、他の図示のユニット220−235によって実行されるソフトウェアである。
【0012】
モジュール210は、プロセッサ205の性能をモニタする。一実施例では、性能モニタリングは、クリティカルパスに対するインスタンス当たりのイベントコストを決定および/または導出することによって行われる。クリティカルパスは、任意の発生、タスクまたはイベントのレイテンシが増加すると仮定した場合に、オペレーション、命令、命令グループ、またはプログラムを完了するためにかかる時間に寄与するであろう発生、タスク、および/またはイベントのシーケンスの任意パスを含む。グラフでは、クリティカルパスは、所定マシン上で実行されるプログラム中のデータ、制御、およびリソースの依存性のグラフを通るパスとして言及されることがある。その所定マシンに対しては、その依存性のグラフにおける任意の円弧(arc)が長引いてそのプログラムの実行レイテンシ増加がもたらされる。
【0013】
したがって、換言すれば、イベント/フィーチャのクリティカルパスへのインスタンス当たりの寄与は、タスクまたはプログラムの完了に見られるレイテンシに対する第2レベルキャッシュミスのようなイベントの寄与、または、分岐予測ユニットのようなマイクロアーキテクチャフィーチャである。実際、イベントまたはフィーチャの寄与は、アプリケーションの領域にわたり著しく変化する。したがって、イベントまたはマイクロアーキテクチャフィーチャのコスト/寄与は、オペレーティングシステムのような所定のユーザレベルアプリケーションに対して決定される。モジュール215が、図3を参照して詳細に説明される。
【0014】
イベントは、レイテンシを導入するプロセッサの任意のオペレーション、発生、またはアクションを含む。マイクロプロセッサにおける一般的なイベントのいくつかの例は以下を含む。低レベルキャッシュミス、セカンダリキャッシュミス、高レベルキャッシュミス、キャッシュアクセス、キャッシュスヌープ、分岐予測ミス、メモリからのフェッチ、リタイアメントにおけるロック、ハードウェアプリフェッチ、フロントエンドストア、キャッシュスプリット、ストア・フォワーディング問題、リソースのストール、ライトバック、命令デコード、アドレス変換、変換バッファへのアクセス、整数演算実行、浮動小数点演算実行、レジスタのリネーミング、命令のスケジューリング、レジスタのリード、および、レジスタのライト。
【0015】
マイクロアーキテクチャフィーチャは、ロジック、機能ユニット、リソース、または前記イベントに関連するその他のフィーチャを含む。マイクロアーキテクチャフィーチャの例は以下を含む。キャッシュ、命令キャッシュ、データキャッシュ、分岐ターゲットアレイ、仮想メモリテーブル、レジスタファイル、変換テーブル、ルックアサイドバッファ、分岐予測ユニット、ハードウェアプリフェッチャ、実行ユニット、アウトオブオーダエンジン、アロケータユニット、レジスタリネーミングロジック、バスインターフェイスユニット、フェッチユニット、デコードユニット、アーキテクチャ状態レジスタ、実行ユニット、浮動小数点実行ユニット、整数実行ユニット、ALU、およびマイクロプロセッサの他の一般的なフィーチャ。
【0016】
命令当たりのクロック数
【0017】
性能の主要なインジケータの一つは、命令当たりのクロック数(clocks per instruction(CPI))である。CPIは、いくつかのコンポーネントにブレークダウンすることができる。これにより、いくつかのファクタ/イベントの各々に帰属するサイクルの一部(fraction)の指標が決定される。上述のように、これらのファクタは、キャッシュをミスしてDRAMに進むことにより導入されるレイテンシ、分岐予測ミスのペナルティ、リタイアメントメカニズムが招くパイプライン遅延、すなわちロック等に対するイベントを含む。ファクタの他の例は、ミスされたキャッシュ、分岐予測に使用される分岐ターゲットアレイにおけるミス、DRAMに進むためのバスインターフェイスの使用、および、ロックを実装するための状態マシンの使用のような、イベントに関連するマイクロアーキテクチャフィーチャを含む。
【0018】
典型的には、ファクタの発生数にサイクルにおけるその影響を乗じ、次にサイクルのトータル数で割ることによって、ファクタの相対的寄与が決定される。かかる内訳が、スカラーで非パイプラインの非投機的マシンに対してはプリサイスに提示される一方で、スーパースカラーでパイプラインのアウトオブオーダかつ高投機的マシンを説明するプリサイスサイクルを与えることは難しい。よくあることだが、かかるマシンによって利用されるワークロードには十分なパラレリズムが存在するので、そのマシンはストールの少なくとも一部を有用なワークを行うことによって隠すことができる。その結果、そのストールの局所的なインパクトは、プログラムのクリティカルパス全体にとっては、インスタンス当たりの理論的コストと比べてかなり小さな寄与となる。驚くべきことに、局所的なストールは、その局所的な遅延がより最適な全体的スケジュールをもたらす場合に、プログラムの全体実行時間に対してプラスの影響さえ有する。
【0019】
インスタンス当たりの寄与/コストの解析
【0020】
インスタンス当たりのイベントコスト、すなわちイベントのまたはマイクロアーキテクチャフィーチャのクリティカルパスへの寄与は、多くの異なる方法で決定できる。その方法は以下を含む。(1)解析上の評価、(2)性能モニタからのデュレーションカウント、(3)ハードウェア性能モニタによりおよびシミュレータにより測定されるようなリタイアメントプッシュアウト、ならびに(4)マイクロベンチマーク、シミュレーション、およびシリコンデフィーチャによって測定されるようなイベント数の変化に起因する全体実行時間の変化。
【0021】
解析上の評価
【0022】
第1実施例において、インスタンス当たりのコスト、すなわち、フィーチャの寄与は理論的に決定される。論理的な寄与は、アーキテクチャのシミュレーションと同様、イベントのフィーチャまたは発生のオペレーションについての実験に基づく知見も含む。これは、マイクロアーキテクチャの理解、およびリタイアメントへのというよりもむしろ実行段階へのフォーカスから導出されることが多い。解析上の評価の最も簡単な形態は、局所的なストールコストに特徴があり、他のオペレーション(実行または命令の段階)をパラレルで実行することから得られるパラレリズムによってそれらのストールがどれほどカバーされるかとは独立している。
【0023】
デュレーションカウント
【0024】
別の実施例において、性能モニタは、デュレーションカウントを介してフィーチャの寄与を決定する。いくつかの性能モニタイベントが定義されて注目事項が発生する各サイクルがカウントされる。これにより、インスタンスカウントの代わりにデュレーションカウントが得られる。かかる2つのカウントは、状態マシンがアクティブなサイクルである。例えばページウォークハンドラ、ロック状態マシン、および、1つ以上のエントリがキュー、例えば著しいキャッシュミスのあるバスのキュー、に存在するサイクルである。これらの例は、実行段階の時間を測定し、実行がロック状態マシンに対する場合となるリタイアメントにない限りは、必ずしもリタイアメントプッシュアウトを測定するわけではない。この特性形態は、ベンチマーク特有のコストを評価する分野において有用である。
【0025】
リタイアメントプッシュアウト
【0026】
リタイアメントプッシュアウトは、局所的なスケールでイベントおよびフィーチャの寄与を決定する上で、その測定をグローバルなスケールまで外挿することと同様に有用である。リタイアメントプッシュアウトは、一つのオペレーションが予測された時刻において、または予測されたサイクル中にリタイアしないときに生じる。例えば、命令(またはマイクロオペレーション)のシーケンシャルなペアに対して、第2命令が第1命令後(通常は同じサイクル内で、または、リタイアメントリソースが制約を受けている場合は次のサイクル内で)直ちにリタイアしない場合、リタイアメントはプッシュアウトされたとみなされる。リタイアメントプッシュアウトにより、後方「領域的」な(純粋に局所的というわけではない)、クリティカルパスへの寄与測定が与えられる。後方とは、リタイアメントプッシュアウトが、時間上の所定ポイントより前にリタイアした全てのオペレーションのオーバラップを認識しているというという意味である。50の局所的ストールコストを有する2つのオペレーションが別々に1サイクルを開始すると、2番目に対するリタイアメントプッシュアウトは、50ではなく、せいぜい1である。
【0027】
リタイアメントプッシュアウトの実測定は、プッシュアウトが測定され始める時に応じて様々である。一例では、その測定はイベントの発生による。別例では、プッシュアウトの測定は、命令またはオペレーションがリタイアしたはずの時からとなる。さらなる別例では、リタイアメントプッシュアウトは、リタイアメントプッシュアウトの発生数をカウンティングすることによってのみ測定される。これは、シーケンシャルなオペレーションのリタイアメントプッシュアウトを参照して以下に説明される。リタイアメントプッシュアウトによってインスタンス当たりの寄与を測定/導出するには様々な方法がある。例えば、リタイアメントプッシュアウトの2つの方法、すなわちシーケンシャルオペレーションとタギング、を説明する。
【0028】
両メカニズムは、ユーザが、異なるしきい値で繰り返し実行することによってリタイアメントプッシュアウト分布のヒストグラムを生成することを可能にする。シーケンシャルオペレーションのリタイアメントプッシュアウトは、プログラム内の全てのオペレーションに対するリタイアメント遅延のプロファイルを生成することができる。さらに、リタイアメントプッシュアウトのタギングは、分岐予測ミスの個別の寄与のような個々の/所定のイベントに対する遅延分布のプロファイルを生成することができる。
【0029】
シーケンシャルオペレーションのリタイアメントプッシュアウト、すなわちスローリタイアメント認定
【0030】
このメカニズムに対しては、シーケンシャルオペレーションのインスタンスは、リタイアしている連続オペレーション間、すなわちマイクロオペレーション間の遅延が、ユーザが特定したしきい値よりも大きい場合にカウントされる。その結果、連続オペレーションに対するプッシュアウトが測定され、所定のしきい値を越えるレイテンシを有するプッシュアウトの数が報告される。
【0031】
一実施例では、スローリタイアメント認定は、専用カウンタを使用して測定される。専用カウンタは、スレッドからの命令がリタイアしていないサイクルをカウントする。カウンタは、第1オペレーションがリタイアするとすぐにユーザ定義値に初期化される。設計に応じて、カウンタが所定の第2命令に対してアンダーフローまたはオーバフローする場合、その第2命令は、スローリタイアメント、すなわちリタイアメントプッシュアウトを有すると見なされる。
【0032】
ダウンカウンタを使用する設計の例として、25サイクルにわたりいくつの命令リタイアメントがプッシュアウトされたのかをユーザがカウントしたい場合、カウンタは所定値25に設定される。アンダーフローの場合、第2命令のリタイアメントはプッシュアウトとみなされる。アップカウンタの実施例では、ユーザ定義値は、0または負の数に初期化される。例えば、カウンタが0に初期化されて、しきい値25までカウントする。カウンタがオーバフローする場合は、リタイアメントプッシュアウトが存在する。別例では、アップカウンタが−25に初期化されて、0までカウントする。これは、カウンタのオーバフローを決定するときにロジック比較を単純化する。
【0033】
リタイアメントプッシュアウトタギング、すなわちリタイアメントプッシュアウトプロファイリング
【0034】
スローリタイアメント認定と非常に類似して、リタイアメントプッシュアウトタギングは、所定しきい値よりも上のリタイアメントプッシュアウトを有していた命令またはオペレーションを認定する。しかし、このメカニズムでは、スローリタイアメント認定は、注目する命令またはオペレーションについての多くの認定の一つに過ぎない。他の認定は、第2レベルキャッシュミスのような、その命令またはオペレーションに対して発生した所定イベントを含む。これらの認定は論理的に結合され、命令またはオペレーションが、特定の認定基準を満たす場合にカウントされる。なお、認定子/イベントは論理的にオペレートされるかまたは結合され、特定のマシン状態レジスタでユーザ定義が可能である。
【0035】
別の実施例では、オペレーションは、特定の単数または複数のイベントの実行に基づいてタギングされる。上述のように、パラレル実行は、所定イベントの実際の影響を隠す。具体例として、第3レベルキャッシュに対するミスは、第2レベルキャッシュに対するミスの影響を矮小化する。結果的に第2レベルキャッシュに対するミスとなるが第3レベルキャッシュをミスしない場合は、第2レベルキャッシュに対するミスの影響を隔離するべく所定のオペレーションがタギングされる。つまり、結果的に第3レベルキャッシュミスになるオペレーションの測定は、測定から除外される。したがって、そのタギングには、所定イベントの発生かつ少なくとも第2イベントの非発生時に、オペレーションを選択することが含まれる。
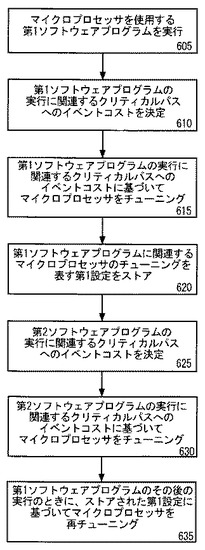
【0036】
図7を手短に参照すると、タギングメカニズムを使用するリタイアメントプッシュアウトを測定するための実施例が示される。フロー705において、所定イベントの発生および/または所定イベントの実行に際してオペレーションがタギングされる。そのオペレーションは、パラレル実行ができるプロセッサにおいて実行される。しかし、プロセッサは、シリアル実行、投機的実行、およびアウトオブオーダ実行もできる。
【0037】
所定イベントは、上述のマイクロプロセッサにおける任意のイベントである。一実施例において、イベントは、リタイアメントイベントにおけるプリサイスイベントに基づくサンプリング(precise event based sampling(PEBS))である。PEBSにおいては、オペレーション(マイクロオペレーションまたは命令)は、キャッシュミスのような注目イベントを経験したものとしてマーキング(タギング)される。そのオペレーションがリタイアすると、リタイアメントロジックは、それがタギングされて特別のアクションを要するということに気付く。フラグおよびアーキテクチャレジスタのような命令およびアーキテクチャ状態のアドレスがメモリバッファ内に保存される。この場合、プッシュアウトレイテンシは、他の情報とともに記録される。プログラム実行は、かかる情報が記録されるメモリバッファが(ほぼ)満杯になるまでこうした特別のアクションをフォローし続ける。それが満杯(またはユーザが特定したウォーターマークよりも上)になると、性能モニタリング割り込みが起こり、ユーザがそのメモリバッファをリードすべきであるという信号が発生する。PEBSにおいて取られたアクションは、マイクロコードの命令を介して、ハードウェアにおける有限状態マシンかまたはその組み合わせのいずれかによって管理される。
【0038】
結果的にオペレーションのタギングとなるイベントのいくつかの具体例は以下を含む。キャッシュミス、キャッシュアクセス、キャッシュスヌープ、分岐予測ミス、リタイアメントのロック、ハードウェアプリフェッチ、ロード、ストア、ライトバック、および変換バッファへのアクセス。タギングは、測定のオペレーションを選択することを含む。なお、これらのイベントはまた、実行のターゲットともなる。これらのイベントの一つが上述の所定イベントとともに発生する場合にも、オペレーションはタギングされないからである。
【0039】
オペレーションのタギングまたは選択の後、フロー710において、そのオペレーションのリタイアメントプッシュアウトが決定される。上述のように、リタイアメントプッシュアウトを決定することは、所定イベントに起因する一の遅延したリタイアメントとしてオペレーションをカウンティングするだけではなく、リタイアメントの遅延を実測定することでもある。
【0040】
リタイアメントプッシュアウトの実測定が目的となる実施例においては、スローリタイアメント認定のために使用されるカウンタのようなカウンタ内のしきい係数(threshold modulus)は0に設定される。その結果、リタイアメントに係る最終値は、リタイアメントプッシュアウトに等しい正の数となる。一例では、第1カウンタが初期化されてリタイアメントプッシュアウトは、第1カウンタの初期化およびストレージレジスタの使用に基づいて決定される。この例では、第1カウンタの状態は、別のマシン状態レジスタにコピーされる。リタイアメントにおいて、ストレージレジスタはフリーズされ、更新されない。したがって、ストレージレジスタは、ソフトウェアがそれを読み出すまで安定である。
【0041】
なお、リタイアメント時の測定に関連してプッシュアウトの測定が参照されてきた。しかし、プッシュアウトは、フェッチ、デコード、イシュー、メモリーオペレーションのメモリーオーダリングバッファへの割り当て、およびメモリーオペレーションのグローバルな可視性のような、アウトオブオーダマシンにおける他のインオーダ渋滞ポイント(choke points)で測定されてよい。
【0042】
全体実行時間
【0043】
局所的なストールコストは、パラレルで行われる他のワークによって部分的にまたは完全にカバーできる。領域的な遅延を捕捉するリタイアメントプッシュアウトもまた、リタイアメントプッシュアウトが測定される時点でまだ進行中のワークまたは他のストールによって部分的にまたは完全にカバーできる。カバーされる一方向リタイアメントプッシュアウトは、上述のように図1に示す。所定オペレーションのストールがプログラムのクリティカルパスに与える寄与の究極の測定は、そのストール原因に起因して発生する実行レイテンシの変化である。
【0044】
グローバルなクリティカルパスに対する平均的な増分寄与の一つの指標は、プログラムの実行全体またはロングトレースを測定することすなわちロングトレース実行モニタリングである。このアプローチは、パイプラインのどこかで発生するクリティカルパスへの寄与をカバーし、他のパラレリズムが局所的な遅延をカバーするという事実を考慮に入れている。増分寄与は、実行時間を変化させるイベントのインスタンス数を変化させること、および、実行時間の変化をイベント数の変化で割って計算することによって導出される。例えば、キャッシュサイズの増加が、キャッシュミス数を100から90まで落ち、かつ、実行時間が2000から1600まで落ちると、増分寄与は、(2000−1600)/(100−90)=40サイクル/ミスとなる。
【0045】
この技術を実装するには複数の方法がある。第一に、マイクロベンチマークの2つのバージョンが形成される。一方はイベントを備え、他方は備えない。第二に、シミュレータ設定がイベントを導入または除去するように変更される。シミュレーションは、一つ以上のプログラムに対して両方の設定で実行される。イベント数と全実行時間との両方が各ケースに対して記録される。最後に、いくつかの製品は、分岐ターゲットアレイのサイズを縮小することまたはポリシーを変更することのような、シリコンデフィーチャをサポートする。これは、例えば、分岐予測速度に影響を与えるために使用される。
【0046】
上述のように、マイクロアーキテクチャフィーチャの寄与、すなわちイベントコストを決定することは、以下を介して行われる。(1)解析上の評価、(2)性能モニタからのデュレーションカウント、(3)ハードウェア性能モニタによりおよびシミュレータにより測定されるようなリタイアメントプッシュアウト、ならびに(4)マイクロベンチマーク、シミュレーション、およびシリコンデフィーチャによって測定されるような全体実行時間の変化。しかし、性能モニタリングおよびクリティカルパスへの寄与の決定は、上述の方法の一つの直接的な実施例に限られない。むしろ、任意の組み合わせが使用されてクリティカルパスへのシリコンフィーチャに係るイベントの寄与が解析される。
【0047】
所定イベントに対するインスタンス当たりのコストの例
【0048】
様々なイベントのインスタンス当たりのコストを評価するべく、インスタンス当たりの寄与の解析のセクションで説明した技術が使用される。もちろん、トレースの包括的なCPI内訳に対しては多数の寄与が存在する。4つの顕著な寄与が選択されて、説明された技術のそれぞれの効果が実証される。しかし、4つの各イベントに対しては、その技術の全てを使用することが必ずしも可能または好都合とは限らない。例えば、性能モニタリングのデュレーションカウントは、考慮中のイベントに対して利用可能ではない。同様に、シミュレータのサイズまたはポリシーを調整することによって実行をかく乱させることは、イベントの発生数に影響を与えること、または、所定トレースの実行時間を変化させることがない。表1は、これら4つの要因のそれぞれに対して、シミュレーションされた実行のかく乱に基づいて評価されたコストの概要を示す。全体的なシミュレーション結果に基づくインパクトの分散指標が与えられる。
【表1】
【0049】
分岐予測ミス
【0050】
分岐予測ミスは、アプリケーションがスローダウンする一般的な原因である。これにより、プロセッサパイプラインの再起動が強制され、投機的なワークが放棄される。分岐予測器は、時を経るにつれて段々正確になる。それにもかかわらず、深く広いパイプラインでは、予測ミスは、有用なワークを完了する機会を相当に喪失する原因となる。
【表2】
【0051】
分岐予測ミスコストの解析上の測定値は、遅延のサイクル数(31)である。分岐予測ミスは通常、実行時に遅延のサイクル数から検知される。通常、命令がトレースキャッシュからフェッチされて実行に戻る。解析上の視点は、マシンのフロントエンドで発生する実遅延を測定する。この遅延は、分岐条件を評価するときになんらかの遅延が存在する場合に、リソース障害または未解決のデータ依存に起因して、特にその依存がキャッシュミスを受けたロードに対する場合に、増加する。マイクロベンチマーク、HWリタイアメントプッシュアウト、およびシミュレーションされたリタイアメントプッシュアウトに見られるように、リタイアメントプッシュアウト遅延が30台半ばから40台になるのは、これらの理由による。表2において、HWリタイアメントプッシュアウトに対しては3つの値を示す。ここで使用されたマイクロベンチマークは、条件分岐を備えるがメモリ参照はしないループボディを有していた。35サイクルの場合と比べて28%多くの分岐が36の遅延を有し、27%多くの分岐が、30のサイクルに対して40の遅延を有し、および43%多くの分岐が40サイクルに対して41の遅延を有していた。マイクロベンチマークは、解析上のモデルに極めて近似する。これは、マイクロベンチマークはほとんどパラレルワークを含まず、複雑なクリーンアップが必要ないからである。
【0052】
しかし、図1に示すように、命令106が分岐予測ミスを有する場合、フロントエンドにおける遅延は、マシンのバックエンドに初期のリタイアメントプッシュアウトがあったとしても、なんらインパクトを与えない。また、後のキャッシュミスは、クリティカルパスへの分岐の寄与を著しく大きな遅延によって消し去る。これは、クリティカルパス全体への平均的な寄与がリタイアメントプッシュアウトよりも著しく低い一つの理由である。クリティカルパスへのシミュレーションされた全体的な寄与は、間接分岐予測器を無効にすることによって導出されるので、最後のターゲットを予測するのみである。さらに、実際のアプリケーションでは、オフパスコードが、有用なデータプリフェッチャおよび、予測ミスのインパクトを低減するDTLBルックアップの役割を果たす場合が多い。最後に、一つの予測ミスの処理を第2の予測ミスの処理に重複させることにより、クリティカルパス全体への平均的な寄与が減少する。
【0053】
この説明から、クリティカルパスへの実際の平均的な寄与がコンテキストに高度に依存し、リタイアメントプッシュアウトがインスタンス当たりのコストを過大評価することは明らかである。約70%のようなスケールファクタが、インスタンス当たりのコストの中央値を導出するべくHW測定リタイアメントプッシュアウトに適用される。なお、このイベントコストは、特定のマイクロアーキテクチャ、および、同一のマイクロアーキテクチャファミリ内の同等な実施例に高度に依存する。
【0054】
第1レベル(L1)キャッシュミス
【0055】
第1レベルキャッシュミスは一般的に発生する。アウトオブオーダプロセッサは、命令ストリームの独立したワークを見出して、そのミスを第2レベルキャッシュにサービスアウトする間プロセッサをビジーに維持すべく設計される。その結果、局所的なL1ミスコスト(例えばリタイアメントプッシュアウト)の小部分のみがクリティカルパス全体に寄与する。
【表3】
【0056】
ここでの解析上のモデルは、通常のロード対ユースコスト(normal load−to−use cost)のトップにおけるL1ミスのオーバヘッドを記述する。このイベントのためのマイクロベンチマークは、18サイクルオーバヘッドの一様分布に遭遇するポインタ追跡ループからなる。全てのL1ミスイベントに対するハードウェアリタイアメントプッシュアウトに−50%のスケールファクタが適用されて、インスタンス当たりのコストの中央値が定まる。
【0057】
第2レベル(L2)キャッシュミス
【0058】
第2レベルキャッシュミスは、より高レベルのキャッシュまたはメモリコントローラ/DRAMのいずれかに送り出される。アウトオブオーダプロセッサは、独立した複数のL2キャッシュミスを見つけ出して、これら長いトランザクションの処理をパイプライン化するように設計される。
【表4】
【0059】
キャッシュミスの解析上の測定値は、ストリーミングDRAMページヒットを伴う306クロックである。これは、3.4GHzプロセッサ上の800MHzのFSBを備える90nsのDRAMによって計算される。マイクロベンチマークは単純なポインタ追跡コードからなり、解析上のモデルと良好に相関する。このカーネルは、DTLBにおいてヒットするように設計されるが、ハードウェアプリフェッチャからの利益をなんらもたらさない。これは、所定のレイテンシを隠すパラレルワークを行う必要がほとんどなく、また、各ロードがDRAMに即座に送り出されるのを防止する独立したワークを行う必要がほとんどないからである。リタイアメントプッシュアウトおよびシミュレーションされた実行は全て結果的には、解析上の値よりも小さなインスタンス当たりのコストとなる。実際、シミュレーションされた実行については、インスタンス当たりのコストが、トレースにわたって広い分散を示し、解析上の値よりも短いのと長いのとの両方になる。明らかなことだが、スペクトルの短いレイテンシ側端部上には、オーバラップされたDRAMアクセスからの利益がある。インスタンス当たりのより長いレイテンシは、プロセッサメモリ要求のキュー深さ制限およびバス帯域幅不足を含むいくつかの態様で発生する。
【0060】
ハードウェアプリフェッチャは、このレイテンシにおいて非常に重要な役割を果たす。適切にスロットル制御されている間、これは多数の要求をメモリシステムに挿入する能力を有し、これによりその後のデマンドロードのレイテンシが増加する。スペクトルの他端において時々あるのは、プリフェッチャが、より若いロードのミスを回避できないほど遅いが、その若いロードの時刻においてデータをDRAMからの途中にしておくには十分早くプリフェッチを開始することである。この結果、インスタンス当たりの有効なミスのコストが減る。一般に、インスタンス当たりのコストの中央値は、HWリタイアメントプッシュアウト測定値に酷似する。
【0061】
上述で示唆したように、コストのバリエーションは、アプリケーションドメインにわたり著しく様々である。したがって、所定アプリケーションに対するコストを測定するためのインフィールドメカニズムを潜在的に有することは、特定のフィーチャの寄与を決定する上で極めて有用となる。このバリエーションに鑑み、マイクロアーキテクチャは、アプリケーション当たりの基準でチューニングされる。
【0062】
マイクロアーキテクチャのチューニング
【0063】
マイクロアーキテクチャは、例えばリタイアメントプッシュアウト測定、および、インスタンス当たりのイベントコストを決定するための全体実行時間測定の間にチューニングされる。しかし、マイクロアーキテクチャは、インスタンス当たりのイベントコストに応じてもチューニングされる。マイクロアーキテクチャフィーチャまたはマイクロアーキテクチャのチューニングは、マイクロアーキテクチャ内のポリシーの変更だけではなく、サイズ、ロジックの有効または無効、フィーチャ、および/またはマイクロアーキテクチャ内のユニットの変更も含む。
【0064】
一実施例において、チューニングは、マイクロアーキテクチャフィーチャの寄与すなわちインスタンス当たりの寄与に基づいて行われる。第一例では、どのアクションがクリティカルパスのレイテンシを低減するかに基づいて、フィーチャのサイズが変更され、フィーチャが有効にされ、フィーチャが無効にされ、または、フィーチャに関連するポリシーが変更される。別例では、電力のような他の考慮が使用されてマイクロアーキテクチャがチューニングされる。この例では、フィーチャを無効にすることは、レイテンシをわずかな量だけ増加させる。しかし、フィーチャの性能上の利益がわずかであること、および、フィーチャを無効にすることが著しく電力を節約することの決定に基づいて、フィーチャはチューニング、例えば無効化される。
【0065】
実験に基づく例では、以前のアーキテクチャについて注目されたのは、いくつかのマイクロワークロードにおいて著しい数のエイリアシングコンフリクトが認識されたということである。エイリアシングコンフリクトが発生した例の一つは、マルチスレッド間での同じキャッシュラインへのアクセスであった。
【0066】
ソフトウェアスレッドは、別のスレッドから独立して操作可能に実行されるプログラムの少なくとも一部である。ハードウェアでのマルチスレッド化までもサポートするマイクロプロセッサもあるが、この場合、プロセッサは、マルチソフトウェアスレッドの実行を独立してスケジュール化するべく、完全かつ独立のアーキテクチャ状態レジスタの少なくとも複数のセットを有する。しかし、これらのハードウェアスレッドは、キャッシュのようないくつかのリソースを共有する。以前は、マルチスレッドによってキャッシュ内の同じラインにアクセスすることは結果的に、キャッシュラインの置換および局所性の低減となった。したがって、スレッド用データメモリの開始アドレスは、スレッド間のキャッシュのライン置換を回避するべく異なる値に設定された。
【0067】
図3を参照すると、プロセッサ205内のモジュール215の所定実施例が示される。モジュール215は、クリティカルパスへのマイクロアーキテクチャフィーチャの寄与に少なくとも基づいて、ユーザレベルのアプリケーションのためのマイクロアーキテクチャフィーチャをチューニングする。
【0068】
このタイプのチューニングの特に具体的な例は以下を含む。アプリケーション実行中のハードウェアプリフェッチャの性能モニタリング、または、ガベージコレクションのようなアプリケーションのフェイズ。ガベージコレクションは、ハードウェアプリフェッチャが有効な状態で実行され、その後無効にされる。いくつかの例では、ガベージコレクションは、ハードウェアプリフェッチャなしでも良好に機能することがわかっている。したがって、ガベージコレクションアプリケーションの実行に際してマイクロアーキテクチャがチューニングされてハードウェアプリフェッチャが無効にされてもよい。
【0069】
性能解析に基づくポリシー変更のその他の例は以下を含む。プリフェッチのアグレッシブ性、同時スレディングマシンにおける異なるスレッドに対するリソースの相対的アロケーション、投機的ページウォーク、TLBに対する投機的更新、および、分岐とメモリ依存とに対する予測メカニズムの選択。
【0070】
図3は、マイクロアーキテクチャフィーチャ、すなわち、メモリサブシステム220、キャッシュ350、フロントエンド225、分岐予測355、フェッチ360、実行ユニット235、キャッシュ350、実行ユニット355、アウトオブオーダエンジン230、および、リタイアメント365を示す。マイクロアーキテクチャフィーチャのその他の例は以下を含む。命令キャッシュ、データキャッシュ、分岐ターゲットアレイ、仮想メモリテーブル、レジスタファイル、変換テーブル、ルックアサイドバッファ、分岐予測ユニット、間接分岐予測器、ハードウェアプリフェッチャ、実行ユニット、アウトオブオーダエンジン、アロケータユニット、レジスタリネーミングロジック、バスインターフェイスユニット、フェッチユニット、デコードユニット、アーキテクチャ状態レジスタ、実行ユニット、浮動小数点実行ユニット、整数実行ユニット、ALU、および、その他の一般的なマイクロプロセッサフィーチャ。
【0071】
上述のように、マイクロアーキテクチャフィーチャをチューニングすることは、マイクロアーキテクチャフィーチャを有効または無効にすることを含む。上述からのハードウェアプリフェッチャに関する例と同様に、プリフェッチャは、寄与が強化されるすなわち良好になると決定されると無効にされる。このとき、そのフィーチャは、所定のソフトウェアプログラムの実行中に無効にされる。
【0072】
ユーザレベルアプリケーションに対するクリティカルパスへのマイクロアーキテクチャの寄与を決定する一つの方法は、ユーザレベルアプリケーションをマイクロアーキテクチャフィーチャを有効にしたままで実行することである。次に、マイクロアーキテクチャフィーチャを無効にしたままでユーザレベルアプリケーションを実行する。最後に、ユーザレベルアプリケーションに対するクリティカルパスへのマイクロアーキテクチャフィーチャの寄与が、フィーチャ有効のままのユーザレベルアプリケーションの実行と、フィーチャ無効のままのユーザレベルアプリケーションの実行との比較に基づいて決定される。単純には、ユーザレベルアプリケーションが実行されるたびに全体実行時間を測定することにより、どの全体実行時間が適しているか、有効または無効なフィーチャに関する全体時間が決定される。
【0073】
具体的な例として、モジュール215はデフィーチャレジスタ305を含む。デフィーチャレジスタ305は、フィールド310−335のような複数のフィールドを含む。フィールドは個別のビットでよく、または、各フィールドは複数のビットを有してよい。さらに、各フィールドは操作可能にマイクロアーキテクチャフィーチャをチューニングする。すなわち、フィールドは、フィールド310が分岐予測355に、フィールド315がフェッチ360に、フィールド320がキャッシュ350に、フィールド325がリタイアメントロジック365に、フィールド330が実行ユニット355に、および、フィールド335がキャッシュ350にというように、マイクロアーキテクチャフィーチャに関連する。フィールド310のようなフィールドの一つがセットされると分岐予測355は無効にされる。
【0074】
例えばソフトウェアプログラムのような、モジュール215に埋め込まれた、またはモジュール215の一部の、モジュール215に関連する別のモジュールは、無効時のクリティカルパスへのそのフィーチャの性能寄与が上述のように強化される場合、例えばフィールド310のようなフィールドをセットする。上述からわかるように、モジュール215はハードウェア、ソフトウェア、もしくはそれらの組み合わせでよく、またはモジュール210に関連するかもしくは部分的にオーバラップする。例えば、モジュール210の機能性の一部として、ユーザレベルプログラム実行中の分岐予測355の寄与を決定するべく、モジュール215に図示されるレジスタ305が使用されて例えば分岐予測355のようなプロセッサ205のフィーチャをチューニングするかまたは無効にする。
【0075】
別の実施例においては、デフィーチャすなわちチューニングは、フィーチャの物理的または仮想的なサイズ変更を含む。上述の例の別例として、ユーザレベルアプリケーションの実行を強化すべく分岐予測355の寄与が示される場合は、それに応じて分岐予測355のサイズがフィールド310を介して増加/減少される。以下の例は、プロセッサをチューニングする能力と、キャッシュミスのようなフィーチャまたはイベントの寄与をキャッシュのサイズをチューニングすることによって見出す能力との両方を示す。
【0076】
ソフトウェアのチューニング
【0077】
図4を参照して、プロセッサモニタリング性能およびソフトウェアのチューニングの実施例を示す。図2および図3に示すプロセッサ205に類似するプロセッサ405は、プロセッサに関連する任意の既知のロジックを有する。図示のように、プロセッサ405は以下のユニット/フィーチャを含む。メモリサブシステム420、フロントエンド425、アウトオブオーダエンジン430、および実行ユニット435。これら機能ブロックの各々の中には、その他多数のマイクロアーキテクチャフィーチャが存在する。例えば、第2レベルキャッシュ421、フェッチ/デコードユニット427、分岐予測426、リタイアメント431、第1レベルキャッシュ436、および実行ユニット437である。
【0078】
上述のように、モジュール410は、ソフトウェアプログラム実行に対するクリティカルパスにおけるインスタンス当たりのイベントコストを決定する。上述からインスタンス当たりのイベントコストを導出する例は、デュレーションカウント、リタイアメントプッシュアウト測定、およびロングトレース実行測定を含む。ここで繰り返すが、モジュール410およびモジュール415は、それらの機能性、ハードウェア、ソフトウェア、またはハードウェアとソフトウェアとの組み合わせがオーバラップするので、ぼやけた境界を有していてよい。
【0079】
モジュール415がフィーチャとのインターフェイスを有することによってマイクロアーキテクチャをチューニングした図3とは対照的に、モジュール415はクリティカルパスにおけるインスタンス当たりのイベントコストに基づいてソフトウェアプログラムをチューニングする。モジュール415は、プロセッサ405上で実行するコードをコンパイルおよび/またはインタプリトするための任意のハードウェア、ソフトウェア、またはそれらの組み合わせを含む。一実施例において、モジュール415は、プログラムのその後のラン(subsequent run)で実行されるコードを再コンパイルして上述のマイクロアーキテクチャフィーチャを利用するが、その頻度は、インスタンス当たりの決定されたイベントコストに基づいて最初にコンパイルされていたコードと比べて多いかまたは少ない。別の実施例において、モジュール415はプログラムの同じラン(same run)の残りに対して異なった態様でコードをコンパイルする。すなわち、動的なコンパイルまたは再コンパイルが使用されて所定のワークロードおよびプラットフォーム上の実行時間が改善される。
【0080】
マイクロアーキテクチャをチューニングすることができることに加え、上述のように、アプリケーションをチューニングしてそのプラットフォーム上でそれが最適に実行されるようにすることによって良好な性能が達成される。ソフトウェアのチューニングはコードを最適化することを含む。アプリケーションのチューニングの一例は、ソフトウェアプログラムの再コンパイルである。ソフトウェアのチューニングはまた以下を含む。キャッシュ内にフィットするブロックデータ構造にソフトウェア/コードを最適化すること、コードを再レイアウトして分岐予測器テーブルリソースの使用を必要としないデフォルト分岐予測条件を有効利用すること、異なる命令アドレスにおいてコードを放出して、分岐予測構造およびコードキャッシュ化構造の局所性管理の問題を引き起こしかねない所定のエイリアシング条件およびコンフリクト条件を回避すること、動的に割り当てられたメモリのまたはスタック(スタックアライメントを含む)のデータを再レイアウトして、キャッシュラインのスパニングが招くペナルティを回避すること、ならびに、アクセスの粒度およびアライメントを調整してストア・フォワーディング問題を回避すること。
【0081】
ソフトウェアのチューニングの具体例として、ソフトウェア450はプロセッサ405とともに/プロセッサ405上で実行される。モジュール410は、例えば分岐予測ロジック426内の分岐予測ミスのコストのような、インスタンス当たりのイベントコストを決定する。この解析に基づき、モジュール415は、ソフトウェア450をソフトウェア460に再レイアウトする。ソフトウェア460は同じユーザレベルアプリケーションであるが、再レイアウトされてプロセッサ405上で異なった態様で実行される。この例では、ソフトウェア460は再レイアウトされて、デフォルト分岐予測条件がより有効利用される。したがって、ソフトウェア460は再コンパイルされて、分岐予測426を異なった態様で利用する。他の例は以下を含む。コードで命令を実行して分岐予測ロジック426を無効にすること、および、分岐予測ロジック426によって使用されるソフトウェアヒントを変更すること。
【0082】
性能モニタリングのためのシステム
【0083】
次に図5を参照して、性能モニタリングを使用するシステムを示す。プロセッサ505はコントローラハブ550に接続され、コントローラハブ550はメモリ560に接続される。コントローラハブ550は、メモリコントローラハブまたはチップセットデバイスの他の部分であってよい。いくつかの例では、コントローラハブ550は、ビデオコントローラ555のような統合型ビデオコントローラを有する。しかし、ビデオコントローラ555はまた、コントローラハブ550に接続されたグラフィックスデバイス上にあってもよい。なお、示されるデバイスの各々の間には、その他のコンポーネント、インタコネクト、デバイス、および回路が存在する。
【0084】
プロセッサ505はモジュール510を含む。モジュール510は、ソフトウェアプログラム実行中のインスタンス当たりのイベント寄与を決定し、そのインスタンス当たりのイベント寄与に基づいてマイクロプロセッサ505のアーキテクチャ設定をチューニングし、そのアーキテクチャ設定をストアし、そのストアされたアーキテクチャ設定に基づきそのソフトウェアプログラムのその後の実行においてアーキテクチャ設定を再チューニングする。
【0085】
具体例として、モジュール510は、寄与モジュール511を利用し、オペレーティングシステムのようなソフトウェアプログラムの実行中のイベント寄与を決定する。ソフトウェアプログラムの他の例は以下を含む。ゲストアプリケーション、オペレーティングシステムアプリケーション、ベンチマーク、マイクロベンチマーク、ドライバ、および組み込みアプリケーション。この例に対しては、第1レベルキャッシュ536に対するミスのようなイベント寄与を仮定することは実行に著しい影響を与えるわけではなく、キャッシュ536はサイズが低減されて、クリティカルパスにおける実行時間に影響を与えることなく電力が節約される。したがって、チューニングモジュール512は、第1レベルキャッシュ536のサイズを低減することによってプロセッサ505のアーキテクチャをチューニングする。チューニングは、上述のようにして、プロセッサ505内の異なるフィーチャに関連するフィールドをレジスタが有したまま行われる。レジスタが使用される場合、アーキテクチャ設定をストアすることは、ストレージ513にレジスタ値をストアすることを含む。ストレージ513は、メモリ560のような単なる別のレジスタまたはメモリデバイスである。ソフトウェアプログラムのその後の実行において、性能モニタリングステップは繰り返す必要がなく、以前にストアされた設定がロードされる。したがって、アーキテクチャは、ストアされた設定に基づいてソフトウェアプログラム用に再チューニングされる。
【0086】
性能モニタリングの方法
【0087】
図6aは、性能をモニタリングしマイクロプロセッサをチューニングするためのフローチャートの実施例を示す。フロー605において、マイクロプロセッサを使用する第1ソフトウェアプログラムが実行される。一実施例において、マイクロプロセッサは、アウトオブオーダパラレル実行が可能である。次に、フロー610において、第1ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストが決定される。
【0088】
図6bを参照して、イベントコストを決定し、マイクロプロセッサをチューニングする例を示す。イベントコストは、フロー611に示すデュレーションカウント、フロー612に示すリタイアメントプッシュアウト、および/または、フロー613に示す全体実行時間を解析することによって決定される。なお、これらの方法の任意の組み合わせが使用されてイベントコストが決定される。
【0089】
マイクロプロセッサにおける一般的なイベントのいくつかの例は以下を含む。低レベルキャッシュミス、セカンダリキャッシュミス、高レベルキャッシュミス、キャッシュアクセス、キャッシュスヌープ、分岐予測ミス、メモリからのフェッチ、リタイアメントにおけるロック、ハードウェアプリフェッチ、ロード、ストア、ライトバック、命令デコード、アドレス変換、変換バッファへのアクセス、整数演算実行、浮動小数点演算実行、レジスタのリネーミング、命令のスケジューリング、レジスタのリード、および、レジスタのライト。
【0090】
図6aを参照すると、フロー615において、マイクロプロセッサは、第1ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストに基づいてチューニングされる。チューニングは、性能強化のためのマイクロアーキテクチャおよび/または実行時間に対する任意の変更を含む。図6bに戻り、チューニングの一例は、フロー617のようなマイクロアーキテクチャフィーチャの有効化または無効化を含む。フィーチャのいくつかの具体例は以下を含む。キャッシュ、変換テーブル、変換ルックアサイドバッファ(TLB)、分岐予測ユニット、ハードウェアプリフェッチャ、実行ユニット、および、アウトオブオーダエンジン。別例は、フロー616のようなマイクロアーキテクチャフィーチャのサイズまたは使用頻度の変更を含む。さらなる別例では、マイクロプロセッサのチューニングは、例えばハードウェアプリフェッチャを利用しないことのような、異なった態様でプロセッサを利用すべく実行されるソフトウェアプログラムのチューニング/コンパイルを含む。
【0091】
これまでのところ、性能モニタリングおよびチューニングが、性能モニタリングを記述するシングルソフトウェアプログラムを参照して説明されてきた。しかし、性能モニタリングおよびチューニングは、プロセッサ上で実行される任意数のアプリケーションによって実装できる。図6cは、第2プログラム用のアーキテクチャをプロファイリング/チューニングするためのフローチャートの実施例を示す。第1アプリケーションを再びロードするときにマイクロプロセッサは再チューニングされる。
【0092】
フロー605−615は、図6aに示すものと同じである。フロー620において、第1ソフトウェアプログラムに関連するマイクロプロセッサのチューニングを表す第1設定がストアされる。第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストがフロー625において決定される。フロー630において、第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストに基づいてマイクロプロセッサがチューニングされる。最後に、フロー635で、第1ソフトウェアプログラムのその後の実行のときに、ストアされた第1設定に基づいてマイクロプロセッサが再チューニングされる。
【0093】
上述からわかるように、個々のアプリケーションの性能に基づいてマイクロプロセッサが動的にチューニングされる。プロセッサの所定フィーチャは異なった態様で利用され、かつ、キャッシュミスのようなイベントのコストはアプリケーションごとに著しく様々であるが、マイクロアーキテクチャおよび/またはソフトウェアアプリケーション自体がより効率的かつ迅速に実行されるべくチューニングされる。フィーチャのイベントコストおよび寄与は、解析方法、シミュレーション、リタイアメントプッシュアウトの測定、および、特にパラレル実行マシンに対して正しい性能がモニタリングされていることを保証する全体実行時間の任意の組み合わせによって測定される。
【0094】
前述の明細書において、本発明がその所定実施例を参照して説明されてきた。しかし、それに対しては、添付の請求項に記載される本発明のより広い要旨および範囲から逸脱することなく、様々な修正および変更がなし得ることは明らかである。したがって、明細書および図面は、限定的な意味ではなく説明的な意味とみなすべきである。
【図面の簡単な説明】
【0095】
【図1】シングルイシューマシンにおける複数のオペレーションに対するフェッチ、実行、およびリタイアメントの実施例を示す。
【図2】第1性能モニタリングモジュールおよび第2マイクロアーキテクチャチューニングモジュールを含むプロセッサの実施例を示す。
【図3】図2の具体的な実施例を示す。
【図4】静的または動的にソフトウェアを再コンパイルするためのモジュールを含むプロセッサの実施例を示す。
【図5】性能をモニタリングし、かつ、プロセッサのマイクロアーキテクチャをチューニングするためのモジュールを有するプロセッサを含むシステムの実施例を示す。
【図6a】性能をモニタリングし、性能に基づいてマイクロプロセッサをチューニングするためのフローチャートの実施例を示す。
【図6b】図6aの具体的な実施例を示す。
【図6c】性能をモニタリングし、マイクロプロセッサをチューニングするための別の実施例を示す。
【図7】所定イベントの発生時にリタイアメントプッシュアウトを測定するための実施例を示す。
【特許請求の範囲】
【請求項1】
一のマイクロプロセッサを使用する一の第1ソフトウェアプログラムを実行することと、
前記第1ソフトウェアプログラムの実行に関連する一のクリティカルパスへの一のイベントコストを決定することと、
前記第1ソフトウェアプログラムの実行に関連する前記クリティカルパスへの前記イベントコストに基づいて前記マイクロプロセッサをチューニングすることと
を含む方法。
【請求項2】
前記マイクロプロセッサはアウトオブオーダパラレル実行可能な、請求項1に記載の方法。
【請求項3】
前記マイクロプロセッサをチューニングすることは、一の命令キャッシュ、一のデータキャッシュ、一の分岐ターゲットアレイ、一の仮想メモリテーブル、および一のレジスタファイルからなる一のグループから選択される一のマイクロアーキテクチャフィーチャのサイズを変更することを含む、請求項1に記載の方法。
【請求項4】
前記マイクロプロセッサをチューニングすることは、一のキャッシュ、一の変換テーブル、一のルックアサイドバッファ、一の分岐予測ユニット、一のハードウェアプリフェッチャ、および一の実行ユニットからなる一のグループから選択される一のマイクロアーキテクチャフィーチャを無効にすることを含む、請求項1に記載の方法。
【請求項5】
前記第1ソフトウェアプログラムに関連するマイクロプロセッサのチューニングを表す一の第1設定をストアすることと、
一の第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストを決定することと、
前記第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストに基づいて前記マイクロプロセッサをチューニングすることと、
前記ストアされた第1設定に基づいて、前記第1ソフトウェアプログラムのその後の実行のときに前記マイクロプロセッサを再チューニングすることと
をさらに含む、請求項1に記載の方法。
【請求項6】
前記第1および第2ソフトウェアプログラムの各々は、一のゲストアプリケーション、一のオペレーティングシステム、一のオペレーティングシステムアプリケーション、一のベンチマークアプリケーション、一のドライバ、および一の組み込みアプリケーションからなる一のグループから選択される、請求項5に記載の方法。
【請求項7】
前記一のクリティカルパスへの一のイベントコストを決定することは、一のデュレーションカウントを実行することを含む、請求項1に記載の方法。
【請求項8】
前記一のデュレーションカウントを実行することは、前記マイクロプロセッサ内の一の状態マシンがアクティブである複数のサイクルのカウンティングを含み、前記状態マシンは、一のページウォークハンドラ、一のロック状態マシン、および未決の複数のキャッシュミスの一のバスキューからなる一のグループから選択される、請求項7に記載の方法。
【請求項9】
前記一のクリティカルパスへの一のイベントコストを決定することは、複数のオペレーションの複数のリタイアメントプッシュアウトを測定することを含む、請求項1に記載の方法。
【請求項10】
前記複数のオペレーションの複数のリタイアメントプッシュアウトを測定することは、複数のオペレーションの一のシーケンシャルペアのリタイアメントにおける一の遅延を測定することを含む、請求項9に記載の方法。
【請求項11】
前記複数のオペレーションの複数のリタイアメントプッシュアウトを測定することは、一の所定イベントを有していた一のオペレーションに対する一のリタイアメント遅延を測定することを含む、請求項9に記載の方法。
【請求項12】
前記イベントは、一の低レベルキャッシュミス、一のセカンダリキャッシュミス、一の高レベルキャッシュミス、一のキャッシュアクセス、一のキャッシュスヌープ、一の分岐予測ミス、メモリからの一のフェッチ、リタイアメントにおける一のロック、一のハードウェアプリフェッチ、一のロード、一のストア、一のライトバック、一の命令デコード、一のアドレス変換、一の変換バッファへの一のアクセス、一の整数演算実行、一の浮動小数点演算実行、一のレジスタの一のリネーミング、一の命令の一のスケジューリング、一のレジスタリード、一のレジスタライトからなる一のグループから選択される、請求項11に記載の方法。
【請求項13】
パラレル実行のできる一のプロセッサ内で実行される一のオペレーションを一の所定イベント発生のときにタギングすることと、
前記オペレーションに対する一のリタイアメントプッシュアウトを決定することと
を含む方法。
【請求項14】
前記一のオペレーションをタギングすることは、前記所定イベント発生のときに前記オペレーションをサンプリングするべく選択することを含む、請求項13に記載の方法。
【請求項15】
前記一のオペレーションをタギングすることは、前記所定イベント発生かつ一の第2イベント非発生のときに前記オペレーションをサンプリングするべく選択することを含む、請求項13に記載の方法。
【請求項16】
前記所定イベントは、一のキャッシュミス、一のキャッシュアクセス、一のキャッシュスヌープ、一の分岐予測ミス、リタイアメントにおける一のロック、一のハードウェアプリフェッチ、一のロード、一のストア、一のライトバック、および一の変換バッファへのアクセスからなる一のグループから選択される、請求項14に記載の方法。
【請求項17】
前記所定イベントは、リタイアメントイベントにおける一のプリサイスイベントに基づくサンプリングである、請求項14に記載の方法。
【請求項18】
前記オペレーションに対する一のリタイアメントプッシュアウト遅延を決定することは、
前記オペレーションをサンプリングするべく選択するときに一の第1カウンタを初期化することと、
前記第1カウンタの初期化および一のストレージレジスタの使用に基づいて前記リタイアメントプッシュアウトを決定することと
を含む、請求項14に記載の方法。
【請求項19】
前記第1カウンタの初期化は、前記第1カウンタを一のユーザ定義値にセットすることを含み、一のストレージレジスタの使用は、前記第1カウンタによって前記リタイアメントプッシュアウトを測定するときに、前記第1カウンタの一の状態を、読み出して前記リタイアメントプッシュアウトを決定するべく前記ストレージレジスタ内にコピーすることを含む、請求項18に記載の方法。
【請求項20】
一のユーザレベルアプリケーションに対する一のマイクロアーキテクチャフィーチャの一の寄与を決定する一の第1モジュールと、
前記ユーザレベルアプリケーションが実行されるときに少なくとも前記マイクロアーキテクチャフィーチャの寄与に基づいて前記マイクロアーキテクチャフィーチャをチューニングする一の第2モジュールと
を含む一のマイクロプロセッサを含む装置。
【請求項21】
一のユーザレベルアプリケーションに対する一のマイクロアーキテクチャフィーチャの一の寄与を決定することは、
前記マイクロアーキテクチャフィーチャが有効なまま前記ユーザレベルアプリケーションを実行することと、
前記マイクロアーキテクチャフィーチャが無効なまま前記ユーザレベルアプリケーションを実行することと、
前記フィーチャが有効なままでの前記ユーザレベルアプリケーションの実行と、前記フィーチャが無効なままでの前記ユーザレベルアプリケーションの実行との比較に基づいて前記ユーザレベルアプリケーションに対する前記マイクロアーキテクチャフィーチャの寄与を決定することと
を含む、請求項20に記載の装置。
【請求項22】
前記マイクロアーキテクチャフィーチャをチューニングすることは、前記マイクロアーキテクチャフィーチャのサイズを変更することを含み、前記マイクロアーキテクチャフィーチャは、一の命令キャッシュ、一のデータキャッシュ、一の分岐ターゲットアレイ、一の仮想メモリテーブル、および一のレジスタファイルからなる一のグループから選択される、請求項20に記載の装置。
【請求項23】
前記マイクロアーキテクチャフィーチャをチューニングすることは、前記マイクロアーキテクチャフィーチャを無効にすることを含み、前記マイクロアーキテクチャフィーチャは、一の命令キャッシュ、一のデータキャッシュ、一の変換テーブル、一のルックアサイドバッファ、一の分岐予測ユニット、一のハードウェアプリフェッチャ、および一の実行ユニットからなる一のグループから選択される、請求項20に記載の装置。
【請求項24】
前記マイクロアーキテクチャフィーチャをチューニングすることは、前記マイクロアーキテクチャフィーチャによって消費される電力の一の量にさらに基づく、請求項20に記載の装置。
【請求項25】
前記第2モジュールは、
前記マイクロアーキテクチャフィーチャに関連する一のフィールドであってセットされると前記マイクロアーキテクチャフィーチャを無効にするフィールドを有する一のレジスタと、
前記マイクロアーキテクチャフィーチャに関連する前記レジスタ内の前記フィールドを、前記フィーチャの性能寄与がその無効時に強化される場合にセットする一のモジュールと
を含む、請求項23に記載の装置。
【請求項26】
一のソフトウェアプログラムの実行に対する一のインスタンス当たりのイベントコストを決定する一のモジュールと、
前記インスタンス当たりのイベントコストに基づいて前記ソフトウェアプログラムをチューニングする一のモジュールと
を含む一のマイクロプロセッサを含む装置。
【請求項27】
一のインスタンス当たりのイベントコストを決定することは、デュレーションカウンティング、リタイアメントプッシュアウト計測、およびロングトレース実行モニタリングからなる一のグループから選択される一の性能モニタリング技術によって前記インスタンス当たりのイベントコストを導出することを含む、請求項26に記載の装置。
【請求項28】
前記ソフトウェアプログラムをチューニングすることは、前記ソフトウェアプログラムを再コンパイルすること、前記ソフトウェアプログラムを最適化すること、前記ソフトウェアプログラムを一のキャッシュ内にフィットする複数のブロックデータ構造に最適化すること、前記ソフトウェアプログラムを一のデフォルト分岐予測条件を有効利用すべく再レイアウトすること、一の異なる命令アドレスにおいてコードを放出すること、動的に割り当てられたメモリ内でデータを再レイアウトすること、ならびに、複数のアクセスの粒度およびアライメントを調整すること、からなる一のグループから選択される、請求項26に記載の装置。
【請求項29】
一のメモリおよび一のビデオコントローラに接続された一のコントローラハブと、
一のソフトウェアプログラム実行中の一のインスタンス当たりのイベント寄与を決定し、前記インスタンス当たりのイベント寄与に基づいてマイクロプロセッサの一のアーキテクチャ設定をチューニングし、前記アーキテクチャ設定をストアし、および、前記ストアされたアーキテクチャ設定に基づいて前記ソフトウェアプログラムのその後の実行のときに前記アーキテクチャ設定を再チューニングする一のモジュールを含むマイクロプロセッサと
を含むシステム。
【請求項30】
前記マイクロプロセッサはアウトオブオーダパラレル実行可能な、請求項29に記載のシステム。
【請求項31】
前記アーキテクチャ設定は前記マイクロプロセッサ内の一のレジスタにストアされる、請求項29に記載のシステム。
【請求項32】
前記一のソフトウェアプログラム実行中の一のインスタンス当たりのイベント寄与を決定することは、
複数の所定イベント発生に対する複数のリタイアメントプッシュアウトを測定することと、
前記複数のリタイアメントプッシュアウトおよび前記所定イベントの発生数に基づいて前記所定イベントに対する前記インスタンス当たりのイベント寄与を導出することと
を含む、請求項29に記載のシステム。
【請求項33】
前記一のソフトウェアプログラム実行中の一のインスタンス当たりのイベント寄与を決定することは、
前記ソフトウェアが実行されるたびごとに、所定イベントの発生回数が変化し、かつ、前記マイクロプロセッサ内の一のクリティカルパスの性能がモニタリングされるように前記ソフトウェアプログラムを複数回実行することと、
前記クリティカルパスの性能の変化と、前記所定イベントの発生回数の変化との比較に基づいて前記所定イベントのインスタンス当たりのイベント寄与を導出することと
を含む、請求項29に記載のシステム。
【請求項1】
一のマイクロプロセッサを使用する一の第1ソフトウェアプログラムを実行することと、
前記第1ソフトウェアプログラムの実行に関連する一のクリティカルパスへの一のイベントコストを決定することと、
前記第1ソフトウェアプログラムの実行に関連する前記クリティカルパスへの前記イベントコストに基づいて前記マイクロプロセッサをチューニングすることと
を含む方法。
【請求項2】
前記マイクロプロセッサはアウトオブオーダパラレル実行可能な、請求項1に記載の方法。
【請求項3】
前記マイクロプロセッサをチューニングすることは、一の命令キャッシュ、一のデータキャッシュ、一の分岐ターゲットアレイ、一の仮想メモリテーブル、および一のレジスタファイルからなる一のグループから選択される一のマイクロアーキテクチャフィーチャのサイズを変更することを含む、請求項1に記載の方法。
【請求項4】
前記マイクロプロセッサをチューニングすることは、一のキャッシュ、一の変換テーブル、一のルックアサイドバッファ、一の分岐予測ユニット、一のハードウェアプリフェッチャ、および一の実行ユニットからなる一のグループから選択される一のマイクロアーキテクチャフィーチャを無効にすることを含む、請求項1に記載の方法。
【請求項5】
前記第1ソフトウェアプログラムに関連するマイクロプロセッサのチューニングを表す一の第1設定をストアすることと、
一の第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストを決定することと、
前記第2ソフトウェアプログラムの実行に関連するクリティカルパスへのイベントコストに基づいて前記マイクロプロセッサをチューニングすることと、
前記ストアされた第1設定に基づいて、前記第1ソフトウェアプログラムのその後の実行のときに前記マイクロプロセッサを再チューニングすることと
をさらに含む、請求項1に記載の方法。
【請求項6】
前記第1および第2ソフトウェアプログラムの各々は、一のゲストアプリケーション、一のオペレーティングシステム、一のオペレーティングシステムアプリケーション、一のベンチマークアプリケーション、一のドライバ、および一の組み込みアプリケーションからなる一のグループから選択される、請求項5に記載の方法。
【請求項7】
前記一のクリティカルパスへの一のイベントコストを決定することは、一のデュレーションカウントを実行することを含む、請求項1に記載の方法。
【請求項8】
前記一のデュレーションカウントを実行することは、前記マイクロプロセッサ内の一の状態マシンがアクティブである複数のサイクルのカウンティングを含み、前記状態マシンは、一のページウォークハンドラ、一のロック状態マシン、および未決の複数のキャッシュミスの一のバスキューからなる一のグループから選択される、請求項7に記載の方法。
【請求項9】
前記一のクリティカルパスへの一のイベントコストを決定することは、複数のオペレーションの複数のリタイアメントプッシュアウトを測定することを含む、請求項1に記載の方法。
【請求項10】
前記複数のオペレーションの複数のリタイアメントプッシュアウトを測定することは、複数のオペレーションの一のシーケンシャルペアのリタイアメントにおける一の遅延を測定することを含む、請求項9に記載の方法。
【請求項11】
前記複数のオペレーションの複数のリタイアメントプッシュアウトを測定することは、一の所定イベントを有していた一のオペレーションに対する一のリタイアメント遅延を測定することを含む、請求項9に記載の方法。
【請求項12】
前記イベントは、一の低レベルキャッシュミス、一のセカンダリキャッシュミス、一の高レベルキャッシュミス、一のキャッシュアクセス、一のキャッシュスヌープ、一の分岐予測ミス、メモリからの一のフェッチ、リタイアメントにおける一のロック、一のハードウェアプリフェッチ、一のロード、一のストア、一のライトバック、一の命令デコード、一のアドレス変換、一の変換バッファへの一のアクセス、一の整数演算実行、一の浮動小数点演算実行、一のレジスタの一のリネーミング、一の命令の一のスケジューリング、一のレジスタリード、一のレジスタライトからなる一のグループから選択される、請求項11に記載の方法。
【請求項13】
パラレル実行のできる一のプロセッサ内で実行される一のオペレーションを一の所定イベント発生のときにタギングすることと、
前記オペレーションに対する一のリタイアメントプッシュアウトを決定することと
を含む方法。
【請求項14】
前記一のオペレーションをタギングすることは、前記所定イベント発生のときに前記オペレーションをサンプリングするべく選択することを含む、請求項13に記載の方法。
【請求項15】
前記一のオペレーションをタギングすることは、前記所定イベント発生かつ一の第2イベント非発生のときに前記オペレーションをサンプリングするべく選択することを含む、請求項13に記載の方法。
【請求項16】
前記所定イベントは、一のキャッシュミス、一のキャッシュアクセス、一のキャッシュスヌープ、一の分岐予測ミス、リタイアメントにおける一のロック、一のハードウェアプリフェッチ、一のロード、一のストア、一のライトバック、および一の変換バッファへのアクセスからなる一のグループから選択される、請求項14に記載の方法。
【請求項17】
前記所定イベントは、リタイアメントイベントにおける一のプリサイスイベントに基づくサンプリングである、請求項14に記載の方法。
【請求項18】
前記オペレーションに対する一のリタイアメントプッシュアウト遅延を決定することは、
前記オペレーションをサンプリングするべく選択するときに一の第1カウンタを初期化することと、
前記第1カウンタの初期化および一のストレージレジスタの使用に基づいて前記リタイアメントプッシュアウトを決定することと
を含む、請求項14に記載の方法。
【請求項19】
前記第1カウンタの初期化は、前記第1カウンタを一のユーザ定義値にセットすることを含み、一のストレージレジスタの使用は、前記第1カウンタによって前記リタイアメントプッシュアウトを測定するときに、前記第1カウンタの一の状態を、読み出して前記リタイアメントプッシュアウトを決定するべく前記ストレージレジスタ内にコピーすることを含む、請求項18に記載の方法。
【請求項20】
一のユーザレベルアプリケーションに対する一のマイクロアーキテクチャフィーチャの一の寄与を決定する一の第1モジュールと、
前記ユーザレベルアプリケーションが実行されるときに少なくとも前記マイクロアーキテクチャフィーチャの寄与に基づいて前記マイクロアーキテクチャフィーチャをチューニングする一の第2モジュールと
を含む一のマイクロプロセッサを含む装置。
【請求項21】
一のユーザレベルアプリケーションに対する一のマイクロアーキテクチャフィーチャの一の寄与を決定することは、
前記マイクロアーキテクチャフィーチャが有効なまま前記ユーザレベルアプリケーションを実行することと、
前記マイクロアーキテクチャフィーチャが無効なまま前記ユーザレベルアプリケーションを実行することと、
前記フィーチャが有効なままでの前記ユーザレベルアプリケーションの実行と、前記フィーチャが無効なままでの前記ユーザレベルアプリケーションの実行との比較に基づいて前記ユーザレベルアプリケーションに対する前記マイクロアーキテクチャフィーチャの寄与を決定することと
を含む、請求項20に記載の装置。
【請求項22】
前記マイクロアーキテクチャフィーチャをチューニングすることは、前記マイクロアーキテクチャフィーチャのサイズを変更することを含み、前記マイクロアーキテクチャフィーチャは、一の命令キャッシュ、一のデータキャッシュ、一の分岐ターゲットアレイ、一の仮想メモリテーブル、および一のレジスタファイルからなる一のグループから選択される、請求項20に記載の装置。
【請求項23】
前記マイクロアーキテクチャフィーチャをチューニングすることは、前記マイクロアーキテクチャフィーチャを無効にすることを含み、前記マイクロアーキテクチャフィーチャは、一の命令キャッシュ、一のデータキャッシュ、一の変換テーブル、一のルックアサイドバッファ、一の分岐予測ユニット、一のハードウェアプリフェッチャ、および一の実行ユニットからなる一のグループから選択される、請求項20に記載の装置。
【請求項24】
前記マイクロアーキテクチャフィーチャをチューニングすることは、前記マイクロアーキテクチャフィーチャによって消費される電力の一の量にさらに基づく、請求項20に記載の装置。
【請求項25】
前記第2モジュールは、
前記マイクロアーキテクチャフィーチャに関連する一のフィールドであってセットされると前記マイクロアーキテクチャフィーチャを無効にするフィールドを有する一のレジスタと、
前記マイクロアーキテクチャフィーチャに関連する前記レジスタ内の前記フィールドを、前記フィーチャの性能寄与がその無効時に強化される場合にセットする一のモジュールと
を含む、請求項23に記載の装置。
【請求項26】
一のソフトウェアプログラムの実行に対する一のインスタンス当たりのイベントコストを決定する一のモジュールと、
前記インスタンス当たりのイベントコストに基づいて前記ソフトウェアプログラムをチューニングする一のモジュールと
を含む一のマイクロプロセッサを含む装置。
【請求項27】
一のインスタンス当たりのイベントコストを決定することは、デュレーションカウンティング、リタイアメントプッシュアウト計測、およびロングトレース実行モニタリングからなる一のグループから選択される一の性能モニタリング技術によって前記インスタンス当たりのイベントコストを導出することを含む、請求項26に記載の装置。
【請求項28】
前記ソフトウェアプログラムをチューニングすることは、前記ソフトウェアプログラムを再コンパイルすること、前記ソフトウェアプログラムを最適化すること、前記ソフトウェアプログラムを一のキャッシュ内にフィットする複数のブロックデータ構造に最適化すること、前記ソフトウェアプログラムを一のデフォルト分岐予測条件を有効利用すべく再レイアウトすること、一の異なる命令アドレスにおいてコードを放出すること、動的に割り当てられたメモリ内でデータを再レイアウトすること、ならびに、複数のアクセスの粒度およびアライメントを調整すること、からなる一のグループから選択される、請求項26に記載の装置。
【請求項29】
一のメモリおよび一のビデオコントローラに接続された一のコントローラハブと、
一のソフトウェアプログラム実行中の一のインスタンス当たりのイベント寄与を決定し、前記インスタンス当たりのイベント寄与に基づいてマイクロプロセッサの一のアーキテクチャ設定をチューニングし、前記アーキテクチャ設定をストアし、および、前記ストアされたアーキテクチャ設定に基づいて前記ソフトウェアプログラムのその後の実行のときに前記アーキテクチャ設定を再チューニングする一のモジュールを含むマイクロプロセッサと
を含むシステム。
【請求項30】
前記マイクロプロセッサはアウトオブオーダパラレル実行可能な、請求項29に記載のシステム。
【請求項31】
前記アーキテクチャ設定は前記マイクロプロセッサ内の一のレジスタにストアされる、請求項29に記載のシステム。
【請求項32】
前記一のソフトウェアプログラム実行中の一のインスタンス当たりのイベント寄与を決定することは、
複数の所定イベント発生に対する複数のリタイアメントプッシュアウトを測定することと、
前記複数のリタイアメントプッシュアウトおよび前記所定イベントの発生数に基づいて前記所定イベントに対する前記インスタンス当たりのイベント寄与を導出することと
を含む、請求項29に記載のシステム。
【請求項33】
前記一のソフトウェアプログラム実行中の一のインスタンス当たりのイベント寄与を決定することは、
前記ソフトウェアが実行されるたびごとに、所定イベントの発生回数が変化し、かつ、前記マイクロプロセッサ内の一のクリティカルパスの性能がモニタリングされるように前記ソフトウェアプログラムを複数回実行することと、
前記クリティカルパスの性能の変化と、前記所定イベントの発生回数の変化との比較に基づいて前記所定イベントのインスタンス当たりのイベント寄与を導出することと
を含む、請求項29に記載のシステム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6a】
【図6b】
【図6c】
【図7】
【図2】
【図3】
【図4】
【図5】
【図6a】
【図6b】
【図6c】
【図7】
【公開番号】特開2012−178173(P2012−178173A)
【公開日】平成24年9月13日(2012.9.13)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−107848(P2012−107848)
【出願日】平成24年5月9日(2012.5.9)
【分割の表示】特願2008−514892(P2008−514892)の分割
【原出願日】平成18年6月1日(2006.6.1)
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
【公開日】平成24年9月13日(2012.9.13)
【国際特許分類】
【出願番号】特願2012−107848(P2012−107848)
【出願日】平成24年5月9日(2012.5.9)
【分割の表示】特願2008−514892(P2008−514892)の分割
【原出願日】平成18年6月1日(2006.6.1)
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
[ Back to top ]