
グラフィックスプロセッサの並列アレイアーキテクチャ
【課題】高い並列度を維持したままで、異なるシェーダーの変動する負荷に適応できるグラフィックスプロセッサを提供する。
【解決手段】グラフィックスプロセッサの並列アレイアーキテクチャは、複数の処理クラスタを含み、各処理クラスタがカバレッジデータから画素データを生成するピクセルシェーダープログラムを実行する少なくとも1個の処理コアを含む、マルチスレッド型コアアレイと、複数の画素のうちの1画素毎にカバレッジデータを生成するラスタライザと、ラスタライザからマルチスレッド型コアアレイ中の処理クラスタのうちの1つにカバレッジデータを配信する画素分配ロジックとを含む。画素分配ロジックは、画像エリアの範囲内の第1画素の位置に少なくとも部分的に依存して第1画素のためのカバレッジデータが配信される処理クラスタのうちの1つを選択する。画素データが処理クラスタから適切なフレームバッファ区画へ直接的に配信される。
【解決手段】グラフィックスプロセッサの並列アレイアーキテクチャは、複数の処理クラスタを含み、各処理クラスタがカバレッジデータから画素データを生成するピクセルシェーダープログラムを実行する少なくとも1個の処理コアを含む、マルチスレッド型コアアレイと、複数の画素のうちの1画素毎にカバレッジデータを生成するラスタライザと、ラスタライザからマルチスレッド型コアアレイ中の処理クラスタのうちの1つにカバレッジデータを配信する画素分配ロジックとを含む。画素分配ロジックは、画像エリアの範囲内の第1画素の位置に少なくとも部分的に依存して第1画素のためのカバレッジデータが配信される処理クラスタのうちの1つを選択する。画素データが処理クラスタから適切なフレームバッファ区画へ直接的に配信される。
【発明の詳細な説明】
【関連出願の相互参照】
【0001】
[0001]本出願は、2005年12月19日に出願され、あらゆる目的のため参照によって全体が本明細書に組み込まれる米国仮出願第60/752,265号の優先権を主張する。
【0002】
[0002]本出願は、あらゆる目的のため参照によって全体がそのまま本明細書に組み込まれる、以下の同一出願人による同時係属中の米国特許出願:2005年11月29日に出願された出願番号第11/290,303号、2005年11月29日に出願された出願番号第11/289,828号、及び、2005年12月19日に出願された出願番号第11/311,933号に関係している。
【発明の背景】
【0003】
[0003]本発明は、一般に、グラフィックスプロセッサに係わり、特に、グラフィックスプロセッサの並列アレイアーキテクチャに関係する。
【0004】
[0004]並列処理技術は、複数の独立した計算が実行される必要があるときにプロセッサ又はマルチプロセッサシステムのスループットを高める。計算はプログラムによって定義されるタスクに分割され、各タスクが別個のスレッドとして実行される。(本明細書で使用されるように、「スレッド」は、一般に、特殊な入力データを使用する特殊なプログラムの実行のインスタンスであり、「プログラム」は入力データから結果データを生成する実行可能な命令のシーケンスである。)並列スレッドは、プロセッサ内部の異なる処理エンジンを使用して同時に実行される。
【0005】
[0005]多数の既存のプロセッサアーキテクチャが並列処理をサポートする。最初のこのようなアーキテクチャは一緒にネットワーク化された複数のディスクリートプロセッサを使用した。最近、複数の処理コアがシングルチップ上に製作されている。これらのコアは様々な方法で制御される。一部の事例では、多重命令多重データ(MIMD)マシンとして知られ、各コアがコア固有の命令を独立にフェッチし、コア固有の処理エンジン(又は複数の処理エンジン)へ発行する。他の事例では、単一命多重データ(SIMD)マシンとして知られ、コアは、異なる入力オペランドに関する命令を実行する複数の処理エンジンへ同じ命令を並列に発行する単一命令ユニットを有する。SIMDマシンは、一般に、(唯一の命令ユニットだけが必要とされるので)チップ面積の点、したがって、コストの点で有利であり、不利な面は、並列化が利用できる程度が、同じ命令の複数のインスタンスが同時に実行され得る程度に限られることである。
【0006】
[0006]従来型のグラフィックスプロセッサは、画像レンダリングアプリケーションにおいて高いスループットを実現するために非常に広範なSIMDアーキテクチャを使用する。このようなアプリケーションは、一般に、多数の物体(頂点又は画素)に同じプログラム(バーテックスシェーダー又はピクセルシェーダー)を実行することを必然的に伴う。各物体は、他のすべての物体と独立に処理されるが、同じ演算のシーケンスを使用するので、SIMDアーキテクチャは妥当なコストでかなりの性能強化を提供する。典型的に、GPUは、バーテックスシェーダープログラムを実行する1個のSIMDコアと、ピクセルシェーダープログラムを実行する匹敵するサイズの別のSIMDコアとを含む。ハイエンドGPUでは、さらに一層高い並列度をサポートするためにSIMDコアの複数の組が設けられることがある。
【0007】
[0007]これらの設計はいくつかの欠点がある。第一に、バーテックスプログラムとシェーダープログラムのための別個の処理コアは別々に設計され試験され、多くの場合に、少なくとも若干の重複した取り組みの原因となる。第二に、頂点演算と画素演算との間のグラフィックス処理負荷の分割はアプリケーションによって大きく変動する。当分野で公知のように、バーテックスシェーダーコア側の負荷を増加させる多くの小さなプリミティブを使用することにより、及び/又は、ピクセルシェーダーコア側の負荷を増加させる複雑なテクスチャマッピング及びピクセルシェーディング演算を使用することによりディテールが画像に追加されることがある。殆どの場合、負荷が完全に均衡することはなく、一方のコア又は他方のコアが十分に利用されない。たとえば、画素集中型のアプリケーションでは、ピクセルシェーダーコアが最大スループットで作動することがあり、一方、バーテックスコアはアイドル状態であり、処理済みの頂点がパイプラインのピクセルシェーダーステージへ移るのを待機している。逆に、頂点集中型のアプリケーションでは、バーテックスシェーダーコアが最大スループットで作動することがあり、一方、ピクセルコアはアイドル状態であり、新しい頂点が供給されるのを待機する。いずれの場合も、利用可能な処理サイクルのうちのある一部分は事実上浪費されている。
【0008】
[0008]したがって、高い並列度を維持したままで、異なるシェーダーの変動する負荷に適応できるグラフィックスプロセッサを提供することが望ましい。
【発明の概要】
【0009】
[0009]本発明の実施形態は、レンダリング演算中にバーテックスシェーダープログラム、ジオメトリシェーダープログラム、及び/又は、ピクセルシェーダープログラムを任意の組み合わせで実行するためにスケーラブルマルチスレッド型コアアレイを使用するグラフィックスプロセッサを提供する。コアアレイは、1つ以上のクラスタに配置されたいくつものマルチスレッド型処理コアを含み、同じクラスタ中のコアが共用コアインターフェイスによって制御される。
【0010】
[0010]ピクセルシェーダープログラムが実行されるべき実施形態では、プログラムを実行すべきクラスタ又はコアは、画像エリア内の画素の位置に基づいて有利に選択される。一実施形態では、スクリーンはタイル化され、各タイルが一方の処理クラスタ又は別の処理クラスタ(或いは、処理クラスタ内の特定のコア)に割り当てられている。所与の処理クラスタ又はコアに割り当てられたタイルは、近似的な負荷均衡化のためスクリーン全体に有利に散在させられる。
【0011】
[0011]ある実施形態では、処理コア又はクラスタは、新たに生成された画素データをフレームバッファ中の既存データと統合するラスタ演算ユニットを含む。フレームバッファは、処理クラスタの個数と一致するように区分け可能であり、各クラスタがこのクラスタのデータの全部を1つのパーティションに書き込む。他の実施形態では、フレームバッファのパーティションの個数は使用されている処理クラスタの個数と一致しなくてもよい。クロスバー又は類似した回路構成が処理クラスタとフレームバッファパーティションとの間に設定可能なカップリングを提供することがあるので、処理クラスタはどれでも、どのフレームバッファパーティションにでも連結させることが可能であり、一部の実施形態では、クロスバーが省かれ、メモリ局所性を高める。
[0012]以下の詳細な説明は、添付図面と共に、本発明の本質及び利点のより良い理解を与える。
【図面の簡単な説明】
【0012】
【図1】本発明の実施形態によるコンピュータシステムのブロック図である。
【図2】本発明の実施形態によるグラフィックスプロセッサで実施され得るレンダリングパイプラインのブロック図である。
【図3】本発明の実施形態によるグラフィックスプロセッサのマルチスレッド型コアアレイのブロック図である。
【図4】本発明の実施形態による画像領域のいくつものタイルへの1つの可能なタイル化の説明図である。
【図5】本発明の実施形態による処理クラスタとフレームバッファとの間のカップリングを説明する略ブロック図である。
【図6】本発明の別の実施形態による処理クラスタとフレームバッファとの間のカップリングを説明する略ブロック図である。
【発明の詳細な説明】
【0013】
システム概要
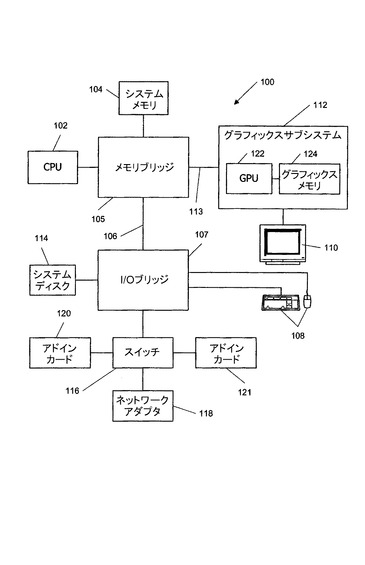
[0019]図1は本発明の実施形態によるコンピュータシステム100のブロック図である。コンピュータシステム100は、中央処理ユニット(CPU)102と、メモリブリッジ105を含むバス経路を介して通信するシステムメモリ104とを含む。メモリブリッジ105は、バス経路106を介して、I/O(入力/出力)ブリッジ107に接続されている。I/Oブリッジ107は、1台以上のユーザ入力装置108(たとえば、キーボード、マウス)からユーザ入力を受信し、バス106及びメモリブリッジ105を介して入力をCPU102へ転送する。可視出力がバス113を介してメモリブリッジ105に連結されたグラフィックスサブシステム112の制御の下で動作する画素ベースの表示装置110(たとえば、従来型のCRT又はLCDベースのモニター)上に提供される。システムディスク114はさらにI/Oブリッジ107に接続されている。スイッチ116は、I/Oブリッジ107と、ネットワークアダプタ118及び種々のアドインカード120、121のような他のコンポーネントとの間で接続を行う。USB又は他のポート接続、CDドライブ、DVDドライブなどを含むその他のコンポーネント(明示的に示されていない)もまたI/Oブリッジ107に接続されてもよい。種々のコンポーネント間でのバス接続は、PCI(ペリフェラル・コンポーネント・インターコネクト)、PCIエクスプレス(PCI−E)、AGP(アクセラレーテッド・グラフィックス・ポート)、ハイパートランスポート、又は、その他の(複数の)バスプロトコルのようなバスプロトコルを使用して実施可能であり、様々な装置間の接続は当分野で公知のような異なるプロトコルを使用してもよい。
【0014】
[0020]グラフィックス処理サブシステム112は、たとえば、プログラマブルプロセッサ、特定用途向け集積回路(ASIC)、及び、メモリ装置のような1台以上の集積回路装置を使用して実施されてもよいグラフィックス処理ユニット(GPU)122及びグラフィックスメモリ124を含む。GPU122は、メモリブリッジ105及びバス113を介してCPU102及び/又はシステムメモリ104によって供給されたグラフィックスデータからの画素データの生成、画素データを格納し更新するためのグラフィックスメモリ124との相互作用などに関連した種々のタスクを実行するように構成されてもよい。たとえば、GPU122は、CPU102上で動く種々のプログラムによって供給された2次元又は3次元シーンデータから画素データを生成してもよい。GPU122は、メモリブリッジ105を介して受信された画素データを、さらなる処理の有無にかかわらず、グラフィックスメモリ124に格納することもある。GPU122は、グラフィックスメモリ124から表示装置110へ画素データを配信するように構成されたスキャンアウトモジュールをさらに含む。
【0015】
[0021]CPU102は、システム100のマスタープロセッサとして動作し、他のシステムコンポーネントの動作を制御し協調させる。特に、CPU102は、GPU122の動作を制御するコマンドを発行する。一部の実施形態では、CPU102は、GPU122のためのコマンドのストリームを、システムメモリ104、グラフィクスメモリ124、又は、CPU102及びCPU122の両方からアクセス可能な別の記憶場所に存在し得るコマンドバッファに書き込む。GPU122は、コマンドバッファからコマンドストリームを読み出し、CPU102の動作と非同期にコマンドを実行する。コマンドは、画像を生成する従来型のレンダリングコマンド、ならびに、画像生成とは無関係であり得るデータ処理のためCPU102上で動くアプリケーションがGPU122の計算パワーを利用することを可能にさせる汎用レンダリングコマンドを含んでもよい。
【0016】
[0022]本明細書で明らかにされているシステムは例示であり、変形及び変更が可能であることがわかるであろう。ブリッジの個数及び配置を含むバストポロジーは必要に応じて変更されてもよい。たとえば、一部の実施形態では、システムメモリ104は、ブリッジ経由ではなく、直接的にCPU102に接続され、他の装置がメモリブリッジ105及びCPU102を介してシステムメモリ104と通信する。他の代替的なトポロジーでは、グラフィックスサブシステム112は、メモリブリッジ105ではなく、I/Oブリッジ107に接続されている。さらに他の実施形態では、I/Oブリッジ107及びメモリブリッジ105はシングルチップに集積化されてもよい。本明細書で明らかにされている特有のコンポーネントは自由に選択でき、たとえば、任意の個数のアドインカード又は周辺装置がサポートされてもよい。一部の実施形態では、スイッチ116は省略され、ネットワークアダプタ118及びアドインカード120、121がI/Oブリッジ107に直接的に接続されている。
【0017】
[0023]システム100の残りの部分へのGPU122の接続もまた変更されてもよい。一部の実施形態では、グラフィックスシステム112は、システム100の拡張スロットに挿入され得るアドインカードとして実施される。他の実施形態では、GPUは、メモリブリッジ105又はI/Oブリッジ107のようなバスブリッジと共にシングルチップに集積化されている。
【0018】
[0024]GPUは、任意の量のローカルグラフィックスメモリが設けられてもよく、ローカルメモリが設けられないこともあり、ローカルメモリとシステムメモリを任意の組み合わせで使用してもよい。たとえば、ユニファイド・メモリ・アーキテクチャ(UMA)の実施形態では、専用グラフィックスメモリ装置が設けられず、GPUはシステムメモリを独占的又はほぼ独占的に使用する。UMAの実施形態では、GPUは、バスブリッジチップに集積化されてもよく、又は、GPUをブリッジチップ及びシステムメモリに接続する高速バス(たとえば、PCI−E)付きのディスクリートチップとして設けられてもよい。
【0019】
[0025]たとえば、複数のGPUを単一のグラフィックスカードに組み込むことにより、又は、複数のグラフィックスカードをバス113に接続することにより、任意の台数のCPUがシステムに組み込まれてもよいこともまた理解されるべきである。
【0020】
[0026]その上、本発明の態様を具現化するGPUは、汎用コンピュータシステムと、ビデオゲームコンソール及びその他の特殊目的コンピュータシステムと、DVDプレーヤーと、携帯電話機又は携帯情報端末のようなハンドヘルド装置などの多種多様の装置に組み込まれてもよい。
【0021】
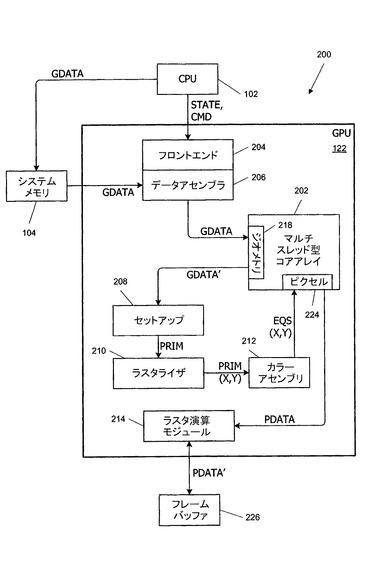
レンダリングパイプライン概要
[0027]図2は本発明の実施形態による図1のGPU122で実施され得るレンダリングパイプライン200のブロック図である。本実施形態では、レンダリングパイプライン200は、適用可能なバーテックスシェーダープログラム、ジオメトリシェーダープログラム、及び、ピクセルシェーダープログラムが、本明細書で「マルチスレッド型コアアレイ」202と呼ばれる同じ並列処理ハードウェアを使用して実行されるアーキテクチャを使用して実施される。マルチスレッド型コアアレイ202は後述されている。
【0022】
[0028]マルチスレッド型コアアレイ202に加えて、レンダリングパイプライン200は、フロントエンド204及びデータアセンブラ206と、セットアップモジュール208と、ラスタライザ210と、カラーアセンブリモジュール212と、ラスタ演算モジュール(ROP)214とを含み、これらの1つずつが従来型の集積回路テクノロジー又はその他のテクノロジーを使用して実施され得る。
【0023】
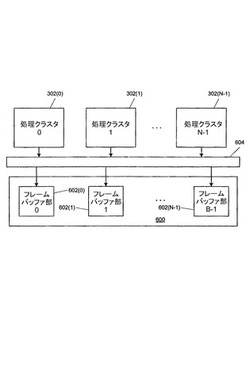
[0029]フロントエンド204は、たとえば、図1のCPU102から、状態情報(STATE)、レンダリングコマンド(CMD)、及び、ジオメトリデータ(GDATA)を受信する。一部の実施形態では、ジオメトリデータを直接的に提供するのではなく、CPU102はジオメトリデータが格納されているシステムメモリ104中の場所への参照情報を提供し、データアセンブラ206がシステムメモリ104からデータを取り出す。状態情報、レンダリングコマンド、及び、ジオメトリデータは、一般的に従来型の内容でもよく、シーンのジオメトリ、照明、陰影、テクスチャ、動き、及び/又は、カメラパラメータを含む所望の描画画像又は複数の描画画像を定義するために使用されてもよい。
【0024】
[0030]一実施形態では、ジオメトリデータは、シーンに存在し得る物体(たとえば、机、椅子、人又は動物)についてのいくつもの物体定義を含む。物体は、頂点への参照情報によって定義されるプリミティブ(たとえば、点、線、三角形、及び/又は、その他の多角形)のグループとして、有利にモデル化される。頂点毎に、位置が物体座標系内で特定され、モデル化されている物体と相対的に頂点の位置を表現する。位置の他に、各頂点は様々なその他の属性が頂点に関連付けられている。一般に、頂点の属性は、頂点毎に特定された任意の特性を含むことがあり、たとえば、一部の実施形態では、頂点属性は、頂点の色、テクスチャ、透明度、照明、陰影及びアニメーションのような質を決定するために使用されるスカラ属性又はベクトル属性と、頂点に付随する幾何プリミティブとを含む。
【0025】
[0031]上述されているようなプリミティブは、一般に、プリミティブの頂点を参照することによって定義され、単一の頂点が任意の個数のプリミティブに含まれていてもよい。一部の実施形態では、各頂点は(一意の識別子であればよい)インデックスが割り当てられ、プリミティブはプリミティブを構成する頂点に関するインデックスの順序付きリストを規定することによって定義される。プリミティブを定義するその他の技術(トライアングルストリップ又はトライアングルファンのような従来型の技術を含む)が使用されてもよい。
【0026】
[0032]状態情報及びレンダリングコマンドは、レンダリングパイプライン200の種々のステージの処理パラメータ及びアクションを定義する。フロントエンド204は、状態情報及びレンダリングコマンドを、(明示的に示されていない)制御経路を介して、レンダリングパイプライン200の他のコンポーネントへ導く。当分野で公知のように、これらのコンポーネントは、処理中にアクセスされる種々の制御レジスタ中の値を記憶又は更新することにより、受信された状態情報に応答でき、パイプライン中で受信されたデータを処理することにより、レンダリングコマンドに応答できる。
【0027】
[0033]フロントエンド204はジオメトリデータをデータアセンブラ206へ導く。データアセンブラ206は、ジオメトリデータをフォーマット化し、マルチスレッド型コアアレイ202中のジオメトリモジュール218への配信のためジオメトリデータを準備する。
【0028】
[0034]ジオメトリモジュール218は、フロントエンド204によって供給された状態情報に応答して選択されているバーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムを頂点データに関して実行するようにマルチスレッド型コアアレイ202内のプログラマブル処理エンジン(明示的に示されていない)に命令する。バーテックス及び/又はジオメトリシェーダープログラムは、当分野で公知のようなレンダリングアプリケーションによって指定することが可能であり、様々なシェーダープログラムが様々な頂点及び/又はプリミティブに適用され得る。使用されるべき(複数の)シェーダープログラムは、システムメモリ又はグラフィックスメモリに格納可能であり、当分野で公知の適当なレンダリングコマンド及び状態情報によってマルチスレッド型コアアレイ202によって特定され得る。一部の実施形態では、バーテックスシェーダー及び/又はジオメトリシェーダープログラムは、複数回の経路で実行可能であり、異なる処理演算が各経路中に実行される。バーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムの1つずつは、経路の回数及び各経路中に実行されるべき演算を決定する。バーテックス及び/又はジオメトリシェーダープログラムは、頂点及びその他のデータに広範囲の数学演算及び論理演算を使用するアルゴリズムを実施可能であり、プログラムは、条件付き又は分岐実行経路と直接及び間接メモリアクセスとを含んでもよい。
【0029】
[0035]バーテックスシェーダープログラム及びジオメトリシェーダープログラムは、照明効果及び陰影効果を含む多種多様の視覚効果を実施するために使用され得る。たとえば、簡単な実施形態では、バーテックスプログラムは、頂点をこの頂点の3次元物体座標系から3次元クリップ空間又はワールド空間座標系に変換する。この変換はシーン中の異なる物体の相対位置を定義する。一実施形態では、変換は、物体の物体座標系からクリップ空間座標に変換する変換行列をレンダリングコマンド及び/又は各物体を定義するデータに組み入れることによりプログラムされ得る。バーテックスシェーダープログラムは、物体を構成するプリミティブの各頂点にこの変換行列を適用する。より複雑なバーテックスシェーダープログラムは、照明及び陰影と、手続き型ジオメトリと、アニメーション演算とを含む多種多様の視覚効果を実施するため使用され得る。このような頂点毎の演算の多数の例は技術的に公知であり、詳細な説明は本発明の理解に重要ではないので省かれている。
【0030】
[0036]ジオメトリシェーダープログラムは、ジオメトリシェーダープログラムが個々の頂点ではなくプリミティブ(頂点のグループ)に作用する点でバーテックスシェーダープログラムと異なる。よって、一部の事例では、ジオメトリプログラムは、新しい頂点を作成し、及び/又は、処理されている物体の組から頂点又はプリミティブを削除してもよい。一部の実施形態では、バーテックスシェーダープログラムを通る経路とジオメトリシェーダープログラムを通る経路はジオメトリデータを処理するために交互にされてもよい。
【0031】
[0037]一部の実施形態では、バーテックスシェーダープログラム及びジオメトリシェーダープログラムは、マルチスレッド型コアアレイ202内の同じプログラマブル処理エンジンを使用して実行される。よって、ある時点で、所与の処理エンジンは、バーテックスシェーダーとして動作し、バーテックスプログラム命令を受信し実行し、他の時点で、同じ処理エンジンがジオメトリシェーダーとして動作し、ジオメトリプログラム命令を受信し実行することができる。処理エンジンはマルチスレッド化が可能であり、異なるタイプのシェーダープログラムを実行する異なるスレッドがマルチスレッド型コアアレイ202内で同時にフライト状態であり得る。
【0032】
[0038]バーテックス及び/又はジオメトリシェーダープログラムが実行された後、ジオメトリモジュール218は、処理済みのジオメトリデータ(GDATA’)をセットアップモジュール208へ送る。一般的に従来型の設計でもよいセットアップモジュール208は、各プリミティブのクリップ空間又はスクリーン空間座標からエッジ方程式を生成し、エッジ方程式はスクリーン空間内の点がプリミティブの内側又は外側のいずれにあるかを判定するため有利に使用できる。
【0033】
[0039]セットアップモジュール208は、各プリミティブ(PRIM)をラスタライザ210へ供給する。一般的に従来型の設計でもよいラスタライザ210は、たとえば、従来型の走査変換アルゴリズムを使用して、プリミティブによって覆われた(もしあるとしたら)画素を判定する。本明細書で使用されているように、「画素」(又は「フラグメント」)は、一般的に、単一のカラー値が決定されるべき2次元スクリーン空間内の領域を指し、画素の個数及び配置はレンダリングパイプライン200の設定可能なパラメータでもよく、特有の表示装置のスクリーン解像度と相関していても相関していなくてもよい。当分野で公知のように、画素カラーは(たとえば、従来型のスーパーサンプリング技術又はマルチサンプリング技術を使用して)画素内の複数の場所でサンプリングされることがあり、一部の実施形態では、スーパーサンプリング又はマルチサンプリングはピクセルシェーダー内で取り扱われる。
【0034】
[0040]プリミティブによって覆われた画素を判定した後、ラスタライザ210は、プリミティブによって覆われた画素のスクリーン座標(X,Y)のリストと共に、プリミティブ(PRIM)をカラーアセンブリモジュール212に供給する。カラーアセンブリモジュール212は、プリミティブ、及び、ラスタライザ210から受信されたカバレッジ情報をプリミティブの頂点の属性(たとえば、色成分、テクスチャ座標、表面法線)と関連付け、スクリーン座標空間内の位置の関数として属性の一部又は全部を定義する平面方程式(又はその他の適当な式)を生成する。
【0035】
[0041]これらの属性式は、プリミティブ内の任意の場所で属性の値を補間するためピクセルシェーダープログラムにおいて有利に使用でき、従来型の技術は式を生成するために使用され得る。たとえば、一実施形態では、カラーアセンブリモジュール212は、属性U毎に、U=Ax+By+Cという形式の平面方程式の係数A、B及びCを生成する。
【0036】
[0042]カラーアセンブリモジュール212は、少なくとも1個の画素を覆うプリミティブ毎の属性式(たとえば、平面方程式の係数A、B及びCを含んでもよいEQS)と覆われた画素のスクリーン座標(X,Y)のリストとをマルチスレッド型コアアレイ202内のピクセルモジュール224へ供給する。ピクセルモジュール224は、プリミティブによって覆われた画素毎に、フロントエンド204によって供給された状態情報に応答して選択される1つ以上のピクセルシェーダープログラムを実行するようにマルチスレッド型コアアレイ202内の(明示的に示されていない)プログラマブル処理エンジンに命令する。バーテックスシェーダープログラム及びジオメトリシェーダープログラムの場合と同様に、レンダリングアプリケーションは、所与の画素の組のため使用されるべきピクセルシェーダープログラムを指定することが可能である。ピクセルシェーダープログラムは、照明及び陰影効果と、反射と、テクスチャブレンディングと、手続き型テクスチャ生成などを含む多種多様な視覚効果を実施するために使用され得る。このような画素当たり演算の多数の実施例は技術的に公知であり、詳細な説明は本発明の理解に重要ではないので省かれている。ピクセルシェーダープログラムは、画素及びその他のデータに広範囲の数学演算及び論理演算を使用してアルゴリズムを実施可能であり、プログラムは、条件付き実行経路又は分岐実行経路と、直接及び間接メモリアクセスとを含んでもよい。
【0037】
[0043]ピクセルシェーダープログラムは、バーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムも実行する同じプログラマブル処理エンジンを使用してマルチスレッド型コアアレイ202で有利に実行される。よって、ある時点で、所与の処理エンジンは、バーテックスシェーダーとして動作し、バーテックスプログラム命令を受信し実行し、他の時点で、同じ処理エンジンがジオメトリシェーダーとして動作し、ジオメトリプログラム命令を受信し実行し、さらに他の時点で、同じ処理エンジンがピクセルシェーダーとして動作し、ピクセルシェーダープログラム命令を受信し実行する。マルチスレッド型コアアレイは、画素処理と頂点処理との間で固有の負荷均衡化を行うことが可能であり、アプリケーションがジオメトリ集中型(たとえば、多数の小さいプリミティブ)であるならば、マルチスレッド型コアアレイ202内の処理サイクルのより多くがバーテックスシェーダー及び/又はジオメトリシェーダーに振り向けられる傾向があり、アプリケーションが画素集中型である(たとえば、少数及び多数のプリミティブが、複数のテクスチャなどと共に、複雑なピクセルシェーダープログラムを使用して陰影を付けられる)ならば、処理サイクルのより多くがピクセルシェーダーに振り向けられる傾向がある。
【0038】
[0044]画素又は画素のグループに対する処理が完了すると、ピクセルモジュール224は、処理済みの画素(PDATA)をROP214へ供給する。一般的に従来型の設計でもよいROP214は、ピクセルモジュール224から受信された画素値を、たとえば、グラフィックスメモリ124内にあるフレームバッファ226において構築中の画像の画素と統合する。一部の実施形態では、ROP214は、描画されている画像に既に書き込まれた画素を用いて画素をマスクし、又は、描画されている画像に既に書き込まれた画素と新しい画素を融合することが可能である。奥行きバッファ、アルファバッファ、及び、ステンシルバッファは、(もしあれば)描画された画像に対する各入力画素の寄与度を決定するためにも使用され得る。各入力画素と既に記憶されている画素値との適切な組み合わせに対応する画素データPDATA’はフレームバッファ226へ書き戻される。画像が完成すると、フレームバッファ226は表示装置へスキャンアウトされ、及び/又は、さらなる処理の対象とされ得る。
【0039】
[0045]本明細書に記載されているレンダリングパイプラインは例示であり、変形及び変更が可能であることがわかる。パイプラインは、図示されているユニットのうちの様々なユニットを含んでもよく、処理イベントのシーケンスは本明細書に記載されているシーケントと異なってもよい。たとえば、一部の実施形態では、ラスタ化は、もしあるとするならば、三角形が覆う(又は部分的に覆う)ブロックがどれであるかを決定するために、スクリーン全体をブロック(たとえば、16×16画素)の単位で処理する「粗い」ラスタライザを用い、その後に、少なくとも部分的に覆われることが決定されるブロック内の個別の画素を処理する「細かい」ラスタライザを用いて、複数のステージで実行されてもよい。このような一実施形態では、細かいラスタライザはピクセルモジュール224内に収容されている。別の実施形態では、従来はROPによって実行される一部の演算が、画素データがROP214へ転送される前に、ピクセルモジュール224内で実行されることもある。
【0040】
[0046]さらに、本明細書に記載されているモジュールの一部又は全部の複数のインスタンスが並列に作動されてもよい。このような一実施形態では、マルチスレッド型コアアレイ202は、2個以上のジオメトリモジュール218と、並列に動作する等しい個数のピクセルモジュール224とを含む。各ジオメトリモジュール及びピクセルモジュールは、マルチスレッド型コアアレイ202内の処理エンジンの異なる一部を共同で制御する。
【0041】
マルチスレッド型コアアレイコンフィギュレーション
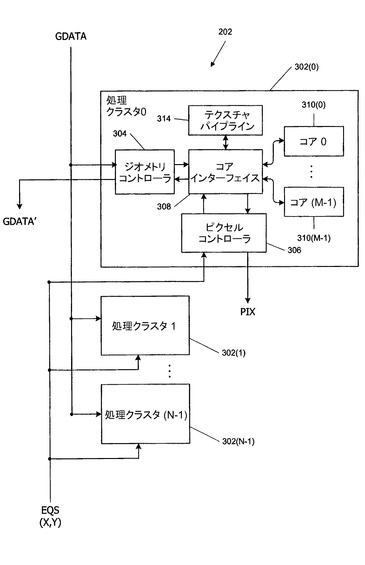
[0047]一実施形態では、マルチスレッド型コアアレイ202は、様々に組み合わされたバーテックスシェーダープログラム、ジオメトリシェーダープログラム、及び/又は、ピクセルシェーダープログラムの非常に多数のインスタンスの同時実行をサポートする高度な並列アーキテクチャを提供する。図3は本発明の実施形態によるマルチスレッド型コアアレイ202のブロック図である。
【0042】
[0048]本実施形態では、マルチスレッド型コアアレイ202は、ある個数(N)の処理クラスタ302を含む。本明細書では、オブジェクトのようなマルチプルインスタンスは、必要に応じて、オブジェクトを特定する参照番号とインスタンスを特定する括弧付き番号とを用いて示されている。処理クラスタの任意の個数N(たとえば、1、4、8又はその他の任意の個数)が与えられてもよい。図3では、1個の処理クラスタ302が詳細に示されているが、他の処理クラスタ302も同様の設計又は同一の設計であることが理解されるべきである。
【0043】
[0049]各処理クラスタ302は、(図2のジオメトリモジュール218を実施する)ジオメトリコントローラ304と、(図2のピクセルモジュール224を実施する)ピクセルコントローラ306とを含む。ジオメトリコントローラ304及びピクセルコントローラ306は、それぞれが、コアインターフェイス308と通信する。コアインターフェイス308は、マルチスレッド型コアアレイ202の処理エンジンを含むある個数(M)のコア310を制御する。任意の個数M(たとえば、1、2、4又はその他の個数)のコア310が単一のコアインターフェイスに接続されてもよい。各コア310は、バーテックススレッド、ジオメトリスレッド及びピクセルスレッドの組を含む多数の(たとえば、100個以上の)同時実行スレッド(ここで、用語「スレッド」は特有の入力データの組に関して動く特有のプログラムのインスタンスを指している)をサポートする能力をもつマルチスレッド型実行コアとして有利に実施される。一実施形態では、各コア310は、P個のスレッドを並列に実行するためにPウェイSIMDアーキテクチャを実施し、ここで、Pは任意の整数(たとえば、8、16、32)であり、P個のスレッドからなる個数G(たとえば、18、24など)のグループを同時に管理する能力がある。コア310の詳細な説明は、あらゆる目的のため参照によって全体がそのまま本明細書に組み込まれる、2005年12月19日に出願された米国仮出願第60/752,265号に見ることができる。
【0044】
[0050]コアインターフェイス308は、コア310の間で共用されるテクスチャパイプライン314をさらに制御する。一般的に従来型の設計でもよいテクスチャパイプライン314は、テクスチャ座標を受信し、メモリからテクスチャ座標に対応するテクスチャデータをフェッチし、種々のアルゴリズムに応じてテクスチャデータをフィルタ処理するように構成された論理回路を有利に含む。バイリニアフィルタリング及びトリリニアフィルタリングを含む従来型のフィルタリングアルゴリズムが使用されてもよい。コア310がコアのスレッドのうちの1つでテクスチャ命令を受けるとき、コアは、コアインターフェイス308を介してテクスチャ座標をテクスチャパイプライン314へ供給する。テクスチャパイプライン314はテクスチャ命令を処理し、コアインターフェイス308を介して結果をコア310へ返す。パイプライン314によるテクスチャ処理は非常に多数のクロックサイクルを消費することがあり、スレッドがテクスチャ結果を待っている間に、コア310は他のスレッドを有利に実行し続ける。
【0045】
[0051]動作中に、データアセンブラ206(図2)は、ジオメトリデータGDATAを処理クラスタ302へ供給する。一実施形態では、データアセンブラ206は、ジオメトリデータの入力ストリームを部分に分割し、たとえば、実行リソースの可用性に基づいて、ジオメトリデータの次の部分を受信する処理クラスタ302を選択する。その部分は選択された処理クラスタ302中のジオメトリコントローラ304へ配信される。
【0046】
[0052]ジオメトリコントローラ304は、受信されたデータをコアインターフェイス308へ転送し、コアインターフェイスは頂点データをコア310にロードし、次に、適切なバーテックスシェーダープログラムを始めるようにコア310に命令する。バーテックスシェーダープログラムの完了時に、コアインターフェイス308はジオメトリコントローラ304に信号を送る。ジオメトリシェーダープログラムが実行されるべきならば、ジオメトリコントローラ304は、ジオメトリシェーダープログラムを始めるようにコアインターフェイス308に命令する。一部の実施形態では、処理済みの頂点データは、バーテックスシェーダープログラムの完了時にジオメトリコントローラ304へ返送され、ジオメトリコントローラ304は、ジオメトリシェーダープログラムを実行する前に、データを再びロードするようにコアインターフェイス308に命令する。バーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムの完了後、ジオメトリコントローラ304は、処理済みのジオメトリデータ(GDATA’)を図2のセットアップモジュール208へ供給する。
【0047】
[0053]画素ステージで、カラーアセンブリモジュール212(図2)は、プリミティブと、プリミティブによって覆われた画素の画素座標(X,Y)とに関する属性式EQSを処理クラスタ302へ供給する。一実施形態では、カラーアセンブリモジュール212は、カバレッジデータの入力ストリームを部分に分割し、たとえば、実行リソースの可用性又はスクリーン座標中のプリミティブの場所に基づいて、データの次の部分を受信すべき処理クラスタ302を選択する。その部分は選択された処理クラスタ302中のピクセルコントローラ306へ配信される。
【0048】
[0054]ピクセルコントローラ306は、データをコアインターフェイス308へ配信し、コアインターフェイスは画素データをコア310にロードし、次に、ピクセルシェーダープログラムを始めるようにコア310に命令する。コア310がマルチスレッド型であるならば、ピクセルシェーダープログラム、ジオメトリシェーダープログラム、及び、バーテックスシェーダープログラムは、すべてが同じコア310中で同時に実行され得る。ピクセルシェーダープログラムの完了時に、コアインターフェイス308は処理済み画素データをピクセルコントローラ306へ配信し、ピクセルコントローラは画素データPDTAをROPユニット214(図2)へ転送する。
【0049】
[0055]本明細書に記載されているマルチスレッド型コアアレイは例示であり、変形及び変更が可能であることがわかる。任意の個数の処理クラスタが設けられ、各処理クラスタは任意の個数のコアを含んでもよい。一部の実施形態では、あるタイプのシェーダーは、ある特定の処理クラスタ又はある特定のコア中での実行に制限されてもよく、たとえば、ジオメトリシェーダーは各処理クラスタのコア310(0)中での実行に制限されてもよい。このような設計上の選択は、当分野で公知のように、ハードウェアサイズ、及び、複雑さと性能の対比を考慮して行われてもよい。共用テクスチャパイプラインもまた随意的であり、一部の実施形態では、各コアは、コアの固有のテクスチャパイプラインを有してもよく、又は、テクスチャ計算を実行するために汎用機能ユニットを利用してもよい。
【0050】
[0056]処理されるべきデータは様々な方法で処理クラスタへ分配され得る。一実施形態では、データアセンブラ(又はジオメトリデータのその他のソース)及びカラーアセンブリモジュール(又はピクセルシェーダー入力データのその他のソース)は、種々のタイプの付加的なスレッドを取り扱うために処理クラスタ又は個別のコアの可用性を示す情報を受信し、スレッド毎に宛先処理クラスタ又はコアを選択する。別の実施形態では、入力データは、データを処理する能力をもつ処理クラスタがデータを受け入れるまで、ある処理クラスタから次の処理クラスタへ転送される。さらに別の実施形態では、処理クラスタは、処理されるべき画素のスクリーン座標のような入力データの特性に基づいて選択される。
【0051】
[0057]マルチスレッド型コアアレイは、レンダリング画像に関係している、又は、関係していないことがある汎用計算を実行するためにも利用され得る。一実施形態では、データ並列分解において表現され得る計算は、シングルコア中で実行するスレッドのアレイとして、マルチスレッド型コアアレイによって取り扱われ得る。このような計算の結果は、フレームバッファに書き込まれ、システムメモリにもう一度読み取られてもよい。
【0052】
ピクセルシェーダー作業の割り付け
[0058]本発明の実施形態によれば、ピクセルシェーダープログラムによって処理されるべき画素は、画像エリア内の画素の位置に基づいて処理クラスタ302(図3)へ向けられる。たとえば、画像エリアはある数のタイルに分割され得る。各タイルは、1つのクラスタに関連付けられたタイルが画像エリアの全体に散在させられるように、処理クラスタ302のうちの1つが関連付けられている(すなわち、1つの処理クラスタに関連付けられているタイルの少なくとも一部は相互に隣接していない)。
【0053】
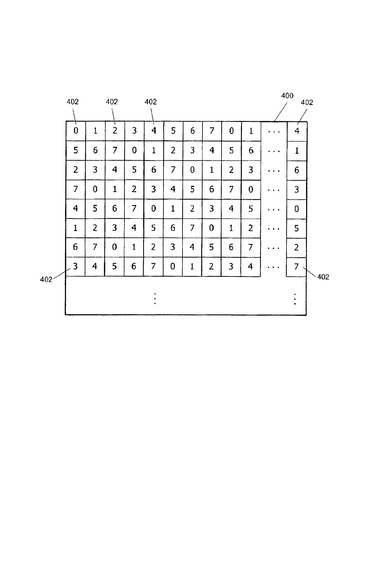
[0059]図4は、本発明の実施形態による、多数のタイル402への画像エリア400の1つの可能なタイル化を示している。各タイル402は、たとえば、16×16個の画素でもよく、又は、その他の都合のよいサイズでもよい。本実施形態では、図3のマルチスレッド型コアアレイ202は、8個の処理クラスタ302(0)〜302(7)を含む。図4の各タイル402は、当該タイル内の画素を処理する処理コア302(i)を示す番号i(0〜7)を格納している。図4においてわかるように、各処理クラスタ302は、画像エリア400内の等しい(又はほぼ等しい)個数のタイル402が割り当てられ、各クラスタ302に割り当てられたタイルは相互に隣接していない。多数のグラフィックアプリケーションに対し、このような分配作業は、処理クラスタ302の間で適切な負荷均衡化を行うことが期待される。適当な画素分配論理は、レンダリングパイプライン200、たとえば、図2のカラーアセンブリモジュール212に組み込まれ得る。
【0054】
[0060]図4に示されているタイル化は例示であり、変形及び変更が可能であることがわかるであろう。タイルはどのようなサイズでもよい。一部の実施形態では、タイルのサイズ及び個数は設定可能であり、サイズは、マルチサンプリングモードが使用されるかどうかといったアプリケーション特性に基づいて選択される。各処理クラスタに割り当てられるタイルの配置は必要に応じて変化し得る。
【0055】
[0061]タイルは、特有のGPUに存在する処理クラスタの総数までの任意の個数の処理クラスタに割り当てられる。一部の実施形態では、タイルは、全部に満たない数の処理クラスタに割り当てられる。したがって、GPUは、ピクセルスレッドを処理するために、GPUの処理クラスタの一部だけを使用して画像を描画することが可能である。少なくとも1個の処理クラスタが利用可能である限り、GPUは、スループットが低下しているが、画像を描画することが可能である。一部のクラスタのピクセルスレッドの処理が無効にされた状態で実行することは、たとえば、(一部のコア又はクラスタは、他のコア又はクラスタが動作している間に、電力が低下する)省電力モードでの動作、(様々なGPUの可用性を要求しない)最低限の性能要件の決定、及び/又は、一方又は別のコア内の欠陥に対する許容度の提供のために役立つことがある。
【0056】
[0062]一部の代替的な実施形態では、タイルは、処理クラスタ302ではなく、特有のコア310に割り当てられる。
【0057】
フレームバッファへのピクセルシェーダーカップリング
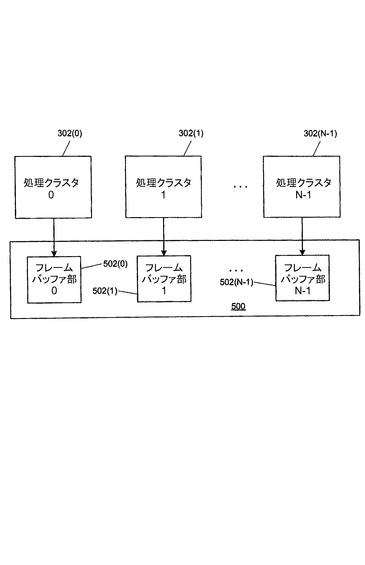
[0063]一部の実施形態では、図2に提案されている集中型ROP214ではなく、図3の各ピクセルコントローラ306は、画素を図2のフレームバッファ226へ通信する固有のROPを含む。このような実施形態では、処理クラスタ302からフレームバッファへのカップリングが行われる。
【0058】
[0064]N個の処理クラスタを含む一実施形態では、フレームバッファ226はN個の区画に区分される。各クラスタ302はN個の区画のうちの別々の1区画に連結されている。
【0059】
[0065]図5は本発明の実施形態による処理クラスタ302とフレームバッファ500との間のカップリングを説明する略ブロック図である。図2のフレームバッファ226は複数のフレームバッファ500を含むことがあり、各フレームバッファ500は同じ画像に対し画素単位で指定された量を格納することが理解されるべきである。たとえば、一実施形態では、フレームバッファ226は、Zバッファと、(たとえば、赤、緑及び青の色成分のための)色成分バッファと、透明度(アルファ)バッファとを含む。任意の個数のフレームバッファ500が設けられ、本明細書で使用されるような「画素」は、所与の表示装置のアクティブ画素の個数に対応する場合と対応しない場合とがある画像内のサンプリング場所を示すことが理解されるべきである。簡単にするため、唯一のフレームバッファ500だけが表されているが、同じ区分法がある画像に対する各フレームバッファに適用され得ることが理解されるべきである。
【0060】
[0066]フレームバッファ500は、N個の区画502に(物理的又は論理的に)区分けされ、各区画は画像中の画素の少なくとも1/Nのデータを格納するために十分な大きさである。N個の処理クラスタ302のそれぞれは、N個の区画502のうちの1つに連結されている。よって、処理クラスタ302(0)は、この処理クラスタの出力画素データのすべてを区画502(0)に格納し、処理クラスタ302(1)は区画502(1)に格納し、以下同様である。所与の処理クラスタ302によって処理されるタイルが隣接しない範囲で、所与のフレームバッファ区画502中のデータは隣接しないタイルに由来することに注意を要する。表示(スキャンアウト)論理は、フレームバッファ500にアクセスするときに、データの正しい表示順を守る方が有利であり、特に、区画が順次に読み出されることを必要としない。
【0061】
[0067]上述されているように、一部の実施形態では、全部の処理コア302に満たない数の処理コアが画素を生成するため使用されてもよい。図5に示されている実施形態では、処理クラスタ302(0)だけが画素をフレームバッファ区画502(0)へ供給する。したがって、処理クラスタ302(0)が画素を生成するため作動されていないならば、フレームバッファ区画502(0)は使用されない。画像エリアは、再タイル化可能であり、又は、エリアがN−1個の処理クラスタの間で分割されるように、タイルが処理クラスタ302(1)〜302(N−1)の間で再割り当て可能である。一部の実施形態では、たとえば、フレームバッファ区画502(1)〜502(N−1)が元のサンプリング分解能で画像の画素データの全部を格納するために十分な空間を提供しないならば、サンプリング分解能は削減されなくてもよい。区画が物理的ではなく論理的である実施形態では、フレームバッファ500は利用可能な処理クラスタ302の個数と一致するように再区分され得る。
【0062】
[0068]代替的な実施形態では、各処理クラスタは複数のフレームバッファ区画にアクセス可能である。図6は本発明の実施形態による処理クラスタ302とフレームバッファ600との間のカップリングを説明する略ブロック図である。図2のフレームバッファ226は複数のフレームバッファ600を含むことがあり、各フレームバッファ600は、フレームバッファ500に関して上述されているように、同じ画像に対し画素単位で指定された量を格納することが理解されるべきである。いかなる個数のフレームバッファ600が設けられてもよいことが理解されるべきである。簡単にするため、唯一のフレームバッファ600だけが示されているが、同じ区分法がある画像に対する各フレームバッファに適用され得ることが理解されるべきである。
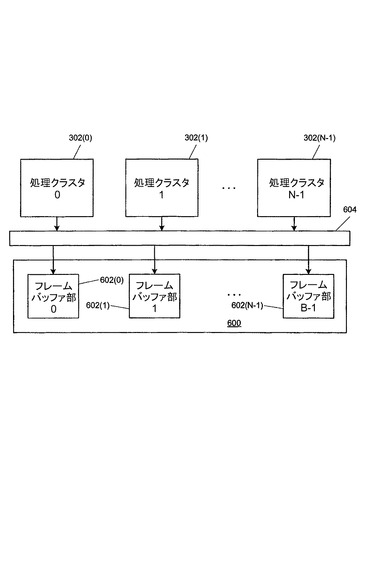
【0063】
[0069]フレームバッファ600はB個の区画602に(物理的又は論理的に)区分けされ、ここで、Bは処理クラスタ302の個数Nと等しくても異なっていてもよい。処理クラスタ302はクロスバー604を介して区画602に連結されている。各クラスタ302は、B個の区画602のうちのいずれか1個(又は1個以上)の区画に画素データを書き込むことが可能である。
【0064】
[0070]本実施形態では、クロスバー604は設定可能であり、処理クラスタ302からフレームバッファ区画602へのカップリングが必要に応じて変更されることを可能にする。たとえば、上述されているように、一部の実施形態では、全部の処理コア302に満たない数の処理コアが画素を生成するため使用されてもよい。図6に示された実施形態では、処理コア302(0)が無効状態にされるならば、クロスバー604は、すべてのフレームバッファ区画602が一方又は別の処理コア302から依然としてアクセスできるように再構成され得る。表示(スキャンアウト)ロジックは、クロスバー604のコンフィギュレーション又は処理コア302へのタイルの割り当てとは無関係にフレームバッファデータが正確にスキャンアウトされるように、有利には設定可能である。
【0065】
[0071]複数のフレームバッファ(たとえば、Zバッファ、カラーバッファ、アルファバッファなど)が存在する場合、各フレームバッファは上述されている方法でB個の区画に区分けされてもよい。一部の実施形態では、区画の個数はすべてのフレームバッファに対し同じではないが、たとえば、Zバッファはカラーバッファより多数又は少数の区画を有してもよい。
【0066】
さらなる実施形態
[0072]本発明は特定の実施形態に関して説明されているが、当業者は数多くの変形例が可能であることを認める。したがって、本発明は特定の実施形態に関して説明されているが、本発明が特許請求の範囲に記載された事項の範囲内のすべての変更及び均等物に及ぶように意図されていることが認められる。
【関連出願の相互参照】
【0001】
[0001]本出願は、2005年12月19日に出願され、あらゆる目的のため参照によって全体が本明細書に組み込まれる米国仮出願第60/752,265号の優先権を主張する。
【0002】
[0002]本出願は、あらゆる目的のため参照によって全体がそのまま本明細書に組み込まれる、以下の同一出願人による同時係属中の米国特許出願:2005年11月29日に出願された出願番号第11/290,303号、2005年11月29日に出願された出願番号第11/289,828号、及び、2005年12月19日に出願された出願番号第11/311,933号に関係している。
【発明の背景】
【0003】
[0003]本発明は、一般に、グラフィックスプロセッサに係わり、特に、グラフィックスプロセッサの並列アレイアーキテクチャに関係する。
【0004】
[0004]並列処理技術は、複数の独立した計算が実行される必要があるときにプロセッサ又はマルチプロセッサシステムのスループットを高める。計算はプログラムによって定義されるタスクに分割され、各タスクが別個のスレッドとして実行される。(本明細書で使用されるように、「スレッド」は、一般に、特殊な入力データを使用する特殊なプログラムの実行のインスタンスであり、「プログラム」は入力データから結果データを生成する実行可能な命令のシーケンスである。)並列スレッドは、プロセッサ内部の異なる処理エンジンを使用して同時に実行される。
【0005】
[0005]多数の既存のプロセッサアーキテクチャが並列処理をサポートする。最初のこのようなアーキテクチャは一緒にネットワーク化された複数のディスクリートプロセッサを使用した。最近、複数の処理コアがシングルチップ上に製作されている。これらのコアは様々な方法で制御される。一部の事例では、多重命令多重データ(MIMD)マシンとして知られ、各コアがコア固有の命令を独立にフェッチし、コア固有の処理エンジン(又は複数の処理エンジン)へ発行する。他の事例では、単一命多重データ(SIMD)マシンとして知られ、コアは、異なる入力オペランドに関する命令を実行する複数の処理エンジンへ同じ命令を並列に発行する単一命令ユニットを有する。SIMDマシンは、一般に、(唯一の命令ユニットだけが必要とされるので)チップ面積の点、したがって、コストの点で有利であり、不利な面は、並列化が利用できる程度が、同じ命令の複数のインスタンスが同時に実行され得る程度に限られることである。
【0006】
[0006]従来型のグラフィックスプロセッサは、画像レンダリングアプリケーションにおいて高いスループットを実現するために非常に広範なSIMDアーキテクチャを使用する。このようなアプリケーションは、一般に、多数の物体(頂点又は画素)に同じプログラム(バーテックスシェーダー又はピクセルシェーダー)を実行することを必然的に伴う。各物体は、他のすべての物体と独立に処理されるが、同じ演算のシーケンスを使用するので、SIMDアーキテクチャは妥当なコストでかなりの性能強化を提供する。典型的に、GPUは、バーテックスシェーダープログラムを実行する1個のSIMDコアと、ピクセルシェーダープログラムを実行する匹敵するサイズの別のSIMDコアとを含む。ハイエンドGPUでは、さらに一層高い並列度をサポートするためにSIMDコアの複数の組が設けられることがある。
【0007】
[0007]これらの設計はいくつかの欠点がある。第一に、バーテックスプログラムとシェーダープログラムのための別個の処理コアは別々に設計され試験され、多くの場合に、少なくとも若干の重複した取り組みの原因となる。第二に、頂点演算と画素演算との間のグラフィックス処理負荷の分割はアプリケーションによって大きく変動する。当分野で公知のように、バーテックスシェーダーコア側の負荷を増加させる多くの小さなプリミティブを使用することにより、及び/又は、ピクセルシェーダーコア側の負荷を増加させる複雑なテクスチャマッピング及びピクセルシェーディング演算を使用することによりディテールが画像に追加されることがある。殆どの場合、負荷が完全に均衡することはなく、一方のコア又は他方のコアが十分に利用されない。たとえば、画素集中型のアプリケーションでは、ピクセルシェーダーコアが最大スループットで作動することがあり、一方、バーテックスコアはアイドル状態であり、処理済みの頂点がパイプラインのピクセルシェーダーステージへ移るのを待機している。逆に、頂点集中型のアプリケーションでは、バーテックスシェーダーコアが最大スループットで作動することがあり、一方、ピクセルコアはアイドル状態であり、新しい頂点が供給されるのを待機する。いずれの場合も、利用可能な処理サイクルのうちのある一部分は事実上浪費されている。
【0008】
[0008]したがって、高い並列度を維持したままで、異なるシェーダーの変動する負荷に適応できるグラフィックスプロセッサを提供することが望ましい。
【発明の概要】
【0009】
[0009]本発明の実施形態は、レンダリング演算中にバーテックスシェーダープログラム、ジオメトリシェーダープログラム、及び/又は、ピクセルシェーダープログラムを任意の組み合わせで実行するためにスケーラブルマルチスレッド型コアアレイを使用するグラフィックスプロセッサを提供する。コアアレイは、1つ以上のクラスタに配置されたいくつものマルチスレッド型処理コアを含み、同じクラスタ中のコアが共用コアインターフェイスによって制御される。
【0010】
[0010]ピクセルシェーダープログラムが実行されるべき実施形態では、プログラムを実行すべきクラスタ又はコアは、画像エリア内の画素の位置に基づいて有利に選択される。一実施形態では、スクリーンはタイル化され、各タイルが一方の処理クラスタ又は別の処理クラスタ(或いは、処理クラスタ内の特定のコア)に割り当てられている。所与の処理クラスタ又はコアに割り当てられたタイルは、近似的な負荷均衡化のためスクリーン全体に有利に散在させられる。
【0011】
[0011]ある実施形態では、処理コア又はクラスタは、新たに生成された画素データをフレームバッファ中の既存データと統合するラスタ演算ユニットを含む。フレームバッファは、処理クラスタの個数と一致するように区分け可能であり、各クラスタがこのクラスタのデータの全部を1つのパーティションに書き込む。他の実施形態では、フレームバッファのパーティションの個数は使用されている処理クラスタの個数と一致しなくてもよい。クロスバー又は類似した回路構成が処理クラスタとフレームバッファパーティションとの間に設定可能なカップリングを提供することがあるので、処理クラスタはどれでも、どのフレームバッファパーティションにでも連結させることが可能であり、一部の実施形態では、クロスバーが省かれ、メモリ局所性を高める。
[0012]以下の詳細な説明は、添付図面と共に、本発明の本質及び利点のより良い理解を与える。
【図面の簡単な説明】
【0012】
【図1】本発明の実施形態によるコンピュータシステムのブロック図である。
【図2】本発明の実施形態によるグラフィックスプロセッサで実施され得るレンダリングパイプラインのブロック図である。
【図3】本発明の実施形態によるグラフィックスプロセッサのマルチスレッド型コアアレイのブロック図である。
【図4】本発明の実施形態による画像領域のいくつものタイルへの1つの可能なタイル化の説明図である。
【図5】本発明の実施形態による処理クラスタとフレームバッファとの間のカップリングを説明する略ブロック図である。
【図6】本発明の別の実施形態による処理クラスタとフレームバッファとの間のカップリングを説明する略ブロック図である。
【発明の詳細な説明】
【0013】
システム概要
[0019]図1は本発明の実施形態によるコンピュータシステム100のブロック図である。コンピュータシステム100は、中央処理ユニット(CPU)102と、メモリブリッジ105を含むバス経路を介して通信するシステムメモリ104とを含む。メモリブリッジ105は、バス経路106を介して、I/O(入力/出力)ブリッジ107に接続されている。I/Oブリッジ107は、1台以上のユーザ入力装置108(たとえば、キーボード、マウス)からユーザ入力を受信し、バス106及びメモリブリッジ105を介して入力をCPU102へ転送する。可視出力がバス113を介してメモリブリッジ105に連結されたグラフィックスサブシステム112の制御の下で動作する画素ベースの表示装置110(たとえば、従来型のCRT又はLCDベースのモニター)上に提供される。システムディスク114はさらにI/Oブリッジ107に接続されている。スイッチ116は、I/Oブリッジ107と、ネットワークアダプタ118及び種々のアドインカード120、121のような他のコンポーネントとの間で接続を行う。USB又は他のポート接続、CDドライブ、DVDドライブなどを含むその他のコンポーネント(明示的に示されていない)もまたI/Oブリッジ107に接続されてもよい。種々のコンポーネント間でのバス接続は、PCI(ペリフェラル・コンポーネント・インターコネクト)、PCIエクスプレス(PCI−E)、AGP(アクセラレーテッド・グラフィックス・ポート)、ハイパートランスポート、又は、その他の(複数の)バスプロトコルのようなバスプロトコルを使用して実施可能であり、様々な装置間の接続は当分野で公知のような異なるプロトコルを使用してもよい。
【0014】
[0020]グラフィックス処理サブシステム112は、たとえば、プログラマブルプロセッサ、特定用途向け集積回路(ASIC)、及び、メモリ装置のような1台以上の集積回路装置を使用して実施されてもよいグラフィックス処理ユニット(GPU)122及びグラフィックスメモリ124を含む。GPU122は、メモリブリッジ105及びバス113を介してCPU102及び/又はシステムメモリ104によって供給されたグラフィックスデータからの画素データの生成、画素データを格納し更新するためのグラフィックスメモリ124との相互作用などに関連した種々のタスクを実行するように構成されてもよい。たとえば、GPU122は、CPU102上で動く種々のプログラムによって供給された2次元又は3次元シーンデータから画素データを生成してもよい。GPU122は、メモリブリッジ105を介して受信された画素データを、さらなる処理の有無にかかわらず、グラフィックスメモリ124に格納することもある。GPU122は、グラフィックスメモリ124から表示装置110へ画素データを配信するように構成されたスキャンアウトモジュールをさらに含む。
【0015】
[0021]CPU102は、システム100のマスタープロセッサとして動作し、他のシステムコンポーネントの動作を制御し協調させる。特に、CPU102は、GPU122の動作を制御するコマンドを発行する。一部の実施形態では、CPU102は、GPU122のためのコマンドのストリームを、システムメモリ104、グラフィクスメモリ124、又は、CPU102及びCPU122の両方からアクセス可能な別の記憶場所に存在し得るコマンドバッファに書き込む。GPU122は、コマンドバッファからコマンドストリームを読み出し、CPU102の動作と非同期にコマンドを実行する。コマンドは、画像を生成する従来型のレンダリングコマンド、ならびに、画像生成とは無関係であり得るデータ処理のためCPU102上で動くアプリケーションがGPU122の計算パワーを利用することを可能にさせる汎用レンダリングコマンドを含んでもよい。
【0016】
[0022]本明細書で明らかにされているシステムは例示であり、変形及び変更が可能であることがわかるであろう。ブリッジの個数及び配置を含むバストポロジーは必要に応じて変更されてもよい。たとえば、一部の実施形態では、システムメモリ104は、ブリッジ経由ではなく、直接的にCPU102に接続され、他の装置がメモリブリッジ105及びCPU102を介してシステムメモリ104と通信する。他の代替的なトポロジーでは、グラフィックスサブシステム112は、メモリブリッジ105ではなく、I/Oブリッジ107に接続されている。さらに他の実施形態では、I/Oブリッジ107及びメモリブリッジ105はシングルチップに集積化されてもよい。本明細書で明らかにされている特有のコンポーネントは自由に選択でき、たとえば、任意の個数のアドインカード又は周辺装置がサポートされてもよい。一部の実施形態では、スイッチ116は省略され、ネットワークアダプタ118及びアドインカード120、121がI/Oブリッジ107に直接的に接続されている。
【0017】
[0023]システム100の残りの部分へのGPU122の接続もまた変更されてもよい。一部の実施形態では、グラフィックスシステム112は、システム100の拡張スロットに挿入され得るアドインカードとして実施される。他の実施形態では、GPUは、メモリブリッジ105又はI/Oブリッジ107のようなバスブリッジと共にシングルチップに集積化されている。
【0018】
[0024]GPUは、任意の量のローカルグラフィックスメモリが設けられてもよく、ローカルメモリが設けられないこともあり、ローカルメモリとシステムメモリを任意の組み合わせで使用してもよい。たとえば、ユニファイド・メモリ・アーキテクチャ(UMA)の実施形態では、専用グラフィックスメモリ装置が設けられず、GPUはシステムメモリを独占的又はほぼ独占的に使用する。UMAの実施形態では、GPUは、バスブリッジチップに集積化されてもよく、又は、GPUをブリッジチップ及びシステムメモリに接続する高速バス(たとえば、PCI−E)付きのディスクリートチップとして設けられてもよい。
【0019】
[0025]たとえば、複数のGPUを単一のグラフィックスカードに組み込むことにより、又は、複数のグラフィックスカードをバス113に接続することにより、任意の台数のCPUがシステムに組み込まれてもよいこともまた理解されるべきである。
【0020】
[0026]その上、本発明の態様を具現化するGPUは、汎用コンピュータシステムと、ビデオゲームコンソール及びその他の特殊目的コンピュータシステムと、DVDプレーヤーと、携帯電話機又は携帯情報端末のようなハンドヘルド装置などの多種多様の装置に組み込まれてもよい。
【0021】
レンダリングパイプライン概要
[0027]図2は本発明の実施形態による図1のGPU122で実施され得るレンダリングパイプライン200のブロック図である。本実施形態では、レンダリングパイプライン200は、適用可能なバーテックスシェーダープログラム、ジオメトリシェーダープログラム、及び、ピクセルシェーダープログラムが、本明細書で「マルチスレッド型コアアレイ」202と呼ばれる同じ並列処理ハードウェアを使用して実行されるアーキテクチャを使用して実施される。マルチスレッド型コアアレイ202は後述されている。
【0022】
[0028]マルチスレッド型コアアレイ202に加えて、レンダリングパイプライン200は、フロントエンド204及びデータアセンブラ206と、セットアップモジュール208と、ラスタライザ210と、カラーアセンブリモジュール212と、ラスタ演算モジュール(ROP)214とを含み、これらの1つずつが従来型の集積回路テクノロジー又はその他のテクノロジーを使用して実施され得る。
【0023】
[0029]フロントエンド204は、たとえば、図1のCPU102から、状態情報(STATE)、レンダリングコマンド(CMD)、及び、ジオメトリデータ(GDATA)を受信する。一部の実施形態では、ジオメトリデータを直接的に提供するのではなく、CPU102はジオメトリデータが格納されているシステムメモリ104中の場所への参照情報を提供し、データアセンブラ206がシステムメモリ104からデータを取り出す。状態情報、レンダリングコマンド、及び、ジオメトリデータは、一般的に従来型の内容でもよく、シーンのジオメトリ、照明、陰影、テクスチャ、動き、及び/又は、カメラパラメータを含む所望の描画画像又は複数の描画画像を定義するために使用されてもよい。
【0024】
[0030]一実施形態では、ジオメトリデータは、シーンに存在し得る物体(たとえば、机、椅子、人又は動物)についてのいくつもの物体定義を含む。物体は、頂点への参照情報によって定義されるプリミティブ(たとえば、点、線、三角形、及び/又は、その他の多角形)のグループとして、有利にモデル化される。頂点毎に、位置が物体座標系内で特定され、モデル化されている物体と相対的に頂点の位置を表現する。位置の他に、各頂点は様々なその他の属性が頂点に関連付けられている。一般に、頂点の属性は、頂点毎に特定された任意の特性を含むことがあり、たとえば、一部の実施形態では、頂点属性は、頂点の色、テクスチャ、透明度、照明、陰影及びアニメーションのような質を決定するために使用されるスカラ属性又はベクトル属性と、頂点に付随する幾何プリミティブとを含む。
【0025】
[0031]上述されているようなプリミティブは、一般に、プリミティブの頂点を参照することによって定義され、単一の頂点が任意の個数のプリミティブに含まれていてもよい。一部の実施形態では、各頂点は(一意の識別子であればよい)インデックスが割り当てられ、プリミティブはプリミティブを構成する頂点に関するインデックスの順序付きリストを規定することによって定義される。プリミティブを定義するその他の技術(トライアングルストリップ又はトライアングルファンのような従来型の技術を含む)が使用されてもよい。
【0026】
[0032]状態情報及びレンダリングコマンドは、レンダリングパイプライン200の種々のステージの処理パラメータ及びアクションを定義する。フロントエンド204は、状態情報及びレンダリングコマンドを、(明示的に示されていない)制御経路を介して、レンダリングパイプライン200の他のコンポーネントへ導く。当分野で公知のように、これらのコンポーネントは、処理中にアクセスされる種々の制御レジスタ中の値を記憶又は更新することにより、受信された状態情報に応答でき、パイプライン中で受信されたデータを処理することにより、レンダリングコマンドに応答できる。
【0027】
[0033]フロントエンド204はジオメトリデータをデータアセンブラ206へ導く。データアセンブラ206は、ジオメトリデータをフォーマット化し、マルチスレッド型コアアレイ202中のジオメトリモジュール218への配信のためジオメトリデータを準備する。
【0028】
[0034]ジオメトリモジュール218は、フロントエンド204によって供給された状態情報に応答して選択されているバーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムを頂点データに関して実行するようにマルチスレッド型コアアレイ202内のプログラマブル処理エンジン(明示的に示されていない)に命令する。バーテックス及び/又はジオメトリシェーダープログラムは、当分野で公知のようなレンダリングアプリケーションによって指定することが可能であり、様々なシェーダープログラムが様々な頂点及び/又はプリミティブに適用され得る。使用されるべき(複数の)シェーダープログラムは、システムメモリ又はグラフィックスメモリに格納可能であり、当分野で公知の適当なレンダリングコマンド及び状態情報によってマルチスレッド型コアアレイ202によって特定され得る。一部の実施形態では、バーテックスシェーダー及び/又はジオメトリシェーダープログラムは、複数回の経路で実行可能であり、異なる処理演算が各経路中に実行される。バーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムの1つずつは、経路の回数及び各経路中に実行されるべき演算を決定する。バーテックス及び/又はジオメトリシェーダープログラムは、頂点及びその他のデータに広範囲の数学演算及び論理演算を使用するアルゴリズムを実施可能であり、プログラムは、条件付き又は分岐実行経路と直接及び間接メモリアクセスとを含んでもよい。
【0029】
[0035]バーテックスシェーダープログラム及びジオメトリシェーダープログラムは、照明効果及び陰影効果を含む多種多様の視覚効果を実施するために使用され得る。たとえば、簡単な実施形態では、バーテックスプログラムは、頂点をこの頂点の3次元物体座標系から3次元クリップ空間又はワールド空間座標系に変換する。この変換はシーン中の異なる物体の相対位置を定義する。一実施形態では、変換は、物体の物体座標系からクリップ空間座標に変換する変換行列をレンダリングコマンド及び/又は各物体を定義するデータに組み入れることによりプログラムされ得る。バーテックスシェーダープログラムは、物体を構成するプリミティブの各頂点にこの変換行列を適用する。より複雑なバーテックスシェーダープログラムは、照明及び陰影と、手続き型ジオメトリと、アニメーション演算とを含む多種多様の視覚効果を実施するため使用され得る。このような頂点毎の演算の多数の例は技術的に公知であり、詳細な説明は本発明の理解に重要ではないので省かれている。
【0030】
[0036]ジオメトリシェーダープログラムは、ジオメトリシェーダープログラムが個々の頂点ではなくプリミティブ(頂点のグループ)に作用する点でバーテックスシェーダープログラムと異なる。よって、一部の事例では、ジオメトリプログラムは、新しい頂点を作成し、及び/又は、処理されている物体の組から頂点又はプリミティブを削除してもよい。一部の実施形態では、バーテックスシェーダープログラムを通る経路とジオメトリシェーダープログラムを通る経路はジオメトリデータを処理するために交互にされてもよい。
【0031】
[0037]一部の実施形態では、バーテックスシェーダープログラム及びジオメトリシェーダープログラムは、マルチスレッド型コアアレイ202内の同じプログラマブル処理エンジンを使用して実行される。よって、ある時点で、所与の処理エンジンは、バーテックスシェーダーとして動作し、バーテックスプログラム命令を受信し実行し、他の時点で、同じ処理エンジンがジオメトリシェーダーとして動作し、ジオメトリプログラム命令を受信し実行することができる。処理エンジンはマルチスレッド化が可能であり、異なるタイプのシェーダープログラムを実行する異なるスレッドがマルチスレッド型コアアレイ202内で同時にフライト状態であり得る。
【0032】
[0038]バーテックス及び/又はジオメトリシェーダープログラムが実行された後、ジオメトリモジュール218は、処理済みのジオメトリデータ(GDATA’)をセットアップモジュール208へ送る。一般的に従来型の設計でもよいセットアップモジュール208は、各プリミティブのクリップ空間又はスクリーン空間座標からエッジ方程式を生成し、エッジ方程式はスクリーン空間内の点がプリミティブの内側又は外側のいずれにあるかを判定するため有利に使用できる。
【0033】
[0039]セットアップモジュール208は、各プリミティブ(PRIM)をラスタライザ210へ供給する。一般的に従来型の設計でもよいラスタライザ210は、たとえば、従来型の走査変換アルゴリズムを使用して、プリミティブによって覆われた(もしあるとしたら)画素を判定する。本明細書で使用されているように、「画素」(又は「フラグメント」)は、一般的に、単一のカラー値が決定されるべき2次元スクリーン空間内の領域を指し、画素の個数及び配置はレンダリングパイプライン200の設定可能なパラメータでもよく、特有の表示装置のスクリーン解像度と相関していても相関していなくてもよい。当分野で公知のように、画素カラーは(たとえば、従来型のスーパーサンプリング技術又はマルチサンプリング技術を使用して)画素内の複数の場所でサンプリングされることがあり、一部の実施形態では、スーパーサンプリング又はマルチサンプリングはピクセルシェーダー内で取り扱われる。
【0034】
[0040]プリミティブによって覆われた画素を判定した後、ラスタライザ210は、プリミティブによって覆われた画素のスクリーン座標(X,Y)のリストと共に、プリミティブ(PRIM)をカラーアセンブリモジュール212に供給する。カラーアセンブリモジュール212は、プリミティブ、及び、ラスタライザ210から受信されたカバレッジ情報をプリミティブの頂点の属性(たとえば、色成分、テクスチャ座標、表面法線)と関連付け、スクリーン座標空間内の位置の関数として属性の一部又は全部を定義する平面方程式(又はその他の適当な式)を生成する。
【0035】
[0041]これらの属性式は、プリミティブ内の任意の場所で属性の値を補間するためピクセルシェーダープログラムにおいて有利に使用でき、従来型の技術は式を生成するために使用され得る。たとえば、一実施形態では、カラーアセンブリモジュール212は、属性U毎に、U=Ax+By+Cという形式の平面方程式の係数A、B及びCを生成する。
【0036】
[0042]カラーアセンブリモジュール212は、少なくとも1個の画素を覆うプリミティブ毎の属性式(たとえば、平面方程式の係数A、B及びCを含んでもよいEQS)と覆われた画素のスクリーン座標(X,Y)のリストとをマルチスレッド型コアアレイ202内のピクセルモジュール224へ供給する。ピクセルモジュール224は、プリミティブによって覆われた画素毎に、フロントエンド204によって供給された状態情報に応答して選択される1つ以上のピクセルシェーダープログラムを実行するようにマルチスレッド型コアアレイ202内の(明示的に示されていない)プログラマブル処理エンジンに命令する。バーテックスシェーダープログラム及びジオメトリシェーダープログラムの場合と同様に、レンダリングアプリケーションは、所与の画素の組のため使用されるべきピクセルシェーダープログラムを指定することが可能である。ピクセルシェーダープログラムは、照明及び陰影効果と、反射と、テクスチャブレンディングと、手続き型テクスチャ生成などを含む多種多様な視覚効果を実施するために使用され得る。このような画素当たり演算の多数の実施例は技術的に公知であり、詳細な説明は本発明の理解に重要ではないので省かれている。ピクセルシェーダープログラムは、画素及びその他のデータに広範囲の数学演算及び論理演算を使用してアルゴリズムを実施可能であり、プログラムは、条件付き実行経路又は分岐実行経路と、直接及び間接メモリアクセスとを含んでもよい。
【0037】
[0043]ピクセルシェーダープログラムは、バーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムも実行する同じプログラマブル処理エンジンを使用してマルチスレッド型コアアレイ202で有利に実行される。よって、ある時点で、所与の処理エンジンは、バーテックスシェーダーとして動作し、バーテックスプログラム命令を受信し実行し、他の時点で、同じ処理エンジンがジオメトリシェーダーとして動作し、ジオメトリプログラム命令を受信し実行し、さらに他の時点で、同じ処理エンジンがピクセルシェーダーとして動作し、ピクセルシェーダープログラム命令を受信し実行する。マルチスレッド型コアアレイは、画素処理と頂点処理との間で固有の負荷均衡化を行うことが可能であり、アプリケーションがジオメトリ集中型(たとえば、多数の小さいプリミティブ)であるならば、マルチスレッド型コアアレイ202内の処理サイクルのより多くがバーテックスシェーダー及び/又はジオメトリシェーダーに振り向けられる傾向があり、アプリケーションが画素集中型である(たとえば、少数及び多数のプリミティブが、複数のテクスチャなどと共に、複雑なピクセルシェーダープログラムを使用して陰影を付けられる)ならば、処理サイクルのより多くがピクセルシェーダーに振り向けられる傾向がある。
【0038】
[0044]画素又は画素のグループに対する処理が完了すると、ピクセルモジュール224は、処理済みの画素(PDATA)をROP214へ供給する。一般的に従来型の設計でもよいROP214は、ピクセルモジュール224から受信された画素値を、たとえば、グラフィックスメモリ124内にあるフレームバッファ226において構築中の画像の画素と統合する。一部の実施形態では、ROP214は、描画されている画像に既に書き込まれた画素を用いて画素をマスクし、又は、描画されている画像に既に書き込まれた画素と新しい画素を融合することが可能である。奥行きバッファ、アルファバッファ、及び、ステンシルバッファは、(もしあれば)描画された画像に対する各入力画素の寄与度を決定するためにも使用され得る。各入力画素と既に記憶されている画素値との適切な組み合わせに対応する画素データPDATA’はフレームバッファ226へ書き戻される。画像が完成すると、フレームバッファ226は表示装置へスキャンアウトされ、及び/又は、さらなる処理の対象とされ得る。
【0039】
[0045]本明細書に記載されているレンダリングパイプラインは例示であり、変形及び変更が可能であることがわかる。パイプラインは、図示されているユニットのうちの様々なユニットを含んでもよく、処理イベントのシーケンスは本明細書に記載されているシーケントと異なってもよい。たとえば、一部の実施形態では、ラスタ化は、もしあるとするならば、三角形が覆う(又は部分的に覆う)ブロックがどれであるかを決定するために、スクリーン全体をブロック(たとえば、16×16画素)の単位で処理する「粗い」ラスタライザを用い、その後に、少なくとも部分的に覆われることが決定されるブロック内の個別の画素を処理する「細かい」ラスタライザを用いて、複数のステージで実行されてもよい。このような一実施形態では、細かいラスタライザはピクセルモジュール224内に収容されている。別の実施形態では、従来はROPによって実行される一部の演算が、画素データがROP214へ転送される前に、ピクセルモジュール224内で実行されることもある。
【0040】
[0046]さらに、本明細書に記載されているモジュールの一部又は全部の複数のインスタンスが並列に作動されてもよい。このような一実施形態では、マルチスレッド型コアアレイ202は、2個以上のジオメトリモジュール218と、並列に動作する等しい個数のピクセルモジュール224とを含む。各ジオメトリモジュール及びピクセルモジュールは、マルチスレッド型コアアレイ202内の処理エンジンの異なる一部を共同で制御する。
【0041】
マルチスレッド型コアアレイコンフィギュレーション
[0047]一実施形態では、マルチスレッド型コアアレイ202は、様々に組み合わされたバーテックスシェーダープログラム、ジオメトリシェーダープログラム、及び/又は、ピクセルシェーダープログラムの非常に多数のインスタンスの同時実行をサポートする高度な並列アーキテクチャを提供する。図3は本発明の実施形態によるマルチスレッド型コアアレイ202のブロック図である。
【0042】
[0048]本実施形態では、マルチスレッド型コアアレイ202は、ある個数(N)の処理クラスタ302を含む。本明細書では、オブジェクトのようなマルチプルインスタンスは、必要に応じて、オブジェクトを特定する参照番号とインスタンスを特定する括弧付き番号とを用いて示されている。処理クラスタの任意の個数N(たとえば、1、4、8又はその他の任意の個数)が与えられてもよい。図3では、1個の処理クラスタ302が詳細に示されているが、他の処理クラスタ302も同様の設計又は同一の設計であることが理解されるべきである。
【0043】
[0049]各処理クラスタ302は、(図2のジオメトリモジュール218を実施する)ジオメトリコントローラ304と、(図2のピクセルモジュール224を実施する)ピクセルコントローラ306とを含む。ジオメトリコントローラ304及びピクセルコントローラ306は、それぞれが、コアインターフェイス308と通信する。コアインターフェイス308は、マルチスレッド型コアアレイ202の処理エンジンを含むある個数(M)のコア310を制御する。任意の個数M(たとえば、1、2、4又はその他の個数)のコア310が単一のコアインターフェイスに接続されてもよい。各コア310は、バーテックススレッド、ジオメトリスレッド及びピクセルスレッドの組を含む多数の(たとえば、100個以上の)同時実行スレッド(ここで、用語「スレッド」は特有の入力データの組に関して動く特有のプログラムのインスタンスを指している)をサポートする能力をもつマルチスレッド型実行コアとして有利に実施される。一実施形態では、各コア310は、P個のスレッドを並列に実行するためにPウェイSIMDアーキテクチャを実施し、ここで、Pは任意の整数(たとえば、8、16、32)であり、P個のスレッドからなる個数G(たとえば、18、24など)のグループを同時に管理する能力がある。コア310の詳細な説明は、あらゆる目的のため参照によって全体がそのまま本明細書に組み込まれる、2005年12月19日に出願された米国仮出願第60/752,265号に見ることができる。
【0044】
[0050]コアインターフェイス308は、コア310の間で共用されるテクスチャパイプライン314をさらに制御する。一般的に従来型の設計でもよいテクスチャパイプライン314は、テクスチャ座標を受信し、メモリからテクスチャ座標に対応するテクスチャデータをフェッチし、種々のアルゴリズムに応じてテクスチャデータをフィルタ処理するように構成された論理回路を有利に含む。バイリニアフィルタリング及びトリリニアフィルタリングを含む従来型のフィルタリングアルゴリズムが使用されてもよい。コア310がコアのスレッドのうちの1つでテクスチャ命令を受けるとき、コアは、コアインターフェイス308を介してテクスチャ座標をテクスチャパイプライン314へ供給する。テクスチャパイプライン314はテクスチャ命令を処理し、コアインターフェイス308を介して結果をコア310へ返す。パイプライン314によるテクスチャ処理は非常に多数のクロックサイクルを消費することがあり、スレッドがテクスチャ結果を待っている間に、コア310は他のスレッドを有利に実行し続ける。
【0045】
[0051]動作中に、データアセンブラ206(図2)は、ジオメトリデータGDATAを処理クラスタ302へ供給する。一実施形態では、データアセンブラ206は、ジオメトリデータの入力ストリームを部分に分割し、たとえば、実行リソースの可用性に基づいて、ジオメトリデータの次の部分を受信する処理クラスタ302を選択する。その部分は選択された処理クラスタ302中のジオメトリコントローラ304へ配信される。
【0046】
[0052]ジオメトリコントローラ304は、受信されたデータをコアインターフェイス308へ転送し、コアインターフェイスは頂点データをコア310にロードし、次に、適切なバーテックスシェーダープログラムを始めるようにコア310に命令する。バーテックスシェーダープログラムの完了時に、コアインターフェイス308はジオメトリコントローラ304に信号を送る。ジオメトリシェーダープログラムが実行されるべきならば、ジオメトリコントローラ304は、ジオメトリシェーダープログラムを始めるようにコアインターフェイス308に命令する。一部の実施形態では、処理済みの頂点データは、バーテックスシェーダープログラムの完了時にジオメトリコントローラ304へ返送され、ジオメトリコントローラ304は、ジオメトリシェーダープログラムを実行する前に、データを再びロードするようにコアインターフェイス308に命令する。バーテックスシェーダープログラム及び/又はジオメトリシェーダープログラムの完了後、ジオメトリコントローラ304は、処理済みのジオメトリデータ(GDATA’)を図2のセットアップモジュール208へ供給する。
【0047】
[0053]画素ステージで、カラーアセンブリモジュール212(図2)は、プリミティブと、プリミティブによって覆われた画素の画素座標(X,Y)とに関する属性式EQSを処理クラスタ302へ供給する。一実施形態では、カラーアセンブリモジュール212は、カバレッジデータの入力ストリームを部分に分割し、たとえば、実行リソースの可用性又はスクリーン座標中のプリミティブの場所に基づいて、データの次の部分を受信すべき処理クラスタ302を選択する。その部分は選択された処理クラスタ302中のピクセルコントローラ306へ配信される。
【0048】
[0054]ピクセルコントローラ306は、データをコアインターフェイス308へ配信し、コアインターフェイスは画素データをコア310にロードし、次に、ピクセルシェーダープログラムを始めるようにコア310に命令する。コア310がマルチスレッド型であるならば、ピクセルシェーダープログラム、ジオメトリシェーダープログラム、及び、バーテックスシェーダープログラムは、すべてが同じコア310中で同時に実行され得る。ピクセルシェーダープログラムの完了時に、コアインターフェイス308は処理済み画素データをピクセルコントローラ306へ配信し、ピクセルコントローラは画素データPDTAをROPユニット214(図2)へ転送する。
【0049】
[0055]本明細書に記載されているマルチスレッド型コアアレイは例示であり、変形及び変更が可能であることがわかる。任意の個数の処理クラスタが設けられ、各処理クラスタは任意の個数のコアを含んでもよい。一部の実施形態では、あるタイプのシェーダーは、ある特定の処理クラスタ又はある特定のコア中での実行に制限されてもよく、たとえば、ジオメトリシェーダーは各処理クラスタのコア310(0)中での実行に制限されてもよい。このような設計上の選択は、当分野で公知のように、ハードウェアサイズ、及び、複雑さと性能の対比を考慮して行われてもよい。共用テクスチャパイプラインもまた随意的であり、一部の実施形態では、各コアは、コアの固有のテクスチャパイプラインを有してもよく、又は、テクスチャ計算を実行するために汎用機能ユニットを利用してもよい。
【0050】
[0056]処理されるべきデータは様々な方法で処理クラスタへ分配され得る。一実施形態では、データアセンブラ(又はジオメトリデータのその他のソース)及びカラーアセンブリモジュール(又はピクセルシェーダー入力データのその他のソース)は、種々のタイプの付加的なスレッドを取り扱うために処理クラスタ又は個別のコアの可用性を示す情報を受信し、スレッド毎に宛先処理クラスタ又はコアを選択する。別の実施形態では、入力データは、データを処理する能力をもつ処理クラスタがデータを受け入れるまで、ある処理クラスタから次の処理クラスタへ転送される。さらに別の実施形態では、処理クラスタは、処理されるべき画素のスクリーン座標のような入力データの特性に基づいて選択される。
【0051】
[0057]マルチスレッド型コアアレイは、レンダリング画像に関係している、又は、関係していないことがある汎用計算を実行するためにも利用され得る。一実施形態では、データ並列分解において表現され得る計算は、シングルコア中で実行するスレッドのアレイとして、マルチスレッド型コアアレイによって取り扱われ得る。このような計算の結果は、フレームバッファに書き込まれ、システムメモリにもう一度読み取られてもよい。
【0052】
ピクセルシェーダー作業の割り付け
[0058]本発明の実施形態によれば、ピクセルシェーダープログラムによって処理されるべき画素は、画像エリア内の画素の位置に基づいて処理クラスタ302(図3)へ向けられる。たとえば、画像エリアはある数のタイルに分割され得る。各タイルは、1つのクラスタに関連付けられたタイルが画像エリアの全体に散在させられるように、処理クラスタ302のうちの1つが関連付けられている(すなわち、1つの処理クラスタに関連付けられているタイルの少なくとも一部は相互に隣接していない)。
【0053】
[0059]図4は、本発明の実施形態による、多数のタイル402への画像エリア400の1つの可能なタイル化を示している。各タイル402は、たとえば、16×16個の画素でもよく、又は、その他の都合のよいサイズでもよい。本実施形態では、図3のマルチスレッド型コアアレイ202は、8個の処理クラスタ302(0)〜302(7)を含む。図4の各タイル402は、当該タイル内の画素を処理する処理コア302(i)を示す番号i(0〜7)を格納している。図4においてわかるように、各処理クラスタ302は、画像エリア400内の等しい(又はほぼ等しい)個数のタイル402が割り当てられ、各クラスタ302に割り当てられたタイルは相互に隣接していない。多数のグラフィックアプリケーションに対し、このような分配作業は、処理クラスタ302の間で適切な負荷均衡化を行うことが期待される。適当な画素分配論理は、レンダリングパイプライン200、たとえば、図2のカラーアセンブリモジュール212に組み込まれ得る。
【0054】
[0060]図4に示されているタイル化は例示であり、変形及び変更が可能であることがわかるであろう。タイルはどのようなサイズでもよい。一部の実施形態では、タイルのサイズ及び個数は設定可能であり、サイズは、マルチサンプリングモードが使用されるかどうかといったアプリケーション特性に基づいて選択される。各処理クラスタに割り当てられるタイルの配置は必要に応じて変化し得る。
【0055】
[0061]タイルは、特有のGPUに存在する処理クラスタの総数までの任意の個数の処理クラスタに割り当てられる。一部の実施形態では、タイルは、全部に満たない数の処理クラスタに割り当てられる。したがって、GPUは、ピクセルスレッドを処理するために、GPUの処理クラスタの一部だけを使用して画像を描画することが可能である。少なくとも1個の処理クラスタが利用可能である限り、GPUは、スループットが低下しているが、画像を描画することが可能である。一部のクラスタのピクセルスレッドの処理が無効にされた状態で実行することは、たとえば、(一部のコア又はクラスタは、他のコア又はクラスタが動作している間に、電力が低下する)省電力モードでの動作、(様々なGPUの可用性を要求しない)最低限の性能要件の決定、及び/又は、一方又は別のコア内の欠陥に対する許容度の提供のために役立つことがある。
【0056】
[0062]一部の代替的な実施形態では、タイルは、処理クラスタ302ではなく、特有のコア310に割り当てられる。
【0057】
フレームバッファへのピクセルシェーダーカップリング
[0063]一部の実施形態では、図2に提案されている集中型ROP214ではなく、図3の各ピクセルコントローラ306は、画素を図2のフレームバッファ226へ通信する固有のROPを含む。このような実施形態では、処理クラスタ302からフレームバッファへのカップリングが行われる。
【0058】
[0064]N個の処理クラスタを含む一実施形態では、フレームバッファ226はN個の区画に区分される。各クラスタ302はN個の区画のうちの別々の1区画に連結されている。
【0059】
[0065]図5は本発明の実施形態による処理クラスタ302とフレームバッファ500との間のカップリングを説明する略ブロック図である。図2のフレームバッファ226は複数のフレームバッファ500を含むことがあり、各フレームバッファ500は同じ画像に対し画素単位で指定された量を格納することが理解されるべきである。たとえば、一実施形態では、フレームバッファ226は、Zバッファと、(たとえば、赤、緑及び青の色成分のための)色成分バッファと、透明度(アルファ)バッファとを含む。任意の個数のフレームバッファ500が設けられ、本明細書で使用されるような「画素」は、所与の表示装置のアクティブ画素の個数に対応する場合と対応しない場合とがある画像内のサンプリング場所を示すことが理解されるべきである。簡単にするため、唯一のフレームバッファ500だけが表されているが、同じ区分法がある画像に対する各フレームバッファに適用され得ることが理解されるべきである。
【0060】
[0066]フレームバッファ500は、N個の区画502に(物理的又は論理的に)区分けされ、各区画は画像中の画素の少なくとも1/Nのデータを格納するために十分な大きさである。N個の処理クラスタ302のそれぞれは、N個の区画502のうちの1つに連結されている。よって、処理クラスタ302(0)は、この処理クラスタの出力画素データのすべてを区画502(0)に格納し、処理クラスタ302(1)は区画502(1)に格納し、以下同様である。所与の処理クラスタ302によって処理されるタイルが隣接しない範囲で、所与のフレームバッファ区画502中のデータは隣接しないタイルに由来することに注意を要する。表示(スキャンアウト)論理は、フレームバッファ500にアクセスするときに、データの正しい表示順を守る方が有利であり、特に、区画が順次に読み出されることを必要としない。
【0061】
[0067]上述されているように、一部の実施形態では、全部の処理コア302に満たない数の処理コアが画素を生成するため使用されてもよい。図5に示されている実施形態では、処理クラスタ302(0)だけが画素をフレームバッファ区画502(0)へ供給する。したがって、処理クラスタ302(0)が画素を生成するため作動されていないならば、フレームバッファ区画502(0)は使用されない。画像エリアは、再タイル化可能であり、又は、エリアがN−1個の処理クラスタの間で分割されるように、タイルが処理クラスタ302(1)〜302(N−1)の間で再割り当て可能である。一部の実施形態では、たとえば、フレームバッファ区画502(1)〜502(N−1)が元のサンプリング分解能で画像の画素データの全部を格納するために十分な空間を提供しないならば、サンプリング分解能は削減されなくてもよい。区画が物理的ではなく論理的である実施形態では、フレームバッファ500は利用可能な処理クラスタ302の個数と一致するように再区分され得る。
【0062】
[0068]代替的な実施形態では、各処理クラスタは複数のフレームバッファ区画にアクセス可能である。図6は本発明の実施形態による処理クラスタ302とフレームバッファ600との間のカップリングを説明する略ブロック図である。図2のフレームバッファ226は複数のフレームバッファ600を含むことがあり、各フレームバッファ600は、フレームバッファ500に関して上述されているように、同じ画像に対し画素単位で指定された量を格納することが理解されるべきである。いかなる個数のフレームバッファ600が設けられてもよいことが理解されるべきである。簡単にするため、唯一のフレームバッファ600だけが示されているが、同じ区分法がある画像に対する各フレームバッファに適用され得ることが理解されるべきである。
【0063】
[0069]フレームバッファ600はB個の区画602に(物理的又は論理的に)区分けされ、ここで、Bは処理クラスタ302の個数Nと等しくても異なっていてもよい。処理クラスタ302はクロスバー604を介して区画602に連結されている。各クラスタ302は、B個の区画602のうちのいずれか1個(又は1個以上)の区画に画素データを書き込むことが可能である。
【0064】
[0070]本実施形態では、クロスバー604は設定可能であり、処理クラスタ302からフレームバッファ区画602へのカップリングが必要に応じて変更されることを可能にする。たとえば、上述されているように、一部の実施形態では、全部の処理コア302に満たない数の処理コアが画素を生成するため使用されてもよい。図6に示された実施形態では、処理コア302(0)が無効状態にされるならば、クロスバー604は、すべてのフレームバッファ区画602が一方又は別の処理コア302から依然としてアクセスできるように再構成され得る。表示(スキャンアウト)ロジックは、クロスバー604のコンフィギュレーション又は処理コア302へのタイルの割り当てとは無関係にフレームバッファデータが正確にスキャンアウトされるように、有利には設定可能である。
【0065】
[0071]複数のフレームバッファ(たとえば、Zバッファ、カラーバッファ、アルファバッファなど)が存在する場合、各フレームバッファは上述されている方法でB個の区画に区分けされてもよい。一部の実施形態では、区画の個数はすべてのフレームバッファに対し同じではないが、たとえば、Zバッファはカラーバッファより多数又は少数の区画を有してもよい。
【0066】
さらなる実施形態
[0072]本発明は特定の実施形態に関して説明されているが、当業者は数多くの変形例が可能であることを認める。したがって、本発明は特定の実施形態に関して説明されているが、本発明が特許請求の範囲に記載された事項の範囲内のすべての変更及び均等物に及ぶように意図されていることが認められる。
【特許請求の範囲】
【請求項1】
複数の処理クラスタを含むマルチスレッド型コアアレイであって、各処理クラスタが、カバレッジデータから画素データを生成するピクセルシェーダープログラムを実行するように動作可能である少なくとも1個の処理コアを含むマルチスレッド型コアアレイと、
複数の画素の1つずつに対しカバレッジデータを生成するように構成されたラスタライザと、
前記ラスタライザから前記マルチスレッド型コアアレイ中の前記処理クラスタのうちの1個の処理クラスタに前記カバレッジデータを配信するように構成された画素分配論理回路と、
を備え、
前記画素分配論理回路が、画像エリア内の第1の画素の場所に少なくとも部分的に基づいて、前記第1の画素のための前記カバレッジデータが配信される、前記処理クラスタのうちの前記1個の処理クラスタを選択し、
各処理コアがバーテックスシェーダープログラム及びジオメトリシェーダープログラムを実行するようにさらに動作可能であり、
各処理コアは、前記三つのシェーダプログラムのうち異なる複数のプログラムを実行する複数のスレッドの同時実行をサポートする、
グラフィックスプロセッサ。
【請求項2】
前記画像エリアが複数のタイルに分割され、各タイルが前記処理クラスタの一つに割り当てられ、
前記画素分配論理回路が、前記複数のタイルのうちどれが前記第1の画素を含むかに関する判断に基づいて、前記処理クラスタのうちの前記1つを選択する、請求項1に記載のグラフィックスプロセッサ。
【請求項3】
前記複数のタイルのうちの少なくとも二つが前記処理クラスタの各々に割り当てられ、
各処理クラスタについて、該処理クラスタに割り当てられた前記タイルが相互に隣接していない、請求項2に記載のグラフィックスプロセッサ。
【請求項4】
前記処理クラスタのうちの各処理クラスタが画素データをフレームバッファの複数の区画のうちの対応する1個の区画に配信するように構成されている、請求項1に記載のグラフィックスプロセッサ。
【請求項5】
前記処理クラスタのうちの各処理クラスタに連結され、前記処理クラスタから複数の区画を有するフレームバッファへ画素データを配信するように構成されているクロスバーをさらに備える、請求項1に記載のグラフィックスプロセッサ。
【請求項6】
前記処理クラスタのうちのいずれか1個の処理クラスタによって生成された画素データが前記フレームバッファの区画のうちのいずれか1個の区画へ配信可能であるように、前記クロスバーが構成されている、請求項5に記載のグラフィックスプロセッサ。
【請求項7】
前記マルチスレッド型コアアレイは、レンダリングアプリケーションが前記三つのシェーダプログラムのいずれかに集中する場合に、該対応するシェーダプログラムに振り向けられる処理サイクルを増大する、請求項1〜6のいずれか一項に記載のグラフィックスプロセッサ。
【請求項1】
複数の処理クラスタを含むマルチスレッド型コアアレイであって、各処理クラスタが、カバレッジデータから画素データを生成するピクセルシェーダープログラムを実行するように動作可能である少なくとも1個の処理コアを含むマルチスレッド型コアアレイと、
複数の画素の1つずつに対しカバレッジデータを生成するように構成されたラスタライザと、
前記ラスタライザから前記マルチスレッド型コアアレイ中の前記処理クラスタのうちの1個の処理クラスタに前記カバレッジデータを配信するように構成された画素分配論理回路と、
を備え、
前記画素分配論理回路が、画像エリア内の第1の画素の場所に少なくとも部分的に基づいて、前記第1の画素のための前記カバレッジデータが配信される、前記処理クラスタのうちの前記1個の処理クラスタを選択し、
各処理コアがバーテックスシェーダープログラム及びジオメトリシェーダープログラムを実行するようにさらに動作可能であり、
各処理コアは、前記三つのシェーダプログラムのうち異なる複数のプログラムを実行する複数のスレッドの同時実行をサポートする、
グラフィックスプロセッサ。
【請求項2】
前記画像エリアが複数のタイルに分割され、各タイルが前記処理クラスタの一つに割り当てられ、
前記画素分配論理回路が、前記複数のタイルのうちどれが前記第1の画素を含むかに関する判断に基づいて、前記処理クラスタのうちの前記1つを選択する、請求項1に記載のグラフィックスプロセッサ。
【請求項3】
前記複数のタイルのうちの少なくとも二つが前記処理クラスタの各々に割り当てられ、
各処理クラスタについて、該処理クラスタに割り当てられた前記タイルが相互に隣接していない、請求項2に記載のグラフィックスプロセッサ。
【請求項4】
前記処理クラスタのうちの各処理クラスタが画素データをフレームバッファの複数の区画のうちの対応する1個の区画に配信するように構成されている、請求項1に記載のグラフィックスプロセッサ。
【請求項5】
前記処理クラスタのうちの各処理クラスタに連結され、前記処理クラスタから複数の区画を有するフレームバッファへ画素データを配信するように構成されているクロスバーをさらに備える、請求項1に記載のグラフィックスプロセッサ。
【請求項6】
前記処理クラスタのうちのいずれか1個の処理クラスタによって生成された画素データが前記フレームバッファの区画のうちのいずれか1個の区画へ配信可能であるように、前記クロスバーが構成されている、請求項5に記載のグラフィックスプロセッサ。
【請求項7】
前記マルチスレッド型コアアレイは、レンダリングアプリケーションが前記三つのシェーダプログラムのいずれかに集中する場合に、該対応するシェーダプログラムに振り向けられる処理サイクルを増大する、請求項1〜6のいずれか一項に記載のグラフィックスプロセッサ。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図2】
【図3】
【図4】
【図5】
【図6】
【公開番号】特開2012−178158(P2012−178158A)
【公開日】平成24年9月13日(2012.9.13)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−40562(P2012−40562)
【出願日】平成24年2月27日(2012.2.27)
【分割の表示】特願2008−547710(P2008−547710)の分割
【原出願日】平成18年12月18日(2006.12.18)
【出願人】(501261300)エヌヴィディア コーポレイション (166)
【Fターム(参考)】
【公開日】平成24年9月13日(2012.9.13)
【国際特許分類】
【出願番号】特願2012−40562(P2012−40562)
【出願日】平成24年2月27日(2012.2.27)
【分割の表示】特願2008−547710(P2008−547710)の分割
【原出願日】平成18年12月18日(2006.12.18)
【出願人】(501261300)エヌヴィディア コーポレイション (166)
【Fターム(参考)】
[ Back to top ]