
グラフィックスプロセッサ上の物理シミュレーション
【課題】本発明は、少なくとも1つのグラフィクスプロセッサユニット(GPU)上で物理シミュレーションを行うための、方法、コンピュータプログラム製品、およびシステムに向けられる。
【解決手段】該方法は、以下のステップを含む。まず、少なくとも1つのメッシュに関連した物理属性を表すデータは、複数のメモリアレイに格納されることによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。ついで、少なくとも1つのピクセルプロセッサを用いて複数のメモリアレイにおけるデータに演算が行われることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す変更されたデータは、複数のデータメモリに格納される。
【解決手段】該方法は、以下のステップを含む。まず、少なくとも1つのメッシュに関連した物理属性を表すデータは、複数のメモリアレイに格納されることによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。ついで、少なくとも1つのピクセルプロセッサを用いて複数のメモリアレイにおけるデータに演算が行われることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す変更されたデータは、複数のデータメモリに格納される。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、概してグラフィックス処理装置に向けられ、より具体的には、グラフィックスプロセッサを用いてゲームの物理シミュレーションを行うことに向けられる。
【背景技術】
【0002】
コンピュータ系上で作動しているビデオゲームなどのアプリケーションは、物理シミュレーションおよびグラフィックスレンダリングの両方を必要とし得る。例えば、図1は、ビデオゲームのシーンにおいて描かれる1つ以上のキャラクターの運動を演算し、そして表示するための、典型的なパイプラインのブロック図100を図示する。ステップ110において、物理シミュレーションが行われることによって、そのシーンに描かれる1つ以上のキャラクターの運動を決定する。次いでステップ120において、物理シミュレーションの結果が、エンドユーザーによって視覚化されるために図形として描写される。
【0003】
概して、ステップ110の物理シミュレーションは、中央処理装置(CPU)上、またはコンピュータ系の専用デバイス上で実行される、物理エンジンによって行われる。次いで、ステップ120のグラフィックスレンダリングが、グラフィックスプロセッシングユニット(GPU)によって行われる。しかし、最終的には、物理エンジンによってもたらされた結果は、ビデオゲーム(または、より一般的には、アプリケーション)のグラフィックスを修正するために用いられ、故に、何らかの形式において、GPUに伝えられることとなる。物理エンジンからの結果は、レンダリングのためにGPUに伝えられなくてはならないので、待ち時間および帯域幅の問題が起こり得る。さらに、一般的なプロセッシングユニットのように、CPUは、GPUの並列処理能力を有さない。
【0004】
上述の事項をふまえると、必要なものは、1つ以上のGPU上で物理シミュレーションを行う方法、コンピュータプログラム製品および系である。
【発明の概要】
【課題を解決するための手段】
【0005】
本発明の実施形態は、方法、コンピュータプログラム製品、およびシステムを含み得、GPU上で利用可能な並行処理能力を利用することによって、一般的なCPU上で実行される物理シミュレーションと比較して、より速いフレーム速度を可能にする。さらに、そのような方法、コンピュータプログラム製品、およびシステムは、物理シミュレーションの実行において、インプリシットな積分技術を利用することによって、エクスプリシットな積分技術において必要な、相対的に小さな時間ステップを防止する。さらに、手続上の力およびトルクは、GPU上で実行するシェーダープログラムとして表され得る。加えて、GPUベースの物理シミュレーターは、通常はコンピュータシステムで物理シミュレーションを実行する、従来型のソフトウェアダイナミクスソルバーを自動的に置換することが可能であり得る。本発明の実施形態は、1つ以上のGPU上で物理シミュレーションを行うための、方法、コンピュータプログラム製品、およびシステムを提供することによって、上記に識別されたニーズを満たす。1つ以上のGPU上で物理シミュレーションを行うための、そのような方法、コンピュータプログラム製品、およびシステムは、GPU上で利用可能な並行処理能力を利用することによって、通常のCPU上で実行される物理シミュレーションと比較してより速いフレーム速度を可能にする。さらに、そのような方法、コンピュータプログラム製品、およびシステムは、実施形態においてインプリシットな積分技術を利用することによって、物理シミュレーションを行い、これによって、エクスプリシットな積分技術において必要な、相対的に小さな時間ステップを防止する。さらに、本発明の実施形態に従うと、手続き上の力および/またはトルクは、GPU上で実行するシェーダープログラムとして表すことが可能である。加えて、本発明の実施形態に従ったGPUベースの物理シミュレーターは、通常はコンピュータシステム上で物理シミュレーションを実行する、従来型のソフトウェアダイナミクスソルバーを自動的に置換するために用いられ得る。
【0006】
本発明の実施形態に従うと、少なくとも1つのGPU上で物理シミュレーションを行うための方法が提供される。該方法は、以下のステップを含む。まず、少なくとも1つのメッシュに関連した物理属性を表すデータは、複数のビデオメモリアレイに格納されることによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。ついで、少なくとも1つのピクセルプロセッサを用いて複数のビデオメモリアレイにおけるデータに演算が行われることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す修正済みデータは、複数のビデオデータメモリに格納される。
【0007】
本発明の別の実施形態に従うと、コンピュータプログラム製品が提供され、該コンピュータプログラム製品は、制御ロジックを中に格納し、少なくとも1つのGPUに物理シミュレーションを行わせる、コンピュータ使用可能媒体を備える。該制御ロジックは、コンピュータ読取可能な第1および第2のプログラムコードを含む。コンピュータ読取可能第1プログラムコードは、少なくとも1つのGPUに、複数のビデオデータアレイに、少なくとも1つのメッシュに関連した物理属性を表すデータを格納することによって、シーンに描写される少なくとも1つのメッシュの運動を支配する、線形方程式系を設定する。コンピュータ読取可能第2プログラムコードは、少なくとも1つのGPUに、複数のビデオメモリアレイにおけるデータに演算を行わせることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す修正済みデータは、複数のビデオデータメモリに格納される。
【0008】
本発明のさらなる実施形態に従うと、物理シミュレーションを行うためのシステムが提供される。該システムは、複数のビデオメモリアレイを格納するメモリと、該メモリに結合された少なくとも1つのピクセルプロセッサとを含む。複数のビデオメモリアレイは、少なくとも1つのメッシュに関連した物理パラメータを表すデータを格納することによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。少なくとも1つのピクセルプロセッサは、複数のビデオメモリアレイにおけるデータに演算を行うことによって、時刻に対する線形方程式系を解き、その結果として、時刻に対する線形方程式系に対する解を表す修正済みデータをもたらす。
【0009】
本発明のさらなる機能および有用性、ならびに本発明のさまざまな実施形態の構造および動作は、添付の図面を参照しながら、以下に詳述される。本発明は、本明細書に記述された特定の実施形態に限定されるものではないことに留意されたい。そのような実施形態は、例示目的のためだけに、本明細書において提示される。追加的な実施形態は、本明細書に含まれる教示を基に、当業者に明確である。
例えば、本発明は、以下の項目を提供する。
(項目1)
少なくとも1つのグラフィックスプロセッサユニット(GPU)上で物理シミュレーションを行う方法であって、該方法は、
少なくとも1つのメッシュに関連した物理パラメータを複数のメモリアレイにマッピングすることによって、シーンに描写された該少なくとも1つのメッシュの運動を支配する線形方程式系を設定することと、
少なくとも1つのピクセルプロセッサを用いて該複数のメモリアレイ中のデータに演算を行うことによって、ある時刻に対する線形方程式系を解くことと
を包含し、
該時刻に対する線形方程式系の該解を表す変更されたデータは、該複数のメモリアレイに格納される、方法。
(項目2)
前記複数のメモリアレイ中の前記変更されたデータに基づいて、前記時刻に対する前記シーンにおいて描写される、前記1つ以上のメッシュの運動を更新することをさらに含む、項目1に記載の方法。
(項目3)
前記時刻に対する前記少なくとも1つのメッシュを含む、少なくとも1つの衝突を識別することと、
(i)前記複数のメモリアレイ中の前記変更されたデータ、および(ii)該識別された少なくとも1つの衝突、に基づいて、前記時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新することと
をさらに含む、項目1に記載の方法。
(項目4)
前記ピクセルプロセッサを用いて前記変更されたデータに演算を行うことによって、次の時刻に対する線形方程式系を解くことをさらに含み、該次の時刻に対する線形方程式系に対する解を表す変更されたデータは、前記複数のメモリアレイに格納される、項目1に記載の方法。
(項目5)
前記複数のメモリアレイ中の前記さらなる変更されたデータに基づいて、前記次の時刻に対する前記シーン中に描写される少なくとも1つのメッシュの運動を更新することをさらに含む、項目4に記載の方法。
(項目6)
前記次の時刻に対する前記少なくとも1つのメッシュを含む、少なくとも1つの衝突を識別することと、
(i)前記複数のメモリアレイ中の前記変更されたデータ、および(ii)該識別された少なくとも1つの衝突、に基づいて、前記次の時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新することと
をさらに含む、項目4に記載の方法。
(項目7)
演算を行うことは、
少なくとも1つのピクセルプロセッサを用いて前記複数のメモリアレイ中のデータに演算を行うことによって、インプリシットに前記線形方程式系を積分することによって、ある時刻に対する該線形方程式系を解くことを含み、
前記時刻に対する該線形方程式系の該解を表す変更されたデータは、該複数のメモリアレイに格納される、項目1に記載の方法。
(項目8)
前記格納することは、
複数のメモリアレイにデータを格納することによって、線形方程式系を設定することを含み、該線形方程式系は、
【数141】

によって与えられ、シーンにおいて描写される少なくとも1つのメッシュの運動を支配し、ここで、
【数142】
であり、Iは、恒等行列であり、Mは該少なくとも1つのメッシュの質量の直交行列であり、
【数143】
は、tk時における該少なくとも1つのメッシュの幾何学的状態を表すベクトルであり、
【数144】
は、tk時における該少なくとも1つのメッシュ中の各点の速度を表すベクトルであり、
【数145】
は、tk時における該少なくとも1つのメッシュの各点上のネット力を表すベクトルである、項目1に記載の方法。
(項目9)
前記方法は、マッピングに先立って、さらに、
ソフトウェアダイナミクスソルバーからシーンを捕捉し、該シーン中に描写される少なくとも1つのメッシュに付けられた属性およびフィールドを、前記複数のメモリアレイにマッピングされる物理パラメータに変換することと、
該ソフトウェアダイナミクスソルバーのシーングラフにシミュレーション結果をインポートすることと
をさらに含み、
該シミュレーション結果は、前記少なくとも1つのピクセルプロセッサによって演算された前記時刻に対する前記線形方程式系に対する解に対応する、項目1に記載の方法。
(項目10)
前記少なくとも1つのGPUで実行するシェーダーとして、該シーンにおいて描写される該メッシュ上に作用する力を表すことをさらに含む、項目1に記載の方法。
(項目11)
制御ロジックを中に格納しているコンピュータ使用可能媒体を備え、少なくとも1つのグラフィックスプロセッサユニット(GPU)に物理シミュレーションを行わせるコンピュータプログラム製品であって、該制御ロジックは、
コンピュータ読取可能第1プログラムコードであって、該コードは、該少なくとも1つのGPUに、少なくとも1つのメッシュに関連した物理パラメータを複数のメモリアレイにマッピングさせることによって、シーンに描写された該少なくとも1つのメッシュの運動を支配する線形方程式系を設定する、コンピュータ読取可能第1プログラムコードと、
コンピュータ読取可能第2プログラムコードであって、該コードは、該少なくとも1つのGPUに、該複数のメモリアレイ中のデータに演算を行わせることによって、ある時刻の線形方程式系を解く、コンピュータ読取可能第2プログラムコードと
を備え、
該時刻に対する線形方程式系に対する解を表す変更されたデータは、該複数のメモリアレイに格納される、コンピュータプログラム製品。
(項目12)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記複数のメモリアレイ中の前記変更されたデータに基づいて、前記少なくとも1つのGPUに、前記時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第3プログラムコードをさらに備える、項目11に記載のコンピュータプログラム製品。
(項目13)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記少なくとも1つのGPUに、前記時刻の前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別させる、コンピュータ読取可能第3プログラムコードと、
コンピュータ読取可能第4プログラムコードであって、該コードは、(i)前記複数のメモリアレイ中の前記変更されたデータ、および(ii)該識別された少なくとも1つの衝突、に基づいて、該少なくとも1つのGPUに、該時刻に対する該シーン中に描写される該少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第4プログラムコードとをさらに備える、項目11に記載のコンピュータプログラム製品。
(項目14)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記少なくとも1つのGPUに、前記変更されたデータに演算を行わせることによって、次の時刻に対する線形方程式系を解く、コンピュータ読取可能第3プログラムコードをさらに含み、
該次の時刻に対する該線形方程式系に対する解を表すさらなる変更されたデータは、前記複数のメモリアレイに格納される、項目11に記載のコンピュータプログラム製品。
(項目15)
コンピュータ読取可能第4プログラムコードであって、該コードは、前記複数のメモリアレイ中の前記さらなる変更されたデータに基づいて、前記少なくとも1つのGPUに、前記次の時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第4プログラムコードをさらに備える、項目14に記載のコンピュータプログラム製品。
(項目16)
コンピュータ読取可能第4プログラムコードであって、該コードは、前記少なくとも1つのGPUに、前記次の時刻に対する前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別させる、コンピュータ読取可能第4プログラムコードと、
コンピュータ読取可能第5プログラムコードであって、該コードは、(i)前記複数のメモリアレイ中の前記さらなる変更されたデータ、および(ii)該コンピュータ読取可能第4プログラムコードによって識別された該少なくとも1つの衝突、に基づいて、該少なくとも1つのGPUに、該次の時刻に対する該シーン中に描写される該少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第5プログラムコードと
をさらに備えている、項目14に記載のコンピュータプログラム製品。
(項目17)
前記コンピュータ読取可能第2プログラムコードは、
コードであって、前記少なくとも1つのGPUに、前記複数のメモリアレイ中の前記データに演算を行わせることによって、インプリシットに前記線形方程式系を積分することによって、ある時刻に対する該線形方程式系を解くコードを含み、
該時刻に対する線形方程式系に対する解を表す変更されたデータは、該複数のメモリアレイに格納される、項目11に記載のコンピュータプログラム製品。
(項目18)
前記コンピュータ読取可能第1プログラムコードは、
コードであって、前記少なくとも1つのGPUに、複数のメモリアレイにデータを格納させることによって、線形方程式系を設定する、コードを備え、該線形方程式系は、
【数146】
によって与えられ、シーンにおいて描写される前記少なくとも1つのメッシュの運動を支配し、ここで、
【数147】
であり、ここで、Iは、恒等行列であり、Mは前記少なくとも1つのメッシュの質量の直交行列であり、
【数148】
は、tk時における該少なくとも1つのメッシュの幾何学的状態を表すベクトルであり、
【数149】
は、tk時における該少なくとも1つのメッシュ中の各点の速度を表すベクトルであり、
【数150】
は、tk時における該少なくとも1つのメッシュ中の各点上のネット力を表すベクトルである、項目11に記載のコンピュータプログラム製品。
(項目19)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記少なくとも1つのGPUに、ソフトウェアダイナミクスソルバーからシーンを捕捉させ、該シーン中に描写される少なくとも1つのメッシュに付けられた属性およびフィールドを、前記複数のメモリアレイにマッピングされる前記物理パラメータに変換する、コンピュータ読取可能第3プログラムコードと、
コンピュータ読取可能第4プログラムコードであって、該コードは、該少なくとも1つのGPUに、該ソフトウェアダイナミクスソルバーのシーングラフにシミュレーション結果をインポートさせる、コンピュータ読取可能第4プログラムコードと
をさらに備え、
該シミュレーション結果は、前記時刻に対する前記線形方程式系に対する解に対応する、項目11に記載のコンピュータプログラム製品。
(項目20)
前記少なくとも1つのGPUに、前記シーンにおいて描写される前記メッシュに作用する力をシミュレーションさせるコンピュータ読取可能第3プログラムコードをさらに備える、項目11に記載のコンピュータプログラム製品。
(項目21)
物理シミュレーションを行うためのシステムであって、該システムは、
メモリであって、少なくとも1つのメッシュに関連した物理パラメータを表すデータを格納する複数のメモリアレイを含み、シーンにおいて描写される該少なくとも1つのメッシュの運動を支配する線形方程式系を設定するための、メモリと、
該複数のメモリアレイにおける該データに演算を行うことによってある時刻に対する該線形方程式系を解く、該メモリに結合された少なくとも1つのピクセルプロセッサと
を備え、
該時刻に対する該線形方程式系の該解を表す変更されたデータは、該複数のメモリアレイに格納される、システム。
(項目22)
レンダリングエンジンであって、前記複数のメモリアレイにおける前記変更されたデータに基づいて、前記時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目21に記載のシステム。
(項目23)
前記ピクセルプロセッサは、前記時刻に対する前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別し、該システムは、
レンダリングエンジンであって、(i)前記複数のメモリアレイにおける前記変更されたデータ、および(ii)該時刻において識別された該少なくとも1つの衝突に基づいて、該時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目21に記載のシステム。
(項目24)
前記ピクセルプロセッサは、前記変更されたデータに演算を行うことによって、次の時刻に対する線形方程式系を解き、該次の時刻に対する該線形方程式系に対する解を表すさらなる変更されたデータは、前記複数のメモリアレイに格納される、項目21に記載のシステム。
(項目25)
レンダリングエンジンであって、前記複数のメモリアレイにおける前記さらなる修正済みのデータに基づいて、前記次の時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目24に記載のシステム。
(項目26)
前記ピクセルプロセッサは、前記次の時刻に対する前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別し、該システムは、
レンダリングエンジンであって、(i)前記複数のメモリアレイにおける前記変更されたデータ、および(ii)該次の時刻において識別された該少なくとも1つの衝突に基づいて、該次の時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目24に記載のシステム。
(項目27)
前記ピクセルプロセッサは、前記複数のメモリアレイにおける前記データに演算を行うことによって、前記線形方程式系をインプリシットに積分することによってある時刻に対する該線形方程式系を解き、該時刻に対する該線形方程式系に対する該解を表す変更されたデータは、該複数のメモリアレイに格納される、項目21に記載のシステム。
(項目28)
前記線形方程式系は、
【数151】
によって与えられ、ここで
【数152】
であり、Iは、恒等行列であり、Mは前記少なくとも1つのメッシュの質量の直交行列であり、
【数153】
は、tk時における該少なくとも1つのメッシュの幾何学的状態を表すベクトルであり、
【数154】
は、tk時における該少なくとも1つのメッシュ中の各点の速度を表すベクトルであり、
【数155】
は、tk時における該少なくとも1つのメッシュ中の各点上のネット力を表すベクトルである、項目21に記載のシステム。
(項目29)
シーンエクスポーターであって、ソフトウェアダイナミクスソルバーからシーンを捕捉し、該シーンにおいて描写される少なくとも1つのメッシュに付けられた属性およびフィールドを、前記複数のメモリアレイにおいて格納される前記物理パラメータに変換する、シーンエクスポーターと、
シーンインポーターであって、該ソフトウェアダイナミクスソルバーのシーングラフにシミュレーション結果をインポートする、シーンインポーターと
をさらに備え、
該シミュレーション結果は、前記少なくとも1つのピクセルプロセッサによって演算された前記時刻に対する前記線形方程式系に対する前記解に対応する、項目21に記載のシステム。
(項目30)
少なくとも1つのGPU上で、前記シーンにおいて描写される前記メッシュに作用する力を表すために実行するシェーダーをさらに備える、項目21に記載のシステム。
(項目31)
少なくとも1つのグラフィックスプロセッサユニット(GPU)上で物理シミュレーションを行うための方法であって、該方法は、
該少なくとも1つのGPUにシミュレーション定義データを送信することと、
該転送されたシミュレーション定義に応答する該少なくとも1つのGPUからのシミュレーション結果を受け取ることと
を包含する、方法。
(項目32)
前記少なくとも1つのGPUにシミュレーション定義データを転送することは、該少なくとも1つのGPUに、シーンデータ、シミュレーションデータ、アクターデータ、ジョイントデータ、およびフィードバックデータのうちの少なくとも1つを送信することを含む、項目31に記載の方法。
(項目33)
前記送信は、前記少なくとも1つのGPUに、マークアップ言語フォーマットのシミュレーション定義データを送信することを含む、項目31に記載の方法。
(項目34)
少なくとも1つのグラフィックスプロセッサユニット(GPU)上で物理シミュレーションを行うための方法であって、該方法は、
シミュレーション定義データをアプリケーションプログラミングインタフェース(API)コマンドに変換することと、
該変換されたシミュレーション定義データに応答して、該少なくとも1つのGPU上で物理シミュレーションを行うことによって、シミュレーション結果データを生成することと
を包含する、方法。
(項目35)
前記変換することは、前記シミュレーション定義データからシーンデータ構造を生成することを含む、項目34に記載の方法。
(項目36)
前記物理シミュレーションを行うことは、
前記シミュレーション定義データに対応する線形方程式系を設定することと、
該線形方程式系を解くことと、
該線形方程式系に対する解に基づいて衝突を検出することと
を含む、項目34に記載の方法。
(項目37)
物理シミュレーションを行うための、コンピュータベースの方法であって、該方法は、
ソフトウェアダイナミクスソルバーデータを、少なくとも1つのグラフィクスプロセッサユニット(GPU)に対するシミュレーション定義データに変換することと、
該変換されたデータに応答して、該少なくとも1つのGPU上で物理シミュレーションを行うことによって、シミュレーション結果データを生成することと
を包含する、方法。
(項目38)
前記シミュレーション結果データをアプリケーションに送信することをさらに含む、項目37に記載の方法。
(項目39)
前記送信することは、前記シミュレーション結果データを前記ソフトウェアダイナミクスソルバーのフォーマットに変換することを含む、項目38に記載の方法。
(項目40)
追加的なソフトウェアダイナミクスソルバーデータに応答して、ソフトウェアダイナミクスソルバーに基づく別の物理シミュレーションを行うことをさらに含む、項目37に記載の方法。
(項目41)
少なくとも1つのグラフィクスプロセッサユニット(GPU)を生成するための命令を含む、コンピュータ読取可能媒体であって、該命令は、実行されるときには、該少なくとも1つのGPUを作成するように適合され、該少なくとも1つのGPUは、
少なくとも1つのメッシュに関連した物理パラメータを複数のメモリアレイにマッピングすることによって、シーンに描写された該少なくとも1つのメッシュの運動を支配する線形方程式系を設定し、
少なくとも1つのピクセルプロセッサを用いて該複数のメモリアレイ中のデータに演算を行うことによって、ある時刻に対する線形方程式系を解く
ように適合され、該時刻に対する該線形方程式系に対する解を表す変更されたデータは、該複数のメモリアレイに格納される、コンピュータ読取可能媒体。
(項目42)
少なくとも1つのグラフィクスプロセッサユニット(GPU)を生成するための命令を含む、コンピュータ読取可能媒体であって、該命令は、実行されるときには、該少なくとも1つのGPUを作成するように適合され、該少なくとも1つのGPUは、
該少なくとも1つのGPUにシミュレーション定義データを送信し、
該送信されたシミュレーション定義データに応答する該少なくとも1つのGPUからのシミュレーション結果を受け取る
ように適合される、コンピュータ読取可能媒体。
(項目43)
少なくとも1つのグラフィクスプロセッサユニット(GPU)を生成するための命令を含む、コンピュータ読取可能媒体であって、該命令は、実行されるときには、該少なくとも1つのGPUを作成するように適合され、該少なくとも1つのGPUは、
ソフトウェアダイナミクスソルバーデータを、該少なくとも1つのGPUに対するシミュレーション定義データに変換し、
該変換されたデータに応答して、該少なくとも1つのGPU上で物理シミュレーションを行うことによって、シミュレーション結果データを生成する
ように適合される、コンピュータ読取可能媒体。
【0010】
添付の図面は、本明細書において具体化され、明細書の一部を構成し、本発明を例示し、本記述とともに、本発明の原理を説明するためにさらに役立ち、当業者が本発明を作成および利用することを可能にする。
【図面の簡単な説明】
【0011】
【図1】図1は、一般的なグラフィクスパイプラインを例示する、ブロック図を図示する。
【図2】図2は、本発明の実施形態に従った、GPU上で物理シミュレーションを行うための例示的なワークフローのブロック図を図示する。
【図3】図3は、本発明の実施形態に従った例示的なピクセルプロセッサのブロック図を図示する。
【図4】図4は、本発明の実施形態に従った、例示的な物理/レンダリングパイプラインのブロック図を示す。
【図5】図5は、本発明の実施形態に従った、GPU上で行われる例示的な物理シミュレーションパイプラインのブロック図を図示する。
【図6】図6は、本発明の実施形態に従った、ソフトウェアダイナミクスソルバーをバイパスし、これによってGPU上で物理シミュレーションを行う、例示的なワークフローのブロック図を図示する。
【図7】図7は、本発明の実施形態に従った、GPU上で物理シミュレーションを行うための例示的な方法を示す、ブロック図を図示する。
【図8】図8は、本発明の実施形態に従った、クロスをモデル化するための例示的な点メッシュを図示する。
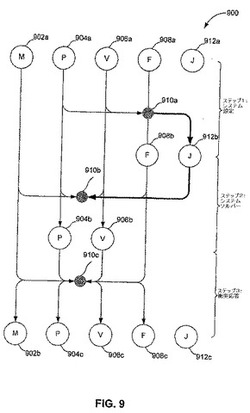
【図9】図9は、本発明の実施形態に従った、GPU上で物理をシミュレーションするための、例示的な高レベルな流れ図を図示する。
【図10】図10は、本発明の実施形態に従った、ビデオメモリに点メッシュに関連した物理パラメータをマッピングするための、例示的な2ステップの流れ図を図示する。
【図11】図11は、本発明の実施形態に従った、ジョイント毎にネット力およびヤコブ行列の対角線上にない部分を決定するための、例示的な流れ図を図示する。
【図12】図12は、本発明の実施形態に従った、ジョイント毎にヤコブ行列の対角線上の部分を決定するための、例示的な流れ図を図示する。
【図13】図13は、本発明の実施形態が実装され得る、例示的なコンピュータシステムのブロック図を図示する。
【図14A】図14Aは、本発明の実施形態に従った、頂点バッファの内容が3×3の成分のアレイ上にマッピングされる、例示的な方法を図示する。
【図14B】図14Bは、本発明の実施形態に従った、インデックスバッファの内容が3×2のグリッド上にマッピングされる、例示的な方法を図示する。
【図15A】図15Aは、頂点バッファが、8個の頂点位置を格納する例を図示する。
【図15B】図15Bは、図15Aに図示された例示的な頂点バッファに格納された頂点位置に対応する、5個の面をインデックスバッファが格納する例を図示する。
【発明を実施するための形態】
【0012】
本発明の機能および有用性は、図面と共に取り入れられるとき、以下に述べられた詳細な記述から、より明確となる。該図面において、同様の参照文字は、一貫して対応する要素を識別する。図面において、同様の参照番号は、概して同一で、機能的に類似した、かつ/または構造的に類似した要素を示す。要素が最初に現れる図面は、対応する参照番号において、最も左側の桁によって示される。
【0013】
I.1つ以上のGPU上での物理シミュレーションのあらまし
A.1つ以上のGPU上で物理シミュレーションを行うための例示的なワークフロー
B.物理シミュレーションを実行する例示的なGPU
II.例示的な物理シミュレーションインターフェース
A.例示的な物理シミュレーションソフトウェアインターフェース(FYSI)
B.例示的な物理シーン記述言語(FYSL)
C.ポイントメッシュ関連の物理パラメータが受信され得る例示的な方法
III.1つ以上のGPU上での物理シミュレーションを行うための例示的な方法
A.方法の概観
B.クロスシミュレーションのための例示的な物理的モデル
C.GPU上でクロスをシミュレートするための例示的な実装
D.FYSLで書き込まれている例示的なコード
IV.例示的なコンピュータ実装
V.結び
I.1つ以上のGPU上での物理シミュレーションのあらまし
本発明の実施形態は、1つ以上のGPU上で物理シミュレーションを行うための方法、コンピュータプログラム製品、および系に向けられる。そのような物理シミュレーションは、例えば、(ビデオゲームなどの)アプリケーションのゲーム演算を行うために用いられ得る。本発明の実施形態に従って1つ以上のGPU上で物理シミュレーションを行うために、メッシュに関連した物理パラメータが、直接的にビデオメモリにマップされる。メッシュは、固体のオブジェクト、容量、流体、またはクロス(cloth)などのあらゆる物理的なオブジェクトを表し得る。ここで詳細に提示されるものは、1つ以上のGPU上でクロスの物理シミュレーションを行う、例示的な方法である。メッシュがビデオメモリにマッピングされた後に、GPUの少なくとも1つのピクセルプロセッサが、コンパイル済みシェーダープログラムを用いてビデオメモリ中のデータに演算を行う。GPUで直接的に物理シミュレーションを行うことは、CPU上で行われる典型的な物理シミュレーションに関連する待ち時間および帯域幅の問題を減少させ得る。
【0014】
明細書を通じて、1つ以上のGPU上で物理シミュレーションを行うための方法、コンピュータプログラム製品、および系は、例示的な物理シミュレーションソフトウェアインターフェース(FYSIと呼ばれる)および物理シーン記述言語(FYSLと呼ばれる)の点から記述される。しかし、本発明は、FYSIおよびFYSLに限定されるものではない。本記述に基づいて、1つ以上のGPU上で物理シミュレーションを行うための方法、コンピュータプログラム製品、および系が、他の種類の物理シミュレーションソフトウェアインタフェースおよび他の種類の物理シーン記述言語を用いて実装され得ることを、当業者は理解されたい。
【0015】
明細書中の「一実施形態」、「一つの実施形態」、「例示的な実施形態」などへの参照は、記述される実施形態が、特定の機能、構造または特性を含み得ることを示すが、全ての実施形態が、必ずしも特定の機能、構造または特性を含み得るとは限らないことに留意されたい。さらに、そのような表現は、必ずしも同一の実施形態を参照するものではない。また、1つの実施形態に関連して特定の機能、構造または特性が記述されるときには、明記されていようとなかろうと、そのような機能、構造または特性を他の実施形態に関連させて作用させることは、当業者の知識の範囲内であることが提示される。
【0016】
以下に詳述されるものは、1つ以上のGPU上において物理シミュレーションをマッピングするための、本発明の実施形態である。第II章において、このマッピングを行うための例示的なインターフェースが記述される。第III章は、1つ以上のGPU上において物理シミュレーションをおこなうための例示的な方法を提示し、GPU上でクロスをシミュレーションするための例示的な方法についての詳しい実装を含む。第IV章においては、1つ以上のGPU上で物理シミュレーションを実装するための例示的なコンピュータ系が記述される。しかし、本発明の実施形態を詳述する前に、1つ以上のGPU上で物理シミュレーションを行う例示的なワークフロー、および物理シミュレーションを実装するための例示的なGPUのあらましを記述することが有用である。
【0017】
A.1つ以上のGPU上で物理シミュレーションを行うための例示的なワークフロー
図2は、GPU上で物理シミュレーションを行うための例示的なワークフローのブロック図200を図示する。ブロック図200は、様々なソフトウェア要素、例えばアプリケーション210、物理シミュレーションソフトウェアインターフェース212、アプリケーションプログラミングインターフェース214、およびドライバ216を含み、それらは、力トコンピュータ系上で実行され、GPU218、(オプション)GPU220、および/または複数のGPU(不図示)などのグラフィックスハードウェア要素と相互作用することによって、物理的現象をシミュレーションし、ディスプレイ222への出力のためのフレームをレンダリングする。ブロック図200の個々の要素が、ここにより詳細に記述される。
【0018】
図2に示されるように、ブロック図200は、アプリケーション210を含む。アプリケーション210は、エンドユーザーアプリケーションであり、ビデオゲームアプリケーションなどのグラフィックス処理能力を必要とする。アプリケーション210は、物理シミュレーションソフトウェアインターフェース212を呼び出す。実施形態において、物理シミュレーションソフトウェアインターフェース212は、ATI Technologies Incによって開発されたFYSIと呼ばれるインターフェースである。FYSIが、ここにより詳細に記述される。しかし、上述のように、本発明は、FYSIに限定されるものではない。当業者に明確であるように、本発明の真意および範囲から逸脱することなく、他の物理シミュレーションソフトウェアインターフェースをも用いられ得る。物理シミュレーションソフトウェアインターフェース212は、物理シミュレーションが行われる、簡単で拡張性のある抽象マシーン(SEAM)を作成する。
【0019】
物理シミュレーションソフトウェアインターフェース212は、API212と通信する。いくつかのAPIは、グラフィックス処理関連における使用のために入手可能である。APIは、アプリケーション210などのアプリケーションソフトウェアと該アプリケーションソフトウェアが作動するグラフィックスハードウェアとの間での媒介物として開発された。新たなチップセットおよび全く新しいハードウェア技術が勢いを増しながら現れる中で、アプリケーションの開発者にとって、最新のハードウェアの機能を考慮に入れたり、利用することは、困難なことである。また、それぞれのハードウェアの予見可能なセットのために特別にアプリケーションを書き込むことは、ますます困難になりつつある。APIは、アプリケーションがあまりにもハードウェアに特有のものであらねばないことを防止する。該アプリケーションは、ハードウェアに直接的に行うのではなく、標準化されたフォーマットでグラフィックスデータおよびコマンドを、APIに出力することが可能である。物理シミュレーションソフトウェアインターフェース212が、直接的にAPI214と通信するため、利用可能なAPIを修正する必要がない。利用可能なAPIの例としては、DirectX(R)またはOpenGL(R)を含む。API210は、グラフィックスアプリケーションをランさせる利用可能なAPIのうちのいずれのものでもあり得る。当業者に認識されるように、本発明の代替的な実施形態は、物理シミュレーションソフトウェアインターフェース212をAPI214中に集約し、故に単一のソフトウェアインターフェースを用いてアプリケーション210を作動させることが可能であり得る。そのような実施形態において、次いでドライバ216が修正されることによって、API214を備える物理シミュレーションソフトウェアインターフェース212の局面を組み込む単一のインターフェースに応じ得る。
【0020】
API210は、ドライバ216と通信する。ドライバ216は、通常はグラフィックスハードウェアの製造者によって書き込まれ、APIから受信した標準コードを、グラフィックスハードウェアによって理解されるネイティブのフォーマットに翻訳する。ドライバ216はまた、グラフィックスハードウェアへのパフォーマンス設定を指示するための入力を受け取る。そのような入力は、ユーザー、アプリケーションまたはプロセスによって提供され得る。例えば、ユーザーは、グラフィカルユーザーインターフェース(GUI)などのユーザーインターフェース(UI)を用いて入力を提供し得、該グラフィカルユーザーインターフェースは、ドライバ216と共にユーザーに供給される。
【0021】
ドライバ216は、第1のGPU218および/または第2のGPU220と通信する。第1のGPU218および第2のGPU220は、グラフィックスチップであり、それぞれが、シェーダーならびに物理シミュレーションおよびグラフィックスレンダリングを行う他の関連ハードウェアを含む。一実施形態において、物理シミュレーションおよびグラフィックスレンダリングは、第1のGPU218などの単一のGPU上で行われる。代替的な実施形態において、物理シミュレーションは第1のGPU218などの1つのGPU(またはコア)において実行され、グラフィックスは、第2のGPU210などの別のGPU(またはコア)においてレンダリングされる。さらなる実施形態において、物理シミュレーションおよびグラフィックスレンダリングは、複数のGPUによって行われる。物理シミュレーションの後に、レンダリングされたグラフィックは、表示ユニット222に送られ、表示される。GPU218およびGPU220は、それぞれ次の章に記述されるように実装され得る。
【0022】
B.物理シミュレーションを実行するための例示的なGPU
本発明の実施形態に従ったGPUのアーキテクチャーは、単一命令多数データ(SIMD)技術を使用可能にし、その結果として、データレベル並列処理をもたらす。そのようなGPUは、プロセッサと、テクスチャ(またはビデオメモリ)を含む。プロセッサは、テクスチャ内のデータに基づきオペレーションを行う。該オペレーションの結果は、レンダーターゲット(ビデオメモリの一部)に書き込まれる。レンダーターゲットは、テクスチャまたは後続演算として再割り当てされ得る。テクスチャは、メモリの1D−、2D−、3D−アレイなどのように、メモリのアレイに配列される。シェーダーは、プロセッサがテクスチャ内のデータに基づき特定の演算を行うために書き込まれた、小さなプログラムまたは一組の命令である。
【0023】
図3は、ブロック図300を図示し、本発明の実施形態に従った、1つ以上のGPU上で物理シミュレーションを実行するための例示的なピクセルプロセッサを説明する。ブロック図300に含まれるものは、6つのテクスチャ310a−310f、8つの定数ストレージレジスタ308a−308h、および1つのピクセルプロセッサ306である。メモリアレイ(1D−、2D−、3D−メモリアレイなど)のテクスチャ座標302は、テクスチャ310に書き込まれ得る。対照的に、定数データ値は、定数ストレージレジスタ308に記憶される。ピクセルプロセッサ306は、テクスチャ310内および/または定数ストレージレジスタ308内のデータに基づきオペレーションを行う。これらのオペレーションを行った後に、ピクセルプロセッサ306は、テクスチャ310にデータを書き込み得、かつ/または、出力314を生成し得る。ピクセルプロセッサ306によって行われるオペレーションは、CPUアッセンブリ言語命令に似た命令によって特定される。
【0024】
ここで、GPU頂点プロセッサにおいてメッシュが表現される、例示的な方法について記述する。メッシュは、1対の1次元リスト、すなわち頂点バッファおよびインデックスバッファから成る。図15Aに例示されるように、頂点バッファは、頂点位置を保持する。図15Aに示される実施形態は、7つの頂点位置を例示している。図15Aは、例示目的のみに用いられ、限定的に用いられるものではない。当業者に明確なように、異なる数の頂点位置が、頂点バッファに記憶され得る。図15Bに例示されるように、インデックスバッファは、面のインデックスを記憶する。図15Bは、例示目的のみに用いられ、限定のために用いられるものではない。当業者に明確なように、異なる数の面のインデックスが、インデックスバッファ記憶され得る。面は、三角形を表し、該面は、頂点バッファに点を載せる。例えば、インデックスバッファに記憶された面は、3つの頂点を含み得、0、1および2と分類される。これら分類された頂点のそれぞれは、頂点バッファの別個の位置を指し示す。
【0025】
ここで、メッシュがビデオメモリにマッピングされる例示的な方法について記述する。この例示的な方法は、例示目的のみに提示され、限定のためではない。メッシュをビデオメモリにマッピングするための他の方法は、本明細書に含まれる記載を基にして、当業者に明確となる。頂点およびインデックスのリストはそれぞれ、ビデオメモリにおける最適化されたN次元のアレイにマッピングされることにより、ピクセルエンジン並列処理がより良く利用される。最適化されたN次元のアレイは、該最適化されたN次元のアレイが、物理シミュレーションを行うために用いられるGPUの最大アドレス指定能力に適合するようになっている。頂点バッファは、n×mの要素のアレイ上にマッピングを行い、インデックスバッファは、l×kグリッド上にマッピングを行う。ビデオメモリ内のそれぞれの要素(例えばピクセル)は、4成分ベクターから成る。はじめの3つの成分は、位置のx、yおよびz成分を表し、4つ目の成分は、境界タグ(以下に記述される)である。
【0026】
一実施形態において、頂点およびインデックスのリストは、それぞれ、図14Aおよび図14Bに示されるように、それぞれがビデオメモリにおける最適化された2次元アレイ上にマッピングされる。本実施形態において、頂点バッファは、3×3成分のアレイ上にマッピングを行い、インデックスバッファは、3×2グリッド上にマッピングを行う。
【0027】
1つのシーンにおける複数のメッシュの場合には、全メッシュが、本発明の実施形態に従った、1つの2次元複合メッシュに一体化される。複合メッシュは、それぞれのサブメッシュに固有の識別子(「id」)をタグ付けすることによって、サブメッシュ境界をビデオメモリに記録する。該idは、それぞれのグリッド要素の第4の構成要素として記録される。メッシュの複合は、ビデオメモリへの小型サイズメッシュのダウンロードに関連したオーバーヘッドを緩和し、かつ、テクスチャ使用の総数によるハードウェアリソースのプレッシャーを軽減する。
【0028】
II.例示的な物理シミュレーションインターフェース
図2に関して上述されたように、物理シミュレーションソフトウェアインターフェース212は、アプリケーション210が、GPU218、GPU220および/または複数のGPU上で物理シミュレーションを行うことを可能にする。この章では、例示的な物理シミュレーションインターフェースが記述される。まず、FYSIと呼ばれる、例示的な物理シミュレーションソフトウェアインターフェースが記述される。続いて、FYSIにおいて具現化される象徴的なコンセプトを表現するための、FYSLと呼ばれる例示的なシーン記述言語が記述される。最後に、FYSIを用いて1つ以上のGPU上で物理シミュレーションを行い、それにより、従来のソフトウェアダイナミックソルバーを回避するための、物理パラメータと属性をFYSLに変換する例示的な方法が記述される。しかし、認識されたいのは、これらの実施形態は、例示的目的のみに提示され、限定のためではないということである。本明細書に含まれる記述を基に、当業者は、1つ以上のGPU上で物理シミュレーションを行うための、他の種類の物理シミュレーションソフトウェアインターフェースの実装方法を理解することとなる。
【0029】
A.例示的な物理シミュレーションソフトウェアインターフェース(FYSI)
FYSI−例示的な物理シミュレーションソフトウェアインターフェース系は、従来のCPUベースのシミュレーション関連の演算をGPU上でマッピングするための伝達手段である。FYSIを用いることによって、ゲーム物理において一般に経験されるものよりも、より高いインタラクション速度が達成され得る。FYSIは、グラフィックスハードウェア上に衝突の検知および解消をマッピングする従来の閉鎖クエリモダリティからはずれたものである。代替的に、FYSIは、ますます増えつつあるハードウェアでのプログラミングが可能なシェーディング力を強化する、グローバルシミュレーション解決法を提案する。
【0030】
図4は、拡張グラフィックスパイプラインのブロック図400を図示し、これによって、物理シミュレーションステージ410が視覚レンダリングステージ420をフィードスル。物理シミュレーションステージ410は、物理記述象徴概念を取り入れる。該記述は、シミュレーションおよびシーンの両方の定義を提供する。シーンは、アクター(actor)から成り、それぞれのアクターは、それ自身の一組の形状、ダイナミクス、および物質の特性を有する。該形状は、参加中のアクターの幾何学的な性質を確立させ、ダイナミクスは、物理的な挙動を構成し、物質は、物質関係の特性を備え付けさせる。加えて、該シーンは、随意的にジョイント(joint)を宣言し、これによって1対のアクターの運動の制約を導入する。シミュレーションの工程は、反復的で別々の一律のステップ、すなわち時間様式によって開始される。物理記述象徴概念は、FYSLと呼ばれる言語の形式をとり、これは、物理シーン記述言語の略である。FYSLは、プラットフォームから独立しており、拡張性があり、かつコンストラクトを提供することによって、必要に応じて複数のGPUに渡ってシミュレーションタスクを分割する。
【0031】
レンダリングブロック420において、物理ブロック410からのシミュレーション結果は、視覚化のためにレンダリングされる。一般的には、いくつかの物理シミュレーションのステップが、レンダリングフレーム毎に行われる。故に、シミュレーションおよび視覚レンダリングの両方のタスクの累積のフレーム速度が、ユーザーに対する最終的なインタラクティブ速度を決定する。FYSIは、物理シミュレーション要件を提供するためのソフトウェア開発環境である。まず、FYSL入力象徴概念は、解析され、内部シーンデータ構造の集合に変換される。次いでシミュレーションは、GPUにおいて開始される。シミュレーション結果は、共有テクスチャを用いて視覚レンダリングスレッドに直接的に進まされるか、または、随意的にプログラマーによって読み返されるように利用可能である。最後に、FYSIは、拡張性を容易にするために、グラフィックスハードウェアインターフェースの頂部に演算象徴概念層(CAL)ラッパー(wrapper)を実装する。一実施形態において、FYSIは、マイクロソフトDirectX(R)(バージョン9.0および10.0)とインターフェースで接続するが、当業者は、FYSIがOpenGL(R)または他のいくつかのAPIとインターフェースで接続し得ることを認識されたい。
【0032】
ゲームにおける物理シミュレーションフィールドは、幾分幅広いものであり、大量の域におけるトピックを範囲に入れる。それらの中には、剛体、クロス、流体、および、一般的には変形可能体のシミュレーションが含まれる。物理シミュレーションの種類は、シミュレーションステージから視覚レンダリングステージ上に移されたデータのフォーマットを示す。剛体の場合には、FYSIは、視覚スレッド変換データに進み、該データは、最近のシミュレーションセッションに入力されたオブジェクトの増分的状態変化を表す。クロスのモデルは、摂動を加えられた元の粒子の位置に戻り、流体または変形可能な体については、結果的にシミュレートされた形状は、初期の形状とはほとんど関連性のないものとなっている。通常、物理シミュレーションの工程は、CPUバウンドであり、物理シミュレーションの工程から視覚レンダリングスレッド上への帯域幅要件は、相対的に限定的である。
【0033】
図5に示されるように、比較的に高いレベルにおいて、包括パイプライン500が形成され、前述の物理シミュレーション局面のほとんどに適用され得る。パイプライン500は、系セットアップステージ510、ソルバーステージ520、および衝突ステージ530を含む。系セットアップステージ510において、入力は、初期シーン記述、または該シーンの増分的な状態の更新のいずれかである。系セットアップステージ510の役割は、物理モデルの統合を行い、方式A*x=bの線形系に到達することである。ここで、Aは行列、xは未知数、bは既知のベクトルである。
【0034】
ソルバーステージ520において、線形系は解かれ、描写されるシーンの状態は、該線形系に対する解に基づいて更新される。線形系は、関連する当業者に利用可能な数値技術を用いることによって解かれる。一実施形態において、線形系は、以下に詳細に記述される修正共役勾配方法、およびDavid BaraffおよびAndrew Witkinによる「Large Steps in Cloth Simulation」、Computer Graphics Proceedings、pp43−54(1998年7月19〜24日)(以降「Baraff引例」と呼ぶ)を用いて解決され、本明細書においてその全体を参照として援用する。
【0035】
衝突ステージ530において、更新されたモデルは、可能性のある衝突のために試験される。算定された接触の結果として、シーンの状態がさらに修正される。衝突検出が、対の点が交差するか否かをチェックすることによって行われる。衝突検出技術は、当業者に周知である。例えば、Baraff引例の50ページを参照されたい。
【0036】
物理パイプライン500は、そのステージ全体を、シミュレーションステージのそれぞれのために繰り返し実行される。一般的に、シーンの中のアクターは、個別に、またはグループベースのいずれかにおいて考慮される。剛体の場合におけるなどの個別のアクターは、パイプライン500の系セットアップステージ510およびソルバーステージ520を通過し、衝突ステージ530のみを行う。クロス、流体および変形可能なエンティティーは、一般的に、明確な相互作用モデルを有するアクターの集合と考えられる。故に、ほとんどの場合において、それらはパイプライン500の全てのステージを実行するように意図される。クロスが物理パイプライン500を通過する例が、第III章に記述される。
【0037】
B.例示的な物理シーン記述言語(FYSL)
FYSI物理シミュレーションインターフェースライブラリへの入力象徴概念は、FYSLと呼ばれるカスタム化シーン記述フォーマットにおいて表される。FYSLは、XMLフォーマットにおいて表され、シーン、シミュレーション、アクター、ジョイント、およびフィードバックの5つのセクションから成る。これらのFYSLセクションのそれぞれは、スキーマタグおよび随意的価値割当を含む。スキーマタグおよび随意的価値割当は、以下に記述される。FYSLプログラムの見本は、この小節の終わりに提供される。
【0038】
FYSLの最初のセクションは、シーンである。このセクションにおいて、描写されるシーンが定義される。例示的なグローバルシーンタグは、表1に提示される。
【0039】
【表1】
FYSLの第2のセクションは、シミュレーションである。FYSIにおけるシミュレーションの工程は、個別的であり、ステップにおいて開始される。FYSLシミュレーション特性は、種類およびシミュレーションステップ間の時間間隔を含む。
【0040】
加えて、全てのシーンのアクターに同じように作用している力を表すグローバルフィールドが、シミュレーション定義に随意的に加えられ得る。本実施形態において、FYSLは、ドラッグフィールド、方向性フィールド、および手続きフィールドの、3種類の力フィールドタグを提供する。ドラッグフィールドは、3つのスカラー値(それぞれの次元に1つ)から成るベクトルであり、該ベクトルは、アクターの線形速度に基づいた制動力を及ぼす。方向性フィールドは、シミュレーションを通して一定な単一成分の力であり、該力は、ベクトルによって特定された方向において作用する。例示的な方向性フィールドは、重力である。手続きフィールドは、時間および空間の両方において変化し得る、より入り組んだフィールドを表す。手続きフィールドに取り付けられたストリングは、GPU上で実行されるシェーダープログラムのコードにさらに翻訳される、機能である。
【0041】
例示的なシミュレーションタグは、表2に示されており、例示的なフィールドタグは、表3に示される。
【0042】
【表2】
FYSLの第3のセクションはアクターである。アクターの一群は、通常は1、2または3次元であり得る論理グリッドにおいて構成される。グリッドは、GPUビデオメモリにおいてアクターの特性を展開する手段として役立つ。表4に示されるように、グリッドタグは、幅、高さ、および深さの値を含む。
【0043】
【表3】
アクターは、グローバルおよび特定の形状およびダイナミクスの特性によって特定される。形状は、対に関する衝突の検出を決定するために用いられ、ダイナミクス特性は、物理的挙動を容易にすることによって応答を解決する。FYSLおよびFYSIは、形状の定義のために左手座標系を用いる。表5に示されるように、グローバルなアクタータグは、名前、種類、およびidの値を含む。
【0044】
【表4】
アクターid(識別子)は、正の整数であり、かつ、同一の階層のアクターの群に渡って固有のものであることが求められる。大体において、FYSIは、FYSL記述において欠いているシーン特性のために、デフォルトのシーン特性を割り当てるように求められる。
【0045】
記述されたFYSL実施形態において支持される形状の定義は、ボックス(軸に対して整列または配向されている)、球、メッシュ、および四面体を含む。アクター形状は、ローカルの基準座標系において定義される。体積を境界付けるボックスおよび球は、1対の中心および半径として表される(中心および半径は、それぞれベクトルまたはスカラーのいずれかである)。メッシュおよび四面体は、頂点位置(四面体については、頂点の数は4に固定されている)および1組の面のインデックス(四面体についてはインプリシット)の集合の形態をとる。メッシュに関しては、面はエクスプリシットであり、一方で、四面体に関しては、面はインプリシットである。形状は、ワールド(world)座標空間へのローカルの座標系の変換を特定する行列と関連している(以下の論述を参照されたい)。表6から表10は、形状に特有のタグを例示する。
【0046】
【表5】
体積を境界付ける質量の中心は、形状の定義によってエクスプリシットである。メッシュおよび四面体については、FYSIは、質量の中心が、線形の運動特性のセットにおいて提供されない限り、質量の中心をインプリシットに演算する。メッシュの質量中心のパラメータは、必ずしもユーザーによって提供される必要はないが、それがあれば、FYSIが内部的に演算したものを上書きする。
【0047】
シミュレーションは、ワールド座標空間において行われる。形状の変換は、平行移動および回転の成分の連結であり、アクターに線形および角の運動のそれぞれを適用する効果によるものである。結果的な行列は、ローカルからワールドの座標空間へと、形状を変換する。変換行列は、視覚レンダリング工程のためにFYSIクライアントによって用いられる。
【0048】
FYSLボックスの形状は、FYSI内部において、軸に対して整列した(AABB)または方向性を有した(OBB)、いずれかの演算経路を取り得る。該選択は、どちらかと言えば動的であり、シミュレーションのステップによって変わり得る。例えば、接触応答に基づき得る。一般的には、衝突検出のためのAABB経路は、OBB経路に比べてより効率的である。
【0049】
動的属性は、線形、角、および物質の種類の任意の組み合わせであり得る。動的属性は、質量、速度、エクスプリシットな質量中心の位置、配向、および及ばされる力を含む、運動学的特性を定義する。加えて、動的特性は、復元および摩擦などの、接触応答物質属性を提供する。線形、角および物質の種類のための動的タグは、表11、表12、および表13にそれぞれ提供される。
【0050】
【表6】
剛体は、行われた物理的な挙動の規則の基礎となる、FYSIに対し、点質量と仮定される。線形の運動および外部的な力は、本体の質量中心に作用し、角運動は、接触点に適用される。
【0051】
FYSLトルクは、それが存在するときには、あらゆるボックスまたはメッシュの形状の頂点に適用される。また、トルクは粒子ベースのアクターの場合にも有意義であり、ここでは、それぞれの粒子が、ゼロ半径の球として定義される。トルクは、アクター(または粒子の場合は親アクター)の質量中心に対する位置に依存する。該トルクは、結果として起こるアクターの角運動に影響する。FYSLトルクは、粒子ベースのアクター(例えば、空間的な範囲を有さない無形のアクター)に対して有意義である。該トルクは、トップレベルアクターの実質的な質量中心に対する位置に依存する。トルクは、粒子の角運動に影響する。
【0052】
アクターに対する配向は、行と列が単位長さの、直交行列であることが求められる。
【0053】
オメガ動的特性は、ラジアンにおける角度のベクトルである。任意の軸に対する正の角度は、軸を中心に反時計回りの回転をもたらし、負の角度は、軸を中心に時計回りの回転をもたらす。
【0054】
メッシュのインデックスおよび四面体の面のインデックスは、ゼロベースであり、それぞれは、反時計回りで三角形を表す。
【0055】
アクターのグリッド展開は、GPUに固有のデータパラレルアーキテクチャを利用する。グリッドはまた、物理的に割り当てられたGPUから読み返される最終的な画像の解像度を提供し、該物理的に割り当てられたGPUは、視覚的レンダリングを行うCPUまたはピアGPU上にシミュレーション結果を移動させる。1Dグリッドは、GPU上では非常に非効率的であり、通常は用いられることはない。通常は、アクターは、2Dグリッド上に分配される。3Dグリッドが用いられるのは、例えば、2Dグリッドのアドレス指定能力がGPUの限界を超えた場合である。グリッドの次元は、2のべき乗である必要はない。最後に、アクターの数は、グリッドセルの数に必ずしも一致する必要はないかもしれない(例えば、後者は、階層におけるアクターの数と等しいかそれ以上でなくてはならない)。結果として、2Dグリッドが、完全に場所を占有されていない最後の行を有し得、3Dグリッドの最後のスライスは、完全に占有されていないかもしれない。FYSIは、全ての生じたスライバをダミーアクターで埋める。
【0056】
アクターは、階層的に作られ得、それぞれの階層レベルにおけるアクターの集合は、グローバルな属性を共有し得る。グリッドは、各レベルにおいて、アクターの集合に付属させられることが求められる。より高い階層レベルでの形状は、より粗い幾何学的表現となると想定される。これは、トップ−ダウンシミュレーションを開始することと連動し、早期の衝突検出が除かれることは、全体的な工程の効率を向上させる。また、アクターの動的特性は、各階層レベルにおいて固有のものにすることができ、その結果、順応性のある物理的特性を実行する自由を提供する。ジョイント(後に記述)は、制約条件をシミュレーションするためにアクターの群に随意的に適用され得る。例えば、ジョイントは、クロスのシミュレーションにおいて用いられ、このことは以下の第III章に詳述される。
【0057】
FYSLの第4のセクションは、ジョイントである。ジョイントは、1対のアクターの間の相互作用の制約を定義する。ジョイントは、本質的にアクターの動作を制限する。ジョイントは、共通のパラメータおよび/またはその種類に基づく固有のパラメータを有し得る。共通のパラメータには、ジョイントの種類、および1対のアクターのメンバーそれぞれに対するハンドルを含む。ジョイントは、FYSL記述フォーマットにおいてアクターと同一のタグレベルにある。従って、ジョイントは、トップのシーンレベルおよび任意のアクター階層の両方において定義され得る。例示的なジョイントタグは、表14、表15、および表16に提供される。
【0058】
【表7】
FYSLの第5のセクションは、フィードバックである。FYSL記述のフィードバックセクションは、シミュレーション結果の戻り経路に対して、FYSIによってのみ提供される。複数ステップのシミュレーションセッションにおいて、ステップごとにフィードバックセクションがある。例示的なフィードバックタグは、表17に示される。
【0059】
【表8】
例示的実施形態は、上記のタグを含み得るが、代替的な実施形態においては、他のタグの種類も用いられ得る。サンプル#1。以下に提供されるものは、FYSLで書かれたコードの例示的なセクションである。コードのこのセクションは、それぞれ角度的および線形のダイナミクスを有する、1対のメッシュ形状のアクターを有する衝突検出物理シミュレーションシーンを図示する。
【0060】
【表9】
【0061】
【表10】
サンプル#2。以下に提供されるものは、FYSLで書かれた例示的なコードの別のセクションである。このコードのセクションは、2×2のグリッドレイアウトの粒子ベースのアクターのための、2つのレベルの階層を例示する。これは、クロスおよび流体のエンティティーを定義するための基本的な構造である。
【0062】
【表11】
【0063】
【表12】
【0064】
【表13】
C.メッシュに関連する物理パラメータが受信され、FYSLに変換され得る、例示的な方法
ソフトウェアダイナミクスソルバー(California州、San RafaelのAutodesk(R)所有、Maya(R)Dynamicsなど)は、CPUによって実行される物理シミュレーションを行うために存在する。本発明の実施形態に従うと、プラグインが用いられることによって、そのようなソフトウェアダイナミクスソルバーを迂回し、これによって、本明細書に記述されるようにGPU上で物理シミュレーションを行う。本実施形態において、プラグインは、シーンを捕捉し、該シーンに描写されるアクターに関連する属性およびフィールドをFYSLに変換する。その結果、物理シミュレーションが、FYSIを用いてGPU上で行われ得る。別の実施形態において、ユーザーは、物理シミュレーションが、GPUによって行われるか、またはソフトウェアダイナミクスソルバーによって行われるかを選択してよい。さらなる実施形態において、GPUの有効性および/または所定の機能に対するソフトウェアサポートなど、所定の基準に基づいて、GPUまたはソフトウェアダイナミクスソルバーが自動的に選択され、物理シミュレーションが行われる。例えば、GPUは、剛体およびクロスの物理シミュレーションを行うために用いられ得るが、ソフトウェアダイナミクスソルバーは、流体の物理シミュレーションを行うために用いられ得る。物理シミュレーションをGPUまたはソフトウェアダイナミクスソルバーによって行うことによって、より速いフレーム速度が達成され得る。特定のソフトウェアダイナミクスソルバー(すなわち、Maya(R)Dynamics)を迂回するための例示的なプラグインが、本章に記述されるが、まず、Maya(R)Dynamicsのあらましが提供される。
【0065】
Maya(R)Dynamicsは、現実世界の物理的特性をシミュレーションすることによって運動を生成する、一種の技術である。Maya(R)におけるダイナミクスは、多様であり力強く、また、モデリング、アニメーションおよびレンダリングに一致した重要性レベルのツールセットを所有する。一般的に、Maya(R)Dynamicsのコンセプトは、キーフレームを用いないシミュレーションベースのアニメーションを含意する。Maya(R)Dynamicsのファミリーには、剛体および軟体、粒子系、クロス、流体および髪メンバーを含む。Maya(R)Dynamicsは、物理的原理に基づく、視覚的に強い印象を与える効果を作成するために、ゲームにおいて用いられる。
【0066】
図6は、ブロック図を図示しており、ここでは、GPUを利用することによって、Maya(R)Dynamicsなどのソフトウェアダイナミクスソルバーと比較して頑強性を妥協することなく、より高いシミュレーション速度を達成する、例示的なワークフロー600を図示している。該ワークフローは、大部分がMaya(R)Dynamicsへのプラグインによって制御されている。そのようなプラグインには、シーンエクスポーター(exporter)、GPU DynamicsシミュレーターFYSI、およびシーンインポーター(importer)が含まれる。
【0067】
ワークフロー600は、ステップ610から始まり、ここでは、シーンエクスポーターが、アーティストによってシーンオブジェクトに添付された属性およびフィールドを受け取る。属性には、初期速度、スピン、配向、および物質の摩擦を含む。フィールドは、運動に影響し、ドラッグ、重力または手続き上定義されたものを含む力を表し、運動は、GPUシェーダープログラムにおいて表される。ユーザーは、GPUベースのシミュレーションを開始するために、全てのシーンオブジェクトまたはそのサブセットのいずれかを選択する。エクスポーターは、オブジェクトの幾何学的形状および動的特性を、GPU向けの物理シミュレーションフォーマットに変換する。GPU向きの物理シミュレーションフォーマットは、一実施形態においては、FYSLである。
【0068】
ステップ620において、物理シミュレーションは、FYSLを用いてGPU上で行われる。一旦適切なFYSIプラグインが現れると、GPUベースのシミュレーターが、シームレスにソフトウェアダイナミクスソルバーノード(例えばMaya(R)Dynamics(R)統合ソルバー)に取って代わる。GPUシミュレーターは、多数の別個のフレームにおいて、再帰的にシミュレーションを実行させる。シミュレーション中に、現在のシーン状態が解決され、FYSL動的アクターのそれぞれの対の中での衝突検出が調べられる。衝突する対は、さらに処理されることにより、関連するアクターの運動に影響するであろう、接触応答を起こす。FYSI GPU援助の物理シミュレーションは、主に頂点プロセッサよりもより高い度合いの同時処理を活用するピクセルエンジンを利用する。GPU上での物理シミュレーションは、グリッドベースであり、ここでは、通信バリヤーは、格子セルに渡ってほとんどまたは全くない。関係する演算カーネルは、大部分において、高い算数効力特性を有し、従って、同等のCPU実装と比較して、改良スピードアップをデモンストレーションするための好ましい候補である。このシミュレーション工程は、効率を向上させるために単一または多数のGPUを活用し、ソフトウェアダイナミクスソルバーとやりとりしているアーティストには、全てがトランスペアレントである。FYSIは、エクスポーターが送ったものと、同一のFYSL表現フォーマットにとなる。FYSI結果は、完全なシミュレーションセッションのために内部的にキャッシュされ、Maya(R)Dynamicsにおいて再使用されるために完全に公開される。
【0069】
ステップ630において、フレーム毎のシミュレーター結果は、Maya(R)Dynamicsのシーングラフにインポートによって戻される。ステップ630の間、幾何学的形状および変換データのみが重要である。FYSIは、シミュレーションステップ毎に、形状の位置的更新および変換の更新の両方を提供する。変換データは、入信してくるシーンの位置および配向に関連する。剛体の場合には、Maya(R)Dynamicsからの変換シーングラフのノードを更新することで十分である。変形する物体(クロスおよび流体など)に対しては、Maya(R)Dynamicsによって提供されるシーンプリミティブのノードにおいて、更新は、全てのメッシュ頂点またはインデックスについて行われる。
【0070】
ステップ640において、シミュレーション結果は、視覚化ためにレンダリングされる。GPUまたはソフトウェアベースのレンダラーが呼び出されることによって、シミュレーション効果を視覚化する。一実施形態において、視覚レンダリングタスクを実行するためのGPUは、物理シミュレーションを行うGPUから物理的に離れている。これは、この場合においても、より高いレベルにおいて並列処理を容易にするためである。
【0071】
ステップ650において、レンダリングされた結果は、シーンにおいて再生される。
【0072】
III.1つ以上のGPU上での物理シミュレーションを行うための例示的方法
A.方法の概観
ここに、FYSIおよびFYSLを用いた、1つ以上のGPU上での物理シミュレーションを行うための例示的方法を記述する。図7は、ブロック図を図示し、本発明の実施形態に従って、1つ以上のGPU上でゲーム物理シミュレーションを行うための例示的な方法700を例示している。方法700は、ステップ710から始まり、ここでは、メッシュに関連した物理パラメータが、ビデオメモリにマッピングされることによって、シーンに図示されたメッシュの運動を決定する線形方程式系をセットアップする。ビデオメモリは、図3に関連して上述された、テクスチャ310を含み得る。当業者に明らかなように、メッシュは、個体のオブジェクト、体積、流体、クロス、または他の種類の物理的オブジェクトなどの、あらゆる種類の物理的なオブジェクトを表し得る。
【0073】
ステップ720において、少なくとも1つのピクセルプロセッサを用いて、演算が、ビデオメモリにおけるデータに基づいて行われることによって、その時刻の線形方程式系を解く。その時刻の線形方程式系への解を表す修正済みデータは、次いでビデオメモリに記憶される。一実施形態において、修正済みデータは、テクスチャ310に記憶され、次いで別のシェーダーが該修正済みデータに対応するグラフィックスをレンダリングする。本実施形態においては、単一のGPUが物理シミュレーションおよびグラフィックスのレンダリングを行う。別の実施形態においては、修正済みデータが、第1のGPUの出力として提供され、次いで第2のGPUのテクスチャに書き込まれる。本実施形態においては、第1のGPUが、物理シミュレーションを行い、第2のGPUがグラフィックスのレンダリングを行う。代替的に、第1のGPUは、第2のGPU(例えば第1のGPUのビデオメモリあるいは系メモリ)にアクセス可能なメモリの領域に修正済みデータを書き込み得る。
【0074】
方法700は、あらゆる種類の物理的オブジェクトをシミュレーションするために実装され得る。以下に提供されるものは、1つ以上のGPUにクロスをシミュレーションするための例示的な実装である。この例示的実装は、例示目的のみに提供され、限定の目的に提供されるものではない。本明細書に含まれる記載に基づいて、当業者は、GPU上で他の種類の物理的オブジェクトのシミュレーションを行う方法を理解することとなる。
【0075】
ここで、1つ以上のGPUでクロスをシミュレーションするためのインプリシットな技術を記述する。まず、クロスの物理モデル、および離散時間にそのモデルをシミュレーションする2つのアプローチが提示される。第2に、インプリシットな離散時間シミュレーションの3ステップ工程が記述される。第3に、この3ステップ工程をGPUにマッピングする方法が提示される。
【0076】
(クロスシミュレーションのための例示的物理モデル)
クロスは、内在する粒子系によってシミュレーションされ得る。そのような内在型粒子系は、内部的な伸張力および減衰力を受ける、点質量のアレイとして表され得る。これら力は、近傍の点の相対的変位および速度に依存する。そのような点質量のアレイは、本明細書において点メッシュと参照される。図8は、例示的な点メッシュを図示する。
【0077】
点メッシュ800を考慮すると、以下の、点メッシュ800に関連した物理パラメータが定義され得る。
【0078】
【数1】
あるいは、Mは、ブロックとして解釈され得、それは、それぞれの要素が{3×3}対角行列である{n×n}対角行列である。
【0079】
ニュートンの第2の法則(すなわち、F=ma)は、点メッシュ800に対して以下のように書かれ得る。
【0080】
【数2】
線形減衰を有する二次質量ばね系に対しては、粒子iに作用するネット力は、相対位置
【0081】
【数3】
および全て(通常は近傍)の粒子の速度
【0082】
【数4】
の関数である。故に、方程式1におけるネット力の各成分は、
【0083】
【数5】
と書かれ得る。そして、点メッシュ800の運動は以下の方程式によって決定される。
【0084】
【数6】
故に、方程式2の解は、点メッシュ800の運動をシミュレーションするために用いられ得る。
【0085】
方程式2が一連のコンピュータの工程(例えば、GPUにおける少なくとも1つのピクセルプロセッサによって行われる工程)によって解かれるためには、方程式2は、離散時間型問題に変換されなくてはならない。時間離散型問題においては、系の次の状態が、その以前の状態によって与えられる。具体的には、時刻tk
【0086】
【数7】
における系の位置および速度が与えられると、最も単純な一次時間離散型問題は、時刻tk+1
【0087】
【数8】
における系の位置および速度を決定する。時間離散型問題に対する解は、時間離散型積分を必要とする。少なくとも2つの一般的な種類の時間離散型積分があり、それらは、エクスプリシットな方法およびインプリシットな方法である。
【0088】
エクスプリシットな方法は、導関数の前進投射を用い、以前の状態の直接的外挿から次の時間のステップにおける状態を演算する。例えば、一次オイラー前進差分は、以下のように近似する。
【0089】
【数9】
離散時間導関数の右辺は、以前の時間ステップにおける値によって左辺において束縛される。将来的な状態は、状態の関数として再び書かれる事となり得、すなわち、以下の通りとなる。
【0090】
【数10】
方程式3の形式を点メッシュ800に適用すると、点メッシュ800の運動を決定する方程式の系(すなわち方程式2)は、
【0091】
【数11】
によって与えられる、時間ステップ毎に適用される、単純な独立した更新の方程式のセットとして書き換えられ得る。
【0092】
エクスプリシットな積分スキームに対する主な欠点は、数値安定度である。一般的に、前進近似を保つために、方程式3の関数a(t)は、
【0093】
【数12】
に関してあまり急激に変化してはならない。すなわち、積
【0094】
【数13】
は、閾値より下でなくてはならない。bkが大きい場合、該系は、「剛(stiff)」と言われ、
【0095】
【数14】
は、比較的に小さくされなくてはならない。
【0096】
インプリシットな方法は、第2種類目の時間離散型積分技術を担う。インプリシットな方法は、外挿された結果から、幾分かの「可逆性」を表す方程式の系からの次の時間ステップにおける状態を演繹する。言い換えると、将来の状態の後退導関数が、以前の状態に対して同時に検証される。例えば、一次オイラー前進差分は、以下のように近似する。
【0097】
【数15】
巧妙なことに、ここで、時間離散型導関数の右辺は、将来の値によって左辺に同時に束縛されるということである。直接的な結果として、将来の状態は、以前の状態の単純な関数としては表現できない。
【0098】
点メッシュ800に適用されることによって、系の支配方程式(すなわち、方程式2)は、3nの未知数
【0099】
【数16】
の同時的な系になり、それは、時間ステップ毎に解かれなくてはならない。
【0100】
【数17】
このタスクは、難題のように見えるかもしれないが、このアプローチは、2つの重要な利点を有する。まず、インプリシットな技術は、ほとんど無条件的に一定している。つまり、インプリシットな技術は、現実的なクロスシミュレーションの特徴的に「剛(stiff)」方程式によって影響されることがより少なく、それ故により大きな時間ステップをサポートすることが可能である。次に、結果的な系は、疎かつ対称的な傾向があり、これらの種類の系は、効率的な数値法を用いて難なく解かれる。
【0101】
方程式4に表されるエクスプリシットな積分法か、方程式5に表されるインプリシットな積分法のいずれかにおいて、ネットの内力のベクトル
【0102】
【数18】
を求めなくてはならない。一般的には、
【0103】
【数19】
は、クロスの内部的な拘束をモデル化する、非線形の関数である。離散時間において、
【0104】
【数20】
は、常に現在の状態の関数である。
【0105】
【数21】
エクスプリシットな積分を用いて、
【0106】
【数22】
が、直接的に求められることによって、
【0107】
【数23】
が更新される。具体的には、方程式4に示されるように、以下となる。
【0108】
【数24】
しかし、安定度を確実にするために、
【0109】
【数25】
は、
【0110】
【数26】
の「剛性(stiffness)」を反映させるために選択されなくてはならない。残念なことに、現実的な内力は、比較的に堅く、比較的に小さな時間ステップを必要とする。先述のBaraffの引例によって証明されたように、現実的に剛の方程式に必要な、これら小さな時間ステップにおける多くの更新の累積のコストは、より粗い時間ステップにおいて大型で疎な線形系を解くコストを次第に超える。David BaraffおよびAndrew Witkinの「Large Steps in Cloth Simulation」、SIGGRAPH 98の集録、pp.43−54(1998)を参照されたい。結果的に、インプリシットなアプローチが、現実的なクロスシミュレーションで主となっている。
【0111】
インプリシットな積分技術は、複雑性がないという訳ではない。特に、インプリシットな積分技術は、
【0112】
【数27】
ではなく、
【0113】
【数28】
に対する式を必要とする。この場合には、近似が用いられる。具体的には、
【0114】
【数29】
が、その一次テイラー展開式によって近似される。
【0115】
【数30】
方程式6における第1の項は、エクスプリシットの場合におけるように求められ、一方で、第2および第3項は、ヤコビ行列
【0116】
【数31】
に依存し、最後の時間ステップにおいて求められる。外力から独立はしているものの、これらヤコブ行列は、大きく、相対的に数値を求めにくい。ヤコブ行列は、実際に、{3×3}サブ行列要素の{n×n}である。
【0117】
ヤコブ行列は、以下の形式を有する。
【0118】
【数32】
ここで、
【0119】
【数33】
であるので、
【0120】
【数34】
の要素は、それ自体は、形式
【0121】
【数35】
の{3×3}ヤコブ行列によって与えられる。
【0122】
【数36】
の数値が求められると仮定すると、時間ステップ毎に解く必要のある線形系(すなわち、方程式5)は、
【0123】
【数37】
の項において、以下のように書き換えられる。
【0124】
【数38】
ここでは、Iは、恒等行列であり、Mはメッシュの質量の直交行列であり、
【0125】
【数39】
は、tk時におけるメッシュ幾何学的状態を表すベクトルであり、
【0126】
【数40】
は、tk時におけるメッシュ中の各点の速度を表すベクトルであり、
【0127】
【数41】
は、tk時におけるメッシュの各点上のネット力を表すベクトルである。従って、点メッシュ800の物理シミュレーションを行うためのインプリシットな積分法は、各時間ステップ
【0128】
【数42】
に対する方程式8を解く事である。
【0129】
方程式8は、
【0130】
【数43】
と書かれ得、ここで、
【0131】
【数44】
である。
【0132】
図5を参照して述べたように、FYSIを用いてGPU上で物理シミュレーションを行うことは、以下の3つのステップを含む。すなわち、(i)系セットアップステップ、(ii)ソルバーステップ、および(iii)衝突ステップ、である。
【0133】
系セットアップステップは、
【0134】
【数45】
における
【0135】
【数46】
に対する値を決定することを伴い、ここでは、定数の時間ステップ
【0136】
【数47】
と、直交質量行列Mと、点メッシュの現在の位置
【0137】
【数48】
および速度
【0138】
【数49】
とが与えられる。これらの入力から、
【0139】
【数50】
に対する中間値が求められ、それらは、方程式9によって与えられる
【0140】
【数51】
に関連している。このサブセクションの残りは、これら中間値の評価を詳述する。
【0141】
矩形の点メッシュ800に対する線形の二つ1組の力モデルが用いられる。点メッシュ800に対する線形の二つ1組の力モデルにおいて、i点とj点との間の稜は、ジョイントと呼ばれており、結合したばねと減衰材を表す。ij=jiの場合には、2つのジョイントは、相補的であり、その場合には、等しいが相反する力(すなわち、ニュートンの第3の法則)が頂点であるiおよびjに適用され、それぞれは
【0142】
【数52】
で与えられる。ジョイントがiおよびjの頂点の間にて定義されないか、またはi=jである場合には、
【0143】
【数53】
であることは明白である。最後に、i番目の点に作用するネットの内力および
【0144】
【数54】
に対するそのヤコビアンに対する式は、以下のように与えられる。
【0145】
【数55】
実際には、ジョイントは、近傍の点の間においてのみ定義され、規則的なパターンで存在する。例えば、図8の点メッシュ800において示されるジョイントトポロジーは、1点につき12個のジョイントまで含む(境界条件によって異なる)。
【0146】
ジョイント毎の力はその頂点のみに依存しているので、
【0147】
【数56】
の行は、疎であるということが示され得る。すなわち、
【0148】
【数57】
であり、
【0149】
【数58】
の左上と右下とを結ぶ対角線上にない要素(すなわちj≠i)に対する式は、以下になる。
【0150】
【数59】
対角線上(すなわち、j=i)では、
【0151】
【数60】
および
【0152】
【数61】
に対する元来の式が当てはまり、点iに対して1つのジョイントのみが存在する場合には、要素は、ゼロ以外となる。従って、ijがジョイントではない場合には、対角線上にない
【0153】
【数62】
であるので、
【0154】
【数63】
の行は、点iに対して定義されたジョイントの数に1をプラスしたものと等しい数だけの、ゼロ以外の要素のみを有し得る。例えば、図8において示されるジョイントトポロジーに対して、点メッシュの次元にかかわりなく、結果的なヤコビアンは、せいぜい13(=1+点毎の12ジョイント)のゼロ以外の要素を有することとなる。
【0155】
点メッシュ800の運動を支配する線形方程式系が、「合致した」系を表すためには、行列Aは、(i)疎であり、かつ(ii)対称的でなくてはならない。(i)項に関しては、Aは、疎である。なぜならば、Aは、ヤコブ行列
【0156】
【数64】
に線形に依存しており、これらヤコブ行列のそれぞれは、疎であることが証明されているからである。(ii)項に関しては、
【0157】
【数65】
のヤコビアンは、以下の
【0158】
【数66】
が非対角線部分に実施され得る場合には、それ自体は対照的である。
【0159】
故に、方程式10が当てはまる場合には、Aは、疎かつ対称的であり、従って、線形方程式系は、効率的に解くことができる。
【0160】
【数67】
および
【0161】
【数68】
の両方であるという基準は、特定の物理的な仮定における誘導的な因子であることが分かるであろう。
【0162】
図8を参照すると、点メッシュ800における点の間のジョイント力は、(i)引っ張りジョイント806、(ii)せん断ジョイント804、および(iii)曲げジョイント802の、3つの種類に分類され得る。隣接するノード間に定義され、引っ張りジョイント806は、最も強い内力をモデル化する。引っ張りジョイント806は、領域における面内変化に抵抗する。対角線上のノード間に定義され、せん断ジョイント804は、2番目に強力である内力をモデル化する。せん断ジョイント804は、クロスが角で引っ張られたときに内方向に狭くなる傾向に抵抗する。最後に、交互のノード間に定義され、曲げジョイント802は、最も弱い内力をモデル化する。曲げジョイント802は、折りたたみに対して抵抗する。
【0163】
より多くの現実的な定義がなされているが、上に提示された、対式ジョイント力毎モデルは、前述のBaraff引例と、Kwang−Jin ChoiおよびHyeong−Seok Ko(「Stable but Responsive Cloth」、In
ACM Transactions on Graphics、SIGGRAPH 2002、pp.604−11(2002))によって教示された対に関するジョイント力のモデルとの混合によって影響され、本明細書においてその全体を参照として援用する。本明細書に開示のモデルに従うと、全てのジョイントは、同一の関数によってモデル化されるが、ジョイントの種類(すなわち、引っ張り、せん断、および曲げ)は、剛性ks、減衰kd、および自然長Lに対する異なる値によって、グローバルにパラメータで表され得る。ジョイント毎に、ばね(ksおよびLによってパラメータで表される)の作用および減衰(kdによってパラメーターで表される)は、線形に独立しており、別個のものと考慮してよい。
【0164】
一般的に、ばね力または減衰力のいずれかに対するジョイント力
【0165】
【数69】
は、2つのプロパティを満たす。すなわち、(i)ジョイント毎の力
【0166】
【数70】
は、ジョイントの方向
【0167】
【数71】
に沿って作用し、(ii)ジョイント毎の力
【0168】
【数72】
は、条件関数
【0169】
【数73】
に比例する。これら2つのプロパティは、数学的に以下のように書かれ得る。
【0170】
【数74】
【0171】
【数75】
ここで、
【0172】
【数76】
であるので、対称に対する基準
【0173】
【数77】
は、
【0174】
【数78】
に対して、以下のものが実施されることを必要とする。
【0175】
【数79】
ここで、ジョイント毎の力
【0176】
【数80】
のばね成分が記述される。理想的な線形移動のばねは、変形の間にエネルギーに抵抗し、かつ該エネルギーを蓄えるものであり、該ばねは、蓄えられたエネルギーを放つように作用する、復原力の作用の表れである反応性の機械的なデバイスである。「移動」とは、含まれる機械的な力の種類に関連する。本明細書に記載のクロスシミュレーションに対するモデルにおいて、力は、ジョイントの方向
【0177】
【数81】
に沿って作用する。「線形」とは、変形(すなわち、xにおける変化)に直接比例する、復原力に関連する。最後に、「理想的な」とは、変形と復原とのサイクルの間に、エネルギーが全く失われないことを意味する。
【0178】
最も単純化された理想の線形移動ばね
【0179】
【数82】
に一致するジョイント毎のばね条件関数が定義される。
【0180】
【数83】
は、現在の頂点位置のみに依存し、
【0181】
【数84】
の両方に対する対称の基準を満たし、かつ、以下の方程式によって与えられた、剛性係数ksおよび自然長Lによってパラメータで表される。
【0182】
【数85】
【0183】
【数86】
ここで、ジョイント毎の力
【0184】
【数87】
の減衰成分が記述される。ダンパーとは、変形に対して抵抗する、受動的な機械的デバイスであるが、ばねとは対照的に、エネルギーを蓄えたり、復原力を表すことはない。その代わりに、ダンパーは、熱という形で加えられたエネルギーを放散させることによって、変形に抵抗する。この特性は、速度の変化に比例する、純粋な抵抗力によって生み出される。
【0185】
本明細書において記述されたクロスのシミュレーションに対するモデルにおいて、理想的な線形移動ダンパーは、ジョイントの方向
【0186】
【数88】
に沿った抵抗力を表し、該ジョイントは、その頂点の速度
【0187】
【数89】
における相対的な変化に直接比例する。より具体的には、該ダンパーは、ジョイント方向における速度
【0188】
【数90】
の相対的な変化に比例する抵抗力を表す。減衰係数kdによってパラメータで表される、ジョイント毎のダンパー条件関数
【0189】
【数91】
が定義される。このジョイント毎のダンパー条件関数は、
【0190】
【数92】
の両方に対する対称の基準を満たす。このステートメントは、数学的に、以下のように表され得る。
【0191】
【数93】
【0192】
【数94】
ここで、点メッシュ800にかかる外力の応答および効果が記述される。外力の例としては、重力、風、および衝突(自身および環境との両方)を含む。外力の応答および効果の間において、明確な区別が存在するということを理解されたい。応答には、現在の状態
【0193】
【数95】
に対する即座の変化が含まれる。故に、応答は、モデル化することが比較的容易である。対照的に、力の効果は、将来の状態を拘束する(すなわち、ファブリックがピン留めされているために、将来の自由度を制限する)。故に、効果は、モデル化することが比較的難しい。
【0194】
外力の応答および効果を解くためのいくつかのアプローチが公知であり、それらには、縮小された座標(reduced coordinates)を用いるアプローチ、ペナルティ法、および/または言語乗算器を含む。例えば、前述のBaraff引例を参照されたい。Barraff引例において議論される別のアプローチは、モデル化された点メッシュにおける所定の点の質量に拘束を与える。上述のように、対角質量行列
【0195】
【数96】
のブロック単位毎の解釈は、i番目の粒子の質量を、{3×3}の対角行列
【0196】
【数97】
として表す。しかし、質量が、異方性の質量であり、方向とともに変化するものであると仮定される場合には、方程式11は、
【0197】
【数98】
として書かれ得る。方程式12において与えられる質量に基づいて、点メッシュに対する運動方程式は、
【0198】
【数99】
となる。故に、異方性質量を効率的に定義するということは、xy面に対する
【0199】
【数100】
の効果を効果的に拘束するということとなり、z方向においては、加速は不可能となる。
【0200】
Baraff引例において開発されたアプローチは、線形系の対称に対して、かかわりを有し、結果的に、効率的な可解性を有する。これらの問題は、修正共役勾配(「修正CG」)法を用いることによって解決され得、該法は、質量ベースの拘束を実施するためのフィルタリング演算を導入する。別のアプローチは、質量ベースの拘束および修正CG法の両方を用い、これは、Kwang−Jin ChoiおよびHyeong−Seok Ko(「Stable but Responsive Cloth」、In ACM Transactions on Graphics、SIGGRAPH 2002、pp.604−11(2002))に記述されており、本明細書においてその全体を参照として援用する。
【0201】
B.GPU上でクロスをシミュレーションするための例示的な実装
インプリシットにクロスをシミュレーションするためのモデルを記述したが、ここで、GPU上での各離散時間ステップに対してクロスのシミュレーションを実装するための、3ステップの方法が記述される。図9は、本発明の実施形態に従った、GPU上でクロスのシミュレーションを実装するための、例示的な流れ図を描写する。言い換えると、図9は、図4を参照して上述された物理シミュレーションブロック410の、特定の実装に関する高レベルな描写である。図9において、大きな円は、テクスチャまたはビデオメモリの配列を表し、図3を参照して上述された、テクスチャ310に類似し得る。テクスチャへのデータの特定のマッピングは、以下の通りである。(i)円902(Mと分類される)は、点メッシュ800における各点の質量に関連したデータを含む、テクスチャを表す。(ii)円904(Pと分類される)は、点メッシュ800における各点の位置に関するデータを含むテクスチャを表す。(iii)円906(Vと分類される)は、点メッシュ800における各点の速度に関するデータを含むテクスチャを表す。(iv)円908(Fと分類される)は、点メッシュ800における各点に作用するネット力に関するデータを含むテクスチャを表す。そして、(v)円912(Jと分類される)は、ヤコビアン行列に関するデータを含むテクスチャを表す。影つきの円910は、カーネル演算(1つ以上のGPUによって行われる数学的演算など)を表す。
【0202】
GPU上でクロスのシミュレーションを実装するための第1のステップには、図9に示されるように、点メッシュの運動を支配する線形方程式系を設定するために、点メッシュに関連した物理パラメータのテクスチャ(すなわち、ビデオメモリ)へのマッピングが含まれる。インプリシットな積分技術を適用することによって、上述されたことは、点メッシュの運動を支配する線形方程式系は、
【0203】
【数101】
と書かれ得るということであり、ここでは、
【0204】
【数102】
となる。モデル化された点メッシュの質量、位置および初期速度は、シーンを作成しているアーティストによって確立される。結果として、テクスチャ902a、904aおよび906a(それぞれ、質量、位置、および初期速度に相当)は、直ちに満たされ得る。対照的に、ヤコビアン行列およびネット力の全ての成分は、アーティストによって確立はされない。結果として、カーネル演算910aは、テクスチャ904a、906aおよび908aからの入力に基づいて、力およびヤコビアン行列
【0205】
【数103】
を評価する。この評価の結果は、テクスチャ908bおよび912bに書き込まれる。これらの結果がテクスチャ908bおよび912bに書き込まれた後に、システムセットアップのステップが、この時間ステップに対して完了する。
【0206】
GPU上でクロスのシミュレーションを実装するための第2のステップには、図9に示されるように、位置および速度の更新済みの値
【0207】
【数104】
に対する線形系を解くことが含まれる。カーネル演算910bは、テクスチャ902a、904a、906a、908bおよび912bからの入力に基づいて、線形方程式系を解く。この解に基づいて、位置および速度の更新済みの値は、それぞれテクスチャ904bおよび906bに書き込まれる。更新済みの値が書き込まれた後に、システムソルバーステップが、この時間ステップに対して完了する。
【0208】
GPU上でクロスのシミュレーションを実装するための最終ステップには、図9に示されるように、衝突検出が含まれる。カーネル演算910cは、テクスチャ902a、904b、906bおよび908bからの入力に基づいて、衝突が起こるか否かを決定する。カーネル演算910cの結果は、テクスチャ902b、904c、906cおよび908cに書き込まれる。これらの結果が書き込まれた後に、衝突応答ステップが、この時間ステップに対して完了する。
【0209】
ここで、GPU上でクロスのシミュレーションを実装するためのステップのそれぞれが、より詳細に記述される。
【0210】
i.ステップ1:システムセットアップ
GPU実装の設計上の大きな難問は、コンパクトであり、かつ単一命令多重データ(SIMD)パラレル化を容易にする、系方程式のテクスチャ表現の開発である。本発明の1つの実施形態は、検討中の矩形点メッシュから直接的に得られた構造を有する、17の持続性テクスチャを利用する。しかし、本発明は、17のテクスチャに限定はされない。本発明の精神および範囲から逸脱することなく、異なる数のテクスチャを用いてGPU上に物理シミュレーションを行う方法を、当業者は理解することとなる。
【0211】
本明細書に記述された、クロスをシミュレーションするために用いられるテクスチャは、点メッシュ800に対応する、「rows」の高さおよび「cols」の幅を有するn個のテクセルの2次元テクスチャである。点メッシュ800は、それぞれ「rows」および「cols」の要素である、行および列に組織化される。従って、各テクスチャの各テクセル位置は、点メッシュ800の特定の点に1対1にマッピングする。各テクスチャは、左から右へ、かつ上から下へと順序付けられる。一般的には、個別のテクスチャが、同一のテクスチャ座標{s、t}における同一点iに属する、異なるプロパティを格納する(明確にするために、本文は、全てのテクスチャ座標を、高さ=‘rows’および幅=‘cols’によって境界付けられた非正規整数として描写する)。点番号から点のテクスチャ座標への、およびその逆のマッピングは、以下によって与えられる。
【0212】
【数105】
さらに、境界の状態を条件として、図8に示されるジョイントトポロジーの点オフセットも、表18に示されるように、2次元テクスチャオフセットにマッピングする。
【0213】
【表14】
17のテクスチャは、P、V、F、A#、B#、C、およびDに分類され、ここでは、A#およびB#は、それぞれ6つのテクスチャの集結である。それぞれの
【0214】
【数106】
に対し、17のテクスチャコンテンツは、次いで以下の定義によって与えられる。第1に、テクスチャP、VおよびFは、それぞれ
【0215】
【数107】
を表す。特に、
・Pは、点の現在位置
【0216】
【数108】
の3成分を格納し、
・Vは、点の現在速度
【0217】
【数109】
の3成分を格納し、
・Fは、点の現在のネット力ベクトル
【0218】
【数110】
の3成分を格納する。第2に、A#およびB#は、それぞれ、
【0219】
【数111】
の下三角(対角線上にない要素)を表す。特に、
・A#は、
【0220】
【数112】
に対応する{3×3}行列を格納し、
・B#は、
【0221】
【数113】
に対応する{3×3}行列を格納し、ここでは、A0−A5およびB0−B5は、以下の6つのジョイントのそれぞれに対して定義される。
【0222】
【数114】
第3に、テクスチャCおよびDは、それぞれ、
【0223】
【数115】
の対角線上の要素を表す。特に、
・Cは、
【0224】
【数116】
に対応する{3×3}行列を格納し、
・Dは、
【0225】
【数117】
に対応する{3×3}行列を格納する。
【0226】
17のテクスチャを定義したので、ここで、これらのテクスチャを埋めるための(すなわち、図9のシステムセットアップのステップを行うための)2段階工程が記述される。図10は、点メッシュ800の運動を支配する線形方程式系を設定するための、2段階工程の流れ図を図示する。図10に含まれるのは、入力テクスチャ1002aおよび1004a
【0227】
【数118】
および出力テクスチャ1006a、1008a、1012a、1014a、および1016a
【0228】
【数119】
である。
【0229】
図10の第1の段階は、6つの同一のサブパスを含み、該サブパスは、ジョイントの相補的な対のジョイントに対して演算を行う、カーネル演算1010a−1010fによって表される。この第1段階において、ネット力ベクトル
【0230】
【数120】
(すなわち、テクスチャF)および
【0231】
【数121】
(すなわち、テクスチャA0−A5およびB0−B5)の下三角(対角線上にない要素)が、決定される。すなわち、カーネル演算1010a−1010fの結果は、テクスチャ1006b、1008bおよび1012bに書き込まれる。
【0232】
図10の第2の段階は、カーネル演算1010gおよび1010hによって表される、2つの同一のサブパスを含み、該カーネル演算は、
【0233】
【数122】
(すなわち、テクスチャCおよびD)の対角線上要素を、その下三角の対角線上にない要素(すなわち、テクスチャA0−A5およびB0−B5)から決定する。すなわち、カーネル演算1010gおよび1010hの結果は、それぞれ、テクスチャ1016bおよび1014bに書き込まれる。第1の段階および第2の段階は、それぞれ以下により詳細に記述される。
【0234】
システムセットアップの第1の段階(図10)は、ネット力ベクトル
【0235】
【数123】
(すなわち、テクスチャC)および
【0236】
【数124】
(すなわち、テクスチャA0−A5およびB0−B5)の下三角(対角線上にない要素)の決定を含む。図10に示されるように、これら出力の評価は、カーネル演算1010a−1010fによって表されるような、ジョイント毎の解析の膨大な重複を含み得る。結果として、この第1の段階は、図11に表されるように、6つの同一のジョイント毎のサブパスに分けられ得る。
【0237】
図11は、ジョイントパスmを表す、流れ図1100を図示する。各ジョイントパスは、2つのサブパスを含み、第1カーネル1110a(EvaJointと分類)および第2カーネル1110b(updateFと分類)によって表される。第1カーネル1110aは、それぞれ一時的なテクスチャT、Am、およびBmに書き込まれる、
【0238】
【数125】
に対するジョイント毎の値を計算する。サブパス毎に解析される特定のジョイントは、
【0239】
【数126】
によって、テクスチャAmおよびBmに関連する。
【0240】
第1カーネル1110a(evalJoint)は、以下の事実を利用する。
【0241】
(1)ジョイント毎の値は、共に、最も容易に評価され、
(2)AmおよびBmに格納された
【0242】
【数127】
の対角線上にない要素は、実際には独立しており、
【0243】
【数128】
に等しく、
(3)対称性
【0244】
【数129】
によって、相補的なジョイントには、同一の解析が行われる。従って、我々のトポロジーにおけるジョイントの固有の半分を解析することが理想的(すなわち、作業の重複がない)である。さらに、対称によって、テクスチャA0−A5およびB0−B5に格納された
【0245】
【数130】
の下三角(対角線上にない要素)は、ヤコビアンにおける全ての対角線上にない要素を表すのに十分である。
【0246】
第2カーネル1110b(updateFと分類)は、解析されているジョイントの力を用いて、ネット力
【0247】
【数131】
(または、テクスチャC)を更新する。第2カーネル(updateF)は、現時点でTに格納されているジョイント毎の力
【0248】
【数132】
の寄与を、(別のサブパスから来るか、または外力を含む)入力ネット力ベクトル
【0249】
【数133】
またはテクスチャCに加える。これには、特に、ジョイント力の線形独立およびニュートンの第3の法則によって提供される対称性を利用する。各サブパスは、ジョイントの相補的な対の力を効率的に計算するので、第2カーネル1110b(updateF)は、両方の寄与を適切に考慮するためにTをアドレスしなくてはならない(境界条件により、T中のジョイント力毎のある値が不規則であり得る)。
【0250】
再び図10を参照すると、システムセットアップの第2および最終の段階は、
【0251】
【数134】
(すなわち、テクスチャCおよびD)の対角線上の要素の決定を含む。この第2の段階において、これらの対角線上の要素がそれらの対角線上にない要素の有利に構成された累積であるという事実は、強化される。特に、以下の累積のそれぞれは、最大12項まで含み、各ジョイントに対するもの(境界条件によって変わる)は、テクスチャA0−A5およびB0−B5において容易に入手できる。
【0252】
【数135】
図12に図解式に図示されるように、方程式13aにおける累積は、カーネル1250aによって評価され(evalDiagonalCと分類)、方程式13bにおける累積は、カーネル1250cによって評価される(evalDiagonalDと分類)。カーネル1250aおよび1250cは、独立しており、それらの入力と出力だけが異なる。カーネル1250aは、テクスチャ1202a、1204a、1206a、1208a、1210aおよび1212aから、入力としてのデータを取得し、それらテクスチャは、集合的に、ヤコブ行列
【0253】
【数136】
の対角線上にない要素を表す。カーネル1250cの出力は、テクスチャ1214b(すなわちテクスチャC)に書き込まれる。カーネル1250cは、テクスチャ1222a、1224a、1226a、1228a、1230aおよび1232aから、入力としてのデータを取得し、それらテクスチャは、集合的に、ヤコブ行列
【0254】
【数137】
の対角線上にない要素を表す。
【0255】
ii.ステップ2:システムソルバー
再び図8を参照すると、GPU上でのクロスのシミュレーションにおける第2のステップは、システムソルバーステップである。システムソルバーステップに対する最も有力なアプローチは、前述のBaraff引例に記述された、線形系
【0256】
【数138】
を反復的に解く、共役勾配(CG)法を用いることである。大型で疎、対称的かつ正定値の系に最適であり、CG法は、
【0257】
【数139】
が、ユーザー定義の閾値より下回るまで、
【0258】
【数140】
を手続き上で近似することを含む。本明細書に記述される例示的方法は、システムソルバーステップに対してCG法を用いるが、他の方法もまた、当業者に認識されるように、本発明の精神および範囲から逸脱することなく、用いられ得る。
【0259】
iii.ステップ3:衝突応答
再び図8を参照すると、GPU上でのクロスのシミュレーションにおける第3および最終のステップは、衝突応答ステップである。衝突検出スキームは、シミュレーションされているメッシュ(例えば点メッシュ800)からの点の対が、(i)メッシュからの別の点の対、または(ii)シミュレーションされている別のオブジェクト(例えば、点メッシュ800として同一のシーンに描写されているボール)からの点の対、のいずれかと交わるかどうかを決定することによって、衝突が起きたかどうかを確認する。前述のBaraff引例によって例示されるように、衝突検出スキームは、当業者に周知である。当業者に公知のあらゆる衝突検出スキームが、本発明の精神および範囲から逸脱することなく、用いられ得る。
【0260】
C.FYSLで書かれた例示的コード
以下に提供されるものは、FYSLで書かれたコードの例示的セクションである。特に、以下に提供されるものは、(i)FYSLで書かれた高レベルシーン記述、(ii)チャイルドアクター展開、および(iii)ファブリックジョイントのプロトタイプ展開、である。
【0261】
i.FYSLで書かれた高レベルシーン記述
【0262】
【表15】
【0263】
【表16】
ii.チャイルドアクター展開
【0264】
【表17】
【0265】
【表18】
【0266】
【表19】
iii.ファブリックジョイントのプロトタイプ展開
【0267】
【表20】
IV.例示的なコンピュータ実装
本発明の実施形態は、ハードウェア、ソフトウェア、またはそれらの組み合わせを用いて実装され得、また、1つ以上のコンピュータシステムまたは他のプロセッシングシステムにおいて実装され得る。しかし、本発明によって行われる操作は、加算や比較などに関して、頻繁に参照されたが、それらは、一般的に、人間のオペレーターによって行われる、頭の中で行うオペレーションに関連する。本発明の一部を形成する、本明細書に記述されるオペレーションのいずれにおいても、そのような人間のオペレーターの能力はなにも必要なく、または、ほとんどの場合において望まれない。むしろ、オペレーションは、機械的なオペレーションである。本発明のオペレーションを行うために有用な機械は、デジタルコンピュータを含み、例えば、パーソナルコンピュータ、ビデオゲームコンソール、携帯電話、携帯情報端末、または同様のデバイスなどである。
【0268】
実際に、一実施形態において、本発明は、本明細書に記述された機能性を実行することが可能な1つ以上のコンピュータシステムに向けられている。コンピュータシステム1300の例は、図13に示される。
【0269】
コンピュータシステム1300は、1つ以上のプロセッサ、例えばプロセッサ1304を含む。プロセッサ1304は、汎用プロセッサ(CPUなど)、または専用プロセッサ(GPUなど)であり得る。プロセッサ1304は、通信インフラストラクチャ1306(例えば、通信バス、クロスオーバーバー、またはネットワーク)に接続される。様々なソフトウェアの実施形態は、この例示的なコンピュータシステムの点から記述される。本記述を読んだ後は、他のコンピュータシステムおよび/またはアーキテクチャーを用いて本発明を実装する方法が、当業者には明らかとなる。
【0270】
コンピュータシステム1300は、ディスプレイインターフェース1302を含み、該ディスプレイインターフェース1302は、ディスプレイユニット1330に表示するために、通信インフラストラクチャ1306(または不図示のフレームバッファ)から、グラフィックス、テキスト、および他のデータを転送する。
【0271】
コンピュータシステム1300はまた、メインメモリ1308、好ましくは、ランダムアクセスメモリ(RAM)を含み、また、二次メモリ1310をも含み得る。二次メモリ1310は、例えば、ハードディスクドライブ1312および/またはリムーバブルストレージドライブ1314を含み得、フロッピー(登録商標)ディスクドライブ、磁気テープドライブ、光学ディスクドライブなどが、その代表である。リムーバブルストレージドライブ1314は、周知の方法で、リムーバブルストレージユニット1318との読み取りおよび書き込みを行う。リムーバブルストレージユニット1318は、フロッピー(登録商標)ディスク、磁気テープ、光学ディスクなどを表し、これは、リムーバブルストレージドライブ1314によって読み書きがされる。認識されるように、リムーバブルストレージユニット1318は、コンピュータソフトウェアおよび/またはデータをその中に格納した、コンピュータ使用可能媒体を含む。
【0272】
代替的な実施形態において、二次メモリ1310は、コンピュータシステム1300にコンピュータプログラムまたは他の命令をロードさせる、他の同様のデバイスを含み得る。そのようなデバイスは、例えば、リムーバブルストレージユニット1322およびインターフェース1320を含み得る。そのような例は、プログラムカートリッジおよびカートリッジインターフェース(ビデオゲーム機に見受けられるようなものなど)、リムーバブルメモリチップ(消去可能プログラマブル読取り専用メモリ(EPROM)またはプログラマブル読取り専用メモリ(PROM)など)および関連ソケット、ならびに他のリムーバブルストレージユニット1322およびインターフェース1320を含み得、これらは、リムーバブルストレージユニット1322からコンピュータシステム1300にソフトウェアおよびデータを転送することを可能にする。
【0273】
コンピュータシステム1300はまた、通信インターフェース1324を含み得る。通信インターフェース1324は、コンピュータシステム1300と外部デバイスとの間でのソフトウェアおよびデータの転送を可能にする。通信インターフェース1324の例は、モデム、ネットワークインターフェース(イーサネット(登録商標)カードなど)、通信ポート、パーソナルコンピュータメモリカードインターナショナルアソシエーション(PCMCIA)スロットおよびカードなどを含み得る。通信インターフェース1324を介して転送されるソフトウェアおよびデータは、信号1328の形式をとり、該信号は、電子、電磁気、光学、または通信インターフェース1324によって受信可能な他の信号であり得る。これらの信号1328は、通信パス(例えばチャネル)1326を介して通信インターフェース1324に提供される。このチャネル1326は信号1328を運び、ワイヤまたはケーブル、光ファイバー、電話線、セルラーリンク、無線周波数(RF)リンクおよび他の通信チャネルを用いて実装され得る。
【0274】
本文において、「コンピュータプログラム媒体」および「コンピュータ使用可能媒体」という用語は、概して、リムーバブルストレージドライブ1314、ハードディスクドライブ1312にインストールされたハードディスクなどの媒体および信号1328を指すために用いられる。これらコンピュータプログラム製品は、コンピュータシステム1300にソフトウェアを提供する。本発明は、そのようなコンピュータプログラム製品に向けられる。
【0275】
コンピュータプログラム(コンピュータ制御ロジックとも呼ばれる)は、メインメモリ1308および/または二次メモリ1310に格納される。コンピュータプログラムはまた、通信インターフェース1324を介して受信され得る。そのようなコンピュータプログラムは、実行されたときには、コンピュータシステム1300が本明細書に議論されたように本発明の機能を行えるようにする。特に、コンピュータプログラムは、実行されたときには、プロセッサ1304が本発明の機能を行えるようにする。従って、そのようなコンピュータプログラムは、コンピュータシステム1300のコントローラを表す。
【0276】
ソフトウェアを用いて本発明が実装される実施形態において、該ソフトウェアは、リムーバブルストレージドライブ1314、ハードドライブ1312、または通信インターフェース1324を用いて、コンピュータプログラム製品に格納され、コンピュータシステム1300にロードされ得る。プロセッサ1304によって実行されるときには、制御ロジック(ソフトウェア)は、プロセッサ1304に、本明細書に記述されたように本発明の機能を行わせる。
【0277】
別の実施形態において、本発明は、例えば、GPUなどのハードウェア構成要素を用いて、主にハードウェアに実装される。本明細書に記述された機能を行うためのハードウェアステートマシーンの実装は、当業者に明らかであろう。
【0278】
さらに別の実施形態において、本発明は、ハードウェアおよびソフトウェアの両方の組み合わせを用いて実装される。
【0279】
V.結論
概要および要約の章ではなく、実施形態の章は、請求項を解釈するために用いられることを意図するということを、認識されたい。概要および要約の章は、発明者によって意図されるように、本発明の、全てではないが、1つ以上の例示的な実施形態を述べ得る。故に、概要および要約の章は、あらゆる方法において、本発明および添付の請求項を限定する意図はない。
【技術分野】
【0001】
本発明は、概してグラフィックス処理装置に向けられ、より具体的には、グラフィックスプロセッサを用いてゲームの物理シミュレーションを行うことに向けられる。
【背景技術】
【0002】
コンピュータ系上で作動しているビデオゲームなどのアプリケーションは、物理シミュレーションおよびグラフィックスレンダリングの両方を必要とし得る。例えば、図1は、ビデオゲームのシーンにおいて描かれる1つ以上のキャラクターの運動を演算し、そして表示するための、典型的なパイプラインのブロック図100を図示する。ステップ110において、物理シミュレーションが行われることによって、そのシーンに描かれる1つ以上のキャラクターの運動を決定する。次いでステップ120において、物理シミュレーションの結果が、エンドユーザーによって視覚化されるために図形として描写される。
【0003】
概して、ステップ110の物理シミュレーションは、中央処理装置(CPU)上、またはコンピュータ系の専用デバイス上で実行される、物理エンジンによって行われる。次いで、ステップ120のグラフィックスレンダリングが、グラフィックスプロセッシングユニット(GPU)によって行われる。しかし、最終的には、物理エンジンによってもたらされた結果は、ビデオゲーム(または、より一般的には、アプリケーション)のグラフィックスを修正するために用いられ、故に、何らかの形式において、GPUに伝えられることとなる。物理エンジンからの結果は、レンダリングのためにGPUに伝えられなくてはならないので、待ち時間および帯域幅の問題が起こり得る。さらに、一般的なプロセッシングユニットのように、CPUは、GPUの並列処理能力を有さない。
【0004】
上述の事項をふまえると、必要なものは、1つ以上のGPU上で物理シミュレーションを行う方法、コンピュータプログラム製品および系である。
【発明の概要】
【課題を解決するための手段】
【0005】
本発明の実施形態は、方法、コンピュータプログラム製品、およびシステムを含み得、GPU上で利用可能な並行処理能力を利用することによって、一般的なCPU上で実行される物理シミュレーションと比較して、より速いフレーム速度を可能にする。さらに、そのような方法、コンピュータプログラム製品、およびシステムは、物理シミュレーションの実行において、インプリシットな積分技術を利用することによって、エクスプリシットな積分技術において必要な、相対的に小さな時間ステップを防止する。さらに、手続上の力およびトルクは、GPU上で実行するシェーダープログラムとして表され得る。加えて、GPUベースの物理シミュレーターは、通常はコンピュータシステムで物理シミュレーションを実行する、従来型のソフトウェアダイナミクスソルバーを自動的に置換することが可能であり得る。本発明の実施形態は、1つ以上のGPU上で物理シミュレーションを行うための、方法、コンピュータプログラム製品、およびシステムを提供することによって、上記に識別されたニーズを満たす。1つ以上のGPU上で物理シミュレーションを行うための、そのような方法、コンピュータプログラム製品、およびシステムは、GPU上で利用可能な並行処理能力を利用することによって、通常のCPU上で実行される物理シミュレーションと比較してより速いフレーム速度を可能にする。さらに、そのような方法、コンピュータプログラム製品、およびシステムは、実施形態においてインプリシットな積分技術を利用することによって、物理シミュレーションを行い、これによって、エクスプリシットな積分技術において必要な、相対的に小さな時間ステップを防止する。さらに、本発明の実施形態に従うと、手続き上の力および/またはトルクは、GPU上で実行するシェーダープログラムとして表すことが可能である。加えて、本発明の実施形態に従ったGPUベースの物理シミュレーターは、通常はコンピュータシステム上で物理シミュレーションを実行する、従来型のソフトウェアダイナミクスソルバーを自動的に置換するために用いられ得る。
【0006】
本発明の実施形態に従うと、少なくとも1つのGPU上で物理シミュレーションを行うための方法が提供される。該方法は、以下のステップを含む。まず、少なくとも1つのメッシュに関連した物理属性を表すデータは、複数のビデオメモリアレイに格納されることによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。ついで、少なくとも1つのピクセルプロセッサを用いて複数のビデオメモリアレイにおけるデータに演算が行われることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す修正済みデータは、複数のビデオデータメモリに格納される。
【0007】
本発明の別の実施形態に従うと、コンピュータプログラム製品が提供され、該コンピュータプログラム製品は、制御ロジックを中に格納し、少なくとも1つのGPUに物理シミュレーションを行わせる、コンピュータ使用可能媒体を備える。該制御ロジックは、コンピュータ読取可能な第1および第2のプログラムコードを含む。コンピュータ読取可能第1プログラムコードは、少なくとも1つのGPUに、複数のビデオデータアレイに、少なくとも1つのメッシュに関連した物理属性を表すデータを格納することによって、シーンに描写される少なくとも1つのメッシュの運動を支配する、線形方程式系を設定する。コンピュータ読取可能第2プログラムコードは、少なくとも1つのGPUに、複数のビデオメモリアレイにおけるデータに演算を行わせることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す修正済みデータは、複数のビデオデータメモリに格納される。
【0008】
本発明のさらなる実施形態に従うと、物理シミュレーションを行うためのシステムが提供される。該システムは、複数のビデオメモリアレイを格納するメモリと、該メモリに結合された少なくとも1つのピクセルプロセッサとを含む。複数のビデオメモリアレイは、少なくとも1つのメッシュに関連した物理パラメータを表すデータを格納することによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。少なくとも1つのピクセルプロセッサは、複数のビデオメモリアレイにおけるデータに演算を行うことによって、時刻に対する線形方程式系を解き、その結果として、時刻に対する線形方程式系に対する解を表す修正済みデータをもたらす。
【0009】
本発明のさらなる機能および有用性、ならびに本発明のさまざまな実施形態の構造および動作は、添付の図面を参照しながら、以下に詳述される。本発明は、本明細書に記述された特定の実施形態に限定されるものではないことに留意されたい。そのような実施形態は、例示目的のためだけに、本明細書において提示される。追加的な実施形態は、本明細書に含まれる教示を基に、当業者に明確である。
例えば、本発明は、以下の項目を提供する。
(項目1)
少なくとも1つのグラフィックスプロセッサユニット(GPU)上で物理シミュレーションを行う方法であって、該方法は、
少なくとも1つのメッシュに関連した物理パラメータを複数のメモリアレイにマッピングすることによって、シーンに描写された該少なくとも1つのメッシュの運動を支配する線形方程式系を設定することと、
少なくとも1つのピクセルプロセッサを用いて該複数のメモリアレイ中のデータに演算を行うことによって、ある時刻に対する線形方程式系を解くことと
を包含し、
該時刻に対する線形方程式系の該解を表す変更されたデータは、該複数のメモリアレイに格納される、方法。
(項目2)
前記複数のメモリアレイ中の前記変更されたデータに基づいて、前記時刻に対する前記シーンにおいて描写される、前記1つ以上のメッシュの運動を更新することをさらに含む、項目1に記載の方法。
(項目3)
前記時刻に対する前記少なくとも1つのメッシュを含む、少なくとも1つの衝突を識別することと、
(i)前記複数のメモリアレイ中の前記変更されたデータ、および(ii)該識別された少なくとも1つの衝突、に基づいて、前記時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新することと
をさらに含む、項目1に記載の方法。
(項目4)
前記ピクセルプロセッサを用いて前記変更されたデータに演算を行うことによって、次の時刻に対する線形方程式系を解くことをさらに含み、該次の時刻に対する線形方程式系に対する解を表す変更されたデータは、前記複数のメモリアレイに格納される、項目1に記載の方法。
(項目5)
前記複数のメモリアレイ中の前記さらなる変更されたデータに基づいて、前記次の時刻に対する前記シーン中に描写される少なくとも1つのメッシュの運動を更新することをさらに含む、項目4に記載の方法。
(項目6)
前記次の時刻に対する前記少なくとも1つのメッシュを含む、少なくとも1つの衝突を識別することと、
(i)前記複数のメモリアレイ中の前記変更されたデータ、および(ii)該識別された少なくとも1つの衝突、に基づいて、前記次の時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新することと
をさらに含む、項目4に記載の方法。
(項目7)
演算を行うことは、
少なくとも1つのピクセルプロセッサを用いて前記複数のメモリアレイ中のデータに演算を行うことによって、インプリシットに前記線形方程式系を積分することによって、ある時刻に対する該線形方程式系を解くことを含み、
前記時刻に対する該線形方程式系の該解を表す変更されたデータは、該複数のメモリアレイに格納される、項目1に記載の方法。
(項目8)
前記格納することは、
複数のメモリアレイにデータを格納することによって、線形方程式系を設定することを含み、該線形方程式系は、
【数141】
によって与えられ、シーンにおいて描写される少なくとも1つのメッシュの運動を支配し、ここで、
【数142】
であり、Iは、恒等行列であり、Mは該少なくとも1つのメッシュの質量の直交行列であり、
【数143】
は、tk時における該少なくとも1つのメッシュの幾何学的状態を表すベクトルであり、
【数144】
は、tk時における該少なくとも1つのメッシュ中の各点の速度を表すベクトルであり、
【数145】
は、tk時における該少なくとも1つのメッシュの各点上のネット力を表すベクトルである、項目1に記載の方法。
(項目9)
前記方法は、マッピングに先立って、さらに、
ソフトウェアダイナミクスソルバーからシーンを捕捉し、該シーン中に描写される少なくとも1つのメッシュに付けられた属性およびフィールドを、前記複数のメモリアレイにマッピングされる物理パラメータに変換することと、
該ソフトウェアダイナミクスソルバーのシーングラフにシミュレーション結果をインポートすることと
をさらに含み、
該シミュレーション結果は、前記少なくとも1つのピクセルプロセッサによって演算された前記時刻に対する前記線形方程式系に対する解に対応する、項目1に記載の方法。
(項目10)
前記少なくとも1つのGPUで実行するシェーダーとして、該シーンにおいて描写される該メッシュ上に作用する力を表すことをさらに含む、項目1に記載の方法。
(項目11)
制御ロジックを中に格納しているコンピュータ使用可能媒体を備え、少なくとも1つのグラフィックスプロセッサユニット(GPU)に物理シミュレーションを行わせるコンピュータプログラム製品であって、該制御ロジックは、
コンピュータ読取可能第1プログラムコードであって、該コードは、該少なくとも1つのGPUに、少なくとも1つのメッシュに関連した物理パラメータを複数のメモリアレイにマッピングさせることによって、シーンに描写された該少なくとも1つのメッシュの運動を支配する線形方程式系を設定する、コンピュータ読取可能第1プログラムコードと、
コンピュータ読取可能第2プログラムコードであって、該コードは、該少なくとも1つのGPUに、該複数のメモリアレイ中のデータに演算を行わせることによって、ある時刻の線形方程式系を解く、コンピュータ読取可能第2プログラムコードと
を備え、
該時刻に対する線形方程式系に対する解を表す変更されたデータは、該複数のメモリアレイに格納される、コンピュータプログラム製品。
(項目12)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記複数のメモリアレイ中の前記変更されたデータに基づいて、前記少なくとも1つのGPUに、前記時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第3プログラムコードをさらに備える、項目11に記載のコンピュータプログラム製品。
(項目13)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記少なくとも1つのGPUに、前記時刻の前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別させる、コンピュータ読取可能第3プログラムコードと、
コンピュータ読取可能第4プログラムコードであって、該コードは、(i)前記複数のメモリアレイ中の前記変更されたデータ、および(ii)該識別された少なくとも1つの衝突、に基づいて、該少なくとも1つのGPUに、該時刻に対する該シーン中に描写される該少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第4プログラムコードとをさらに備える、項目11に記載のコンピュータプログラム製品。
(項目14)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記少なくとも1つのGPUに、前記変更されたデータに演算を行わせることによって、次の時刻に対する線形方程式系を解く、コンピュータ読取可能第3プログラムコードをさらに含み、
該次の時刻に対する該線形方程式系に対する解を表すさらなる変更されたデータは、前記複数のメモリアレイに格納される、項目11に記載のコンピュータプログラム製品。
(項目15)
コンピュータ読取可能第4プログラムコードであって、該コードは、前記複数のメモリアレイ中の前記さらなる変更されたデータに基づいて、前記少なくとも1つのGPUに、前記次の時刻に対する前記シーン中に描写される前記少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第4プログラムコードをさらに備える、項目14に記載のコンピュータプログラム製品。
(項目16)
コンピュータ読取可能第4プログラムコードであって、該コードは、前記少なくとも1つのGPUに、前記次の時刻に対する前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別させる、コンピュータ読取可能第4プログラムコードと、
コンピュータ読取可能第5プログラムコードであって、該コードは、(i)前記複数のメモリアレイ中の前記さらなる変更されたデータ、および(ii)該コンピュータ読取可能第4プログラムコードによって識別された該少なくとも1つの衝突、に基づいて、該少なくとも1つのGPUに、該次の時刻に対する該シーン中に描写される該少なくとも1つのメッシュの運動を更新させる、コンピュータ読取可能第5プログラムコードと
をさらに備えている、項目14に記載のコンピュータプログラム製品。
(項目17)
前記コンピュータ読取可能第2プログラムコードは、
コードであって、前記少なくとも1つのGPUに、前記複数のメモリアレイ中の前記データに演算を行わせることによって、インプリシットに前記線形方程式系を積分することによって、ある時刻に対する該線形方程式系を解くコードを含み、
該時刻に対する線形方程式系に対する解を表す変更されたデータは、該複数のメモリアレイに格納される、項目11に記載のコンピュータプログラム製品。
(項目18)
前記コンピュータ読取可能第1プログラムコードは、
コードであって、前記少なくとも1つのGPUに、複数のメモリアレイにデータを格納させることによって、線形方程式系を設定する、コードを備え、該線形方程式系は、
【数146】
によって与えられ、シーンにおいて描写される前記少なくとも1つのメッシュの運動を支配し、ここで、
【数147】
であり、ここで、Iは、恒等行列であり、Mは前記少なくとも1つのメッシュの質量の直交行列であり、
【数148】
は、tk時における該少なくとも1つのメッシュの幾何学的状態を表すベクトルであり、
【数149】
は、tk時における該少なくとも1つのメッシュ中の各点の速度を表すベクトルであり、
【数150】
は、tk時における該少なくとも1つのメッシュ中の各点上のネット力を表すベクトルである、項目11に記載のコンピュータプログラム製品。
(項目19)
コンピュータ読取可能第3プログラムコードであって、該コードは、前記少なくとも1つのGPUに、ソフトウェアダイナミクスソルバーからシーンを捕捉させ、該シーン中に描写される少なくとも1つのメッシュに付けられた属性およびフィールドを、前記複数のメモリアレイにマッピングされる前記物理パラメータに変換する、コンピュータ読取可能第3プログラムコードと、
コンピュータ読取可能第4プログラムコードであって、該コードは、該少なくとも1つのGPUに、該ソフトウェアダイナミクスソルバーのシーングラフにシミュレーション結果をインポートさせる、コンピュータ読取可能第4プログラムコードと
をさらに備え、
該シミュレーション結果は、前記時刻に対する前記線形方程式系に対する解に対応する、項目11に記載のコンピュータプログラム製品。
(項目20)
前記少なくとも1つのGPUに、前記シーンにおいて描写される前記メッシュに作用する力をシミュレーションさせるコンピュータ読取可能第3プログラムコードをさらに備える、項目11に記載のコンピュータプログラム製品。
(項目21)
物理シミュレーションを行うためのシステムであって、該システムは、
メモリであって、少なくとも1つのメッシュに関連した物理パラメータを表すデータを格納する複数のメモリアレイを含み、シーンにおいて描写される該少なくとも1つのメッシュの運動を支配する線形方程式系を設定するための、メモリと、
該複数のメモリアレイにおける該データに演算を行うことによってある時刻に対する該線形方程式系を解く、該メモリに結合された少なくとも1つのピクセルプロセッサと
を備え、
該時刻に対する該線形方程式系の該解を表す変更されたデータは、該複数のメモリアレイに格納される、システム。
(項目22)
レンダリングエンジンであって、前記複数のメモリアレイにおける前記変更されたデータに基づいて、前記時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目21に記載のシステム。
(項目23)
前記ピクセルプロセッサは、前記時刻に対する前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別し、該システムは、
レンダリングエンジンであって、(i)前記複数のメモリアレイにおける前記変更されたデータ、および(ii)該時刻において識別された該少なくとも1つの衝突に基づいて、該時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目21に記載のシステム。
(項目24)
前記ピクセルプロセッサは、前記変更されたデータに演算を行うことによって、次の時刻に対する線形方程式系を解き、該次の時刻に対する該線形方程式系に対する解を表すさらなる変更されたデータは、前記複数のメモリアレイに格納される、項目21に記載のシステム。
(項目25)
レンダリングエンジンであって、前記複数のメモリアレイにおける前記さらなる修正済みのデータに基づいて、前記次の時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目24に記載のシステム。
(項目26)
前記ピクセルプロセッサは、前記次の時刻に対する前記少なくとも1つのメッシュを含む少なくとも1つの衝突を識別し、該システムは、
レンダリングエンジンであって、(i)前記複数のメモリアレイにおける前記変更されたデータ、および(ii)該次の時刻において識別された該少なくとも1つの衝突に基づいて、該次の時刻に対する前記シーンにおいて描写される前記少なくとも1つのメッシュの描写を更新する、レンダリングエンジンをさらに備える、項目24に記載のシステム。
(項目27)
前記ピクセルプロセッサは、前記複数のメモリアレイにおける前記データに演算を行うことによって、前記線形方程式系をインプリシットに積分することによってある時刻に対する該線形方程式系を解き、該時刻に対する該線形方程式系に対する該解を表す変更されたデータは、該複数のメモリアレイに格納される、項目21に記載のシステム。
(項目28)
前記線形方程式系は、
【数151】
によって与えられ、ここで
【数152】
であり、Iは、恒等行列であり、Mは前記少なくとも1つのメッシュの質量の直交行列であり、
【数153】
は、tk時における該少なくとも1つのメッシュの幾何学的状態を表すベクトルであり、
【数154】
は、tk時における該少なくとも1つのメッシュ中の各点の速度を表すベクトルであり、
【数155】
は、tk時における該少なくとも1つのメッシュ中の各点上のネット力を表すベクトルである、項目21に記載のシステム。
(項目29)
シーンエクスポーターであって、ソフトウェアダイナミクスソルバーからシーンを捕捉し、該シーンにおいて描写される少なくとも1つのメッシュに付けられた属性およびフィールドを、前記複数のメモリアレイにおいて格納される前記物理パラメータに変換する、シーンエクスポーターと、
シーンインポーターであって、該ソフトウェアダイナミクスソルバーのシーングラフにシミュレーション結果をインポートする、シーンインポーターと
をさらに備え、
該シミュレーション結果は、前記少なくとも1つのピクセルプロセッサによって演算された前記時刻に対する前記線形方程式系に対する前記解に対応する、項目21に記載のシステム。
(項目30)
少なくとも1つのGPU上で、前記シーンにおいて描写される前記メッシュに作用する力を表すために実行するシェーダーをさらに備える、項目21に記載のシステム。
(項目31)
少なくとも1つのグラフィックスプロセッサユニット(GPU)上で物理シミュレーションを行うための方法であって、該方法は、
該少なくとも1つのGPUにシミュレーション定義データを送信することと、
該転送されたシミュレーション定義に応答する該少なくとも1つのGPUからのシミュレーション結果を受け取ることと
を包含する、方法。
(項目32)
前記少なくとも1つのGPUにシミュレーション定義データを転送することは、該少なくとも1つのGPUに、シーンデータ、シミュレーションデータ、アクターデータ、ジョイントデータ、およびフィードバックデータのうちの少なくとも1つを送信することを含む、項目31に記載の方法。
(項目33)
前記送信は、前記少なくとも1つのGPUに、マークアップ言語フォーマットのシミュレーション定義データを送信することを含む、項目31に記載の方法。
(項目34)
少なくとも1つのグラフィックスプロセッサユニット(GPU)上で物理シミュレーションを行うための方法であって、該方法は、
シミュレーション定義データをアプリケーションプログラミングインタフェース(API)コマンドに変換することと、
該変換されたシミュレーション定義データに応答して、該少なくとも1つのGPU上で物理シミュレーションを行うことによって、シミュレーション結果データを生成することと
を包含する、方法。
(項目35)
前記変換することは、前記シミュレーション定義データからシーンデータ構造を生成することを含む、項目34に記載の方法。
(項目36)
前記物理シミュレーションを行うことは、
前記シミュレーション定義データに対応する線形方程式系を設定することと、
該線形方程式系を解くことと、
該線形方程式系に対する解に基づいて衝突を検出することと
を含む、項目34に記載の方法。
(項目37)
物理シミュレーションを行うための、コンピュータベースの方法であって、該方法は、
ソフトウェアダイナミクスソルバーデータを、少なくとも1つのグラフィクスプロセッサユニット(GPU)に対するシミュレーション定義データに変換することと、
該変換されたデータに応答して、該少なくとも1つのGPU上で物理シミュレーションを行うことによって、シミュレーション結果データを生成することと
を包含する、方法。
(項目38)
前記シミュレーション結果データをアプリケーションに送信することをさらに含む、項目37に記載の方法。
(項目39)
前記送信することは、前記シミュレーション結果データを前記ソフトウェアダイナミクスソルバーのフォーマットに変換することを含む、項目38に記載の方法。
(項目40)
追加的なソフトウェアダイナミクスソルバーデータに応答して、ソフトウェアダイナミクスソルバーに基づく別の物理シミュレーションを行うことをさらに含む、項目37に記載の方法。
(項目41)
少なくとも1つのグラフィクスプロセッサユニット(GPU)を生成するための命令を含む、コンピュータ読取可能媒体であって、該命令は、実行されるときには、該少なくとも1つのGPUを作成するように適合され、該少なくとも1つのGPUは、
少なくとも1つのメッシュに関連した物理パラメータを複数のメモリアレイにマッピングすることによって、シーンに描写された該少なくとも1つのメッシュの運動を支配する線形方程式系を設定し、
少なくとも1つのピクセルプロセッサを用いて該複数のメモリアレイ中のデータに演算を行うことによって、ある時刻に対する線形方程式系を解く
ように適合され、該時刻に対する該線形方程式系に対する解を表す変更されたデータは、該複数のメモリアレイに格納される、コンピュータ読取可能媒体。
(項目42)
少なくとも1つのグラフィクスプロセッサユニット(GPU)を生成するための命令を含む、コンピュータ読取可能媒体であって、該命令は、実行されるときには、該少なくとも1つのGPUを作成するように適合され、該少なくとも1つのGPUは、
該少なくとも1つのGPUにシミュレーション定義データを送信し、
該送信されたシミュレーション定義データに応答する該少なくとも1つのGPUからのシミュレーション結果を受け取る
ように適合される、コンピュータ読取可能媒体。
(項目43)
少なくとも1つのグラフィクスプロセッサユニット(GPU)を生成するための命令を含む、コンピュータ読取可能媒体であって、該命令は、実行されるときには、該少なくとも1つのGPUを作成するように適合され、該少なくとも1つのGPUは、
ソフトウェアダイナミクスソルバーデータを、該少なくとも1つのGPUに対するシミュレーション定義データに変換し、
該変換されたデータに応答して、該少なくとも1つのGPU上で物理シミュレーションを行うことによって、シミュレーション結果データを生成する
ように適合される、コンピュータ読取可能媒体。
【0010】
添付の図面は、本明細書において具体化され、明細書の一部を構成し、本発明を例示し、本記述とともに、本発明の原理を説明するためにさらに役立ち、当業者が本発明を作成および利用することを可能にする。
【図面の簡単な説明】
【0011】
【図1】図1は、一般的なグラフィクスパイプラインを例示する、ブロック図を図示する。
【図2】図2は、本発明の実施形態に従った、GPU上で物理シミュレーションを行うための例示的なワークフローのブロック図を図示する。
【図3】図3は、本発明の実施形態に従った例示的なピクセルプロセッサのブロック図を図示する。
【図4】図4は、本発明の実施形態に従った、例示的な物理/レンダリングパイプラインのブロック図を示す。
【図5】図5は、本発明の実施形態に従った、GPU上で行われる例示的な物理シミュレーションパイプラインのブロック図を図示する。
【図6】図6は、本発明の実施形態に従った、ソフトウェアダイナミクスソルバーをバイパスし、これによってGPU上で物理シミュレーションを行う、例示的なワークフローのブロック図を図示する。
【図7】図7は、本発明の実施形態に従った、GPU上で物理シミュレーションを行うための例示的な方法を示す、ブロック図を図示する。
【図8】図8は、本発明の実施形態に従った、クロスをモデル化するための例示的な点メッシュを図示する。
【図9】図9は、本発明の実施形態に従った、GPU上で物理をシミュレーションするための、例示的な高レベルな流れ図を図示する。
【図10】図10は、本発明の実施形態に従った、ビデオメモリに点メッシュに関連した物理パラメータをマッピングするための、例示的な2ステップの流れ図を図示する。
【図11】図11は、本発明の実施形態に従った、ジョイント毎にネット力およびヤコブ行列の対角線上にない部分を決定するための、例示的な流れ図を図示する。
【図12】図12は、本発明の実施形態に従った、ジョイント毎にヤコブ行列の対角線上の部分を決定するための、例示的な流れ図を図示する。
【図13】図13は、本発明の実施形態が実装され得る、例示的なコンピュータシステムのブロック図を図示する。
【図14A】図14Aは、本発明の実施形態に従った、頂点バッファの内容が3×3の成分のアレイ上にマッピングされる、例示的な方法を図示する。
【図14B】図14Bは、本発明の実施形態に従った、インデックスバッファの内容が3×2のグリッド上にマッピングされる、例示的な方法を図示する。
【図15A】図15Aは、頂点バッファが、8個の頂点位置を格納する例を図示する。
【図15B】図15Bは、図15Aに図示された例示的な頂点バッファに格納された頂点位置に対応する、5個の面をインデックスバッファが格納する例を図示する。
【発明を実施するための形態】
【0012】
本発明の機能および有用性は、図面と共に取り入れられるとき、以下に述べられた詳細な記述から、より明確となる。該図面において、同様の参照文字は、一貫して対応する要素を識別する。図面において、同様の参照番号は、概して同一で、機能的に類似した、かつ/または構造的に類似した要素を示す。要素が最初に現れる図面は、対応する参照番号において、最も左側の桁によって示される。
【0013】
I.1つ以上のGPU上での物理シミュレーションのあらまし
A.1つ以上のGPU上で物理シミュレーションを行うための例示的なワークフロー
B.物理シミュレーションを実行する例示的なGPU
II.例示的な物理シミュレーションインターフェース
A.例示的な物理シミュレーションソフトウェアインターフェース(FYSI)
B.例示的な物理シーン記述言語(FYSL)
C.ポイントメッシュ関連の物理パラメータが受信され得る例示的な方法
III.1つ以上のGPU上での物理シミュレーションを行うための例示的な方法
A.方法の概観
B.クロスシミュレーションのための例示的な物理的モデル
C.GPU上でクロスをシミュレートするための例示的な実装
D.FYSLで書き込まれている例示的なコード
IV.例示的なコンピュータ実装
V.結び
I.1つ以上のGPU上での物理シミュレーションのあらまし
本発明の実施形態は、1つ以上のGPU上で物理シミュレーションを行うための方法、コンピュータプログラム製品、および系に向けられる。そのような物理シミュレーションは、例えば、(ビデオゲームなどの)アプリケーションのゲーム演算を行うために用いられ得る。本発明の実施形態に従って1つ以上のGPU上で物理シミュレーションを行うために、メッシュに関連した物理パラメータが、直接的にビデオメモリにマップされる。メッシュは、固体のオブジェクト、容量、流体、またはクロス(cloth)などのあらゆる物理的なオブジェクトを表し得る。ここで詳細に提示されるものは、1つ以上のGPU上でクロスの物理シミュレーションを行う、例示的な方法である。メッシュがビデオメモリにマッピングされた後に、GPUの少なくとも1つのピクセルプロセッサが、コンパイル済みシェーダープログラムを用いてビデオメモリ中のデータに演算を行う。GPUで直接的に物理シミュレーションを行うことは、CPU上で行われる典型的な物理シミュレーションに関連する待ち時間および帯域幅の問題を減少させ得る。
【0014】
明細書を通じて、1つ以上のGPU上で物理シミュレーションを行うための方法、コンピュータプログラム製品、および系は、例示的な物理シミュレーションソフトウェアインターフェース(FYSIと呼ばれる)および物理シーン記述言語(FYSLと呼ばれる)の点から記述される。しかし、本発明は、FYSIおよびFYSLに限定されるものではない。本記述に基づいて、1つ以上のGPU上で物理シミュレーションを行うための方法、コンピュータプログラム製品、および系が、他の種類の物理シミュレーションソフトウェアインタフェースおよび他の種類の物理シーン記述言語を用いて実装され得ることを、当業者は理解されたい。
【0015】
明細書中の「一実施形態」、「一つの実施形態」、「例示的な実施形態」などへの参照は、記述される実施形態が、特定の機能、構造または特性を含み得ることを示すが、全ての実施形態が、必ずしも特定の機能、構造または特性を含み得るとは限らないことに留意されたい。さらに、そのような表現は、必ずしも同一の実施形態を参照するものではない。また、1つの実施形態に関連して特定の機能、構造または特性が記述されるときには、明記されていようとなかろうと、そのような機能、構造または特性を他の実施形態に関連させて作用させることは、当業者の知識の範囲内であることが提示される。
【0016】
以下に詳述されるものは、1つ以上のGPU上において物理シミュレーションをマッピングするための、本発明の実施形態である。第II章において、このマッピングを行うための例示的なインターフェースが記述される。第III章は、1つ以上のGPU上において物理シミュレーションをおこなうための例示的な方法を提示し、GPU上でクロスをシミュレーションするための例示的な方法についての詳しい実装を含む。第IV章においては、1つ以上のGPU上で物理シミュレーションを実装するための例示的なコンピュータ系が記述される。しかし、本発明の実施形態を詳述する前に、1つ以上のGPU上で物理シミュレーションを行う例示的なワークフロー、および物理シミュレーションを実装するための例示的なGPUのあらましを記述することが有用である。
【0017】
A.1つ以上のGPU上で物理シミュレーションを行うための例示的なワークフロー
図2は、GPU上で物理シミュレーションを行うための例示的なワークフローのブロック図200を図示する。ブロック図200は、様々なソフトウェア要素、例えばアプリケーション210、物理シミュレーションソフトウェアインターフェース212、アプリケーションプログラミングインターフェース214、およびドライバ216を含み、それらは、力トコンピュータ系上で実行され、GPU218、(オプション)GPU220、および/または複数のGPU(不図示)などのグラフィックスハードウェア要素と相互作用することによって、物理的現象をシミュレーションし、ディスプレイ222への出力のためのフレームをレンダリングする。ブロック図200の個々の要素が、ここにより詳細に記述される。
【0018】
図2に示されるように、ブロック図200は、アプリケーション210を含む。アプリケーション210は、エンドユーザーアプリケーションであり、ビデオゲームアプリケーションなどのグラフィックス処理能力を必要とする。アプリケーション210は、物理シミュレーションソフトウェアインターフェース212を呼び出す。実施形態において、物理シミュレーションソフトウェアインターフェース212は、ATI Technologies Incによって開発されたFYSIと呼ばれるインターフェースである。FYSIが、ここにより詳細に記述される。しかし、上述のように、本発明は、FYSIに限定されるものではない。当業者に明確であるように、本発明の真意および範囲から逸脱することなく、他の物理シミュレーションソフトウェアインターフェースをも用いられ得る。物理シミュレーションソフトウェアインターフェース212は、物理シミュレーションが行われる、簡単で拡張性のある抽象マシーン(SEAM)を作成する。
【0019】
物理シミュレーションソフトウェアインターフェース212は、API212と通信する。いくつかのAPIは、グラフィックス処理関連における使用のために入手可能である。APIは、アプリケーション210などのアプリケーションソフトウェアと該アプリケーションソフトウェアが作動するグラフィックスハードウェアとの間での媒介物として開発された。新たなチップセットおよび全く新しいハードウェア技術が勢いを増しながら現れる中で、アプリケーションの開発者にとって、最新のハードウェアの機能を考慮に入れたり、利用することは、困難なことである。また、それぞれのハードウェアの予見可能なセットのために特別にアプリケーションを書き込むことは、ますます困難になりつつある。APIは、アプリケーションがあまりにもハードウェアに特有のものであらねばないことを防止する。該アプリケーションは、ハードウェアに直接的に行うのではなく、標準化されたフォーマットでグラフィックスデータおよびコマンドを、APIに出力することが可能である。物理シミュレーションソフトウェアインターフェース212が、直接的にAPI214と通信するため、利用可能なAPIを修正する必要がない。利用可能なAPIの例としては、DirectX(R)またはOpenGL(R)を含む。API210は、グラフィックスアプリケーションをランさせる利用可能なAPIのうちのいずれのものでもあり得る。当業者に認識されるように、本発明の代替的な実施形態は、物理シミュレーションソフトウェアインターフェース212をAPI214中に集約し、故に単一のソフトウェアインターフェースを用いてアプリケーション210を作動させることが可能であり得る。そのような実施形態において、次いでドライバ216が修正されることによって、API214を備える物理シミュレーションソフトウェアインターフェース212の局面を組み込む単一のインターフェースに応じ得る。
【0020】
API210は、ドライバ216と通信する。ドライバ216は、通常はグラフィックスハードウェアの製造者によって書き込まれ、APIから受信した標準コードを、グラフィックスハードウェアによって理解されるネイティブのフォーマットに翻訳する。ドライバ216はまた、グラフィックスハードウェアへのパフォーマンス設定を指示するための入力を受け取る。そのような入力は、ユーザー、アプリケーションまたはプロセスによって提供され得る。例えば、ユーザーは、グラフィカルユーザーインターフェース(GUI)などのユーザーインターフェース(UI)を用いて入力を提供し得、該グラフィカルユーザーインターフェースは、ドライバ216と共にユーザーに供給される。
【0021】
ドライバ216は、第1のGPU218および/または第2のGPU220と通信する。第1のGPU218および第2のGPU220は、グラフィックスチップであり、それぞれが、シェーダーならびに物理シミュレーションおよびグラフィックスレンダリングを行う他の関連ハードウェアを含む。一実施形態において、物理シミュレーションおよびグラフィックスレンダリングは、第1のGPU218などの単一のGPU上で行われる。代替的な実施形態において、物理シミュレーションは第1のGPU218などの1つのGPU(またはコア)において実行され、グラフィックスは、第2のGPU210などの別のGPU(またはコア)においてレンダリングされる。さらなる実施形態において、物理シミュレーションおよびグラフィックスレンダリングは、複数のGPUによって行われる。物理シミュレーションの後に、レンダリングされたグラフィックは、表示ユニット222に送られ、表示される。GPU218およびGPU220は、それぞれ次の章に記述されるように実装され得る。
【0022】
B.物理シミュレーションを実行するための例示的なGPU
本発明の実施形態に従ったGPUのアーキテクチャーは、単一命令多数データ(SIMD)技術を使用可能にし、その結果として、データレベル並列処理をもたらす。そのようなGPUは、プロセッサと、テクスチャ(またはビデオメモリ)を含む。プロセッサは、テクスチャ内のデータに基づきオペレーションを行う。該オペレーションの結果は、レンダーターゲット(ビデオメモリの一部)に書き込まれる。レンダーターゲットは、テクスチャまたは後続演算として再割り当てされ得る。テクスチャは、メモリの1D−、2D−、3D−アレイなどのように、メモリのアレイに配列される。シェーダーは、プロセッサがテクスチャ内のデータに基づき特定の演算を行うために書き込まれた、小さなプログラムまたは一組の命令である。
【0023】
図3は、ブロック図300を図示し、本発明の実施形態に従った、1つ以上のGPU上で物理シミュレーションを実行するための例示的なピクセルプロセッサを説明する。ブロック図300に含まれるものは、6つのテクスチャ310a−310f、8つの定数ストレージレジスタ308a−308h、および1つのピクセルプロセッサ306である。メモリアレイ(1D−、2D−、3D−メモリアレイなど)のテクスチャ座標302は、テクスチャ310に書き込まれ得る。対照的に、定数データ値は、定数ストレージレジスタ308に記憶される。ピクセルプロセッサ306は、テクスチャ310内および/または定数ストレージレジスタ308内のデータに基づきオペレーションを行う。これらのオペレーションを行った後に、ピクセルプロセッサ306は、テクスチャ310にデータを書き込み得、かつ/または、出力314を生成し得る。ピクセルプロセッサ306によって行われるオペレーションは、CPUアッセンブリ言語命令に似た命令によって特定される。
【0024】
ここで、GPU頂点プロセッサにおいてメッシュが表現される、例示的な方法について記述する。メッシュは、1対の1次元リスト、すなわち頂点バッファおよびインデックスバッファから成る。図15Aに例示されるように、頂点バッファは、頂点位置を保持する。図15Aに示される実施形態は、7つの頂点位置を例示している。図15Aは、例示目的のみに用いられ、限定的に用いられるものではない。当業者に明確なように、異なる数の頂点位置が、頂点バッファに記憶され得る。図15Bに例示されるように、インデックスバッファは、面のインデックスを記憶する。図15Bは、例示目的のみに用いられ、限定のために用いられるものではない。当業者に明確なように、異なる数の面のインデックスが、インデックスバッファ記憶され得る。面は、三角形を表し、該面は、頂点バッファに点を載せる。例えば、インデックスバッファに記憶された面は、3つの頂点を含み得、0、1および2と分類される。これら分類された頂点のそれぞれは、頂点バッファの別個の位置を指し示す。
【0025】
ここで、メッシュがビデオメモリにマッピングされる例示的な方法について記述する。この例示的な方法は、例示目的のみに提示され、限定のためではない。メッシュをビデオメモリにマッピングするための他の方法は、本明細書に含まれる記載を基にして、当業者に明確となる。頂点およびインデックスのリストはそれぞれ、ビデオメモリにおける最適化されたN次元のアレイにマッピングされることにより、ピクセルエンジン並列処理がより良く利用される。最適化されたN次元のアレイは、該最適化されたN次元のアレイが、物理シミュレーションを行うために用いられるGPUの最大アドレス指定能力に適合するようになっている。頂点バッファは、n×mの要素のアレイ上にマッピングを行い、インデックスバッファは、l×kグリッド上にマッピングを行う。ビデオメモリ内のそれぞれの要素(例えばピクセル)は、4成分ベクターから成る。はじめの3つの成分は、位置のx、yおよびz成分を表し、4つ目の成分は、境界タグ(以下に記述される)である。
【0026】
一実施形態において、頂点およびインデックスのリストは、それぞれ、図14Aおよび図14Bに示されるように、それぞれがビデオメモリにおける最適化された2次元アレイ上にマッピングされる。本実施形態において、頂点バッファは、3×3成分のアレイ上にマッピングを行い、インデックスバッファは、3×2グリッド上にマッピングを行う。
【0027】
1つのシーンにおける複数のメッシュの場合には、全メッシュが、本発明の実施形態に従った、1つの2次元複合メッシュに一体化される。複合メッシュは、それぞれのサブメッシュに固有の識別子(「id」)をタグ付けすることによって、サブメッシュ境界をビデオメモリに記録する。該idは、それぞれのグリッド要素の第4の構成要素として記録される。メッシュの複合は、ビデオメモリへの小型サイズメッシュのダウンロードに関連したオーバーヘッドを緩和し、かつ、テクスチャ使用の総数によるハードウェアリソースのプレッシャーを軽減する。
【0028】
II.例示的な物理シミュレーションインターフェース
図2に関して上述されたように、物理シミュレーションソフトウェアインターフェース212は、アプリケーション210が、GPU218、GPU220および/または複数のGPU上で物理シミュレーションを行うことを可能にする。この章では、例示的な物理シミュレーションインターフェースが記述される。まず、FYSIと呼ばれる、例示的な物理シミュレーションソフトウェアインターフェースが記述される。続いて、FYSIにおいて具現化される象徴的なコンセプトを表現するための、FYSLと呼ばれる例示的なシーン記述言語が記述される。最後に、FYSIを用いて1つ以上のGPU上で物理シミュレーションを行い、それにより、従来のソフトウェアダイナミックソルバーを回避するための、物理パラメータと属性をFYSLに変換する例示的な方法が記述される。しかし、認識されたいのは、これらの実施形態は、例示的目的のみに提示され、限定のためではないということである。本明細書に含まれる記述を基に、当業者は、1つ以上のGPU上で物理シミュレーションを行うための、他の種類の物理シミュレーションソフトウェアインターフェースの実装方法を理解することとなる。
【0029】
A.例示的な物理シミュレーションソフトウェアインターフェース(FYSI)
FYSI−例示的な物理シミュレーションソフトウェアインターフェース系は、従来のCPUベースのシミュレーション関連の演算をGPU上でマッピングするための伝達手段である。FYSIを用いることによって、ゲーム物理において一般に経験されるものよりも、より高いインタラクション速度が達成され得る。FYSIは、グラフィックスハードウェア上に衝突の検知および解消をマッピングする従来の閉鎖クエリモダリティからはずれたものである。代替的に、FYSIは、ますます増えつつあるハードウェアでのプログラミングが可能なシェーディング力を強化する、グローバルシミュレーション解決法を提案する。
【0030】
図4は、拡張グラフィックスパイプラインのブロック図400を図示し、これによって、物理シミュレーションステージ410が視覚レンダリングステージ420をフィードスル。物理シミュレーションステージ410は、物理記述象徴概念を取り入れる。該記述は、シミュレーションおよびシーンの両方の定義を提供する。シーンは、アクター(actor)から成り、それぞれのアクターは、それ自身の一組の形状、ダイナミクス、および物質の特性を有する。該形状は、参加中のアクターの幾何学的な性質を確立させ、ダイナミクスは、物理的な挙動を構成し、物質は、物質関係の特性を備え付けさせる。加えて、該シーンは、随意的にジョイント(joint)を宣言し、これによって1対のアクターの運動の制約を導入する。シミュレーションの工程は、反復的で別々の一律のステップ、すなわち時間様式によって開始される。物理記述象徴概念は、FYSLと呼ばれる言語の形式をとり、これは、物理シーン記述言語の略である。FYSLは、プラットフォームから独立しており、拡張性があり、かつコンストラクトを提供することによって、必要に応じて複数のGPUに渡ってシミュレーションタスクを分割する。
【0031】
レンダリングブロック420において、物理ブロック410からのシミュレーション結果は、視覚化のためにレンダリングされる。一般的には、いくつかの物理シミュレーションのステップが、レンダリングフレーム毎に行われる。故に、シミュレーションおよび視覚レンダリングの両方のタスクの累積のフレーム速度が、ユーザーに対する最終的なインタラクティブ速度を決定する。FYSIは、物理シミュレーション要件を提供するためのソフトウェア開発環境である。まず、FYSL入力象徴概念は、解析され、内部シーンデータ構造の集合に変換される。次いでシミュレーションは、GPUにおいて開始される。シミュレーション結果は、共有テクスチャを用いて視覚レンダリングスレッドに直接的に進まされるか、または、随意的にプログラマーによって読み返されるように利用可能である。最後に、FYSIは、拡張性を容易にするために、グラフィックスハードウェアインターフェースの頂部に演算象徴概念層(CAL)ラッパー(wrapper)を実装する。一実施形態において、FYSIは、マイクロソフトDirectX(R)(バージョン9.0および10.0)とインターフェースで接続するが、当業者は、FYSIがOpenGL(R)または他のいくつかのAPIとインターフェースで接続し得ることを認識されたい。
【0032】
ゲームにおける物理シミュレーションフィールドは、幾分幅広いものであり、大量の域におけるトピックを範囲に入れる。それらの中には、剛体、クロス、流体、および、一般的には変形可能体のシミュレーションが含まれる。物理シミュレーションの種類は、シミュレーションステージから視覚レンダリングステージ上に移されたデータのフォーマットを示す。剛体の場合には、FYSIは、視覚スレッド変換データに進み、該データは、最近のシミュレーションセッションに入力されたオブジェクトの増分的状態変化を表す。クロスのモデルは、摂動を加えられた元の粒子の位置に戻り、流体または変形可能な体については、結果的にシミュレートされた形状は、初期の形状とはほとんど関連性のないものとなっている。通常、物理シミュレーションの工程は、CPUバウンドであり、物理シミュレーションの工程から視覚レンダリングスレッド上への帯域幅要件は、相対的に限定的である。
【0033】
図5に示されるように、比較的に高いレベルにおいて、包括パイプライン500が形成され、前述の物理シミュレーション局面のほとんどに適用され得る。パイプライン500は、系セットアップステージ510、ソルバーステージ520、および衝突ステージ530を含む。系セットアップステージ510において、入力は、初期シーン記述、または該シーンの増分的な状態の更新のいずれかである。系セットアップステージ510の役割は、物理モデルの統合を行い、方式A*x=bの線形系に到達することである。ここで、Aは行列、xは未知数、bは既知のベクトルである。
【0034】
ソルバーステージ520において、線形系は解かれ、描写されるシーンの状態は、該線形系に対する解に基づいて更新される。線形系は、関連する当業者に利用可能な数値技術を用いることによって解かれる。一実施形態において、線形系は、以下に詳細に記述される修正共役勾配方法、およびDavid BaraffおよびAndrew Witkinによる「Large Steps in Cloth Simulation」、Computer Graphics Proceedings、pp43−54(1998年7月19〜24日)(以降「Baraff引例」と呼ぶ)を用いて解決され、本明細書においてその全体を参照として援用する。
【0035】
衝突ステージ530において、更新されたモデルは、可能性のある衝突のために試験される。算定された接触の結果として、シーンの状態がさらに修正される。衝突検出が、対の点が交差するか否かをチェックすることによって行われる。衝突検出技術は、当業者に周知である。例えば、Baraff引例の50ページを参照されたい。
【0036】
物理パイプライン500は、そのステージ全体を、シミュレーションステージのそれぞれのために繰り返し実行される。一般的に、シーンの中のアクターは、個別に、またはグループベースのいずれかにおいて考慮される。剛体の場合におけるなどの個別のアクターは、パイプライン500の系セットアップステージ510およびソルバーステージ520を通過し、衝突ステージ530のみを行う。クロス、流体および変形可能なエンティティーは、一般的に、明確な相互作用モデルを有するアクターの集合と考えられる。故に、ほとんどの場合において、それらはパイプライン500の全てのステージを実行するように意図される。クロスが物理パイプライン500を通過する例が、第III章に記述される。
【0037】
B.例示的な物理シーン記述言語(FYSL)
FYSI物理シミュレーションインターフェースライブラリへの入力象徴概念は、FYSLと呼ばれるカスタム化シーン記述フォーマットにおいて表される。FYSLは、XMLフォーマットにおいて表され、シーン、シミュレーション、アクター、ジョイント、およびフィードバックの5つのセクションから成る。これらのFYSLセクションのそれぞれは、スキーマタグおよび随意的価値割当を含む。スキーマタグおよび随意的価値割当は、以下に記述される。FYSLプログラムの見本は、この小節の終わりに提供される。
【0038】
FYSLの最初のセクションは、シーンである。このセクションにおいて、描写されるシーンが定義される。例示的なグローバルシーンタグは、表1に提示される。
【0039】
【表1】
FYSLの第2のセクションは、シミュレーションである。FYSIにおけるシミュレーションの工程は、個別的であり、ステップにおいて開始される。FYSLシミュレーション特性は、種類およびシミュレーションステップ間の時間間隔を含む。
【0040】
加えて、全てのシーンのアクターに同じように作用している力を表すグローバルフィールドが、シミュレーション定義に随意的に加えられ得る。本実施形態において、FYSLは、ドラッグフィールド、方向性フィールド、および手続きフィールドの、3種類の力フィールドタグを提供する。ドラッグフィールドは、3つのスカラー値(それぞれの次元に1つ)から成るベクトルであり、該ベクトルは、アクターの線形速度に基づいた制動力を及ぼす。方向性フィールドは、シミュレーションを通して一定な単一成分の力であり、該力は、ベクトルによって特定された方向において作用する。例示的な方向性フィールドは、重力である。手続きフィールドは、時間および空間の両方において変化し得る、より入り組んだフィールドを表す。手続きフィールドに取り付けられたストリングは、GPU上で実行されるシェーダープログラムのコードにさらに翻訳される、機能である。
【0041】
例示的なシミュレーションタグは、表2に示されており、例示的なフィールドタグは、表3に示される。
【0042】
【表2】
FYSLの第3のセクションはアクターである。アクターの一群は、通常は1、2または3次元であり得る論理グリッドにおいて構成される。グリッドは、GPUビデオメモリにおいてアクターの特性を展開する手段として役立つ。表4に示されるように、グリッドタグは、幅、高さ、および深さの値を含む。
【0043】
【表3】
アクターは、グローバルおよび特定の形状およびダイナミクスの特性によって特定される。形状は、対に関する衝突の検出を決定するために用いられ、ダイナミクス特性は、物理的挙動を容易にすることによって応答を解決する。FYSLおよびFYSIは、形状の定義のために左手座標系を用いる。表5に示されるように、グローバルなアクタータグは、名前、種類、およびidの値を含む。
【0044】
【表4】
アクターid(識別子)は、正の整数であり、かつ、同一の階層のアクターの群に渡って固有のものであることが求められる。大体において、FYSIは、FYSL記述において欠いているシーン特性のために、デフォルトのシーン特性を割り当てるように求められる。
【0045】
記述されたFYSL実施形態において支持される形状の定義は、ボックス(軸に対して整列または配向されている)、球、メッシュ、および四面体を含む。アクター形状は、ローカルの基準座標系において定義される。体積を境界付けるボックスおよび球は、1対の中心および半径として表される(中心および半径は、それぞれベクトルまたはスカラーのいずれかである)。メッシュおよび四面体は、頂点位置(四面体については、頂点の数は4に固定されている)および1組の面のインデックス(四面体についてはインプリシット)の集合の形態をとる。メッシュに関しては、面はエクスプリシットであり、一方で、四面体に関しては、面はインプリシットである。形状は、ワールド(world)座標空間へのローカルの座標系の変換を特定する行列と関連している(以下の論述を参照されたい)。表6から表10は、形状に特有のタグを例示する。
【0046】
【表5】
体積を境界付ける質量の中心は、形状の定義によってエクスプリシットである。メッシュおよび四面体については、FYSIは、質量の中心が、線形の運動特性のセットにおいて提供されない限り、質量の中心をインプリシットに演算する。メッシュの質量中心のパラメータは、必ずしもユーザーによって提供される必要はないが、それがあれば、FYSIが内部的に演算したものを上書きする。
【0047】
シミュレーションは、ワールド座標空間において行われる。形状の変換は、平行移動および回転の成分の連結であり、アクターに線形および角の運動のそれぞれを適用する効果によるものである。結果的な行列は、ローカルからワールドの座標空間へと、形状を変換する。変換行列は、視覚レンダリング工程のためにFYSIクライアントによって用いられる。
【0048】
FYSLボックスの形状は、FYSI内部において、軸に対して整列した(AABB)または方向性を有した(OBB)、いずれかの演算経路を取り得る。該選択は、どちらかと言えば動的であり、シミュレーションのステップによって変わり得る。例えば、接触応答に基づき得る。一般的には、衝突検出のためのAABB経路は、OBB経路に比べてより効率的である。
【0049】
動的属性は、線形、角、および物質の種類の任意の組み合わせであり得る。動的属性は、質量、速度、エクスプリシットな質量中心の位置、配向、および及ばされる力を含む、運動学的特性を定義する。加えて、動的特性は、復元および摩擦などの、接触応答物質属性を提供する。線形、角および物質の種類のための動的タグは、表11、表12、および表13にそれぞれ提供される。
【0050】
【表6】
剛体は、行われた物理的な挙動の規則の基礎となる、FYSIに対し、点質量と仮定される。線形の運動および外部的な力は、本体の質量中心に作用し、角運動は、接触点に適用される。
【0051】
FYSLトルクは、それが存在するときには、あらゆるボックスまたはメッシュの形状の頂点に適用される。また、トルクは粒子ベースのアクターの場合にも有意義であり、ここでは、それぞれの粒子が、ゼロ半径の球として定義される。トルクは、アクター(または粒子の場合は親アクター)の質量中心に対する位置に依存する。該トルクは、結果として起こるアクターの角運動に影響する。FYSLトルクは、粒子ベースのアクター(例えば、空間的な範囲を有さない無形のアクター)に対して有意義である。該トルクは、トップレベルアクターの実質的な質量中心に対する位置に依存する。トルクは、粒子の角運動に影響する。
【0052】
アクターに対する配向は、行と列が単位長さの、直交行列であることが求められる。
【0053】
オメガ動的特性は、ラジアンにおける角度のベクトルである。任意の軸に対する正の角度は、軸を中心に反時計回りの回転をもたらし、負の角度は、軸を中心に時計回りの回転をもたらす。
【0054】
メッシュのインデックスおよび四面体の面のインデックスは、ゼロベースであり、それぞれは、反時計回りで三角形を表す。
【0055】
アクターのグリッド展開は、GPUに固有のデータパラレルアーキテクチャを利用する。グリッドはまた、物理的に割り当てられたGPUから読み返される最終的な画像の解像度を提供し、該物理的に割り当てられたGPUは、視覚的レンダリングを行うCPUまたはピアGPU上にシミュレーション結果を移動させる。1Dグリッドは、GPU上では非常に非効率的であり、通常は用いられることはない。通常は、アクターは、2Dグリッド上に分配される。3Dグリッドが用いられるのは、例えば、2Dグリッドのアドレス指定能力がGPUの限界を超えた場合である。グリッドの次元は、2のべき乗である必要はない。最後に、アクターの数は、グリッドセルの数に必ずしも一致する必要はないかもしれない(例えば、後者は、階層におけるアクターの数と等しいかそれ以上でなくてはならない)。結果として、2Dグリッドが、完全に場所を占有されていない最後の行を有し得、3Dグリッドの最後のスライスは、完全に占有されていないかもしれない。FYSIは、全ての生じたスライバをダミーアクターで埋める。
【0056】
アクターは、階層的に作られ得、それぞれの階層レベルにおけるアクターの集合は、グローバルな属性を共有し得る。グリッドは、各レベルにおいて、アクターの集合に付属させられることが求められる。より高い階層レベルでの形状は、より粗い幾何学的表現となると想定される。これは、トップ−ダウンシミュレーションを開始することと連動し、早期の衝突検出が除かれることは、全体的な工程の効率を向上させる。また、アクターの動的特性は、各階層レベルにおいて固有のものにすることができ、その結果、順応性のある物理的特性を実行する自由を提供する。ジョイント(後に記述)は、制約条件をシミュレーションするためにアクターの群に随意的に適用され得る。例えば、ジョイントは、クロスのシミュレーションにおいて用いられ、このことは以下の第III章に詳述される。
【0057】
FYSLの第4のセクションは、ジョイントである。ジョイントは、1対のアクターの間の相互作用の制約を定義する。ジョイントは、本質的にアクターの動作を制限する。ジョイントは、共通のパラメータおよび/またはその種類に基づく固有のパラメータを有し得る。共通のパラメータには、ジョイントの種類、および1対のアクターのメンバーそれぞれに対するハンドルを含む。ジョイントは、FYSL記述フォーマットにおいてアクターと同一のタグレベルにある。従って、ジョイントは、トップのシーンレベルおよび任意のアクター階層の両方において定義され得る。例示的なジョイントタグは、表14、表15、および表16に提供される。
【0058】
【表7】
FYSLの第5のセクションは、フィードバックである。FYSL記述のフィードバックセクションは、シミュレーション結果の戻り経路に対して、FYSIによってのみ提供される。複数ステップのシミュレーションセッションにおいて、ステップごとにフィードバックセクションがある。例示的なフィードバックタグは、表17に示される。
【0059】
【表8】
例示的実施形態は、上記のタグを含み得るが、代替的な実施形態においては、他のタグの種類も用いられ得る。サンプル#1。以下に提供されるものは、FYSLで書かれたコードの例示的なセクションである。コードのこのセクションは、それぞれ角度的および線形のダイナミクスを有する、1対のメッシュ形状のアクターを有する衝突検出物理シミュレーションシーンを図示する。
【0060】
【表9】
【0061】
【表10】
サンプル#2。以下に提供されるものは、FYSLで書かれた例示的なコードの別のセクションである。このコードのセクションは、2×2のグリッドレイアウトの粒子ベースのアクターのための、2つのレベルの階層を例示する。これは、クロスおよび流体のエンティティーを定義するための基本的な構造である。
【0062】
【表11】
【0063】
【表12】
【0064】
【表13】
C.メッシュに関連する物理パラメータが受信され、FYSLに変換され得る、例示的な方法
ソフトウェアダイナミクスソルバー(California州、San RafaelのAutodesk(R)所有、Maya(R)Dynamicsなど)は、CPUによって実行される物理シミュレーションを行うために存在する。本発明の実施形態に従うと、プラグインが用いられることによって、そのようなソフトウェアダイナミクスソルバーを迂回し、これによって、本明細書に記述されるようにGPU上で物理シミュレーションを行う。本実施形態において、プラグインは、シーンを捕捉し、該シーンに描写されるアクターに関連する属性およびフィールドをFYSLに変換する。その結果、物理シミュレーションが、FYSIを用いてGPU上で行われ得る。別の実施形態において、ユーザーは、物理シミュレーションが、GPUによって行われるか、またはソフトウェアダイナミクスソルバーによって行われるかを選択してよい。さらなる実施形態において、GPUの有効性および/または所定の機能に対するソフトウェアサポートなど、所定の基準に基づいて、GPUまたはソフトウェアダイナミクスソルバーが自動的に選択され、物理シミュレーションが行われる。例えば、GPUは、剛体およびクロスの物理シミュレーションを行うために用いられ得るが、ソフトウェアダイナミクスソルバーは、流体の物理シミュレーションを行うために用いられ得る。物理シミュレーションをGPUまたはソフトウェアダイナミクスソルバーによって行うことによって、より速いフレーム速度が達成され得る。特定のソフトウェアダイナミクスソルバー(すなわち、Maya(R)Dynamics)を迂回するための例示的なプラグインが、本章に記述されるが、まず、Maya(R)Dynamicsのあらましが提供される。
【0065】
Maya(R)Dynamicsは、現実世界の物理的特性をシミュレーションすることによって運動を生成する、一種の技術である。Maya(R)におけるダイナミクスは、多様であり力強く、また、モデリング、アニメーションおよびレンダリングに一致した重要性レベルのツールセットを所有する。一般的に、Maya(R)Dynamicsのコンセプトは、キーフレームを用いないシミュレーションベースのアニメーションを含意する。Maya(R)Dynamicsのファミリーには、剛体および軟体、粒子系、クロス、流体および髪メンバーを含む。Maya(R)Dynamicsは、物理的原理に基づく、視覚的に強い印象を与える効果を作成するために、ゲームにおいて用いられる。
【0066】
図6は、ブロック図を図示しており、ここでは、GPUを利用することによって、Maya(R)Dynamicsなどのソフトウェアダイナミクスソルバーと比較して頑強性を妥協することなく、より高いシミュレーション速度を達成する、例示的なワークフロー600を図示している。該ワークフローは、大部分がMaya(R)Dynamicsへのプラグインによって制御されている。そのようなプラグインには、シーンエクスポーター(exporter)、GPU DynamicsシミュレーターFYSI、およびシーンインポーター(importer)が含まれる。
【0067】
ワークフロー600は、ステップ610から始まり、ここでは、シーンエクスポーターが、アーティストによってシーンオブジェクトに添付された属性およびフィールドを受け取る。属性には、初期速度、スピン、配向、および物質の摩擦を含む。フィールドは、運動に影響し、ドラッグ、重力または手続き上定義されたものを含む力を表し、運動は、GPUシェーダープログラムにおいて表される。ユーザーは、GPUベースのシミュレーションを開始するために、全てのシーンオブジェクトまたはそのサブセットのいずれかを選択する。エクスポーターは、オブジェクトの幾何学的形状および動的特性を、GPU向けの物理シミュレーションフォーマットに変換する。GPU向きの物理シミュレーションフォーマットは、一実施形態においては、FYSLである。
【0068】
ステップ620において、物理シミュレーションは、FYSLを用いてGPU上で行われる。一旦適切なFYSIプラグインが現れると、GPUベースのシミュレーターが、シームレスにソフトウェアダイナミクスソルバーノード(例えばMaya(R)Dynamics(R)統合ソルバー)に取って代わる。GPUシミュレーターは、多数の別個のフレームにおいて、再帰的にシミュレーションを実行させる。シミュレーション中に、現在のシーン状態が解決され、FYSL動的アクターのそれぞれの対の中での衝突検出が調べられる。衝突する対は、さらに処理されることにより、関連するアクターの運動に影響するであろう、接触応答を起こす。FYSI GPU援助の物理シミュレーションは、主に頂点プロセッサよりもより高い度合いの同時処理を活用するピクセルエンジンを利用する。GPU上での物理シミュレーションは、グリッドベースであり、ここでは、通信バリヤーは、格子セルに渡ってほとんどまたは全くない。関係する演算カーネルは、大部分において、高い算数効力特性を有し、従って、同等のCPU実装と比較して、改良スピードアップをデモンストレーションするための好ましい候補である。このシミュレーション工程は、効率を向上させるために単一または多数のGPUを活用し、ソフトウェアダイナミクスソルバーとやりとりしているアーティストには、全てがトランスペアレントである。FYSIは、エクスポーターが送ったものと、同一のFYSL表現フォーマットにとなる。FYSI結果は、完全なシミュレーションセッションのために内部的にキャッシュされ、Maya(R)Dynamicsにおいて再使用されるために完全に公開される。
【0069】
ステップ630において、フレーム毎のシミュレーター結果は、Maya(R)Dynamicsのシーングラフにインポートによって戻される。ステップ630の間、幾何学的形状および変換データのみが重要である。FYSIは、シミュレーションステップ毎に、形状の位置的更新および変換の更新の両方を提供する。変換データは、入信してくるシーンの位置および配向に関連する。剛体の場合には、Maya(R)Dynamicsからの変換シーングラフのノードを更新することで十分である。変形する物体(クロスおよび流体など)に対しては、Maya(R)Dynamicsによって提供されるシーンプリミティブのノードにおいて、更新は、全てのメッシュ頂点またはインデックスについて行われる。
【0070】
ステップ640において、シミュレーション結果は、視覚化ためにレンダリングされる。GPUまたはソフトウェアベースのレンダラーが呼び出されることによって、シミュレーション効果を視覚化する。一実施形態において、視覚レンダリングタスクを実行するためのGPUは、物理シミュレーションを行うGPUから物理的に離れている。これは、この場合においても、より高いレベルにおいて並列処理を容易にするためである。
【0071】
ステップ650において、レンダリングされた結果は、シーンにおいて再生される。
【0072】
III.1つ以上のGPU上での物理シミュレーションを行うための例示的方法
A.方法の概観
ここに、FYSIおよびFYSLを用いた、1つ以上のGPU上での物理シミュレーションを行うための例示的方法を記述する。図7は、ブロック図を図示し、本発明の実施形態に従って、1つ以上のGPU上でゲーム物理シミュレーションを行うための例示的な方法700を例示している。方法700は、ステップ710から始まり、ここでは、メッシュに関連した物理パラメータが、ビデオメモリにマッピングされることによって、シーンに図示されたメッシュの運動を決定する線形方程式系をセットアップする。ビデオメモリは、図3に関連して上述された、テクスチャ310を含み得る。当業者に明らかなように、メッシュは、個体のオブジェクト、体積、流体、クロス、または他の種類の物理的オブジェクトなどの、あらゆる種類の物理的なオブジェクトを表し得る。
【0073】
ステップ720において、少なくとも1つのピクセルプロセッサを用いて、演算が、ビデオメモリにおけるデータに基づいて行われることによって、その時刻の線形方程式系を解く。その時刻の線形方程式系への解を表す修正済みデータは、次いでビデオメモリに記憶される。一実施形態において、修正済みデータは、テクスチャ310に記憶され、次いで別のシェーダーが該修正済みデータに対応するグラフィックスをレンダリングする。本実施形態においては、単一のGPUが物理シミュレーションおよびグラフィックスのレンダリングを行う。別の実施形態においては、修正済みデータが、第1のGPUの出力として提供され、次いで第2のGPUのテクスチャに書き込まれる。本実施形態においては、第1のGPUが、物理シミュレーションを行い、第2のGPUがグラフィックスのレンダリングを行う。代替的に、第1のGPUは、第2のGPU(例えば第1のGPUのビデオメモリあるいは系メモリ)にアクセス可能なメモリの領域に修正済みデータを書き込み得る。
【0074】
方法700は、あらゆる種類の物理的オブジェクトをシミュレーションするために実装され得る。以下に提供されるものは、1つ以上のGPUにクロスをシミュレーションするための例示的な実装である。この例示的実装は、例示目的のみに提供され、限定の目的に提供されるものではない。本明細書に含まれる記載に基づいて、当業者は、GPU上で他の種類の物理的オブジェクトのシミュレーションを行う方法を理解することとなる。
【0075】
ここで、1つ以上のGPUでクロスをシミュレーションするためのインプリシットな技術を記述する。まず、クロスの物理モデル、および離散時間にそのモデルをシミュレーションする2つのアプローチが提示される。第2に、インプリシットな離散時間シミュレーションの3ステップ工程が記述される。第3に、この3ステップ工程をGPUにマッピングする方法が提示される。
【0076】
(クロスシミュレーションのための例示的物理モデル)
クロスは、内在する粒子系によってシミュレーションされ得る。そのような内在型粒子系は、内部的な伸張力および減衰力を受ける、点質量のアレイとして表され得る。これら力は、近傍の点の相対的変位および速度に依存する。そのような点質量のアレイは、本明細書において点メッシュと参照される。図8は、例示的な点メッシュを図示する。
【0077】
点メッシュ800を考慮すると、以下の、点メッシュ800に関連した物理パラメータが定義され得る。
【0078】
【数1】
あるいは、Mは、ブロックとして解釈され得、それは、それぞれの要素が{3×3}対角行列である{n×n}対角行列である。
【0079】
ニュートンの第2の法則(すなわち、F=ma)は、点メッシュ800に対して以下のように書かれ得る。
【0080】
【数2】
線形減衰を有する二次質量ばね系に対しては、粒子iに作用するネット力は、相対位置
【0081】
【数3】
および全て(通常は近傍)の粒子の速度
【0082】
【数4】
の関数である。故に、方程式1におけるネット力の各成分は、
【0083】
【数5】
と書かれ得る。そして、点メッシュ800の運動は以下の方程式によって決定される。
【0084】
【数6】
故に、方程式2の解は、点メッシュ800の運動をシミュレーションするために用いられ得る。
【0085】
方程式2が一連のコンピュータの工程(例えば、GPUにおける少なくとも1つのピクセルプロセッサによって行われる工程)によって解かれるためには、方程式2は、離散時間型問題に変換されなくてはならない。時間離散型問題においては、系の次の状態が、その以前の状態によって与えられる。具体的には、時刻tk
【0086】
【数7】
における系の位置および速度が与えられると、最も単純な一次時間離散型問題は、時刻tk+1
【0087】
【数8】
における系の位置および速度を決定する。時間離散型問題に対する解は、時間離散型積分を必要とする。少なくとも2つの一般的な種類の時間離散型積分があり、それらは、エクスプリシットな方法およびインプリシットな方法である。
【0088】
エクスプリシットな方法は、導関数の前進投射を用い、以前の状態の直接的外挿から次の時間のステップにおける状態を演算する。例えば、一次オイラー前進差分は、以下のように近似する。
【0089】
【数9】
離散時間導関数の右辺は、以前の時間ステップにおける値によって左辺において束縛される。将来的な状態は、状態の関数として再び書かれる事となり得、すなわち、以下の通りとなる。
【0090】
【数10】
方程式3の形式を点メッシュ800に適用すると、点メッシュ800の運動を決定する方程式の系(すなわち方程式2)は、
【0091】
【数11】
によって与えられる、時間ステップ毎に適用される、単純な独立した更新の方程式のセットとして書き換えられ得る。
【0092】
エクスプリシットな積分スキームに対する主な欠点は、数値安定度である。一般的に、前進近似を保つために、方程式3の関数a(t)は、
【0093】
【数12】
に関してあまり急激に変化してはならない。すなわち、積
【0094】
【数13】
は、閾値より下でなくてはならない。bkが大きい場合、該系は、「剛(stiff)」と言われ、
【0095】
【数14】
は、比較的に小さくされなくてはならない。
【0096】
インプリシットな方法は、第2種類目の時間離散型積分技術を担う。インプリシットな方法は、外挿された結果から、幾分かの「可逆性」を表す方程式の系からの次の時間ステップにおける状態を演繹する。言い換えると、将来の状態の後退導関数が、以前の状態に対して同時に検証される。例えば、一次オイラー前進差分は、以下のように近似する。
【0097】
【数15】
巧妙なことに、ここで、時間離散型導関数の右辺は、将来の値によって左辺に同時に束縛されるということである。直接的な結果として、将来の状態は、以前の状態の単純な関数としては表現できない。
【0098】
点メッシュ800に適用されることによって、系の支配方程式(すなわち、方程式2)は、3nの未知数
【0099】
【数16】
の同時的な系になり、それは、時間ステップ毎に解かれなくてはならない。
【0100】
【数17】
このタスクは、難題のように見えるかもしれないが、このアプローチは、2つの重要な利点を有する。まず、インプリシットな技術は、ほとんど無条件的に一定している。つまり、インプリシットな技術は、現実的なクロスシミュレーションの特徴的に「剛(stiff)」方程式によって影響されることがより少なく、それ故により大きな時間ステップをサポートすることが可能である。次に、結果的な系は、疎かつ対称的な傾向があり、これらの種類の系は、効率的な数値法を用いて難なく解かれる。
【0101】
方程式4に表されるエクスプリシットな積分法か、方程式5に表されるインプリシットな積分法のいずれかにおいて、ネットの内力のベクトル
【0102】
【数18】
を求めなくてはならない。一般的には、
【0103】
【数19】
は、クロスの内部的な拘束をモデル化する、非線形の関数である。離散時間において、
【0104】
【数20】
は、常に現在の状態の関数である。
【0105】
【数21】
エクスプリシットな積分を用いて、
【0106】
【数22】
が、直接的に求められることによって、
【0107】
【数23】
が更新される。具体的には、方程式4に示されるように、以下となる。
【0108】
【数24】
しかし、安定度を確実にするために、
【0109】
【数25】
は、
【0110】
【数26】
の「剛性(stiffness)」を反映させるために選択されなくてはならない。残念なことに、現実的な内力は、比較的に堅く、比較的に小さな時間ステップを必要とする。先述のBaraffの引例によって証明されたように、現実的に剛の方程式に必要な、これら小さな時間ステップにおける多くの更新の累積のコストは、より粗い時間ステップにおいて大型で疎な線形系を解くコストを次第に超える。David BaraffおよびAndrew Witkinの「Large Steps in Cloth Simulation」、SIGGRAPH 98の集録、pp.43−54(1998)を参照されたい。結果的に、インプリシットなアプローチが、現実的なクロスシミュレーションで主となっている。
【0111】
インプリシットな積分技術は、複雑性がないという訳ではない。特に、インプリシットな積分技術は、
【0112】
【数27】
ではなく、
【0113】
【数28】
に対する式を必要とする。この場合には、近似が用いられる。具体的には、
【0114】
【数29】
が、その一次テイラー展開式によって近似される。
【0115】
【数30】
方程式6における第1の項は、エクスプリシットの場合におけるように求められ、一方で、第2および第3項は、ヤコビ行列
【0116】
【数31】
に依存し、最後の時間ステップにおいて求められる。外力から独立はしているものの、これらヤコブ行列は、大きく、相対的に数値を求めにくい。ヤコブ行列は、実際に、{3×3}サブ行列要素の{n×n}である。
【0117】
ヤコブ行列は、以下の形式を有する。
【0118】
【数32】
ここで、
【0119】
【数33】
であるので、
【0120】
【数34】
の要素は、それ自体は、形式
【0121】
【数35】
の{3×3}ヤコブ行列によって与えられる。
【0122】
【数36】
の数値が求められると仮定すると、時間ステップ毎に解く必要のある線形系(すなわち、方程式5)は、
【0123】
【数37】
の項において、以下のように書き換えられる。
【0124】
【数38】
ここでは、Iは、恒等行列であり、Mはメッシュの質量の直交行列であり、
【0125】
【数39】
は、tk時におけるメッシュ幾何学的状態を表すベクトルであり、
【0126】
【数40】
は、tk時におけるメッシュ中の各点の速度を表すベクトルであり、
【0127】
【数41】
は、tk時におけるメッシュの各点上のネット力を表すベクトルである。従って、点メッシュ800の物理シミュレーションを行うためのインプリシットな積分法は、各時間ステップ
【0128】
【数42】
に対する方程式8を解く事である。
【0129】
方程式8は、
【0130】
【数43】
と書かれ得、ここで、
【0131】
【数44】
である。
【0132】
図5を参照して述べたように、FYSIを用いてGPU上で物理シミュレーションを行うことは、以下の3つのステップを含む。すなわち、(i)系セットアップステップ、(ii)ソルバーステップ、および(iii)衝突ステップ、である。
【0133】
系セットアップステップは、
【0134】
【数45】
における
【0135】
【数46】
に対する値を決定することを伴い、ここでは、定数の時間ステップ
【0136】
【数47】
と、直交質量行列Mと、点メッシュの現在の位置
【0137】
【数48】
および速度
【0138】
【数49】
とが与えられる。これらの入力から、
【0139】
【数50】
に対する中間値が求められ、それらは、方程式9によって与えられる
【0140】
【数51】
に関連している。このサブセクションの残りは、これら中間値の評価を詳述する。
【0141】
矩形の点メッシュ800に対する線形の二つ1組の力モデルが用いられる。点メッシュ800に対する線形の二つ1組の力モデルにおいて、i点とj点との間の稜は、ジョイントと呼ばれており、結合したばねと減衰材を表す。ij=jiの場合には、2つのジョイントは、相補的であり、その場合には、等しいが相反する力(すなわち、ニュートンの第3の法則)が頂点であるiおよびjに適用され、それぞれは
【0142】
【数52】
で与えられる。ジョイントがiおよびjの頂点の間にて定義されないか、またはi=jである場合には、
【0143】
【数53】
であることは明白である。最後に、i番目の点に作用するネットの内力および
【0144】
【数54】
に対するそのヤコビアンに対する式は、以下のように与えられる。
【0145】
【数55】
実際には、ジョイントは、近傍の点の間においてのみ定義され、規則的なパターンで存在する。例えば、図8の点メッシュ800において示されるジョイントトポロジーは、1点につき12個のジョイントまで含む(境界条件によって異なる)。
【0146】
ジョイント毎の力はその頂点のみに依存しているので、
【0147】
【数56】
の行は、疎であるということが示され得る。すなわち、
【0148】
【数57】
であり、
【0149】
【数58】
の左上と右下とを結ぶ対角線上にない要素(すなわちj≠i)に対する式は、以下になる。
【0150】
【数59】
対角線上(すなわち、j=i)では、
【0151】
【数60】
および
【0152】
【数61】
に対する元来の式が当てはまり、点iに対して1つのジョイントのみが存在する場合には、要素は、ゼロ以外となる。従って、ijがジョイントではない場合には、対角線上にない
【0153】
【数62】
であるので、
【0154】
【数63】
の行は、点iに対して定義されたジョイントの数に1をプラスしたものと等しい数だけの、ゼロ以外の要素のみを有し得る。例えば、図8において示されるジョイントトポロジーに対して、点メッシュの次元にかかわりなく、結果的なヤコビアンは、せいぜい13(=1+点毎の12ジョイント)のゼロ以外の要素を有することとなる。
【0155】
点メッシュ800の運動を支配する線形方程式系が、「合致した」系を表すためには、行列Aは、(i)疎であり、かつ(ii)対称的でなくてはならない。(i)項に関しては、Aは、疎である。なぜならば、Aは、ヤコブ行列
【0156】
【数64】
に線形に依存しており、これらヤコブ行列のそれぞれは、疎であることが証明されているからである。(ii)項に関しては、
【0157】
【数65】
のヤコビアンは、以下の
【0158】
【数66】
が非対角線部分に実施され得る場合には、それ自体は対照的である。
【0159】
故に、方程式10が当てはまる場合には、Aは、疎かつ対称的であり、従って、線形方程式系は、効率的に解くことができる。
【0160】
【数67】
および
【0161】
【数68】
の両方であるという基準は、特定の物理的な仮定における誘導的な因子であることが分かるであろう。
【0162】
図8を参照すると、点メッシュ800における点の間のジョイント力は、(i)引っ張りジョイント806、(ii)せん断ジョイント804、および(iii)曲げジョイント802の、3つの種類に分類され得る。隣接するノード間に定義され、引っ張りジョイント806は、最も強い内力をモデル化する。引っ張りジョイント806は、領域における面内変化に抵抗する。対角線上のノード間に定義され、せん断ジョイント804は、2番目に強力である内力をモデル化する。せん断ジョイント804は、クロスが角で引っ張られたときに内方向に狭くなる傾向に抵抗する。最後に、交互のノード間に定義され、曲げジョイント802は、最も弱い内力をモデル化する。曲げジョイント802は、折りたたみに対して抵抗する。
【0163】
より多くの現実的な定義がなされているが、上に提示された、対式ジョイント力毎モデルは、前述のBaraff引例と、Kwang−Jin ChoiおよびHyeong−Seok Ko(「Stable but Responsive Cloth」、In
ACM Transactions on Graphics、SIGGRAPH 2002、pp.604−11(2002))によって教示された対に関するジョイント力のモデルとの混合によって影響され、本明細書においてその全体を参照として援用する。本明細書に開示のモデルに従うと、全てのジョイントは、同一の関数によってモデル化されるが、ジョイントの種類(すなわち、引っ張り、せん断、および曲げ)は、剛性ks、減衰kd、および自然長Lに対する異なる値によって、グローバルにパラメータで表され得る。ジョイント毎に、ばね(ksおよびLによってパラメータで表される)の作用および減衰(kdによってパラメーターで表される)は、線形に独立しており、別個のものと考慮してよい。
【0164】
一般的に、ばね力または減衰力のいずれかに対するジョイント力
【0165】
【数69】
は、2つのプロパティを満たす。すなわち、(i)ジョイント毎の力
【0166】
【数70】
は、ジョイントの方向
【0167】
【数71】
に沿って作用し、(ii)ジョイント毎の力
【0168】
【数72】
は、条件関数
【0169】
【数73】
に比例する。これら2つのプロパティは、数学的に以下のように書かれ得る。
【0170】
【数74】
【0171】
【数75】
ここで、
【0172】
【数76】
であるので、対称に対する基準
【0173】
【数77】
は、
【0174】
【数78】
に対して、以下のものが実施されることを必要とする。
【0175】
【数79】
ここで、ジョイント毎の力
【0176】
【数80】
のばね成分が記述される。理想的な線形移動のばねは、変形の間にエネルギーに抵抗し、かつ該エネルギーを蓄えるものであり、該ばねは、蓄えられたエネルギーを放つように作用する、復原力の作用の表れである反応性の機械的なデバイスである。「移動」とは、含まれる機械的な力の種類に関連する。本明細書に記載のクロスシミュレーションに対するモデルにおいて、力は、ジョイントの方向
【0177】
【数81】
に沿って作用する。「線形」とは、変形(すなわち、xにおける変化)に直接比例する、復原力に関連する。最後に、「理想的な」とは、変形と復原とのサイクルの間に、エネルギーが全く失われないことを意味する。
【0178】
最も単純化された理想の線形移動ばね
【0179】
【数82】
に一致するジョイント毎のばね条件関数が定義される。
【0180】
【数83】
は、現在の頂点位置のみに依存し、
【0181】
【数84】
の両方に対する対称の基準を満たし、かつ、以下の方程式によって与えられた、剛性係数ksおよび自然長Lによってパラメータで表される。
【0182】
【数85】
【0183】
【数86】
ここで、ジョイント毎の力
【0184】
【数87】
の減衰成分が記述される。ダンパーとは、変形に対して抵抗する、受動的な機械的デバイスであるが、ばねとは対照的に、エネルギーを蓄えたり、復原力を表すことはない。その代わりに、ダンパーは、熱という形で加えられたエネルギーを放散させることによって、変形に抵抗する。この特性は、速度の変化に比例する、純粋な抵抗力によって生み出される。
【0185】
本明細書において記述されたクロスのシミュレーションに対するモデルにおいて、理想的な線形移動ダンパーは、ジョイントの方向
【0186】
【数88】
に沿った抵抗力を表し、該ジョイントは、その頂点の速度
【0187】
【数89】
における相対的な変化に直接比例する。より具体的には、該ダンパーは、ジョイント方向における速度
【0188】
【数90】
の相対的な変化に比例する抵抗力を表す。減衰係数kdによってパラメータで表される、ジョイント毎のダンパー条件関数
【0189】
【数91】
が定義される。このジョイント毎のダンパー条件関数は、
【0190】
【数92】
の両方に対する対称の基準を満たす。このステートメントは、数学的に、以下のように表され得る。
【0191】
【数93】
【0192】
【数94】
ここで、点メッシュ800にかかる外力の応答および効果が記述される。外力の例としては、重力、風、および衝突(自身および環境との両方)を含む。外力の応答および効果の間において、明確な区別が存在するということを理解されたい。応答には、現在の状態
【0193】
【数95】
に対する即座の変化が含まれる。故に、応答は、モデル化することが比較的容易である。対照的に、力の効果は、将来の状態を拘束する(すなわち、ファブリックがピン留めされているために、将来の自由度を制限する)。故に、効果は、モデル化することが比較的難しい。
【0194】
外力の応答および効果を解くためのいくつかのアプローチが公知であり、それらには、縮小された座標(reduced coordinates)を用いるアプローチ、ペナルティ法、および/または言語乗算器を含む。例えば、前述のBaraff引例を参照されたい。Barraff引例において議論される別のアプローチは、モデル化された点メッシュにおける所定の点の質量に拘束を与える。上述のように、対角質量行列
【0195】
【数96】
のブロック単位毎の解釈は、i番目の粒子の質量を、{3×3}の対角行列
【0196】
【数97】
として表す。しかし、質量が、異方性の質量であり、方向とともに変化するものであると仮定される場合には、方程式11は、
【0197】
【数98】
として書かれ得る。方程式12において与えられる質量に基づいて、点メッシュに対する運動方程式は、
【0198】
【数99】
となる。故に、異方性質量を効率的に定義するということは、xy面に対する
【0199】
【数100】
の効果を効果的に拘束するということとなり、z方向においては、加速は不可能となる。
【0200】
Baraff引例において開発されたアプローチは、線形系の対称に対して、かかわりを有し、結果的に、効率的な可解性を有する。これらの問題は、修正共役勾配(「修正CG」)法を用いることによって解決され得、該法は、質量ベースの拘束を実施するためのフィルタリング演算を導入する。別のアプローチは、質量ベースの拘束および修正CG法の両方を用い、これは、Kwang−Jin ChoiおよびHyeong−Seok Ko(「Stable but Responsive Cloth」、In ACM Transactions on Graphics、SIGGRAPH 2002、pp.604−11(2002))に記述されており、本明細書においてその全体を参照として援用する。
【0201】
B.GPU上でクロスをシミュレーションするための例示的な実装
インプリシットにクロスをシミュレーションするためのモデルを記述したが、ここで、GPU上での各離散時間ステップに対してクロスのシミュレーションを実装するための、3ステップの方法が記述される。図9は、本発明の実施形態に従った、GPU上でクロスのシミュレーションを実装するための、例示的な流れ図を描写する。言い換えると、図9は、図4を参照して上述された物理シミュレーションブロック410の、特定の実装に関する高レベルな描写である。図9において、大きな円は、テクスチャまたはビデオメモリの配列を表し、図3を参照して上述された、テクスチャ310に類似し得る。テクスチャへのデータの特定のマッピングは、以下の通りである。(i)円902(Mと分類される)は、点メッシュ800における各点の質量に関連したデータを含む、テクスチャを表す。(ii)円904(Pと分類される)は、点メッシュ800における各点の位置に関するデータを含むテクスチャを表す。(iii)円906(Vと分類される)は、点メッシュ800における各点の速度に関するデータを含むテクスチャを表す。(iv)円908(Fと分類される)は、点メッシュ800における各点に作用するネット力に関するデータを含むテクスチャを表す。そして、(v)円912(Jと分類される)は、ヤコビアン行列に関するデータを含むテクスチャを表す。影つきの円910は、カーネル演算(1つ以上のGPUによって行われる数学的演算など)を表す。
【0202】
GPU上でクロスのシミュレーションを実装するための第1のステップには、図9に示されるように、点メッシュの運動を支配する線形方程式系を設定するために、点メッシュに関連した物理パラメータのテクスチャ(すなわち、ビデオメモリ)へのマッピングが含まれる。インプリシットな積分技術を適用することによって、上述されたことは、点メッシュの運動を支配する線形方程式系は、
【0203】
【数101】
と書かれ得るということであり、ここでは、
【0204】
【数102】
となる。モデル化された点メッシュの質量、位置および初期速度は、シーンを作成しているアーティストによって確立される。結果として、テクスチャ902a、904aおよび906a(それぞれ、質量、位置、および初期速度に相当)は、直ちに満たされ得る。対照的に、ヤコビアン行列およびネット力の全ての成分は、アーティストによって確立はされない。結果として、カーネル演算910aは、テクスチャ904a、906aおよび908aからの入力に基づいて、力およびヤコビアン行列
【0205】
【数103】
を評価する。この評価の結果は、テクスチャ908bおよび912bに書き込まれる。これらの結果がテクスチャ908bおよび912bに書き込まれた後に、システムセットアップのステップが、この時間ステップに対して完了する。
【0206】
GPU上でクロスのシミュレーションを実装するための第2のステップには、図9に示されるように、位置および速度の更新済みの値
【0207】
【数104】
に対する線形系を解くことが含まれる。カーネル演算910bは、テクスチャ902a、904a、906a、908bおよび912bからの入力に基づいて、線形方程式系を解く。この解に基づいて、位置および速度の更新済みの値は、それぞれテクスチャ904bおよび906bに書き込まれる。更新済みの値が書き込まれた後に、システムソルバーステップが、この時間ステップに対して完了する。
【0208】
GPU上でクロスのシミュレーションを実装するための最終ステップには、図9に示されるように、衝突検出が含まれる。カーネル演算910cは、テクスチャ902a、904b、906bおよび908bからの入力に基づいて、衝突が起こるか否かを決定する。カーネル演算910cの結果は、テクスチャ902b、904c、906cおよび908cに書き込まれる。これらの結果が書き込まれた後に、衝突応答ステップが、この時間ステップに対して完了する。
【0209】
ここで、GPU上でクロスのシミュレーションを実装するためのステップのそれぞれが、より詳細に記述される。
【0210】
i.ステップ1:システムセットアップ
GPU実装の設計上の大きな難問は、コンパクトであり、かつ単一命令多重データ(SIMD)パラレル化を容易にする、系方程式のテクスチャ表現の開発である。本発明の1つの実施形態は、検討中の矩形点メッシュから直接的に得られた構造を有する、17の持続性テクスチャを利用する。しかし、本発明は、17のテクスチャに限定はされない。本発明の精神および範囲から逸脱することなく、異なる数のテクスチャを用いてGPU上に物理シミュレーションを行う方法を、当業者は理解することとなる。
【0211】
本明細書に記述された、クロスをシミュレーションするために用いられるテクスチャは、点メッシュ800に対応する、「rows」の高さおよび「cols」の幅を有するn個のテクセルの2次元テクスチャである。点メッシュ800は、それぞれ「rows」および「cols」の要素である、行および列に組織化される。従って、各テクスチャの各テクセル位置は、点メッシュ800の特定の点に1対1にマッピングする。各テクスチャは、左から右へ、かつ上から下へと順序付けられる。一般的には、個別のテクスチャが、同一のテクスチャ座標{s、t}における同一点iに属する、異なるプロパティを格納する(明確にするために、本文は、全てのテクスチャ座標を、高さ=‘rows’および幅=‘cols’によって境界付けられた非正規整数として描写する)。点番号から点のテクスチャ座標への、およびその逆のマッピングは、以下によって与えられる。
【0212】
【数105】
さらに、境界の状態を条件として、図8に示されるジョイントトポロジーの点オフセットも、表18に示されるように、2次元テクスチャオフセットにマッピングする。
【0213】
【表14】
17のテクスチャは、P、V、F、A#、B#、C、およびDに分類され、ここでは、A#およびB#は、それぞれ6つのテクスチャの集結である。それぞれの
【0214】
【数106】
に対し、17のテクスチャコンテンツは、次いで以下の定義によって与えられる。第1に、テクスチャP、VおよびFは、それぞれ
【0215】
【数107】
を表す。特に、
・Pは、点の現在位置
【0216】
【数108】
の3成分を格納し、
・Vは、点の現在速度
【0217】
【数109】
の3成分を格納し、
・Fは、点の現在のネット力ベクトル
【0218】
【数110】
の3成分を格納する。第2に、A#およびB#は、それぞれ、
【0219】
【数111】
の下三角(対角線上にない要素)を表す。特に、
・A#は、
【0220】
【数112】
に対応する{3×3}行列を格納し、
・B#は、
【0221】
【数113】
に対応する{3×3}行列を格納し、ここでは、A0−A5およびB0−B5は、以下の6つのジョイントのそれぞれに対して定義される。
【0222】
【数114】
第3に、テクスチャCおよびDは、それぞれ、
【0223】
【数115】
の対角線上の要素を表す。特に、
・Cは、
【0224】
【数116】
に対応する{3×3}行列を格納し、
・Dは、
【0225】
【数117】
に対応する{3×3}行列を格納する。
【0226】
17のテクスチャを定義したので、ここで、これらのテクスチャを埋めるための(すなわち、図9のシステムセットアップのステップを行うための)2段階工程が記述される。図10は、点メッシュ800の運動を支配する線形方程式系を設定するための、2段階工程の流れ図を図示する。図10に含まれるのは、入力テクスチャ1002aおよび1004a
【0227】
【数118】
および出力テクスチャ1006a、1008a、1012a、1014a、および1016a
【0228】
【数119】
である。
【0229】
図10の第1の段階は、6つの同一のサブパスを含み、該サブパスは、ジョイントの相補的な対のジョイントに対して演算を行う、カーネル演算1010a−1010fによって表される。この第1段階において、ネット力ベクトル
【0230】
【数120】
(すなわち、テクスチャF)および
【0231】
【数121】
(すなわち、テクスチャA0−A5およびB0−B5)の下三角(対角線上にない要素)が、決定される。すなわち、カーネル演算1010a−1010fの結果は、テクスチャ1006b、1008bおよび1012bに書き込まれる。
【0232】
図10の第2の段階は、カーネル演算1010gおよび1010hによって表される、2つの同一のサブパスを含み、該カーネル演算は、
【0233】
【数122】
(すなわち、テクスチャCおよびD)の対角線上要素を、その下三角の対角線上にない要素(すなわち、テクスチャA0−A5およびB0−B5)から決定する。すなわち、カーネル演算1010gおよび1010hの結果は、それぞれ、テクスチャ1016bおよび1014bに書き込まれる。第1の段階および第2の段階は、それぞれ以下により詳細に記述される。
【0234】
システムセットアップの第1の段階(図10)は、ネット力ベクトル
【0235】
【数123】
(すなわち、テクスチャC)および
【0236】
【数124】
(すなわち、テクスチャA0−A5およびB0−B5)の下三角(対角線上にない要素)の決定を含む。図10に示されるように、これら出力の評価は、カーネル演算1010a−1010fによって表されるような、ジョイント毎の解析の膨大な重複を含み得る。結果として、この第1の段階は、図11に表されるように、6つの同一のジョイント毎のサブパスに分けられ得る。
【0237】
図11は、ジョイントパスmを表す、流れ図1100を図示する。各ジョイントパスは、2つのサブパスを含み、第1カーネル1110a(EvaJointと分類)および第2カーネル1110b(updateFと分類)によって表される。第1カーネル1110aは、それぞれ一時的なテクスチャT、Am、およびBmに書き込まれる、
【0238】
【数125】
に対するジョイント毎の値を計算する。サブパス毎に解析される特定のジョイントは、
【0239】
【数126】
によって、テクスチャAmおよびBmに関連する。
【0240】
第1カーネル1110a(evalJoint)は、以下の事実を利用する。
【0241】
(1)ジョイント毎の値は、共に、最も容易に評価され、
(2)AmおよびBmに格納された
【0242】
【数127】
の対角線上にない要素は、実際には独立しており、
【0243】
【数128】
に等しく、
(3)対称性
【0244】
【数129】
によって、相補的なジョイントには、同一の解析が行われる。従って、我々のトポロジーにおけるジョイントの固有の半分を解析することが理想的(すなわち、作業の重複がない)である。さらに、対称によって、テクスチャA0−A5およびB0−B5に格納された
【0245】
【数130】
の下三角(対角線上にない要素)は、ヤコビアンにおける全ての対角線上にない要素を表すのに十分である。
【0246】
第2カーネル1110b(updateFと分類)は、解析されているジョイントの力を用いて、ネット力
【0247】
【数131】
(または、テクスチャC)を更新する。第2カーネル(updateF)は、現時点でTに格納されているジョイント毎の力
【0248】
【数132】
の寄与を、(別のサブパスから来るか、または外力を含む)入力ネット力ベクトル
【0249】
【数133】
またはテクスチャCに加える。これには、特に、ジョイント力の線形独立およびニュートンの第3の法則によって提供される対称性を利用する。各サブパスは、ジョイントの相補的な対の力を効率的に計算するので、第2カーネル1110b(updateF)は、両方の寄与を適切に考慮するためにTをアドレスしなくてはならない(境界条件により、T中のジョイント力毎のある値が不規則であり得る)。
【0250】
再び図10を参照すると、システムセットアップの第2および最終の段階は、
【0251】
【数134】
(すなわち、テクスチャCおよびD)の対角線上の要素の決定を含む。この第2の段階において、これらの対角線上の要素がそれらの対角線上にない要素の有利に構成された累積であるという事実は、強化される。特に、以下の累積のそれぞれは、最大12項まで含み、各ジョイントに対するもの(境界条件によって変わる)は、テクスチャA0−A5およびB0−B5において容易に入手できる。
【0252】
【数135】
図12に図解式に図示されるように、方程式13aにおける累積は、カーネル1250aによって評価され(evalDiagonalCと分類)、方程式13bにおける累積は、カーネル1250cによって評価される(evalDiagonalDと分類)。カーネル1250aおよび1250cは、独立しており、それらの入力と出力だけが異なる。カーネル1250aは、テクスチャ1202a、1204a、1206a、1208a、1210aおよび1212aから、入力としてのデータを取得し、それらテクスチャは、集合的に、ヤコブ行列
【0253】
【数136】
の対角線上にない要素を表す。カーネル1250cの出力は、テクスチャ1214b(すなわちテクスチャC)に書き込まれる。カーネル1250cは、テクスチャ1222a、1224a、1226a、1228a、1230aおよび1232aから、入力としてのデータを取得し、それらテクスチャは、集合的に、ヤコブ行列
【0254】
【数137】
の対角線上にない要素を表す。
【0255】
ii.ステップ2:システムソルバー
再び図8を参照すると、GPU上でのクロスのシミュレーションにおける第2のステップは、システムソルバーステップである。システムソルバーステップに対する最も有力なアプローチは、前述のBaraff引例に記述された、線形系
【0256】
【数138】
を反復的に解く、共役勾配(CG)法を用いることである。大型で疎、対称的かつ正定値の系に最適であり、CG法は、
【0257】
【数139】
が、ユーザー定義の閾値より下回るまで、
【0258】
【数140】
を手続き上で近似することを含む。本明細書に記述される例示的方法は、システムソルバーステップに対してCG法を用いるが、他の方法もまた、当業者に認識されるように、本発明の精神および範囲から逸脱することなく、用いられ得る。
【0259】
iii.ステップ3:衝突応答
再び図8を参照すると、GPU上でのクロスのシミュレーションにおける第3および最終のステップは、衝突応答ステップである。衝突検出スキームは、シミュレーションされているメッシュ(例えば点メッシュ800)からの点の対が、(i)メッシュからの別の点の対、または(ii)シミュレーションされている別のオブジェクト(例えば、点メッシュ800として同一のシーンに描写されているボール)からの点の対、のいずれかと交わるかどうかを決定することによって、衝突が起きたかどうかを確認する。前述のBaraff引例によって例示されるように、衝突検出スキームは、当業者に周知である。当業者に公知のあらゆる衝突検出スキームが、本発明の精神および範囲から逸脱することなく、用いられ得る。
【0260】
C.FYSLで書かれた例示的コード
以下に提供されるものは、FYSLで書かれたコードの例示的セクションである。特に、以下に提供されるものは、(i)FYSLで書かれた高レベルシーン記述、(ii)チャイルドアクター展開、および(iii)ファブリックジョイントのプロトタイプ展開、である。
【0261】
i.FYSLで書かれた高レベルシーン記述
【0262】
【表15】
【0263】
【表16】
ii.チャイルドアクター展開
【0264】
【表17】
【0265】
【表18】
【0266】
【表19】
iii.ファブリックジョイントのプロトタイプ展開
【0267】
【表20】
IV.例示的なコンピュータ実装
本発明の実施形態は、ハードウェア、ソフトウェア、またはそれらの組み合わせを用いて実装され得、また、1つ以上のコンピュータシステムまたは他のプロセッシングシステムにおいて実装され得る。しかし、本発明によって行われる操作は、加算や比較などに関して、頻繁に参照されたが、それらは、一般的に、人間のオペレーターによって行われる、頭の中で行うオペレーションに関連する。本発明の一部を形成する、本明細書に記述されるオペレーションのいずれにおいても、そのような人間のオペレーターの能力はなにも必要なく、または、ほとんどの場合において望まれない。むしろ、オペレーションは、機械的なオペレーションである。本発明のオペレーションを行うために有用な機械は、デジタルコンピュータを含み、例えば、パーソナルコンピュータ、ビデオゲームコンソール、携帯電話、携帯情報端末、または同様のデバイスなどである。
【0268】
実際に、一実施形態において、本発明は、本明細書に記述された機能性を実行することが可能な1つ以上のコンピュータシステムに向けられている。コンピュータシステム1300の例は、図13に示される。
【0269】
コンピュータシステム1300は、1つ以上のプロセッサ、例えばプロセッサ1304を含む。プロセッサ1304は、汎用プロセッサ(CPUなど)、または専用プロセッサ(GPUなど)であり得る。プロセッサ1304は、通信インフラストラクチャ1306(例えば、通信バス、クロスオーバーバー、またはネットワーク)に接続される。様々なソフトウェアの実施形態は、この例示的なコンピュータシステムの点から記述される。本記述を読んだ後は、他のコンピュータシステムおよび/またはアーキテクチャーを用いて本発明を実装する方法が、当業者には明らかとなる。
【0270】
コンピュータシステム1300は、ディスプレイインターフェース1302を含み、該ディスプレイインターフェース1302は、ディスプレイユニット1330に表示するために、通信インフラストラクチャ1306(または不図示のフレームバッファ)から、グラフィックス、テキスト、および他のデータを転送する。
【0271】
コンピュータシステム1300はまた、メインメモリ1308、好ましくは、ランダムアクセスメモリ(RAM)を含み、また、二次メモリ1310をも含み得る。二次メモリ1310は、例えば、ハードディスクドライブ1312および/またはリムーバブルストレージドライブ1314を含み得、フロッピー(登録商標)ディスクドライブ、磁気テープドライブ、光学ディスクドライブなどが、その代表である。リムーバブルストレージドライブ1314は、周知の方法で、リムーバブルストレージユニット1318との読み取りおよび書き込みを行う。リムーバブルストレージユニット1318は、フロッピー(登録商標)ディスク、磁気テープ、光学ディスクなどを表し、これは、リムーバブルストレージドライブ1314によって読み書きがされる。認識されるように、リムーバブルストレージユニット1318は、コンピュータソフトウェアおよび/またはデータをその中に格納した、コンピュータ使用可能媒体を含む。
【0272】
代替的な実施形態において、二次メモリ1310は、コンピュータシステム1300にコンピュータプログラムまたは他の命令をロードさせる、他の同様のデバイスを含み得る。そのようなデバイスは、例えば、リムーバブルストレージユニット1322およびインターフェース1320を含み得る。そのような例は、プログラムカートリッジおよびカートリッジインターフェース(ビデオゲーム機に見受けられるようなものなど)、リムーバブルメモリチップ(消去可能プログラマブル読取り専用メモリ(EPROM)またはプログラマブル読取り専用メモリ(PROM)など)および関連ソケット、ならびに他のリムーバブルストレージユニット1322およびインターフェース1320を含み得、これらは、リムーバブルストレージユニット1322からコンピュータシステム1300にソフトウェアおよびデータを転送することを可能にする。
【0273】
コンピュータシステム1300はまた、通信インターフェース1324を含み得る。通信インターフェース1324は、コンピュータシステム1300と外部デバイスとの間でのソフトウェアおよびデータの転送を可能にする。通信インターフェース1324の例は、モデム、ネットワークインターフェース(イーサネット(登録商標)カードなど)、通信ポート、パーソナルコンピュータメモリカードインターナショナルアソシエーション(PCMCIA)スロットおよびカードなどを含み得る。通信インターフェース1324を介して転送されるソフトウェアおよびデータは、信号1328の形式をとり、該信号は、電子、電磁気、光学、または通信インターフェース1324によって受信可能な他の信号であり得る。これらの信号1328は、通信パス(例えばチャネル)1326を介して通信インターフェース1324に提供される。このチャネル1326は信号1328を運び、ワイヤまたはケーブル、光ファイバー、電話線、セルラーリンク、無線周波数(RF)リンクおよび他の通信チャネルを用いて実装され得る。
【0274】
本文において、「コンピュータプログラム媒体」および「コンピュータ使用可能媒体」という用語は、概して、リムーバブルストレージドライブ1314、ハードディスクドライブ1312にインストールされたハードディスクなどの媒体および信号1328を指すために用いられる。これらコンピュータプログラム製品は、コンピュータシステム1300にソフトウェアを提供する。本発明は、そのようなコンピュータプログラム製品に向けられる。
【0275】
コンピュータプログラム(コンピュータ制御ロジックとも呼ばれる)は、メインメモリ1308および/または二次メモリ1310に格納される。コンピュータプログラムはまた、通信インターフェース1324を介して受信され得る。そのようなコンピュータプログラムは、実行されたときには、コンピュータシステム1300が本明細書に議論されたように本発明の機能を行えるようにする。特に、コンピュータプログラムは、実行されたときには、プロセッサ1304が本発明の機能を行えるようにする。従って、そのようなコンピュータプログラムは、コンピュータシステム1300のコントローラを表す。
【0276】
ソフトウェアを用いて本発明が実装される実施形態において、該ソフトウェアは、リムーバブルストレージドライブ1314、ハードドライブ1312、または通信インターフェース1324を用いて、コンピュータプログラム製品に格納され、コンピュータシステム1300にロードされ得る。プロセッサ1304によって実行されるときには、制御ロジック(ソフトウェア)は、プロセッサ1304に、本明細書に記述されたように本発明の機能を行わせる。
【0277】
別の実施形態において、本発明は、例えば、GPUなどのハードウェア構成要素を用いて、主にハードウェアに実装される。本明細書に記述された機能を行うためのハードウェアステートマシーンの実装は、当業者に明らかであろう。
【0278】
さらに別の実施形態において、本発明は、ハードウェアおよびソフトウェアの両方の組み合わせを用いて実装される。
【0279】
V.結論
概要および要約の章ではなく、実施形態の章は、請求項を解釈するために用いられることを意図するということを、認識されたい。概要および要約の章は、発明者によって意図されるように、本発明の、全てではないが、1つ以上の例示的な実施形態を述べ得る。故に、概要および要約の章は、あらゆる方法において、本発明および添付の請求項を限定する意図はない。
【特許請求の範囲】
【請求項1】
本明細書に記載の方法。
【請求項1】
本明細書に記載の方法。
【図1】

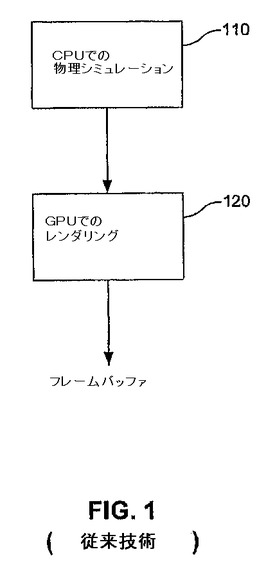
【図2】
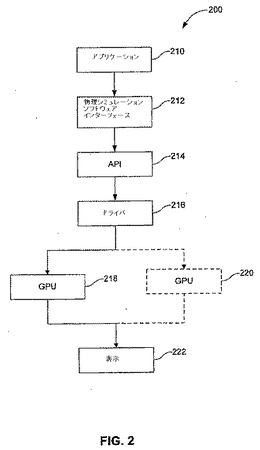
【図3】
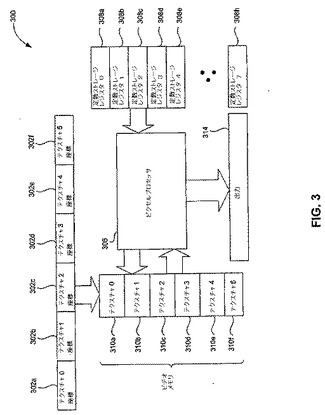
【図4】
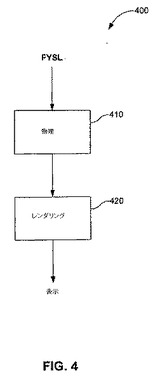
【図5】
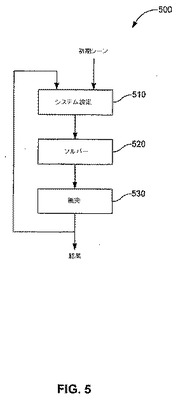
【図6】
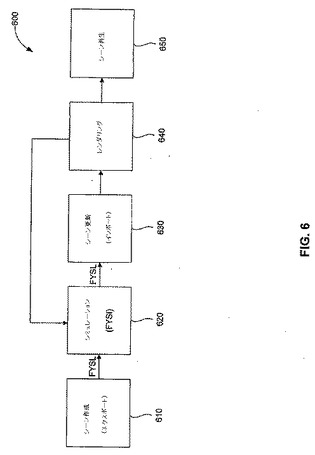
【図7】
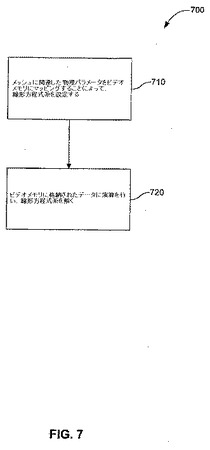
【図9】
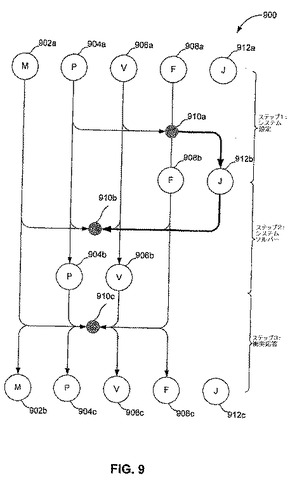
【図10】
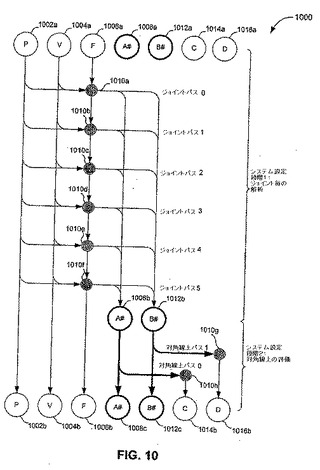
【図11】
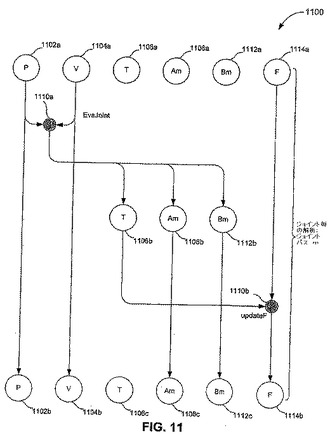
【図12】
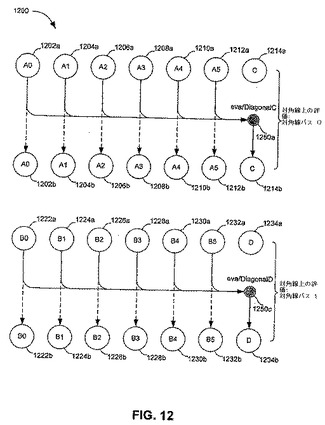
【図13】
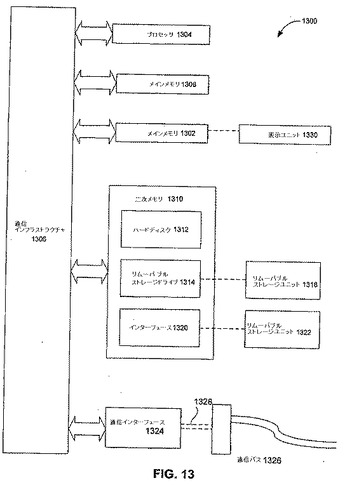
【図14A】
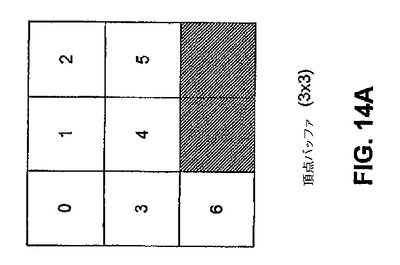
【図14B】
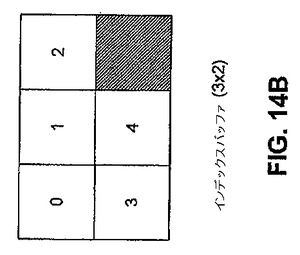
【図15A】

【図15B】
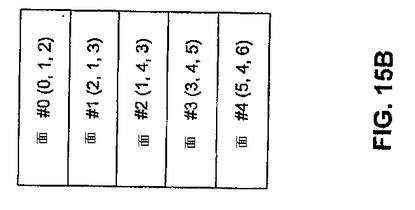
【図8】
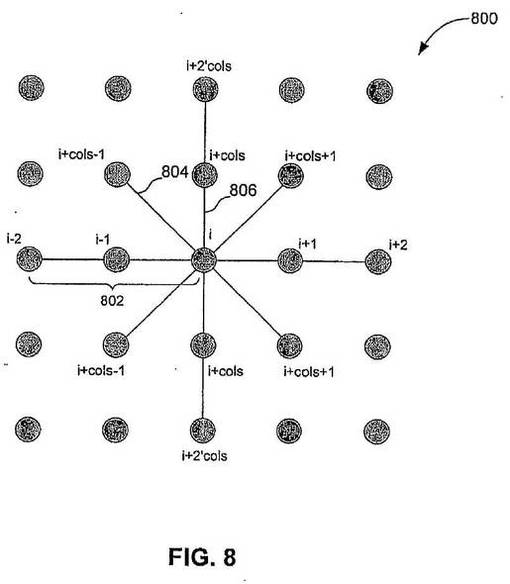
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14A】
【図14B】
【図15A】
【図15B】
【図8】
【公開番号】特開2013−20631(P2013−20631A)
【公開日】平成25年1月31日(2013.1.31)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−188538(P2012−188538)
【出願日】平成24年8月29日(2012.8.29)
【分割の表示】特願2009−521775(P2009−521775)の分割
【原出願日】平成19年7月20日(2007.7.20)
【出願人】(509025751)エーティーアイ テクノロジーズ ユーエルシー (4)
【Fターム(参考)】
【公開日】平成25年1月31日(2013.1.31)
【国際特許分類】
【出願番号】特願2012−188538(P2012−188538)
【出願日】平成24年8月29日(2012.8.29)
【分割の表示】特願2009−521775(P2009−521775)の分割
【原出願日】平成19年7月20日(2007.7.20)
【出願人】(509025751)エーティーアイ テクノロジーズ ユーエルシー (4)
【Fターム(参考)】
[ Back to top ]