
コミュニケーション誘発システム
【課題】ぬいぐるみのような擬人的媒体を使ってユーザからのコミュニケーションを誘発できるシステムを提供する。
【解決手段】コミュニケーション誘発システム10は、ユーザ12の前方に配置されたぬいぐるみ14を含む。視線サーバ18がカメラ16で撮影したユーザ12の顔の画像からユーザの視線の方向を推定する。ぬいぐるみ14に内蔵したコンピュータは、ユーザの発話状態およびユーザの視線状態に応じて両者の間のコミュニケーション状態を推定または特定する。そして、そのコミュニケーション状態に従ってユーザにコミュニケーションを促すことができるように、ぬいぐるみの行動(発話および/または動き)を制御する。
【解決手段】コミュニケーション誘発システム10は、ユーザ12の前方に配置されたぬいぐるみ14を含む。視線サーバ18がカメラ16で撮影したユーザ12の顔の画像からユーザの視線の方向を推定する。ぬいぐるみ14に内蔵したコンピュータは、ユーザの発話状態およびユーザの視線状態に応じて両者の間のコミュニケーション状態を推定または特定する。そして、そのコミュニケーション状態に従ってユーザにコミュニケーションを促すことができるように、ぬいぐるみの行動(発話および/または動き)を制御する。
【発明の詳細な説明】
【技術分野】
【0001】
この発明はコミュニケーション誘発システムに関し、特に、たとえばロボットなどの擬人的媒体を認知症患者などの軽度脳障害を持つユーザが視認できる位置に配置し、その擬人的媒体によってユーザからのコミュニケーションを誘発する、新規なコミュニケーション誘発システムに関する。
【背景技術】
【0002】
特許文献1などで、認知症患者などに右脳刺激を与えることによって、その機能回復が図れることが知られている。
【特許文献1】特開2005−160806号公報[A63B 24/00 23/035]
【発明の開示】
【発明が解決しようとする課題】
【0003】
しかしながら、このような機能回復訓練を受けられるのは少なくとも他人とのコミュニケーションが図れることが条件である。そこで、このような患者ではまずコミュニケーション能力を回復させる必要がある。その場合、患者からコミュニケーションを引出す(誘発する)ように作用するシステムがあれば好都合である。
【0004】
それゆえに、この発明の主たる目的は、新規な、コミュニケーション誘発システムを提供することである。
【0005】
この発明の他の目的は、ユーザからのコミュニケーションを積極的に引き出すことができる、コミュニケーション誘発システムを提供することである。
【課題を解決するための手段】
【0006】
この発明は、上記の課題を解決するために、以下の構成を採用した。なお、括弧内の参照符号および補足説明等は、この発明の理解を助けるために後述する実施形態との対応関係を示したものであって、この発明を何ら限定するものではない。
【0007】
第1の発明は、ユーザが視認できる位置に配置した擬人的媒体によってユーザからのコミュニケーションを誘発するコミュニケーション誘発システムであって、ユーザの視線の状態を判定する視線判定手段、ユーザからの発話の状態を判定する発話判定手段、視線位置判定手段による視線状態判定結果および発話判定手段による発話状態判定結果を記憶する記憶手段、記憶手段に記憶した視線状態判定結果および発話状態判定結果に応じてユーザと擬人的媒体とのコミュニケーション状態を特定するコミュニケーション状態特定手段、およびコミュニケーション状態特定手段が特定したコミュニケーション状態に応じて擬人的媒体の音声および動作を制御する制御手段を備える、コミュニケーション誘発システムである。
【0008】
第1の発明において、擬人的媒体(14:実施例で相当する部分を例示する参照符号。以下同様。)がユーザ(12)の前方の、ユーザの視線が届く位置に配置される。視線判定手段(16,18,32,S1b,S3,S21b)は、たとえば、カメラ(16)によって撮影したユーザの顔画像を視線サーバ(18)で処理することによって、ユーザの視線(12A)の方向または位置をリアルタイムに推定または検出し、そのときのユーザの視線の方向が擬人的媒体の位置に対してどのような位置関係にあるか判定する。たとえば、視線の方向は擬人的媒体の位置か、擬人的媒体の位置に隣接する位置か、擬人的媒体の位置とかなり離れているか、などを判定する。発話判定手段(32,S1a,S21a)はたとえばマイク(50)からの音声入力パワーを計算するなどして、ユーザの発話の有無やその状態などを判定する。コミュニケーション状態特定手段は、記憶手段(36C)に記憶した視線状態判定結果および発話状態判定結果に従って、たとえば、解釈テーブル(36A)を参照して、そのときのユーザと擬人的媒体との間のコミュニケーション状態、たとえばユーザが擬人的媒体を見ながら話しかけているのか、ユーザが擬人的媒体と同じ方向を見ながら発話しているのか、のようなコミュニケーション状態を推定または特定する。そして、制御手段(32,38,46,S11,S27)は、コミュニケーション状態特定手段が特定したコミュニケーション状態に応じて、たとえば反応テーブル
(36B)を参照して、擬人的媒体の動作(発話および/または動き)を制御する。
【0009】
第1の発明によれば、ユーザの視線状態および発話状態の両方の判定結果に応じて擬人的媒体を制御することができるので、そのときのユーザと擬人的媒体との間のコミュニケーション状態に応じて最適のコミュニケーション誘発動作を行なわせることができる。
【0010】
第2の発明は、発話状態判定手段はユーザの発話があったとの視線状態に応じてユーザの発話対象が何かを推定する発話対象推定手段を含み、コミュニケーション状態特定手段は、発話対象推定手段の判定結果および視線状態判定結果に基づいて複数のコミュニケーション状態の1つを特定する、請求項1記載のコミュニケーション誘発システムである。
【0011】
第2の発明では、ユーザが擬人的媒体(ぬいぐるみ)に対して発話したのかあるいは他の対象に向けて発話したのかなどの状況に応じてきめ細かく対応することができる。たとえば、ユーザが擬人的媒体を見ていないで発話したら「擬人的媒体以外への発話の可能性あり」としてその発話に対する反応(リアクション)を保留したり、ユーザが擬人的媒体を見ている状態で発話したら「自分への発話である」としてその発話に対して音声および動作で反応(リアクション)したりすることができる。
【0012】
第3の発明は、視線判定手段はユーザの視線の状態を繰り返し判定し、発話判定手段はユーザからの発話の状態を繰り返し判定し、発話対象推定手段は、少なくとも記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じてユーザの発話が擬人的媒体に向けられたものかどうか推定する、請求項2記載のコミュニケーション誘発システムである。
【0013】
第3の発明では、発話対象推定において、たとえば発話対象テーブル(36D)を参照するなどして、前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果に基づいて、ユーザが擬人的媒体(ぬいぐるみ)に対して発話したのかあるいは他の対象に向けて発話したのかなどの状況を推定する。したがって、発話対象の推定が確実に行なえる。
【0014】
第4の発明は、発話対象推定手段は、さらに前回と今回との時間間隔の長短を考慮して発話対を推定する、請求項3記載のコミュニケーション誘発システムである。
【0015】
第4の発明では、発話対象推定において、前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果に加えて、前回と今回との時間間隔の長短に基づいて、ユーザが擬人的媒体(ぬいぐるみ)に対して発話したのかあるいは他の対象に向けて発話したのかなどの状況を推定する。したがって、発話対象の推定がさらに正確に行なえる。
【0016】
第5の発明は、視線判定手段はユーザの視線の状態を繰り返し判定し、発話判定手段はユーザからの発話の状態を繰り返し判定し、コミュニケーション特定手段は、記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じてユーザと擬人的媒体とのコミュニケーション状態を特定する、請求項1記載のコミュニケーション誘発システムである。
【0017】
第5の発明では、記憶手段に記憶した前回判定結果と今回判定結果とを用いるので、さらにコミュニケーション状態の時間的変化を検出することができ、さらにきめ細かい対応が可能となる。
【発明の効果】
【0018】
この発明によれば、ユーザの視線状態および発話状態に応じて最適のコミュニケーション誘発動作を擬人的媒体に行なわせることができるので、ユーザからのコミュニケーションを積極的に引出すことができる。
【0019】
この発明の上述の目的,その他の目的,特徴,および利点は、図面を参照して行う以下の実施例の詳細な説明から一層明らかとなろう。
【発明を実施するための最良の形態】
【0020】
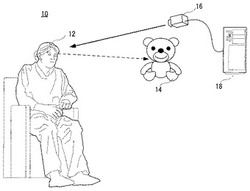
図1に示すこの発明の一実施例のコミュニケーション誘発システム10は、たとえば認知症患者のような軽度脳障害を持つ被験者またはユーザ12からのコミュニケーションを積極的に引き出すように、このユーザ12に働きかける少なくとも1つのぬいぐるみ14を含む。このぬいぐるみ14が擬人的媒体である。擬人的媒体とは、人間のように発話できたり、あるいは人間のような動作ができたりする媒体のことであり、典型的にはぬいぐるみや、ヒューマノイドやコミュニケーションロボットなども、この擬人的媒体として十分機能できる。ただし、2体以上のぬいぐるみを用いるようにしてもよい。
【0021】
この実施例のシステム10では、ユーザ12の主として顔を撮影するカメラ16を用いて、ユーザ12の視線の方向や位置をリアルタイムで検出するとともに、ユーザ12の発話の有無などを検出することによって、その視線の方向や位置(視線の状態)および発話の有無など(発話の状態)に応じてぬいぐるみ14の発話や動作を制御することによって、ユーザ12からのぬいぐるみ14に対するコミュニケーションを誘発する。
【0022】
ユーザ12の視線方向または位置は、後に詳しく説明するように、視線サーバ18がカメラ16からの顔画像データまたは信号を処理することによって、リアルタイムで検出または判定する。
【0023】
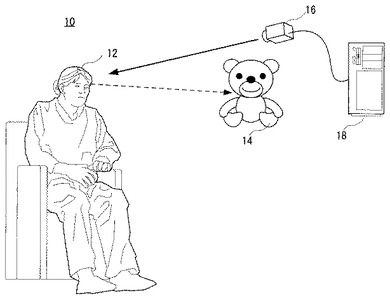
図2は図1実施例を俯瞰した状態を図解する図解図であり、図3はそれを側面から見た図解図である。これらの図からわかるように、患者または被験者ないしユーザ12は部屋のような空間10Aの一方に椅子に腰掛けて存在していて、その前方の、この空間10A内の他方に、ぬいぐるみ14が配置されている。
【0024】
そして、カメラ16は空間10Aの一隅からユーザ12の顔前面を撮影できるように設置されている。
【0025】
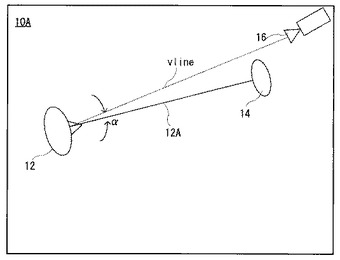
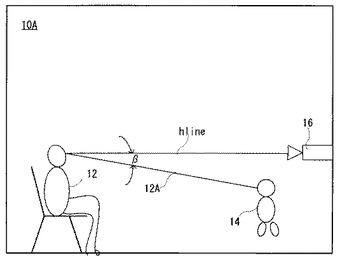
ユーザ12の視線12Aが、カメラ16の光軸に平行な垂直線vlineに対してずれている角度が旋回角αであり、視線12Aがカメラ16の光軸に平行な水平線hlineに対してずれている角度が俯仰角βとして図1の視線サーバ18によってリアルタイムに計算される。そして、各ぬいぐるみ14が、その検出角度αおよびβからその視線12Aの方向または位置を特定し、その視線12Aの方向または位置、およびユーザ12の発話の状態に応じて、異なる動作および/または発話をすることによって、ユーザ12からコミュニケーションを誘発しようとするのである。
【0026】
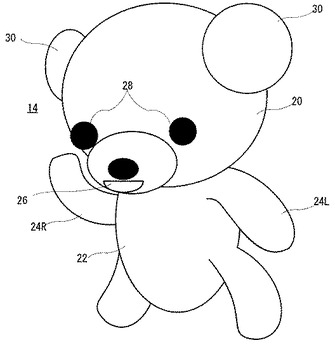
図4にはぬいぐるみ14が図示される。このぬいぐるみ14は、頭部20とそれを支える胴体22とを含む。胴体22の上部に左右の左腕24Lおよび右腕24Rが設けられ、頭部20には、前面に口26が配置され、その口26の上方には眼球28が設けられる。頭部20の上部側面は耳30が取り付けられている。
【0027】
胴部20は胴体22によって、旋回・俯仰可能に支持され、また、眼球28も可動的に保持されている。口26にはスピーカ48(図5)が内蔵されていて、耳30にはマイク50(図5)が内蔵されている。なお、マイク50を両方の耳30にそれぞれ内蔵すれば、ステレオマイクとして機能し、それによって、そのステレオマイクに入力された音声の位置を必要に応じて特定することができる。
【0028】
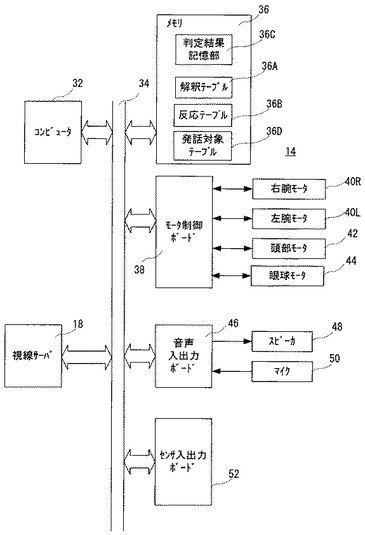
図5はこのぬいぐるみ14の電気的構成を示すブロック図であり、この図5に示すように、実施例のぬいぐるみ14にはコンピュータ32が内蔵されていて、このコンピュータ32が、通信路の一例であるバス34を通して、図1に示す視線サーバ18に結合される。したがって、コンピュータ32は、視線サーバ18が特定または検出したユーザ12の視線方向や位置を示すデータをこのバス34を通して刻々受け取ることができる。ただし、通信路はバス34であっても、その他の形式の通信路であっても、さらには無線であっても、有線であってもよい。
【0029】
コンピュータ32には、バス34を介してメモリ36が結合される。このメモリ36には図示しないROMやRAMが組み込まれていて、ROMには主として、後述のフローチャート(図20,図23)で表現されるプログラムが予め記憶されているとともに、コミュニケーション状態を特定しまたは解釈するための、図21や図24に示すような解釈テーブル36Aや、ユーザの発話の状態や視線の状態に対するぬいぐるみ14の動作と発話(音声)とを対応的に設定している、図23および図25‐26に示すような反応テーブル36Bが予め設定されている。この反応テーブル36Bは、ぬいぐるみ14の動作と発話とを対応させて設定したものである。RAMは、たとえばユーザ12の発話の有無および発話対象などの発話状態の判定結果やおよびユーザ12の視線がぬいぐるみ14に向けられているかどうかなどの視線状態判定結果を、逐次、記憶するための判定結果記憶部36Cや、ユーザ12の発話状態に応じて1または0が設定される発話中フラグ(図示せず)などのための一時記憶メモリとして、さらにはワーキングメモリとして利用され得る。ROMにはさらに、図27および図28に示す発話対象テーブル36Dも予め格納されている。この発話対象推定テーブル36Dは、ユーザ12がした発話が誰を対象としているのか、つまりその発話がぬいぐるみ14に向けられたものであるかどうかを判定または推定するために利用される。
【0030】
モータ制御ボード38は、たとえばDSP(Digital Signal Processor)で構成され、図4に示すぬいぐるみ14の各腕や頭部の各軸モータを制御する。すなわち、モータ制御ボード38は、コンピュータ32からの制御データを受け、右腕24R(図4)を前後や左右に動かすことができるように、X,YおよびZ軸のそれぞれの角度を制御する3つのモータ(図5ではまとめて、「右腕モータ」として示す。)40Rの回転角度を調節する。また、モータ制御ボード38は、左腕24Lの3つのモータ(図5ではまとめて、「左腕モータ」として示す。)40Lの回転角度を調節する。モータ制御ボード38は、また、頭部20の旋回角や俯仰角を制御する3のモータ(図5ではまとめて、「頭部モータ」として示す。)42の回転角度を調節する。モータ制御ボード38は、また、眼球28を動かす眼球モータ44も制御する。
【0031】
なお、上述のモータは、制御を簡単化するためにそれぞれステッピングモータまたはパルスモータであるが、直流モータであってよい。
【0032】
スピーカ48には音声入力/出力ボード46を介して、コンピュータ32から、合成音声データが与えられ、それに応じて、スピーカ48からはそのデータに従った音声または声が出力される。そして、マイク50からの音声入力が、音声入力/出力ボード46を介して、コンピュータ32に取り込まれる。
【0033】
センサ入力/出力ボード52も、同様に、DSPで構成され、各センサやカメラからの信号を取り込んでコンピュータ32に与えるが、実施例ではあまり関係がないので、ここでは、そのセンサなどの詳細な説明は省略する。
【0034】
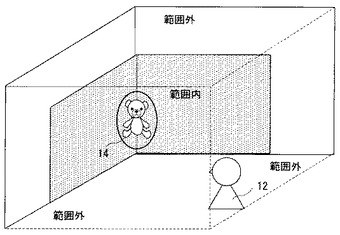
なお、図1に示す実施例において、ユーザ12の前方すなわちぬいぐるみ14の周囲は図6に示すように区画されている。ユーザ12の視線がぬいぐるみ14に向けられているのか、ぬいぐるみ14とユーザ12とが共同注視できる範囲内ではあるがぬいぐるみ以外の対象、たとえば別の擬人的媒体や人などに向けられているのか、共同注視できる範囲の外つまり範囲外に向けられているのか、などに応じて、ぬいぐるみ14がユーザ12に対して行なう発話や動作を決めるためである。
【0035】
ただし、このような区画はもっと細かく規定されて、その細かい区画ごとにぬいぐるみ14がユーザ12に対して行なう発話や動作を決めるようにしてもよい。
【0036】
また、この実施例では、ぬいぐるみ14が自律的に自己の動作や発話を制御する図5のような制御回路を持つものとして説明するが、ぬいぐるみ14を制御するための1台またはそれ以上のコンピュータをぬいぐるみ14とは別に設けるようにしてもよい。
【0037】
このような実施例において、まず、ユーザ12の視線を推定する方法について説明する。この実施例では、以下に説明するように、ユーザ12の視線方向を推定または検出するために1つのカメラ(単眼カメラ)を用いるユニークな方法を採用している。しかしながら、ユーザ12の視線12A(図2,図3)を検出する方法としては、2以上のカメラを利用する従来からの一般的な方法が採用されてもよいことは、勿論である。つまり、この発明では、ユーザ12の視線を推定したり検出したりする必要はあるが、その具体的な方法は重要な意味を持たず、どのような公知の方法が用いられてもよい。
【0038】
図1に示すように、ユーザ12の前方に、たとえばCCD(Charge Coupled Device)
またはCMOS(Complementary Metal-Oxide Semiconductor)センサのような固体撮像
素子を含むカメラ16が設置され、このカメラ16からの顔画像信号が視線サーバ18に取り込まれ、視線サーバ18が画像処理することによって、視線12Aの角度αおよびβを推定する。
【0039】
図7に示すように、カメラ16により撮影された画像は、視線サーバ18に附属して設けたディスプレイ54(図1では図示せず)の撮影画像表示領域56にリアルタイムに動画として表示される。特に限定されないが、たとえば、撮影画像表示領域56上に、視線方向を示す指標として、眉間から視線方向に延びる線分を表示してもよい。
【0040】
視線サーバ18は、一般的なコンピュータであり、特に変わったハードウェア構成ではないので、ハードウェア自体は説明しないが、視線方向や視線位置の推定は、以下に説明するソフトウェアにより実現される。
【0041】
視線サーバ18では、特徴点の追跡処理の安定性を確保するため、同一特徴点に関して異なるフレームにおける複数の観測テクスチャを保持している。初期校正過程では、これらの特徴点と虹彩中心の関係から顔特徴点と眼球中心の相対関係を求める。視線推定過程では、校正過程で得られた関係を元に現フレームで得られている特徴点群から眼球中心位置を推定し、その位置と虹彩中心位置から視線方向を決定する。
【0042】
視線方向の推定処理の動作の前提として、まず、たとえば6分割矩形フィルタを利用して、顔検出処理が実行される。
【0043】
視線サーバ18では、特に限定されないが、たとえば、顔を連続撮影したビデオ画像を処理するにあたり、横が顔幅、縦がその半分程度の大きさの矩形フィルタで画面を走査する。矩形は、たとえば、3×2に6分割されていて、各分割領域の平均明るさが計算され、それらの相対的な明暗関係がある条件を満たすとき、その矩形の中心を眉間候補とする。
【0044】
連続した画素が眉間候補となるときは、それを取囲む枠の中心候補のみを眉間候補として残す。残った眉間候補を標準パターンと比較してテンプレートマッチング等を行うことで、上述した手続きで得られた眉間候補のうちから、偽の眉間候補を捨て、真の眉間を抽出する。以下、さらに詳しく説明する。
【0045】
図8は、眉間候補領域を検出するためのフィルタを説明するための概念図であり、図8(a)は、上述した3×2に6分割された矩形フィルタ(以下、「6分割矩形フィルタ」
と呼ぶ)を示す。
【0046】
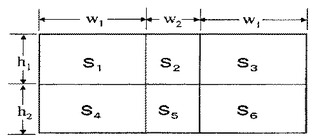
6分割矩形フィルタは、(1) 鼻筋は両目領域よりも明るい、(2) 目領域は頬部よりも暗い、という顔の特徴を抽出し、顔の眉間位置を求めるフィルタである。たとえば、1点(x、y)を中心として、横i画素、縦j画素(i,j:自然数)の矩形の枠を設ける。そして、図8(a)のように、この矩形の枠を、横に3等分、縦に2等分して、6個のブロックS1〜S6に分割する。
【0047】
このような6分割矩形フィルタを顔画像の両目領域および頬部に当てはめてみると、図8(b)のようになる。
【0048】
ただし、図8の6分割フィルタは書く矩形領域が等分されたものであったが、このフィルタは図9に示すように変形されてもよい。
【0049】
鼻筋の部分が目の領域よりも通常は狭いことを考慮すると、ブロックS2およびS5の横幅w2は、ブロックS1,S3,S4およびS6の横幅w1よりも狭い方がより望ましい。好ましくは、幅w2は幅w1の半分とすることができる。図9は、このような場合の6分割矩形フィルタの構成を示す。また、ブロックS1、S2およびS3の縦幅h1と、ブロックS4、S5およびS6の縦幅h2とは、必ずしも同一である必要もない。
【0050】
図9に示す6分割矩形フィルタにおいて、それぞれのブロックSi(1≦i≦6)について、画素の輝度の平均値「バーSi」(Siに上付きの“−”をつける)を求める。
【0051】
ブロックS1に1つの目と眉が存在し、ブロックS3に他の目と眉が存在するものとすると、以下の関係式(1)および(2)が成り立つ。
【0052】
【数1】

【0053】
【数2】
【0054】
そこで、これらの関係を満たす点を眉間候補(顔候補)として抽出する。
【0055】
矩形枠内の画素の総和を求める処理には、公知の文献(P. Viola and M. Jones, “ Rapid Object Detection using a Boosted Cascade of Simple Features,” Proc. Of IEEE
Conf. CVPR, 1, pp.511-518, 2001)において開示されている、インテグラルイメージ(Integral Image)を利用した計算の高速化手法を取り入れることができる。インテグラルイメージを利用することでフィルタの大きさに依らず高速に実行することができる。多重解像度画像に本手法を適用することにより、画像上の顔の大きさが変化した場合にも顔候補の抽出が可能となる。
【0056】
このようにして得られた眉間候補(顔候補)に対しては、両目の標準パターンとのテンプレートマッチングにより、真の眉間位置(真の顔領域)を特定することができる。
【0057】
なお、得られた顔候補に対して、サポートベクトルマシン(SVM)による顔モデルに
よる検証処理を適用し顔領域を決定することもできる。髪型の違いや髭の有無、表情変化による認識率の低下を避けるため、たとえば、図10に示すように、眉間を中心とした画像領域を利用してSVMによるモデル化を行うことができる。なお、このようなSVMによる真の顔領域の決定については、文献:S. Kawato, N. Tetsutaniand K. Hosaka: “Scale-adaptive face detection and tracking in real time with ssr fi1ters and support vector machine”, IEICE Trans.on Info. and Sys., E88−D, 12, pp.2857−2863(2005)に開示されている。6分割矩形フィルタによる高速候補抽出とSVMによる処理とを組み合わせることで実時間の顔検出が可能である。
【0058】
続いて、目、鼻や虹彩中心の位置を、公知の文献、たとえば『川戸、内海、安部:「4つの参照点と3枚のキャリブレーション画像に基づく単眼カメラからの視線推定」画像の認識・理解シンポジウム(MIRU2005),pp.1337−1342(2005)』あるいは、『川戸慎二郎、鉄谷信二:鼻位置の検出とリアルタイム追跡:信学技報IE2002−263、pp.25−29(2003)』などの手法を用いて抽出する。
【0059】
両目の位置については、前節の顔領域検出で眉間のパターンを探索しているため、眉間の両側の暗い領域を再探索することにより、大まかな両目の位置を推定することができる。しかし、視線方向の推定のためには、虹彩中心をより正確に抽出する必要がある。ここでは、上で求まった目の周辺領域に対して、ラプラシアンにより虹彩のエッジ候補を抽出し、円のハフ変換を適用することにより、虹彩および虹彩の中心の投影位置を検出する。
【0060】
鼻の位置は、鼻先が凸曲面であるため周囲に対し明るい点として観測されやすいことと、両目の位置から鼻の存在範囲が限定できることを利用して抽出する。また、両目、鼻の位置を用いて、大体の顔の向きも推定できる。
【0061】
図11は顔検出結果の例を示す図である。検出された顔において、虹彩中心や鼻先や口なども検出されている。たとえば、特徴点としては、鼻先や、左右の目の目尻や目頭、口の両端、鼻腔中心などを用いることができる。
【0062】
視線の推定においては、視線方向は眼球中心と虹彩中心を結ぶ3次元直線として与えられるものとする。
【0063】
図12は視線方向を決定するためのモデルを説明する概念図である。画像上での眼球半径をr、画像上での眼球中心と虹彩中心との距離をdとすると、視線方向とカメラ光軸と
のなす角θは次式(3)で表される。
【0064】
【数3】
【0065】
式(3)により、視線方向を推定するためには、画像上での眼球半径と眼球中心・虹彩中心の投影位置が必要となる。ここで、虹彩中心の投影位置については、上述したとおり、ハフ変換を用いた手法により求めることができる。画像上での眼球直径rは、解剖学的なモデル(標準的な人の眼球直径)を用いてもよいし、別途キャリブレーションにより求めてもよい。
【0066】
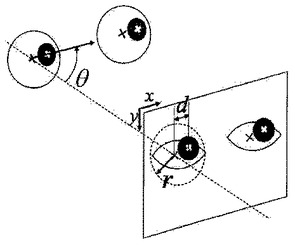
図13は、図12に示した状態からユーザがカメラを注視する状態に移行した後の虹彩中心、眼球中心および投影点の関係を示す概念図である。
【0067】
眼球中心の投影位置については、一般には、画像から直接観測することはできない。しかし、ユーザ12がカメラ16を注視した場合について考えると、図13に示すとおり、カメラ、虹彩中心、眼球中心の3点が1直線上に並ぶため、画像では虹彩中心と眼球中心は同一点に投影されることがわかる。
【0068】
そこで、この実施例での視線推定では、ユーザがカメラを注視しながら、顔の姿勢を変化させている画像フレーム列を撮影し、これらの画像列から虹彩位置と顔特徴点を抽出、追跡することにより、眼球中心と顔特徴点間の相対幾何関係を推定する。
【0069】
後により詳しく説明するように、この実施例の視線方向の推定では、眼球中心と顔特徴点間の相対関係の推定処理と眼球中心の投影位置推定とを行なう。
【0070】
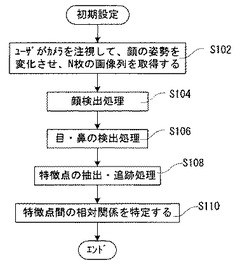
視線方向の推定のための初期設定として、視線サーバ18は、図14に示すフローチャートで表現されるキャリブレーションを実行する。
【0071】
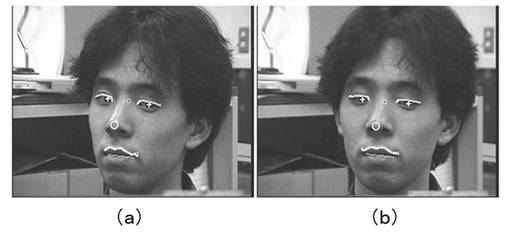
まず、キャリブレーション用の画像列として、ユーザがカメラを注視しながら、顔の姿勢を変化させている画像フレーム列を撮影する(ステップS102)。図15は、このようにしてキャリブレーションにおいて撮影された4枚の画像フレームを示す。
【0072】
ここでは、より一般に、N(N≧2)枚の画像列が得られたとする。各画像フレームを、フレームI1,…INとする。
【0073】
次に、得られた各画像フレーム列に対して、上述したような方法によって顔検出処理を行い(ステップS104)、続いて、目や鼻の検出処理を行なう(ステップS106)。
【0074】
さらに、視線サーバ18は、特徴点の抽出、追跡を行う(ステップS108)。なお、特徴点の抽出方法としては、上述したような方法の他に、たとえば、文献:J. Shi and C. Tomasi: “Good features to track”,Proc. CVPR94, pp. 593−600(1994)で提案された手法を用いることもできる。
【0075】
ここで、各画像フレームIi(i=1,…,N)においてM(M≧4)点の特徴点pj(j=1,…,M)が検出・追跡できたとする。画像フレームIiにおける特徴点pjの2次元観測位置をxj(i)(太字)=[xj(i),yj(i)]t(i=1,…,N,j=1,…,M)とし、両目の虹彩中心の2次元観測位置をそれぞれxr(i)(太字)=[xr(i),yr(i)]t,xl(i)(太字)=[xl(i),yl(i)]t(i=1,…,N)とする。ここで、行列Wを以下のように定義する。
【0076】
【数4】
【0077】
因子分解法により、特徴点の各フレームでの2次元観測位置を縦に並べた行列W(計測行列)は以下のように分解できる。
【0078】
【数5】
【0079】
ここで、行列M(「撮影姿勢行列)と呼ぶ)にはカメラの姿勢に関する情報のみが、行列S(「相対位置関係行列」と呼ぶ)には観測対象物の形状に関する情報のみが含まれており、顔特徴点と眼球中心との3次元的な位置の相対関係は行列Sとして求まる(ステップS110)。すなわち、正射影を仮定すると、行列Mの各要素が画像フレームでのカメラの姿勢を表す単位ベクトルであって、それぞれの大きさが1であり相互には直交するとの拘束条件のもとで、行列Wは、特異値分解により一義的に行列Mと行列Sの積に分解できることが知られている。なお、このような計測行列Wを、因子分解により、カメラの運動の情報を表す行列と対象物の形状情報を表す行列へ分解する点については、文献:金出,ポールマン,森田:因子分解法による物体形状とカメラ運動の復元”,電子通信学会論文誌D−II,J76‐D−II,8,pp.1497−1505(1993)に開示がある。
【0080】
図16は、リアルタイムの視線方向の推定処理のフローチャートを示す。
【0081】
次に、以上で得られた結果を用いて、視線方向を推定する手順について説明する。
【0082】
まず、カメラ16から画像フレームを取得すると(ステップS200)、キャリブレーション時と同様にして、顔の検出および目鼻の検出が行なわれ(ステップS202)、取得された画像フレーム中の特徴点が抽出される(ステップS204)。
【0083】
画像フレームIkが得られたとする。ここで、眼球中心以外の特徴点のうちm点pj(j=j1,…,jm)が、それぞれ、xj(k)(太字)=[xj(k),yj(k)]tに観測されたとする。このとき、観測された特徴点について、上述したように特徴点近傍のテンプレートを用いたテンプレートマッチングを実施することで、キャリブレーション時に特定された特徴点と現画像フレーム中で観測された特徴点との対応付けが行なわれて、現画像フレーム中の特徴点が特定される(ステップS206)。
【0084】
なお、上述のとおり、特徴点を特定するためのテンプレートは、キャリブレーションの時のものに限定されず、たとえば、最近の画像フレームの所定枚数について検出された特徴点の近傍の所定の大きさの領域内の画像を所定個数だけ保持しておき、これら所定枚数のテンプレートについてマッチングをした結果、もっとも一致度の高い特徴点に特定することとしてもよい。
【0085】
顔特徴点pjの2次元観測位置xj(k)(太字)=[xj(k),yj(k)]tとキャリブレーションより求まった3次元位置sj(太字)=[Xj,Yj,Zj]t(j=1,…,M)の間には、M個の特徴点のうち観測されたm個の特徴点について注目すると、次式の関係が得られる。
【0086】
【数6】
【0087】
ただし、行列P(k)は2×3の行列である。右辺の第2項の行列S(k)は行列Sのうち、観測された特徴点に対応する要素のみからなる部分行列である。上述の通り、カメラと顔は十分に離れているとし正射影を仮定している。ここで、4点以上の特徴点が観測されれば、行列P(k)は以下のように計算できる(ステップS208)。
【0088】
【数7】
【0089】
画像フレームIkにおける眼球中心の投影位置xr(i)(太字),xl(i)(太字)は、行列P(k)を用いて以下のように計算できる(ステップS210)。
【0090】
【数8】
【0091】
【数9】
【0092】
したがって、画像フレームIkにおいて特徴点として抽出した虹彩中心の投影位置とこの眼球中心の投影位置を用いると、視線の推定を行なうことができる(ステップS212)。
【0093】
なお、行列PをQR分解により分解することで、顔の姿勢Rが、以下のように計算できる。
【0094】
【数10】
【0095】
【数11】
【0096】
ただしr1、r2はそれぞれ1×3のベクトルである。このような顔の姿勢Rの検出については、文献:L.Quan: “Self-calibration of an affine camera from multiple views”,Int’l Journal of Computer Vision, 19, pp. 93−105(1996)に開示がある。
【0097】
ユーザ等の指示により追跡が終了していると判断されれば(ステップS214)、処理は終了し、終了が指示されていなければ、処理はステップS202に復帰する。
【0098】
以上説明した視線方向の推定装置の有効性を確認するため、実画像を用いた実験を行った結果について以下に説明する。
【0099】
カメラはElmo社製PTC−400Cを用い、被験者から約150[cm]の位置に設置した。
【0100】
まず、50フレームの画像列を用いて、眼球中心と顔特徴点のキャリブレーションを行った。キャリブレーション用の画像フレーム列と抽出した特徴点の例は、図15に示したとおりである。
【0101】
キャリブレーション用画像フレーム列の撮影に要した時間は約3秒であった。(+印は抽出された虹彩中心(眼球中心))、×印は追跡した顔特徴点)。
【0102】
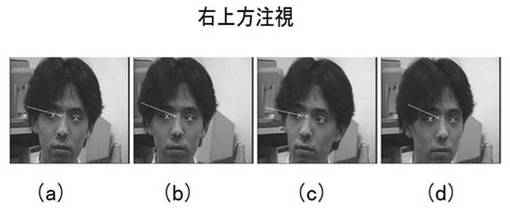
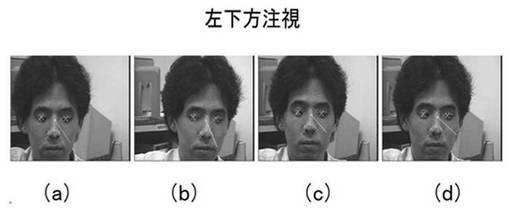
次に、キャリブレーションにより求まった顔モデル(行列S)を用いて、視線推定を行った。ここで、被験者はそれぞれ右上、上、左下の方向を注視しながら、顔の位置・向きを変化させた。
【0103】
図17〜図19は、視線推定結果を示す。図17は、右上方注視の状態であり、図18は、上方注視の状態であり、図19は、左下方向注視の状態である。ここで、視線方向は両目それぞれで計算された視線方向の平均値としている。結果より、顔の位置や向きの変化とは関係なく、視線方向が推定できた。
【0104】
以上説明したとおり、この実施例の視線方向の推定方法では、単眼カメラの観測に基づいて顔特徴点を検出し、追跡することにより視線方向を推定する。つまり、まずキャリブレーションとして視線がカメラ方向を向いたまま顔の向きのみが異なる画像列から得られる虹彩位置と顔特徴点を利用することで、眼球中心と顔特徴点の関係をモデル化し(行列Sを特定し)、その後、その関係に基づいて推定された入力画像中の眼球中心位置と虹彩位置の関係から視線方向の角度α、βを決定する。
【0105】
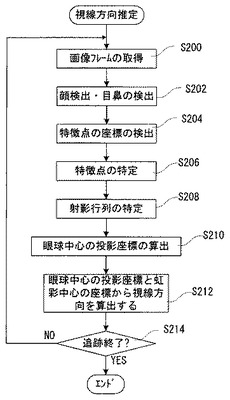
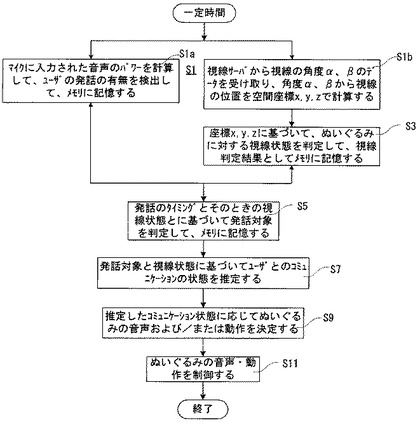
図20に示すフローチャートを実行して、ぬいぐるみ14の発話や動作を制御するのであるが、この図20に示すフローチャートは、後に説明する図23のフローチャートと同様に、一定時間ごと、たとえば1‐2秒の周期で実行されるものとする。
【0106】
図20の最初のステップS1では、ユーザ12の発話を検出するためのステップS1aとユーザ12の視線の状態を判定するためのステップS1bを並行的に処理する。
【0107】
ステップS1aでは、ぬいぐるみ14のコンピュータ32(図5)は、マイク50(図5)からの音声入力のパワーを計算するなどして、ユーザ12が発話したかどうか、つまり、ユーザ12の発話の有無を検出し、その結果(発話の有無)を発話の状態を示すデータとしてメモリ36の判定結果記憶部36Cに格納する。
【0108】
ただし、ユーザ12が発話したかどうかを検出するためには別の方法、たとえば、超指向性マイクを用いる方法、音源とベクトルを計算する方法、音声のパワースペクトルにおける倍音成分を検出する方法などである。この発明では、ユーザの発話の有無を検出する方法としてはいずれの方法を用いてもよい。
【0109】
また、ステップS1bでは、上述のようにして視線サーバ18が推定した視線角度αおよびβのデータが、ぬいぐるみ14のバス34(図5)を通してコンピュータ32に与えられる。コンピュータ32では、その角度データから視線12A(図2,3)の空間10Aにおける空間座標(x,y,z)を、絶対位置として計算する。
【0110】
一方、ぬいぐるみ14はそれぞれ、図6に示すように固定的に配置されている。したがって、このぬいぐるみ14の存在する空間10A内の、図6に示す「範囲」の座標およびその範囲内でのぬいぐるみ14が存在する位置の座標はともに既に計算されて、たとえばメモリ36(図5)に記憶されている。
【0111】
そこで、次のステップS3で、コンピュータ32は、先にステップS1bで計算した視線の空間座標とメモリ36内に予め蓄積されている各座標とを比較し、ユーザ12のそのときの視線の方向、つまり、視線の相対位置がぬいぐるみ14自体に向けられているのか、ぬいぐるみ14ではないが範囲内(図6)に存在する他のもの、たとえば擬人的媒体あるいは人間などに向けられているのか、あるいは図6に示す範囲外に向けられているのかを判定する。そのようにして判定した視線の状態の判定結果は、視線状態データとしてメモリ36の記憶部36Cに記憶される。
【0112】
続くステップS5で、コンピュータ32は、ユーザ12が発話したタイミングにおけるユーザ12の上記視線状態に基づいて、そのときのユーザ12の発話が、ぬいぐるみ14自身に向けられたものか、範囲内の違う対象に向けられたものか、あるいは、わからないかを推定する。わからない、というのは、ユーザ12の視線が図6の範囲外に向けられているとき、または視線が安定しない不安定な状態であるときにそのように推定する。この発話対象推定ステップで推定した発話対象も、発話状態データとして上述の記憶部36Cに記録される。
【0113】
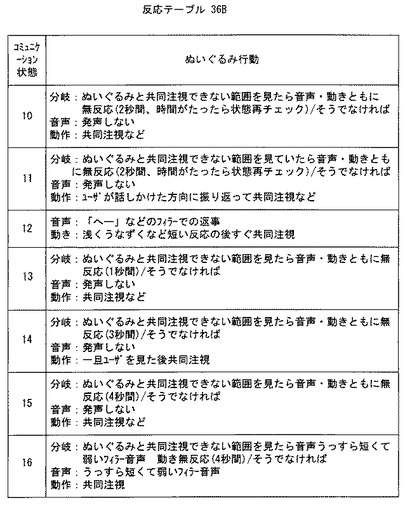
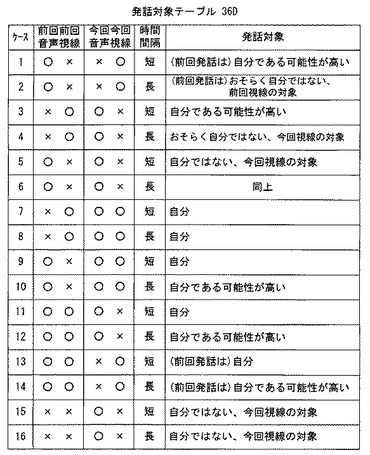
ここで、このステップS5における発話対象推定動作についてより具体的に説明する。発話対象推定においては、図27および図28に示す発話対象テーブル36D(図5)を参照してユーザ12が発話した対象が自分すなわちぬいぐるみ14かどうか推定する。発話対象テーブル36Dでは、前回発話、前回視線、今回発話および今回視線のそれぞれの判定結果(図5に示す判定結果記憶部36Cに蓄積されている。)に加えて、前回発話/視線と今回発話/視線との時間間隔の長短を推定要素として用いる。この時間間隔は、たとえば、1秒以上を「長」と、1秒未満を「短」として登録する。ただし、ケース1−4、9−14では、各判定結果とこの時間間隔とを要素として推定するのであるが、ケース5‐8、15‐16、19−22は単純に発話および視線の判定結果だけで発話対象を推定するようにしている。そして、ケース17‐18、23‐28では、発話が前回も今回もないので、この発話対象ステップでは関係ない状態である。
【0114】
たとえば、図27のケース1および2に示すように、前回の発話判定結果が「○」で前回の視線状態判定結果が「×」であったが今回の発話判定結果は「×」になり、視線状態判定結果は「○」になった場合には、時間間隔の短長によって、「短」(ケース1)の場合は、(前回の発話は)自分(ぬいぐるみ14)である可能性が高いと判定または推定し、「長」(ケース2)の場合は、(前回の発話は)おそらく自分ではなく、単に前回視線の対象であったと推定する。
【0115】
たとえば、図27のケース3および4に示すように、前回の発話判定結果が「×」で前回の視線状態判定結果が「○」であったが今回の発話判定結果は「○」になり、視線状態判定結果は「×」になった場合には、時間間隔の短長によって、「短」(ケース3)の場合は、今回の発話は自分(ぬいぐるみ14)である可能性が高いと推定し、「長」(ケース4)の場合は、おそらく自分ではなく、単に今回視線の対象であったと推定する。
【0116】
これに対して、ケース5および6では、前回も今回も視線が自分に向けられていない(「×」である。)ので、時間間隔の長短に拘わらず、ともに発話対象が自分ではないと推定している。同じく、前回と今回との判定結果だけを利用するケース7および8、ケース19および20、ケース21および22においても、時間間隔の如何にかかわらず同一の推定結果を生じている。
【0117】
このようなテーブル36Dを利用することによって、発話と視線の有無が一致していない状態データも発話対象をおおむね正確に推定することができる。
【0118】
続いて、ステップS7で、コンピュータ32は、ステップS3で判定したユーザの視線状態(ユーザ12の視線がぬいぐるみ14自体に向けられているのか、ぬいぐるみ14ではないが範囲内に存在する他のものに向けられているのか、あるいは範囲外に向けられているのか)と、ステップS5で推定した、ユーザの発話が向けられた発話対象(ぬいぐるみ14に向けたものか、範囲内の違う対象に向けたものか、あるいは、わからないか)とに基づいて、そのときのユーザ12とぬいぐるみ14との間のコミュニケーション状態を推定または特定する。
【0119】
具体的には、図21に示すように、発話対象が「自分」、「自分以外の範囲内」、「範囲外」、または「発話なし」の場合に、視線状態が「自分」、「自分以外の範囲内」、「不明」のいずれかであるとき、両者のコミュニケーション状態がどのような状態なのかを推定する。ただし、視線方向が図6に示す「範囲外」であるとき、または、不安定で定まらない状態のときを「不明」と判定する。たとえば、発話対象も視線状態も「自分」のときには、ユーザ12がぬいぐるみ14に目を合わせて発話している状態であると推定できる。なお、この解釈テーブル36Aによって推定または特定できるコミュニケーション状態は全て図21に詳細に記述しているので、詳細は図21を参照されたい。
【0120】
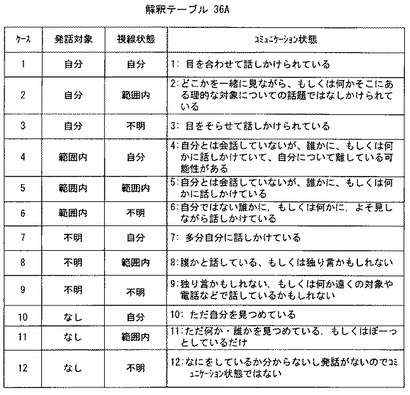
ステップS9では、コンピュータ32は、ステップS7で特定したコミュニケーション状態に応じて、ユーザからぬいぐるみへのコミュニケーションを誘発するのに効果的な、ぬいぐるみの行動(発話および/または動作)を決定する。このぬいぐるみの行動(発話および/または動作)は具体的には、図22に示すが、基本的には、ユーザがぬいぐるみに対して発話しているようなコミュニケーション状態では、コンピュータ32は、ぬいぐるみ14がユーザに対して音声(発話)で返事するような行動を設定する。しかしながら、ユーザが発話していないか、ぬいぐるみに話かけていないか、のときには、ぬいぐるみの行動としては、音声による返事をするようには設定しない。また、ユーザがぬいぐるみに視線を向けているコミュニケーション状態では、コンピュータ32は、ぬいぐるみ14がユーザに対して動作でリアクションを表現するような行動を決定する。そして、ユーザがぬいぐるみは見ていないがユーザの視線が「範囲内」にある、そのようなコミュニケーション状態のときには、コンピュータ32はぬいぐるみ14の行動として、ユーザの視線方向を共同注視するなど、という行動を設定する。ただし、ユーザの視線が「範囲外」のときには、ぬいぐるみには何も反応動作を設定しない。
【0121】
具体的には図22にコミュニケーション状態とぬいぐるみの行動とのテーブルを示すが、これらは単なる例示であり、適宜変更可能であることはいうまでもない。ただし、図22のコミュニケーション状態の番号と図21のコミュニケーション状態の番号とが対応するものと理解されたい。
【0122】
ステップS11では、コンピュータ32はステップS9で決定したぬいぐるみの行動を実際にぬいぐるみ14が生じるように、必要な音声データやモータ制御データを音声入出力ボード46やモータ制御ボード38に出力する。ただし、ぬいぐるみ14が発話するタイミングは、ユーザ12の発話が終わった後であり、そのために、先に説明した「発話中フラグ」が参照される。つまり、発話中フラグはユーザが発話中であるとき「1」であるので、それぞれが「0」になった後にぬいぐるみ14の発話を実行させるようにする。ただし、ぬいぐるみ14の動作は、ユーザの発話中に実行してもよいし、ユーザの発話が終了した後に実行するようにしてもよい。
【0123】
このようにして、ぬいぐるみのコンピュータ32は、ユーザの発話状態の判定結果とユーザの視線状態の判定結果とに基づいて、ユーザのぬいぐるみに対するコミュニケーション状態を推定し、そのコミュニケーション状態から、ユーザのぬいぐるみに対するコミュニケーションを一層増進させ、あるいは誘発するように、ぬいぐるみの行動、すなわち発話や動作を制御する。
【0124】
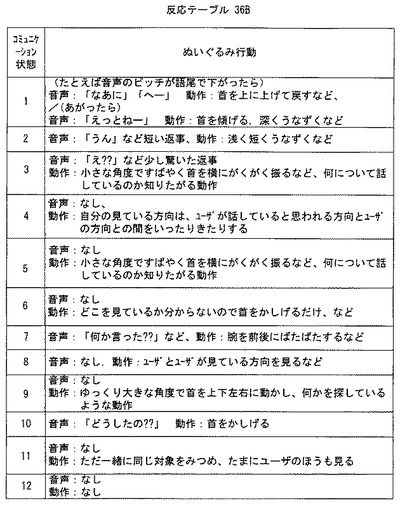
図23はこの発明の他の実施例の動作を示すフローチャートである。先の実施例ではコミュニケーション状態を特定するのに、今回の視線状態および今回の発話状態だけを参照したのに対し、前回の視線状態および前回の発話状態も考慮して、コミュニケーション状態を特定しようとするという点で、この実施例は先の実施例と異なる。
【0125】
図23の最初のステップS21では、ユーザ12の発話を検出するためのステップS21aとユーザ12の視線の状態を判定するためのステップS21bを並行的に処理する。
【0126】
ステップS21aでは、図20のステップS1aと同じように、ユーザ12の発話の有無を検出し、その結果(発話の有無)を発話の状態を示すデータとしてメモリ36の判定結果記憶部36Cに格納する。ここでも、ユーザ12が発話したかどうかを検出するための方法は任意の方法であってよい。
【0127】
また、ステップS21bでは、上述のようにして視線サーバ18が推定した視線角度αおよびβのデータが、ぬいぐるみ14のバス34(図5)を通してコンピュータ32に与えられる。コンピュータ32では、その角度データから視線12A(図2,3)の空間10Aにおける空間座標(x,y,z)を、絶対位置として計算する。
【0128】
一方、ぬいぐるみ14はそれぞれ、図6に示すように固定的に配置されている。したがって、このぬいぐるみ14の存在する空間10A内の、図6に示す「範囲」の座標およびその範囲内でのぬいぐるみ14が存在する位置の座標はともに既に計算されて、たとえばメモリ36(図5)に記憶されている。
【0129】
そこで、ステップS1bで、コンピュータ32は、先に計算した視線の空間座標とメモリ36内に予め蓄積されている各座標とを比較し、ユーザ12のそのときの視線の方向、つまり、視線の相対位置がぬいぐるみ14自体に向けられているのか、あるイはぬいぐるみ14以外に向けられているのかを判定する。そのようにして判定した視線の状態の判定結果は、視線状態データとしてメモリ36の記憶部36Cに記憶される。
【0130】
続くステップS23で、コンピュータ32は、ユーザの前回の発話状態の判定結果および前回の視線状態の判定結果と、今回の発話状態の判定結果および今回の視線状態の判定結果とに基づいて、ユーザ12とぬいぐるみ14との間のコミュニケーション状態を推定または特定する。たとえば、ユーザ12が前回はぬいぐるみ14に話しかけていたけれども、今回は別の対象に話ししているような場合であれば、ぬいぐるみとユーザとはコミュニケーションが完全には途切れてはいないので、「ユーザの話しかけている対象とユーザを注視する必要がある」などと、コミュニケーション状態を解釈する。
【0131】
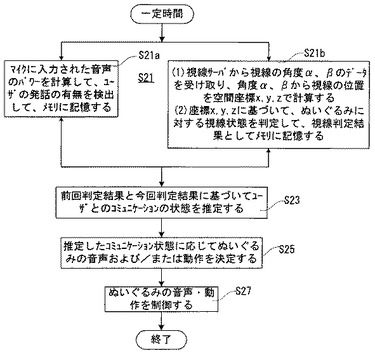
前回判定結果と今回判定結果とに基づいて推定または特定するコミュニケーション状態の具体例が図24に示されている。
【0132】
たとえば、図24のケース1に示すように、前回の発話判定結果が「×」で前回の視線状態判定結果が「○」であったが今回の発話判定結果も視線状態判定結果もともに「○」である場合には、コミュニケーション状態は「ユーザはぬいぐるみに目を合わせた状態でぬいぐるみに話しかけた」と解釈する。ただし、ここで発話判定結果が「×」ということは、ユーザはそのとき発話しなかったことを意味している。視線状態判定結果が「○」ということは、そのときユーザの視線はぬいぐるみに向けられていたことを意味している。
【0133】
ケース2では、前回の発話判定結果が「○」で前回の視線状態判定結果が「×」であったが今回の発話判定結果も視線状態判定結果もともに「○」である。この場合には、コミュニケーション状態は「ユーザは発話しながらぬいぐるみに目を向けた」と解釈する。ただし、ここで発話判定結果が「○」ということは、ユーザはそのとき発話したことを意味していて、視線状態判定結果が「×」ということは、そのときユーザの視線はぬいぐるみには向けられていなかったことを意味している。
【0134】
ケース3のように、前回の発話判定結果が「×」で前回の視線状態判定結果が「×」であったが今回の発話判定結果も視線状態判定結果もともに「○」である場合には、コミュニケーション状態は「ユーザはぬいぐるみを見ると同時に話しかけたに」と解釈する。
【0135】
ケース4に示す状態は、前回の発話判定結果および視線状態判定結果がともにが「○」今回の発話判定結果も視線状態判定結果もともに「○」である場合であり、このような場合には、コミュニケーション状態は「ユーザはずっとぬいぐるみを見ながらぬいぐるみに話しかけている(状態保存)」と解釈できる。
【0136】
以下、各個別のコミュニケーション状態についての詳細な説明は省略するので、必要に応じて図24を参照されたい。
【0137】
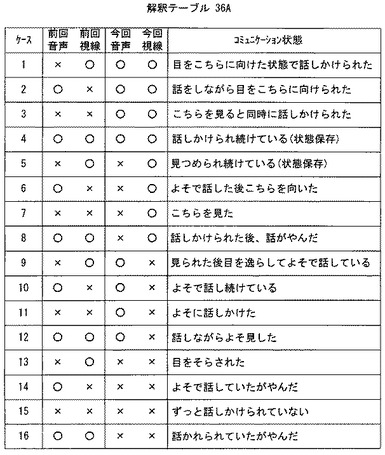
ステップS25では、コンピュータ32は、ステップS23で特定したコミュニケーション状態に応じて、ユーザからぬいぐるみへのコミュニケーションを誘発するのに効果的な、ぬいぐるみの行動(発話および/または動作)を決定する。このぬいぐるみの行動(発話および/または動作)は具体的には、図25-26に示すが、基本的には、発話状態や視線状態の時間変化に対応してコミュニケーション行動を決定する。たとえば、前回は発話視線ともに×であったものが、今回とも○になったような場合、コミュニケーション状態3は「ユーザはぬいぐるみを見ると同時に話しかけてきた」という状態であると推定するが、そのような状態変化に対応してぬいぐるみが実行する行動は、図25のコミュニケーション状態3に示す行動を実行させる。具体的には、音声としては「少し驚いたような返事」をさせ、動作としてはユーザのコミュニケーションを取りたいという発意に気付いたというように「首をがくがく振る」などの動作を行なわせる。このようなぬいぐるみ14の行動によって、ユーザがぬいぐるみに対してコミュニケーションをとりたいという意欲を継続させることができる。
【0138】
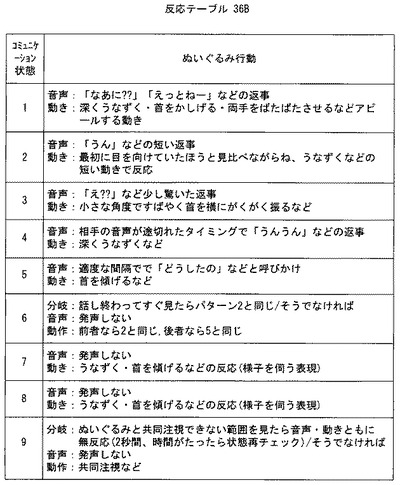
なお、図25-26にコミュニケーション状態とぬいぐるみの行動とのテーブルを示すが、これらは単なる例示であり、適宜変更可能であることはいうまでもない。
【0139】
ステップS27では、コンピュータ32はステップS25で決定したぬいぐるみの行動を実際にぬいぐるみ14が生じるように、必要な音声データやモータ制御データを音声入出力ボード46やモータ制御ボード38に出力する。ただし、実際に発話するタイミングは先の実施例と同様に、ユーザ12の発話を邪魔しないようなタイミングに設定するなどの配慮が必要であろう。
【0140】
このようにして、ぬいぐるみのコンピュータ32は、前回と今回とのユーザの発話状態の判定結果とユーザの視線状態の判定結果とに基づいて、ユーザのぬいぐるみに対するコミュニケーション状態を推定し、そのコミュニケーション状態から、ユーザのぬいぐるみに対するコミュニケーションを一層増進させ、あるいは誘発するように、ぬいぐるみの行動、すなわち発話や動作を制御する。
【0141】
ただし、今回発話の判定結果および今回視線の判定結果だけを用いても、発話対象や視線状態を特定または推定することができるので、必ずしも、前回の判定結果と今回の判定結果の両方を用いる必要はない。そして、この場合には、各判定手段は発話状態や視線状態を一定時間ごとに繰り返し判定する必要はなく、必要な都度判定するようにすることも考えられる。
【図面の簡単な説明】
【0142】
【図1】この発明の一実施例のコミュニケーション誘発システムの概念を示す図解図である。
【図2】図1実施例におけるユーザとぬいぐるみとの平面的な位置関係およびユーザの視線角度を示す図解図である。
【図3】図1実施例におけるユーザとぬいぐるみとの側面的な位置関係およびユーザの視線角度を示す図解図である。
【図4】図1実施例において用いられるぬいぐるみの一例を示す図解図である。
【図5】図1実施例におけるぬいぐるみの制御回路の一例を示すブロック図である。
【図6】図1実施例におけるユーザの視線の状態を判定する範囲の一例を示す図解図である。
【図7】図1実施例における視線サーバのディスプレイに表示されているユーザの顔画像の一例を示す図解図である。
【図8】図8は眉間候補領域を検出するためのフィルタを説明するための概念図である。
【図9】図9は6分割矩形フィルタの他の構成を示す概念図である。
【図10】図10は眉間を中心とした画像領域を利用してSVMによるモデル化を説明する図解図である。
【図11】図11は顔検出結果の例を示す図解図である。
【図12】図12は視線方向を決定するためのモデルを説明する概念図である。
【図13】図13はユーザがカメラを注視する状態に移行した後の虹彩中心、眼球中心および投影点の関係を示す概念図である。
【図14】図14は視線サーバによる初期設定の処理動作を示すフロー図である。
【図15】図15はキャリブレーションにおいて撮影された4枚の画像フレームを示す図解図である。
【図16】図16は視線サーバが実行するリアルタイム視線検出の処理動作を示すフロー図である。
【図17】図17は右上方注視の状態での視線推定結果を示す図解図である。
【図18】図18は上方注視の状態での視線推定結果を示す図解図である。
【図19】図19は左下方向注視の状態での視線推定結果を示す図である。
【図20】図20は図1実施例におけるぬいぐるみのコンピュータの動作を示すフロー図である。
【図21】図21は図1実施例におけるぬいぐるみに対するユーザのコミュニケーション状態の推定または解釈テーブルの一例を示す表である。
【図22】図22は図1実施例におけるコミュニケーション状態に応じたぬいぐるみの行動を規定する反応テーブルの一例を示す表である。
【図23】図23は別の実施例におけるぬいぐるみのコンピュータの動作を示すフロー図である。
【図24】図24は図23実施例におけるぬいぐるみに対するユーザのコミュニケーション状態の推定または解釈テーブルの一例を示す表である。
【図25】図25は図23実施例におけるコミュニケーション状態に応じたぬいぐるみの行動を規定する反応テーブルの一例を示す表である。
【図26】図26は図25の続きを示す表である。
【図27】図27は図20実施例における発話対象テーブルの一例を示す表である。
【図28】図28は図27の続きを示す表である。
【符号の説明】
【0143】
10 …コミュニケーション誘発システム
14 …ぬいぐるみ
16 …カメラ
18 …視線サーバ
32 …コンピュータ
36 …メモリ
50 …マイク
【技術分野】
【0001】
この発明はコミュニケーション誘発システムに関し、特に、たとえばロボットなどの擬人的媒体を認知症患者などの軽度脳障害を持つユーザが視認できる位置に配置し、その擬人的媒体によってユーザからのコミュニケーションを誘発する、新規なコミュニケーション誘発システムに関する。
【背景技術】
【0002】
特許文献1などで、認知症患者などに右脳刺激を与えることによって、その機能回復が図れることが知られている。
【特許文献1】特開2005−160806号公報[A63B 24/00 23/035]
【発明の開示】
【発明が解決しようとする課題】
【0003】
しかしながら、このような機能回復訓練を受けられるのは少なくとも他人とのコミュニケーションが図れることが条件である。そこで、このような患者ではまずコミュニケーション能力を回復させる必要がある。その場合、患者からコミュニケーションを引出す(誘発する)ように作用するシステムがあれば好都合である。
【0004】
それゆえに、この発明の主たる目的は、新規な、コミュニケーション誘発システムを提供することである。
【0005】
この発明の他の目的は、ユーザからのコミュニケーションを積極的に引き出すことができる、コミュニケーション誘発システムを提供することである。
【課題を解決するための手段】
【0006】
この発明は、上記の課題を解決するために、以下の構成を採用した。なお、括弧内の参照符号および補足説明等は、この発明の理解を助けるために後述する実施形態との対応関係を示したものであって、この発明を何ら限定するものではない。
【0007】
第1の発明は、ユーザが視認できる位置に配置した擬人的媒体によってユーザからのコミュニケーションを誘発するコミュニケーション誘発システムであって、ユーザの視線の状態を判定する視線判定手段、ユーザからの発話の状態を判定する発話判定手段、視線位置判定手段による視線状態判定結果および発話判定手段による発話状態判定結果を記憶する記憶手段、記憶手段に記憶した視線状態判定結果および発話状態判定結果に応じてユーザと擬人的媒体とのコミュニケーション状態を特定するコミュニケーション状態特定手段、およびコミュニケーション状態特定手段が特定したコミュニケーション状態に応じて擬人的媒体の音声および動作を制御する制御手段を備える、コミュニケーション誘発システムである。
【0008】
第1の発明において、擬人的媒体(14:実施例で相当する部分を例示する参照符号。以下同様。)がユーザ(12)の前方の、ユーザの視線が届く位置に配置される。視線判定手段(16,18,32,S1b,S3,S21b)は、たとえば、カメラ(16)によって撮影したユーザの顔画像を視線サーバ(18)で処理することによって、ユーザの視線(12A)の方向または位置をリアルタイムに推定または検出し、そのときのユーザの視線の方向が擬人的媒体の位置に対してどのような位置関係にあるか判定する。たとえば、視線の方向は擬人的媒体の位置か、擬人的媒体の位置に隣接する位置か、擬人的媒体の位置とかなり離れているか、などを判定する。発話判定手段(32,S1a,S21a)はたとえばマイク(50)からの音声入力パワーを計算するなどして、ユーザの発話の有無やその状態などを判定する。コミュニケーション状態特定手段は、記憶手段(36C)に記憶した視線状態判定結果および発話状態判定結果に従って、たとえば、解釈テーブル(36A)を参照して、そのときのユーザと擬人的媒体との間のコミュニケーション状態、たとえばユーザが擬人的媒体を見ながら話しかけているのか、ユーザが擬人的媒体と同じ方向を見ながら発話しているのか、のようなコミュニケーション状態を推定または特定する。そして、制御手段(32,38,46,S11,S27)は、コミュニケーション状態特定手段が特定したコミュニケーション状態に応じて、たとえば反応テーブル
(36B)を参照して、擬人的媒体の動作(発話および/または動き)を制御する。
【0009】
第1の発明によれば、ユーザの視線状態および発話状態の両方の判定結果に応じて擬人的媒体を制御することができるので、そのときのユーザと擬人的媒体との間のコミュニケーション状態に応じて最適のコミュニケーション誘発動作を行なわせることができる。
【0010】
第2の発明は、発話状態判定手段はユーザの発話があったとの視線状態に応じてユーザの発話対象が何かを推定する発話対象推定手段を含み、コミュニケーション状態特定手段は、発話対象推定手段の判定結果および視線状態判定結果に基づいて複数のコミュニケーション状態の1つを特定する、請求項1記載のコミュニケーション誘発システムである。
【0011】
第2の発明では、ユーザが擬人的媒体(ぬいぐるみ)に対して発話したのかあるいは他の対象に向けて発話したのかなどの状況に応じてきめ細かく対応することができる。たとえば、ユーザが擬人的媒体を見ていないで発話したら「擬人的媒体以外への発話の可能性あり」としてその発話に対する反応(リアクション)を保留したり、ユーザが擬人的媒体を見ている状態で発話したら「自分への発話である」としてその発話に対して音声および動作で反応(リアクション)したりすることができる。
【0012】
第3の発明は、視線判定手段はユーザの視線の状態を繰り返し判定し、発話判定手段はユーザからの発話の状態を繰り返し判定し、発話対象推定手段は、少なくとも記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じてユーザの発話が擬人的媒体に向けられたものかどうか推定する、請求項2記載のコミュニケーション誘発システムである。
【0013】
第3の発明では、発話対象推定において、たとえば発話対象テーブル(36D)を参照するなどして、前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果に基づいて、ユーザが擬人的媒体(ぬいぐるみ)に対して発話したのかあるいは他の対象に向けて発話したのかなどの状況を推定する。したがって、発話対象の推定が確実に行なえる。
【0014】
第4の発明は、発話対象推定手段は、さらに前回と今回との時間間隔の長短を考慮して発話対を推定する、請求項3記載のコミュニケーション誘発システムである。
【0015】
第4の発明では、発話対象推定において、前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果に加えて、前回と今回との時間間隔の長短に基づいて、ユーザが擬人的媒体(ぬいぐるみ)に対して発話したのかあるいは他の対象に向けて発話したのかなどの状況を推定する。したがって、発話対象の推定がさらに正確に行なえる。
【0016】
第5の発明は、視線判定手段はユーザの視線の状態を繰り返し判定し、発話判定手段はユーザからの発話の状態を繰り返し判定し、コミュニケーション特定手段は、記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じてユーザと擬人的媒体とのコミュニケーション状態を特定する、請求項1記載のコミュニケーション誘発システムである。
【0017】
第5の発明では、記憶手段に記憶した前回判定結果と今回判定結果とを用いるので、さらにコミュニケーション状態の時間的変化を検出することができ、さらにきめ細かい対応が可能となる。
【発明の効果】
【0018】
この発明によれば、ユーザの視線状態および発話状態に応じて最適のコミュニケーション誘発動作を擬人的媒体に行なわせることができるので、ユーザからのコミュニケーションを積極的に引出すことができる。
【0019】
この発明の上述の目的,その他の目的,特徴,および利点は、図面を参照して行う以下の実施例の詳細な説明から一層明らかとなろう。
【発明を実施するための最良の形態】
【0020】
図1に示すこの発明の一実施例のコミュニケーション誘発システム10は、たとえば認知症患者のような軽度脳障害を持つ被験者またはユーザ12からのコミュニケーションを積極的に引き出すように、このユーザ12に働きかける少なくとも1つのぬいぐるみ14を含む。このぬいぐるみ14が擬人的媒体である。擬人的媒体とは、人間のように発話できたり、あるいは人間のような動作ができたりする媒体のことであり、典型的にはぬいぐるみや、ヒューマノイドやコミュニケーションロボットなども、この擬人的媒体として十分機能できる。ただし、2体以上のぬいぐるみを用いるようにしてもよい。
【0021】
この実施例のシステム10では、ユーザ12の主として顔を撮影するカメラ16を用いて、ユーザ12の視線の方向や位置をリアルタイムで検出するとともに、ユーザ12の発話の有無などを検出することによって、その視線の方向や位置(視線の状態)および発話の有無など(発話の状態)に応じてぬいぐるみ14の発話や動作を制御することによって、ユーザ12からのぬいぐるみ14に対するコミュニケーションを誘発する。
【0022】
ユーザ12の視線方向または位置は、後に詳しく説明するように、視線サーバ18がカメラ16からの顔画像データまたは信号を処理することによって、リアルタイムで検出または判定する。
【0023】
図2は図1実施例を俯瞰した状態を図解する図解図であり、図3はそれを側面から見た図解図である。これらの図からわかるように、患者または被験者ないしユーザ12は部屋のような空間10Aの一方に椅子に腰掛けて存在していて、その前方の、この空間10A内の他方に、ぬいぐるみ14が配置されている。
【0024】
そして、カメラ16は空間10Aの一隅からユーザ12の顔前面を撮影できるように設置されている。
【0025】
ユーザ12の視線12Aが、カメラ16の光軸に平行な垂直線vlineに対してずれている角度が旋回角αであり、視線12Aがカメラ16の光軸に平行な水平線hlineに対してずれている角度が俯仰角βとして図1の視線サーバ18によってリアルタイムに計算される。そして、各ぬいぐるみ14が、その検出角度αおよびβからその視線12Aの方向または位置を特定し、その視線12Aの方向または位置、およびユーザ12の発話の状態に応じて、異なる動作および/または発話をすることによって、ユーザ12からコミュニケーションを誘発しようとするのである。
【0026】
図4にはぬいぐるみ14が図示される。このぬいぐるみ14は、頭部20とそれを支える胴体22とを含む。胴体22の上部に左右の左腕24Lおよび右腕24Rが設けられ、頭部20には、前面に口26が配置され、その口26の上方には眼球28が設けられる。頭部20の上部側面は耳30が取り付けられている。
【0027】
胴部20は胴体22によって、旋回・俯仰可能に支持され、また、眼球28も可動的に保持されている。口26にはスピーカ48(図5)が内蔵されていて、耳30にはマイク50(図5)が内蔵されている。なお、マイク50を両方の耳30にそれぞれ内蔵すれば、ステレオマイクとして機能し、それによって、そのステレオマイクに入力された音声の位置を必要に応じて特定することができる。
【0028】
図5はこのぬいぐるみ14の電気的構成を示すブロック図であり、この図5に示すように、実施例のぬいぐるみ14にはコンピュータ32が内蔵されていて、このコンピュータ32が、通信路の一例であるバス34を通して、図1に示す視線サーバ18に結合される。したがって、コンピュータ32は、視線サーバ18が特定または検出したユーザ12の視線方向や位置を示すデータをこのバス34を通して刻々受け取ることができる。ただし、通信路はバス34であっても、その他の形式の通信路であっても、さらには無線であっても、有線であってもよい。
【0029】
コンピュータ32には、バス34を介してメモリ36が結合される。このメモリ36には図示しないROMやRAMが組み込まれていて、ROMには主として、後述のフローチャート(図20,図23)で表現されるプログラムが予め記憶されているとともに、コミュニケーション状態を特定しまたは解釈するための、図21や図24に示すような解釈テーブル36Aや、ユーザの発話の状態や視線の状態に対するぬいぐるみ14の動作と発話(音声)とを対応的に設定している、図23および図25‐26に示すような反応テーブル36Bが予め設定されている。この反応テーブル36Bは、ぬいぐるみ14の動作と発話とを対応させて設定したものである。RAMは、たとえばユーザ12の発話の有無および発話対象などの発話状態の判定結果やおよびユーザ12の視線がぬいぐるみ14に向けられているかどうかなどの視線状態判定結果を、逐次、記憶するための判定結果記憶部36Cや、ユーザ12の発話状態に応じて1または0が設定される発話中フラグ(図示せず)などのための一時記憶メモリとして、さらにはワーキングメモリとして利用され得る。ROMにはさらに、図27および図28に示す発話対象テーブル36Dも予め格納されている。この発話対象推定テーブル36Dは、ユーザ12がした発話が誰を対象としているのか、つまりその発話がぬいぐるみ14に向けられたものであるかどうかを判定または推定するために利用される。
【0030】
モータ制御ボード38は、たとえばDSP(Digital Signal Processor)で構成され、図4に示すぬいぐるみ14の各腕や頭部の各軸モータを制御する。すなわち、モータ制御ボード38は、コンピュータ32からの制御データを受け、右腕24R(図4)を前後や左右に動かすことができるように、X,YおよびZ軸のそれぞれの角度を制御する3つのモータ(図5ではまとめて、「右腕モータ」として示す。)40Rの回転角度を調節する。また、モータ制御ボード38は、左腕24Lの3つのモータ(図5ではまとめて、「左腕モータ」として示す。)40Lの回転角度を調節する。モータ制御ボード38は、また、頭部20の旋回角や俯仰角を制御する3のモータ(図5ではまとめて、「頭部モータ」として示す。)42の回転角度を調節する。モータ制御ボード38は、また、眼球28を動かす眼球モータ44も制御する。
【0031】
なお、上述のモータは、制御を簡単化するためにそれぞれステッピングモータまたはパルスモータであるが、直流モータであってよい。
【0032】
スピーカ48には音声入力/出力ボード46を介して、コンピュータ32から、合成音声データが与えられ、それに応じて、スピーカ48からはそのデータに従った音声または声が出力される。そして、マイク50からの音声入力が、音声入力/出力ボード46を介して、コンピュータ32に取り込まれる。
【0033】
センサ入力/出力ボード52も、同様に、DSPで構成され、各センサやカメラからの信号を取り込んでコンピュータ32に与えるが、実施例ではあまり関係がないので、ここでは、そのセンサなどの詳細な説明は省略する。
【0034】
なお、図1に示す実施例において、ユーザ12の前方すなわちぬいぐるみ14の周囲は図6に示すように区画されている。ユーザ12の視線がぬいぐるみ14に向けられているのか、ぬいぐるみ14とユーザ12とが共同注視できる範囲内ではあるがぬいぐるみ以外の対象、たとえば別の擬人的媒体や人などに向けられているのか、共同注視できる範囲の外つまり範囲外に向けられているのか、などに応じて、ぬいぐるみ14がユーザ12に対して行なう発話や動作を決めるためである。
【0035】
ただし、このような区画はもっと細かく規定されて、その細かい区画ごとにぬいぐるみ14がユーザ12に対して行なう発話や動作を決めるようにしてもよい。
【0036】
また、この実施例では、ぬいぐるみ14が自律的に自己の動作や発話を制御する図5のような制御回路を持つものとして説明するが、ぬいぐるみ14を制御するための1台またはそれ以上のコンピュータをぬいぐるみ14とは別に設けるようにしてもよい。
【0037】
このような実施例において、まず、ユーザ12の視線を推定する方法について説明する。この実施例では、以下に説明するように、ユーザ12の視線方向を推定または検出するために1つのカメラ(単眼カメラ)を用いるユニークな方法を採用している。しかしながら、ユーザ12の視線12A(図2,図3)を検出する方法としては、2以上のカメラを利用する従来からの一般的な方法が採用されてもよいことは、勿論である。つまり、この発明では、ユーザ12の視線を推定したり検出したりする必要はあるが、その具体的な方法は重要な意味を持たず、どのような公知の方法が用いられてもよい。
【0038】
図1に示すように、ユーザ12の前方に、たとえばCCD(Charge Coupled Device)
またはCMOS(Complementary Metal-Oxide Semiconductor)センサのような固体撮像
素子を含むカメラ16が設置され、このカメラ16からの顔画像信号が視線サーバ18に取り込まれ、視線サーバ18が画像処理することによって、視線12Aの角度αおよびβを推定する。
【0039】
図7に示すように、カメラ16により撮影された画像は、視線サーバ18に附属して設けたディスプレイ54(図1では図示せず)の撮影画像表示領域56にリアルタイムに動画として表示される。特に限定されないが、たとえば、撮影画像表示領域56上に、視線方向を示す指標として、眉間から視線方向に延びる線分を表示してもよい。
【0040】
視線サーバ18は、一般的なコンピュータであり、特に変わったハードウェア構成ではないので、ハードウェア自体は説明しないが、視線方向や視線位置の推定は、以下に説明するソフトウェアにより実現される。
【0041】
視線サーバ18では、特徴点の追跡処理の安定性を確保するため、同一特徴点に関して異なるフレームにおける複数の観測テクスチャを保持している。初期校正過程では、これらの特徴点と虹彩中心の関係から顔特徴点と眼球中心の相対関係を求める。視線推定過程では、校正過程で得られた関係を元に現フレームで得られている特徴点群から眼球中心位置を推定し、その位置と虹彩中心位置から視線方向を決定する。
【0042】
視線方向の推定処理の動作の前提として、まず、たとえば6分割矩形フィルタを利用して、顔検出処理が実行される。
【0043】
視線サーバ18では、特に限定されないが、たとえば、顔を連続撮影したビデオ画像を処理するにあたり、横が顔幅、縦がその半分程度の大きさの矩形フィルタで画面を走査する。矩形は、たとえば、3×2に6分割されていて、各分割領域の平均明るさが計算され、それらの相対的な明暗関係がある条件を満たすとき、その矩形の中心を眉間候補とする。
【0044】
連続した画素が眉間候補となるときは、それを取囲む枠の中心候補のみを眉間候補として残す。残った眉間候補を標準パターンと比較してテンプレートマッチング等を行うことで、上述した手続きで得られた眉間候補のうちから、偽の眉間候補を捨て、真の眉間を抽出する。以下、さらに詳しく説明する。
【0045】
図8は、眉間候補領域を検出するためのフィルタを説明するための概念図であり、図8(a)は、上述した3×2に6分割された矩形フィルタ(以下、「6分割矩形フィルタ」
と呼ぶ)を示す。
【0046】
6分割矩形フィルタは、(1) 鼻筋は両目領域よりも明るい、(2) 目領域は頬部よりも暗い、という顔の特徴を抽出し、顔の眉間位置を求めるフィルタである。たとえば、1点(x、y)を中心として、横i画素、縦j画素(i,j:自然数)の矩形の枠を設ける。そして、図8(a)のように、この矩形の枠を、横に3等分、縦に2等分して、6個のブロックS1〜S6に分割する。
【0047】
このような6分割矩形フィルタを顔画像の両目領域および頬部に当てはめてみると、図8(b)のようになる。
【0048】
ただし、図8の6分割フィルタは書く矩形領域が等分されたものであったが、このフィルタは図9に示すように変形されてもよい。
【0049】
鼻筋の部分が目の領域よりも通常は狭いことを考慮すると、ブロックS2およびS5の横幅w2は、ブロックS1,S3,S4およびS6の横幅w1よりも狭い方がより望ましい。好ましくは、幅w2は幅w1の半分とすることができる。図9は、このような場合の6分割矩形フィルタの構成を示す。また、ブロックS1、S2およびS3の縦幅h1と、ブロックS4、S5およびS6の縦幅h2とは、必ずしも同一である必要もない。
【0050】
図9に示す6分割矩形フィルタにおいて、それぞれのブロックSi(1≦i≦6)について、画素の輝度の平均値「バーSi」(Siに上付きの“−”をつける)を求める。
【0051】
ブロックS1に1つの目と眉が存在し、ブロックS3に他の目と眉が存在するものとすると、以下の関係式(1)および(2)が成り立つ。
【0052】
【数1】
【0053】
【数2】
【0054】
そこで、これらの関係を満たす点を眉間候補(顔候補)として抽出する。
【0055】
矩形枠内の画素の総和を求める処理には、公知の文献(P. Viola and M. Jones, “ Rapid Object Detection using a Boosted Cascade of Simple Features,” Proc. Of IEEE
Conf. CVPR, 1, pp.511-518, 2001)において開示されている、インテグラルイメージ(Integral Image)を利用した計算の高速化手法を取り入れることができる。インテグラルイメージを利用することでフィルタの大きさに依らず高速に実行することができる。多重解像度画像に本手法を適用することにより、画像上の顔の大きさが変化した場合にも顔候補の抽出が可能となる。
【0056】
このようにして得られた眉間候補(顔候補)に対しては、両目の標準パターンとのテンプレートマッチングにより、真の眉間位置(真の顔領域)を特定することができる。
【0057】
なお、得られた顔候補に対して、サポートベクトルマシン(SVM)による顔モデルに
よる検証処理を適用し顔領域を決定することもできる。髪型の違いや髭の有無、表情変化による認識率の低下を避けるため、たとえば、図10に示すように、眉間を中心とした画像領域を利用してSVMによるモデル化を行うことができる。なお、このようなSVMによる真の顔領域の決定については、文献:S. Kawato, N. Tetsutaniand K. Hosaka: “Scale-adaptive face detection and tracking in real time with ssr fi1ters and support vector machine”, IEICE Trans.on Info. and Sys., E88−D, 12, pp.2857−2863(2005)に開示されている。6分割矩形フィルタによる高速候補抽出とSVMによる処理とを組み合わせることで実時間の顔検出が可能である。
【0058】
続いて、目、鼻や虹彩中心の位置を、公知の文献、たとえば『川戸、内海、安部:「4つの参照点と3枚のキャリブレーション画像に基づく単眼カメラからの視線推定」画像の認識・理解シンポジウム(MIRU2005),pp.1337−1342(2005)』あるいは、『川戸慎二郎、鉄谷信二:鼻位置の検出とリアルタイム追跡:信学技報IE2002−263、pp.25−29(2003)』などの手法を用いて抽出する。
【0059】
両目の位置については、前節の顔領域検出で眉間のパターンを探索しているため、眉間の両側の暗い領域を再探索することにより、大まかな両目の位置を推定することができる。しかし、視線方向の推定のためには、虹彩中心をより正確に抽出する必要がある。ここでは、上で求まった目の周辺領域に対して、ラプラシアンにより虹彩のエッジ候補を抽出し、円のハフ変換を適用することにより、虹彩および虹彩の中心の投影位置を検出する。
【0060】
鼻の位置は、鼻先が凸曲面であるため周囲に対し明るい点として観測されやすいことと、両目の位置から鼻の存在範囲が限定できることを利用して抽出する。また、両目、鼻の位置を用いて、大体の顔の向きも推定できる。
【0061】
図11は顔検出結果の例を示す図である。検出された顔において、虹彩中心や鼻先や口なども検出されている。たとえば、特徴点としては、鼻先や、左右の目の目尻や目頭、口の両端、鼻腔中心などを用いることができる。
【0062】
視線の推定においては、視線方向は眼球中心と虹彩中心を結ぶ3次元直線として与えられるものとする。
【0063】
図12は視線方向を決定するためのモデルを説明する概念図である。画像上での眼球半径をr、画像上での眼球中心と虹彩中心との距離をdとすると、視線方向とカメラ光軸と
のなす角θは次式(3)で表される。
【0064】
【数3】
【0065】
式(3)により、視線方向を推定するためには、画像上での眼球半径と眼球中心・虹彩中心の投影位置が必要となる。ここで、虹彩中心の投影位置については、上述したとおり、ハフ変換を用いた手法により求めることができる。画像上での眼球直径rは、解剖学的なモデル(標準的な人の眼球直径)を用いてもよいし、別途キャリブレーションにより求めてもよい。
【0066】
図13は、図12に示した状態からユーザがカメラを注視する状態に移行した後の虹彩中心、眼球中心および投影点の関係を示す概念図である。
【0067】
眼球中心の投影位置については、一般には、画像から直接観測することはできない。しかし、ユーザ12がカメラ16を注視した場合について考えると、図13に示すとおり、カメラ、虹彩中心、眼球中心の3点が1直線上に並ぶため、画像では虹彩中心と眼球中心は同一点に投影されることがわかる。
【0068】
そこで、この実施例での視線推定では、ユーザがカメラを注視しながら、顔の姿勢を変化させている画像フレーム列を撮影し、これらの画像列から虹彩位置と顔特徴点を抽出、追跡することにより、眼球中心と顔特徴点間の相対幾何関係を推定する。
【0069】
後により詳しく説明するように、この実施例の視線方向の推定では、眼球中心と顔特徴点間の相対関係の推定処理と眼球中心の投影位置推定とを行なう。
【0070】
視線方向の推定のための初期設定として、視線サーバ18は、図14に示すフローチャートで表現されるキャリブレーションを実行する。
【0071】
まず、キャリブレーション用の画像列として、ユーザがカメラを注視しながら、顔の姿勢を変化させている画像フレーム列を撮影する(ステップS102)。図15は、このようにしてキャリブレーションにおいて撮影された4枚の画像フレームを示す。
【0072】
ここでは、より一般に、N(N≧2)枚の画像列が得られたとする。各画像フレームを、フレームI1,…INとする。
【0073】
次に、得られた各画像フレーム列に対して、上述したような方法によって顔検出処理を行い(ステップS104)、続いて、目や鼻の検出処理を行なう(ステップS106)。
【0074】
さらに、視線サーバ18は、特徴点の抽出、追跡を行う(ステップS108)。なお、特徴点の抽出方法としては、上述したような方法の他に、たとえば、文献:J. Shi and C. Tomasi: “Good features to track”,Proc. CVPR94, pp. 593−600(1994)で提案された手法を用いることもできる。
【0075】
ここで、各画像フレームIi(i=1,…,N)においてM(M≧4)点の特徴点pj(j=1,…,M)が検出・追跡できたとする。画像フレームIiにおける特徴点pjの2次元観測位置をxj(i)(太字)=[xj(i),yj(i)]t(i=1,…,N,j=1,…,M)とし、両目の虹彩中心の2次元観測位置をそれぞれxr(i)(太字)=[xr(i),yr(i)]t,xl(i)(太字)=[xl(i),yl(i)]t(i=1,…,N)とする。ここで、行列Wを以下のように定義する。
【0076】
【数4】
【0077】
因子分解法により、特徴点の各フレームでの2次元観測位置を縦に並べた行列W(計測行列)は以下のように分解できる。
【0078】
【数5】
【0079】
ここで、行列M(「撮影姿勢行列)と呼ぶ)にはカメラの姿勢に関する情報のみが、行列S(「相対位置関係行列」と呼ぶ)には観測対象物の形状に関する情報のみが含まれており、顔特徴点と眼球中心との3次元的な位置の相対関係は行列Sとして求まる(ステップS110)。すなわち、正射影を仮定すると、行列Mの各要素が画像フレームでのカメラの姿勢を表す単位ベクトルであって、それぞれの大きさが1であり相互には直交するとの拘束条件のもとで、行列Wは、特異値分解により一義的に行列Mと行列Sの積に分解できることが知られている。なお、このような計測行列Wを、因子分解により、カメラの運動の情報を表す行列と対象物の形状情報を表す行列へ分解する点については、文献:金出,ポールマン,森田:因子分解法による物体形状とカメラ運動の復元”,電子通信学会論文誌D−II,J76‐D−II,8,pp.1497−1505(1993)に開示がある。
【0080】
図16は、リアルタイムの視線方向の推定処理のフローチャートを示す。
【0081】
次に、以上で得られた結果を用いて、視線方向を推定する手順について説明する。
【0082】
まず、カメラ16から画像フレームを取得すると(ステップS200)、キャリブレーション時と同様にして、顔の検出および目鼻の検出が行なわれ(ステップS202)、取得された画像フレーム中の特徴点が抽出される(ステップS204)。
【0083】
画像フレームIkが得られたとする。ここで、眼球中心以外の特徴点のうちm点pj(j=j1,…,jm)が、それぞれ、xj(k)(太字)=[xj(k),yj(k)]tに観測されたとする。このとき、観測された特徴点について、上述したように特徴点近傍のテンプレートを用いたテンプレートマッチングを実施することで、キャリブレーション時に特定された特徴点と現画像フレーム中で観測された特徴点との対応付けが行なわれて、現画像フレーム中の特徴点が特定される(ステップS206)。
【0084】
なお、上述のとおり、特徴点を特定するためのテンプレートは、キャリブレーションの時のものに限定されず、たとえば、最近の画像フレームの所定枚数について検出された特徴点の近傍の所定の大きさの領域内の画像を所定個数だけ保持しておき、これら所定枚数のテンプレートについてマッチングをした結果、もっとも一致度の高い特徴点に特定することとしてもよい。
【0085】
顔特徴点pjの2次元観測位置xj(k)(太字)=[xj(k),yj(k)]tとキャリブレーションより求まった3次元位置sj(太字)=[Xj,Yj,Zj]t(j=1,…,M)の間には、M個の特徴点のうち観測されたm個の特徴点について注目すると、次式の関係が得られる。
【0086】
【数6】
【0087】
ただし、行列P(k)は2×3の行列である。右辺の第2項の行列S(k)は行列Sのうち、観測された特徴点に対応する要素のみからなる部分行列である。上述の通り、カメラと顔は十分に離れているとし正射影を仮定している。ここで、4点以上の特徴点が観測されれば、行列P(k)は以下のように計算できる(ステップS208)。
【0088】
【数7】
【0089】
画像フレームIkにおける眼球中心の投影位置xr(i)(太字),xl(i)(太字)は、行列P(k)を用いて以下のように計算できる(ステップS210)。
【0090】
【数8】
【0091】
【数9】
【0092】
したがって、画像フレームIkにおいて特徴点として抽出した虹彩中心の投影位置とこの眼球中心の投影位置を用いると、視線の推定を行なうことができる(ステップS212)。
【0093】
なお、行列PをQR分解により分解することで、顔の姿勢Rが、以下のように計算できる。
【0094】
【数10】
【0095】
【数11】
【0096】
ただしr1、r2はそれぞれ1×3のベクトルである。このような顔の姿勢Rの検出については、文献:L.Quan: “Self-calibration of an affine camera from multiple views”,Int’l Journal of Computer Vision, 19, pp. 93−105(1996)に開示がある。
【0097】
ユーザ等の指示により追跡が終了していると判断されれば(ステップS214)、処理は終了し、終了が指示されていなければ、処理はステップS202に復帰する。
【0098】
以上説明した視線方向の推定装置の有効性を確認するため、実画像を用いた実験を行った結果について以下に説明する。
【0099】
カメラはElmo社製PTC−400Cを用い、被験者から約150[cm]の位置に設置した。
【0100】
まず、50フレームの画像列を用いて、眼球中心と顔特徴点のキャリブレーションを行った。キャリブレーション用の画像フレーム列と抽出した特徴点の例は、図15に示したとおりである。
【0101】
キャリブレーション用画像フレーム列の撮影に要した時間は約3秒であった。(+印は抽出された虹彩中心(眼球中心))、×印は追跡した顔特徴点)。
【0102】
次に、キャリブレーションにより求まった顔モデル(行列S)を用いて、視線推定を行った。ここで、被験者はそれぞれ右上、上、左下の方向を注視しながら、顔の位置・向きを変化させた。
【0103】
図17〜図19は、視線推定結果を示す。図17は、右上方注視の状態であり、図18は、上方注視の状態であり、図19は、左下方向注視の状態である。ここで、視線方向は両目それぞれで計算された視線方向の平均値としている。結果より、顔の位置や向きの変化とは関係なく、視線方向が推定できた。
【0104】
以上説明したとおり、この実施例の視線方向の推定方法では、単眼カメラの観測に基づいて顔特徴点を検出し、追跡することにより視線方向を推定する。つまり、まずキャリブレーションとして視線がカメラ方向を向いたまま顔の向きのみが異なる画像列から得られる虹彩位置と顔特徴点を利用することで、眼球中心と顔特徴点の関係をモデル化し(行列Sを特定し)、その後、その関係に基づいて推定された入力画像中の眼球中心位置と虹彩位置の関係から視線方向の角度α、βを決定する。
【0105】
図20に示すフローチャートを実行して、ぬいぐるみ14の発話や動作を制御するのであるが、この図20に示すフローチャートは、後に説明する図23のフローチャートと同様に、一定時間ごと、たとえば1‐2秒の周期で実行されるものとする。
【0106】
図20の最初のステップS1では、ユーザ12の発話を検出するためのステップS1aとユーザ12の視線の状態を判定するためのステップS1bを並行的に処理する。
【0107】
ステップS1aでは、ぬいぐるみ14のコンピュータ32(図5)は、マイク50(図5)からの音声入力のパワーを計算するなどして、ユーザ12が発話したかどうか、つまり、ユーザ12の発話の有無を検出し、その結果(発話の有無)を発話の状態を示すデータとしてメモリ36の判定結果記憶部36Cに格納する。
【0108】
ただし、ユーザ12が発話したかどうかを検出するためには別の方法、たとえば、超指向性マイクを用いる方法、音源とベクトルを計算する方法、音声のパワースペクトルにおける倍音成分を検出する方法などである。この発明では、ユーザの発話の有無を検出する方法としてはいずれの方法を用いてもよい。
【0109】
また、ステップS1bでは、上述のようにして視線サーバ18が推定した視線角度αおよびβのデータが、ぬいぐるみ14のバス34(図5)を通してコンピュータ32に与えられる。コンピュータ32では、その角度データから視線12A(図2,3)の空間10Aにおける空間座標(x,y,z)を、絶対位置として計算する。
【0110】
一方、ぬいぐるみ14はそれぞれ、図6に示すように固定的に配置されている。したがって、このぬいぐるみ14の存在する空間10A内の、図6に示す「範囲」の座標およびその範囲内でのぬいぐるみ14が存在する位置の座標はともに既に計算されて、たとえばメモリ36(図5)に記憶されている。
【0111】
そこで、次のステップS3で、コンピュータ32は、先にステップS1bで計算した視線の空間座標とメモリ36内に予め蓄積されている各座標とを比較し、ユーザ12のそのときの視線の方向、つまり、視線の相対位置がぬいぐるみ14自体に向けられているのか、ぬいぐるみ14ではないが範囲内(図6)に存在する他のもの、たとえば擬人的媒体あるいは人間などに向けられているのか、あるいは図6に示す範囲外に向けられているのかを判定する。そのようにして判定した視線の状態の判定結果は、視線状態データとしてメモリ36の記憶部36Cに記憶される。
【0112】
続くステップS5で、コンピュータ32は、ユーザ12が発話したタイミングにおけるユーザ12の上記視線状態に基づいて、そのときのユーザ12の発話が、ぬいぐるみ14自身に向けられたものか、範囲内の違う対象に向けられたものか、あるいは、わからないかを推定する。わからない、というのは、ユーザ12の視線が図6の範囲外に向けられているとき、または視線が安定しない不安定な状態であるときにそのように推定する。この発話対象推定ステップで推定した発話対象も、発話状態データとして上述の記憶部36Cに記録される。
【0113】
ここで、このステップS5における発話対象推定動作についてより具体的に説明する。発話対象推定においては、図27および図28に示す発話対象テーブル36D(図5)を参照してユーザ12が発話した対象が自分すなわちぬいぐるみ14かどうか推定する。発話対象テーブル36Dでは、前回発話、前回視線、今回発話および今回視線のそれぞれの判定結果(図5に示す判定結果記憶部36Cに蓄積されている。)に加えて、前回発話/視線と今回発話/視線との時間間隔の長短を推定要素として用いる。この時間間隔は、たとえば、1秒以上を「長」と、1秒未満を「短」として登録する。ただし、ケース1−4、9−14では、各判定結果とこの時間間隔とを要素として推定するのであるが、ケース5‐8、15‐16、19−22は単純に発話および視線の判定結果だけで発話対象を推定するようにしている。そして、ケース17‐18、23‐28では、発話が前回も今回もないので、この発話対象ステップでは関係ない状態である。
【0114】
たとえば、図27のケース1および2に示すように、前回の発話判定結果が「○」で前回の視線状態判定結果が「×」であったが今回の発話判定結果は「×」になり、視線状態判定結果は「○」になった場合には、時間間隔の短長によって、「短」(ケース1)の場合は、(前回の発話は)自分(ぬいぐるみ14)である可能性が高いと判定または推定し、「長」(ケース2)の場合は、(前回の発話は)おそらく自分ではなく、単に前回視線の対象であったと推定する。
【0115】
たとえば、図27のケース3および4に示すように、前回の発話判定結果が「×」で前回の視線状態判定結果が「○」であったが今回の発話判定結果は「○」になり、視線状態判定結果は「×」になった場合には、時間間隔の短長によって、「短」(ケース3)の場合は、今回の発話は自分(ぬいぐるみ14)である可能性が高いと推定し、「長」(ケース4)の場合は、おそらく自分ではなく、単に今回視線の対象であったと推定する。
【0116】
これに対して、ケース5および6では、前回も今回も視線が自分に向けられていない(「×」である。)ので、時間間隔の長短に拘わらず、ともに発話対象が自分ではないと推定している。同じく、前回と今回との判定結果だけを利用するケース7および8、ケース19および20、ケース21および22においても、時間間隔の如何にかかわらず同一の推定結果を生じている。
【0117】
このようなテーブル36Dを利用することによって、発話と視線の有無が一致していない状態データも発話対象をおおむね正確に推定することができる。
【0118】
続いて、ステップS7で、コンピュータ32は、ステップS3で判定したユーザの視線状態(ユーザ12の視線がぬいぐるみ14自体に向けられているのか、ぬいぐるみ14ではないが範囲内に存在する他のものに向けられているのか、あるいは範囲外に向けられているのか)と、ステップS5で推定した、ユーザの発話が向けられた発話対象(ぬいぐるみ14に向けたものか、範囲内の違う対象に向けたものか、あるいは、わからないか)とに基づいて、そのときのユーザ12とぬいぐるみ14との間のコミュニケーション状態を推定または特定する。
【0119】
具体的には、図21に示すように、発話対象が「自分」、「自分以外の範囲内」、「範囲外」、または「発話なし」の場合に、視線状態が「自分」、「自分以外の範囲内」、「不明」のいずれかであるとき、両者のコミュニケーション状態がどのような状態なのかを推定する。ただし、視線方向が図6に示す「範囲外」であるとき、または、不安定で定まらない状態のときを「不明」と判定する。たとえば、発話対象も視線状態も「自分」のときには、ユーザ12がぬいぐるみ14に目を合わせて発話している状態であると推定できる。なお、この解釈テーブル36Aによって推定または特定できるコミュニケーション状態は全て図21に詳細に記述しているので、詳細は図21を参照されたい。
【0120】
ステップS9では、コンピュータ32は、ステップS7で特定したコミュニケーション状態に応じて、ユーザからぬいぐるみへのコミュニケーションを誘発するのに効果的な、ぬいぐるみの行動(発話および/または動作)を決定する。このぬいぐるみの行動(発話および/または動作)は具体的には、図22に示すが、基本的には、ユーザがぬいぐるみに対して発話しているようなコミュニケーション状態では、コンピュータ32は、ぬいぐるみ14がユーザに対して音声(発話)で返事するような行動を設定する。しかしながら、ユーザが発話していないか、ぬいぐるみに話かけていないか、のときには、ぬいぐるみの行動としては、音声による返事をするようには設定しない。また、ユーザがぬいぐるみに視線を向けているコミュニケーション状態では、コンピュータ32は、ぬいぐるみ14がユーザに対して動作でリアクションを表現するような行動を決定する。そして、ユーザがぬいぐるみは見ていないがユーザの視線が「範囲内」にある、そのようなコミュニケーション状態のときには、コンピュータ32はぬいぐるみ14の行動として、ユーザの視線方向を共同注視するなど、という行動を設定する。ただし、ユーザの視線が「範囲外」のときには、ぬいぐるみには何も反応動作を設定しない。
【0121】
具体的には図22にコミュニケーション状態とぬいぐるみの行動とのテーブルを示すが、これらは単なる例示であり、適宜変更可能であることはいうまでもない。ただし、図22のコミュニケーション状態の番号と図21のコミュニケーション状態の番号とが対応するものと理解されたい。
【0122】
ステップS11では、コンピュータ32はステップS9で決定したぬいぐるみの行動を実際にぬいぐるみ14が生じるように、必要な音声データやモータ制御データを音声入出力ボード46やモータ制御ボード38に出力する。ただし、ぬいぐるみ14が発話するタイミングは、ユーザ12の発話が終わった後であり、そのために、先に説明した「発話中フラグ」が参照される。つまり、発話中フラグはユーザが発話中であるとき「1」であるので、それぞれが「0」になった後にぬいぐるみ14の発話を実行させるようにする。ただし、ぬいぐるみ14の動作は、ユーザの発話中に実行してもよいし、ユーザの発話が終了した後に実行するようにしてもよい。
【0123】
このようにして、ぬいぐるみのコンピュータ32は、ユーザの発話状態の判定結果とユーザの視線状態の判定結果とに基づいて、ユーザのぬいぐるみに対するコミュニケーション状態を推定し、そのコミュニケーション状態から、ユーザのぬいぐるみに対するコミュニケーションを一層増進させ、あるいは誘発するように、ぬいぐるみの行動、すなわち発話や動作を制御する。
【0124】
図23はこの発明の他の実施例の動作を示すフローチャートである。先の実施例ではコミュニケーション状態を特定するのに、今回の視線状態および今回の発話状態だけを参照したのに対し、前回の視線状態および前回の発話状態も考慮して、コミュニケーション状態を特定しようとするという点で、この実施例は先の実施例と異なる。
【0125】
図23の最初のステップS21では、ユーザ12の発話を検出するためのステップS21aとユーザ12の視線の状態を判定するためのステップS21bを並行的に処理する。
【0126】
ステップS21aでは、図20のステップS1aと同じように、ユーザ12の発話の有無を検出し、その結果(発話の有無)を発話の状態を示すデータとしてメモリ36の判定結果記憶部36Cに格納する。ここでも、ユーザ12が発話したかどうかを検出するための方法は任意の方法であってよい。
【0127】
また、ステップS21bでは、上述のようにして視線サーバ18が推定した視線角度αおよびβのデータが、ぬいぐるみ14のバス34(図5)を通してコンピュータ32に与えられる。コンピュータ32では、その角度データから視線12A(図2,3)の空間10Aにおける空間座標(x,y,z)を、絶対位置として計算する。
【0128】
一方、ぬいぐるみ14はそれぞれ、図6に示すように固定的に配置されている。したがって、このぬいぐるみ14の存在する空間10A内の、図6に示す「範囲」の座標およびその範囲内でのぬいぐるみ14が存在する位置の座標はともに既に計算されて、たとえばメモリ36(図5)に記憶されている。
【0129】
そこで、ステップS1bで、コンピュータ32は、先に計算した視線の空間座標とメモリ36内に予め蓄積されている各座標とを比較し、ユーザ12のそのときの視線の方向、つまり、視線の相対位置がぬいぐるみ14自体に向けられているのか、あるイはぬいぐるみ14以外に向けられているのかを判定する。そのようにして判定した視線の状態の判定結果は、視線状態データとしてメモリ36の記憶部36Cに記憶される。
【0130】
続くステップS23で、コンピュータ32は、ユーザの前回の発話状態の判定結果および前回の視線状態の判定結果と、今回の発話状態の判定結果および今回の視線状態の判定結果とに基づいて、ユーザ12とぬいぐるみ14との間のコミュニケーション状態を推定または特定する。たとえば、ユーザ12が前回はぬいぐるみ14に話しかけていたけれども、今回は別の対象に話ししているような場合であれば、ぬいぐるみとユーザとはコミュニケーションが完全には途切れてはいないので、「ユーザの話しかけている対象とユーザを注視する必要がある」などと、コミュニケーション状態を解釈する。
【0131】
前回判定結果と今回判定結果とに基づいて推定または特定するコミュニケーション状態の具体例が図24に示されている。
【0132】
たとえば、図24のケース1に示すように、前回の発話判定結果が「×」で前回の視線状態判定結果が「○」であったが今回の発話判定結果も視線状態判定結果もともに「○」である場合には、コミュニケーション状態は「ユーザはぬいぐるみに目を合わせた状態でぬいぐるみに話しかけた」と解釈する。ただし、ここで発話判定結果が「×」ということは、ユーザはそのとき発話しなかったことを意味している。視線状態判定結果が「○」ということは、そのときユーザの視線はぬいぐるみに向けられていたことを意味している。
【0133】
ケース2では、前回の発話判定結果が「○」で前回の視線状態判定結果が「×」であったが今回の発話判定結果も視線状態判定結果もともに「○」である。この場合には、コミュニケーション状態は「ユーザは発話しながらぬいぐるみに目を向けた」と解釈する。ただし、ここで発話判定結果が「○」ということは、ユーザはそのとき発話したことを意味していて、視線状態判定結果が「×」ということは、そのときユーザの視線はぬいぐるみには向けられていなかったことを意味している。
【0134】
ケース3のように、前回の発話判定結果が「×」で前回の視線状態判定結果が「×」であったが今回の発話判定結果も視線状態判定結果もともに「○」である場合には、コミュニケーション状態は「ユーザはぬいぐるみを見ると同時に話しかけたに」と解釈する。
【0135】
ケース4に示す状態は、前回の発話判定結果および視線状態判定結果がともにが「○」今回の発話判定結果も視線状態判定結果もともに「○」である場合であり、このような場合には、コミュニケーション状態は「ユーザはずっとぬいぐるみを見ながらぬいぐるみに話しかけている(状態保存)」と解釈できる。
【0136】
以下、各個別のコミュニケーション状態についての詳細な説明は省略するので、必要に応じて図24を参照されたい。
【0137】
ステップS25では、コンピュータ32は、ステップS23で特定したコミュニケーション状態に応じて、ユーザからぬいぐるみへのコミュニケーションを誘発するのに効果的な、ぬいぐるみの行動(発話および/または動作)を決定する。このぬいぐるみの行動(発話および/または動作)は具体的には、図25-26に示すが、基本的には、発話状態や視線状態の時間変化に対応してコミュニケーション行動を決定する。たとえば、前回は発話視線ともに×であったものが、今回とも○になったような場合、コミュニケーション状態3は「ユーザはぬいぐるみを見ると同時に話しかけてきた」という状態であると推定するが、そのような状態変化に対応してぬいぐるみが実行する行動は、図25のコミュニケーション状態3に示す行動を実行させる。具体的には、音声としては「少し驚いたような返事」をさせ、動作としてはユーザのコミュニケーションを取りたいという発意に気付いたというように「首をがくがく振る」などの動作を行なわせる。このようなぬいぐるみ14の行動によって、ユーザがぬいぐるみに対してコミュニケーションをとりたいという意欲を継続させることができる。
【0138】
なお、図25-26にコミュニケーション状態とぬいぐるみの行動とのテーブルを示すが、これらは単なる例示であり、適宜変更可能であることはいうまでもない。
【0139】
ステップS27では、コンピュータ32はステップS25で決定したぬいぐるみの行動を実際にぬいぐるみ14が生じるように、必要な音声データやモータ制御データを音声入出力ボード46やモータ制御ボード38に出力する。ただし、実際に発話するタイミングは先の実施例と同様に、ユーザ12の発話を邪魔しないようなタイミングに設定するなどの配慮が必要であろう。
【0140】
このようにして、ぬいぐるみのコンピュータ32は、前回と今回とのユーザの発話状態の判定結果とユーザの視線状態の判定結果とに基づいて、ユーザのぬいぐるみに対するコミュニケーション状態を推定し、そのコミュニケーション状態から、ユーザのぬいぐるみに対するコミュニケーションを一層増進させ、あるいは誘発するように、ぬいぐるみの行動、すなわち発話や動作を制御する。
【0141】
ただし、今回発話の判定結果および今回視線の判定結果だけを用いても、発話対象や視線状態を特定または推定することができるので、必ずしも、前回の判定結果と今回の判定結果の両方を用いる必要はない。そして、この場合には、各判定手段は発話状態や視線状態を一定時間ごとに繰り返し判定する必要はなく、必要な都度判定するようにすることも考えられる。
【図面の簡単な説明】
【0142】
【図1】この発明の一実施例のコミュニケーション誘発システムの概念を示す図解図である。
【図2】図1実施例におけるユーザとぬいぐるみとの平面的な位置関係およびユーザの視線角度を示す図解図である。
【図3】図1実施例におけるユーザとぬいぐるみとの側面的な位置関係およびユーザの視線角度を示す図解図である。
【図4】図1実施例において用いられるぬいぐるみの一例を示す図解図である。
【図5】図1実施例におけるぬいぐるみの制御回路の一例を示すブロック図である。
【図6】図1実施例におけるユーザの視線の状態を判定する範囲の一例を示す図解図である。
【図7】図1実施例における視線サーバのディスプレイに表示されているユーザの顔画像の一例を示す図解図である。
【図8】図8は眉間候補領域を検出するためのフィルタを説明するための概念図である。
【図9】図9は6分割矩形フィルタの他の構成を示す概念図である。
【図10】図10は眉間を中心とした画像領域を利用してSVMによるモデル化を説明する図解図である。
【図11】図11は顔検出結果の例を示す図解図である。
【図12】図12は視線方向を決定するためのモデルを説明する概念図である。
【図13】図13はユーザがカメラを注視する状態に移行した後の虹彩中心、眼球中心および投影点の関係を示す概念図である。
【図14】図14は視線サーバによる初期設定の処理動作を示すフロー図である。
【図15】図15はキャリブレーションにおいて撮影された4枚の画像フレームを示す図解図である。
【図16】図16は視線サーバが実行するリアルタイム視線検出の処理動作を示すフロー図である。
【図17】図17は右上方注視の状態での視線推定結果を示す図解図である。
【図18】図18は上方注視の状態での視線推定結果を示す図解図である。
【図19】図19は左下方向注視の状態での視線推定結果を示す図である。
【図20】図20は図1実施例におけるぬいぐるみのコンピュータの動作を示すフロー図である。
【図21】図21は図1実施例におけるぬいぐるみに対するユーザのコミュニケーション状態の推定または解釈テーブルの一例を示す表である。
【図22】図22は図1実施例におけるコミュニケーション状態に応じたぬいぐるみの行動を規定する反応テーブルの一例を示す表である。
【図23】図23は別の実施例におけるぬいぐるみのコンピュータの動作を示すフロー図である。
【図24】図24は図23実施例におけるぬいぐるみに対するユーザのコミュニケーション状態の推定または解釈テーブルの一例を示す表である。
【図25】図25は図23実施例におけるコミュニケーション状態に応じたぬいぐるみの行動を規定する反応テーブルの一例を示す表である。
【図26】図26は図25の続きを示す表である。
【図27】図27は図20実施例における発話対象テーブルの一例を示す表である。
【図28】図28は図27の続きを示す表である。
【符号の説明】
【0143】
10 …コミュニケーション誘発システム
14 …ぬいぐるみ
16 …カメラ
18 …視線サーバ
32 …コンピュータ
36 …メモリ
50 …マイク
【特許請求の範囲】
【請求項1】
ユーザが視認できる位置に配置した擬人的媒体によって前記ユーザからのコミュニケーションを誘発するコミュニケーション誘発システムであって、
前記ユーザの視線の状態を判定する視線判定手段、
前記ユーザからの発話の状態を判定する発話判定手段、
前記視線位置判定手段による視線状態判定結果および前記発話判定手段による発話状態判定結果を記憶する記憶手段、
前記記憶手段に記憶した視線状態判定結果および発話状態判定結果に応じて前記ユーザと前記擬人的媒体とのコミュニケーション状態を特定するコミュニケーション状態特定手段、および
前記コミュニケーション状態特定手段が特定したコミュニケーション状態に応じて前記擬人的媒体の音声および動作を制御する制御手段を備える、コミュニケーション誘発システム。
【請求項2】
前記発話状態判定手段は前記ユーザの発話があったとの前記視線状態に応じて前記ユーザの発話対象が何かを推定する発話対象推定手段を含み、前記コミュニケーション状態特定手段は、前記発話対象推定手段の判定結果および前記視線状態判定結果に基づいて複数のコミュニケーション状態の1つを特定する、請求項1記載のコミュニケーション誘発システム。
【請求項3】
前記視線判定手段は前記ユーザの視線の状態を繰り返し判定し、前記発話判定手段は前記ユーザからの発話の状態を繰り返し判定し、
前記発話対象推定手段は、少なくとも前記記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じて前記ユーザの発話が前記擬人的媒体に向けられたものかどうか推定する、請求項2記載のコミュニケーション誘発システム。
【請求項4】
前記発話対象推定手段は、さらに前回と今回との時間間隔の長短を考慮して発話対を推定する、請求項3記載のコミュニケーション誘発システム。
【請求項5】
前記視線判定手段は前記ユーザの視線の状態を繰り返し判定し、前記発話判定手段は前記ユーザからの発話の状態を繰り返し判定し、
前記コミュニケーション特定手段は、前記記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じて前記ユーザと前記擬人的媒体とのコミュニケーション状態を特定する、請求項1記載のコミュニケーション誘発システム。
【請求項1】
ユーザが視認できる位置に配置した擬人的媒体によって前記ユーザからのコミュニケーションを誘発するコミュニケーション誘発システムであって、
前記ユーザの視線の状態を判定する視線判定手段、
前記ユーザからの発話の状態を判定する発話判定手段、
前記視線位置判定手段による視線状態判定結果および前記発話判定手段による発話状態判定結果を記憶する記憶手段、
前記記憶手段に記憶した視線状態判定結果および発話状態判定結果に応じて前記ユーザと前記擬人的媒体とのコミュニケーション状態を特定するコミュニケーション状態特定手段、および
前記コミュニケーション状態特定手段が特定したコミュニケーション状態に応じて前記擬人的媒体の音声および動作を制御する制御手段を備える、コミュニケーション誘発システム。
【請求項2】
前記発話状態判定手段は前記ユーザの発話があったとの前記視線状態に応じて前記ユーザの発話対象が何かを推定する発話対象推定手段を含み、前記コミュニケーション状態特定手段は、前記発話対象推定手段の判定結果および前記視線状態判定結果に基づいて複数のコミュニケーション状態の1つを特定する、請求項1記載のコミュニケーション誘発システム。
【請求項3】
前記視線判定手段は前記ユーザの視線の状態を繰り返し判定し、前記発話判定手段は前記ユーザからの発話の状態を繰り返し判定し、
前記発話対象推定手段は、少なくとも前記記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じて前記ユーザの発話が前記擬人的媒体に向けられたものかどうか推定する、請求項2記載のコミュニケーション誘発システム。
【請求項4】
前記発話対象推定手段は、さらに前回と今回との時間間隔の長短を考慮して発話対を推定する、請求項3記載のコミュニケーション誘発システム。
【請求項5】
前記視線判定手段は前記ユーザの視線の状態を繰り返し判定し、前記発話判定手段は前記ユーザからの発話の状態を繰り返し判定し、
前記コミュニケーション特定手段は、前記記憶手段に記憶した前回の視線状態判定結果および発話状態判定結果と今回の視線状態判定結果および発話状態判定結果とに応じて前記ユーザと前記擬人的媒体とのコミュニケーション状態を特定する、請求項1記載のコミュニケーション誘発システム。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図9】
【図12】
【図13】
【図14】
【図16】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図7】

【図8】

【図10】

【図11】
【図15】

【図17】
【図18】

【図19】
【図2】
【図3】
【図4】
【図5】
【図6】
【図9】
【図12】
【図13】
【図14】
【図16】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図7】
【図8】
【図10】
【図11】
【図15】
【図17】
【図18】
【図19】
【公開番号】特開2009−106325(P2009−106325A)
【公開日】平成21年5月21日(2009.5.21)
【国際特許分類】
【出願番号】特願2007−278479(P2007−278479)
【出願日】平成19年10月26日(2007.10.26)
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成19年度独立行政法人情報通信研究機構「民間基盤技術研究促進制度/軽度脳障害者のための情報セラピーインタフェースの研究開発」、産業技術力強化法第19条の適用を受ける特許出願
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
【公開日】平成21年5月21日(2009.5.21)
【国際特許分類】
【出願日】平成19年10月26日(2007.10.26)
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成19年度独立行政法人情報通信研究機構「民間基盤技術研究促進制度/軽度脳障害者のための情報セラピーインタフェースの研究開発」、産業技術力強化法第19条の適用を受ける特許出願
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
[ Back to top ]