
コンテンツ推薦装置及び方法及びプログラム

【課題】 その時のユーザの興味に沿って、かつ、トレンドにも沿ったアイテム(コンテンツ)をパーソナライズして推薦する。
【解決手段】 本発明は、時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、ユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する。
【解決手段】 本発明は、時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、ユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、コンテンツ推薦装置及び方法及びプログラムに係り、特に、時系列を考慮し、ユーザの興味の持つ商品(コンテンツ)やコンテンツの所属するクラスの変化を捉え、その時に合った商品を推薦するためのコンテンツ推薦装置及び方法及びプログラムに関する。
【背景技術】
【0002】
Webネットワーク上において、ユーザによる対象の意味や概念に対する参照要求が大きくなるにつれ、WikiPedia(登録商標)などの体系化された辞書が普及するようになってきている。また、こうしたユーザの要求を人手ではなく、人の変わりにサービスが処理し、ユーザにカスタマイズして提示可能とするため、機械処理可能な概念参照API(Application Program Interface)が急速に普及しており、DBPedia(登録商標)、Word-Net(登録商標)、FreeBasse(登録商標)など様々な情報プロバイダが、自身の持つ情報を体系化し、APIを通じ安価でかつ無料で提示するようになって着ている(例えば、非特許文献1参照)。
【0003】
一方、ユーザの興味のある概念を推測し、ユーザに代わりに情報を収集提示するような推薦システムも必要とされ、研究されてきた。こうした研究と上記多様なAPIを組み合わせれば、より広範囲にユーザの興味を推定できる。しかし、現状の技術には2点大きな問題がある。
【0004】
(1)多様な興味を取り扱うほど、時間軸に応じた興味の変化は激しいと考えられるが、そうした変換に対応していない。
【0005】
(2)概念体系は頻繁にメンテナンスされる。例えば、映像の体系は、サービスの深化とともに深堀りされたり、新たなグループが人気を博すと、そのグループの体系ができたりし、それに併せ体系も深化する。そうした概念体系(タクソノミ)の変動を考慮していない。
【0006】
本発明では、(1)の問題について取り組む。
【0007】
興味推定を行う技術を以下に示す。
【0008】
まず、タクソノミに基づく興味推定について説明する。
【0009】
ユーザの興味の変動を取り扱っておらず、例え2年前の履歴であっても、最近の履歴と等価に扱っている。特に、クラスのような抽象的な情報でユーザ興味を管理すると、時系列が長くなると、非常に多くのクラスにユーザが興味を持つと見做されるようになりやすくなる(例えば、非特許文献2参照)。
【0010】
次に、ユーザの興味の変動を、特定のtime windowで図りwindowから漏れた消費履歴を使用しないのではなく、全消費履歴を用いる。アイテムに対するユーザの評点の平均値が日時によって、辛めであったり、甘めであったりするという特性を考慮したモデルを構築しており、Matrix Factorizationとk-nearest users/itemsの2通りの手法に適用しており、従来のMF,KN両方の手法の精度を改善している(例えば、非特許文献3参照)。
【先行技術文献】
【非特許文献】
【0011】
【非特許文献1】Linked Open Data Project (http://linkeddata.org/).
【非特許文献2】Makoto Nakatsuji, Yasuhiro Fujiwara, Akimichi Tanaka, Tosho Uchiyama, Ko Fujimura, Toru Ishida, "Classical Music for Rock Fan",The 19th ACM international conference on Information and knowledge management.
【非特許文献3】Collaborative Filtering Temporal Dynamics, Yehuda Koren著
【発明の概要】
【発明が解決しようとする課題】
【0012】
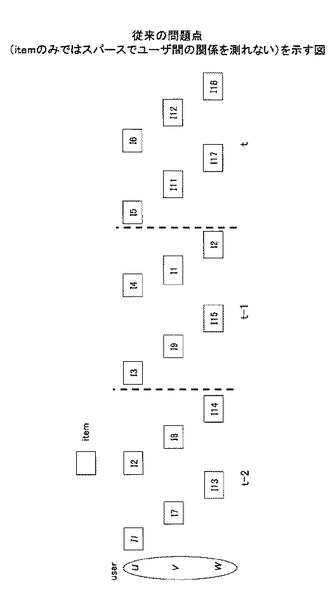
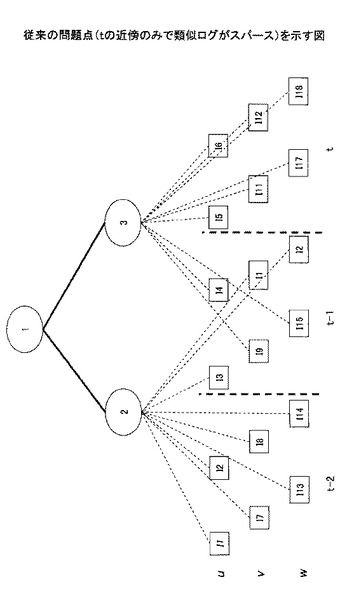
しかしながら、非特許文献2の手法では、図1に示すように、多くのクラスで他のユーザと類似することとなり、精度が落ちる場合がある。一方、図2に示すように最近の履歴のみでは、履歴がスパースになりすぎ、精度が悪くなるという問題もある。
【0013】
また、非特許文献3の手法では、興味を持つアイテムやジャンルの変動そのものは明確に扱っていない。さらに、評点のみを対象とした手法であるため、購買履歴には向かない。
【0014】
本発明は、上記の点に鑑みなされたもので、その時のユーザの興味に沿って、かつ、トレンドにも沿ったアイテム(コンテンツ)をパーソナライズして推薦することが可能なコンテンツ推薦装置及び方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0015】
上記の課題を解決するため、本発明(請求項1)は、ユーザが興味を持つコンテンツをその時に応じて推薦するコンテンツ推薦装置であって、
ユーザのコンテンツに対する評価値と評価した時間情報を持つユーザのコンテンツの消費履歴を格納した消費履歴記憶手段と、
前記消費履歴記憶手段の前記消費履歴と情報源から得られるコンテンツのタクソノミを入力として、該消費履歴の時間情報を時刻に変換して該消費履歴に付与する時刻付与手段と、
時刻が付与された消費履歴からユーザの興味を抽出し、データ構造化してユーザ興味記憶手段に格納するユーザ興味構築手段と、
前記ユーザ興味記憶手段のデータ構造化されたユーザの興味から、被推薦ユーザと類似する他ユーザの消費動向のパターンを抽出し、類似度記憶手段に格納する類似パターン抽出手段と、
前記類似度記憶手段の類似パターン内でのコンテンツの生起頻度に基づいてユーザへ推薦するコンテンツを決定する予測値計測手段と、を有する。
【0016】
また、本発明(請求項2)は、前記ユーザ興味構築手段において、
前記時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、前記ユーザ興味記憶手段に格納する手段を含み、
前記類似パターン抽出手段において、
前記ユーザ興味記憶手段から被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、前記類似度記憶手段に格納する手段を含み、
前記予測値計測手段において、
前記類似度記憶手段のユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する手段を含む。
【発明の効果】
【0017】
本発明によれば、被推薦ユーザの直近の履歴が過去の履歴に類似するユーザのコンテンツを推薦することにより、その時の興味に沿って、かつトレンドにも沿ったアイテムを、パーソナライズして推薦可能となる。クラス情報も踏まえているため、推薦根拠も持ちうる。
【図面の簡単な説明】
【0018】
【図1】従来の問題点(itemのみではスパースでユーザ間の関係を測れない)を示す図である。
【図2】従来の問題点(t近傍のみで類似ログがスパース)を示す図である。
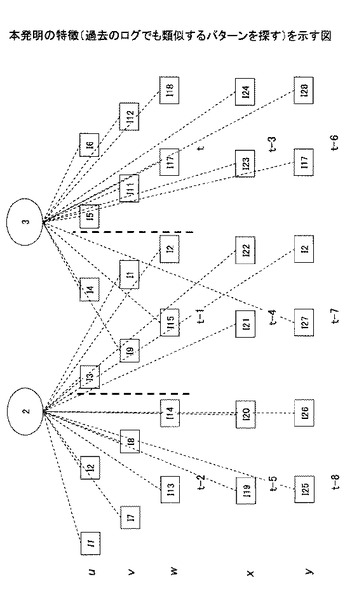
【図3】本発明の特徴(過去のログでも類似するパターンを探す)を示す図である。
【図4】本発明の一実施の形態におけるコンテンツ推薦装置の構成図である。
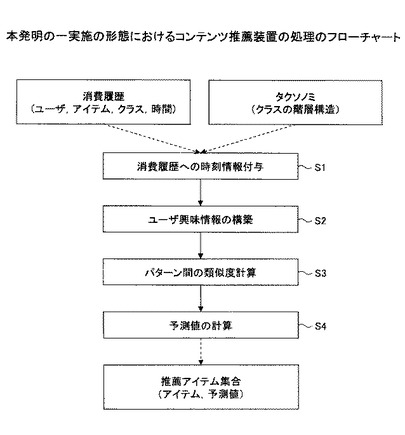
【図5】本発明の一実施の形態におけるコンテンツ推薦装置の処理のフローチャートである。
【発明を実施するための形態】
【0019】
まず、本発明のベースとなる技術について説明する。
【0020】
従来の協調フィルタリングにおいて、ユーザ間の類似度を計測する際には、Cosineベースアプローチ(Breese, Heckerman, & Kadie 1998, Sarwar, Karypis, Konstan, & Ridel 2001)とPearson correlationアプローチ(Resnick,Iacovou, & Suchak 1994, Shardanand & Maes 1995)を用いることが多い。Cosineベースアプローチにおいては、アクティブユーザaとあるユーザuの間の類似度S(a,u)は、aとuの評価ベクトルのCosine角度を計算することで求められる。形式的には、両方のユーザが評価を与えているアイテム数をMとし、ユーザuのアイテムIiに対する評価値を
【0021】
【数1】

とすると、類似度S(a,u)は以下の式(1)で与えられる。
【0022】
【数2】
一方、Pearson correlationアプローチでは、ユーザ間の類似度の計測において、ユーザの評価スキームはユーザ毎に異なるという考え方を採用しており、以下の式(2)で表される。
【0023】
【数3】
ここで、
【0024】
【数4】
は、ユーザuのアイテムへの評価値の平均値を示す。
【0025】
CosineベースアプローチもPearson correlationアプローチも、両方のユーザaとuが評価を与えたアイテムのみに焦点を絞り計算を行っている点に注意が必要である。
【0026】
最終的にNをアクティブユーザaと類似度の高いユーザの数とすると、aのアイテムIiに対する予測値
【0027】
【数5】
は、以下の式(3)で与えられる。
【0028】
【数6】
以下図面と共に、本発明の実施の形態を説明する。
【0029】
本発明では、以下の2つのポイントが要旨である。
【0030】
(1)アイテムレベルではスパース過ぎて見えてこないユーザの興味変動がクラスレベルで抽象的に見るとは見えてくるという考え方に基づく。これは、クラスはアイテムを集約するためスパースなアイテムの情報をクラスで見ると密に観測できる。例えば、rock配下のアイテムi1,i2,i3とあって、それぞれ1回ずつ購入されていても、クラスで見ると3回購入されたと見做せるということである。被推薦ユーザ(a)の最近の消費の変動をクラス(概念)レベルで把握し、最近の消費の変動の傾向が類似するユーザを計算する。そして類似するユーザが最近購入したアイテムを推薦する。
【0031】
(2)現時刻から見て最近の消費行動が似ているのみであると、ログがスパースになりすぎ、精度が落ちる(図2)。つまり、最近の消費の変動がユーザaと近い最近のログのみでは、ログがスパースになりすぎ、精度が劣化するため、本発明では、図3に示すように、過去の消費の変動がユーザaと近いユーザの過去のログパターンも推薦を計算する際に利用し、現在のユーザaに対する推薦アイテムを精度よく計算する。
【0032】
図1は、本発明の一実施の形態におけるコンテンツ推薦装置の構成を示す。
【0033】
同図に示すコンテンツ推薦装置は、消費履歴DB1、ユーザ興味記憶部2、類似度記憶部3、時刻情報付与部10、ユーザ興味構築部20、類似パターン抽出部30、予測値計算部40から構成される。
【0034】
なお、消費履歴DB1、ユーザ興味記憶部2、類似度記憶部3は、ハードディスク等の記憶媒体である。
【0035】
消費履歴DB1は、ユーザのコンテンツに対する評価値として評価した時間情報を持つユーザの消費履歴(ログ)を格納したものであり、ユーザ興味記憶部2はユーザ興味構築部20で、類似度記憶部3は、類似パターン抽出部30で算出されたデータを格納する。
【0036】
時刻情報付与部10は、消費履歴DB1の情報とWikiPedia(登録商標)などの情報源から得られるコンテンツのクラス階層構造であるタクソノミを入力として、コンテンツの消費履歴の時間情報を時刻に変換し、履歴情報に付与し、ユーザ興味構築部20に出力する。
【0037】
ユーザ興味構築部20は、ユーザの興味(履歴情報)をデータ構造として構築し、ユーザ興味記憶部2に格納する。
【0038】
類似パターン抽出部30は、データ構造化されたユーザの興味を入力とし、他ユーザの消費動向の類似パターンを抽出し、類似度記憶部3に格納する。
【0039】
予測値計算部40は、類似度記憶部3の類似パターンの中でコンテンツの生起頻度に基づいて、ユーザに提示するコンテンツを推薦する。
【0040】
以下に、上記の構成におけるコンテンツ推薦装置の動作を説明する。
【0041】
図2は、本発明の一実施の形態におけるコンテンツ推薦装置の処理のフローチャートである。
【0042】
ステップ1) 時刻情報付与部10は、消費履歴DB1から履歴情報を読み込み、タクソノミに基づいて時刻情報を付与する。本発明では、ユーザがアイテム(音楽などのマルチメディアコンテンツ、Webページなど)を消費した時間を、一定期間毎に分離し、離散した時刻として扱う。具体的には、履歴情報中に記載されている時間情報に対し、履歴情報上での最初の時間をSとし、期間を表す値をDとすると、各時刻t(i)は、S+D×iからS+D×(i+1)までの時間を取り扱う。
【0043】
ステップ2) ユーザ興味構築部20は、ステップ1で時刻情報が付与された履歴情報をデータ構造化する。
【0044】
1)ユーザuのある時刻tにおける消費アイテムは、S+D×tからS+D×(t+1)の間にユーザuが消費したアイテムを指す。その期間に消費したアイテムであれば、順序を考慮せず、ユーザuが時刻tに消費したアイテム集合として管理する。
【0045】
2)ユーザuが消費したアイテムi毎にベクトルvu,iを形成する。当該ベクトルの列は、時刻を示し、その列内の要素は、各時刻におけるアイテムiの消費頻度が格納される。
【0046】
3)ユーザuが消費をしたアイテムが所属するクラスc毎にベクトルvu,cを形成する。と該ベクトルの列は時刻を示し、その列内の要素は、各時刻におけるc配下のアイテム消費頻度の和が格納される。また、vu,c (t)が0より大きければ、cの上位クラスに値を伝播させる。計算量の削減のため、0以下であれば値を伝播させない。特にアイテムに関しては、事前に0以上のアイテムのみを集合として管理しておけば、その集合のみをチェックし伝播を決定すれば計算量の削減に繋がる。
【0047】
当該ベクトルvu,c (t)に対応する要素の値は式(4)のように計算される。式(4)において、f(c)は、cの子クラス集合を返す関数であり、csはcのある子クラスである。
【0048】
【数7】
上記のように求めたvu,c (t)をユーザ興味記憶部2に格納する。
【0049】
ステップ3) 類似パターン抽出部30は、ユーザ興味記憶部2からvu,c (t)を読み込み、ユーザa(被推薦ユーザ)の最近の履歴と類似するパターンを抽出する。
【0050】
1) 類似パターン抽出部30は、被推薦ユーザaに対しては、現在の時刻Tから見て、x回直近の時刻までの消費履歴を特に考慮する。具体的には、T−x+1からTまでの履歴情報のみを処理対象とすることで、直近のx時刻の消費履歴を重視した推薦を実現可能とする。このため、ベクトルvu,c (t)を直近の時刻の次元に縮退させる。この直近のx時刻の消費履歴におけるクラスcに関する消費ベクトルra,cを与える。ra,cは、以下の式(5)のように計算される。式(5)において、0はゼロ行列を指し、添字は次元数である。Eは単位行列を指し、添字は次元数である。
【0051】
【数8】
2) 類似パターン抽出部30は、被推薦ユーザaに対し、他ユーザの消費履歴で、クラスcのベクトルra,cと類似するパターンをユーザ興味記憶部2から抽出する。当該処理は、アイテムレベルでのパターン抽出はスパースになり、不正確になるため、クラスレベルで実施する。また、計算量を削減するための工夫として、同じクラスを持たないパターンに関しては、その配下クラス以降のパターン抽出の計算をスキップする。
【0052】
まず、類似パターン抽出部30は、あるユーザuの時刻tを最終時刻とし、t−x+1からtまでのパターンベクトルpu,t,cを式(6)のように計算する。
【0053】
【数9】
3) 次に、類似パターン抽出部30は、あるクラスcに対するユーザaとあるユーザuのある時刻tを最終時刻とするパターンpu,tとの類似度を求める。当該類似度の計算式を式(7)に示す。式(7)において、cos()はcosine類似度を示す。Cはユーザuに対し、上記の2)で計算済みのクラス集合を指し、タクソノミ上の全クラスではない(計算量削減のため)。
【0054】
【数10】
なお、cosine類似度ではなく、時系列の類似性を測る手法であれば、Nグラム法などを利用するのでもよい。
【0055】
なお、ユーザaとユーザuの消費アイテムの類似度の計算は、ログがスパースになりすぎることを避けるためと、計算量の削減のため、時系列を考慮しない。消費アイテムの類似度は、ユーザuのクラスc配下の全時刻でのアイテム集合をIuとすると、非特許文献2と同様に、以下の式(8)から計算する。式(8)において、jac()はjaccard係数を示す。
【0056】
【数11】
なお、アイテムの類似度の計算方式は式(8)以外の公知の方法を用いてもよい。
【0057】
4)類似パターン抽出部30は、ユーザaとあるユーザuのパターン間の類似度Sa,u,tを、式(9)により計算する。式(9)においてNは正規化関数である。
【0058】
【数12】
上記の式(9)により求められたパターン間の類似度を類似度記憶部3に格納する。
【0059】
ステップ4)予測値計算部40は、類似度記憶部3から類似度を読み込み、類似パターンにおけるコンテンツの生起頻度の高いものを抽出する。具体的には、前述の式(3)を用いてユーザへのアイテムの予測値を計算する。このとき、式(3)において、ユーザ類似度の代わりにユーザの持つ各パターン類似度を代入し、アイテムIiは、対尾するパターンに存在するアイテムとする。
【0060】
予測値計算部40は、求められたアイテムの予測値を推薦アイテム集合として出力する。
【0061】
以下に、本発明と非特許文献2との違いを以下に示す。
【0062】
(1)本発明では、ユーザの持つ消費履歴のうち、クラスに関しては全てを利用するのではなく、時系列に沿った一部機関のみを利用する。被推薦ユーザ(ユーザa)に関しては直近の消費履歴のみを用い、類似度計算対象ユーザ(ユーザu)に対しては、時系列に沿った任意の一部期間のみを利用する。これにより、ユーザの興味の変動に対応でき、スパース問題も回避できつつ、長期間に亘り多様な消費行動をとったユーザはクラスレベルで非常のたくさんのユーザと繋がってしまうという従来の問題を回避できる。
【0063】
(2)本発明は、アイテムを予測する際のアイテム集合としては、ユーザ毎の類似度を用いるのではなく、ユーザの持つ消費パターンの類似している部分のみを用いる。これにより、現在のユーザの興味とは外れているアイテムを推薦から除外でき、適合率が高まる。
【0064】
次に、本発明と非特許文献3との違いを示す。
【0065】
非特許文献3は、ユーザの興味対象の違いを予測モデルに導入しているわけではなく、ユーザのレーティングの平均値の変化と、アイテム自身の有名度の変化のモデルに導入しているのであり、個人毎に興味対象の変動の類似性を考慮しているわけではない。そのため、現在のユーザの興味を重視して推薦を提示しているわけではない。本発明は、個人毎に現在の興味変動に応じた、過去の変動パターンを抽出することができ、抽出した変動パターンの中から推薦を決定している点で、現在のユーザの変更パターンに沿ったアイテムを推薦できる。
【0066】
なお、上記の実施の形態では、コンテンツを対象として説明しているが、この例に限定されることなく、一般的な商品に適用することも可能である。
【0067】
本発明は、上記の図1のコンテンツ推薦装置の構成要素の各動作をプログラムとして構築し、コンテンツ推薦装置として利用されるコンピュータにインストールして実行させる、または、ネットワークを介して流通させることが可能である。
【0068】
本発明は、上記の実施の形態に限定されることなく、特許請求の範囲内において、種々変更・応用が可能である。
【符号の説明】
【0069】
1 消費履歴データベース(DB)
2 ユーザ興味記憶部
3 類似度記憶部
10 時刻情報付与部
20 ユーザ興味構築部
30 類似パターン抽出部
40 予測値計算部
【技術分野】
【0001】
本発明は、コンテンツ推薦装置及び方法及びプログラムに係り、特に、時系列を考慮し、ユーザの興味の持つ商品(コンテンツ)やコンテンツの所属するクラスの変化を捉え、その時に合った商品を推薦するためのコンテンツ推薦装置及び方法及びプログラムに関する。
【背景技術】
【0002】
Webネットワーク上において、ユーザによる対象の意味や概念に対する参照要求が大きくなるにつれ、WikiPedia(登録商標)などの体系化された辞書が普及するようになってきている。また、こうしたユーザの要求を人手ではなく、人の変わりにサービスが処理し、ユーザにカスタマイズして提示可能とするため、機械処理可能な概念参照API(Application Program Interface)が急速に普及しており、DBPedia(登録商標)、Word-Net(登録商標)、FreeBasse(登録商標)など様々な情報プロバイダが、自身の持つ情報を体系化し、APIを通じ安価でかつ無料で提示するようになって着ている(例えば、非特許文献1参照)。
【0003】
一方、ユーザの興味のある概念を推測し、ユーザに代わりに情報を収集提示するような推薦システムも必要とされ、研究されてきた。こうした研究と上記多様なAPIを組み合わせれば、より広範囲にユーザの興味を推定できる。しかし、現状の技術には2点大きな問題がある。
【0004】
(1)多様な興味を取り扱うほど、時間軸に応じた興味の変化は激しいと考えられるが、そうした変換に対応していない。
【0005】
(2)概念体系は頻繁にメンテナンスされる。例えば、映像の体系は、サービスの深化とともに深堀りされたり、新たなグループが人気を博すと、そのグループの体系ができたりし、それに併せ体系も深化する。そうした概念体系(タクソノミ)の変動を考慮していない。
【0006】
本発明では、(1)の問題について取り組む。
【0007】
興味推定を行う技術を以下に示す。
【0008】
まず、タクソノミに基づく興味推定について説明する。
【0009】
ユーザの興味の変動を取り扱っておらず、例え2年前の履歴であっても、最近の履歴と等価に扱っている。特に、クラスのような抽象的な情報でユーザ興味を管理すると、時系列が長くなると、非常に多くのクラスにユーザが興味を持つと見做されるようになりやすくなる(例えば、非特許文献2参照)。
【0010】
次に、ユーザの興味の変動を、特定のtime windowで図りwindowから漏れた消費履歴を使用しないのではなく、全消費履歴を用いる。アイテムに対するユーザの評点の平均値が日時によって、辛めであったり、甘めであったりするという特性を考慮したモデルを構築しており、Matrix Factorizationとk-nearest users/itemsの2通りの手法に適用しており、従来のMF,KN両方の手法の精度を改善している(例えば、非特許文献3参照)。
【先行技術文献】
【非特許文献】
【0011】
【非特許文献1】Linked Open Data Project (http://linkeddata.org/).
【非特許文献2】Makoto Nakatsuji, Yasuhiro Fujiwara, Akimichi Tanaka, Tosho Uchiyama, Ko Fujimura, Toru Ishida, "Classical Music for Rock Fan",The 19th ACM international conference on Information and knowledge management.
【非特許文献3】Collaborative Filtering Temporal Dynamics, Yehuda Koren著
【発明の概要】
【発明が解決しようとする課題】
【0012】
しかしながら、非特許文献2の手法では、図1に示すように、多くのクラスで他のユーザと類似することとなり、精度が落ちる場合がある。一方、図2に示すように最近の履歴のみでは、履歴がスパースになりすぎ、精度が悪くなるという問題もある。
【0013】
また、非特許文献3の手法では、興味を持つアイテムやジャンルの変動そのものは明確に扱っていない。さらに、評点のみを対象とした手法であるため、購買履歴には向かない。
【0014】
本発明は、上記の点に鑑みなされたもので、その時のユーザの興味に沿って、かつ、トレンドにも沿ったアイテム(コンテンツ)をパーソナライズして推薦することが可能なコンテンツ推薦装置及び方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0015】
上記の課題を解決するため、本発明(請求項1)は、ユーザが興味を持つコンテンツをその時に応じて推薦するコンテンツ推薦装置であって、
ユーザのコンテンツに対する評価値と評価した時間情報を持つユーザのコンテンツの消費履歴を格納した消費履歴記憶手段と、
前記消費履歴記憶手段の前記消費履歴と情報源から得られるコンテンツのタクソノミを入力として、該消費履歴の時間情報を時刻に変換して該消費履歴に付与する時刻付与手段と、
時刻が付与された消費履歴からユーザの興味を抽出し、データ構造化してユーザ興味記憶手段に格納するユーザ興味構築手段と、
前記ユーザ興味記憶手段のデータ構造化されたユーザの興味から、被推薦ユーザと類似する他ユーザの消費動向のパターンを抽出し、類似度記憶手段に格納する類似パターン抽出手段と、
前記類似度記憶手段の類似パターン内でのコンテンツの生起頻度に基づいてユーザへ推薦するコンテンツを決定する予測値計測手段と、を有する。
【0016】
また、本発明(請求項2)は、前記ユーザ興味構築手段において、
前記時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、前記ユーザ興味記憶手段に格納する手段を含み、
前記類似パターン抽出手段において、
前記ユーザ興味記憶手段から被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、前記類似度記憶手段に格納する手段を含み、
前記予測値計測手段において、
前記類似度記憶手段のユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する手段を含む。
【発明の効果】
【0017】
本発明によれば、被推薦ユーザの直近の履歴が過去の履歴に類似するユーザのコンテンツを推薦することにより、その時の興味に沿って、かつトレンドにも沿ったアイテムを、パーソナライズして推薦可能となる。クラス情報も踏まえているため、推薦根拠も持ちうる。
【図面の簡単な説明】
【0018】
【図1】従来の問題点(itemのみではスパースでユーザ間の関係を測れない)を示す図である。
【図2】従来の問題点(t近傍のみで類似ログがスパース)を示す図である。
【図3】本発明の特徴(過去のログでも類似するパターンを探す)を示す図である。
【図4】本発明の一実施の形態におけるコンテンツ推薦装置の構成図である。
【図5】本発明の一実施の形態におけるコンテンツ推薦装置の処理のフローチャートである。
【発明を実施するための形態】
【0019】
まず、本発明のベースとなる技術について説明する。
【0020】
従来の協調フィルタリングにおいて、ユーザ間の類似度を計測する際には、Cosineベースアプローチ(Breese, Heckerman, & Kadie 1998, Sarwar, Karypis, Konstan, & Ridel 2001)とPearson correlationアプローチ(Resnick,Iacovou, & Suchak 1994, Shardanand & Maes 1995)を用いることが多い。Cosineベースアプローチにおいては、アクティブユーザaとあるユーザuの間の類似度S(a,u)は、aとuの評価ベクトルのCosine角度を計算することで求められる。形式的には、両方のユーザが評価を与えているアイテム数をMとし、ユーザuのアイテムIiに対する評価値を
【0021】
【数1】
とすると、類似度S(a,u)は以下の式(1)で与えられる。
【0022】
【数2】
一方、Pearson correlationアプローチでは、ユーザ間の類似度の計測において、ユーザの評価スキームはユーザ毎に異なるという考え方を採用しており、以下の式(2)で表される。
【0023】
【数3】
ここで、
【0024】
【数4】
は、ユーザuのアイテムへの評価値の平均値を示す。
【0025】
CosineベースアプローチもPearson correlationアプローチも、両方のユーザaとuが評価を与えたアイテムのみに焦点を絞り計算を行っている点に注意が必要である。
【0026】
最終的にNをアクティブユーザaと類似度の高いユーザの数とすると、aのアイテムIiに対する予測値
【0027】
【数5】
は、以下の式(3)で与えられる。
【0028】
【数6】
以下図面と共に、本発明の実施の形態を説明する。
【0029】
本発明では、以下の2つのポイントが要旨である。
【0030】
(1)アイテムレベルではスパース過ぎて見えてこないユーザの興味変動がクラスレベルで抽象的に見るとは見えてくるという考え方に基づく。これは、クラスはアイテムを集約するためスパースなアイテムの情報をクラスで見ると密に観測できる。例えば、rock配下のアイテムi1,i2,i3とあって、それぞれ1回ずつ購入されていても、クラスで見ると3回購入されたと見做せるということである。被推薦ユーザ(a)の最近の消費の変動をクラス(概念)レベルで把握し、最近の消費の変動の傾向が類似するユーザを計算する。そして類似するユーザが最近購入したアイテムを推薦する。
【0031】
(2)現時刻から見て最近の消費行動が似ているのみであると、ログがスパースになりすぎ、精度が落ちる(図2)。つまり、最近の消費の変動がユーザaと近い最近のログのみでは、ログがスパースになりすぎ、精度が劣化するため、本発明では、図3に示すように、過去の消費の変動がユーザaと近いユーザの過去のログパターンも推薦を計算する際に利用し、現在のユーザaに対する推薦アイテムを精度よく計算する。
【0032】
図1は、本発明の一実施の形態におけるコンテンツ推薦装置の構成を示す。
【0033】
同図に示すコンテンツ推薦装置は、消費履歴DB1、ユーザ興味記憶部2、類似度記憶部3、時刻情報付与部10、ユーザ興味構築部20、類似パターン抽出部30、予測値計算部40から構成される。
【0034】
なお、消費履歴DB1、ユーザ興味記憶部2、類似度記憶部3は、ハードディスク等の記憶媒体である。
【0035】
消費履歴DB1は、ユーザのコンテンツに対する評価値として評価した時間情報を持つユーザの消費履歴(ログ)を格納したものであり、ユーザ興味記憶部2はユーザ興味構築部20で、類似度記憶部3は、類似パターン抽出部30で算出されたデータを格納する。
【0036】
時刻情報付与部10は、消費履歴DB1の情報とWikiPedia(登録商標)などの情報源から得られるコンテンツのクラス階層構造であるタクソノミを入力として、コンテンツの消費履歴の時間情報を時刻に変換し、履歴情報に付与し、ユーザ興味構築部20に出力する。
【0037】
ユーザ興味構築部20は、ユーザの興味(履歴情報)をデータ構造として構築し、ユーザ興味記憶部2に格納する。
【0038】
類似パターン抽出部30は、データ構造化されたユーザの興味を入力とし、他ユーザの消費動向の類似パターンを抽出し、類似度記憶部3に格納する。
【0039】
予測値計算部40は、類似度記憶部3の類似パターンの中でコンテンツの生起頻度に基づいて、ユーザに提示するコンテンツを推薦する。
【0040】
以下に、上記の構成におけるコンテンツ推薦装置の動作を説明する。
【0041】
図2は、本発明の一実施の形態におけるコンテンツ推薦装置の処理のフローチャートである。
【0042】
ステップ1) 時刻情報付与部10は、消費履歴DB1から履歴情報を読み込み、タクソノミに基づいて時刻情報を付与する。本発明では、ユーザがアイテム(音楽などのマルチメディアコンテンツ、Webページなど)を消費した時間を、一定期間毎に分離し、離散した時刻として扱う。具体的には、履歴情報中に記載されている時間情報に対し、履歴情報上での最初の時間をSとし、期間を表す値をDとすると、各時刻t(i)は、S+D×iからS+D×(i+1)までの時間を取り扱う。
【0043】
ステップ2) ユーザ興味構築部20は、ステップ1で時刻情報が付与された履歴情報をデータ構造化する。
【0044】
1)ユーザuのある時刻tにおける消費アイテムは、S+D×tからS+D×(t+1)の間にユーザuが消費したアイテムを指す。その期間に消費したアイテムであれば、順序を考慮せず、ユーザuが時刻tに消費したアイテム集合として管理する。
【0045】
2)ユーザuが消費したアイテムi毎にベクトルvu,iを形成する。当該ベクトルの列は、時刻を示し、その列内の要素は、各時刻におけるアイテムiの消費頻度が格納される。
【0046】
3)ユーザuが消費をしたアイテムが所属するクラスc毎にベクトルvu,cを形成する。と該ベクトルの列は時刻を示し、その列内の要素は、各時刻におけるc配下のアイテム消費頻度の和が格納される。また、vu,c (t)が0より大きければ、cの上位クラスに値を伝播させる。計算量の削減のため、0以下であれば値を伝播させない。特にアイテムに関しては、事前に0以上のアイテムのみを集合として管理しておけば、その集合のみをチェックし伝播を決定すれば計算量の削減に繋がる。
【0047】
当該ベクトルvu,c (t)に対応する要素の値は式(4)のように計算される。式(4)において、f(c)は、cの子クラス集合を返す関数であり、csはcのある子クラスである。
【0048】
【数7】
上記のように求めたvu,c (t)をユーザ興味記憶部2に格納する。
【0049】
ステップ3) 類似パターン抽出部30は、ユーザ興味記憶部2からvu,c (t)を読み込み、ユーザa(被推薦ユーザ)の最近の履歴と類似するパターンを抽出する。
【0050】
1) 類似パターン抽出部30は、被推薦ユーザaに対しては、現在の時刻Tから見て、x回直近の時刻までの消費履歴を特に考慮する。具体的には、T−x+1からTまでの履歴情報のみを処理対象とすることで、直近のx時刻の消費履歴を重視した推薦を実現可能とする。このため、ベクトルvu,c (t)を直近の時刻の次元に縮退させる。この直近のx時刻の消費履歴におけるクラスcに関する消費ベクトルra,cを与える。ra,cは、以下の式(5)のように計算される。式(5)において、0はゼロ行列を指し、添字は次元数である。Eは単位行列を指し、添字は次元数である。
【0051】
【数8】
2) 類似パターン抽出部30は、被推薦ユーザaに対し、他ユーザの消費履歴で、クラスcのベクトルra,cと類似するパターンをユーザ興味記憶部2から抽出する。当該処理は、アイテムレベルでのパターン抽出はスパースになり、不正確になるため、クラスレベルで実施する。また、計算量を削減するための工夫として、同じクラスを持たないパターンに関しては、その配下クラス以降のパターン抽出の計算をスキップする。
【0052】
まず、類似パターン抽出部30は、あるユーザuの時刻tを最終時刻とし、t−x+1からtまでのパターンベクトルpu,t,cを式(6)のように計算する。
【0053】
【数9】
3) 次に、類似パターン抽出部30は、あるクラスcに対するユーザaとあるユーザuのある時刻tを最終時刻とするパターンpu,tとの類似度を求める。当該類似度の計算式を式(7)に示す。式(7)において、cos()はcosine類似度を示す。Cはユーザuに対し、上記の2)で計算済みのクラス集合を指し、タクソノミ上の全クラスではない(計算量削減のため)。
【0054】
【数10】
なお、cosine類似度ではなく、時系列の類似性を測る手法であれば、Nグラム法などを利用するのでもよい。
【0055】
なお、ユーザaとユーザuの消費アイテムの類似度の計算は、ログがスパースになりすぎることを避けるためと、計算量の削減のため、時系列を考慮しない。消費アイテムの類似度は、ユーザuのクラスc配下の全時刻でのアイテム集合をIuとすると、非特許文献2と同様に、以下の式(8)から計算する。式(8)において、jac()はjaccard係数を示す。
【0056】
【数11】
なお、アイテムの類似度の計算方式は式(8)以外の公知の方法を用いてもよい。
【0057】
4)類似パターン抽出部30は、ユーザaとあるユーザuのパターン間の類似度Sa,u,tを、式(9)により計算する。式(9)においてNは正規化関数である。
【0058】
【数12】
上記の式(9)により求められたパターン間の類似度を類似度記憶部3に格納する。
【0059】
ステップ4)予測値計算部40は、類似度記憶部3から類似度を読み込み、類似パターンにおけるコンテンツの生起頻度の高いものを抽出する。具体的には、前述の式(3)を用いてユーザへのアイテムの予測値を計算する。このとき、式(3)において、ユーザ類似度の代わりにユーザの持つ各パターン類似度を代入し、アイテムIiは、対尾するパターンに存在するアイテムとする。
【0060】
予測値計算部40は、求められたアイテムの予測値を推薦アイテム集合として出力する。
【0061】
以下に、本発明と非特許文献2との違いを以下に示す。
【0062】
(1)本発明では、ユーザの持つ消費履歴のうち、クラスに関しては全てを利用するのではなく、時系列に沿った一部機関のみを利用する。被推薦ユーザ(ユーザa)に関しては直近の消費履歴のみを用い、類似度計算対象ユーザ(ユーザu)に対しては、時系列に沿った任意の一部期間のみを利用する。これにより、ユーザの興味の変動に対応でき、スパース問題も回避できつつ、長期間に亘り多様な消費行動をとったユーザはクラスレベルで非常のたくさんのユーザと繋がってしまうという従来の問題を回避できる。
【0063】
(2)本発明は、アイテムを予測する際のアイテム集合としては、ユーザ毎の類似度を用いるのではなく、ユーザの持つ消費パターンの類似している部分のみを用いる。これにより、現在のユーザの興味とは外れているアイテムを推薦から除外でき、適合率が高まる。
【0064】
次に、本発明と非特許文献3との違いを示す。
【0065】
非特許文献3は、ユーザの興味対象の違いを予測モデルに導入しているわけではなく、ユーザのレーティングの平均値の変化と、アイテム自身の有名度の変化のモデルに導入しているのであり、個人毎に興味対象の変動の類似性を考慮しているわけではない。そのため、現在のユーザの興味を重視して推薦を提示しているわけではない。本発明は、個人毎に現在の興味変動に応じた、過去の変動パターンを抽出することができ、抽出した変動パターンの中から推薦を決定している点で、現在のユーザの変更パターンに沿ったアイテムを推薦できる。
【0066】
なお、上記の実施の形態では、コンテンツを対象として説明しているが、この例に限定されることなく、一般的な商品に適用することも可能である。
【0067】
本発明は、上記の図1のコンテンツ推薦装置の構成要素の各動作をプログラムとして構築し、コンテンツ推薦装置として利用されるコンピュータにインストールして実行させる、または、ネットワークを介して流通させることが可能である。
【0068】
本発明は、上記の実施の形態に限定されることなく、特許請求の範囲内において、種々変更・応用が可能である。
【符号の説明】
【0069】
1 消費履歴データベース(DB)
2 ユーザ興味記憶部
3 類似度記憶部
10 時刻情報付与部
20 ユーザ興味構築部
30 類似パターン抽出部
40 予測値計算部
【特許請求の範囲】
【請求項1】
ユーザが興味を持つコンテンツをその時に応じて推薦するコンテンツ推薦装置であって、
ユーザのコンテンツに対する評価値と評価した時間情報を持つユーザのコンテンツの消費履歴を格納した消費履歴記憶手段と、
前記消費履歴記憶手段の前記消費履歴と情報源から得られるコンテンツのタクソノミを入力として、該消費履歴の時間情報を時刻に変換して該消費履歴に付与する時刻付与手段と、
時刻が付与された消費履歴からユーザの興味を抽出し、データ構造化してユーザ興味記憶手段に格納するユーザ興味構築手段と、
前記ユーザ興味記憶手段のデータ構造化されたユーザの興味から、被推薦ユーザと類似する他ユーザの消費動向のパターンを抽出し、類似度記憶手段に格納する類似パターン抽出手段と、
前記類似度記憶手段の類似パターン内でのコンテンツの生起頻度に基づいてユーザへ推薦するコンテンツを決定する予測値計測手段と、
を有することを特徴とするコンテンツ推薦装置。
【請求項2】
前記ユーザ興味構築手段は、
前記時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、前記ユーザ興味記憶手段に格納する手段を含み、
前記類似パターン抽出手段は、
前記ユーザ興味記憶手段から被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該被推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、前記類似度記憶手段に格納する手段を含み、
前記予測値計測手段は、
前記類似度記憶手段のユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する手段を含む
請求項1記載のコンテンツ推薦装置。
【請求項3】
ユーザが興味を持つコンテンツをその時に応じて推薦するコンテンツ推薦方法であって、
時刻付与手段が、ユーザのコンテンツに対する評価値と評価した時間情報を持つユーザのコンテンツの消費履歴を格納した消費履歴記憶手段の該消費履歴と情報源から得られるコンテンツのタクソノミを入力として、該消費履歴の時間情報を時刻に変換して該消費履歴に付与する時刻付与ステップと、
ユーザ興味構築手段が、時刻が付与された消費履歴からユーザの興味を抽出し、データ構造化してユーザ興味記憶手段に格納するユーザ興味構築ステップと、
類似パターン抽出手段が、前記ユーザ興味記憶手段のデータ構造化されたユーザの興味から、被推薦ユーザと類似する他ユーザの消費動向のパターンを抽出し、類似度記憶手段に格納する類似パターン抽出ステップと、
予測値計測手段が、前記類似度記憶手段の類似パターン内でのコンテンツの生起頻度に基づいてユーザへ推薦するコンテンツを決定する予測値計測ステップと、
を行うことを特徴とするコンテンツ推薦方法。
【請求項4】
前記ユーザ興味構築ステップにおいて、
前記時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、前記ユーザ興味記憶手段に格納し、
前記類似パターン抽出ステップにおいて、
前記ユーザ興味記憶手段から被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、前記類似度記憶手段に格納し、
前記予測値計測ステップにおいて、
前記類似度記憶手段のユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する
請求項3記載のコンテンツ推薦方法。
【請求項5】
コンピュータを、
請求項1または2記載のコンテンツ推薦装置の各手段として機能させるためのコンテンツ推薦プログラム。
【請求項1】
ユーザが興味を持つコンテンツをその時に応じて推薦するコンテンツ推薦装置であって、
ユーザのコンテンツに対する評価値と評価した時間情報を持つユーザのコンテンツの消費履歴を格納した消費履歴記憶手段と、
前記消費履歴記憶手段の前記消費履歴と情報源から得られるコンテンツのタクソノミを入力として、該消費履歴の時間情報を時刻に変換して該消費履歴に付与する時刻付与手段と、
時刻が付与された消費履歴からユーザの興味を抽出し、データ構造化してユーザ興味記憶手段に格納するユーザ興味構築手段と、
前記ユーザ興味記憶手段のデータ構造化されたユーザの興味から、被推薦ユーザと類似する他ユーザの消費動向のパターンを抽出し、類似度記憶手段に格納する類似パターン抽出手段と、
前記類似度記憶手段の類似パターン内でのコンテンツの生起頻度に基づいてユーザへ推薦するコンテンツを決定する予測値計測手段と、
を有することを特徴とするコンテンツ推薦装置。
【請求項2】
前記ユーザ興味構築手段は、
前記時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、前記ユーザ興味記憶手段に格納する手段を含み、
前記類似パターン抽出手段は、
前記ユーザ興味記憶手段から被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該被推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、前記類似度記憶手段に格納する手段を含み、
前記予測値計測手段は、
前記類似度記憶手段のユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する手段を含む
請求項1記載のコンテンツ推薦装置。
【請求項3】
ユーザが興味を持つコンテンツをその時に応じて推薦するコンテンツ推薦方法であって、
時刻付与手段が、ユーザのコンテンツに対する評価値と評価した時間情報を持つユーザのコンテンツの消費履歴を格納した消費履歴記憶手段の該消費履歴と情報源から得られるコンテンツのタクソノミを入力として、該消費履歴の時間情報を時刻に変換して該消費履歴に付与する時刻付与ステップと、
ユーザ興味構築手段が、時刻が付与された消費履歴からユーザの興味を抽出し、データ構造化してユーザ興味記憶手段に格納するユーザ興味構築ステップと、
類似パターン抽出手段が、前記ユーザ興味記憶手段のデータ構造化されたユーザの興味から、被推薦ユーザと類似する他ユーザの消費動向のパターンを抽出し、類似度記憶手段に格納する類似パターン抽出ステップと、
予測値計測手段が、前記類似度記憶手段の類似パターン内でのコンテンツの生起頻度に基づいてユーザへ推薦するコンテンツを決定する予測値計測ステップと、
を行うことを特徴とするコンテンツ推薦方法。
【請求項4】
前記ユーザ興味構築ステップにおいて、
前記時刻が付与された消費履歴からユーザのコンンテンツの消費回数を、一定時間間隔で区切りベクトルで表現し、コンテンツのクラス別にベクトルの和を求めクラス別ユーザ別のベクトルを生成し、前記ユーザ興味記憶手段に格納し、
前記類似パターン抽出ステップにおいて、
前記ユーザ興味記憶手段から被推薦ユーザの直近のベクトルと他のユーザの時間長が同じ過去の一部のベクトルとを取得し、該推薦ユーザのベクトルのパターンと該他のユーザのベクトルのパターンの類似度を求め、前記類似度記憶手段に格納し、
前記予測値計測ステップにおいて、
前記類似度記憶手段のユーザの持つパターンの類似度と、該パターンに存在するコンテンツを用いて推薦するコンテンツを決定する
請求項3記載のコンテンツ推薦方法。
【請求項5】
コンピュータを、
請求項1または2記載のコンテンツ推薦装置の各手段として機能させるためのコンテンツ推薦プログラム。
【図1】

【図2】
【図3】
【図4】

【図5】
【図2】
【図3】
【図4】
【図5】
【公開番号】特開2013−109425(P2013−109425A)
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願番号】特願2011−252105(P2011−252105)
【出願日】平成23年11月17日(2011.11.17)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願日】平成23年11月17日(2011.11.17)
【出願人】(000004226)日本電信電話株式会社 (13,992)
[ Back to top ]