
コーパス選別装置、コーパス選別方法、およびプログラム

【課題】言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパスを選別するコーパス選別装置、コーパス選別方法、およびプログラムを提供すること。
【解決手段】コーパス選別装置AAは、学習コーパス(全体)を学習コーパス(サブセット1)〜学習コーパス(サブセット3)に分割し、言語モデリングにより、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれに対応するサブセット言語モデル1〜3を生成する。そして、サブセット言語モデル1〜3のそれぞれについて、タスク表現コーパスを用いてperplexityを算出して、perplexity−1〜perplexity−Yを求める。そして、perplexityの低いサブセット言語モデルに対応する学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)を選別する。
【解決手段】コーパス選別装置AAは、学習コーパス(全体)を学習コーパス(サブセット1)〜学習コーパス(サブセット3)に分割し、言語モデリングにより、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれに対応するサブセット言語モデル1〜3を生成する。そして、サブセット言語モデル1〜3のそれぞれについて、タスク表現コーパスを用いてperplexityを算出して、perplexity−1〜perplexity−Yを求める。そして、perplexityの低いサブセット言語モデルに対応する学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)を選別する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、コーパス選別装置、コーパス選別方法、およびプログラムに関する。
【背景技術】
【0002】
従来より、音声認識を行う際に、言語モデルが用いられる場合がある(例えば、特許文献1参照)。この言語モデルは、図13に示すように、言語モデリング(確率統計処理)により、学習コーパスを用いて生成される。
【0003】
学習コーパスとは、いわゆるテキストデータベースのことであり、例えば、形態素解析といった手法により平文から分割された複数の単語と、これら複数の単語のそれぞれの品詞情報と、を含んで構成される。例えば、図13中左側下部に示した「私は驚いた」という平文は、「私」、「は」、「驚い」、「た」の4つの単語に分割することができる。なお、図13では、これら4つの単語について、品詞情報が数字で表現されている。また、学習コーパスは、上述の単語および品詞情報だけでなく、例えば読み方の情報といった、他の情報を含んで構成される場合もある。
【0004】
言語モデリング(確率統計処理)では、図13中左側下部に示したような単語を多数集め、各単語の繋がる確率を求め、求めた結果から言語モデルを生成する。図13中右側下部には、言語モデルの内容として、3つ組の単語の繋がる確率の一例が示されている。例えば、「私」と「は」と「驚い」との繋がる確率は、0.000294であり、「は」と「驚い」と「た」との繋がる確率は、0.711541であることを示しており、これら確率は、3−gram出現確率と呼ばれる。
【0005】
図13中右側下部に示した内容を含む言語モデルを用いると、「私は驚いた」という文の出現確率を求めることができる。具体的には、「私は驚いた」という文には、「私は驚い」と「は驚いた」という2つの3つ組がある。この「私は驚い」の3−gram出現確率と、「は驚いた」の3−gram出現確率と、を掛け合わせると、「私は驚いた」という文の出現確率となる。なお、実際には、文頭および文末にダミーの単語が1つずつ存在するものとして、文の出現確率を求める。
【0006】
なお、文の出現確率の平均を取ったものの逆数を求めると、その文のperplexityを求めることができる。例えば、「私は驚いた」という文のperplexityは、「私は驚いた」という文の出現確率の平均を取ったものの逆数、すなわち、「私は驚い」の3−gram出現確率と、「は驚いた」の3−gram出現確率と、の相乗平均の逆数に等しくなる。
【0007】
3−gram言語モデルについて、図14を用いて以下に説明する。図14中左側下部には、言語モデリング(確率統計処理)により一般的な学習コーパスを分析して得られた単語列の出現頻度が示されている。より具体的には、一般的な学習コーパスにおいて、「僕:14」「は:65」の次に出てきたそれぞれの単語の出現頻度が示されている。一方、図14中右側下部には、上述の言語モデリング(確率統計処理)の結果により生成された3−gram言語モデルの内容が示されている。出現確率は、「僕:14」「は:65」の次に特定の単語が出てきた場合の出現頻度(例えば、特定の単語として「大好き:18」が出てきた場合、出現頻度は「9」)を、「僕:14」「は:65」の次に何らかの単語が出てきた場合の出現頻度である「30」で割ることにより、求められる。なお、次に出てこなかった単語に対しても、出てきた単語と比べて小さい出現確率を割り振る場合がある。
【0008】
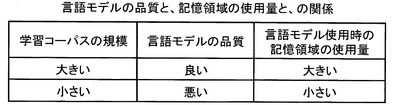
ここで、言語モデルは、音声認識に用いられる際にメモリといった記憶装置に記憶されるが、言語モデルの品質と、記憶領域の使用量と、の間には、図15に示すようなトレードオフの関係がある。すなわち、学習コーパスの規模が大きくなるに従って、言語モデルの品質は向上するが、言語モデル使用時の記憶領域の使用量は大きくなる。一方、学習コーパスの規模が小さくなるに従って、言語モデルの品質は低下するが、言語モデル使用時の記憶領域の使用量は小さくなる。
【0009】
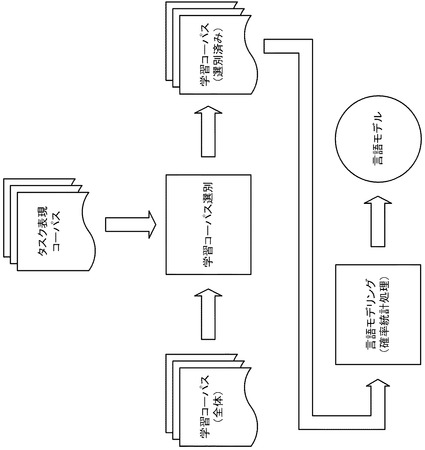
そこで、図16に示すように、学習コーパスをタスク表現コーパスを用いて選別する場合がある。タスク表現コーパスとは、音声認識を行う内容に応じたデータベースのことであり、認識させたい発話内容を含んで構成される。例えばコールセンターにおいて音声認識を行う場合には、タスク表現コーパスとは、コールセンターにおける実際の通話内容を文字に書き起こしたテキストデータベースのことである。このため、タスク表現コーパスに存在している単語列をより多く含んでいるか否かにより、学習コーパスを選別して、音声認識させたい発話内容に近いものだけを学習コーパスの中から抽出することができる。これによれば、認識対象は限定されるものの、言語モデルの品質の向上と、言語モデル使用時の記憶領域の使用量の削減と、を両立することができる。
【先行技術文献】
【特許文献】
【0010】
【特許文献1】特開平5−232987号公報
【発明の概要】
【発明が解決しようとする課題】
【0011】
従来例に係る学習コーパスの選別手法について、図17を用いて以下に説明する。まず、学習コーパス(全体)を学習コーパス(サブセット1)、学習コーパス(サブセット2)、および学習コーパス(サブセット3)の3つに分割するとともに、タスク表現コーパスを言語モデリング(確率統計処理)してシード言語モデルを生成する。ここで、学習コーパス(全体)とは、規模の大きな学習コーパスであり、例えばウェブ上のデータを集めて生成されたもののことである。
【0012】
次に、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれについて、シード言語モデルを用いてperplexityを算出して、perplexity−1、perplexity−2、およびperplexity−3を求める。
【0013】
次に、perplexity−1〜perplexity−3を比較して、最も高いperplexityに対応する学習コーパス(サブセットX(Xは、1≦X≦3を満たす整数))を学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。ここで、最も高いperplexityに対応する学習コーパス(サブセットX)とは、最も高いperplexityを算出する際に用いた学習コーパス(サブセットX)のことであり、例えばperplexity−1〜perplexity−3のうちperplexity−2が最も高い場合には、学習コーパス(サブセット2)のことを示す。
【0014】
しかしながら、図17に示したような従来の手法により選別された学習コーパス(選別済み)では、言語モデルの品質の向上と、記憶領域の使用量の削減と、の両立は不十分であった。
【0015】
そこで、本発明は、上述の課題に鑑みてなされたものであり、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパスを選別するコーパス選別装置、コーパス選別方法、およびプログラムを提供することを目的とする。
【課題を解決するための手段】
【0016】
本発明は、上記の課題を解決するために、以下の事項を提案している。
【0017】
(1) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別装置(例えば、図1のコーパス選別装置AAに相当)であって、コーパス(例えば、図2の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図2の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割するコーパス分割手段(例えば、図1の学習コーパス分割部11に相当)と、前記複数の単位コーパスのそれぞれについて、確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、対応する単位言語モデル(例えば、図2のサブセット言語モデル1〜3に相当)を生成する言語モデリング手段(例えば、図1の言語モデリング部12に相当)と、前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパス(例えば、図2のタスク表現コーパスに相当)を用いて、音声認識の困難性(例えば、図2のperplexityに相当)を求める困難性算出手段(例えば、図1のスコア算出部13に相当)と、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記困難性算出手段により求められた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くコーパス選出手段(例えば、図1の学習コーパス選出部14に相当)と、を備え、前記言語モデリング手段は、前記複数の単位コーパスの中から1つを選択する選択手順(例えば、後述の第1の選択手順に相当)と、前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順(例えば、後述の第1のサブセット言語モデル生成手順に相当)と、前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順(例えば、後述の第1の繰り返し手順に相当)と、を行うことを特徴とするコーパス選別装置を提案している。
【0018】
この発明によれば、コーパス選別装置に、コーパス分割手段、言語モデリング手段、困難性算出手段、およびコーパス選出手段を設けた。そして、コーパス分割手段により、コーパスを複数の単位コーパスに分割することとした。また、言語モデリング手段により、複数の単位コーパスの中から1つを選択する選択手順と、複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行って、複数の単位コーパスのそれぞれに対応する単位言語モデルを生成することとした。また、困難性算出手段により、言語モデリング手段により生成された複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、困難性算出手段により求められた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0019】
このため、(1)のコーパス選別装置は、コーパスを複数の単位コーパスに分割し、これら複数の単位コーパスのそれぞれについて、自身を除く全ての単位コーパスを用いて確率統計処理を行って、対応する単位言語モデルを生成する。そして、複数の単位言語モデルのそれぞれを用いた場合の音声認識の困難性を求める。そして、求めた音声認識の困難性を用いて、複数の単位コーパスの中から音声認識を行う内容に適していないものを求め、求めた単位コーパスをコーパスから除く。したがって、コーパスを構成する複数の単位コーパスについて、音声認識を行う内容に基づいて選別することができるので、音声認識を行う内容に適した情報はコーパスに残しつつ、コーパスの規模を小さくすることができる。よって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立することができる。
【0020】
(2) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別装置(例えば、図4のコーパス選別装置BBに相当)であって、コーパス(例えば、図5の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図5の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割するコーパス分割手段(例えば、図4の学習コーパス分割部11に相当)と、前記複数の単位コーパスの中からT個(Tは、T≧1を満たす整数)の単位コーパスを1組の単位コーパス群として選択する選択手順(例えば、後述の第2の選択手順に相当)と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、当該単位コーパス群に対応する単位言語モデル(例えば、図5のサブセット言語モデル1〜3に相当)を生成する単位言語モデル生成手順(例えば、後述の第2のサブセット言語モデル生成手順に相当)と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順(例えば、後述の第2の繰り返し手順に相当)と、を行う言語モデリング手段(例えば、図4の言語モデリング部12に相当)と、音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパス(例えば、図5のタスク表現コーパス(音声あり)に相当)の音声認識を、前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果(例えば、図5の音声認識結果1〜3に相当)を求める音声認識手段(例えば、図4の音声認識部15に相当)と、前記音声認識手段により求められた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコア(例えば、図5の識別スコア1〜3に相当)を求める識別スコア算出手段(例えば、図4のスコア算出部13Aに相当)と、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除くコーパス選出手段(例えば、図4の学習コーパス選出部14Aに相当)と、を備えることを特徴とするコーパス選別装置を提案している。
【0021】
この発明によれば、コーパス選別装置に、コーパス分割手段、言語モデリング手段、音声認識手段、識別スコア算出手段、およびコーパス選出手段を設けた。そして、コーパス分割手段により、コーパスを複数の単位コーパスに分割することとした。また、言語モデリング手段により、複数の単位コーパスの中からT個の単位コーパスを1組の単位コーパス群として選択する選択手順と、複数の単位コーパスのうち選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを複数の単位コーパスの中から選択手順において選択するまで繰り返す繰り返し手順と、を行うこととした。また、音声認識手段により、タスク表現コーパスの音声認識を、言語モデリング手段により生成された複数の単位言語モデルのそれぞれを用いて行って、複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求めることとした。ここで、タスク表現コーパスとは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータと、を含んで構成されるもののことである。また、識別スコア算出手段により、音声認識手段により求められた複数の音声認識結果のそれぞれについて、タスク表現コーパスを用いて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、コーパスから除くこととした。
【0022】
このため、(2)のコーパス選別装置は、コーパスを複数の単位コーパスに分割し、T個の単位コーパスで構成される単位コーパス群のそれぞれについて、対応する単位言語モデルを生成する。そして、複数の単位言語モデルのそれぞれを用いて音声認識を行う場合の識別スコアを求める。そして、求めた識別スコアを用いて、複数の単位コーパス群の中から音声認識を行う内容に適していないものを求め、求めた単位コーパス群を構成するT個の単位コーパスを、コーパスから除く。したがって、コーパスを構成する複数の単位コーパスについて、音声認識を行う内容に基づいて選別することができるので、音声認識を行う内容に適した情報はコーパスに残しつつ、コーパスの規模を小さくすることができる。よって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立することができる。
【0023】
(3) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最大相互情報量(例えば、図9のMMI(最大相互情報量)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0024】
この発明によれば、識別スコア算出手段により、最大相互情報量に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0025】
このため、(3)のコーパス選別装置は、最大相互情報量学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0026】
(4) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最小識別誤り化(例えば、図10のMCE(最小識別誤り化)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最小となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0027】
この発明によれば、識別スコア算出手段により、最小識別誤り化に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最小となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0028】
このため、(4)のコーパス選別装置は、最小識別誤り化学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0029】
(5) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最小単語誤り化(例えば、図11のMWE(最小単語誤り化)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0030】
この発明によれば、識別スコア算出手段により、最小単語誤り化に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0031】
このため、(5)のコーパス選別装置は、最小単語誤り化学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0032】
(6) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最小音素誤り化(例えば、図11のMPE(最小音素誤り化)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0033】
この発明によれば、識別スコア算出手段により、最小音素誤り化に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0034】
このため、(6)のコーパス選別装置は、最小音素誤り化学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0035】
(7) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法であって、コーパス(例えば、図2の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図2の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスのそれぞれについて、確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、対応する単位言語モデル(例えば、図2のサブセット言語モデル1〜3に相当)を生成する第2のステップと、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパス(例えば、図2のタスク表現コーパスに相当)を用いて、音声認識の困難性(例えば、図2のperplexityに相当)を求める第3のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、を備え、前記第2のステップでは、前記複数の単位コーパスの中から1つを選択する選択手順(例えば、後述の第1の選択手順に相当)と、前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順(例えば、後述の第1のサブセット言語モデル生成手順に相当)と、前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順(例えば、後述の第1の繰り返し手順に相当)と、を行うことを特徴とするコーパス選別方法を提案している。
【0036】
この発明によれば、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中から1つを選択する選択手順と、複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行って、複数の単位コーパスのそれぞれに対応する単位言語モデルを生成する。そして、生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める。そして、生成した複数の単位言語モデルの中から、求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【0037】
(8) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法であって、コーパス(例えば、図5の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図5の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスの中からT個(Tは、T≧1を満たす整数)の単位コーパスを1組の単位コーパス群として選択する選択手順(例えば、後述の第2の選択手順に相当)と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、当該単位コーパス群に対応する単位言語モデル(例えば、図5のサブセット言語モデル1〜3に相当)を生成する単位言語モデル生成手順(例えば、後述の第2のサブセット言語モデル生成手順に相当)と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順(例えば、後述の第2の繰り返し手順に相当)と、を行う第2のステップと、音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパス(例えば、図5のタスク表現コーパス(音声あり)に相当)の音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果(例えば、図5の音声認識結果1〜3に相当)を求める第3のステップと、前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコア(例えば、図5の識別スコア1〜3に相当)を求める第4のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、を備えることを特徴とするコーパス選別方法を提案している。
【0038】
この発明によれば、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中からT個の単位コーパスを1組の単位コーパス群として選択する選択手順と、複数の単位コーパスのうち選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを複数の単位コーパスの中から選択手順において選択するまで繰り返す繰り返し手順と、を行う。そして、タスク表現コーパスの音声認識を、生成した複数の単位言語モデルのそれぞれを用いて行って、これら複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める。ここで、タスク表現コーパスとは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータと、を含んで構成されるもののことである。そして、求めた複数の音声認識結果のそれぞれについて、タスク表現コーパスを用いて識別スコアを求める。そして、生成した複数の単位言語モデルの中から、求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、コーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【0039】
(9) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、コーパス(例えば、図2の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図2の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスのそれぞれについて、確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、対応する単位言語モデル(例えば、図2のサブセット言語モデル1〜3に相当)を生成する第2のステップと、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパス(例えば、図2のタスク表現コーパスに相当)を用いて、音声認識の困難性(例えば、図2のperplexityに相当)を求める第3のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、をコンピュータに実行させ、前記第2のステップでは、前記複数の単位コーパスの中から1つを選択する選択手順(例えば、後述の第1の選択手順に相当)と、前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順(例えば、後述の第1のサブセット言語モデル生成手順に相当)と、前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順(例えば、後述の第1の繰り返し手順に相当)と、をコンピュータに実行させるためのプログラムを提案している。
【0040】
この発明によれば、プログラムをコンピュータに実行させることで、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中から1つを選択する選択手順と、複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行って、複数の単位コーパスのそれぞれに対応する単位言語モデルを生成する。そして、生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める。そして、生成した複数の単位言語モデルの中から、求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【0041】
(10) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、コーパス(例えば、図5の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図5の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスの中からT個(Tは、T≧1を満たす整数)の単位コーパスを1組の単位コーパス群として選択する選択手順(例えば、後述の第2の選択手順に相当)と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、当該単位コーパス群に対応する単位言語モデル(例えば、図5のサブセット言語モデル1〜3に相当)を生成する単位言語モデル生成手順(例えば、後述の第2のサブセット言語モデル生成手順に相当)と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順(例えば、後述の第2の繰り返し手順に相当)と、を行う第2のステップと、音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパス(例えば、図5のタスク表現コーパス(音声あり)に相当)の音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果(例えば、図5の音声認識結果1〜3に相当)を求める第3のステップと、前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコア(例えば、図5の識別スコア1〜3に相当)を求める第4のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、をコンピュータに実行させるためのプログラムを提案している。
【0042】
この発明によれば、プログラムをコンピュータに実行させることで、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中からT個の単位コーパスを1組の単位コーパス群として選択する選択手順と、複数の単位コーパスのうち選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを複数の単位コーパスの中から選択手順において選択するまで繰り返す繰り返し手順と、を行う。そして、タスク表現コーパスの音声認識を、生成した複数の単位言語モデルのそれぞれを用いて行って、これら複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める。ここで、タスク表現コーパスとは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータと、を含んで構成されるもののことである。そして、求めた複数の音声認識結果のそれぞれについて、タスク表現コーパスを用いて識別スコアを求める。そして、生成した複数の単位言語モデルの中から、求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、コーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【発明の効果】
【0043】
本発明によれば、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立することができる。
【図面の簡単な説明】
【0044】
【図1】本発明の第1実施形態に係るコーパス選別装置の構成を示すブロック図である。
【図2】前記コーパス選別装置による学習コーパスの選別手法について説明するための図である。
【図3】3−gram出現確率の調整について説明するための図である。
【図4】本発明の第2実施形態に係るコーパス選別装置の構成を示すブロック図である。
【図5】前記コーパス選別装置による学習コーパスの選別手法について説明するための図である。
【図6】前記コーパス選別装置による学習コーパスの選別手法について説明するための図である。
【図7】M−bestについて説明するための図である。
【図8】音声認識結果の精度算出について説明するための図である。
【図9】MMI学習のスコア定義と選別手法について説明するための図である。
【図10】MCE学習のスコア定義と選別手法について説明するための図である。
【図11】MWE学習およびMPE学習のスコア定義と選別手法について説明するための図である。
【図12】単語の発音およびモーラ・音素について説明するための図である。
【図13】学習コーパスおよび言語モデルについて説明するための図である。
【図14】3−gram言語モデルについて説明するための図である。
【図15】言語モデルの品質と、記憶領域の使用量と、の関係を示す図である。
【図16】学習コーパスをタスク表現コーパスを用いて選別する場合について説明するための図である。
【図17】従来例に係る学習コーパスの選別手法について説明するための図である。
【発明を実施するための形態】
【0045】
以下、本発明の実施の形態について図面を参照しながら説明する。なお、以下の実施形態における構成要素は適宜、既存の構成要素などとの置き換えが可能であり、また、他の既存の構成要素との組合せを含む様々なバリエーションが可能である。したがって、以下の実施形態の記載をもって、特許請求の範囲に記載された発明の内容を限定するものではない。
【0046】
<第1実施形態>
[コーパス選別装置AAの構成]
図1は、本発明の第1実施形態に係るコーパス選別装置AAの構成を示すブロック図である。コーパス選別装置AAは、学習コーパス分割部11、言語モデリング部12、スコア算出部13、および学習コーパス選出部14を備える。
【0047】
学習コーパス分割部11は、学習コーパス(全体)をY個(Yは、Y≧2を満たす整数)に分割して、学習コーパス(サブセット1)〜学習コーパス(サブセットY)を生成する。図2には、学習コーパス分割部11により、学習コーパス(全体)を3つに分割した例が示されている。
【0048】
言語モデリング部12は、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のそれぞれについて、言語モデリング(確率統計処理)を行って、対応するサブセット言語モデル1〜Yを生成する。具体的には、言語モデリング部12は、後述の第1の選択手順、第1のサブセット言語モデル生成手順、および第1の繰り返し手順を行って、サブセット言語モデル1〜Yを生成する。
【0049】
上述の第1の選択手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中から1つを選択する。また、第1のサブセット言語モデル生成手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のうち第1の選択手順において選択したものを除く全ての学習コーパスを用いて、言語モデリング(確率統計処理)を行って、選択した学習コーパスに対応するサブセット言語モデルを生成する。また、第1の繰り返し手順では、上述の第1の選択手順および第1のサブセット言語モデル生成手順を、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のそれぞれに対して1回ずつ行うまで繰り返す。
【0050】
図2に示した例では、サブセット言語モデル1〜3が生成されている。サブセット言語モデル1は、学習コーパス(サブセット2)と学習コーパス(サブセット3)とを用いて言語モデリング(確率統計処理)が行われたことにより、生成されたものである。サブセット言語モデル2は、学習コーパス(サブセット1)と学習コーパス(サブセット3)とを用いて言語モデリング(確率統計処理)が行われたことにより、生成されたものである。サブセット言語モデル3は、学習コーパス(サブセット1)と学習コーパス(サブセット2)とを用いて言語モデリング(確率統計処理)が行われたことにより、生成されたものである。
【0051】
スコア算出部13は、サブセット言語モデル1〜Yのそれぞれについて、タスク表現コーパスを用いてperplexityを算出して、perplexity−1〜perplexity−Yを求める。なお、perplexity−1〜perplexity−Yを求める際には、N−gram出現確率(Nは、任意の自然数)を求め、求めたN−gram出現確率を図3に示す3つの手法のいずれかにより調整する。
【0052】
ここで、perplexity−P(Pは、1≦P≦Yを満たす任意の整数)を求めることとすると、図3に示した第1の手法は、学習コーパス(サブセットP)中に3つ組単語として存在した場合に適用される。第2の手法は、学習コーパス(サブセットP)中に3つ組単語として存在しないが、2つ組単語として存在した場合に適用される。第3の手法は、第1の手法または第2の手法により調整したものを、さらに調整する場合に適用される。なお、図3では、3−gram出現確率を調整する場合について例示している。
【0053】
図1に戻って、学習コーパス選出部14は、まず、サブセット言語モデル1〜Yの中からperplexityの低いものを求める。具体的には、例えばperplexityが予め定められた閾値以下であるものを、perplexityの低いサブセット言語モデルとして求める。なお、求めるサブセット言語モデルの数は、1つに限らず、複数であってもよい。
【0054】
上述のように求めたサブセット言語モデルをサブセット言語モデルQ(Qは、1≦Q≦Yを満たす任意の整数)と表すこととすると、学習コーパス選出部14は、次に、サブセット言語モデルQに対応する学習コーパス(サブセットQ)を学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0055】
以上のコーパス選別装置AAによれば、音声認識を行う内容に基づいて、学習コーパス(全体)から学習コーパス(選別済み)を選別することができる。このため、音声認識を行う内容に適した情報は学習コーパス(選別済み)に残しつつ、学習コーパス(選別済み)の規模を小さくすることができる。したがって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパス(選別済み)を選別することができる。
【0056】
<第2実施形態>
[コーパス選別装置BBの構成]
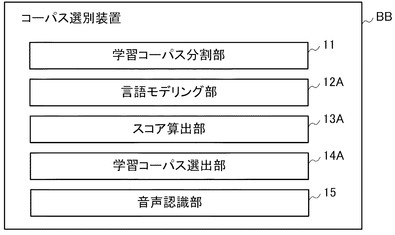
図4は、本発明の第2実施形態に係るコーパス選別装置BBの構成を示すブロック図である。コーパス選別装置BBは、図1に示した本発明の第1実施形態に係るコーパス選別装置AAとは、音声認識部15を備える点と、言語モデリング部12の代わりに言語モデリング部12Aを備える点と、スコア算出部13の代わりにスコア算出部13Aを備える点と、学習コーパス選出部14の代わりに学習コーパス選出部14Aを備える点と、が異なる。なお、コーパス選別装置BBに設けられた学習コーパス分割部11については、コーパス選別装置AAに設けられた学習コーパス分割部11と同様に動作するため、説明を省略する。
【0057】
言語モデリング部12Aは、後述の第2の選択手順、第2のサブセット言語モデル生成手順、および第2の繰り返し手順を行って、サブセット言語モデルを生成する。
【0058】
上述の第2の選択手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中からT個の学習コーパスを1組の学習コーパス群として選択する。また、第2のサブセット言語モデル生成手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のうち第2の選択手順において選択したものを除く全ての学習コーパスを用いて言語モデリング(確率統計処理)を行って、上述の1組の学習コーパス群に対応するサブセット言語モデルを生成する。また、第2の繰り返し手順では、上述の第2の選択手順および第2のサブセット言語モデル生成手順を、T個の学習コーパスの組合せの全てを学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中から第2の選択手順において選択するまで繰り返す。なお、第2の選択手順により第2の選択手順および第2のサブセット言語モデル生成手順を繰り返す回数は、式(1)のように表すことができる。
【0059】
【数1】

【0060】
図5には、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のうちの1つを学習コーパス(全体)から除去する例が示されている。この図5に示した例では、上述のTが「1」であるものとして、上述の第2の選択手順、第2のサブセット言語モデル生成手順、および第2の繰り返し手順を行っている。このため、学習コーパス(サブセット1)で構成される学習コーパス群に対して、サブセット言語モデル1が生成されている。また、学習コーパス(サブセット2)で構成される学習コーパス群に対して、サブセット言語モデル2が生成され、学習コーパス(サブセット3)で構成される学習コーパス群に対して、サブセット言語モデル3が生成されている。
【0061】
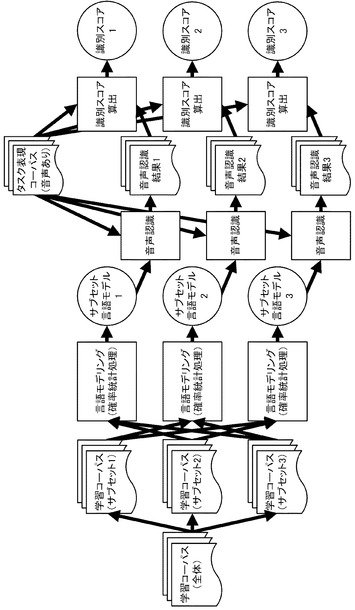
図6には、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のうちの2つを学習コーパス(全体)から除去する例が示されている。この図6に示した例では、上述のTが「2」であるものとして、上述の第2の選択手順、第2のサブセット言語モデル生成手順、および第2の繰り返し手順を行っている。このため、学習コーパス(サブセット1)と学習コーパス(サブセット2)とで構成される学習コーパス群に対して、サブセット言語モデル1、2が生成されている。また、学習コーパス(サブセット2)と学習コーパス(サブセット3)とで構成される学習コーパス群に対して、サブセット言語モデル2、3が生成され、学習コーパス(サブセット3)学習コーパス(サブセット1)とで構成される学習コーパス群に対して、サブセット言語モデル3、1が生成されている。
【0062】
図4に戻って、音声認識部15は、タスク表現コーパス(音声あり)の音声認識を、言語モデリング部12Aにより生成されたサブセット言語モデルを用いて行って、音声認識結果を求める。ここで、タスク表現コーパス(音声あり)とは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータを含んで構成されるデータベースのことである。このため、タスク表現コーパス(音声あり)には、認識させたい発話内容について、音声データおよびテキストデータが含まれている。
【0063】
図5に示した例では、サブセット言語モデル1を用いた場合の音声認識結果1と、サブセット言語モデル2を用いた場合の音声認識結果2と、サブセット言語モデル3を用いた場合の音声認識結果3と、が求められている。一方、図6に示した例では、サブセット言語モデル1、2を用いた場合の音声認識結果1、2と、サブセット言語モデル2、3を用いた場合の音声認識結果2、3と、サブセット言語モデル3、1を用いた場合の音声認識結果3、1と、が求められている。
【0064】
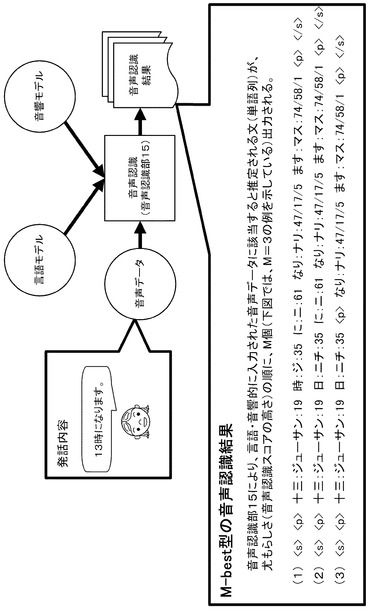
ここで、音声認識部15が出力する音声認識結果の出力形式は、M−best(Mは、M≧1を満たす整数)である。図7では、音声認識部15に3−bestが適用されている場合を示しており、「13時になります。」という発話内容の音声データが音声認識部15に入力され、音声認識結果(1)〜(3)が音声認識部15から出力された例を示している。音声認識結果(3)、音声認識結果(2)、音声認識結果(1)の順に、音声認識スコアが高く、すなわち尤もらしさが大きくなっている。<s>は文頭を示すダミー単語、</s>は文末を示すダミー単語、<p>は無音単語を示すダミー単語である。
【0065】
また、音声認識部15が出力する音声認識結果の精度算出について、図8を用いて以下に説明する。正解文に含まれかつ正しく認識できた単語について、正解単語と呼ぶこととすると、正解単語の総数Sは、図8では「5」となる。また、正解文には含まれていないにもかかわらず認識してしまった単語について、挿入誤り単語と呼ぶこととすると、挿入誤り単語の総数EIは、図8では「1」となる。また、正解文には含まれているにもかかわらず認識できなかった単語について、削除誤り単語と呼ぶこととすると、削除誤り単語の総数EDは、図8では「1」となる。また、正解文に含まれている単語を誤認識してしまったものについて、置換誤り単語と呼ぶこととすると、置換誤り単語の総数ESは、図8では「2」となる。
【0066】
図4に戻って、スコア算出部13Aは、音声認識結果について、タスク表現コーパス(音声あり)を用いて識別スコアを算出して、識別スコアを求める。識別スコアの算出手法としては、図9に示すMMI(最大相互情報量)を用いた手法や、図10に示すMCE(最小識別誤り化)を用いた手法や、図11に示すMWE(最小単語誤り化)またはMPE(最小音素誤り化)を用いた手法を適用することができる。
【0067】
図5に示した例では、音声認識結果1の識別スコア1と、音声認識結果2の識別スコア2と、音声認識結果3の識別スコア3と、が求められている。一方、図6に示した例では、音声認識結果1、2の識別スコア1、2と、音声認識結果2、3の識別スコア2、3と、音声認識結果3、1の識別スコア3、1と、が求められている。
【0068】
学習コーパス選出部14Aは、学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中から1つ以上を除去して、学習コーパス(選別済み)とする。
【0069】
具体的には、スコア算出部13AにおいてMMIを用いた手法が適用される場合には、学習コーパス選出部14Aは、まず、図9に示したスコア定義式(右辺)を最大にするサブセット言語モデルQを求める。次に、サブセット言語モデルQに対応する学習コーパス群を構成するT個の学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0070】
一方、スコア算出部13AにおいてMCEを用いた手法が適用される場合には、学習コーパス選出部14Aは、まず、図10に示したスコア定義式を最小にするサブセット言語モデルQを求める。次に、サブセット言語モデルQに対応する学習コーパス群を構成するT個の学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0071】
また、スコア算出部13AにおいてMWEまたはMPEを用いた手法が適用される場合には、学習コーパス選出部14Aは、まず、図11に示したスコア定義式を最大にするサブセット言語モデルQを求める。次に、サブセット言語モデルQに対応する学習コーパス群を構成するT個の学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0072】
例えば、スコア算出部13AにおいてMMIを用いた手法が適用され、図5に示した識別スコア1〜3のうち識別スコア1が最大となった場合には、サブセット言語モデル1に対応する学習コーパス群を構成する学習コーパス(サブセット1)が、学習コーパス(全体)から除去される。ここで、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれのデータ容量が等しければ、学習コーパス(選別済み)の規模は、学習コーパス(全体)の規模の2/3となる。
【0073】
また、例えば、スコア算出部13AにおいてMCEを用いた手法が適用され、図6に示した識別スコア1、2と、識別スコア2、3と、識別スコア3、1と、のうち識別スコア3、1が最小となった場合には、サブセット言語モデル3、1に対応する学習コーパス群を構成する学習コーパス(サブセット3)および学習コーパス(サブセット1)が、学習コーパス(全体)から除去される。ここで、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれのデータ容量が等しければ、学習コーパス(選別済み)の規模は、学習コーパス(全体)の規模の1/3となる。
【0074】
なお、図11に示したスコア定義式の△(Wr,Wri)は、スコア算出部13AにおいてMWEを用いた手法が適用される場合と、スコア算出部13AにおいてMPEを用いた手法が適用される場合と、で異なる。スコア算出部13AにおいてMWEを用いた手法が適用される場合には、△(Wr,Wri)は、正解単語が多く、かつ、挿入誤り単語や削除誤り単語といった各種誤り単語が少ない場合に大きな値をとる式を示す。一方、スコア算出部13AにおいてMPEを用いた手法が適用される場合には、△(Wr,Wri)は、上述のMWEを単語レベルではなく音素レベル(図12参照)で比較し、正解音素が多く、かつ、各種誤り単語が少ない場合に大きな値をとる式を示す。なお、音素の代わりにモーラ・レベルで比較することもできる。
【0075】
以上のコーパス選別装置BBによれば、音声認識を行う内容に基づいて、学習コーパス(全体)から学習コーパス(選別済み)を選別することができる。このため、音声認識を行う内容に適した情報は学習コーパス(選別済み)に残しつつ、学習コーパス(選別済み)の規模を小さくすることができる。したがって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパス(選別済み)を選別することができる。
【0076】
なお、本発明のコーパス選別装置AAやコーパス選別装置BBの処理を、コンピュータ読み取り可能な記録媒体に記憶し、記録媒体に記録されたプログラムをコーパス選別装置AAやコーパス選別装置BBに読み込ませ、実行することによって、本発明を実現できる。
【0077】
また、上述のプログラムは、このプログラムを記憶装置などに格納したコーパス選別装置AAやコーパス選別装置BBから、伝送媒体を介して、あるいは、伝送媒体中の伝送波により他のコンピュータシステムに伝送されてもよい。ここで、プログラムを伝送する「伝送媒体」は、インターネットなどのネットワーク(通信網)や電話回線などの通信回線(通信線)のように情報を伝送する機能を有する媒体のことをいう。
【0078】
また、上述のプログラムは、上述の機能の一部を実現するためのものであってもよい。さらに、上述の機能をコーパス選別装置AAやコーパス選別装置BBにすでに記録されているプログラムとの組合せで実現できるもの、いわゆる差分ファイル(差分プログラム)であってもよい。
【0079】
以上、この発明の実施形態につき、図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、この発明の要旨を逸脱しない範囲の設計なども含まれる。
【0080】
例えば、上述の各実施形態では、学習コーパス(全体)を3つに分割したが、これに限らず、1以上の任意の整数に分割することができる。
【0081】
また、上述の第2実施形態では、音声認識結果の出力形式としてM−bestを適用した場合について説明したが、これに限らず、例えばラティスを適用してもよい。
【符号の説明】
【0082】
AA、BB・・・コーパス選別装置
11・・・学習コーパス分割部
12、12A・・・言語モデリング部
13、13A・・・スコア算出部
14、14A・・・学習コーパス選出部
15・・・音声識別部
【技術分野】
【0001】
本発明は、コーパス選別装置、コーパス選別方法、およびプログラムに関する。
【背景技術】
【0002】
従来より、音声認識を行う際に、言語モデルが用いられる場合がある(例えば、特許文献1参照)。この言語モデルは、図13に示すように、言語モデリング(確率統計処理)により、学習コーパスを用いて生成される。
【0003】
学習コーパスとは、いわゆるテキストデータベースのことであり、例えば、形態素解析といった手法により平文から分割された複数の単語と、これら複数の単語のそれぞれの品詞情報と、を含んで構成される。例えば、図13中左側下部に示した「私は驚いた」という平文は、「私」、「は」、「驚い」、「た」の4つの単語に分割することができる。なお、図13では、これら4つの単語について、品詞情報が数字で表現されている。また、学習コーパスは、上述の単語および品詞情報だけでなく、例えば読み方の情報といった、他の情報を含んで構成される場合もある。
【0004】
言語モデリング(確率統計処理)では、図13中左側下部に示したような単語を多数集め、各単語の繋がる確率を求め、求めた結果から言語モデルを生成する。図13中右側下部には、言語モデルの内容として、3つ組の単語の繋がる確率の一例が示されている。例えば、「私」と「は」と「驚い」との繋がる確率は、0.000294であり、「は」と「驚い」と「た」との繋がる確率は、0.711541であることを示しており、これら確率は、3−gram出現確率と呼ばれる。
【0005】
図13中右側下部に示した内容を含む言語モデルを用いると、「私は驚いた」という文の出現確率を求めることができる。具体的には、「私は驚いた」という文には、「私は驚い」と「は驚いた」という2つの3つ組がある。この「私は驚い」の3−gram出現確率と、「は驚いた」の3−gram出現確率と、を掛け合わせると、「私は驚いた」という文の出現確率となる。なお、実際には、文頭および文末にダミーの単語が1つずつ存在するものとして、文の出現確率を求める。
【0006】
なお、文の出現確率の平均を取ったものの逆数を求めると、その文のperplexityを求めることができる。例えば、「私は驚いた」という文のperplexityは、「私は驚いた」という文の出現確率の平均を取ったものの逆数、すなわち、「私は驚い」の3−gram出現確率と、「は驚いた」の3−gram出現確率と、の相乗平均の逆数に等しくなる。
【0007】
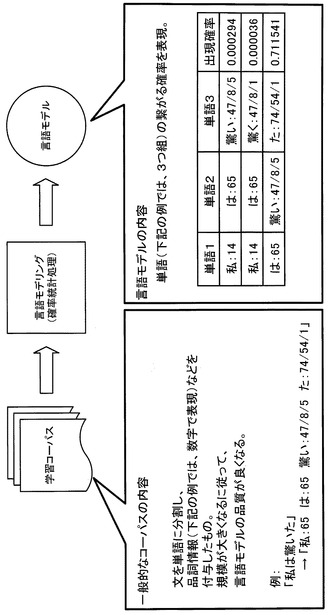
3−gram言語モデルについて、図14を用いて以下に説明する。図14中左側下部には、言語モデリング(確率統計処理)により一般的な学習コーパスを分析して得られた単語列の出現頻度が示されている。より具体的には、一般的な学習コーパスにおいて、「僕:14」「は:65」の次に出てきたそれぞれの単語の出現頻度が示されている。一方、図14中右側下部には、上述の言語モデリング(確率統計処理)の結果により生成された3−gram言語モデルの内容が示されている。出現確率は、「僕:14」「は:65」の次に特定の単語が出てきた場合の出現頻度(例えば、特定の単語として「大好き:18」が出てきた場合、出現頻度は「9」)を、「僕:14」「は:65」の次に何らかの単語が出てきた場合の出現頻度である「30」で割ることにより、求められる。なお、次に出てこなかった単語に対しても、出てきた単語と比べて小さい出現確率を割り振る場合がある。
【0008】
ここで、言語モデルは、音声認識に用いられる際にメモリといった記憶装置に記憶されるが、言語モデルの品質と、記憶領域の使用量と、の間には、図15に示すようなトレードオフの関係がある。すなわち、学習コーパスの規模が大きくなるに従って、言語モデルの品質は向上するが、言語モデル使用時の記憶領域の使用量は大きくなる。一方、学習コーパスの規模が小さくなるに従って、言語モデルの品質は低下するが、言語モデル使用時の記憶領域の使用量は小さくなる。
【0009】
そこで、図16に示すように、学習コーパスをタスク表現コーパスを用いて選別する場合がある。タスク表現コーパスとは、音声認識を行う内容に応じたデータベースのことであり、認識させたい発話内容を含んで構成される。例えばコールセンターにおいて音声認識を行う場合には、タスク表現コーパスとは、コールセンターにおける実際の通話内容を文字に書き起こしたテキストデータベースのことである。このため、タスク表現コーパスに存在している単語列をより多く含んでいるか否かにより、学習コーパスを選別して、音声認識させたい発話内容に近いものだけを学習コーパスの中から抽出することができる。これによれば、認識対象は限定されるものの、言語モデルの品質の向上と、言語モデル使用時の記憶領域の使用量の削減と、を両立することができる。
【先行技術文献】
【特許文献】
【0010】
【特許文献1】特開平5−232987号公報
【発明の概要】
【発明が解決しようとする課題】
【0011】
従来例に係る学習コーパスの選別手法について、図17を用いて以下に説明する。まず、学習コーパス(全体)を学習コーパス(サブセット1)、学習コーパス(サブセット2)、および学習コーパス(サブセット3)の3つに分割するとともに、タスク表現コーパスを言語モデリング(確率統計処理)してシード言語モデルを生成する。ここで、学習コーパス(全体)とは、規模の大きな学習コーパスであり、例えばウェブ上のデータを集めて生成されたもののことである。
【0012】
次に、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれについて、シード言語モデルを用いてperplexityを算出して、perplexity−1、perplexity−2、およびperplexity−3を求める。
【0013】
次に、perplexity−1〜perplexity−3を比較して、最も高いperplexityに対応する学習コーパス(サブセットX(Xは、1≦X≦3を満たす整数))を学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。ここで、最も高いperplexityに対応する学習コーパス(サブセットX)とは、最も高いperplexityを算出する際に用いた学習コーパス(サブセットX)のことであり、例えばperplexity−1〜perplexity−3のうちperplexity−2が最も高い場合には、学習コーパス(サブセット2)のことを示す。
【0014】
しかしながら、図17に示したような従来の手法により選別された学習コーパス(選別済み)では、言語モデルの品質の向上と、記憶領域の使用量の削減と、の両立は不十分であった。
【0015】
そこで、本発明は、上述の課題に鑑みてなされたものであり、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパスを選別するコーパス選別装置、コーパス選別方法、およびプログラムを提供することを目的とする。
【課題を解決するための手段】
【0016】
本発明は、上記の課題を解決するために、以下の事項を提案している。
【0017】
(1) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別装置(例えば、図1のコーパス選別装置AAに相当)であって、コーパス(例えば、図2の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図2の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割するコーパス分割手段(例えば、図1の学習コーパス分割部11に相当)と、前記複数の単位コーパスのそれぞれについて、確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、対応する単位言語モデル(例えば、図2のサブセット言語モデル1〜3に相当)を生成する言語モデリング手段(例えば、図1の言語モデリング部12に相当)と、前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパス(例えば、図2のタスク表現コーパスに相当)を用いて、音声認識の困難性(例えば、図2のperplexityに相当)を求める困難性算出手段(例えば、図1のスコア算出部13に相当)と、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記困難性算出手段により求められた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くコーパス選出手段(例えば、図1の学習コーパス選出部14に相当)と、を備え、前記言語モデリング手段は、前記複数の単位コーパスの中から1つを選択する選択手順(例えば、後述の第1の選択手順に相当)と、前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順(例えば、後述の第1のサブセット言語モデル生成手順に相当)と、前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順(例えば、後述の第1の繰り返し手順に相当)と、を行うことを特徴とするコーパス選別装置を提案している。
【0018】
この発明によれば、コーパス選別装置に、コーパス分割手段、言語モデリング手段、困難性算出手段、およびコーパス選出手段を設けた。そして、コーパス分割手段により、コーパスを複数の単位コーパスに分割することとした。また、言語モデリング手段により、複数の単位コーパスの中から1つを選択する選択手順と、複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行って、複数の単位コーパスのそれぞれに対応する単位言語モデルを生成することとした。また、困難性算出手段により、言語モデリング手段により生成された複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、困難性算出手段により求められた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0019】
このため、(1)のコーパス選別装置は、コーパスを複数の単位コーパスに分割し、これら複数の単位コーパスのそれぞれについて、自身を除く全ての単位コーパスを用いて確率統計処理を行って、対応する単位言語モデルを生成する。そして、複数の単位言語モデルのそれぞれを用いた場合の音声認識の困難性を求める。そして、求めた音声認識の困難性を用いて、複数の単位コーパスの中から音声認識を行う内容に適していないものを求め、求めた単位コーパスをコーパスから除く。したがって、コーパスを構成する複数の単位コーパスについて、音声認識を行う内容に基づいて選別することができるので、音声認識を行う内容に適した情報はコーパスに残しつつ、コーパスの規模を小さくすることができる。よって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立することができる。
【0020】
(2) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別装置(例えば、図4のコーパス選別装置BBに相当)であって、コーパス(例えば、図5の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図5の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割するコーパス分割手段(例えば、図4の学習コーパス分割部11に相当)と、前記複数の単位コーパスの中からT個(Tは、T≧1を満たす整数)の単位コーパスを1組の単位コーパス群として選択する選択手順(例えば、後述の第2の選択手順に相当)と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、当該単位コーパス群に対応する単位言語モデル(例えば、図5のサブセット言語モデル1〜3に相当)を生成する単位言語モデル生成手順(例えば、後述の第2のサブセット言語モデル生成手順に相当)と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順(例えば、後述の第2の繰り返し手順に相当)と、を行う言語モデリング手段(例えば、図4の言語モデリング部12に相当)と、音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパス(例えば、図5のタスク表現コーパス(音声あり)に相当)の音声認識を、前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果(例えば、図5の音声認識結果1〜3に相当)を求める音声認識手段(例えば、図4の音声認識部15に相当)と、前記音声認識手段により求められた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコア(例えば、図5の識別スコア1〜3に相当)を求める識別スコア算出手段(例えば、図4のスコア算出部13Aに相当)と、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除くコーパス選出手段(例えば、図4の学習コーパス選出部14Aに相当)と、を備えることを特徴とするコーパス選別装置を提案している。
【0021】
この発明によれば、コーパス選別装置に、コーパス分割手段、言語モデリング手段、音声認識手段、識別スコア算出手段、およびコーパス選出手段を設けた。そして、コーパス分割手段により、コーパスを複数の単位コーパスに分割することとした。また、言語モデリング手段により、複数の単位コーパスの中からT個の単位コーパスを1組の単位コーパス群として選択する選択手順と、複数の単位コーパスのうち選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを複数の単位コーパスの中から選択手順において選択するまで繰り返す繰り返し手順と、を行うこととした。また、音声認識手段により、タスク表現コーパスの音声認識を、言語モデリング手段により生成された複数の単位言語モデルのそれぞれを用いて行って、複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求めることとした。ここで、タスク表現コーパスとは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータと、を含んで構成されるもののことである。また、識別スコア算出手段により、音声認識手段により求められた複数の音声認識結果のそれぞれについて、タスク表現コーパスを用いて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、コーパスから除くこととした。
【0022】
このため、(2)のコーパス選別装置は、コーパスを複数の単位コーパスに分割し、T個の単位コーパスで構成される単位コーパス群のそれぞれについて、対応する単位言語モデルを生成する。そして、複数の単位言語モデルのそれぞれを用いて音声認識を行う場合の識別スコアを求める。そして、求めた識別スコアを用いて、複数の単位コーパス群の中から音声認識を行う内容に適していないものを求め、求めた単位コーパス群を構成するT個の単位コーパスを、コーパスから除く。したがって、コーパスを構成する複数の単位コーパスについて、音声認識を行う内容に基づいて選別することができるので、音声認識を行う内容に適した情報はコーパスに残しつつ、コーパスの規模を小さくすることができる。よって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立することができる。
【0023】
(3) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最大相互情報量(例えば、図9のMMI(最大相互情報量)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0024】
この発明によれば、識別スコア算出手段により、最大相互情報量に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0025】
このため、(3)のコーパス選別装置は、最大相互情報量学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0026】
(4) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最小識別誤り化(例えば、図10のMCE(最小識別誤り化)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最小となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0027】
この発明によれば、識別スコア算出手段により、最小識別誤り化に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最小となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0028】
このため、(4)のコーパス選別装置は、最小識別誤り化学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0029】
(5) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最小単語誤り化(例えば、図11のMWE(最小単語誤り化)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0030】
この発明によれば、識別スコア算出手段により、最小単語誤り化に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0031】
このため、(5)のコーパス選別装置は、最小単語誤り化学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0032】
(6) 本発明は、(2)のコーパス選別装置について、前記識別スコア算出手段は、最小音素誤り化(例えば、図11のMPE(最小音素誤り化)に相当)に基づいて前記識別スコアを求め、前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とするコーパス選別装置を提案している。
【0033】
この発明によれば、識別スコア算出手段により、最小音素誤り化に基づいて識別スコアを求めることとした。また、コーパス選出手段により、言語モデリング手段により生成された複数の単位言語モデルの中から、識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除くこととした。
【0034】
このため、(6)のコーパス選別装置は、最小音素誤り化学習を利用して、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できるコーパスを選別することができる。
【0035】
(7) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法であって、コーパス(例えば、図2の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図2の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスのそれぞれについて、確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、対応する単位言語モデル(例えば、図2のサブセット言語モデル1〜3に相当)を生成する第2のステップと、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパス(例えば、図2のタスク表現コーパスに相当)を用いて、音声認識の困難性(例えば、図2のperplexityに相当)を求める第3のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、を備え、前記第2のステップでは、前記複数の単位コーパスの中から1つを選択する選択手順(例えば、後述の第1の選択手順に相当)と、前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順(例えば、後述の第1のサブセット言語モデル生成手順に相当)と、前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順(例えば、後述の第1の繰り返し手順に相当)と、を行うことを特徴とするコーパス選別方法を提案している。
【0036】
この発明によれば、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中から1つを選択する選択手順と、複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行って、複数の単位コーパスのそれぞれに対応する単位言語モデルを生成する。そして、生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める。そして、生成した複数の単位言語モデルの中から、求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【0037】
(8) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法であって、コーパス(例えば、図5の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図5の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスの中からT個(Tは、T≧1を満たす整数)の単位コーパスを1組の単位コーパス群として選択する選択手順(例えば、後述の第2の選択手順に相当)と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、当該単位コーパス群に対応する単位言語モデル(例えば、図5のサブセット言語モデル1〜3に相当)を生成する単位言語モデル生成手順(例えば、後述の第2のサブセット言語モデル生成手順に相当)と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順(例えば、後述の第2の繰り返し手順に相当)と、を行う第2のステップと、音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパス(例えば、図5のタスク表現コーパス(音声あり)に相当)の音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果(例えば、図5の音声認識結果1〜3に相当)を求める第3のステップと、前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコア(例えば、図5の識別スコア1〜3に相当)を求める第4のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、を備えることを特徴とするコーパス選別方法を提案している。
【0038】
この発明によれば、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中からT個の単位コーパスを1組の単位コーパス群として選択する選択手順と、複数の単位コーパスのうち選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを複数の単位コーパスの中から選択手順において選択するまで繰り返す繰り返し手順と、を行う。そして、タスク表現コーパスの音声認識を、生成した複数の単位言語モデルのそれぞれを用いて行って、これら複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める。ここで、タスク表現コーパスとは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータと、を含んで構成されるもののことである。そして、求めた複数の音声認識結果のそれぞれについて、タスク表現コーパスを用いて識別スコアを求める。そして、生成した複数の単位言語モデルの中から、求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、コーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【0039】
(9) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、コーパス(例えば、図2の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図2の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスのそれぞれについて、確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、対応する単位言語モデル(例えば、図2のサブセット言語モデル1〜3に相当)を生成する第2のステップと、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパス(例えば、図2のタスク表現コーパスに相当)を用いて、音声認識の困難性(例えば、図2のperplexityに相当)を求める第3のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、をコンピュータに実行させ、前記第2のステップでは、前記複数の単位コーパスの中から1つを選択する選択手順(例えば、後述の第1の選択手順に相当)と、前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順(例えば、後述の第1のサブセット言語モデル生成手順に相当)と、前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順(例えば、後述の第1の繰り返し手順に相当)と、をコンピュータに実行させるためのプログラムを提案している。
【0040】
この発明によれば、プログラムをコンピュータに実行させることで、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中から1つを選択する選択手順と、複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行って、複数の単位コーパスのそれぞれに対応する単位言語モデルを生成する。そして、生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める。そして、生成した複数の単位言語モデルの中から、求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスをコーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【0041】
(10) 本発明は、音声認識に用いられる言語モデルの生成の際に用いられるコーパス(例えば、後述の学習コーパス(選別済み)に相当)を選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、コーパス(例えば、図5の学習コーパス(全体)に相当)を複数の単位コーパス(例えば、図5の学習コーパス(サブセット1)〜学習コーパス(サブセット3)に相当)に分割する第1のステップと、前記複数の単位コーパスの中からT個(Tは、T≧1を満たす整数)の単位コーパスを1組の単位コーパス群として選択する選択手順(例えば、後述の第2の選択手順に相当)と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理(例えば、後述の言語モデリング処理(確率統計処理)に相当)を行って、当該単位コーパス群に対応する単位言語モデル(例えば、図5のサブセット言語モデル1〜3に相当)を生成する単位言語モデル生成手順(例えば、後述の第2のサブセット言語モデル生成手順に相当)と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順(例えば、後述の第2の繰り返し手順に相当)と、を行う第2のステップと、音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパス(例えば、図5のタスク表現コーパス(音声あり)に相当)の音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果(例えば、図5の音声認識結果1〜3に相当)を求める第3のステップと、前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコア(例えば、図5の識別スコア1〜3に相当)を求める第4のステップと、前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、をコンピュータに実行させるためのプログラムを提案している。
【0042】
この発明によれば、プログラムをコンピュータに実行させることで、コーパスを複数の単位コーパスに分割する。そして、複数の単位コーパスの中からT個の単位コーパスを1組の単位コーパス群として選択する選択手順と、複数の単位コーパスのうち選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、選択手順および単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを複数の単位コーパスの中から選択手順において選択するまで繰り返す繰り返し手順と、を行う。そして、タスク表現コーパスの音声認識を、生成した複数の単位言語モデルのそれぞれを用いて行って、これら複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める。ここで、タスク表現コーパスとは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータと、を含んで構成されるもののことである。そして、求めた複数の音声認識結果のそれぞれについて、タスク表現コーパスを用いて識別スコアを求める。そして、生成した複数の単位言語モデルの中から、求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、コーパスから除く。これによれば、上述の効果と同様の効果を奏することができる。
【発明の効果】
【0043】
本発明によれば、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立することができる。
【図面の簡単な説明】
【0044】
【図1】本発明の第1実施形態に係るコーパス選別装置の構成を示すブロック図である。
【図2】前記コーパス選別装置による学習コーパスの選別手法について説明するための図である。
【図3】3−gram出現確率の調整について説明するための図である。
【図4】本発明の第2実施形態に係るコーパス選別装置の構成を示すブロック図である。
【図5】前記コーパス選別装置による学習コーパスの選別手法について説明するための図である。
【図6】前記コーパス選別装置による学習コーパスの選別手法について説明するための図である。
【図7】M−bestについて説明するための図である。
【図8】音声認識結果の精度算出について説明するための図である。
【図9】MMI学習のスコア定義と選別手法について説明するための図である。
【図10】MCE学習のスコア定義と選別手法について説明するための図である。
【図11】MWE学習およびMPE学習のスコア定義と選別手法について説明するための図である。
【図12】単語の発音およびモーラ・音素について説明するための図である。
【図13】学習コーパスおよび言語モデルについて説明するための図である。
【図14】3−gram言語モデルについて説明するための図である。
【図15】言語モデルの品質と、記憶領域の使用量と、の関係を示す図である。
【図16】学習コーパスをタスク表現コーパスを用いて選別する場合について説明するための図である。
【図17】従来例に係る学習コーパスの選別手法について説明するための図である。
【発明を実施するための形態】
【0045】
以下、本発明の実施の形態について図面を参照しながら説明する。なお、以下の実施形態における構成要素は適宜、既存の構成要素などとの置き換えが可能であり、また、他の既存の構成要素との組合せを含む様々なバリエーションが可能である。したがって、以下の実施形態の記載をもって、特許請求の範囲に記載された発明の内容を限定するものではない。
【0046】
<第1実施形態>
[コーパス選別装置AAの構成]
図1は、本発明の第1実施形態に係るコーパス選別装置AAの構成を示すブロック図である。コーパス選別装置AAは、学習コーパス分割部11、言語モデリング部12、スコア算出部13、および学習コーパス選出部14を備える。
【0047】
学習コーパス分割部11は、学習コーパス(全体)をY個(Yは、Y≧2を満たす整数)に分割して、学習コーパス(サブセット1)〜学習コーパス(サブセットY)を生成する。図2には、学習コーパス分割部11により、学習コーパス(全体)を3つに分割した例が示されている。
【0048】
言語モデリング部12は、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のそれぞれについて、言語モデリング(確率統計処理)を行って、対応するサブセット言語モデル1〜Yを生成する。具体的には、言語モデリング部12は、後述の第1の選択手順、第1のサブセット言語モデル生成手順、および第1の繰り返し手順を行って、サブセット言語モデル1〜Yを生成する。
【0049】
上述の第1の選択手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中から1つを選択する。また、第1のサブセット言語モデル生成手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のうち第1の選択手順において選択したものを除く全ての学習コーパスを用いて、言語モデリング(確率統計処理)を行って、選択した学習コーパスに対応するサブセット言語モデルを生成する。また、第1の繰り返し手順では、上述の第1の選択手順および第1のサブセット言語モデル生成手順を、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のそれぞれに対して1回ずつ行うまで繰り返す。
【0050】
図2に示した例では、サブセット言語モデル1〜3が生成されている。サブセット言語モデル1は、学習コーパス(サブセット2)と学習コーパス(サブセット3)とを用いて言語モデリング(確率統計処理)が行われたことにより、生成されたものである。サブセット言語モデル2は、学習コーパス(サブセット1)と学習コーパス(サブセット3)とを用いて言語モデリング(確率統計処理)が行われたことにより、生成されたものである。サブセット言語モデル3は、学習コーパス(サブセット1)と学習コーパス(サブセット2)とを用いて言語モデリング(確率統計処理)が行われたことにより、生成されたものである。
【0051】
スコア算出部13は、サブセット言語モデル1〜Yのそれぞれについて、タスク表現コーパスを用いてperplexityを算出して、perplexity−1〜perplexity−Yを求める。なお、perplexity−1〜perplexity−Yを求める際には、N−gram出現確率(Nは、任意の自然数)を求め、求めたN−gram出現確率を図3に示す3つの手法のいずれかにより調整する。
【0052】
ここで、perplexity−P(Pは、1≦P≦Yを満たす任意の整数)を求めることとすると、図3に示した第1の手法は、学習コーパス(サブセットP)中に3つ組単語として存在した場合に適用される。第2の手法は、学習コーパス(サブセットP)中に3つ組単語として存在しないが、2つ組単語として存在した場合に適用される。第3の手法は、第1の手法または第2の手法により調整したものを、さらに調整する場合に適用される。なお、図3では、3−gram出現確率を調整する場合について例示している。
【0053】
図1に戻って、学習コーパス選出部14は、まず、サブセット言語モデル1〜Yの中からperplexityの低いものを求める。具体的には、例えばperplexityが予め定められた閾値以下であるものを、perplexityの低いサブセット言語モデルとして求める。なお、求めるサブセット言語モデルの数は、1つに限らず、複数であってもよい。
【0054】
上述のように求めたサブセット言語モデルをサブセット言語モデルQ(Qは、1≦Q≦Yを満たす任意の整数)と表すこととすると、学習コーパス選出部14は、次に、サブセット言語モデルQに対応する学習コーパス(サブセットQ)を学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0055】
以上のコーパス選別装置AAによれば、音声認識を行う内容に基づいて、学習コーパス(全体)から学習コーパス(選別済み)を選別することができる。このため、音声認識を行う内容に適した情報は学習コーパス(選別済み)に残しつつ、学習コーパス(選別済み)の規模を小さくすることができる。したがって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパス(選別済み)を選別することができる。
【0056】
<第2実施形態>
[コーパス選別装置BBの構成]
図4は、本発明の第2実施形態に係るコーパス選別装置BBの構成を示すブロック図である。コーパス選別装置BBは、図1に示した本発明の第1実施形態に係るコーパス選別装置AAとは、音声認識部15を備える点と、言語モデリング部12の代わりに言語モデリング部12Aを備える点と、スコア算出部13の代わりにスコア算出部13Aを備える点と、学習コーパス選出部14の代わりに学習コーパス選出部14Aを備える点と、が異なる。なお、コーパス選別装置BBに設けられた学習コーパス分割部11については、コーパス選別装置AAに設けられた学習コーパス分割部11と同様に動作するため、説明を省略する。
【0057】
言語モデリング部12Aは、後述の第2の選択手順、第2のサブセット言語モデル生成手順、および第2の繰り返し手順を行って、サブセット言語モデルを生成する。
【0058】
上述の第2の選択手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中からT個の学習コーパスを1組の学習コーパス群として選択する。また、第2のサブセット言語モデル生成手順では、学習コーパス(サブセット1)〜学習コーパス(サブセットY)のうち第2の選択手順において選択したものを除く全ての学習コーパスを用いて言語モデリング(確率統計処理)を行って、上述の1組の学習コーパス群に対応するサブセット言語モデルを生成する。また、第2の繰り返し手順では、上述の第2の選択手順および第2のサブセット言語モデル生成手順を、T個の学習コーパスの組合せの全てを学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中から第2の選択手順において選択するまで繰り返す。なお、第2の選択手順により第2の選択手順および第2のサブセット言語モデル生成手順を繰り返す回数は、式(1)のように表すことができる。
【0059】
【数1】
【0060】
図5には、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のうちの1つを学習コーパス(全体)から除去する例が示されている。この図5に示した例では、上述のTが「1」であるものとして、上述の第2の選択手順、第2のサブセット言語モデル生成手順、および第2の繰り返し手順を行っている。このため、学習コーパス(サブセット1)で構成される学習コーパス群に対して、サブセット言語モデル1が生成されている。また、学習コーパス(サブセット2)で構成される学習コーパス群に対して、サブセット言語モデル2が生成され、学習コーパス(サブセット3)で構成される学習コーパス群に対して、サブセット言語モデル3が生成されている。
【0061】
図6には、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のうちの2つを学習コーパス(全体)から除去する例が示されている。この図6に示した例では、上述のTが「2」であるものとして、上述の第2の選択手順、第2のサブセット言語モデル生成手順、および第2の繰り返し手順を行っている。このため、学習コーパス(サブセット1)と学習コーパス(サブセット2)とで構成される学習コーパス群に対して、サブセット言語モデル1、2が生成されている。また、学習コーパス(サブセット2)と学習コーパス(サブセット3)とで構成される学習コーパス群に対して、サブセット言語モデル2、3が生成され、学習コーパス(サブセット3)学習コーパス(サブセット1)とで構成される学習コーパス群に対して、サブセット言語モデル3、1が生成されている。
【0062】
図4に戻って、音声認識部15は、タスク表現コーパス(音声あり)の音声認識を、言語モデリング部12Aにより生成されたサブセット言語モデルを用いて行って、音声認識結果を求める。ここで、タスク表現コーパス(音声あり)とは、音声認識を行う内容に応じた音声データと、この音声データを書き起こしたテキストデータを含んで構成されるデータベースのことである。このため、タスク表現コーパス(音声あり)には、認識させたい発話内容について、音声データおよびテキストデータが含まれている。
【0063】
図5に示した例では、サブセット言語モデル1を用いた場合の音声認識結果1と、サブセット言語モデル2を用いた場合の音声認識結果2と、サブセット言語モデル3を用いた場合の音声認識結果3と、が求められている。一方、図6に示した例では、サブセット言語モデル1、2を用いた場合の音声認識結果1、2と、サブセット言語モデル2、3を用いた場合の音声認識結果2、3と、サブセット言語モデル3、1を用いた場合の音声認識結果3、1と、が求められている。
【0064】
ここで、音声認識部15が出力する音声認識結果の出力形式は、M−best(Mは、M≧1を満たす整数)である。図7では、音声認識部15に3−bestが適用されている場合を示しており、「13時になります。」という発話内容の音声データが音声認識部15に入力され、音声認識結果(1)〜(3)が音声認識部15から出力された例を示している。音声認識結果(3)、音声認識結果(2)、音声認識結果(1)の順に、音声認識スコアが高く、すなわち尤もらしさが大きくなっている。<s>は文頭を示すダミー単語、</s>は文末を示すダミー単語、<p>は無音単語を示すダミー単語である。
【0065】
また、音声認識部15が出力する音声認識結果の精度算出について、図8を用いて以下に説明する。正解文に含まれかつ正しく認識できた単語について、正解単語と呼ぶこととすると、正解単語の総数Sは、図8では「5」となる。また、正解文には含まれていないにもかかわらず認識してしまった単語について、挿入誤り単語と呼ぶこととすると、挿入誤り単語の総数EIは、図8では「1」となる。また、正解文には含まれているにもかかわらず認識できなかった単語について、削除誤り単語と呼ぶこととすると、削除誤り単語の総数EDは、図8では「1」となる。また、正解文に含まれている単語を誤認識してしまったものについて、置換誤り単語と呼ぶこととすると、置換誤り単語の総数ESは、図8では「2」となる。
【0066】
図4に戻って、スコア算出部13Aは、音声認識結果について、タスク表現コーパス(音声あり)を用いて識別スコアを算出して、識別スコアを求める。識別スコアの算出手法としては、図9に示すMMI(最大相互情報量)を用いた手法や、図10に示すMCE(最小識別誤り化)を用いた手法や、図11に示すMWE(最小単語誤り化)またはMPE(最小音素誤り化)を用いた手法を適用することができる。
【0067】
図5に示した例では、音声認識結果1の識別スコア1と、音声認識結果2の識別スコア2と、音声認識結果3の識別スコア3と、が求められている。一方、図6に示した例では、音声認識結果1、2の識別スコア1、2と、音声認識結果2、3の識別スコア2、3と、音声認識結果3、1の識別スコア3、1と、が求められている。
【0068】
学習コーパス選出部14Aは、学習コーパス(サブセット1)〜学習コーパス(サブセットY)の中から1つ以上を除去して、学習コーパス(選別済み)とする。
【0069】
具体的には、スコア算出部13AにおいてMMIを用いた手法が適用される場合には、学習コーパス選出部14Aは、まず、図9に示したスコア定義式(右辺)を最大にするサブセット言語モデルQを求める。次に、サブセット言語モデルQに対応する学習コーパス群を構成するT個の学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0070】
一方、スコア算出部13AにおいてMCEを用いた手法が適用される場合には、学習コーパス選出部14Aは、まず、図10に示したスコア定義式を最小にするサブセット言語モデルQを求める。次に、サブセット言語モデルQに対応する学習コーパス群を構成するT個の学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0071】
また、スコア算出部13AにおいてMWEまたはMPEを用いた手法が適用される場合には、学習コーパス選出部14Aは、まず、図11に示したスコア定義式を最大にするサブセット言語モデルQを求める。次に、サブセット言語モデルQに対応する学習コーパス群を構成するT個の学習コーパスを、学習コーパス(全体)から除去して、学習コーパス(選別済み)とする。
【0072】
例えば、スコア算出部13AにおいてMMIを用いた手法が適用され、図5に示した識別スコア1〜3のうち識別スコア1が最大となった場合には、サブセット言語モデル1に対応する学習コーパス群を構成する学習コーパス(サブセット1)が、学習コーパス(全体)から除去される。ここで、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれのデータ容量が等しければ、学習コーパス(選別済み)の規模は、学習コーパス(全体)の規模の2/3となる。
【0073】
また、例えば、スコア算出部13AにおいてMCEを用いた手法が適用され、図6に示した識別スコア1、2と、識別スコア2、3と、識別スコア3、1と、のうち識別スコア3、1が最小となった場合には、サブセット言語モデル3、1に対応する学習コーパス群を構成する学習コーパス(サブセット3)および学習コーパス(サブセット1)が、学習コーパス(全体)から除去される。ここで、学習コーパス(サブセット1)〜学習コーパス(サブセット3)のそれぞれのデータ容量が等しければ、学習コーパス(選別済み)の規模は、学習コーパス(全体)の規模の1/3となる。
【0074】
なお、図11に示したスコア定義式の△(Wr,Wri)は、スコア算出部13AにおいてMWEを用いた手法が適用される場合と、スコア算出部13AにおいてMPEを用いた手法が適用される場合と、で異なる。スコア算出部13AにおいてMWEを用いた手法が適用される場合には、△(Wr,Wri)は、正解単語が多く、かつ、挿入誤り単語や削除誤り単語といった各種誤り単語が少ない場合に大きな値をとる式を示す。一方、スコア算出部13AにおいてMPEを用いた手法が適用される場合には、△(Wr,Wri)は、上述のMWEを単語レベルではなく音素レベル(図12参照)で比較し、正解音素が多く、かつ、各種誤り単語が少ない場合に大きな値をとる式を示す。なお、音素の代わりにモーラ・レベルで比較することもできる。
【0075】
以上のコーパス選別装置BBによれば、音声認識を行う内容に基づいて、学習コーパス(全体)から学習コーパス(選別済み)を選別することができる。このため、音声認識を行う内容に適した情報は学習コーパス(選別済み)に残しつつ、学習コーパス(選別済み)の規模を小さくすることができる。したがって、言語モデルの品質の向上と、記憶領域の使用量の削減と、を両立できる学習コーパス(選別済み)を選別することができる。
【0076】
なお、本発明のコーパス選別装置AAやコーパス選別装置BBの処理を、コンピュータ読み取り可能な記録媒体に記憶し、記録媒体に記録されたプログラムをコーパス選別装置AAやコーパス選別装置BBに読み込ませ、実行することによって、本発明を実現できる。
【0077】
また、上述のプログラムは、このプログラムを記憶装置などに格納したコーパス選別装置AAやコーパス選別装置BBから、伝送媒体を介して、あるいは、伝送媒体中の伝送波により他のコンピュータシステムに伝送されてもよい。ここで、プログラムを伝送する「伝送媒体」は、インターネットなどのネットワーク(通信網)や電話回線などの通信回線(通信線)のように情報を伝送する機能を有する媒体のことをいう。
【0078】
また、上述のプログラムは、上述の機能の一部を実現するためのものであってもよい。さらに、上述の機能をコーパス選別装置AAやコーパス選別装置BBにすでに記録されているプログラムとの組合せで実現できるもの、いわゆる差分ファイル(差分プログラム)であってもよい。
【0079】
以上、この発明の実施形態につき、図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、この発明の要旨を逸脱しない範囲の設計なども含まれる。
【0080】
例えば、上述の各実施形態では、学習コーパス(全体)を3つに分割したが、これに限らず、1以上の任意の整数に分割することができる。
【0081】
また、上述の第2実施形態では、音声認識結果の出力形式としてM−bestを適用した場合について説明したが、これに限らず、例えばラティスを適用してもよい。
【符号の説明】
【0082】
AA、BB・・・コーパス選別装置
11・・・学習コーパス分割部
12、12A・・・言語モデリング部
13、13A・・・スコア算出部
14、14A・・・学習コーパス選出部
15・・・音声識別部
【特許請求の範囲】
【請求項1】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別装置であって、
コーパスを複数の単位コーパスに分割するコーパス分割手段と、
前記複数の単位コーパスのそれぞれについて、確率統計処理を行って、対応する単位言語モデルを生成する言語モデリング手段と、
前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める困難性算出手段と、
前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記困難性算出手段により求められた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くコーパス選出手段と、を備え、
前記言語モデリング手段は、
前記複数の単位コーパスの中から1つを選択する選択手順と、
前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、
前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行うことを特徴とするコーパス選別装置。
【請求項2】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別装置であって、
コーパスを複数の単位コーパスに分割するコーパス分割手段と、
前記複数の単位コーパスの中からT個(Tは、T≧1を満たす任意の整数)の単位コーパスを1組の単位コーパス群として選択する選択手順と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、当該単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順と、を行う言語モデリング手段と、
音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパスの音声認識を、前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める音声認識手段と、
前記音声認識手段により求められた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコアを求める識別スコア算出手段と、
前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除くコーパス選出手段と、を備えることを特徴とするコーパス選別装置。
【請求項3】
前記識別スコア算出手段は、最大相互情報量に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項4】
前記識別スコア算出手段は、最小識別誤り化に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最小となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項5】
前記識別スコア算出手段は、最小単語誤り化に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項6】
前記識別スコア算出手段は、最小音素誤り化に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項7】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法であって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスのそれぞれについて、確率統計処理を行って、対応する単位言語モデルを生成する第2のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める第3のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、を備え、
前記第2のステップでは、
前記複数の単位コーパスの中から1つを選択する選択手順と、
前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、
前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行うことを特徴とするコーパス選別方法。
【請求項8】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法であって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスの中からT個(Tは、T≧1を満たす任意の整数)の単位コーパスを1組の単位コーパス群として選択する選択手順と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、当該単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順と、を行う第2のステップと、
音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパスの音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める第3のステップと、
前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコアを求める第4のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、を備えることを特徴とするコーパス選別方法。
【請求項9】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスのそれぞれについて、確率統計処理を行って、対応する単位言語モデルを生成する第2のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める第3のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、をコンピュータに実行させ、
前記第2のステップでは、
前記複数の単位コーパスの中から1つを選択する選択手順と、
前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、
前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、をコンピュータに実行させるためのプログラム。
【請求項10】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスの中からT個(Tは、T≧1を満たす任意の整数)の単位コーパスを1組の単位コーパス群として選択する選択手順と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、当該単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順と、を行う第2のステップと、
音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパスの音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める第3のステップと、
前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコアを求める第4のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、をコンピュータに実行させるためのプログラム。
【請求項1】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別装置であって、
コーパスを複数の単位コーパスに分割するコーパス分割手段と、
前記複数の単位コーパスのそれぞれについて、確率統計処理を行って、対応する単位言語モデルを生成する言語モデリング手段と、
前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める困難性算出手段と、
前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記困難性算出手段により求められた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くコーパス選出手段と、を備え、
前記言語モデリング手段は、
前記複数の単位コーパスの中から1つを選択する選択手順と、
前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、
前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行うことを特徴とするコーパス選別装置。
【請求項2】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別装置であって、
コーパスを複数の単位コーパスに分割するコーパス分割手段と、
前記複数の単位コーパスの中からT個(Tは、T≧1を満たす任意の整数)の単位コーパスを1組の単位コーパス群として選択する選択手順と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、当該単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順と、を行う言語モデリング手段と、
音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパスの音声認識を、前記言語モデリング手段により生成された複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める音声認識手段と、
前記音声認識手段により求められた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコアを求める識別スコア算出手段と、
前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除くコーパス選出手段と、を備えることを特徴とするコーパス選別装置。
【請求項3】
前記識別スコア算出手段は、最大相互情報量に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項4】
前記識別スコア算出手段は、最小識別誤り化に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最小となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項5】
前記識別スコア算出手段は、最小単語誤り化に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項6】
前記識別スコア算出手段は、最小音素誤り化に基づいて前記識別スコアを求め、
前記コーパス選出手段は、前記言語モデリング手段により生成された複数の単位言語モデルの中から、前記識別スコア算出手段により求められた識別スコアが最大となるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除くことを特徴とする請求項2に記載のコーパス選別装置。
【請求項7】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法であって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスのそれぞれについて、確率統計処理を行って、対応する単位言語モデルを生成する第2のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める第3のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、を備え、
前記第2のステップでは、
前記複数の単位コーパスの中から1つを選択する選択手順と、
前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、
前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、を行うことを特徴とするコーパス選別方法。
【請求項8】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法であって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスの中からT個(Tは、T≧1を満たす任意の整数)の単位コーパスを1組の単位コーパス群として選択する選択手順と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、当該単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順と、を行う第2のステップと、
音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパスの音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める第3のステップと、
前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコアを求める第4のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、を備えることを特徴とするコーパス選別方法。
【請求項9】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスのそれぞれについて、確率統計処理を行って、対応する単位言語モデルを生成する第2のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれについて、音声認識を行う内容に応じたタスク表現コーパスを用いて、音声認識の困難性を求める第3のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第3のステップにおいて求めた困難性が予め定められた閾値以上または以下であるものを求め、求めた単位言語モデルに対応する単位コーパスを前記コーパスから除く第4のステップと、をコンピュータに実行させ、
前記第2のステップでは、
前記複数の単位コーパスの中から1つを選択する選択手順と、
前記複数の単位コーパスのうち選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、選択した単位コーパスに対応する単位言語モデルを生成する単位言語モデル生成手順と、
前記選択手順および前記単位言語モデル生成手順を、前記複数の単位コーパスのそれぞれに対して行うまで繰り返す繰り返し手順と、をコンピュータに実行させるためのプログラム。
【請求項10】
音声認識に用いられる言語モデルの生成の際に用いられるコーパスを選別するコーパス選別方法を、コンピュータに実行させるためのプログラムであって、
コーパスを複数の単位コーパスに分割する第1のステップと、
前記複数の単位コーパスの中からT個(Tは、T≧1を満たす任意の整数)の単位コーパスを1組の単位コーパス群として選択する選択手順と、前記複数の単位コーパスのうち当該選択手順において選択したものを除く全ての単位コーパスを用いて確率統計処理を行って、当該単位コーパス群に対応する単位言語モデルを生成する単位言語モデル生成手順と、当該選択手順および当該単位言語モデル生成手順を、T個の単位コーパスの組合せの全てを前記複数の単位コーパスの中から当該選択手順において選択するまで繰り返す繰り返し手順と、を行う第2のステップと、
音声認識を行う内容に応じた音声データと、当該音声データを書き起こしたテキストデータと、を含んで構成されるタスク表現コーパスの音声認識を、前記第2のステップにおいて生成した複数の単位言語モデルのそれぞれを用いて行って、当該複数の単位言語モデルのそれぞれを用いた場合の音声認識結果を求める第3のステップと、
前記第3のステップにおいて求めた複数の音声認識結果のそれぞれについて、前記タスク表現コーパスを用いて識別スコアを求める第4のステップと、
前記第2のステップにおいて生成した複数の単位言語モデルの中から、前記第4のステップにおいて求めた識別スコアが最大または最小であるものを求め、求めた単位言語モデルに対応する単位コーパス群を構成するT個の単位コーパスを、前記コーパスから除く第5のステップと、をコンピュータに実行させるためのプログラム。
【図1】


【図2】

【図3】

【図4】
【図5】
【図6】

【図7】
【図8】

【図9】

【図10】

【図11】

【図12】

【図13】
【図14】

【図15】
【図16】
【図17】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【公開番号】特開2012−177835(P2012−177835A)
【公開日】平成24年9月13日(2012.9.13)
【国際特許分類】
【出願番号】特願2011−41523(P2011−41523)
【出願日】平成23年2月28日(2011.2.28)
【出願人】(000208891)KDDI株式会社 (2,700)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
【公開日】平成24年9月13日(2012.9.13)
【国際特許分類】
【出願日】平成23年2月28日(2011.2.28)
【出願人】(000208891)KDDI株式会社 (2,700)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
[ Back to top ]