
ショートハンド・オン・キーボード・インタフェースにおいてテキスト入力を改善するためのシステム、コンピュータ・プログラムおよび方法(キーボード上のショートハンド・オン・キーボード・インタフェースにおけるテキスト入力の改良)
【課題】ショートハンド・オン・キーボード・インタフェースを介して入力されるテキスト入力を改善する。
【解決手段】単語認識システムは、ショートハンド・オン・キーボード・インタフェースを介して入力されるテキスト入力を改善する。コア辞書は、ある言語において一般的に用いられる単語を含む。拡張辞書は、コア辞書に含まれない単語を含む。このシステムは、コア辞書からの単語のみを直接出力する。拡張辞書からの候補単語は、ユーザによって選択されると出力され、同時にコア辞書に載ることができる。連結モジュールによって、ユーザは、長い単語の部分を別個に入力することができる。複合単語モジュールは、連結によって1つの長い単語を形成する2つの一般的な短い単語を組み合わせる。
【解決手段】単語認識システムは、ショートハンド・オン・キーボード・インタフェースを介して入力されるテキスト入力を改善する。コア辞書は、ある言語において一般的に用いられる単語を含む。拡張辞書は、コア辞書に含まれない単語を含む。このシステムは、コア辞書からの単語のみを直接出力する。拡張辞書からの候補単語は、ユーザによって選択されると出力され、同時にコア辞書に載ることができる。連結モジュールによって、ユーザは、長い単語の部分を別個に入力することができる。複合単語モジュールは、連結によって1つの長い単語を形成する2つの一般的な短い単語を組み合わせる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、一般に、辞書に基づいたテキスト入力およびテキスト予測システムに関する。更に具体的には、本発明は、グラフィックで表した画面上キーボードの上で幾何学的パターンを描くことによって単語を入力する効率的な方法であるショートハンド・オン・キーボード(shorthand-on-keyboard)を用いたテキスト入力に関する。
【背景技術】
【0002】
グラフィカル・キーボード(graphicalkeyboard)上のショートハンド(簡略な伝達方法)(以降、「ショートハンド・オン・キーボード」と称する)または図表としてのキーボード上のショートハンド(sokgraph)は、物理的なキーボードなしで、典型的には手書き入力用のペンを用いて、効率的にテキストを入力するための入力方法およびシステムを表す。ショートハンド・オン・キーボードによって、ユーザは、グラフィカル・キーボード上の文字または機能キーをたどって、単語およびコマンドをコンピュータに入力することができる。経験豊富なユーザは、キーボードのレイアウト上で頻繁に用いる単語およびコマンドの幾何学的パターンを部分的にまたは完全に記憶し、例えばデジタル・ペンを用いて、記憶力に基づいてこれらのパターンを描くことができる。
【0003】
ショートハンド・オン・キーボードおよび手書き/音声認識およびテキスト予測システム等の単語レベルの認識に基づいたテキスト入力システムは、全て、これらのシステムが認識する単語セットを定義する何らかの形態の辞書に頼っている。ユーザの入力は、辞書内の選択肢に対して照合される。辞書に含まれない単語は、通常、自動的には認識されない。かかる場合、特別なモードを設けなければならない。例えば、ショートハンド・オン・キーボードでは、ユーザは最初に候補リスト(N−ベスト・リスト)を調べることができる。候補リスト上のどの選択肢も目的の単語ではない場合、ユーザは、描いたパターンが間違っていたか否かを判断する。描いたパターンが正しい場合、ユーザは目的の単語がその辞書には載っていないことを認識する。次いで、ユーザは、単語の個々の文字を入力することによって、辞書にこの新しい単語を入力する。理想的には、辞書は、特定のユーザが書く必要がある全ての単語を過不足なく含む。大きすぎたり小さすぎたりする辞書は、ユーザに対して問題を引き起こす可能性がある。
【0004】
辞書が大きくなると、いくつかの問題が生じる恐れがある。なぜなら、各ユーザ入力ごとに、正解以外の選択肢の数が増える可能性があるために、認識の精度が低くなりやすいからである。いずれの言語においても、あらゆる人に共通するコアの語彙集合が存在する傾向がある。このコア集合を超えると、語彙は特定の個人のために専門化しがちである。例えば、エンジニアは、特定の分野またはビジネス領域について高度に技術的な用語および略語を含む電子メールを作成することがある。他のユーザに対しては、これらの専門化した用語は無関係であり、認識プロセスにノイズを生じて、認識プロセスの確実さを低下させる恐れがある。
【0005】
辞書が小さくなると、通常、目的とする単語が辞書に載っている場合にユーザ入力が正しく認識される可能性が高くなるという点で、辞書はいっそう確実なものとなる。辞書が小さくなると、ユーザの入力に対して与えられる柔軟性および許容度が高くなり、目的とする入力選択肢の理想的な形態に比べて大ざっぱで不正確な入力も可能となる。小さい辞書の更に別の利点は、検索空間が小さくなることである。この結果、小さい辞書では、検索の待ち時間を短縮することができる。これは、処理パワーが大きく制限されるモバイル・デバイスでは特に重要である。
【0006】
しかしながら、小さい辞書にユーザが必要とする単語が含まれない場合、ユーザはいらいらする経験をすることがある。ユーザは、入力の前には、辞書に単語が載っているか否かを知らないので、ユーザには不確実さが生じる。従来のシステムでは、単語が間違って入力された場合または単語が辞書に載っていない場合のいずれかに、単語が認識されないということが起こり得る。このため、ユーザにとって、なぜ単語が認識されないかを判断するのが難しいことがある。一般に、ある単語が辞書に載っているか否かを知るには、ユーザはその単語を繰り返し試さなければならない。その単語が辞書に載っていないことが確実になると、ユーザは、認識システムによって与えられるインタフェースを介して、先に述べたように入力することによって、その単語を辞書に追加する。辞書が小さくなると、ユーザが辞書に単語を追加しなければならないことが頻繁に起こる。
【0007】
辞書サイズの問題には、従来からいくつかの解決策がある。一般的に用いられている方法は、大きい辞書を用い、次いで単語レベルのトライグラム(trigram)・モデル等の高水準言語規則を利用して、極めて可能性の低い候補を除去することである。言語モデル手法の欠点は、一般に、大きい言語モデルを生成して効率的に利用することのオーバーヘッドである。更に、言語モデルでは、エラーが生じ、目的とする単語が誤って除去される恐れがある。これは、言語モデルが特定のユーザにカスタマイズされるのではなく汎用的である場合に、特に当てはまる。実際、言語モデルの効率的なカスタマイゼーションは難しい。更に、言語モデルは、ショートハンド・オン・キーボード等の、すでに高い精度を有する認識技法と統合することが難しい。
【0008】
ある代替的な従来の手法では、例えば書面の電子メールおよび他の文書のような、ユーザが発生した書面のテキストを利用することによって、ユーザのためにカスタマイズした辞書を生成する。この手法では、特定のユーザによりいっそう合った辞書が作成されるが、ユーザが発生した以前の文書データは、所望の単語を全てカバーするには小さすぎる場合がある。更に、実際、ユーザが用いている可能性がある様々な電子メールおよび文書フォーマットを全て開いて読むことができるコンピュータ・プログラム・コードを書くことは難しい。この手法では、多くの場合、ユーザが以前の文書の位置を特定して選択する必要があるが、これはユーザにとって不便である。また、カスタム化した辞書は、異なるデバイス間で持ち運ぶのが難しい場合がある。
【発明の概要】
【発明が解決しようとする課題】
【0009】
これらの従来の解決策は意図する目的のためには適切であるが、ユーザの所望の入力に対して無関係な選択肢の数が比較的少ない辞書を可能とし、更に、ほとんどのユーザが頻繁には用いないもっと専門化した単語も含めて、ユーザが必要とし得るほとんど全ての単語に対して容易にアクセスすることができる解決策を見出すことが望ましい。概して、極めて大きい辞書においてユーザが必要とする可能性のある全ての単語を含むことが望ましい。しかしながら、極めて大きい辞書は、同じ照合閾値が与えられた場合、キーボード上に描かれたパターンに合致する単語が増えることを意味し、入力システムにおける信号対雑音比を低下させることになる。従って、辞書を大きくすると、ユーザに対する柔軟性および確実さが低下する。従って、使いやすさと柔軟性および確実さとのバランスを取ったショートハンド・オン・キーボード・システムのための辞書構成が必要とされている。
【0010】
従来のショートハンド・オン・キーボード入力方法の別の問題点は、一度に1つの単語ずつ、単語レベルでテキストを正確に入力しなければならないことである。単語には長いものもある。比較的新しいユーザにとっては、ショートハンド・オン・キーボードを用いて1つの動きで長い単語を描くことは認知的に難しいことがある。この難しさは、英語よりも複合的な長い単語がよくあるいくつかのヨーロッパの言語においては特に切実である。更に、単語の語幹とは別の動きとして一般的な接辞を描くことができれば、ユーザは入力をもっと便利だと感じることができる。例えば、ショートハンド・オン・キーボードを用いて「working」という単語を書く場合、ユーザはグラフィカル・キーボード上でw-o-r-kのパターンを描き、次いでi-n-gを描き、この2つを組み合わせて1つの単語にしたいと考えることがある。このため、キーボード上の部分的な語(「sokgraph」)を自動的に組み合わせてユーザが意図する1つの単語とする効果的なシステムおよび方法が求められている。
【0011】
従って、ショートハンド・オン・キーボード・インタフェースにおいてテキスト入力を改善することが求められている。
【課題を解決するための手段】
【0012】
本発明は、ショートハンド・オン・キーボード・インタフェースにおいてテキスト入力を改善するためのシステム、コンピュータ・プログラム、および関連する方法(ここでは、まとめて「システム」または「本システム」と呼ぶ)を開示する。本システムは、コア辞書および拡張辞書を含む。コア辞書は、ある言語において一般的に用いられる単語を含む。コア辞書は、本システムの用途に応じて、典型的に約5,000から15,000の単語を含む。拡張辞書は、コア辞書に含まれない単語を含む。拡張辞書は、約30,000から100,000の単語を含む。
【0013】
コア辞書によって、本システムは、動きを識別する際に、最高ランクの候補単語として一般的に用いられる単語に的を絞ることができ、より小さい辞書に関連付けていっそう確実な認識性能を提供することができる。本システムでは、コア辞書からの単語のみを直接出力することができる。拡張辞書から追加の候補単語を利用することができ、このためユーザは候補リスト上のあまり知らない単語を見つけることができるが、メニュー選択するだけである。本システムは、大きい辞書からの単語選択を犠牲にすることなく、単語認識の精度を高める。コア辞書によって、目的とする入力選択肢の理想的な形態に比べて大ざっぱで不正確なユーザ入力に対する柔軟性および許容度が高くなる。
【0014】
本システムは、更に、認識モジュール、事前ランク付けモジュール、およびランク付けモジュールを含む。認識モジュールは、入力パターンに対応する候補単語のN−ベスト・リストを発生する。事前ランク付けモジュールは、所定の基準に従ってN−ベスト候補単語をランク付けする。ランク付けモジュールは、候補単語のN−ベスト・リストのランク付けを調節して、コア辞書から得られた単語を、拡張辞書から得られた単語よりも高く配置して、ランク付けた単語候補のリストを発生する。コア辞書に載っている単語のみが、本システムによって出力される。本システムは、拡張辞書に載っている候補単語をN−ベスト・リストにのみ記載する。これらの単語は、出力となるにはユーザに選択されなければならない。いったんユーザによってN−ベスト・リストから選択されると、拡張辞書からの単語をコア辞書に載せることが許可される。
【0015】
更に具体的には、好適な実施形態において、コア辞書に載っている単語のみが認識システムによって出力される。拡張辞書に載っている単語は、N−ベスト・リストに記載することができるだけであり、出力されるためには明示的にユーザに選択されなければならない。いったん選択されると、拡張辞書に載っている単語もコア辞書に載ることが許可される。
【0016】
本システムは、ユーザが動作で示した単語がコア辞書の語彙に含まれない場合にユーザに与えられるオーバーヘッドを低減する。単語が辞書に含まれているのか、またはシステムが入力を誤って認識したのかが不確かであるということではなく、ユーザはN−ベスト・リストをスキャンして所望の候補単語を選択することができる。
【0017】
本システムは、更に、連結モジュールおよび複合単語モジュールを含む。連結モジュールによって、ユーザは、長い単語の部分を別個に入力することができる。本システムは、部分的な「sokgraph」である単語および単語の部分を、ユーザが意図する1つの単語に自動的に結合する。単語の部分は、「work」等の語幹および「ing」「pre」等の接辞である場合がある。複合単語モジュールは、英語の「short+hand」等、連結によって1つの長い単語を形成する1つ以上の一般的な短い単語を組み合わせる。いくつかの短い単語が連結して1つの複合的な単語になることは、スウェーデン語またはドイツ語等のいくつかのヨーロッパ言語ではもっとよくあることである。
【0018】
本システムによって、単語1および単語2の連結および組み合わせた単語の分離を調節するためのユーザ・インタラクションが可能となる。ユーザが、例えば「smokefree」のような連結した単語をクリックすると、メニュー・オプション「smokeとfreeに分割」または同等のオプションがユーザに提示される。あるいは、単語「smokefree」を横切る下向きの動き等のペン・トレースの動きを、分割コマンドとして定義することができる。信頼度が低いために動作が行われない連結可能単語については、単語1および単語2にメニュー・オプションが埋め込まれている。ユーザが単語1をクリックした場合、オプション「右に動く」または同等のオプションが選択可能である。ユーザが単語2をクリックした場合、オプション「左に動く」または同等のオプションが選択可能である。あるいは、単語1および単語2の双方を横切る円などのペンの動きを、2つの単語を1つの連結した長い単語として結び付けるためのコマンドとして定義する。
例えば、本発明は以下の項目を提供する。
(項目1)
ショートハンド・オン・キーボード・インタフェースを介して入力された入力信号を認識するための単語認識システムであって、
一般的に用いられる単語を含むコア辞書と、
前記コア辞書に含まれない単語を含む拡張辞書と、
前記入力信号に関連付けられた単語を認識するための認識モジュールと、
前記入力信号に関連付けられた出力単語を前記コア辞書から出力するための選択モジュールと、
前記入力信号に関連付けられた候補単語がユーザによって選択されると、前記候補単語を前記コア辞書に載せることを許可するためのモジュールと、
を含む、システム。
(項目2)
前記ユーザによる選択のために、前記コア辞書および前記拡張辞書の少なくとも一方からの、前記入力信号に関連付けられた候補単語を提示するユーザ選択インタフェースを更に含む、項目1に記載のシステム。
(項目3)
前記ユーザ選択インタフェースが、前記コア辞書からの候補単語および前記拡張辞書からの候補単語を、容易に区別するために異なる知覚的特徴でリスト化する、項目2に記載のシステム。
(項目4)
前記認識モジュールが、前記コア辞書および前記拡張辞書から候補単語のN−ベスト・リストを発生する、項目1に記載のシステム。
(項目5)
少なくとも1つの基準に従って前記候補単語のN−ベスト・リストをランク付けするための事前ランク付けモジュールを更に含む、項目4に記載のシステム。
(項目6)
前記事前ランク付けモジュールが、前記コア辞書からの最も高いランクの単語を、前記候補単語のN−ベスト・リストにおける最も高いランクの単語として出力する、項目5に記載のシステム。
(項目7)
ショートハンド・オン・キーボード・インタフェースを介して入力された入力信号を認識するための単語認識方法であって、
一般的に用いられる単語をコア辞書にストアするステップと、
前記コア辞書に含まれない単語を拡張辞書にストアするステップと、
前記入力信号に関連付けられた単語を認識するステップと、
前記入力信号に関連付けられた出力単語を前記コア辞書から出力するステップと、
前記入力信号に関連付けられた候補単語がユーザによって選択されると、前記候補単語を前記コア辞書に載せることを許可するステップと、
を含む、方法。
(項目8)
前記ユーザによる選択のために、前記コア辞書および前記拡張辞書の少なくとも一方からの、前記入力信号に関連付けられた候補単語を提示するステップを更に含む、項目7に記載の方法。
(項目9)
前記コア辞書からの候補単語および前記拡張辞書からの候補単語を、容易に区別するために異なる知覚的特徴でリスト化するステップを更に含む、項目8に記載の方法。
(項目10)
ユーザ入力インタフェースを介して入力された入力信号を認識するための、コンピュータが使用可能な媒体上にストアされたプログラム・コードを有するコンピュータ・プログラム製品であって、
一般的に用いられる単語を含むコア辞書と、
前記コア辞書に含まれない単語を含む拡張辞書と、
前記入力信号に関連付けられた単語を認識するためのプログラム・コードと、
前記入力信号に関連付けられた出力単語を前記コア辞書から出力するためのプログラム・コードと、
前記入力信号に関連付けられた候補単語がユーザによって選択されると、前記候補単語を前記コア辞書に載せることを許可するためのプログラム・コードと、
を含む、コンピュータ・プログラム製品。
(項目11)
前記入力信号に係るテキストの語幹および接辞を組み合わせることを可能にするための、項目1に記載のシステムであって、
前記入力信号を入力接辞として認識するための連結モジュールであって、更に、候補単語を隣接候補単語として認識する、連結モジュールと、
前記入力接辞を含む辞書内の1組の単語を検索するための、複合単語出力モジュールであって、前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力する、複合単語出力モジュールと、
前記入力接辞を含む前記1組の単語における各辞書単語を、前記候補単語および前記入力接辞を含むストリングと比較する類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするための、ランク付けモジュールと、
を更に含む、システム。
(項目12)
前記入力接辞が接尾辞である、項目11に記載のシステム。
(項目13)
前記複合単語出力モジュールが前記接尾辞および前記最も高いランクの辞書単語を結合させる、項目12に記載のシステム。
(項目14)
前記入力接辞が接頭辞である、項目11に記載のシステム。
(項目15)
前記複合単語出力モジュールが前記接頭辞および前記最も高いランクの辞書単語を結合させる、項目14に記載のシステム。
(項目16)
前記類似性関数が距離関数を含む、項目14に記載のシステム。
(項目17)
前記隣接候補単語が、前記入力接辞の前に付く候補単語または前記入力接辞の後に付く候補単語のいずれか1つを含む、項目14に記載のシステム。
(項目18)
前記入力信号に係るテキストが前記入力接辞として認識されない場合、前記複合単語モジュールは、前記入力信号に係るテキストおよび前記隣接候補単語の連結の結果として生じるストリングを生成し、前記辞書における前記ストリングの発生頻度を求め、前記ストリングの発生頻度を前記入力信号に係るテキストおよび前記隣接候補単語のそれぞれの発生頻度と比較し、前記ストリングの発生頻度が前記入力テキストおよび前記隣接候補単語のそれぞれの発生頻度を超えた場合、前記複合単語モジュールは前記入力テキストおよび前記隣接候補単語を連結単語として連結し、前記ストリングを前記連結単語によって置換する、項目17に記載のシステム。
(項目19)
前記入力信号に係るテキストおよび前記隣接候補単語の発生頻度に対する前記ストリングの発生頻度の比較が重み付け比較である、項目18に記載のシステム。
(項目20)
前記入力信号に係るテキストの語幹および接辞を組み合わせることを可能にするための、項目7に記載の方法であって、
前記入力信号を入力接辞として認識するステップと、
前記入力信号が前記入力接辞として認識された場合、候補単語を隣接候補単語として認識するステップと、
前記入力接辞を含む辞書内の1組の単語を検索するステップと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較することによる類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするステップと、
前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力するステップと、
を更に含む、方法。
(項目21)
前記接尾辞および前記最も高いランクの辞書単語を結合させるステップを更に含む、請求項19に記載の方法。
(項目22)
前記入力信号に係るテキストの語幹および接辞を組み合わせることを可能にするための、項目10に記載のコンピュータ・プログラム製品であって、
前記入力信号を入力接辞として認識するため、および、候補単語を隣接候補単語として更に認識するためのプログラム・コードと、
前記入力接辞を含む辞書内の1組の単語を検索するためのプログラム・コードと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較することによる類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするためのプログラム・コードと、
前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力するためのプログラム・コードと、
を含む、コンピュータ・プログラム製品。
【0019】
本発明の様々な特徴およびそれらを達成する方法について、以下の説明、特許請求の範囲、および図面を参照して、更に詳細に説明する。図面において、適宜、参照番号を繰り返し用いて、参照した要素間の対応関係を示す。
【図面の簡単な説明】
【0020】
【図1】本発明の単語パターン認識システムを使用可能である例示的な動作環境の概略図である。
【図2】図1の単語パターン認識システムの高レベル・アーキテクチャのブロック図である。
【図3】コア辞書または拡張辞書における位置に従って候補単語をランク付けする際の、図1および図2の単語パターン認識システムの動作の方法を示すプロセス・フロー・チャートである。
【図4】コア辞書からの単語および拡張辞書からの単語を異なる方法で表示する、図1および図2の単語パターン認識システムによって発生されるN−ベスト・リストを示す図である。
【図5】コア辞書からの単語を拡張辞書からの単語よりも高くグループ化してランク付けする、図1および図2の単語パターン認識システムによって発生されるN−ベスト・リストを示す図である。
【図6】単語候補を接尾辞または接頭辞として認識し、認識した接頭尾または接尾辞を適切な方法である原語における認識された単語に結合する際の、図1および図2の単語パターン認識システムの動作の方法を示すプロセス・フロー・チャートである。
【図7】複数の単語を組み合わせて複合的な単語にする際の、図1および図2の単語パターン認識システムの動作の方法を示すプロセス・フロー・チャートである。
【図8A】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューによって、ユーザが複合的な単語を語幹および接尾語に分割することを可能とする。
【図8B】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューによって、ユーザが複合的な単語を語幹および接尾語に分割することを可能とする。
【図8C】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューによって、ユーザが複合的な単語を語幹および接尾語に分割することを可能とする。
【図9】図1および図2の単語パターン認識システムによって提示される複合的な単語上でユーザが行うペンの動きを示す図であり、このペンの動きによって複合的な単語を語幹および接尾語に分割する。
【図10A】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを語幹に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図10B】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを語幹に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図10C】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを語幹に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図11】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを接尾時に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図12】図1および図2の単語パターン認識システムによって提示される語幹および接尾辞の上でユーザが行うペンの動きを示す図であり、このペンの動きによって語幹および接尾辞を複合的な単語に組み合わせる。
【発明を実施するための形態】
【0021】
以下の定義および説明は、本発明の技術分野に関する背景情報を与えるものであり、本発明の範囲を限定することなくその理解を容易にすることを意図していいる。
【0022】
辞書: 認識システムにおけるユーザの入力に対して照合することができる認識可能な要素を定義する要素集合。
【0023】
PDA:パーソナル・デジタル・アシスタント: ポケット・サイズのパーソナル・コンピュータ。PDAは通常、電話番号、約束、予定リストをストアする。PDAには、小さいキーボードを有するものがあり、仮想キーボード上で入力および出力を行うために用いる特別なペンのみを有するものもある。
【0024】
sokgraph: グラフとしてのショートハンド・オン・キーボード。仮想キーボード上での単語のパターン表現。
【0025】
仮想キーボード: タッチスクリーンのインタラクティブな機能を有するコンピュータ・シミュレーションによるキーボードであり、キー入力を用いてキーボードに置き換わるかまたは補足するために使用可能である。仮想キーは通常、手書き入力用のペンによって連続的に入力される。また、これは、グラフィカル・キーボード、オンスクリーン・キーボード、または手書き入力用ペン・キーボードとも呼ばれる。
【0026】
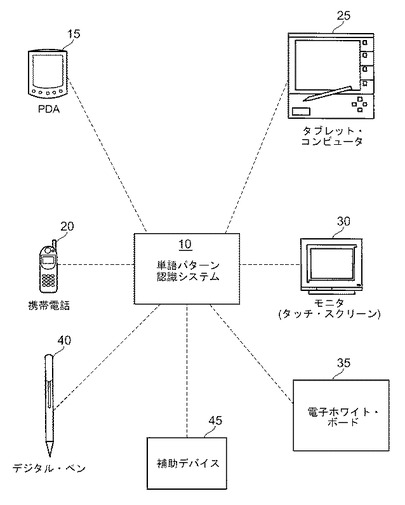
図1は、本発明に従って、ショートハンド・オン・キーボード・インタフェース(単語パターン認識システム10または「システム10」)におけるテキスト入力を改善するためのシステム、コンピュータ・プログラム、および関連する方法を用いることができる例示的な全体的な環境を示す。システム10は、通常コンピュータ内に埋め込まれたかコンピュータ上にインストールされたソフトウェア・プログラム・コードまたはコンピュータ・プログラムを含む。システム10がインストールされたコンピュータは、PDA15または携帯電話20等のモバイル・デバイスとすることができる。また、システム10は、タブレット・コンピュータ25、タッチ・スクリーン・モニタ30、電子ホワイト・ボード35、およびデジタル・ペン40等のデバイスにインストールすることも可能である。
【0027】
システム10は、仮想キーボードまたは補助デバイス45に代表される入力用の同様のインタフェースを用いたあらゆるデバイスにインストールすることができる。システム10は、ディスケット、CD、ハード・ドライブ、または同様のデバイス等、適切なストレージ媒体上に記憶することができる。
【0028】
システム10は、ユーザがグラフィカル・キーボード上に形成するペンの動きの形状および位置から、単語を特定する。システム10は、特定した単語を、例えばアプリケーション、オペレーティング・システム等のソフトウェア受信側に送信する。
【0029】
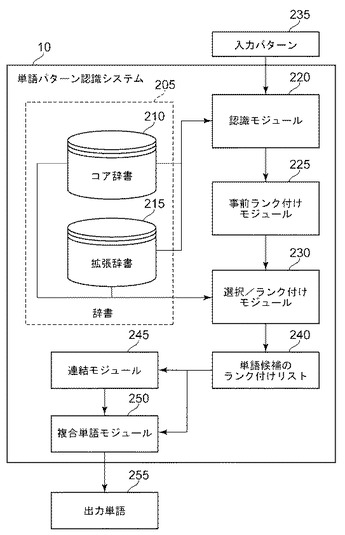
図2は、システム10の高レベルの階層を示す。システム10は、辞書205を含む。辞書205は、コア辞書210および拡張辞書215を含む。コア辞書210は、ある原語において一般的に用いられる単語を含む。コア辞書は、システム10の用途に応じて、典型的に約5,000から15,000の単語を含む。拡張辞書215は、コア辞書215に含まれない単語を含む。拡張辞書215は、約30,000から100,000の単語を含む。
【0030】
システム10は、更に、認識モジュール220、事前ランク付けモジュール225、および選択/ランク付けモジュール230を含む。認識モジュール220は、入力パターン235に対応する候補単語のN−ベスト・リストを発生する。事前ランク付けモジュール225は、所定の基準に従ってN−ベスト候補単語をランク付けする。ランク付けモジュール230は、候補単語のN−ベスト・リストのランク付けを調節して、コア辞書210から得られた単語を、拡張辞書215から得られた単語よりも高く配置して、ランク付けた単語候補のリスト240を発生する。先に説明したように、拡張辞書から得られた単語は出力せず、コア辞書からの単語のみを出力する。
【0031】
システム10は、更に、連結モジュール245および複合単語モジュール250を含む。連結モジュール245は、ランク付けた単語候補のリスト240から選択された語を連結する。例えば、「ing」を「code」と連結して「coding」を形成する。複合単語モジュール250は、ランク付けた単語候補のリスト240から選択された単語を組み合わせてもっと大きい単語にする。出力単語255は、ランク付けた単語候補のリスト240から選択され、必要に応じて連結モジュール245および複合単語モジュール250によって処理された単語である。コア辞書210に載っている単語のみが、システム10によって出力単語255として与えられる。システム10は、拡張辞書215に載っている候補単語をN−ベスト・リストにのみ記載する。これらの単語は、出力単語255となるにはユーザに選択されなければならない。いったんユーザによって選択されると、システム10は、拡張辞書215からの単語をコア辞書210に載せることを許可する。
【0032】
システム10は、認識モジュール220による入力パターン235の認識をユーザの語彙に適合させる一方で、認識システムにおいて最大の信号対雑音比を維持する。システム10によって、コア辞書210および拡張辞書215は、認識モジュール220の認識プロセスに参加することができる。しかしながら、コア辞書210内の単語のみが、認識モジュール220の出力に直接入る。これらの単語は、デフォルトの出力である。入力パターン235に合致する拡張辞書215内の単語は、「N−ベスト」リストに記載されて、ユーザによる選択を待つだけである。ユーザがN−ベスト・リストからこれらの候補単語の1つを選択してデフォルトの出力に置き換えると、選択された単語はコア辞書210に載ることを許可される。単語がコア辞書210に載ることを許可された後、許可された単語が入力パターン235に合致した場合に、この単語が認識モジュールの出力に直接入ることができる。
【0033】
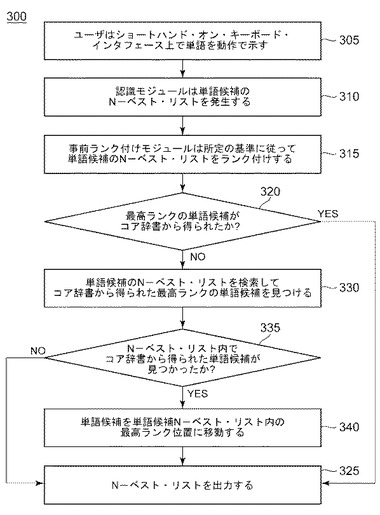
図3は、入力パターン235に合致する候補のN−ベスト・リストを発生させる際のシステム10の方法300を示す。ユーザは、ショートハンド・オン・キーボード・インタフェース上で、ある単語を動作で示す(gesture)(ステップ305)。認識モジュール220は、単語候補のN−ベスト・リストを発生する(ステップ310)。事前ランク付けモジュール225は、信頼値または同様の尺度等の基準に従って、コア辞書210および拡張辞書215から単語候補のN−ベスト・リストをランク付けする(ステップ315)。
【0034】
ランク付けモジュール230は、候補単語のN−ベスト・リスト内の最も高いランクの単語がコア辞書210から得られたか否かを判定する(判断ステップ320)。イエスの場合、ランク付けモジュール230は、ランク付けした単語候補のN−ベスト・リストを、ランク付けた単語候補のリスト240として出力する(ステップ325)。候補単語のN−ベスト・リスト内の最も高いランクの候補がコア辞書210に乗っていない場合、ランク付けモジュール230は、候補単語のN−ベスト・リストを検索して、コア辞書210から得られた最も高いランクの単語候補の位置を見つける(ステップ330)。
【0035】
候補単語のN−ベスト・リスト内において、コア辞書210から得られた単語候補が見つからない場合(判断ステップ335)、ランク付けモジュール230は、ランク付けした単語候補のN−ベスト・リストを、ランク付けた単語候補のリスト240として出力する。その他の場合、ランク付けモジュール230は、見つけた単語候補を単語候補のN−ベスト・リスト内の最も高いランクの位置に移動させる(ステップ335)。ランク付けモジュールは、ランク付けした単語候補のN−ベスト・リストを、ランク付けた単語候補のリスト240として出力する(ステップ340)。
【0036】
最も高いランクでない候補単語をユーザが選択することを可能とするために、ユーザ・インタフェース・コンポーネントは、次のベスト候補リスト(N−ベスト・リスト)を表示し、ここからユーザは入力パターン235に密接に合致する代替的な候補単語を見ることができる。一実施形態においては、このリスト上の候補単語の位置は、その候補単語に関連付けたランクによって決定され、その候補単語がコア辞書210または拡張辞書215のいずれに載っている否かとは無関係である。ただし、コア辞書内の単語がどれもユーザの入力に合致しない場合を除いて、最も高いランクの単語は常にコア辞書内にあるものでなければならない。別の実施形態においては、候補単語は辞書の出典によってグループ化される。すなわち、コア辞書210からの候補単語をグループ化し、拡張辞書215からの候補単語をグループ化する。
【0037】
候補単語の出典は、任意に、候補単語に関連付けた異なる知覚的特徴を強調することによって示して、例えばコア辞書または拡張辞書からという候補単語のソースの認識を容易にすることができる。例示的な知覚的特徴は、例えば、色、背景の陰影、太字のフォント、イタリック対のフォント等を含む。ユーザがどの単語も選ばない場合、システム10はコア辞書から候補単語のN−ベスト・リスト内の最も高いランクの単語を出力する。ユーザが単語を選択しない場合、システム10はコア辞書から候補単語のN−ベスト・リスト内の最も高いランクの単語を出力する。
【0038】
拡張辞書215から得られた単語は、候補単語のN−ベスト・リストからアクセスすることができる。このため、最も高いランクの候補を発生させる際のシステム10のエラー許容度が著しく高まる。なぜなら、システムによって表示される最も高いランクの候補は、小さい方のコア辞書210から得るからである。所望の単語がコア辞書210において見つからないというまれな状況では、ユーザはN−ベスト・リストを活性化して所望の候補を選択する。
【0039】
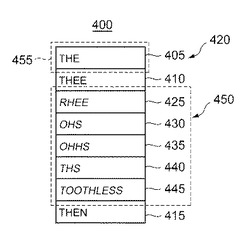
図4は、ランク付けモジュール230によって発生した例示的な候補単語のN−ベスト・リスト400を示す。コア辞書210からの候補単語は、候補単語1、405、候補単語2、410、および候補単語3、415を含み、これらをまとめてコア候補単語420と称する。拡張辞書215からの候補単語は、候補単語4、425、候補5、430、候補6、435、候補7、440、および候補8、445を含み、これらをまとめて拡張候補単語450と称する。コア候補単語420および拡張候補単語450は、異なる強調を用いて表示されている。
【0040】
この例において、コア候補単語420は太字の文字で示し、拡張候補単語450はイタリック体の文字で示す。コア候補単語420および拡張候補単語450を区別するために、例えば、文字の色、色の背景、陰影等、いかなる形態の強調も使用可能である。例示的な候補単語のN−ベスト・リスト400内の候補単語は、認識モジュール220によって与えられるランクに従って位置付けられる。ただし、最上部の単語候補位置455は、コア辞書210から得られる単語のために確保される。これは、コア辞書からのどの単語もユーザの入力に合致しない場合には当てはまらない。この場合は、最上部の単語候補位置455に、拡張辞書からの単語を配置することができる。
【0041】
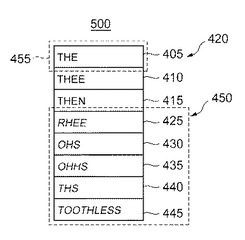
図5は一実施形態を示し、例示的なN−ベスト・リスト500は、ソースに従っておよび認識モジュール200が与えるランク付け基準に従ってランク付けされた候補単語を含む。図4と同様に、コア候補単語420および拡張候補単語450は異なる強調で表示されている。この例では、コア候補単語420を太字の文字で示し、拡張候補単語450をイタリック体の文字で示す。
【0042】
システム10は、ユーザが動作で示した単語がコア辞書210の語彙に含まれない場合にユーザに与えられるオーバーヘッドを著しく低減する。単語がコア辞書210に含まれているのか、またはシステムが入力を誤って認識したのかが不確かであるということではなく、ユーザはN−ベスト・リストをスキャンして所望の候補単語を選択することができる。
【0043】
最新の技術に精通した者には、単語を別個の辞書に分割することが単純な概念的モデルでもある1つの実施であることは明らかであろう。あるいは、辞書205を、コア辞書層および拡張辞書層という層として概念化して、頻度または事前確率(priori probability)によってランク付けすることも可能である。拡張辞書層からの単語がN−ベスト候補インタフェースから選択された場合、選択された単語の頻度または事前確率を、閾値または他の基準に対して調節して、選択された単語をコア層に属するように調節する効果を有する。
【0044】
更に、システム10によって、ユーザは、長い単語の部分を別個に入力することができる。システム10は、部分的な「sokgraphs」を、ユーザが意図する1つの語に自動的に結合する。単語の部分は、「work」等の語幹および「ing」等の接辞である場合があり、または、2つ以上の一般的な短い単語であり、英語の「short+hand」のように連結して長い単語を形成する場合がある。いくつかの短い単語が連結して1つの複合的な単語になることは、スウェーデン語またはドイツ語等のいくつかのヨーロッパ言語ではもっとよくあることである。
【0045】
連結は、連結した語に含まれる個別に認識される部分に基づいている。語幹および接辞の例では、ユーザは最初に語幹を表す語について入力パターン235を動作で示し、次いで接辞の入力パターン235を動作で示す。例えば、「coding」という単語では、ユーザは最初に「code」を動作で書き、次いで「ing」を動作で書く。キーボード上の入力トレースについて、認識モジュール220は、最適な合致を見つけて、これらの合致をストリング
【0046】
【数1】

【0047】
と共にN−ベスト・リストに出力する。ここで、ストリングのランクiは、選択されたストリング合致入力パターン235における認識モジュール220の信頼度を意味する。ランクi=1を有するストリングは、認識モジュール220の最上位の選択肢である。認識モジュール220は、最新のN−ベスト・リストを一時バッファにストアする。規則的な語(語幹)についてのバッファされたN−ベスト・リストを、S0と示す。
【0048】
一実施形態においては、連結可能接尾辞と呼ぶリストに接尾辞がストアされている。そのグラフィカル・キーボード上の幾何学的パターンであるsokgraphsは、一般的な単語のsokgraphと同じ方法で表される。例えば、「ing」という接尾辞では、そのsokgraphは、iキーで開始してnキーへと動きgキーで終了する連続的なトレースである。システムは、「ing」のsokgraphについての入力パターン235を、他のいずれのsokgraphとも同じ方法で認識する。ただし、接尾辞「ing」を連結可能接尾辞のリストにストアする。あるいは、接尾辞および規則的な語の双方を同一の辞書にストアすることも可能であるが、識別子によって規則的な語から接尾辞を区別する。一実施形態においては、連結可能接尾辞を参照テーブルにストアし、ここで、「ing」等の各接尾辞を、その接尾辞で終わる辞書内の入力を指し示す一連のポインタに関連付ける。
【0049】
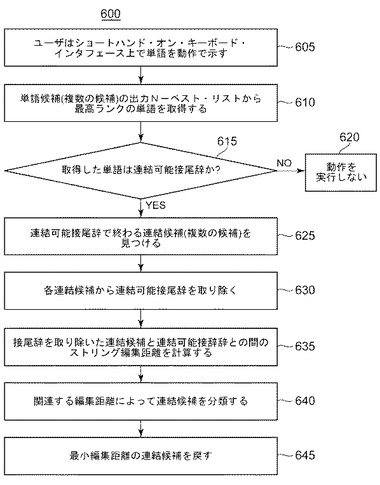
図6は、連結可能接尾辞を語幹の語と結合する際のシステム100の方法600を示す。ユーザは、ショートハンド・オン・キーボード・インタフェース上で、ある単語を動作で示す(ステップ605)。連結モジュール245は、単語候補の出力N−ベスト・リスト240について最高ランクの単語を取得する(ステップ610)。連結モジュール245は、取得した単語が連結可能接尾辞であるか否かを、例えば取得した単語を連結可能接尾辞リストと比較することによって判定する(判断ステップ615)。取得した単語が連結可能接尾辞でない場合、連結モジュール245は何の動作も行わない(ステップ620)。
【0050】
取得した単語が連結可能接尾辞である場合、連結モジュール245は、特定した連結可能接尾辞で終わる連結候補を見つける(ステップ625)。連結モジュール245は、各連結候補から連結可能接尾辞を取り除く(ステップ630)。現在の接尾辞(例えば「ing」)で終わる単語はS1(i)と示し(例えばcodingまたはworking)、接尾辞を取り除いた残りはS2(i)と示す(例えば「code」または「work」)。
【0051】
連結モジュール245は、接尾辞を取り除いた連結候補と連結可能接尾辞との間のストリング編集距離(具体的には、Wagner−Fisherアルゴリズムを用いたMorgan編集エラー)を計算する(ステップ635)。次いで、残りS2(i)を、バッファしたN−ベスト・リスト内の最上位の選択肢S0(i)に対して照合する。S0は、単語の断片でなく単語全体を含むので(例えばS0(1)=code)、照合は正確でない。システム10は、編集距離(単一の文字の挿入、削除、または置換から選択される最少数の編集動作)を用いて、2つのストリングを照合し、S0(1)に最も近いS2(i)(i=1、N)内のストリングを見出して、それをS2minと表す。連結モジュール245は、関連する編集距離によって連結候補を分類する(ステップ640)。連結モジュール245は、最小編集距離を有する連結候補を戻す(ステップ645)。
【0052】
代替的な実施形態においては、単語の頻度または前の確率または高水準言語規則を用いて、同じ編集距離を共有する連結候補をランク付けする。
【0053】
S1(i)におけるS2minに対応する単語を、選択した連結候補として戻す。例えば、「cod」(「coding」の接尾辞を取り除いた部分)に対する「code」は、編集距離について、「work」(「working」の接尾辞を取り除いた部分)に対する「code」よりも近い。一実施形態においては、最低許容可能編集距離不一致として閾値を設定することも可能である。
【0054】
別の実施形態においては、接尾辞は、その接尾辞で終わる単語の全てにはリンクされない。その代わりに、ある接尾辞を認識した場合、システム10は辞書205をスキャンし、認識した接尾辞で終わる単語を見つけ、見つけた単語から最後部分を取り除き、取り除いた残りを直前の単語と照合し、前述したように連結について最も近い合致を選択する。これらの2つの実施形態の違いは、計算時間とメモリ空間とのトレードオフにある。辞書をスキャンすることは、別個のポインタ・リストが必要ないことを意味し、従って、ソフトウェア・コードがアクセスしている媒体内の辞書のストレージ要求が抑えられる。他方で、辞書をスキャンすることは、別個のポインタ・リストによってインデクスをつけた辞書を含むシステムよりも単語の位置を見つけるよりも長い時間を要する。
【0055】
システム10は、接頭辞および語幹を、語幹および接尾辞と同様に扱う。連結モジュール245は、最初に、別個の接頭辞リストまたは接頭辞識別子を有する共通の辞書のいずれかから、ランク付けた単語候補のリスト240の出力から接頭辞に基づいた単語を認識する。次いで、連結モジュール245は、接頭辞の後の単語を認識する。連結モジュール245は、その接頭辞を含む全ての単語を照合し、合致した単語の接頭辞を取り除き、連結のために最も近い合致を戻す。
【0056】
2つの短い単語を1つの長い単語に連結することは、決定的ではない。例えば、スウェーデン語において、「smoke free」および「smokefree」は双方とも許されるが、それらの意味は反対である(「喫煙は許されない」に対して「喫煙は許される」)。複合単語モジュール250は、統計的かつインタラクティブな方法を用いて、2つの単語の連結を処理する。この方法をサポートするため、システム10は、辞書205に、全ての単語の頻度(テキストの文書データ内の各単語の合計発生数に基づく)および全てのバイグラム(bigram)の頻度(2つの並んだ単語の合計発生数に基づく)を含む統計的情報をストアする。
【0057】
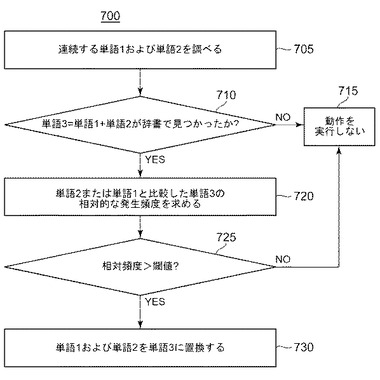
図7は、単語を組み合わせて複合的な単語にする際のシステム10の方法700を示す。方法700は、連続する単語対(単語1、単語2)を調べる(ステップ705)。複合単語モジュール250は、辞書205において、組み合わせた連続する単語(単語1+単語2=単語3)が見つかるか否かを判定する(判断ステップ710)。組み合わせた単語すなわち単語3が見つからない場合、複合単語モジュール250は何も動作を行わない(ステップ715)。合致(単語3=単語1+単語2)が見つかった場合、複合単語モジュール250は、単語3の頻度をバイグラム(単語1、単語2)と比較する(ステップ720)。単語3の頻度が、所定の閾値と比較して、バイグラム(単語1、単語2)の頻度よりも大きい場合、または、バイグラム(単語1、単語2)の頻度に対する単語3の頻度の比が所定の閾値よりも大きい場合(判断ステップ725)、複合単語モジュールは、単語1および単語2を単語3に置き換える(ステップ730)。その他の場合は、何も動作を行わない(ステップ715)。あるいは、単語3の頻度およびバイグラム(単語1、単語2)の頻度の比較は、重み付け比較である。
【0058】
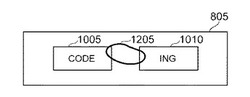
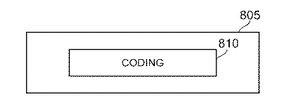
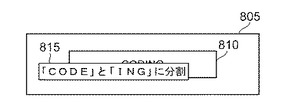
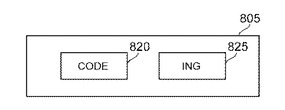
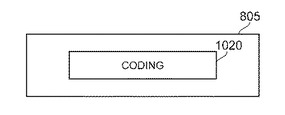
システム10は、連結および分離を調節するためのユーザ・インタラクションを可能とするユーザ・インタフェースを提供する。図8A、図8B、図8Cは、組み合わせた単語を2つの別個の単語または単語の部分に分離することを示す。例示的なスクリーン805は、例示的な連結した単語「coding」810をユーザに対して表示する。ユーザは、例えば単語「coding」810をクリックすることによって、表示した連結単語「coding」を選択する(図8A)。単語「coding」810の選択によって、メニュー・オプション815が表示される。これは、例えば、選択可能な命令「「code」と「ing」に分割」または同等のオプションを含む(図8B)。ユーザがメニュー・オプション815に示された命令を選択すると、システム10は、表示された連結単語「coding」810を、語幹「code」820および接尾辞「ing」825に分割する(図8C)。
【0059】
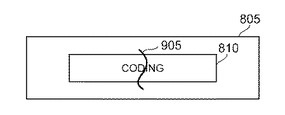
図9は、連結した単語「coding」810を分割するために用いられる代替的な例であるペン・トレースの動き905を示す。スクリーン805は、連結した単語「coding」810をユーザに対して表示する。ユーザは、連結した単語「coding」810上で、ペン・トレースの動き905を行う。システム10は、図8Cに示すように、表示されている連結単語「coding」810を、語幹「code」820および接尾辞「ing」825に分割する。
【0060】
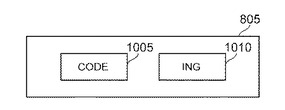
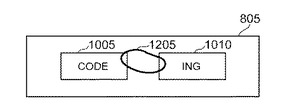
信頼度が低いために動作が行われない連結可能単語については、図10Aから図10Cに示すように、単語1および単語2にメニュー・オプションが埋め込まれている。例えば、スクリーン805は、図10Aに示すように、単語1「code」1005および単語2「ing」1010をユーザに対して表示する。単語1「code」1005を選択すると、オプション・メニュー1015が表示され、これは、選択可能な命令「右に動く」または同等のオプションを含む(図10B)。ユーザが、オプション・メニュー1015に示された命令「右に動く」を選択すると、システム10は、単語1「code」1005および単語2「ing」1010を連結し、連結された単語「coding」1020を形成する(図10C)。
【0061】
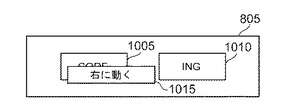
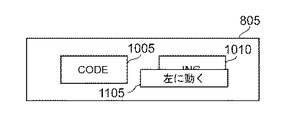
図11は、ユーザが単語2「ing」1010を選択した場合に表示される例示的なオプション・メニュー1105を示す。ユーザが、オプション・メニュー1105に示される命令「左に動く」を選択すると、システム10は、単語1「code」1005および単語2「ing」1010を連結し、図10Cに示すように、連結された単語「coding」1020を形成する。
【0062】
図12は、単語1「code」1005および単語2「ing」1010を連結するために用いられる代替例であるペン・トレースの動き1205を示す。ペン・トレースの動き1205は、例えば、単語1「code」1005および単語2「ing」1010を横切る円を含む。システム10は、ペン・トレースの動き1205によって表されるコマンドを認識し、単語1「code」1205および単語2「ing」1010を連結し、図10Cに示すように、連結された単語「coding」1020を形成する。
【技術分野】
【0001】
本発明は、一般に、辞書に基づいたテキスト入力およびテキスト予測システムに関する。更に具体的には、本発明は、グラフィックで表した画面上キーボードの上で幾何学的パターンを描くことによって単語を入力する効率的な方法であるショートハンド・オン・キーボード(shorthand-on-keyboard)を用いたテキスト入力に関する。
【背景技術】
【0002】
グラフィカル・キーボード(graphicalkeyboard)上のショートハンド(簡略な伝達方法)(以降、「ショートハンド・オン・キーボード」と称する)または図表としてのキーボード上のショートハンド(sokgraph)は、物理的なキーボードなしで、典型的には手書き入力用のペンを用いて、効率的にテキストを入力するための入力方法およびシステムを表す。ショートハンド・オン・キーボードによって、ユーザは、グラフィカル・キーボード上の文字または機能キーをたどって、単語およびコマンドをコンピュータに入力することができる。経験豊富なユーザは、キーボードのレイアウト上で頻繁に用いる単語およびコマンドの幾何学的パターンを部分的にまたは完全に記憶し、例えばデジタル・ペンを用いて、記憶力に基づいてこれらのパターンを描くことができる。
【0003】
ショートハンド・オン・キーボードおよび手書き/音声認識およびテキスト予測システム等の単語レベルの認識に基づいたテキスト入力システムは、全て、これらのシステムが認識する単語セットを定義する何らかの形態の辞書に頼っている。ユーザの入力は、辞書内の選択肢に対して照合される。辞書に含まれない単語は、通常、自動的には認識されない。かかる場合、特別なモードを設けなければならない。例えば、ショートハンド・オン・キーボードでは、ユーザは最初に候補リスト(N−ベスト・リスト)を調べることができる。候補リスト上のどの選択肢も目的の単語ではない場合、ユーザは、描いたパターンが間違っていたか否かを判断する。描いたパターンが正しい場合、ユーザは目的の単語がその辞書には載っていないことを認識する。次いで、ユーザは、単語の個々の文字を入力することによって、辞書にこの新しい単語を入力する。理想的には、辞書は、特定のユーザが書く必要がある全ての単語を過不足なく含む。大きすぎたり小さすぎたりする辞書は、ユーザに対して問題を引き起こす可能性がある。
【0004】
辞書が大きくなると、いくつかの問題が生じる恐れがある。なぜなら、各ユーザ入力ごとに、正解以外の選択肢の数が増える可能性があるために、認識の精度が低くなりやすいからである。いずれの言語においても、あらゆる人に共通するコアの語彙集合が存在する傾向がある。このコア集合を超えると、語彙は特定の個人のために専門化しがちである。例えば、エンジニアは、特定の分野またはビジネス領域について高度に技術的な用語および略語を含む電子メールを作成することがある。他のユーザに対しては、これらの専門化した用語は無関係であり、認識プロセスにノイズを生じて、認識プロセスの確実さを低下させる恐れがある。
【0005】
辞書が小さくなると、通常、目的とする単語が辞書に載っている場合にユーザ入力が正しく認識される可能性が高くなるという点で、辞書はいっそう確実なものとなる。辞書が小さくなると、ユーザの入力に対して与えられる柔軟性および許容度が高くなり、目的とする入力選択肢の理想的な形態に比べて大ざっぱで不正確な入力も可能となる。小さい辞書の更に別の利点は、検索空間が小さくなることである。この結果、小さい辞書では、検索の待ち時間を短縮することができる。これは、処理パワーが大きく制限されるモバイル・デバイスでは特に重要である。
【0006】
しかしながら、小さい辞書にユーザが必要とする単語が含まれない場合、ユーザはいらいらする経験をすることがある。ユーザは、入力の前には、辞書に単語が載っているか否かを知らないので、ユーザには不確実さが生じる。従来のシステムでは、単語が間違って入力された場合または単語が辞書に載っていない場合のいずれかに、単語が認識されないということが起こり得る。このため、ユーザにとって、なぜ単語が認識されないかを判断するのが難しいことがある。一般に、ある単語が辞書に載っているか否かを知るには、ユーザはその単語を繰り返し試さなければならない。その単語が辞書に載っていないことが確実になると、ユーザは、認識システムによって与えられるインタフェースを介して、先に述べたように入力することによって、その単語を辞書に追加する。辞書が小さくなると、ユーザが辞書に単語を追加しなければならないことが頻繁に起こる。
【0007】
辞書サイズの問題には、従来からいくつかの解決策がある。一般的に用いられている方法は、大きい辞書を用い、次いで単語レベルのトライグラム(trigram)・モデル等の高水準言語規則を利用して、極めて可能性の低い候補を除去することである。言語モデル手法の欠点は、一般に、大きい言語モデルを生成して効率的に利用することのオーバーヘッドである。更に、言語モデルでは、エラーが生じ、目的とする単語が誤って除去される恐れがある。これは、言語モデルが特定のユーザにカスタマイズされるのではなく汎用的である場合に、特に当てはまる。実際、言語モデルの効率的なカスタマイゼーションは難しい。更に、言語モデルは、ショートハンド・オン・キーボード等の、すでに高い精度を有する認識技法と統合することが難しい。
【0008】
ある代替的な従来の手法では、例えば書面の電子メールおよび他の文書のような、ユーザが発生した書面のテキストを利用することによって、ユーザのためにカスタマイズした辞書を生成する。この手法では、特定のユーザによりいっそう合った辞書が作成されるが、ユーザが発生した以前の文書データは、所望の単語を全てカバーするには小さすぎる場合がある。更に、実際、ユーザが用いている可能性がある様々な電子メールおよび文書フォーマットを全て開いて読むことができるコンピュータ・プログラム・コードを書くことは難しい。この手法では、多くの場合、ユーザが以前の文書の位置を特定して選択する必要があるが、これはユーザにとって不便である。また、カスタム化した辞書は、異なるデバイス間で持ち運ぶのが難しい場合がある。
【発明の概要】
【発明が解決しようとする課題】
【0009】
これらの従来の解決策は意図する目的のためには適切であるが、ユーザの所望の入力に対して無関係な選択肢の数が比較的少ない辞書を可能とし、更に、ほとんどのユーザが頻繁には用いないもっと専門化した単語も含めて、ユーザが必要とし得るほとんど全ての単語に対して容易にアクセスすることができる解決策を見出すことが望ましい。概して、極めて大きい辞書においてユーザが必要とする可能性のある全ての単語を含むことが望ましい。しかしながら、極めて大きい辞書は、同じ照合閾値が与えられた場合、キーボード上に描かれたパターンに合致する単語が増えることを意味し、入力システムにおける信号対雑音比を低下させることになる。従って、辞書を大きくすると、ユーザに対する柔軟性および確実さが低下する。従って、使いやすさと柔軟性および確実さとのバランスを取ったショートハンド・オン・キーボード・システムのための辞書構成が必要とされている。
【0010】
従来のショートハンド・オン・キーボード入力方法の別の問題点は、一度に1つの単語ずつ、単語レベルでテキストを正確に入力しなければならないことである。単語には長いものもある。比較的新しいユーザにとっては、ショートハンド・オン・キーボードを用いて1つの動きで長い単語を描くことは認知的に難しいことがある。この難しさは、英語よりも複合的な長い単語がよくあるいくつかのヨーロッパの言語においては特に切実である。更に、単語の語幹とは別の動きとして一般的な接辞を描くことができれば、ユーザは入力をもっと便利だと感じることができる。例えば、ショートハンド・オン・キーボードを用いて「working」という単語を書く場合、ユーザはグラフィカル・キーボード上でw-o-r-kのパターンを描き、次いでi-n-gを描き、この2つを組み合わせて1つの単語にしたいと考えることがある。このため、キーボード上の部分的な語(「sokgraph」)を自動的に組み合わせてユーザが意図する1つの単語とする効果的なシステムおよび方法が求められている。
【0011】
従って、ショートハンド・オン・キーボード・インタフェースにおいてテキスト入力を改善することが求められている。
【課題を解決するための手段】
【0012】
本発明は、ショートハンド・オン・キーボード・インタフェースにおいてテキスト入力を改善するためのシステム、コンピュータ・プログラム、および関連する方法(ここでは、まとめて「システム」または「本システム」と呼ぶ)を開示する。本システムは、コア辞書および拡張辞書を含む。コア辞書は、ある言語において一般的に用いられる単語を含む。コア辞書は、本システムの用途に応じて、典型的に約5,000から15,000の単語を含む。拡張辞書は、コア辞書に含まれない単語を含む。拡張辞書は、約30,000から100,000の単語を含む。
【0013】
コア辞書によって、本システムは、動きを識別する際に、最高ランクの候補単語として一般的に用いられる単語に的を絞ることができ、より小さい辞書に関連付けていっそう確実な認識性能を提供することができる。本システムでは、コア辞書からの単語のみを直接出力することができる。拡張辞書から追加の候補単語を利用することができ、このためユーザは候補リスト上のあまり知らない単語を見つけることができるが、メニュー選択するだけである。本システムは、大きい辞書からの単語選択を犠牲にすることなく、単語認識の精度を高める。コア辞書によって、目的とする入力選択肢の理想的な形態に比べて大ざっぱで不正確なユーザ入力に対する柔軟性および許容度が高くなる。
【0014】
本システムは、更に、認識モジュール、事前ランク付けモジュール、およびランク付けモジュールを含む。認識モジュールは、入力パターンに対応する候補単語のN−ベスト・リストを発生する。事前ランク付けモジュールは、所定の基準に従ってN−ベスト候補単語をランク付けする。ランク付けモジュールは、候補単語のN−ベスト・リストのランク付けを調節して、コア辞書から得られた単語を、拡張辞書から得られた単語よりも高く配置して、ランク付けた単語候補のリストを発生する。コア辞書に載っている単語のみが、本システムによって出力される。本システムは、拡張辞書に載っている候補単語をN−ベスト・リストにのみ記載する。これらの単語は、出力となるにはユーザに選択されなければならない。いったんユーザによってN−ベスト・リストから選択されると、拡張辞書からの単語をコア辞書に載せることが許可される。
【0015】
更に具体的には、好適な実施形態において、コア辞書に載っている単語のみが認識システムによって出力される。拡張辞書に載っている単語は、N−ベスト・リストに記載することができるだけであり、出力されるためには明示的にユーザに選択されなければならない。いったん選択されると、拡張辞書に載っている単語もコア辞書に載ることが許可される。
【0016】
本システムは、ユーザが動作で示した単語がコア辞書の語彙に含まれない場合にユーザに与えられるオーバーヘッドを低減する。単語が辞書に含まれているのか、またはシステムが入力を誤って認識したのかが不確かであるということではなく、ユーザはN−ベスト・リストをスキャンして所望の候補単語を選択することができる。
【0017】
本システムは、更に、連結モジュールおよび複合単語モジュールを含む。連結モジュールによって、ユーザは、長い単語の部分を別個に入力することができる。本システムは、部分的な「sokgraph」である単語および単語の部分を、ユーザが意図する1つの単語に自動的に結合する。単語の部分は、「work」等の語幹および「ing」「pre」等の接辞である場合がある。複合単語モジュールは、英語の「short+hand」等、連結によって1つの長い単語を形成する1つ以上の一般的な短い単語を組み合わせる。いくつかの短い単語が連結して1つの複合的な単語になることは、スウェーデン語またはドイツ語等のいくつかのヨーロッパ言語ではもっとよくあることである。
【0018】
本システムによって、単語1および単語2の連結および組み合わせた単語の分離を調節するためのユーザ・インタラクションが可能となる。ユーザが、例えば「smokefree」のような連結した単語をクリックすると、メニュー・オプション「smokeとfreeに分割」または同等のオプションがユーザに提示される。あるいは、単語「smokefree」を横切る下向きの動き等のペン・トレースの動きを、分割コマンドとして定義することができる。信頼度が低いために動作が行われない連結可能単語については、単語1および単語2にメニュー・オプションが埋め込まれている。ユーザが単語1をクリックした場合、オプション「右に動く」または同等のオプションが選択可能である。ユーザが単語2をクリックした場合、オプション「左に動く」または同等のオプションが選択可能である。あるいは、単語1および単語2の双方を横切る円などのペンの動きを、2つの単語を1つの連結した長い単語として結び付けるためのコマンドとして定義する。
例えば、本発明は以下の項目を提供する。
(項目1)
ショートハンド・オン・キーボード・インタフェースを介して入力された入力信号を認識するための単語認識システムであって、
一般的に用いられる単語を含むコア辞書と、
前記コア辞書に含まれない単語を含む拡張辞書と、
前記入力信号に関連付けられた単語を認識するための認識モジュールと、
前記入力信号に関連付けられた出力単語を前記コア辞書から出力するための選択モジュールと、
前記入力信号に関連付けられた候補単語がユーザによって選択されると、前記候補単語を前記コア辞書に載せることを許可するためのモジュールと、
を含む、システム。
(項目2)
前記ユーザによる選択のために、前記コア辞書および前記拡張辞書の少なくとも一方からの、前記入力信号に関連付けられた候補単語を提示するユーザ選択インタフェースを更に含む、項目1に記載のシステム。
(項目3)
前記ユーザ選択インタフェースが、前記コア辞書からの候補単語および前記拡張辞書からの候補単語を、容易に区別するために異なる知覚的特徴でリスト化する、項目2に記載のシステム。
(項目4)
前記認識モジュールが、前記コア辞書および前記拡張辞書から候補単語のN−ベスト・リストを発生する、項目1に記載のシステム。
(項目5)
少なくとも1つの基準に従って前記候補単語のN−ベスト・リストをランク付けするための事前ランク付けモジュールを更に含む、項目4に記載のシステム。
(項目6)
前記事前ランク付けモジュールが、前記コア辞書からの最も高いランクの単語を、前記候補単語のN−ベスト・リストにおける最も高いランクの単語として出力する、項目5に記載のシステム。
(項目7)
ショートハンド・オン・キーボード・インタフェースを介して入力された入力信号を認識するための単語認識方法であって、
一般的に用いられる単語をコア辞書にストアするステップと、
前記コア辞書に含まれない単語を拡張辞書にストアするステップと、
前記入力信号に関連付けられた単語を認識するステップと、
前記入力信号に関連付けられた出力単語を前記コア辞書から出力するステップと、
前記入力信号に関連付けられた候補単語がユーザによって選択されると、前記候補単語を前記コア辞書に載せることを許可するステップと、
を含む、方法。
(項目8)
前記ユーザによる選択のために、前記コア辞書および前記拡張辞書の少なくとも一方からの、前記入力信号に関連付けられた候補単語を提示するステップを更に含む、項目7に記載の方法。
(項目9)
前記コア辞書からの候補単語および前記拡張辞書からの候補単語を、容易に区別するために異なる知覚的特徴でリスト化するステップを更に含む、項目8に記載の方法。
(項目10)
ユーザ入力インタフェースを介して入力された入力信号を認識するための、コンピュータが使用可能な媒体上にストアされたプログラム・コードを有するコンピュータ・プログラム製品であって、
一般的に用いられる単語を含むコア辞書と、
前記コア辞書に含まれない単語を含む拡張辞書と、
前記入力信号に関連付けられた単語を認識するためのプログラム・コードと、
前記入力信号に関連付けられた出力単語を前記コア辞書から出力するためのプログラム・コードと、
前記入力信号に関連付けられた候補単語がユーザによって選択されると、前記候補単語を前記コア辞書に載せることを許可するためのプログラム・コードと、
を含む、コンピュータ・プログラム製品。
(項目11)
前記入力信号に係るテキストの語幹および接辞を組み合わせることを可能にするための、項目1に記載のシステムであって、
前記入力信号を入力接辞として認識するための連結モジュールであって、更に、候補単語を隣接候補単語として認識する、連結モジュールと、
前記入力接辞を含む辞書内の1組の単語を検索するための、複合単語出力モジュールであって、前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力する、複合単語出力モジュールと、
前記入力接辞を含む前記1組の単語における各辞書単語を、前記候補単語および前記入力接辞を含むストリングと比較する類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするための、ランク付けモジュールと、
を更に含む、システム。
(項目12)
前記入力接辞が接尾辞である、項目11に記載のシステム。
(項目13)
前記複合単語出力モジュールが前記接尾辞および前記最も高いランクの辞書単語を結合させる、項目12に記載のシステム。
(項目14)
前記入力接辞が接頭辞である、項目11に記載のシステム。
(項目15)
前記複合単語出力モジュールが前記接頭辞および前記最も高いランクの辞書単語を結合させる、項目14に記載のシステム。
(項目16)
前記類似性関数が距離関数を含む、項目14に記載のシステム。
(項目17)
前記隣接候補単語が、前記入力接辞の前に付く候補単語または前記入力接辞の後に付く候補単語のいずれか1つを含む、項目14に記載のシステム。
(項目18)
前記入力信号に係るテキストが前記入力接辞として認識されない場合、前記複合単語モジュールは、前記入力信号に係るテキストおよび前記隣接候補単語の連結の結果として生じるストリングを生成し、前記辞書における前記ストリングの発生頻度を求め、前記ストリングの発生頻度を前記入力信号に係るテキストおよび前記隣接候補単語のそれぞれの発生頻度と比較し、前記ストリングの発生頻度が前記入力テキストおよび前記隣接候補単語のそれぞれの発生頻度を超えた場合、前記複合単語モジュールは前記入力テキストおよび前記隣接候補単語を連結単語として連結し、前記ストリングを前記連結単語によって置換する、項目17に記載のシステム。
(項目19)
前記入力信号に係るテキストおよび前記隣接候補単語の発生頻度に対する前記ストリングの発生頻度の比較が重み付け比較である、項目18に記載のシステム。
(項目20)
前記入力信号に係るテキストの語幹および接辞を組み合わせることを可能にするための、項目7に記載の方法であって、
前記入力信号を入力接辞として認識するステップと、
前記入力信号が前記入力接辞として認識された場合、候補単語を隣接候補単語として認識するステップと、
前記入力接辞を含む辞書内の1組の単語を検索するステップと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較することによる類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするステップと、
前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力するステップと、
を更に含む、方法。
(項目21)
前記接尾辞および前記最も高いランクの辞書単語を結合させるステップを更に含む、請求項19に記載の方法。
(項目22)
前記入力信号に係るテキストの語幹および接辞を組み合わせることを可能にするための、項目10に記載のコンピュータ・プログラム製品であって、
前記入力信号を入力接辞として認識するため、および、候補単語を隣接候補単語として更に認識するためのプログラム・コードと、
前記入力接辞を含む辞書内の1組の単語を検索するためのプログラム・コードと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較することによる類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするためのプログラム・コードと、
前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力するためのプログラム・コードと、
を含む、コンピュータ・プログラム製品。
【0019】
本発明の様々な特徴およびそれらを達成する方法について、以下の説明、特許請求の範囲、および図面を参照して、更に詳細に説明する。図面において、適宜、参照番号を繰り返し用いて、参照した要素間の対応関係を示す。
【図面の簡単な説明】
【0020】
【図1】本発明の単語パターン認識システムを使用可能である例示的な動作環境の概略図である。
【図2】図1の単語パターン認識システムの高レベル・アーキテクチャのブロック図である。
【図3】コア辞書または拡張辞書における位置に従って候補単語をランク付けする際の、図1および図2の単語パターン認識システムの動作の方法を示すプロセス・フロー・チャートである。
【図4】コア辞書からの単語および拡張辞書からの単語を異なる方法で表示する、図1および図2の単語パターン認識システムによって発生されるN−ベスト・リストを示す図である。
【図5】コア辞書からの単語を拡張辞書からの単語よりも高くグループ化してランク付けする、図1および図2の単語パターン認識システムによって発生されるN−ベスト・リストを示す図である。
【図6】単語候補を接尾辞または接頭辞として認識し、認識した接頭尾または接尾辞を適切な方法である原語における認識された単語に結合する際の、図1および図2の単語パターン認識システムの動作の方法を示すプロセス・フロー・チャートである。
【図7】複数の単語を組み合わせて複合的な単語にする際の、図1および図2の単語パターン認識システムの動作の方法を示すプロセス・フロー・チャートである。
【図8A】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューによって、ユーザが複合的な単語を語幹および接尾語に分割することを可能とする。
【図8B】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューによって、ユーザが複合的な単語を語幹および接尾語に分割することを可能とする。
【図8C】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューによって、ユーザが複合的な単語を語幹および接尾語に分割することを可能とする。
【図9】図1および図2の単語パターン認識システムによって提示される複合的な単語上でユーザが行うペンの動きを示す図であり、このペンの動きによって複合的な単語を語幹および接尾語に分割する。
【図10A】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを語幹に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図10B】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを語幹に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図10C】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを語幹に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図11】図1および図2の単語パターン認識システムのメニューを示す図であり、このメニューを接尾時に適用することで、ユーザは語幹および接尾辞を複合的な単語に組み合わせることができる。
【図12】図1および図2の単語パターン認識システムによって提示される語幹および接尾辞の上でユーザが行うペンの動きを示す図であり、このペンの動きによって語幹および接尾辞を複合的な単語に組み合わせる。
【発明を実施するための形態】
【0021】
以下の定義および説明は、本発明の技術分野に関する背景情報を与えるものであり、本発明の範囲を限定することなくその理解を容易にすることを意図していいる。
【0022】
辞書: 認識システムにおけるユーザの入力に対して照合することができる認識可能な要素を定義する要素集合。
【0023】
PDA:パーソナル・デジタル・アシスタント: ポケット・サイズのパーソナル・コンピュータ。PDAは通常、電話番号、約束、予定リストをストアする。PDAには、小さいキーボードを有するものがあり、仮想キーボード上で入力および出力を行うために用いる特別なペンのみを有するものもある。
【0024】
sokgraph: グラフとしてのショートハンド・オン・キーボード。仮想キーボード上での単語のパターン表現。
【0025】
仮想キーボード: タッチスクリーンのインタラクティブな機能を有するコンピュータ・シミュレーションによるキーボードであり、キー入力を用いてキーボードに置き換わるかまたは補足するために使用可能である。仮想キーは通常、手書き入力用のペンによって連続的に入力される。また、これは、グラフィカル・キーボード、オンスクリーン・キーボード、または手書き入力用ペン・キーボードとも呼ばれる。
【0026】
図1は、本発明に従って、ショートハンド・オン・キーボード・インタフェース(単語パターン認識システム10または「システム10」)におけるテキスト入力を改善するためのシステム、コンピュータ・プログラム、および関連する方法を用いることができる例示的な全体的な環境を示す。システム10は、通常コンピュータ内に埋め込まれたかコンピュータ上にインストールされたソフトウェア・プログラム・コードまたはコンピュータ・プログラムを含む。システム10がインストールされたコンピュータは、PDA15または携帯電話20等のモバイル・デバイスとすることができる。また、システム10は、タブレット・コンピュータ25、タッチ・スクリーン・モニタ30、電子ホワイト・ボード35、およびデジタル・ペン40等のデバイスにインストールすることも可能である。
【0027】
システム10は、仮想キーボードまたは補助デバイス45に代表される入力用の同様のインタフェースを用いたあらゆるデバイスにインストールすることができる。システム10は、ディスケット、CD、ハード・ドライブ、または同様のデバイス等、適切なストレージ媒体上に記憶することができる。
【0028】
システム10は、ユーザがグラフィカル・キーボード上に形成するペンの動きの形状および位置から、単語を特定する。システム10は、特定した単語を、例えばアプリケーション、オペレーティング・システム等のソフトウェア受信側に送信する。
【0029】
図2は、システム10の高レベルの階層を示す。システム10は、辞書205を含む。辞書205は、コア辞書210および拡張辞書215を含む。コア辞書210は、ある原語において一般的に用いられる単語を含む。コア辞書は、システム10の用途に応じて、典型的に約5,000から15,000の単語を含む。拡張辞書215は、コア辞書215に含まれない単語を含む。拡張辞書215は、約30,000から100,000の単語を含む。
【0030】
システム10は、更に、認識モジュール220、事前ランク付けモジュール225、および選択/ランク付けモジュール230を含む。認識モジュール220は、入力パターン235に対応する候補単語のN−ベスト・リストを発生する。事前ランク付けモジュール225は、所定の基準に従ってN−ベスト候補単語をランク付けする。ランク付けモジュール230は、候補単語のN−ベスト・リストのランク付けを調節して、コア辞書210から得られた単語を、拡張辞書215から得られた単語よりも高く配置して、ランク付けた単語候補のリスト240を発生する。先に説明したように、拡張辞書から得られた単語は出力せず、コア辞書からの単語のみを出力する。
【0031】
システム10は、更に、連結モジュール245および複合単語モジュール250を含む。連結モジュール245は、ランク付けた単語候補のリスト240から選択された語を連結する。例えば、「ing」を「code」と連結して「coding」を形成する。複合単語モジュール250は、ランク付けた単語候補のリスト240から選択された単語を組み合わせてもっと大きい単語にする。出力単語255は、ランク付けた単語候補のリスト240から選択され、必要に応じて連結モジュール245および複合単語モジュール250によって処理された単語である。コア辞書210に載っている単語のみが、システム10によって出力単語255として与えられる。システム10は、拡張辞書215に載っている候補単語をN−ベスト・リストにのみ記載する。これらの単語は、出力単語255となるにはユーザに選択されなければならない。いったんユーザによって選択されると、システム10は、拡張辞書215からの単語をコア辞書210に載せることを許可する。
【0032】
システム10は、認識モジュール220による入力パターン235の認識をユーザの語彙に適合させる一方で、認識システムにおいて最大の信号対雑音比を維持する。システム10によって、コア辞書210および拡張辞書215は、認識モジュール220の認識プロセスに参加することができる。しかしながら、コア辞書210内の単語のみが、認識モジュール220の出力に直接入る。これらの単語は、デフォルトの出力である。入力パターン235に合致する拡張辞書215内の単語は、「N−ベスト」リストに記載されて、ユーザによる選択を待つだけである。ユーザがN−ベスト・リストからこれらの候補単語の1つを選択してデフォルトの出力に置き換えると、選択された単語はコア辞書210に載ることを許可される。単語がコア辞書210に載ることを許可された後、許可された単語が入力パターン235に合致した場合に、この単語が認識モジュールの出力に直接入ることができる。
【0033】
図3は、入力パターン235に合致する候補のN−ベスト・リストを発生させる際のシステム10の方法300を示す。ユーザは、ショートハンド・オン・キーボード・インタフェース上で、ある単語を動作で示す(gesture)(ステップ305)。認識モジュール220は、単語候補のN−ベスト・リストを発生する(ステップ310)。事前ランク付けモジュール225は、信頼値または同様の尺度等の基準に従って、コア辞書210および拡張辞書215から単語候補のN−ベスト・リストをランク付けする(ステップ315)。
【0034】
ランク付けモジュール230は、候補単語のN−ベスト・リスト内の最も高いランクの単語がコア辞書210から得られたか否かを判定する(判断ステップ320)。イエスの場合、ランク付けモジュール230は、ランク付けした単語候補のN−ベスト・リストを、ランク付けた単語候補のリスト240として出力する(ステップ325)。候補単語のN−ベスト・リスト内の最も高いランクの候補がコア辞書210に乗っていない場合、ランク付けモジュール230は、候補単語のN−ベスト・リストを検索して、コア辞書210から得られた最も高いランクの単語候補の位置を見つける(ステップ330)。
【0035】
候補単語のN−ベスト・リスト内において、コア辞書210から得られた単語候補が見つからない場合(判断ステップ335)、ランク付けモジュール230は、ランク付けした単語候補のN−ベスト・リストを、ランク付けた単語候補のリスト240として出力する。その他の場合、ランク付けモジュール230は、見つけた単語候補を単語候補のN−ベスト・リスト内の最も高いランクの位置に移動させる(ステップ335)。ランク付けモジュールは、ランク付けした単語候補のN−ベスト・リストを、ランク付けた単語候補のリスト240として出力する(ステップ340)。
【0036】
最も高いランクでない候補単語をユーザが選択することを可能とするために、ユーザ・インタフェース・コンポーネントは、次のベスト候補リスト(N−ベスト・リスト)を表示し、ここからユーザは入力パターン235に密接に合致する代替的な候補単語を見ることができる。一実施形態においては、このリスト上の候補単語の位置は、その候補単語に関連付けたランクによって決定され、その候補単語がコア辞書210または拡張辞書215のいずれに載っている否かとは無関係である。ただし、コア辞書内の単語がどれもユーザの入力に合致しない場合を除いて、最も高いランクの単語は常にコア辞書内にあるものでなければならない。別の実施形態においては、候補単語は辞書の出典によってグループ化される。すなわち、コア辞書210からの候補単語をグループ化し、拡張辞書215からの候補単語をグループ化する。
【0037】
候補単語の出典は、任意に、候補単語に関連付けた異なる知覚的特徴を強調することによって示して、例えばコア辞書または拡張辞書からという候補単語のソースの認識を容易にすることができる。例示的な知覚的特徴は、例えば、色、背景の陰影、太字のフォント、イタリック対のフォント等を含む。ユーザがどの単語も選ばない場合、システム10はコア辞書から候補単語のN−ベスト・リスト内の最も高いランクの単語を出力する。ユーザが単語を選択しない場合、システム10はコア辞書から候補単語のN−ベスト・リスト内の最も高いランクの単語を出力する。
【0038】
拡張辞書215から得られた単語は、候補単語のN−ベスト・リストからアクセスすることができる。このため、最も高いランクの候補を発生させる際のシステム10のエラー許容度が著しく高まる。なぜなら、システムによって表示される最も高いランクの候補は、小さい方のコア辞書210から得るからである。所望の単語がコア辞書210において見つからないというまれな状況では、ユーザはN−ベスト・リストを活性化して所望の候補を選択する。
【0039】
図4は、ランク付けモジュール230によって発生した例示的な候補単語のN−ベスト・リスト400を示す。コア辞書210からの候補単語は、候補単語1、405、候補単語2、410、および候補単語3、415を含み、これらをまとめてコア候補単語420と称する。拡張辞書215からの候補単語は、候補単語4、425、候補5、430、候補6、435、候補7、440、および候補8、445を含み、これらをまとめて拡張候補単語450と称する。コア候補単語420および拡張候補単語450は、異なる強調を用いて表示されている。
【0040】
この例において、コア候補単語420は太字の文字で示し、拡張候補単語450はイタリック体の文字で示す。コア候補単語420および拡張候補単語450を区別するために、例えば、文字の色、色の背景、陰影等、いかなる形態の強調も使用可能である。例示的な候補単語のN−ベスト・リスト400内の候補単語は、認識モジュール220によって与えられるランクに従って位置付けられる。ただし、最上部の単語候補位置455は、コア辞書210から得られる単語のために確保される。これは、コア辞書からのどの単語もユーザの入力に合致しない場合には当てはまらない。この場合は、最上部の単語候補位置455に、拡張辞書からの単語を配置することができる。
【0041】
図5は一実施形態を示し、例示的なN−ベスト・リスト500は、ソースに従っておよび認識モジュール200が与えるランク付け基準に従ってランク付けされた候補単語を含む。図4と同様に、コア候補単語420および拡張候補単語450は異なる強調で表示されている。この例では、コア候補単語420を太字の文字で示し、拡張候補単語450をイタリック体の文字で示す。
【0042】
システム10は、ユーザが動作で示した単語がコア辞書210の語彙に含まれない場合にユーザに与えられるオーバーヘッドを著しく低減する。単語がコア辞書210に含まれているのか、またはシステムが入力を誤って認識したのかが不確かであるということではなく、ユーザはN−ベスト・リストをスキャンして所望の候補単語を選択することができる。
【0043】
最新の技術に精通した者には、単語を別個の辞書に分割することが単純な概念的モデルでもある1つの実施であることは明らかであろう。あるいは、辞書205を、コア辞書層および拡張辞書層という層として概念化して、頻度または事前確率(priori probability)によってランク付けすることも可能である。拡張辞書層からの単語がN−ベスト候補インタフェースから選択された場合、選択された単語の頻度または事前確率を、閾値または他の基準に対して調節して、選択された単語をコア層に属するように調節する効果を有する。
【0044】
更に、システム10によって、ユーザは、長い単語の部分を別個に入力することができる。システム10は、部分的な「sokgraphs」を、ユーザが意図する1つの語に自動的に結合する。単語の部分は、「work」等の語幹および「ing」等の接辞である場合があり、または、2つ以上の一般的な短い単語であり、英語の「short+hand」のように連結して長い単語を形成する場合がある。いくつかの短い単語が連結して1つの複合的な単語になることは、スウェーデン語またはドイツ語等のいくつかのヨーロッパ言語ではもっとよくあることである。
【0045】
連結は、連結した語に含まれる個別に認識される部分に基づいている。語幹および接辞の例では、ユーザは最初に語幹を表す語について入力パターン235を動作で示し、次いで接辞の入力パターン235を動作で示す。例えば、「coding」という単語では、ユーザは最初に「code」を動作で書き、次いで「ing」を動作で書く。キーボード上の入力トレースについて、認識モジュール220は、最適な合致を見つけて、これらの合致をストリング
【0046】
【数1】
【0047】
と共にN−ベスト・リストに出力する。ここで、ストリングのランクiは、選択されたストリング合致入力パターン235における認識モジュール220の信頼度を意味する。ランクi=1を有するストリングは、認識モジュール220の最上位の選択肢である。認識モジュール220は、最新のN−ベスト・リストを一時バッファにストアする。規則的な語(語幹)についてのバッファされたN−ベスト・リストを、S0と示す。
【0048】
一実施形態においては、連結可能接尾辞と呼ぶリストに接尾辞がストアされている。そのグラフィカル・キーボード上の幾何学的パターンであるsokgraphsは、一般的な単語のsokgraphと同じ方法で表される。例えば、「ing」という接尾辞では、そのsokgraphは、iキーで開始してnキーへと動きgキーで終了する連続的なトレースである。システムは、「ing」のsokgraphについての入力パターン235を、他のいずれのsokgraphとも同じ方法で認識する。ただし、接尾辞「ing」を連結可能接尾辞のリストにストアする。あるいは、接尾辞および規則的な語の双方を同一の辞書にストアすることも可能であるが、識別子によって規則的な語から接尾辞を区別する。一実施形態においては、連結可能接尾辞を参照テーブルにストアし、ここで、「ing」等の各接尾辞を、その接尾辞で終わる辞書内の入力を指し示す一連のポインタに関連付ける。
【0049】
図6は、連結可能接尾辞を語幹の語と結合する際のシステム100の方法600を示す。ユーザは、ショートハンド・オン・キーボード・インタフェース上で、ある単語を動作で示す(ステップ605)。連結モジュール245は、単語候補の出力N−ベスト・リスト240について最高ランクの単語を取得する(ステップ610)。連結モジュール245は、取得した単語が連結可能接尾辞であるか否かを、例えば取得した単語を連結可能接尾辞リストと比較することによって判定する(判断ステップ615)。取得した単語が連結可能接尾辞でない場合、連結モジュール245は何の動作も行わない(ステップ620)。
【0050】
取得した単語が連結可能接尾辞である場合、連結モジュール245は、特定した連結可能接尾辞で終わる連結候補を見つける(ステップ625)。連結モジュール245は、各連結候補から連結可能接尾辞を取り除く(ステップ630)。現在の接尾辞(例えば「ing」)で終わる単語はS1(i)と示し(例えばcodingまたはworking)、接尾辞を取り除いた残りはS2(i)と示す(例えば「code」または「work」)。
【0051】
連結モジュール245は、接尾辞を取り除いた連結候補と連結可能接尾辞との間のストリング編集距離(具体的には、Wagner−Fisherアルゴリズムを用いたMorgan編集エラー)を計算する(ステップ635)。次いで、残りS2(i)を、バッファしたN−ベスト・リスト内の最上位の選択肢S0(i)に対して照合する。S0は、単語の断片でなく単語全体を含むので(例えばS0(1)=code)、照合は正確でない。システム10は、編集距離(単一の文字の挿入、削除、または置換から選択される最少数の編集動作)を用いて、2つのストリングを照合し、S0(1)に最も近いS2(i)(i=1、N)内のストリングを見出して、それをS2minと表す。連結モジュール245は、関連する編集距離によって連結候補を分類する(ステップ640)。連結モジュール245は、最小編集距離を有する連結候補を戻す(ステップ645)。
【0052】
代替的な実施形態においては、単語の頻度または前の確率または高水準言語規則を用いて、同じ編集距離を共有する連結候補をランク付けする。
【0053】
S1(i)におけるS2minに対応する単語を、選択した連結候補として戻す。例えば、「cod」(「coding」の接尾辞を取り除いた部分)に対する「code」は、編集距離について、「work」(「working」の接尾辞を取り除いた部分)に対する「code」よりも近い。一実施形態においては、最低許容可能編集距離不一致として閾値を設定することも可能である。
【0054】
別の実施形態においては、接尾辞は、その接尾辞で終わる単語の全てにはリンクされない。その代わりに、ある接尾辞を認識した場合、システム10は辞書205をスキャンし、認識した接尾辞で終わる単語を見つけ、見つけた単語から最後部分を取り除き、取り除いた残りを直前の単語と照合し、前述したように連結について最も近い合致を選択する。これらの2つの実施形態の違いは、計算時間とメモリ空間とのトレードオフにある。辞書をスキャンすることは、別個のポインタ・リストが必要ないことを意味し、従って、ソフトウェア・コードがアクセスしている媒体内の辞書のストレージ要求が抑えられる。他方で、辞書をスキャンすることは、別個のポインタ・リストによってインデクスをつけた辞書を含むシステムよりも単語の位置を見つけるよりも長い時間を要する。
【0055】
システム10は、接頭辞および語幹を、語幹および接尾辞と同様に扱う。連結モジュール245は、最初に、別個の接頭辞リストまたは接頭辞識別子を有する共通の辞書のいずれかから、ランク付けた単語候補のリスト240の出力から接頭辞に基づいた単語を認識する。次いで、連結モジュール245は、接頭辞の後の単語を認識する。連結モジュール245は、その接頭辞を含む全ての単語を照合し、合致した単語の接頭辞を取り除き、連結のために最も近い合致を戻す。
【0056】
2つの短い単語を1つの長い単語に連結することは、決定的ではない。例えば、スウェーデン語において、「smoke free」および「smokefree」は双方とも許されるが、それらの意味は反対である(「喫煙は許されない」に対して「喫煙は許される」)。複合単語モジュール250は、統計的かつインタラクティブな方法を用いて、2つの単語の連結を処理する。この方法をサポートするため、システム10は、辞書205に、全ての単語の頻度(テキストの文書データ内の各単語の合計発生数に基づく)および全てのバイグラム(bigram)の頻度(2つの並んだ単語の合計発生数に基づく)を含む統計的情報をストアする。
【0057】
図7は、単語を組み合わせて複合的な単語にする際のシステム10の方法700を示す。方法700は、連続する単語対(単語1、単語2)を調べる(ステップ705)。複合単語モジュール250は、辞書205において、組み合わせた連続する単語(単語1+単語2=単語3)が見つかるか否かを判定する(判断ステップ710)。組み合わせた単語すなわち単語3が見つからない場合、複合単語モジュール250は何も動作を行わない(ステップ715)。合致(単語3=単語1+単語2)が見つかった場合、複合単語モジュール250は、単語3の頻度をバイグラム(単語1、単語2)と比較する(ステップ720)。単語3の頻度が、所定の閾値と比較して、バイグラム(単語1、単語2)の頻度よりも大きい場合、または、バイグラム(単語1、単語2)の頻度に対する単語3の頻度の比が所定の閾値よりも大きい場合(判断ステップ725)、複合単語モジュールは、単語1および単語2を単語3に置き換える(ステップ730)。その他の場合は、何も動作を行わない(ステップ715)。あるいは、単語3の頻度およびバイグラム(単語1、単語2)の頻度の比較は、重み付け比較である。
【0058】
システム10は、連結および分離を調節するためのユーザ・インタラクションを可能とするユーザ・インタフェースを提供する。図8A、図8B、図8Cは、組み合わせた単語を2つの別個の単語または単語の部分に分離することを示す。例示的なスクリーン805は、例示的な連結した単語「coding」810をユーザに対して表示する。ユーザは、例えば単語「coding」810をクリックすることによって、表示した連結単語「coding」を選択する(図8A)。単語「coding」810の選択によって、メニュー・オプション815が表示される。これは、例えば、選択可能な命令「「code」と「ing」に分割」または同等のオプションを含む(図8B)。ユーザがメニュー・オプション815に示された命令を選択すると、システム10は、表示された連結単語「coding」810を、語幹「code」820および接尾辞「ing」825に分割する(図8C)。
【0059】
図9は、連結した単語「coding」810を分割するために用いられる代替的な例であるペン・トレースの動き905を示す。スクリーン805は、連結した単語「coding」810をユーザに対して表示する。ユーザは、連結した単語「coding」810上で、ペン・トレースの動き905を行う。システム10は、図8Cに示すように、表示されている連結単語「coding」810を、語幹「code」820および接尾辞「ing」825に分割する。
【0060】
信頼度が低いために動作が行われない連結可能単語については、図10Aから図10Cに示すように、単語1および単語2にメニュー・オプションが埋め込まれている。例えば、スクリーン805は、図10Aに示すように、単語1「code」1005および単語2「ing」1010をユーザに対して表示する。単語1「code」1005を選択すると、オプション・メニュー1015が表示され、これは、選択可能な命令「右に動く」または同等のオプションを含む(図10B)。ユーザが、オプション・メニュー1015に示された命令「右に動く」を選択すると、システム10は、単語1「code」1005および単語2「ing」1010を連結し、連結された単語「coding」1020を形成する(図10C)。
【0061】
図11は、ユーザが単語2「ing」1010を選択した場合に表示される例示的なオプション・メニュー1105を示す。ユーザが、オプション・メニュー1105に示される命令「左に動く」を選択すると、システム10は、単語1「code」1005および単語2「ing」1010を連結し、図10Cに示すように、連結された単語「coding」1020を形成する。
【0062】
図12は、単語1「code」1005および単語2「ing」1010を連結するために用いられる代替例であるペン・トレースの動き1205を示す。ペン・トレースの動き1205は、例えば、単語1「code」1005および単語2「ing」1010を横切る円を含む。システム10は、ペン・トレースの動き1205によって表されるコマンドを認識し、単語1「code」1205および単語2「ing」1010を連結し、図10Cに示すように、連結された単語「coding」1020を形成する。
【特許請求の範囲】
【請求項1】
グラフィカル・キーボード・インタフェースを介して入力された入力信号を認識し、かつ、入力テキストの語幹および接辞を組み合わせることを可能にするためのシステムであって、
前記システムは、
メモリと、
前記メモリにストアされた連結モジュールであって、前記連結モジュールは、実行されたときに、前記入力信号を入力接辞として認識するように構成されており、前記連結モジュールは、更に、候補単語を隣接候補単語として認識する、連結モジュールと、
前記メモリにストアされた複合単語モジュールであって、前記複合単語モジュールは、実行されたときに、前記入力接辞を含む辞書内の1組の単語を検索するように構成されている、複合単語モジュールと、
前記メモリにストアされたランク付けモジュールであって、前記ランク付けモジュールは、実行されたときに、前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較する類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするように構成されており、前記複合単語モジュールは、前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力する、ランク付けモジュールと、
前記メモリにストアされたモジュールであって、前記モジュールは、実行されたときに、少なくとも2つの単語または接辞を別個に表示し、前記少なくとも2つの単語または接辞の内側のエッジをタッチする円形の動きに応答して、前記少なくとも2つの単語または接辞を連結するように構成されており、前記少なくとも2つの単語または接辞は、前記候補単語および前記入力接辞に対応する、モジュールと
を備える、システム。
【請求項2】
前記入力接辞が接尾辞である、請求項1に記載のシステム。
【請求項3】
前記複合単語モジュールが前記接尾辞および前記最も高いランクの辞書単語を結合させる、請求項2に記載のシステム。
【請求項4】
前記入力接辞が接頭辞である、請求項1に記載のシステム。
【請求項5】
前記複合単語モジュールが前記接頭辞および前記最も高いランクの辞書単語を結合させる、請求項4に記載のシステム。
【請求項6】
前記類似性関数が距離関数を含む、請求項4に記載のシステム。
【請求項7】
前記隣接候補単語が、前記入力接辞の前に付く候補単語または前記入力接辞の後に付く候補単語のいずれか1つを含む、請求項4に記載のシステム。
【請求項8】
前記入力テキストが前記入力接辞として認識されない場合、前記複合単語モジュールは、前記入力テキストおよび前記隣接候補単語の連結の結果として生じるストリングを生成し、前記辞書における前記ストリングの発生頻度を求め、前記ストリングの発生頻度を前記入力テキストおよび前記隣接候補単語のそれぞれの発生頻度と比較し、前記ストリングの発生頻度が前記入力テキストおよび前記隣接候補単語のそれぞれの発生頻度を超えた場合、前記複合単語モジュールは、前記入力テキストおよび前記隣接候補単語を連結単語として連結し、前記ストリングを前記連結単語によって置換する、請求項7に記載のシステム。
【請求項9】
前記入力テキストおよび前記隣接候補単語の発生頻度に対する前記ストリングの発生頻度の比較が重み付け比較である、請求項8に記載のシステム。
【請求項10】
グラフィカル・キーボード・インタフェースを介して入力された入力信号を認識し、かつ、入力テキストの語幹および接辞を組み合わせることを可能にするための方法であって、前記方法は、コンピュータにより実行され、
前記方法は、
コンピューティング・システムによって、前記入力テキストを入力接辞として認識することと、
前記入力テキストが前記入力接辞として認識された場合に、前記コンピューティング・システムによって、候補単語を隣接候補単語として認識することと、
前記コンピューティング・システムによって、前記入力接辞を含む辞書内の1組の単語を検索することであって、前記辞書は、コンピュータ・データベースにストアされている、ことと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較することによる類似性関数に従って、前記コンピューティング・システムによって、前記入力接辞を含む前記1組の単語をランク付けすることと、
出力ディスプレイ上で、前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力することと、
前記出力ディスプレイ上で、前記最も高いランクの辞書単語を表示し、分割単語を表示することであって、2つの別個に表示された単語は、正方形のボックス内の枠にはめられ、前記2つの別個に表示された単語は、前記候補単語および前記入力接辞に対応する、ことと
を含む、方法。
【請求項11】
前記接辞および前記最も高いランクの辞書単語を結合させることを更に含む、請求項10に記載の方法。
【請求項12】
入力信号を認識し、かつ、入力テキストの語幹および接辞を組み合わせることを可能にするための非一時的なコンピュータが使用可能な媒体にストアされたプログラム・コードを有するコンピュータ・プログラム製品であって、
前記コンピュータ・プログラム製品は、
前記入力信号を入力接辞として認識し、更に、候補単語を隣接候補単語として認識するためのプログラム・コードと、
前記入力接辞を含む辞書内の1組の単語を検索するためのプログラム・コードと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較する類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするためのプログラム・コードと、
前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力するためのプログラム・コードと、
前記最も高いランクの辞書単語を表示し、分割単語を表示するためのプログラム・コードであって、2つの別個に表示された単語は、正方形のボックス内の枠にはめられ、前記2つの別個に表示された単語は、前記候補単語および前記入力接辞に対応する、プログラム・コードと
を備える、コンピュータ・プログラム製品。
【請求項1】
グラフィカル・キーボード・インタフェースを介して入力された入力信号を認識し、かつ、入力テキストの語幹および接辞を組み合わせることを可能にするためのシステムであって、
前記システムは、
メモリと、
前記メモリにストアされた連結モジュールであって、前記連結モジュールは、実行されたときに、前記入力信号を入力接辞として認識するように構成されており、前記連結モジュールは、更に、候補単語を隣接候補単語として認識する、連結モジュールと、
前記メモリにストアされた複合単語モジュールであって、前記複合単語モジュールは、実行されたときに、前記入力接辞を含む辞書内の1組の単語を検索するように構成されている、複合単語モジュールと、
前記メモリにストアされたランク付けモジュールであって、前記ランク付けモジュールは、実行されたときに、前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較する類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするように構成されており、前記複合単語モジュールは、前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力する、ランク付けモジュールと、
前記メモリにストアされたモジュールであって、前記モジュールは、実行されたときに、少なくとも2つの単語または接辞を別個に表示し、前記少なくとも2つの単語または接辞の内側のエッジをタッチする円形の動きに応答して、前記少なくとも2つの単語または接辞を連結するように構成されており、前記少なくとも2つの単語または接辞は、前記候補単語および前記入力接辞に対応する、モジュールと
を備える、システム。
【請求項2】
前記入力接辞が接尾辞である、請求項1に記載のシステム。
【請求項3】
前記複合単語モジュールが前記接尾辞および前記最も高いランクの辞書単語を結合させる、請求項2に記載のシステム。
【請求項4】
前記入力接辞が接頭辞である、請求項1に記載のシステム。
【請求項5】
前記複合単語モジュールが前記接頭辞および前記最も高いランクの辞書単語を結合させる、請求項4に記載のシステム。
【請求項6】
前記類似性関数が距離関数を含む、請求項4に記載のシステム。
【請求項7】
前記隣接候補単語が、前記入力接辞の前に付く候補単語または前記入力接辞の後に付く候補単語のいずれか1つを含む、請求項4に記載のシステム。
【請求項8】
前記入力テキストが前記入力接辞として認識されない場合、前記複合単語モジュールは、前記入力テキストおよび前記隣接候補単語の連結の結果として生じるストリングを生成し、前記辞書における前記ストリングの発生頻度を求め、前記ストリングの発生頻度を前記入力テキストおよび前記隣接候補単語のそれぞれの発生頻度と比較し、前記ストリングの発生頻度が前記入力テキストおよび前記隣接候補単語のそれぞれの発生頻度を超えた場合、前記複合単語モジュールは、前記入力テキストおよび前記隣接候補単語を連結単語として連結し、前記ストリングを前記連結単語によって置換する、請求項7に記載のシステム。
【請求項9】
前記入力テキストおよび前記隣接候補単語の発生頻度に対する前記ストリングの発生頻度の比較が重み付け比較である、請求項8に記載のシステム。
【請求項10】
グラフィカル・キーボード・インタフェースを介して入力された入力信号を認識し、かつ、入力テキストの語幹および接辞を組み合わせることを可能にするための方法であって、前記方法は、コンピュータにより実行され、
前記方法は、
コンピューティング・システムによって、前記入力テキストを入力接辞として認識することと、
前記入力テキストが前記入力接辞として認識された場合に、前記コンピューティング・システムによって、候補単語を隣接候補単語として認識することと、
前記コンピューティング・システムによって、前記入力接辞を含む辞書内の1組の単語を検索することであって、前記辞書は、コンピュータ・データベースにストアされている、ことと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較することによる類似性関数に従って、前記コンピューティング・システムによって、前記入力接辞を含む前記1組の単語をランク付けすることと、
出力ディスプレイ上で、前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力することと、
前記出力ディスプレイ上で、前記最も高いランクの辞書単語を表示し、分割単語を表示することであって、2つの別個に表示された単語は、正方形のボックス内の枠にはめられ、前記2つの別個に表示された単語は、前記候補単語および前記入力接辞に対応する、ことと
を含む、方法。
【請求項11】
前記接辞および前記最も高いランクの辞書単語を結合させることを更に含む、請求項10に記載の方法。
【請求項12】
入力信号を認識し、かつ、入力テキストの語幹および接辞を組み合わせることを可能にするための非一時的なコンピュータが使用可能な媒体にストアされたプログラム・コードを有するコンピュータ・プログラム製品であって、
前記コンピュータ・プログラム製品は、
前記入力信号を入力接辞として認識し、更に、候補単語を隣接候補単語として認識するためのプログラム・コードと、
前記入力接辞を含む辞書内の1組の単語を検索するためのプログラム・コードと、
前記入力接辞を含む前記1組の単語における各辞書単語を前記候補単語および前記入力接辞を含むストリングと比較する類似性関数に従って、前記入力接辞を含む前記1組の単語をランク付けするためのプログラム・コードと、
前記入力接辞を含む前記1組の単語において最も高いランクの辞書単語を出力するためのプログラム・コードと、
前記最も高いランクの辞書単語を表示し、分割単語を表示するためのプログラム・コードであって、2つの別個に表示された単語は、正方形のボックス内の枠にはめられ、前記2つの別個に表示された単語は、前記候補単語および前記入力接辞に対応する、プログラム・コードと
を備える、コンピュータ・プログラム製品。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8A】
【図8B】
【図8C】
【図9】
【図10A】
【図10B】
【図10C】
【図11】
【図12】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8A】
【図8B】
【図8C】
【図9】
【図10A】
【図10B】
【図10C】
【図11】
【図12】
【公開番号】特開2012−256353(P2012−256353A)
【公開日】平成24年12月27日(2012.12.27)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−178642(P2012−178642)
【出願日】平成24年8月10日(2012.8.10)
【分割の表示】特願2008−536022(P2008−536022)の分割
【原出願日】平成18年10月12日(2006.10.12)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MACHINES CORPORATION
【Fターム(参考)】
【公開日】平成24年12月27日(2012.12.27)
【国際特許分類】
【出願番号】特願2012−178642(P2012−178642)
【出願日】平成24年8月10日(2012.8.10)
【分割の表示】特願2008−536022(P2008−536022)の分割
【原出願日】平成18年10月12日(2006.10.12)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MACHINES CORPORATION
【Fターム(参考)】
[ Back to top ]