
スピーチ分析による話者の特徴化
話者の現在の発話を分析することによって所与の状況および場面における話者の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのコンピュータ実装方法、データ処理システム、装置、およびコンピュータプログラム製品。この分析により、第1のピッチから導出された一意の第2の導出結果から成る発話の異なる韻律パラメータと振幅スピーチパラメータとを算出し、これらのパラメータを、様々な行動的、心理的、およびスピーチスタイル上の特徴を表す事前取得済み参照スピーチデータと比較する。この方法は、所与の状況におけるその話者の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するために、話者の発話の分析に加え、分類スピーチパラメータ参照データベースの形成も含む。

【発明の詳細な説明】
【技術分野】
【0001】
本発明は、スピーチ分析の分野に関し、詳細には、具体的な状況における人の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのスピーチの韻律的特性の使用に関する。
【背景技術】
【0002】
スピーチ分析とは、人間の発話が伝える情報を明らかにするために、コンピュータ化された発話処理方法に付与された一般用語のことである。スピーチ分析は、言語科学内の音声秩序の一部として分類されている。
【0003】
スピーチ分析は、2つの主な手法に分割され得る。第1の手法は、語、音節、および音素が発音される方法と、文が配置される方法を学習することによってそのスピーチの内容を明らかにすることに焦点を置いている。「スピーチからテキスト」や「ワードスポッティング」などのスピーチ認識アプリケーションの多くが、スピーチの内容を抽出するためにこの手法を使用している。
【0004】
第2の手法であるスピーチの韻律分析は、抑揚、テンポ、強度、強調、リズムなど、スピーチの非分節的(非語、非内容)特性を分析することにより、発話のされ方に焦点を置いている。
【0005】
発話のされ方によってスピーチの「メロディ」が提供され、このメロディが、スピーチの全体的な意味および場面に重要な洞察を付加する。例えば、人々は文末の上昇調により、文を疑問文と認識する。アクセントは、韻律的な音声パラメータによって単語の発音が変わる様子を表す古典的な例である。俳優は、自身のスピーチの韻律を、特定人物のように聞こえるように改変する。韻律には、例えば男性よりも女性の方が概して周波数が高いといった性差もある。多くの場合、韻律的特性は、スピーチの意味を変える。私たちは、発音のされ方(韻律)の変化によって、同じ文でも冷笑的、皮肉的、あるいは単純な意味を有するものと解釈する。
【0006】
発話の韻律的特性は、話者の感情的状態に関する情報も伝える。この点については、文壇において数々の作品によって長年にわたり示されてきた。また、緊急サービスを呼んでいる興奮した人は、概して話すペースが速く、声が激しく、息が荒く、抑揚するなど、直観的にも把握される。その一方で、悲しんでおり憂鬱な状態にある人は、ゆっくりと話し、活力に乏しく、休止が長く取るなどの傾向がある。これらの特徴は、韻律的なスピーチ特性に反映される。
【0007】
話者の感情的状態を自動的に分析するために韻律的なスピーチ特性を使用することに関する特許は、これまでにいくつか出されている。具体的には、ペトルーシンに対する米国特許第6151571号、異なる感情的状態を分類することを対象としたスラニーに対する米国特許第6173260号、および感情的な覚醒全般を判断することを対象としたデガニとザミールとに対する欧州特許第1423846号などがある。すべての特許は、参照により、全体が本明細書に援用されるものとする。
【0008】
話者の性格とスピーチの韻律的特徴とを相関させるための試みは、ほとんど行われなかった。ボグダシェフスキーに付与された米国特許第6006188号は、性格タイプが似た人々のスピーチ特性を(公知の心理学的分類に従って)判断し、検出された特性を使用して性格タイプを自動的に分類するための方法について記載している。スピーチには性格が反映されるという考えは意味を成しており、直観的にも把握することができる。例えば、外向的の人について、声が大きく衝動的なスピーチパターンを想像できるのに対し、内向的な人については、柔らく遠慮がちなスピーチパターンを想像することができる。
【0009】
性格とスピーチパターンとの結び付けは、スピーチは人格的特徴の様々な面を表すという理解をよく反映している。ただし、実用という点にこの概念の弱点がある。性格は、人の安定した特徴を表すものであるため、相当に一貫して測定されるはずでもある。つまり、話者本人の性格を反映しているスピーチパターンは、変化する状況や様々な内面の状態、異なる場面でも相当程度まで一貫性を保つはずである。しかし実際には、この点が該当しない。例えば、感情的状態とスピーチの韻律との間にある確固たる関係から明らかとなっており、スピーチパターンは状況的要因に大きく影響される傾向がある。上記例で取り上げた内向的な人でさえ、時には腹を立て、その時には、その人のスピーチパターン(および韻律的な音声パラメータ)が大きく変化し、社交的で外向的な人のスピーチパターンに酷似する。もしかしたら統計学的には、その内向的な人のスピーチパターンを数々の異なる状況で測定すれば、その人の性格とスピーチパターンとの間で有意な相関が存在するかもしれない。また、特定の性格を示すスピーチパターンを表す参照データが用いられた状況と酷似する条件下で人のスピーチをサンプリングした場合には信頼できるかもしれない。しかし、介在する状況的要因が支配的な場合には該当しないであろう。実生活においては、状況的要因がスピーチに影響することが多い。そのため、スピーチの韻律による性格測定は、状況に依存しない方法としては認められない。
【発明の概要】
【発明が解決しようとする課題】
【0010】
本発明は、所与の状況と場面における話者の現在の行動的および心理的特徴、ならびに話者の現在のスピーチスタイルを判断するために話者の発話を分析するコンピュータ実装方法と、データ処理システムと、コンピュータプログラム製品と、装置とを提案する。
【課題を解決するための手段】
【0011】
分析は、発話の第1のピッチおよび振幅パラメータから得た一意の第2の導出結果を算出することに基づいており、それらは、併用されると、具体的な状況および場面における話者の現在の行動的、心理的、およびスピーチスタイル上の特徴を表す。
【0012】
現在の行動的、心理的、およびスピーチスタイル上の特徴の分類は、算出された話者の第2のスピーチパラメータと、様々な行動的および心理的な特徴ならびに様々な状況および場面における異なるスピーチスタイルの、これらの第2のスピーチパラメータの値および値の組み合わせを表す事前取得済みデータとを比較することによって実行される。
【0013】
本発明の一態様は、具体的な状況における人のスピーチの韻律的特性を分析することによってその人の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するための、話者に依存しない一般的な方法を提供する。話者の人格的特徴は、一時的な状況依存パラメータ、または性格などの安定した状況独立パラメータのどちらとも関連し得る。本発明の実施形態は、例えば、ある人の現在の様子が直接的か、開放的か、客観的か、表情豊かか、あるいは控え目かを、これらの資質がその人の生来的な性質を反映しているか、あるいは具体的な状況および場面を反映しているかを決定することなく判断することを可能にする。このタイプの情報は、様々なフィードバックおよび研修を目的とした分析対象人物本人と、分析対象人物に対する理解および当該人物とのコミュニケーションを改善するためにその分析対象人物と話をする人々とにとって極めて貴重であり得る。
【0014】
様々な実施形態において、本発明は、開示されている一意の第2のスピーチインジケータから話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴の特徴化するためのコンピュータ実装方法、データ処理システム、コンピュータプログラム製品、および装置として実現される。
【0015】
本発明とみなされる主題は、添付の図面(「図」)を参照して本発明の一例として、および実例を伴う説明のみを目的として提供された本明細書の後述の実施形態を照らし合わせることによって一層明確に理解されるであろう。
【図面の簡単な説明】
【0016】
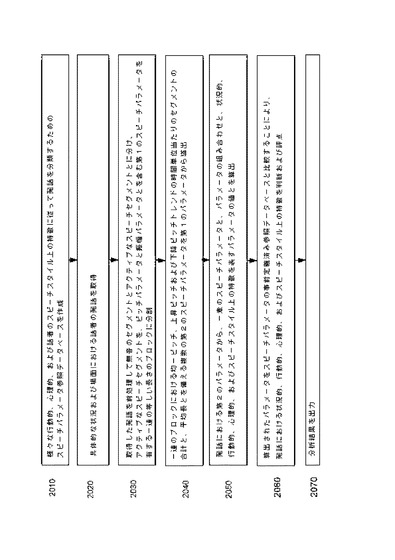
【図1】異なる行動的、心理的、およびスピーチスタイル上の特徴を分類するためのスピーチパラメータ参照データを本発明の方法に準拠して取得および形成する段階を示す高次のフローチャートである。
【0017】
【図2】本発明の実施形態に準拠して、参照データベースを使用しながら、話者の現在の発話を分析し、所与の状況におけるその話者の行動的、心理的、およびスピーチスタイル上の特徴を判断する段階を表す高次のフローチャートである。
【0018】
【図3】本発明の方法に追加および準拠して、本発明のいくつかの実施形態で実施され得る任意の段階のいくつかを示す高次のフローチャートである。
【0019】
【図4】本発明のいくつかの実施形態にかかるデータ処理システムの概略ブロック図である。
【0020】
【図5】本発明のいくつかの実施形態にかかる装置の概略ブロック図である。
【0021】
図面と説明とにより、本発明が実際に実施され得る方法が当業者にとって明らかになる。
【発明を実施するための形態】
【0022】
本発明について詳述する前に、以降で使用される特定の用語の定義を記載しておくのが有用かもしれない。
【0023】
本明細書で使用される「状況的」という用語は、話者の現在の状態に関連または該当する特徴を意味する。逆に言えば、状況的特徴化は、話者に総体的に妥当であるとは限らない。例えば、話者の状況的特徴化は、「話者の話しぶりは(今)断定的である」または「話者の話しぶりは控え目である」あるいは「話者の話しぶりは打算的である」などであり得る。これは、話者が、生来的に断定的、控え目、あるいは打算的であるという意味ではなく、現在の発話分析から、話者の話しぶりがそのように聞こえるということを意味する。当然のことながら、異なる状況であれば、その話者の話しぶりも異なる可能性がある。
【0024】
本明細書で使用される「場面依存的」という語は、文化、言語、アクセント、年齢などの要因を備える話者の経歴的な背景によって、または、対話あるいはモノローグ、記述文の読みあげ、あるいは自由スピーチ、通常のスピーチ状況あるいは身体活動中、演劇での演技中、講義中、演説中、戦闘、非常事態、球技などストレスの多い状況下でのスピーチなど、状況設定の特殊な属性によって導出されたり、それらに起因したり、影響されたりする(スピーチに作用し得る)状況の一般的特徴を表すものと定義される。
【0025】
本明細書で使用される「スピーチスタイル」という用語は、特定の状況で使われる傾向のある典型的なスピーチパターンを意味し、行動的および心理的な特徴のまとまりを表す。例えば、表情豊かなスピーチスタイル、打算的なスピーチスタイル、率直なスピーチスタイルなどがある。人々は、その具体的な状況および場面に従って自らのスピーチスタイルを変える傾向がある。
【0026】
本明細書で使用される「通信システム」という用語は、発語の転移を可能にするあらゆる音声通信システムにも関係する。これらのシステムは、例えば、有線または無線電話通信システム、セルラー方式通信ネットワーク、ウェブベースの通信システム、他のボイスオーバーIPベースの通信システム、コールセンタシステムなどでありえる。
【0027】
以下の詳細な説明の中では、本発明についての理解を徹底するために、数々の具体的な詳細が記載されている。ただし、これら具体的な詳細がなくとも本発明の教示を実践し得るものと理解される。他の事例においては、本発明の教示が曖昧になるのを避けるために、周知の方法、手順、構成要素、および回路が詳細に説明されていない。
【0028】
本発明は、そのいくつかの実施形態において、スピーチ分析技術を利用して話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断するためのコンピュータ実装方法、データ処理システム、装置、およびコンピュータプログラム製品を開示する。
【0029】
本発明は、スピーチパターンが、単なる感情的状態を越えて、話者の広範な行動的および心理的特徴を反映するという事実に基づいている。具体的には、率直、断定的、敏感、開放的、表情豊か、人見知り、控え目、威圧的、冷静、打算的、辛抱強い、短気、共感的など、感情ではなくスピーチパターンによって表現される数々の行動的または心理的特徴について考えることができる。本発明は、発話からこれらの行動的および心理的特徴などを分析できるようにすることを目的としている。
【0030】
本発明の実施形態によれば、本発明の実施は、スピーチパターンに反映されるこれらの特徴が、安定した一定の性質ではなく、主に状況的性質を持つ特徴であるという点を考慮している。かかる行動的特徴は、状況の場面や話者の感情的状態、話者の性格に関連する場合もあるが、多くは全要因の組み合わせであろう。例えば、率直で断定的なスピーチパターンは、試合中(場面)に交わされるコーチと選手との標準的な会話の特徴である場合もあれば、顧客サービスの会話における不満を抱いた顧客の怒り(感情)に関連する場合もある。さらに他のケースでも、このスピーチパターンは、全般的に断定的な話者の性格を反映し得る。スピーチの韻律パラメータ(ペース、抑揚、強度などを反映)は、そのスピーチが現在断定調であるということを明示し得るが、その具体的な場面を示したり、そのスピーチが状況に関連するか、性格に関連するかを区別したりすることはできない。
【0031】
そのため、これらが本発明の2大基底要素である。スピーチの韻律的特性は、話者の幅広い行動的および心理的特徴を反映し、スピーチパターンにおけるこれらの特徴の発現は、強い状況的性質を有する。すなわち、主として話者の現在の状態を表す。
【0032】
そのため、具体的な状況における人のスピーチの韻律的特性を分析することによってその人の現在の行動的および心理的特徴を判断するための、話者に依存しない一般的な方法を提供することが本発明の目的である。
【0033】
本発明は、職業上、教育上、診療上、および娯楽上の目的で行う様々なトレーニング用途の一環として、異なる状況における人々の行動的および心理的特徴について本人にフィードバックを提供する目的で使用され得るという優れた点がある。また、職業上、教育上、診療上、および娯楽上の目的に加え、様々なビジネス用途でも、分析対象人物の現在の行動的および心理的特徴の理解に基づいた、その人物との最良のコミュニケーション方法に関する洞察を他の人に提供する目的でも使用され得る。
【0034】
本発明が対処する課題1つは、話者に依存しない行動的および心理的特徴を表すパラメータを抽出および検出することである。典型的なピッチ、ペース、抑揚など、スピーチに見られる個々の韻律的特徴は人によって大きく異なる。また、人々が特定の行動的および心理的特徴を表す個々の方法も異なる場合がある。例えば、主にスピーチの強度を変えることによって断定を表現する人もいれば、スピーチのペースなどを変更することによって表現する人もいる。話者に依存しない処理に到達するには、行動的および心理的特徴の韻律表現における個人差を克服する必要がある。
【0035】
本発明は、韻律的特性を分析するために、第1のピッチから抽出した一意の第2のスピーチと、振幅スピーチパラメータとを用いて、話者に依存しない処理を実現する。これら第2のパラメータは、発話内の上昇ピッチ、下降ピッチ、および均一ピッチが示す様々な統計インジケータの特徴である。スピーチにおける個人差から受ける影響が小さいことから、重複することのないこれら第2のパラメータは、行動的および心理的特徴そのものをより正確に表す。
【0036】
本発明のさらなる一態様は、スピーチスタイルである。数々の行動的および心理的特徴が持つスピーチパターンを実験的に調べると、かかる特徴を持ついくつかのまとまりをグループ化して、区別されたスピーチスタイルを形成できることがどうやら明らかである。これは、発話を聴いてそれらを分類したときにすでに明らかになる。その発話(同じ状況)内では特定の行動的および心理的特徴が一緒に現れることが多いという傾向があり、そのことは、それらが関連している可能性があることを示唆している。さらに、それらの韻律的特性を分析すると、特定の行動的および心理的特徴は、他と比較して相互の類似性が高く、やはり関連性を示唆している。
【0037】
かかる潜在的スピーチスタイルの具体例を以下にいくつか示す。1つのスタイルは「受動的」または「堅実」なスピーチスタイルと称し得るもので、緩慢、物静か、堅実、穏やか、優柔不断などの行動的および心理的特徴を備える。もう1つのスタイルは「話し好き」と称し得るもので、敏感、開放的、多弁、表情豊かなどの特徴を備える。さらに別のスタイルは、「断定的」と称し得るもので、率直、威圧的、早口、大声、活発などの特徴を備える。さらに別のスタイルは、「打算的」と称し得るもので、分析的、非感情的、冷静、控え目、系統的などの特徴を備える。これらのスピーチスタイルは、本明細書においては例示目的で取り上げるに過ぎない。当然のことながら、韻律的特性を用いて、他にもいくつかのスピーチスタイルを描き出すことができる。
【0038】
これらのスピーチスタイルも強い状況的性質を有することを強調しておくことが重要である。時として、それらは話者の安定した特徴を表すことがあるが、多くの場合、現在の対応パターン、すなわち、その具体的な状況または場面に該当する話者の現在の内的状態を表す。その人物は、異なる場面ではかかるスピーチスタイル間で切り替わることが多いであろう。
【0039】
スピーチ分析を通じてかかるスピーチスタイルを判断することは、分析された状況に関する洞察の包括性を高めることができるため、本発明の上記潜在用途に対して極めて有利となり得る。
【0040】
そのため、具体的な状況における人のスピーチの韻律的特徴を分析することによってその人の現在のスピーチスタイルを判断するための、話者に依存しない一般的な方法を提供することも本発明の目的である。
【0041】
本発明の実施形態は、従来の韻律的なスピーチ分析方法と区別する3つの主態様を利用する。第1の態様は、韻律的なスピーチ分析を通じて判断される話者の人格的特徴の範囲を大きく広げている。この分析により、過去に実証されてきた主な用途であった話者の感情的状態以外にも様々な行動的、心理的、およびスピーチスタイル上の特徴が判断されると主張される。第2の異なる態様は、話者の現在の状況的、行動的属性と、対応するその話者のスピーチの特徴との連結である。第3の異なる態様は、スピーチの基本周波数と振幅パラメータから抽出した一意の第2のパラメータを使用して、話者に依存しない処理を実現することである。これら一意の第2のパラメータとそれらの組み合わせとを使用することにより、スピーチ表現の個人差を克服し、類似の行動的および心理的態様が、異なる人々のスピーチの特徴に同じように表れるようにすることができる。
【0042】
図1は、様々な行動的、心理的、およびスピーチスタイル上の特徴を分類するためのスピーチパラメータ参照データベースを作成する方法のステップを示す、本発明のいくつかの実施形態にかかる高次のフローチャートを表す。この方法は、特定の言語、文化または一意の状況設定など、特定の発語場面を手動で選択すること1010と、選択された場面で分析する行動的、心理的、およびスピーチスタイル上の特徴を手動で選択すること1020と、選択された場面における人々の複数の発話を取得すること1030と、その発話を、類似の行動的、心理的、およびスピーチスタイル上の特徴を表す群に手動でグループ化すること1040と、を含む。この方法は、専門家による評価、ピア評価、自己評価、客観的な試験など、あるいは社会科学および行動科学において使用されており公知であるその他任意の評価方法など、有効かつ公知の評価方法を使用して実行される。かかる状況的特徴は、単なる例に過ぎないものの、率直、断定的、敏感、開放的、表情豊か、人見知り、控え目、威圧的、冷静、打算的、辛抱強い、短気、共感的、またはスピーチパターンで表現または反映され得るその他任意の状況的、行動的、および心理的特徴であり得る。かかるスピーチスタイルは、単なる例に過ぎないものの、緩慢、物静か、堅実、大人しい、優柔不断などいくつかの行動的および心理的特徴を備える「受動的」または「堅実」なスピーチスタイル、敏感、開放的、多弁、表情豊かなどの特徴を備える「話し好き」なスピーチスタイル、率直、威圧的、早口、大声、活発などを備える「断定的」なスピーチスタイル、あるいは分析的、非感情的、冷静、控え目、系統的などの特徴を備える「打算的」なスピーチスタイルであり得る。本発明のいくつかの実施形態によれば、データベースは、任意の数(1つ以上)の行動的、心理的、およびスピーチスタイル上の特徴を表すスピーチパラメータを格納し得る。この方法は、類似する行動的、心理的、およびスピーチスタイル上の特徴を表している発話群における発話の各々を前処理して無音のセグメントとアクティブなスピーチセグメントとに分けること1050と、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、そのブロックがピッチおよび振幅パラメータを含む第1のスピーチパラメータを有すること1060と、第1のスピーチパラメータから複数の第2のスピーチパラメータを導出することであって、その第2のスピーチパラメータが、上記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と、上記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長さとを備えること1070と、一意の第2のスピーチパラメータ、パラメータの組み合わせ、および
各発話群に共通であり、各群の典型的な行動的、心理的、またはスピーチスタイル上の特徴を表すパラメータの値を、上記導出された第2のパラメータから判断すること1080と、も含む。データベースの使用は本発明の単なる一実施形態であり、スピーチパラメータの辞書であるその集合、および具体的な場面における対応する行動的特徴は、参照用のスピーチパラメータを表す任意の方法で一緒に記憶され得ると理解されるべきである。パラメータのデータベースまたは集合は、異なる手段で記憶したり、実際のソフトウェアデータベースを使用せずにコンピュータプログラムによって参照目的で使用したりしても良い。
【0043】
本発明のいくつかの実施形態によれば、複数の第2のスピーチパラメータを導出する段階は、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択されるパラメータをさらに対象とする。
【0044】
図2は、本発明のいくつかの実施形態にかかる所与の状況および場面における話者の発話を分析し、所与の状況における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するコンピュータ実装方法のステップを示す高次のフローチャートを表す。その方法は、様々な行動的、心理的、および話者のスピーチスタイル上の特徴に従って発話を分類するためのスピーチパラメータ参照データベースを作成すること2010と、具体的な状況および場面における話者の発話を取得すること2020と、取得した発語を前処理して無音のセグメントとアクティブなスピーチセグメントとに分け、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、上記ブロックが、ピッチおよび振幅パラメータを含む第1のスピーチパラメータを有すること2030と、その第1のパラメータから複数の第2のスピーチパラメータを導出することであって、上記第2のパラメータが、一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と上記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長さとを備えること2040と、発話における上記第2のパラメータから一意のスピーチパラメータ、パラメータの組み合わせ、および、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値を算出すること2050と、算出されたパラメータをスピーチパラメータの事前定義済み参照データベースと比較することによって、その発話における状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点すること2060と、分析結果を出力すること2070と、を含む。
【0045】
データベースの作成と同様、いくつかの実施形態によれば、複数の第2のスピーチパラメータを導出する段階は、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択されたパラメータをさらに対象とする。
【0046】
図3は、本発明のいくつかの実施形態にかかる所与の状況および場面における話者の発話を分析し、所与の状況における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するコンピュータ実装方法の任意のステップを示す高次のフローチャートを表す。
【0047】
本発明のいくつかの実施形態によれば、分析方法は、話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、この話者に関する現在の分析が話者から独立したものではなく、話者に依存したものになるよう、現在の分析対象話者の一意のスピーチパターンを認識するための、この話者の事前取得済みスピーチサンプルをスピーチパラメータ参照データベース内に含める段階3010をさらに備える。
【0048】
本発明のいくつかの実施形態によれば、分析方法は、話者の人格的特徴を判断し、それらを状況的特徴と区別するために、いくつかの異なる状況でその話者を繰り返し分析し、その異なる状況で反復的かつ共通するスピーチパターンをさらに抽出する段階3020をさらに備える。
【0049】
本発明のいくつかの実施形態によれば、分析方法は、話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、現在の感情的状態を状況的特徴と区別するためのスピーチ分析による感情検知を使用すること3030をさらに備える。
【0050】
本発明のいくつかの実施形態によれば、分析方法は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用する段階3040をさらに備える。
【0051】
本発明のいくつかの実施形態によれば、分析方法は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、スピーチ分析によって補完される話者の視覚分析によるボディランゲージ分析を使用すること3050をさらに備える。
【0052】
本発明のいくつかの実施形態によれば、分析方法は、スピーチパラメータ参照データベースとその分類プロセスとを改善するために話者の行動的、心理的、およびスピーチスタイル上の特徴に関する継続的分析を使用して学習システム特性を提供することをさらに備える。
【0053】
本発明のいくつかの実施形態によれば、分析方法は、複数の話者を備える発話をさらに対象としており、この方法は、複数の話者の声を分別することをさらに備え、上記方法の各段階が話者ごとに別々に実行される。
【0054】
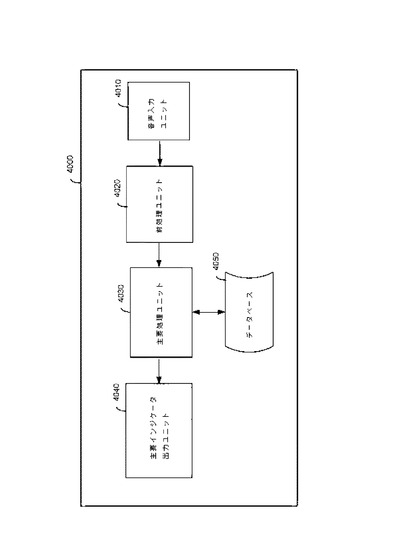
図4は、本発明のいくつかの実施形態に従って話者の発話を分析し、所与の状況および場面における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのデータ処理システムを示している高次の概略ブロック図を表す。システム4000は、話者の発声をサンプリングするか、サンプリングされた発声を取得するように調整された音声入力ユニット4010と、音声入力ユニット4010に連結され、音声入力ユニットからの音声サンプルを前処理するように調整された前処理ユニット4020と、前処理ユニット4020に連結された主要処理ユニット4030と、主要インジケータ出力ユニット4040と、主要処理ユニット4030に連結された話者参照データベース4050とを備える。
【0055】
動作時、音声入力ユニット4010は、具体的な状況および場面における話者のサンプリングされた発話をサンプリングまたは取得するように調整されており、前処理ユニット4020は、サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントに分け、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整されている。これらのブロックは、ピッチおよび振幅パラメータを含む第1のスピーチパラメータを有する。さらに、データベース4050は、行動的、心理的、およびスピーチスタイルの分類と、それらを表す第2のスピーチパラメータおよびパラメータの組み合わせとを格納するように調整されており、かかるパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択される。さらに、主要処理ユニット4030は、その第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、現在分析されている発話から導出するように調整される。主要処理ユニット4030は、発話の上記第2のスピーチパラメータから、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表す一意のスピーチパラメータと、パラメータの組み合わせと、パラメータの値とを算出するようさらに調整される。さらに、その算出されたパラメータをスピーチパラメータの事前定義済み参照データベースと比較することにより、その発話における状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するようにも調整される。最後に、主要インジケータユニット4040は、分析結果を出力するように調整される。
【0056】
本発明のいくつかの実施形態によれば、出力ユニット4040は、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルおよびリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、電子手帳とのインタフェース、および電子出力機器とのインタフェースのうちの少なくとも1つを備える。
【0057】
本発明のいくつかの実施形態によれば、システム4000は、音声通信システム、有線または無線通信システム、セルラー方式通信ネットワーク、ウェブベースの通信システム、その他のボイスオーバーIPベースの通信システム、コールセンタ通信システムを含む群から選択される通信システム内で実装される。
【0058】
本発明のいくつかの実施形態によれば、システム4000は、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つで使用されるように構成されている。
【0059】
本発明のいくつかの実施形態によれば、データベース4050は、現在の分析対象話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、この話者に関する現在の分析が話者から独立したものではなく、話者に依存したものになるよう、この話者の一意のスピーチパターンを認識するための、事前に取得したスピーチサンプルをさらに備える。
【0060】
本発明のいくつかの実施形態によれば、システム4000は、話者の人格的特徴を判断し、それらを状況的特徴と区別するために、いくつかの異なる状況でその話者を繰り返し分析し、その異なる状況で反復的かつ共通するスピーチパターンを抽出するようにさらに調整される。
【0061】
本発明のいくつかの実施形態によれば、システム4000は、話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、現在の感情的状態を状況的特徴と区別するためのスピーチ分析による感情検知を使用するようにさらに調整される。
【0062】
本発明のいくつかの実施形態によれば、システム4000は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用するように調整される。
【0063】
本発明のいくつかの実施形態によれば、システム4000は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、スピーチ分析によって補完される話者の視覚分析によるボディランゲージ分析を使用するようにさらに調整される。
【0064】
本発明のいくつかの実施形態によれば、そのシステム4000は、そのスピーチパラメータ参照データベースおよびその分類プロセスを改善するために話者の行動的、心理的、およびスピーチスタイル上の特徴の継続的分析を用いて学習システム特性を提供するように調整される。
【0065】
本発明のいくつかの実施形態によれば、システム4000は、複数の話者を備える発話を対象としており、このシステムは、複数の話者の声を分別するように調整されており、このシステムは各話者を別々に分析するようにさらに調整される。
【0066】
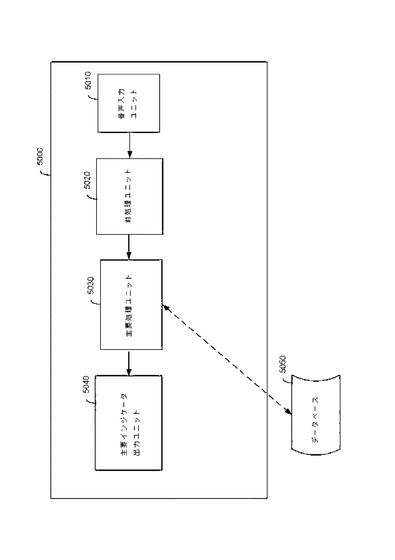
図5は、本発明のいくつかの実施形態に従って話者の発話を分析し、所与の状況および場面における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するための装置を示している高次の概略ブロック図を表す。装置5000は、話者の発声をサンプリングまたはサンプリングされた発声を取得するように調整された音声入力ユニット5010と、音声入力ユニット5010に連結され、音声入力ユニット5010からの音声サンプルを前処理するように調整された前処理ユニット5020と、前処理ユニット5020に連結された主要処理ユニット5030と、主要処理ユニット5030に連結された主要インジケータ出力ユニット5040とを備える。
【0067】
動作時、音声入力ユニット5010は、具体的な状況および場面における話者のサンプリングされた発話をサンプリングまたは取得するように調整され、前処理ユニット5020は、サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントに分け、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整される。これらのブロックは、ピッチおよび振幅パラメータを含む第1のスピーチパラメータを有する。さらに、装置5000は、行動的、心理的、およびスピーチスタイルの分類と、それらを表わす第2のスピーチパラメータおよびパラメータの組み合わせとを格納するように調整された参照データベース5050と動作可能に関連付けられており、かかるパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択される。
【0068】
さらに、主要処理ユニット5030は、上記第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、現在分析されている発話から導出するように調整されている。主要処理ユニット5030は、発話の上記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出するようさらに調整される。さらに、算出されたパラメータをスピーチパラメータの事前定義済み参照データベースと比較することにより、その発話における状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するようにも調整されている。最後に、主要インジケータユニット5040は、その分析結果を出力するように調整される。
【0069】
本発明のいくつかの実施形態によれば、装置5000は、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つを対象に構成されている。
【0070】
本発明のいくつかの実施形態によれば、装置5000は、音声通信デバイス、有線または無線音声デバイス、セルラー方式通信デバイス、ネットワーク化された(またはネットワーク化されていない)パーソナルデバイスアクセサリ(PDA)、音声録音デバイス、パーソナルコンピュータ、およびサーバを含む一覧から選択される。
【0071】
本発明のいくつかの実施形態によれば、出力ユニット5040は、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルまたはリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、および電子手帳とのインタフェースまたはその他任意の電子出力機器とのインタフェースのうちの少なくとも1つを備える。
【0072】
いくつかの実施形態によれば、本発明のコンピュータ実装方法、データ処理システム、およびコンピュータプログラム製品は、無線または有線通信システム内で実装され得る。具体的には、本発明は、セルラー通信システムで実装され得る。本発明は、いくつかの実施形態において、リアルタイム環境で動作するように構成され得るが、オフラインスピーチ分析システムとしても構成され得る。
【0073】
いくつかの実施形態によれば、本発明は、複数のアーキテクチャで実装され得る。例えば、任意の中央物理箇所で携帯電話事業者の集中サーバを通過する通話の音声データに対して上記段階を実行する集中分析モジュールが提供され得る。
【0074】
他の実施形態によれば、本発明は、スピーチ電気通信デバイスなどの通信装置にソフトウェアまたはハードウェアとして組み込まれるスタンドアロンモジュールとして実装され得る。例えば、具体的なエンドユーザ向け携帯電話デバイスを通過する通話の音声データに対して上記段階を実行する分析モジュールが提供され得る。
【0075】
任意で、実施形態は、会話している話者の一方または双方の分析に限らず、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途などの目的でも利用され得る。
【0076】
いくつかの実施形態によれば、本発明のコンピュータ実装方法、データ処理システム、装置、およびコンピュータプログラム製品は、サービス、売上、顧客対応、研修、および他の組織的な目的を改善するために、コールセンタおよびコンタクトセンタにおける会話のリアルタイムまたはオフラインスピーチ分析の範囲内で実装され得る。
【0077】
いくつかの実施形態によれば、本発明は、有線電話での会話をリアルタイムおよびオフラインでスピーチ分析し、会話している話者の一方または双方を上記と同じ目的で分析する。
【0078】
いくつかの実施形態によれば、本発明は、ウェブベースの会話をリアルタイムおよびオフラインでスピーチ分析し、当事者の一方または双方を上記と同じ目的で分析する。
【0079】
いくつかの実施形態によれば、本発明は、対面による会話をリアルタイムおよびオフラインでスピーチ分析し、当事者の一方または双方を上記と同じ目的で分析する。
【0080】
いくつかの実施形態によれば、本発明は、会話、自己スピーチ、または観衆の前でのスピーチかを問わず、任意の記録されたスピーチをリアルタイムおよびオフラインでスピーチ分析し、当事者の一方または双方を上記と同じ目的で分析する。
【0081】
有利に、人々のコミュニケーション上、心理的、人格的、および行動的特徴を評価することは、様々な理由でとてつもなく重要である。まず、話者本人に評価データを提供することにより、認識、進展、および様々な学習目的を促す。加えて、個人的、商業的、教育的、職業的、医療上、心理的など、様々な目的でその話者を知りたい、支援したい、上手に交流したい他者にとって大きな重要性を有する。
【0082】
本発明のいくつかの実施形態によれば、このシステムは、デジタル電子回路で、またはコンピュータハードウェア、ファームウェア、ソフトウェア、あるいはそれらの組み合わせで実装することができる。
【0083】
本発明は、データ記憶システム、少なくとも1つの入力装置、および少なくとも1つの出力装置との間でデータと命令とを送受信するために連結された少なくとも1つのプログラマブルプロセッサを含むプログラマブルシステムで実行可能である1つ以上のコンピュータプログラムで好都合に実装することができる。コンピュータプログラムとは、コンピュータで直接または間接的に使用することができ、特定のアクティビティを実行したり、特定の結果をもたらしたりする命令の集合のことである。コンピュータプログラムは、コンパイルまたは解釈された言語を含む、任意の形状のプログラミング言語で記述することができ、スタンドアロンプログラム、またはコンピュータ環境での使用に適したモジュール、コンポーネント、サブルーチン、あるいは他のユニットを含む任意の形状で展開することができる。
【0084】
命令プログラムを実行するための適切なプロセッサは、例えばデジタル信号プロセッサ(DSP)を含むが、汎用マイクロプロセッサ、および任意の種類のコンピュータの単一プロセッサまたは複数のプロセッサのいずれかも含む。一般にプロセッサは、読み取り専用メモリあるいはランダムアクセスメモリ、またはその両方から命令とデータとを受信する。コンピュータの必須要素は、命令を実行するためのプロセッサ、および命令とデータとを格納するための1つ以上のメモリである。一般にコンピュータは、データファイルを格納するための1つ以上の大容量記憶装置も含むか、それらと通信するように動作可能に連結され、かかる装置は、内蔵ハードディスクおよびリムーバブルディスクなどの磁気ディスク、光磁気ディスク、および光ディスクを含む。コンピュータプログラム命令とデータとを有形的に一体化するのに適した記憶装置は、例えば、EPROM、EEPROM、およびフラッシュメモリ装置などの半導体メモリデバイス、内蔵ハードディスクおよびリムーバブルディスクなどの磁気ディスク、光磁気ディスク、CD−ROMおよびDVD−ROMディスクなどを含む、すべての形状の不揮発性メモリを含む。プロセッサおよびメモリは、ASIC(特定用途向け集積回路)によって補完されたり、その中に組み込まれたりする場合がある。
【0085】
上記説明において、実施形態は、本発明の実施例または実装形態である。「一実施形態」、「実施形態」、または「いくつかの実施形態」が多様に出現しても、それらが必ずしもすべて同じ実施形態を言及するとは限らない。
【0086】
本発明の様々な特徴が単一の実施形態の場面で説明されている場合があるが、それらの特徴は、別個に、あるいは任意の適切な組み合わせで提供されることもある。逆に、明瞭化のために、本明細書において別個の実施形態の場面で本発明が説明されている場合があるが、本発明は単一の実施形態でも実装され得る。
【0087】
明細書における「いくつかの実施形態」、「実施形態」、「一実施形態」または「他の実施形態」という言及は、その実施形態に関連して記載されている特定の特性、構造、または特徴が少なくともいくつかの実施形態に含まれているが、本発明のすべての実施形態に含まれるとは限らないことを意味する。
【0088】
本明細書で用いられている語法および用語は、制限的なものと解釈されるべきではなく、説明のみを目的としていると理解されるべきである。
【0089】
本発明の教示の原理および用途は、添付の説明、図、および実施例を参照することによってさらに良好に理解され得る。
【0090】
本明細書に記載されている詳細は、本発明の用途に対する制限を意味するものではないと理解されるべきである。
【0091】
さらに、本発明は様々な方法で実行または実施することができ、かつ本発明は上記説明に概説された実施形態以外の実施形態で実装可能であると理解されるべきである。
【0092】
「含む」、「備える」、「成る」、およびそれらの文法的変形は、1つ以上の構成要素、機能、ステップ、あるいは整数、またはそれらの群が追加されることを排除するものではなく、この用語は、構成要素、機能、ステップ、または整数を指定するものとして解釈されるべきでないと理解されるべきである。
【0093】
明細書または請求項が「付加」要素を言及している場合、それは付加要素が1つよりも多く存在することを除外しない。
【0094】
請求項または明細書が「1つ」の要素を言及している場合でも、かかる言及はその要素が1つしか存在しないと解釈されるものではないと理解されるべきである。
【0095】
明細書に、構成要素、機能、構造、または特徴が「含み得る」、「含んでも良い」、「含む場合がある」、「含む可能性がある」と述べられている場合には、その特定の構成要素、機能、構造、または特徴を含むことが必須ではないと理解されるべきである。
【0096】
該当する場合には、状態図、流れ図、あるいはその両方が実施形態を説明する目的で使用され得るが、本発明は、それらの図または対応する説明に限定されない。例えば、流れは、図示された各々のボックスまたは状態を通過したり、図示または記載されたとおりの順序で移動したりする必要はない。
【0097】
本発明の方法は、選択されたステップまたは作業を、手動、自動、またはその組み合わせによって実行または完了することによって実装され得る。
【0098】
「方法」という用語は、所与の作業を達成するための方法、手段、技術、および手順であって、本発明が属する当業者の間では公知であるか、公知の方法、手段、技術、および手順から当業者によって容易に開発される方法、手段、技術、および手順を含むがこれらに限定されない方法、手段、技術、および手順を言及し得る。
【0099】
請求項および明細書に明示される説明、実施例、方法、および用具は制限的なものとしてではなく、例証的なものに過ぎないと解釈されるべきである。
【0100】
本明細書で使用される専門的および科学的な用語の意味は、別段の規定がなされていない限り、本発明が属する技術の当業者によって広く理解されるべきである。
【0101】
本発明は、本明細書に記載されているものと同等または同様の方法および用具を用いたテストまたは実践において実装され得る。
【0102】
特許、特許出願、記事など、本明細書で参照または言及されているいかなる出版物も、個々の出版物が本明細書に援用されるよう具体的かつ個別に明示されている場合と同程度に、その全体が本明細書に援用される。加えて、本発明のいくつかの実施形態の説明におけるいかなる参照先の引用または特定も、かかる参照が本発明に対する従来技術として提供されているという承認とは解釈されないものとする。
【0103】
本発明について、限られた数の実施形態を取り上げて説明してきたが、これらは本発明の範囲を制限するものとしてではなく、好適な実施形態のいくつかの実例として解釈されるべきである。その他可能な変形、改変、および応用も、本発明の範囲内である。そのため、本発明の範囲は、ここまでの記載内容によってではなく、添付の特許請求の範囲とそれらの法的均等物とによって制限されるべきである。
【技術分野】
【0001】
本発明は、スピーチ分析の分野に関し、詳細には、具体的な状況における人の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのスピーチの韻律的特性の使用に関する。
【背景技術】
【0002】
スピーチ分析とは、人間の発話が伝える情報を明らかにするために、コンピュータ化された発話処理方法に付与された一般用語のことである。スピーチ分析は、言語科学内の音声秩序の一部として分類されている。
【0003】
スピーチ分析は、2つの主な手法に分割され得る。第1の手法は、語、音節、および音素が発音される方法と、文が配置される方法を学習することによってそのスピーチの内容を明らかにすることに焦点を置いている。「スピーチからテキスト」や「ワードスポッティング」などのスピーチ認識アプリケーションの多くが、スピーチの内容を抽出するためにこの手法を使用している。
【0004】
第2の手法であるスピーチの韻律分析は、抑揚、テンポ、強度、強調、リズムなど、スピーチの非分節的(非語、非内容)特性を分析することにより、発話のされ方に焦点を置いている。
【0005】
発話のされ方によってスピーチの「メロディ」が提供され、このメロディが、スピーチの全体的な意味および場面に重要な洞察を付加する。例えば、人々は文末の上昇調により、文を疑問文と認識する。アクセントは、韻律的な音声パラメータによって単語の発音が変わる様子を表す古典的な例である。俳優は、自身のスピーチの韻律を、特定人物のように聞こえるように改変する。韻律には、例えば男性よりも女性の方が概して周波数が高いといった性差もある。多くの場合、韻律的特性は、スピーチの意味を変える。私たちは、発音のされ方(韻律)の変化によって、同じ文でも冷笑的、皮肉的、あるいは単純な意味を有するものと解釈する。
【0006】
発話の韻律的特性は、話者の感情的状態に関する情報も伝える。この点については、文壇において数々の作品によって長年にわたり示されてきた。また、緊急サービスを呼んでいる興奮した人は、概して話すペースが速く、声が激しく、息が荒く、抑揚するなど、直観的にも把握される。その一方で、悲しんでおり憂鬱な状態にある人は、ゆっくりと話し、活力に乏しく、休止が長く取るなどの傾向がある。これらの特徴は、韻律的なスピーチ特性に反映される。
【0007】
話者の感情的状態を自動的に分析するために韻律的なスピーチ特性を使用することに関する特許は、これまでにいくつか出されている。具体的には、ペトルーシンに対する米国特許第6151571号、異なる感情的状態を分類することを対象としたスラニーに対する米国特許第6173260号、および感情的な覚醒全般を判断することを対象としたデガニとザミールとに対する欧州特許第1423846号などがある。すべての特許は、参照により、全体が本明細書に援用されるものとする。
【0008】
話者の性格とスピーチの韻律的特徴とを相関させるための試みは、ほとんど行われなかった。ボグダシェフスキーに付与された米国特許第6006188号は、性格タイプが似た人々のスピーチ特性を(公知の心理学的分類に従って)判断し、検出された特性を使用して性格タイプを自動的に分類するための方法について記載している。スピーチには性格が反映されるという考えは意味を成しており、直観的にも把握することができる。例えば、外向的の人について、声が大きく衝動的なスピーチパターンを想像できるのに対し、内向的な人については、柔らく遠慮がちなスピーチパターンを想像することができる。
【0009】
性格とスピーチパターンとの結び付けは、スピーチは人格的特徴の様々な面を表すという理解をよく反映している。ただし、実用という点にこの概念の弱点がある。性格は、人の安定した特徴を表すものであるため、相当に一貫して測定されるはずでもある。つまり、話者本人の性格を反映しているスピーチパターンは、変化する状況や様々な内面の状態、異なる場面でも相当程度まで一貫性を保つはずである。しかし実際には、この点が該当しない。例えば、感情的状態とスピーチの韻律との間にある確固たる関係から明らかとなっており、スピーチパターンは状況的要因に大きく影響される傾向がある。上記例で取り上げた内向的な人でさえ、時には腹を立て、その時には、その人のスピーチパターン(および韻律的な音声パラメータ)が大きく変化し、社交的で外向的な人のスピーチパターンに酷似する。もしかしたら統計学的には、その内向的な人のスピーチパターンを数々の異なる状況で測定すれば、その人の性格とスピーチパターンとの間で有意な相関が存在するかもしれない。また、特定の性格を示すスピーチパターンを表す参照データが用いられた状況と酷似する条件下で人のスピーチをサンプリングした場合には信頼できるかもしれない。しかし、介在する状況的要因が支配的な場合には該当しないであろう。実生活においては、状況的要因がスピーチに影響することが多い。そのため、スピーチの韻律による性格測定は、状況に依存しない方法としては認められない。
【発明の概要】
【発明が解決しようとする課題】
【0010】
本発明は、所与の状況と場面における話者の現在の行動的および心理的特徴、ならびに話者の現在のスピーチスタイルを判断するために話者の発話を分析するコンピュータ実装方法と、データ処理システムと、コンピュータプログラム製品と、装置とを提案する。
【課題を解決するための手段】
【0011】
分析は、発話の第1のピッチおよび振幅パラメータから得た一意の第2の導出結果を算出することに基づいており、それらは、併用されると、具体的な状況および場面における話者の現在の行動的、心理的、およびスピーチスタイル上の特徴を表す。
【0012】
現在の行動的、心理的、およびスピーチスタイル上の特徴の分類は、算出された話者の第2のスピーチパラメータと、様々な行動的および心理的な特徴ならびに様々な状況および場面における異なるスピーチスタイルの、これらの第2のスピーチパラメータの値および値の組み合わせを表す事前取得済みデータとを比較することによって実行される。
【0013】
本発明の一態様は、具体的な状況における人のスピーチの韻律的特性を分析することによってその人の現在の行動的、心理的、およびスピーチスタイル上の特徴を判断するための、話者に依存しない一般的な方法を提供する。話者の人格的特徴は、一時的な状況依存パラメータ、または性格などの安定した状況独立パラメータのどちらとも関連し得る。本発明の実施形態は、例えば、ある人の現在の様子が直接的か、開放的か、客観的か、表情豊かか、あるいは控え目かを、これらの資質がその人の生来的な性質を反映しているか、あるいは具体的な状況および場面を反映しているかを決定することなく判断することを可能にする。このタイプの情報は、様々なフィードバックおよび研修を目的とした分析対象人物本人と、分析対象人物に対する理解および当該人物とのコミュニケーションを改善するためにその分析対象人物と話をする人々とにとって極めて貴重であり得る。
【0014】
様々な実施形態において、本発明は、開示されている一意の第2のスピーチインジケータから話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴の特徴化するためのコンピュータ実装方法、データ処理システム、コンピュータプログラム製品、および装置として実現される。
【0015】
本発明とみなされる主題は、添付の図面(「図」)を参照して本発明の一例として、および実例を伴う説明のみを目的として提供された本明細書の後述の実施形態を照らし合わせることによって一層明確に理解されるであろう。
【図面の簡単な説明】
【0016】
【図1】異なる行動的、心理的、およびスピーチスタイル上の特徴を分類するためのスピーチパラメータ参照データを本発明の方法に準拠して取得および形成する段階を示す高次のフローチャートである。
【0017】
【図2】本発明の実施形態に準拠して、参照データベースを使用しながら、話者の現在の発話を分析し、所与の状況におけるその話者の行動的、心理的、およびスピーチスタイル上の特徴を判断する段階を表す高次のフローチャートである。
【0018】
【図3】本発明の方法に追加および準拠して、本発明のいくつかの実施形態で実施され得る任意の段階のいくつかを示す高次のフローチャートである。
【0019】
【図4】本発明のいくつかの実施形態にかかるデータ処理システムの概略ブロック図である。
【0020】
【図5】本発明のいくつかの実施形態にかかる装置の概略ブロック図である。
【0021】
図面と説明とにより、本発明が実際に実施され得る方法が当業者にとって明らかになる。
【発明を実施するための形態】
【0022】
本発明について詳述する前に、以降で使用される特定の用語の定義を記載しておくのが有用かもしれない。
【0023】
本明細書で使用される「状況的」という用語は、話者の現在の状態に関連または該当する特徴を意味する。逆に言えば、状況的特徴化は、話者に総体的に妥当であるとは限らない。例えば、話者の状況的特徴化は、「話者の話しぶりは(今)断定的である」または「話者の話しぶりは控え目である」あるいは「話者の話しぶりは打算的である」などであり得る。これは、話者が、生来的に断定的、控え目、あるいは打算的であるという意味ではなく、現在の発話分析から、話者の話しぶりがそのように聞こえるということを意味する。当然のことながら、異なる状況であれば、その話者の話しぶりも異なる可能性がある。
【0024】
本明細書で使用される「場面依存的」という語は、文化、言語、アクセント、年齢などの要因を備える話者の経歴的な背景によって、または、対話あるいはモノローグ、記述文の読みあげ、あるいは自由スピーチ、通常のスピーチ状況あるいは身体活動中、演劇での演技中、講義中、演説中、戦闘、非常事態、球技などストレスの多い状況下でのスピーチなど、状況設定の特殊な属性によって導出されたり、それらに起因したり、影響されたりする(スピーチに作用し得る)状況の一般的特徴を表すものと定義される。
【0025】
本明細書で使用される「スピーチスタイル」という用語は、特定の状況で使われる傾向のある典型的なスピーチパターンを意味し、行動的および心理的な特徴のまとまりを表す。例えば、表情豊かなスピーチスタイル、打算的なスピーチスタイル、率直なスピーチスタイルなどがある。人々は、その具体的な状況および場面に従って自らのスピーチスタイルを変える傾向がある。
【0026】
本明細書で使用される「通信システム」という用語は、発語の転移を可能にするあらゆる音声通信システムにも関係する。これらのシステムは、例えば、有線または無線電話通信システム、セルラー方式通信ネットワーク、ウェブベースの通信システム、他のボイスオーバーIPベースの通信システム、コールセンタシステムなどでありえる。
【0027】
以下の詳細な説明の中では、本発明についての理解を徹底するために、数々の具体的な詳細が記載されている。ただし、これら具体的な詳細がなくとも本発明の教示を実践し得るものと理解される。他の事例においては、本発明の教示が曖昧になるのを避けるために、周知の方法、手順、構成要素、および回路が詳細に説明されていない。
【0028】
本発明は、そのいくつかの実施形態において、スピーチ分析技術を利用して話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断するためのコンピュータ実装方法、データ処理システム、装置、およびコンピュータプログラム製品を開示する。
【0029】
本発明は、スピーチパターンが、単なる感情的状態を越えて、話者の広範な行動的および心理的特徴を反映するという事実に基づいている。具体的には、率直、断定的、敏感、開放的、表情豊か、人見知り、控え目、威圧的、冷静、打算的、辛抱強い、短気、共感的など、感情ではなくスピーチパターンによって表現される数々の行動的または心理的特徴について考えることができる。本発明は、発話からこれらの行動的および心理的特徴などを分析できるようにすることを目的としている。
【0030】
本発明の実施形態によれば、本発明の実施は、スピーチパターンに反映されるこれらの特徴が、安定した一定の性質ではなく、主に状況的性質を持つ特徴であるという点を考慮している。かかる行動的特徴は、状況の場面や話者の感情的状態、話者の性格に関連する場合もあるが、多くは全要因の組み合わせであろう。例えば、率直で断定的なスピーチパターンは、試合中(場面)に交わされるコーチと選手との標準的な会話の特徴である場合もあれば、顧客サービスの会話における不満を抱いた顧客の怒り(感情)に関連する場合もある。さらに他のケースでも、このスピーチパターンは、全般的に断定的な話者の性格を反映し得る。スピーチの韻律パラメータ(ペース、抑揚、強度などを反映)は、そのスピーチが現在断定調であるということを明示し得るが、その具体的な場面を示したり、そのスピーチが状況に関連するか、性格に関連するかを区別したりすることはできない。
【0031】
そのため、これらが本発明の2大基底要素である。スピーチの韻律的特性は、話者の幅広い行動的および心理的特徴を反映し、スピーチパターンにおけるこれらの特徴の発現は、強い状況的性質を有する。すなわち、主として話者の現在の状態を表す。
【0032】
そのため、具体的な状況における人のスピーチの韻律的特性を分析することによってその人の現在の行動的および心理的特徴を判断するための、話者に依存しない一般的な方法を提供することが本発明の目的である。
【0033】
本発明は、職業上、教育上、診療上、および娯楽上の目的で行う様々なトレーニング用途の一環として、異なる状況における人々の行動的および心理的特徴について本人にフィードバックを提供する目的で使用され得るという優れた点がある。また、職業上、教育上、診療上、および娯楽上の目的に加え、様々なビジネス用途でも、分析対象人物の現在の行動的および心理的特徴の理解に基づいた、その人物との最良のコミュニケーション方法に関する洞察を他の人に提供する目的でも使用され得る。
【0034】
本発明が対処する課題1つは、話者に依存しない行動的および心理的特徴を表すパラメータを抽出および検出することである。典型的なピッチ、ペース、抑揚など、スピーチに見られる個々の韻律的特徴は人によって大きく異なる。また、人々が特定の行動的および心理的特徴を表す個々の方法も異なる場合がある。例えば、主にスピーチの強度を変えることによって断定を表現する人もいれば、スピーチのペースなどを変更することによって表現する人もいる。話者に依存しない処理に到達するには、行動的および心理的特徴の韻律表現における個人差を克服する必要がある。
【0035】
本発明は、韻律的特性を分析するために、第1のピッチから抽出した一意の第2のスピーチと、振幅スピーチパラメータとを用いて、話者に依存しない処理を実現する。これら第2のパラメータは、発話内の上昇ピッチ、下降ピッチ、および均一ピッチが示す様々な統計インジケータの特徴である。スピーチにおける個人差から受ける影響が小さいことから、重複することのないこれら第2のパラメータは、行動的および心理的特徴そのものをより正確に表す。
【0036】
本発明のさらなる一態様は、スピーチスタイルである。数々の行動的および心理的特徴が持つスピーチパターンを実験的に調べると、かかる特徴を持ついくつかのまとまりをグループ化して、区別されたスピーチスタイルを形成できることがどうやら明らかである。これは、発話を聴いてそれらを分類したときにすでに明らかになる。その発話(同じ状況)内では特定の行動的および心理的特徴が一緒に現れることが多いという傾向があり、そのことは、それらが関連している可能性があることを示唆している。さらに、それらの韻律的特性を分析すると、特定の行動的および心理的特徴は、他と比較して相互の類似性が高く、やはり関連性を示唆している。
【0037】
かかる潜在的スピーチスタイルの具体例を以下にいくつか示す。1つのスタイルは「受動的」または「堅実」なスピーチスタイルと称し得るもので、緩慢、物静か、堅実、穏やか、優柔不断などの行動的および心理的特徴を備える。もう1つのスタイルは「話し好き」と称し得るもので、敏感、開放的、多弁、表情豊かなどの特徴を備える。さらに別のスタイルは、「断定的」と称し得るもので、率直、威圧的、早口、大声、活発などの特徴を備える。さらに別のスタイルは、「打算的」と称し得るもので、分析的、非感情的、冷静、控え目、系統的などの特徴を備える。これらのスピーチスタイルは、本明細書においては例示目的で取り上げるに過ぎない。当然のことながら、韻律的特性を用いて、他にもいくつかのスピーチスタイルを描き出すことができる。
【0038】
これらのスピーチスタイルも強い状況的性質を有することを強調しておくことが重要である。時として、それらは話者の安定した特徴を表すことがあるが、多くの場合、現在の対応パターン、すなわち、その具体的な状況または場面に該当する話者の現在の内的状態を表す。その人物は、異なる場面ではかかるスピーチスタイル間で切り替わることが多いであろう。
【0039】
スピーチ分析を通じてかかるスピーチスタイルを判断することは、分析された状況に関する洞察の包括性を高めることができるため、本発明の上記潜在用途に対して極めて有利となり得る。
【0040】
そのため、具体的な状況における人のスピーチの韻律的特徴を分析することによってその人の現在のスピーチスタイルを判断するための、話者に依存しない一般的な方法を提供することも本発明の目的である。
【0041】
本発明の実施形態は、従来の韻律的なスピーチ分析方法と区別する3つの主態様を利用する。第1の態様は、韻律的なスピーチ分析を通じて判断される話者の人格的特徴の範囲を大きく広げている。この分析により、過去に実証されてきた主な用途であった話者の感情的状態以外にも様々な行動的、心理的、およびスピーチスタイル上の特徴が判断されると主張される。第2の異なる態様は、話者の現在の状況的、行動的属性と、対応するその話者のスピーチの特徴との連結である。第3の異なる態様は、スピーチの基本周波数と振幅パラメータから抽出した一意の第2のパラメータを使用して、話者に依存しない処理を実現することである。これら一意の第2のパラメータとそれらの組み合わせとを使用することにより、スピーチ表現の個人差を克服し、類似の行動的および心理的態様が、異なる人々のスピーチの特徴に同じように表れるようにすることができる。
【0042】
図1は、様々な行動的、心理的、およびスピーチスタイル上の特徴を分類するためのスピーチパラメータ参照データベースを作成する方法のステップを示す、本発明のいくつかの実施形態にかかる高次のフローチャートを表す。この方法は、特定の言語、文化または一意の状況設定など、特定の発語場面を手動で選択すること1010と、選択された場面で分析する行動的、心理的、およびスピーチスタイル上の特徴を手動で選択すること1020と、選択された場面における人々の複数の発話を取得すること1030と、その発話を、類似の行動的、心理的、およびスピーチスタイル上の特徴を表す群に手動でグループ化すること1040と、を含む。この方法は、専門家による評価、ピア評価、自己評価、客観的な試験など、あるいは社会科学および行動科学において使用されており公知であるその他任意の評価方法など、有効かつ公知の評価方法を使用して実行される。かかる状況的特徴は、単なる例に過ぎないものの、率直、断定的、敏感、開放的、表情豊か、人見知り、控え目、威圧的、冷静、打算的、辛抱強い、短気、共感的、またはスピーチパターンで表現または反映され得るその他任意の状況的、行動的、および心理的特徴であり得る。かかるスピーチスタイルは、単なる例に過ぎないものの、緩慢、物静か、堅実、大人しい、優柔不断などいくつかの行動的および心理的特徴を備える「受動的」または「堅実」なスピーチスタイル、敏感、開放的、多弁、表情豊かなどの特徴を備える「話し好き」なスピーチスタイル、率直、威圧的、早口、大声、活発などを備える「断定的」なスピーチスタイル、あるいは分析的、非感情的、冷静、控え目、系統的などの特徴を備える「打算的」なスピーチスタイルであり得る。本発明のいくつかの実施形態によれば、データベースは、任意の数(1つ以上)の行動的、心理的、およびスピーチスタイル上の特徴を表すスピーチパラメータを格納し得る。この方法は、類似する行動的、心理的、およびスピーチスタイル上の特徴を表している発話群における発話の各々を前処理して無音のセグメントとアクティブなスピーチセグメントとに分けること1050と、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、そのブロックがピッチおよび振幅パラメータを含む第1のスピーチパラメータを有すること1060と、第1のスピーチパラメータから複数の第2のスピーチパラメータを導出することであって、その第2のスピーチパラメータが、上記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と、上記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長さとを備えること1070と、一意の第2のスピーチパラメータ、パラメータの組み合わせ、および
各発話群に共通であり、各群の典型的な行動的、心理的、またはスピーチスタイル上の特徴を表すパラメータの値を、上記導出された第2のパラメータから判断すること1080と、も含む。データベースの使用は本発明の単なる一実施形態であり、スピーチパラメータの辞書であるその集合、および具体的な場面における対応する行動的特徴は、参照用のスピーチパラメータを表す任意の方法で一緒に記憶され得ると理解されるべきである。パラメータのデータベースまたは集合は、異なる手段で記憶したり、実際のソフトウェアデータベースを使用せずにコンピュータプログラムによって参照目的で使用したりしても良い。
【0043】
本発明のいくつかの実施形態によれば、複数の第2のスピーチパラメータを導出する段階は、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択されるパラメータをさらに対象とする。
【0044】
図2は、本発明のいくつかの実施形態にかかる所与の状況および場面における話者の発話を分析し、所与の状況における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するコンピュータ実装方法のステップを示す高次のフローチャートを表す。その方法は、様々な行動的、心理的、および話者のスピーチスタイル上の特徴に従って発話を分類するためのスピーチパラメータ参照データベースを作成すること2010と、具体的な状況および場面における話者の発話を取得すること2020と、取得した発語を前処理して無音のセグメントとアクティブなスピーチセグメントとに分け、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、上記ブロックが、ピッチおよび振幅パラメータを含む第1のスピーチパラメータを有すること2030と、その第1のパラメータから複数の第2のスピーチパラメータを導出することであって、上記第2のパラメータが、一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と上記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長さとを備えること2040と、発話における上記第2のパラメータから一意のスピーチパラメータ、パラメータの組み合わせ、および、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値を算出すること2050と、算出されたパラメータをスピーチパラメータの事前定義済み参照データベースと比較することによって、その発話における状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点すること2060と、分析結果を出力すること2070と、を含む。
【0045】
データベースの作成と同様、いくつかの実施形態によれば、複数の第2のスピーチパラメータを導出する段階は、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択されたパラメータをさらに対象とする。
【0046】
図3は、本発明のいくつかの実施形態にかかる所与の状況および場面における話者の発話を分析し、所与の状況における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するコンピュータ実装方法の任意のステップを示す高次のフローチャートを表す。
【0047】
本発明のいくつかの実施形態によれば、分析方法は、話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、この話者に関する現在の分析が話者から独立したものではなく、話者に依存したものになるよう、現在の分析対象話者の一意のスピーチパターンを認識するための、この話者の事前取得済みスピーチサンプルをスピーチパラメータ参照データベース内に含める段階3010をさらに備える。
【0048】
本発明のいくつかの実施形態によれば、分析方法は、話者の人格的特徴を判断し、それらを状況的特徴と区別するために、いくつかの異なる状況でその話者を繰り返し分析し、その異なる状況で反復的かつ共通するスピーチパターンをさらに抽出する段階3020をさらに備える。
【0049】
本発明のいくつかの実施形態によれば、分析方法は、話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、現在の感情的状態を状況的特徴と区別するためのスピーチ分析による感情検知を使用すること3030をさらに備える。
【0050】
本発明のいくつかの実施形態によれば、分析方法は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用する段階3040をさらに備える。
【0051】
本発明のいくつかの実施形態によれば、分析方法は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、スピーチ分析によって補完される話者の視覚分析によるボディランゲージ分析を使用すること3050をさらに備える。
【0052】
本発明のいくつかの実施形態によれば、分析方法は、スピーチパラメータ参照データベースとその分類プロセスとを改善するために話者の行動的、心理的、およびスピーチスタイル上の特徴に関する継続的分析を使用して学習システム特性を提供することをさらに備える。
【0053】
本発明のいくつかの実施形態によれば、分析方法は、複数の話者を備える発話をさらに対象としており、この方法は、複数の話者の声を分別することをさらに備え、上記方法の各段階が話者ごとに別々に実行される。
【0054】
図4は、本発明のいくつかの実施形態に従って話者の発話を分析し、所与の状況および場面における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのデータ処理システムを示している高次の概略ブロック図を表す。システム4000は、話者の発声をサンプリングするか、サンプリングされた発声を取得するように調整された音声入力ユニット4010と、音声入力ユニット4010に連結され、音声入力ユニットからの音声サンプルを前処理するように調整された前処理ユニット4020と、前処理ユニット4020に連結された主要処理ユニット4030と、主要インジケータ出力ユニット4040と、主要処理ユニット4030に連結された話者参照データベース4050とを備える。
【0055】
動作時、音声入力ユニット4010は、具体的な状況および場面における話者のサンプリングされた発話をサンプリングまたは取得するように調整されており、前処理ユニット4020は、サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントに分け、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整されている。これらのブロックは、ピッチおよび振幅パラメータを含む第1のスピーチパラメータを有する。さらに、データベース4050は、行動的、心理的、およびスピーチスタイルの分類と、それらを表す第2のスピーチパラメータおよびパラメータの組み合わせとを格納するように調整されており、かかるパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択される。さらに、主要処理ユニット4030は、その第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、現在分析されている発話から導出するように調整される。主要処理ユニット4030は、発話の上記第2のスピーチパラメータから、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表す一意のスピーチパラメータと、パラメータの組み合わせと、パラメータの値とを算出するようさらに調整される。さらに、その算出されたパラメータをスピーチパラメータの事前定義済み参照データベースと比較することにより、その発話における状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するようにも調整される。最後に、主要インジケータユニット4040は、分析結果を出力するように調整される。
【0056】
本発明のいくつかの実施形態によれば、出力ユニット4040は、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルおよびリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、電子手帳とのインタフェース、および電子出力機器とのインタフェースのうちの少なくとも1つを備える。
【0057】
本発明のいくつかの実施形態によれば、システム4000は、音声通信システム、有線または無線通信システム、セルラー方式通信ネットワーク、ウェブベースの通信システム、その他のボイスオーバーIPベースの通信システム、コールセンタ通信システムを含む群から選択される通信システム内で実装される。
【0058】
本発明のいくつかの実施形態によれば、システム4000は、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つで使用されるように構成されている。
【0059】
本発明のいくつかの実施形態によれば、データベース4050は、現在の分析対象話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、この話者に関する現在の分析が話者から独立したものではなく、話者に依存したものになるよう、この話者の一意のスピーチパターンを認識するための、事前に取得したスピーチサンプルをさらに備える。
【0060】
本発明のいくつかの実施形態によれば、システム4000は、話者の人格的特徴を判断し、それらを状況的特徴と区別するために、いくつかの異なる状況でその話者を繰り返し分析し、その異なる状況で反復的かつ共通するスピーチパターンを抽出するようにさらに調整される。
【0061】
本発明のいくつかの実施形態によれば、システム4000は、話者の状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、現在の感情的状態を状況的特徴と区別するためのスピーチ分析による感情検知を使用するようにさらに調整される。
【0062】
本発明のいくつかの実施形態によれば、システム4000は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用するように調整される。
【0063】
本発明のいくつかの実施形態によれば、システム4000は、状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、スピーチ分析によって補完される話者の視覚分析によるボディランゲージ分析を使用するようにさらに調整される。
【0064】
本発明のいくつかの実施形態によれば、そのシステム4000は、そのスピーチパラメータ参照データベースおよびその分類プロセスを改善するために話者の行動的、心理的、およびスピーチスタイル上の特徴の継続的分析を用いて学習システム特性を提供するように調整される。
【0065】
本発明のいくつかの実施形態によれば、システム4000は、複数の話者を備える発話を対象としており、このシステムは、複数の話者の声を分別するように調整されており、このシステムは各話者を別々に分析するようにさらに調整される。
【0066】
図5は、本発明のいくつかの実施形態に従って話者の発話を分析し、所与の状況および場面における話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するための装置を示している高次の概略ブロック図を表す。装置5000は、話者の発声をサンプリングまたはサンプリングされた発声を取得するように調整された音声入力ユニット5010と、音声入力ユニット5010に連結され、音声入力ユニット5010からの音声サンプルを前処理するように調整された前処理ユニット5020と、前処理ユニット5020に連結された主要処理ユニット5030と、主要処理ユニット5030に連結された主要インジケータ出力ユニット5040とを備える。
【0067】
動作時、音声入力ユニット5010は、具体的な状況および場面における話者のサンプリングされた発話をサンプリングまたは取得するように調整され、前処理ユニット5020は、サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントに分け、アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整される。これらのブロックは、ピッチおよび振幅パラメータを含む第1のスピーチパラメータを有する。さらに、装置5000は、行動的、心理的、およびスピーチスタイルの分類と、それらを表わす第2のスピーチパラメータおよびパラメータの組み合わせとを格納するように調整された参照データベース5050と動作可能に関連付けられており、かかるパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンを含む一覧から選択される。
【0068】
さらに、主要処理ユニット5030は、上記第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、現在分析されている発話から導出するように調整されている。主要処理ユニット5030は、発話の上記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出するようさらに調整される。さらに、算出されたパラメータをスピーチパラメータの事前定義済み参照データベースと比較することにより、その発話における状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するようにも調整されている。最後に、主要インジケータユニット5040は、その分析結果を出力するように調整される。
【0069】
本発明のいくつかの実施形態によれば、装置5000は、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つを対象に構成されている。
【0070】
本発明のいくつかの実施形態によれば、装置5000は、音声通信デバイス、有線または無線音声デバイス、セルラー方式通信デバイス、ネットワーク化された(またはネットワーク化されていない)パーソナルデバイスアクセサリ(PDA)、音声録音デバイス、パーソナルコンピュータ、およびサーバを含む一覧から選択される。
【0071】
本発明のいくつかの実施形態によれば、出力ユニット5040は、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルまたはリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、および電子手帳とのインタフェースまたはその他任意の電子出力機器とのインタフェースのうちの少なくとも1つを備える。
【0072】
いくつかの実施形態によれば、本発明のコンピュータ実装方法、データ処理システム、およびコンピュータプログラム製品は、無線または有線通信システム内で実装され得る。具体的には、本発明は、セルラー通信システムで実装され得る。本発明は、いくつかの実施形態において、リアルタイム環境で動作するように構成され得るが、オフラインスピーチ分析システムとしても構成され得る。
【0073】
いくつかの実施形態によれば、本発明は、複数のアーキテクチャで実装され得る。例えば、任意の中央物理箇所で携帯電話事業者の集中サーバを通過する通話の音声データに対して上記段階を実行する集中分析モジュールが提供され得る。
【0074】
他の実施形態によれば、本発明は、スピーチ電気通信デバイスなどの通信装置にソフトウェアまたはハードウェアとして組み込まれるスタンドアロンモジュールとして実装され得る。例えば、具体的なエンドユーザ向け携帯電話デバイスを通過する通話の音声データに対して上記段階を実行する分析モジュールが提供され得る。
【0075】
任意で、実施形態は、会話している話者の一方または双方の分析に限らず、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途などの目的でも利用され得る。
【0076】
いくつかの実施形態によれば、本発明のコンピュータ実装方法、データ処理システム、装置、およびコンピュータプログラム製品は、サービス、売上、顧客対応、研修、および他の組織的な目的を改善するために、コールセンタおよびコンタクトセンタにおける会話のリアルタイムまたはオフラインスピーチ分析の範囲内で実装され得る。
【0077】
いくつかの実施形態によれば、本発明は、有線電話での会話をリアルタイムおよびオフラインでスピーチ分析し、会話している話者の一方または双方を上記と同じ目的で分析する。
【0078】
いくつかの実施形態によれば、本発明は、ウェブベースの会話をリアルタイムおよびオフラインでスピーチ分析し、当事者の一方または双方を上記と同じ目的で分析する。
【0079】
いくつかの実施形態によれば、本発明は、対面による会話をリアルタイムおよびオフラインでスピーチ分析し、当事者の一方または双方を上記と同じ目的で分析する。
【0080】
いくつかの実施形態によれば、本発明は、会話、自己スピーチ、または観衆の前でのスピーチかを問わず、任意の記録されたスピーチをリアルタイムおよびオフラインでスピーチ分析し、当事者の一方または双方を上記と同じ目的で分析する。
【0081】
有利に、人々のコミュニケーション上、心理的、人格的、および行動的特徴を評価することは、様々な理由でとてつもなく重要である。まず、話者本人に評価データを提供することにより、認識、進展、および様々な学習目的を促す。加えて、個人的、商業的、教育的、職業的、医療上、心理的など、様々な目的でその話者を知りたい、支援したい、上手に交流したい他者にとって大きな重要性を有する。
【0082】
本発明のいくつかの実施形態によれば、このシステムは、デジタル電子回路で、またはコンピュータハードウェア、ファームウェア、ソフトウェア、あるいはそれらの組み合わせで実装することができる。
【0083】
本発明は、データ記憶システム、少なくとも1つの入力装置、および少なくとも1つの出力装置との間でデータと命令とを送受信するために連結された少なくとも1つのプログラマブルプロセッサを含むプログラマブルシステムで実行可能である1つ以上のコンピュータプログラムで好都合に実装することができる。コンピュータプログラムとは、コンピュータで直接または間接的に使用することができ、特定のアクティビティを実行したり、特定の結果をもたらしたりする命令の集合のことである。コンピュータプログラムは、コンパイルまたは解釈された言語を含む、任意の形状のプログラミング言語で記述することができ、スタンドアロンプログラム、またはコンピュータ環境での使用に適したモジュール、コンポーネント、サブルーチン、あるいは他のユニットを含む任意の形状で展開することができる。
【0084】
命令プログラムを実行するための適切なプロセッサは、例えばデジタル信号プロセッサ(DSP)を含むが、汎用マイクロプロセッサ、および任意の種類のコンピュータの単一プロセッサまたは複数のプロセッサのいずれかも含む。一般にプロセッサは、読み取り専用メモリあるいはランダムアクセスメモリ、またはその両方から命令とデータとを受信する。コンピュータの必須要素は、命令を実行するためのプロセッサ、および命令とデータとを格納するための1つ以上のメモリである。一般にコンピュータは、データファイルを格納するための1つ以上の大容量記憶装置も含むか、それらと通信するように動作可能に連結され、かかる装置は、内蔵ハードディスクおよびリムーバブルディスクなどの磁気ディスク、光磁気ディスク、および光ディスクを含む。コンピュータプログラム命令とデータとを有形的に一体化するのに適した記憶装置は、例えば、EPROM、EEPROM、およびフラッシュメモリ装置などの半導体メモリデバイス、内蔵ハードディスクおよびリムーバブルディスクなどの磁気ディスク、光磁気ディスク、CD−ROMおよびDVD−ROMディスクなどを含む、すべての形状の不揮発性メモリを含む。プロセッサおよびメモリは、ASIC(特定用途向け集積回路)によって補完されたり、その中に組み込まれたりする場合がある。
【0085】
上記説明において、実施形態は、本発明の実施例または実装形態である。「一実施形態」、「実施形態」、または「いくつかの実施形態」が多様に出現しても、それらが必ずしもすべて同じ実施形態を言及するとは限らない。
【0086】
本発明の様々な特徴が単一の実施形態の場面で説明されている場合があるが、それらの特徴は、別個に、あるいは任意の適切な組み合わせで提供されることもある。逆に、明瞭化のために、本明細書において別個の実施形態の場面で本発明が説明されている場合があるが、本発明は単一の実施形態でも実装され得る。
【0087】
明細書における「いくつかの実施形態」、「実施形態」、「一実施形態」または「他の実施形態」という言及は、その実施形態に関連して記載されている特定の特性、構造、または特徴が少なくともいくつかの実施形態に含まれているが、本発明のすべての実施形態に含まれるとは限らないことを意味する。
【0088】
本明細書で用いられている語法および用語は、制限的なものと解釈されるべきではなく、説明のみを目的としていると理解されるべきである。
【0089】
本発明の教示の原理および用途は、添付の説明、図、および実施例を参照することによってさらに良好に理解され得る。
【0090】
本明細書に記載されている詳細は、本発明の用途に対する制限を意味するものではないと理解されるべきである。
【0091】
さらに、本発明は様々な方法で実行または実施することができ、かつ本発明は上記説明に概説された実施形態以外の実施形態で実装可能であると理解されるべきである。
【0092】
「含む」、「備える」、「成る」、およびそれらの文法的変形は、1つ以上の構成要素、機能、ステップ、あるいは整数、またはそれらの群が追加されることを排除するものではなく、この用語は、構成要素、機能、ステップ、または整数を指定するものとして解釈されるべきでないと理解されるべきである。
【0093】
明細書または請求項が「付加」要素を言及している場合、それは付加要素が1つよりも多く存在することを除外しない。
【0094】
請求項または明細書が「1つ」の要素を言及している場合でも、かかる言及はその要素が1つしか存在しないと解釈されるものではないと理解されるべきである。
【0095】
明細書に、構成要素、機能、構造、または特徴が「含み得る」、「含んでも良い」、「含む場合がある」、「含む可能性がある」と述べられている場合には、その特定の構成要素、機能、構造、または特徴を含むことが必須ではないと理解されるべきである。
【0096】
該当する場合には、状態図、流れ図、あるいはその両方が実施形態を説明する目的で使用され得るが、本発明は、それらの図または対応する説明に限定されない。例えば、流れは、図示された各々のボックスまたは状態を通過したり、図示または記載されたとおりの順序で移動したりする必要はない。
【0097】
本発明の方法は、選択されたステップまたは作業を、手動、自動、またはその組み合わせによって実行または完了することによって実装され得る。
【0098】
「方法」という用語は、所与の作業を達成するための方法、手段、技術、および手順であって、本発明が属する当業者の間では公知であるか、公知の方法、手段、技術、および手順から当業者によって容易に開発される方法、手段、技術、および手順を含むがこれらに限定されない方法、手段、技術、および手順を言及し得る。
【0099】
請求項および明細書に明示される説明、実施例、方法、および用具は制限的なものとしてではなく、例証的なものに過ぎないと解釈されるべきである。
【0100】
本明細書で使用される専門的および科学的な用語の意味は、別段の規定がなされていない限り、本発明が属する技術の当業者によって広く理解されるべきである。
【0101】
本発明は、本明細書に記載されているものと同等または同様の方法および用具を用いたテストまたは実践において実装され得る。
【0102】
特許、特許出願、記事など、本明細書で参照または言及されているいかなる出版物も、個々の出版物が本明細書に援用されるよう具体的かつ個別に明示されている場合と同程度に、その全体が本明細書に援用される。加えて、本発明のいくつかの実施形態の説明におけるいかなる参照先の引用または特定も、かかる参照が本発明に対する従来技術として提供されているという承認とは解釈されないものとする。
【0103】
本発明について、限られた数の実施形態を取り上げて説明してきたが、これらは本発明の範囲を制限するものとしてではなく、好適な実施形態のいくつかの実例として解釈されるべきである。その他可能な変形、改変、および応用も、本発明の範囲内である。そのため、本発明の範囲は、ここまでの記載内容によってではなく、添付の特許請求の範囲とそれらの法的均等物とによって制限されるべきである。
【特許請求の範囲】
【請求項1】
様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するためのスピーチパラメータ参照データベースを作成するコンピュータ実装方法であって、
特定の発語場面を手動で選択することと、
前記選択された場面で分析する前記行動的、心理的、およびスピーチスタイル上の特徴を手動で選択することと、
前記選択された場面における人々の複数の発話を取得することと、
前記発話を類似の行動的、心理的、およびスピーチスタイル上の特徴を表す群に手動でグループ化することと、
類似の行動的、心理的、およびスピーチスタイル上の特徴を表す前記発話群内にある前記発話の各々を前処理して、無音のセグメントとアクティブなスピーチセグメントとに分けることと、
前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、前記ブロックがピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有することと、
前記第1のスピーチパラメータから複数の第2のスピーチパラメータを導出することであって、前記複数の選択されたスピーチパラメータは、前記一連のブロックにおける一連の均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と、前記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長と、のうちの少なくとも1つを含むことと、
一意の第2のスピーチパラメータと、パラメータの組み合わせと、前記第2のパラメータからの各発話群に共通するパラメータの値とを判断することであって、前記一意の第2のスピーチパラメータは、各群の前記典型的な行動的、心理的、またはスピーチスタイル上の特徴を表すことと、
を含む、コンピュータ実装方法。
【請求項2】
導出された複数の第2のスピーチパラメータが、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを備える、請求項1に記載の方法。
【請求項3】
所与の状況および場面における話者の発話を分析し、前記所与の状況における前記話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのコンピュータ実装方法であって、
様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するためのスピーチパラメータ参照データベースを作成することと、
具体的な状況および場面における話者の発話を取得することと、
前記取得した発語を前処理して無音のセグメントとアクティブなスピーチセグメントとに分け、前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、前記ブロックがピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有することと、
前記第1のパラメータから複数の第2のスピーチパラメータを導出することであって、前記複数の選択されたスピーチパラメータは、前記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と、前記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長と、のうちの少なくとも1つを含むことと、
前記発話における前記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出することと、
前記算出されたパラメータをスピーチパラメータの前記事前定義済み参照データベースと比較することにより、前記発話における前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点することと、
前記判断および評点された結果を出力することと、
を含む、コンピュータ実装方法。
【請求項4】
導出された複数の第2のスピーチパラメータが、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを備える、請求項3に記載の方法。
【請求項5】
発話を分類するためのスピーチパラメータ参照データベースを前記作成することが、
特定の発語場面を手動で選択することと、
前記選択された場面で分析する前記行動的、心理的、およびスピーチスタイル上の特徴を手動で選択することと、
前記選択された場面における人々の複数の発話を取得することと、
前記発話を類似の行動的、心理的、およびスピーチスタイル上の特徴を表す群に手動でグループ化することと、
類似の行動的、心理的、およびスピーチスタイル上の特徴を表す前記発話群内にある前記発話の各々を前処理して、無音のセグメントとアクティブなスピーチセグメントとに分けることと、
前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、前記ブロックが、ピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有することと、
複数の第2のスピーチパラメータを導出することであって、前記複数の選択されたスピーチパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを含むことと、
一意の第2のスピーチパラメータと、パラメータの組み合わせと、各発話群に共通し、かつ各群の典型的な行動的、心理的、またはスピーチスタイル上の特徴を表すパラメータの値とを判断することと、
を含む、請求項4に記載の方法。
【請求項6】
現在の分析対象話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記話者に関する現在の分析が話者から独立したものではなく、話者に依存したものとなるように、前記話者の一意のスピーチパターンを認識するための前記話者の事前取得済みスピーチサンプルを前記スピーチパラメータ参照データベース内に備えることをさらに含む、請求項5に記載方法。
【請求項7】
前記話者の人格的特徴を判断し、その人格的特徴を状況的特徴と区別するために、いくつかの異なる状況で前記話者を繰り返し分析し、前記異なる状況で反復的かつ共通する前記スピーチパターンをさらに抽出することをさらに含む、請求項5に記載の方法。
【請求項8】
前記話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記話者の現在の感情的状態を前記状況的特徴と区別するためのスピーチ分析による感情検知を使用することをさらに含む、請求項5に記載の方法。
【請求項9】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用することをさらに含む、請求項5に記載の方法。
【請求項10】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記スピーチ分析によって補完される前記話者の視覚分析によるボディランゲージ分析を使用することをさらに含む、請求項5に記載の方法。
【請求項11】
前記スピーチパラメータ参照データベースと前記分類プロセスとを改善するために、話者の行動的、心理的、およびスピーチスタイル上の特徴に関する継続的分析を使用して学習システム特性を提供することをさらに含む、請求項5に記載の方法。
【請求項12】
複数の話者を備える発話を対象とした方法であって、前記方法が複数の話者の声を分別することをさらに含み、かつ前記方法の各動作が話者ごとに別々に実行される、請求項5に記載の方法。
【請求項13】
所与の状況および場面における話者の発話を分析し、前記所与の状況における前記話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのデータ処理システムであって、
前記話者の前記発語をサンプリングすることと、前記話者のサンプリングされた発声を受信することとのうちの1つを実行するように調整された音声入力ユニットと、
前記音声入力ユニットに連結され、音声入力ユニットから音声サンプルを前処理するように調整された前処理ユニットと、
前記前処理ユニットに連結された主要処理ユニットと、
前記主要処理ユニットに連結された出力ユニットおよび話者参照データベースと、
を備えるデータ処理システムであって、
前記前処理ユニットは、前記サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントと分け、前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整されており、前記ブロックは、ピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有し、
前記データベースが、一意の第2のスピーチパラメータとパラメータの組み合わせとに従い、様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するように調整されており、前記複数の選択されたスピーチパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを含み、
前記主要処理ユニットは、前記第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、前記現在分析されている発話から導出し、
前記発話における前記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出し、
前記算出された一意のスピーチパラメータを第2のスピーチパラメータの前記事前定義済み参照データベースと比較することによって、前記発話における前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するように調整されており、前記出力ユニットは、前記分析結果を出力するように調整されている、
システム。
【請求項14】
前記出力ユニットは、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルおよびリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、電子手帳とのインタフェース、または電子出力機器とのインタフェースのうちの少なくとも1つを備える、請求項13に記載のシステム。
【請求項15】
前記システムは、音声通信システム、有線および無線電話通信システム、セルラー方式通信ネットワーク、ウェブベースの通信システム、ボイスオーバーIPベースの通信システム、およびコールセンタ通信システムから成る群から選択された通信システム内で実装される、請求項13に記載のシステム。
【請求項16】
前記システムは複数の用途向けに構成されており、前記複数の用途が、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つを含む、請求項13に記載のシステム。
【請求項17】
現在の分析対象話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記話者に関する前記現在の分析が話者から独立したものではなく、話者に依存したものとなるように、前記データベースは前記話者の一意のスピーチパターンを認識するための前記話者の事前取得済みスピーチサンプルをさらに備える、請求項13に記載のシステム。
【請求項18】
前記話者の前記人格的特徴を判断し、それらを前記状況的特徴と区別するために、いくつかの異なる状況で前記話者を繰り返し分析し、前記異なる状況で反復的かつ共通する前記スピーチパターンを抽出するように調整されている、請求項13に記載のシステム。
【請求項19】
前記話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記現在の感情的状態を前記状況的特徴と区別するためのスピーチ分析による感情検知を使用するように調整されている、請求項13に記載のシステム。
【請求項20】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用するように調整されている、請求項13に記載のシステム。
【請求項21】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記スピーチ分析によって補完される前記話者の視覚分析によるボディランゲージ分析を使用するように調整されている、請求項13に記載のシステム。
【請求項22】
前記スピーチパラメータ参照データベースと前記分類プロセスとを改善するために、話者の行動的、心理的、およびスピーチスタイル上の特徴に関する継続的分析を使用して学習システム特性を提供するように調整されている、請求項13に記載のシステム。
【請求項23】
前記複数の話者の声を分別するようにさらに調整されており、かつ各話者を別々に分析するように調整されている、複数の話者を備える発話を対象とした、請求項13に記載のシステム。
【請求項24】
話者の発話を分析し、所与の状況および場面における前記話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するための装置であって、
前記話者の前記発声をサンプリングするか、またはサンプリングされた前記話者の発語を取得するように調整された音声入力ユニットと、
前記音声入力ユニットに連結され、音声入力ユニットから音声サンプルを前処理するように調整された前処理ユニットと、
前記前処理ユニットに連結された主要処理ユニットと、
前記主要処理ユニットに連結された主要インジケータ出力ユニットと、
を備え、前記前処理ユニットは、
前記サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントとに分け、前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整されており、前記ブロックは、ピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有し、
前記装置は、参照データベースと動作可能に関連付けられており、前記データベースは、一意の第2のスピーチパラメータとパラメータの組み合わせとに応じた様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するように配置されており、前記複数の選択されたスピーチパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを含み、
前記主要処理ユニット、
前記第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、前記現在分析されている発話から導出し、
前記発話における前記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出し、
前記算出されたパラメータをスピーチパラメータの前記事前定義済み参照データベースと比較することにより、前記発話における前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点し、
前記主要出力インジケータユニットが、前記分析結果を出力するように調整されているシステム。
【請求項25】
自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つを対象に構成されている、請求項24に記載の装置。
【請求項26】
音声通信デバイス、有線または無線音声デバイス、セルラー方式通信デバイス、ネットワーク化されたパーソナルデバイスアクセサリ(PDA)、ネットワーク化されていないPDA、音声録音デバイス、パーソナルコンピュータ、およびサーバを含む一覧から選択される、請求項24に記載の装置。
【請求項27】
前記出力ユニットが、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルおよびリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、電子手帳とのインタフェースまたは電子出力機器とのインタフェースのうちの少なくとも1つを備える、請求項24に記載の装置。
【請求項1】
様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するためのスピーチパラメータ参照データベースを作成するコンピュータ実装方法であって、
特定の発語場面を手動で選択することと、
前記選択された場面で分析する前記行動的、心理的、およびスピーチスタイル上の特徴を手動で選択することと、
前記選択された場面における人々の複数の発話を取得することと、
前記発話を類似の行動的、心理的、およびスピーチスタイル上の特徴を表す群に手動でグループ化することと、
類似の行動的、心理的、およびスピーチスタイル上の特徴を表す前記発話群内にある前記発話の各々を前処理して、無音のセグメントとアクティブなスピーチセグメントとに分けることと、
前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、前記ブロックがピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有することと、
前記第1のスピーチパラメータから複数の第2のスピーチパラメータを導出することであって、前記複数の選択されたスピーチパラメータは、前記一連のブロックにおける一連の均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と、前記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長と、のうちの少なくとも1つを含むことと、
一意の第2のスピーチパラメータと、パラメータの組み合わせと、前記第2のパラメータからの各発話群に共通するパラメータの値とを判断することであって、前記一意の第2のスピーチパラメータは、各群の前記典型的な行動的、心理的、またはスピーチスタイル上の特徴を表すことと、
を含む、コンピュータ実装方法。
【請求項2】
導出された複数の第2のスピーチパラメータが、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを備える、請求項1に記載の方法。
【請求項3】
所与の状況および場面における話者の発話を分析し、前記所与の状況における前記話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのコンピュータ実装方法であって、
様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するためのスピーチパラメータ参照データベースを作成することと、
具体的な状況および場面における話者の発話を取得することと、
前記取得した発語を前処理して無音のセグメントとアクティブなスピーチセグメントとに分け、前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、前記ブロックがピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有することと、
前記第1のパラメータから複数の第2のスピーチパラメータを導出することであって、前記複数の選択されたスピーチパラメータは、前記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドの時間単位当たりのセグメントの合計と、前記一連のブロックにおける均一ピッチ、上昇ピッチ、および下降ピッチトレンドのセグメントの平均長と、のうちの少なくとも1つを含むことと、
前記発話における前記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出することと、
前記算出されたパラメータをスピーチパラメータの前記事前定義済み参照データベースと比較することにより、前記発話における前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点することと、
前記判断および評点された結果を出力することと、
を含む、コンピュータ実装方法。
【請求項4】
導出された複数の第2のスピーチパラメータが、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを備える、請求項3に記載の方法。
【請求項5】
発話を分類するためのスピーチパラメータ参照データベースを前記作成することが、
特定の発語場面を手動で選択することと、
前記選択された場面で分析する前記行動的、心理的、およびスピーチスタイル上の特徴を手動で選択することと、
前記選択された場面における人々の複数の発話を取得することと、
前記発話を類似の行動的、心理的、およびスピーチスタイル上の特徴を表す群に手動でグループ化することと、
類似の行動的、心理的、およびスピーチスタイル上の特徴を表す前記発話群内にある前記発話の各々を前処理して、無音のセグメントとアクティブなスピーチセグメントとに分けることと、
前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割することであって、前記ブロックが、ピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有することと、
複数の第2のスピーチパラメータを導出することであって、前記複数の選択されたスピーチパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを含むことと、
一意の第2のスピーチパラメータと、パラメータの組み合わせと、各発話群に共通し、かつ各群の典型的な行動的、心理的、またはスピーチスタイル上の特徴を表すパラメータの値とを判断することと、
を含む、請求項4に記載の方法。
【請求項6】
現在の分析対象話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記話者に関する現在の分析が話者から独立したものではなく、話者に依存したものとなるように、前記話者の一意のスピーチパターンを認識するための前記話者の事前取得済みスピーチサンプルを前記スピーチパラメータ参照データベース内に備えることをさらに含む、請求項5に記載方法。
【請求項7】
前記話者の人格的特徴を判断し、その人格的特徴を状況的特徴と区別するために、いくつかの異なる状況で前記話者を繰り返し分析し、前記異なる状況で反復的かつ共通する前記スピーチパターンをさらに抽出することをさらに含む、請求項5に記載の方法。
【請求項8】
前記話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記話者の現在の感情的状態を前記状況的特徴と区別するためのスピーチ分析による感情検知を使用することをさらに含む、請求項5に記載の方法。
【請求項9】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用することをさらに含む、請求項5に記載の方法。
【請求項10】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記スピーチ分析によって補完される前記話者の視覚分析によるボディランゲージ分析を使用することをさらに含む、請求項5に記載の方法。
【請求項11】
前記スピーチパラメータ参照データベースと前記分類プロセスとを改善するために、話者の行動的、心理的、およびスピーチスタイル上の特徴に関する継続的分析を使用して学習システム特性を提供することをさらに含む、請求項5に記載の方法。
【請求項12】
複数の話者を備える発話を対象とした方法であって、前記方法が複数の話者の声を分別することをさらに含み、かつ前記方法の各動作が話者ごとに別々に実行される、請求項5に記載の方法。
【請求項13】
所与の状況および場面における話者の発話を分析し、前記所与の状況における前記話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するためのデータ処理システムであって、
前記話者の前記発語をサンプリングすることと、前記話者のサンプリングされた発声を受信することとのうちの1つを実行するように調整された音声入力ユニットと、
前記音声入力ユニットに連結され、音声入力ユニットから音声サンプルを前処理するように調整された前処理ユニットと、
前記前処理ユニットに連結された主要処理ユニットと、
前記主要処理ユニットに連結された出力ユニットおよび話者参照データベースと、
を備えるデータ処理システムであって、
前記前処理ユニットは、前記サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントと分け、前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整されており、前記ブロックは、ピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有し、
前記データベースが、一意の第2のスピーチパラメータとパラメータの組み合わせとに従い、様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するように調整されており、前記複数の選択されたスピーチパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを含み、
前記主要処理ユニットは、前記第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、前記現在分析されている発話から導出し、
前記発話における前記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出し、
前記算出された一意のスピーチパラメータを第2のスピーチパラメータの前記事前定義済み参照データベースと比較することによって、前記発話における前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するように調整されており、前記出力ユニットは、前記分析結果を出力するように調整されている、
システム。
【請求項14】
前記出力ユニットは、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルおよびリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、電子手帳とのインタフェース、または電子出力機器とのインタフェースのうちの少なくとも1つを備える、請求項13に記載のシステム。
【請求項15】
前記システムは、音声通信システム、有線および無線電話通信システム、セルラー方式通信ネットワーク、ウェブベースの通信システム、ボイスオーバーIPベースの通信システム、およびコールセンタ通信システムから成る群から選択された通信システム内で実装される、請求項13に記載のシステム。
【請求項16】
前記システムは複数の用途向けに構成されており、前記複数の用途が、自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つを含む、請求項13に記載のシステム。
【請求項17】
現在の分析対象話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記話者に関する前記現在の分析が話者から独立したものではなく、話者に依存したものとなるように、前記データベースは前記話者の一意のスピーチパターンを認識するための前記話者の事前取得済みスピーチサンプルをさらに備える、請求項13に記載のシステム。
【請求項18】
前記話者の前記人格的特徴を判断し、それらを前記状況的特徴と区別するために、いくつかの異なる状況で前記話者を繰り返し分析し、前記異なる状況で反復的かつ共通する前記スピーチパターンを抽出するように調整されている、請求項13に記載のシステム。
【請求項19】
前記話者の前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記現在の感情的状態を前記状況的特徴と区別するためのスピーチ分析による感情検知を使用するように調整されている、請求項13に記載のシステム。
【請求項20】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、韻律的なスピーチ分析によって補完される音声認識技術による語および内容スピーチ分析を使用するように調整されている、請求項13に記載のシステム。
【請求項21】
前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点するに当たっての精度を高めるために、前記スピーチ分析によって補完される前記話者の視覚分析によるボディランゲージ分析を使用するように調整されている、請求項13に記載のシステム。
【請求項22】
前記スピーチパラメータ参照データベースと前記分類プロセスとを改善するために、話者の行動的、心理的、およびスピーチスタイル上の特徴に関する継続的分析を使用して学習システム特性を提供するように調整されている、請求項13に記載のシステム。
【請求項23】
前記複数の話者の声を分別するようにさらに調整されており、かつ各話者を別々に分析するように調整されている、複数の話者を備える発話を対象とした、請求項13に記載のシステム。
【請求項24】
話者の発話を分析し、所与の状況および場面における前記話者の行動的、心理的、およびスピーチスタイル上の特徴を判断するための装置であって、
前記話者の前記発声をサンプリングするか、またはサンプリングされた前記話者の発語を取得するように調整された音声入力ユニットと、
前記音声入力ユニットに連結され、音声入力ユニットから音声サンプルを前処理するように調整された前処理ユニットと、
前記前処理ユニットに連結された主要処理ユニットと、
前記主要処理ユニットに連結された主要インジケータ出力ユニットと、
を備え、前記前処理ユニットは、
前記サンプリングされた発語を前処理して無音のセグメントとアクティブなスピーチセグメントとに分け、前記アクティブなスピーチセグメントを一連の等しい長さのブロックに分割するように調整されており、前記ブロックは、ピッチパラメータと振幅パラメータとを含む第1のスピーチパラメータを有し、
前記装置は、参照データベースと動作可能に関連付けられており、前記データベースは、一意の第2のスピーチパラメータとパラメータの組み合わせとに応じた様々な行動的、心理的、およびスピーチスタイル上の特徴に従って発話を分類するように配置されており、前記複数の選択されたスピーチパラメータは、平均一時停止長、時間単位当たりの一時停止の合計、短時間無音の平均長、時間単位当たりの短時間無音の合計、均一ピッチセグメントの平均長、時間単位当たりの均一ピッチセグメントの合計、上昇ピッチセグメントの平均長、時間単位当たりの上昇ピッチセグメントの合計、下降ピッチセグメントの平均長、時間単位当たりの下降ピッチセグメントの合計、均一ピッチセグメント内の平均振幅偏差、上昇ピッチセグメント内の平均振幅偏差、下降ピッチセグメント内の平均振幅偏差、時間単位当たりのピッチ変量および範囲、時間単位当たりの平均ピッチ傾斜、スピーチ信号のスペクトル形状およびスペクトル包絡線の経時パターン、上昇、下降、および均一ピッチトレンドの順序の経時パターンのうちの少なくとも1つを含み、
前記主要処理ユニット、
前記第2のスピーチパラメータを含む一覧から選択された複数の第2のスピーチパラメータを、前記現在分析されている発話から導出し、
前記発話における前記第2のパラメータから、一意のスピーチパラメータと、パラメータの組み合わせと、状況的、行動的、心理的、およびスピーチスタイル上の特徴を表すパラメータの値とを算出し、
前記算出されたパラメータをスピーチパラメータの前記事前定義済み参照データベースと比較することにより、前記発話における前記状況的、行動的、心理的、およびスピーチスタイル上の特徴を判断および評点し、
前記主要出力インジケータユニットが、前記分析結果を出力するように調整されているシステム。
【請求項25】
自己フィードバック、自己認識、エンターテインメント、行動トレーニング、営業強化、カスタマーサービス強化、顧客およびビジネスインテリジェンス、防衛およびセキュリティ用途、ビジネス交渉、広告、縁結び、デート、娯楽、ゲーム、玩具、カウンセリング、人材用途、重役研修、従業員および職業訓練、心理的および教育的用途、医療用途といった用途のうちの少なくとも1つを対象に構成されている、請求項24に記載の装置。
【請求項26】
音声通信デバイス、有線または無線音声デバイス、セルラー方式通信デバイス、ネットワーク化されたパーソナルデバイスアクセサリ(PDA)、ネットワーク化されていないPDA、音声録音デバイス、パーソナルコンピュータ、およびサーバを含む一覧から選択される、請求項24に記載の装置。
【請求項27】
前記出力ユニットが、可視要素、可聴要素、記憶装置、テキスト、監視デバイスとのインタフェース、インターネットとのインタフェース、ローカルおよびリモートデバイスまたはコンピュータとのインタフェース、別のネットワークとのインタフェース、有線、無線、または携帯電話とのインタフェース、コンピュータゲームとのインタフェース、玩具とのインタフェース、電子手帳とのインタフェースまたは電子出力機器とのインタフェースのうちの少なくとも1つを備える、請求項24に記載の装置。
【図1】


【図2】
【図3】

【図4】
【図5】
【図2】
【図3】
【図4】
【図5】
【公表番号】特表2011−524551(P2011−524551A)
【公表日】平成23年9月1日(2011.9.1)
【国際特許分類】
【出願番号】特願2011−514199(P2011−514199)
【出願日】平成21年6月17日(2009.6.17)
【国際出願番号】PCT/IL2009/000604
【国際公開番号】WO2009/153788
【国際公開日】平成21年12月23日(2009.12.23)
【出願人】(510331489)ボイスセンス エルティーディー. (1)
【氏名又は名称原語表記】VOICESENSE LTD.
【住所又は居所原語表記】P.O.Box 8844, 8 Hamachshev street, 42507 Netanya (IL)
【Fターム(参考)】
【公表日】平成23年9月1日(2011.9.1)
【国際特許分類】
【出願日】平成21年6月17日(2009.6.17)
【国際出願番号】PCT/IL2009/000604
【国際公開番号】WO2009/153788
【国際公開日】平成21年12月23日(2009.12.23)
【出願人】(510331489)ボイスセンス エルティーディー. (1)
【氏名又は名称原語表記】VOICESENSE LTD.
【住所又は居所原語表記】P.O.Box 8844, 8 Hamachshev street, 42507 Netanya (IL)
【Fターム(参考)】
[ Back to top ]