
ソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラム
【課題】音声参加型のソーシャルネットワーキングサービスシステム等を提供する。
【解決手段】SNSシステムは、SNSを提供するサーバと通話装置とが接続されたSNSシステムであって、サーバは、通話装置から音声を入力する音声入力手段と、音声を解析することにより、少なくとも音声を入力したユーザを識別するユーザ識別情報と音声により入力された命令語と音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、命令語が音声の登録命令を示す場合、該入力された音声と、ユーザ識別情報に基づくユーザ識別子と、分類語とを対応付けて記憶手段に登録する音声登録手段と、命令語が音声の検索命令を示す場合、分類語を検索キーとして分類語に対応付けられた音声を記憶手段から検索する音声検索手段と、通話装置に対し音声検索手段により検索された音声を出力する音声出力手段とを有する。
【解決手段】SNSシステムは、SNSを提供するサーバと通話装置とが接続されたSNSシステムであって、サーバは、通話装置から音声を入力する音声入力手段と、音声を解析することにより、少なくとも音声を入力したユーザを識別するユーザ識別情報と音声により入力された命令語と音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、命令語が音声の登録命令を示す場合、該入力された音声と、ユーザ識別情報に基づくユーザ識別子と、分類語とを対応付けて記憶手段に登録する音声登録手段と、命令語が音声の検索命令を示す場合、分類語を検索キーとして分類語に対応付けられた音声を記憶手段から検索する音声検索手段と、通話装置に対し音声検索手段により検索された音声を出力する音声出力手段とを有する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、ソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラムの分野に関する。
【背景技術】
【0002】
近年、人と人とのつながりを促進、サポートするコミュニティ型のWebサイトとして、ソーシャルネットワーキングサービス(以下SNSという)が知られている。SNSは、友人や知人間のコミュニケーションを円滑にする手段や場を提供したり、趣味や嗜好、居住地域、出身校、あるいは友人の友人といったつながりを通じて新たな人間関係を構築する場等のソーシャルネットワーキングサービスを提供する。具体的には例えば、自身のプロフィール登録公開機能、ユーザ同士のメッセージ送受信(私書箱)機能、ユーザ相互リンク機能、ユーザ検索機能、ユーザの日記(ブログ)機能、コミュニティ機能などが提供されている(例えば特許文献1)。
【発明の概要】
【発明が解決しようとする課題】
【0003】
しかしながら、従来のSNSは、PC(パソコン)や携帯電話等を操作し、インターネット上のWebサイトを日常的に閲覧できるような人たちのみに開かれた情報ツールであった。そのため、様々な理由からPCやインターネットをはじめとする情報・通信技術の利用に困難を抱える人達(いわゆる情報弱者)には使用できない、あるいは使用が困難であるという問題があった。
【0004】
ここで例えば、高齢者はPCやインターネットを使い慣れていないものの、電話をかけることは従前から日常的に行われている行為である。つまり高齢者は音声によるコミュニケーションは慣れているため、音声によりSNSに参加することができれば、PCやインターネットを使い慣れていない者であっても容易にSNSに参加できる。また例えば、視覚障害者にとってWebサイトの閲覧は困難であっても、音声によりSNSに参加することができれば容易にSNSに参加できる。
【0005】
そこで本発明では上記のような点に鑑みて、音声参加型のソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラムを提供することを目的とする。
【課題を解決するための手段】
【0006】
上記課題を解決するため、本発明に係るSNSシステムは、SNSを提供するサーバと、通話装置とがネットワークを介し接続されたSNSシステムであって、サーバは、通話装置から音声を入力する音声入力手段と、前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、を有する。
【0007】
上記課題を解決するため、本発明に係るSNSサーバは、通話装置とネットワークを介し接続されるSNSを提供するSNSサーバあって、通話装置から音声を入力する音声入力手段と、前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、を有する。
【0008】
上記課題を解決するため、本発明に係るSNSプログラムは、コンピュータに、通話装置から音声を入力する音声入力手段と、前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段として機能させる。
【0009】
なお、本発明の構成要素、表現または構成要素の任意の組合せを、方法、装置、システム、コンピュータプログラム、記録媒体、などに適用したものも本発明の態様として有効である。
【発明の効果】
【0010】
本発明によれば、音声参加型のソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本実施形態に係るシステム構成図である。
【図2】SNSサーバ1の一実施形態の主要構成を示すハードウェア構成図である。
【図3】SNSサーバ1の一実施形態の主要機能を示す機能ブロック図である。
【図4】本実施形態に係るユーザDB108a例を示す。
【図5】本実施形態に係る音声DB108b例を示す。
【図6】本実施形態に係るSNSサーバ1のログイン処理を説明するフローチャートである。
【図7】本実施形態に係るSNSサーバ1の音声登録及び音声検索処理を説明するフローチャートである。
【図8】本変形例1に係る公開限定ユーザテーブルの一例を示す。
【図9】本変形例2に係る同義語テーブルの一例を示す。
【図10】本実施形態に係るSNSのWebサイト画面例を示す。
【発明を実施するための形態】
【0012】
以下、本発明を実施するための形態を各実施形態において図面を用いて説明する。
【0013】
[システム構成]
(全体構成)
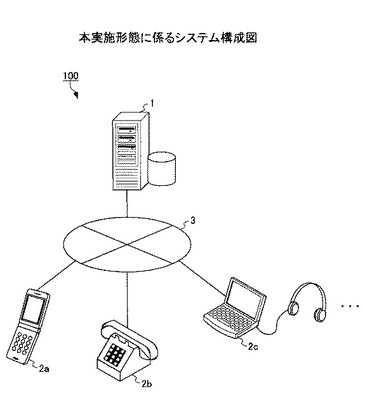
はじめに、具体的な発明の内容を説明する前に、本発明を実施するにあたっての全体構成について説明する。図1は、本実施形態に係るシステム構成図である。図に示されるように、本実施形態に係るSNSシステム100は、SNSサーバ1及び通話端末2がネットワーク3を介し接続される。
【0014】
SNSサーバ1は、ユーザの使用する通話端末2に対し、ソーシャルネットワーキングサービスを提供するサーバである。通話端末2は、ユーザの使用する通話端末2であり、具体的には携帯電話2a、固定電話2b、ヘッドフォン等の音声入出力器付きPC2c等である。ユーザはこれら通話端末2を使用して、SNSサーバ1から音声によるソーシャルネットワーキングサービスを受ける。
【0015】
ネットワーク3は、SNSサーバ1及び通話端末2を接続する通信ネットワークである。本実施形態においては、ユーザの通話端末2はSNSサーバ1から音声によるソーシャルネットワーキングサービスを受けるため、少なくとも音声通信が可能な通信ネットワークとなる。SNSサーバ1はインターネット網に接続されるので、通話端末2が携帯電話2aである場合、ネットワーク3は携帯公衆網及びインターネット網を含む。また通話端末2が固定電話2bである場合、ネットワーク3は固定電話網及びインターネット網を含む。また通話端末2がPC2cである場合、ネットワーク3はインターネット網である。
【0016】
なお、インターネット網に接続されるSNSサーバ1は、各公衆網に接続される通話端末2とはインターネット網のTCP/IP(Transmission Control Protocol/Internet Protocol)ネットワークを使って音声データをパケットとして送受信する必要があることから、VoIP(Voice Over IP)サーバを中継し音声のやり取りが行われることになる(非図示)。また通話端末2からすると、SNSサーバ1は通話先のIP電話に見えるので、SNSサーバ1と接続する際は通常の電話をかけるようにSNSサーバ1に付与されている電話番号に対し電話をかければよい。
【0017】
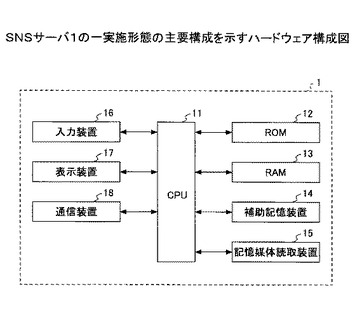
(ハードウェア)
ここで、本実施形態に係るSNSサーバ1のハードウェア構成について説明しておく。図2は、SNSサーバ1の一実施形態の主要構成を示すハードウェア構成図である。SNSサーバ1は、主要な構成として、CPU(Central Processing Unit)11、ROM(Read Only Memory)12、RAM(Random Access Memory)13、補助記憶装置14、記憶媒体読取装置15、入力装置16、表示装置17、及び通信装置18を含む構成である。
【0018】
CPU11は、マイクロプロセッサ及びその周辺回路から構成され、装置全体を制御する回路である。また、ROM12は、CPU11で実行される所定の制御プログラム(ソフトウェア部品)を格納するメモリであり、RAM13は、CPU11がROM12に格納された所定の制御プログラム(ソフトウェア部品)を実行して各種の制御を行うときの作業エリア(ワーク領域)として使用するメモリである。
【0019】
補助記憶装置14は、汎用のOS(Operating System)、プログラムを含む各種情報を格納する装置であり、不揮発性の記憶装置であるHDD(Hard Disk Drive)などが用いられる。記憶媒体読取装置15には、USBメモリ、CD、DVD等の携帯型メディアをセットすることで、外部からの情報を取得できる。
【0020】
入力装置16は、ユーザが各種入力操作を行うための装置である。入力装置16は、マウス、キーボード、表示装置17の表示画面上に重畳するように設けられたタッチパネルスイッチなどを含む。表示装置17は、各種データを表示画面に表示する装置である。例えば、LCD(Liquid Crystal Display)、CRT(Cathode Ray Tube)などから構成される。
【0021】
通信装置18は、ネットワーク3を介して他の機器との通信を行う装置である。有線ネットワークや無線ネットワークなど含む各種ネットワーク形態に応じた通信をサポートする。
【0022】
なお通話端末2については、従来の携帯電話、固定電話、PC等により実現されればよく、その説明は省略する。
【0023】
(機能)
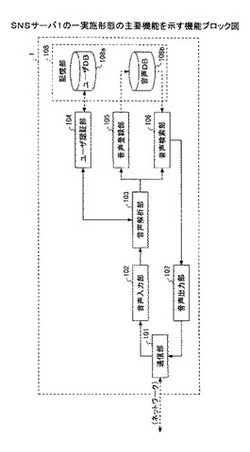
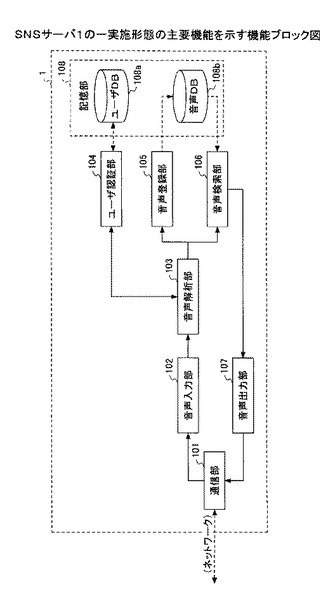
次に、SNSサーバ1の機能構成について説明する。図3は、SNSサーバ1の一実施形態の主要機能を示す機能ブロック図である。図に示されるようにSNSサーバ1は、主要な機能として、通信部101、音声入力部102、音声解析部103、ユーザ認証部104、音声登録部105、音声検索部106、音声出力部107、記憶部108を含む構成である。
【0024】
通信部101は、ネットワーク3と接続され、通話装置2との通信を行う。SNSサーバ1は通話装置2から着呼を受けてから呼を確立する。呼確立後、音声(音声データ)を受信すると、この音声を音声入力102に入力する。音声入力部102は、通信部101を介し通話装置2からの音声を入力する。なおこの音声はユーザによって発話されたユーザの会話音声に相当する。
【0025】
音声解析部103は、通話装置2から入力された音声を解析することにより、該音声を入力したユーザを識別するユーザ識別情報、該音声により入力された命令語と、該音声により入力されその音声が分類されるべきSNSサービス分類を示す分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)を抽出する。音声はユーザの会話音声に相当するが、この会話音声の中から、音声解析技術により音声内の単語を抽出し、また単語の意味から上述の語句を抽出するものであるが、この点詳細は後述する。
【0026】
ユーザ認証部104は、入力された音声から抽出されたユーザ識別情報に基づいてユーザ認証を行う。ユーザ識別情報はユーザを識別するための情報であり、例えば入力された音声の声紋や、音声から抽出されたユーザ識別語(ユーザ名、ユーザのみ知る所定ワード等)である。そして例えば音声によりユーザ認証を行う場合、ユーザDB108a内に予め登録されている音声(声紋)との照合により認証を行うことができ、またユーザ識別語によりユーザ認証を行う場合、ユーザDB108a内に予め登録されているユーザ識別語との照合により認証を行うことができる。
【0027】
音声登録部105は、音声により入力された命令語が、入力された音声の登録命令を示す場合、該入力された音声、ユーザ識別情報に基づくユーザ識別子、抽出された分類語、その他単語(キーワード)などを対応付けて記憶部108に登録する。つまりユーザが自身の音声を音声DB(Data Base)108bに登録したい場合には、その旨を示す命令語を音声により発話することにより、その音声を登録できるようになっている。また登録の際は、その音声の持ち主である登録者を識別するユーザ識別子(例えばユーザID)、その音声が分類されるべきSNSサービス分類を示す分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)などを対応付けて登録する。
【0028】
音声検索部106は、音声により入力された命令語が、記憶部108に登録された音声の検索命令を示す場合、分類語やその他単語(キーワード)を検索キーとして、音声を記憶部108から検索する。つまりユーザが音声DB108bから他の人から登録(投稿)された音声を検索したい場合(聴きたい場合)には、その旨を示す命令語、分類語やその他単語(キーワード)を音声により発話することにより、その条件にマッチする音声を検索できるようになっている。検索の際は、分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)などをキーとして音声DB108b内の音声を検索する。
【0029】
音声出力部107は、通話装置2に対し、検索された音声を出力する。つまりユーザが音声DB108bから検索した他の人の音声をそのユーザに対し出力する。この音声は通話装置2に出力されるので、ユーザはその音声を聴くことにより、他の人から登録(投稿)された音声を認識できる。
【0030】
記憶部108は、入力された音声と、その音声の持ち主である登録者のユーザ識別子と、入力された音声が分類されるべきSNSサービス分類を示す分類語、その他単語(キーワード)とを対応付けて音声DB108b内に記憶する。
【0031】
なお、以上説明したこれらの機能は、実際にはCPU11が実行するプログラムにより実現される。
【0032】
(ユーザDB108a例)
図4は、本実施形態に係るユーザDB108a例を示す。上述のしたようにユーザ認証部104は、入力された音声から抽出されたユーザ識別情報に基づいてユーザ認証を行うが、ユーザDB108aにはこの認証の為のユーザ情報が予め格納されている。
【0033】
「ユーザID」は、サーバ上一意に付番される識別子である。「氏」、「名」は、ユーザの氏名である。「パスワード」は、ユーザパスワードである。「秘密の質問」、「答え」は、ユーザがあらかじめ設定した質問と、その質問に対する答えである。これらはユーザ識別語によりユーザ認証を行う場合、ここに登録されているユーザ識別語との照合により認証を行う。「認証用音声」は、ユーザの音声(声紋)によって認証を行う場合に使用され、ここに登録されている音声(声紋)との照合により認証を行う。
【0034】
なお認証は、これら情報を持ってユーザを認証できる限り、いずれか1又は複数、もしくは全ての情報を用いて認証を行うことができる。言うまでもなく、認証に使用される情報が多いほど、認証の信頼度は向上するので、ある程度複数の情報を用いて認証を行うことが望ましい。
【0035】
(音声DB108b例)
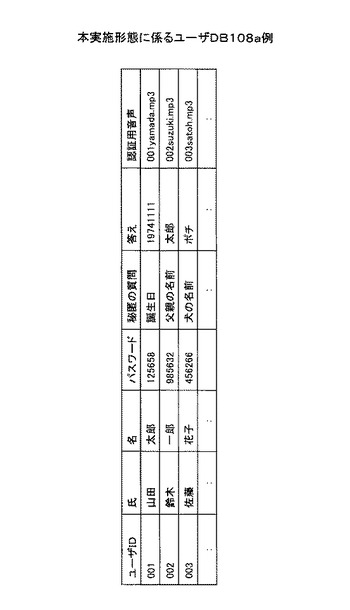
図5は、本実施形態に係る音声DB108b例を示す。上述のしたように音声登録部105は、ユーザが自身の音声をSNSサーバ1に登録したい場合には、その旨を示す命令語を音声により発話することにより、その音声を登録できるようになっており、登録の際は、その音声の持ち主である登録者を識別するユーザ識別子(例えばユーザID)、その音声が分類されるべきSNSサービス分類を示す分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)などを対応付けてこの音声DB108bに登録する。
【0036】
「ユーザID−データNo」は、サーバ上、登録音声に対し一意に付番される識別子である。付番ルールとしては例えば音声を登録したユーザのユーザIDに、データNo(順次昇順で発行)を付加して付番する。「登録音声」は、サーバ上登録される音声である。例えば、「001-001.mp3」はユーザIDが001による1番目に登録された音声実体ファイルを示す。「登録日」は、サーバ上、登録音声が登録された年月日時分を示す。
【0037】
「分類」は、その登録音声が分類されるべきSNSサービス分類を示す。従って分類はSNSサーバ1がユーザに対し提供するサービスの種類・カテゴリに対応し、例えばブログ、掲示板、伝言メール等がある。具体的に例えば、登録音声「001-001.mp3」は「分類」がブログであるので、この登録音声は内容的にSNSサービス内のブログとして投稿された音声内容になっているものである。
【0038】
「タグ」は、その登録音声内に含まれているキーワードが抽出されて格納される。入力された音声は音声解析部103により解析されるが、このとき音声内で音声内容(コンテンツ)をよく表現しうる重要語が抽出され、ここに格納されるようになっている。図に示されるように「タグ」は、「タグ1」、「タグ2」、「タグ3」といったように、複数格納可能であり、またこれら「タグ」は登録音声を検索する際の検索キーとして使用される。
【0039】
「リンク先」は、その登録音声が関連する関連先を示す。SNSサービスはユーザ間のコミニュケーションを図るツールであるので、ブログや掲示板を読んだ他のユーザが感想やコメントを返答することはよくあることである。よって図中、例えば「002-002.mp3」は「リンク先」が001-001になっていることから、この「002-002.mp3」は、「ユーザID−データNo」001-001である登録音声「001-001.mp3」に対し返答された登録音声である。
【0040】
[情報処理]
本実施形態に係るSNSサーバ1の情報処理について説明する。ユーザは通話装置2での通話を通じて、SNSサーバ1に対し、次の3つの操作を行うことができる。ログイン操作、音声登録操作、音声検索操作である。以下場面毎に説明していく。
【0041】
(ログイン操作)
まずユーザは、通常の電話をかけるように通話装置2のダイアルを操作してSNSサーバ1に付与されている電話番号に対し電話をかける。SNSサーバ1は電話網、VoIPサーバを介して通話装置2からの着呼を受け呼を確立する。呼確立するとSNSサーバ1から通信装置2の受話器に対し、「こちらはSNSサービスです。・・・」等のガイダンスが流れるので、ユーザはログイン操作を行うべく、ガイダンス又は所定の手順に従って、通信装置2の受話器からログインの為の通話を行う。以下その一例を示す。
ガイダンス「こちらはSNSサービスです。会員の方はまずユーザIDをお話下さい。会員でない方は、・・・。」
ユーザ「001」
ガイダンス「氏名をお話下さい。」
ユーザ「山田太郎」
ガイダンス「パスワードをお話下さい。」
ユーザ「125658」
ガイダンス「誕生日をお話下さい。」
ユーザ「19741111」
ガイダンス「認証中です。しばらくお待ち下さい。・・・認証されました。」
またもしくは、上述の一問一答形式でなくとも、所定情報をSNSサーバ1が認識しうる所定の手順に従って発話するようにしてもよい。以下その一例を示す。
ガイダンス「こちらはSNSサービスです。会員の方はログイン情報をお話下さい。会員でない方は、・・・。」
ユーザ「001、山田太郎、125658、19741111」
ガイダンス「認証中です。しばらくお待ち下さい。・・・認証されました。」
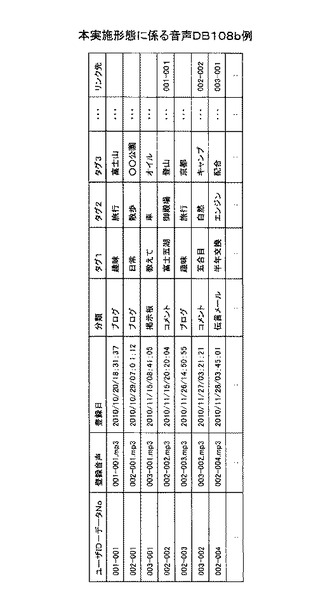
図6は、本実施形態に係るSNSサーバ1のログイン処理を説明するフローチャートである。以下図を参照しながら説明する。
【0042】
S1:ユーザ認証部104は、音声入力部102において、認証のためのユーザ情報を音声入力があったか否かを判定する。認証のためのユーザ情報とは、上述例の場合、ユーザID、氏名、パスワード、誕生日(秘密の質問)である。
【0043】
S2:音声解析部103は、入力された音声の解析を行う。認証のためのユーザ情報を抽出するためである。
【0044】
S3:音声解析部103は、入力された音声から認証のためのユーザ情報を抽出できたか否かを判定する。ここでは、ユーザID、氏名、パスワード、誕生日(秘密の質問)が抽出される必要がある。なお認証のためのユーザ情報を抽出できない場合、S1へ進み、ユーザに再度の音声入力を促す。
【0045】
S4:ユーザ認証部104は、認証のためのユーザ情報を抽出できた場合、その認証のためのユーザ情報を用いて、ユーザDB108aに登録されたユーザ情報があるか否かを検索する。なお併せて、ユーザDB108aの認証用音声を使用して音声(声紋)による照合も行う。
【0046】
S5:ユーザ認証部104は、登録されたユーザあったか否かを判定する。つまり、音声入力があったユーザ情報(認証用音声含む)と、ユーザDB108aに登録されたユーザ情報との照合により、一致した場合、登録されたユーザありと判定する。
【0047】
S6:ユーザ認証部104は、登録されたユーザありと判定した場合、認証OKと判定する。つまりログイン認証OKと判定する。
【0048】
S7:一方ユーザ認証部104は、登録されたユーザなしと判定した場合、認証NGと判定する。このとき、新規にユーザ登録するか否かの判定を行う。この場合、ガイダンスによりその旨を通話により確認することができる。またもしくは冒頭の上述ガイダンス「会員でない方は、・・・。」のところで非会員である旨を通話により確認することもできる。なお新規にユーザ登録しないとの判定がなされた場合、ログイン処理を打ち切ればよい。
【0049】
S8:ユーザ認証部104は、新規にユーザ登録すると判定した場合、登録に必要な情報、つまり認証のためのユーザ情報を音声入力があったか否かを判定する。ここでは認証のためのユーザ情報とは、上述例の場合、ユーザID、氏名、パスワード、誕生日(秘密の質問)であるので、これらユーザ情報をユーザが発話するよう、ガイダンス等によって導くようにする。
【0050】
S9:ユーザ認証部104は、登録に必要な情報、つまり認証のためのユーザ情報を音声入力があったと判定した場合、これらユーザ情報をユーザDB108aに登録する。またこのとき、ユーザが発話した音声を認証用音声として音声ファイルを生成し登録しておく。以上によりユーザ新規登録が完了したので、S6へ進み、この新規登録ユーザに対し認証OKと判定する。
【0051】
(音声登録操作)
次にユーザは、ログインするとSNSサーバ1から通信装置2の受話器に対し、「ログインに成功しました。・・・」等のガイダンスが流れるので、ユーザは音声登録操作を行うべく、ガイダンス又は所定の手順に従って、通信装置2の受話器から音声登録の為の通話を行う。以下その一例を示す。
ガイダンス「ログインに成功しました。どこで何をしますか?」
ユーザ「ブログを書く」
ユーザ「ブログを書く、ですね?」
ユーザ「はい。」
ガイダンス「それでは書き込みたいブログ内容をお話下さい。」
ユーザ「私の趣味は旅行なのですが先日富士山に行ってきました・・・。」
ガイダンス「確認のため、音声を再生します。」
ガイダンス「私の趣味は旅行なのですが先日富士山に行ってきました・・・。」
ガイダンス「登録してよろしいですか?」
ユーザ「はい。」
ガイダンス「登録完了しました。」
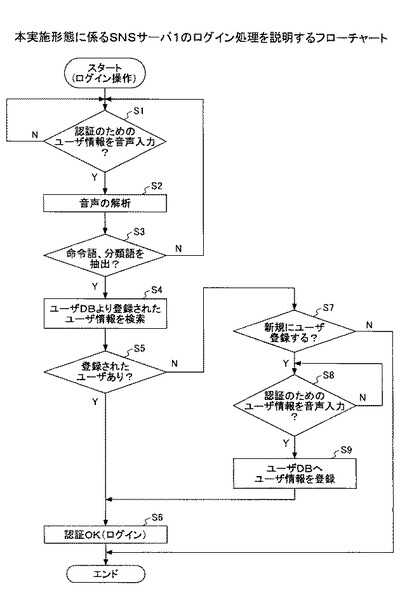
図7は、本実施形態に係るSNSサーバ1の音声登録及び音声検索処理を説明するフローチャートである。以下図を参照しながら説明する。
【0052】
S21:音声解析部103は、音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを書く」、「掲示板に投稿する」など、これから行いたいアクションを示す命令語と、利用対象となるSNSサービス分類を示す分類語が含まれる。上述の例では、ガイダンス「どこで何をしますか?」に導かれ、ユーザは「ブログを書く」と発話していることが分かる。
【0053】
S22:音声解析部103は、入力された音声の解析を行う。命令語、分類語を抽出するためである。
【0054】
S23:音声解析部103は、入力された音声から命令語、分類語を抽出できたか否かを判定する。ここでは、命令語「書く」、分類語「ブログ」が抽出される必要がある。なお命令語、分類語を抽出できない場合、S21へ進み、ユーザに再度の音声入力を促す。
【0055】
S24:ここで、抽出した命令語が、「登録命令」を示すもの、又は「検索命令」を示すものであるかどうかにより処理分岐する。ここでは命令語「書く」が抽出され、この命令語は「登録命令」を示すものであるので、S25へ進むものとする。
【0056】
S25:音声解析部103は、再び音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを書く」場合には書き込みたいブログ内容を、「掲示板に投稿する」場合には書き込みたい投稿内容である。上述の例では、ガイダンス「それでは書き込みたいブログ内容をお話下さい。」に導かれ、ユーザは書き込みたいブログ内容として「私の趣味は旅行なのですが先日富士山に行ってきました・・・」と発話していることが分かる。
【0057】
S26:音声解析部103は、入力された音声の解析を行う。入力音声から検索のためのキーワードとして使用する単語を抽出するためである。解析は、例えばまず音声を解釈し文字への変換を行う。音声から文字への変換は従来技術によればよい。そして文字(群)に対し、形態素解析を行うことにより形態素に分割し、形態素に対し品詞を判定する。特に名詞や動詞は、ユーザが伝えたい音声内容をよく表現するものであるので、名詞や動詞を抽出するとともに、出現率(頻度)等を勘案して、頻度上位所定数の単語をキーワードとして得る。
【0058】
具体的にここでは、ユーザは書き込みたいブログ内容として「私の趣味は旅行なのですが先日富士山に行ってきました。・・・」と発話している。音声解析部103は、この音声の解析を行う場合、まず音声を解釈し文字への変換を行う。そして文字(群)に対し、形態素解析を行うことにより、「私/の/趣味/は/旅行/なのですが/先日/富士山/に/行って/きました/・・・」といった具合で形態素に分割する。品詞判定によりこのうち、名詞として「私/趣味/旅行/先日/富士山」などが抽出され、動詞として「行って」などが抽出され、全体の頻度等を勘案し、頻度上位3の単語「趣味」、「旅行」、「富士山」をキーワードとして得ることができる。
【0059】
S27:音声登録部105は、入力された音声、ユーザ識別子(例えばユーザID)、抽出された分類語、音声内容をよく表現するキーワードなどを対応付けて音声DB108bに登録する。再び図5を参照し、ここでは入力された音声は、「私の趣味は旅行なのですが先日富士山に行ってきました。・・・」であるので「登録音声」欄にこの音声ファイルである「001-001.mp3」を登録し、ユーザ識別子は先のログイン処理から得られるログイン中ユーザのユーザID「001」、またこのユーザにとって1つ目のデータであるとすると「データNo」欄に「001-001」を発行し、「登録日」に現在の年月日時分を取得・登録し、「分類」に「ブログ」を登録し、「タグ」欄にそれぞれ「趣味」、「旅行」、「富士山」を登録する。
【0060】
以上のように、ユーザが自身の音声をSNSシステム100に登録したい場合、つまりユーザが自身の音声を音声DB108bに登録したい場合には、その旨を示す命令語(例えば「書く」)、分類語、登録内容を音声により発話することにより、その音声、音声の持ち主であるユーザのユーザ識別子、その音声が分類されるべきSNSサービス分類を示す分類語、ユーザが伝えたい音声内容をよく表現するキーワードを対応付けて登録することができる。また言い換えると、ユーザが自身の音声を音声DB108bに登録したい場合には、登録音声に対し、ユーザ識別子、分類語、キーワードをタグ付けして登録することができる。
【0061】
(音声検索操作)
一方、ユーザは、ログインするとSNSサーバ1から通信装置2の受話器に対し、「ログインに成功しました。・・・」等のガイダンスが流れるので、ユーザは音声検索操作(音声聴講操作)を行うべく、ガイダンス又は所定の手順に従って、通信装置2の受話器から音声検索の為の通話を行う。以下その一例を示す。
ガイダンス「ログインに成功しました。どこで何をしますか?」
ユーザ「ブログを読む」
ユーザ「ブログを読む、ですね?」
ユーザ「はい。」
ガイダンス「それでは読みたいブログのキーワードをお話下さい。」
ユーザ「京都、旅行、・・・。」
ガイダンス「検索しますので、しばらくお待ち下さい。」
ガイダンス「○件、検索されました。順次読み出しますか?」
ユーザ「はい。」
ガイダンス「1件目。ユーザ003さんのブログです。京都は・・・」
再び図7のフローチャートを参照しながら以下説明する。
【0062】
S21:音声解析部103は、音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを書く」、「掲示板に投稿する」など、これから行いたいアクションを示す命令語と、利用対象となるSNSサービス分類を示す分類語が含まれる。上述の例では、ガイダンス「どこで何をしますか?」に導かれ、ユーザは「ブログを読む」と発話していることが分かる。
【0063】
S22:音声解析部103は、入力された音声の解析を行う。命令語、分類語を抽出するためである。
【0064】
S23:音声解析部103は、入力された音声から命令語、分類語を抽出できたか否かを判定する。ここでは、命令語「読む」、分類語「ブログ」が抽出される必要がある。なお命令語、分類語を抽出できない場合、S21へ進み、ユーザに再度の音声入力を促す。
【0065】
S24:ここで、抽出した命令語が、「登録命令」を示すもの、又は「検索命令」を示すものであるかどうかにより処理分岐する。ここでは命令語「読む」が抽出され、この命令語は「検索命令」を示すものであるので、S28へ進むものとする。
【0066】
S28:音声解析部103は、再び音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを読む」場合には読みたいブログ内容を示すものである。上述の例では、ガイダンス「それでは読みたいブログのキーワードをお話下さい。」に導かれ、ユーザは読みたいブログ内容を示すキーワードとして「京都、旅行、・・・」と発話していることが分かる。
【0067】
S29:音声解析部103は、入力された音声の解析を行う。入力音声から検索のためのキーワードを認識し抽出するためである。ここではユーザは読みたいブログ内容を示すキーワードとして「京都」、「旅行」等が抽出される。
【0068】
S30:音声検索部106は、分類語及びキーワードを検索キーとして、音声DB108bに登録音声の中から、検索キーにマッチする音声を検索する。ユーザが音声DB108bから他の人から登録(投稿)された音声を検索したい場合(聴きたい場合)には、その旨を示す命令語、分類語と、キーワードを音声により発話することにより、その条件にマッチする音声を検索する。
【0069】
ここでは、分類語は「ブログ」、キーワード「京都」、「旅行」であるので、図5を参照すると、検索キーにマッチする音声エントリーは、「002-003.mp3」の1件存在するので、この音声が検索されることになる。
【0070】
S31:音声出力部107は、通話装置2に対し、検索された音声を出力(再生)する。つまりユーザが音声DB108bから検索した条件にマッチする音声をそのユーザに対し出力する。ここでは、音声「002-003.mp3」が通話装置2に出力されるので、ユーザはその音声を聴くことにより、「京都」、「旅行」に関するブログを聴く事ができる。
【0071】
なおユーザは検索された音声を聴いた後、その内容に対し返答(コメント)を行うことも可能である。この場合は、コメントという音声登録を行うので、再び図7のS21へ戻り、例えばガイダンス「どこで何をしますか?」に対し、ユーザ「このブログにコメントを書く」と発話する。以降は、上述と同様の処理により、先の音声に対するコメントとしての音声が登録される。このとき、この音声は先の音声に対するコメントであるので、音声DB108bに登録される際は、「リンク先」欄に先の音声の「ユーザID−データNo」を登録しておくことにより、登録音声間の関係性を保持できる。なおSNSサービスでは具ログや投稿内容に対し、複数のユーザからツリー状にコメントが投稿され付されることはよくあることである。
【0072】
なおまた、ユーザが特定ユーザのブログを指定する場合、キーワードにユーザ名やユーザIDの情報を含めて検索することもできる。この場合、音声解析部103はユーザ名やユーザIDを解析し、音声検索部106はそのユーザ名やユーザIDを検索キーとして、音声DB108bに登録音声の中から、該当の音声エントリーを検索すればよい。以下その一例を示す。
ガイダンス「それでは読みたいブログのキーワードをお話下さい。」
ユーザ「003さん、京都、旅行、・・・。」
ガイダンス「検索しますので、しばらくお待ち下さい。」
ガイダンス「003さん、○件、検索されました?順次読み出しますか?」
ユーザ「はい。」
ガイダンス「1件目。ユーザ003さんのブログです。京都は・・・」
なおまた、本実施形態において、音声を登録する場合、検索する場合を説明する為、命令語として例えば「書く」、「読む」を取り上げた。しかしながら、命令語はこれら以外にも存在してよい。SNSサービスを音声で利用するにあたっては、これ以外の操作も行うのでその操作を示す命令語は必要だからである。
【0073】
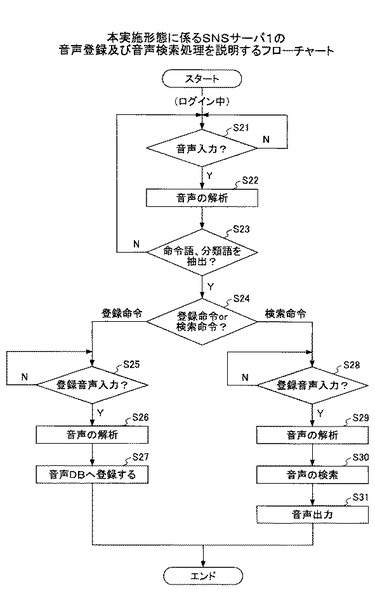
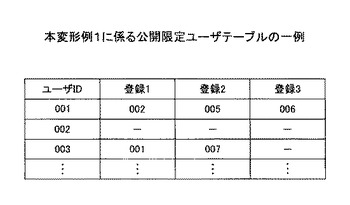
[変形例1]
図8は、本変形例1に係る公開限定ユーザテーブルの一例を示す。公開限定ユーザテーブルは、ユーザがブログや掲示板等において音声を登録したとき、自身が登録した音声を公開したいユーザを限定するため、公開可能なユーザを規定するものである。例えば上述の記憶部108に予め保持され、ユーザによって任意に公開可能なユーザを許可設定できる。
【0074】
上述の実施形態においては、音声検索操作の際、ユーザ(ユーザID:001)により、「ブログを読む」、「京都、旅行、・・・」との発話がなされ、S30にて、音声検索部106は、分類語「ブログ」及びキーワード「京都」、「旅行」を検索キーとし、検索キーにマッチする音声エントリーは、「002-003.mp3」の1件存在検索した。本変形例1において、音声検索部106は、検索キーにマッチする音声エントリーを検索したタイミングでこの公開限定ユーザテーブルを参照し、検索された音声を検索要求者に対し公開してよいか否かの判定を行う。
【0075】
図8の公開限定ユーザテーブルを参照すると、「ユーザID」が003であるユーザは、001(登録1)、007(登録2)に対し、自身が登録した音声の公開許可を設定していることが分かる。従って、検索された「002-003.mp3」の登録者であるユーザ(ユーザID:003)は、ユーザID:001であるユーザに対し、自身が登録した音声「002-003.mp3」の公開を許可しているので、音声検索部106は、「002-003.mp3」を最終的な検索結果とし、ユーザID:001であるユーザに対してこの音声を音声出力部107に出力させる。
【0076】
一方仮に、検索された「002-003.mp3」の登録者であるユーザ(ユーザID:003)が、ユーザID:001であるユーザに対し、自身が登録した音声「002-003.mp3」の公開を許可していない場合には、音声検索部106は、「002-003.mp3」を最終的な検索結果から除外し、ユーザID:001であるユーザに対してこの音声を出力させないようにする。
【0077】
このようにすると、一部のユーザに対してのみ自身の登録した音声を公開することができるので、一部の親しい友人やグループ間でのみでのSNSを楽しむことができる。なお、本変形例1に係る公開限定ユーザテーブルは、自身が登録した音声を公開したいユーザを限定するため、公開可能なユーザを規定するものであるとしたが、逆に、公開不可能なユーザを規定するようにしてもよい。この場合、公開限定ユーザテーブルに登録されているユーザに対しては公開されなくなる。
【0078】
[変形例2]
図9は、本変形例2に係る同義語テーブルの一例を示す。ユーザは上述の如く音声を通じてSNSサーバ1に対し各種操作命令を行うが、音声中に用いられる命令語は、SNSサーバ1上標準で規定されている標準語のみの1語に限られない。つまり、ユーザは予め同義語テーブルに同義語を1以上登録しておくことが可能である。
【0079】
上述の実施形態においては、音声登録操作や音声検索操作の際、ユーザ(ユーザID:001)により、「ブログを書く」や「ブログを読む」との発話がなされたが、このユーザ(ユーザID:001)が図9の同義語テーブルを予め登録している場合、「日記をwrite」や「ダイアリーをread」との発話を行える。
【0080】
音声解析部103は、「日記」、「write」や「ダイアリー」、「read」が解析された場合、同ユーザの同義語テーブルを参照し、それぞれ「ブログ」、「書く」や「ブログ」、「読む」なる標準語への変換を行う。
【0081】
このようにすると、例えば高齢者などは、ブログという概念が理解しにくいと考えられるところ、これを日記と理解する方が受け入れ易い。つまりSNSを利用するに当たり、馴染みのない用語も多く存在するため、同義語テーブルを使用することにより、高齢者などでも理解し易い使い慣れた単語を使用してSNSを利用することができる。
【0082】
[補足]
図10は、本実施形態に係るSNSのWebサイト画面例を示す。これまで説明してきたように本実施形態に係るSNSシステム100は、音声参加型のSNSを提供するものである。しかしながら、SNSサーバ1において、Webサーバとしての機能を備えるようにすれば、一般のPCからでもインターネットを介しSNSサーバ1にアクセスし、通常のSNSと同様に利用することができる。即ちSNSサーバ1は、通話端末2を使用しての音声参加型、一般のPCを使用しての通常参加型のいずれもからSNSを利用できるよう、相互互換性を有するように構成される。
【0083】
よって音声参加型からの入力、通常参加型からの出力ができる。具体的に例えば、通話端末2から登録した登録音声をSNSのWebサイトを通じて一般のPCでも聴くことができる。また音声解析部103により登録音声を全文文字変換し、変換文字をWebサイト上に掲載させれば、一般のPCでからの視覚による閲覧も可能である。
【0084】
また通常参加型からの入力、音声参加型からの出力を行うことも可能である。具体的に例えば、一般のPCから登録した文字を音声解析部103により全文文字をコンピュータ音声変換し、変換音声を音声DB108bに登録すれば、通話端末2からの音声による聴講も可能である。またこのとき、一般のPCから登録した全文文字から分類語やキーワードを抽出し、変換音声とともに音声DB108bに登録しておく。
【0085】
そもそも上述したように、登録音声に対する分類語やキーワードは、文字情報としてタグ化されているので、音声参加型又は通常参加型のいずれの場合でも、容易に登録音声を検索し、また出力(再生)することができることは言うまでもない。
【0086】
図10を参照すると、通話端末2からユーザ(ユーザID:001)が登録した登録音声が、SNSのWebサイトを通じ、一般のPCでも閲覧できるよう001のブログとしてWebサイトに表示されている。また、一般のPCからのユーザ(ユーザID:005、007)のユーザにより、そのブログに対するコメントが投稿されている。このコメントは、音声変換後、音声DB108bに登録されるので、ユーザ(ユーザID:001)は通話端末2からこのコメント内容をコンピュータ音声により聴くことができる。
【0087】
[総括]
以上本実施形態によれば、音声参加型のソーシャルネットワーキングサービスシステム等を提供することが可能となる。なお、本発明は係る特定の実施形態に限定されるものではなく、特許請求の範囲に記載された本発明の要旨の範囲内において、種々の変形・変更が可能である。
【符号の説明】
【0088】
1 SNSサーバ
2 通話端末
3 ネットワーク
11 CPU
12 ROM
13 RAM
14 補助記憶装置
15 記憶媒体読取装置
16 入力装置
17 表示装置
18 通信装置
100 SNSシステム
101 通信部
102 音声入力部
103 音声解析部
104 ユーザ認証部
105 音声登録部
106 音声検索部
107 音声出力部
108 記憶部
108a ユーザDB
108b 音声DB
【先行技術文献】
【特許文献】
【0089】
【特許文献1】特表2010−500649号
【技術分野】
【0001】
本発明は、ソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラムの分野に関する。
【背景技術】
【0002】
近年、人と人とのつながりを促進、サポートするコミュニティ型のWebサイトとして、ソーシャルネットワーキングサービス(以下SNSという)が知られている。SNSは、友人や知人間のコミュニケーションを円滑にする手段や場を提供したり、趣味や嗜好、居住地域、出身校、あるいは友人の友人といったつながりを通じて新たな人間関係を構築する場等のソーシャルネットワーキングサービスを提供する。具体的には例えば、自身のプロフィール登録公開機能、ユーザ同士のメッセージ送受信(私書箱)機能、ユーザ相互リンク機能、ユーザ検索機能、ユーザの日記(ブログ)機能、コミュニティ機能などが提供されている(例えば特許文献1)。
【発明の概要】
【発明が解決しようとする課題】
【0003】
しかしながら、従来のSNSは、PC(パソコン)や携帯電話等を操作し、インターネット上のWebサイトを日常的に閲覧できるような人たちのみに開かれた情報ツールであった。そのため、様々な理由からPCやインターネットをはじめとする情報・通信技術の利用に困難を抱える人達(いわゆる情報弱者)には使用できない、あるいは使用が困難であるという問題があった。
【0004】
ここで例えば、高齢者はPCやインターネットを使い慣れていないものの、電話をかけることは従前から日常的に行われている行為である。つまり高齢者は音声によるコミュニケーションは慣れているため、音声によりSNSに参加することができれば、PCやインターネットを使い慣れていない者であっても容易にSNSに参加できる。また例えば、視覚障害者にとってWebサイトの閲覧は困難であっても、音声によりSNSに参加することができれば容易にSNSに参加できる。
【0005】
そこで本発明では上記のような点に鑑みて、音声参加型のソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラムを提供することを目的とする。
【課題を解決するための手段】
【0006】
上記課題を解決するため、本発明に係るSNSシステムは、SNSを提供するサーバと、通話装置とがネットワークを介し接続されたSNSシステムであって、サーバは、通話装置から音声を入力する音声入力手段と、前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、を有する。
【0007】
上記課題を解決するため、本発明に係るSNSサーバは、通話装置とネットワークを介し接続されるSNSを提供するSNSサーバあって、通話装置から音声を入力する音声入力手段と、前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、を有する。
【0008】
上記課題を解決するため、本発明に係るSNSプログラムは、コンピュータに、通話装置から音声を入力する音声入力手段と、前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段として機能させる。
【0009】
なお、本発明の構成要素、表現または構成要素の任意の組合せを、方法、装置、システム、コンピュータプログラム、記録媒体、などに適用したものも本発明の態様として有効である。
【発明の効果】
【0010】
本発明によれば、音声参加型のソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラムを提供することができる。
【図面の簡単な説明】
【0011】
【図1】本実施形態に係るシステム構成図である。
【図2】SNSサーバ1の一実施形態の主要構成を示すハードウェア構成図である。
【図3】SNSサーバ1の一実施形態の主要機能を示す機能ブロック図である。
【図4】本実施形態に係るユーザDB108a例を示す。
【図5】本実施形態に係る音声DB108b例を示す。
【図6】本実施形態に係るSNSサーバ1のログイン処理を説明するフローチャートである。
【図7】本実施形態に係るSNSサーバ1の音声登録及び音声検索処理を説明するフローチャートである。
【図8】本変形例1に係る公開限定ユーザテーブルの一例を示す。
【図9】本変形例2に係る同義語テーブルの一例を示す。
【図10】本実施形態に係るSNSのWebサイト画面例を示す。
【発明を実施するための形態】
【0012】
以下、本発明を実施するための形態を各実施形態において図面を用いて説明する。
【0013】
[システム構成]
(全体構成)
はじめに、具体的な発明の内容を説明する前に、本発明を実施するにあたっての全体構成について説明する。図1は、本実施形態に係るシステム構成図である。図に示されるように、本実施形態に係るSNSシステム100は、SNSサーバ1及び通話端末2がネットワーク3を介し接続される。
【0014】
SNSサーバ1は、ユーザの使用する通話端末2に対し、ソーシャルネットワーキングサービスを提供するサーバである。通話端末2は、ユーザの使用する通話端末2であり、具体的には携帯電話2a、固定電話2b、ヘッドフォン等の音声入出力器付きPC2c等である。ユーザはこれら通話端末2を使用して、SNSサーバ1から音声によるソーシャルネットワーキングサービスを受ける。
【0015】
ネットワーク3は、SNSサーバ1及び通話端末2を接続する通信ネットワークである。本実施形態においては、ユーザの通話端末2はSNSサーバ1から音声によるソーシャルネットワーキングサービスを受けるため、少なくとも音声通信が可能な通信ネットワークとなる。SNSサーバ1はインターネット網に接続されるので、通話端末2が携帯電話2aである場合、ネットワーク3は携帯公衆網及びインターネット網を含む。また通話端末2が固定電話2bである場合、ネットワーク3は固定電話網及びインターネット網を含む。また通話端末2がPC2cである場合、ネットワーク3はインターネット網である。
【0016】
なお、インターネット網に接続されるSNSサーバ1は、各公衆網に接続される通話端末2とはインターネット網のTCP/IP(Transmission Control Protocol/Internet Protocol)ネットワークを使って音声データをパケットとして送受信する必要があることから、VoIP(Voice Over IP)サーバを中継し音声のやり取りが行われることになる(非図示)。また通話端末2からすると、SNSサーバ1は通話先のIP電話に見えるので、SNSサーバ1と接続する際は通常の電話をかけるようにSNSサーバ1に付与されている電話番号に対し電話をかければよい。
【0017】
(ハードウェア)
ここで、本実施形態に係るSNSサーバ1のハードウェア構成について説明しておく。図2は、SNSサーバ1の一実施形態の主要構成を示すハードウェア構成図である。SNSサーバ1は、主要な構成として、CPU(Central Processing Unit)11、ROM(Read Only Memory)12、RAM(Random Access Memory)13、補助記憶装置14、記憶媒体読取装置15、入力装置16、表示装置17、及び通信装置18を含む構成である。
【0018】
CPU11は、マイクロプロセッサ及びその周辺回路から構成され、装置全体を制御する回路である。また、ROM12は、CPU11で実行される所定の制御プログラム(ソフトウェア部品)を格納するメモリであり、RAM13は、CPU11がROM12に格納された所定の制御プログラム(ソフトウェア部品)を実行して各種の制御を行うときの作業エリア(ワーク領域)として使用するメモリである。
【0019】
補助記憶装置14は、汎用のOS(Operating System)、プログラムを含む各種情報を格納する装置であり、不揮発性の記憶装置であるHDD(Hard Disk Drive)などが用いられる。記憶媒体読取装置15には、USBメモリ、CD、DVD等の携帯型メディアをセットすることで、外部からの情報を取得できる。
【0020】
入力装置16は、ユーザが各種入力操作を行うための装置である。入力装置16は、マウス、キーボード、表示装置17の表示画面上に重畳するように設けられたタッチパネルスイッチなどを含む。表示装置17は、各種データを表示画面に表示する装置である。例えば、LCD(Liquid Crystal Display)、CRT(Cathode Ray Tube)などから構成される。
【0021】
通信装置18は、ネットワーク3を介して他の機器との通信を行う装置である。有線ネットワークや無線ネットワークなど含む各種ネットワーク形態に応じた通信をサポートする。
【0022】
なお通話端末2については、従来の携帯電話、固定電話、PC等により実現されればよく、その説明は省略する。
【0023】
(機能)
次に、SNSサーバ1の機能構成について説明する。図3は、SNSサーバ1の一実施形態の主要機能を示す機能ブロック図である。図に示されるようにSNSサーバ1は、主要な機能として、通信部101、音声入力部102、音声解析部103、ユーザ認証部104、音声登録部105、音声検索部106、音声出力部107、記憶部108を含む構成である。
【0024】
通信部101は、ネットワーク3と接続され、通話装置2との通信を行う。SNSサーバ1は通話装置2から着呼を受けてから呼を確立する。呼確立後、音声(音声データ)を受信すると、この音声を音声入力102に入力する。音声入力部102は、通信部101を介し通話装置2からの音声を入力する。なおこの音声はユーザによって発話されたユーザの会話音声に相当する。
【0025】
音声解析部103は、通話装置2から入力された音声を解析することにより、該音声を入力したユーザを識別するユーザ識別情報、該音声により入力された命令語と、該音声により入力されその音声が分類されるべきSNSサービス分類を示す分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)を抽出する。音声はユーザの会話音声に相当するが、この会話音声の中から、音声解析技術により音声内の単語を抽出し、また単語の意味から上述の語句を抽出するものであるが、この点詳細は後述する。
【0026】
ユーザ認証部104は、入力された音声から抽出されたユーザ識別情報に基づいてユーザ認証を行う。ユーザ識別情報はユーザを識別するための情報であり、例えば入力された音声の声紋や、音声から抽出されたユーザ識別語(ユーザ名、ユーザのみ知る所定ワード等)である。そして例えば音声によりユーザ認証を行う場合、ユーザDB108a内に予め登録されている音声(声紋)との照合により認証を行うことができ、またユーザ識別語によりユーザ認証を行う場合、ユーザDB108a内に予め登録されているユーザ識別語との照合により認証を行うことができる。
【0027】
音声登録部105は、音声により入力された命令語が、入力された音声の登録命令を示す場合、該入力された音声、ユーザ識別情報に基づくユーザ識別子、抽出された分類語、その他単語(キーワード)などを対応付けて記憶部108に登録する。つまりユーザが自身の音声を音声DB(Data Base)108bに登録したい場合には、その旨を示す命令語を音声により発話することにより、その音声を登録できるようになっている。また登録の際は、その音声の持ち主である登録者を識別するユーザ識別子(例えばユーザID)、その音声が分類されるべきSNSサービス分類を示す分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)などを対応付けて登録する。
【0028】
音声検索部106は、音声により入力された命令語が、記憶部108に登録された音声の検索命令を示す場合、分類語やその他単語(キーワード)を検索キーとして、音声を記憶部108から検索する。つまりユーザが音声DB108bから他の人から登録(投稿)された音声を検索したい場合(聴きたい場合)には、その旨を示す命令語、分類語やその他単語(キーワード)を音声により発話することにより、その条件にマッチする音声を検索できるようになっている。検索の際は、分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)などをキーとして音声DB108b内の音声を検索する。
【0029】
音声出力部107は、通話装置2に対し、検索された音声を出力する。つまりユーザが音声DB108bから検索した他の人の音声をそのユーザに対し出力する。この音声は通話装置2に出力されるので、ユーザはその音声を聴くことにより、他の人から登録(投稿)された音声を認識できる。
【0030】
記憶部108は、入力された音声と、その音声の持ち主である登録者のユーザ識別子と、入力された音声が分類されるべきSNSサービス分類を示す分類語、その他単語(キーワード)とを対応付けて音声DB108b内に記憶する。
【0031】
なお、以上説明したこれらの機能は、実際にはCPU11が実行するプログラムにより実現される。
【0032】
(ユーザDB108a例)
図4は、本実施形態に係るユーザDB108a例を示す。上述のしたようにユーザ認証部104は、入力された音声から抽出されたユーザ識別情報に基づいてユーザ認証を行うが、ユーザDB108aにはこの認証の為のユーザ情報が予め格納されている。
【0033】
「ユーザID」は、サーバ上一意に付番される識別子である。「氏」、「名」は、ユーザの氏名である。「パスワード」は、ユーザパスワードである。「秘密の質問」、「答え」は、ユーザがあらかじめ設定した質問と、その質問に対する答えである。これらはユーザ識別語によりユーザ認証を行う場合、ここに登録されているユーザ識別語との照合により認証を行う。「認証用音声」は、ユーザの音声(声紋)によって認証を行う場合に使用され、ここに登録されている音声(声紋)との照合により認証を行う。
【0034】
なお認証は、これら情報を持ってユーザを認証できる限り、いずれか1又は複数、もしくは全ての情報を用いて認証を行うことができる。言うまでもなく、認証に使用される情報が多いほど、認証の信頼度は向上するので、ある程度複数の情報を用いて認証を行うことが望ましい。
【0035】
(音声DB108b例)
図5は、本実施形態に係る音声DB108b例を示す。上述のしたように音声登録部105は、ユーザが自身の音声をSNSサーバ1に登録したい場合には、その旨を示す命令語を音声により発話することにより、その音声を登録できるようになっており、登録の際は、その音声の持ち主である登録者を識別するユーザ識別子(例えばユーザID)、その音声が分類されるべきSNSサービス分類を示す分類語(例えばブログ、掲示板、伝言メール等)、その他単語(キーワード)などを対応付けてこの音声DB108bに登録する。
【0036】
「ユーザID−データNo」は、サーバ上、登録音声に対し一意に付番される識別子である。付番ルールとしては例えば音声を登録したユーザのユーザIDに、データNo(順次昇順で発行)を付加して付番する。「登録音声」は、サーバ上登録される音声である。例えば、「001-001.mp3」はユーザIDが001による1番目に登録された音声実体ファイルを示す。「登録日」は、サーバ上、登録音声が登録された年月日時分を示す。
【0037】
「分類」は、その登録音声が分類されるべきSNSサービス分類を示す。従って分類はSNSサーバ1がユーザに対し提供するサービスの種類・カテゴリに対応し、例えばブログ、掲示板、伝言メール等がある。具体的に例えば、登録音声「001-001.mp3」は「分類」がブログであるので、この登録音声は内容的にSNSサービス内のブログとして投稿された音声内容になっているものである。
【0038】
「タグ」は、その登録音声内に含まれているキーワードが抽出されて格納される。入力された音声は音声解析部103により解析されるが、このとき音声内で音声内容(コンテンツ)をよく表現しうる重要語が抽出され、ここに格納されるようになっている。図に示されるように「タグ」は、「タグ1」、「タグ2」、「タグ3」といったように、複数格納可能であり、またこれら「タグ」は登録音声を検索する際の検索キーとして使用される。
【0039】
「リンク先」は、その登録音声が関連する関連先を示す。SNSサービスはユーザ間のコミニュケーションを図るツールであるので、ブログや掲示板を読んだ他のユーザが感想やコメントを返答することはよくあることである。よって図中、例えば「002-002.mp3」は「リンク先」が001-001になっていることから、この「002-002.mp3」は、「ユーザID−データNo」001-001である登録音声「001-001.mp3」に対し返答された登録音声である。
【0040】
[情報処理]
本実施形態に係るSNSサーバ1の情報処理について説明する。ユーザは通話装置2での通話を通じて、SNSサーバ1に対し、次の3つの操作を行うことができる。ログイン操作、音声登録操作、音声検索操作である。以下場面毎に説明していく。
【0041】
(ログイン操作)
まずユーザは、通常の電話をかけるように通話装置2のダイアルを操作してSNSサーバ1に付与されている電話番号に対し電話をかける。SNSサーバ1は電話網、VoIPサーバを介して通話装置2からの着呼を受け呼を確立する。呼確立するとSNSサーバ1から通信装置2の受話器に対し、「こちらはSNSサービスです。・・・」等のガイダンスが流れるので、ユーザはログイン操作を行うべく、ガイダンス又は所定の手順に従って、通信装置2の受話器からログインの為の通話を行う。以下その一例を示す。
ガイダンス「こちらはSNSサービスです。会員の方はまずユーザIDをお話下さい。会員でない方は、・・・。」
ユーザ「001」
ガイダンス「氏名をお話下さい。」
ユーザ「山田太郎」
ガイダンス「パスワードをお話下さい。」
ユーザ「125658」
ガイダンス「誕生日をお話下さい。」
ユーザ「19741111」
ガイダンス「認証中です。しばらくお待ち下さい。・・・認証されました。」
またもしくは、上述の一問一答形式でなくとも、所定情報をSNSサーバ1が認識しうる所定の手順に従って発話するようにしてもよい。以下その一例を示す。
ガイダンス「こちらはSNSサービスです。会員の方はログイン情報をお話下さい。会員でない方は、・・・。」
ユーザ「001、山田太郎、125658、19741111」
ガイダンス「認証中です。しばらくお待ち下さい。・・・認証されました。」
図6は、本実施形態に係るSNSサーバ1のログイン処理を説明するフローチャートである。以下図を参照しながら説明する。
【0042】
S1:ユーザ認証部104は、音声入力部102において、認証のためのユーザ情報を音声入力があったか否かを判定する。認証のためのユーザ情報とは、上述例の場合、ユーザID、氏名、パスワード、誕生日(秘密の質問)である。
【0043】
S2:音声解析部103は、入力された音声の解析を行う。認証のためのユーザ情報を抽出するためである。
【0044】
S3:音声解析部103は、入力された音声から認証のためのユーザ情報を抽出できたか否かを判定する。ここでは、ユーザID、氏名、パスワード、誕生日(秘密の質問)が抽出される必要がある。なお認証のためのユーザ情報を抽出できない場合、S1へ進み、ユーザに再度の音声入力を促す。
【0045】
S4:ユーザ認証部104は、認証のためのユーザ情報を抽出できた場合、その認証のためのユーザ情報を用いて、ユーザDB108aに登録されたユーザ情報があるか否かを検索する。なお併せて、ユーザDB108aの認証用音声を使用して音声(声紋)による照合も行う。
【0046】
S5:ユーザ認証部104は、登録されたユーザあったか否かを判定する。つまり、音声入力があったユーザ情報(認証用音声含む)と、ユーザDB108aに登録されたユーザ情報との照合により、一致した場合、登録されたユーザありと判定する。
【0047】
S6:ユーザ認証部104は、登録されたユーザありと判定した場合、認証OKと判定する。つまりログイン認証OKと判定する。
【0048】
S7:一方ユーザ認証部104は、登録されたユーザなしと判定した場合、認証NGと判定する。このとき、新規にユーザ登録するか否かの判定を行う。この場合、ガイダンスによりその旨を通話により確認することができる。またもしくは冒頭の上述ガイダンス「会員でない方は、・・・。」のところで非会員である旨を通話により確認することもできる。なお新規にユーザ登録しないとの判定がなされた場合、ログイン処理を打ち切ればよい。
【0049】
S8:ユーザ認証部104は、新規にユーザ登録すると判定した場合、登録に必要な情報、つまり認証のためのユーザ情報を音声入力があったか否かを判定する。ここでは認証のためのユーザ情報とは、上述例の場合、ユーザID、氏名、パスワード、誕生日(秘密の質問)であるので、これらユーザ情報をユーザが発話するよう、ガイダンス等によって導くようにする。
【0050】
S9:ユーザ認証部104は、登録に必要な情報、つまり認証のためのユーザ情報を音声入力があったと判定した場合、これらユーザ情報をユーザDB108aに登録する。またこのとき、ユーザが発話した音声を認証用音声として音声ファイルを生成し登録しておく。以上によりユーザ新規登録が完了したので、S6へ進み、この新規登録ユーザに対し認証OKと判定する。
【0051】
(音声登録操作)
次にユーザは、ログインするとSNSサーバ1から通信装置2の受話器に対し、「ログインに成功しました。・・・」等のガイダンスが流れるので、ユーザは音声登録操作を行うべく、ガイダンス又は所定の手順に従って、通信装置2の受話器から音声登録の為の通話を行う。以下その一例を示す。
ガイダンス「ログインに成功しました。どこで何をしますか?」
ユーザ「ブログを書く」
ユーザ「ブログを書く、ですね?」
ユーザ「はい。」
ガイダンス「それでは書き込みたいブログ内容をお話下さい。」
ユーザ「私の趣味は旅行なのですが先日富士山に行ってきました・・・。」
ガイダンス「確認のため、音声を再生します。」
ガイダンス「私の趣味は旅行なのですが先日富士山に行ってきました・・・。」
ガイダンス「登録してよろしいですか?」
ユーザ「はい。」
ガイダンス「登録完了しました。」
図7は、本実施形態に係るSNSサーバ1の音声登録及び音声検索処理を説明するフローチャートである。以下図を参照しながら説明する。
【0052】
S21:音声解析部103は、音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを書く」、「掲示板に投稿する」など、これから行いたいアクションを示す命令語と、利用対象となるSNSサービス分類を示す分類語が含まれる。上述の例では、ガイダンス「どこで何をしますか?」に導かれ、ユーザは「ブログを書く」と発話していることが分かる。
【0053】
S22:音声解析部103は、入力された音声の解析を行う。命令語、分類語を抽出するためである。
【0054】
S23:音声解析部103は、入力された音声から命令語、分類語を抽出できたか否かを判定する。ここでは、命令語「書く」、分類語「ブログ」が抽出される必要がある。なお命令語、分類語を抽出できない場合、S21へ進み、ユーザに再度の音声入力を促す。
【0055】
S24:ここで、抽出した命令語が、「登録命令」を示すもの、又は「検索命令」を示すものであるかどうかにより処理分岐する。ここでは命令語「書く」が抽出され、この命令語は「登録命令」を示すものであるので、S25へ進むものとする。
【0056】
S25:音声解析部103は、再び音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを書く」場合には書き込みたいブログ内容を、「掲示板に投稿する」場合には書き込みたい投稿内容である。上述の例では、ガイダンス「それでは書き込みたいブログ内容をお話下さい。」に導かれ、ユーザは書き込みたいブログ内容として「私の趣味は旅行なのですが先日富士山に行ってきました・・・」と発話していることが分かる。
【0057】
S26:音声解析部103は、入力された音声の解析を行う。入力音声から検索のためのキーワードとして使用する単語を抽出するためである。解析は、例えばまず音声を解釈し文字への変換を行う。音声から文字への変換は従来技術によればよい。そして文字(群)に対し、形態素解析を行うことにより形態素に分割し、形態素に対し品詞を判定する。特に名詞や動詞は、ユーザが伝えたい音声内容をよく表現するものであるので、名詞や動詞を抽出するとともに、出現率(頻度)等を勘案して、頻度上位所定数の単語をキーワードとして得る。
【0058】
具体的にここでは、ユーザは書き込みたいブログ内容として「私の趣味は旅行なのですが先日富士山に行ってきました。・・・」と発話している。音声解析部103は、この音声の解析を行う場合、まず音声を解釈し文字への変換を行う。そして文字(群)に対し、形態素解析を行うことにより、「私/の/趣味/は/旅行/なのですが/先日/富士山/に/行って/きました/・・・」といった具合で形態素に分割する。品詞判定によりこのうち、名詞として「私/趣味/旅行/先日/富士山」などが抽出され、動詞として「行って」などが抽出され、全体の頻度等を勘案し、頻度上位3の単語「趣味」、「旅行」、「富士山」をキーワードとして得ることができる。
【0059】
S27:音声登録部105は、入力された音声、ユーザ識別子(例えばユーザID)、抽出された分類語、音声内容をよく表現するキーワードなどを対応付けて音声DB108bに登録する。再び図5を参照し、ここでは入力された音声は、「私の趣味は旅行なのですが先日富士山に行ってきました。・・・」であるので「登録音声」欄にこの音声ファイルである「001-001.mp3」を登録し、ユーザ識別子は先のログイン処理から得られるログイン中ユーザのユーザID「001」、またこのユーザにとって1つ目のデータであるとすると「データNo」欄に「001-001」を発行し、「登録日」に現在の年月日時分を取得・登録し、「分類」に「ブログ」を登録し、「タグ」欄にそれぞれ「趣味」、「旅行」、「富士山」を登録する。
【0060】
以上のように、ユーザが自身の音声をSNSシステム100に登録したい場合、つまりユーザが自身の音声を音声DB108bに登録したい場合には、その旨を示す命令語(例えば「書く」)、分類語、登録内容を音声により発話することにより、その音声、音声の持ち主であるユーザのユーザ識別子、その音声が分類されるべきSNSサービス分類を示す分類語、ユーザが伝えたい音声内容をよく表現するキーワードを対応付けて登録することができる。また言い換えると、ユーザが自身の音声を音声DB108bに登録したい場合には、登録音声に対し、ユーザ識別子、分類語、キーワードをタグ付けして登録することができる。
【0061】
(音声検索操作)
一方、ユーザは、ログインするとSNSサーバ1から通信装置2の受話器に対し、「ログインに成功しました。・・・」等のガイダンスが流れるので、ユーザは音声検索操作(音声聴講操作)を行うべく、ガイダンス又は所定の手順に従って、通信装置2の受話器から音声検索の為の通話を行う。以下その一例を示す。
ガイダンス「ログインに成功しました。どこで何をしますか?」
ユーザ「ブログを読む」
ユーザ「ブログを読む、ですね?」
ユーザ「はい。」
ガイダンス「それでは読みたいブログのキーワードをお話下さい。」
ユーザ「京都、旅行、・・・。」
ガイダンス「検索しますので、しばらくお待ち下さい。」
ガイダンス「○件、検索されました。順次読み出しますか?」
ユーザ「はい。」
ガイダンス「1件目。ユーザ003さんのブログです。京都は・・・」
再び図7のフローチャートを参照しながら以下説明する。
【0062】
S21:音声解析部103は、音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを書く」、「掲示板に投稿する」など、これから行いたいアクションを示す命令語と、利用対象となるSNSサービス分類を示す分類語が含まれる。上述の例では、ガイダンス「どこで何をしますか?」に導かれ、ユーザは「ブログを読む」と発話していることが分かる。
【0063】
S22:音声解析部103は、入力された音声の解析を行う。命令語、分類語を抽出するためである。
【0064】
S23:音声解析部103は、入力された音声から命令語、分類語を抽出できたか否かを判定する。ここでは、命令語「読む」、分類語「ブログ」が抽出される必要がある。なお命令語、分類語を抽出できない場合、S21へ進み、ユーザに再度の音声入力を促す。
【0065】
S24:ここで、抽出した命令語が、「登録命令」を示すもの、又は「検索命令」を示すものであるかどうかにより処理分岐する。ここでは命令語「読む」が抽出され、この命令語は「検索命令」を示すものであるので、S28へ進むものとする。
【0066】
S28:音声解析部103は、再び音声入力があったか否かを判定する。ここでいう音声とは、例えば「ブログを読む」場合には読みたいブログ内容を示すものである。上述の例では、ガイダンス「それでは読みたいブログのキーワードをお話下さい。」に導かれ、ユーザは読みたいブログ内容を示すキーワードとして「京都、旅行、・・・」と発話していることが分かる。
【0067】
S29:音声解析部103は、入力された音声の解析を行う。入力音声から検索のためのキーワードを認識し抽出するためである。ここではユーザは読みたいブログ内容を示すキーワードとして「京都」、「旅行」等が抽出される。
【0068】
S30:音声検索部106は、分類語及びキーワードを検索キーとして、音声DB108bに登録音声の中から、検索キーにマッチする音声を検索する。ユーザが音声DB108bから他の人から登録(投稿)された音声を検索したい場合(聴きたい場合)には、その旨を示す命令語、分類語と、キーワードを音声により発話することにより、その条件にマッチする音声を検索する。
【0069】
ここでは、分類語は「ブログ」、キーワード「京都」、「旅行」であるので、図5を参照すると、検索キーにマッチする音声エントリーは、「002-003.mp3」の1件存在するので、この音声が検索されることになる。
【0070】
S31:音声出力部107は、通話装置2に対し、検索された音声を出力(再生)する。つまりユーザが音声DB108bから検索した条件にマッチする音声をそのユーザに対し出力する。ここでは、音声「002-003.mp3」が通話装置2に出力されるので、ユーザはその音声を聴くことにより、「京都」、「旅行」に関するブログを聴く事ができる。
【0071】
なおユーザは検索された音声を聴いた後、その内容に対し返答(コメント)を行うことも可能である。この場合は、コメントという音声登録を行うので、再び図7のS21へ戻り、例えばガイダンス「どこで何をしますか?」に対し、ユーザ「このブログにコメントを書く」と発話する。以降は、上述と同様の処理により、先の音声に対するコメントとしての音声が登録される。このとき、この音声は先の音声に対するコメントであるので、音声DB108bに登録される際は、「リンク先」欄に先の音声の「ユーザID−データNo」を登録しておくことにより、登録音声間の関係性を保持できる。なおSNSサービスでは具ログや投稿内容に対し、複数のユーザからツリー状にコメントが投稿され付されることはよくあることである。
【0072】
なおまた、ユーザが特定ユーザのブログを指定する場合、キーワードにユーザ名やユーザIDの情報を含めて検索することもできる。この場合、音声解析部103はユーザ名やユーザIDを解析し、音声検索部106はそのユーザ名やユーザIDを検索キーとして、音声DB108bに登録音声の中から、該当の音声エントリーを検索すればよい。以下その一例を示す。
ガイダンス「それでは読みたいブログのキーワードをお話下さい。」
ユーザ「003さん、京都、旅行、・・・。」
ガイダンス「検索しますので、しばらくお待ち下さい。」
ガイダンス「003さん、○件、検索されました?順次読み出しますか?」
ユーザ「はい。」
ガイダンス「1件目。ユーザ003さんのブログです。京都は・・・」
なおまた、本実施形態において、音声を登録する場合、検索する場合を説明する為、命令語として例えば「書く」、「読む」を取り上げた。しかしながら、命令語はこれら以外にも存在してよい。SNSサービスを音声で利用するにあたっては、これ以外の操作も行うのでその操作を示す命令語は必要だからである。
【0073】
[変形例1]
図8は、本変形例1に係る公開限定ユーザテーブルの一例を示す。公開限定ユーザテーブルは、ユーザがブログや掲示板等において音声を登録したとき、自身が登録した音声を公開したいユーザを限定するため、公開可能なユーザを規定するものである。例えば上述の記憶部108に予め保持され、ユーザによって任意に公開可能なユーザを許可設定できる。
【0074】
上述の実施形態においては、音声検索操作の際、ユーザ(ユーザID:001)により、「ブログを読む」、「京都、旅行、・・・」との発話がなされ、S30にて、音声検索部106は、分類語「ブログ」及びキーワード「京都」、「旅行」を検索キーとし、検索キーにマッチする音声エントリーは、「002-003.mp3」の1件存在検索した。本変形例1において、音声検索部106は、検索キーにマッチする音声エントリーを検索したタイミングでこの公開限定ユーザテーブルを参照し、検索された音声を検索要求者に対し公開してよいか否かの判定を行う。
【0075】
図8の公開限定ユーザテーブルを参照すると、「ユーザID」が003であるユーザは、001(登録1)、007(登録2)に対し、自身が登録した音声の公開許可を設定していることが分かる。従って、検索された「002-003.mp3」の登録者であるユーザ(ユーザID:003)は、ユーザID:001であるユーザに対し、自身が登録した音声「002-003.mp3」の公開を許可しているので、音声検索部106は、「002-003.mp3」を最終的な検索結果とし、ユーザID:001であるユーザに対してこの音声を音声出力部107に出力させる。
【0076】
一方仮に、検索された「002-003.mp3」の登録者であるユーザ(ユーザID:003)が、ユーザID:001であるユーザに対し、自身が登録した音声「002-003.mp3」の公開を許可していない場合には、音声検索部106は、「002-003.mp3」を最終的な検索結果から除外し、ユーザID:001であるユーザに対してこの音声を出力させないようにする。
【0077】
このようにすると、一部のユーザに対してのみ自身の登録した音声を公開することができるので、一部の親しい友人やグループ間でのみでのSNSを楽しむことができる。なお、本変形例1に係る公開限定ユーザテーブルは、自身が登録した音声を公開したいユーザを限定するため、公開可能なユーザを規定するものであるとしたが、逆に、公開不可能なユーザを規定するようにしてもよい。この場合、公開限定ユーザテーブルに登録されているユーザに対しては公開されなくなる。
【0078】
[変形例2]
図9は、本変形例2に係る同義語テーブルの一例を示す。ユーザは上述の如く音声を通じてSNSサーバ1に対し各種操作命令を行うが、音声中に用いられる命令語は、SNSサーバ1上標準で規定されている標準語のみの1語に限られない。つまり、ユーザは予め同義語テーブルに同義語を1以上登録しておくことが可能である。
【0079】
上述の実施形態においては、音声登録操作や音声検索操作の際、ユーザ(ユーザID:001)により、「ブログを書く」や「ブログを読む」との発話がなされたが、このユーザ(ユーザID:001)が図9の同義語テーブルを予め登録している場合、「日記をwrite」や「ダイアリーをread」との発話を行える。
【0080】
音声解析部103は、「日記」、「write」や「ダイアリー」、「read」が解析された場合、同ユーザの同義語テーブルを参照し、それぞれ「ブログ」、「書く」や「ブログ」、「読む」なる標準語への変換を行う。
【0081】
このようにすると、例えば高齢者などは、ブログという概念が理解しにくいと考えられるところ、これを日記と理解する方が受け入れ易い。つまりSNSを利用するに当たり、馴染みのない用語も多く存在するため、同義語テーブルを使用することにより、高齢者などでも理解し易い使い慣れた単語を使用してSNSを利用することができる。
【0082】
[補足]
図10は、本実施形態に係るSNSのWebサイト画面例を示す。これまで説明してきたように本実施形態に係るSNSシステム100は、音声参加型のSNSを提供するものである。しかしながら、SNSサーバ1において、Webサーバとしての機能を備えるようにすれば、一般のPCからでもインターネットを介しSNSサーバ1にアクセスし、通常のSNSと同様に利用することができる。即ちSNSサーバ1は、通話端末2を使用しての音声参加型、一般のPCを使用しての通常参加型のいずれもからSNSを利用できるよう、相互互換性を有するように構成される。
【0083】
よって音声参加型からの入力、通常参加型からの出力ができる。具体的に例えば、通話端末2から登録した登録音声をSNSのWebサイトを通じて一般のPCでも聴くことができる。また音声解析部103により登録音声を全文文字変換し、変換文字をWebサイト上に掲載させれば、一般のPCでからの視覚による閲覧も可能である。
【0084】
また通常参加型からの入力、音声参加型からの出力を行うことも可能である。具体的に例えば、一般のPCから登録した文字を音声解析部103により全文文字をコンピュータ音声変換し、変換音声を音声DB108bに登録すれば、通話端末2からの音声による聴講も可能である。またこのとき、一般のPCから登録した全文文字から分類語やキーワードを抽出し、変換音声とともに音声DB108bに登録しておく。
【0085】
そもそも上述したように、登録音声に対する分類語やキーワードは、文字情報としてタグ化されているので、音声参加型又は通常参加型のいずれの場合でも、容易に登録音声を検索し、また出力(再生)することができることは言うまでもない。
【0086】
図10を参照すると、通話端末2からユーザ(ユーザID:001)が登録した登録音声が、SNSのWebサイトを通じ、一般のPCでも閲覧できるよう001のブログとしてWebサイトに表示されている。また、一般のPCからのユーザ(ユーザID:005、007)のユーザにより、そのブログに対するコメントが投稿されている。このコメントは、音声変換後、音声DB108bに登録されるので、ユーザ(ユーザID:001)は通話端末2からこのコメント内容をコンピュータ音声により聴くことができる。
【0087】
[総括]
以上本実施形態によれば、音声参加型のソーシャルネットワーキングサービスシステム等を提供することが可能となる。なお、本発明は係る特定の実施形態に限定されるものではなく、特許請求の範囲に記載された本発明の要旨の範囲内において、種々の変形・変更が可能である。
【符号の説明】
【0088】
1 SNSサーバ
2 通話端末
3 ネットワーク
11 CPU
12 ROM
13 RAM
14 補助記憶装置
15 記憶媒体読取装置
16 入力装置
17 表示装置
18 通信装置
100 SNSシステム
101 通信部
102 音声入力部
103 音声解析部
104 ユーザ認証部
105 音声登録部
106 音声検索部
107 音声出力部
108 記憶部
108a ユーザDB
108b 音声DB
【先行技術文献】
【特許文献】
【0089】
【特許文献1】特表2010−500649号
【特許請求の範囲】
【請求項1】
SNSを提供するサーバと、通話装置とがネットワークを介し接続されたSNSシステムであって、
サーバは、
通話装置から音声を入力する音声入力手段と、
前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、
前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、
前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、
通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、
を有することを特徴とするSNSシステム。
【請求項2】
前記音声解析手段は、前記音声を解析することにより、前記ユーザ識別子情報、前記分類語、前記分類語に加え、該音声に含まれる1以上の単語を抽出し、
前記音声登録手段は、前記命令語が音声の登録命令を示す場合、前記入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とに加え、前記1以上の単語を対応付けて記憶手段に登録し、
前記音声検索手段は、前記命令語が音声の検索命令を示す場合、前記分類語及び前記1以上の単語を検索キーとして、前記分類語及び前記1以上の単語に対応付けられた音声を前記記憶手段から検索すること、
を有することを特徴とする請求項1記載のSNSシステム。
【請求項3】
前記ユーザ識別情報は、前記音声入力手段により入力された音声の声紋、又は前記音声解析手段により解析され抽出されたユーザ識別語であって、該ユーザ識別情報に基づいてユーザ認証を行うユーザ認証手段と、
を有することを特徴とする請求項1又は2記載のSNSシステム。
【請求項4】
通話装置とネットワークを介し接続されるSNSを提供するSNSサーバあって、
通話装置から音声を入力する音声入力手段と、
前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、
前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、
前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、
通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、
を有することを特徴とするSNSサーバ。
【請求項5】
コンピュータに、
通話装置から音声を入力する音声入力手段と、
前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、
前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、
前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、
通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段として機能させるためのSNSプログラム。
【請求項1】
SNSを提供するサーバと、通話装置とがネットワークを介し接続されたSNSシステムであって、
サーバは、
通話装置から音声を入力する音声入力手段と、
前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、
前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、
前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、
通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、
を有することを特徴とするSNSシステム。
【請求項2】
前記音声解析手段は、前記音声を解析することにより、前記ユーザ識別子情報、前記分類語、前記分類語に加え、該音声に含まれる1以上の単語を抽出し、
前記音声登録手段は、前記命令語が音声の登録命令を示す場合、前記入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とに加え、前記1以上の単語を対応付けて記憶手段に登録し、
前記音声検索手段は、前記命令語が音声の検索命令を示す場合、前記分類語及び前記1以上の単語を検索キーとして、前記分類語及び前記1以上の単語に対応付けられた音声を前記記憶手段から検索すること、
を有することを特徴とする請求項1記載のSNSシステム。
【請求項3】
前記ユーザ識別情報は、前記音声入力手段により入力された音声の声紋、又は前記音声解析手段により解析され抽出されたユーザ識別語であって、該ユーザ識別情報に基づいてユーザ認証を行うユーザ認証手段と、
を有することを特徴とする請求項1又は2記載のSNSシステム。
【請求項4】
通話装置とネットワークを介し接続されるSNSを提供するSNSサーバあって、
通話装置から音声を入力する音声入力手段と、
前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、
前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、
前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、
通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段と、
を有することを特徴とするSNSサーバ。
【請求項5】
コンピュータに、
通話装置から音声を入力する音声入力手段と、
前記音声を解析することにより、少なくとも、該音声を入力したユーザを識別するユーザ識別情報と、該音声により入力された命令語と、該音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、
前記命令語が音声の登録命令を示す場合、該入力された音声と、前記ユーザ識別情報に基づくユーザ識別子と、前記分類語とを対応付けて記憶手段に登録する音声登録手段と、
前記命令語が音声の検索命令を示す場合、前記分類語を検索キーとして、前記分類語に対応付けられた音声を前記記憶手段から検索する音声検索手段と、
通話装置に対し、前記音声検索手段により検索された音声を出力する音声出力手段として機能させるためのSNSプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】

【図10】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2013−37512(P2013−37512A)
【公開日】平成25年2月21日(2013.2.21)
【国際特許分類】
【出願番号】特願2011−172700(P2011−172700)
【出願日】平成23年8月8日(2011.8.8)
【出願人】(000006747)株式会社リコー (37,907)
【Fターム(参考)】
【公開日】平成25年2月21日(2013.2.21)
【国際特許分類】
【出願日】平成23年8月8日(2011.8.8)
【出願人】(000006747)株式会社リコー (37,907)
【Fターム(参考)】
[ Back to top ]