
ソースコード診断システム
【課題】ソースコード診断システムに、プロジェクトに特化したルールを自動的に作成させ、作成されたルールに従ってソースコードがコーディングされているか否かを診断させる。
【解決手段】診断部210は、ソースコード310の各行がルール定義ファイル320に格納されている複数のルールに適合しているか否か診断し、適合していない行について、ルールとその行の位置とを示す情報を指摘ファイル330に格納する。また、診断部210は、各行を診断しているとき、各行を構成する各構文要素について、各構文要素の使われ方の傾向を示す傾向データを傾向テーブル340に格納する。ルール更新部220は、傾向テーブル340に格納されている傾向データに基づいてルール定義ファイル320に新しいルールを追加する。
【解決手段】診断部210は、ソースコード310の各行がルール定義ファイル320に格納されている複数のルールに適合しているか否か診断し、適合していない行について、ルールとその行の位置とを示す情報を指摘ファイル330に格納する。また、診断部210は、各行を診断しているとき、各行を構成する各構文要素について、各構文要素の使われ方の傾向を示す傾向データを傾向テーブル340に格納する。ルール更新部220は、傾向テーブル340に格納されている傾向データに基づいてルール定義ファイル320に新しいルールを追加する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、ソフトウェア開発プロジェクトにおいて、開発者により作成されたソースコードがコーディング規準に適合するか否かを診断するソースコード診断システムに関する。
【背景技術】
【0002】
一般に、ソフトウェア開発プロジェクトでは、開発対象となるシステムを構成するソースコードに対し、コーディング規準に従うルール集が予め定義されており、各開発者はこれに従ってコーディングする。この場合、実際にコーディング規準に従ってコーディングされているか否かを各開発者自身がチェックするとともに、プロジェクト全体のソースコードについて、インスペクション(検査)担当者がチェックする。
【0003】
しかし、ソースコードのチェック作業は、ルール集に基づき、ソースコードを目視することにより行われるため、チェック作業の工数は多大なものとなる。
そこで、チェック作業の工数を削減するためのツールとして、予め定義されたルール集に基づき、開発者により作成されたソースコードをチェックする診断装置が知られている(例えば、特許文献1参照。)。
また、多数の開発者により作成されたソースコードについて、コーディング規準遵守状況のチェック及びチェック結果の集計等を定期的に行い、集計結果をプロジェクト関係者に提示するコーディング基準遵守状況監視システムが知られている(例えば、特許文献2参照。)。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平06−028165号公報
【特許文献2】特開2006−18735公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
特許文献1や特許文献2に開示されているようなソースコード診断ツールを利用する場合、コーディング規準に従うルール集を予め定義しておく必要がある。ソースコード診断ツールはソースコードを読み込み、そのルール集に基づいて診断する。このように、通常は、ソースコード診断ツールが予め定義されたルール集を持っており、ユーザはそのルール集の中から必要なものだけを選択する。
しかし、プロジェクトに特化したルールに従ってソースコードがコーディングされているか否かをソースコード診断ツールに診断させたい場合には、ユーザはそのプロジェクト用に特化したルールを作成し、ソースコード診断ツールに組み込まなければならない。
【0006】
本発明の目的は、プロジェクトに特化したルールを自動的に作成し、作成されたルールに従ってソースコードがコーディングされているか否かを診断するソースコード診断システムを提供することである。
【課題を解決するための手段】
【0007】
上記目的を達成するために、本発明のソースコード診断システムは、
ソースコードと、複数のルールが格納されているルール定義ファイルと、前記各ルールに適合しない行の位置を示す情報が格納される指摘ファイルと、前記ソースコードの各行に含まれる所定の各構文要素の使われ方の傾向を示す傾向データが格納される傾向テーブルとを記憶する記憶部と、
前記ソースコードの各行が前記ルール定義ファイルに格納されている各ルールに適合しているか否か診断し、適合していない行について、ルールと当該行の位置とを示す情報を指摘ファイルに格納し、前記各行を診断しているとき、前記各行に含まれる所定の各構文要素について、当該各構文要素の使われ方を示す傾向データを前記傾向テーブルに格納する診断部と、
前記傾向テーブルに格納されている傾向データに基づいて新しいルールを前記ルール定義ファイルに追加するルール更新部と、
を備えることを特徴とする。
【0008】
好ましくは、本発明のソースコード診断システムは、
前記所定の各構文要素が、関数であり、
前記傾向データが、ユニーク関数名と呼び出し回数を含み、
前記診断部が、前記各行が関数の呼び出しを含む場合に、当該関数に基づいてユニーク関数名を作成し、当該作成されたユニーク関数名に基づいて前記各ルールに適合しているか否か診断し、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在する場合、当該作成されたユニーク関数名の呼び出し回数を1だけ増加させ、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在しない場合には、呼び出し回数を1として当該作成されたユニーク関数名を含む傾向データを前記傾向テーブルに追加し、
前記ルール更新部が、前記傾向テーブルに格納されている傾向データが同じ関数の呼び出しに基づいて作成された複数のユニーク関数名を含む場合に、当該各ユニーク関数名に対応する呼び出し回数に基づいて当該ユニーク関数名に関するルールを前記ルール定義ファイルに追加するか否かを判断する、
ことを特徴とする。
【発明の効果】
【0009】
本発明によれば、ソースコード診断システムに、プロジェクトに特化したルールを自動的に作成させ、作成されたルールに従ってソースコードがコーディングされているか否かを診断させることができる。
【図面の簡単な説明】
【0010】
【図1】本発明の実施形態に係るソースコード診断システムの構成の一例を示す図である。
【図2】ソースコード診断システムの動作の一例を示す図である。
【図3】ルール定義ファイルのフォーマットとその一例を示す図である。
【図4】指摘ファイルの一例を示す図である。
【図5】診断対象となるソースコードの一例を示す図である。
【図6】傾向テーブルの2つの例を示す図である。
【図7】ソースコード診断システムの処理の流れの一例を示す図である。
【発明を実施するための形態】
【0011】
以下、本発明の実施形態に係るソースコード診断システムについて図面を参照しながら詳細に説明する。
【0012】
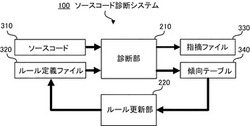
図1は、本発明の実施形態に係るソースコード診断システム100の構成の一例を示す。
ソースコード診断システム100は、CPU(Central Processing Unit)110と、メモリ120と、記憶部130と、入力部140と、表示部150とを有している。
メモリ120は、RAM(Random Access Memory)やROM(Read Only Memory)等で構成される。メモリ120は、ソースコード診断プログラム200を記憶している。CPU110が、ソースコード診断プログラム200を実行することにより、診断部210とルール更新部220との各機能が実現される。
記憶部130は、ハードディスク装置等の磁気ディスク装置やDVD(Digital Versatile Disc)等の光ディスク装置等で構成される。記憶部130は、ソースコード310と、ルール定義ファイル320と、指摘ファイル330と、傾向テーブル340とを記憶する。なお、ソースコード310は、単一のファイルとして記憶されていても、分割されて複数のファイルとして記憶されていてもよい。
入力部140は、キーボードやマウス等で構成される。表示部150は、ディスプレイやプリンタ等で構成される。
【0013】
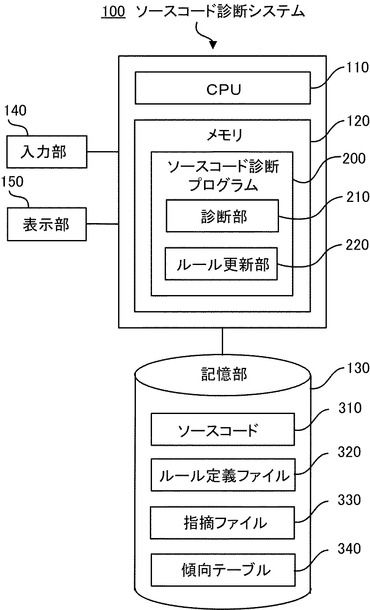
図2は、ソースコード診断システム100の動作の一例を示す。
診断部210は、ソースコード310とルール定義ファイル320を記憶部130からメモリ120に読み込み、診断する。診断部210は、ソースコード310の各行がルール定義ファイル320に記憶されているルール集に適合しているか否か診断し、適合していない行について、そのルールとその行の位置(例えば、その行が含まれるファイル名と、そのファイル内における行の番号)とを示す情報を指摘ファイル330に書き込む。
例えば、「二項演算子の前後には空白を入れる」というルールであれば、診断部210は、ソースコード310から「二項演算子」(例えば’+’,’/’など)が含まれている行を抽出する。そして、診断部210は、抽出された各行について、「二項演算子」の前後に空白があるか否かを検査する。このような検査を行い、「二項演算子」の前後に空白が存在しない場合には、指摘ファイル330に当該行を追加する。
【0014】
既存のソースコード診断ツールはここで処理を終えるが、本実施形態に係るソースコード診断システム100では、診断部210がソースコード310の各行を診断しているときに、各行に含まれる所定の各構文要素について、その各構文要素の使われ方を示す傾向データを作成し、作成された傾向データを傾向テーブル340に格納する。ここで、構文要素とは、関数、変数、配列、構造体、共用体などの文法的な塊を表す単位をいう。そして、診断部210による診断処理が終了した後に、ルール更新部220が傾向テーブル340に格納されている傾向データに基づいて予め定められていない新しいルールを作成し、作成されたルールをルール定義ファイル320に追加する。ルール定義ファイル320を自動的に更新することで、次回診断時にはソースコード310は新しいルールで診断される。
【0015】
診断部210は、ソースコード310の各行を診断しているとき、各行に含まれる所定の各構文要素について、他の行と使われ方が異なるか否かを検査し、各構文要素の使われ方の傾向を示す傾向データを傾向テーブル340に格納する。傾向テーブル340には、複数の傾向データを格納できる。
傾向データは、例えば、ある行に含まれる構文要素が関数である場合、ユニーク関数名と呼び出し回数で構成される。ユニーク関数名とは、呼び出すべき関数が一意に特定できる関数の名前である。関数のオーバーロードが可能な高級言語ではユニーク関数名としてname mangleなどが知られている。name mangleでは、関数名と引数型を文字列で連結させることにより、呼び出すべき関数を一意に特定できるようにしている。どのような方法であれ、ユニーク関数名が作成できればよい。ただし、ユニーク関数名には、引数の型情報が含まれており、引数の数と、その数分の型情報をすべて再現できる必要がある。呼び出し回数は、各ユニーク関数名による関数の呼び出しが行われた回数を記録する。
【0016】
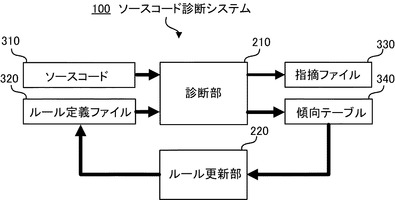
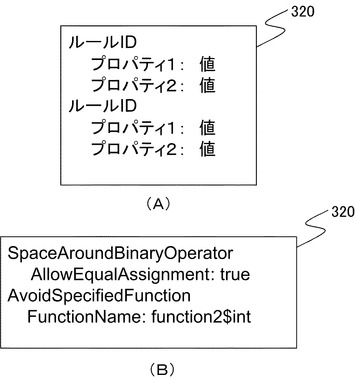
図3(A)はルール定義ファイル320のフォーマットの一例を示す。
ルール定義ファイル320は、例えば、図3(A)に示すように、ルールID(Identifier)と、プロパティおよびその値とを設定できるフォーマットを有する。ルールIDは、各ルールを一意に特定するための記号である。プロパティは、各ルールの動作の詳細を規定するためのオプションを指定する。指定されたルールIDに応じてどのような検査が行われるかは、診断部210に規定されている。診断部210は、各ルールIDに対応する検査を行う。
【0017】
図3(B)はルール定義ファイル320に定義されたルールの一例を示す。このルール定義ファイル320は、SpaceAroundBinaryOperatorとAvoidSpecifiedFunctionという2つのルールを含んでいる。
診断部210は、1行目のSpaceAroundBinaryOperatorルールが指定されると、二項演算子の前後に空白が入っているか否かを検査する。SpaceAroundBinaryOperatorルールのプロパティとして、AllowEqualAssignmentがtrueに設定されている。このプロパティは、代入演算子である'='については前後に空白がなくても指摘しないようにするものである。本例では、trueに設定されているため、診断部210は、代入演算子'='の前後に空白がなくても指摘しない。なお、このような規則は予め定義され、ルール定義ファイル320に内包されている規則であり、ルールIDを指定することで、予め定められた検査を行う。
次の行では、AvoidSpecifiedFunctionルールが指定されている。このルールが指定されると、診断部210は、プロパティで指定された名前を持つ関数名を使用している箇所をすべて指摘する。プロパティFunctionNameでは、ソースコードの中で使用が禁止される関数名が指定される。ここではfunction2(int)という関数名がプロパティで指定されているため、診断部210は、function2(int)関数を使っている箇所を指摘する。
【0018】
図4は、指摘ファイル330の一例を示す。
診断部210は、各ルールに違反する行を検出すると、指摘ファイル330に、そのルールのルールIDと、その行が含まれるファイル名と、ファイル内におけるその行の番号とを順番に出力する。
例えば、図4の1行目と2行目は、ファイル名がfile1.cであるファイルの33行目と35行目に含まれる二項演算子の前後に空白がないことを示す。
また、図4の3行目は、ファイル名がfile5.cであるファイルの72行目で変数が初期化されずに使用されたことを示す。
【0019】
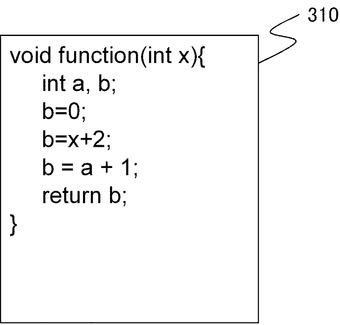
図5は、診断対象となるソースコード310の一例を示す。
図5のソースコード310は、functionという関数を定義しており、引数xと自動変数zとbとを使用して演算を行ったあと、戻値bを返す。
【0020】
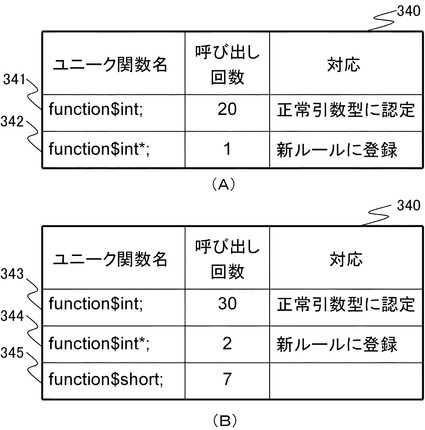
図6(A)は、傾向テーブル340の一例を示す。
傾向テーブル340は、ユニーク関数名と、呼び出し回数と、対応との各フィールドを有する。
図6(A)に示す関数341と関数342は同じ関数から作成されたユニーク関数であるが、関数341の呼び出し時の引数は整数型であり、関数342の呼び出し時の引数は整数ポインタ型である。このため、傾向テーブル340では二つに分けて登録されている。
【0021】
ルール更新部220は、同じ関数から作成されたユニーク関数について呼び出し回数の比率を求め、それが所定の閾値未満のとき、異常ケースと判断する。ソースコード310における関数341と関数342の呼び出し回数はそれぞれ20回と、1回である。関数342は、呼び出し回数比率が1/(20+1)=4.8%である。例えば、所定の値を5%とすると、ルール更新部220は、関数342を異常ケースであると認定する。一方、関数341は呼び出し回数比率が20/(20+1)=95%であるため、ルール更新部220は、正常引数型と認定する。
この場合、ルール更新部220は、ルール定義ファイル320に含まれるルールAvoidSpecifiedFunctionのプロパティとしてユニーク関数名"function$int*"を追加し、傾向テーブル340の関数341と関数342の対応フィールドにそれぞれ「正常引数型に認定」および「新ルールに登録」と記録する。
これにより、診断部210が、更新されたルール定義ファイル320を用いてソースコード310を診断すると、function(int*)の間違った呼び出し箇所がすべて指摘され、function(int*)を呼び出している行が全て指摘ファイル330に記録されることとなる。
【0022】
図6(B)は、傾向テーブル340の別の例を示す。
ルール更新部220は、関数343を正常引数型と認定し、関数344を指摘対象関数としてルール定義ファイル320に登録する。
一方、関数345については、同じ関数から作成された別のユニーク関数が存在しない。このため、ルール更新部220は、関数345については正常引数型か否かの判定は行わない。関数345は、正常引数型に認定されたわけではないが、指摘もされない、という状態である。
【0023】
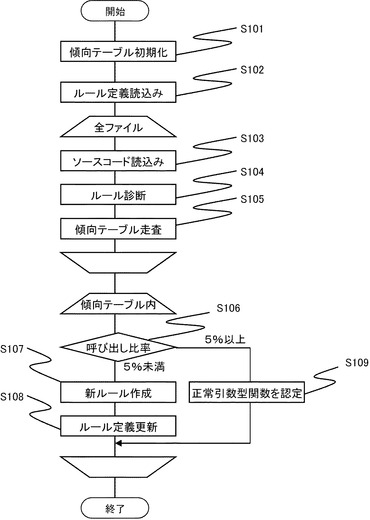
図7は、ソースコード診断システム100の処理の流れの一例を示す。
診断部210は、傾向テーブル340を初期化し(S101)、ルール定義ファイル320を記憶部130からメモリ120に読み込む(S102)。
次に、診断部210は、ソースコード310が分割されて複数のファイルに含まれている場合、全ファイルをターゲットにしてステップS103からステップS105までをループする。なお、診断部210は、ソースコード310が単一のファイルに含まれている場合、ステップS103からステップS105を1回のみ実行する。
【0024】
診断部210は、ソースコード310を1行ずつ記憶部130からメモリ120に読み込みながら(S103)、ルール定義ファイル320に基づいてルールに違反する箇所が有るか否か診断を進める(S104)。
診断部210は、当該行で関数を呼び出しているかどうかを調べる。関数を呼び出している場合には、当該関数に基づいてユニーク関数の名前であるユニーク関数名を作成する。その際、ユニーク関数名に含まれる引数は実際に呼ばれる関数の引数(仮引数)ではなく、呼び出す側の引数(実引数)をユニーク関数名に含める。そして、診断部210は、傾向テーブル340から、作成されたユニーク関数名を探し、傾向テーブル340の中にユニーク関数名が存在する場合、該当のユニーク関数名の呼び出し回数を1増やす。一方、診断部210は、傾向テーブル340にユニーク関数名が存在しない場合には、呼び出し回数を1として新たなユニーク関数名を含む傾向データを傾向テーブル340に追加する(S105)。
【0025】
診断部210が全てのファイルについて診断を終えると、ルール更新部220は、
傾向テーブル340内をすべて走査する。
ルール更新部220は、傾向テーブル340から同じ関数から作成されたユニーク関数名を含む傾向データを見つけ、当該関数の全呼び出し回数を100%として、呼び出し回数の比率が所定の閾値未満(例えば、5%未満)であるユニーク関数を異常ケースであると判断する(S106)。また、ルール更新部220は、呼び出し回数の比率が所定の閾値以上である同じ関数から作成されたユニーク関数の中で最も呼び出し回数比率が高いものを正常引数型と認定する(S109)。なお、呼び出し回数が所定の閾値以上である同じ関数から作成されたユニーク関数の中で最も呼び出し回数比率が高いもの以外のユニーク関数は正常引数型に認定されたわけではないが、指摘もされない、という状態である。
【0026】
ルール更新部220は、異常ケースであると判断したユニーク関数について、「異常と判断された関数の呼び出し引数で、関数呼び出しを行っている箇所を指摘する」新ルールを作成する(S107)。例えば、function2(int)関数に対して、function2(int*)が呼ばれるケースが発見された場合、ルール更新部220は、「function2(int*)関数を呼び出している箇所を指摘する」新ルールを作成する。これは、AviodFunctionルールを追加することである。そして、ルール更新部220は、作成されたルールを、ルール定義ファイルに追加する(S108)。すなわち、ルール定義ファイルに、ルールIDがAvoidFunctionルールで、プロパティFunctionが"function2$int*"となる行を追加する。
【0027】
なお、ステップS101〜S105の処理は診断部210が行い、ステップS106〜S109の処理はルール更新部220が行うが、診断部210がステップS101〜S105の処理を行うとルール更新部220が必ずステップS106〜S109の処理を行うとしてもよいし、診断部210がステップS101〜S105の処理を複数回行うとルール更新部220がステップS106〜S109の処理を行うとしてもよい。
【0028】
以上説明したように、本発明によれば、ソースコード診断システムに、プロジェクトに特化したルールを自動的に作成させ、作成されたルールに従ってソースコードがコーディングされているか否かを診断させることができる。
【符号の説明】
【0029】
100…ソースコード診断システム、110…CPU、120…メモリ、130…記憶部、140…入力部、150…表示部、200…ソースコード診断プログラム、210…診断部、220…ルール更新部、310…ソースコード、320…ルール定義ファイル、330…指摘ファイル、340…傾向テーブル
【技術分野】
【0001】
本発明は、ソフトウェア開発プロジェクトにおいて、開発者により作成されたソースコードがコーディング規準に適合するか否かを診断するソースコード診断システムに関する。
【背景技術】
【0002】
一般に、ソフトウェア開発プロジェクトでは、開発対象となるシステムを構成するソースコードに対し、コーディング規準に従うルール集が予め定義されており、各開発者はこれに従ってコーディングする。この場合、実際にコーディング規準に従ってコーディングされているか否かを各開発者自身がチェックするとともに、プロジェクト全体のソースコードについて、インスペクション(検査)担当者がチェックする。
【0003】
しかし、ソースコードのチェック作業は、ルール集に基づき、ソースコードを目視することにより行われるため、チェック作業の工数は多大なものとなる。
そこで、チェック作業の工数を削減するためのツールとして、予め定義されたルール集に基づき、開発者により作成されたソースコードをチェックする診断装置が知られている(例えば、特許文献1参照。)。
また、多数の開発者により作成されたソースコードについて、コーディング規準遵守状況のチェック及びチェック結果の集計等を定期的に行い、集計結果をプロジェクト関係者に提示するコーディング基準遵守状況監視システムが知られている(例えば、特許文献2参照。)。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平06−028165号公報
【特許文献2】特開2006−18735公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
特許文献1や特許文献2に開示されているようなソースコード診断ツールを利用する場合、コーディング規準に従うルール集を予め定義しておく必要がある。ソースコード診断ツールはソースコードを読み込み、そのルール集に基づいて診断する。このように、通常は、ソースコード診断ツールが予め定義されたルール集を持っており、ユーザはそのルール集の中から必要なものだけを選択する。
しかし、プロジェクトに特化したルールに従ってソースコードがコーディングされているか否かをソースコード診断ツールに診断させたい場合には、ユーザはそのプロジェクト用に特化したルールを作成し、ソースコード診断ツールに組み込まなければならない。
【0006】
本発明の目的は、プロジェクトに特化したルールを自動的に作成し、作成されたルールに従ってソースコードがコーディングされているか否かを診断するソースコード診断システムを提供することである。
【課題を解決するための手段】
【0007】
上記目的を達成するために、本発明のソースコード診断システムは、
ソースコードと、複数のルールが格納されているルール定義ファイルと、前記各ルールに適合しない行の位置を示す情報が格納される指摘ファイルと、前記ソースコードの各行に含まれる所定の各構文要素の使われ方の傾向を示す傾向データが格納される傾向テーブルとを記憶する記憶部と、
前記ソースコードの各行が前記ルール定義ファイルに格納されている各ルールに適合しているか否か診断し、適合していない行について、ルールと当該行の位置とを示す情報を指摘ファイルに格納し、前記各行を診断しているとき、前記各行に含まれる所定の各構文要素について、当該各構文要素の使われ方を示す傾向データを前記傾向テーブルに格納する診断部と、
前記傾向テーブルに格納されている傾向データに基づいて新しいルールを前記ルール定義ファイルに追加するルール更新部と、
を備えることを特徴とする。
【0008】
好ましくは、本発明のソースコード診断システムは、
前記所定の各構文要素が、関数であり、
前記傾向データが、ユニーク関数名と呼び出し回数を含み、
前記診断部が、前記各行が関数の呼び出しを含む場合に、当該関数に基づいてユニーク関数名を作成し、当該作成されたユニーク関数名に基づいて前記各ルールに適合しているか否か診断し、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在する場合、当該作成されたユニーク関数名の呼び出し回数を1だけ増加させ、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在しない場合には、呼び出し回数を1として当該作成されたユニーク関数名を含む傾向データを前記傾向テーブルに追加し、
前記ルール更新部が、前記傾向テーブルに格納されている傾向データが同じ関数の呼び出しに基づいて作成された複数のユニーク関数名を含む場合に、当該各ユニーク関数名に対応する呼び出し回数に基づいて当該ユニーク関数名に関するルールを前記ルール定義ファイルに追加するか否かを判断する、
ことを特徴とする。
【発明の効果】
【0009】
本発明によれば、ソースコード診断システムに、プロジェクトに特化したルールを自動的に作成させ、作成されたルールに従ってソースコードがコーディングされているか否かを診断させることができる。
【図面の簡単な説明】
【0010】
【図1】本発明の実施形態に係るソースコード診断システムの構成の一例を示す図である。
【図2】ソースコード診断システムの動作の一例を示す図である。
【図3】ルール定義ファイルのフォーマットとその一例を示す図である。
【図4】指摘ファイルの一例を示す図である。
【図5】診断対象となるソースコードの一例を示す図である。
【図6】傾向テーブルの2つの例を示す図である。
【図7】ソースコード診断システムの処理の流れの一例を示す図である。
【発明を実施するための形態】
【0011】
以下、本発明の実施形態に係るソースコード診断システムについて図面を参照しながら詳細に説明する。
【0012】
図1は、本発明の実施形態に係るソースコード診断システム100の構成の一例を示す。
ソースコード診断システム100は、CPU(Central Processing Unit)110と、メモリ120と、記憶部130と、入力部140と、表示部150とを有している。
メモリ120は、RAM(Random Access Memory)やROM(Read Only Memory)等で構成される。メモリ120は、ソースコード診断プログラム200を記憶している。CPU110が、ソースコード診断プログラム200を実行することにより、診断部210とルール更新部220との各機能が実現される。
記憶部130は、ハードディスク装置等の磁気ディスク装置やDVD(Digital Versatile Disc)等の光ディスク装置等で構成される。記憶部130は、ソースコード310と、ルール定義ファイル320と、指摘ファイル330と、傾向テーブル340とを記憶する。なお、ソースコード310は、単一のファイルとして記憶されていても、分割されて複数のファイルとして記憶されていてもよい。
入力部140は、キーボードやマウス等で構成される。表示部150は、ディスプレイやプリンタ等で構成される。
【0013】
図2は、ソースコード診断システム100の動作の一例を示す。
診断部210は、ソースコード310とルール定義ファイル320を記憶部130からメモリ120に読み込み、診断する。診断部210は、ソースコード310の各行がルール定義ファイル320に記憶されているルール集に適合しているか否か診断し、適合していない行について、そのルールとその行の位置(例えば、その行が含まれるファイル名と、そのファイル内における行の番号)とを示す情報を指摘ファイル330に書き込む。
例えば、「二項演算子の前後には空白を入れる」というルールであれば、診断部210は、ソースコード310から「二項演算子」(例えば’+’,’/’など)が含まれている行を抽出する。そして、診断部210は、抽出された各行について、「二項演算子」の前後に空白があるか否かを検査する。このような検査を行い、「二項演算子」の前後に空白が存在しない場合には、指摘ファイル330に当該行を追加する。
【0014】
既存のソースコード診断ツールはここで処理を終えるが、本実施形態に係るソースコード診断システム100では、診断部210がソースコード310の各行を診断しているときに、各行に含まれる所定の各構文要素について、その各構文要素の使われ方を示す傾向データを作成し、作成された傾向データを傾向テーブル340に格納する。ここで、構文要素とは、関数、変数、配列、構造体、共用体などの文法的な塊を表す単位をいう。そして、診断部210による診断処理が終了した後に、ルール更新部220が傾向テーブル340に格納されている傾向データに基づいて予め定められていない新しいルールを作成し、作成されたルールをルール定義ファイル320に追加する。ルール定義ファイル320を自動的に更新することで、次回診断時にはソースコード310は新しいルールで診断される。
【0015】
診断部210は、ソースコード310の各行を診断しているとき、各行に含まれる所定の各構文要素について、他の行と使われ方が異なるか否かを検査し、各構文要素の使われ方の傾向を示す傾向データを傾向テーブル340に格納する。傾向テーブル340には、複数の傾向データを格納できる。
傾向データは、例えば、ある行に含まれる構文要素が関数である場合、ユニーク関数名と呼び出し回数で構成される。ユニーク関数名とは、呼び出すべき関数が一意に特定できる関数の名前である。関数のオーバーロードが可能な高級言語ではユニーク関数名としてname mangleなどが知られている。name mangleでは、関数名と引数型を文字列で連結させることにより、呼び出すべき関数を一意に特定できるようにしている。どのような方法であれ、ユニーク関数名が作成できればよい。ただし、ユニーク関数名には、引数の型情報が含まれており、引数の数と、その数分の型情報をすべて再現できる必要がある。呼び出し回数は、各ユニーク関数名による関数の呼び出しが行われた回数を記録する。
【0016】
図3(A)はルール定義ファイル320のフォーマットの一例を示す。
ルール定義ファイル320は、例えば、図3(A)に示すように、ルールID(Identifier)と、プロパティおよびその値とを設定できるフォーマットを有する。ルールIDは、各ルールを一意に特定するための記号である。プロパティは、各ルールの動作の詳細を規定するためのオプションを指定する。指定されたルールIDに応じてどのような検査が行われるかは、診断部210に規定されている。診断部210は、各ルールIDに対応する検査を行う。
【0017】
図3(B)はルール定義ファイル320に定義されたルールの一例を示す。このルール定義ファイル320は、SpaceAroundBinaryOperatorとAvoidSpecifiedFunctionという2つのルールを含んでいる。
診断部210は、1行目のSpaceAroundBinaryOperatorルールが指定されると、二項演算子の前後に空白が入っているか否かを検査する。SpaceAroundBinaryOperatorルールのプロパティとして、AllowEqualAssignmentがtrueに設定されている。このプロパティは、代入演算子である'='については前後に空白がなくても指摘しないようにするものである。本例では、trueに設定されているため、診断部210は、代入演算子'='の前後に空白がなくても指摘しない。なお、このような規則は予め定義され、ルール定義ファイル320に内包されている規則であり、ルールIDを指定することで、予め定められた検査を行う。
次の行では、AvoidSpecifiedFunctionルールが指定されている。このルールが指定されると、診断部210は、プロパティで指定された名前を持つ関数名を使用している箇所をすべて指摘する。プロパティFunctionNameでは、ソースコードの中で使用が禁止される関数名が指定される。ここではfunction2(int)という関数名がプロパティで指定されているため、診断部210は、function2(int)関数を使っている箇所を指摘する。
【0018】
図4は、指摘ファイル330の一例を示す。
診断部210は、各ルールに違反する行を検出すると、指摘ファイル330に、そのルールのルールIDと、その行が含まれるファイル名と、ファイル内におけるその行の番号とを順番に出力する。
例えば、図4の1行目と2行目は、ファイル名がfile1.cであるファイルの33行目と35行目に含まれる二項演算子の前後に空白がないことを示す。
また、図4の3行目は、ファイル名がfile5.cであるファイルの72行目で変数が初期化されずに使用されたことを示す。
【0019】
図5は、診断対象となるソースコード310の一例を示す。
図5のソースコード310は、functionという関数を定義しており、引数xと自動変数zとbとを使用して演算を行ったあと、戻値bを返す。
【0020】
図6(A)は、傾向テーブル340の一例を示す。
傾向テーブル340は、ユニーク関数名と、呼び出し回数と、対応との各フィールドを有する。
図6(A)に示す関数341と関数342は同じ関数から作成されたユニーク関数であるが、関数341の呼び出し時の引数は整数型であり、関数342の呼び出し時の引数は整数ポインタ型である。このため、傾向テーブル340では二つに分けて登録されている。
【0021】
ルール更新部220は、同じ関数から作成されたユニーク関数について呼び出し回数の比率を求め、それが所定の閾値未満のとき、異常ケースと判断する。ソースコード310における関数341と関数342の呼び出し回数はそれぞれ20回と、1回である。関数342は、呼び出し回数比率が1/(20+1)=4.8%である。例えば、所定の値を5%とすると、ルール更新部220は、関数342を異常ケースであると認定する。一方、関数341は呼び出し回数比率が20/(20+1)=95%であるため、ルール更新部220は、正常引数型と認定する。
この場合、ルール更新部220は、ルール定義ファイル320に含まれるルールAvoidSpecifiedFunctionのプロパティとしてユニーク関数名"function$int*"を追加し、傾向テーブル340の関数341と関数342の対応フィールドにそれぞれ「正常引数型に認定」および「新ルールに登録」と記録する。
これにより、診断部210が、更新されたルール定義ファイル320を用いてソースコード310を診断すると、function(int*)の間違った呼び出し箇所がすべて指摘され、function(int*)を呼び出している行が全て指摘ファイル330に記録されることとなる。
【0022】
図6(B)は、傾向テーブル340の別の例を示す。
ルール更新部220は、関数343を正常引数型と認定し、関数344を指摘対象関数としてルール定義ファイル320に登録する。
一方、関数345については、同じ関数から作成された別のユニーク関数が存在しない。このため、ルール更新部220は、関数345については正常引数型か否かの判定は行わない。関数345は、正常引数型に認定されたわけではないが、指摘もされない、という状態である。
【0023】
図7は、ソースコード診断システム100の処理の流れの一例を示す。
診断部210は、傾向テーブル340を初期化し(S101)、ルール定義ファイル320を記憶部130からメモリ120に読み込む(S102)。
次に、診断部210は、ソースコード310が分割されて複数のファイルに含まれている場合、全ファイルをターゲットにしてステップS103からステップS105までをループする。なお、診断部210は、ソースコード310が単一のファイルに含まれている場合、ステップS103からステップS105を1回のみ実行する。
【0024】
診断部210は、ソースコード310を1行ずつ記憶部130からメモリ120に読み込みながら(S103)、ルール定義ファイル320に基づいてルールに違反する箇所が有るか否か診断を進める(S104)。
診断部210は、当該行で関数を呼び出しているかどうかを調べる。関数を呼び出している場合には、当該関数に基づいてユニーク関数の名前であるユニーク関数名を作成する。その際、ユニーク関数名に含まれる引数は実際に呼ばれる関数の引数(仮引数)ではなく、呼び出す側の引数(実引数)をユニーク関数名に含める。そして、診断部210は、傾向テーブル340から、作成されたユニーク関数名を探し、傾向テーブル340の中にユニーク関数名が存在する場合、該当のユニーク関数名の呼び出し回数を1増やす。一方、診断部210は、傾向テーブル340にユニーク関数名が存在しない場合には、呼び出し回数を1として新たなユニーク関数名を含む傾向データを傾向テーブル340に追加する(S105)。
【0025】
診断部210が全てのファイルについて診断を終えると、ルール更新部220は、
傾向テーブル340内をすべて走査する。
ルール更新部220は、傾向テーブル340から同じ関数から作成されたユニーク関数名を含む傾向データを見つけ、当該関数の全呼び出し回数を100%として、呼び出し回数の比率が所定の閾値未満(例えば、5%未満)であるユニーク関数を異常ケースであると判断する(S106)。また、ルール更新部220は、呼び出し回数の比率が所定の閾値以上である同じ関数から作成されたユニーク関数の中で最も呼び出し回数比率が高いものを正常引数型と認定する(S109)。なお、呼び出し回数が所定の閾値以上である同じ関数から作成されたユニーク関数の中で最も呼び出し回数比率が高いもの以外のユニーク関数は正常引数型に認定されたわけではないが、指摘もされない、という状態である。
【0026】
ルール更新部220は、異常ケースであると判断したユニーク関数について、「異常と判断された関数の呼び出し引数で、関数呼び出しを行っている箇所を指摘する」新ルールを作成する(S107)。例えば、function2(int)関数に対して、function2(int*)が呼ばれるケースが発見された場合、ルール更新部220は、「function2(int*)関数を呼び出している箇所を指摘する」新ルールを作成する。これは、AviodFunctionルールを追加することである。そして、ルール更新部220は、作成されたルールを、ルール定義ファイルに追加する(S108)。すなわち、ルール定義ファイルに、ルールIDがAvoidFunctionルールで、プロパティFunctionが"function2$int*"となる行を追加する。
【0027】
なお、ステップS101〜S105の処理は診断部210が行い、ステップS106〜S109の処理はルール更新部220が行うが、診断部210がステップS101〜S105の処理を行うとルール更新部220が必ずステップS106〜S109の処理を行うとしてもよいし、診断部210がステップS101〜S105の処理を複数回行うとルール更新部220がステップS106〜S109の処理を行うとしてもよい。
【0028】
以上説明したように、本発明によれば、ソースコード診断システムに、プロジェクトに特化したルールを自動的に作成させ、作成されたルールに従ってソースコードがコーディングされているか否かを診断させることができる。
【符号の説明】
【0029】
100…ソースコード診断システム、110…CPU、120…メモリ、130…記憶部、140…入力部、150…表示部、200…ソースコード診断プログラム、210…診断部、220…ルール更新部、310…ソースコード、320…ルール定義ファイル、330…指摘ファイル、340…傾向テーブル
【特許請求の範囲】
【請求項1】
ソースコードと、複数のルールが格納されているルール定義ファイルと、前記各ルールに適合しない行の位置を示す情報が格納される指摘ファイルと、前記ソースコードの各行に含まれる所定の各構文要素の使われ方の傾向を示す傾向データが格納される傾向テーブルとを記憶する記憶部と、
前記ソースコードの各行が前記ルール定義ファイルに格納されている各ルールに適合しているか否か診断し、適合していない行について、ルールと当該行の位置とを示す情報を指摘ファイルに格納し、前記各行を診断しているとき、前記各行に含まれる所定の各構文要素について、当該各構文要素の使われ方を示す傾向データを前記傾向テーブルに格納する診断部と、
前記傾向テーブルに格納されている傾向データに基づいて新しいルールを前記ルール定義ファイルに追加するルール更新部と、
を備えることを特徴とするソースコード診断システム。
【請求項2】
前記所定の各構文要素が、関数であり、
前記傾向データが、ユニーク関数の名前であるユニーク関数名と呼び出し回数を含み、
前記診断部が、前記各行が関数の呼び出しを含む場合に、当該関数に基づいてユニーク関数名を作成し、当該作成されたユニーク関数名に基づいて前記各ルールに適合しているか否か診断し、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在する場合、当該作成されたユニーク関数名の呼び出し回数を1だけ増加させ、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在しない場合には、呼び出し回数を1として当該作成されたユニーク関数名を含む傾向データを前記傾向テーブルに追加し、
前記ルール更新部が、前記傾向テーブルに格納されている傾向データが同じ関数の呼び出しに基づいて作成された複数のユニーク関数名を含む場合に、当該各ユニーク関数名に対応する呼び出し回数に基づいて当該ユニーク関数名に関するルールを前記ルール定義ファイルに追加するか否かを判断する、
ことを特徴とする請求項1に記載のソースコード診断システム。
【請求項1】
ソースコードと、複数のルールが格納されているルール定義ファイルと、前記各ルールに適合しない行の位置を示す情報が格納される指摘ファイルと、前記ソースコードの各行に含まれる所定の各構文要素の使われ方の傾向を示す傾向データが格納される傾向テーブルとを記憶する記憶部と、
前記ソースコードの各行が前記ルール定義ファイルに格納されている各ルールに適合しているか否か診断し、適合していない行について、ルールと当該行の位置とを示す情報を指摘ファイルに格納し、前記各行を診断しているとき、前記各行に含まれる所定の各構文要素について、当該各構文要素の使われ方を示す傾向データを前記傾向テーブルに格納する診断部と、
前記傾向テーブルに格納されている傾向データに基づいて新しいルールを前記ルール定義ファイルに追加するルール更新部と、
を備えることを特徴とするソースコード診断システム。
【請求項2】
前記所定の各構文要素が、関数であり、
前記傾向データが、ユニーク関数の名前であるユニーク関数名と呼び出し回数を含み、
前記診断部が、前記各行が関数の呼び出しを含む場合に、当該関数に基づいてユニーク関数名を作成し、当該作成されたユニーク関数名に基づいて前記各ルールに適合しているか否か診断し、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在する場合、当該作成されたユニーク関数名の呼び出し回数を1だけ増加させ、前記傾向テーブルに格納されている傾向データの中に当該作成されたユニーク関数名が存在しない場合には、呼び出し回数を1として当該作成されたユニーク関数名を含む傾向データを前記傾向テーブルに追加し、
前記ルール更新部が、前記傾向テーブルに格納されている傾向データが同じ関数の呼び出しに基づいて作成された複数のユニーク関数名を含む場合に、当該各ユニーク関数名に対応する呼び出し回数に基づいて当該ユニーク関数名に関するルールを前記ルール定義ファイルに追加するか否かを判断する、
ことを特徴とする請求項1に記載のソースコード診断システム。
【図1】


【図2】
【図3】
【図4】

【図5】
【図6】
【図7】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2013−54615(P2013−54615A)
【公開日】平成25年3月21日(2013.3.21)
【国際特許分類】
【出願番号】特願2011−193450(P2011−193450)
【出願日】平成23年9月6日(2011.9.6)
【出願人】(000233055)株式会社日立ソリューションズ (1,610)
【Fターム(参考)】
【公開日】平成25年3月21日(2013.3.21)
【国際特許分類】
【出願日】平成23年9月6日(2011.9.6)
【出願人】(000233055)株式会社日立ソリューションズ (1,610)
【Fターム(参考)】
[ Back to top ]