
テキストデータ管理方法およびテキストデータ管理システム
【課題】特定の分析対象ドメインにおいて、所有する分析対象データに含まれないドメイン知識を有するテキストデータを抽出し、分析対象ドメイン内での分析結果の精度を向上させることができるテキストデータ管理システムを提供する。
【解決手段】テキストデータ管理システムにおいて、入力されたデータ分析要求に基づいて、分析対象データ群501から分析対象データを抽出し、抽出した分析対象データから特徴量を抽出する連携管理サブシステム300と、分析対象データおよび特徴量に基づいて、テキストデータ群503からテキストデータを抽出して、抽出したテキストデータを分析するテキストデータ管理サブシステム400とを備え、テキストデータ管理サブシステム400は、分析に利用したテキストデータと分析対象データの特徴量を関連付けて履歴として管理し、テキストデータの抽出を履歴の特徴量の類似度に基づいて行う。
【解決手段】テキストデータ管理システムにおいて、入力されたデータ分析要求に基づいて、分析対象データ群501から分析対象データを抽出し、抽出した分析対象データから特徴量を抽出する連携管理サブシステム300と、分析対象データおよび特徴量に基づいて、テキストデータ群503からテキストデータを抽出して、抽出したテキストデータを分析するテキストデータ管理サブシステム400とを備え、テキストデータ管理サブシステム400は、分析に利用したテキストデータと分析対象データの特徴量を関連付けて履歴として管理し、テキストデータの抽出を履歴の特徴量の類似度に基づいて行う。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、分析を目的としたテキストデータ管理方法、およびその管理方法を実現するためのシステムに関し、特に、関連度の高いテキストデータを分析対象として抽出する技術に関するものである。
【背景技術】
【0002】
データ分析において、分析対象データが存在し、その分析対象データへの付加的情報としてアンケートやソーシャルメディアデータを利用するケースが増えている。テキストマイニングは、アンケートやソーシャルメディアデータをデータ分析に利用する一般的な分析手法の1つである。
【0003】
テキストマイニングにおいて、分析対象データのドメイン知識を含むテキストデータを利用することは、有効なデータ分析結果を得るためには重要である。
【0004】
例えば、国際公開第2009/96523号パンフレット(特許文献1)では、文書の出現日時をベースとして、文書内の出現単語量を時系列データとして置き換え、文書の特徴量とし、相関する文書を検索する手法が記載されている。
【0005】
また、例えば、特開2010−211438号公報(特許文献2)では、マニュアル文書に含まれる重要語を、文書中に出現する関連語の出現頻度を用いて特徴量としており、その特徴量と検索対象文書に含まれる重要語の特徴量によって、類似度として、類似度が高い文書を分析対象としている。
【0006】
また、例えば、特開2003−167898号公報(特許文献3)には、文書データベースを構文解析して、各文書を構文木データとして表し、精度良く情報検索を行う方法が開示されている。
【先行技術文献】
【特許文献】
【0007】
【特許文献1】国際公開第2009/96523号パンフレット
【特許文献2】特開2010−211438号公報
【特許文献3】特開2003−167898号公報
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかしながら、特許文献1では、単語の出現回数の時系列データを文書の特徴量として利用しているが、時系列上の相関が無い文書を抽出することはできない。
【0009】
また、特許文献2では、定型化された文書であるマニュアルでの関連用語の出現頻度を用いて、単語の特徴量としているが、マニュアルに含まれない特徴から検索することはできない。
【0010】
また、特許文献3においては、自由記述された文書を5W1Hに分割した部分木に解析することで、検索精度を上げているが、文書に含まれない単語を含む文書については、検索できない。
【0011】
一般に、テキストデータのような非構造化データを自動的に収集する際には、文書に含まれる単語やメタ情報といった対象ドメインの特徴量をベースに収集するが、特徴量の元となったデータに検索対象の特徴量が含まれていない場合には、検索されないという問題がある。
【0012】
例えば、ある店舗Aが「商品1、商品2」を取り扱っている場合、「商品1、商品2」を含む文書(口コミなど)が検索されるが、新製品「商品3」に関わる口コミを自動的に収集することは、一般的には期待できない。
【0013】
そこで、本発明は、特定の分析対象ドメインにおいて、所有する分析対象データに含まれないドメイン知識を有するテキストデータを抽出し、分析対象ドメイン内での分析結果の精度を向上させることができ、テキストデータの収集、管理作業を効率化することができるテキストデータ管理方法およびテキストデータ管理システムを提供することを目的とする。
【0014】
本発明の前記ならびにその他の目的と新規な特徴は、本明細書の記述および添付図面から明らかになるであろう。
【課題を解決するための手段】
【0015】
本願において開示される発明のうち、代表的なものの概要を簡単に説明すれば、次の通りである。
【0016】
すなわち、代表的なものの概要は、連携管理部により、入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した分析対象データから特徴量を抽出し、テキストデータ管理部により、分析対象データおよび特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出したテキストデータを分析し、分析に利用したテキストデータと分析対象データの特徴量を関連付けて履歴として管理し、テキストデータの抽出を履歴の特徴量の類似度に基づいて行うものである。
【0017】
また、入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した分析対象データから特徴量を抽出する連携管理部と、分析対象データおよび特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出したテキストデータを分析するテキストデータ管理部とを備え、テキストデータ管理部は、分析に利用したテキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、テキストデータの抽出を履歴の特徴量の類似度に基づいて行うものである。
【発明の効果】
【0018】
本願において開示される発明のうち、代表的なものによって得られる効果を簡単に説明すれば以下の通りである。
【0019】
すなわち、代表的なものによって得られる効果は、分析対象データ値のみに依らず、関連度の高いテキストデータを分析対象として抽出することができ、テキストデータの収集作業や、収集されるテキストデータそのものの量を低減することで、分析担当者、運用者の負担軽減を期待できる。
【図面の簡単な説明】
【0020】
【図1】本発明の実施の形態1に係るテキストデータ管理システムの構成を示す構成図である。
【図2】本発明の実施の形態1に係るテキストデータ管理システムのテキストデータ分析処理を実行する際のシステム全体のデータフローを示す図である。
【図3】本発明の実施の形態1に係るテキストデータ管理システムの連携分析制御部の処理を示すフローチャートである。
【図4】本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象データの一例を示す図である。
【図5】本発明の実施の形態1に係るテキストデータ管理システムのテキスト検索部の処理を示すフローチャートである。
【図6】本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータ利用履歴の一例を示す図である。
【図7】本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータの一例を示す図である。
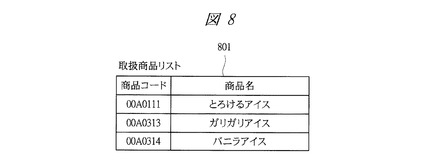
【図8】本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象リストの一例を示す図である。
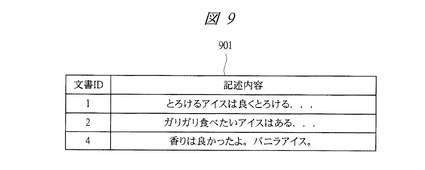
【図9】本発明の実施の形態1に係るテキストデータ管理システムで使用される検索結果のテキストデータの一例を示す図である。
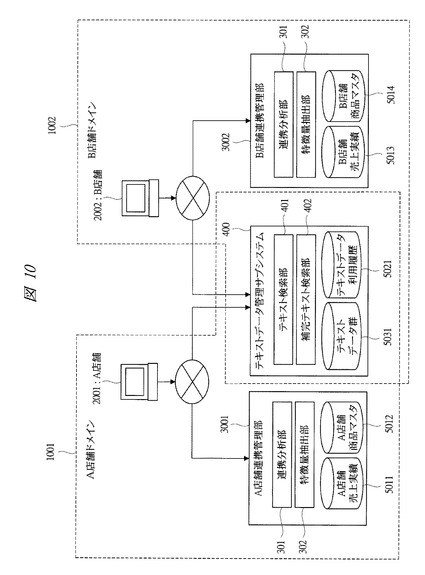
【図10】本発明の実施の形態2に係るテキストデータ管理システムの構成を示す構成図である。
【発明を実施するための形態】
【0021】
以下、本発明の実施の形態を図面に基づいて詳細に説明する。なお、実施の形態を説明するための全図において、同一の部材には原則として同一の符号を付し、その繰り返しの説明は省略する。
【0022】
(実施の形態1)
<テキストデータ管理システムの構成>
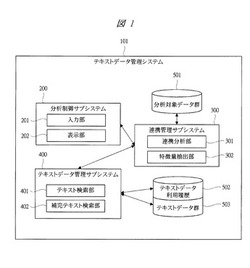
図1により、本発明の実施の形態1に係るテキストデータ管理システムの構成について説明する。図1は本発明の実施の形態1に係るテキストデータ管理システムの構成を示す構成図である。
【0023】
図1において、テキストデータ管理システム101は、中央演算処理装置などの計算処理能力を有する1つ以上の計算機およびネットワークで構成される計算機システム上で動作しており、分析制御サブシステム200、連携管理部である連携管理サブシステム300、テキストデータ管理部であるテキストデータ管理サブシステム400、分析対象データ群501、テキストデータ利用履歴502、テキストデータ群503から構成されている。
【0024】
分析制御サブシステム200は、入力部201、表示部202から構成され、入力部201を介して得た利用者からの要求に応じて、必要なデータを分析対象データ群から抽出し、連携管理サブシステム300に様々な要求を送信し、表示部202に結果を表示するシステムである。
【0025】
連携管理サブシステム300は、連携分析部301、特徴量抽出部302から構成され、分析対象データから特徴量を抽出し、抽出した特徴量を用いてテキストデータ管理サブシステム400に様々な要求を送信し、結果を分析対象結果データと合わせて分析するシステムである。
【0026】
連携分析部301は、分析対象データ群501から抽出したデータと、テキストデータ管理サブシステム400から取得したデータを連携して分析する機能を有する。特徴量抽出部302は分析対象データの特徴を抽出し、特徴量として分析対象データに紐付ける機能を有する。
【0027】
以後、分析対象データ群501から取得したデータのことを分析対象データと呼ぶ。
【0028】
テキストデータ管理サブシステム400は、テキスト検索部401、補完テキスト検索部402から構成され、分析対象データ値や、特徴量に基づいて保有するテキストデータを検索するシステムである。
【0029】
テキスト検索部401では、分析対象データ値と分析対象データの特徴量を入力としており、連携管理サブシステム300からの要求を受けるとデータ値をキーとしてテキストデータ群503を検索する機能を有する。
【0030】
補完テキスト検索部402では、分析対象データの特徴量を入力としており、連携管理サブシステム300から要求を受けると、特徴量を検索キーとしてテキストデータ利用履歴502を抽出する機能を有する。
【0031】
分析対象データ群501は、連携管理サブシステム300が参照する複数の分析対象データを格納するデータベースである。
【0032】
テキストデータ群503は、分析対象ドメインを表し、テキストデータ管理サブシステム400の検索対象となる全てのテキストデータを格納し、テキスト検索部401、補完テキスト検索部402により抽出されるデータベースである。
【0033】
このテキストデータ群503に格納されるテキストデータは、例えばテキストデータ管理サブシステム400により予め登録するようにしても良いし、他のシステムなどから登録するようにしてもよい。また、このテキストデータの登録の際、重複したテキストデータが削除されるようになっている。
【0034】
テキストデータ利用履歴502は、テキストデータを利用した履歴として、特徴量とテキストデータが紐付いたテキストデータのインデックスを格納するデータベースである。
【0035】
<テキストデータ分析処理のデータフロー>
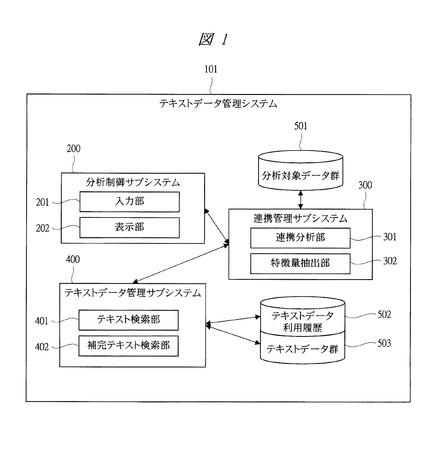
次に、図2により、本発明の実施の形態1に係るテキストデータ管理システムのテキストデータ分析処理を実行する際のシステム全体のデータフローについて説明する。図2は本発明の実施の形態1に係るテキストデータ管理システムのテキストデータ分析処理を実行する際のシステム全体のデータフローを示す図である。
【0036】
テキストデータ分析処理は、大きく2つに分かれる。連携管理サブシステム300の処理とテキストデータ管理サブシステム400の処理である。
【0037】
連携管理サブシステム300の連携分析部301は、連携分析制御部3011、統計処理部3012、文書処理部3013を有している。
【0038】
また、テキストデータ管理サブシステム400のテキスト検索部401は直接指定検索部4011を有し、テキストデータ管理サブシステム400の補完テキスト検索部402は類似特徴履歴検索部4021を有しており、テキスト検索部401と補完テキスト検索部402の共通の構成として検索履歴登録部4001を有している。
【0039】
まず、分析制御サブシステム200は、入力部201を介して利用者のデータ分析要求を連携分析部301に送付する。
【0040】
データ分析要求は、連携分析制御部3011で受信する。連携分析制御部3011は、データ分析要求に基づいて、分析対象データ群501より分析対象データを抽出する。
【0041】
また、連携分析制御部3011は、分析対象データを特徴量抽出部302に送付し、分析対象データを表す特徴量を抽出し、抽出した特徴量と分析対象データをテキスト検索部に送付し、分析対象テキストデータを得る。
【0042】
分析対象データを表す特徴量は、分析対象データ値の時間的変動でもよいし、分析対象データ中の何らかの値の出現割合でもよい。
【0043】
例えば、商品件数や販売数の分散などの分析対象データ全体から算出されるメタデータや商品毎に算出できる前月との販売数の差や変動などであり、単一の値でも複数の値からなる集合でもよい。
【0044】
連携分析制御部3011は、分析対象データを統計処理部3012にて集計などによる分析を実施し、分析対象テキストデータを文書処理部3013にて自然言語処理などを実施し、それぞれの分析結果を紐付けて、表示部202に通知する。
【0045】
直接指定検索部4011は、連携分析制御部3011から分析対象データと特徴量を受信すると、テキストデータ群503から、分析対象ドメインのテキストデータを抽出する。
【0046】
テキストデータを抽出する方法は、分析対象データに含まれる単語を1つまたは複数用いた全文検索でもよいし、抽出する方法やテキストデータを直接指定してもよい。また、直接指定検索部4011は、検索履歴登録部4001に特徴量と抽出したテキストデータを送付し、テキストデータ利用履歴502に履歴を登録する。
【0047】
また、直接指定検索部4011は、類似特徴履歴検索部4021に、分析対象データと特徴量を送付し、過去のテキストデータ検索履歴から、類似した特徴量を持つ分析対象によって検索されたテキストデータを取得する。
【0048】
類似特徴履歴検索部4021は、テキストデータ利用履歴502から送付された分析対象データと特徴量を用いて、テキストデータ履歴を検索し、テキストデータ群503からテキストデータを抽出する。
【0049】
類似特徴履歴検索部4021は、また、検索履歴登録部4001を介して特徴量と検索履歴データをテキストデータ利用履歴502に登録し、次回以降の検索に利用する。
【0050】
類似特徴履歴検索部4021で取得した履歴テキストデータは、検索中の分析対象データには含まれない単語や手法によって検索されたテキストデータであり、特徴量の点から類似するデータを有する。
【0051】
<テキストデータ管理システムの処理>
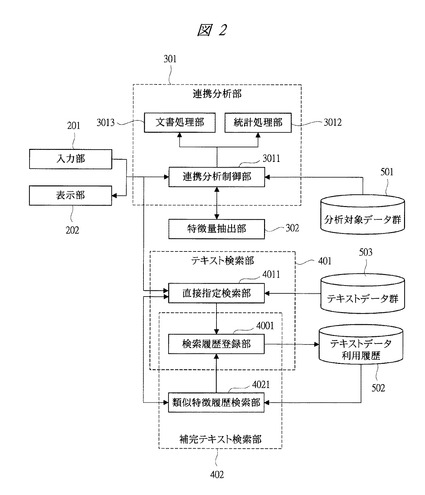
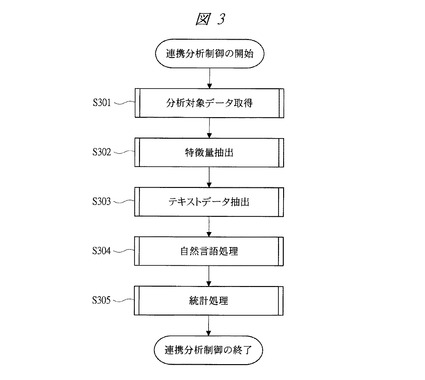
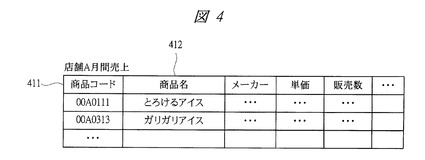
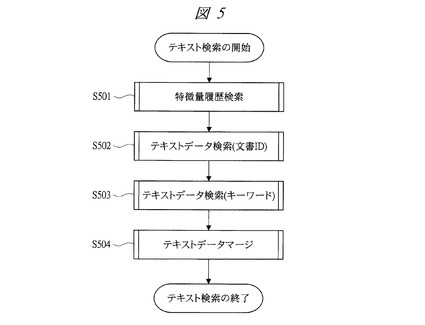
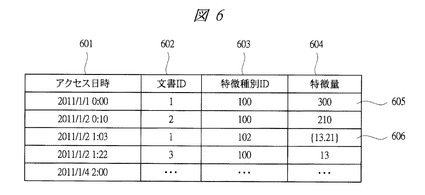
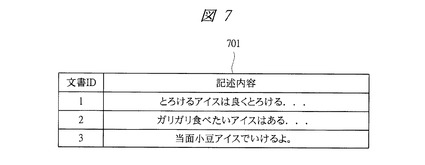
次に、図3〜図9により、本発明の実施の形態1に係るテキストデータ管理システムの処理について説明する。図3は本発明の実施の形態1に係るテキストデータ管理システムの連携分析制御部の処理を示すフローチャート、図4は本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象データの一例を示す図、図5は本発明の実施の形態1に係るテキストデータ管理システムのテキスト検索部の処理を示すフローチャート、図6は本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータ利用履歴の一例を示す図、図7は本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータの一例を示す図、図8は本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象リストの一例を示す図であり、取扱商品リストの例を示している。図9は本発明の実施の形態1に係るテキストデータ管理システムで使用される検索結果のテキストデータの一例を示す図である。
【0052】
まず、連携分析制御部3011の処理は、図3に示すように、分析対象データ取得ステップS301では、入力部201より送付されたデータ分析要求に基づいて、分析対象データを分析対象データ群501から取得する。データ分析要求には「店舗Aの売れ筋商品」といった分析対象ドメインを具体化できる情報が含まれる。
【0053】
分析対象データ取得ステップS301では、データ分析要求の示すドメイン、例えば「店舗Aの売上明細」といった分析対象データを抽出する。
【0054】
分析対象データ群501から取得するデータは図4に示すようなデータとなる。データ分析要求を商品の売上分析として考えた場合、図4に示すように当該商品における商品を一意に示す商品コード411と、商品を表現する商品名412や販売数などが取得される。
【0055】
図4に示す例では、商品コードが「00A0111」の商品名が「とろけるアイス」、商品コードが「00A0313」の商品名が「ガリガリアイス」などの情報が格納されており、その他メーカー、単価、販売数なども格納されている。
【0056】
特徴量抽出ステップS302では、取得した図4に示す分析対象データを利用して特徴量を算出する。特徴量は、分析対象データ量や商品の単価や販売数の分散といった単一値として算出してもよいし、商品分類毎の商品数といったベクトル値として表してもよく、データ分析要求の度に特徴量算出方法を指定してもよい。
【0057】
また、特徴量抽出ステップS302では、分析対象データから分析対象のドメインを表す集合(分析対象リスト)を抽出する。例えば、売上分析においては、図4に示すデータから、図8に示すような商品コードと商品名からなる取扱商品リストを抽出する。
【0058】
図8に示す例では、商品コードが「00A0111」の商品名が「とろけるアイス」、商品コードが「00A0313」の商品名が「ガリガリアイス」、商品コードが「00A0314」の商品名が「バニラアイス」という情報が格納されている。
【0059】
テキストデータ抽出ステップS303では、テキスト検索部401に対して、算出した特徴量と分析対象リストを送信し、分析対象データに関わるテキストデータを取得する。
【0060】
自然言語処理ステップS304は、文書処理部3013にて実施される。取得したテキストデータを自然言語処理することにより、単語や係り受けなどを抽出する。統計処理部3012にて実施される統計処理ステップS305は、自然言語処理結果と、分析対象データに対して統計処理を行い、表示部に結果を送付する。
【0061】
また、テキストデータ抽出ステップS303から呼び出されるテキスト検索部401の処理は図5に示すように、特徴量履歴検索ステップS501では、テキストデータ抽出ステップS303より送付された、特徴量をキーとして、図6に示すようなテキストデータ利用履歴を検索する。
【0062】
テキストデータ利用履歴502は、図6に示すように直接指定検索部4011で過去に検索されたアクセス日時601とアクセスした文書ID602、特徴量604を有しており、直接指定検索部4011から送付された特徴量の範囲指定により検索する。
【0063】
図6に示す例では、アクセス日時601の「2011/1/1 0:00」に対して、文書ID602が「1」、特徴種別ID603が「100」、特徴量604が「300」、アクセス日時601の「2011/1/2 0:10」に対して、文書ID602が「2」、特徴種別ID603が「100」、特徴量604が「210」、アクセス日時601の「2011/1/2 1:03」に対して、文書ID602が「1」、特徴種別ID603が「102」、特徴量604が「{13.21}」などの情報が格納されている。
【0064】
テキストデータ利用履歴502は、また、特徴種別ID603を有する。特徴種別ID603は、特徴量抽出ステップS302にて算出される特徴量の算出方法の種類を表し、例えば、100は分析対象データの行数、102は特定の2商品の売上総数によるベクトル値といった形で、予め定められた値である。
【0065】
履歴検索においては、特徴種別毎に類似特徴量を持つ履歴行が検索される。例えば、単一値605でその差分がある範囲以内であれば類似であり、ベクトル値606で、ユークリッド距離がある範囲以内であれば類似である、といった判定が実施される。
【0066】
テキストデータ検索(文書ID)ステップS502では、特徴量履歴検索ステップS501で検索した利用履歴の文書ID602を利用して、図7に示すようなテキストデータをテキストデータ群503から取得する。テキストデータは、文書IDと記述内容701からなる。
【0067】
図7に示す例では、文書IDが「1」の記述内容が「とろけるアイスは良くとろける」、文書IDが「2」の記述内容が「ガリガリ食べたいアイスはある」、文書IDが「3」の記述内容が「当面小豆アイスでいけるよ」などの情報が格納されている。
【0068】
これらS501〜S502のステップにより、特徴量の点から類似する履歴テキストデータを取得する。
【0069】
テキストデータ検索(キーワード)ステップS503では、テキストデータ抽出ステップS303から送付される分析対象リストを利用してテキストデータ群503から取得する。
【0070】
例えば、図8に示すような取扱商品リストが分析対象リストとして指定された場合、リスト中の商品名801それぞれのキーワードとして、図9に示すように、記述内容901に商品名801が含まれるテキストデータが取得される。
【0071】
テキストデータマージステップS504では、テキストデータ検索(文書ID)ステップS502で取得したテキストデータとテキストデータ検索(キーワード)ステップS503で取得したテキストデータをマージして、テキストデータ検索結果とする。
【0072】
以上により、本実施の形態では、特定の分析対象ドメインにおいて、分析対象データに含まれない関連データを有するテキストデータを抽出可能になる。
【0073】
(実施の形態2)
実施の形態1では、単一ドメインで保有するテキストデータ群から、特徴量に基づいて類似するテキストデータを抽出し、分析する処理を示したが、実施の形態2では、異なるドメイン間でそれぞれ収集したテキストデータ群を共有し、特徴量に基づいてテキストデータを抽出するようにしている。
【0074】
<テキストデータ管理システムの構成>
図10により、本発明の実施の形態2に係るテキストデータ管理システムの構成について説明する。図10は本発明の実施の形態2に係るテキストデータ管理システムの構成を示す構成図である。
【0075】
図10において、テキストデータ管理システムは、異なるドメインをA店舗ドメイン1001、B店舗ドメイン1002とし、連携管理サブシステム300としては、A店舗連携管理部3001とB店舗連携管理部3002を備える。
【0076】
テキストデータ管理サブシステム400は各ドメインにおいて共有されている。A店舗2001、B店舗2002のそれぞれから、各ドメインに有用なテキストデータが収集され、テキストデータ群5031に保管される。
【0077】
各ドメインは、A店舗連携管理部3001、B店舗連携管理部3002として連携分析部301と特徴量抽出部302を有し、ドメイン毎に異なる分析対象データを複数有する(5011、5012、5013、5014)。
【0078】
全てのドメインからのテキストデータ管理サブシステム400へのアクセスは、共通のテキストデータ利用履歴5021に、特徴量と共に記録される。そのため、一方の店舗で収集されたテキストデータは、特徴量を用いた補完テキスト検索部402により、他方の店舗で有効に利用される。
【0079】
また、収集されるテキストデータがテキストデータ群5031にて共通して保存されるため、重複データを削除することにより総テキストデータ量の削減が可能であり、テキストデータ群の更新においても、個々のドメインで更新する場合よりも更新頻度を削減することが可能となる。
【0080】
以上、本発明者によってなされた発明を実施の形態に基づき具体的に説明したが、本発明は前記実施の形態に限定されるものではなく、その要旨を逸脱しない範囲で種々変更可能であることはいうまでもない。
【産業上の利用可能性】
【0081】
本発明は、分析を目的としたテキストデータ管理方法、およびその管理方法を実現するためのシステムに関し、個々に所有するデータの特徴量に依らず、関連度の高いテキストデータを収集・参照する必要のある装置やシステムなどに広く適用可能である。
【符号の説明】
【0082】
101…テキストデータ管理システム、200…分析制御サブシステム、201…入力部、202…表示部、300…連携管理サブシステム、301…連携分析部、302…特徴量抽出部、400…テキストデータ管理サブシステム、401…テキスト検索部、402…補完テキスト検索部、501…分析対象データ群、502…テキストデータ利用履歴、503…テキストデータ群。
【技術分野】
【0001】
本発明は、分析を目的としたテキストデータ管理方法、およびその管理方法を実現するためのシステムに関し、特に、関連度の高いテキストデータを分析対象として抽出する技術に関するものである。
【背景技術】
【0002】
データ分析において、分析対象データが存在し、その分析対象データへの付加的情報としてアンケートやソーシャルメディアデータを利用するケースが増えている。テキストマイニングは、アンケートやソーシャルメディアデータをデータ分析に利用する一般的な分析手法の1つである。
【0003】
テキストマイニングにおいて、分析対象データのドメイン知識を含むテキストデータを利用することは、有効なデータ分析結果を得るためには重要である。
【0004】
例えば、国際公開第2009/96523号パンフレット(特許文献1)では、文書の出現日時をベースとして、文書内の出現単語量を時系列データとして置き換え、文書の特徴量とし、相関する文書を検索する手法が記載されている。
【0005】
また、例えば、特開2010−211438号公報(特許文献2)では、マニュアル文書に含まれる重要語を、文書中に出現する関連語の出現頻度を用いて特徴量としており、その特徴量と検索対象文書に含まれる重要語の特徴量によって、類似度として、類似度が高い文書を分析対象としている。
【0006】
また、例えば、特開2003−167898号公報(特許文献3)には、文書データベースを構文解析して、各文書を構文木データとして表し、精度良く情報検索を行う方法が開示されている。
【先行技術文献】
【特許文献】
【0007】
【特許文献1】国際公開第2009/96523号パンフレット
【特許文献2】特開2010−211438号公報
【特許文献3】特開2003−167898号公報
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかしながら、特許文献1では、単語の出現回数の時系列データを文書の特徴量として利用しているが、時系列上の相関が無い文書を抽出することはできない。
【0009】
また、特許文献2では、定型化された文書であるマニュアルでの関連用語の出現頻度を用いて、単語の特徴量としているが、マニュアルに含まれない特徴から検索することはできない。
【0010】
また、特許文献3においては、自由記述された文書を5W1Hに分割した部分木に解析することで、検索精度を上げているが、文書に含まれない単語を含む文書については、検索できない。
【0011】
一般に、テキストデータのような非構造化データを自動的に収集する際には、文書に含まれる単語やメタ情報といった対象ドメインの特徴量をベースに収集するが、特徴量の元となったデータに検索対象の特徴量が含まれていない場合には、検索されないという問題がある。
【0012】
例えば、ある店舗Aが「商品1、商品2」を取り扱っている場合、「商品1、商品2」を含む文書(口コミなど)が検索されるが、新製品「商品3」に関わる口コミを自動的に収集することは、一般的には期待できない。
【0013】
そこで、本発明は、特定の分析対象ドメインにおいて、所有する分析対象データに含まれないドメイン知識を有するテキストデータを抽出し、分析対象ドメイン内での分析結果の精度を向上させることができ、テキストデータの収集、管理作業を効率化することができるテキストデータ管理方法およびテキストデータ管理システムを提供することを目的とする。
【0014】
本発明の前記ならびにその他の目的と新規な特徴は、本明細書の記述および添付図面から明らかになるであろう。
【課題を解決するための手段】
【0015】
本願において開示される発明のうち、代表的なものの概要を簡単に説明すれば、次の通りである。
【0016】
すなわち、代表的なものの概要は、連携管理部により、入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した分析対象データから特徴量を抽出し、テキストデータ管理部により、分析対象データおよび特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出したテキストデータを分析し、分析に利用したテキストデータと分析対象データの特徴量を関連付けて履歴として管理し、テキストデータの抽出を履歴の特徴量の類似度に基づいて行うものである。
【0017】
また、入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した分析対象データから特徴量を抽出する連携管理部と、分析対象データおよび特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出したテキストデータを分析するテキストデータ管理部とを備え、テキストデータ管理部は、分析に利用したテキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、テキストデータの抽出を履歴の特徴量の類似度に基づいて行うものである。
【発明の効果】
【0018】
本願において開示される発明のうち、代表的なものによって得られる効果を簡単に説明すれば以下の通りである。
【0019】
すなわち、代表的なものによって得られる効果は、分析対象データ値のみに依らず、関連度の高いテキストデータを分析対象として抽出することができ、テキストデータの収集作業や、収集されるテキストデータそのものの量を低減することで、分析担当者、運用者の負担軽減を期待できる。
【図面の簡単な説明】
【0020】
【図1】本発明の実施の形態1に係るテキストデータ管理システムの構成を示す構成図である。
【図2】本発明の実施の形態1に係るテキストデータ管理システムのテキストデータ分析処理を実行する際のシステム全体のデータフローを示す図である。
【図3】本発明の実施の形態1に係るテキストデータ管理システムの連携分析制御部の処理を示すフローチャートである。
【図4】本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象データの一例を示す図である。
【図5】本発明の実施の形態1に係るテキストデータ管理システムのテキスト検索部の処理を示すフローチャートである。
【図6】本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータ利用履歴の一例を示す図である。
【図7】本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータの一例を示す図である。
【図8】本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象リストの一例を示す図である。
【図9】本発明の実施の形態1に係るテキストデータ管理システムで使用される検索結果のテキストデータの一例を示す図である。
【図10】本発明の実施の形態2に係るテキストデータ管理システムの構成を示す構成図である。
【発明を実施するための形態】
【0021】
以下、本発明の実施の形態を図面に基づいて詳細に説明する。なお、実施の形態を説明するための全図において、同一の部材には原則として同一の符号を付し、その繰り返しの説明は省略する。
【0022】
(実施の形態1)
<テキストデータ管理システムの構成>
図1により、本発明の実施の形態1に係るテキストデータ管理システムの構成について説明する。図1は本発明の実施の形態1に係るテキストデータ管理システムの構成を示す構成図である。
【0023】
図1において、テキストデータ管理システム101は、中央演算処理装置などの計算処理能力を有する1つ以上の計算機およびネットワークで構成される計算機システム上で動作しており、分析制御サブシステム200、連携管理部である連携管理サブシステム300、テキストデータ管理部であるテキストデータ管理サブシステム400、分析対象データ群501、テキストデータ利用履歴502、テキストデータ群503から構成されている。
【0024】
分析制御サブシステム200は、入力部201、表示部202から構成され、入力部201を介して得た利用者からの要求に応じて、必要なデータを分析対象データ群から抽出し、連携管理サブシステム300に様々な要求を送信し、表示部202に結果を表示するシステムである。
【0025】
連携管理サブシステム300は、連携分析部301、特徴量抽出部302から構成され、分析対象データから特徴量を抽出し、抽出した特徴量を用いてテキストデータ管理サブシステム400に様々な要求を送信し、結果を分析対象結果データと合わせて分析するシステムである。
【0026】
連携分析部301は、分析対象データ群501から抽出したデータと、テキストデータ管理サブシステム400から取得したデータを連携して分析する機能を有する。特徴量抽出部302は分析対象データの特徴を抽出し、特徴量として分析対象データに紐付ける機能を有する。
【0027】
以後、分析対象データ群501から取得したデータのことを分析対象データと呼ぶ。
【0028】
テキストデータ管理サブシステム400は、テキスト検索部401、補完テキスト検索部402から構成され、分析対象データ値や、特徴量に基づいて保有するテキストデータを検索するシステムである。
【0029】
テキスト検索部401では、分析対象データ値と分析対象データの特徴量を入力としており、連携管理サブシステム300からの要求を受けるとデータ値をキーとしてテキストデータ群503を検索する機能を有する。
【0030】
補完テキスト検索部402では、分析対象データの特徴量を入力としており、連携管理サブシステム300から要求を受けると、特徴量を検索キーとしてテキストデータ利用履歴502を抽出する機能を有する。
【0031】
分析対象データ群501は、連携管理サブシステム300が参照する複数の分析対象データを格納するデータベースである。
【0032】
テキストデータ群503は、分析対象ドメインを表し、テキストデータ管理サブシステム400の検索対象となる全てのテキストデータを格納し、テキスト検索部401、補完テキスト検索部402により抽出されるデータベースである。
【0033】
このテキストデータ群503に格納されるテキストデータは、例えばテキストデータ管理サブシステム400により予め登録するようにしても良いし、他のシステムなどから登録するようにしてもよい。また、このテキストデータの登録の際、重複したテキストデータが削除されるようになっている。
【0034】
テキストデータ利用履歴502は、テキストデータを利用した履歴として、特徴量とテキストデータが紐付いたテキストデータのインデックスを格納するデータベースである。
【0035】
<テキストデータ分析処理のデータフロー>
次に、図2により、本発明の実施の形態1に係るテキストデータ管理システムのテキストデータ分析処理を実行する際のシステム全体のデータフローについて説明する。図2は本発明の実施の形態1に係るテキストデータ管理システムのテキストデータ分析処理を実行する際のシステム全体のデータフローを示す図である。
【0036】
テキストデータ分析処理は、大きく2つに分かれる。連携管理サブシステム300の処理とテキストデータ管理サブシステム400の処理である。
【0037】
連携管理サブシステム300の連携分析部301は、連携分析制御部3011、統計処理部3012、文書処理部3013を有している。
【0038】
また、テキストデータ管理サブシステム400のテキスト検索部401は直接指定検索部4011を有し、テキストデータ管理サブシステム400の補完テキスト検索部402は類似特徴履歴検索部4021を有しており、テキスト検索部401と補完テキスト検索部402の共通の構成として検索履歴登録部4001を有している。
【0039】
まず、分析制御サブシステム200は、入力部201を介して利用者のデータ分析要求を連携分析部301に送付する。
【0040】
データ分析要求は、連携分析制御部3011で受信する。連携分析制御部3011は、データ分析要求に基づいて、分析対象データ群501より分析対象データを抽出する。
【0041】
また、連携分析制御部3011は、分析対象データを特徴量抽出部302に送付し、分析対象データを表す特徴量を抽出し、抽出した特徴量と分析対象データをテキスト検索部に送付し、分析対象テキストデータを得る。
【0042】
分析対象データを表す特徴量は、分析対象データ値の時間的変動でもよいし、分析対象データ中の何らかの値の出現割合でもよい。
【0043】
例えば、商品件数や販売数の分散などの分析対象データ全体から算出されるメタデータや商品毎に算出できる前月との販売数の差や変動などであり、単一の値でも複数の値からなる集合でもよい。
【0044】
連携分析制御部3011は、分析対象データを統計処理部3012にて集計などによる分析を実施し、分析対象テキストデータを文書処理部3013にて自然言語処理などを実施し、それぞれの分析結果を紐付けて、表示部202に通知する。
【0045】
直接指定検索部4011は、連携分析制御部3011から分析対象データと特徴量を受信すると、テキストデータ群503から、分析対象ドメインのテキストデータを抽出する。
【0046】
テキストデータを抽出する方法は、分析対象データに含まれる単語を1つまたは複数用いた全文検索でもよいし、抽出する方法やテキストデータを直接指定してもよい。また、直接指定検索部4011は、検索履歴登録部4001に特徴量と抽出したテキストデータを送付し、テキストデータ利用履歴502に履歴を登録する。
【0047】
また、直接指定検索部4011は、類似特徴履歴検索部4021に、分析対象データと特徴量を送付し、過去のテキストデータ検索履歴から、類似した特徴量を持つ分析対象によって検索されたテキストデータを取得する。
【0048】
類似特徴履歴検索部4021は、テキストデータ利用履歴502から送付された分析対象データと特徴量を用いて、テキストデータ履歴を検索し、テキストデータ群503からテキストデータを抽出する。
【0049】
類似特徴履歴検索部4021は、また、検索履歴登録部4001を介して特徴量と検索履歴データをテキストデータ利用履歴502に登録し、次回以降の検索に利用する。
【0050】
類似特徴履歴検索部4021で取得した履歴テキストデータは、検索中の分析対象データには含まれない単語や手法によって検索されたテキストデータであり、特徴量の点から類似するデータを有する。
【0051】
<テキストデータ管理システムの処理>
次に、図3〜図9により、本発明の実施の形態1に係るテキストデータ管理システムの処理について説明する。図3は本発明の実施の形態1に係るテキストデータ管理システムの連携分析制御部の処理を示すフローチャート、図4は本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象データの一例を示す図、図5は本発明の実施の形態1に係るテキストデータ管理システムのテキスト検索部の処理を示すフローチャート、図6は本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータ利用履歴の一例を示す図、図7は本発明の実施の形態1に係るテキストデータ管理システムで使用されるテキストデータの一例を示す図、図8は本発明の実施の形態1に係るテキストデータ管理システムで使用される分析対象リストの一例を示す図であり、取扱商品リストの例を示している。図9は本発明の実施の形態1に係るテキストデータ管理システムで使用される検索結果のテキストデータの一例を示す図である。
【0052】
まず、連携分析制御部3011の処理は、図3に示すように、分析対象データ取得ステップS301では、入力部201より送付されたデータ分析要求に基づいて、分析対象データを分析対象データ群501から取得する。データ分析要求には「店舗Aの売れ筋商品」といった分析対象ドメインを具体化できる情報が含まれる。
【0053】
分析対象データ取得ステップS301では、データ分析要求の示すドメイン、例えば「店舗Aの売上明細」といった分析対象データを抽出する。
【0054】
分析対象データ群501から取得するデータは図4に示すようなデータとなる。データ分析要求を商品の売上分析として考えた場合、図4に示すように当該商品における商品を一意に示す商品コード411と、商品を表現する商品名412や販売数などが取得される。
【0055】
図4に示す例では、商品コードが「00A0111」の商品名が「とろけるアイス」、商品コードが「00A0313」の商品名が「ガリガリアイス」などの情報が格納されており、その他メーカー、単価、販売数なども格納されている。
【0056】
特徴量抽出ステップS302では、取得した図4に示す分析対象データを利用して特徴量を算出する。特徴量は、分析対象データ量や商品の単価や販売数の分散といった単一値として算出してもよいし、商品分類毎の商品数といったベクトル値として表してもよく、データ分析要求の度に特徴量算出方法を指定してもよい。
【0057】
また、特徴量抽出ステップS302では、分析対象データから分析対象のドメインを表す集合(分析対象リスト)を抽出する。例えば、売上分析においては、図4に示すデータから、図8に示すような商品コードと商品名からなる取扱商品リストを抽出する。
【0058】
図8に示す例では、商品コードが「00A0111」の商品名が「とろけるアイス」、商品コードが「00A0313」の商品名が「ガリガリアイス」、商品コードが「00A0314」の商品名が「バニラアイス」という情報が格納されている。
【0059】
テキストデータ抽出ステップS303では、テキスト検索部401に対して、算出した特徴量と分析対象リストを送信し、分析対象データに関わるテキストデータを取得する。
【0060】
自然言語処理ステップS304は、文書処理部3013にて実施される。取得したテキストデータを自然言語処理することにより、単語や係り受けなどを抽出する。統計処理部3012にて実施される統計処理ステップS305は、自然言語処理結果と、分析対象データに対して統計処理を行い、表示部に結果を送付する。
【0061】
また、テキストデータ抽出ステップS303から呼び出されるテキスト検索部401の処理は図5に示すように、特徴量履歴検索ステップS501では、テキストデータ抽出ステップS303より送付された、特徴量をキーとして、図6に示すようなテキストデータ利用履歴を検索する。
【0062】
テキストデータ利用履歴502は、図6に示すように直接指定検索部4011で過去に検索されたアクセス日時601とアクセスした文書ID602、特徴量604を有しており、直接指定検索部4011から送付された特徴量の範囲指定により検索する。
【0063】
図6に示す例では、アクセス日時601の「2011/1/1 0:00」に対して、文書ID602が「1」、特徴種別ID603が「100」、特徴量604が「300」、アクセス日時601の「2011/1/2 0:10」に対して、文書ID602が「2」、特徴種別ID603が「100」、特徴量604が「210」、アクセス日時601の「2011/1/2 1:03」に対して、文書ID602が「1」、特徴種別ID603が「102」、特徴量604が「{13.21}」などの情報が格納されている。
【0064】
テキストデータ利用履歴502は、また、特徴種別ID603を有する。特徴種別ID603は、特徴量抽出ステップS302にて算出される特徴量の算出方法の種類を表し、例えば、100は分析対象データの行数、102は特定の2商品の売上総数によるベクトル値といった形で、予め定められた値である。
【0065】
履歴検索においては、特徴種別毎に類似特徴量を持つ履歴行が検索される。例えば、単一値605でその差分がある範囲以内であれば類似であり、ベクトル値606で、ユークリッド距離がある範囲以内であれば類似である、といった判定が実施される。
【0066】
テキストデータ検索(文書ID)ステップS502では、特徴量履歴検索ステップS501で検索した利用履歴の文書ID602を利用して、図7に示すようなテキストデータをテキストデータ群503から取得する。テキストデータは、文書IDと記述内容701からなる。
【0067】
図7に示す例では、文書IDが「1」の記述内容が「とろけるアイスは良くとろける」、文書IDが「2」の記述内容が「ガリガリ食べたいアイスはある」、文書IDが「3」の記述内容が「当面小豆アイスでいけるよ」などの情報が格納されている。
【0068】
これらS501〜S502のステップにより、特徴量の点から類似する履歴テキストデータを取得する。
【0069】
テキストデータ検索(キーワード)ステップS503では、テキストデータ抽出ステップS303から送付される分析対象リストを利用してテキストデータ群503から取得する。
【0070】
例えば、図8に示すような取扱商品リストが分析対象リストとして指定された場合、リスト中の商品名801それぞれのキーワードとして、図9に示すように、記述内容901に商品名801が含まれるテキストデータが取得される。
【0071】
テキストデータマージステップS504では、テキストデータ検索(文書ID)ステップS502で取得したテキストデータとテキストデータ検索(キーワード)ステップS503で取得したテキストデータをマージして、テキストデータ検索結果とする。
【0072】
以上により、本実施の形態では、特定の分析対象ドメインにおいて、分析対象データに含まれない関連データを有するテキストデータを抽出可能になる。
【0073】
(実施の形態2)
実施の形態1では、単一ドメインで保有するテキストデータ群から、特徴量に基づいて類似するテキストデータを抽出し、分析する処理を示したが、実施の形態2では、異なるドメイン間でそれぞれ収集したテキストデータ群を共有し、特徴量に基づいてテキストデータを抽出するようにしている。
【0074】
<テキストデータ管理システムの構成>
図10により、本発明の実施の形態2に係るテキストデータ管理システムの構成について説明する。図10は本発明の実施の形態2に係るテキストデータ管理システムの構成を示す構成図である。
【0075】
図10において、テキストデータ管理システムは、異なるドメインをA店舗ドメイン1001、B店舗ドメイン1002とし、連携管理サブシステム300としては、A店舗連携管理部3001とB店舗連携管理部3002を備える。
【0076】
テキストデータ管理サブシステム400は各ドメインにおいて共有されている。A店舗2001、B店舗2002のそれぞれから、各ドメインに有用なテキストデータが収集され、テキストデータ群5031に保管される。
【0077】
各ドメインは、A店舗連携管理部3001、B店舗連携管理部3002として連携分析部301と特徴量抽出部302を有し、ドメイン毎に異なる分析対象データを複数有する(5011、5012、5013、5014)。
【0078】
全てのドメインからのテキストデータ管理サブシステム400へのアクセスは、共通のテキストデータ利用履歴5021に、特徴量と共に記録される。そのため、一方の店舗で収集されたテキストデータは、特徴量を用いた補完テキスト検索部402により、他方の店舗で有効に利用される。
【0079】
また、収集されるテキストデータがテキストデータ群5031にて共通して保存されるため、重複データを削除することにより総テキストデータ量の削減が可能であり、テキストデータ群の更新においても、個々のドメインで更新する場合よりも更新頻度を削減することが可能となる。
【0080】
以上、本発明者によってなされた発明を実施の形態に基づき具体的に説明したが、本発明は前記実施の形態に限定されるものではなく、その要旨を逸脱しない範囲で種々変更可能であることはいうまでもない。
【産業上の利用可能性】
【0081】
本発明は、分析を目的としたテキストデータ管理方法、およびその管理方法を実現するためのシステムに関し、個々に所有するデータの特徴量に依らず、関連度の高いテキストデータを収集・参照する必要のある装置やシステムなどに広く適用可能である。
【符号の説明】
【0082】
101…テキストデータ管理システム、200…分析制御サブシステム、201…入力部、202…表示部、300…連携管理サブシステム、301…連携分析部、302…特徴量抽出部、400…テキストデータ管理サブシステム、401…テキスト検索部、402…補完テキスト検索部、501…分析対象データ群、502…テキストデータ利用履歴、503…テキストデータ群。
【特許請求の範囲】
【請求項1】
入力されたデータ分析要求に基づいて、分析対象データを抽出し、前記分析対象データに関連するテキストデータを分析するテキストデータ管理方法であって、
連携管理部により、前記入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出し、
テキストデータ管理部により、前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析し、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理方法。
【請求項2】
異なるデータ分析要求先から入力されたデータ分析要求に基づいて、分析対象データを抽出し、前記分析対象データに関連するテキストデータを分析するテキストデータ管理方法であって、
連携管理部により、前記異なるデータ分析要求先から入力されたデータ分析要求に基づいて、前記データ分析要求先に対応する分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出し、
テキストデータ管理部により、前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析し、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理方法。
【請求項3】
請求項1または2に記載のテキストデータ管理方法において、
前記テキストデータ管理部により、異なる分析対象データ群を分析するためのテキストデータを前記テキストデータ群に登録し、前記異なる分析対象データ群で重複するテキストデータを削除することを特徴とするテキストデータ管理方法。
【請求項4】
入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出する連携管理部と、
前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析するテキストデータ管理部とを備え、
前記テキストデータ管理部は、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理システム。
【請求項5】
異なるデータ分析要求先から入力されたデータ分析要求に基づいて、前記データ分析要求先に対応する分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出する連携管理部と、
前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析するテキストデータ管理部とを備え、
前記テキストデータ管理部は、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理システム。
【請求項6】
請求項4または5に記載のテキストデータ管理システムにおいて、
前記テキストデータ管理部は、異なる分析対象データ群を分析するためのテキストデータを前記テキストデータ群に登録し、前記異なる分析対象データ群で重複するテキストデータを削除することを特徴とするテキストデータ管理システム。
【請求項1】
入力されたデータ分析要求に基づいて、分析対象データを抽出し、前記分析対象データに関連するテキストデータを分析するテキストデータ管理方法であって、
連携管理部により、前記入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出し、
テキストデータ管理部により、前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析し、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理方法。
【請求項2】
異なるデータ分析要求先から入力されたデータ分析要求に基づいて、分析対象データを抽出し、前記分析対象データに関連するテキストデータを分析するテキストデータ管理方法であって、
連携管理部により、前記異なるデータ分析要求先から入力されたデータ分析要求に基づいて、前記データ分析要求先に対応する分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出し、
テキストデータ管理部により、前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析し、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理方法。
【請求項3】
請求項1または2に記載のテキストデータ管理方法において、
前記テキストデータ管理部により、異なる分析対象データ群を分析するためのテキストデータを前記テキストデータ群に登録し、前記異なる分析対象データ群で重複するテキストデータを削除することを特徴とするテキストデータ管理方法。
【請求項4】
入力されたデータ分析要求に基づいて、分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出する連携管理部と、
前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析するテキストデータ管理部とを備え、
前記テキストデータ管理部は、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理システム。
【請求項5】
異なるデータ分析要求先から入力されたデータ分析要求に基づいて、前記データ分析要求先に対応する分析対象データ群から分析対象データを抽出し、抽出した前記分析対象データから特徴量を抽出する連携管理部と、
前記分析対象データおよび前記特徴量に基づいて、テキストデータ群からテキストデータを抽出して、抽出した前記テキストデータを分析するテキストデータ管理部とを備え、
前記テキストデータ管理部は、分析に利用した前記テキストデータと前記分析対象データの特徴量を関連付けて履歴として管理し、前記テキストデータの抽出を前記履歴の特徴量の類似度に基づいて行うことを特徴とするテキストデータ管理システム。
【請求項6】
請求項4または5に記載のテキストデータ管理システムにおいて、
前記テキストデータ管理部は、異なる分析対象データ群を分析するためのテキストデータを前記テキストデータ群に登録し、前記異なる分析対象データ群で重複するテキストデータを削除することを特徴とするテキストデータ管理システム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2013−114635(P2013−114635A)
【公開日】平成25年6月10日(2013.6.10)
【国際特許分類】
【出願番号】特願2011−263166(P2011−263166)
【出願日】平成23年12月1日(2011.12.1)
【出願人】(000233491)株式会社日立システムズ (394)
【公開日】平成25年6月10日(2013.6.10)
【国際特許分類】
【出願日】平成23年12月1日(2011.12.1)
【出願人】(000233491)株式会社日立システムズ (394)
[ Back to top ]