
テキストマイニング装置
【課題】 回答者から収集された大量のデータの中から、回答者の連想における結びつきが強い概念を抽出する。
【解決手段】 テキストマイニング装置は、複数のテキストT1〜Tm(mは整数)を記憶するテキスト記憶部と、複数のワードW1〜Wn(nは整数)を記憶するワード記憶部と、複数のテキストT1〜Tmの各々に対して、複数のワードW1〜Wnとの照合を実行して一致する文字列が含まれるか否かを示す存在情報P1〜Pnを生成する存在情報生成部と、複数のテキストのうち第i番目の存在情報Piと第j番目の存在情報Pjとが同一であるテキストの数C(i,j)を算出する共起数算出部と、C(i,j)を成分とするクロス集計表のカイ2乗値を算出し出力するカイ2乗値算出部とを備える。
【解決手段】 テキストマイニング装置は、複数のテキストT1〜Tm(mは整数)を記憶するテキスト記憶部と、複数のワードW1〜Wn(nは整数)を記憶するワード記憶部と、複数のテキストT1〜Tmの各々に対して、複数のワードW1〜Wnとの照合を実行して一致する文字列が含まれるか否かを示す存在情報P1〜Pnを生成する存在情報生成部と、複数のテキストのうち第i番目の存在情報Piと第j番目の存在情報Pjとが同一であるテキストの数C(i,j)を算出する共起数算出部と、C(i,j)を成分とするクロス集計表のカイ2乗値を算出し出力するカイ2乗値算出部とを備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、テキストマイニングに関する。
【背景技術】
【0002】
大量のテキストデータの中から価値のあるデータを探索するマイニング技術が注目されている。
【0003】
テキストデータの中から特定の性質の情報を抽出する技術の一例として、コロケーションが知られている。コロケーションは、コーパスの中で、ある語と他の語がどの程度、共起しているかを調べ、よく共起する、いわば相性のよい語の連なりを抽出して辞書化したものである。こうした技術は、「くるま−運転する」、「飛行機−操縦する」という語は連なることは多いが、「くるま−操縦する」、「飛行機−運転する」という語が連なることは少ない、という例のように、ある言語において自然な語の連なりに関する情報を提供する。コロケーションは、例えば翻訳がターゲット言語において自然な表現となることを支援するために利用される。
【0004】
特許文献1には、少なくとも2個以上の文書集合から特徴的な情報を抽出するテキストマイニング方法において、2個以上の文書集合から同時に出現する語の組を抽出し、部分文書集合毎に抽出された語の組の中から特徴的な語の組を抽出することを特徴とするテキストマイニング方法が記載されている。
【特許文献1】特開2002‐183175号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
本発明の目的は、回答者の連想による結びつきが強い概念を抽出するテキストマイニング装置を提供することである。
本発明の他の目的は、少数だが貴重な意見・感想を抽出するテキストマイニング装置を提供することである。
【課題を解決するための手段】
【0006】
以下に、[発明を実施するための最良の形態]で使用される番号を括弧付きで用いて、課題を解決するための手段を説明する。これらの番号は、[特許請求の範囲]の記載と[発明を実施するための最良の形態]との対応関係を明らかにするために付加されたものである。ただし、それらの番号を、[特許請求の範囲]に記載されている発明の技術的範囲の解釈に用いてはならない。
【0007】
本発明によるテキストマイニング装置(2)は、複数のテキストT1〜Tm(mは整数)を記憶するテキスト記憶部(12)と、複数のワードW1〜Wn(nは整数)を記憶するワード記憶部(34)と、複数のテキストT1〜Tmの各々に対して、複数のワードW1〜Wnとの照合を実行して一致する文字列が含まれるか否かを示す存在情報P1〜Pnを生成する存在情報生成部(50)と、複数のテキストのうち第i番目の存在情報Piと第j番目の存在情報Pjとが同一であるテキストの数C(i,j)を算出する共起数算出部(52)と、C(i,j)を成分とするクロス集計表のカイ2乗値を算出し出力するカイ2乗値算出部(54)とを備える。
【0008】
本発明によるテキストマイニング装置(2)は、複数のカテゴリを記憶するカテゴリ記憶部(32)を備える。複数のカテゴリの各々には複数のワードのうちの少なくとも1つのワードが対応づけられる。存在情報生成部(50)は、複数のワードW1〜Wnのうちカテゴリ記憶部(32)において同一のカテゴリに属するワードを区別せずに照合を実行する。
【0009】
本発明によるテキストマイニング装置(2)は、複数のテキストのうちの少なくとも2つのテキストを照合して一致する部分をキーワード候補として抽出し、キーワード候補のうちで文字数が多いものをワードW1〜Wnとしてワード記憶部(34)に登録するために抽出するワード抽出部(48)を備える。
【発明の効果】
【0010】
本発明によれば、回答者の連想による結びつきが強い概念を抽出するテキストマイニング装置が提供される。
更に本発明によれば、少数だが貴重な意見・感想を抽出するテキストマイニング装置が提供される。
【発明を実施するための最良の形態】
【0011】
以下、図面を参照しながら本発明によるテキストマイニング装置を実施するための最良の形態について説明する。
【0012】
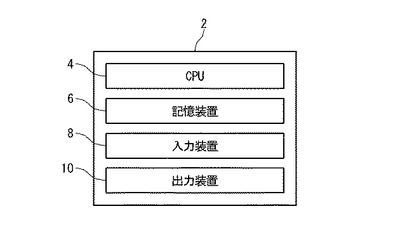
本実施の形態におけるテキストマイニング装置は、パーソナルコンピュータ及びワークステーションに例示されるコンピュータシステムを用いて実現される。図1はテキストマイニング装置2の構成を示す。テキストマイニング装置2は、CPU4、記憶装置6、入力装置8及び出力装置10を備える。
【0013】
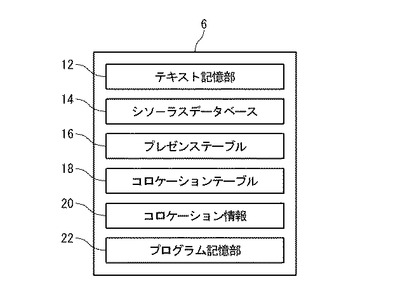
図2は、記憶装置6に格納されるデータを示す。記憶装置6は、テキスト記憶部12、シソーラスデータベース14、プレゼンステーブル16、コロケーションテーブル18、コロケーション情報20及びプログラム記憶部22を備える。
【0014】
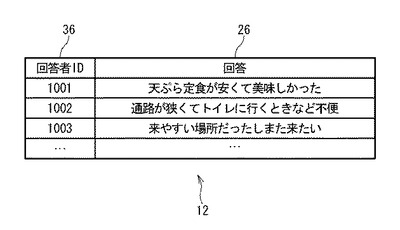
図3は、テキスト記憶部12に格納されるデータの構成を示す。テキスト記憶部12は、調査によって得られた複数の回答者の自由回答文による回答を記憶する。テキスト記憶部12は、回答者ID36と回答26とを対応づけて格納する。
【0015】
図4は、シソーラスデータベース14に格納されるデータの構成を示す。シソーラスデータベース14は、複数の業種の業種名28を格納している。シソーラスデータベース14は、複数の業種名28の各々に対して、カテゴリID30、カテゴリ32及びエントリ34を含むテーブルを格納している。エントリ34は、回答26から抽出される文字列である。カテゴリ32は、少なくとも1つのエントリ34を包摂するカテゴリの名を示す。カテゴリID30は、カテゴリ32の各々を特定するために割り当てられる識別子である。
【0016】
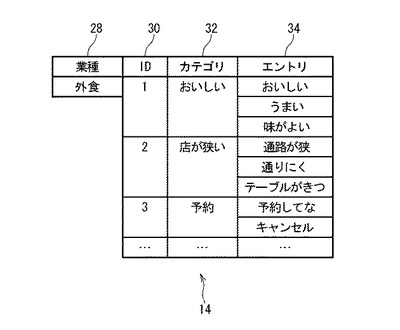
図5は、プレゼンステーブル16の構成を示す。プレゼンステーブル16は、回答者ID36に対応するレコードと、カテゴリID30に対応するフィールドを備える。セルには0と1のいずれかが格納される。1が格納されたセルは、回答者がカテゴリID30に対応する言葉を使用していることを意味する。0が格納されたセルは、回答者がカテゴリID30に対応する言葉を使用していないことを意味する。
【0017】
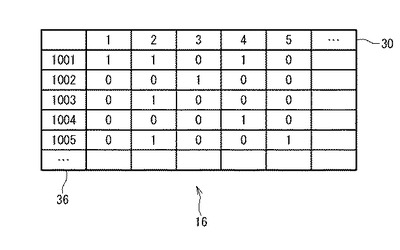
図6は、コロケーションテーブル18の構成を示す。コロケーションテーブル18は、回答者の考えにおける2つの概念のコロケーションの情報を含んでいる。具体的には、2つのカテゴリの出現パターンが共通する回答26の数がマトリクス状に配置されたクロス集計表である。各々のマトリクスの成分は、2語が共に存在する回答の数C(1,1)、2語のうち第1の語が不在で第2の語が存在する回答の数C(0,1)、2語のうち第1の語が存在し第2の語が不在である回答の数C(1,0)及び2語が共に不在である回答の数C(0,0)である。コロケーションテーブル18は更に、各行に含まれる成分の合計TY1、TY0と、各列に含まれる成分の合計TX1、TX0とを格納する。
【0018】
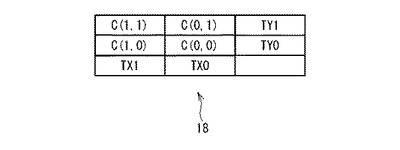
図7は、コロケーション情報20の構成を示す。コロケーション情報20は、順位38と、カイ2乗値40と、人数42と、第1のワード44と、第2のワード46とを対応づけて格納する。
【0019】
図8は、プログラム記憶部22の構成を示す。プログラム記憶部22は、ワード抽出部48、シソーラス処理部49、存在情報生成部50、共起数算出部52、カイ2乗値算出部54、コロケーション出力部56及びテーブル指定情報収集部57を格納する。
【0020】
以上の構成を備えるテキストマイニング装置2の動作が以下に説明される。以下の説明において、CPU4が記憶装置6に記録されている情報を読み出し、その情報に含まれるプログラムに記述された手順に従って実行する動作は、そのプログラム自身が行う動作として記述される。
【0021】
テキストマイニング装置2の動作は、
(1)シソーラスデータベース14が最初に構築される際の動作(図9に示される)、
(2)構築されたシソーラスデータベース14にデータの追加が行われる際の動作(図10に示される)、
(3)構築されたシソーラスデータベース14を用いてテキストマイニングが行われる際の動作(図11と図12に示される)、
(4)回答に含まれるコロケーション情報を抽出する、
に分けて説明される。
【0022】
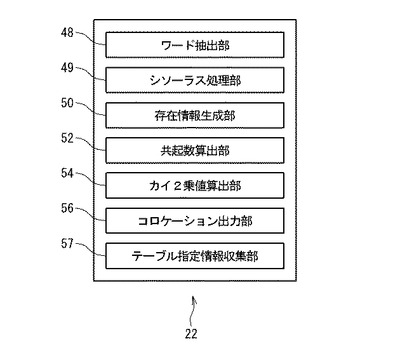
図9を参照すると、シソーラスデータベース14が最初に構築される際のテキストマイニング装置2の動作を示すフローチャートが示されている。
【0023】
ステップS2:シソーラス処理部49は、入力装置8または記憶装置6から複数の回答者の回答を含むデータを収集してテキスト記憶部12に回答26として登録し、各々の回答に対して回答者ID36を発行する。好ましくは回答者の属性も収集されて登録される。
【0024】
ステップS3:テキストマイニング装置2を使用者する使用者は、シソーラス処理部49が収集したテキストデータが関係する業種の業種名28を入力装置8より入力する。入力した業種名28は、記憶装置6に格納される。
【0025】
ステップS4:ワード抽出部48は、テキスト記憶部12の回答26を検索し、少なくとも二つの回答者ID36に対応する回答26に出現する同一の文字列のうち所定の長さよりも長い文字列を抽出する。
【0026】
例えば、第1の回答者ID36に対応する回答26に第1の文字列「ショップの人が親身になって直してくれた」が含まれ、第2の回答者ID36に対応する回答26に第2の文字列「故障してショップの人に連絡したとき回答が遅かった」が含まれている場合、「ショップの人」という文字列が両者に共通しているため抽出される。
【0027】
抽出は、文字列の長さが長い方から短い方に行われることが好ましい。上の例では第1の文字列と第2の文字列とに共通する文字列のうち最も長い文字列である「ショップの人」という文字列がまず抽出される。
【0028】
抽出は、回答26のうちですでに抽出された文字列を省いたテキストデータの中からなされることが更に好ましい。上の例では第1の文字列と第2の文字列とから「ショップの人」という7文字の文字列が省かれた後、残った第1の文字列と第2の文字列の中から6文字の文字列で同一のものが探索される。
【0029】
ステップS6:シソーラス処理部49は、ステップS4において抽出された複数の文字列を所定の順序(例えば五十音順の辞書式順序)に従ってソートする。
【0030】
ステップS8:シソーラス処理部49は、ステップS6においてソートされた複数の文字列の中から同一の文字列(ステップS4において重複して抽出された文字列)を探し出し、それらの同一の文字列の中から一つを残して残りを削除したファイルを生成する。
その結果、回答者から収集した意見に何度も使用されている言葉が一覧表となった、いわば生きた言葉の辞書が作成される。これにより、テキストデータの収集者の考えによるバイアスが少なく、回答者の感性に近い言葉を生かしたマイニングが可能となる。
【0031】
ステップS10:使用者は、ステップS8において生成されたファイルを出力装置10より出力して閲覧し、そのファイルの中に不要な文字列があるか否かを判断する。使用者は、不要な文字列があると判断した場合、シソーラス処理部49に記載された所定の手順によりその不要な文字列を入力装置8を介して不要語として入力する。そのような文字列の例として、「います」「でない」「という」「何とか」が挙げられる。
シソーラス処理部49は、入力された不要語をステップS3において入力され記憶装置6に格納されている業種名28と対応づけて不要語リストに登録する。
【0032】
ステップS12:不要語が不要語リストに登録されると、シソーラス処理部49はステップS8において生成されたファイルの中から不要語と一致する文字列を削除したファイルを生成する。
【0033】
ステップS14:使用者は、ステップS12において生成されたファイルに格納される複数の文字列の各々に対して、文字列の意味に応じてカテゴリ32を付与し、カテゴリ32を個別に特定し管理するためのカテゴリID30を付与する。
【0034】
例えば使用者が、ステップS12において生成されたファイルに格納されている文字列には、ある店舗の料理の質を評価する話題、その店舗の狭さを指摘する話題及び予約に関する話題の3つの話題が含まれていると判断すると、使用者は3つのカテゴリID30、例えば「1」、「2」及び「3」を設定し、その各々に対応するカテゴリ32、「おいしい」、「店が狭い」及び「予約」を入力装置8より入力する。入力されたカテゴリID30とカテゴリ32とはシソーラスデータベース14に格納される。ステップS12において生成されたファイルに格納された文字列は、カテゴリ32に属するエントリ34としてシソーラスデータベース14に格納される。
【0035】
ステップS2からステップS14に示される手順により、シソーラスデータベース14が作成される。こうして作成されたシソーラスデータベース14は、回答者から収集された元データに含まれる語彙であるエントリ34を上位概念化したカテゴリ32を複数格納し、カテゴリ32の各々に対応して少なくとも1つのエントリ34を格納している。
【0036】
ステップS4に示される抽出方法に代えて、形態素を用いてテキストデータを解析し、一致する表現を抽出する方法を採用しても、以下に説明するテキストマイニングの方法を実行することは可能である。
【0037】
形態素を用いてテキストデータを解析した場合、例えば「この商品がもっと値段が安ければ買ってもいいのに」というテキストデータが解析されたとする。このテキストデータは、「値段が高すぎるから買わない」というネガティブな意味合いを含んでいると解釈できるだろう。しかしこのテキストデータを形態素で分解すると、「この」「商品」「もっと」「値段」「安い」「買う」「いい」などに分解され、元データとは反対に高い購買意欲を示しているように解釈される。この形態素から元データの意味の復元を試みるには、多数の文法のルールを適用することが求められる。
【0038】
ステップS2〜S14に示される手順により構築されるシソーラスデータベース14は、回答者から得られた生データに含まれる言葉を直接カットして得られた言葉からなる。そのため値段に関するデータは、例えば
(1)「値段が安い」「値段が安かった」「価格的によい」「お値段が手頃で」
(2)「値段が安ければ」「値段が手頃なら」「価格が安ければ」「料金が安かったら」
(3)「値段が安くない」「リーズナブルでなくて」「価格が納得できない」
と分類される。(1)は値段が安いという判断がなされたことを示し、(2)は値段が安かったらという希望条件を示し、(3)は値段が高いという判断がなされたことを示している。ステップS2〜S14に示される手順により構築されるシソーラスは、こうした意味の違いを容易に取り込むことが可能である。特に、同じ形態素を含んでいて異なる価値評価を示しているテキストデータを弁別したシソーラスを構築することが容易である。
【0039】
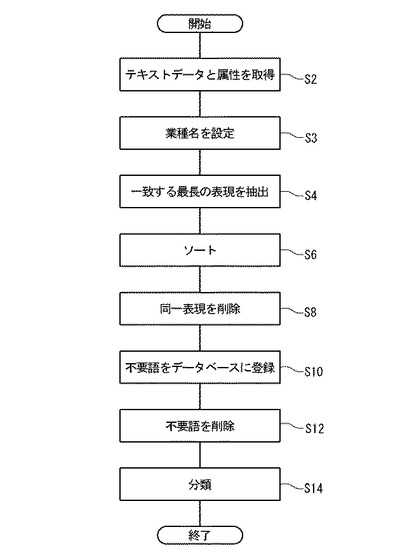
図10を参照すると、構築されたシソーラスデータベース14にデータの追加が行われる際のテキストマイニング装置2の動作を示すフローチャートが示されている。
【0040】
ステップS22:シソーラス処理部49は、入力装置8または記憶装置6から複数の回答者の回答を含むデータを収集し、回答者ID36と対応づけてテキスト記憶部12に回答26として登録する。シソーラス処理部49は、回答者ID36と回答26とを対応づけてテキスト記憶部12に格納する。
【0041】
ステップS24:シソーラス処理部49は、テキストマイニング装置2を使用する使用者から、シソーラスデータベース14に業種名28として示されている業種のうちでいずれの業者を選択するかを示す情報を収集し、記憶装置6に格納する。
【0042】
テーブル指定情報収集部57は、以下の処理において、シソーラスデータベース14の備える複数のシートのうち業種名28がステップS24において収集された業種名に一致するシートが使用されるように設定する。シソーラス処理部49は更に、以下の処理において、不要語リストのうちステップS24において収集された業種名に一致する業種名28に対応する不要語リストが使用されるように設定する。
【0043】
ステップS25:シソーラス処理部49は、回答26に格納されているテキストデータを順次読み出す。最初に処理が行われるときは、回答26のうち第1の回答者に対応する部分が抽出され、その部分に対してステップS26からステップS38までの処理が行われる。二番目に処理が行われるときは、回答26のうち第1の回答者と異なる第2の回答者に対応する部分が抽出され、その部分に対してステップS26からステップS38までの処理が行われる。更に第3、第4…の回答者に対して同じ手順による処理が繰り返される。
【0044】
ステップS26:シソーラス処理部49は、回答26と、不要語リストにおいてステップS24で入力された業種名28に対応する全ての不要語とを照合する。シソーラス処理部49は、照合の結果が一致であった場合、その文字列をテキスト記憶部12から削除し、処理はステップS38に移行される。照合の結果が不一致であったばあい、処理はステップS28に移行される。
【0045】
ステップS28:シソーラス処理部49は、ステップS26において生成されたファイルに含まれる文字列を、シソーラスデータベース14に格納されているエントリ34と照合する。一致するエントリ34があった場合、処理はステップS38に進む。一致するエントリ34がなかった場合、処理はステップS30に進む。
【0046】
ステップS30:シソーラス処理部49は、ステップS26において生成されたファイルから、共通する文字列を抽出する。抽出は、ステップS4におけるテキスト記憶部12の回答26をステップS26において生成されたファイルに置き換えて、ステップS4と同じ方法により行われる。
【0047】
ステップS32:シソーラス処理部49は、ステップS30において複数の文字列が抽出された場合、抽出された複数の文字列を所定の順序(例えば五十音順の辞書式配列の順序)に従ってソートする。シソーラス処理部49は更に、ソートされた複数の文字列の中から同一の文字列(重複している文字列)を探し出し、それらの同一の文字列の中から一つを残して残りを削除したファイルを生成する。
【0048】
ステップS34:使用者は、ステップS32において生成されたファイルを閲覧して、そのファイルの中に不要な文字列があるか否かを判断する。使用者が不要な文字列があると判断した場合、シソーラス処理部49により指定される所定の手順に従って使用者が入力装置8に操作を行うことにより、その不要な文字列は不要語として不要語リストに登録される。不要語が不要語リストに登録されると、シソーラス処理部49はステップS32において生成されたファイルの中から不要語リストと一致する文字列を削除したファイルを生成する。
【0049】
ステップS36:使用者は、シソーラスデータベース14を参照して、ステップS34において生成されたファイルに含まれる文字列の各々に対して、意味的に適合するカテゴリ32を探し、文字列をそのカテゴリ32に対応する新たなエントリ34として登録する。使用者は、ステップS34において生成されたファイルに含まれる文字列に意味的に適合するカテゴリ32が無いと判断すると、新しいカテゴリID30とカテゴリ32とをシソーラスデータベース14に登録し、その文字列を新たに登録されたカテゴリ32に対応するエントリ34として登録する。
【0050】
ステップS38:ステップS25において抽出されたファイルがテキスト記憶部12に格納されている回答26の最後の部分であると判定されたとき以外は、CPU4はステップS25に戻って処理を続行する。ステップS25において抽出されたファイルがテキスト記憶部12に格納されている回答26の最後の部分であると判定された場合、CPU4は処理を終了する。
【0051】
以上のステップS22〜S38により、生情報(回答者から得られたテキストデータ)に含まれる新たな語彙がシソーラスデータベース14に登録される。こうした手順によりシソーラスデータベース14が構築されていくにより、テキストマイニングの精度はより向上していく。さらに、流行語など新たな語彙が発生したり、消費者の嗜好が変わるなど、社会で流通している生きた言葉の変化に柔軟に対応するテキストマイニングが容易に実現できる。
【0052】
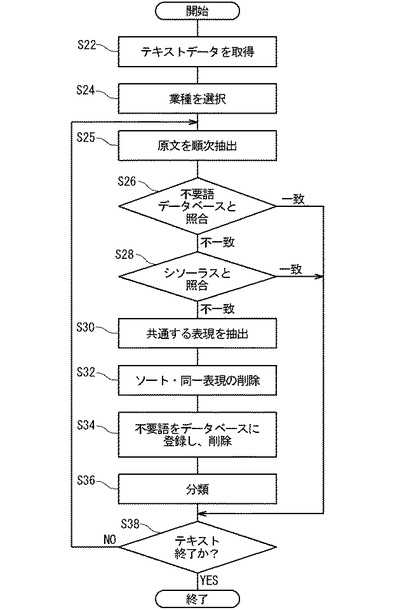
図11は、構築されたシソーラスデータベース14を用いてテキストマイニングが行われる際のテキストマイニング装置2の動作を示すフローチャートを示す。
【0053】
ステップS42:シソーラス処理部49は、入力装置8または記憶装置6から複数の回答者の回答を含むデータを収集し、回答者ID36と対応づけてテキスト記憶部12に回答26として登録する。好ましくは回答者ID36の属性も収集されてテキスト記憶部に格納される。
【0054】
ステップS44:シソーラス処理部49は、テキストマイニング装置2を使用する使用者から入力装置8を介して業種名28を収集する。シソーラス処理部49は、以下の処理において、シソーラスデータベース14の備える複数のシートのうち業種名28がステップS24において収集された業種名に一致するシートが使用されるように設定する。テーブル指定情報収集部57は更に、以下の処理において、不要語リストのうちステップS24において収集された業種名に一致する業種名28に対応する不要語リストが使用されるように設定する。
【0055】
業種名28の選択が行われる際に、顧客を属性によって分類した分析を行いたい場合、使用者はプログラム記憶部22に記憶されたプログラムにより指定される所定の手続きに従って入力装置8から属性を指定する情報の入力を行う。その場合、以下の分析はテキスト記憶部12のなかで、ステップS2において収集された属性が、ステップS42において収集された属性と一致する回答26のみを用いて行われる。これにより、年齢、性別、居住地域、回答に用いた手段等によって区分されたマイニングが行われる。
【0056】
ステップS46:シソーラス処理部49はシソーラスデータベース14を参照して、回答26からステップS4と同じ動作により文字列を抽出する。抽出された文字列は、抽出文字列として記憶装置6に格納される。
【0057】
ステップS48:シソーラス処理部49は、回答26に含まれる抽出文字列の頻度数をカウントする。シソーラス処理部49は、抽出文字列と算出された頻度数とを対応づけて記憶装置6に格納する。
【0058】
ステップS50:シソーラス処理部49は、抽出文字列と、不要語リストに格納されている不要語とを照合し、一致したものを削除したファイルを作成する。
【0059】
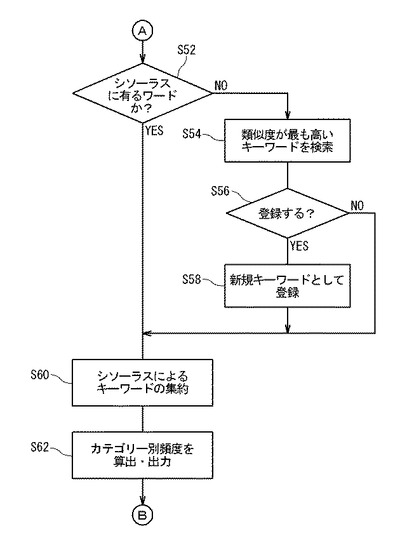
ステップS52:図12を参照して、シソーラス処理部49は、記憶装置6に格納された抽出文字列の各々に対して、シソーラスデータベース14に格納されているエントリ34に同一の文字列が存在するか否かを判定する。
【0060】
シソーラス処理部49は、抽出文字列と同一の文字列がエントリ34に存在しないと判定したとき(ステップS52No)、その文字列を未登録文字列として、対応する頻度数とともに記憶装置6に格納し、処理はステップS54に移行される。同一の文字列が存在すると判定されたとき、処理はステップS60に移行される。
【0061】
ステップS54:シソーラス処理部49は、未登録文字列との類似度が最も大きいエントリ34をシソーラスデータベース14から抽出する。類似度は、例えば一致する文字列の長さが長いほど大きくなるように決められる。シソーラス処理部49は更に、抽出されたエントリ34が属するカテゴリ32を抽出する。
【0062】
ステップS56:シソーラス処理部49は、未登録文字列と、ステップS54において抽出されたカテゴリ32とを出力装置10から出力する。使用者はその出力結果を参照して、未登録文字列を出力されたカテゴリ32に属するエントリ34として新規に登録するか否かを入力装置8より入力する。使用者が新規に登録することを示す情報を入力したとき、シソーラス処理部49は処理をステップS58に移す。使用者が新規に登録しないことを示す情報を入力したとき、シソーラス処理部49は処理をステップS60に移す。
【0063】
ステップS58:ステップS56において使用者により新規に登録することが選択された未登録文字列は、ステップS54において抽出されたカテゴリ32に属するエントリ34としてシソーラスデータベース14に登録され、記憶装置6に格納された未登録文字列のリストから削除される。
【0064】
こうした処理により、シソーラスデータベース14の語彙を豊富化することが容易である。さらに、シソーラスデータベース14の語彙が豊富化すればするほどに、ステップS54において自動的に抽出されたカテゴリ32が未登録文字列に対して意味的に適合するカテゴリである可能性が向上する。
【0065】
そのため、ある程度以上にシソーラスデータベース14の語彙が豊富化した場合、ステップS56における使用者の操作を省略して、自動的に新規文字列をシソーラスデータベース14に登録していく方法が採用されることも好ましい。
【0066】
ステップS60:シソーラス処理部49は、抽出文字列のうちシソーラスデータベース14のエントリ34と一致する文字列を格納する抽出文字列ファイルを生成する。シソーラス処理部49は、ステップS50において作成されたファイルの頻度数を取り込んでエントリ34に対応づけて抽出文字列ファイルに格納する。シソーラス処理部49は更に、シソーラスデータベース14においてエントリ34に対応するカテゴリID30とカテゴリ32とを抽出文字列ファイルに追加する。
【0067】
ステップS62:シソーラス処理部49は、抽出文字列ファイルにおいて同一のカテゴリID30に含まれるエントリ34の頻度数を足し合わせることにより、カテゴリ別の頻度数を算出する。シソーラス処理部はさらに、頻度数が多い順に並ぶようにソートして順位を付け、その順位と、カテゴリID30と、カテゴリ32と、頻度数とを対応づける頻度数ファイルを生成する。シソーラス処理部49はさらに、カテゴリ32ごとの頻度数を示すグラフを作成して出力装置10により出力する。使用者はそのグラフを見ることにより、回答26にどのような話題が多く含まれているのかについての心証を得ることができる。
【0068】
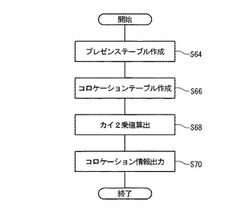
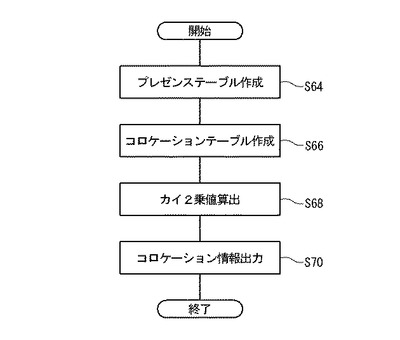
ステップS64:テキスト記憶部12の回答26をT1〜Tm(添字は回答者ID36を示し、mは整数)で表現する。シソーラスデータベース14のカテゴリ32をW1〜Wn(添字はカテゴリID30を示し、nは整数)で表現する。存在情報生成部50は、カテゴリW1〜Wnを順次、選択し、そのカテゴリに属するエントリ34と同一の文字列がT1の中に含まれているか否かを示す存在情報P1〜Pn(添字はカテゴリW1〜Wnの添字に対応する)を生成する。存在情報は、含まれているときは1、含まれていないときは0の値を取る。同じ処理が回答T2〜Tmに対して繰り返される。
【0069】
T1〜Tmの各々に対して存在情報P1〜Pnが生成される。存在情報P1〜Pnは、回答者ID36と対応づけられてプレゼンステーブル16に登録される。各々の回答者ID36に関するデータが一つのレコードに対応する。
【0070】
プレゼンステーブル16には、一人の回答者の回答に、あるカテゴリに属する語が含まれるか含まれないかを示す情報が記録されている。一人の回答者が何度も同じカテゴリの語を使用した場合、その頻度は以後の処理に使用されない。そのため、同じカテゴリの語が特異的に多く使用された回答に結果が影響されることがない。各々の回答は同じ重みで結果に影響する。
【0071】
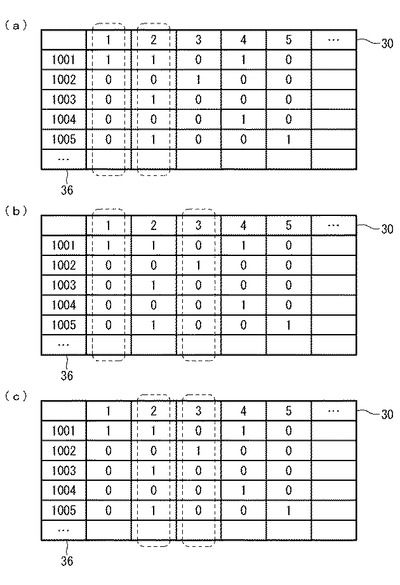
ステップS66:共起数算出部52は、プレゼンステーブル16において、2つのカテゴリの共起のパターンが同じレコードの数を算出する。具体的には、図14を参照して説明がなされる。図14(a)を参照すると、カテゴリID30が「1」のフィールドと「2」のフィールドが点線で囲われて注目されている。回答者ID36が1001〜1005である5つのレコードのみ考えると、カテゴリIDが「1」及び「2」の各々に対応する存在情報が0及び0であるレコードは2つ(すなわち、回答者IDが1002及び1004のレコード)である。これをC(0,0)=2と記述する。括弧の中の第1の0は、注目されている第1のカテゴリの存在情報が0であることを示す。括弧の中の第2の0は、注目されている第2のカテゴリの存在情報が0であることを示す。
【0072】
カテゴリIDが「1」及び「2」の各々に対応する存在情報が1及び0であるレコードの数は0である。すなわち、C(1,0)=0。存在情報が0及び1であるレコードの数は2である(1003と1005に対応)。すなわち、C(0,1)=2。存在情報が1及び1であるレコードの数は1である(1001に対応)。すなわち、C(1,1)=1。
【0073】
図14(b)を参照すると、カテゴリID30が「1」のフィールドと「3」のフィールドが点線で囲われて注目されている。共起数算出部52は、上記した方法でパターンが同じレコードの数を算出する。図14(b)に示された例では、
C(0,0)=3
C(1,0)=1
C(0,1)=1
C(1,1)=0。
【0074】
図14(c)を参照すると、カテゴリID30が「2」のフィールドと「3」のフィールドが点線で囲われて注目されている。共起数算出部52は、上記した方法でパターンが同じレコードの数を算出する。図14(c)に示された例では、
C(0,0)=1
C(1,0)=3
C(0,1)=1
C(1,1)=0。
【0075】
共起数算出部52は、各々のカテゴリIDのペアに対して、C(0,0)、C(1,0)、C(0,1)及びC(1,1)をコロケーションテーブル18に格納する。以下の値が算出される:
TX1=C(1,1)+C(1,0)
TX2=C(0,1)+C(0,0)
TY1=C(1,1)+C(0,1)
TY2=C(1,0)+C(0,0)。
【0076】
C(1,1)は第1のカテゴリと第2のカテゴリとを共に使用した人の数を意味する。C(1,0)は第1のカテゴリを使用し第2のカテゴリを使用しなかった人の数を意味する。C(0,1)は第1のカテゴリを使用せず第2のカテゴリを使用した人の数を意味する。C(0,0)は第1のカテゴリと第2のカテゴリとを共に使用しなかった人の数を意味する。
【0077】
ステップS68:コロケーションテーブル18により、2つのカテゴリの結びつきの強さが示される。TX1、TX2、TY1及びTY2が与えられたときに、2つのカテゴリに全く相関が無い場合と比較して、C(0,0)、C(1,0)、C(0,1)及びC(1,1)の分布がどのように偏っているか(又は偏っていないか)を調べることにより、その相性の良さが判定できる。
【0078】
そうした判定をするために、カイ2乗値算出部54は、カイ2乗値χ2を算出する。カイ2乗値χ2は、大量の計算を計算機で行うために好適な簡便法によれば、次のように算出される。
χ2=CT*(T1+T2+T3+T4−1),
T1=C(0,0)*C(0,0)/(TY0*TX0),
T2=C(1,0)*C(1,0)/(TY0*TX1),
T3=C(0,1)*C(0,1)/(TY1*TX0),
T4=C(1,1)*C(1,1)/(TY1*TX1)且つ
CTはプレゼンステーブル16のレコード数、すなわち回答26の数。
【0079】
ステップS70:コロケーション情報出力部56は、コロケーション情報20を作成し、出力装置10により出力する。コロケーション情報20には、カイ2乗値が大きいレコードから順に登録される。ステップS68で算出されたカイ2乗値χ2がカイ2乗値40に登録される。カテゴリのペアが第1のワード44と第2のワード46とに登録される。そのカテゴリのペアが含まれる回答26の数が人数42に登録される。
【0080】
使用者は、コロケーション情報20を参照することにより、どのカテゴリがペアで使用されるかを把握することができる。たとえ少数の回答であっても、結び付きの強いカテゴリのペアを把握することができる。例えば、料理の品質で有名な外食産業において、回答の多くが料理の内容に関することであったとする。その中で、「トイレ」「濡れていた」というカテゴリのペアのカイ2乗値が大きかった場合、回答に含まれる「トイレ」又は「濡れていた」というカテゴリがごく少なくても検出される。本実施の形態におけるテキストマイニング装置2は、こうした少数の人のなかで強い結びつきを持つ意見を抽出することができる。
【図面の簡単な説明】
【0081】
【図1】図1は、テキストマイニング装置の構成を示す。
【図2】図2は、記憶装置に格納されているデータを示す。
【図3】図3は、テキスト記憶部を示す。
【図4】図4は、シソーラスデータベースを示す。
【図5】図5は、プレゼンステーブルを示す。
【図6】図6は、コロケーションテーブルを示す。
【図7】図7は、コロケーション情報を示す。
【図8】図8は、プログラム記憶部を示す。
【図9】図9は、テキストマイニング装置の動作を示す。
【図10】図10は、テキストマイニング装置の動作を示す。
【図11】図11は、テキストマイニング装置の動作を示す。
【図12】図12は、テキストマイニング装置の動作を示す。
【図13】図13は、テキストマイニング装置の動作を示す。
【図14】図14は、コロケーションテーブルを算出する方法を説明するための図である。
【符号の説明】
【0082】
12…テキスト記憶部
14…シソーラスデータベース
16…プレゼンステーブル
18…コロケーションテーブル
20…コロケーション情報
22…プログラム記憶部
26…回答
28…業種名
30…カテゴリID
32…カテゴリ
34…エントリ
36…回答者ID
【技術分野】
【0001】
本発明は、テキストマイニングに関する。
【背景技術】
【0002】
大量のテキストデータの中から価値のあるデータを探索するマイニング技術が注目されている。
【0003】
テキストデータの中から特定の性質の情報を抽出する技術の一例として、コロケーションが知られている。コロケーションは、コーパスの中で、ある語と他の語がどの程度、共起しているかを調べ、よく共起する、いわば相性のよい語の連なりを抽出して辞書化したものである。こうした技術は、「くるま−運転する」、「飛行機−操縦する」という語は連なることは多いが、「くるま−操縦する」、「飛行機−運転する」という語が連なることは少ない、という例のように、ある言語において自然な語の連なりに関する情報を提供する。コロケーションは、例えば翻訳がターゲット言語において自然な表現となることを支援するために利用される。
【0004】
特許文献1には、少なくとも2個以上の文書集合から特徴的な情報を抽出するテキストマイニング方法において、2個以上の文書集合から同時に出現する語の組を抽出し、部分文書集合毎に抽出された語の組の中から特徴的な語の組を抽出することを特徴とするテキストマイニング方法が記載されている。
【特許文献1】特開2002‐183175号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
本発明の目的は、回答者の連想による結びつきが強い概念を抽出するテキストマイニング装置を提供することである。
本発明の他の目的は、少数だが貴重な意見・感想を抽出するテキストマイニング装置を提供することである。
【課題を解決するための手段】
【0006】
以下に、[発明を実施するための最良の形態]で使用される番号を括弧付きで用いて、課題を解決するための手段を説明する。これらの番号は、[特許請求の範囲]の記載と[発明を実施するための最良の形態]との対応関係を明らかにするために付加されたものである。ただし、それらの番号を、[特許請求の範囲]に記載されている発明の技術的範囲の解釈に用いてはならない。
【0007】
本発明によるテキストマイニング装置(2)は、複数のテキストT1〜Tm(mは整数)を記憶するテキスト記憶部(12)と、複数のワードW1〜Wn(nは整数)を記憶するワード記憶部(34)と、複数のテキストT1〜Tmの各々に対して、複数のワードW1〜Wnとの照合を実行して一致する文字列が含まれるか否かを示す存在情報P1〜Pnを生成する存在情報生成部(50)と、複数のテキストのうち第i番目の存在情報Piと第j番目の存在情報Pjとが同一であるテキストの数C(i,j)を算出する共起数算出部(52)と、C(i,j)を成分とするクロス集計表のカイ2乗値を算出し出力するカイ2乗値算出部(54)とを備える。
【0008】
本発明によるテキストマイニング装置(2)は、複数のカテゴリを記憶するカテゴリ記憶部(32)を備える。複数のカテゴリの各々には複数のワードのうちの少なくとも1つのワードが対応づけられる。存在情報生成部(50)は、複数のワードW1〜Wnのうちカテゴリ記憶部(32)において同一のカテゴリに属するワードを区別せずに照合を実行する。
【0009】
本発明によるテキストマイニング装置(2)は、複数のテキストのうちの少なくとも2つのテキストを照合して一致する部分をキーワード候補として抽出し、キーワード候補のうちで文字数が多いものをワードW1〜Wnとしてワード記憶部(34)に登録するために抽出するワード抽出部(48)を備える。
【発明の効果】
【0010】
本発明によれば、回答者の連想による結びつきが強い概念を抽出するテキストマイニング装置が提供される。
更に本発明によれば、少数だが貴重な意見・感想を抽出するテキストマイニング装置が提供される。
【発明を実施するための最良の形態】
【0011】
以下、図面を参照しながら本発明によるテキストマイニング装置を実施するための最良の形態について説明する。
【0012】
本実施の形態におけるテキストマイニング装置は、パーソナルコンピュータ及びワークステーションに例示されるコンピュータシステムを用いて実現される。図1はテキストマイニング装置2の構成を示す。テキストマイニング装置2は、CPU4、記憶装置6、入力装置8及び出力装置10を備える。
【0013】
図2は、記憶装置6に格納されるデータを示す。記憶装置6は、テキスト記憶部12、シソーラスデータベース14、プレゼンステーブル16、コロケーションテーブル18、コロケーション情報20及びプログラム記憶部22を備える。
【0014】
図3は、テキスト記憶部12に格納されるデータの構成を示す。テキスト記憶部12は、調査によって得られた複数の回答者の自由回答文による回答を記憶する。テキスト記憶部12は、回答者ID36と回答26とを対応づけて格納する。
【0015】
図4は、シソーラスデータベース14に格納されるデータの構成を示す。シソーラスデータベース14は、複数の業種の業種名28を格納している。シソーラスデータベース14は、複数の業種名28の各々に対して、カテゴリID30、カテゴリ32及びエントリ34を含むテーブルを格納している。エントリ34は、回答26から抽出される文字列である。カテゴリ32は、少なくとも1つのエントリ34を包摂するカテゴリの名を示す。カテゴリID30は、カテゴリ32の各々を特定するために割り当てられる識別子である。
【0016】
図5は、プレゼンステーブル16の構成を示す。プレゼンステーブル16は、回答者ID36に対応するレコードと、カテゴリID30に対応するフィールドを備える。セルには0と1のいずれかが格納される。1が格納されたセルは、回答者がカテゴリID30に対応する言葉を使用していることを意味する。0が格納されたセルは、回答者がカテゴリID30に対応する言葉を使用していないことを意味する。
【0017】
図6は、コロケーションテーブル18の構成を示す。コロケーションテーブル18は、回答者の考えにおける2つの概念のコロケーションの情報を含んでいる。具体的には、2つのカテゴリの出現パターンが共通する回答26の数がマトリクス状に配置されたクロス集計表である。各々のマトリクスの成分は、2語が共に存在する回答の数C(1,1)、2語のうち第1の語が不在で第2の語が存在する回答の数C(0,1)、2語のうち第1の語が存在し第2の語が不在である回答の数C(1,0)及び2語が共に不在である回答の数C(0,0)である。コロケーションテーブル18は更に、各行に含まれる成分の合計TY1、TY0と、各列に含まれる成分の合計TX1、TX0とを格納する。
【0018】
図7は、コロケーション情報20の構成を示す。コロケーション情報20は、順位38と、カイ2乗値40と、人数42と、第1のワード44と、第2のワード46とを対応づけて格納する。
【0019】
図8は、プログラム記憶部22の構成を示す。プログラム記憶部22は、ワード抽出部48、シソーラス処理部49、存在情報生成部50、共起数算出部52、カイ2乗値算出部54、コロケーション出力部56及びテーブル指定情報収集部57を格納する。
【0020】
以上の構成を備えるテキストマイニング装置2の動作が以下に説明される。以下の説明において、CPU4が記憶装置6に記録されている情報を読み出し、その情報に含まれるプログラムに記述された手順に従って実行する動作は、そのプログラム自身が行う動作として記述される。
【0021】
テキストマイニング装置2の動作は、
(1)シソーラスデータベース14が最初に構築される際の動作(図9に示される)、
(2)構築されたシソーラスデータベース14にデータの追加が行われる際の動作(図10に示される)、
(3)構築されたシソーラスデータベース14を用いてテキストマイニングが行われる際の動作(図11と図12に示される)、
(4)回答に含まれるコロケーション情報を抽出する、
に分けて説明される。
【0022】
図9を参照すると、シソーラスデータベース14が最初に構築される際のテキストマイニング装置2の動作を示すフローチャートが示されている。
【0023】
ステップS2:シソーラス処理部49は、入力装置8または記憶装置6から複数の回答者の回答を含むデータを収集してテキスト記憶部12に回答26として登録し、各々の回答に対して回答者ID36を発行する。好ましくは回答者の属性も収集されて登録される。
【0024】
ステップS3:テキストマイニング装置2を使用者する使用者は、シソーラス処理部49が収集したテキストデータが関係する業種の業種名28を入力装置8より入力する。入力した業種名28は、記憶装置6に格納される。
【0025】
ステップS4:ワード抽出部48は、テキスト記憶部12の回答26を検索し、少なくとも二つの回答者ID36に対応する回答26に出現する同一の文字列のうち所定の長さよりも長い文字列を抽出する。
【0026】
例えば、第1の回答者ID36に対応する回答26に第1の文字列「ショップの人が親身になって直してくれた」が含まれ、第2の回答者ID36に対応する回答26に第2の文字列「故障してショップの人に連絡したとき回答が遅かった」が含まれている場合、「ショップの人」という文字列が両者に共通しているため抽出される。
【0027】
抽出は、文字列の長さが長い方から短い方に行われることが好ましい。上の例では第1の文字列と第2の文字列とに共通する文字列のうち最も長い文字列である「ショップの人」という文字列がまず抽出される。
【0028】
抽出は、回答26のうちですでに抽出された文字列を省いたテキストデータの中からなされることが更に好ましい。上の例では第1の文字列と第2の文字列とから「ショップの人」という7文字の文字列が省かれた後、残った第1の文字列と第2の文字列の中から6文字の文字列で同一のものが探索される。
【0029】
ステップS6:シソーラス処理部49は、ステップS4において抽出された複数の文字列を所定の順序(例えば五十音順の辞書式順序)に従ってソートする。
【0030】
ステップS8:シソーラス処理部49は、ステップS6においてソートされた複数の文字列の中から同一の文字列(ステップS4において重複して抽出された文字列)を探し出し、それらの同一の文字列の中から一つを残して残りを削除したファイルを生成する。
その結果、回答者から収集した意見に何度も使用されている言葉が一覧表となった、いわば生きた言葉の辞書が作成される。これにより、テキストデータの収集者の考えによるバイアスが少なく、回答者の感性に近い言葉を生かしたマイニングが可能となる。
【0031】
ステップS10:使用者は、ステップS8において生成されたファイルを出力装置10より出力して閲覧し、そのファイルの中に不要な文字列があるか否かを判断する。使用者は、不要な文字列があると判断した場合、シソーラス処理部49に記載された所定の手順によりその不要な文字列を入力装置8を介して不要語として入力する。そのような文字列の例として、「います」「でない」「という」「何とか」が挙げられる。
シソーラス処理部49は、入力された不要語をステップS3において入力され記憶装置6に格納されている業種名28と対応づけて不要語リストに登録する。
【0032】
ステップS12:不要語が不要語リストに登録されると、シソーラス処理部49はステップS8において生成されたファイルの中から不要語と一致する文字列を削除したファイルを生成する。
【0033】
ステップS14:使用者は、ステップS12において生成されたファイルに格納される複数の文字列の各々に対して、文字列の意味に応じてカテゴリ32を付与し、カテゴリ32を個別に特定し管理するためのカテゴリID30を付与する。
【0034】
例えば使用者が、ステップS12において生成されたファイルに格納されている文字列には、ある店舗の料理の質を評価する話題、その店舗の狭さを指摘する話題及び予約に関する話題の3つの話題が含まれていると判断すると、使用者は3つのカテゴリID30、例えば「1」、「2」及び「3」を設定し、その各々に対応するカテゴリ32、「おいしい」、「店が狭い」及び「予約」を入力装置8より入力する。入力されたカテゴリID30とカテゴリ32とはシソーラスデータベース14に格納される。ステップS12において生成されたファイルに格納された文字列は、カテゴリ32に属するエントリ34としてシソーラスデータベース14に格納される。
【0035】
ステップS2からステップS14に示される手順により、シソーラスデータベース14が作成される。こうして作成されたシソーラスデータベース14は、回答者から収集された元データに含まれる語彙であるエントリ34を上位概念化したカテゴリ32を複数格納し、カテゴリ32の各々に対応して少なくとも1つのエントリ34を格納している。
【0036】
ステップS4に示される抽出方法に代えて、形態素を用いてテキストデータを解析し、一致する表現を抽出する方法を採用しても、以下に説明するテキストマイニングの方法を実行することは可能である。
【0037】
形態素を用いてテキストデータを解析した場合、例えば「この商品がもっと値段が安ければ買ってもいいのに」というテキストデータが解析されたとする。このテキストデータは、「値段が高すぎるから買わない」というネガティブな意味合いを含んでいると解釈できるだろう。しかしこのテキストデータを形態素で分解すると、「この」「商品」「もっと」「値段」「安い」「買う」「いい」などに分解され、元データとは反対に高い購買意欲を示しているように解釈される。この形態素から元データの意味の復元を試みるには、多数の文法のルールを適用することが求められる。
【0038】
ステップS2〜S14に示される手順により構築されるシソーラスデータベース14は、回答者から得られた生データに含まれる言葉を直接カットして得られた言葉からなる。そのため値段に関するデータは、例えば
(1)「値段が安い」「値段が安かった」「価格的によい」「お値段が手頃で」
(2)「値段が安ければ」「値段が手頃なら」「価格が安ければ」「料金が安かったら」
(3)「値段が安くない」「リーズナブルでなくて」「価格が納得できない」
と分類される。(1)は値段が安いという判断がなされたことを示し、(2)は値段が安かったらという希望条件を示し、(3)は値段が高いという判断がなされたことを示している。ステップS2〜S14に示される手順により構築されるシソーラスは、こうした意味の違いを容易に取り込むことが可能である。特に、同じ形態素を含んでいて異なる価値評価を示しているテキストデータを弁別したシソーラスを構築することが容易である。
【0039】
図10を参照すると、構築されたシソーラスデータベース14にデータの追加が行われる際のテキストマイニング装置2の動作を示すフローチャートが示されている。
【0040】
ステップS22:シソーラス処理部49は、入力装置8または記憶装置6から複数の回答者の回答を含むデータを収集し、回答者ID36と対応づけてテキスト記憶部12に回答26として登録する。シソーラス処理部49は、回答者ID36と回答26とを対応づけてテキスト記憶部12に格納する。
【0041】
ステップS24:シソーラス処理部49は、テキストマイニング装置2を使用する使用者から、シソーラスデータベース14に業種名28として示されている業種のうちでいずれの業者を選択するかを示す情報を収集し、記憶装置6に格納する。
【0042】
テーブル指定情報収集部57は、以下の処理において、シソーラスデータベース14の備える複数のシートのうち業種名28がステップS24において収集された業種名に一致するシートが使用されるように設定する。シソーラス処理部49は更に、以下の処理において、不要語リストのうちステップS24において収集された業種名に一致する業種名28に対応する不要語リストが使用されるように設定する。
【0043】
ステップS25:シソーラス処理部49は、回答26に格納されているテキストデータを順次読み出す。最初に処理が行われるときは、回答26のうち第1の回答者に対応する部分が抽出され、その部分に対してステップS26からステップS38までの処理が行われる。二番目に処理が行われるときは、回答26のうち第1の回答者と異なる第2の回答者に対応する部分が抽出され、その部分に対してステップS26からステップS38までの処理が行われる。更に第3、第4…の回答者に対して同じ手順による処理が繰り返される。
【0044】
ステップS26:シソーラス処理部49は、回答26と、不要語リストにおいてステップS24で入力された業種名28に対応する全ての不要語とを照合する。シソーラス処理部49は、照合の結果が一致であった場合、その文字列をテキスト記憶部12から削除し、処理はステップS38に移行される。照合の結果が不一致であったばあい、処理はステップS28に移行される。
【0045】
ステップS28:シソーラス処理部49は、ステップS26において生成されたファイルに含まれる文字列を、シソーラスデータベース14に格納されているエントリ34と照合する。一致するエントリ34があった場合、処理はステップS38に進む。一致するエントリ34がなかった場合、処理はステップS30に進む。
【0046】
ステップS30:シソーラス処理部49は、ステップS26において生成されたファイルから、共通する文字列を抽出する。抽出は、ステップS4におけるテキスト記憶部12の回答26をステップS26において生成されたファイルに置き換えて、ステップS4と同じ方法により行われる。
【0047】
ステップS32:シソーラス処理部49は、ステップS30において複数の文字列が抽出された場合、抽出された複数の文字列を所定の順序(例えば五十音順の辞書式配列の順序)に従ってソートする。シソーラス処理部49は更に、ソートされた複数の文字列の中から同一の文字列(重複している文字列)を探し出し、それらの同一の文字列の中から一つを残して残りを削除したファイルを生成する。
【0048】
ステップS34:使用者は、ステップS32において生成されたファイルを閲覧して、そのファイルの中に不要な文字列があるか否かを判断する。使用者が不要な文字列があると判断した場合、シソーラス処理部49により指定される所定の手順に従って使用者が入力装置8に操作を行うことにより、その不要な文字列は不要語として不要語リストに登録される。不要語が不要語リストに登録されると、シソーラス処理部49はステップS32において生成されたファイルの中から不要語リストと一致する文字列を削除したファイルを生成する。
【0049】
ステップS36:使用者は、シソーラスデータベース14を参照して、ステップS34において生成されたファイルに含まれる文字列の各々に対して、意味的に適合するカテゴリ32を探し、文字列をそのカテゴリ32に対応する新たなエントリ34として登録する。使用者は、ステップS34において生成されたファイルに含まれる文字列に意味的に適合するカテゴリ32が無いと判断すると、新しいカテゴリID30とカテゴリ32とをシソーラスデータベース14に登録し、その文字列を新たに登録されたカテゴリ32に対応するエントリ34として登録する。
【0050】
ステップS38:ステップS25において抽出されたファイルがテキスト記憶部12に格納されている回答26の最後の部分であると判定されたとき以外は、CPU4はステップS25に戻って処理を続行する。ステップS25において抽出されたファイルがテキスト記憶部12に格納されている回答26の最後の部分であると判定された場合、CPU4は処理を終了する。
【0051】
以上のステップS22〜S38により、生情報(回答者から得られたテキストデータ)に含まれる新たな語彙がシソーラスデータベース14に登録される。こうした手順によりシソーラスデータベース14が構築されていくにより、テキストマイニングの精度はより向上していく。さらに、流行語など新たな語彙が発生したり、消費者の嗜好が変わるなど、社会で流通している生きた言葉の変化に柔軟に対応するテキストマイニングが容易に実現できる。
【0052】
図11は、構築されたシソーラスデータベース14を用いてテキストマイニングが行われる際のテキストマイニング装置2の動作を示すフローチャートを示す。
【0053】
ステップS42:シソーラス処理部49は、入力装置8または記憶装置6から複数の回答者の回答を含むデータを収集し、回答者ID36と対応づけてテキスト記憶部12に回答26として登録する。好ましくは回答者ID36の属性も収集されてテキスト記憶部に格納される。
【0054】
ステップS44:シソーラス処理部49は、テキストマイニング装置2を使用する使用者から入力装置8を介して業種名28を収集する。シソーラス処理部49は、以下の処理において、シソーラスデータベース14の備える複数のシートのうち業種名28がステップS24において収集された業種名に一致するシートが使用されるように設定する。テーブル指定情報収集部57は更に、以下の処理において、不要語リストのうちステップS24において収集された業種名に一致する業種名28に対応する不要語リストが使用されるように設定する。
【0055】
業種名28の選択が行われる際に、顧客を属性によって分類した分析を行いたい場合、使用者はプログラム記憶部22に記憶されたプログラムにより指定される所定の手続きに従って入力装置8から属性を指定する情報の入力を行う。その場合、以下の分析はテキスト記憶部12のなかで、ステップS2において収集された属性が、ステップS42において収集された属性と一致する回答26のみを用いて行われる。これにより、年齢、性別、居住地域、回答に用いた手段等によって区分されたマイニングが行われる。
【0056】
ステップS46:シソーラス処理部49はシソーラスデータベース14を参照して、回答26からステップS4と同じ動作により文字列を抽出する。抽出された文字列は、抽出文字列として記憶装置6に格納される。
【0057】
ステップS48:シソーラス処理部49は、回答26に含まれる抽出文字列の頻度数をカウントする。シソーラス処理部49は、抽出文字列と算出された頻度数とを対応づけて記憶装置6に格納する。
【0058】
ステップS50:シソーラス処理部49は、抽出文字列と、不要語リストに格納されている不要語とを照合し、一致したものを削除したファイルを作成する。
【0059】
ステップS52:図12を参照して、シソーラス処理部49は、記憶装置6に格納された抽出文字列の各々に対して、シソーラスデータベース14に格納されているエントリ34に同一の文字列が存在するか否かを判定する。
【0060】
シソーラス処理部49は、抽出文字列と同一の文字列がエントリ34に存在しないと判定したとき(ステップS52No)、その文字列を未登録文字列として、対応する頻度数とともに記憶装置6に格納し、処理はステップS54に移行される。同一の文字列が存在すると判定されたとき、処理はステップS60に移行される。
【0061】
ステップS54:シソーラス処理部49は、未登録文字列との類似度が最も大きいエントリ34をシソーラスデータベース14から抽出する。類似度は、例えば一致する文字列の長さが長いほど大きくなるように決められる。シソーラス処理部49は更に、抽出されたエントリ34が属するカテゴリ32を抽出する。
【0062】
ステップS56:シソーラス処理部49は、未登録文字列と、ステップS54において抽出されたカテゴリ32とを出力装置10から出力する。使用者はその出力結果を参照して、未登録文字列を出力されたカテゴリ32に属するエントリ34として新規に登録するか否かを入力装置8より入力する。使用者が新規に登録することを示す情報を入力したとき、シソーラス処理部49は処理をステップS58に移す。使用者が新規に登録しないことを示す情報を入力したとき、シソーラス処理部49は処理をステップS60に移す。
【0063】
ステップS58:ステップS56において使用者により新規に登録することが選択された未登録文字列は、ステップS54において抽出されたカテゴリ32に属するエントリ34としてシソーラスデータベース14に登録され、記憶装置6に格納された未登録文字列のリストから削除される。
【0064】
こうした処理により、シソーラスデータベース14の語彙を豊富化することが容易である。さらに、シソーラスデータベース14の語彙が豊富化すればするほどに、ステップS54において自動的に抽出されたカテゴリ32が未登録文字列に対して意味的に適合するカテゴリである可能性が向上する。
【0065】
そのため、ある程度以上にシソーラスデータベース14の語彙が豊富化した場合、ステップS56における使用者の操作を省略して、自動的に新規文字列をシソーラスデータベース14に登録していく方法が採用されることも好ましい。
【0066】
ステップS60:シソーラス処理部49は、抽出文字列のうちシソーラスデータベース14のエントリ34と一致する文字列を格納する抽出文字列ファイルを生成する。シソーラス処理部49は、ステップS50において作成されたファイルの頻度数を取り込んでエントリ34に対応づけて抽出文字列ファイルに格納する。シソーラス処理部49は更に、シソーラスデータベース14においてエントリ34に対応するカテゴリID30とカテゴリ32とを抽出文字列ファイルに追加する。
【0067】
ステップS62:シソーラス処理部49は、抽出文字列ファイルにおいて同一のカテゴリID30に含まれるエントリ34の頻度数を足し合わせることにより、カテゴリ別の頻度数を算出する。シソーラス処理部はさらに、頻度数が多い順に並ぶようにソートして順位を付け、その順位と、カテゴリID30と、カテゴリ32と、頻度数とを対応づける頻度数ファイルを生成する。シソーラス処理部49はさらに、カテゴリ32ごとの頻度数を示すグラフを作成して出力装置10により出力する。使用者はそのグラフを見ることにより、回答26にどのような話題が多く含まれているのかについての心証を得ることができる。
【0068】
ステップS64:テキスト記憶部12の回答26をT1〜Tm(添字は回答者ID36を示し、mは整数)で表現する。シソーラスデータベース14のカテゴリ32をW1〜Wn(添字はカテゴリID30を示し、nは整数)で表現する。存在情報生成部50は、カテゴリW1〜Wnを順次、選択し、そのカテゴリに属するエントリ34と同一の文字列がT1の中に含まれているか否かを示す存在情報P1〜Pn(添字はカテゴリW1〜Wnの添字に対応する)を生成する。存在情報は、含まれているときは1、含まれていないときは0の値を取る。同じ処理が回答T2〜Tmに対して繰り返される。
【0069】
T1〜Tmの各々に対して存在情報P1〜Pnが生成される。存在情報P1〜Pnは、回答者ID36と対応づけられてプレゼンステーブル16に登録される。各々の回答者ID36に関するデータが一つのレコードに対応する。
【0070】
プレゼンステーブル16には、一人の回答者の回答に、あるカテゴリに属する語が含まれるか含まれないかを示す情報が記録されている。一人の回答者が何度も同じカテゴリの語を使用した場合、その頻度は以後の処理に使用されない。そのため、同じカテゴリの語が特異的に多く使用された回答に結果が影響されることがない。各々の回答は同じ重みで結果に影響する。
【0071】
ステップS66:共起数算出部52は、プレゼンステーブル16において、2つのカテゴリの共起のパターンが同じレコードの数を算出する。具体的には、図14を参照して説明がなされる。図14(a)を参照すると、カテゴリID30が「1」のフィールドと「2」のフィールドが点線で囲われて注目されている。回答者ID36が1001〜1005である5つのレコードのみ考えると、カテゴリIDが「1」及び「2」の各々に対応する存在情報が0及び0であるレコードは2つ(すなわち、回答者IDが1002及び1004のレコード)である。これをC(0,0)=2と記述する。括弧の中の第1の0は、注目されている第1のカテゴリの存在情報が0であることを示す。括弧の中の第2の0は、注目されている第2のカテゴリの存在情報が0であることを示す。
【0072】
カテゴリIDが「1」及び「2」の各々に対応する存在情報が1及び0であるレコードの数は0である。すなわち、C(1,0)=0。存在情報が0及び1であるレコードの数は2である(1003と1005に対応)。すなわち、C(0,1)=2。存在情報が1及び1であるレコードの数は1である(1001に対応)。すなわち、C(1,1)=1。
【0073】
図14(b)を参照すると、カテゴリID30が「1」のフィールドと「3」のフィールドが点線で囲われて注目されている。共起数算出部52は、上記した方法でパターンが同じレコードの数を算出する。図14(b)に示された例では、
C(0,0)=3
C(1,0)=1
C(0,1)=1
C(1,1)=0。
【0074】
図14(c)を参照すると、カテゴリID30が「2」のフィールドと「3」のフィールドが点線で囲われて注目されている。共起数算出部52は、上記した方法でパターンが同じレコードの数を算出する。図14(c)に示された例では、
C(0,0)=1
C(1,0)=3
C(0,1)=1
C(1,1)=0。
【0075】
共起数算出部52は、各々のカテゴリIDのペアに対して、C(0,0)、C(1,0)、C(0,1)及びC(1,1)をコロケーションテーブル18に格納する。以下の値が算出される:
TX1=C(1,1)+C(1,0)
TX2=C(0,1)+C(0,0)
TY1=C(1,1)+C(0,1)
TY2=C(1,0)+C(0,0)。
【0076】
C(1,1)は第1のカテゴリと第2のカテゴリとを共に使用した人の数を意味する。C(1,0)は第1のカテゴリを使用し第2のカテゴリを使用しなかった人の数を意味する。C(0,1)は第1のカテゴリを使用せず第2のカテゴリを使用した人の数を意味する。C(0,0)は第1のカテゴリと第2のカテゴリとを共に使用しなかった人の数を意味する。
【0077】
ステップS68:コロケーションテーブル18により、2つのカテゴリの結びつきの強さが示される。TX1、TX2、TY1及びTY2が与えられたときに、2つのカテゴリに全く相関が無い場合と比較して、C(0,0)、C(1,0)、C(0,1)及びC(1,1)の分布がどのように偏っているか(又は偏っていないか)を調べることにより、その相性の良さが判定できる。
【0078】
そうした判定をするために、カイ2乗値算出部54は、カイ2乗値χ2を算出する。カイ2乗値χ2は、大量の計算を計算機で行うために好適な簡便法によれば、次のように算出される。
χ2=CT*(T1+T2+T3+T4−1),
T1=C(0,0)*C(0,0)/(TY0*TX0),
T2=C(1,0)*C(1,0)/(TY0*TX1),
T3=C(0,1)*C(0,1)/(TY1*TX0),
T4=C(1,1)*C(1,1)/(TY1*TX1)且つ
CTはプレゼンステーブル16のレコード数、すなわち回答26の数。
【0079】
ステップS70:コロケーション情報出力部56は、コロケーション情報20を作成し、出力装置10により出力する。コロケーション情報20には、カイ2乗値が大きいレコードから順に登録される。ステップS68で算出されたカイ2乗値χ2がカイ2乗値40に登録される。カテゴリのペアが第1のワード44と第2のワード46とに登録される。そのカテゴリのペアが含まれる回答26の数が人数42に登録される。
【0080】
使用者は、コロケーション情報20を参照することにより、どのカテゴリがペアで使用されるかを把握することができる。たとえ少数の回答であっても、結び付きの強いカテゴリのペアを把握することができる。例えば、料理の品質で有名な外食産業において、回答の多くが料理の内容に関することであったとする。その中で、「トイレ」「濡れていた」というカテゴリのペアのカイ2乗値が大きかった場合、回答に含まれる「トイレ」又は「濡れていた」というカテゴリがごく少なくても検出される。本実施の形態におけるテキストマイニング装置2は、こうした少数の人のなかで強い結びつきを持つ意見を抽出することができる。
【図面の簡単な説明】
【0081】
【図1】図1は、テキストマイニング装置の構成を示す。
【図2】図2は、記憶装置に格納されているデータを示す。
【図3】図3は、テキスト記憶部を示す。
【図4】図4は、シソーラスデータベースを示す。
【図5】図5は、プレゼンステーブルを示す。
【図6】図6は、コロケーションテーブルを示す。
【図7】図7は、コロケーション情報を示す。
【図8】図8は、プログラム記憶部を示す。
【図9】図9は、テキストマイニング装置の動作を示す。
【図10】図10は、テキストマイニング装置の動作を示す。
【図11】図11は、テキストマイニング装置の動作を示す。
【図12】図12は、テキストマイニング装置の動作を示す。
【図13】図13は、テキストマイニング装置の動作を示す。
【図14】図14は、コロケーションテーブルを算出する方法を説明するための図である。
【符号の説明】
【0082】
12…テキスト記憶部
14…シソーラスデータベース
16…プレゼンステーブル
18…コロケーションテーブル
20…コロケーション情報
22…プログラム記憶部
26…回答
28…業種名
30…カテゴリID
32…カテゴリ
34…エントリ
36…回答者ID
【特許請求の範囲】
【請求項1】
複数のテキストT1〜Tm(mは整数)を記憶するテキスト記憶部と、
複数のワードW1〜Wn(nは整数)を記憶するワード記憶部と、
前記複数のテキストT1〜Tmの各々に対して、前記複数のワードW1〜Wnとの照合を実行して一致する文字列が含まれるか否かを示す存在情報P1〜Pnを生成する存在情報生成部と、
前記複数のテキストのうち第i番目の存在情報Piと第j番目の存在情報Pjとが同一であるテキストの数C(i,j)を算出する共起数算出部と、
前記C(i,j)を成分とするクロス集計表のカイ2乗値を算出し出力するカイ2乗値算出部
とを具備する
テキストマイニング装置。
【請求項2】
請求項1に記載されたテキストマイニング装置であって、
更に、複数のカテゴリを記憶するカテゴリ記憶部
を具備し、
前記複数のカテゴリの各々には前記複数のワードのうちの少なくとも1つのワードが対応づけられ、
前記存在情報生成部は、前記複数のワードW1〜Wnのうち前記カテゴリ記憶部において同一のカテゴリに属するワードを区別せずに前記照合を実行する
テキストマイニング装置。
【請求項3】
請求項1または2に記載されたテキストマイニング装置であって、
更に、前記複数のテキストのうちの少なくとも2つのテキストを照合して一致する部分をキーワード候補として抽出し、前記キーワード候補のうちで文字数が多いものを前記ワードW1〜Wnとして前記ワード記憶部に登録するために抽出するワード抽出部
を具備する
テキストマイニング装置。
【請求項1】
複数のテキストT1〜Tm(mは整数)を記憶するテキスト記憶部と、
複数のワードW1〜Wn(nは整数)を記憶するワード記憶部と、
前記複数のテキストT1〜Tmの各々に対して、前記複数のワードW1〜Wnとの照合を実行して一致する文字列が含まれるか否かを示す存在情報P1〜Pnを生成する存在情報生成部と、
前記複数のテキストのうち第i番目の存在情報Piと第j番目の存在情報Pjとが同一であるテキストの数C(i,j)を算出する共起数算出部と、
前記C(i,j)を成分とするクロス集計表のカイ2乗値を算出し出力するカイ2乗値算出部
とを具備する
テキストマイニング装置。
【請求項2】
請求項1に記載されたテキストマイニング装置であって、
更に、複数のカテゴリを記憶するカテゴリ記憶部
を具備し、
前記複数のカテゴリの各々には前記複数のワードのうちの少なくとも1つのワードが対応づけられ、
前記存在情報生成部は、前記複数のワードW1〜Wnのうち前記カテゴリ記憶部において同一のカテゴリに属するワードを区別せずに前記照合を実行する
テキストマイニング装置。
【請求項3】
請求項1または2に記載されたテキストマイニング装置であって、
更に、前記複数のテキストのうちの少なくとも2つのテキストを照合して一致する部分をキーワード候補として抽出し、前記キーワード候補のうちで文字数が多いものを前記ワードW1〜Wnとして前記ワード記憶部に登録するために抽出するワード抽出部
を具備する
テキストマイニング装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【公開番号】特開2007−80181(P2007−80181A)
【公開日】平成19年3月29日(2007.3.29)
【国際特許分類】
【出願番号】特願2005−270396(P2005−270396)
【出願日】平成17年9月16日(2005.9.16)
【出願人】(500545779)
【出願人】(592188977)株式会社オリエンタルランド (12)
【Fターム(参考)】
【公開日】平成19年3月29日(2007.3.29)
【国際特許分類】
【出願日】平成17年9月16日(2005.9.16)
【出願人】(500545779)
【出願人】(592188977)株式会社オリエンタルランド (12)
【Fターム(参考)】
[ Back to top ]