
テキスト専用アプリケーションのための娯楽オーディオ
【課題】特にステレオ又は3Dオーディオを使用して、SMS及びe−メールのようなテキストアプリケーションをより面白い且つ楽しいものにする方法を提供する。
【解決手段】テキスト専用のアプリケーションのためのオーディオを発生する方法は、発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加し、このタグを処理して、オーディオを発生するためのインストラクションを形成し、テキストが提示される間にこのインストラクションに基づいて前記サウンド効果を伴うオーディオを発生するステップを含む。本発明は、テキストアプリケーションに娯楽価値を追加し、従来のマルチメディアに比して非常にコンパクトなフォーマットを提供し、又、娯楽サウンドを使用して、SMS及びe−メールのようなテキスト専用アプリケーションをより面白い且つ楽しいものにする。
【解決手段】テキスト専用のアプリケーションのためのオーディオを発生する方法は、発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加し、このタグを処理して、オーディオを発生するためのインストラクションを形成し、テキストが提示される間にこのインストラクションに基づいて前記サウンド効果を伴うオーディオを発生するステップを含む。本発明は、テキストアプリケーションに娯楽価値を追加し、従来のマルチメディアに比して非常にコンパクトなフォーマットを提供し、又、娯楽サウンドを使用して、SMS及びe−メールのようなテキスト専用アプリケーションをより面白い且つ楽しいものにする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、一般的に、SMS、e−メール、書籍及び新聞のようなテキスト専用アプリケーションにおけるオーディオの使用及び発生に係る。
【背景技術】
【0002】
大多数のテキストコンテンツは、移動装置のマルチメディア能力に益々焦点が当てられているのも関わらず、グラフィックやサウンドを含むように更新されることがありそうもない。書籍や新聞のような「アーカイブド」フォーマット及びSMSやe−メールのようなメッセージフォーマットは、非常に長い期間にわたり現在の形態で普及し続けている。それ自身あまり興奮することのないテキストフォーマットにマルチメディアの魅力を追加できる技術が、現在、第一歩を踏み出している。
【0003】
この問題に対するほとんどの明確な解決策は、追加のマルチメディアコンテンツをオリジナルテキストコンテンツと共に記憶及び/又は送信することである。しかしながら、これは、テキストフォーマットがグラフィックやサウンドよりも著しくコンパクトであるために、少なくとも一桁、データ量を増加する。米国特許第7,103,548号は、テキストメッセージをオーディオ形態へ変換するシステムを開示しており、テキストメッセージは、感情指示子と、特徴形式の指示を埋め込んでおり、後者は、感情指示子により指示された感情をテキストメッセージのオーディオ形態で表現するために、複数のオーディオ形態プレゼンテーション特徴形式のどれを使用すべきか決定するように働く。又、現在、MSNメッセンジャーは、送信者がテキストにタグを書き込み、これを受信端でピクチャーへと変換できるようにする。しかしながら、コンテンツを前もって準備することは、コンテクスト依存の「サプライズ効果」の可能性を排除する。更に、ある周囲のサウンドスケープ、例えば、雨や風がスピーチに追加されて、従来の移動装置の1つのスピーカを通して再生された場合には、妨害となるバックグランドノイズのような音を発し、明瞭さを低減させる。
【0004】
マルチメディアコンテンツを記憶し提示するのに適したフォーマットは多数ある。知られている最良のものは、SMIL(同期マルチメディアインテグレーション言語)である。ワールドワイドウェブにおいて公衆に向けられる資料の場合、ACSS(オーディオカスケード型スタイルシート)を使用して、サウンドの幾つかのプロパティを定義することができる。SSML(W3により推奨されるスピーチ合成マークアップ言語)との組み合わせにおいて、サウンド及びスピーチのある基本的なリアルタイムレンダリングを行うことができる。
【発明の概要】
【発明が解決しようとする課題】
【0005】
従って、リアルタイムサウンド合成及びサウンド効果のレンダリング、特に、ステレオ又は3Dサウンドをテキストベースアプリケーションにおいて遂行するのに適したマークアップ言語又はそれに対応するソフトウェアアーキテクチャーが存在しない。
【0006】
そこで、本発明の目的は、娯楽サウンド、特に、ステレオ又は3Dオーディオを使用して、SMS及びe−メールのようなテキストアプリケーションを、より面白い且つ楽しいものにする方法を提供することである。
【課題を解決するための手段】
【0007】
この目的を達成するために、本発明は、テキスト専用アプリケーションのためのオーディオを発生する方法において、発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加し、このタグを処理して、オーディオを発生するためのインストラクションを形成し、テキストが提示される間にこのインストラクションに基づいて前記サウンド効果を伴うオーディオを発生することを含む方法を提供する。
【0008】
又、本発明は、テキスト専用アプリケーションのためのオーディオを発生する装置において、発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加するためのタグ追加器と、このタグを処理して、オーディオを発生するインストラクションを形成するためのタグプロセッサと、テキストが提示される間にこのインストラクションに基づいて前記サウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、を備えた装置も提供する。
【0009】
又、本発明は、テキスト専用アプリケーションのためのオーディオを発生することのできる通信ターミナルにおいて、入力テキストに追加されるタグであって発生されたオーディオにサウンド効果を追加するのに使用できるタグを処理して、オーディオを発生するインストラクションを形成するタグプロセッサと、テキストが提示される間にこのインストラクションに基づいてサウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、を備えた通信ターミナルも提供する。
【0010】
通信ターミナルは、更に、入力テキストにタグを追加するためのタグ追加器を備えることもできる。
【発明の効果】
【0011】
本発明を使用することで、3D、空間的増強及び効果の形態でオーディオを発生することができる。例えば、ステレオ又は3Dオーディオを使用すると、スピーチにサウンドを非嵌入的に追加することができ、サウンドスケープがステレオ又は3D効果に対して処理されて、ステレオヘッドホーン又は2つの至近離間されたスピーカを経て再生された場合に、スピーチを妨げることがないように空間分離化(spatialize)することができる。例えば、聴取者が傍らで雨や風を聞き中央でスピーチを聞いた場合には、明瞭さに影響が及ぶことはない。
【0012】
又、本発明は、例えば、オーディオがオンザフライで発生されるときに、レンダリングアルゴリズムが時間(朝/昼/夕方、平日/週末、夏/冬)又はユーザの位置(家/車/オフィス、国)に関する情報を考慮できるように、発生されるオーディオ効果にランダムさを追加することにより、コンテクスト依存の「サプライズ効果又は価値」を高めることが意図される。
【0013】
更に、本発明は、カスタマイズのための優れた可能性を許し、テキストアプリケーションに娯楽的価値を付加し、且つ平易テキストにマルチメディア「クラス」を追加する。又、本発明は、従来のマルチメディアに比して非常にコンパクトなフォーマットを与える。本発明は、プラットホーム特有ではないから、本発明の装置は、どのようにレンダリングするか判断する。
【0014】
本発明の前記及び他の目的、特徴及び効果は、添付図面を参照した好ましい実施形態の以下の詳細な説明から明らかとなろう。
【図面の簡単な説明】
【0015】
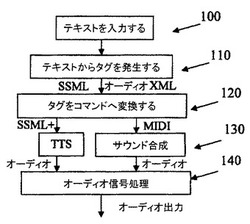
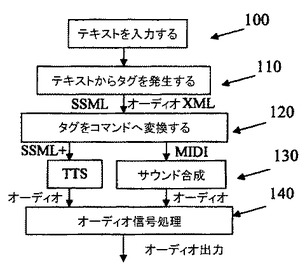
【図1】本発明によりテキスト専用アプリケーションのためにオーディオを発生する方法のフローチャートである。
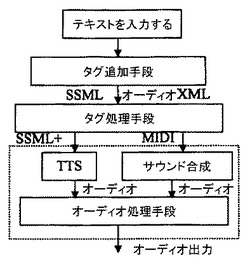
【図2】本発明によりテキスト専用アプリケーションのためにオーディオを発生する装置のブロック図である。
【発明を実施するための形態】
【0016】
以下、添付図面を参照して、本発明を詳細に説明する。
【0017】
図1は、本発明によりテキスト専用アプリケーションのためにオーディオを発生する方法のフローチャートである。
【0018】
ステップ100において、SMS、e−メール、オーディオブック、等のテキストアプリケーションが入力される。
【0019】
ステップ110において、入力テキストからタグが発生される。好ましくは、2セットのタグがオーディオ処理(以下に述べる)のために発生される。これらのタグは、特殊なケースでは、例えば、ユーザにより手で挿入することもできるし、或いは移動電話、PDA(パーソナルデジタルアシスタント)、ラップトップコンピュータ、及びタグをテキストに追加できる他の装置を含むターミナルによって発生することもできる。このステップを実施するために、VoiceXML(ボイスUI及びウェブページのオーディオレンダリングのための)、JSML(Jスピーチマークアップ言語(Java(登録商標)、Sunによる))、STML(スポークンテキストマークアップ言語)、サーブル(JSMLとSTMLを結合する試み)、SSML(W3により推奨されるスピーチ合成マークアップ言語)、SMIL(マルチメディアプレゼンテーションのための同期マルチメディアインテグレーション言語)を含む複数のマークアップ言語を使用することができるが、これらに限定されない。このステップには、ACSS(オーディオカスケード型スタイルシート)を含むこともできる。これは、サウンドの幾つかのプロパティを定義し、スピーチ合成及びオーディオの両方を指定し、そしてボイスをオーディオとオーバーラップするのに使用できる。更に、ACSSは、幾つかの空間的オーディオ特徴(例えば、方位、仰角)を有する。本発明によれば、スピーチ、音楽及びオーディオ効果に適用されるタグを含むオーディオXMLフォーマットのような新規なマークアップ言語を確立して、ステレオ又は3Dサウンド効果のようなサウンド効果をオーディオに追加するように使用することができる。例えば、入力メッセージは、‘Sorry I missed your call. I was playing tennis at the time. I won. (ごめん、あなたの電話を取り損なった。そのとき、テニスをしていた。私が勝った。)’である。例示的な擬似タグは、<continuous play: background music> Sorry I sassed your <audio substitute: call>. I was playing tennis <audio icon: tennis> at the time. W won! <audio icon: fireworks><end play: background music>である。
【0020】
ステップ120において、ステップ110で追加されたタグがコマンドへと変換され、コマンドは、サウンドを合成すると共にメッセージを発生するのに使用でき、メッセージは、オーディオ処理を制御するか、オーディオ処理の入力として使用できる。サウンドを合成する場合には、MIDIメッセージを使用することができる。スピーチを合成する場合には、SSMLの拡張バージョンを使用することができる(ここでは、図1のSSML+を参照)。ステップ120は、特徴:ランダム化を含むことができる。サウンドを厳密に繰り返すだけでは、聴取者にとって直ちに退屈になるか又はうるさいだけである。例えば、ゲームのオーディオ設計では、ユーザが全く同じサンプルを何回も聴取する必要がないように、アクターが同じラインを数回繰り返すことを記録するのが通常である。ランダムさは、多数の異なる方法で挿入することができる。幾つかの例を以下に示す。
【0021】
・一般的
・低レベルのレンダリングパラメータ(ボイス、楽器)を変える
・「サウンドアイコン」(「スマイル」と同等の短いサウンド)の選択を変える
・空間的効果及び後処理を変える
・スピーチ
・発音
・イベント(スピーチリズム、休止)のタイミングを変える
・意味を変更せずにテキストを変更する
・音楽
・アルゴリズム音楽発生を使用する
・サウンドサンプルのピッチ及び/又はテンポを変更する
・効果
・同様のサウンドを異なる仕方でレンダリングする
【0022】
オーディオレンダリングは、幾つかのレンダリングパラメータ(例えば、IMDIメッセージに埋め込まれた値)の低レベル制御をサポートすることができ、例えば、足音は、同じイベントの異なる発生のようなサウンドを常に発するように、タイミング、ピッチ、及び巾を変化させることができる。
【0023】
ランダム化の効果は明らかであり、サプライズの価値を付加し、ユーザが厳密な繰り返しで退屈又はうるさくなるのを防止し、レンダリングされるオーディオが予想可能になり過ぎるのを防止し、更に、個人の好みに基づいて設定を調整する優れた可能性を得ることである。
【0024】
ステップ130において、ステップ120からの入力が出力オーディオへと処理される。スピーチ合成の場合は、TTS(テキスト対スピーチ)エンジンを使用して、タグ付きテキスト(例えば、SSML+)をスピーチへと変換することができる。TTSシステムは、最近の数年間に劇的に改良された。アーチファクトは、スピーチサウンドを「ロボチック(robotic)」ではなく、「チョップアップ(chopped up)」にする。スピーチの質は、非常に自然なものとすることができるが、良質なTTSは、MIPS及びメモリの両方において集中的な計算を意味する。オーディオ合成の場合は、音楽及び効果(例えば、足音、海辺の波音及び鳥のさえずり)を含む2つの形式の合成オーディオが必要とされる。コントロール言語として適当なMIDIは、効果設定(残響、合唱、等)、優先順位(SP−MIDI)、タイムスタンプ、及びサウンドに影響する幾つかの低レベルパラメータを含むことができる。MIDIに使用されるウェーブテーブル合成は、音楽及び効果の両方に合理的である。ウェーブテーブル合成エンジン(オーディオ合成エンジン)(図1を参照)は、GMI準拠(一般的MIDI)であり、又、GM2準拠とすることができ、DLS(ダウンロード可能なサウンド)フォーマット及び全てのメインサンプリングレートをサポートする。
【0025】
次いで、フローは、ステップ140へ進み、ステップ130からの出力オーディオが更に処理される。
【0026】
図2を参照すれば、本発明によるテキスト専用アプリケーションのためのオーディオを発生する装置であって、図1にフローチャートに示された方法を対応的に遂行するための装置が示されている。テキスト専用アプリケーションを受信すると、タグ追加手段は、入力テキストのためのタグのセットを発生する。又、これらのタグは、特殊なケースでは、例えば、ユーザにより手で挿入することもできるし、或いは移動電話、PDA(パーソナルデジタルアシスタント)、ラップトップコンピュータ、及びタグをテキストに追加できる他の装置を含むターミナルによって発生することもできる。好ましくは、タグ追加手段により2つのセットが発生される。一方のセットは、TTSエンジンにとって有効であり、このため、SSMLのようなフォーマットを使用することができる。他方は、サウンド効果及び音楽の両方発生できるオーディオ合成エンジンにとって有効である。このようなフォーマットは、オーディオXMLと称することができる(図2を参照)。SMSのようなアプリケーションの場合には、タグ追加手段は、送信者又は受信者のいずれかのターミナルにおいて動作することができる。
【0027】
次いで、タグ処理手段は、タグを低レベルコマンドへ変換し、コマンドは、サウンドを合成すると共にメッセージを発生するのに使用でき、このメッセージは、オーディオ処理を制御し、「サプライズ価値」を付加する。サウンド合成の場合には、MIDIメッセージを使用することができる。TTSの場合、SSMLの若干拡張されたバージョンを使用することができる(ここでは、図2のSSML+を参照)。タグ処理手段は、聴取者のターミナルで動作されねばならない。タグ処理手段は、特徴:ランダム化を含むことができる。サウンド合成エンジンでは、低レベルコマンドを僅かに変更することで微妙な変化を実施することができる。例えば、足音は、同じイベントの異なる発生のようなサウンドを常に発するように、タイミング、ピッチ、及び巾を変化させることができる。
【0028】
オーディオ発生手段(図2の破線部を参照)は、タグ処理手段からの出力を受信する。スピーチ合成の場合は、TTSエンジンが、処理を遂行するように効果的に使用される。オーディオ合成の場合は、ウェーブテーブル合成エンジンが、音楽及び効果の両方を合理的に行うように効果的に使用される。
【0029】
オーディオ処理手段は、例えば、3Dアルゴリズム及び後効果をTTSからの出力及びオーディオ合成エンジンで遂行する。オーディオ処理手段は、次のファンクション、即ち位置的オーディオ、モノ/3D空間的増強、ステレオ拡幅、残響、EQ(イコライザ)、及びDRC(ダイナミックレンジコントロール)のうちの少なくとも1つを実施することができる。更に、オーディオ処理手段は、任意であるが、サンプルレート変換、ミキシング、パラメータ(3D位置、残響に対するT60)のリアルタイム変化をサポートする。
【0030】
本発明の装置は、テキスト専用アプリケーションのためのオーディオを発生することのできる通信ターミナルにおいて、入力テキストに追加されるタグであって発生されたオーディオにサウンド効果を追加するのに使用できるタグを処理して、オーディオを発生するインストラクションを形成するタグプロセッサと、テキストが提示される間にこのインストラクションに基づいてサウンド効果を伴うオーディオを発生するためのオーディオ発生手段と、を備えた通信ターミナルにおいて実施することができる。或いは又、この通信ターミナルは、更に、入力テキストにタグを追加するためのタグ追加手段を備えることもできる。この通信ターミナルは、例えば、移動ターミナルである。
【0031】
以上、本発明の特定の実施形態を開示したが、当業者であれば、本発明の精神及び範囲から逸脱せずに、特定の実施形態に対し変更をなし得ることが理解できよう。本発明は、オーディオに焦点を当てたが、テキストアプリケーションにグラフィックを追加する等しく強力なケースも考えられる。それ故、本発明の範囲は、特定の実施形態に限定されず、特許請求の範囲は、本発明の範囲内に入るそのような全てのアプリケーション、変更及び実施形態も包含するものとする。
【符号の説明】
【0032】
100、110、120、130、140:方法のステップ
【技術分野】
【0001】
本発明は、一般的に、SMS、e−メール、書籍及び新聞のようなテキスト専用アプリケーションにおけるオーディオの使用及び発生に係る。
【背景技術】
【0002】
大多数のテキストコンテンツは、移動装置のマルチメディア能力に益々焦点が当てられているのも関わらず、グラフィックやサウンドを含むように更新されることがありそうもない。書籍や新聞のような「アーカイブド」フォーマット及びSMSやe−メールのようなメッセージフォーマットは、非常に長い期間にわたり現在の形態で普及し続けている。それ自身あまり興奮することのないテキストフォーマットにマルチメディアの魅力を追加できる技術が、現在、第一歩を踏み出している。
【0003】
この問題に対するほとんどの明確な解決策は、追加のマルチメディアコンテンツをオリジナルテキストコンテンツと共に記憶及び/又は送信することである。しかしながら、これは、テキストフォーマットがグラフィックやサウンドよりも著しくコンパクトであるために、少なくとも一桁、データ量を増加する。米国特許第7,103,548号は、テキストメッセージをオーディオ形態へ変換するシステムを開示しており、テキストメッセージは、感情指示子と、特徴形式の指示を埋め込んでおり、後者は、感情指示子により指示された感情をテキストメッセージのオーディオ形態で表現するために、複数のオーディオ形態プレゼンテーション特徴形式のどれを使用すべきか決定するように働く。又、現在、MSNメッセンジャーは、送信者がテキストにタグを書き込み、これを受信端でピクチャーへと変換できるようにする。しかしながら、コンテンツを前もって準備することは、コンテクスト依存の「サプライズ効果」の可能性を排除する。更に、ある周囲のサウンドスケープ、例えば、雨や風がスピーチに追加されて、従来の移動装置の1つのスピーカを通して再生された場合には、妨害となるバックグランドノイズのような音を発し、明瞭さを低減させる。
【0004】
マルチメディアコンテンツを記憶し提示するのに適したフォーマットは多数ある。知られている最良のものは、SMIL(同期マルチメディアインテグレーション言語)である。ワールドワイドウェブにおいて公衆に向けられる資料の場合、ACSS(オーディオカスケード型スタイルシート)を使用して、サウンドの幾つかのプロパティを定義することができる。SSML(W3により推奨されるスピーチ合成マークアップ言語)との組み合わせにおいて、サウンド及びスピーチのある基本的なリアルタイムレンダリングを行うことができる。
【発明の概要】
【発明が解決しようとする課題】
【0005】
従って、リアルタイムサウンド合成及びサウンド効果のレンダリング、特に、ステレオ又は3Dサウンドをテキストベースアプリケーションにおいて遂行するのに適したマークアップ言語又はそれに対応するソフトウェアアーキテクチャーが存在しない。
【0006】
そこで、本発明の目的は、娯楽サウンド、特に、ステレオ又は3Dオーディオを使用して、SMS及びe−メールのようなテキストアプリケーションを、より面白い且つ楽しいものにする方法を提供することである。
【課題を解決するための手段】
【0007】
この目的を達成するために、本発明は、テキスト専用アプリケーションのためのオーディオを発生する方法において、発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加し、このタグを処理して、オーディオを発生するためのインストラクションを形成し、テキストが提示される間にこのインストラクションに基づいて前記サウンド効果を伴うオーディオを発生することを含む方法を提供する。
【0008】
又、本発明は、テキスト専用アプリケーションのためのオーディオを発生する装置において、発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加するためのタグ追加器と、このタグを処理して、オーディオを発生するインストラクションを形成するためのタグプロセッサと、テキストが提示される間にこのインストラクションに基づいて前記サウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、を備えた装置も提供する。
【0009】
又、本発明は、テキスト専用アプリケーションのためのオーディオを発生することのできる通信ターミナルにおいて、入力テキストに追加されるタグであって発生されたオーディオにサウンド効果を追加するのに使用できるタグを処理して、オーディオを発生するインストラクションを形成するタグプロセッサと、テキストが提示される間にこのインストラクションに基づいてサウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、を備えた通信ターミナルも提供する。
【0010】
通信ターミナルは、更に、入力テキストにタグを追加するためのタグ追加器を備えることもできる。
【発明の効果】
【0011】
本発明を使用することで、3D、空間的増強及び効果の形態でオーディオを発生することができる。例えば、ステレオ又は3Dオーディオを使用すると、スピーチにサウンドを非嵌入的に追加することができ、サウンドスケープがステレオ又は3D効果に対して処理されて、ステレオヘッドホーン又は2つの至近離間されたスピーカを経て再生された場合に、スピーチを妨げることがないように空間分離化(spatialize)することができる。例えば、聴取者が傍らで雨や風を聞き中央でスピーチを聞いた場合には、明瞭さに影響が及ぶことはない。
【0012】
又、本発明は、例えば、オーディオがオンザフライで発生されるときに、レンダリングアルゴリズムが時間(朝/昼/夕方、平日/週末、夏/冬)又はユーザの位置(家/車/オフィス、国)に関する情報を考慮できるように、発生されるオーディオ効果にランダムさを追加することにより、コンテクスト依存の「サプライズ効果又は価値」を高めることが意図される。
【0013】
更に、本発明は、カスタマイズのための優れた可能性を許し、テキストアプリケーションに娯楽的価値を付加し、且つ平易テキストにマルチメディア「クラス」を追加する。又、本発明は、従来のマルチメディアに比して非常にコンパクトなフォーマットを与える。本発明は、プラットホーム特有ではないから、本発明の装置は、どのようにレンダリングするか判断する。
【0014】
本発明の前記及び他の目的、特徴及び効果は、添付図面を参照した好ましい実施形態の以下の詳細な説明から明らかとなろう。
【図面の簡単な説明】
【0015】
【図1】本発明によりテキスト専用アプリケーションのためにオーディオを発生する方法のフローチャートである。
【図2】本発明によりテキスト専用アプリケーションのためにオーディオを発生する装置のブロック図である。
【発明を実施するための形態】
【0016】
以下、添付図面を参照して、本発明を詳細に説明する。
【0017】
図1は、本発明によりテキスト専用アプリケーションのためにオーディオを発生する方法のフローチャートである。
【0018】
ステップ100において、SMS、e−メール、オーディオブック、等のテキストアプリケーションが入力される。
【0019】
ステップ110において、入力テキストからタグが発生される。好ましくは、2セットのタグがオーディオ処理(以下に述べる)のために発生される。これらのタグは、特殊なケースでは、例えば、ユーザにより手で挿入することもできるし、或いは移動電話、PDA(パーソナルデジタルアシスタント)、ラップトップコンピュータ、及びタグをテキストに追加できる他の装置を含むターミナルによって発生することもできる。このステップを実施するために、VoiceXML(ボイスUI及びウェブページのオーディオレンダリングのための)、JSML(Jスピーチマークアップ言語(Java(登録商標)、Sunによる))、STML(スポークンテキストマークアップ言語)、サーブル(JSMLとSTMLを結合する試み)、SSML(W3により推奨されるスピーチ合成マークアップ言語)、SMIL(マルチメディアプレゼンテーションのための同期マルチメディアインテグレーション言語)を含む複数のマークアップ言語を使用することができるが、これらに限定されない。このステップには、ACSS(オーディオカスケード型スタイルシート)を含むこともできる。これは、サウンドの幾つかのプロパティを定義し、スピーチ合成及びオーディオの両方を指定し、そしてボイスをオーディオとオーバーラップするのに使用できる。更に、ACSSは、幾つかの空間的オーディオ特徴(例えば、方位、仰角)を有する。本発明によれば、スピーチ、音楽及びオーディオ効果に適用されるタグを含むオーディオXMLフォーマットのような新規なマークアップ言語を確立して、ステレオ又は3Dサウンド効果のようなサウンド効果をオーディオに追加するように使用することができる。例えば、入力メッセージは、‘Sorry I missed your call. I was playing tennis at the time. I won. (ごめん、あなたの電話を取り損なった。そのとき、テニスをしていた。私が勝った。)’である。例示的な擬似タグは、<continuous play: background music> Sorry I sassed your <audio substitute: call>. I was playing tennis <audio icon: tennis> at the time. W won! <audio icon: fireworks><end play: background music>である。
【0020】
ステップ120において、ステップ110で追加されたタグがコマンドへと変換され、コマンドは、サウンドを合成すると共にメッセージを発生するのに使用でき、メッセージは、オーディオ処理を制御するか、オーディオ処理の入力として使用できる。サウンドを合成する場合には、MIDIメッセージを使用することができる。スピーチを合成する場合には、SSMLの拡張バージョンを使用することができる(ここでは、図1のSSML+を参照)。ステップ120は、特徴:ランダム化を含むことができる。サウンドを厳密に繰り返すだけでは、聴取者にとって直ちに退屈になるか又はうるさいだけである。例えば、ゲームのオーディオ設計では、ユーザが全く同じサンプルを何回も聴取する必要がないように、アクターが同じラインを数回繰り返すことを記録するのが通常である。ランダムさは、多数の異なる方法で挿入することができる。幾つかの例を以下に示す。
【0021】
・一般的
・低レベルのレンダリングパラメータ(ボイス、楽器)を変える
・「サウンドアイコン」(「スマイル」と同等の短いサウンド)の選択を変える
・空間的効果及び後処理を変える
・スピーチ
・発音
・イベント(スピーチリズム、休止)のタイミングを変える
・意味を変更せずにテキストを変更する
・音楽
・アルゴリズム音楽発生を使用する
・サウンドサンプルのピッチ及び/又はテンポを変更する
・効果
・同様のサウンドを異なる仕方でレンダリングする
【0022】
オーディオレンダリングは、幾つかのレンダリングパラメータ(例えば、IMDIメッセージに埋め込まれた値)の低レベル制御をサポートすることができ、例えば、足音は、同じイベントの異なる発生のようなサウンドを常に発するように、タイミング、ピッチ、及び巾を変化させることができる。
【0023】
ランダム化の効果は明らかであり、サプライズの価値を付加し、ユーザが厳密な繰り返しで退屈又はうるさくなるのを防止し、レンダリングされるオーディオが予想可能になり過ぎるのを防止し、更に、個人の好みに基づいて設定を調整する優れた可能性を得ることである。
【0024】
ステップ130において、ステップ120からの入力が出力オーディオへと処理される。スピーチ合成の場合は、TTS(テキスト対スピーチ)エンジンを使用して、タグ付きテキスト(例えば、SSML+)をスピーチへと変換することができる。TTSシステムは、最近の数年間に劇的に改良された。アーチファクトは、スピーチサウンドを「ロボチック(robotic)」ではなく、「チョップアップ(chopped up)」にする。スピーチの質は、非常に自然なものとすることができるが、良質なTTSは、MIPS及びメモリの両方において集中的な計算を意味する。オーディオ合成の場合は、音楽及び効果(例えば、足音、海辺の波音及び鳥のさえずり)を含む2つの形式の合成オーディオが必要とされる。コントロール言語として適当なMIDIは、効果設定(残響、合唱、等)、優先順位(SP−MIDI)、タイムスタンプ、及びサウンドに影響する幾つかの低レベルパラメータを含むことができる。MIDIに使用されるウェーブテーブル合成は、音楽及び効果の両方に合理的である。ウェーブテーブル合成エンジン(オーディオ合成エンジン)(図1を参照)は、GMI準拠(一般的MIDI)であり、又、GM2準拠とすることができ、DLS(ダウンロード可能なサウンド)フォーマット及び全てのメインサンプリングレートをサポートする。
【0025】
次いで、フローは、ステップ140へ進み、ステップ130からの出力オーディオが更に処理される。
【0026】
図2を参照すれば、本発明によるテキスト専用アプリケーションのためのオーディオを発生する装置であって、図1にフローチャートに示された方法を対応的に遂行するための装置が示されている。テキスト専用アプリケーションを受信すると、タグ追加手段は、入力テキストのためのタグのセットを発生する。又、これらのタグは、特殊なケースでは、例えば、ユーザにより手で挿入することもできるし、或いは移動電話、PDA(パーソナルデジタルアシスタント)、ラップトップコンピュータ、及びタグをテキストに追加できる他の装置を含むターミナルによって発生することもできる。好ましくは、タグ追加手段により2つのセットが発生される。一方のセットは、TTSエンジンにとって有効であり、このため、SSMLのようなフォーマットを使用することができる。他方は、サウンド効果及び音楽の両方発生できるオーディオ合成エンジンにとって有効である。このようなフォーマットは、オーディオXMLと称することができる(図2を参照)。SMSのようなアプリケーションの場合には、タグ追加手段は、送信者又は受信者のいずれかのターミナルにおいて動作することができる。
【0027】
次いで、タグ処理手段は、タグを低レベルコマンドへ変換し、コマンドは、サウンドを合成すると共にメッセージを発生するのに使用でき、このメッセージは、オーディオ処理を制御し、「サプライズ価値」を付加する。サウンド合成の場合には、MIDIメッセージを使用することができる。TTSの場合、SSMLの若干拡張されたバージョンを使用することができる(ここでは、図2のSSML+を参照)。タグ処理手段は、聴取者のターミナルで動作されねばならない。タグ処理手段は、特徴:ランダム化を含むことができる。サウンド合成エンジンでは、低レベルコマンドを僅かに変更することで微妙な変化を実施することができる。例えば、足音は、同じイベントの異なる発生のようなサウンドを常に発するように、タイミング、ピッチ、及び巾を変化させることができる。
【0028】
オーディオ発生手段(図2の破線部を参照)は、タグ処理手段からの出力を受信する。スピーチ合成の場合は、TTSエンジンが、処理を遂行するように効果的に使用される。オーディオ合成の場合は、ウェーブテーブル合成エンジンが、音楽及び効果の両方を合理的に行うように効果的に使用される。
【0029】
オーディオ処理手段は、例えば、3Dアルゴリズム及び後効果をTTSからの出力及びオーディオ合成エンジンで遂行する。オーディオ処理手段は、次のファンクション、即ち位置的オーディオ、モノ/3D空間的増強、ステレオ拡幅、残響、EQ(イコライザ)、及びDRC(ダイナミックレンジコントロール)のうちの少なくとも1つを実施することができる。更に、オーディオ処理手段は、任意であるが、サンプルレート変換、ミキシング、パラメータ(3D位置、残響に対するT60)のリアルタイム変化をサポートする。
【0030】
本発明の装置は、テキスト専用アプリケーションのためのオーディオを発生することのできる通信ターミナルにおいて、入力テキストに追加されるタグであって発生されたオーディオにサウンド効果を追加するのに使用できるタグを処理して、オーディオを発生するインストラクションを形成するタグプロセッサと、テキストが提示される間にこのインストラクションに基づいてサウンド効果を伴うオーディオを発生するためのオーディオ発生手段と、を備えた通信ターミナルにおいて実施することができる。或いは又、この通信ターミナルは、更に、入力テキストにタグを追加するためのタグ追加手段を備えることもできる。この通信ターミナルは、例えば、移動ターミナルである。
【0031】
以上、本発明の特定の実施形態を開示したが、当業者であれば、本発明の精神及び範囲から逸脱せずに、特定の実施形態に対し変更をなし得ることが理解できよう。本発明は、オーディオに焦点を当てたが、テキストアプリケーションにグラフィックを追加する等しく強力なケースも考えられる。それ故、本発明の範囲は、特定の実施形態に限定されず、特許請求の範囲は、本発明の範囲内に入るそのような全てのアプリケーション、変更及び実施形態も包含するものとする。
【符号の説明】
【0032】
100、110、120、130、140:方法のステップ
【特許請求の範囲】
【請求項1】
テキスト専用アプリケーションのためのオーディオを発生する方法において、
発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加するステップと、
前記タグを処理して、オーディオを発生するためのインストラクションを形成するステップと、
テキストが提示される間に前記インストラクションに基づいて前記サウンド効果を伴うオーディオを発生するステップと、
を備えた方法。
【請求項2】
前記サウンド効果は、ステレオ効果である、請求項1に記載の方法。
【請求項3】
前記サウンド効果は、3Dサウンド効果である、請求項1に記載の方法。
【請求項4】
前記テキストは、表示されることにより提示されるか、又はテキスト/スピーチ変換の仕方で提示される、請求項1に記載の方法。
【請求項5】
前記タグは、入力テキストから発生されるか、又は手で挿入される、請求項1に記載の方法。
【請求項6】
前記タグは、スピーチ、音楽又はオーディオ効果に適用される、請求項1に記載の方法。
【請求項7】
サウンド効果を伴うオーディオを発生する前記ステップにおいて、前記インストラクションを使用してサウンドを合成すると共に、オーディオ処理を制御する、請求項1に記載の方法。
【請求項8】
タグを処理する前記ステップにおいて、ランダムさを追加するステップを更に含む、請求項1に記載の方法。
【請求項9】
ランダムさを追加する前記ステップは、インストラクションの変更によって実行され、この変更は、オーディオを発生する仕方又はパラメータを変化させる、請求項8に記載の方法。
【請求項10】
前記仕方又はパラメータは、低レベルレンダリングパラメータ、サウンドアイコンの選択、空間的効果及び後処理、発音、イベントのタイミング、意味の変更を伴わないテキストの変更、アルゴリズム音楽発生の使用、及び同様のサウンドの異なるレンダリング、の少なくとも1つを含む、請求項9に記載の方法。
【請求項11】
サウンド効果を伴うオーディオを発生する前記ステップは、TTSエンジンでスピーチ合成を遂行する段階を含む、請求項1に記載の方法。
【請求項12】
サウンド効果を伴うオーディオを発生する前記ステップは、オーディオ合成エンジンでオーディオ合成を遂行する段階を含む、請求項1に記載の方法。
【請求項13】
サウンド効果を伴うオーディオを発生する前記ステップは、オーディオ処理を遂行する段階を含む、請求項1に記載の方法。
【請求項14】
テキスト専用アプリケーションのためのオーディオを発生する装置において、
発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加するためのタグ追加器と、
前記タグを処理して、オーディオを発生するインストラクションを形成するためのタグプロセッサと、
テキストが提示される間に前記インストラクションに基づいて前記サウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、
を備えた装置。
【請求項15】
前記サウンド効果は、ステレオ効果である、請求項14に記載の装置。
【請求項16】
前記サウンド効果は、3Dサウンド効果である、請求項14に記載の装置。
【請求項17】
前記テキストは、表示されることにより提示されるか、又はテキスト/スピーチ変換の仕方で提示される、請求項14に記載の装置。
【請求項18】
前記タグは、入力テキストから発生されるか、又は手で挿入される、請求項14に記載の装置。
【請求項19】
前記タグは、スピーチ、音楽又はオーディオ効果に適用される、請求項14に記載の装置。
【請求項20】
前記オーディオジェネレータは、前記インストラクションを使用してサウンドを合成すると共に、オーディオ処理を制御する、請求項14に記載の装置。
【請求項21】
前記タグプロセッサは、ランダムさを追加する、請求項14に記載の装置。
【請求項22】
前記タグプロセッサは、インストラクションの変更によって前記ランダムさを実行し、この変更は、オーディオを発生する仕方又はパラメータを変化させる、請求項21に記載の装置。
【請求項23】
前記仕方又はパラメータは、低レベルレンダリングパラメータ、サウンドアイコンの選択、空間的効果及び後処理、発音、イベントのタイミング、意味の変更を伴わないテキストの変更、アルゴリズム音楽発生の使用、及び同様のサウンドの異なるレンダリング、の少なくとも1つを含む、請求項22に記載の装置。
【請求項24】
前記オーディオジェネレータは、スピーチ合成を遂行するためのTTSエンジン、及びオーディオ合成を遂行するためのオーディオ合成エンジン、の少なくとも1つを含む、請求項14に記載の装置。
【請求項25】
前記オーディオジェネレータは、オーディオ処理を遂行するためのオーディオプロセッサを更に備えた、請求項14に記載の装置。
【請求項26】
テキスト専用アプリケーションのためのオーディオを発生することのできる通信ターミナルにおいて、
入力テキストに追加されるタグであって発生されたオーディオにサウンド効果を追加するのに使用できるタグを処理して、オーディオを発生するインストラクションを形成するタグプロセッサと、
テキストが提示される間にこのインストラクションに基づいてサウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、
を備えた通信ターミナル。
【請求項27】
入力テキストに前記タグを追加するためのタグ追加器を更に備えた、請求項26に記載の通信ターミナル。
【請求項1】
テキスト専用アプリケーションのためのオーディオを発生する方法において、
発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加するステップと、
前記タグを処理して、オーディオを発生するためのインストラクションを形成するステップと、
テキストが提示される間に前記インストラクションに基づいて前記サウンド効果を伴うオーディオを発生するステップと、
を備えた方法。
【請求項2】
前記サウンド効果は、ステレオ効果である、請求項1に記載の方法。
【請求項3】
前記サウンド効果は、3Dサウンド効果である、請求項1に記載の方法。
【請求項4】
前記テキストは、表示されることにより提示されるか、又はテキスト/スピーチ変換の仕方で提示される、請求項1に記載の方法。
【請求項5】
前記タグは、入力テキストから発生されるか、又は手で挿入される、請求項1に記載の方法。
【請求項6】
前記タグは、スピーチ、音楽又はオーディオ効果に適用される、請求項1に記載の方法。
【請求項7】
サウンド効果を伴うオーディオを発生する前記ステップにおいて、前記インストラクションを使用してサウンドを合成すると共に、オーディオ処理を制御する、請求項1に記載の方法。
【請求項8】
タグを処理する前記ステップにおいて、ランダムさを追加するステップを更に含む、請求項1に記載の方法。
【請求項9】
ランダムさを追加する前記ステップは、インストラクションの変更によって実行され、この変更は、オーディオを発生する仕方又はパラメータを変化させる、請求項8に記載の方法。
【請求項10】
前記仕方又はパラメータは、低レベルレンダリングパラメータ、サウンドアイコンの選択、空間的効果及び後処理、発音、イベントのタイミング、意味の変更を伴わないテキストの変更、アルゴリズム音楽発生の使用、及び同様のサウンドの異なるレンダリング、の少なくとも1つを含む、請求項9に記載の方法。
【請求項11】
サウンド効果を伴うオーディオを発生する前記ステップは、TTSエンジンでスピーチ合成を遂行する段階を含む、請求項1に記載の方法。
【請求項12】
サウンド効果を伴うオーディオを発生する前記ステップは、オーディオ合成エンジンでオーディオ合成を遂行する段階を含む、請求項1に記載の方法。
【請求項13】
サウンド効果を伴うオーディオを発生する前記ステップは、オーディオ処理を遂行する段階を含む、請求項1に記載の方法。
【請求項14】
テキスト専用アプリケーションのためのオーディオを発生する装置において、
発生されたオーディオにサウンド効果を追加するのに使用できるタグを入力テキストに追加するためのタグ追加器と、
前記タグを処理して、オーディオを発生するインストラクションを形成するためのタグプロセッサと、
テキストが提示される間に前記インストラクションに基づいて前記サウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、
を備えた装置。
【請求項15】
前記サウンド効果は、ステレオ効果である、請求項14に記載の装置。
【請求項16】
前記サウンド効果は、3Dサウンド効果である、請求項14に記載の装置。
【請求項17】
前記テキストは、表示されることにより提示されるか、又はテキスト/スピーチ変換の仕方で提示される、請求項14に記載の装置。
【請求項18】
前記タグは、入力テキストから発生されるか、又は手で挿入される、請求項14に記載の装置。
【請求項19】
前記タグは、スピーチ、音楽又はオーディオ効果に適用される、請求項14に記載の装置。
【請求項20】
前記オーディオジェネレータは、前記インストラクションを使用してサウンドを合成すると共に、オーディオ処理を制御する、請求項14に記載の装置。
【請求項21】
前記タグプロセッサは、ランダムさを追加する、請求項14に記載の装置。
【請求項22】
前記タグプロセッサは、インストラクションの変更によって前記ランダムさを実行し、この変更は、オーディオを発生する仕方又はパラメータを変化させる、請求項21に記載の装置。
【請求項23】
前記仕方又はパラメータは、低レベルレンダリングパラメータ、サウンドアイコンの選択、空間的効果及び後処理、発音、イベントのタイミング、意味の変更を伴わないテキストの変更、アルゴリズム音楽発生の使用、及び同様のサウンドの異なるレンダリング、の少なくとも1つを含む、請求項22に記載の装置。
【請求項24】
前記オーディオジェネレータは、スピーチ合成を遂行するためのTTSエンジン、及びオーディオ合成を遂行するためのオーディオ合成エンジン、の少なくとも1つを含む、請求項14に記載の装置。
【請求項25】
前記オーディオジェネレータは、オーディオ処理を遂行するためのオーディオプロセッサを更に備えた、請求項14に記載の装置。
【請求項26】
テキスト専用アプリケーションのためのオーディオを発生することのできる通信ターミナルにおいて、
入力テキストに追加されるタグであって発生されたオーディオにサウンド効果を追加するのに使用できるタグを処理して、オーディオを発生するインストラクションを形成するタグプロセッサと、
テキストが提示される間にこのインストラクションに基づいてサウンド効果を伴うオーディオを発生するためのオーディオジェネレータと、
を備えた通信ターミナル。
【請求項27】
入力テキストに前記タグを追加するためのタグ追加器を更に備えた、請求項26に記載の通信ターミナル。
【図1】


【図2】
【図2】
【公開番号】特開2013−101637(P2013−101637A)
【公開日】平成25年5月23日(2013.5.23)
【国際特許分類】
【出願番号】特願2012−276836(P2012−276836)
【出願日】平成24年12月19日(2012.12.19)
【分割の表示】特願2010−504890(P2010−504890)の分割
【原出願日】平成20年4月24日(2008.4.24)
【出願人】(398012616)ノキア コーポレイション (1,359)
【Fターム(参考)】
【公開日】平成25年5月23日(2013.5.23)
【国際特許分類】
【出願日】平成24年12月19日(2012.12.19)
【分割の表示】特願2010−504890(P2010−504890)の分割
【原出願日】平成20年4月24日(2008.4.24)
【出願人】(398012616)ノキア コーポレイション (1,359)
【Fターム(参考)】
[ Back to top ]