
データ処理装置、およびデータ処理方法、並びにプログラム
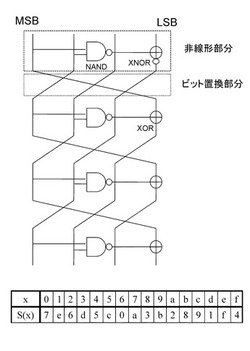
【課題】小型化した非線形変換部を実現する。
【解決手段】データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してラウンド関数を適用したデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、F関数実行部は非線形変換処理を実行する非線形変換処理部を有し、非線形変換処理部は1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、ビット置換部との繰り返し構造を有する。この繰り返し構成により小型化された非線形変換部を実現する。
【解決手段】データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してラウンド関数を適用したデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、F関数実行部は非線形変換処理を実行する非線形変換処理部を有し、非線形変換処理部は1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、ビット置換部との繰り返し構造を有する。この繰り返し構成により小型化された非線形変換部を実現する。
【発明の詳細な説明】
【技術分野】
【0001】
本開示は、データ処理装置、およびデータ処理方法、並びにプログラムに関する。さらに詳細には、例えば共通鍵系暗号を実行するデータ処理装置、およびデータ処理方法、並びにプログラムに関する。
【背景技術】
【0002】
情報化社会が発展すると共に、扱う情報を安全に守るための情報セキュリティ技術の重要性が増してきている。情報セキュリティ技術の構成要素の一つとして暗号技術があり、現在では様々な製品やシステムで暗号技術が利用されている。
【0003】
暗号処理アルゴリズムには様々なものがあるが、基本的な技術の一つとして、共通鍵ブロック暗号と呼ばれるものがある。共通鍵ブロック暗号では、暗号化用の鍵と復号用の鍵が共通のものとなっている。暗号化処理、復号処理共に、その共通鍵から複数の鍵を生成し、あるブロック単位、例えば64ビット、128ビット、256ビット等のブロックデータ単位でデータ変換処理を繰り返し実行する。
【0004】
代表的な共通鍵ブロック暗号のアルゴリズムとしては、過去の米国標準であるDES(Data Encryption Standard)や現在の米国標準であるAES(Advanced Encryption Standard)が知られている。他にも様々な共通鍵ブロック暗号が現在も提案され続けており、2007年にソニー株式会社が提案したCLEFIAも共通鍵ブロック暗号の一つである。
【0005】
このような、共通鍵ブロック暗号のアルゴリズムは、主として、入力データの変換を繰り返し実行するラウンド関数実行部を有する暗号処理部と、ラウンド関数部の各ラウンドで適用するラウンド鍵を生成する鍵スケジュール部とによって構成される。鍵スケジュール部は、秘密鍵であるマスター鍵(主鍵)に基づいて、まずビット数を増加させた拡大鍵を生成し、生成した拡大鍵に基づいて、暗号処理部の各ラウンド関数部で適用するラウンド鍵(副鍵)を生成する。
【0006】
このようなアルゴリズムを実行する具体的な構造として、線形変換部および非線形変換部を有するラウンド関数を繰り返し実行する構造が知られている。例えば代表的な構造にFeistel構造や一般化Feistel構造がある。Feistel構造や一般化Feistel構造は、データ変換関数としてのF関数を含むラウンド関数の単純な繰り返しにより、平文を暗号文に変換する構造を持つ。F関数においては、線形変換処理および非線形変換処理が実行される。なお、Feistel構造を適用した暗号処理について記載した文献としては、例えば非特許文献1、非特許文献2がある。
【0007】
F関数において実行される非線形変換処理は、例えばS−boxと呼ばれる非線形変換関数を適用して行われる。このS−boxは、ブロック暗号やハッシュ関数の構成要素であり、その安全性や実装性能を決定付ける非常に重要な関数である。
このS−boxは、高い安全性が要求される。しかし、高い安全性を保持するために回路規模が大きくなってしまうという問題がある。
【先行技術文献】
【非特許文献】
【0008】
【非特許文献1】K. Nyberg, "Generalized Feistel networks", ASIACRYPT'96, SpringerVerlag, 1996, pp.91--104.
【非特許文献2】Yuliang Zheng, Tsutomu Matsumoto, Hideki Imai: On the Construction of Block Ciphers Provably Secure and Not Relying on Any Unproved Hypotheses. CRYPTO 1989: 461-480
【非特許文献3】US National Institute of Standards and Technology, Advanced Encryption Standard, Federal Information Processing Standards Publications No. 197, 2001.
【非特許文献4】青木,市川,神田,松井,盛合,中嶋,時田,"128ビットブロック暗号 Camellia アルゴリズム仕様書",第 2.0版, 2001.
【非特許文献5】Chae Hoon Lim,, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 0.5)"
【非特許文献6】Chae Hoon Lim, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 1.0)"
【非特許文献7】Paulo S. L. M Barreto, Vincent Rijmen "The WHIRLPOOL Hashing Function", 2003.
【非特許文献8】Pascal Junod and Serge Vaudenay, "FOX : a New Family of Block Ciphers" ,2004
【非特許文献9】Sony Corporation, "The 128−bit Blockcipher CLEFIA Algorithm Specification", Revision 1.0, 2007.
【発明の概要】
【発明が解決しようとする課題】
【0009】
本開示は、例えば上述の状況に鑑みてなされたものであり、小型化可能な安全性を持つS−boxを備えたデータ処理装置、およびデータ処理方法、並びにプログラムを提供することを目的とする。
【課題を解決するための手段】
【0010】
本開示の第1の側面は、
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行するデータ変換処理部を有し、
前記データ変換処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、
前記F関数実行部は、
非線形変換処理を実行する非線形変換処理部を有し、
前記非線形変換処理部は、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有するデータ処理装置にある。
【0011】
さらに、本開示のデータ処理装置の一実施態様において、前記ビット置換部は、前記非線形演算部に対する入出力ビットを入れ替える配線構成を有する。
【0012】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、2ビット入力1ビット出力のNANDまたはNOR演算部における演算結果としての1ビットを、前記XORまたはXNOR演算部に出力して、他の入力1ビットデータとのXORまたはXNOR演算を実行し、XORまたはXNOR演算結果として生成した1ビットデータを非線形変換処理結果の構成ビットとして出力する。
【0013】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部を、n回以上繰り返す繰り返し構造を有する。
【0014】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部をn回、前記ビット置換部をn回の前記非線形演算部の間にn−1回設定した構成である。
【0015】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する。
【0016】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、前記繰り返し構造中に、XOR演算部とXNOR演算部の双方を有する構成である。
【0017】
さらに、本開示のデータ処理装置の一実施態様において、前記データ処理装置は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する。
【0018】
さらに、本開示の第2の側面は、
1つのNANDまたはNOR演算部と、
1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有する非線形変換処理部を有するデータ処理装置にある。
【0019】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する。
【0020】
さらに、本開示の第3の側面は、
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、
複数ラインを構成する1ラインのデータを入力して変換データを生成する非線形関数実行部を有するラウンド関数の繰り返し構造を有するデータ処理装置にある。
【0021】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形関数実行部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する。
【0022】
さらに、本開示の第4の側面は、
データ処理装置において実行するデータ処理方法であり、
データ処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行し、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行し、
前記F関数の実行処理において、非線形変換処理を実行し、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行するデータ処理方法にある。
【0023】
さらに、本開示の第5の側面は、
データ処理装置においてデータ変換処理を実行させるプログラムであり、
データ処理部に、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行させ、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行させ、
前記F関数の実行処理において、非線形変換処理を実行させ、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行させるプログラムにある。
【0024】
なお、本開示のプログラムは、例えば、様々なプログラム・コードを実行可能な情報処理装置やコンピュータ・システムに対して例えば記憶媒体によって提供されるプログラムである。このようなプログラムを情報処理装置やコンピュータ・システム上のプログラム実行部で実行することでプログラムに応じた処理が実現される。
【0025】
本開示のさらに他の目的、特徴や利点は、後述する本発明の実施例や添付する図面に基づくより詳細な説明によって明らかになるであろう。なお、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【発明の効果】
【0026】
本開示の一実施例によれば、小型化した非線形変換部が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してラウンド関数を適用したデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、F関数実行部は非線形変換処理を実行する非線形変換処理部を有し、非線形変換処理部は1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、ビット置換部との繰り返し構造を有する。この繰り返し構成により小型化された非線形変換部が実現される。
【図面の簡単な説明】
【0027】
【図1】kビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムを説明する図である。
【図2】図1に示すkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムに対応する復号アルゴリズムを説明する図である。
【図3】鍵スケジュール部とデータ暗号化部の関係について説明する図である。
【図4】データ暗号化部の構成例について説明する図である。
【図5】SPN構造のラウンド関数の例について説明する図である。
【図6】Feistel構造のラウンド関数の一例について説明する図である。
【図7】拡張Feistel構造の一例について説明する図である。
【図8】拡張Feistel構造の一例について説明する図である。
【図9】非線形変換部の構成例について説明する図である。
【図10】線形変換処理部の構成例について説明する図である。
【図11】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図12】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図13】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図14】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図15】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図16】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図17】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図18】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図19】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図20】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
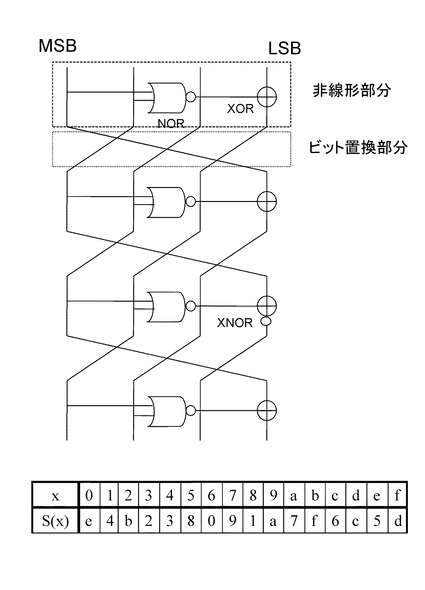
【図21】論理演算とビット置換の繰り返し構造による5ビットS−boxの構成例について説明する図である。
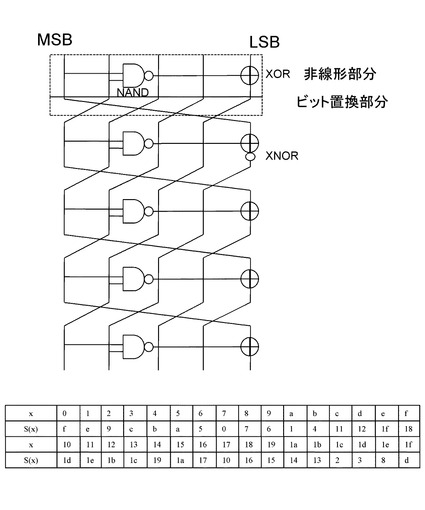
【図22】type−IGFN(Generalized Feistel Network)を基にした小さいS−boxを用いた繰り返し処理による大きなS−boxの構成例について説明する図である。
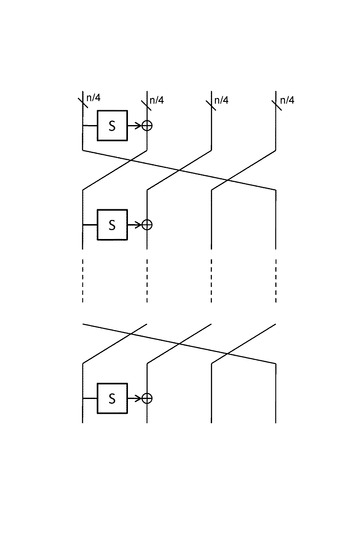
【図23】type−IIGFNを基にした,小さいS−boxを用いた繰り返し処理による大きなS−boxの構成例について説明する図である。
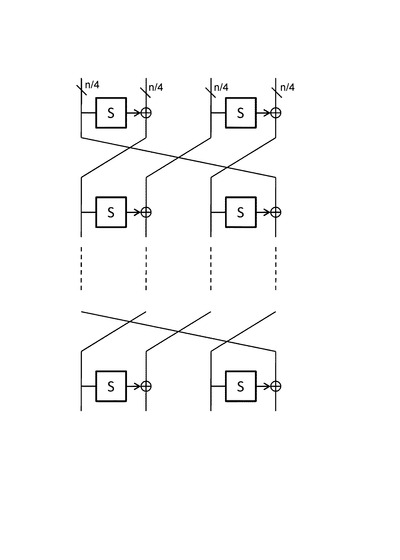
【図24】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図25】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図26】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図27】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図28】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
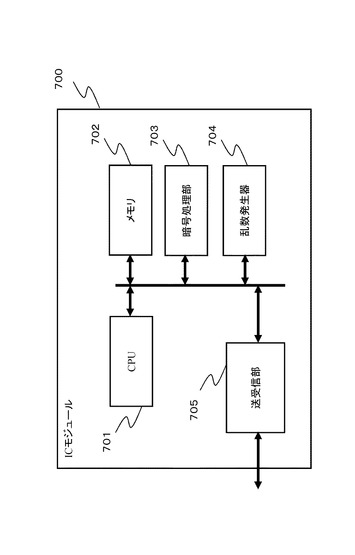
【図29】暗号処理装置としてのICモジュール700の構成例を示す図である。
【発明を実施するための形態】
【0028】
以下、図面を参照しながら本開示に係るデータ処理装置、およびデータ処理方法、並びにプログラムの詳細について説明する。説明は、以下の項目に従って行う。
1.共通鍵ブロック暗号の概要
2.S−boxについて
3.本開示に係るS−boxの概要について
4.暗号処理装置の構成例について
5.本開示の構成のまとめ
【0029】
[1.共通鍵ブロック暗号の概要]
まず、共通鍵ブロック暗号の概要について説明する。
(1−1.共通鍵ブロック暗号)
ここでは共通鍵ブロック暗号(以下ではブロック暗号)としては以下に定義するものを指すものとする。
ブロック暗号は入力として平文Pと鍵Kを取り、暗号文Cを出力する。平文と暗号文のビット長をブロックサイズと呼びここではnで著す。nは任意の整数値を取りうるが、通常、ブロック暗号アルゴリズムごとに、あらかじめひとつに決められている値である。ブロック長がnのブロック暗号のことをnビットブロック暗号と呼ぶこともある。
【0030】
鍵のビット長をkで表す。鍵は任意の整数値を取りうる。共通鍵ブロック暗号アルゴリズムは1つまたは複数の鍵サイズに対応することになる。例えば、あるブロック暗号アルゴリズムAはブロックサイズn=128であり、k=128またはk=192またはk=256の鍵サイズに対応するという構成もありうるものとする。
平文P:nビット
暗号文C:nビット
鍵K:kビット
【0031】
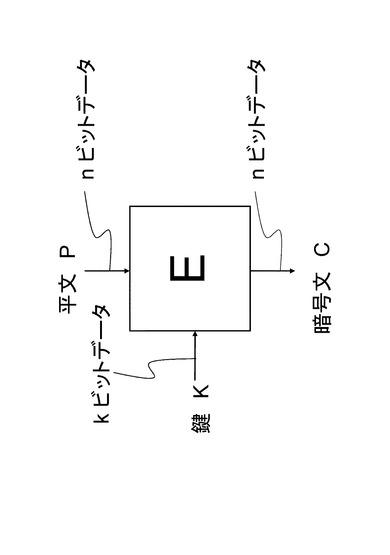
図1にkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムEの図を示す。
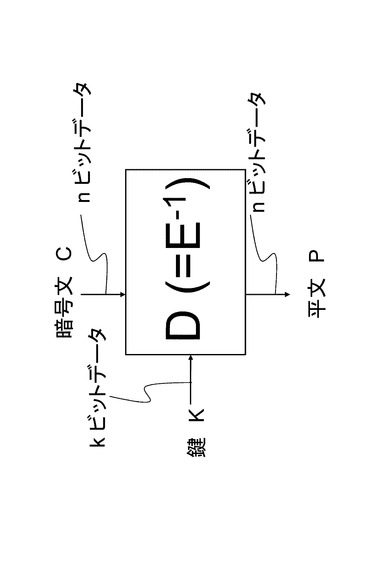
暗号化アルゴリズムEに対応する復号アルゴリズムDは暗号化アルゴリズムEの逆関数E−1と定義でき、入力として暗号文Cと鍵Kを受け取り,平文Pを出力する。図2に図1に示した暗号アルゴリズムEに対応する復号アルゴリズムDの図を示す。
【0032】
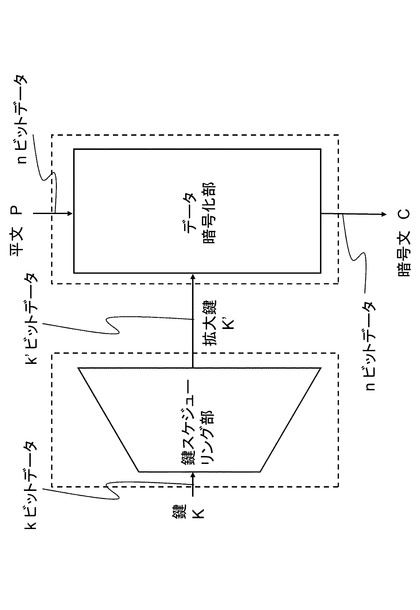
(1−2.内部構成)
ブロック暗号は2つの部分に分けて考えることができる。ひとつは鍵Kを入力とし、
ある定められたステップによりビット長を拡大してできた拡大鍵K'(ビット長k')を出力する「鍵スケジュール部」と、もうひとつは平文Pと鍵スケジュール部から拡大された鍵K'を受け取ってデータの変換を行い暗号文Cを出力する「データ暗号化部」である。
2つの部分の関係は図3に示される。
【0033】
(1−3.データ暗号化部)
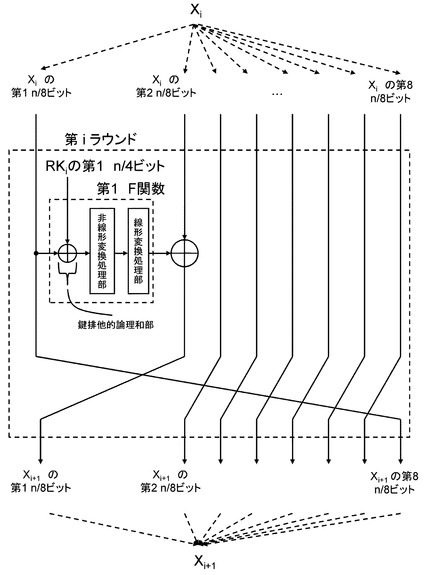
以下の実施例において用いるデータ暗号化部はラウンド関数という処理単位に分割できるものとする。ラウンド関数は入力としての2つのデータを受け取り、内部で処理を施したのち、1つのデータを出力する。入力データの一方は暗号化途中のnビットデータであり、あるラウンドにおけるラウンド関数の出力が次のラウンドの入力として供給される構成となる。もう1つの入力データは鍵スケジュールから出力された拡大鍵の一部のデータが用いられ、この鍵データのことをラウンド鍵と呼ぶものとする。またラウンド関数の総数は総ラウンド数と呼ばれ、暗号アルゴリズムごとにあらかじめ定められている値である。ここでは総ラウンド数をRで表す。
【0034】
データ暗号化部の入力側から見て1ラウンド目の入力データをX1とし、i番目のラウンド関数に入力されるデータをXi、ラウンド鍵をRKiとすると、データ暗号化部全体は図4のように示される。
【0035】
(1−4.ラウンド関数)
ブロック暗号アルゴリズムによってラウンド関数はさまざまな形態をとりうる。ラウンド関数はその暗号アルゴリズムが採用する構造(structure)によって分類できる。代表的な構造としてここではSPN構造、Feistel構造、拡張Feistel構造を例示する。
【0036】
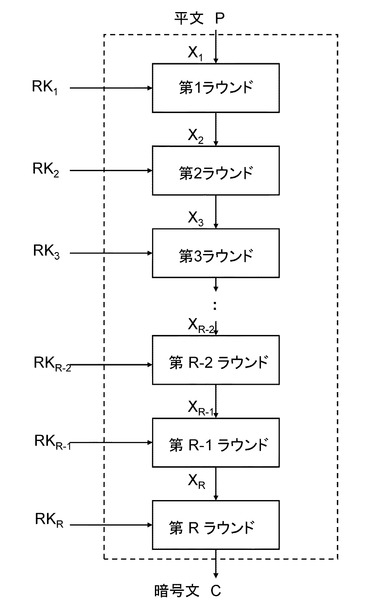
(ア)SPN構造ラウンド関数
nビットの入力データすべてに対して、ラウンド鍵との排他的論理和演算、非線形変換、線形変換処理などが適用される構成。各演算の順番は特に決まっていない。図5にSPN構造のラウンド関数の例を示す。
【0037】
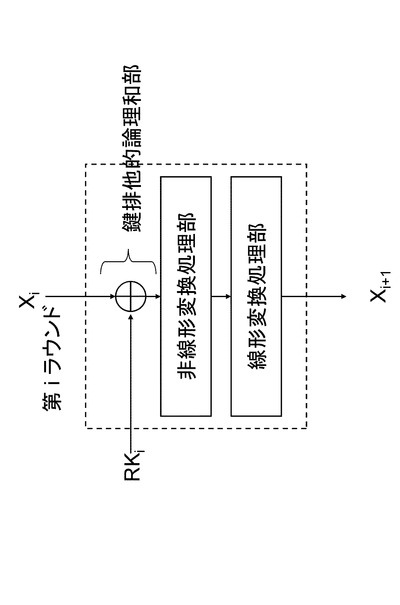
(イ)Feistel構造
nビットの入力データはn/2ビットの2つのデータに分割される。うち片方のデータとラウンド鍵を入力として持つ関数(F関数)が適用され、出力がもう片方のデータに排他的論理和される。そののちデータの左右を入れ替えたものを出力データとする。F関数の内部構成にもさまざまなタイプのものがあるが、基本的にはSPN構造同様にラウンド鍵データとの排他的論理和演算、非線形演算、線形変換の組み合わせで実現される。図6にFeistel構造のラウンド関数の一例を示す。
【0038】
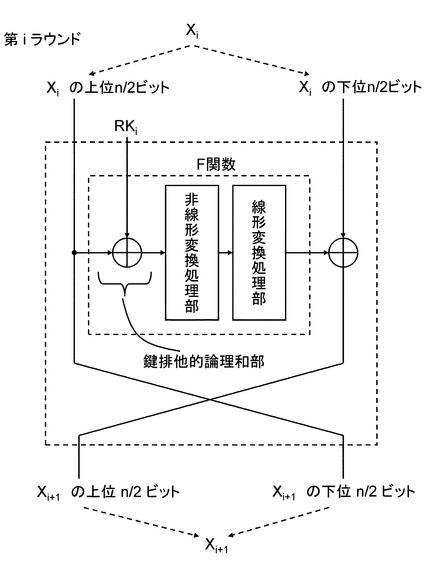
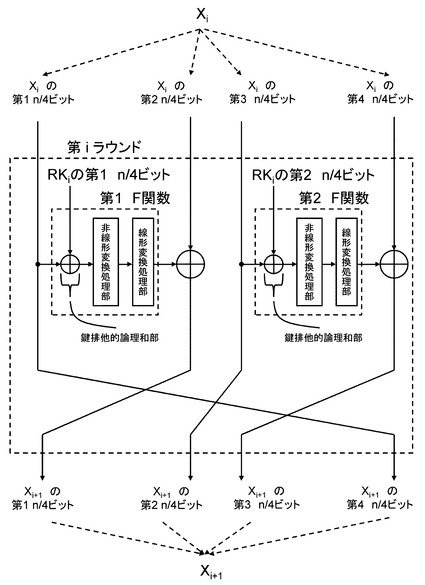
(ウ)拡張Feistel構造
拡張Feistel構造はFeistel構造ではデータ分割数が2であったものを,3以上に分割する形に拡張したものである。分割数をdとすると、dによってさまざまな拡張Feistel構造を定義することができる。F関数の入出力のサイズが相対的に小さくなるため、小型実装に向いているとされる。図7にd=4でかつ、ひとつのラウンド内に2つのF関数が並列に適用される場合の拡張Feistel構造の一例を示す。また,図8にd=8でかつ,ひとつのラウンド内に1つのF関数が適用される場合の拡張Feistel構造の一例を示す。
【0039】
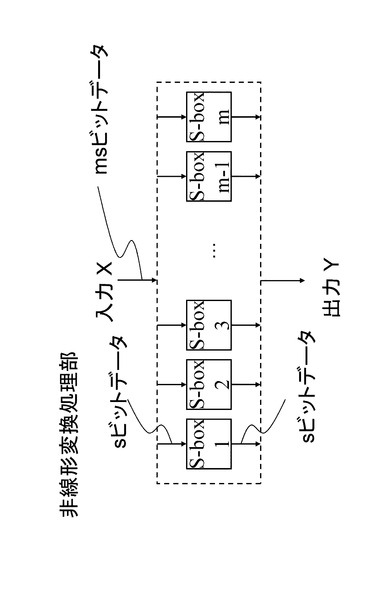
(1−5.非線形変換処理部)
非線形変換処理部は、入力されるデータのサイズが大きくなると実装上のコストが高くなる傾向がある。それを回避するために対象データを複数の単位に分割し、それぞれに対して非線形変換を施す構成がとられることが多い。例えば入力サイズをmsビットとして、それらをsビットずつのm個のデータに分割して、それぞれに対してsビット入出力を持つ非線形変換を行う構成である。それらのsビット単位の非線形変換をS−boxと呼ぶものとする。図9に例を示す。
【0040】
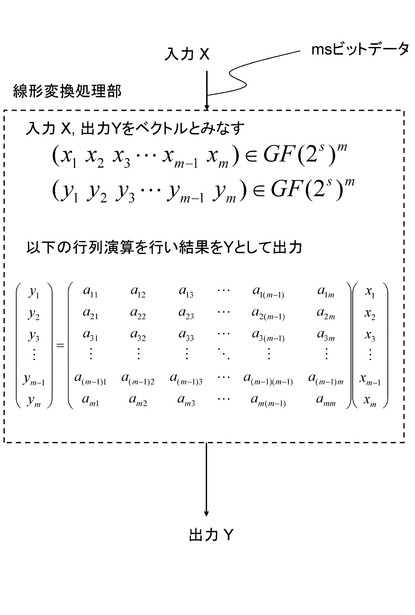
(1−6.線形変換処理部)
線形変換処理部はその性質上、行列として定義することが可能である。行列の要素はGF(28)の体の要素やGF(2)の要素など、一般的にはさまざまな表現ができる。図10にmsビット入出力をもち、GF(2s)の上で定義されるm×mの行列により定義される線形変換処理部の例を示す。
【0041】
[2.S−boxについて]
まず、本発明の構成についての説明の前に、非線形変換部としてのS−boxの概要について説明する。
【0042】
F関数において実行される非線形変換処理は、例えばS−boxと呼ばれる非線形変換関数を適用して行われる。このS−boxは、ブロック暗号やハッシュ関数の構成要素であり、その安全性や実装性能を決定付ける非常に重要な関数である。
【0043】
このS−boxは一般的にはn−bit入力、m−bit出力の非線形変換関数であるが、以降ではn−bit入出力の全単射なS−boxについて話を進める。ここで全単射とは出力の全ての値がただ一つの入力の値からの写像であることを意味する。
【0044】
(安全面)
S−boxの性質は、暗号全体の安全性に大きな影響を与える。暗号全体やラウンド関数自体の厳密な安全性評価はその入出力サイズが大きいことから一般的に困難であるが、S−boxの入出力サイズは一般的には小さい(8−bit入出力程度)ので厳密な評価が可能である。暗号全体の安全性を高くするために、S−boxには、少なくとも以下のような特性(1)〜(4)が求められる。
【0045】
(特性1)最大差分確率が十分小さい
S−boxの差分確率は、任意の入力差分Δxと出力差分Δyに対し、入力変数xが一様に選ばれたとき、
S(x)+S(x+Δx)=Δyを満たす確率である。
ただし、S(x)はあるS−box Sの入力xに対する出力を表す。
【0046】
最大差分確率は,すべての入出力差分の組み合わせのうち,最も高い確率で定義される。以下にそれぞれを式で定義する。
入力差分Δx,および出力差分Δyが与えられたときの関数Sの差分確率をDPs(Δx, Δy)と定義すると、DPs(Δx, Δy)は以下のように定義される。
【0047】
【数1】

【0048】
このとき、関数の最大差分確率MDPsは以下のように定義される。
【0049】
【数2】
【0050】
この差分確率が十分小さいS−boxを設計することで,差分攻撃に耐性を持たせることができる。
【0051】
(特性2)最大線形確率が十分小さい
S−boxの線形確率は、任意の入力マスクΓxと出力マスクΓyに対し、入力変数xが一様に選ばれたとき、
Γx・x=Γy・S(x)
を満たす確率から求められる値である。
ここで,・はnビットベクトル同士の内積演算を意味する。
【0052】
最大線形確率は、すべての入出力マスクの組み合わせのうちで最も高い確率で定義される。
以下にそれぞれを式で定義する。
入力マスクΓx,および、
出力マスクΓy、
が与えられたときの関数Sの線形確率を、
LPs(Γx, Γy)と定義すると,
LPs(Γx, Γy)は以下のように表現できる.
【0053】
【数3】
【0054】
このとき、関数Sの最大差分確率MLPsは以下のように定義される。
【0055】
【数4】
【0056】
この最大線形確率が十分小さいS−boxを設計することで線形攻撃に耐性を持たせることができる.
【0057】
(特性3)ブール多項式表現を行った際のブール代数次数が十分大きい
ブール代数次数は、S−boxの出力のビットを入力ビットのブール式で表現した場合の次数を意味する。すべてのビットに対して十分ブール代数次数の高いS−boxを設計することで、高階差分攻撃等の代数的性質を利用した攻撃に耐性を持たせることができる。
【0058】
(特性4)入出力を多項式表現した際の項数が十分多い
S−boxの出力ビットを入力ビットで多項式表現した場合の項数を十分多くすることで、補間攻撃に耐性を持たせることができる。
【0059】
(実装面について)
S−boxは安全性の要求とは別に高い実装性能も要求される。ソフトウェア実装においては通常、表引き(テーブル実装)と呼ばれる手法により実装されるため、その実装性能はS−boxの内部構造にはあまり依存しない。しかしながら、ハードウェア実装においては、S−boxの内部構造により、実装性能が大きく左右される。よってS−boxの内部構造は特にハードウェアの実装性能において重要だということができる。
【0060】
(従来技術の問題点)
このような要求を満たすS−boxを効率よく生成する手法として、拡大体上のべき乗関数を用いる方法がよく知られている。この手法で拡大体の次数とべき乗の乗数を適切に選べば、非常に特性の良いS−boxが生成できる。
【0061】
実際にn−bit入出力S−boxの入力をx,出力をyとして,それぞれがGF(2n)の元だとした場合、
【0062】
【数5】
【0063】
で与えられる場合、
最大差分確率,最大線形確率の点で最適なS−boxが構成できることがよく知られている(しかしながら、この手法を用いると入出力を多項式表現した際の項数が少なくなってしまうため、適当なaffine変換を加える必要がある)。
このような手法で構成されたS−boxの例としては、AES(非特許文献3:US National Institute of Standards and Technology, Advanced Encryption Standard, Federal Information Processing Standards Publications No. 197, 2001.),Camellia(非特許文献4:青木,市川,神田,松井,盛合,中嶋,時田,"128ビットブロック暗号 Camellia アルゴリズム仕様書",第 2.0版, 2001.)のS−boxなどが挙げられる。
【0064】
AESやCamelliaのS−boxはGF((24)2)上の逆元関数としてS−boxを構成することもできるため、安全性の観点からも特性が非常に良く、さらに非常に高いハードウェア実装性能も持つ。
【0065】
しかしながら、近年このようなS−boxに関して、その特徴的な代数的性質を利用した攻撃法や、そのあまりに均一的な拡散性に関する問題点などが指摘されるようになった。
【0066】
このような点から、特徴的な代数的性質を持たないS−boxの構成法が考えられ、強い代数的構造を持たないように、ランダム、もしくはそれに準ずるような手法で要素を選択するような手法によりS−boxを生成する方法が考えられた。このような手法でS−boxを生成すると、多くの場合、特徴的な代数的構造は持たず、さらに拡大体上のべき乗関数のような均一的な拡散はしないため、上記のような問題に関しては対策がされていると言うことができる。
【0067】
しかしながら、n−bit入出力のS−boxの数は,2nの階乗個存在するため、実際にn−bit入出力のS−boxをランダムに生成し、その特性をひとつひとつチェックするような手法ではnがある程度大きくなると効率的に特性の良いS−boxを生成することは難しくなる。
【0068】
また、要素が完全にランダムである場合、ハードウェアで実装する際も主にテーブル実装と呼ばれる手法しか用いることができなくなってしまうため、実装効率が大きく低下する。
【0069】
このような問題から、小さなサイズの入出力を持つS−boxをランダムに生成、それらを複数個組み合わせて、より大きなS−boxを生成するという試みがなされている。
例えば、CRYPTONver.0.5(非特許文献5:Chae Hoon Lim, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 0.5)"),CRYPTON ver.1.0(非特許文献6:Chae Hoon Lim, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 1.0)"),Whirlpool(非特許文献7:Paulo S. L. M Barreto, Vincent Rijmen "The WHIRLPOOL Hashing Function", 2003.),FOX(非特許文献8:Pascal Junod and Serge Vaudenay, "FOX : a New Family of Block Ciphers" ,2004),CLEFIA(非特許文献9:Sony Corporation, "The 128−bit Blockcipher CLEFIA Algorithm Specification", Revision 1.0, 2007.)に示されたS−boxなどがこのような手法に基づいて生成されたS−boxだと考えることができる。
【0070】
それぞれの構造を図11〜図15に示す。これらの構造は、前述のようにランダムに大きなS−boxを生成した場合と比較して、テーブルサイズが小さくなり、ハードウェアの実装コストは小さくなる。
【0071】
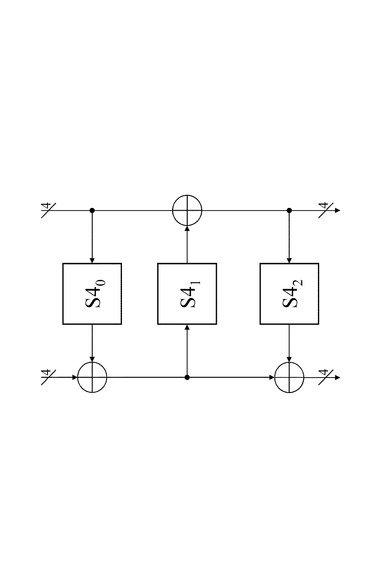
図11は、8ビットの入力データの非線形変換処理を実行する構成である。
4ビットデータの非線形変換処理を実行する3つのS−box:S40,S41,S42、
各S−boxの出力4ビットと他の4ビットとの排他的論理和演算を実行する3つの配置的論理演算部を有する。
8ビットの入力データは、左ライン入力と、右ライン入力にそれぞれ4ビットずつ入力される。
3つのS−box:S40,S41,S42を利用した非線形変換結果としての8ビットデータは、左ライン出力と右ライン出力からそれぞれ4ビットずつ出力される。
【0072】
処理は以下の処理シーケンスに従って実行される。
(1)入力8ビット中の4ビット(右ライン入力)を、第1段のS−box:S40に入力し、非線形変換を実行する。
この非線形変換結果と、入力8ビット中の他の4ビット(左ライン入力)とを排他的論理和演算する。
【0073】
(2)この排他的論理和演算結果を、第2段のS−box:S41に入力し、非線形変換を実行する。
この非線形変換結果と、入力8ビット中の4ビット(右ライン入力)とを排他的論理和演算する。
排他的論理和演算結果を、出力8ビットの4ビット(右ライン出力)として出力する。
【0074】
(3)さらに、この排他的論理和演算結果を、第3段のS−box:S42に入力し、非線形変換を実行する。
この非線形変換結果と、上記処理(1)における排他的論理和演算結果とを排他的論理和演算し、この結果を出力8ビットの4ビット(Out−a)として出力する。
図11は、上記の処理によって、8ビットの入力データの非線形変換処理を実行する構成である。
【0075】
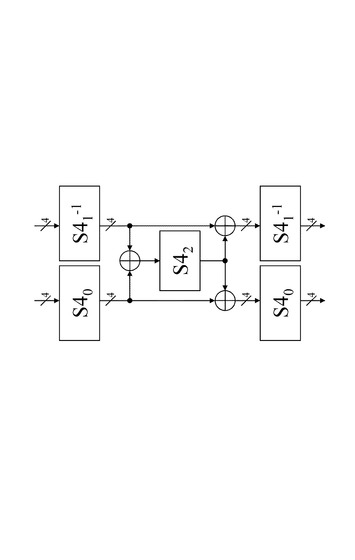
図12に示す構成は、
4ビットデータの非線型変換を実行するS−box:S40,S41、
各S−boxの出力4ビットに対して、2〜3ビット単位の排他的論理和演算を実行する演算実行部、
演算実行部の出力に対して、先のS−box:S40,S41の逆演算を実行する非線形変換部:S41−1,S40−1、
これらによって構成される。
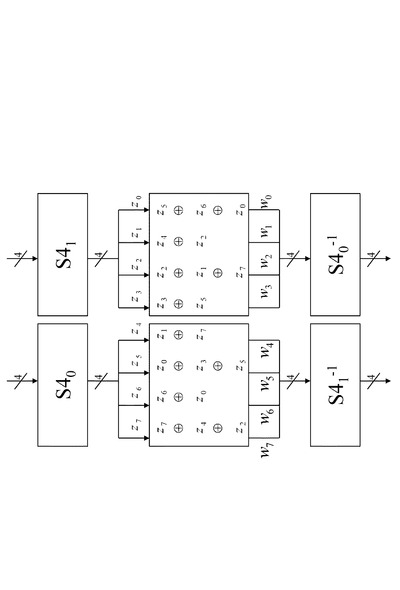
【0076】
図13に示す構成は、
4ビットデータの非線型変換を実行するS−box:S40,S42、
S−box:S41の逆演算を実行する非線形変換部:S41−1、
複数の排他的論理和演算部、
これらの組み合わせによって構成された非線形変換処理構成である。
【0077】
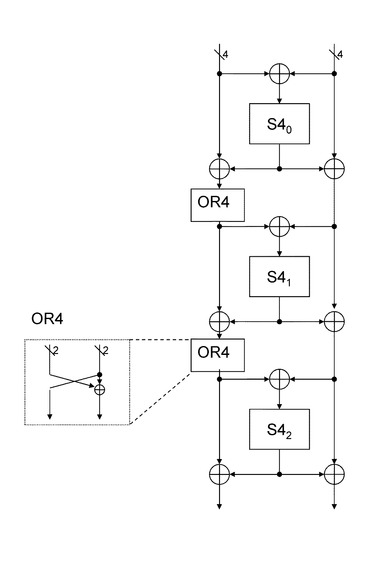
図14は、
4ビットデータの非線型変換を実行するS−box:S40,S41,S42、
複数の排他的論理和演算部、
複数のOR演算部、
これらの組み合わせによって構成された非線形変換処理構成である。
【0078】
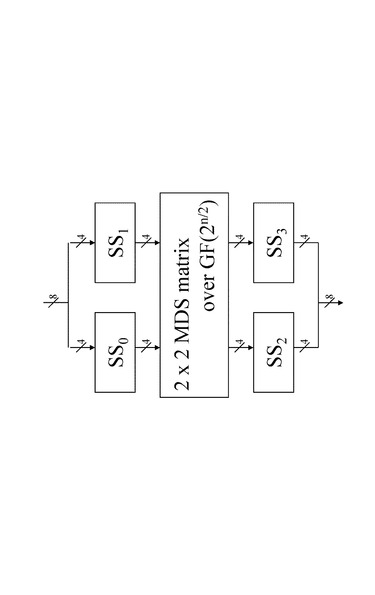
図15は、
4ビットデータの非線型変換を実行するS−box:SS0,SS1,SS2,SS3、
2×2の行列(MDS行列)を適用したデータ変換を実行する行列変換実行部、
これらの組み合わせによって構成された非線形変換処理構成である。
【0079】
このように、図11〜図15に示す小さなS−boxをベースにした大きなS−boxの構成法は従来からいくつか提案されている。このような構成は、ランダムに大きなS−boxを生成した場合と比較して、テーブルサイズが小さくなり、ハードウェアの実装コストは小さくなる。
しかし、このように従来の小さなS−boxをベースにした構成法では、小さなS−boxの設計法、および小さなS−boxの組み合わせ法、それぞれについて以下のような問題がある。
【0080】
(問題点1) それぞれの小さなS−boxの設計に関して
従来法では,それぞれの小さなS−boxはランダムに作成している。よって、それら小さなS−boxはテーブル実装する必要があり、ハードウェア実装に必要な回路規模は依然大きくなってしまう。
【0081】
(問題点2) 小さなS−boxの組み合わせ方法に関して
従来法は単純な繰り返し構造を持っていないため、複数サイクルをかけてS−boxを実行する場合でも、回路の共有化が難しい。単純な繰り返し構造を持つ場合は、回路の共有化が可能であり、実行に複数サイクルが必要になるものの必要な回路規模を小さくできる可能性がある。しかしながら、従来法ではこのような実装手法を行うメリットは少なく、複数サイクルを使えたとしても回路規模を削減することが難しい。
【0082】
[3.本開示に係るS−boxについて]
以上のような問題点を鑑み、以下では、高い安全性を持ち、かつハードウェア実装を行う際に回路規模を従来法と比較して小さくできるS−boxの構成法を提案する。
以下において説明する構成は、ハードウェア実装において、実行スループットよりも実装に必要な回路規模を小さくすることが求められるような場合に特に高い効果を発揮する。なお、以降の説明では簡単のためにn−bit入出力の全単射S−boxのみについて説明する。
【0083】
以下の2つのS−box構成例について、順次説明する。
(1)論理演算とビット置換の繰り返し構造による安全でかつ少ない回路で実装することが可能なS−boxの構成法
(2)小さいサイズのS−boxをベースとした,安全で,かつ少ない回路で実装することが可能な繰り返し構造を持つより大きなサイズのS−boxの構成法
【0084】
なお、上記の(1)は、前述の(問題点1)を解決し、(2)は(問題点2)を解決することが可能な構成である。
(1)と、(2)を組み合わせた構成も可能であり、この組み合わせ構成によって、(問題点1,2)の両方を解決することが可能である。
【0085】
(3−1.論理演算とビット置換の繰り返し構造によるS−boxの構成法)
まず、
(1)論理演算とビット置換の繰り返し構造による安全でかつ少ない回路で実装することが可能なS−boxの構成法
について説明する。
【0086】
(3−1−1.S−boxの構成の概要)
S−boxは、様々な論理回路の組み合わせによって実現できる。
ここで、提案するS−boxは、AND(論理積)、OR(論理和)、NOT(論理否定)等の基本論理演算を基にした"非線形演算部"と、ビット位置の入れ替えを行う"ビット置換部"の2つの部分を基本的な要素として、これらの繰り返しによりS−boxを構成するものである。
【0087】
非線形演算部は、全単射かつ非線形変換になるように、1つの2ビット入力1ビット出力のNAND(否定論理積)、もしくはNOR(否定論理和)演算と、1つの2ビット入力1ビット出力のXOR(排他的論理和)、もしくはXNOR(否定排他的論理和)演算をそれぞれ用い、任意の2ビットに対しNAND、もしくはNOR演算を行った結果を、その2ビット以外の1ビットとXOR、もしくはXNOR演算する構造を有する。
【0088】
ビット置換部は単純にビット位置の入れ変えを行う。
これら非線形演算部、ビット置換部を複数回繰り返すことにより、S−boxを生成する。
非線形演算部、ビット置換部は繰り返すごとに変更しても同じものを使用しても構わない。
【0089】
一般的に、安全なn−bit S−boxを構成するためには,n回以上の非線形演算部分の繰り返しが必要なため,n回の繰り返し構造がこの構成法において安全性を大きく損なわない範囲での最小の構成だと考えられる.また,最終回のビット置換部は安全性,回路規模ともに影響を与えないため,実行せずに省略することも可能である。
【0090】
なお、非線形演算部は、前述したように、NANDまたはNOR演算部と、XORまたはXNOR演算部から構成されるが、n回繰り返し構造中において、XOR演算部と、XNOR演算部とを混在させることで、非線形変換処理における不動点をなくすことが可能となる。従って、不動点を発生させない非線形変換処理を実現するためには、非線形演算部のn回繰り返し構造中において、XOR演算部と、XNOR演算部とを混在させる構成とすることが好ましい。
【0091】
(3−1−2.本手法の効果について)
本手法の効果には以下の3つ効果(効果1〜3)がある。1つめは既存の技術の(問題点1)を解決し、残りの2つは更なる本発明のアドバンテージである。
【0092】
(効果1)従来法より小さな回路で実装することができる。
非線形演算部1つは、1つのNAND、もしくはNOR演算、および1つのXOR、もしくはXNOR演算のみで構成されている。
NAND/NOR演算は入力に対して非線形な処理を行う非線形な基本論理演算のなかでも小さな回路で実装できることが知られている。
このNAND/NOR演算以外は全単射性を担保するためのXOR/XNOR演算しか用いていない.よって,この非線形演算部分は全単射な非線形関数の中で,ハードウェアの実装コスト(必要回路規模)が最小クラスであると言える。
さらに、ビット置換部はハードウェア実装では配線の変更のみで実装可能であり、必要回路規模に影響を与えない。つまり、ハードウェア実装コスト(必要回路規模)はゼロであると言える。
【0093】
本構成は、これら非線形演算部、ビット置換部の繰り返しで構成されているため、実装に必要な回路は従来法に比べて大きく削減できる。
【0094】
(効果2)ハードウェア実装コストを正確に見積もることができる。
従来法では、ランダムにS−boxを生成していたため、必要回路規模を見積もる際は,論理合成ツールなどを用いて毎回評価を行う必要があった。
【0095】
本構成法の場合、論理演算子の数、つまり繰り返し回数を評価することにより、ハードウェア実装コスト(必要回路規模)を論理合成ツールなどを用いることなく容易に見積もることができる。従来では必要回路規模見積もりに時間がかかるため多くのS−boxの中から最適なものを見つけ出すことは難しかったが、本構成では容易に回路規模を見積もれるため最適なS−boxを容易に選択できることになる。
【0096】
(効果3)同じハードウェア実装コスト(必要回路規模)のS−boxを複数種類構成可能である。
非線形演算部で用いる論理演算子と、ビット置換部で使用するビット置換の種類は選択の自由度があり、かつ繰り返し毎に種類が異なってもよいため、必要な回路規模が同じとなる複数個のS−boxを構成することができる。
これは、上位関数やほかの関数との組み合わせで最適なものを、同じハードウェア実装コスト(必要回路規模)のS−boxから選択できることに寄与する。
【0097】
(3−1−3.具体的な構成例について)
次に、論理演算とビット置換の繰り返し構造によるS−boxの具体的な構成例について説明する。
4ビットの場合のS−boxの具体的な構成例を図16に示す。
【0098】
この図16に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形演算部は、4つのNANDと3つのXOR、1つのXNORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0099】
1段目の非線形演算部は、NANDとXNORによって構成されている。
入力4ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
1段目のXNOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNANDに入力される。
【0100】
2段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の2ビットを2段目のNANDに入力し、その出力ビットを2段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
2段目のXOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNANDに入力される。
【0101】
3段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNANDに入力し、その出力ビットを3段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
3段目のXOR演算の実行結果は、出力ビットに設定される。
【0102】
4段目の非線形演算部は、NANDとXORによって構成されている。
1段目のXNOR演算の実行結果と、2段目のXOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0103】
この4ビットS−boxは、前述の項目[2.S−boxについて]において説明した安全性の高いS−boxの条件である最大差分確率,最大線形確率がともに2−2である。これは4ビットS−boxにおいて最適な値であり、ランダムに生成した4ビットS−boxと比較してハードウェア実装コストは小さくなる。
【0104】
よって、この4ビットS−boxは、安全でかつハードウェア実装性能にも優れていると言える。
同じ最適な差分確率、線形確率をもち、かつ同じ回路規模(同じ繰り返し回数)で構成される他のS−boxの具体例を図17〜図20に示す。図16〜図20に示す例では最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0105】
図17に示す4ビットS−boxは、4つのNORと、3つのXNOR、1つのXORから構成されている。
図18に示す4ビットS−boxは、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。
図19に示す4ビットS−boxは、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。
図20に示す4ビットS−boxは、4つのNORと、1つのXNOR、3つのXORから構成されている。
【0106】
各図に示す4ビットS−boxの構成と処理について説明する。
図17に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、4つのNORと、3つのXNOR、1つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0107】
1段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の2ビットを1段目のNORに入力し、その出力ビットを1段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
1段目のXNOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNORに入力される。
【0108】
2段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の2ビットを2段目のNORに入力し、その出力ビットを2段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
2段目のXNOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNORに入力される。
【0109】
3段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNORに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0110】
4段目の非線形演算部は、NORとXORによって構成されている。
1段目のXNOR演算の実行結果と、2段目のXNOR演算の実行結果を4段目のNORに入力し、その出力ビットを4段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0111】
図18に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0112】
1段目の非線形演算部は、NANDとXNORによって構成されている。
入力4ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
1段目のXNOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNORとNANDに入力される。
【0113】
2段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の2ビットを2段目のNANDに入力し、その出力ビットを2段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
2段目のXOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNANDに入力される。
【0114】
3段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNORに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0115】
4段目の非線形演算部は、NANDとXNORによって構成されている。
1段目のXNOR演算の実行結果と、2段目のXOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
4段目のXNOR演算の実行結果は、出力ビットに設定される。
【0116】
図19に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0117】
1段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
1段目のXOR演算の実行結果は、出力ビットに設定され、さらに2〜3段目の非線型部分のNORとNANDに入力される。
【0118】
2段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXOR演算の実行結果を2段目のNORに入力し、その出力ビットを2段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
2段目のXNOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNANDに入力される。
【0119】
3段目の非線形演算部は、NANDとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNANDに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0120】
4段目の非線形演算部は、NANDとXNORによって構成されている。
2段目のXNOR演算の実行結果と、3段目のXNOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
4段目のXNOR演算の実行結果は、出力ビットに設定される。
【0121】
図20に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、4つのNORと、1つのXNOR、3つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0122】
1段目の非線形演算部は、NORとXORによって構成されている。
入力4ビット中の2ビットを1段目のNORに入力し、その出力ビットを1段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
1段目のXOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNORに入力される。
【0123】
2段目の非線形演算部は、NORとXORによって構成されている。
入力4ビット中の2ビットを2段目のNORに入力し、その出力ビットを2段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
2段目のXOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNORに入力される。
【0124】
3段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXOR演算の実行結果を3段目のNORに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0125】
4段目の非線形演算部は、NORとXORによって構成されている。
1段目のXOR演算の実行結果と、2段目のXOR演算の実行結果を4段目のNORに入力し、その出力ビットを4段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0126】
また、上記の例で示した4ビットS−boxと同じ回路規模で実装することができる4ビットS−boxは、非線形演算部の演算が4(=2x2)種類,ビット置換部のビット置換が24(=4!)種類あり、さらに繰り返し毎に種類が異なってもよいため、96の4乗通り存在することが分かる。
【0127】
つまり、同じ回路規模の4ビットS−boxを数多く構成できるため、設計の際に目的に応じた最適なS−boxを選択することができる。
【0128】
もう一つのS−boxの構成例として、5ビットS−boxの構成例を図21に示す。
図21に示す5ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の5段繰り返し構造を有しており、非線形演算部は、5つのNANDと4つのXOR、1つのXNORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0129】
1段目の非線形演算部は、NANDとXORによって構成されている。
入力5ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
1段目のXOR演算の実行結果は、出力ビットに設定され、さらに4〜5段目の非線型部分のNANDに入力される。
【0130】
2段目の非線形演算部は、NANDとXNORによって構成されている。
入力5ビット中の2ビットを2段目のNANDに入力し、その出力ビットを2段目のXNORに入力して、入力5ビット中の1ビットとXNOR演算を実行する。
2段目のXNOR演算の実行結果は、出力ビットに設定され、さらに5段目の非線型部分のNANDに入力される。
【0131】
3段目の非線形演算部は、NANDとXORによって構成されている。
入力5ビット中の2ビットを3段目のNANDに入力し、その出力ビットを3段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
3段目のXOR演算の実行結果は、出力ビットに設定される。
【0132】
4段目の非線形演算部は、NANDとXORによって構成されている。
入力5ビット中の1ビットと、1段目のXOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0133】
5段目の非線形演算部は、NANDとXORによって構成されている。
1段目のXOR演算の実行結果と、2段目のXNOR演算の実行結果を5段目のNANDに入力し、その出力ビットを5段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
5段目のXOR演算の実行結果は、出力ビットに設定される。
【0134】
この5ビットS−boxの差分確率と線形確率は共に2−2である。5ビットS−boxの各々の最適な値は2−4であるため、最も安全性の高いものではないが、回路規模はランダムに作成したものと比較して非常に小さくなる。そのため、実装性能を優先したい場合には、適している。
【0135】
(3−2.小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法)
次に、小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法について説明する。
【0136】
小さいサイズのS−boxから大きなサイズのS−boxを構成する際に,特定の関数の繰り返し構造になるように構成する。具体的には、まず小さいサイズのS−boxからハードウェア実装コスト(必要回路規模)の比較的小さい、大きなS−boxを生成し、その大きなS−boxを繰り返す構造を有する。これにより、小さいS−boxから、繰り返し構造を持った大きなS−boxを構成することができる。
【0137】
(3−2−2.本手法の効果について)
本手法は,H/W実装,特に必要回路規模を削減することを目的とした実装、例えばシリアル実装をした際に利点が大きい。
繰り返し構造を持っている演算に関しては、シリアル実装でS−boxを実装する際にすべての要素を実装する必要がなく、繰り返し単位を実装し、それを任意回反復実行すればよい。
よって、この構造は、繰り返し構造を持たない従来のS−boxに対して、より少ない回路規模で実装できると言える。
【0138】
(3−2−3.具体的な構成例について)
次に、小さいS−boxを用いた繰り返し処理による大きなS−boxの具体的な構成例について、説明する。
以下、具体的な構成法について詳細に述べる。
なお、以下に説明する図22〜図28において、各図にSとして示す矩形領域が、例えば図16〜図21を参照して説明した小さなS−box、すなわち例えば4ビット単位の非線形変換処理を実行するS−boxである。
【0139】
図22〜図28は、いずれも、入力nビットを4つのn/4ビットに分割して4つのラインに入力し、各ラインデータに対して小さなS−boxとXOR回路からなる演算実行部による演算処理と、各ラインデータ単位のローテーション(Rotation)実行部によるローテーションを複数段、繰り返し実行する構成を持つ。
【0140】
図22に示す構成は、各段において1つのS−boxと1つのXOR回路の適用構成を持ち、先行する処理段において、n/4ビットのS−boxとXOR回路の適用結果を生成し、このn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0141】
図23に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、n/4ビットのS−boxとXOR回路の適用結果を2ライン分(2×(n/4)ビット)生成し、この2ラインの演算結果と、その他の2ラインの未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0142】
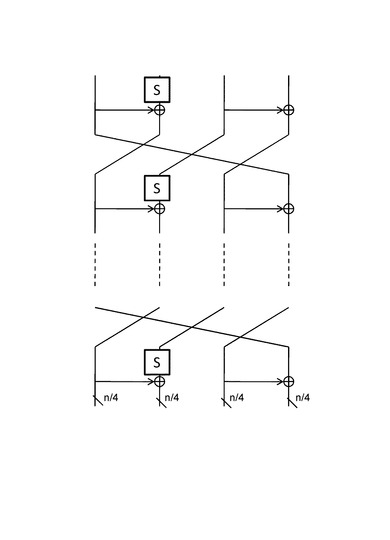
図24に示す構成は、各段において1つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
n/4ビットのS−boxの適用結果と、
n/4ビットのS−boxとXOR回路の適用結果と、
n/4ビットのXOR回路の適用結果、
を生成し、これらの3つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0143】
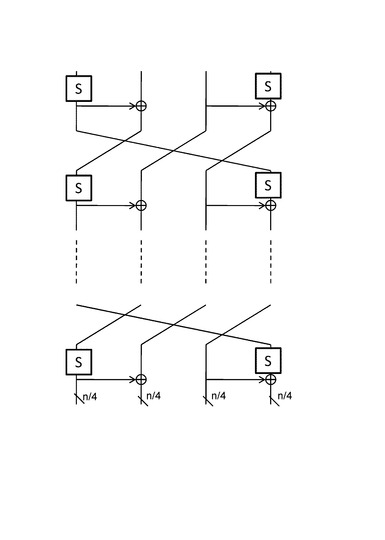
図25に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
2つのn/4ビットのS−boxの適用結果と、
2つのn/4ビットのS−boxとXOR回路の適用結果と、
を生成し、これらの4つのn/4ビットの演算結果に対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0144】
図26に示す構成は、各段において1つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
n/4ビットのS−boxとXOR回路の適用結果と、
n/4ビットのXOR回路の適用結果、
を生成し、これらの2つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0145】
図27に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
2つのn/4ビットのS−boxとXOR回路の適用結果、
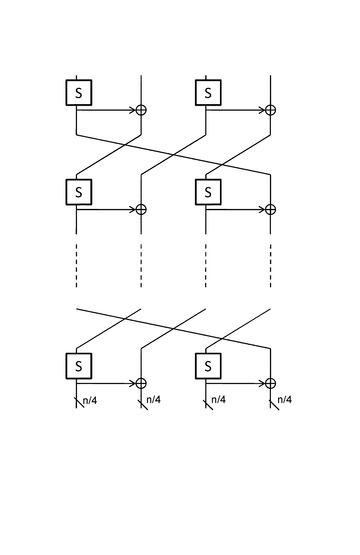
を生成し、これらの2つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0146】
図28に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
n/4ビットのS−boxの適用結果と、
n/4ビットのS−boxとXOR回路の適用結果と、
n/4ビットのXOR回路の適用結果、
を生成し、これらの3つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0147】
図22、図23はそれぞれ、
type−IGFN(Generalized Feistel Network)、
type−IIGFN、
と呼ばれる繰り返し構造である。
【0148】
これらは通常小さな非線形部分に作用する秘密鍵とともに用いられるが、本実施例においては実装効率を考慮して秘密鍵を挿入しない。
このように秘密鍵を用いずに構成することで全体をひとつの固定テーブルとして実装することも可能になる。
【0149】
図22、図23の構成の違いは各段の小さなS−boxの数である。
図22のtype−IGFNは、各段が1つのnビットS−boxとnビットのXOR、nビット単位のRotationから構成される。
【0150】
図22に示す例では入力データはnビットであり4分割されn/4ビット単位で各ラインに入力されている。
なお、入力データの分割数は任意である。すなわち、任意のr分割(r>2)への拡張が可能であり、必要な大きなS−boxの入出力サイズに応じて適時決定することができる。
【0151】
図23に示すtype−IIGFNは、各段単位で、2つの小さなnビットS−boxとnビットのXOR、nビット単位のRotationで構成される。
これらの2つの構成方法の特徴は、順方向からの演算と逆方向からの演算がほとんど同じであり、違いはRotation部分のみとなっている。
【0152】
これにより、順関数と逆関数を両方実装する必要がある場合、回路の共有化が行える。図23の構成法において、図16の4ビットS−boxを用い、16ビットS−boxを生成した場合は、
6回繰り返しで最大差分確率は2−8.3,
最大線形確率は2−7.83であり,
7回繰り返しで最大差分確率は2−9.1,
最大線形確率は2−8になる。
これらの値は16−bitで最適な値ではないが、十分低い確率であり、回路規模はランダムに作成したものと比べて非常に小さくなる。
【0153】
図24〜図28は、図22,図23の構造とは異なる部分に小さなS−boxを配置した構造である。各々の違いはその配置場所と繰り返し単位でのS−boxの数のみである。
【0154】
これらの構造では、小さなS−boxに入力されるデータが、その後の演算では不要となるため、余計な記憶領域は不要であり、繰り返し関数をさらに細かく分割して実装した場合にハードウェアで必要な回路規模をさらに小さくすることが可能である。
【0155】
図25の構成法で、図17を参照して説明した4ビットS−boxを用い、16ビットS−boxを構成した場合は、
6回繰り返しで最大差分確率は2−8.3,
最大線形確率は2−8であり、
7回繰り返しで、最大差分確率は2−9.1,
最大線形確率は2−8.5であり、
16−bitで最適な値ではないが、十分低い確率であり、回路規模はランダムに作成したものと比べて非常に小さくなる。
【0156】
[4.暗号処理装置の構成例について]
最後に、上述した実施例に従った暗号処理を実行する暗号処理装置の実相例について説明する。
上述した実施例に従った暗号処理を実行する暗号処理装置は、暗号処理を実行する様々な情報処理装置に搭載可能である。具体的には、PC、TV、レコーダ、プレーヤ、通信機器、さらに、RFID、スマートカード、センサネットワーク機器、デンチ/バッテリー認証モジュール、健康、医療機器、自立型ネットワーク機器等、例えばデータ処理や通信処理に伴う暗号処理を実行する様々な危機において利用可能である。
【0157】
本開示の暗号処理を実行する装置の一例としてのICモジュール700の構成例を図29に示す。上述の処理は、例えばPC、ICカード、リーダライタ、その他、様々な情報処理装置において実行可能であり、図29に示すICモジュール700は、これら様々な機器に構成することが可能である。
【0158】
図29に示すCPU(Central processing Unit)701は、暗号処理の開始や、終了、データの送受信の制御、各構成部間のデータ転送制御、その他の各種プログラムを実行するプロセッサである。メモリ702は、CPU701が実行するプログラム、あるいは演算パラメータなどの固定データを格納するROM(Read-Only-Memory)、CPU701の処理において実行されるプログラム、およびプログラム処理において適宜変化するパラメータの格納エリア、ワーク領域として使用されるRAM(Random Access Memory)等からなる。また、メモリ702は暗号処理に必要な鍵データや、暗号処理において適用する変換テーブル(置換表)や変換行列に適用するデータ等の格納領域として使用可能である。なおデータ格納領域は、耐タンパ構造を持つメモリとして構成されることが好ましい。
【0159】
暗号処理部703は、上記において説明した暗号処理構成、すなわち、例えば一般化Feistel構造や、Feistel構造を適用した共通鍵ブロック暗号処理アルゴリズムに従った暗号処理、復号処理を実行する。
【0160】
なお、ここでは、暗号処理手段を個別モジュールとした例を示したが、このような独立した暗号処理モジュールを設けず、例えば暗号処理プログラムをROMに格納し、CPU701がROM格納プログラムを読み出して実行するように構成してもよい。
【0161】
乱数発生器704は、暗号処理に必要となる鍵の生成などにおいて必要となる乱数の発生処理を実行する。
【0162】
送受信部705は、外部とのデータ通信を実行するデータ通信処理部であり、例えばリーダライタ等、ICモジュールとのデータ通信を実行し、ICモジュール内で生成した暗号文の出力、あるいは外部のリーダライタ等の機器からのデータ入力などを実行する。
【0163】
なお、上述した実施例において説明したデータ処理装置は、入力データとしての平文を暗号化する暗号化処理に適用可能であるのみならず、入力データとしての暗号文を平文に復元する復号処理にも適用可能である。
暗号化処理、復号処理、双方の処理において、上述した実施例において説明した構成を持つ非線形変換部の構成を適用することが可能である。
【0164】
[5.本開示の構成のまとめ]
以上、特定の実施例を参照しながら、本開示の実施例について詳解してきた。しかしながら、本開示の要旨を逸脱しない範囲で当業者が実施例の修正や代用を成し得ることは自明である。すなわち、例示という形態で本発明を開示してきたのであり、限定的に解釈されるべきではない。本開示の要旨を判断するためには、特許請求の範囲の欄を参酌すべきである。
【0165】
なお、本明細書において開示した技術は、以下のような構成をとることができる。
(1) データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行するデータ変換処理部を有し、
前記データ変換処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、
前記F関数実行部は、
非線形変換処理を実行する非線形変換処理部を有し、
前記非線形変換処理部は、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有するデータ処理装置。
【0166】
(2)前記ビット置換部は、前記非線形演算部に対する入出力ビットを入れ替える配線構成を有する前記(1)に記載のデータ処理装置。
(3)前記非線形変換処理部は、2ビット入力1ビット出力のNANDまたはNOR演算部における演算結果としての1ビットを、前記XORまたはXNOR演算部に出力して、他の入力1ビットデータとのXORまたはXNOR演算を実行し、XORまたはXNOR演算結果として生成した1ビットデータを非線形変換処理結果の構成ビットとして出力する前記(1)または(2)に記載のデータ処理装置。
【0167】
(4)前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部を、n回以上繰り返す繰り返し構造を有する前記(1)〜(3)いずれかに記載のデータ処理装置。
(5)前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部をn回、前記ビット置換部をn回の前記非線形演算部の間にn−1回設定した構成である前記(1)〜(4)いずれかに記載のデータ処理装置。
【0168】
(6)前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する前記(1)〜(5)いずれかに記載のデータ処理装置。
(7)前記非線形変換処理部は、前記繰り返し構造中に、XOR演算部とXNOR演算部の双方を有する構成である前記(1)〜(6)いずれかに記載のデータ処理装置。
(8)前記データ処理装置は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する前記(1)〜(7)いずれかに記載のデータ処理装置。
【0169】
(9)1つのNANDまたはNOR演算部と、
1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有する非線形変換処理部を有するデータ処理装置。
【0170】
(10)前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する前記(9)に記載のデータ処理装置。
【0171】
(11)データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、
複数ラインを構成する1ラインのデータを入力して変換データを生成する非線形関数実行部を有するラウンド関数の繰り返し構造を有するデータ処理装置。
(12)前記非線形関数実行部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する前記(11)に記載のデータ処理装置。
【0172】
さらに、上記した装置およびシステムにおいて実行する処理の方法や、処理を実行させるプログラムも本開示の構成に含まれる。
【0173】
また、明細書中において説明した一連の処理はハードウェア、またはソフトウェア、あるいは両者の複合構成によって実行することが可能である。ソフトウェアによる処理を実行する場合は、処理シーケンスを記録したプログラムを、専用のハードウェアに組み込まれたコンピュータ内のメモリにインストールして実行させるか、あるいは、各種処理が実行可能な汎用コンピュータにプログラムをインストールして実行させることが可能である。例えば、プログラムは記録媒体に予め記録しておくことができる。記録媒体からコンピュータにインストールする他、LAN(Local Area Network)、インターネットといったネットワークを介してプログラムを受信し、内蔵するハードディスク等の記録媒体にインストールすることができる。
【0174】
なお、明細書に記載された各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。また、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【産業上の利用可能性】
【0175】
上述したように、本開示の一実施例の構成によれば、小型化した非線形変換部が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してラウンド関数を適用したデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、F関数実行部は非線形変換処理を実行する非線形変換処理部を有し、非線形変換処理部は1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、ビット置換部との繰り返し構造を有する。この繰り返し構成により小型化された非線形変換部が実現される。
【符号の説明】
【0176】
700 ICモジュール
701 CPU(Central processing Unit)
702 メモリ
703 暗号処理部
704 乱数生成部
705 送受信部
【技術分野】
【0001】
本開示は、データ処理装置、およびデータ処理方法、並びにプログラムに関する。さらに詳細には、例えば共通鍵系暗号を実行するデータ処理装置、およびデータ処理方法、並びにプログラムに関する。
【背景技術】
【0002】
情報化社会が発展すると共に、扱う情報を安全に守るための情報セキュリティ技術の重要性が増してきている。情報セキュリティ技術の構成要素の一つとして暗号技術があり、現在では様々な製品やシステムで暗号技術が利用されている。
【0003】
暗号処理アルゴリズムには様々なものがあるが、基本的な技術の一つとして、共通鍵ブロック暗号と呼ばれるものがある。共通鍵ブロック暗号では、暗号化用の鍵と復号用の鍵が共通のものとなっている。暗号化処理、復号処理共に、その共通鍵から複数の鍵を生成し、あるブロック単位、例えば64ビット、128ビット、256ビット等のブロックデータ単位でデータ変換処理を繰り返し実行する。
【0004】
代表的な共通鍵ブロック暗号のアルゴリズムとしては、過去の米国標準であるDES(Data Encryption Standard)や現在の米国標準であるAES(Advanced Encryption Standard)が知られている。他にも様々な共通鍵ブロック暗号が現在も提案され続けており、2007年にソニー株式会社が提案したCLEFIAも共通鍵ブロック暗号の一つである。
【0005】
このような、共通鍵ブロック暗号のアルゴリズムは、主として、入力データの変換を繰り返し実行するラウンド関数実行部を有する暗号処理部と、ラウンド関数部の各ラウンドで適用するラウンド鍵を生成する鍵スケジュール部とによって構成される。鍵スケジュール部は、秘密鍵であるマスター鍵(主鍵)に基づいて、まずビット数を増加させた拡大鍵を生成し、生成した拡大鍵に基づいて、暗号処理部の各ラウンド関数部で適用するラウンド鍵(副鍵)を生成する。
【0006】
このようなアルゴリズムを実行する具体的な構造として、線形変換部および非線形変換部を有するラウンド関数を繰り返し実行する構造が知られている。例えば代表的な構造にFeistel構造や一般化Feistel構造がある。Feistel構造や一般化Feistel構造は、データ変換関数としてのF関数を含むラウンド関数の単純な繰り返しにより、平文を暗号文に変換する構造を持つ。F関数においては、線形変換処理および非線形変換処理が実行される。なお、Feistel構造を適用した暗号処理について記載した文献としては、例えば非特許文献1、非特許文献2がある。
【0007】
F関数において実行される非線形変換処理は、例えばS−boxと呼ばれる非線形変換関数を適用して行われる。このS−boxは、ブロック暗号やハッシュ関数の構成要素であり、その安全性や実装性能を決定付ける非常に重要な関数である。
このS−boxは、高い安全性が要求される。しかし、高い安全性を保持するために回路規模が大きくなってしまうという問題がある。
【先行技術文献】
【非特許文献】
【0008】
【非特許文献1】K. Nyberg, "Generalized Feistel networks", ASIACRYPT'96, SpringerVerlag, 1996, pp.91--104.
【非特許文献2】Yuliang Zheng, Tsutomu Matsumoto, Hideki Imai: On the Construction of Block Ciphers Provably Secure and Not Relying on Any Unproved Hypotheses. CRYPTO 1989: 461-480
【非特許文献3】US National Institute of Standards and Technology, Advanced Encryption Standard, Federal Information Processing Standards Publications No. 197, 2001.
【非特許文献4】青木,市川,神田,松井,盛合,中嶋,時田,"128ビットブロック暗号 Camellia アルゴリズム仕様書",第 2.0版, 2001.
【非特許文献5】Chae Hoon Lim,, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 0.5)"
【非特許文献6】Chae Hoon Lim, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 1.0)"
【非特許文献7】Paulo S. L. M Barreto, Vincent Rijmen "The WHIRLPOOL Hashing Function", 2003.
【非特許文献8】Pascal Junod and Serge Vaudenay, "FOX : a New Family of Block Ciphers" ,2004
【非特許文献9】Sony Corporation, "The 128−bit Blockcipher CLEFIA Algorithm Specification", Revision 1.0, 2007.
【発明の概要】
【発明が解決しようとする課題】
【0009】
本開示は、例えば上述の状況に鑑みてなされたものであり、小型化可能な安全性を持つS−boxを備えたデータ処理装置、およびデータ処理方法、並びにプログラムを提供することを目的とする。
【課題を解決するための手段】
【0010】
本開示の第1の側面は、
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行するデータ変換処理部を有し、
前記データ変換処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、
前記F関数実行部は、
非線形変換処理を実行する非線形変換処理部を有し、
前記非線形変換処理部は、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有するデータ処理装置にある。
【0011】
さらに、本開示のデータ処理装置の一実施態様において、前記ビット置換部は、前記非線形演算部に対する入出力ビットを入れ替える配線構成を有する。
【0012】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、2ビット入力1ビット出力のNANDまたはNOR演算部における演算結果としての1ビットを、前記XORまたはXNOR演算部に出力して、他の入力1ビットデータとのXORまたはXNOR演算を実行し、XORまたはXNOR演算結果として生成した1ビットデータを非線形変換処理結果の構成ビットとして出力する。
【0013】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部を、n回以上繰り返す繰り返し構造を有する。
【0014】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部をn回、前記ビット置換部をn回の前記非線形演算部の間にn−1回設定した構成である。
【0015】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する。
【0016】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、前記繰り返し構造中に、XOR演算部とXNOR演算部の双方を有する構成である。
【0017】
さらに、本開示のデータ処理装置の一実施態様において、前記データ処理装置は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する。
【0018】
さらに、本開示の第2の側面は、
1つのNANDまたはNOR演算部と、
1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有する非線形変換処理部を有するデータ処理装置にある。
【0019】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する。
【0020】
さらに、本開示の第3の側面は、
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、
複数ラインを構成する1ラインのデータを入力して変換データを生成する非線形関数実行部を有するラウンド関数の繰り返し構造を有するデータ処理装置にある。
【0021】
さらに、本開示のデータ処理装置の一実施態様において、前記非線形関数実行部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する。
【0022】
さらに、本開示の第4の側面は、
データ処理装置において実行するデータ処理方法であり、
データ処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行し、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行し、
前記F関数の実行処理において、非線形変換処理を実行し、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行するデータ処理方法にある。
【0023】
さらに、本開示の第5の側面は、
データ処理装置においてデータ変換処理を実行させるプログラムであり、
データ処理部に、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行させ、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行させ、
前記F関数の実行処理において、非線形変換処理を実行させ、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行させるプログラムにある。
【0024】
なお、本開示のプログラムは、例えば、様々なプログラム・コードを実行可能な情報処理装置やコンピュータ・システムに対して例えば記憶媒体によって提供されるプログラムである。このようなプログラムを情報処理装置やコンピュータ・システム上のプログラム実行部で実行することでプログラムに応じた処理が実現される。
【0025】
本開示のさらに他の目的、特徴や利点は、後述する本発明の実施例や添付する図面に基づくより詳細な説明によって明らかになるであろう。なお、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【発明の効果】
【0026】
本開示の一実施例によれば、小型化した非線形変換部が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してラウンド関数を適用したデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、F関数実行部は非線形変換処理を実行する非線形変換処理部を有し、非線形変換処理部は1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、ビット置換部との繰り返し構造を有する。この繰り返し構成により小型化された非線形変換部が実現される。
【図面の簡単な説明】
【0027】
【図1】kビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムを説明する図である。
【図2】図1に示すkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムに対応する復号アルゴリズムを説明する図である。
【図3】鍵スケジュール部とデータ暗号化部の関係について説明する図である。
【図4】データ暗号化部の構成例について説明する図である。
【図5】SPN構造のラウンド関数の例について説明する図である。
【図6】Feistel構造のラウンド関数の一例について説明する図である。
【図7】拡張Feistel構造の一例について説明する図である。
【図8】拡張Feistel構造の一例について説明する図である。
【図9】非線形変換部の構成例について説明する図である。
【図10】線形変換処理部の構成例について説明する図である。
【図11】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図12】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図13】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図14】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図15】小さなサイズの入出力を持つS−boxを複数個組み合わせて大きなS−boxを生成する構成例について説明する図である。
【図16】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図17】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図18】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図19】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図20】論理演算とビット置換の繰り返し構造による4ビットS−boxの構成例について説明する図である。
【図21】論理演算とビット置換の繰り返し構造による5ビットS−boxの構成例について説明する図である。
【図22】type−IGFN(Generalized Feistel Network)を基にした小さいS−boxを用いた繰り返し処理による大きなS−boxの構成例について説明する図である。
【図23】type−IIGFNを基にした,小さいS−boxを用いた繰り返し処理による大きなS−boxの構成例について説明する図である。
【図24】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図25】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図26】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図27】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図28】小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法の適用例について説明する図である。
【図29】暗号処理装置としてのICモジュール700の構成例を示す図である。
【発明を実施するための形態】
【0028】
以下、図面を参照しながら本開示に係るデータ処理装置、およびデータ処理方法、並びにプログラムの詳細について説明する。説明は、以下の項目に従って行う。
1.共通鍵ブロック暗号の概要
2.S−boxについて
3.本開示に係るS−boxの概要について
4.暗号処理装置の構成例について
5.本開示の構成のまとめ
【0029】
[1.共通鍵ブロック暗号の概要]
まず、共通鍵ブロック暗号の概要について説明する。
(1−1.共通鍵ブロック暗号)
ここでは共通鍵ブロック暗号(以下ではブロック暗号)としては以下に定義するものを指すものとする。
ブロック暗号は入力として平文Pと鍵Kを取り、暗号文Cを出力する。平文と暗号文のビット長をブロックサイズと呼びここではnで著す。nは任意の整数値を取りうるが、通常、ブロック暗号アルゴリズムごとに、あらかじめひとつに決められている値である。ブロック長がnのブロック暗号のことをnビットブロック暗号と呼ぶこともある。
【0030】
鍵のビット長をkで表す。鍵は任意の整数値を取りうる。共通鍵ブロック暗号アルゴリズムは1つまたは複数の鍵サイズに対応することになる。例えば、あるブロック暗号アルゴリズムAはブロックサイズn=128であり、k=128またはk=192またはk=256の鍵サイズに対応するという構成もありうるものとする。
平文P:nビット
暗号文C:nビット
鍵K:kビット
【0031】
図1にkビットの鍵長に対応したnビット共通鍵ブロック暗号アルゴリズムEの図を示す。
暗号化アルゴリズムEに対応する復号アルゴリズムDは暗号化アルゴリズムEの逆関数E−1と定義でき、入力として暗号文Cと鍵Kを受け取り,平文Pを出力する。図2に図1に示した暗号アルゴリズムEに対応する復号アルゴリズムDの図を示す。
【0032】
(1−2.内部構成)
ブロック暗号は2つの部分に分けて考えることができる。ひとつは鍵Kを入力とし、
ある定められたステップによりビット長を拡大してできた拡大鍵K'(ビット長k')を出力する「鍵スケジュール部」と、もうひとつは平文Pと鍵スケジュール部から拡大された鍵K'を受け取ってデータの変換を行い暗号文Cを出力する「データ暗号化部」である。
2つの部分の関係は図3に示される。
【0033】
(1−3.データ暗号化部)
以下の実施例において用いるデータ暗号化部はラウンド関数という処理単位に分割できるものとする。ラウンド関数は入力としての2つのデータを受け取り、内部で処理を施したのち、1つのデータを出力する。入力データの一方は暗号化途中のnビットデータであり、あるラウンドにおけるラウンド関数の出力が次のラウンドの入力として供給される構成となる。もう1つの入力データは鍵スケジュールから出力された拡大鍵の一部のデータが用いられ、この鍵データのことをラウンド鍵と呼ぶものとする。またラウンド関数の総数は総ラウンド数と呼ばれ、暗号アルゴリズムごとにあらかじめ定められている値である。ここでは総ラウンド数をRで表す。
【0034】
データ暗号化部の入力側から見て1ラウンド目の入力データをX1とし、i番目のラウンド関数に入力されるデータをXi、ラウンド鍵をRKiとすると、データ暗号化部全体は図4のように示される。
【0035】
(1−4.ラウンド関数)
ブロック暗号アルゴリズムによってラウンド関数はさまざまな形態をとりうる。ラウンド関数はその暗号アルゴリズムが採用する構造(structure)によって分類できる。代表的な構造としてここではSPN構造、Feistel構造、拡張Feistel構造を例示する。
【0036】
(ア)SPN構造ラウンド関数
nビットの入力データすべてに対して、ラウンド鍵との排他的論理和演算、非線形変換、線形変換処理などが適用される構成。各演算の順番は特に決まっていない。図5にSPN構造のラウンド関数の例を示す。
【0037】
(イ)Feistel構造
nビットの入力データはn/2ビットの2つのデータに分割される。うち片方のデータとラウンド鍵を入力として持つ関数(F関数)が適用され、出力がもう片方のデータに排他的論理和される。そののちデータの左右を入れ替えたものを出力データとする。F関数の内部構成にもさまざまなタイプのものがあるが、基本的にはSPN構造同様にラウンド鍵データとの排他的論理和演算、非線形演算、線形変換の組み合わせで実現される。図6にFeistel構造のラウンド関数の一例を示す。
【0038】
(ウ)拡張Feistel構造
拡張Feistel構造はFeistel構造ではデータ分割数が2であったものを,3以上に分割する形に拡張したものである。分割数をdとすると、dによってさまざまな拡張Feistel構造を定義することができる。F関数の入出力のサイズが相対的に小さくなるため、小型実装に向いているとされる。図7にd=4でかつ、ひとつのラウンド内に2つのF関数が並列に適用される場合の拡張Feistel構造の一例を示す。また,図8にd=8でかつ,ひとつのラウンド内に1つのF関数が適用される場合の拡張Feistel構造の一例を示す。
【0039】
(1−5.非線形変換処理部)
非線形変換処理部は、入力されるデータのサイズが大きくなると実装上のコストが高くなる傾向がある。それを回避するために対象データを複数の単位に分割し、それぞれに対して非線形変換を施す構成がとられることが多い。例えば入力サイズをmsビットとして、それらをsビットずつのm個のデータに分割して、それぞれに対してsビット入出力を持つ非線形変換を行う構成である。それらのsビット単位の非線形変換をS−boxと呼ぶものとする。図9に例を示す。
【0040】
(1−6.線形変換処理部)
線形変換処理部はその性質上、行列として定義することが可能である。行列の要素はGF(28)の体の要素やGF(2)の要素など、一般的にはさまざまな表現ができる。図10にmsビット入出力をもち、GF(2s)の上で定義されるm×mの行列により定義される線形変換処理部の例を示す。
【0041】
[2.S−boxについて]
まず、本発明の構成についての説明の前に、非線形変換部としてのS−boxの概要について説明する。
【0042】
F関数において実行される非線形変換処理は、例えばS−boxと呼ばれる非線形変換関数を適用して行われる。このS−boxは、ブロック暗号やハッシュ関数の構成要素であり、その安全性や実装性能を決定付ける非常に重要な関数である。
【0043】
このS−boxは一般的にはn−bit入力、m−bit出力の非線形変換関数であるが、以降ではn−bit入出力の全単射なS−boxについて話を進める。ここで全単射とは出力の全ての値がただ一つの入力の値からの写像であることを意味する。
【0044】
(安全面)
S−boxの性質は、暗号全体の安全性に大きな影響を与える。暗号全体やラウンド関数自体の厳密な安全性評価はその入出力サイズが大きいことから一般的に困難であるが、S−boxの入出力サイズは一般的には小さい(8−bit入出力程度)ので厳密な評価が可能である。暗号全体の安全性を高くするために、S−boxには、少なくとも以下のような特性(1)〜(4)が求められる。
【0045】
(特性1)最大差分確率が十分小さい
S−boxの差分確率は、任意の入力差分Δxと出力差分Δyに対し、入力変数xが一様に選ばれたとき、
S(x)+S(x+Δx)=Δyを満たす確率である。
ただし、S(x)はあるS−box Sの入力xに対する出力を表す。
【0046】
最大差分確率は,すべての入出力差分の組み合わせのうち,最も高い確率で定義される。以下にそれぞれを式で定義する。
入力差分Δx,および出力差分Δyが与えられたときの関数Sの差分確率をDPs(Δx, Δy)と定義すると、DPs(Δx, Δy)は以下のように定義される。
【0047】
【数1】
【0048】
このとき、関数の最大差分確率MDPsは以下のように定義される。
【0049】
【数2】
【0050】
この差分確率が十分小さいS−boxを設計することで,差分攻撃に耐性を持たせることができる。
【0051】
(特性2)最大線形確率が十分小さい
S−boxの線形確率は、任意の入力マスクΓxと出力マスクΓyに対し、入力変数xが一様に選ばれたとき、
Γx・x=Γy・S(x)
を満たす確率から求められる値である。
ここで,・はnビットベクトル同士の内積演算を意味する。
【0052】
最大線形確率は、すべての入出力マスクの組み合わせのうちで最も高い確率で定義される。
以下にそれぞれを式で定義する。
入力マスクΓx,および、
出力マスクΓy、
が与えられたときの関数Sの線形確率を、
LPs(Γx, Γy)と定義すると,
LPs(Γx, Γy)は以下のように表現できる.
【0053】
【数3】
【0054】
このとき、関数Sの最大差分確率MLPsは以下のように定義される。
【0055】
【数4】
【0056】
この最大線形確率が十分小さいS−boxを設計することで線形攻撃に耐性を持たせることができる.
【0057】
(特性3)ブール多項式表現を行った際のブール代数次数が十分大きい
ブール代数次数は、S−boxの出力のビットを入力ビットのブール式で表現した場合の次数を意味する。すべてのビットに対して十分ブール代数次数の高いS−boxを設計することで、高階差分攻撃等の代数的性質を利用した攻撃に耐性を持たせることができる。
【0058】
(特性4)入出力を多項式表現した際の項数が十分多い
S−boxの出力ビットを入力ビットで多項式表現した場合の項数を十分多くすることで、補間攻撃に耐性を持たせることができる。
【0059】
(実装面について)
S−boxは安全性の要求とは別に高い実装性能も要求される。ソフトウェア実装においては通常、表引き(テーブル実装)と呼ばれる手法により実装されるため、その実装性能はS−boxの内部構造にはあまり依存しない。しかしながら、ハードウェア実装においては、S−boxの内部構造により、実装性能が大きく左右される。よってS−boxの内部構造は特にハードウェアの実装性能において重要だということができる。
【0060】
(従来技術の問題点)
このような要求を満たすS−boxを効率よく生成する手法として、拡大体上のべき乗関数を用いる方法がよく知られている。この手法で拡大体の次数とべき乗の乗数を適切に選べば、非常に特性の良いS−boxが生成できる。
【0061】
実際にn−bit入出力S−boxの入力をx,出力をyとして,それぞれがGF(2n)の元だとした場合、
【0062】
【数5】
【0063】
で与えられる場合、
最大差分確率,最大線形確率の点で最適なS−boxが構成できることがよく知られている(しかしながら、この手法を用いると入出力を多項式表現した際の項数が少なくなってしまうため、適当なaffine変換を加える必要がある)。
このような手法で構成されたS−boxの例としては、AES(非特許文献3:US National Institute of Standards and Technology, Advanced Encryption Standard, Federal Information Processing Standards Publications No. 197, 2001.),Camellia(非特許文献4:青木,市川,神田,松井,盛合,中嶋,時田,"128ビットブロック暗号 Camellia アルゴリズム仕様書",第 2.0版, 2001.)のS−boxなどが挙げられる。
【0064】
AESやCamelliaのS−boxはGF((24)2)上の逆元関数としてS−boxを構成することもできるため、安全性の観点からも特性が非常に良く、さらに非常に高いハードウェア実装性能も持つ。
【0065】
しかしながら、近年このようなS−boxに関して、その特徴的な代数的性質を利用した攻撃法や、そのあまりに均一的な拡散性に関する問題点などが指摘されるようになった。
【0066】
このような点から、特徴的な代数的性質を持たないS−boxの構成法が考えられ、強い代数的構造を持たないように、ランダム、もしくはそれに準ずるような手法で要素を選択するような手法によりS−boxを生成する方法が考えられた。このような手法でS−boxを生成すると、多くの場合、特徴的な代数的構造は持たず、さらに拡大体上のべき乗関数のような均一的な拡散はしないため、上記のような問題に関しては対策がされていると言うことができる。
【0067】
しかしながら、n−bit入出力のS−boxの数は,2nの階乗個存在するため、実際にn−bit入出力のS−boxをランダムに生成し、その特性をひとつひとつチェックするような手法ではnがある程度大きくなると効率的に特性の良いS−boxを生成することは難しくなる。
【0068】
また、要素が完全にランダムである場合、ハードウェアで実装する際も主にテーブル実装と呼ばれる手法しか用いることができなくなってしまうため、実装効率が大きく低下する。
【0069】
このような問題から、小さなサイズの入出力を持つS−boxをランダムに生成、それらを複数個組み合わせて、より大きなS−boxを生成するという試みがなされている。
例えば、CRYPTONver.0.5(非特許文献5:Chae Hoon Lim, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 0.5)"),CRYPTON ver.1.0(非特許文献6:Chae Hoon Lim, "CRYPTON:A New 128−bit Block Cipher -Specification and Analysis (Version 1.0)"),Whirlpool(非特許文献7:Paulo S. L. M Barreto, Vincent Rijmen "The WHIRLPOOL Hashing Function", 2003.),FOX(非特許文献8:Pascal Junod and Serge Vaudenay, "FOX : a New Family of Block Ciphers" ,2004),CLEFIA(非特許文献9:Sony Corporation, "The 128−bit Blockcipher CLEFIA Algorithm Specification", Revision 1.0, 2007.)に示されたS−boxなどがこのような手法に基づいて生成されたS−boxだと考えることができる。
【0070】
それぞれの構造を図11〜図15に示す。これらの構造は、前述のようにランダムに大きなS−boxを生成した場合と比較して、テーブルサイズが小さくなり、ハードウェアの実装コストは小さくなる。
【0071】
図11は、8ビットの入力データの非線形変換処理を実行する構成である。
4ビットデータの非線形変換処理を実行する3つのS−box:S40,S41,S42、
各S−boxの出力4ビットと他の4ビットとの排他的論理和演算を実行する3つの配置的論理演算部を有する。
8ビットの入力データは、左ライン入力と、右ライン入力にそれぞれ4ビットずつ入力される。
3つのS−box:S40,S41,S42を利用した非線形変換結果としての8ビットデータは、左ライン出力と右ライン出力からそれぞれ4ビットずつ出力される。
【0072】
処理は以下の処理シーケンスに従って実行される。
(1)入力8ビット中の4ビット(右ライン入力)を、第1段のS−box:S40に入力し、非線形変換を実行する。
この非線形変換結果と、入力8ビット中の他の4ビット(左ライン入力)とを排他的論理和演算する。
【0073】
(2)この排他的論理和演算結果を、第2段のS−box:S41に入力し、非線形変換を実行する。
この非線形変換結果と、入力8ビット中の4ビット(右ライン入力)とを排他的論理和演算する。
排他的論理和演算結果を、出力8ビットの4ビット(右ライン出力)として出力する。
【0074】
(3)さらに、この排他的論理和演算結果を、第3段のS−box:S42に入力し、非線形変換を実行する。
この非線形変換結果と、上記処理(1)における排他的論理和演算結果とを排他的論理和演算し、この結果を出力8ビットの4ビット(Out−a)として出力する。
図11は、上記の処理によって、8ビットの入力データの非線形変換処理を実行する構成である。
【0075】
図12に示す構成は、
4ビットデータの非線型変換を実行するS−box:S40,S41、
各S−boxの出力4ビットに対して、2〜3ビット単位の排他的論理和演算を実行する演算実行部、
演算実行部の出力に対して、先のS−box:S40,S41の逆演算を実行する非線形変換部:S41−1,S40−1、
これらによって構成される。
【0076】
図13に示す構成は、
4ビットデータの非線型変換を実行するS−box:S40,S42、
S−box:S41の逆演算を実行する非線形変換部:S41−1、
複数の排他的論理和演算部、
これらの組み合わせによって構成された非線形変換処理構成である。
【0077】
図14は、
4ビットデータの非線型変換を実行するS−box:S40,S41,S42、
複数の排他的論理和演算部、
複数のOR演算部、
これらの組み合わせによって構成された非線形変換処理構成である。
【0078】
図15は、
4ビットデータの非線型変換を実行するS−box:SS0,SS1,SS2,SS3、
2×2の行列(MDS行列)を適用したデータ変換を実行する行列変換実行部、
これらの組み合わせによって構成された非線形変換処理構成である。
【0079】
このように、図11〜図15に示す小さなS−boxをベースにした大きなS−boxの構成法は従来からいくつか提案されている。このような構成は、ランダムに大きなS−boxを生成した場合と比較して、テーブルサイズが小さくなり、ハードウェアの実装コストは小さくなる。
しかし、このように従来の小さなS−boxをベースにした構成法では、小さなS−boxの設計法、および小さなS−boxの組み合わせ法、それぞれについて以下のような問題がある。
【0080】
(問題点1) それぞれの小さなS−boxの設計に関して
従来法では,それぞれの小さなS−boxはランダムに作成している。よって、それら小さなS−boxはテーブル実装する必要があり、ハードウェア実装に必要な回路規模は依然大きくなってしまう。
【0081】
(問題点2) 小さなS−boxの組み合わせ方法に関して
従来法は単純な繰り返し構造を持っていないため、複数サイクルをかけてS−boxを実行する場合でも、回路の共有化が難しい。単純な繰り返し構造を持つ場合は、回路の共有化が可能であり、実行に複数サイクルが必要になるものの必要な回路規模を小さくできる可能性がある。しかしながら、従来法ではこのような実装手法を行うメリットは少なく、複数サイクルを使えたとしても回路規模を削減することが難しい。
【0082】
[3.本開示に係るS−boxについて]
以上のような問題点を鑑み、以下では、高い安全性を持ち、かつハードウェア実装を行う際に回路規模を従来法と比較して小さくできるS−boxの構成法を提案する。
以下において説明する構成は、ハードウェア実装において、実行スループットよりも実装に必要な回路規模を小さくすることが求められるような場合に特に高い効果を発揮する。なお、以降の説明では簡単のためにn−bit入出力の全単射S−boxのみについて説明する。
【0083】
以下の2つのS−box構成例について、順次説明する。
(1)論理演算とビット置換の繰り返し構造による安全でかつ少ない回路で実装することが可能なS−boxの構成法
(2)小さいサイズのS−boxをベースとした,安全で,かつ少ない回路で実装することが可能な繰り返し構造を持つより大きなサイズのS−boxの構成法
【0084】
なお、上記の(1)は、前述の(問題点1)を解決し、(2)は(問題点2)を解決することが可能な構成である。
(1)と、(2)を組み合わせた構成も可能であり、この組み合わせ構成によって、(問題点1,2)の両方を解決することが可能である。
【0085】
(3−1.論理演算とビット置換の繰り返し構造によるS−boxの構成法)
まず、
(1)論理演算とビット置換の繰り返し構造による安全でかつ少ない回路で実装することが可能なS−boxの構成法
について説明する。
【0086】
(3−1−1.S−boxの構成の概要)
S−boxは、様々な論理回路の組み合わせによって実現できる。
ここで、提案するS−boxは、AND(論理積)、OR(論理和)、NOT(論理否定)等の基本論理演算を基にした"非線形演算部"と、ビット位置の入れ替えを行う"ビット置換部"の2つの部分を基本的な要素として、これらの繰り返しによりS−boxを構成するものである。
【0087】
非線形演算部は、全単射かつ非線形変換になるように、1つの2ビット入力1ビット出力のNAND(否定論理積)、もしくはNOR(否定論理和)演算と、1つの2ビット入力1ビット出力のXOR(排他的論理和)、もしくはXNOR(否定排他的論理和)演算をそれぞれ用い、任意の2ビットに対しNAND、もしくはNOR演算を行った結果を、その2ビット以外の1ビットとXOR、もしくはXNOR演算する構造を有する。
【0088】
ビット置換部は単純にビット位置の入れ変えを行う。
これら非線形演算部、ビット置換部を複数回繰り返すことにより、S−boxを生成する。
非線形演算部、ビット置換部は繰り返すごとに変更しても同じものを使用しても構わない。
【0089】
一般的に、安全なn−bit S−boxを構成するためには,n回以上の非線形演算部分の繰り返しが必要なため,n回の繰り返し構造がこの構成法において安全性を大きく損なわない範囲での最小の構成だと考えられる.また,最終回のビット置換部は安全性,回路規模ともに影響を与えないため,実行せずに省略することも可能である。
【0090】
なお、非線形演算部は、前述したように、NANDまたはNOR演算部と、XORまたはXNOR演算部から構成されるが、n回繰り返し構造中において、XOR演算部と、XNOR演算部とを混在させることで、非線形変換処理における不動点をなくすことが可能となる。従って、不動点を発生させない非線形変換処理を実現するためには、非線形演算部のn回繰り返し構造中において、XOR演算部と、XNOR演算部とを混在させる構成とすることが好ましい。
【0091】
(3−1−2.本手法の効果について)
本手法の効果には以下の3つ効果(効果1〜3)がある。1つめは既存の技術の(問題点1)を解決し、残りの2つは更なる本発明のアドバンテージである。
【0092】
(効果1)従来法より小さな回路で実装することができる。
非線形演算部1つは、1つのNAND、もしくはNOR演算、および1つのXOR、もしくはXNOR演算のみで構成されている。
NAND/NOR演算は入力に対して非線形な処理を行う非線形な基本論理演算のなかでも小さな回路で実装できることが知られている。
このNAND/NOR演算以外は全単射性を担保するためのXOR/XNOR演算しか用いていない.よって,この非線形演算部分は全単射な非線形関数の中で,ハードウェアの実装コスト(必要回路規模)が最小クラスであると言える。
さらに、ビット置換部はハードウェア実装では配線の変更のみで実装可能であり、必要回路規模に影響を与えない。つまり、ハードウェア実装コスト(必要回路規模)はゼロであると言える。
【0093】
本構成は、これら非線形演算部、ビット置換部の繰り返しで構成されているため、実装に必要な回路は従来法に比べて大きく削減できる。
【0094】
(効果2)ハードウェア実装コストを正確に見積もることができる。
従来法では、ランダムにS−boxを生成していたため、必要回路規模を見積もる際は,論理合成ツールなどを用いて毎回評価を行う必要があった。
【0095】
本構成法の場合、論理演算子の数、つまり繰り返し回数を評価することにより、ハードウェア実装コスト(必要回路規模)を論理合成ツールなどを用いることなく容易に見積もることができる。従来では必要回路規模見積もりに時間がかかるため多くのS−boxの中から最適なものを見つけ出すことは難しかったが、本構成では容易に回路規模を見積もれるため最適なS−boxを容易に選択できることになる。
【0096】
(効果3)同じハードウェア実装コスト(必要回路規模)のS−boxを複数種類構成可能である。
非線形演算部で用いる論理演算子と、ビット置換部で使用するビット置換の種類は選択の自由度があり、かつ繰り返し毎に種類が異なってもよいため、必要な回路規模が同じとなる複数個のS−boxを構成することができる。
これは、上位関数やほかの関数との組み合わせで最適なものを、同じハードウェア実装コスト(必要回路規模)のS−boxから選択できることに寄与する。
【0097】
(3−1−3.具体的な構成例について)
次に、論理演算とビット置換の繰り返し構造によるS−boxの具体的な構成例について説明する。
4ビットの場合のS−boxの具体的な構成例を図16に示す。
【0098】
この図16に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形演算部は、4つのNANDと3つのXOR、1つのXNORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0099】
1段目の非線形演算部は、NANDとXNORによって構成されている。
入力4ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
1段目のXNOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNANDに入力される。
【0100】
2段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の2ビットを2段目のNANDに入力し、その出力ビットを2段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
2段目のXOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNANDに入力される。
【0101】
3段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNANDに入力し、その出力ビットを3段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
3段目のXOR演算の実行結果は、出力ビットに設定される。
【0102】
4段目の非線形演算部は、NANDとXORによって構成されている。
1段目のXNOR演算の実行結果と、2段目のXOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0103】
この4ビットS−boxは、前述の項目[2.S−boxについて]において説明した安全性の高いS−boxの条件である最大差分確率,最大線形確率がともに2−2である。これは4ビットS−boxにおいて最適な値であり、ランダムに生成した4ビットS−boxと比較してハードウェア実装コストは小さくなる。
【0104】
よって、この4ビットS−boxは、安全でかつハードウェア実装性能にも優れていると言える。
同じ最適な差分確率、線形確率をもち、かつ同じ回路規模(同じ繰り返し回数)で構成される他のS−boxの具体例を図17〜図20に示す。図16〜図20に示す例では最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0105】
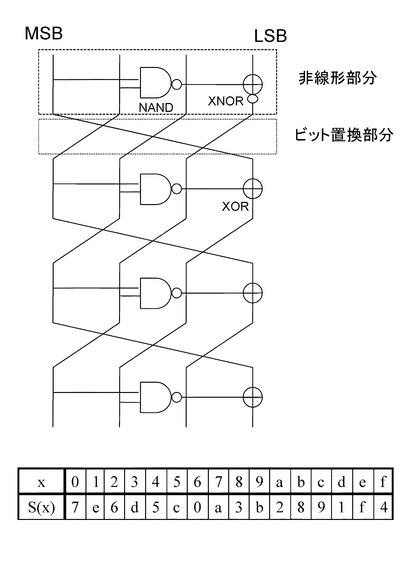
図17に示す4ビットS−boxは、4つのNORと、3つのXNOR、1つのXORから構成されている。
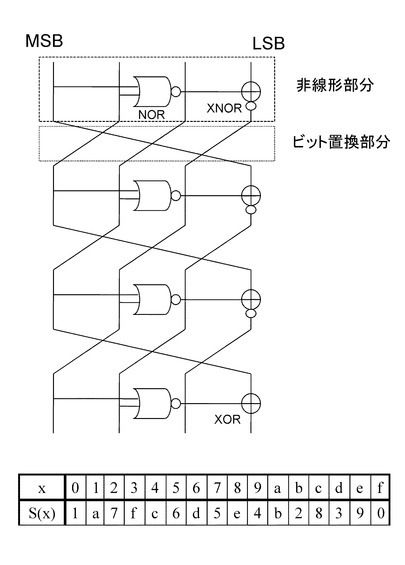
図18に示す4ビットS−boxは、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。
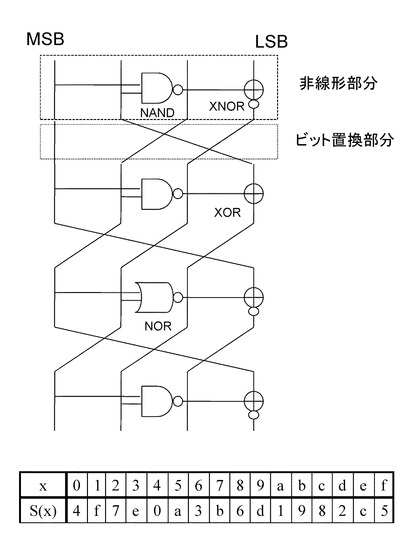
図19に示す4ビットS−boxは、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。
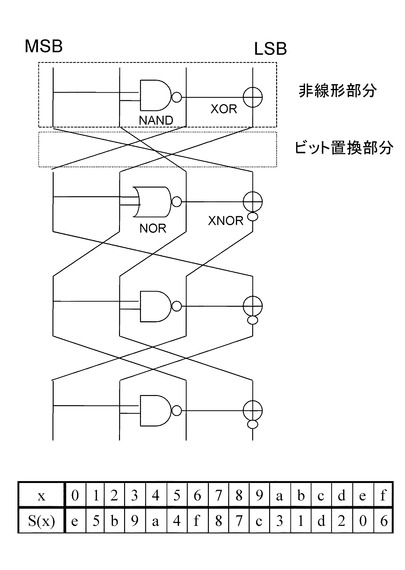
図20に示す4ビットS−boxは、4つのNORと、1つのXNOR、3つのXORから構成されている。
【0106】
各図に示す4ビットS−boxの構成と処理について説明する。
図17に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、4つのNORと、3つのXNOR、1つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0107】
1段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の2ビットを1段目のNORに入力し、その出力ビットを1段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
1段目のXNOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNORに入力される。
【0108】
2段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の2ビットを2段目のNORに入力し、その出力ビットを2段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
2段目のXNOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNORに入力される。
【0109】
3段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNORに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0110】
4段目の非線形演算部は、NORとXORによって構成されている。
1段目のXNOR演算の実行結果と、2段目のXNOR演算の実行結果を4段目のNORに入力し、その出力ビットを4段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0111】
図18に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0112】
1段目の非線形演算部は、NANDとXNORによって構成されている。
入力4ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
1段目のXNOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNORとNANDに入力される。
【0113】
2段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の2ビットを2段目のNANDに入力し、その出力ビットを2段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
2段目のXOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNANDに入力される。
【0114】
3段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNORに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0115】
4段目の非線形演算部は、NANDとXNORによって構成されている。
1段目のXNOR演算の実行結果と、2段目のXOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
4段目のXNOR演算の実行結果は、出力ビットに設定される。
【0116】
図19に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、3つのNANDと、1つのNORと、3つのXNOR、1つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0117】
1段目の非線形演算部は、NANDとXORによって構成されている。
入力4ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
1段目のXOR演算の実行結果は、出力ビットに設定され、さらに2〜3段目の非線型部分のNORとNANDに入力される。
【0118】
2段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXOR演算の実行結果を2段目のNORに入力し、その出力ビットを2段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
2段目のXNOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNANDに入力される。
【0119】
3段目の非線形演算部は、NANDとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXNOR演算の実行結果を3段目のNANDに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0120】
4段目の非線形演算部は、NANDとXNORによって構成されている。
2段目のXNOR演算の実行結果と、3段目のXNOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
4段目のXNOR演算の実行結果は、出力ビットに設定される。
【0121】
図20に示す4ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の4段繰り返し構造を有しており、非線形処理部分は、4つのNORと、1つのXNOR、3つのXORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0122】
1段目の非線形演算部は、NORとXORによって構成されている。
入力4ビット中の2ビットを1段目のNORに入力し、その出力ビットを1段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
1段目のXOR演算の実行結果は、出力ビットに設定され、さらに3〜4段目の非線型部分のNORに入力される。
【0123】
2段目の非線形演算部は、NORとXORによって構成されている。
入力4ビット中の2ビットを2段目のNORに入力し、その出力ビットを2段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
2段目のXOR演算の実行結果は、出力ビットに設定され、さらに4段目の非線型部分のNORに入力される。
【0124】
3段目の非線形演算部は、NORとXNORによって構成されている。
入力4ビット中の1ビットと、1段目のXOR演算の実行結果を3段目のNORに入力し、その出力ビットを3段目のXNORに入力して、入力4ビット中の1ビットとXNOR演算を実行する。
3段目のXNOR演算の実行結果は、出力ビットに設定される。
【0125】
4段目の非線形演算部は、NORとXORによって構成されている。
1段目のXOR演算の実行結果と、2段目のXOR演算の実行結果を4段目のNORに入力し、その出力ビットを4段目のXORに入力して、入力4ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0126】
また、上記の例で示した4ビットS−boxと同じ回路規模で実装することができる4ビットS−boxは、非線形演算部の演算が4(=2x2)種類,ビット置換部のビット置換が24(=4!)種類あり、さらに繰り返し毎に種類が異なってもよいため、96の4乗通り存在することが分かる。
【0127】
つまり、同じ回路規模の4ビットS−boxを数多く構成できるため、設計の際に目的に応じた最適なS−boxを選択することができる。
【0128】
もう一つのS−boxの構成例として、5ビットS−boxの構成例を図21に示す。
図21に示す5ビットS−boxは、非線形演算部とビット置換部の組み合わせ構成の5段繰り返し構造を有しており、非線形演算部は、5つのNANDと4つのXOR、1つのXNORから構成されている。なお、図においては最終段のビット置換は省略しているが、最終段のビット置換については設定する構成としても、省略した構成としても、いずれの構成も可能である。
【0129】
1段目の非線形演算部は、NANDとXORによって構成されている。
入力5ビット中の2ビットを1段目のNANDに入力し、その出力ビットを1段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
1段目のXOR演算の実行結果は、出力ビットに設定され、さらに4〜5段目の非線型部分のNANDに入力される。
【0130】
2段目の非線形演算部は、NANDとXNORによって構成されている。
入力5ビット中の2ビットを2段目のNANDに入力し、その出力ビットを2段目のXNORに入力して、入力5ビット中の1ビットとXNOR演算を実行する。
2段目のXNOR演算の実行結果は、出力ビットに設定され、さらに5段目の非線型部分のNANDに入力される。
【0131】
3段目の非線形演算部は、NANDとXORによって構成されている。
入力5ビット中の2ビットを3段目のNANDに入力し、その出力ビットを3段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
3段目のXOR演算の実行結果は、出力ビットに設定される。
【0132】
4段目の非線形演算部は、NANDとXORによって構成されている。
入力5ビット中の1ビットと、1段目のXOR演算の実行結果を4段目のNANDに入力し、その出力ビットを4段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
4段目のXOR演算の実行結果は、出力ビットに設定される。
【0133】
5段目の非線形演算部は、NANDとXORによって構成されている。
1段目のXOR演算の実行結果と、2段目のXNOR演算の実行結果を5段目のNANDに入力し、その出力ビットを5段目のXORに入力して、入力5ビット中の1ビットとXOR演算を実行する。
5段目のXOR演算の実行結果は、出力ビットに設定される。
【0134】
この5ビットS−boxの差分確率と線形確率は共に2−2である。5ビットS−boxの各々の最適な値は2−4であるため、最も安全性の高いものではないが、回路規模はランダムに作成したものと比較して非常に小さくなる。そのため、実装性能を優先したい場合には、適している。
【0135】
(3−2.小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法)
次に、小さいS−boxを用いた繰り返し処理による大きなS−boxの構成法について説明する。
【0136】
小さいサイズのS−boxから大きなサイズのS−boxを構成する際に,特定の関数の繰り返し構造になるように構成する。具体的には、まず小さいサイズのS−boxからハードウェア実装コスト(必要回路規模)の比較的小さい、大きなS−boxを生成し、その大きなS−boxを繰り返す構造を有する。これにより、小さいS−boxから、繰り返し構造を持った大きなS−boxを構成することができる。
【0137】
(3−2−2.本手法の効果について)
本手法は,H/W実装,特に必要回路規模を削減することを目的とした実装、例えばシリアル実装をした際に利点が大きい。
繰り返し構造を持っている演算に関しては、シリアル実装でS−boxを実装する際にすべての要素を実装する必要がなく、繰り返し単位を実装し、それを任意回反復実行すればよい。
よって、この構造は、繰り返し構造を持たない従来のS−boxに対して、より少ない回路規模で実装できると言える。
【0138】
(3−2−3.具体的な構成例について)
次に、小さいS−boxを用いた繰り返し処理による大きなS−boxの具体的な構成例について、説明する。
以下、具体的な構成法について詳細に述べる。
なお、以下に説明する図22〜図28において、各図にSとして示す矩形領域が、例えば図16〜図21を参照して説明した小さなS−box、すなわち例えば4ビット単位の非線形変換処理を実行するS−boxである。
【0139】
図22〜図28は、いずれも、入力nビットを4つのn/4ビットに分割して4つのラインに入力し、各ラインデータに対して小さなS−boxとXOR回路からなる演算実行部による演算処理と、各ラインデータ単位のローテーション(Rotation)実行部によるローテーションを複数段、繰り返し実行する構成を持つ。
【0140】
図22に示す構成は、各段において1つのS−boxと1つのXOR回路の適用構成を持ち、先行する処理段において、n/4ビットのS−boxとXOR回路の適用結果を生成し、このn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0141】
図23に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、n/4ビットのS−boxとXOR回路の適用結果を2ライン分(2×(n/4)ビット)生成し、この2ラインの演算結果と、その他の2ラインの未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0142】
図24に示す構成は、各段において1つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
n/4ビットのS−boxの適用結果と、
n/4ビットのS−boxとXOR回路の適用結果と、
n/4ビットのXOR回路の適用結果、
を生成し、これらの3つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0143】
図25に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
2つのn/4ビットのS−boxの適用結果と、
2つのn/4ビットのS−boxとXOR回路の適用結果と、
を生成し、これらの4つのn/4ビットの演算結果に対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0144】
図26に示す構成は、各段において1つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
n/4ビットのS−boxとXOR回路の適用結果と、
n/4ビットのXOR回路の適用結果、
を生成し、これらの2つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0145】
図27に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
2つのn/4ビットのS−boxとXOR回路の適用結果、
を生成し、これらの2つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0146】
図28に示す構成は、各段において2つのS−boxと2つのXOR回路の適用構成を持ち、先行する処理段において、
n/4ビットのS−boxの適用結果と、
n/4ビットのS−boxとXOR回路の適用結果と、
n/4ビットのXOR回路の適用結果、
を生成し、これらの3つのn/4ビットの演算結果と、その他の未処理データに対して、n/4ビットのライン単位データのローテーションを行い、ローテーション結果を次の処理段に出力する構成を持つ。
【0147】
図22、図23はそれぞれ、
type−IGFN(Generalized Feistel Network)、
type−IIGFN、
と呼ばれる繰り返し構造である。
【0148】
これらは通常小さな非線形部分に作用する秘密鍵とともに用いられるが、本実施例においては実装効率を考慮して秘密鍵を挿入しない。
このように秘密鍵を用いずに構成することで全体をひとつの固定テーブルとして実装することも可能になる。
【0149】
図22、図23の構成の違いは各段の小さなS−boxの数である。
図22のtype−IGFNは、各段が1つのnビットS−boxとnビットのXOR、nビット単位のRotationから構成される。
【0150】
図22に示す例では入力データはnビットであり4分割されn/4ビット単位で各ラインに入力されている。
なお、入力データの分割数は任意である。すなわち、任意のr分割(r>2)への拡張が可能であり、必要な大きなS−boxの入出力サイズに応じて適時決定することができる。
【0151】
図23に示すtype−IIGFNは、各段単位で、2つの小さなnビットS−boxとnビットのXOR、nビット単位のRotationで構成される。
これらの2つの構成方法の特徴は、順方向からの演算と逆方向からの演算がほとんど同じであり、違いはRotation部分のみとなっている。
【0152】
これにより、順関数と逆関数を両方実装する必要がある場合、回路の共有化が行える。図23の構成法において、図16の4ビットS−boxを用い、16ビットS−boxを生成した場合は、
6回繰り返しで最大差分確率は2−8.3,
最大線形確率は2−7.83であり,
7回繰り返しで最大差分確率は2−9.1,
最大線形確率は2−8になる。
これらの値は16−bitで最適な値ではないが、十分低い確率であり、回路規模はランダムに作成したものと比べて非常に小さくなる。
【0153】
図24〜図28は、図22,図23の構造とは異なる部分に小さなS−boxを配置した構造である。各々の違いはその配置場所と繰り返し単位でのS−boxの数のみである。
【0154】
これらの構造では、小さなS−boxに入力されるデータが、その後の演算では不要となるため、余計な記憶領域は不要であり、繰り返し関数をさらに細かく分割して実装した場合にハードウェアで必要な回路規模をさらに小さくすることが可能である。
【0155】
図25の構成法で、図17を参照して説明した4ビットS−boxを用い、16ビットS−boxを構成した場合は、
6回繰り返しで最大差分確率は2−8.3,
最大線形確率は2−8であり、
7回繰り返しで、最大差分確率は2−9.1,
最大線形確率は2−8.5であり、
16−bitで最適な値ではないが、十分低い確率であり、回路規模はランダムに作成したものと比べて非常に小さくなる。
【0156】
[4.暗号処理装置の構成例について]
最後に、上述した実施例に従った暗号処理を実行する暗号処理装置の実相例について説明する。
上述した実施例に従った暗号処理を実行する暗号処理装置は、暗号処理を実行する様々な情報処理装置に搭載可能である。具体的には、PC、TV、レコーダ、プレーヤ、通信機器、さらに、RFID、スマートカード、センサネットワーク機器、デンチ/バッテリー認証モジュール、健康、医療機器、自立型ネットワーク機器等、例えばデータ処理や通信処理に伴う暗号処理を実行する様々な危機において利用可能である。
【0157】
本開示の暗号処理を実行する装置の一例としてのICモジュール700の構成例を図29に示す。上述の処理は、例えばPC、ICカード、リーダライタ、その他、様々な情報処理装置において実行可能であり、図29に示すICモジュール700は、これら様々な機器に構成することが可能である。
【0158】
図29に示すCPU(Central processing Unit)701は、暗号処理の開始や、終了、データの送受信の制御、各構成部間のデータ転送制御、その他の各種プログラムを実行するプロセッサである。メモリ702は、CPU701が実行するプログラム、あるいは演算パラメータなどの固定データを格納するROM(Read-Only-Memory)、CPU701の処理において実行されるプログラム、およびプログラム処理において適宜変化するパラメータの格納エリア、ワーク領域として使用されるRAM(Random Access Memory)等からなる。また、メモリ702は暗号処理に必要な鍵データや、暗号処理において適用する変換テーブル(置換表)や変換行列に適用するデータ等の格納領域として使用可能である。なおデータ格納領域は、耐タンパ構造を持つメモリとして構成されることが好ましい。
【0159】
暗号処理部703は、上記において説明した暗号処理構成、すなわち、例えば一般化Feistel構造や、Feistel構造を適用した共通鍵ブロック暗号処理アルゴリズムに従った暗号処理、復号処理を実行する。
【0160】
なお、ここでは、暗号処理手段を個別モジュールとした例を示したが、このような独立した暗号処理モジュールを設けず、例えば暗号処理プログラムをROMに格納し、CPU701がROM格納プログラムを読み出して実行するように構成してもよい。
【0161】
乱数発生器704は、暗号処理に必要となる鍵の生成などにおいて必要となる乱数の発生処理を実行する。
【0162】
送受信部705は、外部とのデータ通信を実行するデータ通信処理部であり、例えばリーダライタ等、ICモジュールとのデータ通信を実行し、ICモジュール内で生成した暗号文の出力、あるいは外部のリーダライタ等の機器からのデータ入力などを実行する。
【0163】
なお、上述した実施例において説明したデータ処理装置は、入力データとしての平文を暗号化する暗号化処理に適用可能であるのみならず、入力データとしての暗号文を平文に復元する復号処理にも適用可能である。
暗号化処理、復号処理、双方の処理において、上述した実施例において説明した構成を持つ非線形変換部の構成を適用することが可能である。
【0164】
[5.本開示の構成のまとめ]
以上、特定の実施例を参照しながら、本開示の実施例について詳解してきた。しかしながら、本開示の要旨を逸脱しない範囲で当業者が実施例の修正や代用を成し得ることは自明である。すなわち、例示という形態で本発明を開示してきたのであり、限定的に解釈されるべきではない。本開示の要旨を判断するためには、特許請求の範囲の欄を参酌すべきである。
【0165】
なお、本明細書において開示した技術は、以下のような構成をとることができる。
(1) データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行するデータ変換処理部を有し、
前記データ変換処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、
前記F関数実行部は、
非線形変換処理を実行する非線形変換処理部を有し、
前記非線形変換処理部は、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有するデータ処理装置。
【0166】
(2)前記ビット置換部は、前記非線形演算部に対する入出力ビットを入れ替える配線構成を有する前記(1)に記載のデータ処理装置。
(3)前記非線形変換処理部は、2ビット入力1ビット出力のNANDまたはNOR演算部における演算結果としての1ビットを、前記XORまたはXNOR演算部に出力して、他の入力1ビットデータとのXORまたはXNOR演算を実行し、XORまたはXNOR演算結果として生成した1ビットデータを非線形変換処理結果の構成ビットとして出力する前記(1)または(2)に記載のデータ処理装置。
【0167】
(4)前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部を、n回以上繰り返す繰り返し構造を有する前記(1)〜(3)いずれかに記載のデータ処理装置。
(5)前記非線形変換処理部は、nビットデータの非線型変換結果を出力する構成において、前記非線形演算部をn回、前記ビット置換部をn回の前記非線形演算部の間にn−1回設定した構成である前記(1)〜(4)いずれかに記載のデータ処理装置。
【0168】
(6)前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する前記(1)〜(5)いずれかに記載のデータ処理装置。
(7)前記非線形変換処理部は、前記繰り返し構造中に、XOR演算部とXNOR演算部の双方を有する構成である前記(1)〜(6)いずれかに記載のデータ処理装置。
(8)前記データ処理装置は、入力データとしての平文を暗号文に変換する暗号化処理、または、入力データとしての暗号文を平文に変換する復号処理を実行する前記(1)〜(7)いずれかに記載のデータ処理装置。
【0169】
(9)1つのNANDまたはNOR演算部と、
1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有する非線形変換処理部を有するデータ処理装置。
【0170】
(10)前記非線形変換処理部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する前記(9)に記載のデータ処理装置。
【0171】
(11)データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、
複数ラインを構成する1ラインのデータを入力して変換データを生成する非線形関数実行部を有するラウンド関数の繰り返し構造を有するデータ処理装置。
(12)前記非線形関数実行部は、非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する前記(11)に記載のデータ処理装置。
【0172】
さらに、上記した装置およびシステムにおいて実行する処理の方法や、処理を実行させるプログラムも本開示の構成に含まれる。
【0173】
また、明細書中において説明した一連の処理はハードウェア、またはソフトウェア、あるいは両者の複合構成によって実行することが可能である。ソフトウェアによる処理を実行する場合は、処理シーケンスを記録したプログラムを、専用のハードウェアに組み込まれたコンピュータ内のメモリにインストールして実行させるか、あるいは、各種処理が実行可能な汎用コンピュータにプログラムをインストールして実行させることが可能である。例えば、プログラムは記録媒体に予め記録しておくことができる。記録媒体からコンピュータにインストールする他、LAN(Local Area Network)、インターネットといったネットワークを介してプログラムを受信し、内蔵するハードディスク等の記録媒体にインストールすることができる。
【0174】
なお、明細書に記載された各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。また、本明細書においてシステムとは、複数の装置の論理的集合構成であり、各構成の装置が同一筐体内にあるものには限らない。
【産業上の利用可能性】
【0175】
上述したように、本開示の一実施例の構成によれば、小型化した非線形変換部が実現される。
具体的には、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対してラウンド関数を適用したデータ変換処理を繰り返して実行する暗号処理部を有し、暗号処理部は、複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、F関数実行部は非線形変換処理を実行する非線形変換処理部を有し、非線形変換処理部は1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、ビット置換部との繰り返し構造を有する。この繰り返し構成により小型化された非線形変換部が実現される。
【符号の説明】
【0176】
700 ICモジュール
701 CPU(Central processing Unit)
702 メモリ
703 暗号処理部
704 乱数生成部
705 送受信部
【特許請求の範囲】
【請求項1】
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行するデータ変換処理部を有し、
前記データ変換処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、
前記F関数実行部は、
非線形変換処理を実行する非線形変換処理部を有し、
前記非線形変換処理部は、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有するデータ処理装置。
【請求項2】
前記ビット置換部は、前記非線形演算部に対する入出力ビットを入れ替える配線構成を有する請求項1に記載のデータ処理装置。
【請求項3】
前記非線形変換処理部は、
2ビット入力1ビット出力のNANDまたはNOR演算部における演算結果としての1ビットを、前記XORまたはXNOR演算部に出力して、他の入力1ビットデータとのXORまたはXNOR演算を実行し、XORまたはXNOR演算結果として生成した1ビットデータを非線形変換処理結果の構成ビットとして出力する請求項1に記載のデータ処理装置。
【請求項4】
前記非線形変換処理部は、
nビットデータの非線型変換結果を出力する構成において、
前記非線形演算部を、n回以上繰り返す繰り返し構造を有する請求項1に記載のデータ処理装置。
【請求項5】
前記非線形変換処理部は、
nビットデータの非線型変換結果を出力する構成において、
前記非線形演算部をn回、前記ビット置換部をn回の前記非線形演算部の間にn−1回設定した構成である請求項1に記載のデータ処理装置。
【請求項6】
前記非線形変換処理部は、
非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する請求項1に記載のデータ処理装置。
【請求項7】
前記非線形変換処理部は、
前記繰り返し構造中に、XOR演算部とXNOR演算部の双方を有する構成である請求項1に記載のデータ処理装置。
【請求項8】
前記データ処理装置は、
入力データとしての平文を暗号文に変換する暗号化処理、または、
入力データとしての暗号文を平文に変換する復号処理を実行する請求項1に記載のデータ処理装置。
【請求項9】
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有する非線形変換処理部を有するデータ処理装置。
【請求項10】
前記非線形変換処理部は、
非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する請求項9に記載のデータ処理装置。
【請求項11】
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、
複数ラインを構成する1ラインのデータを入力して変換データを生成する非線形関数実行部を有するラウンド関数の繰り返し構造を有するデータ処理装置。
【請求項12】
前記非線形関数実行部は、
非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する請求項11に記載のデータ処理装置。
【請求項13】
データ処理装置において実行するデータ処理方法であり、
データ処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行し、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行し、
前記F関数の実行処理において、非線形変換処理を実行し、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行するデータ処理方法。
【請求項14】
データ処理装置においてデータ変換処理を実行させるプログラムであり、
データ処理部に、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行させ、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行させ、
前記F関数の実行処理において、非線形変換処理を実行させ、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行させるプログラム。
【請求項1】
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行するデータ変換処理部を有し、
前記データ変換処理部は、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数実行部を有し、
前記F関数実行部は、
非線形変換処理を実行する非線形変換処理部を有し、
前記非線形変換処理部は、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有するデータ処理装置。
【請求項2】
前記ビット置換部は、前記非線形演算部に対する入出力ビットを入れ替える配線構成を有する請求項1に記載のデータ処理装置。
【請求項3】
前記非線形変換処理部は、
2ビット入力1ビット出力のNANDまたはNOR演算部における演算結果としての1ビットを、前記XORまたはXNOR演算部に出力して、他の入力1ビットデータとのXORまたはXNOR演算を実行し、XORまたはXNOR演算結果として生成した1ビットデータを非線形変換処理結果の構成ビットとして出力する請求項1に記載のデータ処理装置。
【請求項4】
前記非線形変換処理部は、
nビットデータの非線型変換結果を出力する構成において、
前記非線形演算部を、n回以上繰り返す繰り返し構造を有する請求項1に記載のデータ処理装置。
【請求項5】
前記非線形変換処理部は、
nビットデータの非線型変換結果を出力する構成において、
前記非線形演算部をn回、前記ビット置換部をn回の前記非線形演算部の間にn−1回設定した構成である請求項1に記載のデータ処理装置。
【請求項6】
前記非線形変換処理部は、
非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する請求項1に記載のデータ処理装置。
【請求項7】
前記非線形変換処理部は、
前記繰り返し構造中に、XOR演算部とXNOR演算部の双方を有する構成である請求項1に記載のデータ処理装置。
【請求項8】
前記データ処理装置は、
入力データとしての平文を暗号文に変換する暗号化処理、または、
入力データとしての暗号文を平文に変換する復号処理を実行する請求項1に記載のデータ処理装置。
【請求項9】
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
の繰り返し構造を有する非線形変換処理部を有するデータ処理装置。
【請求項10】
前記非線形変換処理部は、
非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する請求項9に記載のデータ処理装置。
【請求項11】
データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、
複数ラインを構成する1ラインのデータを入力して変換データを生成する非線形関数実行部を有するラウンド関数の繰り返し構造を有するデータ処理装置。
【請求項12】
前記非線形関数実行部は、
非線形変換対象となるデータの構成ビットの全てに対して、1つのNANDまたはNOR演算部の演算結果とのXORまたはXNOR演算結果を生成し、該XORまたはXNOR演算結果を非線型変換結果の構成ビットとして出力する請求項11に記載のデータ処理装置。
【請求項13】
データ処理装置において実行するデータ処理方法であり、
データ処理部が、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行し、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行し、
前記F関数の実行処理において、非線形変換処理を実行し、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行するデータ処理方法。
【請求項14】
データ処理装置においてデータ変換処理を実行させるプログラムであり、
データ処理部に、データ処理対象となるデータの構成ビットを複数ラインに分割して入力し、各ラインのデータに対するデータ変換処理を繰り返し実行させ、
前記データ変換処理において、
前記複数ラインを構成する1ラインのデータを入力して、変換データを生成するF関数を実行させ、
前記F関数の実行処理において、非線形変換処理を実行させ、
前記非線形変換処理において、
1つのNANDまたはNOR演算部と、1つのXORまたはXNOR演算部からなる非線形演算部と、
ビット置換部と、
を適用した繰り返し演算を実行させるプログラム。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】

【図25】
【図26】
【図27】
【図28】
【図29】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【公開番号】特開2012−215815(P2012−215815A)
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【出願番号】特願2011−207704(P2011−207704)
【出願日】平成23年9月22日(2011.9.22)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【出願日】平成23年9月22日(2011.9.22)
【出願人】(000002185)ソニー株式会社 (34,172)
【Fターム(参考)】
[ Back to top ]