
データ処理装置およびそのデータ処理方法
【課題】可変長データに対する演算処理と、固定長データに対する演算処理とを効率的に行なうことが可能なデータ処理装置を提供すること。
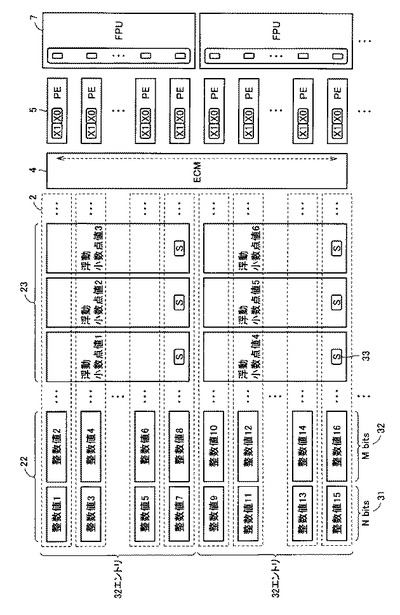
【解決手段】データ処理装置100は、SIMD方式の複数のPE1(5)と、複数のPE1(5)のそれぞれに対応して設けられる複数のSRAMs2と、複数のPE2(7)とを含む。複数のPE1(5)のそれぞれは、対応する1つのSRAMs2に格納されるデータに対して演算を行なう。また、複数のPE2(7)のそれぞれは、対応する複数個のSRAMs2に格納されるデータに対して演算を行なう。したがって、複数のSRAMs2を共有することができ、可変長データに対する演算処理と、固定長データに対する演算処理とを効率的に行なうことが可能となる。
【解決手段】データ処理装置100は、SIMD方式の複数のPE1(5)と、複数のPE1(5)のそれぞれに対応して設けられる複数のSRAMs2と、複数のPE2(7)とを含む。複数のPE1(5)のそれぞれは、対応する1つのSRAMs2に格納されるデータに対して演算を行なう。また、複数のPE2(7)のそれぞれは、対応する複数個のSRAMs2に格納されるデータに対して演算を行なう。したがって、複数のSRAMs2を共有することができ、可変長データに対する演算処理と、固定長データに対する演算処理とを効率的に行なうことが可能となる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、複数のプロセッサを有するデータ処理装置に関し、特に、可変長ビットの演算を行なうことが可能なプロセッサと、主に固定長ビットの演算を行なうプロセッサとを有するデータ処理装置およびそのデータ処理方法に関する。
【背景技術】
【0002】
近年、音声や画像といった大量のデータを高速に処理するデジタル信号処理の重要性が高まってきている。このようなデジタル信号処理においては、一般に専用の半導体装置としてDSP(Digital Signal Processor)が用いられることが多い。しかしながら、信号処理アプリケーション、特に画像処理アプリケーションにおいては、処理対象のデータ量が非常に大きいため、DSPでも処理能力が十分ではない。
【0003】
これに対して、複数の演算器を並列に動作させることによって高い信号処理性能を実現する並列プロセッサ技術の開発が進んでいる。このような専用プロセッサをCPU(Central Processing Unit)に付随するアクセラレータとして用いれば、組み込み機器に搭載されるLSIのように低消費電力、低コストが要求される場合においても高い信号処理性能を実現することができる。
【0004】
このような並列プロセッサの1つとして、単一命令複数データ流(SIMD:Single Instruction Multiple Data stream)の演算方式を採用しているSIMD型プロセッサを挙げることができる。
【0005】
SIMD型プロセッサは、細粒度演算コアを有しており、整数演算や固定小数点演算に適したプロセッサである。ここで、細粒度演算コアとは、複数回の演算によって可変長ビットの演算が可能な演算コアを指すものとする。
【0006】
SIMD型プロセッサの中でも、メモリと密結合した1〜2ビット単位で演算を行なう細粒度演算器(以下、PE(Processor Element)とも呼ぶ。)を1024個搭載した超並列プロセッサ(以下、このようなプロセッサをマトリクス型超並列プロセッサ(MX)とも呼ぶ。)は、大量の整数演算や固定小数点演算を短時間で行なうことができる。
【0007】
また、マトリクス型超並列プロセッサは、細粒度演算器を利用するため、必要なビット長の演算のみを行なうことができ、消費電力を削減することができるため、汎用DSPなどと比較して高い消費電力性能比を得ることができる。
【0008】
また、マトリクス型超並列プロセッサは、予め作成されたプログラムをロードして実行することができるため、これを制御するCPUと同時に並列演算を行なうことが可能である。また、後述のように、演算器間でデータ移動を行なうためのエントリコミュニケータ(ECM)を搭載しており、VLIW(Very Long Instruction Word)命令をサポートしたコントローラによって演算と同時にデータの交換を行なうことができるため、単に演算器を並列配置したプロセッサよりも効率よくデータ供給を行なえる。
【0009】
一方、浮動小数点演算器(FPU)などの粗粒度演算コアは、固定長の浮動小数点演算に特化した演算器であり、CPUに接続して使用される。ここで、粗粒度演算コアとは、1回の演算によって固定長ビットの演算が可能な演算コアを指すものとする。
【0010】
浮動小数点演算器は、浮動小数点演算用のレジスタを有しており、演算対象となるデータはこのレジスタ経由でCPUまたはメモリから供給される。また、CPUが実行命令の解釈を行ない、浮動小数点演算器に対する演算要求を行なう。浮動小数点演算器は、パイプライン構成となっており、単一の演算処理が1サイクルで完了しなくても連続的にデータを供給することによって、実質的には1演算/サイクルを実現する。これらに関連する技術として、下記の特許文献1〜2に開示された発明がある。
【0011】
特許文献1は、異なるデータ型フォーマットの各々に専用のハードウェアを必要としない浮動小数点ユニットを提供することを目的とする。特許文献1に記載の装置は、複数のデータ型フォーマットに対して乗算累算演算を実行できる標準乗算累算ユニット(MAC)を含む浮動小数点ユニットを含む。標準MACは、在来のデータ型フォーマットと単一命令多重データ(SIMD)型フォーマットとに対して演算するよう構成される。従って専用のSIMD用MACユニットが必要ないので、ダイの面積を大幅に節約する。SIMD命令がMACユニットの1つにより演算される場合、データは64ビットワードとして、上位と下位のMACユニットに与えられる。また、各MACユニットは、64ビットワードの上位半分又は下位半分の何れかを選択させる1つ以上のビットを受取る。各MACユニットは各々の32ビットワードに対して演算を行なう。その演算の結果は、浮動小数点ユニットのバイパスブロックにより64ビットワードに合体される。
【0012】
特許文献2は、CPUを代表例とするマイクロプロセッサとFPU(浮動小数点演算処理装置)を代表例とする専用プロセッサとの並行処理を可能とした情報処理装置において、マイクロプロセッサの待ち時間を短縮し処理能力を向上することを目的とする。情報処理装置は、マルチFPU構成とする。FPU接続制御部におけるFPU状態レジスタが複数のFPUの状態を監視しておく。複数のCPUのいずれかからFPU接続制御部におけるFPU状態解読部に要支援命令のリクエストがあると、FPU状態レジスタの情報に基づいて非動作で空いている状態のFPUをリクエストをしたCPUにつなぐようにFPU選択部を制御する。また、一時記憶レジスタ選択制御部から一時記憶レジスタ選択部の制御を介して一時記憶レジスタの使用エリアにデータ破壊の不具合が生じないようにする。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開2001−027945号公報
【特許文献2】特開2001−167058号公報
【発明の概要】
【発明が解決しようとする課題】
【0014】
上述のように、マトリクス型超並列プロセッサは、1〜2ビットの単位でデータに対する演算を行なうため、演算対象データのビット長に応じて処理サイクルが増加するが、任意ビット長の演算が可能である。しかしながら、マトリクス型超並列プロセッサに搭載される細粒度演算器は整数演算を目的としているため、浮動小数点のようなデータに対する演算を行なうためには、「デコード」、「演算」および「エンコード」の各処理を経る必要があり、非常に低速となってしまう。
【0015】
また、マトリクス型超並列プロセッサは、たとえば1024並列で演算処理を行なうため、まとまった量のデータに対する演算でなければ性能を発揮することができない。したがって、小タップのフィルタ処理など、並列度が小さくデータを頻繁に入れ替える必要がある演算には適していない。
【0016】
一方、浮動小数点演算器は、通常CPUとコプロセッサ接続されており、CPUが命令およびデータの供給を制御している。また、1つの浮動小数点演算器が1度に処理できる演算は1種類であり、1演算は複数サイクルで処理される。したがって、パイプラインに命令を連続的に供給すると共に、レジスタにデータを連続的に供給することによって性能を発揮させることは可能ではあるが、CPUが介在して制御を行なうため効率よく稼動させることは難しい。
【0017】
近年、組み込み機器分野においては、低消費電力と高速演算性能とが要求されており、特に、車載機器などでは安全性向上のために画像処理と信号処理とを組み合わせたシステムが採用されつつある。したがって、このようなシステムでは、画像処理と信号処理とを効率的に行なうことが可能な機構が熱望されている。
【0018】
本発明は、上記問題点を解決するためになされたものであり、その目的は、可変長データに対する演算処理と、固定長データに対する演算処理とを効率的に行なうことが可能なデータ処理装置およびそのデータ処理方法を提供することである。
【課題を解決するための手段】
【0019】
本発明の一実施例によれば、複数のプロセッサを含んだデータ処理装置が提供される。データ処理装置は、SIMD方式の複数のPE1と、複数のPE1のそれぞれに対応して設けられる複数のSRAMと、複数のPE2とを含む。複数のPE1のそれぞれは、複数のSRAMの中の対応する1つのSRAMに格納されるデータに対して演算を行なう。また、複数のPE2のそれぞれは、複数のSRAMの中の対応する複数個のSRAMに格納されるデータに対して演算を行なう。
【発明の効果】
【0020】
本発明の一実施例によれば、複数のPE1のそれぞれが、複数のSRAMの中の対応する1つのSRAMに格納されるデータに対して演算を行ない、複数のPE2のそれぞれが、複数のSRAMの中の対応する複数個のSRAMに格納されるデータに対して演算を行なうので、複数のSRAMを共有することができ、可変長データに対する演算処理と、固定長データに対する演算処理とを効率的に行なうことが可能となる。
【図面の簡単な説明】
【0021】
【図1】本発明の第1の実施の形態におけるデータ処理装置の構成例を示すブロック図である。
【図2】SRAM2の内部構成をさらに詳細に説明するための図である。
【図3】PE1(5)の内部構成をさらに詳細に説明するための図である。
【図4】PE2(7)の内部構成をさらに詳細に説明するための図である。
【図5】ECM4の内部構成およびその動作を説明するための図である。
【図6】直交変換器10の動作を説明するための図である。
【図7】命令RAM11に格納されるマイクロコードプログラムの一例を示す図である。
【図8】上述のVLIW命令を用いたアドレッシング制御を説明するための図である。
【図9】図1に示すデータ処理装置100を含んだシステムの処理手順を説明するためのフローチャートである。
【図10】PE1(5)によるPE1命令実行時の処理手順を説明するためのフローチャートである。
【図11】PE2(7)によるPE2命令実行時の処理手順を説明するためのフローチャートである。
【図12】本発明の第2の実施の形態における周辺監視システムのミリ波レーダの信号処理の一例を示す図である。
【図13】本発明の第2の実施の形態におけるFPUによって処理される浮動小数点値のデータ構造を説明するための図である。
【図14】本発明の第2の実施の形態における周辺監視システムのデータ処理装置のデータ配置を説明するための図である。
【図15】本発明の第2の実施の形態における周辺監視システムの処理手順を説明するためのフローチャートである。
【図16】FPU7による浮動小数点演算の一例を示す図である。
【図17】本発明の第2の実施の形態におけるデータ処理装置のアドレッシングモードの一例を示す図である。
【図18】本発明の第2の実施の形態におけるシステムの他の一例を示す図である。
【発明を実施するための形態】
【0022】
(第1の実施の形態)
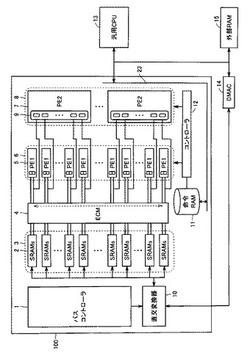
図1は、本発明の第1の実施の形態におけるデータ処理装置の構成例を示すブロック図である。このデータ処理装置100は、バスコントローラ1と、SRAM(Static Random Access Memory)アレイ3と、エントリコミュニケータ(ECM)4と、PE1演算アレイ6と、PE2演算アレイ8と、直交変換器10と、命令RAM11と、コントローラ12とを含む。また、このデータ処理装置100は、汎用CPU13、DMAC(Direct Memory Access Controller)14および外部RAM15と接続されている。
【0023】
汎用CPU13は、外部RAM15に格納されるマイクロコードプログラムを読み出し、データ処理装置100の内部バス23を介して命令RAM11に転送する。データ処理装置100は、命令RAM11に格納されたマイクロコードプログラムを実行することによって演算処理を行なう。このマイクロコードプログラムの転送は、DMAC14によるDMA転送であってもよい。
【0024】
また、汎用CPU13は、DMAC14を制御して、外部RAM15に格納される演算対象データをデータ処理装置100にDMA転送することによって、データ処理装置100に演算対象データを与える。
【0025】
バスコントローラ1は、データ処理装置100の内部バスの制御を行なう。たとえば、DMAC14によってDMA転送されたデータを受け、直交変換器10に入力させる。直交変換器10は、入力したデータをそのまま、または直交変換してSRAMアレイ3に書き込む。また、バスコントローラ1は、汎用CPU13からの要求により、SRAMアレイ3からデータを読み出して直交変換器10に出力する。直交変換器10は、入力したデータをそのまま、または直交変換して外部RAM15にDMA転送する。
【0026】
PE1演算アレイ6は、2ビットの細粒度演算コアであるPE1(5)を256個有しており、PE1(5)のそれぞれが少ビット単位で繰り返し演算処理を行なうことにより、任意ビット長データの演算を行なうことができる。PE1(5)による処理時間は処理対象データのビット長に依存しており、主に信号処理の初段の処理、たとえばA/D変換されたデータの入力直後の処理や、画像処理などの短ビット長の単純な整数演算を大量に行なう処理に適している。なお、PE1(5)の数は、これに限られるものではない。
【0027】
PE2演算アレイ8は、32ビットの粗粒度演算コアであるPE2(7)を8個有しており、PE2(7)のそれぞれが固定ビット長データの演算を行なうことができる。PE2(7)による処理時間は処理対象データのビット長には依存せず、演算するデータ数のみに依存する。PE2(7)は、固定ビット長で演算が行なえるため、浮動小数点演算器などのように特殊な演算を行なうことができ、信号処理に適している。また、PE2(7)は、細粒度演算器に比べて並列度が小さいため、少ないデータの処理にも適している。なお、PE2(7)の数は、これに限られるものではない。
【0028】
SRAMアレイ3は、2ビットバスのSRAMs(2)を256個有している。図1に示すように、256個のPE1(5)と、8個のPE2(7)とがECM4を介して256個のSRAMs2に接続されている。1つのSRAMs2が1つのPE1(5)に対応するように接続され、後述のように全てのPE1(5)が同時にサイクル単位で1ビットまたは2ビットのデータを読み書き可能な構成となっている。なお、SRAMs2の数は、これに限られるものではない。
【0029】
また、32個のSRAMs2が1つのPE2(7)に対応するように接続され、32ビットのデータがビット分解されて、32個のSRAMs(2)のそれぞれに1ビットずつ格納される。これによって、PE2(7)がサイクル単位で32ビット長のデータの読み出し/書き込みを行なえるようになる。
【0030】
コントローラ12は、命令RAM11に格納されるマイクロコードプログラムを順次読み出して解釈し、SRAMアレイ3、ECM4、PE1アレイ6、PE2アレイ8を制御して、演算処理を行なう。
【0031】
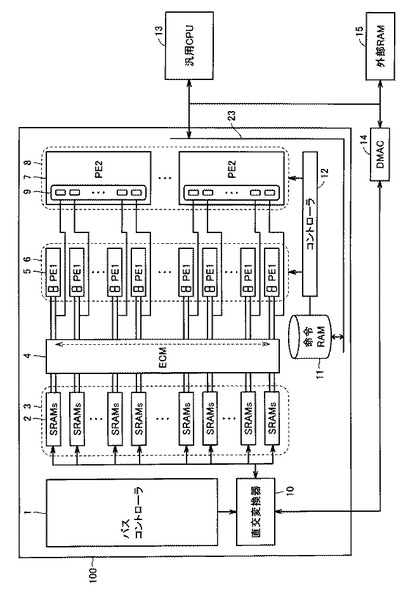
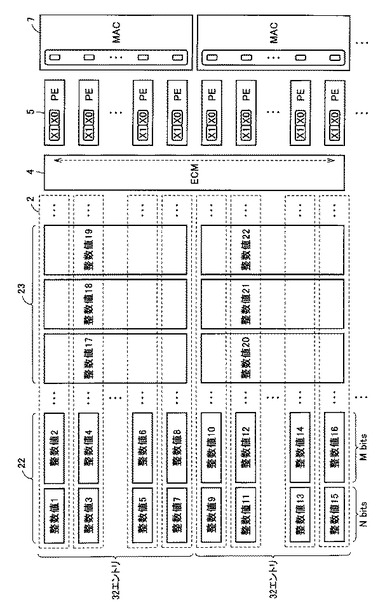
図2は、SRAM2の内部構成をさらに詳細に説明するための図である。SRAM2は、256ビットのSRAM16を4個有しており、これらのSRAM16が連続したアドレスに配置されている。アドレスを指定することによって、SRAM16のそれぞれの任意の位置の1ビットデータ、または偶数ビット番目から格納される連続した2ビットデータを一度に読み出すことができる。これら4つのSRAM16は、同時にデータの読み出し/書込みが可能であり、それぞれをバンク1〜バンク4と呼ぶことにする。
【0032】
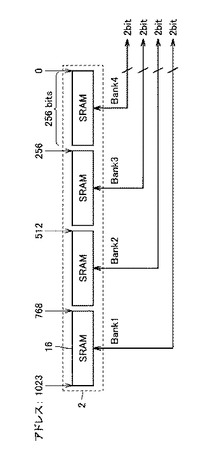
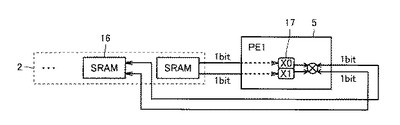
図3は、PE1(5)の内部構成をさらに詳細に説明するための図である。PE1(5)は、SRAMs2内のあるSRAM16(たとえば、バンク4)からの2ビットデータの読み出しと、別のSRAM16(たとえば、バンク3)に対する2ビットデータの読み出し/書き込みとを同時に行なうことができる。また、PE1(5)は、SRAM16内の偶数ビット番目から格納される連続した2ビットデータ、または任意位置の1ビットデータの読み書きが可能である。
【0033】
PE1(5)は、内部に演算用レジスタ(X0,X1)17を有しており、バンク4から読み込んだ2ビットのデータをこの演算用レジスタ17に格納する。それと同時に、PE1(5)は、バンク3から2ビットデータを読み出して、演算用レジスタ17に格納される値との演算を行ない、バンク3の同じアドレスに上書きする。
【0034】
PE1(5)は、2ビットの加算器と、ブースデコーダとを有しており、1ビットまたは2ビットデータの加減算、乗算、1ビット単位の論理演算を行なうことができる。加算器は、キャリー情報を内部レジスタに保持するため、1ビットまたは2ビットデータの演算を繰り返すことで、複数サイクルを要することにはなるが、任意ビット長データの演算を行なうことができる。
【0035】
図4は、PE2(7)の内部構成をさらに詳細に説明するための図である。PE2(7)は、32ビットデータの2つ分(たとえば、バンク3とバンク4)の読み出しと、32ビットデータ(たとえば、バンク2)の書き込みとを同時に行なうことができる。PE8(7)は、32個のSRAM16のそれぞれの下位1ビットをまとめて32ビットのデータとして読み出し/書き込みを行なう。
【0036】
PE2(7)は、内部に2つの32ビットの演算用レジスタ(R0,R1)18を有しており、読み出した2つの32ビットデータをこれらの演算用レジスタ18に格納する。また、PE2(7)は、パイプラインを有する構成の演算器であり、複数サイクル後に先程読み出した2つのデータの演算結果を別の内部レジスタ(R2)に出力する。その後、PE2(7)は、内部レジスタ(R2)に格納される演算結果を別バンクの32個のSRAM16に書き込む。このようにして、パイプラインを停止させることなく、コントローラ12によって要求された命令の連続実行が可能となる。
【0037】
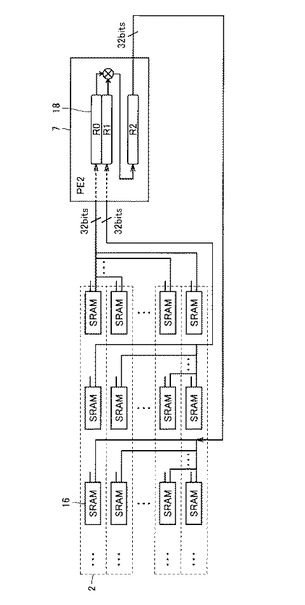
図5は、ECM4の内部構成およびその動作を説明するための図である。図5(a)は、ECM4の内部接続を示している。ECM4は、2のべき乗距離(1,2,4,8,16,32,64,128)にある演算コアに接続されており、接続されている演算コア間では1サイクルでデータを移動、交換することができる。図5(a)においては、セレクタ(SEL)41のそれぞれが、1,2,4の距離にある演算コアに接続される場合を示している。
【0038】
2のべき乗距離にない演算コアへのデータ移動は、2のべき乗距離にある演算器へのデータ移動を複数回組み合わせることにより、シフトレジスタのような動作によって実現可能である。たとえば、6エントリ分のデータ移動を行なう場合には、4エントリ分の移動+2エントリ分の移動のように、2サイクルに分けて実行される。
【0039】
また、PE2(7)によって演算が行なわれる場合には、32のN倍エントリ単位でデータ移動することで、演算コア間のデータ移動に対応することができる。
【0040】
SRAMs2から読み出されたデータは、指定されたECM4内にブロードキャストされる。そして、コントローラ12が全セレクタ41に対して、いずれの距離からのデータを読み出すかを指定し、選択されたデータのみがPE1(5)に入力される。そのため、全エントリのデータは、等しく同じ距離を移動することになる。
【0041】
2ビット演算コアであるPE1(5)に演算を行なわせる場合には、ECM4を使用してデータを移動することで演算対象のデータを入れ替えることができる。また、PE2(7)に演算を行なわせる場合には、演算対象のデータが32個のSRAMs2にまたがって格納されているため、32未満の距離でデータを移動させるとデータのビットシフトを行なうことができる。逆に、32以上の距離でデータを移動させると演算対象のデータを入れ替えることができる。
【0042】
図5(b)は、ECM4を用いた演算処理の一例を示す図である。まず、ステップ1においては、SRAM16のエントリ#0〜#3に格納されるデータa0〜a3がテンポラリレジスタ(Temp.Reg.)にロードされる。
【0043】
ステップ2において、ECM4によってテンポラリレジスタに格納されるデータa0〜a3が1ビットずつシフトされる。そして、ステップ3において、SRAM16に格納されるデータb0〜b3が読み出されて、テンポラリレジスタに格納されるデータとの演算が行なわれ、SRAM16のデータb0〜b3が格納されていたのと同じアドレスに演算結果が上書きされる。
【0044】
図5(c)は、図5(a)に示すセレクタ41の内部構成をさらに詳細に説明するための図である。セレクタ41は、NチャネルMOSトランジスタ42−1〜42−kと、PチャネルMOSトランジスタ43および46と、インバータ44および45とを含む。
【0045】
VCH_IN_1〜VCH_IN_kに、2のべき乗距離にあるエントリの出力が接続される。VCH_SEL_1〜VCH_SEK_kのいずれか1つがハイレベル(以下、Hレベルと略す。)となって、そのNチャネルMOSトランジスタに接続されるエントリの出力が選択される。
【0046】
セレクタ(SEL)51の一方の端子には、セレクタ41によって選択されたエントリの出力が接続され、他方の端子には、そのPE1(5)に対応するSRAMs2の出力が接続される。セレクタ(SEL)51は、VCH_IE信号に応じて、セレクタ41によって選択されたエントリの出力と、PE1(5)に対応するSRAMs2の出力とのいずれかを選択して出力する。
【0047】
テンポラリレジスタ52は、セレクタ(SEL)51からの出力を一時的に保持し、セレクタ(SEL)53に出力する。セレクタ(SEL)53は、テンポラリレジスタ52に保持される値と、PE1(5)に対応するSRAMs2の出力とのいずれかを選択して出力する。
【0048】
他のエントリにデータを転送するときにVCH_OE信号がHレベルとなり、バッファ54がセレクタ(SEL)53から出力される値を他のエントリに出力する。また、セレクタ(SEL)53から出力される値に対して演算を行なう場合には、ALU55がその演算結果(ALU_OUT)を出力する。
【0049】
たとえば、図5(b)のステップ1に示すようにテンポラリレジスタにデータa0〜a3がロードされる場合には、セレクタ(SEL)51がSRAMs2の出力(SRAM_OUT)を選択してテンポラリレジスタ52に出力する。テンポラリレジスタ52は、その値を保持する。
【0050】
図5(b)のステップ2に示すように、テンポラリレジスタが保持する値をシフトする場合には、セレクタ53がテンポラリレジスタ52が保持する値を選択して出力する。バッファ54は、セレクタ53から出力される値をVCH_OUTに出力する。このとき、セレクタ41は、隣のエントリからの出力を選択するように設定されており、セレクタ51は、隣のエントリのデータを選択してテンポラリレジスタ52に出力する。テンポラリレジスタ52は、その値を保持することによって、図5(b)のステップ2に示すシフト動作が完了する。
【0051】
図5(b)のステップ3に示すように、PE1(5)が演算を行なう場合には、演算器(ALU)55が、セレクタ(SEL)53を介してテンポラリレジスタ52に保持される値を受けて演算を行なう。
【0052】
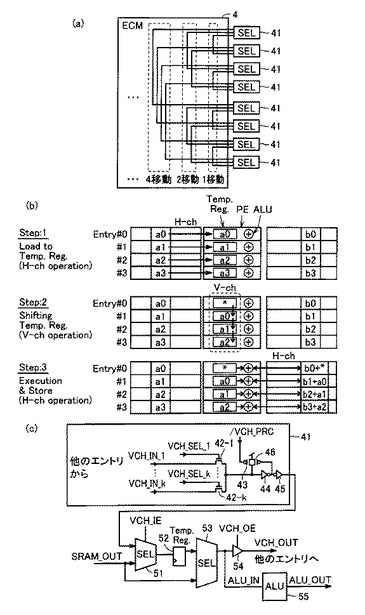
図6は、直交変換器10の動作を説明するための図である。直交変換器10は、2系統のデータ入出力ポートを有しており、一方のポート20を介して外部RAM15に格納されるデータを受け、直交変換した後のデータを他方のポート21を介してSRAM16に格納するか、または、直交変換せずに同じデータを他方のポート21を介してSRAM16に格納する。
【0053】
逆に、直交変換器10は、ポート21を介してSRAM16に格納されるデータを受け、直交変換した後のデータをポート20を介して外部RAM15に転送するか、または、直交変換せずに同じデータをポート20を介して外部RAM15に転送することも可能である。
【0054】
また、直交変換器10は、ポート21を介してSRAM16に格納されるデータを受け、直交変換した後のデータを再度ポート21を介してSRAM16に格納することも可能である。
【0055】
図6(a)は、PE1(5)用のデータをSRAM16に格納するときの直交変換器10の動作を示している。図6(a)においては、外部RAM15に格納される8ビット長データ8個をPE1(5)用に転送する場合を示している。なお、32ビット長データを32個受けて直交変換し、SRAM16に転送するようにしてもよい。
【0056】
上述のように、PE1(5)が使用するデータは対応する1つのSRAM16内にビットストリームとして格納される必要がある。そのため、直交変換器10は、ポート20を介して外部RAM15から8ビット長のデータを受け、8個のデータを順次バッファリングする。そして、直交変換器10は、バッファリングした各データの同じビット位置にあるデータを8個まとめて、ポート21を介してSRAM16にデータ22を転送する。
【0057】
そして、次のビット位置にあるデータを8個まとめて、次のアドレスのSRAM16に転送する。これを繰り返すことによって、外部から入力されたデータを直交変換し、PE1(5)用データとしてSRAM16に格納することができる。
【0058】
図6(b)は、PE2(7)用のデータをSRAM16に格納するときの直交変換器10の動作を示している。図6(b)においては、外部メモリ15に格納される8ビット長データをPE2(7)用に転送する場合を示している。なお、32ビット長データを受けて、そのままSRAM16に転送するようにしてもよい。
【0059】
PE2(7)用のデータは、32個のSRAM16にまたがって格納される必要があるため、直交変換器10はレジスタ操作による直交変換を行なわずにデータをSRAM16に転送する。直交変換器10は、ポート20を介して外部RAM15から8ビット長のデータを受け、ビット分割をせずにそのままポート21を介してSRAM16にデータ23を転送する。
【0060】
このようにして、直交変換器10は、同一のSRAM内にPE1(5)用のデータと、PE2(7)用のデータとを混在して格納することが可能となる。
【0061】
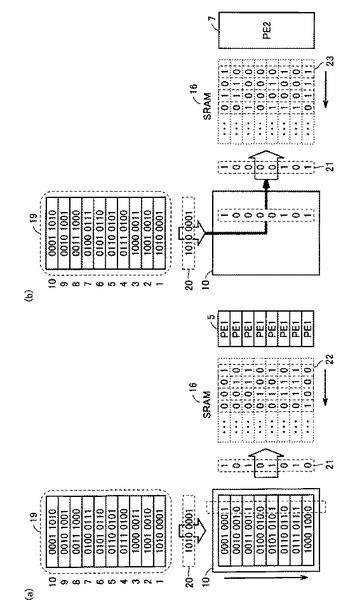
図7は、命令RAM11に格納されるマイクロコードプログラムの一例を示す図である。命令には、“コントローラ命令”、“PE1命令”、“PE2命令”の3種類があり、これらを組み合わせたVLIW命令として命令RAM11に格納される。
【0062】
図7(a)に示すように、MODEレジスタの設定にかかわらず、命令の最上位ビットが“1”の場合には、コントローラ命令であることを示す。また、命令の最上位ビットが“0”の場合には、PE1命令またはPE2命令であることを示す。
【0063】
図7(b)に示すように、MODEレジスタの設定が“0”であり、かつ命令の最上位ビットが“0”の場合には、コントローラ命令とPE1命令との混在であることを示す。図7(b)においては、PE1命令として、“load命令”、“alu命令”、“mode命令”が記述されている。なお、“mode命令”は、1ビットと2ビットとの切り替えを行なう命令である。
【0064】
図7(c)に示すように、MODEレジスタの設定が“1”であり、かつ命令の最上位ビットが“0”の場合には、コントローラ命令とPE2命令との混在であることを示す。
【0065】
図7(d)に示すように、コントローラ12は、まず命令の最上位ビットをデコードし、これが“1”の場合にはコントローラ命令、“0”の場合にはPE1命令またはPE2命令と判断する。そして、コントローラ12は、MODEレジスタの設定によってPE1命令であるか、PE2命令であるかを判断する。
【0066】
コントローラ12は、コントローラ命令によってMODEレジスタ設定を変更することができるため、PE1演算器およびPE2演算器の選択は、命令の実行時に動的に行なうことができる。また、コントローラ12は、命令が“PE1命令”または“PE2命令”とを含む場合には、個々の演算器の命令だけでなくコントローラ命令のサブセットを含めて、複数の命令を同時に実行することができる。
【0067】
コントローラ12は、命令がPE1命令を含む場合には、PE1(5)に“load命令”と“alu命令”とを出力する。PE1(5)は、図3に示すように、“load命令”によって、SRAM16から2ビットデータをPE1(5)内のレジスタに読み込み、“alu命令”によってSRAM16から読み出したデータとレジスタのデータとの演算を行ない、演算結果をSRAM16の2ビットに上書きする。この動作を1サイクルで行なうことができるため、これを連続的に行なうことによって任意ビット長データの演算を行なうことができる。
【0068】
コントローラ12は、命令がPE2命令を含む場合には、PE2(7)にPE2命令を出力する。PE2(7)は、内部にパイプラインを有した高度な演算を行なうことができる演算コアであり、図4に示すように、演算の途中結果を格納するレジスタ18を有している。PE2(7)は、コントローラ12から受けたPE2命令によって、SRAM16からデータを必要個数だけ読み出し、内部のシーケンサにしたがって演算を行なう。そして、PE2(7)は、演算結果をレジスタを経由して再度SRAM16に遅延書き込みする。
【0069】
一般的に、PE2(7)によるデータの入力から演算結果の出力まで数サイクルを要するが、内部レジスタへのデータ読み出しと内部レジスタからのデータ書き込みとを同時に行なうことができる。したがって、パイプライン処理を行なうことによって、コントローラ12がPE2(7)に対して連続的に演算要求を行なうことができ、見かけ上1演算/サイクルを実現することができる。
【0070】
また、上述のように、SRAM16が4バンクで構成されているため、PE2(7)の演算中であっても、すなわち最大3バンクにアクセスしていても、残り1バンクを用いてデータの入出力を行なうことができる。これによって、PE1(5)またはPE2(7)による演算と、汎用CPU13またはDMAC14による外部RAM15とSRAM16との間のデータ転送とを並行して行なうことができ、システム全体の性能を向上させることができる。
【0071】
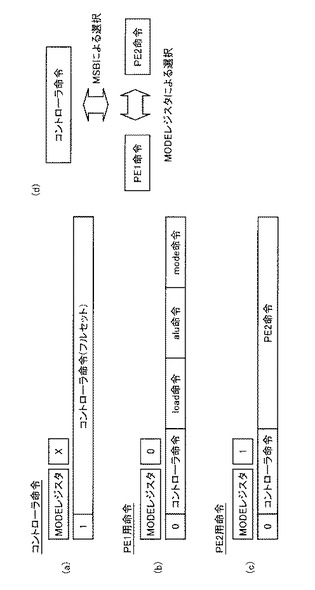
図8は、上述のVLIW命令を用いたアドレッシング制御を説明するための図である。なお、ここではアドレッシング制御について間単に説明するが、詳細な説明は第2の実施の形態において説明するものとする。
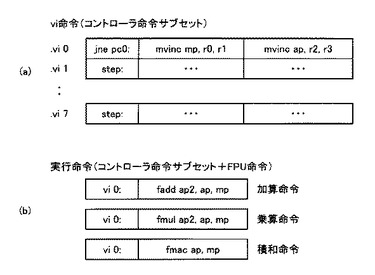
【0072】
図8(a)は、コントローラ命令サブセット(vi命令)を示している。vi0において、“mvinc mp,r0,r1”は、レジスタr0の値をレジスタmpに代入し、レジスタr0の値とレジスタr1の値とを加算してレジスタr0に代入することを示している。また、vi0において、“mvinc ap,r2,r3”は、レジスタr2の値をレジスタapに代入し、レジスタr2の値とレジスタr3の値とを加算してレジスタr2に代入することを示している。
【0073】
図8(b)は、コントローラ命令サブセットとPE2命令(FPU命令)とを含んだVLIW命令を示している。加算命令“fadd ap2,ap,mp”は、レジスタapの値とレジスタmpの値とを加算してレジスタap2に格納することを示している。コントローラ命令として、図8(a)に示すvi0命令が記述されているため、レジスタapにレジスタr2とレジスタr3とを加算した値が代入される。同様に、レジスタmpにレジスタr0とレジスタr1とを加算した値が代入される。これによって、次にデータを読み出すSRAM16のアドレス(ap,mp)を、レジスタr3またはレジスタr1で制御することができる。
【0074】
また、乗算命令“fmul ap2,ap,mp”は、レジスタapの値とレジスタmpの値とを乗算してレジスタap2に格納することを示している。また、積和命令“fmac ap,mp”は、レジスタapの値とレジスタmpの値とを乗算してアキュムレータの値に順次加算することを示している。これらの命令についても同様に、vi0命令によってアドレッシング制御を行なうことができる。
【0075】
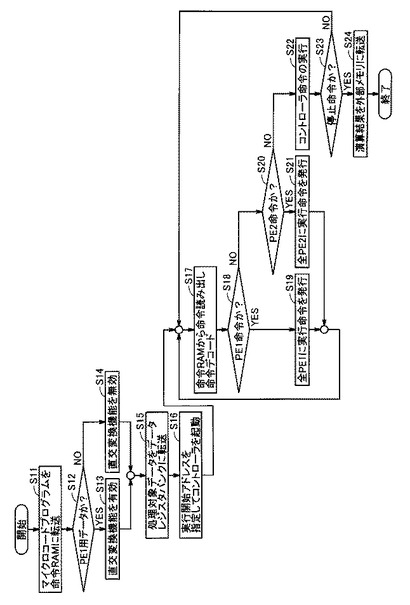
図9は、図1に示すデータ処理装置100を含んだシステムの処理手順を説明するためのフローチャートである。まず、汎用CPU13が、外部RAM15からマイクロコードプログラムを読み出して、データ処理装置100内の命令RAM11に転送する(S11)。そして、汎用CPU13またはDMAC14によって外部RAM15に格納される処理対象のデータが直交変換器10に転送される。
【0076】
次に、転送される処理対象のデータがPE1用データであるか、PE2用データであるかが判定される(S12)。PE1用データであれば(S12,Yes)、直交変換器10が処理対象データに対して直交変換を行ない(S13)、処理対象データをデータレジスタバンク(SRAMs2)に転送する(S15)。また、PE2用データであれば(S12,No)、直交変換器10が処理対象データをそのままデータレジスタバンク(SRAMs2)に転送する(S15)。
【0077】
次に、汎用CPU13は、実行開始アドレスを指定してコントローラ12を起動させる(S16)。
【0078】
コントローラ12は、命令RAM11からの命令読み出しを開始し、読み出した命令をデコードする(S17)。そして、コントローラ12は、命令がPE1命令であるか、PE2命令であるかを判定する(S18)。
【0079】
PE1命令であれば(S18,Yes)、コントローラ12は、全てのPE1(5)に対して実行命令を発行し(S19)、ステップS17に戻って以降の処理を繰り返す。また、PE2命令であれば(S18,No)、コントローラ12は、全てのPE2(7)に対して実行命令を発行し(S21)、ステップS17に戻って以降の処理を繰り返す。
【0080】
また、PE2命令でもなければ、すなわちコントローラ命令であれば(S20,No)、コントローラ12は、そのコントローラ命令を実行する(S22)。このとき、演算完了を示す停止命令であれば(S23,Yes)、コントローラ12は、演算結果を外部RAM15に転送し(S24)、処理を終了する。また、停止命令でなければ(S23,No)、ステップS17に戻って以降の処理を繰り返す。
【0081】
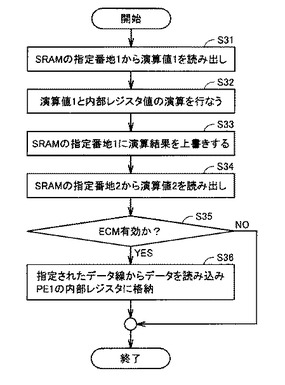
図10は、PE1(5)によるPE1命令実行時の処理手順を説明するためのフローチャートである。まず、PE1(5)は、SRAM16の指定番地1から演算対象データ(演算値1)を読み出す(S31)。そして、PE1(5)は、演算値1と内部レジスタ値との演算を行なう(S32)。
【0082】
次に、PE1(5)は、SRAM16の指定番地1に演算結果を上書きし(S33)、SRAM16の指定番地2から演算値2を読み出す(S34)。そして、ECM4によるデータ移動が有効か否かを判定する(S35)。
【0083】
ECM4によるデータ移動が有効であれば(S35,Yes)、指定されたデータ線(エントリ)からデータを読み込み、PE1(5)の内部レジスタに格納して(S36)、処理を終了する。また、ECM4によるデータ移動が無効であれば(S35,No)、そのまま処理を終了する。
【0084】
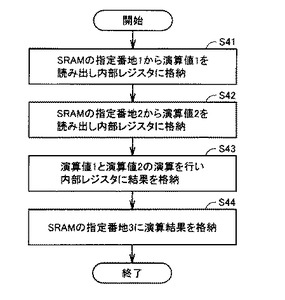
図11は、PE2(7)によるPE2命令実行時の処理手順を説明するためのフローチャートである。まず、PE2(7)は、SRAM16の指定番地1から演算値1を読み出し、内部レジスタに演算値1を格納する(S41)。また、SRAM16の指定番地2から演算値2を読み出し、内部レジスタに演算値2を格納する(S42)。
【0085】
次に、PE2(7)は、演算値1と演算値2との演算を行ない、内部レジスタに演算結果を格納する(S43)。そして、SRAM16の指定番地3に演算結果を格納し(S44)、処理を終了する。
【0086】
以上説明したように、本実施の形態におけるデータ処理装置によれば、PE1(5)のそれぞれに対応してSRAMs2が設けられると共に、32個のSRAMs2に対応してPE2(7)が設けられるようにしたので、PE1(5)とPE2(7)とがSRAMs2を共有することが可能となった。
【0087】
また、直交変換器10は、PE1用データの場合にはデータに対して直交変換を行なってSRAMs2に格納し、PE2用データの場合にはデータをそのままSRAMs2に格納するようにしたので、SRAMs2にPE1用データとPE2用データとを混在して格納することが可能となった。
【0088】
また、コントローラ12が、MODEレジスタの設定に応じてPE1(5)およびPE2(7)に対して選択的に演算を行なわせるようにしたので、PE1(5)に可変長ビットのデータの演算を行なわせ、PE2(7)に固定長ビットのデータの演算を行なわせるといった、演算器が得意とする演算を選択的に行なわせることが可能となった。
【0089】
(第2の実施の形態)
本発明の第2の実施の形態は、第1の実施の形態において説明したデータ処理装置100を車載機器の1つであるミリ波レーダによる周辺監視システムに適用するものである。したがって、重複する構成および機能の詳細な説明は繰り返さない。
【0090】
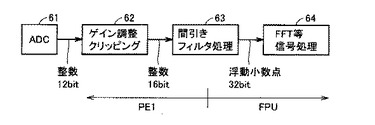
図12は、本発明の第2の実施の形態における周辺監視システムのミリ波レーダの信号処理の一例を示す図である。図示しないミリ波レーダによって得られた情報がADC(Analog Digital Converter)61によって12ビット長のデジタルデータに変換されて、外部RAM15に格納される。データ処理装置100は、第1の実施の形態において説明した手順によって、外部RAM15から12ビット長のデータを入力し、桁合わせや符号拡張などによるゲイン処理、クリッピング処理を行なう(62)。そして、間引き処理を行なった後、データを浮動小数点値に変換してローパスフィルタ等の信号処理演算を行ない(63)、FFT(Fast Fourier Transform)による周波数解析を行なう(64)。
【0091】
通常、汎用CPUなどは、16、32ビットの固定ビット長のレジスタを使用して演算を行なうが、ミリ波レーダのADC61から入力される12ビット長のデータを処理する場合、使用しない上位ビット分の面積や消費電力が無駄になってしまう。このようなデータに対しては、細粒度演算器を用いる方が効率的に処理が行なえる。
【0092】
しかしながら、細粒度演算器は、上述のように信号処理に必要な浮動小数点演算を高速に行なうことができない。そこで、本実施の形態における周辺監視システムでは、図12に示すように、細粒度演算コアであるPE1(5)がゲイン調整、クリッピング処理(62)および間引き処理(63)を行ない、その演算結果を浮動小数点値に変換した後、粗粒度演算コアであるFPUがフィルタ処理(63)およびFFTによる周波数解析(64)を行なうものである。
【0093】
図13は、本発明の第2の実施の形態におけるFPUによって処理される浮動小数点値のデータ構造を説明するための図である。この浮動小数点値は、IEEE754によって規定される単精度の浮動小数点値データ構造であり、最上位の符号ビット(1ビット)と、8ビットの指数部と、23ビットの仮数部とを含む。
【0094】
図14は、本発明の第2の実施の形態における周辺監視システムのデータ処理装置のデータ配置を説明するための図である。図14に示すデータ処理装置は、図1に示す本発明の第1の実施の形態におけるデータ処理装置100と比較して、PE2(7)をFPU7に置換した点のみが異なる。したがって、重複する構成および機能の詳細な説明は繰り返さない。
【0095】
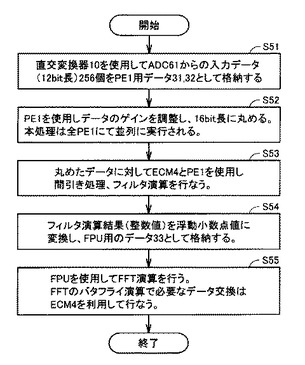
また、図15は、本発明の第2の実施の形態における周辺監視システムの処理手順を説明するためのフローチャートである。図14および図15を参照しながら、本実施の形態における周辺監視システムのミリ波レーダの信号処理について説明する。なお、コントローラ12が命令RAM11に格納されるマイクロコードプログラムを実行することによって、これらの処理が行なわれる。
【0096】
まず、外部RAM15に格納されるADC61からの12ビット長のデータが順次直交変換器10に入力される。直交変換器10は、12ビット長のデータ256個を直交変換し、図14のデータ31,32(整数値1〜16)のように格納する(S51)。なお、図14においては、整数値1〜16のみが記載されているが、256個の整数値が256個のSRAMs2に格納されるものとする。
【0097】
次に、コントローラ12は、PE1(5)に整数値1〜256の演算を行なわせることによりゲイン調整およびクリッピング処理を行ない、16ビット長のデータに丸める(S52)。この処理は、全てのPE1(5)によって並列に実行される。
【0098】
次に、コントローラ12は、ECM4およびPE1(5)を制御して丸めたデータに対して間引き処理およびフィルタ処理を行なう(S53)。そして、フィルタ演算結果を浮動小数点値に変換し、FPU用データ23として浮動小数点値1〜6をSRAMs2に格納する(S54)。この整数値から浮動小数点値への変換は、PE1(5)によって256個のデータを並列にデコード、エンコードすることによって行なうことができるが、FPU7の機能を用いて行なうことも可能である。
【0099】
次に、コントローラ12は、FPU7に浮動小数点値を用いたFFT演算を行なわせる(S55)。FFTのバタフライ演算で必要となるデータ交換は、後述のようにECM4を用いて行なうことが可能である。
【0100】
細粒度演算コアであるPE1(5)は256個のデータを並列に演算することが可能であるが、FPU用のデータ構造では演算の並列度が8並列となってしまう。そのため、データ種別や処理内容に応じてPE1(5)による演算と、FPU7による演算とを適宜切り替える必要があるが、上述のようにコントローラ12がマイクロコードプログラムを解釈することによってこの切り替えを動的に行なう。
【0101】
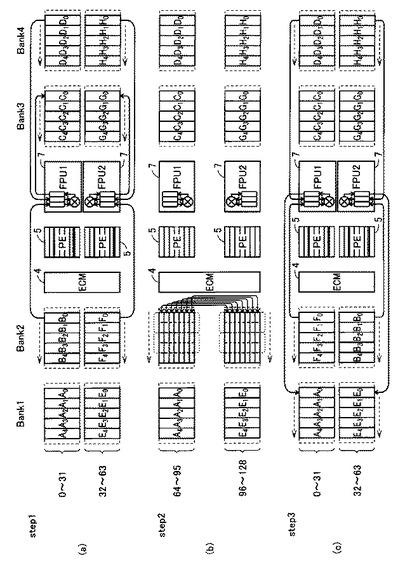
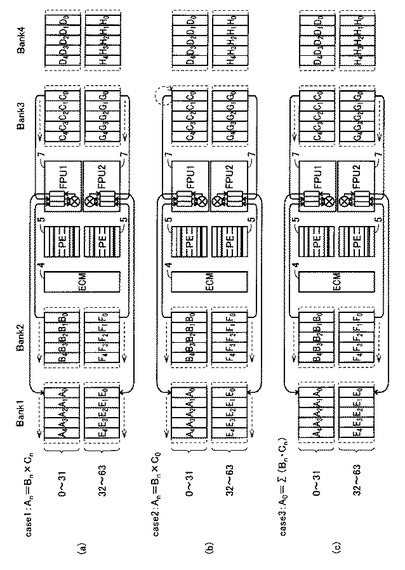
図16は、FPU7による浮動小数点演算の一例を示す図である。図16においては、Cn=Bn+Dn、Gn=Fn+Hnの演算を行なった後、An=Fn+Dn、En=Bn+Hnの演算を行なう場合を示している。
【0102】
まず、図16(a)に示すように、演算に必要なデータBn,Dn、Fn、Hnがバンク2およびバンク4に転送されて配置される。バンク2の0〜31エントリにデータBnが配置され、バンク2の32〜63エントリにデータFnが配置される。また、バンク4の0〜31エントリにデータDnが配置され、バンク4の32〜63エントリにデータHnが配置される。なお、0〜31エントリがFPU1に接続され、32〜63エントリがFPU2に接続されている。
【0103】
最初に、FPU1およびFPU2が、Cn=Bn+DnおよびGn=Fn+Hnの演算を同時に行なう。FPU1とFPU2とがSIMD接続されているため、それぞれがエントリの同じ位置にある異なる内容のデータを対象に同じ演算を行なう。汎用CPUなどを用いた場合には、CnとGnとを別々に演算する必要があるが、本実施の形態においては、FPU1およびFPU2がSIMD型並列演算プロセッサによって構成されるため、CnとGnとを同時に演算することができる。
【0104】
次に、図16(b)に示すように、PE1(5)およびECM4によるエントリ間通信機能によって、データBnとFnとを交換する。上述のように、ECM4は2のべき乗距離にあるエントリに接続しており、1サイクル毎に最大2ビットの値を別エントリに移動、交換することができる。
【0105】
このデータ移動、変換はPE1(5)を用いて行なわれるため、FPU用に格納された浮動小数点値が1ビット毎に分割され、個々のエントリに対応するPE1(5)が32エントリ上下のエントリ値と交換を行なう。このとき、PE1(5)は最大2ビット単位で処理を行なうことができるため、連続的に配置された2つの浮動小数点値を同時に移動、交換することができる。
【0106】
最後に、図16(c)に示すように、FPU1およびFPU2が、An=Fn+DnおよびEn=Bn+Hnの演算を同時に行なう。
【0107】
ここで、Bn、Dn、Fn、Hnのそれぞれに属するデータが10個ずつある場合における演算量を考える。汎用CPUなどでは、全ての演算をシーケンシャルに行なう必要があるため、Cn、Gn、An、Enを求めるためにそれぞれ10回ずつの演算が必要であり、合計40回の演算が必要となる。また、データ交換を行なうためには、テンポラリレジスタtmp=Bn、Bn=Fn、tmp=Fnなどのように3回のデータコピーが必要となる。したがって、CnおよびGn、またはAnおよびEnのデータ演算、移動処理回数は、それぞれ10+30+10=50回となる。
【0108】
一方、本実施の形態においては、FPU1およびFPU2がCnおよびGnの演算、またはAnおよびEnの演算を同時に行なうことができるため、演算回数はそれぞれ10回となる。また、PE1(5)およびECM4によって2つの浮動小数点値を同時に交換できる。したがって、図16(a)に示すステップ1の演算処理が10回、図16(b)に示すステップ2のデータ移動処理が5回、図16(c)に示すステップ3の演算処理が10回の合計25回となる。
【0109】
このように、本実施の形態においては、データ演算、データ移動回数を削減することができる。さらに、PE1(5)は、FPU用データのそれぞれのビットに対して個別に処理を行なえるため、たとえば浮動小数点値の絶対値を計算する場合には、図14に示すようにFPU用に格納されたデータの符号ビット33に対応するPE1(5)のみを動作させることで、FPUを動作させることなく絶対値計算を行なえることになり、消費電力を削減することができる。この絶対値計算の処理としては、符号ビットが“1”であれば符号ビットを“0”にし、符号ビットが“0”であればそのままとする。
【0110】
図17は、本発明の第2の実施の形態におけるデータ処理装置のアドレッシングモードの一例を示す図である。信号処理においては様々なアドレッシングモードが必要となるが、図17(a)〜図17(c)にその具体例を示している。
【0111】
図17(a)は、配列内の対応する各要素を演算し、その演算結果を別の配列の対応する要素に格納する場合を示す。FPU1がAn=Bn×Cnの演算を行なって演算結果Anを格納する場合であるが、データの読み出すアドレスおよびデータを書き込むアドレスの全てが順次インクリメントされる。
【0112】
図17(b)は、配列内の全ての要素Bnに固定係数C0を乗算し、その演算結果を別の配列の対応する要素に格納する場合を示す。要素Bnを読み出すアドレスおよび要素Anを書き込むアドレスが順次インクリメントされ、要素C0を読み出すアドレスが固定とされる。
【0113】
図17(c)は、配列Bnと配列Cnとの乗算結果を順次加算(積算)してアキュムレータに格納しておき、最後にその総和をA0に格納する場合を示す。要素BnおよびCnを読み出すアドレスが順次インクリメントされ、要素A0を書き込むアドレスが固定とされる。この処理は、配列の対応する要素同士の乗算結果を積算することができるので、信号処理でよく使用される畳み込み積分演算などに有効である。
【0114】
これらのアドレッシングモードは、コントローラ12が実行するVLIW命令によって実現可能である。図8に示したように、コントローラ12が、PE1(5)およびFPU7が演算対象とするデータの位置を演算の種類と共に指定する。コントローラ12は、このデータ位置を内部のレジスタ(mp,ap,mp2,ap2)に保持しており、これらのレジスタの値をFPU7の演算命令と同じサイクルで変更することによって、任意の飛び幅でデータをアクセスすることができる。
【0115】
コントローラ12は、共通命令の1つとして図8(a)に示すようなvi命令を実行する。vi命令は、よく使用されるコントローラ12のレジスタ演算式を定義した8個の命令群であり、1つの制御命令と2つの操作命令とを同時に指定することができる。どのvi命令を読み出すかはコントローラ命令サブセットによって指定される。残りのビットには、PE1(5)やFPU7の演算命令が記述される。
【0116】
図8(b)に示すように、1行に記述されたコントローラ命令サブセットとFPU命令とが同時に実行される。たとえば、加算命令が実行されると同時に、コントローラ12がコントローラ命令サブセットで指定されたvi命令を解釈してレジスタの値を更新する。
【0117】
“mvinc mp,r0,r1”においては、レジスタr0に配列の開始位置を指定し、レジスタr1に飛び幅を指定することによって、図17に示すような連続したアドレッシングだけでなく、一定飛び幅のアドレッシングモードも実現することができる。ミリ波レーダ処理で使用されるFFTにおいてはバタフライ演算が行なわれるが、このVLIW命令によってバタフライ演算を効率よく行なうことができる。
【0118】
図18は、本発明の第2の実施の形態におけるシステムの他の一例を示す図である。図18に示すデータ処理装置は、図1に示す本発明の第1の実施の形態におけるデータ処理装置100と比較して、PE2(7)を32ビット整数積和演算器(MAC)7に置換した点のみが異なる。したがって、重複する構成および機能の詳細な説明は繰り返さない。
【0119】
PE1(5)によって、図18に示すMAC演算用データ(整数値17〜22)の任意ビット位置のマスク処理を行なったり、ECM4によって整数値17の上位2ビットを整数値20の下位にビットシフトしたりすることが可能となる。
【0120】
一般的なSIMD型並列演算器においては、各演算器に対応したデータを入れ替えたりする機能が不十分であったため、汎用CPUなどがデータ交換を行なったり、ビットシフトしたりする必要があった。本実施の形態においては、MAC用データを256ビットの循環型データと見なすことができ、PE1(5)がこれらの任意ビットを個別に演算することが可能となる。
【0121】
以上説明したように、本実施の形態における周辺監視システムによれば、入力データに応じて使用する演算コアを選択するようにマイクロコードプログラムを作成することにより、効率的に演算処理が行なえるようになり、電力性能比を向上させることが可能となった。
【0122】
また、SIMD接続したFPU7を並列に動作させて浮動小数点演算を行なうようにしたので、単一の演算しか実行できないCPUやDSPよりも高速に演算処理を行なうことが可能となった。
【0123】
また、PE1(5)およびECM4を用いてFPU間のデータ移動、データ交換を行なうようにしたので、少ないオペレーション数でデータ移動、データ交換を行なうことが可能となった。
【0124】
また、データが連続して並んでいない場合であっても、コントローラ12がVLIW命令によるレジスタ演算を行なうことによって、柔軟なアドレッシングモードをサポートすることが可能となった。
【0125】
今回開示された実施の形態は、すべての点で例示であって制限的なものではないと考えられるべきである。本発明の範囲は上記した説明ではなくて特許請求の範囲によって示され、特許請求の範囲と均等の意味および範囲内でのすべての変更が含まれることが意図される。
【符号の説明】
【0126】
1 バスコントローラ、2 SRAMs、3 SRAMアレイ、4 ECM、5 PE1、6 PE1演算アレイ、7 PE2、8 PE2演算アレイ、9 レジスタ、10 直交変換器、11 命令RAM、12 コントローラ、13 汎用CPU、14 DMAC、15 外部RAM、16 SRAM、23 内部バス、41 セレクタ、42−1〜42−k NチャネルMOSトランジスタ、43,46 PチャネルMOSトランジスタ、44,45 インバータ、51,53 セレクタ、52 テンポラリレジスタ、54 バッファ、55 ALU、100 データ処理装置。
【技術分野】
【0001】
本発明は、複数のプロセッサを有するデータ処理装置に関し、特に、可変長ビットの演算を行なうことが可能なプロセッサと、主に固定長ビットの演算を行なうプロセッサとを有するデータ処理装置およびそのデータ処理方法に関する。
【背景技術】
【0002】
近年、音声や画像といった大量のデータを高速に処理するデジタル信号処理の重要性が高まってきている。このようなデジタル信号処理においては、一般に専用の半導体装置としてDSP(Digital Signal Processor)が用いられることが多い。しかしながら、信号処理アプリケーション、特に画像処理アプリケーションにおいては、処理対象のデータ量が非常に大きいため、DSPでも処理能力が十分ではない。
【0003】
これに対して、複数の演算器を並列に動作させることによって高い信号処理性能を実現する並列プロセッサ技術の開発が進んでいる。このような専用プロセッサをCPU(Central Processing Unit)に付随するアクセラレータとして用いれば、組み込み機器に搭載されるLSIのように低消費電力、低コストが要求される場合においても高い信号処理性能を実現することができる。
【0004】
このような並列プロセッサの1つとして、単一命令複数データ流(SIMD:Single Instruction Multiple Data stream)の演算方式を採用しているSIMD型プロセッサを挙げることができる。
【0005】
SIMD型プロセッサは、細粒度演算コアを有しており、整数演算や固定小数点演算に適したプロセッサである。ここで、細粒度演算コアとは、複数回の演算によって可変長ビットの演算が可能な演算コアを指すものとする。
【0006】
SIMD型プロセッサの中でも、メモリと密結合した1〜2ビット単位で演算を行なう細粒度演算器(以下、PE(Processor Element)とも呼ぶ。)を1024個搭載した超並列プロセッサ(以下、このようなプロセッサをマトリクス型超並列プロセッサ(MX)とも呼ぶ。)は、大量の整数演算や固定小数点演算を短時間で行なうことができる。
【0007】
また、マトリクス型超並列プロセッサは、細粒度演算器を利用するため、必要なビット長の演算のみを行なうことができ、消費電力を削減することができるため、汎用DSPなどと比較して高い消費電力性能比を得ることができる。
【0008】
また、マトリクス型超並列プロセッサは、予め作成されたプログラムをロードして実行することができるため、これを制御するCPUと同時に並列演算を行なうことが可能である。また、後述のように、演算器間でデータ移動を行なうためのエントリコミュニケータ(ECM)を搭載しており、VLIW(Very Long Instruction Word)命令をサポートしたコントローラによって演算と同時にデータの交換を行なうことができるため、単に演算器を並列配置したプロセッサよりも効率よくデータ供給を行なえる。
【0009】
一方、浮動小数点演算器(FPU)などの粗粒度演算コアは、固定長の浮動小数点演算に特化した演算器であり、CPUに接続して使用される。ここで、粗粒度演算コアとは、1回の演算によって固定長ビットの演算が可能な演算コアを指すものとする。
【0010】
浮動小数点演算器は、浮動小数点演算用のレジスタを有しており、演算対象となるデータはこのレジスタ経由でCPUまたはメモリから供給される。また、CPUが実行命令の解釈を行ない、浮動小数点演算器に対する演算要求を行なう。浮動小数点演算器は、パイプライン構成となっており、単一の演算処理が1サイクルで完了しなくても連続的にデータを供給することによって、実質的には1演算/サイクルを実現する。これらに関連する技術として、下記の特許文献1〜2に開示された発明がある。
【0011】
特許文献1は、異なるデータ型フォーマットの各々に専用のハードウェアを必要としない浮動小数点ユニットを提供することを目的とする。特許文献1に記載の装置は、複数のデータ型フォーマットに対して乗算累算演算を実行できる標準乗算累算ユニット(MAC)を含む浮動小数点ユニットを含む。標準MACは、在来のデータ型フォーマットと単一命令多重データ(SIMD)型フォーマットとに対して演算するよう構成される。従って専用のSIMD用MACユニットが必要ないので、ダイの面積を大幅に節約する。SIMD命令がMACユニットの1つにより演算される場合、データは64ビットワードとして、上位と下位のMACユニットに与えられる。また、各MACユニットは、64ビットワードの上位半分又は下位半分の何れかを選択させる1つ以上のビットを受取る。各MACユニットは各々の32ビットワードに対して演算を行なう。その演算の結果は、浮動小数点ユニットのバイパスブロックにより64ビットワードに合体される。
【0012】
特許文献2は、CPUを代表例とするマイクロプロセッサとFPU(浮動小数点演算処理装置)を代表例とする専用プロセッサとの並行処理を可能とした情報処理装置において、マイクロプロセッサの待ち時間を短縮し処理能力を向上することを目的とする。情報処理装置は、マルチFPU構成とする。FPU接続制御部におけるFPU状態レジスタが複数のFPUの状態を監視しておく。複数のCPUのいずれかからFPU接続制御部におけるFPU状態解読部に要支援命令のリクエストがあると、FPU状態レジスタの情報に基づいて非動作で空いている状態のFPUをリクエストをしたCPUにつなぐようにFPU選択部を制御する。また、一時記憶レジスタ選択制御部から一時記憶レジスタ選択部の制御を介して一時記憶レジスタの使用エリアにデータ破壊の不具合が生じないようにする。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開2001−027945号公報
【特許文献2】特開2001−167058号公報
【発明の概要】
【発明が解決しようとする課題】
【0014】
上述のように、マトリクス型超並列プロセッサは、1〜2ビットの単位でデータに対する演算を行なうため、演算対象データのビット長に応じて処理サイクルが増加するが、任意ビット長の演算が可能である。しかしながら、マトリクス型超並列プロセッサに搭載される細粒度演算器は整数演算を目的としているため、浮動小数点のようなデータに対する演算を行なうためには、「デコード」、「演算」および「エンコード」の各処理を経る必要があり、非常に低速となってしまう。
【0015】
また、マトリクス型超並列プロセッサは、たとえば1024並列で演算処理を行なうため、まとまった量のデータに対する演算でなければ性能を発揮することができない。したがって、小タップのフィルタ処理など、並列度が小さくデータを頻繁に入れ替える必要がある演算には適していない。
【0016】
一方、浮動小数点演算器は、通常CPUとコプロセッサ接続されており、CPUが命令およびデータの供給を制御している。また、1つの浮動小数点演算器が1度に処理できる演算は1種類であり、1演算は複数サイクルで処理される。したがって、パイプラインに命令を連続的に供給すると共に、レジスタにデータを連続的に供給することによって性能を発揮させることは可能ではあるが、CPUが介在して制御を行なうため効率よく稼動させることは難しい。
【0017】
近年、組み込み機器分野においては、低消費電力と高速演算性能とが要求されており、特に、車載機器などでは安全性向上のために画像処理と信号処理とを組み合わせたシステムが採用されつつある。したがって、このようなシステムでは、画像処理と信号処理とを効率的に行なうことが可能な機構が熱望されている。
【0018】
本発明は、上記問題点を解決するためになされたものであり、その目的は、可変長データに対する演算処理と、固定長データに対する演算処理とを効率的に行なうことが可能なデータ処理装置およびそのデータ処理方法を提供することである。
【課題を解決するための手段】
【0019】
本発明の一実施例によれば、複数のプロセッサを含んだデータ処理装置が提供される。データ処理装置は、SIMD方式の複数のPE1と、複数のPE1のそれぞれに対応して設けられる複数のSRAMと、複数のPE2とを含む。複数のPE1のそれぞれは、複数のSRAMの中の対応する1つのSRAMに格納されるデータに対して演算を行なう。また、複数のPE2のそれぞれは、複数のSRAMの中の対応する複数個のSRAMに格納されるデータに対して演算を行なう。
【発明の効果】
【0020】
本発明の一実施例によれば、複数のPE1のそれぞれが、複数のSRAMの中の対応する1つのSRAMに格納されるデータに対して演算を行ない、複数のPE2のそれぞれが、複数のSRAMの中の対応する複数個のSRAMに格納されるデータに対して演算を行なうので、複数のSRAMを共有することができ、可変長データに対する演算処理と、固定長データに対する演算処理とを効率的に行なうことが可能となる。
【図面の簡単な説明】
【0021】
【図1】本発明の第1の実施の形態におけるデータ処理装置の構成例を示すブロック図である。
【図2】SRAM2の内部構成をさらに詳細に説明するための図である。
【図3】PE1(5)の内部構成をさらに詳細に説明するための図である。
【図4】PE2(7)の内部構成をさらに詳細に説明するための図である。
【図5】ECM4の内部構成およびその動作を説明するための図である。
【図6】直交変換器10の動作を説明するための図である。
【図7】命令RAM11に格納されるマイクロコードプログラムの一例を示す図である。
【図8】上述のVLIW命令を用いたアドレッシング制御を説明するための図である。
【図9】図1に示すデータ処理装置100を含んだシステムの処理手順を説明するためのフローチャートである。
【図10】PE1(5)によるPE1命令実行時の処理手順を説明するためのフローチャートである。
【図11】PE2(7)によるPE2命令実行時の処理手順を説明するためのフローチャートである。
【図12】本発明の第2の実施の形態における周辺監視システムのミリ波レーダの信号処理の一例を示す図である。
【図13】本発明の第2の実施の形態におけるFPUによって処理される浮動小数点値のデータ構造を説明するための図である。
【図14】本発明の第2の実施の形態における周辺監視システムのデータ処理装置のデータ配置を説明するための図である。
【図15】本発明の第2の実施の形態における周辺監視システムの処理手順を説明するためのフローチャートである。
【図16】FPU7による浮動小数点演算の一例を示す図である。
【図17】本発明の第2の実施の形態におけるデータ処理装置のアドレッシングモードの一例を示す図である。
【図18】本発明の第2の実施の形態におけるシステムの他の一例を示す図である。
【発明を実施するための形態】
【0022】
(第1の実施の形態)
図1は、本発明の第1の実施の形態におけるデータ処理装置の構成例を示すブロック図である。このデータ処理装置100は、バスコントローラ1と、SRAM(Static Random Access Memory)アレイ3と、エントリコミュニケータ(ECM)4と、PE1演算アレイ6と、PE2演算アレイ8と、直交変換器10と、命令RAM11と、コントローラ12とを含む。また、このデータ処理装置100は、汎用CPU13、DMAC(Direct Memory Access Controller)14および外部RAM15と接続されている。
【0023】
汎用CPU13は、外部RAM15に格納されるマイクロコードプログラムを読み出し、データ処理装置100の内部バス23を介して命令RAM11に転送する。データ処理装置100は、命令RAM11に格納されたマイクロコードプログラムを実行することによって演算処理を行なう。このマイクロコードプログラムの転送は、DMAC14によるDMA転送であってもよい。
【0024】
また、汎用CPU13は、DMAC14を制御して、外部RAM15に格納される演算対象データをデータ処理装置100にDMA転送することによって、データ処理装置100に演算対象データを与える。
【0025】
バスコントローラ1は、データ処理装置100の内部バスの制御を行なう。たとえば、DMAC14によってDMA転送されたデータを受け、直交変換器10に入力させる。直交変換器10は、入力したデータをそのまま、または直交変換してSRAMアレイ3に書き込む。また、バスコントローラ1は、汎用CPU13からの要求により、SRAMアレイ3からデータを読み出して直交変換器10に出力する。直交変換器10は、入力したデータをそのまま、または直交変換して外部RAM15にDMA転送する。
【0026】
PE1演算アレイ6は、2ビットの細粒度演算コアであるPE1(5)を256個有しており、PE1(5)のそれぞれが少ビット単位で繰り返し演算処理を行なうことにより、任意ビット長データの演算を行なうことができる。PE1(5)による処理時間は処理対象データのビット長に依存しており、主に信号処理の初段の処理、たとえばA/D変換されたデータの入力直後の処理や、画像処理などの短ビット長の単純な整数演算を大量に行なう処理に適している。なお、PE1(5)の数は、これに限られるものではない。
【0027】
PE2演算アレイ8は、32ビットの粗粒度演算コアであるPE2(7)を8個有しており、PE2(7)のそれぞれが固定ビット長データの演算を行なうことができる。PE2(7)による処理時間は処理対象データのビット長には依存せず、演算するデータ数のみに依存する。PE2(7)は、固定ビット長で演算が行なえるため、浮動小数点演算器などのように特殊な演算を行なうことができ、信号処理に適している。また、PE2(7)は、細粒度演算器に比べて並列度が小さいため、少ないデータの処理にも適している。なお、PE2(7)の数は、これに限られるものではない。
【0028】
SRAMアレイ3は、2ビットバスのSRAMs(2)を256個有している。図1に示すように、256個のPE1(5)と、8個のPE2(7)とがECM4を介して256個のSRAMs2に接続されている。1つのSRAMs2が1つのPE1(5)に対応するように接続され、後述のように全てのPE1(5)が同時にサイクル単位で1ビットまたは2ビットのデータを読み書き可能な構成となっている。なお、SRAMs2の数は、これに限られるものではない。
【0029】
また、32個のSRAMs2が1つのPE2(7)に対応するように接続され、32ビットのデータがビット分解されて、32個のSRAMs(2)のそれぞれに1ビットずつ格納される。これによって、PE2(7)がサイクル単位で32ビット長のデータの読み出し/書き込みを行なえるようになる。
【0030】
コントローラ12は、命令RAM11に格納されるマイクロコードプログラムを順次読み出して解釈し、SRAMアレイ3、ECM4、PE1アレイ6、PE2アレイ8を制御して、演算処理を行なう。
【0031】
図2は、SRAM2の内部構成をさらに詳細に説明するための図である。SRAM2は、256ビットのSRAM16を4個有しており、これらのSRAM16が連続したアドレスに配置されている。アドレスを指定することによって、SRAM16のそれぞれの任意の位置の1ビットデータ、または偶数ビット番目から格納される連続した2ビットデータを一度に読み出すことができる。これら4つのSRAM16は、同時にデータの読み出し/書込みが可能であり、それぞれをバンク1〜バンク4と呼ぶことにする。
【0032】
図3は、PE1(5)の内部構成をさらに詳細に説明するための図である。PE1(5)は、SRAMs2内のあるSRAM16(たとえば、バンク4)からの2ビットデータの読み出しと、別のSRAM16(たとえば、バンク3)に対する2ビットデータの読み出し/書き込みとを同時に行なうことができる。また、PE1(5)は、SRAM16内の偶数ビット番目から格納される連続した2ビットデータ、または任意位置の1ビットデータの読み書きが可能である。
【0033】
PE1(5)は、内部に演算用レジスタ(X0,X1)17を有しており、バンク4から読み込んだ2ビットのデータをこの演算用レジスタ17に格納する。それと同時に、PE1(5)は、バンク3から2ビットデータを読み出して、演算用レジスタ17に格納される値との演算を行ない、バンク3の同じアドレスに上書きする。
【0034】
PE1(5)は、2ビットの加算器と、ブースデコーダとを有しており、1ビットまたは2ビットデータの加減算、乗算、1ビット単位の論理演算を行なうことができる。加算器は、キャリー情報を内部レジスタに保持するため、1ビットまたは2ビットデータの演算を繰り返すことで、複数サイクルを要することにはなるが、任意ビット長データの演算を行なうことができる。
【0035】
図4は、PE2(7)の内部構成をさらに詳細に説明するための図である。PE2(7)は、32ビットデータの2つ分(たとえば、バンク3とバンク4)の読み出しと、32ビットデータ(たとえば、バンク2)の書き込みとを同時に行なうことができる。PE8(7)は、32個のSRAM16のそれぞれの下位1ビットをまとめて32ビットのデータとして読み出し/書き込みを行なう。
【0036】
PE2(7)は、内部に2つの32ビットの演算用レジスタ(R0,R1)18を有しており、読み出した2つの32ビットデータをこれらの演算用レジスタ18に格納する。また、PE2(7)は、パイプラインを有する構成の演算器であり、複数サイクル後に先程読み出した2つのデータの演算結果を別の内部レジスタ(R2)に出力する。その後、PE2(7)は、内部レジスタ(R2)に格納される演算結果を別バンクの32個のSRAM16に書き込む。このようにして、パイプラインを停止させることなく、コントローラ12によって要求された命令の連続実行が可能となる。
【0037】
図5は、ECM4の内部構成およびその動作を説明するための図である。図5(a)は、ECM4の内部接続を示している。ECM4は、2のべき乗距離(1,2,4,8,16,32,64,128)にある演算コアに接続されており、接続されている演算コア間では1サイクルでデータを移動、交換することができる。図5(a)においては、セレクタ(SEL)41のそれぞれが、1,2,4の距離にある演算コアに接続される場合を示している。
【0038】
2のべき乗距離にない演算コアへのデータ移動は、2のべき乗距離にある演算器へのデータ移動を複数回組み合わせることにより、シフトレジスタのような動作によって実現可能である。たとえば、6エントリ分のデータ移動を行なう場合には、4エントリ分の移動+2エントリ分の移動のように、2サイクルに分けて実行される。
【0039】
また、PE2(7)によって演算が行なわれる場合には、32のN倍エントリ単位でデータ移動することで、演算コア間のデータ移動に対応することができる。
【0040】
SRAMs2から読み出されたデータは、指定されたECM4内にブロードキャストされる。そして、コントローラ12が全セレクタ41に対して、いずれの距離からのデータを読み出すかを指定し、選択されたデータのみがPE1(5)に入力される。そのため、全エントリのデータは、等しく同じ距離を移動することになる。
【0041】
2ビット演算コアであるPE1(5)に演算を行なわせる場合には、ECM4を使用してデータを移動することで演算対象のデータを入れ替えることができる。また、PE2(7)に演算を行なわせる場合には、演算対象のデータが32個のSRAMs2にまたがって格納されているため、32未満の距離でデータを移動させるとデータのビットシフトを行なうことができる。逆に、32以上の距離でデータを移動させると演算対象のデータを入れ替えることができる。
【0042】
図5(b)は、ECM4を用いた演算処理の一例を示す図である。まず、ステップ1においては、SRAM16のエントリ#0〜#3に格納されるデータa0〜a3がテンポラリレジスタ(Temp.Reg.)にロードされる。
【0043】
ステップ2において、ECM4によってテンポラリレジスタに格納されるデータa0〜a3が1ビットずつシフトされる。そして、ステップ3において、SRAM16に格納されるデータb0〜b3が読み出されて、テンポラリレジスタに格納されるデータとの演算が行なわれ、SRAM16のデータb0〜b3が格納されていたのと同じアドレスに演算結果が上書きされる。
【0044】
図5(c)は、図5(a)に示すセレクタ41の内部構成をさらに詳細に説明するための図である。セレクタ41は、NチャネルMOSトランジスタ42−1〜42−kと、PチャネルMOSトランジスタ43および46と、インバータ44および45とを含む。
【0045】
VCH_IN_1〜VCH_IN_kに、2のべき乗距離にあるエントリの出力が接続される。VCH_SEL_1〜VCH_SEK_kのいずれか1つがハイレベル(以下、Hレベルと略す。)となって、そのNチャネルMOSトランジスタに接続されるエントリの出力が選択される。
【0046】
セレクタ(SEL)51の一方の端子には、セレクタ41によって選択されたエントリの出力が接続され、他方の端子には、そのPE1(5)に対応するSRAMs2の出力が接続される。セレクタ(SEL)51は、VCH_IE信号に応じて、セレクタ41によって選択されたエントリの出力と、PE1(5)に対応するSRAMs2の出力とのいずれかを選択して出力する。
【0047】
テンポラリレジスタ52は、セレクタ(SEL)51からの出力を一時的に保持し、セレクタ(SEL)53に出力する。セレクタ(SEL)53は、テンポラリレジスタ52に保持される値と、PE1(5)に対応するSRAMs2の出力とのいずれかを選択して出力する。
【0048】
他のエントリにデータを転送するときにVCH_OE信号がHレベルとなり、バッファ54がセレクタ(SEL)53から出力される値を他のエントリに出力する。また、セレクタ(SEL)53から出力される値に対して演算を行なう場合には、ALU55がその演算結果(ALU_OUT)を出力する。
【0049】
たとえば、図5(b)のステップ1に示すようにテンポラリレジスタにデータa0〜a3がロードされる場合には、セレクタ(SEL)51がSRAMs2の出力(SRAM_OUT)を選択してテンポラリレジスタ52に出力する。テンポラリレジスタ52は、その値を保持する。
【0050】
図5(b)のステップ2に示すように、テンポラリレジスタが保持する値をシフトする場合には、セレクタ53がテンポラリレジスタ52が保持する値を選択して出力する。バッファ54は、セレクタ53から出力される値をVCH_OUTに出力する。このとき、セレクタ41は、隣のエントリからの出力を選択するように設定されており、セレクタ51は、隣のエントリのデータを選択してテンポラリレジスタ52に出力する。テンポラリレジスタ52は、その値を保持することによって、図5(b)のステップ2に示すシフト動作が完了する。
【0051】
図5(b)のステップ3に示すように、PE1(5)が演算を行なう場合には、演算器(ALU)55が、セレクタ(SEL)53を介してテンポラリレジスタ52に保持される値を受けて演算を行なう。
【0052】
図6は、直交変換器10の動作を説明するための図である。直交変換器10は、2系統のデータ入出力ポートを有しており、一方のポート20を介して外部RAM15に格納されるデータを受け、直交変換した後のデータを他方のポート21を介してSRAM16に格納するか、または、直交変換せずに同じデータを他方のポート21を介してSRAM16に格納する。
【0053】
逆に、直交変換器10は、ポート21を介してSRAM16に格納されるデータを受け、直交変換した後のデータをポート20を介して外部RAM15に転送するか、または、直交変換せずに同じデータをポート20を介して外部RAM15に転送することも可能である。
【0054】
また、直交変換器10は、ポート21を介してSRAM16に格納されるデータを受け、直交変換した後のデータを再度ポート21を介してSRAM16に格納することも可能である。
【0055】
図6(a)は、PE1(5)用のデータをSRAM16に格納するときの直交変換器10の動作を示している。図6(a)においては、外部RAM15に格納される8ビット長データ8個をPE1(5)用に転送する場合を示している。なお、32ビット長データを32個受けて直交変換し、SRAM16に転送するようにしてもよい。
【0056】
上述のように、PE1(5)が使用するデータは対応する1つのSRAM16内にビットストリームとして格納される必要がある。そのため、直交変換器10は、ポート20を介して外部RAM15から8ビット長のデータを受け、8個のデータを順次バッファリングする。そして、直交変換器10は、バッファリングした各データの同じビット位置にあるデータを8個まとめて、ポート21を介してSRAM16にデータ22を転送する。
【0057】
そして、次のビット位置にあるデータを8個まとめて、次のアドレスのSRAM16に転送する。これを繰り返すことによって、外部から入力されたデータを直交変換し、PE1(5)用データとしてSRAM16に格納することができる。
【0058】
図6(b)は、PE2(7)用のデータをSRAM16に格納するときの直交変換器10の動作を示している。図6(b)においては、外部メモリ15に格納される8ビット長データをPE2(7)用に転送する場合を示している。なお、32ビット長データを受けて、そのままSRAM16に転送するようにしてもよい。
【0059】
PE2(7)用のデータは、32個のSRAM16にまたがって格納される必要があるため、直交変換器10はレジスタ操作による直交変換を行なわずにデータをSRAM16に転送する。直交変換器10は、ポート20を介して外部RAM15から8ビット長のデータを受け、ビット分割をせずにそのままポート21を介してSRAM16にデータ23を転送する。
【0060】
このようにして、直交変換器10は、同一のSRAM内にPE1(5)用のデータと、PE2(7)用のデータとを混在して格納することが可能となる。
【0061】
図7は、命令RAM11に格納されるマイクロコードプログラムの一例を示す図である。命令には、“コントローラ命令”、“PE1命令”、“PE2命令”の3種類があり、これらを組み合わせたVLIW命令として命令RAM11に格納される。
【0062】
図7(a)に示すように、MODEレジスタの設定にかかわらず、命令の最上位ビットが“1”の場合には、コントローラ命令であることを示す。また、命令の最上位ビットが“0”の場合には、PE1命令またはPE2命令であることを示す。
【0063】
図7(b)に示すように、MODEレジスタの設定が“0”であり、かつ命令の最上位ビットが“0”の場合には、コントローラ命令とPE1命令との混在であることを示す。図7(b)においては、PE1命令として、“load命令”、“alu命令”、“mode命令”が記述されている。なお、“mode命令”は、1ビットと2ビットとの切り替えを行なう命令である。
【0064】
図7(c)に示すように、MODEレジスタの設定が“1”であり、かつ命令の最上位ビットが“0”の場合には、コントローラ命令とPE2命令との混在であることを示す。
【0065】
図7(d)に示すように、コントローラ12は、まず命令の最上位ビットをデコードし、これが“1”の場合にはコントローラ命令、“0”の場合にはPE1命令またはPE2命令と判断する。そして、コントローラ12は、MODEレジスタの設定によってPE1命令であるか、PE2命令であるかを判断する。
【0066】
コントローラ12は、コントローラ命令によってMODEレジスタ設定を変更することができるため、PE1演算器およびPE2演算器の選択は、命令の実行時に動的に行なうことができる。また、コントローラ12は、命令が“PE1命令”または“PE2命令”とを含む場合には、個々の演算器の命令だけでなくコントローラ命令のサブセットを含めて、複数の命令を同時に実行することができる。
【0067】
コントローラ12は、命令がPE1命令を含む場合には、PE1(5)に“load命令”と“alu命令”とを出力する。PE1(5)は、図3に示すように、“load命令”によって、SRAM16から2ビットデータをPE1(5)内のレジスタに読み込み、“alu命令”によってSRAM16から読み出したデータとレジスタのデータとの演算を行ない、演算結果をSRAM16の2ビットに上書きする。この動作を1サイクルで行なうことができるため、これを連続的に行なうことによって任意ビット長データの演算を行なうことができる。
【0068】
コントローラ12は、命令がPE2命令を含む場合には、PE2(7)にPE2命令を出力する。PE2(7)は、内部にパイプラインを有した高度な演算を行なうことができる演算コアであり、図4に示すように、演算の途中結果を格納するレジスタ18を有している。PE2(7)は、コントローラ12から受けたPE2命令によって、SRAM16からデータを必要個数だけ読み出し、内部のシーケンサにしたがって演算を行なう。そして、PE2(7)は、演算結果をレジスタを経由して再度SRAM16に遅延書き込みする。
【0069】
一般的に、PE2(7)によるデータの入力から演算結果の出力まで数サイクルを要するが、内部レジスタへのデータ読み出しと内部レジスタからのデータ書き込みとを同時に行なうことができる。したがって、パイプライン処理を行なうことによって、コントローラ12がPE2(7)に対して連続的に演算要求を行なうことができ、見かけ上1演算/サイクルを実現することができる。
【0070】
また、上述のように、SRAM16が4バンクで構成されているため、PE2(7)の演算中であっても、すなわち最大3バンクにアクセスしていても、残り1バンクを用いてデータの入出力を行なうことができる。これによって、PE1(5)またはPE2(7)による演算と、汎用CPU13またはDMAC14による外部RAM15とSRAM16との間のデータ転送とを並行して行なうことができ、システム全体の性能を向上させることができる。
【0071】
図8は、上述のVLIW命令を用いたアドレッシング制御を説明するための図である。なお、ここではアドレッシング制御について間単に説明するが、詳細な説明は第2の実施の形態において説明するものとする。
【0072】
図8(a)は、コントローラ命令サブセット(vi命令)を示している。vi0において、“mvinc mp,r0,r1”は、レジスタr0の値をレジスタmpに代入し、レジスタr0の値とレジスタr1の値とを加算してレジスタr0に代入することを示している。また、vi0において、“mvinc ap,r2,r3”は、レジスタr2の値をレジスタapに代入し、レジスタr2の値とレジスタr3の値とを加算してレジスタr2に代入することを示している。
【0073】
図8(b)は、コントローラ命令サブセットとPE2命令(FPU命令)とを含んだVLIW命令を示している。加算命令“fadd ap2,ap,mp”は、レジスタapの値とレジスタmpの値とを加算してレジスタap2に格納することを示している。コントローラ命令として、図8(a)に示すvi0命令が記述されているため、レジスタapにレジスタr2とレジスタr3とを加算した値が代入される。同様に、レジスタmpにレジスタr0とレジスタr1とを加算した値が代入される。これによって、次にデータを読み出すSRAM16のアドレス(ap,mp)を、レジスタr3またはレジスタr1で制御することができる。
【0074】
また、乗算命令“fmul ap2,ap,mp”は、レジスタapの値とレジスタmpの値とを乗算してレジスタap2に格納することを示している。また、積和命令“fmac ap,mp”は、レジスタapの値とレジスタmpの値とを乗算してアキュムレータの値に順次加算することを示している。これらの命令についても同様に、vi0命令によってアドレッシング制御を行なうことができる。
【0075】
図9は、図1に示すデータ処理装置100を含んだシステムの処理手順を説明するためのフローチャートである。まず、汎用CPU13が、外部RAM15からマイクロコードプログラムを読み出して、データ処理装置100内の命令RAM11に転送する(S11)。そして、汎用CPU13またはDMAC14によって外部RAM15に格納される処理対象のデータが直交変換器10に転送される。
【0076】
次に、転送される処理対象のデータがPE1用データであるか、PE2用データであるかが判定される(S12)。PE1用データであれば(S12,Yes)、直交変換器10が処理対象データに対して直交変換を行ない(S13)、処理対象データをデータレジスタバンク(SRAMs2)に転送する(S15)。また、PE2用データであれば(S12,No)、直交変換器10が処理対象データをそのままデータレジスタバンク(SRAMs2)に転送する(S15)。
【0077】
次に、汎用CPU13は、実行開始アドレスを指定してコントローラ12を起動させる(S16)。
【0078】
コントローラ12は、命令RAM11からの命令読み出しを開始し、読み出した命令をデコードする(S17)。そして、コントローラ12は、命令がPE1命令であるか、PE2命令であるかを判定する(S18)。
【0079】
PE1命令であれば(S18,Yes)、コントローラ12は、全てのPE1(5)に対して実行命令を発行し(S19)、ステップS17に戻って以降の処理を繰り返す。また、PE2命令であれば(S18,No)、コントローラ12は、全てのPE2(7)に対して実行命令を発行し(S21)、ステップS17に戻って以降の処理を繰り返す。
【0080】
また、PE2命令でもなければ、すなわちコントローラ命令であれば(S20,No)、コントローラ12は、そのコントローラ命令を実行する(S22)。このとき、演算完了を示す停止命令であれば(S23,Yes)、コントローラ12は、演算結果を外部RAM15に転送し(S24)、処理を終了する。また、停止命令でなければ(S23,No)、ステップS17に戻って以降の処理を繰り返す。
【0081】
図10は、PE1(5)によるPE1命令実行時の処理手順を説明するためのフローチャートである。まず、PE1(5)は、SRAM16の指定番地1から演算対象データ(演算値1)を読み出す(S31)。そして、PE1(5)は、演算値1と内部レジスタ値との演算を行なう(S32)。
【0082】
次に、PE1(5)は、SRAM16の指定番地1に演算結果を上書きし(S33)、SRAM16の指定番地2から演算値2を読み出す(S34)。そして、ECM4によるデータ移動が有効か否かを判定する(S35)。
【0083】
ECM4によるデータ移動が有効であれば(S35,Yes)、指定されたデータ線(エントリ)からデータを読み込み、PE1(5)の内部レジスタに格納して(S36)、処理を終了する。また、ECM4によるデータ移動が無効であれば(S35,No)、そのまま処理を終了する。
【0084】
図11は、PE2(7)によるPE2命令実行時の処理手順を説明するためのフローチャートである。まず、PE2(7)は、SRAM16の指定番地1から演算値1を読み出し、内部レジスタに演算値1を格納する(S41)。また、SRAM16の指定番地2から演算値2を読み出し、内部レジスタに演算値2を格納する(S42)。
【0085】
次に、PE2(7)は、演算値1と演算値2との演算を行ない、内部レジスタに演算結果を格納する(S43)。そして、SRAM16の指定番地3に演算結果を格納し(S44)、処理を終了する。
【0086】
以上説明したように、本実施の形態におけるデータ処理装置によれば、PE1(5)のそれぞれに対応してSRAMs2が設けられると共に、32個のSRAMs2に対応してPE2(7)が設けられるようにしたので、PE1(5)とPE2(7)とがSRAMs2を共有することが可能となった。
【0087】
また、直交変換器10は、PE1用データの場合にはデータに対して直交変換を行なってSRAMs2に格納し、PE2用データの場合にはデータをそのままSRAMs2に格納するようにしたので、SRAMs2にPE1用データとPE2用データとを混在して格納することが可能となった。
【0088】
また、コントローラ12が、MODEレジスタの設定に応じてPE1(5)およびPE2(7)に対して選択的に演算を行なわせるようにしたので、PE1(5)に可変長ビットのデータの演算を行なわせ、PE2(7)に固定長ビットのデータの演算を行なわせるといった、演算器が得意とする演算を選択的に行なわせることが可能となった。
【0089】
(第2の実施の形態)
本発明の第2の実施の形態は、第1の実施の形態において説明したデータ処理装置100を車載機器の1つであるミリ波レーダによる周辺監視システムに適用するものである。したがって、重複する構成および機能の詳細な説明は繰り返さない。
【0090】
図12は、本発明の第2の実施の形態における周辺監視システムのミリ波レーダの信号処理の一例を示す図である。図示しないミリ波レーダによって得られた情報がADC(Analog Digital Converter)61によって12ビット長のデジタルデータに変換されて、外部RAM15に格納される。データ処理装置100は、第1の実施の形態において説明した手順によって、外部RAM15から12ビット長のデータを入力し、桁合わせや符号拡張などによるゲイン処理、クリッピング処理を行なう(62)。そして、間引き処理を行なった後、データを浮動小数点値に変換してローパスフィルタ等の信号処理演算を行ない(63)、FFT(Fast Fourier Transform)による周波数解析を行なう(64)。
【0091】
通常、汎用CPUなどは、16、32ビットの固定ビット長のレジスタを使用して演算を行なうが、ミリ波レーダのADC61から入力される12ビット長のデータを処理する場合、使用しない上位ビット分の面積や消費電力が無駄になってしまう。このようなデータに対しては、細粒度演算器を用いる方が効率的に処理が行なえる。
【0092】
しかしながら、細粒度演算器は、上述のように信号処理に必要な浮動小数点演算を高速に行なうことができない。そこで、本実施の形態における周辺監視システムでは、図12に示すように、細粒度演算コアであるPE1(5)がゲイン調整、クリッピング処理(62)および間引き処理(63)を行ない、その演算結果を浮動小数点値に変換した後、粗粒度演算コアであるFPUがフィルタ処理(63)およびFFTによる周波数解析(64)を行なうものである。
【0093】
図13は、本発明の第2の実施の形態におけるFPUによって処理される浮動小数点値のデータ構造を説明するための図である。この浮動小数点値は、IEEE754によって規定される単精度の浮動小数点値データ構造であり、最上位の符号ビット(1ビット)と、8ビットの指数部と、23ビットの仮数部とを含む。
【0094】
図14は、本発明の第2の実施の形態における周辺監視システムのデータ処理装置のデータ配置を説明するための図である。図14に示すデータ処理装置は、図1に示す本発明の第1の実施の形態におけるデータ処理装置100と比較して、PE2(7)をFPU7に置換した点のみが異なる。したがって、重複する構成および機能の詳細な説明は繰り返さない。
【0095】
また、図15は、本発明の第2の実施の形態における周辺監視システムの処理手順を説明するためのフローチャートである。図14および図15を参照しながら、本実施の形態における周辺監視システムのミリ波レーダの信号処理について説明する。なお、コントローラ12が命令RAM11に格納されるマイクロコードプログラムを実行することによって、これらの処理が行なわれる。
【0096】
まず、外部RAM15に格納されるADC61からの12ビット長のデータが順次直交変換器10に入力される。直交変換器10は、12ビット長のデータ256個を直交変換し、図14のデータ31,32(整数値1〜16)のように格納する(S51)。なお、図14においては、整数値1〜16のみが記載されているが、256個の整数値が256個のSRAMs2に格納されるものとする。
【0097】
次に、コントローラ12は、PE1(5)に整数値1〜256の演算を行なわせることによりゲイン調整およびクリッピング処理を行ない、16ビット長のデータに丸める(S52)。この処理は、全てのPE1(5)によって並列に実行される。
【0098】
次に、コントローラ12は、ECM4およびPE1(5)を制御して丸めたデータに対して間引き処理およびフィルタ処理を行なう(S53)。そして、フィルタ演算結果を浮動小数点値に変換し、FPU用データ23として浮動小数点値1〜6をSRAMs2に格納する(S54)。この整数値から浮動小数点値への変換は、PE1(5)によって256個のデータを並列にデコード、エンコードすることによって行なうことができるが、FPU7の機能を用いて行なうことも可能である。
【0099】
次に、コントローラ12は、FPU7に浮動小数点値を用いたFFT演算を行なわせる(S55)。FFTのバタフライ演算で必要となるデータ交換は、後述のようにECM4を用いて行なうことが可能である。
【0100】
細粒度演算コアであるPE1(5)は256個のデータを並列に演算することが可能であるが、FPU用のデータ構造では演算の並列度が8並列となってしまう。そのため、データ種別や処理内容に応じてPE1(5)による演算と、FPU7による演算とを適宜切り替える必要があるが、上述のようにコントローラ12がマイクロコードプログラムを解釈することによってこの切り替えを動的に行なう。
【0101】
図16は、FPU7による浮動小数点演算の一例を示す図である。図16においては、Cn=Bn+Dn、Gn=Fn+Hnの演算を行なった後、An=Fn+Dn、En=Bn+Hnの演算を行なう場合を示している。
【0102】
まず、図16(a)に示すように、演算に必要なデータBn,Dn、Fn、Hnがバンク2およびバンク4に転送されて配置される。バンク2の0〜31エントリにデータBnが配置され、バンク2の32〜63エントリにデータFnが配置される。また、バンク4の0〜31エントリにデータDnが配置され、バンク4の32〜63エントリにデータHnが配置される。なお、0〜31エントリがFPU1に接続され、32〜63エントリがFPU2に接続されている。
【0103】
最初に、FPU1およびFPU2が、Cn=Bn+DnおよびGn=Fn+Hnの演算を同時に行なう。FPU1とFPU2とがSIMD接続されているため、それぞれがエントリの同じ位置にある異なる内容のデータを対象に同じ演算を行なう。汎用CPUなどを用いた場合には、CnとGnとを別々に演算する必要があるが、本実施の形態においては、FPU1およびFPU2がSIMD型並列演算プロセッサによって構成されるため、CnとGnとを同時に演算することができる。
【0104】
次に、図16(b)に示すように、PE1(5)およびECM4によるエントリ間通信機能によって、データBnとFnとを交換する。上述のように、ECM4は2のべき乗距離にあるエントリに接続しており、1サイクル毎に最大2ビットの値を別エントリに移動、交換することができる。
【0105】
このデータ移動、変換はPE1(5)を用いて行なわれるため、FPU用に格納された浮動小数点値が1ビット毎に分割され、個々のエントリに対応するPE1(5)が32エントリ上下のエントリ値と交換を行なう。このとき、PE1(5)は最大2ビット単位で処理を行なうことができるため、連続的に配置された2つの浮動小数点値を同時に移動、交換することができる。
【0106】
最後に、図16(c)に示すように、FPU1およびFPU2が、An=Fn+DnおよびEn=Bn+Hnの演算を同時に行なう。
【0107】
ここで、Bn、Dn、Fn、Hnのそれぞれに属するデータが10個ずつある場合における演算量を考える。汎用CPUなどでは、全ての演算をシーケンシャルに行なう必要があるため、Cn、Gn、An、Enを求めるためにそれぞれ10回ずつの演算が必要であり、合計40回の演算が必要となる。また、データ交換を行なうためには、テンポラリレジスタtmp=Bn、Bn=Fn、tmp=Fnなどのように3回のデータコピーが必要となる。したがって、CnおよびGn、またはAnおよびEnのデータ演算、移動処理回数は、それぞれ10+30+10=50回となる。
【0108】
一方、本実施の形態においては、FPU1およびFPU2がCnおよびGnの演算、またはAnおよびEnの演算を同時に行なうことができるため、演算回数はそれぞれ10回となる。また、PE1(5)およびECM4によって2つの浮動小数点値を同時に交換できる。したがって、図16(a)に示すステップ1の演算処理が10回、図16(b)に示すステップ2のデータ移動処理が5回、図16(c)に示すステップ3の演算処理が10回の合計25回となる。
【0109】
このように、本実施の形態においては、データ演算、データ移動回数を削減することができる。さらに、PE1(5)は、FPU用データのそれぞれのビットに対して個別に処理を行なえるため、たとえば浮動小数点値の絶対値を計算する場合には、図14に示すようにFPU用に格納されたデータの符号ビット33に対応するPE1(5)のみを動作させることで、FPUを動作させることなく絶対値計算を行なえることになり、消費電力を削減することができる。この絶対値計算の処理としては、符号ビットが“1”であれば符号ビットを“0”にし、符号ビットが“0”であればそのままとする。
【0110】
図17は、本発明の第2の実施の形態におけるデータ処理装置のアドレッシングモードの一例を示す図である。信号処理においては様々なアドレッシングモードが必要となるが、図17(a)〜図17(c)にその具体例を示している。
【0111】
図17(a)は、配列内の対応する各要素を演算し、その演算結果を別の配列の対応する要素に格納する場合を示す。FPU1がAn=Bn×Cnの演算を行なって演算結果Anを格納する場合であるが、データの読み出すアドレスおよびデータを書き込むアドレスの全てが順次インクリメントされる。
【0112】
図17(b)は、配列内の全ての要素Bnに固定係数C0を乗算し、その演算結果を別の配列の対応する要素に格納する場合を示す。要素Bnを読み出すアドレスおよび要素Anを書き込むアドレスが順次インクリメントされ、要素C0を読み出すアドレスが固定とされる。
【0113】
図17(c)は、配列Bnと配列Cnとの乗算結果を順次加算(積算)してアキュムレータに格納しておき、最後にその総和をA0に格納する場合を示す。要素BnおよびCnを読み出すアドレスが順次インクリメントされ、要素A0を書き込むアドレスが固定とされる。この処理は、配列の対応する要素同士の乗算結果を積算することができるので、信号処理でよく使用される畳み込み積分演算などに有効である。
【0114】
これらのアドレッシングモードは、コントローラ12が実行するVLIW命令によって実現可能である。図8に示したように、コントローラ12が、PE1(5)およびFPU7が演算対象とするデータの位置を演算の種類と共に指定する。コントローラ12は、このデータ位置を内部のレジスタ(mp,ap,mp2,ap2)に保持しており、これらのレジスタの値をFPU7の演算命令と同じサイクルで変更することによって、任意の飛び幅でデータをアクセスすることができる。
【0115】
コントローラ12は、共通命令の1つとして図8(a)に示すようなvi命令を実行する。vi命令は、よく使用されるコントローラ12のレジスタ演算式を定義した8個の命令群であり、1つの制御命令と2つの操作命令とを同時に指定することができる。どのvi命令を読み出すかはコントローラ命令サブセットによって指定される。残りのビットには、PE1(5)やFPU7の演算命令が記述される。
【0116】
図8(b)に示すように、1行に記述されたコントローラ命令サブセットとFPU命令とが同時に実行される。たとえば、加算命令が実行されると同時に、コントローラ12がコントローラ命令サブセットで指定されたvi命令を解釈してレジスタの値を更新する。
【0117】
“mvinc mp,r0,r1”においては、レジスタr0に配列の開始位置を指定し、レジスタr1に飛び幅を指定することによって、図17に示すような連続したアドレッシングだけでなく、一定飛び幅のアドレッシングモードも実現することができる。ミリ波レーダ処理で使用されるFFTにおいてはバタフライ演算が行なわれるが、このVLIW命令によってバタフライ演算を効率よく行なうことができる。
【0118】
図18は、本発明の第2の実施の形態におけるシステムの他の一例を示す図である。図18に示すデータ処理装置は、図1に示す本発明の第1の実施の形態におけるデータ処理装置100と比較して、PE2(7)を32ビット整数積和演算器(MAC)7に置換した点のみが異なる。したがって、重複する構成および機能の詳細な説明は繰り返さない。
【0119】
PE1(5)によって、図18に示すMAC演算用データ(整数値17〜22)の任意ビット位置のマスク処理を行なったり、ECM4によって整数値17の上位2ビットを整数値20の下位にビットシフトしたりすることが可能となる。
【0120】
一般的なSIMD型並列演算器においては、各演算器に対応したデータを入れ替えたりする機能が不十分であったため、汎用CPUなどがデータ交換を行なったり、ビットシフトしたりする必要があった。本実施の形態においては、MAC用データを256ビットの循環型データと見なすことができ、PE1(5)がこれらの任意ビットを個別に演算することが可能となる。
【0121】
以上説明したように、本実施の形態における周辺監視システムによれば、入力データに応じて使用する演算コアを選択するようにマイクロコードプログラムを作成することにより、効率的に演算処理が行なえるようになり、電力性能比を向上させることが可能となった。
【0122】
また、SIMD接続したFPU7を並列に動作させて浮動小数点演算を行なうようにしたので、単一の演算しか実行できないCPUやDSPよりも高速に演算処理を行なうことが可能となった。
【0123】
また、PE1(5)およびECM4を用いてFPU間のデータ移動、データ交換を行なうようにしたので、少ないオペレーション数でデータ移動、データ交換を行なうことが可能となった。
【0124】
また、データが連続して並んでいない場合であっても、コントローラ12がVLIW命令によるレジスタ演算を行なうことによって、柔軟なアドレッシングモードをサポートすることが可能となった。
【0125】
今回開示された実施の形態は、すべての点で例示であって制限的なものではないと考えられるべきである。本発明の範囲は上記した説明ではなくて特許請求の範囲によって示され、特許請求の範囲と均等の意味および範囲内でのすべての変更が含まれることが意図される。
【符号の説明】
【0126】
1 バスコントローラ、2 SRAMs、3 SRAMアレイ、4 ECM、5 PE1、6 PE1演算アレイ、7 PE2、8 PE2演算アレイ、9 レジスタ、10 直交変換器、11 命令RAM、12 コントローラ、13 汎用CPU、14 DMAC、15 外部RAM、16 SRAM、23 内部バス、41 セレクタ、42−1〜42−k NチャネルMOSトランジスタ、43,46 PチャネルMOSトランジスタ、44,45 インバータ、51,53 セレクタ、52 テンポラリレジスタ、54 バッファ、55 ALU、100 データ処理装置。
【特許請求の範囲】
【請求項1】
SIMD演算方式の複数の第1のプロセッサと、
前記複数の第1のプロセッサのそれぞれに対応して設けられる複数の記憶手段と、
複数の第2のプロセッサとを含み、
前記複数の第1のプロセッサのそれぞれは、前記複数の記憶手段の中の対応する1つの記憶手段に格納されるデータに対して演算を行ない、
前記複数の第2のプロセッサのそれぞれは、前記複数の記憶手段の中の対応する複数個の記憶手段に格納されるデータに対して演算を行なう、データ処理装置。
【請求項2】
前記第1のプロセッサは可変ビット長データの演算を行ない、前記第2のプロセッサは固定ビット長データの演算を行なうことを特徴とする、請求項1記載のデータ処理装置。
【請求項3】
前記データ処理装置はさらに、データを直交変換するための直交変換手段を含み、
前記直交変換手段は、外部から受けたデータを直交変換して、前記複数の第1のプロセッサ用のデータとして前記複数の記憶手段に格納し、外部から受けたデータをそのまま前記複数の第2のプロセッサ用のデータとして前記複数の記憶手段に格納する、請求項1記載のデータ処理装置。
【請求項4】
前記直交変換手段は、前記複数の記憶手段に記憶される前記複数の第1のプロセッサによる演算結果を直交変換して外部に出力し、前記複数の記憶手段に記憶される前記複数の第2のプロセッサによる演算結果をそのまま外部に出力する、請求項3記載のデータ処理装置。
【請求項5】
前記データ処理装置はさらに、前記複数の第1のプロセッサおよび前記複数の第2のプロセッサと、前記複数の記憶手段との間に設けられ、前記複数の記憶手段に格納されるデータを対応する第1のプロセッサ以外の別の第1のプロセッサに移動して供給するデータ移動手段を含む、請求項1〜4のいずれかに記載のデータ処理装置。
【請求項6】
前記データ処理装置はさらに、マイクロコードプログラムを記憶する命令記憶手段と、
前記命令記憶手段に記憶されるマイクロコードプログラムを解釈して、前記複数の第1のプロセッサおよび前記複数の第2のプロセッサに選択的に演算処理を行なわせる制御手段とを含む、請求項1〜5のいずれかに記載のデータ処理装置。
【請求項7】
前記複数の第2のプロセッサのそれぞれが浮動小数点演算器によって構成され、前記複数の記憶手段の中の前記浮動小数点演算器のデータ長に対応する個数の記憶手段からデータを受けて演算処理を行なう、請求項1〜6のいずれかに記載のデータ処理装置。
【請求項8】
前記複数の第2のプロセッサのそれぞれが積和演算器によって構成され、前記複数の記憶手段の中の前記積和演算器のデータ長に対応する個数の記憶手段からデータを受けて演算処理を行なう、請求項1〜6のいずれかに記載のデータ処理装置。
【請求項9】
データ処理装置にミリ波レーダの信号処理を行なわせるデータ処理方法であって、
前記データ処理装置は、SIMD演算方式の複数の第1のプロセッサと、
前記複数の第1のプロセッサのそれぞれに対応して設けられる複数の記憶手段と、
前記複数の記憶手段の中の複数個の記憶手段に対応して設けられる複数の第2のプロセッサとを含み、
前記複数の第1のプロセッサに前記複数の記憶手段に記憶されるデータの演算を行なわせることにより、前記ミリ波レーダによって得られた情報がデジタルに変換された後のデータに対してゲイン調整およびクリッピング処理を行なわせるステップと、
前記複数の第1のプロセッサに、前記クリッピング処理後のデータに対して間引き処理およびフィルタ処理を行なわせるステップと、
前記複数の第1のプロセッサまたは前記複数の第2のプロセッサに、前記フィルタ処理後のデータを浮動小数点値に変換させて前記複数の記憶手段に格納させるステップと、
前記複数の第2のプロセッサに、前記複数の記憶手段に記憶される前記浮動小数点値を用いた高速フーリエ変換を行なわせるステップとを含む、データ処理方法。
【請求項1】
SIMD演算方式の複数の第1のプロセッサと、
前記複数の第1のプロセッサのそれぞれに対応して設けられる複数の記憶手段と、
複数の第2のプロセッサとを含み、
前記複数の第1のプロセッサのそれぞれは、前記複数の記憶手段の中の対応する1つの記憶手段に格納されるデータに対して演算を行ない、
前記複数の第2のプロセッサのそれぞれは、前記複数の記憶手段の中の対応する複数個の記憶手段に格納されるデータに対して演算を行なう、データ処理装置。
【請求項2】
前記第1のプロセッサは可変ビット長データの演算を行ない、前記第2のプロセッサは固定ビット長データの演算を行なうことを特徴とする、請求項1記載のデータ処理装置。
【請求項3】
前記データ処理装置はさらに、データを直交変換するための直交変換手段を含み、
前記直交変換手段は、外部から受けたデータを直交変換して、前記複数の第1のプロセッサ用のデータとして前記複数の記憶手段に格納し、外部から受けたデータをそのまま前記複数の第2のプロセッサ用のデータとして前記複数の記憶手段に格納する、請求項1記載のデータ処理装置。
【請求項4】
前記直交変換手段は、前記複数の記憶手段に記憶される前記複数の第1のプロセッサによる演算結果を直交変換して外部に出力し、前記複数の記憶手段に記憶される前記複数の第2のプロセッサによる演算結果をそのまま外部に出力する、請求項3記載のデータ処理装置。
【請求項5】
前記データ処理装置はさらに、前記複数の第1のプロセッサおよび前記複数の第2のプロセッサと、前記複数の記憶手段との間に設けられ、前記複数の記憶手段に格納されるデータを対応する第1のプロセッサ以外の別の第1のプロセッサに移動して供給するデータ移動手段を含む、請求項1〜4のいずれかに記載のデータ処理装置。
【請求項6】
前記データ処理装置はさらに、マイクロコードプログラムを記憶する命令記憶手段と、
前記命令記憶手段に記憶されるマイクロコードプログラムを解釈して、前記複数の第1のプロセッサおよび前記複数の第2のプロセッサに選択的に演算処理を行なわせる制御手段とを含む、請求項1〜5のいずれかに記載のデータ処理装置。
【請求項7】
前記複数の第2のプロセッサのそれぞれが浮動小数点演算器によって構成され、前記複数の記憶手段の中の前記浮動小数点演算器のデータ長に対応する個数の記憶手段からデータを受けて演算処理を行なう、請求項1〜6のいずれかに記載のデータ処理装置。
【請求項8】
前記複数の第2のプロセッサのそれぞれが積和演算器によって構成され、前記複数の記憶手段の中の前記積和演算器のデータ長に対応する個数の記憶手段からデータを受けて演算処理を行なう、請求項1〜6のいずれかに記載のデータ処理装置。
【請求項9】
データ処理装置にミリ波レーダの信号処理を行なわせるデータ処理方法であって、
前記データ処理装置は、SIMD演算方式の複数の第1のプロセッサと、
前記複数の第1のプロセッサのそれぞれに対応して設けられる複数の記憶手段と、
前記複数の記憶手段の中の複数個の記憶手段に対応して設けられる複数の第2のプロセッサとを含み、
前記複数の第1のプロセッサに前記複数の記憶手段に記憶されるデータの演算を行なわせることにより、前記ミリ波レーダによって得られた情報がデジタルに変換された後のデータに対してゲイン調整およびクリッピング処理を行なわせるステップと、
前記複数の第1のプロセッサに、前記クリッピング処理後のデータに対して間引き処理およびフィルタ処理を行なわせるステップと、
前記複数の第1のプロセッサまたは前記複数の第2のプロセッサに、前記フィルタ処理後のデータを浮動小数点値に変換させて前記複数の記憶手段に格納させるステップと、
前記複数の第2のプロセッサに、前記複数の記憶手段に記憶される前記浮動小数点値を用いた高速フーリエ変換を行なわせるステップとを含む、データ処理方法。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】

【図14】
【図15】
【図16】
【図17】
【図18】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【公開番号】特開2012−174016(P2012−174016A)
【公開日】平成24年9月10日(2012.9.10)
【国際特許分類】
【出願番号】特願2011−35762(P2011−35762)
【出願日】平成23年2月22日(2011.2.22)
【出願人】(302062931)ルネサスエレクトロニクス株式会社 (8,021)
【Fターム(参考)】
【公開日】平成24年9月10日(2012.9.10)
【国際特許分類】
【出願日】平成23年2月22日(2011.2.22)
【出願人】(302062931)ルネサスエレクトロニクス株式会社 (8,021)
【Fターム(参考)】
[ Back to top ]