
データ利用システム
【課題】大規模な情報処理システムにおけるAPサーバ及びDBサーバの構成を最適化することにより、システム全体の処理速度を向上させる。
【解決手段】APサーバ14の検索条件分割処理部は、検索条件を分割して複数の検索処理部に割り当て、各検索処理部は、対応のSQLを対応のDBサーバ16に発行し、一定量の検索結果が送信される度に演算処理をデータ加工処理部に割り当て、加工処理結果が揃った時点で検索結果統合処理部に集計結果を出力し、検索結果統合処理部は、各検索処理部からの集計結果を集計し、検索結果として出力し、追加データ受付部は、入力された追加データのコピーを各登録処理部に割り当て、各登録処理部は、追加データの登録を求めるSQLを対応のDBサーバ16に発行する。
【解決手段】APサーバ14の検索条件分割処理部は、検索条件を分割して複数の検索処理部に割り当て、各検索処理部は、対応のSQLを対応のDBサーバ16に発行し、一定量の検索結果が送信される度に演算処理をデータ加工処理部に割り当て、加工処理結果が揃った時点で検索結果統合処理部に集計結果を出力し、検索結果統合処理部は、各検索処理部からの集計結果を集計し、検索結果として出力し、追加データ受付部は、入力された追加データのコピーを各登録処理部に割り当て、各登録処理部は、追加データの登録を求めるSQLを対応のDBサーバ16に発行する。
【発明の詳細な説明】
【技術分野】
【0001】
この発明はデータ利用システムに係り、特に、アプリケーションサーバとデータベースサーバとの連携により、データベースサーバに格納されたデータの利用を効率化する技術に関する。
【背景技術】
【0002】
巨大流通チェーンのように、大規模な業務システムを構築し、日々運用している企業においては、データベースサーバ(以下「DBサーバ」)が多数のテーブルを管理しており、複数のアプリケーションサーバ(以下「APサーバ」)によって構成されるサブシステム(受発注システム、仕入れシステム、経理システム等)が、上記のテーブルを共同利用する形式をとっている。
【非特許文献1】Webシステム入門/第1回 Webサイトの構成とJ2EEサーバ インターネットURL:http://www.atmarkit.co.jp/fjava/rensai2/websys01/websys01.html 検索日:2011年10月20日
【発明の開示】
【発明が解決しようとする課題】
【0003】
しかしながら、システムの規模が拡大するにつれて、テーブルの数が増大すると共に、テーブル間の関係も複雑化し、その分、テーブルを操作するためのSQLの発行数の増大や処理内容の複雑化が生じ、この結果、DBサーバ16側の演算処理の負担が増加し、応答の遅れが生じていた。
【0004】
これを回避するため、サブシステム毎に必要性の高いデータ項目を組み合わせると共に独自のビジネスルールを反映させた中間テーブルを生成し、DBサーバ16に管理させる方法が一般に採られている。
この結果、当該サブシステムから発行させるSQLは確かに簡素化され、サブシステム単位での演算処理量を低減することはできるが、システム全体としてのデータ一元性を担保するため、DBサーバ16にはバッチ処理によってデータの変換・更新処理を行う必要性が生じる。そして、最近では取扱いデータ量の増大に伴い、夜間バッチ処理では上記の変換・更新処理が間に合わなくなるという事態が生じ始めている。
【0005】
この発明は、従来のこのような問題を解決するために案出されたものであり、大規模な情報処理システムにおけるAPサーバ及びDBサーバの構成を最適化することにより、システム全体の処理速度を向上させ得る技術の実現を目的としている。
【課題を解決するための手段】
【0006】
上記の目的を達成するため、請求項1に記載したデータ利用システムは、複数のデータベースサーバと、各データベースサーバにネットワークを介して接続されたアプリケーションサーバとからなるデータ利用システムであって、上記の各データベースサーバは、DB管理システムとデータ記憶領域を備えており、各データベースサーバのデータ記憶領域には、データベースサーバ相互間に共通するデータを保持した共通のテーブルがそれぞれ複数格納されており、上記の各テーブルには、キー項目が一つに限定される制約と、データの更新及び削除が禁止される制約が設けられており、上記アプリケーションサーバは、検索条件分割処理部と、複数の検索処理部と、複数のデータ加工処理部と、検索結果統合処理部と、追加データ受付部と、複数の登録処理部を備え、上記検索条件分割処理部は、入力された検索条件を解析して複数の検索条件に分割すると共に、各検索条件及び対応データベースサーバを上記複数の検索処理部に割り当てる処理を実行し、上記の各検索処理部は、自己に割り当てられた検索条件に対応したSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理と、データベースサーバから一定量の検索結果データが送信される度に、必要な演算処理を上記の各データ加工処理部に割り当てる処理と、各データ加工処理部から部分的な加工処理結果データが返される度に、これをメモリに格納すると共に、データベースサーバから送信されたデータをメモリ上から削除する処理と、データベースサーバからのデータ送信が完了し、部分的な検索結果データに基づく部分的な加工処理結果データが全て揃った時点で、これらを集計して上記検索結果統合処理部に集計結果を出力する処理を実行し、上記検索結果統合処理部は、各検索処理部から渡された集計結果を集計し、検索結果として出力する処理を実行し、上記追加データ受付部は、入力された追加データのコピーと、対応データベースサーバの特定情報を含むデータ追加リクエストを上記の各登録処理部に割り当てる処理を実行し、上記の各登録処理部は、上記追加データの登録を求めるSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理を実行することを特徴としている。
【0007】
請求項2に記載したデータ利用システムは、請求項1のシステムを前提とし、さらに上記検索条件分割処理部は、入力された検索条件が時間的な範囲を含んでいる場合に、これをより短い時間的な範囲に分割することを特徴としている。
【0008】
請求項3に記載したデータ利用システムは、請求項1のシステムを前提とし、さらに上記検索条件分割処理部は、入力された検索条件が地域的な範囲を含んでいる場合に、これをより狭い地域的な範囲に分割することを特徴としている。
【0009】
請求項4に記載したデータ利用システムは、請求項1〜3のシステムを前提とし、さらに、インデックス生成部及びインデックス記憶部を有するインデックスサーバを備えており、また上記の各データベースサーバは、暫定記憶領域及び永続記憶領域を備えており、上記DB管理システムは、上記アプリケーションサーバから送信された追加データを上記暫定記憶領域に格納する処理と、所定の時間間隔で暫定記憶領域内の追加データを上記永続記憶領域に移動する処理を実行し、上記インデックスサーバのインデックス生成部は、所定の時間間隔で上記データベースサーバの暫定記憶領域に格納された追加データを取得する処理と、この追加データに基づいてインデックスを生成し、上記インデックス記憶部に格納する処理を実行し、上記アプリケーションサーバの各検索処理部は、自己に割り当てられた検索条件に対応した上記SQLを生成するに際し、上記インデックスサーバのインデックス記憶部を参照し、検索条件に該当する各データの主キーを取得する処理と、この主キーによって取得データを指定したSQLを生成する処理を実行することを特徴としている。
【0010】
請求項5に記載したデータ利用システムは、請求項1〜4のシステムを前提とし、さらに、上記の各データベースサーバはメモリ上に設けられた更新ログ記憶領域を備えており、各データベースサーバのOSが、上記アプリケーションサーバから送信された追加データを上記更新ログ記憶領域に順次格納する処理を実行することを特徴としている。
【発明の効果】
【0011】
請求項1に記載のデータ利用システムの場合、データベースサーバが管理する各テーブルの正規化が極限まで追求され、構造の単純化が実現される一方で、テーブルから抽出したデータの加工処理(ソートやマッチング、コントロールブレイク等)はアプリケーションサーバ側で実行され、データベースサーバはデータの出し入れに専念できるため、テーブル数の増大やテーブル間の関係の複雑化に伴いSQLの発行数が増大しても、データベースサーバ側の負担増を抑制することが可能となる。
【0012】
また、データベースサーバが物理的に複数台用意され、検索処理時には検索条件が各データベースサーバに分散される仕組みであるため、個々のデータベースサーバにおけるデータ抽出処理が軽減される結果、システム全体の処理速度を向上させることができる。
【0013】
しかも、アプリケーションサーバにおいては、入力された検索条件が複数に分割され、それぞれ複数の検索処理部を介してデータベースサーバにデータの検索依頼が送信されると共に、データベースサーバから各検索処理部に対して返された検索結果データに対しても、一定量単位で複数のデータ加工処理部による並列処理が実行されるため、データベースサーバから大量のデータが送信される場合であっても、多数のCPUコアを用いることで効率的な処理が可能となる。また、このようにデータベースサーバからの検索結果データが全て揃うまで待機することなく、一定量のデータが揃った時点で部分的な加工処理に移行することにより、データベースサーバ側のDISK/IOによる遅延を緩和することも可能となる。
【0014】
これまで、DNA解析や気象解析のように純粋な演算処理を主体とした科学技術計算と異なり、データベースに蓄積された大量のデータを参照する必要のある業務系処理の場合には、データベースサーバからの応答を待つDISK/IOがボトルネックとなるため、アプリケーションサーバ側のCPUコアの数を増やしたとしても、直ちに処理速度の向上には結びつかないという問題があった。
これに対し、上記のような仕組みをアプリケーションサーバに設けることにより、テーブルの正規化の追求に伴うデータベースサーバ側の負担増を、アプリケーションサーバ側の処理の効率化によってカバーすることが可能となった。
【0015】
請求項4に記載のデータ利用システムの場合、インデックス(二次索引)の作成処理が外部の独立したインデックスサーバに移譲されているため、これに纏わるデータベースサーバ側の負担を解消することができる。
しかも、データ参照時には個々のデータの主キーを指定した形のSQLがアプリケーションサーバから発行されるため、データベースサーバ側でテーブルをソートする必要がなくなり、その分、データベースサーバの負荷を低減することができる。
【0016】
請求項5に記載のデータ利用システムの場合、データベースサーバの更新ログがメモリ上に格納される機構を備えているため、更新ログをディスク上に格納する場合に比べて、データベースサーバ側のDISK/IOを低減することができる。
この更新ログ記憶領域は、各データベースサーバのOSによってメモリ上に設定されると共に、更新ログの格納処理もOSの機能によって実現される仕組みであるため、データベースサーバ用のアプリケーションプログラムが機能停止しても、OSがダウンしない限り復旧は可能である。
しかも、データベースサーバが物理的に複数台用意されると共に、各データベースサーバにおいては同一の追加データが更新ログとして更新ログ記憶領域に蓄積される仕組みであるため、停電等の事故によって一のデータベースサーバにおいて更新ログが消えてしまった場合でも、他のデータベースサーバに格納された更新ログによって容易に復旧可能となる。
【発明を実施するための最良の形態】
【0017】
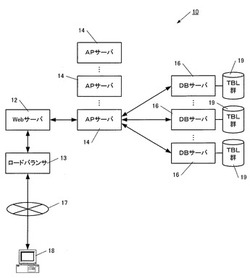
図1は、この発明に係るデータ利用システム10の全体構成を示す模式図であり、ロードバランサ13と、Webサーバ12と、複数のAPサーバ14と、複数のDBサーバ16とを備えている。
Webサーバ12には、インターネット17を介してクライアント端末18が接続されている。
各DBサーバ16は、全DBサーバ16間に共通するデータを格納した複数のテーブル(テーブル群19)と、DB管理システム(RDBMS)とを備えており、DBサーバ16の中の少なくとも一部は、データ保全の観点から遠隔地に配置されている。
【0018】
最初に、本システム10における処理内容について大まかに説明し、個々の具体的な構成や処理内容については後に詳説する。
まず、クライアント端末18にはWebサーバ12からデータ利用画面が送信され、Webブラウザ上に表示される(図示省略)。
そして、ユーザがこのデータ利用画面を通じて検索条件を指定し、データの検索をリクエストすると、Webサーバ12からAPサーバ14に対して検索リクエストが送信される。この際、ロードバランサ13を介して、最も負荷の小さい一のAPサーバ14に対して、検索リクエストが振り分けられる。
【0019】
この検索リクエストを受け取ったAPサーバ14は、検索条件を論理的に複数に分割し、分割された検索条件に対応した複数のSQLをそれぞれ別個のDBサーバ16に発行し、検索条件に合致するデータの抽出を依頼する。
これを受けた各DBサーバ16は、SQLで指定されたデータを抽出し、APサーバ14に送信する。
【0020】
APサーバ14は、各DBサーバ16から受け取ったデータを統合し、Webサーバ12に送信する。
これに対しWebサーバ12は、APサーバ14から受け取った検索結果データを表示する画面(図示省略)を生成し、クライアント端末18に送信する。
【0021】
また、クライアント端末18からデータ追加のリクエストがWebサーバ12に送信された場合、ロードバランサ13によって選択された一のAPサーバ14に当該リクエストが送信される。
これを受けたAPサーバ14は、各DBサーバ16に対して同一のSQLを発行し、同データの追加を依頼する。
これに対し各DBサーバ16は、上記追加データを対応のテーブルに格納する処理を実行する。
【0022】
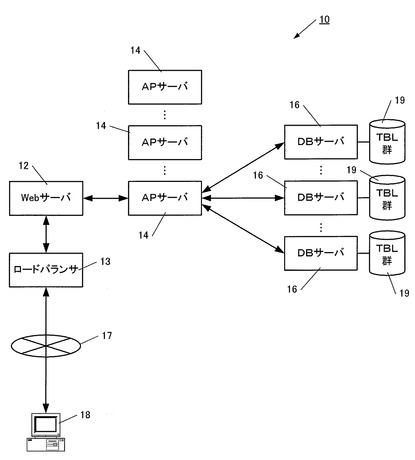
図2は、クライアント端末18から送信された検索リクエストが、Webサーバ12及びAPサーバ14を経由してDBサーバ16に送信される場面での機能構成を表しており、APサーバ14は、検索条件分割処理部20と、複数の検索処理部22を備えている。
【0023】
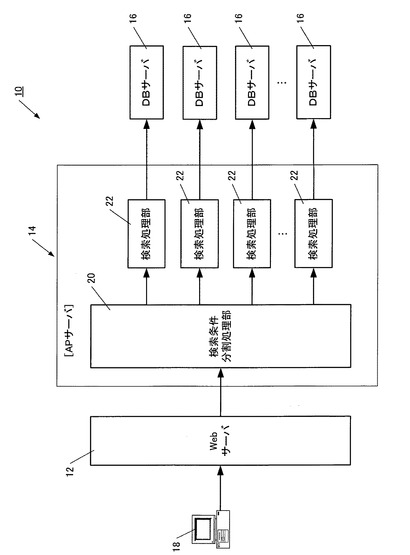
また図3は、DBサーバ16から検索結果が送信される場面での機能構成を表しており、APサーバ14は、各検索処理部22単位で複数割り当てられたデータ加工処理部24と、検索結果統合処理部26を備えている。
【0024】
図4は、クライアント端末18から送信されたデータ追加のリクエストが、DBサーバ16に送信される場面での機能構成を表しており、APサーバ14は、追加データ受付部27と、複数の登録処理部28を備えている。
【0025】
APサーバ14内に設けられた上記の検索条件分割処理部20、複数の検索処理部22、複数のデータ加工処理部24、検索結果統合処理部26、追加データ受付部27、複数の登録処理部28は、APサーバ14に搭載された多数のCPUコアが、専用のアプリケーションプログラムに従って所定の処理を実行することで実現されるのであるが、この際、OSによって複数のスレッドが起動されて各CPUコアに割り当てられることにより、マルチタスク処理が実現される。
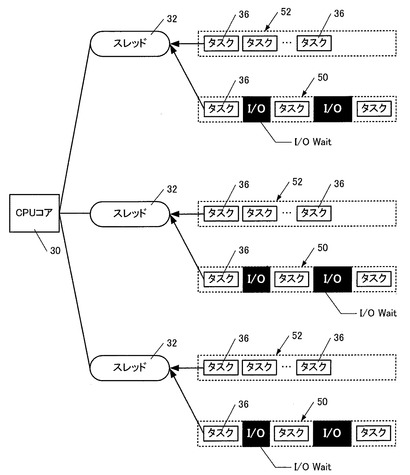
【0026】
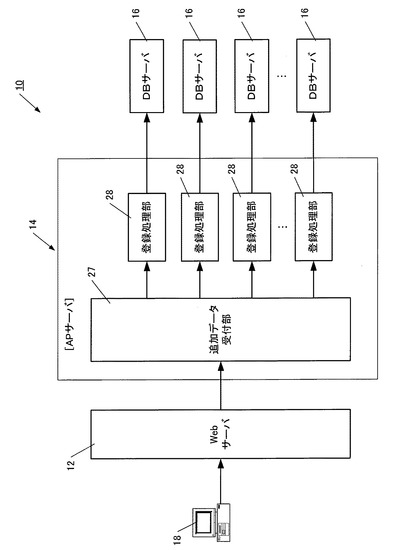
図5は、各CPUコア30とスレッド32との対応関係を表しており、各スレッド32にはスレッドプール34が設けられ、そこに配置された複数のタスク36をスレッド32が順次処理していくイメージが描かれている。
この図におけるスレッド32が、図2〜図4に表された検索条件分割処理部20、複数の検索処理部22、複数のデータ加工処理部24、検索結果統合処理部26、追加データ受付部27、複数の登録処理部28として機能し、これらの機能構成部が実行する具体的な処理がタスク36に相当する。
【0027】
各スレッド32は、スレッドプール34に蓄積されたタスクを古い順に次々と実行していき、自己のスレッドプール34が空になった場合には、他のスレッド32のスレッドプール34に蓄積されたタスク36を、新しい順に実行していく。
【0028】
つぎに、図6〜図9のフローチャートに従い、このシステム10における処理手順を詳細に説明する。
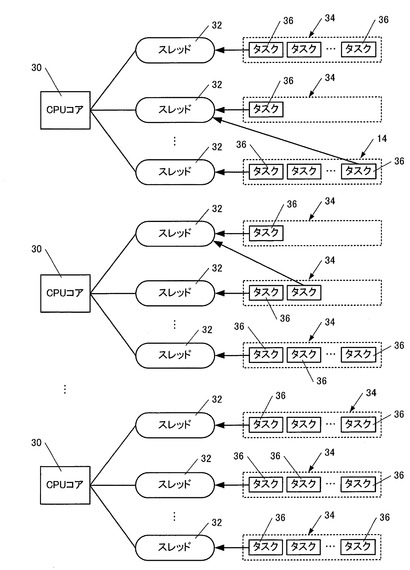
まず、図6に従い、検索条件分割処理部20による処理手順を説明する。
すなわち、クライアント端末18から送信された検索条件をWebサーバ12経由でAPサーバ14が受信すると(S10)、検索条件分割処理部20は検索条件を解析し、検索条件の内容に応じて複数の検索条件に分割する(S12)。
【0029】
ここで分割の基準となるのは、時間(日、週、月、年等)や地域(都道府県、市町村等)など、検索対象データを論理的に複数に区分できるものが該当する。
例えば、「2010年における全チェーン店の売上を集計する」という検索条件が与えられた場合に、「2010年1月分の全チェーン店の売上」、「2010年2月の全チェーン店の売上」、「2010年3月の全チェーン店の売上」…というように、年を月単位に12分割することが該当する。
また、各チェーン店の所在地データに着目し、「2010年における東京所在チェーン店の売上」、「2010年における北海道所在チェーン店の売上」、「2010年における沖縄所在チェーン店の売上」…というように、全国を都道府県単位に47分割することも該当する。
もちろん、「2010年1月分の東京所在チェーン店の売上」や「2010年1月の北海道所在チェーン店の売上」のように、月×都道府県単位で564分割することもできる。
【0030】
これらの分割基準は、クライアント端末18から発せられると予測される検索条件や、対象となるデータの量等に鑑みて、事前に幾つかの分割パターンがプログラム設計者によって策定され、検索条件分割処理部20を実現するためのプログラム中にコーディングされている。
【0031】
ここでは、都道府県単位で47分割されたものとして話を進める。
すなわち、検索条件分割処理部20は、47個の検索処理部22に対して、上記都道府県単位の検索処理と、対応DBサーバ16を割り当てる(S14)。
【0032】
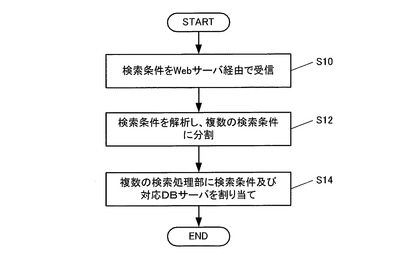
つぎに図7に従い、各検索処理部22における処理手順を説明する。
まず検索処理部22は、自己に割り当てられた検索処理に必要な都道府県を指定したSQLを自動生成し、自己に割り当てられた特定のDBサーバ16に対して発行する(S20)。
【0033】
ここで検索処理部22は、対応のDBサーバ16から全ての検索結果データが送信されるのを待つことなく、予め設定された一定量(例えばレコード1,000件分)のデータが送信された時点で(S22/Y)、必要な演算処理を複数のデータ加工処理部24に割り当てる(S24)。
この結果、一部のデータ加工処理部24は、受信データをキー項目でソートすると共に、キー項目の値に基づいて複数のデータに分割する処理を実行する。また、他のデータ加工処理部24は、分割されたデータに基づく値の集計処理や、当該値を指定したデータの抽出をDBサーバ16に依頼する処理などを実行する。
受信データの分割手法については後に例示するが、検索条件の内容に応じて論理的に分割する検索条件分割処理部20による分割と異なり、受信データの値や分量に応じた分割手法となる。データ加工処理部24による具体的な処理についても、後に例示する。
【0034】
検索処理部22は、データ加工処理部24から処理結果データが返信された時点で(S26/Y)、この単位データ量当たりの処理結果をメモリに格納すると共に、DBサーバ16から送信されたデータをメモリ上から削除する(S28)。
各検索処理部22は、DBサーバ16からのデータ送信が完了するまで、DBサーバ16から送信されるデータが一定量に達する度にS24〜S28の処理を繰り返す(S30/N、S22/Y)。
そして、DBサーバ16からのデータ送信が完了し、S24〜S28の最後の処理が完了した時点で(S30/Y)、検索処理部22はこれまでの部分的な処理結果の集計値を集計し(S32)、検索結果統合処理部26に集計結果を出力する(S34)。
【0035】
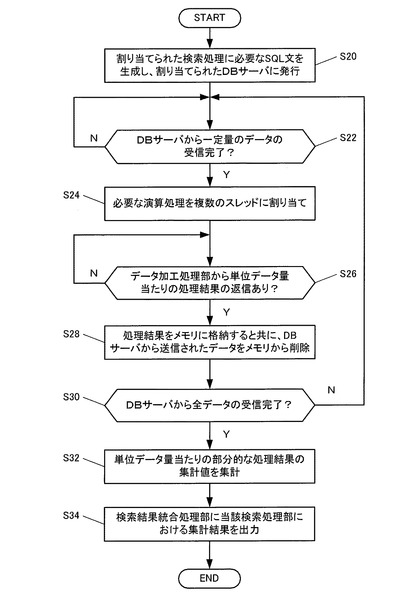
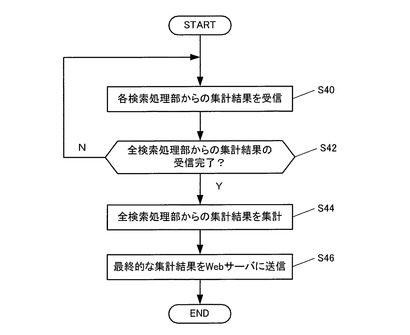
つぎに図8に従い、検索結果統合処理部26による処理手順を説明する。
まず検索結果統合処理部26は、各検索処理部22から集計結果が送信される度に、全ての検索処理部22からの集計結果が揃ったか否かをチェックし(S40、S42)、全てが揃った段階で全検索処理部の集計結果を集計する(S44)。
そして、その最終的な集計結果をWebサーバ12に送信する(S46)。
Webサーバ12は、この集計結果を含むWebファイルを生成し、クライアント端末18に送信することになる。
【0036】
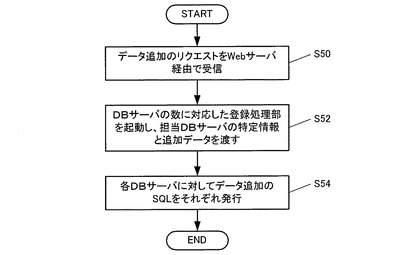
つぎに図9に従い、データ追加時におけるAPサーバ14側の処理手順を説明する。
まず、クライアント端末18から送信されたデータ追加のリクエストをWebサーバ12経由でAPサーバ14が受信すると(S50)、追加データ受付部27がDBサーバ16の数に対応した登録処理部28を起動させ、それぞれに担当DBサーバ16の特定情報及び追加データを渡す(S52)。
これを受けた各登録処理部28は、自己が担当するDBサーバ16に対して上記の追加データの登録を求めるSQLを発行する(S54)。
これを受けた各DBサーバ16は、対応のテーブルに対して一斉にデータを追加する。この結果、各DBサーバ16が管理するデータの同一性が確保される。
【0037】
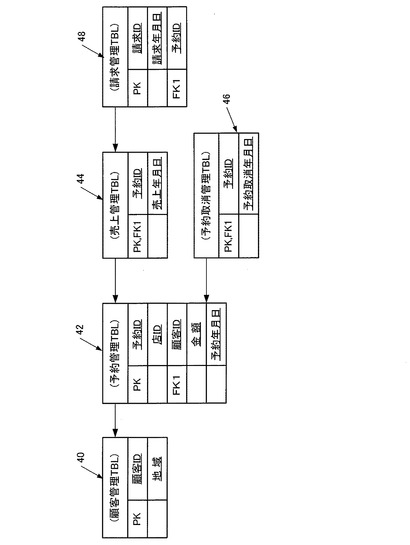
図10は、各DBサーバ16に格納されたテーブル群の具体例を示しており、顧客管理テーブル40と、予約管理テーブル42と、売上管理テーブル44と、予約取消管理テーブル46と、請求管理テーブル48とによって、各店舗の売り上げが管理されている。
【0038】
顧客管理テーブル40は、「顧客ID(主キー)」及び「地域」のデータ項目を備えている。
また、予約管理テーブル42は、「予約ID(主キー)」、「店ID」、「顧客ID(外部キー)」、「金額」及び「予約年月日」のデータ項目を備えている。
売上管理テーブル44は、「予約ID(主キー/外部キー)」及び「売上年月日」のデータ項目を備えている。
予約取消管理テーブル46は、「予約ID(主キー/外部キー)」及び「予約取消年月日」のデータ項目を備えている。
請求管理テーブル48は、「請求ID(主キー)」、「請求年月日」及び「予約ID(外部キー)」のデータ項目を備えている。
【0039】
上記の各テーブル40〜48には、以下の(1)〜(3)の制約が予め課せられている。
(1)キー項目は一つに限定される。
したがって、複数の項目の組合せによってキー項目を構成すること(複合キー)は、禁止される。
【0040】
(2)各テーブルにはレコードの追加のみが許容され、既存レコードの値の更新は禁止される。
したがって、値に変更が生じた場合など、発生タイミングの異なる情報は別テーブルに格納されることとなる。
【0041】
(3)各テーブルのカラムには、NULL値禁止制約、フラグ値禁止制約、区分値禁止制約が課せられる。
まず「NULL値禁止制約」とは、データ項目の値としてNULL(値なし)を充填することが禁止されることを意味しており、このようなNULL値の充填を想定したデータ項目の設定自体が許容されないことになる。
つぎに「フラグ値禁止制約」とは、データ項目の値としてフラグ値(「1/0」、「ON/OFF」、「TRUE/FALSE」等の2値データ)を充填することが禁止されることを意味しており、このようなフラグ値の充填を想定したデータ項目の設定自体が許容されないことになる。
「区分値禁止制約」とは、データ項目の値として区分値(「1:正社員」、「2:パート」、「3:アルバイト」等)を充填することが禁止されることを意味しており、このような区分値の充填を想定したデータ項目の設定自体が許容されないことになる。
【0042】
これらの制約ルールは、新規テーブルの設計時やSQL発行時に、DBサーバ16のデータ管理システム(RDBMS)によって適否がチェックされ、制約ルールに違反する処理の実行が拒絶されることにより、その実効性が担保される。
【0043】
図10より明らかなように、各テーブルは単一のデータ項目によって主キー(PK)が構成されている。
また、「予約取消」に関するデータも、通常であれば予約管理テーブル42において「予約取消フラグ」等のデータ項目が設けられ、各レコードに「1/0」等のフラグ値を充填することで状態が管理されるところであるが、予約取消管理テーブル46を予約管理テーブル42とは別個に設けることにより、予約取消の状態管理がなされている。すなわち、この予約取消管理テーブル46に登録された予約IDが「予約取消」状態にあることとなり、レコードの有無によって予約取消の有無が表現されている。
【0044】
各テーブルには上記(2)の制約(値の更新禁止)が課せられているため、例えばある顧客の「地域」に変動が生じた場合でも、顧客管理テーブル40における該当レコードの「地域」の値が書き換えられることはない。
図示は省略したが、このような場合には例えば「顧客ID」、「変更地域」、「変更年月日」等のデータ項目を備えた「顧客地域変更管理テーブル」が新たに設けられて、当該顧客の顧客ID、変更後の地域、変更年月日が格納される。
【0045】
この結果、顧客の地域別に売上を集計する必要が生じた場合、APサーバ14側では顧客管理テーブル40を参照して各顧客の地域情報を取得した後、顧客地域変更管理テーブルを参照して地域変更の生じた顧客を特定し、変更後の地域に差し替える処理を実行することになる。
【0046】
このようなテーブルがDBサーバ16において管理されている場合に、クライアント端末18から「A店の8月分の請求額を地域毎に集計せよ」という内容の検索リクエストが送信された場合、検索条件分割処理部20は、まず「8月=31日間」というカレンダー情報に従い、「8月1日分」、「8月2日分」、「8月3日分」…「8月31日分」というように、検索条件を31分割する。
【0047】
つぎに検索条件分割処理部20は、これらの分割された検索条件(「A店の8月1日分の請求額を地域毎に集計せよ」等)を31個の検索処理部22に割り当てる。
【0048】
これを受けた各検索処理部22は、自己に割り当てられた請求日を指定した、請求管理テーブル48から請求データを取得するためのSQLを生成し、自己が担当するDBサーバ16に発行する。
そして、DBサーバ16から該当日の請求年月日を備えた請求データが送信されると、検索処理部22は一定量のデータ(例えば1,000件のレコード相当分)単位で受信データを分割し、複数のデータ加工処理部24に以下の処理を割り当てる。
(1)各請求データの「予約ID」を指定したSQLを生成してDBサーバ16に発行し、「予約管理テーブル42」から対応の予約データを取得する。
(2)送信された予約データの中で、該当店舗の「店ID」を有するデータのみを抽出し、他の店IDのデータを除外する。
(3)各予約データの「顧客ID」を指定したSQLを生成してDBサーバ16に発行し、顧客管理テーブル40から対応の顧客データを取得する。
(4)顧客データの「地域」毎に、予約データ中の「金額」の値を集計する。
これら(1)〜(4)の処理は、具体的にはタスク36として各データ加工処理部24のスレッドプール34に配置される。
【0049】
検索処理部22は、データ加工処理部24から上がってきた1,OOO件単位の処理結果データをメモリに格納すると共に、DBサーバ16から送信されたデータをメモリ上から削除する。そして、1日分の処理結果データが揃った時点で、全処理結果データを集計する。この集計結果は、検索結果統合処理部26に出力される。
検索結果統合処理部26は、全検索処理部22から8月1日〜8月31日までの全集計結果が集まった時点でこれらを集計し、Webサーバ12に出力する。
【0050】
このシステム10の場合、DBサーバ16からのフェッチが完了するまでAPサーバ14が待つことはなく、一定量のデータを受信する度に複数のデータ加工処理部24による処理が開始される仕組みであるため、DBサーバ16のDISK/IOによるボトルネックを解消することができる。
【0051】
また、APサーバ14における部分的な集計が完了する度に、DBサーバ16から送信されたデータが占めていたメモリが解放され、データ量が格段に小さな集計結果データのみがメモリに格納される仕組みであるため、APサーバ14のメモリが大きなデータに占拠され続けることを回避できる。
【0052】
さらに、各検索処理部22は、それぞれ別個のDBサーバ16に対しSQLを分散して発行するため、個々のDBサーバ16における処理の負担が必然的に低減することとなり、全体の処理速度を高速化することができる。
上記の通り、各DBサーバ16は同じ内容のデータを保持しているため、検索処理部22にDBサーバ16を割り振る際にはDBサーバ16毎の特性を考慮することなく、機械的に対応付けることができる。
【0053】
なお、処理速度の向上という観点からは、分割した検索条件と等しい数の検索処理部22及びDBサーバ16を用意することが望ましいが、検索処理部及びDBサーバ16に数はこれに限定されるものではない。
例えば、分割された検索条件が31個あり、検索処理部が31個設けられたにもかかわらず、DBサーバ16が物理的に10台しか用意されていない場合には、各DBサーバ16に対して3〜4個の検索条件が割り振られることになる。この場合でも、1台のDBサーバ16のみで全てを処理する場合に比べ、大幅な高速化が期待できる。
【0054】
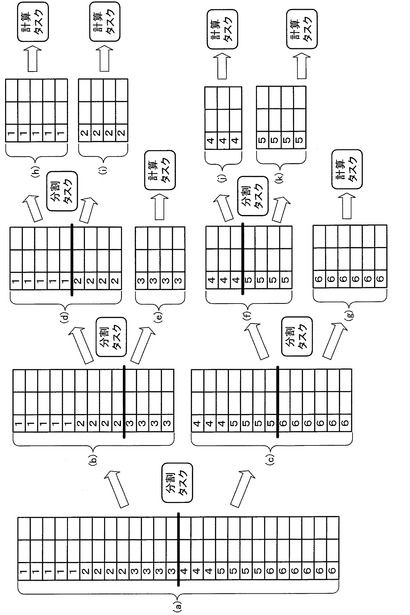
ここで、図11を参照して、DBサーバ16から送信された一定量単位のデータに対する分割手順について説明する。
まず一のデータ加工処理部24は、DBサーバ16から送信されたデータを2等分する位置を探索し、そこから前方不一致検索によってキー項目の変わり目を探しだし、データを2分割させる。
例えば、(a)のデータ列はキー項目の値が1〜6があるが、データ加工処理部24は「3」と「4」との間を境にこれを2分割させ、(b)及び(c)のデータ列を生成する。
【0055】
つぎに、他のデータ加工処理部24は、(b)のデータ列を「2」と「3」との間で2分割させ、(d)及び(e)のデータ列を生成する。
この時点で、(e)のデータ列のキー項目の値は「3」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(e)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0056】
これに対し、(d)のデータ列の場合には「1」と「2」の間で2分割可能であるため、データ加工処理部24はここでデータ列を2分割させ、(h)及び(i)のデータ列を生成する。
この時点で、(h)のデータ列のキー項目の値は「1」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(h)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
同様に、(i)のデータ列のキー項目の値は「2」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(i)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0057】
一方、(c)のデータ列については、他のデータ加工処理部24が「5」と「6」との間で2分割させ、(f)及び(g)のデータ列を生成する。
この時点で、(g)のデータ列のキー項目の値は「6」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(g)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0058】
これに対し、(f)のデータ列の場合には「4」と「5」の間で2分割可能であるため、データ加工処理部24はここでデータ列を2分割させ、(j)及び(k)のデータ列を生成する。
この時点で、(j)のデータ列のキー項目の値は「4」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(j)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
同様に、(k)のデータ列のキー項目の値は「5」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(k)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0059】
図11の例では、説明の便宜上簡略化されたデータ列を例示したが、各データ加工処理部24は、実際にはDBサーバ16から送信された一定量(例えばレコード1,000件分)のデータ列に対して、ソートやマッチング、コントロールブレイクの都度、上記の分割処理を実行する。
この結果、大量のデータに対して複数のデータ加工処理部24による並列処理が可能となり、APサーバ14に複数搭載されたCPUコアの有効利用が可能となる。
このデータ加工処理部24による分割処理に際し、分割の回数(階層の深さ)に一定の限度を設けることもできる。
【0060】
上記のように、データ加工処理部24は検索処理部22から渡されたデータ列の特定のデータ項目の値を指定してDBサーバ16にSQLを発行し、検索処理を依頼する場合があるため、必然的にDBサーバ16からの応答待ち(I/O Wait)が発生することになる。
【0061】
そこで図12に示すように、各スレッド32にI/O Waitを伴う処理用の第1のスレッドプール50と、I/O Waitを伴わない処理用の第2のスレッドプール52を設けることが望ましい。
この結果、第1のスレッドプール50に配置されたタスク36の実行によってI/O Waitが発生した場合、スレッド32は第2のスレッドプール52に配置されたタスク36を待ち時間の間に処理することが可能となり、処理の効率化を図ることが可能となる。
【0062】
この発明にあっては、上記のようにDBサーバ16が管理する各テーブルの構造が極限まで単純化される分、テーブルの数が増え、SQLの発行数自体は増大するが、演算処理は多数のCPUコアを用いた並列処理によって高速化されたAPサーバ14側で行われ、DBサーバ16は単純化されたデータの管理(インサートとセレクト)に専念でき、データの更新や削除から解放されるため、DBサーバ16の負担は大幅に軽減される。
しかも、DBサーバ16は筐体レベルで複数台用意され、検索時にはデータの抽出処理がそれぞれに分散される。
このため、テーブルの正規化の追求に伴いDBサーバ16側の処理速度が低下することを、有効に回避できる。
【0063】
また、フラグ値や区分値のように、特殊なビジネスルールに基づいた値の格納が禁止される結果、データモデルの見通しが良好となり、テスト・データの作成効率が向上するという効果も期待できる。
【0064】
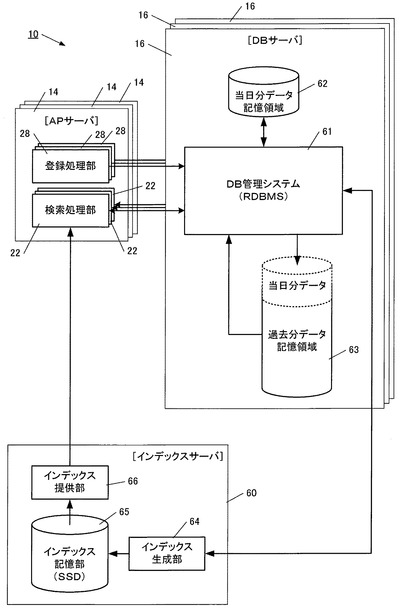
図13に示すように、各DBサーバ16と各APサーバ14との間にインデックスサーバ60を設けることにより、このシステム10における検索処理をより高速化することができる。
この場合、各DBサーバ16は、DB管理システム(RDBMS)61と、当日分データ記憶領域(暫定記憶領域)62と、過去分データ記憶領域(永続記憶領域)63とを備える。
【0065】
また、インデックスサーバ60は、インデックス生成部64と、インデックス記憶部65と、インデックス提供部66とを備えている。
インデックス生成部64及びインデックス提供部66は、インデックスサーバ60のCPUが専用のプログラムに従って動作することにより実現され、インデックス記憶部65は、インデックスサーバ60のSSD(Solid State Drive)内に設けられている。
【0066】
APサーバ14の登録処理部28から送信された追加データは、DBサーバ16のDB管理システム61によって当日分データ記憶領域62に一旦格納された後、夜間バッチ処理によって過去分データ記憶領域63に移される。
また、インデックスサーバ60のインデックス生成部64は、夜間バッチ処理により、DB管理システム61から当日分データ記憶領域62内に格納された追加データを取得し、追加分のインデックスを作成した後、インデックス記憶部65に格納する。
【0067】
この場合、APサーバ14の各検索処理部22は、各DBサーバ16に対してSQLを発行するに際し、インデックスサーバ60のインデックス提供部66を介してインデックス記憶部65を参照し、過去分データ記憶領域63に格納されたデータに関しては、検索条件の範囲に含まれる個々のデータの主キーを取得した後、個々の主キーを特定したSQLを生成する。
【0068】
例えば、Webサーバ12から送信された検索条件が、特定店舗における過去1年分の売上データを取得するものであった場合、検索処理部22はこの条件に合致する全データの主キーをインデックスサーバ60から取得した上で、SQL中にこれらの主キーを記述してDBサーバ16に発行する。
【0069】
このため、DBサーバ16のDB管理システム61は、データの検索処理を行うことなく、過去分データ記憶領域63に格納された各テーブルから主キーによって指定されたデータをダイレクトに取り出し、検索処理部22に迅速に返すことが可能となる。
しかも、インデックスはハードディスクよりも高速な動作が可能なSSDに格納されているため、APサーバ14がインデックスを参照する際のDISK/IOを低減することができる。
【0070】
なお、インデックスは上記の通り夜間バッチにて生成されるため、当日分データについてはインデクスが用意されていない。このため、当日分データを取得する必要がある場合、検索処理部22は主キーを指定することなく、検索条件を指定したSQLをDBサーバ16に発行する。
【0071】
このシステム10においては、上記の通り、個々のレコードに関して更新や削除が生じることがなく、新規レコードの追加のみが許される仕組みを採用しているため、DBサーバ16において当日分データと過去分データを明確に分離することが可能となる。
【0072】
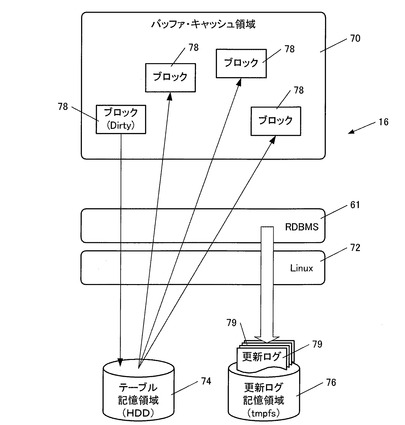
図14は、各DBサーバ16の内部構造をより詳細に示すものであり、メモリ上に設けられたバッファ・キャッシュ領域70と、DB管理システム(RDBMS)61と、OS(Linux)72と、テーブル記憶領域74と、更新ログ記憶領域76とが描かれている。
ここでテーブル記憶領域74は、ハードディスク(HDD)内に設けられており、上記した顧客管理テーブル40や予約管理テーブル42等が格納されている。また更新ログ記憶領域76は、OSによってメモリ(tmpfs)内に設けられている。
【0073】
この図に示されているように、DBサーバ16においては一般に、テーブル内のデータはブロック78単位でテーブル記憶領域74からバッファ・キャッシュ領域70に取り出されると共に、バッファ・キャッシュ領域70に書き込まれたデータはブロック78単位でテーブル記憶領域74に格納される。
このため、上記のように各テーブルに格納されるレコードの構造が極限まで簡素化されていると、1つのブロック78に収納できるレコード数を増やすことが可能となり、その分、DBサーバ16における処理の効率化を実現することが可能となる。
【0074】
また、更新ログ79をハードディスクよりも高速に動作するメモリ上に設けられた更新ログ記憶領域76に格納することにより、その分DISK/IOを削減することが可能となり、DBサーバ16における処理のさらなる高速化を実現可能となる。
【0075】
ところで、更新ログ79はDBサーバ16に何らかのトラブルが発生した場合に、データを復旧させるための最後の拠り所となる重要な構成要素であるため、通常は電源OFFによってデータが消失してしまうメモリ上に設けられることはない。
これに対し、このシステム10の場合には、上記のようにDBサーバ16が物理的に複数台設けられており、各DBサーバ16には同一内容のデータが保存される仕組みを備えているため、データ消失の危険を有効に分散させることが可能となる。
【0076】
しかも、各テーブルにはデータの更新や削除が許容されないというルールが適用されているため、一のDBサーバ16の更新ログが消失してしまい、他のDBサーバ16の更新ログに基づいてデータを復旧させる必要性が生じた場合であっても、ハードディスクに格納された既存のデータとの間で整合性を確保する必要がなく、新たに追加された当日分のデータのみを追記させれば済むという利点も生じる。因みに、この復旧が完了するまでの間、当該DBサーバ16についてはWRITE ONLY状態(データの書き込み可/読み込み不可)に置かれる。
【0077】
なお、上記の更新ログ記憶領域76は、上記のように各DBサーバ16のOSによってメモリ上に設定されると共に、更新ログの格納処理もOSの機能によって実現される仕組みであるため、DBサーバ用のアプリケーションプログラムがクラッシュ等しても、OSがダウンしない限り当該DBサーバ内で復旧可能である。
【図面の簡単な説明】
【0078】
【図1】この発明に係るデータ利用システムの全体構成を示す模式図である。
【図2】この発明に係るデータ利用システムの、検索リクエストがDBサーバに送信される場面での機能構成を示すブロック図である。
【図3】この発明に係るデータ利用システムの、DBサーバから検索結果が送信される場面での機能構成を示すブロック図である。
【図4】この発明に係るデータ利用システムの、クライアント端末から送信されたデータ追加のリクエストが、DBサーバに送信される場面での機能構成を示すブロック図である。
【図5】CPUコアとスレッドとの対応関係を示す模式図である。
【図6】検索条件分割処理部による処理手順を示すフローチャートである。
【図7】検索処理部による処理手順を示すフローチャートである。
【図8】検索結果統合処理部による処理手順を示すフローチャートである。
【図9】クライアント端末から送信されたデータ追加のリクエストがDBサーバに送信される際の処理手順を示すフローチャートである。
【図10】DBサーバに格納されたテーブルを例示する図である。
【図11】データ加工処理部によるデータ分割の手順を示す模式図である。
【図12】スレッド毎に複数のスレッドプールを設けた例を示す模式図である。
【図13】この発明に係るデータ利用システムにインデックスサーバを追加した例を示すブロック図である。
【図14】DBサーバの内部構造を示す模式図である。
【符号の説明】
【0079】
10 データ利用システム
12 Webサーバ
13 ロードバランサ
14 APサーバ
16 DBサーバ
17 インターネット
18 クライアント端末
19 テーブル群
20 検索条件分割処理部
22 検索処理部
24 データ加工処理部
26 検索結果統合処理部
27 追加データ受付部
28 登録処理部
30 CPUコア
32 スレッド
34 スレッドプール
36 タスク
40 顧客管理テーブル
42 予約管理テーブル
44 売上管理テーブル
46 予約取消管理テーブル
48 請求管理テーブル
50 第1のスレッドプール
52 第2のスレッドプール
60 インデックスサーバ
61 DB管理システム
62 当日分データ記憶領域
63 過去分データ記憶領域
64 インデックス生成部
65 インデックス記憶部
66 インデックス提供部
70 バッファ・キャッシュ領域
74 テーブル記憶領域
76 更新ログ記憶領域
78 ブロック
79 更新ログ
【技術分野】
【0001】
この発明はデータ利用システムに係り、特に、アプリケーションサーバとデータベースサーバとの連携により、データベースサーバに格納されたデータの利用を効率化する技術に関する。
【背景技術】
【0002】
巨大流通チェーンのように、大規模な業務システムを構築し、日々運用している企業においては、データベースサーバ(以下「DBサーバ」)が多数のテーブルを管理しており、複数のアプリケーションサーバ(以下「APサーバ」)によって構成されるサブシステム(受発注システム、仕入れシステム、経理システム等)が、上記のテーブルを共同利用する形式をとっている。
【非特許文献1】Webシステム入門/第1回 Webサイトの構成とJ2EEサーバ インターネットURL:http://www.atmarkit.co.jp/fjava/rensai2/websys01/websys01.html 検索日:2011年10月20日
【発明の開示】
【発明が解決しようとする課題】
【0003】
しかしながら、システムの規模が拡大するにつれて、テーブルの数が増大すると共に、テーブル間の関係も複雑化し、その分、テーブルを操作するためのSQLの発行数の増大や処理内容の複雑化が生じ、この結果、DBサーバ16側の演算処理の負担が増加し、応答の遅れが生じていた。
【0004】
これを回避するため、サブシステム毎に必要性の高いデータ項目を組み合わせると共に独自のビジネスルールを反映させた中間テーブルを生成し、DBサーバ16に管理させる方法が一般に採られている。
この結果、当該サブシステムから発行させるSQLは確かに簡素化され、サブシステム単位での演算処理量を低減することはできるが、システム全体としてのデータ一元性を担保するため、DBサーバ16にはバッチ処理によってデータの変換・更新処理を行う必要性が生じる。そして、最近では取扱いデータ量の増大に伴い、夜間バッチ処理では上記の変換・更新処理が間に合わなくなるという事態が生じ始めている。
【0005】
この発明は、従来のこのような問題を解決するために案出されたものであり、大規模な情報処理システムにおけるAPサーバ及びDBサーバの構成を最適化することにより、システム全体の処理速度を向上させ得る技術の実現を目的としている。
【課題を解決するための手段】
【0006】
上記の目的を達成するため、請求項1に記載したデータ利用システムは、複数のデータベースサーバと、各データベースサーバにネットワークを介して接続されたアプリケーションサーバとからなるデータ利用システムであって、上記の各データベースサーバは、DB管理システムとデータ記憶領域を備えており、各データベースサーバのデータ記憶領域には、データベースサーバ相互間に共通するデータを保持した共通のテーブルがそれぞれ複数格納されており、上記の各テーブルには、キー項目が一つに限定される制約と、データの更新及び削除が禁止される制約が設けられており、上記アプリケーションサーバは、検索条件分割処理部と、複数の検索処理部と、複数のデータ加工処理部と、検索結果統合処理部と、追加データ受付部と、複数の登録処理部を備え、上記検索条件分割処理部は、入力された検索条件を解析して複数の検索条件に分割すると共に、各検索条件及び対応データベースサーバを上記複数の検索処理部に割り当てる処理を実行し、上記の各検索処理部は、自己に割り当てられた検索条件に対応したSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理と、データベースサーバから一定量の検索結果データが送信される度に、必要な演算処理を上記の各データ加工処理部に割り当てる処理と、各データ加工処理部から部分的な加工処理結果データが返される度に、これをメモリに格納すると共に、データベースサーバから送信されたデータをメモリ上から削除する処理と、データベースサーバからのデータ送信が完了し、部分的な検索結果データに基づく部分的な加工処理結果データが全て揃った時点で、これらを集計して上記検索結果統合処理部に集計結果を出力する処理を実行し、上記検索結果統合処理部は、各検索処理部から渡された集計結果を集計し、検索結果として出力する処理を実行し、上記追加データ受付部は、入力された追加データのコピーと、対応データベースサーバの特定情報を含むデータ追加リクエストを上記の各登録処理部に割り当てる処理を実行し、上記の各登録処理部は、上記追加データの登録を求めるSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理を実行することを特徴としている。
【0007】
請求項2に記載したデータ利用システムは、請求項1のシステムを前提とし、さらに上記検索条件分割処理部は、入力された検索条件が時間的な範囲を含んでいる場合に、これをより短い時間的な範囲に分割することを特徴としている。
【0008】
請求項3に記載したデータ利用システムは、請求項1のシステムを前提とし、さらに上記検索条件分割処理部は、入力された検索条件が地域的な範囲を含んでいる場合に、これをより狭い地域的な範囲に分割することを特徴としている。
【0009】
請求項4に記載したデータ利用システムは、請求項1〜3のシステムを前提とし、さらに、インデックス生成部及びインデックス記憶部を有するインデックスサーバを備えており、また上記の各データベースサーバは、暫定記憶領域及び永続記憶領域を備えており、上記DB管理システムは、上記アプリケーションサーバから送信された追加データを上記暫定記憶領域に格納する処理と、所定の時間間隔で暫定記憶領域内の追加データを上記永続記憶領域に移動する処理を実行し、上記インデックスサーバのインデックス生成部は、所定の時間間隔で上記データベースサーバの暫定記憶領域に格納された追加データを取得する処理と、この追加データに基づいてインデックスを生成し、上記インデックス記憶部に格納する処理を実行し、上記アプリケーションサーバの各検索処理部は、自己に割り当てられた検索条件に対応した上記SQLを生成するに際し、上記インデックスサーバのインデックス記憶部を参照し、検索条件に該当する各データの主キーを取得する処理と、この主キーによって取得データを指定したSQLを生成する処理を実行することを特徴としている。
【0010】
請求項5に記載したデータ利用システムは、請求項1〜4のシステムを前提とし、さらに、上記の各データベースサーバはメモリ上に設けられた更新ログ記憶領域を備えており、各データベースサーバのOSが、上記アプリケーションサーバから送信された追加データを上記更新ログ記憶領域に順次格納する処理を実行することを特徴としている。
【発明の効果】
【0011】
請求項1に記載のデータ利用システムの場合、データベースサーバが管理する各テーブルの正規化が極限まで追求され、構造の単純化が実現される一方で、テーブルから抽出したデータの加工処理(ソートやマッチング、コントロールブレイク等)はアプリケーションサーバ側で実行され、データベースサーバはデータの出し入れに専念できるため、テーブル数の増大やテーブル間の関係の複雑化に伴いSQLの発行数が増大しても、データベースサーバ側の負担増を抑制することが可能となる。
【0012】
また、データベースサーバが物理的に複数台用意され、検索処理時には検索条件が各データベースサーバに分散される仕組みであるため、個々のデータベースサーバにおけるデータ抽出処理が軽減される結果、システム全体の処理速度を向上させることができる。
【0013】
しかも、アプリケーションサーバにおいては、入力された検索条件が複数に分割され、それぞれ複数の検索処理部を介してデータベースサーバにデータの検索依頼が送信されると共に、データベースサーバから各検索処理部に対して返された検索結果データに対しても、一定量単位で複数のデータ加工処理部による並列処理が実行されるため、データベースサーバから大量のデータが送信される場合であっても、多数のCPUコアを用いることで効率的な処理が可能となる。また、このようにデータベースサーバからの検索結果データが全て揃うまで待機することなく、一定量のデータが揃った時点で部分的な加工処理に移行することにより、データベースサーバ側のDISK/IOによる遅延を緩和することも可能となる。
【0014】
これまで、DNA解析や気象解析のように純粋な演算処理を主体とした科学技術計算と異なり、データベースに蓄積された大量のデータを参照する必要のある業務系処理の場合には、データベースサーバからの応答を待つDISK/IOがボトルネックとなるため、アプリケーションサーバ側のCPUコアの数を増やしたとしても、直ちに処理速度の向上には結びつかないという問題があった。
これに対し、上記のような仕組みをアプリケーションサーバに設けることにより、テーブルの正規化の追求に伴うデータベースサーバ側の負担増を、アプリケーションサーバ側の処理の効率化によってカバーすることが可能となった。
【0015】
請求項4に記載のデータ利用システムの場合、インデックス(二次索引)の作成処理が外部の独立したインデックスサーバに移譲されているため、これに纏わるデータベースサーバ側の負担を解消することができる。
しかも、データ参照時には個々のデータの主キーを指定した形のSQLがアプリケーションサーバから発行されるため、データベースサーバ側でテーブルをソートする必要がなくなり、その分、データベースサーバの負荷を低減することができる。
【0016】
請求項5に記載のデータ利用システムの場合、データベースサーバの更新ログがメモリ上に格納される機構を備えているため、更新ログをディスク上に格納する場合に比べて、データベースサーバ側のDISK/IOを低減することができる。
この更新ログ記憶領域は、各データベースサーバのOSによってメモリ上に設定されると共に、更新ログの格納処理もOSの機能によって実現される仕組みであるため、データベースサーバ用のアプリケーションプログラムが機能停止しても、OSがダウンしない限り復旧は可能である。
しかも、データベースサーバが物理的に複数台用意されると共に、各データベースサーバにおいては同一の追加データが更新ログとして更新ログ記憶領域に蓄積される仕組みであるため、停電等の事故によって一のデータベースサーバにおいて更新ログが消えてしまった場合でも、他のデータベースサーバに格納された更新ログによって容易に復旧可能となる。
【発明を実施するための最良の形態】
【0017】
図1は、この発明に係るデータ利用システム10の全体構成を示す模式図であり、ロードバランサ13と、Webサーバ12と、複数のAPサーバ14と、複数のDBサーバ16とを備えている。
Webサーバ12には、インターネット17を介してクライアント端末18が接続されている。
各DBサーバ16は、全DBサーバ16間に共通するデータを格納した複数のテーブル(テーブル群19)と、DB管理システム(RDBMS)とを備えており、DBサーバ16の中の少なくとも一部は、データ保全の観点から遠隔地に配置されている。
【0018】
最初に、本システム10における処理内容について大まかに説明し、個々の具体的な構成や処理内容については後に詳説する。
まず、クライアント端末18にはWebサーバ12からデータ利用画面が送信され、Webブラウザ上に表示される(図示省略)。
そして、ユーザがこのデータ利用画面を通じて検索条件を指定し、データの検索をリクエストすると、Webサーバ12からAPサーバ14に対して検索リクエストが送信される。この際、ロードバランサ13を介して、最も負荷の小さい一のAPサーバ14に対して、検索リクエストが振り分けられる。
【0019】
この検索リクエストを受け取ったAPサーバ14は、検索条件を論理的に複数に分割し、分割された検索条件に対応した複数のSQLをそれぞれ別個のDBサーバ16に発行し、検索条件に合致するデータの抽出を依頼する。
これを受けた各DBサーバ16は、SQLで指定されたデータを抽出し、APサーバ14に送信する。
【0020】
APサーバ14は、各DBサーバ16から受け取ったデータを統合し、Webサーバ12に送信する。
これに対しWebサーバ12は、APサーバ14から受け取った検索結果データを表示する画面(図示省略)を生成し、クライアント端末18に送信する。
【0021】
また、クライアント端末18からデータ追加のリクエストがWebサーバ12に送信された場合、ロードバランサ13によって選択された一のAPサーバ14に当該リクエストが送信される。
これを受けたAPサーバ14は、各DBサーバ16に対して同一のSQLを発行し、同データの追加を依頼する。
これに対し各DBサーバ16は、上記追加データを対応のテーブルに格納する処理を実行する。
【0022】
図2は、クライアント端末18から送信された検索リクエストが、Webサーバ12及びAPサーバ14を経由してDBサーバ16に送信される場面での機能構成を表しており、APサーバ14は、検索条件分割処理部20と、複数の検索処理部22を備えている。
【0023】
また図3は、DBサーバ16から検索結果が送信される場面での機能構成を表しており、APサーバ14は、各検索処理部22単位で複数割り当てられたデータ加工処理部24と、検索結果統合処理部26を備えている。
【0024】
図4は、クライアント端末18から送信されたデータ追加のリクエストが、DBサーバ16に送信される場面での機能構成を表しており、APサーバ14は、追加データ受付部27と、複数の登録処理部28を備えている。
【0025】
APサーバ14内に設けられた上記の検索条件分割処理部20、複数の検索処理部22、複数のデータ加工処理部24、検索結果統合処理部26、追加データ受付部27、複数の登録処理部28は、APサーバ14に搭載された多数のCPUコアが、専用のアプリケーションプログラムに従って所定の処理を実行することで実現されるのであるが、この際、OSによって複数のスレッドが起動されて各CPUコアに割り当てられることにより、マルチタスク処理が実現される。
【0026】
図5は、各CPUコア30とスレッド32との対応関係を表しており、各スレッド32にはスレッドプール34が設けられ、そこに配置された複数のタスク36をスレッド32が順次処理していくイメージが描かれている。
この図におけるスレッド32が、図2〜図4に表された検索条件分割処理部20、複数の検索処理部22、複数のデータ加工処理部24、検索結果統合処理部26、追加データ受付部27、複数の登録処理部28として機能し、これらの機能構成部が実行する具体的な処理がタスク36に相当する。
【0027】
各スレッド32は、スレッドプール34に蓄積されたタスクを古い順に次々と実行していき、自己のスレッドプール34が空になった場合には、他のスレッド32のスレッドプール34に蓄積されたタスク36を、新しい順に実行していく。
【0028】
つぎに、図6〜図9のフローチャートに従い、このシステム10における処理手順を詳細に説明する。
まず、図6に従い、検索条件分割処理部20による処理手順を説明する。
すなわち、クライアント端末18から送信された検索条件をWebサーバ12経由でAPサーバ14が受信すると(S10)、検索条件分割処理部20は検索条件を解析し、検索条件の内容に応じて複数の検索条件に分割する(S12)。
【0029】
ここで分割の基準となるのは、時間(日、週、月、年等)や地域(都道府県、市町村等)など、検索対象データを論理的に複数に区分できるものが該当する。
例えば、「2010年における全チェーン店の売上を集計する」という検索条件が与えられた場合に、「2010年1月分の全チェーン店の売上」、「2010年2月の全チェーン店の売上」、「2010年3月の全チェーン店の売上」…というように、年を月単位に12分割することが該当する。
また、各チェーン店の所在地データに着目し、「2010年における東京所在チェーン店の売上」、「2010年における北海道所在チェーン店の売上」、「2010年における沖縄所在チェーン店の売上」…というように、全国を都道府県単位に47分割することも該当する。
もちろん、「2010年1月分の東京所在チェーン店の売上」や「2010年1月の北海道所在チェーン店の売上」のように、月×都道府県単位で564分割することもできる。
【0030】
これらの分割基準は、クライアント端末18から発せられると予測される検索条件や、対象となるデータの量等に鑑みて、事前に幾つかの分割パターンがプログラム設計者によって策定され、検索条件分割処理部20を実現するためのプログラム中にコーディングされている。
【0031】
ここでは、都道府県単位で47分割されたものとして話を進める。
すなわち、検索条件分割処理部20は、47個の検索処理部22に対して、上記都道府県単位の検索処理と、対応DBサーバ16を割り当てる(S14)。
【0032】
つぎに図7に従い、各検索処理部22における処理手順を説明する。
まず検索処理部22は、自己に割り当てられた検索処理に必要な都道府県を指定したSQLを自動生成し、自己に割り当てられた特定のDBサーバ16に対して発行する(S20)。
【0033】
ここで検索処理部22は、対応のDBサーバ16から全ての検索結果データが送信されるのを待つことなく、予め設定された一定量(例えばレコード1,000件分)のデータが送信された時点で(S22/Y)、必要な演算処理を複数のデータ加工処理部24に割り当てる(S24)。
この結果、一部のデータ加工処理部24は、受信データをキー項目でソートすると共に、キー項目の値に基づいて複数のデータに分割する処理を実行する。また、他のデータ加工処理部24は、分割されたデータに基づく値の集計処理や、当該値を指定したデータの抽出をDBサーバ16に依頼する処理などを実行する。
受信データの分割手法については後に例示するが、検索条件の内容に応じて論理的に分割する検索条件分割処理部20による分割と異なり、受信データの値や分量に応じた分割手法となる。データ加工処理部24による具体的な処理についても、後に例示する。
【0034】
検索処理部22は、データ加工処理部24から処理結果データが返信された時点で(S26/Y)、この単位データ量当たりの処理結果をメモリに格納すると共に、DBサーバ16から送信されたデータをメモリ上から削除する(S28)。
各検索処理部22は、DBサーバ16からのデータ送信が完了するまで、DBサーバ16から送信されるデータが一定量に達する度にS24〜S28の処理を繰り返す(S30/N、S22/Y)。
そして、DBサーバ16からのデータ送信が完了し、S24〜S28の最後の処理が完了した時点で(S30/Y)、検索処理部22はこれまでの部分的な処理結果の集計値を集計し(S32)、検索結果統合処理部26に集計結果を出力する(S34)。
【0035】
つぎに図8に従い、検索結果統合処理部26による処理手順を説明する。
まず検索結果統合処理部26は、各検索処理部22から集計結果が送信される度に、全ての検索処理部22からの集計結果が揃ったか否かをチェックし(S40、S42)、全てが揃った段階で全検索処理部の集計結果を集計する(S44)。
そして、その最終的な集計結果をWebサーバ12に送信する(S46)。
Webサーバ12は、この集計結果を含むWebファイルを生成し、クライアント端末18に送信することになる。
【0036】
つぎに図9に従い、データ追加時におけるAPサーバ14側の処理手順を説明する。
まず、クライアント端末18から送信されたデータ追加のリクエストをWebサーバ12経由でAPサーバ14が受信すると(S50)、追加データ受付部27がDBサーバ16の数に対応した登録処理部28を起動させ、それぞれに担当DBサーバ16の特定情報及び追加データを渡す(S52)。
これを受けた各登録処理部28は、自己が担当するDBサーバ16に対して上記の追加データの登録を求めるSQLを発行する(S54)。
これを受けた各DBサーバ16は、対応のテーブルに対して一斉にデータを追加する。この結果、各DBサーバ16が管理するデータの同一性が確保される。
【0037】
図10は、各DBサーバ16に格納されたテーブル群の具体例を示しており、顧客管理テーブル40と、予約管理テーブル42と、売上管理テーブル44と、予約取消管理テーブル46と、請求管理テーブル48とによって、各店舗の売り上げが管理されている。
【0038】
顧客管理テーブル40は、「顧客ID(主キー)」及び「地域」のデータ項目を備えている。
また、予約管理テーブル42は、「予約ID(主キー)」、「店ID」、「顧客ID(外部キー)」、「金額」及び「予約年月日」のデータ項目を備えている。
売上管理テーブル44は、「予約ID(主キー/外部キー)」及び「売上年月日」のデータ項目を備えている。
予約取消管理テーブル46は、「予約ID(主キー/外部キー)」及び「予約取消年月日」のデータ項目を備えている。
請求管理テーブル48は、「請求ID(主キー)」、「請求年月日」及び「予約ID(外部キー)」のデータ項目を備えている。
【0039】
上記の各テーブル40〜48には、以下の(1)〜(3)の制約が予め課せられている。
(1)キー項目は一つに限定される。
したがって、複数の項目の組合せによってキー項目を構成すること(複合キー)は、禁止される。
【0040】
(2)各テーブルにはレコードの追加のみが許容され、既存レコードの値の更新は禁止される。
したがって、値に変更が生じた場合など、発生タイミングの異なる情報は別テーブルに格納されることとなる。
【0041】
(3)各テーブルのカラムには、NULL値禁止制約、フラグ値禁止制約、区分値禁止制約が課せられる。
まず「NULL値禁止制約」とは、データ項目の値としてNULL(値なし)を充填することが禁止されることを意味しており、このようなNULL値の充填を想定したデータ項目の設定自体が許容されないことになる。
つぎに「フラグ値禁止制約」とは、データ項目の値としてフラグ値(「1/0」、「ON/OFF」、「TRUE/FALSE」等の2値データ)を充填することが禁止されることを意味しており、このようなフラグ値の充填を想定したデータ項目の設定自体が許容されないことになる。
「区分値禁止制約」とは、データ項目の値として区分値(「1:正社員」、「2:パート」、「3:アルバイト」等)を充填することが禁止されることを意味しており、このような区分値の充填を想定したデータ項目の設定自体が許容されないことになる。
【0042】
これらの制約ルールは、新規テーブルの設計時やSQL発行時に、DBサーバ16のデータ管理システム(RDBMS)によって適否がチェックされ、制約ルールに違反する処理の実行が拒絶されることにより、その実効性が担保される。
【0043】
図10より明らかなように、各テーブルは単一のデータ項目によって主キー(PK)が構成されている。
また、「予約取消」に関するデータも、通常であれば予約管理テーブル42において「予約取消フラグ」等のデータ項目が設けられ、各レコードに「1/0」等のフラグ値を充填することで状態が管理されるところであるが、予約取消管理テーブル46を予約管理テーブル42とは別個に設けることにより、予約取消の状態管理がなされている。すなわち、この予約取消管理テーブル46に登録された予約IDが「予約取消」状態にあることとなり、レコードの有無によって予約取消の有無が表現されている。
【0044】
各テーブルには上記(2)の制約(値の更新禁止)が課せられているため、例えばある顧客の「地域」に変動が生じた場合でも、顧客管理テーブル40における該当レコードの「地域」の値が書き換えられることはない。
図示は省略したが、このような場合には例えば「顧客ID」、「変更地域」、「変更年月日」等のデータ項目を備えた「顧客地域変更管理テーブル」が新たに設けられて、当該顧客の顧客ID、変更後の地域、変更年月日が格納される。
【0045】
この結果、顧客の地域別に売上を集計する必要が生じた場合、APサーバ14側では顧客管理テーブル40を参照して各顧客の地域情報を取得した後、顧客地域変更管理テーブルを参照して地域変更の生じた顧客を特定し、変更後の地域に差し替える処理を実行することになる。
【0046】
このようなテーブルがDBサーバ16において管理されている場合に、クライアント端末18から「A店の8月分の請求額を地域毎に集計せよ」という内容の検索リクエストが送信された場合、検索条件分割処理部20は、まず「8月=31日間」というカレンダー情報に従い、「8月1日分」、「8月2日分」、「8月3日分」…「8月31日分」というように、検索条件を31分割する。
【0047】
つぎに検索条件分割処理部20は、これらの分割された検索条件(「A店の8月1日分の請求額を地域毎に集計せよ」等)を31個の検索処理部22に割り当てる。
【0048】
これを受けた各検索処理部22は、自己に割り当てられた請求日を指定した、請求管理テーブル48から請求データを取得するためのSQLを生成し、自己が担当するDBサーバ16に発行する。
そして、DBサーバ16から該当日の請求年月日を備えた請求データが送信されると、検索処理部22は一定量のデータ(例えば1,000件のレコード相当分)単位で受信データを分割し、複数のデータ加工処理部24に以下の処理を割り当てる。
(1)各請求データの「予約ID」を指定したSQLを生成してDBサーバ16に発行し、「予約管理テーブル42」から対応の予約データを取得する。
(2)送信された予約データの中で、該当店舗の「店ID」を有するデータのみを抽出し、他の店IDのデータを除外する。
(3)各予約データの「顧客ID」を指定したSQLを生成してDBサーバ16に発行し、顧客管理テーブル40から対応の顧客データを取得する。
(4)顧客データの「地域」毎に、予約データ中の「金額」の値を集計する。
これら(1)〜(4)の処理は、具体的にはタスク36として各データ加工処理部24のスレッドプール34に配置される。
【0049】
検索処理部22は、データ加工処理部24から上がってきた1,OOO件単位の処理結果データをメモリに格納すると共に、DBサーバ16から送信されたデータをメモリ上から削除する。そして、1日分の処理結果データが揃った時点で、全処理結果データを集計する。この集計結果は、検索結果統合処理部26に出力される。
検索結果統合処理部26は、全検索処理部22から8月1日〜8月31日までの全集計結果が集まった時点でこれらを集計し、Webサーバ12に出力する。
【0050】
このシステム10の場合、DBサーバ16からのフェッチが完了するまでAPサーバ14が待つことはなく、一定量のデータを受信する度に複数のデータ加工処理部24による処理が開始される仕組みであるため、DBサーバ16のDISK/IOによるボトルネックを解消することができる。
【0051】
また、APサーバ14における部分的な集計が完了する度に、DBサーバ16から送信されたデータが占めていたメモリが解放され、データ量が格段に小さな集計結果データのみがメモリに格納される仕組みであるため、APサーバ14のメモリが大きなデータに占拠され続けることを回避できる。
【0052】
さらに、各検索処理部22は、それぞれ別個のDBサーバ16に対しSQLを分散して発行するため、個々のDBサーバ16における処理の負担が必然的に低減することとなり、全体の処理速度を高速化することができる。
上記の通り、各DBサーバ16は同じ内容のデータを保持しているため、検索処理部22にDBサーバ16を割り振る際にはDBサーバ16毎の特性を考慮することなく、機械的に対応付けることができる。
【0053】
なお、処理速度の向上という観点からは、分割した検索条件と等しい数の検索処理部22及びDBサーバ16を用意することが望ましいが、検索処理部及びDBサーバ16に数はこれに限定されるものではない。
例えば、分割された検索条件が31個あり、検索処理部が31個設けられたにもかかわらず、DBサーバ16が物理的に10台しか用意されていない場合には、各DBサーバ16に対して3〜4個の検索条件が割り振られることになる。この場合でも、1台のDBサーバ16のみで全てを処理する場合に比べ、大幅な高速化が期待できる。
【0054】
ここで、図11を参照して、DBサーバ16から送信された一定量単位のデータに対する分割手順について説明する。
まず一のデータ加工処理部24は、DBサーバ16から送信されたデータを2等分する位置を探索し、そこから前方不一致検索によってキー項目の変わり目を探しだし、データを2分割させる。
例えば、(a)のデータ列はキー項目の値が1〜6があるが、データ加工処理部24は「3」と「4」との間を境にこれを2分割させ、(b)及び(c)のデータ列を生成する。
【0055】
つぎに、他のデータ加工処理部24は、(b)のデータ列を「2」と「3」との間で2分割させ、(d)及び(e)のデータ列を生成する。
この時点で、(e)のデータ列のキー項目の値は「3」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(e)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0056】
これに対し、(d)のデータ列の場合には「1」と「2」の間で2分割可能であるため、データ加工処理部24はここでデータ列を2分割させ、(h)及び(i)のデータ列を生成する。
この時点で、(h)のデータ列のキー項目の値は「1」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(h)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
同様に、(i)のデータ列のキー項目の値は「2」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(i)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0057】
一方、(c)のデータ列については、他のデータ加工処理部24が「5」と「6」との間で2分割させ、(f)及び(g)のデータ列を生成する。
この時点で、(g)のデータ列のキー項目の値は「6」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(g)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0058】
これに対し、(f)のデータ列の場合には「4」と「5」の間で2分割可能であるため、データ加工処理部24はここでデータ列を2分割させ、(j)及び(k)のデータ列を生成する。
この時点で、(j)のデータ列のキー項目の値は「4」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(j)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
同様に、(k)のデータ列のキー項目の値は「5」のみとなるため、データ加工処理部24はそれ以上の分割を停止する。この(k)のデータ列については、他のデータ加工処理部24によって必要な計算処理等が実行される。
【0059】
図11の例では、説明の便宜上簡略化されたデータ列を例示したが、各データ加工処理部24は、実際にはDBサーバ16から送信された一定量(例えばレコード1,000件分)のデータ列に対して、ソートやマッチング、コントロールブレイクの都度、上記の分割処理を実行する。
この結果、大量のデータに対して複数のデータ加工処理部24による並列処理が可能となり、APサーバ14に複数搭載されたCPUコアの有効利用が可能となる。
このデータ加工処理部24による分割処理に際し、分割の回数(階層の深さ)に一定の限度を設けることもできる。
【0060】
上記のように、データ加工処理部24は検索処理部22から渡されたデータ列の特定のデータ項目の値を指定してDBサーバ16にSQLを発行し、検索処理を依頼する場合があるため、必然的にDBサーバ16からの応答待ち(I/O Wait)が発生することになる。
【0061】
そこで図12に示すように、各スレッド32にI/O Waitを伴う処理用の第1のスレッドプール50と、I/O Waitを伴わない処理用の第2のスレッドプール52を設けることが望ましい。
この結果、第1のスレッドプール50に配置されたタスク36の実行によってI/O Waitが発生した場合、スレッド32は第2のスレッドプール52に配置されたタスク36を待ち時間の間に処理することが可能となり、処理の効率化を図ることが可能となる。
【0062】
この発明にあっては、上記のようにDBサーバ16が管理する各テーブルの構造が極限まで単純化される分、テーブルの数が増え、SQLの発行数自体は増大するが、演算処理は多数のCPUコアを用いた並列処理によって高速化されたAPサーバ14側で行われ、DBサーバ16は単純化されたデータの管理(インサートとセレクト)に専念でき、データの更新や削除から解放されるため、DBサーバ16の負担は大幅に軽減される。
しかも、DBサーバ16は筐体レベルで複数台用意され、検索時にはデータの抽出処理がそれぞれに分散される。
このため、テーブルの正規化の追求に伴いDBサーバ16側の処理速度が低下することを、有効に回避できる。
【0063】
また、フラグ値や区分値のように、特殊なビジネスルールに基づいた値の格納が禁止される結果、データモデルの見通しが良好となり、テスト・データの作成効率が向上するという効果も期待できる。
【0064】
図13に示すように、各DBサーバ16と各APサーバ14との間にインデックスサーバ60を設けることにより、このシステム10における検索処理をより高速化することができる。
この場合、各DBサーバ16は、DB管理システム(RDBMS)61と、当日分データ記憶領域(暫定記憶領域)62と、過去分データ記憶領域(永続記憶領域)63とを備える。
【0065】
また、インデックスサーバ60は、インデックス生成部64と、インデックス記憶部65と、インデックス提供部66とを備えている。
インデックス生成部64及びインデックス提供部66は、インデックスサーバ60のCPUが専用のプログラムに従って動作することにより実現され、インデックス記憶部65は、インデックスサーバ60のSSD(Solid State Drive)内に設けられている。
【0066】
APサーバ14の登録処理部28から送信された追加データは、DBサーバ16のDB管理システム61によって当日分データ記憶領域62に一旦格納された後、夜間バッチ処理によって過去分データ記憶領域63に移される。
また、インデックスサーバ60のインデックス生成部64は、夜間バッチ処理により、DB管理システム61から当日分データ記憶領域62内に格納された追加データを取得し、追加分のインデックスを作成した後、インデックス記憶部65に格納する。
【0067】
この場合、APサーバ14の各検索処理部22は、各DBサーバ16に対してSQLを発行するに際し、インデックスサーバ60のインデックス提供部66を介してインデックス記憶部65を参照し、過去分データ記憶領域63に格納されたデータに関しては、検索条件の範囲に含まれる個々のデータの主キーを取得した後、個々の主キーを特定したSQLを生成する。
【0068】
例えば、Webサーバ12から送信された検索条件が、特定店舗における過去1年分の売上データを取得するものであった場合、検索処理部22はこの条件に合致する全データの主キーをインデックスサーバ60から取得した上で、SQL中にこれらの主キーを記述してDBサーバ16に発行する。
【0069】
このため、DBサーバ16のDB管理システム61は、データの検索処理を行うことなく、過去分データ記憶領域63に格納された各テーブルから主キーによって指定されたデータをダイレクトに取り出し、検索処理部22に迅速に返すことが可能となる。
しかも、インデックスはハードディスクよりも高速な動作が可能なSSDに格納されているため、APサーバ14がインデックスを参照する際のDISK/IOを低減することができる。
【0070】
なお、インデックスは上記の通り夜間バッチにて生成されるため、当日分データについてはインデクスが用意されていない。このため、当日分データを取得する必要がある場合、検索処理部22は主キーを指定することなく、検索条件を指定したSQLをDBサーバ16に発行する。
【0071】
このシステム10においては、上記の通り、個々のレコードに関して更新や削除が生じることがなく、新規レコードの追加のみが許される仕組みを採用しているため、DBサーバ16において当日分データと過去分データを明確に分離することが可能となる。
【0072】
図14は、各DBサーバ16の内部構造をより詳細に示すものであり、メモリ上に設けられたバッファ・キャッシュ領域70と、DB管理システム(RDBMS)61と、OS(Linux)72と、テーブル記憶領域74と、更新ログ記憶領域76とが描かれている。
ここでテーブル記憶領域74は、ハードディスク(HDD)内に設けられており、上記した顧客管理テーブル40や予約管理テーブル42等が格納されている。また更新ログ記憶領域76は、OSによってメモリ(tmpfs)内に設けられている。
【0073】
この図に示されているように、DBサーバ16においては一般に、テーブル内のデータはブロック78単位でテーブル記憶領域74からバッファ・キャッシュ領域70に取り出されると共に、バッファ・キャッシュ領域70に書き込まれたデータはブロック78単位でテーブル記憶領域74に格納される。
このため、上記のように各テーブルに格納されるレコードの構造が極限まで簡素化されていると、1つのブロック78に収納できるレコード数を増やすことが可能となり、その分、DBサーバ16における処理の効率化を実現することが可能となる。
【0074】
また、更新ログ79をハードディスクよりも高速に動作するメモリ上に設けられた更新ログ記憶領域76に格納することにより、その分DISK/IOを削減することが可能となり、DBサーバ16における処理のさらなる高速化を実現可能となる。
【0075】
ところで、更新ログ79はDBサーバ16に何らかのトラブルが発生した場合に、データを復旧させるための最後の拠り所となる重要な構成要素であるため、通常は電源OFFによってデータが消失してしまうメモリ上に設けられることはない。
これに対し、このシステム10の場合には、上記のようにDBサーバ16が物理的に複数台設けられており、各DBサーバ16には同一内容のデータが保存される仕組みを備えているため、データ消失の危険を有効に分散させることが可能となる。
【0076】
しかも、各テーブルにはデータの更新や削除が許容されないというルールが適用されているため、一のDBサーバ16の更新ログが消失してしまい、他のDBサーバ16の更新ログに基づいてデータを復旧させる必要性が生じた場合であっても、ハードディスクに格納された既存のデータとの間で整合性を確保する必要がなく、新たに追加された当日分のデータのみを追記させれば済むという利点も生じる。因みに、この復旧が完了するまでの間、当該DBサーバ16についてはWRITE ONLY状態(データの書き込み可/読み込み不可)に置かれる。
【0077】
なお、上記の更新ログ記憶領域76は、上記のように各DBサーバ16のOSによってメモリ上に設定されると共に、更新ログの格納処理もOSの機能によって実現される仕組みであるため、DBサーバ用のアプリケーションプログラムがクラッシュ等しても、OSがダウンしない限り当該DBサーバ内で復旧可能である。
【図面の簡単な説明】
【0078】
【図1】この発明に係るデータ利用システムの全体構成を示す模式図である。
【図2】この発明に係るデータ利用システムの、検索リクエストがDBサーバに送信される場面での機能構成を示すブロック図である。
【図3】この発明に係るデータ利用システムの、DBサーバから検索結果が送信される場面での機能構成を示すブロック図である。
【図4】この発明に係るデータ利用システムの、クライアント端末から送信されたデータ追加のリクエストが、DBサーバに送信される場面での機能構成を示すブロック図である。
【図5】CPUコアとスレッドとの対応関係を示す模式図である。
【図6】検索条件分割処理部による処理手順を示すフローチャートである。
【図7】検索処理部による処理手順を示すフローチャートである。
【図8】検索結果統合処理部による処理手順を示すフローチャートである。
【図9】クライアント端末から送信されたデータ追加のリクエストがDBサーバに送信される際の処理手順を示すフローチャートである。
【図10】DBサーバに格納されたテーブルを例示する図である。
【図11】データ加工処理部によるデータ分割の手順を示す模式図である。
【図12】スレッド毎に複数のスレッドプールを設けた例を示す模式図である。
【図13】この発明に係るデータ利用システムにインデックスサーバを追加した例を示すブロック図である。
【図14】DBサーバの内部構造を示す模式図である。
【符号の説明】
【0079】
10 データ利用システム
12 Webサーバ
13 ロードバランサ
14 APサーバ
16 DBサーバ
17 インターネット
18 クライアント端末
19 テーブル群
20 検索条件分割処理部
22 検索処理部
24 データ加工処理部
26 検索結果統合処理部
27 追加データ受付部
28 登録処理部
30 CPUコア
32 スレッド
34 スレッドプール
36 タスク
40 顧客管理テーブル
42 予約管理テーブル
44 売上管理テーブル
46 予約取消管理テーブル
48 請求管理テーブル
50 第1のスレッドプール
52 第2のスレッドプール
60 インデックスサーバ
61 DB管理システム
62 当日分データ記憶領域
63 過去分データ記憶領域
64 インデックス生成部
65 インデックス記憶部
66 インデックス提供部
70 バッファ・キャッシュ領域
74 テーブル記憶領域
76 更新ログ記憶領域
78 ブロック
79 更新ログ
【特許請求の範囲】
【請求項1】
複数のデータベースサーバと、各データベースサーバにネットワークを介して接続されたアプリケーションサーバとからなるデータ利用システムであって、
上記の各データベースサーバは、DB管理システムとデータ記憶領域を備えており、
各データベースサーバのデータ記憶領域には、データベースサーバ相互間に共通するデータを保持した共通のテーブルがそれぞれ複数格納されており、
上記の各テーブルには、キー項目が一つに限定される制約と、データの更新及び削除が禁止される制約が設けられており、
上記アプリケーションサーバは、検索条件分割処理部と、複数の検索処理部と、複数のデータ加工処理部と、検索結果統合処理部と、追加データ受付部と、複数の登録処理部を備え、
上記検索条件分割処理部は、入力された検索条件を解析して複数の検索条件に分割すると共に、各検索条件及び対応データベースサーバを上記複数の検索処理部に割り当てる処理を実行し、
上記の各検索処理部は、自己に割り当てられた検索条件に対応したSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理と、データベースサーバから一定量の検索結果データが送信される度に、必要な演算処理を上記の各データ加工処理部に割り当てる処理と、各データ加工処理部から部分的な加工処理結果データが返される度に、これをメモリに格納すると共に、データベースサーバから送信されたデータをメモリ上から削除する処理と、データベースサーバからのデータ送信が完了し、部分的な検索結果データに基づく部分的な加工処理結果データが全て揃った時点で、これらを集計して上記検索結果統合処理部に集計結果を出力する処理を実行し、
上記検索結果統合処理部は、各検索処理部から渡された集計結果を集計し、検索結果として出力する処理を実行し、
上記追加データ受付部は、入力された追加データのコピーと、対応データベースサーバの特定情報を含むデータ追加リクエストを上記の各登録処理部に割り当てる処理を実行し、
上記の各登録処理部は、上記追加データの登録を求めるSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理を実行することを特徴とするデータ利用システム。
【請求項2】
上記検索条件分割処理部は、入力された検索条件が時間的な範囲を含んでいる場合に、これをより短い時間的な範囲に分割することを特徴とする請求項1に記載のデータ利用システム。
【請求項3】
上記検索条件分割処理部は、入力された検索条件が地域的な範囲を含んでいる場合に、これをより狭い地域的な範囲に分割することを特徴とする請求項1に記載のデータ利用システム。
【請求項4】
請求項1〜3の何れかに記載のデータ利用システムであって、
インデックス生成部及びインデックス記憶部を有するインデックスサーバを備えており、
また上記の各データベースサーバは、暫定記憶領域及び永続記憶領域を備えており、
上記DB管理システムは、上記アプリケーションサーバから送信された追加データを上記暫定記憶領域に格納する処理と、所定の時間間隔で暫定記憶領域内の追加データを上記永続記憶領域に移動する処理を実行し、
上記インデックスサーバのインデックス生成部は、所定の時間間隔で上記データベースサーバの暫定記憶領域に格納された追加データを取得する処理と、この追加データに基づいてインデックスを生成し、上記インデックス記憶部に格納する処理を実行し、
上記アプリケーションサーバの各検索処理部は、自己に割り当てられた検索条件に対応した上記SQLを生成するに際し、上記インデックスサーバのインデックス記憶部を参照し、検索条件に該当する各データの主キーを取得する処理と、この主キーによって取得データを指定したSQLを生成する処理を実行することを特徴とするデータ利用システム。
【請求項5】
上記の各データベースサーバは、メモリ上に設けられた更新ログ記憶領域を備えており、
各データベースサーバのOSが、上記アプリケーションサーバから送信された追加データを上記更新ログ記憶領域に順次格納する処理を実行することを特徴とする請求項1〜4の何れかに記載のデータ利用システム。
【請求項1】
複数のデータベースサーバと、各データベースサーバにネットワークを介して接続されたアプリケーションサーバとからなるデータ利用システムであって、
上記の各データベースサーバは、DB管理システムとデータ記憶領域を備えており、
各データベースサーバのデータ記憶領域には、データベースサーバ相互間に共通するデータを保持した共通のテーブルがそれぞれ複数格納されており、
上記の各テーブルには、キー項目が一つに限定される制約と、データの更新及び削除が禁止される制約が設けられており、
上記アプリケーションサーバは、検索条件分割処理部と、複数の検索処理部と、複数のデータ加工処理部と、検索結果統合処理部と、追加データ受付部と、複数の登録処理部を備え、
上記検索条件分割処理部は、入力された検索条件を解析して複数の検索条件に分割すると共に、各検索条件及び対応データベースサーバを上記複数の検索処理部に割り当てる処理を実行し、
上記の各検索処理部は、自己に割り当てられた検索条件に対応したSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理と、データベースサーバから一定量の検索結果データが送信される度に、必要な演算処理を上記の各データ加工処理部に割り当てる処理と、各データ加工処理部から部分的な加工処理結果データが返される度に、これをメモリに格納すると共に、データベースサーバから送信されたデータをメモリ上から削除する処理と、データベースサーバからのデータ送信が完了し、部分的な検索結果データに基づく部分的な加工処理結果データが全て揃った時点で、これらを集計して上記検索結果統合処理部に集計結果を出力する処理を実行し、
上記検索結果統合処理部は、各検索処理部から渡された集計結果を集計し、検索結果として出力する処理を実行し、
上記追加データ受付部は、入力された追加データのコピーと、対応データベースサーバの特定情報を含むデータ追加リクエストを上記の各登録処理部に割り当てる処理を実行し、
上記の各登録処理部は、上記追加データの登録を求めるSQLを生成し、自己に割り当てられたデータベースサーバに発行する処理を実行することを特徴とするデータ利用システム。
【請求項2】
上記検索条件分割処理部は、入力された検索条件が時間的な範囲を含んでいる場合に、これをより短い時間的な範囲に分割することを特徴とする請求項1に記載のデータ利用システム。
【請求項3】
上記検索条件分割処理部は、入力された検索条件が地域的な範囲を含んでいる場合に、これをより狭い地域的な範囲に分割することを特徴とする請求項1に記載のデータ利用システム。
【請求項4】
請求項1〜3の何れかに記載のデータ利用システムであって、
インデックス生成部及びインデックス記憶部を有するインデックスサーバを備えており、
また上記の各データベースサーバは、暫定記憶領域及び永続記憶領域を備えており、
上記DB管理システムは、上記アプリケーションサーバから送信された追加データを上記暫定記憶領域に格納する処理と、所定の時間間隔で暫定記憶領域内の追加データを上記永続記憶領域に移動する処理を実行し、
上記インデックスサーバのインデックス生成部は、所定の時間間隔で上記データベースサーバの暫定記憶領域に格納された追加データを取得する処理と、この追加データに基づいてインデックスを生成し、上記インデックス記憶部に格納する処理を実行し、
上記アプリケーションサーバの各検索処理部は、自己に割り当てられた検索条件に対応した上記SQLを生成するに際し、上記インデックスサーバのインデックス記憶部を参照し、検索条件に該当する各データの主キーを取得する処理と、この主キーによって取得データを指定したSQLを生成する処理を実行することを特徴とするデータ利用システム。
【請求項5】
上記の各データベースサーバは、メモリ上に設けられた更新ログ記憶領域を備えており、
各データベースサーバのOSが、上記アプリケーションサーバから送信された追加データを上記更新ログ記憶領域に順次格納する処理を実行することを特徴とする請求項1〜4の何れかに記載のデータ利用システム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【公開番号】特開2013−92945(P2013−92945A)
【公開日】平成25年5月16日(2013.5.16)
【国際特許分類】
【出願番号】特願2011−235380(P2011−235380)
【出願日】平成23年10月26日(2011.10.26)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.Linux
【出願人】(000155469)株式会社野村総合研究所 (1,067)
【公開日】平成25年5月16日(2013.5.16)
【国際特許分類】
【出願日】平成23年10月26日(2011.10.26)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.Linux
【出願人】(000155469)株式会社野村総合研究所 (1,067)
[ Back to top ]