
データ圧縮装置及び方法,データ解析装置及び方法並びにデータ管理システム
【課題】 膨大なデータを圧縮できるようにするとともに、圧縮したデータから元のデータの特性をより正確に再現できるようにすることを目的とする。
【解決手段】 対象体の動作時に、この動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出手段4と、検出手段4により検出された各データセットをn次元空間内に入力し、データセット数よりも少ない所定数のニューロンをn次元空間内に配置してニューラルネットワークの教師なし学習法によりニューロンの学習を行い、上記の複数のデータセットを、学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮するデータ圧縮手段6とをそなえる構成にする。
【解決手段】 対象体の動作時に、この動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出手段4と、検出手段4により検出された各データセットをn次元空間内に入力し、データセット数よりも少ない所定数のニューロンをn次元空間内に配置してニューラルネットワークの教師なし学習法によりニューロンの学習を行い、上記の複数のデータセットを、学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮するデータ圧縮手段6とをそなえる構成にする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、膨大なデータを圧縮処理するのに用いて好適なデータ圧縮装置及び方法,データ解析装置及び方法並びにデータ管理システムに関する。
【背景技術】
【0002】
近年、地球資源が有限であることや、一部の地域では環境負荷が限界を超えつつあることから、持続可能な社会へ転換していくために、資源の循環や環境負荷の削減に視点を置いた機械類に関する新しいメンテナンスのあり方が強く求められている。
従来の機械類のメンテナンスでは、機械類に故障が発生してから修復する事後保全や、機械類の使用時間を基準にした画一的な予防保全が一般に行なわれている。事後保全では、修理に大幅な時間やコストがかかってしまい、また、予防保全では、画一的な処理のため、不必要な部品やオイルの廃棄が発生し顧客の費用負担が増大し、また、労働集約型からくる高コスト化という課題があったが、今後はこうした従来のメンテナンスから脱却して、予知保全への転換を図っていく必要がある。
【0003】
予知保全とは、稼動時の負荷・環境情報、過去のメンテナンス歴データベース、故障物理の理解などから、推論により健全度を診断して劣化・余寿命を予測することで、機械の異常を早期に発見して安全な動作環境を提供するものである。
このような予知保全を行なうシステムでは、通常、対象となる機械に取り付けたセンサにより機械の稼動状態を検出し、機械に備えたデータ収集装置により上記の稼動状態の生データを収集するとともに、この生データをリアルタイムに或いは所定の周期で管理センター(例えば機械のメンテナンスを行なう企業のサービス部門)に送信し、管理センター側において生データを解析して機械の健全度を診断するようになっている。
【0004】
しかし、データ収集装置により収集する生データは膨大であり、このような膨大な生データを通信により機械から管理センターに送信するため、通信の信頼性に問題が生じたり、通信コストが高くなってしまう。そこで、生データを圧縮してから通信することが考えられる。例えば特許文献1には、センサからの時系列稼動信号を頻度分布データもしくは周波数分布データに圧縮する手法が開示されている。また、特許文献2には、故障確率(バスタブ曲線)に応じて稼動信号の送信時間の間隔を変える手法が開示されている。さらに、特許文献3には、メモリの記憶容量を小さくするために単位時間毎の検出頻度を積算し、その頻度分布から機械の状態を判定する手法が開示されている。
【特許文献1】特開2003−083848
【特許文献2】特開2002−180502
【特許文献3】特開平10−273920号
【発明の開示】
【発明が解決しようとする課題】
【0005】
しかしながら、上述した特許文献1〜3の手法はいずれも、圧縮したデータから元のデータ(生データ)の特性を再現することは困難である。
また、例えば、生データの移動平均をとることで生データよりも少ない数のデータに圧縮して送信することが考えられるが、上記と同様に、生データの特性をより正確に再現することはできない。
【0006】
本発明は、このような課題に鑑み創案されたもので、膨大なデータを圧縮できるようにするとともに、圧縮したデータから元のデータの特性をより正確に再現できるようにした、データ圧縮装置及び方法を提供することを目的とする。
また、上記のデータ圧縮装置及び方法により圧縮したデータを解析できるようにした、データ解析装置及び方法、さらには、上記のデータ圧縮装置及びデータ解析装置を備えたデータ管理システムを提供することを目的とする。
【課題を解決するための手段】
【0007】
このため、請求項1記載の本発明のデータ圧縮装置は、対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出手段と、該検出手段により検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行ない、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮する圧縮手段とをそなえたことを特徴としている。
【0008】
請求項2記載の本発明のデータ圧縮装置は、請求項1記載の装置において、該圧縮手段は、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいることを特徴としている。
【0009】
請求項3記載の本発明のデータ圧縮装置は、請求項2記載の装置において、該データ圧縮手段は、該学習の終了後、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去することを特徴としている。
請求項4記載の本発明のデータ圧縮装置は、請求項1〜3の何れか1項に記載の装置において、上記ニューロンモデルパラメータを外部へ送信する送信手段をそなえていることを特徴としている。
【0010】
請求項5記載の本発明のデータ解析装置は、請求項4記載のデータ処理装置の該送信手段により送信された上記ニューロンモデルパラメータを受信する受信手段と、該受信手段により受信された上記ニューロンモデルパラメータに基づいて該データセットを解析する解析手段とをそなえたことを特徴としている。
請求項6記載の本発明のデータ解析装置は、請求項5記載の装置において、該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析することを特徴としている。
【0011】
請求項7記載の本発明のデータ解析装置は、請求項5記載の装置において、該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該データセットの分布密度を求めることにより解析することを特徴としている。
請求項8記載の本発明のデータ管理システムは、請求項4記載のデータ圧縮装置と、請求項5〜7の何れか1項に記載のデータ解析装置とをそなえたことを特徴としている。
【0012】
請求項9記載の本発明のデータ管理システムは、請求項8記載のシステムにおいて、該対象体は建設機械であり、上記のn個のパラメータは該建設機械の動作に応じて変動するパラメータであることを特徴としている。
請求項10記載の本発明のデータ圧縮方法は、対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出ステップと、該検出ステップで検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行ない、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮するデータ圧縮ステップとをそなえたことを特徴としている。
【0013】
請求項11記載の本発明のデータ圧縮方法は、請求項10記載の方法において、該データ圧縮ステップでは、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいることを特徴としている。
【0014】
請求項12記載の本発明のデータ圧縮方法は、請求項11記載の方法において、該データ圧縮ステップでは、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去することを特徴としている。
請求項13記載の本発明のデータ解析方法は、請求項12記載のデータ圧縮方法により得られた上記ニューロンモデルパラメータを取得する取得ステップと、該取得ステップで取得した上記ニューロンモデルパラメータに基づいて該データセットを解析する解析ステップとをそなえたことを特徴としている。
【0015】
請求項14記載の本発明のデータ解析方法は、請求項13記載の方法において、該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析することを特徴としている。
請求項15記載の本発明のデータ解析方法は、請求項13記載の方法において、該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該データセットの分布密度を求めることにより解析することを特徴としている。
【発明の効果】
【0016】
本発明のデータ圧縮装置及び方法によれば、n個のパラメータの値からなる複数のデータセット(生データ)を、このデータセット数よりも少ない所定数のニューロンから得られるニューロンモデルを特徴付けるニューロンモデルパラメータに圧縮することができる。また、圧縮されたニューロンモデルパラメータ(圧縮データ)は、ニューロンモデルを特徴付けるもの、即ち複数のデータセットを特徴付けるものであるので、圧縮データから元のデータセットの特性をより正確に再現することが可能となる。
【0017】
また、本発明のデータ解析装置及び方法によれば、ニューロンモデルパラメータを用いて、元のデータセット(生データ)を解析することができる。この場合、ニューロンの移動平均や、データセットの分布密度を解析することで、対象体の診断を行なうことができる。
さらに、本発明のデータ管理システムによれば、上記のデータ圧縮装置及びデータ解析装置の両方の効果が得られる。
【発明を実施するための最良の形態】
【0018】
以下、図面を参照しながら本発明の実施形態について説明する。
本実施形態に係るデータ管理システムは、建設機械等の機械類に異常があるか否かを診断するために用いられる。以下では、建設機械として油圧ショベルに適用した場合のデータ管理システムについて説明する。なお、本データ管理システムの適用対象はこれに限定されるものではなく、動作或いは環境に応じて変動しうる種々の対象体全てに適用することができる。
【0019】
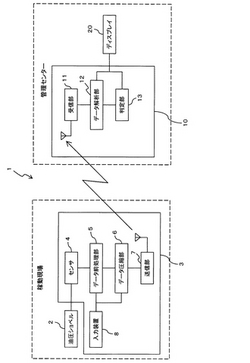
図1は本発明の一実施形態に係るデータ管理システムを模式的に示すブロック図である。図1に示すように、本データ管理システム1は、建設現場などの稼動現場で使用される油圧ショベル2から、稼動現場と離れて油圧ショベル2を管理する管理センター(例えば油圧ショベル2のメンテナンスを行なう企業のサービス部門)10へ、油圧ショベル2に関するデータを送信し、管理センター10側において、油圧ショベル2から受信したデータに基づいて推論により油圧ショベル2の健全度を診断できるようになっている。このため、本データ管理システム1は、油圧ショベル2に備えられた車載型のデータ圧縮装置3と、管理センターに設けられたデータ解析装置10とを主に備えて構成されている。
【0020】
データ圧縮装置3は、センサ4,データ前処理部(前処理手段)5,データ圧縮部(圧縮手段)6,送信部(送信手段)7,入力装置(キーボードやマウスなど)8を主に備えて構成されている。なお、センサ4及びデータ前処理部5で検出手段が構成される。また、データ前処理部5,データ圧縮部6の各機能を実現するために、図示しないがコンピュータなどのECU(電子コントロールユニット)に所要の処理プログラムが組み込まれている。ECUは、入出力装置,記憶装置(RAM,ROM等のメモリ),中央処理装置(CPU)等を備えて構成される。
【0021】
センサ4は、油圧ショベル2に関するn個のパラメータ(変動要素)に対応して備えられ、油圧ショベル2の動作時に、油圧ショベル2の動作に応じて変動する各パラメータの値x1,x2,…,xnを検出(計測)するようになっている。
なお、このセンサ4は、対応するパラメータの値を直接検出するもののほか、ある検出データを演算等によって処理して、対応するパラメータの値を計算値又は推定値として求めるものも含む。ここでいう油圧ショベル2に関するパラメータとは、例えばエンジン回転数,エンジンオイル温度,エンジンオイル圧力,エンジン冷却水温,ブースト圧力(過給後の給気圧力),燃料消費量,排ガス温度,パワーシフト圧,ハイドロリックオイル圧力,ハイドロリックオイル温度,ハイドロリックオイル微粒子カウンター,エンジン稼動時間などの油圧ショベル2の動作に応じて変動する各要素のことをいう。
【0022】
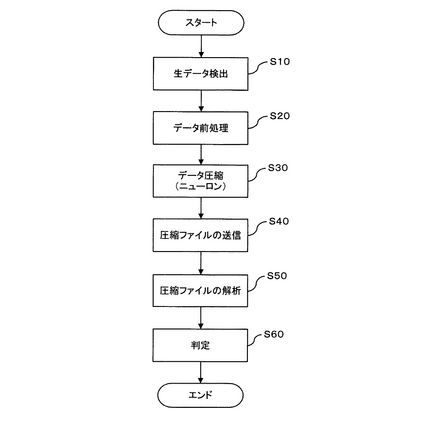
データ前処理部5は、前述のごとく所要の処理プログラム(データ前処理プログラム)によってその機能を実現されるが、このデータ前処理プログラムは図9に示す処理手順を実現しうるものである。すなわち、まず、エンジンが回転中か否かを判定し(ステップT10)、エンジンが回転中であれば、次に、エンジンオイル温度が設定値以上であるか否かを判定する(ステップT20)。そして、エンジンオイル温度が設定値以上になったら、センサ4が検出した生データを取得し(ステップT30)、次に、エンジンが停止したか否かを判定する(ステップT40)。つまり、エンジンが停止するまで生データを取得し続ける。そして、エンジンが停止したら、運転ダイヤル毎に生データを整理し(ステップT50)、運転ダイヤル毎にファイルを作成して生データを保存する(ステップT60)。なお、上記の運転ダイヤルとは、オペレータが作業内容(作業負荷)に応じてエンジン回転数を設定するダイヤルのことをいう。
【0023】
以下、データ前処理部5についてより具体的に説明する。
データ前処理部5は、油圧ショベル2のエンジンが回転し、且つ、エンジンオイル温度が設定値以上になったら(即ち、油圧ショベル2が通常動作を開始したら)センサ4により検出される各パラメータの値からなるデータセットを例えば一秒周期で取得(収集)して記憶装置に保存するようになっている。なお、エンジンが回転しているか否かは、エンジン回転数を検出するセンサからの情報により判定することができ、エンジンオイル温度が設定値以上になったか否かは、エンジンオイル温度を検出するセンサからの情報により判定することができる。また、本実施形態ではセンサ4からのデータ取得の周期を一秒に設定しているが、この周期は入力装置8からの入力により任意に設定することが可能となっている。
【0024】
上述のようにしてデータ前処理部5は、各パラメータからなるデータセットを油圧ショベル2の動作開始時から動作終了時(即ちエンジン停止時)まで記憶装置に保存し続ける。また、データ前処理部5は、油圧ショベル2のエンジン停止後、記憶装置に保存された複数のデータセットを運転ダイヤル毎に整理するとともに、運転ダイヤル毎にファイルを作成して、対応する各ファイルにデータセットを保存するようになっている。
【0025】
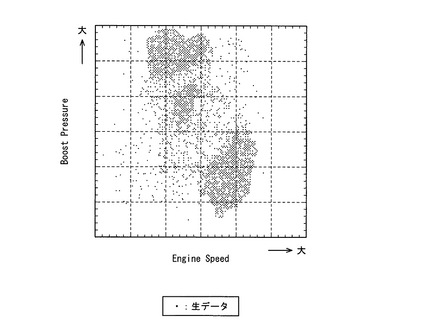
したがって、各ファイルに保存されるデータセットの数は、例えば数千や数万個であり膨大な数である。例えば図2は、ある運転ダイヤルにおけるエンジン回転数(Engine Speed)とブースト圧力(Boost Pressure)とのデータセット(即ち生データ)の点をプロットした図であるが、この図2からわかるように、データセットは膨大な数となる。なお、当然のことながら、図2中のエンジン回転数の軸(横軸)は通常運転時の回転数領域について示している。また、以下で用いる図3,図5,図6及び図7においても同様に、エンジン回転数の軸は通常運転時の回転数領域について示している。
【0026】
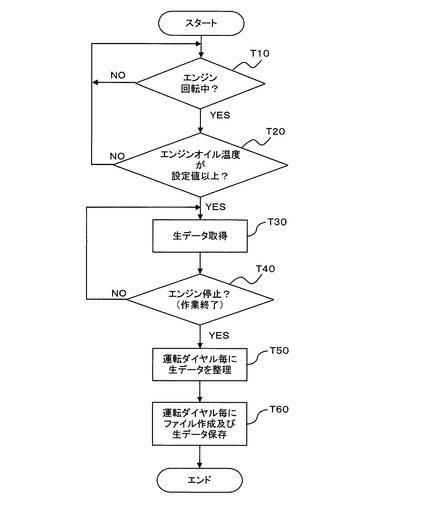
データ圧縮部6は、前述のごとく所要の処理プログラム(データ圧縮プログラム)によってその機能を実現されるが、このデータ圧縮プログラムは図10に示す処理手順を実現しうるものである。すなわち、運転ダイヤルのファイルを読み込んだ後(ステップU10)、所定数のニューロンを乱数でn次元に配置し(ステップU20)、ニューロンの学習を実施する(ステップU30)。このとき、学習を設定数だけ反復して行ない、学習が終了したらアイドリングニューロン及び弱いニューロン(これらについては後述する)を削除する(ステップU40)。そして、ニューロンのn次元座標,平均距離,ウェイトの情報からなる圧縮ファイルデータ(以下、単に圧縮ファイルともいう)を作成する(ステップU50)。上記のステップU10〜U50までの処理を各運転ダイヤルについて行なう(ステップU60)。
【0027】
以下、データ圧縮部6についてより具体的に説明する。
データ圧縮部6は、データ前処理部5により前処理された膨大な数のデータセットを、これらデータセットの数よりも格段に少ない数のデータに圧縮するように機能している。本実施形態では、データの圧縮手法として、ニューラルネットワークの教師なし学習法の一つである自己組織化マップ〔Self - Organizing Map(SOM)〕を用いている点が特徴の一つである。
【0028】
教師なし学習とは、入力されるデータセット(以下、入力データセットという)に対して明確なターゲット値(即ち「答え」)がない場合に、入力データセットのみを用いて学習を行なうことをいい、この学習は、以下で説明するいくつかの原則に基づいて行われる。また、自己組織化マップは、入力層(入力データ、即ち入力データセット群)と競合層(ニューロン群)とから構成されており、入力データセット群中に隠れた特徴を自動的に抽出して学習を行なうアルゴリズムであって、入力データセットの類似度を自動的に見出して、互いに似た入力データセット同士をネットワーク上の近くに配列するものである。
【0029】
以下、データ圧縮部6で行われるデータ圧縮の手法について具体的に説明する。なお、以下では、データ前処理部5で作成されたある一つの運転ダイヤルのフォルダに保存された入力データセットの圧縮について説明する。他の運転ダイヤルのフォルダに保存された入力データセットの圧縮も同様に行われる。
〔1〕学習条件の設定
まず、学習条件として、入力データセット群の分布をニューロンに代表させる計算に必要なニューロン数k,初期学習率α0,初期近傍領域Nc0,設定総学習回数Tを設定する。この学習条件の設定は、入力装置8により予め任意に設定しておくことができる。なお、入力データセットは下式(1)に示す構造をしている。また、ニューロン数kは、入力データセット数l(エル)よりも格段に少ない数(例えば数十個。k<<l)に設定している。
【0030】
【数1】

【0031】
〔2〕入力層及び競合層間の初期重みの設定
次に、〔1〕で設定された全ニューロンを乱数を用いて(ランダムに)n次元空間に配置するとともに、全ニューロンに対し、入力層(入力データセット群)と競合層(ニューロン群)間の初期結合重みmiを乱数を用いて設定する。初期結合重みmiは下式(2)に示す構造をしている。
【0032】
【数2】
【0033】
〔3〕入力データセットのベクトルの設定
入力データセットのベクトルxjを設定する。ベクトルxjは下式(3)に示す構造をしている。
【0034】
【数3】
【0035】
〔4〕ニューロンと入力データセットとの類似度の計算
i番目のニューロンとj番目のデータセットとのユーグリッド距離diを計算する。ユーグリッド距離diは下式(4)により求めることができる。
【0036】
【数4】
【0037】
〔5〕勝者ニューロン及び近傍領域の決定
上記の〔4〕においてユーグリッド距離diが最も小さい(即ち、最も類似している)ニューロンを入力データセットxjの勝者ニューロンとして決定する。また、これと同時に、勝者ニューロンの周りに予め設定した近傍領域Nctに該当するニューロンも決定する。近傍領域Nctは下式(5)により求めることができる。
【0038】
【数5】
【0039】
〔6〕勝者ニューロン及び近傍ニューロンの学習
勝者ニューロンmcは学習率αtにより重みが更新され、入力データセットに近づく。また、選択された近傍ニューロンも同様に勝者ニューロンよりも小さい更新量で入力データセットに近づくが、その更新量の度合いは、近傍ニューロン及び勝者ニューロン間の距離と近傍関数とに依存する。更新後の勝者ニューロンは下式(6)により求めることができる。
【0040】
【数6】
【0041】
〔7〕次の入力データセットの読み込み
上記の〔2〕〜〔6〕を、入力データセットx1からxl(エル)までの各入力データセットについて繰り返し行なう。
〔8〕次の反復学習開始
上記の〔2〕〜〔7〕までのステップを設定学習回数Tまで繰り返し行なう。このとき、近傍領域Nctと学習率αtは徐々に減少する。
【0042】
〔9〕アイドリングニューロン及び弱いニューロンの削除
上記の学習が終了した後、一度も勝者ニューロンにならなかったニューロン(これを「アイドリングニューロン」ともいう)及び非常に少ない数(所定数以下。例えば1個や2個)の入力データセットの代表にしかならなかったニューロン(これを「弱いニューロン」ともいう)をして削除する。
【0043】
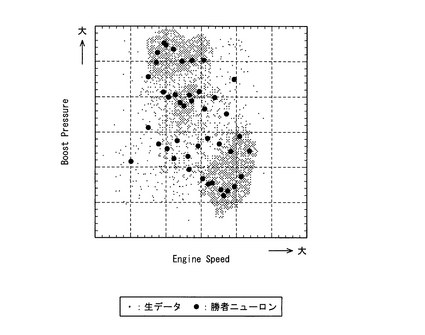
このように、データ圧縮部6では、各入力データセットをn次元空間内に入力し、入力データセットの数l(エル)よりも非常に少ない所定数kのニューロンをn次元空間内にランダムに配置して、ニューラルネットワークの教師なし学習法によりニューロンの学習を行なう。そして、この学習の後アイドリングニューロン及び弱いニューロンを削除することで、膨大な数の入力データセット(即ち、センサ4により検出された加工されていない生データ)を代表する所定数k以下のニューロンからなるニューロンモデル(ニューロン配置)を作成する。例えば図3は、図2に示すエンジン回転数とブースト圧力との入力データセット群をニューロンモデルに変換した時(アイドリングニューロン及び弱いニューロンは削除済み)の図を示しているが、この図3からわかるように、膨大な数の入力データセットが、入力データセットの数よりも格段に少ない数のニューロンで表される。つまり、膨大な数の入力データセットを、ニューロンモデルを特徴付けるニューロンがもつパラメータ(以下、これをニューロンモデルパラメータという)に変換することにより圧縮する。また、上述のようにアイドリングニューロンや弱いニューロンを削除することで、入力データセットを最もよく特徴付けるニューロンのみに圧縮することができる。
【0044】
ニューロンモデルパラメータは、アイドリングニューロンや弱いニューロンの削除後に残ったニューロンが持っている種々の情報、即ち、n次元空間内におけるニューロンの座標情報と、ニューロンから各入力データセットまでの平均距離情報と、ニューロンが何個のデータセットを代表しているかを表わすウェイト(重み)情報とを含んでいる。したがって、膨大な数の入力データセットは下式(7)に示す数のニューロンモデルパラメータに圧縮される。
【0045】
【数7】
【0046】
すなわち、膨大な数の入力データセットは、「k0個(アイドリングニューロン及び弱いニューロンを削除した後のニューロン数。k0≦k)×〔n個(ニューロンの座標情報の数であり、センサ4が検出するn個のパラメータ数に相当)+n個(平均距離情報の数であり、センサ4が検出するn個のパラメータ数に相当)+1(ウェイト情報の数)〕」で表わされる数のニューロンモデルパラメータに圧縮される。
【0047】
また、データ圧縮部6では、上述した生データの圧縮を各ファイル毎(即ち各運転ダイヤル毎)に行なった後、各ファイルに対応した圧縮ファイルを記憶装置に作成して、この圧縮ファイルにニューロンモデルパラメータを保存しておくようになっている。
送信部7は、データ圧縮部6で作成された圧縮ファイルを外部へ送信するもので、本実施形態ではアンテナを用いて無線で送信を行っているが、通信ケーブルを用いて行ってももちろんよい。
【0048】
一方、管理センターのデータ解析装置10は、受信部(受信手段)11,データ解析部(解析手段)12,判定部13を主に備えて構成されている。なお、データ解析部12及び判定部13の各機能は、図示しないがコンピュータなどのECU(電子コントロールユニット)に組み込まれた処理プログラムにて実現されるようになっている。ECUは、入出力装置,記憶装置(RAM,ROM等のメモリ),中央処理装置(CPU)等を備えて構成される。
【0049】
受信部11は、送信部6から送信された圧縮ファイルを受信するようになっている。また、受信した圧縮ファイルは、図示しない記憶装置に保存される。
データ解析部12は、受信部11により受信された圧縮ファイル内のニューロンモデルパラメータに基づいて入力データセットを解析するようになっている。本実施形態では、データ解析部12は、後述するいくつかの処理プログラム(データ解析プログラム)によってその機能を実現されるが、以下に説明するような2つの手法で解析を行なえるようになっている。
【0050】
〔A〕ウェイトを考慮したニューロンの移動平均
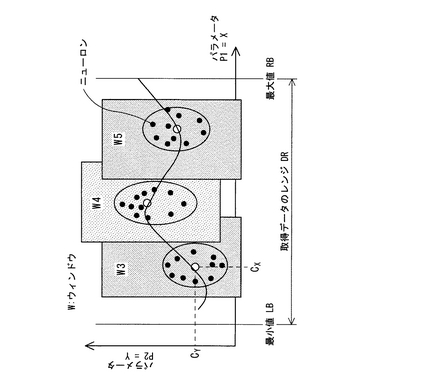
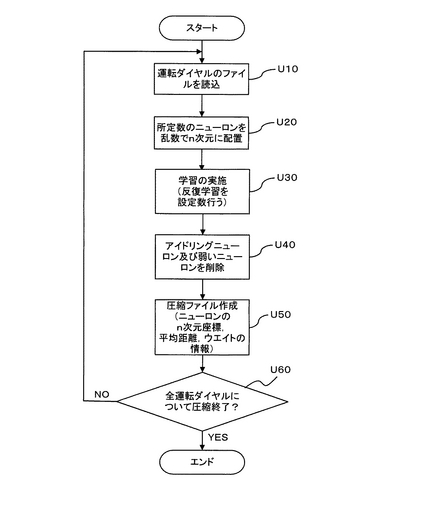
データ解析部12は、ウェイトを考慮したニューロンの移動平均による解析を実現するための処理プログラムをそなえており、この処理プログラムは図11に示す処理手順を実現しうるものである。すなわち、まず、ある1つの運転ダイヤルの圧縮ファイルを読み込み(ステップV10)、n次元パラメータのうち任意の2つのパラメータ(例えばエンジン回転数とブースト圧力)を選択する(ステップV20)。各ニューロンはパラメータ(計測項目)毎の座標,ウェイト,平均距離の情報を持っているので、任意のパラメータ間の関係を容易に知ることができる。次に、ニューロンモデルパラメータに含まれるニューロンの座標情報及びウェイト情報を用い、図4に示すように、ニューロンの最大値RB及び最小値LBを決定した後、所定数の領域(ウィンドウという)に分割し(ステップV30)、各ウィンドウについてニューロンのウェイトを考慮して重心点(Cx,Cy)を求める(ステップV40)。その後、各ウィンドウの重心点を結んで移動平均のグラフを作成する(ステップV50)。上記のステップV20〜V50の処理を、n次元パラメータの全てのパラメータについて行なった後(ステップV60)、上記のステップV20〜V60の処理を、全運転ダイヤルの圧縮ファイルについて行なう(ステップV70)。なお、重心点は下式(8)を用いて算出される。
【0051】
【数8】
【0052】
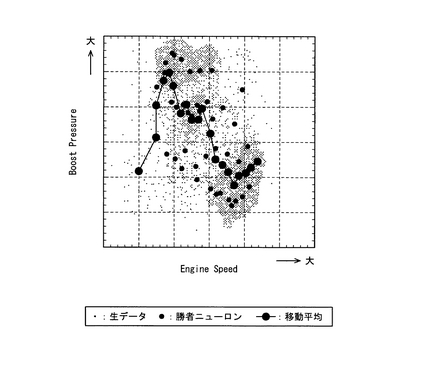
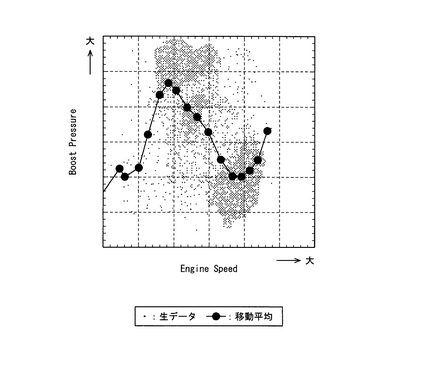
また、データ解析部12は、このようにして作成したグラフをディスプレイ(出力手段)20に表示できるようになっている。例えば図5はウェイトを考慮したニューロンの移動平均により求めたエンジン回転数とブースト圧力との関係を示すグラフである。なお、図5では入力データセット(即ち生データ)の点と学習終了後のニューロンの点も併せて表示している。この図5からわかるように、ニューロンの移動平均で求めた重心点のグラフは、入力データセット群(入力データセットの分布)に非常に近似した形状となっている。一方、図6は入力データセットの移動平均を直接求めた場合のグラフであるが、入力データセット群から大きくはみ出している入力データセットの点が少しでも存在すると、重心点が入力データセット群からはみ出してしまうこともある。図5と図6とを比べると、ウェイトを考慮したニューロンの移動平均を求めて作成したグラフ(図5)の方が、入力データセットから直接移動平均を求めて作成したグラフ(図6)よりも、入力データセット群の特性をより正確に再現していることがわかる。
【0053】
〔B〕入力データセットの分布密度
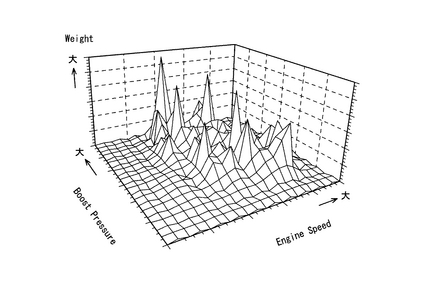
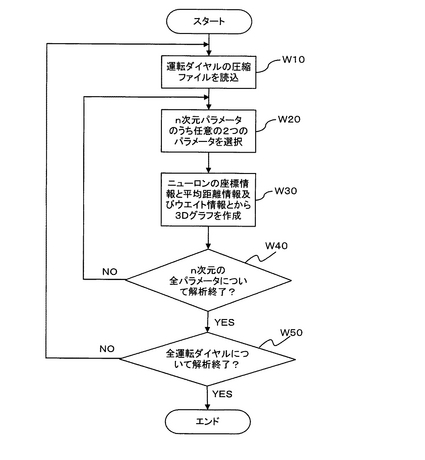
データ解析部12は、入力データセットの分布密度による解析を実現するための処理プログラムをそなえており、この処理プログラムは図12に示す処理手順を実現しうるものである。すなわち、まず、ある1つの運転ダイヤルの圧縮ファイルを読み込み(ステップW10)、n次元パラメータのうち任意の2つのパラメータ(例えばエンジン回転数とブースト圧力)を選択する(ステップW20)。前述したように、各ニューロンはパラメータ(計測項目)毎の座標,ウェイト,平均距離の情報を持っているので、任意のパラメータ間の関係を容易に知ることができる。次に、ニューロンモデルパラメータに含まれるニューロンの座標情報と平均距離情報及びウェイト情報とを用い、図7に示すような3次元(ここではエンジン回転数,ブースト圧力,入力データ密度)のグラフを作成する(ステップW30)。図7中、ニューロンの座標情報から得られたニューロンの位置がピーク(山)の位置を表わし、ニューロンのウェイト情報から得られたニューロンのウェイトの大きさがピークの高さを表わしている。また、平均距離情報から得られた入力データセットとの平均距離がピークの傾斜面の傾きに対応しており、例えば、平均距離が大きい(即ち、入力データセットがニューロンの位置近傍に比較的低密度で存在している)ほどピークの傾斜面の傾きは小さく(なだらかに)なり、平均距離が小さい(即ち、入力データセットがニューロンの位置近傍に比較的高密度で存在している)ほどピークの傾斜面の傾きは大きく(急に)なる。上記のステップW20及びW30の処理を、n次元パラメータの全てのパラメータについて行なった後(ステップW40)、上記のステップW20〜W40の処理を、全運転ダイヤルの圧縮ファイルについて行なう(ステップW50)。
【0054】
また、データ解析部12は、このようにして作成したグラフをディスプレイ20に表示できるようになっている。
上述したように、データ解析部12は2つの手法によりニューロンモデルパラメータを解析できるようになっている。また、上記では、一例としてエンジン回転数とブースト圧力との関係について解析を行なったが、解析は各運転ダイヤルに対し全てのパラメータについて行なわれる。
【0055】
判定部13では、データ解析部12で求めた各グラフ(実際には、グラフの元となるニューロンモデルパラメータの各情報)に基づいて、油圧ショベル2の診断を行なうようになっている。例えば、正常運転時のグラフとの類似度を算出して、この類似度が予め設定した値よりも小さくなったら(即ち、正常運転時のグラフとのずれが大きくなったら)、油圧ショベル2に異常又は劣化が発生していると判定するようになっている。また、判定部13では、油圧ショベル2に異常が発生している場合には、その旨をディスプレイ20に表示してオペレータにその旨を報知するようになっている。
【0056】
さらに、油圧ショベル2の過去のメンテナンス歴に基づく知識ベースや、エンジンオイル或いは油圧機器作動オイルの分析結果も判定材料として加えることで、油圧ショベル2の故障,余寿命の予測や、オイル交換時期の予測も行なうことが可能になる。
本発明の一実施形態に係るデータ管理システム1は、上述のごとく構成されているので、データ圧縮及びデータ解析は図8に示すフローに沿って行なわれる。すなわち、まず、センサ4により油圧ショベル2の各パラメータの生データ(入力データセット)を検出した後(ステップS10)、この生データの前処理を行なう(ステップS20)。その後、ニューロンを用いて生データの圧縮を行ない(ステップS30)、圧縮したデータ(即ちニューロンモデルパラメータ)を圧縮ファイルとして管理センターに送信する(ステップS40)。管理センターでは、受信した圧縮ファイルを解析し(ステップS50)、油圧ショベル2に異常がないか否かを判定する(ステップS60)。
【0057】
なお、前述したように、図8に示すステップS20の処理はデータ前処理部5にて図9に示すフローに沿って実行され、図8に示すステップS30の処理はデータ圧縮部6にて図10に示すフローに沿って実行され、図8に示すステップS50の処理はデータ解析部12にて図11,図12に示すフローに沿ってそれぞれ実行される。
上述したように、本発明の一実施形態に係るデータ圧縮装置及び方法によれば、n個のパラメータの値からなる複数の入力データセット(即ち生データ:図2参照)を、この入力データセット数よりも少ない所定数のニューロンから得られるニューロンモデルを特徴付けるパラメータ(ニューロンモデルパラメータ:図3参照)に圧縮することができ、これにより通信コストを低減することが可能になる。また、このように圧縮されたニューロンモデルパラメータ(圧縮データ)は、ニューロンモデルを特徴付けるもの、即ち複数の入力データセットを特徴付けるものであるので、圧縮データから元の入力データセット(即ち生データ)の特性をより正確に再現することが可能となる(図5,図7参照)。
【0058】
また、本発明の一実施形態に係るデータ解析装置及び方法によれば、ニューロンモデルパラメータを用いて、元の入力データセットを解析することができる。この場合、ニューロンの移動平均(図5参照)や入力データセットの分布密度(図7参照)を解析することで、油圧ショベル2の診断を行なうことができる。
そして、本発明のデータ管理システムによれば、上記のデータ圧縮装置及びデータ解析装置の両方の効果が得られる。
【0059】
以上、本発明の実施形態について説明したが、本発明は上記の実施形態に限定されるものではなく、本発明の趣旨を逸脱しない範囲で種々変形して実施することができる。例えば、本実施形態では判定部13により診断を行なったが、ディスプレイ20に表示される各グラフの違いから視覚的に診断を行なうことももちろん可能である。また、本実施形態ではディスプレイ20に解析結果を表示するようにしたが、ディスプレイ20の代わりに、図示しないプリンタなどの印刷装置に解析結果を出力してオペレータが診断を行なうようにしてもよい。
【図面の簡単な説明】
【0060】
【図1】本発明の一実施形態に係るデータ管理システムを模式的に示すブロック図である。
【図2】ある運転ダイヤルにおけるエンジン回転数とブースト圧力との入力データセットの点をプロットした図である。
【図3】図2に示すエンジン回転数とブースト圧力との入力データセット群をニューロンモデルに変換した時(アイドリングニューロン及び弱いニューロンは削除済み)の図である。
【図4】ウェイトを考慮したニューロンの移動平均を説明するための図である。
【図5】ウェイトを考慮したニューロンの移動平均により求めたエンジン回転数とブースト圧力との関係を示すグラフである。
【図6】入力データセットの移動平均を直接求めた場合のグラフである。
【図7】入力データセットの分布密度を示す図である。
【図8】本発明の一実施形態に係るデータ圧縮及びデータ解析の手順を示すフローチャートである。
【図9】データ前処理の具体的な手順を示すフローチャートである。
【図10】データ圧縮の具体的な手順を示すフローチャートである。
【図11】ウェイトを考慮したニューロンの移動平均による解析の手順を示すフローチャートである。
【図12】入力データセットの分布密度による解析の手順を示すフローチャートである。
【符号の説明】
【0061】
1 データ管理システム
2 油圧ショベル(対象体)
3 データ圧縮装置
4 センサ(検出手段)
5 データ前処理部(前処理手段)
6 データ圧縮部(圧縮手段)
7 送信部(送信手段)
8 入力装置(入力手段)
10 データ解析装置
11 受信部(受信手段)
12 データ解析部(解析手段)
13 判定部(判定手段)
20 ディスプレイ(出力手段)
【技術分野】
【0001】
本発明は、膨大なデータを圧縮処理するのに用いて好適なデータ圧縮装置及び方法,データ解析装置及び方法並びにデータ管理システムに関する。
【背景技術】
【0002】
近年、地球資源が有限であることや、一部の地域では環境負荷が限界を超えつつあることから、持続可能な社会へ転換していくために、資源の循環や環境負荷の削減に視点を置いた機械類に関する新しいメンテナンスのあり方が強く求められている。
従来の機械類のメンテナンスでは、機械類に故障が発生してから修復する事後保全や、機械類の使用時間を基準にした画一的な予防保全が一般に行なわれている。事後保全では、修理に大幅な時間やコストがかかってしまい、また、予防保全では、画一的な処理のため、不必要な部品やオイルの廃棄が発生し顧客の費用負担が増大し、また、労働集約型からくる高コスト化という課題があったが、今後はこうした従来のメンテナンスから脱却して、予知保全への転換を図っていく必要がある。
【0003】
予知保全とは、稼動時の負荷・環境情報、過去のメンテナンス歴データベース、故障物理の理解などから、推論により健全度を診断して劣化・余寿命を予測することで、機械の異常を早期に発見して安全な動作環境を提供するものである。
このような予知保全を行なうシステムでは、通常、対象となる機械に取り付けたセンサにより機械の稼動状態を検出し、機械に備えたデータ収集装置により上記の稼動状態の生データを収集するとともに、この生データをリアルタイムに或いは所定の周期で管理センター(例えば機械のメンテナンスを行なう企業のサービス部門)に送信し、管理センター側において生データを解析して機械の健全度を診断するようになっている。
【0004】
しかし、データ収集装置により収集する生データは膨大であり、このような膨大な生データを通信により機械から管理センターに送信するため、通信の信頼性に問題が生じたり、通信コストが高くなってしまう。そこで、生データを圧縮してから通信することが考えられる。例えば特許文献1には、センサからの時系列稼動信号を頻度分布データもしくは周波数分布データに圧縮する手法が開示されている。また、特許文献2には、故障確率(バスタブ曲線)に応じて稼動信号の送信時間の間隔を変える手法が開示されている。さらに、特許文献3には、メモリの記憶容量を小さくするために単位時間毎の検出頻度を積算し、その頻度分布から機械の状態を判定する手法が開示されている。
【特許文献1】特開2003−083848
【特許文献2】特開2002−180502
【特許文献3】特開平10−273920号
【発明の開示】
【発明が解決しようとする課題】
【0005】
しかしながら、上述した特許文献1〜3の手法はいずれも、圧縮したデータから元のデータ(生データ)の特性を再現することは困難である。
また、例えば、生データの移動平均をとることで生データよりも少ない数のデータに圧縮して送信することが考えられるが、上記と同様に、生データの特性をより正確に再現することはできない。
【0006】
本発明は、このような課題に鑑み創案されたもので、膨大なデータを圧縮できるようにするとともに、圧縮したデータから元のデータの特性をより正確に再現できるようにした、データ圧縮装置及び方法を提供することを目的とする。
また、上記のデータ圧縮装置及び方法により圧縮したデータを解析できるようにした、データ解析装置及び方法、さらには、上記のデータ圧縮装置及びデータ解析装置を備えたデータ管理システムを提供することを目的とする。
【課題を解決するための手段】
【0007】
このため、請求項1記載の本発明のデータ圧縮装置は、対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出手段と、該検出手段により検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行ない、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮する圧縮手段とをそなえたことを特徴としている。
【0008】
請求項2記載の本発明のデータ圧縮装置は、請求項1記載の装置において、該圧縮手段は、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいることを特徴としている。
【0009】
請求項3記載の本発明のデータ圧縮装置は、請求項2記載の装置において、該データ圧縮手段は、該学習の終了後、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去することを特徴としている。
請求項4記載の本発明のデータ圧縮装置は、請求項1〜3の何れか1項に記載の装置において、上記ニューロンモデルパラメータを外部へ送信する送信手段をそなえていることを特徴としている。
【0010】
請求項5記載の本発明のデータ解析装置は、請求項4記載のデータ処理装置の該送信手段により送信された上記ニューロンモデルパラメータを受信する受信手段と、該受信手段により受信された上記ニューロンモデルパラメータに基づいて該データセットを解析する解析手段とをそなえたことを特徴としている。
請求項6記載の本発明のデータ解析装置は、請求項5記載の装置において、該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析することを特徴としている。
【0011】
請求項7記載の本発明のデータ解析装置は、請求項5記載の装置において、該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該データセットの分布密度を求めることにより解析することを特徴としている。
請求項8記載の本発明のデータ管理システムは、請求項4記載のデータ圧縮装置と、請求項5〜7の何れか1項に記載のデータ解析装置とをそなえたことを特徴としている。
【0012】
請求項9記載の本発明のデータ管理システムは、請求項8記載のシステムにおいて、該対象体は建設機械であり、上記のn個のパラメータは該建設機械の動作に応じて変動するパラメータであることを特徴としている。
請求項10記載の本発明のデータ圧縮方法は、対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出ステップと、該検出ステップで検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行ない、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮するデータ圧縮ステップとをそなえたことを特徴としている。
【0013】
請求項11記載の本発明のデータ圧縮方法は、請求項10記載の方法において、該データ圧縮ステップでは、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいることを特徴としている。
【0014】
請求項12記載の本発明のデータ圧縮方法は、請求項11記載の方法において、該データ圧縮ステップでは、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去することを特徴としている。
請求項13記載の本発明のデータ解析方法は、請求項12記載のデータ圧縮方法により得られた上記ニューロンモデルパラメータを取得する取得ステップと、該取得ステップで取得した上記ニューロンモデルパラメータに基づいて該データセットを解析する解析ステップとをそなえたことを特徴としている。
【0015】
請求項14記載の本発明のデータ解析方法は、請求項13記載の方法において、該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析することを特徴としている。
請求項15記載の本発明のデータ解析方法は、請求項13記載の方法において、該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該データセットの分布密度を求めることにより解析することを特徴としている。
【発明の効果】
【0016】
本発明のデータ圧縮装置及び方法によれば、n個のパラメータの値からなる複数のデータセット(生データ)を、このデータセット数よりも少ない所定数のニューロンから得られるニューロンモデルを特徴付けるニューロンモデルパラメータに圧縮することができる。また、圧縮されたニューロンモデルパラメータ(圧縮データ)は、ニューロンモデルを特徴付けるもの、即ち複数のデータセットを特徴付けるものであるので、圧縮データから元のデータセットの特性をより正確に再現することが可能となる。
【0017】
また、本発明のデータ解析装置及び方法によれば、ニューロンモデルパラメータを用いて、元のデータセット(生データ)を解析することができる。この場合、ニューロンの移動平均や、データセットの分布密度を解析することで、対象体の診断を行なうことができる。
さらに、本発明のデータ管理システムによれば、上記のデータ圧縮装置及びデータ解析装置の両方の効果が得られる。
【発明を実施するための最良の形態】
【0018】
以下、図面を参照しながら本発明の実施形態について説明する。
本実施形態に係るデータ管理システムは、建設機械等の機械類に異常があるか否かを診断するために用いられる。以下では、建設機械として油圧ショベルに適用した場合のデータ管理システムについて説明する。なお、本データ管理システムの適用対象はこれに限定されるものではなく、動作或いは環境に応じて変動しうる種々の対象体全てに適用することができる。
【0019】
図1は本発明の一実施形態に係るデータ管理システムを模式的に示すブロック図である。図1に示すように、本データ管理システム1は、建設現場などの稼動現場で使用される油圧ショベル2から、稼動現場と離れて油圧ショベル2を管理する管理センター(例えば油圧ショベル2のメンテナンスを行なう企業のサービス部門)10へ、油圧ショベル2に関するデータを送信し、管理センター10側において、油圧ショベル2から受信したデータに基づいて推論により油圧ショベル2の健全度を診断できるようになっている。このため、本データ管理システム1は、油圧ショベル2に備えられた車載型のデータ圧縮装置3と、管理センターに設けられたデータ解析装置10とを主に備えて構成されている。
【0020】
データ圧縮装置3は、センサ4,データ前処理部(前処理手段)5,データ圧縮部(圧縮手段)6,送信部(送信手段)7,入力装置(キーボードやマウスなど)8を主に備えて構成されている。なお、センサ4及びデータ前処理部5で検出手段が構成される。また、データ前処理部5,データ圧縮部6の各機能を実現するために、図示しないがコンピュータなどのECU(電子コントロールユニット)に所要の処理プログラムが組み込まれている。ECUは、入出力装置,記憶装置(RAM,ROM等のメモリ),中央処理装置(CPU)等を備えて構成される。
【0021】
センサ4は、油圧ショベル2に関するn個のパラメータ(変動要素)に対応して備えられ、油圧ショベル2の動作時に、油圧ショベル2の動作に応じて変動する各パラメータの値x1,x2,…,xnを検出(計測)するようになっている。
なお、このセンサ4は、対応するパラメータの値を直接検出するもののほか、ある検出データを演算等によって処理して、対応するパラメータの値を計算値又は推定値として求めるものも含む。ここでいう油圧ショベル2に関するパラメータとは、例えばエンジン回転数,エンジンオイル温度,エンジンオイル圧力,エンジン冷却水温,ブースト圧力(過給後の給気圧力),燃料消費量,排ガス温度,パワーシフト圧,ハイドロリックオイル圧力,ハイドロリックオイル温度,ハイドロリックオイル微粒子カウンター,エンジン稼動時間などの油圧ショベル2の動作に応じて変動する各要素のことをいう。
【0022】
データ前処理部5は、前述のごとく所要の処理プログラム(データ前処理プログラム)によってその機能を実現されるが、このデータ前処理プログラムは図9に示す処理手順を実現しうるものである。すなわち、まず、エンジンが回転中か否かを判定し(ステップT10)、エンジンが回転中であれば、次に、エンジンオイル温度が設定値以上であるか否かを判定する(ステップT20)。そして、エンジンオイル温度が設定値以上になったら、センサ4が検出した生データを取得し(ステップT30)、次に、エンジンが停止したか否かを判定する(ステップT40)。つまり、エンジンが停止するまで生データを取得し続ける。そして、エンジンが停止したら、運転ダイヤル毎に生データを整理し(ステップT50)、運転ダイヤル毎にファイルを作成して生データを保存する(ステップT60)。なお、上記の運転ダイヤルとは、オペレータが作業内容(作業負荷)に応じてエンジン回転数を設定するダイヤルのことをいう。
【0023】
以下、データ前処理部5についてより具体的に説明する。
データ前処理部5は、油圧ショベル2のエンジンが回転し、且つ、エンジンオイル温度が設定値以上になったら(即ち、油圧ショベル2が通常動作を開始したら)センサ4により検出される各パラメータの値からなるデータセットを例えば一秒周期で取得(収集)して記憶装置に保存するようになっている。なお、エンジンが回転しているか否かは、エンジン回転数を検出するセンサからの情報により判定することができ、エンジンオイル温度が設定値以上になったか否かは、エンジンオイル温度を検出するセンサからの情報により判定することができる。また、本実施形態ではセンサ4からのデータ取得の周期を一秒に設定しているが、この周期は入力装置8からの入力により任意に設定することが可能となっている。
【0024】
上述のようにしてデータ前処理部5は、各パラメータからなるデータセットを油圧ショベル2の動作開始時から動作終了時(即ちエンジン停止時)まで記憶装置に保存し続ける。また、データ前処理部5は、油圧ショベル2のエンジン停止後、記憶装置に保存された複数のデータセットを運転ダイヤル毎に整理するとともに、運転ダイヤル毎にファイルを作成して、対応する各ファイルにデータセットを保存するようになっている。
【0025】
したがって、各ファイルに保存されるデータセットの数は、例えば数千や数万個であり膨大な数である。例えば図2は、ある運転ダイヤルにおけるエンジン回転数(Engine Speed)とブースト圧力(Boost Pressure)とのデータセット(即ち生データ)の点をプロットした図であるが、この図2からわかるように、データセットは膨大な数となる。なお、当然のことながら、図2中のエンジン回転数の軸(横軸)は通常運転時の回転数領域について示している。また、以下で用いる図3,図5,図6及び図7においても同様に、エンジン回転数の軸は通常運転時の回転数領域について示している。
【0026】
データ圧縮部6は、前述のごとく所要の処理プログラム(データ圧縮プログラム)によってその機能を実現されるが、このデータ圧縮プログラムは図10に示す処理手順を実現しうるものである。すなわち、運転ダイヤルのファイルを読み込んだ後(ステップU10)、所定数のニューロンを乱数でn次元に配置し(ステップU20)、ニューロンの学習を実施する(ステップU30)。このとき、学習を設定数だけ反復して行ない、学習が終了したらアイドリングニューロン及び弱いニューロン(これらについては後述する)を削除する(ステップU40)。そして、ニューロンのn次元座標,平均距離,ウェイトの情報からなる圧縮ファイルデータ(以下、単に圧縮ファイルともいう)を作成する(ステップU50)。上記のステップU10〜U50までの処理を各運転ダイヤルについて行なう(ステップU60)。
【0027】
以下、データ圧縮部6についてより具体的に説明する。
データ圧縮部6は、データ前処理部5により前処理された膨大な数のデータセットを、これらデータセットの数よりも格段に少ない数のデータに圧縮するように機能している。本実施形態では、データの圧縮手法として、ニューラルネットワークの教師なし学習法の一つである自己組織化マップ〔Self - Organizing Map(SOM)〕を用いている点が特徴の一つである。
【0028】
教師なし学習とは、入力されるデータセット(以下、入力データセットという)に対して明確なターゲット値(即ち「答え」)がない場合に、入力データセットのみを用いて学習を行なうことをいい、この学習は、以下で説明するいくつかの原則に基づいて行われる。また、自己組織化マップは、入力層(入力データ、即ち入力データセット群)と競合層(ニューロン群)とから構成されており、入力データセット群中に隠れた特徴を自動的に抽出して学習を行なうアルゴリズムであって、入力データセットの類似度を自動的に見出して、互いに似た入力データセット同士をネットワーク上の近くに配列するものである。
【0029】
以下、データ圧縮部6で行われるデータ圧縮の手法について具体的に説明する。なお、以下では、データ前処理部5で作成されたある一つの運転ダイヤルのフォルダに保存された入力データセットの圧縮について説明する。他の運転ダイヤルのフォルダに保存された入力データセットの圧縮も同様に行われる。
〔1〕学習条件の設定
まず、学習条件として、入力データセット群の分布をニューロンに代表させる計算に必要なニューロン数k,初期学習率α0,初期近傍領域Nc0,設定総学習回数Tを設定する。この学習条件の設定は、入力装置8により予め任意に設定しておくことができる。なお、入力データセットは下式(1)に示す構造をしている。また、ニューロン数kは、入力データセット数l(エル)よりも格段に少ない数(例えば数十個。k<<l)に設定している。
【0030】
【数1】
【0031】
〔2〕入力層及び競合層間の初期重みの設定
次に、〔1〕で設定された全ニューロンを乱数を用いて(ランダムに)n次元空間に配置するとともに、全ニューロンに対し、入力層(入力データセット群)と競合層(ニューロン群)間の初期結合重みmiを乱数を用いて設定する。初期結合重みmiは下式(2)に示す構造をしている。
【0032】
【数2】
【0033】
〔3〕入力データセットのベクトルの設定
入力データセットのベクトルxjを設定する。ベクトルxjは下式(3)に示す構造をしている。
【0034】
【数3】
【0035】
〔4〕ニューロンと入力データセットとの類似度の計算
i番目のニューロンとj番目のデータセットとのユーグリッド距離diを計算する。ユーグリッド距離diは下式(4)により求めることができる。
【0036】
【数4】
【0037】
〔5〕勝者ニューロン及び近傍領域の決定
上記の〔4〕においてユーグリッド距離diが最も小さい(即ち、最も類似している)ニューロンを入力データセットxjの勝者ニューロンとして決定する。また、これと同時に、勝者ニューロンの周りに予め設定した近傍領域Nctに該当するニューロンも決定する。近傍領域Nctは下式(5)により求めることができる。
【0038】
【数5】
【0039】
〔6〕勝者ニューロン及び近傍ニューロンの学習
勝者ニューロンmcは学習率αtにより重みが更新され、入力データセットに近づく。また、選択された近傍ニューロンも同様に勝者ニューロンよりも小さい更新量で入力データセットに近づくが、その更新量の度合いは、近傍ニューロン及び勝者ニューロン間の距離と近傍関数とに依存する。更新後の勝者ニューロンは下式(6)により求めることができる。
【0040】
【数6】
【0041】
〔7〕次の入力データセットの読み込み
上記の〔2〕〜〔6〕を、入力データセットx1からxl(エル)までの各入力データセットについて繰り返し行なう。
〔8〕次の反復学習開始
上記の〔2〕〜〔7〕までのステップを設定学習回数Tまで繰り返し行なう。このとき、近傍領域Nctと学習率αtは徐々に減少する。
【0042】
〔9〕アイドリングニューロン及び弱いニューロンの削除
上記の学習が終了した後、一度も勝者ニューロンにならなかったニューロン(これを「アイドリングニューロン」ともいう)及び非常に少ない数(所定数以下。例えば1個や2個)の入力データセットの代表にしかならなかったニューロン(これを「弱いニューロン」ともいう)をして削除する。
【0043】
このように、データ圧縮部6では、各入力データセットをn次元空間内に入力し、入力データセットの数l(エル)よりも非常に少ない所定数kのニューロンをn次元空間内にランダムに配置して、ニューラルネットワークの教師なし学習法によりニューロンの学習を行なう。そして、この学習の後アイドリングニューロン及び弱いニューロンを削除することで、膨大な数の入力データセット(即ち、センサ4により検出された加工されていない生データ)を代表する所定数k以下のニューロンからなるニューロンモデル(ニューロン配置)を作成する。例えば図3は、図2に示すエンジン回転数とブースト圧力との入力データセット群をニューロンモデルに変換した時(アイドリングニューロン及び弱いニューロンは削除済み)の図を示しているが、この図3からわかるように、膨大な数の入力データセットが、入力データセットの数よりも格段に少ない数のニューロンで表される。つまり、膨大な数の入力データセットを、ニューロンモデルを特徴付けるニューロンがもつパラメータ(以下、これをニューロンモデルパラメータという)に変換することにより圧縮する。また、上述のようにアイドリングニューロンや弱いニューロンを削除することで、入力データセットを最もよく特徴付けるニューロンのみに圧縮することができる。
【0044】
ニューロンモデルパラメータは、アイドリングニューロンや弱いニューロンの削除後に残ったニューロンが持っている種々の情報、即ち、n次元空間内におけるニューロンの座標情報と、ニューロンから各入力データセットまでの平均距離情報と、ニューロンが何個のデータセットを代表しているかを表わすウェイト(重み)情報とを含んでいる。したがって、膨大な数の入力データセットは下式(7)に示す数のニューロンモデルパラメータに圧縮される。
【0045】
【数7】
【0046】
すなわち、膨大な数の入力データセットは、「k0個(アイドリングニューロン及び弱いニューロンを削除した後のニューロン数。k0≦k)×〔n個(ニューロンの座標情報の数であり、センサ4が検出するn個のパラメータ数に相当)+n個(平均距離情報の数であり、センサ4が検出するn個のパラメータ数に相当)+1(ウェイト情報の数)〕」で表わされる数のニューロンモデルパラメータに圧縮される。
【0047】
また、データ圧縮部6では、上述した生データの圧縮を各ファイル毎(即ち各運転ダイヤル毎)に行なった後、各ファイルに対応した圧縮ファイルを記憶装置に作成して、この圧縮ファイルにニューロンモデルパラメータを保存しておくようになっている。
送信部7は、データ圧縮部6で作成された圧縮ファイルを外部へ送信するもので、本実施形態ではアンテナを用いて無線で送信を行っているが、通信ケーブルを用いて行ってももちろんよい。
【0048】
一方、管理センターのデータ解析装置10は、受信部(受信手段)11,データ解析部(解析手段)12,判定部13を主に備えて構成されている。なお、データ解析部12及び判定部13の各機能は、図示しないがコンピュータなどのECU(電子コントロールユニット)に組み込まれた処理プログラムにて実現されるようになっている。ECUは、入出力装置,記憶装置(RAM,ROM等のメモリ),中央処理装置(CPU)等を備えて構成される。
【0049】
受信部11は、送信部6から送信された圧縮ファイルを受信するようになっている。また、受信した圧縮ファイルは、図示しない記憶装置に保存される。
データ解析部12は、受信部11により受信された圧縮ファイル内のニューロンモデルパラメータに基づいて入力データセットを解析するようになっている。本実施形態では、データ解析部12は、後述するいくつかの処理プログラム(データ解析プログラム)によってその機能を実現されるが、以下に説明するような2つの手法で解析を行なえるようになっている。
【0050】
〔A〕ウェイトを考慮したニューロンの移動平均
データ解析部12は、ウェイトを考慮したニューロンの移動平均による解析を実現するための処理プログラムをそなえており、この処理プログラムは図11に示す処理手順を実現しうるものである。すなわち、まず、ある1つの運転ダイヤルの圧縮ファイルを読み込み(ステップV10)、n次元パラメータのうち任意の2つのパラメータ(例えばエンジン回転数とブースト圧力)を選択する(ステップV20)。各ニューロンはパラメータ(計測項目)毎の座標,ウェイト,平均距離の情報を持っているので、任意のパラメータ間の関係を容易に知ることができる。次に、ニューロンモデルパラメータに含まれるニューロンの座標情報及びウェイト情報を用い、図4に示すように、ニューロンの最大値RB及び最小値LBを決定した後、所定数の領域(ウィンドウという)に分割し(ステップV30)、各ウィンドウについてニューロンのウェイトを考慮して重心点(Cx,Cy)を求める(ステップV40)。その後、各ウィンドウの重心点を結んで移動平均のグラフを作成する(ステップV50)。上記のステップV20〜V50の処理を、n次元パラメータの全てのパラメータについて行なった後(ステップV60)、上記のステップV20〜V60の処理を、全運転ダイヤルの圧縮ファイルについて行なう(ステップV70)。なお、重心点は下式(8)を用いて算出される。
【0051】
【数8】
【0052】
また、データ解析部12は、このようにして作成したグラフをディスプレイ(出力手段)20に表示できるようになっている。例えば図5はウェイトを考慮したニューロンの移動平均により求めたエンジン回転数とブースト圧力との関係を示すグラフである。なお、図5では入力データセット(即ち生データ)の点と学習終了後のニューロンの点も併せて表示している。この図5からわかるように、ニューロンの移動平均で求めた重心点のグラフは、入力データセット群(入力データセットの分布)に非常に近似した形状となっている。一方、図6は入力データセットの移動平均を直接求めた場合のグラフであるが、入力データセット群から大きくはみ出している入力データセットの点が少しでも存在すると、重心点が入力データセット群からはみ出してしまうこともある。図5と図6とを比べると、ウェイトを考慮したニューロンの移動平均を求めて作成したグラフ(図5)の方が、入力データセットから直接移動平均を求めて作成したグラフ(図6)よりも、入力データセット群の特性をより正確に再現していることがわかる。
【0053】
〔B〕入力データセットの分布密度
データ解析部12は、入力データセットの分布密度による解析を実現するための処理プログラムをそなえており、この処理プログラムは図12に示す処理手順を実現しうるものである。すなわち、まず、ある1つの運転ダイヤルの圧縮ファイルを読み込み(ステップW10)、n次元パラメータのうち任意の2つのパラメータ(例えばエンジン回転数とブースト圧力)を選択する(ステップW20)。前述したように、各ニューロンはパラメータ(計測項目)毎の座標,ウェイト,平均距離の情報を持っているので、任意のパラメータ間の関係を容易に知ることができる。次に、ニューロンモデルパラメータに含まれるニューロンの座標情報と平均距離情報及びウェイト情報とを用い、図7に示すような3次元(ここではエンジン回転数,ブースト圧力,入力データ密度)のグラフを作成する(ステップW30)。図7中、ニューロンの座標情報から得られたニューロンの位置がピーク(山)の位置を表わし、ニューロンのウェイト情報から得られたニューロンのウェイトの大きさがピークの高さを表わしている。また、平均距離情報から得られた入力データセットとの平均距離がピークの傾斜面の傾きに対応しており、例えば、平均距離が大きい(即ち、入力データセットがニューロンの位置近傍に比較的低密度で存在している)ほどピークの傾斜面の傾きは小さく(なだらかに)なり、平均距離が小さい(即ち、入力データセットがニューロンの位置近傍に比較的高密度で存在している)ほどピークの傾斜面の傾きは大きく(急に)なる。上記のステップW20及びW30の処理を、n次元パラメータの全てのパラメータについて行なった後(ステップW40)、上記のステップW20〜W40の処理を、全運転ダイヤルの圧縮ファイルについて行なう(ステップW50)。
【0054】
また、データ解析部12は、このようにして作成したグラフをディスプレイ20に表示できるようになっている。
上述したように、データ解析部12は2つの手法によりニューロンモデルパラメータを解析できるようになっている。また、上記では、一例としてエンジン回転数とブースト圧力との関係について解析を行なったが、解析は各運転ダイヤルに対し全てのパラメータについて行なわれる。
【0055】
判定部13では、データ解析部12で求めた各グラフ(実際には、グラフの元となるニューロンモデルパラメータの各情報)に基づいて、油圧ショベル2の診断を行なうようになっている。例えば、正常運転時のグラフとの類似度を算出して、この類似度が予め設定した値よりも小さくなったら(即ち、正常運転時のグラフとのずれが大きくなったら)、油圧ショベル2に異常又は劣化が発生していると判定するようになっている。また、判定部13では、油圧ショベル2に異常が発生している場合には、その旨をディスプレイ20に表示してオペレータにその旨を報知するようになっている。
【0056】
さらに、油圧ショベル2の過去のメンテナンス歴に基づく知識ベースや、エンジンオイル或いは油圧機器作動オイルの分析結果も判定材料として加えることで、油圧ショベル2の故障,余寿命の予測や、オイル交換時期の予測も行なうことが可能になる。
本発明の一実施形態に係るデータ管理システム1は、上述のごとく構成されているので、データ圧縮及びデータ解析は図8に示すフローに沿って行なわれる。すなわち、まず、センサ4により油圧ショベル2の各パラメータの生データ(入力データセット)を検出した後(ステップS10)、この生データの前処理を行なう(ステップS20)。その後、ニューロンを用いて生データの圧縮を行ない(ステップS30)、圧縮したデータ(即ちニューロンモデルパラメータ)を圧縮ファイルとして管理センターに送信する(ステップS40)。管理センターでは、受信した圧縮ファイルを解析し(ステップS50)、油圧ショベル2に異常がないか否かを判定する(ステップS60)。
【0057】
なお、前述したように、図8に示すステップS20の処理はデータ前処理部5にて図9に示すフローに沿って実行され、図8に示すステップS30の処理はデータ圧縮部6にて図10に示すフローに沿って実行され、図8に示すステップS50の処理はデータ解析部12にて図11,図12に示すフローに沿ってそれぞれ実行される。
上述したように、本発明の一実施形態に係るデータ圧縮装置及び方法によれば、n個のパラメータの値からなる複数の入力データセット(即ち生データ:図2参照)を、この入力データセット数よりも少ない所定数のニューロンから得られるニューロンモデルを特徴付けるパラメータ(ニューロンモデルパラメータ:図3参照)に圧縮することができ、これにより通信コストを低減することが可能になる。また、このように圧縮されたニューロンモデルパラメータ(圧縮データ)は、ニューロンモデルを特徴付けるもの、即ち複数の入力データセットを特徴付けるものであるので、圧縮データから元の入力データセット(即ち生データ)の特性をより正確に再現することが可能となる(図5,図7参照)。
【0058】
また、本発明の一実施形態に係るデータ解析装置及び方法によれば、ニューロンモデルパラメータを用いて、元の入力データセットを解析することができる。この場合、ニューロンの移動平均(図5参照)や入力データセットの分布密度(図7参照)を解析することで、油圧ショベル2の診断を行なうことができる。
そして、本発明のデータ管理システムによれば、上記のデータ圧縮装置及びデータ解析装置の両方の効果が得られる。
【0059】
以上、本発明の実施形態について説明したが、本発明は上記の実施形態に限定されるものではなく、本発明の趣旨を逸脱しない範囲で種々変形して実施することができる。例えば、本実施形態では判定部13により診断を行なったが、ディスプレイ20に表示される各グラフの違いから視覚的に診断を行なうことももちろん可能である。また、本実施形態ではディスプレイ20に解析結果を表示するようにしたが、ディスプレイ20の代わりに、図示しないプリンタなどの印刷装置に解析結果を出力してオペレータが診断を行なうようにしてもよい。
【図面の簡単な説明】
【0060】
【図1】本発明の一実施形態に係るデータ管理システムを模式的に示すブロック図である。
【図2】ある運転ダイヤルにおけるエンジン回転数とブースト圧力との入力データセットの点をプロットした図である。
【図3】図2に示すエンジン回転数とブースト圧力との入力データセット群をニューロンモデルに変換した時(アイドリングニューロン及び弱いニューロンは削除済み)の図である。
【図4】ウェイトを考慮したニューロンの移動平均を説明するための図である。
【図5】ウェイトを考慮したニューロンの移動平均により求めたエンジン回転数とブースト圧力との関係を示すグラフである。
【図6】入力データセットの移動平均を直接求めた場合のグラフである。
【図7】入力データセットの分布密度を示す図である。
【図8】本発明の一実施形態に係るデータ圧縮及びデータ解析の手順を示すフローチャートである。
【図9】データ前処理の具体的な手順を示すフローチャートである。
【図10】データ圧縮の具体的な手順を示すフローチャートである。
【図11】ウェイトを考慮したニューロンの移動平均による解析の手順を示すフローチャートである。
【図12】入力データセットの分布密度による解析の手順を示すフローチャートである。
【符号の説明】
【0061】
1 データ管理システム
2 油圧ショベル(対象体)
3 データ圧縮装置
4 センサ(検出手段)
5 データ前処理部(前処理手段)
6 データ圧縮部(圧縮手段)
7 送信部(送信手段)
8 入力装置(入力手段)
10 データ解析装置
11 受信部(受信手段)
12 データ解析部(解析手段)
13 判定部(判定手段)
20 ディスプレイ(出力手段)
【特許請求の範囲】
【請求項1】
対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出手段と、
該検出手段により検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行い、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮する圧縮手段とをそなえた
ことを特徴とする、データ圧縮装置。
【請求項2】
該圧縮手段は、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、
上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいる
ことを特徴とする、請求項1記載のデータ圧縮装置。
【請求項3】
該データ圧縮手段は、該学習の終了後、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去する
ことを特徴とする、請求項2記載のデータ圧縮装置。
【請求項4】
上記ニューロンモデルパラメータを外部へ送信する送信手段をそなえている
ことを特徴とする、請求項1〜3の何れか1項に記載のデータ圧縮装置。
【請求項5】
請求項4記載のデータ処理装置の該送信手段により送信された上記ニューロンモデルパラメータを受信する受信手段と、
該受信手段により受信された上記ニューロンモデルパラメータに基づいて該データセットを解析する解析手段とをそなえた
ことを特徴とする、データ解析装置。
【請求項6】
該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析する
ことを特徴とする、請求項5記載のデータ解析装置。
【請求項7】
該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該データセットの分布密度を求めることにより解析する
ことを特徴とする、請求項5記載のデータ解析装置。
【請求項8】
請求項4記載のデータ圧縮装置と、
請求項5〜7の何れか1項に記載のデータ解析装置とをそなえた
ことを特徴とする、データ管理システム。
【請求項9】
該対象体は建設機械であり、上記のn個のパラメータは該建設機械の動作に応じて変動するパラメータである
ことを特徴とする、請求項8記載のデータ管理システム。
【請求項10】
対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出ステップと、
該検出ステップで検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行い、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮するデータ圧縮ステップとをそなえた
ことを特徴とする、データ圧縮方法。
【請求項11】
該データ圧縮ステップでは、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、
上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいる
ことを特徴とする、請求項10記載のデータ圧縮方法。
【請求項12】
該データ圧縮ステップでは、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去する
ことを特徴とする、請求項11記載のデータ圧縮方法。
【請求項13】
請求項12記載のデータ圧縮方法により得られた上記ニューロンモデルパラメータを取得する取得ステップと、
該取得ステップで取得した上記ニューロンモデルパラメータに基づいて該データセットを解析する解析ステップとをそなえた
ことを特徴とする、データ解析方法。
【請求項14】
該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析する
ことを特徴とする、請求項13記載のデータ解析方法。
【請求項15】
該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該ニューロンの分布密度を求めることにより解析する
ことを特徴とする、請求項13記載のデータ解析方法。
【請求項1】
対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出手段と、
該検出手段により検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行い、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮する圧縮手段とをそなえた
ことを特徴とする、データ圧縮装置。
【請求項2】
該圧縮手段は、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、
上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいる
ことを特徴とする、請求項1記載のデータ圧縮装置。
【請求項3】
該データ圧縮手段は、該学習の終了後、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去する
ことを特徴とする、請求項2記載のデータ圧縮装置。
【請求項4】
上記ニューロンモデルパラメータを外部へ送信する送信手段をそなえている
ことを特徴とする、請求項1〜3の何れか1項に記載のデータ圧縮装置。
【請求項5】
請求項4記載のデータ処理装置の該送信手段により送信された上記ニューロンモデルパラメータを受信する受信手段と、
該受信手段により受信された上記ニューロンモデルパラメータに基づいて該データセットを解析する解析手段とをそなえた
ことを特徴とする、データ解析装置。
【請求項6】
該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析する
ことを特徴とする、請求項5記載のデータ解析装置。
【請求項7】
該解析手段が、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該データセットの分布密度を求めることにより解析する
ことを特徴とする、請求項5記載のデータ解析装置。
【請求項8】
請求項4記載のデータ圧縮装置と、
請求項5〜7の何れか1項に記載のデータ解析装置とをそなえた
ことを特徴とする、データ管理システム。
【請求項9】
該対象体は建設機械であり、上記のn個のパラメータは該建設機械の動作に応じて変動するパラメータである
ことを特徴とする、請求項8記載のデータ管理システム。
【請求項10】
対象体の動作時に該動作に応じて変動するn個(n:自然数)のパラメータの値からなるデータセットを複数検出する検出ステップと、
該検出ステップで検出された各データセットをn次元空間内に入力し、該データセット数よりも少ない所定数のニューロンを該n次元空間内に配置してニューラルネットワークの教師なし学習法により該ニューロンの学習を行い、上記の複数のデータセットを、該学習により得られたニューロンモデルを特徴付けるニューロンモデルパラメータに変換することにより圧縮するデータ圧縮ステップとをそなえた
ことを特徴とする、データ圧縮方法。
【請求項11】
該データ圧縮ステップでは、各データセットについて最も距離が近いニューロンを勝者ニューロンとして設定するとともに、
上記ニューロンモデルパラメータは、該n次元空間内における該ニューロンの座標情報,該ニューロンから各データセットまでの平均距離情報,該ニューロンが何個のデータセットを代表しているかを表わすウェイト情報を含んでいる
ことを特徴とする、請求項10記載のデータ圧縮方法。
【請求項12】
該データ圧縮ステップでは、上記の所定数のニューロンのうち一度も勝者ニューロンに設定されなかったニューロンを消去する
ことを特徴とする、請求項11記載のデータ圧縮方法。
【請求項13】
請求項12記載のデータ圧縮方法により得られた上記ニューロンモデルパラメータを取得する取得ステップと、
該取得ステップで取得した上記ニューロンモデルパラメータに基づいて該データセットを解析する解析ステップとをそなえた
ことを特徴とする、データ解析方法。
【請求項14】
該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報及びウェイト情報に基づいて該ニューロンの移動平均を求めることにより解析する
ことを特徴とする、請求項13記載のデータ解析方法。
【請求項15】
該解析ステップでは、上記ニューロンモデルパラメータに含まれる座標情報とウェイト情報及び平均距離情報とに基づいて該ニューロンの分布密度を求めることにより解析する
ことを特徴とする、請求項13記載のデータ解析方法。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【公開番号】特開2006−11849(P2006−11849A)
【公開日】平成18年1月12日(2006.1.12)
【国際特許分類】
【出願番号】特願2004−188419(P2004−188419)
【出願日】平成16年6月25日(2004.6.25)
【出願人】(304028346)国立大学法人 香川大学 (285)
【出願人】(000190297)新キャタピラー三菱株式会社 (1,189)
【Fターム(参考)】
【公開日】平成18年1月12日(2006.1.12)
【国際特許分類】
【出願日】平成16年6月25日(2004.6.25)
【出願人】(304028346)国立大学法人 香川大学 (285)
【出願人】(000190297)新キャタピラー三菱株式会社 (1,189)
【Fターム(参考)】
[ Back to top ]