
データ編集装置およびデータ編集方法
【課題】データオブジェクトに対するユーザの操作を支援する。
【解決手段】データ編集装置10のデータ保持部12は、編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持する。コード取得部20は、データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、編集対象のデータに対する基底にもとづく編集内容が記述されたユーザコードを取得する。コード生成部22は、データの編集内容を外延的記法により記述するための第2プログラム言語と第1プログラム言語との所定の対応関係にしたがって、ユーザコードから、第2プログラム言語で記述された実行コードを生成する。編集処理部24は、実行コードにしたがって編集対象のデータを編集する。
【解決手段】データ編集装置10のデータ保持部12は、編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持する。コード取得部20は、データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、編集対象のデータに対する基底にもとづく編集内容が記述されたユーザコードを取得する。コード生成部22は、データの編集内容を外延的記法により記述するための第2プログラム言語と第1プログラム言語との所定の対応関係にしたがって、ユーザコードから、第2プログラム言語で記述された実行コードを生成する。編集処理部24は、実行コードにしたがって編集対象のデータを編集する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明はデータ処理技術に関し、特に、データ編集装置およびデータ編集方法に関する。
【背景技術】
【0002】
これまでのデータベース(例えば、RDBやXMLDB等)は、予め定められたスキーマにしたがってデータをストレージへ蓄積していた。データベースの提供する機能は次の3つに大別することができる。すなわち(1)ストレージ上でのデータ蓄積および検索機能、(2)蓄積されたデータへのアクセス制御機能、(3)検索されたデータから必要な部分を抽出し、必要に応じて変換するデータ編集機能、である。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2010−266996号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
上記(3)のデータ編集機能に関して、データをメモり内でデータオブジェクトとして表現する方法は標準的に定められておらず、どのような形式のオブジェクトとして表現するかというOR(Object Relation)マッピングと呼ばれる課題が存在した。また、データオブジェクトを操作するためのプログラムの記述は複雑になりやすく、データ編集の内容をユーザが直観的に把握することが難しい場合があった。
【0005】
本発明は上記課題を鑑みてなされたものであり、その主な目的は、データオブジェクトに対するユーザの操作を支援するための技術を提供することにある。
【課題を解決するための手段】
【0006】
上記課題を解決するために、本発明のある態様のデータ編集装置は、編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するデータ保持部と、データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、編集対象のデータに対する基底にもとづく編集内容が記述された第1コードを取得するコード取得部と、データの編集内容を外延的記法により記述するための第2プログラム言語と第1プログラム言語との予め定められた対応関係にしたがって、第1コードから、第2プログラム言語で記述されたコードである第2コードを生成するコード生成部と、第2コードにしたがって編集対象のデータを編集する編集処理部と、を備える。
【0007】
本発明の別の態様は、データ編集方法である。この方法は、編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するステップと、データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、編集対象のデータに対する基底にもとづく編集内容が記述された第1コードを取得するステップと、データの編集内容を外延的記法により記述するための第2プログラム言語と第1プログラム言語との予め定められた対応関係にしたがって、第1コードから、第2プログラム言語で記述されたコードである第2コードを生成するステップと、第2コードにしたがって編集対象のデータを編集するステップと、をコンピュータが実行する。
【0008】
なお、以上の構成要素の任意の組合せ、本発明の表現を装置、方法、システム、プログラム、プログラムを格納した記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0009】
本発明によれば、データオブジェクトに対するユーザの操作を支援することができる。
【図面の簡単な説明】
【0010】
【図1】売上伝票の例を示す図である。
【図2】実施の形態のデータ編集装置の機能構成を示すブロック図である。
【図3】会計型データを操作するためのユーザコードの一例を示す図である。
【図4(a)】図3のユーザコードに対応する実行コードを示す図である。
【図4(b)】図3のユーザコードに対応する実行コードを示す図である。
【図5】レコード型データを操作するためのユーザコードの一例を示す図である。
【図6(a)】図5のユーザコードに対応する実行コードを示す図である。
【図6(b)】図5のユーザコードに対応する実行コードを示す図である。
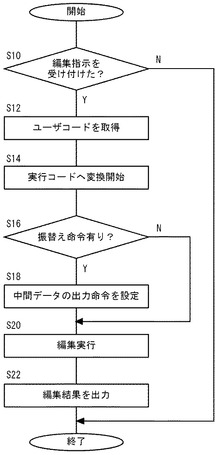
【図7】データ編集装置の動作を示すフローチャートである。
【発明を実施するための形態】
【0011】
(前提技術)
本発明の実施の形態の構成を説明する前に、本実施の形態で示すデータ編集技術の前提となる交換代数について説明する。
【0012】
本発明者は、以下に示す2つのデータ構造により、企業等の組織における8〜9割のデータを表現することができると考えた。
1.多分類数値型(以下、「会計型データ」とも呼ぶ。)
データの値とデータの属性(以下、「基底」とも呼ぶ。)の組み合わせであり、データの値として数値が用いられ、データの属性として名称・単位・時間・主体が用いられる。例えば、40<現金,円>+30<ミカン,個>・・・と表現される。
2.多分類混合型(以下、「レコード型データ」とも呼ぶ。)
データの値と基底の組み合わせであり、データの値および基底には数値や数値以外の様々なリテラルが用いられる。例えば、55<年齢>+山田太郎<名前>+津軽<好きな果物>・・・と表現される。
以下では、主に会計型データについて詳細に説明する。
【0013】
会計型データは、何らかの分類された項目ごとに与えられた数値データをまとめて表現し、その上で演算を行うための代数系(以下、「交換代数」とも呼ぶ。)に属するものであり、交換代数データとも言える。会計型データにおける基底(すなわち分類項目)は、<名称,単位,時間,主体>と4つの項目からなる。データは、1以上の基底に対する値の組み合わせ、言い換えれば、1以上の基底に対する値の和で表現される。
例1:x=200<リンゴ,円,#,#>+400<さんま,円,#,#>
例2:y=200<リンゴ,円,2006年第1四半期,#>+400<リンゴ,円,2006年第2四半期,#>+720<リンゴ,円,2006年第3四半期,#>
上記の例1では時間と主体が省略されており、例2では主体が省略されている。例2は時系列データが表現されたものとも言える。また基底の主体には企業名等の組織の識別情報が設定されてもよい。
【0014】
交換代数による表現のメリットとして、様々な基底(分類)を用いてデータを表現できること、またプログラムコードではなく人間に解釈容易な文字で基底を表現できることが挙げられる。さらにまた、後述するように振替という演算による統一的なデータ編集が可能になる。
【0015】
実施の形態の交換代数では、マイナスの数値の代わりに^(ハット)という記号を用いる。例えばx=20^<リンゴ,#,#,#>はリンゴが20減ることを示す。言い換えれば、^はある項目に対して相殺すべき反対項目を意味する基底を示す。また相殺操作を表す作用素(オペレータ)として「〜(バー)」を導入する。以下例を示す。
x1=30<現金>+20<リンゴ>+50<負債>
y1=^x1=30^<現金>+20^<リンゴ>+50^<負債>
〜(y1+x1)=(30^<現金>+20^<リンゴ>+50^<負債>)+(30<現金>+20<リンゴ>+50<負債>)=0
【0016】
次に、交換代数による振替え操作について説明する。簿記では振替という操作がある。これは一種の分類替え(基底変換)の操作と言える。ここでは、図1の(a)に示す八百屋の売上伝票を図1の(b)に示す売上伝票へ振替える例を示す。
【0017】
図1の(a)および(b)で示す取引は円表示で以下のように表現できる。
x1=200<現金,円>+100^<リンゴ,円>+100<利益,円>
x2=50<光熱費,円>+50^<現金,円>
x3=100^<利益,円>+100<営業収益,円>
x4=50^<営業収益,円>+50^<光熱費,円>
y=x1+x2+x3+x4=(200<現金,円>+100^<リンゴ,円>+100<利益,円>)+(50<光熱費,円>+50^<現金,円>)+(100^<利益,円>+100<営業収益,円>)+(50^<営業収益,円>+50^<光熱費,円>)
〜y=150<現金,円>+100^<リンゴ,円>+50<営業収益,円>
【0018】
次に、振替え操作と見なすアグリゲーション(合併)と按分について説明する。
1.アグリゲーション
300円の津軽と200円の富士と100円の紅玉(いずれもリンゴの1品種)があったとする。これを、x=300<津軽,円>+200<富士,円>+100<紅玉,円>と表現する。この津軽・富士・紅玉を「リンゴ」とまとめて分類する操作も一種の振替であり、アグリゲーションとよぶ。なお前提として{津軽,富士,紅玉}-->{リンゴ}という対応関係のマップが与えられている必要がある。
【0019】
この例では上記の対応関係のマップにしたがって、F(x)=300^<津軽,円>+200^<富士,円>+100^<紅玉,円>+300<リンゴ,円>+200<リンゴ,円>+100<リンゴ,円>、という元を生成する。基底<リンゴ>の値は、集約対象の基底<津軽>、<富士>、<紅玉>のそれぞれに対する値である。言い換えれば、集約対象の基底<津軽>、<富士>、<紅玉>のそれぞれに対する値の集計値が、基底<リンゴ>の値として算出される。
【0020】
アグリゲーションを表す振替G(x)は、F(x)を用いて、〜{x+F(x)}で与えられる。すなわち、G(x)=〜{x+F(x)}=(300<津軽,円>+200<富士,円>+100<紅玉,円>)+(300^<津軽,円>+200^<富士,円>+100^<紅玉,円>+300<リンゴ,円>+200<リンゴ,円>+100<リンゴ,円>)=600<リンゴ,円>、となる。
【0021】
2.按分
按分とは、1つの分類項目をさらに細かく複数の分類項目へ分割することである。例えば、アグリゲーションに示した例では基底<リンゴ>に対応する値を、津軽・富士・紅玉へ分割することを意味する。なお前提として{リンゴ}-->{津軽,富士,紅玉}の按分比率が与えられている必要があり、ここでは1:1:1であることとする。
【0022】
この例では上記の按分比率にしたがって、x=600<リンゴ,円>に対して、F(x)=600^<リンゴ,円>+200<津軽,円>+200<富士,円>+200<紅玉,円>、という元を生成する。
按分を表す振替えG(x)は、F(x)を用いて、〜{x+F(x)}で与えられる。すなわち、G(x)=〜{x+F(x)}=600<リンゴ,円>+(600^<リンゴ,円>+200<津軽,円>+200<富士,円>+200<紅玉,円>)=200<津軽,円>+200<富士,円>+200<紅玉,円>、となる。
【0023】
(実施の形態)
以下、上記の交換代数の考え方を利用してデータ編集処理を実行する情報処理装置(以下、「データ編集装置」と呼ぶ。)について説明する。本実施の形態において、ユーザは、対象がその集合に属するための必要十分条件を与えることによって集合を記述する方法である内包的記法を用いて、データの編集内容を記述する。実施の形態のデータ編集装置は、内包的記法により記述された編集内容に基づいて、集合の要素をすべて列挙することで集合を記述する方法である外延的記法で記述されたプログラムコードを出力する。そして、編集対象のデータを、交換代数に対応する形式のデータオブジェクトとしてメモリに読み込み、上記のプログラムコードを実行することによりデータの編集処理を実行する。
【0024】
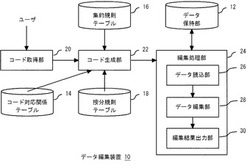
図2は、実施の形態のデータ編集装置10の機能構成を示すブロック図である。データ編集装置10は、データ保持部12と、コード対応関係テーブル14と、集約規則テーブル16と、按分規則テーブル18と、コード取得部20と、コード生成部22と、編集処理部24を備える。
【0025】
本明細書のブロック図において示される各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。例えば、図2の各機能ブロックは、ソフトウェアとして記録媒体に格納されデータ編集装置10のハードディスクにインストールされ、データ編集装置10のメインメモリに適宜読み出されてCPUにて実行されてもよい。
【0026】
データ保持部12は、編集対象となる編集前のデータと編集後のデータとを保持する記憶領域である。データ保持部12は、編集前のデータと編集後のデータのそれぞれについて、データの値と基底とを対応づけたCSV(Comma Separated Values)ファイルを保持する。例えば、CSVファイルの一行が「値,ハットの有無,名称,単位,時間,主体」となり、空白行が元(げん)の区切りを示してもよい。なおデータ保持部12は、データ編集装置10とは異なる情報処理装置、例えばデータベースサーバ内に設けられてもよいことはもちろんである。この場合、LAN・WAN・インターネット等の通信網を介して当該データベースサーバとデータ編集装置10が接続された情報処理システムが構築されてもよい。
【0027】
コード対応関係テーブル14は、データの編集内容(編集操作)を内包的記法により記述するためのプログラム言語(以下、「内包的記法言語」とも呼ぶ。)と、データの編集内容を外延的記法により記述するためのプログラム言語(以下、「外延的記法言語」)との対応関係を保持する記憶領域である。実施の形態における外延的記法言語はJava(登録商標)言語であることとするが、C言語等、他のプログラム言語であってもよい。
【0028】
内包的記法言語と外延的記法言語との対応関係は、例えば、内包的記法言語における編集操作を示すキーワードと、外延的記法言語におけるその編集操作を実現するためのロジックを実装したコード(関数)とを対応づけたものである。より具体的には、内包的記法言語における複数のデータから特定のデータを抽出する条件の記述は、外延的記法言語における複数のデータを逐次列挙するための繰り返し命令の記述と対応づけられる。また例えば、内包的記法言語において入力データを指定するコードと、外延的記法言語においてその入力データをメモリ内に読み込むロジックを実装したコードとを対応づけたものである。なお、対応関係の具体例は図3〜図6において後述する。
【0029】
集約規則テーブル16は、アグリゲーション操作時に参照されるべき複数種類の基底の集約関係を定めた集約規則を保持する記憶領域である。集約規則は、例えば上述の{津軽,富士,紅玉}-->{リンゴ}という集約関係を定めたものである。複数種類の基底を集約する基底(上記例ではリンゴ)を以下では「集約基底」と呼ぶこととする。按分規則テーブル18は、按分操作時に参照される複数種類の基底の按分比率を定めた按分規則を保持する記憶領域である。按分規則は、例えば上述の{リンゴ}-->{津軽,富士,紅玉}という按分関係と、1:1:1という按分比率を定めたものである。
【0030】
コード取得部20は、キーボード等の所定の入力装置を介してユーザにより入力されたプログラムコード(以下、「ユーザコード」とも呼ぶ。)を取得する。このユーザコードは、内包的記法言語で記述される。具体的なユーザコード例は後述する。
【0031】
コード生成部22は、コード対応関係テーブル14に保持された対応関係にしたがって、ユーザコードから、ユーザコードに記述されたデータ編集内容が外延的記法言語で記述されたプログラムコード(以下、「実行コード」とも呼ぶ。)を生成する。実施の形態における実行コードはJavaバイトコードであることとする。具体的には、ユーザコードに対応するJavaソースコードを生成し、そのソースコードをコンパイルすることによりJavaバイトコードを生成する。具体的な実行コード例は後述する。
【0032】
編集処理部24は、コード生成部22において生成された実行コードにしたがって、データ保持部12に保持された編集対象のデータを編集する。編集処理部24は、データ読込部26とデータ編集部28と編集結果出力部30を含む。なお、実行コードが所定の実行エンジンにおいて実行されることにより、編集処理部24(データ読込部26〜編集結果出力部30)の機能が実現されてもよいことはもちろんである。例えば、実行コードがJavaバイトコードの場合、実行エンジンはJVM(Java Virtual Machine)となる。
【0033】
データ読込部26は、データ保持部12から編集対象のデータを読み込み、そのデータから、データの値と基底とが対応づけられたデータオブジェクトをメモリ上に生成する。データ編集部28は、データ読込部26において生成されたデータオブジェクトに対する操作を実行して編集結果のデータを設定する。編集結果出力部30は、データ読込部26において設定された編集結果のデータをCSVファイルとして記録し、データ保持部12へ格納する。
【0034】
図3は、会計型データを操作するためのユーザコードの一例を示す。以下のコード例では、左端に行番号を示しており、その行番号によりコードの位置を適宜示す。図3では、編集対象データとして、200<現金>+100<小麦>という元と、200<現金>+200<大豆>という元を含む集合Cが指定されている。ここでは説明の簡明化のため編集対象データを直接入力しているが、典型的には入力ファイルとしてのCSVファイルの名称や、そのCSVファイルにおける入力データの記述位置が指定されることにより入力データを示すデータオブジェクトが生成される。
【0035】
図3の4行目では、交換代数のプロジェクション処理、すなわち指定された基底と一致する部分要素を抽出する射影操作が指定されている。具体的には、集合Cから基底<現金>もしくは<小麦>に該当し、かつ、値が設定済という条件を充足する元を抽出して集合asetへ代入する処理が指定されている。そして5行目でaset内の元の加算処理が指定されている。asetは200<現金>、100<小麦>、200<現金>を含むため、加算結果alphaは400<現金>+100<小麦>となる。ここでは説明の簡明化のため編集結果を標準出力へ出力することとしているが、典型的には出力ファイルとしてのCSVファイルが指定されて、当該CSVファイルに編集結果(ここでは加算結果alphaの内容)が記録される。
【0036】
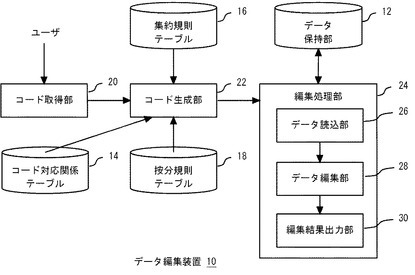
図4(a)は、図3のユーザコードに対応する実行コードを示す。具体的には図3の2行目に応じてコード生成部22が生成する実行コードであり、データ読込部26の機能に対応する。なお、実施の形態の説明では実行コードとして便宜的にJavaソースプログラムを示す。同図では、集合Cに対応するExAlgeSetオブジェクトに、200<現金>+100<小麦>という元に対応するExAlgeオブジェクト(15〜23行目)と、200<現金>+200<大豆>という元に対応するExAlgeオブジェクト(24〜32行目)が格納されている。
【0037】
図4(b)は、図3のユーザコードに対応する実行コードを示す。具体的には図3の4行目に応じてコード生成部22が生成する実行コードであり、データ編集部28の機能に対応する。同図では、集合Cに含まれる複数の元に対応するExAlgeオブジェクトを列挙するforループと、集合Dに含まれる複数の基底に対応するExBaseオブジェクトを列挙するforループとの2重ループの中で、プロジェクションメソッドが呼び出され、プロジェクション処理の結果がリストへ追加される。そして、そのリストから集合asetが設定されている。
【0038】
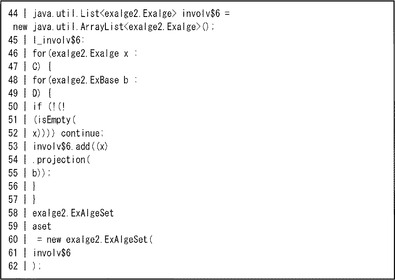
図5は、レコード型データを操作するためのユーザコードの一例を示す。同図では、山田<name>+5<score>、田中<name>+3<score>、鈴木<name>+4<score>、佐藤<name>+2<score>、本田<name>+5<score>の5つの元を含む集合datasetが指定されている。
【0039】
図5の9行目では、基底<score>に対応づけられた値が4以上の元が存在するたびに、元「1<4以上,人,#,#>」を集合asetへ代入する処理が指定されている。そして、11行目でaset内の元の加算処理が指定されている。この結果として、asetには元「1<4以上,人,#,#>」が3個含まれることになり、ret=3<4以上,人,#,#>となる。すなわちこの例は、scoreが4以上の人数を集計するものとなる。
【0040】
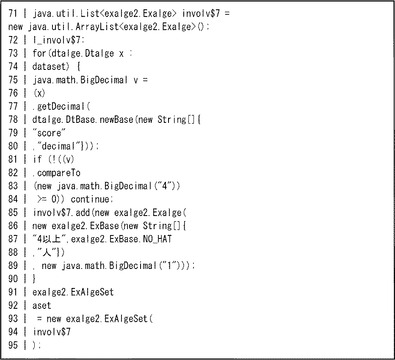
図6(a)は、図5のユーザコードに対応する実行コードを示す。具体的には図5の2〜7行目に応じてコード生成部22が生成する実行コードであり、データ読込部26の機能に対応する。同図では、集合datasetに対応するDtAlgeSetオブジェクトに、上記5つのレコード型データの元のそれぞれに対応するDtalgeオブジェクトが格納される。レコード型データは値と基底の両方で様々なデータ型を許容するため、値と基底のそれぞれのデータ型を示す情報もDtalgeオブジェクトに設定される。
【0041】
図6(b)は、図5のユーザコードに対応する実行コードを示す。具体的には図5の9行目に応じてコード生成部22が生成する実行コードであり、データ編集部28の機能に対応する。同図では、集合datasetに含まれる複数の元に対応するDtAlgeSetオブジェクトを列挙するforループの中で、基底<score>に対応する値が4以上の場合に、元「1<4以上,人,#,#>」がリストへ追加される。そして、そのリストから集合asetが設定されている。
【0042】
なおユーザコードにアグリゲーション命令(関数)が設定された場合、コード生成部22は、集約規則テーブル16に保持された集約規則を参照して、まず簿記の記載に対応するオブジェクト(以下、「中間オブジェクト」とも呼ぶ。)を設定する実行コードを生成する。具体的には、集約対象の複数のデータの集計値を算出し、その集計値と集約基底とを対応づけたデータと、集約対象の複数のデータそれぞれの値を差し引くことを示すデータ(すなわち集約対象の複数のオリジナルデータにハット属性を付加したデータ)とを加算する元を示すオブジェクトを、中間オブジェクトとして設定する実行コードを生成する。この中間オブジェクトは、前提技術のアグリゲーションで示したF(x)に対応する。
【0043】
そしてコード生成部22は、集約対象の複数のオリジナルデータが加算される元を示すオブジェクトと中間オブジェクトとを加算する、言い換えれば、集約対象の複数のオリジナルデータとそれらのデータにハット属性を付加したデータとを相殺することにより、集約対象の複数のデータの集計値と集約基底とを対応づけたデータを、集計結果のオブジェクトへ格納する実行コードを生成する。この実行コードは、前提技術のアグリゲーションで示した〜(x+F(x))に対応するコードである。なおコード生成部22は、中間オブジェクトの内容を所定のファイルへ出力する実行コードをさらに生成してもよい。この態様によると、中間オブジェクトの内容をユーザへ提示することにより、効率的なデバッグを支援するとともに、簿記の振替計算に利用可能な情報をユーザへ提供できる。
【0044】
またユーザコードに按分命令(関数)が設定された場合、コード生成部22は、按分規則テーブル18に保持された集約規則を参照して、アグリゲーション時と同様にまず中間オブジェクトを設定する実行コードを生成する。具体的には、按分対象のデータの値を按分比率にしたがって按分し、按分した値と按分先の各基底とを対応づけたデータと、按分対象のオリジナルデータにハット属性を付加したデータとを加算する元を示すオブジェクトを、中間オブジェクトとして設定する実行コードを生成する。この中間オブジェクトは、前提技術の按分で示したF(x)に対応する。
【0045】
そしてコード生成部22は、按分対象のオリジナルデータの元を示すオブジェクトと中間オブジェクトとを加算する、言い換えれば、按分対象のオリジナルデータとそのデータにハット属性を付加したデータとを相殺することにより、按分した値と按分先の各基底とを対応づけたデータを、按分結果のオブジェクトへ格納する実行コードを生成する。この実行コードは、前提技術の按分で示した〜(x+F(x))に対応するコードである。なおコード生成部22は、アグリゲーションと同様に、中間オブジェクトの内容を所定のファイルへ出力する実行コードをさらに生成してもよい。
【0046】
以上の構成による動作を以下説明する。
図7は、データ編集装置10の動作を示すフローチャートである。まずユーザは、内包的記法言語を用いてデータの編集内容を内包的記法により記述し、そのプログラムコードを指定したデータの編集指示をデータ編集装置10へ入力する。データ編集装置10が所定の入力装置を介してデータの編集指示を受け付けた場合(S10のY)、データ編集装置10のコード取得部20は、ユーザにより入力されたプログラムコードをユーザコードとして取得する(S12)。コード生成部22は、コード対応関係テーブル14に保持されたユーザコードと実行コード間の対応関係にしたがって、ユーザコードから実行コードの生成処理を開始する(S14)。
【0047】
ユーザコードにアグリゲーション命令や按分命令等の振替え命令が存在する場合(S16のY)、コード生成部22はその振替え命令に応じた相殺処理のための中間オブジェクトの出力命令を実行コードへ設定する(S18)。ユーザコードに振替え命令がなければ(S16のN)、S18をスキップする。編集処理部24は、生成された実行コードにしたがって編集対象データに対する編集処理を実行する(S20)。例えば、データ読込部26は、データ保持部12の入力データ格納用のCSVファイルから、ユーザコードおよびユーザコードから生成された実行コードにおいて指定された編集対象のデータを読み込みデータオブジェクトを生成する。そしてデータ編集部28は、生成されたデータオブジェクトに対して実行コードにて指定された編集操作(基底に基づく射影操作・アグリゲーション操作・按分操作等)を実行し、編集結果を示すデータオブジェクトを生成する。編集結果出力部30は、編集処理部24による編集結果、例えばデータ編集部28により生成された編集結果を示すデータオブジェクトの内容(属性値等)を、データ保持部12の編集結果格納用のCSVファイルへ出力する(S22)。データ編集装置10がデータの編集指示を受け付けなければ(S10のN)、S12以降はスキップされる。
【0048】
本実施の形態のデータ編集装置10によれば、従来RDBで扱われていたデータを、会計型データに対応するデータオブジェクト、もしくは、レコード型データに対応するデータオブジェクトとして表現することができる。これにより、コンピュータ上におけるデータオブジェクト表現の標準化を支援することができる。また、編集対象のデータの蓄積においてRDBのような複雑な仕組みを必要とせず、可視性の高いCSVファイルで蓄積することができる。
【0049】
またデータ編集装置10によれば、ユーザはデータの編集内容を内包的記法言語で記述できるため、データの編集内容を正しく理解しているユーザであれば、実際にコンピュータを動作させるための外延的記法言語について理解していなくても、正しいデータ編集を実現させることができる。またデータ編集装置10では編集対象のデータが値と基底との組み合わせとして保持されるため、ユーザは内包的記法を用いることで、規定に基づく編集内容を容易に記述することができる。また内包的記法はコンピュータに依存せず、データ編集の仕様を反映するものであるため、ユーザは正しい仕様記述を行えば、正しいデータ編集を実現させることができる。例えば、forループ等を意識せずに、ユーザはデータの編集内容を仕様通りに記載すればよい。したがって、ユーザコードへのバグの混入を低減させることができ、言い換えれば、バグの発生箇所をデータそのもののバグに限定させやすくなる。例えば、会計型データの操作においては、アグリゲーションや按分等、様々な振替処理をロバストに記述することができる。
【0050】
またデータ編集装置10によれば、データの基底に基づいて値の編集処理が行われることにより、データの形式(スキーマ)に変更があった場合でも、その影響範囲を限定することができる。例えば、編集対象のデータを格納したテーブルにおいてカラムの入れ替えが発生しても、ユーザコードにおける編集ロジックへの影響を排除することができる。
【0051】
またデータ編集装置10によれば、アグリゲーションや按分等の振替処理の規則がプログラムコード外のテーブルに保持されるため、規則に変更が生じてもテーブルのデータを変更すればよく、プログラムコードへの影響を排除できる。
【0052】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0053】
例えば、データ編集装置10は振替規則テーブルをさらに備えてもよい。振替規則テーブルは、振替操作(ここではアグリゲーションや按分を伴わない基底の変換操作であることとする)において参照されるべき振替規則を保持する記憶領域である。振替規則は、振替元の基底と振替先の基底とを対応づけたデータである。コード生成部22は、ユーザコードに振替命令が設定された場合、振替規則テーブルに保持された振替規則を参照して、中間オブジェクトF(x)を設定する実行コードを生成する。例えば、x=数値A<振替元の基底>の場合、F(x)=数値A^<振替元の基底>+数値A<振替先の基底>となる。そしてコード生成部22は、〜(x+F(x))に対応した実行コードを生成する。当該コードの実行結果として、上記の例では、数値A<振替元の基底>が、数値A<振替先の基底>に変換されることになる。
【0054】
上述した実施の形態、変形例の任意の組み合わせもまた本発明の実施の形態として有用である。組み合わせによって生じる新たな実施の形態は、組み合わされる実施の形態、変形例それぞれの効果をあわせもつ。
【0055】
請求項に記載の各構成要件が果たすべき機能は、実施の形態および変形例において示された各構成要素の単体もしくはそれらの連携によって実現されることも当業者には理解されるところである。
【符号の説明】
【0056】
10 データ編集装置、 12 データ保持部、 14 コード対応関係テーブル、 16 集約規則テーブル、 18 按分規則テーブル、 20 コード取得部、 22 コード生成部、 24 編集処理部、 26 データ読込部、 28 データ編集部、 30 編集結果出力部。
【技術分野】
【0001】
本発明はデータ処理技術に関し、特に、データ編集装置およびデータ編集方法に関する。
【背景技術】
【0002】
これまでのデータベース(例えば、RDBやXMLDB等)は、予め定められたスキーマにしたがってデータをストレージへ蓄積していた。データベースの提供する機能は次の3つに大別することができる。すなわち(1)ストレージ上でのデータ蓄積および検索機能、(2)蓄積されたデータへのアクセス制御機能、(3)検索されたデータから必要な部分を抽出し、必要に応じて変換するデータ編集機能、である。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2010−266996号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
上記(3)のデータ編集機能に関して、データをメモり内でデータオブジェクトとして表現する方法は標準的に定められておらず、どのような形式のオブジェクトとして表現するかというOR(Object Relation)マッピングと呼ばれる課題が存在した。また、データオブジェクトを操作するためのプログラムの記述は複雑になりやすく、データ編集の内容をユーザが直観的に把握することが難しい場合があった。
【0005】
本発明は上記課題を鑑みてなされたものであり、その主な目的は、データオブジェクトに対するユーザの操作を支援するための技術を提供することにある。
【課題を解決するための手段】
【0006】
上記課題を解決するために、本発明のある態様のデータ編集装置は、編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するデータ保持部と、データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、編集対象のデータに対する基底にもとづく編集内容が記述された第1コードを取得するコード取得部と、データの編集内容を外延的記法により記述するための第2プログラム言語と第1プログラム言語との予め定められた対応関係にしたがって、第1コードから、第2プログラム言語で記述されたコードである第2コードを生成するコード生成部と、第2コードにしたがって編集対象のデータを編集する編集処理部と、を備える。
【0007】
本発明の別の態様は、データ編集方法である。この方法は、編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するステップと、データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、編集対象のデータに対する基底にもとづく編集内容が記述された第1コードを取得するステップと、データの編集内容を外延的記法により記述するための第2プログラム言語と第1プログラム言語との予め定められた対応関係にしたがって、第1コードから、第2プログラム言語で記述されたコードである第2コードを生成するステップと、第2コードにしたがって編集対象のデータを編集するステップと、をコンピュータが実行する。
【0008】
なお、以上の構成要素の任意の組合せ、本発明の表現を装置、方法、システム、プログラム、プログラムを格納した記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0009】
本発明によれば、データオブジェクトに対するユーザの操作を支援することができる。
【図面の簡単な説明】
【0010】
【図1】売上伝票の例を示す図である。
【図2】実施の形態のデータ編集装置の機能構成を示すブロック図である。
【図3】会計型データを操作するためのユーザコードの一例を示す図である。
【図4(a)】図3のユーザコードに対応する実行コードを示す図である。
【図4(b)】図3のユーザコードに対応する実行コードを示す図である。
【図5】レコード型データを操作するためのユーザコードの一例を示す図である。
【図6(a)】図5のユーザコードに対応する実行コードを示す図である。
【図6(b)】図5のユーザコードに対応する実行コードを示す図である。
【図7】データ編集装置の動作を示すフローチャートである。
【発明を実施するための形態】
【0011】
(前提技術)
本発明の実施の形態の構成を説明する前に、本実施の形態で示すデータ編集技術の前提となる交換代数について説明する。
【0012】
本発明者は、以下に示す2つのデータ構造により、企業等の組織における8〜9割のデータを表現することができると考えた。
1.多分類数値型(以下、「会計型データ」とも呼ぶ。)
データの値とデータの属性(以下、「基底」とも呼ぶ。)の組み合わせであり、データの値として数値が用いられ、データの属性として名称・単位・時間・主体が用いられる。例えば、40<現金,円>+30<ミカン,個>・・・と表現される。
2.多分類混合型(以下、「レコード型データ」とも呼ぶ。)
データの値と基底の組み合わせであり、データの値および基底には数値や数値以外の様々なリテラルが用いられる。例えば、55<年齢>+山田太郎<名前>+津軽<好きな果物>・・・と表現される。
以下では、主に会計型データについて詳細に説明する。
【0013】
会計型データは、何らかの分類された項目ごとに与えられた数値データをまとめて表現し、その上で演算を行うための代数系(以下、「交換代数」とも呼ぶ。)に属するものであり、交換代数データとも言える。会計型データにおける基底(すなわち分類項目)は、<名称,単位,時間,主体>と4つの項目からなる。データは、1以上の基底に対する値の組み合わせ、言い換えれば、1以上の基底に対する値の和で表現される。
例1:x=200<リンゴ,円,#,#>+400<さんま,円,#,#>
例2:y=200<リンゴ,円,2006年第1四半期,#>+400<リンゴ,円,2006年第2四半期,#>+720<リンゴ,円,2006年第3四半期,#>
上記の例1では時間と主体が省略されており、例2では主体が省略されている。例2は時系列データが表現されたものとも言える。また基底の主体には企業名等の組織の識別情報が設定されてもよい。
【0014】
交換代数による表現のメリットとして、様々な基底(分類)を用いてデータを表現できること、またプログラムコードではなく人間に解釈容易な文字で基底を表現できることが挙げられる。さらにまた、後述するように振替という演算による統一的なデータ編集が可能になる。
【0015】
実施の形態の交換代数では、マイナスの数値の代わりに^(ハット)という記号を用いる。例えばx=20^<リンゴ,#,#,#>はリンゴが20減ることを示す。言い換えれば、^はある項目に対して相殺すべき反対項目を意味する基底を示す。また相殺操作を表す作用素(オペレータ)として「〜(バー)」を導入する。以下例を示す。
x1=30<現金>+20<リンゴ>+50<負債>
y1=^x1=30^<現金>+20^<リンゴ>+50^<負債>
〜(y1+x1)=(30^<現金>+20^<リンゴ>+50^<負債>)+(30<現金>+20<リンゴ>+50<負債>)=0
【0016】
次に、交換代数による振替え操作について説明する。簿記では振替という操作がある。これは一種の分類替え(基底変換)の操作と言える。ここでは、図1の(a)に示す八百屋の売上伝票を図1の(b)に示す売上伝票へ振替える例を示す。
【0017】
図1の(a)および(b)で示す取引は円表示で以下のように表現できる。
x1=200<現金,円>+100^<リンゴ,円>+100<利益,円>
x2=50<光熱費,円>+50^<現金,円>
x3=100^<利益,円>+100<営業収益,円>
x4=50^<営業収益,円>+50^<光熱費,円>
y=x1+x2+x3+x4=(200<現金,円>+100^<リンゴ,円>+100<利益,円>)+(50<光熱費,円>+50^<現金,円>)+(100^<利益,円>+100<営業収益,円>)+(50^<営業収益,円>+50^<光熱費,円>)
〜y=150<現金,円>+100^<リンゴ,円>+50<営業収益,円>
【0018】
次に、振替え操作と見なすアグリゲーション(合併)と按分について説明する。
1.アグリゲーション
300円の津軽と200円の富士と100円の紅玉(いずれもリンゴの1品種)があったとする。これを、x=300<津軽,円>+200<富士,円>+100<紅玉,円>と表現する。この津軽・富士・紅玉を「リンゴ」とまとめて分類する操作も一種の振替であり、アグリゲーションとよぶ。なお前提として{津軽,富士,紅玉}-->{リンゴ}という対応関係のマップが与えられている必要がある。
【0019】
この例では上記の対応関係のマップにしたがって、F(x)=300^<津軽,円>+200^<富士,円>+100^<紅玉,円>+300<リンゴ,円>+200<リンゴ,円>+100<リンゴ,円>、という元を生成する。基底<リンゴ>の値は、集約対象の基底<津軽>、<富士>、<紅玉>のそれぞれに対する値である。言い換えれば、集約対象の基底<津軽>、<富士>、<紅玉>のそれぞれに対する値の集計値が、基底<リンゴ>の値として算出される。
【0020】
アグリゲーションを表す振替G(x)は、F(x)を用いて、〜{x+F(x)}で与えられる。すなわち、G(x)=〜{x+F(x)}=(300<津軽,円>+200<富士,円>+100<紅玉,円>)+(300^<津軽,円>+200^<富士,円>+100^<紅玉,円>+300<リンゴ,円>+200<リンゴ,円>+100<リンゴ,円>)=600<リンゴ,円>、となる。
【0021】
2.按分
按分とは、1つの分類項目をさらに細かく複数の分類項目へ分割することである。例えば、アグリゲーションに示した例では基底<リンゴ>に対応する値を、津軽・富士・紅玉へ分割することを意味する。なお前提として{リンゴ}-->{津軽,富士,紅玉}の按分比率が与えられている必要があり、ここでは1:1:1であることとする。
【0022】
この例では上記の按分比率にしたがって、x=600<リンゴ,円>に対して、F(x)=600^<リンゴ,円>+200<津軽,円>+200<富士,円>+200<紅玉,円>、という元を生成する。
按分を表す振替えG(x)は、F(x)を用いて、〜{x+F(x)}で与えられる。すなわち、G(x)=〜{x+F(x)}=600<リンゴ,円>+(600^<リンゴ,円>+200<津軽,円>+200<富士,円>+200<紅玉,円>)=200<津軽,円>+200<富士,円>+200<紅玉,円>、となる。
【0023】
(実施の形態)
以下、上記の交換代数の考え方を利用してデータ編集処理を実行する情報処理装置(以下、「データ編集装置」と呼ぶ。)について説明する。本実施の形態において、ユーザは、対象がその集合に属するための必要十分条件を与えることによって集合を記述する方法である内包的記法を用いて、データの編集内容を記述する。実施の形態のデータ編集装置は、内包的記法により記述された編集内容に基づいて、集合の要素をすべて列挙することで集合を記述する方法である外延的記法で記述されたプログラムコードを出力する。そして、編集対象のデータを、交換代数に対応する形式のデータオブジェクトとしてメモリに読み込み、上記のプログラムコードを実行することによりデータの編集処理を実行する。
【0024】
図2は、実施の形態のデータ編集装置10の機能構成を示すブロック図である。データ編集装置10は、データ保持部12と、コード対応関係テーブル14と、集約規則テーブル16と、按分規則テーブル18と、コード取得部20と、コード生成部22と、編集処理部24を備える。
【0025】
本明細書のブロック図において示される各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。例えば、図2の各機能ブロックは、ソフトウェアとして記録媒体に格納されデータ編集装置10のハードディスクにインストールされ、データ編集装置10のメインメモリに適宜読み出されてCPUにて実行されてもよい。
【0026】
データ保持部12は、編集対象となる編集前のデータと編集後のデータとを保持する記憶領域である。データ保持部12は、編集前のデータと編集後のデータのそれぞれについて、データの値と基底とを対応づけたCSV(Comma Separated Values)ファイルを保持する。例えば、CSVファイルの一行が「値,ハットの有無,名称,単位,時間,主体」となり、空白行が元(げん)の区切りを示してもよい。なおデータ保持部12は、データ編集装置10とは異なる情報処理装置、例えばデータベースサーバ内に設けられてもよいことはもちろんである。この場合、LAN・WAN・インターネット等の通信網を介して当該データベースサーバとデータ編集装置10が接続された情報処理システムが構築されてもよい。
【0027】
コード対応関係テーブル14は、データの編集内容(編集操作)を内包的記法により記述するためのプログラム言語(以下、「内包的記法言語」とも呼ぶ。)と、データの編集内容を外延的記法により記述するためのプログラム言語(以下、「外延的記法言語」)との対応関係を保持する記憶領域である。実施の形態における外延的記法言語はJava(登録商標)言語であることとするが、C言語等、他のプログラム言語であってもよい。
【0028】
内包的記法言語と外延的記法言語との対応関係は、例えば、内包的記法言語における編集操作を示すキーワードと、外延的記法言語におけるその編集操作を実現するためのロジックを実装したコード(関数)とを対応づけたものである。より具体的には、内包的記法言語における複数のデータから特定のデータを抽出する条件の記述は、外延的記法言語における複数のデータを逐次列挙するための繰り返し命令の記述と対応づけられる。また例えば、内包的記法言語において入力データを指定するコードと、外延的記法言語においてその入力データをメモリ内に読み込むロジックを実装したコードとを対応づけたものである。なお、対応関係の具体例は図3〜図6において後述する。
【0029】
集約規則テーブル16は、アグリゲーション操作時に参照されるべき複数種類の基底の集約関係を定めた集約規則を保持する記憶領域である。集約規則は、例えば上述の{津軽,富士,紅玉}-->{リンゴ}という集約関係を定めたものである。複数種類の基底を集約する基底(上記例ではリンゴ)を以下では「集約基底」と呼ぶこととする。按分規則テーブル18は、按分操作時に参照される複数種類の基底の按分比率を定めた按分規則を保持する記憶領域である。按分規則は、例えば上述の{リンゴ}-->{津軽,富士,紅玉}という按分関係と、1:1:1という按分比率を定めたものである。
【0030】
コード取得部20は、キーボード等の所定の入力装置を介してユーザにより入力されたプログラムコード(以下、「ユーザコード」とも呼ぶ。)を取得する。このユーザコードは、内包的記法言語で記述される。具体的なユーザコード例は後述する。
【0031】
コード生成部22は、コード対応関係テーブル14に保持された対応関係にしたがって、ユーザコードから、ユーザコードに記述されたデータ編集内容が外延的記法言語で記述されたプログラムコード(以下、「実行コード」とも呼ぶ。)を生成する。実施の形態における実行コードはJavaバイトコードであることとする。具体的には、ユーザコードに対応するJavaソースコードを生成し、そのソースコードをコンパイルすることによりJavaバイトコードを生成する。具体的な実行コード例は後述する。
【0032】
編集処理部24は、コード生成部22において生成された実行コードにしたがって、データ保持部12に保持された編集対象のデータを編集する。編集処理部24は、データ読込部26とデータ編集部28と編集結果出力部30を含む。なお、実行コードが所定の実行エンジンにおいて実行されることにより、編集処理部24(データ読込部26〜編集結果出力部30)の機能が実現されてもよいことはもちろんである。例えば、実行コードがJavaバイトコードの場合、実行エンジンはJVM(Java Virtual Machine)となる。
【0033】
データ読込部26は、データ保持部12から編集対象のデータを読み込み、そのデータから、データの値と基底とが対応づけられたデータオブジェクトをメモリ上に生成する。データ編集部28は、データ読込部26において生成されたデータオブジェクトに対する操作を実行して編集結果のデータを設定する。編集結果出力部30は、データ読込部26において設定された編集結果のデータをCSVファイルとして記録し、データ保持部12へ格納する。
【0034】
図3は、会計型データを操作するためのユーザコードの一例を示す。以下のコード例では、左端に行番号を示しており、その行番号によりコードの位置を適宜示す。図3では、編集対象データとして、200<現金>+100<小麦>という元と、200<現金>+200<大豆>という元を含む集合Cが指定されている。ここでは説明の簡明化のため編集対象データを直接入力しているが、典型的には入力ファイルとしてのCSVファイルの名称や、そのCSVファイルにおける入力データの記述位置が指定されることにより入力データを示すデータオブジェクトが生成される。
【0035】
図3の4行目では、交換代数のプロジェクション処理、すなわち指定された基底と一致する部分要素を抽出する射影操作が指定されている。具体的には、集合Cから基底<現金>もしくは<小麦>に該当し、かつ、値が設定済という条件を充足する元を抽出して集合asetへ代入する処理が指定されている。そして5行目でaset内の元の加算処理が指定されている。asetは200<現金>、100<小麦>、200<現金>を含むため、加算結果alphaは400<現金>+100<小麦>となる。ここでは説明の簡明化のため編集結果を標準出力へ出力することとしているが、典型的には出力ファイルとしてのCSVファイルが指定されて、当該CSVファイルに編集結果(ここでは加算結果alphaの内容)が記録される。
【0036】
図4(a)は、図3のユーザコードに対応する実行コードを示す。具体的には図3の2行目に応じてコード生成部22が生成する実行コードであり、データ読込部26の機能に対応する。なお、実施の形態の説明では実行コードとして便宜的にJavaソースプログラムを示す。同図では、集合Cに対応するExAlgeSetオブジェクトに、200<現金>+100<小麦>という元に対応するExAlgeオブジェクト(15〜23行目)と、200<現金>+200<大豆>という元に対応するExAlgeオブジェクト(24〜32行目)が格納されている。
【0037】
図4(b)は、図3のユーザコードに対応する実行コードを示す。具体的には図3の4行目に応じてコード生成部22が生成する実行コードであり、データ編集部28の機能に対応する。同図では、集合Cに含まれる複数の元に対応するExAlgeオブジェクトを列挙するforループと、集合Dに含まれる複数の基底に対応するExBaseオブジェクトを列挙するforループとの2重ループの中で、プロジェクションメソッドが呼び出され、プロジェクション処理の結果がリストへ追加される。そして、そのリストから集合asetが設定されている。
【0038】
図5は、レコード型データを操作するためのユーザコードの一例を示す。同図では、山田<name>+5<score>、田中<name>+3<score>、鈴木<name>+4<score>、佐藤<name>+2<score>、本田<name>+5<score>の5つの元を含む集合datasetが指定されている。
【0039】
図5の9行目では、基底<score>に対応づけられた値が4以上の元が存在するたびに、元「1<4以上,人,#,#>」を集合asetへ代入する処理が指定されている。そして、11行目でaset内の元の加算処理が指定されている。この結果として、asetには元「1<4以上,人,#,#>」が3個含まれることになり、ret=3<4以上,人,#,#>となる。すなわちこの例は、scoreが4以上の人数を集計するものとなる。
【0040】
図6(a)は、図5のユーザコードに対応する実行コードを示す。具体的には図5の2〜7行目に応じてコード生成部22が生成する実行コードであり、データ読込部26の機能に対応する。同図では、集合datasetに対応するDtAlgeSetオブジェクトに、上記5つのレコード型データの元のそれぞれに対応するDtalgeオブジェクトが格納される。レコード型データは値と基底の両方で様々なデータ型を許容するため、値と基底のそれぞれのデータ型を示す情報もDtalgeオブジェクトに設定される。
【0041】
図6(b)は、図5のユーザコードに対応する実行コードを示す。具体的には図5の9行目に応じてコード生成部22が生成する実行コードであり、データ編集部28の機能に対応する。同図では、集合datasetに含まれる複数の元に対応するDtAlgeSetオブジェクトを列挙するforループの中で、基底<score>に対応する値が4以上の場合に、元「1<4以上,人,#,#>」がリストへ追加される。そして、そのリストから集合asetが設定されている。
【0042】
なおユーザコードにアグリゲーション命令(関数)が設定された場合、コード生成部22は、集約規則テーブル16に保持された集約規則を参照して、まず簿記の記載に対応するオブジェクト(以下、「中間オブジェクト」とも呼ぶ。)を設定する実行コードを生成する。具体的には、集約対象の複数のデータの集計値を算出し、その集計値と集約基底とを対応づけたデータと、集約対象の複数のデータそれぞれの値を差し引くことを示すデータ(すなわち集約対象の複数のオリジナルデータにハット属性を付加したデータ)とを加算する元を示すオブジェクトを、中間オブジェクトとして設定する実行コードを生成する。この中間オブジェクトは、前提技術のアグリゲーションで示したF(x)に対応する。
【0043】
そしてコード生成部22は、集約対象の複数のオリジナルデータが加算される元を示すオブジェクトと中間オブジェクトとを加算する、言い換えれば、集約対象の複数のオリジナルデータとそれらのデータにハット属性を付加したデータとを相殺することにより、集約対象の複数のデータの集計値と集約基底とを対応づけたデータを、集計結果のオブジェクトへ格納する実行コードを生成する。この実行コードは、前提技術のアグリゲーションで示した〜(x+F(x))に対応するコードである。なおコード生成部22は、中間オブジェクトの内容を所定のファイルへ出力する実行コードをさらに生成してもよい。この態様によると、中間オブジェクトの内容をユーザへ提示することにより、効率的なデバッグを支援するとともに、簿記の振替計算に利用可能な情報をユーザへ提供できる。
【0044】
またユーザコードに按分命令(関数)が設定された場合、コード生成部22は、按分規則テーブル18に保持された集約規則を参照して、アグリゲーション時と同様にまず中間オブジェクトを設定する実行コードを生成する。具体的には、按分対象のデータの値を按分比率にしたがって按分し、按分した値と按分先の各基底とを対応づけたデータと、按分対象のオリジナルデータにハット属性を付加したデータとを加算する元を示すオブジェクトを、中間オブジェクトとして設定する実行コードを生成する。この中間オブジェクトは、前提技術の按分で示したF(x)に対応する。
【0045】
そしてコード生成部22は、按分対象のオリジナルデータの元を示すオブジェクトと中間オブジェクトとを加算する、言い換えれば、按分対象のオリジナルデータとそのデータにハット属性を付加したデータとを相殺することにより、按分した値と按分先の各基底とを対応づけたデータを、按分結果のオブジェクトへ格納する実行コードを生成する。この実行コードは、前提技術の按分で示した〜(x+F(x))に対応するコードである。なおコード生成部22は、アグリゲーションと同様に、中間オブジェクトの内容を所定のファイルへ出力する実行コードをさらに生成してもよい。
【0046】
以上の構成による動作を以下説明する。
図7は、データ編集装置10の動作を示すフローチャートである。まずユーザは、内包的記法言語を用いてデータの編集内容を内包的記法により記述し、そのプログラムコードを指定したデータの編集指示をデータ編集装置10へ入力する。データ編集装置10が所定の入力装置を介してデータの編集指示を受け付けた場合(S10のY)、データ編集装置10のコード取得部20は、ユーザにより入力されたプログラムコードをユーザコードとして取得する(S12)。コード生成部22は、コード対応関係テーブル14に保持されたユーザコードと実行コード間の対応関係にしたがって、ユーザコードから実行コードの生成処理を開始する(S14)。
【0047】
ユーザコードにアグリゲーション命令や按分命令等の振替え命令が存在する場合(S16のY)、コード生成部22はその振替え命令に応じた相殺処理のための中間オブジェクトの出力命令を実行コードへ設定する(S18)。ユーザコードに振替え命令がなければ(S16のN)、S18をスキップする。編集処理部24は、生成された実行コードにしたがって編集対象データに対する編集処理を実行する(S20)。例えば、データ読込部26は、データ保持部12の入力データ格納用のCSVファイルから、ユーザコードおよびユーザコードから生成された実行コードにおいて指定された編集対象のデータを読み込みデータオブジェクトを生成する。そしてデータ編集部28は、生成されたデータオブジェクトに対して実行コードにて指定された編集操作(基底に基づく射影操作・アグリゲーション操作・按分操作等)を実行し、編集結果を示すデータオブジェクトを生成する。編集結果出力部30は、編集処理部24による編集結果、例えばデータ編集部28により生成された編集結果を示すデータオブジェクトの内容(属性値等)を、データ保持部12の編集結果格納用のCSVファイルへ出力する(S22)。データ編集装置10がデータの編集指示を受け付けなければ(S10のN)、S12以降はスキップされる。
【0048】
本実施の形態のデータ編集装置10によれば、従来RDBで扱われていたデータを、会計型データに対応するデータオブジェクト、もしくは、レコード型データに対応するデータオブジェクトとして表現することができる。これにより、コンピュータ上におけるデータオブジェクト表現の標準化を支援することができる。また、編集対象のデータの蓄積においてRDBのような複雑な仕組みを必要とせず、可視性の高いCSVファイルで蓄積することができる。
【0049】
またデータ編集装置10によれば、ユーザはデータの編集内容を内包的記法言語で記述できるため、データの編集内容を正しく理解しているユーザであれば、実際にコンピュータを動作させるための外延的記法言語について理解していなくても、正しいデータ編集を実現させることができる。またデータ編集装置10では編集対象のデータが値と基底との組み合わせとして保持されるため、ユーザは内包的記法を用いることで、規定に基づく編集内容を容易に記述することができる。また内包的記法はコンピュータに依存せず、データ編集の仕様を反映するものであるため、ユーザは正しい仕様記述を行えば、正しいデータ編集を実現させることができる。例えば、forループ等を意識せずに、ユーザはデータの編集内容を仕様通りに記載すればよい。したがって、ユーザコードへのバグの混入を低減させることができ、言い換えれば、バグの発生箇所をデータそのもののバグに限定させやすくなる。例えば、会計型データの操作においては、アグリゲーションや按分等、様々な振替処理をロバストに記述することができる。
【0050】
またデータ編集装置10によれば、データの基底に基づいて値の編集処理が行われることにより、データの形式(スキーマ)に変更があった場合でも、その影響範囲を限定することができる。例えば、編集対象のデータを格納したテーブルにおいてカラムの入れ替えが発生しても、ユーザコードにおける編集ロジックへの影響を排除することができる。
【0051】
またデータ編集装置10によれば、アグリゲーションや按分等の振替処理の規則がプログラムコード外のテーブルに保持されるため、規則に変更が生じてもテーブルのデータを変更すればよく、プログラムコードへの影響を排除できる。
【0052】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【0053】
例えば、データ編集装置10は振替規則テーブルをさらに備えてもよい。振替規則テーブルは、振替操作(ここではアグリゲーションや按分を伴わない基底の変換操作であることとする)において参照されるべき振替規則を保持する記憶領域である。振替規則は、振替元の基底と振替先の基底とを対応づけたデータである。コード生成部22は、ユーザコードに振替命令が設定された場合、振替規則テーブルに保持された振替規則を参照して、中間オブジェクトF(x)を設定する実行コードを生成する。例えば、x=数値A<振替元の基底>の場合、F(x)=数値A^<振替元の基底>+数値A<振替先の基底>となる。そしてコード生成部22は、〜(x+F(x))に対応した実行コードを生成する。当該コードの実行結果として、上記の例では、数値A<振替元の基底>が、数値A<振替先の基底>に変換されることになる。
【0054】
上述した実施の形態、変形例の任意の組み合わせもまた本発明の実施の形態として有用である。組み合わせによって生じる新たな実施の形態は、組み合わされる実施の形態、変形例それぞれの効果をあわせもつ。
【0055】
請求項に記載の各構成要件が果たすべき機能は、実施の形態および変形例において示された各構成要素の単体もしくはそれらの連携によって実現されることも当業者には理解されるところである。
【符号の説明】
【0056】
10 データ編集装置、 12 データ保持部、 14 コード対応関係テーブル、 16 集約規則テーブル、 18 按分規則テーブル、 20 コード取得部、 22 コード生成部、 24 編集処理部、 26 データ読込部、 28 データ編集部、 30 編集結果出力部。
【特許請求の範囲】
【請求項1】
編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するデータ保持部と、
データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、前記編集対象のデータに対する前記基底にもとづく編集内容が記述された第1コードを取得するコード取得部と、
データの編集内容を外延的記法により記述するための第2プログラム言語と前記第1プログラム言語との予め定められた対応関係にしたがって、前記第1コードから、前記第2プログラム言語で記述されたコードである第2コードを生成するコード生成部と、
前記第2コードにしたがって前記編集対象のデータを編集する編集処理部と、
を備えることを特徴とするデータ編集装置。
【請求項2】
前記編集対象のデータは、前記データの値として数値が用いられ、前記基底として名称、単位、期間、主体のうち少なくとも1つが用いられることを特徴とする請求項1に記載のデータ編集装置。
【請求項3】
前記コード生成部は、母集団から抽出すべき要素の条件が内包的記法により記述されて前記第1コードに含まれる場合、母集団に含まれる各要素を列挙するための繰り返し命令を含む第2コードを生成することを特徴とする請求項1または2に記載のデータ編集装置。
【請求項4】
前記第1コードは、複数のデータを集約させるための集約命令を含むものであり、
前記コード生成部は、前記第1コードに集約命令が含まれる場合、前記複数のデータの基底を集約する基底である集約基底を予め定めた情報にしたがって、前記複数のデータの値の集計値と前記集約基底とを対応づけた集計結果を出力する第2コードを生成することを特徴とする請求項1から3のいずれかに記載のデータ編集装置。
【請求項5】
前記コード生成部は、前記第1コードに集約命令が含まれる場合、集約対象の複数のデータそれぞれの値を差し引くことを示すデータと前記集計結果とを対応づけた中間データを出力する第2コードをさらに生成することを特徴とする請求項4に記載のデータ編集装置。
【請求項6】
編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するステップと、
データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、前記編集対象のデータに対する前記基底にもとづく編集内容が記述された第1コードを取得するステップと、
データの編集内容を外延的記法により記述するための第2プログラム言語と前記第1プログラム言語との予め定められた対応関係にしたがって、前記第1コードから、前記第2プログラム言語で記述されたコードである第2コードを生成するステップと、
前記第2コードにしたがって前記編集対象のデータを編集するステップと、
をコンピュータが実行することを特徴とするデータ編集方法。
【請求項7】
編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持する機能と、
データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、前記編集対象のデータに対する前記基底にもとづく編集内容が記述された第1コードを取得する機能と、
データの編集内容を外延的記法により記述するための第2プログラム言語と前記第1プログラム言語との予め定められた対応関係にしたがって、前記第1コードから、前記第2プログラム言語で記述されたコードである第2コードを生成する機能と、
前記第2コードにしたがって前記編集対象のデータを編集する機能と、
をコンピュータに実現させるためのコンピュータプログラム。
【請求項1】
編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するデータ保持部と、
データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、前記編集対象のデータに対する前記基底にもとづく編集内容が記述された第1コードを取得するコード取得部と、
データの編集内容を外延的記法により記述するための第2プログラム言語と前記第1プログラム言語との予め定められた対応関係にしたがって、前記第1コードから、前記第2プログラム言語で記述されたコードである第2コードを生成するコード生成部と、
前記第2コードにしたがって前記編集対象のデータを編集する編集処理部と、
を備えることを特徴とするデータ編集装置。
【請求項2】
前記編集対象のデータは、前記データの値として数値が用いられ、前記基底として名称、単位、期間、主体のうち少なくとも1つが用いられることを特徴とする請求項1に記載のデータ編集装置。
【請求項3】
前記コード生成部は、母集団から抽出すべき要素の条件が内包的記法により記述されて前記第1コードに含まれる場合、母集団に含まれる各要素を列挙するための繰り返し命令を含む第2コードを生成することを特徴とする請求項1または2に記載のデータ編集装置。
【請求項4】
前記第1コードは、複数のデータを集約させるための集約命令を含むものであり、
前記コード生成部は、前記第1コードに集約命令が含まれる場合、前記複数のデータの基底を集約する基底である集約基底を予め定めた情報にしたがって、前記複数のデータの値の集計値と前記集約基底とを対応づけた集計結果を出力する第2コードを生成することを特徴とする請求項1から3のいずれかに記載のデータ編集装置。
【請求項5】
前記コード生成部は、前記第1コードに集約命令が含まれる場合、集約対象の複数のデータそれぞれの値を差し引くことを示すデータと前記集計結果とを対応づけた中間データを出力する第2コードをさらに生成することを特徴とする請求項4に記載のデータ編集装置。
【請求項6】
編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持するステップと、
データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、前記編集対象のデータに対する前記基底にもとづく編集内容が記述された第1コードを取得するステップと、
データの編集内容を外延的記法により記述するための第2プログラム言語と前記第1プログラム言語との予め定められた対応関係にしたがって、前記第1コードから、前記第2プログラム言語で記述されたコードである第2コードを生成するステップと、
前記第2コードにしたがって前記編集対象のデータを編集するステップと、
をコンピュータが実行することを特徴とするデータ編集方法。
【請求項7】
編集対象のデータとして、データの属性を示す基底とデータの値とを対応付けて保持する機能と、
データの編集内容を内包的記法により記述するための第1プログラム言語で記述されたコードであって、前記編集対象のデータに対する前記基底にもとづく編集内容が記述された第1コードを取得する機能と、
データの編集内容を外延的記法により記述するための第2プログラム言語と前記第1プログラム言語との予め定められた対応関係にしたがって、前記第1コードから、前記第2プログラム言語で記述されたコードである第2コードを生成する機能と、
前記第2コードにしたがって前記編集対象のデータを編集する機能と、
をコンピュータに実現させるためのコンピュータプログラム。
【図1】



【図2】
【図3】

【図4(a)】

【図4(b)】
【図5】

【図6(a)】

【図6(b)】
【図7】
【図2】
【図3】
【図4(a)】
【図4(b)】
【図5】
【図6(a)】
【図6(b)】
【図7】
【公開番号】特開2013−54433(P2013−54433A)
【公開日】平成25年3月21日(2013.3.21)
【国際特許分類】
【出願番号】特願2011−190601(P2011−190601)
【出願日】平成23年9月1日(2011.9.1)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
【公開日】平成25年3月21日(2013.3.21)
【国際特許分類】
【出願日】平成23年9月1日(2011.9.1)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
[ Back to top ]