
トピックモデリング装置、トピックモデリング方法、及びプログラム
【課題】従来よりも人間にとって理解し易く、確率的に解釈可能なトピック情報を得ることができ、パラメータ数が少ないトピックモデルを生成する。
【解決手段】入力された各テキストデータに含まれる各文字列に対して語義を付与し、語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dg、テキストデータ集合dgが含む文字列の集合を文字列集合wg、テキストデータ集合dg中の文字列vの出現回数をn(dg,v)、p(v|z)=βzv、(z|dg)=ηgz、トピック情報zの全体集合をZとした場合におけるトピックモデルp(vg|dg)=Πv{Σz βzv・ηgz}n(dg,v)の多項分布パラメータβzvを得る。
【解決手段】入力された各テキストデータに含まれる各文字列に対して語義を付与し、語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dg、テキストデータ集合dgが含む文字列の集合を文字列集合wg、テキストデータ集合dg中の文字列vの出現回数をn(dg,v)、p(v|z)=βzv、(z|dg)=ηgz、トピック情報zの全体集合をZとした場合におけるトピックモデルp(vg|dg)=Πv{Σz βzv・ηgz}n(dg,v)の多項分布パラメータβzvを得る。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、テキストデータに含まれる文字列に対応するトピックのモデリング技術に関する。
【背景技術】
【0002】
現在様々な自然言語処理技術の研究開発が進み、前後数単語の局所的な文脈情報だけでなく、テキストデータのトピックを捉えることができるトピックモデルの利用が盛んになっている。「トピックモデル」とは、文書などのテキストデータに対応するトピックに対応するトピック情報とそのテキストデータが含む単語などの文字列との関係を記述するモデル(関数、数式)を意味する。「トピック」とは、ジャンルや書き手のスタイル等を含む大域的な情報を表す。テキストデータがトピックを表す文字列そのものを含んでいるとは限らない。
【0003】
テキストデータのトピックを的確に捉えることで、当該テキストデータではそのトピックに関連性の強い文字列の出現確率が高いという情報を得ることができる。例えば文書のトピックがスポーツであるなら、その文書には「サッカー」といったスポーツに関する単語が出現しやすく、「国会」といった単語が出現しにくい、といった大域的情報を得ることができる。トピックに対応するトピック情報はテキストデータに付与されたラベル情報等(例えば新聞の場合だと「スポーツ面」等の見出し)から得られる場合もあるが、常にそのように明示的なトピック情報がテキストデータに付与されているとは限らない。そのため、たとえラベル情報が付与されていないテキストデータであってもトピックを捉えることができるトピックモデルの利用価値は高い。
【0004】
トピックモデルの先行技術としては、LSA(Latent Semantic Analysis,非特許文献1)、PLSA(Probabilistic Latent Semantic Analysis,非特許文献2)、LDA(Latent Dirichlet Allocation)等が知られている。トピックモデルの先駆けはLSAである。LSAでは、単語と文書の共起行列を特異値分解して次元圧縮を行ってモデルを得る。これを確率的に拡張させたモデルがPLSAである。また、LSAやPLSAが直接単語と文書の関係からトピックモデルを生成するのに対し、単語と語義の関係からトピックモデルを生成する技術としてConceptron(特許文献1)が知られている。以下にPLSAとConceptronの概要について述べる。
【0005】
<PLSA>
PLSAは2つの確率分布パラメータによって文書を表現する。1つ目はある文書dにおける各トピック情報zの生成し易さを表す多項分布パラメータp(z|d)で、2つ目はトピック情報zにおける各単語vの生成し易さを表す多項分布パラメータp(v|z)である。PLSAは以下の式で定義される。
【数1】

【0006】
ここでwdは文書d中の単語集合、zdnは文書d中のn(n=1,...,Nd)番目の単語wnのトピック情報、Σzdは文書dにおける単語トピック情報系列の全ての可能な組み合わせの和、γzwはトピック情報zにおける単語vの多項分布(ユニグラム確率)パラメータp(v|z)、δdz(Σzδdz=1)は文書dにおけるトピック情報zの多項分布パラメータp(z|d)、n(d,v)は文書d中の単語vの出現回数、Zはトピック情報の全体集合、Vは単語vの全体集合を表す。PLSAはその確率的理論に基づくロバスト性からLSAよりも性能が高いことが知られており、さらに後のLDAへ拡張されるように、モデルとしての拡張性も高い。
【0007】
<Conceptron>
LSAやPLSAが直接単語と文書の関係からトピックモデルを生成したのに対し、Conceptronは単語と語義の関係からトピックモデルを生成する。「語義」とは、各文字列の意味を考慮して各文字列に付与された分類を表す。語義の例は、日本語語彙大系において単語や固有表現などの各文字列に付与された分類の1クラスである。「日本語語彙大系」とは、日本語の単語を人手によって2715の意味クラスに分類したものを指す。例えば「快速」という単語には「乗り物(本体(移動(陸圏)))」という語義がある。Conceptronでは、文書中の単語vと共起した語義gの数を数え上げることで単語vと語義gの共起行列を作り、それを特異値分解して次元圧縮を行ってモデルを得る。
【0008】
Conceptronでは、人間が定めた語義にトピックを従わせることができるため、人間の直観に合ったトピックモデリングが得られる。またConceptronでは、モデル学習中に語義総数|G|×単語総数|V|の共起行列の次元圧縮を行ってモデルを得る。語義総数|G|は文書総数|D|よりも非常に小さい(|G|≪|D|)。よってConceptronでは、文書数|D|×単語数|V|の共起行列を特異値分解して次元圧縮を行ってモデルを得るLSAよりも、小さな主記憶装置でも実装可能でかつ高速である。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特許第4099197号公報
【非特許文献】
【0010】
【非特許文献1】Deerwester, S. C. et al., “Indexing by Latent Semantic Analysis,” Journal of the American Society for Information Science, 1990.
【非特許文献2】Hofmann, T., “Probabilistic Latent Semantic Indexing,” In Proc. of the 22nd Annual ACM Conf. on Research and Development in Information Retrieval, 1999.
【発明の概要】
【発明が解決しようとする課題】
【0011】
PLSAでは単語の語義が考慮されていないため、生成されたトピックモデルを用いて得られるトピックが人間にとって理解しづらいという問題がある。また、式(1)に示した多項分布パラメータδdzは文書dとトピック情報zとの組ごとに対応し、トピックモデルを構成するパラメータの数が多いという問題もある。Conceptronでは、単語の語義を考慮したトピックモデルを生成することができるが、確率的に解釈することができるトピック情報を得ることができないという問題がある。
【0012】
本発明はこのような点に鑑みてなされたものであり、従来よりも人間にとって理解し易く、確率的に解釈可能なトピック情報を得ることができ、パラメータ数が少ないトピックモデルを生成できる技術を提供することを目的とする。
【課題を解決するための手段】
【0013】
本発明では、入力された各テキストデータに含まれる各文字列に対して語義を付与し、語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、テキストデータ集合dgが与えられたときの文字列集合wgの条件付き確率をp(wg|dg)とし、テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzvとし、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとした場合におけるトピックモデル
【数2】
の多項分布パラメータβzvを得る。
【発明の効果】
【0014】
本発明では、語義を考慮したトピックモデルを生成できるため人間にとって理解し易いトピック情報を得ることができる。また、本発明のトピックモデルを適用して得られるトピック情報は確率的に解釈可能な情報となる。さらに、多項分布パラメータηgzはテキストデータ集合dgとトピック情報zとの組ごとに対応するため、従来よりもトピックモデルを構成するパラメータの数が少ない。
【図面の簡単な説明】
【0015】
【図1】図1は、実施形態のトピックモデリング装置の機能構成を例示するためのブロック図である。
【図2】図2Aは、実施形態のトピックモデリング方法を例示するためのフローチャートである。図2Bは、ステップS12の処理を例示するためのフローチャートである。
【図3】図3は、実施形態の共起行列を例示するための図である。
【図4】図4は、第2実施形態の語義付与部の機能構成を例示するためのブロック図である。
【発明を実施するための形態】
【0016】
以下、図面を参照して本発明の実施形態を説明する。
〔原理〕
実施形態の原理を説明した後、各実施形態の説明を行う。
各実施形態では、入力された各テキストデータに含まれる各文字列に対して語義を付与し、以下のトピックモデルの多項分布パラメータβzvを得る。
【数3】
ここで、同じ語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、テキストデータ集合dgが与えられたときの文字列集合wgの条件付き確率(事後確率)をp(wg|dg)とし、テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzvとし(p(v|z)はユニグラム確率)、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとする。本形態のβzv=p(v|z)はユニグラム確率であり、ηgzはΣz∈Zηgz=1を満たす。
【0017】
「語義」とは、各文字列の意味を考慮して各文字列に付与された分類を表す。「テキストデータ」とは文字及び/又は記号を含むデータを意味する。テキストデータの具体例は、文書、各段落の文書、単語列、フレーズ、文、クエリ、語句を含む図表、記号列などである。「文字列」の具体例は、単語、単語列、フレーズ、文、文字、固有表現、記号、記号列などである。「トピック」とは、ジャンルや書き手のスタイル等を含む大域的な情報を表す。テキストデータに対応するトピックの具体例は、テキストデータの題目、話題、事柄、出来事、論題、分類、様式、言語、ジャンルなどや、テキストデータの書き手のスタイルなどである。テキストデータがトピックを表す文字列そのものを含んでいるとは限らない。「トピック情報」は、テキストデータに対応するトピックに対応する情報であればどのようなものであってもよい。例えば、テキストデータに対応するトピックの候補(例えば<球団名>や<企業名>など)ごとに、当該テキストデータに対応する各トピックの候補の適切さを表す指標(例えば、確率、重み係数、確率や重み係数の関数値であるスコアなど)が与えられ、それらの指標の少なくとも一部が当該テキストデータのトピック情報とされてもよい。
【0018】
本形態では、語義を考慮したトピックモデルを生成できるため人間にとって理解し易いトピック情報を得ることができる。また、多項分布パラメータηgzはテキストデータ集合dgとトピック情報zとの組ごとに対応するため、従来よりもトピックモデルを構成するパラメータの数が少ない。すなわち、PLSAでのパラメータ数が|V|×|Z|+|Z|×|D|であるのに対し、本形態におけるパラメータ数は|V|×|Z|+|Z|×|G|であり、|D|>>|V|>>|G|であることを考えると、大幅にパラメータ数を削減できる。なお、|V|は単語総数、|Z|はトピック情報の総数、|D|は文書総数である。
【0019】
さらに、本形態のトピックモデルを適用して得られるトピック情報は確率的に解釈可能な情報となる。トピック情報を確率的に取り扱うことにより、その用途が広がる。例えば、或るトピックにおいて或る単語がどれくらい出現し易いかということや、文書Aと文書Bのどちらの方がよりスポーツについて述べられているかということや、トピック毎の特徴的単語(後述する)はどのようなものであるかということなども評価できるようになる。また、トピック情報が確率的に表現されるモデルにすることにより、トピック情報の正規化が自然になされ、かつ目的関数がL2ノルムからKL-divergenceに変わることで、ロバストなモデル推定が可能となる。
【0020】
多項分布パラメータβzvの計算方法に限定はないが、例えばEMアルゴリズムを用いた学習やベイズ学習などによって多項分布パラメータβzvを得ることができる。EMアルゴリズムが用いられる場合のE-step及びM-stepは以下のようになる。
【数4】
【0021】
ここで、tはイテレーションの回数を表し、ηgz(t)及びβzv(t)はt回目のイテレーションでの多項分布パラメータを表し、ηgz(0)及びβzv(0)は多項分布パラメータの初期値を表し、η(t)はt回目のイテレーションでのすべてのトピック情報z∈Z及びテキストデータ集合dg(g∈G)についての多項分布パラメータηgz(t)の集合を表し、β(t)はt回目のイテレーションでのすべてのトピック情報z∈Z及び文字列v∈Vについての多項分布パラメータβzv(t)の集合を表す。zgvはテキストデータ集合dg中の文字列vのトピック情報を表し、P(zgv|v,η(t),β(t))はv,η(t),β(t)が与えられたときのトピック情報zgvの条件付き確率を表す。argmaxη,β[・]は「・」を最大化するη(t)及びβ(t)を表す。
【0022】
式(4)の各項に対してラグランジュの未定係数法を用いることで以下の更新式が得られる。
【数5】
【0023】
すなわち、EMアルゴリズムが用いられる場合には、多項分布パラメータηgz(t)及びβzv(t)を用いて式(3)に従って条件付き確率P(zgv|v,η(t),β(t))を得るE-stepと、出現回数n(dg,v)及び条件付き確率P(zgv|v,η(t),β(t))を用いて式(5)(6)に従って多項分布パラメータηgz(t+1)及びβzv(t+1)を得るM-stepとを含む繰り返し処理が、繰り返しのたびにt+1を新たなtとしながら実行される。このような繰り返し処理は終了条件を満たすまで実行され、終了条件を満たした際のβzv(t+1)又はβzv(t)が多項分布パラメータβzvとされる。多項分布パラメータηgz(t)及びβzv(t)の初期値ηgz(0)及びβzv(0)は任意値でよい。
【0024】
また、入力された各テキストデータに含まれる各文字列に対して語義を付与するための方法に限定はない。例えば、文字列とそれに対応する語義とが対応付けられたテーブルである辞書を参照して、各文字列に対して語義を付与されてもよい。このような辞書の例は、各単語が日本語語彙大系のどの分類(語義)になり易いかが順位として記述された辞書(以下これを日本語語彙大系辞書と呼ぶ)などである。しかしながら、このような辞書によって付与される語義の正確性が低い場合があり、このような辞書がカバーする単語などの文字列にも限りがある。よって、このような方法では適切な語義を付与することができない場合がある。例えばConceptronでは、入力された文書が含む単語に対し、日本語語彙大系辞書で最も高い順位が付与されている分類を常にその単語の語義として選択する。そのため、付与された語義が正しくない場合もある。例えば「東京」という単語の語義は、文脈に応じて「都」「大学・高専」「駅名等」「中・高校」「地区名」などとなる可能性があるが、Conceptronでは文脈にかかわらず「東京」に対して常に同一の語義が選択される。また、日本語語彙大系辞書では「巨人」という単語に対して「男」「魔物・化け物」「偉人」「幹部」などの分類が対応しているが、「球団名」は対応していない。これは日本語語彙大系辞書の「球団名」の分類には「巨人軍」という単語が対応付けされているからであるが、これも語義を正確に付与する上での課題となる。
【0025】
そのため、文字列に対して適切な語義を自動的に付与するモデルである語義タガーを生成し、このような語義タガーを用い、各テキストデータに含まれる各文字列に対して語義を付与してもよい。これにより、付与される語義の精度が向上し、式(2)のトピックモデルの多項分布パラメータβzvの算出精度が向上する。
【0026】
語義タガーの従来技術としては、HMMを用いた参考文献1(H. Taira, S. Yoshida and M. Nagata, "BaseNP Supersense Tagging for Japanese Texts," PACLIC, 2009.)のものがある。その他、ロジスティック回帰モデルやサポートベクタマシン等の分類モデルやHMMやCRF等のシーケンシャルモデルなどを語義タガーとして用いることができる。ただし、シーケンシャルモデルを用いた場合には計算量が膨大となり、全クラスをカバーするには多くの記憶容量を必要とする。そのため、計算量や記憶容量の削減という観点からは、分類モデルを本形態の語義タガーとして用いることが望ましい。分類モデルを語義タガーとする場合の学習方法は以下の通りである。
【0027】
[学習データの素性変換]
初めに文書などのテキストデータに含まれる単語などの文字列に対して語義の付与された学習データを用意しておき、テキストデータに含まれる文字列の当該テキストデータに対する特徴を表す情報を当該文字列の素性として付与する。例えば、素性化の対象となる文字列(対象文字列)の周辺情報、係り受け情報、単語を構成する文字等から当該対象文字列を素性変換(素性化)する。例えば、テキストデータに含まれる対象文字列から前後所定単語数以内(第1正例テキスト内)に位置する単語(周辺単語)の表記と当該対象文字列に対する当該周辺単語の相対位置を表す情報との組(表層素性)、対象文字列又は周辺単語の品詞情報(品詞素性)や固有名詞情報(固有名詞素性)や構文情報(構文素性)、テキストデータ内での対象文字列の出現回数やテキストデータの集合内での対象文字列の出現回数(出現回数素性)のうち、少なくとも一つに対応する情報を対象文字列の素性とする。
【0028】
また、対象文字列が日本語語彙大系辞書などの辞書に含まれるか否かを表す情報を対象文字列の素性の少なくとも一部としてもよい。すなわち、日本語語彙大系辞書などの文字列の語義を表す辞書に含まれる単語などの文字列については、辞書において対応付けられている語義をそのまま付与することで、或る程度の精度で語義を付与できると考えられる。しかしながら、辞書の語義をそのまま付与したのでは前述の日本語語彙大系辞書のような問題がある。そのため、対象文字列が辞書に含まれていること自体を素性とし、精度の高い語義タガーを生成する。辞書が文字列の語義の的確性を表す場合には、学習データに含まれる対象文字列に対応する語義の的確性を表す情報を当該対象文字列の素性の少なくとも一部としてもよい。この例の語義の的確性を表す情報は、文字列が含まれるテキストデータの文脈に依存せずに文字列ごとに設定された語義の的確性を表す情報である。語義の的確性を表す情報の例は、前述した日本語語彙大系辞書に記述された各単語に対応する分類の順位である。例えば、学習データが含む対象文字列αとそれに対応する語義C(α)との組が辞書においても組みとして記述されており、かつ、辞書においてその語義C(α)の順位も記述されている場合、当該辞書に記述された語義C(α)の順位に対応する情報を当該対象文字列αの素性の一部としてもよい。この場合には、語義C(α)の順位を表す情報を当該対象文字列αの素性の一部としてもよいし、語義C(α)の順位が高いこと(例えば1位〜5位であること)を表す情報を当該対象文字列αの素性の一部としてもよい。これにより、順位が高い語義C(α)に対応する対象文字列αの素性の重みが大きくなるように学習されることが期待される。
【0029】
[語義タガーの学習]
上述のように文字列に対して付与された素性と当該文字列に付与された語義との組が教師あり学習データすることで、「任意の文字列の素性を入力として当該任意の文字列の語義を特定するための情報を得るモデル」である語義タガーを生成することができる。このようなモデルであればどのようなモデルを語義タガーとしてもよく、その学習方法も通常の方法でよい。例えば、正則化項付き最大エントロピーモデル(参考文献2「Berger, A.L. , Pietra, V.J.D. and Pietra, "A maximum entropy approach to natural language processing", S.A.D. 1996.」)、正則化項付きの条件付きランダム場(CRFs、参考文献3「Lafferty, J. and McCallum, A. and Pereira, F. "Conditional random fields: Probabilistic models for segmenting and labeling sequence data", MACHINE LEARNING, pp. 282-289, 2001.」、サポートベクタマシン(SVMs、参考文献4「Vapnik, V. N. "The nature of statistical learning theory", Springer Verlag, 1995.」)などの分類モデルを語義タガーとして利用でき、それらの学習方法はよく知られている。以下、正則化項付き最大エントロピーモデルを語義タガーとする場合の学習方法を例示する。
【0030】
正則化項付き最大エントロピーモデルが語義タガーとして用いられる場合、文字列に対応する素性xと当該文字列に付与された語義yとの組が学習データ(x,y)とされ、条件付き確率
【数6】
に対するエントロピー
【数7】
を最大化する各重み(パラメータ)λqに対応するPλ(y|x)であるP(y|x)が語義タガーとされる。ただし、
【数8】
であり、qは各学習データ(x,y)の組にそれぞれ対応するラベルであり、p'(x)は学習データ(x,y)におけるxの出現頻度であり、fq(x,y)はqに対応する素性関数(feature function)である。
【0031】
[語義タガーを用いた語義の付与]
語義タガーを用いてテキストデータに含まれる文字列に対する語義を付与する方法を説明する。まず、入力されたテキストデータに含まれる任意の文字列を上述の[学習データの素性変換]と同様に素性化する。学習データの素性変換方法と同様に行うのであれば、入力されたテキストデータに含まれる文字列の当該テキストデータに対する特徴を表す情報を当該文字列の素性の少なくとも一部してもよいし、当該文字列が辞書に含まれるか否かを表す情報を当該文字列の素性の少なくとも一部としてもよいし、当該文字列の語義の的確性を表す情報当該文字列の素性の少なくとも一部としてもよい。
【0032】
入力されたテキストデータに含まれる任意の文字列の素性は語義タガーに入力され、当該語義タガーを用いることで得られた当該文字列の語義が当該文字列に付与される。例えば、語義タガーが文字列に対応する語義の確率を出力する場合には、最も確率の高い語義がその文字列に付与される。例えば、正則化項付き最大エントロピーモデルが語義タガーとして用いられる場合には、任意の文字列の素性xに対する条件付き確率P(y|x)を最大とするyが当該文字列の語義とされる。
【0033】
〔第1実施形態〕
本発明の第1実施形態を説明する。第1実施形態ではEMアルゴリズムを用い、式(2)のトピックモデルの多項分布パラメータβzvを求める。
<構成>
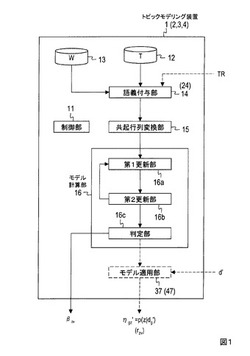
図1に例示するように、本形態のトピックモデリング装置1は、制御部11と記憶部12,13と語義付与部14と共起行列変換部15とモデル計算部16とを有する。この例のモデル計算部16は、第1更新部16aと第2更新部16bと判定部16cとを有する。なお、トピックモデリング装置1は、例えば、CPU(central processing unit)、RAM(random-access memory)及びROM(read-only memory)等を含む公知又は専用のコンピュータに特別なプログラムが読み込まれて構成される特別な装置である。例えば、記憶部12,13はハードディスクや半導体メモリなどであり、制御部11と語義付与部14と共起行列変換部15とモデル計算部16とは、特別なプログラムが読み込まれたCPUなどである。これらの少なくとも一部が集積回路などによって構成されてもよい。トピックモデリング装置1は制御部11の制御のもとで各処理を行い、各処理で得られたデータは一時メモリ(図示せず)に格納され、必要に応じて呼び出されて他の処理で利用される。図1に表記された矢印は情報の流れを表すが、表記の都合上一部の矢印が省略されている。
【0034】
<事前処理>
事前処理として、記憶部12に処理対象のテキストデータの集合Tが格納され、記憶部13に各文字列の語義を表す辞書Wが格納される。本形態では、形態素解析、固有表現抽出、係り受け解析、文境界同定などの前処理を行った後の文書データの集合(コーパスを)をテキストデータの集合とし、日本語語彙大系辞書を辞書とした例を示す。
【0035】
<トピックモデリング処理>
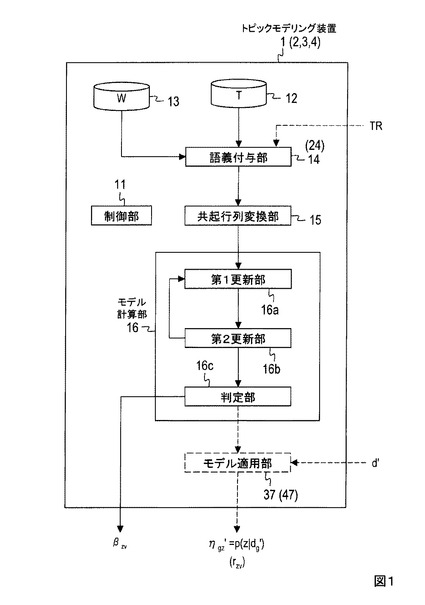
図2Aを用いて本形態のトピックモデリング処理を説明する。
記憶部12に格納されたテキストデータの集合Tに含まれる各テキストデータが語義付与部14に入力される。語義付与部14は、記憶部13に格納された辞書を用い、入力された各テキストデータに含まれる各文字列に対して語義を付与する。テキストデータとそれに含まれる各文字列とそれらに付与された語義とは互いに対応付けられ、共起行列変換部15に送られる(ステップS11)。
【0036】
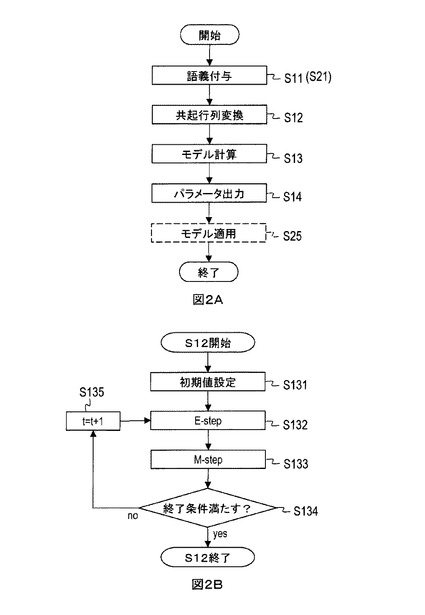
共起行列変換部15は、語義付与部14で同じ語義g∈Gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとする。例えば、或るテキストデータに含まれる各文字列がX種類の語義g1,...,gX∈Gに分類される場合、このテキストデータはX個のテキストデータとして複製され、各語義g1,...,gXにそれぞれ対応するX個のテキストデータ集合dg1,...,dgXの一部とされる。本形態の共起行列変換部15は、テキストデータ集合dgごとに、それに含まれる文字列と各語義との共起回数をカウントし、各テキストデータ集合dgにそれぞれ対応する共起行列を生成する。すなわち、テキストデータ集合dgに含まれる文字列と語義との共起回数を各要素とする共起行列が当該テキストデータ集合dgに対して生成される(図3)。図3の例では、文字列(例えば「NTT」)に対する各語義(「企業」「通信」「人(管理職)」「長」「発言」)の各共起回数が、当該文字列に対応する行の各要素とされる。図3の例では、テキストデータ集合dgに含まれる文字列「NTT」と語義「企業」「通信」「人(管理職)」「長」「発言」との共起回数がそれぞれ1,1,0,0,0であるため、共起行列の文字列「NTT」に対応する行の要素が1,1,0,0,0とされる。各テキストデータ集合dgに対応する各共起行列は対応するテキストデータ集合dgに対応付けられてモデル計算部16に送られる(ステップS12)。
【0037】
モデル計算部16は各テキストデータ集合dgに対応する各共起行列を用い、テキストデータ集合dgごとに、式(2)で表されるトピックモデルの多項分布パラメータβzvを得る(ステップS13)。本形態ではEMアルゴリズムを用いて多項分布パラメータβzvを得る例を示す。
【0038】
[ステップS13でEMアルゴリズムを用いる例]
図2Bに例示するように、モデル計算部16の第1更新部16aは、t=0とし、多項分布パラメータの初期値ηgz(0)及びβzv(0)を定める。ηgz(0)及びβzv(0)は任意の値でよく、例えば0以上1以下の規定値がηgz(0)及びβzv(0)とされる(ステップS131)。
【0039】
モデル計算部16の第1更新部16aは、ηgz(t)及びβzv(t)を用い、式(3)に従って[E-step]の処理を行って条件付き確率P(zgv|v,η(t),β(t))を求める。条件付き確率P(zgv|v,η(t),β(t))は第2更新部16bに送られる(ステップS132)。
【0040】
第2更新部16bは、条件付き確率P(zgv|v,η(t),β(t))と出現回数n(dg,v)とを用い、式(5)(6)に従って[M-step]の処理を行って多項分布パラメータηgz(t+1)及びβzv(t+1)を求める。出現回数n(dg,v)はテキストデータ集合dgに対応する共起行列を用いて特定される。図3に例示した共起行列の場合、例えばn(dg,“NTT”)=2, n(dg,“は”)=6,..., n(dg,“語る”)=3となる。多項分布パラメータηgz(t+1)及びβzv(t+1)は、第1更新部16aと判定部16cに送られる(ステップS133)。
【0041】
判定部16cは、終了条件を満たしたかを判定する。以下に終了条件を例示する。
[終了条件の例1]
テキストデータ全体に対する対数尤度の変化率Σg∈G log Pt+1(wg|dg)/Σg∈G log Pt(wg|dg)が規定値以上であることを終了条件とする。ただし、
【数9】
である。
[終了条件の例2]
t回目のイテレーションで得られたβ(t)、η(t)とt+1回目のイテレーションで得られたβ(t+1)、η(t+1)との変化率や変化量が規定値以下であることを終了条件とする。例えば、t回目のイテレーションで得られたβ(t)、η(t)を要素とするベクトルと、t+1回目のイテレーションで得られたβ(t+1)、η(t+1)を要素とするベクトルとの距離が規定値以下であることを終了条件とする。
[終了条件の例3]
tが所定のイテレーション回数に達したことを終了条件とする。
[終了条件の例4]
終了条件の例1−3の終了条件のうちのいずれか複数を満たすことを終了条件とする(終了条件の例の説明終わり)。
【0042】
終了条件を満たしていないと判定された場合には、t+1を新たなtとしてステップS132に進む(ステップS135)。終了条件を満たしたと判定された場合には、ステップS13の処理を終了し、判定部16cはβzv(t+1)を多項分布パラメータβzvとして出力する。多項分布パラメータβzvを出力するのはトピックモデルを適用する際にはβzvがあれば十分であるからであるが、必要に応じてηgz(t+1)を多項分布パラメータηgzとして出力されてもよい。また、βzv(t)が多項分布パラメータβzvとして出力されてもよいし、ηgz(t)が多項分布パラメータηgzとして出力されてもよい(ステップS14)。
【0043】
〔第2実施形態〕
第2実施形態は第1実施形態の変形例であり、語義タガーを用いて文字列に語義が付与される形態である。以下では第1実施形態との相違点を中心に説明し、第1実施形態と共通する事項については、第1実施形態と同じ参照番号を用いて説明を省略する。
<構成>
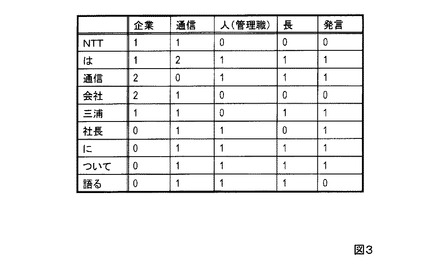
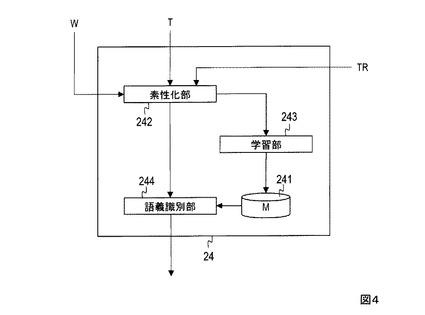
図1に例示するように、本形態のトピックモデリング装置2は、制御部11と記憶部12,13と語義付与部24と共起行列変換部15とモデル計算部16とを有する。第1実施形態との相違点は語義付与部24のみである。図4に例示するように、語義付与部24は、記憶部241と素性化部242と学習部243と語義識別部244とを有する。
【0044】
<事前処理>
事前処理として、第1実施形態と同様に、記憶部12に処理対象のテキストデータの集合Tが格納され、記憶部12に各文字列の語義を表す辞書Wが格納される。
さらに本形態では語義タガーの学習が行われ、それによって得られた語義タガーが記憶部241に格納される。すなわち、文書などのテキストデータに含まれる単語などの文字列に対して語義の付与された学習データTRが素性化部242(図4)に入力される。素性化部242は、前述したように([学習データの素性変換]及び[語義タガーの学習])、学習データが含む文字列を素性変換し、文字列に対応する素性と当該文字列に付与された語義との組を用いて前述のような学習を行い、「任意の文字列の素性を入力として当該任意の文字列の語義を特定するための情報を得るモデル」である語義タガーMを生成して記憶部241に格納する。
【0045】
<トピックモデリング処理>
図2Aを用いて本形態のトピックモデリング処理を説明する。
記憶部12に格納されたテキストデータの集合Tに含まれる各テキストデータが語義付与部24に入力される。語義付与部24は、記憶部241に格納された語義タガーMを用い、入力された各テキストデータに含まれる各文字列に対して語義を付与する。すなわち語義付与部24の素性化部242(図4)は、入力されたテキストデータに含まれる文字列を前述のように素性化する。例えば、入力されたテキストデータに含まれる文字列の当該テキストデータに対する特徴を表す情報や、文字列が文字列の語義を表す辞書Wに含まれるか否かを表す情報や、辞書Wに示された文字列の語義の的確性を表す情報などが当該文字列の素性の少なくとも一部とされる。入力されたテキストデータに含まれる文字列の素性は語義識別部244に送られる。語義識別部244は、記憶部241から読み込んだ語義タガーMに、テキストデータに含まれる文字列の素性を入力し、前述のように([語義タガーを用いた語義の付与])当該文字列の語義を求める。テキストデータとそれに含まれる各文字列とそれらに付与された語義とは互いに対応付けられ、共起行列変換部15に送られる(ステップS21)。
【0046】
それ以降の処理は第1実施形態と同じであるため説明を省略する。
【0047】
〔第3実施形態〕
第3実施形態は第1及び第2実施形態の応用例であり、第1又は第2実施形態で得られたトピックモデルの適用方法を例示するものである。本形態では、得られたトピックモデルを用い、入力テキストデータにトピック情報を付与する。以下では、第1及び第2実施形態との相違点のみを説明する。
【0048】
<構成>
図1に例示するように、本形態のトピックモデリング装置3は、第1実施形態のトピックモデリング装置1又は第2実施形態のトピックモデリング装置2にモデル適用部37が付加されたものである。
【0049】
<事前処理・トピックモデリング処理>
第1及び第2実施形態で説明した通りである。
【0050】
<モデル適用処理>
モデル適用部37に、第1又は第2実施形態の判定部16cから出力された多項分布パラメータβzvが入力される。さらに、入力テキストデータd'がモデル適用部37に入力される。モデル適用部37は、入力テキストデータd'が含む文字列の集合を入力文字列集合w'とし、入力テキストデータd'が与えられたときの各文字列v'∈Vの条件付き確率をp(v'|d')とし、入力テキストデータd'中の文字列v'∈Vの出現回数をn(d',v')とし、入力テキストデータd'が与えられたときのトピック情報zの条件付き確率p(z|d')である多項分布パラメータをηd’zとした場合における
【数10】
の多項分布パラメータηd’zを求めて出力する。多項分布パラメータηd’zは、入力テキストデータd'に対応するトピック情報がz∈Zであることの条件付き確率p(z|d')である。
【0051】
多項分布パラメータηd’zの生成方法には限定はないが、例えばEMアルゴリズムを用いることができる。この場合には、以下のE-stepとM-stepとを、繰り返しのたびにt+1を新たなtとしながら繰り返し、終了条件を満たした際のηd’z(t+1)又はηd’z(t)を多項分布パラメータηd’zとすればよい。この繰り返し処理のηd’z(t)の初期値P(zd’v|v,η(0),β)及びηd’z(0)は任意な値でよく、この繰り返し処理で多項分布パラメータβzvは更新されない。
【数11】
【0052】
<実験>
本発明の実施形態の手法(p-Conceptron)と従来手法(Conceptron)を比較するために文書分類実験を行った。すなわちp-Conceptronを用いて条件付き確率p(z|d')(トピック重み)を求め、それらを文書分類のための素性の一部として文書分類を行った場合と、従来手法のConceptronで得られたトピックを文書分類のための素性の一部として用いて文書分類を行った場合とで分類性能を比較した。この実験では、毎日新聞の記事文書をテキストデータとし、単語を文字列とし、新聞記事の文書を分類する。毎日新聞の記事には記事ラベルがついている。これを分類の正解ラベルとし、正解ラベルを知ることなくp-Conceptron及びConceptronがいかに正しくラベルを推測できるかを比べ、p-Conceptron及びConceptronの性能を比較する。総ラベル種は17種類である。上述のトピック重みやトピック以外の素性としては文書に含まれる単語のユニグラム素性(単語そのもの)を用いる。実験に用いたConceptron及びp-Conceptronのトピックモデルは毎日新聞2001年版から2007年版から学習されたものである。
【0053】
[クローズテスト]
毎日新聞2001年版からランダムに10000記事をトピックモデルの学習用に用い、それらの記事に含まれる1000記事を分類テスト用に用いた。Conceptronと実験条件を揃えるため、p-Conceptronのトピックモデルの学習には語義タガーを用いていない。トピックモデルの学習にはEMアルゴリズムを採用した。また、Conceptronとp-Conceptronとに共通する素性としてユニグラム素性を用い、さらに素性としてp-Conceptronのトピックモデルで得られるすべてのトピック重みを用いた場合と、Conceptronのトピックモデルで得られるトピックを用いた場合とで、テスト用の1000記事の分類性能が変化したかをみる。なお、テスト用の1000記事にも正解ラベルが存在するが、分類処理にはそれらの正解ラベルはConceptron及びp-Conceptronは与えられていない。
【0054】
Conceptron、p-Conceptronのそれぞれにおいて10、50、100、500トピックの4つのモデルを作成し、最も性能の高かったものを比べる。p-Conceptronのトピック重みの素性化として、全てのトピックの重みを利用した場合と、最大の重み(最大確率)を持つトピックについてだけ素性化することとして場合について実験を行った。実験結果を以下に示す。
【表1】
括弧内は最適だったトピック数(混合数)を示す。ユニグラム素性のみを用いた場合のベースラインの正解率が58.7%だったのに対し、p-Conceptronで最大確率のトピック利用の100トピック(100混合)において正解率63.8%とベースラインに比べて5.1ポイントの精度向上を達成した。さらにConceptronに対しては1ポイントの精度向上を達成した。
【0055】
[オープンテスト]
トピックモデルの学習に用いた記事に含まれない記事についても分類結果を比較した。毎日新聞1997年版からランダムに10000記事をトピックモデルの学習用に用い、学習用の10000記事を除く1000記事を分類テスト用に用いた。素性はクローズテストと同様に設定した。以下に実験結果を示す。
【表2】
ユニグラム素性のみを用いた場合のベースラインの正解率が58.7%だったのに対し、最高値p-Conceptronの50トピック(50混合)においてベースラインに比べて1.4ポイントの精度向上を達成した。さらにConceptronに対しては0.7ポイントの精度向上を達成した。
【0056】
〔第4実施形態〕
第4実施形態は第1及び第2実施形態の応用例であり、第1又は第2実施形態で得られたトピックモデルの他の適用方法を例示するものである。本形態では、得られたトピックモデルを用い、各トピックにおいて特徴的な単語などの文字列を得る。以下では、第1及び第2実施形態との相違点のみを説明する。
【0057】
<構成>
図1に例示するように、本形態のトピックモデリング装置4は、第1実施形態のトピックモデリング装置1又は第2実施形態のトピックモデリング装置2にモデル適用部47が付加されたものである。
【0058】
<事前処理・トピックモデリング処理>
第1及び第2実施形態で説明した通りである。
【0059】
モデル適用部47に、第1又は第2実施形態の判定部16cから出力された多項分布パラメータβzvが入力される。さらに、入力テキストデータd'がモデル適用部47に入力される。モデル適用部47は、多項分布パラメータβzvと入力テキストデータd'中の文字列vの出現確率(ユニグラム確率)p(v)との比rzvを求めて出力する。例えば、モデル適用部47は、rzv=βzv/p(v)を求めて出力する。p(v)に対するβzv=p(v|z)の比率が大きい文字列vほどトピック情報zに対応するトピックにおいて特徴的な単語であると見込まれる。
【0060】
以下に、テキストデータが文書であり、それに含まれる文字列が単語である場合に本形態を適用した結果を例示する。以下では、各トピックについてrzv=βzv/p(v)の高い順に上位10個の単語を列挙する。なお、左側カラムのトピック名は特徴的単語を見て人手で付与されたラベル名である。
【表3】
このように、本形態の方法によって各トピックにおいて特徴的な単語を抽出できることが分かる。
【0061】
〔その他の変形例等〕
なお、本発明は上述の実施の形態に限定されるものではない。例えば上記の各実施形態ではステップS12で共起行列を生成し、生起行列を用いてトピックモデルを生成していた。しかし、生起行列を生成することなく、入力された各テキストデータに含まれる各文字列に対して語義を付与して得られるデータからn(dg,v)を求め、トピックモデルを生成してもよい。また、EMアルゴリズムの更新の順序に限定はなく、M-stepを実行してからE-stepを実行する繰り返し処理が実行されてもよい。この場合のM-stepでのP(zgv|v,η(t),β(t))の初期値P(zgv|v,η(0),β(0))は任意値でよい。
【0062】
第1又は第2実施形態で得られたトピックモデルの適用方法にも限定はなく、多様な用途に適用できる。すなわち、得られたトピックモデルは文書に対するトピック付与のみでなく、文や段落などといったテキストに対するトピック付与に利用されてもよい。また、得られたトピックモデルの多項分布パラメータの距離や類似度を指標として、対応する文書等のテキストデータの類似度を判定してもよい。
【0063】
また、上述の各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能であることはいうまでもない。
また、上述の構成をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。
【0064】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体は、非一時的(non-transitory)な記録媒体である。このような記録媒体の例は、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等である。
【0065】
このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0066】
このようなプログラムを実行するコンピュータは、例えば、まず、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、一旦、自己の記憶装置に格納する。そして、処理の実行時、このコンピュータは、自己の記録装置に格納されたプログラムを読み取り、読み取ったプログラムに従った処理を実行する。また、このプログラムの別の実行形態として、コンピュータが可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することとしてもよく、さらに、このコンピュータにサーバコンピュータからプログラムが転送されるたびに、逐次、受け取ったプログラムに従った処理を実行することとしてもよい。また、サーバコンピュータから、このコンピュータへのプログラムの転送は行わず、その実行指示と結果取得のみによって処理機能を実現する、いわゆるASP(Application Service Provider)型のサービスによって、上述の処理を実行する構成としてもよい。なお、本形態におけるプログラムには、電子計算機による処理の用に供する情報であってプログラムに準ずるもの(コンピュータに対する直接の指令ではないがコンピュータの処理を規定する性質を有するデータ等)を含むものとする。
【0067】
また、上記の実施形態では、コンピュータ上で所定のプログラムを実行させることにより、本装置を構成することとしたが、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
【符号の説明】
【0068】
1−4 トピックモデリング装置
【技術分野】
【0001】
本発明は、テキストデータに含まれる文字列に対応するトピックのモデリング技術に関する。
【背景技術】
【0002】
現在様々な自然言語処理技術の研究開発が進み、前後数単語の局所的な文脈情報だけでなく、テキストデータのトピックを捉えることができるトピックモデルの利用が盛んになっている。「トピックモデル」とは、文書などのテキストデータに対応するトピックに対応するトピック情報とそのテキストデータが含む単語などの文字列との関係を記述するモデル(関数、数式)を意味する。「トピック」とは、ジャンルや書き手のスタイル等を含む大域的な情報を表す。テキストデータがトピックを表す文字列そのものを含んでいるとは限らない。
【0003】
テキストデータのトピックを的確に捉えることで、当該テキストデータではそのトピックに関連性の強い文字列の出現確率が高いという情報を得ることができる。例えば文書のトピックがスポーツであるなら、その文書には「サッカー」といったスポーツに関する単語が出現しやすく、「国会」といった単語が出現しにくい、といった大域的情報を得ることができる。トピックに対応するトピック情報はテキストデータに付与されたラベル情報等(例えば新聞の場合だと「スポーツ面」等の見出し)から得られる場合もあるが、常にそのように明示的なトピック情報がテキストデータに付与されているとは限らない。そのため、たとえラベル情報が付与されていないテキストデータであってもトピックを捉えることができるトピックモデルの利用価値は高い。
【0004】
トピックモデルの先行技術としては、LSA(Latent Semantic Analysis,非特許文献1)、PLSA(Probabilistic Latent Semantic Analysis,非特許文献2)、LDA(Latent Dirichlet Allocation)等が知られている。トピックモデルの先駆けはLSAである。LSAでは、単語と文書の共起行列を特異値分解して次元圧縮を行ってモデルを得る。これを確率的に拡張させたモデルがPLSAである。また、LSAやPLSAが直接単語と文書の関係からトピックモデルを生成するのに対し、単語と語義の関係からトピックモデルを生成する技術としてConceptron(特許文献1)が知られている。以下にPLSAとConceptronの概要について述べる。
【0005】
<PLSA>
PLSAは2つの確率分布パラメータによって文書を表現する。1つ目はある文書dにおける各トピック情報zの生成し易さを表す多項分布パラメータp(z|d)で、2つ目はトピック情報zにおける各単語vの生成し易さを表す多項分布パラメータp(v|z)である。PLSAは以下の式で定義される。
【数1】
【0006】
ここでwdは文書d中の単語集合、zdnは文書d中のn(n=1,...,Nd)番目の単語wnのトピック情報、Σzdは文書dにおける単語トピック情報系列の全ての可能な組み合わせの和、γzwはトピック情報zにおける単語vの多項分布(ユニグラム確率)パラメータp(v|z)、δdz(Σzδdz=1)は文書dにおけるトピック情報zの多項分布パラメータp(z|d)、n(d,v)は文書d中の単語vの出現回数、Zはトピック情報の全体集合、Vは単語vの全体集合を表す。PLSAはその確率的理論に基づくロバスト性からLSAよりも性能が高いことが知られており、さらに後のLDAへ拡張されるように、モデルとしての拡張性も高い。
【0007】
<Conceptron>
LSAやPLSAが直接単語と文書の関係からトピックモデルを生成したのに対し、Conceptronは単語と語義の関係からトピックモデルを生成する。「語義」とは、各文字列の意味を考慮して各文字列に付与された分類を表す。語義の例は、日本語語彙大系において単語や固有表現などの各文字列に付与された分類の1クラスである。「日本語語彙大系」とは、日本語の単語を人手によって2715の意味クラスに分類したものを指す。例えば「快速」という単語には「乗り物(本体(移動(陸圏)))」という語義がある。Conceptronでは、文書中の単語vと共起した語義gの数を数え上げることで単語vと語義gの共起行列を作り、それを特異値分解して次元圧縮を行ってモデルを得る。
【0008】
Conceptronでは、人間が定めた語義にトピックを従わせることができるため、人間の直観に合ったトピックモデリングが得られる。またConceptronでは、モデル学習中に語義総数|G|×単語総数|V|の共起行列の次元圧縮を行ってモデルを得る。語義総数|G|は文書総数|D|よりも非常に小さい(|G|≪|D|)。よってConceptronでは、文書数|D|×単語数|V|の共起行列を特異値分解して次元圧縮を行ってモデルを得るLSAよりも、小さな主記憶装置でも実装可能でかつ高速である。
【先行技術文献】
【特許文献】
【0009】
【特許文献1】特許第4099197号公報
【非特許文献】
【0010】
【非特許文献1】Deerwester, S. C. et al., “Indexing by Latent Semantic Analysis,” Journal of the American Society for Information Science, 1990.
【非特許文献2】Hofmann, T., “Probabilistic Latent Semantic Indexing,” In Proc. of the 22nd Annual ACM Conf. on Research and Development in Information Retrieval, 1999.
【発明の概要】
【発明が解決しようとする課題】
【0011】
PLSAでは単語の語義が考慮されていないため、生成されたトピックモデルを用いて得られるトピックが人間にとって理解しづらいという問題がある。また、式(1)に示した多項分布パラメータδdzは文書dとトピック情報zとの組ごとに対応し、トピックモデルを構成するパラメータの数が多いという問題もある。Conceptronでは、単語の語義を考慮したトピックモデルを生成することができるが、確率的に解釈することができるトピック情報を得ることができないという問題がある。
【0012】
本発明はこのような点に鑑みてなされたものであり、従来よりも人間にとって理解し易く、確率的に解釈可能なトピック情報を得ることができ、パラメータ数が少ないトピックモデルを生成できる技術を提供することを目的とする。
【課題を解決するための手段】
【0013】
本発明では、入力された各テキストデータに含まれる各文字列に対して語義を付与し、語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、テキストデータ集合dgが与えられたときの文字列集合wgの条件付き確率をp(wg|dg)とし、テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzvとし、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとした場合におけるトピックモデル
【数2】
の多項分布パラメータβzvを得る。
【発明の効果】
【0014】
本発明では、語義を考慮したトピックモデルを生成できるため人間にとって理解し易いトピック情報を得ることができる。また、本発明のトピックモデルを適用して得られるトピック情報は確率的に解釈可能な情報となる。さらに、多項分布パラメータηgzはテキストデータ集合dgとトピック情報zとの組ごとに対応するため、従来よりもトピックモデルを構成するパラメータの数が少ない。
【図面の簡単な説明】
【0015】
【図1】図1は、実施形態のトピックモデリング装置の機能構成を例示するためのブロック図である。
【図2】図2Aは、実施形態のトピックモデリング方法を例示するためのフローチャートである。図2Bは、ステップS12の処理を例示するためのフローチャートである。
【図3】図3は、実施形態の共起行列を例示するための図である。
【図4】図4は、第2実施形態の語義付与部の機能構成を例示するためのブロック図である。
【発明を実施するための形態】
【0016】
以下、図面を参照して本発明の実施形態を説明する。
〔原理〕
実施形態の原理を説明した後、各実施形態の説明を行う。
各実施形態では、入力された各テキストデータに含まれる各文字列に対して語義を付与し、以下のトピックモデルの多項分布パラメータβzvを得る。
【数3】
ここで、同じ語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、テキストデータ集合dgが与えられたときの文字列集合wgの条件付き確率(事後確率)をp(wg|dg)とし、テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzvとし(p(v|z)はユニグラム確率)、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとする。本形態のβzv=p(v|z)はユニグラム確率であり、ηgzはΣz∈Zηgz=1を満たす。
【0017】
「語義」とは、各文字列の意味を考慮して各文字列に付与された分類を表す。「テキストデータ」とは文字及び/又は記号を含むデータを意味する。テキストデータの具体例は、文書、各段落の文書、単語列、フレーズ、文、クエリ、語句を含む図表、記号列などである。「文字列」の具体例は、単語、単語列、フレーズ、文、文字、固有表現、記号、記号列などである。「トピック」とは、ジャンルや書き手のスタイル等を含む大域的な情報を表す。テキストデータに対応するトピックの具体例は、テキストデータの題目、話題、事柄、出来事、論題、分類、様式、言語、ジャンルなどや、テキストデータの書き手のスタイルなどである。テキストデータがトピックを表す文字列そのものを含んでいるとは限らない。「トピック情報」は、テキストデータに対応するトピックに対応する情報であればどのようなものであってもよい。例えば、テキストデータに対応するトピックの候補(例えば<球団名>や<企業名>など)ごとに、当該テキストデータに対応する各トピックの候補の適切さを表す指標(例えば、確率、重み係数、確率や重み係数の関数値であるスコアなど)が与えられ、それらの指標の少なくとも一部が当該テキストデータのトピック情報とされてもよい。
【0018】
本形態では、語義を考慮したトピックモデルを生成できるため人間にとって理解し易いトピック情報を得ることができる。また、多項分布パラメータηgzはテキストデータ集合dgとトピック情報zとの組ごとに対応するため、従来よりもトピックモデルを構成するパラメータの数が少ない。すなわち、PLSAでのパラメータ数が|V|×|Z|+|Z|×|D|であるのに対し、本形態におけるパラメータ数は|V|×|Z|+|Z|×|G|であり、|D|>>|V|>>|G|であることを考えると、大幅にパラメータ数を削減できる。なお、|V|は単語総数、|Z|はトピック情報の総数、|D|は文書総数である。
【0019】
さらに、本形態のトピックモデルを適用して得られるトピック情報は確率的に解釈可能な情報となる。トピック情報を確率的に取り扱うことにより、その用途が広がる。例えば、或るトピックにおいて或る単語がどれくらい出現し易いかということや、文書Aと文書Bのどちらの方がよりスポーツについて述べられているかということや、トピック毎の特徴的単語(後述する)はどのようなものであるかということなども評価できるようになる。また、トピック情報が確率的に表現されるモデルにすることにより、トピック情報の正規化が自然になされ、かつ目的関数がL2ノルムからKL-divergenceに変わることで、ロバストなモデル推定が可能となる。
【0020】
多項分布パラメータβzvの計算方法に限定はないが、例えばEMアルゴリズムを用いた学習やベイズ学習などによって多項分布パラメータβzvを得ることができる。EMアルゴリズムが用いられる場合のE-step及びM-stepは以下のようになる。
【数4】
【0021】
ここで、tはイテレーションの回数を表し、ηgz(t)及びβzv(t)はt回目のイテレーションでの多項分布パラメータを表し、ηgz(0)及びβzv(0)は多項分布パラメータの初期値を表し、η(t)はt回目のイテレーションでのすべてのトピック情報z∈Z及びテキストデータ集合dg(g∈G)についての多項分布パラメータηgz(t)の集合を表し、β(t)はt回目のイテレーションでのすべてのトピック情報z∈Z及び文字列v∈Vについての多項分布パラメータβzv(t)の集合を表す。zgvはテキストデータ集合dg中の文字列vのトピック情報を表し、P(zgv|v,η(t),β(t))はv,η(t),β(t)が与えられたときのトピック情報zgvの条件付き確率を表す。argmaxη,β[・]は「・」を最大化するη(t)及びβ(t)を表す。
【0022】
式(4)の各項に対してラグランジュの未定係数法を用いることで以下の更新式が得られる。
【数5】
【0023】
すなわち、EMアルゴリズムが用いられる場合には、多項分布パラメータηgz(t)及びβzv(t)を用いて式(3)に従って条件付き確率P(zgv|v,η(t),β(t))を得るE-stepと、出現回数n(dg,v)及び条件付き確率P(zgv|v,η(t),β(t))を用いて式(5)(6)に従って多項分布パラメータηgz(t+1)及びβzv(t+1)を得るM-stepとを含む繰り返し処理が、繰り返しのたびにt+1を新たなtとしながら実行される。このような繰り返し処理は終了条件を満たすまで実行され、終了条件を満たした際のβzv(t+1)又はβzv(t)が多項分布パラメータβzvとされる。多項分布パラメータηgz(t)及びβzv(t)の初期値ηgz(0)及びβzv(0)は任意値でよい。
【0024】
また、入力された各テキストデータに含まれる各文字列に対して語義を付与するための方法に限定はない。例えば、文字列とそれに対応する語義とが対応付けられたテーブルである辞書を参照して、各文字列に対して語義を付与されてもよい。このような辞書の例は、各単語が日本語語彙大系のどの分類(語義)になり易いかが順位として記述された辞書(以下これを日本語語彙大系辞書と呼ぶ)などである。しかしながら、このような辞書によって付与される語義の正確性が低い場合があり、このような辞書がカバーする単語などの文字列にも限りがある。よって、このような方法では適切な語義を付与することができない場合がある。例えばConceptronでは、入力された文書が含む単語に対し、日本語語彙大系辞書で最も高い順位が付与されている分類を常にその単語の語義として選択する。そのため、付与された語義が正しくない場合もある。例えば「東京」という単語の語義は、文脈に応じて「都」「大学・高専」「駅名等」「中・高校」「地区名」などとなる可能性があるが、Conceptronでは文脈にかかわらず「東京」に対して常に同一の語義が選択される。また、日本語語彙大系辞書では「巨人」という単語に対して「男」「魔物・化け物」「偉人」「幹部」などの分類が対応しているが、「球団名」は対応していない。これは日本語語彙大系辞書の「球団名」の分類には「巨人軍」という単語が対応付けされているからであるが、これも語義を正確に付与する上での課題となる。
【0025】
そのため、文字列に対して適切な語義を自動的に付与するモデルである語義タガーを生成し、このような語義タガーを用い、各テキストデータに含まれる各文字列に対して語義を付与してもよい。これにより、付与される語義の精度が向上し、式(2)のトピックモデルの多項分布パラメータβzvの算出精度が向上する。
【0026】
語義タガーの従来技術としては、HMMを用いた参考文献1(H. Taira, S. Yoshida and M. Nagata, "BaseNP Supersense Tagging for Japanese Texts," PACLIC, 2009.)のものがある。その他、ロジスティック回帰モデルやサポートベクタマシン等の分類モデルやHMMやCRF等のシーケンシャルモデルなどを語義タガーとして用いることができる。ただし、シーケンシャルモデルを用いた場合には計算量が膨大となり、全クラスをカバーするには多くの記憶容量を必要とする。そのため、計算量や記憶容量の削減という観点からは、分類モデルを本形態の語義タガーとして用いることが望ましい。分類モデルを語義タガーとする場合の学習方法は以下の通りである。
【0027】
[学習データの素性変換]
初めに文書などのテキストデータに含まれる単語などの文字列に対して語義の付与された学習データを用意しておき、テキストデータに含まれる文字列の当該テキストデータに対する特徴を表す情報を当該文字列の素性として付与する。例えば、素性化の対象となる文字列(対象文字列)の周辺情報、係り受け情報、単語を構成する文字等から当該対象文字列を素性変換(素性化)する。例えば、テキストデータに含まれる対象文字列から前後所定単語数以内(第1正例テキスト内)に位置する単語(周辺単語)の表記と当該対象文字列に対する当該周辺単語の相対位置を表す情報との組(表層素性)、対象文字列又は周辺単語の品詞情報(品詞素性)や固有名詞情報(固有名詞素性)や構文情報(構文素性)、テキストデータ内での対象文字列の出現回数やテキストデータの集合内での対象文字列の出現回数(出現回数素性)のうち、少なくとも一つに対応する情報を対象文字列の素性とする。
【0028】
また、対象文字列が日本語語彙大系辞書などの辞書に含まれるか否かを表す情報を対象文字列の素性の少なくとも一部としてもよい。すなわち、日本語語彙大系辞書などの文字列の語義を表す辞書に含まれる単語などの文字列については、辞書において対応付けられている語義をそのまま付与することで、或る程度の精度で語義を付与できると考えられる。しかしながら、辞書の語義をそのまま付与したのでは前述の日本語語彙大系辞書のような問題がある。そのため、対象文字列が辞書に含まれていること自体を素性とし、精度の高い語義タガーを生成する。辞書が文字列の語義の的確性を表す場合には、学習データに含まれる対象文字列に対応する語義の的確性を表す情報を当該対象文字列の素性の少なくとも一部としてもよい。この例の語義の的確性を表す情報は、文字列が含まれるテキストデータの文脈に依存せずに文字列ごとに設定された語義の的確性を表す情報である。語義の的確性を表す情報の例は、前述した日本語語彙大系辞書に記述された各単語に対応する分類の順位である。例えば、学習データが含む対象文字列αとそれに対応する語義C(α)との組が辞書においても組みとして記述されており、かつ、辞書においてその語義C(α)の順位も記述されている場合、当該辞書に記述された語義C(α)の順位に対応する情報を当該対象文字列αの素性の一部としてもよい。この場合には、語義C(α)の順位を表す情報を当該対象文字列αの素性の一部としてもよいし、語義C(α)の順位が高いこと(例えば1位〜5位であること)を表す情報を当該対象文字列αの素性の一部としてもよい。これにより、順位が高い語義C(α)に対応する対象文字列αの素性の重みが大きくなるように学習されることが期待される。
【0029】
[語義タガーの学習]
上述のように文字列に対して付与された素性と当該文字列に付与された語義との組が教師あり学習データすることで、「任意の文字列の素性を入力として当該任意の文字列の語義を特定するための情報を得るモデル」である語義タガーを生成することができる。このようなモデルであればどのようなモデルを語義タガーとしてもよく、その学習方法も通常の方法でよい。例えば、正則化項付き最大エントロピーモデル(参考文献2「Berger, A.L. , Pietra, V.J.D. and Pietra, "A maximum entropy approach to natural language processing", S.A.D. 1996.」)、正則化項付きの条件付きランダム場(CRFs、参考文献3「Lafferty, J. and McCallum, A. and Pereira, F. "Conditional random fields: Probabilistic models for segmenting and labeling sequence data", MACHINE LEARNING, pp. 282-289, 2001.」、サポートベクタマシン(SVMs、参考文献4「Vapnik, V. N. "The nature of statistical learning theory", Springer Verlag, 1995.」)などの分類モデルを語義タガーとして利用でき、それらの学習方法はよく知られている。以下、正則化項付き最大エントロピーモデルを語義タガーとする場合の学習方法を例示する。
【0030】
正則化項付き最大エントロピーモデルが語義タガーとして用いられる場合、文字列に対応する素性xと当該文字列に付与された語義yとの組が学習データ(x,y)とされ、条件付き確率
【数6】
に対するエントロピー
【数7】
を最大化する各重み(パラメータ)λqに対応するPλ(y|x)であるP(y|x)が語義タガーとされる。ただし、
【数8】
であり、qは各学習データ(x,y)の組にそれぞれ対応するラベルであり、p'(x)は学習データ(x,y)におけるxの出現頻度であり、fq(x,y)はqに対応する素性関数(feature function)である。
【0031】
[語義タガーを用いた語義の付与]
語義タガーを用いてテキストデータに含まれる文字列に対する語義を付与する方法を説明する。まず、入力されたテキストデータに含まれる任意の文字列を上述の[学習データの素性変換]と同様に素性化する。学習データの素性変換方法と同様に行うのであれば、入力されたテキストデータに含まれる文字列の当該テキストデータに対する特徴を表す情報を当該文字列の素性の少なくとも一部してもよいし、当該文字列が辞書に含まれるか否かを表す情報を当該文字列の素性の少なくとも一部としてもよいし、当該文字列の語義の的確性を表す情報当該文字列の素性の少なくとも一部としてもよい。
【0032】
入力されたテキストデータに含まれる任意の文字列の素性は語義タガーに入力され、当該語義タガーを用いることで得られた当該文字列の語義が当該文字列に付与される。例えば、語義タガーが文字列に対応する語義の確率を出力する場合には、最も確率の高い語義がその文字列に付与される。例えば、正則化項付き最大エントロピーモデルが語義タガーとして用いられる場合には、任意の文字列の素性xに対する条件付き確率P(y|x)を最大とするyが当該文字列の語義とされる。
【0033】
〔第1実施形態〕
本発明の第1実施形態を説明する。第1実施形態ではEMアルゴリズムを用い、式(2)のトピックモデルの多項分布パラメータβzvを求める。
<構成>
図1に例示するように、本形態のトピックモデリング装置1は、制御部11と記憶部12,13と語義付与部14と共起行列変換部15とモデル計算部16とを有する。この例のモデル計算部16は、第1更新部16aと第2更新部16bと判定部16cとを有する。なお、トピックモデリング装置1は、例えば、CPU(central processing unit)、RAM(random-access memory)及びROM(read-only memory)等を含む公知又は専用のコンピュータに特別なプログラムが読み込まれて構成される特別な装置である。例えば、記憶部12,13はハードディスクや半導体メモリなどであり、制御部11と語義付与部14と共起行列変換部15とモデル計算部16とは、特別なプログラムが読み込まれたCPUなどである。これらの少なくとも一部が集積回路などによって構成されてもよい。トピックモデリング装置1は制御部11の制御のもとで各処理を行い、各処理で得られたデータは一時メモリ(図示せず)に格納され、必要に応じて呼び出されて他の処理で利用される。図1に表記された矢印は情報の流れを表すが、表記の都合上一部の矢印が省略されている。
【0034】
<事前処理>
事前処理として、記憶部12に処理対象のテキストデータの集合Tが格納され、記憶部13に各文字列の語義を表す辞書Wが格納される。本形態では、形態素解析、固有表現抽出、係り受け解析、文境界同定などの前処理を行った後の文書データの集合(コーパスを)をテキストデータの集合とし、日本語語彙大系辞書を辞書とした例を示す。
【0035】
<トピックモデリング処理>
図2Aを用いて本形態のトピックモデリング処理を説明する。
記憶部12に格納されたテキストデータの集合Tに含まれる各テキストデータが語義付与部14に入力される。語義付与部14は、記憶部13に格納された辞書を用い、入力された各テキストデータに含まれる各文字列に対して語義を付与する。テキストデータとそれに含まれる各文字列とそれらに付与された語義とは互いに対応付けられ、共起行列変換部15に送られる(ステップS11)。
【0036】
共起行列変換部15は、語義付与部14で同じ語義g∈Gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとする。例えば、或るテキストデータに含まれる各文字列がX種類の語義g1,...,gX∈Gに分類される場合、このテキストデータはX個のテキストデータとして複製され、各語義g1,...,gXにそれぞれ対応するX個のテキストデータ集合dg1,...,dgXの一部とされる。本形態の共起行列変換部15は、テキストデータ集合dgごとに、それに含まれる文字列と各語義との共起回数をカウントし、各テキストデータ集合dgにそれぞれ対応する共起行列を生成する。すなわち、テキストデータ集合dgに含まれる文字列と語義との共起回数を各要素とする共起行列が当該テキストデータ集合dgに対して生成される(図3)。図3の例では、文字列(例えば「NTT」)に対する各語義(「企業」「通信」「人(管理職)」「長」「発言」)の各共起回数が、当該文字列に対応する行の各要素とされる。図3の例では、テキストデータ集合dgに含まれる文字列「NTT」と語義「企業」「通信」「人(管理職)」「長」「発言」との共起回数がそれぞれ1,1,0,0,0であるため、共起行列の文字列「NTT」に対応する行の要素が1,1,0,0,0とされる。各テキストデータ集合dgに対応する各共起行列は対応するテキストデータ集合dgに対応付けられてモデル計算部16に送られる(ステップS12)。
【0037】
モデル計算部16は各テキストデータ集合dgに対応する各共起行列を用い、テキストデータ集合dgごとに、式(2)で表されるトピックモデルの多項分布パラメータβzvを得る(ステップS13)。本形態ではEMアルゴリズムを用いて多項分布パラメータβzvを得る例を示す。
【0038】
[ステップS13でEMアルゴリズムを用いる例]
図2Bに例示するように、モデル計算部16の第1更新部16aは、t=0とし、多項分布パラメータの初期値ηgz(0)及びβzv(0)を定める。ηgz(0)及びβzv(0)は任意の値でよく、例えば0以上1以下の規定値がηgz(0)及びβzv(0)とされる(ステップS131)。
【0039】
モデル計算部16の第1更新部16aは、ηgz(t)及びβzv(t)を用い、式(3)に従って[E-step]の処理を行って条件付き確率P(zgv|v,η(t),β(t))を求める。条件付き確率P(zgv|v,η(t),β(t))は第2更新部16bに送られる(ステップS132)。
【0040】
第2更新部16bは、条件付き確率P(zgv|v,η(t),β(t))と出現回数n(dg,v)とを用い、式(5)(6)に従って[M-step]の処理を行って多項分布パラメータηgz(t+1)及びβzv(t+1)を求める。出現回数n(dg,v)はテキストデータ集合dgに対応する共起行列を用いて特定される。図3に例示した共起行列の場合、例えばn(dg,“NTT”)=2, n(dg,“は”)=6,..., n(dg,“語る”)=3となる。多項分布パラメータηgz(t+1)及びβzv(t+1)は、第1更新部16aと判定部16cに送られる(ステップS133)。
【0041】
判定部16cは、終了条件を満たしたかを判定する。以下に終了条件を例示する。
[終了条件の例1]
テキストデータ全体に対する対数尤度の変化率Σg∈G log Pt+1(wg|dg)/Σg∈G log Pt(wg|dg)が規定値以上であることを終了条件とする。ただし、
【数9】
である。
[終了条件の例2]
t回目のイテレーションで得られたβ(t)、η(t)とt+1回目のイテレーションで得られたβ(t+1)、η(t+1)との変化率や変化量が規定値以下であることを終了条件とする。例えば、t回目のイテレーションで得られたβ(t)、η(t)を要素とするベクトルと、t+1回目のイテレーションで得られたβ(t+1)、η(t+1)を要素とするベクトルとの距離が規定値以下であることを終了条件とする。
[終了条件の例3]
tが所定のイテレーション回数に達したことを終了条件とする。
[終了条件の例4]
終了条件の例1−3の終了条件のうちのいずれか複数を満たすことを終了条件とする(終了条件の例の説明終わり)。
【0042】
終了条件を満たしていないと判定された場合には、t+1を新たなtとしてステップS132に進む(ステップS135)。終了条件を満たしたと判定された場合には、ステップS13の処理を終了し、判定部16cはβzv(t+1)を多項分布パラメータβzvとして出力する。多項分布パラメータβzvを出力するのはトピックモデルを適用する際にはβzvがあれば十分であるからであるが、必要に応じてηgz(t+1)を多項分布パラメータηgzとして出力されてもよい。また、βzv(t)が多項分布パラメータβzvとして出力されてもよいし、ηgz(t)が多項分布パラメータηgzとして出力されてもよい(ステップS14)。
【0043】
〔第2実施形態〕
第2実施形態は第1実施形態の変形例であり、語義タガーを用いて文字列に語義が付与される形態である。以下では第1実施形態との相違点を中心に説明し、第1実施形態と共通する事項については、第1実施形態と同じ参照番号を用いて説明を省略する。
<構成>
図1に例示するように、本形態のトピックモデリング装置2は、制御部11と記憶部12,13と語義付与部24と共起行列変換部15とモデル計算部16とを有する。第1実施形態との相違点は語義付与部24のみである。図4に例示するように、語義付与部24は、記憶部241と素性化部242と学習部243と語義識別部244とを有する。
【0044】
<事前処理>
事前処理として、第1実施形態と同様に、記憶部12に処理対象のテキストデータの集合Tが格納され、記憶部12に各文字列の語義を表す辞書Wが格納される。
さらに本形態では語義タガーの学習が行われ、それによって得られた語義タガーが記憶部241に格納される。すなわち、文書などのテキストデータに含まれる単語などの文字列に対して語義の付与された学習データTRが素性化部242(図4)に入力される。素性化部242は、前述したように([学習データの素性変換]及び[語義タガーの学習])、学習データが含む文字列を素性変換し、文字列に対応する素性と当該文字列に付与された語義との組を用いて前述のような学習を行い、「任意の文字列の素性を入力として当該任意の文字列の語義を特定するための情報を得るモデル」である語義タガーMを生成して記憶部241に格納する。
【0045】
<トピックモデリング処理>
図2Aを用いて本形態のトピックモデリング処理を説明する。
記憶部12に格納されたテキストデータの集合Tに含まれる各テキストデータが語義付与部24に入力される。語義付与部24は、記憶部241に格納された語義タガーMを用い、入力された各テキストデータに含まれる各文字列に対して語義を付与する。すなわち語義付与部24の素性化部242(図4)は、入力されたテキストデータに含まれる文字列を前述のように素性化する。例えば、入力されたテキストデータに含まれる文字列の当該テキストデータに対する特徴を表す情報や、文字列が文字列の語義を表す辞書Wに含まれるか否かを表す情報や、辞書Wに示された文字列の語義の的確性を表す情報などが当該文字列の素性の少なくとも一部とされる。入力されたテキストデータに含まれる文字列の素性は語義識別部244に送られる。語義識別部244は、記憶部241から読み込んだ語義タガーMに、テキストデータに含まれる文字列の素性を入力し、前述のように([語義タガーを用いた語義の付与])当該文字列の語義を求める。テキストデータとそれに含まれる各文字列とそれらに付与された語義とは互いに対応付けられ、共起行列変換部15に送られる(ステップS21)。
【0046】
それ以降の処理は第1実施形態と同じであるため説明を省略する。
【0047】
〔第3実施形態〕
第3実施形態は第1及び第2実施形態の応用例であり、第1又は第2実施形態で得られたトピックモデルの適用方法を例示するものである。本形態では、得られたトピックモデルを用い、入力テキストデータにトピック情報を付与する。以下では、第1及び第2実施形態との相違点のみを説明する。
【0048】
<構成>
図1に例示するように、本形態のトピックモデリング装置3は、第1実施形態のトピックモデリング装置1又は第2実施形態のトピックモデリング装置2にモデル適用部37が付加されたものである。
【0049】
<事前処理・トピックモデリング処理>
第1及び第2実施形態で説明した通りである。
【0050】
<モデル適用処理>
モデル適用部37に、第1又は第2実施形態の判定部16cから出力された多項分布パラメータβzvが入力される。さらに、入力テキストデータd'がモデル適用部37に入力される。モデル適用部37は、入力テキストデータd'が含む文字列の集合を入力文字列集合w'とし、入力テキストデータd'が与えられたときの各文字列v'∈Vの条件付き確率をp(v'|d')とし、入力テキストデータd'中の文字列v'∈Vの出現回数をn(d',v')とし、入力テキストデータd'が与えられたときのトピック情報zの条件付き確率p(z|d')である多項分布パラメータをηd’zとした場合における
【数10】
の多項分布パラメータηd’zを求めて出力する。多項分布パラメータηd’zは、入力テキストデータd'に対応するトピック情報がz∈Zであることの条件付き確率p(z|d')である。
【0051】
多項分布パラメータηd’zの生成方法には限定はないが、例えばEMアルゴリズムを用いることができる。この場合には、以下のE-stepとM-stepとを、繰り返しのたびにt+1を新たなtとしながら繰り返し、終了条件を満たした際のηd’z(t+1)又はηd’z(t)を多項分布パラメータηd’zとすればよい。この繰り返し処理のηd’z(t)の初期値P(zd’v|v,η(0),β)及びηd’z(0)は任意な値でよく、この繰り返し処理で多項分布パラメータβzvは更新されない。
【数11】
【0052】
<実験>
本発明の実施形態の手法(p-Conceptron)と従来手法(Conceptron)を比較するために文書分類実験を行った。すなわちp-Conceptronを用いて条件付き確率p(z|d')(トピック重み)を求め、それらを文書分類のための素性の一部として文書分類を行った場合と、従来手法のConceptronで得られたトピックを文書分類のための素性の一部として用いて文書分類を行った場合とで分類性能を比較した。この実験では、毎日新聞の記事文書をテキストデータとし、単語を文字列とし、新聞記事の文書を分類する。毎日新聞の記事には記事ラベルがついている。これを分類の正解ラベルとし、正解ラベルを知ることなくp-Conceptron及びConceptronがいかに正しくラベルを推測できるかを比べ、p-Conceptron及びConceptronの性能を比較する。総ラベル種は17種類である。上述のトピック重みやトピック以外の素性としては文書に含まれる単語のユニグラム素性(単語そのもの)を用いる。実験に用いたConceptron及びp-Conceptronのトピックモデルは毎日新聞2001年版から2007年版から学習されたものである。
【0053】
[クローズテスト]
毎日新聞2001年版からランダムに10000記事をトピックモデルの学習用に用い、それらの記事に含まれる1000記事を分類テスト用に用いた。Conceptronと実験条件を揃えるため、p-Conceptronのトピックモデルの学習には語義タガーを用いていない。トピックモデルの学習にはEMアルゴリズムを採用した。また、Conceptronとp-Conceptronとに共通する素性としてユニグラム素性を用い、さらに素性としてp-Conceptronのトピックモデルで得られるすべてのトピック重みを用いた場合と、Conceptronのトピックモデルで得られるトピックを用いた場合とで、テスト用の1000記事の分類性能が変化したかをみる。なお、テスト用の1000記事にも正解ラベルが存在するが、分類処理にはそれらの正解ラベルはConceptron及びp-Conceptronは与えられていない。
【0054】
Conceptron、p-Conceptronのそれぞれにおいて10、50、100、500トピックの4つのモデルを作成し、最も性能の高かったものを比べる。p-Conceptronのトピック重みの素性化として、全てのトピックの重みを利用した場合と、最大の重み(最大確率)を持つトピックについてだけ素性化することとして場合について実験を行った。実験結果を以下に示す。
【表1】
括弧内は最適だったトピック数(混合数)を示す。ユニグラム素性のみを用いた場合のベースラインの正解率が58.7%だったのに対し、p-Conceptronで最大確率のトピック利用の100トピック(100混合)において正解率63.8%とベースラインに比べて5.1ポイントの精度向上を達成した。さらにConceptronに対しては1ポイントの精度向上を達成した。
【0055】
[オープンテスト]
トピックモデルの学習に用いた記事に含まれない記事についても分類結果を比較した。毎日新聞1997年版からランダムに10000記事をトピックモデルの学習用に用い、学習用の10000記事を除く1000記事を分類テスト用に用いた。素性はクローズテストと同様に設定した。以下に実験結果を示す。
【表2】
ユニグラム素性のみを用いた場合のベースラインの正解率が58.7%だったのに対し、最高値p-Conceptronの50トピック(50混合)においてベースラインに比べて1.4ポイントの精度向上を達成した。さらにConceptronに対しては0.7ポイントの精度向上を達成した。
【0056】
〔第4実施形態〕
第4実施形態は第1及び第2実施形態の応用例であり、第1又は第2実施形態で得られたトピックモデルの他の適用方法を例示するものである。本形態では、得られたトピックモデルを用い、各トピックにおいて特徴的な単語などの文字列を得る。以下では、第1及び第2実施形態との相違点のみを説明する。
【0057】
<構成>
図1に例示するように、本形態のトピックモデリング装置4は、第1実施形態のトピックモデリング装置1又は第2実施形態のトピックモデリング装置2にモデル適用部47が付加されたものである。
【0058】
<事前処理・トピックモデリング処理>
第1及び第2実施形態で説明した通りである。
【0059】
モデル適用部47に、第1又は第2実施形態の判定部16cから出力された多項分布パラメータβzvが入力される。さらに、入力テキストデータd'がモデル適用部47に入力される。モデル適用部47は、多項分布パラメータβzvと入力テキストデータd'中の文字列vの出現確率(ユニグラム確率)p(v)との比rzvを求めて出力する。例えば、モデル適用部47は、rzv=βzv/p(v)を求めて出力する。p(v)に対するβzv=p(v|z)の比率が大きい文字列vほどトピック情報zに対応するトピックにおいて特徴的な単語であると見込まれる。
【0060】
以下に、テキストデータが文書であり、それに含まれる文字列が単語である場合に本形態を適用した結果を例示する。以下では、各トピックについてrzv=βzv/p(v)の高い順に上位10個の単語を列挙する。なお、左側カラムのトピック名は特徴的単語を見て人手で付与されたラベル名である。
【表3】
このように、本形態の方法によって各トピックにおいて特徴的な単語を抽出できることが分かる。
【0061】
〔その他の変形例等〕
なお、本発明は上述の実施の形態に限定されるものではない。例えば上記の各実施形態ではステップS12で共起行列を生成し、生起行列を用いてトピックモデルを生成していた。しかし、生起行列を生成することなく、入力された各テキストデータに含まれる各文字列に対して語義を付与して得られるデータからn(dg,v)を求め、トピックモデルを生成してもよい。また、EMアルゴリズムの更新の順序に限定はなく、M-stepを実行してからE-stepを実行する繰り返し処理が実行されてもよい。この場合のM-stepでのP(zgv|v,η(t),β(t))の初期値P(zgv|v,η(0),β(0))は任意値でよい。
【0062】
第1又は第2実施形態で得られたトピックモデルの適用方法にも限定はなく、多様な用途に適用できる。すなわち、得られたトピックモデルは文書に対するトピック付与のみでなく、文や段落などといったテキストに対するトピック付与に利用されてもよい。また、得られたトピックモデルの多項分布パラメータの距離や類似度を指標として、対応する文書等のテキストデータの類似度を判定してもよい。
【0063】
また、上述の各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能であることはいうまでもない。
また、上述の構成をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。
【0064】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体は、非一時的(non-transitory)な記録媒体である。このような記録媒体の例は、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等である。
【0065】
このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0066】
このようなプログラムを実行するコンピュータは、例えば、まず、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、一旦、自己の記憶装置に格納する。そして、処理の実行時、このコンピュータは、自己の記録装置に格納されたプログラムを読み取り、読み取ったプログラムに従った処理を実行する。また、このプログラムの別の実行形態として、コンピュータが可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することとしてもよく、さらに、このコンピュータにサーバコンピュータからプログラムが転送されるたびに、逐次、受け取ったプログラムに従った処理を実行することとしてもよい。また、サーバコンピュータから、このコンピュータへのプログラムの転送は行わず、その実行指示と結果取得のみによって処理機能を実現する、いわゆるASP(Application Service Provider)型のサービスによって、上述の処理を実行する構成としてもよい。なお、本形態におけるプログラムには、電子計算機による処理の用に供する情報であってプログラムに準ずるもの(コンピュータに対する直接の指令ではないがコンピュータの処理を規定する性質を有するデータ等)を含むものとする。
【0067】
また、上記の実施形態では、コンピュータ上で所定のプログラムを実行させることにより、本装置を構成することとしたが、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
【符号の説明】
【0068】
1−4 トピックモデリング装置
【特許請求の範囲】
【請求項1】
入力された各テキストデータに含まれる各文字列に対して語義を付与する語義付与部と、
前記語義付与部で同じ語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、前記テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、前記テキストデータ集合dgが与えられたときの前記文字列集合vgの条件付き確率をp(wg|dg)とし、前記テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzvとし、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとした場合におけるトピックモデル
【数12】
の前記多項分布パラメータβzvを得るモデル計算部と、
を有するトピックモデリング装置。
【請求項2】
請求項1のトピックモデリング装置であって、
前記モデル計算部は、
多項分布パラメータηgz(t)及びβzv(t)を用い、文字列vとすべてのトピック情報z∈Z、文字列v∈V及びテキストデータ集合dg(g∈G)についての前記多項分布パラメータηgz(t)及びβzv(t)とが与えられたときの前記テキストデータ集合dg中の文字列vのトピック情報zgvの条件付き確率
【数13】
を得る第1更新部と、
前記出現回数n(dg,v)及び前記条件付き確率P(zgv|v,η(t),β(t))を用い、前記テキストデータ集合dgの全体集合{dg|g∈G}をDとした場合における多項分布パラメータ
【数14】
を得る第2更新部と、を含み、
前記第1更新部の処理及び前記第2更新部の処理を含む繰り返し処理が、繰り返しのたびにt+1を新たなtとしながら実行され、
前記多項分布パラメータβzvは、終了条件を満たした際のβzv(t+1)又はβzv(t)である、
ことを特徴とするトピックモデリング装置。
【請求項3】
請求項1又は2のトピックモデリング装置であって、
前記語義付与部は、
前記テキストデータに含まれる前記文字列の当該テキストデータに対する特徴を表す情報を当該文字列の素性の少なくとも一部とする素性付与部と、
任意の文字列の素性を入力として当該任意の文字列の語義を特定するための情報を得るモデルに、前記テキストデータに含まれる前記文字列の素性を入力して当該文字列の語義を得る識別部と、を含む、
ことを特徴とするトピックモデリング装置。
【請求項4】
請求項1から3の何れかのトピックモデリング装置であって、
前記文字列の素性は、当該文字列が文字列の語義を表す辞書に含まれるか否かを表す情報を含む、
ことを特徴とするトピックモデリング装置。
【請求項5】
請求項4のトピックモデリング装置であって、
前記辞書は前記文字列の語義の的確性を表し、
前記文字列の素性は当該文字列の語義の的確性を表す情報を含む、
ことを特徴とするトピックモデリング装置。
【請求項6】
請求項1から5の何れかのトピックモデリング装置であって、
入力テキストデータd'と前記多項分布パラメータβzvとが入力され、前記入力テキストデータd'が含む文字列の集合を入力文字列集合w'とし、前記入力テキストデータd'が与えられたときの前記入力文字列集合w'の条件付き確率をp(w'|d')とし、前記入力テキストデータd'中の文字列v'∈Vの出現回数をn(d',v')とし、前記入力テキストデータd'が与えられたときのトピック情報zの条件付き確率p(z|d')である多項分布パラメータをηd’zとした場合における
【数15】
の前記多項分布パラメータηd’zを得るモデル適用部をさらに有する、
ことを特徴とするトピックモデリング装置。
【請求項7】
請求項1から5の何れかのトピックモデリング装置であって、
前記多項分布パラメータβzvが入力され、前記多項分布パラメータβzvと入力テキストデータd'中の文字列vの出現確率p(v)との比rzvを得るモデル適用部をさらに有する、
ことを特徴とするトピックモデリング装置。
【請求項8】
(a) 語義付与部で、入力された各テキストデータに含まれる各文字列に対して語義を付与するステップと、
(b) 前記ステップ(a)で同じ語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、前記テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、前記テキストデータ集合dgが与えられたときの前記文字列集合wgの条件付き確率をp(wg|dg)とし、前記テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzwとし、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとした場合におけるトピックモデル
【数16】
の前記多項分布パラメータβzvをモデル計算部で得るステップと、
を有するトピックモデリング方法。
【請求項9】
請求項1から7の何れかのトピックモデリング装置としてコンピュータを機能させるためのプログラム。
【請求項1】
入力された各テキストデータに含まれる各文字列に対して語義を付与する語義付与部と、
前記語義付与部で同じ語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、前記テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、前記テキストデータ集合dgが与えられたときの前記文字列集合vgの条件付き確率をp(wg|dg)とし、前記テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzvとし、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとした場合におけるトピックモデル
【数12】
の前記多項分布パラメータβzvを得るモデル計算部と、
を有するトピックモデリング装置。
【請求項2】
請求項1のトピックモデリング装置であって、
前記モデル計算部は、
多項分布パラメータηgz(t)及びβzv(t)を用い、文字列vとすべてのトピック情報z∈Z、文字列v∈V及びテキストデータ集合dg(g∈G)についての前記多項分布パラメータηgz(t)及びβzv(t)とが与えられたときの前記テキストデータ集合dg中の文字列vのトピック情報zgvの条件付き確率
【数13】
を得る第1更新部と、
前記出現回数n(dg,v)及び前記条件付き確率P(zgv|v,η(t),β(t))を用い、前記テキストデータ集合dgの全体集合{dg|g∈G}をDとした場合における多項分布パラメータ
【数14】
を得る第2更新部と、を含み、
前記第1更新部の処理及び前記第2更新部の処理を含む繰り返し処理が、繰り返しのたびにt+1を新たなtとしながら実行され、
前記多項分布パラメータβzvは、終了条件を満たした際のβzv(t+1)又はβzv(t)である、
ことを特徴とするトピックモデリング装置。
【請求項3】
請求項1又は2のトピックモデリング装置であって、
前記語義付与部は、
前記テキストデータに含まれる前記文字列の当該テキストデータに対する特徴を表す情報を当該文字列の素性の少なくとも一部とする素性付与部と、
任意の文字列の素性を入力として当該任意の文字列の語義を特定するための情報を得るモデルに、前記テキストデータに含まれる前記文字列の素性を入力して当該文字列の語義を得る識別部と、を含む、
ことを特徴とするトピックモデリング装置。
【請求項4】
請求項1から3の何れかのトピックモデリング装置であって、
前記文字列の素性は、当該文字列が文字列の語義を表す辞書に含まれるか否かを表す情報を含む、
ことを特徴とするトピックモデリング装置。
【請求項5】
請求項4のトピックモデリング装置であって、
前記辞書は前記文字列の語義の的確性を表し、
前記文字列の素性は当該文字列の語義の的確性を表す情報を含む、
ことを特徴とするトピックモデリング装置。
【請求項6】
請求項1から5の何れかのトピックモデリング装置であって、
入力テキストデータd'と前記多項分布パラメータβzvとが入力され、前記入力テキストデータd'が含む文字列の集合を入力文字列集合w'とし、前記入力テキストデータd'が与えられたときの前記入力文字列集合w'の条件付き確率をp(w'|d')とし、前記入力テキストデータd'中の文字列v'∈Vの出現回数をn(d',v')とし、前記入力テキストデータd'が与えられたときのトピック情報zの条件付き確率p(z|d')である多項分布パラメータをηd’zとした場合における
【数15】
の前記多項分布パラメータηd’zを得るモデル適用部をさらに有する、
ことを特徴とするトピックモデリング装置。
【請求項7】
請求項1から5の何れかのトピックモデリング装置であって、
前記多項分布パラメータβzvが入力され、前記多項分布パラメータβzvと入力テキストデータd'中の文字列vの出現確率p(v)との比rzvを得るモデル適用部をさらに有する、
ことを特徴とするトピックモデリング装置。
【請求項8】
(a) 語義付与部で、入力された各テキストデータに含まれる各文字列に対して語義を付与するステップと、
(b) 前記ステップ(a)で同じ語義gが付与された文字列を含むテキストデータの集合をテキストデータ集合dgとし、語義gの全体集合をGとし、前記テキストデータ集合dgが含む文字列の集合を文字列集合wgとし、前記テキストデータ集合dgが与えられたときの前記文字列集合wgの条件付き確率をp(wg|dg)とし、前記テキストデータ集合dg中の文字列vの出現回数をn(dg,v)とし、文字列vの全体集合をVとし、トピック情報zが与えられたときの文字列vの条件付き確率p(v|z)である多項分布パラメータをβzwとし、テキストデータ集合dgが与えられたときのトピック情報zの条件付き確率p(z|dg)である多項分布パラメータをηgzとし、トピック情報zの全体集合をZとした場合におけるトピックモデル
【数16】
の前記多項分布パラメータβzvをモデル計算部で得るステップと、
を有するトピックモデリング方法。
【請求項9】
請求項1から7の何れかのトピックモデリング装置としてコンピュータを機能させるためのプログラム。
【図1】

【図2】
【図3】
【図4】
【図2】
【図3】
【図4】
【公開番号】特開2012−164220(P2012−164220A)
【公開日】平成24年8月30日(2012.8.30)
【国際特許分類】
【出願番号】特願2011−25356(P2011−25356)
【出願日】平成23年2月8日(2011.2.8)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
【公開日】平成24年8月30日(2012.8.30)
【国際特許分類】
【出願日】平成23年2月8日(2011.2.8)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
[ Back to top ]