
ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all−to−allcommunication)を含む、複数の計算処理をスケジューリングする方法、プログラム及び並列計算機システム。
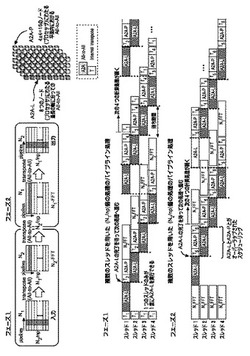
【課題】n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、最適にスケジューリングすること。
【解決手段】ネットワークを構成している複数のノード(プロセッサ)を、第1の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−L)と、第2の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−Pとに分け、複数のスレッド(スレッド1、スレッド2、スレッド3、スレッド4)にわたって、それぞれのフェーズをオーバーラップさせて並列処理する。FFT(Fast Fourier Transform)(高速フーリエ変換)やT(transpose)((内部:internal)転置)という複数の計算処理についてもあわせて、並列処理することができる。
【解決手段】ネットワークを構成している複数のノード(プロセッサ)を、第1の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−L)と、第2の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−Pとに分け、複数のスレッド(スレッド1、スレッド2、スレッド3、スレッド4)にわたって、それぞれのフェーズをオーバーラップさせて並列処理する。FFT(Fast Fourier Transform)(高速フーリエ変換)やT(transpose)((内部:internal)転置)という複数の計算処理についてもあわせて、並列処理することができる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、最適にスケジューリングすることに関する。
【背景技術】
【0002】
トーラスまたはメッシュなどのネットワークで接続された並列計算機においては、複数のノード(プロセッサ)間の通信の性能が計算処理の速度に大きく影響する。代表的な通信のパターンとして、全てのノードが他の全てのノードにノードごとに異なるデータを送信する全対全通信(all-to-all communication、略して「A2A」)が知られており、最も多くの通信転送量を必要とする。全対全通信は、行列または配列(マトリックス)の転置(transpose、略して「T」)や高速フーリエ変換(Fast FourierTransform、略して「FFT」)などの多くの計算において、頻繁に利用される通信の形態であることが知られている。
【0003】
特許文献1は、FFTの計算において、配列を転置することや、1次元(1D)FFTの計算において2次元(2D)FFTとして処理することが、一般的技術水準であることを示している。第1次元を複数のプロセッサにまたがって処理し、第2次元を複数のプロセッサにまたがって処理する。
【0004】
特許文献2は、n次元トーラスにおける全対全通信内部の処理において、フェーズを重ね合わせて効率化を図る工夫について記載している。ここで、特許文献2と本発明との対比説明をしておく。本発明は、全対全通信を複数の部分的な全対全通信に変換し全対全通信単位でパイプライン化するもので、全対全通信内部の実装方式を含まず、発明の適用対象が異なる。また、スケジュールの対象が異なり、本発明のような全対全通信以外の処理と全対全通信内の処理の重ね合わせは、特許文献2には含まれない。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特許第3675537号
【特許文献2】特許第2601591号
【発明の概要】
【発明が解決しようとする課題】
【0006】
n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、さらに効率化することが望まれる。
【課題を解決するための手段】
【0007】
ネットワークを構成している複数のノード(プロセッサ)を、第1の部分グループに含まれる複数のノード間のみについての全対全通信に要する計算処理フェーズ(A2A−L)と、第2の部分グループに含まれる複数のノード間のみについての全対全通信に要する計算処理フェーズ(A2A−Pとに分け、Nt個の複数のスレッド(スレッド1、スレッド2、スレッド3、スレッド4、...スレッドNt)にわたって、それぞれのフェーズをオーバーラップさせて並列処理する。
【発明の効果】
【0008】
n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、最適にスケジューリングすることができ、計算性能を向上させることができる。
【図面の簡単な説明】
【0009】
【図1】1次元(1D)FFT(長さN)を並列計算機において計算処理することを説明する模式図である。
【図2】ノード(プロセッサ)の構成を示す模式図である。
【図3】ネットワークの次元と最長の軸を説明するための模式図として4次元トーラスネットワークを図示したものである。
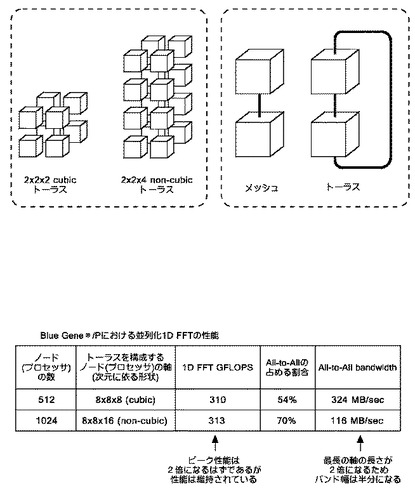
【図4】トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。
【図5】本発明を適用して、複数のノード(プロセッサ)間において 全対全通信(A2A:all-to-allcommunication)を含む複数の計算処理をスケジューリングする方法を示す図である。
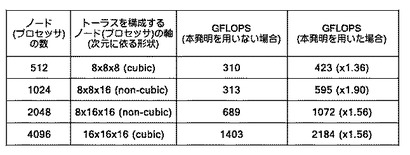
【図6】本発明を適用した場合の効果として、トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。
【発明を実施するための形態】
【0010】
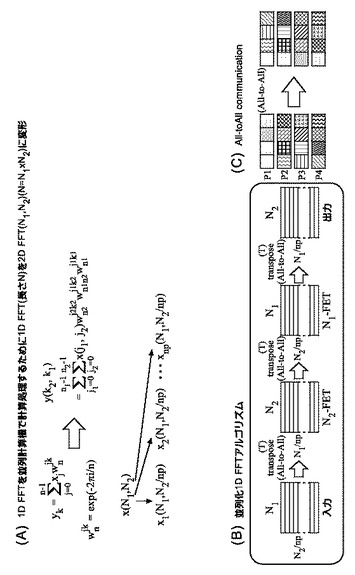
図1は、1次元(1D)FFT(長さN)を並列計算機において計算処理することを説明する模式図である。
【0011】
図1の(A)は、1次元(1D)FFT(長さN)を並列計算機で計算処理するために、2次元(2D)FFT(N1,N2)(N=N1×N2)という形に変形して、N1とN2の長さの2つのFFTに分けて並列処理することを示す。言い換えると、N1とN2との2次元(2D)として、並列処理の方向を変えて処理することを示す。ここで、npは、プロセッサ(ノード)の数(number of processor)である。
【0012】
図1の(B)は、並列化1次元(1D)FFTアルゴリズムを示す。並列化された1次元(1D)FFTにおける計算処理においては、入力から出力を得る過程において3回の転置(transpose「T」)が必要となることが知られている。このことは、例えば特許文献1においても、一般的技術水準として示されている。
【0013】
図1の(C)は、転置(transpose「T」)が、行と列とが入れ替るような処理であることを示す。iを行番号としjを列番号とした場合に、ijに相当する模様の箇所が、jiに相当する模様の箇所へと置き換わることが図示されている。第1段階としては、全体全通信(A2A:all-to-all communication)を用いて模様の箇所を単位としてブロック化されて処理されているため、第2段階として、そのブロックの内部においても内部転置(internal transpose 「IT」)をする必要がある。
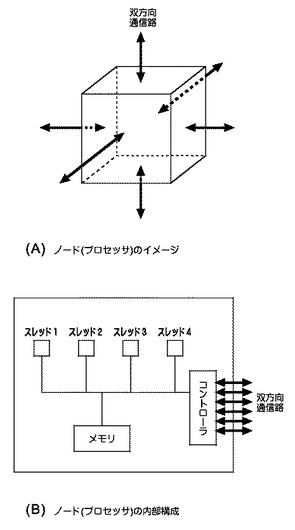
【0014】
図2は、ノード(プロセッサ)の構成を示す模式図である。図2の(A)では、1つのノードを、立方体(cubic)のイメージとして表現している。このような表現に従うと、空間的に隣接する他のノード(プロセッサ)との間において、立方体の6つの面から通信する6本の双方向通信路(12本の片方向通信路でもよい)をイメージし易く、3次元ネットワークの構成がイメージし易い。
【0015】
図2の(B)では、ノード(プロセッサ)の内部構成を示す。並列計算機の特徴として、スレッドが複数存在しており、マルチスレッドと呼ばれるものがある。類似するものとして、マルチコア、マルチプロセッサ、など、様々な表現で呼ばれるものがあって、それらが必ずしも一義的に区別されて用いられてはいない。もっとも、本発明の適用は、ノード(プロセッサ)内において、並列に処理(パイプライン化)でき、処理すべき内容をオーバーラップさせることができるということにあるため、本発明を適用することができる対象としては、これらをあえて区別する意義はない。
【0016】
1つのノード(プロセッサ)内におけるスレッドの数については、様々な製品が存在していることが知られている。ここでは、4つのスレッドとして、スレッド1、スレッド2、スレッド3、スレッド4が示される。スレッドは、典型的にはハードウエアであるが、ハードウエアを共有するように工夫されたソフトウエアとして、または、ハードウエアとソフトウエアとの組合せとして具現化することができる。
【0017】
さらに、ノード(プロセッサ)内にはメモリがあって、現時点において、どの通信処理がスレッドを専有している状態にあるのかについての情報、次にはどの通信処理をスレッドに実行させるかについての情報(例えば、テーブルのようなもの)等を記憶している。メモリは、典型的にはハードウエアとして具現化されるが、ソフトウエアとの組合せにおいて仮想的な領域を形成することもできる。
【0018】
また、ノード(プロセッサ)内にはコントローラがあって、通信路を通じて送受信されるメッセージのアクセス許可の制御を行なっている。コントローラは、ハードウエアとして、ソフトウエアとして、または、ハードウエアとソフトウエアとの組合せとして、具現化することができる。
【0019】
本発明のスケジューリング方法は、単数のノード(プロセッサ)毎に自律的に動作することも可能であるし、部分グループを構成する隣接する複数のノード(プロセッサ)との間で協働して動作することも可能である。スケジューリング方法は、各ノード(プロセッサ)が動作できるような複数のコードを有するプログラム(またはプログラム製品)として提供することもできる。また、複数のノード(プロセッサ)のグループとして、本発明のスケジューリングを可能とする、並列計算機システムとして提供することもできる。
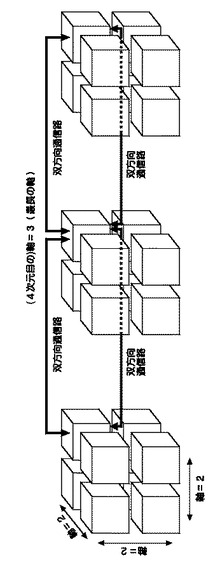
【0020】
図3は、ネットワークの次元と最長の軸を説明するための模式図として4次元トーラスネットワークを図示したものである。既に説明したように、3次元ネットワークであれば、図2の立方体(cubic)の6面を通じて通信する6本の双方向通信路として、直感的にもイメージし易いであろう。
【0021】
ここでは、隣接する8つの立方体が1つの部分グループ(サブグループ)を形成していて、その部分グループが横に3つ並んでいる。1つの部分グループあたりの軸の数は、x軸、y軸、z軸という馴染みのある座標系に沿って、L個、M個、N個、というようにノード(プロセッサ)の数を数えて、x軸に2、y軸に2、z軸に2、と数える。ここでは、全ての軸の長さが等しく2×2×2と表現され、これら3軸は同じ長さの軸である。
【0022】
さらに、4次元ネットワークを説明する。ここでは、横に3つ並んだ部分グループ間を結ぶ双方向通信路として、1つのノード(プロセッサ)からさらに2本の双方向通信路が追加されて(3次元空間でも見える態様で)示されており、1つのノード(プロセッサ)については、8本の双方向通信路をイメージすることができる。新たに追加された双方向通信路に沿う軸をt軸としてノード(プロセッサ)の数を数えると3になり2×2×2×3と表現されるため、この例における最長の軸は、この4次元目にあたる軸である3ということになる。本発明において、「最長の軸」は重要な意義を有する。さらに、n次元ネットワークについては、当業者であれば、本発明を容易に拡張して適用することが可能であろう。
【0023】
図4は、トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。
【0024】
まず、点線内において、3次元ネットワークの立方体(cubic)イメージとして、2×2×2(=8)の立方体(cubic)トーラスと、2×2×4(=16)の非立方体(non-cubic)トーラスとを図示している。ノード(プロセッサ)の数の制限があると、例えば、3×3×3(=27)の立方体(cubic)に構成できるとは限らないので、非立方体(non-cubic)の構成を利用する状況は多い。
【0025】
2×1×1の構成における、メッシュとトーラスとの区別は、点線内に図示したように立体の各軸の両端のノード(プロセッサ)を結ぶ双方向通信路が存在しているかどうかの差である。グループを形成している状態では表現上煩雑になるため、これら双方向通信路は図示しないこととする。
【0026】
性能比較のために、並列化1次元(1D)FFTの性能を、8×8×8(=512)のトーラスと、8×8×16(=1024)の非立方体(non-cubic)トーラスとで比較している。「次元による形状」というのが、この図では「3次元に依る形状」なのであって、立方体(cubic)であったり、非立方体(non-cubic)であったりする。
【0027】
Blue Gene /P(Blue Gene およびBlue Gene /Pは、IBM Corporation の商標)においてその性能を測定した。GFLOPSは、ギガフロップスの単位である。本来であれば512→1024と利用できるノード(プロセッサ)の数が2倍になっているのであるから、性能も2倍になることが期待されるが、ピーク性能は維持されたままになってしまっている。
【0028】
また、全体の通信におけるall-to-all 通信が占める割合は54%から70%へと増大してしまっており、最長の軸の長さが16と、8の2倍になるため、 all-to-all 通信のバンド幅は半分以下になってしまっている。
【0029】
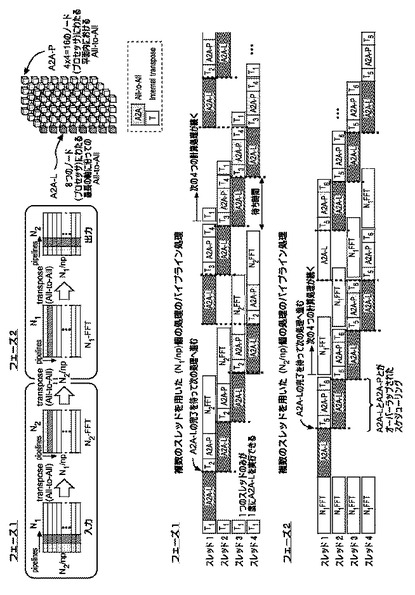
図5は、本発明を適用して、複数のノード(プロセッサ)間において 全対全通信(A2A:all-to-allcommunication)を含む複数の計算処理をスケジューリングする方法を示す図である。図1の(B)の並列化1D(1次元)FFTアルゴリズムに従って、図示のように、フェーズ1と、フェーズ2とに分けて処理を行なう。その際、図2の(B)のノード(プロセッサ)の内部構成に従って、4つのスレッドがあることを想定して、複数のスレッドを用いたパイプライン処理をスケジューリングする。
【0030】
3次元ネットワークを複数のノード(プロセッサ)4×4×8(=128)で構成している非立方体(non-cubic)トーラスについて、最長の軸は8であるが、軸状内にある8つの複数のノード(プロセッサ)が最長の軸を含む第1の部分グループとして選択される。この第1の部分グループに含まれる8つの複数のノード(プロセッサ)間のみについての全対全通信を処理するための通信フェーズを、A2A−L(Lは、Longest の頭文字をとったもの)と呼ぶことにする。
【0031】
3次元ネットワークを複数のノード(プロセッサ)4×4×8(=128)で構成している非立方体(non-cubic)トーラスについて、最長の軸以外の全ての軸(4×4)を含む第2の部分グループ内のノード(プロセッサ)は平面(すなわち、軸の数である2として2次元であることに依る形状)になるが、この第2の部分グループに含まれる16(4×4)の複数のノード(プロセッサ)間のみについての全対全通信を処理するための通信フェーズを、A2A−P(Pは、Plane の頭文字をとったもの)と呼ぶことにする。
【0032】
最長となる軸が1つでない場合は最長となる軸の数を次元数とすることに依る形状の第1の部分グループになるが、ここでは図示しない。同様に、複数の最長となる軸がある場合、第2の部分グループの形状は平面や多次元の立体ではなく、軸あるいは空集合(0次元)となることもあるが、ここでは図示しない。
【0033】
ここで、第1の部分グループに含まれるノード(プロセッサ)と、第2の部分グループに含まれるノード(プロセッサ)との両方に共通して含まれるノード(プロセッサ)があることに注意されたい。この場合には1つのノード(プロセッサ)のみであるが、ここを通じて、第1の部分グループの計算処理の結果と、第2の部分グループの計算処理の結果とが、つながりを持つことになる。
【0034】
次に、フェーズ1とフェーズ2とのパイプライン処理のスケジューリングであるが、スレッド1、スレッド2、スレッド3、スレッド4にわけて、複数の計算処理を並列に処理(パイプライン化)できるように(オーバーラップさせ)していることが見てとれる。
【0035】
また、1つのスレッドのみが1度にA2A−Lを実行できるようにスケジューリングされていることが特徴的である。点線で示すように、A2A−Lの処理の完了を待って次の処理へ進むようにスケジューリングされている。典型的には、点線で示す部分に継ぎ目無く、シーケンシャルに(またはシームレスに)実行されるようにスケジューリングされる。
【0036】
A2A−LとA2A−Pとがオーバーラップされていることも特徴的であり、このことによってA2A−Lに要してしまう時間をうまく有効利用することができる。例えば、FFTの計算処理や、T(転置、ここでは内部転置(internal transpose))の計算処理をはめ込んで有効利用することができる。
【0037】
図6は、本発明を適用した場合の効果として、トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。表の一部は、図4におけるものと共通している。
【0038】
本発明を用いた場合には、本発明を用いない場合に比べて、処理速度が上がっていることがわかる。特に、ノード(プロセッサ)の軸が、非立方体(non-cubic)トーラスとして構成された場合において、特にその優位さが目立っている。
【技術分野】
【0001】
本発明は、n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、最適にスケジューリングすることに関する。
【背景技術】
【0002】
トーラスまたはメッシュなどのネットワークで接続された並列計算機においては、複数のノード(プロセッサ)間の通信の性能が計算処理の速度に大きく影響する。代表的な通信のパターンとして、全てのノードが他の全てのノードにノードごとに異なるデータを送信する全対全通信(all-to-all communication、略して「A2A」)が知られており、最も多くの通信転送量を必要とする。全対全通信は、行列または配列(マトリックス)の転置(transpose、略して「T」)や高速フーリエ変換(Fast FourierTransform、略して「FFT」)などの多くの計算において、頻繁に利用される通信の形態であることが知られている。
【0003】
特許文献1は、FFTの計算において、配列を転置することや、1次元(1D)FFTの計算において2次元(2D)FFTとして処理することが、一般的技術水準であることを示している。第1次元を複数のプロセッサにまたがって処理し、第2次元を複数のプロセッサにまたがって処理する。
【0004】
特許文献2は、n次元トーラスにおける全対全通信内部の処理において、フェーズを重ね合わせて効率化を図る工夫について記載している。ここで、特許文献2と本発明との対比説明をしておく。本発明は、全対全通信を複数の部分的な全対全通信に変換し全対全通信単位でパイプライン化するもので、全対全通信内部の実装方式を含まず、発明の適用対象が異なる。また、スケジュールの対象が異なり、本発明のような全対全通信以外の処理と全対全通信内の処理の重ね合わせは、特許文献2には含まれない。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特許第3675537号
【特許文献2】特許第2601591号
【発明の概要】
【発明が解決しようとする課題】
【0006】
n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、さらに効率化することが望まれる。
【課題を解決するための手段】
【0007】
ネットワークを構成している複数のノード(プロセッサ)を、第1の部分グループに含まれる複数のノード間のみについての全対全通信に要する計算処理フェーズ(A2A−L)と、第2の部分グループに含まれる複数のノード間のみについての全対全通信に要する計算処理フェーズ(A2A−Pとに分け、Nt個の複数のスレッド(スレッド1、スレッド2、スレッド3、スレッド4、...スレッドNt)にわたって、それぞれのフェーズをオーバーラップさせて並列処理する。
【発明の効果】
【0008】
n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、最適にスケジューリングすることができ、計算性能を向上させることができる。
【図面の簡単な説明】
【0009】
【図1】1次元(1D)FFT(長さN)を並列計算機において計算処理することを説明する模式図である。
【図2】ノード(プロセッサ)の構成を示す模式図である。
【図3】ネットワークの次元と最長の軸を説明するための模式図として4次元トーラスネットワークを図示したものである。
【図4】トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。
【図5】本発明を適用して、複数のノード(プロセッサ)間において 全対全通信(A2A:all-to-allcommunication)を含む複数の計算処理をスケジューリングする方法を示す図である。
【図6】本発明を適用した場合の効果として、トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。
【発明を実施するための形態】
【0010】
図1は、1次元(1D)FFT(長さN)を並列計算機において計算処理することを説明する模式図である。
【0011】
図1の(A)は、1次元(1D)FFT(長さN)を並列計算機で計算処理するために、2次元(2D)FFT(N1,N2)(N=N1×N2)という形に変形して、N1とN2の長さの2つのFFTに分けて並列処理することを示す。言い換えると、N1とN2との2次元(2D)として、並列処理の方向を変えて処理することを示す。ここで、npは、プロセッサ(ノード)の数(number of processor)である。
【0012】
図1の(B)は、並列化1次元(1D)FFTアルゴリズムを示す。並列化された1次元(1D)FFTにおける計算処理においては、入力から出力を得る過程において3回の転置(transpose「T」)が必要となることが知られている。このことは、例えば特許文献1においても、一般的技術水準として示されている。
【0013】
図1の(C)は、転置(transpose「T」)が、行と列とが入れ替るような処理であることを示す。iを行番号としjを列番号とした場合に、ijに相当する模様の箇所が、jiに相当する模様の箇所へと置き換わることが図示されている。第1段階としては、全体全通信(A2A:all-to-all communication)を用いて模様の箇所を単位としてブロック化されて処理されているため、第2段階として、そのブロックの内部においても内部転置(internal transpose 「IT」)をする必要がある。
【0014】
図2は、ノード(プロセッサ)の構成を示す模式図である。図2の(A)では、1つのノードを、立方体(cubic)のイメージとして表現している。このような表現に従うと、空間的に隣接する他のノード(プロセッサ)との間において、立方体の6つの面から通信する6本の双方向通信路(12本の片方向通信路でもよい)をイメージし易く、3次元ネットワークの構成がイメージし易い。
【0015】
図2の(B)では、ノード(プロセッサ)の内部構成を示す。並列計算機の特徴として、スレッドが複数存在しており、マルチスレッドと呼ばれるものがある。類似するものとして、マルチコア、マルチプロセッサ、など、様々な表現で呼ばれるものがあって、それらが必ずしも一義的に区別されて用いられてはいない。もっとも、本発明の適用は、ノード(プロセッサ)内において、並列に処理(パイプライン化)でき、処理すべき内容をオーバーラップさせることができるということにあるため、本発明を適用することができる対象としては、これらをあえて区別する意義はない。
【0016】
1つのノード(プロセッサ)内におけるスレッドの数については、様々な製品が存在していることが知られている。ここでは、4つのスレッドとして、スレッド1、スレッド2、スレッド3、スレッド4が示される。スレッドは、典型的にはハードウエアであるが、ハードウエアを共有するように工夫されたソフトウエアとして、または、ハードウエアとソフトウエアとの組合せとして具現化することができる。
【0017】
さらに、ノード(プロセッサ)内にはメモリがあって、現時点において、どの通信処理がスレッドを専有している状態にあるのかについての情報、次にはどの通信処理をスレッドに実行させるかについての情報(例えば、テーブルのようなもの)等を記憶している。メモリは、典型的にはハードウエアとして具現化されるが、ソフトウエアとの組合せにおいて仮想的な領域を形成することもできる。
【0018】
また、ノード(プロセッサ)内にはコントローラがあって、通信路を通じて送受信されるメッセージのアクセス許可の制御を行なっている。コントローラは、ハードウエアとして、ソフトウエアとして、または、ハードウエアとソフトウエアとの組合せとして、具現化することができる。
【0019】
本発明のスケジューリング方法は、単数のノード(プロセッサ)毎に自律的に動作することも可能であるし、部分グループを構成する隣接する複数のノード(プロセッサ)との間で協働して動作することも可能である。スケジューリング方法は、各ノード(プロセッサ)が動作できるような複数のコードを有するプログラム(またはプログラム製品)として提供することもできる。また、複数のノード(プロセッサ)のグループとして、本発明のスケジューリングを可能とする、並列計算機システムとして提供することもできる。
【0020】
図3は、ネットワークの次元と最長の軸を説明するための模式図として4次元トーラスネットワークを図示したものである。既に説明したように、3次元ネットワークであれば、図2の立方体(cubic)の6面を通じて通信する6本の双方向通信路として、直感的にもイメージし易いであろう。
【0021】
ここでは、隣接する8つの立方体が1つの部分グループ(サブグループ)を形成していて、その部分グループが横に3つ並んでいる。1つの部分グループあたりの軸の数は、x軸、y軸、z軸という馴染みのある座標系に沿って、L個、M個、N個、というようにノード(プロセッサ)の数を数えて、x軸に2、y軸に2、z軸に2、と数える。ここでは、全ての軸の長さが等しく2×2×2と表現され、これら3軸は同じ長さの軸である。
【0022】
さらに、4次元ネットワークを説明する。ここでは、横に3つ並んだ部分グループ間を結ぶ双方向通信路として、1つのノード(プロセッサ)からさらに2本の双方向通信路が追加されて(3次元空間でも見える態様で)示されており、1つのノード(プロセッサ)については、8本の双方向通信路をイメージすることができる。新たに追加された双方向通信路に沿う軸をt軸としてノード(プロセッサ)の数を数えると3になり2×2×2×3と表現されるため、この例における最長の軸は、この4次元目にあたる軸である3ということになる。本発明において、「最長の軸」は重要な意義を有する。さらに、n次元ネットワークについては、当業者であれば、本発明を容易に拡張して適用することが可能であろう。
【0023】
図4は、トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。
【0024】
まず、点線内において、3次元ネットワークの立方体(cubic)イメージとして、2×2×2(=8)の立方体(cubic)トーラスと、2×2×4(=16)の非立方体(non-cubic)トーラスとを図示している。ノード(プロセッサ)の数の制限があると、例えば、3×3×3(=27)の立方体(cubic)に構成できるとは限らないので、非立方体(non-cubic)の構成を利用する状況は多い。
【0025】
2×1×1の構成における、メッシュとトーラスとの区別は、点線内に図示したように立体の各軸の両端のノード(プロセッサ)を結ぶ双方向通信路が存在しているかどうかの差である。グループを形成している状態では表現上煩雑になるため、これら双方向通信路は図示しないこととする。
【0026】
性能比較のために、並列化1次元(1D)FFTの性能を、8×8×8(=512)のトーラスと、8×8×16(=1024)の非立方体(non-cubic)トーラスとで比較している。「次元による形状」というのが、この図では「3次元に依る形状」なのであって、立方体(cubic)であったり、非立方体(non-cubic)であったりする。
【0027】
Blue Gene /P(Blue Gene およびBlue Gene /Pは、IBM Corporation の商標)においてその性能を測定した。GFLOPSは、ギガフロップスの単位である。本来であれば512→1024と利用できるノード(プロセッサ)の数が2倍になっているのであるから、性能も2倍になることが期待されるが、ピーク性能は維持されたままになってしまっている。
【0028】
また、全体の通信におけるall-to-all 通信が占める割合は54%から70%へと増大してしまっており、最長の軸の長さが16と、8の2倍になるため、 all-to-all 通信のバンド幅は半分以下になってしまっている。
【0029】
図5は、本発明を適用して、複数のノード(プロセッサ)間において 全対全通信(A2A:all-to-allcommunication)を含む複数の計算処理をスケジューリングする方法を示す図である。図1の(B)の並列化1D(1次元)FFTアルゴリズムに従って、図示のように、フェーズ1と、フェーズ2とに分けて処理を行なう。その際、図2の(B)のノード(プロセッサ)の内部構成に従って、4つのスレッドがあることを想定して、複数のスレッドを用いたパイプライン処理をスケジューリングする。
【0030】
3次元ネットワークを複数のノード(プロセッサ)4×4×8(=128)で構成している非立方体(non-cubic)トーラスについて、最長の軸は8であるが、軸状内にある8つの複数のノード(プロセッサ)が最長の軸を含む第1の部分グループとして選択される。この第1の部分グループに含まれる8つの複数のノード(プロセッサ)間のみについての全対全通信を処理するための通信フェーズを、A2A−L(Lは、Longest の頭文字をとったもの)と呼ぶことにする。
【0031】
3次元ネットワークを複数のノード(プロセッサ)4×4×8(=128)で構成している非立方体(non-cubic)トーラスについて、最長の軸以外の全ての軸(4×4)を含む第2の部分グループ内のノード(プロセッサ)は平面(すなわち、軸の数である2として2次元であることに依る形状)になるが、この第2の部分グループに含まれる16(4×4)の複数のノード(プロセッサ)間のみについての全対全通信を処理するための通信フェーズを、A2A−P(Pは、Plane の頭文字をとったもの)と呼ぶことにする。
【0032】
最長となる軸が1つでない場合は最長となる軸の数を次元数とすることに依る形状の第1の部分グループになるが、ここでは図示しない。同様に、複数の最長となる軸がある場合、第2の部分グループの形状は平面や多次元の立体ではなく、軸あるいは空集合(0次元)となることもあるが、ここでは図示しない。
【0033】
ここで、第1の部分グループに含まれるノード(プロセッサ)と、第2の部分グループに含まれるノード(プロセッサ)との両方に共通して含まれるノード(プロセッサ)があることに注意されたい。この場合には1つのノード(プロセッサ)のみであるが、ここを通じて、第1の部分グループの計算処理の結果と、第2の部分グループの計算処理の結果とが、つながりを持つことになる。
【0034】
次に、フェーズ1とフェーズ2とのパイプライン処理のスケジューリングであるが、スレッド1、スレッド2、スレッド3、スレッド4にわけて、複数の計算処理を並列に処理(パイプライン化)できるように(オーバーラップさせ)していることが見てとれる。
【0035】
また、1つのスレッドのみが1度にA2A−Lを実行できるようにスケジューリングされていることが特徴的である。点線で示すように、A2A−Lの処理の完了を待って次の処理へ進むようにスケジューリングされている。典型的には、点線で示す部分に継ぎ目無く、シーケンシャルに(またはシームレスに)実行されるようにスケジューリングされる。
【0036】
A2A−LとA2A−Pとがオーバーラップされていることも特徴的であり、このことによってA2A−Lに要してしまう時間をうまく有効利用することができる。例えば、FFTの計算処理や、T(転置、ここでは内部転置(internal transpose))の計算処理をはめ込んで有効利用することができる。
【0037】
図6は、本発明を適用した場合の効果として、トーラスを構成するノード(プロセッサ)の軸の数の構成によって、並列化1次元(1D)FFTの性能がどのように違うかを示す図である。表の一部は、図4におけるものと共通している。
【0038】
本発明を用いた場合には、本発明を用いない場合に比べて、処理速度が上がっていることがわかる。特に、ノード(プロセッサ)の軸が、非立方体(non-cubic)トーラスとして構成された場合において、特にその優位さが目立っている。
【特許請求の範囲】
【請求項1】
n(n>2)次元の軸上にその次元に依る形状の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む、複数の計算処理をスケジューリングする方法であって、
最長の軸を含むグループ(最長の軸が1つであれば軸状、それ以外の場合は最長の軸の数を次元数とすることに依る形状)内の複数のノードを、第1の部分グループとして選択するステップと、
この第1の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第1の通信フェーズ(A2A−L)を提供するステップと、
最長の軸以外の残りの全ての軸を含むグループ内の複数のノードを、第2の部分グループとして選択するステップと、
この第2の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第2の通信フェーズ(A2A−P)を提供するステップと、
第1の通信フェーズ(A2A−L)と第2の通信フェーズ(A2A−P) とがノード内で並列に処理(パイプライン化)できるように(オーバーラップさせ)、かつ、第1の部分グループにおける全ての全対全通信が完了するのを待って次の処理に進むことができるように、複数の計算処理をスケジューリングするステップとを有する、
前記方法。
【請求項2】
全ての軸の長さが等しい場合は、全てのノードを含むグループを第一のグループとして選択し、第1の部分グループにおける全対全通信が、シーケンシャルに実行されるようにスケジューリングするステップとを有する、
請求項1に記載の方法。
【請求項3】
さらに、第1の通信フェーズ(A2A−L)と、FFTの計算処理または行列転置の計算処理とが並列に処理(パイプライン化)できるように(オーバーラップさせ)、スケジューリングするステップとを有する、
請求項1に記載の方法。
【請求項4】
n(n>2)次元の軸上にその次元に依る形状の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、単数または複数のノード(プロセッサ)に対して、全対全通信(A2A:all-to-all communication)を含む、複数の計算処理をスケジューリングして実行させるプログラムであって、
最長の軸を含むグループ(最長の軸が1つであれば軸状,それ以外の場合は最長の軸の数を次元数とすることに依る形状)内の複数のノードを、第1の部分グループとして選択することを実行させるコードと、
この第1の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第1の通信フェーズ(A2A−L)を提供することを実行させるコードと、
最長の軸以外の残りの全ての軸を含むグループ内の複数のノードを、第2の部分グループとして選択することを実行させるコードと、
この第2の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第2の通信フェーズ(A2A−P)を提供することを実行させるコードと、
第1の通信フェーズ(A2A−L)と第2の通信フェーズ(A2A−P) とがノード内で並列に処理(パイプライン化)できるように(オーバーラップさせ)、かつ、第1の部分グループにおける全ての全対全通信が完了するのを待って次の処理に進むことができるように、複数の計算処理をスケジューリングすることを実行させるコードとを有する
前記プログラム。
【請求項5】
全ての軸の長さが等しい場合は、全てのノードを含むグループを第一のグループとして選択し、第1の部分グループにおける全対全通信が、シーケンシャルに実行されるようにスケジューリングすることを実行させるコードを有する、
請求項4に記載のプログラム。
【請求項6】
さらに、第1の通信フェーズ(A2A−L)と、FFTの計算処理または行列転置の計算処理とが並列に処理(パイプライン化)できるように(オーバーラップさせ)、スケジューリングすることを実行させるコードを有する、
請求項4に記載のプログラム。
【請求項7】
n(n>2)次元の軸上にその次元に依る形状の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む、複数の計算処理を並列に処理する並列計算機システムであって、
最長の軸を含むグループ(最長の軸が1つであれば軸状,それ以外の場合は最長の軸の数を次元数とすることに依る形状)内の複数のノードを、第1の部分グループとして選択し、
この第1の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第1の通信フェーズ(A2A−L)を提供し、
最長の軸以外の残りの全ての軸を含むグループ内の複数のノードを、第2の部分グループとして選択し、
この第2の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第2の通信フェーズ(A2A−P)を提供し、
第1の通信フェーズ(A2A−L)と第2の通信フェーズ(A2A−P) とがノード内で並列に処理(パイプライン化)できるように(オーバーラップさせ)、かつ、第1の部分グループにおける全ての全対全通信が完了するのを待って次の処理に進むことができるように、複数の計算処理をスケジューリングして並列に処理する、
前記並列計算機システム。
【請求項1】
n(n>2)次元の軸上にその次元に依る形状の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む、複数の計算処理をスケジューリングする方法であって、
最長の軸を含むグループ(最長の軸が1つであれば軸状、それ以外の場合は最長の軸の数を次元数とすることに依る形状)内の複数のノードを、第1の部分グループとして選択するステップと、
この第1の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第1の通信フェーズ(A2A−L)を提供するステップと、
最長の軸以外の残りの全ての軸を含むグループ内の複数のノードを、第2の部分グループとして選択するステップと、
この第2の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第2の通信フェーズ(A2A−P)を提供するステップと、
第1の通信フェーズ(A2A−L)と第2の通信フェーズ(A2A−P) とがノード内で並列に処理(パイプライン化)できるように(オーバーラップさせ)、かつ、第1の部分グループにおける全ての全対全通信が完了するのを待って次の処理に進むことができるように、複数の計算処理をスケジューリングするステップとを有する、
前記方法。
【請求項2】
全ての軸の長さが等しい場合は、全てのノードを含むグループを第一のグループとして選択し、第1の部分グループにおける全対全通信が、シーケンシャルに実行されるようにスケジューリングするステップとを有する、
請求項1に記載の方法。
【請求項3】
さらに、第1の通信フェーズ(A2A−L)と、FFTの計算処理または行列転置の計算処理とが並列に処理(パイプライン化)できるように(オーバーラップさせ)、スケジューリングするステップとを有する、
請求項1に記載の方法。
【請求項4】
n(n>2)次元の軸上にその次元に依る形状の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、単数または複数のノード(プロセッサ)に対して、全対全通信(A2A:all-to-all communication)を含む、複数の計算処理をスケジューリングして実行させるプログラムであって、
最長の軸を含むグループ(最長の軸が1つであれば軸状,それ以外の場合は最長の軸の数を次元数とすることに依る形状)内の複数のノードを、第1の部分グループとして選択することを実行させるコードと、
この第1の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第1の通信フェーズ(A2A−L)を提供することを実行させるコードと、
最長の軸以外の残りの全ての軸を含むグループ内の複数のノードを、第2の部分グループとして選択することを実行させるコードと、
この第2の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第2の通信フェーズ(A2A−P)を提供することを実行させるコードと、
第1の通信フェーズ(A2A−L)と第2の通信フェーズ(A2A−P) とがノード内で並列に処理(パイプライン化)できるように(オーバーラップさせ)、かつ、第1の部分グループにおける全ての全対全通信が完了するのを待って次の処理に進むことができるように、複数の計算処理をスケジューリングすることを実行させるコードとを有する
前記プログラム。
【請求項5】
全ての軸の長さが等しい場合は、全てのノードを含むグループを第一のグループとして選択し、第1の部分グループにおける全対全通信が、シーケンシャルに実行されるようにスケジューリングすることを実行させるコードを有する、
請求項4に記載のプログラム。
【請求項6】
さらに、第1の通信フェーズ(A2A−L)と、FFTの計算処理または行列転置の計算処理とが並列に処理(パイプライン化)できるように(オーバーラップさせ)、スケジューリングすることを実行させるコードを有する、
請求項4に記載のプログラム。
【請求項7】
n(n>2)次元の軸上にその次元に依る形状の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む、複数の計算処理を並列に処理する並列計算機システムであって、
最長の軸を含むグループ(最長の軸が1つであれば軸状,それ以外の場合は最長の軸の数を次元数とすることに依る形状)内の複数のノードを、第1の部分グループとして選択し、
この第1の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第1の通信フェーズ(A2A−L)を提供し、
最長の軸以外の残りの全ての軸を含むグループ内の複数のノードを、第2の部分グループとして選択し、
この第2の部分グループに含まれる複数のノード間のみについての全対全通信を処理するための、第2の通信フェーズ(A2A−P)を提供し、
第1の通信フェーズ(A2A−L)と第2の通信フェーズ(A2A−P) とがノード内で並列に処理(パイプライン化)できるように(オーバーラップさせ)、かつ、第1の部分グループにおける全ての全対全通信が完了するのを待って次の処理に進むことができるように、複数の計算処理をスケジューリングして並列に処理する、
前記並列計算機システム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図2】
【図3】
【図4】
【図5】
【図6】
【公開番号】特開2013−37723(P2013−37723A)
【公開日】平成25年2月21日(2013.2.21)
【国際特許分類】
【出願番号】特願2012−230730(P2012−230730)
【出願日】平成24年10月18日(2012.10.18)
【分割の表示】特願2011−540576(P2011−540576)の分割
【原出願日】平成22年11月15日(2010.11.15)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MACHINES CORPORATION
【Fターム(参考)】
【公開日】平成25年2月21日(2013.2.21)
【国際特許分類】
【出願日】平成24年10月18日(2012.10.18)
【分割の表示】特願2011−540576(P2011−540576)の分割
【原出願日】平成22年11月15日(2010.11.15)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MACHINES CORPORATION
【Fターム(参考)】
[ Back to top ]