
ネットワークプロセッサシステムおよびネットワークプロトコル処理方法
【課題】リモートダイレクトメモリアクセス(RDMA)を利用するためには、RDMA対応のNICが必要であり、コストがかかる。
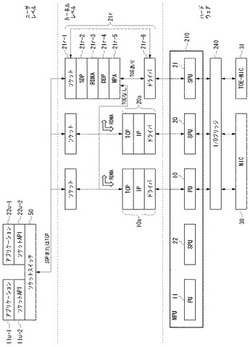
【解決手段】RDMA機能をエミュレートするマルチプロセッサシステムを提供する。第1のサブプロセッシングユニット(SPU)22は、送信すべきメッセージを生成する。第2のSPU21は、リモートダイレクトメモリアクセス機能をエミュレートするプロセッサであり、第1のSPU22からの通知を受けて、メッセージをRDMAプロトコルにしたがったパケットに組み立てる。第3のSPU20は、TCP/IPプロトコル処理を実行するプロセッサであり、第2のSPU21からの通知を受けて、RDMAプロトコルにしたがって生成されたパケットをTCP/IPパケットに組み立て、ネットワークインターフェースカード(NIC)30から送出する。
【解決手段】RDMA機能をエミュレートするマルチプロセッサシステムを提供する。第1のサブプロセッシングユニット(SPU)22は、送信すべきメッセージを生成する。第2のSPU21は、リモートダイレクトメモリアクセス機能をエミュレートするプロセッサであり、第1のSPU22からの通知を受けて、メッセージをRDMAプロトコルにしたがったパケットに組み立てる。第3のSPU20は、TCP/IPプロトコル処理を実行するプロセッサであり、第2のSPU21からの通知を受けて、RDMAプロトコルにしたがって生成されたパケットをTCP/IPパケットに組み立て、ネットワークインターフェースカード(NIC)30から送出する。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、ネットワークプロセッサシステムおよびネットワークプロトコル処理方法に関する。
【背景技術】
【0002】
近年のネットワーク技術の進歩により、ギガビットネットワークの利用が広がるなど、ネットワークの帯域が著しく伸びている。その一方で、ネットワークを流れるパケットを処理するマイクロプロセッサの処理性能はネットワーク性能に比べてそれほど向上していないのが現状である。そのため、高速なネットワークを流れるパケットをマイクロプロセッサが十分な速度で処理することは難しい。特に、ネットワークの帯域幅が1Gbps(giga bit per second)を越えるあたりからマイクロプロセッサの処理性能がネットワークの帯域幅に対してボトルネックとなる。
【0003】
プロセッサの処理性能がボトルネックになる原因は、大きく分けて次の3つである。
(1)TCP(Transmission Control Protocol)処理
(2)コンテキストスイッチ
(3)メモリ間コピー
【0004】
(1)のTCP処理とは、TCPにおけるチェックサムや再送制御など、計算量の多い処理であり、プロセッサへの負荷が大きくなる。この問題を解決するために、TCPオフロードエンジン(TCP Offload Engine; TOE)と呼ばれる技術があり、TCPにおける各処理を実行する専用のハードウェアがネットワークインタフェースカード(NIC)に実装される。このようなTCPオフロードエンジンが搭載されたネットワークインタフェースカードはTOE−NICと呼ばれる。この場合、送受信バッファはTOE−NIC内に設けられる。
【0005】
(2)のコンテキストスイッチとは、パケット処理をするためにユーザモードとカーネルモードの間でコンテキストスイッチが行われることであり、このコンテキストスイッチがオーバーヘッドとなり、全体の処理性能のボトルネックとなる。この問題を解決するために、カーネルによるプロトコル処理をスキップするカーネルバイパスなどの実装技術が検討されている。
【0006】
(3)のメモリ間コピーとは、パケットを処理する過程でパケットのデータが複数のメモリ間でコピーされることである。まず、ネットワークインタフェースカードがカーネルのバッファに受信パケットを書き込む。CPUはカーネルのバッファ内のパケットを解析した後、アプリケーションのバッファにパケットを書き込む。この処理過程でカーネルバッファからアプリケーションバッファへパケットのデータがコピーされており、このメモリ間コピーがオーバーヘッドとなる。
【0007】
メモリ間コピーの問題を解決するために、リモートダイレクトメモリアクセス(RDMA)と呼ばれる技術の実装が行われている。CPUを介さずに各種デバイスとRAMの間で直接データ転送する方式がダイレクトメモリアクセス(DMA)であるが、RDMAは、このDMA機能をネットワークに拡張したものである。RDMAは、あるコンピュータのメモリから別のコンピュータのメモリに直接データを移動させることで、CPU処理のオーバーヘッドをなくす。RDMAを利用するためには、TCP/IPネットワークの場合、RDMA対応のネットワークインタフェースカード(RNIC;RDMA-enabled NIC)を用いる必要がある。一般に、RNICはTOE機能とRDMA機能を合わせもつネットワークインタフェースカードである。
【発明の開示】
【発明が解決しようとする課題】
【0008】
今後ますます高速化するネットワークに対応するために、マイクロプロセッサへの処理負荷を減らすことが通信の効率化のために重要な課題となっている。そのためのひとつの解決策が前述のRDMAである。しかしながら、RDMAを利用するためには、RNICと呼ばれる、RDMA対応の特別なネットワークインタフェースカードが必要であり、これまで使用されていた通常のネットワークインタフェースカードでは、RDMAを利用することができない。現在使用中のNICをすべてRDMA対応のRNICに入れ換えることは、たいへんなコストがかかる。これはRDMAの普及を遅らせている一因である。
【0009】
また、一部のネットワークインタフェースカードだけをRDMA対応にすることで従来のNICとRNICとが混在するネットワークを構成した場合、従来のNICとRNICの間で通信ができないという問題が生じる。
【0010】
本発明はこうした課題に鑑みてなされたものであり、その目的は、RDMA機能を前提とした通信を効率良く行うことのできる通信技術を提供することにある。
【課題を解決するための手段】
【0011】
上記課題を解決するために、本発明のある態様のネットワークプロセッサシステムは、リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記バッファからパケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含む。
【0012】
本発明の別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、カーネルレベルでTCP/IPプロトコル処理を実行するプロセッサであって、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てる第3プロセッサと、前記第3プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含む。
【0013】
本発明のさらに別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、リモートダイレクトメモリアクセス機能をエミュレートするプロセッサと、前記プロセッサから出力されるリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつネットワークインタフェースカードとを含む。
【0014】
本発明のさらに別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すTCP/IPオフロード機能をもつネットワークインタフェースカードとを含む。
【0015】
本発明のさらに別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信する第1ネットワークインタフェースカードと、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつ第2ネットワークインタフェースカードとを含む。前記第1プロセッサは、前記パケットの送信元IPアドレスを前記第1ネットワークインタフェースカードのMACアドレスまたは前記第2ネットワークインタフェースカードのMACアドレスに対応づけたテーブルを参照して、前記パケットの送信元IPアドレスに応じて、前記パケットを送出するためのネットワークインタフェースを前記第1ネットワークインタフェースカードまたは前記第2ネットワークインタフェースカードのいずれかに振り分ける機能を有する。前記パケットが前記第1ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2プロセッサによりTCP/IPプロトコル処理がなされて、前記第1ネットワークインタフェースカードから送出され、前記パケットが前記第2ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2ネットワークインタフェースカードのTCP/IPオフロード機能によりTCP/IPプロトコル処理がなされて、前記第2ネットワークインタフェースカードから送出される。
【0016】
本発明のさらに別の態様は、ネットワークプロトコル処理方法である。この方法は、ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、カーネルレベルでTCP/IPプロトコル処理を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てるステップとを含む。
【0017】
本発明のさらに別の態様もまた、ネットワークプロトコル処理方法である。この方法は、ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、ネットワークインタフェースカード内でTCP/IPオフロード機能を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すステップを実行する。
【0018】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、システム、コンピュータプログラム、プログラム製品、データ構造、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0019】
本発明によれば、RMDA機能を利用した効率の良い通信を行うことができる。
【発明を実施するための最良の形態】
【0020】
以下、図面を参照し、本発明の実施の形態を説明する。なお、以下に述べる実施の形態は、本発明の好適な具体例であるから、技術的に好ましい種々の限定が付されているが、本発明の範囲は以下の説明において、特に本発明を限定する旨の記載がない限り、これらの形態に限定されるものではない。
【0021】
また、実施の形態では、カーネルモードおよびユーザモードに分けてプロトコル処理を説明するが、これは一例に過ぎず、各プロトコルスタックが実装されるべきモードを限定する趣旨ではない。なお、カーネルモード、ユーザモードは、それぞれカーネルレベル、ユーザレベルとも呼ばれる。
【0022】
さらに、RDMA機能を実行するプロセッシングエレメントとして、マルチプロセッサのひとつを用いたが、RDMA機能だけを実行するために、別チップのCPUを用いることも可能である。
【0023】
実施の形態1
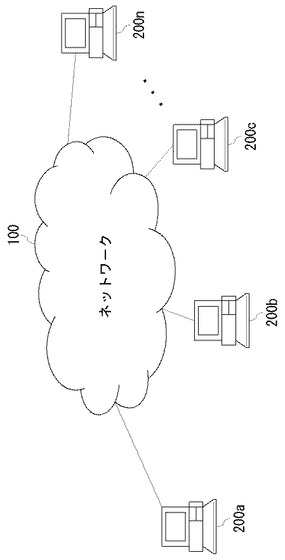
図1は、本発明の実施の形態に係るネットワークシステムを示す図である。ネットワーク100には、複数のノード200a、200b、200c、…、200nが接続されている。以下、ネットワーク100に接続されたノードを総称するときは、単にノード200という。ネットワーク100はルータを含み、IP(Internet Protocol)にしたがってパケットを転送する。
【0024】
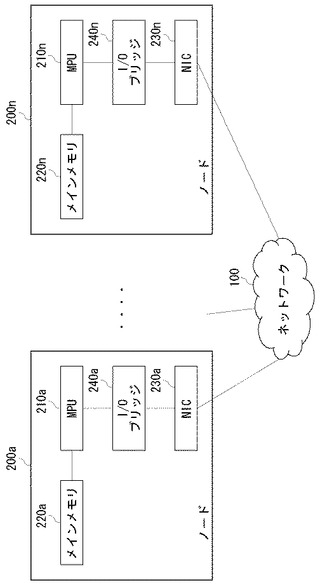
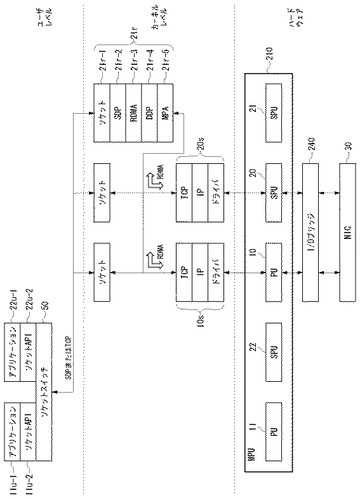
図2は、図1のノード200の構成図である。各ノード200は、マイクロプロセッシングユニット(MPU)210、メインメモリ220、I/Oブリッジ240、およびネットワークインタフェースカード(NIC)230を含む。
【0025】
MPU210は、メインメモリ220に保持された送信すべきデータに宛先アドレスなどのヘッダ情報を付加したパケットを生成し、I/Oブリッジ240を介してNIC230のバッファにパケットを渡す。NIC230は、バッファ内に蓄積されたパケットをネットワーク100に送出する。
【0026】
NIC230はネットワーク100から受信されたパケットをバッファに蓄積し、I/Oブリッジ240を介してMPU210にパケットを渡す。MPU210はパケットのヘッダを解析し、パケット内のデータをメインメモリ220に格納する。
【0027】
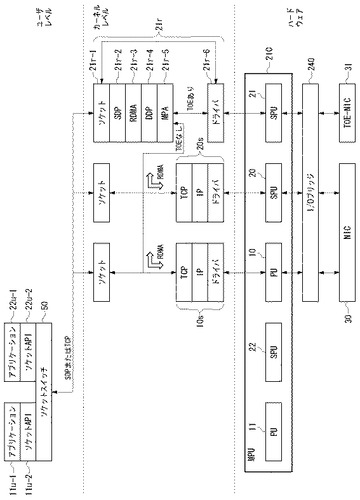
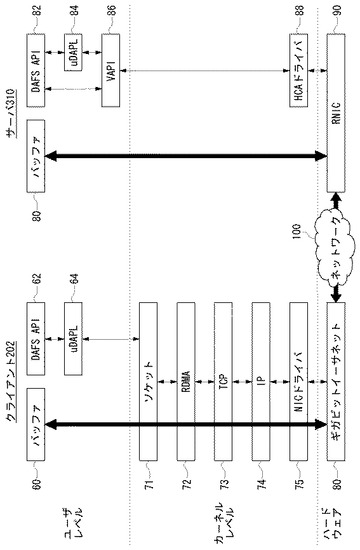
図3は、図2のノード200のMPU210に実装されたTCP/IPプロトコルスタックおよびRDMA機能を説明する図である。これらの機能は、ハードウェアとソフトウェアの組み合わせにより構成され、ソフトウェアはユーザモードおよびカーネルモードで動作する。
【0028】
ハードウェアの構成として各ノード200にはNIC230とMPU210がある。NIC230として、同図に示したように、TOE機能のないNIC30またはTOE機能が搭載されたTOE−NIC31のいずれか、あるいは両方が用いられる。MPU210は、ここでは、プロセッシングユニット(PU)とサブプロセッシングユニット(SPU)を含むマルチプロセッサで構成される。ここで、PUとSPUは処理性能や構成が異なるプロセッシングエレメントである。一例としてPUは、メインメモリ220のデータをキャッシュするためのハードウェアキャッシュ機構を有するが、SPUは、ハードウェアキャッシュ機構がなく、ローカルメモリをもつ。
【0029】
ユーザモードで動作するソフトウェアとして、アプリケーションプログラム11u−1、22u−1、ソケットAPI11u−2、22u−2およびソケットスイッチ50がある。ソケットスイッチ50は、パケットのプロトコルがTCPあるいはSDP(ソケットダイレクトプロトコル)のどちらであるかを判別して、パケットの供給先を切り替える。ここで、SDPとは、既存のソケットプログラムへ変更を加えることなくRDMA機能を実現するためのプロトコルである。ソケットスイッチ50の働きにより、RDMA機能を前提とするパケットはRDMA機能を実装したカーネルレベルのプロトコルスタック21rに渡され、RDMA機能を必要としない通常のTCPのパケットはRDMA機能が実装されていないカーネルレベルのプロトコルスタック10s、20sに渡される。
【0030】
カーネルモードで動作するソフトウェアとして、次の3つがある。
(1)PU10上で動作するTCP/IPプロトコルスタック10s、
(2)SPU20上で動作するTCP/IPプロトコルスタック20s、および
(3)SPU21上で動作するRDMAプロトコルスタック21r。
【0031】
RDMAプロトコルスタック21rは、既存のソケットプログラムを変更することなしにRDMA動作を可能とするために、ソケット層21r−1とSDP層21r−2を含む。これらのレイヤの下にRDMA層21r−3があり、RDMAリード(read)、RDMAライト(write)などのRDMAコマンドがDDP(Direct Data Placement)メッセージに変換される。RDMA層21r−3の下には、DDP層21r−4がある。DDP層21r−4は、送信の際、DDPメッセージを1つまたは複数のDDPセグメントに分割し、受信の際、1つまたは複数のDDPセグメントをDDPメッセージにリアセンブルする。
【0032】
DDP層21r−4の下には、MPA(Marker Protocol-data-unit Aligned)層21r−5がある。MPA層21r−5は、DDPセグメントに一定間隔で逆変換マーカーを付加し、各MPAセグメントにDDPセグメントのデータ長と誤り検出のためのCRC(Cyclic Redundancy Check)を付加する。MPA層21r−5の下には、TCP/IPプロトコルスタックが実装される。
【0033】
TCP/IPプロトコルスタックの実装方法として、(a)PU10またはSPU20にカーネルモードで動作するソフトウェアとして実装する方法と、(b)TOE−NIC31内のTCPオフロードエンジン(TOE)機能としてハードウェアで実装する方法とがある。後者の場合、RDMAプロトコルスタック21rにより処理されたパケットは、デバイスドライバ21r−6、SPU21、I/Oブリッジ240を経由して、TOE−NIC31に渡され、TOE機能によりTCP/IPプロトコル処理がなされ、ネットワークに送出される。
【0034】
一方、TOE機能が実装されていないNIC30の場合には、PU10またはSPU20にカーネルモードで動作するソフトウェアとして実装された、TCP/IPプロトコルスタック10s、20sを用いてTCP/IPプロトコル処理を行う必要がある。
【0035】
上記の(a)TOE機能なしの実装と(b)TOE機能ありの実装の切り換えは、システム起動時に設定ファイルの情報を用いて行う。以下、(a)TOE機能なしの実装の構成と動作を実施例1として説明し、(b)TOE機能ありの実装の構成と動作を実施例2として説明する。また、ノード200内にTOE機能のない通常のNIC30とTOE機能付きのTOE−NIC31がともに実装されている場合の構成と動作を実施例3として説明する。
【0036】
RDMAプロトコルスタック21rとTCP/IPプロトコルスタック10s、20sはMPU210の各プロセッサ上に常駐することを基本とするが、RDMA機能を用いない場合には、RDMAプロトコルスタック21rはサスペンドされ、他のプロセスが動作してもよい。これは、TCP/IPプロトコルスタック10s、20sについても同様である。
【0037】
実施例1
図4は、実施例1のノード200の構成図である。実施例1では、ノード200にはTOE機能のない通常のNIC30が搭載されており、システム起動時の設定により、NIC30が動作可能になるため、動作しないTOE−NIC31に関わる構成については図示していない。実施例1では、TCP/IPプロトコルスタックはPU10またはSPU20上に実装される。PU10およびSPU20上のTCP/IPプロトコルスタック10sおよび20sは同時に動作することも可能であるし、どちらかが休止していてもかまわない。
【0038】
RDMA動作の一例として、RDMAライトについて説明する。図1の2つのノード200aと200b間でRDMAライトが実行されるとする。発行元ノード200aが発行先ノード200bに対してRDMAライト命令を発行し、RDMAライトされるべきデータを発行先ノード200bに送信する。
【0039】
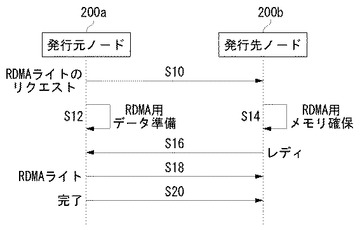
図5は、発行元ノード200aと発行先ノード200bの間で行われるRDMAライト処理のシーケンス図である。はじめに、発行元ノード200aから発行先ノード200bへRDMAライトのリクエストが発行される(S10)。このリクエスト時にRDMAライトされるデータのサイズ等の情報が送信される。その後、発行元ノード200aは、自ノード内のメインメモリ220aにRDMAライトすべきデータを準備する(S12)。
【0040】
一方、発行先ノード200bは、発行元ノード200aから発行されたRDMAライトのリクエストに対して、自ノード内のメインメモリ220bにRDMAライト用のメモリ領域を確保する(S14)。発行先ノード200bにデータが受信されると、自ノードのNIC30bがカーネルモードのソフトウェアに割り込み信号を送ることで、受信データの存在をカーネルに知らせる。
【0041】
発行先ノード200bは、RDMAライト用メモリ領域を確保した後、発行元ノード200aに向けて、レディ(Ready)メッセージを送信する(S16)。
【0042】
発行元ノード200aは、発行先ノード200bからレディメッセージを受信した後、RDMAライトを実行する(S18)。なお、発行元のノード200aは、メッセージの受信を自ノードのNIC30から割り込みが入ることで検出することができる。
【0043】
発行元のノード200aは、RDMAライトが完了した後に、完了メッセージを発行先ノード200bに送信する(S20)。以上で、RDMAライトの処理が完了する。
【0044】
図6および図7Aを参照し、図5のRDMAライト処理シーケンスの各ステップが図4の構成によって実行される様子を詳しく説明する。図6は、図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。一方、図7Aは、図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。
【0045】
以下では、TCP/IPプロトコルスタックがSPU20に実装されている場合について動作を説明するが、TCP/IPプロトコルスタックがPU10に実装されている場合の動作も基本的には同様である。
【0046】
(1)ステップS10の動作
図4において、発行元ノード200aのユーザ空間にあるアプリケーションプログラム11u−1または22u−1により、RDMAライトのリクエストが発行される。ここで、アプリケーションプログラム11u−1、22u−1はそれぞれ発行元ノード200aのPU11、SPU22で実行される。ここでは、アプリケーションプログラム11u−1、22u−1を実行するPU11、SPU22と、プロトコルスタックを実行するPU10a、SPU20、21は異なるものとして説明するが、アプリケーションプログラムとプロトコルスタックを実行するPUあるいはSPUは同一であってもかまわない。
【0047】
発行元ノード200aのソケットスイッチ50は、RDMAライトのリクエストが通常のTCP/IPにより送信されるべきであることを識別する。この識別は、発行元ノード200aのソケットAPI11u−2あるいは22u−2において、以下のコマンドを実行することで実現される。
socket(AF_INET, SOCK_STREAM, 0);
ここで、socketコマンドの第1引数AF_INETは、IPv4のインターネットプロトコルであることを示す。第2引数SOCK_STREAMは通信がコネクション型であることを示す。第3引数の0は通常のTCP/IPプロトコルを用いることを示す。
【0048】
RDMAライトのリクエストメッセージは、発行元ノード200aのSPU20上に実装されたTCP/IPプロトコルスタック20sを経由することで、RDMAライトのリクエストパケットへと組み立てられる。
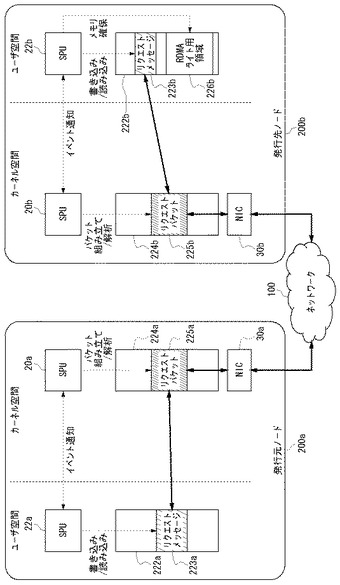
【0049】
図6を参照して、RDMAライトのリクエストパケットの生成過程を説明する。発行元ノード200aにおいて、ユーザレベルで動作中のSPU22aは、ユーザ空間にあるアプリケーション用バッファ222aにRDMAライトのリクエストメッセージ223aを生成する。その後、ユーザレベルで動作中のSPU22aは、カーネルレベルで動作中のSPU20aに対してイベント通知することにより、パケットの組み立ての開始を通知する。このイベント通知には、アトミック命令のような同期機能を用いてもよく、SPUにイベント通知用のレジスタやメールボックスなどを設けることにより実現してもよい。
【0050】
カーネルレベルのSPU20aは、アプリケーション用バッファ222aからRDMAライトのリクエストメッセージ223aを読み出し、そのリクエストメッセージ223aにヘッダを付加し、カーネル空間にあるTCP/IP送受信バッファ224aにRDMAライトのリクエストパケット225aを生成する。生成されたリクエストパケット225aは発行元ノード200aのNIC30aから送出される。
【0051】
(2)ステップS12の動作
発行元ノード200aにおいてRDMAライトのリクエストの発行が終わると、図7Aに示すように、発行元ノード200aのユーザモードにあるSPU22aがアプリケーションを実行し、RDMAライトにより書き込むべきRDMAメッセージ227aをアプリケーション用バッファ222aに書き込み、RDMAライト用のデータを準備する。
【0052】
(3)ステップS14の動作
一方、発行先ノード200bは、ステップS10において発行元ノード200aが発行したRDMAライトのリクエストを受け取り、RDMAライト用のメモリ領域を準備する。図6に示すように、発行先ノード200bのNIC30bはネットワーク100からRDMAライトのリクエストパケット225bを受信し、TCP/IP送受信バッファ224bにコピーする。
【0053】
発行先ノード200bのカーネルモードにあるSPU20bは、TCP/IP送受信バッファ224bに受信されたRDMAライトのリクエストパケット225bを解析し、パケット内のリクエストメッセージ223bをリアセンブルしてユーザ空間のアプリケーション用バッファ222bにコピーする。その後、カーネルモードにあるSPU20bは、ユーザモードにあるSPU22bにイベント通知し、RDMAライトのリクエストメッセージが受信されたことを通知する。
【0054】
カーネルモードにあるSPU20bからイベント通知を受けた、ユーザモードにあるSPU22bはアプリケーション22u−1を実行し、RDMAライトのリクエストメッセージ223bを読み、アプリケーション用バッファ222b内にRDMAライトに必要なメモリ領域(「RDMAライト用領域」という)226bを確保する。
【0055】
(4)ステップS16の動作
その後、発行先ノード200bのユーザ空間にあるアプリケーション22u−1は、レディメッセージを発行元ノード200aに返信する。RDMAライトのリクエストメッセージの場合と同様、レディメッセージは、発行先ノード200bのソケットスイッチ50がTCP/IPプロトコルを指定したコマンドを実行することにより、通常のTCP/IPプロトコルにしたがって、TCP/IPプロトコルスタック20sにより処理され、NIC30bから送信される。
【0056】
(5)ステップS18の動作
図4および図7Aを参照して、RDMAライトの動作を詳しく説明をする。発行元ノード200aにおいてアプリケーションプログラム11u−1あるいは22u−1がRDMAライトのコマンドを発行する。その際、ソケットAPI11u−2あるいは22u−2は、
socket(AF_INET_SDP, SOCK_STREAM, 0);
というコマンドを用いる。ここで、第1引数"AF_INET_SDP"は、通信プロトコルとしてSDPを用いてRDMA機能を実行することを意味する。それ以外のパラメータは前述の通りである。
【0057】
ソケットスイッチ50がsocketコマンドの第1引数によってRDMA動作であることを認識し、RDMAプロトコルスタックが実装されているSPU21aにイベント通知し、SPU21aがRDMAパケットを生成する。
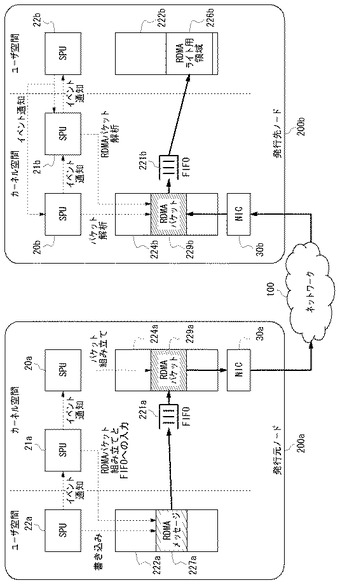
【0058】
図7Aを参照して、RDMAパケットの生成過程を説明する。発行元ノード200aにおいて、ユーザモードのSPU22aからイベント通知を受け取ったカーネルモードのSPU21aは、ユーザ空間にあるアプリケーション用バッファ222a内のRDMAメッセージ227aをセグメント化し、RDMAパケットを組み立て、FIFOバッファ221aにRDMAパケットをキューイングする。
【0059】
FIFOバッファ221aは、RDMAプロトコルスタックが実装されたSPU21aと、TCP/IPプロトコルスタックが実装されたSPU20aとの間で共有されており、SPU21aはSPU20aにイベント通知し、FIFOバッファ221aに送信すべきRDMAパケットがあることを知らせる。イベント通知されたSPU20aは、FIFOバッファ221aにあるRDMAパケットをTCP/IPパケットに組み立て、TCP/IP送受信バッファ224aにコピーする。NIC30aは、TCP/IP送受信バッファ224a内のRDMAパケット229aをネットワーク100に送出する。
【0060】
一方、発行先ノード200bにおいても、ソケットAPI11u−1あるいは22u−2によってRDMA機能を使用することがsocketコマンドにより宣言される。そして、ソケットスイッチ50により、ユーザレベルのSPU22bからカーネルレベルのSPU21bおよびSPU20bへRDMAイベントがあることが通知される。
【0061】
発行先ノード200bのNIC30bは、ネットワーク100からRDMAパケット229bを受信し、TCP/IP送受信バッファ224bへコピーする。TCP/IPプロトコルスタック20sが実装されたSPU20bは、TCP/IP送受信バッファ224b内のRDMAパケット229bをTCP/IPプロトコルにしたがって解析し、FIFOバッファ221bにTCP/IPパケットをキューイングする。FIFOバッファ221bは、TCP/IPプロトコルスタック20sが実装されたSPU20bとRDMAプロトコルスタック21rが実装されたSPU21bの間で共有されている。TCP/IPプロトコル処理の後、SPU20bは、RDMAプロトコル処理を行うSPU21bにイベント通知し、RDMAパケットが受信されたことを知らせる。
【0062】
RDMAプロトコルスタック21rが実装されたSPU21bは、RDMAプロトコルにしたがってFIFOバッファ221bにあるRDMAパケットを解析し、RDMAライトすべきメッセージをリアセンブルし、アプリケーション用バッファ222bのRDMAライト用領域226bに書き込む。
【0063】
(6)ステップS20の動作
RDMAライトの発行が終わると、発行元ノード200aは「完了」メッセージを発行先ノード200bに送信する。「完了メッセージ」は、図6で説明した、RDMA機能を用いない通常のTCP/IPパケットで送信される。発行先ノード200bは「完了」メッセージを受信し、RDMAライト用領域226bを解放し、RDMAライトの動作を終了する。
【0064】
以上述べたように、実施例1によれば、RDMAプロトコル処理をソフトウェアでエミュレートすることにより、RDMA対応のNICでなくてもRDMA機能を用いた通信を行うことができる。また、実施例1では、ノード200内の複数のプロセッサが、TCP/IPプロトコル処理やRDMAプロトコル処理など個別の特定処理を専門に行う。同一のプロセッサがTCP/IPプロトコル処理とRDMAプロトコル処理を担当すると、異なるプロトコル処理を行う際、コンテキストスイッチが生じ、オーバーヘッドとなる。実施例1では、マルチプロセッサシステムであることを利用して、TCP/IPプロトコル処理を行うプロセッサと、RDMAプロトコル処理を行うプロセッサを別々に分けたため、コンテキストスイッチによるオーバーヘッドを低減することができ、高速なネットワーク処理を実現することができる。また、RDMA機能を使わない通信の際は、TCP/IPプロトコルスタックが実装されたプロセッサだけを利用して通信を行うことができる。
【0065】
上記の実施の形態では、各ノード200内にあるメインメモリ220にTCP/IP送受信バッファ224を設ける構成を説明したが、図7Bに示すように、各ノード200に搭載されたNIC30内にTCP/IP送受信バッファ224を設ける構成であってもよい。この場合、メインメモリ220とNIC30内のバッファの間でRDMAパケット229をコピーする必要がなく、いわゆる「ゼロコピー」を実現することができ、メモリ間コピーによるオーバーヘッドをなくすことができる。
【0066】
実施例2
図8は、実施例2のノード200の構成図である。実施例1では、TOE機能をもたない通常のNIC30がノード200に搭載されている場合を説明したが、実施例2では、TOE機能をもつTOE−NIC31がノード200に搭載されている場合を説明する。システム起動時の設定により、TOE−NIC31が動作可能になるため、動作しないNIC30に関わる構成については図示していない。TOE−NIC31にはTCP/IPプロトコルスタックが実装されており、TOE−NIC31内部でTCP/IPのプロトコル処理を行うことができる。
【0067】
実施例2でも、実施例1と同様に、発行元ノード200aと発行先ノード200bの間でRDMAライトが実行される場合の動作を説明する。発行元ノード200aと発行先ノード200bの間で行われるRDMAライト処理のシーケンスは、実施例1の図5と同じである。図9および図10を参照し、実施例2において、図5のRDMAライト処理シーケンスの各ステップが図8の構成によって実行される様子を詳しく説明する。図9は、図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。一方、図10は、図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。以下、実施例1と同様の動作については適宜説明を簡略にする。
【0068】
(1)ステップS10の動作
図8において、発行元ノード200aのユーザ空間にあるアプリケーションプログラム11u−1または22u−1により、RDMAライトのリクエストが発行される。実施例1で説明したように、発行元ノード200aのソケットスイッチ50は、RDMAライトのリクエストが通常のTCP/IPにより送信されるべきであることを識別する。実施例2では、RDMA動作をしない通常の通信もRDMAプロトコルスタックが実装されたSPU21aにおいて実行される。
【0069】
発行元ノード200aのソケット層21r−1は、ソケットスイッチ50のコマンドの引数により、RDMAプロトコル処理を必要としない通常のTCP/IPの通信であることを識別し、SDP層21r−2、RDMA層21r−3、DDP層21r−4、およびMPA層21r−5のRDMAプロトコルスタックをバイパスして、直接デバイスドライバ21r−6にRDMAライトのリクエストメッセージを渡す。
【0070】
図9を参照する。発行元ノード200aにおいて、ユーザモードで動作しているSPU22aがTOE−NIC31a内のプロセッサ32aにイベント通知する。プロセッサ32aは、ユーザ空間のアプリケーション用バッファ222aに書きこまれたRDMAライトのリクエストメッセージ223aを読み出し、TCP/IPパケットとして組み立て、TOE−NIC31a内に設けられたTCP/IP送受信バッファ224aにRDMAライトのリクエストパケット225aを書き込む。TOE−NIC31aは、TCP/IP送受信バッファ224a内のリクエストパケット225aをネットワーク100に送信する。
【0071】
(2)ステップS12の動作
発行元ノード200aにおいてRDMAライトのリクエストの発行が終わると、図10に示すように、発行元ノード200aのユーザモードにあるSPU22aがアプリケーションを実行し、RDMAライトすべきRDMAメッセージ227aをアプリケーション用バッファ222aに書き込む。
【0072】
(3)ステップS14の動作
一方、発行先ノード200bは、ステップS10において発行元ノード200aが発行したRDMAライトのリクエストを受け取り、RDMAライト用のメモリ領域を準備する。図9に示すように、発行先ノード200bのTOE−NIC31bはネットワーク100からRDMAライトのリクエストパケット225bを受信し、TOE−NIC31b内に設けられたTCP/IP送受信バッファ224bに格納する。
【0073】
TOE−NIC31b内のプロセッサ32bは、TCP/IP送受信バッファ224bに受信されたRDMAライトのリクエストパケット225bを解析し、パケット内のリクエストメッセージ223bをリアセンブルしてユーザ空間のアプリケーション用バッファ222bにコピーする。その後、プロセッサ32bは、ユーザモードにあるSPU22bにイベント通知し、RDMAライトのリクエストメッセージが受信されたことを通知する。
【0074】
プロセッサ32bからイベント通知を受けたSPU22bはアプリケーション22u−1を実行し、RDMAライトのリクエストメッセージ223bを読み、アプリケーション用バッファ222b内にRDMAライトに必要なメモリ領域(「RDMAライト用領域」)226bを確保する。
【0075】
(4)ステップS16の動作
その後、発行先ノード200bのユーザ空間にあるアプリケーション22u−1は、レディメッセージを発行元ノード200aに返信する。RDMAライトのリクエストメッセージの場合と同様、レディメッセージは、発行先ノード200bのソケットスイッチ50がTCP/IPプロトコルを指定したコマンドを実行することにより、SPU21においてRDMAプロトコルスタックをスキップしてデバイスドライバ21r−6に渡され、TOE−NIC31bのTOE機能によりTCP/IPプロトコル処理がなされ、ネットワーク100に送信される。
【0076】
(5)ステップS18の動作
図8および図10を参照して、RDMAライトの動作を詳しく説明をする。発行元ノード200aにおいてアプリケーションプログラム11u−1あるいは22u−1がRDMAライトのコマンドを発行する。
【0077】
ソケットスイッチ50がsocketコマンドの引数によってRDMA動作であることを認識し、RDMAプロトコルスタックが実装されているSPU21aにイベント通知し、SPU21aがRDMAパケットを生成する。
【0078】
図10を参照して、RDMAパケットの生成過程を説明する。発行元ノード200aにおいて、ユーザモードのSPU22aからイベント通知を受け取ったカーネルモードのSPU21aは、ユーザ空間にあるアプリケーション用バッファ222aに書き込まれたRDMAメッセージ227aをセグメント化し、RDMAパケットを組み立て、FIFOバッファ221aにRDMAパケットをキューイングする。
【0079】
FIFOバッファ221aは、RDMAプロトコルスタックが実装されたSPU21と、TCP/IPプロトコルスタックが実装されたプロセッサ32aとの間で共有されており、SPU21は、TOE−NIC31a内のプロセッサ32aにイベント通知し、FIFOバッファ221aに送信すべきRDMAパケットがあることを知らせる。イベント通知されたプロセッサ32aは、FIFOバッファ221aにあるRDMAパケットをTCP/IPパケットに組み立て、TOE−NIC31a内に設けられたTCP/IP送受信バッファ224aにコピーする。TOE−NIC31aは、TCP/IP送受信バッファ224a内のRDMAパケット229aをネットワーク100に送出する。
【0080】
一方、発行先ノード200bにおいても、ソケットAPI11u−1あるいは22u−2によってRDMA機能を使用することが宣言される。ソケットスイッチ50により、ユーザレベルのSPU22bからカーネルレベルのSPU21bおよびTOE−NIC31b内のプロセッサ32bへRDMAイベントがあることが通知される。
【0081】
発行先ノード200bのTOE−NIC31bは、ネットワーク100からRDMAパケット229bを受信し、TCP/IP送受信バッファ224bに格納する。TOE−NIC31b内のプロセッサ32bは、TCP/IP送受信バッファ224b内のRDMAパケット229bをTCP/IPプロトコルにしたがって解析し、FIFOバッファ221bにTCP/IPパケットをキューイングする。FIFOバッファ221bは、TOE−NIC31b内のプロセッサ32bとRDMAプロトコルスタック21rが実装されたSPU21bの間で共有されている。TCP/IPプロトコル処理の後、プロセッサ32bは、RDMAプロトコル処理を行うSPU21bにイベント通知し、RDMAパケットが受信されたことを知らせる。
【0082】
RDMAプロトコルスタック21rが実装されたSPU21bは、RDMAプロトコルにしたがってFIFOバッファ221bにあるRDMAパケットを解析し、RDMAライトすべきメッセージをリアセンブルし、アプリケーション用バッファ222bのRDMAライト用領域226bに書き込む。
【0083】
なお、ここで述べたFIFOバッファ221a、221bは必ずしも、各ノード200a、200b内のメインメモリにある必要はなく、TOE−NIC31a、31b内に設けられてもよい。
【0084】
(6)ステップS20の動作
RDMAライトの発行が終わると、発行元ノード200aは「完了」メッセージを発行先ノード200bに送信する。「完了メッセージ」は、図9で説明した、RDMA機能を用いない通常のTCP/IPパケットで送信される。発行先ノード200bは「完了」メッセージを受信し、RDMAライト用領域226bを解放し、RDMAライトの動作を終了する。
【0085】
以上述べたように、実施例2によれば、RDMAプロトコル処理をソフトウェアでエミュレートすることにより、RDMA対応のNICでなくてもRDMA機能を用いた通信を行うことができる。また、実施例2では、マルチプロセッサシステムにおいて、RDMAプロトコル処理を行うプロセッサをユーザレベルでアプリケーションを実行するプロセッサとは別に設けたことで、RDMAプロトコル処理を効率良く実行することができる。また、NIC内のTOE機能を実行するプロセッサが、RDMAプロトコル処理を担当するプロセッサに負荷をかけないで、RDMAプロトコル処理されたパケットをTCP/IPプロトコル処理することができる。
【0086】
実施例3
実施例1ではTOE機能をもたない通常のNIC30を用いたRDMA動作を説明し、実施例2ではTOE機能をもつTOE−NIC31を用いたRDMA動作を説明した。実際には、NICが複数枚実装されており、TOE機能のないNICとTOE機能のあるNICが共存するネットワークノードの存在する。そのようなネットワークノードの一例としてルータがある。ルータはポート毎に異なるNICを搭載するため、複数の異なる種類のNICが共存することがある。また、別の例として、マルチプロセッサシステムにおいて各プロセッサに異なるIPアドレスを割り当て、プロセッサ毎にNICを設ける構成もある。以下では、実施例3として、TOE機能のないNICとTOE機能のあるNICが共存するネットワークノードの構成を取り上げ、TOE機能のないNICとTOE機能のあるNICを動的に切り替えて、通信する仕組みを説明する。
【0087】
図11は、実施例3のノード200の構成図である。ノード200内には、TOE機能のないNIC30とTOE機能のあるTOE−NIC31とが搭載されており、I/Oブリッジ240を介してMPU210の各プロセッサと接続している。TCP/IPプロトコルスタック10s、20sが実装されたPU10、SPU20は、TOE機能のないNIC30を利用して通信し、RDMAプロトコルスタック21rが実装されたSPU21は、TOE機能のあるTOE−NIC31を利用して通信する。
【0088】
RDMAプロトコルスタック21rのMPA層21r−5の下に、パケットのIPアドレスを判別するためのIPA(Internet Protocol Address)判別層21r−7を新たに設ける。IPA判別層21r−7には、送信元IPアドレスをNICのMACアドレスに対応づけたアドレステーブルをあらかじめ用意しておく。ここで、MACアドレスは、一つ一つのNICに割り当てられた固有のアドレスである。IPA判別層21r−7は、メッセージを送信する際に、IPパケットの送信元アドレスを取得し、このアドレステーブルを参照することにより、どのNICから送信すべきパケットであるかを判定する。
【0089】
IPA判別層21r−7において、パケットの送信元IPアドレスがTOE機能のないNIC30のMACアドレスに対応づけられていることが判明すると、RDMAプロトコルスタック21rが実装されたSPU21は、TCP/IPプロトコルスタック20sが実装されたSPU20にイベント通知する。これにより、当該パケットはSPU20のTCP/IPプロトコルスタック20sによりプロトコル処理され、NIC30から送信される。
【0090】
IPA判別層21r−7において、パケットの送信元IPアドレスがTOE機能のあるTOE−NIC31のMACアドレスに対応づけられていることが判明すると、DMAプロトコルスタック21rが実装されたSPU21は、自分自身にイベント通知するか、あるいは、ドライバ21r−6へとパケットを渡す。これにより、当該パケットはTOE−NIC31に供給され、TOE−NIC31のTOE機能を用いてTCP/IPにしたがったプロトコル処理がなされ、ネットワークに送信される。
【0091】
ネットワークからパケットを受信する際は、通常のTCP/IP通信であるか、あるいは、RDMA機能を用いた通信であるかは、通信を開始するときに指定されるため、TCP/IPプロトコルスタック10s、20sに特別な機能を設ける必要はない。
【0092】
実施例3によれば、TOE機能のないNICとTOE機能のあるNICが混在するシステムにおいても、両者を動的に切り替えて通信を行うことができ、システムに柔軟性と拡張性をもたせることができる。
【0093】
実施の形態2
実施の形態2では、実施の形態1で説明したノード200の応用例として、RDMA機能を利用したサーバ−クライアントシステムを説明する。
【0094】
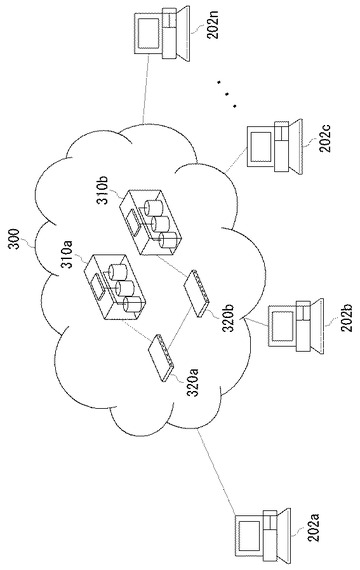
図12は、実施の形態2に係るネットワークシステムの構成図である。このネットワークシステムは、複数のサーバ310a、310bと複数のクライアント202a〜202nがネットワークで接続されて構成される。複数のサーバ310a、310bは、スイッチ320a、320bを介してネットワークに接続しており、これらはサーバクラスタ300を構成し、クライアント202a〜202nから見た場合、ひとつのサーバとして機能する。以下、複数のサーバ310a、310bを総称してサーバ310と呼び、複数のクライアント202a〜202nを総称してクライアント202と呼ぶ。
【0095】
サーバ310にはRDMA対応のNICが搭載されており、サーバ310のCPUの負荷を低減させることができる。一方、クライアント202には、ソフトウェアでRDMAをエミュレートするRDMA機能が実装されており、いわゆるiWARPが実現して、サーバ310との間でRDMAによる通信が可能となり、サーバ310の負荷を低減させるのに貢献する。
【0096】
図13は、クライアント202とサーバ310の構成図である。クライアント202は、実施の形態1で説明したマルチプロセッサシステムのように、RDMAプロトコルスタックが実装されるプロセッサとTCP/IPプロトコルスタックが実装されるプロセッサが異なってもよいが、実施の形態2では、クライアント202はシングルプロセッサシステムであり、RDMAプロトコルスタックとTCP/IPプロトコルスタックが1つのプロセッサで実行される場合を説明する。
【0097】
クライアント202のユーザレベルにはバッファ60が設けられ、サーバ310に送信するデータとサーバ310から受信するデータが格納される。DAFS(Direct Access File System)API62は、RDMAプロトコル上で動作するファイルシステムであるDAFSのアプリケーションプログラムインタフェース(API)である。uDAPL(user Direct Access Programming Library)64は、RDMA機能を実現するための汎用APIである。クライアント202は、これらのAPIを使用して、RDMA機能を用いてサーバ310のデータにアクセスする。
【0098】
カーネルレベルには、ソケット層71、RDMA層72、TCP層73、IP層74、NICドライバ75が実装され、RDMAリードあるいはRDMAライトのパケットがプロトコル処理され、ギガビットイーサネット(商標または登録商標)80を介してネットワーク100に送信される。
【0099】
サーバ310のユーザレベルにはバッファ80が設けられ、クライアント202に送信するデータとクライアント202から受信するデータが格納される。また、クライアント202と同様に、DAFSAPI82とuDAPL84が実装される。また、カーネルレベルのHCAドライバ88にアクセスするための仮想的なAPIであるVAPI86が実装される。
【0100】
サーバ310にはRDMA対応のNIC(以下、「RNIC」という)90が搭載されており、カーネルレベルのHCAドライバ88により制御される。RNIC90においてRDMAプロトコル処理がハードウェアで実行され、サーバ310のCPUを用いることなく、バッファ80に対してデータが直接読み書きされる。なお、RNIC90にはTOE機能も搭載されており、ハードウェアでTCP/IPプロトコル処理もなされる。
【0101】
図13において、クライアント202からサーバ310に対してRDMAリードあるいはRDMAライトが発行されると、クライアント202のRDMA層72においてソフトウェアでRDMA機能が実行され、サーバ310のRNIC90においてハードウェアでRDMA機能が実行される。これにより、クライアント202は、サーバ310のCPUに負荷をかけないで、サーバ310のバッファ80に直接アクセスすることができる。
【0102】
実施の形態2によれば、サーバ−クライアントシステムにおいて、サーバ側にRDMA機能が実装されており、クライアント側に必ずしもRNICが実装されていない場合でも、クライアント側でRDMA機能をエミュレートするため、サーバとクライアント間でRDMA機能を前提とした通信を行うことができる。これにより、サーバに搭載されたRDMA機能を有効活用して、高速な通信を行うことができる。特定のクライアントにおいてRNICの搭載ができなかったり、RNICの搭載が遅れる事情があっても、サーバ側でRDMA機能を停止させる必要がないため、RNICが搭載されているかどうかに関係なく、システムにクライアントを追加していくことができ、サーバ−クライアントシステムの拡張が容易である。
【0103】
以上説明したように、いずれの実施の形態においてもマルチプロセッサシステム上に、RDMAプロトコルおよびTCPプロトコルを常駐させるので、新規にRDMA対応のNICを購入することなく、低コストで、RDMA機能をエミュレートすることが可能となる。実施の形態ではRDMAプロトコルスタックをカーネルレベルに実装する例を説明したが、RDMAプロトコルスタックをユーザレベルに実装してもよい。RDMA機能をTCP/IP上に実装する技術は、一般にiWARPと呼ばれ、ネットワーク上の通信先のノードのメモリに直接データを書き込むことで処理遅延を減らすことができる。実施の形態では、iWARPをソフトウェアで実装することで、RDMAのハードウェアをもたないシステムでもRDMA機能を実現可能である。
【0104】
以上、本発明を実施の形態をもとに説明した。実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。そのような変形例を説明する。
【0105】
実施の形態では、プロセッサ間でイベント通知をすることにより、送受信データの存在を他のプロセッサに知らせたが、これ以外にも、たとえば、PUあるいはSPUが受信バッファをポーリングすることにより、イベントを検知してもよい。
【0106】
また、各ノード200内のメインメモリ220を用いて、パケット用のバッファを構築したが、たとえば、図2における、MPU210内の各プロセッサが個別にローカルメモリをもっており、そのローカルメモリを用いてパケット用のバッファを構築してもよい。
【0107】
なお、ソケットプログラムでは、送受信時にsendあるいはrecvコマンドを発行するが、実施の形態では説明の簡略化のため、ソケットの処理の詳細は省略した。
【図面の簡単な説明】
【0108】
【図1】本発明の実施の形態に係るネットワークシステムを示す図である。
【図2】図1のノードの構成図である。
【図3】図2のノードのMPUに実装されたTCP/IPプロトコルスタックおよびRDMA機能を説明する図である。
【図4】実施例1のノードの構成図である。
【図5】実施例1における発行元ノードと発行先ノードの間で行われるRDMAライト処理のシーケンス図である。
【図6】図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。
【図7A】図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。
【図7B】各ノードに搭載されたNIC内にTCP/IP送受信バッファを設ける構成を説明する図である。
【図8】実施例2のノードの構成図である。
【図9】実施例2において、図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。
【図10】実施例2において、図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。
【図11】実施例3のノードの構成図である。
【図12】実施の形態2に係るネットワークシステムの構成図である。
【図13】図12のクライアントとサーバの構成図である。
【符号の説明】
【0109】
10 PU、 11 PU、20 SPU、 21 SPU、 22 SPU、 30 NIC、 31 TOE−NIC、 50 ソケットスイッチ、 100 ネットワーク、 200 ノード、 210 MPU、 220 メインメモリ、 222 アプリケーション用バッファ、 224 TCP/IP送受信バッファ、 230 NIC、 240 I/Oブリッジ。
【技術分野】
【0001】
この発明は、ネットワークプロセッサシステムおよびネットワークプロトコル処理方法に関する。
【背景技術】
【0002】
近年のネットワーク技術の進歩により、ギガビットネットワークの利用が広がるなど、ネットワークの帯域が著しく伸びている。その一方で、ネットワークを流れるパケットを処理するマイクロプロセッサの処理性能はネットワーク性能に比べてそれほど向上していないのが現状である。そのため、高速なネットワークを流れるパケットをマイクロプロセッサが十分な速度で処理することは難しい。特に、ネットワークの帯域幅が1Gbps(giga bit per second)を越えるあたりからマイクロプロセッサの処理性能がネットワークの帯域幅に対してボトルネックとなる。
【0003】
プロセッサの処理性能がボトルネックになる原因は、大きく分けて次の3つである。
(1)TCP(Transmission Control Protocol)処理
(2)コンテキストスイッチ
(3)メモリ間コピー
【0004】
(1)のTCP処理とは、TCPにおけるチェックサムや再送制御など、計算量の多い処理であり、プロセッサへの負荷が大きくなる。この問題を解決するために、TCPオフロードエンジン(TCP Offload Engine; TOE)と呼ばれる技術があり、TCPにおける各処理を実行する専用のハードウェアがネットワークインタフェースカード(NIC)に実装される。このようなTCPオフロードエンジンが搭載されたネットワークインタフェースカードはTOE−NICと呼ばれる。この場合、送受信バッファはTOE−NIC内に設けられる。
【0005】
(2)のコンテキストスイッチとは、パケット処理をするためにユーザモードとカーネルモードの間でコンテキストスイッチが行われることであり、このコンテキストスイッチがオーバーヘッドとなり、全体の処理性能のボトルネックとなる。この問題を解決するために、カーネルによるプロトコル処理をスキップするカーネルバイパスなどの実装技術が検討されている。
【0006】
(3)のメモリ間コピーとは、パケットを処理する過程でパケットのデータが複数のメモリ間でコピーされることである。まず、ネットワークインタフェースカードがカーネルのバッファに受信パケットを書き込む。CPUはカーネルのバッファ内のパケットを解析した後、アプリケーションのバッファにパケットを書き込む。この処理過程でカーネルバッファからアプリケーションバッファへパケットのデータがコピーされており、このメモリ間コピーがオーバーヘッドとなる。
【0007】
メモリ間コピーの問題を解決するために、リモートダイレクトメモリアクセス(RDMA)と呼ばれる技術の実装が行われている。CPUを介さずに各種デバイスとRAMの間で直接データ転送する方式がダイレクトメモリアクセス(DMA)であるが、RDMAは、このDMA機能をネットワークに拡張したものである。RDMAは、あるコンピュータのメモリから別のコンピュータのメモリに直接データを移動させることで、CPU処理のオーバーヘッドをなくす。RDMAを利用するためには、TCP/IPネットワークの場合、RDMA対応のネットワークインタフェースカード(RNIC;RDMA-enabled NIC)を用いる必要がある。一般に、RNICはTOE機能とRDMA機能を合わせもつネットワークインタフェースカードである。
【発明の開示】
【発明が解決しようとする課題】
【0008】
今後ますます高速化するネットワークに対応するために、マイクロプロセッサへの処理負荷を減らすことが通信の効率化のために重要な課題となっている。そのためのひとつの解決策が前述のRDMAである。しかしながら、RDMAを利用するためには、RNICと呼ばれる、RDMA対応の特別なネットワークインタフェースカードが必要であり、これまで使用されていた通常のネットワークインタフェースカードでは、RDMAを利用することができない。現在使用中のNICをすべてRDMA対応のRNICに入れ換えることは、たいへんなコストがかかる。これはRDMAの普及を遅らせている一因である。
【0009】
また、一部のネットワークインタフェースカードだけをRDMA対応にすることで従来のNICとRNICとが混在するネットワークを構成した場合、従来のNICとRNICの間で通信ができないという問題が生じる。
【0010】
本発明はこうした課題に鑑みてなされたものであり、その目的は、RDMA機能を前提とした通信を効率良く行うことのできる通信技術を提供することにある。
【課題を解決するための手段】
【0011】
上記課題を解決するために、本発明のある態様のネットワークプロセッサシステムは、リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記バッファからパケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含む。
【0012】
本発明の別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、カーネルレベルでTCP/IPプロトコル処理を実行するプロセッサであって、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てる第3プロセッサと、前記第3プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含む。
【0013】
本発明のさらに別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、リモートダイレクトメモリアクセス機能をエミュレートするプロセッサと、前記プロセッサから出力されるリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつネットワークインタフェースカードとを含む。
【0014】
本発明のさらに別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すTCP/IPオフロード機能をもつネットワークインタフェースカードとを含む。
【0015】
本発明のさらに別の態様もまた、ネットワークプロセッサシステムである。このネットワークプロセッサシステムは、リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信する第1ネットワークインタフェースカードと、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつ第2ネットワークインタフェースカードとを含む。前記第1プロセッサは、前記パケットの送信元IPアドレスを前記第1ネットワークインタフェースカードのMACアドレスまたは前記第2ネットワークインタフェースカードのMACアドレスに対応づけたテーブルを参照して、前記パケットの送信元IPアドレスに応じて、前記パケットを送出するためのネットワークインタフェースを前記第1ネットワークインタフェースカードまたは前記第2ネットワークインタフェースカードのいずれかに振り分ける機能を有する。前記パケットが前記第1ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2プロセッサによりTCP/IPプロトコル処理がなされて、前記第1ネットワークインタフェースカードから送出され、前記パケットが前記第2ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2ネットワークインタフェースカードのTCP/IPオフロード機能によりTCP/IPプロトコル処理がなされて、前記第2ネットワークインタフェースカードから送出される。
【0016】
本発明のさらに別の態様は、ネットワークプロトコル処理方法である。この方法は、ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、カーネルレベルでTCP/IPプロトコル処理を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てるステップとを含む。
【0017】
本発明のさらに別の態様もまた、ネットワークプロトコル処理方法である。この方法は、ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、ネットワークインタフェースカード内でTCP/IPオフロード機能を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すステップを実行する。
【0018】
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、システム、コンピュータプログラム、プログラム製品、データ構造、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0019】
本発明によれば、RMDA機能を利用した効率の良い通信を行うことができる。
【発明を実施するための最良の形態】
【0020】
以下、図面を参照し、本発明の実施の形態を説明する。なお、以下に述べる実施の形態は、本発明の好適な具体例であるから、技術的に好ましい種々の限定が付されているが、本発明の範囲は以下の説明において、特に本発明を限定する旨の記載がない限り、これらの形態に限定されるものではない。
【0021】
また、実施の形態では、カーネルモードおよびユーザモードに分けてプロトコル処理を説明するが、これは一例に過ぎず、各プロトコルスタックが実装されるべきモードを限定する趣旨ではない。なお、カーネルモード、ユーザモードは、それぞれカーネルレベル、ユーザレベルとも呼ばれる。
【0022】
さらに、RDMA機能を実行するプロセッシングエレメントとして、マルチプロセッサのひとつを用いたが、RDMA機能だけを実行するために、別チップのCPUを用いることも可能である。
【0023】
実施の形態1
図1は、本発明の実施の形態に係るネットワークシステムを示す図である。ネットワーク100には、複数のノード200a、200b、200c、…、200nが接続されている。以下、ネットワーク100に接続されたノードを総称するときは、単にノード200という。ネットワーク100はルータを含み、IP(Internet Protocol)にしたがってパケットを転送する。
【0024】
図2は、図1のノード200の構成図である。各ノード200は、マイクロプロセッシングユニット(MPU)210、メインメモリ220、I/Oブリッジ240、およびネットワークインタフェースカード(NIC)230を含む。
【0025】
MPU210は、メインメモリ220に保持された送信すべきデータに宛先アドレスなどのヘッダ情報を付加したパケットを生成し、I/Oブリッジ240を介してNIC230のバッファにパケットを渡す。NIC230は、バッファ内に蓄積されたパケットをネットワーク100に送出する。
【0026】
NIC230はネットワーク100から受信されたパケットをバッファに蓄積し、I/Oブリッジ240を介してMPU210にパケットを渡す。MPU210はパケットのヘッダを解析し、パケット内のデータをメインメモリ220に格納する。
【0027】
図3は、図2のノード200のMPU210に実装されたTCP/IPプロトコルスタックおよびRDMA機能を説明する図である。これらの機能は、ハードウェアとソフトウェアの組み合わせにより構成され、ソフトウェアはユーザモードおよびカーネルモードで動作する。
【0028】
ハードウェアの構成として各ノード200にはNIC230とMPU210がある。NIC230として、同図に示したように、TOE機能のないNIC30またはTOE機能が搭載されたTOE−NIC31のいずれか、あるいは両方が用いられる。MPU210は、ここでは、プロセッシングユニット(PU)とサブプロセッシングユニット(SPU)を含むマルチプロセッサで構成される。ここで、PUとSPUは処理性能や構成が異なるプロセッシングエレメントである。一例としてPUは、メインメモリ220のデータをキャッシュするためのハードウェアキャッシュ機構を有するが、SPUは、ハードウェアキャッシュ機構がなく、ローカルメモリをもつ。
【0029】
ユーザモードで動作するソフトウェアとして、アプリケーションプログラム11u−1、22u−1、ソケットAPI11u−2、22u−2およびソケットスイッチ50がある。ソケットスイッチ50は、パケットのプロトコルがTCPあるいはSDP(ソケットダイレクトプロトコル)のどちらであるかを判別して、パケットの供給先を切り替える。ここで、SDPとは、既存のソケットプログラムへ変更を加えることなくRDMA機能を実現するためのプロトコルである。ソケットスイッチ50の働きにより、RDMA機能を前提とするパケットはRDMA機能を実装したカーネルレベルのプロトコルスタック21rに渡され、RDMA機能を必要としない通常のTCPのパケットはRDMA機能が実装されていないカーネルレベルのプロトコルスタック10s、20sに渡される。
【0030】
カーネルモードで動作するソフトウェアとして、次の3つがある。
(1)PU10上で動作するTCP/IPプロトコルスタック10s、
(2)SPU20上で動作するTCP/IPプロトコルスタック20s、および
(3)SPU21上で動作するRDMAプロトコルスタック21r。
【0031】
RDMAプロトコルスタック21rは、既存のソケットプログラムを変更することなしにRDMA動作を可能とするために、ソケット層21r−1とSDP層21r−2を含む。これらのレイヤの下にRDMA層21r−3があり、RDMAリード(read)、RDMAライト(write)などのRDMAコマンドがDDP(Direct Data Placement)メッセージに変換される。RDMA層21r−3の下には、DDP層21r−4がある。DDP層21r−4は、送信の際、DDPメッセージを1つまたは複数のDDPセグメントに分割し、受信の際、1つまたは複数のDDPセグメントをDDPメッセージにリアセンブルする。
【0032】
DDP層21r−4の下には、MPA(Marker Protocol-data-unit Aligned)層21r−5がある。MPA層21r−5は、DDPセグメントに一定間隔で逆変換マーカーを付加し、各MPAセグメントにDDPセグメントのデータ長と誤り検出のためのCRC(Cyclic Redundancy Check)を付加する。MPA層21r−5の下には、TCP/IPプロトコルスタックが実装される。
【0033】
TCP/IPプロトコルスタックの実装方法として、(a)PU10またはSPU20にカーネルモードで動作するソフトウェアとして実装する方法と、(b)TOE−NIC31内のTCPオフロードエンジン(TOE)機能としてハードウェアで実装する方法とがある。後者の場合、RDMAプロトコルスタック21rにより処理されたパケットは、デバイスドライバ21r−6、SPU21、I/Oブリッジ240を経由して、TOE−NIC31に渡され、TOE機能によりTCP/IPプロトコル処理がなされ、ネットワークに送出される。
【0034】
一方、TOE機能が実装されていないNIC30の場合には、PU10またはSPU20にカーネルモードで動作するソフトウェアとして実装された、TCP/IPプロトコルスタック10s、20sを用いてTCP/IPプロトコル処理を行う必要がある。
【0035】
上記の(a)TOE機能なしの実装と(b)TOE機能ありの実装の切り換えは、システム起動時に設定ファイルの情報を用いて行う。以下、(a)TOE機能なしの実装の構成と動作を実施例1として説明し、(b)TOE機能ありの実装の構成と動作を実施例2として説明する。また、ノード200内にTOE機能のない通常のNIC30とTOE機能付きのTOE−NIC31がともに実装されている場合の構成と動作を実施例3として説明する。
【0036】
RDMAプロトコルスタック21rとTCP/IPプロトコルスタック10s、20sはMPU210の各プロセッサ上に常駐することを基本とするが、RDMA機能を用いない場合には、RDMAプロトコルスタック21rはサスペンドされ、他のプロセスが動作してもよい。これは、TCP/IPプロトコルスタック10s、20sについても同様である。
【0037】
実施例1
図4は、実施例1のノード200の構成図である。実施例1では、ノード200にはTOE機能のない通常のNIC30が搭載されており、システム起動時の設定により、NIC30が動作可能になるため、動作しないTOE−NIC31に関わる構成については図示していない。実施例1では、TCP/IPプロトコルスタックはPU10またはSPU20上に実装される。PU10およびSPU20上のTCP/IPプロトコルスタック10sおよび20sは同時に動作することも可能であるし、どちらかが休止していてもかまわない。
【0038】
RDMA動作の一例として、RDMAライトについて説明する。図1の2つのノード200aと200b間でRDMAライトが実行されるとする。発行元ノード200aが発行先ノード200bに対してRDMAライト命令を発行し、RDMAライトされるべきデータを発行先ノード200bに送信する。
【0039】
図5は、発行元ノード200aと発行先ノード200bの間で行われるRDMAライト処理のシーケンス図である。はじめに、発行元ノード200aから発行先ノード200bへRDMAライトのリクエストが発行される(S10)。このリクエスト時にRDMAライトされるデータのサイズ等の情報が送信される。その後、発行元ノード200aは、自ノード内のメインメモリ220aにRDMAライトすべきデータを準備する(S12)。
【0040】
一方、発行先ノード200bは、発行元ノード200aから発行されたRDMAライトのリクエストに対して、自ノード内のメインメモリ220bにRDMAライト用のメモリ領域を確保する(S14)。発行先ノード200bにデータが受信されると、自ノードのNIC30bがカーネルモードのソフトウェアに割り込み信号を送ることで、受信データの存在をカーネルに知らせる。
【0041】
発行先ノード200bは、RDMAライト用メモリ領域を確保した後、発行元ノード200aに向けて、レディ(Ready)メッセージを送信する(S16)。
【0042】
発行元ノード200aは、発行先ノード200bからレディメッセージを受信した後、RDMAライトを実行する(S18)。なお、発行元のノード200aは、メッセージの受信を自ノードのNIC30から割り込みが入ることで検出することができる。
【0043】
発行元のノード200aは、RDMAライトが完了した後に、完了メッセージを発行先ノード200bに送信する(S20)。以上で、RDMAライトの処理が完了する。
【0044】
図6および図7Aを参照し、図5のRDMAライト処理シーケンスの各ステップが図4の構成によって実行される様子を詳しく説明する。図6は、図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。一方、図7Aは、図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。
【0045】
以下では、TCP/IPプロトコルスタックがSPU20に実装されている場合について動作を説明するが、TCP/IPプロトコルスタックがPU10に実装されている場合の動作も基本的には同様である。
【0046】
(1)ステップS10の動作
図4において、発行元ノード200aのユーザ空間にあるアプリケーションプログラム11u−1または22u−1により、RDMAライトのリクエストが発行される。ここで、アプリケーションプログラム11u−1、22u−1はそれぞれ発行元ノード200aのPU11、SPU22で実行される。ここでは、アプリケーションプログラム11u−1、22u−1を実行するPU11、SPU22と、プロトコルスタックを実行するPU10a、SPU20、21は異なるものとして説明するが、アプリケーションプログラムとプロトコルスタックを実行するPUあるいはSPUは同一であってもかまわない。
【0047】
発行元ノード200aのソケットスイッチ50は、RDMAライトのリクエストが通常のTCP/IPにより送信されるべきであることを識別する。この識別は、発行元ノード200aのソケットAPI11u−2あるいは22u−2において、以下のコマンドを実行することで実現される。
socket(AF_INET, SOCK_STREAM, 0);
ここで、socketコマンドの第1引数AF_INETは、IPv4のインターネットプロトコルであることを示す。第2引数SOCK_STREAMは通信がコネクション型であることを示す。第3引数の0は通常のTCP/IPプロトコルを用いることを示す。
【0048】
RDMAライトのリクエストメッセージは、発行元ノード200aのSPU20上に実装されたTCP/IPプロトコルスタック20sを経由することで、RDMAライトのリクエストパケットへと組み立てられる。
【0049】
図6を参照して、RDMAライトのリクエストパケットの生成過程を説明する。発行元ノード200aにおいて、ユーザレベルで動作中のSPU22aは、ユーザ空間にあるアプリケーション用バッファ222aにRDMAライトのリクエストメッセージ223aを生成する。その後、ユーザレベルで動作中のSPU22aは、カーネルレベルで動作中のSPU20aに対してイベント通知することにより、パケットの組み立ての開始を通知する。このイベント通知には、アトミック命令のような同期機能を用いてもよく、SPUにイベント通知用のレジスタやメールボックスなどを設けることにより実現してもよい。
【0050】
カーネルレベルのSPU20aは、アプリケーション用バッファ222aからRDMAライトのリクエストメッセージ223aを読み出し、そのリクエストメッセージ223aにヘッダを付加し、カーネル空間にあるTCP/IP送受信バッファ224aにRDMAライトのリクエストパケット225aを生成する。生成されたリクエストパケット225aは発行元ノード200aのNIC30aから送出される。
【0051】
(2)ステップS12の動作
発行元ノード200aにおいてRDMAライトのリクエストの発行が終わると、図7Aに示すように、発行元ノード200aのユーザモードにあるSPU22aがアプリケーションを実行し、RDMAライトにより書き込むべきRDMAメッセージ227aをアプリケーション用バッファ222aに書き込み、RDMAライト用のデータを準備する。
【0052】
(3)ステップS14の動作
一方、発行先ノード200bは、ステップS10において発行元ノード200aが発行したRDMAライトのリクエストを受け取り、RDMAライト用のメモリ領域を準備する。図6に示すように、発行先ノード200bのNIC30bはネットワーク100からRDMAライトのリクエストパケット225bを受信し、TCP/IP送受信バッファ224bにコピーする。
【0053】
発行先ノード200bのカーネルモードにあるSPU20bは、TCP/IP送受信バッファ224bに受信されたRDMAライトのリクエストパケット225bを解析し、パケット内のリクエストメッセージ223bをリアセンブルしてユーザ空間のアプリケーション用バッファ222bにコピーする。その後、カーネルモードにあるSPU20bは、ユーザモードにあるSPU22bにイベント通知し、RDMAライトのリクエストメッセージが受信されたことを通知する。
【0054】
カーネルモードにあるSPU20bからイベント通知を受けた、ユーザモードにあるSPU22bはアプリケーション22u−1を実行し、RDMAライトのリクエストメッセージ223bを読み、アプリケーション用バッファ222b内にRDMAライトに必要なメモリ領域(「RDMAライト用領域」という)226bを確保する。
【0055】
(4)ステップS16の動作
その後、発行先ノード200bのユーザ空間にあるアプリケーション22u−1は、レディメッセージを発行元ノード200aに返信する。RDMAライトのリクエストメッセージの場合と同様、レディメッセージは、発行先ノード200bのソケットスイッチ50がTCP/IPプロトコルを指定したコマンドを実行することにより、通常のTCP/IPプロトコルにしたがって、TCP/IPプロトコルスタック20sにより処理され、NIC30bから送信される。
【0056】
(5)ステップS18の動作
図4および図7Aを参照して、RDMAライトの動作を詳しく説明をする。発行元ノード200aにおいてアプリケーションプログラム11u−1あるいは22u−1がRDMAライトのコマンドを発行する。その際、ソケットAPI11u−2あるいは22u−2は、
socket(AF_INET_SDP, SOCK_STREAM, 0);
というコマンドを用いる。ここで、第1引数"AF_INET_SDP"は、通信プロトコルとしてSDPを用いてRDMA機能を実行することを意味する。それ以外のパラメータは前述の通りである。
【0057】
ソケットスイッチ50がsocketコマンドの第1引数によってRDMA動作であることを認識し、RDMAプロトコルスタックが実装されているSPU21aにイベント通知し、SPU21aがRDMAパケットを生成する。
【0058】
図7Aを参照して、RDMAパケットの生成過程を説明する。発行元ノード200aにおいて、ユーザモードのSPU22aからイベント通知を受け取ったカーネルモードのSPU21aは、ユーザ空間にあるアプリケーション用バッファ222a内のRDMAメッセージ227aをセグメント化し、RDMAパケットを組み立て、FIFOバッファ221aにRDMAパケットをキューイングする。
【0059】
FIFOバッファ221aは、RDMAプロトコルスタックが実装されたSPU21aと、TCP/IPプロトコルスタックが実装されたSPU20aとの間で共有されており、SPU21aはSPU20aにイベント通知し、FIFOバッファ221aに送信すべきRDMAパケットがあることを知らせる。イベント通知されたSPU20aは、FIFOバッファ221aにあるRDMAパケットをTCP/IPパケットに組み立て、TCP/IP送受信バッファ224aにコピーする。NIC30aは、TCP/IP送受信バッファ224a内のRDMAパケット229aをネットワーク100に送出する。
【0060】
一方、発行先ノード200bにおいても、ソケットAPI11u−1あるいは22u−2によってRDMA機能を使用することがsocketコマンドにより宣言される。そして、ソケットスイッチ50により、ユーザレベルのSPU22bからカーネルレベルのSPU21bおよびSPU20bへRDMAイベントがあることが通知される。
【0061】
発行先ノード200bのNIC30bは、ネットワーク100からRDMAパケット229bを受信し、TCP/IP送受信バッファ224bへコピーする。TCP/IPプロトコルスタック20sが実装されたSPU20bは、TCP/IP送受信バッファ224b内のRDMAパケット229bをTCP/IPプロトコルにしたがって解析し、FIFOバッファ221bにTCP/IPパケットをキューイングする。FIFOバッファ221bは、TCP/IPプロトコルスタック20sが実装されたSPU20bとRDMAプロトコルスタック21rが実装されたSPU21bの間で共有されている。TCP/IPプロトコル処理の後、SPU20bは、RDMAプロトコル処理を行うSPU21bにイベント通知し、RDMAパケットが受信されたことを知らせる。
【0062】
RDMAプロトコルスタック21rが実装されたSPU21bは、RDMAプロトコルにしたがってFIFOバッファ221bにあるRDMAパケットを解析し、RDMAライトすべきメッセージをリアセンブルし、アプリケーション用バッファ222bのRDMAライト用領域226bに書き込む。
【0063】
(6)ステップS20の動作
RDMAライトの発行が終わると、発行元ノード200aは「完了」メッセージを発行先ノード200bに送信する。「完了メッセージ」は、図6で説明した、RDMA機能を用いない通常のTCP/IPパケットで送信される。発行先ノード200bは「完了」メッセージを受信し、RDMAライト用領域226bを解放し、RDMAライトの動作を終了する。
【0064】
以上述べたように、実施例1によれば、RDMAプロトコル処理をソフトウェアでエミュレートすることにより、RDMA対応のNICでなくてもRDMA機能を用いた通信を行うことができる。また、実施例1では、ノード200内の複数のプロセッサが、TCP/IPプロトコル処理やRDMAプロトコル処理など個別の特定処理を専門に行う。同一のプロセッサがTCP/IPプロトコル処理とRDMAプロトコル処理を担当すると、異なるプロトコル処理を行う際、コンテキストスイッチが生じ、オーバーヘッドとなる。実施例1では、マルチプロセッサシステムであることを利用して、TCP/IPプロトコル処理を行うプロセッサと、RDMAプロトコル処理を行うプロセッサを別々に分けたため、コンテキストスイッチによるオーバーヘッドを低減することができ、高速なネットワーク処理を実現することができる。また、RDMA機能を使わない通信の際は、TCP/IPプロトコルスタックが実装されたプロセッサだけを利用して通信を行うことができる。
【0065】
上記の実施の形態では、各ノード200内にあるメインメモリ220にTCP/IP送受信バッファ224を設ける構成を説明したが、図7Bに示すように、各ノード200に搭載されたNIC30内にTCP/IP送受信バッファ224を設ける構成であってもよい。この場合、メインメモリ220とNIC30内のバッファの間でRDMAパケット229をコピーする必要がなく、いわゆる「ゼロコピー」を実現することができ、メモリ間コピーによるオーバーヘッドをなくすことができる。
【0066】
実施例2
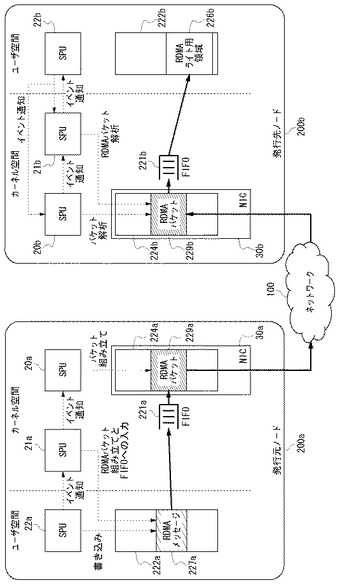
図8は、実施例2のノード200の構成図である。実施例1では、TOE機能をもたない通常のNIC30がノード200に搭載されている場合を説明したが、実施例2では、TOE機能をもつTOE−NIC31がノード200に搭載されている場合を説明する。システム起動時の設定により、TOE−NIC31が動作可能になるため、動作しないNIC30に関わる構成については図示していない。TOE−NIC31にはTCP/IPプロトコルスタックが実装されており、TOE−NIC31内部でTCP/IPのプロトコル処理を行うことができる。
【0067】
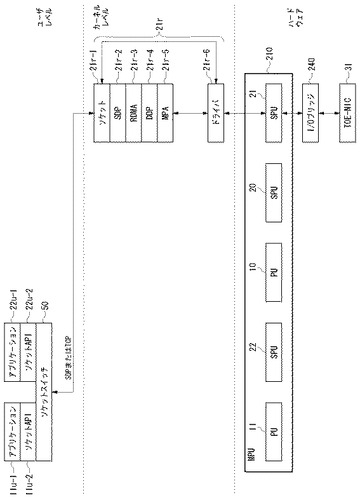
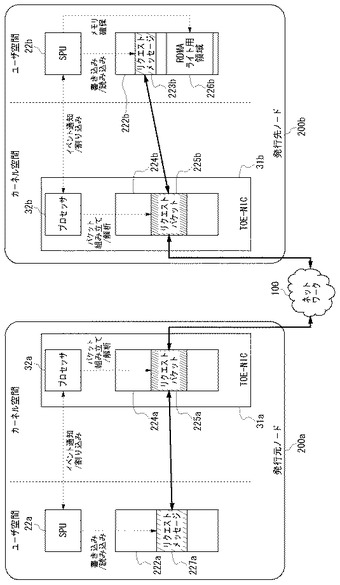
実施例2でも、実施例1と同様に、発行元ノード200aと発行先ノード200bの間でRDMAライトが実行される場合の動作を説明する。発行元ノード200aと発行先ノード200bの間で行われるRDMAライト処理のシーケンスは、実施例1の図5と同じである。図9および図10を参照し、実施例2において、図5のRDMAライト処理シーケンスの各ステップが図8の構成によって実行される様子を詳しく説明する。図9は、図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。一方、図10は、図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。以下、実施例1と同様の動作については適宜説明を簡略にする。
【0068】
(1)ステップS10の動作
図8において、発行元ノード200aのユーザ空間にあるアプリケーションプログラム11u−1または22u−1により、RDMAライトのリクエストが発行される。実施例1で説明したように、発行元ノード200aのソケットスイッチ50は、RDMAライトのリクエストが通常のTCP/IPにより送信されるべきであることを識別する。実施例2では、RDMA動作をしない通常の通信もRDMAプロトコルスタックが実装されたSPU21aにおいて実行される。
【0069】
発行元ノード200aのソケット層21r−1は、ソケットスイッチ50のコマンドの引数により、RDMAプロトコル処理を必要としない通常のTCP/IPの通信であることを識別し、SDP層21r−2、RDMA層21r−3、DDP層21r−4、およびMPA層21r−5のRDMAプロトコルスタックをバイパスして、直接デバイスドライバ21r−6にRDMAライトのリクエストメッセージを渡す。
【0070】
図9を参照する。発行元ノード200aにおいて、ユーザモードで動作しているSPU22aがTOE−NIC31a内のプロセッサ32aにイベント通知する。プロセッサ32aは、ユーザ空間のアプリケーション用バッファ222aに書きこまれたRDMAライトのリクエストメッセージ223aを読み出し、TCP/IPパケットとして組み立て、TOE−NIC31a内に設けられたTCP/IP送受信バッファ224aにRDMAライトのリクエストパケット225aを書き込む。TOE−NIC31aは、TCP/IP送受信バッファ224a内のリクエストパケット225aをネットワーク100に送信する。
【0071】
(2)ステップS12の動作
発行元ノード200aにおいてRDMAライトのリクエストの発行が終わると、図10に示すように、発行元ノード200aのユーザモードにあるSPU22aがアプリケーションを実行し、RDMAライトすべきRDMAメッセージ227aをアプリケーション用バッファ222aに書き込む。
【0072】
(3)ステップS14の動作
一方、発行先ノード200bは、ステップS10において発行元ノード200aが発行したRDMAライトのリクエストを受け取り、RDMAライト用のメモリ領域を準備する。図9に示すように、発行先ノード200bのTOE−NIC31bはネットワーク100からRDMAライトのリクエストパケット225bを受信し、TOE−NIC31b内に設けられたTCP/IP送受信バッファ224bに格納する。
【0073】
TOE−NIC31b内のプロセッサ32bは、TCP/IP送受信バッファ224bに受信されたRDMAライトのリクエストパケット225bを解析し、パケット内のリクエストメッセージ223bをリアセンブルしてユーザ空間のアプリケーション用バッファ222bにコピーする。その後、プロセッサ32bは、ユーザモードにあるSPU22bにイベント通知し、RDMAライトのリクエストメッセージが受信されたことを通知する。
【0074】
プロセッサ32bからイベント通知を受けたSPU22bはアプリケーション22u−1を実行し、RDMAライトのリクエストメッセージ223bを読み、アプリケーション用バッファ222b内にRDMAライトに必要なメモリ領域(「RDMAライト用領域」)226bを確保する。
【0075】
(4)ステップS16の動作
その後、発行先ノード200bのユーザ空間にあるアプリケーション22u−1は、レディメッセージを発行元ノード200aに返信する。RDMAライトのリクエストメッセージの場合と同様、レディメッセージは、発行先ノード200bのソケットスイッチ50がTCP/IPプロトコルを指定したコマンドを実行することにより、SPU21においてRDMAプロトコルスタックをスキップしてデバイスドライバ21r−6に渡され、TOE−NIC31bのTOE機能によりTCP/IPプロトコル処理がなされ、ネットワーク100に送信される。
【0076】
(5)ステップS18の動作
図8および図10を参照して、RDMAライトの動作を詳しく説明をする。発行元ノード200aにおいてアプリケーションプログラム11u−1あるいは22u−1がRDMAライトのコマンドを発行する。
【0077】
ソケットスイッチ50がsocketコマンドの引数によってRDMA動作であることを認識し、RDMAプロトコルスタックが実装されているSPU21aにイベント通知し、SPU21aがRDMAパケットを生成する。
【0078】
図10を参照して、RDMAパケットの生成過程を説明する。発行元ノード200aにおいて、ユーザモードのSPU22aからイベント通知を受け取ったカーネルモードのSPU21aは、ユーザ空間にあるアプリケーション用バッファ222aに書き込まれたRDMAメッセージ227aをセグメント化し、RDMAパケットを組み立て、FIFOバッファ221aにRDMAパケットをキューイングする。
【0079】
FIFOバッファ221aは、RDMAプロトコルスタックが実装されたSPU21と、TCP/IPプロトコルスタックが実装されたプロセッサ32aとの間で共有されており、SPU21は、TOE−NIC31a内のプロセッサ32aにイベント通知し、FIFOバッファ221aに送信すべきRDMAパケットがあることを知らせる。イベント通知されたプロセッサ32aは、FIFOバッファ221aにあるRDMAパケットをTCP/IPパケットに組み立て、TOE−NIC31a内に設けられたTCP/IP送受信バッファ224aにコピーする。TOE−NIC31aは、TCP/IP送受信バッファ224a内のRDMAパケット229aをネットワーク100に送出する。
【0080】
一方、発行先ノード200bにおいても、ソケットAPI11u−1あるいは22u−2によってRDMA機能を使用することが宣言される。ソケットスイッチ50により、ユーザレベルのSPU22bからカーネルレベルのSPU21bおよびTOE−NIC31b内のプロセッサ32bへRDMAイベントがあることが通知される。
【0081】
発行先ノード200bのTOE−NIC31bは、ネットワーク100からRDMAパケット229bを受信し、TCP/IP送受信バッファ224bに格納する。TOE−NIC31b内のプロセッサ32bは、TCP/IP送受信バッファ224b内のRDMAパケット229bをTCP/IPプロトコルにしたがって解析し、FIFOバッファ221bにTCP/IPパケットをキューイングする。FIFOバッファ221bは、TOE−NIC31b内のプロセッサ32bとRDMAプロトコルスタック21rが実装されたSPU21bの間で共有されている。TCP/IPプロトコル処理の後、プロセッサ32bは、RDMAプロトコル処理を行うSPU21bにイベント通知し、RDMAパケットが受信されたことを知らせる。
【0082】
RDMAプロトコルスタック21rが実装されたSPU21bは、RDMAプロトコルにしたがってFIFOバッファ221bにあるRDMAパケットを解析し、RDMAライトすべきメッセージをリアセンブルし、アプリケーション用バッファ222bのRDMAライト用領域226bに書き込む。
【0083】
なお、ここで述べたFIFOバッファ221a、221bは必ずしも、各ノード200a、200b内のメインメモリにある必要はなく、TOE−NIC31a、31b内に設けられてもよい。
【0084】
(6)ステップS20の動作
RDMAライトの発行が終わると、発行元ノード200aは「完了」メッセージを発行先ノード200bに送信する。「完了メッセージ」は、図9で説明した、RDMA機能を用いない通常のTCP/IPパケットで送信される。発行先ノード200bは「完了」メッセージを受信し、RDMAライト用領域226bを解放し、RDMAライトの動作を終了する。
【0085】
以上述べたように、実施例2によれば、RDMAプロトコル処理をソフトウェアでエミュレートすることにより、RDMA対応のNICでなくてもRDMA機能を用いた通信を行うことができる。また、実施例2では、マルチプロセッサシステムにおいて、RDMAプロトコル処理を行うプロセッサをユーザレベルでアプリケーションを実行するプロセッサとは別に設けたことで、RDMAプロトコル処理を効率良く実行することができる。また、NIC内のTOE機能を実行するプロセッサが、RDMAプロトコル処理を担当するプロセッサに負荷をかけないで、RDMAプロトコル処理されたパケットをTCP/IPプロトコル処理することができる。
【0086】
実施例3
実施例1ではTOE機能をもたない通常のNIC30を用いたRDMA動作を説明し、実施例2ではTOE機能をもつTOE−NIC31を用いたRDMA動作を説明した。実際には、NICが複数枚実装されており、TOE機能のないNICとTOE機能のあるNICが共存するネットワークノードの存在する。そのようなネットワークノードの一例としてルータがある。ルータはポート毎に異なるNICを搭載するため、複数の異なる種類のNICが共存することがある。また、別の例として、マルチプロセッサシステムにおいて各プロセッサに異なるIPアドレスを割り当て、プロセッサ毎にNICを設ける構成もある。以下では、実施例3として、TOE機能のないNICとTOE機能のあるNICが共存するネットワークノードの構成を取り上げ、TOE機能のないNICとTOE機能のあるNICを動的に切り替えて、通信する仕組みを説明する。
【0087】
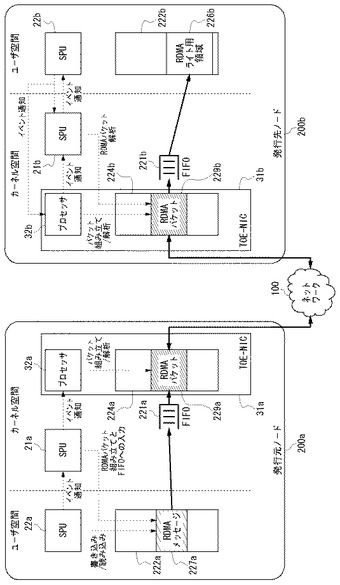
図11は、実施例3のノード200の構成図である。ノード200内には、TOE機能のないNIC30とTOE機能のあるTOE−NIC31とが搭載されており、I/Oブリッジ240を介してMPU210の各プロセッサと接続している。TCP/IPプロトコルスタック10s、20sが実装されたPU10、SPU20は、TOE機能のないNIC30を利用して通信し、RDMAプロトコルスタック21rが実装されたSPU21は、TOE機能のあるTOE−NIC31を利用して通信する。
【0088】
RDMAプロトコルスタック21rのMPA層21r−5の下に、パケットのIPアドレスを判別するためのIPA(Internet Protocol Address)判別層21r−7を新たに設ける。IPA判別層21r−7には、送信元IPアドレスをNICのMACアドレスに対応づけたアドレステーブルをあらかじめ用意しておく。ここで、MACアドレスは、一つ一つのNICに割り当てられた固有のアドレスである。IPA判別層21r−7は、メッセージを送信する際に、IPパケットの送信元アドレスを取得し、このアドレステーブルを参照することにより、どのNICから送信すべきパケットであるかを判定する。
【0089】
IPA判別層21r−7において、パケットの送信元IPアドレスがTOE機能のないNIC30のMACアドレスに対応づけられていることが判明すると、RDMAプロトコルスタック21rが実装されたSPU21は、TCP/IPプロトコルスタック20sが実装されたSPU20にイベント通知する。これにより、当該パケットはSPU20のTCP/IPプロトコルスタック20sによりプロトコル処理され、NIC30から送信される。
【0090】
IPA判別層21r−7において、パケットの送信元IPアドレスがTOE機能のあるTOE−NIC31のMACアドレスに対応づけられていることが判明すると、DMAプロトコルスタック21rが実装されたSPU21は、自分自身にイベント通知するか、あるいは、ドライバ21r−6へとパケットを渡す。これにより、当該パケットはTOE−NIC31に供給され、TOE−NIC31のTOE機能を用いてTCP/IPにしたがったプロトコル処理がなされ、ネットワークに送信される。
【0091】
ネットワークからパケットを受信する際は、通常のTCP/IP通信であるか、あるいは、RDMA機能を用いた通信であるかは、通信を開始するときに指定されるため、TCP/IPプロトコルスタック10s、20sに特別な機能を設ける必要はない。
【0092】
実施例3によれば、TOE機能のないNICとTOE機能のあるNICが混在するシステムにおいても、両者を動的に切り替えて通信を行うことができ、システムに柔軟性と拡張性をもたせることができる。
【0093】
実施の形態2
実施の形態2では、実施の形態1で説明したノード200の応用例として、RDMA機能を利用したサーバ−クライアントシステムを説明する。
【0094】
図12は、実施の形態2に係るネットワークシステムの構成図である。このネットワークシステムは、複数のサーバ310a、310bと複数のクライアント202a〜202nがネットワークで接続されて構成される。複数のサーバ310a、310bは、スイッチ320a、320bを介してネットワークに接続しており、これらはサーバクラスタ300を構成し、クライアント202a〜202nから見た場合、ひとつのサーバとして機能する。以下、複数のサーバ310a、310bを総称してサーバ310と呼び、複数のクライアント202a〜202nを総称してクライアント202と呼ぶ。
【0095】
サーバ310にはRDMA対応のNICが搭載されており、サーバ310のCPUの負荷を低減させることができる。一方、クライアント202には、ソフトウェアでRDMAをエミュレートするRDMA機能が実装されており、いわゆるiWARPが実現して、サーバ310との間でRDMAによる通信が可能となり、サーバ310の負荷を低減させるのに貢献する。
【0096】
図13は、クライアント202とサーバ310の構成図である。クライアント202は、実施の形態1で説明したマルチプロセッサシステムのように、RDMAプロトコルスタックが実装されるプロセッサとTCP/IPプロトコルスタックが実装されるプロセッサが異なってもよいが、実施の形態2では、クライアント202はシングルプロセッサシステムであり、RDMAプロトコルスタックとTCP/IPプロトコルスタックが1つのプロセッサで実行される場合を説明する。
【0097】
クライアント202のユーザレベルにはバッファ60が設けられ、サーバ310に送信するデータとサーバ310から受信するデータが格納される。DAFS(Direct Access File System)API62は、RDMAプロトコル上で動作するファイルシステムであるDAFSのアプリケーションプログラムインタフェース(API)である。uDAPL(user Direct Access Programming Library)64は、RDMA機能を実現するための汎用APIである。クライアント202は、これらのAPIを使用して、RDMA機能を用いてサーバ310のデータにアクセスする。
【0098】
カーネルレベルには、ソケット層71、RDMA層72、TCP層73、IP層74、NICドライバ75が実装され、RDMAリードあるいはRDMAライトのパケットがプロトコル処理され、ギガビットイーサネット(商標または登録商標)80を介してネットワーク100に送信される。
【0099】
サーバ310のユーザレベルにはバッファ80が設けられ、クライアント202に送信するデータとクライアント202から受信するデータが格納される。また、クライアント202と同様に、DAFSAPI82とuDAPL84が実装される。また、カーネルレベルのHCAドライバ88にアクセスするための仮想的なAPIであるVAPI86が実装される。
【0100】
サーバ310にはRDMA対応のNIC(以下、「RNIC」という)90が搭載されており、カーネルレベルのHCAドライバ88により制御される。RNIC90においてRDMAプロトコル処理がハードウェアで実行され、サーバ310のCPUを用いることなく、バッファ80に対してデータが直接読み書きされる。なお、RNIC90にはTOE機能も搭載されており、ハードウェアでTCP/IPプロトコル処理もなされる。
【0101】
図13において、クライアント202からサーバ310に対してRDMAリードあるいはRDMAライトが発行されると、クライアント202のRDMA層72においてソフトウェアでRDMA機能が実行され、サーバ310のRNIC90においてハードウェアでRDMA機能が実行される。これにより、クライアント202は、サーバ310のCPUに負荷をかけないで、サーバ310のバッファ80に直接アクセスすることができる。
【0102】
実施の形態2によれば、サーバ−クライアントシステムにおいて、サーバ側にRDMA機能が実装されており、クライアント側に必ずしもRNICが実装されていない場合でも、クライアント側でRDMA機能をエミュレートするため、サーバとクライアント間でRDMA機能を前提とした通信を行うことができる。これにより、サーバに搭載されたRDMA機能を有効活用して、高速な通信を行うことができる。特定のクライアントにおいてRNICの搭載ができなかったり、RNICの搭載が遅れる事情があっても、サーバ側でRDMA機能を停止させる必要がないため、RNICが搭載されているかどうかに関係なく、システムにクライアントを追加していくことができ、サーバ−クライアントシステムの拡張が容易である。
【0103】
以上説明したように、いずれの実施の形態においてもマルチプロセッサシステム上に、RDMAプロトコルおよびTCPプロトコルを常駐させるので、新規にRDMA対応のNICを購入することなく、低コストで、RDMA機能をエミュレートすることが可能となる。実施の形態ではRDMAプロトコルスタックをカーネルレベルに実装する例を説明したが、RDMAプロトコルスタックをユーザレベルに実装してもよい。RDMA機能をTCP/IP上に実装する技術は、一般にiWARPと呼ばれ、ネットワーク上の通信先のノードのメモリに直接データを書き込むことで処理遅延を減らすことができる。実施の形態では、iWARPをソフトウェアで実装することで、RDMAのハードウェアをもたないシステムでもRDMA機能を実現可能である。
【0104】
以上、本発明を実施の形態をもとに説明した。実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。そのような変形例を説明する。
【0105】
実施の形態では、プロセッサ間でイベント通知をすることにより、送受信データの存在を他のプロセッサに知らせたが、これ以外にも、たとえば、PUあるいはSPUが受信バッファをポーリングすることにより、イベントを検知してもよい。
【0106】
また、各ノード200内のメインメモリ220を用いて、パケット用のバッファを構築したが、たとえば、図2における、MPU210内の各プロセッサが個別にローカルメモリをもっており、そのローカルメモリを用いてパケット用のバッファを構築してもよい。
【0107】
なお、ソケットプログラムでは、送受信時にsendあるいはrecvコマンドを発行するが、実施の形態では説明の簡略化のため、ソケットの処理の詳細は省略した。
【図面の簡単な説明】
【0108】
【図1】本発明の実施の形態に係るネットワークシステムを示す図である。
【図2】図1のノードの構成図である。
【図3】図2のノードのMPUに実装されたTCP/IPプロトコルスタックおよびRDMA機能を説明する図である。
【図4】実施例1のノードの構成図である。
【図5】実施例1における発行元ノードと発行先ノードの間で行われるRDMAライト処理のシーケンス図である。
【図6】図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。
【図7A】図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。
【図7B】各ノードに搭載されたNIC内にTCP/IP送受信バッファを設ける構成を説明する図である。
【図8】実施例2のノードの構成図である。
【図9】実施例2において、図5のRDMAライト処理シーケンスの内、RDMA機能を使用しないTCPによる送受信動作を示す図である。
【図10】実施例2において、図5のRDMAライト処理シーケンスの内、RDMA機能を使用するSDPによる送受信動作を示す図である。
【図11】実施例3のノードの構成図である。
【図12】実施の形態2に係るネットワークシステムの構成図である。
【図13】図12のクライアントとサーバの構成図である。
【符号の説明】
【0109】
10 PU、 11 PU、20 SPU、 21 SPU、 22 SPU、 30 NIC、 31 TOE−NIC、 50 ソケットスイッチ、 100 ネットワーク、 200 ノード、 210 MPU、 220 メインメモリ、 222 アプリケーション用バッファ、 224 TCP/IP送受信バッファ、 230 NIC、 240 I/Oブリッジ。
【特許請求の範囲】
【請求項1】
リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、
前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記バッファからパケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、
前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項2】
ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、
前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
カーネルレベルでTCP/IPプロトコル処理を実行するプロセッサであって、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てる第3プロセッサと、
前記第3プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項3】
送信すべきメッセージをリモートダイレクトメモリアクセス機能を用いることなく送信する場合、前記第3プロセッサは、前記第1プロセッサからの通知を受けて、前記メッセージをTCP/IPにしたがったパケットに組み立てることを特徴とする請求項2に記載のネットワークプロセッサシステム。
【請求項4】
前記第1プロセッサは、指定されたプロトコルの違いを判別してイベント通知先を変更するプロトコルスイッチの機能を有し、
前記プロトコルスイッチは、
リモートダイレクトメモリアクセスのプロトコルが指定された場合、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てるために前記第2プロセッサにイベント通知し、
リモートダイレクトメモリアクセスのプロトコルが指定されない場合、前記メッセージをTCP/IPにしたがったパケットに組み立てるために前記第3プロセッサにイベント通知することを特徴とする請求項3に記載のネットワークプロセッサシステム。
【請求項5】
リモートダイレクトメモリアクセス機能をエミュレートするプロセッサと、
前記プロセッサから出力されるリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつネットワークインタフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項6】
ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、
前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すTCP/IPオフロード機能をもつネットワークインタフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項7】
送信すべきメッセージをリモートダイレクトメモリアクセス機能を用いることなく送信する場合、前記TCP/IPオフロード機能をもつネットワークインタフェースカードは、前記第1プロセッサからの通知を受けて、前記メッセージをTCP/IPにしたがったパケットに組み立てることを特徴とする請求項6に記載のネットワークプロセッサシステム。
【請求項8】
前記第1プロセッサは、指定されたプロトコルの違いを判別してイベント通知先を変更するプロトコルスイッチの機能を有し、
前記プロトコルスイッチは、
リモートダイレクトメモリアクセスのプロトコルが指定された場合、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てるために前記第2プロセッサにイベント通知し、
リモートダイレクトメモリアクセスのプロトコルが指定されない場合、前記メッセージをTCP/IPにしたがったパケットに組み立てるために前記TCP/IPオフロード機能をもつネットワークインタフェースカードにイベント通知することを特徴とする請求項7に記載のネットワークプロセッサシステム。
【請求項9】
リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、
前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、
前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信する第1ネットワークインタフェースカードと、
前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつ第2ネットワークインタフェースカードとを含み、
前記第1プロセッサは、前記パケットの送信元IPアドレスを前記第1ネットワークインタフェースカードのMACアドレスまたは前記第2ネットワークインタフェースカードのMACアドレスに対応づけたテーブルを参照して、前記パケットの送信元IPアドレスに応じて、前記パケットを送出するためのネットワークインタフェースを前記第1ネットワークインタフェースカードまたは前記第2ネットワークインタフェースカードのいずれかに振り分ける機能を有し、
前記パケットが前記第1ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2プロセッサによりTCP/IPプロトコル処理がなされて、前記第1ネットワークインタフェースカードから送出され、
前記パケットが前記第2ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2ネットワークインタフェースカードのTCP/IPオフロード機能によりTCP/IPプロトコル処理がなされて、前記第2ネットワークインタフェースカードから送出されることを特徴とするネットワークプロセッサシステム。
【請求項10】
ユーザレベルで処理を実行する第1プロセッサに、送信すべきメッセージをユーザ空間に生成するステップを実行させ、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサに、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップを実行させ、
カーネルレベルでTCP/IPプロトコル処理を実行する第3プロセッサに、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てるステップを実行させることを特徴とするプログラム。
【請求項11】
ユーザレベルで処理を実行する第1プロセッサに、送信すべきメッセージをユーザ空間に生成するステップを実行させ、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサに、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップを実行させ、
ネットワークインタフェースカード内でTCP/IPオフロード機能を実行する第3プロセッサに、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すステップを実行させることを特徴とするプログラム。
【請求項12】
ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、
カーネルレベルでTCP/IPプロトコル処理を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てるステップとを含むことを特徴とするネットワークプロトコル処理方法。
【請求項13】
ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、
ネットワークインタフェースカード内でTCP/IPオフロード機能を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すステップを実行することを特徴とするネットワークプロトコル処理方法。
【請求項1】
リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、
前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記バッファからパケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、
前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項2】
ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、
前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
カーネルレベルでTCP/IPプロトコル処理を実行するプロセッサであって、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てる第3プロセッサと、
前記第3プロセッサにより生成されたTCP/IPパケットをネットワークに送信するネットワークインターフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項3】
送信すべきメッセージをリモートダイレクトメモリアクセス機能を用いることなく送信する場合、前記第3プロセッサは、前記第1プロセッサからの通知を受けて、前記メッセージをTCP/IPにしたがったパケットに組み立てることを特徴とする請求項2に記載のネットワークプロセッサシステム。
【請求項4】
前記第1プロセッサは、指定されたプロトコルの違いを判別してイベント通知先を変更するプロトコルスイッチの機能を有し、
前記プロトコルスイッチは、
リモートダイレクトメモリアクセスのプロトコルが指定された場合、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てるために前記第2プロセッサにイベント通知し、
リモートダイレクトメモリアクセスのプロトコルが指定されない場合、前記メッセージをTCP/IPにしたがったパケットに組み立てるために前記第3プロセッサにイベント通知することを特徴とする請求項3に記載のネットワークプロセッサシステム。
【請求項5】
リモートダイレクトメモリアクセス機能をエミュレートするプロセッサと、
前記プロセッサから出力されるリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつネットワークインタフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項6】
ユーザレベルで処理を実行するプロセッサであって、送信すべきメッセージをユーザ空間に生成する第1プロセッサと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートするプロセッサであって、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てる第2プロセッサと、
前記第2プロセッサから出力される前記リモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すTCP/IPオフロード機能をもつネットワークインタフェースカードとを含むことを特徴とするネットワークプロセッサシステム。
【請求項7】
送信すべきメッセージをリモートダイレクトメモリアクセス機能を用いることなく送信する場合、前記TCP/IPオフロード機能をもつネットワークインタフェースカードは、前記第1プロセッサからの通知を受けて、前記メッセージをTCP/IPにしたがったパケットに組み立てることを特徴とする請求項6に記載のネットワークプロセッサシステム。
【請求項8】
前記第1プロセッサは、指定されたプロトコルの違いを判別してイベント通知先を変更するプロトコルスイッチの機能を有し、
前記プロトコルスイッチは、
リモートダイレクトメモリアクセスのプロトコルが指定された場合、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立てるために前記第2プロセッサにイベント通知し、
リモートダイレクトメモリアクセスのプロトコルが指定されない場合、前記メッセージをTCP/IPにしたがったパケットに組み立てるために前記TCP/IPオフロード機能をもつネットワークインタフェースカードにイベント通知することを特徴とする請求項7に記載のネットワークプロセッサシステム。
【請求項9】
リモートダイレクトメモリアクセス機能をエミュレートする第1プロセッサと、
前記第1プロセッサによりリモートダイレクトメモリアクセスのプロトコルにしたがって生成されたパケットをキューイングするバッファと、
前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施す第2プロセッサと、
前記第2プロセッサにより生成されたTCP/IPパケットをネットワークに送信する第1ネットワークインタフェースカードと、
前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すためのTCP/IPオフロード機能をもつ第2ネットワークインタフェースカードとを含み、
前記第1プロセッサは、前記パケットの送信元IPアドレスを前記第1ネットワークインタフェースカードのMACアドレスまたは前記第2ネットワークインタフェースカードのMACアドレスに対応づけたテーブルを参照して、前記パケットの送信元IPアドレスに応じて、前記パケットを送出するためのネットワークインタフェースを前記第1ネットワークインタフェースカードまたは前記第2ネットワークインタフェースカードのいずれかに振り分ける機能を有し、
前記パケットが前記第1ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2プロセッサによりTCP/IPプロトコル処理がなされて、前記第1ネットワークインタフェースカードから送出され、
前記パケットが前記第2ネットワークインタフェースカードに振り分けられる場合は、前記パケットは、前記第2ネットワークインタフェースカードのTCP/IPオフロード機能によりTCP/IPプロトコル処理がなされて、前記第2ネットワークインタフェースカードから送出されることを特徴とするネットワークプロセッサシステム。
【請求項10】
ユーザレベルで処理を実行する第1プロセッサに、送信すべきメッセージをユーザ空間に生成するステップを実行させ、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサに、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップを実行させ、
カーネルレベルでTCP/IPプロトコル処理を実行する第3プロセッサに、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てるステップを実行させることを特徴とするプログラム。
【請求項11】
ユーザレベルで処理を実行する第1プロセッサに、送信すべきメッセージをユーザ空間に生成するステップを実行させ、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサに、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップを実行させ、
ネットワークインタフェースカード内でTCP/IPオフロード機能を実行する第3プロセッサに、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すステップを実行させることを特徴とするプログラム。
【請求項12】
ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、
カーネルレベルでTCP/IPプロトコル処理を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコルにしたがったパケットに組み立てるステップとを含むことを特徴とするネットワークプロトコル処理方法。
【請求項13】
ユーザレベルで処理を実行する第1プロセッサが、送信すべきメッセージをユーザ空間に生成するステップと、
カーネルレベルでリモートダイレクトメモリアクセス機能をエミュレートする第2プロセッサが、前記第1プロセッサからの通知を受けて、前記メッセージをリモートダイレクトメモリアクセスのプロトコルにしたがったパケットに組み立て、バッファにキューイングするステップと、
ネットワークインタフェースカード内でTCP/IPオフロード機能を実行する第3プロセッサが、前記第2プロセッサからの通知を受けて、前記バッファから前記パケットを読み込み、TCP/IPプロトコル処理を施すステップを実行することを特徴とするネットワークプロトコル処理方法。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7A】
【図7B】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7A】
【図7B】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2008−20977(P2008−20977A)
【公開日】平成20年1月31日(2008.1.31)
【国際特許分類】
【出願番号】特願2006−190053(P2006−190053)
【出願日】平成18年7月11日(2006.7.11)
【出願人】(395015319)株式会社ソニー・コンピュータエンタテインメント (871)
【Fターム(参考)】
【公開日】平成20年1月31日(2008.1.31)
【国際特許分類】
【出願日】平成18年7月11日(2006.7.11)
【出願人】(395015319)株式会社ソニー・コンピュータエンタテインメント (871)
【Fターム(参考)】
[ Back to top ]