
パターン認識装置、パターン認識方法、及びプログラム
【課題】状態数及び各状態の出力分布を自動的に決定して、時系列データの頑健なモデル化をすることができるパターン認識装置、パターン認識方法、及びプログラムを提供すること。
【解決手段】本発明に係るパターン認識装置1は、入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワーク12を用いて、入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成部10と、生成されたテンプレートモデルと入力パターンをマッチングして当該入力パターンを認識する認識部20とを有するものである。
【解決手段】本発明に係るパターン認識装置1は、入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワーク12を用いて、入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成部10と、生成されたテンプレートモデルと入力パターンをマッチングして当該入力パターンを認識する認識部20とを有するものである。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、自己増殖型ニューラルネットワークを用いてパターン認識を行うパターン認識装置、パターン認識方法、及びプログラムに関する。
【背景技術】
【0002】
時系列パターンの認識・モデル化は動画像処理、音声情報処理、DNA解析などの様々な分野における重要な基盤技術である。一般的に時系列パターンは、特徴空間内での変動及び時間方向の伸縮を含む。時系列パターンを頑健に認識するためには、これらの特徴を吸収可能なモデル及び学習器を構築する必要がある。このため、予めグラフ構造を保持したモデルを持つことで時系列パターンの学習・認識を行う、モデルに基づく手法が頻繁に用いられている。
【0003】
モデルに基づく手法としてHMM(Hidden Markov Model)は、音声認識の分野における標準的な手法として大きな成功を収めている(非特許文献1参照)。HMMは音声認識以外にも、話者適応技術や音声合成技術などに用いられており、音声情報処理全般における標準的手法となっている。この音声情報処理における成功事例や、統計的理論の裏づけがあることから、HMMは動画像および動作の認識にも多く用いられてきた。音声認識や動画像認識における手法としては、離散HMM(Discrete HMM)を用いるものや、連続分布HMM(Continuous HMM)を用いるものがある(非特許文献2及び3参照)。また各状態における持続時間を正確にモデル化するために、各状態の持続長分布を明示的に持たせたSegment modelも提案されている。
【0004】
HMMなどに対し、動的計画法の一種であるDPマッチング法は、短時間の特徴パラメータ(各フレーム)同士の局所距離に基づいて、過度的な時系列パターン間の距離を算出することが可能である。DPマッチングは音声認識、動作認識の他、時系列パターンの検索などに用いられている。
【0005】
DPマッチング及びHMMに基づいた手法として、非特許文献4に開示された手法(以下、ストキャスティックDP法という。)が提案されている。ストキャスティックDP法では、DPマッチングにおける局所距離の尺度については確率の尺度を用いており、パスコストの代わりにパス遷移確率を用いている。また、ストキャスティックDP法はテンプレートパターンの1フレームを1状態に対応させており、状態数を多くしたHMMの連続出力分布を持つleft−to−rightモデルに相当する。
【非特許文献1】L. R. Rabiner, "A tutorial on hidden markov models and selected applications in speech recognition", Proc. IEEE, pp. 257-286(1989).
【非特許文献2】A. Wilson and A. Bobick, "Learning visual behavior for gesture analysis", Proc. IEEE International Symposium on Computer Vision, Vol. 5A Motion II(1995).
【非特許文献3】R. Hamdan, F. Heits and L. Thoraval, "Gesture localization and recognition using probabilistic visual learning", Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vol. 98-103(1999).
【非特許文献4】中川聖一,"ストキャスティックDP法および統計的手法による不特定話者の英語子音の認識",信学論(D),vol.J70-D, no.1(1987).
【発明の開示】
【発明が解決しようとする課題】
【0006】
HMMでは、パラメタ推定の容易性の理由で、音声データについて一音韻に対して3〜5状態のマルコフモデルが多く用いられる。しかしながら、このような少数の状態では、過度的な時系列パターンを正確にモデル化できない可能性がある。
また、DPマッチング法では標準パターンそのものをモデルとするため、HMMに比べて特徴空間の分布を詳細にモデル化することが困難である。
一方、ストキャスティックDP法は、DPマッチングの利点及びHMMの頑健性の両方を活かした手法であるものの、各状態の出力分布には単一の多次元正規分布が用いられている。一般に、各状態の出力分布は特徴量の次元数及び特性に応じて異なるため、このような単一の多次元正規分布を用いた場合には、出力分布を正確に近似することができないという問題がある。
【0007】
このように、従来のパターン認識モデルでは、予め適切な状態数及び各状態の出力分布を決定する必要があり、また、各状態の出力分布を単一の多次元正規分布を用いては、出力分布を十分に近似することができないという問題がある。
【0008】
本発明は係る課題を解決するためになされたものであり、状態数及び各状態の出力分布を自動的に決定し、時系列データの頑健なモデル化をすることができるパターン認識装置、パターン認識方法、及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
本発明に係るパターン認識装置は、入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成部と、生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識部を有するものである。
【0010】
これにより、テンプレートモデルにおける状態数及び各状態の出力分布を自動的に決定することができると共に、各状態の出力分布を詳細に近似することができるため、時系列データの頑健なモデル化を実現することができる。
【0011】
また、前記認識部は、前記ノードに基づいて、前記テンプレートモデルにおける状態の出力分布を算出する尤度算出部を有し、算出された前記テンプレートモデルにおける状態の出力分布を用いて、前記テンプレートモデルと前記入力パターンとの一致度を算出するようにしてもよい。これにより、テンプレートモデルにおける各状態の出力分布を詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0012】
さらにまた、前記尤度算出部は、前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部を有し、前記大域的尤度から前記テンプレートモデルにおける状態の出力分布を算出するようにしてもよい。これにより、入力パターンの特徴量を大域的尤度によって反映させることにより、テンプレートモデルにおける各状態の出力分布を詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0013】
また、前記尤度算出部は、辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部を有し、前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出するようにしてもよい。これにより、入力パターンの特徴量を局所域的尤度によって反映させることにより、各状態の出力分布が単一の多次元正規分布では近似できない場合であっても、テンプレートモデルにおける各状態の出力分布を詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0014】
さらにまた、前記尤度算出部は、前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部と、辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部とを有し、前記大域的尤度及び/又は前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出するようにしてもよい。これにより、入力パターンの特徴量を大域的尤度及び局所域的尤度を用いて反映させることにより、各状態の出力分布が単一の多次元正規分布では近似できない場合であっても、テンプレートモデルにおける各状態の出力分布をより詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0015】
また、前記テンプレートモデル生成部は、前記入力パターン間のマッチングにより、当該入力パターンが属するクラスの標準パターンを選択する標準パターン選択部を有し、前記入力パターンの大きさを前記標準パターンの大きさに正規化して、前記標準パターンの各フレームに対応する各前記入力パターンの一部又は全部を、前記テンプレートモデルにおける各状態に対応させるようにしてもよい。これにより、事前にテンプレートモデルにおける状態数を決定せずに、標準パターンのフレーム数に応じてテンプレートモデルにおける状態数を決定することができる。
【0016】
さらにまた、前記テンプレートモデル生成部は、前記テンプレートモデルにおける各状態に対応させた各前記入力パターンの一部又は全部からなる要素の集合について、前記入力パターンの入力パターン数及び当該入力パターンの特徴量の次元数に基づいて、当該要素集合を前記自己増殖型ニューラルネットワークに入力するようにしてもよい。これにより、1つの状態に対応する要素集合の要素数が少ない場合であっても、入力パターン数及び入力パターンの次元数に応じて要素数を決定することにより、分布を近似するのに必要な多さの要素数を確保して入力することができ、認識精度の低下を防止することができる。
【0017】
また、前記テンプレートモデル生成部は、逐次的に入力パターンを追加して入力するときに、当該逐次的に追加される入力パターンの属するクラスに対応する前記テンプレートモデルについて、当該テンプレートモデルにおける状態の出力分布を前記逐次的に追加される入力パターンに応じて更新するようにしてもよい。これにより、追加的に入力される入力パターンを容易に追加学習することができるとともに、事前に多量のデータを必要とせず、逐次的に与えられる少量のデータに基づいて認識精度を向上させてゆくことができる。
【0018】
さらにまた、DPマッチング法を用いて前記マッチング処理を行うようにしてもよい。これにより、効率的にマッチング処理を行うことができる。
【0019】
また、前記自己増殖型ニューラルネットワークは、入力される前記入力ベクトルに最も近い重みベクトルを持つノードと2番目に近い重みベクトルを持つノードの間に辺を接続したとき、注目するノードと他のノード間の距離に基づいて算出される当該注目するノードの類似度閾値、及び前記入力ベクトルと当該注目するノード間の距離に基づいて、前記入力ベクトルをノードとして挿入するクラス間ノード挿入部と、前記入力ベクトルに最も近いノードに対応する重みベクトル及び当該ノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ前記入力ベクトルに更に近づけるように更新する重みベクトル更新部とを有するようにしてもよい。これにより、類似度閾値に基づいて、挿入されるノードの個数を自律的に管理することができるため、ノードの数を事前に決定することなく、逐次的に入力される新たな入力パターンを既存の知識を壊すことなく追加学習することができる。
【0020】
さらにまた、前記クラス間ノード挿入部は、入力される前記入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、当該第1勝者ノード及び当該第2勝者ノードの間に辺を接続したとき、注目するノードについて、当該注目するノードと辺によって直接的に接続されるノードが存在する場合には、当該直接的に接続されるノードのうち当該注目するノードからの距離が最大であるノード間の距離を前記類似度閾値とし、当該注目するノードと辺によって直接的に接続されるノードが存在しない場合には、当該注目するノードからの距離が最小であるノード間の距離を前記類似度閾値として算出する類似度閾値算出部と、前記入力ベクトルと前記第1勝者ノード間の距離が当該第1勝者ノードの類似度閾値より大きいか否か、及び、前記入力ベクトルと前記第2勝者ノード間の距離が当該第2勝者ノードの類似度閾値より大きいか否かを判定する類似度閾値判定部と、類似度閾値判定結果に基づいて、前記入力ベクトルをノードとして当該入力ベクトルと同じ位置に挿入するノード挿入部とを有するようにしてもよい。これにより、入力ベクトルに応じて変化する類似度閾値によれば、挿入されるノードの個数を自律的に管理することができるため、ノードの数を事前に決定することなく、逐次的に入力される新たな入力パターンを既存の知識を壊すことなく追加学習することができる。
【0021】
また、前記自己増殖型ニューラルネットワークは、前記辺に対応付けられる辺の年齢に基づいて、当該辺を削除する辺削除部と、注目するノードについて、当該注目するノードに直接的に接続される辺の本数に基づいて、当該注目するノードを削除するノード削除部とを更に有するようにしてもよい。これにより、不要な入力パターンから生成されたノードを効果的かつ動的に削除することができる。
【0022】
さらにまた、前記自己増殖型ニューラルネットワークは1層構造であるようにしてもよい。これにより、非特許文献:F. Shen and O. Hasegawa, "An Incremental Network for On-line Unsupervised Classification and Topology Learning, " Neural Networks, vol. 19, pp. 90-106, 2006.に開示された技術であるSelf-Organizing Incremental Neural Network(以下、SOINNという。)と比べて、2層目の学習を開始するタイミングを指定せずに追加学習を実行することができる。
【0023】
本発明に係るパターン認識方法は、入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成ステップと、生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識ステップを有するものである。
【0024】
本発明に係るプログラムは、上述のような情報処理をコンピュータに実行させるものである。
【発明の効果】
【0025】
本発明によれば、状態数及び各状態の出力分布を自動的に決定して、時系列データの頑健なモデル化をすることができるパターン認識装置、パターン認識方法、及びプログラムを提供することができる。
【発明を実施するための最良の形態】
【0026】
以下、本発明を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。尚、各図面において、同一要素には同一の符号を付しており、説明の明確化のため、必要に応じて重複説明を省略する。
【0027】
発明の実施の形態1.
本実施の形態1は、本発明を、時系列パターンを認識するパターン認識装置に適用したものである。パターン認識装置は、オンライン教師なし学習手法である自己増殖型ニューラルネットワークを用いて、時系列パターンの特徴量に応じたテンプレートモデルを生成し、生成されたテンプレートモデルと時系列パターンをマッチングしてその時系列パターンを認識する。
自己増殖型ニューラルネットワークとして後述するSOINNを利用することによって、テンプレートモデルにおける各状態の出力分布を自動的に決定した上で、詳細に近似することができる。ここで、パターン認識装置は、時系列パターンの一部又は全部をSOINNへと入力し、SOINNにおいて形成される位相構造(ノード及び辺の集合)に基づいて尤度を算出して、状態の出力分布を近似する。尤度として大域的尤度及び局所的尤度を算出することによって、時系列パターンの特徴量に応じた状態の出力分布を詳細に表現できるため、時系列パターンの頑健なモデル化が可能となる。
【0028】
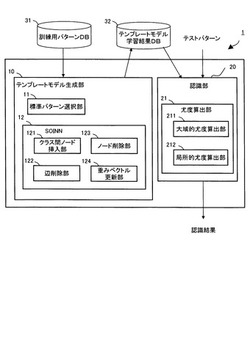
図1は、本発明の実施の形態1に係るパターン認識装置1を示すブロック図である。パターン認識装置1は、テンプレートモデル生成部10及び認識部20を備え、学習用の訓練パターンが格納された訓練用パターンデータベース(DB)31及び学習の結果生成されたテンプレートモデルが格納されたテンプレートモデル学習結果データベース(DB)32と接続されている。
【0029】
テンプレートモデル生成部10は、標準パターン選択部11及びSOINN12を備える。自己増殖型ニューラルネットワークとしてのSOINN12は、クラス間ノード挿入部121と、辺削除部122と、ノード削除部123と、重みベクトル更新部124とを備える。認識部20は、尤度算出部21を備える。尤度算出部21は、大域的尤度算出部211及び局所的尤度算出部212を備える。
【0030】
次に、各ブロックについて以下詳細に説明する。
テンプレートモデル生成部10は、後述するSOINN12を用いて、入力パターンの特徴量に応じた各クラスのモデル(以下、テンプレートモデルという。)を生成する。より具体的には、まず、後述する標準パターン選択部11により訓練データの中から中心となる標準パターンを選択し、この標準パターン及び他の訓練パターンとの間でDPマッチングを行うことによって、各訓練パターンを標準パターンの時系列長に正規化する。次に、標準パターンの各フレームに対応する入力パターンの一部又は全部からなるデータの集合をテンプレートモデルにおける1つの状態に対応させ、このデータ集合の分布をSOINN12によって近似する。この結果、テンプレートモデルは、標準パターンのフレーム数分だけ状態数を保持し、各状態の出力分布をSOINN12により近似することができる。以下、この手法をSOINN−DP法という。
【0031】
標準パターン選択部11は、入力パターン間のマッチングにより、その入力パターンが属するクラスの標準パターンを選択する。ここで、マッチング処理にはDPマッチング法を使用する。DPマッチング法を使用することによって効率的にマッチング処理を行うことができる。DPマッチングを行うことによって、2つのパターンX及びY間の累積距離D(X,Y)、及びパターン間の最適な対応付けj=wi(i=1,2,・・・,I)を得ることができる。
【0032】
以下、DPマッチング法について簡単に説明する。
本実施の形態1においては、フレーム数Iの時系列パターンX={x1,x2,・・・,xi,・・・,xI}、及びフレーム数Jの時系列パターンY={y1,y2,・・・,yj,・・・,yJ}とのDPマッチングを考え、この2つの時系列パターンの累積距離D(X,Y)を算出する。ここで、i及びjはそれぞれ時系列パターンX及びYのフレーム番号を示す。また、Xの各フレームの特徴ベクトルxiを、Xのiフレーム目の要素、もしくはi番目の要素という。本実施の形態1においては、時系列パターンX及び時系列パターンYの累積距離D(X,Y)を、以下に示す対称型漸化式を用いて算出する。
【数1】

【数2】
そして、上記数2に示した漸化式を用いて、以下の式に基づいて累積距離D(X,Y)を算出する。
【数3】
【0033】
このように、DPマッチングによれば、累積距離に現時点の局所距離を累積する演算を漸化的に繰り返すことによって累積距離D(X,Y)を算出することができる。また、DPマッチングによって、Xの第i番目(フレーム目)の要素xi及びYの第j番目の要素yjとの最適な対応付けj=wi(i=1,2,・・・,I)を得ることができる。
尚、DPマッチングに用いられる漸化式としては、上記の対称型漸化式以外にも、以下の式に示す非対称型漸化式がある。
【数4】
【0034】
SOINN12は、入力ベクトル及びニューラルネットワークに配置されるノードに基づいて、ノードを自動的に増加させる自己増殖型ニューラルネットワークであり、本実施の形態1においては、下記に説明するSOINNの1層目を用いて学習を行う。1層構造とすることにより、SOINNと比べて、2層目の学習を開始するタイミングを指定せずに追加学習を実行することができる。また、SOINNに限定されず、後述するEnhanced−SOINN(以下、E−SOINNという。)などとしても1層構造とすることができ、2層目の学習を開始するタイミングを指定せずに追加学習を実行することができる。
【0035】
以下、まず、従来技術であるSOINNについて簡単に説明し、次いで本実施の形態1にかかるSOINN12について説明する。SOINNは、非特許文献:Fritzke.B, "A growing neural gas network learns topologies, " Advances in neural information processing systems(NIPS), pp 625-632, 1995.に開示された技術であるGrowing Neural Gas(以下、GNGという。)を拡張した、いわゆる自己増殖型ニューラルネットワークと呼ばれる教師なし追加学習手法である。ノードを自己増殖しながら入力ベクトルを逐次的に学習することにより、入力データの分布を表現するネットワークを追加的に構築することができる。SOINNは、次の4つの利点を有する。
(1)過去に学習したクラスタを壊さずに、新規に入力される未知クラスの入力ベクトルを追加的に学習して、新規のクラスタを構築することができる。
(2)入力データに対して独立なノイズを、効果的かつ動的に除去することができる。
(3)逐次的に与えられる教師無しデータについて、その位相構造を表現するネットワークを自律的に構築することができる。
(4)ノード数を事前に決定せずに、入力ベクトルを近似することができる。
【0036】
図2は、従来技術であるSOINNによる学習処理を説明するためのフローチャートである。以下、図2を用いてSOINNの処理を簡単に説明する。ここで、SOINNは2層ネットワーク構造を有し、1層目及び2層目において同様の学習処理を実施する。また、SOINNは1層目の出力である学習結果を2層目への入力ベクトルとして利用する。
【0037】
S101:SOINNに対して入力ベクトルを与える。
S102:与えられた入力ベクトルに最も近いノード(以下、第1勝者ノードという。)、及び2番目に近いノード(以下、第2勝者ノードという。)を探索する。
S103:第1勝者ノード及び第2勝者ノードの類似度閾値に基づいて、入力ベクトルがこれら勝者ノードの少なくともいずれか一方と同一のクラスタに属すか否かを判定する。ここで、ノードの類似度閾値はボロノイ領域の考えに基づいて算出する。学習過程において、ノードの位置は入力ベクトルの分布を近似するため次第に変化し、それに伴いボロノイ領域も変化する。即ち、類似度閾値もノードの位置変化に応じて適応的に変化してゆく。
S104:S103における判定の結果、入力ベクトルが勝者ノードと異なるクラスタに属す場合は、入力ベクトルと同じ位置にノードを挿入し、S101へと進み次の入力ベクトルを処理する。尚、このときの挿入をクラス間挿入と呼ぶ。
【0038】
S105:一方、入力ベクトルが勝者ノードと同一のクラスタに属す場合は、第1勝者ノード及び第2勝者ノード間に辺を生成し、ノード間を辺によって直接的に接続する。
S106:第1勝者ノード及び第1勝者ノードと辺によって直接的に接続しているノードの重みベクトルをそれぞれ更新する。
S107:S105において生成された辺は年齢を有しており、予め設定された閾値を超えた年齢を持つ辺を削除する。入力ベクトルを逐次的に与えてゆくオンライン学習においては、ノードの位置が常に徐々に変化してゆくため、初期の学習で構成した隣接関係が以後の学習によって成立しない可能性がある。このため、一定期間を経ても更新されないような辺について、辺の年齢が高くなるように構成することにより、学習に不要な辺を削除することができる。
【0039】
S108:入力ベクトルの入力総数が、予め設定されたλの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がλの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がλの倍数となった場合には以下の処理を実行する。
【0040】
S109:局所累積誤差が最大であるノードを探索し、そのノード付近に新たなノードを挿入する(このときの挿入をクラス内挿入と呼ぶ。)。そして、ノードの持つ平均誤差を示す誤差半径に基づいて、ノード挿入が成功であったか否かを判定する。ここで、ノード及び入力ベクトル間の距離差をノードの持つ誤差として、入力ベクトルの入力に応じてノードの誤差を累積することにより局所累積誤差を算出する。誤差半径はノードの持つ誤差及びノードが第1勝者となった回数に基づいて算出する。
【0041】
S110:クラス内挿入によるノード挿入が成功であると判定した場合には、クラス内挿入により挿入されたノード及び局所累積誤差が最大のノードを辺によって直接的に接続する。一方、クラス内挿入によるノード挿入が失敗であると判定した場合には、クラス内挿入により挿入したノードを削除してS111へと進む。
S111:隣接ノード数及びノードが第1勝者となった回数に基づいて、ノイズノードを削除する。
ここで、隣接ノードとは、ノードと辺によって直接的に接続されるノードを示し、隣接ノードの個数が1以下であるノードを削除対象とする。また、第1勝者となった回数の累積回数を予め設定されたパラメタcを使用して算出される閾値と比較し、第1勝者累積回数が閾値を下回るノードを削除対象とする。
【0042】
S112:入力ベクトルの入力総数が予め設定されたLTの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がLTの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がLTの倍数となった場合には、以下の処理を実行する。
S113:1層目の学習を終了するか否かを判定する。判定の結果、2層目の学習へと進む場合には、S101へと進み1層目の学習結果であるノードを2層目への入力ベクトルとして入力する。ただし、追加学習を行う場合は、2層目に残っている以前の学習結果を消去した上で2層目の学習を開始する。
2層目への入力回数が予め設定された回数LTの倍数となり、2層目の学習を終了する場合には、ノードを異なるクラスに分類し、クラス数及び各クラスの代表的なプロトタイプベクトルを出力し停止する。ここで、プロトタイプベクトルはノードの重みベクトルに相当する。
【0043】
ここで、SOINNの機能を検証するために人工データセットを用いて行った実験を示す。
図3は、SOINNへと入力する2次元の人工データを示す画像である。図3に示した入力データセットは、2つのガウス分布、2つの同心円、及びサイン曲線の合計5つの信号発生源(クラス)からなる。また、実環境を想定して、5つの信号発生源から発生する信号に対して、10%の一様ノイズを加えた。SOINNに対して、図3に示した人工データセットをオンラインで追加的に入力し、教師無しのクラス分類を行わせた。
【0044】
図4は、図3に示した2次元の人工データをSOINNへと追加的に入力した場合における出力結果を示す画像である。図4に示すように、SOINNは、入力データに含まれるノイズを削除することが可能であると共に、入力データのクラス数及びそのトポロジ(位相構造)を正しく抽出することができる。
【0045】
このように、SOINNは、ノード数を自律的に管理することにより非定常的な入力を学習することができ、分布に複雑な形状を持つクラスに対しても適切なクラス数及び位相構造を抽出できるなど多くの利点を持つ。SOINNの応用例として、例えばパターン認識においては、ひらがな文字のクラスを学習させた後に、カタカナ文字のクラスなどを追加的に学習させることができる。また、自己増殖型ニューラルネットワークとしてSOINNを使用することにより、ノードを自動的に増加させることができるため、入力ベクトル空間からランダムに入力ベクトルが与えられる定常的な環境に限られず、例えば一定期間毎に入力ベクトルの属するクラスが切替えられて、切替後のクラスからランダムに入力ベクトルが与えられる非定常的な環境にも対応することができる。
【0046】
次いで、本実施の形態1に係るSOINN12について説明する。
SOINN12は、クラス間ノード挿入部121と、辺削除部122と、ノード削除部123と、重みベクトル更新部124とを備える。
クラス間ノード挿入部121は、類似度閾値算出部、類似度閾値判定部、及びノード挿入部を備える。クラス間ノード挿入部121は、入力される入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、第1勝者ノード及び第2勝者ノードの間に辺を接続したとき、以下に述べるようにしてノードを挿入する。
【0047】
まず、類似度閾値算出部は、注目するノードについて、注目するノードと辺によって直接的に接続されるノードが存在する場合には、直接的に接続されるノードのうち注目するノードからの距離が最大であるノード間の距離を類似度閾値とし、注目するノードと辺によって直接的に接続されるノードが存在しない場合には、注目するノードからの距離が最小であるノード間の距離を類似度閾値として算出する。
【0048】
次いで、類似度閾値判定部は、入力ベクトルと第1勝者ノード間の距離が第1勝者ノードの類似度閾値より大きいか否か、及び、入力ベクトルと第2勝者ノード間の距離が第2勝者ノードの類似度閾値より大きいか否かを判定する。
次いで、ノード挿入部は、類似度閾値判定結果に基づいて、入力ベクトルをノードとして入力ベクトルと同じ位置に挿入する。
【0049】
このようにして、入力ベクトルに応じて変化する類似度閾値によれば、挿入されるノードの個数を自律的に管理することができるため、ノードの数を事前に決定することなく、逐次的に入力される新たな連想対を既存の知識を壊すことなく追加学習することができる。
【0050】
重みベクトル更新部124は、入力ベクトルに最も近いノードに対応する重みベクトル、及びそのノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ入力ベクトルに更に近づけるように更新する。
辺削除部122は、辺に対応付けられる辺の年齢に基づいて、辺を削除する。ノード削除部123は、注目するノードについて、注目するノードに直接的に接続される辺の本数に基づいて、注目するノードを削除する。これにより、誤って生成された辺を適切に削除することができる。辺が存在しないノードは、そのノードの持つ結合重みベクトルに近い入力の頻度が極めて低いことを示しており、ノードの保持している情報は学習すべきデータと無関係なノイズであるものとみなすことができるためである。
【0051】
図5は、SOINN12による学習処理を説明するためのフローチャートである。以下、図5を用いてSOINN12の処理を説明する。
S201:SOINN12は、2つの入力ベクトルを取得し、ノード集合Aをそれらに対応する2つのノードのみを含む集合として初期化し、その結果を一時記憶部に格納する。また、辺集合C⊂A×Aを空集合として初期化し、その結果を一時記憶部に格納する。
【0052】
S202:SOINN12は、新しい入力ベクトルξを入力し、その結果を一時記憶部に格納する。
S203:SOINN12は、一時記憶部に格納された入力ベクトル及びノードについて、入力ベクトルξに最も近い重みベクトルを持つ第1勝者ノードa1及び2番目に近い重みベクトルを持つ第2勝者ノードa2を探索し、その結果を一時記憶部に格納する。
S204:クラス間ノード挿入部121は、一時記憶部に格納された入力ベクトル、ノード、ノードの類似度閾値について、入力ベクトルξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きいか否か、及び、入力ベクトルξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きいか否かを判定し、その結果を一時記憶部に格納する。ここで、一時記憶部に格納された第1勝者ノードa1の類似度閾値T1及び第2勝者ノードa2の類似度閾値T2は、SOINNと同様にして算出され、その結果が一時記憶部に格納される。
【0053】
S205:一時記憶部に格納されたS204における判定の結果、入力ベクトルξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きい、又は、入力ベクトルξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きい場合には、クラス間ノード挿入部121は、一時記憶部に格納された入力ベクトル及びノードについて、入力ベクトルξを新たなノードiとして、入力ベクトルξと同じ位置に挿入し、その結果を一時記憶部に格納する。
S206:一方、一時記憶部に格納されたS204における判定の結果、入力ベクトルξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1以下であり、かつ、入力ベクトルξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2以下である場合には、SOINN12は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0054】
S207:一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、SOINN12は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。そして、SOINN12は、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
一方、一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S208へと処理を進めるが、既にノード間に辺が生成されていた場合には、SOINN12は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
次いで、SOINN12は、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0055】
S208:重みベクトル更新部124は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力ベクトルξに更に近づけるように更新し、その結果を一時記憶部に格納する。ここで、重みベクトルの更新量の算出には、一時記憶部に格納されるMa1をtとして使用する。
S209:辺削除部122は、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。尚、agetはノイズなどの影響により誤って生成される辺を削除するために使用する。agetに小さな値を設定することにより、辺が削除されやすくなりノイズによる影響を防ぐことができるものの、値を極端に小さくすると、頻繁に辺が削除されるようになり学習結果が不安定になる。一方、極端に大きな値をagetに設定すると、ノイズの影響で生成された辺を適切に取り除くことができない。これらを考慮して、パラメタagetは実験により予め算出し一時記憶部に格納される。
【0056】
S210:SOINN12は、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がλの倍数でない場合にはS202へと戻り、次の入力ベクトルξを処理する。一方、入力ベクトルξの総数がλの倍数となった場合には以下の処理を実行する。尚、λはノイズと見なされるノードを削除する周期である。λに小さな値を設定することにより、頻繁にノイズ処理を実施することができるものの、値を極端に小さくすると、実際にはノイズではないノードを誤って削除してしまう。一方、極端に大きな値をλに設定すると、ノイズの影響で生成されたノードを適切に取り除くことができない。これらを考慮して、パラメタλは実験により予め算出し一時記憶部に格納される。
S211:ノード削除部123は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。
【0057】
S212:SOINN12は、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がLTの倍数でない場合にはS202へと戻り、次の入力パターンξを処理する。一方、入力ベクトルξの総数がLTの倍数となった場合には以下の処理を実行する。
S213:SOINN12は、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、SOINN12による学習を停止する。
【0058】
認識部20は、各クラスの訓練パターンから構成されたテンプレートモデルと入力パターンをマッチングすることにより、入力パターンがどのクラスに属するかを認識する。クラスcのテンプレートモデルTMcと入力パターンIPとのDPマッチングには対称型漸化式を使用し、以下の漸化式を用いる。尚、尤度C(xi,Sj)はテンプレートモデルTMcのj番目の状態Sjに対する、入力パターンIPのi番目の要素xiの尤度を示し、後述する尤度算出部21により算出される。
【数5】
ここでは、上記数2と同様の対称型漸化式を用いた。これにより、実データの認識実験において、非対称型漸化式を用いた場合に比べて、認識精度を向上させることができる。
【0059】
そして、認識部20は、尤度C(xi,Sj)の和が最大になるようにDPマッチングを行う。即ち、上記数2においては、累積距離g(i,j)を最小化するためminが用いられたが、上記数5においては、Q(i,j)を最大化するためmaxが用いられる。
DPマッチングの結果、テンプレートモデルTMcと入力パターンIPの累積一致度E(IP,TMc)を以下の式に基づいて算出する。尚、IIPは入力パターンIPの時系列長、JcはTMcの時系列長を示す。
【数6】
従って、認識部20は、入力パターンを以下の式に基づいて認識する。ここで以下の式は、入力パターンIPと累積一致度E(IP,TMc)が最も大きなテンプレートモデルのクラス番号を出力する関数であり、この場合に、入力パターンIPの帰属クラスはc*であるものと認識する。
【数7】
【0060】
尤度算出部21は、大域的尤度算出部211及び局所的尤度算出部212を有し、ノードに基づいて、テンプレートモデルにおける状態の出力分布を算出する。以下詳細に説明する。
尤度算出部21は、SOINN12に配置されたノード、及び辺によって接続されたノードからなるクラスタとに基づいて、尤度C(xi,Sj)を算出する。具体的には、以下の式に基づいて、大域的尤度log(Pwhole(xi|Sj))及び局所的尤度Pclass(xi|Ujk)を用いて、尤度C(xi,Sj)を算出する。図6は、SOINN12によってクラスタリングされ、SOINN12に存在する複数の内部クラス(ここでは、Class1乃至3)を示す図である。SOINN12によって生成された1つのクラスタを内部クラスと定義する。内部クラスはノードの参照ベクトル(プロトタイプベクトル群)により表現される。
【数8】
ここで、wkを以下の式に基づいて算出する。尚、Nallは状態SjのSOINN12内に存在する全ノードの総数を示し、Kは状態SjのSOINN12内の内部クラス数を示す。
【数9】
【0061】
これにより、入力パターンの特徴量を大域的尤度及び局所域的尤度を用いて反映させることにより、各状態の出力分布が単一の多次元正規分布では近似できない場合であっても、テンプレートモデルにおける各状態の出力分布をより詳細に近似することができるため、時系列データをより精度良く認識することができる。また、入力パターンに応じて大域的尤度及び局所域的尤度を反映させることにより、各状態の出力分布に対してより柔軟に対応することができる。
【0062】
大域的尤度算出部211は、SOINN12に配置された全てのノードに基づいて大域的尤度を算出する。具体的には、大域的尤度の算出にはj番目の状態SjのSOINN12内に存在する全ノードを用いる。大域的尤度は、状態のSOINN12内に存在する全ノードを多次元正規分布の確率密度関数で近似し、この密度関数からの生起確率Pwhole(xi|Sj)によって算出する。生起確率Pwhole(xi|Sj)を以下の式に基づいて算出する。ここで、μiは状態SjのSOINN12内に存在する全ノードの平均ベクトル、Σjは共分散行列である。これらの2つのパラメタは最尤推定により算出する。生起確率Pwhole(xi|Sj)の対数尤度log(Pwhole(xi|Sj))を、大域的尤度として定義する。
【数10】
【0063】
局所的尤度算出部212は、SOINN12に存在する複数のクラスタについて、そのクラスタに属するノードに基づいて局所的尤度を算出する。局所的尤度は、SOINN12によってクラスタリングされた、複数の内部クラスの情報を用いて算出する。例えば図6に示した各内部クラス(Class1乃至3)を、多変量正規分布に基づく核関数で近似する。ここで核関数を用いた理由は、各内部クラスが保有するノード数は少数の場合(最低で二個)が多く、このような少数データから多次元正規分布を推定することが困難なためである。SOINN12におけるk番目の内部クラスをUjkと定義し、Ujkから推定される局所的尤度Pclass(xi|Ujk)を以下の式に基づいて算出する。
【数11】
ここで、xjkはSOINN12内の内部クラスUjkに存在する全ノードの平均ベクトル、hjkは核関数の領域の大きさを示すパラメタであり、以下の式に基づいて算出する。尚、atは内部クラスUjkのノードtの位置ベクトルを示し、Njkは内部クラスUjkに含まれるノードの総数を示す。
【数12】
【0064】
以上のようなパターン認識装置1は、専用コンピュータ、パーソナルコンピュータ(PC)などのコンピュータにより実現可能である。但し、コンピュータは、物理的に単一である必要はなく、分散処理を実行する場合には、複数であってもよい。
【0065】
図7は、本実施の形態1に係るパターン認識装置1を実現するためのシステム構成の一例を示す図である。図7に示すように、コンピュータ40は、CPU41(Central Processing Unit)、ROM42(Read Only Memory)及びRAM43(Random Access Memory)を有し、これらがバス44を介して相互に接続されている。尚、コンピュータを動作させるためのOSソフトなどは、説明を省略するが、このパターン認識装置1を構築するコンピュータも当然備えているものとする。
【0066】
バス44には又、入出力インターフェイス45も接続されている。入出力インターフェイス45には、例えば、キーボード、マウス、センサなどよりなる入力部46、CRT、LCDなどよりなるディスプレイ、並びにヘッドフォンやスピーカなどよりなる出力部47、ハードディスクなどより構成される記憶部48、モデム、ターミナルアダプタなどより構成される通信部49などが接続されている。
【0067】
CPU41は、ROM42に記憶されている各種プログラム、又は記憶部48からRAM43にロードされた各種プログラムに従って各種の処理、本実施の形態においては、例えば点プレーモデル生成処理や認識処理を実行する。RAM43には又、CPU41が各種の処理を実行する上において必要なデータなども適宜記憶される。通信部49は、例えば図示しないインターネットを介しての通信処理を行ったり、CPU41から提供されたデータを送信したり、通信相手から受信したデータをCPU41、RAM43、記憶部48に出力したりする。記憶部48はCPU41との間でやり取りし、情報の保存・消去を行う。通信部49は又、他の装置との間で、アナログ信号又はディジタル信号の通信処理を行う。入出力インターフェイス45は又、必要に応じてドライブ50が接続され、例えば、磁気ディスク501、光ディスク502、フレキシブルディスク503、又は半導体メモリ504などが適宜装着され、それらから読み出されたコンピュータプログラムが必要に応じて記憶部48にインストールされる。
【0068】
続いて、本実施の形態1に係るテンプレートモデル生成処理及び認識処理について説明する。図8は、パターン認識装置1によるテンプレートモデル生成処理の概要を示すフローチャートである。以下、図8を参照しながらパターン認識装置1によるテンプレートモデル生成処理について説明する。テンプレートモデル生成部10は、クラスCに属するテンプレートモデルを以下のようにして生成する。ここで、テンプレートモデル生成部10は、クラスごとにテンプレートモデルを生成する。
【0069】
S301:訓練用パターンDB31より、N個の訓練パターンが与えられ、標準パターン選択部11は、訓練パターン群から1つの標準パターンを選択する。より具体的には、クラスCに含まれるある訓練パターンPmと、クラスCに含まれるPmを除いた他の訓練パターンとの間でDPマッチングを行う。この処理を、クラスC内の訓練パターンの全組合せ(総当り)によって行う。DPマッチングの結果より得られるパターン間同士の累積距離の和を算出し、累積距離の和が最小となるパターンを標準パターンとして選択する。即ち、以下の式に基づいて標準パターンを選択する。ここで、argは、各訓練パターン間の累積距離の和が最小となる訓練パターンの番号m*を出力する。
【数13】
このようにして、クラスCのm*番目の訓練パターンを、テンプレートモデルの中心となる標準パターンP*として選択する。尚、P*のフレーム数T*を、テンプレートモデルの時系列長とする。
【0070】
S302:DPマッチングにおいて対応付けられた訓練パターンのフレームデータを、テンプレートモデルにおける状態としてのSOINN12へと入力する。より具体的には、SOINN12への入力は、DPマッチングによる結果を用いて実現することができる。即ち、標準パターンP*と、その他N−1個の訓練パターンとの間でDPマッチングを行った結果、その他の全訓練パターンの時系列長は標準パターンP*の時系列長に正規化される。また、標準パターンP*の各要素と、その他N−1個の訓練パターンの各要素との対応付けが得られる。このようなDPマッチングの結果に基づいて、以下に説明するようにして、対応関係にある要素(ベクトル)群を各SOINN12空間(各状態)に入力する。
【0071】
まず、標準パターンP*の第j番目の要素をp*j、訓練パターンPn(n∈C)の第i番目(iフレーム目)の要素をpniとし、このp*jとpniとの最適な対応付けwnを以下のように定義する。
【数14】
上記数14に従って、訓練パターンのi番目の要素をj番目の状態(SOINN12空間)に分配する。このような分配操作を、標準パターンと、その他N−1個の訓練パターンとの間で行った後、N−1個の最適経路wnを(n=1,・・・,N−1)を得ることができる。このN−1個の最適経路に従って、各状態に対して訓練パターンの各要素を分配する。
【0072】
ここで、本実施の形態1では、ある時間の範囲(状態間)に分配された要素集合群を、1つのSOINN12へと入力する。具体的には、j番目の状態に分配された要素集合群をZ*jとして以下の式に示すように定義し、ZjからZj+L−1までの要素集合を、j番目の状態(SOINN12)に入力する。
【数15】
尚、Lはパラメタであり、このパラメタをSegment数として定義する。パラメタの設定方法については後述する。ここで、テンプレートモデルの状態数はSegment数L及び標準パターンの時系列長T*を用いて、T*−L−1として決定することができる。これにより、事前にテンプレートモデルにおける状態数を決定せずに、標準パターンのフレーム数に応じてテンプレートモデルにおける状態数を決定することができる。
【0073】
図9は、訓練パターンをSOINN12へと入力するようすを示す図である。図9において、Criterion Dataは標準パターンを示し、Data1乃至3は訓練パターンを示す。Data及びCriterion Dataの各ブロックは、各時刻(フレーム)の要素ベクトルを示す。各ブロックにおいて同色の部分は、DPマッチング後の最適経路における対応箇所を示している。例えば、Criterion Dataの1フレーム目の要素に対応した要素は、Data1の1及び2番目の要素、Data2の1番目の要素、及びData3の1番目の要素であり、これらの要素集合がZ1となる。実線は対応する要素集合Z1を結ぶ線である。破線はZ2の要素集合、Z3の要素集合をそれぞれ示す。Z1からZLまでの要素集合群Z*1が、クラスCのテンプレートモデルにおける状態1(SOINN12)に対して入力される。
【0074】
S303:SOINN12は、フレームデータに基づいて学習を行う。各状態jにおいて、フレームデータとしての要素集合群Z*jをSOINN12空間に入力する。ここでSOINN12がオンライン学習可能な手法であるため、要素集合群Z*jを入力する際、要素集合群Z*jの各要素を1つずつランダムに入力する。ランダムに入力されるベクトルがSOINN12空間に入力されると、SOINN12空間ではノード及び辺の生成、削除が繰り返され、最終的に複数の代表的ノード集合(クラスタ)が形成される。SOINN12による学習結果が、テンプレートモデル学習結果DB32に格納される。上述したように、尤度算出部21は、このようにして形成された複数の代表的ノード集合から、状態の出力分布を推定する。
【0075】
次に、認識処理について説明する。図10は、パターン認識装置1による認識処理の概要を示すフローチャートである。以下、図10を参照しながらパターン認識装置1による認識処理について説明する。
【0076】
S401:時系列パターンであるテストパターンXが入力される。
S402:認識部20は、テンプレートモデル学習結果DB32に格納されたSOINN12の学習結果より尤度C(xi,Sj)を算出して、各クラスのテンプレートモデルとテストパターンXとをDPマッチングする。
S403:尤度Q(i,j)が最大となったテンプレートモデルの帰属クラスを出力する。これにより、例えば、クラス3のテンプレートモデルに対する尤度が最大となった場合には、テストパターンXはクラス3であるものと認識する。
【0077】
続いて、本発明の実施の形態1に係るパターン認識装置1による効果について説明する。尚、以下においては、パターン認識装置1をモデル化した手法をSOINN−DP法と呼ぶ。
SOINN−DP法の有効性を確認するため、実データを用いて検証実験を行った。実験においては、時系列データの汎用的学習機能を評価するため、音素データ及び動画像より得られる動作データの2種類のデータセットを使用した。また、従来手法であるHMM及びストキャスティックDP法との比較実験を行った。以下、各手法による検証実験及び結果について説明する前に、まず従来手法であるHMM及びストキャスティックDP法について簡単に説明し、次にSOINN−DP法に関するパラメタ設定について説明する。
【0078】
まず、従来手法であるHidden Markov Model(HMM)について簡単に説明する。HMMは、不確定な時系列のデータをモデル化するための有効な統計的手法であり、出力シンボルによって一意に状態遷移先が決定しないという意味において、非決定性確率有限オートマトンとして定義される。ここで、HMMのパラメタには、状態遷移確率、シンボル出力確率、及び初期状態確率の3つのパラメタがある。
HMMは、シンボル出力確率の算出方法によって、離散型HMM及び連続分布型HMMに分類される。音声認識・動作認識においては連続分布型HMMが一般的に使用されるため、本実施の形態1においては、連続分布型HMMを比較手法として採用する。
また、HMMは、トポロジ(状態の接続関係)によって、あるひとつの状態から全ての状態に遷移可能な全遷移型(Ergodic)モデルや、状態遷移が一定方向に進むleft to rightモデルなどに分類される。音声認識や動作認識の分野においては、left to rightモデルが一般的に用いられるため、本実施の形態1においては、left to rightモデルを比較手法として採用する。
HMMのパラメタ推定方法には、一般的に使用されるBaum Welchアルゴリズムを用いた。また、Baum Welchアルゴリズムによるパラメタ推定精度を向上させるため、パラメタの初期値設定についてSegmental kmeans法を使用する。
【0079】
次に、従来手法であるストキャスティックDP法について簡単に説明する。
ストキャスティックDP法において用いられる漸化式を次式に示す。漸化式は上記数4に示した非対称型の漸化式を基盤として構成されている。
【数16】
【0080】
上記数16に示した漸化式における条件確率P(ai|j)及び状態遷移確率PDP1,2,3(j)は非特許文献4に記載された手法により算出した。ここで、条件付確率P(ai|j)は多次元正規分布である。P(ai|j)の共分散行列に関しては、ある範囲において同一のものを使用した。例えば、10個の状態により同じ共分散行列を使用する場合に、状態1から10に対して分配された全てのデータから、最尤推定により1つの共分散行列を算出し、状態1から10の各状態において同一のσを用いる。状態11から20、状態21から30においても同様の操作により算出し、それらの状態に対して同一のσを用いる。
【0081】
続いて、SOINN−DP法に関するパラメタ設定について説明する。孤立単語を用いて予備実験を行い、SOINN−DP法のパラメタを設定した。実験には、男性話者3人が50回ずつ5単語を発話したデータ(1単語につき150個、計750個)を用いた。単語は「こんばんは」、「こんにちは」、「またあした」、「おはよう」、「さようなら」の5単語である。音声特徴量には、20次元MFCC、フレーム長25ms、フレーム周期5msを用いた。一クラスにつき、訓練データを50、テストデータを100として、訓練データ及びテストデータを交換しながら計20回のクロスバリデーション実験を行った。20回のクロスバリデーション実験より、各実験におけるテストデータに対する認識率を求め、その平均値を認識結果とした。テストデータに対して平均認識率が最大となるパラメタを、後述する音素認識実験及び動作認識実験に用いた。
【0082】
まず、SOINN−DP法におけるSOINN12のパラメタ設定について説明する。
SOINNと同様にSOINN12においては、ノイズ除去を適切に行うため、λ及びagedeadという2つのパラメタを設定する必要がある。各クラスタはノードとノード間を接続する辺により表現され、このノード及び辺は、入力データに応じて生成・削除を繰り返す。このため、ノイズデータに対してノードを生成した場合には、分類結果が悪化するものの、パラメタλ及びagedeadを適切に設定することによってこれを回避することができる。
【0083】
λは、ノイズとおぼしきノードを削除する周期を示す。λを小さな値に設定することにより、頻繁にノイズ処理を行うことができるものの、極端に小さくした場合には、実際にはノイズではないノードを誤って削除してしまう。一方、λを極端に大きくした場合には、ノイズの影響により生成されたノードを適切に取り除くことができない。そこで、パラメタ設定のための上記予備実験の結果から、SOINN12への入力回数を30000回に設定し、λ=10000と設定した。即ち、学習中に、ノイズとおぼしきノードの削除を3回行った。
【0084】
agedeadは、ノイズなどの影響により誤って生成された辺を削除するために用いる。agedeadを小さな値に設定することにより、辺が削除されやすくなりノイズによる影響を低減させることができるものの、極端に小さくした場合には、頻繁に辺が削除され学習結果が不安定になる。一方、agedeadを極端に大きくした場合には、ノイズの影響により生成された辺を適切に取り除くことができない。SOINN−DP法においては、1つの状態に分配される要素ベクトル数が少数であるため、agedeadを小さくした場合には学習結果が不安定となった。従って、本実施の形態1においては、agedeadを機能させないものとし、辺を削除しないものとした。即ち、agedead=30000とし、学習中に辺の削除は行わないものとした。
【0085】
以上より、上記予備実験の結果から、SOINN12のパラメタ設定について、λ=10000、agedead=30000と設定した。尚、SOINN12には、パラメタλ及びagedead以外にも、パラメタc1、α1、α2、α3、β、γが存在するものの、これらのパラメタについてはSOINNと同じ値を使用した(c1=1、α1=1/4、α2=3/4、α3=1/4、β=2/3、γ=3/4)。
【0086】
次に、SOINN−DPのパラメタ設定について説明する。
ここでは、上記数15に示したセグメント数Lについて、その設定方法を説明する。セグメント数Lを大きくした場合には、各状態のSOINN12への入力データが多くなるため、SOINN12の学習精度が向上するものと考えられる。しかし、セグメント数Lを極端に大きな値に設定した場合には、時系列的に離れたデータを1つの状態に入力することになり、時系列データを無視することになってしまう。このため、過度的な時系列データの特徴をモデル化することができず、テストデータに対する認識率の低下を招く。一方、セグメント数Lを極端に小さな値に設定した場合には、SOINN12においてネットワーク(ノード及び辺の集合)が形成されない。ノード集合が生成されない場合、上記数10に示した共分散行列Σを正確に算出することが困難となる。即ち、上記数10に示した共分散行列Σを算出するため、十分な量のデータを1つの状態(SOINN12)に対して入力する必要がある。尚、非特許文献4においては、特徴量の次元数pに対して、少なくともp×4〜5倍以上のデータ数が必要とされ、p2個以上が好ましいものとされている。
【0087】
ここで、訓練データN個をモデルの学習に用いた場合において、各状態に分配される要素ベクトル数が平均N個であるものと仮定する。かかる場合に、1つのSOINN12に対して入力されるデータ集合Z*iの要素数(データ数DN)を、以下の式によって定義する。
【数17】
従って、上記数17より、セグメント数Lは以下の式に示す範囲となる。
【数18】
パラメタ設定のための上記予備実験を通して、上記数18の範囲内における最適なセグメント数Lについて、L≧6p/Nを満たす最小の値として決定した。
また、セグメント数LはストキャスティックDP法における共分散行列を共有する範囲に対応するものと考えられるため、ストキャスティックDP法を用いて同様の予備実験を行った。その結果、ストキャスティックDP法において、共分散行列を共有する範囲について、最大の認識率を得ることができる範囲はセグメント数Lと等しいことを確認することができた。
従って、以下の本実験においては、ストキャスティックDP法における共分散行列を共有する範囲はLとした。尚、セグメント数LによるSOINN−DP法における認識率への寄与については後述する。
【0088】
続いて、SOINN−DP法の有効性を確認するため、音素データとして英語音素を対象に認識実験を行った。認識対象として、ked−TIMITデータベース(University of Edinburgh, Center for Speech Technology Research, "CSTR US KED TIMIT"(2002), http://festvox.org/dbs/dbs_kdt.html.)中に含まれる英語文章から抽出した音素39クラスを100個ずつ、計3900個を使用した。図11は、認識対象実験における詳細を示す表である。尚、SOINN−DPのパラメタについて、セグメント数Lは上記数18より、訓練データが40個の場合にはL=6とし、訓練データが80個の場合にはL=3と決定した。
【0089】
また、従来手法との比較においても、図11に示したのと同じ条件において実験を行った。HMMの各状態の出力確率は、全共分散行列を持つ混合正規分布とした。HMMについては、最大の認識率を得ることができるパラメタ(状態数及び混合正規分布の混合数)について、それらのパラメタを変化させながら実験を行って最適なパラメタを探索した。そして、そのような最適なパラメタを用いた場合に認識率を算出して、HMMによる認識結果とした。
ストキャスティックDP法については、上記数16に示した非対称型漸化式を用いた場合に加えて、対称型漸化式を用いた場合の実験も行った。対称型漸化式を用いたSOINN−DP法に対して、同様の対称型漸化式を用いたストキャスティックDP法を比較するためのである。尚、対称型漸化式には上記数5に示したC()を条件付確率P(ai|j)に交換した式を用いた。また、共分散行列を共有する範囲は、SOINN−DPにおけるセグメント数Lと同様に、訓練データが40個の場合には6状態の間とし、訓練データが80個の場合には3状態の間とした。
【0090】
図12は、10回のクロスバリデーション実験の結果から得られた、テストデータに対する平均認識結果を示す表である。図12において、1段目は訓練データが40個の場合(TD40)における平均認識率、2段目は訓練データ数が80個(TD80)の場合の平均認識率をそれぞれ示している。「SO−DP」はSOINN−DP法、「ST−DP(1)」は非対称型漸化式を用いたストキャスティックDP法、「ST−DP(2)」は対称型漸化式を用いたストキャスティックDP法をそれぞれ示している。また、HMMの認識率の右側括弧内は、最大の認識率を得た時のパラメタ(S:状態数、M:混合数)を示している。図12に示すように、SOINN−DP法の平均認識率は、ストキャスティックDP法及びHMMによる平均認識率よりも高く、良好であった。
【0091】
また、HMMを用いた実験において、比較のため状態数を1から13個まで変動させて実験を行った結果、状態数が3〜7の付近において認識率が最大であったため、実験に使用した音素データに対して最適な状態数は3〜7であるものと推定した。このため、状態数が3〜7において、各状態に割り当てられている出力確率を混合連続確率分布に変更し、混合数を変化させ図11に示した条件において実験を行った。その結果、訓練データが40個の場合には5状態2混合、訓練データが80個の場合には5状態4混合において認識率が最大となった。
さらにまた、ストキャスティックDP法について、非特許文献4に開示された非対称型漸化式を用いた場合よりも、対称型漸化式を用いた場合のほうが高い認識結果となった。これは、対称型漸化式を用いることにより、時系列の伸縮を吸収しやすくなるためだと考えられる。
以上より、音声認識実験の結果、SOINN−DP法では、ストキャスティックDP法及びHMMより得られる最大の認識率に比べて、より良好な認識率を得ることができた。即ち、SOINN−DP法は従来手法と比較して高い認識精度を有するものである。
【0092】
続いて、SOINN−DP法の有効性を確認するため、動画像より得られる動作データを対象に認識実験を行った。動作データとして、単眼カメラより直接撮像した、人間による7種類の全身運動(動作)を用いた。図13は、実験に用いた7種類の動作内容(動作M1乃至7)を示す画像である。動画のフレーム率は29フレーム毎秒とし、各動作の時間長は最小で110フレーム、最大で440フレームである。入力パターンには個人差を含み、動作の各部分において伸縮性も含まれている。
【0093】
また、実験においては、モーションキャプチャなどの器具を使用せずに、動画像より動作の特徴を直接取得した。ここで、本実施の形態1においては、位置不変特徴である局所自己相関特徴(大津展之,"パターン認識における特徴抽出に関する数理的研究",vol.818,(1981))を学習に用いることにより、動的特徴を抽出した。実験に用いた動画像の処理手順を以下に示す。
S501:入力動画像を平滑化し、フレーム間における差分を取得する。
S502:差分画像のRGB値を輝度値に変換し、輝度値に対する閾値より、2値化する。
S503:差分画像間において、時間方向の自己相関特徴を抽出する。非特許文献(T. Kobayashi and N. Otsu, "Action and simultaneous multiple persons identification using cubic higher-order local auto-correlation", Proc. International Conference on Pattern Recognition, Vol. 19, pp. 741-744 (2004).)に開示される自己相関特徴について、ここでは、3×3サイズのマスクを用いて自己相関特徴を抽出し、各フレーム間の時系列方向のみ抽出した。尚、中央位置のマスク値には、「動き」の方向性特徴が現れないため、このマスク値については除外した。結果的に、各フレームにおいて計8次元の入力ベクトル(要素ベクトル)を得た。
【0094】
図14は、認識対象実験における詳細を示す表である。SOINN−DPにおけるパラメタは、音素認識実験における場合と同様のパラメタを用いた。ただし、セグメント数Lについては、上記数18より訓練データが10個の場合に、入力次元が8であるためL=5と算出した。
HMMの各状態の出力確率は、全共分散行列を持つ正規分布とした。尚、音素認識実験と同様に、状態数を変化させながら実験を行って最適なパラメタを探索し、そのパラメタを用いた上での認識率を認識結果とした。
また、ストキャスティックDP法については、上記数16に示した非対称型漸化式を用いた場合に加えて、対称型漸化式を用いた場合における実験も行った。尚、ストキャスティックDP法について、共分散行列を共有する範囲は5状態の間とした。
【0095】
図15は、動作データに対する認識結果を示す表である。図15において、「SO−DP」はSOINN−DP法、「ST−DP(1)」は非対称型漸化式を用いたストキャスティックDP法、「ST−DP(2)」は対称型漸化式を用いたストキャスティックDP法をそれぞれ示している。また、HMMの認識率の右側括弧内は、最大の認識率を得た時のパラメタ(S:状態数)を示している。図15に示すように、音素認識実験の場合と同様に、SOINN−DP法の識別率は、ストキャスティックDP法及びHMMによる認識率よりも高く、良好であった。
また、HMMを用いた実験において、比較のため状態数を1から15個まで変動させて実験を行った結果、状態数が11おいて認識率が最大であった。
さらにまた、ストキャスティックDP法について、音素認識実験の場合と同様に、非特許文献4に開示された非対称型漸化式を用いた場合よりも、対称型漸化式を用いた場合のほうが高い認識結果となった。
このように、音素データに比較して状態数及びその出力分布を決定することが困難である動作データに対しても、SOINN−DP法は高い認識精度を有するものである。
【0096】
以上より、音素認識実験の場合と同様に、動作認識実験についても、SOINN−DP法では、ストキャスティックDP法及びHMMより得られる最大の認識率に比べて、より良好な認識率を得ることができた。即ち、SOINN−DP法は時系列パターン全体の認識に使用することができ、従来手法と比較して高い認識精度を有するものである。
【0097】
ここで、音素認識実験及び動作認識実験結果から、SOINN−DP法が、従来手法であるストキャスティックDP法及びHMMより優れている点についてさらに説明する。
まず、SOINN−DP法は、SOINN12を用いて1つの状態を詳細に近似することによって頑健なテンプレートモデルを構築する。これにより、SOINN−DP法は、ストキャスティックDP法と比較して優れた認識率を有しており、時系列データの頑健なモデル化を行うことができる。
そして、SOINN−DP法は、各状態の出力分布をSOINN12によって自動的に決定することができる。また、状態数を標準パターンの時系列数として決定することができるため、状態数を予め決定する必要がない。これにより、時系列データを学習する際に、HMMでは事前に状態数及び状態の出力分布(連続分布の場合には混合数)を決定する必要があるが、SOINN−DP法では不要である。即ち、実験においては、HMMの状態数及び混合数について、認識率が最も高くなる場合の値を採用し、これらの値に基づいて認識結果を得た。SOINN−DP法は、このようなHMMによる認識結果よりも良好であった。従って、SOINN−DP法は、事前に状態数及び出力分布のパラメタを設定せずに、高い認識率を得ることができる。
【0098】
ここで、セグメント数LによるSOINN−DP法の認識率への寄与について説明する。SOINN−DP法のパラメタであるセグメント数Lは、SOINN−DP法の認識性能に影響を与える。このため、セグメント数の変化による認識精度への影響について検証する。
本実施の形態1においては、上記数18に基づいてセグメント数Lを算出する。検証は、図11に示した表と同様の条件下において音素認識実験を行った。1回の実験に用いる1クラスあたりの訓練データは40個とした。また、セグメント数を1〜10まで変化させ、それぞれのセグメント数を用いた場合において、計10回のクロスバリデーション実験を行った。
図16は、検証結果を示す図である。図16に示すように、セグメント数をL=1から増加させるにつれて徐々に認識率が上昇し、L=5において最大認識率(57.04%)を得た。さらにセグメント数を増加させた場合には、認識率は下降した。
一方、予備実験の結果から算出したセグメント数は、訓練パターンが40個の場合に、L=6であり、図16においては、L=6の場合は、全体で3番目に認識率が高いものであった。従って、本実施の形態1において用いたセグメント数の推定方法は妥当なものであり、この推定方法によって適切なセグメント数を決定することができる。
【0099】
ここで、SOINN−DP法の認識性能に対して、SOINN12による寄与について説明する。
SOINN−DP法では、DPマッチングによって各状態jに対して要素ベクトル群Z*jを分配する。分配されたZ*jはSOINN12によって分類され、その分類結果より大域的尤度Pwhole(xi|Sj)及び局所的尤度Pclass(xi|Ujk)を算出し、これらの確率値に基づいて尤度C(xi,Sj)を算出する。そこで、SOINN−DP法に加えて、SOINN12を用いない手法を2つ定義し、これらの手法を比較した。SOINN12による学習結果を用いない手法と比較することにより、SOINN12による認識精度への寄与を検証した。SOINN12の学習結果を用いない比較手法として、以下の2つの手法を定義した。
【0100】
手法1:要素ベクトル群Z*jをSOINN12に入力せず、Z*jより直接、最尤推定により多次元正規分布P(x|Sj)を算出した。尤度C(xi,Sj)=log(P(x|Sj))とし、この尤度C(xi,Sj)を用いた漸化式により入力データの認識を行った。
手法2:要素ベクトル群Z*jをSOINN12に入力し、SOINN12の分類結果より、Pwhole(xi|Sj)を算出した。ただし、SOINN12のクラスタリング結果より得られるPclass(xi|Ujk)については、入力パターンの認識には用いないものとした。即ち、尤度C(xi,Sj)を以下の式に基づいて算出し、α=0とした。
【数19】
尚、検証実験は図11に示した表と同様の条件下において行い、1回の実験に用いる1クラスあたりの訓練データは80個とし、セグメント数L=3とした。αを0〜1.0まで0.05ずつ変化させながら、それぞれのαを用いた場合について、計10回のクロスバリデーション実験を行った。
【0101】
図17は、[手法1]、[手法2]、SOINN−DP法により得られた検証実験の結果を示す表である。図17に示すように、SOINN−DP法による認識結果は、[手法1]及び[手法2]による認識率を約4%上回っている。従って、SOINN12を用いたことに加えて、さらに、SOINN12の学習結果の内部クラスの情報を用いたSOINN−DP法は、この情報を用いなかった[手法1]及び[手法2]に比べて高い認識率を有するものである。尚、テストデータに対する[手法1]及び[手法2]による認識率はほぼ同程度であった。即ち、SOINN−DPは、SOINN12の学習結果である内部クラスの情報を用いることにより、認識率をより向上させることができる。
【0102】
さらに、内部クラスの情報について、αの変化によるSOINN−DPの認識率への寄与について説明する。図18は、αの変化に対する認識率の変化を示す図である。図18においては、x軸方向がαの値を示し、y軸方向が各々のα値に対応する認識率を示す。図18に示すように、認識率はα=0.45において最大となり、以降低下した。最終的に、認識率はα=1.0において最低となった。α=1.0の状態は、上記数19において右辺の第二項(log(ΣjPcぁss(x)))のみにより尤度を算出することに等しく、内部クラスの情報のみを用いて尤度を算出していることになる。この場合には、各内部クラスを核関数により近似しているため、次元間の相関を多次元正規分布のようにモデル化することができない。このため、各内部クラスによる情報のみを用いて尤度を算出した場合において、テストデータに対する認識率が低下したものと考えられる。
一方、図17に示した結果より、各内部クラスによる情報に加えて、大域的情報(SOINNの全ノード)を併せて用いることによって、SOINN−DP法は認識率を向上させることができた。
また、図18に示すように、α=0.45において最大の認識率を得た。これは、αをデータにフィッティングさせることによって、さらにSOINN−DP法による認識精度を向上させることが可能であることを示している。
【0103】
尚、本実施の形態1においては、パターン認識装置1がテンプレートモデル生成処理及び認識処理を行うものとして説明したが、本発明はこれに限定されるものではない。例えば、テンプレートモデル生成部10を、自己増殖型ニューラルネットワークを用いてテンプレートモデルを生成するテンプレートモデル生成装置としても使用することができる。また、認識部20を、自己増殖型ニューラルネットワークを用いて認識を行う認識装置としても使用することができる。
また、本実施の形態1において示したパターン認識はこれに限定されず、SOINN−DPは実環境における他の時系列パターンの認識についても適用することができる。
さらにまた、実環境において動作する知能ロボットにSOINN−DPを適用することができる。SOINN−DPを適用することにより、知能ロボットに例えば手話などの動作を認識させることができる。また、逐次的にテンプレートモデルを更新することによって、環境に適応して発達させてゆくことができる。即ち、例えば、人間が英語を徐々に聞き取ることができるようになっていくのと同様に、認知発達機能を実現することができる。
【0104】
尚、本実施の形態1においては、テンプレートモデル生成には予め十分な個数の訓練パターンが用意され、バッチ学習としてテンプレートモデルが生成される場合を説明したが本発明はこれに限定されない。即ち、テンプレートモデル生成部10は、逐次的に入力パターンを追加して入力するときに、その逐次的に追加される入力パターンの属するクラスに対応するテンプレートモデルについて、そのテンプレートモデルにおける状態の出力分布を逐次的に追加される入力パターンに応じて更新するようにしてもよい。これにより、追加的に入力される入力パターンを容易に追加学習することができるとともに、事前に多量のデータを必要とせず、逐次的に与えられる少量のデータに基づいて認識精度を向上させてゆくことができる。即ち、テンプレートモデルを少量の訓練パターンを用いて生成した後、オンラインで与えられる教師付きデータを用いて、テンプレートモデルを更新することができる。
【0105】
図19は、テンプレートモデルを更新する様子を説明するための図である。図19に示すように、オンラインで追加的に与えられたData1乃至3について、上記同様にしてSOINN−DP法によってマッチング処理が実施された後、教師付きデータより更新対象となるテンプレートモデル(Target Template)を特定することができる。そして、テンプレートモデルにおける各状態(SOINN−1Frame乃至SOINN−3Frame)が、更新前のデータ、及び追加されたデータによって更新される。図20は、SOINN12における更新の様子を説明するための図である。図20に示すように、既にSOINN12に存在しているノードに加えて、追加的に入力されたノードからなるクラス(Class generated by update data)が既存の知識を壊すことなく生成される。図21は、オンライン教師付き学習による検証結果を示す表である。図21に示すように、まずバッチ学習において所定の個数の(10、20、40個)データを用いてテンプレートモデルを生成し、オンラインでデータを追加してテンプレートモデルを更新した場合において、認識率の向上結果を検証した。検証結果より、オンラインでデータを追加してゆくにつれて、認識率が向上していくことが分かる。即ち、オンライン教師付き学習による、時系列モデルの頑健な更新が可能である。
【0106】
その他の発明の実施の形態.
以上、本発明をその実施の形態により説明したが、本発明はその趣旨の範囲において種々の変形が可能である。例えばSOINN12に代えて、SOINNに基づくEnhanced−SOINN(以下E−SOINNという。)を使用しても良い。
【0107】
E−SOINNはSOINNに比べて、入力パターンの分布に高密度の重なりのあるクラスを分離することができる。そして、分布の重なり領域の検出処理においては、平滑化の手法を導入したことより、SOINNに比べてより安定的に動作することができる。さらに、1層構造であっても効率的にノイズノードを削除することができる。さらにまた、SOINNに比べて、より少ないパラメタで動作するため、処理をより容易に実行することができる。
【0108】
以下にE−SOINNを簡単に説明する。図22は、E−SOINNによる学習処理の処理概要を示すフローチャートである。尚、上述したSOINN12と同様の処理については説明を省略する。まず、図22に示すS601乃至S605については、図5に示したSOINN12と同様の処理を実施する。従って、以下では図22に示すS606からの処理について説明する。
【0109】
S606:辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2のノード密度に基づいて、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
S607:一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。そして、E−SOINNは、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0110】
一方、一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S608へと処理を進めるが、既にノード間に辺が生成されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
次いで、一時記憶部に格納されたノード及びノード密度のポイント値について、第1勝者ノードa1について、ノード密度算出手段は、一時記憶部に格納された第1勝者ノードa1のノード密度のポイント値を算出しその結果を一時記憶部に格納し、算出され一時記憶部に格納されたノード密度のポイント値を以前までに算出され一時記憶部に格納されたポイント値に加算することで、ノード密度ポイントとして累積し、その結果を一時記憶部に格納する。
次いで、E−SOINNは、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0111】
S608:重みベクトル更新手段は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力ベクトルξに更に近づけるように更新し、その結果を一時記憶部に格納する。尚、E−SOINNにおいては、追加学習に対応するため、入力ベクトルの入力回数tに代えて、一時記憶部に格納される第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1を用いる。
S609:E−SOINNは、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。
【0112】
S610:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がλの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。一方、入力ベクトルξの総数がλの倍数となった場合には以下の処理を実行する。
【0113】
S611:分布重なり領域検出手段は、一時記憶部に格納されたサブクラスタ及び分布の重なり領域について、上述のS301乃至S305において示したようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
S612:ノード密度算出手段は、一時記憶部に格納されて累積されたノード密度ポイントを単位入力数あたりの割合として算出しその結果を一時記憶部に格納し、単位入力数あたりのノードのノード密度を算出し、その結果を一時記憶部に格納する。
S613:ノイズノード削除手段は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。尚、S613においてノイズノード削除手段が使用するパラメタc1及びc2はノードをノイズと見なすか否かの判定に使用する。通常、隣接ノード数が2であるノードはノイズではないことが多いため、c1は0に近い値を使用する。また、隣接ノード数が1であるノードはノイズであることが多いため、c2は1に近い値を使用するものとし、これらのパラメタは予め設定され一時記憶部に格納される。
【0114】
S614:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がLTの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。
一方、入力ベクトルξの総数がLTの倍数となった場合には、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、学習を停止する。
【0115】
ノード密度算出手段は、一時記憶部に格納されたノード及びノード密度について、注目するノードについて、その隣接ノード間の平均距離に基づいて、注目するノードのノード密度を算出し、その結果を一時記憶部に格納する。具体的には、ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiに与えられるノード密度のポイント値piを算出し、その結果を一時記憶部に格納する。尚、ノードiに与えられるポイント値piは、ノードiが第1勝者ノードとなった場合には一時記憶部に格納される以下の式に基づいて算出されるポイント値が与えられるが、ノードiが第1勝者ノードでない場合にはノードiにはポイントは与えられないものとする。
【数20】
【0116】
ここで、eiはノードiからその隣接ノードまでの平均距離を示し、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【数21】
尚、mは一時記憶部に格納されたノードiの隣接ノードの個数を示し、Wiは一時記憶部に格納されたノードiの重みベクトルを示す。
【0117】
ここで、隣接ノードへの平均距離が大きくなる場合には、ノードを含むその領域にはノードが少ないものと考えられ、逆に平均距離が小さくなる場合には、その領域にはノードが多いものと考えられる。従って、ノードの多い領域で第1勝者ノードとなった場合には高いポイントが与えられ、ノードの少ない領域で第1勝者ノードとなった場合には低いポイントが与えられるようにノードの密度のポイント値の算出方法を上述のように構成する。これにより、ノードを含むある程度の範囲の領域におけるノードの密集具合を推定することができるため、ノードの分布が高密度の領域に位置するノードであっても、ノードが第1勝者回数となった回数をノードの密度とするSOINNに比べて、入力ベクトルの入力分布密度により近似した密度となるノード密度ポイントを算出することができる。
【0118】
単位ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiの単位入力数あたりのノード密度densityiを算出し、その結果を一時記憶部に格納する。
【数22】
【0119】
ここで、連続して与えられる入力ベクトルの入力回数を予め設定され一時記憶部に格納される一定の入力回数λごとの区間に分け、各区間においてノードiに与えられたポイントについてその合計を累積ポイントsiと定める。尚、入力ベクトルの総入力回数を予め設定され一時記憶部に格納されるLTとする場合に、LT/λを区間の総数nとしその結果を一時記憶部に格納し、nのうち、ノードに与えられたポイントの合計が0以上であった区間の数をNとして算出し、その結果を一時記憶部に格納する(Nとnは必ずしも同じとならない点に注意する)。
【0120】
累積ポイントsiは、例えば一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【数23】
ここで、pi(j,k)はj番目の区間におけるk番目の入力によってノードiに与えられたポイントを示し、上述のノード密度ポイント算出部により算出され、その結果を一時記憶部に格納する。このように、単位ノード密度ポイント算出部は、一時記憶部に格納されたノードiの密度densityiを累積ポイントsiの平均として算出し、その結果を一時記憶部に格納する。
【0121】
尚、E−SOINNにおいては追加学習に対応するため、nに代えてNを用いる。これは、追加学習において、以前の学習で生成されたノードにはポイントが与えられないことが多く、nを用いて密度を算出すると、以前学習したノードの密度が次第に低くなってしまうという問題を回避するためである。即ち、nに代えてNを用いてノード密度を算出することで、追加学習を長時間行った場合であっても、追加されるデータが以前学習したノードの近くに入力されない限りは、そのノードの密度を変化させずに保持することができる。これにより、追加学習を長時間実施する場合であっても、ノードのノード密度が相対的に小さくなってしまうことを防ぐことができ、SOINNを含む従来の手法に比べて、入力ベクトルの入力分布密度により近似したノード密度を変化させずに保持して算出することができる。
【0122】
分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、辺によって接続されるノードの集合であるクラスタを、ノード密度算出手段によって算出されるノード密度に基づいてクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納し、サブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0123】
さらに、分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索するノード探索部と、探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与する第1のラベル付与部と、第1のラベル付与部によりラベルが付与されなかったノードのうち、そのノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与する第2のラベル付与部と、それぞれ異なるラベルが付与されたノード間に辺によって直接的に接続がある場合に、その辺によって接続されるノードの集合であるクラスタをクラスタの部分集合であるサブクラスタに分割するクラスタ分割部と、注目するノード及びその隣接ノードがそれぞれ異なるサブクラスタに属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出する分布重なり領域検出部を有する。具体的には、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、例えば以下のようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0124】
S701:ノード探索部は、一時記憶部に格納されたノード及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索し、その結果を一時記憶部に格納する。
S702:第1のラベル付与部は、一時記憶部に格納されたノード、及びノードのラベルについて、S701において探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与し、その結果を一時記憶部に格納する。
S703:第2のラベル付与部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、S702において第1のラベル付与部によりラベルが付与されなかったノードについて、第1のラベル付与部にラベルが付与されたノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与し、その結果を一時記憶部に格納する。即ち、密度が局所的に最大の隣接ノードと同じラベルを付与する。
S704:クラスタ分割部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、一時記憶部に格納された辺によって接続されるノードの集合であるクラスタを、同じラベルが付与されたノードからなるクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納する。
S705:分布重なり領域検出部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、注目するノードとその隣接ノードが異なるサブクラスタにそれぞれ属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出し、その結果を一時記憶部に格納する。
【0125】
辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、及び分布重なり領域について、第1勝者ノード及び第2勝者ノードが分布重なり領域に位置するノードである場合に、第1勝者ノード及び第2勝者ノードのノード密度に基づいて第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。さらに辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタについて、ノードが属しているサブクラスタを判定する所属サブクラスタ判定部と、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定する辺接続判定部を有する。
【0126】
辺接続手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
辺削除手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。
具体的には、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタ、及びノード間の辺について、例えば以下のようにして辺接続判定手段は辺を接続するか否かを判定し、辺接続手段及び辺削除手段は辺の生成及び削除処理を実施し、その結果を一時記憶部に格納する。
【0127】
S801:所属サブクラスタ判定部は、一時記憶部に格納されたノード、ノードのサブクラスタについて、第1勝者ノード及び第2勝者ノードが属するサブクラスタをそれぞれ判定し、その結果を一時記憶部に格納する。
S802:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードがどのサブクラスタにも属していない場合、又は、第1勝者ノード及び第2勝者ノードが同じサブクラスタに属している場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成することによりノード間を接続し、その結果を一時記憶部に格納する。
S803:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードが互いに異なるサブクラスタに属す場合には、辺接続判定部は、一時記憶部に格納されたノード、ノード密度、及びノード間の辺について、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
S804:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要がないと判定した場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間を辺によって接続せず、既にノード間が辺によって接続されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、一時記憶部に格納された第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。
S805:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要があると判定した場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成しノード間を接続する。
【0128】
ここで、辺接続判定部による判定処理について詳細に説明する。
まず、辺接続判定部は、一時記憶部に格納されたノード及びノード密度について、第1勝者ノードのノード密度densitywin及び第2勝者ノード密度densitysec−winのうち、最小のノード密度mを例えば一時記憶部に格納される以下の式に基いて算出し、その結果を一時記憶部に格納する。
【数24】
【0129】
次に、一時記憶部に格納されたノード、ノードのノード密度、及びノードのサブクラスについて、第1勝者ノード及び第2勝者ノードがそれぞれ属するサブクラスタA及びサブクラスタBについて、サブクラスタAの頂点の密度Amax及びサブクラスタBの頂点の密度Bmaxを算出し、その結果を一時記憶部に格納する。尚、サブクラスタに含まれるノードのうち、ノード密度が最大であるノード密度をサブクラスタの頂点の密度とする。
【0130】
そして、一時記憶部に格納されたノードが属するサブクラスタの頂点の密度Amax及びBmax、及びノードの密度mについて、mがαAAmaxより小さく、かつ、mがαBBmaxより小さいか否かを判定し、その結果を一時記憶部に格納する。即ち、一時記憶部に格納される以下の不等式を満足するか否かを判定し、その結果を一時記憶部に格納する。
【数25】
【0131】
判定の結果、mがαAAmaxより小さく、かつ、mがαBBmaxより小さい場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間には辺は不要であると判定し、その結果を一時記憶部に格納する。
一方、判定の結果、mがαAAmax以上、または、mがαBBmax以上である場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺は必要であると判定し、その結果を一時記憶部に格納する。
【0132】
このように、第1勝者ノード及び第2勝者ノードの最小ノード密度mを、第1勝者ノード及び第2勝者ノードをそれぞれ含むサブクラスタの平均的なノード密度と比較することで、第1勝者ノード及び第2勝者ノードを含む領域におけるノード密度の凹凸の大きさを判定することができる。即ち、サブクラスタA及びサブクラスタBの間に存在する分布の谷間のノード密度mが、閾値αAAmax又はαBBmaxより大きな場合には、ノード密度の形状は小さな凹凸であると判定することができる。
【0133】
ここで、αA及びαBは一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。尚、αBについてもαAと同様にして算出することができるためここでは説明を省略する。
i) Amax/meanA−1≦1の場合には、αA=0.0とする。
ii) 1<Amax/meanA−1≦2の場合には、αA=0.5とする。
iii) 2<Amax/meanA−1の場合には、αA=1.0とする。
【0134】
Amax/meanAの値が1以下となるi)の場合には、AmaxとmeanAの値は同程度であり、密度の凹凸はノイズの影響によるものと判断する。そして、αの値を0.0とすることで、サブクラスタが統合されるようにする。
また、Amax/meanAの値が2を超えるiii)の場合には、AmaxはmeanAに比べて十分大きく、明らかな密度の凹凸が存在するものと判断する。そして、αの値を1.0とすることで、サブクラスタが分離されるようにする。
そして、Amax/meanAの値が上述した場合以外となる i i)の場合には、αの値を0.5とすることで、密度の凹凸の大きさに応じてサブクラスタが統合又は分離されるようにする。
【0135】
尚、meanAはサブクラスタAに属すノードiのノード密度densityiの平均値を示し、NAをサブクラスタAに属するノードの数として、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【数26】
【0136】
このように、サブクラスタへの分離を行う際に、サブクラスタに含まれるノード密度の凹凸の程度を判定し、ある基準を満たした2つのサブクラスタを1つに統合することで、分布の重なり領域の検出におけるサブクラスタの分けすぎによる不安定化を防止することができる。例えば、ノイズや学習サンプルが少ないことが原因で、密度の分布に多くの細かい凹凸が形成されることがある。このような場合に、第1勝者ノード及び第2勝者ノードがサブクラスタA及びBの間にある分布の重なり領域に位置する場合に、ノード間の接続を行う際にある基準を満たした2つのサブクラスタを1つに統合することで、密度の分布に多くの細かい凹凸が含まれる場合であっても平滑化することができる。
【0137】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードについて、ノード密度算出手段により算出されるノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。さらにノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードのノード密度を所定の閾値と比較するノード密度比較部と、注目するノードの隣接ノードの個数を算出する隣接ノード数算出部と、注目するノードをノイズノードとみなして削除するノイズノード削除部を有する。具体的には、例えば以下のようにして一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、ノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。
【0138】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード間の辺、隣接ノードの個数について、注目するノードiについて、隣接ノード数算出部によりその隣接ノードの個数を算出し、その結果を一時記憶部に格納する。そして、一時記憶部に格納された隣接ノードの個数に応じて、以下の処理を実施する。
i) 一時記憶部に格納された隣接ノード数が2の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【数27】
一時記憶部に格納された比較結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
【0139】
ii) 一時記憶部に格納された隣接ノード数が1の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【数28】
一時記憶部に格納された比較の結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
【0140】
iii) 一時記憶部に格納された隣接ノード数について、隣接ノードを持たない場合、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
ここで、予め設定され一時記憶部に格納される所定のパラメタc1及びc2を調整することで、ノイズノード削除手段によるノイズノードの削除の振る舞いを調整することができる。
【0141】
本発明の目的は、上述した実施形態の機能を実現するソフトウェアのプログラムコードを記録した記録媒体(または記憶媒体)を、システムあるいは装置に供給し、そのシステムあるいは装置のコンピュータ(またはCPUやMPU)が記録媒体に格納されたプログラムコードを読み出し実行することによっても、達成されることは当然である。この場合、記録媒体から読み出されたプログラムコード自体が上述の実施形態の機能を実現することになり、そのプログラムコードを記録した記録媒体は本発明を構成することになる。
【0142】
また、コンピュータが読み出したプログラムコードを実行することにより、上述した実施形態の機能が実現されるだけでなく、そのプログラムコードの指示に基き、コンピュータ上で稼動しているオペレーティングシステム(OS)などが実際の処理の一部又は全部を行い、その処理によって上述した実施形態の機能が実現される場合も当然含まれる。
【0143】
さらに、記録媒体から読み出されたプログラムコードが、コンピュータに挿入された機能拡張カードやコンピュータに接続された機能拡張ユニットに備わるメモリに書き込まれた後、そのプログラムコードの指示に基き、その機能拡張カードや機能拡張ユニットに備わるCPUなどが実際の処理の一部又は全部を行い、その処理によって上述した実施形態の機能が実現される場合も当然含まれる。本発明を上記記録媒体に適用する場合、その記録媒体には、上述したフローチャートに対応するプログラムコードが格納されることになる。
【図面の簡単な説明】
【0144】
【図1】本発明を実施するための機能ブロックを示す図である。
【図2】従来手法であるSOINNによる学習処理の処理概要を示すフローチャートである。
【図3】従来手法であるSOINNに対して入力した人工データセットを示す図である。
【図4】人工データセットに対するSOINNの出力結果を示す図である。
【図5】本実施形態に係るSOINN12による学習処理の処理概要を示すフローチャートである。
【図6】本実施形態に係るSOINN12に存在する複数の内部クラスを示す図である。
【図7】本実施形態に係るパターン認識装置のシステム構成を示す図である。
【図8】パターン認識装置によるテンプレートモデル生成処理の処理概要を示すフローチャートである。
【図9】訓練パターンをSOINN12へと入力するようすを示す図である。
【図10】パターン認識装置による認識処理の処理概要を示すフローチャートである。
【図11】音素認識実験における実験条件を示す表である。
【図12】音素認識実験における実験結果を示す表である。
【図13】動作実験における動作内容を示す画像である。
【図14】動作認識実験における実験条件を示す表である。
【図15】動作認識実験における実験結果を示す表である。
【図16】セグメント数に対する認識率の変化を示す図である。
【図17】SOINN12を用いない手法との比較結果を示す表である。
【図18】大域的尤度及び局所的尤度の反映具合による認識率の変化を示す図である。
【図19】テンプレートモデルを更新する様子を説明するための図である。
【図20】SOINN12における更新の様子を説明するための図である。
【図21】オンライン教師付き学習による検証結果を示す表である。
【図22】従来手法であるE―SOINNによる学習処理の処理概要を示すフローチャートである。
【符号の説明】
【0145】
1 パターン認識装置
10 テンプレートモデル生成部
11 標準パターン選択部
12 SOINN
121 クラス間ノード挿入部
122 辺削除部
123 ノード削除部
124 重みベクトル更新部
20 認識部
21 尤度算出部
211 大域的尤度算出部
212 局所的尤度算出部
31 訓練用パターンDB
32 テンプレートモデル学習結果DB
40 コンピュータ
41 CPU
42 ROM
43 RAM
44 バス
45 入出力インターフェイス
46 入力部
47 出力部
48 記憶部
49 通信部
50 ドライブ
501 磁気ディスク
502 光ディスク
503 フレキシブルディスク
504 半導体メモリ
【技術分野】
【0001】
本発明は、自己増殖型ニューラルネットワークを用いてパターン認識を行うパターン認識装置、パターン認識方法、及びプログラムに関する。
【背景技術】
【0002】
時系列パターンの認識・モデル化は動画像処理、音声情報処理、DNA解析などの様々な分野における重要な基盤技術である。一般的に時系列パターンは、特徴空間内での変動及び時間方向の伸縮を含む。時系列パターンを頑健に認識するためには、これらの特徴を吸収可能なモデル及び学習器を構築する必要がある。このため、予めグラフ構造を保持したモデルを持つことで時系列パターンの学習・認識を行う、モデルに基づく手法が頻繁に用いられている。
【0003】
モデルに基づく手法としてHMM(Hidden Markov Model)は、音声認識の分野における標準的な手法として大きな成功を収めている(非特許文献1参照)。HMMは音声認識以外にも、話者適応技術や音声合成技術などに用いられており、音声情報処理全般における標準的手法となっている。この音声情報処理における成功事例や、統計的理論の裏づけがあることから、HMMは動画像および動作の認識にも多く用いられてきた。音声認識や動画像認識における手法としては、離散HMM(Discrete HMM)を用いるものや、連続分布HMM(Continuous HMM)を用いるものがある(非特許文献2及び3参照)。また各状態における持続時間を正確にモデル化するために、各状態の持続長分布を明示的に持たせたSegment modelも提案されている。
【0004】
HMMなどに対し、動的計画法の一種であるDPマッチング法は、短時間の特徴パラメータ(各フレーム)同士の局所距離に基づいて、過度的な時系列パターン間の距離を算出することが可能である。DPマッチングは音声認識、動作認識の他、時系列パターンの検索などに用いられている。
【0005】
DPマッチング及びHMMに基づいた手法として、非特許文献4に開示された手法(以下、ストキャスティックDP法という。)が提案されている。ストキャスティックDP法では、DPマッチングにおける局所距離の尺度については確率の尺度を用いており、パスコストの代わりにパス遷移確率を用いている。また、ストキャスティックDP法はテンプレートパターンの1フレームを1状態に対応させており、状態数を多くしたHMMの連続出力分布を持つleft−to−rightモデルに相当する。
【非特許文献1】L. R. Rabiner, "A tutorial on hidden markov models and selected applications in speech recognition", Proc. IEEE, pp. 257-286(1989).
【非特許文献2】A. Wilson and A. Bobick, "Learning visual behavior for gesture analysis", Proc. IEEE International Symposium on Computer Vision, Vol. 5A Motion II(1995).
【非特許文献3】R. Hamdan, F. Heits and L. Thoraval, "Gesture localization and recognition using probabilistic visual learning", Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vol. 98-103(1999).
【非特許文献4】中川聖一,"ストキャスティックDP法および統計的手法による不特定話者の英語子音の認識",信学論(D),vol.J70-D, no.1(1987).
【発明の開示】
【発明が解決しようとする課題】
【0006】
HMMでは、パラメタ推定の容易性の理由で、音声データについて一音韻に対して3〜5状態のマルコフモデルが多く用いられる。しかしながら、このような少数の状態では、過度的な時系列パターンを正確にモデル化できない可能性がある。
また、DPマッチング法では標準パターンそのものをモデルとするため、HMMに比べて特徴空間の分布を詳細にモデル化することが困難である。
一方、ストキャスティックDP法は、DPマッチングの利点及びHMMの頑健性の両方を活かした手法であるものの、各状態の出力分布には単一の多次元正規分布が用いられている。一般に、各状態の出力分布は特徴量の次元数及び特性に応じて異なるため、このような単一の多次元正規分布を用いた場合には、出力分布を正確に近似することができないという問題がある。
【0007】
このように、従来のパターン認識モデルでは、予め適切な状態数及び各状態の出力分布を決定する必要があり、また、各状態の出力分布を単一の多次元正規分布を用いては、出力分布を十分に近似することができないという問題がある。
【0008】
本発明は係る課題を解決するためになされたものであり、状態数及び各状態の出力分布を自動的に決定し、時系列データの頑健なモデル化をすることができるパターン認識装置、パターン認識方法、及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
本発明に係るパターン認識装置は、入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成部と、生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識部を有するものである。
【0010】
これにより、テンプレートモデルにおける状態数及び各状態の出力分布を自動的に決定することができると共に、各状態の出力分布を詳細に近似することができるため、時系列データの頑健なモデル化を実現することができる。
【0011】
また、前記認識部は、前記ノードに基づいて、前記テンプレートモデルにおける状態の出力分布を算出する尤度算出部を有し、算出された前記テンプレートモデルにおける状態の出力分布を用いて、前記テンプレートモデルと前記入力パターンとの一致度を算出するようにしてもよい。これにより、テンプレートモデルにおける各状態の出力分布を詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0012】
さらにまた、前記尤度算出部は、前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部を有し、前記大域的尤度から前記テンプレートモデルにおける状態の出力分布を算出するようにしてもよい。これにより、入力パターンの特徴量を大域的尤度によって反映させることにより、テンプレートモデルにおける各状態の出力分布を詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0013】
また、前記尤度算出部は、辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部を有し、前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出するようにしてもよい。これにより、入力パターンの特徴量を局所域的尤度によって反映させることにより、各状態の出力分布が単一の多次元正規分布では近似できない場合であっても、テンプレートモデルにおける各状態の出力分布を詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0014】
さらにまた、前記尤度算出部は、前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部と、辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部とを有し、前記大域的尤度及び/又は前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出するようにしてもよい。これにより、入力パターンの特徴量を大域的尤度及び局所域的尤度を用いて反映させることにより、各状態の出力分布が単一の多次元正規分布では近似できない場合であっても、テンプレートモデルにおける各状態の出力分布をより詳細に近似することができるため、時系列データをより精度良く認識することができる。
【0015】
また、前記テンプレートモデル生成部は、前記入力パターン間のマッチングにより、当該入力パターンが属するクラスの標準パターンを選択する標準パターン選択部を有し、前記入力パターンの大きさを前記標準パターンの大きさに正規化して、前記標準パターンの各フレームに対応する各前記入力パターンの一部又は全部を、前記テンプレートモデルにおける各状態に対応させるようにしてもよい。これにより、事前にテンプレートモデルにおける状態数を決定せずに、標準パターンのフレーム数に応じてテンプレートモデルにおける状態数を決定することができる。
【0016】
さらにまた、前記テンプレートモデル生成部は、前記テンプレートモデルにおける各状態に対応させた各前記入力パターンの一部又は全部からなる要素の集合について、前記入力パターンの入力パターン数及び当該入力パターンの特徴量の次元数に基づいて、当該要素集合を前記自己増殖型ニューラルネットワークに入力するようにしてもよい。これにより、1つの状態に対応する要素集合の要素数が少ない場合であっても、入力パターン数及び入力パターンの次元数に応じて要素数を決定することにより、分布を近似するのに必要な多さの要素数を確保して入力することができ、認識精度の低下を防止することができる。
【0017】
また、前記テンプレートモデル生成部は、逐次的に入力パターンを追加して入力するときに、当該逐次的に追加される入力パターンの属するクラスに対応する前記テンプレートモデルについて、当該テンプレートモデルにおける状態の出力分布を前記逐次的に追加される入力パターンに応じて更新するようにしてもよい。これにより、追加的に入力される入力パターンを容易に追加学習することができるとともに、事前に多量のデータを必要とせず、逐次的に与えられる少量のデータに基づいて認識精度を向上させてゆくことができる。
【0018】
さらにまた、DPマッチング法を用いて前記マッチング処理を行うようにしてもよい。これにより、効率的にマッチング処理を行うことができる。
【0019】
また、前記自己増殖型ニューラルネットワークは、入力される前記入力ベクトルに最も近い重みベクトルを持つノードと2番目に近い重みベクトルを持つノードの間に辺を接続したとき、注目するノードと他のノード間の距離に基づいて算出される当該注目するノードの類似度閾値、及び前記入力ベクトルと当該注目するノード間の距離に基づいて、前記入力ベクトルをノードとして挿入するクラス間ノード挿入部と、前記入力ベクトルに最も近いノードに対応する重みベクトル及び当該ノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ前記入力ベクトルに更に近づけるように更新する重みベクトル更新部とを有するようにしてもよい。これにより、類似度閾値に基づいて、挿入されるノードの個数を自律的に管理することができるため、ノードの数を事前に決定することなく、逐次的に入力される新たな入力パターンを既存の知識を壊すことなく追加学習することができる。
【0020】
さらにまた、前記クラス間ノード挿入部は、入力される前記入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、当該第1勝者ノード及び当該第2勝者ノードの間に辺を接続したとき、注目するノードについて、当該注目するノードと辺によって直接的に接続されるノードが存在する場合には、当該直接的に接続されるノードのうち当該注目するノードからの距離が最大であるノード間の距離を前記類似度閾値とし、当該注目するノードと辺によって直接的に接続されるノードが存在しない場合には、当該注目するノードからの距離が最小であるノード間の距離を前記類似度閾値として算出する類似度閾値算出部と、前記入力ベクトルと前記第1勝者ノード間の距離が当該第1勝者ノードの類似度閾値より大きいか否か、及び、前記入力ベクトルと前記第2勝者ノード間の距離が当該第2勝者ノードの類似度閾値より大きいか否かを判定する類似度閾値判定部と、類似度閾値判定結果に基づいて、前記入力ベクトルをノードとして当該入力ベクトルと同じ位置に挿入するノード挿入部とを有するようにしてもよい。これにより、入力ベクトルに応じて変化する類似度閾値によれば、挿入されるノードの個数を自律的に管理することができるため、ノードの数を事前に決定することなく、逐次的に入力される新たな入力パターンを既存の知識を壊すことなく追加学習することができる。
【0021】
また、前記自己増殖型ニューラルネットワークは、前記辺に対応付けられる辺の年齢に基づいて、当該辺を削除する辺削除部と、注目するノードについて、当該注目するノードに直接的に接続される辺の本数に基づいて、当該注目するノードを削除するノード削除部とを更に有するようにしてもよい。これにより、不要な入力パターンから生成されたノードを効果的かつ動的に削除することができる。
【0022】
さらにまた、前記自己増殖型ニューラルネットワークは1層構造であるようにしてもよい。これにより、非特許文献:F. Shen and O. Hasegawa, "An Incremental Network for On-line Unsupervised Classification and Topology Learning, " Neural Networks, vol. 19, pp. 90-106, 2006.に開示された技術であるSelf-Organizing Incremental Neural Network(以下、SOINNという。)と比べて、2層目の学習を開始するタイミングを指定せずに追加学習を実行することができる。
【0023】
本発明に係るパターン認識方法は、入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成ステップと、生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識ステップを有するものである。
【0024】
本発明に係るプログラムは、上述のような情報処理をコンピュータに実行させるものである。
【発明の効果】
【0025】
本発明によれば、状態数及び各状態の出力分布を自動的に決定して、時系列データの頑健なモデル化をすることができるパターン認識装置、パターン認識方法、及びプログラムを提供することができる。
【発明を実施するための最良の形態】
【0026】
以下、本発明を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。尚、各図面において、同一要素には同一の符号を付しており、説明の明確化のため、必要に応じて重複説明を省略する。
【0027】
発明の実施の形態1.
本実施の形態1は、本発明を、時系列パターンを認識するパターン認識装置に適用したものである。パターン認識装置は、オンライン教師なし学習手法である自己増殖型ニューラルネットワークを用いて、時系列パターンの特徴量に応じたテンプレートモデルを生成し、生成されたテンプレートモデルと時系列パターンをマッチングしてその時系列パターンを認識する。
自己増殖型ニューラルネットワークとして後述するSOINNを利用することによって、テンプレートモデルにおける各状態の出力分布を自動的に決定した上で、詳細に近似することができる。ここで、パターン認識装置は、時系列パターンの一部又は全部をSOINNへと入力し、SOINNにおいて形成される位相構造(ノード及び辺の集合)に基づいて尤度を算出して、状態の出力分布を近似する。尤度として大域的尤度及び局所的尤度を算出することによって、時系列パターンの特徴量に応じた状態の出力分布を詳細に表現できるため、時系列パターンの頑健なモデル化が可能となる。
【0028】
図1は、本発明の実施の形態1に係るパターン認識装置1を示すブロック図である。パターン認識装置1は、テンプレートモデル生成部10及び認識部20を備え、学習用の訓練パターンが格納された訓練用パターンデータベース(DB)31及び学習の結果生成されたテンプレートモデルが格納されたテンプレートモデル学習結果データベース(DB)32と接続されている。
【0029】
テンプレートモデル生成部10は、標準パターン選択部11及びSOINN12を備える。自己増殖型ニューラルネットワークとしてのSOINN12は、クラス間ノード挿入部121と、辺削除部122と、ノード削除部123と、重みベクトル更新部124とを備える。認識部20は、尤度算出部21を備える。尤度算出部21は、大域的尤度算出部211及び局所的尤度算出部212を備える。
【0030】
次に、各ブロックについて以下詳細に説明する。
テンプレートモデル生成部10は、後述するSOINN12を用いて、入力パターンの特徴量に応じた各クラスのモデル(以下、テンプレートモデルという。)を生成する。より具体的には、まず、後述する標準パターン選択部11により訓練データの中から中心となる標準パターンを選択し、この標準パターン及び他の訓練パターンとの間でDPマッチングを行うことによって、各訓練パターンを標準パターンの時系列長に正規化する。次に、標準パターンの各フレームに対応する入力パターンの一部又は全部からなるデータの集合をテンプレートモデルにおける1つの状態に対応させ、このデータ集合の分布をSOINN12によって近似する。この結果、テンプレートモデルは、標準パターンのフレーム数分だけ状態数を保持し、各状態の出力分布をSOINN12により近似することができる。以下、この手法をSOINN−DP法という。
【0031】
標準パターン選択部11は、入力パターン間のマッチングにより、その入力パターンが属するクラスの標準パターンを選択する。ここで、マッチング処理にはDPマッチング法を使用する。DPマッチング法を使用することによって効率的にマッチング処理を行うことができる。DPマッチングを行うことによって、2つのパターンX及びY間の累積距離D(X,Y)、及びパターン間の最適な対応付けj=wi(i=1,2,・・・,I)を得ることができる。
【0032】
以下、DPマッチング法について簡単に説明する。
本実施の形態1においては、フレーム数Iの時系列パターンX={x1,x2,・・・,xi,・・・,xI}、及びフレーム数Jの時系列パターンY={y1,y2,・・・,yj,・・・,yJ}とのDPマッチングを考え、この2つの時系列パターンの累積距離D(X,Y)を算出する。ここで、i及びjはそれぞれ時系列パターンX及びYのフレーム番号を示す。また、Xの各フレームの特徴ベクトルxiを、Xのiフレーム目の要素、もしくはi番目の要素という。本実施の形態1においては、時系列パターンX及び時系列パターンYの累積距離D(X,Y)を、以下に示す対称型漸化式を用いて算出する。
【数1】
【数2】
そして、上記数2に示した漸化式を用いて、以下の式に基づいて累積距離D(X,Y)を算出する。
【数3】
【0033】
このように、DPマッチングによれば、累積距離に現時点の局所距離を累積する演算を漸化的に繰り返すことによって累積距離D(X,Y)を算出することができる。また、DPマッチングによって、Xの第i番目(フレーム目)の要素xi及びYの第j番目の要素yjとの最適な対応付けj=wi(i=1,2,・・・,I)を得ることができる。
尚、DPマッチングに用いられる漸化式としては、上記の対称型漸化式以外にも、以下の式に示す非対称型漸化式がある。
【数4】
【0034】
SOINN12は、入力ベクトル及びニューラルネットワークに配置されるノードに基づいて、ノードを自動的に増加させる自己増殖型ニューラルネットワークであり、本実施の形態1においては、下記に説明するSOINNの1層目を用いて学習を行う。1層構造とすることにより、SOINNと比べて、2層目の学習を開始するタイミングを指定せずに追加学習を実行することができる。また、SOINNに限定されず、後述するEnhanced−SOINN(以下、E−SOINNという。)などとしても1層構造とすることができ、2層目の学習を開始するタイミングを指定せずに追加学習を実行することができる。
【0035】
以下、まず、従来技術であるSOINNについて簡単に説明し、次いで本実施の形態1にかかるSOINN12について説明する。SOINNは、非特許文献:Fritzke.B, "A growing neural gas network learns topologies, " Advances in neural information processing systems(NIPS), pp 625-632, 1995.に開示された技術であるGrowing Neural Gas(以下、GNGという。)を拡張した、いわゆる自己増殖型ニューラルネットワークと呼ばれる教師なし追加学習手法である。ノードを自己増殖しながら入力ベクトルを逐次的に学習することにより、入力データの分布を表現するネットワークを追加的に構築することができる。SOINNは、次の4つの利点を有する。
(1)過去に学習したクラスタを壊さずに、新規に入力される未知クラスの入力ベクトルを追加的に学習して、新規のクラスタを構築することができる。
(2)入力データに対して独立なノイズを、効果的かつ動的に除去することができる。
(3)逐次的に与えられる教師無しデータについて、その位相構造を表現するネットワークを自律的に構築することができる。
(4)ノード数を事前に決定せずに、入力ベクトルを近似することができる。
【0036】
図2は、従来技術であるSOINNによる学習処理を説明するためのフローチャートである。以下、図2を用いてSOINNの処理を簡単に説明する。ここで、SOINNは2層ネットワーク構造を有し、1層目及び2層目において同様の学習処理を実施する。また、SOINNは1層目の出力である学習結果を2層目への入力ベクトルとして利用する。
【0037】
S101:SOINNに対して入力ベクトルを与える。
S102:与えられた入力ベクトルに最も近いノード(以下、第1勝者ノードという。)、及び2番目に近いノード(以下、第2勝者ノードという。)を探索する。
S103:第1勝者ノード及び第2勝者ノードの類似度閾値に基づいて、入力ベクトルがこれら勝者ノードの少なくともいずれか一方と同一のクラスタに属すか否かを判定する。ここで、ノードの類似度閾値はボロノイ領域の考えに基づいて算出する。学習過程において、ノードの位置は入力ベクトルの分布を近似するため次第に変化し、それに伴いボロノイ領域も変化する。即ち、類似度閾値もノードの位置変化に応じて適応的に変化してゆく。
S104:S103における判定の結果、入力ベクトルが勝者ノードと異なるクラスタに属す場合は、入力ベクトルと同じ位置にノードを挿入し、S101へと進み次の入力ベクトルを処理する。尚、このときの挿入をクラス間挿入と呼ぶ。
【0038】
S105:一方、入力ベクトルが勝者ノードと同一のクラスタに属す場合は、第1勝者ノード及び第2勝者ノード間に辺を生成し、ノード間を辺によって直接的に接続する。
S106:第1勝者ノード及び第1勝者ノードと辺によって直接的に接続しているノードの重みベクトルをそれぞれ更新する。
S107:S105において生成された辺は年齢を有しており、予め設定された閾値を超えた年齢を持つ辺を削除する。入力ベクトルを逐次的に与えてゆくオンライン学習においては、ノードの位置が常に徐々に変化してゆくため、初期の学習で構成した隣接関係が以後の学習によって成立しない可能性がある。このため、一定期間を経ても更新されないような辺について、辺の年齢が高くなるように構成することにより、学習に不要な辺を削除することができる。
【0039】
S108:入力ベクトルの入力総数が、予め設定されたλの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がλの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がλの倍数となった場合には以下の処理を実行する。
【0040】
S109:局所累積誤差が最大であるノードを探索し、そのノード付近に新たなノードを挿入する(このときの挿入をクラス内挿入と呼ぶ。)。そして、ノードの持つ平均誤差を示す誤差半径に基づいて、ノード挿入が成功であったか否かを判定する。ここで、ノード及び入力ベクトル間の距離差をノードの持つ誤差として、入力ベクトルの入力に応じてノードの誤差を累積することにより局所累積誤差を算出する。誤差半径はノードの持つ誤差及びノードが第1勝者となった回数に基づいて算出する。
【0041】
S110:クラス内挿入によるノード挿入が成功であると判定した場合には、クラス内挿入により挿入されたノード及び局所累積誤差が最大のノードを辺によって直接的に接続する。一方、クラス内挿入によるノード挿入が失敗であると判定した場合には、クラス内挿入により挿入したノードを削除してS111へと進む。
S111:隣接ノード数及びノードが第1勝者となった回数に基づいて、ノイズノードを削除する。
ここで、隣接ノードとは、ノードと辺によって直接的に接続されるノードを示し、隣接ノードの個数が1以下であるノードを削除対象とする。また、第1勝者となった回数の累積回数を予め設定されたパラメタcを使用して算出される閾値と比較し、第1勝者累積回数が閾値を下回るノードを削除対象とする。
【0042】
S112:入力ベクトルの入力総数が予め設定されたLTの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がLTの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がLTの倍数となった場合には、以下の処理を実行する。
S113:1層目の学習を終了するか否かを判定する。判定の結果、2層目の学習へと進む場合には、S101へと進み1層目の学習結果であるノードを2層目への入力ベクトルとして入力する。ただし、追加学習を行う場合は、2層目に残っている以前の学習結果を消去した上で2層目の学習を開始する。
2層目への入力回数が予め設定された回数LTの倍数となり、2層目の学習を終了する場合には、ノードを異なるクラスに分類し、クラス数及び各クラスの代表的なプロトタイプベクトルを出力し停止する。ここで、プロトタイプベクトルはノードの重みベクトルに相当する。
【0043】
ここで、SOINNの機能を検証するために人工データセットを用いて行った実験を示す。
図3は、SOINNへと入力する2次元の人工データを示す画像である。図3に示した入力データセットは、2つのガウス分布、2つの同心円、及びサイン曲線の合計5つの信号発生源(クラス)からなる。また、実環境を想定して、5つの信号発生源から発生する信号に対して、10%の一様ノイズを加えた。SOINNに対して、図3に示した人工データセットをオンラインで追加的に入力し、教師無しのクラス分類を行わせた。
【0044】
図4は、図3に示した2次元の人工データをSOINNへと追加的に入力した場合における出力結果を示す画像である。図4に示すように、SOINNは、入力データに含まれるノイズを削除することが可能であると共に、入力データのクラス数及びそのトポロジ(位相構造)を正しく抽出することができる。
【0045】
このように、SOINNは、ノード数を自律的に管理することにより非定常的な入力を学習することができ、分布に複雑な形状を持つクラスに対しても適切なクラス数及び位相構造を抽出できるなど多くの利点を持つ。SOINNの応用例として、例えばパターン認識においては、ひらがな文字のクラスを学習させた後に、カタカナ文字のクラスなどを追加的に学習させることができる。また、自己増殖型ニューラルネットワークとしてSOINNを使用することにより、ノードを自動的に増加させることができるため、入力ベクトル空間からランダムに入力ベクトルが与えられる定常的な環境に限られず、例えば一定期間毎に入力ベクトルの属するクラスが切替えられて、切替後のクラスからランダムに入力ベクトルが与えられる非定常的な環境にも対応することができる。
【0046】
次いで、本実施の形態1に係るSOINN12について説明する。
SOINN12は、クラス間ノード挿入部121と、辺削除部122と、ノード削除部123と、重みベクトル更新部124とを備える。
クラス間ノード挿入部121は、類似度閾値算出部、類似度閾値判定部、及びノード挿入部を備える。クラス間ノード挿入部121は、入力される入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、第1勝者ノード及び第2勝者ノードの間に辺を接続したとき、以下に述べるようにしてノードを挿入する。
【0047】
まず、類似度閾値算出部は、注目するノードについて、注目するノードと辺によって直接的に接続されるノードが存在する場合には、直接的に接続されるノードのうち注目するノードからの距離が最大であるノード間の距離を類似度閾値とし、注目するノードと辺によって直接的に接続されるノードが存在しない場合には、注目するノードからの距離が最小であるノード間の距離を類似度閾値として算出する。
【0048】
次いで、類似度閾値判定部は、入力ベクトルと第1勝者ノード間の距離が第1勝者ノードの類似度閾値より大きいか否か、及び、入力ベクトルと第2勝者ノード間の距離が第2勝者ノードの類似度閾値より大きいか否かを判定する。
次いで、ノード挿入部は、類似度閾値判定結果に基づいて、入力ベクトルをノードとして入力ベクトルと同じ位置に挿入する。
【0049】
このようにして、入力ベクトルに応じて変化する類似度閾値によれば、挿入されるノードの個数を自律的に管理することができるため、ノードの数を事前に決定することなく、逐次的に入力される新たな連想対を既存の知識を壊すことなく追加学習することができる。
【0050】
重みベクトル更新部124は、入力ベクトルに最も近いノードに対応する重みベクトル、及びそのノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ入力ベクトルに更に近づけるように更新する。
辺削除部122は、辺に対応付けられる辺の年齢に基づいて、辺を削除する。ノード削除部123は、注目するノードについて、注目するノードに直接的に接続される辺の本数に基づいて、注目するノードを削除する。これにより、誤って生成された辺を適切に削除することができる。辺が存在しないノードは、そのノードの持つ結合重みベクトルに近い入力の頻度が極めて低いことを示しており、ノードの保持している情報は学習すべきデータと無関係なノイズであるものとみなすことができるためである。
【0051】
図5は、SOINN12による学習処理を説明するためのフローチャートである。以下、図5を用いてSOINN12の処理を説明する。
S201:SOINN12は、2つの入力ベクトルを取得し、ノード集合Aをそれらに対応する2つのノードのみを含む集合として初期化し、その結果を一時記憶部に格納する。また、辺集合C⊂A×Aを空集合として初期化し、その結果を一時記憶部に格納する。
【0052】
S202:SOINN12は、新しい入力ベクトルξを入力し、その結果を一時記憶部に格納する。
S203:SOINN12は、一時記憶部に格納された入力ベクトル及びノードについて、入力ベクトルξに最も近い重みベクトルを持つ第1勝者ノードa1及び2番目に近い重みベクトルを持つ第2勝者ノードa2を探索し、その結果を一時記憶部に格納する。
S204:クラス間ノード挿入部121は、一時記憶部に格納された入力ベクトル、ノード、ノードの類似度閾値について、入力ベクトルξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きいか否か、及び、入力ベクトルξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きいか否かを判定し、その結果を一時記憶部に格納する。ここで、一時記憶部に格納された第1勝者ノードa1の類似度閾値T1及び第2勝者ノードa2の類似度閾値T2は、SOINNと同様にして算出され、その結果が一時記憶部に格納される。
【0053】
S205:一時記憶部に格納されたS204における判定の結果、入力ベクトルξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きい、又は、入力ベクトルξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きい場合には、クラス間ノード挿入部121は、一時記憶部に格納された入力ベクトル及びノードについて、入力ベクトルξを新たなノードiとして、入力ベクトルξと同じ位置に挿入し、その結果を一時記憶部に格納する。
S206:一方、一時記憶部に格納されたS204における判定の結果、入力ベクトルξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1以下であり、かつ、入力ベクトルξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2以下である場合には、SOINN12は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0054】
S207:一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、SOINN12は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。そして、SOINN12は、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
一方、一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S208へと処理を進めるが、既にノード間に辺が生成されていた場合には、SOINN12は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
次いで、SOINN12は、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0055】
S208:重みベクトル更新部124は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力ベクトルξに更に近づけるように更新し、その結果を一時記憶部に格納する。ここで、重みベクトルの更新量の算出には、一時記憶部に格納されるMa1をtとして使用する。
S209:辺削除部122は、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。尚、agetはノイズなどの影響により誤って生成される辺を削除するために使用する。agetに小さな値を設定することにより、辺が削除されやすくなりノイズによる影響を防ぐことができるものの、値を極端に小さくすると、頻繁に辺が削除されるようになり学習結果が不安定になる。一方、極端に大きな値をagetに設定すると、ノイズの影響で生成された辺を適切に取り除くことができない。これらを考慮して、パラメタagetは実験により予め算出し一時記憶部に格納される。
【0056】
S210:SOINN12は、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がλの倍数でない場合にはS202へと戻り、次の入力ベクトルξを処理する。一方、入力ベクトルξの総数がλの倍数となった場合には以下の処理を実行する。尚、λはノイズと見なされるノードを削除する周期である。λに小さな値を設定することにより、頻繁にノイズ処理を実施することができるものの、値を極端に小さくすると、実際にはノイズではないノードを誤って削除してしまう。一方、極端に大きな値をλに設定すると、ノイズの影響で生成されたノードを適切に取り除くことができない。これらを考慮して、パラメタλは実験により予め算出し一時記憶部に格納される。
S211:ノード削除部123は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。
【0057】
S212:SOINN12は、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がLTの倍数でない場合にはS202へと戻り、次の入力パターンξを処理する。一方、入力ベクトルξの総数がLTの倍数となった場合には以下の処理を実行する。
S213:SOINN12は、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、SOINN12による学習を停止する。
【0058】
認識部20は、各クラスの訓練パターンから構成されたテンプレートモデルと入力パターンをマッチングすることにより、入力パターンがどのクラスに属するかを認識する。クラスcのテンプレートモデルTMcと入力パターンIPとのDPマッチングには対称型漸化式を使用し、以下の漸化式を用いる。尚、尤度C(xi,Sj)はテンプレートモデルTMcのj番目の状態Sjに対する、入力パターンIPのi番目の要素xiの尤度を示し、後述する尤度算出部21により算出される。
【数5】
ここでは、上記数2と同様の対称型漸化式を用いた。これにより、実データの認識実験において、非対称型漸化式を用いた場合に比べて、認識精度を向上させることができる。
【0059】
そして、認識部20は、尤度C(xi,Sj)の和が最大になるようにDPマッチングを行う。即ち、上記数2においては、累積距離g(i,j)を最小化するためminが用いられたが、上記数5においては、Q(i,j)を最大化するためmaxが用いられる。
DPマッチングの結果、テンプレートモデルTMcと入力パターンIPの累積一致度E(IP,TMc)を以下の式に基づいて算出する。尚、IIPは入力パターンIPの時系列長、JcはTMcの時系列長を示す。
【数6】
従って、認識部20は、入力パターンを以下の式に基づいて認識する。ここで以下の式は、入力パターンIPと累積一致度E(IP,TMc)が最も大きなテンプレートモデルのクラス番号を出力する関数であり、この場合に、入力パターンIPの帰属クラスはc*であるものと認識する。
【数7】
【0060】
尤度算出部21は、大域的尤度算出部211及び局所的尤度算出部212を有し、ノードに基づいて、テンプレートモデルにおける状態の出力分布を算出する。以下詳細に説明する。
尤度算出部21は、SOINN12に配置されたノード、及び辺によって接続されたノードからなるクラスタとに基づいて、尤度C(xi,Sj)を算出する。具体的には、以下の式に基づいて、大域的尤度log(Pwhole(xi|Sj))及び局所的尤度Pclass(xi|Ujk)を用いて、尤度C(xi,Sj)を算出する。図6は、SOINN12によってクラスタリングされ、SOINN12に存在する複数の内部クラス(ここでは、Class1乃至3)を示す図である。SOINN12によって生成された1つのクラスタを内部クラスと定義する。内部クラスはノードの参照ベクトル(プロトタイプベクトル群)により表現される。
【数8】
ここで、wkを以下の式に基づいて算出する。尚、Nallは状態SjのSOINN12内に存在する全ノードの総数を示し、Kは状態SjのSOINN12内の内部クラス数を示す。
【数9】
【0061】
これにより、入力パターンの特徴量を大域的尤度及び局所域的尤度を用いて反映させることにより、各状態の出力分布が単一の多次元正規分布では近似できない場合であっても、テンプレートモデルにおける各状態の出力分布をより詳細に近似することができるため、時系列データをより精度良く認識することができる。また、入力パターンに応じて大域的尤度及び局所域的尤度を反映させることにより、各状態の出力分布に対してより柔軟に対応することができる。
【0062】
大域的尤度算出部211は、SOINN12に配置された全てのノードに基づいて大域的尤度を算出する。具体的には、大域的尤度の算出にはj番目の状態SjのSOINN12内に存在する全ノードを用いる。大域的尤度は、状態のSOINN12内に存在する全ノードを多次元正規分布の確率密度関数で近似し、この密度関数からの生起確率Pwhole(xi|Sj)によって算出する。生起確率Pwhole(xi|Sj)を以下の式に基づいて算出する。ここで、μiは状態SjのSOINN12内に存在する全ノードの平均ベクトル、Σjは共分散行列である。これらの2つのパラメタは最尤推定により算出する。生起確率Pwhole(xi|Sj)の対数尤度log(Pwhole(xi|Sj))を、大域的尤度として定義する。
【数10】
【0063】
局所的尤度算出部212は、SOINN12に存在する複数のクラスタについて、そのクラスタに属するノードに基づいて局所的尤度を算出する。局所的尤度は、SOINN12によってクラスタリングされた、複数の内部クラスの情報を用いて算出する。例えば図6に示した各内部クラス(Class1乃至3)を、多変量正規分布に基づく核関数で近似する。ここで核関数を用いた理由は、各内部クラスが保有するノード数は少数の場合(最低で二個)が多く、このような少数データから多次元正規分布を推定することが困難なためである。SOINN12におけるk番目の内部クラスをUjkと定義し、Ujkから推定される局所的尤度Pclass(xi|Ujk)を以下の式に基づいて算出する。
【数11】
ここで、xjkはSOINN12内の内部クラスUjkに存在する全ノードの平均ベクトル、hjkは核関数の領域の大きさを示すパラメタであり、以下の式に基づいて算出する。尚、atは内部クラスUjkのノードtの位置ベクトルを示し、Njkは内部クラスUjkに含まれるノードの総数を示す。
【数12】
【0064】
以上のようなパターン認識装置1は、専用コンピュータ、パーソナルコンピュータ(PC)などのコンピュータにより実現可能である。但し、コンピュータは、物理的に単一である必要はなく、分散処理を実行する場合には、複数であってもよい。
【0065】
図7は、本実施の形態1に係るパターン認識装置1を実現するためのシステム構成の一例を示す図である。図7に示すように、コンピュータ40は、CPU41(Central Processing Unit)、ROM42(Read Only Memory)及びRAM43(Random Access Memory)を有し、これらがバス44を介して相互に接続されている。尚、コンピュータを動作させるためのOSソフトなどは、説明を省略するが、このパターン認識装置1を構築するコンピュータも当然備えているものとする。
【0066】
バス44には又、入出力インターフェイス45も接続されている。入出力インターフェイス45には、例えば、キーボード、マウス、センサなどよりなる入力部46、CRT、LCDなどよりなるディスプレイ、並びにヘッドフォンやスピーカなどよりなる出力部47、ハードディスクなどより構成される記憶部48、モデム、ターミナルアダプタなどより構成される通信部49などが接続されている。
【0067】
CPU41は、ROM42に記憶されている各種プログラム、又は記憶部48からRAM43にロードされた各種プログラムに従って各種の処理、本実施の形態においては、例えば点プレーモデル生成処理や認識処理を実行する。RAM43には又、CPU41が各種の処理を実行する上において必要なデータなども適宜記憶される。通信部49は、例えば図示しないインターネットを介しての通信処理を行ったり、CPU41から提供されたデータを送信したり、通信相手から受信したデータをCPU41、RAM43、記憶部48に出力したりする。記憶部48はCPU41との間でやり取りし、情報の保存・消去を行う。通信部49は又、他の装置との間で、アナログ信号又はディジタル信号の通信処理を行う。入出力インターフェイス45は又、必要に応じてドライブ50が接続され、例えば、磁気ディスク501、光ディスク502、フレキシブルディスク503、又は半導体メモリ504などが適宜装着され、それらから読み出されたコンピュータプログラムが必要に応じて記憶部48にインストールされる。
【0068】
続いて、本実施の形態1に係るテンプレートモデル生成処理及び認識処理について説明する。図8は、パターン認識装置1によるテンプレートモデル生成処理の概要を示すフローチャートである。以下、図8を参照しながらパターン認識装置1によるテンプレートモデル生成処理について説明する。テンプレートモデル生成部10は、クラスCに属するテンプレートモデルを以下のようにして生成する。ここで、テンプレートモデル生成部10は、クラスごとにテンプレートモデルを生成する。
【0069】
S301:訓練用パターンDB31より、N個の訓練パターンが与えられ、標準パターン選択部11は、訓練パターン群から1つの標準パターンを選択する。より具体的には、クラスCに含まれるある訓練パターンPmと、クラスCに含まれるPmを除いた他の訓練パターンとの間でDPマッチングを行う。この処理を、クラスC内の訓練パターンの全組合せ(総当り)によって行う。DPマッチングの結果より得られるパターン間同士の累積距離の和を算出し、累積距離の和が最小となるパターンを標準パターンとして選択する。即ち、以下の式に基づいて標準パターンを選択する。ここで、argは、各訓練パターン間の累積距離の和が最小となる訓練パターンの番号m*を出力する。
【数13】
このようにして、クラスCのm*番目の訓練パターンを、テンプレートモデルの中心となる標準パターンP*として選択する。尚、P*のフレーム数T*を、テンプレートモデルの時系列長とする。
【0070】
S302:DPマッチングにおいて対応付けられた訓練パターンのフレームデータを、テンプレートモデルにおける状態としてのSOINN12へと入力する。より具体的には、SOINN12への入力は、DPマッチングによる結果を用いて実現することができる。即ち、標準パターンP*と、その他N−1個の訓練パターンとの間でDPマッチングを行った結果、その他の全訓練パターンの時系列長は標準パターンP*の時系列長に正規化される。また、標準パターンP*の各要素と、その他N−1個の訓練パターンの各要素との対応付けが得られる。このようなDPマッチングの結果に基づいて、以下に説明するようにして、対応関係にある要素(ベクトル)群を各SOINN12空間(各状態)に入力する。
【0071】
まず、標準パターンP*の第j番目の要素をp*j、訓練パターンPn(n∈C)の第i番目(iフレーム目)の要素をpniとし、このp*jとpniとの最適な対応付けwnを以下のように定義する。
【数14】
上記数14に従って、訓練パターンのi番目の要素をj番目の状態(SOINN12空間)に分配する。このような分配操作を、標準パターンと、その他N−1個の訓練パターンとの間で行った後、N−1個の最適経路wnを(n=1,・・・,N−1)を得ることができる。このN−1個の最適経路に従って、各状態に対して訓練パターンの各要素を分配する。
【0072】
ここで、本実施の形態1では、ある時間の範囲(状態間)に分配された要素集合群を、1つのSOINN12へと入力する。具体的には、j番目の状態に分配された要素集合群をZ*jとして以下の式に示すように定義し、ZjからZj+L−1までの要素集合を、j番目の状態(SOINN12)に入力する。
【数15】
尚、Lはパラメタであり、このパラメタをSegment数として定義する。パラメタの設定方法については後述する。ここで、テンプレートモデルの状態数はSegment数L及び標準パターンの時系列長T*を用いて、T*−L−1として決定することができる。これにより、事前にテンプレートモデルにおける状態数を決定せずに、標準パターンのフレーム数に応じてテンプレートモデルにおける状態数を決定することができる。
【0073】
図9は、訓練パターンをSOINN12へと入力するようすを示す図である。図9において、Criterion Dataは標準パターンを示し、Data1乃至3は訓練パターンを示す。Data及びCriterion Dataの各ブロックは、各時刻(フレーム)の要素ベクトルを示す。各ブロックにおいて同色の部分は、DPマッチング後の最適経路における対応箇所を示している。例えば、Criterion Dataの1フレーム目の要素に対応した要素は、Data1の1及び2番目の要素、Data2の1番目の要素、及びData3の1番目の要素であり、これらの要素集合がZ1となる。実線は対応する要素集合Z1を結ぶ線である。破線はZ2の要素集合、Z3の要素集合をそれぞれ示す。Z1からZLまでの要素集合群Z*1が、クラスCのテンプレートモデルにおける状態1(SOINN12)に対して入力される。
【0074】
S303:SOINN12は、フレームデータに基づいて学習を行う。各状態jにおいて、フレームデータとしての要素集合群Z*jをSOINN12空間に入力する。ここでSOINN12がオンライン学習可能な手法であるため、要素集合群Z*jを入力する際、要素集合群Z*jの各要素を1つずつランダムに入力する。ランダムに入力されるベクトルがSOINN12空間に入力されると、SOINN12空間ではノード及び辺の生成、削除が繰り返され、最終的に複数の代表的ノード集合(クラスタ)が形成される。SOINN12による学習結果が、テンプレートモデル学習結果DB32に格納される。上述したように、尤度算出部21は、このようにして形成された複数の代表的ノード集合から、状態の出力分布を推定する。
【0075】
次に、認識処理について説明する。図10は、パターン認識装置1による認識処理の概要を示すフローチャートである。以下、図10を参照しながらパターン認識装置1による認識処理について説明する。
【0076】
S401:時系列パターンであるテストパターンXが入力される。
S402:認識部20は、テンプレートモデル学習結果DB32に格納されたSOINN12の学習結果より尤度C(xi,Sj)を算出して、各クラスのテンプレートモデルとテストパターンXとをDPマッチングする。
S403:尤度Q(i,j)が最大となったテンプレートモデルの帰属クラスを出力する。これにより、例えば、クラス3のテンプレートモデルに対する尤度が最大となった場合には、テストパターンXはクラス3であるものと認識する。
【0077】
続いて、本発明の実施の形態1に係るパターン認識装置1による効果について説明する。尚、以下においては、パターン認識装置1をモデル化した手法をSOINN−DP法と呼ぶ。
SOINN−DP法の有効性を確認するため、実データを用いて検証実験を行った。実験においては、時系列データの汎用的学習機能を評価するため、音素データ及び動画像より得られる動作データの2種類のデータセットを使用した。また、従来手法であるHMM及びストキャスティックDP法との比較実験を行った。以下、各手法による検証実験及び結果について説明する前に、まず従来手法であるHMM及びストキャスティックDP法について簡単に説明し、次にSOINN−DP法に関するパラメタ設定について説明する。
【0078】
まず、従来手法であるHidden Markov Model(HMM)について簡単に説明する。HMMは、不確定な時系列のデータをモデル化するための有効な統計的手法であり、出力シンボルによって一意に状態遷移先が決定しないという意味において、非決定性確率有限オートマトンとして定義される。ここで、HMMのパラメタには、状態遷移確率、シンボル出力確率、及び初期状態確率の3つのパラメタがある。
HMMは、シンボル出力確率の算出方法によって、離散型HMM及び連続分布型HMMに分類される。音声認識・動作認識においては連続分布型HMMが一般的に使用されるため、本実施の形態1においては、連続分布型HMMを比較手法として採用する。
また、HMMは、トポロジ(状態の接続関係)によって、あるひとつの状態から全ての状態に遷移可能な全遷移型(Ergodic)モデルや、状態遷移が一定方向に進むleft to rightモデルなどに分類される。音声認識や動作認識の分野においては、left to rightモデルが一般的に用いられるため、本実施の形態1においては、left to rightモデルを比較手法として採用する。
HMMのパラメタ推定方法には、一般的に使用されるBaum Welchアルゴリズムを用いた。また、Baum Welchアルゴリズムによるパラメタ推定精度を向上させるため、パラメタの初期値設定についてSegmental kmeans法を使用する。
【0079】
次に、従来手法であるストキャスティックDP法について簡単に説明する。
ストキャスティックDP法において用いられる漸化式を次式に示す。漸化式は上記数4に示した非対称型の漸化式を基盤として構成されている。
【数16】
【0080】
上記数16に示した漸化式における条件確率P(ai|j)及び状態遷移確率PDP1,2,3(j)は非特許文献4に記載された手法により算出した。ここで、条件付確率P(ai|j)は多次元正規分布である。P(ai|j)の共分散行列に関しては、ある範囲において同一のものを使用した。例えば、10個の状態により同じ共分散行列を使用する場合に、状態1から10に対して分配された全てのデータから、最尤推定により1つの共分散行列を算出し、状態1から10の各状態において同一のσを用いる。状態11から20、状態21から30においても同様の操作により算出し、それらの状態に対して同一のσを用いる。
【0081】
続いて、SOINN−DP法に関するパラメタ設定について説明する。孤立単語を用いて予備実験を行い、SOINN−DP法のパラメタを設定した。実験には、男性話者3人が50回ずつ5単語を発話したデータ(1単語につき150個、計750個)を用いた。単語は「こんばんは」、「こんにちは」、「またあした」、「おはよう」、「さようなら」の5単語である。音声特徴量には、20次元MFCC、フレーム長25ms、フレーム周期5msを用いた。一クラスにつき、訓練データを50、テストデータを100として、訓練データ及びテストデータを交換しながら計20回のクロスバリデーション実験を行った。20回のクロスバリデーション実験より、各実験におけるテストデータに対する認識率を求め、その平均値を認識結果とした。テストデータに対して平均認識率が最大となるパラメタを、後述する音素認識実験及び動作認識実験に用いた。
【0082】
まず、SOINN−DP法におけるSOINN12のパラメタ設定について説明する。
SOINNと同様にSOINN12においては、ノイズ除去を適切に行うため、λ及びagedeadという2つのパラメタを設定する必要がある。各クラスタはノードとノード間を接続する辺により表現され、このノード及び辺は、入力データに応じて生成・削除を繰り返す。このため、ノイズデータに対してノードを生成した場合には、分類結果が悪化するものの、パラメタλ及びagedeadを適切に設定することによってこれを回避することができる。
【0083】
λは、ノイズとおぼしきノードを削除する周期を示す。λを小さな値に設定することにより、頻繁にノイズ処理を行うことができるものの、極端に小さくした場合には、実際にはノイズではないノードを誤って削除してしまう。一方、λを極端に大きくした場合には、ノイズの影響により生成されたノードを適切に取り除くことができない。そこで、パラメタ設定のための上記予備実験の結果から、SOINN12への入力回数を30000回に設定し、λ=10000と設定した。即ち、学習中に、ノイズとおぼしきノードの削除を3回行った。
【0084】
agedeadは、ノイズなどの影響により誤って生成された辺を削除するために用いる。agedeadを小さな値に設定することにより、辺が削除されやすくなりノイズによる影響を低減させることができるものの、極端に小さくした場合には、頻繁に辺が削除され学習結果が不安定になる。一方、agedeadを極端に大きくした場合には、ノイズの影響により生成された辺を適切に取り除くことができない。SOINN−DP法においては、1つの状態に分配される要素ベクトル数が少数であるため、agedeadを小さくした場合には学習結果が不安定となった。従って、本実施の形態1においては、agedeadを機能させないものとし、辺を削除しないものとした。即ち、agedead=30000とし、学習中に辺の削除は行わないものとした。
【0085】
以上より、上記予備実験の結果から、SOINN12のパラメタ設定について、λ=10000、agedead=30000と設定した。尚、SOINN12には、パラメタλ及びagedead以外にも、パラメタc1、α1、α2、α3、β、γが存在するものの、これらのパラメタについてはSOINNと同じ値を使用した(c1=1、α1=1/4、α2=3/4、α3=1/4、β=2/3、γ=3/4)。
【0086】
次に、SOINN−DPのパラメタ設定について説明する。
ここでは、上記数15に示したセグメント数Lについて、その設定方法を説明する。セグメント数Lを大きくした場合には、各状態のSOINN12への入力データが多くなるため、SOINN12の学習精度が向上するものと考えられる。しかし、セグメント数Lを極端に大きな値に設定した場合には、時系列的に離れたデータを1つの状態に入力することになり、時系列データを無視することになってしまう。このため、過度的な時系列データの特徴をモデル化することができず、テストデータに対する認識率の低下を招く。一方、セグメント数Lを極端に小さな値に設定した場合には、SOINN12においてネットワーク(ノード及び辺の集合)が形成されない。ノード集合が生成されない場合、上記数10に示した共分散行列Σを正確に算出することが困難となる。即ち、上記数10に示した共分散行列Σを算出するため、十分な量のデータを1つの状態(SOINN12)に対して入力する必要がある。尚、非特許文献4においては、特徴量の次元数pに対して、少なくともp×4〜5倍以上のデータ数が必要とされ、p2個以上が好ましいものとされている。
【0087】
ここで、訓練データN個をモデルの学習に用いた場合において、各状態に分配される要素ベクトル数が平均N個であるものと仮定する。かかる場合に、1つのSOINN12に対して入力されるデータ集合Z*iの要素数(データ数DN)を、以下の式によって定義する。
【数17】
従って、上記数17より、セグメント数Lは以下の式に示す範囲となる。
【数18】
パラメタ設定のための上記予備実験を通して、上記数18の範囲内における最適なセグメント数Lについて、L≧6p/Nを満たす最小の値として決定した。
また、セグメント数LはストキャスティックDP法における共分散行列を共有する範囲に対応するものと考えられるため、ストキャスティックDP法を用いて同様の予備実験を行った。その結果、ストキャスティックDP法において、共分散行列を共有する範囲について、最大の認識率を得ることができる範囲はセグメント数Lと等しいことを確認することができた。
従って、以下の本実験においては、ストキャスティックDP法における共分散行列を共有する範囲はLとした。尚、セグメント数LによるSOINN−DP法における認識率への寄与については後述する。
【0088】
続いて、SOINN−DP法の有効性を確認するため、音素データとして英語音素を対象に認識実験を行った。認識対象として、ked−TIMITデータベース(University of Edinburgh, Center for Speech Technology Research, "CSTR US KED TIMIT"(2002), http://festvox.org/dbs/dbs_kdt.html.)中に含まれる英語文章から抽出した音素39クラスを100個ずつ、計3900個を使用した。図11は、認識対象実験における詳細を示す表である。尚、SOINN−DPのパラメタについて、セグメント数Lは上記数18より、訓練データが40個の場合にはL=6とし、訓練データが80個の場合にはL=3と決定した。
【0089】
また、従来手法との比較においても、図11に示したのと同じ条件において実験を行った。HMMの各状態の出力確率は、全共分散行列を持つ混合正規分布とした。HMMについては、最大の認識率を得ることができるパラメタ(状態数及び混合正規分布の混合数)について、それらのパラメタを変化させながら実験を行って最適なパラメタを探索した。そして、そのような最適なパラメタを用いた場合に認識率を算出して、HMMによる認識結果とした。
ストキャスティックDP法については、上記数16に示した非対称型漸化式を用いた場合に加えて、対称型漸化式を用いた場合の実験も行った。対称型漸化式を用いたSOINN−DP法に対して、同様の対称型漸化式を用いたストキャスティックDP法を比較するためのである。尚、対称型漸化式には上記数5に示したC()を条件付確率P(ai|j)に交換した式を用いた。また、共分散行列を共有する範囲は、SOINN−DPにおけるセグメント数Lと同様に、訓練データが40個の場合には6状態の間とし、訓練データが80個の場合には3状態の間とした。
【0090】
図12は、10回のクロスバリデーション実験の結果から得られた、テストデータに対する平均認識結果を示す表である。図12において、1段目は訓練データが40個の場合(TD40)における平均認識率、2段目は訓練データ数が80個(TD80)の場合の平均認識率をそれぞれ示している。「SO−DP」はSOINN−DP法、「ST−DP(1)」は非対称型漸化式を用いたストキャスティックDP法、「ST−DP(2)」は対称型漸化式を用いたストキャスティックDP法をそれぞれ示している。また、HMMの認識率の右側括弧内は、最大の認識率を得た時のパラメタ(S:状態数、M:混合数)を示している。図12に示すように、SOINN−DP法の平均認識率は、ストキャスティックDP法及びHMMによる平均認識率よりも高く、良好であった。
【0091】
また、HMMを用いた実験において、比較のため状態数を1から13個まで変動させて実験を行った結果、状態数が3〜7の付近において認識率が最大であったため、実験に使用した音素データに対して最適な状態数は3〜7であるものと推定した。このため、状態数が3〜7において、各状態に割り当てられている出力確率を混合連続確率分布に変更し、混合数を変化させ図11に示した条件において実験を行った。その結果、訓練データが40個の場合には5状態2混合、訓練データが80個の場合には5状態4混合において認識率が最大となった。
さらにまた、ストキャスティックDP法について、非特許文献4に開示された非対称型漸化式を用いた場合よりも、対称型漸化式を用いた場合のほうが高い認識結果となった。これは、対称型漸化式を用いることにより、時系列の伸縮を吸収しやすくなるためだと考えられる。
以上より、音声認識実験の結果、SOINN−DP法では、ストキャスティックDP法及びHMMより得られる最大の認識率に比べて、より良好な認識率を得ることができた。即ち、SOINN−DP法は従来手法と比較して高い認識精度を有するものである。
【0092】
続いて、SOINN−DP法の有効性を確認するため、動画像より得られる動作データを対象に認識実験を行った。動作データとして、単眼カメラより直接撮像した、人間による7種類の全身運動(動作)を用いた。図13は、実験に用いた7種類の動作内容(動作M1乃至7)を示す画像である。動画のフレーム率は29フレーム毎秒とし、各動作の時間長は最小で110フレーム、最大で440フレームである。入力パターンには個人差を含み、動作の各部分において伸縮性も含まれている。
【0093】
また、実験においては、モーションキャプチャなどの器具を使用せずに、動画像より動作の特徴を直接取得した。ここで、本実施の形態1においては、位置不変特徴である局所自己相関特徴(大津展之,"パターン認識における特徴抽出に関する数理的研究",vol.818,(1981))を学習に用いることにより、動的特徴を抽出した。実験に用いた動画像の処理手順を以下に示す。
S501:入力動画像を平滑化し、フレーム間における差分を取得する。
S502:差分画像のRGB値を輝度値に変換し、輝度値に対する閾値より、2値化する。
S503:差分画像間において、時間方向の自己相関特徴を抽出する。非特許文献(T. Kobayashi and N. Otsu, "Action and simultaneous multiple persons identification using cubic higher-order local auto-correlation", Proc. International Conference on Pattern Recognition, Vol. 19, pp. 741-744 (2004).)に開示される自己相関特徴について、ここでは、3×3サイズのマスクを用いて自己相関特徴を抽出し、各フレーム間の時系列方向のみ抽出した。尚、中央位置のマスク値には、「動き」の方向性特徴が現れないため、このマスク値については除外した。結果的に、各フレームにおいて計8次元の入力ベクトル(要素ベクトル)を得た。
【0094】
図14は、認識対象実験における詳細を示す表である。SOINN−DPにおけるパラメタは、音素認識実験における場合と同様のパラメタを用いた。ただし、セグメント数Lについては、上記数18より訓練データが10個の場合に、入力次元が8であるためL=5と算出した。
HMMの各状態の出力確率は、全共分散行列を持つ正規分布とした。尚、音素認識実験と同様に、状態数を変化させながら実験を行って最適なパラメタを探索し、そのパラメタを用いた上での認識率を認識結果とした。
また、ストキャスティックDP法については、上記数16に示した非対称型漸化式を用いた場合に加えて、対称型漸化式を用いた場合における実験も行った。尚、ストキャスティックDP法について、共分散行列を共有する範囲は5状態の間とした。
【0095】
図15は、動作データに対する認識結果を示す表である。図15において、「SO−DP」はSOINN−DP法、「ST−DP(1)」は非対称型漸化式を用いたストキャスティックDP法、「ST−DP(2)」は対称型漸化式を用いたストキャスティックDP法をそれぞれ示している。また、HMMの認識率の右側括弧内は、最大の認識率を得た時のパラメタ(S:状態数)を示している。図15に示すように、音素認識実験の場合と同様に、SOINN−DP法の識別率は、ストキャスティックDP法及びHMMによる認識率よりも高く、良好であった。
また、HMMを用いた実験において、比較のため状態数を1から15個まで変動させて実験を行った結果、状態数が11おいて認識率が最大であった。
さらにまた、ストキャスティックDP法について、音素認識実験の場合と同様に、非特許文献4に開示された非対称型漸化式を用いた場合よりも、対称型漸化式を用いた場合のほうが高い認識結果となった。
このように、音素データに比較して状態数及びその出力分布を決定することが困難である動作データに対しても、SOINN−DP法は高い認識精度を有するものである。
【0096】
以上より、音素認識実験の場合と同様に、動作認識実験についても、SOINN−DP法では、ストキャスティックDP法及びHMMより得られる最大の認識率に比べて、より良好な認識率を得ることができた。即ち、SOINN−DP法は時系列パターン全体の認識に使用することができ、従来手法と比較して高い認識精度を有するものである。
【0097】
ここで、音素認識実験及び動作認識実験結果から、SOINN−DP法が、従来手法であるストキャスティックDP法及びHMMより優れている点についてさらに説明する。
まず、SOINN−DP法は、SOINN12を用いて1つの状態を詳細に近似することによって頑健なテンプレートモデルを構築する。これにより、SOINN−DP法は、ストキャスティックDP法と比較して優れた認識率を有しており、時系列データの頑健なモデル化を行うことができる。
そして、SOINN−DP法は、各状態の出力分布をSOINN12によって自動的に決定することができる。また、状態数を標準パターンの時系列数として決定することができるため、状態数を予め決定する必要がない。これにより、時系列データを学習する際に、HMMでは事前に状態数及び状態の出力分布(連続分布の場合には混合数)を決定する必要があるが、SOINN−DP法では不要である。即ち、実験においては、HMMの状態数及び混合数について、認識率が最も高くなる場合の値を採用し、これらの値に基づいて認識結果を得た。SOINN−DP法は、このようなHMMによる認識結果よりも良好であった。従って、SOINN−DP法は、事前に状態数及び出力分布のパラメタを設定せずに、高い認識率を得ることができる。
【0098】
ここで、セグメント数LによるSOINN−DP法の認識率への寄与について説明する。SOINN−DP法のパラメタであるセグメント数Lは、SOINN−DP法の認識性能に影響を与える。このため、セグメント数の変化による認識精度への影響について検証する。
本実施の形態1においては、上記数18に基づいてセグメント数Lを算出する。検証は、図11に示した表と同様の条件下において音素認識実験を行った。1回の実験に用いる1クラスあたりの訓練データは40個とした。また、セグメント数を1〜10まで変化させ、それぞれのセグメント数を用いた場合において、計10回のクロスバリデーション実験を行った。
図16は、検証結果を示す図である。図16に示すように、セグメント数をL=1から増加させるにつれて徐々に認識率が上昇し、L=5において最大認識率(57.04%)を得た。さらにセグメント数を増加させた場合には、認識率は下降した。
一方、予備実験の結果から算出したセグメント数は、訓練パターンが40個の場合に、L=6であり、図16においては、L=6の場合は、全体で3番目に認識率が高いものであった。従って、本実施の形態1において用いたセグメント数の推定方法は妥当なものであり、この推定方法によって適切なセグメント数を決定することができる。
【0099】
ここで、SOINN−DP法の認識性能に対して、SOINN12による寄与について説明する。
SOINN−DP法では、DPマッチングによって各状態jに対して要素ベクトル群Z*jを分配する。分配されたZ*jはSOINN12によって分類され、その分類結果より大域的尤度Pwhole(xi|Sj)及び局所的尤度Pclass(xi|Ujk)を算出し、これらの確率値に基づいて尤度C(xi,Sj)を算出する。そこで、SOINN−DP法に加えて、SOINN12を用いない手法を2つ定義し、これらの手法を比較した。SOINN12による学習結果を用いない手法と比較することにより、SOINN12による認識精度への寄与を検証した。SOINN12の学習結果を用いない比較手法として、以下の2つの手法を定義した。
【0100】
手法1:要素ベクトル群Z*jをSOINN12に入力せず、Z*jより直接、最尤推定により多次元正規分布P(x|Sj)を算出した。尤度C(xi,Sj)=log(P(x|Sj))とし、この尤度C(xi,Sj)を用いた漸化式により入力データの認識を行った。
手法2:要素ベクトル群Z*jをSOINN12に入力し、SOINN12の分類結果より、Pwhole(xi|Sj)を算出した。ただし、SOINN12のクラスタリング結果より得られるPclass(xi|Ujk)については、入力パターンの認識には用いないものとした。即ち、尤度C(xi,Sj)を以下の式に基づいて算出し、α=0とした。
【数19】
尚、検証実験は図11に示した表と同様の条件下において行い、1回の実験に用いる1クラスあたりの訓練データは80個とし、セグメント数L=3とした。αを0〜1.0まで0.05ずつ変化させながら、それぞれのαを用いた場合について、計10回のクロスバリデーション実験を行った。
【0101】
図17は、[手法1]、[手法2]、SOINN−DP法により得られた検証実験の結果を示す表である。図17に示すように、SOINN−DP法による認識結果は、[手法1]及び[手法2]による認識率を約4%上回っている。従って、SOINN12を用いたことに加えて、さらに、SOINN12の学習結果の内部クラスの情報を用いたSOINN−DP法は、この情報を用いなかった[手法1]及び[手法2]に比べて高い認識率を有するものである。尚、テストデータに対する[手法1]及び[手法2]による認識率はほぼ同程度であった。即ち、SOINN−DPは、SOINN12の学習結果である内部クラスの情報を用いることにより、認識率をより向上させることができる。
【0102】
さらに、内部クラスの情報について、αの変化によるSOINN−DPの認識率への寄与について説明する。図18は、αの変化に対する認識率の変化を示す図である。図18においては、x軸方向がαの値を示し、y軸方向が各々のα値に対応する認識率を示す。図18に示すように、認識率はα=0.45において最大となり、以降低下した。最終的に、認識率はα=1.0において最低となった。α=1.0の状態は、上記数19において右辺の第二項(log(ΣjPcぁss(x)))のみにより尤度を算出することに等しく、内部クラスの情報のみを用いて尤度を算出していることになる。この場合には、各内部クラスを核関数により近似しているため、次元間の相関を多次元正規分布のようにモデル化することができない。このため、各内部クラスによる情報のみを用いて尤度を算出した場合において、テストデータに対する認識率が低下したものと考えられる。
一方、図17に示した結果より、各内部クラスによる情報に加えて、大域的情報(SOINNの全ノード)を併せて用いることによって、SOINN−DP法は認識率を向上させることができた。
また、図18に示すように、α=0.45において最大の認識率を得た。これは、αをデータにフィッティングさせることによって、さらにSOINN−DP法による認識精度を向上させることが可能であることを示している。
【0103】
尚、本実施の形態1においては、パターン認識装置1がテンプレートモデル生成処理及び認識処理を行うものとして説明したが、本発明はこれに限定されるものではない。例えば、テンプレートモデル生成部10を、自己増殖型ニューラルネットワークを用いてテンプレートモデルを生成するテンプレートモデル生成装置としても使用することができる。また、認識部20を、自己増殖型ニューラルネットワークを用いて認識を行う認識装置としても使用することができる。
また、本実施の形態1において示したパターン認識はこれに限定されず、SOINN−DPは実環境における他の時系列パターンの認識についても適用することができる。
さらにまた、実環境において動作する知能ロボットにSOINN−DPを適用することができる。SOINN−DPを適用することにより、知能ロボットに例えば手話などの動作を認識させることができる。また、逐次的にテンプレートモデルを更新することによって、環境に適応して発達させてゆくことができる。即ち、例えば、人間が英語を徐々に聞き取ることができるようになっていくのと同様に、認知発達機能を実現することができる。
【0104】
尚、本実施の形態1においては、テンプレートモデル生成には予め十分な個数の訓練パターンが用意され、バッチ学習としてテンプレートモデルが生成される場合を説明したが本発明はこれに限定されない。即ち、テンプレートモデル生成部10は、逐次的に入力パターンを追加して入力するときに、その逐次的に追加される入力パターンの属するクラスに対応するテンプレートモデルについて、そのテンプレートモデルにおける状態の出力分布を逐次的に追加される入力パターンに応じて更新するようにしてもよい。これにより、追加的に入力される入力パターンを容易に追加学習することができるとともに、事前に多量のデータを必要とせず、逐次的に与えられる少量のデータに基づいて認識精度を向上させてゆくことができる。即ち、テンプレートモデルを少量の訓練パターンを用いて生成した後、オンラインで与えられる教師付きデータを用いて、テンプレートモデルを更新することができる。
【0105】
図19は、テンプレートモデルを更新する様子を説明するための図である。図19に示すように、オンラインで追加的に与えられたData1乃至3について、上記同様にしてSOINN−DP法によってマッチング処理が実施された後、教師付きデータより更新対象となるテンプレートモデル(Target Template)を特定することができる。そして、テンプレートモデルにおける各状態(SOINN−1Frame乃至SOINN−3Frame)が、更新前のデータ、及び追加されたデータによって更新される。図20は、SOINN12における更新の様子を説明するための図である。図20に示すように、既にSOINN12に存在しているノードに加えて、追加的に入力されたノードからなるクラス(Class generated by update data)が既存の知識を壊すことなく生成される。図21は、オンライン教師付き学習による検証結果を示す表である。図21に示すように、まずバッチ学習において所定の個数の(10、20、40個)データを用いてテンプレートモデルを生成し、オンラインでデータを追加してテンプレートモデルを更新した場合において、認識率の向上結果を検証した。検証結果より、オンラインでデータを追加してゆくにつれて、認識率が向上していくことが分かる。即ち、オンライン教師付き学習による、時系列モデルの頑健な更新が可能である。
【0106】
その他の発明の実施の形態.
以上、本発明をその実施の形態により説明したが、本発明はその趣旨の範囲において種々の変形が可能である。例えばSOINN12に代えて、SOINNに基づくEnhanced−SOINN(以下E−SOINNという。)を使用しても良い。
【0107】
E−SOINNはSOINNに比べて、入力パターンの分布に高密度の重なりのあるクラスを分離することができる。そして、分布の重なり領域の検出処理においては、平滑化の手法を導入したことより、SOINNに比べてより安定的に動作することができる。さらに、1層構造であっても効率的にノイズノードを削除することができる。さらにまた、SOINNに比べて、より少ないパラメタで動作するため、処理をより容易に実行することができる。
【0108】
以下にE−SOINNを簡単に説明する。図22は、E−SOINNによる学習処理の処理概要を示すフローチャートである。尚、上述したSOINN12と同様の処理については説明を省略する。まず、図22に示すS601乃至S605については、図5に示したSOINN12と同様の処理を実施する。従って、以下では図22に示すS606からの処理について説明する。
【0109】
S606:辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2のノード密度に基づいて、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
S607:一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。そして、E−SOINNは、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0110】
一方、一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S608へと処理を進めるが、既にノード間に辺が生成されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
次いで、一時記憶部に格納されたノード及びノード密度のポイント値について、第1勝者ノードa1について、ノード密度算出手段は、一時記憶部に格納された第1勝者ノードa1のノード密度のポイント値を算出しその結果を一時記憶部に格納し、算出され一時記憶部に格納されたノード密度のポイント値を以前までに算出され一時記憶部に格納されたポイント値に加算することで、ノード密度ポイントとして累積し、その結果を一時記憶部に格納する。
次いで、E−SOINNは、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0111】
S608:重みベクトル更新手段は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力ベクトルξに更に近づけるように更新し、その結果を一時記憶部に格納する。尚、E−SOINNにおいては、追加学習に対応するため、入力ベクトルの入力回数tに代えて、一時記憶部に格納される第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1を用いる。
S609:E−SOINNは、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。
【0112】
S610:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がλの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。一方、入力ベクトルξの総数がλの倍数となった場合には以下の処理を実行する。
【0113】
S611:分布重なり領域検出手段は、一時記憶部に格納されたサブクラスタ及び分布の重なり領域について、上述のS301乃至S305において示したようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
S612:ノード密度算出手段は、一時記憶部に格納されて累積されたノード密度ポイントを単位入力数あたりの割合として算出しその結果を一時記憶部に格納し、単位入力数あたりのノードのノード密度を算出し、その結果を一時記憶部に格納する。
S613:ノイズノード削除手段は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。尚、S613においてノイズノード削除手段が使用するパラメタc1及びc2はノードをノイズと見なすか否かの判定に使用する。通常、隣接ノード数が2であるノードはノイズではないことが多いため、c1は0に近い値を使用する。また、隣接ノード数が1であるノードはノイズであることが多いため、c2は1に近い値を使用するものとし、これらのパラメタは予め設定され一時記憶部に格納される。
【0114】
S614:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がLTの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。
一方、入力ベクトルξの総数がLTの倍数となった場合には、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、学習を停止する。
【0115】
ノード密度算出手段は、一時記憶部に格納されたノード及びノード密度について、注目するノードについて、その隣接ノード間の平均距離に基づいて、注目するノードのノード密度を算出し、その結果を一時記憶部に格納する。具体的には、ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiに与えられるノード密度のポイント値piを算出し、その結果を一時記憶部に格納する。尚、ノードiに与えられるポイント値piは、ノードiが第1勝者ノードとなった場合には一時記憶部に格納される以下の式に基づいて算出されるポイント値が与えられるが、ノードiが第1勝者ノードでない場合にはノードiにはポイントは与えられないものとする。
【数20】
【0116】
ここで、eiはノードiからその隣接ノードまでの平均距離を示し、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【数21】
尚、mは一時記憶部に格納されたノードiの隣接ノードの個数を示し、Wiは一時記憶部に格納されたノードiの重みベクトルを示す。
【0117】
ここで、隣接ノードへの平均距離が大きくなる場合には、ノードを含むその領域にはノードが少ないものと考えられ、逆に平均距離が小さくなる場合には、その領域にはノードが多いものと考えられる。従って、ノードの多い領域で第1勝者ノードとなった場合には高いポイントが与えられ、ノードの少ない領域で第1勝者ノードとなった場合には低いポイントが与えられるようにノードの密度のポイント値の算出方法を上述のように構成する。これにより、ノードを含むある程度の範囲の領域におけるノードの密集具合を推定することができるため、ノードの分布が高密度の領域に位置するノードであっても、ノードが第1勝者回数となった回数をノードの密度とするSOINNに比べて、入力ベクトルの入力分布密度により近似した密度となるノード密度ポイントを算出することができる。
【0118】
単位ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiの単位入力数あたりのノード密度densityiを算出し、その結果を一時記憶部に格納する。
【数22】
【0119】
ここで、連続して与えられる入力ベクトルの入力回数を予め設定され一時記憶部に格納される一定の入力回数λごとの区間に分け、各区間においてノードiに与えられたポイントについてその合計を累積ポイントsiと定める。尚、入力ベクトルの総入力回数を予め設定され一時記憶部に格納されるLTとする場合に、LT/λを区間の総数nとしその結果を一時記憶部に格納し、nのうち、ノードに与えられたポイントの合計が0以上であった区間の数をNとして算出し、その結果を一時記憶部に格納する(Nとnは必ずしも同じとならない点に注意する)。
【0120】
累積ポイントsiは、例えば一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【数23】
ここで、pi(j,k)はj番目の区間におけるk番目の入力によってノードiに与えられたポイントを示し、上述のノード密度ポイント算出部により算出され、その結果を一時記憶部に格納する。このように、単位ノード密度ポイント算出部は、一時記憶部に格納されたノードiの密度densityiを累積ポイントsiの平均として算出し、その結果を一時記憶部に格納する。
【0121】
尚、E−SOINNにおいては追加学習に対応するため、nに代えてNを用いる。これは、追加学習において、以前の学習で生成されたノードにはポイントが与えられないことが多く、nを用いて密度を算出すると、以前学習したノードの密度が次第に低くなってしまうという問題を回避するためである。即ち、nに代えてNを用いてノード密度を算出することで、追加学習を長時間行った場合であっても、追加されるデータが以前学習したノードの近くに入力されない限りは、そのノードの密度を変化させずに保持することができる。これにより、追加学習を長時間実施する場合であっても、ノードのノード密度が相対的に小さくなってしまうことを防ぐことができ、SOINNを含む従来の手法に比べて、入力ベクトルの入力分布密度により近似したノード密度を変化させずに保持して算出することができる。
【0122】
分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、辺によって接続されるノードの集合であるクラスタを、ノード密度算出手段によって算出されるノード密度に基づいてクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納し、サブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0123】
さらに、分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索するノード探索部と、探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与する第1のラベル付与部と、第1のラベル付与部によりラベルが付与されなかったノードのうち、そのノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与する第2のラベル付与部と、それぞれ異なるラベルが付与されたノード間に辺によって直接的に接続がある場合に、その辺によって接続されるノードの集合であるクラスタをクラスタの部分集合であるサブクラスタに分割するクラスタ分割部と、注目するノード及びその隣接ノードがそれぞれ異なるサブクラスタに属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出する分布重なり領域検出部を有する。具体的には、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、例えば以下のようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0124】
S701:ノード探索部は、一時記憶部に格納されたノード及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索し、その結果を一時記憶部に格納する。
S702:第1のラベル付与部は、一時記憶部に格納されたノード、及びノードのラベルについて、S701において探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与し、その結果を一時記憶部に格納する。
S703:第2のラベル付与部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、S702において第1のラベル付与部によりラベルが付与されなかったノードについて、第1のラベル付与部にラベルが付与されたノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与し、その結果を一時記憶部に格納する。即ち、密度が局所的に最大の隣接ノードと同じラベルを付与する。
S704:クラスタ分割部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、一時記憶部に格納された辺によって接続されるノードの集合であるクラスタを、同じラベルが付与されたノードからなるクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納する。
S705:分布重なり領域検出部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、注目するノードとその隣接ノードが異なるサブクラスタにそれぞれ属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出し、その結果を一時記憶部に格納する。
【0125】
辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、及び分布重なり領域について、第1勝者ノード及び第2勝者ノードが分布重なり領域に位置するノードである場合に、第1勝者ノード及び第2勝者ノードのノード密度に基づいて第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。さらに辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタについて、ノードが属しているサブクラスタを判定する所属サブクラスタ判定部と、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定する辺接続判定部を有する。
【0126】
辺接続手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
辺削除手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。
具体的には、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタ、及びノード間の辺について、例えば以下のようにして辺接続判定手段は辺を接続するか否かを判定し、辺接続手段及び辺削除手段は辺の生成及び削除処理を実施し、その結果を一時記憶部に格納する。
【0127】
S801:所属サブクラスタ判定部は、一時記憶部に格納されたノード、ノードのサブクラスタについて、第1勝者ノード及び第2勝者ノードが属するサブクラスタをそれぞれ判定し、その結果を一時記憶部に格納する。
S802:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードがどのサブクラスタにも属していない場合、又は、第1勝者ノード及び第2勝者ノードが同じサブクラスタに属している場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成することによりノード間を接続し、その結果を一時記憶部に格納する。
S803:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードが互いに異なるサブクラスタに属す場合には、辺接続判定部は、一時記憶部に格納されたノード、ノード密度、及びノード間の辺について、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
S804:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要がないと判定した場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間を辺によって接続せず、既にノード間が辺によって接続されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、一時記憶部に格納された第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。
S805:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要があると判定した場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成しノード間を接続する。
【0128】
ここで、辺接続判定部による判定処理について詳細に説明する。
まず、辺接続判定部は、一時記憶部に格納されたノード及びノード密度について、第1勝者ノードのノード密度densitywin及び第2勝者ノード密度densitysec−winのうち、最小のノード密度mを例えば一時記憶部に格納される以下の式に基いて算出し、その結果を一時記憶部に格納する。
【数24】
【0129】
次に、一時記憶部に格納されたノード、ノードのノード密度、及びノードのサブクラスについて、第1勝者ノード及び第2勝者ノードがそれぞれ属するサブクラスタA及びサブクラスタBについて、サブクラスタAの頂点の密度Amax及びサブクラスタBの頂点の密度Bmaxを算出し、その結果を一時記憶部に格納する。尚、サブクラスタに含まれるノードのうち、ノード密度が最大であるノード密度をサブクラスタの頂点の密度とする。
【0130】
そして、一時記憶部に格納されたノードが属するサブクラスタの頂点の密度Amax及びBmax、及びノードの密度mについて、mがαAAmaxより小さく、かつ、mがαBBmaxより小さいか否かを判定し、その結果を一時記憶部に格納する。即ち、一時記憶部に格納される以下の不等式を満足するか否かを判定し、その結果を一時記憶部に格納する。
【数25】
【0131】
判定の結果、mがαAAmaxより小さく、かつ、mがαBBmaxより小さい場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間には辺は不要であると判定し、その結果を一時記憶部に格納する。
一方、判定の結果、mがαAAmax以上、または、mがαBBmax以上である場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺は必要であると判定し、その結果を一時記憶部に格納する。
【0132】
このように、第1勝者ノード及び第2勝者ノードの最小ノード密度mを、第1勝者ノード及び第2勝者ノードをそれぞれ含むサブクラスタの平均的なノード密度と比較することで、第1勝者ノード及び第2勝者ノードを含む領域におけるノード密度の凹凸の大きさを判定することができる。即ち、サブクラスタA及びサブクラスタBの間に存在する分布の谷間のノード密度mが、閾値αAAmax又はαBBmaxより大きな場合には、ノード密度の形状は小さな凹凸であると判定することができる。
【0133】
ここで、αA及びαBは一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。尚、αBについてもαAと同様にして算出することができるためここでは説明を省略する。
i) Amax/meanA−1≦1の場合には、αA=0.0とする。
ii) 1<Amax/meanA−1≦2の場合には、αA=0.5とする。
iii) 2<Amax/meanA−1の場合には、αA=1.0とする。
【0134】
Amax/meanAの値が1以下となるi)の場合には、AmaxとmeanAの値は同程度であり、密度の凹凸はノイズの影響によるものと判断する。そして、αの値を0.0とすることで、サブクラスタが統合されるようにする。
また、Amax/meanAの値が2を超えるiii)の場合には、AmaxはmeanAに比べて十分大きく、明らかな密度の凹凸が存在するものと判断する。そして、αの値を1.0とすることで、サブクラスタが分離されるようにする。
そして、Amax/meanAの値が上述した場合以外となる i i)の場合には、αの値を0.5とすることで、密度の凹凸の大きさに応じてサブクラスタが統合又は分離されるようにする。
【0135】
尚、meanAはサブクラスタAに属すノードiのノード密度densityiの平均値を示し、NAをサブクラスタAに属するノードの数として、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【数26】
【0136】
このように、サブクラスタへの分離を行う際に、サブクラスタに含まれるノード密度の凹凸の程度を判定し、ある基準を満たした2つのサブクラスタを1つに統合することで、分布の重なり領域の検出におけるサブクラスタの分けすぎによる不安定化を防止することができる。例えば、ノイズや学習サンプルが少ないことが原因で、密度の分布に多くの細かい凹凸が形成されることがある。このような場合に、第1勝者ノード及び第2勝者ノードがサブクラスタA及びBの間にある分布の重なり領域に位置する場合に、ノード間の接続を行う際にある基準を満たした2つのサブクラスタを1つに統合することで、密度の分布に多くの細かい凹凸が含まれる場合であっても平滑化することができる。
【0137】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードについて、ノード密度算出手段により算出されるノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。さらにノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードのノード密度を所定の閾値と比較するノード密度比較部と、注目するノードの隣接ノードの個数を算出する隣接ノード数算出部と、注目するノードをノイズノードとみなして削除するノイズノード削除部を有する。具体的には、例えば以下のようにして一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、ノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。
【0138】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード間の辺、隣接ノードの個数について、注目するノードiについて、隣接ノード数算出部によりその隣接ノードの個数を算出し、その結果を一時記憶部に格納する。そして、一時記憶部に格納された隣接ノードの個数に応じて、以下の処理を実施する。
i) 一時記憶部に格納された隣接ノード数が2の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【数27】
一時記憶部に格納された比較結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
【0139】
ii) 一時記憶部に格納された隣接ノード数が1の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【数28】
一時記憶部に格納された比較の結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
【0140】
iii) 一時記憶部に格納された隣接ノード数について、隣接ノードを持たない場合、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
ここで、予め設定され一時記憶部に格納される所定のパラメタc1及びc2を調整することで、ノイズノード削除手段によるノイズノードの削除の振る舞いを調整することができる。
【0141】
本発明の目的は、上述した実施形態の機能を実現するソフトウェアのプログラムコードを記録した記録媒体(または記憶媒体)を、システムあるいは装置に供給し、そのシステムあるいは装置のコンピュータ(またはCPUやMPU)が記録媒体に格納されたプログラムコードを読み出し実行することによっても、達成されることは当然である。この場合、記録媒体から読み出されたプログラムコード自体が上述の実施形態の機能を実現することになり、そのプログラムコードを記録した記録媒体は本発明を構成することになる。
【0142】
また、コンピュータが読み出したプログラムコードを実行することにより、上述した実施形態の機能が実現されるだけでなく、そのプログラムコードの指示に基き、コンピュータ上で稼動しているオペレーティングシステム(OS)などが実際の処理の一部又は全部を行い、その処理によって上述した実施形態の機能が実現される場合も当然含まれる。
【0143】
さらに、記録媒体から読み出されたプログラムコードが、コンピュータに挿入された機能拡張カードやコンピュータに接続された機能拡張ユニットに備わるメモリに書き込まれた後、そのプログラムコードの指示に基き、その機能拡張カードや機能拡張ユニットに備わるCPUなどが実際の処理の一部又は全部を行い、その処理によって上述した実施形態の機能が実現される場合も当然含まれる。本発明を上記記録媒体に適用する場合、その記録媒体には、上述したフローチャートに対応するプログラムコードが格納されることになる。
【図面の簡単な説明】
【0144】
【図1】本発明を実施するための機能ブロックを示す図である。
【図2】従来手法であるSOINNによる学習処理の処理概要を示すフローチャートである。
【図3】従来手法であるSOINNに対して入力した人工データセットを示す図である。
【図4】人工データセットに対するSOINNの出力結果を示す図である。
【図5】本実施形態に係るSOINN12による学習処理の処理概要を示すフローチャートである。
【図6】本実施形態に係るSOINN12に存在する複数の内部クラスを示す図である。
【図7】本実施形態に係るパターン認識装置のシステム構成を示す図である。
【図8】パターン認識装置によるテンプレートモデル生成処理の処理概要を示すフローチャートである。
【図9】訓練パターンをSOINN12へと入力するようすを示す図である。
【図10】パターン認識装置による認識処理の処理概要を示すフローチャートである。
【図11】音素認識実験における実験条件を示す表である。
【図12】音素認識実験における実験結果を示す表である。
【図13】動作実験における動作内容を示す画像である。
【図14】動作認識実験における実験条件を示す表である。
【図15】動作認識実験における実験結果を示す表である。
【図16】セグメント数に対する認識率の変化を示す図である。
【図17】SOINN12を用いない手法との比較結果を示す表である。
【図18】大域的尤度及び局所的尤度の反映具合による認識率の変化を示す図である。
【図19】テンプレートモデルを更新する様子を説明するための図である。
【図20】SOINN12における更新の様子を説明するための図である。
【図21】オンライン教師付き学習による検証結果を示す表である。
【図22】従来手法であるE―SOINNによる学習処理の処理概要を示すフローチャートである。
【符号の説明】
【0145】
1 パターン認識装置
10 テンプレートモデル生成部
11 標準パターン選択部
12 SOINN
121 クラス間ノード挿入部
122 辺削除部
123 ノード削除部
124 重みベクトル更新部
20 認識部
21 尤度算出部
211 大域的尤度算出部
212 局所的尤度算出部
31 訓練用パターンDB
32 テンプレートモデル学習結果DB
40 コンピュータ
41 CPU
42 ROM
43 RAM
44 バス
45 入出力インターフェイス
46 入力部
47 出力部
48 記憶部
49 通信部
50 ドライブ
501 磁気ディスク
502 光ディスク
503 フレキシブルディスク
504 半導体メモリ
【特許請求の範囲】
【請求項1】
入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、
前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成部と、
生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識部とを有する
ことを特徴とするパターン認識装置。
【請求項2】
前記認識部は、
前記ノードに基づいて、前記テンプレートモデルにおける状態の出力分布を算出する尤度算出部を有し、
算出された前記テンプレートモデルにおける状態の出力分布を用いて、前記テンプレートモデルと前記入力パターンとの一致度を算出する
ことを特徴とする請求項1記載のパターン認識装置。
【請求項3】
前記尤度算出部は、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部を有し、
前記大域的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項2記載のパターン認識装置。
【請求項4】
前記尤度算出部は、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部を有し、
前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項2記載のパターン認識装置。
【請求項5】
前記尤度算出部は、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部と、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部とを有し、
前記大域的尤度及び/又は前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項2記載のパターン認識装置。
【請求項6】
前記テンプレートモデル生成部は、
前記入力パターン間のマッチングにより、当該入力パターンが属するクラスの標準パターンを選択する標準パターン選択部を有し、
前記入力パターンの大きさを前記標準パターンの大きさに正規化して、前記標準パターンの各フレームに対応する各前記入力パターンの一部又は全部を、前記テンプレートモデルにおける各状態に対応させる
ことを特徴とする請求項1記載のパターン認識装置。
【請求項7】
前記テンプレートモデル生成部は、
前記テンプレートモデルにおける各状態に対応させた各前記入力パターンの一部又は全部からなる要素の集合について、前記入力パターンの入力パターン数及び当該入力パターンの特徴量の次元数に基づいて、当該要素集合を前記自己増殖型ニューラルネットワークに入力する
ことを特徴とする請求項6記載のパターン認識装置。
【請求項8】
前記テンプレートモデル生成部は、
逐次的に入力パターンを追加して入力するときに、当該逐次的に追加される入力パターンの属するクラスに対応する前記テンプレートモデルについて、当該テンプレートモデルにおける状態の出力分布を前記逐次的に追加される入力パターンに応じて更新する
ことを特徴とする請求項1記載のパターン認識装置。
【請求項9】
DPマッチング法を用いて前記マッチング処理を行う
ことを特徴とする請求項1乃至6記載のパターン認識装置。
【請求項10】
前記自己増殖型ニューラルネットワークは、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードと2番目に近い重みベクトルを持つノードの間に辺を接続したとき、
注目するノードと他のノード間の距離に基づいて算出される当該注目するノードの類似度閾値、及び前記入力ベクトルと当該注目するノード間の距離に基づいて、前記入力ベクトルをノードとして挿入するクラス間ノード挿入部と、
前記入力ベクトルに最も近いノードに対応する重みベクトル及び当該ノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ前記入力ベクトルに更に近づけるように更新する重みベクトル更新部とを有する
ことを特徴とする請求項1記載のパターン認識装置。
【請求項11】
前記クラス間ノード挿入部は、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、当該第1勝者ノード及び当該第2勝者ノードの間に辺を接続したとき、
注目するノードについて、当該注目するノードと辺によって直接的に接続されるノードが存在する場合には、当該直接的に接続されるノードのうち当該注目するノードからの距離が最大であるノード間の距離を前記類似度閾値とし、当該注目するノードと辺によって直接的に接続されるノードが存在しない場合には、当該注目するノードからの距離が最小であるノード間の距離を前記類似度閾値として算出する類似度閾値算出部と、
前記入力ベクトルと前記第1勝者ノード間の距離が当該第1勝者ノードの類似度閾値より大きいか否か、及び、前記入力ベクトルと前記第2勝者ノード間の距離が当該第2勝者ノードの類似度閾値より大きいか否かを判定する類似度閾値判定部と、
類似度閾値判定結果に基づいて、前記入力ベクトルをノードとして当該入力ベクトルと同じ位置に挿入するノード挿入部とを有する
ことを特徴とする請求項10記載のパターン認識装置。
【請求項12】
前記自己増殖型ニューラルネットワークは、
前記辺に対応付けられる辺の年齢に基づいて、当該辺を削除する辺削除部と、
注目するノードについて、当該注目するノードに直接的に接続される辺の本数に基づいて、当該注目するノードを削除するノード削除部とを更に有する
ことを特徴とする請求項10記載のパターン認識装置。
【請求項13】
前記自己増殖型ニューラルネットワークは1層構造である
ことを特徴とする請求項1記載のパターン認識装置。
【請求項14】
入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、
前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成ステップと、
生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識ステップとを有する
ことを特徴とするパターン認識方法。
【請求項15】
前記認識ステップは、
前記ノードに基づいて、前記テンプレートモデルにおける状態の出力分布を算出する尤度算出ステップを有し、
算出された前記テンプレートモデルにおける状態の出力分布を用いて、前記テンプレートモデルと前記入力パターンとの一致度を算出する
ことを特徴とする請求項14記載のパターン認識方法。
【請求項16】
前記尤度算出ステップは、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出ステップを有し、
前記大域的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項15記載のパターン認識方法。
【請求項17】
前記尤度算出ステップは、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出ステップを有し、
前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項15記載のパターン認識方法。
【請求項18】
前記尤度算出ステップは、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出ステップと、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出ステップとを有し、
前記大域的尤度及び/又は前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項15記載のパターン認識方法。
【請求項19】
前記テンプレートモデル生成ステップは、
前記入力パターン間のマッチングにより、当該入力パターンが属するクラスの標準パターンを選択する標準パターン選択ステップを有し、
前記入力パターンの大きさを前記標準パターンの大きさに正規化して、前記標準パターンの各フレームに対応する各前記入力パターンの一部又は全部を、前記テンプレートモデルにおける各状態に対応させる
ことを特徴とする請求項14記載のパターン認識方法。
【請求項20】
前記テンプレートモデル生成ステップでは、
前記テンプレートモデルにおける各状態に対応させた各前記入力パターンの一部又は全部からなる要素の集合について、前記入力パターンの入力パターン数及び当該入力パターンの特徴量の次元数に基づいて、当該要素集合を前記自己増殖型ニューラルネットワークに入力する
ことを特徴とする請求項19記載のパターン認識方法。
【請求項21】
前記テンプレートモデル生成ステップでは、
逐次的に入力パターンを追加して入力するときに、当該逐次的に追加される入力パターンの属するクラスに対応する前記テンプレートモデルについて、当該テンプレートモデルにおける状態の出力分布を前記逐次的に追加される入力パターンに応じて更新する
ことを特徴とする請求項14記載のパターン認識方法。
【請求項22】
DPマッチング法を用いて前記マッチング処理を行う
ことを特徴とする請求項14乃至19記載のパターン認識方法。
【請求項23】
前記自己増殖型ニューラルネットワークは、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードと2番目に近い重みベクトルを持つノードの間に辺を接続したとき、
注目するノードと他のノード間の距離に基づいて算出される当該注目するノードの類似度閾値、及び前記入力ベクトルと当該注目するノード間の距離に基づいて、前記入力ベクトルをノードとして挿入するクラス間ノード挿入ステップと、
前記入力ベクトルに最も近いノードに対応する重みベクトル及び当該ノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ前記入力ベクトルに更に近づけるように更新する重みベクトル更新ステップとを有する
ことを特徴とする請求項14記載のパターン認識方法。
【請求項24】
前記クラス間ノード挿入ステップは、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、当該第1勝者ノード及び当該第2勝者ノードの間に辺を接続したとき、
注目するノードについて、当該注目するノードと辺によって直接的に接続されるノードが存在する場合には、当該直接的に接続されるノードのうち当該注目するノードからの距離が最大であるノード間の距離を前記類似度閾値とし、当該注目するノードと辺によって直接的に接続されるノードが存在しない場合には、当該注目するノードからの距離が最小であるノード間の距離を前記類似度閾値として算出する類似度閾値算出ステップと、
前記入力ベクトルと前記第1勝者ノード間の距離が当該第1勝者ノードの類似度閾値より大きいか否か、及び、前記入力ベクトルと前記第2勝者ノード間の距離が当該第2勝者ノードの類似度閾値より大きいか否かを判定する類似度閾値判定ステップと、
類似度閾値判定結果に基づいて、前記入力ベクトルをノードとして当該入力ベクトルと同じ位置に挿入するノード挿入ステップとを有する
ことを特徴とする請求項23記載のパターン認識方法。
【請求項25】
前記自己増殖型ニューラルネットワークは、
前記辺に対応付けられる辺の年齢に基づいて、当該辺を削除する辺削除ステップと、
注目するノードについて、当該注目するノードに直接的に接続される辺の本数に基づいて、当該注目するノードを削除するノード削除ステップとを更に有する
ことを特徴とする請求項23記載のパターン認識方法。
【請求項26】
前記自己増殖型ニューラルネットワークは1層構造である
ことを特徴とする請求項14記載のパターン認識方法。
【請求項27】
請求項14乃至26いずれか1項記載のパターン認識処理をコンピュータに実行させることを特徴とするプログラム。
【請求項1】
入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、
前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成部と、
生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識部とを有する
ことを特徴とするパターン認識装置。
【請求項2】
前記認識部は、
前記ノードに基づいて、前記テンプレートモデルにおける状態の出力分布を算出する尤度算出部を有し、
算出された前記テンプレートモデルにおける状態の出力分布を用いて、前記テンプレートモデルと前記入力パターンとの一致度を算出する
ことを特徴とする請求項1記載のパターン認識装置。
【請求項3】
前記尤度算出部は、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部を有し、
前記大域的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項2記載のパターン認識装置。
【請求項4】
前記尤度算出部は、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部を有し、
前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項2記載のパターン認識装置。
【請求項5】
前記尤度算出部は、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出部と、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出部とを有し、
前記大域的尤度及び/又は前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項2記載のパターン認識装置。
【請求項6】
前記テンプレートモデル生成部は、
前記入力パターン間のマッチングにより、当該入力パターンが属するクラスの標準パターンを選択する標準パターン選択部を有し、
前記入力パターンの大きさを前記標準パターンの大きさに正規化して、前記標準パターンの各フレームに対応する各前記入力パターンの一部又は全部を、前記テンプレートモデルにおける各状態に対応させる
ことを特徴とする請求項1記載のパターン認識装置。
【請求項7】
前記テンプレートモデル生成部は、
前記テンプレートモデルにおける各状態に対応させた各前記入力パターンの一部又は全部からなる要素の集合について、前記入力パターンの入力パターン数及び当該入力パターンの特徴量の次元数に基づいて、当該要素集合を前記自己増殖型ニューラルネットワークに入力する
ことを特徴とする請求項6記載のパターン認識装置。
【請求項8】
前記テンプレートモデル生成部は、
逐次的に入力パターンを追加して入力するときに、当該逐次的に追加される入力パターンの属するクラスに対応する前記テンプレートモデルについて、当該テンプレートモデルにおける状態の出力分布を前記逐次的に追加される入力パターンに応じて更新する
ことを特徴とする請求項1記載のパターン認識装置。
【請求項9】
DPマッチング法を用いて前記マッチング処理を行う
ことを特徴とする請求項1乃至6記載のパターン認識装置。
【請求項10】
前記自己増殖型ニューラルネットワークは、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードと2番目に近い重みベクトルを持つノードの間に辺を接続したとき、
注目するノードと他のノード間の距離に基づいて算出される当該注目するノードの類似度閾値、及び前記入力ベクトルと当該注目するノード間の距離に基づいて、前記入力ベクトルをノードとして挿入するクラス間ノード挿入部と、
前記入力ベクトルに最も近いノードに対応する重みベクトル及び当該ノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ前記入力ベクトルに更に近づけるように更新する重みベクトル更新部とを有する
ことを特徴とする請求項1記載のパターン認識装置。
【請求項11】
前記クラス間ノード挿入部は、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、当該第1勝者ノード及び当該第2勝者ノードの間に辺を接続したとき、
注目するノードについて、当該注目するノードと辺によって直接的に接続されるノードが存在する場合には、当該直接的に接続されるノードのうち当該注目するノードからの距離が最大であるノード間の距離を前記類似度閾値とし、当該注目するノードと辺によって直接的に接続されるノードが存在しない場合には、当該注目するノードからの距離が最小であるノード間の距離を前記類似度閾値として算出する類似度閾値算出部と、
前記入力ベクトルと前記第1勝者ノード間の距離が当該第1勝者ノードの類似度閾値より大きいか否か、及び、前記入力ベクトルと前記第2勝者ノード間の距離が当該第2勝者ノードの類似度閾値より大きいか否かを判定する類似度閾値判定部と、
類似度閾値判定結果に基づいて、前記入力ベクトルをノードとして当該入力ベクトルと同じ位置に挿入するノード挿入部とを有する
ことを特徴とする請求項10記載のパターン認識装置。
【請求項12】
前記自己増殖型ニューラルネットワークは、
前記辺に対応付けられる辺の年齢に基づいて、当該辺を削除する辺削除部と、
注目するノードについて、当該注目するノードに直接的に接続される辺の本数に基づいて、当該注目するノードを削除するノード削除部とを更に有する
ことを特徴とする請求項10記載のパターン認識装置。
【請求項13】
前記自己増殖型ニューラルネットワークは1層構造である
ことを特徴とする請求項1記載のパターン認識装置。
【請求項14】
入力パターンの一部又は全部を入力ベクトルとしてニューラルネットワークに順次入力し、当該入力ベクトル、及び当該ニューラルネットワークに配置される多次元ベクトルで記述されるノードに基づいて、当該ノードを自動的に増加させる自己増殖型ニューラルネットワークを用いて、
前記入力パターンの特徴量に応じたテンプレートモデルを生成するテンプレートモデル生成ステップと、
生成された前記テンプレートモデルと前記入力パターンをマッチングして当該入力パターンを認識する認識ステップとを有する
ことを特徴とするパターン認識方法。
【請求項15】
前記認識ステップは、
前記ノードに基づいて、前記テンプレートモデルにおける状態の出力分布を算出する尤度算出ステップを有し、
算出された前記テンプレートモデルにおける状態の出力分布を用いて、前記テンプレートモデルと前記入力パターンとの一致度を算出する
ことを特徴とする請求項14記載のパターン認識方法。
【請求項16】
前記尤度算出ステップは、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出ステップを有し、
前記大域的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項15記載のパターン認識方法。
【請求項17】
前記尤度算出ステップは、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出ステップを有し、
前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項15記載のパターン認識方法。
【請求項18】
前記尤度算出ステップは、
前記自己増殖型ニューラルネットワークに配置される全てのノードに基づいて、大域的尤度を算出する大域的尤度算出ステップと、
辺によって接続されたノードからなるクラスタについて、当該クラスタに属するノードに基づいて、局所的尤度を算出する局所的尤度算出ステップとを有し、
前記大域的尤度及び/又は前記局所的尤度から前記テンプレートモデルにおける状態の出力分布を算出する
ことを特徴とする請求項15記載のパターン認識方法。
【請求項19】
前記テンプレートモデル生成ステップは、
前記入力パターン間のマッチングにより、当該入力パターンが属するクラスの標準パターンを選択する標準パターン選択ステップを有し、
前記入力パターンの大きさを前記標準パターンの大きさに正規化して、前記標準パターンの各フレームに対応する各前記入力パターンの一部又は全部を、前記テンプレートモデルにおける各状態に対応させる
ことを特徴とする請求項14記載のパターン認識方法。
【請求項20】
前記テンプレートモデル生成ステップでは、
前記テンプレートモデルにおける各状態に対応させた各前記入力パターンの一部又は全部からなる要素の集合について、前記入力パターンの入力パターン数及び当該入力パターンの特徴量の次元数に基づいて、当該要素集合を前記自己増殖型ニューラルネットワークに入力する
ことを特徴とする請求項19記載のパターン認識方法。
【請求項21】
前記テンプレートモデル生成ステップでは、
逐次的に入力パターンを追加して入力するときに、当該逐次的に追加される入力パターンの属するクラスに対応する前記テンプレートモデルについて、当該テンプレートモデルにおける状態の出力分布を前記逐次的に追加される入力パターンに応じて更新する
ことを特徴とする請求項14記載のパターン認識方法。
【請求項22】
DPマッチング法を用いて前記マッチング処理を行う
ことを特徴とする請求項14乃至19記載のパターン認識方法。
【請求項23】
前記自己増殖型ニューラルネットワークは、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードと2番目に近い重みベクトルを持つノードの間に辺を接続したとき、
注目するノードと他のノード間の距離に基づいて算出される当該注目するノードの類似度閾値、及び前記入力ベクトルと当該注目するノード間の距離に基づいて、前記入力ベクトルをノードとして挿入するクラス間ノード挿入ステップと、
前記入力ベクトルに最も近いノードに対応する重みベクトル及び当該ノードと辺によって直接的に接続されるノードに対応する重みベクトルをそれぞれ前記入力ベクトルに更に近づけるように更新する重みベクトル更新ステップとを有する
ことを特徴とする請求項14記載のパターン認識方法。
【請求項24】
前記クラス間ノード挿入ステップは、
入力される前記入力ベクトルに最も近い重みベクトルを持つノードを第1勝者ノードとし、2番目に近い重みベクトルを持つノードを第2勝者ノードとし、当該第1勝者ノード及び当該第2勝者ノードの間に辺を接続したとき、
注目するノードについて、当該注目するノードと辺によって直接的に接続されるノードが存在する場合には、当該直接的に接続されるノードのうち当該注目するノードからの距離が最大であるノード間の距離を前記類似度閾値とし、当該注目するノードと辺によって直接的に接続されるノードが存在しない場合には、当該注目するノードからの距離が最小であるノード間の距離を前記類似度閾値として算出する類似度閾値算出ステップと、
前記入力ベクトルと前記第1勝者ノード間の距離が当該第1勝者ノードの類似度閾値より大きいか否か、及び、前記入力ベクトルと前記第2勝者ノード間の距離が当該第2勝者ノードの類似度閾値より大きいか否かを判定する類似度閾値判定ステップと、
類似度閾値判定結果に基づいて、前記入力ベクトルをノードとして当該入力ベクトルと同じ位置に挿入するノード挿入ステップとを有する
ことを特徴とする請求項23記載のパターン認識方法。
【請求項25】
前記自己増殖型ニューラルネットワークは、
前記辺に対応付けられる辺の年齢に基づいて、当該辺を削除する辺削除ステップと、
注目するノードについて、当該注目するノードに直接的に接続される辺の本数に基づいて、当該注目するノードを削除するノード削除ステップとを更に有する
ことを特徴とする請求項23記載のパターン認識方法。
【請求項26】
前記自己増殖型ニューラルネットワークは1層構造である
ことを特徴とする請求項14記載のパターン認識方法。
【請求項27】
請求項14乃至26いずれか1項記載のパターン認識処理をコンピュータに実行させることを特徴とするプログラム。
【図1】

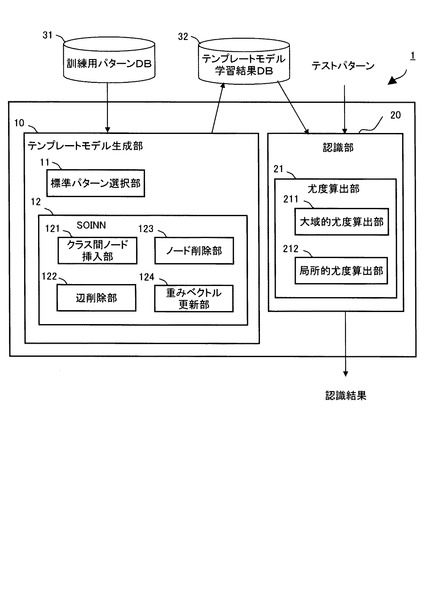
【図2】
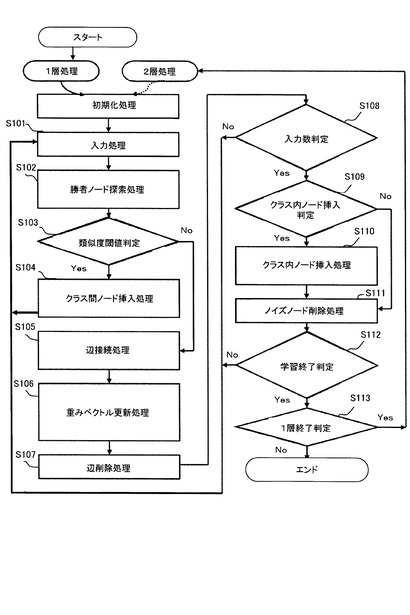
【図5】
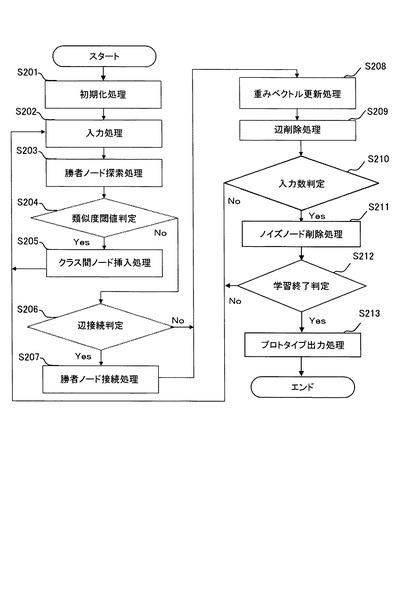
【図6】
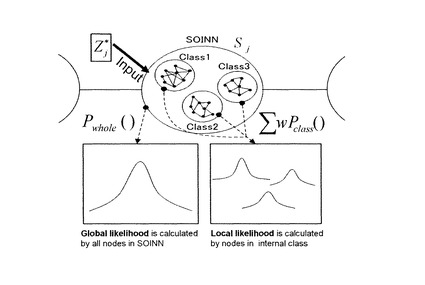
【図7】
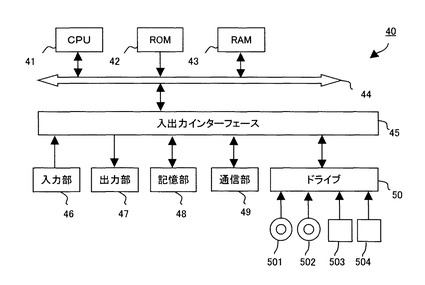
【図8】
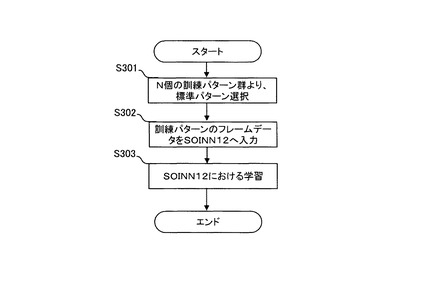
【図9】
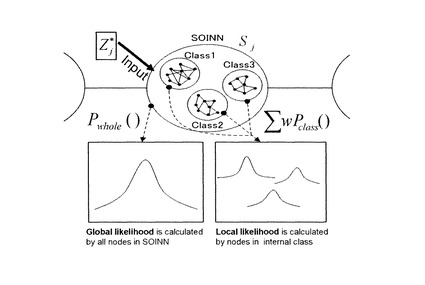
【図10】
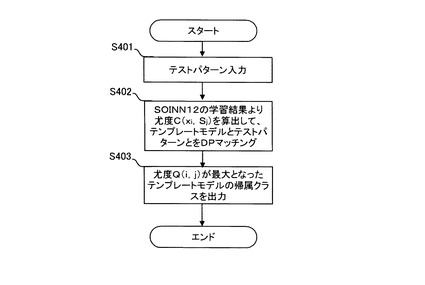
【図11】

【図12】
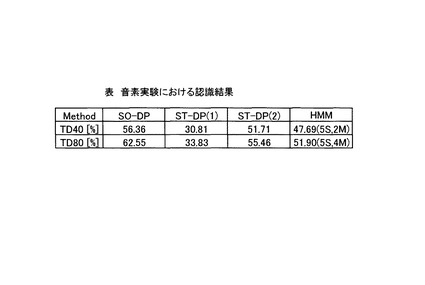
【図14】

【図15】
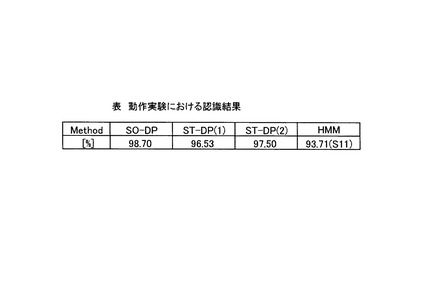
【図17】
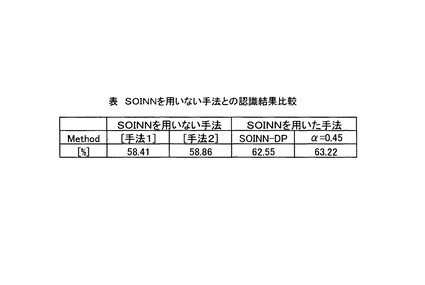
【図20】
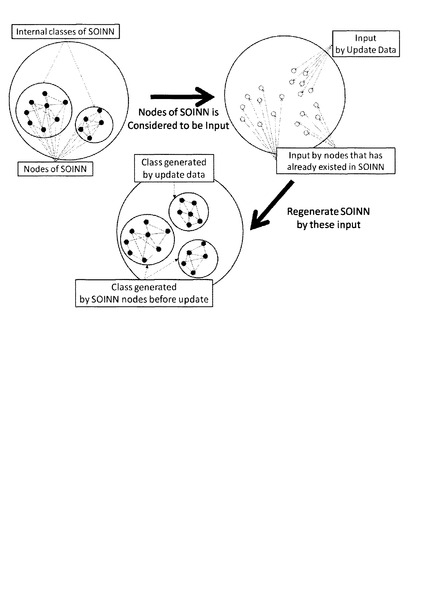
【図21】
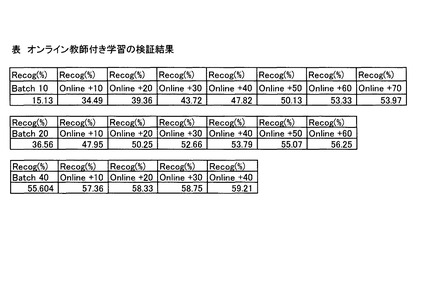
【図22】
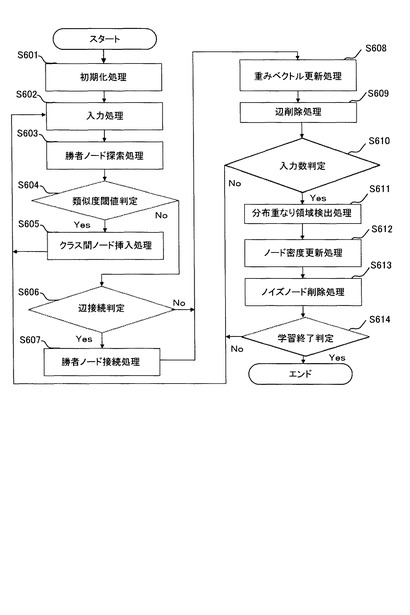
【図3】

【図4】

【図13】
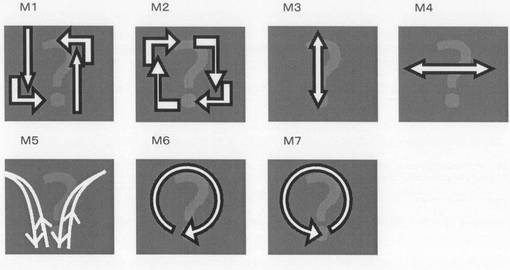
【図16】
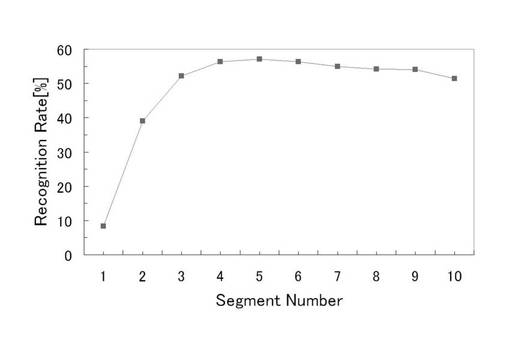
【図18】
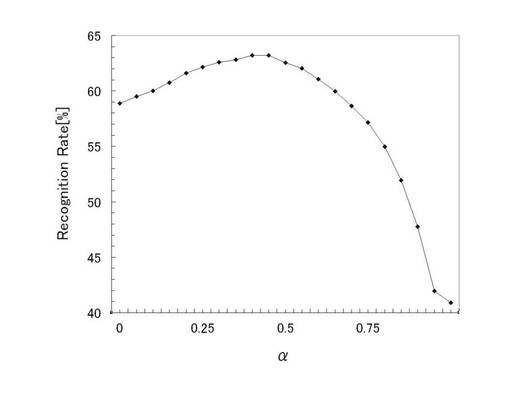
【図19】
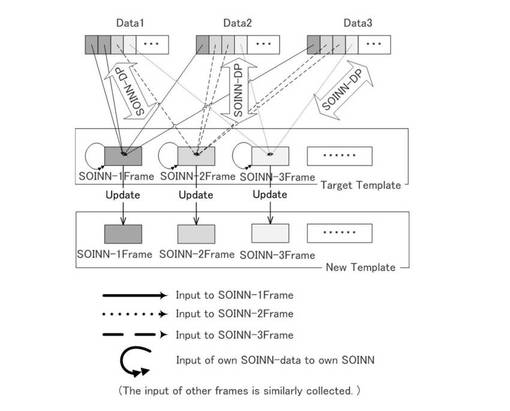
【図2】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図14】
【図15】
【図17】
【図20】
【図21】
【図22】
【図3】
【図4】
【図13】
【図16】
【図18】
【図19】
【公開番号】特開2008−299640(P2008−299640A)
【公開日】平成20年12月11日(2008.12.11)
【国際特許分類】
【出願番号】特願2007−145601(P2007−145601)
【出願日】平成19年5月31日(2007.5.31)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
【公開日】平成20年12月11日(2008.12.11)
【国際特許分類】
【出願日】平成19年5月31日(2007.5.31)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
[ Back to top ]