
ヒトニーマンピックC1様1遺伝子(NPC1L1)多型及びその使用方法
本発明は、ニーマンピックC1様1(NPC1L1)遺伝子中の一塩基多型及びハプロタイプの同定及び使用に関する。特に、NPC1L1多型及びハプロタイプを、ヒト対象に投与される医薬として活性な化合物の応答性と相関させるための方法が提供される。本発明は、さらに、ヒト対象に投与された医薬として活性な化合物の応答性を推測する方法に関し、本方法は、NPC1L1遺伝子中の少なくとも1つの多型を決定することを含む。本発明は、さらに、本明細書に規定されている多型をそれらの配列中に含む単離された核酸に、このような核酸にハイブリダイズすることが可能な核酸プライマー及びオリゴヌクレオチドプローブに、並びにNPC1L1遺伝子中の多型を検出するためのこのようなプライマー及びプローブの1つ又はそれ以上を含む診断キットに関する。

【発明の詳細な説明】
【技術分野】
【0001】
本願は、2005年3月30日に出願された米国仮特許出願06/667,047号及び2005年9月14日に出願された米国仮特許出願60/717,465号の優先権を主張し、これらの各々は、参照により、その全体が本明細書中に組み込まれる。
【背景技術】
【0002】
薬理遺伝学は、薬物代謝及び薬物応答の変動における遺伝学の役割の研究である。薬理遺伝学は、特定の薬剤を用いた治療法に患者が最も適していることを明らかにするのに役立つ。このアプローチは、薬物選択プロセスを補助するための薬学的研究において使用することが可能であり、臨床試験に参加するための患者を選択するのに役立ち得る。薬理遺伝学及び多型検出のその他の使用に関する詳細は、「Linder et al.,(1997) Clinical Chemistry,43:254;Marshall(1997) Nature Biotechnology,15:1249;PCT特許出願WO 97/40462,Spectra Biomedical;and Schafer et al.,(1998) Nature Biotechnology 16:33」に見出すことができる。
【0003】
さらに、DNA挿入、欠失、重複及びヌクレオチド置換から生じる2000を上回るヒトの病理的症候群において、多型が関与するものと考えられている。個体中に遺伝的多型を見出し、これらの変動を家族内で追跡することは、臨床診断を確認し、保有者並びに前臨床及び無症候性の個体における素因及び病状をともに診断するための手段となる。さらに、別の治療的処置に比べて、ある治療的処置に対してより大きな反応性を示し得る個体を特定するために、遺伝的な多型を使用し得る。
【0004】
表現型と関連する多型を特定することは困難である。遺伝子内に複数の対立遺伝子が存在するのが一般的であるので、疾病に関連する対立遺伝子を、中立的な(非疾病関連)多型と区別しなければならない。多くの対立遺伝子は、識別不能で、通常活性な遺伝子産物を産生するか、又は眼の色のように通常可変的な特徴を発現する中立的多型である。これに対して、一部の多型対立遺伝子は、鎌型赤血球貧血などの臨床的疾病と関連している。さらに、疾病に関連する多型の構造は極めて可変的であり、鎌型赤血球貧血症で見られるように単一の点変異に起因し得るか、又は脆弱性X症候群及びハンチントン舞踏病で見られるようにヌクレオチド反復の伸長に起因し得る。
【0005】
先進国における主要な死因である血管系疾患の発症をもたらす因子は、上昇した血清コレステロールである。20歳〜74歳のアメリカ人の19%が高血清コレステロールを有すると推定されている。血管系疾患の最も多い形態は、動脈壁の肥厚と硬化を伴う症状である、動脈硬化症である。巨大な血管の動脈硬化症は、アテローム性硬化症と呼ばれている。アテローム性硬化症は、冠動脈疾患、大動脈瘤、下肢の動脈疾患及び脳血管疾患など、血管系疾患の基礎を為す主な要因である。
【0006】
コレステロールエステルは、アテローム性硬化症の病変の主な構成要素であり、動脈壁細胞中でのコレステロールの主な貯蔵形態である。コレステロールエステルの形成は、食物コレステロールの腸吸収における段階でもある。従って、コレステロールエステル形成の阻害及び血清コレステロールの低減の阻害によって、アテローム性硬化症の病変形成の進行を阻害し、動脈壁中へのコレステロールエステルの蓄積を減少させ、食物コレステロールの腸吸収を遮断することができる。
【0007】
哺乳類及び動物における全身コレステロール恒常性の制御は、腸コレステロール吸収、細胞のコレステロール輸送、食物コレステロールの制御及びコレステロール生合成、胆汁酸生合成、ステロイド合成の調節及びコレステロール含有血漿リポタンパク質の異化を含む。腸コレステロール吸収の制御は、血清コレステロールレベルを制御するための有効な手段であることが明らかとなっている。例えば、コレステロール吸収阻害剤であるエゼチミブは、これに関して有効であることが示されている(Kropp et al.,(2002) Int.J.Clin.Pract.57:363−8)。
【0008】
最近、ニーマンピックC1様1(NPC1L1)遺伝子は、タンパク質であって、コレステロール薬エゼチミブ(ZETIA(R))が、このタンパク質を通じてコレステロールの腸吸収を遮断するように作用するようなタンパク質をコードすると同定された(Altmann,et al.,(2004) Science,303:1201−04;and Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。エゼチミブは、単独療法及びシンバスタチン(ZOCOR(R))などのスタチンとの組み合わせの両方において、LDLコレステロール(LDL−C)を低下させる上で有効である。
【0009】
NPC1L1は、形質膜輸送シグナルのためのトランスゴルジネットワークとして機能する4アミノ酸モチーフを含むNグリコシル化されたタンパク質である(Bos,et al.,(1993) EMBO J.12:2219−28;Humphrey,et al.,(1993) J.Cell.Biol.120:1123−35;Ponnambalam,et al.,(1994) J.Cell.Biol.125:253−268 and Rothman,et al.,(1996) Science 272:227−34参照)。NPC1L1タンパク質は、組織分布が限定されており、胃腸内に豊富に存在する。また、ヒトNPC1L1プロモーター領域は、ステロール制御要素結合タンパク質1(SREBP1;Sterol Regulated Element Binding Protein 1)結合コンセンサス配列を含む(Athanikar,et al.,(1998) Proc.Natl.Acad.Sci.USA 95:4935−40;Ericsson,et al.,(1996) Proc.Natl.Acad.Sci.93:945−50;Metherall,et al.,(1989) J.Biol.Chem.264:15634−41;Smith,et al.,(1990) J.Biol.Chem.265:2306−10;Bennett,et al.,(1999) J.Biol.Chem.274:13025−32 and Brown,et al.,(1997) Cell 89:331−40)。NPC1L1は、ニーマンピックC1病の原因となる受容体であるヒトNPC1に対して42%のアミノ酸配列相同性を有する(Genbank Accession No.AF002020)(Carstea,et al.,(1997) Science 277:228−31)。
【0010】
ニーマンピック病C型は、ヒトの稀な遺伝病であり、リソゾーム中に低密度リポタンパク質(LDL)由来非エステル化コレステロールの蓄積をもたらす(Pentchev,et al.,(1994) Biochim.Biophys.Acta.1225:235−43 and Vanier,et al.,(1991) Biochim.Biophys.Acta.1096:328−37)。さらに、コレステロールは、NPC1を欠く細胞のトランスゴルジネットワーク中に蓄積し、形質膜へのコレステロールの再配置及び形質膜からの再配置が遅延する。NPC1及びNPC1L1は、それぞれ、13個の膜貫通セグメントと、ステロール感知ドメイン(SSD;sterol−sensing domain)を有する。HMG−CoA還元酵素(HMG−R)、パッチ化された(PTC)及びステロール制御要素結合タンパク質切断活性化タンパク質(SCAP)など幾つかの他のタンパク質は、おそらくは、直接のコレステロール結合を伴う機序によって、コレステロールレベルの感知に関与するSSDを含む(Gil,et al.,(1985) Cell 41:249−58;Kumagai,et al.,(1995) J.Biol.Chem.270:19107−13 and Hua,et al.,(1996) Cell 87:415−26)。NPC1L1タンパク質は、ニーマンピックC1型(NPC1)に対する相同性の高い程度並びに3−ヒドロキシ−3−メチルグルタリルコエンザイムA還元酵素(HMGR)及びステロール制御要素結合タンパク質切断活性化タンパク質(SCAP)のステロール感知ドメイン(SSD)に対して相同性を有するステロール感知ドメイン(SSD)の候補など、コレステロール輸送における役割と合致する多くの特性を有する。しかしながら、NPC1及びNPC1L1は、それらの標的誘導シグナルの候補が著しく異なっており、異なる細胞局在化を示唆する(Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。
【0011】
NPC1L1は、相対的に低いレベルで発現されているが、一般的には、多数のヒト組織及び細胞株にわたって発現されており、小腸内に豊富に存在し、インシチュハイブリダイゼーションによって示されるように、腸細胞に限定されている(Altmann et al.,(2004) Science,303:1201−04)。NPC1L1発現の最高レベルは、コレステロール吸収の主要な部位でもある近位空腸内に観察されている。さらに、最近の研究によって、外来胆汁酸塩による食事的補充による救済を受けていないか、又はコレステロール吸収阻害剤であるエゼチミブを用いた治療を経て、さらに低減されている野生型と比べて、NPC1L1−ヌル(−/−)マウスが、食事性コレステロール吸収の69%の低下を示すことが示されている(Altmann et al.,(2004),303:1201−04)。従って、NPC1L1は、腸コレステロールの吸収に重要な役割を果たしており、エゼチミブ感受性経路内に存在するようである。
【0012】
幾つかの臨床研究は、LDL−Cを低下させる上でのエゼチミブ単独療法の効果を示している(Knopp,et al.,(2003) Int.J.Clin.Pract.57:363−8;Knopp,et al.,(2003) Eur.Heart J.24:729−41)。エゼチミブ10mg/日の単独療法において、18−19%の平均的減少が観察され(Ezzet,et al.,(2001) J.Clin.Pharmaco.,41:943−9)、エゼチミブ同時投与又はスタチンに対する追加的治療においても、同様の減少が見られる(Davidson,et al.,(2002) J.Am.Coll.Cardiol.40:2125−34;Pearson,et al.,(2005) Mayo Clinic Proceedings,80:587−95)。その薬理学的作用機序と合致して、ヒトでの研究は、エゼチミブによって媒介される血漿LDL−Cの減少は、腸コレステロール吸収の阻害に起因することを示唆している(Sudhop and von Bergmann(2002) Drugs,62:2333−47)。興味深いことに、基底時及びエゼチミブ処理後の両者において、腸吸収及びLDL−C減少の速度に対して、著しい個体間のばらつきが観察されている。
【0013】
ヒトの健康におけるコレステロール管理の重要な役割のために、1つ又はそれ以上の薬物応答と関連する多型及びハプロタイプなどの遺伝的要素は、健康管理の意思決定を行う上で有用である。ヒト対象に投与される医薬として活性な化合物、例えばNPC1L1アンタゴニストの応答性を推定するためにNPC1L1遺伝子中の多型及びハプロタイプを使用できることが、ここに見出された。
【0014】
ヒトNPC1L1遺伝子は染色体7p13にマッピングされ、約29kbに及び、20個のエキソンを含有する(Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。ヒトNPC1L1遺伝子に対する基準配列が、配列番号1に列記されている。ヒトNPC1L1遺伝子中の多数の一塩基多型(SNP)が報告されている(例えば、国立バイオテクノロジー情報センターによって管理されている一塩基多型データベース(dpSNP)を参照。)。しかしながら、これらのSNPのうち僅か数個が、10%を超える報告された非主要対立遺伝子頻度(MAF;minor allele frequency)を有するに過ぎない。
【0015】
最近の報告は、エゼチミブに対して応答しない8人(すなわち、LDLコレステロールの変化が、6%の減少から10%の増加までの範囲)及びエゼチミブに応答した6人のNPC1L1遺伝子のエキソン及びイントロン−エキソン境界の多型について調べた研究を記載している(Wang J.et al.,(Feb.2005)Clin.Genet.67(2):175−177)。本報告は、応答しなかった8人のうち1人が、6人の対照被験者者中には存在しない2つの稀なNPC1L1多型について複合ヘテロ接合であることを記述しているが、他の非応答者の何れかに、何れかの多型が検出されたかどうかについては記述していない。1つの多型は、55位のアミノ酸バリンのロイシンへの置換(V55L)をもたらすエキソン2中のG219Tであり、他の多型は、1233位のアミノ酸イソロイシンのアスパラギンへの置換(I1223N)をもたらすエキソン18中のT3754Aであった。このデータに対する多くの可能な説明の1つは、エゼチミブ応答とNPC1L1変動との間に関係が存在する可能性があると、著者らは述べている。しかしながら、著者らは、13個の他のNPC1L1多型の非主要対立遺伝子頻度は、非応答者中にのみ見られる6つのSNPも含み、応答者と非応答者の間で統計的に有意に異ならないことも報告した。従って、エゼチミブに対する増加した応答とNPC1L1遺伝子の何れの一般的な対立遺伝子(>5%の頻度)との間に首尾よく相関を同定できることを、当業者はこの参考文献から予想できなかったと思われる。
【発明の開示】
【0016】
本発明は、NPC1L1アンタゴニストに対する増加した応答に関連するSNP及びハプロタイプに関する。本発明の多型を有する患者は、例えば、血清低密度リポタンパク質コレステロールレベルの平均的な低下の増加によって示されるように、本発明の多型を有しない個体に比べて、NPC1L1アンタゴニストに対して平均より高い応答を示す。さらに、NPC1L1SNPは、上昇したLDL−Cの増加したリスクと関連することが明らかとされた。増加したLDL−Cの低下と関連するSNP及びハプロタイプは、スタチン化合物が与えられた患者とスタチン+エゼチミブが与えられた患者の遺伝子型を調べることによって特定された。検査された患者の集団は、スタチンのみによっては、LDL−Cの推奨レベルを満たしていなかった。エゼチミブは、治療を受けた患者全員に、LDL−Cの低下をもたらしたが、エゼチミブによるLDL−Cの低下は、患者の異なる群において異なっていた。異なる患者の遺伝子型分析を通じて、エゼチミブに対する増加した応答に関連するSNP及びハプロタイプが特定された。
【0017】
NPC1L1アンタゴニストによるLDL−C低下の増加に関連する前記特定されたSNP及びハプロタイプは、化合物に対して応答性の患者(すなわち、ヒト)の程度についての指標を与える上で特に有用である。本指標は、ある治療の結果の予測を補助するために、医師によって使用することが可能である。さらに、本明細書に記載されているNPC1L1マーカーの表現型効果は、診断方法及びキット;NPC1L1アンタゴニストに対する応答に関連するNPC1L1マーカーに対する患者の検査が陽性又は陰性であるかに基づいて、患者の薬物治療を個別的に適合化することを含む薬理遺伝学的治療方法;薬物開発及び販売、並びに薬理遺伝学的薬品を含む(但し、これらに限定されない。)、様々な方法及び製品において、これらのマーカーを使用することの土台となっている。
【0018】
一態様において、本発明は、NPC1L1遺伝子中の一塩基多型及びハプロタイプを、ヒト対象に対して投与された医薬として活性な化合物の活性と相関させる方法を提供する。本方法は、NPC1L1遺伝子中の一塩基多型又はハプロタイプに対する参照によって、ヒト対象のNPC1L1遺伝子中の一塩基多型又はハプロタイプを、医薬として活性な活性化合物が投与された前記ヒト対象の状態と関連付けることを含む。幾つかの実施形態において、対象の状態は、化合物の投与前及び投与後に、例えば、低密度リポタンパク質コレステロール(LDL−C)、総コレステロール、非高密度リポタンパク質コレステロール(非HDL−C)及びアポリポタンパク質Bなど、血漿成分レベルを測定することによって決定される。特定の実施形態において、血漿成分がLDL−Cであり、及び化合物活性が、化合物の投与前の対象における血漿LDL−Cのレベルに比した、対象中の血漿LDL−Cの低下である。他の実施形態において、一塩基多型は、g.−133A>G、g.−18C>A、g.l679C>G及びg.28650A>Gからなる群から選択される。さらに別の実施形態において、一塩基多型はg.−18C>A又はg.1679C>Gであり、及び化合物はコレステロール吸収を阻害する。別の実施形態において、ハプロタイプは[A(−133)、A(−18)、G(1679)]又は[G(−133)、C(−18)、C(1679)]であり、化合物がエゼチミブである。本発明は、さらに、NPC1L1多型g.−133A>G、g.−18C>A又はg.28650A>Gの少なくとも1つを、それらの配列内に含む単離された核酸に関する。本発明は、このような核酸にハイブリダイズすることができる核酸プライマー及びオリゴヌクレオチドプローブ並びにNPC1L1遺伝子中のこのような多型を検出するために、このようなプライマー及びプローブの1つ又はそれ以上を含む診断キットも含む。例えば、1つのこのような実施形態は、配列番号1の少なくとも12個の連続するヌクレオチド又はその相補物からなる単離されたポリヌクレオチドを含み、ここにおいて、前記ポリヌクレオチドは、配列番号1のヌクレオチド位置5,285にアデニン塩基を有する一塩基多型を含む。別の実施形態において、単離されたポリヌクレオチドは、配列番号1のヌクレオチド位置5,400にアデニン塩基を有する一塩基多型を含む。さらに別の実施形態において、単離されたポリヌクレオチドは、配列番号1のヌクレオチド位置34,067にグアニン塩基を有する一塩基多型を含む。
【0019】
本発明の別の態様は、対象が、NPC1L1アンタゴニストに対するヒトの平均より高い反応と関連する遺伝子型を有するかどうかを決定する方法を提供する。本方法は、対象が、多型g.−18C>A若しくはg.1679C>Gに対してヘテロ接合若しくはホモ接合であるかどうか、又はハプロタイプ[A(−133)、A(−18)、G(1679)]に対してヘテロ接合若しくはホモ接合であるかどうかを決定する工程を含み、ここにおいて、前記多型又はハプロタイプの一方又は両方の何れかのヘテロ接合又はホモ接合形態の存在は、対象が、NPC1L1アンタゴニストに対する、ヒトにおける平均応答より高い応答に関連する遺伝子型を有することを示す。
【0020】
対象は、多型若しくはハプロタイプが少なくとも1つの対立遺伝子上に存在するかを決定するかによって、又は多型若しくはハプロタイプを含有する対立遺伝子の数を決定するかによって、特定の多型又はハプロタイプに対してヘテロ接合又はホモ接合であると同定することが可能である。
【0021】
本発明の別の態様は、NPC1L1機能に影響を与える、すなわち、腸コレステロール吸収を阻害する化合物(エゼチミブなど)に対する対象の応答性を推測する方法に関する。本方法は、対象から生物学的試料を取得する工程、及び前記生物学的試料中の配列番号1の位置に存在するヌクレオチド塩基を決定する工程を含み、配列番号1の5,400位にアデノシンヘテロ接合性又はホモ接合性が存在することが、アデノシンヘテロ接合性又はホモ接合性を欠如する個体に比べて、対象が、前記化合物に対して平均応答より高い応答を有する可能性が統計的により高いことを示す。本発明の別の実施形態において、配列番号1の7,096位にグアニンヘテロ接合性又はホモ接合性が存在することが、グアニンヘテロ接合性又はホモ接合性を欠如する個体に比べて、対象が化合物に対して平均応答性より高い応答性を有する可能性が統計的により高いことを示す。本発明の別の実施形態において、ハプロタイプ[A(−133)、A(−18)、G(1679)]ヘテロ接合性又はホモ接合性が存在することが、[A(−133)、A(−18)、G(1679)]ハプロタイプを欠如する個体に比べて、対象が化合物に対して平均応答性より高い応答性を有する可能性が統計的により高いことを示す。
【0022】
本発明の別の態様は、ヒト対象中の血漿コレステロールの健康リスクレベルに対する素因を検出する方法を提供する。本方法は、ヒト対象において、ヒトNPC1L1対立遺伝子のゲノム配列中の多型の存在又は不存在を検出することを含み、ここにおいて、ヒトNPC1L1対立遺伝子は配列番号1の34,067位のグアニンからなる。グアニンの存在は、対象中の血漿コレステロールの健康リスクレベルに対する素因の指標である。
【0023】
本発明の方法には、上記多型及びハプロタイプの何れかの中に存在するヌクレオチド塩基の決定を可能とする全てのアッセイが含まれる。典型的なアッセイには、直接的なヌクレオチド配列分析、DNAマイクロアレイ分析を含む識別的核酸ハイブリダイゼーション分析、制限断片長多型分析及びポリメラーゼ連鎖反応分析が含まれるが、これらに限定されない。
【0024】
本発明の別の態様は、患者中のコレステロールを低下させる方法を提供する。本方法は、NPC1L1アンタゴニストの有効量を患者に投与する工程を含み、ここにおいて、前記患者は、g.−18C>A及びg.1679C>Gからなる群から選択されるSNPを有するものと同定される。別の実施形態において、患者は、[A(−133)、A(−18)、G(1679)]ハプロタイプを有するとして同定される。
【0025】
本発明の別の態様は、診断キットであり、配列番号1の5,285位、5,400位、7,096位及び34,067位の1つ又はそれ以上におけるNPC1L1遺伝子中の多型を検出可能な少なくとも1つの対立遺伝子特異的核酸プライマーと、並びに核酸に対して特異的にハイブリダイズ可能な、NPC1L1遺伝子中の多型を検出するためのオリゴヌクレオチドプローブとを含み、NPC1L1遺伝子中のヌクレオチド多型が、配列番号1中の5,285位のA又はG、配列番号1中の5,400位のC又はA、配列番号1中の7,096位のC又はG、及び配列番号1中の34,067位のA又はG及びこれらの組み合わせ並びにこれらの逆相補物の少なくとも1つから選択される、前記診断キットを提供する。
【発明を実施するための最良の形態】
【0026】
この節は、本発明の詳細な説明とその応用を記す。この説明は、詳細さと具体性が増加した、本発明の一般的な方法の幾つかの典型的な例示によってなされる。これらの例は非限定的なものであり、当業者に自明な関連する変形例は、添付の特許請求の範囲によって包含されるものとする。また、本明細書及び添付の特許請求の範囲で使用されている単数形(「a」、「an」及び「the」)には、文脈から別段の意味であることが明らかである場合を除き、複数表記も含まれる。従って、例えば、「複合体」という表記は、このような複合体の複数を含み、「製剤」という表記は、当業者に公知の1つ又はそれ以上の製剤及びそれらの均等物という表記が含まれる。
【0027】
I.定義
別段の定義がなければ、本明細書に使用されている全ての技術的及び科学的用語は、本発明が属する分野の当業者が一般的に理解する意味を有する。
【0028】
本明細書において使用される[A(−133)、A(−18)、G(1679)]は、配列番号1の5,285に対応するヌクレオチド位置のアデニン塩基、配列番号1の5,400に対応するヌクレオチド位置のアデニン塩基及び配列番号1の7,096に対応するヌクレオチド位置のグアニン塩基から構成されるNPC1L1ハプロタイプを表す。「対応する」という表記は、配列番号1に関する、ハプロタイプ中の各多型の位置を示す。幾つかの文脈において、[A(−133)、A(−18)、G(1679)]という表記は、NPC1L1遺伝子の2つ又はそれ以上のハプロタイプ対立遺伝子上に存在し得るサブハプロタイプを表すことが明らかである。
【0029】
本明細書において使用される[G(−133)、C(−18)、C(1679)]は、配列番号1の5,285に対応するヌクレオチド位置のグアニン塩基、配列番号1の5,400に対応するヌクレオチド位置のシトシン塩基及び配列番号1の7,096に対応するヌクレオチド位置のシトシン塩基から構成されるハプロタイプを表す。「対応する」という表記は、配列番号1に関する、ハプロタイプ中の各多型の位置を示す。幾つかの文脈において、[G(−133)、C(−18)、C(1679)]という表記は、NPC1L1遺伝子の2つ又はそれ以上のハプロタイプ対立遺伝子上に存在し得るサブハプロタイプを表すことが明らかである。
【0030】
本明細書において使用される「g.−133A>G」は、配列番号1の5,285に対応するヌクレオチド位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの133塩基上流に存在する位置のグアニン塩基を表す。「対応する」という表記は、配列番号1に関する、多型の位置を示す。g.−133−A>G多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0031】
本明細書において使用される「g.−18C>A」は、配列番号1の5,400に対応するヌクレオチド位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの18塩基上流に存在する位置のアデニン塩基を表す。「対応する」という表記は、配列番号1に関する多型の位置を示す。g.−18C>A多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0032】
本明細書において使用される「g.1679C>G」は、配列番号1の7,096に対応するヌクレオチド位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの1679塩基下流に存在する位置のグアニン塩基を表す。「対応する」という表記は、配列番号1に関する多型の位置を示す。g.1679C>G多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0033】
本明細書において使用される「g.28650A>G」は、配列番号1の34,067に対応するヌクレオチド位置のグアニン塩基を表す。「対応する」という表記は、配列番号1に関する多型の位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの28,650塩基下流に位置する多型の位置を示す。g.28650A>G多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0034】
本明細書において使用される「対立遺伝子」は、遺伝子の特定のヌクレオチド配列又はその他の遺伝子座である。対立遺伝子は、1つ若しくはそれ以上のSNP又はNPC1L1遺伝子中の多型部位の特定された組み合わせに対して本明細書中に記載されているハプロタイプの1つを含み得る。7番染色体は常染色体であり、従って、個体中の体細胞は、座に対して2つの対立遺伝子を通常有するので、対立遺伝子という表記には、個体から得られた体細胞中の単一の7番染色体上に存在する座の形態が含まれ得る。同一である2つの対立遺伝子を有する個体は、その座に対してホモ接合である。座に対して2つの異なる対立遺伝子を有する個体は、ヘテロ接合である。
【0035】
本明細書において使用される「NPC1L1アンタゴニスト」には、直接的に又は間接的に、いかなる程度であれ、NPC1L1による食事性コレステロール及び/又は関連する植物ステロールの取り込みを阻害する小分子、タンパク質、抗体又は核酸など(これらに限定されない。)、あらゆる化合物、物質又は因子が含まれる。好ましくは、NPC1L1アンタゴニストは、NPC1L1に結合し、好ましくは、NPC1L1活性を有意に阻害する。「NPC1L1アンタゴニスト」という表記は、特定の作用の様式を意味しない。エゼチミブは、NPC1L1アンタゴニストの例である。
【0036】
本明細書において使用される「遺伝子型」とは、個体中の相同な染色体の対上にある座内の1つ若しくはそれ以上の多型部位のセット内の各多型部位において見出される2つの対立遺伝子の非移相化された(unphased)5’→3’配列(典型的には、ヌクレオチド対)である。
【0037】
本明細書において使用される「遺伝子型決定」とは、個体の遺伝子型を決定するための方法である。
【0038】
本明細書において使用される「ハプロタイプ対」は、単一の個体中の座に対して見出される2つのハプロタイプを表す。
【0039】
本明細書において使用される「ハプロタイプ決定」は、個体中の1つ又はそれ以上のハプロタイプ(PSの特定のセットに対するハプロタイプ対を含む。)を決定するためのあらゆる方法を表し、家系図、分子技術及び/又は統計的な推定の使用が含まれる。
【0040】
本明細書において使用される「増加したエゼチミド(ezetimide)応答」とは、遺伝子型によって規定された患者の群内でのエゼチミド処理によって、異なる遺伝子型を有する患者に比べて、LDL−Cの平均パーセント減少が増加することを表す。エゼチミド処理には、単独療法として、又はLDL−Cを低下させるために使用される少なくとも1つの他の化合物と組み合わせて、エゼチミブ又はNPC1L1アンタゴニストを投与することが含まれる。増加した平均パーセントの減少は、遺伝子型によって規定された異なる群において統計的に有意である。幾つかの実施形態において、個体及び集団は、類似の民族的又は地理的起源を有する。幾つかの実施形態において、治療計画は、10mg/日のエゼチミブでの少なくとも6週の治療及びNPC1L1マーカーを有する群内でのLDL−Cの平均減少は、NPC1L1マーカーを欠如する群内での平均LDL−C減少に比べて、少なくとも15%超上回る。好ましい実施形態において、増加したエゼチミブ応答は、少なくとも、少なくとも27%のLDL−Cの平均減少である。別の特に好ましい実施形態において、NPC1L1プラス及びマイナス群は、エゼチミブに対する極端な応答者(すなわち、そのパーセントLDL−C減少が、エゼチミブの臨床研究において観察される応答分布の上位又は下位10分位に収まる。)である個体のみから構成される。NPC1L1マーカーを有する極端な応答者における好ましい増加されたエゼチミブ応答は、マーカーを欠如する極端な応答者におけるLDL−Cの−17%の変化と比べて、LDL−Cの−34%の変化である。
【0041】
本明細書において使用される「NPC1L1アンタゴニストに対する増加されたLDL−C応答」とは、遺伝子型によって規定された患者群でのNPC1L1アンタゴニスト処理によって、異なる遺伝子型を有する患者に比べて、LDL−Cの平均パーセント減少が増加することをいう。NPC1L1アンタゴニスト処理には、単独療法として、又はLDL−Cを低下させるために使用される少なくとも1つの他の化合物と組み合わせて、NPC1L1アンタゴニストを投与することが含まれる。増加した平均パーセントの減少は、遺伝子型によって規定された異なる群において統計的に有意である。幾つかの実施形態において、個体及び集団は、類似の民族的又は地理的起源を有する。幾つかの実施形態において、治療計画は、NPC1L1アンタゴニストの治療的有効量での少なくとも6週の治療を含み、NPC1L1マーカーを有する群内でのLDL−Cの平均減少は、NPC1L1マーカーを欠如する群内での平均LDL−C減少に比べて、少なくとも15%超上回る。好ましい実施形態において、NPC1L1アンタゴニストに対する増加したLDL−C応答は、少なくとも、少なくとも20%のLDL−Cの平均減少である。別の特に好ましい実施形態において、NPC1L1プラス及びマイナス群は、NPC1L1アンタゴニストに対する極端な応答者(すなわち、そのパーセントLDL−C減少が、NPC1L1アンタゴニストの臨床研究において観察される応答分布の上位又は下位10分位に収まる。)である個体のみから構成される。
【0042】
本明細書において使用される「単離されたポリヌクレオチド」は、自然の状態で見出される同じ配列の何れの核酸分子に対しても同一でない物理的形態で存在する核酸分子である。
【0043】
本明細書において使用される「座」とは、染色体又はDNA分子上での位置を表す。座は、遺伝子又はその一部、表現型と関連する他のゲノム領域、及び特定されたゲノム領域中の単一の多型部位又は多型部位の特異的な組み合わせに対応し得る。
【0044】
臨床的パラメータ(LDL−Cなど)の量に関連して、本明細書において使用される「正常」とは、類似の年齢、体重及び/又は性別の健康な対象で典型的に観察されるパラメータの具体的な数字又は数的範囲を意味し、又は当該分野に従事する臨床医が正常であると理解する前記パラメータの具体的な数字又は数的範囲を意味する。逆に、「異常」とは、正常な数字若しくは正常な数的範囲より低い若しくは高い臨床パラメータに対する具体的な数字若しくは数的範囲を表し、又は当該分野に従事する臨床医が異常であると理解する臨床パラメータに対する具体的な数字若しくは数的範囲を表す。
【0045】
本明細書において使用される「NPC1L1」とは、ヒトニーマンピックC1様1タンパク質(AAR97886)を表す。
【0046】
本明細書において使用される「NPC1L1」とは、NPC1L1をコードするポリヌクレオチドを表す。
【0047】
本明細書において使用される「NPC1L1遺伝子」は、ヒト染色体7p13上に位置する配列番号1中の核酸配列内に存在する配列を表す。NPC1L1遺伝子は、20のエキソン領域と、エキソン配列の間に介在する19のイントロン配列と、並びに配列番号1に示されているNPC1L1遺伝子配列のプロモーター領域を含む、3’及び5’非翻訳領域(3’UTR及び5’UTR)とを含む。最初のインフレームATGはエキソン1中(又は配列番号1中の5,418位)に存在するのに対して、TGA停止コドンはエキソン20中(又は配列番号1中の33,228位)に存在する。
【0048】
本発明に関連して、本明細書において使用される、「NPC1L1マーカー」とは、LDL−Cの健康リスクレベル又は増加されたエゼチミブ応答に関連する特異的な遺伝的バリアントの特異的なコピー数である。好ましいNPC1L1マーカーは、表1に示されているもの、及び表1中の何れかのマーカー中の少なくとも1つのバリアントが代替ハプロタイプ又は連鎖したバリアントの同じコピー数(本明細書において、その各々は、代替遺伝的マーカーと称される。)によって置換されている遺伝的マーカーである。代替ハプロタイプは、表1に示されているハプロタイプの何れかの配列に類似している配列を含むが、当該ハプロタイプ中の特異的に同定された多型部位の1つにおける(但し、全部より少ない)対立遺伝子が、異なる多型部位において、対立遺伝子で置換されており、この代替対立遺伝子は、特異的に同定された多型部位において、前記遺伝子と高い連鎖不均衡(LD)の状態にある。連鎖したバリアントは、表1に示されているバリアントの任意の1つと高いLD状態にあるバリアント(SNP又はハプロタイプを含む。)のあらゆる種類である。同じ染色体上の異なる座に存在する2つの特定の対立遺伝子は、1つの座における対立遺伝子の1つの存在が、他の座における他の対立遺伝子の存在を予測する傾向にあれば、連鎖不均衡状態にあるといわれる。以下でさらに記載されている代替遺伝的マーカーは、インデル、RFLP、反復など、SNP以外の変異の種類を含み得る。
【0049】
本明細書において使用される「ヌクレオチド対」とは、個体から得られた染色体の2つのコピー上の多型部位に見出される2つのヌクレオチドのセット(同一又は別異であり得る。)である。
【0050】
本明細書において「薬理遺伝学的な指標」とは、薬物の適応症とされる疾病の他に、薬物で治療を試みている個体を特定する遺伝的プロファイルを表す。遺伝的プロファイルは、NPC1L1薬物応答マーカーの存在を含む。好ましい実施形態において、遺伝的プロファイルは、LDL−Cの健康リスクレベルに関連するNPC1L1マーカーの存在を含む。
【0051】
本明細書において使用される「移相化された配列」とは、両染色体中の多型部位の同じセットに見出されるヌクレオチド対の配列を表すために通例使用される移相化されていない配列とは異なり、多型部位の組において、単一の染色体上に存在するヌクレオチドの組み合わせを表す。
【0052】
本明細書において使用される「多型部位」又は「PS」とは、SNP又はその他の非ハプロタイプ多型が生じる遺伝子座又は遺伝子中の位置を表す。多型部位には、通常、関心対象の集団中の高度に保存された配列が先行及び後続し、従って、多型部位の位置決定は、通例、多型部位を囲む30〜60個のヌクレオチドのコンセンサス核酸配列を基準として行われ、SNP多型の場合、これは、一般に、「SNPコンテクスト配列」と称される。多型部位の位置は、タンパク質翻訳のための開始コドン(ATG)と比較して、コンセンサス又は基準配列中のその位置によっても特定され得る。当業者は、コンセンサス又は基準配列と比較して、特定の多型部位の位置が、その個体中に1つ又はそれ以上の挿入又は欠失が存在するために、関心対照の集団中の各個体中の参照又はコンテクスト配列中の正確に同じ位置に存在しない場合があり得ることを理解する。さらに、検出されるべき多型部位における代替対立遺伝子の正体及び多型部位が存在する基準配列又はコンテクスト配列の一方又は両方が当業者に提供された場合、当業者は、何れかの個体中の多型部位において代替対立遺伝子を検出するための、強固で、特異的で、及び正確なアッセイを設計するのが通常である。従って、基準配列又はコンテクスト配列中の特定の位置に対する(又は、このような配列中の開始コドンに対する)参照によって、本明細書中に記載されている何れかのPSの位置を特定することは、便宜上のものに過ぎず、具体的に列挙されている全てのヌクレオチド位置は、本明細書に記載されている遺伝子型決定法又は本分野で周知の他の遺伝子型決定法の何れかを用いて、本発明の遺伝的マーカーの存在又は不存在について検査されている何れかの個体中の同じ座の中に同じ多型部位が実際に存在している全てのヌクレオチド位置を文字通り含むことが、当業者によって理解される。
【0053】
本明細書において使用される「多型」は、集団中の遺伝子又は座に対して生じる2つ又はそれ以上の遺伝的に決定された別の配列又は対立遺伝子の出現を表す。ヒト個体は、存在する異なる対立遺伝子に対してホモ接合又はヘテロ接合であり得る。多型の異なる対立遺伝子は、典型的には、選択された集団中に最も頻繁に出現する対立遺伝子(時折、「主要な」又は「野生型」対立遺伝子と表記される。)と異なる頻度で集団中に出現する。二対立遺伝子多型は2つの対立遺伝子を有し、非主要対立遺伝子は、選択された集団中で、1%と2%の間、2%と10%の間、10%と20%の間、20%と30%の間の頻度など、ゼロより大きく、50%未満の何れかの頻度で出現し得る。SNPは、典型的には、二対立遺伝子の多型である。三対立遺伝子多型は、3つの対立遺伝子を有する。好ましくは、多型という用語は、各対立遺伝子が1%、より好ましくは5%を上回る頻度で出現する多型座位を記載するために使用される。多型の種類には、一塩基多型又はSNPなどの、単一の多型部位における配列の変異、及び対象遺伝子又は座中の2つ又はそれ以上の多型部位のセットにおいて、単一の染色体上に出現するヌクレオチドの配列中の変異が含まれる。多型部位の特定のセットに対して出現する各配列は、その座に対する対立遺伝子であり、本明細書では、ハプロタイプとも称される。SNP及びハプロタイプに加えて、多型の例には、制限断片長多型(RFLP)、タンデムリピートの可変数(VNTR)、二ヌクレオチドリピート、三ヌクレオチドリピート、四ヌクレオチドリピート、単純配列リピート、Aluなどの挿入要素及び1つ又はそれ以上のヌクレオチドの欠失が含まれる。
【0054】
本明細書において使用される「精製された核酸」は、試料又は調製物中に存在する総核酸の少なくとも10%を表す。好ましい実施形態において、精製された核酸は、単離された核酸試料又は調製物中の総核酸の少なくとも約50%、少なくとも約75%又は少なくとも約95%を表す。「精製された核酸」という表記は、核酸が何れかの精製を経ていることを要求せず、例えば、精製されていない、化学的に合成された核酸を含み得る。
【0055】
本明細書において使用される「ポリヌクレオチド」及び「核酸」とは、ヌクレオチド塩基A(アデニン)、T(チミン)、C(シトシン)及びG(グアニン)から構成されるDNAであり得、又は塩基A、(ウラシル)(Tに対する代替物)、C及びGから構成されるRNAであり得る一本鎖又は二本鎖分子を表す。ポリヌクレオチドは、コード鎖又はその相補物を表し得る。タンパク質をコードするポリヌクレオチド分子又は核酸は、天然に存在する配列に対して、配列が同一であり得るか、又は、天然に存在する配列中で見出されるもののように、同じアミノ酸をコードする別のコドンを含み得る(Lewin “Genes V” Oxford University Press Chapter 7,1994,171−174を参照。)。さらに、このようなコード分子は、記載されているアミノ酸の保存的置換を表すコドンを含み得る。例えば、ポリヌクレオチドは、ゲノムDNA、mRNA、cDNA、プライマー及びプローブを表し得る。
【0056】
本明細書において使用される「治療する」又は「治療している」とは、臨床的に測定可能な任意の程度まで、治療されている患者中の1つ又はそれ以上の疾病症候の退行を誘導し、又は進行を阻害することによって、患者中の1つ又はそれ以上の疾病症候を緩和するために、患者に、体内的に又は体外的に薬物の有効量を投与することを意味する。何らかの特定の疾病症候を緩和するのに有効である薬物の量(「治療的有効量」とも称される。)は、病状、患者の年齢及び重量並びに患者内に所望される応答を惹起する薬物の能力などの要因に応じて変動し得る。疾病症候が緩和されたかどうかは、その症候の重篤度又は進行状態を評価するために、医師又はその他の熟練した医療従事者によって典型的に使用される何れかの臨床的測定によって評価することが可能である。本発明の実施形態(例えば、治療方法又は製品)は、全ての患者で、目標とする疾病症候を緩和する上では効果的でない場合があり得るが、スチューデントのt検定、χ2乗検定、マン及びホイットニーによるU検定、クルスカル−ウォリス検定(H検定)、ヨンクヒール−タプストラ検定及びウィルコクソン検定など、本分野において公知の何れかの統計学的検定によって測定した場合に、患者の統計的に有意な数において、標的疾病症候を緩和すべきである。
【0057】
II.本発明のNPCDL1マーカーの組成及び表現型効果
上述及び以下の実施例のように、本発明のNPC1L1マーカーは、NPC1L1マーカーが存在する個体によって示される可能性がある特定の表現型、すなわち、LDL−Cの健康リスクレベル又はエゼチミブに対する増加された平均応答の何れかを予測する。本発明の各NPC1L1マーカーは、これらの表現型の1つと関連する特定の対立遺伝子とこの対立遺伝子のコピー数の組み合わせである。
【0058】
表1は、本発明の好ましいNPC1L1マーカーを列記する。NPC1L1マーカー1(例えば、34067Gの少なくとも1コピー)を有する個体は、NPC1L1マーカー1を欠如する(例えば、34067Gのゼロコピー)個体より、LDL−Cの健康リスクレベルを有する可能性がより高い。少なくとも1コピーのNPC1L1マーカー2、3、4又は5を有する個体は、それぞれ、NPC1L1マーカー2、3、4又は5を欠如する個体のエゼチミブ応答に比べて、増加したエゼチミブ応答を示す可能性が高い。
【0059】
【表1】
【0060】
これらのNPC1L1マーカーを含む多型部位は、NPC1L1遺伝子座中の、上記定義及び配列番号1に特定されている位置に対応する位置に存在する。本発明のマーカー中の多型部位を記載する際には、便宜上、遺伝子のセンス鎖を基準とする。しかしながら、当業者であれば認識できるように、NPC1L1遺伝子を含有する核酸分子は相補的な二本鎖分子であり得るので、センス鎖上の特定の部位に対する参照は、相補的なアンチセンス鎖上の対応する部位への参照でもある。
【0061】
さらに、当業者は、本明細書に記載されている本発明の実施形態の全ては、表1中の遺伝子マーカーの何れかに対する代替遺伝的マーカーを用いて実施され得ることを理解する。代替ハプロタイプを含む代替遺伝的マーカーは、表1中のマーカーの1つ中の多型部位における対立遺伝子と、NPC1L1遺伝子中又は7番染色体上の別の場所に位置する多型部位における候補代替対立遺伝子との間の連鎖不均衡(LD)の程度を決定することによって容易に同定される。同様に、連鎖バリアントを含む代替遺伝的マーカーは、表1中のハプロタイプとNPC1L1中の他の場所に存在する候補連鎖バリアントとの間の連鎖不均衡の程度を決定することによって容易に同定される。候補代替対立遺伝子又は連鎖バリアントは、現在公知である多型の対立遺伝子であり得る。他の候補代替対立遺伝子及び連鎖バリアントは、多型を発見するために本分野で周知の何らかの技術を用いて、当業者によって容易に同定され得る。
【0062】
表1中の遺伝的マーカーと候補代替マーカーとの間のLDの程度は、本分野で公知のあらゆるLD測定を用いて決定され得る。ゲノム領域中のLDパターンは、いずれかの2つの対立遺伝子(例えば、異なる多型部位におけるSNPの間、又は2つのハプロタイプの間)が連鎖不均衡にあるかどうかを決定するための、本分野で公知の様々な技術を用いて、適切に選択された試料中において、容易に経験的に決定される(例えば、GENETIC DATA ANALYSIS II,Weir,Sineuer Associates,Inc.Publisher,sSunderland,MA 1996)。当業者は、LDを測定する何れの方法が、特定の試料サイズ及びゲノム領域に対して最適であるかを容易に選択し得る。
【0063】
連鎖不均衡の最も頻繁に使用される指標の1つは、Devlinら(Genomics,29(2):311−22(1995))によって記載された式を用いて計算されるΔ2である。Δ2は、第一の座における対立遺伝子Xが、同じ染色体上の第二の座における対立遺伝子Yの出現をどれほど上手く予測できるかという指標である。本指標は、予測が完璧である場合にのみ1.0に達する(例えば、Xの時かつXの時に限りY)。
【0064】
好ましい代替遺伝的マーカーにおいて、代替対立遺伝子又は連鎖バリアントの座は、NPC1L1遺伝子を貫く約100キロ塩基のゲノム領域中にあり、より好ましくは、座はNPC1L1遺伝子中にある。他の好ましい代替遺伝的マーカーは、関連する対立遺伝子間の(例えば、代替SNP及び代替されたSNPとの間の、又はマーカー中の連鎖バリアントとハプロタイプとの間の)LDが適切な参照集団中で測定された場合に、少なくとも0.75、より好ましくは少なくとも0.80、より好ましくは少なくとも0.85又は少なくとも0.90、さらに好ましくは少なくとも0.95、最も好ましくは1.0のΔ2値を有する。このΔ2の測定のために使用される参照集団は、好ましくは、NPC1L1アンタゴニストを含有する薬物で治療されるべき患者の集団の遺伝的多様性を反映する。例えば、参照集団は、一般的な集団、薬物を使用している集団、薬物の効力が示されている特定の症状(高コレステロール血症など)を有すると診断された集団又は類似の民族的背景の集団であり得る。
【0065】
本明細書に記載されている本発明の実施形態の全てにおいて、当業者であれば、表1中の対立遺伝子と代替マーカーとの間に完全な連鎖不均衡が存在する場合に、表1中の特定のNPC1L1マーカーが個体中に存在するか又は存在しないかを検出することは、代替遺伝的マーカーの存在又は不存在を検出ことと文字通り等しいことが理解される。
【0066】
一態様において、本発明は、客観的な遺伝的基準に基づいて、コレステロール治療を必要としている患者を応答群に分類するための手段を提供する。さらに、患者がどの階級内に属するかに基づいて、本発明は、その患者に対する最も適切な薬物治療を選択するための客観的な基礎を与える。別の態様において、本発明は、コレステロールの健康リスクレベル及び/又は健康リスクコレステロール関連症状を治療又は予防するために使用することができる治療剤をスクリーニングし、開発するために使用可能なさらなるNPC1L1多型の同定方法を提供する。
【0067】
本発明の様々な態様は、NPC1L1遺伝子中の一塩基多型(SNP)の発見に基づいている。特に、NPC1L1遺伝子中の新規g.−18C>A多型(配列番号1の5,400位)が、NPC1L1遺伝子のプロモーター領域中に同定された。遺伝子型決定の結果及び血液成分測定の統計学的解析の結果は、ホモ接合又はヘテロ接合状態の何れかで(すなわち、1コピー又は2コピー)g.−18C>A多型が存在することは、主要な対立遺伝子(すなわち、配列番号1の5,400位にシトシンを有する。)に対してホモ接合の個体に比べて、エゼチミブでの治療に応答した総コレステロール、LDL−C、非HDL−C及びアポBレベルの変化に有意に関連することを示した。別のNPC1L1多型g1679C>G(代替的NCBI表記、rs2072183)は、主要な対立遺伝子(すなわち、配列番号1の7,096位にシトシンを有する。)に対してホモ接合の個体に比べて、エゼチミブでの処理に応答したLDL−Cレベルの変化に関連することも見出された。ハプロタイプ分析は、エゼチミブでの治療に応答して、LDL−Cレベルの変化に有意に関連する3つのSNPを含む2つのNPC1L1ハプロタイプも同定した。ハプロタイプ[A(−133)、A(−18)、G(1679)]は、配列番号1の5,285位、5,400位及び7,096位に異なるハプロタイプを有する個体に比べて、エゼチミブ治療に対する平均的な応答(すなわち、LDL−Cの低下)より高い応答を伴うことが見出された。ハプロタイプ[G(−133)、C(−18)、C(1679)]は、配列番号1の5,285位、5,400位及び7,096位に異なるハプロタイプを有する個体に比べて、エゼチミブ治療に対する平均的な応答(すなわち、LDL−Cの低下)より低い応答を伴うことが見出された。これらのNPC1L1バリアントとエゼチミブ治療に対するLDL−C応答間の遺伝的関連は、エゼチミブ治療に対して感受性である経路中でのコレステロール吸収に対する中心的遺伝子としてのNPC1L1の役割を裏付ける。
【0068】
本発明の別の態様は、対象のNPC1L1遺伝子中の一塩基多型又はハプロタイプを決定すること、及びNPC1L1遺伝子中の前記多型又はハプロタイプに対する参照により、医薬として活性な化合物が投与された前記対象の状態を決定することを含む、NPC1L1遺伝子中の一塩基多型又はハプロタイプを、対象に投与された医薬として活性な化合物の効力と相関させる方法に関する。一実施形態において、対象の状態は、化合物の投与前及び投与後における病状の測定に基づく。対象に投与された医薬として活性な化合物の効力は、特定の一塩基多型又は特定のハプロタイプが、多型配列位置又はハプロタイプ配列位置に異なる遺伝子型を有する個体の状態の変化に比べて、化合物の投与に応答して、対象の状態の統計的に有意な変化と相関するかどうかを決定することによって評価される。典型的な病状には、アテローム性動脈硬化症、急性冠症候群、冠動脈疾患などが含まれる。常にではないが、一般に、病状には、例えば、低密度脂質コレステロール、総コレステロール、非高密度脂質コレステロール及びアポリポタンパク質(アポB)など、血液若しくは血液血漿コレステロールレベル又は血液タンパク質関連脂質レベルが関連する。
【0069】
本発明のさらなる態様によれば、ヒト対象のNPC1L1遺伝子中の一塩基多型を決定すること、5,285位、5,400位、7,096位又は34,067位を含むNPC1L1遺伝子を含む配列番号1の少なくとも1つ又はそれ以上の位置における多型に対する参照により、医薬として活性な化合物が投与された前記ヒトの状態を決定することを含む、NPC1L1遺伝子中の一塩基多型を、ヒト対象に投与された医薬として活性な化合物の効力と相関させる方法が提供される。ヒト対象の状態は、1つ、2つ、3つ、4つの位置又は4つの全ての位置における対立遺伝子変異に対する参照により決定され得る。ヒト対象の状態は、他の1つ又はそれ以上の一塩基多型と組み合わせた、本明細書中に同定された特定の多型の1つ又はそれ以上によっても決定され得る。
【0070】
本発明の別の態様は、NPC1L1機能に影響を与える薬物に対する対象の応答性を予測する方法を提供する。本方法は、対照から生物学的試料を取得すること、前記生物学的試料中で配列番号1の位置に存在するヌクレオチド塩基を測定することを含み、前記位置は、5,400位及び7,096位からなる群から選択され、5,400位のアデニン塩基の存在又は7,096位のグアニンの存在は、薬物に対する対象の応答性の増加したレベルの指標である。別の実施形態において、配列番号1の5,400位のシトシン塩基又は7,096位のシトシン塩基の存在は、薬物に対する対象の応答性の減少したレベルの指標である。
【0071】
本発明の別の態様は、ヒト対象中の血漿低密度脂質コレステロールの健康リスクレベルに対する素因を検出する方法を提供する。本方法は、ヒトNPC1L1対立遺伝子のゲノム配列中の多型の存在を対象中に検出することを含み、ここにおいて、ヒトNPC1L1対立遺伝子は配列番号1の34,067位のグアニンからなる。34,067位のグアニン塩基の存在は、血漿コレステロールの健康リスクレベルに対する対象の素因の指標である。別の実施形態において、34,067位のグアニン塩基の検出は、冠状動脈性心臓病(CHD)に対する対象の素因の指標である。
【0072】
本発明の一実施形態において、LDL−Cの健康リスクレベルは、当業者によって認められた、教育、医学、政府又はその他の機関によって記されたガイドラインを参照することによって決定される。例えば、米国では、国立コレステロール教育プログラムが、様々なコレステロールレベルと関連する健康リスクを詳述するレポートを定期的に発行している。特に、NCEP成人治療パネルは、CHDリスクのレベルに従って、特異的なLDL−C目標レベルを確定するガイドラインを発行した(JAMA(2001)285:2486−97)。最近、新たに得られつつある臨床試験データに基づき、これらのガイドラインに対する更新が、極めて高いリスクにあると考える者に対して、LDL−C<70mg/dLという任意的な目標を確立した(Circulation(2004)110:227−239)。本発明の実施において、ヒトをリスクに曝す血漿低密度脂質コレステロールのレベルは、更新されたNCEP ATPガイドラインに基づいて決定される(Circulation(2004)110:227−239)。一実施形態において、血漿低密度脂質コレステロールの健康リスクレベルは、約70mg/dLと約130mg/dLの間にある。
【0073】
本発明の別の態様によれば、患者が、配列番号1の5,400位のアデニン塩基ヘテロ接合性又はホモ接合性、配列番号1の7,096位のグアニン塩基ヘテロ接合性又はホモ接合性及び配列番号1の5,285位、5,400位及び7,096位に対応する[A(−133)、A(−18)、G(1679)]ハプロタイプヘテロ接合性又はホモ接合性からなる群から選択される遺伝子型を有するかどうかを決定する工程を含む、患者がNPC1L1アンタゴニストに応答した平均的な増加を上回る増加と関連する遺伝子型を有するかどうかを決定する方法が提供される。幾つかの実施形態において、患者は、コレステロールの健康リスクレベルを有する。他の実施形態において、患者は、現在、スタチン治療を受けているか、又は過去にスタチン治療を受けたことがある。典型的なスタチンは、以下で、より詳しく記載されている。他の実施形態において、患者は、スタチン治療を用いて、コレステロールの十分な低下を達成することに失敗している。患者に対するコレステロールの十分な低下は、患者の様々な特性、例えば、年齢、一般的な健康などに鑑みて、本分野で認められた何れかのコレステロール標的レベルに対する参照によって測定され得る。特に、このような標的レベル及び健康リスク因子は、教育、医学又は政府機関によって用意された様々な冊子に記載されている。特定の実施形態において、患者に対するコレステロール目標レベルは、NCEPATPガイドラインを参照することによって決定される。一実施形態において、患者が約100mg/dL未満又は約70mg/dL未満のLDL−Cの血漿レベルを有する場合に、血漿LDl−C中の十分な低下が達成される。
【0074】
本発明の別の態様によれば、患者中のコレステロールを低下させる方法であり、NPC1L1アンタゴニストの有効量を前記患者に投与する工程を含み、前記患者が、配列番号1の5,400位のアデニン塩基ヘテロ接合性又はホモ接合性、配列番号1の7,096位のグアニン塩基ヘテロ接合性又はホモ接合性及び配列番号1の5,285位、5,400位及び7,096位に対応する[A(−133)、A(−18)、G(1679)]ハプロタイプヘテロ接合性又はホモ接合性からなる群から選択される遺伝子型を有すると特定される、前記方法を提供する。患者から生物学的試料を取得し、NPC1L遺伝子配列の対応する位置にどのヌクレオチド塩基が存在するかを決定することによって、患者は、上記特定された遺伝子型の1つを有すると特定される。患者が本明細書に特定されている遺伝子型の1つ、例えば、上記NPC1L1マーカーの1つを有することが知られている場合に、患者の遺伝子型は特定されている。NPC1L1アンタゴニストの有効量とは、コレステロールの腸輸送を低下させる量である。例えば、一実施形態において、NPC1L1アンタゴニストはエゼチミブであり、有効量は10mgであり、毎日1回投与される。他のNPC1L1アンタゴニストは、本明細書の以下に記載されている。
【0075】
本発明の別の態様は、g.−133A>G、g.−18C>A及びg.28650A>G又はハプロタイプ[A(−133)、A(−18)、G(1679)]からなる群から選択される一塩基多型を有する患者中の高コレステロール又は高コレステロール関連疾患を治療するための薬品の使用を、目標とする対象者に対して宣伝することを含む、エゼチミブを含む薬品を広告する方法であり、前記選択された一塩基多型又はハプロタイプを有する個体が、前記選択された一塩基多型又はハプロタイプを欠如する個体より、エゼチミブに対して平均応答より高い応答を示す可能性が高い、前記方法を含む。
【0076】
本発明において、ヒト対象の組織に由来する核酸分子の操作は、NPC1L1遺伝子型の分析、並びにNPC1L1SNP及びハプロタイプマーカー、特に、NPC1L1−g.−133A>G、NPC1L1−g.−18C>A、NPC1L1−g.1679C>G及びNPC1L1−g.28650A>Gから選択される1つ若しくはそれ以上のSNP又は[A(5285)−A(5400)−G(7096)]及び[G(5285)−C(5400)−C(7096)]から選択される1つ若しくはそれ以上の3SNPハプロタイプに関連するスクリーニング及び診断方法を提供するために実施することが可能である。これらの文脈において使用される核酸分子は、以下に記載されているように、増幅することが可能であり、RNA、ゲノムDNA及びRNA由来のcDNAを一般的に含む。
【0077】
III.ポリヌクレオチド及びポリヌクレオチドスクリーニング法
個体中にNPC1L1マーカーが存在することは、その個体がマーカーを含むバリアントの必要とされるコピー数を有するかどうかの決定を可能とする本分野で周知の様々な方法の何れによっても決定し得る。例えば、必要とされるコピー数が1又は2であれば、前記方法は、個体がバリアントの少なくとも1コピーを有することを決定する必要があるに過ぎない。好ましい実施形態において、前記方法は、実際のコピー数の決定を提供する。
【0078】
典型的には、これらの方法は、マーカー中の1つ又はそれ以上の多型部位に存在するヌクレオチド又はヌクレオチド対の正体を決定するために個人から取得された生物学的試料から調製された核酸試料をアッセイすることを含む。核酸試料は、実質的にあらゆる生物学的試料から調製され得る。例えば、都合のよい試料には、全血血清、精液、唾液、涙、糞便、尿、汗、口腔内物質、皮膚及び毛髪が含まれる。マーカーバリアントの実際のコピー数を決定するのであれば、体細胞が好ましい、核酸試料は、当業者に公知のあらゆる技術を用いて、分析のために調製し得る。好ましくは、このような技術は、核酸分子中の多型部位の所望されるセットに対して遺伝子型又はハプロタイプ対を決定するのに十分に純粋なゲノムDNAの産生をもたらす。このような技術は、例えば、「Sambrook et al.,Molecular Cloning:A Laboratory Manual,(Cold Spring Harbor Laboratory New York)(2001)」中に見出し得る。
【0079】
指定された多型がハプロタイプであるマーカーの場合、核酸試料中のハプロタイプのコピー数は、直接的なハプロタイプ決定法によって決定されるか、又はマーカーを含む多型部位のセットに対するハプロタイプ対が、多型部位のセットに対する個体のハプロタイプ遺伝子型から推測される間接的なハプロタイプ決定法によって決定され得る。核酸試料が調製される様式は、直接又は間接的なハプロタイプ決定法が使用されるかどうかに依存する。
【0080】
直接的なハプロタイプ決定法、又は分子ハプロタイプ決定法は、典型的には、当業者によって容易に理解されるように同一の対立遺伝子又は異なる対立遺伝子であり得る、座に対する個体の2つの対立遺伝子のうち1つのみを含有するヘミ接合性DNA試料を産生する様式で個体から取得された血液試料又は口頬試料から単離されたゲノムDNA試料を処理すること、及び目的の各多型部位に存在するヌクレオチドを検出することを含む。核酸試料は、ヘミ接合性DNA試料を調製するための本分野で公知の様々な方法を用いて取得することができ、WO98/01573、米国特許第5,866,404号及び米国特許第5,972、614号に記載されているような、酵母中での標的化されたインビボクローニング(TIVC;targeted in vivo cloning);米国特許第5,972,614号に記載されているプライマー伸長及びエキソヌクレアーゼ分解と組み合わせて、対立遺伝子特異的オリゴヌクレオチドを使用する、ヘミ接合性DNA標的の作製;「Ruano et al,Proc.Natl.Acad.Sci. 87:6296−300(1990)」に記載されている単一分子希釈(SMD);及び対立遺伝子特異的PCR(Ruano et al,Nucl.Acids Res.17:8392(1989);Ruano et al,Nucl.Acids Res.19:6877−82(1991);Michalatos−Beloin et al、上記)が含まれる。
【0081】
当業者によって容易に理解されるとおり、個体中の座の何れの個別のクローンも、2つの対立遺伝子のうち1つのみに対するハプロタイプを直接決定することが可能であり、従って、他の対立遺伝子に対するハプロタイプの正体を直接決定するためには、さらなるクローンを調べる必要がある。典型的には、両対立遺伝子を決定する90%超の確率を有するためには、個体中に存在するゲノム遺伝子座の少なくとも5つのクローンを調べるべきである。しかしながら、幾つかの事例では、一旦、1つの対立遺伝子に対するハプロタイプが直接決定されると、個体がマーカーを含む多型部位に対して公知の遺伝子型を有するか、又は適切な参照集団中で座に対するハプロタイプ又はハプロタイプ対の頻度が入手可能であれば、他の対立遺伝子に対するハプロタイプを推測し得る。
【0082】
両対立遺伝子の直接のハプロタイプ決定は、別個の容器中に配置された2つのヘミ接合性DNA(各対立遺伝子に対して1つ)試料をアッセイすることによって実施し得る。あるいは、2つの試料が異なるタグで標識されているか、又は各試料に対するアッセイ結果が、その他の方法で、別々に識別可能若しくは特定可能であれば、2つのヘミ接合性試料は、同じ容器中でアッセイし得る。例えば、試料が第一及び第二の蛍光色素で標識されていれば、座中の多型部位は、対立遺伝子の1つに対して特異的であり、及び第三の蛍光色素で標識されたオリゴヌクレオチドプローブを用いて、座中の多型部位がアッセイされ、次いで、第一及び第三の色素の組み合わせを検出すことにより、第一の試料中の多型部位に存在するヌクレオチドを特定するとともに、第二及び第三の色素の組み合わせを検出することにより、第二の試料中の多型部位に存在するヌクレオチドを特定する。
【0083】
間接的なハプロタイプ決定法は、典型的には、座中の各多型部位に対する個体の遺伝子型を正確に決定できる様式で、個体から得られた血液試料又は口頬試料から単離されたゲノムDNA試料を調製することを含む。ついで、座に対して個体のハプロタイプの少なくとも1つの正体を推定するために遺伝子型が使用され、好ましくは、遺伝子座に対する個体のハプロタイプ対の正体を推定するために遺伝子型が使用される。
【0084】
1つの間接的なハプロタイプ決定法において、対象ハプロタイプのゼロ、1又は2コピー数が存在することは、マーカー中の多型部位に対する個体の遺伝子型を、多型部位の同じセットに対する参照ハプロタイプ対のセットと比較し、個体中に存在する可能性がより高い参照ハプロタイプ対を前記個体に対して割り振ることによって決定することが可能である。マーカーを含むハプロタイプに対する個体のコピー数は、割り振られた参照ハプロタイプ対中のハプロタイプのコピーの数である。
【0085】
参照ハプロタイプ対とは、一般的な集団中に又は参照集団中に存在することが知られているハプロタイプ対である。参照集団は、世界の主要な民族地理的群を代表する無作為に選択された個体から構成され得る。好ましい参照集団は、マーカーの存在について検査されている個体と類似の民族地理的背景を有する集団である。参照集団の大きさは、観察が確保されることを望んでいるハプロタイプがどれだけ稀であるかに基づいて選択される。例えば、参照集団中での発生頻度がp%で集団中に存在するハプロタイプを見逃さない確率をq%としたいのであれば、標本としなければならない個体の数(n)は、2n=log(1−q)/log(1−p)(p及びqは、割合として表される。)によって表される。特に好ましい参照集団は、ハプロタイプ決定手法の品質をチェックするための対照としての役割を果たすために、1つ又はそれ以上の3世代家族を含む。参照集団が、2以上の民族地理的群を含む場合には、ハーディー−ワインベルグ平衡と合致するかどうかを決定するために、各群に対する頻度データが調べられる。ハーディー−ワインベルグ平衡(D.L.Hard et al.,Principles of Population Genomics,Sinauer Associates(Sunderland,MA),3rdEd.,1997)は、ハプロタイプ対H1/H2を見出す頻度が、H1とH2が等しくなければ、PH−W(H1/H2)=2p(H1)p(H2)であり、H1とH2が等しくければ、PH−W(H1/H2)=p(H1)p(H2)であることを仮定する。観察されたハプロタイプ頻度と予測されたハプロタイプ間の統計的に有意な差は、集団群中の著しい近親交配、遺伝子に対する強い選択圧、標本抽出の偏り及び/又は遺伝子型決定プロセスにおける誤りなどの1つ又はそれ以上の要因に起因し得る。民族地理的群中にハーディー−ワインベルグからの大きな解離が観察されれば、解離が標本抽出の偏りによるものかを明らかにするために、その群中の個体の数を増加させることが可能である。より大きな試料サイズが、観察されたハプロタイプ対の頻度と予測されたハプロタイプ対の頻度の間の差を減少させないのであれば、直接的な分子ハプロタイプ決定法を用いて、個体のハプロタイプを決定したいと考える場合があり得る。
【0086】
ハプロタイプ対の割り当ては、個人の遺伝子型と合致する参照ハプロタイプ対を選択することによって実施し得る。個体の遺伝子型が2以上の参照ハプロタイプ対と合致する場合には、これらの合致するハプロタイプのうち、個体中に存在する可能性が最も高いのは何れかを決定するために参照ハプロタイプ対の頻度を使用し得る。特定の合致するハプロタイプ対が、他の合致するハプロタイプ対より、参照集団中でより頻度が高いのであれば、最も高い頻度を有する、合致するハプロタイプ対が、個体中に存在する可能性が最も高い。時折、参照ハプロタイプ対中に提示される唯一のハプロタイプが、個体の遺伝子型を説明することができる、可能なハプロタイプ対の全てと合致するが、このような場合には、この公知のハプロタイプと可能なハプロタイプ対から公知のハプロタイプを差し引くことによって得られる新しいハプロタイプとを含有するハプロタイプ対が個体に割り当てられる。稀な事例では、参照集団中の何れのハプロタイプも個体の遺伝子型と合致しないか、あるいは、複数の参照ハプロタイプ対が遺伝子型と合致する。このような事例では、好ましくは、直接の分子ハプロタイプ決定法を用いて、個体のハプロタイプが決定される。
【0087】
上記間接的なハプロタイプ決定法中の全工程の何れも、視覚的な検査と適切な計算の実行により、手動で実施され得るが、好ましくは、コンピュータで読み取り可能な規格で格納された、個体の遺伝子型及び参照ハプロタイプ対に関するデータにアクセスする、コンピュータによって実行されるアルゴリズムによって行われる。このようなアルゴリズムは、WO01/80156及びWO2005048012A2に記載されている。あるいは、個体中のハプロタイプ対は、報告されている他のハプロタイプ決定アルゴリズム(例えば、Clark et al.1990,Mol Bio Evol 7:111−22;PHASEv2ソフトウェア(University of Washington Technology Transferからライセンスを入手可能、Stefens,M.et al.,(2001) Am J Hum Genet 68:978−989に記載されている。);WO 02/064617;Niu T.et al(2002) Am J.Hum Genet 70:157−169;Zhang et al.(2003) BMC Bioinformatics 4(1):3)の補助を得て、又はGenaissance Pharmaceuticals,Inc.(New Haven,CT)によって提供されるような、民間のハプロタイプ決定サービスを通じて、当該遺伝子に対する個体の遺伝子型から予測し得る。
【0088】
本明細書中に記載されている全ての直接的及び間接的ハプロタイプ決定法は、典型的には、個体から得られた核酸試料中の多型部位における対立遺伝子少なくとも1つの正体を決定することを含む。この決定の感受性と特異性を増大させるために、遺伝子座中の1つ又はそれ以上の標的領域を核酸試料から増幅することがしばしば望ましい。増幅された標的領域は、遺伝子全体など、関心対象の座を包含するか、又は1つ若しくはそれ以上の多型部位を含有するその領域を包含し得る。マーカー中の各多型部位に対して、分離した標的領域を増幅し得る。
【0089】
本発明によれば、NPC1L1遺伝子中の多型を、医薬として活性な化合物のヒト対象での効力と相関させる方法が提供される。本方法は、ヒト対象のNPC1L1遺伝子中の多型を決定すること、及びNPC1L1遺伝子中の一塩基多型への参照によって、医薬として活性な化合物が投与された前記ヒト対象の状態を決定することを含む。
【0090】
本発明の有用な多型核酸分子には、NPC1L1プロモーター領域中のg.−18C>ASNPに相当するCからAへの塩基転換の領域中において、NPC1L1配列に特異的にハイブリダイズするものが含まれる。典型的には、このようなポリヌクレオチドは、少なくとも約12ヌクレオチド長であり、NPC1L1配列(配列番号1)の5,400位におけるCからAへの塩基転換の領域に対応するヌクレオチド配列を有する。1つのこのような代表的ポリヌクレオチドは、5’GGAGG(C)TGCCTT3’(配列番号2)であり、ここで、カッコ内のヌクレオチド塩基は、多型g.−18C>A部位の「主要な」対立遺伝子、すなわち、NPC1L1遺伝子の5,400位のシトシンを表す。
【0091】
提供される核酸分子は、放射線標識、蛍光標識、酵素標識、配列タグなど、本分野で公知のあらゆる技術によって標識することが可能である。本発明の別の態様によれば、核酸分子は、配列番号1の5,400位に、CからAへの塩基転換を含有する。このような分子は、対立遺伝子特異的オリゴヌクレオチドプローブとして使用することが可能である。有用なポリヌクレオチドは、少なくとも約12ヌクレオチド長であり、多型g.−18C>A部位が含まれる。1つのこのような代表的ポリヌクレオチドは、5’GGAGG(A)TGCCTT3’(配列番号3)であり、ここで、カッコ内のヌクレオチド塩基は、多型g.−18C>A部位の「主要でない」対立遺伝子、すなわち、NPC1L1遺伝子の5,400位のアデニンを表す。
【0092】
組織試料は、何れの核酸塩基がNPC1L1多型部位に存在するかを決定するために検査することが可能である。検査のための適切な身体試料には、血液から得られるDNA若しくはRNAを含むもの又はDNA若しくはRNAを含有する対象から得られた他の何れかの細胞試料が含まれる。例えば、都合のよい試料には、全血血清、精液、唾液、涙、糞便、尿、汗、口腔内物質、皮膚及び毛髪が含まれる。マーカーバリアントの実際のコピー数を決定するのであれば、体細胞が好ましい、核酸試料は、当業者に公知のあらゆる技術を用いて、分析のために調製し得る。好ましくは、このような技術は、核酸分子中の多型部位の所望されるセットに対して遺伝子型又はハプロタイプ対を決定するのに十分に純粋なゲノムDNAの産生をもたらす。このような技術は、例えば、「Sambrook et al.,Molecular Cloning:A Laboratory Manual,(Cold Spring Harbor Laboratory New York)(2001)」中に見出し得る。
【0093】
本発明の一実施形態において、単離されたオリゴヌクレオチドプライマーの対は、例えば、本明細書の実施例1に開示されている配列番号4及び5など、NPC1L1g.−18C>A多型領域の核酸増幅のために提供される。プライマーのこのセットは、NPC1L1遺伝子、特に5’UTR及びエキソン1領域に由来する。2つの適切に配置されたg.−18C>A増幅オリゴヌクレオチドプライマーは、何れのヌクレオチド塩基が配列番号1の5,400位に存在するかを決定するためにg.−18C>A多型領域の配列を決定するための十分な核酸材料を取得するために使用される。同様に、他の単離されたオリゴヌクレオチドプライマーは、NPC1L1g.−133A>G、g.1679C>G及びg.28650A>G多型領域を増幅するために使用できる本明細書の実施例中に開示されている。
【0094】
本発明の別の実施形態において、単離された対立遺伝子特異的オリゴヌクレオチド(ASO)が提供され、例えば、本明細書の実施例3に記載されているASOを参照されたい。このようなASOは、市販の試薬及び特注の対立遺伝子識別遺伝子型アッセイサービスと組み合わせて、Livak((1999) Genet.Anal.,14:143−9)及びApplied Biosystems(Foster City,CA)によって提供された文書に記載されているTaqMan Allelic Discrimination遺伝子型アッセイの実施に際して使用することが可能である。これに実質的に類似する配列も、本発明に従って提供される。ASOは、高コレステロールを有し、その治療を必要としている対象における各NPC1L1多型の存在又は不存在の同定において有用である。これらのユニークなNPC1L1オリゴヌクレオチドプライマーは、それぞれ、g.−133A>G、g.−18C>A、g.1679C>G及びg.28650A>Gに対応する塩基の変化に基づいて設計及び作製される。プライマーハイブリダイゼーションのために使用することが可能な他のプライマーは、本明細書におけるNPC1L1g.−133A>G、g.−18C>A、g.1679C>G及びg.28650A>G多型の開示に基づいて、当業者が容易に解明可能である。
【0095】
本発明のプライマーは、多型遺伝子座中の核酸の有意な数に対してポリマー化の開始を提供するために、十分な長さ及び適切な配列のオリゴヌクレオチドを有する。具体的には、本明細書において使用される「プライマー」という用語は、2つ又はそれ以上のデオキシリボヌクレオチド又はリボヌクレオチド、幾つかの実施例においては、NPC1L1遺伝子の4以上、別の実施形態において9以上、他の実施形態においては13以上、さらに別の実施形態においては少なくとも約20ヌクレオチドを含む配列を表し、ここにおいて、DNA配列は、各々、それぞれ、g.−133A>G、g.−18C>A、g.1679C>G及びg.28650A>Gに対応する多型部位を含有する。例えば、NPC1L1−g.−18C>Aの場合には、配列番号1の5,400位におけるCからAへの塩基転換がオリゴヌクレオチド内に含有されている。配列番号1の5,400位にシスチン(cystine)(C)を含む対立遺伝子は、本明細書において、「5,400主要対立遺伝子」と称される。配列番号1の5,400位にアデニン(A)を含む対立遺伝子は、本明細書において、「5,400非主要対立遺伝子」と称される。
【0096】
NPC1L1遺伝子の5,400主要対立遺伝子と5,400非主要対立遺伝子とを識別するオリゴヌクレオチドも、本発明に従って提供され、ここで、前記オリゴヌクレオチドは、ヌクレオチド5,400がシトシンである場合には、NPC1L1遺伝子に対応するポリヌクレオチドのヌクレオチド5,400を含むNPC1L1遺伝子の一部にハイブリダイズするが、ヌクレオチド5,400がアデニンである場合には、NPC1L1遺伝子の一部とハイブリダイズしない。NPC1L1遺伝子の5,400主要対立遺伝子と5,400非主要対立遺伝子とを識別するオリゴヌクレオチドも、本発明に従って提供され、ここで、前記オリゴヌクレオチドは、ヌクレオチド5,400がアデニンである場合には、NPC1L1遺伝子に対応するポリヌクレオチドのヌクレオチド5,400を含むNPC1L1遺伝子の一部にハイブリダイズするが、ヌクレオチド5,400がシトシンである場合には、NPC1L1遺伝子の一部とハイブリダイズしない。このようなオリゴヌクレオチドは、好ましくは、10塩基長と30塩基長の間である。このようなオリゴヌクレオチドは、場合により、検出可能な標識をさらに含むことが可能である。本明細書に提供されている情報に基づいて、それぞれ、NPC1L1g.−133A>G、g.1679C>G及びg.28650A>Gの主要及び非主要対立遺伝子に対して類似のASOを設計することが可能である。
【0097】
幾つかの例で、擬陽性の検出を防ぐために、対立遺伝子特異的ハイブリダイゼーションアッセイの特異性を増加させることが望ましい。このような場合には、対立遺伝子特異的プライマー(SNP対立遺伝子に合致する塩基)の3’末端に、鍵型核酸残基が配置され、それぞれの各NPC1L1主要及び非主要対立遺伝子間の増加したミスマッチ識別を与える。鍵型核酸残基を含有する適切な高特異性NPC1L1ASOプライマーは、Proligo LLC(Boulder,Colorado)から取得し得る。
【0098】
ポリヌクレオチド合成を基礎とする増幅方法に対して伝導性がある環境条件には、ヌクレオシド三リン酸及びDNAポリメラーゼなどの重合化のための薬剤並びに適切な温度及びpHの存在が含まれる。プライマーは、好ましくは、増幅の効率化を最大化するために一本鎖であるが、二本鎖とすることも可能である。二本鎖である場合には、伸長産物を調製するために使用する前に、その鎖を分離するために、まず、プライマーが処理される。プライマーは、重合化のための誘導剤の存在下で、伸長産物の合成を開始させるのに十分に長くなければならない。プライマーの正確な長さは、温度、緩衝液及びヌクレオチド組成を含む多くの因子に依存する。オリゴヌクレオチドプライマーは、典型的には、12〜20又はこれ以上のヌクレオチドを含有するが、これより少ないヌクレオチドを含有することが可能である。
【0099】
本発明のプライマーは、増幅されるべきゲノム遺伝子座の各鎖に対して「実質的に」相補的であるように設計される。このことは、前記薬剤が重合化を実施できる条件下で、それらのそれぞれの鎖とハイブリダイズするために、プライマーが十分に相補的でなければならないことを意味する。換言すれば、プライマーは、転位に隣接する5’及び3’配列とハイブリダイズするために、及びゲノム遺伝子座の増幅を可能とするために、転位に隣接する5’及び3’配列と十分な相補性を有するべきである。
【0100】
本発明のオリゴヌクレオチドプライマーは、関与する反応工程の数に比べて、多型遺伝子座の指数関数的量を産生する酵素的連鎖反応である増幅反応において使用される。典型的には、一方のプライマーは多型遺伝子座の負(−)鎖に対して相補的であり、他方のプライマーは正(+)鎖に対して相補的である。変性された核酸にプライマーをアニールさせた後、DNAポリメラーゼI(クレノウ)の巨大断片などの酵素及びヌクレオチドを用いて伸長させることにより、標的多型遺伝子座配列を含有する新たに合成された+及び−鎖をもたらす。これらの新たに合成された配列はテンプレートでもあるので、変性、プライマーアニーリング及び伸長の反復サイクルは、プライマーによって規定される領域(すなわち、標的多型遺伝子座配列)の指数関数的産生をもたらす。連鎖反応の産物は、使用される特異的プライマーの末端に対応する末端を有する慎重な(discreet)核酸二本鎖である。
【0101】
本発明のオリゴヌクレオチドプライマーは、慣用のホスホトリエステル及びホスホジエステル法又はこれらの自動化された実施形態など、あらゆる適切な方法を用いて調製することが可能である。1つのこのような自動化された実施形態において、ジエチルホスホルアミダイトが出発材料として使用され、「Beaucage et al.,Tetrahedron Letters 22:1859−1862(1981)」によって記載されているとおりに合成することが可能である。修飾された固体支持体上にオリゴヌクレオチドを合成するための1つの方法は、米国特許第4,458,066号に記載されている。
【0102】
多型遺伝子座を含有する核酸配列を含有するか、又は含有すると疑われる限り、精製された形態又は精製されていない形態の全ての核酸試料を、出発核酸として使用することが可能である。従って、前記方法は、例えば、DNA又はRNA(メッセンジャーRNAを含む。)を増幅することが可能であり、ここで、DNA又はRNAは、一本鎖又は二本鎖とすることができる。RNAがテンプレートとして使用されるべき場合には、テンプレートをDNAへ逆転写するために最適な酵素及び/又は条件が使用される。さらに、それぞれの1つの鎖を含有するDNA−RNAハイブリッドを使用することが可能である。核酸の混合物も使用することが可能であり、又は同一又は別異のプライマーを用いて、本明細書中の前記増幅反応で産生された核酸をこのようにして使用することが可能である。増幅されるべき特定の核酸配列、すなわち多型遺伝子座は、特定の配列が完全な核酸を構成するように、より巨大な分子の一部であることが可能であり、又は別個の分子として当初存在することが可能である。増幅されるべき配列が当初純粋な形態で存在する必要はなく、完全なヒトDNA中に含有されるなど、複雑な混合物の微少な割合とすることが可能である。
【0103】
本発明において使用されるDNAは、「Maniatis et.al.in Molecular Cloning:A Laboratory Manual,Cold Spring Harbor,N.Y.,p 280−281(1982)」によって記載された技術などの、様々な技術によって、血液、組織材料(例えば、脂肪組織)などの身体試料から抽出することが可能である。抽出された試料が純粋でない場合には、試料の細胞又は動物細胞膜を開放し、核酸の鎖を曝露及び/又は分離するのに有効な試薬の量で、増幅前に処理することが可能である。鎖を曝露及び分離するためのこの溶解及び核酸変性工程は、増幅がずっと容易に起こるようにすることができる。
【0104】
デオキシリボヌクレオチド三リン酸dATP、dCTP、dGTP及びdTTPが、別々に、又はプライマーと一緒に、十分な量で合成混合物に添加され、得られた溶液は、約1〜10分間、好ましくは1〜4分間、約90〜100℃まで加熱される。この加熱期間後、溶液は冷却され、これはプライマーハイブリダイゼーションのために好ましい。冷却された混合物に、プライマー伸長反応を実施するのに適切な薬剤(本明細書において、「重合化のための薬剤」と称される。)を添加し、本分野において公知の条件下で反応を起こさせる。重合化のための薬剤は、熱に安定であれば、他の試薬と一緒に添加することも可能である。この合成(又は増幅)反応は、室温から重合化のための薬剤がもはや機能しない温度を上回る温度までで行うことができる。従って、例えば、DNAポリメラーゼが薬剤として使用される場合には、温度は、一般的には、約40℃を上回らない。最も都合よく、反応は室温で起こる。
【0105】
重合化のための薬剤は、プライマー伸長産物の合成を達成するように機能するあらゆる化合物又は系とすることができ、酵素が含まれる。この目的のために適切な酵素には、E.コリDNAポリメラーゼI、E.コリDNAポリメラーゼのクレノウ断片、ポリメラーゼ変異体、逆転写酵素、Taqポリメラーゼなどの他の酵素(熱安定的な酵素(すなわち、変性を引き起こすために十分に上昇された温度に供した後にも、プライマー伸長を実行する酵素)を含む。)が含まれるが、これらに限定されない。適切な酵素は、各多型遺伝子座の核酸鎖に対して相補的であるプライマー伸長産物を形成するのに適切な様式で、ヌクレオチドの結合を促進する。一般的に、合成は、各プライマーの3’末端から開始し、合成が終了するまで、テンプレート鎖に沿って5’方向に進行し、異なる長さの分子を産生する。
【0106】
新たに合成された鎖及びその相補的核酸鎖は、本明細書に記載されているハイブリダイズ条件下で二本鎖分子を形成し、このハイブリッドは、前記方法のその後の工程で使用される。次の工程で、新たに合成された二本鎖分子は、一本鎖分子を提供するために、上記手順の何れかを用いて変性条件に供される。
【0107】
変性、アニーリング及び伸長産物合成の工程は、検出に必要な程度まで、標的多型遺伝子座核酸配列を増幅するために必要とされるだけ多くの回数を反復することが可能である。産生された特異的な核酸配列の量は、指数関数的な様式で蓄積する。さらなる方法については、「“PCR A Practical Approach”,ILR Press,Eds.McPherson et al.(1992)」を参照されたい。
【0108】
増幅産物は、放射性プローブを用いた、又は用いないサザンブロット分析によって検出することが可能である。1つのこのような方法において、例えば、多型遺伝子座の核酸配列の極めて低いレベルを含有するDNAの少量の試料が、増幅され、そして、サザンブロッティング技術を用いて、又は同様に、ドットブロット分析を用いて分析される。非放射性プローブ又は標識の使用は、増幅されたシグナルの高いレベルによって促進される。あるいは、増幅された産物を検出するために使用されるプローブは、例えば、放射性同位体、蛍光化合物、生物発光化合物、化学発光化合物、金属キレート物質又は酵素で、直接的又は間接的に、検出可能に標識することが可能である。当業者は、プローブに結合するための他の適切な標識を知悉しており、又は、日常的な実験操作を用いて、これを解明することができる。
【0109】
本発明の方法によって増幅される配列については、溶液中で、又は固体支持体への結合後に、ジデオキシ配列決定、PCR、オリゴマー制限(Saiki et al.,Bio/Technology3:1008−1012(1985)、対立遺伝子特異的オリゴヌクレオチド(ASO)プローブ分析(Conner et al.,Proc.Natl.Acad.Sci.U.S.A.80:278(1983))、オリゴヌクレオチド連結アッセイ(OLA)(Landgren et.al.,Science 241:1007,1988)などの、特異的なDNA配列の検出のために通常適用される何れかの方法によって、さらに評価、検出、クローニング、配列決定などを行うことが可能である。DNA分析のための分子技術が、概説されている(Landgren et.al.,Science 242:229−237(1988))。
【0110】
好ましくは、増幅の方法は、本明細書並びに米国特許第4,683,193号;同第4,683,202号;及び同第4,965,188号(各々、参照により、本明細書中に組み込まれる。)に記載されており、当業者によって一般的に使用されているようなPCRによる。増幅の別の方法が記載されており、本発明のプライマーを用いたPCRによって増幅されるNPC1L1遺伝子座が別の技術によって同様に増幅される限り、同じく使用することが可能である。このような別の増幅システムには、目的のRNAの短い配列及びT7プロモーターから始まる自律的配列複製が含まれるが、これに限定されない。逆転写酵素はRNAをcDNAへと複製し、及びRNAを分解し、続いて、逆転写酵素はDNAの第二の鎖を重合させる。
【0111】
別の核酸増幅技術は、逆転写及びT7RNAポリメラーゼを使用する核酸配列を基礎とした増幅(NASMATM)であり、これは、逆転写及びT7RNAポリメラーゼを使用し、そのサイクリングスキームを標的とするために2つのプライマーを取り込む。NASBATM増幅は、DNA又はRNAの何れかを用いて開始し、及び何れかを用いて終結し、60〜90分以内に約108コピーまで増幅することが可能である。
【0112】
あるいは、核酸は、連結活性化された転写(LAT;ligation activated transcription)によって増幅することが可能である。LATは、部分的に一本鎖であり、及び部分的に二本鎖である単一プライマーを用いて、一本鎖テンプレートから作動する。増幅は、cDNAをプロモーターオリゴヌクレオチドへ連結することによって開始され、数時間以内に、増幅は、約108〜約109倍になる。Qβレプリカーゼ系は、目的のDNA配列に対して相補的なRNAに、MDV−1と称されるRNA配列を付着させることによって使用することが可能である。試料を混合すると、ハイブリッドRNAは、試料のmRNAの中にその相補物を見出し、レプリカーゼを結合し、活性化して、目的のタグ−アロング(tag−along)配列を複製する。
【0113】
別の核酸増幅技術であるリガーゼ連鎖反応(LCR)は、試料中の連続配列の存在下で、リガーゼによって共有結合される目的の配列の、異なって標識された2つの半分を使用し、新しい標的を形成することによって機能する。修復連鎖反応(RCR)核酸増幅技術は、標的とされる配列を幾何的に増幅するために、2つの相補的及び標的特異的オリゴヌクレオチドプローブ対、熱安定性ポリメラーゼ及びリガーゼ並びにDNAヌクレオチドを使用する。2塩基のギャップがオリゴプローブ対を隔て、RCRがギャップを充填及び連結し、正常なDNA修復を模倣する。
【0114】
鎖置換活性化(SDA)による核酸増幅は、標的DNAに結合する短い突出を5’末端に有する、HindIIIに対する認識部位を含有する短いプライマーを使用する。DNAポリメラーゼは、含硫アデニン類縁体により、突出とは反対側のプライマーの一部を充填する。HincIIが添加されるが、修飾されていないDNA鎖のみを切断する。5’エキソヌクレアーゼ活性を欠如するDNAポリメラーゼは、切れ目の部位に入り、重合を開始し、初期プライマー鎖を下流に置換し、より多くのプライマーとして機能する新しいプライマー鎖を構築する。
【0115】
SDAは、37℃で、2時間に約107倍を超える増幅をもたらす。PCR及びLCRとは異なり、SDAは、機器化された温度サイクリングは必要としない。本発明の方法において有用な別の増幅系は、Qβレプリカーゼ系である。本発明では、PCRが好ましい増幅方法であるが、本発明の方法に記載されているように、NPC1L1−g.−18C>A座を増幅するために、これらの他の方法も使用することが可能である。
【0116】
本発明の別の実施形態において、好ましくは標的NPC1L1核酸の増幅後に、ジデオキシ配列決定により、対象から得た試料の標的NPC1L1核酸を配列決定することを含む、NPC1L1アンタゴニスト療法に関連する多型を有する対象を診断又は特定する方法が提供される。
【0117】
本発明の別の実施形態において、対象から得た試料の標的核酸を、NPC1L1多型の存在を検出する試薬と接触させること及び前記試薬を検出することを含む、NPC1L1アンタゴニスト療法に対する平均応答より高い応答を示す可能性がより高い対象を特定する方法が提供される。
【0118】
別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.133A>G多型と関連するAからGへの移行の存在を検出する試薬と接触させること及び前記移行を検出することを含む。別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.18C>A多型と関連するCからAへの塩基転換の存在を検出する試薬と接触させること及び前記塩基転換を検出することを含む。別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.1680G>T多型と関連するGからTへの塩基転換の存在を検出する試薬と接触させること及び前記塩基転換を検出することを含む。別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.28650A>G多型と関連するAからGへの移行の存在を検出する試薬と接触させること及び前記移行を検出することを含む。多数のハイブリダイゼーション法が、当業者に周知である。それらの多くは、本発明を実施する上で有用である。
【0119】
核酸ハイブリダイゼーションは、当業者によって容易に理解されるとおり、塩基組成、相補鎖の長さ及びハイブリダイズする核酸間のヌクレオチド塩基のミスマッチの数に加えて、塩濃度、温度又は有機溶媒のような条件によって影響を受ける。ストリンジェントな温度条件には、一般的に、30℃を超える温度、典型的には37℃を超える温度、好ましくは45℃を超える温度が含まれる。ストリンジェントな塩条件は、通常1000mM未満、典型的には500mMであり、好ましくは200mM未満である。しかしながら、パラメータの組み合わせは、何れの単一パラメータの測定より、ずっと重要である。例えば、Wetmur & Davidson,(1968)J.MoI.Biol.31:349−70)を参照されたい。
【0120】
従って、本発明のヌクレオチド配列は、NPC1L1遺伝子の相補的伸長部を有する二重鎖分子を選択的に形成できるその能力を有するために使用することが可能である。想定される用途に応じて、標的配列に対するプローブの選択性の異なる程度を達成するためにハイブリダイゼーションの変動する条件が使用される。選択性の高い程度を必要とする用途の場合、典型的には、ハイブリッドを形成するために相対的にストリンジェントな条件を使用する。例えば、約50℃〜約70℃、特に約55℃、約60℃及び約65℃の温度を含む温度で、0.02M〜0.15Mの塩によって提供される条件など、相対的に低い塩及び/又は高い温度条件を選択する。このような条件は特に選択的であり、プローブとテンプレート又は標的鎖間のミスマッチを許容するとしても、ごく僅か許容するに過ぎない。
【0121】
ある種の実施形態において、ハイブリダイゼーションを測定するための標識など、適切な試薬と組み合わせて、本発明の核酸配列を使用することが有利である。検出可能な信号を与えることができる、アビジン/ビオチンなどの放射性、酵素的又は他のリガンドを含む様々な適切な指示試薬が、本分野において公知である。幾つかの実施形態において、放射性試薬又はその他の環境的に望ましくない試薬に代えて、ウレアーゼ、アルカリホスファターゼ又はペルオキシダーゼなどの酵素タグが使用される可能性がある。酵素タグの場合には、肉眼的に又は分光光度的に可視的な試薬を与えて、相補的な核酸含有試薬との特異的ハイブリダイゼーションを特定するために使用することが可能な熱量測定指示薬基質が公知である。
【0122】
一般的に、本明細書に記載されているハイブリダイゼーションプローブは、溶液ハイブリダイゼーション中での試薬として有用であり、及び固相を用いる実施形態において有用である。固相を伴う実施形態において、検査DNA(又はRNA)を含有する試料は、選択されたマトリックス又は表面に吸着され、又はその他の方法で取り付けられる。次いで、この固定された一本鎖核酸は、所望の条件下で、選択されたプローブとの特異的ハイブリダイゼーションに供される。選択された条件は、とりわけ、必要とされる具体的な基準に基づいて、具体的な環境に依存する(例えば、G+C含量、標的核酸の種類、核酸の入手源、ハイブリダイゼーションプローブのサイズなどに依存する。)。非特異的に結合されたプローブ分子を除去するために、ハイブリダイズされた表面を洗浄した後、標識を介して、特異的ハイブリダイゼーションが検出されるか、又は定量される場合さえある。
【0123】
IV.他のSNP検出法
動的対立遺伝子特異的ハイブリダイゼーション(DASH;dynamic allele−specific hybridization)(Howell,et al.,(1999),Nat.Biotechnol.,17:87−8)、マイクロプレートアレイ対角ゲル電気泳動(MADGE)(Day,et al.,(1995) Biotechniques,19:830−5)、TaqMan システム(Holland,et al.,(1991),Proc Natl Acad Sci USA.88:7276−80)並びにLipshutzら2001の米国特許第6,300,063号に開示されているGENECHIP(R)マイクロアレイ(例えば、Affymetrix SNPアレイ)、Goeletらによって記載されている(PCT出願第92/15712号)Genetic Bit Analysis(GBA(R))、ペプチド核酸(PNA)(Ren,et al.,(2004) Nucleic Acids Res.32:e42)及び鍵型核酸(LNA;locked nucleic acid)プローブ、(Latorra,et al.,(2003) Hum.Mutat,22:79−85)、Molecular Beacons(Abravaya,et al.,(2003) Clin.Chem.Lab.Med.,41:468−74)、インターカレート色素(Germer and Higuchi,Genome Res.,9:72−78(1999)、FRETプライマー(Solinas et al.,(2001) Nucleic Acids Res.29:E96)、AlphaScreen(Beaudet,et al.,(2001) Genome Res.,11:600−8),SNPstream(Bell et al.,(2002) Biotechniques.Suppl.:70−2,74,76−7)、Multiplexミニシークエンシング(Curcio,et al.,(2002) Electrophoresis,23:1467−72)、SnaPshot(Turner,et al.,(2002) Hum.Immunol.,63:508−13)、MassEXTEND(Cashman,et al.,(2001) Drug Metab.Dispos.,29:1629−37)、GOODアッセイ(Sauer and Gut(2003) Rapid Commun.Mass.Spectrom.,17:1265−72)、Microarrayミニシークエンシング(Liljedahl,et al.,(2003) Pharmacogenetics,13:7−17)、アレイ化されたプライマー伸長(APEX;arrayed primer extension)(Tonisson,et al.,(2000) Clin.Chem.Lab.Med.,38:165−70)、マイクロアレイプライマー伸長(O’Meara,et al.,(2002) Nucleic Acids Res.,30:p.75)、タグアレイ(Fan,et al.,(2000) Genome Res.,10:853−60)、テンプレートによって誘導される取り込み(TDI;Template−directed incorporation)(Akula,et al.,(2002) Biotechniques,32:1072−8)、蛍光分極(fluorescence polarization)(Kwok,(2002) Human Mutation,19:315−23)、比色分析オリゴヌクレオチド連結アッセイ(OLA;oligonucleotide ligation assay)(Nickerson,et al.,(1990),Proc.Natl.Acad.Sci.USA,87:8923−7)、配列によってコードされたOLA(Gasparini,et al.,(1999) J.Med.Screen,6:67−9)、マイクロアレイ連結、リガーゼ連鎖反応、南京錠プローブ、ローリングサークル増幅、インベーダーアッセイ(Shi,(2001) Clin Chem.,47:164−72中に概説)、コード化された小球体(Rao,et al.,(2003) Nucleic Acids Res.31:p.66)及びMassArray(Leushner and Chiu,(2000) Mol.Diagn.,5:341−80)などの様々なDNA「マイクロアレイ」技術など、SNP検出の分野での進歩により、正確で、簡易且つ安価なさらなる大規模遺伝子型決定技術が提供されていることが理解される。上記方法の多くは、一塩基多型の遺伝子型を決定するための方法を概説する論文中にも論述されている(Kwak,(2001) Annu.Rev.Genomics Hum.Genet.,2:235−58)。
【0124】
V.コレステロール治療薬に対する応答性との遺伝子型マーカーとの関連
本発明において、NPC1L1遺伝子中の一塩基多型及びハプロタイプとコレステロール治療薬であるエゼチミブに対する応答性との間の関連が発見された。本明細書に記載されているものと同様の方法が、他のNPC1L1多型とNPC1L1機能を修飾する他の薬剤の効力との関連を見出すために使用し得る。
【0125】
エゼチミブに関連するコレステロールレベルの低下に対する遺伝的な原因を調査及び特定するために、関連分析を実施した。このアプローチは、エゼチミブの標的をコードするNPC1L1遺伝子中の多型マーカーを同定すること、及びエゼチミブを用いた治療時の減少したコレステロールレベルに関連する多型マーカー対立遺伝子又はハプロタイプを同定するために関連研究を実施することを含んだ。
【0126】
目的の表現型形質の存在若しくは不存在について検査された個体の集団に対して、又は定量的表現型の測定がその者に対して評価された個人の集団に対して、及び多型マーカーのセットに対して、統計的な関連分析が行われる。このような分析を実施するために、多型のセット(多型セット)の存在又は不存在を、個体の組に対して測定し、そのうち幾人かは特定の形質を示し、幾人かは形質の欠如を示す。これ以外に、定量的表現型が目的の測定である場合には、これらの個体は定量的表現型に対してスコア付けされる。関連分析は、ある変数が別の変数に対して線形的に関連する程度を記載するために使用される。典型的には、関連分析は、最小二乗線がデータにどの程度良好にフィットするかを測定するための回帰分析フレームワークにおいて検定される。関連分析は、分類形質及び表に関連して、χ二乗統計又はこれと同等の統計で検定することも可能である。
【0127】
前記セットの各多型の対立遺伝子は、次いで、特定の対立遺伝子の存在又は不存在が目的の形質と関連するかどうかを決定するために調査される。相関は、χ二乗検定などの標準的な統計法によって行うことが可能であり、多型形態及び表現型の特徴との間の統計的に有意な相関が注目される。例えば、多型Aにおける対立遺伝子A1の存在は、正常なコレステロールレベルなどの正常な表現型とともに生じるより、高コレステロールレベルなどの疾病に関連する表現型とともに生じることがより多いことを見出し得る。さらなる例として、多型Aにおける対立遺伝子A2の存在と多型Bにおける対立遺伝子B1の組み合わされた存在は、多型部位A及びBにおける他の対立遺伝子の組み合わせと比べて、薬物治療に対する増加した平均応答と関連することを見出し得る。
【0128】
遺伝的関連分析は、典型的には、医薬として活性な化合物又は薬物を与える群と与えられない群という少なくとも2つの群に分けられるヒト対象の研究集団内で実施される。各群の状態は、例えば、血漿コレステロールの低下などの医薬として活性な化合物に対する応答の適切な指標を参照することによって測定される。さらに、核酸試料は、各群中の各ヒト対象から採取される。しかしながら、無薬物群、すなわちプラセボ群中の個体の遺伝子型を決定する必要はないことに注目すべきである。次いで、各SNP、ハプロタイプ及びハプロタイプの組み合わせは、例えば、統計ソフトウェアプログラムを用いて、データの統計解析における主要説明変数として検定される。
【0129】
一実施形態において、解析技術は、SAS/STAT(R)Software(SAS Institute,Inc.,Gary,N.C.)中のPROC GLMツールであり、さらなる継続的測定によって説明されるモデル変動の幾つかを考慮に入れながら、群間の平均を比較することを含む。継続的応答、例えば、「ベースラインLDL−Cからのパーセント変化」が測定され、分類変数(ここでは、遺伝子型カテゴリー)がスコア付けされる。応答中の変動は、分類における効果によるものとして説明され、ランダムなエラーが残りの変動を説明する(継続的な結果を説明する上で、先験的に、重要であると認められない効果)。これらの技術の統計学的な理論は十分に確立されており、応用的な統計学的問題においてこれらのツールが一般に使用される(例えば、Fisher,R.A.(1942),The design of Experiments,3d edition,Edinburgh:Oliver and Boydを参照。)。特に、SASソフトウェアプログラムは、その手順の幾つかにおいて、これらの統計学的方法の多くを実装している。これに関して、ツールPROC GLM、PROC FREQ及びPROC HAPLOTYPESを実装したSASは、関連分析において、及びその後関連分析において使用することが可能なハプロタイプの特定において特に有用である。他のソフトウェア及び統計学的方法が、関連分析の実施に際して使用することができ、本分野において周知である。薬物応答性表現型測定などのベースラインパラメータ、例えば、LDL−Cレベル、性別、年齢及び人種が有意な効果を生じるからどうかを決定するために、それらを調べることが可能である。別の実施形態において、関連分析は、より一般的な「General Linear Model」ツール:PROC GLMを用いて行われる。SAS PROC GLMツールによって、別の観察された連続変数(例えば、ここでは、「ベースラインLDL−Cレベル」)によって説明される変動を、ベースラインLDL−C結果からのパーセント変化の分析へ考慮に入れることが可能となる。関連分析に関するさらなる詳細は、本明細書の実施例3に記されている。
【0130】
VI.診断キット
本発明のキットは、例えば、ハイブリダイゼーションプローブ、制限酵素(例えば、RFLP分析用)、又は対立遺伝子特異的オリゴヌクレオチド、本明細書に記載されているSNP若しくはハプロタイプ中に含まれる少なくとも1つの遺伝的マーカーを含むプローブ若しくはASO、SNP若しくはハプロタイプ配列を含有するNPC1L1を含む核酸の増幅用手段及びNPC1L1の核酸配列を分析するための手段など、本明細書に記載されている方法の何れかにおいて有用な成分を含む。さらに、キットは、本発明の方法と組み合わせて使用されるべきアッセイのための試薬、例えば、総コレステロール、非高密度脂質−コレステロール(非HDL−c)、低密度脂質−コレステロール(LDL−c)、LDL−c:HDL−c比率、トリグリセリド、血液ヘモグロビンAlc及びアポリポタンパク質Bの1つ又はそれ以上を決定する上で使用するための試薬を提供することが可能である。
【0131】
診断の方法において有用なキット(例えば、試薬キット)は、例えば、本明細書に記載されているハイブリダイゼーションプローブ又はプライマー(例えば、標識されたプローブ又はプライマー)、標識された分子の検出用試薬、(例えば、RFLP分析用の)制限酵素、対立遺伝子特異的オリゴヌクレオチド、NPC1L1を含む核酸の増幅のための手段、NPC1L1核酸の核酸配列を分析するための手段、使用説明書などを含む、本明細書に記載されている方法の何れかにおいて有用な成分を含む。
【0132】
本発明のキットは、さらに、対象から得られた生物試料から核酸試料を抽出するための溶液、緩衝液又はその他の試薬を含むことが可能である。具体例としては、核酸試料を捕捉するためのガラスビーズの懸濁液とともに組織又は細胞用の適切な溶解緩衝液及びガラスビーズから核酸試料を溶出するための溶出緩衝液は、対象から得られた生物学的試料から核酸試料を抽出するための試薬を含む。
【0133】
他の例には、GENOMIC ISOLATION KIT A.S.A.P.TM(Boehringer Mannheim,Indianapolis,Ind.)、Genomic DNA Isolation System(GIBCO BRL,Gaithersburg,Md.)、ELU−QUIK(R)DNA Purification Kit(Schleicher & Schuell,Keene,N.H.)、DNA Extraction Kit(Stratagene,La Jolla,Calif.)、TURBOGENTMIsolation Kit(Invitrogen,San Diego,Calif.)などの、市販の抽出キットが含まれる。製造業者の指示書に従ったこれらのキットの使用は、一般的に、本発明の方法を実施する前のDNAの精製に対して許容される。
【0134】
一実施形態において、本発明は、対象中のNPC1L1機能に影響を与える薬物に対する対象の応答性を予測するために対象から得られた試料をアッセイするためのキットであり、本キットは、NPC1L1遺伝子と関連するエゼチミブ応答予測的SNP又はハプロタイプを検出するための1つ又はそれ以上の試薬を含む。特定の実施形態において、前記キットは、例えば、g.−18C>Aなど、エゼチミブ応答予測的SNP又はハプロタイプの少なくとも1つを含む領域に対して完全に相補的である少なくとも1つの連続するヌクレオチド配列、エゼチミブ応答予測的SNP又はハプロタイプの1つ又はそれ以上を検出することが可能な1つ又はそれ以上の核酸を含むことが可能である。このような核酸(例えば、オリゴヌクレオチドプライマー)は、エゼチミブ応答性又はNPC1L1コレステロール関連機能に影響を与える他のあらゆる化合物の応答性の指標であるSNPに隣接する核酸の一部を用いて設計することが可能である。このような核酸(例えば、オリゴヌクレオチドプライマー)は、コレステロール関連症状に対するエゼチミブ応答予測的SNP又はハプロタイプと関連するNPC1L1核酸(及び/又は隣接配列)の領域を増幅するために設計される。別の実施形態において、前記キットは、NPC1L1遺伝子と関連する1つ又はそれ以上のエゼチミブ応答予測的SNP又はハプロタイプを検出することが可能な1つ又はそれ以上の標識された核酸と、及び標識の検出用試薬とを含む。適切な標識には、例えば、放射性同位体、蛍光標識、酵素標識、酵素補因子標識、磁気標識、スピン標識、エピトープ標識が含まれる。適切なエゼチミブ応答予測的SNPには、g.−18C>A及びg.1679C>Gが含まれ、適切なハプロタイプには、[A(−133)、A(−18)、G(1679)]又は[G(−133)、C(−18)、C(1679)]が含まれる。
【0135】
幾つかの実施形態において、キット中のオリゴヌクレオチドのセットは、対立遺伝子特異的オリゴヌクレオチドである。本明細書において使用される対立遺伝子特異的オリゴヌクレオチド(ASO)という用語は、十分にストリンジェントな条件下で、異なる対立遺伝子を含有する同じ領域ひハイブリダイズせずに、多型部位を含有する標的領域において、多型部位の1つの対立遺伝子に特異的にハイブリダイズすることが可能なオリゴヌクレオチドを意味する。対立遺伝子の特異性は、塩及びホルムアミド濃度並びにハイブリダイゼーション及び洗浄工程の両方に対する温度など、容易に最適化される様々なストリンジェンシー条件に依存する。ASOプローブ及びプライマーに対して典型的に使用されるハイブリダイゼーション及び洗浄条件の例は、「Kogan et al,“Genetic Prediction of Hemophilia A” in PCR PROTOCOLS,A GUIDE TO METHODS AND APPLICATIONS,Academic Press,1990,and Ruano et al,Proc.Natl.Acad.Sci.USA 87:6296−300(1990)」に見出される。
【0136】
典型的には、ASOは、ある対立遺伝子に対して完全に相補的であるが、別の対立遺伝子に対して単一のミスマッチを含有する。ASOプローブにおいて、単一のミスマッチは、標的領域中の多型部位と並列しているので、単一のミスマッチは、好ましくは、オリゴヌクレオチドプローブの中央位置内に存在する(例えば、16塩基のASOプローブ中の概ね8番目又は9番目の位置並びに20塩基のASOプローブ中の10番目又は11番目の位置)。ASOプリマー中の単一のミスマッチは、3’末端のヌクレオチドに位置し得るが、好ましくは、3’の最後から2番目のヌクレオチドに位置する。コード鎖又は非コード鎖の何れかにハイブリダイズするASOプローブ及びプライマーが、本発明によって想定される。非コード鎖にハイブリダイズするプライマーは、本明細書において、フォワードプライマーと称され、コード鎖にハイブリダイズするプライマーは、本明細書において、リバースプライマーと称される。
【0137】
他の実施形態において、前記キットは、アッセイされるべき各多型部位に対する対立遺伝子特異的オリゴヌクレオチドの対を含み、前記対の1つのメンバーは一方の対立遺伝子に対して特異的であり、他のメンバーは他の対立遺伝子に対して特異的である。このような実施形態において、キットの使用者が、何れの対立遺伝子特異的オリゴヌクレオチドが標的領域に特異的にハイブリダイズしたかを決定し、従って、何れの対立遺伝子が、アッセイされた多型部位において、前記個体中に存在するかを決定するかを決定できるようにするために、前記対中のオリゴヌクレオチドは異なる長さを有し、又は異なる検出可能な標識を有し得る。
【0138】
表1に示されているNPC1L1マーカー中の各多型部位における対立遺伝子を検出するための典型的なASOプローブは、表2A及び2B中に列記されているASOプローブ配列又はそれらの相補物を含む。表2A及び2Bは、対立遺伝子特異的PCRによるこれらのNPC1L1多型部位を遺伝子決定するための好ましいASOフォワード及びリバースプライマーを含む配列も列記する。
【0139】
さらに別の実施形態において、キット中のオリゴヌクレオチドは、ポリメラーゼによって媒介される伸長法で使用するためのプライマー伸長オリゴヌクレオチドである。これらのオリゴヌクレオチドの何れかから得られるポリメラーゼ媒介性伸長に対する終結混合物は、多型部位に存在する別のヌクレオチドに応じて、目的の多型部位又はその1つ後の塩基においてオリゴヌクレオチドの伸長を終結するように選択される。表2A及び2Bは、表1に示されているNPC1L1マーカー中の各多型部位において対立遺伝子を検出するための好ましいフォワード及びリバースプライマー伸長オリゴヌクレオチドを含む配列も列記している。
【0140】
【表2】
【0141】
【表3】
【0142】
表2A及び2B中の配列は、プローブ又はプライマーが、対応するオリゴヌクレオチド位置に2つの択一的対立遺伝子のうちの1つを含有することを示すために、各多型部位における表記択一的対立遺伝子に対して一般的に受容されている記号を使用する。これらの記号は、K=G又はT/U;M=A又はC;R=G又はA;S=G又はC及びY=T/U又はCである(World Intellectual Property Organization Handbook on Industrial Property Information and Documentation,Standard ST.25 1998)。
【0143】
さらなる実施形態において、キット中のオリゴヌクレオチドは、TaqMan Systemに対して対立遺伝子識別アッセイを行うために設計されている。このようなアッセイは、典型的には、PCRプライマーの対(主要対立遺伝子を検出するために蛍光的に標識されたプローブ及び非主要対立遺伝子を検出するために蛍光的に標識された異なるプローブ)を使用する。実施例中の表3は、TaqManSystemを用いて、NPC1L1マーカー中のSNPをアッセイするための好ましいオリゴヌクレオチドを列記する。
【0144】
本発明の方法及びキットには、以下の具体的な実施形態が含まれる。
【0145】
1.血漿コレステロールの健康リスクレベルに対する感受性についてヒト個体を検査する方法であり、前記個体のニーマンピックC1様1(NPC1L1)遺伝子中の配列番号1の34,067位におけるグアニンの存在又は不存在を検出すること、及びグアニンが前記個体中に存在するか、又は存在しないかを示す前記個体に対する検査報告を生成することを含む。幾つかの実施形態において、検査報告は、検査研究室によって作成された書面であり、ハードコピーとして又は電子メールを介して、前記個体又は個体の医師に送付される。他の実施形態において、検査報告は、コンピュータプログラムによって作成され、医師の職場中のビデオモニター上に表示される。検査報告は、患者又は患者の医師又は医師の職場において権限を有する従業員へ直接、検査結果を口頭伝達することも含み得る。同様に、検査報告は、患者のファイル中に医師が作製する検査結果の記録を含み得る。好ましい実施形態において、グアニンが存在すれば、検査報告は、さらに、検査を受けた個体が、血漿コレステロールの健康リスクレベルと関連する多型に対して陽性であることをさらに示す。別の好ましい実施形態において、グアニンが存在しなければ、検査報告は、検査を受けた個体が、血漿コレステロールの健康リスクレベルと関連する多型に対して陰性であることをさらに示す。検査報告は、個体によって指定された医師に、又はその個別のNPC1L1遺伝子が検査されている個体に送付され得る。特に好ましい実施形態において、前記個体は、白色人種であると自ら特定されている。
【0146】
2.NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するニーマンピックC1様1(NPC1L1)遺伝子中のマーカーの存在又は不存在に対するヒト個体を検査する方法であり、前記個体から得られた生物学的試料に対して、LDL−C応答と関連するNPC1L1遺伝子中の対立遺伝子のコピー数を決定すること、遺伝的マーカーの存在又は不存在を前記個体に対して割り当てるために前記決定されたコピー数を使用すること、及び前記個体中にNPC1L1マーカーが存在するか、又は存在しないかを示す検査報告を作成することを含む、前記方法。好ましくは、NPC1L1マーカーの存在が個体に対して割り当てられた場合には、さらに、検査報告は、個体が、NPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を示す可能性があることを示し、NPC1L1マーカーの不存在が個体に対して割り当てられた場合には、さらに、検査報告は、個体が、NPC1L1アンタゴニストに対する平均LDL−C応答を示す可能性があることを示す。検査報告は、個体によって指定された医師又はNPC1L1遺伝子が検査されている個体に送付され得る。特に好ましい幾つかの実施形態において、前記個体は、白人であると自ら特定されている。他の特に好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブである。
【0147】
a.幾つかの好ましい実施形態において、対立遺伝子は、(1)配列番号の5,400位のアデニン、(2)配列番号1の7,096位のグアニン又は(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンを含む。対立遺伝子に対して決定されたコピー数が1又は2であれば、NPC1L1マーカーの存在が個体に対して割り当てられ、対立遺伝子に対して決定されたコピー数が0であれば、NPC1L1マーカーの不存在が個体に対して割り当てられる。
【0148】
b.別の好ましい実施形態において、対立遺伝子は、それぞれ、配列番号1の5,285、5,400及び7,096位のグアニン、シトシン及びシトシンを含み、対立遺伝子に対して決定されたコピー数が0であれば、NPC1L1マーカーの存在が個体に対して割り当てられ、対立遺伝子に対して決定されたコピー数が1又は2であれば、NPC1L1マーカーの不存在が個体に対して割り当てられる。
【0149】
c.このセクションA.2の(a)又は(b)において、ハロタイプ対立遺伝子に対してコピー数を決定することは、好ましくは、配列番号1の5,285、5,400及び7,096位に対して個体の遺伝子型を取得すること及びこれらの位置に対する個体のハプロタイプ対を推測するためにコンピュータプログラムを実行するコンピュータ中に遺伝子型を入力することを含む。
【0150】
3.ニーマンピックC1様1(NPC1L1)遺伝子のアンタゴニストに対するヒト個体のLDL−C応答を予測する方法であり、アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの、前記個体における存在又は不存在を決定すること、決定工程の結果に基づいて予測を作成することを含み、NPC1L1マーカーが存在すれば、予測は、個体がNPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を示す可能性があるという予測であり、NPC1L1マーカーが存在しなければ、予測は、個体がNPC1L1アンタゴニストに対する平均LDL−C応答を示す可能性があるという予測である。予測は、個体又は個体を治療している医師に対して報告され得る。幾つかの特に好ましい実施形態において、前記個体は、白人であると自ら特定されている。他の特に好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブである。
【0151】
a.幾つかの好ましい実施形態において、NPC1L1マーカーは、(1)配列番号1の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。
【0152】
b.別の好ましい実施形態において、NPC1L1マーカーは、それぞれ、配列番号1の5,285、5,400及び7,096位にグアニン、シトシン及びシトシンの0コピーを含む。
【0153】
c.本セクションA.3の(a)又は(b)に規定されているNPC1L1マーカーの存在又は不存在を決定することは、好ましくは、検査研究室によって検査が実施されるように命令すること、及びNPC1L1マーカーが個体中に存在又は不存在であるかどうかを示す検査報告を研究室から受領することを含む。
(i)好ましくは、前記検査は、個体から得られた生物学的試料について、配列番号1の5,285、5,400及び7,096位に対して個体の遺伝子型を決定すること、決定された遺伝子型から、これらの位置に対する個体のハプロタイプ対を推測すること、並びに推測されたハプロタイプ対からNPC1L1マーカーの存在又は不存在を前記個体に対して割り当てることを含み、ここにおいて、推測されたハプロタイプ対がアデニン、アデニン及びの少なくとも1コピー又はグアニン、シトシン及びシトシンの0コピーを含有すれば、NPC1L1マーカーの存在が個体に割り当てられ、推測されたハプロタイプ対がアデニン、アデニン及びグアニンの0コピーを含有し、又はグアニン、シトシン及びシトシンの少なくとも1コピーを含有すれば、NPC1L1マーカーの不存在が個体に割り当てられる。好ましくは、配列番号1の5,285、5,400及び7,096位について、前記決定された遺伝子型を参照ハプロタイプ対のセットと比較するコンピュータプログラムを実行し、個体中に存在する可能性が最も高いセットから得られた参照ハプロタイプ対を前記決定された遺伝子型に割り当てるコンピュータ中に前記決定された遺伝子型を入力することによって、ハプロタイプ対が推測される。
【0154】
4.NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するヒトニーマンピックC1様1(NPC1L1)遺伝子中の遺伝的マーカーを検出するためのキットであり、本キットは、NPC1L1マーカー中の各多型部位(PS)に対立遺伝子の各々を同定するために設計されたオリゴヌクレオチドのセットを含む。好ましくは、NPC1L1アンタゴニストはエゼチミブである。
【0155】
a.幾つかの実施形態において、NPC1L1マーカーは、(i)配列番号1の5,285位に多型部位を含む。
【0156】
b.別の好ましい実施形態において、NPC1L1マーカーは、さらに、配列番号5,400及び7,096位の各々に多型部位を含む。
【0157】
(1)このキットは、好ましくは、さらに、配列番号1の5,285、5,400及び7,096位における試料の遺伝子型を決定するために、ヒト核酸試料に対して1つ又はそれ以上の反応を実施するための指示書とともにマニュアルを含む。より好ましくは、キットは、さらに、配列番号1の5,285、5,400及び7,096位に対するハプロタイプ対を試料に割り当てるために前記決定された遺伝子型を使用する工程をコンピュータに実施させるために、コンピュータ読み取り可能なプログラムがその上に保存されたコンピュータ使用可能な媒体を含む。
【0158】
(2)特に好ましい一実施形態において、オリゴヌクレオチドのセットは、5,285位のアデニン及びグアニン対立遺伝子の各々、5,400位のシトシン及びアデニン対立遺伝子の各々、並びに7,096位のシトシン及びグアニン対立遺伝子の各々に対する対立遺伝子特異的オリゴヌクレオチド(ASO)プローブを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号161を含む第一のASOプローブ、配列番号166を含む第二のASOプローブ及び配列番号171を含む第三のASOプローブを含む。
【0159】
(3)特に好ましい第二の実施形態において、オリゴヌクレオチドのセットは、各多型部位に対するプライマー伸長オリゴヌクレオチドを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号164を含む第一のプライマー伸長オリゴ、配列番号165を含む第二のプライマー伸長オリゴ、配列番号169を含む第三のプライマー伸長オリゴ、配列番号170を含む第四のプライマー伸長オリゴ、配列番号174を含む第五のプライマー伸長オリゴ、及び配列番号175を含む第六のプライマー伸長オリゴを含む。
【0160】
(4)特に好ましい第三の実施形態において、オリゴヌクレオチドのセットは、PCRプライマーの第一の対及び5,285位を遺伝子型決定するために設計されたASOプローブの第一の対、PCRプライマーの第二の対及び5,400位を遺伝子型決定するために設計されたASOプローブの第二の対並びにPCRプライマーの第三の対及び配列番号1の7,096位を遺伝子型決定するために設計されたASOプローブの第三の対を含む。好ましくは、PCRプライマーの第一の対は、配列番号104を含むオリゴヌクレオチドと配列番号105を含むオリゴヌクレオチドからなり、プローブ配列の第一の対は、配列番号106を含むオリゴヌクレオチドと配列番号107を含むオリゴヌクレオチドからなり、PCRプライマーの第二の対は、配列番号108を含むオリゴヌクレオチドと配列番号109を含むオリゴヌクレオチドからなり、プローブ配列の第二の対は、配列番号110を含むオリゴヌクレオチドと配列番号111を含むオリゴヌクレオチドからなり、PCRプライマーの第三の対は、配列番号112を含むオリゴヌクレオチドと配列番号113を含むオリゴヌクレオチドからなり、及びプローブ配列の第三の対は、配列番号114を含むオリゴヌクレオチドと配列番号115を含むオリゴヌクレオチドからなる。
【0161】
5.LDL−Cの健康リスクレベルと関連するヒトニーマンピックC1様1(NPC1L1)遺伝子中の遺伝的マーカーを検出するためのキットであり、本キットは、配列番号1の28,650位の対立遺伝子の各々を同定するために設計されたオリゴヌクレオチドのセットを含む。
【0162】
a.好ましい一実施形態において、オリゴヌクレオチドのセットは、28,650位のアデニン及びグアニン対立遺伝子の各々に対する対立遺伝子特異的オリゴヌクレオチド(ASO)プローブを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号156を含む第一のASOプローブ(R=アデニン)及び配列番号156を含む第二のASOプローブ(R=グアニン)を含む。
【0163】
b.第二の好ましい実施形態において、オリゴヌクレオチドのセットは、28,650位のアデニン及びグアニン対立遺伝子の各々に対するプライマー伸長オリゴヌクレオチドを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号159を含む第一のプライマー及び配列番号160を含む第二のプライマーを含む。
【0164】
b.第三の好ましい実施形態において、オリゴヌクレオチドのセットは、PCRプライマーの対及び28,650位の遺伝子型を決定するために設計されたASOプローブの対を含む。好ましくは、PCRプライマーの対は、配列番号152を含むオリゴヌクレオチド及び配列番号153を含むオリゴヌクレオチドからなり、並びにASOプローブの対は、配列番号154を含むオリゴヌクレオチド及び配列番号155を含むオリゴヌクレオチドからなる。
【0165】
上述されているように、コレステロールレベルは、様々な遺伝的要因と環境的要因によって決定される。高いコレステロールレベルを有する個体は、冠動脈疾患、急性冠症候群、大動脈瘤、下肢の動脈疾患及び脳血管疾患などの血管系疾患の基礎を為す主な要因であるアテローム性動脈硬化症を発症する増加したリスクを有する。従って、コレステロールの管理は、コレステロールを低下させることにより、アテローム性動脈硬化症を予防する薬物の早期及び定期的な使用に依存する。結果として、高いコレステロールを有する患者に対する効率的及び安全な治療の機会に対する必要性が存在する。現在では、コレステロール生合成を阻害するスタチン及びコレステロールの腸吸収を阻害するエゼチミブという、コレステロール薬の2つの主なカテゴリーが存在する。全ての個体が、スタチン若しくはエゼチミブの何れか、又はこれらの組み合わせに対する同一の応答を示す。従って、一実施形態において、本発明のキットは、1つ又はそれ以上の薬物に対する有益な応答を示す個体を特定するために使用される。他の実施形態において、前記キットは、臨床試験の実施において使用される。
【0166】
一態様において、本発明は、高コレステロール又は高コレステロールを伴う疾病の治療のための療法の臨床試験の亜群においてヒト対象を階層化するための方法を提供する。本発明の方法は、配列番号1のヌクレオチド位5,400におけるヒト対象のNPC1L1遺伝子の遺伝子型を決定することを含む。対象は、NPC1L1遺伝子の配列番号1の5,400位に存在するヌクレオチド塩基に基づいて、臨床試験の1つ又はそれ以上の亜群へ階層化される。別の実施形態において、5,285位、5,400位、7,096位及び34,067位からなる群から選択される1つ又はそれ以上のNPC1L1ヌクレオチド位置における遺伝子型の決定に基づいて、本方法が実施される。
【0167】
別の態様において、高コレステロール薬又は治療の臨床試験に含めるための個体を選択する方法が提供される。本方法は、個体から核酸試料を取得すること、核酸試料中のNPC1L1関連一塩基多型における多型塩基の種類を決定すること(ここにおいて、多型塩基の種類は、NPC1L1関連一塩基多型における個体の遺伝子型を決定し、NPC1L1関連一塩基多型は配列番号1中に位置する。)、NPC1L1関連一塩基多型が、前記同定された多型を有しない者に比べて、薬物又は治療に対する平均応答より高い応答又は平均応答より低い応答を伴うかどうかを決定すること、並びに核酸試料が薬物若しくは治療に対する平均応答より高い応答と関連する少なくとも1つの一塩基多型を含有しているか、又は核酸試料が薬物若しくは治療に対する平均応答より低い応答と関連する少なくとも1つの一塩基多型を欠如していれば、前記個体を臨床試験に含めることを含む。
【0168】
VI.治療計画
増加したエゼチミブ応答と関連する本発明のNPC1L1マーカーは、医師が上昇したLDL−Cを有する患者に対する具体的な治療計画の有効性を予測するのを補助するのに有用である。マーカー情報は、LDL−Cの既存レベル及びLDL−Cの所望されるレベルなどの他の患者情報と協同して使用される。
【0169】
NPC1L1マーカー情報に基づいて好まれ得る可能な患者治療計画の例には、より低いスタチン容量(又はその他のLDL−C低下薬)及び/又はより高いNPC1L1アンタゴニスト用量の使用が含まれる。例えば、所望されるLDL−Cの低下に応じて、患者検査が薬物応答マーカーに対して陽性である幾つかの事例では、医師は、単独療法としてのNPC1L1アンタゴニストを使用して、又はNPC1L1アンタゴニストと組み合わせた、より低いスタチンレベルを使用して処方することを決定し得る。あるいは、マーカーが存在しないのであれば、医師は、NPC1L1アンタゴニストのより高い用量及び/又はNPC1L1アンタゴニストを伴うより長い治療計画を使用することを検討し得る。
【0170】
特定の患者に対して医師によって考案された治療アルゴリズムは、典型的には、血管疾患に対する他のリスク因子の存在、血管疾患の症候並びにNPC1L1アンタゴニスト及び他のコレステロール低下薬による療法に対する患者の耐性など、他の患者特異的要因の考慮を取り込む。例えば、幾つかの実施形態において、患者は、血漿LDL−Cの健康リスクレベルを有する。他の実施形態において、患者は、血漿LDL−Cの健康リスクレベルと相関する遺伝的マーカーに対して陽性であると検査され、LDL−Cに対する他のリスク因子も有し得る。さらなる実施形態において、患者は、別のコレステロール低下薬を用いた以前の療法後に、コレステロールの健康リスクレベルを有する。エゼチミブなどのNPC1L1アンタゴニストとともに処方することが可能な好ましいコレステロール低下薬には、HMGCoA還元酵素活性を阻害する化合物のクラスであるスタチンが含まれる。
【0171】
典型的なスタチンには、米国特許第3,983,140号に開示されているようなメバスタチン及び関連化合物、米国特許第4,231,938号に開示されているようなロバスタチン(メビノリン)及び関連化合物、米国特許第4,346,227号に開示されているようなプラバスタチン及び関連化合物、米国特許第4,448,784号及び同第4,450,171号に開示されているようなシンバスタチン及び関連化合物が含まれるが、これらに限定されるものではない。本発明に使用され得る他のHMGCoA還元酵素阻害剤には、米国特許第5,354,772号に開示されているフルバスタチン、米国特許第5,006,530号及び同第5,177,080号に開示されているセリバスタチン、米国特許第4,681,893号、同第5,273,995号、同第5,385,929号及び同第5,686,104号に開示されているアトロバスタチン、米国特許第5,011,930号に開示されているピタバスタチン(Nissan/Sankyoのニスバスタチン(Ne−104)又はイタバスタチン)、米国特許第5,260,440号に開示されているShionogi−AstratZenecaロスバスタチン(ビサスタチン(ZD−4522))、及び米国特許第5,753,675号に開示されている関連スタチン化合物、米国特許第4,613,610号中に開示されているメバロノラクトン誘導体のピラゾール類縁体、PCT出願WO86/03488号に開示されているメバロノラクトン誘導体のインデン類縁体、米国特許第4,647,576号に開示されている6−[2−(置換されたピロール−1−イル)−アルキル)ピラン−2−オン及びその誘導体、SearleのSC−45355(3置換されたペンタン二酸誘導体)二クロロアセタート、PCT出願WO86/07054号に開示されているメバロノラクトンのイミダゾール類縁体、フランス特許2,596,393号に開示されている3−カルボキシ−2−ヒドロキシ−プロパン−ホスホン酸誘導体、欧州特許出願0221025号に開示されている1,3−二置換された、ピロール、フラン及びチオフェン誘導体、米国特許第4,686,237号に開示されているメバロノラクトンのナフチル類縁体、米国特許第4,499,289号に開示されているようなオクタヒドロナフタレン、欧州特許出願0,142,146A2号に開示されているメビノリンのケト類縁体(ロバスタチン)並びに米国特許第5,506,219号及び同第5,691,322号に開示されているキノリン及びピリジン誘導体が含まれるが、これらに限定されない。
【0172】
本方法の別の実施形態において、高コレステロール療法は、NPC1L1タンパク質に結合する化合物を用いた治療である。典型的には、NPC1L1結合化合物による治療は、治療を受けている対象中の低密度脂質コレステロールのレベルの減少をもたらす。本発明の方法のさらに別の実施形態において、高コレステロール療法は、エゼチミブなどのNPC1L1媒介性薬物治療とスタチン薬物治療を組み合わせた二重療法である。
【0173】
VII.典型的なNPC1L1アンタゴニスト
本発明の幾つかの態様は、例えば、直接又は間接に、NPC1L1によって媒介される腸コレステロールの吸収を妨害する薬物など、NPC1L1の活性に影響を与える薬物に対する対象の応答性に接近するのに有用である。本発明の1つの具体的な実施形態において、NPC1L1アンタゴニストはエゼチミブである。エゼチミブは、コレステロール及び関連の植物ステロールの腸吸収を選択的に阻害する、アゼチジノンとして知られる脂質低下化合物のクラスに属する。エゼチミブの化学名は、1−(4−フルオロフェニル)−3(R)−[3−(4−フルオロフェニル)−3(S)−ヒドロキシプロピル]−4(S)−(4−ヒドロキシフェニル)−2−アゼチジノンである。実験式は、C24H21F2NO3である。
【0174】
一実施形態において、NPC1L1アンタゴニストは、構造式I:
【0175】
【化1】
若しくはそれらの異性体、又は式(I)の化合物若しくはそれらの異性体の、医薬として許容される塩若しくは溶媒和物又は式(I)の化合物の、若しくはそれらの異性体、塩若しくは溶媒和物のプロドラッグによって表され、上記式(I)において、
Ar1及びAr2は、アリール及びR4置換されたアリールからなる群から独立に選択され;
Ar3は、アリール又はR5置換されたアリールであり;
X、Y及びZは、−CH2−、−CH(低級アルキル)−及び−C(二低級アルキル)−からなる群から独立に選択され;
R及びR2は、−OR6、−O(CO)R6、−O(CO)OR9及び−O(CO)NR6R7からなる群から独立に選択され;
R1及びR3は、水素、低級アルキル及びアリールからなる群から独立に選択され;
qは、0又は1であり;
rは、0又は1であり;
m、n及びpは、独立に、0、1、2、3又は4から選択され;但し、q及びrの少なくとも1つは1であり、並びにm、n、p、q及びrの合計は、1、2、3、4、5又は6であり;並びに、但し、pが0である場合には、rは1であり、m、q及びnの合計は、1、2、3、4又は5であり;
R4は、低級アルキル、−OR6,−O(CO)R6,−O(CO)OR9、−O(CH2)1−5OR6、−O(CO)NR6R7、−NR6R7、−NR6(CO)R7、−NR6(CO)OR9、−NR6(CO)NR7R8、−NR6SO2R9、−COOR6、−CONR6R7、−COR6、−SO2NR6R7、S(O)0−2R9、−O(CH2)1−10−COOR6、−O(CH2)1−10CONR6R7、−(低級アルキレン)COOR6、−CH=CH−COOR6、−CF3、−CN、−NO2及びハロゲンからなる群から独立に選択される1〜5個の置換基であり;
R5は、−OR6、−O(CO)R6、−O(CO)OR9、−O(CH2)1−5OR6、−O(CO)NR6R7、−NR6R7、−NR6(CO)R7、−NR6(CO)OR9、−NR6(CO)NR7R8、−NR6SO2R9、−COOR6、−CONR6R7、−COR6、−SO2NR6R7、S(O)0−2R9、−O(CH2)1−10−COOR6、−O(CH2)1−10CONR6R7、−(低級アルキレン)COOR6及び−CH=CH−COOR6からなる群から独立に選択される1〜5個の置換基であり;
R6、R7及びR8は、水素、低級アルキル、アリール及びアリール置換された低級アルキルからなる群から独立に選択され;並びに
R9は、低級アルキル、アリール又はアリール置換された低級アルキルである。
【0176】
別の実施形態において、アゼチジノン又は置換されたβラクタムは、構造式II:
【0177】
【化2】
又は医薬として許容されるその塩若しくは溶媒和物、又は式(II)の化合物の、若しくはその塩若しくは溶媒和物のプロドラッグによって表される。
【0178】
本発明の一実施形態において、前記薬物又は化合物には、米国特許出願公報US2002/0151536A1に開示されている全てのアゼチジノン若しくは置換されたβラクタム又は米国特許第5,756,470号に記載されている全ての糖置換された2−アゼチジノンが含まれる。
【0179】
VIII.さらなる実施形態
さらなる実施形態において、本発明は、血漿コレステロールの健康リスクレベルに対する感受性について対象を検査する方法を提供する。本方法は、対象のNPC1L1遺伝子中における配列番号1の34,067位のグアニンの存在又は不存在を検出すること、及びグアニンが対象中に存在するか又は存在しないかを示す、対象に対する検査報告を作成することを含む。好ましい実施形態において、グアニンが存在すれば、検査報告は、血漿コレステロールの健康リスクレベルに対して対象が感受性であることを示す。別の好ましい実施形態において、グアニンが存在しなければ、検査報告は、検査を受けた対象が、血漿コレステロールの健康リスクレベルと関連する多型に対して陰性であることを示す。
【0180】
別の態様において、本発明は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの存在又は不存在について、ヒト対象を検査する方法を提供する。本方法は、対象のNPC1L1遺伝子における、前記応答と関連する対立遺伝子のコピー数を決定すること、前記対象をNPC1L1マーカーの存在又は不存在に割り当てるために、決定されたコピー数を使用すること、及びNPC1L1マーカーが個体中に存在するか、又は存在しないかを示す検査報告を作成することを含む。「コピー数を決定すること」という用語は、対象のNPC1L1遺伝子の少なくとも1コピーの遺伝子型が決定されており、従って、対象のNPC1L1遺伝子の両コピーの遺伝子型が決定されている必要性は存在しないが、典型的には、両コピーの遺伝子型が決定される必要性が存在することを意味することになっている。従って、本明細書に示されているように、本発明のNPC1L1マーカーの1コピーの存在を決定することが、本発明の実施のために十分である。一実施形態において、対立遺伝子は、配列番号1の5,400のアデニン又は配列番号1の7,096位のグアニンを含み、対立遺伝子に対する対象のコピー数が1又は2であれば、NPC1L1マーカーの存在が対象に対して割り当てられるのに対して、対立遺伝子に対する対象のコピー数が0であれば、NPC1L1マーカーの不存在が対象に対して割り当てられる。好ましくは、対立遺伝子は、それぞれ、配列番号1の5,285位、5,400位及び7,096位にアデニン、アデニン及びグアニンを含む。別の実施形態において、対立遺伝子は、それぞれ、配列番号1の5,285位、5,400位及び7,096位のグアニン、シトシン及びシトシンを含み、対立遺伝子に対する対象のコピー数が0であれば、NPC1L1マーカーの存在が対象に対して割り当てられ、対立遺伝子に対する対象のコピー数が1又は2であれば、NPC1L1マーカーの不存在が対象に対して割り当てられる。好ましい実施形態において、NPC1L1マーカーの存在が対象に対して割り当てられた場合には、検査報告は、さらに、対象が、NPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を示す可能性があることを示し、NPC1L1マーカーの不存在が対象に対して割り当てられた場合には、検査報告は、対象が、NPC1L1アンタゴニストに対する平均LDL−C応答を示す可能性があることを示す。
【0181】
さらに別の態様において、本発明は、NPC1L1アンタゴニストに対する対象のLDL−C応答を予測する方法を提供する。本方法は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの、対象における存在又は不存在を決定すること、及び決定工程の決定の結果に基づいて予測を行うことを含む。マーカーが存在すれば、予測は、NPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を対象が示す可能性があるというものであり、マーカーが存在しなければ、予測は、NPC1L1アンタゴニストに対する平均LDL−C応答を対象が示す可能性があるというものである。
【0182】
本発明のさらに別の態様は、LDL−Cを低下させることを必要とする患者に対する療法を選択する方法を提供することである。本方法は、NPC1L1マーカーの患者における存在又は不存在を決定すること、及び決定工程の結果に基づいて療法を選択することを含む。
【0183】
本発明の別の態様は、ヒトにおいてLDL−Cを低下させるための医薬の製造におけるNPC1L1アンタゴニストの使用であり、ここにおいて、前記医薬は、NPC1L1遺伝的マーカーを有するとして同定された患者にNPC1L1アンタゴニストの有効量を送達するために設計されている。
【0184】
さらなる態様において、本発明は、NPC1L1アンタゴニストを含む医薬製剤に対して薬理遺伝学的適応症の規制当局の認可を求める方法を提供する。本方法は、NPC1L1マーカーを有する患者の第一の群が、統計的に有意な程度まで、NPC1L1マーカーを欠如する患者の第二の群の平均LDL−C応答より高い、アンタゴニストに対する平均LDL−C応答を示すことを実証すること、NPC1L1マーカーが患者中に存在するか、又は存在しないかに基づいて、患者に対する製剤の出発用量を選択することを推奨するラベルとともに製剤を市販するための認可に対する申請を規制当局に提出することを含む。
【0185】
さらなる態様において、本発明は、NPC1L1遺伝子中の遺伝的バリアントがNPC1L1アンタゴニストの効力と相関するかどうかを決定する方法を提供する。一実施形態において、本方法は、アンタゴニストで処理された個体の群において、各個体に対する効力測定を取得すること、前記群中の各個体におけるNPC1L1バリアントに対して遺伝子型を特定すること、並びに効力測定及び遺伝子型を用いて、遺伝的関連分析を実施することを含む。別の実施形態において、本方法は、遺伝的バリアントとNPC1L1マーカー中の対立遺伝子との間の連鎖不均衡の程度を測定することを含み、ここにおいて、連鎖不均衡の高い程度は遺伝的バリアントがアンタゴニストの効力と相関することを示し、連鎖不均衡の低い程度は遺伝的バリアントが前記効力と相関しないことを示す。好ましい実施形態において、効力測定は、アンタゴニストに対する個体のLDL−C応答である。
【0186】
A.薬理遺伝学的治療方法
本発明の薬理遺伝学的治療法は、表1中のNPC1L1マーカー2−5の、各々の個体における存在又は不存在を決定することを含み得る。薬理遺伝学的治療方法には、以下の具体的な実施形態が含まれる。
【0187】
血漿LDL−Cのレベルを低下させる必要があるヒト個体に対して治療法を選択する方法であり、本方法は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するヒトニーマンピックC1様1(NPC1L1)遺伝子中のマーカーの、個体における存在又は不存在を決定すること、及び決定工程の結果に基づいて、治療法を選択することを含む。幾つかの実施形態において、個体は、LDL−Cの健康リスクレベルに関連するNPC1L1マーカーに対して陽性であるか検査される。
【0188】
B.薬理遺伝学的医薬品:製造及び販売
本発明の薬理遺伝学的医薬品には、以下の具体的な実施形態が含まれる。
【0189】
1.ヒトにおいてLDL−Cレベルを低下させるための医薬の製造におけるニーマンピックC1様1(NPC1L1)のアンタゴニストの使用であり、ここにおいて、前記医薬は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーに対して陽性であるか検査を受ける患者に、NPC1L1アンタゴニストの有効量を送達するように調合される。
【0190】
a.好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブである。好ましくは、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。
【0191】
エゼチミブを含む医薬品を市販する方法であり、本方法は、ニーマンピックC1様1(NPC1L1)マーカーを考慮に入れながら、特定の出発NPC1L1アンタゴニスト(例えば、エゼチミブ)及び/又はスタチンを使用することを、目標とする対象者に対して宣伝することを含む。好ましくは、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は、(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。さらに好ましい実施形態において、宣伝を行う工程は、NPC1L1マーカーに対して患者をどのように検査するかについて、目標とする対象者に情報を提供することをさらに含む。情報は、好ましくは、規制当局によって認可された特定の検査を含む。
【0192】
2.ニーマンピックC1様1(NPC1L1)のアンタゴニストを含む医薬製剤と、並びにNPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの存在又は不存在について患者を検査すること、及び患者がLDL−C応答マーカーに対して陽性又は陰性の検査結果であるかどうかに基づいて、患者に対して、医薬品の出発用量を選択することを推奨する情報を指示することを含む、製造された医薬品。
【0193】
a.好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブであり、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は、(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。特に好ましい一実施形態において、医薬製剤は、エゼチミブと医薬として許容される担体とを含む錠剤である。好ましくは、錠剤は、スタチンの医薬的有効量をさらに含む。薬理遺伝学的医薬品を製造する方法であり、本方法は、エゼチミブを含む医薬製剤と指示情報をパッケージ中に同封することを含む。指示情報は、エゼチミブに対する増加したLDL−C応答と関連するニーマンピックC1様1(NPC1L1)遺伝子中のマーカーの存在又は不存在について患者を検査し、患者の検査結果に基づいて医薬品の出発用量を選択するための指示書を含む。
【0194】
b.好ましい一実施形態において、NPC1L1アンタゴニストはエゼチミブであり、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は、(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。
【0195】
c.別の好ましい実施形態において、医薬製剤は、さらにスタチンを含む。
【0196】
実施例
本発明の様々な特徴及び利点をさらに記すために、以下に、実施例が記載されている。本実施例は、本発明を実施するための有用な方法も例示している。これらの実施例は、特許請求の範囲に記載されている発明を限定するものではない。
【0197】
ヒトNPC1L1遺伝子は染色体7p13にマッピングされ、約29kbに及び、20個のエキソンを含有する(Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。公的なSNPマッピングへの尽力を通じて、NPC1L1内に幾つかの一塩基多型(SNP)が報告されている(http://www.ncbi.nlm.nih.gov/SNP)。しかしながら、これらのバリアントの機能的重要性は不明であり、比較的少数が、10%を超える報告された非主要対立遺伝子頻度(MAF)を有するに過ぎない。NPC1L1中のDNA配列の変動の程度をより完全に性質決定するために、並びにNPC1L1中の多型が選択された血液成分レベルの変化と関連しているかどうかを評価するために、とりわけ、直接的な機能的重要性を有し得る新規多型を同定するために、並びに公知及び新規の多型における対立遺伝子の頻度をよりよく推定するために、3つの異なる自己申告による民族集団に由来する多くの個体中で、遺伝子を再度配列決定した。2%を超える非主要対立遺伝子頻度を有する多数の新規及び公知の一般的バリアントに対して、遺伝子型決定アッセイが開発された。次いで、様々な血漿及び血液成分レベル、特に、エゼチミブを用いた薬物療法に応じた、総血漿コレステロール、低密度リポタンパク質コレステロール(LDL−C)、非高密度リポタンパク質コレステロール(非HDL−C)、血漿トリグリセリドレベル、血液アポリポタンパク質A−1又は血液アポリポタンパク質B(アポB)レベルの変化と、NPC1L1中のDNA配列多型が関連するかどうかを評価するために、臨床試験コホート中のこれらの多型を用いて、遺伝的関連分析を行った(実施例3、表4a−d参照)。
【0198】
NPC1L1中の変動の程度を特徴付けるために、3つの民族群を代表する375人の正常な個体において、全てのエキソン、保存された制御領域、プロモーター領域及び特定のイントロン領域の配列を再決定した。合計140のSNP及び5つの挿入/欠失が、このコホート中に同定された。これらの多型の完全なリストが、実施例1に記載されている。同定された140のSNPのうち、14は5’UTR又はプロモーター領域中に、89はイントロン中に、3つは3’UTR中に、及び34はコード領域中に位置し、これらのうち20がアミノ酸の変化をもたらす(実施例1、表4参照)。表5(実施例2)は、少なくとも1つの民族群中に検出された4%を超える非主要対立遺伝子頻度(MAF)を有する24個のSNPを列記する。遺伝子のより広いセットにわたって報告された数値と合致して、共通のSNPについて、キロ塩基当りのSNPの平均数が0.083725であり、全てのSNPにわたって6.96725であるように、NPC1L1の再配列決定された領域は20,094塩基にわたった(Crawford,et al.,2004)。上で同定されたSNPに基づいて選択された遺伝子型アッセイを用いて、NPC1L1遺伝子内のSNPのサブセット及びSNPの組み合わせ(ハプロタイプ)は、コレステロール管理薬であるエゼチミブに対するヒトの応答性を増強させることが見出された。NPC1L1中の各SNP及び3NPC1L1SNPハプロタイプ及び同じ臨床試験被験者中でのエゼチミブによる治療後のLDL−Cの減少の程度の間には、有意な関連が観察された(実施例3、表8−12参照)。
【実施例1】
【0199】
NPC1L1多型の同定
NPC1L1中のSNPを同定するために、白色人種(n=198)、黒人(n=99)又はヒスパニック(n=78)として自己申告している、健康と報告された匿名の個体から、NPC1L1のプロモーター及びコード領域を配列決定した。DNA試料は、Human Genetic Cell Repository of the National Institute for General Medical Sciences(NIGMS;Coriell Cell Repository,Camden,NJ)によって収集されたCaucasian and African American Human Variation Panels及びSchering−Plough Corporationからの匿名のドナーから取得した。全ての試料は、DNA多型発見資料の一部であるというインフォームドコンセントを与えた個体から得た。資料をまとめるために、各個体に対して民族及び性別に関する情報が収集されたが、各ドナーへの関連が不可逆的に遮断されるように、全ての身元特定情報及び表現型情報は、各試料から除外した。
【0200】
ポリメラーゼ連鎖反応
SNP発見に対する一般的な戦略は、詳述されているように修飾を加えられているが、以前に記載されているとおりである(Nickerson et al,(1998) Nat.Genet.,19:233−40)。NPC1L1コード領域の400〜650塩基対セグメント並びに5’プロモーター領域の約2キロ塩基対及びイントロン/エキソンスプライス結合部に連結する100ヌクレオチドを増幅するために、Primer3ソフトウェア(Rozen and Skaletsky,(2000) Methods MoI.Biol.,132:365−86;http://www.genome.wi.mit.edu/cgi−bin/primer/primer3.cgiで入手可能)を用いて、PCRプライマーを設計した。SNP分析用に様々なNPC1L1遺伝子領域を増幅するために使用されるフォワード及びリバースプライマーの5’尾部には、それぞれ、汎用配列決定プライマー:21M13;5’TGTAAAACGACGGCCAGT(配列番号6)及びM13REV;CAGGAAACAGCTATGACC(配列番号7)を付加した。表3は、5’尾部に汎用配列決定プライマー(配列番号6又は配列番号7)が付加されたNPC1L1PCRアッセイプライマー配列及び配列番号1に記載されているゲノムNPC1L1遺伝子配列と比較した、それらの対応する位置を示している。
【0201】
【表4】
【0202】
PCR反応は、12μLの総容量中に、Platinum PCR Supermix High Fidelity(100μMdNTPs、1.5mMMgCl2、0.1UPlatinum Taq polymerase High Fidelity,Invitrogen Corp.,Carlsbad,CA)の存在下にあるゲノムDNA(24ng)、並びに0.2pmol/μLのフォワード及びリバースプライマーを含有した。94℃で5分間の最初の変性後、94℃で30秒間の変性、30秒間のプライマーアニーリング(プライマー特異的な温度については、表3を参照。)及び68℃で1分間のプライマー伸長の35サイクルを用いて、96ウェルのマイクロプレート(PTC−200サーモサイクラー、MJ Research)中で、サーモサイクリングを行った。35サイクル後、68℃で7分間、最終伸長を実施した。
【0203】
DNA配列決定及び分析
DNA増幅後、ExoSAP−IT(USB Corporation,Cleveland,OH)0.5μLを含有するPCR緩衝液中で、PCR反応物を50μLまで希釈し、37℃で15分間温置した後、80℃で15分間、酵素の不活化を行った。フォワード及びリバース方向でのサイクル配列決定は、製造業者の指示書に従って、ABI PRISM BigDye terminator v3.1 Cycle Sequencing DNA Sequencing Kit(Applied Biosystems,Foster City,CA)を用いて行った。要約すると、各PCR産物1μLをテンプレートとして用いて、5pmolのM13配列決定プライマー(−21M13又はM13Rev)、0.5×配列決定緩衝液及び0.25μLBDTv3.1ミックスを含有する4μLの配列決定反応混合物と混合した。96℃で1分間、配列決定反応物を変性させた後、96℃で10秒間、50℃で5秒間及び60℃で4分間の25サイクルを行った。Montage SEQ384プレート(Millipore Corp.Bedford,MA)を用いたろ過によって、配列決定反応を精製し、25μLの脱イオン水中に溶解し、Applied Biosystems 3730XL DNA Analyzer上でのキャピラリーゲル電気泳動によって分離した。クロマトグラムを、Unix(登録商標)ワークステーション(DEC alpha,Compaq Corp)に移動し、Phredソフトウェア(version 0.990722.g)を用いて、呼び出された塩基を実施し、Phrap software(version 3.01)(Nickerson,et al.,(1997) Nucleic Acid Res.,25:2745−51)を用いて配列を集合し、Polyphredソフトウェア(バージョン3.5)(Nickerson,et al.,(1997) Nucleic Acid Res.,25:2745−51)を用いて走査し、Consedソフトウェア(バージョン9.0)(Gordon et al.,(1998) Genome Res.,8:195−202)を用いて、結果を図示した。分析パラメータは、全て、各ソフトウェアの初期設定に維持した。Phred、Phrap及びConsedソフトウェアプログラムは、http://www.genome.washington.eduから入手可能であり、PolyPhredソフトウェアプログラムは、http://droog.mbt.washington.eduから入手可能である。
【0204】
SNP分析の結果
ヒトNPC1L1遺伝子は染色体7p13にマッピングされ、ゲノムDNAの約29kbにわたる20エキソンを含有する。公的なSNPマッピングへの尽力を通じて、NPC1L1内に幾つかの一塩基多型(SNP)が報告されている(http://www.ncbi.nlm.nih.gov/SNP)。しかしながら、これらのバリアントの機能的重要性は不明であり、相対的に少数が、10%を超える非主要対立遺伝子頻度(MAF)を有すると報告されているに過ぎない。NPC1L1中の変動の程度を特徴付けるために、3つの民族群(再配列決定コホート)を代表する375人の正常な個体において、全てのエキソン、保存された制御領域、プロモーター領域及び特定のイントロン領域の配列を再決定した。合計140のSNP及び5つの挿入/欠失が、このコホート中に同定された。SNP名は、den Dunnen and Anonarakis((2000),Hum.Mutat.15:7−12)によって提案された慣例に従って割り当てられている。140のNPC1L1多型の完全なリストが、表4に記載されている。
【0205】
【表5】
【0206】
表4に列記されている140の多型のうち、14は5’UTR又はプロモーター領域中に、89はイントロン中に、3つは3’UTR中に、及び34はコード領域中に位置し、これらのうち20がアミノ酸の変化をもたらす(表4)。遺伝子のより広いセットにわたって報告された数値と合致して、共通のSNPについて、キロ塩基当りのSNPの平均数が0.083725であり、全てのSNPにわたって6.96725であるように、NPC1L1の再配列決定された領域は20,094塩基にわたった(Crawford,et al.,(2004) Am.J.Hum.Genet.74:610−22)。
【0207】
表5は、少なくとも1つの民族群中に検出された4%を超える非主要対立遺伝子頻度(MAF)を有する、表4から選択された24個のSNPに焦点を当てている。
【0208】
【表6】
【実施例2】
【0209】
再配列決定コホートにおけるNPC1L1遺伝子の連鎖不均衡(LD)分析
観察された遺伝子型頻度と予測された遺伝子型頻度とを比較する標準的な分割表(予測された頻度は、Haploviewソフトウェアパッケージ(Barrett,et al.,(2005) Bioinformatics,25:263−5)中に実装された正確な検定手法によって推定した。)を用いて、全ての各多型に対して、ハーディー・ワインベルグ平衡を評価した。全てのSNP対に対して図1Aに示されている、対を為す連鎖不均衡値は、Haploviewプログラムを用いて計算した。各SNPに対する観察された対立遺伝子頻度を用いて、全てのSNP対に対して、レウォンティンの不均衡係数(D’)を計算した。PHASE v2.0ソフトウェアパッケージ中に実装されたハプロタイプ再構築のためのベーズのアプローチ(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)を用いて、再配列決定コホートにおいてハプロタイプを推定した。ハプロタイプ再構築プロセスでは、MAFが4%を超えるSNPを使用した。以前に記載されているように(Crawford,et al.,(2004) Nat.Genet.,36:700−6)、Phase v2.0ソフトウェアパッケージを用いて、組換えホットスポット強度を計算した。対立遺伝子の類似性に従った群ハプロタイプとSNPに対してCrawfordら((2004) Am.J.Hum.Genet.,74:610−22)によって提供された方法の僅かな変法を用いて、民族群のそれぞれにわたって同定された8つの最も一般的なハプロタイプが同定された。次いで、集積的階層クラスタリング手法を用いて、観察された全ての染色体に対するハプロタイプを、類似性によってクラスター化した。同様に、クラスタリング手法の同じ種類を用いて、SNPを対立遺伝子の類似性によってクラスター化した(図2)。次いで、図2中の得られたグレースケールマトリックスプロットから、一般的なハプロタイプ(頻度>2%)を識別するタギングSNPを視覚的に同定した。
【0210】
各SNPに対する非主要対立遺伝子頻度が全ての民族群について等しいかどうかを決定するために、各民族群に対する非主要対立遺伝子の予測される数に基づいて、ピアソンのχ2統計指標を算出した(ここで、該予測される数は、民族群中の個体数に、コホート中の全個体にわたって観察された非主要対立遺伝子の割合を乗ずることによって概算した。)。全ての民族群にわたって頻度が同一であるという帰無仮説の下で、ピアソンのχ2統計指標は、民族群の数−1に等しい自由度の漸近χ2分布を有する。民族群の何れかにおける所定のSNPに対する非主要対立遺伝子頻度(MAF)が漸近を保持するには小さすぎる場合には、有意度を経験的に推定するために、可能であれば、順列検定を実施した。このような場合には、順列工程は、所定のコホート中の個体を、目的のSNPに対する遺伝子型に対して無作為に割り当てること、コホート中に観察された全体的対立遺伝子カウント数を保存すること、ついで、ピアソンのχ2統計指標を算出することからなった。350を超える個体に対する遺伝子型情報を有したにも関わらず、異なる民族群に対して、強固なLDブロックは明瞭には規定されなかった。図1Aは、再配列決定コホートから得た白色人種に対するLDマップを強調する。数個の物理的に隣接するSNP対に対してのみ、対を為すD’値が高かった。この図で強調されているブロックは、Four Gamete Rule(Wang,et al.,(2002) Am.J.Hum.Genet.,71:1227−34)を用いて同定されたが、この構造を実現するために、4番目の配偶子に対する最小頻度の閾値は、0.05に設定しなければならなかった。興味深いことに、この遺伝子は、45の組換えホットスポット強度を有しており、以前に記載されているように(Crawford,et al.,(2004) Nat.Genet.,74:610−22)、Phase v2.0ソフトウェアパッケージ(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)を用いて算出された。このことは、NPC1L1が、他の遺伝子に比べて、組換えの有意に増加した割合を有することを示唆する。PHASE v2.0ソフトウェアパッケージ中に実装されたハプロタイプ再構築のためのベーズのアプローチ(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)を用いて、ハプロタイプも推定した。ハプロタイプ再構築プロセスでは、MAFが4%を超えるSNPを使用した。アフリカ系アメリカ人、白色人種及びヒスパニック集団中に推測されたハプロタイプの数は、それぞれ、139、156及び189であった。この数字は、遺伝子のより大きなセットにわたる調査で報告された平均数より有意に大きく(Crawford,et al.,(2004) Am.J.Hum.Genet.,74:610−22)、標本のより大きな数から達成された増加した多様性及び本遺伝子における組換えの割合が増加した可能性を明らかにしたものである可能性が最も高い。
【0211】
アフリカ系アメリカ人、白色人種及びヒスパニック集団中の一般的なハプロタイプ(>5%頻度)の数は、それぞれ、2、4及び4であり、これらの一般的なハプロタイプは、これらの同じ集団中の染色体の53%、57%及び48%を説明した。ハプロタイプの多様性の程度は、幾つかの方法で評価した。まず、合わせた集団中で推定された345のハプロタイプのうち、3つの全ての集団間で26が共有されていた。これらの26のハプロタイプによって説明された各集団中の染色体のパーセントは、アフリカ系アメリカ人集団で73%、白色人種集団中で67%及びヒスパニック集団中で62%であり、染色体の最大のパーセントを有するアフリカ系アメリカ人及び白色人種集団が、一般的なハプロタイプ(80%)によって説明される。異なる集団から個体のサブセットが再標本化され、ハプロタイプがこれらのサブセットから推定されるのであれば、これらの比にはほとんど変動が存在せず、個体のより大きな数は、Kruglyak and Nickerson((2001) Nat.Genet.,27:234−6)文献で予想されるように、より小さなコホートを用いて達成されたものを超えるほどには、一般的なハプロタイプの多様性を有意に増加させなかったことを示している。
【実施例3】
【0212】
エゼチミブとスタチンを用いた二重(追加)薬物療法に対する治療応答とのNPC1L1多型の関連
本実施例におけるデータは、幾つかのNPC1L1SNPとハプロタイプが、スタチン治療へのエゼチミブの追加に対する対象の応答のレベルと有意に関連していることを示す。実施例1で同定された4%を超える非主要対立遺伝子頻度を有する多数の新規及び公知の一般的バリアントに対して、遺伝子型決定アッセイが開発された。NPC1L1中のDNA配列バリアントが、スタチン及びプラセボで治療された患者と比べて、エゼチミブとスタチンでの薬物療法と応答して、高コレステロール血症患者中の様々な血漿コレステロール成分のレベルの変化と関連しているかどうかを評価するために、以下に記載されている、臨床試験コホート(EASE)中で、これらのSNPを用いて、遺伝的関連分析を行った。
【0213】
EASEコホート
NPC1L1中の変動がスタチン療法に対して追加されたエゼチミブに対する応答と関連しているかどうかを研究するために、スタチンへのエゼチミブ追加の有効性(EASE)試験(Pearson et al.,(2005) Mayo Clinic Proceedings、出版中)から研究集団を得た。スタチン療法の安定な治療計画に対して追加されたエゼチミブ10mg/日の6週間が、冠状動脈性心臓病(CHD)リスクカテゴリーに対する国立コレステロール教育プログラム(NCEP)成人治療パネル(ATP)IIIガイドラインを超えたLDL−Cレベルの高コレステロール血症患者中の脂質生物マーカーに対して及ぼす影響を評価するために、EASE試験は、地域を基礎とした、無作為化された、二重盲検の、プラセボ対照化された研究であった。参加の時点で、スタチンの安定用量(用量、製品名は問わない。)及び研究への参加前の少なくとも6週間にわたって、NCEPステップ1食又は類似のコレステロール低下食を摂取している患者を、エゼチミブ(n=2020、2009人が治療を受けた。)又はプラセボ(n=1010、1009人が治療を受けた。)治療群の何れかに、無作為に割り振った。エゼチミブ群からは、1208人の患者がゲノム解析に対して同意を与え、本研究に含めた。全ての試験参加者から得られた試料から、様々な心血管リスク因子に対応する一連の臨床的指標を測定し、上記Pearsonらによって要約されている。
【0214】
EASEコホートにおけるSNP選択及び遺伝子型決定
表4から得られる21のSNP(実施例1)を、有効な遺伝子型決定アッセイへ変換し、そのうち13個が、全てのEASE亜集団中で2%を超える対立遺伝子頻度を有していた。TaqMan Allelic Discriminationアッセイ(Livak,(1999) Genet.Anal.14:143−49)は、Applied Biosystems(Foster City,CA)によって提供されたPrimer Expressソフトウェア及びAssay−by−Designサービスを用いて行った。表6は、全てのEASE亜集団中で2%を超える対立遺伝子頻度を有する選択された13のNPC1L1SNPに対する対立遺伝子識別アッセイを実行するために使用したPCRプライマー及び蛍光発生的プローブ配列を示している。全てのプローブ/プライマーのセットは、汎用の反応及びサイクリング条件を用いて機能するように設計された。
【0215】
【表7】
【0216】
PCR増幅後、Applied Biosystems 7900 HT Sequence Detection System(SDS)を用いて、評価項目プレートの読み取りを行った。95%を下回る品質スコアを有する遺伝子型を繰り返した。
【0217】
EASE試験のエゼチミブ+スタチン治療群に参加した1,208人の個体において、21個の選択されたSNPの遺伝子型を決定した。全ての試験参加者に対して、様々な心血管リスク因子に対応する一連の臨床的指標を採取した(表4a−d)。EASEコホート中で遺伝子決定された13の選択されたSNPは、このコホート中に一般的な対立遺伝子頻度(すなわち、全てのEASE亜集団中の2%を超える対立遺伝子頻度)を有すると確認された。SNPのより大きなパーセントは、再配列決定コホートに比べて、EASEコホート中の民族群の間で、有意に異なる対立遺伝子頻度を有していた。これは、このような検出を行うためのより大きなEASEコホートにおける増加した検出力を反映している(表5参照)。
【0218】
EASEコホートの連鎖不均衡分析
EASEコホート中で多数の個体の遺伝子型が決定されると、NPC1L1遺伝子を通じたLD構造がより明瞭となった。対を為すD’値(図1B)は、再配列決定コホート中に同定されたLDブロックを通じて高かった。SNPg.1680G>Tを除き、D’値は、遺伝子の長さ全体を通じて、全てのSNP対に対して合理的に高く、強調されたLDブロックが明確に規定されていないこと、及び全てのSNPが、ある程度LDの状態にあることを示唆する。EASEコホート中の遺伝子決定された13のSNPに対するハプロタイプ、及び全ての民族群中で4%以上の非主要対立遺伝子頻度を有するハプロタイプを、初期設定のPHASEv2.0ソフトウェアパッケージを用いて推定した(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)。対立遺伝子の類似性に従ったハプロタイプとSNPをまとめるために、Crawfordら((2004) Am.J.Hum.Genet.,74:610−22)によって提供された方法の僅かな変法を用いて、民族群のそれぞれにわたって同定された8つの最も一般的なハプロタイプが同定された。次いで、集積的階層クラスタリング手法を用いて、観察された全ての染色体に対するハプロタイプを、類似性によってクラスター化した(図2)。同様に、クラスタリング手法の同じ種類を用いて、対立遺伝子の類似性によってSNPをクラスター化した。EASEコホート中のハプロタイプ多様性の80%超を説明する8つの異なる一般的なハプロタイプを代表することができる6つのタギングSNPが同定された。エゼチミブを用いた治療に対するNPC1L1とLDL−C応答間の遺伝的関連を特徴付けるために、これらの6つのタギングSNPを使用した。
【0219】
遺伝的関連検定
EASE試験への参加者は、62.0(11.3)の平均(SD)年齢を有しており、男性1,522人(52.3%)及び女性1,386人(47.7%)であった。総血漿コレステロール、HDLコレステロール(HDL−C)及びLDLコレステロール(LDL−C)に対する平均(SD)は、それぞれ、211.0(34.9)、48.6(11.5)及び129.1(30.0)mg/dLであった(Pearson et al.,上記)。エゼチミブ群中の被験者は、プラセボで治療された対象者と比べて、LDL−Cの有意により大きな低下を有していた(25.8%対2.7%、p<0.001)。これらの測定の分布は、本遺伝的研究に参加した被験者において類似していた(Pearson et al.,上記)。Pearsonら、上記に列記されているベースライン臨床指標は、互いに有意に相関しており(表7)、及びエゼチミブでの治療に対するLDL−C応答(平行して行われるスタチン治療に追加されたエゼチミブの6週後におけるLDL−Cレベルの、ベースラインからのパーセント減少として定義される。)(表8)と相関していた。年齢、人種、性別及びBMIは、エゼチミブ応答を統計的に有意に予測しなかった。これらのLDL−C応答予測ベースライン変数がNPC1L1遺伝子中に同定された6つのタギングSNPの何れかと有意に関連しているかどうかを評価するために、一般的な線形モデルを使用した。これらの応答予測変数とタギングSNPの何れかとの間には、有意な関連は見出されなかった。
【0220】
【表8】
【0221】
【表9】
【0222】
エゼチミブ治療に対するLDL−C応答を主要結果変数として考える、遺伝的関連分析をEASEコホートにおいて実施した。各SNP、ハプロタイプ及びハプロタイプの組み合わせが、本分析で使用される主な説明変数であった。LDL−C応答表現型に対する遺伝子型、ハプロタイプ及びディプロタイプの効果を推定するために、一般的な線形モデルを使用した。ベースラインLDL−Cレベル、性別、年齢及び人種が有意な効果を生じるかどうかを決定するために、これらを調査した。ベースラインLDL−Cレベルは全てのモデルで有意な効果と関連し、従って、全ての分析に含めた。しかしながら、モデル中にベースライン値を含めるか否かに関わらず、ベースラインからのパーセント変化に対するSNPの効果は同一のままであった。タギングSNPの何れかとベースラインLDL−C値の間には関連が存在しなかったので、本発明者らは、予想変数としてSNPを含めるのみのモデルに対してp値を報告する。
【0223】
エゼチミブ及びNPC1L1SNPを用いた治療に対するLDL−Cレベル応答の関連は、一般的な線形モデル回帰フレームワークで検定した。表9は、表5において同定された6つのタギングSNPに対する関連性の結果を要約する。表9では、最初の2つ欄は、ソフトウェアプログラムSAS PROC GLM(SAS Institute,Inc.)中に実装された線形モデルに対する結果を報告する。結果は、ベースラインLDL−Cからのパーセント変化であり、SNPは、3つのカテゴリーとしてモデル化された予想因子である。同様に、表9の欄8及び9は、LDL−C分布のパーセント変化が極端であった被験者のみを含む、同じモデルに対する結果を示している。4〜9欄は、本文に記載されているように、EASEコホートの治療群の極端な応答者における検定結果を表す。p値は、SASソフトウェア手法PROCFREQから得られた一般的関連p値である。応答とSNP遺伝子型との間の関連について有意なp値が達成されれば(0.05のレベル)、ボンフェローニ補正されたp値が括弧内に記される。
【0224】
【表10】
【0225】
NPC1L1コード配列の開始ATGの18ヌクレオチド上流に位置するSNPg.−18C>Aは、EASEコホートにおいて、エゼチミブ治療に対するLDL−C応答と有意に関連することが見出された(p値=0.0043)。g.−18C>Aの一般的な対立遺伝子に対してホモ接合である患者(n=875/1195;73.2%)は、非主要対立遺伝子(298/1195;25.0%)に対してヘテロ接合である患者の27.8%に比べて、ベースラインから24.2%の平均LDL−C変化(15%の増加した応答)を有した。非主要対立遺伝子についてホモ接合の個体(n=22/1195;1.8%)は、27.3%のLDL−Cの平均変化を有し、ヘテロ接合体と有意に異なっていなかった。表9に示されているように、SNPg.−18C>Aへの関連は、解析が全てのEASE集団を含んでいたときに、検定が行われた6つの全てのSNPに対して保存的な補正後に有意であり続けた唯一の関連であった。g.−18C>Aに加えて、1つの追加のSNP(g.1679C>G)は、多重検定(p値=0.012)に対する補正前のLDL−C応答に対して有意に関連していた。
【0226】
白色人種は、EASEコホートにおいて代表される主な民族(1003/1195;83.9%)であったので、白色人種の被験者のみを用いた本分析を繰り返した(表10)。白色人種のみのEASEサブセットにおけるLDL−C応答とg.−18C>Aとの関連は、同じく、統計的に有意であることが見出された(表10)。
【0227】
【表11】
【0228】
興味深いことに、EASEコホートの黒人民族群中の5つのSNPに対する対立遺伝子頻度は、再配列決定コホート中の対応する頻度とは有意に異なっており、これら2つの群間の異なる集団構造を示唆する可能性がある。さらに、再配列決定コホート中のSNPg.28650A>Gに対する対立遺伝子頻度(例えば、白人では4.9%)は、EASEコホートの対立遺伝子頻度(白人では21%、p=6.7×10−14)とは有意に異なっていた。EASE参加者を登録するための要件の1つが、スタチン療法時に、低密度リポタンパク質コレステロール(LDL−C)低下目標を満たせなかったことであること、及びこのSNPg.28605A>Gとコレステロールベースライン値の間に関連が観察されなかったことに鑑みれば、この偏りは、スタチン療法に対する応答との関連を反映し得る。あるいは、EASEコホート被験者が全て異脂肪血症であるのに対して、再配列決定コホートは、コレステロール代謝の正常な分布をおそらく有する集団対照であった点で、これは、高コレステロール血症との関連を反映し得る。
【0229】
極端な応答者の解析
g.−18C>Aとエゼチミブ治療に対する脂質応答間の関連をさらに調べるために、EASEコホート中の最も極端な応答者(エゼチミブ治療に対するLDL−C応答者の上位及び下位10分位として定義される。)を調べた。表9は、これらの極端な応答者に対する関連分析の結果を明らかにする。LDL−C応答に対する関連は、全ての治療された試験参加者に比べて、極端な応答者の亜群において、より有意であることが見出された(表8、p値=0.0003対0.0043)。極端な応答者中の一般的な対立遺伝子(176/239個体又は73.6%)についてホモ接合である患者は、16.8%の平均LDL−Cパーセント応答を有していたが、ヘテロ接合体は、33.98%の平均パーセント応答を有していた(効力の100%の増加)。
【0230】
LDL−C応答に対するSNPg.−18C>Aの有意な関連及び図1Bに示されているLDブロック1中の本SNPに隣接する2つのSNPに鑑みて、上で定義されている極端な応答者でのLDL−C応答に対する関連について、全ての3−SNPハプロタイプ(表11)及びディプロタイプ(表11)を調べた。表11及び12に対するハプロタイプは、EASEコホートにおいて、統計的ソフトウェアパッケージSAS(SAS Institute,Inc.,Gary,NC)を用いて推定した。
【0231】
表11は、極端な応答者で検査されたSNPg.−133A>G、g.−18C>A、g.l678C>Gから構築された5つの最も一般的な3SNPハプロタイプに対する関連検査の結果を示している。所定のハプロタイプの異なる数を保有する個体が応答に関して有意に異なるかどうかを決定するために、ハプロタイプ傾向検査を使用した。3番目の欄は、ハプロタイプの0、1又は2コピーを保有していると個体を分類するために使用されるコーディングを表す。カウント数は、一般的な線形モデルにおけるカテゴリー変数として処理した。表10では、ハプロタイプのコピー数(SAS program PROC HAPLOTYPESで推定)は、同じく、SASソフトウェアPROCGLMを用いて、カテゴリー結果としてモデル化する。
【0232】
【表12】
【0233】
表12は、ディプロタイプをカテゴリー変数として処理し、極端な応答者データの組みを用いた一般的な線形モデルに、LDL−C応答をフィッティングさせることによって求めたディプロタイプカウント数及び平均LDL−C応答率を示している。
【0234】
【表13】
【0235】
表12では、ハプロタイプ対カテゴリーの全ての対は、同じくSASプログラムPROC GLM中で、10の自由度を用いて、カテゴリー結果としてモデル化される。表12は、高応答者と低応答者に対するこれらのカテゴリーに対するカウント数、カテゴリー試験一般関連p値、及び結果としてLDL−Cベースライン値からのパーセント変化を結果として用いたモデルから得られたp値を表している。
【0236】
SNPg.−18C>Aの非主要対立遺伝子を含有する[A(−133)、A(−18)、G(1679)]ハプロタイプ(表11及び12では、A−A−Gと表記されている。)の保有者は、非保有者に比べて、有意に改善されたLDL−C応答を有していた(p値=0.0008)。このパターンは、ハプロタイプの解析及びハプロタイプ対の解析の両方で明らかであった(ディプロタイプの解析において得られた細胞カウント数の幾つかは小さく、検査の統計指標に影響を与えたかもしれない。)。SNPg.−18C>Aより、応答とより有意に関連している個別のハプロタイプ又はディプロタイプの関連は見出されなかった。さらに、EASEコホート中で遺伝子決定された7つの非タギングSNPは全て、SNPG.−18C>Aと同程度にLDL−C応答と有意に関連していないことが見出された。さらに、EASEコホート中で同定された8つの最も一般的なハプロタイプも、SNPG.−18C>A及び[A(−133)、A(−18)、G(1679)]ハプロタイプと同程度にLDL−C応答と有意に関連していないことが見出された。重要なことに、SNPG.−18C>A及び[A(−133)、A(−18)、G(1679)]ハプロタイプは、ベースラインLDL−Cレベルに対してLDL−C応答レベルを調整した後にも、LDL−C応答に対して有意に関連し続けていた。LDL−Cベースライン値は、SNPG.−18C>A又は検査された他の5つのタギングSNPの何れかと有意に関連することが見出されなかった。
【0237】
要約
この実施例は、エゼチミブ感受性経路中のタンパク質をコードする遺伝子であるNPC1L1遺伝子のDNAの変化の詳細な性質決定について記載している。提示されているデータは、本遺伝子中の一般的な多型が、エゼチミブ治療に対するLDL−C応答と有意に関連しているが、ベースラインLDL−Cレベルに対するLDL−C応答とは有意に関連していないことを示している。再配列決定コホート(実施例1)中で、140を超える多型がNPC1L1中に同定され、25がdbSNP中に以前に提示された。1つの一般的なSNPであるg.−18C>Aが、進行中のスタチン療法に追加されたエゼチミブによる治療の6週後に、ホモ接合の主要対立遺伝子と比べて、LDL−Cレベルの減少が15%増加することと有意に関連していることが明らかとなった。本治療に対する極端なLDL−C応答者の亜群では、g.−18C>ASNPに対する関連は、LDL−Cの減少の100%増加にまで増強された。(全ての被験者にわたる)一次関連は、解析で検討された全てのSNPに対する保存的補正後並びに年齢、性別及びベースラインLDL−C共変量について考慮した後にも、有意なままであった。さらに、NPC1L1の3’末端にマッピングされるG.28650A>Gは、EASEコホート中の対応する非主要対立遺伝子頻度と比べて有意に減少した、再配列決定コホートの3つの民族全てに非主要対立遺伝子頻度を示した。EASEコホート中で使用されたものと同じアッセイを用いて、再配列決定コホートの遺伝子型を再度決定することによって、この低下を確認した。
【0238】
エゼチミブは、小腸コレステロール輸送体であるNPC1L1を遮断することによってLDL−Cを低下させる。単独療法として、エゼチミブは、LDL−Cを約18%低下させる(Kropp et al.,(2003) Int.J.Clin.Pract.57:363−8)。スタチンと同時投与されると、エゼチミブに起因する低下の増加は、約14〜15%である。EASEで研究されているように、スタチンの安定用量を服用している患者において、進行中のスタチン療法に添加すると、エゼチミブは、進行するスタチン療法へのプラセボの添加と比べて、LDL−Cをさらに約23%減少させる(Pearson,et al.,(出版中) Mayo Clinic Proceedings)。20mgの同様のスタチン用量で、エゼチミブ10mgの添加は(混合バイトリン錠剤として投与された場合に)、34%から52%まで、LDL−Cのベースラインからの変化をさらに減少させる。脂質低下療法に対するコレステロール応答(スタチン及びエゼチミブ)は、変動的である。HMGCoA還元酵素遺伝子における約5%の対立遺伝子頻度を有するSNPは、プラバスタチンに対する19%のより小さな応答と関連することを最近の研究は実証した(Chasman et al.,(2004) Jama,291:2821−7)。この観察は、脂質低下療法に対する応答の遺伝的な予測因子の存在を示唆しており、関心対象のベースライン特性への関連が存在しなくても、標的中の変動が薬物応答に影響を与える可能性があることを示す、増加しつつある文献に加えられる。
【0239】
EASEコホートは、エゼチミブに対する臨床的に妥当な薬理遺伝学的応答を評価するための興味深い集団である。エゼチミブを服用している患者の多くは、スタチンとの二重療法を受けており、シンバスタチン−エゼチミブ混合錠剤を服用しているか、又は市販されているスタチンの1つとともにエゼチミブを個別に服用している。エゼチミブとスタチンを用いた治療を研究した臨床試験の多くは、患者がスタチン除去期間に入った後、プラセボ又は二重治療を受けるように無作為化される同時投与試験であった。この設定で薬理遺伝学的応答の評価を行うことが可能であるが、NPC1L1バリアントがスタチン応答及びエゼチミブの応答に対して影響を与える可能性によって結果が混乱する。
【0240】
ここに記された結果は、NPC1L1プロモーターの変動がエゼチミブ応答と強く関連していることを示す。g.−18C>Aと安定なスタチン療法に追加されたエゼチミブに対する応答との間に、有意な関連が同定された。本コホートでは、非主要対立遺伝子の少なくとも1つのコピーを保有する患者は、ホモ接合の主要対立遺伝子型を有する患者と比べて、平均して、LDL−Cの低下が15%増加していた。非主要対立遺伝子のホモ接合性は、応答に対して統計的に有意な付加的効果を有しておらず(非主要対立遺伝子ホモ接合体の数が小さかったので、検出されなかった可能性がある。)、優性応答モデルを示唆する。エゼチミブ応答分布の高い範囲及び低い範囲(LDL−Cの40%を上回る低下vs.LDL−Cの5%未満の低下)を示す患者(それぞれ、n=120及びn=119)に対する制限分析は、関連の有意性を拡大した。g.−18C>Aの有意な関連は、遺伝子型が決定されたEASE被験者の完全な組の間で分析された他の臨床的な評価項目(総コレステロール、非HDL−C及びアポBを含むが、HDL−C又はアポA1は含まない。)についても観察された。これらの結果は、エゼチミブ+スタチン治療群中の患者は、プラセボに比べて、総コレステロール、LDL−C、非HDL−C及びアポBの有意な低下を示したが、HDL−C又はアポA1の有意な低下は示さなかったEASEデータと合致した(EASE研究では、プラセボに比べて、HDL−Cの有意なプラセボが存在したことに注目されたい。)。
【0241】
総じて、SNPg.−18C>Aは、エゼチミブを与えたEASE患者内の応答の変動の約1%を占めた。コレステロール代謝の複雑さ、LDL−Cを調節する複数の恒常性経路及びLDL−Cレベルに対する複数の環境的寄与(血漿コレステロールに著しい影響を与える食物脂肪摂取など)に鑑みれば、この薬理遺伝学的相互作用の規模は顕著である。顕著であるg.−18C>A(一般的な集団では約15%)と同程度の高い頻度を有するバリアントに対する薬理遺伝学的相互作用の例が数例存在する。プラバスタチンに対するより小さな応答を予測するHMG CoAイントロンSNPは、これまでに報告された、スタチンに対する最も強固な報告された薬理学的決定因子の1つであるが、スタチン使用者の小さなパーセント(約5%)を特定するに過ぎない。
【0242】
研究は、コレステロール吸収のかなりの変動性を示している(Sudhop and von Bergmann(2002) Drugs,62:2333−47)。NPC1L1中のSNPの、LDL−Cの変化との関連は、NPC1L1中のDNA配列の変動性によって、ベースラインLDL−Cの変動性を説明できないことを示唆している。本研究中のバリアントはベースラインLDL−Cと関連していなかったが、全ての患者は高脂血症であり、スタチン療法時には、ベースラインレベルへのあらゆる関連に混乱を与える。しかしながら、集団対照再配列群と比べて、高脂血症EASE集団中には、NPC1L1 3’UTRSNPの予測されない過剰な発現量が存在した。g.28650A>Gの頻度の顕著な3倍の増加が、対照コホートに比べて、EASEに見出された。EASEコホート中で使用されたものと同じアッセイを用いて、再配列決定コホートの遺伝子型を再度決定することによって、この差が確認された。EASEに参加した患者に対する平均ベースラインコレステロールは、約130mg/dLであり、これは、被験者の多くにおいて、高スタチン用量で評価されたので、明らかに、潜在的に危険性のある高脂血症集団であった。脂質データは、再配列決定コホートからは入手されないので、これらの被験者は、健康であると自己申告され、EASEコホート中の被験者に対して、年齢と性別を概ね合致させた。2つの集団間の他の差が、高脂血症EASE患者中の対立遺伝子頻度の大きな増加を説明する可能性があるが、説得力のある1つの説明は、g.28650A>GSNPが上昇したLDL−Cに対するリスクを予測するということである。ベースラインレベルとg.28650A>GSNPの間には関連が見出されなかったが、本分析は、スタチン治療によって混乱する(すなわち、スタチン治療前のLDL−Cレベルが測定されなかった。)。
【0243】
LDL−Cの低下の15%の相対的増加は、絶対的LDL−Cレベルのさらなる約5mg/dLの増加に相当する。疫学的研究は、LDLコレステロールレベルの1mg/dLの変化ごとに、心臓病のリスクが2〜3%増加することを示している(Gould,et al.,(1998) Circulation,97:946−52)。このような疫学的データに基づけば、g.−18C>Aヘテロ接合体中で見られた増加した応答は、集団のかなりのパーセントの冠状動脈性心臓病の大幅な低下をもたらすと予測される。
【0244】
本明細書及び添付の特許請求の範囲で使用されている単数形(「a」、「an」 and 「the」)には、文脈から別段の意味であることが明らかである場合を除き、複数表記も含まれることに留意しなければならない。従って、例えば、「複合体」という表記は、このような複合体の複数を含み、「製剤」という表記は、当業者に公知の1つ又はそれ以上の製剤及びそれらの均等物に対する表記を含む。
【0245】
別段の定義がなければ、本明細書に使用されている全ての技術的及び科学的用語は、本発明が属する分野の当業者が一般的に理解する意味と同一の意味を有する。本発明の実施又は検査においては、本明細書に記載されているものと類似又は均等な、あらゆる方法、装置及び材料を使用可能であるが、ここでは、好ましい方法、装置及び材料が記載されている。
【0246】
本明細書に挙げられている全ての公報は、例えば、公報中に記載された、本明細書に記載されている発明に関連して使用され得る細胞株、構築物及び方法を記載及び開示する目的で、参照により本明細書に組み込まれる。上で及び本文を通じて論述されている公報は、専ら、本願の出願日より前の開示に対してのみ提供される。本明細書の記載は、以前の発明に基づいて、本発明がこのような開示の日付を先行させる権利を有することを認めるものと解釈すべきではない。
【0247】
本発明の好ましい例示的な実施形態が示され、記載されているが、当業者であれば、例示の目的のためのみに示され、限定のために示されているのではない、本発明が記載された実施形態以外によって実施され得ることを理解する。本発明の精神及び範囲から逸脱することなく、本明細書に記載された実施形態に対して、様々な改変を施し得る。本発明は、以下の特許請求の範囲のみによって限定される。
【図面の簡単な説明】
【0248】
【図1A】再配列コホート中に同定された一般的なバリアントに対するD’プロット。D’プロットは、Haploviewソフトウェアプログラムによって作製された。三角のマトリックスは、白色人種民族群中の一般的なSNPの全てのペア間で算出されたD’値を表している。白は、SNP間に連鎖不均衡が存在しないか、又は弱い連鎖不均衡が存在することを示す低いD’値を示し、最も狭い斜めの縞模様入りの線は、SNP間の有意な連鎖不均衡を示す高いD’値を示し、斑のパターンはオッズ比の低い対数を有する高いD’値を示す。
【図1B】EASEコホートで検査された遺伝子型に対するD’プロット。D’プロットは、Haploviewソフトウェアプログラムによって作製された。三角のマトリックスは、白色人種民族群中の一般的なSNPの全てのペア間で算出されたD’値を表している。白は、SNP間に連鎖不均衡が存在しないか、又は弱い連鎖不均衡が存在することを示す低いD’値を示し、最も狭い斜めの縞模様入りの線は、SNP間の有意な連鎖不均衡を示す高いD’値を示し、斑のパターンはオッズ比の低い対数を有する高いD’値を示す。
【図2】EASEコホート中に同定された一般的なハプロタイプ。各カラムは、EASEコホート中の、遺伝子型が決定された12個の一般的なSNPの1つを表す(実施例1、表4参照)。各列は、7p13染色体を表し、EASEコホート中で観察された2,430の7p13染色体から、250の7p13染色体のランダムな組を採取した。各SNPに対する微量の対立遺伝子には、狭い斜めの縞模様が付されているが、一般的な対立遺伝子には、より幅広い斜めの縞模様が付されている。太字で強調された6つのSNPは、本プロット中に表記されている8つの一般的なハプロタイプを一意的に特定するタギングSNPを表している。これらの6つのSNPは、エゼチミブ応答に対して実施例3に記載されている関連研究において使用された。
【技術分野】
【0001】
本願は、2005年3月30日に出願された米国仮特許出願06/667,047号及び2005年9月14日に出願された米国仮特許出願60/717,465号の優先権を主張し、これらの各々は、参照により、その全体が本明細書中に組み込まれる。
【背景技術】
【0002】
薬理遺伝学は、薬物代謝及び薬物応答の変動における遺伝学の役割の研究である。薬理遺伝学は、特定の薬剤を用いた治療法に患者が最も適していることを明らかにするのに役立つ。このアプローチは、薬物選択プロセスを補助するための薬学的研究において使用することが可能であり、臨床試験に参加するための患者を選択するのに役立ち得る。薬理遺伝学及び多型検出のその他の使用に関する詳細は、「Linder et al.,(1997) Clinical Chemistry,43:254;Marshall(1997) Nature Biotechnology,15:1249;PCT特許出願WO 97/40462,Spectra Biomedical;and Schafer et al.,(1998) Nature Biotechnology 16:33」に見出すことができる。
【0003】
さらに、DNA挿入、欠失、重複及びヌクレオチド置換から生じる2000を上回るヒトの病理的症候群において、多型が関与するものと考えられている。個体中に遺伝的多型を見出し、これらの変動を家族内で追跡することは、臨床診断を確認し、保有者並びに前臨床及び無症候性の個体における素因及び病状をともに診断するための手段となる。さらに、別の治療的処置に比べて、ある治療的処置に対してより大きな反応性を示し得る個体を特定するために、遺伝的な多型を使用し得る。
【0004】
表現型と関連する多型を特定することは困難である。遺伝子内に複数の対立遺伝子が存在するのが一般的であるので、疾病に関連する対立遺伝子を、中立的な(非疾病関連)多型と区別しなければならない。多くの対立遺伝子は、識別不能で、通常活性な遺伝子産物を産生するか、又は眼の色のように通常可変的な特徴を発現する中立的多型である。これに対して、一部の多型対立遺伝子は、鎌型赤血球貧血などの臨床的疾病と関連している。さらに、疾病に関連する多型の構造は極めて可変的であり、鎌型赤血球貧血症で見られるように単一の点変異に起因し得るか、又は脆弱性X症候群及びハンチントン舞踏病で見られるようにヌクレオチド反復の伸長に起因し得る。
【0005】
先進国における主要な死因である血管系疾患の発症をもたらす因子は、上昇した血清コレステロールである。20歳〜74歳のアメリカ人の19%が高血清コレステロールを有すると推定されている。血管系疾患の最も多い形態は、動脈壁の肥厚と硬化を伴う症状である、動脈硬化症である。巨大な血管の動脈硬化症は、アテローム性硬化症と呼ばれている。アテローム性硬化症は、冠動脈疾患、大動脈瘤、下肢の動脈疾患及び脳血管疾患など、血管系疾患の基礎を為す主な要因である。
【0006】
コレステロールエステルは、アテローム性硬化症の病変の主な構成要素であり、動脈壁細胞中でのコレステロールの主な貯蔵形態である。コレステロールエステルの形成は、食物コレステロールの腸吸収における段階でもある。従って、コレステロールエステル形成の阻害及び血清コレステロールの低減の阻害によって、アテローム性硬化症の病変形成の進行を阻害し、動脈壁中へのコレステロールエステルの蓄積を減少させ、食物コレステロールの腸吸収を遮断することができる。
【0007】
哺乳類及び動物における全身コレステロール恒常性の制御は、腸コレステロール吸収、細胞のコレステロール輸送、食物コレステロールの制御及びコレステロール生合成、胆汁酸生合成、ステロイド合成の調節及びコレステロール含有血漿リポタンパク質の異化を含む。腸コレステロール吸収の制御は、血清コレステロールレベルを制御するための有効な手段であることが明らかとなっている。例えば、コレステロール吸収阻害剤であるエゼチミブは、これに関して有効であることが示されている(Kropp et al.,(2002) Int.J.Clin.Pract.57:363−8)。
【0008】
最近、ニーマンピックC1様1(NPC1L1)遺伝子は、タンパク質であって、コレステロール薬エゼチミブ(ZETIA(R))が、このタンパク質を通じてコレステロールの腸吸収を遮断するように作用するようなタンパク質をコードすると同定された(Altmann,et al.,(2004) Science,303:1201−04;and Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。エゼチミブは、単独療法及びシンバスタチン(ZOCOR(R))などのスタチンとの組み合わせの両方において、LDLコレステロール(LDL−C)を低下させる上で有効である。
【0009】
NPC1L1は、形質膜輸送シグナルのためのトランスゴルジネットワークとして機能する4アミノ酸モチーフを含むNグリコシル化されたタンパク質である(Bos,et al.,(1993) EMBO J.12:2219−28;Humphrey,et al.,(1993) J.Cell.Biol.120:1123−35;Ponnambalam,et al.,(1994) J.Cell.Biol.125:253−268 and Rothman,et al.,(1996) Science 272:227−34参照)。NPC1L1タンパク質は、組織分布が限定されており、胃腸内に豊富に存在する。また、ヒトNPC1L1プロモーター領域は、ステロール制御要素結合タンパク質1(SREBP1;Sterol Regulated Element Binding Protein 1)結合コンセンサス配列を含む(Athanikar,et al.,(1998) Proc.Natl.Acad.Sci.USA 95:4935−40;Ericsson,et al.,(1996) Proc.Natl.Acad.Sci.93:945−50;Metherall,et al.,(1989) J.Biol.Chem.264:15634−41;Smith,et al.,(1990) J.Biol.Chem.265:2306−10;Bennett,et al.,(1999) J.Biol.Chem.274:13025−32 and Brown,et al.,(1997) Cell 89:331−40)。NPC1L1は、ニーマンピックC1病の原因となる受容体であるヒトNPC1に対して42%のアミノ酸配列相同性を有する(Genbank Accession No.AF002020)(Carstea,et al.,(1997) Science 277:228−31)。
【0010】
ニーマンピック病C型は、ヒトの稀な遺伝病であり、リソゾーム中に低密度リポタンパク質(LDL)由来非エステル化コレステロールの蓄積をもたらす(Pentchev,et al.,(1994) Biochim.Biophys.Acta.1225:235−43 and Vanier,et al.,(1991) Biochim.Biophys.Acta.1096:328−37)。さらに、コレステロールは、NPC1を欠く細胞のトランスゴルジネットワーク中に蓄積し、形質膜へのコレステロールの再配置及び形質膜からの再配置が遅延する。NPC1及びNPC1L1は、それぞれ、13個の膜貫通セグメントと、ステロール感知ドメイン(SSD;sterol−sensing domain)を有する。HMG−CoA還元酵素(HMG−R)、パッチ化された(PTC)及びステロール制御要素結合タンパク質切断活性化タンパク質(SCAP)など幾つかの他のタンパク質は、おそらくは、直接のコレステロール結合を伴う機序によって、コレステロールレベルの感知に関与するSSDを含む(Gil,et al.,(1985) Cell 41:249−58;Kumagai,et al.,(1995) J.Biol.Chem.270:19107−13 and Hua,et al.,(1996) Cell 87:415−26)。NPC1L1タンパク質は、ニーマンピックC1型(NPC1)に対する相同性の高い程度並びに3−ヒドロキシ−3−メチルグルタリルコエンザイムA還元酵素(HMGR)及びステロール制御要素結合タンパク質切断活性化タンパク質(SCAP)のステロール感知ドメイン(SSD)に対して相同性を有するステロール感知ドメイン(SSD)の候補など、コレステロール輸送における役割と合致する多くの特性を有する。しかしながら、NPC1及びNPC1L1は、それらの標的誘導シグナルの候補が著しく異なっており、異なる細胞局在化を示唆する(Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。
【0011】
NPC1L1は、相対的に低いレベルで発現されているが、一般的には、多数のヒト組織及び細胞株にわたって発現されており、小腸内に豊富に存在し、インシチュハイブリダイゼーションによって示されるように、腸細胞に限定されている(Altmann et al.,(2004) Science,303:1201−04)。NPC1L1発現の最高レベルは、コレステロール吸収の主要な部位でもある近位空腸内に観察されている。さらに、最近の研究によって、外来胆汁酸塩による食事的補充による救済を受けていないか、又はコレステロール吸収阻害剤であるエゼチミブを用いた治療を経て、さらに低減されている野生型と比べて、NPC1L1−ヌル(−/−)マウスが、食事性コレステロール吸収の69%の低下を示すことが示されている(Altmann et al.,(2004),303:1201−04)。従って、NPC1L1は、腸コレステロールの吸収に重要な役割を果たしており、エゼチミブ感受性経路内に存在するようである。
【0012】
幾つかの臨床研究は、LDL−Cを低下させる上でのエゼチミブ単独療法の効果を示している(Knopp,et al.,(2003) Int.J.Clin.Pract.57:363−8;Knopp,et al.,(2003) Eur.Heart J.24:729−41)。エゼチミブ10mg/日の単独療法において、18−19%の平均的減少が観察され(Ezzet,et al.,(2001) J.Clin.Pharmaco.,41:943−9)、エゼチミブ同時投与又はスタチンに対する追加的治療においても、同様の減少が見られる(Davidson,et al.,(2002) J.Am.Coll.Cardiol.40:2125−34;Pearson,et al.,(2005) Mayo Clinic Proceedings,80:587−95)。その薬理学的作用機序と合致して、ヒトでの研究は、エゼチミブによって媒介される血漿LDL−Cの減少は、腸コレステロール吸収の阻害に起因することを示唆している(Sudhop and von Bergmann(2002) Drugs,62:2333−47)。興味深いことに、基底時及びエゼチミブ処理後の両者において、腸吸収及びLDL−C減少の速度に対して、著しい個体間のばらつきが観察されている。
【0013】
ヒトの健康におけるコレステロール管理の重要な役割のために、1つ又はそれ以上の薬物応答と関連する多型及びハプロタイプなどの遺伝的要素は、健康管理の意思決定を行う上で有用である。ヒト対象に投与される医薬として活性な化合物、例えばNPC1L1アンタゴニストの応答性を推定するためにNPC1L1遺伝子中の多型及びハプロタイプを使用できることが、ここに見出された。
【0014】
ヒトNPC1L1遺伝子は染色体7p13にマッピングされ、約29kbに及び、20個のエキソンを含有する(Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。ヒトNPC1L1遺伝子に対する基準配列が、配列番号1に列記されている。ヒトNPC1L1遺伝子中の多数の一塩基多型(SNP)が報告されている(例えば、国立バイオテクノロジー情報センターによって管理されている一塩基多型データベース(dpSNP)を参照。)。しかしながら、これらのSNPのうち僅か数個が、10%を超える報告された非主要対立遺伝子頻度(MAF;minor allele frequency)を有するに過ぎない。
【0015】
最近の報告は、エゼチミブに対して応答しない8人(すなわち、LDLコレステロールの変化が、6%の減少から10%の増加までの範囲)及びエゼチミブに応答した6人のNPC1L1遺伝子のエキソン及びイントロン−エキソン境界の多型について調べた研究を記載している(Wang J.et al.,(Feb.2005)Clin.Genet.67(2):175−177)。本報告は、応答しなかった8人のうち1人が、6人の対照被験者者中には存在しない2つの稀なNPC1L1多型について複合ヘテロ接合であることを記述しているが、他の非応答者の何れかに、何れかの多型が検出されたかどうかについては記述していない。1つの多型は、55位のアミノ酸バリンのロイシンへの置換(V55L)をもたらすエキソン2中のG219Tであり、他の多型は、1233位のアミノ酸イソロイシンのアスパラギンへの置換(I1223N)をもたらすエキソン18中のT3754Aであった。このデータに対する多くの可能な説明の1つは、エゼチミブ応答とNPC1L1変動との間に関係が存在する可能性があると、著者らは述べている。しかしながら、著者らは、13個の他のNPC1L1多型の非主要対立遺伝子頻度は、非応答者中にのみ見られる6つのSNPも含み、応答者と非応答者の間で統計的に有意に異ならないことも報告した。従って、エゼチミブに対する増加した応答とNPC1L1遺伝子の何れの一般的な対立遺伝子(>5%の頻度)との間に首尾よく相関を同定できることを、当業者はこの参考文献から予想できなかったと思われる。
【発明の開示】
【0016】
本発明は、NPC1L1アンタゴニストに対する増加した応答に関連するSNP及びハプロタイプに関する。本発明の多型を有する患者は、例えば、血清低密度リポタンパク質コレステロールレベルの平均的な低下の増加によって示されるように、本発明の多型を有しない個体に比べて、NPC1L1アンタゴニストに対して平均より高い応答を示す。さらに、NPC1L1SNPは、上昇したLDL−Cの増加したリスクと関連することが明らかとされた。増加したLDL−Cの低下と関連するSNP及びハプロタイプは、スタチン化合物が与えられた患者とスタチン+エゼチミブが与えられた患者の遺伝子型を調べることによって特定された。検査された患者の集団は、スタチンのみによっては、LDL−Cの推奨レベルを満たしていなかった。エゼチミブは、治療を受けた患者全員に、LDL−Cの低下をもたらしたが、エゼチミブによるLDL−Cの低下は、患者の異なる群において異なっていた。異なる患者の遺伝子型分析を通じて、エゼチミブに対する増加した応答に関連するSNP及びハプロタイプが特定された。
【0017】
NPC1L1アンタゴニストによるLDL−C低下の増加に関連する前記特定されたSNP及びハプロタイプは、化合物に対して応答性の患者(すなわち、ヒト)の程度についての指標を与える上で特に有用である。本指標は、ある治療の結果の予測を補助するために、医師によって使用することが可能である。さらに、本明細書に記載されているNPC1L1マーカーの表現型効果は、診断方法及びキット;NPC1L1アンタゴニストに対する応答に関連するNPC1L1マーカーに対する患者の検査が陽性又は陰性であるかに基づいて、患者の薬物治療を個別的に適合化することを含む薬理遺伝学的治療方法;薬物開発及び販売、並びに薬理遺伝学的薬品を含む(但し、これらに限定されない。)、様々な方法及び製品において、これらのマーカーを使用することの土台となっている。
【0018】
一態様において、本発明は、NPC1L1遺伝子中の一塩基多型及びハプロタイプを、ヒト対象に対して投与された医薬として活性な化合物の活性と相関させる方法を提供する。本方法は、NPC1L1遺伝子中の一塩基多型又はハプロタイプに対する参照によって、ヒト対象のNPC1L1遺伝子中の一塩基多型又はハプロタイプを、医薬として活性な活性化合物が投与された前記ヒト対象の状態と関連付けることを含む。幾つかの実施形態において、対象の状態は、化合物の投与前及び投与後に、例えば、低密度リポタンパク質コレステロール(LDL−C)、総コレステロール、非高密度リポタンパク質コレステロール(非HDL−C)及びアポリポタンパク質Bなど、血漿成分レベルを測定することによって決定される。特定の実施形態において、血漿成分がLDL−Cであり、及び化合物活性が、化合物の投与前の対象における血漿LDL−Cのレベルに比した、対象中の血漿LDL−Cの低下である。他の実施形態において、一塩基多型は、g.−133A>G、g.−18C>A、g.l679C>G及びg.28650A>Gからなる群から選択される。さらに別の実施形態において、一塩基多型はg.−18C>A又はg.1679C>Gであり、及び化合物はコレステロール吸収を阻害する。別の実施形態において、ハプロタイプは[A(−133)、A(−18)、G(1679)]又は[G(−133)、C(−18)、C(1679)]であり、化合物がエゼチミブである。本発明は、さらに、NPC1L1多型g.−133A>G、g.−18C>A又はg.28650A>Gの少なくとも1つを、それらの配列内に含む単離された核酸に関する。本発明は、このような核酸にハイブリダイズすることができる核酸プライマー及びオリゴヌクレオチドプローブ並びにNPC1L1遺伝子中のこのような多型を検出するために、このようなプライマー及びプローブの1つ又はそれ以上を含む診断キットも含む。例えば、1つのこのような実施形態は、配列番号1の少なくとも12個の連続するヌクレオチド又はその相補物からなる単離されたポリヌクレオチドを含み、ここにおいて、前記ポリヌクレオチドは、配列番号1のヌクレオチド位置5,285にアデニン塩基を有する一塩基多型を含む。別の実施形態において、単離されたポリヌクレオチドは、配列番号1のヌクレオチド位置5,400にアデニン塩基を有する一塩基多型を含む。さらに別の実施形態において、単離されたポリヌクレオチドは、配列番号1のヌクレオチド位置34,067にグアニン塩基を有する一塩基多型を含む。
【0019】
本発明の別の態様は、対象が、NPC1L1アンタゴニストに対するヒトの平均より高い反応と関連する遺伝子型を有するかどうかを決定する方法を提供する。本方法は、対象が、多型g.−18C>A若しくはg.1679C>Gに対してヘテロ接合若しくはホモ接合であるかどうか、又はハプロタイプ[A(−133)、A(−18)、G(1679)]に対してヘテロ接合若しくはホモ接合であるかどうかを決定する工程を含み、ここにおいて、前記多型又はハプロタイプの一方又は両方の何れかのヘテロ接合又はホモ接合形態の存在は、対象が、NPC1L1アンタゴニストに対する、ヒトにおける平均応答より高い応答に関連する遺伝子型を有することを示す。
【0020】
対象は、多型若しくはハプロタイプが少なくとも1つの対立遺伝子上に存在するかを決定するかによって、又は多型若しくはハプロタイプを含有する対立遺伝子の数を決定するかによって、特定の多型又はハプロタイプに対してヘテロ接合又はホモ接合であると同定することが可能である。
【0021】
本発明の別の態様は、NPC1L1機能に影響を与える、すなわち、腸コレステロール吸収を阻害する化合物(エゼチミブなど)に対する対象の応答性を推測する方法に関する。本方法は、対象から生物学的試料を取得する工程、及び前記生物学的試料中の配列番号1の位置に存在するヌクレオチド塩基を決定する工程を含み、配列番号1の5,400位にアデノシンヘテロ接合性又はホモ接合性が存在することが、アデノシンヘテロ接合性又はホモ接合性を欠如する個体に比べて、対象が、前記化合物に対して平均応答より高い応答を有する可能性が統計的により高いことを示す。本発明の別の実施形態において、配列番号1の7,096位にグアニンヘテロ接合性又はホモ接合性が存在することが、グアニンヘテロ接合性又はホモ接合性を欠如する個体に比べて、対象が化合物に対して平均応答性より高い応答性を有する可能性が統計的により高いことを示す。本発明の別の実施形態において、ハプロタイプ[A(−133)、A(−18)、G(1679)]ヘテロ接合性又はホモ接合性が存在することが、[A(−133)、A(−18)、G(1679)]ハプロタイプを欠如する個体に比べて、対象が化合物に対して平均応答性より高い応答性を有する可能性が統計的により高いことを示す。
【0022】
本発明の別の態様は、ヒト対象中の血漿コレステロールの健康リスクレベルに対する素因を検出する方法を提供する。本方法は、ヒト対象において、ヒトNPC1L1対立遺伝子のゲノム配列中の多型の存在又は不存在を検出することを含み、ここにおいて、ヒトNPC1L1対立遺伝子は配列番号1の34,067位のグアニンからなる。グアニンの存在は、対象中の血漿コレステロールの健康リスクレベルに対する素因の指標である。
【0023】
本発明の方法には、上記多型及びハプロタイプの何れかの中に存在するヌクレオチド塩基の決定を可能とする全てのアッセイが含まれる。典型的なアッセイには、直接的なヌクレオチド配列分析、DNAマイクロアレイ分析を含む識別的核酸ハイブリダイゼーション分析、制限断片長多型分析及びポリメラーゼ連鎖反応分析が含まれるが、これらに限定されない。
【0024】
本発明の別の態様は、患者中のコレステロールを低下させる方法を提供する。本方法は、NPC1L1アンタゴニストの有効量を患者に投与する工程を含み、ここにおいて、前記患者は、g.−18C>A及びg.1679C>Gからなる群から選択されるSNPを有するものと同定される。別の実施形態において、患者は、[A(−133)、A(−18)、G(1679)]ハプロタイプを有するとして同定される。
【0025】
本発明の別の態様は、診断キットであり、配列番号1の5,285位、5,400位、7,096位及び34,067位の1つ又はそれ以上におけるNPC1L1遺伝子中の多型を検出可能な少なくとも1つの対立遺伝子特異的核酸プライマーと、並びに核酸に対して特異的にハイブリダイズ可能な、NPC1L1遺伝子中の多型を検出するためのオリゴヌクレオチドプローブとを含み、NPC1L1遺伝子中のヌクレオチド多型が、配列番号1中の5,285位のA又はG、配列番号1中の5,400位のC又はA、配列番号1中の7,096位のC又はG、及び配列番号1中の34,067位のA又はG及びこれらの組み合わせ並びにこれらの逆相補物の少なくとも1つから選択される、前記診断キットを提供する。
【発明を実施するための最良の形態】
【0026】
この節は、本発明の詳細な説明とその応用を記す。この説明は、詳細さと具体性が増加した、本発明の一般的な方法の幾つかの典型的な例示によってなされる。これらの例は非限定的なものであり、当業者に自明な関連する変形例は、添付の特許請求の範囲によって包含されるものとする。また、本明細書及び添付の特許請求の範囲で使用されている単数形(「a」、「an」及び「the」)には、文脈から別段の意味であることが明らかである場合を除き、複数表記も含まれる。従って、例えば、「複合体」という表記は、このような複合体の複数を含み、「製剤」という表記は、当業者に公知の1つ又はそれ以上の製剤及びそれらの均等物という表記が含まれる。
【0027】
I.定義
別段の定義がなければ、本明細書に使用されている全ての技術的及び科学的用語は、本発明が属する分野の当業者が一般的に理解する意味を有する。
【0028】
本明細書において使用される[A(−133)、A(−18)、G(1679)]は、配列番号1の5,285に対応するヌクレオチド位置のアデニン塩基、配列番号1の5,400に対応するヌクレオチド位置のアデニン塩基及び配列番号1の7,096に対応するヌクレオチド位置のグアニン塩基から構成されるNPC1L1ハプロタイプを表す。「対応する」という表記は、配列番号1に関する、ハプロタイプ中の各多型の位置を示す。幾つかの文脈において、[A(−133)、A(−18)、G(1679)]という表記は、NPC1L1遺伝子の2つ又はそれ以上のハプロタイプ対立遺伝子上に存在し得るサブハプロタイプを表すことが明らかである。
【0029】
本明細書において使用される[G(−133)、C(−18)、C(1679)]は、配列番号1の5,285に対応するヌクレオチド位置のグアニン塩基、配列番号1の5,400に対応するヌクレオチド位置のシトシン塩基及び配列番号1の7,096に対応するヌクレオチド位置のシトシン塩基から構成されるハプロタイプを表す。「対応する」という表記は、配列番号1に関する、ハプロタイプ中の各多型の位置を示す。幾つかの文脈において、[G(−133)、C(−18)、C(1679)]という表記は、NPC1L1遺伝子の2つ又はそれ以上のハプロタイプ対立遺伝子上に存在し得るサブハプロタイプを表すことが明らかである。
【0030】
本明細書において使用される「g.−133A>G」は、配列番号1の5,285に対応するヌクレオチド位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの133塩基上流に存在する位置のグアニン塩基を表す。「対応する」という表記は、配列番号1に関する、多型の位置を示す。g.−133−A>G多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0031】
本明細書において使用される「g.−18C>A」は、配列番号1の5,400に対応するヌクレオチド位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの18塩基上流に存在する位置のアデニン塩基を表す。「対応する」という表記は、配列番号1に関する多型の位置を示す。g.−18C>A多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0032】
本明細書において使用される「g.1679C>G」は、配列番号1の7,096に対応するヌクレオチド位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの1679塩基下流に存在する位置のグアニン塩基を表す。「対応する」という表記は、配列番号1に関する多型の位置を示す。g.1679C>G多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0033】
本明細書において使用される「g.28650A>G」は、配列番号1の34,067に対応するヌクレオチド位置のグアニン塩基を表す。「対応する」という表記は、配列番号1に関する多型の位置、すなわちゲノムDNA中のNPC1L1遺伝子のATG開始コドンの28,650塩基下流に位置する多型の位置を示す。g.28650A>G多型は、配列番号1に関連するその他の配列中に存在し得、例えば、配列は他のNPC1L1遺伝子多型を含有し得る。
【0034】
本明細書において使用される「対立遺伝子」は、遺伝子の特定のヌクレオチド配列又はその他の遺伝子座である。対立遺伝子は、1つ若しくはそれ以上のSNP又はNPC1L1遺伝子中の多型部位の特定された組み合わせに対して本明細書中に記載されているハプロタイプの1つを含み得る。7番染色体は常染色体であり、従って、個体中の体細胞は、座に対して2つの対立遺伝子を通常有するので、対立遺伝子という表記には、個体から得られた体細胞中の単一の7番染色体上に存在する座の形態が含まれ得る。同一である2つの対立遺伝子を有する個体は、その座に対してホモ接合である。座に対して2つの異なる対立遺伝子を有する個体は、ヘテロ接合である。
【0035】
本明細書において使用される「NPC1L1アンタゴニスト」には、直接的に又は間接的に、いかなる程度であれ、NPC1L1による食事性コレステロール及び/又は関連する植物ステロールの取り込みを阻害する小分子、タンパク質、抗体又は核酸など(これらに限定されない。)、あらゆる化合物、物質又は因子が含まれる。好ましくは、NPC1L1アンタゴニストは、NPC1L1に結合し、好ましくは、NPC1L1活性を有意に阻害する。「NPC1L1アンタゴニスト」という表記は、特定の作用の様式を意味しない。エゼチミブは、NPC1L1アンタゴニストの例である。
【0036】
本明細書において使用される「遺伝子型」とは、個体中の相同な染色体の対上にある座内の1つ若しくはそれ以上の多型部位のセット内の各多型部位において見出される2つの対立遺伝子の非移相化された(unphased)5’→3’配列(典型的には、ヌクレオチド対)である。
【0037】
本明細書において使用される「遺伝子型決定」とは、個体の遺伝子型を決定するための方法である。
【0038】
本明細書において使用される「ハプロタイプ対」は、単一の個体中の座に対して見出される2つのハプロタイプを表す。
【0039】
本明細書において使用される「ハプロタイプ決定」は、個体中の1つ又はそれ以上のハプロタイプ(PSの特定のセットに対するハプロタイプ対を含む。)を決定するためのあらゆる方法を表し、家系図、分子技術及び/又は統計的な推定の使用が含まれる。
【0040】
本明細書において使用される「増加したエゼチミド(ezetimide)応答」とは、遺伝子型によって規定された患者の群内でのエゼチミド処理によって、異なる遺伝子型を有する患者に比べて、LDL−Cの平均パーセント減少が増加することを表す。エゼチミド処理には、単独療法として、又はLDL−Cを低下させるために使用される少なくとも1つの他の化合物と組み合わせて、エゼチミブ又はNPC1L1アンタゴニストを投与することが含まれる。増加した平均パーセントの減少は、遺伝子型によって規定された異なる群において統計的に有意である。幾つかの実施形態において、個体及び集団は、類似の民族的又は地理的起源を有する。幾つかの実施形態において、治療計画は、10mg/日のエゼチミブでの少なくとも6週の治療及びNPC1L1マーカーを有する群内でのLDL−Cの平均減少は、NPC1L1マーカーを欠如する群内での平均LDL−C減少に比べて、少なくとも15%超上回る。好ましい実施形態において、増加したエゼチミブ応答は、少なくとも、少なくとも27%のLDL−Cの平均減少である。別の特に好ましい実施形態において、NPC1L1プラス及びマイナス群は、エゼチミブに対する極端な応答者(すなわち、そのパーセントLDL−C減少が、エゼチミブの臨床研究において観察される応答分布の上位又は下位10分位に収まる。)である個体のみから構成される。NPC1L1マーカーを有する極端な応答者における好ましい増加されたエゼチミブ応答は、マーカーを欠如する極端な応答者におけるLDL−Cの−17%の変化と比べて、LDL−Cの−34%の変化である。
【0041】
本明細書において使用される「NPC1L1アンタゴニストに対する増加されたLDL−C応答」とは、遺伝子型によって規定された患者群でのNPC1L1アンタゴニスト処理によって、異なる遺伝子型を有する患者に比べて、LDL−Cの平均パーセント減少が増加することをいう。NPC1L1アンタゴニスト処理には、単独療法として、又はLDL−Cを低下させるために使用される少なくとも1つの他の化合物と組み合わせて、NPC1L1アンタゴニストを投与することが含まれる。増加した平均パーセントの減少は、遺伝子型によって規定された異なる群において統計的に有意である。幾つかの実施形態において、個体及び集団は、類似の民族的又は地理的起源を有する。幾つかの実施形態において、治療計画は、NPC1L1アンタゴニストの治療的有効量での少なくとも6週の治療を含み、NPC1L1マーカーを有する群内でのLDL−Cの平均減少は、NPC1L1マーカーを欠如する群内での平均LDL−C減少に比べて、少なくとも15%超上回る。好ましい実施形態において、NPC1L1アンタゴニストに対する増加したLDL−C応答は、少なくとも、少なくとも20%のLDL−Cの平均減少である。別の特に好ましい実施形態において、NPC1L1プラス及びマイナス群は、NPC1L1アンタゴニストに対する極端な応答者(すなわち、そのパーセントLDL−C減少が、NPC1L1アンタゴニストの臨床研究において観察される応答分布の上位又は下位10分位に収まる。)である個体のみから構成される。
【0042】
本明細書において使用される「単離されたポリヌクレオチド」は、自然の状態で見出される同じ配列の何れの核酸分子に対しても同一でない物理的形態で存在する核酸分子である。
【0043】
本明細書において使用される「座」とは、染色体又はDNA分子上での位置を表す。座は、遺伝子又はその一部、表現型と関連する他のゲノム領域、及び特定されたゲノム領域中の単一の多型部位又は多型部位の特異的な組み合わせに対応し得る。
【0044】
臨床的パラメータ(LDL−Cなど)の量に関連して、本明細書において使用される「正常」とは、類似の年齢、体重及び/又は性別の健康な対象で典型的に観察されるパラメータの具体的な数字又は数的範囲を意味し、又は当該分野に従事する臨床医が正常であると理解する前記パラメータの具体的な数字又は数的範囲を意味する。逆に、「異常」とは、正常な数字若しくは正常な数的範囲より低い若しくは高い臨床パラメータに対する具体的な数字若しくは数的範囲を表し、又は当該分野に従事する臨床医が異常であると理解する臨床パラメータに対する具体的な数字若しくは数的範囲を表す。
【0045】
本明細書において使用される「NPC1L1」とは、ヒトニーマンピックC1様1タンパク質(AAR97886)を表す。
【0046】
本明細書において使用される「NPC1L1」とは、NPC1L1をコードするポリヌクレオチドを表す。
【0047】
本明細書において使用される「NPC1L1遺伝子」は、ヒト染色体7p13上に位置する配列番号1中の核酸配列内に存在する配列を表す。NPC1L1遺伝子は、20のエキソン領域と、エキソン配列の間に介在する19のイントロン配列と、並びに配列番号1に示されているNPC1L1遺伝子配列のプロモーター領域を含む、3’及び5’非翻訳領域(3’UTR及び5’UTR)とを含む。最初のインフレームATGはエキソン1中(又は配列番号1中の5,418位)に存在するのに対して、TGA停止コドンはエキソン20中(又は配列番号1中の33,228位)に存在する。
【0048】
本発明に関連して、本明細書において使用される、「NPC1L1マーカー」とは、LDL−Cの健康リスクレベル又は増加されたエゼチミブ応答に関連する特異的な遺伝的バリアントの特異的なコピー数である。好ましいNPC1L1マーカーは、表1に示されているもの、及び表1中の何れかのマーカー中の少なくとも1つのバリアントが代替ハプロタイプ又は連鎖したバリアントの同じコピー数(本明細書において、その各々は、代替遺伝的マーカーと称される。)によって置換されている遺伝的マーカーである。代替ハプロタイプは、表1に示されているハプロタイプの何れかの配列に類似している配列を含むが、当該ハプロタイプ中の特異的に同定された多型部位の1つにおける(但し、全部より少ない)対立遺伝子が、異なる多型部位において、対立遺伝子で置換されており、この代替対立遺伝子は、特異的に同定された多型部位において、前記遺伝子と高い連鎖不均衡(LD)の状態にある。連鎖したバリアントは、表1に示されているバリアントの任意の1つと高いLD状態にあるバリアント(SNP又はハプロタイプを含む。)のあらゆる種類である。同じ染色体上の異なる座に存在する2つの特定の対立遺伝子は、1つの座における対立遺伝子の1つの存在が、他の座における他の対立遺伝子の存在を予測する傾向にあれば、連鎖不均衡状態にあるといわれる。以下でさらに記載されている代替遺伝的マーカーは、インデル、RFLP、反復など、SNP以外の変異の種類を含み得る。
【0049】
本明細書において使用される「ヌクレオチド対」とは、個体から得られた染色体の2つのコピー上の多型部位に見出される2つのヌクレオチドのセット(同一又は別異であり得る。)である。
【0050】
本明細書において「薬理遺伝学的な指標」とは、薬物の適応症とされる疾病の他に、薬物で治療を試みている個体を特定する遺伝的プロファイルを表す。遺伝的プロファイルは、NPC1L1薬物応答マーカーの存在を含む。好ましい実施形態において、遺伝的プロファイルは、LDL−Cの健康リスクレベルに関連するNPC1L1マーカーの存在を含む。
【0051】
本明細書において使用される「移相化された配列」とは、両染色体中の多型部位の同じセットに見出されるヌクレオチド対の配列を表すために通例使用される移相化されていない配列とは異なり、多型部位の組において、単一の染色体上に存在するヌクレオチドの組み合わせを表す。
【0052】
本明細書において使用される「多型部位」又は「PS」とは、SNP又はその他の非ハプロタイプ多型が生じる遺伝子座又は遺伝子中の位置を表す。多型部位には、通常、関心対象の集団中の高度に保存された配列が先行及び後続し、従って、多型部位の位置決定は、通例、多型部位を囲む30〜60個のヌクレオチドのコンセンサス核酸配列を基準として行われ、SNP多型の場合、これは、一般に、「SNPコンテクスト配列」と称される。多型部位の位置は、タンパク質翻訳のための開始コドン(ATG)と比較して、コンセンサス又は基準配列中のその位置によっても特定され得る。当業者は、コンセンサス又は基準配列と比較して、特定の多型部位の位置が、その個体中に1つ又はそれ以上の挿入又は欠失が存在するために、関心対照の集団中の各個体中の参照又はコンテクスト配列中の正確に同じ位置に存在しない場合があり得ることを理解する。さらに、検出されるべき多型部位における代替対立遺伝子の正体及び多型部位が存在する基準配列又はコンテクスト配列の一方又は両方が当業者に提供された場合、当業者は、何れかの個体中の多型部位において代替対立遺伝子を検出するための、強固で、特異的で、及び正確なアッセイを設計するのが通常である。従って、基準配列又はコンテクスト配列中の特定の位置に対する(又は、このような配列中の開始コドンに対する)参照によって、本明細書中に記載されている何れかのPSの位置を特定することは、便宜上のものに過ぎず、具体的に列挙されている全てのヌクレオチド位置は、本明細書に記載されている遺伝子型決定法又は本分野で周知の他の遺伝子型決定法の何れかを用いて、本発明の遺伝的マーカーの存在又は不存在について検査されている何れかの個体中の同じ座の中に同じ多型部位が実際に存在している全てのヌクレオチド位置を文字通り含むことが、当業者によって理解される。
【0053】
本明細書において使用される「多型」は、集団中の遺伝子又は座に対して生じる2つ又はそれ以上の遺伝的に決定された別の配列又は対立遺伝子の出現を表す。ヒト個体は、存在する異なる対立遺伝子に対してホモ接合又はヘテロ接合であり得る。多型の異なる対立遺伝子は、典型的には、選択された集団中に最も頻繁に出現する対立遺伝子(時折、「主要な」又は「野生型」対立遺伝子と表記される。)と異なる頻度で集団中に出現する。二対立遺伝子多型は2つの対立遺伝子を有し、非主要対立遺伝子は、選択された集団中で、1%と2%の間、2%と10%の間、10%と20%の間、20%と30%の間の頻度など、ゼロより大きく、50%未満の何れかの頻度で出現し得る。SNPは、典型的には、二対立遺伝子の多型である。三対立遺伝子多型は、3つの対立遺伝子を有する。好ましくは、多型という用語は、各対立遺伝子が1%、より好ましくは5%を上回る頻度で出現する多型座位を記載するために使用される。多型の種類には、一塩基多型又はSNPなどの、単一の多型部位における配列の変異、及び対象遺伝子又は座中の2つ又はそれ以上の多型部位のセットにおいて、単一の染色体上に出現するヌクレオチドの配列中の変異が含まれる。多型部位の特定のセットに対して出現する各配列は、その座に対する対立遺伝子であり、本明細書では、ハプロタイプとも称される。SNP及びハプロタイプに加えて、多型の例には、制限断片長多型(RFLP)、タンデムリピートの可変数(VNTR)、二ヌクレオチドリピート、三ヌクレオチドリピート、四ヌクレオチドリピート、単純配列リピート、Aluなどの挿入要素及び1つ又はそれ以上のヌクレオチドの欠失が含まれる。
【0054】
本明細書において使用される「精製された核酸」は、試料又は調製物中に存在する総核酸の少なくとも10%を表す。好ましい実施形態において、精製された核酸は、単離された核酸試料又は調製物中の総核酸の少なくとも約50%、少なくとも約75%又は少なくとも約95%を表す。「精製された核酸」という表記は、核酸が何れかの精製を経ていることを要求せず、例えば、精製されていない、化学的に合成された核酸を含み得る。
【0055】
本明細書において使用される「ポリヌクレオチド」及び「核酸」とは、ヌクレオチド塩基A(アデニン)、T(チミン)、C(シトシン)及びG(グアニン)から構成されるDNAであり得、又は塩基A、(ウラシル)(Tに対する代替物)、C及びGから構成されるRNAであり得る一本鎖又は二本鎖分子を表す。ポリヌクレオチドは、コード鎖又はその相補物を表し得る。タンパク質をコードするポリヌクレオチド分子又は核酸は、天然に存在する配列に対して、配列が同一であり得るか、又は、天然に存在する配列中で見出されるもののように、同じアミノ酸をコードする別のコドンを含み得る(Lewin “Genes V” Oxford University Press Chapter 7,1994,171−174を参照。)。さらに、このようなコード分子は、記載されているアミノ酸の保存的置換を表すコドンを含み得る。例えば、ポリヌクレオチドは、ゲノムDNA、mRNA、cDNA、プライマー及びプローブを表し得る。
【0056】
本明細書において使用される「治療する」又は「治療している」とは、臨床的に測定可能な任意の程度まで、治療されている患者中の1つ又はそれ以上の疾病症候の退行を誘導し、又は進行を阻害することによって、患者中の1つ又はそれ以上の疾病症候を緩和するために、患者に、体内的に又は体外的に薬物の有効量を投与することを意味する。何らかの特定の疾病症候を緩和するのに有効である薬物の量(「治療的有効量」とも称される。)は、病状、患者の年齢及び重量並びに患者内に所望される応答を惹起する薬物の能力などの要因に応じて変動し得る。疾病症候が緩和されたかどうかは、その症候の重篤度又は進行状態を評価するために、医師又はその他の熟練した医療従事者によって典型的に使用される何れかの臨床的測定によって評価することが可能である。本発明の実施形態(例えば、治療方法又は製品)は、全ての患者で、目標とする疾病症候を緩和する上では効果的でない場合があり得るが、スチューデントのt検定、χ2乗検定、マン及びホイットニーによるU検定、クルスカル−ウォリス検定(H検定)、ヨンクヒール−タプストラ検定及びウィルコクソン検定など、本分野において公知の何れかの統計学的検定によって測定した場合に、患者の統計的に有意な数において、標的疾病症候を緩和すべきである。
【0057】
II.本発明のNPCDL1マーカーの組成及び表現型効果
上述及び以下の実施例のように、本発明のNPC1L1マーカーは、NPC1L1マーカーが存在する個体によって示される可能性がある特定の表現型、すなわち、LDL−Cの健康リスクレベル又はエゼチミブに対する増加された平均応答の何れかを予測する。本発明の各NPC1L1マーカーは、これらの表現型の1つと関連する特定の対立遺伝子とこの対立遺伝子のコピー数の組み合わせである。
【0058】
表1は、本発明の好ましいNPC1L1マーカーを列記する。NPC1L1マーカー1(例えば、34067Gの少なくとも1コピー)を有する個体は、NPC1L1マーカー1を欠如する(例えば、34067Gのゼロコピー)個体より、LDL−Cの健康リスクレベルを有する可能性がより高い。少なくとも1コピーのNPC1L1マーカー2、3、4又は5を有する個体は、それぞれ、NPC1L1マーカー2、3、4又は5を欠如する個体のエゼチミブ応答に比べて、増加したエゼチミブ応答を示す可能性が高い。
【0059】
【表1】
【0060】
これらのNPC1L1マーカーを含む多型部位は、NPC1L1遺伝子座中の、上記定義及び配列番号1に特定されている位置に対応する位置に存在する。本発明のマーカー中の多型部位を記載する際には、便宜上、遺伝子のセンス鎖を基準とする。しかしながら、当業者であれば認識できるように、NPC1L1遺伝子を含有する核酸分子は相補的な二本鎖分子であり得るので、センス鎖上の特定の部位に対する参照は、相補的なアンチセンス鎖上の対応する部位への参照でもある。
【0061】
さらに、当業者は、本明細書に記載されている本発明の実施形態の全ては、表1中の遺伝子マーカーの何れかに対する代替遺伝的マーカーを用いて実施され得ることを理解する。代替ハプロタイプを含む代替遺伝的マーカーは、表1中のマーカーの1つ中の多型部位における対立遺伝子と、NPC1L1遺伝子中又は7番染色体上の別の場所に位置する多型部位における候補代替対立遺伝子との間の連鎖不均衡(LD)の程度を決定することによって容易に同定される。同様に、連鎖バリアントを含む代替遺伝的マーカーは、表1中のハプロタイプとNPC1L1中の他の場所に存在する候補連鎖バリアントとの間の連鎖不均衡の程度を決定することによって容易に同定される。候補代替対立遺伝子又は連鎖バリアントは、現在公知である多型の対立遺伝子であり得る。他の候補代替対立遺伝子及び連鎖バリアントは、多型を発見するために本分野で周知の何らかの技術を用いて、当業者によって容易に同定され得る。
【0062】
表1中の遺伝的マーカーと候補代替マーカーとの間のLDの程度は、本分野で公知のあらゆるLD測定を用いて決定され得る。ゲノム領域中のLDパターンは、いずれかの2つの対立遺伝子(例えば、異なる多型部位におけるSNPの間、又は2つのハプロタイプの間)が連鎖不均衡にあるかどうかを決定するための、本分野で公知の様々な技術を用いて、適切に選択された試料中において、容易に経験的に決定される(例えば、GENETIC DATA ANALYSIS II,Weir,Sineuer Associates,Inc.Publisher,sSunderland,MA 1996)。当業者は、LDを測定する何れの方法が、特定の試料サイズ及びゲノム領域に対して最適であるかを容易に選択し得る。
【0063】
連鎖不均衡の最も頻繁に使用される指標の1つは、Devlinら(Genomics,29(2):311−22(1995))によって記載された式を用いて計算されるΔ2である。Δ2は、第一の座における対立遺伝子Xが、同じ染色体上の第二の座における対立遺伝子Yの出現をどれほど上手く予測できるかという指標である。本指標は、予測が完璧である場合にのみ1.0に達する(例えば、Xの時かつXの時に限りY)。
【0064】
好ましい代替遺伝的マーカーにおいて、代替対立遺伝子又は連鎖バリアントの座は、NPC1L1遺伝子を貫く約100キロ塩基のゲノム領域中にあり、より好ましくは、座はNPC1L1遺伝子中にある。他の好ましい代替遺伝的マーカーは、関連する対立遺伝子間の(例えば、代替SNP及び代替されたSNPとの間の、又はマーカー中の連鎖バリアントとハプロタイプとの間の)LDが適切な参照集団中で測定された場合に、少なくとも0.75、より好ましくは少なくとも0.80、より好ましくは少なくとも0.85又は少なくとも0.90、さらに好ましくは少なくとも0.95、最も好ましくは1.0のΔ2値を有する。このΔ2の測定のために使用される参照集団は、好ましくは、NPC1L1アンタゴニストを含有する薬物で治療されるべき患者の集団の遺伝的多様性を反映する。例えば、参照集団は、一般的な集団、薬物を使用している集団、薬物の効力が示されている特定の症状(高コレステロール血症など)を有すると診断された集団又は類似の民族的背景の集団であり得る。
【0065】
本明細書に記載されている本発明の実施形態の全てにおいて、当業者であれば、表1中の対立遺伝子と代替マーカーとの間に完全な連鎖不均衡が存在する場合に、表1中の特定のNPC1L1マーカーが個体中に存在するか又は存在しないかを検出することは、代替遺伝的マーカーの存在又は不存在を検出ことと文字通り等しいことが理解される。
【0066】
一態様において、本発明は、客観的な遺伝的基準に基づいて、コレステロール治療を必要としている患者を応答群に分類するための手段を提供する。さらに、患者がどの階級内に属するかに基づいて、本発明は、その患者に対する最も適切な薬物治療を選択するための客観的な基礎を与える。別の態様において、本発明は、コレステロールの健康リスクレベル及び/又は健康リスクコレステロール関連症状を治療又は予防するために使用することができる治療剤をスクリーニングし、開発するために使用可能なさらなるNPC1L1多型の同定方法を提供する。
【0067】
本発明の様々な態様は、NPC1L1遺伝子中の一塩基多型(SNP)の発見に基づいている。特に、NPC1L1遺伝子中の新規g.−18C>A多型(配列番号1の5,400位)が、NPC1L1遺伝子のプロモーター領域中に同定された。遺伝子型決定の結果及び血液成分測定の統計学的解析の結果は、ホモ接合又はヘテロ接合状態の何れかで(すなわち、1コピー又は2コピー)g.−18C>A多型が存在することは、主要な対立遺伝子(すなわち、配列番号1の5,400位にシトシンを有する。)に対してホモ接合の個体に比べて、エゼチミブでの治療に応答した総コレステロール、LDL−C、非HDL−C及びアポBレベルの変化に有意に関連することを示した。別のNPC1L1多型g1679C>G(代替的NCBI表記、rs2072183)は、主要な対立遺伝子(すなわち、配列番号1の7,096位にシトシンを有する。)に対してホモ接合の個体に比べて、エゼチミブでの処理に応答したLDL−Cレベルの変化に関連することも見出された。ハプロタイプ分析は、エゼチミブでの治療に応答して、LDL−Cレベルの変化に有意に関連する3つのSNPを含む2つのNPC1L1ハプロタイプも同定した。ハプロタイプ[A(−133)、A(−18)、G(1679)]は、配列番号1の5,285位、5,400位及び7,096位に異なるハプロタイプを有する個体に比べて、エゼチミブ治療に対する平均的な応答(すなわち、LDL−Cの低下)より高い応答を伴うことが見出された。ハプロタイプ[G(−133)、C(−18)、C(1679)]は、配列番号1の5,285位、5,400位及び7,096位に異なるハプロタイプを有する個体に比べて、エゼチミブ治療に対する平均的な応答(すなわち、LDL−Cの低下)より低い応答を伴うことが見出された。これらのNPC1L1バリアントとエゼチミブ治療に対するLDL−C応答間の遺伝的関連は、エゼチミブ治療に対して感受性である経路中でのコレステロール吸収に対する中心的遺伝子としてのNPC1L1の役割を裏付ける。
【0068】
本発明の別の態様は、対象のNPC1L1遺伝子中の一塩基多型又はハプロタイプを決定すること、及びNPC1L1遺伝子中の前記多型又はハプロタイプに対する参照により、医薬として活性な化合物が投与された前記対象の状態を決定することを含む、NPC1L1遺伝子中の一塩基多型又はハプロタイプを、対象に投与された医薬として活性な化合物の効力と相関させる方法に関する。一実施形態において、対象の状態は、化合物の投与前及び投与後における病状の測定に基づく。対象に投与された医薬として活性な化合物の効力は、特定の一塩基多型又は特定のハプロタイプが、多型配列位置又はハプロタイプ配列位置に異なる遺伝子型を有する個体の状態の変化に比べて、化合物の投与に応答して、対象の状態の統計的に有意な変化と相関するかどうかを決定することによって評価される。典型的な病状には、アテローム性動脈硬化症、急性冠症候群、冠動脈疾患などが含まれる。常にではないが、一般に、病状には、例えば、低密度脂質コレステロール、総コレステロール、非高密度脂質コレステロール及びアポリポタンパク質(アポB)など、血液若しくは血液血漿コレステロールレベル又は血液タンパク質関連脂質レベルが関連する。
【0069】
本発明のさらなる態様によれば、ヒト対象のNPC1L1遺伝子中の一塩基多型を決定すること、5,285位、5,400位、7,096位又は34,067位を含むNPC1L1遺伝子を含む配列番号1の少なくとも1つ又はそれ以上の位置における多型に対する参照により、医薬として活性な化合物が投与された前記ヒトの状態を決定することを含む、NPC1L1遺伝子中の一塩基多型を、ヒト対象に投与された医薬として活性な化合物の効力と相関させる方法が提供される。ヒト対象の状態は、1つ、2つ、3つ、4つの位置又は4つの全ての位置における対立遺伝子変異に対する参照により決定され得る。ヒト対象の状態は、他の1つ又はそれ以上の一塩基多型と組み合わせた、本明細書中に同定された特定の多型の1つ又はそれ以上によっても決定され得る。
【0070】
本発明の別の態様は、NPC1L1機能に影響を与える薬物に対する対象の応答性を予測する方法を提供する。本方法は、対照から生物学的試料を取得すること、前記生物学的試料中で配列番号1の位置に存在するヌクレオチド塩基を測定することを含み、前記位置は、5,400位及び7,096位からなる群から選択され、5,400位のアデニン塩基の存在又は7,096位のグアニンの存在は、薬物に対する対象の応答性の増加したレベルの指標である。別の実施形態において、配列番号1の5,400位のシトシン塩基又は7,096位のシトシン塩基の存在は、薬物に対する対象の応答性の減少したレベルの指標である。
【0071】
本発明の別の態様は、ヒト対象中の血漿低密度脂質コレステロールの健康リスクレベルに対する素因を検出する方法を提供する。本方法は、ヒトNPC1L1対立遺伝子のゲノム配列中の多型の存在を対象中に検出することを含み、ここにおいて、ヒトNPC1L1対立遺伝子は配列番号1の34,067位のグアニンからなる。34,067位のグアニン塩基の存在は、血漿コレステロールの健康リスクレベルに対する対象の素因の指標である。別の実施形態において、34,067位のグアニン塩基の検出は、冠状動脈性心臓病(CHD)に対する対象の素因の指標である。
【0072】
本発明の一実施形態において、LDL−Cの健康リスクレベルは、当業者によって認められた、教育、医学、政府又はその他の機関によって記されたガイドラインを参照することによって決定される。例えば、米国では、国立コレステロール教育プログラムが、様々なコレステロールレベルと関連する健康リスクを詳述するレポートを定期的に発行している。特に、NCEP成人治療パネルは、CHDリスクのレベルに従って、特異的なLDL−C目標レベルを確定するガイドラインを発行した(JAMA(2001)285:2486−97)。最近、新たに得られつつある臨床試験データに基づき、これらのガイドラインに対する更新が、極めて高いリスクにあると考える者に対して、LDL−C<70mg/dLという任意的な目標を確立した(Circulation(2004)110:227−239)。本発明の実施において、ヒトをリスクに曝す血漿低密度脂質コレステロールのレベルは、更新されたNCEP ATPガイドラインに基づいて決定される(Circulation(2004)110:227−239)。一実施形態において、血漿低密度脂質コレステロールの健康リスクレベルは、約70mg/dLと約130mg/dLの間にある。
【0073】
本発明の別の態様によれば、患者が、配列番号1の5,400位のアデニン塩基ヘテロ接合性又はホモ接合性、配列番号1の7,096位のグアニン塩基ヘテロ接合性又はホモ接合性及び配列番号1の5,285位、5,400位及び7,096位に対応する[A(−133)、A(−18)、G(1679)]ハプロタイプヘテロ接合性又はホモ接合性からなる群から選択される遺伝子型を有するかどうかを決定する工程を含む、患者がNPC1L1アンタゴニストに応答した平均的な増加を上回る増加と関連する遺伝子型を有するかどうかを決定する方法が提供される。幾つかの実施形態において、患者は、コレステロールの健康リスクレベルを有する。他の実施形態において、患者は、現在、スタチン治療を受けているか、又は過去にスタチン治療を受けたことがある。典型的なスタチンは、以下で、より詳しく記載されている。他の実施形態において、患者は、スタチン治療を用いて、コレステロールの十分な低下を達成することに失敗している。患者に対するコレステロールの十分な低下は、患者の様々な特性、例えば、年齢、一般的な健康などに鑑みて、本分野で認められた何れかのコレステロール標的レベルに対する参照によって測定され得る。特に、このような標的レベル及び健康リスク因子は、教育、医学又は政府機関によって用意された様々な冊子に記載されている。特定の実施形態において、患者に対するコレステロール目標レベルは、NCEPATPガイドラインを参照することによって決定される。一実施形態において、患者が約100mg/dL未満又は約70mg/dL未満のLDL−Cの血漿レベルを有する場合に、血漿LDl−C中の十分な低下が達成される。
【0074】
本発明の別の態様によれば、患者中のコレステロールを低下させる方法であり、NPC1L1アンタゴニストの有効量を前記患者に投与する工程を含み、前記患者が、配列番号1の5,400位のアデニン塩基ヘテロ接合性又はホモ接合性、配列番号1の7,096位のグアニン塩基ヘテロ接合性又はホモ接合性及び配列番号1の5,285位、5,400位及び7,096位に対応する[A(−133)、A(−18)、G(1679)]ハプロタイプヘテロ接合性又はホモ接合性からなる群から選択される遺伝子型を有すると特定される、前記方法を提供する。患者から生物学的試料を取得し、NPC1L遺伝子配列の対応する位置にどのヌクレオチド塩基が存在するかを決定することによって、患者は、上記特定された遺伝子型の1つを有すると特定される。患者が本明細書に特定されている遺伝子型の1つ、例えば、上記NPC1L1マーカーの1つを有することが知られている場合に、患者の遺伝子型は特定されている。NPC1L1アンタゴニストの有効量とは、コレステロールの腸輸送を低下させる量である。例えば、一実施形態において、NPC1L1アンタゴニストはエゼチミブであり、有効量は10mgであり、毎日1回投与される。他のNPC1L1アンタゴニストは、本明細書の以下に記載されている。
【0075】
本発明の別の態様は、g.−133A>G、g.−18C>A及びg.28650A>G又はハプロタイプ[A(−133)、A(−18)、G(1679)]からなる群から選択される一塩基多型を有する患者中の高コレステロール又は高コレステロール関連疾患を治療するための薬品の使用を、目標とする対象者に対して宣伝することを含む、エゼチミブを含む薬品を広告する方法であり、前記選択された一塩基多型又はハプロタイプを有する個体が、前記選択された一塩基多型又はハプロタイプを欠如する個体より、エゼチミブに対して平均応答より高い応答を示す可能性が高い、前記方法を含む。
【0076】
本発明において、ヒト対象の組織に由来する核酸分子の操作は、NPC1L1遺伝子型の分析、並びにNPC1L1SNP及びハプロタイプマーカー、特に、NPC1L1−g.−133A>G、NPC1L1−g.−18C>A、NPC1L1−g.1679C>G及びNPC1L1−g.28650A>Gから選択される1つ若しくはそれ以上のSNP又は[A(5285)−A(5400)−G(7096)]及び[G(5285)−C(5400)−C(7096)]から選択される1つ若しくはそれ以上の3SNPハプロタイプに関連するスクリーニング及び診断方法を提供するために実施することが可能である。これらの文脈において使用される核酸分子は、以下に記載されているように、増幅することが可能であり、RNA、ゲノムDNA及びRNA由来のcDNAを一般的に含む。
【0077】
III.ポリヌクレオチド及びポリヌクレオチドスクリーニング法
個体中にNPC1L1マーカーが存在することは、その個体がマーカーを含むバリアントの必要とされるコピー数を有するかどうかの決定を可能とする本分野で周知の様々な方法の何れによっても決定し得る。例えば、必要とされるコピー数が1又は2であれば、前記方法は、個体がバリアントの少なくとも1コピーを有することを決定する必要があるに過ぎない。好ましい実施形態において、前記方法は、実際のコピー数の決定を提供する。
【0078】
典型的には、これらの方法は、マーカー中の1つ又はそれ以上の多型部位に存在するヌクレオチド又はヌクレオチド対の正体を決定するために個人から取得された生物学的試料から調製された核酸試料をアッセイすることを含む。核酸試料は、実質的にあらゆる生物学的試料から調製され得る。例えば、都合のよい試料には、全血血清、精液、唾液、涙、糞便、尿、汗、口腔内物質、皮膚及び毛髪が含まれる。マーカーバリアントの実際のコピー数を決定するのであれば、体細胞が好ましい、核酸試料は、当業者に公知のあらゆる技術を用いて、分析のために調製し得る。好ましくは、このような技術は、核酸分子中の多型部位の所望されるセットに対して遺伝子型又はハプロタイプ対を決定するのに十分に純粋なゲノムDNAの産生をもたらす。このような技術は、例えば、「Sambrook et al.,Molecular Cloning:A Laboratory Manual,(Cold Spring Harbor Laboratory New York)(2001)」中に見出し得る。
【0079】
指定された多型がハプロタイプであるマーカーの場合、核酸試料中のハプロタイプのコピー数は、直接的なハプロタイプ決定法によって決定されるか、又はマーカーを含む多型部位のセットに対するハプロタイプ対が、多型部位のセットに対する個体のハプロタイプ遺伝子型から推測される間接的なハプロタイプ決定法によって決定され得る。核酸試料が調製される様式は、直接又は間接的なハプロタイプ決定法が使用されるかどうかに依存する。
【0080】
直接的なハプロタイプ決定法、又は分子ハプロタイプ決定法は、典型的には、当業者によって容易に理解されるように同一の対立遺伝子又は異なる対立遺伝子であり得る、座に対する個体の2つの対立遺伝子のうち1つのみを含有するヘミ接合性DNA試料を産生する様式で個体から取得された血液試料又は口頬試料から単離されたゲノムDNA試料を処理すること、及び目的の各多型部位に存在するヌクレオチドを検出することを含む。核酸試料は、ヘミ接合性DNA試料を調製するための本分野で公知の様々な方法を用いて取得することができ、WO98/01573、米国特許第5,866,404号及び米国特許第5,972、614号に記載されているような、酵母中での標的化されたインビボクローニング(TIVC;targeted in vivo cloning);米国特許第5,972,614号に記載されているプライマー伸長及びエキソヌクレアーゼ分解と組み合わせて、対立遺伝子特異的オリゴヌクレオチドを使用する、ヘミ接合性DNA標的の作製;「Ruano et al,Proc.Natl.Acad.Sci. 87:6296−300(1990)」に記載されている単一分子希釈(SMD);及び対立遺伝子特異的PCR(Ruano et al,Nucl.Acids Res.17:8392(1989);Ruano et al,Nucl.Acids Res.19:6877−82(1991);Michalatos−Beloin et al、上記)が含まれる。
【0081】
当業者によって容易に理解されるとおり、個体中の座の何れの個別のクローンも、2つの対立遺伝子のうち1つのみに対するハプロタイプを直接決定することが可能であり、従って、他の対立遺伝子に対するハプロタイプの正体を直接決定するためには、さらなるクローンを調べる必要がある。典型的には、両対立遺伝子を決定する90%超の確率を有するためには、個体中に存在するゲノム遺伝子座の少なくとも5つのクローンを調べるべきである。しかしながら、幾つかの事例では、一旦、1つの対立遺伝子に対するハプロタイプが直接決定されると、個体がマーカーを含む多型部位に対して公知の遺伝子型を有するか、又は適切な参照集団中で座に対するハプロタイプ又はハプロタイプ対の頻度が入手可能であれば、他の対立遺伝子に対するハプロタイプを推測し得る。
【0082】
両対立遺伝子の直接のハプロタイプ決定は、別個の容器中に配置された2つのヘミ接合性DNA(各対立遺伝子に対して1つ)試料をアッセイすることによって実施し得る。あるいは、2つの試料が異なるタグで標識されているか、又は各試料に対するアッセイ結果が、その他の方法で、別々に識別可能若しくは特定可能であれば、2つのヘミ接合性試料は、同じ容器中でアッセイし得る。例えば、試料が第一及び第二の蛍光色素で標識されていれば、座中の多型部位は、対立遺伝子の1つに対して特異的であり、及び第三の蛍光色素で標識されたオリゴヌクレオチドプローブを用いて、座中の多型部位がアッセイされ、次いで、第一及び第三の色素の組み合わせを検出すことにより、第一の試料中の多型部位に存在するヌクレオチドを特定するとともに、第二及び第三の色素の組み合わせを検出することにより、第二の試料中の多型部位に存在するヌクレオチドを特定する。
【0083】
間接的なハプロタイプ決定法は、典型的には、座中の各多型部位に対する個体の遺伝子型を正確に決定できる様式で、個体から得られた血液試料又は口頬試料から単離されたゲノムDNA試料を調製することを含む。ついで、座に対して個体のハプロタイプの少なくとも1つの正体を推定するために遺伝子型が使用され、好ましくは、遺伝子座に対する個体のハプロタイプ対の正体を推定するために遺伝子型が使用される。
【0084】
1つの間接的なハプロタイプ決定法において、対象ハプロタイプのゼロ、1又は2コピー数が存在することは、マーカー中の多型部位に対する個体の遺伝子型を、多型部位の同じセットに対する参照ハプロタイプ対のセットと比較し、個体中に存在する可能性がより高い参照ハプロタイプ対を前記個体に対して割り振ることによって決定することが可能である。マーカーを含むハプロタイプに対する個体のコピー数は、割り振られた参照ハプロタイプ対中のハプロタイプのコピーの数である。
【0085】
参照ハプロタイプ対とは、一般的な集団中に又は参照集団中に存在することが知られているハプロタイプ対である。参照集団は、世界の主要な民族地理的群を代表する無作為に選択された個体から構成され得る。好ましい参照集団は、マーカーの存在について検査されている個体と類似の民族地理的背景を有する集団である。参照集団の大きさは、観察が確保されることを望んでいるハプロタイプがどれだけ稀であるかに基づいて選択される。例えば、参照集団中での発生頻度がp%で集団中に存在するハプロタイプを見逃さない確率をq%としたいのであれば、標本としなければならない個体の数(n)は、2n=log(1−q)/log(1−p)(p及びqは、割合として表される。)によって表される。特に好ましい参照集団は、ハプロタイプ決定手法の品質をチェックするための対照としての役割を果たすために、1つ又はそれ以上の3世代家族を含む。参照集団が、2以上の民族地理的群を含む場合には、ハーディー−ワインベルグ平衡と合致するかどうかを決定するために、各群に対する頻度データが調べられる。ハーディー−ワインベルグ平衡(D.L.Hard et al.,Principles of Population Genomics,Sinauer Associates(Sunderland,MA),3rdEd.,1997)は、ハプロタイプ対H1/H2を見出す頻度が、H1とH2が等しくなければ、PH−W(H1/H2)=2p(H1)p(H2)であり、H1とH2が等しくければ、PH−W(H1/H2)=p(H1)p(H2)であることを仮定する。観察されたハプロタイプ頻度と予測されたハプロタイプ間の統計的に有意な差は、集団群中の著しい近親交配、遺伝子に対する強い選択圧、標本抽出の偏り及び/又は遺伝子型決定プロセスにおける誤りなどの1つ又はそれ以上の要因に起因し得る。民族地理的群中にハーディー−ワインベルグからの大きな解離が観察されれば、解離が標本抽出の偏りによるものかを明らかにするために、その群中の個体の数を増加させることが可能である。より大きな試料サイズが、観察されたハプロタイプ対の頻度と予測されたハプロタイプ対の頻度の間の差を減少させないのであれば、直接的な分子ハプロタイプ決定法を用いて、個体のハプロタイプを決定したいと考える場合があり得る。
【0086】
ハプロタイプ対の割り当ては、個人の遺伝子型と合致する参照ハプロタイプ対を選択することによって実施し得る。個体の遺伝子型が2以上の参照ハプロタイプ対と合致する場合には、これらの合致するハプロタイプのうち、個体中に存在する可能性が最も高いのは何れかを決定するために参照ハプロタイプ対の頻度を使用し得る。特定の合致するハプロタイプ対が、他の合致するハプロタイプ対より、参照集団中でより頻度が高いのであれば、最も高い頻度を有する、合致するハプロタイプ対が、個体中に存在する可能性が最も高い。時折、参照ハプロタイプ対中に提示される唯一のハプロタイプが、個体の遺伝子型を説明することができる、可能なハプロタイプ対の全てと合致するが、このような場合には、この公知のハプロタイプと可能なハプロタイプ対から公知のハプロタイプを差し引くことによって得られる新しいハプロタイプとを含有するハプロタイプ対が個体に割り当てられる。稀な事例では、参照集団中の何れのハプロタイプも個体の遺伝子型と合致しないか、あるいは、複数の参照ハプロタイプ対が遺伝子型と合致する。このような事例では、好ましくは、直接の分子ハプロタイプ決定法を用いて、個体のハプロタイプが決定される。
【0087】
上記間接的なハプロタイプ決定法中の全工程の何れも、視覚的な検査と適切な計算の実行により、手動で実施され得るが、好ましくは、コンピュータで読み取り可能な規格で格納された、個体の遺伝子型及び参照ハプロタイプ対に関するデータにアクセスする、コンピュータによって実行されるアルゴリズムによって行われる。このようなアルゴリズムは、WO01/80156及びWO2005048012A2に記載されている。あるいは、個体中のハプロタイプ対は、報告されている他のハプロタイプ決定アルゴリズム(例えば、Clark et al.1990,Mol Bio Evol 7:111−22;PHASEv2ソフトウェア(University of Washington Technology Transferからライセンスを入手可能、Stefens,M.et al.,(2001) Am J Hum Genet 68:978−989に記載されている。);WO 02/064617;Niu T.et al(2002) Am J.Hum Genet 70:157−169;Zhang et al.(2003) BMC Bioinformatics 4(1):3)の補助を得て、又はGenaissance Pharmaceuticals,Inc.(New Haven,CT)によって提供されるような、民間のハプロタイプ決定サービスを通じて、当該遺伝子に対する個体の遺伝子型から予測し得る。
【0088】
本明細書中に記載されている全ての直接的及び間接的ハプロタイプ決定法は、典型的には、個体から得られた核酸試料中の多型部位における対立遺伝子少なくとも1つの正体を決定することを含む。この決定の感受性と特異性を増大させるために、遺伝子座中の1つ又はそれ以上の標的領域を核酸試料から増幅することがしばしば望ましい。増幅された標的領域は、遺伝子全体など、関心対象の座を包含するか、又は1つ若しくはそれ以上の多型部位を含有するその領域を包含し得る。マーカー中の各多型部位に対して、分離した標的領域を増幅し得る。
【0089】
本発明によれば、NPC1L1遺伝子中の多型を、医薬として活性な化合物のヒト対象での効力と相関させる方法が提供される。本方法は、ヒト対象のNPC1L1遺伝子中の多型を決定すること、及びNPC1L1遺伝子中の一塩基多型への参照によって、医薬として活性な化合物が投与された前記ヒト対象の状態を決定することを含む。
【0090】
本発明の有用な多型核酸分子には、NPC1L1プロモーター領域中のg.−18C>ASNPに相当するCからAへの塩基転換の領域中において、NPC1L1配列に特異的にハイブリダイズするものが含まれる。典型的には、このようなポリヌクレオチドは、少なくとも約12ヌクレオチド長であり、NPC1L1配列(配列番号1)の5,400位におけるCからAへの塩基転換の領域に対応するヌクレオチド配列を有する。1つのこのような代表的ポリヌクレオチドは、5’GGAGG(C)TGCCTT3’(配列番号2)であり、ここで、カッコ内のヌクレオチド塩基は、多型g.−18C>A部位の「主要な」対立遺伝子、すなわち、NPC1L1遺伝子の5,400位のシトシンを表す。
【0091】
提供される核酸分子は、放射線標識、蛍光標識、酵素標識、配列タグなど、本分野で公知のあらゆる技術によって標識することが可能である。本発明の別の態様によれば、核酸分子は、配列番号1の5,400位に、CからAへの塩基転換を含有する。このような分子は、対立遺伝子特異的オリゴヌクレオチドプローブとして使用することが可能である。有用なポリヌクレオチドは、少なくとも約12ヌクレオチド長であり、多型g.−18C>A部位が含まれる。1つのこのような代表的ポリヌクレオチドは、5’GGAGG(A)TGCCTT3’(配列番号3)であり、ここで、カッコ内のヌクレオチド塩基は、多型g.−18C>A部位の「主要でない」対立遺伝子、すなわち、NPC1L1遺伝子の5,400位のアデニンを表す。
【0092】
組織試料は、何れの核酸塩基がNPC1L1多型部位に存在するかを決定するために検査することが可能である。検査のための適切な身体試料には、血液から得られるDNA若しくはRNAを含むもの又はDNA若しくはRNAを含有する対象から得られた他の何れかの細胞試料が含まれる。例えば、都合のよい試料には、全血血清、精液、唾液、涙、糞便、尿、汗、口腔内物質、皮膚及び毛髪が含まれる。マーカーバリアントの実際のコピー数を決定するのであれば、体細胞が好ましい、核酸試料は、当業者に公知のあらゆる技術を用いて、分析のために調製し得る。好ましくは、このような技術は、核酸分子中の多型部位の所望されるセットに対して遺伝子型又はハプロタイプ対を決定するのに十分に純粋なゲノムDNAの産生をもたらす。このような技術は、例えば、「Sambrook et al.,Molecular Cloning:A Laboratory Manual,(Cold Spring Harbor Laboratory New York)(2001)」中に見出し得る。
【0093】
本発明の一実施形態において、単離されたオリゴヌクレオチドプライマーの対は、例えば、本明細書の実施例1に開示されている配列番号4及び5など、NPC1L1g.−18C>A多型領域の核酸増幅のために提供される。プライマーのこのセットは、NPC1L1遺伝子、特に5’UTR及びエキソン1領域に由来する。2つの適切に配置されたg.−18C>A増幅オリゴヌクレオチドプライマーは、何れのヌクレオチド塩基が配列番号1の5,400位に存在するかを決定するためにg.−18C>A多型領域の配列を決定するための十分な核酸材料を取得するために使用される。同様に、他の単離されたオリゴヌクレオチドプライマーは、NPC1L1g.−133A>G、g.1679C>G及びg.28650A>G多型領域を増幅するために使用できる本明細書の実施例中に開示されている。
【0094】
本発明の別の実施形態において、単離された対立遺伝子特異的オリゴヌクレオチド(ASO)が提供され、例えば、本明細書の実施例3に記載されているASOを参照されたい。このようなASOは、市販の試薬及び特注の対立遺伝子識別遺伝子型アッセイサービスと組み合わせて、Livak((1999) Genet.Anal.,14:143−9)及びApplied Biosystems(Foster City,CA)によって提供された文書に記載されているTaqMan Allelic Discrimination遺伝子型アッセイの実施に際して使用することが可能である。これに実質的に類似する配列も、本発明に従って提供される。ASOは、高コレステロールを有し、その治療を必要としている対象における各NPC1L1多型の存在又は不存在の同定において有用である。これらのユニークなNPC1L1オリゴヌクレオチドプライマーは、それぞれ、g.−133A>G、g.−18C>A、g.1679C>G及びg.28650A>Gに対応する塩基の変化に基づいて設計及び作製される。プライマーハイブリダイゼーションのために使用することが可能な他のプライマーは、本明細書におけるNPC1L1g.−133A>G、g.−18C>A、g.1679C>G及びg.28650A>G多型の開示に基づいて、当業者が容易に解明可能である。
【0095】
本発明のプライマーは、多型遺伝子座中の核酸の有意な数に対してポリマー化の開始を提供するために、十分な長さ及び適切な配列のオリゴヌクレオチドを有する。具体的には、本明細書において使用される「プライマー」という用語は、2つ又はそれ以上のデオキシリボヌクレオチド又はリボヌクレオチド、幾つかの実施例においては、NPC1L1遺伝子の4以上、別の実施形態において9以上、他の実施形態においては13以上、さらに別の実施形態においては少なくとも約20ヌクレオチドを含む配列を表し、ここにおいて、DNA配列は、各々、それぞれ、g.−133A>G、g.−18C>A、g.1679C>G及びg.28650A>Gに対応する多型部位を含有する。例えば、NPC1L1−g.−18C>Aの場合には、配列番号1の5,400位におけるCからAへの塩基転換がオリゴヌクレオチド内に含有されている。配列番号1の5,400位にシスチン(cystine)(C)を含む対立遺伝子は、本明細書において、「5,400主要対立遺伝子」と称される。配列番号1の5,400位にアデニン(A)を含む対立遺伝子は、本明細書において、「5,400非主要対立遺伝子」と称される。
【0096】
NPC1L1遺伝子の5,400主要対立遺伝子と5,400非主要対立遺伝子とを識別するオリゴヌクレオチドも、本発明に従って提供され、ここで、前記オリゴヌクレオチドは、ヌクレオチド5,400がシトシンである場合には、NPC1L1遺伝子に対応するポリヌクレオチドのヌクレオチド5,400を含むNPC1L1遺伝子の一部にハイブリダイズするが、ヌクレオチド5,400がアデニンである場合には、NPC1L1遺伝子の一部とハイブリダイズしない。NPC1L1遺伝子の5,400主要対立遺伝子と5,400非主要対立遺伝子とを識別するオリゴヌクレオチドも、本発明に従って提供され、ここで、前記オリゴヌクレオチドは、ヌクレオチド5,400がアデニンである場合には、NPC1L1遺伝子に対応するポリヌクレオチドのヌクレオチド5,400を含むNPC1L1遺伝子の一部にハイブリダイズするが、ヌクレオチド5,400がシトシンである場合には、NPC1L1遺伝子の一部とハイブリダイズしない。このようなオリゴヌクレオチドは、好ましくは、10塩基長と30塩基長の間である。このようなオリゴヌクレオチドは、場合により、検出可能な標識をさらに含むことが可能である。本明細書に提供されている情報に基づいて、それぞれ、NPC1L1g.−133A>G、g.1679C>G及びg.28650A>Gの主要及び非主要対立遺伝子に対して類似のASOを設計することが可能である。
【0097】
幾つかの例で、擬陽性の検出を防ぐために、対立遺伝子特異的ハイブリダイゼーションアッセイの特異性を増加させることが望ましい。このような場合には、対立遺伝子特異的プライマー(SNP対立遺伝子に合致する塩基)の3’末端に、鍵型核酸残基が配置され、それぞれの各NPC1L1主要及び非主要対立遺伝子間の増加したミスマッチ識別を与える。鍵型核酸残基を含有する適切な高特異性NPC1L1ASOプライマーは、Proligo LLC(Boulder,Colorado)から取得し得る。
【0098】
ポリヌクレオチド合成を基礎とする増幅方法に対して伝導性がある環境条件には、ヌクレオシド三リン酸及びDNAポリメラーゼなどの重合化のための薬剤並びに適切な温度及びpHの存在が含まれる。プライマーは、好ましくは、増幅の効率化を最大化するために一本鎖であるが、二本鎖とすることも可能である。二本鎖である場合には、伸長産物を調製するために使用する前に、その鎖を分離するために、まず、プライマーが処理される。プライマーは、重合化のための誘導剤の存在下で、伸長産物の合成を開始させるのに十分に長くなければならない。プライマーの正確な長さは、温度、緩衝液及びヌクレオチド組成を含む多くの因子に依存する。オリゴヌクレオチドプライマーは、典型的には、12〜20又はこれ以上のヌクレオチドを含有するが、これより少ないヌクレオチドを含有することが可能である。
【0099】
本発明のプライマーは、増幅されるべきゲノム遺伝子座の各鎖に対して「実質的に」相補的であるように設計される。このことは、前記薬剤が重合化を実施できる条件下で、それらのそれぞれの鎖とハイブリダイズするために、プライマーが十分に相補的でなければならないことを意味する。換言すれば、プライマーは、転位に隣接する5’及び3’配列とハイブリダイズするために、及びゲノム遺伝子座の増幅を可能とするために、転位に隣接する5’及び3’配列と十分な相補性を有するべきである。
【0100】
本発明のオリゴヌクレオチドプライマーは、関与する反応工程の数に比べて、多型遺伝子座の指数関数的量を産生する酵素的連鎖反応である増幅反応において使用される。典型的には、一方のプライマーは多型遺伝子座の負(−)鎖に対して相補的であり、他方のプライマーは正(+)鎖に対して相補的である。変性された核酸にプライマーをアニールさせた後、DNAポリメラーゼI(クレノウ)の巨大断片などの酵素及びヌクレオチドを用いて伸長させることにより、標的多型遺伝子座配列を含有する新たに合成された+及び−鎖をもたらす。これらの新たに合成された配列はテンプレートでもあるので、変性、プライマーアニーリング及び伸長の反復サイクルは、プライマーによって規定される領域(すなわち、標的多型遺伝子座配列)の指数関数的産生をもたらす。連鎖反応の産物は、使用される特異的プライマーの末端に対応する末端を有する慎重な(discreet)核酸二本鎖である。
【0101】
本発明のオリゴヌクレオチドプライマーは、慣用のホスホトリエステル及びホスホジエステル法又はこれらの自動化された実施形態など、あらゆる適切な方法を用いて調製することが可能である。1つのこのような自動化された実施形態において、ジエチルホスホルアミダイトが出発材料として使用され、「Beaucage et al.,Tetrahedron Letters 22:1859−1862(1981)」によって記載されているとおりに合成することが可能である。修飾された固体支持体上にオリゴヌクレオチドを合成するための1つの方法は、米国特許第4,458,066号に記載されている。
【0102】
多型遺伝子座を含有する核酸配列を含有するか、又は含有すると疑われる限り、精製された形態又は精製されていない形態の全ての核酸試料を、出発核酸として使用することが可能である。従って、前記方法は、例えば、DNA又はRNA(メッセンジャーRNAを含む。)を増幅することが可能であり、ここで、DNA又はRNAは、一本鎖又は二本鎖とすることができる。RNAがテンプレートとして使用されるべき場合には、テンプレートをDNAへ逆転写するために最適な酵素及び/又は条件が使用される。さらに、それぞれの1つの鎖を含有するDNA−RNAハイブリッドを使用することが可能である。核酸の混合物も使用することが可能であり、又は同一又は別異のプライマーを用いて、本明細書中の前記増幅反応で産生された核酸をこのようにして使用することが可能である。増幅されるべき特定の核酸配列、すなわち多型遺伝子座は、特定の配列が完全な核酸を構成するように、より巨大な分子の一部であることが可能であり、又は別個の分子として当初存在することが可能である。増幅されるべき配列が当初純粋な形態で存在する必要はなく、完全なヒトDNA中に含有されるなど、複雑な混合物の微少な割合とすることが可能である。
【0103】
本発明において使用されるDNAは、「Maniatis et.al.in Molecular Cloning:A Laboratory Manual,Cold Spring Harbor,N.Y.,p 280−281(1982)」によって記載された技術などの、様々な技術によって、血液、組織材料(例えば、脂肪組織)などの身体試料から抽出することが可能である。抽出された試料が純粋でない場合には、試料の細胞又は動物細胞膜を開放し、核酸の鎖を曝露及び/又は分離するのに有効な試薬の量で、増幅前に処理することが可能である。鎖を曝露及び分離するためのこの溶解及び核酸変性工程は、増幅がずっと容易に起こるようにすることができる。
【0104】
デオキシリボヌクレオチド三リン酸dATP、dCTP、dGTP及びdTTPが、別々に、又はプライマーと一緒に、十分な量で合成混合物に添加され、得られた溶液は、約1〜10分間、好ましくは1〜4分間、約90〜100℃まで加熱される。この加熱期間後、溶液は冷却され、これはプライマーハイブリダイゼーションのために好ましい。冷却された混合物に、プライマー伸長反応を実施するのに適切な薬剤(本明細書において、「重合化のための薬剤」と称される。)を添加し、本分野において公知の条件下で反応を起こさせる。重合化のための薬剤は、熱に安定であれば、他の試薬と一緒に添加することも可能である。この合成(又は増幅)反応は、室温から重合化のための薬剤がもはや機能しない温度を上回る温度までで行うことができる。従って、例えば、DNAポリメラーゼが薬剤として使用される場合には、温度は、一般的には、約40℃を上回らない。最も都合よく、反応は室温で起こる。
【0105】
重合化のための薬剤は、プライマー伸長産物の合成を達成するように機能するあらゆる化合物又は系とすることができ、酵素が含まれる。この目的のために適切な酵素には、E.コリDNAポリメラーゼI、E.コリDNAポリメラーゼのクレノウ断片、ポリメラーゼ変異体、逆転写酵素、Taqポリメラーゼなどの他の酵素(熱安定的な酵素(すなわち、変性を引き起こすために十分に上昇された温度に供した後にも、プライマー伸長を実行する酵素)を含む。)が含まれるが、これらに限定されない。適切な酵素は、各多型遺伝子座の核酸鎖に対して相補的であるプライマー伸長産物を形成するのに適切な様式で、ヌクレオチドの結合を促進する。一般的に、合成は、各プライマーの3’末端から開始し、合成が終了するまで、テンプレート鎖に沿って5’方向に進行し、異なる長さの分子を産生する。
【0106】
新たに合成された鎖及びその相補的核酸鎖は、本明細書に記載されているハイブリダイズ条件下で二本鎖分子を形成し、このハイブリッドは、前記方法のその後の工程で使用される。次の工程で、新たに合成された二本鎖分子は、一本鎖分子を提供するために、上記手順の何れかを用いて変性条件に供される。
【0107】
変性、アニーリング及び伸長産物合成の工程は、検出に必要な程度まで、標的多型遺伝子座核酸配列を増幅するために必要とされるだけ多くの回数を反復することが可能である。産生された特異的な核酸配列の量は、指数関数的な様式で蓄積する。さらなる方法については、「“PCR A Practical Approach”,ILR Press,Eds.McPherson et al.(1992)」を参照されたい。
【0108】
増幅産物は、放射性プローブを用いた、又は用いないサザンブロット分析によって検出することが可能である。1つのこのような方法において、例えば、多型遺伝子座の核酸配列の極めて低いレベルを含有するDNAの少量の試料が、増幅され、そして、サザンブロッティング技術を用いて、又は同様に、ドットブロット分析を用いて分析される。非放射性プローブ又は標識の使用は、増幅されたシグナルの高いレベルによって促進される。あるいは、増幅された産物を検出するために使用されるプローブは、例えば、放射性同位体、蛍光化合物、生物発光化合物、化学発光化合物、金属キレート物質又は酵素で、直接的又は間接的に、検出可能に標識することが可能である。当業者は、プローブに結合するための他の適切な標識を知悉しており、又は、日常的な実験操作を用いて、これを解明することができる。
【0109】
本発明の方法によって増幅される配列については、溶液中で、又は固体支持体への結合後に、ジデオキシ配列決定、PCR、オリゴマー制限(Saiki et al.,Bio/Technology3:1008−1012(1985)、対立遺伝子特異的オリゴヌクレオチド(ASO)プローブ分析(Conner et al.,Proc.Natl.Acad.Sci.U.S.A.80:278(1983))、オリゴヌクレオチド連結アッセイ(OLA)(Landgren et.al.,Science 241:1007,1988)などの、特異的なDNA配列の検出のために通常適用される何れかの方法によって、さらに評価、検出、クローニング、配列決定などを行うことが可能である。DNA分析のための分子技術が、概説されている(Landgren et.al.,Science 242:229−237(1988))。
【0110】
好ましくは、増幅の方法は、本明細書並びに米国特許第4,683,193号;同第4,683,202号;及び同第4,965,188号(各々、参照により、本明細書中に組み込まれる。)に記載されており、当業者によって一般的に使用されているようなPCRによる。増幅の別の方法が記載されており、本発明のプライマーを用いたPCRによって増幅されるNPC1L1遺伝子座が別の技術によって同様に増幅される限り、同じく使用することが可能である。このような別の増幅システムには、目的のRNAの短い配列及びT7プロモーターから始まる自律的配列複製が含まれるが、これに限定されない。逆転写酵素はRNAをcDNAへと複製し、及びRNAを分解し、続いて、逆転写酵素はDNAの第二の鎖を重合させる。
【0111】
別の核酸増幅技術は、逆転写及びT7RNAポリメラーゼを使用する核酸配列を基礎とした増幅(NASMATM)であり、これは、逆転写及びT7RNAポリメラーゼを使用し、そのサイクリングスキームを標的とするために2つのプライマーを取り込む。NASBATM増幅は、DNA又はRNAの何れかを用いて開始し、及び何れかを用いて終結し、60〜90分以内に約108コピーまで増幅することが可能である。
【0112】
あるいは、核酸は、連結活性化された転写(LAT;ligation activated transcription)によって増幅することが可能である。LATは、部分的に一本鎖であり、及び部分的に二本鎖である単一プライマーを用いて、一本鎖テンプレートから作動する。増幅は、cDNAをプロモーターオリゴヌクレオチドへ連結することによって開始され、数時間以内に、増幅は、約108〜約109倍になる。Qβレプリカーゼ系は、目的のDNA配列に対して相補的なRNAに、MDV−1と称されるRNA配列を付着させることによって使用することが可能である。試料を混合すると、ハイブリッドRNAは、試料のmRNAの中にその相補物を見出し、レプリカーゼを結合し、活性化して、目的のタグ−アロング(tag−along)配列を複製する。
【0113】
別の核酸増幅技術であるリガーゼ連鎖反応(LCR)は、試料中の連続配列の存在下で、リガーゼによって共有結合される目的の配列の、異なって標識された2つの半分を使用し、新しい標的を形成することによって機能する。修復連鎖反応(RCR)核酸増幅技術は、標的とされる配列を幾何的に増幅するために、2つの相補的及び標的特異的オリゴヌクレオチドプローブ対、熱安定性ポリメラーゼ及びリガーゼ並びにDNAヌクレオチドを使用する。2塩基のギャップがオリゴプローブ対を隔て、RCRがギャップを充填及び連結し、正常なDNA修復を模倣する。
【0114】
鎖置換活性化(SDA)による核酸増幅は、標的DNAに結合する短い突出を5’末端に有する、HindIIIに対する認識部位を含有する短いプライマーを使用する。DNAポリメラーゼは、含硫アデニン類縁体により、突出とは反対側のプライマーの一部を充填する。HincIIが添加されるが、修飾されていないDNA鎖のみを切断する。5’エキソヌクレアーゼ活性を欠如するDNAポリメラーゼは、切れ目の部位に入り、重合を開始し、初期プライマー鎖を下流に置換し、より多くのプライマーとして機能する新しいプライマー鎖を構築する。
【0115】
SDAは、37℃で、2時間に約107倍を超える増幅をもたらす。PCR及びLCRとは異なり、SDAは、機器化された温度サイクリングは必要としない。本発明の方法において有用な別の増幅系は、Qβレプリカーゼ系である。本発明では、PCRが好ましい増幅方法であるが、本発明の方法に記載されているように、NPC1L1−g.−18C>A座を増幅するために、これらの他の方法も使用することが可能である。
【0116】
本発明の別の実施形態において、好ましくは標的NPC1L1核酸の増幅後に、ジデオキシ配列決定により、対象から得た試料の標的NPC1L1核酸を配列決定することを含む、NPC1L1アンタゴニスト療法に関連する多型を有する対象を診断又は特定する方法が提供される。
【0117】
本発明の別の実施形態において、対象から得た試料の標的核酸を、NPC1L1多型の存在を検出する試薬と接触させること及び前記試薬を検出することを含む、NPC1L1アンタゴニスト療法に対する平均応答より高い応答を示す可能性がより高い対象を特定する方法が提供される。
【0118】
別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.133A>G多型と関連するAからGへの移行の存在を検出する試薬と接触させること及び前記移行を検出することを含む。別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.18C>A多型と関連するCからAへの塩基転換の存在を検出する試薬と接触させること及び前記塩基転換を検出することを含む。別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.1680G>T多型と関連するGからTへの塩基転換の存在を検出する試薬と接触させること及び前記塩基転換を検出することを含む。別の方法は、対象から得た試料の標的核酸を、NPC1L1−g.28650A>G多型と関連するAからGへの移行の存在を検出する試薬と接触させること及び前記移行を検出することを含む。多数のハイブリダイゼーション法が、当業者に周知である。それらの多くは、本発明を実施する上で有用である。
【0119】
核酸ハイブリダイゼーションは、当業者によって容易に理解されるとおり、塩基組成、相補鎖の長さ及びハイブリダイズする核酸間のヌクレオチド塩基のミスマッチの数に加えて、塩濃度、温度又は有機溶媒のような条件によって影響を受ける。ストリンジェントな温度条件には、一般的に、30℃を超える温度、典型的には37℃を超える温度、好ましくは45℃を超える温度が含まれる。ストリンジェントな塩条件は、通常1000mM未満、典型的には500mMであり、好ましくは200mM未満である。しかしながら、パラメータの組み合わせは、何れの単一パラメータの測定より、ずっと重要である。例えば、Wetmur & Davidson,(1968)J.MoI.Biol.31:349−70)を参照されたい。
【0120】
従って、本発明のヌクレオチド配列は、NPC1L1遺伝子の相補的伸長部を有する二重鎖分子を選択的に形成できるその能力を有するために使用することが可能である。想定される用途に応じて、標的配列に対するプローブの選択性の異なる程度を達成するためにハイブリダイゼーションの変動する条件が使用される。選択性の高い程度を必要とする用途の場合、典型的には、ハイブリッドを形成するために相対的にストリンジェントな条件を使用する。例えば、約50℃〜約70℃、特に約55℃、約60℃及び約65℃の温度を含む温度で、0.02M〜0.15Mの塩によって提供される条件など、相対的に低い塩及び/又は高い温度条件を選択する。このような条件は特に選択的であり、プローブとテンプレート又は標的鎖間のミスマッチを許容するとしても、ごく僅か許容するに過ぎない。
【0121】
ある種の実施形態において、ハイブリダイゼーションを測定するための標識など、適切な試薬と組み合わせて、本発明の核酸配列を使用することが有利である。検出可能な信号を与えることができる、アビジン/ビオチンなどの放射性、酵素的又は他のリガンドを含む様々な適切な指示試薬が、本分野において公知である。幾つかの実施形態において、放射性試薬又はその他の環境的に望ましくない試薬に代えて、ウレアーゼ、アルカリホスファターゼ又はペルオキシダーゼなどの酵素タグが使用される可能性がある。酵素タグの場合には、肉眼的に又は分光光度的に可視的な試薬を与えて、相補的な核酸含有試薬との特異的ハイブリダイゼーションを特定するために使用することが可能な熱量測定指示薬基質が公知である。
【0122】
一般的に、本明細書に記載されているハイブリダイゼーションプローブは、溶液ハイブリダイゼーション中での試薬として有用であり、及び固相を用いる実施形態において有用である。固相を伴う実施形態において、検査DNA(又はRNA)を含有する試料は、選択されたマトリックス又は表面に吸着され、又はその他の方法で取り付けられる。次いで、この固定された一本鎖核酸は、所望の条件下で、選択されたプローブとの特異的ハイブリダイゼーションに供される。選択された条件は、とりわけ、必要とされる具体的な基準に基づいて、具体的な環境に依存する(例えば、G+C含量、標的核酸の種類、核酸の入手源、ハイブリダイゼーションプローブのサイズなどに依存する。)。非特異的に結合されたプローブ分子を除去するために、ハイブリダイズされた表面を洗浄した後、標識を介して、特異的ハイブリダイゼーションが検出されるか、又は定量される場合さえある。
【0123】
IV.他のSNP検出法
動的対立遺伝子特異的ハイブリダイゼーション(DASH;dynamic allele−specific hybridization)(Howell,et al.,(1999),Nat.Biotechnol.,17:87−8)、マイクロプレートアレイ対角ゲル電気泳動(MADGE)(Day,et al.,(1995) Biotechniques,19:830−5)、TaqMan システム(Holland,et al.,(1991),Proc Natl Acad Sci USA.88:7276−80)並びにLipshutzら2001の米国特許第6,300,063号に開示されているGENECHIP(R)マイクロアレイ(例えば、Affymetrix SNPアレイ)、Goeletらによって記載されている(PCT出願第92/15712号)Genetic Bit Analysis(GBA(R))、ペプチド核酸(PNA)(Ren,et al.,(2004) Nucleic Acids Res.32:e42)及び鍵型核酸(LNA;locked nucleic acid)プローブ、(Latorra,et al.,(2003) Hum.Mutat,22:79−85)、Molecular Beacons(Abravaya,et al.,(2003) Clin.Chem.Lab.Med.,41:468−74)、インターカレート色素(Germer and Higuchi,Genome Res.,9:72−78(1999)、FRETプライマー(Solinas et al.,(2001) Nucleic Acids Res.29:E96)、AlphaScreen(Beaudet,et al.,(2001) Genome Res.,11:600−8),SNPstream(Bell et al.,(2002) Biotechniques.Suppl.:70−2,74,76−7)、Multiplexミニシークエンシング(Curcio,et al.,(2002) Electrophoresis,23:1467−72)、SnaPshot(Turner,et al.,(2002) Hum.Immunol.,63:508−13)、MassEXTEND(Cashman,et al.,(2001) Drug Metab.Dispos.,29:1629−37)、GOODアッセイ(Sauer and Gut(2003) Rapid Commun.Mass.Spectrom.,17:1265−72)、Microarrayミニシークエンシング(Liljedahl,et al.,(2003) Pharmacogenetics,13:7−17)、アレイ化されたプライマー伸長(APEX;arrayed primer extension)(Tonisson,et al.,(2000) Clin.Chem.Lab.Med.,38:165−70)、マイクロアレイプライマー伸長(O’Meara,et al.,(2002) Nucleic Acids Res.,30:p.75)、タグアレイ(Fan,et al.,(2000) Genome Res.,10:853−60)、テンプレートによって誘導される取り込み(TDI;Template−directed incorporation)(Akula,et al.,(2002) Biotechniques,32:1072−8)、蛍光分極(fluorescence polarization)(Kwok,(2002) Human Mutation,19:315−23)、比色分析オリゴヌクレオチド連結アッセイ(OLA;oligonucleotide ligation assay)(Nickerson,et al.,(1990),Proc.Natl.Acad.Sci.USA,87:8923−7)、配列によってコードされたOLA(Gasparini,et al.,(1999) J.Med.Screen,6:67−9)、マイクロアレイ連結、リガーゼ連鎖反応、南京錠プローブ、ローリングサークル増幅、インベーダーアッセイ(Shi,(2001) Clin Chem.,47:164−72中に概説)、コード化された小球体(Rao,et al.,(2003) Nucleic Acids Res.31:p.66)及びMassArray(Leushner and Chiu,(2000) Mol.Diagn.,5:341−80)などの様々なDNA「マイクロアレイ」技術など、SNP検出の分野での進歩により、正確で、簡易且つ安価なさらなる大規模遺伝子型決定技術が提供されていることが理解される。上記方法の多くは、一塩基多型の遺伝子型を決定するための方法を概説する論文中にも論述されている(Kwak,(2001) Annu.Rev.Genomics Hum.Genet.,2:235−58)。
【0124】
V.コレステロール治療薬に対する応答性との遺伝子型マーカーとの関連
本発明において、NPC1L1遺伝子中の一塩基多型及びハプロタイプとコレステロール治療薬であるエゼチミブに対する応答性との間の関連が発見された。本明細書に記載されているものと同様の方法が、他のNPC1L1多型とNPC1L1機能を修飾する他の薬剤の効力との関連を見出すために使用し得る。
【0125】
エゼチミブに関連するコレステロールレベルの低下に対する遺伝的な原因を調査及び特定するために、関連分析を実施した。このアプローチは、エゼチミブの標的をコードするNPC1L1遺伝子中の多型マーカーを同定すること、及びエゼチミブを用いた治療時の減少したコレステロールレベルに関連する多型マーカー対立遺伝子又はハプロタイプを同定するために関連研究を実施することを含んだ。
【0126】
目的の表現型形質の存在若しくは不存在について検査された個体の集団に対して、又は定量的表現型の測定がその者に対して評価された個人の集団に対して、及び多型マーカーのセットに対して、統計的な関連分析が行われる。このような分析を実施するために、多型のセット(多型セット)の存在又は不存在を、個体の組に対して測定し、そのうち幾人かは特定の形質を示し、幾人かは形質の欠如を示す。これ以外に、定量的表現型が目的の測定である場合には、これらの個体は定量的表現型に対してスコア付けされる。関連分析は、ある変数が別の変数に対して線形的に関連する程度を記載するために使用される。典型的には、関連分析は、最小二乗線がデータにどの程度良好にフィットするかを測定するための回帰分析フレームワークにおいて検定される。関連分析は、分類形質及び表に関連して、χ二乗統計又はこれと同等の統計で検定することも可能である。
【0127】
前記セットの各多型の対立遺伝子は、次いで、特定の対立遺伝子の存在又は不存在が目的の形質と関連するかどうかを決定するために調査される。相関は、χ二乗検定などの標準的な統計法によって行うことが可能であり、多型形態及び表現型の特徴との間の統計的に有意な相関が注目される。例えば、多型Aにおける対立遺伝子A1の存在は、正常なコレステロールレベルなどの正常な表現型とともに生じるより、高コレステロールレベルなどの疾病に関連する表現型とともに生じることがより多いことを見出し得る。さらなる例として、多型Aにおける対立遺伝子A2の存在と多型Bにおける対立遺伝子B1の組み合わされた存在は、多型部位A及びBにおける他の対立遺伝子の組み合わせと比べて、薬物治療に対する増加した平均応答と関連することを見出し得る。
【0128】
遺伝的関連分析は、典型的には、医薬として活性な化合物又は薬物を与える群と与えられない群という少なくとも2つの群に分けられるヒト対象の研究集団内で実施される。各群の状態は、例えば、血漿コレステロールの低下などの医薬として活性な化合物に対する応答の適切な指標を参照することによって測定される。さらに、核酸試料は、各群中の各ヒト対象から採取される。しかしながら、無薬物群、すなわちプラセボ群中の個体の遺伝子型を決定する必要はないことに注目すべきである。次いで、各SNP、ハプロタイプ及びハプロタイプの組み合わせは、例えば、統計ソフトウェアプログラムを用いて、データの統計解析における主要説明変数として検定される。
【0129】
一実施形態において、解析技術は、SAS/STAT(R)Software(SAS Institute,Inc.,Gary,N.C.)中のPROC GLMツールであり、さらなる継続的測定によって説明されるモデル変動の幾つかを考慮に入れながら、群間の平均を比較することを含む。継続的応答、例えば、「ベースラインLDL−Cからのパーセント変化」が測定され、分類変数(ここでは、遺伝子型カテゴリー)がスコア付けされる。応答中の変動は、分類における効果によるものとして説明され、ランダムなエラーが残りの変動を説明する(継続的な結果を説明する上で、先験的に、重要であると認められない効果)。これらの技術の統計学的な理論は十分に確立されており、応用的な統計学的問題においてこれらのツールが一般に使用される(例えば、Fisher,R.A.(1942),The design of Experiments,3d edition,Edinburgh:Oliver and Boydを参照。)。特に、SASソフトウェアプログラムは、その手順の幾つかにおいて、これらの統計学的方法の多くを実装している。これに関して、ツールPROC GLM、PROC FREQ及びPROC HAPLOTYPESを実装したSASは、関連分析において、及びその後関連分析において使用することが可能なハプロタイプの特定において特に有用である。他のソフトウェア及び統計学的方法が、関連分析の実施に際して使用することができ、本分野において周知である。薬物応答性表現型測定などのベースラインパラメータ、例えば、LDL−Cレベル、性別、年齢及び人種が有意な効果を生じるからどうかを決定するために、それらを調べることが可能である。別の実施形態において、関連分析は、より一般的な「General Linear Model」ツール:PROC GLMを用いて行われる。SAS PROC GLMツールによって、別の観察された連続変数(例えば、ここでは、「ベースラインLDL−Cレベル」)によって説明される変動を、ベースラインLDL−C結果からのパーセント変化の分析へ考慮に入れることが可能となる。関連分析に関するさらなる詳細は、本明細書の実施例3に記されている。
【0130】
VI.診断キット
本発明のキットは、例えば、ハイブリダイゼーションプローブ、制限酵素(例えば、RFLP分析用)、又は対立遺伝子特異的オリゴヌクレオチド、本明細書に記載されているSNP若しくはハプロタイプ中に含まれる少なくとも1つの遺伝的マーカーを含むプローブ若しくはASO、SNP若しくはハプロタイプ配列を含有するNPC1L1を含む核酸の増幅用手段及びNPC1L1の核酸配列を分析するための手段など、本明細書に記載されている方法の何れかにおいて有用な成分を含む。さらに、キットは、本発明の方法と組み合わせて使用されるべきアッセイのための試薬、例えば、総コレステロール、非高密度脂質−コレステロール(非HDL−c)、低密度脂質−コレステロール(LDL−c)、LDL−c:HDL−c比率、トリグリセリド、血液ヘモグロビンAlc及びアポリポタンパク質Bの1つ又はそれ以上を決定する上で使用するための試薬を提供することが可能である。
【0131】
診断の方法において有用なキット(例えば、試薬キット)は、例えば、本明細書に記載されているハイブリダイゼーションプローブ又はプライマー(例えば、標識されたプローブ又はプライマー)、標識された分子の検出用試薬、(例えば、RFLP分析用の)制限酵素、対立遺伝子特異的オリゴヌクレオチド、NPC1L1を含む核酸の増幅のための手段、NPC1L1核酸の核酸配列を分析するための手段、使用説明書などを含む、本明細書に記載されている方法の何れかにおいて有用な成分を含む。
【0132】
本発明のキットは、さらに、対象から得られた生物試料から核酸試料を抽出するための溶液、緩衝液又はその他の試薬を含むことが可能である。具体例としては、核酸試料を捕捉するためのガラスビーズの懸濁液とともに組織又は細胞用の適切な溶解緩衝液及びガラスビーズから核酸試料を溶出するための溶出緩衝液は、対象から得られた生物学的試料から核酸試料を抽出するための試薬を含む。
【0133】
他の例には、GENOMIC ISOLATION KIT A.S.A.P.TM(Boehringer Mannheim,Indianapolis,Ind.)、Genomic DNA Isolation System(GIBCO BRL,Gaithersburg,Md.)、ELU−QUIK(R)DNA Purification Kit(Schleicher & Schuell,Keene,N.H.)、DNA Extraction Kit(Stratagene,La Jolla,Calif.)、TURBOGENTMIsolation Kit(Invitrogen,San Diego,Calif.)などの、市販の抽出キットが含まれる。製造業者の指示書に従ったこれらのキットの使用は、一般的に、本発明の方法を実施する前のDNAの精製に対して許容される。
【0134】
一実施形態において、本発明は、対象中のNPC1L1機能に影響を与える薬物に対する対象の応答性を予測するために対象から得られた試料をアッセイするためのキットであり、本キットは、NPC1L1遺伝子と関連するエゼチミブ応答予測的SNP又はハプロタイプを検出するための1つ又はそれ以上の試薬を含む。特定の実施形態において、前記キットは、例えば、g.−18C>Aなど、エゼチミブ応答予測的SNP又はハプロタイプの少なくとも1つを含む領域に対して完全に相補的である少なくとも1つの連続するヌクレオチド配列、エゼチミブ応答予測的SNP又はハプロタイプの1つ又はそれ以上を検出することが可能な1つ又はそれ以上の核酸を含むことが可能である。このような核酸(例えば、オリゴヌクレオチドプライマー)は、エゼチミブ応答性又はNPC1L1コレステロール関連機能に影響を与える他のあらゆる化合物の応答性の指標であるSNPに隣接する核酸の一部を用いて設計することが可能である。このような核酸(例えば、オリゴヌクレオチドプライマー)は、コレステロール関連症状に対するエゼチミブ応答予測的SNP又はハプロタイプと関連するNPC1L1核酸(及び/又は隣接配列)の領域を増幅するために設計される。別の実施形態において、前記キットは、NPC1L1遺伝子と関連する1つ又はそれ以上のエゼチミブ応答予測的SNP又はハプロタイプを検出することが可能な1つ又はそれ以上の標識された核酸と、及び標識の検出用試薬とを含む。適切な標識には、例えば、放射性同位体、蛍光標識、酵素標識、酵素補因子標識、磁気標識、スピン標識、エピトープ標識が含まれる。適切なエゼチミブ応答予測的SNPには、g.−18C>A及びg.1679C>Gが含まれ、適切なハプロタイプには、[A(−133)、A(−18)、G(1679)]又は[G(−133)、C(−18)、C(1679)]が含まれる。
【0135】
幾つかの実施形態において、キット中のオリゴヌクレオチドのセットは、対立遺伝子特異的オリゴヌクレオチドである。本明細書において使用される対立遺伝子特異的オリゴヌクレオチド(ASO)という用語は、十分にストリンジェントな条件下で、異なる対立遺伝子を含有する同じ領域ひハイブリダイズせずに、多型部位を含有する標的領域において、多型部位の1つの対立遺伝子に特異的にハイブリダイズすることが可能なオリゴヌクレオチドを意味する。対立遺伝子の特異性は、塩及びホルムアミド濃度並びにハイブリダイゼーション及び洗浄工程の両方に対する温度など、容易に最適化される様々なストリンジェンシー条件に依存する。ASOプローブ及びプライマーに対して典型的に使用されるハイブリダイゼーション及び洗浄条件の例は、「Kogan et al,“Genetic Prediction of Hemophilia A” in PCR PROTOCOLS,A GUIDE TO METHODS AND APPLICATIONS,Academic Press,1990,and Ruano et al,Proc.Natl.Acad.Sci.USA 87:6296−300(1990)」に見出される。
【0136】
典型的には、ASOは、ある対立遺伝子に対して完全に相補的であるが、別の対立遺伝子に対して単一のミスマッチを含有する。ASOプローブにおいて、単一のミスマッチは、標的領域中の多型部位と並列しているので、単一のミスマッチは、好ましくは、オリゴヌクレオチドプローブの中央位置内に存在する(例えば、16塩基のASOプローブ中の概ね8番目又は9番目の位置並びに20塩基のASOプローブ中の10番目又は11番目の位置)。ASOプリマー中の単一のミスマッチは、3’末端のヌクレオチドに位置し得るが、好ましくは、3’の最後から2番目のヌクレオチドに位置する。コード鎖又は非コード鎖の何れかにハイブリダイズするASOプローブ及びプライマーが、本発明によって想定される。非コード鎖にハイブリダイズするプライマーは、本明細書において、フォワードプライマーと称され、コード鎖にハイブリダイズするプライマーは、本明細書において、リバースプライマーと称される。
【0137】
他の実施形態において、前記キットは、アッセイされるべき各多型部位に対する対立遺伝子特異的オリゴヌクレオチドの対を含み、前記対の1つのメンバーは一方の対立遺伝子に対して特異的であり、他のメンバーは他の対立遺伝子に対して特異的である。このような実施形態において、キットの使用者が、何れの対立遺伝子特異的オリゴヌクレオチドが標的領域に特異的にハイブリダイズしたかを決定し、従って、何れの対立遺伝子が、アッセイされた多型部位において、前記個体中に存在するかを決定するかを決定できるようにするために、前記対中のオリゴヌクレオチドは異なる長さを有し、又は異なる検出可能な標識を有し得る。
【0138】
表1に示されているNPC1L1マーカー中の各多型部位における対立遺伝子を検出するための典型的なASOプローブは、表2A及び2B中に列記されているASOプローブ配列又はそれらの相補物を含む。表2A及び2Bは、対立遺伝子特異的PCRによるこれらのNPC1L1多型部位を遺伝子決定するための好ましいASOフォワード及びリバースプライマーを含む配列も列記する。
【0139】
さらに別の実施形態において、キット中のオリゴヌクレオチドは、ポリメラーゼによって媒介される伸長法で使用するためのプライマー伸長オリゴヌクレオチドである。これらのオリゴヌクレオチドの何れかから得られるポリメラーゼ媒介性伸長に対する終結混合物は、多型部位に存在する別のヌクレオチドに応じて、目的の多型部位又はその1つ後の塩基においてオリゴヌクレオチドの伸長を終結するように選択される。表2A及び2Bは、表1に示されているNPC1L1マーカー中の各多型部位において対立遺伝子を検出するための好ましいフォワード及びリバースプライマー伸長オリゴヌクレオチドを含む配列も列記している。
【0140】
【表2】
【0141】
【表3】
【0142】
表2A及び2B中の配列は、プローブ又はプライマーが、対応するオリゴヌクレオチド位置に2つの択一的対立遺伝子のうちの1つを含有することを示すために、各多型部位における表記択一的対立遺伝子に対して一般的に受容されている記号を使用する。これらの記号は、K=G又はT/U;M=A又はC;R=G又はA;S=G又はC及びY=T/U又はCである(World Intellectual Property Organization Handbook on Industrial Property Information and Documentation,Standard ST.25 1998)。
【0143】
さらなる実施形態において、キット中のオリゴヌクレオチドは、TaqMan Systemに対して対立遺伝子識別アッセイを行うために設計されている。このようなアッセイは、典型的には、PCRプライマーの対(主要対立遺伝子を検出するために蛍光的に標識されたプローブ及び非主要対立遺伝子を検出するために蛍光的に標識された異なるプローブ)を使用する。実施例中の表3は、TaqManSystemを用いて、NPC1L1マーカー中のSNPをアッセイするための好ましいオリゴヌクレオチドを列記する。
【0144】
本発明の方法及びキットには、以下の具体的な実施形態が含まれる。
【0145】
1.血漿コレステロールの健康リスクレベルに対する感受性についてヒト個体を検査する方法であり、前記個体のニーマンピックC1様1(NPC1L1)遺伝子中の配列番号1の34,067位におけるグアニンの存在又は不存在を検出すること、及びグアニンが前記個体中に存在するか、又は存在しないかを示す前記個体に対する検査報告を生成することを含む。幾つかの実施形態において、検査報告は、検査研究室によって作成された書面であり、ハードコピーとして又は電子メールを介して、前記個体又は個体の医師に送付される。他の実施形態において、検査報告は、コンピュータプログラムによって作成され、医師の職場中のビデオモニター上に表示される。検査報告は、患者又は患者の医師又は医師の職場において権限を有する従業員へ直接、検査結果を口頭伝達することも含み得る。同様に、検査報告は、患者のファイル中に医師が作製する検査結果の記録を含み得る。好ましい実施形態において、グアニンが存在すれば、検査報告は、さらに、検査を受けた個体が、血漿コレステロールの健康リスクレベルと関連する多型に対して陽性であることをさらに示す。別の好ましい実施形態において、グアニンが存在しなければ、検査報告は、検査を受けた個体が、血漿コレステロールの健康リスクレベルと関連する多型に対して陰性であることをさらに示す。検査報告は、個体によって指定された医師に、又はその個別のNPC1L1遺伝子が検査されている個体に送付され得る。特に好ましい実施形態において、前記個体は、白色人種であると自ら特定されている。
【0146】
2.NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するニーマンピックC1様1(NPC1L1)遺伝子中のマーカーの存在又は不存在に対するヒト個体を検査する方法であり、前記個体から得られた生物学的試料に対して、LDL−C応答と関連するNPC1L1遺伝子中の対立遺伝子のコピー数を決定すること、遺伝的マーカーの存在又は不存在を前記個体に対して割り当てるために前記決定されたコピー数を使用すること、及び前記個体中にNPC1L1マーカーが存在するか、又は存在しないかを示す検査報告を作成することを含む、前記方法。好ましくは、NPC1L1マーカーの存在が個体に対して割り当てられた場合には、さらに、検査報告は、個体が、NPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を示す可能性があることを示し、NPC1L1マーカーの不存在が個体に対して割り当てられた場合には、さらに、検査報告は、個体が、NPC1L1アンタゴニストに対する平均LDL−C応答を示す可能性があることを示す。検査報告は、個体によって指定された医師又はNPC1L1遺伝子が検査されている個体に送付され得る。特に好ましい幾つかの実施形態において、前記個体は、白人であると自ら特定されている。他の特に好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブである。
【0147】
a.幾つかの好ましい実施形態において、対立遺伝子は、(1)配列番号の5,400位のアデニン、(2)配列番号1の7,096位のグアニン又は(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンを含む。対立遺伝子に対して決定されたコピー数が1又は2であれば、NPC1L1マーカーの存在が個体に対して割り当てられ、対立遺伝子に対して決定されたコピー数が0であれば、NPC1L1マーカーの不存在が個体に対して割り当てられる。
【0148】
b.別の好ましい実施形態において、対立遺伝子は、それぞれ、配列番号1の5,285、5,400及び7,096位のグアニン、シトシン及びシトシンを含み、対立遺伝子に対して決定されたコピー数が0であれば、NPC1L1マーカーの存在が個体に対して割り当てられ、対立遺伝子に対して決定されたコピー数が1又は2であれば、NPC1L1マーカーの不存在が個体に対して割り当てられる。
【0149】
c.このセクションA.2の(a)又は(b)において、ハロタイプ対立遺伝子に対してコピー数を決定することは、好ましくは、配列番号1の5,285、5,400及び7,096位に対して個体の遺伝子型を取得すること及びこれらの位置に対する個体のハプロタイプ対を推測するためにコンピュータプログラムを実行するコンピュータ中に遺伝子型を入力することを含む。
【0150】
3.ニーマンピックC1様1(NPC1L1)遺伝子のアンタゴニストに対するヒト個体のLDL−C応答を予測する方法であり、アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの、前記個体における存在又は不存在を決定すること、決定工程の結果に基づいて予測を作成することを含み、NPC1L1マーカーが存在すれば、予測は、個体がNPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を示す可能性があるという予測であり、NPC1L1マーカーが存在しなければ、予測は、個体がNPC1L1アンタゴニストに対する平均LDL−C応答を示す可能性があるという予測である。予測は、個体又は個体を治療している医師に対して報告され得る。幾つかの特に好ましい実施形態において、前記個体は、白人であると自ら特定されている。他の特に好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブである。
【0151】
a.幾つかの好ましい実施形態において、NPC1L1マーカーは、(1)配列番号1の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。
【0152】
b.別の好ましい実施形態において、NPC1L1マーカーは、それぞれ、配列番号1の5,285、5,400及び7,096位にグアニン、シトシン及びシトシンの0コピーを含む。
【0153】
c.本セクションA.3の(a)又は(b)に規定されているNPC1L1マーカーの存在又は不存在を決定することは、好ましくは、検査研究室によって検査が実施されるように命令すること、及びNPC1L1マーカーが個体中に存在又は不存在であるかどうかを示す検査報告を研究室から受領することを含む。
(i)好ましくは、前記検査は、個体から得られた生物学的試料について、配列番号1の5,285、5,400及び7,096位に対して個体の遺伝子型を決定すること、決定された遺伝子型から、これらの位置に対する個体のハプロタイプ対を推測すること、並びに推測されたハプロタイプ対からNPC1L1マーカーの存在又は不存在を前記個体に対して割り当てることを含み、ここにおいて、推測されたハプロタイプ対がアデニン、アデニン及びの少なくとも1コピー又はグアニン、シトシン及びシトシンの0コピーを含有すれば、NPC1L1マーカーの存在が個体に割り当てられ、推測されたハプロタイプ対がアデニン、アデニン及びグアニンの0コピーを含有し、又はグアニン、シトシン及びシトシンの少なくとも1コピーを含有すれば、NPC1L1マーカーの不存在が個体に割り当てられる。好ましくは、配列番号1の5,285、5,400及び7,096位について、前記決定された遺伝子型を参照ハプロタイプ対のセットと比較するコンピュータプログラムを実行し、個体中に存在する可能性が最も高いセットから得られた参照ハプロタイプ対を前記決定された遺伝子型に割り当てるコンピュータ中に前記決定された遺伝子型を入力することによって、ハプロタイプ対が推測される。
【0154】
4.NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するヒトニーマンピックC1様1(NPC1L1)遺伝子中の遺伝的マーカーを検出するためのキットであり、本キットは、NPC1L1マーカー中の各多型部位(PS)に対立遺伝子の各々を同定するために設計されたオリゴヌクレオチドのセットを含む。好ましくは、NPC1L1アンタゴニストはエゼチミブである。
【0155】
a.幾つかの実施形態において、NPC1L1マーカーは、(i)配列番号1の5,285位に多型部位を含む。
【0156】
b.別の好ましい実施形態において、NPC1L1マーカーは、さらに、配列番号5,400及び7,096位の各々に多型部位を含む。
【0157】
(1)このキットは、好ましくは、さらに、配列番号1の5,285、5,400及び7,096位における試料の遺伝子型を決定するために、ヒト核酸試料に対して1つ又はそれ以上の反応を実施するための指示書とともにマニュアルを含む。より好ましくは、キットは、さらに、配列番号1の5,285、5,400及び7,096位に対するハプロタイプ対を試料に割り当てるために前記決定された遺伝子型を使用する工程をコンピュータに実施させるために、コンピュータ読み取り可能なプログラムがその上に保存されたコンピュータ使用可能な媒体を含む。
【0158】
(2)特に好ましい一実施形態において、オリゴヌクレオチドのセットは、5,285位のアデニン及びグアニン対立遺伝子の各々、5,400位のシトシン及びアデニン対立遺伝子の各々、並びに7,096位のシトシン及びグアニン対立遺伝子の各々に対する対立遺伝子特異的オリゴヌクレオチド(ASO)プローブを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号161を含む第一のASOプローブ、配列番号166を含む第二のASOプローブ及び配列番号171を含む第三のASOプローブを含む。
【0159】
(3)特に好ましい第二の実施形態において、オリゴヌクレオチドのセットは、各多型部位に対するプライマー伸長オリゴヌクレオチドを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号164を含む第一のプライマー伸長オリゴ、配列番号165を含む第二のプライマー伸長オリゴ、配列番号169を含む第三のプライマー伸長オリゴ、配列番号170を含む第四のプライマー伸長オリゴ、配列番号174を含む第五のプライマー伸長オリゴ、及び配列番号175を含む第六のプライマー伸長オリゴを含む。
【0160】
(4)特に好ましい第三の実施形態において、オリゴヌクレオチドのセットは、PCRプライマーの第一の対及び5,285位を遺伝子型決定するために設計されたASOプローブの第一の対、PCRプライマーの第二の対及び5,400位を遺伝子型決定するために設計されたASOプローブの第二の対並びにPCRプライマーの第三の対及び配列番号1の7,096位を遺伝子型決定するために設計されたASOプローブの第三の対を含む。好ましくは、PCRプライマーの第一の対は、配列番号104を含むオリゴヌクレオチドと配列番号105を含むオリゴヌクレオチドからなり、プローブ配列の第一の対は、配列番号106を含むオリゴヌクレオチドと配列番号107を含むオリゴヌクレオチドからなり、PCRプライマーの第二の対は、配列番号108を含むオリゴヌクレオチドと配列番号109を含むオリゴヌクレオチドからなり、プローブ配列の第二の対は、配列番号110を含むオリゴヌクレオチドと配列番号111を含むオリゴヌクレオチドからなり、PCRプライマーの第三の対は、配列番号112を含むオリゴヌクレオチドと配列番号113を含むオリゴヌクレオチドからなり、及びプローブ配列の第三の対は、配列番号114を含むオリゴヌクレオチドと配列番号115を含むオリゴヌクレオチドからなる。
【0161】
5.LDL−Cの健康リスクレベルと関連するヒトニーマンピックC1様1(NPC1L1)遺伝子中の遺伝的マーカーを検出するためのキットであり、本キットは、配列番号1の28,650位の対立遺伝子の各々を同定するために設計されたオリゴヌクレオチドのセットを含む。
【0162】
a.好ましい一実施形態において、オリゴヌクレオチドのセットは、28,650位のアデニン及びグアニン対立遺伝子の各々に対する対立遺伝子特異的オリゴヌクレオチド(ASO)プローブを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号156を含む第一のASOプローブ(R=アデニン)及び配列番号156を含む第二のASOプローブ(R=グアニン)を含む。
【0163】
b.第二の好ましい実施形態において、オリゴヌクレオチドのセットは、28,650位のアデニン及びグアニン対立遺伝子の各々に対するプライマー伸長オリゴヌクレオチドを含む。好ましくは、オリゴヌクレオチドのセットは、配列番号159を含む第一のプライマー及び配列番号160を含む第二のプライマーを含む。
【0164】
b.第三の好ましい実施形態において、オリゴヌクレオチドのセットは、PCRプライマーの対及び28,650位の遺伝子型を決定するために設計されたASOプローブの対を含む。好ましくは、PCRプライマーの対は、配列番号152を含むオリゴヌクレオチド及び配列番号153を含むオリゴヌクレオチドからなり、並びにASOプローブの対は、配列番号154を含むオリゴヌクレオチド及び配列番号155を含むオリゴヌクレオチドからなる。
【0165】
上述されているように、コレステロールレベルは、様々な遺伝的要因と環境的要因によって決定される。高いコレステロールレベルを有する個体は、冠動脈疾患、急性冠症候群、大動脈瘤、下肢の動脈疾患及び脳血管疾患などの血管系疾患の基礎を為す主な要因であるアテローム性動脈硬化症を発症する増加したリスクを有する。従って、コレステロールの管理は、コレステロールを低下させることにより、アテローム性動脈硬化症を予防する薬物の早期及び定期的な使用に依存する。結果として、高いコレステロールを有する患者に対する効率的及び安全な治療の機会に対する必要性が存在する。現在では、コレステロール生合成を阻害するスタチン及びコレステロールの腸吸収を阻害するエゼチミブという、コレステロール薬の2つの主なカテゴリーが存在する。全ての個体が、スタチン若しくはエゼチミブの何れか、又はこれらの組み合わせに対する同一の応答を示す。従って、一実施形態において、本発明のキットは、1つ又はそれ以上の薬物に対する有益な応答を示す個体を特定するために使用される。他の実施形態において、前記キットは、臨床試験の実施において使用される。
【0166】
一態様において、本発明は、高コレステロール又は高コレステロールを伴う疾病の治療のための療法の臨床試験の亜群においてヒト対象を階層化するための方法を提供する。本発明の方法は、配列番号1のヌクレオチド位5,400におけるヒト対象のNPC1L1遺伝子の遺伝子型を決定することを含む。対象は、NPC1L1遺伝子の配列番号1の5,400位に存在するヌクレオチド塩基に基づいて、臨床試験の1つ又はそれ以上の亜群へ階層化される。別の実施形態において、5,285位、5,400位、7,096位及び34,067位からなる群から選択される1つ又はそれ以上のNPC1L1ヌクレオチド位置における遺伝子型の決定に基づいて、本方法が実施される。
【0167】
別の態様において、高コレステロール薬又は治療の臨床試験に含めるための個体を選択する方法が提供される。本方法は、個体から核酸試料を取得すること、核酸試料中のNPC1L1関連一塩基多型における多型塩基の種類を決定すること(ここにおいて、多型塩基の種類は、NPC1L1関連一塩基多型における個体の遺伝子型を決定し、NPC1L1関連一塩基多型は配列番号1中に位置する。)、NPC1L1関連一塩基多型が、前記同定された多型を有しない者に比べて、薬物又は治療に対する平均応答より高い応答又は平均応答より低い応答を伴うかどうかを決定すること、並びに核酸試料が薬物若しくは治療に対する平均応答より高い応答と関連する少なくとも1つの一塩基多型を含有しているか、又は核酸試料が薬物若しくは治療に対する平均応答より低い応答と関連する少なくとも1つの一塩基多型を欠如していれば、前記個体を臨床試験に含めることを含む。
【0168】
VI.治療計画
増加したエゼチミブ応答と関連する本発明のNPC1L1マーカーは、医師が上昇したLDL−Cを有する患者に対する具体的な治療計画の有効性を予測するのを補助するのに有用である。マーカー情報は、LDL−Cの既存レベル及びLDL−Cの所望されるレベルなどの他の患者情報と協同して使用される。
【0169】
NPC1L1マーカー情報に基づいて好まれ得る可能な患者治療計画の例には、より低いスタチン容量(又はその他のLDL−C低下薬)及び/又はより高いNPC1L1アンタゴニスト用量の使用が含まれる。例えば、所望されるLDL−Cの低下に応じて、患者検査が薬物応答マーカーに対して陽性である幾つかの事例では、医師は、単独療法としてのNPC1L1アンタゴニストを使用して、又はNPC1L1アンタゴニストと組み合わせた、より低いスタチンレベルを使用して処方することを決定し得る。あるいは、マーカーが存在しないのであれば、医師は、NPC1L1アンタゴニストのより高い用量及び/又はNPC1L1アンタゴニストを伴うより長い治療計画を使用することを検討し得る。
【0170】
特定の患者に対して医師によって考案された治療アルゴリズムは、典型的には、血管疾患に対する他のリスク因子の存在、血管疾患の症候並びにNPC1L1アンタゴニスト及び他のコレステロール低下薬による療法に対する患者の耐性など、他の患者特異的要因の考慮を取り込む。例えば、幾つかの実施形態において、患者は、血漿LDL−Cの健康リスクレベルを有する。他の実施形態において、患者は、血漿LDL−Cの健康リスクレベルと相関する遺伝的マーカーに対して陽性であると検査され、LDL−Cに対する他のリスク因子も有し得る。さらなる実施形態において、患者は、別のコレステロール低下薬を用いた以前の療法後に、コレステロールの健康リスクレベルを有する。エゼチミブなどのNPC1L1アンタゴニストとともに処方することが可能な好ましいコレステロール低下薬には、HMGCoA還元酵素活性を阻害する化合物のクラスであるスタチンが含まれる。
【0171】
典型的なスタチンには、米国特許第3,983,140号に開示されているようなメバスタチン及び関連化合物、米国特許第4,231,938号に開示されているようなロバスタチン(メビノリン)及び関連化合物、米国特許第4,346,227号に開示されているようなプラバスタチン及び関連化合物、米国特許第4,448,784号及び同第4,450,171号に開示されているようなシンバスタチン及び関連化合物が含まれるが、これらに限定されるものではない。本発明に使用され得る他のHMGCoA還元酵素阻害剤には、米国特許第5,354,772号に開示されているフルバスタチン、米国特許第5,006,530号及び同第5,177,080号に開示されているセリバスタチン、米国特許第4,681,893号、同第5,273,995号、同第5,385,929号及び同第5,686,104号に開示されているアトロバスタチン、米国特許第5,011,930号に開示されているピタバスタチン(Nissan/Sankyoのニスバスタチン(Ne−104)又はイタバスタチン)、米国特許第5,260,440号に開示されているShionogi−AstratZenecaロスバスタチン(ビサスタチン(ZD−4522))、及び米国特許第5,753,675号に開示されている関連スタチン化合物、米国特許第4,613,610号中に開示されているメバロノラクトン誘導体のピラゾール類縁体、PCT出願WO86/03488号に開示されているメバロノラクトン誘導体のインデン類縁体、米国特許第4,647,576号に開示されている6−[2−(置換されたピロール−1−イル)−アルキル)ピラン−2−オン及びその誘導体、SearleのSC−45355(3置換されたペンタン二酸誘導体)二クロロアセタート、PCT出願WO86/07054号に開示されているメバロノラクトンのイミダゾール類縁体、フランス特許2,596,393号に開示されている3−カルボキシ−2−ヒドロキシ−プロパン−ホスホン酸誘導体、欧州特許出願0221025号に開示されている1,3−二置換された、ピロール、フラン及びチオフェン誘導体、米国特許第4,686,237号に開示されているメバロノラクトンのナフチル類縁体、米国特許第4,499,289号に開示されているようなオクタヒドロナフタレン、欧州特許出願0,142,146A2号に開示されているメビノリンのケト類縁体(ロバスタチン)並びに米国特許第5,506,219号及び同第5,691,322号に開示されているキノリン及びピリジン誘導体が含まれるが、これらに限定されない。
【0172】
本方法の別の実施形態において、高コレステロール療法は、NPC1L1タンパク質に結合する化合物を用いた治療である。典型的には、NPC1L1結合化合物による治療は、治療を受けている対象中の低密度脂質コレステロールのレベルの減少をもたらす。本発明の方法のさらに別の実施形態において、高コレステロール療法は、エゼチミブなどのNPC1L1媒介性薬物治療とスタチン薬物治療を組み合わせた二重療法である。
【0173】
VII.典型的なNPC1L1アンタゴニスト
本発明の幾つかの態様は、例えば、直接又は間接に、NPC1L1によって媒介される腸コレステロールの吸収を妨害する薬物など、NPC1L1の活性に影響を与える薬物に対する対象の応答性に接近するのに有用である。本発明の1つの具体的な実施形態において、NPC1L1アンタゴニストはエゼチミブである。エゼチミブは、コレステロール及び関連の植物ステロールの腸吸収を選択的に阻害する、アゼチジノンとして知られる脂質低下化合物のクラスに属する。エゼチミブの化学名は、1−(4−フルオロフェニル)−3(R)−[3−(4−フルオロフェニル)−3(S)−ヒドロキシプロピル]−4(S)−(4−ヒドロキシフェニル)−2−アゼチジノンである。実験式は、C24H21F2NO3である。
【0174】
一実施形態において、NPC1L1アンタゴニストは、構造式I:
【0175】
【化1】
若しくはそれらの異性体、又は式(I)の化合物若しくはそれらの異性体の、医薬として許容される塩若しくは溶媒和物又は式(I)の化合物の、若しくはそれらの異性体、塩若しくは溶媒和物のプロドラッグによって表され、上記式(I)において、
Ar1及びAr2は、アリール及びR4置換されたアリールからなる群から独立に選択され;
Ar3は、アリール又はR5置換されたアリールであり;
X、Y及びZは、−CH2−、−CH(低級アルキル)−及び−C(二低級アルキル)−からなる群から独立に選択され;
R及びR2は、−OR6、−O(CO)R6、−O(CO)OR9及び−O(CO)NR6R7からなる群から独立に選択され;
R1及びR3は、水素、低級アルキル及びアリールからなる群から独立に選択され;
qは、0又は1であり;
rは、0又は1であり;
m、n及びpは、独立に、0、1、2、3又は4から選択され;但し、q及びrの少なくとも1つは1であり、並びにm、n、p、q及びrの合計は、1、2、3、4、5又は6であり;並びに、但し、pが0である場合には、rは1であり、m、q及びnの合計は、1、2、3、4又は5であり;
R4は、低級アルキル、−OR6,−O(CO)R6,−O(CO)OR9、−O(CH2)1−5OR6、−O(CO)NR6R7、−NR6R7、−NR6(CO)R7、−NR6(CO)OR9、−NR6(CO)NR7R8、−NR6SO2R9、−COOR6、−CONR6R7、−COR6、−SO2NR6R7、S(O)0−2R9、−O(CH2)1−10−COOR6、−O(CH2)1−10CONR6R7、−(低級アルキレン)COOR6、−CH=CH−COOR6、−CF3、−CN、−NO2及びハロゲンからなる群から独立に選択される1〜5個の置換基であり;
R5は、−OR6、−O(CO)R6、−O(CO)OR9、−O(CH2)1−5OR6、−O(CO)NR6R7、−NR6R7、−NR6(CO)R7、−NR6(CO)OR9、−NR6(CO)NR7R8、−NR6SO2R9、−COOR6、−CONR6R7、−COR6、−SO2NR6R7、S(O)0−2R9、−O(CH2)1−10−COOR6、−O(CH2)1−10CONR6R7、−(低級アルキレン)COOR6及び−CH=CH−COOR6からなる群から独立に選択される1〜5個の置換基であり;
R6、R7及びR8は、水素、低級アルキル、アリール及びアリール置換された低級アルキルからなる群から独立に選択され;並びに
R9は、低級アルキル、アリール又はアリール置換された低級アルキルである。
【0176】
別の実施形態において、アゼチジノン又は置換されたβラクタムは、構造式II:
【0177】
【化2】
又は医薬として許容されるその塩若しくは溶媒和物、又は式(II)の化合物の、若しくはその塩若しくは溶媒和物のプロドラッグによって表される。
【0178】
本発明の一実施形態において、前記薬物又は化合物には、米国特許出願公報US2002/0151536A1に開示されている全てのアゼチジノン若しくは置換されたβラクタム又は米国特許第5,756,470号に記載されている全ての糖置換された2−アゼチジノンが含まれる。
【0179】
VIII.さらなる実施形態
さらなる実施形態において、本発明は、血漿コレステロールの健康リスクレベルに対する感受性について対象を検査する方法を提供する。本方法は、対象のNPC1L1遺伝子中における配列番号1の34,067位のグアニンの存在又は不存在を検出すること、及びグアニンが対象中に存在するか又は存在しないかを示す、対象に対する検査報告を作成することを含む。好ましい実施形態において、グアニンが存在すれば、検査報告は、血漿コレステロールの健康リスクレベルに対して対象が感受性であることを示す。別の好ましい実施形態において、グアニンが存在しなければ、検査報告は、検査を受けた対象が、血漿コレステロールの健康リスクレベルと関連する多型に対して陰性であることを示す。
【0180】
別の態様において、本発明は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの存在又は不存在について、ヒト対象を検査する方法を提供する。本方法は、対象のNPC1L1遺伝子における、前記応答と関連する対立遺伝子のコピー数を決定すること、前記対象をNPC1L1マーカーの存在又は不存在に割り当てるために、決定されたコピー数を使用すること、及びNPC1L1マーカーが個体中に存在するか、又は存在しないかを示す検査報告を作成することを含む。「コピー数を決定すること」という用語は、対象のNPC1L1遺伝子の少なくとも1コピーの遺伝子型が決定されており、従って、対象のNPC1L1遺伝子の両コピーの遺伝子型が決定されている必要性は存在しないが、典型的には、両コピーの遺伝子型が決定される必要性が存在することを意味することになっている。従って、本明細書に示されているように、本発明のNPC1L1マーカーの1コピーの存在を決定することが、本発明の実施のために十分である。一実施形態において、対立遺伝子は、配列番号1の5,400のアデニン又は配列番号1の7,096位のグアニンを含み、対立遺伝子に対する対象のコピー数が1又は2であれば、NPC1L1マーカーの存在が対象に対して割り当てられるのに対して、対立遺伝子に対する対象のコピー数が0であれば、NPC1L1マーカーの不存在が対象に対して割り当てられる。好ましくは、対立遺伝子は、それぞれ、配列番号1の5,285位、5,400位及び7,096位にアデニン、アデニン及びグアニンを含む。別の実施形態において、対立遺伝子は、それぞれ、配列番号1の5,285位、5,400位及び7,096位のグアニン、シトシン及びシトシンを含み、対立遺伝子に対する対象のコピー数が0であれば、NPC1L1マーカーの存在が対象に対して割り当てられ、対立遺伝子に対する対象のコピー数が1又は2であれば、NPC1L1マーカーの不存在が対象に対して割り当てられる。好ましい実施形態において、NPC1L1マーカーの存在が対象に対して割り当てられた場合には、検査報告は、さらに、対象が、NPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を示す可能性があることを示し、NPC1L1マーカーの不存在が対象に対して割り当てられた場合には、検査報告は、対象が、NPC1L1アンタゴニストに対する平均LDL−C応答を示す可能性があることを示す。
【0181】
さらに別の態様において、本発明は、NPC1L1アンタゴニストに対する対象のLDL−C応答を予測する方法を提供する。本方法は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの、対象における存在又は不存在を決定すること、及び決定工程の決定の結果に基づいて予測を行うことを含む。マーカーが存在すれば、予測は、NPC1L1アンタゴニストに対する平均LDL−C応答より高い応答を対象が示す可能性があるというものであり、マーカーが存在しなければ、予測は、NPC1L1アンタゴニストに対する平均LDL−C応答を対象が示す可能性があるというものである。
【0182】
本発明のさらに別の態様は、LDL−Cを低下させることを必要とする患者に対する療法を選択する方法を提供することである。本方法は、NPC1L1マーカーの患者における存在又は不存在を決定すること、及び決定工程の結果に基づいて療法を選択することを含む。
【0183】
本発明の別の態様は、ヒトにおいてLDL−Cを低下させるための医薬の製造におけるNPC1L1アンタゴニストの使用であり、ここにおいて、前記医薬は、NPC1L1遺伝的マーカーを有するとして同定された患者にNPC1L1アンタゴニストの有効量を送達するために設計されている。
【0184】
さらなる態様において、本発明は、NPC1L1アンタゴニストを含む医薬製剤に対して薬理遺伝学的適応症の規制当局の認可を求める方法を提供する。本方法は、NPC1L1マーカーを有する患者の第一の群が、統計的に有意な程度まで、NPC1L1マーカーを欠如する患者の第二の群の平均LDL−C応答より高い、アンタゴニストに対する平均LDL−C応答を示すことを実証すること、NPC1L1マーカーが患者中に存在するか、又は存在しないかに基づいて、患者に対する製剤の出発用量を選択することを推奨するラベルとともに製剤を市販するための認可に対する申請を規制当局に提出することを含む。
【0185】
さらなる態様において、本発明は、NPC1L1遺伝子中の遺伝的バリアントがNPC1L1アンタゴニストの効力と相関するかどうかを決定する方法を提供する。一実施形態において、本方法は、アンタゴニストで処理された個体の群において、各個体に対する効力測定を取得すること、前記群中の各個体におけるNPC1L1バリアントに対して遺伝子型を特定すること、並びに効力測定及び遺伝子型を用いて、遺伝的関連分析を実施することを含む。別の実施形態において、本方法は、遺伝的バリアントとNPC1L1マーカー中の対立遺伝子との間の連鎖不均衡の程度を測定することを含み、ここにおいて、連鎖不均衡の高い程度は遺伝的バリアントがアンタゴニストの効力と相関することを示し、連鎖不均衡の低い程度は遺伝的バリアントが前記効力と相関しないことを示す。好ましい実施形態において、効力測定は、アンタゴニストに対する個体のLDL−C応答である。
【0186】
A.薬理遺伝学的治療方法
本発明の薬理遺伝学的治療法は、表1中のNPC1L1マーカー2−5の、各々の個体における存在又は不存在を決定することを含み得る。薬理遺伝学的治療方法には、以下の具体的な実施形態が含まれる。
【0187】
血漿LDL−Cのレベルを低下させる必要があるヒト個体に対して治療法を選択する方法であり、本方法は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するヒトニーマンピックC1様1(NPC1L1)遺伝子中のマーカーの、個体における存在又は不存在を決定すること、及び決定工程の結果に基づいて、治療法を選択することを含む。幾つかの実施形態において、個体は、LDL−Cの健康リスクレベルに関連するNPC1L1マーカーに対して陽性であるか検査される。
【0188】
B.薬理遺伝学的医薬品:製造及び販売
本発明の薬理遺伝学的医薬品には、以下の具体的な実施形態が含まれる。
【0189】
1.ヒトにおいてLDL−Cレベルを低下させるための医薬の製造におけるニーマンピックC1様1(NPC1L1)のアンタゴニストの使用であり、ここにおいて、前記医薬は、NPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーに対して陽性であるか検査を受ける患者に、NPC1L1アンタゴニストの有効量を送達するように調合される。
【0190】
a.好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブである。好ましくは、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。
【0191】
エゼチミブを含む医薬品を市販する方法であり、本方法は、ニーマンピックC1様1(NPC1L1)マーカーを考慮に入れながら、特定の出発NPC1L1アンタゴニスト(例えば、エゼチミブ)及び/又はスタチンを使用することを、目標とする対象者に対して宣伝することを含む。好ましくは、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は、(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。さらに好ましい実施形態において、宣伝を行う工程は、NPC1L1マーカーに対して患者をどのように検査するかについて、目標とする対象者に情報を提供することをさらに含む。情報は、好ましくは、規制当局によって認可された特定の検査を含む。
【0192】
2.ニーマンピックC1様1(NPC1L1)のアンタゴニストを含む医薬製剤と、並びにNPC1L1アンタゴニストに対する増加したLDL−C応答と関連するNPC1L1マーカーの存在又は不存在について患者を検査すること、及び患者がLDL−C応答マーカーに対して陽性又は陰性の検査結果であるかどうかに基づいて、患者に対して、医薬品の出発用量を選択することを推奨する情報を指示することを含む、製造された医薬品。
【0193】
a.好ましい実施形態において、NPC1L1アンタゴニストはエゼチミブであり、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は、(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。特に好ましい一実施形態において、医薬製剤は、エゼチミブと医薬として許容される担体とを含む錠剤である。好ましくは、錠剤は、スタチンの医薬的有効量をさらに含む。薬理遺伝学的医薬品を製造する方法であり、本方法は、エゼチミブを含む医薬製剤と指示情報をパッケージ中に同封することを含む。指示情報は、エゼチミブに対する増加したLDL−C応答と関連するニーマンピックC1様1(NPC1L1)遺伝子中のマーカーの存在又は不存在について患者を検査し、患者の検査結果に基づいて医薬品の出発用量を選択するための指示書を含む。
【0194】
b.好ましい一実施形態において、NPC1L1アンタゴニストはエゼチミブであり、NPC1L1マーカーは、(1)配列番号の5,400位のアデニンの1若しくは2コピー、(2)配列番号1の7,096位のグアニンの1若しくは2コピー、又は、(3)それぞれ、配列番号1の5,285、5,400及び7,096位のアデニン、アデニン及びグアニンの1若しくは2コピーを含む。
【0195】
c.別の好ましい実施形態において、医薬製剤は、さらにスタチンを含む。
【0196】
実施例
本発明の様々な特徴及び利点をさらに記すために、以下に、実施例が記載されている。本実施例は、本発明を実施するための有用な方法も例示している。これらの実施例は、特許請求の範囲に記載されている発明を限定するものではない。
【0197】
ヒトNPC1L1遺伝子は染色体7p13にマッピングされ、約29kbに及び、20個のエキソンを含有する(Davis,et al.,(2004) J.Biol.Chem.,279:33586−92)。公的なSNPマッピングへの尽力を通じて、NPC1L1内に幾つかの一塩基多型(SNP)が報告されている(http://www.ncbi.nlm.nih.gov/SNP)。しかしながら、これらのバリアントの機能的重要性は不明であり、比較的少数が、10%を超える報告された非主要対立遺伝子頻度(MAF)を有するに過ぎない。NPC1L1中のDNA配列の変動の程度をより完全に性質決定するために、並びにNPC1L1中の多型が選択された血液成分レベルの変化と関連しているかどうかを評価するために、とりわけ、直接的な機能的重要性を有し得る新規多型を同定するために、並びに公知及び新規の多型における対立遺伝子の頻度をよりよく推定するために、3つの異なる自己申告による民族集団に由来する多くの個体中で、遺伝子を再度配列決定した。2%を超える非主要対立遺伝子頻度を有する多数の新規及び公知の一般的バリアントに対して、遺伝子型決定アッセイが開発された。次いで、様々な血漿及び血液成分レベル、特に、エゼチミブを用いた薬物療法に応じた、総血漿コレステロール、低密度リポタンパク質コレステロール(LDL−C)、非高密度リポタンパク質コレステロール(非HDL−C)、血漿トリグリセリドレベル、血液アポリポタンパク質A−1又は血液アポリポタンパク質B(アポB)レベルの変化と、NPC1L1中のDNA配列多型が関連するかどうかを評価するために、臨床試験コホート中のこれらの多型を用いて、遺伝的関連分析を行った(実施例3、表4a−d参照)。
【0198】
NPC1L1中の変動の程度を特徴付けるために、3つの民族群を代表する375人の正常な個体において、全てのエキソン、保存された制御領域、プロモーター領域及び特定のイントロン領域の配列を再決定した。合計140のSNP及び5つの挿入/欠失が、このコホート中に同定された。これらの多型の完全なリストが、実施例1に記載されている。同定された140のSNPのうち、14は5’UTR又はプロモーター領域中に、89はイントロン中に、3つは3’UTR中に、及び34はコード領域中に位置し、これらのうち20がアミノ酸の変化をもたらす(実施例1、表4参照)。表5(実施例2)は、少なくとも1つの民族群中に検出された4%を超える非主要対立遺伝子頻度(MAF)を有する24個のSNPを列記する。遺伝子のより広いセットにわたって報告された数値と合致して、共通のSNPについて、キロ塩基当りのSNPの平均数が0.083725であり、全てのSNPにわたって6.96725であるように、NPC1L1の再配列決定された領域は20,094塩基にわたった(Crawford,et al.,2004)。上で同定されたSNPに基づいて選択された遺伝子型アッセイを用いて、NPC1L1遺伝子内のSNPのサブセット及びSNPの組み合わせ(ハプロタイプ)は、コレステロール管理薬であるエゼチミブに対するヒトの応答性を増強させることが見出された。NPC1L1中の各SNP及び3NPC1L1SNPハプロタイプ及び同じ臨床試験被験者中でのエゼチミブによる治療後のLDL−Cの減少の程度の間には、有意な関連が観察された(実施例3、表8−12参照)。
【実施例1】
【0199】
NPC1L1多型の同定
NPC1L1中のSNPを同定するために、白色人種(n=198)、黒人(n=99)又はヒスパニック(n=78)として自己申告している、健康と報告された匿名の個体から、NPC1L1のプロモーター及びコード領域を配列決定した。DNA試料は、Human Genetic Cell Repository of the National Institute for General Medical Sciences(NIGMS;Coriell Cell Repository,Camden,NJ)によって収集されたCaucasian and African American Human Variation Panels及びSchering−Plough Corporationからの匿名のドナーから取得した。全ての試料は、DNA多型発見資料の一部であるというインフォームドコンセントを与えた個体から得た。資料をまとめるために、各個体に対して民族及び性別に関する情報が収集されたが、各ドナーへの関連が不可逆的に遮断されるように、全ての身元特定情報及び表現型情報は、各試料から除外した。
【0200】
ポリメラーゼ連鎖反応
SNP発見に対する一般的な戦略は、詳述されているように修飾を加えられているが、以前に記載されているとおりである(Nickerson et al,(1998) Nat.Genet.,19:233−40)。NPC1L1コード領域の400〜650塩基対セグメント並びに5’プロモーター領域の約2キロ塩基対及びイントロン/エキソンスプライス結合部に連結する100ヌクレオチドを増幅するために、Primer3ソフトウェア(Rozen and Skaletsky,(2000) Methods MoI.Biol.,132:365−86;http://www.genome.wi.mit.edu/cgi−bin/primer/primer3.cgiで入手可能)を用いて、PCRプライマーを設計した。SNP分析用に様々なNPC1L1遺伝子領域を増幅するために使用されるフォワード及びリバースプライマーの5’尾部には、それぞれ、汎用配列決定プライマー:21M13;5’TGTAAAACGACGGCCAGT(配列番号6)及びM13REV;CAGGAAACAGCTATGACC(配列番号7)を付加した。表3は、5’尾部に汎用配列決定プライマー(配列番号6又は配列番号7)が付加されたNPC1L1PCRアッセイプライマー配列及び配列番号1に記載されているゲノムNPC1L1遺伝子配列と比較した、それらの対応する位置を示している。
【0201】
【表4】
【0202】
PCR反応は、12μLの総容量中に、Platinum PCR Supermix High Fidelity(100μMdNTPs、1.5mMMgCl2、0.1UPlatinum Taq polymerase High Fidelity,Invitrogen Corp.,Carlsbad,CA)の存在下にあるゲノムDNA(24ng)、並びに0.2pmol/μLのフォワード及びリバースプライマーを含有した。94℃で5分間の最初の変性後、94℃で30秒間の変性、30秒間のプライマーアニーリング(プライマー特異的な温度については、表3を参照。)及び68℃で1分間のプライマー伸長の35サイクルを用いて、96ウェルのマイクロプレート(PTC−200サーモサイクラー、MJ Research)中で、サーモサイクリングを行った。35サイクル後、68℃で7分間、最終伸長を実施した。
【0203】
DNA配列決定及び分析
DNA増幅後、ExoSAP−IT(USB Corporation,Cleveland,OH)0.5μLを含有するPCR緩衝液中で、PCR反応物を50μLまで希釈し、37℃で15分間温置した後、80℃で15分間、酵素の不活化を行った。フォワード及びリバース方向でのサイクル配列決定は、製造業者の指示書に従って、ABI PRISM BigDye terminator v3.1 Cycle Sequencing DNA Sequencing Kit(Applied Biosystems,Foster City,CA)を用いて行った。要約すると、各PCR産物1μLをテンプレートとして用いて、5pmolのM13配列決定プライマー(−21M13又はM13Rev)、0.5×配列決定緩衝液及び0.25μLBDTv3.1ミックスを含有する4μLの配列決定反応混合物と混合した。96℃で1分間、配列決定反応物を変性させた後、96℃で10秒間、50℃で5秒間及び60℃で4分間の25サイクルを行った。Montage SEQ384プレート(Millipore Corp.Bedford,MA)を用いたろ過によって、配列決定反応を精製し、25μLの脱イオン水中に溶解し、Applied Biosystems 3730XL DNA Analyzer上でのキャピラリーゲル電気泳動によって分離した。クロマトグラムを、Unix(登録商標)ワークステーション(DEC alpha,Compaq Corp)に移動し、Phredソフトウェア(version 0.990722.g)を用いて、呼び出された塩基を実施し、Phrap software(version 3.01)(Nickerson,et al.,(1997) Nucleic Acid Res.,25:2745−51)を用いて配列を集合し、Polyphredソフトウェア(バージョン3.5)(Nickerson,et al.,(1997) Nucleic Acid Res.,25:2745−51)を用いて走査し、Consedソフトウェア(バージョン9.0)(Gordon et al.,(1998) Genome Res.,8:195−202)を用いて、結果を図示した。分析パラメータは、全て、各ソフトウェアの初期設定に維持した。Phred、Phrap及びConsedソフトウェアプログラムは、http://www.genome.washington.eduから入手可能であり、PolyPhredソフトウェアプログラムは、http://droog.mbt.washington.eduから入手可能である。
【0204】
SNP分析の結果
ヒトNPC1L1遺伝子は染色体7p13にマッピングされ、ゲノムDNAの約29kbにわたる20エキソンを含有する。公的なSNPマッピングへの尽力を通じて、NPC1L1内に幾つかの一塩基多型(SNP)が報告されている(http://www.ncbi.nlm.nih.gov/SNP)。しかしながら、これらのバリアントの機能的重要性は不明であり、相対的に少数が、10%を超える非主要対立遺伝子頻度(MAF)を有すると報告されているに過ぎない。NPC1L1中の変動の程度を特徴付けるために、3つの民族群(再配列決定コホート)を代表する375人の正常な個体において、全てのエキソン、保存された制御領域、プロモーター領域及び特定のイントロン領域の配列を再決定した。合計140のSNP及び5つの挿入/欠失が、このコホート中に同定された。SNP名は、den Dunnen and Anonarakis((2000),Hum.Mutat.15:7−12)によって提案された慣例に従って割り当てられている。140のNPC1L1多型の完全なリストが、表4に記載されている。
【0205】
【表5】
【0206】
表4に列記されている140の多型のうち、14は5’UTR又はプロモーター領域中に、89はイントロン中に、3つは3’UTR中に、及び34はコード領域中に位置し、これらのうち20がアミノ酸の変化をもたらす(表4)。遺伝子のより広いセットにわたって報告された数値と合致して、共通のSNPについて、キロ塩基当りのSNPの平均数が0.083725であり、全てのSNPにわたって6.96725であるように、NPC1L1の再配列決定された領域は20,094塩基にわたった(Crawford,et al.,(2004) Am.J.Hum.Genet.74:610−22)。
【0207】
表5は、少なくとも1つの民族群中に検出された4%を超える非主要対立遺伝子頻度(MAF)を有する、表4から選択された24個のSNPに焦点を当てている。
【0208】
【表6】
【実施例2】
【0209】
再配列決定コホートにおけるNPC1L1遺伝子の連鎖不均衡(LD)分析
観察された遺伝子型頻度と予測された遺伝子型頻度とを比較する標準的な分割表(予測された頻度は、Haploviewソフトウェアパッケージ(Barrett,et al.,(2005) Bioinformatics,25:263−5)中に実装された正確な検定手法によって推定した。)を用いて、全ての各多型に対して、ハーディー・ワインベルグ平衡を評価した。全てのSNP対に対して図1Aに示されている、対を為す連鎖不均衡値は、Haploviewプログラムを用いて計算した。各SNPに対する観察された対立遺伝子頻度を用いて、全てのSNP対に対して、レウォンティンの不均衡係数(D’)を計算した。PHASE v2.0ソフトウェアパッケージ中に実装されたハプロタイプ再構築のためのベーズのアプローチ(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)を用いて、再配列決定コホートにおいてハプロタイプを推定した。ハプロタイプ再構築プロセスでは、MAFが4%を超えるSNPを使用した。以前に記載されているように(Crawford,et al.,(2004) Nat.Genet.,36:700−6)、Phase v2.0ソフトウェアパッケージを用いて、組換えホットスポット強度を計算した。対立遺伝子の類似性に従った群ハプロタイプとSNPに対してCrawfordら((2004) Am.J.Hum.Genet.,74:610−22)によって提供された方法の僅かな変法を用いて、民族群のそれぞれにわたって同定された8つの最も一般的なハプロタイプが同定された。次いで、集積的階層クラスタリング手法を用いて、観察された全ての染色体に対するハプロタイプを、類似性によってクラスター化した。同様に、クラスタリング手法の同じ種類を用いて、SNPを対立遺伝子の類似性によってクラスター化した(図2)。次いで、図2中の得られたグレースケールマトリックスプロットから、一般的なハプロタイプ(頻度>2%)を識別するタギングSNPを視覚的に同定した。
【0210】
各SNPに対する非主要対立遺伝子頻度が全ての民族群について等しいかどうかを決定するために、各民族群に対する非主要対立遺伝子の予測される数に基づいて、ピアソンのχ2統計指標を算出した(ここで、該予測される数は、民族群中の個体数に、コホート中の全個体にわたって観察された非主要対立遺伝子の割合を乗ずることによって概算した。)。全ての民族群にわたって頻度が同一であるという帰無仮説の下で、ピアソンのχ2統計指標は、民族群の数−1に等しい自由度の漸近χ2分布を有する。民族群の何れかにおける所定のSNPに対する非主要対立遺伝子頻度(MAF)が漸近を保持するには小さすぎる場合には、有意度を経験的に推定するために、可能であれば、順列検定を実施した。このような場合には、順列工程は、所定のコホート中の個体を、目的のSNPに対する遺伝子型に対して無作為に割り当てること、コホート中に観察された全体的対立遺伝子カウント数を保存すること、ついで、ピアソンのχ2統計指標を算出することからなった。350を超える個体に対する遺伝子型情報を有したにも関わらず、異なる民族群に対して、強固なLDブロックは明瞭には規定されなかった。図1Aは、再配列決定コホートから得た白色人種に対するLDマップを強調する。数個の物理的に隣接するSNP対に対してのみ、対を為すD’値が高かった。この図で強調されているブロックは、Four Gamete Rule(Wang,et al.,(2002) Am.J.Hum.Genet.,71:1227−34)を用いて同定されたが、この構造を実現するために、4番目の配偶子に対する最小頻度の閾値は、0.05に設定しなければならなかった。興味深いことに、この遺伝子は、45の組換えホットスポット強度を有しており、以前に記載されているように(Crawford,et al.,(2004) Nat.Genet.,74:610−22)、Phase v2.0ソフトウェアパッケージ(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)を用いて算出された。このことは、NPC1L1が、他の遺伝子に比べて、組換えの有意に増加した割合を有することを示唆する。PHASE v2.0ソフトウェアパッケージ中に実装されたハプロタイプ再構築のためのベーズのアプローチ(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)を用いて、ハプロタイプも推定した。ハプロタイプ再構築プロセスでは、MAFが4%を超えるSNPを使用した。アフリカ系アメリカ人、白色人種及びヒスパニック集団中に推測されたハプロタイプの数は、それぞれ、139、156及び189であった。この数字は、遺伝子のより大きなセットにわたる調査で報告された平均数より有意に大きく(Crawford,et al.,(2004) Am.J.Hum.Genet.,74:610−22)、標本のより大きな数から達成された増加した多様性及び本遺伝子における組換えの割合が増加した可能性を明らかにしたものである可能性が最も高い。
【0211】
アフリカ系アメリカ人、白色人種及びヒスパニック集団中の一般的なハプロタイプ(>5%頻度)の数は、それぞれ、2、4及び4であり、これらの一般的なハプロタイプは、これらの同じ集団中の染色体の53%、57%及び48%を説明した。ハプロタイプの多様性の程度は、幾つかの方法で評価した。まず、合わせた集団中で推定された345のハプロタイプのうち、3つの全ての集団間で26が共有されていた。これらの26のハプロタイプによって説明された各集団中の染色体のパーセントは、アフリカ系アメリカ人集団で73%、白色人種集団中で67%及びヒスパニック集団中で62%であり、染色体の最大のパーセントを有するアフリカ系アメリカ人及び白色人種集団が、一般的なハプロタイプ(80%)によって説明される。異なる集団から個体のサブセットが再標本化され、ハプロタイプがこれらのサブセットから推定されるのであれば、これらの比にはほとんど変動が存在せず、個体のより大きな数は、Kruglyak and Nickerson((2001) Nat.Genet.,27:234−6)文献で予想されるように、より小さなコホートを用いて達成されたものを超えるほどには、一般的なハプロタイプの多様性を有意に増加させなかったことを示している。
【実施例3】
【0212】
エゼチミブとスタチンを用いた二重(追加)薬物療法に対する治療応答とのNPC1L1多型の関連
本実施例におけるデータは、幾つかのNPC1L1SNPとハプロタイプが、スタチン治療へのエゼチミブの追加に対する対象の応答のレベルと有意に関連していることを示す。実施例1で同定された4%を超える非主要対立遺伝子頻度を有する多数の新規及び公知の一般的バリアントに対して、遺伝子型決定アッセイが開発された。NPC1L1中のDNA配列バリアントが、スタチン及びプラセボで治療された患者と比べて、エゼチミブとスタチンでの薬物療法と応答して、高コレステロール血症患者中の様々な血漿コレステロール成分のレベルの変化と関連しているかどうかを評価するために、以下に記載されている、臨床試験コホート(EASE)中で、これらのSNPを用いて、遺伝的関連分析を行った。
【0213】
EASEコホート
NPC1L1中の変動がスタチン療法に対して追加されたエゼチミブに対する応答と関連しているかどうかを研究するために、スタチンへのエゼチミブ追加の有効性(EASE)試験(Pearson et al.,(2005) Mayo Clinic Proceedings、出版中)から研究集団を得た。スタチン療法の安定な治療計画に対して追加されたエゼチミブ10mg/日の6週間が、冠状動脈性心臓病(CHD)リスクカテゴリーに対する国立コレステロール教育プログラム(NCEP)成人治療パネル(ATP)IIIガイドラインを超えたLDL−Cレベルの高コレステロール血症患者中の脂質生物マーカーに対して及ぼす影響を評価するために、EASE試験は、地域を基礎とした、無作為化された、二重盲検の、プラセボ対照化された研究であった。参加の時点で、スタチンの安定用量(用量、製品名は問わない。)及び研究への参加前の少なくとも6週間にわたって、NCEPステップ1食又は類似のコレステロール低下食を摂取している患者を、エゼチミブ(n=2020、2009人が治療を受けた。)又はプラセボ(n=1010、1009人が治療を受けた。)治療群の何れかに、無作為に割り振った。エゼチミブ群からは、1208人の患者がゲノム解析に対して同意を与え、本研究に含めた。全ての試験参加者から得られた試料から、様々な心血管リスク因子に対応する一連の臨床的指標を測定し、上記Pearsonらによって要約されている。
【0214】
EASEコホートにおけるSNP選択及び遺伝子型決定
表4から得られる21のSNP(実施例1)を、有効な遺伝子型決定アッセイへ変換し、そのうち13個が、全てのEASE亜集団中で2%を超える対立遺伝子頻度を有していた。TaqMan Allelic Discriminationアッセイ(Livak,(1999) Genet.Anal.14:143−49)は、Applied Biosystems(Foster City,CA)によって提供されたPrimer Expressソフトウェア及びAssay−by−Designサービスを用いて行った。表6は、全てのEASE亜集団中で2%を超える対立遺伝子頻度を有する選択された13のNPC1L1SNPに対する対立遺伝子識別アッセイを実行するために使用したPCRプライマー及び蛍光発生的プローブ配列を示している。全てのプローブ/プライマーのセットは、汎用の反応及びサイクリング条件を用いて機能するように設計された。
【0215】
【表7】
【0216】
PCR増幅後、Applied Biosystems 7900 HT Sequence Detection System(SDS)を用いて、評価項目プレートの読み取りを行った。95%を下回る品質スコアを有する遺伝子型を繰り返した。
【0217】
EASE試験のエゼチミブ+スタチン治療群に参加した1,208人の個体において、21個の選択されたSNPの遺伝子型を決定した。全ての試験参加者に対して、様々な心血管リスク因子に対応する一連の臨床的指標を採取した(表4a−d)。EASEコホート中で遺伝子決定された13の選択されたSNPは、このコホート中に一般的な対立遺伝子頻度(すなわち、全てのEASE亜集団中の2%を超える対立遺伝子頻度)を有すると確認された。SNPのより大きなパーセントは、再配列決定コホートに比べて、EASEコホート中の民族群の間で、有意に異なる対立遺伝子頻度を有していた。これは、このような検出を行うためのより大きなEASEコホートにおける増加した検出力を反映している(表5参照)。
【0218】
EASEコホートの連鎖不均衡分析
EASEコホート中で多数の個体の遺伝子型が決定されると、NPC1L1遺伝子を通じたLD構造がより明瞭となった。対を為すD’値(図1B)は、再配列決定コホート中に同定されたLDブロックを通じて高かった。SNPg.1680G>Tを除き、D’値は、遺伝子の長さ全体を通じて、全てのSNP対に対して合理的に高く、強調されたLDブロックが明確に規定されていないこと、及び全てのSNPが、ある程度LDの状態にあることを示唆する。EASEコホート中の遺伝子決定された13のSNPに対するハプロタイプ、及び全ての民族群中で4%以上の非主要対立遺伝子頻度を有するハプロタイプを、初期設定のPHASEv2.0ソフトウェアパッケージを用いて推定した(Stephens,et al.,(2001) Am.J.Hum.Genet.,68:978−89)。対立遺伝子の類似性に従ったハプロタイプとSNPをまとめるために、Crawfordら((2004) Am.J.Hum.Genet.,74:610−22)によって提供された方法の僅かな変法を用いて、民族群のそれぞれにわたって同定された8つの最も一般的なハプロタイプが同定された。次いで、集積的階層クラスタリング手法を用いて、観察された全ての染色体に対するハプロタイプを、類似性によってクラスター化した(図2)。同様に、クラスタリング手法の同じ種類を用いて、対立遺伝子の類似性によってSNPをクラスター化した。EASEコホート中のハプロタイプ多様性の80%超を説明する8つの異なる一般的なハプロタイプを代表することができる6つのタギングSNPが同定された。エゼチミブを用いた治療に対するNPC1L1とLDL−C応答間の遺伝的関連を特徴付けるために、これらの6つのタギングSNPを使用した。
【0219】
遺伝的関連検定
EASE試験への参加者は、62.0(11.3)の平均(SD)年齢を有しており、男性1,522人(52.3%)及び女性1,386人(47.7%)であった。総血漿コレステロール、HDLコレステロール(HDL−C)及びLDLコレステロール(LDL−C)に対する平均(SD)は、それぞれ、211.0(34.9)、48.6(11.5)及び129.1(30.0)mg/dLであった(Pearson et al.,上記)。エゼチミブ群中の被験者は、プラセボで治療された対象者と比べて、LDL−Cの有意により大きな低下を有していた(25.8%対2.7%、p<0.001)。これらの測定の分布は、本遺伝的研究に参加した被験者において類似していた(Pearson et al.,上記)。Pearsonら、上記に列記されているベースライン臨床指標は、互いに有意に相関しており(表7)、及びエゼチミブでの治療に対するLDL−C応答(平行して行われるスタチン治療に追加されたエゼチミブの6週後におけるLDL−Cレベルの、ベースラインからのパーセント減少として定義される。)(表8)と相関していた。年齢、人種、性別及びBMIは、エゼチミブ応答を統計的に有意に予測しなかった。これらのLDL−C応答予測ベースライン変数がNPC1L1遺伝子中に同定された6つのタギングSNPの何れかと有意に関連しているかどうかを評価するために、一般的な線形モデルを使用した。これらの応答予測変数とタギングSNPの何れかとの間には、有意な関連は見出されなかった。
【0220】
【表8】
【0221】
【表9】
【0222】
エゼチミブ治療に対するLDL−C応答を主要結果変数として考える、遺伝的関連分析をEASEコホートにおいて実施した。各SNP、ハプロタイプ及びハプロタイプの組み合わせが、本分析で使用される主な説明変数であった。LDL−C応答表現型に対する遺伝子型、ハプロタイプ及びディプロタイプの効果を推定するために、一般的な線形モデルを使用した。ベースラインLDL−Cレベル、性別、年齢及び人種が有意な効果を生じるかどうかを決定するために、これらを調査した。ベースラインLDL−Cレベルは全てのモデルで有意な効果と関連し、従って、全ての分析に含めた。しかしながら、モデル中にベースライン値を含めるか否かに関わらず、ベースラインからのパーセント変化に対するSNPの効果は同一のままであった。タギングSNPの何れかとベースラインLDL−C値の間には関連が存在しなかったので、本発明者らは、予想変数としてSNPを含めるのみのモデルに対してp値を報告する。
【0223】
エゼチミブ及びNPC1L1SNPを用いた治療に対するLDL−Cレベル応答の関連は、一般的な線形モデル回帰フレームワークで検定した。表9は、表5において同定された6つのタギングSNPに対する関連性の結果を要約する。表9では、最初の2つ欄は、ソフトウェアプログラムSAS PROC GLM(SAS Institute,Inc.)中に実装された線形モデルに対する結果を報告する。結果は、ベースラインLDL−Cからのパーセント変化であり、SNPは、3つのカテゴリーとしてモデル化された予想因子である。同様に、表9の欄8及び9は、LDL−C分布のパーセント変化が極端であった被験者のみを含む、同じモデルに対する結果を示している。4〜9欄は、本文に記載されているように、EASEコホートの治療群の極端な応答者における検定結果を表す。p値は、SASソフトウェア手法PROCFREQから得られた一般的関連p値である。応答とSNP遺伝子型との間の関連について有意なp値が達成されれば(0.05のレベル)、ボンフェローニ補正されたp値が括弧内に記される。
【0224】
【表10】
【0225】
NPC1L1コード配列の開始ATGの18ヌクレオチド上流に位置するSNPg.−18C>Aは、EASEコホートにおいて、エゼチミブ治療に対するLDL−C応答と有意に関連することが見出された(p値=0.0043)。g.−18C>Aの一般的な対立遺伝子に対してホモ接合である患者(n=875/1195;73.2%)は、非主要対立遺伝子(298/1195;25.0%)に対してヘテロ接合である患者の27.8%に比べて、ベースラインから24.2%の平均LDL−C変化(15%の増加した応答)を有した。非主要対立遺伝子についてホモ接合の個体(n=22/1195;1.8%)は、27.3%のLDL−Cの平均変化を有し、ヘテロ接合体と有意に異なっていなかった。表9に示されているように、SNPg.−18C>Aへの関連は、解析が全てのEASE集団を含んでいたときに、検定が行われた6つの全てのSNPに対して保存的な補正後に有意であり続けた唯一の関連であった。g.−18C>Aに加えて、1つの追加のSNP(g.1679C>G)は、多重検定(p値=0.012)に対する補正前のLDL−C応答に対して有意に関連していた。
【0226】
白色人種は、EASEコホートにおいて代表される主な民族(1003/1195;83.9%)であったので、白色人種の被験者のみを用いた本分析を繰り返した(表10)。白色人種のみのEASEサブセットにおけるLDL−C応答とg.−18C>Aとの関連は、同じく、統計的に有意であることが見出された(表10)。
【0227】
【表11】
【0228】
興味深いことに、EASEコホートの黒人民族群中の5つのSNPに対する対立遺伝子頻度は、再配列決定コホート中の対応する頻度とは有意に異なっており、これら2つの群間の異なる集団構造を示唆する可能性がある。さらに、再配列決定コホート中のSNPg.28650A>Gに対する対立遺伝子頻度(例えば、白人では4.9%)は、EASEコホートの対立遺伝子頻度(白人では21%、p=6.7×10−14)とは有意に異なっていた。EASE参加者を登録するための要件の1つが、スタチン療法時に、低密度リポタンパク質コレステロール(LDL−C)低下目標を満たせなかったことであること、及びこのSNPg.28605A>Gとコレステロールベースライン値の間に関連が観察されなかったことに鑑みれば、この偏りは、スタチン療法に対する応答との関連を反映し得る。あるいは、EASEコホート被験者が全て異脂肪血症であるのに対して、再配列決定コホートは、コレステロール代謝の正常な分布をおそらく有する集団対照であった点で、これは、高コレステロール血症との関連を反映し得る。
【0229】
極端な応答者の解析
g.−18C>Aとエゼチミブ治療に対する脂質応答間の関連をさらに調べるために、EASEコホート中の最も極端な応答者(エゼチミブ治療に対するLDL−C応答者の上位及び下位10分位として定義される。)を調べた。表9は、これらの極端な応答者に対する関連分析の結果を明らかにする。LDL−C応答に対する関連は、全ての治療された試験参加者に比べて、極端な応答者の亜群において、より有意であることが見出された(表8、p値=0.0003対0.0043)。極端な応答者中の一般的な対立遺伝子(176/239個体又は73.6%)についてホモ接合である患者は、16.8%の平均LDL−Cパーセント応答を有していたが、ヘテロ接合体は、33.98%の平均パーセント応答を有していた(効力の100%の増加)。
【0230】
LDL−C応答に対するSNPg.−18C>Aの有意な関連及び図1Bに示されているLDブロック1中の本SNPに隣接する2つのSNPに鑑みて、上で定義されている極端な応答者でのLDL−C応答に対する関連について、全ての3−SNPハプロタイプ(表11)及びディプロタイプ(表11)を調べた。表11及び12に対するハプロタイプは、EASEコホートにおいて、統計的ソフトウェアパッケージSAS(SAS Institute,Inc.,Gary,NC)を用いて推定した。
【0231】
表11は、極端な応答者で検査されたSNPg.−133A>G、g.−18C>A、g.l678C>Gから構築された5つの最も一般的な3SNPハプロタイプに対する関連検査の結果を示している。所定のハプロタイプの異なる数を保有する個体が応答に関して有意に異なるかどうかを決定するために、ハプロタイプ傾向検査を使用した。3番目の欄は、ハプロタイプの0、1又は2コピーを保有していると個体を分類するために使用されるコーディングを表す。カウント数は、一般的な線形モデルにおけるカテゴリー変数として処理した。表10では、ハプロタイプのコピー数(SAS program PROC HAPLOTYPESで推定)は、同じく、SASソフトウェアPROCGLMを用いて、カテゴリー結果としてモデル化する。
【0232】
【表12】
【0233】
表12は、ディプロタイプをカテゴリー変数として処理し、極端な応答者データの組みを用いた一般的な線形モデルに、LDL−C応答をフィッティングさせることによって求めたディプロタイプカウント数及び平均LDL−C応答率を示している。
【0234】
【表13】
【0235】
表12では、ハプロタイプ対カテゴリーの全ての対は、同じくSASプログラムPROC GLM中で、10の自由度を用いて、カテゴリー結果としてモデル化される。表12は、高応答者と低応答者に対するこれらのカテゴリーに対するカウント数、カテゴリー試験一般関連p値、及び結果としてLDL−Cベースライン値からのパーセント変化を結果として用いたモデルから得られたp値を表している。
【0236】
SNPg.−18C>Aの非主要対立遺伝子を含有する[A(−133)、A(−18)、G(1679)]ハプロタイプ(表11及び12では、A−A−Gと表記されている。)の保有者は、非保有者に比べて、有意に改善されたLDL−C応答を有していた(p値=0.0008)。このパターンは、ハプロタイプの解析及びハプロタイプ対の解析の両方で明らかであった(ディプロタイプの解析において得られた細胞カウント数の幾つかは小さく、検査の統計指標に影響を与えたかもしれない。)。SNPg.−18C>Aより、応答とより有意に関連している個別のハプロタイプ又はディプロタイプの関連は見出されなかった。さらに、EASEコホート中で遺伝子決定された7つの非タギングSNPは全て、SNPG.−18C>Aと同程度にLDL−C応答と有意に関連していないことが見出された。さらに、EASEコホート中で同定された8つの最も一般的なハプロタイプも、SNPG.−18C>A及び[A(−133)、A(−18)、G(1679)]ハプロタイプと同程度にLDL−C応答と有意に関連していないことが見出された。重要なことに、SNPG.−18C>A及び[A(−133)、A(−18)、G(1679)]ハプロタイプは、ベースラインLDL−Cレベルに対してLDL−C応答レベルを調整した後にも、LDL−C応答に対して有意に関連し続けていた。LDL−Cベースライン値は、SNPG.−18C>A又は検査された他の5つのタギングSNPの何れかと有意に関連することが見出されなかった。
【0237】
要約
この実施例は、エゼチミブ感受性経路中のタンパク質をコードする遺伝子であるNPC1L1遺伝子のDNAの変化の詳細な性質決定について記載している。提示されているデータは、本遺伝子中の一般的な多型が、エゼチミブ治療に対するLDL−C応答と有意に関連しているが、ベースラインLDL−Cレベルに対するLDL−C応答とは有意に関連していないことを示している。再配列決定コホート(実施例1)中で、140を超える多型がNPC1L1中に同定され、25がdbSNP中に以前に提示された。1つの一般的なSNPであるg.−18C>Aが、進行中のスタチン療法に追加されたエゼチミブによる治療の6週後に、ホモ接合の主要対立遺伝子と比べて、LDL−Cレベルの減少が15%増加することと有意に関連していることが明らかとなった。本治療に対する極端なLDL−C応答者の亜群では、g.−18C>ASNPに対する関連は、LDL−Cの減少の100%増加にまで増強された。(全ての被験者にわたる)一次関連は、解析で検討された全てのSNPに対する保存的補正後並びに年齢、性別及びベースラインLDL−C共変量について考慮した後にも、有意なままであった。さらに、NPC1L1の3’末端にマッピングされるG.28650A>Gは、EASEコホート中の対応する非主要対立遺伝子頻度と比べて有意に減少した、再配列決定コホートの3つの民族全てに非主要対立遺伝子頻度を示した。EASEコホート中で使用されたものと同じアッセイを用いて、再配列決定コホートの遺伝子型を再度決定することによって、この低下を確認した。
【0238】
エゼチミブは、小腸コレステロール輸送体であるNPC1L1を遮断することによってLDL−Cを低下させる。単独療法として、エゼチミブは、LDL−Cを約18%低下させる(Kropp et al.,(2003) Int.J.Clin.Pract.57:363−8)。スタチンと同時投与されると、エゼチミブに起因する低下の増加は、約14〜15%である。EASEで研究されているように、スタチンの安定用量を服用している患者において、進行中のスタチン療法に添加すると、エゼチミブは、進行するスタチン療法へのプラセボの添加と比べて、LDL−Cをさらに約23%減少させる(Pearson,et al.,(出版中) Mayo Clinic Proceedings)。20mgの同様のスタチン用量で、エゼチミブ10mgの添加は(混合バイトリン錠剤として投与された場合に)、34%から52%まで、LDL−Cのベースラインからの変化をさらに減少させる。脂質低下療法に対するコレステロール応答(スタチン及びエゼチミブ)は、変動的である。HMGCoA還元酵素遺伝子における約5%の対立遺伝子頻度を有するSNPは、プラバスタチンに対する19%のより小さな応答と関連することを最近の研究は実証した(Chasman et al.,(2004) Jama,291:2821−7)。この観察は、脂質低下療法に対する応答の遺伝的な予測因子の存在を示唆しており、関心対象のベースライン特性への関連が存在しなくても、標的中の変動が薬物応答に影響を与える可能性があることを示す、増加しつつある文献に加えられる。
【0239】
EASEコホートは、エゼチミブに対する臨床的に妥当な薬理遺伝学的応答を評価するための興味深い集団である。エゼチミブを服用している患者の多くは、スタチンとの二重療法を受けており、シンバスタチン−エゼチミブ混合錠剤を服用しているか、又は市販されているスタチンの1つとともにエゼチミブを個別に服用している。エゼチミブとスタチンを用いた治療を研究した臨床試験の多くは、患者がスタチン除去期間に入った後、プラセボ又は二重治療を受けるように無作為化される同時投与試験であった。この設定で薬理遺伝学的応答の評価を行うことが可能であるが、NPC1L1バリアントがスタチン応答及びエゼチミブの応答に対して影響を与える可能性によって結果が混乱する。
【0240】
ここに記された結果は、NPC1L1プロモーターの変動がエゼチミブ応答と強く関連していることを示す。g.−18C>Aと安定なスタチン療法に追加されたエゼチミブに対する応答との間に、有意な関連が同定された。本コホートでは、非主要対立遺伝子の少なくとも1つのコピーを保有する患者は、ホモ接合の主要対立遺伝子型を有する患者と比べて、平均して、LDL−Cの低下が15%増加していた。非主要対立遺伝子のホモ接合性は、応答に対して統計的に有意な付加的効果を有しておらず(非主要対立遺伝子ホモ接合体の数が小さかったので、検出されなかった可能性がある。)、優性応答モデルを示唆する。エゼチミブ応答分布の高い範囲及び低い範囲(LDL−Cの40%を上回る低下vs.LDL−Cの5%未満の低下)を示す患者(それぞれ、n=120及びn=119)に対する制限分析は、関連の有意性を拡大した。g.−18C>Aの有意な関連は、遺伝子型が決定されたEASE被験者の完全な組の間で分析された他の臨床的な評価項目(総コレステロール、非HDL−C及びアポBを含むが、HDL−C又はアポA1は含まない。)についても観察された。これらの結果は、エゼチミブ+スタチン治療群中の患者は、プラセボに比べて、総コレステロール、LDL−C、非HDL−C及びアポBの有意な低下を示したが、HDL−C又はアポA1の有意な低下は示さなかったEASEデータと合致した(EASE研究では、プラセボに比べて、HDL−Cの有意なプラセボが存在したことに注目されたい。)。
【0241】
総じて、SNPg.−18C>Aは、エゼチミブを与えたEASE患者内の応答の変動の約1%を占めた。コレステロール代謝の複雑さ、LDL−Cを調節する複数の恒常性経路及びLDL−Cレベルに対する複数の環境的寄与(血漿コレステロールに著しい影響を与える食物脂肪摂取など)に鑑みれば、この薬理遺伝学的相互作用の規模は顕著である。顕著であるg.−18C>A(一般的な集団では約15%)と同程度の高い頻度を有するバリアントに対する薬理遺伝学的相互作用の例が数例存在する。プラバスタチンに対するより小さな応答を予測するHMG CoAイントロンSNPは、これまでに報告された、スタチンに対する最も強固な報告された薬理学的決定因子の1つであるが、スタチン使用者の小さなパーセント(約5%)を特定するに過ぎない。
【0242】
研究は、コレステロール吸収のかなりの変動性を示している(Sudhop and von Bergmann(2002) Drugs,62:2333−47)。NPC1L1中のSNPの、LDL−Cの変化との関連は、NPC1L1中のDNA配列の変動性によって、ベースラインLDL−Cの変動性を説明できないことを示唆している。本研究中のバリアントはベースラインLDL−Cと関連していなかったが、全ての患者は高脂血症であり、スタチン療法時には、ベースラインレベルへのあらゆる関連に混乱を与える。しかしながら、集団対照再配列群と比べて、高脂血症EASE集団中には、NPC1L1 3’UTRSNPの予測されない過剰な発現量が存在した。g.28650A>Gの頻度の顕著な3倍の増加が、対照コホートに比べて、EASEに見出された。EASEコホート中で使用されたものと同じアッセイを用いて、再配列決定コホートの遺伝子型を再度決定することによって、この差が確認された。EASEに参加した患者に対する平均ベースラインコレステロールは、約130mg/dLであり、これは、被験者の多くにおいて、高スタチン用量で評価されたので、明らかに、潜在的に危険性のある高脂血症集団であった。脂質データは、再配列決定コホートからは入手されないので、これらの被験者は、健康であると自己申告され、EASEコホート中の被験者に対して、年齢と性別を概ね合致させた。2つの集団間の他の差が、高脂血症EASE患者中の対立遺伝子頻度の大きな増加を説明する可能性があるが、説得力のある1つの説明は、g.28650A>GSNPが上昇したLDL−Cに対するリスクを予測するということである。ベースラインレベルとg.28650A>GSNPの間には関連が見出されなかったが、本分析は、スタチン治療によって混乱する(すなわち、スタチン治療前のLDL−Cレベルが測定されなかった。)。
【0243】
LDL−Cの低下の15%の相対的増加は、絶対的LDL−Cレベルのさらなる約5mg/dLの増加に相当する。疫学的研究は、LDLコレステロールレベルの1mg/dLの変化ごとに、心臓病のリスクが2〜3%増加することを示している(Gould,et al.,(1998) Circulation,97:946−52)。このような疫学的データに基づけば、g.−18C>Aヘテロ接合体中で見られた増加した応答は、集団のかなりのパーセントの冠状動脈性心臓病の大幅な低下をもたらすと予測される。
【0244】
本明細書及び添付の特許請求の範囲で使用されている単数形(「a」、「an」 and 「the」)には、文脈から別段の意味であることが明らかである場合を除き、複数表記も含まれることに留意しなければならない。従って、例えば、「複合体」という表記は、このような複合体の複数を含み、「製剤」という表記は、当業者に公知の1つ又はそれ以上の製剤及びそれらの均等物に対する表記を含む。
【0245】
別段の定義がなければ、本明細書に使用されている全ての技術的及び科学的用語は、本発明が属する分野の当業者が一般的に理解する意味と同一の意味を有する。本発明の実施又は検査においては、本明細書に記載されているものと類似又は均等な、あらゆる方法、装置及び材料を使用可能であるが、ここでは、好ましい方法、装置及び材料が記載されている。
【0246】
本明細書に挙げられている全ての公報は、例えば、公報中に記載された、本明細書に記載されている発明に関連して使用され得る細胞株、構築物及び方法を記載及び開示する目的で、参照により本明細書に組み込まれる。上で及び本文を通じて論述されている公報は、専ら、本願の出願日より前の開示に対してのみ提供される。本明細書の記載は、以前の発明に基づいて、本発明がこのような開示の日付を先行させる権利を有することを認めるものと解釈すべきではない。
【0247】
本発明の好ましい例示的な実施形態が示され、記載されているが、当業者であれば、例示の目的のためのみに示され、限定のために示されているのではない、本発明が記載された実施形態以外によって実施され得ることを理解する。本発明の精神及び範囲から逸脱することなく、本明細書に記載された実施形態に対して、様々な改変を施し得る。本発明は、以下の特許請求の範囲のみによって限定される。
【図面の簡単な説明】
【0248】
【図1A】再配列コホート中に同定された一般的なバリアントに対するD’プロット。D’プロットは、Haploviewソフトウェアプログラムによって作製された。三角のマトリックスは、白色人種民族群中の一般的なSNPの全てのペア間で算出されたD’値を表している。白は、SNP間に連鎖不均衡が存在しないか、又は弱い連鎖不均衡が存在することを示す低いD’値を示し、最も狭い斜めの縞模様入りの線は、SNP間の有意な連鎖不均衡を示す高いD’値を示し、斑のパターンはオッズ比の低い対数を有する高いD’値を示す。
【図1B】EASEコホートで検査された遺伝子型に対するD’プロット。D’プロットは、Haploviewソフトウェアプログラムによって作製された。三角のマトリックスは、白色人種民族群中の一般的なSNPの全てのペア間で算出されたD’値を表している。白は、SNP間に連鎖不均衡が存在しないか、又は弱い連鎖不均衡が存在することを示す低いD’値を示し、最も狭い斜めの縞模様入りの線は、SNP間の有意な連鎖不均衡を示す高いD’値を示し、斑のパターンはオッズ比の低い対数を有する高いD’値を示す。
【図2】EASEコホート中に同定された一般的なハプロタイプ。各カラムは、EASEコホート中の、遺伝子型が決定された12個の一般的なSNPの1つを表す(実施例1、表4参照)。各列は、7p13染色体を表し、EASEコホート中で観察された2,430の7p13染色体から、250の7p13染色体のランダムな組を採取した。各SNPに対する微量の対立遺伝子には、狭い斜めの縞模様が付されているが、一般的な対立遺伝子には、より幅広い斜めの縞模様が付されている。太字で強調された6つのSNPは、本プロット中に表記されている8つの一般的なハプロタイプを一意的に特定するタギングSNPを表している。これらの6つのSNPは、エゼチミブ応答に対して実施例3に記載されている関連研究において使用された。
【特許請求の範囲】
【請求項1】
NPC1L1遺伝子中の一塩基多型又はハプロタイプに対する参照によって、ヒト対象の前記NPC1L1遺伝子中の一塩基多型又はハプロタイプを、医薬として活性な活性化合物が投与された前記ヒト対象の状態と関連付けることを含む、NPC1L1遺伝子中の一塩基多型又はハプロタイプを、ヒト対象に投与された医薬として活性な化合物の活性と相関させる方法。
【請求項2】
対象の状態が、化合物の投与前及び投与後に、低密度リポタンパク質コレステロール(LDL−C)、総コレステロール、非高密度リポタンパク質コレステロール(非HDL−C)及びアポリポタンパク質Bからなる群から選択される血漿成分レベルを測定することによって決定される、請求項1に記載の方法。
【請求項3】
血漿成分がLDL−Cであり、及び化合物の活性が、化合物の投与前の対象における血漿LDL−Cのレベルと比較した、対象中の血漿LDL−Cの低下である、請求項2に記載の方法。
【請求項4】
一塩基多型が、g.−133A>G、g.−18C>A、g.l679C>G及びg.28650A>Gからなる群から選択される、請求項1に記載の方法。
【請求項5】
一塩基多型がg.−18C>A又はg.1679C>Gであり、及び化合物がコレステロール吸収を阻害する、請求項1に記載の方法。
【請求項6】
化合物がエゼチミブである、請求項5に記載の方法。
【請求項7】
ハプロタイプが[A(−133)、A(−18)、G(1679)]又は[G(−133)、C(−18)、C(1679)]であり、及び化合物がエゼチミブである、請求項1に記載の方法。
【請求項8】
NPC1L1機能に影響を与える薬物に対する対象の応答性を評価する方法であり、
対象から生物学的試料を取得すること、及び
前記生物学的試料中の配列番号1中の1つの位置に存在するヌクレオチド塩基を決定することを含み、
前記位置が5,400位及び7,096位からなる群から選択され、
配列番号1の5,400位のアデニン塩基又は7,096位のグアニン塩基の存在が、配列番号1の5,400位のアデニン塩基又は7,096位のグアニン塩基を欠如する個体に比べて、前記対象が化合物への平均応答より高い応答を有する可能性がより大きいことを示し、及び配列番号1の5,400位のシトシン塩基ホモ接合性又は7,096位のシトシン塩基ホモ接合性の存在が、配列番号1の5,400位のシトシン塩基ホモ接合性又は7,096位のシトシン塩基ホモ接合性を欠如する個体に比べて、前記対象が化合物への平均応答より低い応答を有する可能性がより大きいことを示す、前記方法。
【請求項9】
配列番号1の5,400位又は7,096位に存在するヌクレオチド塩基が、対立遺伝子識別分析、直接配列分析、識別的核酸分析、制限断片長多型分析、DNAマイクロアレイ分析及びポリメラーゼ連鎖反応分析からなる群から選択されるアッセイによって決定される、請求項8に記載の方法。
【請求項10】
配列番号1の5,400位又は7,096位に存在するヌクレオチド塩基が、配列番号1の2つの異なる部分に対して相補的である2つの異なるプライマーを用いたポリメラーゼ連鎖反応によって決定される、請求項8に記載の方法。
【請求項11】
生物学的試料が核酸試料を含む、請求項8に記載の方法。
【請求項12】
NPC1L1機能に影響を与える薬物がエゼチミブである、請求項8に記載の方法。
【請求項13】
g.−133A>G、g.−18C>A及びg.28650A>Gからなる群から選択される一塩基多型を含む、配列番号1の少なくとも12個の連続するヌクレオチド又はその相補物からなる単離されたポリヌクレオチド。
【請求項14】
NPC1L1アンタゴニストの有効量を患者に投与する工程を含み、前記患者が、g.−18C>A及びg.28650A>Gからなる群から選択される少なくとも1つのSNPを有するものと同定される、患者中のコレステロールを低下させる方法。
【請求項15】
患者が[A(−133)、A(−18)、G(1679)]ハプロタイプを有するとして同定される、請求項14に記載の方法。
【請求項16】
ヒト対象中の血漿コレステロールの健康リスクレベルに対する素因を検出する方法であり、ヒト対象中に、ヒトNPC1L1対立遺伝子のゲノム配列中の多型の存在を検出することを含み、前記ヒトNPC1L1対立遺伝子が、配列番号1の34,067位のグアニンからなり、前記グアニンの存在が前記対象中の血漿コレステロールの健康リスクレベルに対する素因の指標である、前記方法。
【請求項17】
血漿コレステロールの健康リスクレベルが、対象に対する米国コレステロール教育プログラム成人治療パネルIII目標レベルより高い、請求項16に記載の方法。
【請求項18】
診断キットであり、配列番号1の5,285位、5,400位、7,096位及び34,067位の1つ又はそれ以上におけるNPC1L1遺伝子中の多型を検出可能な少なくとも1つの対立遺伝子特異的核酸プライマーと、並びに核酸に対して特異的にハイブリダイズ可能な、NPC1L1遺伝子中の多型を検出するためのオリゴヌクレオチドプローブとを含み、NPC1L1遺伝子中のヌクレオチド多型が、配列番号1の5,285位のA又はG、配列番号1の5,400位のC又はA、配列番号1の7,096位のC又はG、及び配列番号1の34,067位のA又はG及びこれらの組み合わせ並びにこれらの逆相補物の少なくとも1つから選択される、前記診断キット。
【請求項1】
NPC1L1遺伝子中の一塩基多型又はハプロタイプに対する参照によって、ヒト対象の前記NPC1L1遺伝子中の一塩基多型又はハプロタイプを、医薬として活性な活性化合物が投与された前記ヒト対象の状態と関連付けることを含む、NPC1L1遺伝子中の一塩基多型又はハプロタイプを、ヒト対象に投与された医薬として活性な化合物の活性と相関させる方法。
【請求項2】
対象の状態が、化合物の投与前及び投与後に、低密度リポタンパク質コレステロール(LDL−C)、総コレステロール、非高密度リポタンパク質コレステロール(非HDL−C)及びアポリポタンパク質Bからなる群から選択される血漿成分レベルを測定することによって決定される、請求項1に記載の方法。
【請求項3】
血漿成分がLDL−Cであり、及び化合物の活性が、化合物の投与前の対象における血漿LDL−Cのレベルと比較した、対象中の血漿LDL−Cの低下である、請求項2に記載の方法。
【請求項4】
一塩基多型が、g.−133A>G、g.−18C>A、g.l679C>G及びg.28650A>Gからなる群から選択される、請求項1に記載の方法。
【請求項5】
一塩基多型がg.−18C>A又はg.1679C>Gであり、及び化合物がコレステロール吸収を阻害する、請求項1に記載の方法。
【請求項6】
化合物がエゼチミブである、請求項5に記載の方法。
【請求項7】
ハプロタイプが[A(−133)、A(−18)、G(1679)]又は[G(−133)、C(−18)、C(1679)]であり、及び化合物がエゼチミブである、請求項1に記載の方法。
【請求項8】
NPC1L1機能に影響を与える薬物に対する対象の応答性を評価する方法であり、
対象から生物学的試料を取得すること、及び
前記生物学的試料中の配列番号1中の1つの位置に存在するヌクレオチド塩基を決定することを含み、
前記位置が5,400位及び7,096位からなる群から選択され、
配列番号1の5,400位のアデニン塩基又は7,096位のグアニン塩基の存在が、配列番号1の5,400位のアデニン塩基又は7,096位のグアニン塩基を欠如する個体に比べて、前記対象が化合物への平均応答より高い応答を有する可能性がより大きいことを示し、及び配列番号1の5,400位のシトシン塩基ホモ接合性又は7,096位のシトシン塩基ホモ接合性の存在が、配列番号1の5,400位のシトシン塩基ホモ接合性又は7,096位のシトシン塩基ホモ接合性を欠如する個体に比べて、前記対象が化合物への平均応答より低い応答を有する可能性がより大きいことを示す、前記方法。
【請求項9】
配列番号1の5,400位又は7,096位に存在するヌクレオチド塩基が、対立遺伝子識別分析、直接配列分析、識別的核酸分析、制限断片長多型分析、DNAマイクロアレイ分析及びポリメラーゼ連鎖反応分析からなる群から選択されるアッセイによって決定される、請求項8に記載の方法。
【請求項10】
配列番号1の5,400位又は7,096位に存在するヌクレオチド塩基が、配列番号1の2つの異なる部分に対して相補的である2つの異なるプライマーを用いたポリメラーゼ連鎖反応によって決定される、請求項8に記載の方法。
【請求項11】
生物学的試料が核酸試料を含む、請求項8に記載の方法。
【請求項12】
NPC1L1機能に影響を与える薬物がエゼチミブである、請求項8に記載の方法。
【請求項13】
g.−133A>G、g.−18C>A及びg.28650A>Gからなる群から選択される一塩基多型を含む、配列番号1の少なくとも12個の連続するヌクレオチド又はその相補物からなる単離されたポリヌクレオチド。
【請求項14】
NPC1L1アンタゴニストの有効量を患者に投与する工程を含み、前記患者が、g.−18C>A及びg.28650A>Gからなる群から選択される少なくとも1つのSNPを有するものと同定される、患者中のコレステロールを低下させる方法。
【請求項15】
患者が[A(−133)、A(−18)、G(1679)]ハプロタイプを有するとして同定される、請求項14に記載の方法。
【請求項16】
ヒト対象中の血漿コレステロールの健康リスクレベルに対する素因を検出する方法であり、ヒト対象中に、ヒトNPC1L1対立遺伝子のゲノム配列中の多型の存在を検出することを含み、前記ヒトNPC1L1対立遺伝子が、配列番号1の34,067位のグアニンからなり、前記グアニンの存在が前記対象中の血漿コレステロールの健康リスクレベルに対する素因の指標である、前記方法。
【請求項17】
血漿コレステロールの健康リスクレベルが、対象に対する米国コレステロール教育プログラム成人治療パネルIII目標レベルより高い、請求項16に記載の方法。
【請求項18】
診断キットであり、配列番号1の5,285位、5,400位、7,096位及び34,067位の1つ又はそれ以上におけるNPC1L1遺伝子中の多型を検出可能な少なくとも1つの対立遺伝子特異的核酸プライマーと、並びに核酸に対して特異的にハイブリダイズ可能な、NPC1L1遺伝子中の多型を検出するためのオリゴヌクレオチドプローブとを含み、NPC1L1遺伝子中のヌクレオチド多型が、配列番号1の5,285位のA又はG、配列番号1の5,400位のC又はA、配列番号1の7,096位のC又はG、及び配列番号1の34,067位のA又はG及びこれらの組み合わせ並びにこれらの逆相補物の少なくとも1つから選択される、前記診断キット。
【図1A】

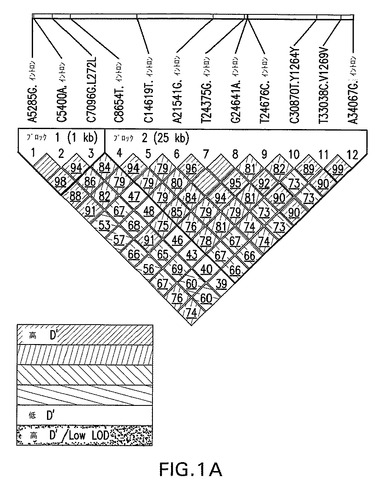
【図1B】
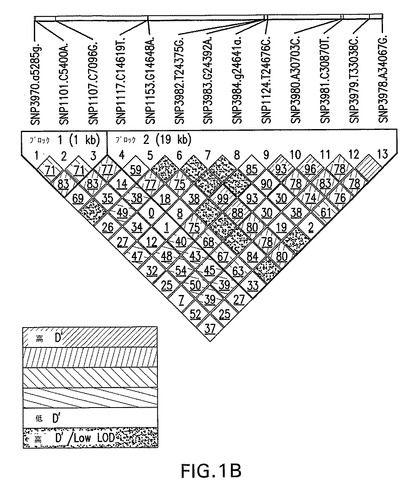
【図2】
【図1B】
【図2】
【公表番号】特表2008−534019(P2008−534019A)
【公表日】平成20年8月28日(2008.8.28)
【国際特許分類】
【出願番号】特願2008−504539(P2008−504539)
【出願日】平成18年3月28日(2006.3.28)
【国際出願番号】PCT/US2006/012727
【国際公開番号】WO2006/105537
【国際公開日】平成18年10月5日(2006.10.5)
【出願人】(596129215)シェーリング コーポレイション (785)
【氏名又は名称原語表記】Schering Corporation
【出願人】(390023526)メルク エンド カムパニー インコーポレーテッド (924)
【氏名又は名称原語表記】MERCK & COMPANY INCOPORATED
【出願人】(505441904)ロゼッタ インファーマティックス エルエルシー (9)
【Fターム(参考)】
【公表日】平成20年8月28日(2008.8.28)
【国際特許分類】
【出願日】平成18年3月28日(2006.3.28)
【国際出願番号】PCT/US2006/012727
【国際公開番号】WO2006/105537
【国際公開日】平成18年10月5日(2006.10.5)
【出願人】(596129215)シェーリング コーポレイション (785)
【氏名又は名称原語表記】Schering Corporation
【出願人】(390023526)メルク エンド カムパニー インコーポレーテッド (924)
【氏名又は名称原語表記】MERCK & COMPANY INCOPORATED
【出願人】(505441904)ロゼッタ インファーマティックス エルエルシー (9)
【Fターム(参考)】
[ Back to top ]