
ビデオ画像を利用したモーションキャプチャのシステム、方法、及び装置
人物のデジタル表現を生成するために、さまざまな方法、装置、及び記憶媒体が実装される。そのような1つのコンピュータに実装された方法によれば、人物の立体表現が、その人物の画像に相関づけられる。人物の時間的に異なる2つの視覚画像のそれぞれに共通する、2つの画像間での人物の動きを表す基準点が見出される。その基準点と、人物の立体表現の相関との関数として、立体変形が人物のデジタル表現に対して適用される。粗/立体変形の関数として、精密変形が行われる。行われた変形に応答して、人物の更新されたデジタル表現が生成される。

【発明の詳細な説明】
【技術分野】
【0001】
本出願は、2008年12月24日に出願された、「ビデオ画像を利用したモーションキャプチャのシステム、方法、及び装置」と題する、米国特許出願第12/343,654号の優先権を主張する。本出願はまた、米国特許法第119条(e)に基づき、2008年5月13日に出願された、「多視点ビデオを利用した動画キャプチャシステム、方法、及び装置」と題する、米国仮特許出願第61/052,900号の利益を主張し、その付属書類を含むこの仮出願文献の内容は、引用によりそのすべてが本願に援用される。
【0002】
本発明は、モーションキャプチャ、及び運動中の人間、動物及びその他の物体をトラッキングし記録するような、被写体のキャプチャを支援するアルゴリズムに関する。
【背景技術】
【0003】
最近公開された、フォトリアリスティックなCGI映画ベオウルフ(パラマウント社、2007年)は、将来において数多くのCGI映画が製作され、公開されるであろうことを印象的に予感させる。以前のアニメーション映画と違って、目的とするのは漫画風の外観ではなく、バーチャルなセット及び俳優をフォトリアリスティック(写実的)に表示することである。実世界の俳優の、真正な仮想代役を創造するには、まだ非常に大きな努力を要する。仮想的な代役上へマッピングするために、人間のパフォーマンス、即ち、実世界における俳優の動作、或いは場合によっては動的なジオメトリ(幾何学的配列)を、キャプチャすることは、今でも最大課題の1つである。身体及び顔の動きを計測するために、スタジオでは、マーカをベースとするモーションキャプチャ技術に頼っている。この方法は高精度なデータをもたらすが、多くの制限がある。マーカをベースとするモーションキャプチャ技術は、かなりの準備時間を必要とし、肌に密着し光学信号を発する不自然な衣装を被写体が着ることが必要となり、また、何時間もかかるデータの手動クリーンアップを必要とすることもしばしばである。このためにスタジオでは、任意の普通の衣服を纏った俳優の動的形状、動き、及びテクスチャ外観の正確なキャプチャを実現しようとしても、人間のパフォーマンスを空間的、時間的に密度濃くキャプチャすることはできない。
【0004】
最近のモーションキャプチャアルゴリズムは、主として、再構築の対象である複雑なシーン表示の部分要素のキャプチャに集中している。多くのゲームや映画制作会社において、マーカベースのモーションキャプチャシステムは、実際の演技者の動きを計測するためにもっとも多用されているシステムである。この手法で高精度を得るためには、制約の多いキャプチャ条件と、被写体が体にぴったりとしたボディスーツと反射マーカを着用するという特徴的条件と、が要求されるが、このような条件では、形状とテクスチャとをキャプチャすることは不可能である。これとは別にこれらの条件を克服するために、数百のマーカを利用して人間の皮膚の変形モデルを抽出しようとした例がある。そのアニメーション結果は非常に説得力のあるものであるが、このような設定では、手動のマークアップやデータのクリーンアップ時間が膨大となり、普通の衣服を着た被写体への一般化は困難である。このようなマーカをベースとする手法は、本質的に、負荷のあるマーカを含むことによりシーンの修正が必要となる。
【0005】
マーカベース技術のいくつかの制約を取り除くことを狙って、光学的シーン修正なしでのパフォーマンス記録を可能とする、マーカなしのモーションキャプチャ手法が考案されている。このような手法は、煩雑な(マーカベースの)方法に比べて柔軟性はあるが、同じ精度及び同様の応用範囲を実現することは困難である。更に、そのような手法は通常動力学的な身体モデルを用いるので、ゆったりした普段着を着た人に関しては、その動きは元より、詳細な形状をキャプチャすることは困難である。ある手法は、モデルを観察されるシルエットにより近いものに適応させ、又はキャプチャレンジスキャンを利用して、骨格の関節のパラメータに加えて、より詳細な体の変形をキャプチャしようとする。しかしそのようなアルゴリズムは通常、被写体がぴったりした衣服を着ることを必要とする。例えば動的な身体モデルと衣装モデルとを合わせて利用するなどして、より一般的な衣装を着た人間のキャプチャを目指した手法は非常に少ない。残念なことに、そのような方法は概して、個々の衣類に対する形状と動力学の手細工を必要と、正確なジオメトリのキャプチャよりもむしろ、オクルージョン(隠蔽)の下での合同パラメータ推定に集中する。動いている衣類の非常に正確なジオメトリを、ビデオから明確に再構築する他の関連研究もある。その方法は、個々の衣装上に特別に誂えたカラーパターンとシーンとの視覚的干渉を利用するが、それは形状とテクスチャとの同時取得を阻害する。
【0006】
これに関連する概念でもう少し集中的なパフォーマンスキャプチャが、3D(三次元)ビデオ方式で提唱されている。これは、実際のカメラでは見えない、新規の合成カメラ視野から再構築された実世界のシーンの外観をレンダリングすることを目指している。初期のシェイプフロムシルエット法(shape−from silhouette methods)は、多視点シルエットコーンの交差によって、どちらかと言うと粗い近似的3Dビデオジオメトリを再構築する。計算上の効率にもかかわらず、並みの品質の、テクスチャのついた粗いシーン再構築は、映画やゲーム業界の制作基準を満たさないことが多い。3Dビデオ品質を向上させるために研究者は、画像ベース法、多視点ステレオ法、アクティブ照明のある多視点ステレオ法、又はモデルベース自由視点ビデオキャプチャについて実験を行った。前の3つの方法は、空間、時間的にコヒーレントなジオメトリも、360度シェイプモデルも作れない。この2つはいずれも、アニメーションの後処理に必要不可欠な前提条件である。それと同時に、以前の動的モデルベースの3Dビデオ方式は、普通の衣類を着た演技者をキャプチャするのには適さなかった。データ駆動型の3Dビデオ方式は、高密度にサンプリングされる入力視点をピクセル的に混ぜ合わせることにより、新規の透視図を合成する。新しい照明の下で均一のレンダリングを高忠実度で作製することが可能ではあるが、何百もの高密度に配置されたカメラを必要とする複雑な取得装置は、実際の適用を困難にすることが多い。ジオメトリの不足は、後の編集を大きな課題としてしまう。
【0007】
骨格形状と運動パラメータ化には基づかず、表面モデルと一般形状変形手法とに基づく、最近のアニメーション設計、アニメーション編集、変形変換、及びアニメーションキャプチャ法が提案されてきている。この運動学的なパラメータ化の放棄は、パフォーマンスキャプチャをはるかに困難な問題にする。
【0008】
同様に、他の手法のあるものは、ビデオからのメッシュベースのモーションキャプチャを可能とし、これは、3D(即ち立体)の変形可能モデルの生成を含み、レーザスキャンモデルと、より基本的な形状変形フレームワークとを使用する。別の最近の手法は、アニメーション再構築法に基づいており、モデル生成と、スキャナデータからの変形キャプチャとを連携して実行する。しかしながら、これらの問題設定は異なっており、計算機的に非常に課題が多く、高視覚品質を生成することを困難にしている。他の手法は、メッシュモデルを、個別にアクティブスキャナデータ又は視覚的外殻(hulls)に変形することが可能な技術を提案している。
【発明の概要】
【課題を解決するための手段】
【0009】
本発明は、ビデオに基づくパフォーマンスキャプチャを含む、システム、方法、及び/又はアニメーションソフトウェアパッケージに関し、多くの実施形態において、時空的にコヒーレントな形状、動き、及びテクスチャの受動的再構築を提供する。本発明の前述及びその他の態様は、いくつかの説明された実装と応用で例示され、その内のあるものは図示され、後述の特許請求の範囲において特徴づけられる。
【0010】
本発明の別の態様によれば、先ずパフォーマンスがキャプチャされ、多重解像度方式で変形モデルが構築される。例えば、低分解能トラッキング手法と詳細を推定又は推測する技術との両方を利用した粗モデルを使って、全体的な(グローバル)モデル姿勢が推測される。その次に、高品質モデルに基づいて、より細部の形状及び動きの詳細が推定される。
【0011】
本発明の別の形態によれば、ビデオデータプロセッサ装置(統合された、又は個別の、1つ以上のカメラ又は記録ツール)が、(ほぼ、又は完全に)未修正のビデオストリームから、任意の衣服を着た1人以上の演技者のコヒーレントな動的ジオメトリ(幾何学配列)をキャプチャする。この入力データは、このデータから抽出される動きの制約の下で、このような演技者のそれぞれの粗モデル姿勢を復元するのに利用されて、推定された演技者の動きに適用できる、変形の(数学)モデルを提供する。このモデルは、例えば形状の精緻化などの、(表面の)詳細の復元をするためのガイドとして利用される。
【0012】
本発明の更に特定の実施形態は、骨格なしの形状変形方法と、姿勢復元のための合成解析(analysis-through-synthesis)フレームワークと、形状精緻化のためにモデル誘導型(表面)詳細復元手法との効果的組み合わせを利用して、俳優の時空的にコヒーレントな形状、動き、テクスチャを高品質に受動再構築する、ビデオベースのパフォーマンスキャプチャを含む。これに関し、多くのアプリケーションが、ユーザにより、緩い衣類を着た人、及び高速で複雑な動きをする人を記録することが可能となるという恩恵を受ける。日常的な衣類を着た人の形状、動き、及びテクスチャを、同時にキャプチャすることが可能である。
【0013】
本発明の一実施形態は、以下の方法を実装するように構成及び配置されたプロセッサと、実行することにより以下の方法を遂行する命令を含む記憶媒体とに関している。この方法は、
人物の視覚画像をその人物に関する3次元情報に関連付けることによって人物のデジタル表現(R)を生成することであって、人物のデジタル表現は、人物の表面メッシュと、複数の3次元形状を用いた人物の立体表現とを含み、
マーカなしキャプチャを利用して、人物の時間的に異なる2つの視覚画像のそれぞれに共通な、2つの画像間の人物の動きを表す基準点を見出し、
2つの画像間の複数の3次元形状の動きに課せられた位置制約に対応して、複数の3次元形状の3次元の動きを特徴づけるために基準点の関数として、人物の立体表現を変形し、
人物の表面メッシュを、立体変形の関数として変形し、
人物の変形された表面メッシュと、変形された立体的表現とに対応した、人物の更新されたデジタル表現と、を生成すること、を含む。
【0014】
上記の概要は、ある態様を特徴づけることに限定され、全ての説明された実施形態や本発明のすべての実装を記述することを意図するものではない。添付の特許請求の範囲で説明されるものを含む、図面とそれに続く詳細な説明とが、これらの実施形態をより詳しく例示する。
【0015】
本発明は、以下の付随する図面と共に、本発明の様々な実施形態の詳細な説明を検討することにより、より完全に理解できるであろう。
【図面の簡単な説明】
【0016】
【図1】本発明の一実施形態による、8台のビデオ記録装置からキャプチャされたカポエイラ回し蹴りの一連の姿勢のシーケンスを示す図である。
【図2a】女優の表面スキャンTtetを示す図である。
【図2b】本発明の一実施形態による、図2aの画像に対応する四面体Ttetを分解図で示した図である。
【図3】本発明の一実施形態による、時刻tとt+1における個別の入力カメラ視野内の、対応する尺度不変特徴変換(SIFT)特徴量から抽出した3次元対応を示す図である。
【図4a】本発明の一実施形態による、1つのカメラ視野に対して示された画像シルエットの等高線からの、色分けされた距離フィールドを示す図である。
【図4b】本発明の一実施形態による、3Dモデル上で拡大ドットでマークされた1つのカメラ視野に関する縁(リム)頂点を示す図である。
【図5】(a)は本発明の一実施形態による、モデルとシルエットの重ね合わせを示す図であり、(b)は本発明の一実施形態による、縁(リム)ステップ後の重ね合わせを示す図であり、(c)及び(d)は本発明の一実施形態によるキー頂点最適化後に、これらの姿勢の不正確さが除去されてモデルが正しい姿勢を取ることを示す図である。
【図6a】本発明の一実施形態による、シルエット等高線からの変形制約が推定された、小寸法表面の詳細のキャプチャリングを示す図である。
【図6b】本発明の一実施形態による、モデルで誘導された多視点ステレオを介して計算された三次元点(3Dポイント)クラウドから抽出された、追加の変形ハンドルを示す図である。
【図6c】本発明の一実施形態による、両方の制約のセットが共に表面スキャンを変形させて高度に正確な姿勢とすることを示す図である。
【図6d】本発明の一実施形態による、全体(グローバル)姿勢推定後(下側の線)と表面詳細再構築後(上側の線)における、フレームごとのシルエットの重なりを百分率で表したグラフを示す。
【図6e】本発明の一実施形態による、ほぼ完全なアライメント結果を示す、入力画像と再構築モデルとの一体化オーバレイを示す図である。
【図7a】本発明の一実施形態による、高信頼度にキャプチャされた、相互にねじれた腕の動きを持つ、ジャズダンスの体勢を示す図である。
【図7b】本発明の一実施形態による、入力と仮想視点とが最小限の差異しかない、高速のカポエイラの回し蹴りの一瞬間を示す図である。
【図8】本発明の一実施形態による、スカートをはいた踊る若い女性の入力と再構築とを横並びに比較した図である(入力と仮想視点とが最小限の差異しかない)。
【図9a】本発明の一実施形態による、入力の1フレームを示す図である。
【図9b】本発明の一実施形態による、詳細モデルを利用した再構築例を示す図である。
【図9c】本発明の一実施形態による、粗モデルを利用した再構築例を示す図である。
【図10a】本発明の一実施形態による、スカートをはいたダンサーの、高品質3Dビデオのレンダリングを示す図である。
【図10b】本発明の一実施形態による、スカートをはいたダンサーの、高品質3Dビデオのレンダリングを示す図である。
【図10c】本発明の一実施形態による、カポエイラ回し蹴りの出力から自動的に推定された、完全模造キャラクタを示す図である。
【図11】本発明の一実施形態による、人物のデジタル表現を生成する方法を示す図である。
【発明を実施するための形態】
【0017】
本発明は様々な変更形や代替形を受け入れることができるが、その特定例を例示として図面に示し、以下でその詳細を述べる。しかしながら、本発明は説明した特定の実施形態に限定されるものではないことを理解されたい。逆に、本発明はその精神及び範囲内にある全ての変更、等価物、及び代替を包含することが意図されている。
【0018】
本発明は、人間、動物、その他を問わず、現実の被写体のビデオベースのパフォーマンスなどの画像の動きをキャプチャし、再構築するのに有用である。本発明の具体的な適用例は、生のパフォーマンスに対して、空間的にコヒーレントな(一貫した)形状、動き、及びテクスチャを受動的に再構築することを支援する。本明細書で開示される例示的実施形態の多くの態様は、この分野における従来の開発に関連し、かつ明らかにそれを基礎として構築されているので、以下の議論では、そのような従来の開発を要約して、本発明の実装の詳細及び変更が導き出される、基礎及び基調を成す教示に関する確実な理解を提供する。このような趣旨で以下の議論が与えられ、これらの文献中の教示は、引用によって本明細書に援用されるものとする。本発明は必ずしもそのような適用例に限定されるわけではないが、この背景を利用した様々な実施例の議論を通して、本発明の様々な態様が理解されるであろう。
【0019】
本発明の一態様によれば、多重解像度方式、例えば低分解能トラッキング手法と全体的(グローバル)なモデル姿勢の推定或いは詳細を推測するための別の技術との2つを利用して、変形モデルを構築するために、パフォーマンスを先ずキャプチャし、次いで、粗モデルを使って推測する。その次に、高品質モデルに基づいて、より細部の形状及び動きの詳細を推定する。
【0020】
本発明の特定の実施形態は、プロセッサに実装された、
人物の視覚画像をその人物に関する3次元情報に関連付けることによって人物のデジタル表現(R)を生成するステップであって、人物のデジタル表現が、人物の表面メッシュと、複数の3次元形状を用いた人物の立体表現とを含む、デジタル表現(R)を生成するステップと、
マーカなしキャプチャを利用して、人物の時間的に異なる2つの視覚画像のそれぞれに共通する、2つの画像間の人物の動きを表す基準点を見出すステップと、
2つの画像間の複数の3次元形状の動きに課せられた位置制約に対応して、複数の3次元形状の3次元の動きを特徴づけるため、人物の立体表現を基準点の関数として変形するステップと、
人物の表面メッシュを、立体的変形の関数として変形するステップと、
人物の変形された表面メッシュと、変形された立体的表現とに対応して、人物の更新されたデジタル表現を生成するステップと、に関連する。
【0021】
本発明の別の特定の実施形態は、プロセッサに実装された以下の1つ以上のステップを含む。
【0022】
キャプチャされる被写体Rの基準姿勢におけるジオメトリを記述する、初期の3D形状モデルを生成又は受信するステップ。モデルは、Rの表面上に三次元の点(3Dポイント)Pの高密度の集合(セット)、並びに表面上の点間の接続を含み(例えば、多角形面として)、このモデルの姿勢は、Pの各点の3D座標によって規定される。
【0023】
基準姿勢での被写体の形状を四面体のメッシュで表す、Rの粗い(密でない)立体版Vを生成又は利用するステップ。モデルは(四面体の)頂点Qの集合を含み、このモデルの姿勢はQの各点の3D座標により規定される。
【0024】
点制約のセットに基づいて粗モデルVの変形を記述する、数学的変形モデルを生成又は利用するステップ。別の数学的変形モデルは、点制約のセットに基づいてRの変形を記述する。3Dの点制約は、新たな変形された構成における、Rの表面ポイントの部分集合の位置を規定する。
【0025】
動きの各時間ステップにおいて、キャプチャされた被写体のジオメトリと(任意選択的に)テクスチャ外観とを記述する、キャプチャされたパフォーマンスモデルMを生成又は利用するステップ。モデルMは、パフォーマンスの各時間ステップにおいて、Rの全ての点Pに対する、3次元の点位置の集合を有する。モデルMは又、Vの各頂点Qに対する位置の集合も有する。
【0026】
各時間ステップにおける実世界の被写体の動きと外観の表現Iを生成又は利用するステップ。この生成は、センサの測定値から得られる。モデルIは、被写体の時間変化する多視点画像データを有する。この時間変化する多視点画像データは、ビデオカメラ又は3次元情報を伝達できる他のタイプのセンサにより記録することができる。モデルIは、入力(ビデオ)映像から抽出される、特徴Fのセットも含む。特徴Fは、ビデオの時間ステップ間での、被写体の表面点同士の対応を記述する。モデルIは又、各時間ステップにおける被写体の体勢及び詳細な表面外観を記述する特徴、即ち、シルエットデータ、並びに多視点対応検索により再構築される空間における3D点を含むこともできる。
【0027】
光学的或いは電子的なマーカ等などのような基準マーカを適用することなしに、入力(ビデオ)データからアニメーションモデルMを推定する、マーカなしトラッキング方法によるデータを利用又は受信し、それにより実世界の被写体Iの表現と位置合わせすることにより、Mのパラメータを推定するステップ。
【0028】
マーカなしトラッキング手法からのデータを利用又は受信して、Iを最もよく説明できるようなVの最適変形を見つけることにより、各時間ステップにおける被写体の大まかな姿勢を先ずキャプチャするステップ。マーカなしトラッキング手法からのデータを利用又は受信して、大まかな姿勢の推定から始めて、Rの精密表面モデルを利用してパフォーマンスの各時刻ステップにおける詳細な表面推定を計算し、それによりパフォーマンスアニメーションモデルMを生成するステップ。
【0029】
本発明の更に特定の実施形態は、骨格なしの形状変形方法と、姿勢復元のための合成解析フレームワークと、形状精緻化のためにモデル誘導型の(表面の)詳細復元手法との効果的組み合わせを利用して、空間的にコヒーレントな(一貫した)、俳優の形状、動き、テクスチャを高品質に受動的再構築する、ビデオベースのパフォーマンスキャプチャを含む。これに関し、本発明の態様を適用することにより、緩い衣類を着た人及び高速で複雑な動きをする人を記録し、コンピュータモデル化することを支援する、沢山のアプリケーションが恩恵を受けることが可能となる。即ち、普段着を着た人々の形状、動き、及びテクスチャを、同時にキャプチャすることが可能である。
【0030】
更なる特定の例示的な実施形態において、本発明は、合成解析トラッキングフレームワークの利用、立体的変形技術、及びその後の小寸法の動的表面詳細の復元を対象とする。合成解析トラッキングフレームワークは、従来のフローベース、又はフロー及び特徴ベースの方法では復元することが不可能なレベルの複雑さとスピードを持つ動きのキャプチャを可能とする。立体的変形技術は姿勢復元のロバストネスを大幅に向上させ、例えば、モデル誘導型多視点ステレオ又は3D光学フローを適用することによって変形モデルを展開した後に、小寸法の動的表面詳細が復元される。
【0031】
更に別の特定の例示的実施形態において、本発明の態様は、マーカなしの高密度パフォーマンスキャプチャ技術を利用して実装される。本技術は、ゆったりした、又はひらひらした普通の衣服を着た演技者を、少数(例えば3〜8程度)の多視点ビデオで記録したものを利用して、演技者の動きと空間的にコヒーレントな、時間変化するジオメトリ(即ち一定の接続性を持ったジオメトリ)を、適切な詳細さで再構築し、微妙な変形の細部までもキャプチャする。実装の詳細のオプションの1つとして、光学マークを全く使用しないことにより、形状とテクスチャとを同時取得することも又簡単になる。
【0032】
別の特定の例示的実施形態は、パフォーマンスキャプチャを変形キャプチャとすることで、従来の骨格形状や動きのパラメータ化を必要とせずに高度の柔軟性と汎用性とを達成することができる。シーンの表現に関しては、実施形態のあるものは、例えば、記録対象の被写体の詳細な固定レーザスキャン又は3D光学フローを使用する。パフォーマンスは多分解能方式でキャプチャされる。これは、例えば、最初のモデルの全体姿勢は粗モデル(後で説明)を利用して推定され、その後、小寸法形状と動きの詳細が高品質モデル(後で説明)に基づいて推定される。全体姿勢のキャプチャは、入力映像から一セットの位置制約を確実に抽出する、合成解析手順を使用する。これらは、スキャン映像が実世界の等価物の動きをそっくりまねられるように、物理的に妥当な高効率形状変形手法(後で説明)へ供給される。各フレームで全体姿勢が復元された後、モデル誘導型多視点ステレオと等高線アライメント法が、各時間ステップにおけるより微細な表面の詳細を再構築する。この手法はスピードと変動(ダイナミクス)を伴う非常に複雑な動きを確実に再構築することが可能であり、従来の骨格ベースの光学キャプチャ手法の限界にさえ挑戦するものである(後で説明)。
【0033】
本発明の一実施形態によると、被写体の入力データが、人のパフォーマンスをビデオ記録する前に取られる。これは例えば、Vitus Smart(登録商標)レーザスキャナにより、衣服を着たままの被写体を全身レーザスキャンすることにより達成される。スキャンした後、被写体は直ちに隣接する多視点記録領域へ移動する。以降で述べる多視点キャプチャの実験設備は、異なるK個(ここではK=8)の、同期され、ジオメトリと光度測定で較正されたビデオカメラを特徴とし、このカメラは24fpsで動作し、フレーム解像度が1004x1004である。カメラは、シーンの中心の周りにほぼ円形に配置される。キャプチャされる演技者のシルエット画像を得るために、前処理の一部として、ビデオの全長に対してカラーベースの背景除去が適用される。
【0034】
全てのデータがキャプチャされると、自動的なパフォーマンス再構築パイプラインが開始される。驚くべきことに、この再構築パイプラインは、前処理中のマニュアル操作が殆ど又は全くなしで実行することができる。形状と動きの計算モデルを取得するために、生のスキャン映像は、ns個の頂点Vtri={v1...vns}と、ms個の三角形Ttri={t1...tms}とを有する高品質表面メッシュTtri=(Vtri,Ttri)に変換される(図2a参照)。このような方法の更なる詳細に関しては、引用により全文が本明細書に援用される、KAZHDAN,M.、BOLITHO,M.及びHOPPE,H.による「ポアソン表面の再構築(Poisson surface reconstruction)」、(Proc.SGP,61−70,2006)を参照されたい。更に、表面スキャンの粗四面体版Ttet=(Vtet,Ttet)(nt個の頂点Vtetと、mt個の四面体Ttetから成る)が、二次曲面誤差デシメーション(quadric error decimation)とその後に制約付きドロネー四面体分割(constrained Delaunay tetrahedralization)を適用することにより生成される(図2b参照)。一般的に、Ttriは30000〜40000の三角形を含み、対応する四面体版は、5000〜6000の四面体を含む。2つのモデルは、ICP(iterative closest points)法に基づいた手順により、入力画像中の俳優の第1の姿勢に自動的に合せ込まれる。姿勢の初期化は、立体スキャンの時に保持した姿勢と同じ姿勢をビデオの最初のフレームで俳優に取らせることにより、単純化することができる。これにより、最初のビデオ画像とスキャン画像との間の差分を減少でき、両者間の相関を単純化できる。
【0035】
本発明の実施形態は、シーンの表現に変形可能モデルを利用する。本発明の態様は、骨格運動パラメータ化は全く利用せず、シーン表現としては変型可能モデルに頼る。これにより、トラッキングが困難になる問題はあるが、非剛性の変形する面(幅の広い衣服や、束ねてない髪のような)を剛性変形するモデルと同じようにトラッキングすることが可能であり、素材の分布やモデルの分割を事前に仮定することを必要としないという、興味ある利点が得られる。例えば、人がまとっているゆったりした、又は幅の広い衣服は、人の骨格の動きではトラッキングできないような動きをすることがある。非剛性の変形部分が、人の剛性変形部分とは実質的に独立して動きうるような場合においても、本発明の態様は、人の非剛性変形部分をトラッキングすることが可能となる。このように、人物の非剛性変形部分は、その下にあるその人物の剛性変形部分とは逆方向に移動したり、大きく圧縮又は伸長したり、及び/又は、人物の剛性変形部分が動きを止めた後も動いたりすることが可能となる。
【0036】
特定の実装においては、メッシュ基準パフォーマンスキャプチャのアルゴリズムの一要素は、いくつかの点ハンドルによってモデル全体の変形を表現する、高速かつ高信頼度の形状変形フレームワークである。一例として、人物/俳優のパフォーマンス/動きは、信頼度を上げるために、多分解能方式でキャプチャされる。先ず、画像とシルエットとに基づく、合成解析法で、低詳細度四面体入力モデルに基づいて、各フレームでの俳優の全体姿勢を推測する。処理ステップのシーケンスは、最適化ベースのメッシュ変形が高度にマルチモーダル(多形態)な解空間であるにもかかわらず、妥当な姿勢への信頼性ある収束を可能とするように設計されている。全体姿勢が見つけられれば、パフォーマンスの高周波態様がキャプチャされる。例えば、スカートの襞の動きはこのステップで復元される。この目的のために、全体姿勢は高詳細度表面スキャンへ変換され、等高線アライメントとモデル誘導型ステレオとを実行することにより、表面形状が微調整される。
【0037】
本方法の出力は、空間と時間の両方における、パフォーマンスの高密度の表現である。出力は、元入力の生き生きとした様子と動きと形状の詳細とを精密にキャプチャした、正確に変形された空間的にコヒーレントなジオメトリを含む。
【0038】
上記の実施形態に関連して、パフォーマンスキャプチャ技術は、ラプラス形状編集の2つの変形を利用する。例えば、低周波トラッキングは、反復立体ラプラス変形アルゴリズムを利用して実装される。この変形アルゴリズムは四面体メッシュTtetに基づいており、位置制約から回転を推測し、また局所的断面積等の保存されるべき形状特性に関する予備知識を暗黙のうちに織り込むことを支援する。高周波表面の詳細を復元するために、キャプチャされた姿勢のTtetは、高分解能表面スキャンに変換することができる。既に大雑把には正しい姿勢にあるので、表面ベースのラプラス変形の単純な非反復変形を利用して、シルエットとステレオ制約から形状の詳細を推測することができる。
【0039】
ある実装において、四面体メッシュTtetは、線形ラプラス変形のステップの繰り返しと、それに続く、線形変形に本質的に含まれる(主として回転の)誤差を補償するための更新ステップとによって、一セットの位置制約
の影響下で変形される。この手順は、各四面体が受ける非剛性変形の量を低減し、従って弾性変形の性質を表すのに効果的である。三角形メッシュ構築アルゴリズムの更なる背景となる詳細については、引用により全文が本明細書に援用される、SORKINE,O.とALEXA,M.による「可及的に剛直な面モデリング(As−rigid−as−possible surface modeling)」(Proc.SGP,109−116,(2007))を参照されたい。しかし、四面体構築の利用は(即ち、三角形メッシュの構築ではなくて)、断面積のような特定の形状特性が変形後に暗黙的に保存されることを可能とする。後者は、それらしくないモデル姿勢(例えば局所的な平板化による)の出現が大幅に減少するため、トラッキングのロバストネスを向上させるのに特に有効であり得る。
【0040】
ある実施形態に関連し、また本発明の特定の態様によれば、変形技術は、
L=GTDG, (1)
であり、
δ=GTDg (2)
である、四面体ラプラス系Lv=δを解くことに基づいている。ここで、Gはメッシュに対する離散的勾配演算子行列であり、Dは四面体の体積を含む4mtx4mtの対角行列であり、gはそれぞれがgj=GjPjとして計算される、四面体勾配の集合である。変形技術の背景の詳細に関しては、引用により全文が本明細書に援用される、BOTSCH,M.、とSORKINE,O.による「線形変分表面変形法について(On linear variational surface deformation methods)」(IEEE TVCG 14,1,213−230,(2008))を参照されたい。ここで、pjは四面体tjの頂点座標を含む行列である。制約qjは、行列の対応する行と列を消去し、右辺のδにその値を代入することにより、行列Lに因数分解することができる。
【0041】
次に、以下のステップが繰り返される。
【0042】
線形ラプラス変形:上記の系を解くことにより、頂点の新しい位置V’tet={v’i...v’nt}が得られる。線形公式により、この変形されたモデルは、単純なラプラス技術に一般的なアーチファクト(結果)を示す。即ち、局所的な要素が制約により回転せず、むしろ、所望の姿勢に合わせるために単に拡大縮小及びせん断される。
【0043】
回転抽出:次に、変換行列Tiが各四面体に対して抽出され、tiを構成t’iに変換する。これらの変換行例は更に、極分解することにより、剛性部分Riと非剛性部分Siとに分離できる。回転成分のみを保持することにより、局所成分から線形変形ステップの非剛性部分の影響が取り除かれる。
【0044】
微分更新:次に、式(2)を用いて四面体の勾配に回転Riを掛けることにより、右辺のδが更新される。
【0045】
この手順を繰り返すことにより、各四面体に残っている、非剛性変形Siの量が最小化される。以後、この変形エネルギをEDと呼ぶ。これに続くトラッキングステップは、各種の物理的に妥当な変形又はシミュレーション方法や技法で実装することができるが、本発明の態様は、極めて高速で、実装が非常に容易であり、かつ仮に材料の特性が未知であったとしても妥当な結果がもたらされることにより、再構築に特に有用である。このような物理的に妥当な変形又はシミュレーション方法の背景的情報としては、引用により全文が本明細書に援用される、BICKEL,B.、BOTSCH,M.、ANGST,R.、MATUSIK,W.、OTADUY,M.、PFISTER,H.及びGROSS,M.による「顔ジオメトリと動きのマルチスケールキャプチャ(Multi−scale capture of facial geometry and motion)」(Proc. of SIGGRAPH,33,(2007))、及びMULLER,M.、DORSEY,J.、MCMILLAN,L.、JAGNOW,R.及びCUTLER,B.による「安定したリアルタイム変形(Stable real−time deformations)」(Proc. of SCA,ACM,49−54,(2002))を参照されたい。
【0046】
姿勢をTtetからTtriへ変換するために、Ttri中の各頂点viは、Ttet中の頂点の線形結合として表される。これらの係数cjが残りの姿勢に対して計算され、後で、三角形メッシュの姿勢更新に利用される。
線形係数ciは、Ttetの中から、半径r(すべての場合、rはメッシュを囲む四角の対角線の5%とした)のローカル球の中に存在し、viと同じような面法線を有する境界面を含む、全ての四面体の部分集合Tr(vj)を見つけることにより生成される。その後、頂点の重心座標係数ci(j)(必ずしも正ではない)が、全ての
に関して計算され、それを次のように、1つの大きな係数ベクトルciに結合する。
【0047】
【数1】
【0048】
j(vi,tj)は、四面体tjの重心までの距離viに関する、コンパクトにサポートされた半径ベースの関数である。この重み付き平均化は、各点を数個の四面体で表現し、従って、四面体メッシュから三角形メッシュへのスムーズな変形変換が可能となる。全てのTtriの頂点に対する係数は行列Bにまとめられる。一義的項のスムーズな分割とパラメータ化のローカルサポートとにより、現在の四面体メッシュVtetの頂点の現在位置にBを掛けることにより、変換された姿勢V’triにおけるメッシュが迅速に計算できる。
【0049】
面ベースの変形を実行するために、最小二乗ラプラス系が実行される。最小二乗ラプラス系の背景情報に関しては、引用により全文が本明細書に援用される、BOTSCH,M.及びSORKINE,O.による「線形変分面変形法(On linear variational surface deformation methods)」(IEEE TVCG 14,1,213−230,(2008))を参照されたい。三角形メッシュTtriが与えられたとして、離散的最小二乗ラプラシアンが、位置制約の集合
の影響下での面変形に余接荷重を用いて適用される。これは、エネルギを最小化することで達成される。
【0050】
【数2】
【0051】
ここで、Lは余接ラプラス行列、δは微分座標、Cは対角行列であって、制約された頂点vjに対してのみ、ゼロでない項Cj,j=wjを持つ(ここでwjは追加項の重み付けである)。この定式は、ラプラシアンを制約により規定される変形の正則化項として使用する。
【0052】
本明細書に開示のある実施形態に関しては、第1のステップは、ビデオの各時間ステップに対して、実際の俳優の姿勢に一致する、四面体入力モデルの全体姿勢を復元することを目指す。簡単に言えば、この全体姿勢抽出方法は、時刻tとt+1とにおける、連続する多視点入力ビデオフレームの各ペアから変形制約を計算することを含むと言える。次に立体形状変形手順を適用して、時刻tにおける(以前に見出された)姿勢を、その姿勢が時刻t+1における入力データに整合するまで変形する。この高度に多様な適合度基準の下で妥当な姿勢に収束させるためには、適正なシーケンスで、適正なタイプの特徴を画像から抽出し、結果として得られる変形制約を正しい順序で適用することが重要である。
【0053】
この目的のために、姿勢復元プロセスは、シーンの動きが早い場合でも、モデルを最終姿勢に近づける、信頼性の高い画像特徴から3D頂点変位を抽出することから開始される。モデル表面上にある3D特徴の分布は、例えばテクスチャ等のシーン構造に依存し、一般には、不均一又はまばらである。従って、結果として得られる姿勢は完全には正しくない可能性がある。更に、対応関係における潜在的な孤立値があり、追加的な姿勢更新ステップを必須となる。従って、全体姿勢を完全に復元するためにシルエットデータを活用する、2つの追加的なステップが実行される。第1のステップは、モデルの外形輪郭の形状を、多視点入力シルエット境界に一致するまで、改良する。第2のステップは、キー頂点ハンドルの3D移動を最適化して、多視点シルエットの最適オーバラップが得られるようにする。多視点シルエットオーバラップは、GPU上でのXOR演算として、簡単に計算することができる。
【0054】
更に、トラッキングのロバストさは、前処理の間に、立体モデルの表面を、同様の寸法の、約100〜200の領域の集合Rに再分割することにより得られる。前処理における立体モデルの再分割に関する背景的情報は、引用により全文が本明細書に援用される、YAMAUCHI,H.、GUMHOLD,S.、ZAYER,R.及びSEIDEL,H.−P.による「ガウス曲率によるメッシュ分割(Mesh segmentation driven by gaussian curvature)」(Visual Computer 21,8−10,649−658,(2005))を参照されたい。前記したように、各頂点の変位を推測するというより、各領域の代表的な変位を判定することができる。
【0055】
本発明の態様は、画像特徴からの姿勢初期化に関する。連続する時間ステップから、2つの多視点ビデオフレームの集合I1(t),...,Ik(t)とI1(t+1),...,Ik(t+1)とが与えられると、第1の処理ステップは、各フレームから、スケール不変特徴変換(SIFT)特徴量を抽出する(図3参照)。SIFT特徴量抽出に関する背景的情報については、引用により全文が本明細書に援用される、LOWE,D.G.による「局所的スケール不変特徴量からの物体認識(Object recognition from local scale−invariant features)」(Proc. ICCV,Vol.2,1150ff,(1999))を参照されたい。
【0056】
【0057】
【0058】
【0059】
実際には、この初期の割り当ては、外れ値を含む可能性があり、従って、時間的対応関係の最終的なセットは、ロバストなスペクトルマッチによって計算されてもよい。スペクトルマッチングの背景的情報に関しては、引用により全文が本明細書に援用される、LEORDEANU,M及びHEBERT,M.による「ペア制約を利用した対応問題のスペクトル技術(A spectral technique for correspondence problems using pairwise constraints)」(Proc.ICCV,(2005))を参照されたい。このような方法は、グラフ隣接行列上のスペクトル解析問題として閉形式で定式化することによって、対応関係の問題の複雑さを効率的に回避する。時間を越えて特徴記述子の値が一貫し、かつペアとしての特徴距離が時間を越えて一定であるような割り当てを求めることにより、不正確な組み合わせが除外される。
【0060】
【0061】
本技術は、全てのシーケンスにわたって特徴をトラッキングする必要はなく、このことが、本方法の信頼性に大きく寄与する。このステップの出力は、特徴ベースの姿勢推定
【0062】
【数3】
である。
【0063】
【0064】
それぞれの要素
に対して、元々リムを画定していた頂点のカメラkへの投影位置uk,t+iを解析して、3D変位が計算される。投影位置における輪郭からの距離場の値が、頂点の法線方向への全変位長を定義する(図4a)。このようにして、リム頂点に対して変形制約が得られ、それが以下で検討する、同様のステップでの変形手順に適用される。この結果は新しいモデル構成
【0065】
【数4】
となり、ここでは、モデルの外側輪郭の投影は、入力されたシルエット境界によりよく一致する。
【0066】
【0067】
しかし、シーンの動きが早いか、SIFTからの初期姿勢の推測が必ずしも正しくない場合に、姿勢誤差がそのまま残る。これに対応するために、追加の最適化ステップが実行されて、変形ハンドルの部分集合の位置を、シルエットのオーバラップがよくなるまで全体的に最適化することにより、そのような残存誤差を補正する。
【0068】
立体モデルの1000〜2000の頂点全部の位置を最適化する代わりに、典型的な15〜25のキー頂点
に対して、四面体変形が最適なシルエットのオーバラップを形成するまで、最適化をすることができる。キーハンドル間の表面距離が保持され、歪エネルギEDの小さい姿勢構成を選択するように、エネルギ関数を設計することにより、トラッキングのロバストネスが向上する。ユーザはキー頂点を手動で特定するように指示されてもよく、これは全てのモデルに対して1回だけ行えばよい手順である。一般的にキー頂点は解剖学的な関節の近くにマークされ、ゆったりした衣服を示すモデル部分の場合には、単純な一様なハンドル分布がよい結果をもたらす。
【0069】
【0070】
【数5】
【0071】
ここで、SIL(Ttet(Vk),t+1)は、現在の変形された姿勢Ttet(Vk)での四面体メッシュの多視点シルエットオーバラップ誤差を表し、それはVkの新しい位置によって定義される。EDは変形エネルギである。当然の結果として、低エネルギ構成がより妥当であることになる。ECは、隣接するキー頂点間の距離の変更に不利となる。3つの項はすべて規格化され、重みwS、wD、wCは、SIL(Ttet(Vk),t+1)が主要な項となるように選択される。大規模境界制約又は非制約準ニュートン最適化法(LBFGS−B)が、式(4)の最小化に利用できる。このようなLBFGS−B方法論の背景については、引用により全文が本明細書に援用される、BYRD, R.、LU, P.、NOCEDAL, J.及びZHU, C.による「境界制約最適化のための限定メモリアルゴリズム(A limited memory algorithm for bound constrained optimization)」(SIAM J.Sci.omp.16,5,1190−1208,(1995))を参照されたい。しかし、本発明の実施形態では、勾配降下法や確率的抽出法などの他の形式の最適化手段を利用することもできる。
【0072】
図5は、キーハンドル最適化により達成された、新しい出力姿勢
【0073】
【数6】
【0074】
における改善結果を示す。
【0075】
上記ステップのシーケンスは、連続する時点の各ペアに対して実行される。表面詳細のキャプチャは、全てのフレームに対して全体姿勢が求められた後で開始される。典型的には、以下に述べるリム処理(ステップ)が、最後のシルエット最適化ステップの後に少なくとももう一度実行される。これは、場合に依っては、モデルのより良い一致を導く。潜在的な自分自身との交差を修正するために、低周波の姿勢キャプチャの出力上での一貫性チェックも実行される。この目的のために、他の四面体内部にある全ての頂点に対して立体変形法を用いて、交差がなくなるまでこの頂点を法線方向外側に向けて変位させる。
【0076】
各フレームに対して全体姿勢が復元されると、Ttetの姿勢のシーケンスがTtriにマッピングされる。以下においては、1つの時間ステップにおける形状詳細キャプチャのプロセス例を説明する。
【0077】
本発明の態様は、シルエット輪郭に沿って適合させることに関する。最初のステップにおいて、微細メッシュのシルエットリムが、入力シルエット輪郭により良く一致するように適合される。表面メッシュは既に正しい構成に非常に近くなっているので、(立体の場合に比べて相対的に)より広範で、より粗い領域での変形が許される。これによりモデルが、入力データとより良く一致する。それと同時に、この場合にはデータ中のノイズが劣化により大きな影響を有するので、制約が注意深く選択される。
【0078】
上で述べたように、リム頂点を計算することが可能だが、それは高解像度表面メッシュ上で計算される(図6a参照)。各リム頂点に対して、リム状態を規定する、シルエット境界上の最近接二次元(2D)点をカメラ視野内で探す。次に、入力シルエット点での画像勾配について、再投影されたモデルの輪郭画像中の画像勾配と類似の方向がないかどうかがチェックされる。もしある場合には、逆投影された入力輪郭点は、リム頂点に対するターゲット位置を規定する。逆投影された位置と元の位置との間の距離が閾値ERIMよりも小さい場合、制約として式(3)に追加される。ここでは、小さな重み(セグメント化の品質に依存して、0.25〜0.5の間)がリム制約ポイントに対して使われる。これは、変形に対する正規化及び減衰効果を与え、ノイズが存在する状態において、妥当でない形状に適合されることを最小化する。全ての頂点を処理した後、新しい表面が求められる。このリムの投影と変形のステップは、最大20回、又はシルエットオーバラップがそれ以上改善されなくなるまで、反復される。
【0079】
本発明の態様は、モデル誘導型多視点ステレオを含む。シルエットのリムは外部境界上に信頼性のある制約を与えるだけであるが、通常それらは表面に均一に分布している。従って、一般的な変形方法は、画像輪郭上に投影のない領域の全体モデルの形状をうまく適合させる。俳優の表面が、沢山の凹面を持った複雑な形状でない限り、リム適合の結果は既に、現実に即した正しい形状の表現となっている。
【0080】
スカートの襞や凹面等のような、シルエット境界に投影されないモデル領域の詳細形状を復元するために、写実的に一貫した(photo-consistency)情報が利用される。この目的のために、多視点ステレオを適用することにより、追加的な変形制約が導出される。多視点ステレオの適用方法に関する背景的情報は、引用により全文が本明細書に援用される、GOESELE,M.、CURLESS,B.及びSEITZ,S.M.による「多視点ステレオ再考(Multiview stereo revisited)」(Proc. CVPR,2402−2409,(2006))を参照されたい。モデルは既に正しい表面に近いので、ステレオ最適化は現行の表面推測から始めて、Ttriからせいぜい±2cm離れた3D点の相関検索に限定される。
【0081】
原則として、任意の数の異なる多視点ステレオ法、又は形状復元法(shape−from−X)法を、最終表面上の時間変化する精細な詳細を復元するために利用することが可能である。従って本発明は、Goeseleにより教示された多視点法に限定されない。実際、多くのその他の多視点ステレオ手法、或いは陰影からの形状の復元法(shape−from−shading)やテクスチャからの形状の復元法(shape−from−texture)等のようなその他のshape−from−X手法を、潜在的に計算コストが高くなるが、利用することも可能である。また、精緻化の段階において、異なる技術の組合せを利用することもまた可能である。
【0082】
様々な他の方法で教示されるものより被写体の視点がはるかに少なく、また俳優はテクスチャの少ない衣服を着ることができるので、結果として得られる深度マップ(各入力視点に対し1つの)は、まばらでノイズが多いことがしばしばである。しかしながら、これはオブジェクト形状に関して重要な追加的な手がかりを与える。深度マップはマージされ、ステレオによって単一の点クラウドPに生成され(図6b)、その後、点をVtriからP上へ投影する。そのようなマージ方法については、引用により全文が本明細書に援用される、STOLL,C.、KARNI,Z.、ROSSL,C.、YAMAUCHI,H.及びSEIDEL,H.−P.による「ポイントクラウドフィッティングのためのテンプレート変形(Template deformation for point cloud fitting)」(Proc. SGP,27−35,(2006))を参照されたい。
これらの投影点は、表面ベースの変形フレームワーク(式(3))でのリム頂点と共に利用することができる、追加的な位置制約を提供する。データの不確かさがあるものとして、ラプラス系はステレオ制約よりも小さな重み付けで解かれる。
【0083】
本明細書で開示するさまざまな実施形態を理解するのに必須ではないが、以下の議論は、本発明の一実施形態の特定の実装から得られた実験結果を含んでいる。
【0084】
テストデータは前述した取得設定で記録され、4人の異なる俳優を写した12シーケンスから成り、それぞれが200〜600フレームのものである。アルゴリズムの適用範囲が広いことを示すために、キャプチャされた演技者は、ぴったりしたものからゆったりしたもの、及び目につきやすいテクスチャの生地でできたものから地味な色だけのもの、等にわたる、広範な異なる衣服を着た。また、復元される一連の動きは、単純な歩行から、異なるダンススタイル、動きの速いカポエイラのシーケンスにまで及んだ。図1、7、8の画像に示すように、本アルゴリズムはこの広範囲のシーンを忠実に再構築する。人間の演技者に注目したが、このアルゴリズムは、レーザスキャンをすることができる動物やその他のオブジェクトに同様に使うことができる。
【0085】
図1は、俳優が一連の回し蹴りを行っている、非常に高速のカポエイラのシーケンスをキャプチャした幾つかの姿勢を示している。24fpsの記録では、連続するフレーム間で俳優は25度を超える角度の回転をするという事実にも拘わらず、形状と動きの両方が非常に忠実に再構築されている。結果として得られるアニメーションでは、ズボンの脚が波打っているような変形の詳細まで示している。更には、入力では俳優は地味な白い衣類を着ており、これは数少ないトレース可能なSIFT特徴点しか示さないが、本方法ではリム及びシルエットを追加の情報源として利用することができるので、信頼度の高い性能を示す。蹴りの1つの瞬間を入力フレームと比較すると、図7bに示されているように、高品質の再構築がされていることが確認できる(入力視点と仮想カメラ視点では僅かに違いがあることに留意されたい)。
【0086】
生成されたビデオはさらに、キャプチャされたカポエイラのシーケンスに静止した格子縞のテクスチャがあることを示している。この結果は、頂点位置の接線面ドリフト等の、時間的エイリアシングが殆どわからないほどで、全体としてのメッシュの品質が非常に安定していることを示している。
【0087】
図7aには、キャプチャされたジャズダンスのパフォーマンスからの1つの姿勢が示されている。入力画像とビデオとの比較は、この高速で流れるような動きをキャプチャできることを示している。更に、図7aに見られるような、胴体の前で相互にねじれた腕の動きなどの複雑な自己遮蔽(self-occlusion)を持つ多くの姿勢もまた再構築することができる。
【0088】
図8は、スカートを着た踊り子の時間変化する形状全体をキャプチャできることを示している。スカートはほぼ一様な色であるが、結果は、布地の自然なうねりと本物のような躍動感とをキャプチャしている。全てのフレームにおいて、ユーザが事前にモデルの分割を指定することなしに、全身の体勢とスカートの襞がうまく再現されている。これらのスカートのシーケンスにおいて、凹面の復元についてのステレオ処理の有用さが最も明確に示されている。これ以外のテストシーンにおいては、ステレオ処理の効果はそれほど顕著ではなく、従って計算時間短縮のためにその機能を停止した。このスカートシーケンスの中には、手に僅かなジッタが見られるが、これは、この人物が手を広げて動いているのに、スキャンは手を握って撮られているという事実によるものと思われる。全般的に、頂点位置の最終シーケンスには円滑化処理を施して、残存する時間ノイズを除去した。
【0089】
表1(下)は、実験アルゴリズムにおける、各個別ステップに対する平均時間の詳細を示す。これらの時間は、2.0GHzのIntel Core Duo T2500ラップトップ上での高度に最適化されていない単一スレッドコードで取得されたものである。更に最適化を行えば大きな改善が得られると思われ、並列処理化すれば、実行時間の顕著な削減をもたらすものと予想できる。この特定の実装には、汎用プロセッサを用いた。このプロセッサには記憶媒体が含まれ、プロセッサがアクセスすると本明細書で述べた種々の工程(ステップ)が実行されるように構成されている。勿論、本明細書で述べた種々の機能を実装するために、さまざまな処理回路を用い得ることは当然である。さまざまな処理回路としては、特製ロジック回路、プログラマブルロジックアレイ、マルチプロセッサ、及びそれらの組み合わせもまた含むことができるが、これらに限定されるものではない。
【0090】
【表1】
【0091】
本発明の高いキャプチャ品質と、広い適用範囲及び実装の汎用性とが示された。精度を公式に立証するために、トラッキングされた出力モデルに対するシルエットのオーバラップを、セグメント化された入力フレームと比較した。正確な時間変化3Dデータを提供する、絶対標準的な代替キャプチャ手法がないので、この判断基準が選択された。最終的な結果としての再投影(画像)は、標準的には、全体姿勢のキャプチャのみの後で既に、入力シルエットピクセルの85%超のオーバラップとなっている(図6dの下側の曲線)。表面の詳細キャプチャでこのオーバラップは、上側の曲線で示されるように90%を超えるオーバラップに改善される。この測定は、いくつかのフレームの前景のセグメント化における、誤ったシルエットピクセルとして見える誤差により、若干負方向に偏っている。従って、シルエットオーバラップの目視検査では、モデルと実際の人のシルエットとはほぼ完全なアライメントとなっていることが確認される。図6eは、このことを示す、レンダリングされたモデルと入力フレームとの間の一体化オーバレイである。
【0092】
ある実施例によれば、本発明の実施形態は、例えばカラーベースのセグメント化で一般的に見られるセグメント化誤差によるノイズのある入力ですら、確実に処理する。最小限のユーザの手動入力の後に、12の入力シーケンス全部が完全に自動的に再構築された。処理の一部として、ユーザは各モデルの頭と足の領域をマークして、表面の詳細キャプチャから除外するようにさせた。そうしなければ、これらの領域においては非常に軽微なシルエット誤差でさえも(特に、床への影と黒い髪の色とにより)、不自然な変形を起こしてしまう。更に、各モデルに対して、キーハンドル最適化ステップに必要な最大25個の変形ハンドルを一度マークする。
【0093】
カポエイラの回し蹴りの3つのシーケンスの内の2つの個別フレーム(約1000フレーム中の11フレーム)、並びにスカートの各シーケンスの1つのフレーム(850フレーム中の2フレーム)において、全体姿勢復元の出力に、四肢の1つに軽微なアライメント不良が見られる。これらの個別の姿勢誤差にも拘らず、本方法は、ドリフトなしに全体シーケンスを直ちに復元し、トラッキングする。即ち、これらの実施形態は、監視なしで実行することが可能であり、後から結果をチェックすることができる。観察された姿勢のアライメント不良のすべては、動きのブレ又は床上の強い影に起因する、専らシルエット領域のサイズオーバーによるものである。これらは両方とも、照明とシャッタスピードの調節、及び更に進歩したセグメント化方式によって防止できたであろう。全体姿勢のアライメント不良のいずれの場合も、最大でも2つの変形ハンドル位置をユーザが少し調節すれば対応できたものである。処理された3500の入力フレームの内、表面の詳細キャプチャの出力を手動修正する必要があるものは1つもなかった。
【0094】
比較のために、文献からの2つの関連する手法を実行した。引用により全文が本明細書に援用される、DE AGUIAR,E.、THEOBALT,C,、STOLL,C,及びSEIDEL,H.−P.による「人の形状と動きのキャプチャ用マーカなし可変メッシュのトラッキング(Marker−less deformable mesh tracking for human shape and motion capture)」(Proc. VPR, IEEE,1−8,(2007))に記載の方法は、多視点ビデオから可変メッシュをトラッキングするための表面ベース変形及び光学フローを利用する。著者が指摘しているように、光学フローはカポエイラキックのような高速の動きでは失敗するため、この手法によるトラッキングは実行不可能になる。これに対し、本発明の立体変形フレームワークは、マルチキューの合成を通した解析手法との組合せで、このビデオを信頼性高くキャプチャする。引用により全文が本明細書に援用される、DE AGUIAR,E.、THEOBALT,C,、STOLL,C,及びSEIDEL,H.による「メッシュベースの人の動きをキャプチャするためのマーカなし3D特徴トラッキング(Marker−less 3d feature tracking for mesh−based human motion capture)」(ICCV HUMO07,1−15,(2007))で提案されている方法は、連続する3D特徴の軌跡を3Dシーンジオメトリのない多視点ビデオからキャプチャすると言う、少し異なる問題の解法を提案している。しかし、この論文に示されているように、表面スキャンを変形させてビデオの俳優のように動かすために軌跡を用いることができる。実験の結果、人が時に急に動いたり、大きく回転したり、自己交差する複雑な姿勢をとったりする場合には、この方法では途切れることなく軌跡を維持することは困難であることがわかった。本発明の実施形態は、このような状況に対しても、確実なハンドリングを可能とする。更には、最終結果の自然さに大きく寄与する、輪郭アライメントの改良と実時間変化する表面詳細や凹面の推定とに対して有効な、ステレオベースの精緻化ステップが実行される。
【0095】
本発明の実施形態の現行シルエットリムマッチングは、入力シルエットの位相構造が、再投影(再構成)されたモデルシルエットと余りに異なる場合には、間違った変形を作ることがある。しかし、テストシーンのいずれにおいてもこのことが問題になることはなかった。他の実施形態において、この問題を全体的に緩和するために、より巧妙な画像位置合わせ手法が用いられる。例えば、ある実装においては、良好なセグメント化をする際に、管理されたスタジオ環境で画像をキャプチャすることができる。そして別の(例えば、より進んだ背景セグメント化を有する)実装においては、戸外のシーンのハンドリングを可能とする。
【0096】
更に、上記の変形キャプチャ技術の実施形態のあるものには、分解能の限界がある。衣類の細かいしわや顔の詳細などのような、最終結果における高周波の詳細のあるものは、もともとレーザスキャンの役割とする部分であった。このレベルの詳細さの変形は、実際にはキャプチャされるのではなく、微細な詳細が変形される表面に“焼き付けられる”のである。再構築される詳細さのレベルを示すために、微細な表面詳細度のない、粗スキャンで結果を生成した。図9aは入力フレームを示す。図9bは、詳細スキャンを用いた再構築を示す。図9cは、粗スキャンを用いた再構築を示す。前述したように、図9cの最も精細な詳細は、高分解能のレーザスキャンによるものであり、粗スキャンであっても、本方法は、重要な実物の動きと全ての表面の変形を十分な詳細さを以ってキャプチャする。最終結果の品質に対する、詳細キャプチャステップの重要度は、全体姿勢の復元のみと、粗いテンプレートの最終結果と、元の詳細スキャンによる最終結果と、をビデオベースで横並びに比較することによって、確認された。
【0097】
又、本システムにおいては、入力されたスキャンモデルの形態は、全シーケンスにわたって保存される。このために、時間と共に任意に変化する見掛け上の形態を有する表面(例えば、髪の毛の動きや自己衝突による深い襞など)は、トラッキングしなかった。更には、全体姿勢のキャプチャ時に自己遮蔽は防止されるが、現在の処、表面詳細キャプチャの出力での修正は行わなかった。しかし、それが起きることはむしろ稀である。衝突検出による手動又は自動の修正を行うことも実行可能であろう。
【0098】
体積ベースの変形技術は、基本的には弾性変形を模倣したものであり、低周波のトラッキングで生成されたジオメトリは、場合によっては、ゴムのような見え方をすることがある。例えば、腕は肘の所で曲がるだけではなく、全長にわたって曲がるような場合もある。表面の詳細キャプチャが、一般にはそのようなアーチファクトを排除する。そして、演算は遅いがより精巧である有限要素変形を使えば、全体姿勢のキャプチャ段階で既にこの問題をなくすことができる。
【0099】
本実験は、ビデオからの時空的に密なパフォーマンスをキャプチャするための、新規の、煩雑でない手法を呈示した。広範囲の実世界のシーンを時空的にコヒーレントに(一貫させて)、かつ高度な詳細さで再構築するために、従来の運動骨格法は意図的に放棄した。
【0100】
以下の議論において、メディア制作において重要な2つの実践的なアプリケーション(適用例)における本アルゴリズムの強みと有用性とを例示する。
【0101】
実践的なアプリケーションの1つは、3Dビデオである。この手法は光学マークなしで使えるので、例えば一体化(混合)方式の利用によって、入力カメラ視野からのキャプチャされたビデオ映像と動いている幾何学配置のテクスチャとを使用することが可能である。そのような混合方式の背景に関しては、引用により全文が本明細書に援用される、CARRANZA,J.、THEOBALT,C,、MAGNOR,M.及びSEIDEL,H.−P.による「俳優に対する自由視点ビデオ(Free−viewpoint video of human actors)」(Proc. SIGGRAPH,569−577,(2003))を参照されたい。この結果は、任意の合成視野からレンダリングすることができる、3Dビデオ表現である(図10a、10b参照)。非常に詳細な、背景シーンのジオメトリのお蔭で、以前のモデルベース、あるいは、シェイプフロムシルエット法ベースの3Dビデオ法を用いた場合に比べて、はるかに良い視覚結果となる。
【0102】
もう1つの実践的なアプリケーションは、完全装備の(fully-rigged)キャラクタの再構築である。この方法は、実質的に経時的接線歪のない、時空的にコヒーレントなシーンのジオメトリを制作するので、そのシーンに対して好適なパラメータ化となる場合には、図10cに示すように完全装備のキャラクタ、即ちアニメーション骨格、表面メッシュ、及び関連するスキニングウェイトとを特徴とするキャラクタの再構築が可能である。この目的のために、結果のシーケンスは自動リギング法に供給され、そこで、骨格とブレンディングウェイトとがメッシュシーケンスから全自動で学習される。そのような自動リギング法の背景的情報に関しては、引用により全文が本明細書に援用される、DE AGUIAR,E.、THEOBALT,C.、THRUN,S.及びSEIDEL,H.−P.による「メッシュアニメーションから骨格ベースアニメーションへの自動変換(Automatic conversion of mesh animations into skeleton based animations)」(Computer Graphics Forum(Proc. EurographicsEG’08)27,2(4),389−397,(2008))を参照されたい。この文献の実験は、システムでキャプチャされたデータを、従来のアニメーションツールでの変更にそのまま適するフォーマットへ任意選択的に変換することが可能であることを示している。
【0103】
本発明の実装により、(変更されていない)ビデオストリームから、任意の、しかも幅広でもよい、普段着を着た人物のコヒーレントな動的ジオメトリをキャプチャできる。この手法はロバストでもあり、最低限の手動作業と後処理しか必要ではない。従って製作費がはるかに少なくて済む。
【0104】
様々な方法の基本バージョンは、映画やゲーム制作に幅広く利用されている現在の技術を置き替えることが可能であり、更なる精緻化も実装可能である。本発明の実施形態により設計されたソフトウェアは、多くの制作会社が既に利用している既存設備(レーザスキャナ、カメラ、記録用ハードウェア、及びその他のデータ処理ツール)とシームレスに結びつく。かかる状況において、本発明の態様は、方法、装置、システム、アセンブリ、そのような技術を実装したコンピュータにより実行される格納されたソフトウェア命令、そのような技術のコンピュータ実装を支援するためのコンピュータアクセス用記憶データ、及び/又はソフトウェアベースのパッケージを格納したコンピュータ媒体、として実装することが可能である。当業者であれば、そのような実装手法は、引用により本明細書に援用された参考文献中に例示されていることがわかるであろう。
【0105】
特に明記されていない限り、本明細書の様々な実施形態に関して、ソフトウェアと言う用語は、処理回路(例えば、計算機処理ユニット“CPU”)を含むシステムの物理的状態への変更を表すために用いられる。従って、“ソフトウェア”と言う用語は、概念の理念や実体のないもののみを表すことには用いられない。その代わりにこの用語は、本明細書で使用されているように、特に実体のある回路構成に向けられている。そこでは回路が、ソフトウェアがなければ決して実行されることのない機能を与えるステップシーケンスを行う様に構成されている。従って本発明の複数の実施形態は、記載した機能を実行するためのハードウェア回路によって実装される。その構成は、回路部品の選択又は配置を含むことができ、或いは、実体的な記憶媒体を変換してプロセッサによる実行のための格納された命令を含むようにすることができる。
【0106】
従って、本発明に沿うように実装されたシステムと実施形態は、完全な形のアニメーション表現を提供することができる。結果として、キャプチャされたデータを用いた多くの新規な作業方法が実行可能となる。例えば、そのようなシステムや実施形態は、システムに別のコンポーネントを追加させて、キャプチャされたパフォーマンスを自動的にリギング(操作)したり、及び/又は、骨格をデータに自動的に合せ込んで、業界標準のアニメーションソフトウェアパッケージ(例えば、Autodesk 3D StudioやSoftimage)で変更できるようにしたりすることができる。他の変形についても以下で説明するが、これらに限定されない。
【0107】
変形例の1つでは、取得のために使用するカメラの数を、所与のアプリケーションに必要なものに変更する。本発明によれば、実験システムは取得のために8台のビデオカメラを使用する。しかしこれは、設計上の厳格な制約ではなく、システムとしては、カメラが1台しかない場合でも、又は8台より多い場合でも結果を得ることは可能である。例えば、ごく僅かの(又は、より少ない)視点しか使えない場合には、キャプチャできる動きの範囲内又は再構築の品質内に、一連の差分が低い再構築品質となって現れる。また、入力センサは、厳密には、光学カメラのみである必要はない。他の実施形態では、タイムオブフライトカメラ(S. Burak Gokturk Hakan Yalcin及びCyrus Bamjiによる「タイムオブフライト・デプスセンサ−システムとその課題及び解決策(A Time−Of−Flight Depth Sensor − System Description, Issues and Solutions)」(www.canesta.com),及び、Thierry Oggierらによる「SwissRanger SR3000と小型化3D−TOFカメラによる最初の経験(SwissRanger SR3000 and First Experiences based on Miniaturized 3D−TOF Cameras)」(http://www.mesa−imaging.ch/pdf/Application_SR3000_vl_l.pdf)を参照のこと。引用によりいずれの文献もその全文を本明細書に援用する。)、構造化光スキャン装置(例えば、レーザ三角測量スキャナ又は活性パターン投影を利用したシステム)、及び/又はステレオカメラ構成、等の深度センサを利用する。更に別の実施形態では、上記の深度センサとビデオカメラとの任意の組み合わせを利用する。
【0108】
上記の例示システムは、人間の演技者に関連して説明した。しかし、このシステムは、動物、又は機械装置のトラッキングにもまた好適である。
【0109】
上記の例示システムでは、実際の記録が開始される前に演技者の身体モデルを得るためにレーザスキャナを利用することを説明したが、それに替わる形式のスキャニング又は再構築技術を用いて、トラッキングする被写体の面表現、又は立体表現を得ることができる。一例として、演技者モデルを、例えば、シェイプフロムシルエット法、又はシェイプフロムシルエット法とステレオ法との組合せを用いて、ビデオから再構築することが可能である。
【0110】
上記の実験システムは、SIFT特徴抽出アルゴリズムを利用する。しかし、画像からであれ、3Dジオメトリからであれ、2つの隣接する時間ステップの間の対応関係を確立することができるそれ以外の任意のアルゴリズムも同様に有用かつ好適である。代替法の例としては、その他の任意の疎画像特徴点マッチング法(sparse image feature matching method)、任意の3D特徴点マッチング法、並びに2Dと3Dの両方の光学フロー手法、がある。
【0111】
また、同様の結果を達成できる、代替のメッシュ変形フレームワークがある。立体ラプラスフレームワークの代わりに、恐らく実行時間が長くなるという犠牲があるとしても、完全な物理ベース非線形変形手法、又は有限要素法の任意の変形が適用可能である。面全体の変形を少数の制約で記述できる、面変形フレームワークの任意の代替法は、面ラプラスアルゴリズムに対する適切な代用となるであろう。繰り返すが、実行時間の制約と変形品質に関する懸念とにより、そのような代用案は所与のアプリケーションへは適用禁止とされるかもしれない。
【0112】
本明細書で説明したステレオ制約を導入する特定の方法は、小スケールの時間変化形状の詳細を復元することのできる唯一のアルゴリズムではない。数多い多視点ステレオアルゴリズムの任意のものが、代用として利用可能である。但し、潜在的に再構築の品質が低い、もしくは長い計算時間という犠牲を伴う、という可能性がある。
【0113】
特定の実施形態において、低周波のトラッキングステップを高周波の面適応ステップに入念に結合することで、所与の入力ビデオから、俳優と衣類とを確実にトラッキングすることが可能である。低周波のトラッキングステップが最初に実装される。これは、画像−(SIFT特徴点)と、オブジェクトの弾性的挙動をシミュレートする立体変形法に結び付いたシルエットベースの(リムとオーバラップ最適化)手法との独特の組み合わせであり、姿勢推定のロバストな技術となる。結果として得られる姿勢は、アルゴリズムの面適応段階へ供給され、そこで、更なる画像(多視点ステレオ)とシルエット(リム最適化)特徴とがロバストなラプラス面変形法に融合されて、観察された俳優の姿勢と形状がうまく再構築される。
【0114】
図11は、本発明の一実施形態による、人物のデジタル表現を生成する方法を示す図である。ステップ1102で、人物の画像が、人物の立体表現に関連付けられる。本明細書で説明したように、これを実行する1つの技法として、人物をレーザスキャンして、その人物の3次元表現を得る方法がある。人物の1つまたは複数の空間的に全く異なる画像の集合もキャプチャされる。立体表現と画像との相関付けを支援するために、レーザスキャンと画像キャプチャの両方に対して、人物を同じような場所に配置することができる。これによって、両者間の差分が最小であることの確認を支援できる。
【0115】
ステップ1104において、時間的に異なる2つの画像に間の共通の基準点が識別される。例えば、動いている人物のビデオキャプチャは、画像キャプチャ装置/カメラのセットを利用して取得できる。ビデオキャプチャされた画像間での人物の動きは、共通基準点の位置の画像間での差分で表される。特定の実装によれば、基準点の部分集合は、一連の基準に合致しない基準点を除去することにより決定される。そのような基準の一例は、基準点の予想位置から大きく外れた基準点を除去することである。
【0116】
ステップ1106において、選択された基準点の集合を用いて、人物の粗/立体変形が行われる。これは、基準点の空間移動と人物の立体表現との関数として実行される。
【0117】
ステップ1108において、微細/面変形が実行される。この変形は、人物に対する粗/立体変形の適用、並びに処理に微細画像分解能を使用した結果を考慮に入れる。レーザスキャニングでキャプチャされた精緻な詳細は、行われた変形に従って変更されることが可能であり、人物の表現に付加される。
【0118】
ステップ1110において、人物のデジタル表現が、適用された変形結果から生成される。この表現は次に、人物の対応画像生成に利用される。
【0119】
本明細書で説明した実施形態の多くは、骨格やその他の剛体モデリングを用いることなしに、キャプチャされた画像から人物のデジタル版を信頼性よく再現することが可能である。しかし、これらの実施形態は、骨格と共に利用するために更に変更することが可能である。例えば、被写体のあるサブパーツのトラッキングは、骨格/剛体モデルの利用で支援され得る。骨格のような剛性変形することがわかっているパーツは、剛体モデルに従うことができ、その他のパーツはより自由に変形できるようにすることが可能である。本明細書で説明した変形フレームワークの態様の融通性は、変形モデルにそのような剛性セグメントの指定を許容し、実効的に骨格を利用するようなものとなる。このことは、トレースが困難な場合において、トラッキングのロバストさの向上支援に特に有効である。
【0120】
本発明の様々な例示的実施形態は、単一人物のトラッキングを対象としている。しかし、他の実施形態は、同一画像中の複数の人物をトラッキングすることが可能である。例えば、一群の人々をトラッキングすることが可能である。更に他の例示的実施形態では、単一人物の複数の部分をそれぞれ個別にトラッキングすることが可能である。このことは、帽子や手に持った物などのような、人物から分離可能な部分に対して特に有効である。
【0121】
本明細書で説明した様々な実施形態は、シーンを変更することなしに、即ち、表面ポイントの時間変化のトラッキングを容易にする一方で、自然の外観を損なってしまうあらゆる形態のマーカも配置することなしに、信頼性のよいトラッキング/キャプチャのデータ取得を可能とする。しかしそれにも拘らず、実施形態のあるものでは、そのような基準マークを利用することも可能である。基準マークのいくつかの例としては、これに限定されるものではないが、カメラに写る反射マーカ、その他の任意の光学センサ又は非光学センサにより検知される電子マーカ、任意の形態の可視、又は非可視ペイント、等が含まれる。一般的にいえば、表面ポイントの動き方の判定の助けとなる、シーンへの任意の変更は、基準マーカの一部として利用可能である。また、ごく少数の基準マーカが付与され、画像間の共通ポイントの多くはマーカなしのキャプチャで判定されるような、混合型の方式を利用することも可能である。例えば、基準マーカに加えて、衣服/表面の自然のテクスチャから、特徴点を抽出することが可能である。
【0122】
ビデオベースのパフォーマンスキャプチャに関する様々な手法は、時空的にコヒーレントな高品質のジオメトリと、生きているような動きのデータと、任意選択としての記録される俳優の表面テクスチャとから成る、高密度で、特徴のはっきりした出力フォーマットを制作するのに有効である。効率的な立体ベース及び面ベースの変形方式と、多視点の合成を通した解析手順と、多視点のステレオ手法との融合が、広範な日常的な衣料を纏い、極めて高速でエネルギッシュな動きをする人のパフォーマンスのキャプチャを容易にする。これらの方法は、マーカベースの光学キャプチャシステム(例えば、映画(特殊効果、他)とかコンピュータゲーム産業に適用可能なような)の性能を補足、及び/又は凌ぐために利用可能であり、また、実世界のコンテンツの取得と変更に高度のフレキシビリティを提供することにより、アニメーション作者やCGアーティストにとっても有益であり得る。当業者であれば、以上で説明した実装は単に例示的なものであり、本発明の真の趣旨と範囲から逸脱することなしに多くの変更を成し得ることは理解されるであろう。それ故に、添付の特許請求の範囲により、本発明の真の趣旨と範囲内にあるそのような変更と修正のすべてが包含されることが意図されている。
【技術分野】
【0001】
本出願は、2008年12月24日に出願された、「ビデオ画像を利用したモーションキャプチャのシステム、方法、及び装置」と題する、米国特許出願第12/343,654号の優先権を主張する。本出願はまた、米国特許法第119条(e)に基づき、2008年5月13日に出願された、「多視点ビデオを利用した動画キャプチャシステム、方法、及び装置」と題する、米国仮特許出願第61/052,900号の利益を主張し、その付属書類を含むこの仮出願文献の内容は、引用によりそのすべてが本願に援用される。
【0002】
本発明は、モーションキャプチャ、及び運動中の人間、動物及びその他の物体をトラッキングし記録するような、被写体のキャプチャを支援するアルゴリズムに関する。
【背景技術】
【0003】
最近公開された、フォトリアリスティックなCGI映画ベオウルフ(パラマウント社、2007年)は、将来において数多くのCGI映画が製作され、公開されるであろうことを印象的に予感させる。以前のアニメーション映画と違って、目的とするのは漫画風の外観ではなく、バーチャルなセット及び俳優をフォトリアリスティック(写実的)に表示することである。実世界の俳優の、真正な仮想代役を創造するには、まだ非常に大きな努力を要する。仮想的な代役上へマッピングするために、人間のパフォーマンス、即ち、実世界における俳優の動作、或いは場合によっては動的なジオメトリ(幾何学的配列)を、キャプチャすることは、今でも最大課題の1つである。身体及び顔の動きを計測するために、スタジオでは、マーカをベースとするモーションキャプチャ技術に頼っている。この方法は高精度なデータをもたらすが、多くの制限がある。マーカをベースとするモーションキャプチャ技術は、かなりの準備時間を必要とし、肌に密着し光学信号を発する不自然な衣装を被写体が着ることが必要となり、また、何時間もかかるデータの手動クリーンアップを必要とすることもしばしばである。このためにスタジオでは、任意の普通の衣服を纏った俳優の動的形状、動き、及びテクスチャ外観の正確なキャプチャを実現しようとしても、人間のパフォーマンスを空間的、時間的に密度濃くキャプチャすることはできない。
【0004】
最近のモーションキャプチャアルゴリズムは、主として、再構築の対象である複雑なシーン表示の部分要素のキャプチャに集中している。多くのゲームや映画制作会社において、マーカベースのモーションキャプチャシステムは、実際の演技者の動きを計測するためにもっとも多用されているシステムである。この手法で高精度を得るためには、制約の多いキャプチャ条件と、被写体が体にぴったりとしたボディスーツと反射マーカを着用するという特徴的条件と、が要求されるが、このような条件では、形状とテクスチャとをキャプチャすることは不可能である。これとは別にこれらの条件を克服するために、数百のマーカを利用して人間の皮膚の変形モデルを抽出しようとした例がある。そのアニメーション結果は非常に説得力のあるものであるが、このような設定では、手動のマークアップやデータのクリーンアップ時間が膨大となり、普通の衣服を着た被写体への一般化は困難である。このようなマーカをベースとする手法は、本質的に、負荷のあるマーカを含むことによりシーンの修正が必要となる。
【0005】
マーカベース技術のいくつかの制約を取り除くことを狙って、光学的シーン修正なしでのパフォーマンス記録を可能とする、マーカなしのモーションキャプチャ手法が考案されている。このような手法は、煩雑な(マーカベースの)方法に比べて柔軟性はあるが、同じ精度及び同様の応用範囲を実現することは困難である。更に、そのような手法は通常動力学的な身体モデルを用いるので、ゆったりした普段着を着た人に関しては、その動きは元より、詳細な形状をキャプチャすることは困難である。ある手法は、モデルを観察されるシルエットにより近いものに適応させ、又はキャプチャレンジスキャンを利用して、骨格の関節のパラメータに加えて、より詳細な体の変形をキャプチャしようとする。しかしそのようなアルゴリズムは通常、被写体がぴったりした衣服を着ることを必要とする。例えば動的な身体モデルと衣装モデルとを合わせて利用するなどして、より一般的な衣装を着た人間のキャプチャを目指した手法は非常に少ない。残念なことに、そのような方法は概して、個々の衣類に対する形状と動力学の手細工を必要と、正確なジオメトリのキャプチャよりもむしろ、オクルージョン(隠蔽)の下での合同パラメータ推定に集中する。動いている衣類の非常に正確なジオメトリを、ビデオから明確に再構築する他の関連研究もある。その方法は、個々の衣装上に特別に誂えたカラーパターンとシーンとの視覚的干渉を利用するが、それは形状とテクスチャとの同時取得を阻害する。
【0006】
これに関連する概念でもう少し集中的なパフォーマンスキャプチャが、3D(三次元)ビデオ方式で提唱されている。これは、実際のカメラでは見えない、新規の合成カメラ視野から再構築された実世界のシーンの外観をレンダリングすることを目指している。初期のシェイプフロムシルエット法(shape−from silhouette methods)は、多視点シルエットコーンの交差によって、どちらかと言うと粗い近似的3Dビデオジオメトリを再構築する。計算上の効率にもかかわらず、並みの品質の、テクスチャのついた粗いシーン再構築は、映画やゲーム業界の制作基準を満たさないことが多い。3Dビデオ品質を向上させるために研究者は、画像ベース法、多視点ステレオ法、アクティブ照明のある多視点ステレオ法、又はモデルベース自由視点ビデオキャプチャについて実験を行った。前の3つの方法は、空間、時間的にコヒーレントなジオメトリも、360度シェイプモデルも作れない。この2つはいずれも、アニメーションの後処理に必要不可欠な前提条件である。それと同時に、以前の動的モデルベースの3Dビデオ方式は、普通の衣類を着た演技者をキャプチャするのには適さなかった。データ駆動型の3Dビデオ方式は、高密度にサンプリングされる入力視点をピクセル的に混ぜ合わせることにより、新規の透視図を合成する。新しい照明の下で均一のレンダリングを高忠実度で作製することが可能ではあるが、何百もの高密度に配置されたカメラを必要とする複雑な取得装置は、実際の適用を困難にすることが多い。ジオメトリの不足は、後の編集を大きな課題としてしまう。
【0007】
骨格形状と運動パラメータ化には基づかず、表面モデルと一般形状変形手法とに基づく、最近のアニメーション設計、アニメーション編集、変形変換、及びアニメーションキャプチャ法が提案されてきている。この運動学的なパラメータ化の放棄は、パフォーマンスキャプチャをはるかに困難な問題にする。
【0008】
同様に、他の手法のあるものは、ビデオからのメッシュベースのモーションキャプチャを可能とし、これは、3D(即ち立体)の変形可能モデルの生成を含み、レーザスキャンモデルと、より基本的な形状変形フレームワークとを使用する。別の最近の手法は、アニメーション再構築法に基づいており、モデル生成と、スキャナデータからの変形キャプチャとを連携して実行する。しかしながら、これらの問題設定は異なっており、計算機的に非常に課題が多く、高視覚品質を生成することを困難にしている。他の手法は、メッシュモデルを、個別にアクティブスキャナデータ又は視覚的外殻(hulls)に変形することが可能な技術を提案している。
【発明の概要】
【課題を解決するための手段】
【0009】
本発明は、ビデオに基づくパフォーマンスキャプチャを含む、システム、方法、及び/又はアニメーションソフトウェアパッケージに関し、多くの実施形態において、時空的にコヒーレントな形状、動き、及びテクスチャの受動的再構築を提供する。本発明の前述及びその他の態様は、いくつかの説明された実装と応用で例示され、その内のあるものは図示され、後述の特許請求の範囲において特徴づけられる。
【0010】
本発明の別の態様によれば、先ずパフォーマンスがキャプチャされ、多重解像度方式で変形モデルが構築される。例えば、低分解能トラッキング手法と詳細を推定又は推測する技術との両方を利用した粗モデルを使って、全体的な(グローバル)モデル姿勢が推測される。その次に、高品質モデルに基づいて、より細部の形状及び動きの詳細が推定される。
【0011】
本発明の別の形態によれば、ビデオデータプロセッサ装置(統合された、又は個別の、1つ以上のカメラ又は記録ツール)が、(ほぼ、又は完全に)未修正のビデオストリームから、任意の衣服を着た1人以上の演技者のコヒーレントな動的ジオメトリ(幾何学配列)をキャプチャする。この入力データは、このデータから抽出される動きの制約の下で、このような演技者のそれぞれの粗モデル姿勢を復元するのに利用されて、推定された演技者の動きに適用できる、変形の(数学)モデルを提供する。このモデルは、例えば形状の精緻化などの、(表面の)詳細の復元をするためのガイドとして利用される。
【0012】
本発明の更に特定の実施形態は、骨格なしの形状変形方法と、姿勢復元のための合成解析(analysis-through-synthesis)フレームワークと、形状精緻化のためにモデル誘導型(表面)詳細復元手法との効果的組み合わせを利用して、俳優の時空的にコヒーレントな形状、動き、テクスチャを高品質に受動再構築する、ビデオベースのパフォーマンスキャプチャを含む。これに関し、多くのアプリケーションが、ユーザにより、緩い衣類を着た人、及び高速で複雑な動きをする人を記録することが可能となるという恩恵を受ける。日常的な衣類を着た人の形状、動き、及びテクスチャを、同時にキャプチャすることが可能である。
【0013】
本発明の一実施形態は、以下の方法を実装するように構成及び配置されたプロセッサと、実行することにより以下の方法を遂行する命令を含む記憶媒体とに関している。この方法は、
人物の視覚画像をその人物に関する3次元情報に関連付けることによって人物のデジタル表現(R)を生成することであって、人物のデジタル表現は、人物の表面メッシュと、複数の3次元形状を用いた人物の立体表現とを含み、
マーカなしキャプチャを利用して、人物の時間的に異なる2つの視覚画像のそれぞれに共通な、2つの画像間の人物の動きを表す基準点を見出し、
2つの画像間の複数の3次元形状の動きに課せられた位置制約に対応して、複数の3次元形状の3次元の動きを特徴づけるために基準点の関数として、人物の立体表現を変形し、
人物の表面メッシュを、立体変形の関数として変形し、
人物の変形された表面メッシュと、変形された立体的表現とに対応した、人物の更新されたデジタル表現と、を生成すること、を含む。
【0014】
上記の概要は、ある態様を特徴づけることに限定され、全ての説明された実施形態や本発明のすべての実装を記述することを意図するものではない。添付の特許請求の範囲で説明されるものを含む、図面とそれに続く詳細な説明とが、これらの実施形態をより詳しく例示する。
【0015】
本発明は、以下の付随する図面と共に、本発明の様々な実施形態の詳細な説明を検討することにより、より完全に理解できるであろう。
【図面の簡単な説明】
【0016】
【図1】本発明の一実施形態による、8台のビデオ記録装置からキャプチャされたカポエイラ回し蹴りの一連の姿勢のシーケンスを示す図である。
【図2a】女優の表面スキャンTtetを示す図である。
【図2b】本発明の一実施形態による、図2aの画像に対応する四面体Ttetを分解図で示した図である。
【図3】本発明の一実施形態による、時刻tとt+1における個別の入力カメラ視野内の、対応する尺度不変特徴変換(SIFT)特徴量から抽出した3次元対応を示す図である。
【図4a】本発明の一実施形態による、1つのカメラ視野に対して示された画像シルエットの等高線からの、色分けされた距離フィールドを示す図である。
【図4b】本発明の一実施形態による、3Dモデル上で拡大ドットでマークされた1つのカメラ視野に関する縁(リム)頂点を示す図である。
【図5】(a)は本発明の一実施形態による、モデルとシルエットの重ね合わせを示す図であり、(b)は本発明の一実施形態による、縁(リム)ステップ後の重ね合わせを示す図であり、(c)及び(d)は本発明の一実施形態によるキー頂点最適化後に、これらの姿勢の不正確さが除去されてモデルが正しい姿勢を取ることを示す図である。
【図6a】本発明の一実施形態による、シルエット等高線からの変形制約が推定された、小寸法表面の詳細のキャプチャリングを示す図である。
【図6b】本発明の一実施形態による、モデルで誘導された多視点ステレオを介して計算された三次元点(3Dポイント)クラウドから抽出された、追加の変形ハンドルを示す図である。
【図6c】本発明の一実施形態による、両方の制約のセットが共に表面スキャンを変形させて高度に正確な姿勢とすることを示す図である。
【図6d】本発明の一実施形態による、全体(グローバル)姿勢推定後(下側の線)と表面詳細再構築後(上側の線)における、フレームごとのシルエットの重なりを百分率で表したグラフを示す。
【図6e】本発明の一実施形態による、ほぼ完全なアライメント結果を示す、入力画像と再構築モデルとの一体化オーバレイを示す図である。
【図7a】本発明の一実施形態による、高信頼度にキャプチャされた、相互にねじれた腕の動きを持つ、ジャズダンスの体勢を示す図である。
【図7b】本発明の一実施形態による、入力と仮想視点とが最小限の差異しかない、高速のカポエイラの回し蹴りの一瞬間を示す図である。
【図8】本発明の一実施形態による、スカートをはいた踊る若い女性の入力と再構築とを横並びに比較した図である(入力と仮想視点とが最小限の差異しかない)。
【図9a】本発明の一実施形態による、入力の1フレームを示す図である。
【図9b】本発明の一実施形態による、詳細モデルを利用した再構築例を示す図である。
【図9c】本発明の一実施形態による、粗モデルを利用した再構築例を示す図である。
【図10a】本発明の一実施形態による、スカートをはいたダンサーの、高品質3Dビデオのレンダリングを示す図である。
【図10b】本発明の一実施形態による、スカートをはいたダンサーの、高品質3Dビデオのレンダリングを示す図である。
【図10c】本発明の一実施形態による、カポエイラ回し蹴りの出力から自動的に推定された、完全模造キャラクタを示す図である。
【図11】本発明の一実施形態による、人物のデジタル表現を生成する方法を示す図である。
【発明を実施するための形態】
【0017】
本発明は様々な変更形や代替形を受け入れることができるが、その特定例を例示として図面に示し、以下でその詳細を述べる。しかしながら、本発明は説明した特定の実施形態に限定されるものではないことを理解されたい。逆に、本発明はその精神及び範囲内にある全ての変更、等価物、及び代替を包含することが意図されている。
【0018】
本発明は、人間、動物、その他を問わず、現実の被写体のビデオベースのパフォーマンスなどの画像の動きをキャプチャし、再構築するのに有用である。本発明の具体的な適用例は、生のパフォーマンスに対して、空間的にコヒーレントな(一貫した)形状、動き、及びテクスチャを受動的に再構築することを支援する。本明細書で開示される例示的実施形態の多くの態様は、この分野における従来の開発に関連し、かつ明らかにそれを基礎として構築されているので、以下の議論では、そのような従来の開発を要約して、本発明の実装の詳細及び変更が導き出される、基礎及び基調を成す教示に関する確実な理解を提供する。このような趣旨で以下の議論が与えられ、これらの文献中の教示は、引用によって本明細書に援用されるものとする。本発明は必ずしもそのような適用例に限定されるわけではないが、この背景を利用した様々な実施例の議論を通して、本発明の様々な態様が理解されるであろう。
【0019】
本発明の一態様によれば、多重解像度方式、例えば低分解能トラッキング手法と全体的(グローバル)なモデル姿勢の推定或いは詳細を推測するための別の技術との2つを利用して、変形モデルを構築するために、パフォーマンスを先ずキャプチャし、次いで、粗モデルを使って推測する。その次に、高品質モデルに基づいて、より細部の形状及び動きの詳細を推定する。
【0020】
本発明の特定の実施形態は、プロセッサに実装された、
人物の視覚画像をその人物に関する3次元情報に関連付けることによって人物のデジタル表現(R)を生成するステップであって、人物のデジタル表現が、人物の表面メッシュと、複数の3次元形状を用いた人物の立体表現とを含む、デジタル表現(R)を生成するステップと、
マーカなしキャプチャを利用して、人物の時間的に異なる2つの視覚画像のそれぞれに共通する、2つの画像間の人物の動きを表す基準点を見出すステップと、
2つの画像間の複数の3次元形状の動きに課せられた位置制約に対応して、複数の3次元形状の3次元の動きを特徴づけるため、人物の立体表現を基準点の関数として変形するステップと、
人物の表面メッシュを、立体的変形の関数として変形するステップと、
人物の変形された表面メッシュと、変形された立体的表現とに対応して、人物の更新されたデジタル表現を生成するステップと、に関連する。
【0021】
本発明の別の特定の実施形態は、プロセッサに実装された以下の1つ以上のステップを含む。
【0022】
キャプチャされる被写体Rの基準姿勢におけるジオメトリを記述する、初期の3D形状モデルを生成又は受信するステップ。モデルは、Rの表面上に三次元の点(3Dポイント)Pの高密度の集合(セット)、並びに表面上の点間の接続を含み(例えば、多角形面として)、このモデルの姿勢は、Pの各点の3D座標によって規定される。
【0023】
基準姿勢での被写体の形状を四面体のメッシュで表す、Rの粗い(密でない)立体版Vを生成又は利用するステップ。モデルは(四面体の)頂点Qの集合を含み、このモデルの姿勢はQの各点の3D座標により規定される。
【0024】
点制約のセットに基づいて粗モデルVの変形を記述する、数学的変形モデルを生成又は利用するステップ。別の数学的変形モデルは、点制約のセットに基づいてRの変形を記述する。3Dの点制約は、新たな変形された構成における、Rの表面ポイントの部分集合の位置を規定する。
【0025】
動きの各時間ステップにおいて、キャプチャされた被写体のジオメトリと(任意選択的に)テクスチャ外観とを記述する、キャプチャされたパフォーマンスモデルMを生成又は利用するステップ。モデルMは、パフォーマンスの各時間ステップにおいて、Rの全ての点Pに対する、3次元の点位置の集合を有する。モデルMは又、Vの各頂点Qに対する位置の集合も有する。
【0026】
各時間ステップにおける実世界の被写体の動きと外観の表現Iを生成又は利用するステップ。この生成は、センサの測定値から得られる。モデルIは、被写体の時間変化する多視点画像データを有する。この時間変化する多視点画像データは、ビデオカメラ又は3次元情報を伝達できる他のタイプのセンサにより記録することができる。モデルIは、入力(ビデオ)映像から抽出される、特徴Fのセットも含む。特徴Fは、ビデオの時間ステップ間での、被写体の表面点同士の対応を記述する。モデルIは又、各時間ステップにおける被写体の体勢及び詳細な表面外観を記述する特徴、即ち、シルエットデータ、並びに多視点対応検索により再構築される空間における3D点を含むこともできる。
【0027】
光学的或いは電子的なマーカ等などのような基準マーカを適用することなしに、入力(ビデオ)データからアニメーションモデルMを推定する、マーカなしトラッキング方法によるデータを利用又は受信し、それにより実世界の被写体Iの表現と位置合わせすることにより、Mのパラメータを推定するステップ。
【0028】
マーカなしトラッキング手法からのデータを利用又は受信して、Iを最もよく説明できるようなVの最適変形を見つけることにより、各時間ステップにおける被写体の大まかな姿勢を先ずキャプチャするステップ。マーカなしトラッキング手法からのデータを利用又は受信して、大まかな姿勢の推定から始めて、Rの精密表面モデルを利用してパフォーマンスの各時刻ステップにおける詳細な表面推定を計算し、それによりパフォーマンスアニメーションモデルMを生成するステップ。
【0029】
本発明の更に特定の実施形態は、骨格なしの形状変形方法と、姿勢復元のための合成解析フレームワークと、形状精緻化のためにモデル誘導型の(表面の)詳細復元手法との効果的組み合わせを利用して、空間的にコヒーレントな(一貫した)、俳優の形状、動き、テクスチャを高品質に受動的再構築する、ビデオベースのパフォーマンスキャプチャを含む。これに関し、本発明の態様を適用することにより、緩い衣類を着た人及び高速で複雑な動きをする人を記録し、コンピュータモデル化することを支援する、沢山のアプリケーションが恩恵を受けることが可能となる。即ち、普段着を着た人々の形状、動き、及びテクスチャを、同時にキャプチャすることが可能である。
【0030】
更なる特定の例示的な実施形態において、本発明は、合成解析トラッキングフレームワークの利用、立体的変形技術、及びその後の小寸法の動的表面詳細の復元を対象とする。合成解析トラッキングフレームワークは、従来のフローベース、又はフロー及び特徴ベースの方法では復元することが不可能なレベルの複雑さとスピードを持つ動きのキャプチャを可能とする。立体的変形技術は姿勢復元のロバストネスを大幅に向上させ、例えば、モデル誘導型多視点ステレオ又は3D光学フローを適用することによって変形モデルを展開した後に、小寸法の動的表面詳細が復元される。
【0031】
更に別の特定の例示的実施形態において、本発明の態様は、マーカなしの高密度パフォーマンスキャプチャ技術を利用して実装される。本技術は、ゆったりした、又はひらひらした普通の衣服を着た演技者を、少数(例えば3〜8程度)の多視点ビデオで記録したものを利用して、演技者の動きと空間的にコヒーレントな、時間変化するジオメトリ(即ち一定の接続性を持ったジオメトリ)を、適切な詳細さで再構築し、微妙な変形の細部までもキャプチャする。実装の詳細のオプションの1つとして、光学マークを全く使用しないことにより、形状とテクスチャとを同時取得することも又簡単になる。
【0032】
別の特定の例示的実施形態は、パフォーマンスキャプチャを変形キャプチャとすることで、従来の骨格形状や動きのパラメータ化を必要とせずに高度の柔軟性と汎用性とを達成することができる。シーンの表現に関しては、実施形態のあるものは、例えば、記録対象の被写体の詳細な固定レーザスキャン又は3D光学フローを使用する。パフォーマンスは多分解能方式でキャプチャされる。これは、例えば、最初のモデルの全体姿勢は粗モデル(後で説明)を利用して推定され、その後、小寸法形状と動きの詳細が高品質モデル(後で説明)に基づいて推定される。全体姿勢のキャプチャは、入力映像から一セットの位置制約を確実に抽出する、合成解析手順を使用する。これらは、スキャン映像が実世界の等価物の動きをそっくりまねられるように、物理的に妥当な高効率形状変形手法(後で説明)へ供給される。各フレームで全体姿勢が復元された後、モデル誘導型多視点ステレオと等高線アライメント法が、各時間ステップにおけるより微細な表面の詳細を再構築する。この手法はスピードと変動(ダイナミクス)を伴う非常に複雑な動きを確実に再構築することが可能であり、従来の骨格ベースの光学キャプチャ手法の限界にさえ挑戦するものである(後で説明)。
【0033】
本発明の一実施形態によると、被写体の入力データが、人のパフォーマンスをビデオ記録する前に取られる。これは例えば、Vitus Smart(登録商標)レーザスキャナにより、衣服を着たままの被写体を全身レーザスキャンすることにより達成される。スキャンした後、被写体は直ちに隣接する多視点記録領域へ移動する。以降で述べる多視点キャプチャの実験設備は、異なるK個(ここではK=8)の、同期され、ジオメトリと光度測定で較正されたビデオカメラを特徴とし、このカメラは24fpsで動作し、フレーム解像度が1004x1004である。カメラは、シーンの中心の周りにほぼ円形に配置される。キャプチャされる演技者のシルエット画像を得るために、前処理の一部として、ビデオの全長に対してカラーベースの背景除去が適用される。
【0034】
全てのデータがキャプチャされると、自動的なパフォーマンス再構築パイプラインが開始される。驚くべきことに、この再構築パイプラインは、前処理中のマニュアル操作が殆ど又は全くなしで実行することができる。形状と動きの計算モデルを取得するために、生のスキャン映像は、ns個の頂点Vtri={v1...vns}と、ms個の三角形Ttri={t1...tms}とを有する高品質表面メッシュTtri=(Vtri,Ttri)に変換される(図2a参照)。このような方法の更なる詳細に関しては、引用により全文が本明細書に援用される、KAZHDAN,M.、BOLITHO,M.及びHOPPE,H.による「ポアソン表面の再構築(Poisson surface reconstruction)」、(Proc.SGP,61−70,2006)を参照されたい。更に、表面スキャンの粗四面体版Ttet=(Vtet,Ttet)(nt個の頂点Vtetと、mt個の四面体Ttetから成る)が、二次曲面誤差デシメーション(quadric error decimation)とその後に制約付きドロネー四面体分割(constrained Delaunay tetrahedralization)を適用することにより生成される(図2b参照)。一般的に、Ttriは30000〜40000の三角形を含み、対応する四面体版は、5000〜6000の四面体を含む。2つのモデルは、ICP(iterative closest points)法に基づいた手順により、入力画像中の俳優の第1の姿勢に自動的に合せ込まれる。姿勢の初期化は、立体スキャンの時に保持した姿勢と同じ姿勢をビデオの最初のフレームで俳優に取らせることにより、単純化することができる。これにより、最初のビデオ画像とスキャン画像との間の差分を減少でき、両者間の相関を単純化できる。
【0035】
本発明の実施形態は、シーンの表現に変形可能モデルを利用する。本発明の態様は、骨格運動パラメータ化は全く利用せず、シーン表現としては変型可能モデルに頼る。これにより、トラッキングが困難になる問題はあるが、非剛性の変形する面(幅の広い衣服や、束ねてない髪のような)を剛性変形するモデルと同じようにトラッキングすることが可能であり、素材の分布やモデルの分割を事前に仮定することを必要としないという、興味ある利点が得られる。例えば、人がまとっているゆったりした、又は幅の広い衣服は、人の骨格の動きではトラッキングできないような動きをすることがある。非剛性の変形部分が、人の剛性変形部分とは実質的に独立して動きうるような場合においても、本発明の態様は、人の非剛性変形部分をトラッキングすることが可能となる。このように、人物の非剛性変形部分は、その下にあるその人物の剛性変形部分とは逆方向に移動したり、大きく圧縮又は伸長したり、及び/又は、人物の剛性変形部分が動きを止めた後も動いたりすることが可能となる。
【0036】
特定の実装においては、メッシュ基準パフォーマンスキャプチャのアルゴリズムの一要素は、いくつかの点ハンドルによってモデル全体の変形を表現する、高速かつ高信頼度の形状変形フレームワークである。一例として、人物/俳優のパフォーマンス/動きは、信頼度を上げるために、多分解能方式でキャプチャされる。先ず、画像とシルエットとに基づく、合成解析法で、低詳細度四面体入力モデルに基づいて、各フレームでの俳優の全体姿勢を推測する。処理ステップのシーケンスは、最適化ベースのメッシュ変形が高度にマルチモーダル(多形態)な解空間であるにもかかわらず、妥当な姿勢への信頼性ある収束を可能とするように設計されている。全体姿勢が見つけられれば、パフォーマンスの高周波態様がキャプチャされる。例えば、スカートの襞の動きはこのステップで復元される。この目的のために、全体姿勢は高詳細度表面スキャンへ変換され、等高線アライメントとモデル誘導型ステレオとを実行することにより、表面形状が微調整される。
【0037】
本方法の出力は、空間と時間の両方における、パフォーマンスの高密度の表現である。出力は、元入力の生き生きとした様子と動きと形状の詳細とを精密にキャプチャした、正確に変形された空間的にコヒーレントなジオメトリを含む。
【0038】
上記の実施形態に関連して、パフォーマンスキャプチャ技術は、ラプラス形状編集の2つの変形を利用する。例えば、低周波トラッキングは、反復立体ラプラス変形アルゴリズムを利用して実装される。この変形アルゴリズムは四面体メッシュTtetに基づいており、位置制約から回転を推測し、また局所的断面積等の保存されるべき形状特性に関する予備知識を暗黙のうちに織り込むことを支援する。高周波表面の詳細を復元するために、キャプチャされた姿勢のTtetは、高分解能表面スキャンに変換することができる。既に大雑把には正しい姿勢にあるので、表面ベースのラプラス変形の単純な非反復変形を利用して、シルエットとステレオ制約から形状の詳細を推測することができる。
【0039】
ある実装において、四面体メッシュTtetは、線形ラプラス変形のステップの繰り返しと、それに続く、線形変形に本質的に含まれる(主として回転の)誤差を補償するための更新ステップとによって、一セットの位置制約
の影響下で変形される。この手順は、各四面体が受ける非剛性変形の量を低減し、従って弾性変形の性質を表すのに効果的である。三角形メッシュ構築アルゴリズムの更なる背景となる詳細については、引用により全文が本明細書に援用される、SORKINE,O.とALEXA,M.による「可及的に剛直な面モデリング(As−rigid−as−possible surface modeling)」(Proc.SGP,109−116,(2007))を参照されたい。しかし、四面体構築の利用は(即ち、三角形メッシュの構築ではなくて)、断面積のような特定の形状特性が変形後に暗黙的に保存されることを可能とする。後者は、それらしくないモデル姿勢(例えば局所的な平板化による)の出現が大幅に減少するため、トラッキングのロバストネスを向上させるのに特に有効であり得る。
【0040】
ある実施形態に関連し、また本発明の特定の態様によれば、変形技術は、
L=GTDG, (1)
であり、
δ=GTDg (2)
である、四面体ラプラス系Lv=δを解くことに基づいている。ここで、Gはメッシュに対する離散的勾配演算子行列であり、Dは四面体の体積を含む4mtx4mtの対角行列であり、gはそれぞれがgj=GjPjとして計算される、四面体勾配の集合である。変形技術の背景の詳細に関しては、引用により全文が本明細書に援用される、BOTSCH,M.、とSORKINE,O.による「線形変分表面変形法について(On linear variational surface deformation methods)」(IEEE TVCG 14,1,213−230,(2008))を参照されたい。ここで、pjは四面体tjの頂点座標を含む行列である。制約qjは、行列の対応する行と列を消去し、右辺のδにその値を代入することにより、行列Lに因数分解することができる。
【0041】
次に、以下のステップが繰り返される。
【0042】
線形ラプラス変形:上記の系を解くことにより、頂点の新しい位置V’tet={v’i...v’nt}が得られる。線形公式により、この変形されたモデルは、単純なラプラス技術に一般的なアーチファクト(結果)を示す。即ち、局所的な要素が制約により回転せず、むしろ、所望の姿勢に合わせるために単に拡大縮小及びせん断される。
【0043】
回転抽出:次に、変換行列Tiが各四面体に対して抽出され、tiを構成t’iに変換する。これらの変換行例は更に、極分解することにより、剛性部分Riと非剛性部分Siとに分離できる。回転成分のみを保持することにより、局所成分から線形変形ステップの非剛性部分の影響が取り除かれる。
【0044】
微分更新:次に、式(2)を用いて四面体の勾配に回転Riを掛けることにより、右辺のδが更新される。
【0045】
この手順を繰り返すことにより、各四面体に残っている、非剛性変形Siの量が最小化される。以後、この変形エネルギをEDと呼ぶ。これに続くトラッキングステップは、各種の物理的に妥当な変形又はシミュレーション方法や技法で実装することができるが、本発明の態様は、極めて高速で、実装が非常に容易であり、かつ仮に材料の特性が未知であったとしても妥当な結果がもたらされることにより、再構築に特に有用である。このような物理的に妥当な変形又はシミュレーション方法の背景的情報としては、引用により全文が本明細書に援用される、BICKEL,B.、BOTSCH,M.、ANGST,R.、MATUSIK,W.、OTADUY,M.、PFISTER,H.及びGROSS,M.による「顔ジオメトリと動きのマルチスケールキャプチャ(Multi−scale capture of facial geometry and motion)」(Proc. of SIGGRAPH,33,(2007))、及びMULLER,M.、DORSEY,J.、MCMILLAN,L.、JAGNOW,R.及びCUTLER,B.による「安定したリアルタイム変形(Stable real−time deformations)」(Proc. of SCA,ACM,49−54,(2002))を参照されたい。
【0046】
姿勢をTtetからTtriへ変換するために、Ttri中の各頂点viは、Ttet中の頂点の線形結合として表される。これらの係数cjが残りの姿勢に対して計算され、後で、三角形メッシュの姿勢更新に利用される。
線形係数ciは、Ttetの中から、半径r(すべての場合、rはメッシュを囲む四角の対角線の5%とした)のローカル球の中に存在し、viと同じような面法線を有する境界面を含む、全ての四面体の部分集合Tr(vj)を見つけることにより生成される。その後、頂点の重心座標係数ci(j)(必ずしも正ではない)が、全ての
に関して計算され、それを次のように、1つの大きな係数ベクトルciに結合する。
【0047】
【数1】
【0048】
j(vi,tj)は、四面体tjの重心までの距離viに関する、コンパクトにサポートされた半径ベースの関数である。この重み付き平均化は、各点を数個の四面体で表現し、従って、四面体メッシュから三角形メッシュへのスムーズな変形変換が可能となる。全てのTtriの頂点に対する係数は行列Bにまとめられる。一義的項のスムーズな分割とパラメータ化のローカルサポートとにより、現在の四面体メッシュVtetの頂点の現在位置にBを掛けることにより、変換された姿勢V’triにおけるメッシュが迅速に計算できる。
【0049】
面ベースの変形を実行するために、最小二乗ラプラス系が実行される。最小二乗ラプラス系の背景情報に関しては、引用により全文が本明細書に援用される、BOTSCH,M.及びSORKINE,O.による「線形変分面変形法(On linear variational surface deformation methods)」(IEEE TVCG 14,1,213−230,(2008))を参照されたい。三角形メッシュTtriが与えられたとして、離散的最小二乗ラプラシアンが、位置制約の集合
の影響下での面変形に余接荷重を用いて適用される。これは、エネルギを最小化することで達成される。
【0050】
【数2】
【0051】
ここで、Lは余接ラプラス行列、δは微分座標、Cは対角行列であって、制約された頂点vjに対してのみ、ゼロでない項Cj,j=wjを持つ(ここでwjは追加項の重み付けである)。この定式は、ラプラシアンを制約により規定される変形の正則化項として使用する。
【0052】
本明細書に開示のある実施形態に関しては、第1のステップは、ビデオの各時間ステップに対して、実際の俳優の姿勢に一致する、四面体入力モデルの全体姿勢を復元することを目指す。簡単に言えば、この全体姿勢抽出方法は、時刻tとt+1とにおける、連続する多視点入力ビデオフレームの各ペアから変形制約を計算することを含むと言える。次に立体形状変形手順を適用して、時刻tにおける(以前に見出された)姿勢を、その姿勢が時刻t+1における入力データに整合するまで変形する。この高度に多様な適合度基準の下で妥当な姿勢に収束させるためには、適正なシーケンスで、適正なタイプの特徴を画像から抽出し、結果として得られる変形制約を正しい順序で適用することが重要である。
【0053】
この目的のために、姿勢復元プロセスは、シーンの動きが早い場合でも、モデルを最終姿勢に近づける、信頼性の高い画像特徴から3D頂点変位を抽出することから開始される。モデル表面上にある3D特徴の分布は、例えばテクスチャ等のシーン構造に依存し、一般には、不均一又はまばらである。従って、結果として得られる姿勢は完全には正しくない可能性がある。更に、対応関係における潜在的な孤立値があり、追加的な姿勢更新ステップを必須となる。従って、全体姿勢を完全に復元するためにシルエットデータを活用する、2つの追加的なステップが実行される。第1のステップは、モデルの外形輪郭の形状を、多視点入力シルエット境界に一致するまで、改良する。第2のステップは、キー頂点ハンドルの3D移動を最適化して、多視点シルエットの最適オーバラップが得られるようにする。多視点シルエットオーバラップは、GPU上でのXOR演算として、簡単に計算することができる。
【0054】
更に、トラッキングのロバストさは、前処理の間に、立体モデルの表面を、同様の寸法の、約100〜200の領域の集合Rに再分割することにより得られる。前処理における立体モデルの再分割に関する背景的情報は、引用により全文が本明細書に援用される、YAMAUCHI,H.、GUMHOLD,S.、ZAYER,R.及びSEIDEL,H.−P.による「ガウス曲率によるメッシュ分割(Mesh segmentation driven by gaussian curvature)」(Visual Computer 21,8−10,649−658,(2005))を参照されたい。前記したように、各頂点の変位を推測するというより、各領域の代表的な変位を判定することができる。
【0055】
本発明の態様は、画像特徴からの姿勢初期化に関する。連続する時間ステップから、2つの多視点ビデオフレームの集合I1(t),...,Ik(t)とI1(t+1),...,Ik(t+1)とが与えられると、第1の処理ステップは、各フレームから、スケール不変特徴変換(SIFT)特徴量を抽出する(図3参照)。SIFT特徴量抽出に関する背景的情報については、引用により全文が本明細書に援用される、LOWE,D.G.による「局所的スケール不変特徴量からの物体認識(Object recognition from local scale−invariant features)」(Proc. ICCV,Vol.2,1150ff,(1999))を参照されたい。
【0056】
【0057】
【0058】
【0059】
実際には、この初期の割り当ては、外れ値を含む可能性があり、従って、時間的対応関係の最終的なセットは、ロバストなスペクトルマッチによって計算されてもよい。スペクトルマッチングの背景的情報に関しては、引用により全文が本明細書に援用される、LEORDEANU,M及びHEBERT,M.による「ペア制約を利用した対応問題のスペクトル技術(A spectral technique for correspondence problems using pairwise constraints)」(Proc.ICCV,(2005))を参照されたい。このような方法は、グラフ隣接行列上のスペクトル解析問題として閉形式で定式化することによって、対応関係の問題の複雑さを効率的に回避する。時間を越えて特徴記述子の値が一貫し、かつペアとしての特徴距離が時間を越えて一定であるような割り当てを求めることにより、不正確な組み合わせが除外される。
【0060】
【0061】
本技術は、全てのシーケンスにわたって特徴をトラッキングする必要はなく、このことが、本方法の信頼性に大きく寄与する。このステップの出力は、特徴ベースの姿勢推定
【0062】
【数3】
である。
【0063】
【0064】
それぞれの要素
に対して、元々リムを画定していた頂点のカメラkへの投影位置uk,t+iを解析して、3D変位が計算される。投影位置における輪郭からの距離場の値が、頂点の法線方向への全変位長を定義する(図4a)。このようにして、リム頂点に対して変形制約が得られ、それが以下で検討する、同様のステップでの変形手順に適用される。この結果は新しいモデル構成
【0065】
【数4】
となり、ここでは、モデルの外側輪郭の投影は、入力されたシルエット境界によりよく一致する。
【0066】
【0067】
しかし、シーンの動きが早いか、SIFTからの初期姿勢の推測が必ずしも正しくない場合に、姿勢誤差がそのまま残る。これに対応するために、追加の最適化ステップが実行されて、変形ハンドルの部分集合の位置を、シルエットのオーバラップがよくなるまで全体的に最適化することにより、そのような残存誤差を補正する。
【0068】
立体モデルの1000〜2000の頂点全部の位置を最適化する代わりに、典型的な15〜25のキー頂点
に対して、四面体変形が最適なシルエットのオーバラップを形成するまで、最適化をすることができる。キーハンドル間の表面距離が保持され、歪エネルギEDの小さい姿勢構成を選択するように、エネルギ関数を設計することにより、トラッキングのロバストネスが向上する。ユーザはキー頂点を手動で特定するように指示されてもよく、これは全てのモデルに対して1回だけ行えばよい手順である。一般的にキー頂点は解剖学的な関節の近くにマークされ、ゆったりした衣服を示すモデル部分の場合には、単純な一様なハンドル分布がよい結果をもたらす。
【0069】
【0070】
【数5】
【0071】
ここで、SIL(Ttet(Vk),t+1)は、現在の変形された姿勢Ttet(Vk)での四面体メッシュの多視点シルエットオーバラップ誤差を表し、それはVkの新しい位置によって定義される。EDは変形エネルギである。当然の結果として、低エネルギ構成がより妥当であることになる。ECは、隣接するキー頂点間の距離の変更に不利となる。3つの項はすべて規格化され、重みwS、wD、wCは、SIL(Ttet(Vk),t+1)が主要な項となるように選択される。大規模境界制約又は非制約準ニュートン最適化法(LBFGS−B)が、式(4)の最小化に利用できる。このようなLBFGS−B方法論の背景については、引用により全文が本明細書に援用される、BYRD, R.、LU, P.、NOCEDAL, J.及びZHU, C.による「境界制約最適化のための限定メモリアルゴリズム(A limited memory algorithm for bound constrained optimization)」(SIAM J.Sci.omp.16,5,1190−1208,(1995))を参照されたい。しかし、本発明の実施形態では、勾配降下法や確率的抽出法などの他の形式の最適化手段を利用することもできる。
【0072】
図5は、キーハンドル最適化により達成された、新しい出力姿勢
【0073】
【数6】
【0074】
における改善結果を示す。
【0075】
上記ステップのシーケンスは、連続する時点の各ペアに対して実行される。表面詳細のキャプチャは、全てのフレームに対して全体姿勢が求められた後で開始される。典型的には、以下に述べるリム処理(ステップ)が、最後のシルエット最適化ステップの後に少なくとももう一度実行される。これは、場合に依っては、モデルのより良い一致を導く。潜在的な自分自身との交差を修正するために、低周波の姿勢キャプチャの出力上での一貫性チェックも実行される。この目的のために、他の四面体内部にある全ての頂点に対して立体変形法を用いて、交差がなくなるまでこの頂点を法線方向外側に向けて変位させる。
【0076】
各フレームに対して全体姿勢が復元されると、Ttetの姿勢のシーケンスがTtriにマッピングされる。以下においては、1つの時間ステップにおける形状詳細キャプチャのプロセス例を説明する。
【0077】
本発明の態様は、シルエット輪郭に沿って適合させることに関する。最初のステップにおいて、微細メッシュのシルエットリムが、入力シルエット輪郭により良く一致するように適合される。表面メッシュは既に正しい構成に非常に近くなっているので、(立体の場合に比べて相対的に)より広範で、より粗い領域での変形が許される。これによりモデルが、入力データとより良く一致する。それと同時に、この場合にはデータ中のノイズが劣化により大きな影響を有するので、制約が注意深く選択される。
【0078】
上で述べたように、リム頂点を計算することが可能だが、それは高解像度表面メッシュ上で計算される(図6a参照)。各リム頂点に対して、リム状態を規定する、シルエット境界上の最近接二次元(2D)点をカメラ視野内で探す。次に、入力シルエット点での画像勾配について、再投影されたモデルの輪郭画像中の画像勾配と類似の方向がないかどうかがチェックされる。もしある場合には、逆投影された入力輪郭点は、リム頂点に対するターゲット位置を規定する。逆投影された位置と元の位置との間の距離が閾値ERIMよりも小さい場合、制約として式(3)に追加される。ここでは、小さな重み(セグメント化の品質に依存して、0.25〜0.5の間)がリム制約ポイントに対して使われる。これは、変形に対する正規化及び減衰効果を与え、ノイズが存在する状態において、妥当でない形状に適合されることを最小化する。全ての頂点を処理した後、新しい表面が求められる。このリムの投影と変形のステップは、最大20回、又はシルエットオーバラップがそれ以上改善されなくなるまで、反復される。
【0079】
本発明の態様は、モデル誘導型多視点ステレオを含む。シルエットのリムは外部境界上に信頼性のある制約を与えるだけであるが、通常それらは表面に均一に分布している。従って、一般的な変形方法は、画像輪郭上に投影のない領域の全体モデルの形状をうまく適合させる。俳優の表面が、沢山の凹面を持った複雑な形状でない限り、リム適合の結果は既に、現実に即した正しい形状の表現となっている。
【0080】
スカートの襞や凹面等のような、シルエット境界に投影されないモデル領域の詳細形状を復元するために、写実的に一貫した(photo-consistency)情報が利用される。この目的のために、多視点ステレオを適用することにより、追加的な変形制約が導出される。多視点ステレオの適用方法に関する背景的情報は、引用により全文が本明細書に援用される、GOESELE,M.、CURLESS,B.及びSEITZ,S.M.による「多視点ステレオ再考(Multiview stereo revisited)」(Proc. CVPR,2402−2409,(2006))を参照されたい。モデルは既に正しい表面に近いので、ステレオ最適化は現行の表面推測から始めて、Ttriからせいぜい±2cm離れた3D点の相関検索に限定される。
【0081】
原則として、任意の数の異なる多視点ステレオ法、又は形状復元法(shape−from−X)法を、最終表面上の時間変化する精細な詳細を復元するために利用することが可能である。従って本発明は、Goeseleにより教示された多視点法に限定されない。実際、多くのその他の多視点ステレオ手法、或いは陰影からの形状の復元法(shape−from−shading)やテクスチャからの形状の復元法(shape−from−texture)等のようなその他のshape−from−X手法を、潜在的に計算コストが高くなるが、利用することも可能である。また、精緻化の段階において、異なる技術の組合せを利用することもまた可能である。
【0082】
様々な他の方法で教示されるものより被写体の視点がはるかに少なく、また俳優はテクスチャの少ない衣服を着ることができるので、結果として得られる深度マップ(各入力視点に対し1つの)は、まばらでノイズが多いことがしばしばである。しかしながら、これはオブジェクト形状に関して重要な追加的な手がかりを与える。深度マップはマージされ、ステレオによって単一の点クラウドPに生成され(図6b)、その後、点をVtriからP上へ投影する。そのようなマージ方法については、引用により全文が本明細書に援用される、STOLL,C.、KARNI,Z.、ROSSL,C.、YAMAUCHI,H.及びSEIDEL,H.−P.による「ポイントクラウドフィッティングのためのテンプレート変形(Template deformation for point cloud fitting)」(Proc. SGP,27−35,(2006))を参照されたい。
これらの投影点は、表面ベースの変形フレームワーク(式(3))でのリム頂点と共に利用することができる、追加的な位置制約を提供する。データの不確かさがあるものとして、ラプラス系はステレオ制約よりも小さな重み付けで解かれる。
【0083】
本明細書で開示するさまざまな実施形態を理解するのに必須ではないが、以下の議論は、本発明の一実施形態の特定の実装から得られた実験結果を含んでいる。
【0084】
テストデータは前述した取得設定で記録され、4人の異なる俳優を写した12シーケンスから成り、それぞれが200〜600フレームのものである。アルゴリズムの適用範囲が広いことを示すために、キャプチャされた演技者は、ぴったりしたものからゆったりしたもの、及び目につきやすいテクスチャの生地でできたものから地味な色だけのもの、等にわたる、広範な異なる衣服を着た。また、復元される一連の動きは、単純な歩行から、異なるダンススタイル、動きの速いカポエイラのシーケンスにまで及んだ。図1、7、8の画像に示すように、本アルゴリズムはこの広範囲のシーンを忠実に再構築する。人間の演技者に注目したが、このアルゴリズムは、レーザスキャンをすることができる動物やその他のオブジェクトに同様に使うことができる。
【0085】
図1は、俳優が一連の回し蹴りを行っている、非常に高速のカポエイラのシーケンスをキャプチャした幾つかの姿勢を示している。24fpsの記録では、連続するフレーム間で俳優は25度を超える角度の回転をするという事実にも拘わらず、形状と動きの両方が非常に忠実に再構築されている。結果として得られるアニメーションでは、ズボンの脚が波打っているような変形の詳細まで示している。更には、入力では俳優は地味な白い衣類を着ており、これは数少ないトレース可能なSIFT特徴点しか示さないが、本方法ではリム及びシルエットを追加の情報源として利用することができるので、信頼度の高い性能を示す。蹴りの1つの瞬間を入力フレームと比較すると、図7bに示されているように、高品質の再構築がされていることが確認できる(入力視点と仮想カメラ視点では僅かに違いがあることに留意されたい)。
【0086】
生成されたビデオはさらに、キャプチャされたカポエイラのシーケンスに静止した格子縞のテクスチャがあることを示している。この結果は、頂点位置の接線面ドリフト等の、時間的エイリアシングが殆どわからないほどで、全体としてのメッシュの品質が非常に安定していることを示している。
【0087】
図7aには、キャプチャされたジャズダンスのパフォーマンスからの1つの姿勢が示されている。入力画像とビデオとの比較は、この高速で流れるような動きをキャプチャできることを示している。更に、図7aに見られるような、胴体の前で相互にねじれた腕の動きなどの複雑な自己遮蔽(self-occlusion)を持つ多くの姿勢もまた再構築することができる。
【0088】
図8は、スカートを着た踊り子の時間変化する形状全体をキャプチャできることを示している。スカートはほぼ一様な色であるが、結果は、布地の自然なうねりと本物のような躍動感とをキャプチャしている。全てのフレームにおいて、ユーザが事前にモデルの分割を指定することなしに、全身の体勢とスカートの襞がうまく再現されている。これらのスカートのシーケンスにおいて、凹面の復元についてのステレオ処理の有用さが最も明確に示されている。これ以外のテストシーンにおいては、ステレオ処理の効果はそれほど顕著ではなく、従って計算時間短縮のためにその機能を停止した。このスカートシーケンスの中には、手に僅かなジッタが見られるが、これは、この人物が手を広げて動いているのに、スキャンは手を握って撮られているという事実によるものと思われる。全般的に、頂点位置の最終シーケンスには円滑化処理を施して、残存する時間ノイズを除去した。
【0089】
表1(下)は、実験アルゴリズムにおける、各個別ステップに対する平均時間の詳細を示す。これらの時間は、2.0GHzのIntel Core Duo T2500ラップトップ上での高度に最適化されていない単一スレッドコードで取得されたものである。更に最適化を行えば大きな改善が得られると思われ、並列処理化すれば、実行時間の顕著な削減をもたらすものと予想できる。この特定の実装には、汎用プロセッサを用いた。このプロセッサには記憶媒体が含まれ、プロセッサがアクセスすると本明細書で述べた種々の工程(ステップ)が実行されるように構成されている。勿論、本明細書で述べた種々の機能を実装するために、さまざまな処理回路を用い得ることは当然である。さまざまな処理回路としては、特製ロジック回路、プログラマブルロジックアレイ、マルチプロセッサ、及びそれらの組み合わせもまた含むことができるが、これらに限定されるものではない。
【0090】
【表1】
【0091】
本発明の高いキャプチャ品質と、広い適用範囲及び実装の汎用性とが示された。精度を公式に立証するために、トラッキングされた出力モデルに対するシルエットのオーバラップを、セグメント化された入力フレームと比較した。正確な時間変化3Dデータを提供する、絶対標準的な代替キャプチャ手法がないので、この判断基準が選択された。最終的な結果としての再投影(画像)は、標準的には、全体姿勢のキャプチャのみの後で既に、入力シルエットピクセルの85%超のオーバラップとなっている(図6dの下側の曲線)。表面の詳細キャプチャでこのオーバラップは、上側の曲線で示されるように90%を超えるオーバラップに改善される。この測定は、いくつかのフレームの前景のセグメント化における、誤ったシルエットピクセルとして見える誤差により、若干負方向に偏っている。従って、シルエットオーバラップの目視検査では、モデルと実際の人のシルエットとはほぼ完全なアライメントとなっていることが確認される。図6eは、このことを示す、レンダリングされたモデルと入力フレームとの間の一体化オーバレイである。
【0092】
ある実施例によれば、本発明の実施形態は、例えばカラーベースのセグメント化で一般的に見られるセグメント化誤差によるノイズのある入力ですら、確実に処理する。最小限のユーザの手動入力の後に、12の入力シーケンス全部が完全に自動的に再構築された。処理の一部として、ユーザは各モデルの頭と足の領域をマークして、表面の詳細キャプチャから除外するようにさせた。そうしなければ、これらの領域においては非常に軽微なシルエット誤差でさえも(特に、床への影と黒い髪の色とにより)、不自然な変形を起こしてしまう。更に、各モデルに対して、キーハンドル最適化ステップに必要な最大25個の変形ハンドルを一度マークする。
【0093】
カポエイラの回し蹴りの3つのシーケンスの内の2つの個別フレーム(約1000フレーム中の11フレーム)、並びにスカートの各シーケンスの1つのフレーム(850フレーム中の2フレーム)において、全体姿勢復元の出力に、四肢の1つに軽微なアライメント不良が見られる。これらの個別の姿勢誤差にも拘らず、本方法は、ドリフトなしに全体シーケンスを直ちに復元し、トラッキングする。即ち、これらの実施形態は、監視なしで実行することが可能であり、後から結果をチェックすることができる。観察された姿勢のアライメント不良のすべては、動きのブレ又は床上の強い影に起因する、専らシルエット領域のサイズオーバーによるものである。これらは両方とも、照明とシャッタスピードの調節、及び更に進歩したセグメント化方式によって防止できたであろう。全体姿勢のアライメント不良のいずれの場合も、最大でも2つの変形ハンドル位置をユーザが少し調節すれば対応できたものである。処理された3500の入力フレームの内、表面の詳細キャプチャの出力を手動修正する必要があるものは1つもなかった。
【0094】
比較のために、文献からの2つの関連する手法を実行した。引用により全文が本明細書に援用される、DE AGUIAR,E.、THEOBALT,C,、STOLL,C,及びSEIDEL,H.−P.による「人の形状と動きのキャプチャ用マーカなし可変メッシュのトラッキング(Marker−less deformable mesh tracking for human shape and motion capture)」(Proc. VPR, IEEE,1−8,(2007))に記載の方法は、多視点ビデオから可変メッシュをトラッキングするための表面ベース変形及び光学フローを利用する。著者が指摘しているように、光学フローはカポエイラキックのような高速の動きでは失敗するため、この手法によるトラッキングは実行不可能になる。これに対し、本発明の立体変形フレームワークは、マルチキューの合成を通した解析手法との組合せで、このビデオを信頼性高くキャプチャする。引用により全文が本明細書に援用される、DE AGUIAR,E.、THEOBALT,C,、STOLL,C,及びSEIDEL,H.による「メッシュベースの人の動きをキャプチャするためのマーカなし3D特徴トラッキング(Marker−less 3d feature tracking for mesh−based human motion capture)」(ICCV HUMO07,1−15,(2007))で提案されている方法は、連続する3D特徴の軌跡を3Dシーンジオメトリのない多視点ビデオからキャプチャすると言う、少し異なる問題の解法を提案している。しかし、この論文に示されているように、表面スキャンを変形させてビデオの俳優のように動かすために軌跡を用いることができる。実験の結果、人が時に急に動いたり、大きく回転したり、自己交差する複雑な姿勢をとったりする場合には、この方法では途切れることなく軌跡を維持することは困難であることがわかった。本発明の実施形態は、このような状況に対しても、確実なハンドリングを可能とする。更には、最終結果の自然さに大きく寄与する、輪郭アライメントの改良と実時間変化する表面詳細や凹面の推定とに対して有効な、ステレオベースの精緻化ステップが実行される。
【0095】
本発明の実施形態の現行シルエットリムマッチングは、入力シルエットの位相構造が、再投影(再構成)されたモデルシルエットと余りに異なる場合には、間違った変形を作ることがある。しかし、テストシーンのいずれにおいてもこのことが問題になることはなかった。他の実施形態において、この問題を全体的に緩和するために、より巧妙な画像位置合わせ手法が用いられる。例えば、ある実装においては、良好なセグメント化をする際に、管理されたスタジオ環境で画像をキャプチャすることができる。そして別の(例えば、より進んだ背景セグメント化を有する)実装においては、戸外のシーンのハンドリングを可能とする。
【0096】
更に、上記の変形キャプチャ技術の実施形態のあるものには、分解能の限界がある。衣類の細かいしわや顔の詳細などのような、最終結果における高周波の詳細のあるものは、もともとレーザスキャンの役割とする部分であった。このレベルの詳細さの変形は、実際にはキャプチャされるのではなく、微細な詳細が変形される表面に“焼き付けられる”のである。再構築される詳細さのレベルを示すために、微細な表面詳細度のない、粗スキャンで結果を生成した。図9aは入力フレームを示す。図9bは、詳細スキャンを用いた再構築を示す。図9cは、粗スキャンを用いた再構築を示す。前述したように、図9cの最も精細な詳細は、高分解能のレーザスキャンによるものであり、粗スキャンであっても、本方法は、重要な実物の動きと全ての表面の変形を十分な詳細さを以ってキャプチャする。最終結果の品質に対する、詳細キャプチャステップの重要度は、全体姿勢の復元のみと、粗いテンプレートの最終結果と、元の詳細スキャンによる最終結果と、をビデオベースで横並びに比較することによって、確認された。
【0097】
又、本システムにおいては、入力されたスキャンモデルの形態は、全シーケンスにわたって保存される。このために、時間と共に任意に変化する見掛け上の形態を有する表面(例えば、髪の毛の動きや自己衝突による深い襞など)は、トラッキングしなかった。更には、全体姿勢のキャプチャ時に自己遮蔽は防止されるが、現在の処、表面詳細キャプチャの出力での修正は行わなかった。しかし、それが起きることはむしろ稀である。衝突検出による手動又は自動の修正を行うことも実行可能であろう。
【0098】
体積ベースの変形技術は、基本的には弾性変形を模倣したものであり、低周波のトラッキングで生成されたジオメトリは、場合によっては、ゴムのような見え方をすることがある。例えば、腕は肘の所で曲がるだけではなく、全長にわたって曲がるような場合もある。表面の詳細キャプチャが、一般にはそのようなアーチファクトを排除する。そして、演算は遅いがより精巧である有限要素変形を使えば、全体姿勢のキャプチャ段階で既にこの問題をなくすことができる。
【0099】
本実験は、ビデオからの時空的に密なパフォーマンスをキャプチャするための、新規の、煩雑でない手法を呈示した。広範囲の実世界のシーンを時空的にコヒーレントに(一貫させて)、かつ高度な詳細さで再構築するために、従来の運動骨格法は意図的に放棄した。
【0100】
以下の議論において、メディア制作において重要な2つの実践的なアプリケーション(適用例)における本アルゴリズムの強みと有用性とを例示する。
【0101】
実践的なアプリケーションの1つは、3Dビデオである。この手法は光学マークなしで使えるので、例えば一体化(混合)方式の利用によって、入力カメラ視野からのキャプチャされたビデオ映像と動いている幾何学配置のテクスチャとを使用することが可能である。そのような混合方式の背景に関しては、引用により全文が本明細書に援用される、CARRANZA,J.、THEOBALT,C,、MAGNOR,M.及びSEIDEL,H.−P.による「俳優に対する自由視点ビデオ(Free−viewpoint video of human actors)」(Proc. SIGGRAPH,569−577,(2003))を参照されたい。この結果は、任意の合成視野からレンダリングすることができる、3Dビデオ表現である(図10a、10b参照)。非常に詳細な、背景シーンのジオメトリのお蔭で、以前のモデルベース、あるいは、シェイプフロムシルエット法ベースの3Dビデオ法を用いた場合に比べて、はるかに良い視覚結果となる。
【0102】
もう1つの実践的なアプリケーションは、完全装備の(fully-rigged)キャラクタの再構築である。この方法は、実質的に経時的接線歪のない、時空的にコヒーレントなシーンのジオメトリを制作するので、そのシーンに対して好適なパラメータ化となる場合には、図10cに示すように完全装備のキャラクタ、即ちアニメーション骨格、表面メッシュ、及び関連するスキニングウェイトとを特徴とするキャラクタの再構築が可能である。この目的のために、結果のシーケンスは自動リギング法に供給され、そこで、骨格とブレンディングウェイトとがメッシュシーケンスから全自動で学習される。そのような自動リギング法の背景的情報に関しては、引用により全文が本明細書に援用される、DE AGUIAR,E.、THEOBALT,C.、THRUN,S.及びSEIDEL,H.−P.による「メッシュアニメーションから骨格ベースアニメーションへの自動変換(Automatic conversion of mesh animations into skeleton based animations)」(Computer Graphics Forum(Proc. EurographicsEG’08)27,2(4),389−397,(2008))を参照されたい。この文献の実験は、システムでキャプチャされたデータを、従来のアニメーションツールでの変更にそのまま適するフォーマットへ任意選択的に変換することが可能であることを示している。
【0103】
本発明の実装により、(変更されていない)ビデオストリームから、任意の、しかも幅広でもよい、普段着を着た人物のコヒーレントな動的ジオメトリをキャプチャできる。この手法はロバストでもあり、最低限の手動作業と後処理しか必要ではない。従って製作費がはるかに少なくて済む。
【0104】
様々な方法の基本バージョンは、映画やゲーム制作に幅広く利用されている現在の技術を置き替えることが可能であり、更なる精緻化も実装可能である。本発明の実施形態により設計されたソフトウェアは、多くの制作会社が既に利用している既存設備(レーザスキャナ、カメラ、記録用ハードウェア、及びその他のデータ処理ツール)とシームレスに結びつく。かかる状況において、本発明の態様は、方法、装置、システム、アセンブリ、そのような技術を実装したコンピュータにより実行される格納されたソフトウェア命令、そのような技術のコンピュータ実装を支援するためのコンピュータアクセス用記憶データ、及び/又はソフトウェアベースのパッケージを格納したコンピュータ媒体、として実装することが可能である。当業者であれば、そのような実装手法は、引用により本明細書に援用された参考文献中に例示されていることがわかるであろう。
【0105】
特に明記されていない限り、本明細書の様々な実施形態に関して、ソフトウェアと言う用語は、処理回路(例えば、計算機処理ユニット“CPU”)を含むシステムの物理的状態への変更を表すために用いられる。従って、“ソフトウェア”と言う用語は、概念の理念や実体のないもののみを表すことには用いられない。その代わりにこの用語は、本明細書で使用されているように、特に実体のある回路構成に向けられている。そこでは回路が、ソフトウェアがなければ決して実行されることのない機能を与えるステップシーケンスを行う様に構成されている。従って本発明の複数の実施形態は、記載した機能を実行するためのハードウェア回路によって実装される。その構成は、回路部品の選択又は配置を含むことができ、或いは、実体的な記憶媒体を変換してプロセッサによる実行のための格納された命令を含むようにすることができる。
【0106】
従って、本発明に沿うように実装されたシステムと実施形態は、完全な形のアニメーション表現を提供することができる。結果として、キャプチャされたデータを用いた多くの新規な作業方法が実行可能となる。例えば、そのようなシステムや実施形態は、システムに別のコンポーネントを追加させて、キャプチャされたパフォーマンスを自動的にリギング(操作)したり、及び/又は、骨格をデータに自動的に合せ込んで、業界標準のアニメーションソフトウェアパッケージ(例えば、Autodesk 3D StudioやSoftimage)で変更できるようにしたりすることができる。他の変形についても以下で説明するが、これらに限定されない。
【0107】
変形例の1つでは、取得のために使用するカメラの数を、所与のアプリケーションに必要なものに変更する。本発明によれば、実験システムは取得のために8台のビデオカメラを使用する。しかしこれは、設計上の厳格な制約ではなく、システムとしては、カメラが1台しかない場合でも、又は8台より多い場合でも結果を得ることは可能である。例えば、ごく僅かの(又は、より少ない)視点しか使えない場合には、キャプチャできる動きの範囲内又は再構築の品質内に、一連の差分が低い再構築品質となって現れる。また、入力センサは、厳密には、光学カメラのみである必要はない。他の実施形態では、タイムオブフライトカメラ(S. Burak Gokturk Hakan Yalcin及びCyrus Bamjiによる「タイムオブフライト・デプスセンサ−システムとその課題及び解決策(A Time−Of−Flight Depth Sensor − System Description, Issues and Solutions)」(www.canesta.com),及び、Thierry Oggierらによる「SwissRanger SR3000と小型化3D−TOFカメラによる最初の経験(SwissRanger SR3000 and First Experiences based on Miniaturized 3D−TOF Cameras)」(http://www.mesa−imaging.ch/pdf/Application_SR3000_vl_l.pdf)を参照のこと。引用によりいずれの文献もその全文を本明細書に援用する。)、構造化光スキャン装置(例えば、レーザ三角測量スキャナ又は活性パターン投影を利用したシステム)、及び/又はステレオカメラ構成、等の深度センサを利用する。更に別の実施形態では、上記の深度センサとビデオカメラとの任意の組み合わせを利用する。
【0108】
上記の例示システムは、人間の演技者に関連して説明した。しかし、このシステムは、動物、又は機械装置のトラッキングにもまた好適である。
【0109】
上記の例示システムでは、実際の記録が開始される前に演技者の身体モデルを得るためにレーザスキャナを利用することを説明したが、それに替わる形式のスキャニング又は再構築技術を用いて、トラッキングする被写体の面表現、又は立体表現を得ることができる。一例として、演技者モデルを、例えば、シェイプフロムシルエット法、又はシェイプフロムシルエット法とステレオ法との組合せを用いて、ビデオから再構築することが可能である。
【0110】
上記の実験システムは、SIFT特徴抽出アルゴリズムを利用する。しかし、画像からであれ、3Dジオメトリからであれ、2つの隣接する時間ステップの間の対応関係を確立することができるそれ以外の任意のアルゴリズムも同様に有用かつ好適である。代替法の例としては、その他の任意の疎画像特徴点マッチング法(sparse image feature matching method)、任意の3D特徴点マッチング法、並びに2Dと3Dの両方の光学フロー手法、がある。
【0111】
また、同様の結果を達成できる、代替のメッシュ変形フレームワークがある。立体ラプラスフレームワークの代わりに、恐らく実行時間が長くなるという犠牲があるとしても、完全な物理ベース非線形変形手法、又は有限要素法の任意の変形が適用可能である。面全体の変形を少数の制約で記述できる、面変形フレームワークの任意の代替法は、面ラプラスアルゴリズムに対する適切な代用となるであろう。繰り返すが、実行時間の制約と変形品質に関する懸念とにより、そのような代用案は所与のアプリケーションへは適用禁止とされるかもしれない。
【0112】
本明細書で説明したステレオ制約を導入する特定の方法は、小スケールの時間変化形状の詳細を復元することのできる唯一のアルゴリズムではない。数多い多視点ステレオアルゴリズムの任意のものが、代用として利用可能である。但し、潜在的に再構築の品質が低い、もしくは長い計算時間という犠牲を伴う、という可能性がある。
【0113】
特定の実施形態において、低周波のトラッキングステップを高周波の面適応ステップに入念に結合することで、所与の入力ビデオから、俳優と衣類とを確実にトラッキングすることが可能である。低周波のトラッキングステップが最初に実装される。これは、画像−(SIFT特徴点)と、オブジェクトの弾性的挙動をシミュレートする立体変形法に結び付いたシルエットベースの(リムとオーバラップ最適化)手法との独特の組み合わせであり、姿勢推定のロバストな技術となる。結果として得られる姿勢は、アルゴリズムの面適応段階へ供給され、そこで、更なる画像(多視点ステレオ)とシルエット(リム最適化)特徴とがロバストなラプラス面変形法に融合されて、観察された俳優の姿勢と形状がうまく再構築される。
【0114】
図11は、本発明の一実施形態による、人物のデジタル表現を生成する方法を示す図である。ステップ1102で、人物の画像が、人物の立体表現に関連付けられる。本明細書で説明したように、これを実行する1つの技法として、人物をレーザスキャンして、その人物の3次元表現を得る方法がある。人物の1つまたは複数の空間的に全く異なる画像の集合もキャプチャされる。立体表現と画像との相関付けを支援するために、レーザスキャンと画像キャプチャの両方に対して、人物を同じような場所に配置することができる。これによって、両者間の差分が最小であることの確認を支援できる。
【0115】
ステップ1104において、時間的に異なる2つの画像に間の共通の基準点が識別される。例えば、動いている人物のビデオキャプチャは、画像キャプチャ装置/カメラのセットを利用して取得できる。ビデオキャプチャされた画像間での人物の動きは、共通基準点の位置の画像間での差分で表される。特定の実装によれば、基準点の部分集合は、一連の基準に合致しない基準点を除去することにより決定される。そのような基準の一例は、基準点の予想位置から大きく外れた基準点を除去することである。
【0116】
ステップ1106において、選択された基準点の集合を用いて、人物の粗/立体変形が行われる。これは、基準点の空間移動と人物の立体表現との関数として実行される。
【0117】
ステップ1108において、微細/面変形が実行される。この変形は、人物に対する粗/立体変形の適用、並びに処理に微細画像分解能を使用した結果を考慮に入れる。レーザスキャニングでキャプチャされた精緻な詳細は、行われた変形に従って変更されることが可能であり、人物の表現に付加される。
【0118】
ステップ1110において、人物のデジタル表現が、適用された変形結果から生成される。この表現は次に、人物の対応画像生成に利用される。
【0119】
本明細書で説明した実施形態の多くは、骨格やその他の剛体モデリングを用いることなしに、キャプチャされた画像から人物のデジタル版を信頼性よく再現することが可能である。しかし、これらの実施形態は、骨格と共に利用するために更に変更することが可能である。例えば、被写体のあるサブパーツのトラッキングは、骨格/剛体モデルの利用で支援され得る。骨格のような剛性変形することがわかっているパーツは、剛体モデルに従うことができ、その他のパーツはより自由に変形できるようにすることが可能である。本明細書で説明した変形フレームワークの態様の融通性は、変形モデルにそのような剛性セグメントの指定を許容し、実効的に骨格を利用するようなものとなる。このことは、トレースが困難な場合において、トラッキングのロバストさの向上支援に特に有効である。
【0120】
本発明の様々な例示的実施形態は、単一人物のトラッキングを対象としている。しかし、他の実施形態は、同一画像中の複数の人物をトラッキングすることが可能である。例えば、一群の人々をトラッキングすることが可能である。更に他の例示的実施形態では、単一人物の複数の部分をそれぞれ個別にトラッキングすることが可能である。このことは、帽子や手に持った物などのような、人物から分離可能な部分に対して特に有効である。
【0121】
本明細書で説明した様々な実施形態は、シーンを変更することなしに、即ち、表面ポイントの時間変化のトラッキングを容易にする一方で、自然の外観を損なってしまうあらゆる形態のマーカも配置することなしに、信頼性のよいトラッキング/キャプチャのデータ取得を可能とする。しかしそれにも拘らず、実施形態のあるものでは、そのような基準マークを利用することも可能である。基準マークのいくつかの例としては、これに限定されるものではないが、カメラに写る反射マーカ、その他の任意の光学センサ又は非光学センサにより検知される電子マーカ、任意の形態の可視、又は非可視ペイント、等が含まれる。一般的にいえば、表面ポイントの動き方の判定の助けとなる、シーンへの任意の変更は、基準マーカの一部として利用可能である。また、ごく少数の基準マーカが付与され、画像間の共通ポイントの多くはマーカなしのキャプチャで判定されるような、混合型の方式を利用することも可能である。例えば、基準マーカに加えて、衣服/表面の自然のテクスチャから、特徴点を抽出することが可能である。
【0122】
ビデオベースのパフォーマンスキャプチャに関する様々な手法は、時空的にコヒーレントな高品質のジオメトリと、生きているような動きのデータと、任意選択としての記録される俳優の表面テクスチャとから成る、高密度で、特徴のはっきりした出力フォーマットを制作するのに有効である。効率的な立体ベース及び面ベースの変形方式と、多視点の合成を通した解析手順と、多視点のステレオ手法との融合が、広範な日常的な衣料を纏い、極めて高速でエネルギッシュな動きをする人のパフォーマンスのキャプチャを容易にする。これらの方法は、マーカベースの光学キャプチャシステム(例えば、映画(特殊効果、他)とかコンピュータゲーム産業に適用可能なような)の性能を補足、及び/又は凌ぐために利用可能であり、また、実世界のコンテンツの取得と変更に高度のフレキシビリティを提供することにより、アニメーション作者やCGアーティストにとっても有益であり得る。当業者であれば、以上で説明した実装は単に例示的なものであり、本発明の真の趣旨と範囲から逸脱することなしに多くの変更を成し得ることは理解されるであろう。それ故に、添付の特許請求の範囲により、本発明の真の趣旨と範囲内にあるそのような変更と修正のすべてが包含されることが意図されている。
【特許請求の範囲】
【請求項1】
プロセッサにより実行される方法であって、
人物の視覚画像を前記人物に関する3次元情報に関連付けることによって前記人物のデジタル表現(R)を生成するステップであって、前記人物のデジタル表現は、前記人物の表面メッシュと、複数の3次元形状を用いた前記人物の立体表現とを含む、デジタル表現(R)を生成し、
マーカなしキャプチャを利用して、前記人物の時間的に異なる2つの視覚画像のそれぞれに共通する、前記2つの画像間の前記人物の動きを表す基準点を見出し、
前記2つの画像間の複数の3次元形状の動きに課せられた位置制約に応じて、前記複数の3次元形状の3次元的動きを特徴づけるために、前記人物の立体表現を前記基準点の関数として変形し、
前記人物の前記表面メッシュを、前記立体変形の関数として変形し、
前記人物の変形された前記2次元表面メッシュと変形された前記立体表現とに応じて、前記人物の更新されたデジタル表現を生成すること、
を含む、方法。
【請求項2】
前記表面メッシュは三角形の集合を含み、前記複数の3次元形状は四面体を含む、請求項1に記載の方法。
【請求項3】
前記デジタル表現(R)を生成するステップは、
Rの表面上の3次元の点ポイント(P)の高密度の集合と、前記表面上のポイント間の接続性とを特徴づけ、
Pにおける各点の座標の集合によって前記人物を画定し、
参照姿勢における前記人物の形状を表す、Rの疎な立体版(V)を特徴づけること、
により前記デジタル表現を生成することを更に含み、
ここで、Vは四面体頂点(Q)の集合として表され、姿勢はQの各点の3次元座標で画定される、請求項1に記載の方法。
【請求項4】
前記人物の表面メッシュを変形する前記ステップは、前記人物の前記立体表現の変形ステップにおける前記基準点とは異なる、ひと組の基準点の集合から構築される、第2の
点制約の集合を利用することを更に含む、請求項3に記載の方法。
【請求項5】
前記人物の更新されたデジタル表現を生成する前記ステップは、
前記人物の前記変形された表面メッシュと、前記変形された立体表現とに応じて、3次元点制約に関する位置情報を画定し、
前記画定された位置情報に応じて、それぞれの時刻における前記人物の幾何配列を表す、キャプチャされたパフォーマンスモデル(M)を生成することであって、Mは各個別時刻におけるRの全ての点Pに対する、3次元点位置の集合と、Vの各頂点Qの位置の集合と、を含み、
画像センサからの測定値に対応して、各時刻ステップにおける外観の表現(I)を生成すること、
を含む、請求項3に記載の方法。
【請求項6】
表現(I)を生成する前記ステップは、
前記人物の時間変化する多視点画像データと、時刻が異なる画像データにおける前記人物の表面ポイント間の対応関係を記述する特徴と、各時刻ステップにおける前記人物の体勢及び詳細な表面外観を記述する特徴と、
を含む、画像センサからのデータを利用するステップを含む、請求項5に記載の方法。
【請求項7】
画像センサからの測定値を利用し、基準マーカを利用しない、アニメーションモデルMを推定するステップと、
実世界被写体Iの表現とのアライメントによりMのパラメータを推定するステップと、
を更に含む、請求項3に記載の方法。
【請求項8】
Iを考慮してVの最適変形を見つけることにより、各時刻ステップにおける前記人物の大まかな姿勢をキャプチャするステップと、
前記の大まかな姿勢推定を利用して前記人物をトラッキングすることにより、Rの精密表面モデルを利用してパフォーマンスの各時刻ステップにおける詳細な表面推定を算出するためのモデルMを生成するステップと、
を更に含む、請求項5に記載の方法。
【請求項9】
前記立体表現の変形ステップが、各四面体に対して前記人物の骨格モデルから独立した、3次元での動きの自由度を含む、請求項2に記載の方法。
【請求項10】
時刻の異なる画像シーケンスに対して、時空間的にコヒーレントな形状、動き、及びテクスチャを受動的に再構築することを更に含む、請求項1に記載の方法。
【請求項11】
前記立体表現を変形するステップは、局所的に体積が一定となるように前記モデルの形状を局所的に保存することを含む、請求項1に記載の方法。
【請求項12】
基準点を見つけるために低分解能でトラッキングするステップと、
精密変形を行うために高分解能でトラッキングするステップと、
を更に含む、請求項1に記載の方法。
【請求項13】
1組の頂点の集合を有する3次元形状の集合として前記人物を表現するステップと、
前記頂点集合の投影位置と、前記投影位置と前記頂点集合の実位置との間の距離との関数として、前記頂点集合の部分集合を選択するステップと、
を更に含む、請求項1に記載の方法。
【請求項14】
立体変形を適用する前記ステップは、前記人物の剛直的変形部分とは実質的に独立して動く、前記人物の非剛直的変形部分に対応することを含む、請求項1に記載の方法。
【請求項15】
人物の視覚画像をその人物に関する3次元情報に関連付けることによって前記人物のデジタル表現(R)を生成し、前記人物のデジタル表現は、前記人物の表面メッシュと、複数の3次元形状を用いた前記人物の立体表現とを含み、
マーカなしキャプチャを利用して、前記人物の時間的に異なる2つの視覚画像のそれぞれに共通する、前記2つの画像間の前記人物の動きを表す基準点を見出し、
前記2つの画像間の複数の3次元形状の動きに課せられた位置制約に応答して、前記複数の3次元形状の3次元的の動きを特徴づけることを可能とする前記基準点の関数として、前記人物の立体表現を変形し、
前記人物の前記表面メッシュを、前記立体変形の関数として変形し、
変形された前記表面メッシュと、前記人物の変形された前記立体表現とに応じて、前記人物の更新されたデジタル表現を生成する
ように構成適合され、準備された処理回路を含む、装置。
【請求項16】
前記処理回路は更に、
基準点を見つけるために低分解能トラッキング手法を利用するステップと、
精密変形を適用するために高分解能手法を利用するステップと、
のためのものである、請求項15に記載の装置。
【請求項17】
前記処理回路は更に、前記低分解能トラッキング手法から導かれる、低精細度モデルを利用して前記人物の姿勢を判定する、請求項16に記載の装置。
【請求項18】
前記処理装置は、時刻の異なる画像シーケンスに対して、時空間的にコヒーレントな形状、運き、及びテクスチャを受動的に再構築する、請求項15に記載の装置。
【請求項19】
前記処理回路は更に、前記人物の骨格から独立し、かつ各3次元形状に対して3次元の動きの自由度を以って、前記人物モデルを立体変形させる、請求項15に記載の装置。
【請求項20】
前記処理回路は更に、前記人物をモデル化する四面体メッシュを利用するデジタル表現を立体変形させる、請求項15に記載の装置。
【請求項21】
前記処理回路は更に、
3次元の点制約に従って、前記人物の立体表現を立体変形させ、かつ
立体モデルの姿勢と更なる3次元のポイント制約に従って、前記表面メッシュを変形させる、請求項15に記載の装置。
【請求項22】
前記処理回路は更に、
前記全頂点集合の投影位置と、前記投影位置と前記全頂点集合の実位置との間の距離との関数として、前記3次元形状の全頂点集合から頂点を選択する、請求項15に記載の装置。
【請求項23】
前記処理回路は更に、前記立体表現変形を行う前記ステップにおいて、前記人物の剛直的変形部分の動きとは実質的に独立した動きをする、前記人物の非剛直的変形部分に対応する、請求項15に記載の装置。
【請求項24】
記憶データを含む記憶媒体であって、アクセスされると、
人物の視覚画像をその人物に関する3次元情報に関連付けることによって前記人物のデジタル表現(R)を生成するステップであって、前記人物のデジタル表現は、前記人物の表面メッシュと、複数の3次元形状を用いた前記人物の立体表現とを含む、デジタル表現(R)を生成するステップと、
マーカなしキャプチャを利用して、前記人物の時間的に異なる2つの視覚画像のそれぞれに共通する、前記2つの画像間の前記人物の動きを表す、基準点を見出すステップと、
前記2つの画像間の複数の3次元形状の動きに課せられた位置制約に応じて、前記複数の3次元形状の3次元の動きを特徴づけることを可能とする前記基準点の関数として、前記人物の立体表現を変形するステップと、
前記人物の前記表面メッシュを、前記立体変形の関数として変形するステップと、
変形された前記表面メッシュと、前記人物の変形された前記立体表現とに応答して、前記人物の更新されたデジタル表現を生成するステップと、
を処理回路に実行させる記憶データを含む、記憶媒体。
【請求項25】
前記記憶データは、アクセスされると、
3次元のポイント制約に従って、前記人物の立体表現を立体変形させるステップtp、
立体モデルの姿勢と更なる3次元の点制約に従って、前記表面メッシュを変形させるステップと、
を、処理回路に更に実行させる、請求項24に記載の記憶媒体。
【請求項26】
アクセスされると前記記憶データは、前記人物の体積を維持するために局所形状を保持するステップを処理回路に更に実行させる、請求項24に記載の記憶媒体。
【請求項1】
プロセッサにより実行される方法であって、
人物の視覚画像を前記人物に関する3次元情報に関連付けることによって前記人物のデジタル表現(R)を生成するステップであって、前記人物のデジタル表現は、前記人物の表面メッシュと、複数の3次元形状を用いた前記人物の立体表現とを含む、デジタル表現(R)を生成し、
マーカなしキャプチャを利用して、前記人物の時間的に異なる2つの視覚画像のそれぞれに共通する、前記2つの画像間の前記人物の動きを表す基準点を見出し、
前記2つの画像間の複数の3次元形状の動きに課せられた位置制約に応じて、前記複数の3次元形状の3次元的動きを特徴づけるために、前記人物の立体表現を前記基準点の関数として変形し、
前記人物の前記表面メッシュを、前記立体変形の関数として変形し、
前記人物の変形された前記2次元表面メッシュと変形された前記立体表現とに応じて、前記人物の更新されたデジタル表現を生成すること、
を含む、方法。
【請求項2】
前記表面メッシュは三角形の集合を含み、前記複数の3次元形状は四面体を含む、請求項1に記載の方法。
【請求項3】
前記デジタル表現(R)を生成するステップは、
Rの表面上の3次元の点ポイント(P)の高密度の集合と、前記表面上のポイント間の接続性とを特徴づけ、
Pにおける各点の座標の集合によって前記人物を画定し、
参照姿勢における前記人物の形状を表す、Rの疎な立体版(V)を特徴づけること、
により前記デジタル表現を生成することを更に含み、
ここで、Vは四面体頂点(Q)の集合として表され、姿勢はQの各点の3次元座標で画定される、請求項1に記載の方法。
【請求項4】
前記人物の表面メッシュを変形する前記ステップは、前記人物の前記立体表現の変形ステップにおける前記基準点とは異なる、ひと組の基準点の集合から構築される、第2の
点制約の集合を利用することを更に含む、請求項3に記載の方法。
【請求項5】
前記人物の更新されたデジタル表現を生成する前記ステップは、
前記人物の前記変形された表面メッシュと、前記変形された立体表現とに応じて、3次元点制約に関する位置情報を画定し、
前記画定された位置情報に応じて、それぞれの時刻における前記人物の幾何配列を表す、キャプチャされたパフォーマンスモデル(M)を生成することであって、Mは各個別時刻におけるRの全ての点Pに対する、3次元点位置の集合と、Vの各頂点Qの位置の集合と、を含み、
画像センサからの測定値に対応して、各時刻ステップにおける外観の表現(I)を生成すること、
を含む、請求項3に記載の方法。
【請求項6】
表現(I)を生成する前記ステップは、
前記人物の時間変化する多視点画像データと、時刻が異なる画像データにおける前記人物の表面ポイント間の対応関係を記述する特徴と、各時刻ステップにおける前記人物の体勢及び詳細な表面外観を記述する特徴と、
を含む、画像センサからのデータを利用するステップを含む、請求項5に記載の方法。
【請求項7】
画像センサからの測定値を利用し、基準マーカを利用しない、アニメーションモデルMを推定するステップと、
実世界被写体Iの表現とのアライメントによりMのパラメータを推定するステップと、
を更に含む、請求項3に記載の方法。
【請求項8】
Iを考慮してVの最適変形を見つけることにより、各時刻ステップにおける前記人物の大まかな姿勢をキャプチャするステップと、
前記の大まかな姿勢推定を利用して前記人物をトラッキングすることにより、Rの精密表面モデルを利用してパフォーマンスの各時刻ステップにおける詳細な表面推定を算出するためのモデルMを生成するステップと、
を更に含む、請求項5に記載の方法。
【請求項9】
前記立体表現の変形ステップが、各四面体に対して前記人物の骨格モデルから独立した、3次元での動きの自由度を含む、請求項2に記載の方法。
【請求項10】
時刻の異なる画像シーケンスに対して、時空間的にコヒーレントな形状、動き、及びテクスチャを受動的に再構築することを更に含む、請求項1に記載の方法。
【請求項11】
前記立体表現を変形するステップは、局所的に体積が一定となるように前記モデルの形状を局所的に保存することを含む、請求項1に記載の方法。
【請求項12】
基準点を見つけるために低分解能でトラッキングするステップと、
精密変形を行うために高分解能でトラッキングするステップと、
を更に含む、請求項1に記載の方法。
【請求項13】
1組の頂点の集合を有する3次元形状の集合として前記人物を表現するステップと、
前記頂点集合の投影位置と、前記投影位置と前記頂点集合の実位置との間の距離との関数として、前記頂点集合の部分集合を選択するステップと、
を更に含む、請求項1に記載の方法。
【請求項14】
立体変形を適用する前記ステップは、前記人物の剛直的変形部分とは実質的に独立して動く、前記人物の非剛直的変形部分に対応することを含む、請求項1に記載の方法。
【請求項15】
人物の視覚画像をその人物に関する3次元情報に関連付けることによって前記人物のデジタル表現(R)を生成し、前記人物のデジタル表現は、前記人物の表面メッシュと、複数の3次元形状を用いた前記人物の立体表現とを含み、
マーカなしキャプチャを利用して、前記人物の時間的に異なる2つの視覚画像のそれぞれに共通する、前記2つの画像間の前記人物の動きを表す基準点を見出し、
前記2つの画像間の複数の3次元形状の動きに課せられた位置制約に応答して、前記複数の3次元形状の3次元的の動きを特徴づけることを可能とする前記基準点の関数として、前記人物の立体表現を変形し、
前記人物の前記表面メッシュを、前記立体変形の関数として変形し、
変形された前記表面メッシュと、前記人物の変形された前記立体表現とに応じて、前記人物の更新されたデジタル表現を生成する
ように構成適合され、準備された処理回路を含む、装置。
【請求項16】
前記処理回路は更に、
基準点を見つけるために低分解能トラッキング手法を利用するステップと、
精密変形を適用するために高分解能手法を利用するステップと、
のためのものである、請求項15に記載の装置。
【請求項17】
前記処理回路は更に、前記低分解能トラッキング手法から導かれる、低精細度モデルを利用して前記人物の姿勢を判定する、請求項16に記載の装置。
【請求項18】
前記処理装置は、時刻の異なる画像シーケンスに対して、時空間的にコヒーレントな形状、運き、及びテクスチャを受動的に再構築する、請求項15に記載の装置。
【請求項19】
前記処理回路は更に、前記人物の骨格から独立し、かつ各3次元形状に対して3次元の動きの自由度を以って、前記人物モデルを立体変形させる、請求項15に記載の装置。
【請求項20】
前記処理回路は更に、前記人物をモデル化する四面体メッシュを利用するデジタル表現を立体変形させる、請求項15に記載の装置。
【請求項21】
前記処理回路は更に、
3次元の点制約に従って、前記人物の立体表現を立体変形させ、かつ
立体モデルの姿勢と更なる3次元のポイント制約に従って、前記表面メッシュを変形させる、請求項15に記載の装置。
【請求項22】
前記処理回路は更に、
前記全頂点集合の投影位置と、前記投影位置と前記全頂点集合の実位置との間の距離との関数として、前記3次元形状の全頂点集合から頂点を選択する、請求項15に記載の装置。
【請求項23】
前記処理回路は更に、前記立体表現変形を行う前記ステップにおいて、前記人物の剛直的変形部分の動きとは実質的に独立した動きをする、前記人物の非剛直的変形部分に対応する、請求項15に記載の装置。
【請求項24】
記憶データを含む記憶媒体であって、アクセスされると、
人物の視覚画像をその人物に関する3次元情報に関連付けることによって前記人物のデジタル表現(R)を生成するステップであって、前記人物のデジタル表現は、前記人物の表面メッシュと、複数の3次元形状を用いた前記人物の立体表現とを含む、デジタル表現(R)を生成するステップと、
マーカなしキャプチャを利用して、前記人物の時間的に異なる2つの視覚画像のそれぞれに共通する、前記2つの画像間の前記人物の動きを表す、基準点を見出すステップと、
前記2つの画像間の複数の3次元形状の動きに課せられた位置制約に応じて、前記複数の3次元形状の3次元の動きを特徴づけることを可能とする前記基準点の関数として、前記人物の立体表現を変形するステップと、
前記人物の前記表面メッシュを、前記立体変形の関数として変形するステップと、
変形された前記表面メッシュと、前記人物の変形された前記立体表現とに応答して、前記人物の更新されたデジタル表現を生成するステップと、
を処理回路に実行させる記憶データを含む、記憶媒体。
【請求項25】
前記記憶データは、アクセスされると、
3次元のポイント制約に従って、前記人物の立体表現を立体変形させるステップtp、
立体モデルの姿勢と更なる3次元の点制約に従って、前記表面メッシュを変形させるステップと、
を、処理回路に更に実行させる、請求項24に記載の記憶媒体。
【請求項26】
アクセスされると前記記憶データは、前記人物の体積を維持するために局所形状を保持するステップを処理回路に更に実行させる、請求項24に記載の記憶媒体。
【図1】


【図2a】

【図2b】

【図4a】

【図5(a)】
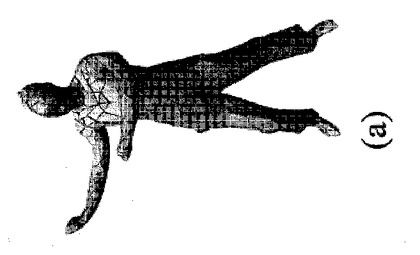
【図5(b)】
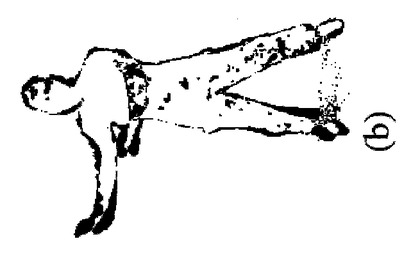
【図5(c)】
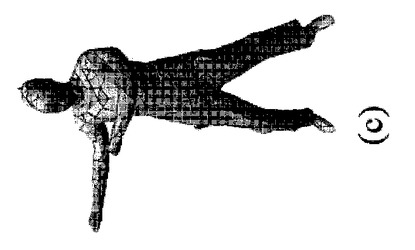
【図5(d)】

【図6b】

【図6c】
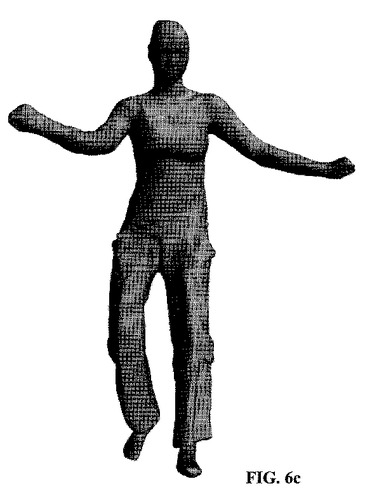
【図6e】

【図7a】

【図7b】

【図8】

【図9a】

【図9b】

【図9c】
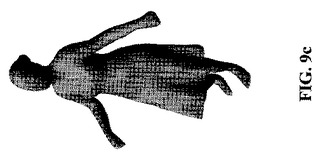
【図10a】
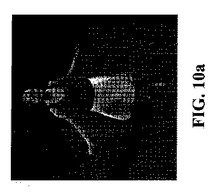
【図10b】
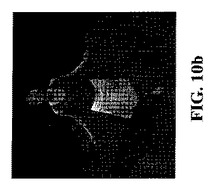
【図10c】

【図11】
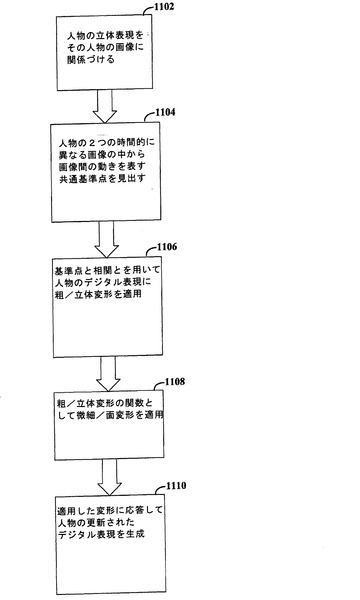
【図3】
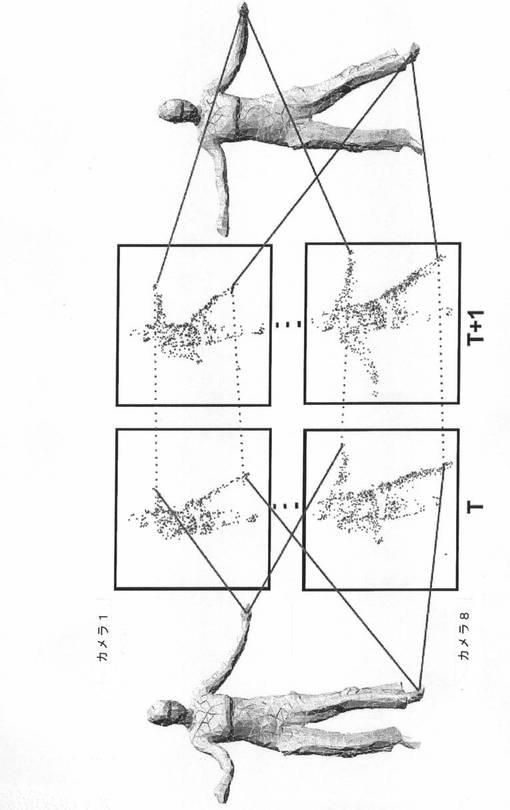
【図4b】
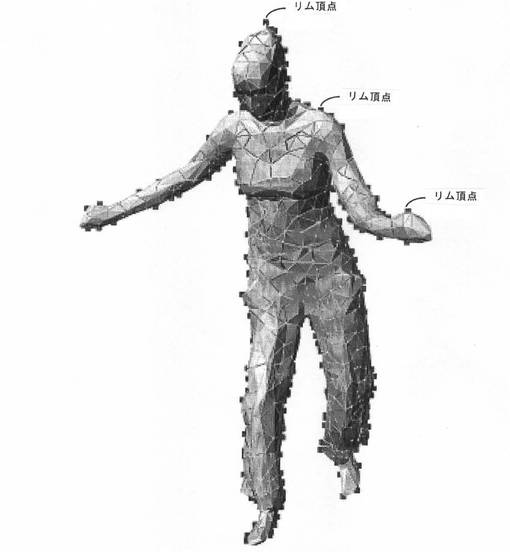
【図6a】
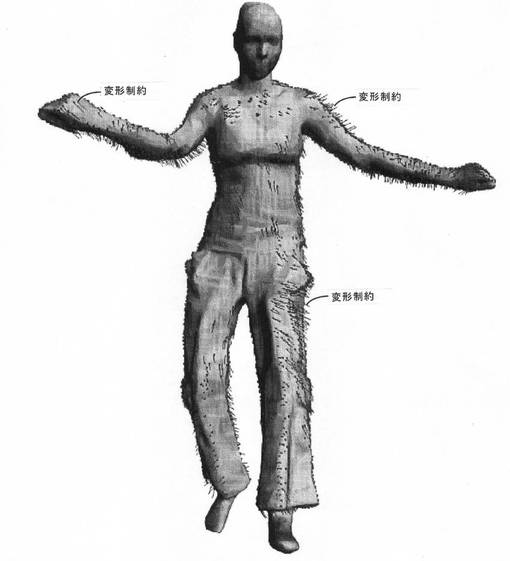
【図6d】
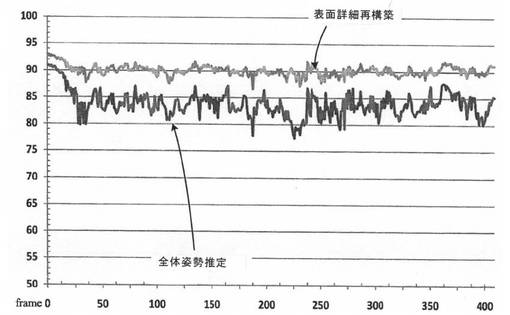
【図2a】
【図2b】
【図4a】
【図5(a)】
【図5(b)】
【図5(c)】
【図5(d)】
【図6b】
【図6c】
【図6e】
【図7a】
【図7b】
【図8】
【図9a】
【図9b】
【図9c】
【図10a】
【図10b】
【図10c】
【図11】
【図3】
【図4b】
【図6a】
【図6d】
【公表番号】特表2011−521357(P2011−521357A)
【公表日】平成23年7月21日(2011.7.21)
【国際特許分類】
【出願番号】特願2011−509614(P2011−509614)
【出願日】平成21年5月12日(2009.5.12)
【国際出願番号】PCT/US2009/043602
【国際公開番号】WO2009/140261
【国際公開日】平成21年11月19日(2009.11.19)
【出願人】(503115205)ボード オブ トラスティーズ オブ ザ レランド スタンフォード ジュニア ユニバーシティ (69)
【出願人】(500449363)マックス−プランク−ゲゼルシャフト ツール フェルデルンク デル ヴィッセンシャフテン エー.ファウ. (5)
【Fターム(参考)】
【公表日】平成23年7月21日(2011.7.21)
【国際特許分類】
【出願日】平成21年5月12日(2009.5.12)
【国際出願番号】PCT/US2009/043602
【国際公開番号】WO2009/140261
【国際公開日】平成21年11月19日(2009.11.19)
【出願人】(503115205)ボード オブ トラスティーズ オブ ザ レランド スタンフォード ジュニア ユニバーシティ (69)
【出願人】(500449363)マックス−プランク−ゲゼルシャフト ツール フェルデルンク デル ヴィッセンシャフテン エー.ファウ. (5)
【Fターム(参考)】
[ Back to top ]