
フィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置
【課題】設定処理の負担を軽減させ、かつ、効率的に処理精度を向上させるための学習をおこなう機能を備えたフィルタリング処理を提供すること。
【解決手段】フィルタリング装置200は、第1フィルタによって処理対象データ301を構成する各要素について前記処理対象データにおける出力確率を算出し、この出力確率に基づいて有効値/無効値に離散化する。そして、第2フィルタによって、第1フィルタによって有効値/無効値に離散化された要素を、処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出し、算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する。
【解決手段】フィルタリング装置200は、第1フィルタによって処理対象データ301を構成する各要素について前記処理対象データにおける出力確率を算出し、この出力確率に基づいて有効値/無効値に離散化する。そして、第2フィルタによって、第1フィルタによって有効値/無効値に離散化された要素を、処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出し、算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、処理対象データが所望のデータであるか否かを判定するフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置に関する。
【背景技術】
【0002】
従来より、ユーザが、所定の判定処理機能を持ったフィルタリング装置を利用すると、この利用結果をフィルタリング装置に学習させることによってフィルタリング機能を向上させるフィルタリング処理が広く提供されている。たとえば、フィルタリング機能の学習にベイジアンネットワークで用いられている学習方法を適用させたものがある。この学習方法では、学習対象のフィルタリング装置は、学習用の入力値として二値素性を必要とするため、連続値を所定の閾値によって離散化して入力値として与えられる。
【0003】
具体的に説明すると、まず、離散化に用いる閾値を決定するために、あらかじめ適当な閾値をいくつか設定しておく。そして、設定した各閾値を利用して連続値を離散化することにより二値素性を抽出する。その後、閾値ごとに、抽出された二値素性の出力確率を算出する。この算出結果から各カテゴリへの分類にとって効果のない素性を排除する。このような処理によって、二値素性の数を絞り込むことができるため、ベイジアンネットワークの学習方法を実行する際の計算量を削減することができる(たとえば、下記特許文献1参照。)。
【0004】
【特許文献1】特開2004−326465号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
一般的に、学習対象となるフィルタリング装置への入力値として二値素性を利用する場合、これらの二値素性の出力確率の分布を求めたとき、その分布が分散している値が、入力値として有用であるとされている。しかしながら、上記特許文献1に記載の技術を用いた場合、閾値ごとに算出された二値素性の出力確率の分布が偏ってしまうといった問題があった。
【0006】
また、上述の学習方法に限らず、閾値を用意して離散化した値を利用する場合、どのような閾値を設定するかが処理内容に大きく影響する。したがって、閾値の設定には事前の試行錯誤が欠かせない。また、学習の際、フィルタリング装置の判定傾向が大きく変わってしまった場合には、閾値の設定も見直さなければならない。このように、従来の学習方法を適用させたフィルタリング装置の場合、閾値設定にかかる処理がユーザにとって大きな負担となるという問題があった。
【0007】
この発明は、上述した従来技術による問題点を解消するため、設定処理の負担を軽減させ、かつ、効率的に処理精度を向上させるための学習をおこなう機能を備えたフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置を提供することを目的とする。
【課題を解決するための手段】
【0008】
上述した課題を解決し、目的を達成するため、請求項1の発明にかかるフィルタリング処理方法は、処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング処理方法であって、前記処理対象データを構成する要素を解析する解析工程と、前記解析工程によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出工程と、前記解析工程によって解析された各要素を、前記第1の算出工程によって算出された出力確率に基づいて有効値/無効値に離散化する第1の離散化工程と、前記第1の離散化工程によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出工程と、前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化工程と、を含むことを特徴とする。
【0009】
この請求項1の発明によれば、処理対象データを構成する要素の出力確率に基づいて、各要素を有効値/無効値の二値素性に離散化する。この離散化結果を用いて、処理対象データがユーザの所望のデータであるかを判定する。すなわち、ユーザが閾値などのパラメータを用意しなくとも算出結果を利用して離散化をおこなうことができる。また、第1離散化工程による離散化結果は、後段の第2の離散化に反映されるため、精度の高い判定処理が可能となる。
【0010】
また、請求項2の発明にかかるフィルタリング処理方法は、請求項1に記載の発明において、前記第2の離散化工程による判断の正誤を受け付ける受付工程と、前記受付工程によって誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整する調整工程と、を含むことを特徴とする。
【0011】
この請求項2の発明によれば、フィルタリング処理による判定結果が、ユーザの所望データと一致していなかった場合に、この誤判定の内容をフィードバックする。具体的には、第1の算出工程において算出される要素の出力確率が調整される。したがって、誤判定された処理判定データと同じ構成のデータのフィルタリング処理がおこなわれた場合には、当該データはユーザが所望するデータではないと判定するため、判定精度を向上させることができる。
【0012】
また、請求項3の発明にかかるフィルタリング処理方法は、請求項1または2に記載の発明において、前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素を任意の関数に写像して得られた値を用いて離散化をおこなうことを特徴とする。
【0013】
この請求項3の発明によれば、関数変換によって離散化対象の要素の出力確率分布の挙動が強調されるため離散化の調整が容易になる。
【0014】
また、請求項4の発明にかかるフィルタリング処理方法は、請求項1または2に記載の発明において、前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素の出力確率と、あらかじめ設定した閾値との比較結果から有効値/無効値に離散化することを特徴とする。
【0015】
この請求項4の発明によれば、最適な閾値が判別しているような場合には、この閾値を設定して離散化をおこなわせることができる。
【0016】
また、請求項5の発明にかかるフィルタリング処理方法は、請求項1〜4のいずれか一つに記載の発明において、前記解析工程では、前記処理対象データが電子メールデータである場合、当該電子メールデータのヘッダと本文に対して解析をおこなうことを特徴とする。
【0017】
この請求項5の発明によれば、不特定多数のメールが送信された場合であっても、フィルタリング処理方法を利用して、ユーザの所望しないメールを排除することができる。
【0018】
また、請求項6の発明にかかるフィルタリング処理プログラムは、処理対象データがユーザの所望するデータであるか否かをコンピュータに判定させるフィルタリング処理プログラムであって、前記処理対象データを構成する要素を解析させる解析工程と、前記解析工程によって解析させた各要素について前記処理対象データにおける出力確率を算出させる第1の算出工程と、前記解析工程によって解析させた各要素を、前記算出工程によって算出させた出力確率に基づいて有効値/無効値に離散化させる第1の離散化工程と、前記第1の離散化工程によって有効値/無効値に離散化させた要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出させる第2の算出工程と、前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化させることにより、処理対象データが所望のデータであるか否かを判定させる第2の離散化工程と、をコンピュータに実行させることを特徴とする。
【0019】
この請求項6の発明によれば、処理対象データを構成する要素の出力確率に基づいて、各要素を有効値/無効値の二値素性に離散化する。この離散化結果を用いて、処理対象データがユーザの所望のデータであるかを判定する。すなわち、ユーザが閾値などのパラメータを用意しなくとも算出結果を利用して離散化をおこなうことができる。また、第1離散化工程による離散化結果は、後段の第2の離散化に反映されるため、精度の高い判定処理が可能となる。
【0020】
また、請求項7の発明にかかるフィルタリング処理プログラムは、請求項6に記載の発明において、前記第2の離散化工程による判断の正誤を受け付ける受付工程と、前記受付工程によって誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整させる調整工程と、をコンピュータに実行させることを特徴とする。
【0021】
この請求項7の発明によれば、フィルタリング処理による判定結果が、ユーザの所望データと一致していなかった場合に、この誤判定の内容をフィードバックする。具体的には、誤判定に含まれている各要素について、第1の算出工程によって算出される出力確率が調整される。したがって、誤判定された処理判定データと同じ構成のデータのフィルタリング処理がおこなわれた場合には、当該データはユーザが所望するデータではないと判定するため、判定精度を向上させることができる。
【0022】
また、請求項8の発明にかかるフィルタリング装置は、処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング装置であって、前記処理対象データを構成する要素を解析する解析手段と、前記解析手段によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出手段と、前記解析手段によって解析された各要素を、前記第1の算出手段によって算出された出力確率に基づいて有効値/無効値に離散化する第2の離散化手段と、前記第1の離散化手段によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出手段と、前記第2の算出手段によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化手段と、前記第2の離散化手段による判断の正誤を受け付ける受付手段と、前記受付手段によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出手段にて算出される出力確率を調整する調整手段と、を備えることを特徴とする。
【0023】
この請求項8の発明によれば、処理対象データを構成する要素の出力確率に基づいて、各要素を有効値/無効値の二値素性に離散化する。この離散化結果を用いて、さらに出力確率が算出され、この算出結果を用いて再度離散化をおこなうことによって、処理対象データがユーザの所望のデータであるかを判定する。さらに、判定結果は、以後の離散化にフィードバックされる。すなわち、ユーザが閾値などのパラメータを用意しなくとも算出結果を利用して離散化をおこなうとともに、判定精度の向上も可能となる。
【発明の効果】
【0024】
本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置によれば、設定処理の負担を軽減させ、かつ、効率的に処理精度を向上させるための学習をおこなう機能を実現することができるという効果を奏する。
【発明を実施するための最良の形態】
【0025】
以下に添付図面を参照して、この発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置の好適な実施の形態を詳細に説明する。
【0026】
(フィルタリング処理の概要)
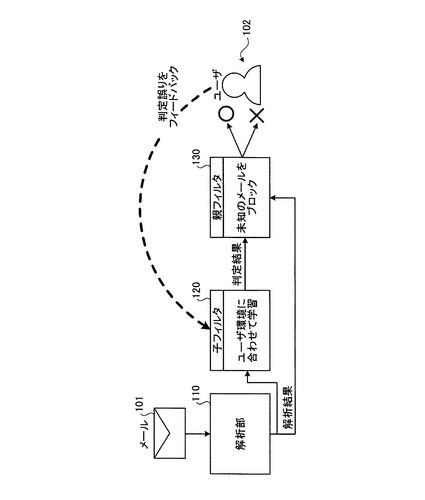
まず、本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置におけるフィルタリング処理の概要について説明する。図1は、本発明にかかるフィルタリング処理の概要を示す説明図である。
【0027】
図1では、まず、受信したメール101を解析部110によって解析する。そして、子フィルタ120と、親フィルタ130とのカスケードに接続された2種類のフィルタにメール101を入力し単一の判定結果を出力させる構成になっている。このとき、子フィルタ120は、ユーザ環境に合わせて設定された判定基準に基づいてメールのブロックをおこなう。一方、親フィルタ130は、未知のメールをブロックする。
【0028】
また、子フィルタ120と、親フィルタ130との2種類のフィルタを透過したメール101に対して、ユーザ102は、正しくフィルタリングされたか否かの判定をおこなう。ここで、フィルタ120,130による判定誤りがあった場合には、この判定誤り情報が、子フィルタ120にフィードバックされる。子フィルタ120は、フィードバックされた判定誤り情報に基づいて、判定基準を調整する。このフィードバックにより、子フィルタ120は、よりユーザ環境に合致した判定をおこなうようになる。
【0029】
以上説明したように、本発明のフィルタリング処理では、子フィルタ120は、フィルタリング処理をおこなうごとに、ユーザ判定情報によって処理内容が妥当であったか否かを学習することができる。その結果、子フィルタ120の処理能力は向上し、親フィルタ130による判定処理は、子フィルタ120の判定結果を追認する程度の役割となる。
【0030】
以下の実施の形態では、上述したようなフィルタリング処理を実行するフィルタリング装置を実現するための具体的な構成と、その処理内容について説明する。
【0031】
(フィルタリング装置のハードウェア構成)
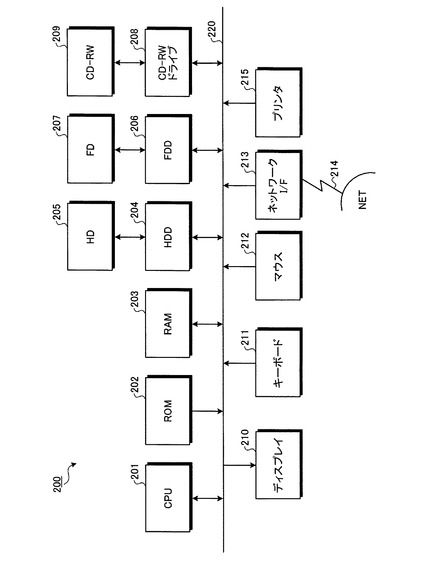
まず、本実施の形態にかかるフィルタリング装置のハードウェア構成について説明する。図2は、本実施の形態にかかるフィルタリング装置のハードウェア構成の一例を示すブロック図である。
【0032】
図2において、フィルタリング装置200は、CPU(Central Processing Unit)201と、ROM(Read Only Memory)202と、RAM(Random Access Memory)203と、HDD(Hard Disc Drive)204と、HD(Hard Disc)205と、FDD(Flexible Disk Drive)206と、FD(Flexible Disk)207と、CD−RW(Compact Disc ReWritable)ドライブ208と、CD−RW209と、ディスプレイ210と、キーボード211と、マウス212と、ネットワークI/F(インタフェース)213と、通信ケーブル214と、プリンタ215と、バス220とを備えて構成されている。
【0033】
CPU201は、フィルタリング装置200全体を制御する。ROM202は、各種制御プログラムや本発明にかかるフィルタリング処理プログラムなどを格納する。RAM203は、可変的なデータを書き換え自在に記憶し、CPU201のワークエリアとして機能する。HDD204は、CPU201の制御にしたがってHD205に対するデータのリード/ライトを制御する。HD205は、HDD204の制御にしたがって書き込まれたデータを記憶する。
【0034】
FDD206は、CPU201の制御にしたがってFD207に対するデータのリード/ライトを制御する。FD207は、着脱自在であり、FDD206の制御にしたがって書き込まれたデータを記憶する。CD−RWドライブ208は、CPU201の制御にしたがってCD−RW(または、CD−R、CD−ROM)209に対するデータのリード/ライトを制御する。CD−RW209は、着脱自在であり、CD−RWドライブ208の制御にしたがって書き込まれたデータを記憶する。
【0035】
ディスプレイ210は、カーソル、メニュー、ウィンドウ、あるいは文字や画像などの各種データを表示する。キーボード211は、文字、数値、各種指示などの入力のための複数のキーを備える。マウス212は、各種指示の選択や実行、処理対象の選択、マウスポインタの移動などをおこなう。ネットワークI/F213は、通信ケーブル214を介してLAN、WAN、インターネットなどのネットワークに接続され、当該ネットワークとCPU201とのインタフェースとして機能する。プリンタ215は、文字や画像などの各種データを印刷する。バス220は上記各部を接続する。
【0036】
(フィルタリング装置の機能的構成)
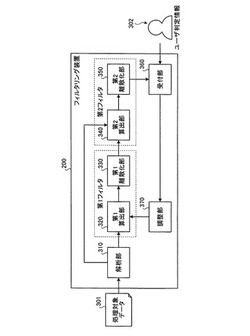
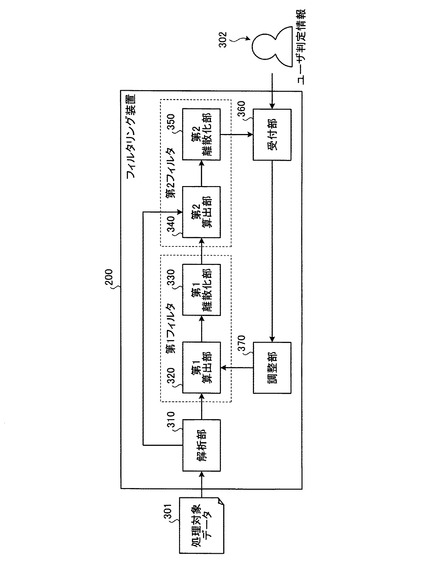
つぎに、本実施の形態にかかるフィルタリング装置200の機能的構成について説明する。図3は、本実施の形態にかかるフィルタリング装置の機能的構成を示すブロック図である。図3に示すように、フィルタリング装置200は、解析部310と、第1算出部320および第1離散化部330からなる第1フィルタと、第2算出部340および第2離散化部350からなる第2フィルタと、受付部360と、調整部370とを含んで構成される。
【0037】
解析部310は、処理対象データ301を構成する要素を解析する。要素の解析とは、処理対象データを構成する連続値を所定の意味を持つ要素に分ける処理である。たとえば、文章を構成するテキストデータであれば、それぞれの単語の要素に解析する。また、解析部310は、たとえば、対象データが電子メールデータである場合、当該電子メールデータのヘッダと本文に対して解析をおこなうなど、処理対象データをフィルタリングする際の判定に影響する要素を含んだデータのみを解析対象としてもよい。
【0038】
第1算出部320は、解析部310によって解析された各要素について処理対象データ301における出力確率を算出する。このとき第1算出部320にて用いられる出力確率の算出手法は任意である。
【0039】
第1離散化部330は、解析部310によって解析された各要素を、第1算出部320によって算出された出力確率に基づいて有効値/無効値に離散化する。このとき、第1離散化部330は、各要素をたとえばシグモイド関数などの任意の関数に写像して得られた値を用いて離散化をおこなってもよい。このような関数を適用させることによって、出力確率の分布が強調され、有効値/無効値の判定を容易におこなうことができる。
【0040】
第1離散化部330では、上述したように、離散化に従来のような閾値の設定を必要としないが、ユーザがフィルタリング処理に適した閾値の情報を保有している場合には、この閾値を利用してもよい。このような場合、第1離散化部330では、各要素の出力確率と、あらかじめ設定した閾値との比較結果から各要素を有効値/無効値に離散化する。
【0041】
第2算出部340は、第1離散化部330によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する。また、第2算出部340による出力確率の算出手法は、第1算出部320と同様に任意であるが、第1算出部320と異なる算出手法が適用されている。
【0042】
第2離散化部350は、第2算出部340によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データ301が所望のデータであるか否かを判定する。この第2離散化部350によって所望するデータであると判定された場合、処理対象データ301は、ユーザに提供される。
【0043】
なお、第2離散化部350も、上述した第1離散化部330と同様に、任意の関数に写像して得られた値を用いて離散化をおこなってもよいし、フィルタリング処理に適した閾値の情報を保有している場合には、この閾値を利用してもよい。
【0044】
受付部360は、ユーザから処理対象データ301についてのユーザ判定情報302を受け付ける。ユーザ判定情報302とは、すなわち、第2離散化部350による判断の正誤をあらわす情報である。
【0045】
調整部370は、受付部360によって誤判定、すなわち、ユーザに提供された処理対象データ301がユーザの所望するデータではなかった旨の指示を受け付けた場合に、この誤判断を、以後の判定処理に反映させる。
【0046】
具体的には、誤判定とされた処理対象データ301を構成する各要素に関して、第1算出部320にて算出される出力確率を調整する。したがって、誤判断がなされた処理対象データを構成する要素(たとえば要素A)の出力確率が低くなり、以後フィルタリング装置200にて処理される処理対象データ201の場合、上述した要素Aは、以前よりも多く含まれていなければ高い出力確率とはならず、後段の第1離散化部330では、有効値として離散化されない。したがって、同じ構成の処理対象データが再度入力された場合には、第1離散化部330では、無効値として離散化され、ユーザの所望するデータは判別されなくなる。
【0047】
以上説明したように、各構成のうち、解析部310は、図1にて説明した解析部110に相当する。また、第1算出部320および第1離散化部330による第1フィルタによって、図1の子フィルタ120を構成する。そして、第2算出部340および第2離散化部350による第2フィルタによって図1の親フィルタ130を構成する。そして、受付部360および調整部370は、フィルタリング処理の精度を向上させるためのフィードバックをおこなう機能部となる。
【0048】
(フィルタリング装置の処理手順)
つぎに、本実施の形態にかかるフィルタリング装置200の処理手順について説明する。図4は、本実施の形態にかかるフィルタリング装置の処理手順を示すフローチャートである。図4のフローチャートにおいて、まず、フィルタリング装置200に処理対象データ301が入力されたか否かを判定する(ステップS401)。
【0049】
ステップS401において、処理対象データ301が入力されるまで待ち(ステップS401:Noのループ)、処理対象データ301が入力されると(ステップS401:Yes)、解析部310において、処理対象データ301の構成要素を解析する(ステップS402)。
【0050】
ステップS402において、各要素に解析されると、フィルタリング処理のために各要素を離散化する処理に移行する。まず、第1算出部320によって、処理対象データ301を構成する各要素の出力確率を算出する(ステップS403)。そして、第1離散化部330によって、ステップS403によって算出された出力確率に基づいた離散化をおこない(ステップS404)、第1フィルタにおけるフィルタリング処理が完了する。
【0051】
つぎに、第2算出部340によって、ステップS404によって離散化された各要素の離散化結果および処理対象データ301との出力確率を算出する(ステップS405)。さらに、第2離散化部350によってステップS405によって算出された出力確率から各要素を離散化し、処理対象データ301をユーザの所望するデータか否かの判定をおこない(ステップS406)、第2フィルタにおけるフィルタリング処理が完了する。
【0052】
以上説明したステップS406までの処理によって処理対象データ301に対するフィルタリング処理が終了する。フィルタリング装置200では、処理対象データ301に対するフィルタリング処理終了後、今回おこなったフィルタリング処理の正誤を自装置に反映させる処理に移行する。
【0053】
まず、受付部360によって、ステップS405にておこなわれた処理対象データ301に対する判定結果が正しいか否かの判断を受け付ける(ステップS407)。この正誤判断は、ユーザによっておこなわれる。ここで、判定結果が正しいとの判断を受け付けた場合には(ステップS407:Yes)、今回のフィルタリング処理に問題はなかったことになり、そのまま一連の処理を終了する。
【0054】
一方、判定結果が誤っているとの判断を受け付けた場合には(ステップS407:No)、今回のフィルタリング処理に問題があったため、その問題点を修正するため、調整部370によって第1算出部320における出力確率算出の設定を調整し(ステップS408)、一連の処理を終了する。
【0055】
以上説明したように、フィルタリング装置200では、複数のフィルタを直列に連結した場合に、それぞれでは独自の判定をおこなわせるが、後段の第2フィルタには、前段の第1フィルタの判定結果を処理対象データ201と併せて入力する。このような手順をとることによって、後段の第2フィルタは、自身の判定に加えて、第1フィルタの判定結果も取り入れることになる。
【0056】
さらに、ユーザがフィードバックをかけたいときは、前段の第1フィルタに反映され、次回からは、前回までの誤判定を起こさないような判定が可能となる。また、第1フィルタの判定結果が更新されると、自動的に第2フィルタの判定結果も更新されるため、フィルタ間の閾値や、判定結果の比較に相当する機能は、すべて第1フィルタによる出力確率算出処理の調整によって制御できることになる。
【0057】
(離散化の手法)
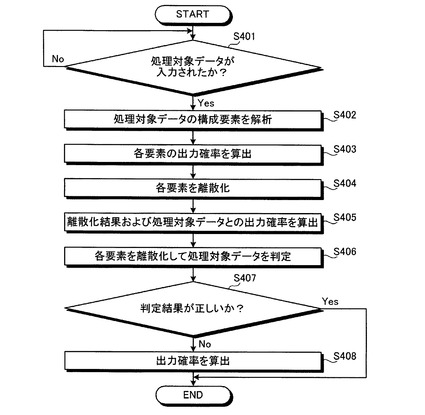
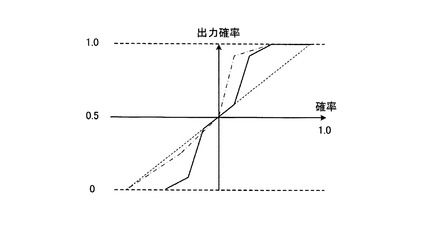
つぎに、第1離散化部330および第2離散化部350における離散化の手法について説明する。上述したように、第1離散化部330および第2離散化部350における離散化の手法に特に限定はない。ここで、簡易で効率的な手法の一例として、任意の関数に写像する手法を説明する。図5は、ある単語の出力確率を任意の関数により写像した図である。また、図6は、単語数ごとの出力確率を任意の関数により写像した図である。
【0058】
ここでは、図5や図6では、第1算出部320や第2算出部340(図3参照)にて算出された出力確率の確率値を元に、任意の関数によって写像した場合における、ある単語の出力確率の分布(図5)や、単語数に応じた出力確率の分布(図6)をあらわしている。
【0059】
また、図5、6における3種類の曲線(実線、破線、一点鎖線)は、それぞれ、適応させている関数の違いをあらわしている。たとえば実線の曲線は、出力確率が0.5より離れている場合、単語の確率がより強まるようなシグモイド関数であり、比較的標準的で癖のない挙動になると予想される。
【0060】
また、破線の曲線は、図5に示した単語の確率については線形だが、図6に示した単語数の場合、0.5付近から立ち上がりが急になっているため、学習結果が反映されやすいことをあらわしている。また、一点鎖線の曲線は、0に近いか、1に近いかによって偏りを持たせた関数となっている。この関数によると、1に近い判定ほど学習結果に反映されやすいことをあらわしている。このように、適用させる関数によって、学習傾向を解析的に制御することが可能となる。
【0061】
以上説明したように、本発明にかかるフィルタリング処理をおこなった場合、各フィルタの判定処理をおこなう際に、入力された処理対象データを利用(解析、出力確率算出など)して離散化をおこなう。したがって、従来のフィルタリング処理のような、ユーザによるパラメータの設定処理を大幅に簡略することができる。
【0062】
また、判定誤りがあった場合は、ユーザはフィルタリング処理に誤り内容をフィードバックする。したがって、フィルタリング処理は、学習され、次回の判定時にはより高精度な判定をおこなうことができる。
【0063】
以上説明したように、本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置によれば、設定処理の負担を軽減させ、かつ、効率的に処理精度を向上させるための学習をおこなう機能を実現することができる。
【0064】
また、本発明のフィルタリング処理は、上述したような電子メールのフィルタリングに適用する以外にも、スパムフィルタやWebフィルタとして適用させてもよい。また、フィルタリング機能を検索エンジンのプロファイルや、自然言語処理における学習機能の最適化などに適用させることもできる。
【0065】
なお、本実施の形態で説明したフィルタリング処理方法は、あらかじめ用意されたプログラムをパーソナル・コンピュータやワークステーションなどのコンピュータで実行することにより実現することができる。このプログラムは、ハードディスク、フレキシブルディスク、CD−ROM、MO、DVDなどのコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。またこのプログラムは、インターネットなどのネットワークを介して配布することが可能な伝送媒体であってもよい。
【産業上の利用可能性】
【0066】
以上のように、本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置は、連続値からなるデータのフィルタリング処理にて有用であり、特に、個々のユーザ環境に適応させる必要のあるメールフィルタに適している。
【図面の簡単な説明】
【0067】
【図1】本発明にかかるフィルタリング処理の概要を示す説明図である。
【図2】本実施の形態にかかるフィルタリング装置のハードウェア構成の一例を示すブロック図である。
【図3】本実施の形態にかかるフィルタリング装置の機能的構成を示すブロック図である。
【図4】本実施の形態にかかるフィルタリング装置の処理手順を示すフローチャートである。
【図5】ある単語の出力確率を任意の関数により写像した図である。
【図6】単語数ごとの出力確率を任意の関数により写像した図である。
【符号の説明】
【0068】
200 フィルタリング装置
201 CPU
202 ROM
203 RAM
204 HDD
205 HD
206 FDD
207 FD
208 CD−RWドライブ
209 CD−RW
210 ディスプレイ
211 キーボード
212 マウス
213 ネットワークI/F
214 通信ケーブル
215 プリンタ
220 バス
301 処理対象データ
302 ユーザ判定情報
310 解析部
320 第1算出部
330 第1離散化部
340 第2算出部
350 第2離散化部
360 受付部
370 調整部
【技術分野】
【0001】
この発明は、処理対象データが所望のデータであるか否かを判定するフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置に関する。
【背景技術】
【0002】
従来より、ユーザが、所定の判定処理機能を持ったフィルタリング装置を利用すると、この利用結果をフィルタリング装置に学習させることによってフィルタリング機能を向上させるフィルタリング処理が広く提供されている。たとえば、フィルタリング機能の学習にベイジアンネットワークで用いられている学習方法を適用させたものがある。この学習方法では、学習対象のフィルタリング装置は、学習用の入力値として二値素性を必要とするため、連続値を所定の閾値によって離散化して入力値として与えられる。
【0003】
具体的に説明すると、まず、離散化に用いる閾値を決定するために、あらかじめ適当な閾値をいくつか設定しておく。そして、設定した各閾値を利用して連続値を離散化することにより二値素性を抽出する。その後、閾値ごとに、抽出された二値素性の出力確率を算出する。この算出結果から各カテゴリへの分類にとって効果のない素性を排除する。このような処理によって、二値素性の数を絞り込むことができるため、ベイジアンネットワークの学習方法を実行する際の計算量を削減することができる(たとえば、下記特許文献1参照。)。
【0004】
【特許文献1】特開2004−326465号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
一般的に、学習対象となるフィルタリング装置への入力値として二値素性を利用する場合、これらの二値素性の出力確率の分布を求めたとき、その分布が分散している値が、入力値として有用であるとされている。しかしながら、上記特許文献1に記載の技術を用いた場合、閾値ごとに算出された二値素性の出力確率の分布が偏ってしまうといった問題があった。
【0006】
また、上述の学習方法に限らず、閾値を用意して離散化した値を利用する場合、どのような閾値を設定するかが処理内容に大きく影響する。したがって、閾値の設定には事前の試行錯誤が欠かせない。また、学習の際、フィルタリング装置の判定傾向が大きく変わってしまった場合には、閾値の設定も見直さなければならない。このように、従来の学習方法を適用させたフィルタリング装置の場合、閾値設定にかかる処理がユーザにとって大きな負担となるという問題があった。
【0007】
この発明は、上述した従来技術による問題点を解消するため、設定処理の負担を軽減させ、かつ、効率的に処理精度を向上させるための学習をおこなう機能を備えたフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置を提供することを目的とする。
【課題を解決するための手段】
【0008】
上述した課題を解決し、目的を達成するため、請求項1の発明にかかるフィルタリング処理方法は、処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング処理方法であって、前記処理対象データを構成する要素を解析する解析工程と、前記解析工程によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出工程と、前記解析工程によって解析された各要素を、前記第1の算出工程によって算出された出力確率に基づいて有効値/無効値に離散化する第1の離散化工程と、前記第1の離散化工程によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出工程と、前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化工程と、を含むことを特徴とする。
【0009】
この請求項1の発明によれば、処理対象データを構成する要素の出力確率に基づいて、各要素を有効値/無効値の二値素性に離散化する。この離散化結果を用いて、処理対象データがユーザの所望のデータであるかを判定する。すなわち、ユーザが閾値などのパラメータを用意しなくとも算出結果を利用して離散化をおこなうことができる。また、第1離散化工程による離散化結果は、後段の第2の離散化に反映されるため、精度の高い判定処理が可能となる。
【0010】
また、請求項2の発明にかかるフィルタリング処理方法は、請求項1に記載の発明において、前記第2の離散化工程による判断の正誤を受け付ける受付工程と、前記受付工程によって誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整する調整工程と、を含むことを特徴とする。
【0011】
この請求項2の発明によれば、フィルタリング処理による判定結果が、ユーザの所望データと一致していなかった場合に、この誤判定の内容をフィードバックする。具体的には、第1の算出工程において算出される要素の出力確率が調整される。したがって、誤判定された処理判定データと同じ構成のデータのフィルタリング処理がおこなわれた場合には、当該データはユーザが所望するデータではないと判定するため、判定精度を向上させることができる。
【0012】
また、請求項3の発明にかかるフィルタリング処理方法は、請求項1または2に記載の発明において、前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素を任意の関数に写像して得られた値を用いて離散化をおこなうことを特徴とする。
【0013】
この請求項3の発明によれば、関数変換によって離散化対象の要素の出力確率分布の挙動が強調されるため離散化の調整が容易になる。
【0014】
また、請求項4の発明にかかるフィルタリング処理方法は、請求項1または2に記載の発明において、前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素の出力確率と、あらかじめ設定した閾値との比較結果から有効値/無効値に離散化することを特徴とする。
【0015】
この請求項4の発明によれば、最適な閾値が判別しているような場合には、この閾値を設定して離散化をおこなわせることができる。
【0016】
また、請求項5の発明にかかるフィルタリング処理方法は、請求項1〜4のいずれか一つに記載の発明において、前記解析工程では、前記処理対象データが電子メールデータである場合、当該電子メールデータのヘッダと本文に対して解析をおこなうことを特徴とする。
【0017】
この請求項5の発明によれば、不特定多数のメールが送信された場合であっても、フィルタリング処理方法を利用して、ユーザの所望しないメールを排除することができる。
【0018】
また、請求項6の発明にかかるフィルタリング処理プログラムは、処理対象データがユーザの所望するデータであるか否かをコンピュータに判定させるフィルタリング処理プログラムであって、前記処理対象データを構成する要素を解析させる解析工程と、前記解析工程によって解析させた各要素について前記処理対象データにおける出力確率を算出させる第1の算出工程と、前記解析工程によって解析させた各要素を、前記算出工程によって算出させた出力確率に基づいて有効値/無効値に離散化させる第1の離散化工程と、前記第1の離散化工程によって有効値/無効値に離散化させた要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出させる第2の算出工程と、前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化させることにより、処理対象データが所望のデータであるか否かを判定させる第2の離散化工程と、をコンピュータに実行させることを特徴とする。
【0019】
この請求項6の発明によれば、処理対象データを構成する要素の出力確率に基づいて、各要素を有効値/無効値の二値素性に離散化する。この離散化結果を用いて、処理対象データがユーザの所望のデータであるかを判定する。すなわち、ユーザが閾値などのパラメータを用意しなくとも算出結果を利用して離散化をおこなうことができる。また、第1離散化工程による離散化結果は、後段の第2の離散化に反映されるため、精度の高い判定処理が可能となる。
【0020】
また、請求項7の発明にかかるフィルタリング処理プログラムは、請求項6に記載の発明において、前記第2の離散化工程による判断の正誤を受け付ける受付工程と、前記受付工程によって誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整させる調整工程と、をコンピュータに実行させることを特徴とする。
【0021】
この請求項7の発明によれば、フィルタリング処理による判定結果が、ユーザの所望データと一致していなかった場合に、この誤判定の内容をフィードバックする。具体的には、誤判定に含まれている各要素について、第1の算出工程によって算出される出力確率が調整される。したがって、誤判定された処理判定データと同じ構成のデータのフィルタリング処理がおこなわれた場合には、当該データはユーザが所望するデータではないと判定するため、判定精度を向上させることができる。
【0022】
また、請求項8の発明にかかるフィルタリング装置は、処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング装置であって、前記処理対象データを構成する要素を解析する解析手段と、前記解析手段によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出手段と、前記解析手段によって解析された各要素を、前記第1の算出手段によって算出された出力確率に基づいて有効値/無効値に離散化する第2の離散化手段と、前記第1の離散化手段によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出手段と、前記第2の算出手段によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化手段と、前記第2の離散化手段による判断の正誤を受け付ける受付手段と、前記受付手段によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出手段にて算出される出力確率を調整する調整手段と、を備えることを特徴とする。
【0023】
この請求項8の発明によれば、処理対象データを構成する要素の出力確率に基づいて、各要素を有効値/無効値の二値素性に離散化する。この離散化結果を用いて、さらに出力確率が算出され、この算出結果を用いて再度離散化をおこなうことによって、処理対象データがユーザの所望のデータであるかを判定する。さらに、判定結果は、以後の離散化にフィードバックされる。すなわち、ユーザが閾値などのパラメータを用意しなくとも算出結果を利用して離散化をおこなうとともに、判定精度の向上も可能となる。
【発明の効果】
【0024】
本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置によれば、設定処理の負担を軽減させ、かつ、効率的に処理精度を向上させるための学習をおこなう機能を実現することができるという効果を奏する。
【発明を実施するための最良の形態】
【0025】
以下に添付図面を参照して、この発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置の好適な実施の形態を詳細に説明する。
【0026】
(フィルタリング処理の概要)
まず、本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置におけるフィルタリング処理の概要について説明する。図1は、本発明にかかるフィルタリング処理の概要を示す説明図である。
【0027】
図1では、まず、受信したメール101を解析部110によって解析する。そして、子フィルタ120と、親フィルタ130とのカスケードに接続された2種類のフィルタにメール101を入力し単一の判定結果を出力させる構成になっている。このとき、子フィルタ120は、ユーザ環境に合わせて設定された判定基準に基づいてメールのブロックをおこなう。一方、親フィルタ130は、未知のメールをブロックする。
【0028】
また、子フィルタ120と、親フィルタ130との2種類のフィルタを透過したメール101に対して、ユーザ102は、正しくフィルタリングされたか否かの判定をおこなう。ここで、フィルタ120,130による判定誤りがあった場合には、この判定誤り情報が、子フィルタ120にフィードバックされる。子フィルタ120は、フィードバックされた判定誤り情報に基づいて、判定基準を調整する。このフィードバックにより、子フィルタ120は、よりユーザ環境に合致した判定をおこなうようになる。
【0029】
以上説明したように、本発明のフィルタリング処理では、子フィルタ120は、フィルタリング処理をおこなうごとに、ユーザ判定情報によって処理内容が妥当であったか否かを学習することができる。その結果、子フィルタ120の処理能力は向上し、親フィルタ130による判定処理は、子フィルタ120の判定結果を追認する程度の役割となる。
【0030】
以下の実施の形態では、上述したようなフィルタリング処理を実行するフィルタリング装置を実現するための具体的な構成と、その処理内容について説明する。
【0031】
(フィルタリング装置のハードウェア構成)
まず、本実施の形態にかかるフィルタリング装置のハードウェア構成について説明する。図2は、本実施の形態にかかるフィルタリング装置のハードウェア構成の一例を示すブロック図である。
【0032】
図2において、フィルタリング装置200は、CPU(Central Processing Unit)201と、ROM(Read Only Memory)202と、RAM(Random Access Memory)203と、HDD(Hard Disc Drive)204と、HD(Hard Disc)205と、FDD(Flexible Disk Drive)206と、FD(Flexible Disk)207と、CD−RW(Compact Disc ReWritable)ドライブ208と、CD−RW209と、ディスプレイ210と、キーボード211と、マウス212と、ネットワークI/F(インタフェース)213と、通信ケーブル214と、プリンタ215と、バス220とを備えて構成されている。
【0033】
CPU201は、フィルタリング装置200全体を制御する。ROM202は、各種制御プログラムや本発明にかかるフィルタリング処理プログラムなどを格納する。RAM203は、可変的なデータを書き換え自在に記憶し、CPU201のワークエリアとして機能する。HDD204は、CPU201の制御にしたがってHD205に対するデータのリード/ライトを制御する。HD205は、HDD204の制御にしたがって書き込まれたデータを記憶する。
【0034】
FDD206は、CPU201の制御にしたがってFD207に対するデータのリード/ライトを制御する。FD207は、着脱自在であり、FDD206の制御にしたがって書き込まれたデータを記憶する。CD−RWドライブ208は、CPU201の制御にしたがってCD−RW(または、CD−R、CD−ROM)209に対するデータのリード/ライトを制御する。CD−RW209は、着脱自在であり、CD−RWドライブ208の制御にしたがって書き込まれたデータを記憶する。
【0035】
ディスプレイ210は、カーソル、メニュー、ウィンドウ、あるいは文字や画像などの各種データを表示する。キーボード211は、文字、数値、各種指示などの入力のための複数のキーを備える。マウス212は、各種指示の選択や実行、処理対象の選択、マウスポインタの移動などをおこなう。ネットワークI/F213は、通信ケーブル214を介してLAN、WAN、インターネットなどのネットワークに接続され、当該ネットワークとCPU201とのインタフェースとして機能する。プリンタ215は、文字や画像などの各種データを印刷する。バス220は上記各部を接続する。
【0036】
(フィルタリング装置の機能的構成)
つぎに、本実施の形態にかかるフィルタリング装置200の機能的構成について説明する。図3は、本実施の形態にかかるフィルタリング装置の機能的構成を示すブロック図である。図3に示すように、フィルタリング装置200は、解析部310と、第1算出部320および第1離散化部330からなる第1フィルタと、第2算出部340および第2離散化部350からなる第2フィルタと、受付部360と、調整部370とを含んで構成される。
【0037】
解析部310は、処理対象データ301を構成する要素を解析する。要素の解析とは、処理対象データを構成する連続値を所定の意味を持つ要素に分ける処理である。たとえば、文章を構成するテキストデータであれば、それぞれの単語の要素に解析する。また、解析部310は、たとえば、対象データが電子メールデータである場合、当該電子メールデータのヘッダと本文に対して解析をおこなうなど、処理対象データをフィルタリングする際の判定に影響する要素を含んだデータのみを解析対象としてもよい。
【0038】
第1算出部320は、解析部310によって解析された各要素について処理対象データ301における出力確率を算出する。このとき第1算出部320にて用いられる出力確率の算出手法は任意である。
【0039】
第1離散化部330は、解析部310によって解析された各要素を、第1算出部320によって算出された出力確率に基づいて有効値/無効値に離散化する。このとき、第1離散化部330は、各要素をたとえばシグモイド関数などの任意の関数に写像して得られた値を用いて離散化をおこなってもよい。このような関数を適用させることによって、出力確率の分布が強調され、有効値/無効値の判定を容易におこなうことができる。
【0040】
第1離散化部330では、上述したように、離散化に従来のような閾値の設定を必要としないが、ユーザがフィルタリング処理に適した閾値の情報を保有している場合には、この閾値を利用してもよい。このような場合、第1離散化部330では、各要素の出力確率と、あらかじめ設定した閾値との比較結果から各要素を有効値/無効値に離散化する。
【0041】
第2算出部340は、第1離散化部330によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する。また、第2算出部340による出力確率の算出手法は、第1算出部320と同様に任意であるが、第1算出部320と異なる算出手法が適用されている。
【0042】
第2離散化部350は、第2算出部340によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データ301が所望のデータであるか否かを判定する。この第2離散化部350によって所望するデータであると判定された場合、処理対象データ301は、ユーザに提供される。
【0043】
なお、第2離散化部350も、上述した第1離散化部330と同様に、任意の関数に写像して得られた値を用いて離散化をおこなってもよいし、フィルタリング処理に適した閾値の情報を保有している場合には、この閾値を利用してもよい。
【0044】
受付部360は、ユーザから処理対象データ301についてのユーザ判定情報302を受け付ける。ユーザ判定情報302とは、すなわち、第2離散化部350による判断の正誤をあらわす情報である。
【0045】
調整部370は、受付部360によって誤判定、すなわち、ユーザに提供された処理対象データ301がユーザの所望するデータではなかった旨の指示を受け付けた場合に、この誤判断を、以後の判定処理に反映させる。
【0046】
具体的には、誤判定とされた処理対象データ301を構成する各要素に関して、第1算出部320にて算出される出力確率を調整する。したがって、誤判断がなされた処理対象データを構成する要素(たとえば要素A)の出力確率が低くなり、以後フィルタリング装置200にて処理される処理対象データ201の場合、上述した要素Aは、以前よりも多く含まれていなければ高い出力確率とはならず、後段の第1離散化部330では、有効値として離散化されない。したがって、同じ構成の処理対象データが再度入力された場合には、第1離散化部330では、無効値として離散化され、ユーザの所望するデータは判別されなくなる。
【0047】
以上説明したように、各構成のうち、解析部310は、図1にて説明した解析部110に相当する。また、第1算出部320および第1離散化部330による第1フィルタによって、図1の子フィルタ120を構成する。そして、第2算出部340および第2離散化部350による第2フィルタによって図1の親フィルタ130を構成する。そして、受付部360および調整部370は、フィルタリング処理の精度を向上させるためのフィードバックをおこなう機能部となる。
【0048】
(フィルタリング装置の処理手順)
つぎに、本実施の形態にかかるフィルタリング装置200の処理手順について説明する。図4は、本実施の形態にかかるフィルタリング装置の処理手順を示すフローチャートである。図4のフローチャートにおいて、まず、フィルタリング装置200に処理対象データ301が入力されたか否かを判定する(ステップS401)。
【0049】
ステップS401において、処理対象データ301が入力されるまで待ち(ステップS401:Noのループ)、処理対象データ301が入力されると(ステップS401:Yes)、解析部310において、処理対象データ301の構成要素を解析する(ステップS402)。
【0050】
ステップS402において、各要素に解析されると、フィルタリング処理のために各要素を離散化する処理に移行する。まず、第1算出部320によって、処理対象データ301を構成する各要素の出力確率を算出する(ステップS403)。そして、第1離散化部330によって、ステップS403によって算出された出力確率に基づいた離散化をおこない(ステップS404)、第1フィルタにおけるフィルタリング処理が完了する。
【0051】
つぎに、第2算出部340によって、ステップS404によって離散化された各要素の離散化結果および処理対象データ301との出力確率を算出する(ステップS405)。さらに、第2離散化部350によってステップS405によって算出された出力確率から各要素を離散化し、処理対象データ301をユーザの所望するデータか否かの判定をおこない(ステップS406)、第2フィルタにおけるフィルタリング処理が完了する。
【0052】
以上説明したステップS406までの処理によって処理対象データ301に対するフィルタリング処理が終了する。フィルタリング装置200では、処理対象データ301に対するフィルタリング処理終了後、今回おこなったフィルタリング処理の正誤を自装置に反映させる処理に移行する。
【0053】
まず、受付部360によって、ステップS405にておこなわれた処理対象データ301に対する判定結果が正しいか否かの判断を受け付ける(ステップS407)。この正誤判断は、ユーザによっておこなわれる。ここで、判定結果が正しいとの判断を受け付けた場合には(ステップS407:Yes)、今回のフィルタリング処理に問題はなかったことになり、そのまま一連の処理を終了する。
【0054】
一方、判定結果が誤っているとの判断を受け付けた場合には(ステップS407:No)、今回のフィルタリング処理に問題があったため、その問題点を修正するため、調整部370によって第1算出部320における出力確率算出の設定を調整し(ステップS408)、一連の処理を終了する。
【0055】
以上説明したように、フィルタリング装置200では、複数のフィルタを直列に連結した場合に、それぞれでは独自の判定をおこなわせるが、後段の第2フィルタには、前段の第1フィルタの判定結果を処理対象データ201と併せて入力する。このような手順をとることによって、後段の第2フィルタは、自身の判定に加えて、第1フィルタの判定結果も取り入れることになる。
【0056】
さらに、ユーザがフィードバックをかけたいときは、前段の第1フィルタに反映され、次回からは、前回までの誤判定を起こさないような判定が可能となる。また、第1フィルタの判定結果が更新されると、自動的に第2フィルタの判定結果も更新されるため、フィルタ間の閾値や、判定結果の比較に相当する機能は、すべて第1フィルタによる出力確率算出処理の調整によって制御できることになる。
【0057】
(離散化の手法)
つぎに、第1離散化部330および第2離散化部350における離散化の手法について説明する。上述したように、第1離散化部330および第2離散化部350における離散化の手法に特に限定はない。ここで、簡易で効率的な手法の一例として、任意の関数に写像する手法を説明する。図5は、ある単語の出力確率を任意の関数により写像した図である。また、図6は、単語数ごとの出力確率を任意の関数により写像した図である。
【0058】
ここでは、図5や図6では、第1算出部320や第2算出部340(図3参照)にて算出された出力確率の確率値を元に、任意の関数によって写像した場合における、ある単語の出力確率の分布(図5)や、単語数に応じた出力確率の分布(図6)をあらわしている。
【0059】
また、図5、6における3種類の曲線(実線、破線、一点鎖線)は、それぞれ、適応させている関数の違いをあらわしている。たとえば実線の曲線は、出力確率が0.5より離れている場合、単語の確率がより強まるようなシグモイド関数であり、比較的標準的で癖のない挙動になると予想される。
【0060】
また、破線の曲線は、図5に示した単語の確率については線形だが、図6に示した単語数の場合、0.5付近から立ち上がりが急になっているため、学習結果が反映されやすいことをあらわしている。また、一点鎖線の曲線は、0に近いか、1に近いかによって偏りを持たせた関数となっている。この関数によると、1に近い判定ほど学習結果に反映されやすいことをあらわしている。このように、適用させる関数によって、学習傾向を解析的に制御することが可能となる。
【0061】
以上説明したように、本発明にかかるフィルタリング処理をおこなった場合、各フィルタの判定処理をおこなう際に、入力された処理対象データを利用(解析、出力確率算出など)して離散化をおこなう。したがって、従来のフィルタリング処理のような、ユーザによるパラメータの設定処理を大幅に簡略することができる。
【0062】
また、判定誤りがあった場合は、ユーザはフィルタリング処理に誤り内容をフィードバックする。したがって、フィルタリング処理は、学習され、次回の判定時にはより高精度な判定をおこなうことができる。
【0063】
以上説明したように、本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置によれば、設定処理の負担を軽減させ、かつ、効率的に処理精度を向上させるための学習をおこなう機能を実現することができる。
【0064】
また、本発明のフィルタリング処理は、上述したような電子メールのフィルタリングに適用する以外にも、スパムフィルタやWebフィルタとして適用させてもよい。また、フィルタリング機能を検索エンジンのプロファイルや、自然言語処理における学習機能の最適化などに適用させることもできる。
【0065】
なお、本実施の形態で説明したフィルタリング処理方法は、あらかじめ用意されたプログラムをパーソナル・コンピュータやワークステーションなどのコンピュータで実行することにより実現することができる。このプログラムは、ハードディスク、フレキシブルディスク、CD−ROM、MO、DVDなどのコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。またこのプログラムは、インターネットなどのネットワークを介して配布することが可能な伝送媒体であってもよい。
【産業上の利用可能性】
【0066】
以上のように、本発明にかかるフィルタリング処理方法、フィルタリング処理プログラムおよびフィルタリング装置は、連続値からなるデータのフィルタリング処理にて有用であり、特に、個々のユーザ環境に適応させる必要のあるメールフィルタに適している。
【図面の簡単な説明】
【0067】
【図1】本発明にかかるフィルタリング処理の概要を示す説明図である。
【図2】本実施の形態にかかるフィルタリング装置のハードウェア構成の一例を示すブロック図である。
【図3】本実施の形態にかかるフィルタリング装置の機能的構成を示すブロック図である。
【図4】本実施の形態にかかるフィルタリング装置の処理手順を示すフローチャートである。
【図5】ある単語の出力確率を任意の関数により写像した図である。
【図6】単語数ごとの出力確率を任意の関数により写像した図である。
【符号の説明】
【0068】
200 フィルタリング装置
201 CPU
202 ROM
203 RAM
204 HDD
205 HD
206 FDD
207 FD
208 CD−RWドライブ
209 CD−RW
210 ディスプレイ
211 キーボード
212 マウス
213 ネットワークI/F
214 通信ケーブル
215 プリンタ
220 バス
301 処理対象データ
302 ユーザ判定情報
310 解析部
320 第1算出部
330 第1離散化部
340 第2算出部
350 第2離散化部
360 受付部
370 調整部
【特許請求の範囲】
【請求項1】
処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング処理方法であって、
前記処理対象データを構成する要素を解析する解析工程と、
前記解析工程によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出工程と、
前記解析工程によって解析された各要素を、前記第1の算出工程によって算出された出力確率に基づいて有効値/無効値に離散化する第1の離散化工程と、
前記第1の離散化工程によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出工程と、
前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化工程と、
を含むことを特徴とするフィルタリング処理方法。
【請求項2】
前記第2の離散化工程による判断の正誤を受け付ける受付工程と、
前記受付工程によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整する調整工程と、
を含むことを特徴とする請求項1に記載のフィルタリング処理方法。
【請求項3】
前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素を任意の関数に写像して得られた値を用いて離散化をおこなうことを特徴とする請求項1または2に記載のフィルタリング処理方法。
【請求項4】
前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素の出力確率と、あらかじめ設定した閾値との比較結果から有効値/無効値に離散化することを特徴とする請求項1または2に記載のフィルタリング処理方法。
【請求項5】
前記解析工程では、前記処理対象データが電子メールデータである場合、当該電子メールデータのヘッダと本文に対して解析をおこなうことを特徴とする請求項1〜4のいずれか一つに記載のフィルタリング処理方法。
【請求項6】
処理対象データがユーザの所望するデータであるか否かをコンピュータに判定させるフィルタリング処理プログラムであって、
前記処理対象データを構成する要素を解析させる解析工程と、
前記解析工程によって解析させた各要素について前記処理対象データにおける出力確率を算出させる第1の算出工程と、
前記解析工程によって解析させた各要素を、前記算出工程によって算出させた出力確率に基づいて有効値/無効値に離散化させる第1の離散化工程と、
前記第1の離散化工程によって有効値/無効値に離散化させた要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出させる第2の算出工程と、
前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化させることにより、処理対象データが所望のデータであるか否かを判定させる第2の離散化工程と、
をコンピュータに実行させることを特徴とするフィルタリング処理プログラム。
【請求項7】
前記第2の離散化工程による判断の正誤を受け付ける受付工程と、
前記受付工程によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整させる調整工程と、
をコンピュータに実行させることを特徴とする請求項6に記載のフィルタリング処理プログラム。
【請求項8】
処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング装置であって、
前記処理対象データを構成する要素を解析する解析手段と、
前記解析手段によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出手段と、
前記解析手段によって解析された各要素を、前記第1の算出手段によって算出された出力確率に基づいて有効値/無効値に離散化する第2の離散化手段と、
前記第1の離散化手段によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出手段と、
前記第2の算出手段によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化手段と、
前記第2の離散化手段による判断の正誤を受け付ける受付手段と、
前記受付手段によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出手段にて算出される出力確率を調整する調整手段と、
を備えることを特徴とするフィルタリング装置。
【請求項1】
処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング処理方法であって、
前記処理対象データを構成する要素を解析する解析工程と、
前記解析工程によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出工程と、
前記解析工程によって解析された各要素を、前記第1の算出工程によって算出された出力確率に基づいて有効値/無効値に離散化する第1の離散化工程と、
前記第1の離散化工程によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出工程と、
前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化工程と、
を含むことを特徴とするフィルタリング処理方法。
【請求項2】
前記第2の離散化工程による判断の正誤を受け付ける受付工程と、
前記受付工程によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整する調整工程と、
を含むことを特徴とする請求項1に記載のフィルタリング処理方法。
【請求項3】
前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素を任意の関数に写像して得られた値を用いて離散化をおこなうことを特徴とする請求項1または2に記載のフィルタリング処理方法。
【請求項4】
前記第1の離散化工程および第2の離散化工程の少なくとも一方では、前記各要素の出力確率と、あらかじめ設定した閾値との比較結果から有効値/無効値に離散化することを特徴とする請求項1または2に記載のフィルタリング処理方法。
【請求項5】
前記解析工程では、前記処理対象データが電子メールデータである場合、当該電子メールデータのヘッダと本文に対して解析をおこなうことを特徴とする請求項1〜4のいずれか一つに記載のフィルタリング処理方法。
【請求項6】
処理対象データがユーザの所望するデータであるか否かをコンピュータに判定させるフィルタリング処理プログラムであって、
前記処理対象データを構成する要素を解析させる解析工程と、
前記解析工程によって解析させた各要素について前記処理対象データにおける出力確率を算出させる第1の算出工程と、
前記解析工程によって解析させた各要素を、前記算出工程によって算出させた出力確率に基づいて有効値/無効値に離散化させる第1の離散化工程と、
前記第1の離散化工程によって有効値/無効値に離散化させた要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出させる第2の算出工程と、
前記第2の算出工程によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化させることにより、処理対象データが所望のデータであるか否かを判定させる第2の離散化工程と、
をコンピュータに実行させることを特徴とするフィルタリング処理プログラム。
【請求項7】
前記第2の離散化工程による判断の正誤を受け付ける受付工程と、
前記受付工程によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出工程にて算出される出力確率を調整させる調整工程と、
をコンピュータに実行させることを特徴とする請求項6に記載のフィルタリング処理プログラム。
【請求項8】
処理対象データがユーザの所望するデータであるか否かを判定するフィルタリング装置であって、
前記処理対象データを構成する要素を解析する解析手段と、
前記解析手段によって解析された各要素について前記処理対象データにおける出力確率を算出する第1の算出手段と、
前記解析手段によって解析された各要素を、前記第1の算出手段によって算出された出力確率に基づいて有効値/無効値に離散化する第2の離散化手段と、
前記第1の離散化手段によって有効値/無効値に離散化された要素を、前記処理対象データを構成する要素に追加し、当該追加された要素を含んだ各要素の出力確率を算出する第2の算出手段と、
前記第2の算出手段によって算出された出力確率に基づいて前記各要素を有効値/無効値に離散化することにより、処理対象データが所望のデータであるか否かを判定する第2の離散化手段と、
前記第2の離散化手段による判断の正誤を受け付ける受付手段と、
前記受付手段によって受け付けた誤判定とされた処理対象データを構成する各要素に関して、前記第1の算出手段にて算出される出力確率を調整する調整手段と、
を備えることを特徴とするフィルタリング装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図2】
【図3】
【図4】
【図5】
【図6】
【公開番号】特開2009−140437(P2009−140437A)
【公開日】平成21年6月25日(2009.6.25)
【国際特許分類】
【出願番号】特願2007−318833(P2007−318833)
【出願日】平成19年12月10日(2007.12.10)
【出願人】(390024350)株式会社ジャストシステム (123)
【公開日】平成21年6月25日(2009.6.25)
【国際特許分類】
【出願日】平成19年12月10日(2007.12.10)
【出願人】(390024350)株式会社ジャストシステム (123)
[ Back to top ]