
マトリクスディスプレイの駆動方法
独立した画素(ij)を有する複数のラインを備えたマトリクスディスプレイ(D)の駆動方法であって、該ラインは行(i)及び列(j)として構成されており、個々のラインは、該行(i)を所定のロウアドレス時間(ti)の間アクティブ化し、該画素(ij)の所望の輝度(Dij)に対応する該アクティブ化された行(i)に対して相関関係を有する該列(j)に動作電流(I)又はそれに対応する電圧を印加することによって選択的に駆動される駆動方法を開示する。ディスプレイの性能を向上するために、各行(i)のロウアドレス時間(ti)は、該行(i)の全ての列の最大輝度(Dimax)の関数として決定される。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、独立した画素を有する行列状に構成された複数のラインからなるマトリクスディスプレイを駆動する方法であって、個々のラインは、所定のロウアドレス時間の間にアクティブ化される行によって選択的に駆動され、動作電流又はそれに対応する電圧つまり電気駆動信号が、画素の所望の輝度に応じて、アクティブ化された行に相関している列に印加されることを特徴とするマトリクスディスプレイを駆動する方法に関する。
【背景技術】
【0002】
以下のテキストにおいて、水平方向に延びたラインを行と呼び、行に対して直交する垂直方向に延びたラインを列と呼ぶ。これは、説明をわかりやすくするためである。しかし、本発明は、厳密にこの構成に限定されるものではない。具体的には、行と列の機能を交換すること、若しくは、行と列との関係として非線形の関係を選択することが可能である。
【0003】
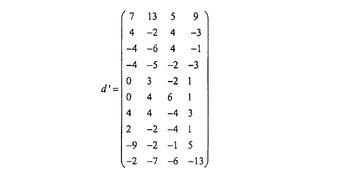
画像データ、つまり個々の画素ijの所望の輝度Dijは、以下に示す行列Dで説明する。
【数1】

【0004】
添字の数値は、マトリクス又はマトリクスディスプレイDによって与えられるディスプレイ上の画素の位置に対応している。マトリクスDの各行i及びマトリクスD上の各列jは、それぞれの場合において、ディスプレイ上の幾何学的行及び列に対応している。ディスプレイの画素を生成するために、画素ダイオード又は同様の素子が、マトリクスディスプレイDの各駆動可能画素ijに割り当てられる。各画素における時間平均した光強度(輝度Dijに対応)は、マトリクスD内の対応する素子に対応している。マトリクスDの全エントリが一体となり、表示しようとする画像を生成する。
【0005】
マトリクスディスプレイD上の画素ij(各々が具体的にはOLED(有機発光ダイオード)として構成され得る)は、一定の範囲内では行毎にアクティブ化されている。この目的のために、選択された行のOLEDは、スイッチによって、例えばグランドに接続されることによりアクティブ化される。動作電流Iは、列jの各々において印加され、この印加された電流により、この行i及び列jの交点に存在する画素ijが発光する。光強度Lは、第1の近似において、アクティブ相(ロウアドレス時間)の間に印加され且つOLED画素において放射再結合される電荷に比例する。比較的高いフレームレートでディスプレイマトリクス又はマトリクスディスプレイDをアドレシングする場合、ヒトの目は、以下の式に示す光の強度Lの平均値を認識する:
【数2】
【0006】
TFrameは、マトリクスディスプレイDのn行全てを一度にアクティブ化する場合に完全な画像を形成するのに必要な合計時間である。動作電流IOLED、I、又はI0が各画素に印加される。周波数変調を用いて輝度を制御する場合、ロウアドレス時間に対応する期間TFrame/nの間、動作電流はアクティブである。パルス幅変調を行うと、動作電流の長さは短くなり、すなわちd*TFrame/nとなる。ここで、dはパルス幅変調デューティ比であり、その範囲は0〜1である。
【数3】
【0007】
電流I0は、ここでは、画素の光強度に関係なく一定である。強度Lは、デューティ比dによって調節される。電子機器における時間単位は非常に正確に調節され、その結果、dの値も非常に正確なので、このタイプの輝度制御は、振幅変調と比べてより単純で且つより正確である。基準電流I0は、全ての画素ijを駆動するのに十分である。それに対して、振幅変調を行った場合、各ケースにおいて、振幅は所望の輝度Dijに応じて調節する必要がある。
【0008】
各ケースにおいて、1つの行iのみに対応する全ての列jを駆動することにより、各ダイオード又は各画素ijを、合計時間TFrameのn分の1の最大時間の間のみアクティブにし得る。規定された平均輝度Dijを達成するために、合計時間TFrameの間1つの画素に動作電流が供給される場合と比較して、対応する動作電流に行数nを乗じる必要がある。つまり、行数が増えるにしたがい、パルス状の動作電流I又はI0を増大させる必要がある。さらに、パルス幅変調を用いて輝度を調節する場合、駆動しようとする画素ijが非常に暗い場合であっても、動作電流は常に高い。この場合、動作電流の印加時間は非常に短い。
【発明の開示】
【発明が解決しようとする課題】
【0009】
しかし、高い動作電流を用いた結果、OLEDの寿命は著しく短くなり得る。必要な高さの動作電流を達成するために、OLEDの電圧を高くする必要もあり、その結果、消費電力が増大し、効率が低下する。この電力損失の増大により、充電池又は使いきり電池の放電がより速く進むだけでなく、ディスプレイの温度が上昇し、その結果、寿命も同様に低下する。
【0010】
にもかかわらず、大型で解像度の高いディスプレイを実現するために、LCD(液晶ディスプレイ)と同様に「アクティブマトリクス」を用い得、このことにより、動作電流はパルス状では供給されず、定電流として存在する。しかし、アクティブマトリクス駆動(TFTバックプレーン)は、OLEDディスプレイのためにかなりの追加コストを要求する。
【0011】
本発明の目的は、冒頭で述べたタイプに対応するマトリクスディスプレイを駆動する方法であって、OLEDディスプレイの寿命を長くし得るか又は任意のマトリクスディスプレイの性能を向上し得るような駆動方法を提案することである。
【課題を解決するための手段】
【0012】
この目的は、各行iのロウアドレス時間tiが、該行iの全ての列jの最大輝度Dimaxの関数として決定されることを特徴とする本発明により達成される。ロウアドレス時間tiは、動作電圧を印加して最大画素輝度Dmaxが達成される長さだけマトリクスディスプレイの各行がアドレシングされる場合に生成される一定のロウアドレス時間tL以下の長さになるように選択され得る。本発明によると、ロウアドレス時間tiは、該一定のロウアドレス時間tLに行iの全ての列jにおける画素の最大輝度Dimaxのマトリクスディスプレイ全体における可能最大画素輝度Dmaxに対する比を乗算した結果に対応する。
【0013】
最大輝度値Dmaxは、1つの画素ijに動作電流I0が一定のロウアドレス時間tLだけ印加される場合に得られる、当該画素における光強度(輝度)として規定される。この結果、全ての行(n行)に亘るロウアドレス時間tiの合計時間TSumがn行全てをアクティブ化する合計時間TFrame以下になる(アクティブ化はn×一定のロウアドレス時間tL)。動作電流I0が一定の場合、本発明によると、マトリクスディスプレイを駆動する合計時間は、合計時間TSum<ロウアドレス時間のTFrameとなるように低減され得る。これにより、例えば、より高いフレームレートが可能になり、マトリクスディスプレイの達成可能な性能が向上する。
【0014】
第1の近似における画素ijの光強度は画素ijに印加される電荷に比例する、つまり、ロウアドレス時間tiと動作電流との積に比例するので、ある行の複数の列に亘りロウアドレス時間tiが最大輝度に応じて変化することを利用して、動作電流を低減することもできる。この目的のために、全ての行nに亘るロウアドレス時間t’iの合計が合計時間TFrameに対応するように、全ての行iをアクティブ化するための合計時間TFrameを一定に維持できる。したがって、ロウアドレス時間t’iは、本発明の方法のこの変形例にしたがって、その合計が合計時間TFrameに等しくなるように延長される。同時に、本発明によると、全ての行nの(完全に必要な)ロウアドレス時間tiの合計時間TSumの一定のロウアドレス時間tLで全ての行をアクティブ化するための合計時間(TFrame)に対する比により動作電流I0を低減して、動作電流I1とすることができる。ロウアドレス時間と動作電流との積ti*I0=t’i*I1は一定に維持されるので、個々の画素の光強度は変化しない。OLEDの場合、より低い動作電流範囲における量子効率ηは、原則として、より高い動作電流での量子効率よりも大きい。したがって、動作電流I1は、量子効率の比η(I1)/η(I0)によりさらに低減され得る。簡潔に説明するため、以下の説明では、(TFrameに延長又は標準化された)ロウアドレス時間t’iをtiと呼ぶ。
【0015】
本発明による、ロウアドレス時間tiのダイオード画素のアドレシングへの適合により、ディスプレイDの個々のダイオード画素ijの選択的位相(ロウアドレス時間)、つまり、動作電流Iがダイオード画素ijに印加される時間を、かなり長くすることができる。アクティブの動作電流I1は、選択された位相の長さに反比例して低減され得る。マトリクスディスプレイDの効率は全体として向上し得、特にOLEDディスプレイの場合、寿命が延び得る。したがって、本発明の基本的なアイデアは、行に基づく短縮又はロウアドレス時間の適合によって動作電流の長さを延長する点にある。電荷は規定された光強度に対して何よりも重要なので、動作電流の印加時間が長くなるということは、電流の振幅が低減されるということを意味する。
【0016】
マトリクスディスプレイDを、個々に駆動される複数のマトリクスS,Mに分解した場合、向上した取り扱い及び動作電流のさらなる低減が達成され得る。全てのマトリクスを重ね合わせることにより、それぞれの画素ijの所望の輝度Dijで、マトリクスディスプレイDの画像が生成される。複数のマトリクスのそれぞれの輝度Sij,Mijの合計から得られる合計輝度Dijは、画素ijにおけるマトリクスディスプレイDの所望の合計輝度Dijに対応している必要がある。本発明によると、マトリクスは、好適には各ケースにおいて行単位又は列単位で上記方法を用いて、次々と表示され得るか又は互いに入れ子状に組み合わされ得る。2つのマトリクスに分割して、一方のマトリクスSが1つの行iの駆動を提供し、他方のマトリクスM2が2つの行iの同時駆動を提供する場合、マトリクスS,M2の行は、交互にアドレシングされる。OLEDディスプレイ又はLCD等のパッシブマトリクスディスプレイ型の場合、マトリクスディスプレイD内に表現されるソース画像は、複数の画像マトリクスに分解され得る。これらの得られたマトリクスの各々は、例えば以下に説明するマルチラインアドレシングによって、画像の合計が、元のマトリクスDに基づいてディスプレイを直接駆動する場合よりも良好に実施されるように、当該ディスプレイ型に対して良好に実施される必要がある。
【0017】
本発明によると、複数の行iが同時に駆動されるという前提である限り、駆動される行iの各列jにおける画素ijは、各ケースにおいて、同じ信号及び同じ光強度を有する。画素ijの光強度が1つの行iだけを駆動した場合の光強度に対応するように、動作電流I0,I1は、同時に駆動される行の数に対応する倍数分だけ増加される。つまり、2つの行が同時に駆動される場合、2倍に増加される。複数の行の同時駆動を、「シングルラインアドレシング(SLA)」と呼ばれる1行だけの駆動と区別して、「マルチラインアドレシング(MLA)」と呼ぶ。
【0018】
複数の行が同時に駆動される場合、好適には、隣り合う行(i,i+1)が駆動され得る。しかし、本発明によると、好適には、互いから数行離れた行iを同時に駆動することも可能である。例えば、1行おきに存在する行を同時に駆動することができる。同時に駆動される行が近位に存在することが特に賢明である。なぜなら、マトリクスディスプレイDの画像内で隣り合う行は、多くの場合、同様の輝度分布を有するからである。
【0019】
複数の行が同時に駆動される場合に個々の行及び/又は列の間に強度の差を生じることができるように、本発明によると、1つの行(i)が駆動されるマトリクス(S)と複数の行(i)が駆動される1つ又は複数のマトリクス(M2,M3,M4)を互いに組合せ得る。マトリクスSにシングルラインアドレシングを適用することにより、所望の輝度Dijが各画素ijについて独立して適合され得る。このマトリクスSを、残留シングルラインマトリクスと呼ぶ。
【0020】
本発明によると、輝度を制御するために、パルス幅変調を用い得る。つまり、例えば、ロウアドレス時間tiの間にロウアドレス時間tiの一部の間だけ動作電流Iを印加し、ロウアドレス時間tiの残りの時間の間は動作電流Iはオフに切り替えられる。
【0021】
あるいは、輝度を制御するために、振幅制御を用い得る。つまり、動作電流Iの振幅を、所望の輝度Dijに対応するように適合させる。本発明によると、輝度を制御するために、パルス幅変調及び振幅変調を互いに組み合わせることもできる。これは、輝度Dijが量子化された段階として予め規定されている場合に特に有利である。なぜなら、動作電流の振幅は量子化された段階にしたがって低減可能であり、一方で、パルス幅のデューティ比がこれに対応して増加するからである。この駆動は、各種機器において特に単純に実施され得る。1つの列jにおいて動作電流Iを印加する時間がパルス幅デューティ比の増加後にロウアドレス時間tiを越えない場合、この組み合わせた方法を特に柔軟に用いることができる。したがって、振幅変調をパルス幅変調と組み合わせる決定は、これに必要な動作電流印加時間及びマトリクスディスプレイDの各行i及び列jに割り当てられたロウアドレス時間に応じて個々に為し得る。組み合わされたパルス幅変調及び振幅変調を用いる場合、振幅は量子化された段階にしたがって低減され、一方、これに応じてパルス幅変調デューティ比が増大する。量子化は、マルチラインアドレシングも実施し得る複数のトランジスタセルを用いて実施され得る。
【0022】
マトリクス画素を駆動するために用いるマトリクスを生成するために、好適な実施形態によると、マトリクスディスプレイを、それぞれの列の個々の画素の輝度又は輝度の差についてのデマンドに対応するエントリとして頂点を有するフローマトリクスに変換することが提案される。このことは、上記方法が実施され且つ個々の処理工程を実行する適切なプロセッサ手段を有する適切な制御システムを用いて行われ得る。また、このタイプの制御システムは、本発明の主題を構成する。この変換により、公知のMaxFlow/MinCut原理に基づく組合せ方法を用いてマトリクス分解を実行することができる。このタイプの組合せアルゴリズムのハードウェアの実施費用は低いことが知られている。さらに、組合せアルゴリズムは、素早く処理され得るので、これらのアルゴリズムは、マトリクスディスプレイを制御するのに特に適している。
【0023】
フローマトリクスが2つのマトリクス(第1のマトリクスは、マトリクスディスプレイ及び該マトリクスディスプレイの末尾に取り付けられたゼロエントリを有する行からなり、第2のマトリクスは、マトリクスディスプレイ及び該マトリクスディスプレイの上流側に取り付けられたゼロエントリを有する行からなる)の差分から生成される場合、それが有利であることが証明されている。マトリクスをマルチラインマトリクス及び(残留)シングルラインマトリクスに分解する場合、列の個々の画素の輝度の差分を最適に隠すのが重要である。本発明により提案されるフローマトリクスは、列における画素間の差を説明するものであり、組合せ方法を用いた最適化のための基板又は最適な開始点を提供する。
【0024】
本発明によるフローマトリクスにおいて、頂点は、好適には、弧と呼ばれる、割り当てが指定された、好適にはその長さに応じて複数の別個に駆動されるマトリクス(例えば、S,M2,M3,M4)のエントリに対応し、マトリクスディスプレイが上述のように分解され得る矢印によって繋がれている。それにより、マトリクスの分解は、フロー最適化へと完全に変換される。フロー最適化の結果、つまり、弧の割り当ては、直接的には、シングルラインマトリクス及びマルチラインマトリクスS,M2,M3,M4等の対応するマトリクス要素である。
【0025】
フロー最適化のために、特にパッシブマトリクスディスプレイを駆動する場合、容量又は容量値を関係するマトリクス(S,M2,M3,M4)の各行に対して指定するのが有利である。容量値は、それぞれの行の最大画素値に対応する。全ての容量の合計を最小化する必要がある。
【0026】
公知のMinCut法又はMaxFlow法の場合、容量は一定に維持され且つフローは最大化されるが、本発明の方法では、フローはソースマトリクス(マトリクスディスプレイD)から得られるので、予め規定されている。最適化の目的は、全ての容量の合計を最小化することである。したがって、本発明によると、容量は変動可能であるように設計される。容量は、全てのフローが均一又は平衡になるまで、以下に説明する戦略にしたがって増加する。その後、弧の有効な割り当てが達成され、マトリクスの分解が完了する。容量値の合計が最小か又は非常に小さいと仮定し得る。理論上の最小値と容量値の合計との比を、最適化の質と呼ぶ。容量値を増加させるために必要な反復の回数を低減するために、弧の割り当てを、初期化における開始値として生成し得る。
【0027】
本発明によると、反復のたびに、有効な解決を妨げるボトルネックとなる容量が選択され増加される。この弧のセット(最小カット(MinCut)とも呼ぶ)は、増加させる容量についての選択基準として使用され得る。
【0028】
さらに、先行するMinCutの情報は、本発明によると、選択基準として使用可能であり、最後の反復のMinCutが重み付けされ得る。このことにより、素早く効率的な解決が可能になる。
【0029】
反復を促進するために、容量値を増加させる増加幅の大きさは、動的に適合され得る。それにより、最小の増加幅の大きさ「1」に対して、最適化の品質をほとんど低下することなく、必要な反復の回数を少なくすることができる。
【0030】
計算速度を向上し且つ要求されるメモリサイズを低減するために、マトリクスディスプレイを複数のより小さなサブマトリクスに分割し得、これらサブマトリクスをフローサブマトリクスへと個々に分解し得る。このタイプの最適化は局所最適化と考えられ、一方、一回の最適化におけるマトリクスの分解は全体最適化と考えられる。比較的小さなマトリクスを最適化する場合はかなり低減された回数の反復で済むので、S,M2,M3,M4等の結果を、これらのマトリクスのためにバッファメモリを設ける必要なく、出力ドライバ用のレジスタに行単位で直接転送することもできる。これにより、メモリにかかる費用はかなり低くなる。
【0031】
さらに、本発明による、1行又は数行のマルチラインマトリクス(M2,M3,M4)並びに/若しくは残留シングルラインマトリクス(S)がフローサブマトリクスから得られる混合型局所・全体最適化を実施し得る。これにより、局所・全体最適化つまり速度及びメモリサイズについての要件と、最適化の質との間で、良好な妥協が達成される。結果は行単位又はサブマトリクス単位で出力され、マトリクス全体を格納するためのメモリサイズは必要無い。
【0032】
上記方法の好ましいアプリケーションは、自己発光ディスプレイ(例えばOLEDディスプレイ)又は非自己発光ディスプレイ(例えばLCD)の駆動である。マトリクスディスプレイの駆動には関係のない、上記方法の本発明によるさらなるアプリケーションは、概して、マトリクス(例えばCCDカメラにおけるセンサマトリクス)の読み出しに関する。
【0033】
本発明のさらなる利点、特徴及びアプリケーションは、例示実施形態についての以下の説明及び図面において見つけ得る。説明する特徴及び/又は図で示す特徴は、それらがどのように特許請求の範囲において記載されているかやそれらの参照には関係なく、本発明の主題を構成するものである。
【発明を実施するための最良の形態】
【0034】
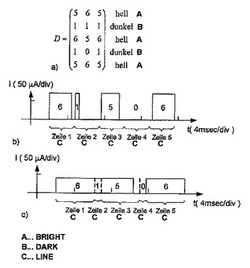
図1は、4行i×4列jからなるマトリクスディスプレイDを模式的に示す。マトリクスディスプレイDは、したがって、合計で16個の画素ijを有し、各画素は輝度Dijを有する。各画素ijは、1つの四角いマスで示され、そのマスの中の数値がデジタル輝度値Dijを示す。画素値「0」は暗画素ijを示し、画素値「1」は低輝度の明画素ijを示し、画素値「2」は高輝度の明画素ijを示す。
【0035】
図1a)は、十字形が見えるマトリクスディスプレイDを示す。低輝度の画素ij=23が十字形の中心であり、そのアーチ部分に4つの明画素が存在する。従来のシングルラインアドレシング(SLA)において、マトリクスディスプレイDは、値「1」(任意単位)で示された一定のロウアドレス時間tLの間、第1〜第4の行が連続的にアクティブにされるように駆動される。第1の行がアクティブである間、動作電流Iが第3の列に印加され、この電流が、所望の輝度「2」に対応する電荷を画素ij=13に与える。ロウアドレス時間tL=1の後、処理は第2の行に切り替わる。第2の行において、第2及び第4の列には輝度「2」に対応する動作電流Iが供給され、これと同時に、第3の行には輝度「1」に対応する動作電流Iが供給される。非自己発光型ディスプレイの場合、個々の列における駆動のために印加される電圧のために、類似の動作が行われる。典型的なアプリケーションは、LCD(液晶ディスプレイ)である。
【0036】
さらなるロウアドレス時間tL=1の後、第3の行が第1の行と同様に駆動される。最後に、第4の行が、さらなるロウアドレス時間tL=1の間アクティブになる。しかし、この行は完全に暗い、つまり第4の行が選択された段階(第4の行のロウアドレス時間)の間、第1〜第4の列のいずれにおいても、画素ijに動作電圧が印加されない。
【0037】
合計時間TFrame=4*tLの後、イメージマトリクスDの全ての画素ijは一度駆動されたことになる。ヒトの目は、連続的に照明された画素ijを、1つの全体的な画像に統合する。
【0038】
この従来のシングルラインアドレシングを用いたマトリクスディスプレイDを駆動する方法を、図1b)に示すように本発明によって、各行iに対するロウアドレス時間tiが、全ての列jと当該行iとの交点における全画素の最高輝度Dimaxの関数として規定されるように改変する。この方法は、以下の説明において、「改良シングルラインアドレシング(ISLA)」とも呼ぶ。ロウアドレス時間tiは、この場合、4つの行全てに亘るロウアドレス時間tiの合計TSumが合計時間TFrame=4*tLに対応するように設定される。
【0039】
ロウアドレス時間tiを設定する場合、以下のような処理を行い得る。全列の最高輝度Dimaxは、初めの3つの行ではそれぞれ「2」であるので、これらの行に対するロウアドレス時間tiは互いに等しくする必要がある。第4の行において、最高輝度は「0」であるので、この行は全く駆動する必要が無く、ti=0が選択され得る。したがって、合計時間TFrame=4*tLは、3つのロウアドレス時間tiに分割できるので、第1〜第3の行に対して、一定のロウアドレス時間tLよりも1/3長いti、すなわち、
【数4】
が選択され得る。したがって、初めの3つの行はそれぞれ、図1a)の駆動方法と比べて1/3長くアクティブにすることができる。OLEDディスプレイにおける光強度は、印加された動作電流とロウアドレス時間との積によって得られる、OLEDに印加される電荷に応じて変化する。したがって、同じ統合輝度値Dijを得るためには、動作電流は1/4だけ減少させることができ、
【数5】
となる。tLとI0との積は、tiとI1との積に等しい。このことは、図2a)と図2b)とを比較することによっても理解され得る。図2は、図1の駆動方法において、第1〜第4の行に亘って第3の列に印加される動作電流と、それに比例する動作電圧とを図示している。印加される電流(又はそれに対応して印加される電圧)は、ロウアドレス時間の間プロットしている。図2a)で理解され得るように、図示した空欄1つの幅は、上述の例において標準化変数として用いた一定のロウアドレス時間tLに直接対応している。1つの空欄は、1つの行のアクティブ時間に対応している。4つの空欄からなる合計幅は、マトリクスディスプレイの1面の画像が完全に構成される合計時間TFrameに対応している。
【0040】
図2a)において、公知のシングルラインアドレシングに用いる電流波形を説明する。第1のラインにおいて、所望の輝度「2」に応じて電流は最大である。明瞭に説明するため、第3の列と第1のラインとの交点の画素について関連する駆動パルス(電流×時間)に斜線で網掛けした。このことは、図2b)及び図2c)にもそれぞれ適用される。輝度値が「1」である第2の行において、電流は半分である。第3の行において、輝度値「2」を得るために電流は再び最大である。画素がオフに切り替えられた最後の行において、電流はオフに切り替えられる。このタイプの駆動は、振幅変調に対応している。
【0041】
図2b)は、本発明による改良型シングルラインアドレシングに用いる電流波形を示す。上述のように、ロウアドレス時間tiは、1/3だけ延長されている。このことを波線で示している。第4の行は、全くアクティブ化されていない。画素ijの輝度は、時間に対して積分された電流(動作電流)によって決定される印加電荷量に比例する。図2b)において理解できるように、図2b)における電流曲線の下の面積は、図2a)における電流曲線の下の面積に等しい。それに対して、電流(及びそれぞれの印加電圧)はそれぞれ1/4に低減され得る。このことは、OLEDの寿命にとって有利である。
【0042】
本発明のさらなる実施形態を、図1c)を参照して説明する。この駆動方法では、複数の行が同時に駆動される(マルチラインアドレシング)。この例では、第1、第3の行にそれぞれ、第3の列に輝度「2」である画素を生じる必要がある(図1a)参照)。2つの行が組み合わされているので、ロウアドレス時間が2倍になり得る。動作電流(及びそれぞれの対応する電圧)は、それに対応して、各画素について1/2にされる(1つの画素については図2c)参照)。
【0043】
図1d)に示すように、図1c)を参照して説明したマルチラインアドレシング法を、図1b)の改良型シングルラインアドレシングと組み合わせるのが特に有利である。マルチラインアドレシングでは全てのアクティブ化された行が同一の様態で駆動されるので、マルチラインアドレシングで任意の画像を生成することができる。残りの差分及び/又は残りの行は、改良型シングルラインアドレシング(MISLA)によって均一にされ得る。
【0044】
図1d)において、図1a)における第2の行は、第2のマトリクスの分離駆動によって生成される。このことは、マトリクスディスプレイDを、それぞれ独立して駆動されるが一体となってマトリクスディスプレイDの所望の画像を生成する複数のマトリクスに、分解することに対応している。駆動は、ヒトの目が各行及び/又はマトリクスを順次駆動する処理を分離することができずに、それらをまとめて1つの全体的な画像を形成するような、速い時間サイクルで行われる。したがって、複数のマトリクスを駆動に用いる場合、1つの画像を完成するのに必要な合計時間TFrameが長くなってはならない。全てのマトリクスにおいて駆動しようとする全ての行をアクティブ化する合計時間TFrameを一定に維持し、それに応じた各ロウアドレス時間tiを採用するのが有利な手順である。この場合、1つの行に対するロウアドレス時間tiは、各行における列の最高輝度に応じて、別の行のそれとは著しく異なり得る。しかし、このことは、ここで説明している例においては起こらない。
【0045】
図1c)及び図1d)によるマトリクスの組み合わせについて、以下の方法が得られる。駆動のためには、正確な1期間のロウアドレス時間が、マトリクス毎に必要である。得ようとする最高輝度Dijはそれぞれ等しい。このことは、合計時間TFrame=4*tLを得るために、2つの等しいロウアドレス時間ti=2*tLが必要であることを意味する。図1c)のシングルラインアドレシングに対してロウアドレス時間が2倍になるのに応じて、各々の画素ijに対する動作電流又は電圧は半分になり得る。2ラインアドレシングの場合、複数の行の列毎の駆動の回路設計が並列回路に対応し、したがって、印加動作電流が全てのアクティブ化された行の画素に均等に分配されるということを考慮する必要がある。マトリクスにおける2ラインアドレシングの場合、各画素において同じ動作電流が利用可能となるように、印加動作電流を2倍にする必要がある。
【0046】
図1c)及び図1d)による組み合わせ駆動のための電流分配は、図2c)において理解され得る。ここでは、マトリクスディスプレイDの輝度を低下させることなく、最大動作電流がさらに低減されている。
【0047】
図1及び図2を用いて説明する駆動方法は、実際のアプリケーションと比べてはるかに単純化された構成を示すが、基礎となるアイデアを説明するのには十分である。本発明によると、この方法は、従来の方法又は公知の方法の要素、例えばプリチャージ技術及び放電技術などと組み合わせるのが有利であり得る。
【0048】
マトリクスディスプレイ駆動のより複雑な例を以下に説明するが、以下に説明する特徴の全てが本発明の主題を形成し且つ本発明の一部をなすものである。
【0049】
まず、図3に示すマトリクスディスプレイDの特性から説明を始める。マトリクスディスプレイの輝度Dijは、デジタル値で与えられ得る。値「0」はオフに切り替えられた画素を意味している。マトリクスにおける最高輝度はDmaxである(例えば、8ビットの場合は値「255」)。対応する動作電流はI0である。I0のレベルは、アプリケーションによって予め規定されているか又は調節される。それは、ディスプレイの所望の輝度を示す。
【0050】
従来技術に対応する前述のSLA(シングルラインアドレシング)法によると、フレーム期間(合計時間TFrame)内の各行は、均等な、固定された、又は一定のロウアドレス時間tLを割り当てられる。この期間内に最高輝度Dmaxが生成され得る。正確な輝度1ビットに対して、それに対応する時間サイクルt0は、
【数6】
となる。
【0051】
特定の輝度が、輝度制御の間に、パルス幅変調(PWM)によって時間サイクルt0の数に変換される。最高輝度について、ロウアドレス時間ti=Dmax*t0に対して動作電流I0が流れる。
【0052】
本発明において、ある行に必要な選択期間、つまり、この行について選択されたロウアドレス時間tiは、選択された行iの全ての画素ijの最高輝度Dijによって決定される。この行における最高輝度がDmax未満の場合、次の行がより早くアクティブ化され得る。つまり、選択されたロウアドレス時間tiをtLよりも短くし得る。したがって、1つの画像を形成するのに必要な合計時間は、
【数7】
となる。この式中、
【数8】
は、1つの行の最高輝度Dimaxの、全ての行に亘る合計である。したがって、Dimaxは、行iにおける全ての列の最高輝度である。
【0053】
この時間TSumは、合計時間TFrame以下であり、動作電流I0を動作電流I1に低減することによりTFrameに延長することができる。所望の輝度に適合される動作電流I1は、以下の式によって与えられる。
【数9】
すなわち、低減された動作電流I1は、ある行のアクティブな又は選択された段階(ロウアドレス時間ti)がtLに拘束されない、ということで得られている。その代わり、各行iは、この行における輝度Dimaxを有する最も明るい画素ijがそれを要求する限りにおいて、アクティブな状態を維持する。最も明るい画素について要求される時間に達すると、処理は直ちに次の行へと切り替わる。
【0054】
本発明によると、この時間最適化された制御方法を用いた場合、動作電流I1及びロウアドレス時間tiに対する時間サイクルが可変である。動作電流はI1に低減され、正確な輝度1ビット(LSB;最下位ビット)に対する時間サイクルは、t0からt1へと増加する:
【数10】
【0055】
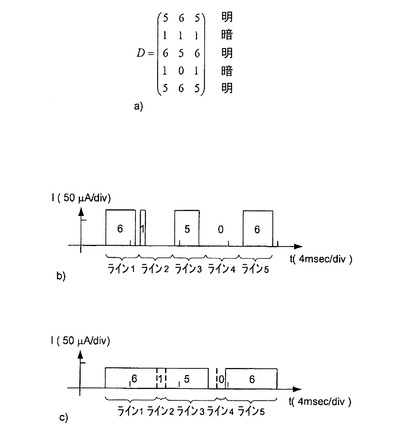
これの簡単な例を図3に示す。図3a)のマトリクスディスプレイの画像を、個々の画素位置ijにおいて輝度値Dijを含むマトリクスDを示す図1に対応付けて説明する。
【0056】
マトリクスDは、3本の明ストライプとその間にそれぞれ存在する暗ストライプとを示している。単純に示すために、3ビットまでのグレイスケール(最高輝度Dmax=7)を仮定している。したがって、マトリクスディスプレイDは、全体で5つの行及び3つの列を含む。
【0057】
図3b)及び図3c)に、第2の列において印加される(動作)電流の遷移波形を示す。図3b)は、従来のシングルラインアドレシング(SLA)における電流波形を示す。それと比較する形で、本発明による改良型シングルラインアドレシングの遷移波形を図3c)に示す。
【0058】
シングルラインアドレシング(図3b))の場合、電流振幅は例えば70μAで一定であり、各行は一定のロウアドレス時間tL=2.8msecの間アクティブであるが、改良されたシングルラインアドレシング(図3c))の場合、電流振幅は40μAである。第1、第3及び第5の行はそれぞれ、4.2msecの期間(ロウアドレス時間ti)の間アクティブであり、第2の行及び第4の行は、0.7msecの期間(ロウアドレス時間ti)の間アクティブである。
【0059】
マトリクスD全体を駆動するために同じ様態で用いる動作電流I1及び正確な輝度1ビットに対する時間サイクルt1は、表示しようとする画像に応じてそれぞれ変化する。パッシブマトリクスOLEDの場合、ダイオード電流は多重モード(multiplex mode)のために非常に高いので、単位電流あたりの量子効率又は光強度は比較的低い。量子効率は、動作電流の減少に応じて向上する。この結果、動作電流はさらに低減される。
【数11】
η(I)は電流Iに対する量子効率であり、単位Cd/Aで示している。量子効率のプロフィールは、ガンマテーブルに格納されており、上記方法を実施する本発明の駆動電子機器によって上記計算のために使用し得る。
【0060】
公知の駆動方法と比べて動作電流I1が低減されるので、OLEDダイオードのフロー電圧(flow voltage)も低下する。消費エネルギはフレーム期間における電流と電圧の積の積分に等しいので、単位Lm/Wの効率も向上する。より高い効率が達成されたということは、ディスプレイの自己加熱が低下したということであり、この結果ディスプレイの寿命が延びる、ということを意味する。
【0061】
この方法の実施コストは低い。なぜなら、ディスプレイの動作電流I1は1度だけ設定すればよく、時間サイクルt1は設定が容易だからである。
【0062】
上で説明した駆動法の変形例において、行の最大輝度Dimaxの合計DSumは、予め規定された不変の量である。マトリクスにおいて複数の行を組み合わせて同時に駆動する場合、DSumを最小化するか又はさらに低減する可能性がある。ロウアドレス時間tiの間、複数の行を同時に選択して、画像マトリクス全体を駆動するのに必要な時間が全体として低減することができる。これにより、動作電流もさらに低減することができる。
【0063】
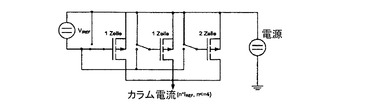
図4は、どのようにして2つの行Ri,Ri+1を同時にアドレシングするかを示す回路図である。ここで、印加されたカラム電流は2*I1であり、各行Ri,Ri+1の2つのダイオードに均等に分配される。残りの行のダイオードはパッシブであり、寄生容量Cpのみを示している。同時にアドレシングされる行におけるある列の各ダイオードは、それぞれ同じ電流が印加されるので、光強度が等しい。したがって、シングルラインアドレシングとは異なり、駆動される画素において同じ輝度を得るために、2つの行に対して1つのロウアドレス時間tiだけでよい。
【0064】
このアプローチは、2を越える行数の行が同時にアドレシングされる際にもあてはまる。組み合わされる行数が増えるにしたがい、より多くの時間が節約される。これを、マルチラインアドレシングと呼ぶ。
【0065】
しかし、ここでは、複数の行におけるある列の複数の画素が均等に駆動されるので、複数の行の組み合わせは容易に可能ではない。したがって、輝度については、これらの画素の間に差はなく、よって、差情報が失われるか、又は、解像度が低下する。
【0066】
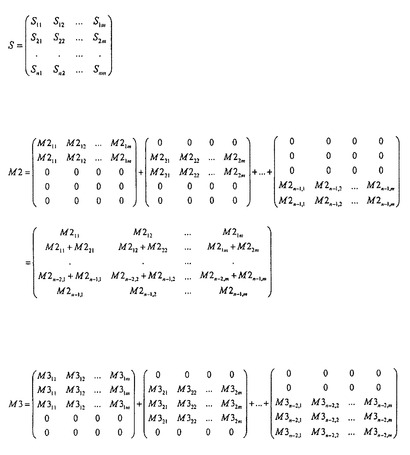
この問題は、所望のマトリクスディスプレイDを複数のマトリクスに分解することによって、マルチラインアドレシング(MLA)を上記のように最適化された改良型シングルラインアドレシング(ISLA)と組み合わせることによって解決する。すなわち、異なるマトリクスS,Mにおけるある行が単独で且つ他の行と一緒にアドレシングされる。マルチラインアドレシングでは一緒に駆動される、異なる行におけるある列の画素間の光強度の差は、マトリクスSを用いて改良型シングルラインアドレシングによって実現される。マルチラインアドレシングは、必要な合計時間TSumを最小化する。マトリクスディスプレイDのシングルラインマトリクスS及びマルチラインマトリクスMへの変換は、数学的には以下のように示される:
【数12】
式中、M2は2ラインアドレシングのためのマトリクスである。マトリクスSは、残差シングルラインマトリクスとも呼ぶ。マトリクスの基本構造は、図5において理解できる。
【0067】
マトリクスディスプレイDの個々の画素輝度Dijについてのソースデータ(このデータが集められて所望の画像を形成する)は、2つのマトリクスS,M2に分解される。Sは、改良型シングルラインアドレシングによって駆動されるシングルラインマトリクスである。M2は、駆動のために、2つの行がそれぞれ組み合わされて一緒にアドレシング又はアクティブ化される、マルチラインマトリクスである。n―1個のマトリクスによるM2の表現(nはマトリクスディスプレイDの行数)は、これらのマトリクスMの各々について2つの行が組み合わされている(これら2つの行における要素が同一なので)ことを示している。2つの行の組み合わせは、好適には、連続する2つの行について行われる。なぜなら、画像において連続する行は類似性が最も高く、実際のディスプレイでは、動作電流が最も同質に分配されるのは連続する行の2つの画素だからである。さらに、この制約条件により、数学的分解は、2つの任意の行が組み合わされる場合よりも単純になる。そして、このアルゴリズムは低コストで実施できる。以下に、本発明によるその実施態様をより詳細に説明する。
【0068】
当然、アプリケーションに応じて、隣接していない行を組み合わせてもよい。例えば、チェスボードパターン(市松模様)は、マルチラインアドレシングを用いて、間に1行挟んで離れた2つの行を組み合わせることにより非常に良く生成され得る。
【0069】
各行ペアがアクティブ化のために与えられるロウアドレス時間tiは、上述の実施態様と同様に、この行ペアにおける画素の最大輝度Mijに応じて変化する。シングルラインアドレシングの場合について上で説明した時間最適化された駆動方法を、ここでも用いる。したがって、ロウアドレス時間の合計は、以下のように計算される:
【数13】
ここで、max(Si1,…Sim)及びmax(M2i1,…,M2im)はそれぞれ、行の最大輝度を与えるものであり、それぞれのロウアドレス時間tiに比例している。
【0070】
複数のマトリクスに分解する目的は、動作電流I1をさらに低減すること、つまり、DSumを最小化することである。このことは、シングルラインマトリクスにおける2つの要素すなわちSij及びSi+1,jを、オリジナルデータDij及びDi+1,jからマルチラインマトリクスM2の各輝度M2ijだけ低減して得ることによって、達成される。しかしこのために、1つのロウアドレス時間ti、つまり、M2ijをアドレシングする時間が必要である。それに応じて、複数の行について影響が大きくなる。
【0071】
複数のマルチラインマトリクスにおけるソースデータ(マトリクスディスプレイD)の変換は、同様に、次のように規定される:
【数14】
式中、M3は、3つの行を同時に駆動することを意味する(図5参照)。同様に、さらに多くの行を同時にアドレシングすることが行われる。
【0072】
例えば次の定義にしたがって、いくつかのマルチラインマトリクスを省略することも可能である:
【数15】
式中、マトリクスM3はゼロ(0)に設定されている。また、シングルラインアドレシングは、マルチラインマトリクスMxの全要素がゼロ(0)に設定されていると解釈できる。
【0073】
画像又は画像マトリクスDを駆動がより簡単な複数の画像又は画像マトリクスS,Mに分割するというアイデアは、LCD及びプラズマディスプレイを含む全てのタイプのマトリクスディスプレイに用い得る。マルチラインマトリクスは、単純で効率の良い駆動の好例である。
【0074】
以下に、シングルラインアドレシングを含む完全なマルチラインアドレシングについて、具体的な例を用いて説明する。実行される変換の目的は、DSumの最小化である。その結果、動作電流は、もはやI0ではなく、I0よりもかなり小さな値(画像に応じた値)になっている:
【数16】
【0075】
図6に示す例において、4×9のマトリクスDは、2つのマトリクスM2,Sに分解される。このマトリクスDにおける行の数は、n=9である。Dmaxは、輝度値「15」(4ビット)を有する。
【0076】
図6における第1のマトリクスは、マトリクスディスプレイDの所望の輝度Dijを与える。第2のマトリクスは2ラインマトリクスM2であり、第3のマトリクスは残差シングルラインマトリクスSである。M2は、また別途図示されており、そこでは加算表現によって、同時アドレシングにおいてどのように輝度が2つの隣接する行に分配されるかが理解できるようになっている。DSumつまり同時にアクティブ化される行の最大輝度の合計は、2ラインマトリクスを用いた場合、DSum=72である。改良型シングルラインアドレシングのみを用いた場合、DSum=107である。したがって、n*Dmax=9*15=135と比較して、必要な動作電流は、2ラインマトリクスを用いることにより、従来の駆動方法の53%に低減される。
【0077】
図7による3ラインマトリクスアドレシングM3を用いた場合、DSumはさらに低減され得る。図7による第1のマトリクスは、図6のソースマトリクスと同じであり、マトリクスディスプレイDの所望の輝度Dijを再生する。第2のマトリクスは3ラインマトリクスM3であり、第3のマトリクスは2ラインマトリクスM2であり、第4のマトリクスは残差シングルラインマトリクスSである。この場合、DSumは、58までさらに低減される。したがって、n*Dmax=135と比べて、動作電流振幅の57%の減少が達成される。
【0078】
図8は、図6に示す2ラインアドレシングの場合の、第8の行の電圧波形、第2の列の電流及び電圧波形、並びにダイオード(D82)における電圧を示す。
【0079】
図示の例において、従来のシングルラインアドレシングの場合の動作電流I0は100μAである。したがって、53%にまで低下するのに応じて、1つの行の駆動の間の動作電流はI1=53μAとなる。53μAの場合のOLEDのフロー電圧は6Vである。OLEDの閾値電圧は3Vである。フレーム期間、すなわち合計時間TFrameは13.5msecである。従来のシングルラインアドレシングにおいて、一定のロウアドレス時間は、t0=0.1msecである。図6のマルチラインアドレシングにおいて、t1=0.1875msecである。ここで、1フレームは、72(DSum)t1サイクルである。
【0080】
Sマトリクス及びM2マトリクスは交互にアクティブ化される。例えば、はじめに、Sマトリクスの第1の行がアドレシングされ、次に、M2マトリクスの第1の行ペア(つまり第1及び第2の行)がアドレシングされ、その次に、Sマトリクスの第2の行がアドレシングされ、その次に、M2マトリクスの第2の行ペア(つまり第2及び第3の行)がアドレシングされる。
【0081】
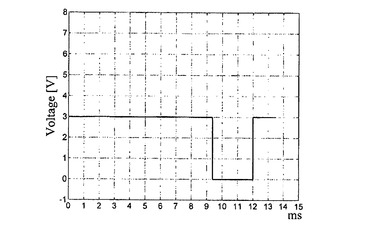
図8aは、第8の行の電圧波形を示す。この行がアドレシングされると対応する行のスイッチ(図4参照)が閉じ、電流が流れる。その後、電圧はゼロ(0)になる。さもなければ、行のスイッチはオープンである。カラム電圧は常時流れているので、少なくとも6Vのカラム電圧が存在する。3Vのロウ電圧は、OLEDの場合、6Vのカラム電圧から例えば3Vの閾値電圧を引いた差分によって与えられる。第8の行は、2.625msec(9.375msec〜12msec)の間アドレシングされる。
【0082】
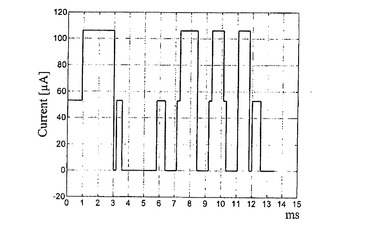
図8bは、第2の列における動作電流を示す。電流波形は3つのレベルを示している。すなわち、画素ダイオードのいずれもアクティブでない場合はゼロ(0)、画素ダイオードが1つだけアクティブである場合は53μA、(2ラインアドレシングの場合に)2つの画素ダイオードがアクティブである場合は106μA。2ラインアドレシングの場合、各ダイオードにおける電流振幅も53μAである。なぜなら、合計電流が、同時に駆動される画素ダイオードの両方に均等に分配されるからである。
【0083】
第8の行がアクティブ化されている期間(ロウアドレス時間ti)は、3つの段階からなる。はじめの4サイクルの間(9.375msec〜10.125msec)、第7の行及び第8の行が一緒にアドレシングされる。したがって、電流は2*53μAである。これは、M272の行アドレシングに対応している。
【0084】
次の5サイクルにおいて、S82の第8の行がアドレシングされる。5サイクル分のロウアドレス時間tiの合計は、マトリクスSの第8の行の輝度Sijの最大値「5」(第1の列、第8の行を参照)に由来する。53μAの電流が、0.1875msec(1サイクル)の間流れる。その後、電流は4サイクルに亘ってゼロ(0)になる。なぜならば、Sマトリクス(S81)の第8の行の最大値が5であり、パルス幅変調によって輝度制御がなされるからである。
【0085】
最後の段階は5サイクルに亘って続く。この間、マトリクスM2の第8及び第9の行がアドレシングされる。電流は、再び106μAになる。しかし、M282は4なので、電流は4サイクルの間だけ流れる。電流は、1サイクルの間ゼロ(0)に下降する。第3の列における最大輝度はM283=5なので、最後のサイクル(図示せず)においても、依然として第3の列に電流が流れている。動作電流が画素ij=82に印加される合計時間(アクティブ時間)は9サイクルであり、これはD82に対応している。
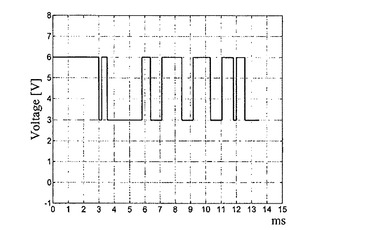
【0086】
第2の列の電圧の遷移波形を図8cに示す。動作電流が流れている場合、その動作電流が53μAか106μAかにかかわらず、6Vである。というのは、106μAにおいて、動作電流は2つのダイオードによって分割されるからである。電流が流れていない場合、電圧は3Vに下降する。これは、それ未満の場合にダイオード電流が流れない閾値電圧に対応している。
【0087】
図8dは、画素ij=82におけるダイオードの電圧の遷移波形を示す。53μAの動作電流がこのダイオードを流れる場合、電圧は6Vである。第8の行のアドレス時間の間、4サイクルに亘って電流が流れない。この時間の間、画素の電圧は3V(閾値電圧)である。第2の列に電流が流れていない場合、行スイッチ及び列スイッチの電圧は3Vであり、したがって、この画素における電圧はゼロ(0)である。第2の列に電流が流れている場合、列電圧は6Vであり、このアドレシングされていない第8の行の電位を3V(6V−閾値電圧)に遷移させる。
【0088】
本発明によるマトリクスディスプレイの駆動方法の技術的な実施は、従来のシングルラインアドレシング法と同程度に簡単である。各行にスイッチを設け、各列に電流源を設ける。電流源は、従来のシングルラインアドレシング法の場合には2つの電流レベル(例えば0及び1)のみであるのに対して、2ラインアドレシングの場合には3つの電流レベル(例えば0、1及び2)を有する。これは、複数の行が同時にアドレシングされる場合に、それに対応して電流を増加させる必要があるからである。一般に、n個の行が同時にアドレシングされる場合にはn+1段階に亘る階調(段階的変化)が必要になる。しかし、これを低コストで実施する必要がある。輝度を制御するために振幅・パルス幅混合変調のための具体的な回路を、以下により詳細に説明する。
【0089】
上述の例において、動作電流のパルス幅変調を用いた。S及びM2マトリクスは、当然ながら、動作電流の振幅変調によって生成され得る。振幅変調において、この行又は複数の行における最大値に達するまで、各行又は各複数の行がアドレシングされる。これは、パルス幅変調においても同じである。唯一の違いは、ロウアドレス時間tiの間、動作電流は常に流れ、その振幅レベルが調整される点である。
【0090】
ソースマトリクス(マトリクスディスプレイD)からマルチラインマトリクスM及びシングルラインマトリクスSへの最適化された効率的な変換は、動作電流を最小化するための決定的な要素である。「最適化された」とは、最大輝度DSumの合計を最小化することを意味し、「効率的」とは、迅速にかつ低コストのハードウェアで変換を行えることを意味する。
【0091】
マトリクスM及びSは、原則的に、線形計画法などの公知の方法と標準ソフトウェアを用いて得られるか又は決定され得る。しかし、乗算及び除算などの複雑な算術演算を用いる必要があり、その結果、この方法は非常に遅く且つ計算集約的(calculation-intensive)である。さらに、複雑さは、画像マトリクスのサイズに応じて二次的に増大する。
【0092】
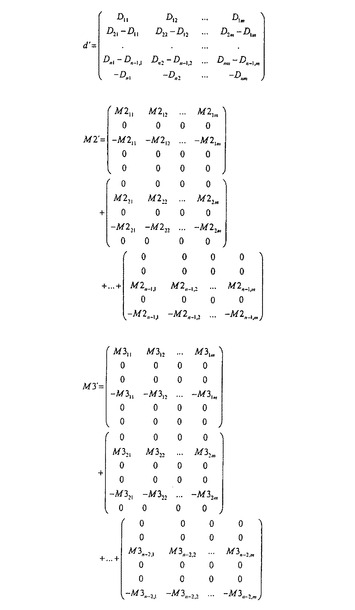
したがって、「MaxFlow/MinCut」原理として公知のものに基づく、本発明による組み合わせ法が提案される。最適度の質は、基本的に、2つの連続する行がどのように異なるかということに依存するので、副次的条件D=S+M2+M3+...は、解空間を変更することなく2つの連続する等式の間に差を生じさせることによって再整理される。マトリクスd’,S’及びM2’,M3’は、図9に示すように生成される。マトリクスS’は、マトリクスd’と類似の様態で形成される。マトリクスの各列の合計はゼロ(0)である。
【0093】
再整理された副次的条件は、図10に示すグラフによって視覚化され得る。
【0094】
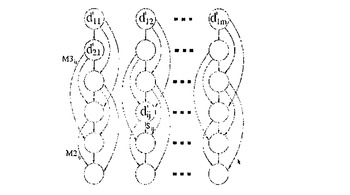
ここで、図中に白丸で示す(頂点集合Vの)各頂点は、再整理されたマトリクスd’内の要素を示す。白丸内のd’ijは、図9に示すマトリクスd’の対応する要素を示す。したがって、この頂点の値は、マトリクスの要素d’ijの値に等しい。マトリクス要素d’ij間の弧は、ある頂点(白丸)から別の頂点(白丸)への矢印である。これらの弧の各々は、矢印で示し且つ数が割り当てられた方向を有する。この(弧の組Aの)弧の割り当て(数)は、ソースデータマトリクスディスプレイの分解において対応する変数が有する値を反映している。ある1つの行から次の行へと延びた弧はマトリクスSに属する。1行とばしている弧(つまり長さ「2」を有する弧)は、マトリクスM2に割り当てられる。長さ「3」を有する弧は、同様にマトリクスM3に割り当てられている。マトリクスM4、M5などについても、類似の様態で割り当てが行われる。弧にはインデックスとしてijが与えられ、「i」は開始頂点(白丸)についての行番号であり、「j」は列の番号である。
【0095】
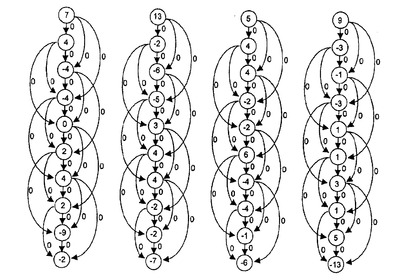
このことについて、図6及び図7で既に取り上げた例を用いて以下に説明する。図6の4×9マトリクスDを、図11に示す4×10のフローマトリクスd’に変換する。このマトリクスd’を、平衡にすべきフローとして図12に示す。
【0096】
d’マトリクスの各要素は、対応する位置の頂点に対応している。全ての弧にゼロ(0)が割り当てられている。というのは、これは、マトリクス分解の最初だからである。各頂点(白丸)について、出る弧(白丸から延びた矢印)の割り当て(数)の合計から入る弧(弧に到達した矢印)の割り当て(数)の合計を引いた差分が、その頂点の値(デマンド)に等しい場合、有効な分解が正確に達成される。全ての弧の割り当ては負にならない。
【0097】
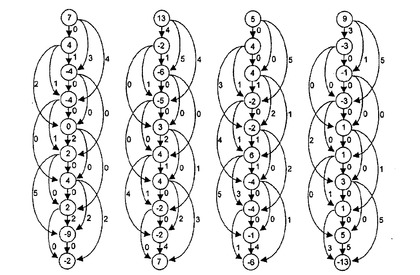
図13は、平衡になったフローの結果を示す。マトリクスM3,M2,Sの全ての要素が、弧の割り当てから得られる。
【0098】
図13に示す平衡になったフローを生成するのに用いる数学的方法について、以下に詳細に説明する。
【0099】
図13において、始めと終わりの頂点がそれぞれ同じ行内にある2つの弧(矢印)は、同じタイプである必要がある。目的は、ある弧タイプの最大弧の合計が最小化されるような弧の有効な割り当てを見つけることである。このことは、以下のように数学的に説明することができる。弧集合Aがタイプに応じて、
【数17】
に分割された有向グラフG=(V,A)が与えられる。pは、マルチラインマトリクスM及び残差シングルラインマトリクスSの行数である。さらに、各頂点にそのデマンドを割り当てる関数
【数18】
が存在する。Zは全体の数(整数)である。関数
【数19】
は、各頂点v∈Vについて、次式
【数20】
が適用され、且つ、
【数21】
が最小になるように定義される。上側の等式は、「フロー保存(flow conservation)」とも呼ばれ、キルヒホッフの電流則に対応している。b(v)は、この頂点のデマンドであり、グランドからこの頂点への電流の流れ(負のデマンドの場合、電流は頂点からグランドに流れる)とみなし得る。DSumは最小化される。
【0100】
上記目的は、(容量として知られている)負でない数を、各弧のタイプ
【数22】
に、これらの容量の合計が最小になり且つ容量を越えない有効な弧の割り当てが存在するように、割り当てる問題に等しい。
【0101】
この新規な方法の特別な特徴は、所与の行の規定された長さを有する全ての弧について容量が有効である点である。これらの弧の各々へのフローは、この容量以下である。容量自体は可変であり、所定の様態で最適化のためのコスト又は費用を示している。全ての容量の合計を最小化する必要がある。この場合、所与の容量の場合にフローが最大化される公知のMaxFlow/MinCut法とは異なり、所与のフローの場合に容量が最小化される。
【0102】
容量は関数
【数23】
であり、全ての
【数24】
及び
【数25】
について、次の不等式
【数26】
が適用される。
【0103】
上で説明した最小化は、原則的には線形計画法としてモデル化され解かれるが、上述のように、非常に計算集約的(calculation-intensive)である。以下に説明するように、本発明による上述の方法は、少ないコストで数学的に実施され得る。
【0104】
この目的のために、容量は連続的に、つまり段階的に、ゼロ(0)から上方へと、有効な分解が可能になるまで増加する。このことはまた、容量がゼロ(0)以上であることを確実にする。各反復において、割り当てが容量に等しく、したがって有効な解を妨げるボトルネックを構成する弧集合が決定される。この弧集合(最小カットとも呼ぶ)は、負のデマンドを有する頂点から正のデマンドを有する頂点を分離する。弧の容量は、その後、最小カットから増加する。しかし、このことは、好適には、弧の大部分がボトルネックから離れることを可能にする容量についてのみ起こる。ここでは、割り当ては、有効な解が見つかるか又は新たなボトルネックが起こるまで増大し、その後、上記工程が繰り返される。
【0105】
この方法のシーケンスの数学的定式化は、図14において理解され得る。プログラムモジュール「MaxFlow」及び「MinCut」は、文献から公知である標準的な方法である。プログラムモジュール「Initialise」は、uについての開始値を規定する。例えば、u(k)=0が全ての
【数27】
について適用される。しかし、好適には、データの前処理によって得られる下限値が用いられる。集合Hは、計算されたMinCutの履歴を記載している。現在のMinCutの出る弧を、
【数28】
とし、反復iのMinCutの出る弧を、
【数29】
とする。パラメータΔuは、個々の容量が増加するステップサイズを決定する。好適には、数個の容量のみが、反復毎に増加する(例えば、kについてのみか、
【数30】
についてか、若しくは、重み付けした合計
【数31】
が最大である。なお、ステップが前であればあるほど、重みは小さくなる。wは履歴の重み付けを示す。ステップのサイズの選択により、方法の質(小さなΔu値、例えばΔu=1)と所要時間(より大きなΔu値)との間の妥協を動的に適合させることもできる。
【0106】
本発明の方法は、当然、画像マトリクスの一部の領域について用いることも可能である。このようにして、画像を複数の部分に分割し、分割された各部分を個々に最適化することが可能である。これは、局所最適化に対応している。
【0107】
規定されたサイズの部分領域を行毎に又は複数の行毎にずらすことにより、全体・局所混合型の最適化を同様に行うことができる。サブマトリクスは、規定された行数分の行から形成される。それは、まず、ソースマトリクスの上側の行から形成される。各最適化により、最上位の行又は上から数行分の行について、マトリクスの要素(S、M2、M3など)が得られる。したがって、次のサブマトリクスは、1行又は複数行だけ下方にずらされる。この新しいサブマトリクスに対する先に得られたマルチラインマトリクスの行の影響を減算する必要がある。1つまたは複数の行が、S、M2、M3などから再度得られる。サブマトリクスは、ソースマトリクスの最後まで進み、その後、完全に分解される。このようにして、S、M2、M3などの全てのエントリが得られる。
【0108】
比較的小さなマトリクスの分解に必要なメモリサイズは小さく、反復の数も少ない。マトリクスが概して大きいときに全体最適化を行う場合、マトリクス分解の結果を、SRAM等のバッファメモリに保存する必要がある。情報は、アクティブ化されると直ちに、出力ドライバ用のレジスタ内に行毎に読み込まれる。分割/局所型又は混合型の最適化の場合、容量は、まずサブマトリクス分解によって、そしてそれらの合計すなわちtl及びI1によって、得ることができる。急速分解のおかげで、行の結果が連続して再び計算され、出力ドライバ用のレジスタに直接転送される。それにより、大きなバッファメモリを省略することができる。ハードウェアのコストは、分割/局所型又は混合型の最適化によって低減され得る。但し、この場合、最適化の質はいくぶん低下し得る。
【0109】
対応する輝度を有する個々の画素ijを備えたマトリクスM,Sが定められた場合、それに対応してダイオードを駆動する必要がある。個々のロウアドレス時間tiは、行毎に異なり得、その行の最大輝度値に応じてそれぞれ変化し得る。輝度は、電流のパルス幅変調又は振幅変調によって制御され得る。
【0110】
パルス幅変調の場合、最大輝度を有する画素ijのみがロウアドレス時間全体に亘ってスイッチオンされる。つまり、当該画素を動作電流が流れる。残りの画素ijは、一時的に点灯されるのみであり、それぞれの点灯時間はそれぞれの輝度値Sij,Mijとの相関関係を有する。
【0111】
或いは、振幅変調を用いて輝度を制御することもできる。すなわち、アクティブ段階にある全ての画素ijがそれぞれロウアドレス時間tiの間スイッチオンされ、輝度の低い画素ijについては動作電流がそれに応じて低減される。しかし、振幅変調は、ハードウェア面で実施するのがより難しい。このことは、特に、色深度が高い場合又は階調数が多い場合にあてはまる。これに対してパルス幅変調は、ハードウェアに要するコストが高くなく、比較的単純且つ正確に実施できる。
【0112】
輝度の低い画素ijにおける動作電流の低減には、パルス幅変調を振幅変調と組み合わせるのが特に有利である。この、本発明による混合型の、つまり組合せ型の振幅・パルス幅変調について、図15〜図18を参照しつつ以下に説明する。
【0113】
本発明による上記マルチラインアドレシングについて、シングルライン、2ライン及びマルチラインアドレシングのための電流を列内に供給して、それに応じて電流のレベルを調節するために、動作電流を定量化する、つまり、複数の異なるレベルに分割する必要がある。例えば、マルチラインアドレシングM4において同時に駆動される4つの行について、動作電流の4倍の電流(4*I1)を印加する必要がある。
【0114】
この目的のために、電流源を、図15に示すように2つのシングルトランジスタセルと1つの2トランジスタセルとからなる3つのトランジスタで実現し得る。4つの行に対して動作電流I=4*I1が必要な場合、これら3つのトランジスタは、同じ制御電圧をゲートに受け取る。動作電圧I=3*I1が必要な場合、一方のシングルトランジスタセルには制御電圧が印加されず、2トランジスタセル及び他方のシングルトランジスタセルのそれぞれのゲートに制御電圧が印加される。動作電流I=2*I1の場合、2トランジスタセルがアクティブであり且つ2つのシングルトランジスタセルがパッシブであるか、若しくはその逆である。動作電流I=I1の場合、1つのシングルトランジスタセルのみがアクティブである。
【0115】
輝度値がMij,Sijが最大ではないマトリクスエントリの場合に、定量化された動作電流を用いて動作電流を再度低減することも可能である。輝度値Mijについて図18に示すアルゴリズムは、例えば、この目的のために用い得る。結果は、輝度制御のための混合型パルス幅・振幅変調に対応している。
【0116】
組合せ型輝度制御の結果を、輝度制御のための純粋なパルス幅変調(図16)と比較する形で図17に示す。純粋なパルス幅変調において、電流振幅は、例えば一定の100μAである。第1のパルスのパルス幅は、この行のアクティブ時間を10単位(10単位のロウアドレス時間)とした場合、10単位中6単位(6/10)である。6単位は10単位の半分よりも大きく且つ10単位の3/4よりも小さいので、第1のパルスのパルス幅は、混合型振幅/パルス幅変調を用いて、元の値の4/3に拡大される。同時に、振幅が元の振幅の3/4(この例では75μA)に低減される。このことは、図16と比較して図17を参照することにより理解できる。第2のパルスのパルス幅が2倍にされ、その一方で、振幅が類似の様態で1/2にされる。第3及び第5のパルスを拡大することはできない。なぜなら、それらのパルス幅はそれぞれの行のアクティブ期間(ロウアドレス時間)に近いからである。対照的に、第4のパルスの幅は4倍にされ得る。
【0117】
輝度制御のための混合(組合せ)型振幅・パルス幅変調において、動作電流の平均振幅が低減されることが、図17から明らかに理解し得る。
【0118】
当然ながら、図18に示す上記アルゴリズムの一部のみを用いることが可能である。これらのアルゴリズムはまた、シングルラインマトリクスにも適用される。異なる行数のマルチラインアドレシングにおいて、その行数に対応する様態でアルゴリズムが定められる。アルゴリズムは、電流源の定量化に応じて変化する。
【0119】
本発明によるマトリクスディスプレイの駆動方法及び本発明が関係する上記方法を実行するように設定されたディスプレイ制御システムを用いると、マトリクスディスプレイの最適化された駆動が達成できる。これは、性能を向上するため(例えばフレームレートを高めるため)及び/又は個々の画素を駆動するのに必要な動作電流を低減するために用い得る。本質的な特徴は、各行のロウアドレス時間が、この行の画素が得るべき最大輝度に応じて変化すること、及び/又は、マトリクスディスプレイを複数の独立したマトリクスに分解し、そのいくつかがマルチライン駆動を表すことである。
【0120】
本発明はまた、上記方法を実行する制御システムに関する。この目的のために、例えばディスプレイコントローラ及びディスプレイドライバが1つのチップに集約される場合、請求の範囲に記載の方法が、特定用途向けIC(ASIC)において実施され得る。t1及びI1はドライバ内で生成される。マトリクスの分解は、単純且つ高速の組み合わせ論理を用いて実現される。
【0121】
画像、ひいては得られたマトリクスは、常にデータ集約的(data intensive)であるので、メモリも必要である。この要件は、現代の半導体プロセスを用いた場合、又は、上述のように局所又は混合型の最適化を用いた場合に緩和され得る。本発明の方法は、当然ながら、複数のチップ間で分割することもできる。
【図面の簡単な説明】
【0122】
【図1】具体的にシングルラインアドレシング及びマルチラインアドレシングを説明するために、本発明によるマトリクスディスプレイを駆動するさまざまな実施形態を模式的に示す図である。
【図2】図1に示すマトリクスディスプレイの或る列の画素を駆動するための動作電流(又は関連する電圧)を時間軸上に模式的に示す図である。
【図3】3列×5行からなるマトリクスディスプレイD及び1つの列を駆動するのに必要な電流を示す図である。
【図4】m列(Cm)×n行(Rn)のマトリクスディスプレイの等価回路を示す図である。
【図5】シングルラインマトリクス及びマルチラインマトリクスの定義を示す図である。
【図6】本発明による、マトリクスディスプレイDを2ラインマトリクス及びシングルラインマトリクスに分解する例を示す図である。
【図7】本発明による、図6に示すマトリクスディスプレイDを3ラインマトリクス、2ラインマトリクス及びシングルラインマトリクスに分解する例を示す図である。
【図8a】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図8b】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図8c】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図8d】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図9】マトリクスディスプレイDをフローマトリクスd’に分解する例を示す図である。
【図10】図9によるフローマトリクスd’のフロー図である。
【図11】図6によるマトリクスDをフローマトリクスd’に変換した具体例を示す図である。
【図12】図11によるフローマトリクスd’の第1の最適化ステップにおけるフロー図である。
【図13】図11によるフローマトリクスd’の最適化ステップ後のフロー図である。
【図14】フローマトリクスd’を形成するための数学的流れ図及び最適化されたフロー図を示す図である。
【図15】本発明による、動作電流を生成する実施形態を示す図である。
【図16】パルス幅変調を用いた輝度制御を示す図である。
【図17】混合型振幅・パルス幅変調を用いた輝度制御を示す図である。
【図18】図17による輝度制御を実行するためのアルゴリズムを示す図である。
【技術分野】
【0001】
本発明は、独立した画素を有する行列状に構成された複数のラインからなるマトリクスディスプレイを駆動する方法であって、個々のラインは、所定のロウアドレス時間の間にアクティブ化される行によって選択的に駆動され、動作電流又はそれに対応する電圧つまり電気駆動信号が、画素の所望の輝度に応じて、アクティブ化された行に相関している列に印加されることを特徴とするマトリクスディスプレイを駆動する方法に関する。
【背景技術】
【0002】
以下のテキストにおいて、水平方向に延びたラインを行と呼び、行に対して直交する垂直方向に延びたラインを列と呼ぶ。これは、説明をわかりやすくするためである。しかし、本発明は、厳密にこの構成に限定されるものではない。具体的には、行と列の機能を交換すること、若しくは、行と列との関係として非線形の関係を選択することが可能である。
【0003】
画像データ、つまり個々の画素ijの所望の輝度Dijは、以下に示す行列Dで説明する。
【数1】
【0004】
添字の数値は、マトリクス又はマトリクスディスプレイDによって与えられるディスプレイ上の画素の位置に対応している。マトリクスDの各行i及びマトリクスD上の各列jは、それぞれの場合において、ディスプレイ上の幾何学的行及び列に対応している。ディスプレイの画素を生成するために、画素ダイオード又は同様の素子が、マトリクスディスプレイDの各駆動可能画素ijに割り当てられる。各画素における時間平均した光強度(輝度Dijに対応)は、マトリクスD内の対応する素子に対応している。マトリクスDの全エントリが一体となり、表示しようとする画像を生成する。
【0005】
マトリクスディスプレイD上の画素ij(各々が具体的にはOLED(有機発光ダイオード)として構成され得る)は、一定の範囲内では行毎にアクティブ化されている。この目的のために、選択された行のOLEDは、スイッチによって、例えばグランドに接続されることによりアクティブ化される。動作電流Iは、列jの各々において印加され、この印加された電流により、この行i及び列jの交点に存在する画素ijが発光する。光強度Lは、第1の近似において、アクティブ相(ロウアドレス時間)の間に印加され且つOLED画素において放射再結合される電荷に比例する。比較的高いフレームレートでディスプレイマトリクス又はマトリクスディスプレイDをアドレシングする場合、ヒトの目は、以下の式に示す光の強度Lの平均値を認識する:
【数2】
【0006】
TFrameは、マトリクスディスプレイDのn行全てを一度にアクティブ化する場合に完全な画像を形成するのに必要な合計時間である。動作電流IOLED、I、又はI0が各画素に印加される。周波数変調を用いて輝度を制御する場合、ロウアドレス時間に対応する期間TFrame/nの間、動作電流はアクティブである。パルス幅変調を行うと、動作電流の長さは短くなり、すなわちd*TFrame/nとなる。ここで、dはパルス幅変調デューティ比であり、その範囲は0〜1である。
【数3】
【0007】
電流I0は、ここでは、画素の光強度に関係なく一定である。強度Lは、デューティ比dによって調節される。電子機器における時間単位は非常に正確に調節され、その結果、dの値も非常に正確なので、このタイプの輝度制御は、振幅変調と比べてより単純で且つより正確である。基準電流I0は、全ての画素ijを駆動するのに十分である。それに対して、振幅変調を行った場合、各ケースにおいて、振幅は所望の輝度Dijに応じて調節する必要がある。
【0008】
各ケースにおいて、1つの行iのみに対応する全ての列jを駆動することにより、各ダイオード又は各画素ijを、合計時間TFrameのn分の1の最大時間の間のみアクティブにし得る。規定された平均輝度Dijを達成するために、合計時間TFrameの間1つの画素に動作電流が供給される場合と比較して、対応する動作電流に行数nを乗じる必要がある。つまり、行数が増えるにしたがい、パルス状の動作電流I又はI0を増大させる必要がある。さらに、パルス幅変調を用いて輝度を調節する場合、駆動しようとする画素ijが非常に暗い場合であっても、動作電流は常に高い。この場合、動作電流の印加時間は非常に短い。
【発明の開示】
【発明が解決しようとする課題】
【0009】
しかし、高い動作電流を用いた結果、OLEDの寿命は著しく短くなり得る。必要な高さの動作電流を達成するために、OLEDの電圧を高くする必要もあり、その結果、消費電力が増大し、効率が低下する。この電力損失の増大により、充電池又は使いきり電池の放電がより速く進むだけでなく、ディスプレイの温度が上昇し、その結果、寿命も同様に低下する。
【0010】
にもかかわらず、大型で解像度の高いディスプレイを実現するために、LCD(液晶ディスプレイ)と同様に「アクティブマトリクス」を用い得、このことにより、動作電流はパルス状では供給されず、定電流として存在する。しかし、アクティブマトリクス駆動(TFTバックプレーン)は、OLEDディスプレイのためにかなりの追加コストを要求する。
【0011】
本発明の目的は、冒頭で述べたタイプに対応するマトリクスディスプレイを駆動する方法であって、OLEDディスプレイの寿命を長くし得るか又は任意のマトリクスディスプレイの性能を向上し得るような駆動方法を提案することである。
【課題を解決するための手段】
【0012】
この目的は、各行iのロウアドレス時間tiが、該行iの全ての列jの最大輝度Dimaxの関数として決定されることを特徴とする本発明により達成される。ロウアドレス時間tiは、動作電圧を印加して最大画素輝度Dmaxが達成される長さだけマトリクスディスプレイの各行がアドレシングされる場合に生成される一定のロウアドレス時間tL以下の長さになるように選択され得る。本発明によると、ロウアドレス時間tiは、該一定のロウアドレス時間tLに行iの全ての列jにおける画素の最大輝度Dimaxのマトリクスディスプレイ全体における可能最大画素輝度Dmaxに対する比を乗算した結果に対応する。
【0013】
最大輝度値Dmaxは、1つの画素ijに動作電流I0が一定のロウアドレス時間tLだけ印加される場合に得られる、当該画素における光強度(輝度)として規定される。この結果、全ての行(n行)に亘るロウアドレス時間tiの合計時間TSumがn行全てをアクティブ化する合計時間TFrame以下になる(アクティブ化はn×一定のロウアドレス時間tL)。動作電流I0が一定の場合、本発明によると、マトリクスディスプレイを駆動する合計時間は、合計時間TSum<ロウアドレス時間のTFrameとなるように低減され得る。これにより、例えば、より高いフレームレートが可能になり、マトリクスディスプレイの達成可能な性能が向上する。
【0014】
第1の近似における画素ijの光強度は画素ijに印加される電荷に比例する、つまり、ロウアドレス時間tiと動作電流との積に比例するので、ある行の複数の列に亘りロウアドレス時間tiが最大輝度に応じて変化することを利用して、動作電流を低減することもできる。この目的のために、全ての行nに亘るロウアドレス時間t’iの合計が合計時間TFrameに対応するように、全ての行iをアクティブ化するための合計時間TFrameを一定に維持できる。したがって、ロウアドレス時間t’iは、本発明の方法のこの変形例にしたがって、その合計が合計時間TFrameに等しくなるように延長される。同時に、本発明によると、全ての行nの(完全に必要な)ロウアドレス時間tiの合計時間TSumの一定のロウアドレス時間tLで全ての行をアクティブ化するための合計時間(TFrame)に対する比により動作電流I0を低減して、動作電流I1とすることができる。ロウアドレス時間と動作電流との積ti*I0=t’i*I1は一定に維持されるので、個々の画素の光強度は変化しない。OLEDの場合、より低い動作電流範囲における量子効率ηは、原則として、より高い動作電流での量子効率よりも大きい。したがって、動作電流I1は、量子効率の比η(I1)/η(I0)によりさらに低減され得る。簡潔に説明するため、以下の説明では、(TFrameに延長又は標準化された)ロウアドレス時間t’iをtiと呼ぶ。
【0015】
本発明による、ロウアドレス時間tiのダイオード画素のアドレシングへの適合により、ディスプレイDの個々のダイオード画素ijの選択的位相(ロウアドレス時間)、つまり、動作電流Iがダイオード画素ijに印加される時間を、かなり長くすることができる。アクティブの動作電流I1は、選択された位相の長さに反比例して低減され得る。マトリクスディスプレイDの効率は全体として向上し得、特にOLEDディスプレイの場合、寿命が延び得る。したがって、本発明の基本的なアイデアは、行に基づく短縮又はロウアドレス時間の適合によって動作電流の長さを延長する点にある。電荷は規定された光強度に対して何よりも重要なので、動作電流の印加時間が長くなるということは、電流の振幅が低減されるということを意味する。
【0016】
マトリクスディスプレイDを、個々に駆動される複数のマトリクスS,Mに分解した場合、向上した取り扱い及び動作電流のさらなる低減が達成され得る。全てのマトリクスを重ね合わせることにより、それぞれの画素ijの所望の輝度Dijで、マトリクスディスプレイDの画像が生成される。複数のマトリクスのそれぞれの輝度Sij,Mijの合計から得られる合計輝度Dijは、画素ijにおけるマトリクスディスプレイDの所望の合計輝度Dijに対応している必要がある。本発明によると、マトリクスは、好適には各ケースにおいて行単位又は列単位で上記方法を用いて、次々と表示され得るか又は互いに入れ子状に組み合わされ得る。2つのマトリクスに分割して、一方のマトリクスSが1つの行iの駆動を提供し、他方のマトリクスM2が2つの行iの同時駆動を提供する場合、マトリクスS,M2の行は、交互にアドレシングされる。OLEDディスプレイ又はLCD等のパッシブマトリクスディスプレイ型の場合、マトリクスディスプレイD内に表現されるソース画像は、複数の画像マトリクスに分解され得る。これらの得られたマトリクスの各々は、例えば以下に説明するマルチラインアドレシングによって、画像の合計が、元のマトリクスDに基づいてディスプレイを直接駆動する場合よりも良好に実施されるように、当該ディスプレイ型に対して良好に実施される必要がある。
【0017】
本発明によると、複数の行iが同時に駆動されるという前提である限り、駆動される行iの各列jにおける画素ijは、各ケースにおいて、同じ信号及び同じ光強度を有する。画素ijの光強度が1つの行iだけを駆動した場合の光強度に対応するように、動作電流I0,I1は、同時に駆動される行の数に対応する倍数分だけ増加される。つまり、2つの行が同時に駆動される場合、2倍に増加される。複数の行の同時駆動を、「シングルラインアドレシング(SLA)」と呼ばれる1行だけの駆動と区別して、「マルチラインアドレシング(MLA)」と呼ぶ。
【0018】
複数の行が同時に駆動される場合、好適には、隣り合う行(i,i+1)が駆動され得る。しかし、本発明によると、好適には、互いから数行離れた行iを同時に駆動することも可能である。例えば、1行おきに存在する行を同時に駆動することができる。同時に駆動される行が近位に存在することが特に賢明である。なぜなら、マトリクスディスプレイDの画像内で隣り合う行は、多くの場合、同様の輝度分布を有するからである。
【0019】
複数の行が同時に駆動される場合に個々の行及び/又は列の間に強度の差を生じることができるように、本発明によると、1つの行(i)が駆動されるマトリクス(S)と複数の行(i)が駆動される1つ又は複数のマトリクス(M2,M3,M4)を互いに組合せ得る。マトリクスSにシングルラインアドレシングを適用することにより、所望の輝度Dijが各画素ijについて独立して適合され得る。このマトリクスSを、残留シングルラインマトリクスと呼ぶ。
【0020】
本発明によると、輝度を制御するために、パルス幅変調を用い得る。つまり、例えば、ロウアドレス時間tiの間にロウアドレス時間tiの一部の間だけ動作電流Iを印加し、ロウアドレス時間tiの残りの時間の間は動作電流Iはオフに切り替えられる。
【0021】
あるいは、輝度を制御するために、振幅制御を用い得る。つまり、動作電流Iの振幅を、所望の輝度Dijに対応するように適合させる。本発明によると、輝度を制御するために、パルス幅変調及び振幅変調を互いに組み合わせることもできる。これは、輝度Dijが量子化された段階として予め規定されている場合に特に有利である。なぜなら、動作電流の振幅は量子化された段階にしたがって低減可能であり、一方で、パルス幅のデューティ比がこれに対応して増加するからである。この駆動は、各種機器において特に単純に実施され得る。1つの列jにおいて動作電流Iを印加する時間がパルス幅デューティ比の増加後にロウアドレス時間tiを越えない場合、この組み合わせた方法を特に柔軟に用いることができる。したがって、振幅変調をパルス幅変調と組み合わせる決定は、これに必要な動作電流印加時間及びマトリクスディスプレイDの各行i及び列jに割り当てられたロウアドレス時間に応じて個々に為し得る。組み合わされたパルス幅変調及び振幅変調を用いる場合、振幅は量子化された段階にしたがって低減され、一方、これに応じてパルス幅変調デューティ比が増大する。量子化は、マルチラインアドレシングも実施し得る複数のトランジスタセルを用いて実施され得る。
【0022】
マトリクス画素を駆動するために用いるマトリクスを生成するために、好適な実施形態によると、マトリクスディスプレイを、それぞれの列の個々の画素の輝度又は輝度の差についてのデマンドに対応するエントリとして頂点を有するフローマトリクスに変換することが提案される。このことは、上記方法が実施され且つ個々の処理工程を実行する適切なプロセッサ手段を有する適切な制御システムを用いて行われ得る。また、このタイプの制御システムは、本発明の主題を構成する。この変換により、公知のMaxFlow/MinCut原理に基づく組合せ方法を用いてマトリクス分解を実行することができる。このタイプの組合せアルゴリズムのハードウェアの実施費用は低いことが知られている。さらに、組合せアルゴリズムは、素早く処理され得るので、これらのアルゴリズムは、マトリクスディスプレイを制御するのに特に適している。
【0023】
フローマトリクスが2つのマトリクス(第1のマトリクスは、マトリクスディスプレイ及び該マトリクスディスプレイの末尾に取り付けられたゼロエントリを有する行からなり、第2のマトリクスは、マトリクスディスプレイ及び該マトリクスディスプレイの上流側に取り付けられたゼロエントリを有する行からなる)の差分から生成される場合、それが有利であることが証明されている。マトリクスをマルチラインマトリクス及び(残留)シングルラインマトリクスに分解する場合、列の個々の画素の輝度の差分を最適に隠すのが重要である。本発明により提案されるフローマトリクスは、列における画素間の差を説明するものであり、組合せ方法を用いた最適化のための基板又は最適な開始点を提供する。
【0024】
本発明によるフローマトリクスにおいて、頂点は、好適には、弧と呼ばれる、割り当てが指定された、好適にはその長さに応じて複数の別個に駆動されるマトリクス(例えば、S,M2,M3,M4)のエントリに対応し、マトリクスディスプレイが上述のように分解され得る矢印によって繋がれている。それにより、マトリクスの分解は、フロー最適化へと完全に変換される。フロー最適化の結果、つまり、弧の割り当ては、直接的には、シングルラインマトリクス及びマルチラインマトリクスS,M2,M3,M4等の対応するマトリクス要素である。
【0025】
フロー最適化のために、特にパッシブマトリクスディスプレイを駆動する場合、容量又は容量値を関係するマトリクス(S,M2,M3,M4)の各行に対して指定するのが有利である。容量値は、それぞれの行の最大画素値に対応する。全ての容量の合計を最小化する必要がある。
【0026】
公知のMinCut法又はMaxFlow法の場合、容量は一定に維持され且つフローは最大化されるが、本発明の方法では、フローはソースマトリクス(マトリクスディスプレイD)から得られるので、予め規定されている。最適化の目的は、全ての容量の合計を最小化することである。したがって、本発明によると、容量は変動可能であるように設計される。容量は、全てのフローが均一又は平衡になるまで、以下に説明する戦略にしたがって増加する。その後、弧の有効な割り当てが達成され、マトリクスの分解が完了する。容量値の合計が最小か又は非常に小さいと仮定し得る。理論上の最小値と容量値の合計との比を、最適化の質と呼ぶ。容量値を増加させるために必要な反復の回数を低減するために、弧の割り当てを、初期化における開始値として生成し得る。
【0027】
本発明によると、反復のたびに、有効な解決を妨げるボトルネックとなる容量が選択され増加される。この弧のセット(最小カット(MinCut)とも呼ぶ)は、増加させる容量についての選択基準として使用され得る。
【0028】
さらに、先行するMinCutの情報は、本発明によると、選択基準として使用可能であり、最後の反復のMinCutが重み付けされ得る。このことにより、素早く効率的な解決が可能になる。
【0029】
反復を促進するために、容量値を増加させる増加幅の大きさは、動的に適合され得る。それにより、最小の増加幅の大きさ「1」に対して、最適化の品質をほとんど低下することなく、必要な反復の回数を少なくすることができる。
【0030】
計算速度を向上し且つ要求されるメモリサイズを低減するために、マトリクスディスプレイを複数のより小さなサブマトリクスに分割し得、これらサブマトリクスをフローサブマトリクスへと個々に分解し得る。このタイプの最適化は局所最適化と考えられ、一方、一回の最適化におけるマトリクスの分解は全体最適化と考えられる。比較的小さなマトリクスを最適化する場合はかなり低減された回数の反復で済むので、S,M2,M3,M4等の結果を、これらのマトリクスのためにバッファメモリを設ける必要なく、出力ドライバ用のレジスタに行単位で直接転送することもできる。これにより、メモリにかかる費用はかなり低くなる。
【0031】
さらに、本発明による、1行又は数行のマルチラインマトリクス(M2,M3,M4)並びに/若しくは残留シングルラインマトリクス(S)がフローサブマトリクスから得られる混合型局所・全体最適化を実施し得る。これにより、局所・全体最適化つまり速度及びメモリサイズについての要件と、最適化の質との間で、良好な妥協が達成される。結果は行単位又はサブマトリクス単位で出力され、マトリクス全体を格納するためのメモリサイズは必要無い。
【0032】
上記方法の好ましいアプリケーションは、自己発光ディスプレイ(例えばOLEDディスプレイ)又は非自己発光ディスプレイ(例えばLCD)の駆動である。マトリクスディスプレイの駆動には関係のない、上記方法の本発明によるさらなるアプリケーションは、概して、マトリクス(例えばCCDカメラにおけるセンサマトリクス)の読み出しに関する。
【0033】
本発明のさらなる利点、特徴及びアプリケーションは、例示実施形態についての以下の説明及び図面において見つけ得る。説明する特徴及び/又は図で示す特徴は、それらがどのように特許請求の範囲において記載されているかやそれらの参照には関係なく、本発明の主題を構成するものである。
【発明を実施するための最良の形態】
【0034】
図1は、4行i×4列jからなるマトリクスディスプレイDを模式的に示す。マトリクスディスプレイDは、したがって、合計で16個の画素ijを有し、各画素は輝度Dijを有する。各画素ijは、1つの四角いマスで示され、そのマスの中の数値がデジタル輝度値Dijを示す。画素値「0」は暗画素ijを示し、画素値「1」は低輝度の明画素ijを示し、画素値「2」は高輝度の明画素ijを示す。
【0035】
図1a)は、十字形が見えるマトリクスディスプレイDを示す。低輝度の画素ij=23が十字形の中心であり、そのアーチ部分に4つの明画素が存在する。従来のシングルラインアドレシング(SLA)において、マトリクスディスプレイDは、値「1」(任意単位)で示された一定のロウアドレス時間tLの間、第1〜第4の行が連続的にアクティブにされるように駆動される。第1の行がアクティブである間、動作電流Iが第3の列に印加され、この電流が、所望の輝度「2」に対応する電荷を画素ij=13に与える。ロウアドレス時間tL=1の後、処理は第2の行に切り替わる。第2の行において、第2及び第4の列には輝度「2」に対応する動作電流Iが供給され、これと同時に、第3の行には輝度「1」に対応する動作電流Iが供給される。非自己発光型ディスプレイの場合、個々の列における駆動のために印加される電圧のために、類似の動作が行われる。典型的なアプリケーションは、LCD(液晶ディスプレイ)である。
【0036】
さらなるロウアドレス時間tL=1の後、第3の行が第1の行と同様に駆動される。最後に、第4の行が、さらなるロウアドレス時間tL=1の間アクティブになる。しかし、この行は完全に暗い、つまり第4の行が選択された段階(第4の行のロウアドレス時間)の間、第1〜第4の列のいずれにおいても、画素ijに動作電圧が印加されない。
【0037】
合計時間TFrame=4*tLの後、イメージマトリクスDの全ての画素ijは一度駆動されたことになる。ヒトの目は、連続的に照明された画素ijを、1つの全体的な画像に統合する。
【0038】
この従来のシングルラインアドレシングを用いたマトリクスディスプレイDを駆動する方法を、図1b)に示すように本発明によって、各行iに対するロウアドレス時間tiが、全ての列jと当該行iとの交点における全画素の最高輝度Dimaxの関数として規定されるように改変する。この方法は、以下の説明において、「改良シングルラインアドレシング(ISLA)」とも呼ぶ。ロウアドレス時間tiは、この場合、4つの行全てに亘るロウアドレス時間tiの合計TSumが合計時間TFrame=4*tLに対応するように設定される。
【0039】
ロウアドレス時間tiを設定する場合、以下のような処理を行い得る。全列の最高輝度Dimaxは、初めの3つの行ではそれぞれ「2」であるので、これらの行に対するロウアドレス時間tiは互いに等しくする必要がある。第4の行において、最高輝度は「0」であるので、この行は全く駆動する必要が無く、ti=0が選択され得る。したがって、合計時間TFrame=4*tLは、3つのロウアドレス時間tiに分割できるので、第1〜第3の行に対して、一定のロウアドレス時間tLよりも1/3長いti、すなわち、
【数4】
が選択され得る。したがって、初めの3つの行はそれぞれ、図1a)の駆動方法と比べて1/3長くアクティブにすることができる。OLEDディスプレイにおける光強度は、印加された動作電流とロウアドレス時間との積によって得られる、OLEDに印加される電荷に応じて変化する。したがって、同じ統合輝度値Dijを得るためには、動作電流は1/4だけ減少させることができ、
【数5】
となる。tLとI0との積は、tiとI1との積に等しい。このことは、図2a)と図2b)とを比較することによっても理解され得る。図2は、図1の駆動方法において、第1〜第4の行に亘って第3の列に印加される動作電流と、それに比例する動作電圧とを図示している。印加される電流(又はそれに対応して印加される電圧)は、ロウアドレス時間の間プロットしている。図2a)で理解され得るように、図示した空欄1つの幅は、上述の例において標準化変数として用いた一定のロウアドレス時間tLに直接対応している。1つの空欄は、1つの行のアクティブ時間に対応している。4つの空欄からなる合計幅は、マトリクスディスプレイの1面の画像が完全に構成される合計時間TFrameに対応している。
【0040】
図2a)において、公知のシングルラインアドレシングに用いる電流波形を説明する。第1のラインにおいて、所望の輝度「2」に応じて電流は最大である。明瞭に説明するため、第3の列と第1のラインとの交点の画素について関連する駆動パルス(電流×時間)に斜線で網掛けした。このことは、図2b)及び図2c)にもそれぞれ適用される。輝度値が「1」である第2の行において、電流は半分である。第3の行において、輝度値「2」を得るために電流は再び最大である。画素がオフに切り替えられた最後の行において、電流はオフに切り替えられる。このタイプの駆動は、振幅変調に対応している。
【0041】
図2b)は、本発明による改良型シングルラインアドレシングに用いる電流波形を示す。上述のように、ロウアドレス時間tiは、1/3だけ延長されている。このことを波線で示している。第4の行は、全くアクティブ化されていない。画素ijの輝度は、時間に対して積分された電流(動作電流)によって決定される印加電荷量に比例する。図2b)において理解できるように、図2b)における電流曲線の下の面積は、図2a)における電流曲線の下の面積に等しい。それに対して、電流(及びそれぞれの印加電圧)はそれぞれ1/4に低減され得る。このことは、OLEDの寿命にとって有利である。
【0042】
本発明のさらなる実施形態を、図1c)を参照して説明する。この駆動方法では、複数の行が同時に駆動される(マルチラインアドレシング)。この例では、第1、第3の行にそれぞれ、第3の列に輝度「2」である画素を生じる必要がある(図1a)参照)。2つの行が組み合わされているので、ロウアドレス時間が2倍になり得る。動作電流(及びそれぞれの対応する電圧)は、それに対応して、各画素について1/2にされる(1つの画素については図2c)参照)。
【0043】
図1d)に示すように、図1c)を参照して説明したマルチラインアドレシング法を、図1b)の改良型シングルラインアドレシングと組み合わせるのが特に有利である。マルチラインアドレシングでは全てのアクティブ化された行が同一の様態で駆動されるので、マルチラインアドレシングで任意の画像を生成することができる。残りの差分及び/又は残りの行は、改良型シングルラインアドレシング(MISLA)によって均一にされ得る。
【0044】
図1d)において、図1a)における第2の行は、第2のマトリクスの分離駆動によって生成される。このことは、マトリクスディスプレイDを、それぞれ独立して駆動されるが一体となってマトリクスディスプレイDの所望の画像を生成する複数のマトリクスに、分解することに対応している。駆動は、ヒトの目が各行及び/又はマトリクスを順次駆動する処理を分離することができずに、それらをまとめて1つの全体的な画像を形成するような、速い時間サイクルで行われる。したがって、複数のマトリクスを駆動に用いる場合、1つの画像を完成するのに必要な合計時間TFrameが長くなってはならない。全てのマトリクスにおいて駆動しようとする全ての行をアクティブ化する合計時間TFrameを一定に維持し、それに応じた各ロウアドレス時間tiを採用するのが有利な手順である。この場合、1つの行に対するロウアドレス時間tiは、各行における列の最高輝度に応じて、別の行のそれとは著しく異なり得る。しかし、このことは、ここで説明している例においては起こらない。
【0045】
図1c)及び図1d)によるマトリクスの組み合わせについて、以下の方法が得られる。駆動のためには、正確な1期間のロウアドレス時間が、マトリクス毎に必要である。得ようとする最高輝度Dijはそれぞれ等しい。このことは、合計時間TFrame=4*tLを得るために、2つの等しいロウアドレス時間ti=2*tLが必要であることを意味する。図1c)のシングルラインアドレシングに対してロウアドレス時間が2倍になるのに応じて、各々の画素ijに対する動作電流又は電圧は半分になり得る。2ラインアドレシングの場合、複数の行の列毎の駆動の回路設計が並列回路に対応し、したがって、印加動作電流が全てのアクティブ化された行の画素に均等に分配されるということを考慮する必要がある。マトリクスにおける2ラインアドレシングの場合、各画素において同じ動作電流が利用可能となるように、印加動作電流を2倍にする必要がある。
【0046】
図1c)及び図1d)による組み合わせ駆動のための電流分配は、図2c)において理解され得る。ここでは、マトリクスディスプレイDの輝度を低下させることなく、最大動作電流がさらに低減されている。
【0047】
図1及び図2を用いて説明する駆動方法は、実際のアプリケーションと比べてはるかに単純化された構成を示すが、基礎となるアイデアを説明するのには十分である。本発明によると、この方法は、従来の方法又は公知の方法の要素、例えばプリチャージ技術及び放電技術などと組み合わせるのが有利であり得る。
【0048】
マトリクスディスプレイ駆動のより複雑な例を以下に説明するが、以下に説明する特徴の全てが本発明の主題を形成し且つ本発明の一部をなすものである。
【0049】
まず、図3に示すマトリクスディスプレイDの特性から説明を始める。マトリクスディスプレイの輝度Dijは、デジタル値で与えられ得る。値「0」はオフに切り替えられた画素を意味している。マトリクスにおける最高輝度はDmaxである(例えば、8ビットの場合は値「255」)。対応する動作電流はI0である。I0のレベルは、アプリケーションによって予め規定されているか又は調節される。それは、ディスプレイの所望の輝度を示す。
【0050】
従来技術に対応する前述のSLA(シングルラインアドレシング)法によると、フレーム期間(合計時間TFrame)内の各行は、均等な、固定された、又は一定のロウアドレス時間tLを割り当てられる。この期間内に最高輝度Dmaxが生成され得る。正確な輝度1ビットに対して、それに対応する時間サイクルt0は、
【数6】
となる。
【0051】
特定の輝度が、輝度制御の間に、パルス幅変調(PWM)によって時間サイクルt0の数に変換される。最高輝度について、ロウアドレス時間ti=Dmax*t0に対して動作電流I0が流れる。
【0052】
本発明において、ある行に必要な選択期間、つまり、この行について選択されたロウアドレス時間tiは、選択された行iの全ての画素ijの最高輝度Dijによって決定される。この行における最高輝度がDmax未満の場合、次の行がより早くアクティブ化され得る。つまり、選択されたロウアドレス時間tiをtLよりも短くし得る。したがって、1つの画像を形成するのに必要な合計時間は、
【数7】
となる。この式中、
【数8】
は、1つの行の最高輝度Dimaxの、全ての行に亘る合計である。したがって、Dimaxは、行iにおける全ての列の最高輝度である。
【0053】
この時間TSumは、合計時間TFrame以下であり、動作電流I0を動作電流I1に低減することによりTFrameに延長することができる。所望の輝度に適合される動作電流I1は、以下の式によって与えられる。
【数9】
すなわち、低減された動作電流I1は、ある行のアクティブな又は選択された段階(ロウアドレス時間ti)がtLに拘束されない、ということで得られている。その代わり、各行iは、この行における輝度Dimaxを有する最も明るい画素ijがそれを要求する限りにおいて、アクティブな状態を維持する。最も明るい画素について要求される時間に達すると、処理は直ちに次の行へと切り替わる。
【0054】
本発明によると、この時間最適化された制御方法を用いた場合、動作電流I1及びロウアドレス時間tiに対する時間サイクルが可変である。動作電流はI1に低減され、正確な輝度1ビット(LSB;最下位ビット)に対する時間サイクルは、t0からt1へと増加する:
【数10】
【0055】
これの簡単な例を図3に示す。図3a)のマトリクスディスプレイの画像を、個々の画素位置ijにおいて輝度値Dijを含むマトリクスDを示す図1に対応付けて説明する。
【0056】
マトリクスDは、3本の明ストライプとその間にそれぞれ存在する暗ストライプとを示している。単純に示すために、3ビットまでのグレイスケール(最高輝度Dmax=7)を仮定している。したがって、マトリクスディスプレイDは、全体で5つの行及び3つの列を含む。
【0057】
図3b)及び図3c)に、第2の列において印加される(動作)電流の遷移波形を示す。図3b)は、従来のシングルラインアドレシング(SLA)における電流波形を示す。それと比較する形で、本発明による改良型シングルラインアドレシングの遷移波形を図3c)に示す。
【0058】
シングルラインアドレシング(図3b))の場合、電流振幅は例えば70μAで一定であり、各行は一定のロウアドレス時間tL=2.8msecの間アクティブであるが、改良されたシングルラインアドレシング(図3c))の場合、電流振幅は40μAである。第1、第3及び第5の行はそれぞれ、4.2msecの期間(ロウアドレス時間ti)の間アクティブであり、第2の行及び第4の行は、0.7msecの期間(ロウアドレス時間ti)の間アクティブである。
【0059】
マトリクスD全体を駆動するために同じ様態で用いる動作電流I1及び正確な輝度1ビットに対する時間サイクルt1は、表示しようとする画像に応じてそれぞれ変化する。パッシブマトリクスOLEDの場合、ダイオード電流は多重モード(multiplex mode)のために非常に高いので、単位電流あたりの量子効率又は光強度は比較的低い。量子効率は、動作電流の減少に応じて向上する。この結果、動作電流はさらに低減される。
【数11】
η(I)は電流Iに対する量子効率であり、単位Cd/Aで示している。量子効率のプロフィールは、ガンマテーブルに格納されており、上記方法を実施する本発明の駆動電子機器によって上記計算のために使用し得る。
【0060】
公知の駆動方法と比べて動作電流I1が低減されるので、OLEDダイオードのフロー電圧(flow voltage)も低下する。消費エネルギはフレーム期間における電流と電圧の積の積分に等しいので、単位Lm/Wの効率も向上する。より高い効率が達成されたということは、ディスプレイの自己加熱が低下したということであり、この結果ディスプレイの寿命が延びる、ということを意味する。
【0061】
この方法の実施コストは低い。なぜなら、ディスプレイの動作電流I1は1度だけ設定すればよく、時間サイクルt1は設定が容易だからである。
【0062】
上で説明した駆動法の変形例において、行の最大輝度Dimaxの合計DSumは、予め規定された不変の量である。マトリクスにおいて複数の行を組み合わせて同時に駆動する場合、DSumを最小化するか又はさらに低減する可能性がある。ロウアドレス時間tiの間、複数の行を同時に選択して、画像マトリクス全体を駆動するのに必要な時間が全体として低減することができる。これにより、動作電流もさらに低減することができる。
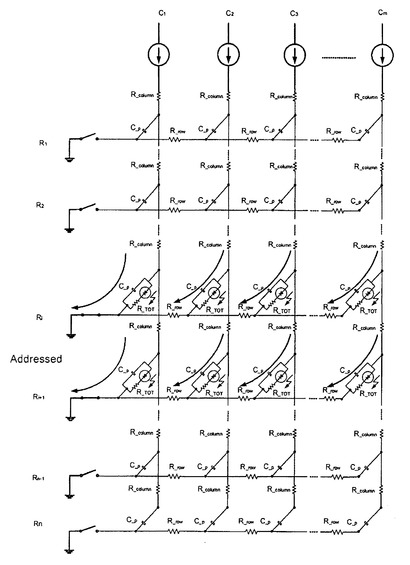
【0063】
図4は、どのようにして2つの行Ri,Ri+1を同時にアドレシングするかを示す回路図である。ここで、印加されたカラム電流は2*I1であり、各行Ri,Ri+1の2つのダイオードに均等に分配される。残りの行のダイオードはパッシブであり、寄生容量Cpのみを示している。同時にアドレシングされる行におけるある列の各ダイオードは、それぞれ同じ電流が印加されるので、光強度が等しい。したがって、シングルラインアドレシングとは異なり、駆動される画素において同じ輝度を得るために、2つの行に対して1つのロウアドレス時間tiだけでよい。
【0064】
このアプローチは、2を越える行数の行が同時にアドレシングされる際にもあてはまる。組み合わされる行数が増えるにしたがい、より多くの時間が節約される。これを、マルチラインアドレシングと呼ぶ。
【0065】
しかし、ここでは、複数の行におけるある列の複数の画素が均等に駆動されるので、複数の行の組み合わせは容易に可能ではない。したがって、輝度については、これらの画素の間に差はなく、よって、差情報が失われるか、又は、解像度が低下する。
【0066】
この問題は、所望のマトリクスディスプレイDを複数のマトリクスに分解することによって、マルチラインアドレシング(MLA)を上記のように最適化された改良型シングルラインアドレシング(ISLA)と組み合わせることによって解決する。すなわち、異なるマトリクスS,Mにおけるある行が単独で且つ他の行と一緒にアドレシングされる。マルチラインアドレシングでは一緒に駆動される、異なる行におけるある列の画素間の光強度の差は、マトリクスSを用いて改良型シングルラインアドレシングによって実現される。マルチラインアドレシングは、必要な合計時間TSumを最小化する。マトリクスディスプレイDのシングルラインマトリクスS及びマルチラインマトリクスMへの変換は、数学的には以下のように示される:
【数12】
式中、M2は2ラインアドレシングのためのマトリクスである。マトリクスSは、残差シングルラインマトリクスとも呼ぶ。マトリクスの基本構造は、図5において理解できる。
【0067】
マトリクスディスプレイDの個々の画素輝度Dijについてのソースデータ(このデータが集められて所望の画像を形成する)は、2つのマトリクスS,M2に分解される。Sは、改良型シングルラインアドレシングによって駆動されるシングルラインマトリクスである。M2は、駆動のために、2つの行がそれぞれ組み合わされて一緒にアドレシング又はアクティブ化される、マルチラインマトリクスである。n―1個のマトリクスによるM2の表現(nはマトリクスディスプレイDの行数)は、これらのマトリクスMの各々について2つの行が組み合わされている(これら2つの行における要素が同一なので)ことを示している。2つの行の組み合わせは、好適には、連続する2つの行について行われる。なぜなら、画像において連続する行は類似性が最も高く、実際のディスプレイでは、動作電流が最も同質に分配されるのは連続する行の2つの画素だからである。さらに、この制約条件により、数学的分解は、2つの任意の行が組み合わされる場合よりも単純になる。そして、このアルゴリズムは低コストで実施できる。以下に、本発明によるその実施態様をより詳細に説明する。
【0068】
当然、アプリケーションに応じて、隣接していない行を組み合わせてもよい。例えば、チェスボードパターン(市松模様)は、マルチラインアドレシングを用いて、間に1行挟んで離れた2つの行を組み合わせることにより非常に良く生成され得る。
【0069】
各行ペアがアクティブ化のために与えられるロウアドレス時間tiは、上述の実施態様と同様に、この行ペアにおける画素の最大輝度Mijに応じて変化する。シングルラインアドレシングの場合について上で説明した時間最適化された駆動方法を、ここでも用いる。したがって、ロウアドレス時間の合計は、以下のように計算される:
【数13】
ここで、max(Si1,…Sim)及びmax(M2i1,…,M2im)はそれぞれ、行の最大輝度を与えるものであり、それぞれのロウアドレス時間tiに比例している。
【0070】
複数のマトリクスに分解する目的は、動作電流I1をさらに低減すること、つまり、DSumを最小化することである。このことは、シングルラインマトリクスにおける2つの要素すなわちSij及びSi+1,jを、オリジナルデータDij及びDi+1,jからマルチラインマトリクスM2の各輝度M2ijだけ低減して得ることによって、達成される。しかしこのために、1つのロウアドレス時間ti、つまり、M2ijをアドレシングする時間が必要である。それに応じて、複数の行について影響が大きくなる。
【0071】
複数のマルチラインマトリクスにおけるソースデータ(マトリクスディスプレイD)の変換は、同様に、次のように規定される:
【数14】
式中、M3は、3つの行を同時に駆動することを意味する(図5参照)。同様に、さらに多くの行を同時にアドレシングすることが行われる。
【0072】
例えば次の定義にしたがって、いくつかのマルチラインマトリクスを省略することも可能である:
【数15】
式中、マトリクスM3はゼロ(0)に設定されている。また、シングルラインアドレシングは、マルチラインマトリクスMxの全要素がゼロ(0)に設定されていると解釈できる。
【0073】
画像又は画像マトリクスDを駆動がより簡単な複数の画像又は画像マトリクスS,Mに分割するというアイデアは、LCD及びプラズマディスプレイを含む全てのタイプのマトリクスディスプレイに用い得る。マルチラインマトリクスは、単純で効率の良い駆動の好例である。
【0074】
以下に、シングルラインアドレシングを含む完全なマルチラインアドレシングについて、具体的な例を用いて説明する。実行される変換の目的は、DSumの最小化である。その結果、動作電流は、もはやI0ではなく、I0よりもかなり小さな値(画像に応じた値)になっている:
【数16】
【0075】
図6に示す例において、4×9のマトリクスDは、2つのマトリクスM2,Sに分解される。このマトリクスDにおける行の数は、n=9である。Dmaxは、輝度値「15」(4ビット)を有する。
【0076】
図6における第1のマトリクスは、マトリクスディスプレイDの所望の輝度Dijを与える。第2のマトリクスは2ラインマトリクスM2であり、第3のマトリクスは残差シングルラインマトリクスSである。M2は、また別途図示されており、そこでは加算表現によって、同時アドレシングにおいてどのように輝度が2つの隣接する行に分配されるかが理解できるようになっている。DSumつまり同時にアクティブ化される行の最大輝度の合計は、2ラインマトリクスを用いた場合、DSum=72である。改良型シングルラインアドレシングのみを用いた場合、DSum=107である。したがって、n*Dmax=9*15=135と比較して、必要な動作電流は、2ラインマトリクスを用いることにより、従来の駆動方法の53%に低減される。
【0077】
図7による3ラインマトリクスアドレシングM3を用いた場合、DSumはさらに低減され得る。図7による第1のマトリクスは、図6のソースマトリクスと同じであり、マトリクスディスプレイDの所望の輝度Dijを再生する。第2のマトリクスは3ラインマトリクスM3であり、第3のマトリクスは2ラインマトリクスM2であり、第4のマトリクスは残差シングルラインマトリクスSである。この場合、DSumは、58までさらに低減される。したがって、n*Dmax=135と比べて、動作電流振幅の57%の減少が達成される。
【0078】
図8は、図6に示す2ラインアドレシングの場合の、第8の行の電圧波形、第2の列の電流及び電圧波形、並びにダイオード(D82)における電圧を示す。
【0079】
図示の例において、従来のシングルラインアドレシングの場合の動作電流I0は100μAである。したがって、53%にまで低下するのに応じて、1つの行の駆動の間の動作電流はI1=53μAとなる。53μAの場合のOLEDのフロー電圧は6Vである。OLEDの閾値電圧は3Vである。フレーム期間、すなわち合計時間TFrameは13.5msecである。従来のシングルラインアドレシングにおいて、一定のロウアドレス時間は、t0=0.1msecである。図6のマルチラインアドレシングにおいて、t1=0.1875msecである。ここで、1フレームは、72(DSum)t1サイクルである。
【0080】
Sマトリクス及びM2マトリクスは交互にアクティブ化される。例えば、はじめに、Sマトリクスの第1の行がアドレシングされ、次に、M2マトリクスの第1の行ペア(つまり第1及び第2の行)がアドレシングされ、その次に、Sマトリクスの第2の行がアドレシングされ、その次に、M2マトリクスの第2の行ペア(つまり第2及び第3の行)がアドレシングされる。
【0081】
図8aは、第8の行の電圧波形を示す。この行がアドレシングされると対応する行のスイッチ(図4参照)が閉じ、電流が流れる。その後、電圧はゼロ(0)になる。さもなければ、行のスイッチはオープンである。カラム電圧は常時流れているので、少なくとも6Vのカラム電圧が存在する。3Vのロウ電圧は、OLEDの場合、6Vのカラム電圧から例えば3Vの閾値電圧を引いた差分によって与えられる。第8の行は、2.625msec(9.375msec〜12msec)の間アドレシングされる。
【0082】
図8bは、第2の列における動作電流を示す。電流波形は3つのレベルを示している。すなわち、画素ダイオードのいずれもアクティブでない場合はゼロ(0)、画素ダイオードが1つだけアクティブである場合は53μA、(2ラインアドレシングの場合に)2つの画素ダイオードがアクティブである場合は106μA。2ラインアドレシングの場合、各ダイオードにおける電流振幅も53μAである。なぜなら、合計電流が、同時に駆動される画素ダイオードの両方に均等に分配されるからである。
【0083】
第8の行がアクティブ化されている期間(ロウアドレス時間ti)は、3つの段階からなる。はじめの4サイクルの間(9.375msec〜10.125msec)、第7の行及び第8の行が一緒にアドレシングされる。したがって、電流は2*53μAである。これは、M272の行アドレシングに対応している。
【0084】
次の5サイクルにおいて、S82の第8の行がアドレシングされる。5サイクル分のロウアドレス時間tiの合計は、マトリクスSの第8の行の輝度Sijの最大値「5」(第1の列、第8の行を参照)に由来する。53μAの電流が、0.1875msec(1サイクル)の間流れる。その後、電流は4サイクルに亘ってゼロ(0)になる。なぜならば、Sマトリクス(S81)の第8の行の最大値が5であり、パルス幅変調によって輝度制御がなされるからである。
【0085】
最後の段階は5サイクルに亘って続く。この間、マトリクスM2の第8及び第9の行がアドレシングされる。電流は、再び106μAになる。しかし、M282は4なので、電流は4サイクルの間だけ流れる。電流は、1サイクルの間ゼロ(0)に下降する。第3の列における最大輝度はM283=5なので、最後のサイクル(図示せず)においても、依然として第3の列に電流が流れている。動作電流が画素ij=82に印加される合計時間(アクティブ時間)は9サイクルであり、これはD82に対応している。
【0086】
第2の列の電圧の遷移波形を図8cに示す。動作電流が流れている場合、その動作電流が53μAか106μAかにかかわらず、6Vである。というのは、106μAにおいて、動作電流は2つのダイオードによって分割されるからである。電流が流れていない場合、電圧は3Vに下降する。これは、それ未満の場合にダイオード電流が流れない閾値電圧に対応している。
【0087】
図8dは、画素ij=82におけるダイオードの電圧の遷移波形を示す。53μAの動作電流がこのダイオードを流れる場合、電圧は6Vである。第8の行のアドレス時間の間、4サイクルに亘って電流が流れない。この時間の間、画素の電圧は3V(閾値電圧)である。第2の列に電流が流れていない場合、行スイッチ及び列スイッチの電圧は3Vであり、したがって、この画素における電圧はゼロ(0)である。第2の列に電流が流れている場合、列電圧は6Vであり、このアドレシングされていない第8の行の電位を3V(6V−閾値電圧)に遷移させる。
【0088】
本発明によるマトリクスディスプレイの駆動方法の技術的な実施は、従来のシングルラインアドレシング法と同程度に簡単である。各行にスイッチを設け、各列に電流源を設ける。電流源は、従来のシングルラインアドレシング法の場合には2つの電流レベル(例えば0及び1)のみであるのに対して、2ラインアドレシングの場合には3つの電流レベル(例えば0、1及び2)を有する。これは、複数の行が同時にアドレシングされる場合に、それに対応して電流を増加させる必要があるからである。一般に、n個の行が同時にアドレシングされる場合にはn+1段階に亘る階調(段階的変化)が必要になる。しかし、これを低コストで実施する必要がある。輝度を制御するために振幅・パルス幅混合変調のための具体的な回路を、以下により詳細に説明する。
【0089】
上述の例において、動作電流のパルス幅変調を用いた。S及びM2マトリクスは、当然ながら、動作電流の振幅変調によって生成され得る。振幅変調において、この行又は複数の行における最大値に達するまで、各行又は各複数の行がアドレシングされる。これは、パルス幅変調においても同じである。唯一の違いは、ロウアドレス時間tiの間、動作電流は常に流れ、その振幅レベルが調整される点である。
【0090】
ソースマトリクス(マトリクスディスプレイD)からマルチラインマトリクスM及びシングルラインマトリクスSへの最適化された効率的な変換は、動作電流を最小化するための決定的な要素である。「最適化された」とは、最大輝度DSumの合計を最小化することを意味し、「効率的」とは、迅速にかつ低コストのハードウェアで変換を行えることを意味する。
【0091】
マトリクスM及びSは、原則的に、線形計画法などの公知の方法と標準ソフトウェアを用いて得られるか又は決定され得る。しかし、乗算及び除算などの複雑な算術演算を用いる必要があり、その結果、この方法は非常に遅く且つ計算集約的(calculation-intensive)である。さらに、複雑さは、画像マトリクスのサイズに応じて二次的に増大する。
【0092】
したがって、「MaxFlow/MinCut」原理として公知のものに基づく、本発明による組み合わせ法が提案される。最適度の質は、基本的に、2つの連続する行がどのように異なるかということに依存するので、副次的条件D=S+M2+M3+...は、解空間を変更することなく2つの連続する等式の間に差を生じさせることによって再整理される。マトリクスd’,S’及びM2’,M3’は、図9に示すように生成される。マトリクスS’は、マトリクスd’と類似の様態で形成される。マトリクスの各列の合計はゼロ(0)である。
【0093】
再整理された副次的条件は、図10に示すグラフによって視覚化され得る。
【0094】
ここで、図中に白丸で示す(頂点集合Vの)各頂点は、再整理されたマトリクスd’内の要素を示す。白丸内のd’ijは、図9に示すマトリクスd’の対応する要素を示す。したがって、この頂点の値は、マトリクスの要素d’ijの値に等しい。マトリクス要素d’ij間の弧は、ある頂点(白丸)から別の頂点(白丸)への矢印である。これらの弧の各々は、矢印で示し且つ数が割り当てられた方向を有する。この(弧の組Aの)弧の割り当て(数)は、ソースデータマトリクスディスプレイの分解において対応する変数が有する値を反映している。ある1つの行から次の行へと延びた弧はマトリクスSに属する。1行とばしている弧(つまり長さ「2」を有する弧)は、マトリクスM2に割り当てられる。長さ「3」を有する弧は、同様にマトリクスM3に割り当てられている。マトリクスM4、M5などについても、類似の様態で割り当てが行われる。弧にはインデックスとしてijが与えられ、「i」は開始頂点(白丸)についての行番号であり、「j」は列の番号である。
【0095】
このことについて、図6及び図7で既に取り上げた例を用いて以下に説明する。図6の4×9マトリクスDを、図11に示す4×10のフローマトリクスd’に変換する。このマトリクスd’を、平衡にすべきフローとして図12に示す。
【0096】
d’マトリクスの各要素は、対応する位置の頂点に対応している。全ての弧にゼロ(0)が割り当てられている。というのは、これは、マトリクス分解の最初だからである。各頂点(白丸)について、出る弧(白丸から延びた矢印)の割り当て(数)の合計から入る弧(弧に到達した矢印)の割り当て(数)の合計を引いた差分が、その頂点の値(デマンド)に等しい場合、有効な分解が正確に達成される。全ての弧の割り当ては負にならない。
【0097】
図13は、平衡になったフローの結果を示す。マトリクスM3,M2,Sの全ての要素が、弧の割り当てから得られる。
【0098】
図13に示す平衡になったフローを生成するのに用いる数学的方法について、以下に詳細に説明する。
【0099】
図13において、始めと終わりの頂点がそれぞれ同じ行内にある2つの弧(矢印)は、同じタイプである必要がある。目的は、ある弧タイプの最大弧の合計が最小化されるような弧の有効な割り当てを見つけることである。このことは、以下のように数学的に説明することができる。弧集合Aがタイプに応じて、
【数17】
に分割された有向グラフG=(V,A)が与えられる。pは、マルチラインマトリクスM及び残差シングルラインマトリクスSの行数である。さらに、各頂点にそのデマンドを割り当てる関数
【数18】
が存在する。Zは全体の数(整数)である。関数
【数19】
は、各頂点v∈Vについて、次式
【数20】
が適用され、且つ、
【数21】
が最小になるように定義される。上側の等式は、「フロー保存(flow conservation)」とも呼ばれ、キルヒホッフの電流則に対応している。b(v)は、この頂点のデマンドであり、グランドからこの頂点への電流の流れ(負のデマンドの場合、電流は頂点からグランドに流れる)とみなし得る。DSumは最小化される。
【0100】
上記目的は、(容量として知られている)負でない数を、各弧のタイプ
【数22】
に、これらの容量の合計が最小になり且つ容量を越えない有効な弧の割り当てが存在するように、割り当てる問題に等しい。
【0101】
この新規な方法の特別な特徴は、所与の行の規定された長さを有する全ての弧について容量が有効である点である。これらの弧の各々へのフローは、この容量以下である。容量自体は可変であり、所定の様態で最適化のためのコスト又は費用を示している。全ての容量の合計を最小化する必要がある。この場合、所与の容量の場合にフローが最大化される公知のMaxFlow/MinCut法とは異なり、所与のフローの場合に容量が最小化される。
【0102】
容量は関数
【数23】
であり、全ての
【数24】
及び
【数25】
について、次の不等式
【数26】
が適用される。
【0103】
上で説明した最小化は、原則的には線形計画法としてモデル化され解かれるが、上述のように、非常に計算集約的(calculation-intensive)である。以下に説明するように、本発明による上述の方法は、少ないコストで数学的に実施され得る。
【0104】
この目的のために、容量は連続的に、つまり段階的に、ゼロ(0)から上方へと、有効な分解が可能になるまで増加する。このことはまた、容量がゼロ(0)以上であることを確実にする。各反復において、割り当てが容量に等しく、したがって有効な解を妨げるボトルネックを構成する弧集合が決定される。この弧集合(最小カットとも呼ぶ)は、負のデマンドを有する頂点から正のデマンドを有する頂点を分離する。弧の容量は、その後、最小カットから増加する。しかし、このことは、好適には、弧の大部分がボトルネックから離れることを可能にする容量についてのみ起こる。ここでは、割り当ては、有効な解が見つかるか又は新たなボトルネックが起こるまで増大し、その後、上記工程が繰り返される。
【0105】
この方法のシーケンスの数学的定式化は、図14において理解され得る。プログラムモジュール「MaxFlow」及び「MinCut」は、文献から公知である標準的な方法である。プログラムモジュール「Initialise」は、uについての開始値を規定する。例えば、u(k)=0が全ての
【数27】
について適用される。しかし、好適には、データの前処理によって得られる下限値が用いられる。集合Hは、計算されたMinCutの履歴を記載している。現在のMinCutの出る弧を、
【数28】
とし、反復iのMinCutの出る弧を、
【数29】
とする。パラメータΔuは、個々の容量が増加するステップサイズを決定する。好適には、数個の容量のみが、反復毎に増加する(例えば、kについてのみか、
【数30】
についてか、若しくは、重み付けした合計
【数31】
が最大である。なお、ステップが前であればあるほど、重みは小さくなる。wは履歴の重み付けを示す。ステップのサイズの選択により、方法の質(小さなΔu値、例えばΔu=1)と所要時間(より大きなΔu値)との間の妥協を動的に適合させることもできる。
【0106】
本発明の方法は、当然、画像マトリクスの一部の領域について用いることも可能である。このようにして、画像を複数の部分に分割し、分割された各部分を個々に最適化することが可能である。これは、局所最適化に対応している。
【0107】
規定されたサイズの部分領域を行毎に又は複数の行毎にずらすことにより、全体・局所混合型の最適化を同様に行うことができる。サブマトリクスは、規定された行数分の行から形成される。それは、まず、ソースマトリクスの上側の行から形成される。各最適化により、最上位の行又は上から数行分の行について、マトリクスの要素(S、M2、M3など)が得られる。したがって、次のサブマトリクスは、1行又は複数行だけ下方にずらされる。この新しいサブマトリクスに対する先に得られたマルチラインマトリクスの行の影響を減算する必要がある。1つまたは複数の行が、S、M2、M3などから再度得られる。サブマトリクスは、ソースマトリクスの最後まで進み、その後、完全に分解される。このようにして、S、M2、M3などの全てのエントリが得られる。
【0108】
比較的小さなマトリクスの分解に必要なメモリサイズは小さく、反復の数も少ない。マトリクスが概して大きいときに全体最適化を行う場合、マトリクス分解の結果を、SRAM等のバッファメモリに保存する必要がある。情報は、アクティブ化されると直ちに、出力ドライバ用のレジスタ内に行毎に読み込まれる。分割/局所型又は混合型の最適化の場合、容量は、まずサブマトリクス分解によって、そしてそれらの合計すなわちtl及びI1によって、得ることができる。急速分解のおかげで、行の結果が連続して再び計算され、出力ドライバ用のレジスタに直接転送される。それにより、大きなバッファメモリを省略することができる。ハードウェアのコストは、分割/局所型又は混合型の最適化によって低減され得る。但し、この場合、最適化の質はいくぶん低下し得る。
【0109】
対応する輝度を有する個々の画素ijを備えたマトリクスM,Sが定められた場合、それに対応してダイオードを駆動する必要がある。個々のロウアドレス時間tiは、行毎に異なり得、その行の最大輝度値に応じてそれぞれ変化し得る。輝度は、電流のパルス幅変調又は振幅変調によって制御され得る。
【0110】
パルス幅変調の場合、最大輝度を有する画素ijのみがロウアドレス時間全体に亘ってスイッチオンされる。つまり、当該画素を動作電流が流れる。残りの画素ijは、一時的に点灯されるのみであり、それぞれの点灯時間はそれぞれの輝度値Sij,Mijとの相関関係を有する。
【0111】
或いは、振幅変調を用いて輝度を制御することもできる。すなわち、アクティブ段階にある全ての画素ijがそれぞれロウアドレス時間tiの間スイッチオンされ、輝度の低い画素ijについては動作電流がそれに応じて低減される。しかし、振幅変調は、ハードウェア面で実施するのがより難しい。このことは、特に、色深度が高い場合又は階調数が多い場合にあてはまる。これに対してパルス幅変調は、ハードウェアに要するコストが高くなく、比較的単純且つ正確に実施できる。
【0112】
輝度の低い画素ijにおける動作電流の低減には、パルス幅変調を振幅変調と組み合わせるのが特に有利である。この、本発明による混合型の、つまり組合せ型の振幅・パルス幅変調について、図15〜図18を参照しつつ以下に説明する。
【0113】
本発明による上記マルチラインアドレシングについて、シングルライン、2ライン及びマルチラインアドレシングのための電流を列内に供給して、それに応じて電流のレベルを調節するために、動作電流を定量化する、つまり、複数の異なるレベルに分割する必要がある。例えば、マルチラインアドレシングM4において同時に駆動される4つの行について、動作電流の4倍の電流(4*I1)を印加する必要がある。
【0114】
この目的のために、電流源を、図15に示すように2つのシングルトランジスタセルと1つの2トランジスタセルとからなる3つのトランジスタで実現し得る。4つの行に対して動作電流I=4*I1が必要な場合、これら3つのトランジスタは、同じ制御電圧をゲートに受け取る。動作電圧I=3*I1が必要な場合、一方のシングルトランジスタセルには制御電圧が印加されず、2トランジスタセル及び他方のシングルトランジスタセルのそれぞれのゲートに制御電圧が印加される。動作電流I=2*I1の場合、2トランジスタセルがアクティブであり且つ2つのシングルトランジスタセルがパッシブであるか、若しくはその逆である。動作電流I=I1の場合、1つのシングルトランジスタセルのみがアクティブである。
【0115】
輝度値がMij,Sijが最大ではないマトリクスエントリの場合に、定量化された動作電流を用いて動作電流を再度低減することも可能である。輝度値Mijについて図18に示すアルゴリズムは、例えば、この目的のために用い得る。結果は、輝度制御のための混合型パルス幅・振幅変調に対応している。
【0116】
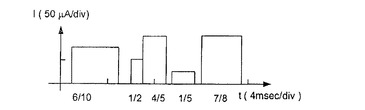
組合せ型輝度制御の結果を、輝度制御のための純粋なパルス幅変調(図16)と比較する形で図17に示す。純粋なパルス幅変調において、電流振幅は、例えば一定の100μAである。第1のパルスのパルス幅は、この行のアクティブ時間を10単位(10単位のロウアドレス時間)とした場合、10単位中6単位(6/10)である。6単位は10単位の半分よりも大きく且つ10単位の3/4よりも小さいので、第1のパルスのパルス幅は、混合型振幅/パルス幅変調を用いて、元の値の4/3に拡大される。同時に、振幅が元の振幅の3/4(この例では75μA)に低減される。このことは、図16と比較して図17を参照することにより理解できる。第2のパルスのパルス幅が2倍にされ、その一方で、振幅が類似の様態で1/2にされる。第3及び第5のパルスを拡大することはできない。なぜなら、それらのパルス幅はそれぞれの行のアクティブ期間(ロウアドレス時間)に近いからである。対照的に、第4のパルスの幅は4倍にされ得る。
【0117】
輝度制御のための混合(組合せ)型振幅・パルス幅変調において、動作電流の平均振幅が低減されることが、図17から明らかに理解し得る。
【0118】
当然ながら、図18に示す上記アルゴリズムの一部のみを用いることが可能である。これらのアルゴリズムはまた、シングルラインマトリクスにも適用される。異なる行数のマルチラインアドレシングにおいて、その行数に対応する様態でアルゴリズムが定められる。アルゴリズムは、電流源の定量化に応じて変化する。
【0119】
本発明によるマトリクスディスプレイの駆動方法及び本発明が関係する上記方法を実行するように設定されたディスプレイ制御システムを用いると、マトリクスディスプレイの最適化された駆動が達成できる。これは、性能を向上するため(例えばフレームレートを高めるため)及び/又は個々の画素を駆動するのに必要な動作電流を低減するために用い得る。本質的な特徴は、各行のロウアドレス時間が、この行の画素が得るべき最大輝度に応じて変化すること、及び/又は、マトリクスディスプレイを複数の独立したマトリクスに分解し、そのいくつかがマルチライン駆動を表すことである。
【0120】
本発明はまた、上記方法を実行する制御システムに関する。この目的のために、例えばディスプレイコントローラ及びディスプレイドライバが1つのチップに集約される場合、請求の範囲に記載の方法が、特定用途向けIC(ASIC)において実施され得る。t1及びI1はドライバ内で生成される。マトリクスの分解は、単純且つ高速の組み合わせ論理を用いて実現される。
【0121】
画像、ひいては得られたマトリクスは、常にデータ集約的(data intensive)であるので、メモリも必要である。この要件は、現代の半導体プロセスを用いた場合、又は、上述のように局所又は混合型の最適化を用いた場合に緩和され得る。本発明の方法は、当然ながら、複数のチップ間で分割することもできる。
【図面の簡単な説明】
【0122】
【図1】具体的にシングルラインアドレシング及びマルチラインアドレシングを説明するために、本発明によるマトリクスディスプレイを駆動するさまざまな実施形態を模式的に示す図である。
【図2】図1に示すマトリクスディスプレイの或る列の画素を駆動するための動作電流(又は関連する電圧)を時間軸上に模式的に示す図である。
【図3】3列×5行からなるマトリクスディスプレイD及び1つの列を駆動するのに必要な電流を示す図である。
【図4】m列(Cm)×n行(Rn)のマトリクスディスプレイの等価回路を示す図である。
【図5】シングルラインマトリクス及びマルチラインマトリクスの定義を示す図である。
【図6】本発明による、マトリクスディスプレイDを2ラインマトリクス及びシングルラインマトリクスに分解する例を示す図である。
【図7】本発明による、図6に示すマトリクスディスプレイDを3ラインマトリクス、2ラインマトリクス及びシングルラインマトリクスに分解する例を示す図である。
【図8a】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図8b】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図8c】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図8d】図6によるマトリクスの選択されたラインについての電圧波形及び電流波形を示す図である。
【図9】マトリクスディスプレイDをフローマトリクスd’に分解する例を示す図である。
【図10】図9によるフローマトリクスd’のフロー図である。
【図11】図6によるマトリクスDをフローマトリクスd’に変換した具体例を示す図である。
【図12】図11によるフローマトリクスd’の第1の最適化ステップにおけるフロー図である。
【図13】図11によるフローマトリクスd’の最適化ステップ後のフロー図である。
【図14】フローマトリクスd’を形成するための数学的流れ図及び最適化されたフロー図を示す図である。
【図15】本発明による、動作電流を生成する実施形態を示す図である。
【図16】パルス幅変調を用いた輝度制御を示す図である。
【図17】混合型振幅・パルス幅変調を用いた輝度制御を示す図である。
【図18】図17による輝度制御を実行するためのアルゴリズムを示す図である。
【特許請求の範囲】
【請求項1】
独立した画素(ij)を有する複数のラインを備えたマトリクスディスプレイ(D)の駆動方法であって、
前記ラインは行(i)及び列(j)として構成されており、
個々のラインは、行(i)を所定のロウアドレス時間(ti)の間アクティブ化し、画素(ij)の所望の輝度(Dij)に応じて、前記アクティブ化された行(i)に対して相関関係を有する列(j)に動作電流(I)又はそれに対応する電圧を印加することによって、選択的に駆動されるものであり、
各行(i)のロウアドレス時間(ti)は、この行(i)の全ての列の最大輝度(Dimax)の関数として決定される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項2】
請求項1において、
全ての行(i)をアクティブ化する合計時間(TFrame)は、一定に維持されており、全ての行に亘る前記ロウアドレス時間(ti)の合計(TSum)が前記合計時間(TFrame)に対応している
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項3】
請求項1又は2において、
前記マトリクスディスプレイ(D)は、個別に駆動される複数のマトリクス(S,M2,M3,M4)に分解される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項4】
請求項1〜3のうちいずれか1項において、
複数の行(i)が同時に駆動される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項5】
請求項4において、
隣接する行(i,i+1)が同時に駆動される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項6】
請求項3および請求項4又は5において、
1つの行(i)が駆動されるマトリクス(S)と、複数の行(i)が駆動される1つ又は複数のマトリクス(M2,M3,M4)とが互いに組み合わされる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項7】
請求項1〜6のうちいずれか1項において、
パルス幅変調を用いて輝度の制御を行う
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項8】
請求項1〜7のうちいずれか1項において、
振幅変調を用いて輝度の制御を行う
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項9】
請求項1〜6のうちいずれか1項において、
パルス幅変調を振幅変調と組み合わせて輝度の制御を行う
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項10】
請求項1〜9のうちいずれか1項において、
前記マトリクスディスプレイ(D)は、前記列内の個々の画素の輝度差についてのデマンドに対応する頂点を要素として有するフローマトリクス(d’)に変換される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項11】
請求項10において、
前記フローマトリクス(d’)は2つのマトリクスの差分から生成され、前記2つのマトリクスのうち、第1のマトリクスは、前記マトリクスディスプレイ(D)とその末尾に付された、要素がゼロの行とからなり、第2のマトリクスは、前記マトリクスディスプレイ(D)とその先頭に付された、要素がゼロの行とからなる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項12】
請求項10又は11において、
前記頂点は、割り当てが指定された、好適にはその長さに応じて前記複数の個々に駆動されるマトリクス(S,M2,M3,M4)の要素に対応する、弧と呼ばれる矢印によって繋がれる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項13】
請求項12において、
マトリクス(S,M2,M3,M4)の各行に、容量が割り当てられる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項14】
請求項13において、
前記容量値は、可変であり、前記弧の有効な指定が得られるまで増加する
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項15】
請求項13又は14において、
局所基準(local criteria)に応じて選択された前記容量が増加する
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項16】
請求項15において、
前記局所基準はMinCutである
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項17】
請求項15又は16において、
先行するMinCutsに関する情報を選択基準としても用いる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項18】
請求項14〜17のうちいずれか1項において、
前記容量値が増加するステップサイズは動的に適合される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項19】
請求項10〜18のうちいずれか1項において、
前記マトリクスディスプレイ(D)は複数のサブマトリクスに分解され、前記サブマトリクス(S,M2,M3,M4)はそれぞれフローサブマトリクスに分解される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項20】
請求項10〜19のうちいずれか1項において、
混合型局所・全体最適化が実行され、1行又は数行のマルチラインマトリクス(M2,M3,M4)並びに/若しくは(残差)シングルラインマトリクス(S)がフローサブマトリクスから得られる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項21】
請求項1〜20のうちいずれか1項の方法の、自己発光型ディスプレイの駆動のための使用。
【請求項22】
請求項1〜20のうちいずれか1項の方法の、非自己発光型ディスプレイの駆動のための使用。
【請求項1】
独立した画素(ij)を有する複数のラインを備えたマトリクスディスプレイ(D)の駆動方法であって、
前記ラインは行(i)及び列(j)として構成されており、
個々のラインは、行(i)を所定のロウアドレス時間(ti)の間アクティブ化し、画素(ij)の所望の輝度(Dij)に応じて、前記アクティブ化された行(i)に対して相関関係を有する列(j)に動作電流(I)又はそれに対応する電圧を印加することによって、選択的に駆動されるものであり、
各行(i)のロウアドレス時間(ti)は、この行(i)の全ての列の最大輝度(Dimax)の関数として決定される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項2】
請求項1において、
全ての行(i)をアクティブ化する合計時間(TFrame)は、一定に維持されており、全ての行に亘る前記ロウアドレス時間(ti)の合計(TSum)が前記合計時間(TFrame)に対応している
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項3】
請求項1又は2において、
前記マトリクスディスプレイ(D)は、個別に駆動される複数のマトリクス(S,M2,M3,M4)に分解される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項4】
請求項1〜3のうちいずれか1項において、
複数の行(i)が同時に駆動される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項5】
請求項4において、
隣接する行(i,i+1)が同時に駆動される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項6】
請求項3および請求項4又は5において、
1つの行(i)が駆動されるマトリクス(S)と、複数の行(i)が駆動される1つ又は複数のマトリクス(M2,M3,M4)とが互いに組み合わされる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項7】
請求項1〜6のうちいずれか1項において、
パルス幅変調を用いて輝度の制御を行う
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項8】
請求項1〜7のうちいずれか1項において、
振幅変調を用いて輝度の制御を行う
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項9】
請求項1〜6のうちいずれか1項において、
パルス幅変調を振幅変調と組み合わせて輝度の制御を行う
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項10】
請求項1〜9のうちいずれか1項において、
前記マトリクスディスプレイ(D)は、前記列内の個々の画素の輝度差についてのデマンドに対応する頂点を要素として有するフローマトリクス(d’)に変換される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項11】
請求項10において、
前記フローマトリクス(d’)は2つのマトリクスの差分から生成され、前記2つのマトリクスのうち、第1のマトリクスは、前記マトリクスディスプレイ(D)とその末尾に付された、要素がゼロの行とからなり、第2のマトリクスは、前記マトリクスディスプレイ(D)とその先頭に付された、要素がゼロの行とからなる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項12】
請求項10又は11において、
前記頂点は、割り当てが指定された、好適にはその長さに応じて前記複数の個々に駆動されるマトリクス(S,M2,M3,M4)の要素に対応する、弧と呼ばれる矢印によって繋がれる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項13】
請求項12において、
マトリクス(S,M2,M3,M4)の各行に、容量が割り当てられる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項14】
請求項13において、
前記容量値は、可変であり、前記弧の有効な指定が得られるまで増加する
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項15】
請求項13又は14において、
局所基準(local criteria)に応じて選択された前記容量が増加する
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項16】
請求項15において、
前記局所基準はMinCutである
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項17】
請求項15又は16において、
先行するMinCutsに関する情報を選択基準としても用いる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項18】
請求項14〜17のうちいずれか1項において、
前記容量値が増加するステップサイズは動的に適合される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項19】
請求項10〜18のうちいずれか1項において、
前記マトリクスディスプレイ(D)は複数のサブマトリクスに分解され、前記サブマトリクス(S,M2,M3,M4)はそれぞれフローサブマトリクスに分解される
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項20】
請求項10〜19のうちいずれか1項において、
混合型局所・全体最適化が実行され、1行又は数行のマルチラインマトリクス(M2,M3,M4)並びに/若しくは(残差)シングルラインマトリクス(S)がフローサブマトリクスから得られる
ことを特徴とするマトリクスディスプレイの駆動方法。
【請求項21】
請求項1〜20のうちいずれか1項の方法の、自己発光型ディスプレイの駆動のための使用。
【請求項22】
請求項1〜20のうちいずれか1項の方法の、非自己発光型ディスプレイの駆動のための使用。
【図1】


【図2】

【図3】
【図4】
【図5】
【図6】

【図7】

【図8a】
【図8b】
【図8c】
【図8d】

【図9】
【図10】
【図11】
【図12】
【図13】
【図14】

【図15】
【図16】

【図17】
【図18】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8a】
【図8b】
【図8c】
【図8d】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【公表番号】特表2009−522590(P2009−522590A)
【公表日】平成21年6月11日(2009.6.11)
【国際特許分類】
【出願番号】特願2008−547884(P2008−547884)
【出願日】平成18年12月21日(2006.12.21)
【国際出願番号】PCT/EP2006/012362
【国際公開番号】WO2007/079947
【国際公開日】平成19年7月19日(2007.7.19)
【出願人】(508196737)エックス−モーティフ ゲーエムベーハー (1)
【出願人】(508196726)オプトレックス ヨーロップ ゲーエムベーハー (1)
【出願人】(506011249)マックス‐プランク‐ゲゼルシャフト・ツア・フェルデルンク・デア・ヴィッセンシャフテン・アインゲトラーゲナー・フェライン (2)
【Fターム(参考)】
【公表日】平成21年6月11日(2009.6.11)
【国際特許分類】
【出願日】平成18年12月21日(2006.12.21)
【国際出願番号】PCT/EP2006/012362
【国際公開番号】WO2007/079947
【国際公開日】平成19年7月19日(2007.7.19)
【出願人】(508196737)エックス−モーティフ ゲーエムベーハー (1)
【出願人】(508196726)オプトレックス ヨーロップ ゲーエムベーハー (1)
【出願人】(506011249)マックス‐プランク‐ゲゼルシャフト・ツア・フェルデルンク・デア・ヴィッセンシャフテン・アインゲトラーゲナー・フェライン (2)
【Fターム(参考)】
[ Back to top ]