
マルチコアアーキテクチャにおけるリソース管理
【課題】少なくとも1つがマスタ処理装置である複数の相互接続されたプロセッサ要素を有するマルチコアプロセッサにおいて、実行可能トランザクションを処理するためのリソース管理/タスク割り振りコントローラを提供する。
【解決手段】リソース管理/タスク割り振りコントローラは、マスタ処理装置を含むプロセッサ要素のそれぞれと通信するように適合されており、事前定義された割り振りパラメータに従って個々のプロセッサ要素にマルチコアプロセッサ内の実行可能トランザクションを割り振る制御論理を備える。
【解決手段】リソース管理/タスク割り振りコントローラは、マスタ処理装置を含むプロセッサ要素のそれぞれと通信するように適合されており、事前定義された割り振りパラメータに従って個々のプロセッサ要素にマルチコアプロセッサ内の実行可能トランザクションを割り振る制御論理を備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、マルチコアアーキテクチャにおけるリソース管理の方法および装置に関する。
【背景技術】
【0002】
今日、複雑な異種混合マルチコアアーキテクチャを組み込んだ半導体デバイスが、ユビキタスなデスクトップコンピュータから、携帯電話機、携帯情報端末、高速電気通信/ネットワーク交換装置などといった最新型の電子機器に至るまで、多種多様なシステムおよび機器で利用されている。
【0003】
任意のコンピュータプロセッサの使用目的がどのようなものであれ、プロセッサ製造者は、現在のプロセッサの性能を高めると同時に、それらの単位「コスト」を維持し、または低減しようと努力し続ける。
【0004】
プロセッサの「コスト」は、様々なパラメータを使って評価され得る。多くの場合、コストは、純粋に、金銭的コストであるが、多くの適用分野、特に組み込み式プロセッサ市場において、コスト計算は、電力消費、冷却要件、効率、商品化に要する時間などの付随的考慮事項も含む。
【0005】
任意のプロセッサが有用な機能を果たす絶対的能力は、達成可能なMIPS(100万命令/秒)比として特徴付けることができ、よって、任意のプロセッサの「価格/性能」比は、例えば、MIPS/mm2、MIPS/$、あるいはMIPS/mWなどによって特徴付けることができる。
【0006】
しかしながら、実際には、すべての命令が同量の有用な作業を達成するとは限らず、したがって、「純粋な」MIPS評価は、容易に比較することができない。よって、ディジタル信号プロセッサ(DSP)は、携帯電話機の無線インターフェースの近くにおける数学的な集中処理の解決には適しているが、その電話機の画面上で実行されるWebブラウザの実行においては極めて効率が悪い。事実上、これは、プロセッサが、「アプリケーション利用可能」価格/性能の観点からの方がより有効に分類され得ることを意味している。
【0007】
しかも、プロセッサを制御し、カスタマイズして個々のアプリケーションを実施するのに使用されなければならないプログラミング、すなわちソフトウェアツールの非効率性によって、有効性能のさらなる低下が引き起こされ得る。よって、個々のアプリケーションのためにプロセッサから抽出され得る最終的な性能レベルは、使用可能な、または「達成可能なアプリケーション利用可能」価格/性能のレベルとみなされ得る。
【0008】
半導体企業による、プロセッサのアプリケーション利用可能価格/性能を改善しようとする取り組みにおいて、新しいクラスのプロセッサ、すなわち、マルチコアデバイスが開発されている。マルチコアデバイスは、プロセッサによって実行され得るアプリケーションの特定の態様での最大レベルの有効価格/性能比を提供するために、それぞれが高度に特化されていてもよい、様々な要素(コア)から構築される高度に集積されたプロセッサである。そのようなデバイスは、「異種混合」、すなわち複数の、異種のコアを組み込んだものとすることも、「同種」、すなわち複数の類似のコアを組み込んだものとすることもできる。
【0009】
また、ほとんどのマルチコアデバイスは、システムオンチップ(SoC)デバイスとして分類することができる。というのは、その集積が、複数のプロセッシングコアのみならず、任意の個別製品のハードウェア要件の(全部ではないにしろ)大部分を処理するのに必要とされるメモリ、入出力およびその他のシステム(コア)も含むからである。すべてのSoCデバイスが複数のプロセッシングコアを有するとは限らないが、複数のコアとSoCという用語は、しばしば、互いに入れ替えて使用される。マルチコアSoCの好例を多くの携帯電話機に見ることができ、それらには、無線インターフェースを実行するための1つ以上のDSPを含む単一のプロセッサと、電話機でユーザアプリケーションを実行するための汎用プロセッサが搭載されている。
【0010】
マルチコアデバイスの出現は、ムーアの法則によって可能となったものであり、この法則によれば、シリコンの任意の所与の面積に組み込まれ得るトランジスタの数は、製造工程の改善により18ヶ月ごとに倍増することになる。したがって、ムーアの法則は、シリコンダイ上の任意の所与の面積により多くの個別トランジスタを組み込むことを可能にし、単一のシリコン片上により一層複雑なデバイスを製作することを、技術的にも経済的にも実行可能にする。同様に、各トランジスタのサイズを縮小することにより、トランジスタは、より一層高速で切り換わることができる。
【0011】
従来、ムーアの法則は、基礎となるアーキテクチャに大きな変更を加えずに、より高速な、または使用されるシリコンの点でより費用対効果の高い、より小型の新世代プロセッサを製作するのに使用された(すなわち、改善は、デバイスの論理的マクロアーキテクチャの改善ではなく、製造工程およびデバイスの物理的マイクロアーキテクチャの改善であった)。
【0012】
事実上、マルチコア/SoCプロセッサに向かう傾向は、より高レベルの集積へのマクロアーキテクチャ的移行とみなすことができ、これは、まず、シリコンダイ自体への入出力(通信)機能の導入から始まった。今や、入出力、メモリ、および複数の処理装置、DSPおよびコプロセッサの機能を同じシリコンダイ上に集積することができる。これらのプロセッサは、個々のアプリケーションクラスに最低コストで、最高性能のプロセッサを提供することによって、最終製品の製造コストを低減するはずである。また、システム構成部品の大部分を単一プロセッサ上に集積することにより、部品点数も削減され、したがって、信頼性を高め、電力消費を低減することができる。
【0013】
重要な問題は、可能な限り高い「アプリケーション利用可能」価格/性能を達成するために、そのようなマルチコアデバイスにおける基礎的なハードウェアの使用をどのようにして最適化し得るかである。
【0014】
プロセッサおよびシステムの設計者らが、アプリケーションソフトウェア内での並列処理(アプリケーションレベルの並列処理)および命令ストリーム内での並列処理(命令レベルの並列処理)を利用することのできる多くのやり方がある。それら様々な発現では、並列処理がどこで管理されるか、および並列処理が、システムが実行しているとき/実行時に管理される(動的システム)か、それともアプリケーションソフトウェアがコンパイルされているとき/コンパイル時に管理される(静的システム)かが異なる。実際には、動的システムと静的システムおよびハードウェア集約的解決とソフトウェア集約的解決の間の区分は明確なものではなく、ある分野からの技法が、しばしば、その他の分野によって流用される。
【0015】
個別プロセッシングコアレベルにおいて、単一ストリームからの並列の多数命令で動作する複数発行プロセッサまたはマシンの概念は、当分野では十分に確立している。これらは、スーパースカラプロセッサと超長命令語(VLIW)プロセッサという2つの基本的種類で供給される。スーパースカラプロセッサは、実行時(動的にスケジュールされる)またはコンパイル時(静的にスケジュールされる)のどちらかに識別される、様々な数の1クロックサイクル当たりの命令を発行する。VLIWプロセッサは、コンパイラによって定義されるように、非常に長い命令語を形成する固定数の命令を発行する。通常、プログラマは、このプロセスに全く気付かない。というのは、システムのプログラミングモデルが、標準的なシングルプロセッサ抽象化であるからである。
【0016】
スーパースレッディングとハイパースレッディングは、両方とも、複数の仮想プロセッサの間で複数の実行スレッドを多重化することによって複数のプロセッサをエミュレートする技術である。通常、これらの仮想プロセッサは、統計的に、単一のスレッドによって常に使用されるとは限らないはずのいくつかのリソースを共用する。スーパスレッディングアーキテクチャおよびハイパースレッディングアーキテクチャは、複数の独立のプロセッサの役割を演じ、したがって、効率よく働くために、あるレベルのアプリケーション並列処理が存在することを必要とする。通常、プロセッサコアのハードウェア制約条件により、サポートされ得るスレッド数が、実質上100未満に制限される。
【0017】
さらに、多くのアプリケーションにおける固有の並列処理の利用では、いくつかのシステムアーキテクチャ上の選択肢が存在する。各プロセッサが、なんらかの共用リソース(例えば、メモリおよび/または相互接続など)を介してそのピアと協働しながら、独自の命令を実行し、独自のデータセットに基づいて動作する多重命令多重データ(MIMD)マシンは、それらが多種多様なアプリケーションに対処することができるために普及している。
【0018】
性能需要が高まるにつれて、組み込みシステムは、ますます、複数の異種または同種の処理リソースを使用する、マルチコアMIMDアーキテクチャを利用して、必要なレベルのシリコン効率を提供するようになってきている。通常、これらは、集中型共用メモリアーキテクチャと呼ばれるMIMDマシンのクラスであり、複数の処理リソース間で単一のアドレス空間(またはその一部)が共用されるが、よりアプリケーション特有のハイブリッドアーキテクチャもよく見られる。
【0019】
MIMDアレイの各処理リソースは、命令レベルの並列処理(ILP)を利用することができるが、MIMDマシンは、スレッドレベルの並列処理(TLP)を利用して、基礎となるハードウェアの潜在的性能を実現することもできる。実行時に(特定のハードウェアによって)、またはコンパイル時に(コンパイルツールを最適化することによって)識別されるILPに対して、TLPは、アプリケーション設計時に高水準プログラミングソフトウェア内で定義される。
【0020】
スレッディングは、長年にわたり、ソフトウェア業界内で、並列処理の高レベル表現として使用されてきた概念である。スレッドとは、定義上、他のスレッドと同時に実行され得る実行状態、命令ストリームおよびデータセットを含む自律的作業パッケージを定義するものである。命令ストリームの複雑度は重要ではない。スレッドは、単純なデータ転送から複雑な数学的変換に至るまで何でも記述することができる。
【0021】
従来から、オペレーティングシステムは、ソフトウェア技術者が基礎となるデバイスアーキテクチャを詳細に理解することを必要とせずにマルチコアアーキテクチャのある一定の構成上でアプリケーションが実行されることを可能にするスレッド割り振り機能を含めて、システム管理の提供を支援している。しかしながら、ユニコアデバイス内のスレッド管理のための既存のソフトウェア技術は、マルチコアアーキテクチャに一貫して容易に適合することができない。これまでの解決策は、設計ごとにカスタマイズされた解決策を必要とする、専用のものであり、通常は、性能および拡張性を損なうものであった。
【0022】
従来、異種混合マルチコアシステム(すなわち、ほぼ異種の処理リソースを有するシステム)の場合には、多種多様な手法を用いて異なる処理リソースが協働することを可能にしている。しかしながら、これらは、大まかに、「プロキシホスト」と「連携」(「ピアツーピア」ともいう)という2つのカテゴリに分けられる。前者の場合、指定された汎用ホストプロセッサ(バスベースのシステムでは、しばしば、CPUと呼ばれる)は、システム全体を統括し、システム全体のタスクを仲介し、メモリやデバイスなどのリソースへのアクセスを同期させる。そのようなシステム統括管理は、通常、オペレーティングシステムのカーネルで操作され、システムアプリケーションおよびホストプロセッサ上の非同期イベントの処理とタイムスライスを求めて競合する。言い換えると、この汎用プロセッサは、マルチコアデバイス上のすべての処理リソースのための集中型プロキシスレッドマネージャとして働くと共に、主要なアプリケーションプロセッサとしても働かなければならない。
【0023】
この構成で使用されるとき、汎用プロセッサは、事前設定のスケジューリングポリシに応じた各処理リソースごとの実行可能なスレッドの待ち行列、すなわち、スレッドの優先度(すなわちディスパッチまたは作動可能待ち行列)、ならびに、スレッド自体が実行され始める前に、何らかのイベント、または別のスレッドの結果を待ち受けるスレッドの待ち行列(すなわち保留およびタイミング待ち行列)を維持しなければならない。これらが、スレッド実行前のプロセッサ構成など、他のシステムオーバーヘッドに加えられる。
【0024】
汎用プロセッサが、例えば、スレッドの完了のために発行された割り込み(したがって、そのスレッドを完了したばかりの処理リソースの解放)の結果として、その処理時間を、プロセッサが現在実行しているスレッドから、(スレッド管理を含む)システムの管理に転じるときにはいつでも、汎用プロセッサは、コンテキスト変更を行わなければならない。
【0025】
コンテキスト変更には、休止されるスレッドの現在の進捗状況をメモリに格納し、その他のスレッド/処理リソースのサービス提供のための管理ルーチンに関連する命令をフェッチし、次いで、任意の構成要件を含めてそれらの命令を実行することを伴う。元の、休止されたスレッドに戻るには、さらなるコンテキスト変更が実行されなければならない。これらのコンテキスト変更は、通常、割り込みを受け取り時に実行され、組み込みシステムでは、これらの割り込みが、汎用プロセッサ上で実行中のアプリケーションコードにとって、頻繁、かつ非同期的であることがしばしばある。したがって、システム全体として、著しい性能劣化を呈する。また、コンテキスト切換えは、ホストプロセッサキャッシュに悪影響を及ぼす(いわゆる「コールドキャッシュ」効果)。
【0026】
連携システムの場合、各処理リソースは、オペレーティングシステムの別々のインスタンスを実行し、その一部が、リソース間通信を可能にする。したがって、そのような構成は、ピア間の割り込みの特定の経路指定の結果として、比較的厳格なアーキテクチャ上の区分化を有する。この種のシステムは、アプリケーションを生成するのに必要なプリミティブを提供するが、実施性能は、依然として、オペレーティングシステムのカーネルアクティビティに関連付する頻繁なコンテキスト切換えによって損なわれる。
【0027】
要約すると、従来のアーキテクチャ(汎用プロセッサ、ソフトウェアエグゼクティブなど)でのシステム管理実現の現在の設計および方法は、複雑な異種混合マルチコアアーキテクチャのシステムおよびスレッド管理には適さない。実際、汎用プロセッサは、マイクロ(命令セット)アーキテクチャレベルでも、マクロ(キャッシュ、レジスタファイル管理)アーキテクチャレベルでも、十分に最適化されない。マルチコアプロセッサの相互接続は、別々の処理リソース間の相互運用のための物理的媒体を提供するが、システム管理の一貫性した手法を可能にする、すべての処理リソース間で共用される、システム規模のタスク管理通信層がない。最悪の場合、これは、従来から、それぞれが、随時、ソフトウェアにおいて別々に解決されなければならない、あらゆる処理リソース間のあらゆる可能な通信チャネルに関連付けられる明確な問題をもたらしかねない。
【0028】
よって、これらの非常に複雑なマルチコアアーキテクチャの効率的なシステム管理の方法が求められている。ソフトウェア抽象化だけでは、複雑なマルチコアアーキテクチャの必要なレベルの性能を提供することができない。
【発明の概要】
【0029】
本発明の第1の態様によれば、請求項1で定義されるマルチコアプロセッサのリソース管理/タスク割り振りコントローラが提供される。
【0030】
好ましい実施形態では、請求項1のコントローラは、リソース管理およびタスク割り振り専用であり、それ以上の処理リソースを提供しない。
【0031】
本発明の実施形態において、「従来の」マスタ処理装置(すなわち、本発明のリソース管理/タスク割り振りコントローラがない場合に、タスク割り振りを実行すると共に、利用可能な処理リソースの1つとしても働くはずの一般的な処理リソース)は、システムの電源投入時にマスタとして始動することができ、リソース管理/タスク割り振りコントローラは、初期設定シーケンスの間のMPUからマスタステータスを引き受ける。
【0032】
また、本発明の実施形態は、通常は、個々のタスクを処理する際の使用で無視されるはずの処理リソースへのタスクの割り振りを可能にする異種混合マルチコアプロセッサの機能も提供する。そのようにして、本発明のコントローラは、利用可能なリソースのより効率のよい使用を可能にする。
【0033】
別個のリソース管理/タスク割り振りコントローラを設けることによって、本発明は、マルチコアプロセッサのための改善されたタスク割り振り/管理システムを提供し、利用可能な処理リソース間でのより効率のよいタスク割り振りを可能にする。コントローラは、システム管理および例外処理の要素を、専用の、効率のよい、ハードコードされた実施形態に抽象化する。
【0034】
本発明の実施形態は、「プロキシエージェント」の役割を強制するのではなく、コントローラと共にコントローラクライアントを用いる。コントローラクライアントは、ハードウェアまたはソフトウェアとして実施され得る。そのような構成は、基礎となるシステムの「実行時」アクティビティを効率よく制御する。特に、コントローラは、事前定義された割り振りパラメータの範囲に基づいて、システムスレッドの状態およびスケジューリング決定の正確さを絶えず(「貪欲に」)維持する。
【0035】
したがって、好ましい実施形態のアーキテクチャは、複雑度を問わずに、構成コンポーネント間の作業分配、および個々の処理リソースの自律性の点で、大きなメリットを提供する。すべての処理リソースが、デフォルトでは「怠惰」であるスレーブデバイスになる。すなわち、好ましい実施形態では、専用の割り込みを介して、リソース管理/タスク割り振りコントローラによってタスクを実行するよう明示的に指示されるのを待つ。同様に、他の実施形態では、リソース管理/タスク割り振りコントローラと処理リソースの間で、ポーリングベースの通信が使用されてもよい。
【0036】
本発明のコントローラを用いるシステムでは、アーキテクチャ外部から引き起こされるすべての非同期イベントは、直接ピンを介してであれ、間接的に処理リソースの1つ(すなわち入出力装置)の外部操作によってであれ、好ましくは、コントローラに経路指定され、そこで、「ブート時」に構成された1組のスケジューリングポリシを使って、ターゲット処理リソース上で現在実行されているタスクと比較される。処理リソースは、外部イベントに関連付けられた割り込みサービススレッド(IST)が、現在実行中のトランザクション(スレッドまたはタスク)を統括する場合に限って割り込まれ、それによって、当分野で問題であった、任意の処理リソースにおける不必要なコンテキスト切換えを未然に防ぐ。さらに、好ましい実施形態のコントローラクライアントは、任意の複雑度の処理リソースが、共用リソースおよびコントローラ自体で基本的なシステム管理操作を行う(スレッドを作成する、同期プリミティブを発行する、スレッドを削除する、メモリコピーなど)ことを可能にし、命令セットベースのマシンが、これらのタスクをプロキシによって実行する必要を回避する。
【0037】
本発明のさらなる態様では、そのようなコントローラを備えるマルチコアプロセッサが提供される。
【0038】
また、本発明は、請求項40で定義される、マルチコアプロセッサ内のリソースを制御し、割り振る方法にも適用される。
【0039】
添付の従属請求項には、さらなる利点および特徴が定義されている。
【0040】
本発明は、いくつかのやり方で実施することができ、次に、例としてあげるにすぎないが、添付の図面を参照していくつかの実施形態を説明する。
【好ましい実施形態の詳細な説明】
【0041】
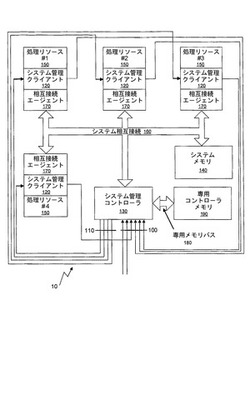
図1に、本発明の一実施形態による機構を組み込んだシステムフレームワーク10の論理図を示す。フレームワーク10は、それぞれが他の処理リソース150と同種であっても、異種であってもよく、それぞれが任意の複雑度のものとすることのできる複数の処理リソース150を備える。各処理リソースは、相互接続160を介して共用データが格納される共通のシステムメモリ140へのアクセスを共用する。当然ながら、すべてのシステムメモリ140が必ずしもすべての処理リソース150に共通であるとは限らないことが理解されるであろう。
【0042】
また、システムフレームワークは、本発明の一実施形態による、集中型タスク割り振り/管理システム20も備える。集中型タスク割り振り/管理システム20は、システム管理コントローラ130と、専用の密結合メモリ190に接続された専用の密結合メモリインターフェース180とを含む。各処理リソース150は、相互接続115を介してコントローラ130にアクセスすることができる。図1の構成の実施においては、どんな特定の相互接続戦略(すなわち、コントローラ130が各処理リソース150と、またその逆方向に通信するための構成、および各処理リソース150がシステムメモリ140と通信するための構成)も必要とされないことを理解すべきである。特に、処理リソースのそれぞれが、コントローラ130と直接的または間接的に(すなわち、他の処理リソースを介して、または別のやり方で)通信することができる必要があることだけを別として、ポイントツーポイントリンク、中央システムバスまたはパイプライン型アーキテクチャでさえも等しく用いることができる。
【0043】
図2に、やはり一例にすぎないが、図1の論理構成を実施するマルチコアプロセッサを示す。図2のマルチコアプロセッサは、それぞれがシステム相互接続160を介して接続された、複数の処理リソース150を用いる。システム相互接続160は、さらに、入力インターフェース100、および出力インターフェース110を介して、システム管理コントローラ130と通信する。図2の例で、システム相互接続160は、処理リソース150のそれぞれを相互に接続し、コントローラ130と接続すると共に、システムメモリ140などの共用システムリソースとも接続する従来の中央バスとして配置される。メモリ140とのインターフェースは、いくつかの現在利用可能なインターフェース技術のいずれか1つによって達成されてもよい。メモリは、例えば、静的ランダムアクセスメモリ(SRAM)や、2倍速ランダムアクセスメモリ(DDR RAM)といった、現在利用可能な中央コンピュータメモリ技術のいずれで構成されてもよい。
【0044】
図2にみられるように、複数の処理リソース150のそれぞれは、中央コントローラ130から制御情報を受け取り、受け取った制御情報に従って処理リソース150を管理するように構成された、関連付けられたシステム管理コントローラクライアント120を有する。コントローラクライアント120の機能および目的は、以下で、図7および8に関連してより詳細に説明する。また、各処理リソースは、システム相互接続160を介したコントローラ130との通信のための、関連付けられた相互接続エージェント170も有する。相互接続エージェント170は、システム相互接続160上で使用される基礎となる相互接続プロトコルから独立の、コントローラクライアント120への汎用インターフェースを提供する。すなわち、相互接続エージェント170は、システム相互接続160上で使用される通信プロトコルとコントローラクライアント120によって使用される通信プロトコルの間のプロトコル変換を提供する。相互接続エージェント170の使用により、本発明の実施形態のコントローラクライアント120は、現在利用可能な任意のシステム相互接続プロトコルと共に使用することができる。
【0045】
マルチコアプロセッサは、全体として、スレッドと呼ばれるいくつかの個別タスクに分割することのできるターゲットアプリケーションを実行するように構成される。各処理リソース150は、それだけに限らないが、当該のスレッドの優先度、各処理リソース150の利用可能性および個々のスレッドの実行への個々の処理リソースの適合性を含むいくつかのパラメータに従い、コントローラ130によって適切なスレッドに割り振られる。これについても、やはり、以下でより詳細に説明する。
【0046】
しかしながら、システム管理コントローラ130およびその専用メモリ190の追加は、その他の点ではプロセッサ10の配置の再設計を必要としないことを理解すべきである。
【0047】
図3に、1つの具体的な構成を示す。図3には、ブロック図の形で、典型的なシステムオンチップ(SoC)アーキテクチャが示され、実際のアプリケーションにおいてコントローラ130のリソース管理下に置かれ得る様々な処理リソースが説明されている。処理リソースは、具体的には、DSPなど、比較的一般的な機能のものとすることもでき、周辺入出力など、比較的限定された機能のものとすることもできることが認められる。
【0048】
(システム管理コントローラインターフェースグループ)
図4に、コントローラ130と、コントローラ130の周辺に位置する、コントローラ130に関連付けられたインターフェースグループ200〜250を示す。
【0049】
システム制御グループ200は、システム管理コントローラ130の正しい動作を保証するのに必要な2つのシステム入力信号を備える。2つのシステム入力信号は、システムクロックに接続されるCLK入力と、RST入力からなる。システム管理コントローラ130からのすべての出力信号がシステムクロックに同期し、システム管理コントローラ130へのすべての入力信号が、このクロックを使ってサンプリングされる。RST入力は、システム管理コントローラ130をリセットするための同期リセット信号である。
【0050】
外部割り込みグループ210は、システム管理システム外部から供給される同期外部割り込みのグループからなる。これらの信号は、システム管理コントローラ130周辺に接続される前にCLKに同期されなければならない。外部割り込みグループ210内の信号は、例えば、外界との入力インターフェースから、またはピンを介してマルチコアプロセッサ外部から直接駆動され得る。外部割り込み入力の数は、マルチコアプロセッサ10設計段階において定義される。
【0051】
内部制御グループ220は、各コントローラクライアント120およびそれに関連付けられた処理リソース150ごとの単一の同期割り込みからなる。したがって、信号のグループの数は、通常、システム内の処理リソース150の数に対応し、マルチコアプロセッサ10設計段階において定義される。内部割り込み信号は、そのコントローラクライアント120に関連付けられた特定の処理リソース150に割り当てられている、実行可能なスレッドを示す。
【0052】
密結合メモリインターフェースグループ180は、システム管理コントローラ130を、独自の専用密結合メモリリソース190にインターフェースする。図5に、専用密結合メモリ190の典型的な構造を示す。アドレスパスおよびデータパスの幅は、マルチコアプロセッサ10設計段階において定義される。専用密結合メモリインターフェースは、メモリアドレスバス191、メモリ読取りデータバス192、メモリ書込みデータバス193、ならびに書込み194および読取り196イネーブル信号を含む。
【0053】
接続されるメモリは、同期SRAMデバイスであるものとする。専用密結合メモリ190は、ターゲットアプリケーションの必要に従って、マルチコアプロセッサ10設計段階において定義される、整数個のコントローラメモリ要素195を含む。現在の好ましい実施形態において、各コントローラメモリ要素195は、256ビットのメモリ空間を消費する。やはり現在の好ましい実施形態において、コントローラは、最大65536個のコントローラメモリ要素(すなわち、16MBメモリ)をサポートする。後述するように、待ち行列記述子はコントローラメモリ要素195を消費するが、典型的なシステムにおいて、必要なコントローラメモリ要素195の数は、スレッドサポート要件によって決まるはずである。例えば、システム管理コントローラ130内で同時に400スレッドをサポートすることのできるシステムは、おおよそ128KBの接続メモリを必要とするはずである。
【0054】
図4の相互接続インターフェースグループ230は、マルチコアプロセッサ10と、マルチコアプロセッサ設計段階において定義される相互接続エージェント170で使用される選択された相互接続プロトコルに従う。
【0055】
(コントローラサブブロック記述および機能)
図6に、システム管理コントローラ130の主要な論理コンポーネントを示す。コントローラ130の機能は、以下の各機能を実行する4つの1次内部並列処理サブブロック間で分担される。
【0056】
1.専用密結合メモリ190内の空いているコントローラメモリ要素195のリストを維持し、コントローラメモリ要素195回復を監視するように構成されたスレッド入力マネージャ(TSIM)300。
【0057】
2.専用密結合メモリ190内の保留リストおよびタイマ待ち行列を維持し、スレッド間の同期を実行し、必要に応じて、専用密結合メモリ190内の作動可能待ち行列構造へのスレッドの格上げを行うように構成されたスレッド同期マネージャ(TSPM)310。スレッド同期マネージャ310は、専用密結合メモリ190内での保留スレッド記述子の挿入および抽出によって、保留およびタイマ待ち行列構造の保全性を維持する。
【0058】
3.専用密結合メモリ190内の作動可能待ち行列構造と、専用密結合メモリ190内の各処理リソース150ごとのディスパッチ待ち行列とを維持するように構成されたスレッド出力マネージャ(TSOM)320。スレッド出力マネージャ(TSOM)320は、さらに、コントローラクライアント120に送られる割り込み220を生成するように構成される。作動可能待ち行列構造の保全性の維持は、専用密結合メモリ190内のコントローラメモリ要素195で保持されるスレッド記述子の挿入および抽出によって行われる。
【0059】
4.専用密結合メモリ190内に位置する作動可能待ち行列構造内の各処理リソース150ごとにスケジューリング決定を提供するように構成されたスレッドスケジュールマネージャ(TSSM)330。
【0060】
さらに、いくつかの2次処理サブブロックが、以下のサポート機能を提供する。
【0061】
5.相互に排他およびロッキングを含む、接続された専用密結合メモリ190への集約アクセスを提供するように構成されたスレッドメモリマネージャ(TSMM)340。
【0062】
6.入力される外部システム割り込みを内部同期プリミティブに変換するように構成された割り込みマネージャ(TSIC)350。
【0063】
7.各処理リソース150に同期のためのタイマ機能および監視タイマ機能を提供するように構成されたタイムマネージャ(TSTC)360。
【0064】
8.処理リソース150に相互接続インターフェースおよび構成および実行時アクセスを提供するように構成されたシステムインターフェース(TSIF)380。
【0065】
続いて、システム管理コントローラ130内の上記1次および2次処理サブブロックの対話の詳細な説明を行う。
【0066】
各サブブロックは、他のサブブロックに1組の関数を提示し、それぞれが、そのピアに、専用密結合メモリ190内のそれぞれに維持される構造に対する操作を実行するよう指示することができるようにする。各関数は、コントローラソフトウェアのアプリケーションプログラミングインターフェース(API)において受け取られたのと類似のコマンドを受け取り次第、個々のサブブロックによって呼び出される。
【0067】
(スレッド入力マネージャ関数)
スレッド入力マネージャ300は、システム管理コントローラ130内の他のサブブロックに3つの共通関数を提供する。
【0068】
FreeListStatus関数は、コントローラメモリ要素195フリーリスト内の先頭ポインタおよび要素数を返す。フリーリストは、現在未使用のコントローラメモリ要素195のリストである。この関数は、コントローラ130ソフトウェアAPIにおける類似コマンドの受け取り時に、システムインターフェース380によってのみ呼び出され得る。
【0069】
PushFreeIndex機能は、解放されたコントローラメモリ要素195インデックスをフリーリスト上にプッシュバックするのに使用される。この関数は、スレッドスケジュールマネージャ330によってのみ呼び出され得る。
【0070】
PopFreeIndex関数は、フリーリストから空いているコントローラメモリ要素195インデックスをポップするのに使用される。これは、通常、システムインターフェース380内のAPI呼び出しサービスルーチン内から呼び出される。
【0071】
(スレッド同期マネージャ関数)
スレッド同期マネージャ310は、システム管理コントローラ130内の他のサブブロックに7つの共通関数を提供する。
【0072】
以下の5つの関数は、コントローラ130ソフトウェアAPIによって受け取られた類似のコマンドに応答して、システムインターフェース380によってのみ呼び出され得る。
【0073】
PushPendingDescriptor関数は、ブートプロセスの間に、保留待ち行列記述子のリストに保留待ち行列記述子を加えるのに使用される。
【0074】
PushThread関数は、実行時に、所与の保留待ち行列に従属スレッドを加えるのに使用される。
【0075】
SetTimerStatusは、タイマ待ち行列内の先頭ポインタおよび要素数を設定する。
【0076】
GetTimerStatus関数は、タイマ待ち行列内の先頭ポインタおよび要素数を返す。
【0077】
SetPendingStatus関数は、保留待ち行列記述子リストの状況を設定する。
【0078】
GetPendingStatus関数は、保留記述子待ち行列内の先頭ポインタおよび要素数を返す。
【0079】
SyncEvent関数は、所与の保留待ち行列に同期プリミティブを発行するのに使用される。この関数は、スレッド割り込みマネージャ350およびシステム管理コントローラ380によって呼び出される。
【0080】
TimeEvent関数は、タイマ待ち行列に、タイマベースの同期プリミティブを発行するのに使用される。この関数は、タイムマネージャ360によってのみ呼び出される。
【0081】
(スレッド出力マネージャ関数)
スレッド出力マネージャ320は、システム管理コントローラ130内の他のサブブロックに5つの共通関数を提供する。
【0082】
Push関数は、作動可能待ち行列構造内にスレッド記述子を配置する。このメソッドは、(例えば、割り込みを処理するなどの)処理速度を速めるために、高い優先度で呼び出され得る。スレッドが独立である(即座に作動可能である)場合、呼び出しは、システムインターフェース380から行われ、スレッド記述子が元々依存関係を有していた場合、呼び出しは、スレッド同期マネージャ310から行われる。
【0083】
以下の3つの関数は、コントローラ130ソフトウェアAPIにおける類似コマンドの受け取りに応答して、システムインターフェース380によってのみ呼び出され得る。
【0084】
GetDispatchQueueStatus関数は、ディスパッチ待ち行列リスト内の先頭ポインタおよび要素数を返す。
【0085】
SetDispatchQueueStatus関数は、ディスパッチ待ち行列リスト内の先頭ポインタおよび要素数を設定する。
【0086】
DispatchQueuePop関数は、ディスパッチ待ち行列の先頭からスレッド記述子をポップする。
【0087】
DispatchWorkQueuePush関数は、スレッド出力マネージャ320作業待ち行列上にディスパッチ待ち行列をプッシュする。この関数は、スレッドスケジュールマネージャ330によってのみ呼び出され、スレッドスケジュールマネージャ330は、この関数を使って、出力マネージャ320に、スケジュール更新の結果としてディスパッチ待ち行列内で必要とされる変更を知らせる。
【0088】
(スレッドスケジュールマネージャ関数)
スレッドスケジュールマネージャ330は、システム管理コントローラ130内に位置するスレッド出力マネージャ320およびシステムインターフェース(TSIF)380に3つの共通関数を提供する。
【0089】
PushPushWorkEvent関数は、スレッド出力マネージャ320が作動可能待ち行列構造にスレッド記述子を加えた直後に、スレッド出力マネージャ320によって呼び出される。
【0090】
PushPopWorkEventは、スレッド出力マネージャ320が作動可能待ち行列構造からスレッド記述子を除去した直後に、スレッド出力マネージャ320によって呼び出される。
【0091】
FreeIndex関数は、コントローラメモリ要素195の解放が、スレッドスケジュールマネージャ330内で進行中のスケジューリングアクティビティと適正に同期されることを可能にする。呼び出しは、コントローラ130ソフトウェアAPIにおいて類似のコマンドを受け取り次第、またはスレッド出力マネージャ320内のポップ操作の結果として発行されてもよい。
【0092】
(コントローラクライアント)
前述のように、処理リソース150という用語は、命令がどれほど初歩的なものであるかに関わらず、その命令を実行し得る任意のリソースに適用される。したがって、入出力モジュールなど、固定機能を有するリソースも含まれる。処理リソース150の種類に応じて、システム管理コアクライアント120を介した、システム相互接続160と処理リソース150の間の接続は、単方向とすることも、双方向とすることもできる。
【0093】
図7に、システム管理コントローラ130と共に使用するためのコントローラクライアント120の概略的ブロック図の一例を示す。
【0094】
例えば、汎用プロセッサやディジタル信号プロセッサなどの適切な処理リソース150上で、コントローラクライアント120は、通常、ソフトウェアとして実施される。しかしながら、処理リソース150が限定された機能のものである場合、コントローラクライアント120は、ハードウェアコンポーネントを必要とすることもある。
【0095】
システム相互接続160と処理リソース150の間でハードウェアコンポーネントが使用されるとき、コントローラクライアント120は、やはり、同じインターフェースを使って処理リソース150にインターフェースする。すなわち、コントローラクライアントは、処理リソース150のコントローラクライアントへのインターフェースと同一のインターフェースを相互接続エージェント170に提示する。場合によっては、例えば、入出力装置の場合には、処理リソースへのデータパスを、処理リソースからのデータパスと異なるものとして処理するのが妥当なこともある。
【0096】
主要なインターフェースに加えて、コントローラクライアント120は、実行時およびデバッグイベントの出力として使用するために帯域外インターフェースも提供する。ソフトウェアコントローラクライアント120が使用される場合、これらは、適切なサービスルーチンを呼び出す標準割り込みを使って提供される。
【0097】
(コントローラクライアント動作モード)
各コントローラクライアント120は、完全に割り込み駆動型である。コントローラ130から内部割り込みを受け取り次第、コントローラクライアント120は、専用密結合メモリ190内に保持されているその特定の処理リソース150に関連付けられたディスパッチ待ち行列の先頭から、スレッド記述子をポップする。次いで、スレッド記述子内の一意の参照を使って、メインメモリリソース140さらなるスレッド制御情報、スレッド制御ブロック(TCB)が読み取られる。TCB内に含まれる情報は以下のいずれかとすることができる。
【0098】
1.コントローラクライアント120構成内容。この情報は、コントローラクライアント120システムリソース使用ポリシング、データプレゼンテーションモードなどを構成するのに使用され得る。
【0099】
2.処理リソース150構成内容。これは、個々のスレッドの実行のために処理リソース150を準備するのに必要とされる情報である。これは、このスレッド前の部分実行からの回復、または、オーディオCODECなどの、専用ハードウェアアクセラレータの構成を含んでいてもよい。
【0100】
3.命令内容。固定機能ハードウェアアクセラレータの場合、例えば、処理リソース150が出力モジュールであるときの出力命令など、「命令」は、目的のハードウェア処理リソース150では暗黙的となり、任意の必要な専門化または構成が、構成情報内に収容されることになる。ソフトウェアコントローラクライアント120の状況では、これは、通常、スレッドに関連付けられた機能コードを指示すポインタになる。
【0101】
4.データ内容。この内容は、システムメモリ140内の開始アドレスまたは複数のアドレス、およびスレッドが動作し得るデータ範囲を定義することができる。
【0102】
5.コントローラクライアント120後処理内容。この内容は、スレッド実行完了後のコントローラクライアント120のアクションを決定する。
【0103】
コントローラクライアント120の3つの異なる動作段階がある。
【0104】
1.処理リソース150およびコントローラクライアント120が個々のスレッドの実行のために準備される構成段階。最も単純な場合、構成段階はヌルになる。
【0105】
2.スレッドが実行され、コントローラクライアント120がデータを供給し、かつ/またはリソース利用を監視し得る実行段階。
【0106】
3.完了段階。処理の完了は、結果として、アクションなし、別のスレッドの作成、同期プリミティブの発行、またはスレッド作成と同期の組み合わせを生じ得る。さらに、コントローラクライアント120は、スケジューラメトリックを設定または更新し、スレッドを終了させるように要求されることもある。スレッド実行時に、結果を格納するためにさらなるメモリが必要とされる場合、コントローラクライアント120は、このメソッドも実行しなければならない。
【0107】
個別のハードウェアコントローラクライアント120bが、アクティブ期間において利用可能なシステム相互接続160帯域幅を完全に利用する状況において、1つの最適化された解決策は、コントローラクライアント120bが、複数のハードウェア処理リソース150のプロキシとして動作するのを可能にすることであろう。そのような構成を図7bに示す。前述の場合と同様に、プロキシコントローラクライアント120bは割り込み駆動型である。しかしながら、前述の例では、コントローラ130から単一の割り込みだけが経路指定されたが、プロキシコントローラクライアントモデルでは、処理リソース150ごとの割り込みがある。コントローラ130から受け取られる割り込みのインデックスに従って、プロキシコントローラクライアント120bは、識別された処理リソース150で同じステップを実行する。システム相互接続160使用ポリシングが必要とされるプロキシコントローラクライアントモデルでは、ハードウェアアダプタ120cが、処理リソース150とシステム相互接続160の間に残る。
【0108】
前述のように、コントローラクライアント120は、ソフトウェアとして実施されてもよい。この場合、コントローラクライアント120の機能の一部、例えば、共用リソース使用ポリシングは、通常、処理リソース150ハードウェア(例えば、メモリ管理ユニット(MMU)など)にすでに存在する既存のハードウェアコンポーネントを利用することになる。
【0109】
結果として、ソフトウェアコントローラクライアント120アーキテクチャおよび実施は、処理リソース150特有のものになる。
【0110】
また、ハードウェアコントローラクライアント120は、関連付けられた処理リソース150の特質による専門要件を有することもある。以下の項では、大部分の場合に好適となる汎用アーキテクチャを説明する。
【0111】
(ハードウェアコントローラクライアントの一般例)
図8に、ハードウェアコントローラクライアント120の基本構造を示す。設計の機能的中心にあるのは、コントローラクライアント有限状態機械(FSM)500である。この有限状態機械(FSM)500は、3段階すべてにおいてアクティブとすることができる。コントローラクライアントFSM500は、コントローラ130からの割り込み220によって活動化される。
【0112】
まず、コントローラクライアントFSM500は、システム相互接続160を制御して、独自の命令への参照を含む共用メモリリソース140からTCBを読み取らせる。構成段階の間、コントローラクライアント120は、処理リソースを制御して、構成コマンドを解釈し、コマンドを、処理リソース150に発行される書込みサイクルに変換することができる。さらに、コントローラクライアント120は、独自のリソースポリシングを構成する。構成状態から実行状態への遷移の仕方は処理リソース150特有のものであるが、明示的な実行プリミティブによってマークされてもよく、単に、データ転移状態に入ることとしてもよい。
【0113】
コントローラクライアント120から見て、最も単純なアーキテクチャは、処理リソース150とシステム側の両方で同一のインターフェースプロトコルを有する。この場合、実行段階の間に、処理リソース150読取り/書込みサイクルが、適切な場合にはチェックを伴って、単に、システムインターフェースにマップされるだけである。
【0114】
最も単純なコントローラクライアント120実施は、システムから処理リソースへのパス510と処理リソースからシステムへのパス520の両方でFIFOスタイルのインターフェースを必要とするはずである。この性質のコントローラクライアント120の実行段階の間、データは、メッセージまたはストリーミングモードによって処理リソース150に提示され得る。データセット全体が、処理の前にコントローラクライアント120内においてローカルで蓄積されるメッセージモードは、より複雑な相互接続アービタを円滑化し得る、より粗くむらのある相互接続挙動を生じさせる。データがシステムメモリから処理リソース150に直接ストリーミングされるストリーミングモードは、ハンドシェークのより慎重な考察を必要とし、細かい相互接続トランザクションおよび相互接続への密結合を呈する、よりシリコン効率の高い解決策を提示する。
【0115】
実行段階から完了段階への遷移は、処理リソース150へのデータの提示を測定することによって推断されてもよく、処理リソース150自体によって明示的に通知されてもよい。完了段階の間、コントローラクライアント120は、再度、元のスレッド制御ブロックによって提供される命令セットから実行する。
【0116】
場合によっては、処理リソース150に入るディスパッチ(例えば、入出力装置など)と処理リソース150から出るパスとを区別して扱うことが妥当であることに留意されたい。これに対して、同じコントローラクライアント120フレームワーク内でデータの消費側と生成側を結合すべき場合(例えば、DSPなどのアルゴリズム的アクセラレータ)もある。
【0117】
処理リソース150とその他のシステムリソースの間で減結合のレベルを提供するために、コントローラクライアント120によって、以下のようないくつかの追加機能が提供され得る。
a)処理リソース150によって生成されるアドレスが、比較器530および比較アドレスレジスタ540を使って、基底アドレスおよびオフセット定義によって定義される期待される挙動に照らしてチェックされてもよい。
b)処理リソース150によって生成されるアドレスが、減算機550およびオフセットアドレスレジスタ560を使ってオフセットされ、処理リソース150が、通常、アドレス0×0前後に正規化される、任意の所与のスレッドのアドレスマップの正規化ビューを有することを可能にする。
【0118】
(オブジェクト)
システム管理コントローラ130内で使用されるデータ型のインスタンスは、公開(システム一般から見ることができ、システム一般によって操作される)と専用可視(システム管理コントローラ130内でのみ見ることができ、システム管理コントローラ130サブブロックによってのみ操作される)とに分けられる。複数のエンドアプリケーションにまたがる設計の移植性を保証するために、すべてのスレッド、待ち行列および集約待ち行列記述子が、共通基底クラスを使用する専用密結合メモリ190、コントローラメモリ要素195内に格納される。
【0119】
(コントローラメモリ要素)
各コントローラメモリ要素195は、以下の7つの記述子型のいずれかを表すことができる。
【0120】
1.フリーリスト要素。この要素は、その他の記述子型のいずれによっても自由に利用される。ユーザ初期設定も実行時操作も必要とされない。
【0121】
2.スレッド記述子(TD)。これは、アプリケーション/OSスレッドのデータ構造表現である。この記述子は、専用密結合メモリ190内の保留待ち行列、作動可能待ち行列またはディスパッチ待ち行列に存在し得る。ユーザ初期設定は必要とされないが、実行時操作は必要である。
【0122】
3.スケジューラルート記述子(SRD)。これは、スケジューラ階層の最上位の記述子である。ユーザ初期設定は必要であるが、実行時操作は必要とされない。ルート記述子は親を持たないが、子は、SSTD、DSTDまたはTDのいずれかとすることができる。
【0123】
4.静的スケジューラ層記述子(SSTD)。これは、SRDまたは別のSSTDを親とすることのできる静的スケジューラ層記述子である。SSTDの子は、別のSSTD、DSTDまたはTDのいずれかとすることができる。
【0124】
5.動的スケジューラ層記述子(DSTC)。これは、動的スケジューラ層記述子である。ユーザ初期設定は必要とされないが、実行時操作は必要である。DSTDの親は、SRDまたはSSTDのどちらかとすることができるが、DSTDは、TDの子だけしか持つことができない。
【0125】
6.ディスパッチ待ち行列記述子。この種の記述子は、関連付けられた処理リソース150からのポップ操作を待ち受けるスレッド記述子のリストを記述する。ユーザ初期設定は必要であるが、実行時操作は必要とされない。
【0126】
7.保留待ち行列記述子。この種の記述子は、同期イベントを待ち受けるスレッド記述子のリストを記述する。ユーザ初期設定は必要であるが、実行時操作は必要とされない。
【0127】
以下の各項では、これらの記述子をより詳細に説明する。
【0128】
コントローラメモリ要素195の様々な形、およびそのそれぞれを、図9aから9lに示す。
【0129】
(スレッド表現)
記述子が初期設定または実行時操作を必要とする場合、操作は、コントローラ130APIを介して行われる。集中型タスク割り振り/管理システムは、リアルタイム対話が、ハードウェア実施に十分適する/ハードウェア実施に十分なほど単純化されるように設計される。
【0130】
図10に、スレッド記述子と、システム管理コントローラ130と、処理リソース150と、共用システムメモリ140の間の典型的な関係を示す。各スレッドプリミティブは、一意の参照、pReferenceを含む。この参照は、システム管理コントローラ130によって解釈も、変更もされない。pReferenceは、実行されるべきタスクを定義するシステムメモリ140内のデータ構造を指し示すポインタを提供する。通常、これは、コントローラクライアント制御ブロック125であり、少なくとも、(図10に処理リソース命令ブロック145として示す)関数ポインタ、スタックポインタおよび(図10にデータブロック135として共に示す)引数ポインタという要素を含むはずである。帯域内構成または共用システムリソースのセキュリティを提供する追加フィールドが定義されてもよい。
【0131】
しかしながら、アプリケーションおよび/またはターゲット処理リソース150によって、コントローラクライアント制御ブロック125の複雑度は異なり得る。特に、適切な「制御」命令コードおよび対応する「ディスパッチ」コードが与えられた場合に、異なる処理リソース150が、一定の状況下で、同じデータに対して同じ関数を実行することを可能にし得る別のレベルの間接化も含まれ得ることに留意されたい。
【0132】
図11に、スケジューリング階層が、2つの異種の処理リソース(図11のタイプIおよびタイプII)150aと150bにまたがってタスクを負荷均衡化する一例を示す。(この階層の待ち行列に入れられるスレッド記述子内の)pReferenceフィールドは、前述のようにコントローラクライアント制御ブロック125を参照するが、この場合、それぞれの異種の命令セットによって必要とされる個々の命令ストリームに対応する処理リソースの種類ごとにポインタがある。コントローラクライアント120は、コントローラクライアント制御ブロック125内のフラグに従って適切な命令ストリーム(命令ブロック145aまたは145b)を選択する。
【0133】
この機能は、例えば、いくつかの処理リソースの電源遮断機能と関連させると役立つことがある。所与のタスクに最適なプロセッサが電源遮断された場合、高くつくリブートサイクルを発生させるのではなく、次善のプロセッサがそのタスクを実行する方が望ましいことがある。さらに、例外的な負荷の状況下では、例えば、負荷の軽い汎用プロセッサが、負荷の思いDSPの負担を軽減することができるようにしてもよい。
【0134】
処理リソース150がスレッドを処理することが可能な状態になると、スレッドは、その処理リソース150と一意に関連付けられた適切なディスパッチ待ち行列からポップされる。ポップ操作は、pReference、スケジューリングイベントを生じたスケジューラメトリック、およびスレッドが作動可能になったのはタイムアウトによるものか、それとも同期プリミティブによるものかを示す指示を含む1組のフラグを含むオブジェクトを返す。スレッド記述子に使用されるコントローラメモリ要素195は、後のスレッド記述子が使用するためにフリーリストに自動的に返される。
【0135】
(共用オブジェクト)
この項では、コントローラ130APIを介してシステムから見ることのできるオブジェクトを説明する。通常、これらのオブジェクトは、実行時に、コントローラ130とクライアント120とそれらに関連付けられた処理リソース150とを備える集中型タスク割り振り/管理システムによって操作される。
【0136】
実行時コントローラ130APIは、アプリケーションが、新しいスレッドを導入し、新しい動的スケジューラ要素を導入し、同期プリミティブを発行し、スケジュールされたスレッドをポップし、割り込みされたスレッドをプッシュし、またはスレッドを除去することを可能にする。
【0137】
図12に、システム管理コントローラ130内のスレッド管理の典型的な全体図を示す。
【0138】
(スレッドプリミティブ)
図9cおよび9dにスレッドプリミティブのフォーマットを示す。その依存関係に従って、スレッド記述子は、保留待ち行列構造に、または直接作動可能待ち行列構造に配置され得る。スレッドが保留待ち行列構造内に配置されるべきである場合、アプリケーションは、スレッドの依存関係を定義しなければならない。外部イベントへの依存性は、依存参照として現れる。コントローラ130は、この依存参照を解釈しない。これは、スレッド記述子を作動可能待ち行列構造にいつ移行させるべきか決定する、入力同期プリミティブとの比較のために維持される。
【0139】
従属スレッドでは、タイムアウトを指定することができ、ヌル依存参照と関連させて、この機能をスレッドベースのハードウェアタイミング機能として使用することができる。依存関係と関わりなく、タイムアウトは、スレッドを、特定の時刻にスケジュールさせる。
【0140】
スレッドは、スレッドを作動可能待ち行列構造に格上げさせる同期イベント(タイマまたはプリミティブ)に従ってタグ付けされる。
【0141】
(同期プリミティブ)
同期プリミティブは、保留待ち行列とインターフェースし、1つ以上のスレッド記述子の保留待ち行列構造から作動可能待ち行列構造への移行を生じさせることができる。
【0142】
各同期プリミティブは、識別された保留待ち行列内の各スレッド記述子内に格納された依存参照と比較される一意の参照を含む。比較は、スレッドプリミティブによって識別される優先度の順に進められる。
【0143】
その種類に従って、同期は、保留待ち行列内の最高優先度のマッチングスレッド記述子またはすべてのマッチングスレッド記述子を稼動状態にすることができる。さらに、特殊なブロードキャストプリミティブが、すべての保留待ち行列内のすべてのマッチングスレッド記述子を活動化する。
【0144】
(割り込み処理)
割り込みサービススレッド(IST)法は、非同期イベントによって処理リソース150に課される負荷を最小限に抑える有益な手段を提供する。さらに、本発明に基づくシステムにおける加速されたリアルタイム応答は、小さなシステム変更を加えるだけでISTのさらなる普及を可能にする。
【0145】
コントローラ130は、コントローラ周辺での外部割り込み入力210から自動的に同期プリミティブを作成する。保留待ち行列内の事前に構成された割り込みサービススレッド記述子が、これらの割り込み同期プリミティブの受け取り時に、作動可能待ち行列構造に格上げされる。
【0146】
アプリケーションは、通常、システム初期設定時に、外部割り込み210に関連付けられたスレッド記述子を構成し、関連付けられた割り込みサービススレッドの各実行内でも構成する。
【0147】
この機能は、事実上、システム内の他の任意の専用割り込みサービス提供処理リソース150の必要をなくす。さらに、この機能は、これらの外部割り込み210を、同じ優先度構造により、すべてのプロセッサタスクに使用される同じポリシに従って処理し、すでにより優先度の高いタスクを実行している処理リソース内でのコンテキスト切換えの必要をなくす。通常の優先使用ルーチンを使って現在実行中のスレッドを作動可能待ち行列にプッシュバックすることができるために、任意の数のネストされた割り込みがサポートされる。
【0148】
タイマベースの割り込み(ウォッチドッグおよび周期的イベント)も同様のやり方で処理される。(周期的または1回限りの)タイムベースのタスクは、タイマ待ち行列に挿入されなければならず、タイムアウト依存関係を有するスレッドと類似のやり方で処理される。設計により、この方法は、有用な処理要件を持たないタイムベースの例外を除外する。
【0149】
割り込み優先度は、応答時間を速くするために、割り込みルーチンが現在実行中のタスクに取って代わることを許されるように設定される。
【0150】
(専用オブジェクト)
専用オブジェクトは、通常、ブート時、すなわち、電源遮断サイクル後のシステム初期設定時に構成される。処理リソース150が、実行時に内部オブジェクトと直接対話することはまれである。
【0151】
内部オブジェクトは、主として、待ち行列構造である。システム管理コントローラ130は、保留待ち行列、タイマ待ち行列、作動可能待ち行列およびディスパッチ待ち行列という4種類の主要な待ち行列を管理する。
【0152】
システム管理コントローラ130内には、内部操作を円滑化するために、さらに2次的待ち行列が存在する。待ち行列間のスレッド記述子の移動は、ポインタ操作のみで行われる。スレッド記述子は、絶対にコピーされることはない。
【0153】
(保留待ち行列構造)
スレッドは、同期イベントまたはタイマイベントによって、保留待ち行列構造から作動可能待ち行列構造に格上げされ得る。スレッドは、これらのイベントクラスの両方に反応しても、一方だけに反応してもよい。スレッドが両方に反応する場合、そのスレッドは、保留待ち行列とタイマ待ち行列の両方に存在する。
【0154】
保留待ち行列は、同期イベントを待ち受ける従属スレッドを保持する。スレッドは、処理リソース150からの同期プリミティブによって、またはタイムマネージャ360によって内部で生成されたタイマイベントによってこれらの構造から除去される。複数の競合有効範囲および割り込みサービススレッドをサポートするために、アプリケーションプログラマが、構成可能な数の保留待ち行列を利用することができる。各保留待ち行列内の要素は、それらの優先度に従って処理されなければならない。優先度に従った処理には、挿入時のソートと抽出時のソートという2つの選択肢がある。挿入時のソートは、保留リストを厳密な優先順位で格納し、新しいスレッドをその優先度に従ってリスト内の位置に挿入するためのプロセスを定義する。抽出時のソートは、新しいスレッドをどこに挿入すべきかの任意の選択を行い、同期後の適格なスレッド記述子の優先度に基づくソートを行う。本発明の好ましい実施形態は、挿入時ソートの技法を用いる。
【0155】
図13に、保留待ち行列の典型的な構造を示す。各エントリは、厳密な優先順位で格納される。新しいスレッドの挿入が達成され得る速度は、スキップリストの使用によって加速される。図14に、典型的な保留待ち行列スキップリストを示す。
【0156】
前述のように、スレッドは、ブロックされて、同期またはタイマイベントを待ち受けてもよい。スレッドの中には、排他的に同期イベントを待ち受けるものもあり、同様に、排他的にタイマイベントを待ち受けるものもある。その都度、スレッドは、単一の待ち行列にのみ存在することになる。各スレッドは、名目上、保留待ち行列とタイマ待ち行列の両方に関連付けられた、2組のポインタを含む。これらの場合、設けられるタイマ待ち行列および保留待ち行列のポインタは、それぞれ、スペアである。スキップリストは、これらのスペアポインタを利用することができる。すなわち、例えば、スレッドがタイマ待ち行列内に見当たらない場合、これらのポインタを再利用して、保留待ち行列内における可能な前方ジャンプが指示されてもよい。これは、通常は逐次のサーチが、新しい従属スレッドの正しい挿入点に反復的に接近しながら、スレッド記述子のブロックをジャンプすることを可能にする。
【0157】
一代替方法が、スキップノード記述子であり、この一例を、関連付けられたフィールド(図9l)と共に図9kに示す。スキップノード記述子は、事前定義されたメトリックに従って、保留およびタイマ待ち行列構造に周期的に挿入され得る。スキップノード記述子は、スキップノード記述子間の、または関与するスレッド記述子間の、定義された最大観測数のスレッド記述子に従って挿入される。スキップノード記述子は、保留待ち行列とタイマ待ち行列のスキップリストの一部を同時に形成することができる。
【0158】
それぞれの新しい従属スレッドが、その優先度に従って挿入されなければならない。このプロセスでは、典型的に、始めに、新しいスレッドの優先度がスキップリストノードの優先度より高くなるまでスキップリストをトラバースする。その後、サーチは、そのスキップリストノードから、スレッド記述子ごとに、正しい挿入点が見つかるまで続けられる。これは、通常は線形のサーチが、新しい従属スレッドの正しい挿入点に向かって進むときに、保留スレッドのブロックをスキップすることを可能にする。
【0159】
同期イベントには、以下の3つの異なる種類がある。
ユニキャスト:同期イベントは、指定された保留待ち行列で見つかった最初の(最高優先順位の)適切な従属スレッドで状態遷移をトリガする。
マルチキャスト:同期イベントは、指定された保留待ち行列内のすべての適切な従属スレッドで状態遷移をトリガする。
ブロードキャスト:同期イベントは、すべての保留待ち行列内のすべての適切な従属スレッドで状態遷移をトリガする。
【0160】
保留待ち行列は、図9iおよび9jに示すように、保留待ち行列記述子によって定義される。保留待ち行列記述子は、システム初期設定時に一度構成され、単一のコントローラメモリ要素195を消費する。保留待ち行列は、従属スレッド記述子とスキップリストノードをだけを含む。
【0161】
(タイマ待ち行列構造)
タイムアウトイベントを待ち受けるスレッド記述子を格納する単一システム規模のタイマ待ち行列が設けられる。図15に、タイマ待ち行列の例示的実施形態を示す。
【0162】
また、スキップリストは、前述のタイマ待ち行列構造へのスレッドの挿入を迅速化するためにも使用される。しかしながら、この場合、それは、スキップリストに使用される、時間的依存関係(もしあるとすれば)だけを有するスレッドである。
【0163】
タイマ待ち行列記述子は、レジスタ内に格納され、同時比較が、タイマ待ち行列の先頭と現在時刻の間で進行することを可能にする。これは、タイマティックのメモリ帯域幅に対する影響を大幅に低減する。
【0164】
(作動可能待ち行列構造)
作動可能待ち行列構造は、実行可能な状態のスレッドを保持する。これらのスレッドは、独立のスレッドプリミティブを用いて作成されたスレッドであり、または依存対象とする同期プリミティブを受け取っているスレッドである。同期スレッドは、あらかじめ保留待ち行列構造から移行している。
【0165】
作動可能待ち行列構造は、スケジューラノード記述子と、独立の同期されたスレッド記述子を含むことができる。この構造は、システム初期設定時におおむね定義されるが、スレッド記述子および動的スケジューラ層記述子は、リアルタイムで出入りすることを許される。
【0166】
作動可能待ち行列は、スレッドを特定の処理リソース150、または処理リソース150のプールに対してスケジュールすることができる。これは、特定のタスクを特定の処理リソース150、例えば、ハードウェアアクセラレータや入出力装置などに向けることができる状態を維持しつつ、複数の処理リソース150にまたがる負荷均衡化を可能にする。
【0167】
図16に、2つの処理リソース150での典型的な作動可能待ち行列構造を示す。動的スケジューラ層2は、両方のルートスケジューラ層から利用可能であることに留意されたい。これは、システム管理コントローラ130が、ルート層1および2と関連付けられた処理リソース150の間の動的な層2の下でスレッドを負荷均衡化することができるようにする。
【0168】
(スケジューラ層)
スケジューラ層は、スレッド記述子をスケジュールするのに使用される階層を定義する。各スケジューラ層は、通常、スケジューリングアルゴリズム、スケジューリング決定を行うのに使用されるいくつかのメトリック、および別のスケジューラ層またはスレッド記述子とすることのできる子要素のリストを定義する。ルート、静的および動的の3種類のスケジューラ層記述子がある。スケジューラ層メモリ要素のフォーマットを図9eおよび9fに示す。
【0169】
ルートスケジューラ記述子は、ディスパッチ待ち行列と1対1マッピングを有する。これらは、作動可能待ち行列構造における最終ノードを表す。スケジューラルート記述子は、システム初期設定時に構成され、永久に存在する。
【0170】
静的スケジューラ記述子は、スケジューリング階層内のルートノードの下に存在する。静的スケジューラ記述子の親は、他の静的スケジューラ記述子とすることも、ルート記述子とすることもできる。静的スケジューラ記述子は、その親の定義するスケジューラアルゴリズムおよびそのスケジューラメトリックに従って、兄弟ノードと競合する。静的スケジューラ記述子は、システム初期設定時に構成され、永久に存在する。動作時に、システム管理コントローラ130は、選択されたスケジューリングアルゴリズム、例えば、ラウンドロビンスケジューリングなどに従ってスケジューラメトリックを維持する。
【0171】
動的スケジューラ記述子は、スケジューリング階層内のルートおよび、おそらく、静的ノードの下に存在する。動的スケジューラ記述子の親は、静的スケジューラ記述子またはルート記述子とすることができる。動的スケジューラ記述子は、その親の定義するスケジューラアルゴリズムおよび独自のスケジューラメトリックに従って兄弟ノードと競合する。動的スケジューラ記述子は、いつでも構成することができ、特定の状況下において廃棄することができる。これは、システムが、純粋に静的な条件で可能なはずの数よりずっと多くのスケジューリング層をサポートすることを可能にする。システム管理コントローラ130は、多数の多様なスレッドおよび動的スケジューラ層が常に使用されるが、ある有限期間の間、一時要求がより小さいくなる可能性を利用することによってこれを実現する。例えば、最大4000の動的要素(スレッドおよび動的スケジューラ記述子)をサポートするメモリが接続されたネットワークシステムでは、16000接続をサポートすることが可能であると考えられる。というのは、任意の瞬間に、コントローラには、全接続空間のほんの一部からのデータ単位だけがあるからである。この柔軟性は、性能をわずかに犠牲にして達成される。というのは、動的スケジューラ記述子が存在しない場合、それが子スレッド記述子の追加の前に作成されなければならないからである。
【0172】
動作時に、システム管理コントローラ130は、選択されたスケジューリングアルゴリズムに従ってスケジューラメトリックを維持する。いくつかの状況下では、動的スケジューラ記述子は、コントローラメモリ要素195フリーリストに戻される。これは、動的スケジューラ層記述子にその層内で処理されるべき最後のスレッドからのpReferenceを格納することによって達成される。コントローラ130APIは、動的スケジューラ記述子が後続の類似のスレッドの間に持続するかどうか判定するために、コントローラメモリ要素195の問合せをサポートする。
【0173】
(ディスパッチ待ち行列)
ディスパッチ待ち行列は、関連付けられた処理リソース150からのサービスを待ち受ける先入れ先出し(FIFO)待ち行列としてスケジュールされたスレッド記述子を保持する。現在の好ましい実施形態では、最大32のディスパッチ待ち行列が許容される。ディスパッチ待ち行列は、図9gおよび9hに示すディスパッチ待ち行列記述子によって定義される。ディスパッチ待ち行列記述子は、システム初期設定時に構成される。
【0174】
スレッド記述子を作動可能待ち行列構造からディスパッチ待ち行列構造に遷移させるプロセスは、ハードウェアとして実行され、コントローラ130API対話を必要としない。
【0175】
図17に、本発明の特徴を実施する典型的な単一のディスパッチ待ち行列構造の例示的実施形態を示す。ディスパッチ待ち行列記述子は、フル閾値を定義する。ディスパッチ待ち行列長は、スレッドバンドルがスケジュールされている場合、または割り込みスレッドプッシュが行われた場合にのみフル閾値を上回ることを許される。
【0176】
各要素は、処理リソースによってコントローラ130APIを介して呼び出されるポップ操作によってディスパッチ待ち行列から除去される。
【0177】
ディスパッチ待ち行列記述子には優先度フィールドが含まれる。ディスパッチ待ち行列からスレッドがポップされるときに、優先度フィールドに、現在実行中のスレッドの優先度が取り込まれる。別のAPI呼び出しが、優先度が実行中のプロセッサによって別の値にリセットされるようにして、優先度逆転を回避する。優先度逆転は、異なる優先度の少なくとも3つのスレッドが関与する、同期とスケジューリング要件の間の競合をいう。優先度逆転は、優先度の低いスレッドが、優先度の高いスレッドを無期限にブロックすることを可能にする。例えば、優先度の低いスレッドが共用リソースをロックし、次いで、より優先度の高いスレッドに取って代わられる。次いで、優先度の高いスレッドは、優先度の低いスレッドによってロックされているリソースでブロックする。今度は、優先度の高いスレッドがブロックされているため、通常は、ロックされているリソースから独立の、現在自由に実行できる第3の中間スレッドがなかった場合、優先度の低いスレッドが再開するはずである。優先度の低いスレッドは、決して共用リソースをロック解除する機会を得ることができず、したがって、優先度の高いスレッドは無期限にブロックされる。「優先度上限」プロトコルとは、スレッドが共用リソースを所有している間、それが指定された優先度で実行されることを意味する。これは、前述の優先度の「低い」スレッドが優先度の高いスレッドと共用されるリソースを所有している間、それが「高い」優先度を有することを保証する。
【0178】
スレッドバンドルは、同じスケジューラ層を起源とするスレッド記述子のグループをいう。各スケジューラ記述子には、更新するよう求めるスケジューリング決定が強制される前に、作動可能待ち行列のその層からディスパッチ待ち行列に遷移され得るスレッドの数を定義するパラメータが存在する。この機能を利用すると共に、スケジューラ層のメンバが共通の属性を有するように構成することによって、処理リソース150に、通常観測されるはずのものより著しく高いキャッシュ局所性を呈するスレッドのブロックを提示することができ、その結果、キャッシュミスが低減され、システム性能が向上する。
【0179】
図18に、本発明の一実施形態による、スレッドバンドリングを含む2層のスケジューリング階層の例を示す。ルート層から最も遠い層である、子層は、FIFOスケジューリングアルゴリズムを使う。ルート層スケジューラアルゴリズムは、ラウンドロビンとして構成される。この実施形態では、各FIFO待ち行列内の要素は、同じ待ち行列の他のメンバとの高レベルのキャッシュ局所性を呈する。
【0180】
図18(a)に、子層のスレッドバンドル限界が1に設定されているスケジューリング結果を示す。この結果は、完全にインターリーブされている。この方式は、各待ち行列に最小の待ち時間を提示するが、メモリ管理がほとんど考慮されない(すなわち、低いキャッシュ性能を呈する可能性が最も高い)。スケジュールされたスレッドごとにコンテキスト切換えが必要である。ルート層がキャッシュを使用する処理リソース150と関連付けられる場合、強制的なキャッシュミスがシステム性能に影響を及ぼす可能性がある。
【0181】
図18(b)に、子層のスレッドバンドル限界が4に設定されているスケジューリング結果を示す。スケジューラはより粗い更新特性を呈し、それは、このスレッドバンドル限界によって設定された限界を有する同じ待ち行列からスケジュールされているスレッドのブロックとして現れる。このバースト性挙動は、状況によっては理想的ではないこともあるが、はるかに優れたキャッシュ性能を呈する。というのは、コンテキスト切換えを必要とされることが比較的まれだからである。結果として得られる効果は、きめ細かな手法の優れたプログラミングモデルを維持しつつ、粗いマルチスレッディングの優れたキャッシュ性能に匹敵するものである。
【0182】
システムが外界と対話する場合には、スレッドバンドリングのバースト性が極めて有害になる可能性が高い。しかしながら、スレッドバンドリングは、ターゲット処理リソース150がキャッシュを使用する場合にだけ有益であり、したがって、外界と対話する専門処理リソース150、例えば入出力装置などは、キャッシュ技術を使用する可能性が低く、したがって、スレッドバンドリングを利用しない。
【0183】
図17に戻って、各要素は、処理リソース150によりコントローラ130APIを介して呼び出されるポップ操作によってディスパッチ待ち行列から除去される。各要素は、優先使用の場合には、作動可能待ち行列にプッシュバックされてもよい。
【0184】
ディスパッチ待ち行列記述子には、優先度上限プロトコルの実施を可能にする優先度フィールドが含まれ、共用データでの優先度逆転を防ぐ。各処理リソース150は、一意のディスパッチ待ち行列を有する。
【0185】
(スケジューリング)
アプリケーションおよびシステムのスケジューリング要件は様々に異なり、実際には、実際の動作環境での試験後に初めて明らかになることもある。これに対応するために、システム管理コントローラ130は、使用されるスケジューリングポリシとスケジューリングアルゴリズムの両方に柔軟性を与え、これらは、マルチコアプロセッサ設計段階全体を通して変更、調整することができる。
【0186】
スケジューリングポリシは、以下の3種類に分けられる。
1.連携スケジューラが現在実行中のタスクを利用して新しいタスクをスケジュールする前に処理リソース150を解放する。この種のシステムは、(例えば、処理リソース150にとってローカルのキャッシュが必要な命令を含まず、したがって、より低速の上位メモリから足りない命令をロードしなければならないなどの場合の)コールドキャッシュ効果の最小化、および固定機能ハードウェアアクセラレータと適合するが、より複雑な組み込みアプリケーションには適さないことがある。
2.静的アルゴリズム駆動型スケジューラが、より適格性の高いタスクを実行するために、現在実行中のタスクに取って代わることができる。事前定義されたスケジューリングパラメータおよびアルゴリズムによる最も適格なスレッドが、常に、これらのシステムにおける実行中のスレッドである。任意の所与のタスクの適格性は、システムが実行を開始する前に定められる。
3.動的アルゴリズム駆動型スケジューラが、実行時に適格性を再定義することができる。前述のように、現在実行中のプロセスは、依然として、適格性が最も高いものであるが、タスクが実行を開始した後で、適格性メトリックが変更されている可能性がある。
【0187】
システム管理コントローラ130は、適切な構成およびターゲットアプリケーションとの実行時対話によって3つのスケジューリングポリシすべてを満足させる。
【0188】
システム管理コントローラ130は、例えば、先入れ先出し待ち行列法、優先度待ち行列法または重み付き公平待ち行列法など、オペレーティングシステムおよび通信業界で見られる多くのスケジューリングアルゴリズムをサポートする。スケジューリングアルゴリズムを適切に選択すれば、特に、主観的品質メトリックが関与する場合には、明白な利点が呈示される。
【0189】
スレッド記述子内では、システム管理コントローラ130内のスケジューリング挙動をサポートするために2つのスケジューラメトリックが設けられる。第1のメトリックは、あらゆる場合におけるスレッドの優先度を表し、保留待ち行列構造、優先度ベースのスケジューラおよびディスパッチ待ち行列構造内で使用される。必要な場合には、第2のメトリックを使って、個別スレッドとそのピアの間で選択が行われる。さらに、どちらかのメトリックを使って親記述子内のメトリックが更新されてもよい。スレッド記述子の第2のプリミティブ内に配置される値は、そのスケジューラ階層内で生じるスケジューリングの種類を反映しなければならない。
【0190】
これら2つのスケジューラメトリックは、スケジューラ記述子とスレッド記述子の両方で使用される。しかしながら、スレッドメトリックは処理リソース150内で計算されるが、これはスケジューラ層には不可能である。したがって、スケジューラ層がそれ自体のメトリックを更新することができるようにするには、所与の層のスケジュールされたスレッドから十分なパラメータが渡されなければならない。各スケジューラ層ごとに、どのようにしてメトリックが子から親に伝播されるかを定義する1組の命令が定義される。
【0191】
スケジューラ階層全体に多少注意すれば、アプリケーションシステムにおける洗練されたトラフィックおよびタスク管理機能を提供するための、スケジューラアルゴリズムの複雑な組み合わせを容易に作成することができる。
【0192】
(パラメータ継承例)
図19に、通信システムに一般的に見られる簡略化された待ち行列構造の例示的実施形態を示す。この構造は、入出力装置の出力待ち行列を表す。FIFO待ち行列を共用するすべてのスレッドが同じ接続上にあり、そのため、これは、接続ごとの待ち行列構造である。第2のスケジューリング層は、この例では重み付き公平待ち行列(WFQ)アルゴリズムを使用する。このアルゴリズムは、所与のタスクの完了時刻を、その長さと重み係数に基づいて計算する。次いで、最も早い完了時刻を有するパケットを選択する。WFQはスレッドが表すパケットの長さの知識を利用するものであるが、最初のFIFO待ち行列は、この情報とは無関係である。この場合、アプリケーションプログラマは、パケットの長さが、各スレッドごとのスケジューラメトリックに存在するようにしなければならない。階層内の上位のスケジューラ層は、それら自体のスケジューリングアルゴリズムのためにこのパラメータを継承する。
【0193】
WFQでは、以下の変数が必要とされる。
P 接続に割り振られるパイプ帯域幅の部分
I パケットの長さ
B 総パイプ帯域幅
c 接続帯域幅
d スケジューラ層デッドライン
【0194】
接続帯域幅cを計算する式は以下の通りである。
P*B=c
チャネルを帯域幅1に正規化した場合、pはcに等しくなる。その場合、パケット処理の完了時刻tは次式で与えられる。
(1/p)*l=t
その場合、必要なメトリック1/pとlである。pは元々分数であるため、これらの値(1/pおよびl)は両方とも整数である。スケジュールされたパケットの長さは、スケジューラ階層を介して上方に渡され、その層のデッドラインを漸進的に更新する。各更新内で行われる計算は、詳細には、以下の通りである。
d=d+[(1/p)*l]式中、dおよび1/p(重み)は、スケジューラ層記述子内に格納され、lはスケジュール更新の間に階層を介して渡される。この計算は、スケジューラマネージャ330内で実行される。
【0195】
以上、本発明の具体的実施形態について説明したが、これは一例にすぎず、様々な変更が考えられることを理解すべきである。さらに、本発明は、それだけに限らないが、例えば、携帯電話機やインターネットプロトコル上の音声(VoIP)など、マルチコアプロセッサを用いる任意の装置またはアプリケーションにおける一般的な用途のものである。したがって、この具体的実施形態は、添付の特許請求の範囲によって決定されるべきである保護の範囲を限定するものとみなされるべきではない。
【図面の簡単な説明】
【0196】
【図1】本発明の一実施形態によるリソース管理/タスク割り振りコントローラを組み込んだシステムの論理的レイアウトを示す概略的ブロック図である。
【図2】本発明を実施するコントローラが、専用メモリデバイスおよびコントローラクライアントと共に、汎用マルチコアプロセッサアーキテクチャ内に組み込まれている、図1の論理的レイアウトの1つの例示的実施を示す概略的ブロック図である。
【図3】図2の要素を組み込んだ最新のシステムオンチップ(SoC)バスベースアーキテクチャの一例を、やはりブロック図として示す図である。
【図4】図1、2および3のコントローラへの外部接続をより詳細に示す図である。
【図5】図2および3のメモリデバイスをより詳細に示す図である。
【図6】図2、3および4のコントローラの内部構成をより詳細に示す図である。
【図7】図2および3に示すコントローラクライアントを示す概略的ブロック図である。
【図7b】複数の処理リソースのプロキシとして働く単一のコントローラクライアントの場合のシステムを示す概略的ブロック図である。
【図8】ハードウェアコントローラクライアントをより詳細に示す概略的ブロック図である。
【図9a】総称記述子を示す図である。
【図9b】総称記述子に関連付けられるフィールドを示す図である。
【図9c】スレッド記述子を示す図である。
【図9d】スレッド記述子に関連付けられるフィールドを示す図である。
【図9e】スケジューラ層記述子を示す図である。
【図9f】スケジューラ層記述子に関連付けられるフィールドを示す図である。
【図9g】ディスパッチ待ち行列記述子を示す図である。
【図9h】ディスパッチ待ち行列記述子に関連付けられるフィールドを示す図である。
【図9i】保留待ち行列記述子を示す図である。
【図9j】保留待ち行列記述子に関連付けられるフィールドを示す図である。
【図9k】スキップリスト記述子を示す図である。
【図9l】スキップリスト記述子に関連付けられるフィールドを示す図である。
【図10】スレッド記述子と、システム管理コントローラと、処理リソースと、共用システムメモリの間の典型的な関係を示す図である。
【図11】2つの異種の処理リソースが存在する、図10の構成における間接化の原理を示す図である。
【図12】図4のコントローラ内のスレッド管理を示す典型的な全体図である。
【図13】典型的な保留待ち行列構造を示す図である。
【図14】典型的な保留待ち行列スキップリストを示す図である。
【図15】典型的なタイマ待ち行列を示す図である。
【図16】2つの処理ソースでの典型的な作動可能待ち行列構造を示す図である。
【図17】典型的な単一ディスパッチ待ち行列構造の例示的実施形態を示す図である。
【図18】スレッドバンドリングを含む、2層スケジューリング階層を示す図である。
【図19】通信システムにおいて一般に見られる簡略化された待ち行列構造の一例を示す図である。
【技術分野】
【0001】
本発明は、マルチコアアーキテクチャにおけるリソース管理の方法および装置に関する。
【背景技術】
【0002】
今日、複雑な異種混合マルチコアアーキテクチャを組み込んだ半導体デバイスが、ユビキタスなデスクトップコンピュータから、携帯電話機、携帯情報端末、高速電気通信/ネットワーク交換装置などといった最新型の電子機器に至るまで、多種多様なシステムおよび機器で利用されている。
【0003】
任意のコンピュータプロセッサの使用目的がどのようなものであれ、プロセッサ製造者は、現在のプロセッサの性能を高めると同時に、それらの単位「コスト」を維持し、または低減しようと努力し続ける。
【0004】
プロセッサの「コスト」は、様々なパラメータを使って評価され得る。多くの場合、コストは、純粋に、金銭的コストであるが、多くの適用分野、特に組み込み式プロセッサ市場において、コスト計算は、電力消費、冷却要件、効率、商品化に要する時間などの付随的考慮事項も含む。
【0005】
任意のプロセッサが有用な機能を果たす絶対的能力は、達成可能なMIPS(100万命令/秒)比として特徴付けることができ、よって、任意のプロセッサの「価格/性能」比は、例えば、MIPS/mm2、MIPS/$、あるいはMIPS/mWなどによって特徴付けることができる。
【0006】
しかしながら、実際には、すべての命令が同量の有用な作業を達成するとは限らず、したがって、「純粋な」MIPS評価は、容易に比較することができない。よって、ディジタル信号プロセッサ(DSP)は、携帯電話機の無線インターフェースの近くにおける数学的な集中処理の解決には適しているが、その電話機の画面上で実行されるWebブラウザの実行においては極めて効率が悪い。事実上、これは、プロセッサが、「アプリケーション利用可能」価格/性能の観点からの方がより有効に分類され得ることを意味している。
【0007】
しかも、プロセッサを制御し、カスタマイズして個々のアプリケーションを実施するのに使用されなければならないプログラミング、すなわちソフトウェアツールの非効率性によって、有効性能のさらなる低下が引き起こされ得る。よって、個々のアプリケーションのためにプロセッサから抽出され得る最終的な性能レベルは、使用可能な、または「達成可能なアプリケーション利用可能」価格/性能のレベルとみなされ得る。
【0008】
半導体企業による、プロセッサのアプリケーション利用可能価格/性能を改善しようとする取り組みにおいて、新しいクラスのプロセッサ、すなわち、マルチコアデバイスが開発されている。マルチコアデバイスは、プロセッサによって実行され得るアプリケーションの特定の態様での最大レベルの有効価格/性能比を提供するために、それぞれが高度に特化されていてもよい、様々な要素(コア)から構築される高度に集積されたプロセッサである。そのようなデバイスは、「異種混合」、すなわち複数の、異種のコアを組み込んだものとすることも、「同種」、すなわち複数の類似のコアを組み込んだものとすることもできる。
【0009】
また、ほとんどのマルチコアデバイスは、システムオンチップ(SoC)デバイスとして分類することができる。というのは、その集積が、複数のプロセッシングコアのみならず、任意の個別製品のハードウェア要件の(全部ではないにしろ)大部分を処理するのに必要とされるメモリ、入出力およびその他のシステム(コア)も含むからである。すべてのSoCデバイスが複数のプロセッシングコアを有するとは限らないが、複数のコアとSoCという用語は、しばしば、互いに入れ替えて使用される。マルチコアSoCの好例を多くの携帯電話機に見ることができ、それらには、無線インターフェースを実行するための1つ以上のDSPを含む単一のプロセッサと、電話機でユーザアプリケーションを実行するための汎用プロセッサが搭載されている。
【0010】
マルチコアデバイスの出現は、ムーアの法則によって可能となったものであり、この法則によれば、シリコンの任意の所与の面積に組み込まれ得るトランジスタの数は、製造工程の改善により18ヶ月ごとに倍増することになる。したがって、ムーアの法則は、シリコンダイ上の任意の所与の面積により多くの個別トランジスタを組み込むことを可能にし、単一のシリコン片上により一層複雑なデバイスを製作することを、技術的にも経済的にも実行可能にする。同様に、各トランジスタのサイズを縮小することにより、トランジスタは、より一層高速で切り換わることができる。
【0011】
従来、ムーアの法則は、基礎となるアーキテクチャに大きな変更を加えずに、より高速な、または使用されるシリコンの点でより費用対効果の高い、より小型の新世代プロセッサを製作するのに使用された(すなわち、改善は、デバイスの論理的マクロアーキテクチャの改善ではなく、製造工程およびデバイスの物理的マイクロアーキテクチャの改善であった)。
【0012】
事実上、マルチコア/SoCプロセッサに向かう傾向は、より高レベルの集積へのマクロアーキテクチャ的移行とみなすことができ、これは、まず、シリコンダイ自体への入出力(通信)機能の導入から始まった。今や、入出力、メモリ、および複数の処理装置、DSPおよびコプロセッサの機能を同じシリコンダイ上に集積することができる。これらのプロセッサは、個々のアプリケーションクラスに最低コストで、最高性能のプロセッサを提供することによって、最終製品の製造コストを低減するはずである。また、システム構成部品の大部分を単一プロセッサ上に集積することにより、部品点数も削減され、したがって、信頼性を高め、電力消費を低減することができる。
【0013】
重要な問題は、可能な限り高い「アプリケーション利用可能」価格/性能を達成するために、そのようなマルチコアデバイスにおける基礎的なハードウェアの使用をどのようにして最適化し得るかである。
【0014】
プロセッサおよびシステムの設計者らが、アプリケーションソフトウェア内での並列処理(アプリケーションレベルの並列処理)および命令ストリーム内での並列処理(命令レベルの並列処理)を利用することのできる多くのやり方がある。それら様々な発現では、並列処理がどこで管理されるか、および並列処理が、システムが実行しているとき/実行時に管理される(動的システム)か、それともアプリケーションソフトウェアがコンパイルされているとき/コンパイル時に管理される(静的システム)かが異なる。実際には、動的システムと静的システムおよびハードウェア集約的解決とソフトウェア集約的解決の間の区分は明確なものではなく、ある分野からの技法が、しばしば、その他の分野によって流用される。
【0015】
個別プロセッシングコアレベルにおいて、単一ストリームからの並列の多数命令で動作する複数発行プロセッサまたはマシンの概念は、当分野では十分に確立している。これらは、スーパースカラプロセッサと超長命令語(VLIW)プロセッサという2つの基本的種類で供給される。スーパースカラプロセッサは、実行時(動的にスケジュールされる)またはコンパイル時(静的にスケジュールされる)のどちらかに識別される、様々な数の1クロックサイクル当たりの命令を発行する。VLIWプロセッサは、コンパイラによって定義されるように、非常に長い命令語を形成する固定数の命令を発行する。通常、プログラマは、このプロセスに全く気付かない。というのは、システムのプログラミングモデルが、標準的なシングルプロセッサ抽象化であるからである。
【0016】
スーパースレッディングとハイパースレッディングは、両方とも、複数の仮想プロセッサの間で複数の実行スレッドを多重化することによって複数のプロセッサをエミュレートする技術である。通常、これらの仮想プロセッサは、統計的に、単一のスレッドによって常に使用されるとは限らないはずのいくつかのリソースを共用する。スーパスレッディングアーキテクチャおよびハイパースレッディングアーキテクチャは、複数の独立のプロセッサの役割を演じ、したがって、効率よく働くために、あるレベルのアプリケーション並列処理が存在することを必要とする。通常、プロセッサコアのハードウェア制約条件により、サポートされ得るスレッド数が、実質上100未満に制限される。
【0017】
さらに、多くのアプリケーションにおける固有の並列処理の利用では、いくつかのシステムアーキテクチャ上の選択肢が存在する。各プロセッサが、なんらかの共用リソース(例えば、メモリおよび/または相互接続など)を介してそのピアと協働しながら、独自の命令を実行し、独自のデータセットに基づいて動作する多重命令多重データ(MIMD)マシンは、それらが多種多様なアプリケーションに対処することができるために普及している。
【0018】
性能需要が高まるにつれて、組み込みシステムは、ますます、複数の異種または同種の処理リソースを使用する、マルチコアMIMDアーキテクチャを利用して、必要なレベルのシリコン効率を提供するようになってきている。通常、これらは、集中型共用メモリアーキテクチャと呼ばれるMIMDマシンのクラスであり、複数の処理リソース間で単一のアドレス空間(またはその一部)が共用されるが、よりアプリケーション特有のハイブリッドアーキテクチャもよく見られる。
【0019】
MIMDアレイの各処理リソースは、命令レベルの並列処理(ILP)を利用することができるが、MIMDマシンは、スレッドレベルの並列処理(TLP)を利用して、基礎となるハードウェアの潜在的性能を実現することもできる。実行時に(特定のハードウェアによって)、またはコンパイル時に(コンパイルツールを最適化することによって)識別されるILPに対して、TLPは、アプリケーション設計時に高水準プログラミングソフトウェア内で定義される。
【0020】
スレッディングは、長年にわたり、ソフトウェア業界内で、並列処理の高レベル表現として使用されてきた概念である。スレッドとは、定義上、他のスレッドと同時に実行され得る実行状態、命令ストリームおよびデータセットを含む自律的作業パッケージを定義するものである。命令ストリームの複雑度は重要ではない。スレッドは、単純なデータ転送から複雑な数学的変換に至るまで何でも記述することができる。
【0021】
従来から、オペレーティングシステムは、ソフトウェア技術者が基礎となるデバイスアーキテクチャを詳細に理解することを必要とせずにマルチコアアーキテクチャのある一定の構成上でアプリケーションが実行されることを可能にするスレッド割り振り機能を含めて、システム管理の提供を支援している。しかしながら、ユニコアデバイス内のスレッド管理のための既存のソフトウェア技術は、マルチコアアーキテクチャに一貫して容易に適合することができない。これまでの解決策は、設計ごとにカスタマイズされた解決策を必要とする、専用のものであり、通常は、性能および拡張性を損なうものであった。
【0022】
従来、異種混合マルチコアシステム(すなわち、ほぼ異種の処理リソースを有するシステム)の場合には、多種多様な手法を用いて異なる処理リソースが協働することを可能にしている。しかしながら、これらは、大まかに、「プロキシホスト」と「連携」(「ピアツーピア」ともいう)という2つのカテゴリに分けられる。前者の場合、指定された汎用ホストプロセッサ(バスベースのシステムでは、しばしば、CPUと呼ばれる)は、システム全体を統括し、システム全体のタスクを仲介し、メモリやデバイスなどのリソースへのアクセスを同期させる。そのようなシステム統括管理は、通常、オペレーティングシステムのカーネルで操作され、システムアプリケーションおよびホストプロセッサ上の非同期イベントの処理とタイムスライスを求めて競合する。言い換えると、この汎用プロセッサは、マルチコアデバイス上のすべての処理リソースのための集中型プロキシスレッドマネージャとして働くと共に、主要なアプリケーションプロセッサとしても働かなければならない。
【0023】
この構成で使用されるとき、汎用プロセッサは、事前設定のスケジューリングポリシに応じた各処理リソースごとの実行可能なスレッドの待ち行列、すなわち、スレッドの優先度(すなわちディスパッチまたは作動可能待ち行列)、ならびに、スレッド自体が実行され始める前に、何らかのイベント、または別のスレッドの結果を待ち受けるスレッドの待ち行列(すなわち保留およびタイミング待ち行列)を維持しなければならない。これらが、スレッド実行前のプロセッサ構成など、他のシステムオーバーヘッドに加えられる。
【0024】
汎用プロセッサが、例えば、スレッドの完了のために発行された割り込み(したがって、そのスレッドを完了したばかりの処理リソースの解放)の結果として、その処理時間を、プロセッサが現在実行しているスレッドから、(スレッド管理を含む)システムの管理に転じるときにはいつでも、汎用プロセッサは、コンテキスト変更を行わなければならない。
【0025】
コンテキスト変更には、休止されるスレッドの現在の進捗状況をメモリに格納し、その他のスレッド/処理リソースのサービス提供のための管理ルーチンに関連する命令をフェッチし、次いで、任意の構成要件を含めてそれらの命令を実行することを伴う。元の、休止されたスレッドに戻るには、さらなるコンテキスト変更が実行されなければならない。これらのコンテキスト変更は、通常、割り込みを受け取り時に実行され、組み込みシステムでは、これらの割り込みが、汎用プロセッサ上で実行中のアプリケーションコードにとって、頻繁、かつ非同期的であることがしばしばある。したがって、システム全体として、著しい性能劣化を呈する。また、コンテキスト切換えは、ホストプロセッサキャッシュに悪影響を及ぼす(いわゆる「コールドキャッシュ」効果)。
【0026】
連携システムの場合、各処理リソースは、オペレーティングシステムの別々のインスタンスを実行し、その一部が、リソース間通信を可能にする。したがって、そのような構成は、ピア間の割り込みの特定の経路指定の結果として、比較的厳格なアーキテクチャ上の区分化を有する。この種のシステムは、アプリケーションを生成するのに必要なプリミティブを提供するが、実施性能は、依然として、オペレーティングシステムのカーネルアクティビティに関連付する頻繁なコンテキスト切換えによって損なわれる。
【0027】
要約すると、従来のアーキテクチャ(汎用プロセッサ、ソフトウェアエグゼクティブなど)でのシステム管理実現の現在の設計および方法は、複雑な異種混合マルチコアアーキテクチャのシステムおよびスレッド管理には適さない。実際、汎用プロセッサは、マイクロ(命令セット)アーキテクチャレベルでも、マクロ(キャッシュ、レジスタファイル管理)アーキテクチャレベルでも、十分に最適化されない。マルチコアプロセッサの相互接続は、別々の処理リソース間の相互運用のための物理的媒体を提供するが、システム管理の一貫性した手法を可能にする、すべての処理リソース間で共用される、システム規模のタスク管理通信層がない。最悪の場合、これは、従来から、それぞれが、随時、ソフトウェアにおいて別々に解決されなければならない、あらゆる処理リソース間のあらゆる可能な通信チャネルに関連付けられる明確な問題をもたらしかねない。
【0028】
よって、これらの非常に複雑なマルチコアアーキテクチャの効率的なシステム管理の方法が求められている。ソフトウェア抽象化だけでは、複雑なマルチコアアーキテクチャの必要なレベルの性能を提供することができない。
【発明の概要】
【0029】
本発明の第1の態様によれば、請求項1で定義されるマルチコアプロセッサのリソース管理/タスク割り振りコントローラが提供される。
【0030】
好ましい実施形態では、請求項1のコントローラは、リソース管理およびタスク割り振り専用であり、それ以上の処理リソースを提供しない。
【0031】
本発明の実施形態において、「従来の」マスタ処理装置(すなわち、本発明のリソース管理/タスク割り振りコントローラがない場合に、タスク割り振りを実行すると共に、利用可能な処理リソースの1つとしても働くはずの一般的な処理リソース)は、システムの電源投入時にマスタとして始動することができ、リソース管理/タスク割り振りコントローラは、初期設定シーケンスの間のMPUからマスタステータスを引き受ける。
【0032】
また、本発明の実施形態は、通常は、個々のタスクを処理する際の使用で無視されるはずの処理リソースへのタスクの割り振りを可能にする異種混合マルチコアプロセッサの機能も提供する。そのようにして、本発明のコントローラは、利用可能なリソースのより効率のよい使用を可能にする。
【0033】
別個のリソース管理/タスク割り振りコントローラを設けることによって、本発明は、マルチコアプロセッサのための改善されたタスク割り振り/管理システムを提供し、利用可能な処理リソース間でのより効率のよいタスク割り振りを可能にする。コントローラは、システム管理および例外処理の要素を、専用の、効率のよい、ハードコードされた実施形態に抽象化する。
【0034】
本発明の実施形態は、「プロキシエージェント」の役割を強制するのではなく、コントローラと共にコントローラクライアントを用いる。コントローラクライアントは、ハードウェアまたはソフトウェアとして実施され得る。そのような構成は、基礎となるシステムの「実行時」アクティビティを効率よく制御する。特に、コントローラは、事前定義された割り振りパラメータの範囲に基づいて、システムスレッドの状態およびスケジューリング決定の正確さを絶えず(「貪欲に」)維持する。
【0035】
したがって、好ましい実施形態のアーキテクチャは、複雑度を問わずに、構成コンポーネント間の作業分配、および個々の処理リソースの自律性の点で、大きなメリットを提供する。すべての処理リソースが、デフォルトでは「怠惰」であるスレーブデバイスになる。すなわち、好ましい実施形態では、専用の割り込みを介して、リソース管理/タスク割り振りコントローラによってタスクを実行するよう明示的に指示されるのを待つ。同様に、他の実施形態では、リソース管理/タスク割り振りコントローラと処理リソースの間で、ポーリングベースの通信が使用されてもよい。
【0036】
本発明のコントローラを用いるシステムでは、アーキテクチャ外部から引き起こされるすべての非同期イベントは、直接ピンを介してであれ、間接的に処理リソースの1つ(すなわち入出力装置)の外部操作によってであれ、好ましくは、コントローラに経路指定され、そこで、「ブート時」に構成された1組のスケジューリングポリシを使って、ターゲット処理リソース上で現在実行されているタスクと比較される。処理リソースは、外部イベントに関連付けられた割り込みサービススレッド(IST)が、現在実行中のトランザクション(スレッドまたはタスク)を統括する場合に限って割り込まれ、それによって、当分野で問題であった、任意の処理リソースにおける不必要なコンテキスト切換えを未然に防ぐ。さらに、好ましい実施形態のコントローラクライアントは、任意の複雑度の処理リソースが、共用リソースおよびコントローラ自体で基本的なシステム管理操作を行う(スレッドを作成する、同期プリミティブを発行する、スレッドを削除する、メモリコピーなど)ことを可能にし、命令セットベースのマシンが、これらのタスクをプロキシによって実行する必要を回避する。
【0037】
本発明のさらなる態様では、そのようなコントローラを備えるマルチコアプロセッサが提供される。
【0038】
また、本発明は、請求項40で定義される、マルチコアプロセッサ内のリソースを制御し、割り振る方法にも適用される。
【0039】
添付の従属請求項には、さらなる利点および特徴が定義されている。
【0040】
本発明は、いくつかのやり方で実施することができ、次に、例としてあげるにすぎないが、添付の図面を参照していくつかの実施形態を説明する。
【好ましい実施形態の詳細な説明】
【0041】
図1に、本発明の一実施形態による機構を組み込んだシステムフレームワーク10の論理図を示す。フレームワーク10は、それぞれが他の処理リソース150と同種であっても、異種であってもよく、それぞれが任意の複雑度のものとすることのできる複数の処理リソース150を備える。各処理リソースは、相互接続160を介して共用データが格納される共通のシステムメモリ140へのアクセスを共用する。当然ながら、すべてのシステムメモリ140が必ずしもすべての処理リソース150に共通であるとは限らないことが理解されるであろう。
【0042】
また、システムフレームワークは、本発明の一実施形態による、集中型タスク割り振り/管理システム20も備える。集中型タスク割り振り/管理システム20は、システム管理コントローラ130と、専用の密結合メモリ190に接続された専用の密結合メモリインターフェース180とを含む。各処理リソース150は、相互接続115を介してコントローラ130にアクセスすることができる。図1の構成の実施においては、どんな特定の相互接続戦略(すなわち、コントローラ130が各処理リソース150と、またその逆方向に通信するための構成、および各処理リソース150がシステムメモリ140と通信するための構成)も必要とされないことを理解すべきである。特に、処理リソースのそれぞれが、コントローラ130と直接的または間接的に(すなわち、他の処理リソースを介して、または別のやり方で)通信することができる必要があることだけを別として、ポイントツーポイントリンク、中央システムバスまたはパイプライン型アーキテクチャでさえも等しく用いることができる。
【0043】
図2に、やはり一例にすぎないが、図1の論理構成を実施するマルチコアプロセッサを示す。図2のマルチコアプロセッサは、それぞれがシステム相互接続160を介して接続された、複数の処理リソース150を用いる。システム相互接続160は、さらに、入力インターフェース100、および出力インターフェース110を介して、システム管理コントローラ130と通信する。図2の例で、システム相互接続160は、処理リソース150のそれぞれを相互に接続し、コントローラ130と接続すると共に、システムメモリ140などの共用システムリソースとも接続する従来の中央バスとして配置される。メモリ140とのインターフェースは、いくつかの現在利用可能なインターフェース技術のいずれか1つによって達成されてもよい。メモリは、例えば、静的ランダムアクセスメモリ(SRAM)や、2倍速ランダムアクセスメモリ(DDR RAM)といった、現在利用可能な中央コンピュータメモリ技術のいずれで構成されてもよい。
【0044】
図2にみられるように、複数の処理リソース150のそれぞれは、中央コントローラ130から制御情報を受け取り、受け取った制御情報に従って処理リソース150を管理するように構成された、関連付けられたシステム管理コントローラクライアント120を有する。コントローラクライアント120の機能および目的は、以下で、図7および8に関連してより詳細に説明する。また、各処理リソースは、システム相互接続160を介したコントローラ130との通信のための、関連付けられた相互接続エージェント170も有する。相互接続エージェント170は、システム相互接続160上で使用される基礎となる相互接続プロトコルから独立の、コントローラクライアント120への汎用インターフェースを提供する。すなわち、相互接続エージェント170は、システム相互接続160上で使用される通信プロトコルとコントローラクライアント120によって使用される通信プロトコルの間のプロトコル変換を提供する。相互接続エージェント170の使用により、本発明の実施形態のコントローラクライアント120は、現在利用可能な任意のシステム相互接続プロトコルと共に使用することができる。
【0045】
マルチコアプロセッサは、全体として、スレッドと呼ばれるいくつかの個別タスクに分割することのできるターゲットアプリケーションを実行するように構成される。各処理リソース150は、それだけに限らないが、当該のスレッドの優先度、各処理リソース150の利用可能性および個々のスレッドの実行への個々の処理リソースの適合性を含むいくつかのパラメータに従い、コントローラ130によって適切なスレッドに割り振られる。これについても、やはり、以下でより詳細に説明する。
【0046】
しかしながら、システム管理コントローラ130およびその専用メモリ190の追加は、その他の点ではプロセッサ10の配置の再設計を必要としないことを理解すべきである。
【0047】
図3に、1つの具体的な構成を示す。図3には、ブロック図の形で、典型的なシステムオンチップ(SoC)アーキテクチャが示され、実際のアプリケーションにおいてコントローラ130のリソース管理下に置かれ得る様々な処理リソースが説明されている。処理リソースは、具体的には、DSPなど、比較的一般的な機能のものとすることもでき、周辺入出力など、比較的限定された機能のものとすることもできることが認められる。
【0048】
(システム管理コントローラインターフェースグループ)
図4に、コントローラ130と、コントローラ130の周辺に位置する、コントローラ130に関連付けられたインターフェースグループ200〜250を示す。
【0049】
システム制御グループ200は、システム管理コントローラ130の正しい動作を保証するのに必要な2つのシステム入力信号を備える。2つのシステム入力信号は、システムクロックに接続されるCLK入力と、RST入力からなる。システム管理コントローラ130からのすべての出力信号がシステムクロックに同期し、システム管理コントローラ130へのすべての入力信号が、このクロックを使ってサンプリングされる。RST入力は、システム管理コントローラ130をリセットするための同期リセット信号である。
【0050】
外部割り込みグループ210は、システム管理システム外部から供給される同期外部割り込みのグループからなる。これらの信号は、システム管理コントローラ130周辺に接続される前にCLKに同期されなければならない。外部割り込みグループ210内の信号は、例えば、外界との入力インターフェースから、またはピンを介してマルチコアプロセッサ外部から直接駆動され得る。外部割り込み入力の数は、マルチコアプロセッサ10設計段階において定義される。
【0051】
内部制御グループ220は、各コントローラクライアント120およびそれに関連付けられた処理リソース150ごとの単一の同期割り込みからなる。したがって、信号のグループの数は、通常、システム内の処理リソース150の数に対応し、マルチコアプロセッサ10設計段階において定義される。内部割り込み信号は、そのコントローラクライアント120に関連付けられた特定の処理リソース150に割り当てられている、実行可能なスレッドを示す。
【0052】
密結合メモリインターフェースグループ180は、システム管理コントローラ130を、独自の専用密結合メモリリソース190にインターフェースする。図5に、専用密結合メモリ190の典型的な構造を示す。アドレスパスおよびデータパスの幅は、マルチコアプロセッサ10設計段階において定義される。専用密結合メモリインターフェースは、メモリアドレスバス191、メモリ読取りデータバス192、メモリ書込みデータバス193、ならびに書込み194および読取り196イネーブル信号を含む。
【0053】
接続されるメモリは、同期SRAMデバイスであるものとする。専用密結合メモリ190は、ターゲットアプリケーションの必要に従って、マルチコアプロセッサ10設計段階において定義される、整数個のコントローラメモリ要素195を含む。現在の好ましい実施形態において、各コントローラメモリ要素195は、256ビットのメモリ空間を消費する。やはり現在の好ましい実施形態において、コントローラは、最大65536個のコントローラメモリ要素(すなわち、16MBメモリ)をサポートする。後述するように、待ち行列記述子はコントローラメモリ要素195を消費するが、典型的なシステムにおいて、必要なコントローラメモリ要素195の数は、スレッドサポート要件によって決まるはずである。例えば、システム管理コントローラ130内で同時に400スレッドをサポートすることのできるシステムは、おおよそ128KBの接続メモリを必要とするはずである。
【0054】
図4の相互接続インターフェースグループ230は、マルチコアプロセッサ10と、マルチコアプロセッサ設計段階において定義される相互接続エージェント170で使用される選択された相互接続プロトコルに従う。
【0055】
(コントローラサブブロック記述および機能)
図6に、システム管理コントローラ130の主要な論理コンポーネントを示す。コントローラ130の機能は、以下の各機能を実行する4つの1次内部並列処理サブブロック間で分担される。
【0056】
1.専用密結合メモリ190内の空いているコントローラメモリ要素195のリストを維持し、コントローラメモリ要素195回復を監視するように構成されたスレッド入力マネージャ(TSIM)300。
【0057】
2.専用密結合メモリ190内の保留リストおよびタイマ待ち行列を維持し、スレッド間の同期を実行し、必要に応じて、専用密結合メモリ190内の作動可能待ち行列構造へのスレッドの格上げを行うように構成されたスレッド同期マネージャ(TSPM)310。スレッド同期マネージャ310は、専用密結合メモリ190内での保留スレッド記述子の挿入および抽出によって、保留およびタイマ待ち行列構造の保全性を維持する。
【0058】
3.専用密結合メモリ190内の作動可能待ち行列構造と、専用密結合メモリ190内の各処理リソース150ごとのディスパッチ待ち行列とを維持するように構成されたスレッド出力マネージャ(TSOM)320。スレッド出力マネージャ(TSOM)320は、さらに、コントローラクライアント120に送られる割り込み220を生成するように構成される。作動可能待ち行列構造の保全性の維持は、専用密結合メモリ190内のコントローラメモリ要素195で保持されるスレッド記述子の挿入および抽出によって行われる。
【0059】
4.専用密結合メモリ190内に位置する作動可能待ち行列構造内の各処理リソース150ごとにスケジューリング決定を提供するように構成されたスレッドスケジュールマネージャ(TSSM)330。
【0060】
さらに、いくつかの2次処理サブブロックが、以下のサポート機能を提供する。
【0061】
5.相互に排他およびロッキングを含む、接続された専用密結合メモリ190への集約アクセスを提供するように構成されたスレッドメモリマネージャ(TSMM)340。
【0062】
6.入力される外部システム割り込みを内部同期プリミティブに変換するように構成された割り込みマネージャ(TSIC)350。
【0063】
7.各処理リソース150に同期のためのタイマ機能および監視タイマ機能を提供するように構成されたタイムマネージャ(TSTC)360。
【0064】
8.処理リソース150に相互接続インターフェースおよび構成および実行時アクセスを提供するように構成されたシステムインターフェース(TSIF)380。
【0065】
続いて、システム管理コントローラ130内の上記1次および2次処理サブブロックの対話の詳細な説明を行う。
【0066】
各サブブロックは、他のサブブロックに1組の関数を提示し、それぞれが、そのピアに、専用密結合メモリ190内のそれぞれに維持される構造に対する操作を実行するよう指示することができるようにする。各関数は、コントローラソフトウェアのアプリケーションプログラミングインターフェース(API)において受け取られたのと類似のコマンドを受け取り次第、個々のサブブロックによって呼び出される。
【0067】
(スレッド入力マネージャ関数)
スレッド入力マネージャ300は、システム管理コントローラ130内の他のサブブロックに3つの共通関数を提供する。
【0068】
FreeListStatus関数は、コントローラメモリ要素195フリーリスト内の先頭ポインタおよび要素数を返す。フリーリストは、現在未使用のコントローラメモリ要素195のリストである。この関数は、コントローラ130ソフトウェアAPIにおける類似コマンドの受け取り時に、システムインターフェース380によってのみ呼び出され得る。
【0069】
PushFreeIndex機能は、解放されたコントローラメモリ要素195インデックスをフリーリスト上にプッシュバックするのに使用される。この関数は、スレッドスケジュールマネージャ330によってのみ呼び出され得る。
【0070】
PopFreeIndex関数は、フリーリストから空いているコントローラメモリ要素195インデックスをポップするのに使用される。これは、通常、システムインターフェース380内のAPI呼び出しサービスルーチン内から呼び出される。
【0071】
(スレッド同期マネージャ関数)
スレッド同期マネージャ310は、システム管理コントローラ130内の他のサブブロックに7つの共通関数を提供する。
【0072】
以下の5つの関数は、コントローラ130ソフトウェアAPIによって受け取られた類似のコマンドに応答して、システムインターフェース380によってのみ呼び出され得る。
【0073】
PushPendingDescriptor関数は、ブートプロセスの間に、保留待ち行列記述子のリストに保留待ち行列記述子を加えるのに使用される。
【0074】
PushThread関数は、実行時に、所与の保留待ち行列に従属スレッドを加えるのに使用される。
【0075】
SetTimerStatusは、タイマ待ち行列内の先頭ポインタおよび要素数を設定する。
【0076】
GetTimerStatus関数は、タイマ待ち行列内の先頭ポインタおよび要素数を返す。
【0077】
SetPendingStatus関数は、保留待ち行列記述子リストの状況を設定する。
【0078】
GetPendingStatus関数は、保留記述子待ち行列内の先頭ポインタおよび要素数を返す。
【0079】
SyncEvent関数は、所与の保留待ち行列に同期プリミティブを発行するのに使用される。この関数は、スレッド割り込みマネージャ350およびシステム管理コントローラ380によって呼び出される。
【0080】
TimeEvent関数は、タイマ待ち行列に、タイマベースの同期プリミティブを発行するのに使用される。この関数は、タイムマネージャ360によってのみ呼び出される。
【0081】
(スレッド出力マネージャ関数)
スレッド出力マネージャ320は、システム管理コントローラ130内の他のサブブロックに5つの共通関数を提供する。
【0082】
Push関数は、作動可能待ち行列構造内にスレッド記述子を配置する。このメソッドは、(例えば、割り込みを処理するなどの)処理速度を速めるために、高い優先度で呼び出され得る。スレッドが独立である(即座に作動可能である)場合、呼び出しは、システムインターフェース380から行われ、スレッド記述子が元々依存関係を有していた場合、呼び出しは、スレッド同期マネージャ310から行われる。
【0083】
以下の3つの関数は、コントローラ130ソフトウェアAPIにおける類似コマンドの受け取りに応答して、システムインターフェース380によってのみ呼び出され得る。
【0084】
GetDispatchQueueStatus関数は、ディスパッチ待ち行列リスト内の先頭ポインタおよび要素数を返す。
【0085】
SetDispatchQueueStatus関数は、ディスパッチ待ち行列リスト内の先頭ポインタおよび要素数を設定する。
【0086】
DispatchQueuePop関数は、ディスパッチ待ち行列の先頭からスレッド記述子をポップする。
【0087】
DispatchWorkQueuePush関数は、スレッド出力マネージャ320作業待ち行列上にディスパッチ待ち行列をプッシュする。この関数は、スレッドスケジュールマネージャ330によってのみ呼び出され、スレッドスケジュールマネージャ330は、この関数を使って、出力マネージャ320に、スケジュール更新の結果としてディスパッチ待ち行列内で必要とされる変更を知らせる。
【0088】
(スレッドスケジュールマネージャ関数)
スレッドスケジュールマネージャ330は、システム管理コントローラ130内に位置するスレッド出力マネージャ320およびシステムインターフェース(TSIF)380に3つの共通関数を提供する。
【0089】
PushPushWorkEvent関数は、スレッド出力マネージャ320が作動可能待ち行列構造にスレッド記述子を加えた直後に、スレッド出力マネージャ320によって呼び出される。
【0090】
PushPopWorkEventは、スレッド出力マネージャ320が作動可能待ち行列構造からスレッド記述子を除去した直後に、スレッド出力マネージャ320によって呼び出される。
【0091】
FreeIndex関数は、コントローラメモリ要素195の解放が、スレッドスケジュールマネージャ330内で進行中のスケジューリングアクティビティと適正に同期されることを可能にする。呼び出しは、コントローラ130ソフトウェアAPIにおいて類似のコマンドを受け取り次第、またはスレッド出力マネージャ320内のポップ操作の結果として発行されてもよい。
【0092】
(コントローラクライアント)
前述のように、処理リソース150という用語は、命令がどれほど初歩的なものであるかに関わらず、その命令を実行し得る任意のリソースに適用される。したがって、入出力モジュールなど、固定機能を有するリソースも含まれる。処理リソース150の種類に応じて、システム管理コアクライアント120を介した、システム相互接続160と処理リソース150の間の接続は、単方向とすることも、双方向とすることもできる。
【0093】
図7に、システム管理コントローラ130と共に使用するためのコントローラクライアント120の概略的ブロック図の一例を示す。
【0094】
例えば、汎用プロセッサやディジタル信号プロセッサなどの適切な処理リソース150上で、コントローラクライアント120は、通常、ソフトウェアとして実施される。しかしながら、処理リソース150が限定された機能のものである場合、コントローラクライアント120は、ハードウェアコンポーネントを必要とすることもある。
【0095】
システム相互接続160と処理リソース150の間でハードウェアコンポーネントが使用されるとき、コントローラクライアント120は、やはり、同じインターフェースを使って処理リソース150にインターフェースする。すなわち、コントローラクライアントは、処理リソース150のコントローラクライアントへのインターフェースと同一のインターフェースを相互接続エージェント170に提示する。場合によっては、例えば、入出力装置の場合には、処理リソースへのデータパスを、処理リソースからのデータパスと異なるものとして処理するのが妥当なこともある。
【0096】
主要なインターフェースに加えて、コントローラクライアント120は、実行時およびデバッグイベントの出力として使用するために帯域外インターフェースも提供する。ソフトウェアコントローラクライアント120が使用される場合、これらは、適切なサービスルーチンを呼び出す標準割り込みを使って提供される。
【0097】
(コントローラクライアント動作モード)
各コントローラクライアント120は、完全に割り込み駆動型である。コントローラ130から内部割り込みを受け取り次第、コントローラクライアント120は、専用密結合メモリ190内に保持されているその特定の処理リソース150に関連付けられたディスパッチ待ち行列の先頭から、スレッド記述子をポップする。次いで、スレッド記述子内の一意の参照を使って、メインメモリリソース140さらなるスレッド制御情報、スレッド制御ブロック(TCB)が読み取られる。TCB内に含まれる情報は以下のいずれかとすることができる。
【0098】
1.コントローラクライアント120構成内容。この情報は、コントローラクライアント120システムリソース使用ポリシング、データプレゼンテーションモードなどを構成するのに使用され得る。
【0099】
2.処理リソース150構成内容。これは、個々のスレッドの実行のために処理リソース150を準備するのに必要とされる情報である。これは、このスレッド前の部分実行からの回復、または、オーディオCODECなどの、専用ハードウェアアクセラレータの構成を含んでいてもよい。
【0100】
3.命令内容。固定機能ハードウェアアクセラレータの場合、例えば、処理リソース150が出力モジュールであるときの出力命令など、「命令」は、目的のハードウェア処理リソース150では暗黙的となり、任意の必要な専門化または構成が、構成情報内に収容されることになる。ソフトウェアコントローラクライアント120の状況では、これは、通常、スレッドに関連付けられた機能コードを指示すポインタになる。
【0101】
4.データ内容。この内容は、システムメモリ140内の開始アドレスまたは複数のアドレス、およびスレッドが動作し得るデータ範囲を定義することができる。
【0102】
5.コントローラクライアント120後処理内容。この内容は、スレッド実行完了後のコントローラクライアント120のアクションを決定する。
【0103】
コントローラクライアント120の3つの異なる動作段階がある。
【0104】
1.処理リソース150およびコントローラクライアント120が個々のスレッドの実行のために準備される構成段階。最も単純な場合、構成段階はヌルになる。
【0105】
2.スレッドが実行され、コントローラクライアント120がデータを供給し、かつ/またはリソース利用を監視し得る実行段階。
【0106】
3.完了段階。処理の完了は、結果として、アクションなし、別のスレッドの作成、同期プリミティブの発行、またはスレッド作成と同期の組み合わせを生じ得る。さらに、コントローラクライアント120は、スケジューラメトリックを設定または更新し、スレッドを終了させるように要求されることもある。スレッド実行時に、結果を格納するためにさらなるメモリが必要とされる場合、コントローラクライアント120は、このメソッドも実行しなければならない。
【0107】
個別のハードウェアコントローラクライアント120bが、アクティブ期間において利用可能なシステム相互接続160帯域幅を完全に利用する状況において、1つの最適化された解決策は、コントローラクライアント120bが、複数のハードウェア処理リソース150のプロキシとして動作するのを可能にすることであろう。そのような構成を図7bに示す。前述の場合と同様に、プロキシコントローラクライアント120bは割り込み駆動型である。しかしながら、前述の例では、コントローラ130から単一の割り込みだけが経路指定されたが、プロキシコントローラクライアントモデルでは、処理リソース150ごとの割り込みがある。コントローラ130から受け取られる割り込みのインデックスに従って、プロキシコントローラクライアント120bは、識別された処理リソース150で同じステップを実行する。システム相互接続160使用ポリシングが必要とされるプロキシコントローラクライアントモデルでは、ハードウェアアダプタ120cが、処理リソース150とシステム相互接続160の間に残る。
【0108】
前述のように、コントローラクライアント120は、ソフトウェアとして実施されてもよい。この場合、コントローラクライアント120の機能の一部、例えば、共用リソース使用ポリシングは、通常、処理リソース150ハードウェア(例えば、メモリ管理ユニット(MMU)など)にすでに存在する既存のハードウェアコンポーネントを利用することになる。
【0109】
結果として、ソフトウェアコントローラクライアント120アーキテクチャおよび実施は、処理リソース150特有のものになる。
【0110】
また、ハードウェアコントローラクライアント120は、関連付けられた処理リソース150の特質による専門要件を有することもある。以下の項では、大部分の場合に好適となる汎用アーキテクチャを説明する。
【0111】
(ハードウェアコントローラクライアントの一般例)
図8に、ハードウェアコントローラクライアント120の基本構造を示す。設計の機能的中心にあるのは、コントローラクライアント有限状態機械(FSM)500である。この有限状態機械(FSM)500は、3段階すべてにおいてアクティブとすることができる。コントローラクライアントFSM500は、コントローラ130からの割り込み220によって活動化される。
【0112】
まず、コントローラクライアントFSM500は、システム相互接続160を制御して、独自の命令への参照を含む共用メモリリソース140からTCBを読み取らせる。構成段階の間、コントローラクライアント120は、処理リソースを制御して、構成コマンドを解釈し、コマンドを、処理リソース150に発行される書込みサイクルに変換することができる。さらに、コントローラクライアント120は、独自のリソースポリシングを構成する。構成状態から実行状態への遷移の仕方は処理リソース150特有のものであるが、明示的な実行プリミティブによってマークされてもよく、単に、データ転移状態に入ることとしてもよい。
【0113】
コントローラクライアント120から見て、最も単純なアーキテクチャは、処理リソース150とシステム側の両方で同一のインターフェースプロトコルを有する。この場合、実行段階の間に、処理リソース150読取り/書込みサイクルが、適切な場合にはチェックを伴って、単に、システムインターフェースにマップされるだけである。
【0114】
最も単純なコントローラクライアント120実施は、システムから処理リソースへのパス510と処理リソースからシステムへのパス520の両方でFIFOスタイルのインターフェースを必要とするはずである。この性質のコントローラクライアント120の実行段階の間、データは、メッセージまたはストリーミングモードによって処理リソース150に提示され得る。データセット全体が、処理の前にコントローラクライアント120内においてローカルで蓄積されるメッセージモードは、より複雑な相互接続アービタを円滑化し得る、より粗くむらのある相互接続挙動を生じさせる。データがシステムメモリから処理リソース150に直接ストリーミングされるストリーミングモードは、ハンドシェークのより慎重な考察を必要とし、細かい相互接続トランザクションおよび相互接続への密結合を呈する、よりシリコン効率の高い解決策を提示する。
【0115】
実行段階から完了段階への遷移は、処理リソース150へのデータの提示を測定することによって推断されてもよく、処理リソース150自体によって明示的に通知されてもよい。完了段階の間、コントローラクライアント120は、再度、元のスレッド制御ブロックによって提供される命令セットから実行する。
【0116】
場合によっては、処理リソース150に入るディスパッチ(例えば、入出力装置など)と処理リソース150から出るパスとを区別して扱うことが妥当であることに留意されたい。これに対して、同じコントローラクライアント120フレームワーク内でデータの消費側と生成側を結合すべき場合(例えば、DSPなどのアルゴリズム的アクセラレータ)もある。
【0117】
処理リソース150とその他のシステムリソースの間で減結合のレベルを提供するために、コントローラクライアント120によって、以下のようないくつかの追加機能が提供され得る。
a)処理リソース150によって生成されるアドレスが、比較器530および比較アドレスレジスタ540を使って、基底アドレスおよびオフセット定義によって定義される期待される挙動に照らしてチェックされてもよい。
b)処理リソース150によって生成されるアドレスが、減算機550およびオフセットアドレスレジスタ560を使ってオフセットされ、処理リソース150が、通常、アドレス0×0前後に正規化される、任意の所与のスレッドのアドレスマップの正規化ビューを有することを可能にする。
【0118】
(オブジェクト)
システム管理コントローラ130内で使用されるデータ型のインスタンスは、公開(システム一般から見ることができ、システム一般によって操作される)と専用可視(システム管理コントローラ130内でのみ見ることができ、システム管理コントローラ130サブブロックによってのみ操作される)とに分けられる。複数のエンドアプリケーションにまたがる設計の移植性を保証するために、すべてのスレッド、待ち行列および集約待ち行列記述子が、共通基底クラスを使用する専用密結合メモリ190、コントローラメモリ要素195内に格納される。
【0119】
(コントローラメモリ要素)
各コントローラメモリ要素195は、以下の7つの記述子型のいずれかを表すことができる。
【0120】
1.フリーリスト要素。この要素は、その他の記述子型のいずれによっても自由に利用される。ユーザ初期設定も実行時操作も必要とされない。
【0121】
2.スレッド記述子(TD)。これは、アプリケーション/OSスレッドのデータ構造表現である。この記述子は、専用密結合メモリ190内の保留待ち行列、作動可能待ち行列またはディスパッチ待ち行列に存在し得る。ユーザ初期設定は必要とされないが、実行時操作は必要である。
【0122】
3.スケジューラルート記述子(SRD)。これは、スケジューラ階層の最上位の記述子である。ユーザ初期設定は必要であるが、実行時操作は必要とされない。ルート記述子は親を持たないが、子は、SSTD、DSTDまたはTDのいずれかとすることができる。
【0123】
4.静的スケジューラ層記述子(SSTD)。これは、SRDまたは別のSSTDを親とすることのできる静的スケジューラ層記述子である。SSTDの子は、別のSSTD、DSTDまたはTDのいずれかとすることができる。
【0124】
5.動的スケジューラ層記述子(DSTC)。これは、動的スケジューラ層記述子である。ユーザ初期設定は必要とされないが、実行時操作は必要である。DSTDの親は、SRDまたはSSTDのどちらかとすることができるが、DSTDは、TDの子だけしか持つことができない。
【0125】
6.ディスパッチ待ち行列記述子。この種の記述子は、関連付けられた処理リソース150からのポップ操作を待ち受けるスレッド記述子のリストを記述する。ユーザ初期設定は必要であるが、実行時操作は必要とされない。
【0126】
7.保留待ち行列記述子。この種の記述子は、同期イベントを待ち受けるスレッド記述子のリストを記述する。ユーザ初期設定は必要であるが、実行時操作は必要とされない。
【0127】
以下の各項では、これらの記述子をより詳細に説明する。
【0128】
コントローラメモリ要素195の様々な形、およびそのそれぞれを、図9aから9lに示す。
【0129】
(スレッド表現)
記述子が初期設定または実行時操作を必要とする場合、操作は、コントローラ130APIを介して行われる。集中型タスク割り振り/管理システムは、リアルタイム対話が、ハードウェア実施に十分適する/ハードウェア実施に十分なほど単純化されるように設計される。
【0130】
図10に、スレッド記述子と、システム管理コントローラ130と、処理リソース150と、共用システムメモリ140の間の典型的な関係を示す。各スレッドプリミティブは、一意の参照、pReferenceを含む。この参照は、システム管理コントローラ130によって解釈も、変更もされない。pReferenceは、実行されるべきタスクを定義するシステムメモリ140内のデータ構造を指し示すポインタを提供する。通常、これは、コントローラクライアント制御ブロック125であり、少なくとも、(図10に処理リソース命令ブロック145として示す)関数ポインタ、スタックポインタおよび(図10にデータブロック135として共に示す)引数ポインタという要素を含むはずである。帯域内構成または共用システムリソースのセキュリティを提供する追加フィールドが定義されてもよい。
【0131】
しかしながら、アプリケーションおよび/またはターゲット処理リソース150によって、コントローラクライアント制御ブロック125の複雑度は異なり得る。特に、適切な「制御」命令コードおよび対応する「ディスパッチ」コードが与えられた場合に、異なる処理リソース150が、一定の状況下で、同じデータに対して同じ関数を実行することを可能にし得る別のレベルの間接化も含まれ得ることに留意されたい。
【0132】
図11に、スケジューリング階層が、2つの異種の処理リソース(図11のタイプIおよびタイプII)150aと150bにまたがってタスクを負荷均衡化する一例を示す。(この階層の待ち行列に入れられるスレッド記述子内の)pReferenceフィールドは、前述のようにコントローラクライアント制御ブロック125を参照するが、この場合、それぞれの異種の命令セットによって必要とされる個々の命令ストリームに対応する処理リソースの種類ごとにポインタがある。コントローラクライアント120は、コントローラクライアント制御ブロック125内のフラグに従って適切な命令ストリーム(命令ブロック145aまたは145b)を選択する。
【0133】
この機能は、例えば、いくつかの処理リソースの電源遮断機能と関連させると役立つことがある。所与のタスクに最適なプロセッサが電源遮断された場合、高くつくリブートサイクルを発生させるのではなく、次善のプロセッサがそのタスクを実行する方が望ましいことがある。さらに、例外的な負荷の状況下では、例えば、負荷の軽い汎用プロセッサが、負荷の思いDSPの負担を軽減することができるようにしてもよい。
【0134】
処理リソース150がスレッドを処理することが可能な状態になると、スレッドは、その処理リソース150と一意に関連付けられた適切なディスパッチ待ち行列からポップされる。ポップ操作は、pReference、スケジューリングイベントを生じたスケジューラメトリック、およびスレッドが作動可能になったのはタイムアウトによるものか、それとも同期プリミティブによるものかを示す指示を含む1組のフラグを含むオブジェクトを返す。スレッド記述子に使用されるコントローラメモリ要素195は、後のスレッド記述子が使用するためにフリーリストに自動的に返される。
【0135】
(共用オブジェクト)
この項では、コントローラ130APIを介してシステムから見ることのできるオブジェクトを説明する。通常、これらのオブジェクトは、実行時に、コントローラ130とクライアント120とそれらに関連付けられた処理リソース150とを備える集中型タスク割り振り/管理システムによって操作される。
【0136】
実行時コントローラ130APIは、アプリケーションが、新しいスレッドを導入し、新しい動的スケジューラ要素を導入し、同期プリミティブを発行し、スケジュールされたスレッドをポップし、割り込みされたスレッドをプッシュし、またはスレッドを除去することを可能にする。
【0137】
図12に、システム管理コントローラ130内のスレッド管理の典型的な全体図を示す。
【0138】
(スレッドプリミティブ)
図9cおよび9dにスレッドプリミティブのフォーマットを示す。その依存関係に従って、スレッド記述子は、保留待ち行列構造に、または直接作動可能待ち行列構造に配置され得る。スレッドが保留待ち行列構造内に配置されるべきである場合、アプリケーションは、スレッドの依存関係を定義しなければならない。外部イベントへの依存性は、依存参照として現れる。コントローラ130は、この依存参照を解釈しない。これは、スレッド記述子を作動可能待ち行列構造にいつ移行させるべきか決定する、入力同期プリミティブとの比較のために維持される。
【0139】
従属スレッドでは、タイムアウトを指定することができ、ヌル依存参照と関連させて、この機能をスレッドベースのハードウェアタイミング機能として使用することができる。依存関係と関わりなく、タイムアウトは、スレッドを、特定の時刻にスケジュールさせる。
【0140】
スレッドは、スレッドを作動可能待ち行列構造に格上げさせる同期イベント(タイマまたはプリミティブ)に従ってタグ付けされる。
【0141】
(同期プリミティブ)
同期プリミティブは、保留待ち行列とインターフェースし、1つ以上のスレッド記述子の保留待ち行列構造から作動可能待ち行列構造への移行を生じさせることができる。
【0142】
各同期プリミティブは、識別された保留待ち行列内の各スレッド記述子内に格納された依存参照と比較される一意の参照を含む。比較は、スレッドプリミティブによって識別される優先度の順に進められる。
【0143】
その種類に従って、同期は、保留待ち行列内の最高優先度のマッチングスレッド記述子またはすべてのマッチングスレッド記述子を稼動状態にすることができる。さらに、特殊なブロードキャストプリミティブが、すべての保留待ち行列内のすべてのマッチングスレッド記述子を活動化する。
【0144】
(割り込み処理)
割り込みサービススレッド(IST)法は、非同期イベントによって処理リソース150に課される負荷を最小限に抑える有益な手段を提供する。さらに、本発明に基づくシステムにおける加速されたリアルタイム応答は、小さなシステム変更を加えるだけでISTのさらなる普及を可能にする。
【0145】
コントローラ130は、コントローラ周辺での外部割り込み入力210から自動的に同期プリミティブを作成する。保留待ち行列内の事前に構成された割り込みサービススレッド記述子が、これらの割り込み同期プリミティブの受け取り時に、作動可能待ち行列構造に格上げされる。
【0146】
アプリケーションは、通常、システム初期設定時に、外部割り込み210に関連付けられたスレッド記述子を構成し、関連付けられた割り込みサービススレッドの各実行内でも構成する。
【0147】
この機能は、事実上、システム内の他の任意の専用割り込みサービス提供処理リソース150の必要をなくす。さらに、この機能は、これらの外部割り込み210を、同じ優先度構造により、すべてのプロセッサタスクに使用される同じポリシに従って処理し、すでにより優先度の高いタスクを実行している処理リソース内でのコンテキスト切換えの必要をなくす。通常の優先使用ルーチンを使って現在実行中のスレッドを作動可能待ち行列にプッシュバックすることができるために、任意の数のネストされた割り込みがサポートされる。
【0148】
タイマベースの割り込み(ウォッチドッグおよび周期的イベント)も同様のやり方で処理される。(周期的または1回限りの)タイムベースのタスクは、タイマ待ち行列に挿入されなければならず、タイムアウト依存関係を有するスレッドと類似のやり方で処理される。設計により、この方法は、有用な処理要件を持たないタイムベースの例外を除外する。
【0149】
割り込み優先度は、応答時間を速くするために、割り込みルーチンが現在実行中のタスクに取って代わることを許されるように設定される。
【0150】
(専用オブジェクト)
専用オブジェクトは、通常、ブート時、すなわち、電源遮断サイクル後のシステム初期設定時に構成される。処理リソース150が、実行時に内部オブジェクトと直接対話することはまれである。
【0151】
内部オブジェクトは、主として、待ち行列構造である。システム管理コントローラ130は、保留待ち行列、タイマ待ち行列、作動可能待ち行列およびディスパッチ待ち行列という4種類の主要な待ち行列を管理する。
【0152】
システム管理コントローラ130内には、内部操作を円滑化するために、さらに2次的待ち行列が存在する。待ち行列間のスレッド記述子の移動は、ポインタ操作のみで行われる。スレッド記述子は、絶対にコピーされることはない。
【0153】
(保留待ち行列構造)
スレッドは、同期イベントまたはタイマイベントによって、保留待ち行列構造から作動可能待ち行列構造に格上げされ得る。スレッドは、これらのイベントクラスの両方に反応しても、一方だけに反応してもよい。スレッドが両方に反応する場合、そのスレッドは、保留待ち行列とタイマ待ち行列の両方に存在する。
【0154】
保留待ち行列は、同期イベントを待ち受ける従属スレッドを保持する。スレッドは、処理リソース150からの同期プリミティブによって、またはタイムマネージャ360によって内部で生成されたタイマイベントによってこれらの構造から除去される。複数の競合有効範囲および割り込みサービススレッドをサポートするために、アプリケーションプログラマが、構成可能な数の保留待ち行列を利用することができる。各保留待ち行列内の要素は、それらの優先度に従って処理されなければならない。優先度に従った処理には、挿入時のソートと抽出時のソートという2つの選択肢がある。挿入時のソートは、保留リストを厳密な優先順位で格納し、新しいスレッドをその優先度に従ってリスト内の位置に挿入するためのプロセスを定義する。抽出時のソートは、新しいスレッドをどこに挿入すべきかの任意の選択を行い、同期後の適格なスレッド記述子の優先度に基づくソートを行う。本発明の好ましい実施形態は、挿入時ソートの技法を用いる。
【0155】
図13に、保留待ち行列の典型的な構造を示す。各エントリは、厳密な優先順位で格納される。新しいスレッドの挿入が達成され得る速度は、スキップリストの使用によって加速される。図14に、典型的な保留待ち行列スキップリストを示す。
【0156】
前述のように、スレッドは、ブロックされて、同期またはタイマイベントを待ち受けてもよい。スレッドの中には、排他的に同期イベントを待ち受けるものもあり、同様に、排他的にタイマイベントを待ち受けるものもある。その都度、スレッドは、単一の待ち行列にのみ存在することになる。各スレッドは、名目上、保留待ち行列とタイマ待ち行列の両方に関連付けられた、2組のポインタを含む。これらの場合、設けられるタイマ待ち行列および保留待ち行列のポインタは、それぞれ、スペアである。スキップリストは、これらのスペアポインタを利用することができる。すなわち、例えば、スレッドがタイマ待ち行列内に見当たらない場合、これらのポインタを再利用して、保留待ち行列内における可能な前方ジャンプが指示されてもよい。これは、通常は逐次のサーチが、新しい従属スレッドの正しい挿入点に反復的に接近しながら、スレッド記述子のブロックをジャンプすることを可能にする。
【0157】
一代替方法が、スキップノード記述子であり、この一例を、関連付けられたフィールド(図9l)と共に図9kに示す。スキップノード記述子は、事前定義されたメトリックに従って、保留およびタイマ待ち行列構造に周期的に挿入され得る。スキップノード記述子は、スキップノード記述子間の、または関与するスレッド記述子間の、定義された最大観測数のスレッド記述子に従って挿入される。スキップノード記述子は、保留待ち行列とタイマ待ち行列のスキップリストの一部を同時に形成することができる。
【0158】
それぞれの新しい従属スレッドが、その優先度に従って挿入されなければならない。このプロセスでは、典型的に、始めに、新しいスレッドの優先度がスキップリストノードの優先度より高くなるまでスキップリストをトラバースする。その後、サーチは、そのスキップリストノードから、スレッド記述子ごとに、正しい挿入点が見つかるまで続けられる。これは、通常は線形のサーチが、新しい従属スレッドの正しい挿入点に向かって進むときに、保留スレッドのブロックをスキップすることを可能にする。
【0159】
同期イベントには、以下の3つの異なる種類がある。
ユニキャスト:同期イベントは、指定された保留待ち行列で見つかった最初の(最高優先順位の)適切な従属スレッドで状態遷移をトリガする。
マルチキャスト:同期イベントは、指定された保留待ち行列内のすべての適切な従属スレッドで状態遷移をトリガする。
ブロードキャスト:同期イベントは、すべての保留待ち行列内のすべての適切な従属スレッドで状態遷移をトリガする。
【0160】
保留待ち行列は、図9iおよび9jに示すように、保留待ち行列記述子によって定義される。保留待ち行列記述子は、システム初期設定時に一度構成され、単一のコントローラメモリ要素195を消費する。保留待ち行列は、従属スレッド記述子とスキップリストノードをだけを含む。
【0161】
(タイマ待ち行列構造)
タイムアウトイベントを待ち受けるスレッド記述子を格納する単一システム規模のタイマ待ち行列が設けられる。図15に、タイマ待ち行列の例示的実施形態を示す。
【0162】
また、スキップリストは、前述のタイマ待ち行列構造へのスレッドの挿入を迅速化するためにも使用される。しかしながら、この場合、それは、スキップリストに使用される、時間的依存関係(もしあるとすれば)だけを有するスレッドである。
【0163】
タイマ待ち行列記述子は、レジスタ内に格納され、同時比較が、タイマ待ち行列の先頭と現在時刻の間で進行することを可能にする。これは、タイマティックのメモリ帯域幅に対する影響を大幅に低減する。
【0164】
(作動可能待ち行列構造)
作動可能待ち行列構造は、実行可能な状態のスレッドを保持する。これらのスレッドは、独立のスレッドプリミティブを用いて作成されたスレッドであり、または依存対象とする同期プリミティブを受け取っているスレッドである。同期スレッドは、あらかじめ保留待ち行列構造から移行している。
【0165】
作動可能待ち行列構造は、スケジューラノード記述子と、独立の同期されたスレッド記述子を含むことができる。この構造は、システム初期設定時におおむね定義されるが、スレッド記述子および動的スケジューラ層記述子は、リアルタイムで出入りすることを許される。
【0166】
作動可能待ち行列は、スレッドを特定の処理リソース150、または処理リソース150のプールに対してスケジュールすることができる。これは、特定のタスクを特定の処理リソース150、例えば、ハードウェアアクセラレータや入出力装置などに向けることができる状態を維持しつつ、複数の処理リソース150にまたがる負荷均衡化を可能にする。
【0167】
図16に、2つの処理リソース150での典型的な作動可能待ち行列構造を示す。動的スケジューラ層2は、両方のルートスケジューラ層から利用可能であることに留意されたい。これは、システム管理コントローラ130が、ルート層1および2と関連付けられた処理リソース150の間の動的な層2の下でスレッドを負荷均衡化することができるようにする。
【0168】
(スケジューラ層)
スケジューラ層は、スレッド記述子をスケジュールするのに使用される階層を定義する。各スケジューラ層は、通常、スケジューリングアルゴリズム、スケジューリング決定を行うのに使用されるいくつかのメトリック、および別のスケジューラ層またはスレッド記述子とすることのできる子要素のリストを定義する。ルート、静的および動的の3種類のスケジューラ層記述子がある。スケジューラ層メモリ要素のフォーマットを図9eおよび9fに示す。
【0169】
ルートスケジューラ記述子は、ディスパッチ待ち行列と1対1マッピングを有する。これらは、作動可能待ち行列構造における最終ノードを表す。スケジューラルート記述子は、システム初期設定時に構成され、永久に存在する。
【0170】
静的スケジューラ記述子は、スケジューリング階層内のルートノードの下に存在する。静的スケジューラ記述子の親は、他の静的スケジューラ記述子とすることも、ルート記述子とすることもできる。静的スケジューラ記述子は、その親の定義するスケジューラアルゴリズムおよびそのスケジューラメトリックに従って、兄弟ノードと競合する。静的スケジューラ記述子は、システム初期設定時に構成され、永久に存在する。動作時に、システム管理コントローラ130は、選択されたスケジューリングアルゴリズム、例えば、ラウンドロビンスケジューリングなどに従ってスケジューラメトリックを維持する。
【0171】
動的スケジューラ記述子は、スケジューリング階層内のルートおよび、おそらく、静的ノードの下に存在する。動的スケジューラ記述子の親は、静的スケジューラ記述子またはルート記述子とすることができる。動的スケジューラ記述子は、その親の定義するスケジューラアルゴリズムおよび独自のスケジューラメトリックに従って兄弟ノードと競合する。動的スケジューラ記述子は、いつでも構成することができ、特定の状況下において廃棄することができる。これは、システムが、純粋に静的な条件で可能なはずの数よりずっと多くのスケジューリング層をサポートすることを可能にする。システム管理コントローラ130は、多数の多様なスレッドおよび動的スケジューラ層が常に使用されるが、ある有限期間の間、一時要求がより小さいくなる可能性を利用することによってこれを実現する。例えば、最大4000の動的要素(スレッドおよび動的スケジューラ記述子)をサポートするメモリが接続されたネットワークシステムでは、16000接続をサポートすることが可能であると考えられる。というのは、任意の瞬間に、コントローラには、全接続空間のほんの一部からのデータ単位だけがあるからである。この柔軟性は、性能をわずかに犠牲にして達成される。というのは、動的スケジューラ記述子が存在しない場合、それが子スレッド記述子の追加の前に作成されなければならないからである。
【0172】
動作時に、システム管理コントローラ130は、選択されたスケジューリングアルゴリズムに従ってスケジューラメトリックを維持する。いくつかの状況下では、動的スケジューラ記述子は、コントローラメモリ要素195フリーリストに戻される。これは、動的スケジューラ層記述子にその層内で処理されるべき最後のスレッドからのpReferenceを格納することによって達成される。コントローラ130APIは、動的スケジューラ記述子が後続の類似のスレッドの間に持続するかどうか判定するために、コントローラメモリ要素195の問合せをサポートする。
【0173】
(ディスパッチ待ち行列)
ディスパッチ待ち行列は、関連付けられた処理リソース150からのサービスを待ち受ける先入れ先出し(FIFO)待ち行列としてスケジュールされたスレッド記述子を保持する。現在の好ましい実施形態では、最大32のディスパッチ待ち行列が許容される。ディスパッチ待ち行列は、図9gおよび9hに示すディスパッチ待ち行列記述子によって定義される。ディスパッチ待ち行列記述子は、システム初期設定時に構成される。
【0174】
スレッド記述子を作動可能待ち行列構造からディスパッチ待ち行列構造に遷移させるプロセスは、ハードウェアとして実行され、コントローラ130API対話を必要としない。
【0175】
図17に、本発明の特徴を実施する典型的な単一のディスパッチ待ち行列構造の例示的実施形態を示す。ディスパッチ待ち行列記述子は、フル閾値を定義する。ディスパッチ待ち行列長は、スレッドバンドルがスケジュールされている場合、または割り込みスレッドプッシュが行われた場合にのみフル閾値を上回ることを許される。
【0176】
各要素は、処理リソースによってコントローラ130APIを介して呼び出されるポップ操作によってディスパッチ待ち行列から除去される。
【0177】
ディスパッチ待ち行列記述子には優先度フィールドが含まれる。ディスパッチ待ち行列からスレッドがポップされるときに、優先度フィールドに、現在実行中のスレッドの優先度が取り込まれる。別のAPI呼び出しが、優先度が実行中のプロセッサによって別の値にリセットされるようにして、優先度逆転を回避する。優先度逆転は、異なる優先度の少なくとも3つのスレッドが関与する、同期とスケジューリング要件の間の競合をいう。優先度逆転は、優先度の低いスレッドが、優先度の高いスレッドを無期限にブロックすることを可能にする。例えば、優先度の低いスレッドが共用リソースをロックし、次いで、より優先度の高いスレッドに取って代わられる。次いで、優先度の高いスレッドは、優先度の低いスレッドによってロックされているリソースでブロックする。今度は、優先度の高いスレッドがブロックされているため、通常は、ロックされているリソースから独立の、現在自由に実行できる第3の中間スレッドがなかった場合、優先度の低いスレッドが再開するはずである。優先度の低いスレッドは、決して共用リソースをロック解除する機会を得ることができず、したがって、優先度の高いスレッドは無期限にブロックされる。「優先度上限」プロトコルとは、スレッドが共用リソースを所有している間、それが指定された優先度で実行されることを意味する。これは、前述の優先度の「低い」スレッドが優先度の高いスレッドと共用されるリソースを所有している間、それが「高い」優先度を有することを保証する。
【0178】
スレッドバンドルは、同じスケジューラ層を起源とするスレッド記述子のグループをいう。各スケジューラ記述子には、更新するよう求めるスケジューリング決定が強制される前に、作動可能待ち行列のその層からディスパッチ待ち行列に遷移され得るスレッドの数を定義するパラメータが存在する。この機能を利用すると共に、スケジューラ層のメンバが共通の属性を有するように構成することによって、処理リソース150に、通常観測されるはずのものより著しく高いキャッシュ局所性を呈するスレッドのブロックを提示することができ、その結果、キャッシュミスが低減され、システム性能が向上する。
【0179】
図18に、本発明の一実施形態による、スレッドバンドリングを含む2層のスケジューリング階層の例を示す。ルート層から最も遠い層である、子層は、FIFOスケジューリングアルゴリズムを使う。ルート層スケジューラアルゴリズムは、ラウンドロビンとして構成される。この実施形態では、各FIFO待ち行列内の要素は、同じ待ち行列の他のメンバとの高レベルのキャッシュ局所性を呈する。
【0180】
図18(a)に、子層のスレッドバンドル限界が1に設定されているスケジューリング結果を示す。この結果は、完全にインターリーブされている。この方式は、各待ち行列に最小の待ち時間を提示するが、メモリ管理がほとんど考慮されない(すなわち、低いキャッシュ性能を呈する可能性が最も高い)。スケジュールされたスレッドごとにコンテキスト切換えが必要である。ルート層がキャッシュを使用する処理リソース150と関連付けられる場合、強制的なキャッシュミスがシステム性能に影響を及ぼす可能性がある。
【0181】
図18(b)に、子層のスレッドバンドル限界が4に設定されているスケジューリング結果を示す。スケジューラはより粗い更新特性を呈し、それは、このスレッドバンドル限界によって設定された限界を有する同じ待ち行列からスケジュールされているスレッドのブロックとして現れる。このバースト性挙動は、状況によっては理想的ではないこともあるが、はるかに優れたキャッシュ性能を呈する。というのは、コンテキスト切換えを必要とされることが比較的まれだからである。結果として得られる効果は、きめ細かな手法の優れたプログラミングモデルを維持しつつ、粗いマルチスレッディングの優れたキャッシュ性能に匹敵するものである。
【0182】
システムが外界と対話する場合には、スレッドバンドリングのバースト性が極めて有害になる可能性が高い。しかしながら、スレッドバンドリングは、ターゲット処理リソース150がキャッシュを使用する場合にだけ有益であり、したがって、外界と対話する専門処理リソース150、例えば入出力装置などは、キャッシュ技術を使用する可能性が低く、したがって、スレッドバンドリングを利用しない。
【0183】
図17に戻って、各要素は、処理リソース150によりコントローラ130APIを介して呼び出されるポップ操作によってディスパッチ待ち行列から除去される。各要素は、優先使用の場合には、作動可能待ち行列にプッシュバックされてもよい。
【0184】
ディスパッチ待ち行列記述子には、優先度上限プロトコルの実施を可能にする優先度フィールドが含まれ、共用データでの優先度逆転を防ぐ。各処理リソース150は、一意のディスパッチ待ち行列を有する。
【0185】
(スケジューリング)
アプリケーションおよびシステムのスケジューリング要件は様々に異なり、実際には、実際の動作環境での試験後に初めて明らかになることもある。これに対応するために、システム管理コントローラ130は、使用されるスケジューリングポリシとスケジューリングアルゴリズムの両方に柔軟性を与え、これらは、マルチコアプロセッサ設計段階全体を通して変更、調整することができる。
【0186】
スケジューリングポリシは、以下の3種類に分けられる。
1.連携スケジューラが現在実行中のタスクを利用して新しいタスクをスケジュールする前に処理リソース150を解放する。この種のシステムは、(例えば、処理リソース150にとってローカルのキャッシュが必要な命令を含まず、したがって、より低速の上位メモリから足りない命令をロードしなければならないなどの場合の)コールドキャッシュ効果の最小化、および固定機能ハードウェアアクセラレータと適合するが、より複雑な組み込みアプリケーションには適さないことがある。
2.静的アルゴリズム駆動型スケジューラが、より適格性の高いタスクを実行するために、現在実行中のタスクに取って代わることができる。事前定義されたスケジューリングパラメータおよびアルゴリズムによる最も適格なスレッドが、常に、これらのシステムにおける実行中のスレッドである。任意の所与のタスクの適格性は、システムが実行を開始する前に定められる。
3.動的アルゴリズム駆動型スケジューラが、実行時に適格性を再定義することができる。前述のように、現在実行中のプロセスは、依然として、適格性が最も高いものであるが、タスクが実行を開始した後で、適格性メトリックが変更されている可能性がある。
【0187】
システム管理コントローラ130は、適切な構成およびターゲットアプリケーションとの実行時対話によって3つのスケジューリングポリシすべてを満足させる。
【0188】
システム管理コントローラ130は、例えば、先入れ先出し待ち行列法、優先度待ち行列法または重み付き公平待ち行列法など、オペレーティングシステムおよび通信業界で見られる多くのスケジューリングアルゴリズムをサポートする。スケジューリングアルゴリズムを適切に選択すれば、特に、主観的品質メトリックが関与する場合には、明白な利点が呈示される。
【0189】
スレッド記述子内では、システム管理コントローラ130内のスケジューリング挙動をサポートするために2つのスケジューラメトリックが設けられる。第1のメトリックは、あらゆる場合におけるスレッドの優先度を表し、保留待ち行列構造、優先度ベースのスケジューラおよびディスパッチ待ち行列構造内で使用される。必要な場合には、第2のメトリックを使って、個別スレッドとそのピアの間で選択が行われる。さらに、どちらかのメトリックを使って親記述子内のメトリックが更新されてもよい。スレッド記述子の第2のプリミティブ内に配置される値は、そのスケジューラ階層内で生じるスケジューリングの種類を反映しなければならない。
【0190】
これら2つのスケジューラメトリックは、スケジューラ記述子とスレッド記述子の両方で使用される。しかしながら、スレッドメトリックは処理リソース150内で計算されるが、これはスケジューラ層には不可能である。したがって、スケジューラ層がそれ自体のメトリックを更新することができるようにするには、所与の層のスケジュールされたスレッドから十分なパラメータが渡されなければならない。各スケジューラ層ごとに、どのようにしてメトリックが子から親に伝播されるかを定義する1組の命令が定義される。
【0191】
スケジューラ階層全体に多少注意すれば、アプリケーションシステムにおける洗練されたトラフィックおよびタスク管理機能を提供するための、スケジューラアルゴリズムの複雑な組み合わせを容易に作成することができる。
【0192】
(パラメータ継承例)
図19に、通信システムに一般的に見られる簡略化された待ち行列構造の例示的実施形態を示す。この構造は、入出力装置の出力待ち行列を表す。FIFO待ち行列を共用するすべてのスレッドが同じ接続上にあり、そのため、これは、接続ごとの待ち行列構造である。第2のスケジューリング層は、この例では重み付き公平待ち行列(WFQ)アルゴリズムを使用する。このアルゴリズムは、所与のタスクの完了時刻を、その長さと重み係数に基づいて計算する。次いで、最も早い完了時刻を有するパケットを選択する。WFQはスレッドが表すパケットの長さの知識を利用するものであるが、最初のFIFO待ち行列は、この情報とは無関係である。この場合、アプリケーションプログラマは、パケットの長さが、各スレッドごとのスケジューラメトリックに存在するようにしなければならない。階層内の上位のスケジューラ層は、それら自体のスケジューリングアルゴリズムのためにこのパラメータを継承する。
【0193】
WFQでは、以下の変数が必要とされる。
P 接続に割り振られるパイプ帯域幅の部分
I パケットの長さ
B 総パイプ帯域幅
c 接続帯域幅
d スケジューラ層デッドライン
【0194】
接続帯域幅cを計算する式は以下の通りである。
P*B=c
チャネルを帯域幅1に正規化した場合、pはcに等しくなる。その場合、パケット処理の完了時刻tは次式で与えられる。
(1/p)*l=t
その場合、必要なメトリック1/pとlである。pは元々分数であるため、これらの値(1/pおよびl)は両方とも整数である。スケジュールされたパケットの長さは、スケジューラ階層を介して上方に渡され、その層のデッドラインを漸進的に更新する。各更新内で行われる計算は、詳細には、以下の通りである。
d=d+[(1/p)*l]式中、dおよび1/p(重み)は、スケジューラ層記述子内に格納され、lはスケジュール更新の間に階層を介して渡される。この計算は、スケジューラマネージャ330内で実行される。
【0195】
以上、本発明の具体的実施形態について説明したが、これは一例にすぎず、様々な変更が考えられることを理解すべきである。さらに、本発明は、それだけに限らないが、例えば、携帯電話機やインターネットプロトコル上の音声(VoIP)など、マルチコアプロセッサを用いる任意の装置またはアプリケーションにおける一般的な用途のものである。したがって、この具体的実施形態は、添付の特許請求の範囲によって決定されるべきである保護の範囲を限定するものとみなされるべきではない。
【図面の簡単な説明】
【0196】
【図1】本発明の一実施形態によるリソース管理/タスク割り振りコントローラを組み込んだシステムの論理的レイアウトを示す概略的ブロック図である。
【図2】本発明を実施するコントローラが、専用メモリデバイスおよびコントローラクライアントと共に、汎用マルチコアプロセッサアーキテクチャ内に組み込まれている、図1の論理的レイアウトの1つの例示的実施を示す概略的ブロック図である。
【図3】図2の要素を組み込んだ最新のシステムオンチップ(SoC)バスベースアーキテクチャの一例を、やはりブロック図として示す図である。
【図4】図1、2および3のコントローラへの外部接続をより詳細に示す図である。
【図5】図2および3のメモリデバイスをより詳細に示す図である。
【図6】図2、3および4のコントローラの内部構成をより詳細に示す図である。
【図7】図2および3に示すコントローラクライアントを示す概略的ブロック図である。
【図7b】複数の処理リソースのプロキシとして働く単一のコントローラクライアントの場合のシステムを示す概略的ブロック図である。
【図8】ハードウェアコントローラクライアントをより詳細に示す概略的ブロック図である。
【図9a】総称記述子を示す図である。
【図9b】総称記述子に関連付けられるフィールドを示す図である。
【図9c】スレッド記述子を示す図である。
【図9d】スレッド記述子に関連付けられるフィールドを示す図である。
【図9e】スケジューラ層記述子を示す図である。
【図9f】スケジューラ層記述子に関連付けられるフィールドを示す図である。
【図9g】ディスパッチ待ち行列記述子を示す図である。
【図9h】ディスパッチ待ち行列記述子に関連付けられるフィールドを示す図である。
【図9i】保留待ち行列記述子を示す図である。
【図9j】保留待ち行列記述子に関連付けられるフィールドを示す図である。
【図9k】スキップリスト記述子を示す図である。
【図9l】スキップリスト記述子に関連付けられるフィールドを示す図である。
【図10】スレッド記述子と、システム管理コントローラと、処理リソースと、共用システムメモリの間の典型的な関係を示す図である。
【図11】2つの異種の処理リソースが存在する、図10の構成における間接化の原理を示す図である。
【図12】図4のコントローラ内のスレッド管理を示す典型的な全体図である。
【図13】典型的な保留待ち行列構造を示す図である。
【図14】典型的な保留待ち行列スキップリストを示す図である。
【図15】典型的なタイマ待ち行列を示す図である。
【図16】2つの処理ソースでの典型的な作動可能待ち行列構造を示す図である。
【図17】典型的な単一ディスパッチ待ち行列構造の例示的実施形態を示す図である。
【図18】スレッドバンドリングを含む、2層スケジューリング階層を示す図である。
【図19】通信システムにおいて一般に見られる簡略化された待ち行列構造の一例を示す図である。
【特許請求の範囲】
【請求項1】
複数のプロセッサ要素を含むマルチコアプロセッサにおける外部割り込みを扱う方法であって、
マルチコアプロセッサの初期の待ち行列であって、実行のためのイベントの発生を待っているスレッドを示す前記初期の待ち行列内に割り込みサービススレッドを構成するステップと、
マルチコアプロセッサのコントローラにおいて、マルチコアプロセッサ外部から外部割り込みを受信するステップと、
受信された前記外部割り込みに応じて、複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるステップであって、前記割り込みサービススレッドを前記初期の待ち行列から前記割り当てられたプロセッサ要素のディスパッチ待ち行列に移動させることにより前記割り込みサービススレッドを割り当てる該ステップと、
を含む方法。
【請求項2】
前記初期の待ち行列は、保留待ち行列であり、
前記受信された前記外部割り込みに応じて、複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるステップは、マルチコアプロセッサのコントローラにおいて同期プリミティブを作成することを含む、
請求項1に記載の方法。
【請求項3】
前記初期の待ち行列は、タイマ待ち行列であり、
前記割り込みサービススレッドを構成するステップは、受信された外部割り込みに応じて発生し、
前記複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるステップは、前記割り込みサービススレッドを構成するステップの後の特定の時に発生する、
請求項1に記載の方法。
【請求項4】
前記マルチコアプロセッサの前記初期の待ち行列にさらなるスレッドを構成するステップと、
受信されたいずれの外部割り込みから独立に、複数のプロセッサ要素のうちの一つに前記さらなるスレッドを割り当てるステップであって、前記さらなるスレッドを前記初期の待ち行列から前記割り当てられたプロセッサ要素のディスパッチ待ち行列に移動させることにより前記さらなるスレッドを割り当てる該ステップと、を更に含む、
請求項1〜3のいずれか1項に記載の方法。
【請求項5】
前記受信された外部割り込みは、システム割り込みである、請求項1〜4のいずれか1項に記載の方法。
【請求項6】
複数のスケジューリング規則に基づき、ディスパッチ待ち行列のいずれのスレッドのプロセッサ要素による実行のタイミング及び実行の順序のうちのいずれか、または両方をスケジュールするステップと、をさらに含む、
請求項1〜5のいずれか1項に記載の方法。
【請求項7】
前記スケジュールするステップは、ディスパッチ待ち行列内の他のスレッドと比較して、割り込みサービススレッドの実行に優先順位をつけることを含む、
請求項6に記載の方法。
【請求項8】
前記コントローラは、複数のプロセッサ要素のうちの一つに割り込みサービススレッドを割り当てるステップを実行する割り込みマネージャを含む、
請求項1〜7のいずれか1項に記載の方法。
【請求項9】
前記コントローラは、前記初期の待ち行列及び前記ディスパッチ待ち行列を維持するトランザクションマネージャを更に含み、
前記割り込みマネージャは、受信された、前記マルチコアプロセッサ内で用いられる第1のフォーマットの外部割り込みを、前記第1のフォーマットとは異なる第2のフォーマットの割り込みサービススレッドに変換し、
前記第2のフォーマットは、前記トランザクションマネージャが理解可能である、
請求項8に記載の方法。
【請求項10】
前記複数のプロセッサ要素の各々は、それぞれに対応付けられたディスパッチ待ち行列を有し、
前記受信された外部割り込みに応じて前記割り込みサービススレッドを複数のプロセッサ要素のうちの一つに割り当てるステップは、
前記割り込みサービススレッドを、前記初期の待ち行列から作動可能待ち行列に移動させ、前記作動可能待ち行列から前記割り当てられたプロセッサ要素の前記ディスパッチ待ち行列に移動させ、
前記作動可能待ち行列は、前記割り込みサービススレッドが割り当てられたディスパッチ待ち行列を判定する、ことを含む、
請求項1〜9のいずれか1項に記載の方法。
【請求項11】
前記マルチコアプロセッサの前記プロセッサ要素のうちの少なくとも一つは、マスタ処理装置であり、
前記コントローラは、前記マスタ処理装置を含む前記プロセッサ要素の各々と通信し、事前定義された割り振りパラメータに従って個々のプロセッサ要素に前記マルチコアプロセッサ内のスレッドを割り当てる制御論理を含む、
請求項1〜10のいずれか1項に記載の方法。
【請求項12】
スレッドを処理するためのリソースを提供する、複数の相互接続されたプロセッサ要素を有するマルチコアプロセッサにインストールすることを目的とするリソース管理/タスク割り振りコントローラであって、
実行のためのイベントの発生を待っているスレッドを示す初期の待ち行列と、
前記マルチコアプロセッサ外部からの外部割り込みを受信するように構成された入力と、
1または複数の前記相互接続されたプロセッサ要素のためのディスパッチ待ち行列と、を含み、
前記コントローラは、
前記初期の待ち行列内の割り込みサービススレッドを構成し、
外部割り込みの受信に応じて、前記割り込みサービススレッドを前記初期の待ち行列から前記ディスパッチ待ち行列に移動させることにより、複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるように調整されている、
コントローラ。
【請求項13】
前記初期の待ち行列は、保留待ち行列であり、
前記コントローラは、同期プリミティブを作成することにより複数の前記プロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるように調整されている、
請求項12に記載のコントローラ。
【請求項14】
前記初期の待ち行列は、タイマ待ち行列であり、
前記コントローラは、
前記外部割り込みの受信に応じて前記割り込みサービススレッドを構成するように調整されており、
さらに、前記割り込みサービススレッドの構成の後の特定の時に、前記複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるように調整されている、
請求項12に記載のコントローラ。
【請求項15】
前記コントローラは、
前記初期の待ち行列にさらなるスレッドを構成し、受信されたいずれの外部割り込みから独立に、複数のプロセッサ要素のうちの一つに前記さらなるスレッドを割り当てるように調整されており、
前記スレッドは、前記さらなるスレッドを前記初期の待ち行列から前記割り当てられたプロセッサ要素のディスパッチ待ち行列に移動させることにより割り当てられる、
請求項12〜14のいずれか1項に記載のコントローラ。
【請求項16】
前記受信された外部割り込みは、システム割り込みである、請求項12〜15のいずれか1項に記載のコントローラ。
【請求項17】
前記コントローラは、
複数のスケジューリング規則に基づき、ディスパッチ待ち行列のいずれのスレッドのプロセッサ要素による実行のタイミング及び実行の順序のうちのいずれか、または両方をスケジュールするように更に調整されている、
請求項12〜16のいずれか1項に記載のコントローラ。
【請求項18】
前記コントローラは、
ディスパッチ待ち行列内の他のスレッドと比較して、割り込みサービススレッドの実行に優先順位をつけることによりスケジュールするように構成されている、
請求項17に記載のコントローラ。
【請求項19】
複数のプロセッサ要素のうちの一つに割り込みサービススレッドを割り当てるように調整された割り込みマネージャを更に含む、
請求項12〜18のいずれか1項に記載のコントローラ。
【請求項20】
前記コントローラは、前記初期の待ち行列及び前記ディスパッチ待ち行列を維持するように調整されたトランザクションマネージャを更に含み、
前記割り込みマネージャは、受信された、前記マルチコアプロセッサ内で用いられる第1のフォーマットの外部割り込みを、前記第1のフォーマットとは異なる第2のフォーマットの割り込みサービススレッドに変換するように構成されており、
前記第2のフォーマットは、前記トランザクションマネージャにより理解可能である、
請求項18に記載のコントローラ。
【請求項21】
前記複数のプロセッサ要素の各々は、それぞれに対応付けられたディスパッチ待ち行列を有し、
前記コントローラは、前記初期の待ち行列からスレッドを受信し、前記割り込みサービススレッドが割り当てられたディスパッチ待ち行列を判定するように調整された作動可能待ち行列を更に含み、
前記コントローラは、前記受信された外部割り込みに応じて前記割り込みサービススレッドを複数のプロセッサ要素のうちの一つに割り当てるように調整されており、
前記割り込みサービススレッドの割り当ては、前記割り込みサービススレッドを、前記初期の待ち行列から作動可能待ち行列に移動させ、前記作動可能待ち行列から前記割り当てられたプロセッサ要素の前記ディスパッチ待ち行列に移動させることにより行われる、
請求項12〜20のいずれか1項に記載のコントローラ。
【請求項22】
前記マルチコアプロセッサの前記プロセッサ要素のうちの少なくとも一つは、マスタ処理装置であり、
前記コントローラは、前記マスタ処理装置を含む前記プロセッサ要素の各々と通信するようにさらに調整されており、
前記コントローラは、事前定義された割り振りパラメータに従って個々のプロセッサ要素に前記マルチコアプロセッサ内のスレッドを割り当てる制御論理を更に含む、
請求項12〜22のいずれか1項に記載のコントローラ。
【請求項23】
複数のプロセッサ要素を含むマルチコアプロセッサアーキテクチャにおけるスレッドの処理を制御するコントローラであって、実行するスレッドは、前記コントローラのスレッド入力マネージャを介して受信され、受信されたスレッドは、前記コントローラのスレッド出力マネージャを介して複数のプロセッサ要素のうちの一つに割り当てられる該コントローラであって、
各スレッドが前記スレッド出力マネージャを介して割り当てられる場合に、少なくとも一つの他のスレッドの実行時におけるスレッドそれぞれの依存の要求により、制御するように構成されたスレッド同期マネージャと、
前記スレッド出力マネージャを介して割り当てられたスレッドの実行の順序を、各スレッドの優先度に基づき判定するように構成されたスレッドスケジュールマネージャと、をさらに含む、
コントローラ。
【請求項1】
複数のプロセッサ要素を含むマルチコアプロセッサにおける外部割り込みを扱う方法であって、
マルチコアプロセッサの初期の待ち行列であって、実行のためのイベントの発生を待っているスレッドを示す前記初期の待ち行列内に割り込みサービススレッドを構成するステップと、
マルチコアプロセッサのコントローラにおいて、マルチコアプロセッサ外部から外部割り込みを受信するステップと、
受信された前記外部割り込みに応じて、複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるステップであって、前記割り込みサービススレッドを前記初期の待ち行列から前記割り当てられたプロセッサ要素のディスパッチ待ち行列に移動させることにより前記割り込みサービススレッドを割り当てる該ステップと、
を含む方法。
【請求項2】
前記初期の待ち行列は、保留待ち行列であり、
前記受信された前記外部割り込みに応じて、複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるステップは、マルチコアプロセッサのコントローラにおいて同期プリミティブを作成することを含む、
請求項1に記載の方法。
【請求項3】
前記初期の待ち行列は、タイマ待ち行列であり、
前記割り込みサービススレッドを構成するステップは、受信された外部割り込みに応じて発生し、
前記複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるステップは、前記割り込みサービススレッドを構成するステップの後の特定の時に発生する、
請求項1に記載の方法。
【請求項4】
前記マルチコアプロセッサの前記初期の待ち行列にさらなるスレッドを構成するステップと、
受信されたいずれの外部割り込みから独立に、複数のプロセッサ要素のうちの一つに前記さらなるスレッドを割り当てるステップであって、前記さらなるスレッドを前記初期の待ち行列から前記割り当てられたプロセッサ要素のディスパッチ待ち行列に移動させることにより前記さらなるスレッドを割り当てる該ステップと、を更に含む、
請求項1〜3のいずれか1項に記載の方法。
【請求項5】
前記受信された外部割り込みは、システム割り込みである、請求項1〜4のいずれか1項に記載の方法。
【請求項6】
複数のスケジューリング規則に基づき、ディスパッチ待ち行列のいずれのスレッドのプロセッサ要素による実行のタイミング及び実行の順序のうちのいずれか、または両方をスケジュールするステップと、をさらに含む、
請求項1〜5のいずれか1項に記載の方法。
【請求項7】
前記スケジュールするステップは、ディスパッチ待ち行列内の他のスレッドと比較して、割り込みサービススレッドの実行に優先順位をつけることを含む、
請求項6に記載の方法。
【請求項8】
前記コントローラは、複数のプロセッサ要素のうちの一つに割り込みサービススレッドを割り当てるステップを実行する割り込みマネージャを含む、
請求項1〜7のいずれか1項に記載の方法。
【請求項9】
前記コントローラは、前記初期の待ち行列及び前記ディスパッチ待ち行列を維持するトランザクションマネージャを更に含み、
前記割り込みマネージャは、受信された、前記マルチコアプロセッサ内で用いられる第1のフォーマットの外部割り込みを、前記第1のフォーマットとは異なる第2のフォーマットの割り込みサービススレッドに変換し、
前記第2のフォーマットは、前記トランザクションマネージャが理解可能である、
請求項8に記載の方法。
【請求項10】
前記複数のプロセッサ要素の各々は、それぞれに対応付けられたディスパッチ待ち行列を有し、
前記受信された外部割り込みに応じて前記割り込みサービススレッドを複数のプロセッサ要素のうちの一つに割り当てるステップは、
前記割り込みサービススレッドを、前記初期の待ち行列から作動可能待ち行列に移動させ、前記作動可能待ち行列から前記割り当てられたプロセッサ要素の前記ディスパッチ待ち行列に移動させ、
前記作動可能待ち行列は、前記割り込みサービススレッドが割り当てられたディスパッチ待ち行列を判定する、ことを含む、
請求項1〜9のいずれか1項に記載の方法。
【請求項11】
前記マルチコアプロセッサの前記プロセッサ要素のうちの少なくとも一つは、マスタ処理装置であり、
前記コントローラは、前記マスタ処理装置を含む前記プロセッサ要素の各々と通信し、事前定義された割り振りパラメータに従って個々のプロセッサ要素に前記マルチコアプロセッサ内のスレッドを割り当てる制御論理を含む、
請求項1〜10のいずれか1項に記載の方法。
【請求項12】
スレッドを処理するためのリソースを提供する、複数の相互接続されたプロセッサ要素を有するマルチコアプロセッサにインストールすることを目的とするリソース管理/タスク割り振りコントローラであって、
実行のためのイベントの発生を待っているスレッドを示す初期の待ち行列と、
前記マルチコアプロセッサ外部からの外部割り込みを受信するように構成された入力と、
1または複数の前記相互接続されたプロセッサ要素のためのディスパッチ待ち行列と、を含み、
前記コントローラは、
前記初期の待ち行列内の割り込みサービススレッドを構成し、
外部割り込みの受信に応じて、前記割り込みサービススレッドを前記初期の待ち行列から前記ディスパッチ待ち行列に移動させることにより、複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるように調整されている、
コントローラ。
【請求項13】
前記初期の待ち行列は、保留待ち行列であり、
前記コントローラは、同期プリミティブを作成することにより複数の前記プロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるように調整されている、
請求項12に記載のコントローラ。
【請求項14】
前記初期の待ち行列は、タイマ待ち行列であり、
前記コントローラは、
前記外部割り込みの受信に応じて前記割り込みサービススレッドを構成するように調整されており、
さらに、前記割り込みサービススレッドの構成の後の特定の時に、前記複数のプロセッサ要素のうちの一つに前記割り込みサービススレッドを割り当てるように調整されている、
請求項12に記載のコントローラ。
【請求項15】
前記コントローラは、
前記初期の待ち行列にさらなるスレッドを構成し、受信されたいずれの外部割り込みから独立に、複数のプロセッサ要素のうちの一つに前記さらなるスレッドを割り当てるように調整されており、
前記スレッドは、前記さらなるスレッドを前記初期の待ち行列から前記割り当てられたプロセッサ要素のディスパッチ待ち行列に移動させることにより割り当てられる、
請求項12〜14のいずれか1項に記載のコントローラ。
【請求項16】
前記受信された外部割り込みは、システム割り込みである、請求項12〜15のいずれか1項に記載のコントローラ。
【請求項17】
前記コントローラは、
複数のスケジューリング規則に基づき、ディスパッチ待ち行列のいずれのスレッドのプロセッサ要素による実行のタイミング及び実行の順序のうちのいずれか、または両方をスケジュールするように更に調整されている、
請求項12〜16のいずれか1項に記載のコントローラ。
【請求項18】
前記コントローラは、
ディスパッチ待ち行列内の他のスレッドと比較して、割り込みサービススレッドの実行に優先順位をつけることによりスケジュールするように構成されている、
請求項17に記載のコントローラ。
【請求項19】
複数のプロセッサ要素のうちの一つに割り込みサービススレッドを割り当てるように調整された割り込みマネージャを更に含む、
請求項12〜18のいずれか1項に記載のコントローラ。
【請求項20】
前記コントローラは、前記初期の待ち行列及び前記ディスパッチ待ち行列を維持するように調整されたトランザクションマネージャを更に含み、
前記割り込みマネージャは、受信された、前記マルチコアプロセッサ内で用いられる第1のフォーマットの外部割り込みを、前記第1のフォーマットとは異なる第2のフォーマットの割り込みサービススレッドに変換するように構成されており、
前記第2のフォーマットは、前記トランザクションマネージャにより理解可能である、
請求項18に記載のコントローラ。
【請求項21】
前記複数のプロセッサ要素の各々は、それぞれに対応付けられたディスパッチ待ち行列を有し、
前記コントローラは、前記初期の待ち行列からスレッドを受信し、前記割り込みサービススレッドが割り当てられたディスパッチ待ち行列を判定するように調整された作動可能待ち行列を更に含み、
前記コントローラは、前記受信された外部割り込みに応じて前記割り込みサービススレッドを複数のプロセッサ要素のうちの一つに割り当てるように調整されており、
前記割り込みサービススレッドの割り当ては、前記割り込みサービススレッドを、前記初期の待ち行列から作動可能待ち行列に移動させ、前記作動可能待ち行列から前記割り当てられたプロセッサ要素の前記ディスパッチ待ち行列に移動させることにより行われる、
請求項12〜20のいずれか1項に記載のコントローラ。
【請求項22】
前記マルチコアプロセッサの前記プロセッサ要素のうちの少なくとも一つは、マスタ処理装置であり、
前記コントローラは、前記マスタ処理装置を含む前記プロセッサ要素の各々と通信するようにさらに調整されており、
前記コントローラは、事前定義された割り振りパラメータに従って個々のプロセッサ要素に前記マルチコアプロセッサ内のスレッドを割り当てる制御論理を更に含む、
請求項12〜22のいずれか1項に記載のコントローラ。
【請求項23】
複数のプロセッサ要素を含むマルチコアプロセッサアーキテクチャにおけるスレッドの処理を制御するコントローラであって、実行するスレッドは、前記コントローラのスレッド入力マネージャを介して受信され、受信されたスレッドは、前記コントローラのスレッド出力マネージャを介して複数のプロセッサ要素のうちの一つに割り当てられる該コントローラであって、
各スレッドが前記スレッド出力マネージャを介して割り当てられる場合に、少なくとも一つの他のスレッドの実行時におけるスレッドそれぞれの依存の要求により、制御するように構成されたスレッド同期マネージャと、
前記スレッド出力マネージャを介して割り当てられたスレッドの実行の順序を、各スレッドの優先度に基づき判定するように構成されたスレッドスケジュールマネージャと、をさらに含む、
コントローラ。
【図1】


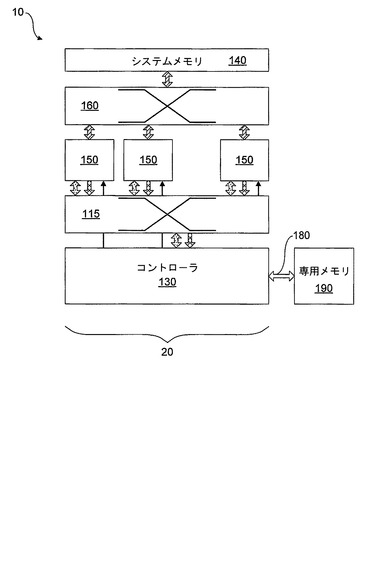
【図2】
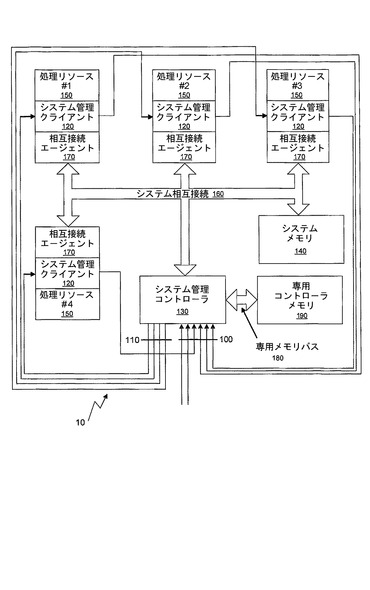
【図3】
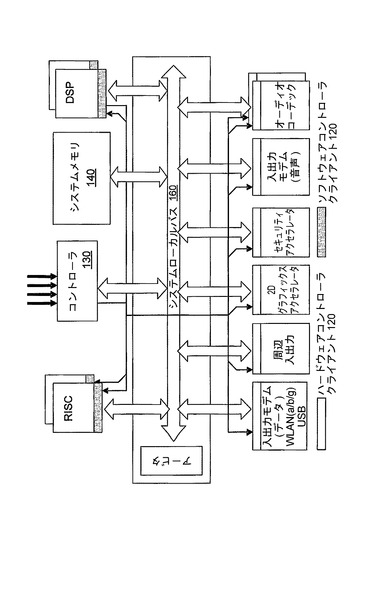
【図4】
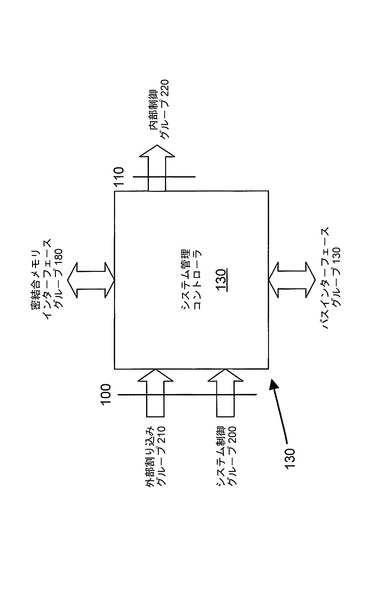
【図5】
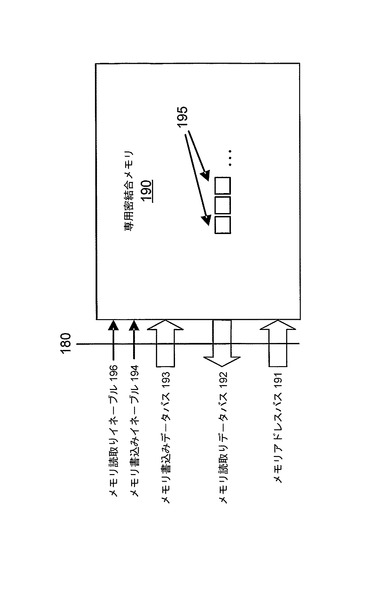
【図6】
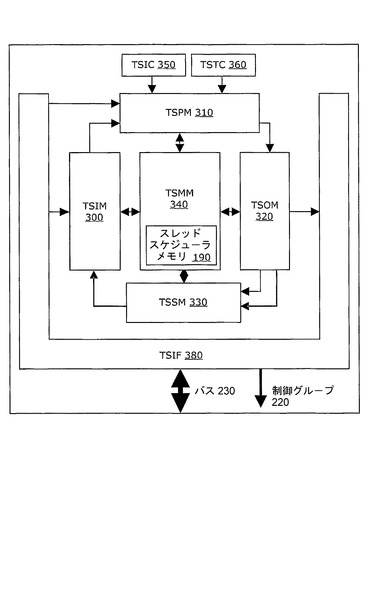
【図7】
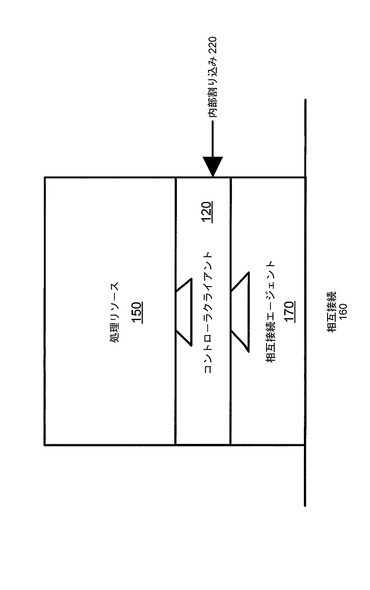
【図7b】
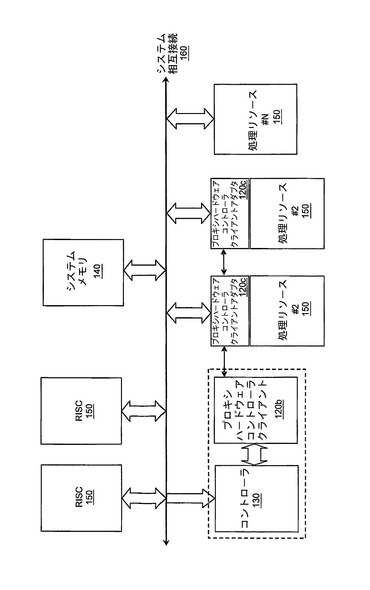
【図8】
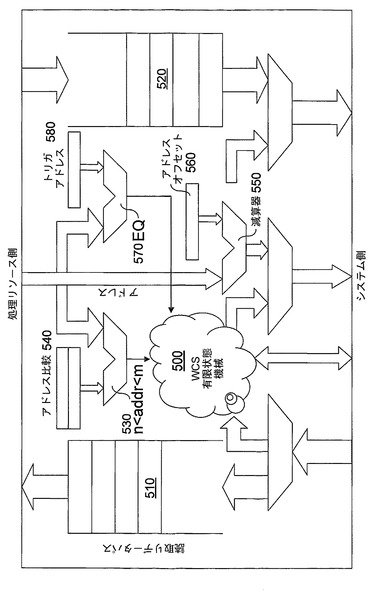
【図9a】
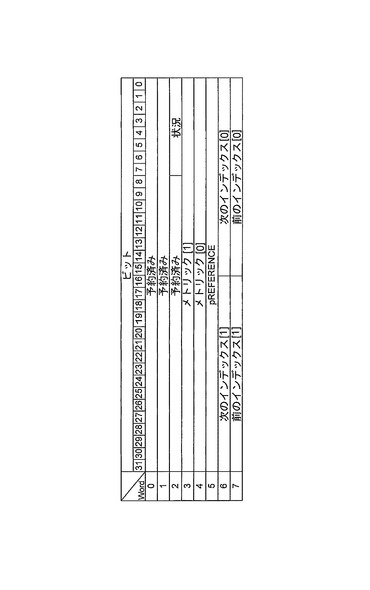
【図9b】

【図9c】
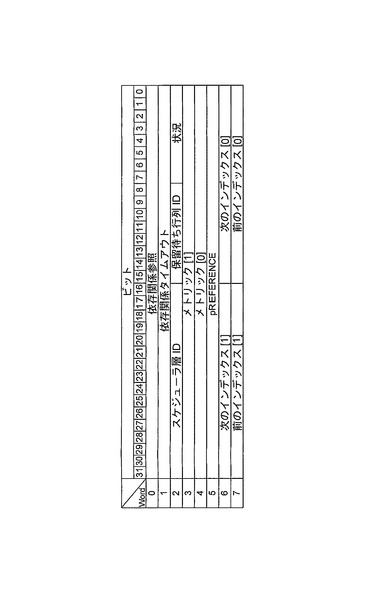
【図9d】

【図9e】
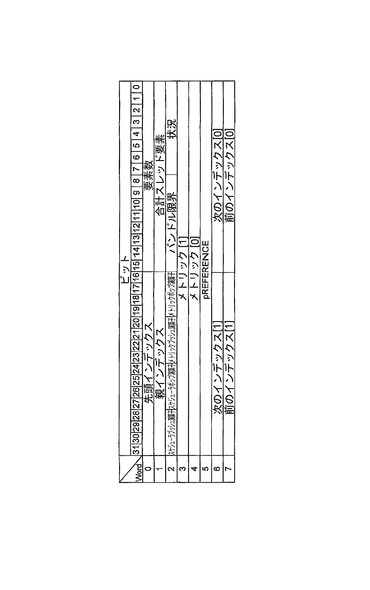
【図9f】

【図9g】
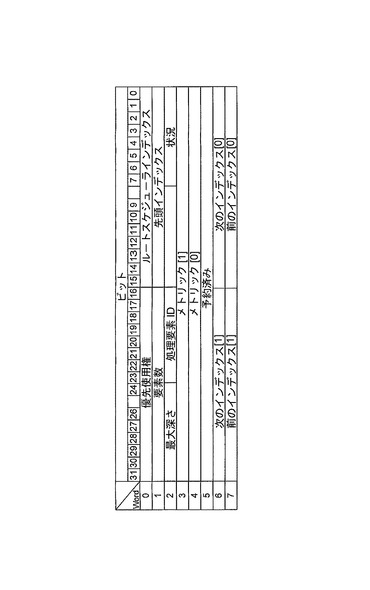
【図9h】
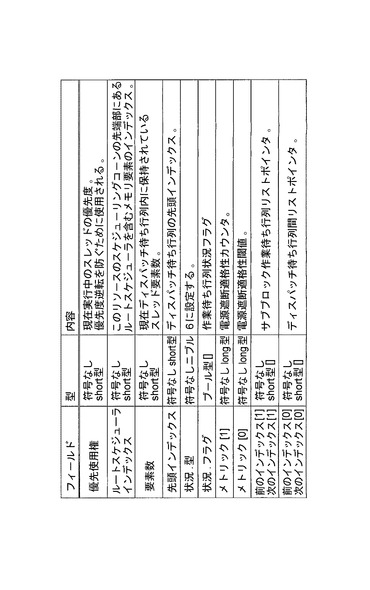
【図9i】
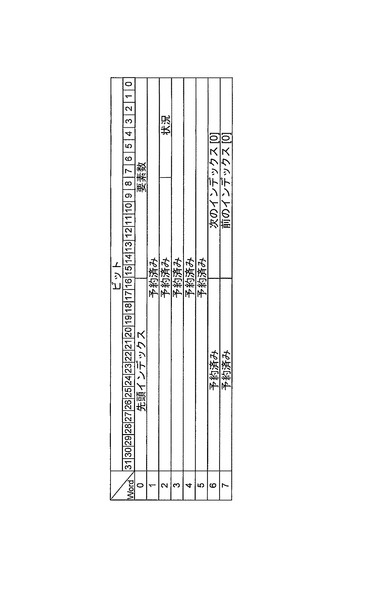
【図9j】
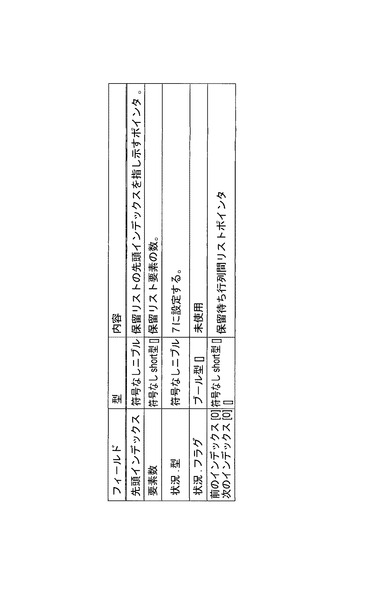
【図9k】
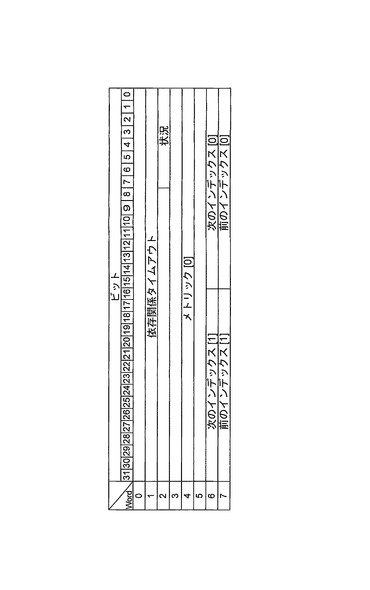
【図9l】
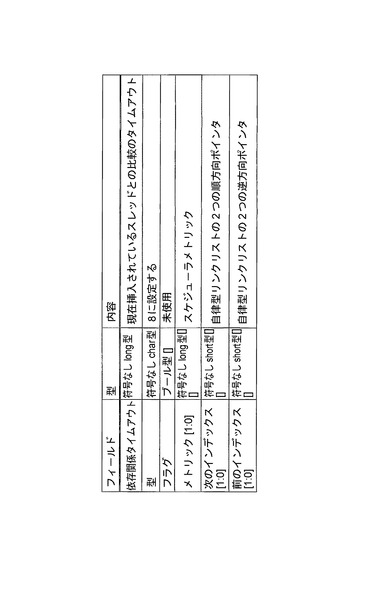
【図10】
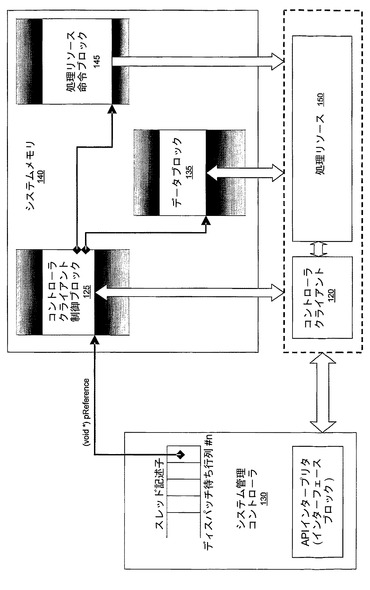
【図11】
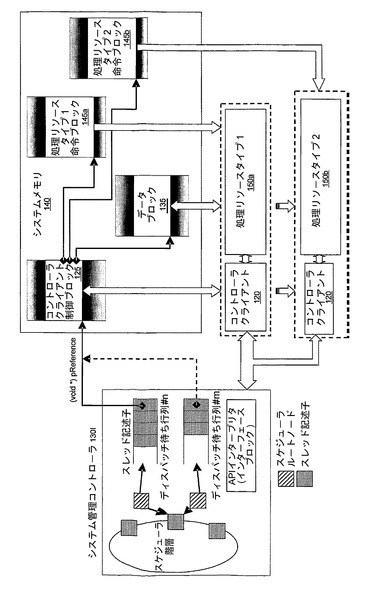
【図12】
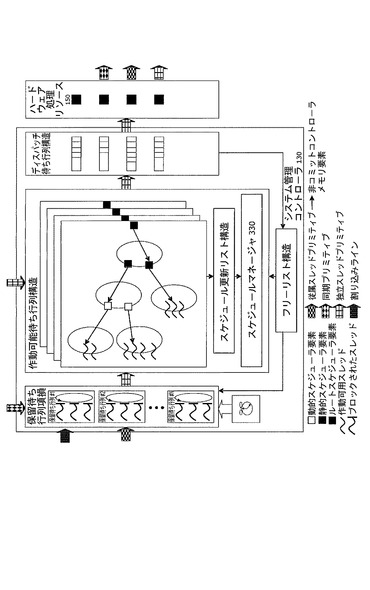
【図13】
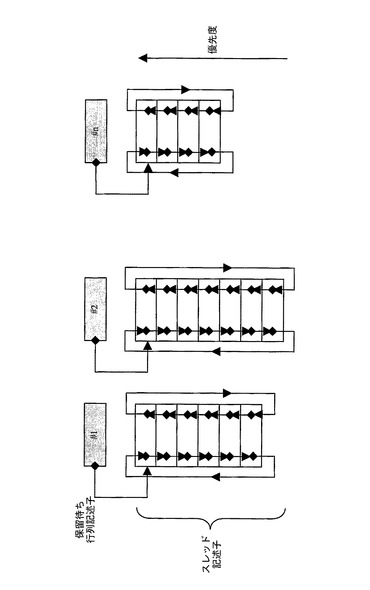
【図14】
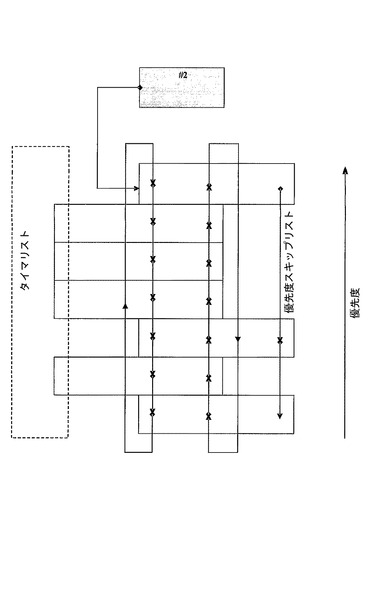
【図15】
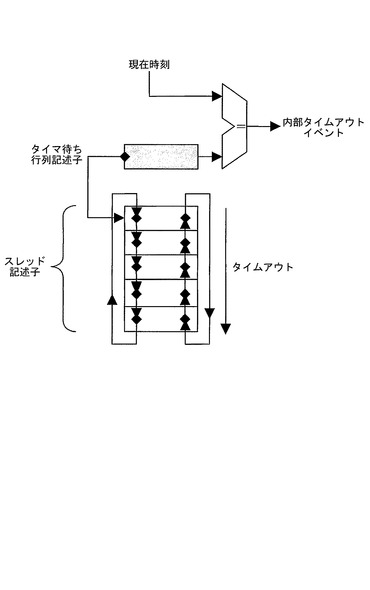
【図16】

【図17】
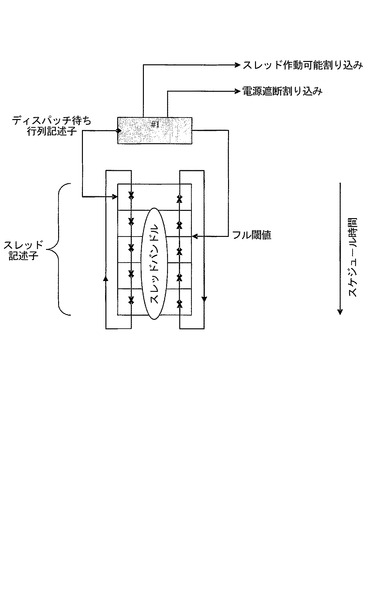
【図18】
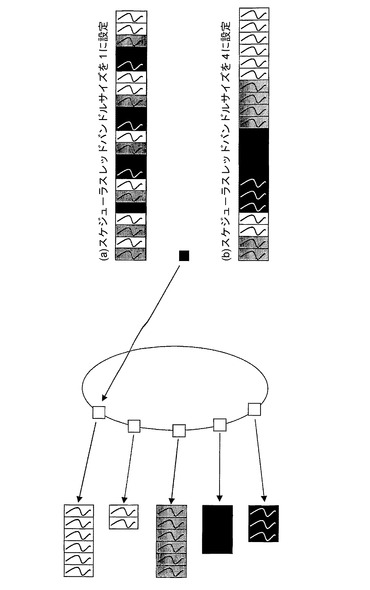
【図19】
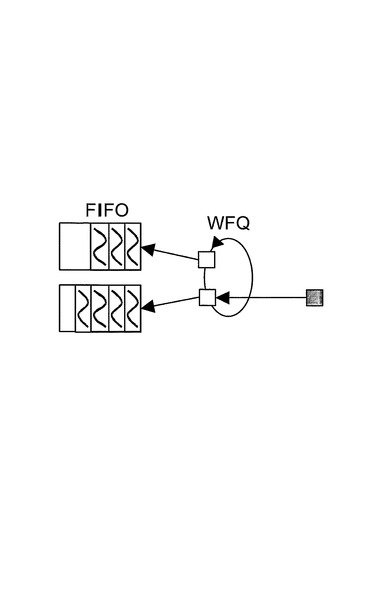
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図7b】
【図8】
【図9a】
【図9b】
【図9c】
【図9d】
【図9e】
【図9f】
【図9g】
【図9h】
【図9i】
【図9j】
【図9k】
【図9l】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【公開番号】特開2013−61947(P2013−61947A)
【公開日】平成25年4月4日(2013.4.4)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−221414(P2012−221414)
【出願日】平成24年10月3日(2012.10.3)
【分割の表示】特願2007−505624(P2007−505624)の分割
【原出願日】平成17年3月30日(2005.3.30)
【出願人】(597035274)シノプシス, インコーポレイテッド (33)
【氏名又は名称原語表記】SYN0PSYS, INC.
【出願人】(308014341)富士通セミコンダクター株式会社 (2,507)
【公開日】平成25年4月4日(2013.4.4)
【国際特許分類】
【出願番号】特願2012−221414(P2012−221414)
【出願日】平成24年10月3日(2012.10.3)
【分割の表示】特願2007−505624(P2007−505624)の分割
【原出願日】平成17年3月30日(2005.3.30)
【出願人】(597035274)シノプシス, インコーポレイテッド (33)
【氏名又は名称原語表記】SYN0PSYS, INC.
【出願人】(308014341)富士通セミコンダクター株式会社 (2,507)
[ Back to top ]