
メタボロームデータの解析方法および代謝関与マーカー
【課題】多数のメタボロームデータを同時に解析してデータマイニングを行う手段を提供する。
【解決手段】代謝物のMS解析(蛋白質の質量分析)から得られるMSピークのデータを用いて機械学習法に適用する。詳しくは、複数の決定木の解から多数決を採択するランダム森を用いてメタボロームデータのマイニング方法およびそれらを実現する装置。
【解決手段】代謝物のMS解析(蛋白質の質量分析)から得られるMSピークのデータを用いて機械学習法に適用する。詳しくは、複数の決定木の解から多数決を採択するランダム森を用いてメタボロームデータのマイニング方法およびそれらを実現する装置。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、代謝全体像(以下、メタボローム)の全体像内から得られる情報(メタボロームデータ)の解析、またはマーカー候補となり得る低分子化合物の取得等におけるメタボロームデータのマイニング方法およびそれらを実現する装置に関する。
【背景技術】
【0002】
メタボロームは、新陳代謝、細胞、組織、器官、個体、種等でそれぞれに異なる代謝経路の多様性の総体に関し、バイオインフォマティクスの手法を基に研究されている分子生物学である。
メタボロームは蛋白質、RNA、DNA等の概念も含み、半経験的帰属を形成する回路から構成される代謝経路から産生される代謝物を解析することによって、創薬等に有用な代謝経路の探索または、生態の生理的変化を指標する化合物(以下、マーカー)を見出すことに応用されている。
メタボロームデータを解析することで代謝機能を明らかにし、創薬、薬理学、毒性学、診断に供する知見を得るための研究がなされている。例えば、主成分分析(PCA)および部分最小自乗法(PLS)などの統計解析を用い、取得したスコアの座標配置による群分けを行い、ローディングプロットによる化合物を同定してマーカーを選別する等メタボロームデータのマイニングを実施した例がある(非特許文献1)。
【0003】
【非特許文献1】J Pharm Biomed Anal. 2005 Jul 1;38(3):465-71.
【発明の開示】
【発明が解決しようとする課題】
【0004】
しかしながら、多数のメタボロームデータを同時に解析してデータマイニングを行う手段については、いまだに確立されたとはいえない状況である。例えばPCAおよびPLSでは、固有値計算による次元の集約、スコアの取得および座標配置のプロファイリングによる群分けおよび、ローディングプロットによってマーカーを選別する等多数の工程を経るため、多くの時間を費やしている。
また、PCAでは、主成分の寄与が分散すると判定が困難なること、主成分軸の選択に解析者の主観が必要であることから解析者の知識に依存することが大きかったため、一連の作業の完全自動化は困難であった。
【課題を解決するための手段】
【0005】
本発明の目的は、メタボロームデータによるプロファイルのセットを解析するための方法および装置を提供することである。更に詳しくは、MS(蛋白質の質量分析方法)から得られたデータを、統計的解析手段を用いてメタボロームデータのプロファイルのセットから、創薬、薬理学、毒性学、診断に有用なマーカー群の抽出およびそれら有用マーカー群に共通する規則を抽出し、データマイニングする方法を提供することである。
本発明者らは、一連の作業の自動化、解析者の主観に依存されない一意な結果の取得による正確なプロファイリングによるデータマイニング、前記データマイニングによって同定されたマーカの選抜等を目的に、従来とは異なる工程を検討した結果、代謝物のMS解析(蛋白質の質量分析)から得られるMSピークのデータを用いて機械学習法に適用する解析方法を見出した。
特に、創薬、または病気の診断に直接結びつくマーカーの選抜については、正確なプロファイリングが必要であることから、機械学習方法の中から複数の決定木の解から多数決を採択するランダム森(「ランダム・フォーレスト(RandomForest(登録商標))」以下、RF)を用いてメタボロームデータのマイニング方法およびそれらを実現する装置を完成した。
即ち本発明は、
〔1〕下記(1)〜(8)の工程を含むメタボロームの解析方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得する工程、
(2)前記マススペクトルの出現情報および、化合物情報を入力する工程、
(3)前記(2)で入力した情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する工程;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する工程
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する工程、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する工程
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する工程
〔2〕前記1に記載された方法をコンピュータに実行させることを特徴とするコンピュータ読み取り可能なプログラム。
〔3〕前記2に記載されたコンピュータ読み取り可能なプログラムを格納した電子媒体。
〔4〕下記(1)〜(8)の装置を含むメタボロームの解析システム;
(1)代謝物をMS解析して得られたマススペクトルの出現情報および、化合物情報を入力する装置、
(2)前記マススペクトルの出現情報および、化合物情報を入力する装置、
(3)前記(2)で入力した情報から分子量(m/z)、イオンの検出強度、化合物情報をを数値化したデータのいずれか一つ以上を取得する装置
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する装置;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する装置
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する装置、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する装置
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する装置
(10)前記(4)〜(7)の何れかの装置で行った解析結果を記録する装置
(11)前記(7)の装置で記録した結果を出力する装置
【発明の効果】
【0006】
本発明により、一連の作業を自動化することが可能になり、メタボロームデータのデータマイニングにおいて、解析者の主観に左右されない一意な解析結果を提供することで、正確なメタボロームデータのプロファイルのセットから、データマイニングすることが可能になった。
さらには、創薬、薬理学、毒性学、診断に有用なマーカー群の抽出およびそれら有用マーカー群に共通する規則を抽出することでマーカー選別の有用なスクリーニング方法となった。
【発明を実施するための最良の形態】
【0007】
以下に、本発明における請求項記載の語句の定義について説明する。
「メタボローム」とは、蛋白質、RNA、DNA等の概念も含み、新陳代謝、細胞、組織、器官、個体、種等でそれぞれに異なる代謝経路の多様性の総体に関し、バイオインフォマティクスの手法を基に研究されている分子生物学を指す。
「MS解析」とは蛋白質の質量分析を指し、分析する試料をイオン化させて導入し,電気力や磁気力により質量ごとの差をつくり、イオンの質量を分析することである。上記分析を行う装置である質量分析計を含め以下MSと略す。MSには、イオントラップ型MS、フーリエ変換イオンサイクロトロン共鳴質量分析(FT-ICR/MS)、イオンスキャン法、 Q-TOF型MSなどが挙げられる。これらは、1方法だけで分析しても複数のMSを連結させて分析(以下MS/MS解析)させても良い。
また、前記MS解析結果に基づいてタンパク質を同定することも含む、蛋白質を同定とは、MSデータから分子量が合致するペプチドフラグメントの候補の検出、さらに前記フラグメントからペプチド全体を予測する解析することで、同定するソフトウエアが市販されている。例えば、Mascot、Sonar MS/MS等が挙げられる。
「マススペクトル」は、蛋白質の質量分析の結果得られる、横軸に質量(m/z 値)、縦軸に検出強度をとったスペクトルを指す。
「化合物情報」とは、化合物の物性を表す数値等を指し、例えば構造式を記述化した情報、薬物情報等があげられ、例えば化合物に対する薬理活性の有無や強度、Biological TestingからLaunchedに至るまでの開発ステージ情報などが含まれる。例えば、MDL社のMDDR(MDL Drug Data Report)、NCBIのPubChem等が挙げられる。
また、化合物には蛋白質のアミノ酸情報も含む。アミノ酸情報とは例えば、配列、機能、立体構造などが含まれる。配列、機能については、既知情報、バイオインフォマティクスから推定された情報、複数種類のアノテーション情報、プロテオームの解析情報、体系的な機能分類を指向したオントロジー情報等が挙げられる。
立体構造については、既知情報として、公共のデータベースとしてPDB(Protein Data Bank)、ホモロジーモデリングにより構築された商用もしくはインハウスのデータベース等が挙げられる。商用のホモロジーモデリングデータベースには、SGI社から販売されているFAMSBASE等が挙げられる。
物性には、例えば、構造式を記述化した情報、薬物活性情報、または疾患との関係を示すマーカー情報等を用いることができる。
「バイオマーカー」とは、生体が生理的変化等を生じた際に分泌される核酸、蛋白質、低分子の有機化合物などを指す。本発明においては特に代謝に関与する化合物を指す。
「分類条件」とは、代謝物をサンプリングする検体、MSピークの測定値による任意の規準等が挙げられる。前述の代謝物をサンプリングする検体とは、薬物投与等の医療処置等の有無、遺伝性疾患の有無、アレルギーの有無または、外傷等の刺激等を与えた検体等が挙げられる。
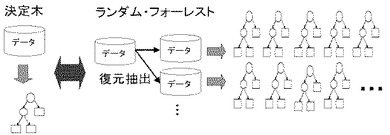
本発明の「ランダム森」とは決定木(CART法など)を下位学習アルゴリズムに持つアンサンブル学習アルゴリズムである(図1)。ランダム森を実行するためのソフトウエアは、市販のランダム・フォーレスト(RandomForest(登録商標))、http://cran.r-project.org/から入手できるフリーソフトウェア等がある。
教師つき学習の場合は説明変数のランダムサンプリングも行いながら、CARTとbaggingを組み合わせる。教師なし学習の場合はクラスラベルがないので、データのランダムサンプリングから擬似的に別クラスのデータを生成した後、教師つき学習と同様のアルゴリズムに帰着させる。この場合、潜在的なクラスを発見することが可能であり、複数の情報から1つのマーカー等目的の化合物に割り当てた場合の考察に有用な情報を与えることが期待できる。
【0008】
前記の教師付き学習とは、入出力データが与えられているが、それらを近似する関数が分からない時に、データから関数のパラメータを推定することをいう。学習とは、学習機⇒学習器のパラメータを適当な学習則を用いることで、変化させることを示し、本発明でいう学習器とは「ランダム・フォーレスト」を指すが、一般的には入出力関係を持ったもので、ニューラル・ネットワーク(Neural Network) 、ラジアル・ベーシス・ファンクション・ネットワーク(Radial Basis Function Network)等、神経回路を模倣したもの或いはサポート・ベクター・マシン等、統計モデル全般を示す。
【0009】
本発明における代謝データベースとは、代謝経路、代謝に関与する化合物等に関するデータベースで主に、京都大学化学研究所が提供するKEGG 代謝データベースなどが挙げられる。
【0010】
本発明のシステムの大枠は、「検索」、「出力」、「閲覧」および「解析」に立て分け、「出力」、「閲覧」については既設環境をそのまま用いる。化合物リストの入出力機能をもち、化合物情報およびバイオ情報が関連付けられた形式で閲覧できるシステムがよく、例えば、クライアントサーバ型システム、Webベースのシステムなどが挙げられる。好ましくは、Webベースでの開発が挙げられる。
本発明のシステムは、複数のデータベースにアクセスして、入力リストを反映した形での表示や、出力対象を個別に指定することが可能である。プログラムの記述言語は、C、C++、JAVA(登録商標)、HTML、XML等が挙げられる。
Webベースにおける構造式の閲覧には、・・・・等(MDL社から無償で提供されている「Chime」等?)の既存プログラムを用いることが可能である。
本発明の第一の態様は、代謝に関与するバイオマーカー選抜方法に関する。
詳しくは、代謝物からMS解析によって得られたマススペクトルの出現情報および、公共の化合物データベースまたは自社の化合物データベースから得られた化合物の情報をコンピュータを用いて、ランダム森に適用し複数の決定木でのアンサンブルアルゴリズムでモデルを学習し、または、学習を行わずに直接クラス情報を取得して共通規則を導き出しそれに基づいた分類条件を用いて分子量(m/z)(以下、MSピークと称する)の値から代謝に関与する化合物の情報をデータマイニングしてマーカーとなりうる化合物を同定することである。
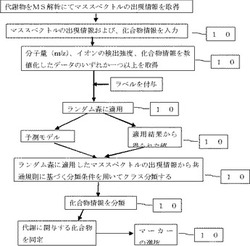
以下に、本発明の方法の手順を図1を参照して説明する。
【0011】
I. MS解析データのランダム森適用による分類解析
(1)代謝物をMS解析して取得したマススペクトルの出現情報、および、化合物情報を、本発明解析装置に入力する(101)。代謝物は、例えば、薬物を投与した検体(例えば、マウス、ラット等の哺乳類)の尿、血液、唾液等が挙げられる。
マススペクトルの出現情報には、分子量(m/z)、イオンの検出強度、前記分子量が検出されるために所有する時間等が挙げられる。化合物情報は、化合物の物性を表す数値等を指し、例えば構造式を記述化した情報、MS解析から得られたMSピーク等が挙げられる。
(2)前記(1)の工程で入力した情報から前記MSピーク、前記MSピークと相関する化合物情報を数値化したデータ、化合物情報を数値化したデータのいずれか一つ以上の値を得る(102)。
さらに、ランダム森に適用するために、前記101で入力した値から必要に応じてラベルを付与する。例えば、薬物投与群、非投与群を群分けの規準に用いた場合、対照群投与前=A、対照群投与=B、投薬群投与前=C、投薬群投与後=D等のアルファベットをラベルとして付与する。便宜上このラベル群をα群とする。
MS解析で得られたマススペクトルの出現情報にラベルを付与する。例えば各出現ピークにP1、P2、P3・・・Pnと連番等を付与する。このラベル群をβ群とする。
本発明で用いるラベルは文字、数字、記号、任意のコード等コンピュータで読み取り可能な記述子であればなんでも良い。
(3)前記(2)で取得した値をランダム森に適用する。ランダム森への適用は、教師なし学習と教師あり学習のどちらでもよい。具体的には、教師なし学習の場合は説明変数としてβ群のみを、教師あり学習の場合は説明変数をβ群そして教師データとしてα群を与えてランダム森を用いてブートストラップにより決定木を作成し、得られた結果の多数決で帰属させ、重要度の低い変数はドロップさせて取得した各クラス情報に基づいて共通規則を抽出し、さらに該規則に基づく分類条件を用いて分類する(103)。
(4)前記(3)のランダム森へ適用した分類結果を数値化した値(以下、スコア)に基づく分類条件を用いてクラス分類を取得し、多次元距離尺度表示しスコアの共通群を視覚的に表示する(104)
(8)上記1〜4の工程に従って電子計算機等の情報資源を用いて計算させる。
II.代謝に関与するマーカー化合物の検出
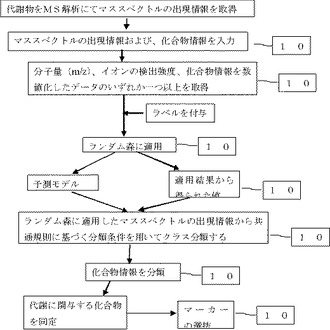
(1)代謝物からMS解析でMSピークを検出する。
(2)前記II−(1)で選抜されたMSピークに前記I−(2)記載のX群の情報をブラインドとして与え、ランダム森に適用し、前記(3)の方法で分類された分類条件で解析する(106)
(3)前記(2)で解析し、選抜されたMSピークの各クラス分類を取得し、多次元距離尺度表示しスコアの共通群を視覚的に表示する(105)
(4)さらに、前記I−(1)で得られたマススペクトルのピークを変数とし所属する群を与えて教師あり学習を行う
(4−1)学習結果から各変数(ピーク)の重要度を出力させる(106)
(4−2)上記(4−1)の工程を10回以上繰り返し平均をとる。本発明では100回繰り返して平均をとった。
(4−3)いずれかの群で重要度が75パーセンタイルより上にある変数(ピーク)を選抜する。
(4−4)代謝データベースを用いて代謝物として知られている化合物にヒットする 変数(ピーク)だけを選抜する。
(4−5)pearson距離計算により階層クラスタリングを行う。距離の計算手法は通常のeuclidデモ構わないが、pearsonやspearmanのほうが良好とされる。
(4−6)階層クラスタリングの結果から、マーカーの挙動を推定する。
(5) 次に、代謝経路に帰属させ、マーカーを探索する。代謝経路の帰属方法は半経験的方法または非経験的方法が挙げられる。手順を以下に示す。(107)
半経験的方法
1.は探索開始する化合物は間違いないとし、PCAのローディングと一致する化合物が代謝マップ上に化合物があれば当りとする。
2.隣接する代謝マップを再帰的に調査する。
非経験的方法
1.すべての可能性を考える
2.最も代謝経路が広範に及んだ化合物と代謝経路の組み合わせが最適解とする
(6)上記1〜4の工程に従って電子計算機等の情報資源を用いて計算させる。
本発明の第二の態様は、メタボロームの解析方法に関する。
詳しくは、代謝物からMS解析によって得られたマススペクトルの出現情報および、公共の化合物データベースまたは自社の化合物データベースから得られた化合物の情報をコンピュータを用いて、ランダム森に適用し複数の決定木でのアンサンブルアルゴリズムでモデルを学習し、または、学習を行わずに直接クラス情報を取得して共通規則を導き出しそれに基づいた分類条件を用いて分子量(m/z)(以下、MSピークと称する)の値から代謝に関与する化合物の情報をデータマイニングする方法である。
以下に、本発明の方法の手順を図1を参照して説明する。図2は、本発明の請求項1記載の発明の要旨を説明するための図である。
【0012】
MS解析データのランダム森適用による分類解析
(1)代謝物をMS解析して取得したマススペクトルの出現情報、および、化合物情報を、本発明解析装置に入力する(101)。代謝物は、例えば、薬物を投与した検体(例えば、マウス、ラット等の哺乳類)の尿、血液、唾液等が挙げられる。
マススペクトルの出現情報には、分子量(m/z)、イオンの検出強度、前記分子量が検出されるために所有する時間等が挙げられる。化合物情報は、化合物の物性を表す数値等を指し、例えば構造式を記述化した情報、MS解析から得られたMSピーク等が挙げられる。
(2)前記(1)の工程で入力した情報から前記MSピーク、前記MSピークと相関する化合物情報を数値化したデータ、化合物情報を数値化したデータのいずれか一つ以上の値を得る(102)。
さらに、ランダム森に適用するために、前記101で入力した値から必要に応じてラベルを付与する。例えば、薬物投与群、非投与群を群分けの規準に用いた場合、対照群投与前=A、対照群投与=B、投薬群投与前=C、投薬群投与後=D等のアルファベットをラベルとして付与する。便宜上このラベル群をα群とする。
MS解析で得られたマススペクトルの出現情報にラベルを付与する。例えば各出現ピークにP1、P2、P3・・・Pnと連番等を付与する。このラベル群をβ群とする。
本発明で用いるラベルは文字、数字、記号、任意のコード等コンピュータで読み取り可能な記述子であればなんでも良い。
(3)前記(2)で取得した値をランダム森に適用する。ランダム森への適用は、教師なし学習と教師あり学習のどちらでもよい。具体的には、教師なし学習の場合は説明変数としてβ群のみを、教師あり学習の場合は説明変数をβ群そして教師データとしてα群を与えてランダム森を用いてブートストラップにより決定木を作成し、得られた結果の多数決で帰属させ、重要度の低い変数はドロップさせて取得した各クラス情報に基づいて共通規則を抽出し、さらに該規則に基づく分類条件を用いて分類する(103)。
(4)前記(3)のランダム森へ適用した分類結果を数値化した値(以下、スコア)に基づく分類条件を用いてクラス分類を取得し、多次元距離尺度表示しスコアの共通群を視覚的に表示する(104)
【0013】
本発明の方法によって得られた解析結果は、紙、磁気、磁気光ディスク、または光ディスク等の記録媒体に記録されていてもよい。
【0014】
本発明の第2の態様は、本発明の解析方法を実行させるコンピュータで読みとり可能なプログラムである。
図1の101〜105の解析方法を実行させるプログラムで、これらは、図1に示したアルゴリズムの手順にそって1つのモジュールであっても、それぞれのパート毎に書かれたモジュールを組み合わせて使用してもよい。これらは磁気または、磁気光ディスク、光ディスク等の記録媒体に記録されている。
【0015】
本発明の第3の態様は、本発明の配列解析方法を実行させるシステム(装置)である。
本発明解析方法を実行させる装置の構成を図4に示す。201〜204は、前記I−(1)〜I−(4)および、II−(1)〜II−(4)の工程にてデータ入力、演算、解析、予測に使用するためのシステムである。205〜208は、前記I−(1)〜I−(4)および、II−(1)〜II−(4)の解析方法の実行結果を出力するおよび/または記録するための装置である。
【0016】
201〜205の装置の実行結果は206の装置の出力部で紙などの記録媒体に印刷することもでき、207の装置の画像処理部で表示することもでき、208の装置で、FD,MO,CD−RW,DVD−RW等の磁気または、磁気光ディスク、光ディスク等の記録媒体に出力することもできる。
201〜208の装置は、全てが含まれて一体化した装置でも、各々が分離した装置でも、一部の手段を実行させる装置を含んだ装置を複数組み合わせた装置であってもよい。
上記の装置は、電子計算機であればよく、サーバー、パーソナルコンピュータ(以下PC)等が挙げられ、計算機の能力は制限しない。
本発明解析方法を実行させるプログラムを動作させるオペレーションシステムも汎用ソフトウェア例えば、Linux系OS、マイクロソフトウインドウズ(登録商標)シリーズ等でよい。
【0017】
以下、本発の解析方法の実施例を挙げる。但し、本実施例によって本発明を限定されるものではない。
【実施例1】
【0018】
(実施例1)
抗狭心症薬のメタボローム解析
抗狭心症薬であるAmiodaroneを投与するとリン脂質症(Phospholipidosis)の副作用が現れる。このときの代謝物の変動をMSピークのデータによりプロファイリングした。
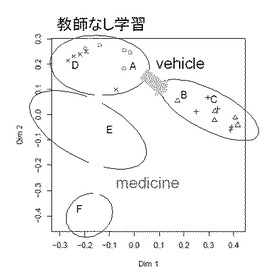
Amiodaroneを投与したラットおよび、非投与のラットから採取した尿をMS解析機(FT-ICR-MS)で測定(n=5)し436ピークを取得した。ランダム森へ適用するため投与群にA〜Fのラベルを付与した。各ラベルと投与群の関係を表1に示す。パラメータは規定値mtry = 20、ntree = 500を設定し、教師なし学習を行った。学習させた結果の多次元距離尺度表示を図4に示す。ここでAとD、BとC、EそしてFの四つのクラスタが形成されている。AとDは投薬する前なので、同じクラスタに属する。BとCは投薬によるvehicleにより代謝物に影響を与えた結果AとDとは別のクラスタを形成している。EはAmiodaroneの投薬により代謝物に影響を与えた結果AとDそしてBとCとはまた異なるクラスタを形成している。FはAmiodaroneの二回目の投与によりさらに病態が進行し、Eとはまた異なるクラスタを形成したことを示している。
表1
A 対照群投与前
B 対照群24時間後 一回目投与
C 対照群48時間後 二回目投与
D 投薬群投与前
E 投薬群24時間後 一回目投与
F 投薬群48時間後 二回目投与
(実施例2)
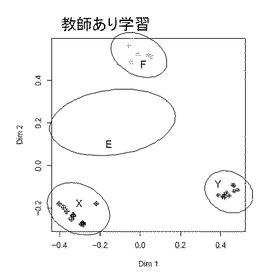
実施例1と同じMSピークを入力データとして用い、パラメータは規定値mtry = 20、ntree = 500とし実施例1での四つのクラスタで、AとDをXそしてBとCをYに再分類したものを教師データとしてランダム森教師あり学習を実施した。学習結果の交差検証結果を表3に、多次元距離尺度表示結果を図5に示す。
上記の実施結果から、MSピークをランダム森に適用することで薬物投与の薬効や病態の分類が高精度で行うことが確認された。
(実施例3)
実施例1の方法により解析されたピークから代謝データベース(KEGG)にヒットするものだけを選抜し、pearson距離計算によって化合物の階層クラスタリングを作成した。数個のクラスターに分類された、マーカー図4においてはE,Fに特徴を示したものについてプロファイルし、ピークの挙動を推定推定した。
次に、代謝経路に帰属させ、半経験的方法によって代謝マップ上に化合物があれば当りとし、隣接する代謝マップを再帰的に調査した。
代謝経路の帰属は、半径検定方法と以下に述べる非経験的方法が挙げられるが、本実施例では半径系的方法によって帰属させた
非経験的方法
1.すべての可能性を考える
3.最も代謝経路が広範に及んだ化合物と代謝経路の組み合わせが最適解とする
して抗狭心症薬の副作用を示す以下のバイオマーカーを同定した。
1.2-Hydroxy-6-ketononatrienedioate
2.2-Hydroxy-1,2,3-propanetricarboxylic acid
3.2-Hydoroxytricarballylic acid
4.1-Hydoroxytricarballylic acid
5.1-Hydoroxypropane-1,2,3-tricarboxylic acid
6.2-Carboxy-2,3-dihydro-5,6-dihydroxyindole;Leucodopachrome
7.Shikimate 3-phosphate
8.Sikimate 5-phosphate
9.Acetyl adenylate
10.Scopolin
【産業上の利用可能性】
【0019】
メタボロームデータのデータマイニングにおいて、MS解析データを特に加工することなく使用でき、解析者の主観に左右されない一意な解析結果を提供することで、正確なメタボロームデータのプロファイルのセットから、データマイニングすることが可能になった。
さらには、創薬、薬理学、毒性学、診断に有用なマーカー群の抽出およびそれら有用マーカー群に共通する規則を抽出することでマーカー選別の有用なスクリーニング方法として提供できる。
【図面の簡単な説明】
【0020】
【図1】本発明方法の原理を説明した図である。
【図2】ランダム・フォーレストのモデル化の概念図である
【図3】実施例1の結果多次元距離尺度表示した図である。
【図4】実施例2の結果多次元距離尺度表示した図である。
【技術分野】
【0001】
本発明は、代謝全体像(以下、メタボローム)の全体像内から得られる情報(メタボロームデータ)の解析、またはマーカー候補となり得る低分子化合物の取得等におけるメタボロームデータのマイニング方法およびそれらを実現する装置に関する。
【背景技術】
【0002】
メタボロームは、新陳代謝、細胞、組織、器官、個体、種等でそれぞれに異なる代謝経路の多様性の総体に関し、バイオインフォマティクスの手法を基に研究されている分子生物学である。
メタボロームは蛋白質、RNA、DNA等の概念も含み、半経験的帰属を形成する回路から構成される代謝経路から産生される代謝物を解析することによって、創薬等に有用な代謝経路の探索または、生態の生理的変化を指標する化合物(以下、マーカー)を見出すことに応用されている。
メタボロームデータを解析することで代謝機能を明らかにし、創薬、薬理学、毒性学、診断に供する知見を得るための研究がなされている。例えば、主成分分析(PCA)および部分最小自乗法(PLS)などの統計解析を用い、取得したスコアの座標配置による群分けを行い、ローディングプロットによる化合物を同定してマーカーを選別する等メタボロームデータのマイニングを実施した例がある(非特許文献1)。
【0003】
【非特許文献1】J Pharm Biomed Anal. 2005 Jul 1;38(3):465-71.
【発明の開示】
【発明が解決しようとする課題】
【0004】
しかしながら、多数のメタボロームデータを同時に解析してデータマイニングを行う手段については、いまだに確立されたとはいえない状況である。例えばPCAおよびPLSでは、固有値計算による次元の集約、スコアの取得および座標配置のプロファイリングによる群分けおよび、ローディングプロットによってマーカーを選別する等多数の工程を経るため、多くの時間を費やしている。
また、PCAでは、主成分の寄与が分散すると判定が困難なること、主成分軸の選択に解析者の主観が必要であることから解析者の知識に依存することが大きかったため、一連の作業の完全自動化は困難であった。
【課題を解決するための手段】
【0005】
本発明の目的は、メタボロームデータによるプロファイルのセットを解析するための方法および装置を提供することである。更に詳しくは、MS(蛋白質の質量分析方法)から得られたデータを、統計的解析手段を用いてメタボロームデータのプロファイルのセットから、創薬、薬理学、毒性学、診断に有用なマーカー群の抽出およびそれら有用マーカー群に共通する規則を抽出し、データマイニングする方法を提供することである。
本発明者らは、一連の作業の自動化、解析者の主観に依存されない一意な結果の取得による正確なプロファイリングによるデータマイニング、前記データマイニングによって同定されたマーカの選抜等を目的に、従来とは異なる工程を検討した結果、代謝物のMS解析(蛋白質の質量分析)から得られるMSピークのデータを用いて機械学習法に適用する解析方法を見出した。
特に、創薬、または病気の診断に直接結びつくマーカーの選抜については、正確なプロファイリングが必要であることから、機械学習方法の中から複数の決定木の解から多数決を採択するランダム森(「ランダム・フォーレスト(RandomForest(登録商標))」以下、RF)を用いてメタボロームデータのマイニング方法およびそれらを実現する装置を完成した。
即ち本発明は、
〔1〕下記(1)〜(8)の工程を含むメタボロームの解析方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得する工程、
(2)前記マススペクトルの出現情報および、化合物情報を入力する工程、
(3)前記(2)で入力した情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する工程;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する工程
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する工程、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する工程
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する工程
〔2〕前記1に記載された方法をコンピュータに実行させることを特徴とするコンピュータ読み取り可能なプログラム。
〔3〕前記2に記載されたコンピュータ読み取り可能なプログラムを格納した電子媒体。
〔4〕下記(1)〜(8)の装置を含むメタボロームの解析システム;
(1)代謝物をMS解析して得られたマススペクトルの出現情報および、化合物情報を入力する装置、
(2)前記マススペクトルの出現情報および、化合物情報を入力する装置、
(3)前記(2)で入力した情報から分子量(m/z)、イオンの検出強度、化合物情報をを数値化したデータのいずれか一つ以上を取得する装置
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する装置;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する装置
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する装置、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する装置
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する装置
(10)前記(4)〜(7)の何れかの装置で行った解析結果を記録する装置
(11)前記(7)の装置で記録した結果を出力する装置
【発明の効果】
【0006】
本発明により、一連の作業を自動化することが可能になり、メタボロームデータのデータマイニングにおいて、解析者の主観に左右されない一意な解析結果を提供することで、正確なメタボロームデータのプロファイルのセットから、データマイニングすることが可能になった。
さらには、創薬、薬理学、毒性学、診断に有用なマーカー群の抽出およびそれら有用マーカー群に共通する規則を抽出することでマーカー選別の有用なスクリーニング方法となった。
【発明を実施するための最良の形態】
【0007】
以下に、本発明における請求項記載の語句の定義について説明する。
「メタボローム」とは、蛋白質、RNA、DNA等の概念も含み、新陳代謝、細胞、組織、器官、個体、種等でそれぞれに異なる代謝経路の多様性の総体に関し、バイオインフォマティクスの手法を基に研究されている分子生物学を指す。
「MS解析」とは蛋白質の質量分析を指し、分析する試料をイオン化させて導入し,電気力や磁気力により質量ごとの差をつくり、イオンの質量を分析することである。上記分析を行う装置である質量分析計を含め以下MSと略す。MSには、イオントラップ型MS、フーリエ変換イオンサイクロトロン共鳴質量分析(FT-ICR/MS)、イオンスキャン法、 Q-TOF型MSなどが挙げられる。これらは、1方法だけで分析しても複数のMSを連結させて分析(以下MS/MS解析)させても良い。
また、前記MS解析結果に基づいてタンパク質を同定することも含む、蛋白質を同定とは、MSデータから分子量が合致するペプチドフラグメントの候補の検出、さらに前記フラグメントからペプチド全体を予測する解析することで、同定するソフトウエアが市販されている。例えば、Mascot、Sonar MS/MS等が挙げられる。
「マススペクトル」は、蛋白質の質量分析の結果得られる、横軸に質量(m/z 値)、縦軸に検出強度をとったスペクトルを指す。
「化合物情報」とは、化合物の物性を表す数値等を指し、例えば構造式を記述化した情報、薬物情報等があげられ、例えば化合物に対する薬理活性の有無や強度、Biological TestingからLaunchedに至るまでの開発ステージ情報などが含まれる。例えば、MDL社のMDDR(MDL Drug Data Report)、NCBIのPubChem等が挙げられる。
また、化合物には蛋白質のアミノ酸情報も含む。アミノ酸情報とは例えば、配列、機能、立体構造などが含まれる。配列、機能については、既知情報、バイオインフォマティクスから推定された情報、複数種類のアノテーション情報、プロテオームの解析情報、体系的な機能分類を指向したオントロジー情報等が挙げられる。
立体構造については、既知情報として、公共のデータベースとしてPDB(Protein Data Bank)、ホモロジーモデリングにより構築された商用もしくはインハウスのデータベース等が挙げられる。商用のホモロジーモデリングデータベースには、SGI社から販売されているFAMSBASE等が挙げられる。
物性には、例えば、構造式を記述化した情報、薬物活性情報、または疾患との関係を示すマーカー情報等を用いることができる。
「バイオマーカー」とは、生体が生理的変化等を生じた際に分泌される核酸、蛋白質、低分子の有機化合物などを指す。本発明においては特に代謝に関与する化合物を指す。
「分類条件」とは、代謝物をサンプリングする検体、MSピークの測定値による任意の規準等が挙げられる。前述の代謝物をサンプリングする検体とは、薬物投与等の医療処置等の有無、遺伝性疾患の有無、アレルギーの有無または、外傷等の刺激等を与えた検体等が挙げられる。
本発明の「ランダム森」とは決定木(CART法など)を下位学習アルゴリズムに持つアンサンブル学習アルゴリズムである(図1)。ランダム森を実行するためのソフトウエアは、市販のランダム・フォーレスト(RandomForest(登録商標))、http://cran.r-project.org/から入手できるフリーソフトウェア等がある。
教師つき学習の場合は説明変数のランダムサンプリングも行いながら、CARTとbaggingを組み合わせる。教師なし学習の場合はクラスラベルがないので、データのランダムサンプリングから擬似的に別クラスのデータを生成した後、教師つき学習と同様のアルゴリズムに帰着させる。この場合、潜在的なクラスを発見することが可能であり、複数の情報から1つのマーカー等目的の化合物に割り当てた場合の考察に有用な情報を与えることが期待できる。
【0008】
前記の教師付き学習とは、入出力データが与えられているが、それらを近似する関数が分からない時に、データから関数のパラメータを推定することをいう。学習とは、学習機⇒学習器のパラメータを適当な学習則を用いることで、変化させることを示し、本発明でいう学習器とは「ランダム・フォーレスト」を指すが、一般的には入出力関係を持ったもので、ニューラル・ネットワーク(Neural Network) 、ラジアル・ベーシス・ファンクション・ネットワーク(Radial Basis Function Network)等、神経回路を模倣したもの或いはサポート・ベクター・マシン等、統計モデル全般を示す。
【0009】
本発明における代謝データベースとは、代謝経路、代謝に関与する化合物等に関するデータベースで主に、京都大学化学研究所が提供するKEGG 代謝データベースなどが挙げられる。
【0010】
本発明のシステムの大枠は、「検索」、「出力」、「閲覧」および「解析」に立て分け、「出力」、「閲覧」については既設環境をそのまま用いる。化合物リストの入出力機能をもち、化合物情報およびバイオ情報が関連付けられた形式で閲覧できるシステムがよく、例えば、クライアントサーバ型システム、Webベースのシステムなどが挙げられる。好ましくは、Webベースでの開発が挙げられる。
本発明のシステムは、複数のデータベースにアクセスして、入力リストを反映した形での表示や、出力対象を個別に指定することが可能である。プログラムの記述言語は、C、C++、JAVA(登録商標)、HTML、XML等が挙げられる。
Webベースにおける構造式の閲覧には、・・・・等(MDL社から無償で提供されている「Chime」等?)の既存プログラムを用いることが可能である。
本発明の第一の態様は、代謝に関与するバイオマーカー選抜方法に関する。
詳しくは、代謝物からMS解析によって得られたマススペクトルの出現情報および、公共の化合物データベースまたは自社の化合物データベースから得られた化合物の情報をコンピュータを用いて、ランダム森に適用し複数の決定木でのアンサンブルアルゴリズムでモデルを学習し、または、学習を行わずに直接クラス情報を取得して共通規則を導き出しそれに基づいた分類条件を用いて分子量(m/z)(以下、MSピークと称する)の値から代謝に関与する化合物の情報をデータマイニングしてマーカーとなりうる化合物を同定することである。
以下に、本発明の方法の手順を図1を参照して説明する。
【0011】
I. MS解析データのランダム森適用による分類解析
(1)代謝物をMS解析して取得したマススペクトルの出現情報、および、化合物情報を、本発明解析装置に入力する(101)。代謝物は、例えば、薬物を投与した検体(例えば、マウス、ラット等の哺乳類)の尿、血液、唾液等が挙げられる。
マススペクトルの出現情報には、分子量(m/z)、イオンの検出強度、前記分子量が検出されるために所有する時間等が挙げられる。化合物情報は、化合物の物性を表す数値等を指し、例えば構造式を記述化した情報、MS解析から得られたMSピーク等が挙げられる。
(2)前記(1)の工程で入力した情報から前記MSピーク、前記MSピークと相関する化合物情報を数値化したデータ、化合物情報を数値化したデータのいずれか一つ以上の値を得る(102)。
さらに、ランダム森に適用するために、前記101で入力した値から必要に応じてラベルを付与する。例えば、薬物投与群、非投与群を群分けの規準に用いた場合、対照群投与前=A、対照群投与=B、投薬群投与前=C、投薬群投与後=D等のアルファベットをラベルとして付与する。便宜上このラベル群をα群とする。
MS解析で得られたマススペクトルの出現情報にラベルを付与する。例えば各出現ピークにP1、P2、P3・・・Pnと連番等を付与する。このラベル群をβ群とする。
本発明で用いるラベルは文字、数字、記号、任意のコード等コンピュータで読み取り可能な記述子であればなんでも良い。
(3)前記(2)で取得した値をランダム森に適用する。ランダム森への適用は、教師なし学習と教師あり学習のどちらでもよい。具体的には、教師なし学習の場合は説明変数としてβ群のみを、教師あり学習の場合は説明変数をβ群そして教師データとしてα群を与えてランダム森を用いてブートストラップにより決定木を作成し、得られた結果の多数決で帰属させ、重要度の低い変数はドロップさせて取得した各クラス情報に基づいて共通規則を抽出し、さらに該規則に基づく分類条件を用いて分類する(103)。
(4)前記(3)のランダム森へ適用した分類結果を数値化した値(以下、スコア)に基づく分類条件を用いてクラス分類を取得し、多次元距離尺度表示しスコアの共通群を視覚的に表示する(104)
(8)上記1〜4の工程に従って電子計算機等の情報資源を用いて計算させる。
II.代謝に関与するマーカー化合物の検出
(1)代謝物からMS解析でMSピークを検出する。
(2)前記II−(1)で選抜されたMSピークに前記I−(2)記載のX群の情報をブラインドとして与え、ランダム森に適用し、前記(3)の方法で分類された分類条件で解析する(106)
(3)前記(2)で解析し、選抜されたMSピークの各クラス分類を取得し、多次元距離尺度表示しスコアの共通群を視覚的に表示する(105)
(4)さらに、前記I−(1)で得られたマススペクトルのピークを変数とし所属する群を与えて教師あり学習を行う
(4−1)学習結果から各変数(ピーク)の重要度を出力させる(106)
(4−2)上記(4−1)の工程を10回以上繰り返し平均をとる。本発明では100回繰り返して平均をとった。
(4−3)いずれかの群で重要度が75パーセンタイルより上にある変数(ピーク)を選抜する。
(4−4)代謝データベースを用いて代謝物として知られている化合物にヒットする 変数(ピーク)だけを選抜する。
(4−5)pearson距離計算により階層クラスタリングを行う。距離の計算手法は通常のeuclidデモ構わないが、pearsonやspearmanのほうが良好とされる。
(4−6)階層クラスタリングの結果から、マーカーの挙動を推定する。
(5) 次に、代謝経路に帰属させ、マーカーを探索する。代謝経路の帰属方法は半経験的方法または非経験的方法が挙げられる。手順を以下に示す。(107)
半経験的方法
1.は探索開始する化合物は間違いないとし、PCAのローディングと一致する化合物が代謝マップ上に化合物があれば当りとする。
2.隣接する代謝マップを再帰的に調査する。
非経験的方法
1.すべての可能性を考える
2.最も代謝経路が広範に及んだ化合物と代謝経路の組み合わせが最適解とする
(6)上記1〜4の工程に従って電子計算機等の情報資源を用いて計算させる。
本発明の第二の態様は、メタボロームの解析方法に関する。
詳しくは、代謝物からMS解析によって得られたマススペクトルの出現情報および、公共の化合物データベースまたは自社の化合物データベースから得られた化合物の情報をコンピュータを用いて、ランダム森に適用し複数の決定木でのアンサンブルアルゴリズムでモデルを学習し、または、学習を行わずに直接クラス情報を取得して共通規則を導き出しそれに基づいた分類条件を用いて分子量(m/z)(以下、MSピークと称する)の値から代謝に関与する化合物の情報をデータマイニングする方法である。
以下に、本発明の方法の手順を図1を参照して説明する。図2は、本発明の請求項1記載の発明の要旨を説明するための図である。
【0012】
MS解析データのランダム森適用による分類解析
(1)代謝物をMS解析して取得したマススペクトルの出現情報、および、化合物情報を、本発明解析装置に入力する(101)。代謝物は、例えば、薬物を投与した検体(例えば、マウス、ラット等の哺乳類)の尿、血液、唾液等が挙げられる。
マススペクトルの出現情報には、分子量(m/z)、イオンの検出強度、前記分子量が検出されるために所有する時間等が挙げられる。化合物情報は、化合物の物性を表す数値等を指し、例えば構造式を記述化した情報、MS解析から得られたMSピーク等が挙げられる。
(2)前記(1)の工程で入力した情報から前記MSピーク、前記MSピークと相関する化合物情報を数値化したデータ、化合物情報を数値化したデータのいずれか一つ以上の値を得る(102)。
さらに、ランダム森に適用するために、前記101で入力した値から必要に応じてラベルを付与する。例えば、薬物投与群、非投与群を群分けの規準に用いた場合、対照群投与前=A、対照群投与=B、投薬群投与前=C、投薬群投与後=D等のアルファベットをラベルとして付与する。便宜上このラベル群をα群とする。
MS解析で得られたマススペクトルの出現情報にラベルを付与する。例えば各出現ピークにP1、P2、P3・・・Pnと連番等を付与する。このラベル群をβ群とする。
本発明で用いるラベルは文字、数字、記号、任意のコード等コンピュータで読み取り可能な記述子であればなんでも良い。
(3)前記(2)で取得した値をランダム森に適用する。ランダム森への適用は、教師なし学習と教師あり学習のどちらでもよい。具体的には、教師なし学習の場合は説明変数としてβ群のみを、教師あり学習の場合は説明変数をβ群そして教師データとしてα群を与えてランダム森を用いてブートストラップにより決定木を作成し、得られた結果の多数決で帰属させ、重要度の低い変数はドロップさせて取得した各クラス情報に基づいて共通規則を抽出し、さらに該規則に基づく分類条件を用いて分類する(103)。
(4)前記(3)のランダム森へ適用した分類結果を数値化した値(以下、スコア)に基づく分類条件を用いてクラス分類を取得し、多次元距離尺度表示しスコアの共通群を視覚的に表示する(104)
【0013】
本発明の方法によって得られた解析結果は、紙、磁気、磁気光ディスク、または光ディスク等の記録媒体に記録されていてもよい。
【0014】
本発明の第2の態様は、本発明の解析方法を実行させるコンピュータで読みとり可能なプログラムである。
図1の101〜105の解析方法を実行させるプログラムで、これらは、図1に示したアルゴリズムの手順にそって1つのモジュールであっても、それぞれのパート毎に書かれたモジュールを組み合わせて使用してもよい。これらは磁気または、磁気光ディスク、光ディスク等の記録媒体に記録されている。
【0015】
本発明の第3の態様は、本発明の配列解析方法を実行させるシステム(装置)である。
本発明解析方法を実行させる装置の構成を図4に示す。201〜204は、前記I−(1)〜I−(4)および、II−(1)〜II−(4)の工程にてデータ入力、演算、解析、予測に使用するためのシステムである。205〜208は、前記I−(1)〜I−(4)および、II−(1)〜II−(4)の解析方法の実行結果を出力するおよび/または記録するための装置である。
【0016】
201〜205の装置の実行結果は206の装置の出力部で紙などの記録媒体に印刷することもでき、207の装置の画像処理部で表示することもでき、208の装置で、FD,MO,CD−RW,DVD−RW等の磁気または、磁気光ディスク、光ディスク等の記録媒体に出力することもできる。
201〜208の装置は、全てが含まれて一体化した装置でも、各々が分離した装置でも、一部の手段を実行させる装置を含んだ装置を複数組み合わせた装置であってもよい。
上記の装置は、電子計算機であればよく、サーバー、パーソナルコンピュータ(以下PC)等が挙げられ、計算機の能力は制限しない。
本発明解析方法を実行させるプログラムを動作させるオペレーションシステムも汎用ソフトウェア例えば、Linux系OS、マイクロソフトウインドウズ(登録商標)シリーズ等でよい。
【0017】
以下、本発の解析方法の実施例を挙げる。但し、本実施例によって本発明を限定されるものではない。
【実施例1】
【0018】
(実施例1)
抗狭心症薬のメタボローム解析
抗狭心症薬であるAmiodaroneを投与するとリン脂質症(Phospholipidosis)の副作用が現れる。このときの代謝物の変動をMSピークのデータによりプロファイリングした。
Amiodaroneを投与したラットおよび、非投与のラットから採取した尿をMS解析機(FT-ICR-MS)で測定(n=5)し436ピークを取得した。ランダム森へ適用するため投与群にA〜Fのラベルを付与した。各ラベルと投与群の関係を表1に示す。パラメータは規定値mtry = 20、ntree = 500を設定し、教師なし学習を行った。学習させた結果の多次元距離尺度表示を図4に示す。ここでAとD、BとC、EそしてFの四つのクラスタが形成されている。AとDは投薬する前なので、同じクラスタに属する。BとCは投薬によるvehicleにより代謝物に影響を与えた結果AとDとは別のクラスタを形成している。EはAmiodaroneの投薬により代謝物に影響を与えた結果AとDそしてBとCとはまた異なるクラスタを形成している。FはAmiodaroneの二回目の投与によりさらに病態が進行し、Eとはまた異なるクラスタを形成したことを示している。
表1
A 対照群投与前
B 対照群24時間後 一回目投与
C 対照群48時間後 二回目投与
D 投薬群投与前
E 投薬群24時間後 一回目投与
F 投薬群48時間後 二回目投与
(実施例2)
実施例1と同じMSピークを入力データとして用い、パラメータは規定値mtry = 20、ntree = 500とし実施例1での四つのクラスタで、AとDをXそしてBとCをYに再分類したものを教師データとしてランダム森教師あり学習を実施した。学習結果の交差検証結果を表3に、多次元距離尺度表示結果を図5に示す。
上記の実施結果から、MSピークをランダム森に適用することで薬物投与の薬効や病態の分類が高精度で行うことが確認された。
(実施例3)
実施例1の方法により解析されたピークから代謝データベース(KEGG)にヒットするものだけを選抜し、pearson距離計算によって化合物の階層クラスタリングを作成した。数個のクラスターに分類された、マーカー図4においてはE,Fに特徴を示したものについてプロファイルし、ピークの挙動を推定推定した。
次に、代謝経路に帰属させ、半経験的方法によって代謝マップ上に化合物があれば当りとし、隣接する代謝マップを再帰的に調査した。
代謝経路の帰属は、半径検定方法と以下に述べる非経験的方法が挙げられるが、本実施例では半径系的方法によって帰属させた
非経験的方法
1.すべての可能性を考える
3.最も代謝経路が広範に及んだ化合物と代謝経路の組み合わせが最適解とする
して抗狭心症薬の副作用を示す以下のバイオマーカーを同定した。
1.2-Hydroxy-6-ketononatrienedioate
2.2-Hydroxy-1,2,3-propanetricarboxylic acid
3.2-Hydoroxytricarballylic acid
4.1-Hydoroxytricarballylic acid
5.1-Hydoroxypropane-1,2,3-tricarboxylic acid
6.2-Carboxy-2,3-dihydro-5,6-dihydroxyindole;Leucodopachrome
7.Shikimate 3-phosphate
8.Sikimate 5-phosphate
9.Acetyl adenylate
10.Scopolin
【産業上の利用可能性】
【0019】
メタボロームデータのデータマイニングにおいて、MS解析データを特に加工することなく使用でき、解析者の主観に左右されない一意な解析結果を提供することで、正確なメタボロームデータのプロファイルのセットから、データマイニングすることが可能になった。
さらには、創薬、薬理学、毒性学、診断に有用なマーカー群の抽出およびそれら有用マーカー群に共通する規則を抽出することでマーカー選別の有用なスクリーニング方法として提供できる。
【図面の簡単な説明】
【0020】
【図1】本発明方法の原理を説明した図である。
【図2】ランダム・フォーレストのモデル化の概念図である
【図3】実施例1の結果多次元距離尺度表示した図である。
【図4】実施例2の結果多次元距離尺度表示した図である。
【特許請求の範囲】
【請求項1】
下記(1)〜(7)の工程を含む代謝に関与するバイオマーカー選抜方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得する工程、
(2)前記マススペクトルの出現情報および、化合物情報を入力する工程、
(3)前記(2)で入力した情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する工程;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する工程
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する工程、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する工程
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する工程
【請求項2】
前記工程(4)の工程においてにさらに下記(1)〜(7)工程を追加することを特徴とするバイオマーカー選抜方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得し、前記マススペクトルの出現情報および、化合物情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程から選抜したマススペクトルのピークを変数とし所属する群を与えて教師あり学習を行う
(2)学習結果から各変数(ピーク)の重要度を出力させる、
(3)上記(2)の工程を10回以上繰り返し平均をとる、
(4)いずれかの群で重要度が75パーセンタイルより上にある変数(ピーク)を選抜する、
(5)代謝データベースを用いて代謝物として知られている化合物にヒットする 変数(ピーク)だけを選抜する、
(6)pearson距離計算により階層クラスタリングを行う、
(7)階層クラスタリングの結果から、マーカーの挙動を推定する。
【請求項3】
下記(1)〜(7)の工程を含むメタボロームの解析方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得する工程、
(2)前記マススペクトルの出現情報および、化合物情報を入力する工程、
(3)前記(2)で入力した情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する工程;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する工程
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する工程、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する工程
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する工程
【請求項4】
前記1〜3のいずれかに記載された方法をコンピュータに実行させることを特徴とするコンピュータ読み取り可能なプログラム。
【請求項5】
前記4に記載されたコンピュータ読み取り可能なプログラムを格納した電子媒体。
【請求項6】
下記(1)〜(8)の装置を含むメタボロームの解析システム;
(1)代謝物をMS解析して得られたマススペクトルの出現情報および、化合物情報を入力する装置、
(2)前記マススペクトルの出現情報および、化合物情報を入力する装置、
(3)前記(2)で入力した情報から分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する装置
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する装置;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する装置
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する装置、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する装置
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する装置
(10)前記(4)〜(7)の何れかの装置で行った解析結果を記録する装置
(11)前記(7)の装置で記録した結果を出力する装置
【請求項7】
請求項1または2記載の方法で選抜された以下の化合物から選ばれるバイオマーカー
【請求項8】
請求項7記載の化合物から選ばれる1以上の化合物からなる抗狭心症薬投与の副作用の発症の判定に関するバイオマーカーの使用
【請求項1】
下記(1)〜(7)の工程を含む代謝に関与するバイオマーカー選抜方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得する工程、
(2)前記マススペクトルの出現情報および、化合物情報を入力する工程、
(3)前記(2)で入力した情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する工程;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する工程
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する工程、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する工程
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する工程
【請求項2】
前記工程(4)の工程においてにさらに下記(1)〜(7)工程を追加することを特徴とするバイオマーカー選抜方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得し、前記マススペクトルの出現情報および、化合物情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程から選抜したマススペクトルのピークを変数とし所属する群を与えて教師あり学習を行う
(2)学習結果から各変数(ピーク)の重要度を出力させる、
(3)上記(2)の工程を10回以上繰り返し平均をとる、
(4)いずれかの群で重要度が75パーセンタイルより上にある変数(ピーク)を選抜する、
(5)代謝データベースを用いて代謝物として知られている化合物にヒットする 変数(ピーク)だけを選抜する、
(6)pearson距離計算により階層クラスタリングを行う、
(7)階層クラスタリングの結果から、マーカーの挙動を推定する。
【請求項3】
下記(1)〜(7)の工程を含むメタボロームの解析方法;
(1)代謝物をMS解析にてマススペクトルの出現情報を取得する工程、
(2)前記マススペクトルの出現情報および、化合物情報を入力する工程、
(3)前記(2)で入力した情報から、分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する工程
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する工程;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する工程
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する工程、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する工程
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する工程
【請求項4】
前記1〜3のいずれかに記載された方法をコンピュータに実行させることを特徴とするコンピュータ読み取り可能なプログラム。
【請求項5】
前記4に記載されたコンピュータ読み取り可能なプログラムを格納した電子媒体。
【請求項6】
下記(1)〜(8)の装置を含むメタボロームの解析システム;
(1)代謝物をMS解析して得られたマススペクトルの出現情報および、化合物情報を入力する装置、
(2)前記マススペクトルの出現情報および、化合物情報を入力する装置、
(3)前記(2)で入力した情報から分子量(m/z)、イオンの検出強度、化合物情報を数値化したデータのいずれか一つ以上を取得する装置
(4)下記(4a)〜(4c)のいずれか一つ以上にランダム森を適用する装置;
(4a)前記(3)で取得した値、
(4b)前記(3)で取得した値をもとにランダム森に適用し構築した予測モデル、
(4c)前記(4b)取得した予測モデルおよび前記(4a)で取得した値
(5)前記(4)でランダム森に適用したマススペクトルの出現情報から共通規則に基づく分類条件を用いてクラス分類する装置
(6)前記(5)でクラス分類されたデータを多次元距離尺度表示で座標配置する装置、
(7)前記(1)〜(6)の解析方法を用いて化合物情報を分類する装置
(8)前記(7)で分類された化合物情報から代謝に関与する化合物を同定する装置
(10)前記(4)〜(7)の何れかの装置で行った解析結果を記録する装置
(11)前記(7)の装置で記録した結果を出力する装置
【請求項7】
請求項1または2記載の方法で選抜された以下の化合物から選ばれるバイオマーカー
【請求項8】
請求項7記載の化合物から選ばれる1以上の化合物からなる抗狭心症薬投与の副作用の発症の判定に関するバイオマーカーの使用
【図1】


【図2】
【図3】
【図4】
【図2】
【図3】
【図4】
【公開番号】特開2009−57337(P2009−57337A)
【公開日】平成21年3月19日(2009.3.19)
【国際特許分類】
【出願番号】特願2007−227195(P2007−227195)
【出願日】平成19年8月31日(2007.8.31)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.Linux
【出願人】(000002912)大日本住友製薬株式会社 (332)
【出願人】(000002093)住友化学株式会社 (8,981)
【公開日】平成21年3月19日(2009.3.19)
【国際特許分類】
【出願日】平成19年8月31日(2007.8.31)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.Linux
【出願人】(000002912)大日本住友製薬株式会社 (332)
【出願人】(000002093)住友化学株式会社 (8,981)
[ Back to top ]