
メモリコントローラ及びSIMDプロセッサ
【課題】2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際に、SIMDプロセッサの効率低下を抑制する。
【解決手段】SIMDプロセッサにおけるメモリコントローラ140のアドレス記憶部142は、コントロールプロセッサにより、外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能である。パラメータ記憶部144は、コントロールプロセッサにより、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能である。データ転送部146は、アドレス記憶部142とパラメータ設定部144の内容に基づいて、外部メモリと、該SIMDプロセッサに含まれるN個のプロセッサ要素のバッファとの間でデータ転送を行う。
【解決手段】SIMDプロセッサにおけるメモリコントローラ140のアドレス記憶部142は、コントロールプロセッサにより、外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能である。パラメータ記憶部144は、コントロールプロセッサにより、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能である。データ転送部146は、アドレス記憶部142とパラメータ設定部144の内容に基づいて、外部メモリと、該SIMDプロセッサに含まれるN個のプロセッサ要素のバッファとの間でデータ転送を行う。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、メモリアクセス制御、より具体的にはSIMD(Single Instruction Multiple Data)プロセッサ向けのメモリアクセス制御技術に関する。
【背景技術】
【0002】
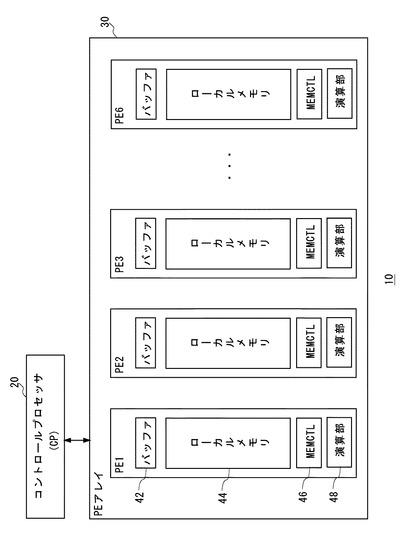
SIMDプロセッサは、1回の命令により複数のデータに対して同一の処理を同時に行うことができる。図12は、SIMDプロセッサの構成例を示す。
【0003】
図12に示すSIMDプロセッサ10は、コントロールプロセッサ20と、プロセッサアレイ30を備える。プロセッサアレイ30は、1次元結合の分散メモリ型プロセッサアレイであり、複数(図示の例では6個)のプロセッサ要素を有し、これらのプロセッサ要素は、コントロールプロセッサ20からの命令に従って、同一の処理を行う。なお、コントロールプロセッサ20がPEアレイ30に命令を出す際に、マスクビットやマスクフラグ(以下、「マスクフラグ」に統一する)によって、処理をしないプロセッサ要素を指定することができる。すなわち、PEアレイ30に含まれる複数プロセッサ要素は、同一の処理を行っているか、処理をしてないかのいずれかの状態にある。
【0004】
以下において、コントロールプロセッサを「CP」、プロセッサアレイとプロセッサ要素を夫々「PEアレイ」と「PE」という。
【0005】
PEアレイ30に含まれる各PE(PE1〜PE6)は、構成が同様であるため、ここで、PE1を代表にして説明する。図示のように、PE1は、バッファ42、ローカルメモリ44、MEMCTL46、演算部48を備える。
【0006】
演算部48は、演算を実行するものであり、隣接するPEとデータの送受信ができる。MEMCTL46は、ローカルメモリアクセスと外部メモリアクセスの制御を行う。
【0007】
ローカルメモリアクセスは、PEアレイ30内部に生じたメモリアクセスであり、具体的には、演算部48からの書込要求と読出要求がある。MEMCTL46は、演算部48の書込み要求に応じて演算部48からのデータをローカルメモリ44に書き込み、演算部48の読出し要求に応じてローカルメモリ44からデータを読み出して演算部48に供する機能を担う。
【0008】
また、MEMCTL46は、PEアレイ30の外部(CP20を含む)からメモリアクセスがあった際に、ライトアクセスの場合にはライト要求されたデータをローカルメモリ44に書込み、リードアクセスの場合にはリード要求されたデータをローカルメモリ44メモリから読み出して出力する機能を備える。
【0009】
バッファ42は、PE1と外部のデータ交換用のものであり、交換されるデータを一時的に格納する。具体的には、例えば、CP20は、ローカルメモリ44へのライトアクセスに際して、まず、ライトするデータをバッファ42に格納し、ライト命令を出す。PE1は、ライト命令を受けると、MEMCTL46が、バッファ42に格納されたデータをローカルメモリ44に書き込む。また、CP20は、ローカルメモリ44へのリードアクセスに際して、リードするデータの情報を含むリード命令を出す。PE1は、リード命令を受けると、MEMCTL46が、当該データをローカルメモリ44から読み出してバッファ42に出力する。そして、CP20は、バッファ42からデータを読み出して外部に出力する。
【0010】
このようなSIMDプロセッサ10は、複数のデータが2次元に配列されてなるデータ群(以下「2次元データ」という)の処理に特に有用である。2次元データは、例えば、1画面の画素のデータからなる画像や、2次元の表の夫々のマスに入れるデータの集合などがある。ここで、1行の画素数が6個である画像に対して、注目画素と、注目画素の右隣の画素との平均をとるフィルタ処理をする場合を例にしてSIMDプロセッサ10の動作を説明する。なお、以下において、特に説明が無い限り、「画素」と「画素値」を同じ意味で用いる。
【0011】
この場合、画像の列と、PEアレイ30のPEとが一対一の関係にある。画像の注目行を見ると、該行に含まれる6個の画素は、バッファ42を介してPEアレイ30の6個のローカルメモリ44に夫々格納される。各PEのローカルメモリ44は、同一の行の画素を同一のアドレスに格納する。
【0012】
画像のA行の各画素が、各PEのローカルメモリのアドレスBに格納されているとする。この場合、A行のフィルタ処理に際して、コントローラ20は、各PEに対して、「A行の画素について、右隣の画素との平均値を求める」の命令を発行する。各PEは、自身のローカルメモリからアドレスBの画素を読み出すと共に、右隣のPEに対してアドレスBの画素を要求する。そして、この要求に応じて右隣のPEから送信してきたデータと、自身のローカルメモリから読み出したアドレスBの画素との平均演算を行うと共に、左隣のPEからの要求に応じて自身のローカルメモリから読み出したアドレスBの画素を左隣のPEに出力する。
【0013】
このように、注目行の全ての画素に対するフィルタ処理が同時にでき、効率がよい。
なお、本明細書において、画像の「行」方向は、該画像を再生した場合の横方向の意味ではなく、PEの配列方向に割り当てた方向を意味する。例えば、画像を再生した場合の1行の各画素を各PEに夫々割り当てたとき、画像を再生した場合の「行」と本明細書でいう「行」とは一致するが、画像を再生した場合の1列の各画素を各PEに夫々割り当てたとき、画像を再生した場合の「列」が本明細書でいう「行」になる。画像以外の2次元データについても同様である。
【0014】
なお、画像の1行の画素数は、PEの数と同一であるとは限らず、通常、PE数より多い。この場合、画像をブロック分けし、ブロック毎に処理を行うことがなされている。これらの各ブロックの行方向の画素数については、PE数と同一にすればよい。
【0015】
外部から各PEのローカルメモリにデータを格納するまでの処理は、様々な視点から手法が提案されている(特許文献1や非特許文献1)。例えば、非特許文献1には、この処理を工夫することで、SIMDプロセッサの効率を向上させる手法が提案されている。
【0016】
ここで、非特許文献1の手法を説明する。また、SIMDプロセッサの例として、図12に示すSIMDプロセッサ10を用いる。また、分かりやすいように、外部メモリからPEアレイ30の各PEのローカルメモリに上述したA行の6画素をPE1〜PE6の夫々のローカルメモリ44に格納する場合を例にする。
【0017】
この手法によれば、SIMDプロセッサ10は、図12に示す各機能ブロック以外に、さらにDMAコントローラ(DMA:Direct Memory Acess)をさらに備える。また、PE1〜PE6のバッファ42は、同一のシフトレジスタを構成しており、夫々のバッファ42は、該シフトレジスタの一段である。
【0018】
まず、CP20は、読出アドレスとして、上記A行の6画素のうちの1番目の画素の外部メモリにおけるアドレスを設定する。
【0019】
DMAコントローラは、設定された読出アドレスのデータ(A行の6画素のうちの1番目の画素)を外部メモリから読み出してPE1のバッファ42に格納する。次に、DMAコントローラは、読出アドレスを1つ増分して、増分した読出アドレスのデータすなわち2番目の画素を外部メモリから読み出してPE1のバッファ42に格納する。同時に、PE1のバッファ42に先に格納されたデータ(1番目の画素)は、シフトによってPE1のバッファ42からPE2のバッファ42に出力され、PE2のバッファ42に格納される。このような格納とシフトが繰り返された結果、PE1のバッファ42には6番目の画素が格納されたときに、PE2〜PE6のバッファ42には、6番目〜2番目の画素が夫々格納されたことになる。
【0020】
この時点で、DMAコントローラが割込みを発生させることにより、CP20は、各PEに対してライト命令を発行する。各PEは、MEMCTL46により、自身のバッファ42に格納されたデータをローカルメモリ44に書き込む。
【0021】
この手法では、1回のライト命令により、外部メモリから各PEのローカルメモリローカルメモリ44に格納すべきデータがバッファ42を介して、夫々のPEのローカルメモリローカルメモリ44に格納される。各バッファへのデータの格納は、DMAコントローラにより担われるため、DMAコントローラがバッファへデータを格納している間では、各PEは、演算処理を行うことができる。
【0022】
そのため、外部メモリからPEのローカルメモリへデータをライトする処理がPEの演算処理へ与える影響を抑制することができる。なお、PEのローカルメモリから外部メモリへデータを読み出す際についても同様である。
【先行技術文献】
【特許文献】
【0023】
【特許文献1】特開平11−66033号公報
【非特許文献】
【0024】
【非特許文献1】京 昭倫著「128個の4ウェイVLIW型RISCコアを集積した車載向け動画認識LSI」電子情報通信学会研究会報告、集積回路研究会(ICD),2003年5月、Vol.103,No.89,pp.19−24
【発明の概要】
【発明が解決しようとする課題】
【0025】
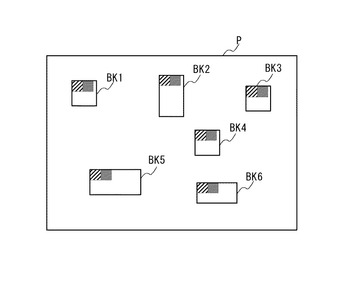
2次元データにおける複数の領域のデータに対して同一の処理を施す場合を考える。例えば、図13に示す画像Pに対して所定の対象物(例えば顔)の検出を行い、検出した複数の領域(図中矩形領域BK1〜BK6)に対して同一の処理を施す場合がある。勿論、各矩形領域内には、複数の画素が含まれる。
【0026】
図13において、各矩形領域内において、斜線により塗り潰された小さい枠は、該矩形領域の1番目の画素(通常、左上端の画素)を示し、黒く塗りつぶされた小さい枠は、該矩形領域の2番目の画素を示す。
【0027】
この場合、1矩形領域が1PEに対応するように、これらの複数の矩形領域のデータを、SIMDプロセッサの複数のPEのローカルメモリに夫々書き込んでおき、各PEに上記同一の処理を行わせるようにすれば、効率が良い。
【0028】
ここで、非特許文献1の手法を適用して、画像Pを格納した外部メモリからSIMDプロセッサ10の夫々のPEのローカルメモリ44に矩形領域BK1〜BK6のデータを書き込むまでの処理を考える。この場合、下記のような流れが考えられる。
【0029】
まず、CP20は、矩形領域BK1の1番目の画素の先頭アドレスを読出アドレスとしてDMAコントローラに対して設定する。
【0030】
DMAコントローラは、設定された読出アドレスのデータ(矩形領域BK1の1番目の画素)を外部メモリから読み出してPE1のバッファ42に格納する。この画素は、最終的にPE6のローカルメモリ44に書込むべき画素である。
【0031】
ここで、非特許文献1の手法の流れでは、DMAコントローラが次に読み出すべき画素は、PE5のローカルメモリ44に書き込むべき画素、すなわち矩形領域BK2の1番目の画素である。しかし、DMAコントローラは、読出アドレスを1つ増分して読出しを行うと、次に読み出したデータは、矩形領域BK1の2番目の画素である。
【0032】
そのため、DMAコントローラは、続けて読み出すべき画素を読み出すことができない。そのため、再びCP20により読出アドレス(ここでは、矩形領域BK2の1番目の画素のアドレスになる)をDMAコントローラに設定し、DMAコントローラは、設定された読出アドレスのデータを外部メモリから読み出してPE1のバッファ42に格納する。この画素は、最終的にPE5のローカルメモリ44に書込むべき画素である。同時に、シフトにより、先にPE1のバッファ42に格納されたデータ(矩形領域BK1の1番目の画素)は、PE2のバッファ42に格納される。
【0033】
これでは、1つの画素の読出しとバッファ42への格納は、必ずCP20による読出アドレスの設定が必要になり、DMAコントローラの効果を発揮することができず、SIMDプロセッサ10の効率向上を図ることができない。
【0034】
また、各PEのバッファ42により1つのシフトレジスタを形成する構成ではなく、各バッファ42は、別々に書き込むことができる構成とした場合にも、同様である。
【0035】
非特許文献1の手法を適用しない場合には、SIMDプロセッサ10の効率がより低下する。この場合の流れの例を説明する。なお、各PEのバッファ42は、別々に書き込むことができるとする。
【0036】
まず、CP20は、矩形領域BK1の1番目の画素を外部メモリから読み出してPE6のバッファ42に格納する。そして、PE1〜PE5を動作させないマスクフラグ付きのライト命令を出す。
【0037】
これにより、PE6のMEMCTL46は、ライト動作を実行し、バッファ42から矩形領域BK1の1番目の画素をローカルメモリ44に書き込む。
【0038】
同様の処理が、CP20と、PE6のMEMCTL46とにより、矩形領域BK1の画素数分回繰り返され、最後に、矩形領域BK1の全ての画素は、PE6のローカルメモリ44に書き込まれる。
【0039】
そして、CP20と、PE5のMEMCTL46とにより、同様の処理が矩形領域BK2の画素数分回繰り返され、最後に、矩形領域BK2の全ての画素は、PE5のローカルメモリ44に書き込まれる。
【0040】
矩形領域BK3〜BK6のデータも、同様の処理によりPE4〜PE1のローカルメモリ44に書き込まれる。
【0041】
上述の流れから分かるように、この場合、1つの矩形領域につき、CP20によるバッファ42へのデータの格納と、PEによるライト動作が、該領域内の画素数分回繰り返される。この間、CP20は、PEアレイ30に対して命令を放送することができず、PEアレイ30での演算処理が停止してしまうという問題がある。
【0042】
また、ローカルメモリ44へのデータの書込みは、矩形領域を1個ずつ行われるので、当該PEのローカルメモリ44へのアクセスが高い頻度で発生する。そのため、仮に、別の手段でPEアレイ30に対し命令を放送できるようにしたとしても、該PEのローカルメモリ44がデータ転送によって占有されてしまうため、PEアレイ30での演算処理がやはり停止してしまう。
【0043】
本発明は、上記事情に鑑みてなされたものであり、2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際に、SIMDプロセッサの効率低下を抑制するメモリアクセス制御技術を提供する。
【課題を解決するための手段】
【0044】
本発明の1つの態様は、SIMDプロセッサに設けられたDMAコントローラである。該SIMDプロセッサは、N個(N:2以上の整数)のプロセッサ要素を有し、各前記プロセッサ要素が、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有する。
【0045】
前記メモリコントローラは、アドレス記憶部と、パラメータ記憶部と、データ転送部とを備える。
【0046】
前記アドレス記憶部は、前記外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能である。
【0047】
前記パラメータ設定部は、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能である。
【0048】
前記データ転送部は、前記外部メモリと、前記N個のプロセッサ要素のバッファとの間でデータ転送を行うものであり、前記データ転送の指示に応じて、第1の処理を前記パラメータ記憶部に記憶された前記第3のパラメータLに合致する回数分繰り返す。
【0049】
前記第1の処理は、前記第2の処理をすると共に第3の処理を行うことを式(1)に示すM回繰り返した後に、前記第2の処理をすると共に第4の処理を行う処理である。
M=W/S−1 (1)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
【0050】
前記第2の処理は、前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、前記アドレス記憶部に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するプロセッサ要素のバッファに格納する処理である。
【0051】
また、前記第2の処理は、前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、夫々の前記プロセッサ要素のバッファに格納されたデータを読み出して、前記アドレス記憶部に記憶されているN個のアドレスのうちの、対応するアドレスに書き込む処理である。
【0052】
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(2)に従って増分させる処理である。
Ai=Ai+S (2)
但し,Ai:i個目のアドレス
S:単位サイズ
【0053】
前記第4の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(3)に従って増分させる処理である。
Ai=Ai+OSV (3)
但し,Ai:i個目のアドレス
OSV:パラメータ記憶部に記憶された第1のパラメータ
【0054】
本発明の別の態様は、SIMDプロセッサである。該SIMDプロセッサは、コントロールプロセッサと、前記コントロールプロセッサにより制御されるN個(N:2以上の整数)のプロセッサ要素と、上記態様のメモリコントローラとを備える。各前記プロセッサ要素は、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有する。
【0055】
前記コントロールプロセッサは、前記メモリコントローラによる前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に、各前記プロセッサ要素にライト命令をする。
【0056】
また、前記コントロールプロセッサは、前記DMAコントローラによる前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に、各前記プロセッサ要素にリード命令をする。
【0057】
なお、上記態様のメモリコントローラやコントロールプロセッサを方法や装置、システムなどに置換えて表示したものや、これらの方法をコンピュータに実行せしめるプログラムなども、本発明の態様としては有効である。
【発明の効果】
【0058】
本発明にかかるメモリアクセス制御技術によれば、例えば、2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際に、SIMDプロセッサの効率低下を抑制することができる。
【図面の簡単な説明】
【0059】
【図1】本発明の第1の実施の形態にかかるSIMDプロセッサを示す図である。
【図2】図1に示すSIMDプロセッサにおけるメモリコントローラを示す図である。
【図3】図1に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図4】図1に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図5】本発明の第2の実施の形態にかかるSIMDプロセッサを示す図である。
【図6】図5に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図7】図5に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図8】本発明の第2の実施の形態にかかるSIMDプロセッサを示す図である。
【図9】図8に示すSIMDプロセッサにおけるメモリコントローラを示す図である。
【図10】図8に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図11】図8に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図12】通常のSIMDプロセッサの構成例を示す図である。
【図13】2次元データの例となる画像を示す図である。
【発明を実施するための形態】
【0060】
以下、図面を参照して本発明の実施の形態について説明する。説明の明確化のため、以下の記載及び図面は、適宜、省略、及び簡略化がなされている。また、様々な処理を行う機能ブロックとして図面に記載される各要素は、ハードウェアとソフトウェア(プログラム)の組合せによっていろいろな形で実現できることは当業者には理解されるところであり、ハードウェアとソフトウェアのいずれかに限定されるものではない。なお、各図面において、同一の要素には同一の符号が付されており、必要に応じて重複説明は省略されている。
【0061】
また、上述したプログラムは、様々なタイプの非一時的なコンピュータ可読媒体(non−transitory computer readable medium)を用いて格納され、コンピュータに供給することができる。非一時的なコンピュータ可読媒体は、様々なタイプの実体のある記録媒体(tangible storage medium)を含む。非一時的なコンピュータ可読媒体の例は、磁気記録媒体(例えばフレキシブルディスク、磁気テープ、ハードディスクドライブ)、光磁気記録媒体(例えば光磁気ディスク)、CD−ROM(Read Only Memory)CD−R、CD−R/W、半導体メモリ(例えば、マスクROM、PROM(Programmable ROM)、EPROM(Erasable PROM)、フラッシュROM、RAM(Random Access Memory))を含む。また、プログラムは、様々なタイプの一時的なコンピュータ可読媒体(transitory computer readable medium)によってコンピュータに供給されてもよい。一時的なコンピュータ可読媒体の例は、電気信号、光信号、及び電磁波を含む。一時的なコンピュータ可読媒体は、電線及び光ファイバ等の有線通信路、又は無線通信路を介して、プログラムをコンピュータに供給できる。
【0062】
<第1の実施の形態>
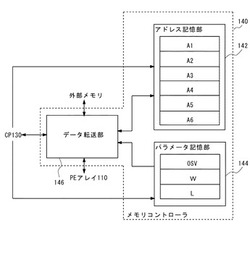
図1は、本発明の第1の実施の形態にかかるSIMDプロセッサ100を示す。SIMDプロセッサ100は、PEアレイ110、制御ユニット120を備える。
【0063】
PEアレイ110は、N個(N:2以上の整数であり、ここでは例として、N=6)のプロセッサ要素(PE)1〜6を有する。各PEは、同一の構成を有するため、ここで、PE1を代表にする。
【0064】
PE1は、外部メモリとの間で交換されるデータを一時的に格納するバッファ112と、ローカルメモリ114を備える。バッファ112の容量は、所定の単位サイズSである。なお、この種のPEに通常備えられる演算部などの機能ブロックの図示は、省略する。
【0065】
PE1は、制御ユニット120における後述するコントロールプロセッサ(CP)130により制御される。外部メモリとのデータ交換に際して、PE1は、CP130からのリード命令に応じて、該当するデータをローカルメモリ114から読み出してバッファ112に格納し、また、CP130からのライト命令に応じて、バッファ112に格納されたデータを読み出して、ローカルメモリ114の該当する番地に書き込む。
【0066】
制御ユニット120は、CP130と、メモリコントローラ140を備える。CP130は、PEアレイ110と、メモリコントローラ140の制御を行う。
【0067】
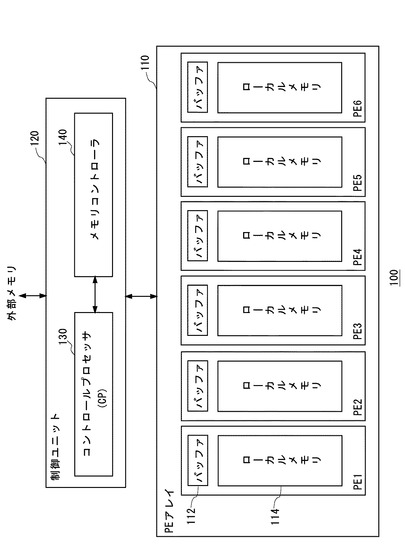
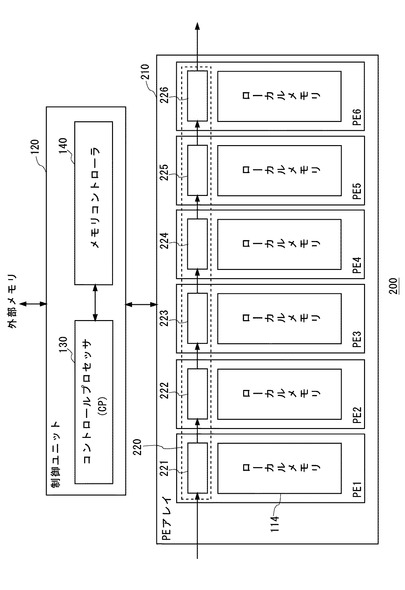
メモリコントローラ140は、データ転送の指示(以下、単に転送指示という)をCP130から受けると、PEアレイ110の各PEと、外部メモリとの間で交換されるデータのDMA転送を行う。図2を参照してメモリコントローラ140を詳細に説明する。
【0068】
図2に示すように、メモリコントローラ140は、アドレス記憶部142、パラメータ記憶部144、データ転送部146を備える。
【0069】
アドレス記憶部142は、CP130により、外部メモリにおけるN個(ここでは6個)のアドレスAi(i=1〜6)を設定可能である。また、アドレス記憶部142内に記憶された各アドレスAiは、データ転送部146により変更可能である。
【0070】
パラメータ記憶部144は、CP130により、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能である。
【0071】
データ転送部146は、CP130からの転送指示に応じて、外部メモリと、PE1〜PE6のバッファ112の間でデータ転送を行う。該データ転送に際して、データ転送部146は、アドレス記憶部142とパラメータ記憶部144の内容に基づいて、第1の処理を、パラメータ記憶部144に記憶された第3のパラメータLに合致する回数分繰り返す。
【0072】
第1の処理は、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返した後に、第2の処理をすると共に第4の処理を行う処理である。
M=W/S−1 (6)
但し,W:パラメータ記憶部144に記憶された第2のパラメータ
S:単位サイズ
【0073】
外部メモリからPEアレイ110(具体的には、PEアレイ110の各PEのバッファ112)へのデータ転送の際に、第2の処理は、外部メモリから、1アドレスが1PEに対応するように、アドレス記憶部142に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するPEのバッファ112に格納する処理である。
【0074】
PEアレイ110から外部メモリへのデータ転送の際に、第2の処理は、1アドレスが1プロセッサ要素に対応するように、夫々のPEのバッファ112に格納されたデータを読み出して、アドレス記憶部142に記憶されている6個のアドレスのうちの、対応するアドレスに書き込む処理である。
【0075】
第3の処理は、アドレス記憶部142に記憶されている各アドレスAiを式(7)に従って増分させる処理である。
Ai=Ai+S (7)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
S:単位サイズ
【0076】
第4の処理は、アドレス記憶部142に記憶されている各アドレスAiを式(8)に従って増分させる処理である。
Ai=Ai+OSV (8)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
OSV:パラメータ記憶部144に記憶された第1のパラメータ
【0077】
CP130は、外部メモリからPEアレイ110へのデータ転送の際に、PE1〜PE6のバッファ112の全てがフルになる度に、PE1〜PE6にライト命令をする。また、CP130は、PEアレイ110から外部メモリへのデータ転送の際に、PE1〜PE6のバッファ112の全てが空になる度に、PE1〜PE6にリード命令をする。
【0078】
本実施の形態のSIMDプロセッサ100は、例えば、複数の単位サイズSのデータが2次元に配列してなる2次元データにおける複数の矩形領域のデータを、1矩形領域が1PEに対応するように、該SIMDプロセッサ100に含まれる複数のPEと外部メモリとの間で交換する際に、SIMDプロセッサの効率低下を抑制することができる。
【0079】
図13に示す画像Pを2次元データの具体例として、画像Pにおける6個の矩形領域(矩形領域BK1〜BK6)のデータを、外部メモリから、PEアレイ110におけるPE1〜PE6のローカルメモリ114へ夫々書き込む処理の流れを説明する。
【0080】
まず、CP130は、メモリコントローラ140のアドレス記憶部142とパラメータ記憶部144に対して設定を行う。
【0081】
アドレス記憶部142に対して、CP130は、各矩形領域の外部メモリにおける先頭アドレスを設定する。これにより、アドレス記憶部142は、アドレスAi(i=1〜6)として、矩形領域BKi(i=1〜6)の先頭アドレスが設定される。
【0082】
パラメータ記憶部144に対して、CP130は、画像Pの同一行における先端と末尾の画素のアドレスの差分を第1のパラメータOSVとして設定し、矩形領域の行方向のサイズを第2のパラメータWとして設定し、矩形領域内に含まれるデータ(画素)の行数を第3のパラメータLとして設定する。
【0083】
なお、CP130は、矩形領域BK1〜BK6の行方向のサイズが同一である場合には、該同一のサイズを第2のパラメータWに設定し、矩形領域BK1〜BK6の行方向のサイズが異なる場合には、これらのサイズのうちの最大値を第2のパラメータWに設定する。例えば、図13に示す6個の矩形領域の場合、BK5の行方向のサイズが第2のパラメータWに設定される。
【0084】
また、CP130は、矩形領域BK1〜BK6の行数が同一である場合には、該行数を第3のパラメータLに設定し、矩形領域BK1〜BK6の行数が異なる場合には、これらの行数のうちの各前記行数のうちの最大値を第3のパラメータLに設定する。例えば、図13に示す6個の矩形領域の場合、矩形領域BK2の行数が第3のパラメータLに設定される。
【0085】
CP130は、アドレス記憶部142とパラメータ記憶部144を設定すると、データ転送部146に転送指示をする。
【0086】
メモリコントローラ140は、CP130から転送指示を受けると、外部メモリからデータを読み出してPE1〜PE6のバッファ112に格納する。図3と図4を参照して説明する。なお、図3と図4において、各PEのバッファ112とローカルメモリ114内の小さい枠は、画素を示し、画素を示す枠内の数字は、該画素が属する矩形領域の番号である。例えば、図3の最上部において、PE6のバッファ112には、矩形領域BK1の1番目の画素が格納されていることを示す。
【0087】
図3に示すように、メモリコントローラ140のデータ転送部146は、CP130から転送指示を受けた後の1サイクル目(図中サイクル1)において、外部メモリから、アドレス記憶部142に記憶されたアドレスA1に格納された1画素分のデータを読み出してPE6のバッファ112に格納する。これにより、矩形領域BK1の1番目の画素がPE6のバッファ112に転送される。
【0088】
そして、サイクル2において、データ転送部146は、外部メモリから、アドレス記憶部142に記憶されたアドレスA2に格納された1画素分のデータを読み出してPE5のバッファ112に格納する。これにより、矩形領域BK2の1番目の画素がPE5のバッファ112に転送される。
【0089】
データ転送部146は、その後、外部メモリから、アドレス記憶部142に記憶された当該アドレスAi(i=3〜6)に格納された1画素分のデータを読み出して該アドレスAi(i=3〜6)に対応するPEi(i=4〜1)のバッファ112に格納する処理を繰り返す。その結果、サイクル6において、矩形領域BK6の1番目の画素がPE1のバッファ112に転送される。
【0090】
サイクル1〜6までの処理は、1回目の前述した第2の処理に該当する。データ転送部146は、ここで、第3の処理として、アドレス記憶部142に記憶されている各アドレスAi(i=1〜6)を式(7)に従って増分させる。分かりやすいように、式(7)を再度示す。
【0091】
Ai=Ai+S (7)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
S:単位サイズ
【0092】
式(7)における単位サイズ「S」は、ここで、1画素のサイズに該当する。そのため、増分後の各アドレスAi(i=1〜6)は、夫々の矩形領域の2番目の画素のアドレスになる。
【0093】
また、各PEのバッファ112の全てがフルになったため、データ転送部146は、割込みを発生させる。この割込みに応じて、CP130は、PE1〜PE6の演算処理に割り込み、ライト命令を出す。
【0094】
各PEは、CP130からのライト命令に応じて、バッファ112に格納されているデータをローカルメモリ114に書き込む。図示のように、サイクル7において、各矩形領域(BK1〜BK6)の1番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれる。
【0095】
そして、データ転送部146は、第2の処理をすると共に第3の処理を行うことを繰り返す。
【0096】
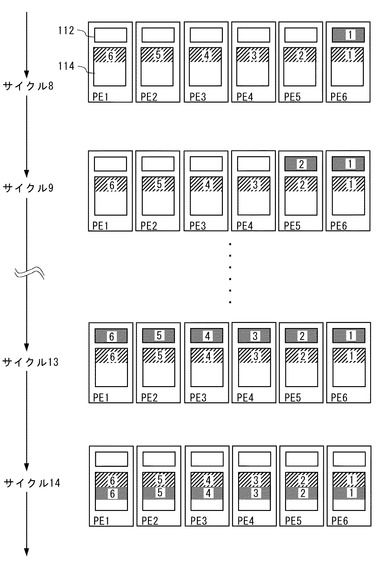
図4に示すように、サイクル8において、矩形領域BK1の2番目の画素がPE6のバッファ112に転送され、サイクル9において、矩形領域BK2の2番目の画素がPE5のバッファ112に転送される。
【0097】
同様の処理が続き、サイクル13において、矩形領域BK6の2番目の画素がPE1のバッファ112に転送される。
【0098】
サイクル8〜13までの処理は、2回目の第2の処理に該当する。ここで、データ転送部146は、割込みを発生させると共に、2回目の第3の処理として、第3アドレス記憶部142に記憶されている各アドレスAi(i=1〜6)を式(6)に従って増分させる。これにより、アドレス記憶部142に記憶されている各アドレスAi(i=1〜6)は、夫々の矩形領域の3番目の画素の先頭アドレスになる。また、図示のように、サイクル14において、各矩形領域(BK1〜BK6)の2番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれている。
【0099】
データ転送部146は、その後、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返す。分かりやすいように、式(6)を再度示す。
【0100】
M=W/S−1 (6)
但し,W:パラメータ記憶部144に記憶された第2のパラメータ
S:単位サイズ
【0101】
第2のパラメータWが矩形領域の行方向の最大サイズであり、単位サイズSが1画素のサイズであるため、式(6)に示すMは、矩形領域の行方向の最多画素数から1を引いた値になる。すなわち、第2の処理をすると共に第3の処理を行うことをM回繰り返した後、アドレス記憶部142に格納された各アドレスAiは、当該矩形領域について、当該行の転送すべき画素のうちの、最後の画素のアドレスになる。
【0102】
データ転送部146は、第2の処理をすると共に第3の処理を行うことをM回繰り返した後に、第2の処理をすると共に、第4の処理として、アドレス記憶部142に記憶されている各アドレスAiを式(8)に従って増分させる。分かりやすいように、式(8)を再度示す。
【0103】
Ai=Ai+OSV (8)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
OSV:パラメータ記憶部144に記憶された第1のパラメータ
【0104】
前述したように、第1のパラメータOSVは、画像Pの同一行における先端と末尾の画素のアドレスの差分であるため、第4の処理により、アドレス記憶部142に格納された各アドレスAiは、各矩形領域の次の行の1番目の画素のアドレスになる。
【0105】
なお、1回目の第2の処理から、1回目の第4の処理の完了までの処理は、前述した第1の処理に該当する。データ転送部146は、この第1の処理を、データ転送部146に記憶された第3のパラメータL回繰り返す。第3のパラメータLは、矩形領域の最大行数であるため、第1の処理がL回繰り返され、加えて、各PEのバッファ112がフルになる度にパラメータ記憶部144への書込みが行われた結果、各矩形領域(BK1〜BK6)のデータは、対応するPE(PE6〜PE1)のローカルメモリ114に転送される。
【0106】
図3と図4を参照して、外部メモリからPEアレイ110にデータを転送する場合を説明した。PEアレイ110から外部メモリにデータ転送する場合には、CP130が、PEアレイ110にリード命令を出した後にメモリコントローラ140に転送指示を出す点と、その後、各PEのバッファ112の全てが空になる度に、PEアレイ110にリード命令をする点と、第2の処理のデータ転送方向が上述したのと逆になる点とを除き、外部メモリからPEアレイ110にデータを転送する場合と同様であるため、ここで詳細な説明を省略する。
【0107】
このように、本第1の実施の形態のSIMDプロセッサ100によれば、CP130が1回の転送指示を出せば、メモリコントローラ140は、夫々の矩形領域のデータを、外部メモリと、該矩形領域に対応するPEのバッファ112との間で転送する。メモリコントローラ140による転送の間、CP130は、PEアレイ110に対して命令を出すことができ、PEアレイ110の各PEも、演算処理を停止することが無い。従って、2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際にも、SIMDプロセッサの効率低下を抑制することができる。
【0108】
本実施の形態のSIMDプロセッサ100において、PEアレイ110の各PEのバッファ112は、互いに独立した機能ブロックとして示されているが、これらのバッファは、例えば、同一のバッファの異なる領域であってもよい。
【0109】
さらに、SIMDプロセッサ100では、各バッファ112は、別々にデータを書き込まれる構成となっているが、例えば、これらのバッファ112が1つのシフトレジスタを形成する構成であってもよい。これについて、第2の実施の形態を用いて説明する。
【0110】
<第2の実施の形態>
図5は、本発明の第2の実施の形態にかかるSIMDプロセッサ200を示す。該SIMDプロセッサ200は、PEアレイ110の代わりにPEアレイ210が設けられている点を除き、図1に示すSIMDプロセッサ100と同様の構成を有する。また、PEアレイ210は、各PEのバッファ112の代わりにシフトレジスタ220が設けられた点を除き、SIMDプロセッサ100におけるPEアレイ110と同様の構成を有する。そのため、SIMDプロセッサ200について、SIMDプロセッサ100と異なる点についてのみ詳細に説明する。SIMDプロセッサ200による処理の例についても、SIMDプロセッサ100を説明する際と同様に、図13に示す画像Pの各矩形領域のデータをPEアレイ210の各PEに夫々転送することを用いる。
【0111】
シフトレジスタ220は、PEアレイ210に含まれるPE数(ここでは6)と同数段を有する。シフトレジスタ220の各段(1段目221〜6段目226)は、単位サイズS(ここでは画像Pの1画素のサイズ)を有する。シフトレジスタ220の入力端(1段目221)にデータが入力される度に、出力端(6段目226)に向かってシフトが行われる。また、シフトレジスタ220の各段(1段目221〜6段目226)は、各PE(PE1〜PE6)に夫々対応し、各PEは、自身に対応する段に対してデータの読出しと書込みができる。
【0112】
図13に示す画像Pにおける6個の矩形領域(矩形領域BK1〜BK6)のデータを、外部メモリから、PEアレイ210におけるPE1〜PE6のローカルメモリ114へ夫々書き込むために、まず、CP130は、メモリコントローラ140のアドレス記憶部142とパラメータ記憶部144に対して設定を行う。設定後、CP130は、メモリコントローラ140に転送指示をする。
【0113】
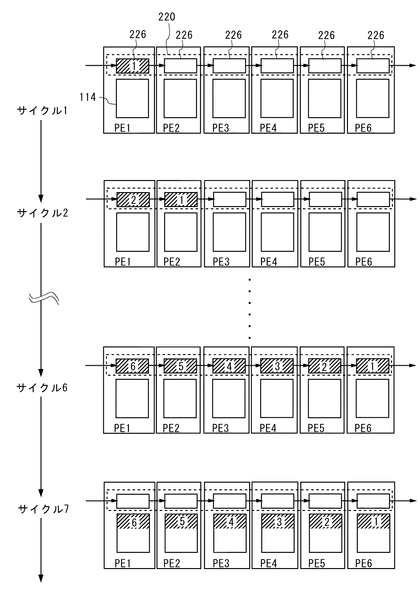
メモリコントローラ140は、CP130から転送指示を受けると、外部メモリからデータを読み出してSIMDプロセッサ200に順次入力する。図6と図7を参照して説明する。
【0114】
図6に示すように、メモリコントローラ140のデータ転送部146は、CP130から転送指示を受けた後の1サイクル目(図中サイクル1)において、外部メモリから、アドレス記憶部142に記憶されたアドレスA1に格納された1画素分のデータを読み出してシフトレジスタ220に入力する。これにより、矩形領域BK1の1番目の画素がシフトレジスタ220の1段目221に格納される。
【0115】
そして、サイクル2において、データ転送部146は、外部メモリから、アドレス記憶部142に記憶されたアドレスA2に格納された1画素分のデータを読み出してシフトレジスタ220に入力する。これにより、矩形領域BK2の1番目の画素がシフトレジスタ220の1段目221に格納され、矩形領域BK1の1番目の画素がシフトにより2段目222に格納される。
【0116】
サイクル1〜6までの処理、すなわち1回目の第2の処理が完了した際に、矩形領域BK1〜BK6の各1番目の画素は、シフトレジスタ220の6段目226〜1段目221に夫々格納される。また、アドレス記憶部142内の各アドレスAiは、1画素サイズ分増分される。
【0117】
サイクル7において、各PEは、CP130からのライト命令に応じて、シフトレジスタ220の、自身に対応する段に格納されているデータをローカルメモリ114に書き込む。これにより、各矩形領域(BK1〜BK6)の1番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれる。
【0118】
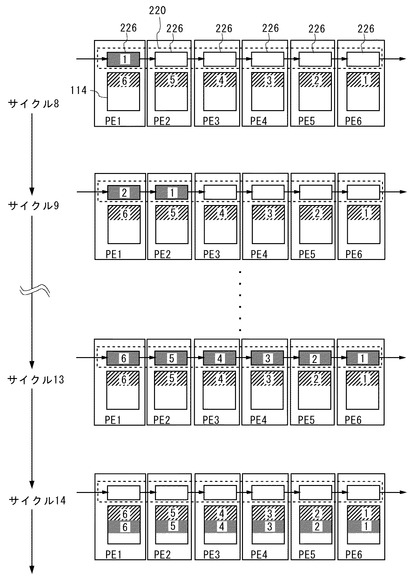
次に、図7に示すように、サイクル8において、矩形領域BK1の2番目の画素は、シフトレジスタ220の1段目221に入力され、1段目221に格納される。そして、サイクル9において、矩形領域BK2の2番目の画素がシフトレジスタ220の1段目221に入力され、1段目221に格納される。同時に、矩形領域BK1の2番目の画素がシフトにより2段目222に格納される。
【0119】
同様の処理が続き、サイクル13において、矩形領域BK6の2番目の画素がシフトレジスタ220の1段目221に入力され、1段目221に格納される。同時に、シフトにより、矩形領域BK5〜矩形領域BK1の2番目の画素は、6段目226〜2段目222に夫々格納される。また、アドレス記憶部142内の各アドレスAiは、1画素サイズ分増分される。
【0120】
そして、サイクル14において、各PEは、CP130からのライト命令に応じて、シフトレジスタ220の、自身に対応する段に格納されているデータをローカルメモリ114に書き込む。これにより、各矩形領域(BK1〜BK6)の2番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれる。図示のように、サイクル14において、各矩形領域(BK1〜BK6)の2番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれている。
【0121】
以降の処理は、データ転送部146が、外部メモリから読み出したデータをシフトレジスタ220の1段目221に入力する点を除き、SIMDプロセッサ100による相対応の処理と同様であるので、ここで詳細な説明を省略する。
【0122】
なお、PEアレイ210から外部メモリへデータ転送をする場合にも、SIMDプロセッサ100におけるメモリコントローラ140が各バッファ112からデータを読み出す動作を、SIMDプロセッサ200におけるメモリコントローラ140が、シフトレジスタ220をシフトアウトさせると共に、6段目226からシフトアウトされたデータを受け取る動作に置き換えれば、SIMDプロセッサ200とSIMDプロセッサ100の動作が同様である。
【0123】
本実施の形態のSIMDプロセッサ200も、SIMDプロセッサ100と同様の効果を発揮することができる。
【0124】
<第3の実施の形態>
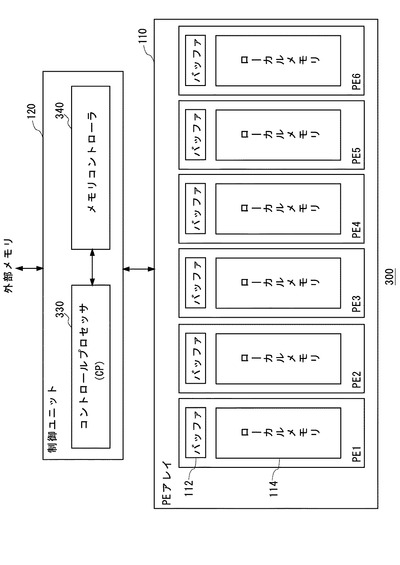
図8は、本発明の第3の実施の形態にかかるSIMDプロセッサ300を示す。SIMDプロセッサ300は、PEアレイ110と、制御ユニット320を備え、PEアレイ110は、図1に示すSIMDプロセッサ100のPEアレイ110と同一のものであり、制御ユニット320は、CP330とメモリコントローラ340を備える。
【0125】
図9は、メモリコントローラ340を示す。メモリコントローラ340は、アドレス記憶部142、パラメータ記憶部344、データ転送部346を備える。
【0126】
アドレス記憶部142は、SIMDプロセッサ100におけるメモリコントローラ140のアドレス記憶部142と同様のものである。
【0127】
パラメータ記憶部344は、第1のパラメータOSV、第2のパラメータW、第3のパラメータLに加え、さらに、CP330により第4のパラメータTを設定可能である。
【0128】
CP330は、外部メモリとPEアレイ110のデータ転送に際して、アドレス記憶部142とパラメータ記憶部344に対して設定を行う。なお、CP330は、PEアレイ110に含まれるPEの数Nの約数を第4のパラメータTとしてパラメータ記憶部344に設定する。ここでは、Nが6であるため、CP330は、第4のパラメータTとして、1、2、3のいずれかを設定可能である。
【0129】
データ転送部346は、CP330からの転送指示に応じて、外部メモリと、PE1〜PE6のバッファ112の間でデータ転送を行う。該データ転送に際して、データ転送部346は、アドレス記憶部142とパラメータ記憶部344の内容に基づいて、第1の処理を、パラメータ記憶部344に記憶された第3のパラメータLに合致する回数分繰り返す。
【0130】
SIMDプロセッサ100とSIMDプロセッサ200を説明する際に、第1の処理は、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返した後に、第2の処理をすると共に第4の処理を行う処理であると説明した。
【0131】
本第3の実施の形態にかかるSIMDプロセッサ300では、第1の処理は、第2の処理をすると共に第3の処理を行うことを、式(9)に示すM1回繰り返した後に、第2の処理をすると共に第4の処理を行う処理である。
M1=[W/(T×S)]−1 (9)
但し,W:パラメータ記憶部344に記憶された第2のパラメータ
S:単位サイズ
T:パラメータ記憶部344に記憶された第4のパラメータ
【0132】
また、第2の処理と第3の処理は、SIMDプロセッサ100のときに説明した第2の処理と第3の処理と夫々異なる。なお、第4の処理については、SIMDプロセッサ100のときに説明した第4の処理と同様である。
【0133】
まず、第2の処理を説明する。
本実施の形態のSIMDプロセッサ300において、第2の処理は、第5の処理をT回繰り返す処理である。
【0134】
外部メモリからPEアレイ110へのデータ転送の際に、第5の処理は、1アドレスが隣接するT個のPEに対応するように、アドレス記憶部142に記憶されているN(ここでは6)個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる「N/T」個のアドレスから夫々単位サイズSのT倍分のデータを読み出して、対応するT個のPEのバッファ112に夫々格納する処理である。
【0135】
また、PEアレイ110から外部メモリへのデータ転送の際に、第5の処理は、各PEのバッファ112に格納されたデータ(単位サイズSのデータ)を読み出すと共に、1アドレスが隣接するT個のPEに対応するように、隣接するT個のPEからなるグループ毎に、該グループ内のT個のPEのバッファ112から読み出したデータを、アドレス記憶部142に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる「N/T」個のアドレスのうちの、上記グループに対応する1つのアドレスに書き込む処理である。
【0136】
本実施の形態のSIMDプロセッサ300において、第3の処理は、アドレス記憶部142に記憶されている各アドレスAiを式(10)に従って増分させる処理である。
Ai=Ai+S×T (10)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部344に記憶された第4のパラメータ
【0137】
すなわち、SIMDプロセッサ300では、第3の処理によるアドレスAiの1回の増分量は、SIMDプロセッサ100のときの第3の処理によるアドレスAiの1回の増分量のT倍である。
【0138】
なお、前述したように、本実施の形態のSIMDプロセッサ300における第4の処理は、SIMDプロセッサ100のときに説明した第4の処理と同一である。
【0139】
CP330については、外部メモリからPEアレイ110へのデータ転送の際に、PE1〜PE6のバッファ112の全てがフルになる度に、PE1〜PE6にライト命令をし、PEアレイ110から外部メモリへのデータ転送の際に、PE1〜PE6のバッファ112の全てが空になる度に、PE1〜PE6にリード命令をする点において、SIMDプロセッサ100のCP130と同様である。
【0140】
SIMDプロセッサ300は、さらに、PEアレイ110から外部メモリへのデータ転送の際にはメモリコントローラ340に対してデータ転送の指示をする前に、外部メモリからPEアレイ110へのデータ転送の際には該データ転送の完了後に、PEアレイ110に対してデータ交換の命令をする。
【0141】
この「データ交換」は、ローカルメモリ間のデータ交換を意味する。PEアレイ110の各PEは、該データ交換の命令に応じて、隣接するPE同士で、ローカルメモリ上のデータを交換する。
【0142】
ここで、図13に示す画像Pにおける6個の矩形領域(矩形領域BK1〜BK6)のデータを、外部メモリから、PEアレイ110におけるPE1〜PE6のローカルメモリ114へ夫々書き込む処理を例にして、SIMDプロセッサ300の処理の流れを説明する。
【0143】
まず、CP330は、メモリコントローラ340のアドレス記憶部142とパラメータ記憶部344に対して設定を行う。
【0144】
アドレス記憶部142に対する設定は、SIMDプロセッサ100におけるCP130が行ったものと同様である。
【0145】
また、パラメータ記憶部344に対する設定のうちの第1のパラメータOSV、第2のパラメータW、第3のパラメータLについても、SIMDプロセッサ100におけるCP130が行ったものと同様である。
【0146】
CP330は、パラメータ記憶部344に対して、第4のパラメータTとして、PEアレイ110に含まれるPE数の約数、例えば「2」を設定する。
【0147】
CP330は、アドレス記憶部142とパラメータ記憶部344を設定すると、データ転送部346に転送指示をする。
【0148】
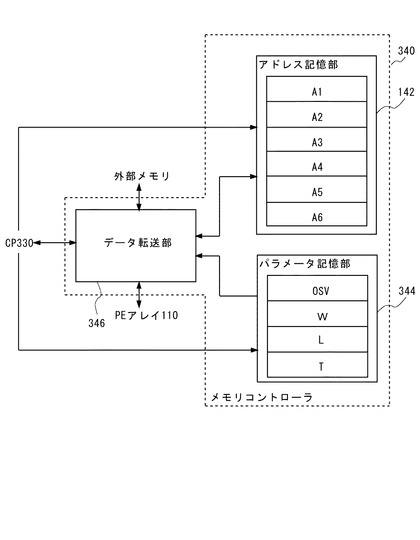
メモリコントローラ340は、CP330から転送指示を受けると、外部メモリからデータを読み出してPE1〜PE6のバッファ112に格納する。図10と図11を参照して説明する。
【0149】
図10に示すように、データ転送部346は、CP330から転送指示を受けた後の1サイクル目(図中サイクル1)において、外部メモリから、アドレス記憶部142に記憶されたアドレスA1に格納されたT画素(ここでは2画素)分のデータを読み出してPE6とPE5のバッファ112に夫々格納する。これにより、矩形領域BK1の1番目の画素がPE6のバッファ112に転送され、矩形領域BK1の2番目の画素がPE5のバッファ112に転送される。
【0150】
そして、サイクル2において、データ転送部346は、外部メモリから、アドレス記憶部142に記憶されたアドレスA2に格納されたT画素分のデータを読み出してPE4とPE3のバッファ112に夫々格納する。これにより、矩形領域BK2の1番目の画素がPE4のバッファ112に転送され、矩形領域BK2の2番目の画素がPE3のバッファ112に転送される。
【0151】
次に、サイクル3において、データ転送部346は、外部メモリから、アドレス記憶部142に記憶されたアドレスA3に格納されたT画素分のデータを読み出してPE2とPE1のバッファ112に夫々格納する。これにより、矩形領域BK3の1番目の画素がPE2のバッファ112に転送され、矩形領域BK3の2番目の画素がPE1のバッファ112に転送される。
【0152】
サイクル1〜3までの処理は、1回目の前述した第5の処理に該当する。ここで、PE1〜PE6のバッファ112の全てがフルになったため、データ転送部346は、割込みを発生させる。この割込みに応じて、CP330は、PE1〜PE6の演算処理に割り込み、ライト命令を出す。
【0153】
各PEは、CP330からのライト命令に応じて、バッファ112に格納されているデータをローカルメモリ114に書き込む。図示のように、サイクル4において、矩形領域BK1〜BK3の1番目の画素は、PE6、PE4、PE2のローカルメモリ114に夫々書き込まれ、矩形領域BK1〜BK3の2番目の画素は、PE5、PE3、PE1のローカルメモリ114に夫々書き込まれる。
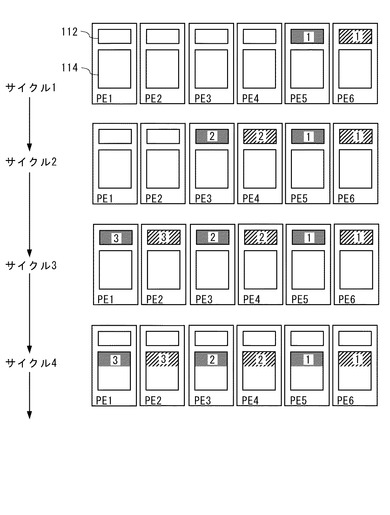
【0154】
次に、データ転送部346は、2回目の第5の処理として、図11に示すサイクル5〜7の処理を行う。図示のように、サイクル5において、矩形領域BK4の1番目の画素がPE6のバッファ112に転送され、矩形領域BK4の2番目の画素がPE5のバッファ112に転送される。
【0155】
そして、サイクル6において、矩形領域BK5の1番目の画素がPE4のバッファ112に転送され、矩形領域BK5の2番目の画素がPE3のバッファ112に転送される。
【0156】
次いで、サイクル7において、矩形領域BK6の1番目の画素がPE2のバッファ112に転送され、矩形領域BK6の2番目の画素がPE1のバッファ112に転送される。
【0157】
第5の処理がT回(2回)繰り返したため、データ転送部346は、ここで、第3の処理として、アドレス記憶部142に記憶されている各アドレスAiを式(10)に従って増分させる。分かりやすいように、式(10)を再度示す。
Ai=Ai+S×T (10)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部344に記憶された第4のパラメータ
【0158】
式(10)における単位サイズ「S」は、1画素のサイズに該当し、第4のパラメータTは、「2」に設定されている。そのため、増分後の各アドレスAi(i=1〜6)は、矩形領域BK1〜BK6の3番目の画素のアドレスになる。
【0159】
また、PE1〜PE6のバッファ112の全てがフルになったため、データ転送部346は、再度割込みを発生させる。この割込みに応じて、CP330は、PE1〜PE6の演算処理に割り込み、ライト命令を出す。これにより、図11に示すように、サイクル8において、矩形領域BK4〜BK6の1番目の画素は、PE6、PE4、PE2のローカルメモリ114に夫々書き込まれ、矩形領域BK4〜BK6の2番目の画素は、PE5、PE3、PE1のローカルメモリ114に夫々書き込まれる。
【0160】
その後、上述した処理がM1回繰り返される。なお、「M1」は、前述した式(9)に示すM1である。そのため、上述した処理がM1回繰り返された後、夫々の矩形領域の該行について、まだ外部メモリからPEアレイ110に転送されていない画素は、末尾のT個(ここでは2個)であり、アドレス記憶部142に格納されているアドレスAi(i=1〜6)は、当該矩形領域について、末尾の2つの画素のうちの先頭の画素のアドレスになっている。
【0161】
ここで、データ転送部346は、第2の処理を行うと共に、第4の処理として、アドレス記憶部142に格納されている各アドレスAi(i=1〜6)に対して、第1のパラメータOSV分増分させる。これにより、アドレス記憶部142に格納された各アドレスAiは、対応する矩形領域の次の行の先頭アドレスになる。
【0162】
矩形領域BK1〜BK6の以降の各行に対して、上記と同様の処理が繰り返される。最後に、矩形領域BK1〜BK3について、行方向において奇数番(1番目、3番目など)の画素はPE6、PE4、PE2のローカルメモリ114に夫々格納され、偶数番の画素はPE5、PE3、PE1のローカルメモリ114に夫々格納される。
【0163】
また、矩形領域BK4〜BK6についても同様に、行方向において奇数番(1番目、3番目など)の画素はPE6、PE4、PE2のローカルメモリ114に夫々格納され、偶数番の画素はPE5、PE3、PE1のローカルメモリ114に夫々格納される。
【0164】
これにて外部メモリからPEアレイ110へのデータ転送が完了するが、同一の矩形領域の全ての画素が同一のPEのローカルメモリ114に格納されるようにするために、CP330は、PEアレイ110に対してデータ交換の命令をする。
【0165】
PEアレイ110の各PEは、該命令に応じて、隣接するPE同士間でローカルメモリのデータを交換する。例えば、PE5とPE6間で、PE5のローカルメモリ114に書き込まれた矩形領域BK1の2番目の画素と、PE6のローカルメモリ114に書き込まれた矩形領域BK4の1番目の画素との交換により、矩形領域BK1の2番目の画素は、矩形領域BK1の1番目の画素と同様に、PE6のローカルメモリ114に格納されることになる。このような交換は、PEアレイ110の各隣接するPE同士間で行われた結果、図11に示すように、矩形領域BK1〜BK6のデータは、対応するPE(PE6〜PE1)のローカルメモリ114に夫々格納される。
【0166】
上記において、第4のパラメータTが「2」に設定された場合を説明した。第4のパラメータTが「1」に設定された場合には、SIMDプロセッサ300は、SIMDプロセッサ100と同様の動作をする。
【0167】
本実施の形態のSIMDプロセッサ300は、第4のパラメータTが「1」に設定されている場合には、SIMDプロセッサ100と同様の効果を得ることができる。第4のパラメータTが「2」以上に設定された場合には、上記効果に加え、外部メモリとPEアレイ110間のデータ転送をより高速にできる。
【0168】
これは、データ転送部346は、1つの矩形領域について、外部メモリに対する1度の読出でアドレスが連続するT画素分のデータを読み出してPEアレイ110のバッファ112に転送するためである。一般的に知られているように、外部メモリへのアクセスは、通常、連続したアドレスに存在するデータを同時にアクセスした方が効率良い。
【0169】
なお、この場合、データ転送部346によるデータ転送の後に、同一の矩形領域のデータが同一のPEのローカルメモリに格納されるようにする処理が必要であるものの、この処理は、隣接するPE同士間でデータ交換をするだけで実現できるので、高速に行うことができる。従って、この処理に伴うオーバーヘッドが小さい。
【0170】
以上、実施の形態をもとに本発明を説明した。実施の形態は例示であり、本発明の主旨から逸脱しない限り、上述した各実施の形態に対してさまざまな変更、増減、組合せを行ってもよい。これらの変更、増減、組合せが行われた変形例も本発明の範囲にあることは、当業者に理解されるところである。
【0171】
例えば、上述した各実施の形態において、第2のパラメータWとして、矩形領域の行方向のサイズを設定しているが、他の値、例えば、矩形領域の行方向の画素数を設定するようにしてもよい。
【0172】
また、上述した各実施の形態の動作について、画像の場合を例にしたが、本発明にかかる技術は、画像以外の2次元データの処理にも適用することができる。
【符号の説明】
【0173】
1〜6 PE 10 SIMDプロセッサ
20 コントロールプロセッサ(CP) 30 PEアレイ
42 バッファ 44 ローカルメモリ
46 MEMCTL 48 演算部
100 SIMDプロセッサ 110 PEアレイ
112 バッファ 114 ローカルメモリ
120 制御ユニット 130 CP
140 メモリコントローラ 142 アドレス記憶部
144 パラメータ記憶部 146 データ転送部
200 SIMDプロセッサ 210 PEアレイ
220 シフトレジスタ 221〜226 1段目〜6段目
300 SIMDプロセッサ 320 制御ユニット
330 コントロールプロセッサ(CP) 340 メモリコントローラ
344 パラメータ記憶部 346 データ転送部
A1〜A6 アドレス BK1〜BK6 矩形領域
P 画像 S 単位サイズ
OSV 第1のパラメータ
W 第2のパラメータ
L 第3のパラメータ
T 第4のパラメータ
【技術分野】
【0001】
本発明は、メモリアクセス制御、より具体的にはSIMD(Single Instruction Multiple Data)プロセッサ向けのメモリアクセス制御技術に関する。
【背景技術】
【0002】
SIMDプロセッサは、1回の命令により複数のデータに対して同一の処理を同時に行うことができる。図12は、SIMDプロセッサの構成例を示す。
【0003】
図12に示すSIMDプロセッサ10は、コントロールプロセッサ20と、プロセッサアレイ30を備える。プロセッサアレイ30は、1次元結合の分散メモリ型プロセッサアレイであり、複数(図示の例では6個)のプロセッサ要素を有し、これらのプロセッサ要素は、コントロールプロセッサ20からの命令に従って、同一の処理を行う。なお、コントロールプロセッサ20がPEアレイ30に命令を出す際に、マスクビットやマスクフラグ(以下、「マスクフラグ」に統一する)によって、処理をしないプロセッサ要素を指定することができる。すなわち、PEアレイ30に含まれる複数プロセッサ要素は、同一の処理を行っているか、処理をしてないかのいずれかの状態にある。
【0004】
以下において、コントロールプロセッサを「CP」、プロセッサアレイとプロセッサ要素を夫々「PEアレイ」と「PE」という。
【0005】
PEアレイ30に含まれる各PE(PE1〜PE6)は、構成が同様であるため、ここで、PE1を代表にして説明する。図示のように、PE1は、バッファ42、ローカルメモリ44、MEMCTL46、演算部48を備える。
【0006】
演算部48は、演算を実行するものであり、隣接するPEとデータの送受信ができる。MEMCTL46は、ローカルメモリアクセスと外部メモリアクセスの制御を行う。
【0007】
ローカルメモリアクセスは、PEアレイ30内部に生じたメモリアクセスであり、具体的には、演算部48からの書込要求と読出要求がある。MEMCTL46は、演算部48の書込み要求に応じて演算部48からのデータをローカルメモリ44に書き込み、演算部48の読出し要求に応じてローカルメモリ44からデータを読み出して演算部48に供する機能を担う。
【0008】
また、MEMCTL46は、PEアレイ30の外部(CP20を含む)からメモリアクセスがあった際に、ライトアクセスの場合にはライト要求されたデータをローカルメモリ44に書込み、リードアクセスの場合にはリード要求されたデータをローカルメモリ44メモリから読み出して出力する機能を備える。
【0009】
バッファ42は、PE1と外部のデータ交換用のものであり、交換されるデータを一時的に格納する。具体的には、例えば、CP20は、ローカルメモリ44へのライトアクセスに際して、まず、ライトするデータをバッファ42に格納し、ライト命令を出す。PE1は、ライト命令を受けると、MEMCTL46が、バッファ42に格納されたデータをローカルメモリ44に書き込む。また、CP20は、ローカルメモリ44へのリードアクセスに際して、リードするデータの情報を含むリード命令を出す。PE1は、リード命令を受けると、MEMCTL46が、当該データをローカルメモリ44から読み出してバッファ42に出力する。そして、CP20は、バッファ42からデータを読み出して外部に出力する。
【0010】
このようなSIMDプロセッサ10は、複数のデータが2次元に配列されてなるデータ群(以下「2次元データ」という)の処理に特に有用である。2次元データは、例えば、1画面の画素のデータからなる画像や、2次元の表の夫々のマスに入れるデータの集合などがある。ここで、1行の画素数が6個である画像に対して、注目画素と、注目画素の右隣の画素との平均をとるフィルタ処理をする場合を例にしてSIMDプロセッサ10の動作を説明する。なお、以下において、特に説明が無い限り、「画素」と「画素値」を同じ意味で用いる。
【0011】
この場合、画像の列と、PEアレイ30のPEとが一対一の関係にある。画像の注目行を見ると、該行に含まれる6個の画素は、バッファ42を介してPEアレイ30の6個のローカルメモリ44に夫々格納される。各PEのローカルメモリ44は、同一の行の画素を同一のアドレスに格納する。
【0012】
画像のA行の各画素が、各PEのローカルメモリのアドレスBに格納されているとする。この場合、A行のフィルタ処理に際して、コントローラ20は、各PEに対して、「A行の画素について、右隣の画素との平均値を求める」の命令を発行する。各PEは、自身のローカルメモリからアドレスBの画素を読み出すと共に、右隣のPEに対してアドレスBの画素を要求する。そして、この要求に応じて右隣のPEから送信してきたデータと、自身のローカルメモリから読み出したアドレスBの画素との平均演算を行うと共に、左隣のPEからの要求に応じて自身のローカルメモリから読み出したアドレスBの画素を左隣のPEに出力する。
【0013】
このように、注目行の全ての画素に対するフィルタ処理が同時にでき、効率がよい。
なお、本明細書において、画像の「行」方向は、該画像を再生した場合の横方向の意味ではなく、PEの配列方向に割り当てた方向を意味する。例えば、画像を再生した場合の1行の各画素を各PEに夫々割り当てたとき、画像を再生した場合の「行」と本明細書でいう「行」とは一致するが、画像を再生した場合の1列の各画素を各PEに夫々割り当てたとき、画像を再生した場合の「列」が本明細書でいう「行」になる。画像以外の2次元データについても同様である。
【0014】
なお、画像の1行の画素数は、PEの数と同一であるとは限らず、通常、PE数より多い。この場合、画像をブロック分けし、ブロック毎に処理を行うことがなされている。これらの各ブロックの行方向の画素数については、PE数と同一にすればよい。
【0015】
外部から各PEのローカルメモリにデータを格納するまでの処理は、様々な視点から手法が提案されている(特許文献1や非特許文献1)。例えば、非特許文献1には、この処理を工夫することで、SIMDプロセッサの効率を向上させる手法が提案されている。
【0016】
ここで、非特許文献1の手法を説明する。また、SIMDプロセッサの例として、図12に示すSIMDプロセッサ10を用いる。また、分かりやすいように、外部メモリからPEアレイ30の各PEのローカルメモリに上述したA行の6画素をPE1〜PE6の夫々のローカルメモリ44に格納する場合を例にする。
【0017】
この手法によれば、SIMDプロセッサ10は、図12に示す各機能ブロック以外に、さらにDMAコントローラ(DMA:Direct Memory Acess)をさらに備える。また、PE1〜PE6のバッファ42は、同一のシフトレジスタを構成しており、夫々のバッファ42は、該シフトレジスタの一段である。
【0018】
まず、CP20は、読出アドレスとして、上記A行の6画素のうちの1番目の画素の外部メモリにおけるアドレスを設定する。
【0019】
DMAコントローラは、設定された読出アドレスのデータ(A行の6画素のうちの1番目の画素)を外部メモリから読み出してPE1のバッファ42に格納する。次に、DMAコントローラは、読出アドレスを1つ増分して、増分した読出アドレスのデータすなわち2番目の画素を外部メモリから読み出してPE1のバッファ42に格納する。同時に、PE1のバッファ42に先に格納されたデータ(1番目の画素)は、シフトによってPE1のバッファ42からPE2のバッファ42に出力され、PE2のバッファ42に格納される。このような格納とシフトが繰り返された結果、PE1のバッファ42には6番目の画素が格納されたときに、PE2〜PE6のバッファ42には、6番目〜2番目の画素が夫々格納されたことになる。
【0020】
この時点で、DMAコントローラが割込みを発生させることにより、CP20は、各PEに対してライト命令を発行する。各PEは、MEMCTL46により、自身のバッファ42に格納されたデータをローカルメモリ44に書き込む。
【0021】
この手法では、1回のライト命令により、外部メモリから各PEのローカルメモリローカルメモリ44に格納すべきデータがバッファ42を介して、夫々のPEのローカルメモリローカルメモリ44に格納される。各バッファへのデータの格納は、DMAコントローラにより担われるため、DMAコントローラがバッファへデータを格納している間では、各PEは、演算処理を行うことができる。
【0022】
そのため、外部メモリからPEのローカルメモリへデータをライトする処理がPEの演算処理へ与える影響を抑制することができる。なお、PEのローカルメモリから外部メモリへデータを読み出す際についても同様である。
【先行技術文献】
【特許文献】
【0023】
【特許文献1】特開平11−66033号公報
【非特許文献】
【0024】
【非特許文献1】京 昭倫著「128個の4ウェイVLIW型RISCコアを集積した車載向け動画認識LSI」電子情報通信学会研究会報告、集積回路研究会(ICD),2003年5月、Vol.103,No.89,pp.19−24
【発明の概要】
【発明が解決しようとする課題】
【0025】
2次元データにおける複数の領域のデータに対して同一の処理を施す場合を考える。例えば、図13に示す画像Pに対して所定の対象物(例えば顔)の検出を行い、検出した複数の領域(図中矩形領域BK1〜BK6)に対して同一の処理を施す場合がある。勿論、各矩形領域内には、複数の画素が含まれる。
【0026】
図13において、各矩形領域内において、斜線により塗り潰された小さい枠は、該矩形領域の1番目の画素(通常、左上端の画素)を示し、黒く塗りつぶされた小さい枠は、該矩形領域の2番目の画素を示す。
【0027】
この場合、1矩形領域が1PEに対応するように、これらの複数の矩形領域のデータを、SIMDプロセッサの複数のPEのローカルメモリに夫々書き込んでおき、各PEに上記同一の処理を行わせるようにすれば、効率が良い。
【0028】
ここで、非特許文献1の手法を適用して、画像Pを格納した外部メモリからSIMDプロセッサ10の夫々のPEのローカルメモリ44に矩形領域BK1〜BK6のデータを書き込むまでの処理を考える。この場合、下記のような流れが考えられる。
【0029】
まず、CP20は、矩形領域BK1の1番目の画素の先頭アドレスを読出アドレスとしてDMAコントローラに対して設定する。
【0030】
DMAコントローラは、設定された読出アドレスのデータ(矩形領域BK1の1番目の画素)を外部メモリから読み出してPE1のバッファ42に格納する。この画素は、最終的にPE6のローカルメモリ44に書込むべき画素である。
【0031】
ここで、非特許文献1の手法の流れでは、DMAコントローラが次に読み出すべき画素は、PE5のローカルメモリ44に書き込むべき画素、すなわち矩形領域BK2の1番目の画素である。しかし、DMAコントローラは、読出アドレスを1つ増分して読出しを行うと、次に読み出したデータは、矩形領域BK1の2番目の画素である。
【0032】
そのため、DMAコントローラは、続けて読み出すべき画素を読み出すことができない。そのため、再びCP20により読出アドレス(ここでは、矩形領域BK2の1番目の画素のアドレスになる)をDMAコントローラに設定し、DMAコントローラは、設定された読出アドレスのデータを外部メモリから読み出してPE1のバッファ42に格納する。この画素は、最終的にPE5のローカルメモリ44に書込むべき画素である。同時に、シフトにより、先にPE1のバッファ42に格納されたデータ(矩形領域BK1の1番目の画素)は、PE2のバッファ42に格納される。
【0033】
これでは、1つの画素の読出しとバッファ42への格納は、必ずCP20による読出アドレスの設定が必要になり、DMAコントローラの効果を発揮することができず、SIMDプロセッサ10の効率向上を図ることができない。
【0034】
また、各PEのバッファ42により1つのシフトレジスタを形成する構成ではなく、各バッファ42は、別々に書き込むことができる構成とした場合にも、同様である。
【0035】
非特許文献1の手法を適用しない場合には、SIMDプロセッサ10の効率がより低下する。この場合の流れの例を説明する。なお、各PEのバッファ42は、別々に書き込むことができるとする。
【0036】
まず、CP20は、矩形領域BK1の1番目の画素を外部メモリから読み出してPE6のバッファ42に格納する。そして、PE1〜PE5を動作させないマスクフラグ付きのライト命令を出す。
【0037】
これにより、PE6のMEMCTL46は、ライト動作を実行し、バッファ42から矩形領域BK1の1番目の画素をローカルメモリ44に書き込む。
【0038】
同様の処理が、CP20と、PE6のMEMCTL46とにより、矩形領域BK1の画素数分回繰り返され、最後に、矩形領域BK1の全ての画素は、PE6のローカルメモリ44に書き込まれる。
【0039】
そして、CP20と、PE5のMEMCTL46とにより、同様の処理が矩形領域BK2の画素数分回繰り返され、最後に、矩形領域BK2の全ての画素は、PE5のローカルメモリ44に書き込まれる。
【0040】
矩形領域BK3〜BK6のデータも、同様の処理によりPE4〜PE1のローカルメモリ44に書き込まれる。
【0041】
上述の流れから分かるように、この場合、1つの矩形領域につき、CP20によるバッファ42へのデータの格納と、PEによるライト動作が、該領域内の画素数分回繰り返される。この間、CP20は、PEアレイ30に対して命令を放送することができず、PEアレイ30での演算処理が停止してしまうという問題がある。
【0042】
また、ローカルメモリ44へのデータの書込みは、矩形領域を1個ずつ行われるので、当該PEのローカルメモリ44へのアクセスが高い頻度で発生する。そのため、仮に、別の手段でPEアレイ30に対し命令を放送できるようにしたとしても、該PEのローカルメモリ44がデータ転送によって占有されてしまうため、PEアレイ30での演算処理がやはり停止してしまう。
【0043】
本発明は、上記事情に鑑みてなされたものであり、2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際に、SIMDプロセッサの効率低下を抑制するメモリアクセス制御技術を提供する。
【課題を解決するための手段】
【0044】
本発明の1つの態様は、SIMDプロセッサに設けられたDMAコントローラである。該SIMDプロセッサは、N個(N:2以上の整数)のプロセッサ要素を有し、各前記プロセッサ要素が、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有する。
【0045】
前記メモリコントローラは、アドレス記憶部と、パラメータ記憶部と、データ転送部とを備える。
【0046】
前記アドレス記憶部は、前記外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能である。
【0047】
前記パラメータ設定部は、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能である。
【0048】
前記データ転送部は、前記外部メモリと、前記N個のプロセッサ要素のバッファとの間でデータ転送を行うものであり、前記データ転送の指示に応じて、第1の処理を前記パラメータ記憶部に記憶された前記第3のパラメータLに合致する回数分繰り返す。
【0049】
前記第1の処理は、前記第2の処理をすると共に第3の処理を行うことを式(1)に示すM回繰り返した後に、前記第2の処理をすると共に第4の処理を行う処理である。
M=W/S−1 (1)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
【0050】
前記第2の処理は、前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、前記アドレス記憶部に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するプロセッサ要素のバッファに格納する処理である。
【0051】
また、前記第2の処理は、前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、夫々の前記プロセッサ要素のバッファに格納されたデータを読み出して、前記アドレス記憶部に記憶されているN個のアドレスのうちの、対応するアドレスに書き込む処理である。
【0052】
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(2)に従って増分させる処理である。
Ai=Ai+S (2)
但し,Ai:i個目のアドレス
S:単位サイズ
【0053】
前記第4の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(3)に従って増分させる処理である。
Ai=Ai+OSV (3)
但し,Ai:i個目のアドレス
OSV:パラメータ記憶部に記憶された第1のパラメータ
【0054】
本発明の別の態様は、SIMDプロセッサである。該SIMDプロセッサは、コントロールプロセッサと、前記コントロールプロセッサにより制御されるN個(N:2以上の整数)のプロセッサ要素と、上記態様のメモリコントローラとを備える。各前記プロセッサ要素は、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有する。
【0055】
前記コントロールプロセッサは、前記メモリコントローラによる前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に、各前記プロセッサ要素にライト命令をする。
【0056】
また、前記コントロールプロセッサは、前記DMAコントローラによる前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に、各前記プロセッサ要素にリード命令をする。
【0057】
なお、上記態様のメモリコントローラやコントロールプロセッサを方法や装置、システムなどに置換えて表示したものや、これらの方法をコンピュータに実行せしめるプログラムなども、本発明の態様としては有効である。
【発明の効果】
【0058】
本発明にかかるメモリアクセス制御技術によれば、例えば、2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際に、SIMDプロセッサの効率低下を抑制することができる。
【図面の簡単な説明】
【0059】
【図1】本発明の第1の実施の形態にかかるSIMDプロセッサを示す図である。
【図2】図1に示すSIMDプロセッサにおけるメモリコントローラを示す図である。
【図3】図1に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図4】図1に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図5】本発明の第2の実施の形態にかかるSIMDプロセッサを示す図である。
【図6】図5に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図7】図5に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図8】本発明の第2の実施の形態にかかるSIMDプロセッサを示す図である。
【図9】図8に示すSIMDプロセッサにおけるメモリコントローラを示す図である。
【図10】図8に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図11】図8に示すSIMDプロセッサの動作を説明するための図である(その1)。
【図12】通常のSIMDプロセッサの構成例を示す図である。
【図13】2次元データの例となる画像を示す図である。
【発明を実施するための形態】
【0060】
以下、図面を参照して本発明の実施の形態について説明する。説明の明確化のため、以下の記載及び図面は、適宜、省略、及び簡略化がなされている。また、様々な処理を行う機能ブロックとして図面に記載される各要素は、ハードウェアとソフトウェア(プログラム)の組合せによっていろいろな形で実現できることは当業者には理解されるところであり、ハードウェアとソフトウェアのいずれかに限定されるものではない。なお、各図面において、同一の要素には同一の符号が付されており、必要に応じて重複説明は省略されている。
【0061】
また、上述したプログラムは、様々なタイプの非一時的なコンピュータ可読媒体(non−transitory computer readable medium)を用いて格納され、コンピュータに供給することができる。非一時的なコンピュータ可読媒体は、様々なタイプの実体のある記録媒体(tangible storage medium)を含む。非一時的なコンピュータ可読媒体の例は、磁気記録媒体(例えばフレキシブルディスク、磁気テープ、ハードディスクドライブ)、光磁気記録媒体(例えば光磁気ディスク)、CD−ROM(Read Only Memory)CD−R、CD−R/W、半導体メモリ(例えば、マスクROM、PROM(Programmable ROM)、EPROM(Erasable PROM)、フラッシュROM、RAM(Random Access Memory))を含む。また、プログラムは、様々なタイプの一時的なコンピュータ可読媒体(transitory computer readable medium)によってコンピュータに供給されてもよい。一時的なコンピュータ可読媒体の例は、電気信号、光信号、及び電磁波を含む。一時的なコンピュータ可読媒体は、電線及び光ファイバ等の有線通信路、又は無線通信路を介して、プログラムをコンピュータに供給できる。
【0062】
<第1の実施の形態>
図1は、本発明の第1の実施の形態にかかるSIMDプロセッサ100を示す。SIMDプロセッサ100は、PEアレイ110、制御ユニット120を備える。
【0063】
PEアレイ110は、N個(N:2以上の整数であり、ここでは例として、N=6)のプロセッサ要素(PE)1〜6を有する。各PEは、同一の構成を有するため、ここで、PE1を代表にする。
【0064】
PE1は、外部メモリとの間で交換されるデータを一時的に格納するバッファ112と、ローカルメモリ114を備える。バッファ112の容量は、所定の単位サイズSである。なお、この種のPEに通常備えられる演算部などの機能ブロックの図示は、省略する。
【0065】
PE1は、制御ユニット120における後述するコントロールプロセッサ(CP)130により制御される。外部メモリとのデータ交換に際して、PE1は、CP130からのリード命令に応じて、該当するデータをローカルメモリ114から読み出してバッファ112に格納し、また、CP130からのライト命令に応じて、バッファ112に格納されたデータを読み出して、ローカルメモリ114の該当する番地に書き込む。
【0066】
制御ユニット120は、CP130と、メモリコントローラ140を備える。CP130は、PEアレイ110と、メモリコントローラ140の制御を行う。
【0067】
メモリコントローラ140は、データ転送の指示(以下、単に転送指示という)をCP130から受けると、PEアレイ110の各PEと、外部メモリとの間で交換されるデータのDMA転送を行う。図2を参照してメモリコントローラ140を詳細に説明する。
【0068】
図2に示すように、メモリコントローラ140は、アドレス記憶部142、パラメータ記憶部144、データ転送部146を備える。
【0069】
アドレス記憶部142は、CP130により、外部メモリにおけるN個(ここでは6個)のアドレスAi(i=1〜6)を設定可能である。また、アドレス記憶部142内に記憶された各アドレスAiは、データ転送部146により変更可能である。
【0070】
パラメータ記憶部144は、CP130により、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能である。
【0071】
データ転送部146は、CP130からの転送指示に応じて、外部メモリと、PE1〜PE6のバッファ112の間でデータ転送を行う。該データ転送に際して、データ転送部146は、アドレス記憶部142とパラメータ記憶部144の内容に基づいて、第1の処理を、パラメータ記憶部144に記憶された第3のパラメータLに合致する回数分繰り返す。
【0072】
第1の処理は、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返した後に、第2の処理をすると共に第4の処理を行う処理である。
M=W/S−1 (6)
但し,W:パラメータ記憶部144に記憶された第2のパラメータ
S:単位サイズ
【0073】
外部メモリからPEアレイ110(具体的には、PEアレイ110の各PEのバッファ112)へのデータ転送の際に、第2の処理は、外部メモリから、1アドレスが1PEに対応するように、アドレス記憶部142に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するPEのバッファ112に格納する処理である。
【0074】
PEアレイ110から外部メモリへのデータ転送の際に、第2の処理は、1アドレスが1プロセッサ要素に対応するように、夫々のPEのバッファ112に格納されたデータを読み出して、アドレス記憶部142に記憶されている6個のアドレスのうちの、対応するアドレスに書き込む処理である。
【0075】
第3の処理は、アドレス記憶部142に記憶されている各アドレスAiを式(7)に従って増分させる処理である。
Ai=Ai+S (7)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
S:単位サイズ
【0076】
第4の処理は、アドレス記憶部142に記憶されている各アドレスAiを式(8)に従って増分させる処理である。
Ai=Ai+OSV (8)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
OSV:パラメータ記憶部144に記憶された第1のパラメータ
【0077】
CP130は、外部メモリからPEアレイ110へのデータ転送の際に、PE1〜PE6のバッファ112の全てがフルになる度に、PE1〜PE6にライト命令をする。また、CP130は、PEアレイ110から外部メモリへのデータ転送の際に、PE1〜PE6のバッファ112の全てが空になる度に、PE1〜PE6にリード命令をする。
【0078】
本実施の形態のSIMDプロセッサ100は、例えば、複数の単位サイズSのデータが2次元に配列してなる2次元データにおける複数の矩形領域のデータを、1矩形領域が1PEに対応するように、該SIMDプロセッサ100に含まれる複数のPEと外部メモリとの間で交換する際に、SIMDプロセッサの効率低下を抑制することができる。
【0079】
図13に示す画像Pを2次元データの具体例として、画像Pにおける6個の矩形領域(矩形領域BK1〜BK6)のデータを、外部メモリから、PEアレイ110におけるPE1〜PE6のローカルメモリ114へ夫々書き込む処理の流れを説明する。
【0080】
まず、CP130は、メモリコントローラ140のアドレス記憶部142とパラメータ記憶部144に対して設定を行う。
【0081】
アドレス記憶部142に対して、CP130は、各矩形領域の外部メモリにおける先頭アドレスを設定する。これにより、アドレス記憶部142は、アドレスAi(i=1〜6)として、矩形領域BKi(i=1〜6)の先頭アドレスが設定される。
【0082】
パラメータ記憶部144に対して、CP130は、画像Pの同一行における先端と末尾の画素のアドレスの差分を第1のパラメータOSVとして設定し、矩形領域の行方向のサイズを第2のパラメータWとして設定し、矩形領域内に含まれるデータ(画素)の行数を第3のパラメータLとして設定する。
【0083】
なお、CP130は、矩形領域BK1〜BK6の行方向のサイズが同一である場合には、該同一のサイズを第2のパラメータWに設定し、矩形領域BK1〜BK6の行方向のサイズが異なる場合には、これらのサイズのうちの最大値を第2のパラメータWに設定する。例えば、図13に示す6個の矩形領域の場合、BK5の行方向のサイズが第2のパラメータWに設定される。
【0084】
また、CP130は、矩形領域BK1〜BK6の行数が同一である場合には、該行数を第3のパラメータLに設定し、矩形領域BK1〜BK6の行数が異なる場合には、これらの行数のうちの各前記行数のうちの最大値を第3のパラメータLに設定する。例えば、図13に示す6個の矩形領域の場合、矩形領域BK2の行数が第3のパラメータLに設定される。
【0085】
CP130は、アドレス記憶部142とパラメータ記憶部144を設定すると、データ転送部146に転送指示をする。
【0086】
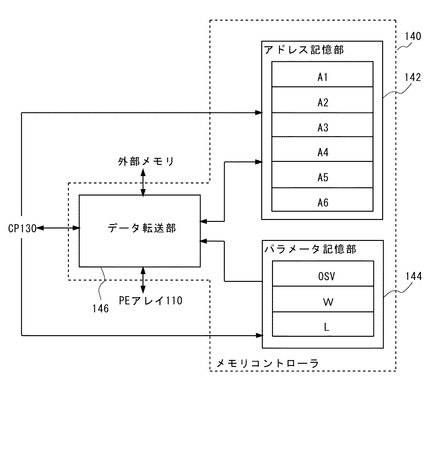
メモリコントローラ140は、CP130から転送指示を受けると、外部メモリからデータを読み出してPE1〜PE6のバッファ112に格納する。図3と図4を参照して説明する。なお、図3と図4において、各PEのバッファ112とローカルメモリ114内の小さい枠は、画素を示し、画素を示す枠内の数字は、該画素が属する矩形領域の番号である。例えば、図3の最上部において、PE6のバッファ112には、矩形領域BK1の1番目の画素が格納されていることを示す。
【0087】
図3に示すように、メモリコントローラ140のデータ転送部146は、CP130から転送指示を受けた後の1サイクル目(図中サイクル1)において、外部メモリから、アドレス記憶部142に記憶されたアドレスA1に格納された1画素分のデータを読み出してPE6のバッファ112に格納する。これにより、矩形領域BK1の1番目の画素がPE6のバッファ112に転送される。
【0088】
そして、サイクル2において、データ転送部146は、外部メモリから、アドレス記憶部142に記憶されたアドレスA2に格納された1画素分のデータを読み出してPE5のバッファ112に格納する。これにより、矩形領域BK2の1番目の画素がPE5のバッファ112に転送される。
【0089】
データ転送部146は、その後、外部メモリから、アドレス記憶部142に記憶された当該アドレスAi(i=3〜6)に格納された1画素分のデータを読み出して該アドレスAi(i=3〜6)に対応するPEi(i=4〜1)のバッファ112に格納する処理を繰り返す。その結果、サイクル6において、矩形領域BK6の1番目の画素がPE1のバッファ112に転送される。
【0090】
サイクル1〜6までの処理は、1回目の前述した第2の処理に該当する。データ転送部146は、ここで、第3の処理として、アドレス記憶部142に記憶されている各アドレスAi(i=1〜6)を式(7)に従って増分させる。分かりやすいように、式(7)を再度示す。
【0091】
Ai=Ai+S (7)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
S:単位サイズ
【0092】
式(7)における単位サイズ「S」は、ここで、1画素のサイズに該当する。そのため、増分後の各アドレスAi(i=1〜6)は、夫々の矩形領域の2番目の画素のアドレスになる。
【0093】
また、各PEのバッファ112の全てがフルになったため、データ転送部146は、割込みを発生させる。この割込みに応じて、CP130は、PE1〜PE6の演算処理に割り込み、ライト命令を出す。
【0094】
各PEは、CP130からのライト命令に応じて、バッファ112に格納されているデータをローカルメモリ114に書き込む。図示のように、サイクル7において、各矩形領域(BK1〜BK6)の1番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれる。
【0095】
そして、データ転送部146は、第2の処理をすると共に第3の処理を行うことを繰り返す。
【0096】
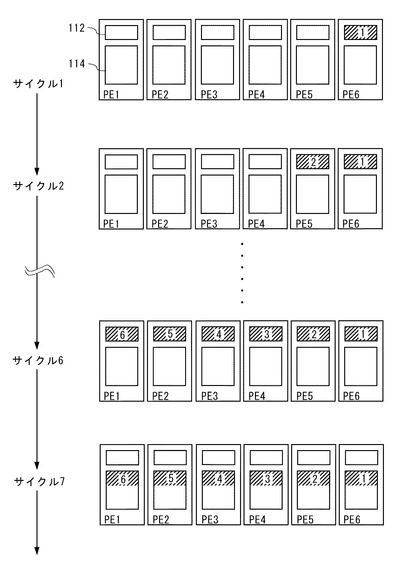
図4に示すように、サイクル8において、矩形領域BK1の2番目の画素がPE6のバッファ112に転送され、サイクル9において、矩形領域BK2の2番目の画素がPE5のバッファ112に転送される。
【0097】
同様の処理が続き、サイクル13において、矩形領域BK6の2番目の画素がPE1のバッファ112に転送される。
【0098】
サイクル8〜13までの処理は、2回目の第2の処理に該当する。ここで、データ転送部146は、割込みを発生させると共に、2回目の第3の処理として、第3アドレス記憶部142に記憶されている各アドレスAi(i=1〜6)を式(6)に従って増分させる。これにより、アドレス記憶部142に記憶されている各アドレスAi(i=1〜6)は、夫々の矩形領域の3番目の画素の先頭アドレスになる。また、図示のように、サイクル14において、各矩形領域(BK1〜BK6)の2番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれている。
【0099】
データ転送部146は、その後、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返す。分かりやすいように、式(6)を再度示す。
【0100】
M=W/S−1 (6)
但し,W:パラメータ記憶部144に記憶された第2のパラメータ
S:単位サイズ
【0101】
第2のパラメータWが矩形領域の行方向の最大サイズであり、単位サイズSが1画素のサイズであるため、式(6)に示すMは、矩形領域の行方向の最多画素数から1を引いた値になる。すなわち、第2の処理をすると共に第3の処理を行うことをM回繰り返した後、アドレス記憶部142に格納された各アドレスAiは、当該矩形領域について、当該行の転送すべき画素のうちの、最後の画素のアドレスになる。
【0102】
データ転送部146は、第2の処理をすると共に第3の処理を行うことをM回繰り返した後に、第2の処理をすると共に、第4の処理として、アドレス記憶部142に記憶されている各アドレスAiを式(8)に従って増分させる。分かりやすいように、式(8)を再度示す。
【0103】
Ai=Ai+OSV (8)
但し,Ai:アドレス記憶部142に記憶されたi個目のアドレス
OSV:パラメータ記憶部144に記憶された第1のパラメータ
【0104】
前述したように、第1のパラメータOSVは、画像Pの同一行における先端と末尾の画素のアドレスの差分であるため、第4の処理により、アドレス記憶部142に格納された各アドレスAiは、各矩形領域の次の行の1番目の画素のアドレスになる。
【0105】
なお、1回目の第2の処理から、1回目の第4の処理の完了までの処理は、前述した第1の処理に該当する。データ転送部146は、この第1の処理を、データ転送部146に記憶された第3のパラメータL回繰り返す。第3のパラメータLは、矩形領域の最大行数であるため、第1の処理がL回繰り返され、加えて、各PEのバッファ112がフルになる度にパラメータ記憶部144への書込みが行われた結果、各矩形領域(BK1〜BK6)のデータは、対応するPE(PE6〜PE1)のローカルメモリ114に転送される。
【0106】
図3と図4を参照して、外部メモリからPEアレイ110にデータを転送する場合を説明した。PEアレイ110から外部メモリにデータ転送する場合には、CP130が、PEアレイ110にリード命令を出した後にメモリコントローラ140に転送指示を出す点と、その後、各PEのバッファ112の全てが空になる度に、PEアレイ110にリード命令をする点と、第2の処理のデータ転送方向が上述したのと逆になる点とを除き、外部メモリからPEアレイ110にデータを転送する場合と同様であるため、ここで詳細な説明を省略する。
【0107】
このように、本第1の実施の形態のSIMDプロセッサ100によれば、CP130が1回の転送指示を出せば、メモリコントローラ140は、夫々の矩形領域のデータを、外部メモリと、該矩形領域に対応するPEのバッファ112との間で転送する。メモリコントローラ140による転送の間、CP130は、PEアレイ110に対して命令を出すことができ、PEアレイ110の各PEも、演算処理を停止することが無い。従って、2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際にも、SIMDプロセッサの効率低下を抑制することができる。
【0108】
本実施の形態のSIMDプロセッサ100において、PEアレイ110の各PEのバッファ112は、互いに独立した機能ブロックとして示されているが、これらのバッファは、例えば、同一のバッファの異なる領域であってもよい。
【0109】
さらに、SIMDプロセッサ100では、各バッファ112は、別々にデータを書き込まれる構成となっているが、例えば、これらのバッファ112が1つのシフトレジスタを形成する構成であってもよい。これについて、第2の実施の形態を用いて説明する。
【0110】
<第2の実施の形態>
図5は、本発明の第2の実施の形態にかかるSIMDプロセッサ200を示す。該SIMDプロセッサ200は、PEアレイ110の代わりにPEアレイ210が設けられている点を除き、図1に示すSIMDプロセッサ100と同様の構成を有する。また、PEアレイ210は、各PEのバッファ112の代わりにシフトレジスタ220が設けられた点を除き、SIMDプロセッサ100におけるPEアレイ110と同様の構成を有する。そのため、SIMDプロセッサ200について、SIMDプロセッサ100と異なる点についてのみ詳細に説明する。SIMDプロセッサ200による処理の例についても、SIMDプロセッサ100を説明する際と同様に、図13に示す画像Pの各矩形領域のデータをPEアレイ210の各PEに夫々転送することを用いる。
【0111】
シフトレジスタ220は、PEアレイ210に含まれるPE数(ここでは6)と同数段を有する。シフトレジスタ220の各段(1段目221〜6段目226)は、単位サイズS(ここでは画像Pの1画素のサイズ)を有する。シフトレジスタ220の入力端(1段目221)にデータが入力される度に、出力端(6段目226)に向かってシフトが行われる。また、シフトレジスタ220の各段(1段目221〜6段目226)は、各PE(PE1〜PE6)に夫々対応し、各PEは、自身に対応する段に対してデータの読出しと書込みができる。
【0112】
図13に示す画像Pにおける6個の矩形領域(矩形領域BK1〜BK6)のデータを、外部メモリから、PEアレイ210におけるPE1〜PE6のローカルメモリ114へ夫々書き込むために、まず、CP130は、メモリコントローラ140のアドレス記憶部142とパラメータ記憶部144に対して設定を行う。設定後、CP130は、メモリコントローラ140に転送指示をする。
【0113】
メモリコントローラ140は、CP130から転送指示を受けると、外部メモリからデータを読み出してSIMDプロセッサ200に順次入力する。図6と図7を参照して説明する。
【0114】
図6に示すように、メモリコントローラ140のデータ転送部146は、CP130から転送指示を受けた後の1サイクル目(図中サイクル1)において、外部メモリから、アドレス記憶部142に記憶されたアドレスA1に格納された1画素分のデータを読み出してシフトレジスタ220に入力する。これにより、矩形領域BK1の1番目の画素がシフトレジスタ220の1段目221に格納される。
【0115】
そして、サイクル2において、データ転送部146は、外部メモリから、アドレス記憶部142に記憶されたアドレスA2に格納された1画素分のデータを読み出してシフトレジスタ220に入力する。これにより、矩形領域BK2の1番目の画素がシフトレジスタ220の1段目221に格納され、矩形領域BK1の1番目の画素がシフトにより2段目222に格納される。
【0116】
サイクル1〜6までの処理、すなわち1回目の第2の処理が完了した際に、矩形領域BK1〜BK6の各1番目の画素は、シフトレジスタ220の6段目226〜1段目221に夫々格納される。また、アドレス記憶部142内の各アドレスAiは、1画素サイズ分増分される。
【0117】
サイクル7において、各PEは、CP130からのライト命令に応じて、シフトレジスタ220の、自身に対応する段に格納されているデータをローカルメモリ114に書き込む。これにより、各矩形領域(BK1〜BK6)の1番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれる。
【0118】
次に、図7に示すように、サイクル8において、矩形領域BK1の2番目の画素は、シフトレジスタ220の1段目221に入力され、1段目221に格納される。そして、サイクル9において、矩形領域BK2の2番目の画素がシフトレジスタ220の1段目221に入力され、1段目221に格納される。同時に、矩形領域BK1の2番目の画素がシフトにより2段目222に格納される。
【0119】
同様の処理が続き、サイクル13において、矩形領域BK6の2番目の画素がシフトレジスタ220の1段目221に入力され、1段目221に格納される。同時に、シフトにより、矩形領域BK5〜矩形領域BK1の2番目の画素は、6段目226〜2段目222に夫々格納される。また、アドレス記憶部142内の各アドレスAiは、1画素サイズ分増分される。
【0120】
そして、サイクル14において、各PEは、CP130からのライト命令に応じて、シフトレジスタ220の、自身に対応する段に格納されているデータをローカルメモリ114に書き込む。これにより、各矩形領域(BK1〜BK6)の2番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれる。図示のように、サイクル14において、各矩形領域(BK1〜BK6)の2番目の画素が、対応するPE(PE6〜PE1)のローカルメモリ114に夫々書き込まれている。
【0121】
以降の処理は、データ転送部146が、外部メモリから読み出したデータをシフトレジスタ220の1段目221に入力する点を除き、SIMDプロセッサ100による相対応の処理と同様であるので、ここで詳細な説明を省略する。
【0122】
なお、PEアレイ210から外部メモリへデータ転送をする場合にも、SIMDプロセッサ100におけるメモリコントローラ140が各バッファ112からデータを読み出す動作を、SIMDプロセッサ200におけるメモリコントローラ140が、シフトレジスタ220をシフトアウトさせると共に、6段目226からシフトアウトされたデータを受け取る動作に置き換えれば、SIMDプロセッサ200とSIMDプロセッサ100の動作が同様である。
【0123】
本実施の形態のSIMDプロセッサ200も、SIMDプロセッサ100と同様の効果を発揮することができる。
【0124】
<第3の実施の形態>
図8は、本発明の第3の実施の形態にかかるSIMDプロセッサ300を示す。SIMDプロセッサ300は、PEアレイ110と、制御ユニット320を備え、PEアレイ110は、図1に示すSIMDプロセッサ100のPEアレイ110と同一のものであり、制御ユニット320は、CP330とメモリコントローラ340を備える。
【0125】
図9は、メモリコントローラ340を示す。メモリコントローラ340は、アドレス記憶部142、パラメータ記憶部344、データ転送部346を備える。
【0126】
アドレス記憶部142は、SIMDプロセッサ100におけるメモリコントローラ140のアドレス記憶部142と同様のものである。
【0127】
パラメータ記憶部344は、第1のパラメータOSV、第2のパラメータW、第3のパラメータLに加え、さらに、CP330により第4のパラメータTを設定可能である。
【0128】
CP330は、外部メモリとPEアレイ110のデータ転送に際して、アドレス記憶部142とパラメータ記憶部344に対して設定を行う。なお、CP330は、PEアレイ110に含まれるPEの数Nの約数を第4のパラメータTとしてパラメータ記憶部344に設定する。ここでは、Nが6であるため、CP330は、第4のパラメータTとして、1、2、3のいずれかを設定可能である。
【0129】
データ転送部346は、CP330からの転送指示に応じて、外部メモリと、PE1〜PE6のバッファ112の間でデータ転送を行う。該データ転送に際して、データ転送部346は、アドレス記憶部142とパラメータ記憶部344の内容に基づいて、第1の処理を、パラメータ記憶部344に記憶された第3のパラメータLに合致する回数分繰り返す。
【0130】
SIMDプロセッサ100とSIMDプロセッサ200を説明する際に、第1の処理は、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返した後に、第2の処理をすると共に第4の処理を行う処理であると説明した。
【0131】
本第3の実施の形態にかかるSIMDプロセッサ300では、第1の処理は、第2の処理をすると共に第3の処理を行うことを、式(9)に示すM1回繰り返した後に、第2の処理をすると共に第4の処理を行う処理である。
M1=[W/(T×S)]−1 (9)
但し,W:パラメータ記憶部344に記憶された第2のパラメータ
S:単位サイズ
T:パラメータ記憶部344に記憶された第4のパラメータ
【0132】
また、第2の処理と第3の処理は、SIMDプロセッサ100のときに説明した第2の処理と第3の処理と夫々異なる。なお、第4の処理については、SIMDプロセッサ100のときに説明した第4の処理と同様である。
【0133】
まず、第2の処理を説明する。
本実施の形態のSIMDプロセッサ300において、第2の処理は、第5の処理をT回繰り返す処理である。
【0134】
外部メモリからPEアレイ110へのデータ転送の際に、第5の処理は、1アドレスが隣接するT個のPEに対応するように、アドレス記憶部142に記憶されているN(ここでは6)個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる「N/T」個のアドレスから夫々単位サイズSのT倍分のデータを読み出して、対応するT個のPEのバッファ112に夫々格納する処理である。
【0135】
また、PEアレイ110から外部メモリへのデータ転送の際に、第5の処理は、各PEのバッファ112に格納されたデータ(単位サイズSのデータ)を読み出すと共に、1アドレスが隣接するT個のPEに対応するように、隣接するT個のPEからなるグループ毎に、該グループ内のT個のPEのバッファ112から読み出したデータを、アドレス記憶部142に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる「N/T」個のアドレスのうちの、上記グループに対応する1つのアドレスに書き込む処理である。
【0136】
本実施の形態のSIMDプロセッサ300において、第3の処理は、アドレス記憶部142に記憶されている各アドレスAiを式(10)に従って増分させる処理である。
Ai=Ai+S×T (10)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部344に記憶された第4のパラメータ
【0137】
すなわち、SIMDプロセッサ300では、第3の処理によるアドレスAiの1回の増分量は、SIMDプロセッサ100のときの第3の処理によるアドレスAiの1回の増分量のT倍である。
【0138】
なお、前述したように、本実施の形態のSIMDプロセッサ300における第4の処理は、SIMDプロセッサ100のときに説明した第4の処理と同一である。
【0139】
CP330については、外部メモリからPEアレイ110へのデータ転送の際に、PE1〜PE6のバッファ112の全てがフルになる度に、PE1〜PE6にライト命令をし、PEアレイ110から外部メモリへのデータ転送の際に、PE1〜PE6のバッファ112の全てが空になる度に、PE1〜PE6にリード命令をする点において、SIMDプロセッサ100のCP130と同様である。
【0140】
SIMDプロセッサ300は、さらに、PEアレイ110から外部メモリへのデータ転送の際にはメモリコントローラ340に対してデータ転送の指示をする前に、外部メモリからPEアレイ110へのデータ転送の際には該データ転送の完了後に、PEアレイ110に対してデータ交換の命令をする。
【0141】
この「データ交換」は、ローカルメモリ間のデータ交換を意味する。PEアレイ110の各PEは、該データ交換の命令に応じて、隣接するPE同士で、ローカルメモリ上のデータを交換する。
【0142】
ここで、図13に示す画像Pにおける6個の矩形領域(矩形領域BK1〜BK6)のデータを、外部メモリから、PEアレイ110におけるPE1〜PE6のローカルメモリ114へ夫々書き込む処理を例にして、SIMDプロセッサ300の処理の流れを説明する。
【0143】
まず、CP330は、メモリコントローラ340のアドレス記憶部142とパラメータ記憶部344に対して設定を行う。
【0144】
アドレス記憶部142に対する設定は、SIMDプロセッサ100におけるCP130が行ったものと同様である。
【0145】
また、パラメータ記憶部344に対する設定のうちの第1のパラメータOSV、第2のパラメータW、第3のパラメータLについても、SIMDプロセッサ100におけるCP130が行ったものと同様である。
【0146】
CP330は、パラメータ記憶部344に対して、第4のパラメータTとして、PEアレイ110に含まれるPE数の約数、例えば「2」を設定する。
【0147】
CP330は、アドレス記憶部142とパラメータ記憶部344を設定すると、データ転送部346に転送指示をする。
【0148】
メモリコントローラ340は、CP330から転送指示を受けると、外部メモリからデータを読み出してPE1〜PE6のバッファ112に格納する。図10と図11を参照して説明する。
【0149】
図10に示すように、データ転送部346は、CP330から転送指示を受けた後の1サイクル目(図中サイクル1)において、外部メモリから、アドレス記憶部142に記憶されたアドレスA1に格納されたT画素(ここでは2画素)分のデータを読み出してPE6とPE5のバッファ112に夫々格納する。これにより、矩形領域BK1の1番目の画素がPE6のバッファ112に転送され、矩形領域BK1の2番目の画素がPE5のバッファ112に転送される。
【0150】
そして、サイクル2において、データ転送部346は、外部メモリから、アドレス記憶部142に記憶されたアドレスA2に格納されたT画素分のデータを読み出してPE4とPE3のバッファ112に夫々格納する。これにより、矩形領域BK2の1番目の画素がPE4のバッファ112に転送され、矩形領域BK2の2番目の画素がPE3のバッファ112に転送される。
【0151】
次に、サイクル3において、データ転送部346は、外部メモリから、アドレス記憶部142に記憶されたアドレスA3に格納されたT画素分のデータを読み出してPE2とPE1のバッファ112に夫々格納する。これにより、矩形領域BK3の1番目の画素がPE2のバッファ112に転送され、矩形領域BK3の2番目の画素がPE1のバッファ112に転送される。
【0152】
サイクル1〜3までの処理は、1回目の前述した第5の処理に該当する。ここで、PE1〜PE6のバッファ112の全てがフルになったため、データ転送部346は、割込みを発生させる。この割込みに応じて、CP330は、PE1〜PE6の演算処理に割り込み、ライト命令を出す。
【0153】
各PEは、CP330からのライト命令に応じて、バッファ112に格納されているデータをローカルメモリ114に書き込む。図示のように、サイクル4において、矩形領域BK1〜BK3の1番目の画素は、PE6、PE4、PE2のローカルメモリ114に夫々書き込まれ、矩形領域BK1〜BK3の2番目の画素は、PE5、PE3、PE1のローカルメモリ114に夫々書き込まれる。
【0154】
次に、データ転送部346は、2回目の第5の処理として、図11に示すサイクル5〜7の処理を行う。図示のように、サイクル5において、矩形領域BK4の1番目の画素がPE6のバッファ112に転送され、矩形領域BK4の2番目の画素がPE5のバッファ112に転送される。
【0155】
そして、サイクル6において、矩形領域BK5の1番目の画素がPE4のバッファ112に転送され、矩形領域BK5の2番目の画素がPE3のバッファ112に転送される。
【0156】
次いで、サイクル7において、矩形領域BK6の1番目の画素がPE2のバッファ112に転送され、矩形領域BK6の2番目の画素がPE1のバッファ112に転送される。
【0157】
第5の処理がT回(2回)繰り返したため、データ転送部346は、ここで、第3の処理として、アドレス記憶部142に記憶されている各アドレスAiを式(10)に従って増分させる。分かりやすいように、式(10)を再度示す。
Ai=Ai+S×T (10)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部344に記憶された第4のパラメータ
【0158】
式(10)における単位サイズ「S」は、1画素のサイズに該当し、第4のパラメータTは、「2」に設定されている。そのため、増分後の各アドレスAi(i=1〜6)は、矩形領域BK1〜BK6の3番目の画素のアドレスになる。
【0159】
また、PE1〜PE6のバッファ112の全てがフルになったため、データ転送部346は、再度割込みを発生させる。この割込みに応じて、CP330は、PE1〜PE6の演算処理に割り込み、ライト命令を出す。これにより、図11に示すように、サイクル8において、矩形領域BK4〜BK6の1番目の画素は、PE6、PE4、PE2のローカルメモリ114に夫々書き込まれ、矩形領域BK4〜BK6の2番目の画素は、PE5、PE3、PE1のローカルメモリ114に夫々書き込まれる。
【0160】
その後、上述した処理がM1回繰り返される。なお、「M1」は、前述した式(9)に示すM1である。そのため、上述した処理がM1回繰り返された後、夫々の矩形領域の該行について、まだ外部メモリからPEアレイ110に転送されていない画素は、末尾のT個(ここでは2個)であり、アドレス記憶部142に格納されているアドレスAi(i=1〜6)は、当該矩形領域について、末尾の2つの画素のうちの先頭の画素のアドレスになっている。
【0161】
ここで、データ転送部346は、第2の処理を行うと共に、第4の処理として、アドレス記憶部142に格納されている各アドレスAi(i=1〜6)に対して、第1のパラメータOSV分増分させる。これにより、アドレス記憶部142に格納された各アドレスAiは、対応する矩形領域の次の行の先頭アドレスになる。
【0162】
矩形領域BK1〜BK6の以降の各行に対して、上記と同様の処理が繰り返される。最後に、矩形領域BK1〜BK3について、行方向において奇数番(1番目、3番目など)の画素はPE6、PE4、PE2のローカルメモリ114に夫々格納され、偶数番の画素はPE5、PE3、PE1のローカルメモリ114に夫々格納される。
【0163】
また、矩形領域BK4〜BK6についても同様に、行方向において奇数番(1番目、3番目など)の画素はPE6、PE4、PE2のローカルメモリ114に夫々格納され、偶数番の画素はPE5、PE3、PE1のローカルメモリ114に夫々格納される。
【0164】
これにて外部メモリからPEアレイ110へのデータ転送が完了するが、同一の矩形領域の全ての画素が同一のPEのローカルメモリ114に格納されるようにするために、CP330は、PEアレイ110に対してデータ交換の命令をする。
【0165】
PEアレイ110の各PEは、該命令に応じて、隣接するPE同士間でローカルメモリのデータを交換する。例えば、PE5とPE6間で、PE5のローカルメモリ114に書き込まれた矩形領域BK1の2番目の画素と、PE6のローカルメモリ114に書き込まれた矩形領域BK4の1番目の画素との交換により、矩形領域BK1の2番目の画素は、矩形領域BK1の1番目の画素と同様に、PE6のローカルメモリ114に格納されることになる。このような交換は、PEアレイ110の各隣接するPE同士間で行われた結果、図11に示すように、矩形領域BK1〜BK6のデータは、対応するPE(PE6〜PE1)のローカルメモリ114に夫々格納される。
【0166】
上記において、第4のパラメータTが「2」に設定された場合を説明した。第4のパラメータTが「1」に設定された場合には、SIMDプロセッサ300は、SIMDプロセッサ100と同様の動作をする。
【0167】
本実施の形態のSIMDプロセッサ300は、第4のパラメータTが「1」に設定されている場合には、SIMDプロセッサ100と同様の効果を得ることができる。第4のパラメータTが「2」以上に設定された場合には、上記効果に加え、外部メモリとPEアレイ110間のデータ転送をより高速にできる。
【0168】
これは、データ転送部346は、1つの矩形領域について、外部メモリに対する1度の読出でアドレスが連続するT画素分のデータを読み出してPEアレイ110のバッファ112に転送するためである。一般的に知られているように、外部メモリへのアクセスは、通常、連続したアドレスに存在するデータを同時にアクセスした方が効率良い。
【0169】
なお、この場合、データ転送部346によるデータ転送の後に、同一の矩形領域のデータが同一のPEのローカルメモリに格納されるようにする処理が必要であるものの、この処理は、隣接するPE同士間でデータ交換をするだけで実現できるので、高速に行うことができる。従って、この処理に伴うオーバーヘッドが小さい。
【0170】
以上、実施の形態をもとに本発明を説明した。実施の形態は例示であり、本発明の主旨から逸脱しない限り、上述した各実施の形態に対してさまざまな変更、増減、組合せを行ってもよい。これらの変更、増減、組合せが行われた変形例も本発明の範囲にあることは、当業者に理解されるところである。
【0171】
例えば、上述した各実施の形態において、第2のパラメータWとして、矩形領域の行方向のサイズを設定しているが、他の値、例えば、矩形領域の行方向の画素数を設定するようにしてもよい。
【0172】
また、上述した各実施の形態の動作について、画像の場合を例にしたが、本発明にかかる技術は、画像以外の2次元データの処理にも適用することができる。
【符号の説明】
【0173】
1〜6 PE 10 SIMDプロセッサ
20 コントロールプロセッサ(CP) 30 PEアレイ
42 バッファ 44 ローカルメモリ
46 MEMCTL 48 演算部
100 SIMDプロセッサ 110 PEアレイ
112 バッファ 114 ローカルメモリ
120 制御ユニット 130 CP
140 メモリコントローラ 142 アドレス記憶部
144 パラメータ記憶部 146 データ転送部
200 SIMDプロセッサ 210 PEアレイ
220 シフトレジスタ 221〜226 1段目〜6段目
300 SIMDプロセッサ 320 制御ユニット
330 コントロールプロセッサ(CP) 340 メモリコントローラ
344 パラメータ記憶部 346 データ転送部
A1〜A6 アドレス BK1〜BK6 矩形領域
P 画像 S 単位サイズ
OSV 第1のパラメータ
W 第2のパラメータ
L 第3のパラメータ
T 第4のパラメータ
【特許請求の範囲】
【請求項1】
N個(N:2以上の整数)のプロセッサ要素を有し、各前記プロセッサ要素が、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有するSIMD(SiNgle INstructioN Multiple Data)プロセッサに設けられたメモリコントローラであって、
前記外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能なアドレス記憶部と、
第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能なパラメータ記憶部と、
前記外部メモリと、前記N個のプロセッサ要素のバッファとの間でデータ転送を行うデータ転送部とを有し、
前記データ転送部は、
前記データ転送の指示に応じて、第1の処理を前記パラメータ記憶部に記憶された前記第3のパラメータLに合致する回数分繰り返し、
前記第1の処理は、第2の処理をすると共に第3の処理を行うことを式(1)に示すM回繰り返した後に、前記第2の処理をすると共に第4の処理を行う処理であり、
前記第2の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、前記アドレス記憶部に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するプロセッサ要素のバッファに格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、夫々の前記プロセッサ要素のバッファに格納されたデータを読み出して、前記アドレス記憶部に記憶されているN個のアドレスのうちの、対応するアドレスに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(2)に従って増分させる処理であり、
前記第4の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(3)に従って増分させる処理であることを特徴とするメモリコントローラ。
M=W/S−1 (1)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
Ai=Ai+S (2)
但し,Ai:i個目のアドレス
S:単位サイズ
Ai=Ai+OSV (3)
但し,Ai:i個目のアドレス
OSV:パラメータ記憶部に記憶された第1のパラメータ
【請求項2】
前記パラメータ記憶部は、第4のパラメータTをさらに設定可能であり、
前記第1の処理は、第2の処理をすると共に第3の処理を行うことを式(4)に示すM1回繰り返した後に、前記第2の処理をすると共に前記第4の処理を行う処理であり、
前記第2の処理は、第5の処理をT回繰り返す処理であり、
前記第5の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが隣接するT個のプロセッサ要素に対応するように、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスから夫々単位サイズSのT倍分のデータを読み出して、対応するT個のプロセッサ要素のバッファに夫々格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、各前記プロセッサ要素のバッファに格納されたデータを読み出すと共に、1アドレスが隣接するT個のプロセッサ要素に対応するように、隣接するT個のプロセッサ要素からなるグループ毎に、該グループ内のT個のプロセッサ要素のバッファから読み出したデータを、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスのうちの、前記グループに対応する1つに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(5)に従って増分させる処理であることを特徴とするメモリコントローラ。
M1=[W/(T×S)]−1 (4)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
Ai=Ai+S×T (5)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
【請求項3】
前記データ転送部は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に割込みを発生させ、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に割込みを発生させることを特徴とする請求項1または2に記載のメモリコントローラ。
【請求項4】
コントロールプロセッサと、
前記コントロールプロセッサにより制御されるN個(N:2以上の整数)のプロセッサ要素と、
メモリコントローラとを備えるSIMD(SiNgle INstructioN Multiple Data)プロセッサ)であって、
各前記プロセッサ要素は、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有し、
前記メモリコントローラは、
前記コントロールプロセッサにより、前記外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能なアドレス記憶部と、
前記コントロールプロセッサにより、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能なパラメータ記憶部と、
前記コントロールプロセッサからのデータ転送の指示に応じて、前記外部メモリと、前記N個のプロセッサ要素のバッファとの間でデータ転送を行うデータ転送部とを有し、
前記データ転送部は、
前記データ転送に際して、第1の処理を前記パラメータ記憶部に記憶された前記第3のパラメータLに合致する回数分繰り返し、
前記第1の処理は、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返した後に、前記第2の処理をすると共に第4の処理を行う処理であり、
前記第2の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、前記アドレス記憶部に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するプロセッサ要素のバッファに格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、夫々の前記プロセッサ要素のバッファに格納されたデータを読み出して、前記アドレス記憶部に記憶されているN個のアドレスのうちの、対応するアドレスに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(7)に従って増分させる処理であり、
前記第4の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(8)に従って増分させる処理であり、
M=W/S−1 (6)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
Ai=Ai+S (7)
但し,Ai:i個目のアドレス
S:単位サイズ
Ai=Ai+OSV (8)
但し,Ai:i個目のアドレス
OSV:パラメータ記憶部に記憶された第1のパラメータ
前記コントロールプロセッサは、
前記メモリコントローラによる前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に、各前記プロセッサ要素にライト命令をし、
前記DMAコントローラによる前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に、各前記プロセッサ要素にリード命令をすることを特徴とするSIMDプロセッサ。
【請求項5】
前記コントロールプロセッサは、
前記N個のアドレスAi(i=1〜N)として、複数の単位サイズSのデータが2次元に配列してなる2次元データを記憶した前記外部メモリにおける、前記2次元データに含まれるN個の矩形領域の先頭アドレスを前記アドレス記憶部に設定し、
前記2次元データの同一行における先端と末尾の単位サイズSのデータのアドレスの差分と、前記矩形領域の行方向のサイズと、前記矩形領域の行数とを、夫々前記第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとして前記パラメータ設定部に設定することを特徴とする請求項4に記載のSIMDプロセッサ。
【請求項6】
前記コントロールプロセッサは、
前記N個の矩形領域が異なる行方向のサイズを有するときに、各前記行方向のサイズのうちの最大値を前記第2のパラメータWとして設定し、
前記N個の矩形領域が異なる行数を有するときに、各前記行数のうちの最大値を前記第3のパラメータLとして設定することを特徴とする請求項5に記載のSIMDプロセッサ。
【請求項7】
前記2次元データは、画像データであり、
前記単位サイズSのデータは、1画素のデータであることを特徴とする請求項5または6に記載のSIMDプロセッサ。
【請求項8】
前記パラメータ記憶部は、前記コントロールプロセッサにより第4のパラメータTをさらに設定可能であり、
前記コントロールプロセッサは、Nの約数を前記第4のパラメータTとして前記パラメータ記憶部に設定し、
前記メモリコントローラにおける前記データ転送部は、
前記第1の処理として、第2の処理をすると共に第3の処理を行うことを式(9)に示すM1回繰り返した後に、前記第2の処理をすると共に前記第4の処理を行い、
前記第2の処理として、第5の処理をT回繰り返し、
前記第5の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが隣接するT個のプロセッサ要素に対応するように、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスから夫々単位サイズSのT倍分のデータを読み出して、対応するT個のプロセッサ要素のバッファに夫々格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、各前記プロセッサ要素のバッファに格納されたデータを読み出すと共に、1アドレスが隣接するT個のプロセッサ要素に対応するように、隣接するT個のプロセッサ要素からなるグループ毎に、該グループ内のT個のプロセッサ要素のバッファから読み出したデータを、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスのうちの、前記グループに対応する1つに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(10)に従って増分させる処理であり、
M1=[W/(T×S)]−1 (9)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
Ai=Ai+S×T (10)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
前記コントロールプロセッサは、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際には該データ転送の指示の前に、前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際には該データ転送の指示に応じて前記DMAコントローラが該データ転送を完了した後に、前記N個のプロセッサ要素に対してデータ交換の命令をし、
前記N個のプロセッサ要素は、前記データ交換の命令に応じて、隣接するプロセッサ要素同士間で、ローカルメモリ上のデータを交換することを特徴とする請求項4から7のいずれか1項に記載のSIMDプロセッサ。
【請求項9】
前記DMAコントローラは、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に割込みを発生させ、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に割込みを発生させ、
前記コントロールプロセッサは、前記割込みに応じて、前記N個のプロセッサ要素にリード命令またはライト命令をすることを特徴とする請求項4から8のいずれか1項に記載のコントロールプロセッサ。
【請求項1】
N個(N:2以上の整数)のプロセッサ要素を有し、各前記プロセッサ要素が、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有するSIMD(SiNgle INstructioN Multiple Data)プロセッサに設けられたメモリコントローラであって、
前記外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能なアドレス記憶部と、
第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能なパラメータ記憶部と、
前記外部メモリと、前記N個のプロセッサ要素のバッファとの間でデータ転送を行うデータ転送部とを有し、
前記データ転送部は、
前記データ転送の指示に応じて、第1の処理を前記パラメータ記憶部に記憶された前記第3のパラメータLに合致する回数分繰り返し、
前記第1の処理は、第2の処理をすると共に第3の処理を行うことを式(1)に示すM回繰り返した後に、前記第2の処理をすると共に第4の処理を行う処理であり、
前記第2の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、前記アドレス記憶部に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するプロセッサ要素のバッファに格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、夫々の前記プロセッサ要素のバッファに格納されたデータを読み出して、前記アドレス記憶部に記憶されているN個のアドレスのうちの、対応するアドレスに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(2)に従って増分させる処理であり、
前記第4の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(3)に従って増分させる処理であることを特徴とするメモリコントローラ。
M=W/S−1 (1)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
Ai=Ai+S (2)
但し,Ai:i個目のアドレス
S:単位サイズ
Ai=Ai+OSV (3)
但し,Ai:i個目のアドレス
OSV:パラメータ記憶部に記憶された第1のパラメータ
【請求項2】
前記パラメータ記憶部は、第4のパラメータTをさらに設定可能であり、
前記第1の処理は、第2の処理をすると共に第3の処理を行うことを式(4)に示すM1回繰り返した後に、前記第2の処理をすると共に前記第4の処理を行う処理であり、
前記第2の処理は、第5の処理をT回繰り返す処理であり、
前記第5の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが隣接するT個のプロセッサ要素に対応するように、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスから夫々単位サイズSのT倍分のデータを読み出して、対応するT個のプロセッサ要素のバッファに夫々格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、各前記プロセッサ要素のバッファに格納されたデータを読み出すと共に、1アドレスが隣接するT個のプロセッサ要素に対応するように、隣接するT個のプロセッサ要素からなるグループ毎に、該グループ内のT個のプロセッサ要素のバッファから読み出したデータを、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスのうちの、前記グループに対応する1つに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(5)に従って増分させる処理であることを特徴とするメモリコントローラ。
M1=[W/(T×S)]−1 (4)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
Ai=Ai+S×T (5)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
【請求項3】
前記データ転送部は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に割込みを発生させ、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に割込みを発生させることを特徴とする請求項1または2に記載のメモリコントローラ。
【請求項4】
コントロールプロセッサと、
前記コントロールプロセッサにより制御されるN個(N:2以上の整数)のプロセッサ要素と、
メモリコントローラとを備えるSIMD(SiNgle INstructioN Multiple Data)プロセッサ)であって、
各前記プロセッサ要素は、容量が単位サイズSであり、該プロセッサ要素と外部メモリとの間で転送されるデータを一時的に格納するバッファを有し、
前記メモリコントローラは、
前記コントロールプロセッサにより、前記外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能なアドレス記憶部と、
前記コントロールプロセッサにより、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能なパラメータ記憶部と、
前記コントロールプロセッサからのデータ転送の指示に応じて、前記外部メモリと、前記N個のプロセッサ要素のバッファとの間でデータ転送を行うデータ転送部とを有し、
前記データ転送部は、
前記データ転送に際して、第1の処理を前記パラメータ記憶部に記憶された前記第3のパラメータLに合致する回数分繰り返し、
前記第1の処理は、第2の処理をすると共に第3の処理を行うことを式(6)に示すM回繰り返した後に、前記第2の処理をすると共に第4の処理を行う処理であり、
前記第2の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、前記アドレス記憶部に記憶されている各アドレスから夫々単位サイズS分のデータを読み出して、対応するプロセッサ要素のバッファに格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、1アドレスが1プロセッサ要素に対応するように、夫々の前記プロセッサ要素のバッファに格納されたデータを読み出して、前記アドレス記憶部に記憶されているN個のアドレスのうちの、対応するアドレスに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(7)に従って増分させる処理であり、
前記第4の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(8)に従って増分させる処理であり、
M=W/S−1 (6)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
Ai=Ai+S (7)
但し,Ai:i個目のアドレス
S:単位サイズ
Ai=Ai+OSV (8)
但し,Ai:i個目のアドレス
OSV:パラメータ記憶部に記憶された第1のパラメータ
前記コントロールプロセッサは、
前記メモリコントローラによる前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に、各前記プロセッサ要素にライト命令をし、
前記DMAコントローラによる前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に、各前記プロセッサ要素にリード命令をすることを特徴とするSIMDプロセッサ。
【請求項5】
前記コントロールプロセッサは、
前記N個のアドレスAi(i=1〜N)として、複数の単位サイズSのデータが2次元に配列してなる2次元データを記憶した前記外部メモリにおける、前記2次元データに含まれるN個の矩形領域の先頭アドレスを前記アドレス記憶部に設定し、
前記2次元データの同一行における先端と末尾の単位サイズSのデータのアドレスの差分と、前記矩形領域の行方向のサイズと、前記矩形領域の行数とを、夫々前記第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとして前記パラメータ設定部に設定することを特徴とする請求項4に記載のSIMDプロセッサ。
【請求項6】
前記コントロールプロセッサは、
前記N個の矩形領域が異なる行方向のサイズを有するときに、各前記行方向のサイズのうちの最大値を前記第2のパラメータWとして設定し、
前記N個の矩形領域が異なる行数を有するときに、各前記行数のうちの最大値を前記第3のパラメータLとして設定することを特徴とする請求項5に記載のSIMDプロセッサ。
【請求項7】
前記2次元データは、画像データであり、
前記単位サイズSのデータは、1画素のデータであることを特徴とする請求項5または6に記載のSIMDプロセッサ。
【請求項8】
前記パラメータ記憶部は、前記コントロールプロセッサにより第4のパラメータTをさらに設定可能であり、
前記コントロールプロセッサは、Nの約数を前記第4のパラメータTとして前記パラメータ記憶部に設定し、
前記メモリコントローラにおける前記データ転送部は、
前記第1の処理として、第2の処理をすると共に第3の処理を行うことを式(9)に示すM1回繰り返した後に、前記第2の処理をすると共に前記第4の処理を行い、
前記第2の処理として、第5の処理をT回繰り返し、
前記第5の処理は、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、1アドレスが隣接するT個のプロセッサ要素に対応するように、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスから夫々単位サイズSのT倍分のデータを読み出して、対応するT個のプロセッサ要素のバッファに夫々格納する処理であり、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、各前記プロセッサ要素のバッファに格納されたデータを読み出すと共に、1アドレスが隣接するT個のプロセッサ要素に対応するように、隣接するT個のプロセッサ要素からなるグループ毎に、該グループ内のT個のプロセッサ要素のバッファから読み出したデータを、前記アドレス記憶部に記憶されているN個のアドレスのうちの「N/T」個のアドレスであって、かつ、回毎に異なる前記「N/T」個のアドレスのうちの、前記グループに対応する1つに書き込む処理であり、
前記第3の処理は、前記アドレス記憶部に記憶されている各アドレスAiを式(10)に従って増分させる処理であり、
M1=[W/(T×S)]−1 (9)
但し,W:パラメータ記憶部に記憶された第2のパラメータ
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
Ai=Ai+S×T (10)
但し,Ai:i個目のアドレス
S:単位サイズ
T:パラメータ記憶部に記憶された第4のパラメータ
前記コントロールプロセッサは、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際には該データ転送の指示の前に、前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際には該データ転送の指示に応じて前記DMAコントローラが該データ転送を完了した後に、前記N個のプロセッサ要素に対してデータ交換の命令をし、
前記N個のプロセッサ要素は、前記データ交換の命令に応じて、隣接するプロセッサ要素同士間で、ローカルメモリ上のデータを交換することを特徴とする請求項4から7のいずれか1項に記載のSIMDプロセッサ。
【請求項9】
前記DMAコントローラは、
前記外部メモリから前記N個のプロセッサ要素のバッファへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てがフルになる度に割込みを発生させ、
前記N個のプロセッサ要素のバッファから前記外部メモリへのデータ転送の際に、前記N個のプロセッサ要素のバッファの全てが空になる度に割込みを発生させ、
前記コントロールプロセッサは、前記割込みに応じて、前記N個のプロセッサ要素にリード命令またはライト命令をすることを特徴とする請求項4から8のいずれか1項に記載のコントロールプロセッサ。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2013−25563(P2013−25563A)
【公開日】平成25年2月4日(2013.2.4)
【国際特許分類】
【出願番号】特願2011−159752(P2011−159752)
【出願日】平成23年7月21日(2011.7.21)
【出願人】(302062931)ルネサスエレクトロニクス株式会社 (8,021)
【Fターム(参考)】
【公開日】平成25年2月4日(2013.2.4)
【国際特許分類】
【出願日】平成23年7月21日(2011.7.21)
【出願人】(302062931)ルネサスエレクトロニクス株式会社 (8,021)
【Fターム(参考)】
[ Back to top ]