
モンテカルロ法の効率的な並列処理手法
【課題】
モンテカルロ法を用いたシミュレーションあるいは数値積分のための効率的な並列処理手法を提供する。
【解決手段】
状態変数生成記憶部(481)と複数のスレッド(440、450、460、470)を用いて並列処理によりモンテカルロ法を実行する方法であって、状態変数生成記憶部(481)に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、状態変数生成記憶部(481)に排他ロックをかけるステップと、状態変数生成記憶部(481)に記憶されている状態変数を順次スキップ処理するステップと、排他ロックを解除するステップとを含み、前記の各ステップを他のスレッドにおいても順次実行してゆく方法である。
モンテカルロ法を用いたシミュレーションあるいは数値積分のための効率的な並列処理手法を提供する。
【解決手段】
状態変数生成記憶部(481)と複数のスレッド(440、450、460、470)を用いて並列処理によりモンテカルロ法を実行する方法であって、状態変数生成記憶部(481)に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、状態変数生成記憶部(481)に排他ロックをかけるステップと、状態変数生成記憶部(481)に記憶されている状態変数を順次スキップ処理するステップと、排他ロックを解除するステップとを含み、前記の各ステップを他のスレッドにおいても順次実行してゆく方法である。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、モンテカルロ法の並列処理手法に関し、特に、並列計算機を効率的に用いるモンテカルロ法の並列処理手法と、それを実行するための装置およびコンピュータプログラムに関する。
【背景技術】
【0002】
モンテカルロ法(Monte Carlo method)は、自然現象や社会現象をはじめとする確率的な現象の分析や、複雑な数値積分などに広く用いられる手法である。このモンテカルロ法は、解析的に解くことが難しい問題に対して特に威力を発揮する。自然現象および社会現象は、不確実性を有するものが大半を占めるため、モンテカルロ法の適用範囲は学術分野から実務にわたり極めて広い。さらに、モンテカルロ法のアルゴリズム(計算手順)は理解が容易であることもモンテカルロ法が広く普及している一因である。例えば、モンテカルロ法を産業上利用している具体例としては、流体力学の分野におけるシミュレーションや、金融機関におけるリスク量の算出や各種金融商品の価格算出などが挙げられる(例えば、特許文献1、非特許文献1参照)。
【0003】
一方で、モンテカルロ法の計算精度を確保するためには試行回数を十分に取る必要があり、その結果、計算時間が増大するという短所をもつ。近年では、複数のプロセッサコアを搭載したコンピュータが続々と登場し、従来は単一のスレッドで実行していたところ、複数のプロセッサコアのそれぞれにおいてスレッドを立てて並列に処理することによって計算時間を短縮することが比較的容易になった。ここで、スレッドとは、プロセス内の処理の流れのことを指す。モンテカルロ法についても並列処理によって計算時間を短縮することができる。特に、モンテカルロ法のアルゴリズムは並列処理と親和性が非常に高く、モンテカルロ法の並列処理による高速化の要請は高まっている。
【0004】
モンテカルロ法に並列処理を施すこと自体は従来から行われている。すなわち、モンテカルロ法の試行全体を複数のスレッドで分担して、1台のコンピュータあるいは1個のプロセッサコアにつき1個のスレッドを割り当てることにより、各コンピュータまたはプロセッサコアが独立して処理を行うことができる。例えば試行回数を10000回として4台のコンピュータで並列処理する場合には、各コンピュータでそれぞれ2500回の試行を行えばよい。
【0005】
しかし、実用上は、次に挙げる2つの問題を克服しなければならない。一つは、計算結果の再現性の問題であり、もう一つは、乱数系列間に生じる相関の問題である。
【0006】
一つ目の計算結果の再現性とは、同じ乱数シード、すなわち、同じ乱数系列を用いてモンテカルロ法による数値計算を繰り返し行った場合に、同じ計算結果が得られるという意味である。この再現性は、バックテストを行うときや計算条件を変更した際の影響を検証する際に欠かせないものである。一般に、プログラムを並列化すると処理の逐次性が失われるため、計算結果の再現性を確保するには乱数の生成法と使用法に関する工夫が必要となる。
【0007】
二つ目の乱数系列間に生じる相関とは、モンテカルロ法の並列処理にあたって、スレッド毎に用いる乱数系列の間に有意にゼロとは言えない相関が生じることを指す。このような相関が生じると計算結果の信頼性が低下するため、コンピュータあるいはプロセッサコアごとにそれぞれ別の乱数系列を生成する場合には、乱数列間の相関が非常に小さいものを用いる必要がある。その解決策としては、一つの乱数系列を用いて並列処理を行うか、あるいは、互いに相関が非常に小さい乱数系列を生成し単純に並列処理を行うかのいずれかが考えられる。後者についてのアルゴリズムは存在するが、モンテカルロ法を実行する以前に乱数系列を生成するための処理や乱数列の独立性に関する検証が必要となるなど、課題が多い。したがって、一つの乱数列を用い、かつ、計算結果の再現性を保持しつつ、並列処理を行うことが実用上は重要となる。
【0008】
一つの乱数列を用い、計算結果の再現性を保持しつつ、並列処理を行う際には、モンテカルロ法実行時の乱数の生成方法が本質的に重要となる。モンテカルロ法の並列処理に関する既存の技術としては以下のものがある。
【0009】
[従来技術1]
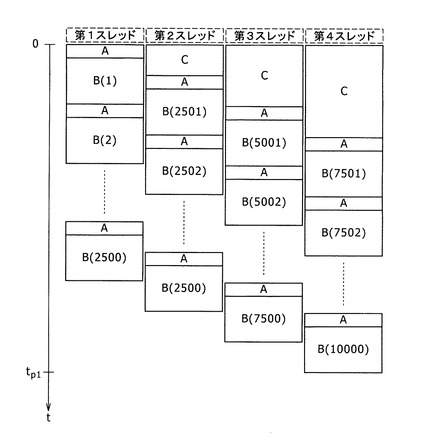
図1は、従来技術(以下、従来技術1とも呼ぶ。)として、4個のスレッドを有する並列処理システムを用いて並列処理を行う場合の各スレッドの試行番号の担当を示す図である。横軸は第1スレッドから第4スレッドを示しており、縦軸は時間tを示している。そして、符号Aは、後続で行う試行に用いる乱数の生成処理を示している。符号Bは、各試行の実行処理を示している。符号Bの後に続くかっこ書きの数字は、試行番号である。符号Cは、後述する乱数捨象処理もしくは状態変数のスキップ処理を示している。
【0010】
図1に示すように、従来技術1では各スレッドに対して試行回数を均等に配分する。具体的には、前述のように10000回の試行を4個のスレッドで実行すると考えて、第1スレッドは第1番目から第2500番目の試行を担当する。そして、第2スレッドは第2501番目から第5000番目の試行を担当し、第3スレッドは第5001番目から第7500番目の試行を担当し、第4スレッドは第7501番目から第10000番目の試行を担当する。すなわち、それぞれのスレッドは2500回分の試行を実行する。
【0011】
乱数生成部をスレッドごとにそれぞれ用意し、全ての乱数生成部に同一の乱数シード(乱数系列)を与える。各スレッドは、自己が担当する試行にとって不要な乱数を捨象した上で、各自が割り当てられた試行を行う。
【0012】
例えば、1回の試行に100個の乱数を用いるとすると、第1スレッドは、100×2500=25万個の乱数を生成して試行を行う。
【0013】
第2スレッドも同様に25万個の乱数を必要とする。しかし、第2スレッドは、50万個の乱数を生成した上で、前半の25万個を捨象し、後半の25万個を試行に用いる必要がある。前半の25万個の乱数は、第1スレッドが試行のために使用するものであり、第2スレッドは前半の25万個の乱数を使用することができない。第2スレッドも前半の25万個の乱数を使用してしまうと、第1スレッドと第2スレッドのいずれもが同じ乱数を用いて試行を行うこととなり、モンテカルロ法の結果の信頼性が低下してしまう。この乱数捨象処理を図1において符号Cで示している。
【0014】
これは、擬似乱数が、ランダムな物理現象、例えばサイコロを振って出た目を利用して生成する物理乱数とは異なり、前回の乱数を算術式に代入して、新たな乱数を生成するという逐次的な性質を有するからである。したがって、第2スレッドにおいては、第1番目から第25万番目の乱数を生成しないと、第25万1番目以降の乱数を生成することができない。
【0015】
第3スレッドは、75万個の乱数を生成する。そして、第1スレッドで使用する最初の25万個の乱数と、第2スレッドで使用する次の25万個の乱数とを足し合わせた50万個の乱数を捨象した上で、第50万1番目の乱数から始めて25万個の乱数を用いて試行を行う。
【0016】
最後に、第4スレッドは、100万個の乱数を生成する。そして、第1スレッドで使用する最初の25万個の乱数と、第2スレッドで使用する次の25万個の乱数と、第3スレッドで使用するさらに次の25万個の乱数とを足し合わせた75万個の乱数を捨象した上で、第75万1番目から始めて25万個の乱数を用いて試行を行う。
【0017】
ここで、第1スレッドは乱数の捨象処理を行わないことに留意されたい。
【0018】
これにより上記二つの問題を克服した並列処理が可能となる。ただし、この方法では、後続の試行を担当するスレッドほどより多くの乱数を捨象しなければならないため、試行回数は均等であるが、各スレッドの処理負荷は不均等となる。図1の例では、第1スレッドは乱数の捨象処理を行わないため、4つのスレッドの中で最も処理負荷が小さい。そして、第2スレッド、第3スレッド、第4スレッドの順に、生成する乱数の個数が増えるため、処理の負荷も同じ順番で大きくなる。すなわち、第4スレッドは、4個のスレッドの中で最も処理負荷が大きい。
【0019】
第4スレッドが第10000番目の試行の試行を終えた時点で、モンテカルロ法の処理は終了する。第4スレッドが第10000番目の試行を終えるまでに要する理論的な計算時間tp1は、以下のように表現することができる。
【数1】

ここで、NSimはモンテカルロ法の試行回数であり、NTは並列処理を行うスレッドの数であり、tSimは1回の試行に要する時間であり、tSkipは1回の試行に用いる乱数の捨象に要する時間である。
【0020】
この処理方法では、スレッド数が多いほど処理負荷の不均等が如実に現れるため、スレッド数が増加するに従って並列処理の効率が悪化していく。
【0021】
[従来技術2]
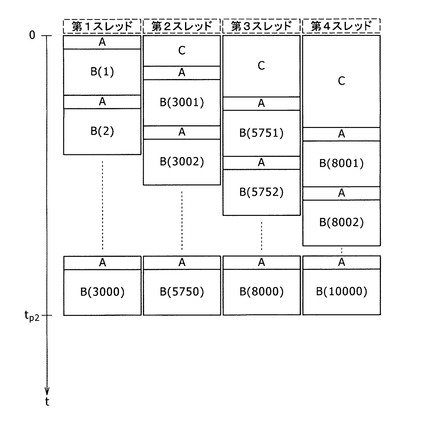
上記の方法を改善したものが特許文献1に記載されている。特許文献1によれば、金融工学の種々の計算におけるモンテカルロ法において、各スレッドが担当する試行回数を均等に割り当てるのではなく、後続の試行を担当するスレッドの試行回数を少なくすることにより、各スレッドの処理負荷の均一化を図るように改善されている。その様子を図2に示している。図1と同様に、符号Aは、後続で行うモンテカルロ法に用いる乱数生成処理を示している。符号Bは、試行の実行処理を示している。符号Bの後に続くかっこ書きの数字は、試行番号である。符号Cは、乱数捨象処理を示している。
【0022】
図2に示すように、例えば、第1スレッドは第1番目から第3000番目の試行を担当する。第2スレッドは第3001番目から第5750番目の試行を担当する。第3スレッドは第5751番目から第8000番目の試行を担当する。第4スレッドは第8001番目から第10000番目の試行を担当する。
【0023】
つまり、第1スレッドは3000回分の試行を担当し、第2スレッドは2750回分の試行を担当し、第3スレッドは2250回分の試行を担当し、第4スレッドは2000回分の試行を担当する。
【0024】
このように、従来技術2では、乱数を多く生成する必要があるスレッドの試行担当回数を他のスレッドよりも減らすことにより、全体として、4個のスレッドの負荷の均等化を図っている。
【0025】
この従来技術において、各プロセッサコアの処理負荷が均一になるように試行回数を割り当てた場合に試行の実行に要する理論的な計算時間tp2は、以下のように表現することができる。
【数2】
ここで、NSimはモンテカルロ法の試行回数であり、NTは並列処理を行うスレッドの数であり、tSimは1回の試行に要する時間であり、tSkipは1回の試行に用いる乱数の捨象に要する時間である。
【0026】
この技術にも次のような問題点がある。一つは、処理負荷が均一になるように各スレッドに最適な試行回数を割り当てるためには、tSimとtSkipの値を計測する必要があり、そのための追加的なプログラムが必要となる点である。もう一つは、依然として各スレッドで乱数の捨象処理を行う必要があるため、従来技術1と比べて改善はするものの、やはりスレッド数が増えるにつれて並列処理の効率が落ちるという点である。
【0027】
なお、式(2)および式(3)において、スレッド数NT→∞の極限をとると、いずれもNSimtSkipとなる。すなわち、どんなにスレッド数を増やしても、NSimtSkipの計算時間を要する。これは、乱数の生成は逐次的に行うものであって、モンテカルロ法全体を完全には並列化することができないからである。
【先行技術文献】
【特許文献】
【0028】
【特許文献1】特許4032339号公報
【非特許文献1】石川達也、内田善彦、「モンテカルロ法によるプライシングとリスク量の算出について―正規乱数を用いる場合の適切な実装方法の考察―」、金融研究、日本銀行金融研究所、2002年6月、第21巻、別冊第1号、p.51−90
【発明の概要】
【発明が解決しようとする課題】
【0029】
本発明は、従来技術で行っていた、各スレッドにおける無駄な乱数の捨象を行わず、かつ、処理負荷の均一化を図るために各スレッドが担当する試行回数を予め計算して決めておく必要のない、効率的な並列処理手法を提供することを目的とする。
【課題を解決するための手段】
【0030】
本発明は、コンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、状態変数を状態変数生成記憶部に記憶するステップと、一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行って、乱数を生成する乱数生成ステップと、前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップとを含み、前記乱数生成ステップと試行演算ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法を提供する。
【0031】
本発明はまた、前記乱数生成ステップが、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行う処理ステップと、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に対する排他ロックを解除するステップとを含むものである前記並列処理方法を提供する。
【0032】
さらに、本発明はコンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、状態変数を状態変数生成記憶部に記憶するステップと、一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数を取得するとともに、該状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理ステップと、前記一のスレッドのプロセッサコアが、前記取得した状態変数に対し、所定の回数にわたり変換処理とスキップ処理を行って乱数を生成するステップと、前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップとを含み、前記各ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法を提供する。
【0033】
ここで、前記状態変数スキップ処理ステップは、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部から状態変数の値を取得するステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う処理ステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に対する排他ロックを解除するステップとを含むものであってよい。
【0034】
これらの並列処理方法は、金融工学の分野において、複数の債権を含むポートフォリオの信用リスク量を計測するため、金融市場の変化をモデル化して金融商品の価格を算出するため、さらには、金融市場の変動によって生ずる市場リスク量を計測するために、モンテカルロ法を実行するのに用いることができる。
【0035】
本発明は、これらの並列処理方法の各ステップをコンピュータに実行させるためのプログラムも提供する。
【0036】
さらに、本発明は、コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理により実行する並列処理システムであって、前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次変換処理とスキップ処理を行って乱数を生成する乱数生成部と、各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部とを備える並列処理システムを提供する。
【0037】
そして、本発明は、コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理することにより実行する並列処理システムであって、前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理部と、各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、前記状態変数生成記憶部から状態変数の値を取得してメモリに保存する状態変数取得部と、メモリに保存されている状態変数に対して、所定の回数にわたり変換処理とスキップ処理を行い、乱数を生成する乱数生成部と、前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部とを備える並列処理システムをも提供する。
【0038】
本発明の一実施形態によれば、モンテカルロ法を用いて金融工学の分野における信用リスク量の計測を行うことができる。すなわち、個々の債務者(通常、企業)の価値の変化をモデル化して、そのポートフォリオまたは銀行の信用リスク量(信用VaR、条件付き信用VaRなど)を計測する場合に、本発明の方法を用いてモンテカルロシミュレーションを実行することにより、全体的な信用リスク量を算出することができる。
【0039】
また、同様にして本発明のモンテカルロ法を用いて金融市場における市場リスク量の計測を行うことができる。具体的には、株式市場における株価の変化や債券市場における債券価格の変化をモデル化して、本発明の方法を用いてモンテカルロシミュレーションを実行することにより、これらの市場の変動によって生ずる市場リスク量を計測することができる。
【0040】
あるいは、本発明のモンテカルロ法を用いて金融商品の価格算出を行うことができる。すなわち、金融市場の変化をモデル化して、本発明の方法を用いてモンテカルロシミュレーションを実行することにより、各種有価証券やデリバティブなどの金融商品の価格を算出することができる。
【発明の効果】
【0041】
本発明では、ほぼ理想的な並列化効率を実現したモンテカルロ法の並列処理が実現される。また、本発明は実装が容易であるという特長を持つ。本発明は、一般のモンテカルロ法についての技術であって、適用分野を問わないため、上述のように、本発明によりモンテカルロ法の計算負荷の軽減のメリットを享受できる分野は極めて広いと考えられる。金融工学の各分野のほか、流体力学や分子動力学などの種々の分野において有用なものである。また、従来技術の上記二つの欠点、すなわち、無駄な乱数の捨象によりスレッド数が増えるに従って並列化の効率が落ちるという欠点と、各スレッドに割り当てる試行回数をあらかじめ計算しなければならないという欠点とをいずれも解消でき、より一層効率的な並列処理が可能となる。
【図面の簡単な説明】
【0042】
【図1】従来技術に基づいて、各スレッドに試行回数を割り当てる様子を示す模式図である。
【図2】従来技術に基づいて、各スレッドに試行回数を割り当てる様子を示す模式図である。
【図3】乱数を生成する処理の流れを示す模式図である。
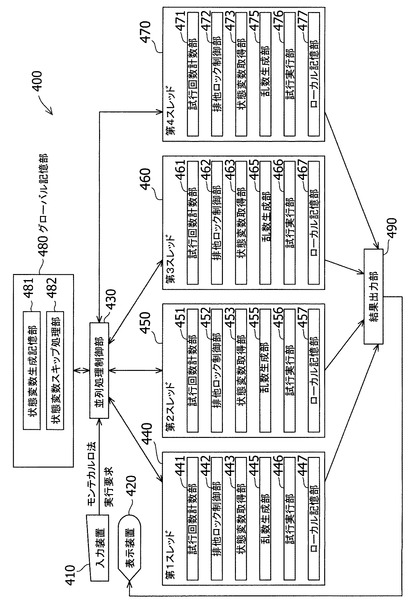
【図4】モンテカルロ法の並列処理を行う並列処理システムのブロック図である。
【図5】モンテカルロ法の並列処理の流れを示すフローチャートである。
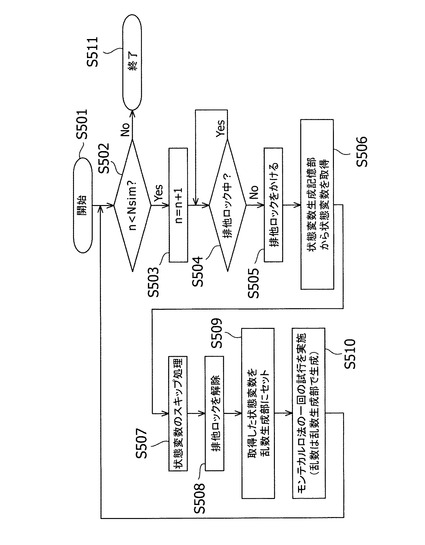
【図6】各スレッドに試行回数を割り当てる様子を示す模式図である。
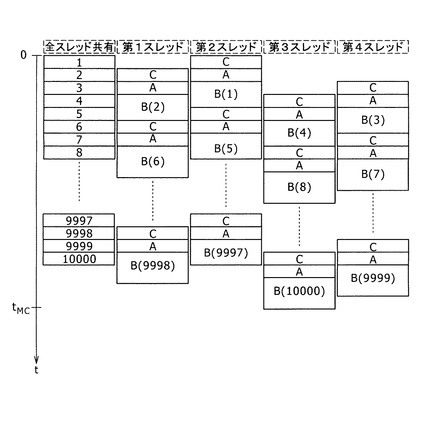
【図7】従来技術1との計算時間の比較を示す表である。
【図8】従来技術2との計算時間の比較を示す表である。
【図9】モンテカルロ法を逐次処理することにより、半径0.5の円の面積を求めるプログラム例である。
【図10】モンテカルロ法を並列処理することにより、半径0.5の円の面積を求めるプログラム例である。
【図11】モンテカルロ法を並列処理することにより、半径0.5の円の面積を求めるプログラム例である。
【図12】乱数生成クラスのプログラム例である。
【発明を実施するための形態】
【0043】
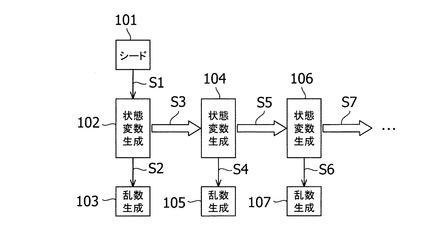
まず、乱数生成処理について述べる。図3は、乱数を生成する処理の流れを示す模式図である。乱数を生成するためには、最初にシード(乱数種)と呼ばれる、擬似乱数を生成する元となる値を用意する。このシードを符号101で示している。シード101は、キーボードを通して入力するか、あるいは、専用のプログラムを用いて準備することもできる。
【0044】
そして、ステップS1として、用意されたシード101から状態変数102を計算する。状態変数とは、一般には整数を要素とするベクトルである。次にステップS2として、初期状態変数102から乱数103を生成する。ステップS3では、初期状態変数102から新たな状態変数104を計算する。ステップS4では、状態変数104から乱数105を生成する。ステップS5では、状態変数104から新たな状態変数106を計算する。ステップS6では、状態変数106から乱数107を生成する。
【0045】
あるいは、ステップS1、S3、S5、S7、・・・を実行して、状態変数を必要な乱数個分生成する。その上で、ステップS2、S4、S6、・・・を実行して乱数を生成することもできる。
【0046】
このようにして、状態変数の計算と乱数の生成とを繰り返すことにより、複数の乱数を生成することができる。この乱数生成方法の具体例として、メルセンヌ・ツイスター(Mersenne Twister)法や線形合同法を挙げることができる。線形合同法は、状態変数そのものが乱数であると考えることにより、上述の乱数生成処理の枠組みで捉えることが可能である。
【0047】
ステップS3、S5、S7のように、ある状態変数から新たな状態変数を計算する処理を状態変数のスキップ処理と呼ぶ。このように、状態変数に対してスキップ処理を行うと、状態変数の値は更新される。
【0048】
上述したように、乱数の生成は、状態変数のスキップ処理と、状態変数を乱数に変換する変換処理とに分けることができる。また、各スキップ処理の後すぐに乱数の生成を実行することもできる。本発明は、排他制御を利用しつつ、状態変数の値を全てのスレッドで共有することにより、従来技術における無駄な乱数の捨象処理が不要となるという知見に基づいている。
【0049】
本発明を実現する一つの方法として、次のような実施形態が考えられる。すなわち、状態変数の情報を保持することができる乱数生成モジュールを1個用意し、全スレッドで共有する。このモジュールおよび、並列タスク・スケジューリングを以下のように組み合わせることにより、無駄な捨象のない乱数の割り当てを実現する。
【0050】
例えば、ある試行において、第1スレッドが乱数生成処理に入る場合を考える。このとき、排他制御の下、第1スレッドが、前記モジュールにおいて順次変換処理とスキップ処理を行い、1回の試行で必要な乱数を生成してスレッド内のローカルメモリに保存する。この処理により、前記モジュールには最後のスキップ処理によって得られた状態変数が保存された状態となる。その後、排他制御が解除され、第1スレッドは上記ローカルメモリに保存された乱数を元に、モンテカルロ法の1回の試行を実施する。次に、第2スレッドは、同じく排他制御の下、前記モジュールにおいて1回の試行で必要な乱数のスキップ処理と変換処理を行うことになる。このようにして、その他のスレッドについても同様にして処理が進行していく。
【0051】
上記の実施形態では、1回の試行に使用する乱数が多くなるにつれ、各スレッドで使用するローカルメモリの容量も多くなり、また、乱数の保存および呼び出しに伴うメモリアクセスの回数も増える。このため、1回の試行に使用する乱数の数が多い場合には、メモリへのアクセスに要する時間が無視できなくなり、処理時間が増大する可能性がある。メモリの使用量を最小限に留めることにより、上記の処理時間増大の可能性を回避する方法を、次の実施形態で示す。
【0052】
本発明を実現する他の一つの方法として、次のような実施形態が考えられる。すなわち、スキップ処理と変換処理のそれぞれの目的に応じて、二つのメモリ保持形態を有するモジュールを用意する。その上で、状態変数の保存とスキップ処理を行うためのモジュールを1つ用意し(以下、モジュールm0とする)、全スレッドで共有する。さらに、状態変数に変換処理とスキップ処理を施して乱数を生成するためのモジュールをスレッドごとに用意する(以下、m1,m2,・・・,mNTとする)。
【0053】
これらの(NT+1)個のモジュールおよび、並列タスク・スケジューリングを以下のように組み合わせることにより、無駄な捨象がない乱数の割り当てを実現する。例えば、ある試行において、第1スレッドが乱数生成処理に入る場合を考える。このとき排他制御の下、第1スレッドがモジュールm0に保存されている状態変数をモジュールm1にコピーする。さらに、1回の試行で必要な乱数分のスキップ処理をモジュールm0において行う。この処理により、モジュールm0には、最後のスキップ処理によって得られた状態変数が保存された状態となる。その後、排他制御が解除され、第1スレッドはモジュールm1を用いてローカルに変換処理とスキップ処理を行い、試行の実行に必要な乱数を生成する。次に、第2スレッドは、同じく排他制御の下、モジュールm0に保存されている状態変数の情報をモジュールm2へコピーしたうえで、モジュールm0のスキップ処理を行うことになる。このようにして、その他のスレッドについても同様にして処理が進行していく。
【0054】
上記の一連の操作でも、無駄な乱数の捨象は発生しない。また、各試行にはどのスレッドが任意の順番で担当しても同じ乱数が割り当てられるため、計算結果の再現性が得られ、各スレッドに担当させる試行の回数をあらかじめ決めておく必要はない。
【0055】
上記の一連の操作においては、各スレッドのローカルメモリ上にコピーされるのはモジュールm0に保存されている状態変数だけであり、最初に示した実施形態に比べて、メモリへのアクセスを減らすことができる。一方で、各スレッドは状態変数のスキップ処理をモジュールm0のほか、各スレッドで行われる乱数生成時にも行う必要がある。このため、どちらの実施形態の処理時間が速いかは、ハードウエアや分析の対象に依存する。
【0056】
なお、上記の2つの実施形態からも分かるように、本発明では状態変数のスキップ処理に対する排他制御を行う必要がある。排他制御を実現する方法には様々なものが知られているが、本発明は特定の排他制御の方法を前提としたものではない。各スレッドに共有された状態変数のスキップ処理が複数のスレッドで同時に行われることを回避できさえすれば、どのような排他制御方法を用いても実現可能である。この排他制御は、例えば、同期オブジェクトと排他ロックという概念を用いて実行することができる。排他制御が必要となる部分、すなわちある特定のセッションに入る前に、あるオブジェクトに鍵をかける。鍵がかかっている間、他のスレッドは同じオブジェクトに鍵をかけることできず、鍵が外されるまで待たされる。そして、鍵をかけたスレッドはその特定のセッションを終えた後にそのオブジェクトに対する鍵を外す。このとき、鍵をかける対象となるオブジェクトのことを同期オブジェクトと、鍵をかける操作のことを排他ロックと呼ぶ。この同期オブジェクトは、以下に説明する状態変数生成記憶部としてとらえることもできるし、それ以外の対象あるいは抽象的なデータとしてとらえることもできる。
【0057】
図4は、ある一実施の形態に基づいてモンテカルロ法を並列に実行する並列処理システム400のブロック図である。並列処理システム400は、キーボードおよびマウスを含む入力装置410と、LCD(Liquid Crystal Display)ディスプレイなどの表示装置420とを有している。
【0058】
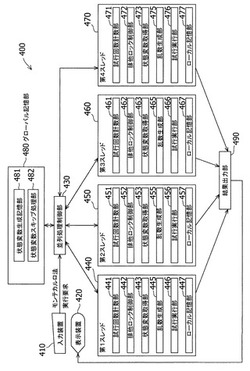
並列処理システム400は、さらに、並列処理制御部430と、第1スレッド440と、第2スレッド450と、第3スレッド460と、第4スレッド470と、グローバル記憶部480とを有している。この第1から第4のスレッド440、450、460、470は、4個以上のプロセッサコアを有するコンピュータを用いて実現することもできるし、4台以上のコンピュータを用いて実現することができる。また、並列処理システム400自体を、4個以上のプロセッサを有するマルチプロセッサコンピュータを含むコンピュータシステムを用いて実現することもできる。
【0059】
グローバル記憶部480は、状態変数を記憶する状態変数生成記憶部481と状態変数スキップ処理部482とを有している。状態変数生成記憶部481および状態変数スキップ処理部482には、第1スレッドから第4スレッドの各スレッドのいずれもがアクセスして状態変数の値の取得やスキップ処理を行うことができる。
【0060】
並列処理制御部430は、入力装置410からの指示を受けて、状態変数生成記憶部481と、状態変数スキップ処理部482と、第1スレッド440と、第2スレッド450と、第3スレッド460と、第4スレッド470とに対し、モンテカルロ法を並列に処理するよう指示を送る。各スレッドは、一つのプロセッサコアが担当して実行することができる。
【0061】
このとき、並列処理制御部430は、入力装置410から受け取ったシードを用いて状態変数を生成し、状態変数生成記憶部481に保存する。あるいは、並列処理制御部430が自ら専用のプログラムを用いてシードを生成し、そのシードから状態変数を生成して状態変数生成記憶部481に保存することができる。
【0062】
第1スレッド440と、第2スレッド450と、第3スレッド460と、第4スレッド470とは、並列処理制御部430による制御を受けて、モンテカルロ法を並列に実行する。本実施形態の並列処理システム400は4個のスレッドを有しているが、これに限定されない。スレッド数は任意の整数とすることができ、ハードウエアの構成に応じて変更することもできる。
【0063】
第1から第4のスレッド440、450、460、470は、いずれも同じ構造をとっている。例えば、第1スレッドは、試行回数計数部441と、排他ロック制御部442と、状態変数取得部443と、乱数生成部445と、試行実行部446と、ローカル記憶部447とを有している。
【0064】
並列処理システム400は、結果出力部490も有している。結果出力部490は、4個のスレッド440、450、460、470でそれぞれ実行された試行により得られた結果をまとめて、表示装置420へ出力することができる。
【0065】
図5は、図4に示した第1から第4のスレッド440、450、460、470がそれぞれ並列に行う処理のフローチャートである。一例として、試行回数Nsimを10000回(Nsim=10000)とする。
【0066】
以下、第1スレッド440を例にとって処理の流れを説明する。まず、ステップS501で処理を開始する。ステップS502において、試行回数計数部441が、第何番目の試行であるかを表す変数nと、試行回数Nsimとの大小関係を判断する。なお、変数nの値は、処理の開始時点で0に初期化されているものとする。
【0067】
ステップS502において、試行回数計数部441がn<Nsimと判断した場合には、ステップS503に進む。他方、試行回数計数部441が、n<Nsimと判断しなかった場合には、ステップS511に進み、処理を終了する。
【0068】
ステップS503では、試行回数計数部441がnをインクリメントする。すなわち、n+1を計算して得られた結果を新たなnの値とする。このとき得られた新たなnの値が、これから実行する試行の番号である。
【0069】
ステップS504では、排他ロック制御部442が、状態変数生成記憶部481へのアクセスを試みる。第2から第4のスレッドの排他ロック制御部452、462、472のいずれもが状態変数生成記憶部481に対して排他ロックをかけていない場合には、第1スレッド440が状態変数生成記憶部481へアクセスすることができ、次いでステップS505に進む。
【0070】
他方、ステップS504の段階で、第2から第4のスレッドの排他ロック制御部452、462、472のいずれか、例えば第4スレッド内の排他ロック制御部472が状態変数生成記憶部481に対して排他ロックをかけている場合には、第1から第3のスレッド440、450、460は状態変数生成記憶部481へアクセスすることができない。その場合は、ステップS504をある一定の時間をおいてから再度実行する。
【0071】
ステップS505では、第1スレッド440の排他ロック制御部442が状態変数生成記憶部481に対して排他ロックをかける。その結果、第2、第3、第4のスレッド450、460、470は、いずれも状態変数生成記憶部481に対してアクセスすることができなくなる。
【0072】
状態変数生成記憶部481に対するアクセスの排他制御を行わないとすると、同時に複数のスレッドがアクセスでき、複数のスレッドが同じ状態変数を用いて乱数を生成することとなる。この場合、異なるスレッドで使用する乱数の一部に重複が生じ、得られるモンテカルロ法の結果も信頼性に欠けるものとなる。このように、同じ状態変数を複数のスレッドが重複して用いないようにするために、上述した排他的なアクセス制御が有効である。
【0073】
次にステップS506では、第1スレッドの状態変数取得部443が状態変数生成記憶部481にアクセスし、状態変数生成記憶部481に保存されている状態変数の値を取得して、ローカル記憶部447に保存する。
【0074】
次にステップS507では、状態変数スキップ処理部482が状態変数生成記憶部481に保存されている状態変数に対しスキップ処理を実行する。具体的には、状態変数スキップ処理部482が、図3に示したステップS3、S5、S7、・・・を繰り返して実行する。このとき、繰り返す回数は、1回のシミュレーションを行うのに必要な乱数の個数と同じ値である。
【0075】
例えば、1回の試行に100個の乱数を要する場合は、ステップS507で、状態変数スキップ処理部482が、図3に示した状態変数スキップ処理(ステップS3、S5、S7、・・・)を100回繰り返して実行する。
【0076】
この時点で、第1スレッド440のローカル記憶部447には、ステップS506で取得された状態変数が保存されている。また、状態変数生成記憶部481には、次の試行で用いる最初の乱数に対応する状態変数が保存されている。
【0077】
次にステップS508では、第1スレッド440の排他ロック制御部442が、状態変数生成記憶部481に対する排他ロックを解除する。その結果、第2から第4のスレッド
450、460、470が状態変数生成記憶部481へアクセスできることとなる。
【0078】
ステップS509では、ローカル記憶部447に保存されている状態変数を呼び出し、乱数生成部445にその値を渡す。
【0079】
ステップS510では、乱数生成部445が100個の乱数を生成しながら、試行実行部446が1回の試行を実行する。その後、ステップS502に進む。
【0080】
以上のようにして、第1スレッド440は、自己が担当するモンテカルロ法を実行することができる。第2スレッド450、第3スレッド460、第4スレッド470も、図5に示した処理を実行することにより、自己が担当するモンテカルロ法をそれぞれ実行することができる。その結果、第1スレッド440、第2スレッド450、第3スレッド460、第4スレッド470が、全ての試行を並列に実行することができる。
【0081】
上記実施形態を通して説明したように、本発明においては、排他制御を利用しつつ、状態変数の情報を全スレッドで共有することにより、無駄な状態変数のスキップ処理を排除している。
【0082】
図6は、上記実施形態による各スレッドの試行の担当例を示す図である。横軸は第1スレッドから第4スレッドを示しており、縦軸は時間tを示している。図1および図2と同様に、符号Aは、後続で行うモンテカルロ法の試行に用いる乱数の生成処理を示している。符号Bは、試行の実行処理を示している。符号Bの後に続くかっこ書きの数字は、試行番号である。ここで、従来技術1を示す図1および従来技術2を示す図2とは異なり、上記実施形態においては乱数捨象処理を表す符号Cが各スレッドに分散しており、処理負荷の均一化が図られていることがわかる。このように各スレッドの負荷が均一化できるのは、状態変数生成記憶部を利用することにより、試行に用いる状態変数の情報を全スレッドが共有しているためである。
【0083】
図6に示した例では、第1スレッドは、n=2,6,・・・,9998の試行を実行し、第2スレッドは、n=1,5,・・・,9997の試行を実行し、第3スレッドは、n=4,8,・・・,10000の試行を実行し、第4スレッドは、n=3,7,・・・,9999の試行を実行している。ただし、各スレッドに対する試行番号の割り当てはOSの並列タスク・スケジューリングにより自動的に決められるため、一般に各スレッドに割り当てられる試行番号は実行のたびに異なるものとなる。また、各スレッドが実行する試行回数は必ずしも同一の回数になるとも限らない。一方で、本発明の方法では、同一の試行番号の試行には必ず同じ乱数が割り当てられるため、モンテカルロ法の実行結果には再現性がある。
【0084】
マルチタスクOSでは、試行実行中であっても、OSによってプロセッサコアに他のタスクが割り当てられることがあり、計算量が均等になるように各スレッドに処理を割り当てたとしても、各プロセッサコアが処理の終了までに要する時間は必ずしも均一になるとは限らない。本発明の方法によれば、他のタスクによる負荷が少ないプロセッサコアに自動的に多くの試行処理が割り当てられ、プロセッサコア間の負荷が自動的に分散化されるという利点もある。
【0085】
上記実施形態における並列処理は、第10000番目の試行を終えた時点で、処理終了となる。第10000番目の試行を終えるまでに要する理論的な計算時間tMCは、以下のように表現することができる。
【数3】
ここで、NSimはモンテカルロ法の試行回数であり、NTは試行を実行するスレッドの数であり、tSimは1回の試行に要する時間であり、tSkipは1回の試行に用いる乱数のスキップ処理に要する時間である。
【0086】
スレッド数NT≦tSim/tSkipの場合には、試行の実行処理を行っている間に、他のスレッドのスキップ処理が終わるため、排他ロックによる処理の待ち時間は生じない。この場合、式(4)からわかるように、スレッド数NTを増加させると、それに応じて計算時間tMCは短くなる。他方、スレッド数NT≧tSim/tSkipの場合には、スレッド数NTを増加させても計算時間tMCは変化しない。これは、この場合には排他ロックによる処理の待ち時間が生じるためである。
【0087】
図7に示す表1は、本発明の一実施形態と、上述した従来技術1との理論的な計算時間の比較を表している。横軸はスレッド数であり、縦軸はtSim/tskipである。そして、表内の値は、(本発明の一実施形態による理論的な計算時間)/(従来技術1の理論的な計算時間)である。
【0088】
tSim/tskipの値が大きくほど、乱数発生以外の処理に掛かる時間が長い複雑な試行であることを意味する。なお、tSim/tskip=1の場合、すなわち、1回の試行に要する時間tSimと、1回の試行に用いる乱数のスキップ処理に要する時間tSkipとが等しい場合は、乱数を生成させただけで、乱数を用いた演算を行わないことを意味している。これは、実用的には意味のないものであるが、計算時間の比較として参考までに載せるものである。
【0089】
表1によれば、スレッド数を20とし、tSim/tskip=20である場合には、(本発明の一実施形態による理論的な計算時間)/(従来技術1の理論的な計算時間)=0.54である。すなわち、従来技術1と比べて計算時間をほぼ半減できることを意味している。
【0090】
図8に示す表2は、本発明の一実施形態と、上述した従来技術2との理論的な計算時間の比較を表している。表1と同様に、横軸はスレッド数であり、縦軸はtSim/tskipである。そして、表内の値は、(本発明の一実施形態による理論的な計算時間)/(従来技術2の理論的な計算時間)である。なお、従来技術2では、理論的な計算時間を達成するためにモンテカルロ法実行前にtSimとtskipを計測する必要があるが、ここでの比較ではその計測に要する時間は考慮していない。
【0091】
表2によれば、スレッド数を20とし、tSim/tskip=20である場合には、(本発明の一実施形態による理論的な計算時間)/(従来技術2の理論的な計算時間)=0.67である。すなわち、従来技術1より優れている従来技術2と比較しても計算時間をほぼ3分の2に短縮できることを意味している。
【0092】
[実施例]
以下、モンテカルロ法を用いて、半径0.5の円の面積を求める実施例について説明する。まず、図9は、モンテカルロ法を並列にではなく、逐次的に行うプログラム例である。ここでは、プログラミング言語としてC++言語を用いる。図9に示されているプログラムの各行の左側に示されている「1」、「2」、・・・、「20」は、プログラムの行番号を表すものであって、プログラム自体を構成するものではない。
【0093】
第1行目の「AreaOfCircle」は、モンテカルロ法により半径0.5の円の面積を求める関数である。この関数の引数「NSim」は試行回数を表す変数であり、引数「seed」は、擬似乱数を生成する元となる値である。関数「AreaOfCircle」が第2行目から第20行目において定義されている。
【0094】
第4行目の変数「x」および「y」は、生成した乱数をx座標値およびy座標値とするための変数である。第5行目の変数「r_sq」は、半径0.5の円の中心点(0.5,0.5)と、乱数生成により求めたXY平面上の点との距離を二乗した値を保存する変数である。第6行目の変数「s」は、乱数生成により求めたXY平面上の複数の点のうち、半径0.5の円内に含まれる点の数を保存する変数である。
【0095】
第7行目の「RandomNumberGenerator」は、(0,1)区間の一様乱数を生成するクラスである。その詳細については後述する。第10行目では、関数「AreaOfCircle」の引数「seed」の初期化を行う。
【0096】
第13行目から第18行目は、モンテカルロ法を行うループである。試行番号を表す変数SimNo=0から始めてNSim回の試行を逐次的に行う。第14行目および第15行目でそれぞれ1個の乱数を生成して、それぞれの値をX座標値およびY座標値とする。これにより、XY平面上の点をランダムに定めることができる。第16行目では、ピタゴラスの定理を用いて、第14行目および第15行目で定められたXY平面上の点と、円の中心点(0.5、0.5)との距離の二乗を計算し、変数r_sqに保存する。第17行目では、r_sqと0.25(=0.5*0.5)との大小関係を判断して、r_sq<0.25を満たす場合、すなわち、ランダムに定められたXY平面上の点が半径0.5の円内に含まれる場合に、変数sをインクリメントする。そして、第19行目のs/NSimが関数AreaOfCircleの戻り値、すなわち、求められた円の面積である。試行の実行回数NSimの値が大きければ大きいほど、求まる円の面積は、π*0.5*0.5に近くなる。
【0097】
図10は、図9のプログラム例を並列化したプログラム例である。図10に示すプログラム例では、並列計算を行うための標準規格であるOpenMPを用いて並列化を行っている。OpenMPは、主に共有メモリ型の並列計算機で用いられている。
【0098】
第1行目は、図9と同様に、変数NSimおよび変数seedを引数とする関数AreaOfCircleの宣言文である。
【0099】
第5行目は、状態変数の値を取得するための乱数生成クラスRandomNumberGeneratorを宣言している。この乱数生成クラスRandomNumberGeneratorは、全てのスレッドが共有するクラスである。後に図12に示すように、このクラスには状態変数に相当するメンバ変数が含まれており、状態変数生成記憶部481の役割を果たすことができる。また、状態変数のスキップ処理や状態変数の値の取得処理、乱数の生成処理を行うメソッドも含まれている。
【0100】
第6行目の変数sは、図9と同様に、乱数生成により求めたXY平面上の複数の点のうち、半径0.5の円内に含まれる点の数を保存する変数である。
【0101】
第12行目から第32行目は、各スレッドが並列に処理を実行する部分である。すなわち、変数SimNo=0から始めてNSim回の試行を図4に示したスレッド440、450、460、470が分担して実行する。
【0102】
第22行目および第27行目は、状態変数生成記憶部481に対する排他ロックの制御を行う処理である。これは、図4の排他ロック制御部442、452、462、472が行う処理に相当する。この処理により、あるスレッドが乱数の生成処理を行っている場合(第25、26行目)においては、他のスレッドは、乱数生成処理を実行することができなくなる。
【0103】
第33行目で計算するs/NSimは、関数AreaOfCircleの戻り値、すなわち、求められた円の面積である。この計算は、図4の結果出力部490の処理に相当する。
【0104】
第12行目、第19行目、第22行目の記述は、OpenMPによる並列処理の指示を示している。
【0105】
なお、図10に示したプログラム例では、図4で示したブロック図とは異なり、乱数生成部は全スレッドに共有されており、各スレッドには状態変数取得部や乱数生成部は存在しない。一方で、排他制御を利用しつつ状態変数の情報を全スレッドで共有する、という発明の特徴は備えている。このような例も、本発明の範囲に含まれる。
【0106】
図10のプログラム例では、1回の試行に用いる乱数は2個と少ないが、1回の試行に多くの乱数を使用するシミュレーションでは、各スレッドで使用するメモリの容量が増え、メモリへのアクセス回数も増える。このため、ハードウエアや分析の対象によっては、図10と同様のプログラムではメモリへのアクセスに要する時間が無視できなくなる場合がある。
【0107】
図10のプログラム例における排他制御部での処理を最小限に留めることにより、上記の処理時間増大の可能性を軽減する方法も考えられる。それが、図11で示すプログラム例である。
【0108】
第5行目は、図10と同様に、全てのスレッドで共有する、乱数生成クラスRandomNumberGeneratorを宣言している。このクラスには状態変数にあたるメンバ変数が含まれており、これによって状態変数の情報が全クラスで共有されることとなる。
【0109】
第6行目では、1回のモンテカルロ法で用いる乱数の個数を表す変数NRandを定めている。本例では、NRand=2と定めている。これは、1回の試行につき、X座標値とするための乱数と、Y座標値とするための乱数とをあわせた合計2個の乱数が必要となるからである。
【0110】
第28行目および第34行目は、状態変数生成記憶部481に対する排他ロックの制御を行う処理である。この処理により、あるスレッドが状態変数の値の取得(第31行目)を行っている場合と、状態変数のスキップ処理(第33行目)を行っている場合とにおいては、他のスレッドは、状態変数の値の取得およびスキップ処理をいずれも行うことができなくなる。
【0111】
第37行目では、先に取得した状態変数を各スレッドの乱数生成クラスにセットする。そして、第38行目および第39行目で乱数を生成して、それぞれX座標値およびY座標値とする。
【0112】
図12は、図9、図10、図11の各プログラム例で用いる乱数生成クラス「RandomNumberGenerator」を宣言するプログラム例である。図12の第10行目では、状態変数に相当するメンバ変数state_vecが宣言されている。この変数に状態変数の値を格納することにより、このクラスは状態変数生成記憶部481の役割を果たすことができる。また、このクラスRandomNumberGeneratorには、乱数の生成処理を行うメソッド(第23行目)や、状態変数のスキップ処理を行うメソッド(第26行目)、状態変数の値の取得処理を行うメソッド(第29行目)が用意されている。これらは、図4のブロック図でいえば、それぞれ乱数生成部(符号445、455、465、475)、状態変数スキップ処理部(符号482)、状態変数取得部(符号443、453、463、473)に相当する役割を果たすものである。このクラスの実際の処理は、乱数生成アルゴリズムとして、メルセンヌ・ツイスター法、線形合同法、あるいはその他の方法のいずれを使用するかによって変わる。
【0113】
並列計算機は、共有メモリ型並列計算機と、分散メモリ型並列計算機とに大別できる。共有メモリ型並列計算機は、全てのプロセッサコアがメモリを共同で使用するタイプの計算機である。このメモリは、共有メモリと呼ばれている。共有メモリ型並列計算機は、プロセッサコア間のデータの交換が容易であるという長所を有する。一方で、プロセッサコア数が多い場合には、共有メモリへの書き込みが競合し、性能が低下する場合があるという短所を有する。共有メモリ型並列計算機への実装にはOpenMPを用いることができる。
【0114】
分散メモリ型並列計算機は、図4に示した第1から第4のスレッド440、450、460、470のそれぞれを、個別にメモリを持ついくつかのプロセッサにより実行することができるものである。プロセッサ間でデータを交換するためには、プロセッサ間で通信を行う必要がある。分散メモリ型並列計算機への実装には、MPI(Message Passing Interface)を用いることができる。
【0115】
上記実施形態は、共有メモリ型並列計算機、および分散メモリ型並列計算機のいずれにも実装することができる。すなわち、図4に示した第1から第4のスレッド440、450、460、470の全てが、状態変数の情報を共有できさえすれば、共有メモリ型並列計算機、および分散メモリ型並列計算機のいずれにも実装することができる。また、各スレッドを1個のプロセッサコアが担当するように構成することもできるし、各スレッド自体を2個以上のプロセッサコアにより処理することもできる。
【0116】
なお、本発明の各実施の形態を実装するためのコンピュータのハードウエア構成は特段図示した構成に限定されるものではなく、数値演算の形式に併せて専用の数値演算ユニットを一つ以上有していたり、複数の筐体に分かれて互いにネットワークにより接続されているクラスタ構成にされていたりすることができる。なお、本実施例のみならず、本発明全般に、区別して記載された機能手段は、実質的にそのような区別された機能を果たす任意の構成要素によって実現される。このとき、その構成要素が、物理的にいくつの数を有するか、あるいは、複数であり互いにどのような位置関係にあるかなどの機能を果たす上で制限とならない属性によって本発明が制限されることはない。例えば、複数の区別された機能が単一の構成要素によって経時的に異なるタイミングで実行されることも本発明の範囲に含まれる。
【0117】
本発明の各実施の形態の機能処理を実装するコンピュータにおいて数値計算をするためのソフトウエア構成は、本発明の各実施の形態の数値情報処理を実現する限り任意の構成とすることができる。そのコンピュータは、基本入出力システム(BIOS)などのハードウエア制御のためのソフトウエアを搭載しており、これと連携して動作し、ファイル入出力やハードウエアリソースの割り振りを担当するオペレーティングシステム(OS)によって管理されている。当該OSは、OSやハードウエアと連携して動作するアプリケーションプログラムを、例えばユーザーからの明示の命令や、ユーザーからの間接的な命令や他のプログラムからの命令に基づいて実行することができる。アプリケーションプログラムは、このような動作を可能とし、OSと関連して動作するように、OSの規定する手続に依存して、あるいはOSに依存しないように適切にプログラムされている。本発明の各実施の形態を実装する場合には、一般に、専用のアプリケーションプログラムの形式で数値計算やファイル入出力等の処理を実装するが、本発明がそれのみに限定されるものではなく、複数の専用または汎用アプリケーションプログラムを用いたり、既成の数値計算ライブラリを部分的に用いたり、他のコンピュータのハードウエアによって処理されるようにネットワークプログラミング手法によって実現されていたり、その他の任意の実装形態によって実現されうる。したがって、本発明の各実施の形態の計算手法をコンピュータ上に実装するための一連の命令を表現するソフトウエアを、単にプログラムと呼ぶ。プログラムは、コンピュータにより実行可能な任意の形式あるいはそのような形式に最終的に変換可能な任意の形式によって表現される。
【0118】
本発明の各実施の形態のプログラムは、ハードウエア資源であるMPUなどの演算手段が、OSを介してあるいはOSを介することなく計算プログラムからの指令を受け、ハードウエア資源であるメインメモリや補助記憶装置などの記憶手段と協働して、ハードウエア資源である適当なバスなどを通じて演算処理を行うように構成される。つまり、本発明の各実施の形態の計算手法を実現するソフトウエアによる情報処理が、これらのハードウエア資源によって実現されるように実装される。記憶手段あるいは記憶部は、任意の単位によって論理的に区分されているコンピュータが可読な情報記憶媒体の一部または全部またはそれらの組み合わせをいう。この記憶手段は、例えば、MPU内のキャッシュメモリや、MPUと接続されたメインメモリや、MPUと適当なバスによって接続されたハードディスクドライブなどの不揮発性記憶媒体など、任意のハードウエア資源によって実現される。ここで、記憶手段は、MPUのアーキテクチャによって規定されるメモリ内の領域や、OSが管理するファイルシステム上のファイルやフォルダ、同じコンピュータ内やネットワーク上のいずれかのコンピュータにあってアクセス可能なデータベースマネージメントシステム内のリストやレコード、リレーショナルデータベースによって相互にリレーションがある複数のリストで管理されたレコードなど任意の形式によって実現され、論理的に他と区分され、情報を識別可能に少なくとも一時的に記憶または記録できる任意のものを含む。
【符号の説明】
【0119】
400 並列処理システム
410 入力装置
420 表示装置
430 並列処理制御部
440 第1スレッド
450 第2スレッド
460 第3スレッド
470 第4スレッド
441、451、461、471 試行回数計数部
442、452、462、472 排他ロック制御部
443、453、463、473 状態変数取得部
445、455、465、475 乱数生成部
446、456、466、476 試行実行部
447、457、467、477 ローカル記憶部
480 グローバル記憶部
481 状態変数生成記憶部
482 状態変数スキップ処理部
490 結果出力部
【技術分野】
【0001】
本発明は、モンテカルロ法の並列処理手法に関し、特に、並列計算機を効率的に用いるモンテカルロ法の並列処理手法と、それを実行するための装置およびコンピュータプログラムに関する。
【背景技術】
【0002】
モンテカルロ法(Monte Carlo method)は、自然現象や社会現象をはじめとする確率的な現象の分析や、複雑な数値積分などに広く用いられる手法である。このモンテカルロ法は、解析的に解くことが難しい問題に対して特に威力を発揮する。自然現象および社会現象は、不確実性を有するものが大半を占めるため、モンテカルロ法の適用範囲は学術分野から実務にわたり極めて広い。さらに、モンテカルロ法のアルゴリズム(計算手順)は理解が容易であることもモンテカルロ法が広く普及している一因である。例えば、モンテカルロ法を産業上利用している具体例としては、流体力学の分野におけるシミュレーションや、金融機関におけるリスク量の算出や各種金融商品の価格算出などが挙げられる(例えば、特許文献1、非特許文献1参照)。
【0003】
一方で、モンテカルロ法の計算精度を確保するためには試行回数を十分に取る必要があり、その結果、計算時間が増大するという短所をもつ。近年では、複数のプロセッサコアを搭載したコンピュータが続々と登場し、従来は単一のスレッドで実行していたところ、複数のプロセッサコアのそれぞれにおいてスレッドを立てて並列に処理することによって計算時間を短縮することが比較的容易になった。ここで、スレッドとは、プロセス内の処理の流れのことを指す。モンテカルロ法についても並列処理によって計算時間を短縮することができる。特に、モンテカルロ法のアルゴリズムは並列処理と親和性が非常に高く、モンテカルロ法の並列処理による高速化の要請は高まっている。
【0004】
モンテカルロ法に並列処理を施すこと自体は従来から行われている。すなわち、モンテカルロ法の試行全体を複数のスレッドで分担して、1台のコンピュータあるいは1個のプロセッサコアにつき1個のスレッドを割り当てることにより、各コンピュータまたはプロセッサコアが独立して処理を行うことができる。例えば試行回数を10000回として4台のコンピュータで並列処理する場合には、各コンピュータでそれぞれ2500回の試行を行えばよい。
【0005】
しかし、実用上は、次に挙げる2つの問題を克服しなければならない。一つは、計算結果の再現性の問題であり、もう一つは、乱数系列間に生じる相関の問題である。
【0006】
一つ目の計算結果の再現性とは、同じ乱数シード、すなわち、同じ乱数系列を用いてモンテカルロ法による数値計算を繰り返し行った場合に、同じ計算結果が得られるという意味である。この再現性は、バックテストを行うときや計算条件を変更した際の影響を検証する際に欠かせないものである。一般に、プログラムを並列化すると処理の逐次性が失われるため、計算結果の再現性を確保するには乱数の生成法と使用法に関する工夫が必要となる。
【0007】
二つ目の乱数系列間に生じる相関とは、モンテカルロ法の並列処理にあたって、スレッド毎に用いる乱数系列の間に有意にゼロとは言えない相関が生じることを指す。このような相関が生じると計算結果の信頼性が低下するため、コンピュータあるいはプロセッサコアごとにそれぞれ別の乱数系列を生成する場合には、乱数列間の相関が非常に小さいものを用いる必要がある。その解決策としては、一つの乱数系列を用いて並列処理を行うか、あるいは、互いに相関が非常に小さい乱数系列を生成し単純に並列処理を行うかのいずれかが考えられる。後者についてのアルゴリズムは存在するが、モンテカルロ法を実行する以前に乱数系列を生成するための処理や乱数列の独立性に関する検証が必要となるなど、課題が多い。したがって、一つの乱数列を用い、かつ、計算結果の再現性を保持しつつ、並列処理を行うことが実用上は重要となる。
【0008】
一つの乱数列を用い、計算結果の再現性を保持しつつ、並列処理を行う際には、モンテカルロ法実行時の乱数の生成方法が本質的に重要となる。モンテカルロ法の並列処理に関する既存の技術としては以下のものがある。
【0009】
[従来技術1]
図1は、従来技術(以下、従来技術1とも呼ぶ。)として、4個のスレッドを有する並列処理システムを用いて並列処理を行う場合の各スレッドの試行番号の担当を示す図である。横軸は第1スレッドから第4スレッドを示しており、縦軸は時間tを示している。そして、符号Aは、後続で行う試行に用いる乱数の生成処理を示している。符号Bは、各試行の実行処理を示している。符号Bの後に続くかっこ書きの数字は、試行番号である。符号Cは、後述する乱数捨象処理もしくは状態変数のスキップ処理を示している。
【0010】
図1に示すように、従来技術1では各スレッドに対して試行回数を均等に配分する。具体的には、前述のように10000回の試行を4個のスレッドで実行すると考えて、第1スレッドは第1番目から第2500番目の試行を担当する。そして、第2スレッドは第2501番目から第5000番目の試行を担当し、第3スレッドは第5001番目から第7500番目の試行を担当し、第4スレッドは第7501番目から第10000番目の試行を担当する。すなわち、それぞれのスレッドは2500回分の試行を実行する。
【0011】
乱数生成部をスレッドごとにそれぞれ用意し、全ての乱数生成部に同一の乱数シード(乱数系列)を与える。各スレッドは、自己が担当する試行にとって不要な乱数を捨象した上で、各自が割り当てられた試行を行う。
【0012】
例えば、1回の試行に100個の乱数を用いるとすると、第1スレッドは、100×2500=25万個の乱数を生成して試行を行う。
【0013】
第2スレッドも同様に25万個の乱数を必要とする。しかし、第2スレッドは、50万個の乱数を生成した上で、前半の25万個を捨象し、後半の25万個を試行に用いる必要がある。前半の25万個の乱数は、第1スレッドが試行のために使用するものであり、第2スレッドは前半の25万個の乱数を使用することができない。第2スレッドも前半の25万個の乱数を使用してしまうと、第1スレッドと第2スレッドのいずれもが同じ乱数を用いて試行を行うこととなり、モンテカルロ法の結果の信頼性が低下してしまう。この乱数捨象処理を図1において符号Cで示している。
【0014】
これは、擬似乱数が、ランダムな物理現象、例えばサイコロを振って出た目を利用して生成する物理乱数とは異なり、前回の乱数を算術式に代入して、新たな乱数を生成するという逐次的な性質を有するからである。したがって、第2スレッドにおいては、第1番目から第25万番目の乱数を生成しないと、第25万1番目以降の乱数を生成することができない。
【0015】
第3スレッドは、75万個の乱数を生成する。そして、第1スレッドで使用する最初の25万個の乱数と、第2スレッドで使用する次の25万個の乱数とを足し合わせた50万個の乱数を捨象した上で、第50万1番目の乱数から始めて25万個の乱数を用いて試行を行う。
【0016】
最後に、第4スレッドは、100万個の乱数を生成する。そして、第1スレッドで使用する最初の25万個の乱数と、第2スレッドで使用する次の25万個の乱数と、第3スレッドで使用するさらに次の25万個の乱数とを足し合わせた75万個の乱数を捨象した上で、第75万1番目から始めて25万個の乱数を用いて試行を行う。
【0017】
ここで、第1スレッドは乱数の捨象処理を行わないことに留意されたい。
【0018】
これにより上記二つの問題を克服した並列処理が可能となる。ただし、この方法では、後続の試行を担当するスレッドほどより多くの乱数を捨象しなければならないため、試行回数は均等であるが、各スレッドの処理負荷は不均等となる。図1の例では、第1スレッドは乱数の捨象処理を行わないため、4つのスレッドの中で最も処理負荷が小さい。そして、第2スレッド、第3スレッド、第4スレッドの順に、生成する乱数の個数が増えるため、処理の負荷も同じ順番で大きくなる。すなわち、第4スレッドは、4個のスレッドの中で最も処理負荷が大きい。
【0019】
第4スレッドが第10000番目の試行の試行を終えた時点で、モンテカルロ法の処理は終了する。第4スレッドが第10000番目の試行を終えるまでに要する理論的な計算時間tp1は、以下のように表現することができる。
【数1】
ここで、NSimはモンテカルロ法の試行回数であり、NTは並列処理を行うスレッドの数であり、tSimは1回の試行に要する時間であり、tSkipは1回の試行に用いる乱数の捨象に要する時間である。
【0020】
この処理方法では、スレッド数が多いほど処理負荷の不均等が如実に現れるため、スレッド数が増加するに従って並列処理の効率が悪化していく。
【0021】
[従来技術2]
上記の方法を改善したものが特許文献1に記載されている。特許文献1によれば、金融工学の種々の計算におけるモンテカルロ法において、各スレッドが担当する試行回数を均等に割り当てるのではなく、後続の試行を担当するスレッドの試行回数を少なくすることにより、各スレッドの処理負荷の均一化を図るように改善されている。その様子を図2に示している。図1と同様に、符号Aは、後続で行うモンテカルロ法に用いる乱数生成処理を示している。符号Bは、試行の実行処理を示している。符号Bの後に続くかっこ書きの数字は、試行番号である。符号Cは、乱数捨象処理を示している。
【0022】
図2に示すように、例えば、第1スレッドは第1番目から第3000番目の試行を担当する。第2スレッドは第3001番目から第5750番目の試行を担当する。第3スレッドは第5751番目から第8000番目の試行を担当する。第4スレッドは第8001番目から第10000番目の試行を担当する。
【0023】
つまり、第1スレッドは3000回分の試行を担当し、第2スレッドは2750回分の試行を担当し、第3スレッドは2250回分の試行を担当し、第4スレッドは2000回分の試行を担当する。
【0024】
このように、従来技術2では、乱数を多く生成する必要があるスレッドの試行担当回数を他のスレッドよりも減らすことにより、全体として、4個のスレッドの負荷の均等化を図っている。
【0025】
この従来技術において、各プロセッサコアの処理負荷が均一になるように試行回数を割り当てた場合に試行の実行に要する理論的な計算時間tp2は、以下のように表現することができる。
【数2】
ここで、NSimはモンテカルロ法の試行回数であり、NTは並列処理を行うスレッドの数であり、tSimは1回の試行に要する時間であり、tSkipは1回の試行に用いる乱数の捨象に要する時間である。
【0026】
この技術にも次のような問題点がある。一つは、処理負荷が均一になるように各スレッドに最適な試行回数を割り当てるためには、tSimとtSkipの値を計測する必要があり、そのための追加的なプログラムが必要となる点である。もう一つは、依然として各スレッドで乱数の捨象処理を行う必要があるため、従来技術1と比べて改善はするものの、やはりスレッド数が増えるにつれて並列処理の効率が落ちるという点である。
【0027】
なお、式(2)および式(3)において、スレッド数NT→∞の極限をとると、いずれもNSimtSkipとなる。すなわち、どんなにスレッド数を増やしても、NSimtSkipの計算時間を要する。これは、乱数の生成は逐次的に行うものであって、モンテカルロ法全体を完全には並列化することができないからである。
【先行技術文献】
【特許文献】
【0028】
【特許文献1】特許4032339号公報
【非特許文献1】石川達也、内田善彦、「モンテカルロ法によるプライシングとリスク量の算出について―正規乱数を用いる場合の適切な実装方法の考察―」、金融研究、日本銀行金融研究所、2002年6月、第21巻、別冊第1号、p.51−90
【発明の概要】
【発明が解決しようとする課題】
【0029】
本発明は、従来技術で行っていた、各スレッドにおける無駄な乱数の捨象を行わず、かつ、処理負荷の均一化を図るために各スレッドが担当する試行回数を予め計算して決めておく必要のない、効率的な並列処理手法を提供することを目的とする。
【課題を解決するための手段】
【0030】
本発明は、コンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、状態変数を状態変数生成記憶部に記憶するステップと、一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行って、乱数を生成する乱数生成ステップと、前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップとを含み、前記乱数生成ステップと試行演算ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法を提供する。
【0031】
本発明はまた、前記乱数生成ステップが、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行う処理ステップと、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に対する排他ロックを解除するステップとを含むものである前記並列処理方法を提供する。
【0032】
さらに、本発明はコンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、状態変数を状態変数生成記憶部に記憶するステップと、一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数を取得するとともに、該状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理ステップと、前記一のスレッドのプロセッサコアが、前記取得した状態変数に対し、所定の回数にわたり変換処理とスキップ処理を行って乱数を生成するステップと、前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップとを含み、前記各ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法を提供する。
【0033】
ここで、前記状態変数スキップ処理ステップは、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部から状態変数の値を取得するステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う処理ステップと、前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に対する排他ロックを解除するステップとを含むものであってよい。
【0034】
これらの並列処理方法は、金融工学の分野において、複数の債権を含むポートフォリオの信用リスク量を計測するため、金融市場の変化をモデル化して金融商品の価格を算出するため、さらには、金融市場の変動によって生ずる市場リスク量を計測するために、モンテカルロ法を実行するのに用いることができる。
【0035】
本発明は、これらの並列処理方法の各ステップをコンピュータに実行させるためのプログラムも提供する。
【0036】
さらに、本発明は、コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理により実行する並列処理システムであって、前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次変換処理とスキップ処理を行って乱数を生成する乱数生成部と、各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部とを備える並列処理システムを提供する。
【0037】
そして、本発明は、コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理することにより実行する並列処理システムであって、前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理部と、各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、前記状態変数生成記憶部から状態変数の値を取得してメモリに保存する状態変数取得部と、メモリに保存されている状態変数に対して、所定の回数にわたり変換処理とスキップ処理を行い、乱数を生成する乱数生成部と、前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部とを備える並列処理システムをも提供する。
【0038】
本発明の一実施形態によれば、モンテカルロ法を用いて金融工学の分野における信用リスク量の計測を行うことができる。すなわち、個々の債務者(通常、企業)の価値の変化をモデル化して、そのポートフォリオまたは銀行の信用リスク量(信用VaR、条件付き信用VaRなど)を計測する場合に、本発明の方法を用いてモンテカルロシミュレーションを実行することにより、全体的な信用リスク量を算出することができる。
【0039】
また、同様にして本発明のモンテカルロ法を用いて金融市場における市場リスク量の計測を行うことができる。具体的には、株式市場における株価の変化や債券市場における債券価格の変化をモデル化して、本発明の方法を用いてモンテカルロシミュレーションを実行することにより、これらの市場の変動によって生ずる市場リスク量を計測することができる。
【0040】
あるいは、本発明のモンテカルロ法を用いて金融商品の価格算出を行うことができる。すなわち、金融市場の変化をモデル化して、本発明の方法を用いてモンテカルロシミュレーションを実行することにより、各種有価証券やデリバティブなどの金融商品の価格を算出することができる。
【発明の効果】
【0041】
本発明では、ほぼ理想的な並列化効率を実現したモンテカルロ法の並列処理が実現される。また、本発明は実装が容易であるという特長を持つ。本発明は、一般のモンテカルロ法についての技術であって、適用分野を問わないため、上述のように、本発明によりモンテカルロ法の計算負荷の軽減のメリットを享受できる分野は極めて広いと考えられる。金融工学の各分野のほか、流体力学や分子動力学などの種々の分野において有用なものである。また、従来技術の上記二つの欠点、すなわち、無駄な乱数の捨象によりスレッド数が増えるに従って並列化の効率が落ちるという欠点と、各スレッドに割り当てる試行回数をあらかじめ計算しなければならないという欠点とをいずれも解消でき、より一層効率的な並列処理が可能となる。
【図面の簡単な説明】
【0042】
【図1】従来技術に基づいて、各スレッドに試行回数を割り当てる様子を示す模式図である。
【図2】従来技術に基づいて、各スレッドに試行回数を割り当てる様子を示す模式図である。
【図3】乱数を生成する処理の流れを示す模式図である。
【図4】モンテカルロ法の並列処理を行う並列処理システムのブロック図である。
【図5】モンテカルロ法の並列処理の流れを示すフローチャートである。
【図6】各スレッドに試行回数を割り当てる様子を示す模式図である。
【図7】従来技術1との計算時間の比較を示す表である。
【図8】従来技術2との計算時間の比較を示す表である。
【図9】モンテカルロ法を逐次処理することにより、半径0.5の円の面積を求めるプログラム例である。
【図10】モンテカルロ法を並列処理することにより、半径0.5の円の面積を求めるプログラム例である。
【図11】モンテカルロ法を並列処理することにより、半径0.5の円の面積を求めるプログラム例である。
【図12】乱数生成クラスのプログラム例である。
【発明を実施するための形態】
【0043】
まず、乱数生成処理について述べる。図3は、乱数を生成する処理の流れを示す模式図である。乱数を生成するためには、最初にシード(乱数種)と呼ばれる、擬似乱数を生成する元となる値を用意する。このシードを符号101で示している。シード101は、キーボードを通して入力するか、あるいは、専用のプログラムを用いて準備することもできる。
【0044】
そして、ステップS1として、用意されたシード101から状態変数102を計算する。状態変数とは、一般には整数を要素とするベクトルである。次にステップS2として、初期状態変数102から乱数103を生成する。ステップS3では、初期状態変数102から新たな状態変数104を計算する。ステップS4では、状態変数104から乱数105を生成する。ステップS5では、状態変数104から新たな状態変数106を計算する。ステップS6では、状態変数106から乱数107を生成する。
【0045】
あるいは、ステップS1、S3、S5、S7、・・・を実行して、状態変数を必要な乱数個分生成する。その上で、ステップS2、S4、S6、・・・を実行して乱数を生成することもできる。
【0046】
このようにして、状態変数の計算と乱数の生成とを繰り返すことにより、複数の乱数を生成することができる。この乱数生成方法の具体例として、メルセンヌ・ツイスター(Mersenne Twister)法や線形合同法を挙げることができる。線形合同法は、状態変数そのものが乱数であると考えることにより、上述の乱数生成処理の枠組みで捉えることが可能である。
【0047】
ステップS3、S5、S7のように、ある状態変数から新たな状態変数を計算する処理を状態変数のスキップ処理と呼ぶ。このように、状態変数に対してスキップ処理を行うと、状態変数の値は更新される。
【0048】
上述したように、乱数の生成は、状態変数のスキップ処理と、状態変数を乱数に変換する変換処理とに分けることができる。また、各スキップ処理の後すぐに乱数の生成を実行することもできる。本発明は、排他制御を利用しつつ、状態変数の値を全てのスレッドで共有することにより、従来技術における無駄な乱数の捨象処理が不要となるという知見に基づいている。
【0049】
本発明を実現する一つの方法として、次のような実施形態が考えられる。すなわち、状態変数の情報を保持することができる乱数生成モジュールを1個用意し、全スレッドで共有する。このモジュールおよび、並列タスク・スケジューリングを以下のように組み合わせることにより、無駄な捨象のない乱数の割り当てを実現する。
【0050】
例えば、ある試行において、第1スレッドが乱数生成処理に入る場合を考える。このとき、排他制御の下、第1スレッドが、前記モジュールにおいて順次変換処理とスキップ処理を行い、1回の試行で必要な乱数を生成してスレッド内のローカルメモリに保存する。この処理により、前記モジュールには最後のスキップ処理によって得られた状態変数が保存された状態となる。その後、排他制御が解除され、第1スレッドは上記ローカルメモリに保存された乱数を元に、モンテカルロ法の1回の試行を実施する。次に、第2スレッドは、同じく排他制御の下、前記モジュールにおいて1回の試行で必要な乱数のスキップ処理と変換処理を行うことになる。このようにして、その他のスレッドについても同様にして処理が進行していく。
【0051】
上記の実施形態では、1回の試行に使用する乱数が多くなるにつれ、各スレッドで使用するローカルメモリの容量も多くなり、また、乱数の保存および呼び出しに伴うメモリアクセスの回数も増える。このため、1回の試行に使用する乱数の数が多い場合には、メモリへのアクセスに要する時間が無視できなくなり、処理時間が増大する可能性がある。メモリの使用量を最小限に留めることにより、上記の処理時間増大の可能性を回避する方法を、次の実施形態で示す。
【0052】
本発明を実現する他の一つの方法として、次のような実施形態が考えられる。すなわち、スキップ処理と変換処理のそれぞれの目的に応じて、二つのメモリ保持形態を有するモジュールを用意する。その上で、状態変数の保存とスキップ処理を行うためのモジュールを1つ用意し(以下、モジュールm0とする)、全スレッドで共有する。さらに、状態変数に変換処理とスキップ処理を施して乱数を生成するためのモジュールをスレッドごとに用意する(以下、m1,m2,・・・,mNTとする)。
【0053】
これらの(NT+1)個のモジュールおよび、並列タスク・スケジューリングを以下のように組み合わせることにより、無駄な捨象がない乱数の割り当てを実現する。例えば、ある試行において、第1スレッドが乱数生成処理に入る場合を考える。このとき排他制御の下、第1スレッドがモジュールm0に保存されている状態変数をモジュールm1にコピーする。さらに、1回の試行で必要な乱数分のスキップ処理をモジュールm0において行う。この処理により、モジュールm0には、最後のスキップ処理によって得られた状態変数が保存された状態となる。その後、排他制御が解除され、第1スレッドはモジュールm1を用いてローカルに変換処理とスキップ処理を行い、試行の実行に必要な乱数を生成する。次に、第2スレッドは、同じく排他制御の下、モジュールm0に保存されている状態変数の情報をモジュールm2へコピーしたうえで、モジュールm0のスキップ処理を行うことになる。このようにして、その他のスレッドについても同様にして処理が進行していく。
【0054】
上記の一連の操作でも、無駄な乱数の捨象は発生しない。また、各試行にはどのスレッドが任意の順番で担当しても同じ乱数が割り当てられるため、計算結果の再現性が得られ、各スレッドに担当させる試行の回数をあらかじめ決めておく必要はない。
【0055】
上記の一連の操作においては、各スレッドのローカルメモリ上にコピーされるのはモジュールm0に保存されている状態変数だけであり、最初に示した実施形態に比べて、メモリへのアクセスを減らすことができる。一方で、各スレッドは状態変数のスキップ処理をモジュールm0のほか、各スレッドで行われる乱数生成時にも行う必要がある。このため、どちらの実施形態の処理時間が速いかは、ハードウエアや分析の対象に依存する。
【0056】
なお、上記の2つの実施形態からも分かるように、本発明では状態変数のスキップ処理に対する排他制御を行う必要がある。排他制御を実現する方法には様々なものが知られているが、本発明は特定の排他制御の方法を前提としたものではない。各スレッドに共有された状態変数のスキップ処理が複数のスレッドで同時に行われることを回避できさえすれば、どのような排他制御方法を用いても実現可能である。この排他制御は、例えば、同期オブジェクトと排他ロックという概念を用いて実行することができる。排他制御が必要となる部分、すなわちある特定のセッションに入る前に、あるオブジェクトに鍵をかける。鍵がかかっている間、他のスレッドは同じオブジェクトに鍵をかけることできず、鍵が外されるまで待たされる。そして、鍵をかけたスレッドはその特定のセッションを終えた後にそのオブジェクトに対する鍵を外す。このとき、鍵をかける対象となるオブジェクトのことを同期オブジェクトと、鍵をかける操作のことを排他ロックと呼ぶ。この同期オブジェクトは、以下に説明する状態変数生成記憶部としてとらえることもできるし、それ以外の対象あるいは抽象的なデータとしてとらえることもできる。
【0057】
図4は、ある一実施の形態に基づいてモンテカルロ法を並列に実行する並列処理システム400のブロック図である。並列処理システム400は、キーボードおよびマウスを含む入力装置410と、LCD(Liquid Crystal Display)ディスプレイなどの表示装置420とを有している。
【0058】
並列処理システム400は、さらに、並列処理制御部430と、第1スレッド440と、第2スレッド450と、第3スレッド460と、第4スレッド470と、グローバル記憶部480とを有している。この第1から第4のスレッド440、450、460、470は、4個以上のプロセッサコアを有するコンピュータを用いて実現することもできるし、4台以上のコンピュータを用いて実現することができる。また、並列処理システム400自体を、4個以上のプロセッサを有するマルチプロセッサコンピュータを含むコンピュータシステムを用いて実現することもできる。
【0059】
グローバル記憶部480は、状態変数を記憶する状態変数生成記憶部481と状態変数スキップ処理部482とを有している。状態変数生成記憶部481および状態変数スキップ処理部482には、第1スレッドから第4スレッドの各スレッドのいずれもがアクセスして状態変数の値の取得やスキップ処理を行うことができる。
【0060】
並列処理制御部430は、入力装置410からの指示を受けて、状態変数生成記憶部481と、状態変数スキップ処理部482と、第1スレッド440と、第2スレッド450と、第3スレッド460と、第4スレッド470とに対し、モンテカルロ法を並列に処理するよう指示を送る。各スレッドは、一つのプロセッサコアが担当して実行することができる。
【0061】
このとき、並列処理制御部430は、入力装置410から受け取ったシードを用いて状態変数を生成し、状態変数生成記憶部481に保存する。あるいは、並列処理制御部430が自ら専用のプログラムを用いてシードを生成し、そのシードから状態変数を生成して状態変数生成記憶部481に保存することができる。
【0062】
第1スレッド440と、第2スレッド450と、第3スレッド460と、第4スレッド470とは、並列処理制御部430による制御を受けて、モンテカルロ法を並列に実行する。本実施形態の並列処理システム400は4個のスレッドを有しているが、これに限定されない。スレッド数は任意の整数とすることができ、ハードウエアの構成に応じて変更することもできる。
【0063】
第1から第4のスレッド440、450、460、470は、いずれも同じ構造をとっている。例えば、第1スレッドは、試行回数計数部441と、排他ロック制御部442と、状態変数取得部443と、乱数生成部445と、試行実行部446と、ローカル記憶部447とを有している。
【0064】
並列処理システム400は、結果出力部490も有している。結果出力部490は、4個のスレッド440、450、460、470でそれぞれ実行された試行により得られた結果をまとめて、表示装置420へ出力することができる。
【0065】
図5は、図4に示した第1から第4のスレッド440、450、460、470がそれぞれ並列に行う処理のフローチャートである。一例として、試行回数Nsimを10000回(Nsim=10000)とする。
【0066】
以下、第1スレッド440を例にとって処理の流れを説明する。まず、ステップS501で処理を開始する。ステップS502において、試行回数計数部441が、第何番目の試行であるかを表す変数nと、試行回数Nsimとの大小関係を判断する。なお、変数nの値は、処理の開始時点で0に初期化されているものとする。
【0067】
ステップS502において、試行回数計数部441がn<Nsimと判断した場合には、ステップS503に進む。他方、試行回数計数部441が、n<Nsimと判断しなかった場合には、ステップS511に進み、処理を終了する。
【0068】
ステップS503では、試行回数計数部441がnをインクリメントする。すなわち、n+1を計算して得られた結果を新たなnの値とする。このとき得られた新たなnの値が、これから実行する試行の番号である。
【0069】
ステップS504では、排他ロック制御部442が、状態変数生成記憶部481へのアクセスを試みる。第2から第4のスレッドの排他ロック制御部452、462、472のいずれもが状態変数生成記憶部481に対して排他ロックをかけていない場合には、第1スレッド440が状態変数生成記憶部481へアクセスすることができ、次いでステップS505に進む。
【0070】
他方、ステップS504の段階で、第2から第4のスレッドの排他ロック制御部452、462、472のいずれか、例えば第4スレッド内の排他ロック制御部472が状態変数生成記憶部481に対して排他ロックをかけている場合には、第1から第3のスレッド440、450、460は状態変数生成記憶部481へアクセスすることができない。その場合は、ステップS504をある一定の時間をおいてから再度実行する。
【0071】
ステップS505では、第1スレッド440の排他ロック制御部442が状態変数生成記憶部481に対して排他ロックをかける。その結果、第2、第3、第4のスレッド450、460、470は、いずれも状態変数生成記憶部481に対してアクセスすることができなくなる。
【0072】
状態変数生成記憶部481に対するアクセスの排他制御を行わないとすると、同時に複数のスレッドがアクセスでき、複数のスレッドが同じ状態変数を用いて乱数を生成することとなる。この場合、異なるスレッドで使用する乱数の一部に重複が生じ、得られるモンテカルロ法の結果も信頼性に欠けるものとなる。このように、同じ状態変数を複数のスレッドが重複して用いないようにするために、上述した排他的なアクセス制御が有効である。
【0073】
次にステップS506では、第1スレッドの状態変数取得部443が状態変数生成記憶部481にアクセスし、状態変数生成記憶部481に保存されている状態変数の値を取得して、ローカル記憶部447に保存する。
【0074】
次にステップS507では、状態変数スキップ処理部482が状態変数生成記憶部481に保存されている状態変数に対しスキップ処理を実行する。具体的には、状態変数スキップ処理部482が、図3に示したステップS3、S5、S7、・・・を繰り返して実行する。このとき、繰り返す回数は、1回のシミュレーションを行うのに必要な乱数の個数と同じ値である。
【0075】
例えば、1回の試行に100個の乱数を要する場合は、ステップS507で、状態変数スキップ処理部482が、図3に示した状態変数スキップ処理(ステップS3、S5、S7、・・・)を100回繰り返して実行する。
【0076】
この時点で、第1スレッド440のローカル記憶部447には、ステップS506で取得された状態変数が保存されている。また、状態変数生成記憶部481には、次の試行で用いる最初の乱数に対応する状態変数が保存されている。
【0077】
次にステップS508では、第1スレッド440の排他ロック制御部442が、状態変数生成記憶部481に対する排他ロックを解除する。その結果、第2から第4のスレッド
450、460、470が状態変数生成記憶部481へアクセスできることとなる。
【0078】
ステップS509では、ローカル記憶部447に保存されている状態変数を呼び出し、乱数生成部445にその値を渡す。
【0079】
ステップS510では、乱数生成部445が100個の乱数を生成しながら、試行実行部446が1回の試行を実行する。その後、ステップS502に進む。
【0080】
以上のようにして、第1スレッド440は、自己が担当するモンテカルロ法を実行することができる。第2スレッド450、第3スレッド460、第4スレッド470も、図5に示した処理を実行することにより、自己が担当するモンテカルロ法をそれぞれ実行することができる。その結果、第1スレッド440、第2スレッド450、第3スレッド460、第4スレッド470が、全ての試行を並列に実行することができる。
【0081】
上記実施形態を通して説明したように、本発明においては、排他制御を利用しつつ、状態変数の情報を全スレッドで共有することにより、無駄な状態変数のスキップ処理を排除している。
【0082】
図6は、上記実施形態による各スレッドの試行の担当例を示す図である。横軸は第1スレッドから第4スレッドを示しており、縦軸は時間tを示している。図1および図2と同様に、符号Aは、後続で行うモンテカルロ法の試行に用いる乱数の生成処理を示している。符号Bは、試行の実行処理を示している。符号Bの後に続くかっこ書きの数字は、試行番号である。ここで、従来技術1を示す図1および従来技術2を示す図2とは異なり、上記実施形態においては乱数捨象処理を表す符号Cが各スレッドに分散しており、処理負荷の均一化が図られていることがわかる。このように各スレッドの負荷が均一化できるのは、状態変数生成記憶部を利用することにより、試行に用いる状態変数の情報を全スレッドが共有しているためである。
【0083】
図6に示した例では、第1スレッドは、n=2,6,・・・,9998の試行を実行し、第2スレッドは、n=1,5,・・・,9997の試行を実行し、第3スレッドは、n=4,8,・・・,10000の試行を実行し、第4スレッドは、n=3,7,・・・,9999の試行を実行している。ただし、各スレッドに対する試行番号の割り当てはOSの並列タスク・スケジューリングにより自動的に決められるため、一般に各スレッドに割り当てられる試行番号は実行のたびに異なるものとなる。また、各スレッドが実行する試行回数は必ずしも同一の回数になるとも限らない。一方で、本発明の方法では、同一の試行番号の試行には必ず同じ乱数が割り当てられるため、モンテカルロ法の実行結果には再現性がある。
【0084】
マルチタスクOSでは、試行実行中であっても、OSによってプロセッサコアに他のタスクが割り当てられることがあり、計算量が均等になるように各スレッドに処理を割り当てたとしても、各プロセッサコアが処理の終了までに要する時間は必ずしも均一になるとは限らない。本発明の方法によれば、他のタスクによる負荷が少ないプロセッサコアに自動的に多くの試行処理が割り当てられ、プロセッサコア間の負荷が自動的に分散化されるという利点もある。
【0085】
上記実施形態における並列処理は、第10000番目の試行を終えた時点で、処理終了となる。第10000番目の試行を終えるまでに要する理論的な計算時間tMCは、以下のように表現することができる。
【数3】
ここで、NSimはモンテカルロ法の試行回数であり、NTは試行を実行するスレッドの数であり、tSimは1回の試行に要する時間であり、tSkipは1回の試行に用いる乱数のスキップ処理に要する時間である。
【0086】
スレッド数NT≦tSim/tSkipの場合には、試行の実行処理を行っている間に、他のスレッドのスキップ処理が終わるため、排他ロックによる処理の待ち時間は生じない。この場合、式(4)からわかるように、スレッド数NTを増加させると、それに応じて計算時間tMCは短くなる。他方、スレッド数NT≧tSim/tSkipの場合には、スレッド数NTを増加させても計算時間tMCは変化しない。これは、この場合には排他ロックによる処理の待ち時間が生じるためである。
【0087】
図7に示す表1は、本発明の一実施形態と、上述した従来技術1との理論的な計算時間の比較を表している。横軸はスレッド数であり、縦軸はtSim/tskipである。そして、表内の値は、(本発明の一実施形態による理論的な計算時間)/(従来技術1の理論的な計算時間)である。
【0088】
tSim/tskipの値が大きくほど、乱数発生以外の処理に掛かる時間が長い複雑な試行であることを意味する。なお、tSim/tskip=1の場合、すなわち、1回の試行に要する時間tSimと、1回の試行に用いる乱数のスキップ処理に要する時間tSkipとが等しい場合は、乱数を生成させただけで、乱数を用いた演算を行わないことを意味している。これは、実用的には意味のないものであるが、計算時間の比較として参考までに載せるものである。
【0089】
表1によれば、スレッド数を20とし、tSim/tskip=20である場合には、(本発明の一実施形態による理論的な計算時間)/(従来技術1の理論的な計算時間)=0.54である。すなわち、従来技術1と比べて計算時間をほぼ半減できることを意味している。
【0090】
図8に示す表2は、本発明の一実施形態と、上述した従来技術2との理論的な計算時間の比較を表している。表1と同様に、横軸はスレッド数であり、縦軸はtSim/tskipである。そして、表内の値は、(本発明の一実施形態による理論的な計算時間)/(従来技術2の理論的な計算時間)である。なお、従来技術2では、理論的な計算時間を達成するためにモンテカルロ法実行前にtSimとtskipを計測する必要があるが、ここでの比較ではその計測に要する時間は考慮していない。
【0091】
表2によれば、スレッド数を20とし、tSim/tskip=20である場合には、(本発明の一実施形態による理論的な計算時間)/(従来技術2の理論的な計算時間)=0.67である。すなわち、従来技術1より優れている従来技術2と比較しても計算時間をほぼ3分の2に短縮できることを意味している。
【0092】
[実施例]
以下、モンテカルロ法を用いて、半径0.5の円の面積を求める実施例について説明する。まず、図9は、モンテカルロ法を並列にではなく、逐次的に行うプログラム例である。ここでは、プログラミング言語としてC++言語を用いる。図9に示されているプログラムの各行の左側に示されている「1」、「2」、・・・、「20」は、プログラムの行番号を表すものであって、プログラム自体を構成するものではない。
【0093】
第1行目の「AreaOfCircle」は、モンテカルロ法により半径0.5の円の面積を求める関数である。この関数の引数「NSim」は試行回数を表す変数であり、引数「seed」は、擬似乱数を生成する元となる値である。関数「AreaOfCircle」が第2行目から第20行目において定義されている。
【0094】
第4行目の変数「x」および「y」は、生成した乱数をx座標値およびy座標値とするための変数である。第5行目の変数「r_sq」は、半径0.5の円の中心点(0.5,0.5)と、乱数生成により求めたXY平面上の点との距離を二乗した値を保存する変数である。第6行目の変数「s」は、乱数生成により求めたXY平面上の複数の点のうち、半径0.5の円内に含まれる点の数を保存する変数である。
【0095】
第7行目の「RandomNumberGenerator」は、(0,1)区間の一様乱数を生成するクラスである。その詳細については後述する。第10行目では、関数「AreaOfCircle」の引数「seed」の初期化を行う。
【0096】
第13行目から第18行目は、モンテカルロ法を行うループである。試行番号を表す変数SimNo=0から始めてNSim回の試行を逐次的に行う。第14行目および第15行目でそれぞれ1個の乱数を生成して、それぞれの値をX座標値およびY座標値とする。これにより、XY平面上の点をランダムに定めることができる。第16行目では、ピタゴラスの定理を用いて、第14行目および第15行目で定められたXY平面上の点と、円の中心点(0.5、0.5)との距離の二乗を計算し、変数r_sqに保存する。第17行目では、r_sqと0.25(=0.5*0.5)との大小関係を判断して、r_sq<0.25を満たす場合、すなわち、ランダムに定められたXY平面上の点が半径0.5の円内に含まれる場合に、変数sをインクリメントする。そして、第19行目のs/NSimが関数AreaOfCircleの戻り値、すなわち、求められた円の面積である。試行の実行回数NSimの値が大きければ大きいほど、求まる円の面積は、π*0.5*0.5に近くなる。
【0097】
図10は、図9のプログラム例を並列化したプログラム例である。図10に示すプログラム例では、並列計算を行うための標準規格であるOpenMPを用いて並列化を行っている。OpenMPは、主に共有メモリ型の並列計算機で用いられている。
【0098】
第1行目は、図9と同様に、変数NSimおよび変数seedを引数とする関数AreaOfCircleの宣言文である。
【0099】
第5行目は、状態変数の値を取得するための乱数生成クラスRandomNumberGeneratorを宣言している。この乱数生成クラスRandomNumberGeneratorは、全てのスレッドが共有するクラスである。後に図12に示すように、このクラスには状態変数に相当するメンバ変数が含まれており、状態変数生成記憶部481の役割を果たすことができる。また、状態変数のスキップ処理や状態変数の値の取得処理、乱数の生成処理を行うメソッドも含まれている。
【0100】
第6行目の変数sは、図9と同様に、乱数生成により求めたXY平面上の複数の点のうち、半径0.5の円内に含まれる点の数を保存する変数である。
【0101】
第12行目から第32行目は、各スレッドが並列に処理を実行する部分である。すなわち、変数SimNo=0から始めてNSim回の試行を図4に示したスレッド440、450、460、470が分担して実行する。
【0102】
第22行目および第27行目は、状態変数生成記憶部481に対する排他ロックの制御を行う処理である。これは、図4の排他ロック制御部442、452、462、472が行う処理に相当する。この処理により、あるスレッドが乱数の生成処理を行っている場合(第25、26行目)においては、他のスレッドは、乱数生成処理を実行することができなくなる。
【0103】
第33行目で計算するs/NSimは、関数AreaOfCircleの戻り値、すなわち、求められた円の面積である。この計算は、図4の結果出力部490の処理に相当する。
【0104】
第12行目、第19行目、第22行目の記述は、OpenMPによる並列処理の指示を示している。
【0105】
なお、図10に示したプログラム例では、図4で示したブロック図とは異なり、乱数生成部は全スレッドに共有されており、各スレッドには状態変数取得部や乱数生成部は存在しない。一方で、排他制御を利用しつつ状態変数の情報を全スレッドで共有する、という発明の特徴は備えている。このような例も、本発明の範囲に含まれる。
【0106】
図10のプログラム例では、1回の試行に用いる乱数は2個と少ないが、1回の試行に多くの乱数を使用するシミュレーションでは、各スレッドで使用するメモリの容量が増え、メモリへのアクセス回数も増える。このため、ハードウエアや分析の対象によっては、図10と同様のプログラムではメモリへのアクセスに要する時間が無視できなくなる場合がある。
【0107】
図10のプログラム例における排他制御部での処理を最小限に留めることにより、上記の処理時間増大の可能性を軽減する方法も考えられる。それが、図11で示すプログラム例である。
【0108】
第5行目は、図10と同様に、全てのスレッドで共有する、乱数生成クラスRandomNumberGeneratorを宣言している。このクラスには状態変数にあたるメンバ変数が含まれており、これによって状態変数の情報が全クラスで共有されることとなる。
【0109】
第6行目では、1回のモンテカルロ法で用いる乱数の個数を表す変数NRandを定めている。本例では、NRand=2と定めている。これは、1回の試行につき、X座標値とするための乱数と、Y座標値とするための乱数とをあわせた合計2個の乱数が必要となるからである。
【0110】
第28行目および第34行目は、状態変数生成記憶部481に対する排他ロックの制御を行う処理である。この処理により、あるスレッドが状態変数の値の取得(第31行目)を行っている場合と、状態変数のスキップ処理(第33行目)を行っている場合とにおいては、他のスレッドは、状態変数の値の取得およびスキップ処理をいずれも行うことができなくなる。
【0111】
第37行目では、先に取得した状態変数を各スレッドの乱数生成クラスにセットする。そして、第38行目および第39行目で乱数を生成して、それぞれX座標値およびY座標値とする。
【0112】
図12は、図9、図10、図11の各プログラム例で用いる乱数生成クラス「RandomNumberGenerator」を宣言するプログラム例である。図12の第10行目では、状態変数に相当するメンバ変数state_vecが宣言されている。この変数に状態変数の値を格納することにより、このクラスは状態変数生成記憶部481の役割を果たすことができる。また、このクラスRandomNumberGeneratorには、乱数の生成処理を行うメソッド(第23行目)や、状態変数のスキップ処理を行うメソッド(第26行目)、状態変数の値の取得処理を行うメソッド(第29行目)が用意されている。これらは、図4のブロック図でいえば、それぞれ乱数生成部(符号445、455、465、475)、状態変数スキップ処理部(符号482)、状態変数取得部(符号443、453、463、473)に相当する役割を果たすものである。このクラスの実際の処理は、乱数生成アルゴリズムとして、メルセンヌ・ツイスター法、線形合同法、あるいはその他の方法のいずれを使用するかによって変わる。
【0113】
並列計算機は、共有メモリ型並列計算機と、分散メモリ型並列計算機とに大別できる。共有メモリ型並列計算機は、全てのプロセッサコアがメモリを共同で使用するタイプの計算機である。このメモリは、共有メモリと呼ばれている。共有メモリ型並列計算機は、プロセッサコア間のデータの交換が容易であるという長所を有する。一方で、プロセッサコア数が多い場合には、共有メモリへの書き込みが競合し、性能が低下する場合があるという短所を有する。共有メモリ型並列計算機への実装にはOpenMPを用いることができる。
【0114】
分散メモリ型並列計算機は、図4に示した第1から第4のスレッド440、450、460、470のそれぞれを、個別にメモリを持ついくつかのプロセッサにより実行することができるものである。プロセッサ間でデータを交換するためには、プロセッサ間で通信を行う必要がある。分散メモリ型並列計算機への実装には、MPI(Message Passing Interface)を用いることができる。
【0115】
上記実施形態は、共有メモリ型並列計算機、および分散メモリ型並列計算機のいずれにも実装することができる。すなわち、図4に示した第1から第4のスレッド440、450、460、470の全てが、状態変数の情報を共有できさえすれば、共有メモリ型並列計算機、および分散メモリ型並列計算機のいずれにも実装することができる。また、各スレッドを1個のプロセッサコアが担当するように構成することもできるし、各スレッド自体を2個以上のプロセッサコアにより処理することもできる。
【0116】
なお、本発明の各実施の形態を実装するためのコンピュータのハードウエア構成は特段図示した構成に限定されるものではなく、数値演算の形式に併せて専用の数値演算ユニットを一つ以上有していたり、複数の筐体に分かれて互いにネットワークにより接続されているクラスタ構成にされていたりすることができる。なお、本実施例のみならず、本発明全般に、区別して記載された機能手段は、実質的にそのような区別された機能を果たす任意の構成要素によって実現される。このとき、その構成要素が、物理的にいくつの数を有するか、あるいは、複数であり互いにどのような位置関係にあるかなどの機能を果たす上で制限とならない属性によって本発明が制限されることはない。例えば、複数の区別された機能が単一の構成要素によって経時的に異なるタイミングで実行されることも本発明の範囲に含まれる。
【0117】
本発明の各実施の形態の機能処理を実装するコンピュータにおいて数値計算をするためのソフトウエア構成は、本発明の各実施の形態の数値情報処理を実現する限り任意の構成とすることができる。そのコンピュータは、基本入出力システム(BIOS)などのハードウエア制御のためのソフトウエアを搭載しており、これと連携して動作し、ファイル入出力やハードウエアリソースの割り振りを担当するオペレーティングシステム(OS)によって管理されている。当該OSは、OSやハードウエアと連携して動作するアプリケーションプログラムを、例えばユーザーからの明示の命令や、ユーザーからの間接的な命令や他のプログラムからの命令に基づいて実行することができる。アプリケーションプログラムは、このような動作を可能とし、OSと関連して動作するように、OSの規定する手続に依存して、あるいはOSに依存しないように適切にプログラムされている。本発明の各実施の形態を実装する場合には、一般に、専用のアプリケーションプログラムの形式で数値計算やファイル入出力等の処理を実装するが、本発明がそれのみに限定されるものではなく、複数の専用または汎用アプリケーションプログラムを用いたり、既成の数値計算ライブラリを部分的に用いたり、他のコンピュータのハードウエアによって処理されるようにネットワークプログラミング手法によって実現されていたり、その他の任意の実装形態によって実現されうる。したがって、本発明の各実施の形態の計算手法をコンピュータ上に実装するための一連の命令を表現するソフトウエアを、単にプログラムと呼ぶ。プログラムは、コンピュータにより実行可能な任意の形式あるいはそのような形式に最終的に変換可能な任意の形式によって表現される。
【0118】
本発明の各実施の形態のプログラムは、ハードウエア資源であるMPUなどの演算手段が、OSを介してあるいはOSを介することなく計算プログラムからの指令を受け、ハードウエア資源であるメインメモリや補助記憶装置などの記憶手段と協働して、ハードウエア資源である適当なバスなどを通じて演算処理を行うように構成される。つまり、本発明の各実施の形態の計算手法を実現するソフトウエアによる情報処理が、これらのハードウエア資源によって実現されるように実装される。記憶手段あるいは記憶部は、任意の単位によって論理的に区分されているコンピュータが可読な情報記憶媒体の一部または全部またはそれらの組み合わせをいう。この記憶手段は、例えば、MPU内のキャッシュメモリや、MPUと接続されたメインメモリや、MPUと適当なバスによって接続されたハードディスクドライブなどの不揮発性記憶媒体など、任意のハードウエア資源によって実現される。ここで、記憶手段は、MPUのアーキテクチャによって規定されるメモリ内の領域や、OSが管理するファイルシステム上のファイルやフォルダ、同じコンピュータ内やネットワーク上のいずれかのコンピュータにあってアクセス可能なデータベースマネージメントシステム内のリストやレコード、リレーショナルデータベースによって相互にリレーションがある複数のリストで管理されたレコードなど任意の形式によって実現され、論理的に他と区分され、情報を識別可能に少なくとも一時的に記憶または記録できる任意のものを含む。
【符号の説明】
【0119】
400 並列処理システム
410 入力装置
420 表示装置
430 並列処理制御部
440 第1スレッド
450 第2スレッド
460 第3スレッド
470 第4スレッド
441、451、461、471 試行回数計数部
442、452、462、472 排他ロック制御部
443、453、463、473 状態変数取得部
445、455、465、475 乱数生成部
446、456、466、476 試行実行部
447、457、467、477 ローカル記憶部
480 グローバル記憶部
481 状態変数生成記憶部
482 状態変数スキップ処理部
490 結果出力部
【特許請求の範囲】
【請求項1】
コンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、
状態変数を状態変数生成記憶部に記憶するステップと、
一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行って、乱数を生成する乱数生成ステップと、
前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップと
を含み、前記乱数生成ステップと試行演算ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法。
【請求項2】
前記乱数生成ステップが、
乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、
前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行う処理ステップと、
前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に対する排他ロックを解除するステップと
を含む請求項1に記載の並列処理方法。
【請求項3】
コンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、
状態変数を状態変数生成記憶部に記憶するステップと、
一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数を取得するとともに、該状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理ステップと、
前記一のスレッドのプロセッサコアが、前記取得した状態変数に対し、所定の回数にわたり変換処理とスキップ処理を行って乱数を生成するステップと、
前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップと
を含み、前記各ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法。
【請求項4】
前記状態変数スキップ処理ステップが、
乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、
前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部から状態変数の値を取得するステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う処理ステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に対する排他ロックを解除するステップと
を含む請求項3に記載の並列処理方法。
【請求項5】
複数の債権を含むポートフォリオの信用リスク量を計測する方法であって、請求項1〜4のいずれか一項に記載の方法を用いてモンテカルロ法を実行することにより信用リスク量を計測する方法。
【請求項6】
請求項1〜4のいずれか一項に記載の方法を用いてモンテカルロ法を実行することにより、金融市場の変動によって生ずる市場リスク量を計測する方法。
【請求項7】
金融市場の変化をモデル化し、請求項1〜4のいずれか一項に記載の方法を用いてモンテカルロ法を実行することにより、金融商品の価格を算出する方法。
【請求項8】
コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理により実行する並列処理システムであって、
前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、
前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次変換処理とスキップ処理を行って乱数を生成する乱数生成部と、
各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、
前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部と
を備える並列処理システム。
【請求項9】
コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理することにより実行する並列処理システムであって、
前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、
前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理部と、
各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、
前記状態変数生成記憶部から状態変数の値を取得してメモリに保存する状態変数取得部と、
メモリに保存されている状態変数に対して、所定の回数にわたり変換処理とスキップ処理を行い、乱数を生成する乱数生成部と、
前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部と
を備える並列処理システム。
【請求項10】
複数の債権を含むポートフォリオの信用リスク量を計測する請求項8または9に記載の並列処理システム。
【請求項11】
金融市場の変動によって生ずる市場リスク量を計測する請求項8または9に記載の並列処理システム。
【請求項12】
金融商品の価格を算出するために、金融市場の変化をモデル化し、並列処理システムを用いてモンテカルロ法を実行する請求項8または9に記載の並列処理システム。
【請求項13】
コンピュータに請求項1〜7のいずれかに記載の方法の各ステップを実行させるためのプログラム。
【請求項1】
コンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、
状態変数を状態変数生成記憶部に記憶するステップと、
一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行って、乱数を生成する乱数生成ステップと、
前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップと
を含み、前記乱数生成ステップと試行演算ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法。
【請求項2】
前記乱数生成ステップが、
乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、
前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理と変換処理を行う処理ステップと、
前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に対する排他ロックを解除するステップと
を含む請求項1に記載の並列処理方法。
【請求項3】
コンピュータによるモンテカルロ法の実行を状態変数生成記憶部と複数のスレッドを用いて並列処理する並列処理方法であって、
状態変数を状態変数生成記憶部に記憶するステップと、
一のスレッドのプロセッサコアが、排他制御のもと前記一のスレッドのプロセッサコアのみがアクセスできる状態で、前記状態変数生成記憶部に記憶されている状態変数を取得するとともに、該状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理ステップと、
前記一のスレッドのプロセッサコアが、前記取得した状態変数に対し、所定の回数にわたり変換処理とスキップ処理を行って乱数を生成するステップと、
前記一のスレッドのプロセッサコアが、前記生成した乱数を用いて前記一のスレッドに割り当てられた試行の演算を行う試行演算ステップと
を含み、前記各ステップを他のスレッドにおいても並行して順次実行してゆく並列処理方法。
【請求項4】
前記状態変数スキップ処理ステップが、
乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部に排他ロックがかかっているか否かを一のスレッドにおいてプロセッサコアが判断するステップと、
前記状態変数生成記憶部に排他ロックがかかっていない場合には、前記一のスレッドのプロセッサコアが前記状態変数生成記憶部に排他ロックをかけるステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部から状態変数の値を取得するステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う処理ステップと、
前記一のスレッドのプロセッサコアが、前記状態変数生成記憶部に対する排他ロックを解除するステップと
を含む請求項3に記載の並列処理方法。
【請求項5】
複数の債権を含むポートフォリオの信用リスク量を計測する方法であって、請求項1〜4のいずれか一項に記載の方法を用いてモンテカルロ法を実行することにより信用リスク量を計測する方法。
【請求項6】
請求項1〜4のいずれか一項に記載の方法を用いてモンテカルロ法を実行することにより、金融市場の変動によって生ずる市場リスク量を計測する方法。
【請求項7】
金融市場の変化をモデル化し、請求項1〜4のいずれか一項に記載の方法を用いてモンテカルロ法を実行することにより、金融商品の価格を算出する方法。
【請求項8】
コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理により実行する並列処理システムであって、
前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、
前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次変換処理とスキップ処理を行って乱数を生成する乱数生成部と、
各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、
前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部と
を備える並列処理システム。
【請求項9】
コンピュータによるモンテカルロ法を状態変数生成記憶部と複数のスレッドを用いて並列処理することにより実行する並列処理システムであって、
前記複数のスレッドで共有される、乱数を生成するために用いる状態変数が記憶されている状態変数生成記憶部と、
前記状態変数生成記憶部に記憶されている状態変数に対し、所定の回数にわたり順次スキップ処理を行う状態変数スキップ処理部と、
各スレッドについて、前記状態変数生成記憶部に排他ロックをかけるか、あるいは排他ロックを解除する排他ロック制御部と、
前記状態変数生成記憶部から状態変数の値を取得してメモリに保存する状態変数取得部と、
メモリに保存されている状態変数に対して、所定の回数にわたり変換処理とスキップ処理を行い、乱数を生成する乱数生成部と、
前記乱数生成部で生成された乱数を用いて試行の演算を行う演算処理実行部と
を備える並列処理システム。
【請求項10】
複数の債権を含むポートフォリオの信用リスク量を計測する請求項8または9に記載の並列処理システム。
【請求項11】
金融市場の変動によって生ずる市場リスク量を計測する請求項8または9に記載の並列処理システム。
【請求項12】
金融商品の価格を算出するために、金融市場の変化をモデル化し、並列処理システムを用いてモンテカルロ法を実行する請求項8または9に記載の並列処理システム。
【請求項13】
コンピュータに請求項1〜7のいずれかに記載の方法の各ステップを実行させるためのプログラム。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】

【図8】
【図9】

【図10】

【図11】

【図12】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【公開番号】特開2012−14591(P2012−14591A)
【公開日】平成24年1月19日(2012.1.19)
【国際特許分類】
【出願番号】特願2010−152357(P2010−152357)
【出願日】平成22年7月2日(2010.7.2)
【出願人】(599151008)みずほ第一フィナンシャルテクノロジー株式会社 (6)
【公開日】平成24年1月19日(2012.1.19)
【国際特許分類】
【出願日】平成22年7月2日(2010.7.2)
【出願人】(599151008)みずほ第一フィナンシャルテクノロジー株式会社 (6)
[ Back to top ]