
ラベリング装置、ラベリング方法及びプログラム
【課題】適切な画像ラベリング処理を自動的に行うことができる画像ラベリング装置、画像ラベリング方法及びプログラムを提供すること。
【解決手段】ラベリング装置1は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるものであって、画像全体の特徴を大域特徴として算出する大域特徴算出部22と、予めラベリングされた学習画像と入力画像との大域特徴の類似度に基づき学習画像の中から類似画像を抽出する類似画像抽出部23と、類似画像の各画素における各ラベルの存在確率、及び類似画像と入力画像との類似度に基づき入力画像の各画素のラベルを推定する大域単項ポテンシャル演算部24とを有する。
【解決手段】ラベリング装置1は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるものであって、画像全体の特徴を大域特徴として算出する大域特徴算出部22と、予めラベリングされた学習画像と入力画像との大域特徴の類似度に基づき学習画像の中から類似画像を抽出する類似画像抽出部23と、類似画像の各画素における各ラベルの存在確率、及び類似画像と入力画像との類似度に基づき入力画像の各画素のラベルを推定する大域単項ポテンシャル演算部24とを有する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置、ラベリング方法及びプログラムに関する。
【背景技術】
【0002】
画像ラベリングでは、確率場モデルを用いて画像とラベルの関係をモデル化する手法が広く利用される。ここで、画像ラベリングとは、予め設定したカテゴリのラベル(例えば「車」、「空」など)のうち最も適当なものを、画像中のすべての画素に割り当てる処理である。特に条件付確率場(Conditional Random Field; CRF)が最近ではよく用いられている。
【0003】
CRFは局所情報を表す2種類のポテンシャル関数から構成される。ひとつは画像の局所的な特徴とラベルの関係を表す単項ポテンシャル関数、もうひとつは画像の局所的な特徴を基に局所的な2つのラベルの関係を表す二項ポテンシャル関数である。
【0004】
以下にCRFを用いたラベリングのモデルを数式で表す。ただし変数は次のようにする。画像X中のサイトiにおける特徴をXi(例えば画素iの輝度値)とし、画像XはすべてのサイトSにおける特徴xiの集合X={xi}i∈S、サイトiのラベルはli、画像全体のラベリングはL={li}i∈Sとしたとき画像ラベリングは、画像Xが与えられたときに適切なラベリングLを推定する課題といえる。すなわち、条件付確率P(L|X)を最大とするラベリングLを推定する課題である。
【0005】
CRFは入力画像Xに対するラベリングLの条件付確率P(L|X)をモデル化する。モデル化には上述の局所単項ポテンシャル関数をfiと局所二項ポテンシャル関数をfij利用する。
【数1】

ここでαは係数、Zは正規化のための定数、Niはiの近傍のサイト集合を表す。このP(L|X)を最大とするラベリングLを推定する。
【非特許文献1】X. He, R. Zemel, and D. Ray. "Learning and incorporating topdown cues in image segmentation", 2006, In Proc. European conference on Computer Vision, pages I, p338-p351
【非特許文献2】X. He, R. Zemel, and M. A. Carreria-Perpinan., "Multiscale conditional random field for image labeling", In Proc. Computer Vision and Pattern Recognition, 2004, volume 2, p695-p702
【非特許文献3】S. Kumar and M. Hebert. A hierarchical field framework for unified context-based classification, In Proc. Int. Conf. on Computer Vision, 2005, volume 2, p1284-p1291
【発明の開示】
【発明が解決しようとする課題】
【0006】
しかしながら、従来の確率場モデルは上記のCRFのように局所情報を表す2つの関数fi、fij(以下、それぞれ局所単項ポテンシャル関数、局所二項ポテンシャル関数という。)によって構成されている。このとき画像の大域的な情報はモデルに含まれていない。そのため、得られるラベリング結果が局所的には整合していても、大域的には整合していないことがある。すなわち、従来の画像ラベリング技術では画像の局所的な情報しかモデル化していないため、大域的な視点から不適当なラベリング結果となることがある。
【0007】
図21及び図22は、入力画像及びCRFによるラベリング結果を示す図である。図21に示すように、例えば、「道路」ラベルが「空」ラベルの領域にあるといった非現実的なラベル配置になったり(符号301)、図22に示すように、「カバ(302)」と「白熊(303)」と「雪(304)」のラベルがひとつの画像に同時に存在するといった不適当なラベルの組み合せが生じたりする(現実にはカバと白熊、カバと雪は同時に存在しない)。従来のCFRにおいては、このような大域的な視点から明らかな誤りを修正できないという問題点がある。
【0008】
近時、実環境で自律的に働く機械が増加してきており、人間共存型ロボットや、自律走行車など、今後もその増加が予想される。これらの装置においては、周囲の環境・状況を的確に認識する能力が必要となる。その場合、このような画像ラベリング技術を基に、周囲の視覚情報から周囲の環境・情報を認識できることが必要となる。すなわち、人間の視覚のように、周囲の状況を的確に認識することができることが望まれる。
【0009】
本発明は、このような問題点を解決するためになされたものであり、適切な画像ラベリング処理を自動的に行うことができる画像ラベリング装置、画像ラベリング方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0010】
本発明にかかるラベリング装置は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置であって、画像全体の特徴を大域特徴として算出する大域特徴算出部と、予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出部と、前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出部とを有するものである。
【0011】
画像ラベリングでは確率場モデルによって画像とラベルの関係を数理的にモデル化する手法が有効である。特に条件付確率場(CRF)が広く用いられている。しかし、CRFは画像の局所的な情報しかモデル化しないため、ラベリングの大域的な整合性が得られないことがある。そこで本発明においては、大域的な情報をモデル化することで、大域的に整合性ある画像ラベリングを実現することができる。
【0012】
さらに、前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出部と、前記第1の整合性行列算出部が算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出部と、前記第1の確率算出部が推定したラベルと前記第2の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有することができる。このことにより、ラベルの位置が一枚の画像内において適当であり、また同時に存在するラベルの組み合わせが妥当であるようにモデルを構成することができる。
【0013】
さらにまた、各画素毎の特徴を局所特徴として算出する局所特徴算出部と、前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出部と、前記第1の確率算出部が推定したラベルと前記第3の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有することができる。適切な画像ラベリングのためには、ラベリングの局所的な整合性と大域的な整合性の両方を考慮する必要があるため、大域的な情報に局所的な情報も含めてモデル化することで、局所的にも大域的にも整合性ある画像ラベリングを実現することができる。
【0014】
また、前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部と、前記第1の確率算出部が推定したラベルと前記第4の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有することができる。このことにより、大域的な情報に局所的な情報も含めてモデル化することで、局所的にも大域的にも整合性ある画像ラベリングを実現することができる。
【0015】
さらに、前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を有し、ラベルの推定を前記スーパーピクセル単位で行なうことができる。このことにより、各処理を画素単位ではなく、スーパーピクセル単位で行なうことにより、処理の高速化を図ることができる。
【0016】
さらにまた、前記類似画像抽出部は、前記入力画像及び学習画像を2以上の領域に分割し、各領域毎の類似度に基づき前記類似画像を抽出することができる。このことにより、より類似した領域を有する類似画像を得ることができ、ラベリング性能が向上する。
【0017】
また、前記学習画像から予め得られる各カテゴリの特徴ベクトルは、各カテゴリを表す1又は複数の代表ベクトルとすることができる。学習画像から代表ベクトルを求めることで、多数の特徴ベクトルを少数の特徴ベクトルで表すことができ処理演算量が低減する。
【0018】
さらに、前記大域特徴算出部は、前記入力画像又は前記入力画像を複数に分割した分割領域毎に、RGBの3種類のヒストグラムを生成したり、M×M(Mは整数)画素の輝度値に基づき輝度値の勾配方向を求めたヒストグラムを生成したり、前記入力画像にラプラシアンフィルタを施し得られたヒストグラムを生成したり、又は、大域特徴算出部は、前記入力画像又は前記入力画像を縮小した縮小画像のCIE L*a*値を求めて大域特徴とすることができる。これらの大域特徴により、精度良くラベリングすることができる。
【0019】
本発明にかかるラベリング方法は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング方法であって、画像全体の特徴を示す大域特徴を算出する大域特徴算出工程と、予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出工程と、前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出工程とを有するものである。
【0020】
本発明にかかるプログラムは、上述したラベリング処理をコンピュータに実行させるものである。
【発明の効果】
【0021】
本発明によれば、適切な画像ラベリング処理を自動的に行うことができる画像ラベリング装置、画像ラベリング方法及びプログラムを提供することができる。
【発明を実施するための最良の形態】
【0022】
以下、本発明を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。この実施の形態は、本発明を、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置に適用したものである。
【0023】
上述したように、画像ラベリングでは局所的な整合性と大域的な整合性の両方を考慮する必要がある。しかし、従来の確率場モデルでは局所的な情報しかモデル化されていない。具体的には、画像の局所的な特徴とラベルの関係を表す局所単項ポテンシャル関数fiと、局所的な2つのラベル間の関係を表す局所二項ポテンシャル関数fijのみから構成されており、大域的な情報は含まれていない。
【0024】
本実施の形態においては大域的な情報もモデルに含めるために、従来の局所単項ポテンシャル関数fiと局所二項ポテンシャル関数fijに対応させて、大域的な特徴を示す単項ポテンシャル関数gi(以下、これを大域単項ポテンシャルという。)及び二項ポテンシャル関数gij(以下、これを大域二項ポテンシャルという。)を導入する。そしてこれら4つのポテンシャル関数を用いてモデルを設計する。
【0025】
大域単項ポテンシャル関数giは画像全体における大域的な特徴と各位置におけるラベルの関係を表す。一方、大域二項ポテンシャル関数gijは、局所二項ポテンシャル関数fijのように局所的なラベル間の関係のみでなく、ひとつの画像に存在するすべてのラベル間の関係をモデル化する。そしてそれらの整合性を評価する。
【0026】
このように、本実施の形態においては、従来の局所的なポテンシャル関数fi、fijに加え、大域的なポテンシャル関数gi、gijも用いることで、画像の局所情報と大域情報が効果的に表現されるようになる。このようにしてラベリングの局所的な整合性と大域的な整合性を同時に満たすようにする。
【0027】
すなわち、本実施の形態にかかる確率場モデルは、従来の局所単項ポテンシャル関数fiと局所二項ポテンシャル関数fijに加え、新たに導入する大域単項ポテンシャル関数giと大域二項ポテンシャル関数gijを用いて以下の式で表される。
【0028】
【数2】
【0029】
ここでα、β、γは係数、Zは正規化のための定数、Niはiの近傍のサイト集合(スーパーピクセル)を表す。なお、スーパーピクセルは、隣接する類似画素を一纏めにした集合であるが、その詳細は後述する。また、画像XからラベリングL={li}i∈Sが与えられる。iはSに含まれるサイト、li∈Lは画素iのラベルを示す。
【0030】
なお、大域単項ポテンシャル関数giのみで画像ラベリングを行なうことも可能である。また、大域単項ポテンシャル関数giと他のポテンシャル関数との組み合わせでもよい。例えば、大域単項ポテンシャル関数giのみで画像ラベリングを行なえば処理速度が向上する。本実施の形態においては、さらにラベリング能力を向上させるため、大域二項ポテンシャル関数gijと、従来手法である局所単項ポテンシャル関数fi及び局所二項ポテンシャル関数fijを使用する。
【0031】
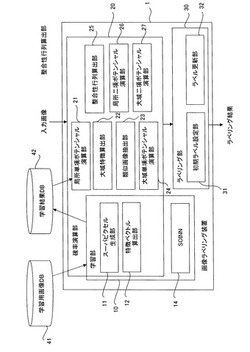
図1は、本実施の形態にかかるラベリング装置を示すブロック図である。ラベリング装置1は、学習部10と、確率演算部20と、ラベリング部30とを有し、学習用画像が格納された学習用画像データベース(DB)41及び学習結果が格納される学習結果DB42と接続されている。
【0032】
学習部10は、スーパーピクセル生成部11及び特徴ベクトル算出部12を有し、これらは確率演算部20と共有される。なお、個別に設けてもよいことは勿論である。更に、学習部10は、後述するSOINN(Self-Organizing Incremental Neural Network)13を有する。
【0033】
確率演算部20は、上記の他に、第3の確率算出部として機能する局所単項ポテンシャル演算部21、大域特徴算出部22、類似画像抽出部23、第1の確率演算部として機能する大域単項ポテンシャル演算部24、第1の整合性行列算出部及び第2の整合性行列算出部として機能する整合性行列算出部25、第4の確率算出部として機能する局所二項ポテンシャル演算部26、及び第2の確率算出部として機能する大域二項ポテンシャル演算部27を有する。ラベリング部30は、初期ラベル設定部31及びラベル更新部32を有する。なお、これらの処理ブロックは適宜変更可能であって、あるブロックの処理の一部又は全部を他のブロックで行なってもよく、また2以上のブロックの処理を一の処理としてもよい。
【0034】
次に、各ブロックについて詳細に説明する。スーパーピクセル生成部11は、特徴(輝度値や色)の類似している画素同士を連結してできる均質な小領域をsuperpixel(スーパーピクセル)として生成する。本実施の形態においては、スーパーピクセルの数が元の画像の画素数の数百分の一になるように生成し、ラベリング処理は画素単位でなく、スーパーピクセル単位で行う。このことにより処理の高速化を図ることができる。なお、画素単位で各処理を行なってもよい。
【0035】
特徴ベクトル算出部12は、スーパーピクセルの色特徴ベクトル(Vcolor)、テクスチャ特徴ベクトル(Vtexture)を計算する。学習画像を含めて入力画像はRGB値を有するカラー画像であるが、RGB値は照明条件の変化に敏感で明るさの変化で大きく変化することから、本実施の形態においては、各画素値のRGB値をCIE(国際照明委員会)L*a*b*(JIS Z 8729)色空間に変換した3値を色特徴ベクトルVcolor(以下、単に色特徴ともいう。)として求める。L*a*b*は、均等色空間であり、知覚的な色の違いが空間上での距離に相当するため、カラー画像を扱うのに適している。
【0036】
テクスチャ特徴ベクトルVtexture(以下、単にテクスチャ特徴ともいう。)は、色の多様性に対応するために、RGB値をグレースケールに変換した画像から抽出する。本実施の形態においては、照明条件の変化に頑健なlocal binary pattern(LBP)(T.Ojala, M. Pietikainen and Manpaa: "Multiresolution gray-scale and rotation-invariant texture classification with local binary patterns", IEEE Trans.Pattern Anal. Mach. Intell., 24, 7, pp. 971-987 (2002).)をテクスチャ特徴の抽出に利用する。半径R,近傍画素PのLBP(VBPP,R)は以下のように定義される。
【0037】
【数3】
【0038】
ここで、gcは着目しているが画素cの輝度値、gpは、cを中心とする半径Rの円周上に等間隔に並んだ近傍画素pの輝度値を示す。LBPは着目画素とP個の近傍画素との輝度値の大小関係により、2P通りの局所的なパターンに識別する。上記論文では、"uniform"パターンと呼ばれる代表的な局所パターンを導入し、"uniform"パターン以外はすべて"その他"のパターンとしてひとつにまとめている。具体的には以下のようにU(LBPP,R)を定義し,U(LBPP,R)≦2であるLBPP,Rを"uniform"パターンとしている。
【0039】
【数4】
【0040】
本実施の形態においては、P=8、R=1のLBPを用いるが、その場合"uniform"パターンは58個存在する。LBPは輝度値の大小関係のみに着目しているため、輝度値の階調変化に対して不変である。しかし一方で、わずかな輝度値の変化でも大小関係が変化すると局所パターンも変わってしまう。これは用いる画像の質にも依存するが、ノイズなど外乱の多い実環境中で利用するには敏感すぎると考えられる。そこで本実施の形態においては、LBPに改良を加え、輝度値の変化に対しより頑健な"改良LBP"を定義して用いることにする。改良LBPでは式(3)においてs(x)の代わりに、閾値θLBPを導入した以下のs'(x)を用いる。
【0041】
【数5】
【0042】
改良LBPでは輝度値の差が閾値θLBP以上のものに対して大小関係を定める。この改良により輝度値の階調変化に対する不変性はなくなるが、ノイズなどによる輝度値の変動に対して頑健となる。
【0043】
テクスチャ特徴は着目している画素を中心とする周囲の正方形領域RLBP(=9×9画素)に、改良LBPを適用することで得る。改良LBPが出力する領域内の局所パターンの頻度(ヒストグラム)がテクスチャ特徴となる。
【0044】
SOINN13は、スーパーピクセルの各特徴ベクトルをクラスタリングして代表ベクトルの集合を生成する。生成した代表ベクトルは、学習結果DB42に保存する。SOINNは、ノード数を自律的に管理することにより非定常的な入力を学習することができ、分布に複雑な形状を持つクラスに対しても適切なクラス数及び位相構造を抽出できる。なお、SOINNの応用例としては、例えばパターン認識においては、ひらがな文字のクラスを学習させた後に、カタカナ文字のクラスなどを追加的に学習させることができる。
【0045】
SOINNを使用することで、自己増殖型ニューラルネットワークを用いてノードを自動的に増加させることができるため、入力パターン空間からランダムに入力パターンが与えられる定常的な環境に限られず、例えば一定期間毎に入力パターンの属するクラスが切替えられて、切替後のクラスからランダムに入力パターンが与えられる非定常的な環境にも対応することができる。
【0046】
また、adjusted SOINNや、Enhanced−SOINN(以下E−SOINNという。)などとすると、1層構造とすることができ、2層目の学習を開始するタイミングを指定せずに追加学習を実施することができる。このSOINN、adjusted SOINN、E−SOINNについての詳細は後述する。なお、代表ベクトルを求めなくてもよく、また、SOINNやE−SOINN以外の一般的な識別器、例えばニューラルネットワークやサポートベクタマシン(Support vector machine:SVM)であっても使用可能である。
【0047】
確率演算部20は、上述したスーパーピクセル生成部11及び特徴ベクトル算出部12の他、局所単項ポテンシャル演算部21、大域単項ポテンシャル演算部24、局所二項ポテンシャル演算部26及び大域二項ポテンシャル演算部27等の演算部を有する。
【0048】
局所単項ポテンシャル、局所二項ポテンシャル、大域単項ポテンシャル、及び大域二項ポテンシャルについて簡単に説明すると、局所単項ポテンシャル及び局所二項ポテンシャルは、隣接するパーツ間の存在確率を過去のデータと比較して認識する。すなわち、局所単項ポテンシャルは、画像の局所的な特徴とラベルの関係を表す。そして、色やテクスチャを利用して、青い領域だから空だろう、などと判定する。
【0049】
局所二項ポテンシャルは、画像の局所的な特徴を基に局所的な2つのラベルの関係を表す。そして、隣接同士の領域が空だから、正しいだろう、などと判定する。
【0050】
大域単項ポテンシャルは、画像全体における大域的な特徴と各位置におけるラベルの関係を表す。先ず、画像の大域的な特徴を抽出し、それを基に描かれているシーンを特定する。そして、そのシーンから画像上でのラベルを推定するが、この場合、このようなシーンだから、この位置の画素は地面だろう、などと判定する。
【0051】
大域二項ポテンシャルはひとつの画像に存在するすべてのラベル間の関係をモデル化する、1枚の画像に同時に存在するラベルの整合性を評価する。すなわち、カバは雪の中にいないだろう、などの情報を基にラベルを推測する。以下、各ブロックについて説明する。
【0052】
局所単項ポテンシャル演算部21は、色特徴、テクスチャ特徴と代表ベクトルとの特徴間距離を計算し、各ラベルについて、色特徴及びテクスチャ特徴それぞれの局所単項ポテンシャル関数fiを算出する。
【0053】
この局所単項ポテンシャル関数fiは、局所的な画像特徴として色特徴とテクスチャ特徴を利用し、青い領域だから空だろう、白い画素だから雪だろう、のように識別器により各画素のラベルを独立に推定する。具体的には、局所単項ポテンシャル関数fiは下記式(6)で定義される。
【0054】
【数6】
【0055】
ここで、確率P(li|vcolor(i))、P(li|texture(i))は、識別器によって演算することができる。先ず、上述の学習部10により、各カテゴリの代表特徴ベクトルのセットを生成する。そして、下記式(7)に示すように、P(li|vcolor(i))は、入力特徴vcolor(i)と各カテゴリcにおける最近傍の代表特徴uとのユークリッド距離dcolorc(i)により表される。P(li|texture(i)も同様に求められる。下記の式(7)〜(9)を使用して局所単項ポテンシャル関数fiを求める。
【0056】
【数7】
【0057】
ここで、||・||はユークリッド距離、Ucolorcは計算によってカテゴリcから得られる代表特徴、σcolor、σtexturerはパラメータを示す。以上により、局所単項ポテンシャル関数fiは式(10)のように表すことができる。
【0058】
【数8】
【0059】
大域特徴算出部22は、画像の大域的な特徴を使って各スーパーピクセルのラベルを推定する。大域特徴算出部22が演算する大域的な特徴には、画像全体における色のヒストグラム、勾配方向のヒストグラム、ラプラシアンのヒストグラム、縮小した画像(低解像度化した画像)のCIE L*a*b*値を用いる。
【0060】
1)RGBヒストグラム
画像を左上、右上、左下、右下の4つ領域に分割し、各領域でRGBの3つのヒストグラムを作成する。この場合、たとえば各ヒストグラムのビン数を16とする。
【0061】
2)勾配方向ヒストグラム
4領域内の最外側を除く各画素において、3×3画素の領域を考え、周囲8画素のうちグレースケールの輝度値の差が最大である画素に対して勾配方向を特定する。勾配なしも含め9ビンのヒストグラムにより勾配方向の頻度を表す。すなわち、各領域において9次元の特徴が抽出される。
【0062】
3)ラプラシアンのヒストグラム
画像に対してラプラシアンフィルタを施し、例えば256ビンのヒストグラムを作成する。すなわち、各領域で256次元の特徴を抽出する。
【0063】
4)CIE L*a*b*値
画像サイズを基の10分の1に縮小した画像を作成し、そのCIE L*a*b*値を画像全体の特徴とする。縮小画像には、10×10画素領域の平均CIE L*a*b*を用いる。
【0064】
次に、これらの大域特徴を基に学習用データから特徴の類似した画像を検索し、ラベルの推定に用いる。検索した学習用データの類似画像にはラベル付きデータが与えられている。それらを用いて未知のテスト用データ画像のラベルの分布を推定する。なお、実施例では画像を上下左右に4分割し、各領域のラベル分布を別々に推定する。これは、限られた学習用データの中から画像全体が類似している画像を検索するのが困難なことによる。
【0065】
先ず、類似画像抽出部23は、大域特徴の類似度を基に、類似シーン画像(学習用画像)を検索する。4つの領域が相互に関連しているので、4つの大域特徴を重み付け加算し、2つの画像I1、I2の領域kにおける類似度S(I1k、I2k)を算出する。なお、本実施の形態においては、入力画像を4等分するものとして説明するが、分割せずに類似シーン画像を検索するようにしてもよい。また、4等分に限らず、2等分、6等分などであってもよい。さらに、等分ではなく、各領域の大きさが異なっていてもよい。
【0066】
【数9】
ここで、Ikは、k(=左上、右上、左下、左上)の画像、vhist、vLabは、それぞれヒストグラム、CIE L*a*の値である。ヒストグラムは、3つのヒストグラムを連結して用いる。k'は左上、右上、などの画像の領域、σhist、σLabはパラメータである。ここで、重み関数wk(k')の重みw=3とする。これにより、着目領域と、その他の領域の和が同じ重みになるようにする。(11)式で算出される類似度S(I1t、I2t)が高い順にN枚の類似シーン画像を検索する。本実施の形態においては、N=3とする。よって、4つの領域それぞれ3枚ずつ、合計12枚の学習画像が各入力画像毎に抽出される。
【0067】
大域単項ポテンシャル演算部24は、大域単項ポテンシャル関数giを計算する。大域単項ポテンシャル関数giは、画像全体の様子を表す大域的な画像特徴と、画像上でのラベルの分布との関係をモデル化する。一般のシーン画像では、ラベルの分布は描かれているシーンに大きく依存し、またシーンの様子は大域的な画像特徴に反映されやすいことによる。例えば、街のシーンでは画像の上部に「空」、下部に「道路」が分布していることが多い。このような性質を利用して画像全体におけるラベルの分布を推定する。まず、画像の大域的な特徴を抽出し、それを基に描かれているシーンを特定する。さらに、そのシーンから画像上でのラベルの分布を推定する。具体的な画像特徴としては、画像全体における色や輝度値の勾配、粗さ等を利用する。
【0068】
すなわち、大域単項ポテンシャルは、学習データの中から大域特徴(色、勾配、・・・)の類似した画像を検索し、ラベルの分布を推定する。すなわち、このようなシーンだから、ここは「地面」だろう、ここは「空」だろう、などの確率計算を行なう。
【0069】
具体的には、検索した類似シーン画像から、下記式(13)〜(16)により確率P(li=c|vG)を算出し、この確率P(li=c|vG)に基づき式(16)から大域単項ポテンシャルgi(li|X)を求める。
【0070】
【数10】
【0071】
ここで、Bcは、類似画像抽出部23が抽出した12枚の類似シーン画像から得られるカテゴリcの分布を示し、li*は、手動で付けられた正しいカテゴリを示す。演算子*は畳み込み積分を示す。さらに、Gは、Bcをより一般化するためのもので、平均値0、標準偏差σgaussのガウシアン関数を示す。2次元の等方的なガウス関数を用いてカテゴリの分布を平滑化する。標準偏差σgaussは例えば下記のように定めることができる。
【0072】
【数11】
ここで、w、hは、それぞれ画像の幅及び高さである。
【0073】
領域k(左上、右上、左下、右下)のカテゴリ分布は、式(11)の類似度Sを重みとして上記式(15)のように表すことができる。ここで、Ik,n、Bk,ncは、n番目の類似画像、及びそのk領域におけるラベル分布、vGは、大域的な特徴を示す。
【0074】
整合性行列算出部25は、検索した類似シーン画像から、第2の整合性行列としての局所的なカテゴリの整合性行列(local category compatibility matrix)ΘLと、第1の整合性行列としての大域的なカテゴリの整合性行列(global category compatibility matrix)を作成する。局所的なカテゴリの整合性行列ΘLは、全カテゴリラベルLから行、列が構成される行列であって、注目する注目画素と、その注目画素に隣接する隣接画素のラベルの関係を示す。整合性行列ΘLは、入力画像に依存する値であるため、上述の12枚の学習画像を使用してトップダウン情報に基づき生成することができる。先ず、隣り合うカテゴリペア(li,lj)(liが注目画素、ljを注目画素に隣接する隣接画素とする)の発生率を類似画像抽出部が抽出した12枚の類似シーン画像の各画像から求める。そして、12枚の類似シーン画像について、ljの発生率を正規化して求める。
【0075】
大域的なカテゴリの整合性行列ΘGは、1つの画像も2つのカテゴリが存在する確率を示す。この整合性行列ΘGもトップダウン情報に基づき生成する。整合性行列ΘGは、学習結果DB42にある学習データに基づき求められる。すなわち、上記12の類似シーン画像において2つのカテゴリが一緒に出現する画像の割合として求めることができる。
【0076】
局所二項ポテンシャル演算部26は、隣接するすべてのスーパーピクセルの組に対して局所二項ポテンシャル関数fijを計算する。fijは隣接するスーパーピクセルのラベルの整合性を評価するもので、学習用データにおいて隣接するラベルの組み合わせの確率から計算される。また、fijの大きさは2つのスーパーピクセルの特徴間の類似度が高いほど値が大きくなる。
【0077】
この局所二項ポテンシャル関数fijは、隣接同士が「空」だから注目ラベルも「空」で正しいだろう、周囲のラベルが「水」だからこのラベルも「水」だろう、のように、周囲のラベルがなるべく同じになるようにモデル化する。すなわち、滑らかならラベル分布となるように確率計算を行なう。
【0078】
下記式(17)、(18)と、上記局所的なカテゴリの整合行列ΘLとから局所二項ポテンシャルを演算する。
【0079】
【数12】
wijは、iとjとの間の相互作用の強さを変調する変数で、ユークリッド距離dcolor(i,j)とdtexture(i,j)に基づき算出され、隣接スーパーピクセルが似ているほど大きな値となる。P(lj|X)は、ljの推定された分布、kwはパラメータである。ΘLは、|L|×|L|(Lはラベル数)の局所的なカテゴリの整合性行列であり、隣接するカテゴリペアの発生率を示す。ΘL(li|lj,X)は、liに隣接するラベルlj及び入力画像Xのときのliの分布を示す。
【0080】
大域二項ポテンシャル演算部27は、式(14)と上記大域的なカテゴリの整合性行列ΘGを用いて、大域二項ポテンシャルを演算する。
【0081】
【数13】
【0082】
大域二項ポテンシャル関数gijは一枚の画像に同時に存在するラベルの整合性を評価する。すなわち、画像全体のラベルの関係をモデル化するもので、ひとつの画像上で同時に生じやすいか否かに応じてその確率計算をする。例えば、「車」と「道路」は同じ画像中に存在しやすい、「カバ」と「白熊」は同時には存在しにくい、「カバ」は「雪」の中にいない、などの1つの画像に生じるラベルの整合性を評価する。このような同時に生じやすいか否かの関係をすべてのラベルの組についてモデル化し、生じにくいラベリングの組が出てこないようにする。このため、各ラベルの組がどのくらいの確率で学習用データに生じたかを学習段階において計算する。
【0083】
ラベリング部30の初期ラベル設定部31は、局所単項ポテンシャル関数fiと、大域単項ポテンシャル関数giから初期ラベルを決定する。
【0084】
ラベル更新部32は、局所単項ポテンシャル関数fi、局所二項ポテンシャル関数fij、大域単項ポテンシャル関数gi、大域二項ポテンシャル関数gij、を考慮してラベルを更新していく。そして全体のラベリングが安定すると、その結果をラベリング結果として出力する。
【0085】
図2及び図3は、それぞれ入力画像及びラベリング結果を示す図である。入力画像の各画素にカテゴリラベル(道路、空、車など)を割り当てる。そして、画像全体がどのようなシーンであるか、画像中のどこになにがあるかなどに基づき図2の入力画像から図3に示すラベリング画像を得る。
【0086】
以上のようなラベリング装置は、専用コンピュータ、又はパーソナルコンピュータ(PC)などのコンピュータにより実現可能である。但し、コンピュータは、物理的に単一である必要はなく、分散処理を実行する場合には、複数であってもよい。図4に示すように、コンピュータ100は、CPU101(Central Processing Unit)、ROM102(Read Only Memory)及びRAM103(Random Access Memory)を有し、これらがバス104を介して相互に接続されている。尚、コンピュータを動作させるためのOSソフトなどは、説明を省略するが、この情報処理装置を構築するコンピュータも当然備えているものとする。
【0087】
バス104には又、入出力インターフェイス105も接続されている。入出力インターフェイス105には、例えば、キーボード、マウス、センサなどよりなる入力部106、CRT、LCDなどよりなるディスプレイ、並びにヘッドフォンやスピーカなどよりなる出力部107、ハードディスクなどより構成される記憶部108、モデム、ターミナルアダプタなどより構成される通信部109などが接続されている。
【0088】
CPU101は、ROM102に記憶されている各種プログラム、又は記憶部108からRAM103にロードされた各種プログラムに従って各種の処理、本実施の形態においては、学習処理や、確率演算処理、ラベリング処理等を実行する。RAM103には又、CPU101が各種の処理を実行する上において必要なデータなども適宜記憶される。
【0089】
通信部109は、例えば図示しないインターネットを介しての通信処理を行ったり、CPU101から提供されたデータを送信したり、通信相手から受信したデータをCPU101、RAM103、記憶部108に出力したりする。記憶部108はCPU101との間でやり取りし、情報の保存・消去を行う。通信部109は又、他の装置との間で、アナログ信号又はディジタル信号の通信処理を行う。
【0090】
入出力インターフェイス105は又、必要に応じてドライブ110が接続され、例えば、磁気ディスク111、光ディスク112、フレキシブルディスク113、又は半導体メモリ114などが適宜装着され、それらから読み出されたコンピュータプログラムが必要に応じて記憶部108にインストールされる。
【0091】
次に、本実施の形態にかかる学習方法、ラベリング方法について説明する。先ず、学習方法について説明する。図5は、学習方法を示すフローチャートである。学習部10には、先ず学習用画像が入力される(ステップS1)。学習用画像は、例えば学習用画像DB41に保存されている。または、上述の通信部を介してネットワークを通じて取得するようにしてもよい。
【0092】
次に、スーパーピクセル生成部11は、入力された学習用画像をセグメンテーションし、得られるセグメントをスーパーピクセルとして生成する(ステップS2)。スーパーピクセルは、例えば"Efficient Graph-Based Image Segmentation" Pedro F. Felzenszwalb and Daniel P. Huttenlocher. International Journal of Computer Vision, Volume 59, Number 2, September 2004. に記載の方法で生成することができる。以下、これを第1の方法という。
【0093】
この第1の方法では、セグメントにおいて、セグメント内の変動は、セグメント間の変動よりも小さくなるようにセグメンテーションする。すなわち、セグメント内の類似度を高く、セグメント間の類似度は低くなるようにする。具体的には、学習用画像をグラフ(ノードと辺)で表す。ノードは画素を表し、辺は隣接する2つの画素を繋ぐ。各辺の重みは隣接画素間の特徴の距離(RGB値の差)を表す。出力はノードをグルーピングしたコンポーネントの集合となる。
【0094】
次に、m個の辺を重みの小さい順(類似度の高い順)に並べる。そして、すべての画素をそれぞれ単独でコンポーネントとする。次いで、着目している辺の重みが、その辺によって繋げられている2つのコンポーネントの内部変動よりも小さければ、2つのコンポーネントを結合する。大きければ何もしない、という処理を、辺1から辺mまでm回繰り返す。そして、コンポーネントの集合を出力する。こうしてスーパーピクセルを生成する。
【0095】
この第1の方法においては、初期段階においてすべての画素は単独でセグメントとなっている。これらを逐次的に結合することによりセグメンテーションを行う。一方、他の手法(以下、第2の方法という、)として、初期段階において画像全体をひとつのセグメントとし、これの辺を削除して分割することによりセグメンテーションを行う方法もある("Normalized Cuts and Image Segmentation"J. Shi and J. Malik. IEEE TPAMI, 22(8) Aug. 2000、又は"Learning and incorporating top-down cues in image segmentation" Xuming He, Richard Zemel, and Deb Ray (2006), In ECCV 2006)
【0096】
この第2の方法においては、先ず、画像をグラフで表現する。ノードは画素を表し、辺はすべての画素の組に対して作成する(例えばN×N画素の画像では、N×N本の辺を作成)。各辺の重みは画素間の近さと画素間の特徴の類似度とする。セグメンテーションは、辺を削除することによってグラフを分割し、ノード集合の組を作成することにより行う。セグメンテーションの良し悪しを評価する基準として"Normalized cut"を用いる。"Normalized cut"はセグメント間の類似度が高くなるように、同時にセグメントサイズが大きくなるように定義される(単純な評価基準では、セグメントのサイズが小さいほど類似度が高くなる)。
【0097】
さらに、第3の方法として、次のような方法がある("Recovering Surface Layout from an Image" D. Hoiem, A.A. Efros, and M. Hebert, IJCV. 参照)。図5に示すように、先ず、複数の細かさでセグメンテーションを行う。すなわち、スーパーピクセルのサイズを大きくしたり小さくしたりする。本例では3種類のセグメンテーションを行なっている。これらの複数のセグメンテーションのそれぞれに対し、独立にラベリングを行う。そして、最終的な出力は複数のラベリング結果を統合して決定する。
【0098】
図6(a)、図7(a)は、学習用画像であり、図6(b)、図7(b)は、上記の第1の方法により、スーパーピクセルに分割した場合の画像を示している。図6(b)、図7(b)に示すように、1つのスーパーピクセルは、同じカテゴリラベル内に生成されている。
【0099】
次に、特徴ベクトル算出部12により、スーパーピクセルの色特徴及びテクスチャ特徴を計算する。各スーパーピクセルの色特徴(CIE L*a*b*)と、テクスチャ特徴(LBP)のヒストグラムを求める。例えば色特徴のビン数は、L*、a*、b*で各20個ずつとすることができ、全体で60ビン(60次元)の色特徴ヒストグラムを得る。また、テクスチャ特徴は、上述の(2)乃至(5)の式において、例えばP=8、R=1とした場合、ビン数59のヒストグラムを求めることができる。また左右対称不変とした場合は39ビンのヒストグラムとして求めることができる。
【0100】
次に、SOINNによりクラスタリングして代表ベクトルを求める(ステップS4)。後述するSOINN、adjusted SOINN、E−SOINNは、いずれも多次元ベクトルで記述されるプロトタイプが配置される少なくとも1層以上の構造を有し、任意のクラスに属する多次元ベクトルで記述される入力パターンを識別するための入力パターンの標準的なパターンであるプロトタイプを取得するものである。これにより、各スーパーピクセルのベクトルの代表ベクトルが求まる。
【0101】
次に、ラベリング処理について説明する。図8は、ラベリング処理を示すフローチャートである。ステップS12、S13は、学習段階のステップS2、3と同一である。スーパーピクセル生成部11でスーパーピクセルを生成し、各スーパーピクセルについて、特徴ベクトル算出部12がそれぞれL*、a*、b*で各20ビンのヒストグラム、59又は39ビンのテクスチャ特徴のヒストグラムを求める。
【0102】
そして、局所単項ポテンシャル演算部21は、色特徴、テクスチャ特徴と、ステップS4で求めた各代表ベクトルとの特徴間距離を計算する(ステップS14)。すなわち、各ラベルについて、局所単項ポテンシャル演算部21が式(6)〜(9)を使用して色特徴とテクスチャ特徴と、代表ベクトルとから、特徴間距離として、ユークリッド距離dcolorc(i)、ユークリッド距離dtexturec(i)を算出し、これに基づきそれぞれの局所単項ポテンシャルを、式(10)により算出する。
【0103】
以上のステップS12〜S14と並列に以下のステップS15乃至S18を実施する。ステップS15では、大域特徴算出部22により、大域特徴を算出する。大域特徴は、上述した大域特徴部が、入力画像に対し、RGBのヒストグラム、勾配方向のヒストグラム、ラプラシアンのヒストグラム、縮小した画像(低解像度化した画像)のCIE L*a*b*値を計算する。例えばRGBのヒストグラムは16ビン、勾配方向のヒストグラムが、周囲8近傍+勾配なしで9ビン、ラプラシアンのヒストグラムが256ビンとすることができる。また、CIE L*a*b*は、入力画像を10分の1に縮小した画像のCIE L*a*b*とすることができる。例えば入力画像が96×64の場合、縮小画像サイズは、9×6となり、CIE L*a*b*特徴は、9×6×3次元の特徴ベクトルとなる。
【0104】
次のステップS16では、類似画像抽出部23が大域特徴の類似度を基に類似シーン画像(学習用画像)を検索する。このとき、各ラベルに対する大域単項ポテンシャルを計算し、共起モデルを作成する。
【0105】
先ず、入力画像を4等分して、それぞれに対して、式(11)、(12)から類似度S(I1k、I2k)を求める。そして、類似度S(I1k、I2k)の大きなものから、N=3まで収集する。これにより、類似画像抽出部23により、入力画像に類似する類似画像である合計12枚の学習用画像(以下、類似シーン画像という。)が抽出される。
【0106】
次のステップS17では、大域単項ポテンシャル演算部24が検索した類似シーン画像から、式(13)乃至(15)により、P(li=c|vG)を求め、このP(li=c|vG)に基づき、式(16)に示す大域単項ポテンシャルgi(li|X)を求める。
【0107】
図9(a)は、入力画像、図9(b)は類似シーン画像、図10(a)乃至図10(c)は、類似シーン画像を基に、カテゴリ分布を推定した結果を示す。それぞれ、空、道路、建物のカテゴリを示し、明るい領域がカテゴリの分布している可能性が高いことを表している。この例では、空は上部に、道路は下部に、建物は道路の回りに広がっている可能性が高いことを示す。ここでは、各画素の局所的な特徴は用いておらず、画像の大域的な特徴のみから推定しているが、極めてよい精度で推定を行なうことができる。
【0108】
そして、ステップS18では、整合性行列算出部25が検索した類似シーン画像から、上述した局所的なカテゴリの整合性行列ΘL、大域的なカテゴリの整合性行列ΘGを算出する。これは、ステップS21の局所二項ポテンシャル、大域二項ポテンシャルの演算に使用する。
【0109】
以上の処理が終了したら、ラベリング部30にてステップS19乃至S23のラベリング処理を実行する。先ず、初期ラベルを決定する(ステップS19)。初期ラベルは、ステプS4で求めた局所単項ポテンシャルfi(li|X)と、ステップS17で求めた大域単項ポテンシャルgi(li|X)のみを式(1)に適用して初期値を求める。これを初期ラベルとする。
【0110】
次に、スーパーピクセルをランダムに1つ選択し(ステップS20)、局所単項ポテンシャル、局所二項ポテンシャル、大域単項ポテンシャル、大域二項ポテンシャルを考慮してラベルを更新する(ステップS21)。局所二項ポテンシャルは、局所二項ポテンシャル演算部26がステップS18で求めた局所的なカテゴリの整合性行列ΘLと、式(17)、(18)から算出する。大域二項ポテンシャルは、大域二項ポテンシャル演算部27がステップS18で生成した大域的なカテゴリの整合性行列ΘGと、式(19)から算出する。各値を式(1)に代入してラベルを更新する。
【0111】
次に、ラベリングが安定するか否かを判断し(ステップS22)、ラベリング結果を出力する(ステップS23)。
【0112】
本実施の形態においては、従来のように局所情報のみでモデル化するのではなく、大域情報も含めてモデル化する。これにより、従来手法では生じていた、大域的な視点から明らかな誤りを修正できるようになる。例えば、大域単項ポテンシャル関数giは、画像の大域的な特徴から位置情報も含めてラベルを推定するため、「道路」が「空」まで延びるようなラベリングを修正する。また、大域二項ポテンシャル関数gijは、一枚の画像に同時に生じるラベルの整合性をモデル化するため、「カバ」と「白熊」のように不適当なラベルの組が生じるラベリングを修正する。
【0113】
さらに、本実施の形態においては上記(1)に示すモデルとsuperpixel(スーパーピクセル)を組み合わせて利用することでラベリング処理の高速化を図る。スーパーピクセルは、特徴(輝度値や色)の類似している画素同士を連結してできる均質な小領域であり、ラベリング処理の前にこの連結処理を行うことで生成する。
【0114】
次に、本発明の実施の形態にかかる効果について説明する。先ず、Sowerbyのデータセット(X. Feng, C. Williams and S. Felderhof: "Combining belief networks and neural networks for scene segmenting and labeling sequence data", IEEE Trans. Pattern Anal. Mach. Intell., 24, 4, pp467-483)(以下、第1データセットという。)と、Corelのデータセット(X. He, R. S. Zemel and M. A. Carreira-Perpinan: "Multiscale condition random field for image labeling", Proc. Computer Vision and Pattern Recognition, Vol. 2, pp.695-702 (2004))(以下、第2のデータセットという。)を使用して入力画像のラベリングテストを行なった。図11乃至図16はその結果を示す。図には、入力画像(a)と、実施例(e)の比較として、手動でラベリングしたもの(正解ラベル)(b)、と、比較例1として局所単項ポテンシャル関数のみを利用したもの(c)、比較例2として局所単項ポテンシャル関数及び局所二項ポテンシャル関数を利用したもの(CRF)(d)も示す。図17は、実施例及び比較例の正答率を示す図である。
【0115】
第1及び第2のデータセットをそれぞれ2つに分け、1つは学習用、1つはテスト用に使用した。学習用データは、学習用画像とそれに対応する正しいラベルの付いたデータのセットから成り、学習段階においてモデルを構成するために使われる。一方、テスト用データは、学習段階で構成したモデルのラベリング性能を評価するために使われる。
【0116】
第1のデータセットは、104枚の画像からなり、空、草木、道路マーキング、道路表面、建物、障害物、及び車の7つにカテゴライズされている。60画像を学習に使用し、44画像をテストに使用した。画像は、96×64ピクセルからなる。
【0117】
第2のデータセットは、100画像からなり、カバ、白熊、水、雪、草木、土及び空の7つにカテゴライズされている、60枚を学習に、40枚をテストに使用した。180×120画素からなる。
【0118】
本実施の形態においては、処理の迅速化のためスーパーピクセルを使用する。スーパーピクセルは誤差を含むため、ラベリングの上限は92%となる。特徴ベクトルの演算において、L*、a*、b*は各20個ずつ、全部で60ビンの色特徴ヒストグラムを生成する。LBPのパラメータは、P=8、R=1とし、第1のデータセットでは59ビン、第2のデータセットでは39ビンのテクスチャ特徴を生成する。
【0119】
後述するSOINNのパラメータλ=700、agedead=700とする。第1及び第2のデータセットでそれぞれ100、150の特徴カテゴリ(代表ベクトル)が抽出される。式(1)において、パラメータα=0.1、β=0.005、γ=0.1とした。また、式(10)のσcolor=1.0、σtexture=0.6(第1のデータセット)、σtexture=0.3(第2のデータセット)、式(18)のkw=0.1(第1のデータセット)、kw=0.05(第2のデータセット)とする。さらに、式(11)のσhist=7.5(第1のデータセット)、σhist=3.0(第2のデータセット)、σLab=600(第1のデータセット)、σLab=180(第2のデータセット)とする。ラベリングの精度は正しいラベルが割り当てられた画素の割合で評価する。また、ラベリングの処理時間は3.2GHzのCPUを用いたときのものである。
【0120】
ラベリング正解率(正しくラベルが割り当てられた画素の割合)は、第1のデータセットにおいて、比較例2は86.1%だったのに対し、本実施例では89.8%になった。また、第2のデータセットにおいては、比較例2では66.2%だったのに対し、本実施例では80.7%となった。
【0121】
例えば、第1のデータセットにおいては、比較例1、2では、建物が道路に現れたり、地面が空まで伸びてしまったりしている。また、第2のデータセットにおいては、カバと白熊が結合して現れたり、カバと雪が同じ画面に現れたりしている。これに対し、本実施例では、大域単項ポテンシャル及び大域二項ポテンシャルを使用するため、大域的なカテゴリの互換性を保つことができる。
【0122】
さらに、一枚の画像のラベリング処理に要する時間は、これまでに発表されている手法では数秒から数分掛かったのに対し、本実施例ではそれぞれ0.3、0.9秒で済ませることができた。これは処理速度が他の手法と比較して数十倍から数百倍向上したことを示す。
【0123】
次に、上述のSOINN、Adjusted SOINN、E−SOINNについて説明する。SOINNは2層ネットワーク構造を有し、1層目及び2層目において同様の学習処理を実施する。SOINNは、1層目の出力である学習結果を2層目への入力ベクトルとして利用する。
【0124】
図18は、SOINNによる学習処理を説明するためのフローチャートである。以下、図18を用いてSOINNの処理を説明する。S101:SOINNに対して入力ベクトルを与える。
【0125】
S102:与えられた入力ベクトルに最も近いノード(以下、第1勝者ノードという。)及び2番目に近いノード(以下、第2勝者ノードという。)を探索する。
【0126】
S103:第1勝者ノード及び第2勝者ノードの類似度閾値に基づいて、入力ベクトルがこれら勝者ノードの少なくともいずれか一方と同一のクラスタに属すか否かを判定する。ここで、ノードの類似度閾値はボロノイ領域の考えに基づいて算出する。学習過程において、ノードの位置は入力ベクトルの分布を近似するため次第に変化し、それに伴いボロノイ領域も変化する。即ち、類似度閾値もノードの位置変化に応じて適応的に変化してゆく。
【0127】
S104:S103における判定の結果、入力ベクトルが勝者ノードと異なるクラスタに属す場合は、入力ベクトルと同じ位置にノードを挿入し、S101へと進み次の入力ベクトルを処理する。尚、このときの挿入をクラス間挿入と呼ぶ。
【0128】
S105:一方、入力ベクトルが勝者ノードと同一のクラスタに属す場合は、第1勝者ノード及び第2勝者ノード間に辺を生成し、ノード間を辺によって直接的に接続する。
【0129】
S106:第1勝者ノード及び第1勝者ノードと辺によって直接的に接続しているノードの重みベクトルをそれぞれ更新する。
【0130】
S107:S105において生成された辺は年齢を有しており、予め設定された閾値を超えた年齢を持つ辺を削除する。入力ベクトルを逐次的に与えてゆくオンライン学習においては、ノードの位置が常に徐々に変化してゆくため、初期の学習で構成した隣接関係が以後の学習によって成立しない可能性がある。このため、一定期間を経ても更新されないような辺について、辺の年齢が高くなるように構成することにより、学習に不要な辺を削除する。
【0131】
S108:入力ベクトルの入力総数が、予め設定されたλの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がλの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がλの倍数となった場合には以下の処理を実行する。
【0132】
S109:局所累積誤差が最大であるノードを探索し、そのノード付近に新たなノードを挿入する。ノードの持つ平均誤差を示す誤差半径に基づいて、ノード挿入が成功であったか否かを判定する。尚、このときの挿入をクラス内挿入と呼ぶ。
【0133】
ここで、ノード及び入力ベクトル間の距離差をノードの持つ誤差として、入力ベクトルの入力に応じてノードの誤差を累積することにより局所累積誤差を算出する。誤差半径はノードの持つ誤差及びノードが第1勝者となった回数に基づいて算出する。
【0134】
S110:クラス内挿入によるノード挿入が成功であると判定した場合には、クラス内挿入により挿入されたノード及び局所累積誤差が最大のノードを辺によって直接的に接続する。一方、クラス内挿入によるノード挿入が失敗であると判定した場合には、クラス内挿入により挿入したノードを削除してS111へと進む。
【0135】
S111:隣接ノード数及びノードが第1勝者となった回数に基づいて、ノイズノードを削除する。ここで、隣接ノードとは、ノードと辺によって直接的に接続されるノードを示し、隣接ノードの個数が1以下であるノードを削除対象とする。また、第1勝者となった回数の累積回数を予め設定されたパラメータcを使用して算出される閾値と比較し、第1勝者累積回数が閾値を下回るノードを削除対象とする。
【0136】
S112:入力ベクトルの入力総数が予め設定されたLTの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がLTの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がLTの倍数となった場合には、以下の処理を実行する。
【0137】
S113:1層目の学習を終了するか否かを判定する。判定の結果、2層目の学習へと進む場合には、S101へと進み1層目の学習結果であるノードを2層目への入力ベクトルとして入力する。ただし、追加学習を行う場合は、2層目に残っている以前の学習結果を消去した上で2層目の学習を開始する。
【0138】
2層目への入力回数が予め設定された回数LTの倍数となり2層目の学習を終了する場合には、ノードを異なるクラスに分類し、クラス数及び各クラスの代表的なプロトタイプベクトルを出力し停止する。ここで、プロトタイプベクトルはノードの重みベクトルに相当する。
【0139】
このように、SOINNは、ノード数を自律的に管理することにより非定常的な入力を学習することができ、分布に複雑な形状を持つクラスに対しても適切なクラス数及び位相構造を抽出できるなど多くの利点を持つ。SOINNの応用例として、例えばパターン認識においては、ひらがな文字のクラスを学習させた後に、カタカナ文字のクラスなどを追加的に学習させることができる。
【0140】
次に、図19を用いてadjusted SOINNの処理を説明する。adjusted SOINNは、SOINNと比べて、学習に際して事前に指定するパラメータの数を少なくすることができ、より簡単に学習を実施することができる。
【0141】
S201:入力情報取得手段は、ランダムに2つの入力パターンを取得し、ノード集合Aをそれらに対応する2つのノードのみを含む集合として初期化し、その結果を一時記憶部に格納する。また、辺集合C⊂A×Aを空集合として初期化し、その結果を一時記憶部に格納する。
【0142】
S202:入力情報取得手段は、新しい入力パターンξを入力し、その結果を一時記憶部に格納する。
【0143】
S203:勝者ノード探索手段は、一時記憶部に格納された入力パターン及びノードについて、入力パターンξに最も近い重みベクトルを持つ第1勝者ノードa1及び2番目に近い重みベクトルを持つ第2勝者ノードa2を探索し、その結果を一時記憶部に格納する。
【0144】
S204:類似度閾値判定手段は、一時記憶部に格納された入力パターン、ノード、ノードの類似度閾値について、入力パターンξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きいか否か、及び、入力パターンξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きいか否かを判定し、その結果を一時記憶部に格納する。
【0145】
ここで、一時記憶部に格納された第1勝者ノードa1の類似度閾値T1及び第2勝者ノードa2の類似度閾値T2は、上述のS101乃至S104において示したように類似度閾値算出手段により算出され、その結果が一時記憶部に格納される。
【0146】
S205:一時記憶部に格納されたS204における判定の結果、入力パターンξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きい、又は、入力パターンξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きい場合には、ノード挿入手段は、一時記憶部に格納された入力パターン及びノードについて、入力パターンξを新たなノードiとして、入力パターンξと同じ位置に挿入し、その結果を一時記憶部に格納する。
【0147】
S206:一方、一時記憶部に格納されたS204における判定の結果、入力パターンξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1以下であり、かつ、入力パターンξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2以下である場合には、辺接続判定手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0148】
S207:一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
【0149】
そして、adjusted SOINNは、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0150】
一方、一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S208へと処理を進めるが、既にノード間に辺が生成されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
【0151】
次いで、adjusted SOINNは、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0152】
S208:重みベクトル更新手段は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力パターンξに更に近づけるように更新し、その結果を一時記憶部に格納する。ここで、重みベクトルの更新量の算出には、一時記憶部に格納されるMa1をtとして使用する。
【0153】
S209:adjusted SOINNは、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。尚、agetはノイズなどの影響により誤って生成される辺を削除するために使用する。agetに小さな値を設定することにより、辺が削除されやすくなりノイズによる影響を防ぐことができるものの、値を極端に小さくすると、頻繁に辺が削除されるようになり学習結果が不安定になる。一方、極端に大きな値をagetに設定すると、ノイズの影響で生成された辺を適切に取り除くことができない。これらを考慮して、パラメータagetは実験により予め算出し一時記憶部に格納される。
【0154】
S210:adjusted SOINNは、一時記憶部に格納された与えられた入力パターンξの総数について、与えられた入力パターンξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力パターンの総数がλの倍数でない場合にはS202へと戻り、次の入力パターンξを処理する。一方、入力パターンξの総数がλの倍数となった場合には以下の処理を実行する。
【0155】
尚、λはノイズと見なされるノードを削除する周期である。λに小さな値を設定することにより、頻繁にノイズ処理を実施することができるものの、値を極端に小さくすると、実際にはノイズではないノードを誤って削除してしまう。一方、極端に大きな値をλに設定すると、ノイズの影響で生成されたノードを適切に取り除くことができない。これらを考慮して、パラメータλは実験により予め算出し一時記憶部に格納される。
【0156】
S211:ノイズノード削除手段は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。
【0157】
S212:adjusted SOINNは、一時記憶部に格納された与えられた入力パターンξの総数について、与えられた入力パターンξの総数が予め設定されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力パターンの総数がLTの倍数でない場合にはS202へと戻り、次の入力パターンξを処理する。一方、入力パターンξの総数がLTの倍数となった場合には以下の処理を実行する。
【0158】
S213:adjusted SOINNは、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、adjusted SOINNによる学習を停止する。
【0159】
次に、Enhanced−SOINN(以下E−SOINNという。)について説明する。E−SOINNはSOINNに比べて、入力パターンの分布に高密度の重なりのあるクラスを分離することができる。そして、分布の重なり領域の検出処理においては、平滑化の手法を導入したことより、SOINNに比べてより安定的に動作することができる。さらに、1層構造であっても効率的にノイズノードを削除することができる。さらにまた、SOINNに比べて、より少ないパラメータで動作するため、処理をより容易に実行することができる。
【0160】
以下にE−SOINNを簡単に説明する。図20は、E−SOINNによる学習処理の処理概要を示すフローチャートである。尚、上述したadjusted SOINNと同様の処理については説明を省略する。
【0161】
まず、図24に示すS601乃至S605については、図19に示すadjusted SOINNと同様の処理を実施する。従って、以下では図20に示すS606からの処理について説明する。
【0162】
S606:後述する辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2のノード密度に基づいて、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0163】
S607:一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、後述する辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
【0164】
そして、E−SOINNは、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0165】
一方、一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S608へと処理を進めるが、既にノード間に辺が生成されていた場合には、後述する辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
【0166】
次いで、一時記憶部に格納されたノード及びノード密度のポイント値について、第1勝者ノードa1について、後述するノード密度算出手段は、一時記憶部に格納された第1勝者ノードa1のノード密度のポイント値を算出しその結果を一時記憶部に格納し、算出され一時記憶部に格納されたノード密度のポイント値を以前までに算出され一時記憶部に格納されたポイント値に加算することで、ノード密度ポイントとして累積し、その結果を一時記憶部に格納する。
【0167】
次いで、E−SOINNは、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0168】
S608:adjusted SOINNと同様の重みベクトル更新手段は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力ベクトルξに更に近づけるように更新し、その結果を一時記憶部に格納する。尚、E−SOINNにおいては、追加学習に対応するため、入力ベクトルの入力回数tに代えて、一時記憶部に格納される第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1を用いる。
【0169】
S609:E−SOINNは、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。
【0170】
S610:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がλの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。一方、入力ベクトルξの総数がλの倍数となった場合には以下の処理を実行する。
【0171】
S611:後述する分布重なり領域検出手段は、一時記憶部に格納されたサブクラスタ及び分布の重なり領域について、上述のS301乃至S305において示したようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0172】
S612:後述するノード密度算出手段は、一時記憶部に格納されて累積されたノード密度ポイントを単位入力数あたりの割合として算出しその結果を一時記憶部に格納し、単位入力数あたりのノードのノード密度を算出し、その結果を一時記憶部に格納する。
【0173】
S613:後述するノイズノード削除手段は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。尚、S613においてノイズノード削除手段が使用するパラメータc1及びc2はノードをノイズと見なすか否かの判定に使用する。通常、隣接ノード数が2であるノードはノイズではないことが多いため、c1は0に近い値を使用する。また、隣接ノード数が1であるノードはノイズであることが多いため、c2は1に近い値を使用するものとし、これらのパラメータは予め設定され一時記憶部に格納される。
【0174】
S614:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がLTの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。
【0175】
一方、入力ベクトルξの総数がLTの倍数となった場合には、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、学習を停止する。ノード密度算出手段は、一時記憶部に格納されたノード及びノード密度について、注目するノードについて、その隣接ノード間の平均距離に基づいて、注目するノードのノード密度を算出し、その結果を一時記憶部に格納する。
【0176】
さらに、ノード密度算出手段は、単位ノード密度算出部を有し、単位ノード密度算出部は、追加学習に対応するため、一時記憶部に格納された第1勝者ノード及びノード密度について、第1勝者ノードとその隣接ノード間の平均距離に基づいて、第1勝者ノードのノード密度を単位入力数あたりの割合として算出し、その結果を一時記憶部に格納する。
【0177】
さらにまた、ノード密度算出手段は、一時記憶部に格納されたノード及びノード密度ポイントについて、第1勝者ノード及びその隣接ノード間の平均距離に基づいて、第1勝者ノードのノード密度のポイント値を算出するノード密度ポイント算出部と、入力ベクトルの入力数が所定の単位入力数となるまでノード密度ポイントを一時記憶部に格納して累積し、入力ベクトルの入力数が所定の単位入力数になった場合に、一時記憶部に格納して累積されたノード密度ポイントを単位入力数あたりの割合として算出し、単位入力数あたりのノードのノード密度を算出し、その結果を一時記憶部に格納する単位ノード密度ポイント算出部を有する。
【0178】
具体的には、ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiに与えられるノード密度のポイント値piを算出し、その結果を一時記憶部に格納する。尚、ノードiに与えられるポイント値piは、ノードiが第1勝者ノードとなった場合には一時記憶部に格納される以下の式に基づいて算出されるポイント値が与えられるが、ノードiが第1勝者ノードでない場合にはノードiにはポイントは与えられないものとする。
【0179】
【数14】
【0180】
ここで、eiはノードiからその隣接ノードまでの平均距離を示し、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【0181】
【数15】
【0182】
尚、mは一時記憶部に格納されたノードiの隣接ノードの個数を示し、Wiは一時記憶部に格納されたノードiの重みベクトルを示す。ここで、隣接ノードへの平均距離が大きくなる場合には、ノードを含むその領域にはノードが少ないものと考えられ、逆に平均距離が小さくなる場合には、その領域にはノードが多いものと考えられる。
【0183】
従って、ノードの多い領域で第1勝者ノードとなった場合には高いポイントが与えられ、ノードの少ない領域で第1勝者ノードとなった場合には低いポイントが与えられるようにノードの密度のポイント値の算出方法を上述のように構成する。
【0184】
これにより、ノードを含むある程度の範囲の領域におけるノードの密集具合を推定することができるため、ノードの分布が高密度の領域に位置するノードであっても、ノードが第1勝者回数となった回数をノードの密度とするSOINNに比べて、入力ベクトルの入力分布密度により近似した密度となるノード密度ポイントを算出することができる。
【0185】
単位ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiの単位入力数あたりのノード密度densityiを算出し、その結果を一時記憶部に格納する。
【0186】
【数16】
【0187】
ここで、連続して与えられる入力ベクトルの入力回数を予め設定され一時記憶部に格納される一定の入力回数λごとの区間に分け、各区間においてノードiに与えられたポイントについてその合計を累積ポイントsiと定める。尚、入力ベクトルの総入力回数を予め設定され一時記憶部に格納されるLTとする場合に、LT/λを区間の総数nとしその結果を一時記憶部に格納し、nのうち、ノードに与えられたポイントの合計が0以上であった区間の数をNとして算出し、その結果を一時記憶部に格納する(Nとnは必ずしも同じとならない点に注意する)。
【0188】
累積ポイントsiは、例えば一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【0189】
【数17】
【0190】
ここで、pi(j,k)はj番目の区間におけるk番目の入力によってノードiに与えられたポイントを示し、上述のノード密度ポイント算出部により算出され、その結果を一時記憶部に格納する。
【0191】
このように、単位ノード密度ポイント算出部は、一時記憶部に格納されたノードiの密度densityiを累積ポイントsiの平均として算出し、その結果を一時記憶部に格納する。尚、E−SOINNにおいては追加学習に対応するため、nに代えてNを用いる。これは、追加学習において、以前の学習で生成されたノードにはポイントが与えられないことが多く、nを用いて密度を算出すると、以前学習したノードの密度が次第に低くなってしまうという問題を回避するためである。即ち、nに代えてNを用いてノード密度を算出することで、追加学習を長時間行った場合であっても、追加されるデータが以前学習したノードの近くに入力されない限りは、そのノードの密度を変化させずに保持することができる。
【0192】
これにより、追加学習を長時間実施する場合であっても、ノードのノード密度が相対的に小さくなってしまうことを防ぐことができ、SOINNを含む従来の手法に比べて、入力ベクトルの入力分布密度により近似したノード密度を変化させずに保持して算出することができる。
【0193】
分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、辺によって接続されるノードの集合であるクラスタを、ノード密度算出手段によって算出されるノード密度に基づいてクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納し、サブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0194】
さらに、分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索するノード探索部と、探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与する第1のラベル付与部と、第1のラベル付与部によりラベルが付与されなかったノードのうち、そのノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与する第2のラベル付与部と、それぞれ異なるラベルが付与されたノード間に辺によって直接的に接続がある場合に、その辺によって接続されるノードの集合であるクラスタをクラスタの部分集合であるサブクラスタに分割するクラスタ分割部と、注目するノード及びその隣接ノードがそれぞれ異なるサブクラスタに属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出する分布重なり領域検出部を有する。
【0195】
具体的には、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、例えば以下のようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0196】
S701:ノード探索部は、一時記憶部に格納されたノード及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索し、その結果を一時記憶部に格納する。
【0197】
S702:第1のラベル付与部は、一時記憶部に格納されたノード、及びノードのラベルについて、S701において探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与し、その結果を一時記憶部に格納する。
【0198】
S703:第2のラベル付与部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、S702において第1のラベル付与部によりラベルが付与されなかったノードについて、第1のラベル付与部にラベルが付与されたノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与し、その結果を一時記憶部に格納する。即ち、密度が局所的に最大の隣接ノードと同じラベルを付与する。
【0199】
S704:クラスタ分割部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、一時記憶部に格納された辺によって接続されるノードの集合であるクラスタを、同じラベルが付与されたノードからなるクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納する。
【0200】
S705:分布重なり領域検出部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、注目するノードとその隣接ノードが異なるサブクラスタにそれぞれ属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出し、その結果を一時記憶部に格納する。
【0201】
辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、及び分布重なり領域について、第1勝者ノード及び第2勝者ノードが分布重なり領域に位置するノードである場合に、第1勝者ノード及び第2勝者ノードのノード密度に基づいて第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0202】
さらに辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタについて、ノードが属しているサブクラスタを判定する所属サブクラスタ判定部と、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定する辺接続判定部を有する。
【0203】
辺接続手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
【0204】
辺削除手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。具体的には、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタ、及びノード間の辺について、例えば以下のようにして辺接続判定手段は辺を接続するか否かを判定し、辺接続手段及び辺削除手段は辺の生成及び削除処理を実施し、その結果を一時記憶部に格納する。
【0205】
S801:所属サブクラスタ判定部は、一時記憶部に格納されたノード、ノードのサブクラスタについて、第1勝者ノード及び第2勝者ノードが属するサブクラスタをそれぞれ判定し、その結果を一時記憶部に格納する。
【0206】
S802:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードがどのサブクラスタにも属していない場合、又は、第1勝者ノード及び第2勝者ノードが同じサブクラスタに属している場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成することによりノード間を接続し、その結果を一時記憶部に格納する。
【0207】
S803:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードが互いに異なるサブクラスタに属す場合には、辺接続判定部は、一時記憶部に格納されたノード、ノード密度、及びノード間の辺について、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0208】
S804:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要がないと判定した場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間を辺によって接続せず、既にノード間が辺によって接続されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、一時記憶部に格納された第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。
【0209】
S805:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要があると判定した場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成しノード間を接続する。ここで、辺接続判定部による判定処理について詳細に説明する。
【0210】
まず、辺接続判定部は、一時記憶部に格納されたノード及びノード密度について、第1勝者ノードのノード密度densitywin及び第2勝者ノード密度densitysec−winのうち、最小のノード密度mを例えば一時記憶部に格納される以下の式に基いて算出し、その結果を一時記憶部に格納する。
【0211】
【数18】
【0212】
次に、一時記憶部に格納されたノード、ノードのノード密度、及びノードのサブクラスについて、第1勝者ノード及び第2勝者ノードがそれぞれ属するサブクラスタA及びサブクラスタBについて、サブクラスタAの頂点の密度Amax及びサブクラスタBの頂点の密度Bmaxを算出し、その結果を一時記憶部に格納する。尚、サブクラスタに含まれるノードのうち、ノード密度が最大であるノード密度をサブクラスタの頂点の密度とする。
【0213】
そして、一時記憶部に格納されたノードが属するサブクラスタの頂点の密度Amax及びBmax、及びノードの密度mについて、mがαAAmaxより小さく、かつ、mがαBBmaxより小さいか否かを判定し、その結果を一時記憶部に格納する。即ち、一時記憶部に格納される以下の不等式を満足するか否かを判定し、その結果を一時記憶部に格納する。
【0214】
【数19】
【0215】
判定の結果、mがαAAmaxより小さく、かつ、mがαBBmaxより小さい場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間には辺は不要であると判定し、その結果を一時記憶部に格納する。一方、判定の結果、mがαAAmax以上、または、mがαBBmax以上である場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺は必要であると判定し、その結果を一時記憶部に格納する。
【0216】
このように、第1勝者ノード及び第2勝者ノードの最小ノード密度mを、第1勝者ノード及び第2勝者ノードをそれぞれ含むサブクラスタの平均的なノード密度と比較することで、第1勝者ノード及び第2勝者ノードを含む領域におけるノード密度の凹凸の大きさを判定することができる。即ち、サブクラスタA及びサブクラスタBの間に存在する分布の谷間のノード密度mが、閾値αAAmax又はαBBmaxより大きな場合には、ノード密度の形状は小さな凹凸であると判定することができる。
【0217】
ここで、αA及びαBは一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。尚、αBについてもαAと同様にして算出することができるためここでは説明を省略する。
i) Amax/meanA−1≦1の場合には、αA=0.0とする。
ii) 1<Amax/meanA−1≦2の場合には、αA=0.5とする。
iii) 2<Amax/meanA−1の場合には、αA=1.0とする。
【0218】
Amax/meanAの値が1以下となるi)の場合には、AmaxとmeanAの値は同程度であり、密度の凹凸はノイズの影響によるものと判断する。そして、αの値を0.0とすることで、サブクラスタが統合されるようにする。また、Amax/meanAの値が2を超えるi i i)の場合には、AmaxはmeanAに比べて十分大きく、明らかな密度の凹凸が存在するものと判断する。そして、αの値を1.0とすることで、サブクラスタが分離されるようにする。
【0219】
そして、Amax/meanAの値が上述した場合以外となる i i)の場合には、αの値を0.5とすることで、密度の凹凸の大きさに応じてサブクラスタが統合又は分離されるようにする。尚、meanAはサブクラスタAに属すノードiのノード密度densityiの平均値を示し、NAをサブクラスタAに属するノードの数として、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【0220】
【数20】
【0221】
このように、サブクラスタへの分離を行う際に、サブクラスタに含まれるノード密度の凹凸の程度を判定し、ある基準を満たした2つのサブクラスタを1つに統合することで、分布の重なり領域の検出におけるサブクラスタの分けすぎによる不安定化を防止することができる。
【0222】
例えばノイズや学習サンプルが少ないことが原因で、密度の分布に多くの細かい凹凸が形成されることがある。このような場合に、第1勝者ノード及び第2勝者ノードがサブクラスタA及びBの間にある分布の重なり領域に位置する場合に、ノード間の接続を行う際にある基準を満たした2つのサブクラスタを1つに統合することで、密度の分布に多くの細かい凹凸が含まれる場合であっても密度の分布を平滑化することができる。
【0223】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードについて、ノード密度算出手段により算出されるノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。
【0224】
さらにノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードのノード密度を所定の閾値と比較するノード密度比較部と、注目するノードの隣接ノードの個数を算出する隣接ノード数算出部と、注目するノードをノイズノードとみなして削除するノイズノード削除部を有する。
【0225】
具体的には、例えば以下のようにして一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、ノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。
【0226】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード間の辺、隣接ノードの個数について、注目するノードiについて、隣接ノード数算出部によりその隣接ノードの個数を算出し、その結果を一時記憶部に格納する。そして、一時記憶部に格納された隣接ノードの個数に応じて、以下の処理を実施する。
i)一時記憶部に格納された隣接ノード数が2の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【0227】
【数21】
【0228】
一時記憶部に格納された比較結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
ii)一時記憶部に格納された隣接ノード数が1の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【0229】
【数22】
【0230】
一時記憶部に格納された比較の結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
iii)一時記憶部に格納された隣接ノード数について、隣接ノードを持たない場合、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
【0231】
ここで、予め設定され一時記憶部に格納される所定のパラメータc1及びc2を調整することで、ノイズノード削除手段によるノイズノードの削除の振る舞いを調整することができる。
【0232】
なお、本発明は上述した実施の形態のみに限定されるものではなく、本発明の要旨を逸脱しない範囲において種々の変更が可能であることは勿論である。
【0233】
例えば、上述の実施の形態では、各ブロックの処理を、CPU(Central Processing Unit)にコンピュータプログラムを実行させることにより実現するソフトウェアとして説明したが、これに限定されるものではなく、任意の処理をハードウェアの構成とすることも可能である。また、ソフトウェアで行う場合、コンピュータプログラムは、記録媒体に記録して提供することも可能であり、また、インターネットその他の伝送媒体を介して伝送することにより提供することも可能である。
【0234】
さらに、本実施の形態においては、静止画像のラベリングについて説明したが動画像のラベリングとすることも可能である。この場合は、時系列情報、例えば存在している物体、その動きなどを考慮することになる。これにより現在の状態や動きから未来の動きを予測することができる。この場合、確率モデルは下記のように記載することができる。
【0235】
【数23】
hijは時系列情報を含めたモデルであり、l'jは前フレームの近傍ラベルを示す。時系列情報では、ラベルの位置は、ラベルは前フレームと同位置またはその近傍に存在する可能性が高い(連続性)とすることができ、ラベルの位置を推定することができる。また、車が動いた後には道路が出現するなどラベルの変化の仕方には特徴があり、ラベルの変化の仕方を推定することができる。さらに、車や歩行者を背景から分離するなど、移動している物体の検出が可能であり、動き情報を取得することができる。
【0236】
このような時系列情報を使用することで、過去から現在までのフレームとラベルの動きから未来の状態、例えば直進車の動きを予測したり、周囲の環境・状況から、例えば交差点で歩行者が出てくるなど、着目している対象の位置の推定・予測が可能となる。
【図面の簡単な説明】
【0237】
【図1】本発明の実施の形態にかかるラベリング装置を示すブロック図である。ラベリング装
【図2】入力画像を示す図である。
【図3】ラベリング結果を示す図である。
【図4】本発明の実施の形態にかかるラベリング装置のハードウェア構成の一例を示す図である。
【図5】本発明の実施の形態にかかる学習方法を示すフローチャートである。
【図6】(a)は、学習用画像であり、(b)は、第1の方法により、スーパーピクセルに分割した場合の画像を示している。
【図7】(a)は、学習用画像であり、(b)は、第1の方法により、スーパーピクセルに分割した場合の画像を示している。
【図8】本発明の実施の形態にかかるラベリング処理を示すフローチャートである。
【図9】(a)は入力画像、(b)は類似シーン画像を示す図である。
【図10】(a)乃至(c)は、類似シーン画像を基に、カテゴリ分布を推定した結果を示す図である。
【図11】(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図12】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図13】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図14】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図15】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図16】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図17】本発明の実施例及び比較例の正答率を示す図である。
【図18】SOINNによる学習処理を説明するためのフローチャートである。
【図19】adjusted SOINNの処理方法を示すフローチャートである。
【図20】E−SOINNによる学習処理の処理概要を示すフローチャートである。
【図21】(a)及び(b)は、それぞれ入力画像及びCRFによるラベリング結果を示す図である。
【図22】同じく、(a)及び(b)は、それぞれ入力画像及びCRFによるラベリング結果を示す図である。
【符号の説明】
【0238】
10 学習部
11 スーパーピクセル生成部
12 特徴ベクトル算出部
20 確率演算部
21 局所単項ポテンシャル演算部
22 大域特徴算出部
23 類似画像抽出部
24 大域単項ポテンシャル演算部
25 整合性行列算出部
26 局所二項ポテンシャル演算部
27 大域二項ポテンシャル演算部
30 ラベリング部
31 初期ラベル設定部
100 コンピュータ
101 CPU
102 ROM
103 RAM
104 バス
105 入出力インターフェース
106 入力部
107 出力部
108 記憶部
109 通信部
111 磁気ディスク
112 光ディスク
113 フレキシブルディスク
114 半導体メモリ
【技術分野】
【0001】
本発明は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置、ラベリング方法及びプログラムに関する。
【背景技術】
【0002】
画像ラベリングでは、確率場モデルを用いて画像とラベルの関係をモデル化する手法が広く利用される。ここで、画像ラベリングとは、予め設定したカテゴリのラベル(例えば「車」、「空」など)のうち最も適当なものを、画像中のすべての画素に割り当てる処理である。特に条件付確率場(Conditional Random Field; CRF)が最近ではよく用いられている。
【0003】
CRFは局所情報を表す2種類のポテンシャル関数から構成される。ひとつは画像の局所的な特徴とラベルの関係を表す単項ポテンシャル関数、もうひとつは画像の局所的な特徴を基に局所的な2つのラベルの関係を表す二項ポテンシャル関数である。
【0004】
以下にCRFを用いたラベリングのモデルを数式で表す。ただし変数は次のようにする。画像X中のサイトiにおける特徴をXi(例えば画素iの輝度値)とし、画像XはすべてのサイトSにおける特徴xiの集合X={xi}i∈S、サイトiのラベルはli、画像全体のラベリングはL={li}i∈Sとしたとき画像ラベリングは、画像Xが与えられたときに適切なラベリングLを推定する課題といえる。すなわち、条件付確率P(L|X)を最大とするラベリングLを推定する課題である。
【0005】
CRFは入力画像Xに対するラベリングLの条件付確率P(L|X)をモデル化する。モデル化には上述の局所単項ポテンシャル関数をfiと局所二項ポテンシャル関数をfij利用する。
【数1】
ここでαは係数、Zは正規化のための定数、Niはiの近傍のサイト集合を表す。このP(L|X)を最大とするラベリングLを推定する。
【非特許文献1】X. He, R. Zemel, and D. Ray. "Learning and incorporating topdown cues in image segmentation", 2006, In Proc. European conference on Computer Vision, pages I, p338-p351
【非特許文献2】X. He, R. Zemel, and M. A. Carreria-Perpinan., "Multiscale conditional random field for image labeling", In Proc. Computer Vision and Pattern Recognition, 2004, volume 2, p695-p702
【非特許文献3】S. Kumar and M. Hebert. A hierarchical field framework for unified context-based classification, In Proc. Int. Conf. on Computer Vision, 2005, volume 2, p1284-p1291
【発明の開示】
【発明が解決しようとする課題】
【0006】
しかしながら、従来の確率場モデルは上記のCRFのように局所情報を表す2つの関数fi、fij(以下、それぞれ局所単項ポテンシャル関数、局所二項ポテンシャル関数という。)によって構成されている。このとき画像の大域的な情報はモデルに含まれていない。そのため、得られるラベリング結果が局所的には整合していても、大域的には整合していないことがある。すなわち、従来の画像ラベリング技術では画像の局所的な情報しかモデル化していないため、大域的な視点から不適当なラベリング結果となることがある。
【0007】
図21及び図22は、入力画像及びCRFによるラベリング結果を示す図である。図21に示すように、例えば、「道路」ラベルが「空」ラベルの領域にあるといった非現実的なラベル配置になったり(符号301)、図22に示すように、「カバ(302)」と「白熊(303)」と「雪(304)」のラベルがひとつの画像に同時に存在するといった不適当なラベルの組み合せが生じたりする(現実にはカバと白熊、カバと雪は同時に存在しない)。従来のCFRにおいては、このような大域的な視点から明らかな誤りを修正できないという問題点がある。
【0008】
近時、実環境で自律的に働く機械が増加してきており、人間共存型ロボットや、自律走行車など、今後もその増加が予想される。これらの装置においては、周囲の環境・状況を的確に認識する能力が必要となる。その場合、このような画像ラベリング技術を基に、周囲の視覚情報から周囲の環境・情報を認識できることが必要となる。すなわち、人間の視覚のように、周囲の状況を的確に認識することができることが望まれる。
【0009】
本発明は、このような問題点を解決するためになされたものであり、適切な画像ラベリング処理を自動的に行うことができる画像ラベリング装置、画像ラベリング方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0010】
本発明にかかるラベリング装置は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置であって、画像全体の特徴を大域特徴として算出する大域特徴算出部と、予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出部と、前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出部とを有するものである。
【0011】
画像ラベリングでは確率場モデルによって画像とラベルの関係を数理的にモデル化する手法が有効である。特に条件付確率場(CRF)が広く用いられている。しかし、CRFは画像の局所的な情報しかモデル化しないため、ラベリングの大域的な整合性が得られないことがある。そこで本発明においては、大域的な情報をモデル化することで、大域的に整合性ある画像ラベリングを実現することができる。
【0012】
さらに、前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出部と、前記第1の整合性行列算出部が算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出部と、前記第1の確率算出部が推定したラベルと前記第2の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有することができる。このことにより、ラベルの位置が一枚の画像内において適当であり、また同時に存在するラベルの組み合わせが妥当であるようにモデルを構成することができる。
【0013】
さらにまた、各画素毎の特徴を局所特徴として算出する局所特徴算出部と、前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出部と、前記第1の確率算出部が推定したラベルと前記第3の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有することができる。適切な画像ラベリングのためには、ラベリングの局所的な整合性と大域的な整合性の両方を考慮する必要があるため、大域的な情報に局所的な情報も含めてモデル化することで、局所的にも大域的にも整合性ある画像ラベリングを実現することができる。
【0014】
また、前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部と、前記第1の確率算出部が推定したラベルと前記第4の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有することができる。このことにより、大域的な情報に局所的な情報も含めてモデル化することで、局所的にも大域的にも整合性ある画像ラベリングを実現することができる。
【0015】
さらに、前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を有し、ラベルの推定を前記スーパーピクセル単位で行なうことができる。このことにより、各処理を画素単位ではなく、スーパーピクセル単位で行なうことにより、処理の高速化を図ることができる。
【0016】
さらにまた、前記類似画像抽出部は、前記入力画像及び学習画像を2以上の領域に分割し、各領域毎の類似度に基づき前記類似画像を抽出することができる。このことにより、より類似した領域を有する類似画像を得ることができ、ラベリング性能が向上する。
【0017】
また、前記学習画像から予め得られる各カテゴリの特徴ベクトルは、各カテゴリを表す1又は複数の代表ベクトルとすることができる。学習画像から代表ベクトルを求めることで、多数の特徴ベクトルを少数の特徴ベクトルで表すことができ処理演算量が低減する。
【0018】
さらに、前記大域特徴算出部は、前記入力画像又は前記入力画像を複数に分割した分割領域毎に、RGBの3種類のヒストグラムを生成したり、M×M(Mは整数)画素の輝度値に基づき輝度値の勾配方向を求めたヒストグラムを生成したり、前記入力画像にラプラシアンフィルタを施し得られたヒストグラムを生成したり、又は、大域特徴算出部は、前記入力画像又は前記入力画像を縮小した縮小画像のCIE L*a*値を求めて大域特徴とすることができる。これらの大域特徴により、精度良くラベリングすることができる。
【0019】
本発明にかかるラベリング方法は、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング方法であって、画像全体の特徴を示す大域特徴を算出する大域特徴算出工程と、予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出工程と、前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出工程とを有するものである。
【0020】
本発明にかかるプログラムは、上述したラベリング処理をコンピュータに実行させるものである。
【発明の効果】
【0021】
本発明によれば、適切な画像ラベリング処理を自動的に行うことができる画像ラベリング装置、画像ラベリング方法及びプログラムを提供することができる。
【発明を実施するための最良の形態】
【0022】
以下、本発明を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。この実施の形態は、本発明を、入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置に適用したものである。
【0023】
上述したように、画像ラベリングでは局所的な整合性と大域的な整合性の両方を考慮する必要がある。しかし、従来の確率場モデルでは局所的な情報しかモデル化されていない。具体的には、画像の局所的な特徴とラベルの関係を表す局所単項ポテンシャル関数fiと、局所的な2つのラベル間の関係を表す局所二項ポテンシャル関数fijのみから構成されており、大域的な情報は含まれていない。
【0024】
本実施の形態においては大域的な情報もモデルに含めるために、従来の局所単項ポテンシャル関数fiと局所二項ポテンシャル関数fijに対応させて、大域的な特徴を示す単項ポテンシャル関数gi(以下、これを大域単項ポテンシャルという。)及び二項ポテンシャル関数gij(以下、これを大域二項ポテンシャルという。)を導入する。そしてこれら4つのポテンシャル関数を用いてモデルを設計する。
【0025】
大域単項ポテンシャル関数giは画像全体における大域的な特徴と各位置におけるラベルの関係を表す。一方、大域二項ポテンシャル関数gijは、局所二項ポテンシャル関数fijのように局所的なラベル間の関係のみでなく、ひとつの画像に存在するすべてのラベル間の関係をモデル化する。そしてそれらの整合性を評価する。
【0026】
このように、本実施の形態においては、従来の局所的なポテンシャル関数fi、fijに加え、大域的なポテンシャル関数gi、gijも用いることで、画像の局所情報と大域情報が効果的に表現されるようになる。このようにしてラベリングの局所的な整合性と大域的な整合性を同時に満たすようにする。
【0027】
すなわち、本実施の形態にかかる確率場モデルは、従来の局所単項ポテンシャル関数fiと局所二項ポテンシャル関数fijに加え、新たに導入する大域単項ポテンシャル関数giと大域二項ポテンシャル関数gijを用いて以下の式で表される。
【0028】
【数2】
【0029】
ここでα、β、γは係数、Zは正規化のための定数、Niはiの近傍のサイト集合(スーパーピクセル)を表す。なお、スーパーピクセルは、隣接する類似画素を一纏めにした集合であるが、その詳細は後述する。また、画像XからラベリングL={li}i∈Sが与えられる。iはSに含まれるサイト、li∈Lは画素iのラベルを示す。
【0030】
なお、大域単項ポテンシャル関数giのみで画像ラベリングを行なうことも可能である。また、大域単項ポテンシャル関数giと他のポテンシャル関数との組み合わせでもよい。例えば、大域単項ポテンシャル関数giのみで画像ラベリングを行なえば処理速度が向上する。本実施の形態においては、さらにラベリング能力を向上させるため、大域二項ポテンシャル関数gijと、従来手法である局所単項ポテンシャル関数fi及び局所二項ポテンシャル関数fijを使用する。
【0031】
図1は、本実施の形態にかかるラベリング装置を示すブロック図である。ラベリング装置1は、学習部10と、確率演算部20と、ラベリング部30とを有し、学習用画像が格納された学習用画像データベース(DB)41及び学習結果が格納される学習結果DB42と接続されている。
【0032】
学習部10は、スーパーピクセル生成部11及び特徴ベクトル算出部12を有し、これらは確率演算部20と共有される。なお、個別に設けてもよいことは勿論である。更に、学習部10は、後述するSOINN(Self-Organizing Incremental Neural Network)13を有する。
【0033】
確率演算部20は、上記の他に、第3の確率算出部として機能する局所単項ポテンシャル演算部21、大域特徴算出部22、類似画像抽出部23、第1の確率演算部として機能する大域単項ポテンシャル演算部24、第1の整合性行列算出部及び第2の整合性行列算出部として機能する整合性行列算出部25、第4の確率算出部として機能する局所二項ポテンシャル演算部26、及び第2の確率算出部として機能する大域二項ポテンシャル演算部27を有する。ラベリング部30は、初期ラベル設定部31及びラベル更新部32を有する。なお、これらの処理ブロックは適宜変更可能であって、あるブロックの処理の一部又は全部を他のブロックで行なってもよく、また2以上のブロックの処理を一の処理としてもよい。
【0034】
次に、各ブロックについて詳細に説明する。スーパーピクセル生成部11は、特徴(輝度値や色)の類似している画素同士を連結してできる均質な小領域をsuperpixel(スーパーピクセル)として生成する。本実施の形態においては、スーパーピクセルの数が元の画像の画素数の数百分の一になるように生成し、ラベリング処理は画素単位でなく、スーパーピクセル単位で行う。このことにより処理の高速化を図ることができる。なお、画素単位で各処理を行なってもよい。
【0035】
特徴ベクトル算出部12は、スーパーピクセルの色特徴ベクトル(Vcolor)、テクスチャ特徴ベクトル(Vtexture)を計算する。学習画像を含めて入力画像はRGB値を有するカラー画像であるが、RGB値は照明条件の変化に敏感で明るさの変化で大きく変化することから、本実施の形態においては、各画素値のRGB値をCIE(国際照明委員会)L*a*b*(JIS Z 8729)色空間に変換した3値を色特徴ベクトルVcolor(以下、単に色特徴ともいう。)として求める。L*a*b*は、均等色空間であり、知覚的な色の違いが空間上での距離に相当するため、カラー画像を扱うのに適している。
【0036】
テクスチャ特徴ベクトルVtexture(以下、単にテクスチャ特徴ともいう。)は、色の多様性に対応するために、RGB値をグレースケールに変換した画像から抽出する。本実施の形態においては、照明条件の変化に頑健なlocal binary pattern(LBP)(T.Ojala, M. Pietikainen and Manpaa: "Multiresolution gray-scale and rotation-invariant texture classification with local binary patterns", IEEE Trans.Pattern Anal. Mach. Intell., 24, 7, pp. 971-987 (2002).)をテクスチャ特徴の抽出に利用する。半径R,近傍画素PのLBP(VBPP,R)は以下のように定義される。
【0037】
【数3】
【0038】
ここで、gcは着目しているが画素cの輝度値、gpは、cを中心とする半径Rの円周上に等間隔に並んだ近傍画素pの輝度値を示す。LBPは着目画素とP個の近傍画素との輝度値の大小関係により、2P通りの局所的なパターンに識別する。上記論文では、"uniform"パターンと呼ばれる代表的な局所パターンを導入し、"uniform"パターン以外はすべて"その他"のパターンとしてひとつにまとめている。具体的には以下のようにU(LBPP,R)を定義し,U(LBPP,R)≦2であるLBPP,Rを"uniform"パターンとしている。
【0039】
【数4】
【0040】
本実施の形態においては、P=8、R=1のLBPを用いるが、その場合"uniform"パターンは58個存在する。LBPは輝度値の大小関係のみに着目しているため、輝度値の階調変化に対して不変である。しかし一方で、わずかな輝度値の変化でも大小関係が変化すると局所パターンも変わってしまう。これは用いる画像の質にも依存するが、ノイズなど外乱の多い実環境中で利用するには敏感すぎると考えられる。そこで本実施の形態においては、LBPに改良を加え、輝度値の変化に対しより頑健な"改良LBP"を定義して用いることにする。改良LBPでは式(3)においてs(x)の代わりに、閾値θLBPを導入した以下のs'(x)を用いる。
【0041】
【数5】
【0042】
改良LBPでは輝度値の差が閾値θLBP以上のものに対して大小関係を定める。この改良により輝度値の階調変化に対する不変性はなくなるが、ノイズなどによる輝度値の変動に対して頑健となる。
【0043】
テクスチャ特徴は着目している画素を中心とする周囲の正方形領域RLBP(=9×9画素)に、改良LBPを適用することで得る。改良LBPが出力する領域内の局所パターンの頻度(ヒストグラム)がテクスチャ特徴となる。
【0044】
SOINN13は、スーパーピクセルの各特徴ベクトルをクラスタリングして代表ベクトルの集合を生成する。生成した代表ベクトルは、学習結果DB42に保存する。SOINNは、ノード数を自律的に管理することにより非定常的な入力を学習することができ、分布に複雑な形状を持つクラスに対しても適切なクラス数及び位相構造を抽出できる。なお、SOINNの応用例としては、例えばパターン認識においては、ひらがな文字のクラスを学習させた後に、カタカナ文字のクラスなどを追加的に学習させることができる。
【0045】
SOINNを使用することで、自己増殖型ニューラルネットワークを用いてノードを自動的に増加させることができるため、入力パターン空間からランダムに入力パターンが与えられる定常的な環境に限られず、例えば一定期間毎に入力パターンの属するクラスが切替えられて、切替後のクラスからランダムに入力パターンが与えられる非定常的な環境にも対応することができる。
【0046】
また、adjusted SOINNや、Enhanced−SOINN(以下E−SOINNという。)などとすると、1層構造とすることができ、2層目の学習を開始するタイミングを指定せずに追加学習を実施することができる。このSOINN、adjusted SOINN、E−SOINNについての詳細は後述する。なお、代表ベクトルを求めなくてもよく、また、SOINNやE−SOINN以外の一般的な識別器、例えばニューラルネットワークやサポートベクタマシン(Support vector machine:SVM)であっても使用可能である。
【0047】
確率演算部20は、上述したスーパーピクセル生成部11及び特徴ベクトル算出部12の他、局所単項ポテンシャル演算部21、大域単項ポテンシャル演算部24、局所二項ポテンシャル演算部26及び大域二項ポテンシャル演算部27等の演算部を有する。
【0048】
局所単項ポテンシャル、局所二項ポテンシャル、大域単項ポテンシャル、及び大域二項ポテンシャルについて簡単に説明すると、局所単項ポテンシャル及び局所二項ポテンシャルは、隣接するパーツ間の存在確率を過去のデータと比較して認識する。すなわち、局所単項ポテンシャルは、画像の局所的な特徴とラベルの関係を表す。そして、色やテクスチャを利用して、青い領域だから空だろう、などと判定する。
【0049】
局所二項ポテンシャルは、画像の局所的な特徴を基に局所的な2つのラベルの関係を表す。そして、隣接同士の領域が空だから、正しいだろう、などと判定する。
【0050】
大域単項ポテンシャルは、画像全体における大域的な特徴と各位置におけるラベルの関係を表す。先ず、画像の大域的な特徴を抽出し、それを基に描かれているシーンを特定する。そして、そのシーンから画像上でのラベルを推定するが、この場合、このようなシーンだから、この位置の画素は地面だろう、などと判定する。
【0051】
大域二項ポテンシャルはひとつの画像に存在するすべてのラベル間の関係をモデル化する、1枚の画像に同時に存在するラベルの整合性を評価する。すなわち、カバは雪の中にいないだろう、などの情報を基にラベルを推測する。以下、各ブロックについて説明する。
【0052】
局所単項ポテンシャル演算部21は、色特徴、テクスチャ特徴と代表ベクトルとの特徴間距離を計算し、各ラベルについて、色特徴及びテクスチャ特徴それぞれの局所単項ポテンシャル関数fiを算出する。
【0053】
この局所単項ポテンシャル関数fiは、局所的な画像特徴として色特徴とテクスチャ特徴を利用し、青い領域だから空だろう、白い画素だから雪だろう、のように識別器により各画素のラベルを独立に推定する。具体的には、局所単項ポテンシャル関数fiは下記式(6)で定義される。
【0054】
【数6】
【0055】
ここで、確率P(li|vcolor(i))、P(li|texture(i))は、識別器によって演算することができる。先ず、上述の学習部10により、各カテゴリの代表特徴ベクトルのセットを生成する。そして、下記式(7)に示すように、P(li|vcolor(i))は、入力特徴vcolor(i)と各カテゴリcにおける最近傍の代表特徴uとのユークリッド距離dcolorc(i)により表される。P(li|texture(i)も同様に求められる。下記の式(7)〜(9)を使用して局所単項ポテンシャル関数fiを求める。
【0056】
【数7】
【0057】
ここで、||・||はユークリッド距離、Ucolorcは計算によってカテゴリcから得られる代表特徴、σcolor、σtexturerはパラメータを示す。以上により、局所単項ポテンシャル関数fiは式(10)のように表すことができる。
【0058】
【数8】
【0059】
大域特徴算出部22は、画像の大域的な特徴を使って各スーパーピクセルのラベルを推定する。大域特徴算出部22が演算する大域的な特徴には、画像全体における色のヒストグラム、勾配方向のヒストグラム、ラプラシアンのヒストグラム、縮小した画像(低解像度化した画像)のCIE L*a*b*値を用いる。
【0060】
1)RGBヒストグラム
画像を左上、右上、左下、右下の4つ領域に分割し、各領域でRGBの3つのヒストグラムを作成する。この場合、たとえば各ヒストグラムのビン数を16とする。
【0061】
2)勾配方向ヒストグラム
4領域内の最外側を除く各画素において、3×3画素の領域を考え、周囲8画素のうちグレースケールの輝度値の差が最大である画素に対して勾配方向を特定する。勾配なしも含め9ビンのヒストグラムにより勾配方向の頻度を表す。すなわち、各領域において9次元の特徴が抽出される。
【0062】
3)ラプラシアンのヒストグラム
画像に対してラプラシアンフィルタを施し、例えば256ビンのヒストグラムを作成する。すなわち、各領域で256次元の特徴を抽出する。
【0063】
4)CIE L*a*b*値
画像サイズを基の10分の1に縮小した画像を作成し、そのCIE L*a*b*値を画像全体の特徴とする。縮小画像には、10×10画素領域の平均CIE L*a*b*を用いる。
【0064】
次に、これらの大域特徴を基に学習用データから特徴の類似した画像を検索し、ラベルの推定に用いる。検索した学習用データの類似画像にはラベル付きデータが与えられている。それらを用いて未知のテスト用データ画像のラベルの分布を推定する。なお、実施例では画像を上下左右に4分割し、各領域のラベル分布を別々に推定する。これは、限られた学習用データの中から画像全体が類似している画像を検索するのが困難なことによる。
【0065】
先ず、類似画像抽出部23は、大域特徴の類似度を基に、類似シーン画像(学習用画像)を検索する。4つの領域が相互に関連しているので、4つの大域特徴を重み付け加算し、2つの画像I1、I2の領域kにおける類似度S(I1k、I2k)を算出する。なお、本実施の形態においては、入力画像を4等分するものとして説明するが、分割せずに類似シーン画像を検索するようにしてもよい。また、4等分に限らず、2等分、6等分などであってもよい。さらに、等分ではなく、各領域の大きさが異なっていてもよい。
【0066】
【数9】
ここで、Ikは、k(=左上、右上、左下、左上)の画像、vhist、vLabは、それぞれヒストグラム、CIE L*a*の値である。ヒストグラムは、3つのヒストグラムを連結して用いる。k'は左上、右上、などの画像の領域、σhist、σLabはパラメータである。ここで、重み関数wk(k')の重みw=3とする。これにより、着目領域と、その他の領域の和が同じ重みになるようにする。(11)式で算出される類似度S(I1t、I2t)が高い順にN枚の類似シーン画像を検索する。本実施の形態においては、N=3とする。よって、4つの領域それぞれ3枚ずつ、合計12枚の学習画像が各入力画像毎に抽出される。
【0067】
大域単項ポテンシャル演算部24は、大域単項ポテンシャル関数giを計算する。大域単項ポテンシャル関数giは、画像全体の様子を表す大域的な画像特徴と、画像上でのラベルの分布との関係をモデル化する。一般のシーン画像では、ラベルの分布は描かれているシーンに大きく依存し、またシーンの様子は大域的な画像特徴に反映されやすいことによる。例えば、街のシーンでは画像の上部に「空」、下部に「道路」が分布していることが多い。このような性質を利用して画像全体におけるラベルの分布を推定する。まず、画像の大域的な特徴を抽出し、それを基に描かれているシーンを特定する。さらに、そのシーンから画像上でのラベルの分布を推定する。具体的な画像特徴としては、画像全体における色や輝度値の勾配、粗さ等を利用する。
【0068】
すなわち、大域単項ポテンシャルは、学習データの中から大域特徴(色、勾配、・・・)の類似した画像を検索し、ラベルの分布を推定する。すなわち、このようなシーンだから、ここは「地面」だろう、ここは「空」だろう、などの確率計算を行なう。
【0069】
具体的には、検索した類似シーン画像から、下記式(13)〜(16)により確率P(li=c|vG)を算出し、この確率P(li=c|vG)に基づき式(16)から大域単項ポテンシャルgi(li|X)を求める。
【0070】
【数10】
【0071】
ここで、Bcは、類似画像抽出部23が抽出した12枚の類似シーン画像から得られるカテゴリcの分布を示し、li*は、手動で付けられた正しいカテゴリを示す。演算子*は畳み込み積分を示す。さらに、Gは、Bcをより一般化するためのもので、平均値0、標準偏差σgaussのガウシアン関数を示す。2次元の等方的なガウス関数を用いてカテゴリの分布を平滑化する。標準偏差σgaussは例えば下記のように定めることができる。
【0072】
【数11】
ここで、w、hは、それぞれ画像の幅及び高さである。
【0073】
領域k(左上、右上、左下、右下)のカテゴリ分布は、式(11)の類似度Sを重みとして上記式(15)のように表すことができる。ここで、Ik,n、Bk,ncは、n番目の類似画像、及びそのk領域におけるラベル分布、vGは、大域的な特徴を示す。
【0074】
整合性行列算出部25は、検索した類似シーン画像から、第2の整合性行列としての局所的なカテゴリの整合性行列(local category compatibility matrix)ΘLと、第1の整合性行列としての大域的なカテゴリの整合性行列(global category compatibility matrix)を作成する。局所的なカテゴリの整合性行列ΘLは、全カテゴリラベルLから行、列が構成される行列であって、注目する注目画素と、その注目画素に隣接する隣接画素のラベルの関係を示す。整合性行列ΘLは、入力画像に依存する値であるため、上述の12枚の学習画像を使用してトップダウン情報に基づき生成することができる。先ず、隣り合うカテゴリペア(li,lj)(liが注目画素、ljを注目画素に隣接する隣接画素とする)の発生率を類似画像抽出部が抽出した12枚の類似シーン画像の各画像から求める。そして、12枚の類似シーン画像について、ljの発生率を正規化して求める。
【0075】
大域的なカテゴリの整合性行列ΘGは、1つの画像も2つのカテゴリが存在する確率を示す。この整合性行列ΘGもトップダウン情報に基づき生成する。整合性行列ΘGは、学習結果DB42にある学習データに基づき求められる。すなわち、上記12の類似シーン画像において2つのカテゴリが一緒に出現する画像の割合として求めることができる。
【0076】
局所二項ポテンシャル演算部26は、隣接するすべてのスーパーピクセルの組に対して局所二項ポテンシャル関数fijを計算する。fijは隣接するスーパーピクセルのラベルの整合性を評価するもので、学習用データにおいて隣接するラベルの組み合わせの確率から計算される。また、fijの大きさは2つのスーパーピクセルの特徴間の類似度が高いほど値が大きくなる。
【0077】
この局所二項ポテンシャル関数fijは、隣接同士が「空」だから注目ラベルも「空」で正しいだろう、周囲のラベルが「水」だからこのラベルも「水」だろう、のように、周囲のラベルがなるべく同じになるようにモデル化する。すなわち、滑らかならラベル分布となるように確率計算を行なう。
【0078】
下記式(17)、(18)と、上記局所的なカテゴリの整合行列ΘLとから局所二項ポテンシャルを演算する。
【0079】
【数12】
wijは、iとjとの間の相互作用の強さを変調する変数で、ユークリッド距離dcolor(i,j)とdtexture(i,j)に基づき算出され、隣接スーパーピクセルが似ているほど大きな値となる。P(lj|X)は、ljの推定された分布、kwはパラメータである。ΘLは、|L|×|L|(Lはラベル数)の局所的なカテゴリの整合性行列であり、隣接するカテゴリペアの発生率を示す。ΘL(li|lj,X)は、liに隣接するラベルlj及び入力画像Xのときのliの分布を示す。
【0080】
大域二項ポテンシャル演算部27は、式(14)と上記大域的なカテゴリの整合性行列ΘGを用いて、大域二項ポテンシャルを演算する。
【0081】
【数13】
【0082】
大域二項ポテンシャル関数gijは一枚の画像に同時に存在するラベルの整合性を評価する。すなわち、画像全体のラベルの関係をモデル化するもので、ひとつの画像上で同時に生じやすいか否かに応じてその確率計算をする。例えば、「車」と「道路」は同じ画像中に存在しやすい、「カバ」と「白熊」は同時には存在しにくい、「カバ」は「雪」の中にいない、などの1つの画像に生じるラベルの整合性を評価する。このような同時に生じやすいか否かの関係をすべてのラベルの組についてモデル化し、生じにくいラベリングの組が出てこないようにする。このため、各ラベルの組がどのくらいの確率で学習用データに生じたかを学習段階において計算する。
【0083】
ラベリング部30の初期ラベル設定部31は、局所単項ポテンシャル関数fiと、大域単項ポテンシャル関数giから初期ラベルを決定する。
【0084】
ラベル更新部32は、局所単項ポテンシャル関数fi、局所二項ポテンシャル関数fij、大域単項ポテンシャル関数gi、大域二項ポテンシャル関数gij、を考慮してラベルを更新していく。そして全体のラベリングが安定すると、その結果をラベリング結果として出力する。
【0085】
図2及び図3は、それぞれ入力画像及びラベリング結果を示す図である。入力画像の各画素にカテゴリラベル(道路、空、車など)を割り当てる。そして、画像全体がどのようなシーンであるか、画像中のどこになにがあるかなどに基づき図2の入力画像から図3に示すラベリング画像を得る。
【0086】
以上のようなラベリング装置は、専用コンピュータ、又はパーソナルコンピュータ(PC)などのコンピュータにより実現可能である。但し、コンピュータは、物理的に単一である必要はなく、分散処理を実行する場合には、複数であってもよい。図4に示すように、コンピュータ100は、CPU101(Central Processing Unit)、ROM102(Read Only Memory)及びRAM103(Random Access Memory)を有し、これらがバス104を介して相互に接続されている。尚、コンピュータを動作させるためのOSソフトなどは、説明を省略するが、この情報処理装置を構築するコンピュータも当然備えているものとする。
【0087】
バス104には又、入出力インターフェイス105も接続されている。入出力インターフェイス105には、例えば、キーボード、マウス、センサなどよりなる入力部106、CRT、LCDなどよりなるディスプレイ、並びにヘッドフォンやスピーカなどよりなる出力部107、ハードディスクなどより構成される記憶部108、モデム、ターミナルアダプタなどより構成される通信部109などが接続されている。
【0088】
CPU101は、ROM102に記憶されている各種プログラム、又は記憶部108からRAM103にロードされた各種プログラムに従って各種の処理、本実施の形態においては、学習処理や、確率演算処理、ラベリング処理等を実行する。RAM103には又、CPU101が各種の処理を実行する上において必要なデータなども適宜記憶される。
【0089】
通信部109は、例えば図示しないインターネットを介しての通信処理を行ったり、CPU101から提供されたデータを送信したり、通信相手から受信したデータをCPU101、RAM103、記憶部108に出力したりする。記憶部108はCPU101との間でやり取りし、情報の保存・消去を行う。通信部109は又、他の装置との間で、アナログ信号又はディジタル信号の通信処理を行う。
【0090】
入出力インターフェイス105は又、必要に応じてドライブ110が接続され、例えば、磁気ディスク111、光ディスク112、フレキシブルディスク113、又は半導体メモリ114などが適宜装着され、それらから読み出されたコンピュータプログラムが必要に応じて記憶部108にインストールされる。
【0091】
次に、本実施の形態にかかる学習方法、ラベリング方法について説明する。先ず、学習方法について説明する。図5は、学習方法を示すフローチャートである。学習部10には、先ず学習用画像が入力される(ステップS1)。学習用画像は、例えば学習用画像DB41に保存されている。または、上述の通信部を介してネットワークを通じて取得するようにしてもよい。
【0092】
次に、スーパーピクセル生成部11は、入力された学習用画像をセグメンテーションし、得られるセグメントをスーパーピクセルとして生成する(ステップS2)。スーパーピクセルは、例えば"Efficient Graph-Based Image Segmentation" Pedro F. Felzenszwalb and Daniel P. Huttenlocher. International Journal of Computer Vision, Volume 59, Number 2, September 2004. に記載の方法で生成することができる。以下、これを第1の方法という。
【0093】
この第1の方法では、セグメントにおいて、セグメント内の変動は、セグメント間の変動よりも小さくなるようにセグメンテーションする。すなわち、セグメント内の類似度を高く、セグメント間の類似度は低くなるようにする。具体的には、学習用画像をグラフ(ノードと辺)で表す。ノードは画素を表し、辺は隣接する2つの画素を繋ぐ。各辺の重みは隣接画素間の特徴の距離(RGB値の差)を表す。出力はノードをグルーピングしたコンポーネントの集合となる。
【0094】
次に、m個の辺を重みの小さい順(類似度の高い順)に並べる。そして、すべての画素をそれぞれ単独でコンポーネントとする。次いで、着目している辺の重みが、その辺によって繋げられている2つのコンポーネントの内部変動よりも小さければ、2つのコンポーネントを結合する。大きければ何もしない、という処理を、辺1から辺mまでm回繰り返す。そして、コンポーネントの集合を出力する。こうしてスーパーピクセルを生成する。
【0095】
この第1の方法においては、初期段階においてすべての画素は単独でセグメントとなっている。これらを逐次的に結合することによりセグメンテーションを行う。一方、他の手法(以下、第2の方法という、)として、初期段階において画像全体をひとつのセグメントとし、これの辺を削除して分割することによりセグメンテーションを行う方法もある("Normalized Cuts and Image Segmentation"J. Shi and J. Malik. IEEE TPAMI, 22(8) Aug. 2000、又は"Learning and incorporating top-down cues in image segmentation" Xuming He, Richard Zemel, and Deb Ray (2006), In ECCV 2006)
【0096】
この第2の方法においては、先ず、画像をグラフで表現する。ノードは画素を表し、辺はすべての画素の組に対して作成する(例えばN×N画素の画像では、N×N本の辺を作成)。各辺の重みは画素間の近さと画素間の特徴の類似度とする。セグメンテーションは、辺を削除することによってグラフを分割し、ノード集合の組を作成することにより行う。セグメンテーションの良し悪しを評価する基準として"Normalized cut"を用いる。"Normalized cut"はセグメント間の類似度が高くなるように、同時にセグメントサイズが大きくなるように定義される(単純な評価基準では、セグメントのサイズが小さいほど類似度が高くなる)。
【0097】
さらに、第3の方法として、次のような方法がある("Recovering Surface Layout from an Image" D. Hoiem, A.A. Efros, and M. Hebert, IJCV. 参照)。図5に示すように、先ず、複数の細かさでセグメンテーションを行う。すなわち、スーパーピクセルのサイズを大きくしたり小さくしたりする。本例では3種類のセグメンテーションを行なっている。これらの複数のセグメンテーションのそれぞれに対し、独立にラベリングを行う。そして、最終的な出力は複数のラベリング結果を統合して決定する。
【0098】
図6(a)、図7(a)は、学習用画像であり、図6(b)、図7(b)は、上記の第1の方法により、スーパーピクセルに分割した場合の画像を示している。図6(b)、図7(b)に示すように、1つのスーパーピクセルは、同じカテゴリラベル内に生成されている。
【0099】
次に、特徴ベクトル算出部12により、スーパーピクセルの色特徴及びテクスチャ特徴を計算する。各スーパーピクセルの色特徴(CIE L*a*b*)と、テクスチャ特徴(LBP)のヒストグラムを求める。例えば色特徴のビン数は、L*、a*、b*で各20個ずつとすることができ、全体で60ビン(60次元)の色特徴ヒストグラムを得る。また、テクスチャ特徴は、上述の(2)乃至(5)の式において、例えばP=8、R=1とした場合、ビン数59のヒストグラムを求めることができる。また左右対称不変とした場合は39ビンのヒストグラムとして求めることができる。
【0100】
次に、SOINNによりクラスタリングして代表ベクトルを求める(ステップS4)。後述するSOINN、adjusted SOINN、E−SOINNは、いずれも多次元ベクトルで記述されるプロトタイプが配置される少なくとも1層以上の構造を有し、任意のクラスに属する多次元ベクトルで記述される入力パターンを識別するための入力パターンの標準的なパターンであるプロトタイプを取得するものである。これにより、各スーパーピクセルのベクトルの代表ベクトルが求まる。
【0101】
次に、ラベリング処理について説明する。図8は、ラベリング処理を示すフローチャートである。ステップS12、S13は、学習段階のステップS2、3と同一である。スーパーピクセル生成部11でスーパーピクセルを生成し、各スーパーピクセルについて、特徴ベクトル算出部12がそれぞれL*、a*、b*で各20ビンのヒストグラム、59又は39ビンのテクスチャ特徴のヒストグラムを求める。
【0102】
そして、局所単項ポテンシャル演算部21は、色特徴、テクスチャ特徴と、ステップS4で求めた各代表ベクトルとの特徴間距離を計算する(ステップS14)。すなわち、各ラベルについて、局所単項ポテンシャル演算部21が式(6)〜(9)を使用して色特徴とテクスチャ特徴と、代表ベクトルとから、特徴間距離として、ユークリッド距離dcolorc(i)、ユークリッド距離dtexturec(i)を算出し、これに基づきそれぞれの局所単項ポテンシャルを、式(10)により算出する。
【0103】
以上のステップS12〜S14と並列に以下のステップS15乃至S18を実施する。ステップS15では、大域特徴算出部22により、大域特徴を算出する。大域特徴は、上述した大域特徴部が、入力画像に対し、RGBのヒストグラム、勾配方向のヒストグラム、ラプラシアンのヒストグラム、縮小した画像(低解像度化した画像)のCIE L*a*b*値を計算する。例えばRGBのヒストグラムは16ビン、勾配方向のヒストグラムが、周囲8近傍+勾配なしで9ビン、ラプラシアンのヒストグラムが256ビンとすることができる。また、CIE L*a*b*は、入力画像を10分の1に縮小した画像のCIE L*a*b*とすることができる。例えば入力画像が96×64の場合、縮小画像サイズは、9×6となり、CIE L*a*b*特徴は、9×6×3次元の特徴ベクトルとなる。
【0104】
次のステップS16では、類似画像抽出部23が大域特徴の類似度を基に類似シーン画像(学習用画像)を検索する。このとき、各ラベルに対する大域単項ポテンシャルを計算し、共起モデルを作成する。
【0105】
先ず、入力画像を4等分して、それぞれに対して、式(11)、(12)から類似度S(I1k、I2k)を求める。そして、類似度S(I1k、I2k)の大きなものから、N=3まで収集する。これにより、類似画像抽出部23により、入力画像に類似する類似画像である合計12枚の学習用画像(以下、類似シーン画像という。)が抽出される。
【0106】
次のステップS17では、大域単項ポテンシャル演算部24が検索した類似シーン画像から、式(13)乃至(15)により、P(li=c|vG)を求め、このP(li=c|vG)に基づき、式(16)に示す大域単項ポテンシャルgi(li|X)を求める。
【0107】
図9(a)は、入力画像、図9(b)は類似シーン画像、図10(a)乃至図10(c)は、類似シーン画像を基に、カテゴリ分布を推定した結果を示す。それぞれ、空、道路、建物のカテゴリを示し、明るい領域がカテゴリの分布している可能性が高いことを表している。この例では、空は上部に、道路は下部に、建物は道路の回りに広がっている可能性が高いことを示す。ここでは、各画素の局所的な特徴は用いておらず、画像の大域的な特徴のみから推定しているが、極めてよい精度で推定を行なうことができる。
【0108】
そして、ステップS18では、整合性行列算出部25が検索した類似シーン画像から、上述した局所的なカテゴリの整合性行列ΘL、大域的なカテゴリの整合性行列ΘGを算出する。これは、ステップS21の局所二項ポテンシャル、大域二項ポテンシャルの演算に使用する。
【0109】
以上の処理が終了したら、ラベリング部30にてステップS19乃至S23のラベリング処理を実行する。先ず、初期ラベルを決定する(ステップS19)。初期ラベルは、ステプS4で求めた局所単項ポテンシャルfi(li|X)と、ステップS17で求めた大域単項ポテンシャルgi(li|X)のみを式(1)に適用して初期値を求める。これを初期ラベルとする。
【0110】
次に、スーパーピクセルをランダムに1つ選択し(ステップS20)、局所単項ポテンシャル、局所二項ポテンシャル、大域単項ポテンシャル、大域二項ポテンシャルを考慮してラベルを更新する(ステップS21)。局所二項ポテンシャルは、局所二項ポテンシャル演算部26がステップS18で求めた局所的なカテゴリの整合性行列ΘLと、式(17)、(18)から算出する。大域二項ポテンシャルは、大域二項ポテンシャル演算部27がステップS18で生成した大域的なカテゴリの整合性行列ΘGと、式(19)から算出する。各値を式(1)に代入してラベルを更新する。
【0111】
次に、ラベリングが安定するか否かを判断し(ステップS22)、ラベリング結果を出力する(ステップS23)。
【0112】
本実施の形態においては、従来のように局所情報のみでモデル化するのではなく、大域情報も含めてモデル化する。これにより、従来手法では生じていた、大域的な視点から明らかな誤りを修正できるようになる。例えば、大域単項ポテンシャル関数giは、画像の大域的な特徴から位置情報も含めてラベルを推定するため、「道路」が「空」まで延びるようなラベリングを修正する。また、大域二項ポテンシャル関数gijは、一枚の画像に同時に生じるラベルの整合性をモデル化するため、「カバ」と「白熊」のように不適当なラベルの組が生じるラベリングを修正する。
【0113】
さらに、本実施の形態においては上記(1)に示すモデルとsuperpixel(スーパーピクセル)を組み合わせて利用することでラベリング処理の高速化を図る。スーパーピクセルは、特徴(輝度値や色)の類似している画素同士を連結してできる均質な小領域であり、ラベリング処理の前にこの連結処理を行うことで生成する。
【0114】
次に、本発明の実施の形態にかかる効果について説明する。先ず、Sowerbyのデータセット(X. Feng, C. Williams and S. Felderhof: "Combining belief networks and neural networks for scene segmenting and labeling sequence data", IEEE Trans. Pattern Anal. Mach. Intell., 24, 4, pp467-483)(以下、第1データセットという。)と、Corelのデータセット(X. He, R. S. Zemel and M. A. Carreira-Perpinan: "Multiscale condition random field for image labeling", Proc. Computer Vision and Pattern Recognition, Vol. 2, pp.695-702 (2004))(以下、第2のデータセットという。)を使用して入力画像のラベリングテストを行なった。図11乃至図16はその結果を示す。図には、入力画像(a)と、実施例(e)の比較として、手動でラベリングしたもの(正解ラベル)(b)、と、比較例1として局所単項ポテンシャル関数のみを利用したもの(c)、比較例2として局所単項ポテンシャル関数及び局所二項ポテンシャル関数を利用したもの(CRF)(d)も示す。図17は、実施例及び比較例の正答率を示す図である。
【0115】
第1及び第2のデータセットをそれぞれ2つに分け、1つは学習用、1つはテスト用に使用した。学習用データは、学習用画像とそれに対応する正しいラベルの付いたデータのセットから成り、学習段階においてモデルを構成するために使われる。一方、テスト用データは、学習段階で構成したモデルのラベリング性能を評価するために使われる。
【0116】
第1のデータセットは、104枚の画像からなり、空、草木、道路マーキング、道路表面、建物、障害物、及び車の7つにカテゴライズされている。60画像を学習に使用し、44画像をテストに使用した。画像は、96×64ピクセルからなる。
【0117】
第2のデータセットは、100画像からなり、カバ、白熊、水、雪、草木、土及び空の7つにカテゴライズされている、60枚を学習に、40枚をテストに使用した。180×120画素からなる。
【0118】
本実施の形態においては、処理の迅速化のためスーパーピクセルを使用する。スーパーピクセルは誤差を含むため、ラベリングの上限は92%となる。特徴ベクトルの演算において、L*、a*、b*は各20個ずつ、全部で60ビンの色特徴ヒストグラムを生成する。LBPのパラメータは、P=8、R=1とし、第1のデータセットでは59ビン、第2のデータセットでは39ビンのテクスチャ特徴を生成する。
【0119】
後述するSOINNのパラメータλ=700、agedead=700とする。第1及び第2のデータセットでそれぞれ100、150の特徴カテゴリ(代表ベクトル)が抽出される。式(1)において、パラメータα=0.1、β=0.005、γ=0.1とした。また、式(10)のσcolor=1.0、σtexture=0.6(第1のデータセット)、σtexture=0.3(第2のデータセット)、式(18)のkw=0.1(第1のデータセット)、kw=0.05(第2のデータセット)とする。さらに、式(11)のσhist=7.5(第1のデータセット)、σhist=3.0(第2のデータセット)、σLab=600(第1のデータセット)、σLab=180(第2のデータセット)とする。ラベリングの精度は正しいラベルが割り当てられた画素の割合で評価する。また、ラベリングの処理時間は3.2GHzのCPUを用いたときのものである。
【0120】
ラベリング正解率(正しくラベルが割り当てられた画素の割合)は、第1のデータセットにおいて、比較例2は86.1%だったのに対し、本実施例では89.8%になった。また、第2のデータセットにおいては、比較例2では66.2%だったのに対し、本実施例では80.7%となった。
【0121】
例えば、第1のデータセットにおいては、比較例1、2では、建物が道路に現れたり、地面が空まで伸びてしまったりしている。また、第2のデータセットにおいては、カバと白熊が結合して現れたり、カバと雪が同じ画面に現れたりしている。これに対し、本実施例では、大域単項ポテンシャル及び大域二項ポテンシャルを使用するため、大域的なカテゴリの互換性を保つことができる。
【0122】
さらに、一枚の画像のラベリング処理に要する時間は、これまでに発表されている手法では数秒から数分掛かったのに対し、本実施例ではそれぞれ0.3、0.9秒で済ませることができた。これは処理速度が他の手法と比較して数十倍から数百倍向上したことを示す。
【0123】
次に、上述のSOINN、Adjusted SOINN、E−SOINNについて説明する。SOINNは2層ネットワーク構造を有し、1層目及び2層目において同様の学習処理を実施する。SOINNは、1層目の出力である学習結果を2層目への入力ベクトルとして利用する。
【0124】
図18は、SOINNによる学習処理を説明するためのフローチャートである。以下、図18を用いてSOINNの処理を説明する。S101:SOINNに対して入力ベクトルを与える。
【0125】
S102:与えられた入力ベクトルに最も近いノード(以下、第1勝者ノードという。)及び2番目に近いノード(以下、第2勝者ノードという。)を探索する。
【0126】
S103:第1勝者ノード及び第2勝者ノードの類似度閾値に基づいて、入力ベクトルがこれら勝者ノードの少なくともいずれか一方と同一のクラスタに属すか否かを判定する。ここで、ノードの類似度閾値はボロノイ領域の考えに基づいて算出する。学習過程において、ノードの位置は入力ベクトルの分布を近似するため次第に変化し、それに伴いボロノイ領域も変化する。即ち、類似度閾値もノードの位置変化に応じて適応的に変化してゆく。
【0127】
S104:S103における判定の結果、入力ベクトルが勝者ノードと異なるクラスタに属す場合は、入力ベクトルと同じ位置にノードを挿入し、S101へと進み次の入力ベクトルを処理する。尚、このときの挿入をクラス間挿入と呼ぶ。
【0128】
S105:一方、入力ベクトルが勝者ノードと同一のクラスタに属す場合は、第1勝者ノード及び第2勝者ノード間に辺を生成し、ノード間を辺によって直接的に接続する。
【0129】
S106:第1勝者ノード及び第1勝者ノードと辺によって直接的に接続しているノードの重みベクトルをそれぞれ更新する。
【0130】
S107:S105において生成された辺は年齢を有しており、予め設定された閾値を超えた年齢を持つ辺を削除する。入力ベクトルを逐次的に与えてゆくオンライン学習においては、ノードの位置が常に徐々に変化してゆくため、初期の学習で構成した隣接関係が以後の学習によって成立しない可能性がある。このため、一定期間を経ても更新されないような辺について、辺の年齢が高くなるように構成することにより、学習に不要な辺を削除する。
【0131】
S108:入力ベクトルの入力総数が、予め設定されたλの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がλの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がλの倍数となった場合には以下の処理を実行する。
【0132】
S109:局所累積誤差が最大であるノードを探索し、そのノード付近に新たなノードを挿入する。ノードの持つ平均誤差を示す誤差半径に基づいて、ノード挿入が成功であったか否かを判定する。尚、このときの挿入をクラス内挿入と呼ぶ。
【0133】
ここで、ノード及び入力ベクトル間の距離差をノードの持つ誤差として、入力ベクトルの入力に応じてノードの誤差を累積することにより局所累積誤差を算出する。誤差半径はノードの持つ誤差及びノードが第1勝者となった回数に基づいて算出する。
【0134】
S110:クラス内挿入によるノード挿入が成功であると判定した場合には、クラス内挿入により挿入されたノード及び局所累積誤差が最大のノードを辺によって直接的に接続する。一方、クラス内挿入によるノード挿入が失敗であると判定した場合には、クラス内挿入により挿入したノードを削除してS111へと進む。
【0135】
S111:隣接ノード数及びノードが第1勝者となった回数に基づいて、ノイズノードを削除する。ここで、隣接ノードとは、ノードと辺によって直接的に接続されるノードを示し、隣接ノードの個数が1以下であるノードを削除対象とする。また、第1勝者となった回数の累積回数を予め設定されたパラメータcを使用して算出される閾値と比較し、第1勝者累積回数が閾値を下回るノードを削除対象とする。
【0136】
S112:入力ベクトルの入力総数が予め設定されたLTの倍数であるか否かを判定する。判定の結果、入力ベクトルの入力総数がLTの倍数でない場合には、S101へと戻り次の入力ベクトルを処理する。一方、入力ベクトルの総数がLTの倍数となった場合には、以下の処理を実行する。
【0137】
S113:1層目の学習を終了するか否かを判定する。判定の結果、2層目の学習へと進む場合には、S101へと進み1層目の学習結果であるノードを2層目への入力ベクトルとして入力する。ただし、追加学習を行う場合は、2層目に残っている以前の学習結果を消去した上で2層目の学習を開始する。
【0138】
2層目への入力回数が予め設定された回数LTの倍数となり2層目の学習を終了する場合には、ノードを異なるクラスに分類し、クラス数及び各クラスの代表的なプロトタイプベクトルを出力し停止する。ここで、プロトタイプベクトルはノードの重みベクトルに相当する。
【0139】
このように、SOINNは、ノード数を自律的に管理することにより非定常的な入力を学習することができ、分布に複雑な形状を持つクラスに対しても適切なクラス数及び位相構造を抽出できるなど多くの利点を持つ。SOINNの応用例として、例えばパターン認識においては、ひらがな文字のクラスを学習させた後に、カタカナ文字のクラスなどを追加的に学習させることができる。
【0140】
次に、図19を用いてadjusted SOINNの処理を説明する。adjusted SOINNは、SOINNと比べて、学習に際して事前に指定するパラメータの数を少なくすることができ、より簡単に学習を実施することができる。
【0141】
S201:入力情報取得手段は、ランダムに2つの入力パターンを取得し、ノード集合Aをそれらに対応する2つのノードのみを含む集合として初期化し、その結果を一時記憶部に格納する。また、辺集合C⊂A×Aを空集合として初期化し、その結果を一時記憶部に格納する。
【0142】
S202:入力情報取得手段は、新しい入力パターンξを入力し、その結果を一時記憶部に格納する。
【0143】
S203:勝者ノード探索手段は、一時記憶部に格納された入力パターン及びノードについて、入力パターンξに最も近い重みベクトルを持つ第1勝者ノードa1及び2番目に近い重みベクトルを持つ第2勝者ノードa2を探索し、その結果を一時記憶部に格納する。
【0144】
S204:類似度閾値判定手段は、一時記憶部に格納された入力パターン、ノード、ノードの類似度閾値について、入力パターンξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きいか否か、及び、入力パターンξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きいか否かを判定し、その結果を一時記憶部に格納する。
【0145】
ここで、一時記憶部に格納された第1勝者ノードa1の類似度閾値T1及び第2勝者ノードa2の類似度閾値T2は、上述のS101乃至S104において示したように類似度閾値算出手段により算出され、その結果が一時記憶部に格納される。
【0146】
S205:一時記憶部に格納されたS204における判定の結果、入力パターンξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1より大きい、又は、入力パターンξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2より大きい場合には、ノード挿入手段は、一時記憶部に格納された入力パターン及びノードについて、入力パターンξを新たなノードiとして、入力パターンξと同じ位置に挿入し、その結果を一時記憶部に格納する。
【0147】
S206:一方、一時記憶部に格納されたS204における判定の結果、入力パターンξと第1勝者ノードa1間の距離が第1勝者ノードa1の類似度閾値T1以下であり、かつ、入力パターンξと第2勝者ノードa2間の距離が第2勝者ノードa2の類似度閾値T2以下である場合には、辺接続判定手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0148】
S207:一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
【0149】
そして、adjusted SOINNは、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0150】
一方、一時記憶部に格納されたS206における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S208へと処理を進めるが、既にノード間に辺が生成されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
【0151】
次いで、adjusted SOINNは、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0152】
S208:重みベクトル更新手段は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力パターンξに更に近づけるように更新し、その結果を一時記憶部に格納する。ここで、重みベクトルの更新量の算出には、一時記憶部に格納されるMa1をtとして使用する。
【0153】
S209:adjusted SOINNは、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。尚、agetはノイズなどの影響により誤って生成される辺を削除するために使用する。agetに小さな値を設定することにより、辺が削除されやすくなりノイズによる影響を防ぐことができるものの、値を極端に小さくすると、頻繁に辺が削除されるようになり学習結果が不安定になる。一方、極端に大きな値をagetに設定すると、ノイズの影響で生成された辺を適切に取り除くことができない。これらを考慮して、パラメータagetは実験により予め算出し一時記憶部に格納される。
【0154】
S210:adjusted SOINNは、一時記憶部に格納された与えられた入力パターンξの総数について、与えられた入力パターンξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力パターンの総数がλの倍数でない場合にはS202へと戻り、次の入力パターンξを処理する。一方、入力パターンξの総数がλの倍数となった場合には以下の処理を実行する。
【0155】
尚、λはノイズと見なされるノードを削除する周期である。λに小さな値を設定することにより、頻繁にノイズ処理を実施することができるものの、値を極端に小さくすると、実際にはノイズではないノードを誤って削除してしまう。一方、極端に大きな値をλに設定すると、ノイズの影響で生成されたノードを適切に取り除くことができない。これらを考慮して、パラメータλは実験により予め算出し一時記憶部に格納される。
【0156】
S211:ノイズノード削除手段は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。
【0157】
S212:adjusted SOINNは、一時記憶部に格納された与えられた入力パターンξの総数について、与えられた入力パターンξの総数が予め設定されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力パターンの総数がLTの倍数でない場合にはS202へと戻り、次の入力パターンξを処理する。一方、入力パターンξの総数がLTの倍数となった場合には以下の処理を実行する。
【0158】
S213:adjusted SOINNは、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、adjusted SOINNによる学習を停止する。
【0159】
次に、Enhanced−SOINN(以下E−SOINNという。)について説明する。E−SOINNはSOINNに比べて、入力パターンの分布に高密度の重なりのあるクラスを分離することができる。そして、分布の重なり領域の検出処理においては、平滑化の手法を導入したことより、SOINNに比べてより安定的に動作することができる。さらに、1層構造であっても効率的にノイズノードを削除することができる。さらにまた、SOINNに比べて、より少ないパラメータで動作するため、処理をより容易に実行することができる。
【0160】
以下にE−SOINNを簡単に説明する。図20は、E−SOINNによる学習処理の処理概要を示すフローチャートである。尚、上述したadjusted SOINNと同様の処理については説明を省略する。
【0161】
まず、図24に示すS601乃至S605については、図19に示すadjusted SOINNと同様の処理を実施する。従って、以下では図20に示すS606からの処理について説明する。
【0162】
S606:後述する辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2のノード密度に基づいて、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0163】
S607:一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を生成して接続する場合には、後述する辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
【0164】
そして、E−SOINNは、一時記憶部に格納された辺及び辺の年齢について、新しく生成された辺、及び、既にノード間に辺が生成されていた場合にはその辺について、辺の年齢を0に設定しその結果を一時記憶部に格納し、第1勝者ノードa1と直接的に接続される辺の年齢をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0165】
一方、一時記憶部に格納されたS606における判定の結果、第1勝者ノードa1及び第2勝者ノードa2間に辺を接続しない場合には、S608へと処理を進めるが、既にノード間に辺が生成されていた場合には、後述する辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノードa1及び第2勝者ノードa2間の辺を削除し、その結果を一時記憶部に格納する。
【0166】
次いで、一時記憶部に格納されたノード及びノード密度のポイント値について、第1勝者ノードa1について、後述するノード密度算出手段は、一時記憶部に格納された第1勝者ノードa1のノード密度のポイント値を算出しその結果を一時記憶部に格納し、算出され一時記憶部に格納されたノード密度のポイント値を以前までに算出され一時記憶部に格納されたポイント値に加算することで、ノード密度ポイントとして累積し、その結果を一時記憶部に格納する。
【0167】
次いで、E−SOINNは、一時記憶部に格納された第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1をインクリメントし(1増やす)、その結果を一時記憶部に格納する。
【0168】
S608:adjusted SOINNと同様の重みベクトル更新手段は、一時記憶部に格納されたノード及びノードの重みベクトルについて、第1勝者ノードa1の重みベクトル及び第1勝者ノードa1の隣接ノードの重みベクトルをそれぞれ入力ベクトルξに更に近づけるように更新し、その結果を一時記憶部に格納する。尚、E−SOINNにおいては、追加学習に対応するため、入力ベクトルの入力回数tに代えて、一時記憶部に格納される第1勝者ノードa1が第1勝者ノードとなった累積回数Ma1を用いる。
【0169】
S609:E−SOINNは、一時記憶部に格納された辺について、予め設定され一時記憶部に格納された閾値agetを超えた年齢を持つ辺を削除し、その結果を一時記憶部に格納する。
【0170】
S610:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたλの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がλの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。一方、入力ベクトルξの総数がλの倍数となった場合には以下の処理を実行する。
【0171】
S611:後述する分布重なり領域検出手段は、一時記憶部に格納されたサブクラスタ及び分布の重なり領域について、上述のS301乃至S305において示したようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0172】
S612:後述するノード密度算出手段は、一時記憶部に格納されて累積されたノード密度ポイントを単位入力数あたりの割合として算出しその結果を一時記憶部に格納し、単位入力数あたりのノードのノード密度を算出し、その結果を一時記憶部に格納する。
【0173】
S613:後述するノイズノード削除手段は、一時記憶部に格納されたノードについて、ノイズノードと見なしたノードを削除し、その結果を一時記憶部に格納する。尚、S613においてノイズノード削除手段が使用するパラメータc1及びc2はノードをノイズと見なすか否かの判定に使用する。通常、隣接ノード数が2であるノードはノイズではないことが多いため、c1は0に近い値を使用する。また、隣接ノード数が1であるノードはノイズであることが多いため、c2は1に近い値を使用するものとし、これらのパラメータは予め設定され一時記憶部に格納される。
【0174】
S614:E−SOINNは、一時記憶部に格納された与えられた入力ベクトルξの総数について、与えられた入力ベクトルξの総数が予め設定され一時記憶部に格納されたLTの倍数であるか否かを判定し、その結果を一時記憶部に格納する。一時記憶部に格納された判定の結果、入力ベクトルの総数がLTの倍数でない場合にはS602へと戻り、次の入力ベクトルξを処理する。
【0175】
一方、入力ベクトルξの総数がLTの倍数となった場合には、一時記憶部に格納されたノードをプロトタイプとして出力する。以上の処理を終了した後、学習を停止する。ノード密度算出手段は、一時記憶部に格納されたノード及びノード密度について、注目するノードについて、その隣接ノード間の平均距離に基づいて、注目するノードのノード密度を算出し、その結果を一時記憶部に格納する。
【0176】
さらに、ノード密度算出手段は、単位ノード密度算出部を有し、単位ノード密度算出部は、追加学習に対応するため、一時記憶部に格納された第1勝者ノード及びノード密度について、第1勝者ノードとその隣接ノード間の平均距離に基づいて、第1勝者ノードのノード密度を単位入力数あたりの割合として算出し、その結果を一時記憶部に格納する。
【0177】
さらにまた、ノード密度算出手段は、一時記憶部に格納されたノード及びノード密度ポイントについて、第1勝者ノード及びその隣接ノード間の平均距離に基づいて、第1勝者ノードのノード密度のポイント値を算出するノード密度ポイント算出部と、入力ベクトルの入力数が所定の単位入力数となるまでノード密度ポイントを一時記憶部に格納して累積し、入力ベクトルの入力数が所定の単位入力数になった場合に、一時記憶部に格納して累積されたノード密度ポイントを単位入力数あたりの割合として算出し、単位入力数あたりのノードのノード密度を算出し、その結果を一時記憶部に格納する単位ノード密度ポイント算出部を有する。
【0178】
具体的には、ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiに与えられるノード密度のポイント値piを算出し、その結果を一時記憶部に格納する。尚、ノードiに与えられるポイント値piは、ノードiが第1勝者ノードとなった場合には一時記憶部に格納される以下の式に基づいて算出されるポイント値が与えられるが、ノードiが第1勝者ノードでない場合にはノードiにはポイントは与えられないものとする。
【0179】
【数14】
【0180】
ここで、eiはノードiからその隣接ノードまでの平均距離を示し、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【0181】
【数15】
【0182】
尚、mは一時記憶部に格納されたノードiの隣接ノードの個数を示し、Wiは一時記憶部に格納されたノードiの重みベクトルを示す。ここで、隣接ノードへの平均距離が大きくなる場合には、ノードを含むその領域にはノードが少ないものと考えられ、逆に平均距離が小さくなる場合には、その領域にはノードが多いものと考えられる。
【0183】
従って、ノードの多い領域で第1勝者ノードとなった場合には高いポイントが与えられ、ノードの少ない領域で第1勝者ノードとなった場合には低いポイントが与えられるようにノードの密度のポイント値の算出方法を上述のように構成する。
【0184】
これにより、ノードを含むある程度の範囲の領域におけるノードの密集具合を推定することができるため、ノードの分布が高密度の領域に位置するノードであっても、ノードが第1勝者回数となった回数をノードの密度とするSOINNに比べて、入力ベクトルの入力分布密度により近似した密度となるノード密度ポイントを算出することができる。
【0185】
単位ノード密度ポイント算出部は、例えば一時記憶部に格納される以下の式に基づいてノードiの単位入力数あたりのノード密度densityiを算出し、その結果を一時記憶部に格納する。
【0186】
【数16】
【0187】
ここで、連続して与えられる入力ベクトルの入力回数を予め設定され一時記憶部に格納される一定の入力回数λごとの区間に分け、各区間においてノードiに与えられたポイントについてその合計を累積ポイントsiと定める。尚、入力ベクトルの総入力回数を予め設定され一時記憶部に格納されるLTとする場合に、LT/λを区間の総数nとしその結果を一時記憶部に格納し、nのうち、ノードに与えられたポイントの合計が0以上であった区間の数をNとして算出し、その結果を一時記憶部に格納する(Nとnは必ずしも同じとならない点に注意する)。
【0188】
累積ポイントsiは、例えば一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【0189】
【数17】
【0190】
ここで、pi(j,k)はj番目の区間におけるk番目の入力によってノードiに与えられたポイントを示し、上述のノード密度ポイント算出部により算出され、その結果を一時記憶部に格納する。
【0191】
このように、単位ノード密度ポイント算出部は、一時記憶部に格納されたノードiの密度densityiを累積ポイントsiの平均として算出し、その結果を一時記憶部に格納する。尚、E−SOINNにおいては追加学習に対応するため、nに代えてNを用いる。これは、追加学習において、以前の学習で生成されたノードにはポイントが与えられないことが多く、nを用いて密度を算出すると、以前学習したノードの密度が次第に低くなってしまうという問題を回避するためである。即ち、nに代えてNを用いてノード密度を算出することで、追加学習を長時間行った場合であっても、追加されるデータが以前学習したノードの近くに入力されない限りは、そのノードの密度を変化させずに保持することができる。
【0192】
これにより、追加学習を長時間実施する場合であっても、ノードのノード密度が相対的に小さくなってしまうことを防ぐことができ、SOINNを含む従来の手法に比べて、入力ベクトルの入力分布密度により近似したノード密度を変化させずに保持して算出することができる。
【0193】
分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、辺によって接続されるノードの集合であるクラスタを、ノード密度算出手段によって算出されるノード密度に基づいてクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納し、サブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0194】
さらに、分布重なり領域検出手段は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索するノード探索部と、探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与する第1のラベル付与部と、第1のラベル付与部によりラベルが付与されなかったノードのうち、そのノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与する第2のラベル付与部と、それぞれ異なるラベルが付与されたノード間に辺によって直接的に接続がある場合に、その辺によって接続されるノードの集合であるクラスタをクラスタの部分集合であるサブクラスタに分割するクラスタ分割部と、注目するノード及びその隣接ノードがそれぞれ異なるサブクラスタに属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出する分布重なり領域検出部を有する。
【0195】
具体的には、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードの密度について、例えば以下のようにしてサブクラスタの境界である分布の重なり領域を検出し、その結果を一時記憶部に格納する。
【0196】
S701:ノード探索部は、一時記憶部に格納されたノード及びノードの密度について、ノード密度算出手段により算出されたノード密度に基づいて、ノード密度が局所的に最大であるノードを探索し、その結果を一時記憶部に格納する。
【0197】
S702:第1のラベル付与部は、一時記憶部に格納されたノード、及びノードのラベルについて、S701において探索したノードに対して、既に他のノードに付与済みのラベルとは異なるラベルを付与し、その結果を一時記憶部に格納する。
【0198】
S703:第2のラベル付与部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、S702において第1のラベル付与部によりラベルが付与されなかったノードについて、第1のラベル付与部にラベルが付与されたノードと辺によって接続されるノードについて、第1のラベル付与部によりラベルが付与されたノードのラベルと同じラベルを付与し、その結果を一時記憶部に格納する。即ち、密度が局所的に最大の隣接ノードと同じラベルを付与する。
【0199】
S704:クラスタ分割部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、一時記憶部に格納された辺によって接続されるノードの集合であるクラスタを、同じラベルが付与されたノードからなるクラスタの部分集合であるサブクラスタに分割し、その結果を一時記憶部に格納する。
【0200】
S705:分布重なり領域検出部は、一時記憶部に格納されたノード、ノード間を接続する辺、及びノードのラベルについて、注目するノードとその隣接ノードが異なるサブクラスタにそれぞれ属する場合に、その注目するノード及びその隣接ノードを含む領域を、サブクラスタの境界である分布の重なり領域として検出し、その結果を一時記憶部に格納する。
【0201】
辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、及び分布重なり領域について、第1勝者ノード及び第2勝者ノードが分布重なり領域に位置するノードである場合に、第1勝者ノード及び第2勝者ノードのノード密度に基づいて第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0202】
さらに辺接続判定手段は、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタについて、ノードが属しているサブクラスタを判定する所属サブクラスタ判定部と、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定する辺接続判定部を有する。
【0203】
辺接続手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を接続し、その結果を一時記憶部に格納する。
【0204】
辺削除手段は、一時記憶部に格納された辺接続判定手段の判定結果に基づいて、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。具体的には、一時記憶部に格納されたノード、ノード密度、ノードのサブクラスタ、及びノード間の辺について、例えば以下のようにして辺接続判定手段は辺を接続するか否かを判定し、辺接続手段及び辺削除手段は辺の生成及び削除処理を実施し、その結果を一時記憶部に格納する。
【0205】
S801:所属サブクラスタ判定部は、一時記憶部に格納されたノード、ノードのサブクラスタについて、第1勝者ノード及び第2勝者ノードが属するサブクラスタをそれぞれ判定し、その結果を一時記憶部に格納する。
【0206】
S802:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードがどのサブクラスタにも属していない場合、又は、第1勝者ノード及び第2勝者ノードが同じサブクラスタに属している場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成することによりノード間を接続し、その結果を一時記憶部に格納する。
【0207】
S803:一時記憶部に格納されたS801における判定の結果、第1勝者ノード及び第2勝者ノードが互いに異なるサブクラスタに属す場合には、辺接続判定部は、一時記憶部に格納されたノード、ノード密度、及びノード間の辺について、ノードが属するサブクラスタの頂点の密度及びノードの密度に基づいて、第1勝者ノード及び第2勝者ノード間に辺を接続するか否かを判定し、その結果を一時記憶部に格納する。
【0208】
S804:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要がないと判定した場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間を辺によって接続せず、既にノード間が辺によって接続されていた場合には、辺削除手段は、一時記憶部に格納されたノード及びノード間の辺について、一時記憶部に格納された第1勝者ノード及び第2勝者ノード間の辺を削除し、その結果を一時記憶部に格納する。
【0209】
S805:一時記憶部に格納されたS803における辺接続判定部による判定の結果、辺を接続する必要があると判定した場合には、辺接続手段は、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺を生成しノード間を接続する。ここで、辺接続判定部による判定処理について詳細に説明する。
【0210】
まず、辺接続判定部は、一時記憶部に格納されたノード及びノード密度について、第1勝者ノードのノード密度densitywin及び第2勝者ノード密度densitysec−winのうち、最小のノード密度mを例えば一時記憶部に格納される以下の式に基いて算出し、その結果を一時記憶部に格納する。
【0211】
【数18】
【0212】
次に、一時記憶部に格納されたノード、ノードのノード密度、及びノードのサブクラスについて、第1勝者ノード及び第2勝者ノードがそれぞれ属するサブクラスタA及びサブクラスタBについて、サブクラスタAの頂点の密度Amax及びサブクラスタBの頂点の密度Bmaxを算出し、その結果を一時記憶部に格納する。尚、サブクラスタに含まれるノードのうち、ノード密度が最大であるノード密度をサブクラスタの頂点の密度とする。
【0213】
そして、一時記憶部に格納されたノードが属するサブクラスタの頂点の密度Amax及びBmax、及びノードの密度mについて、mがαAAmaxより小さく、かつ、mがαBBmaxより小さいか否かを判定し、その結果を一時記憶部に格納する。即ち、一時記憶部に格納される以下の不等式を満足するか否かを判定し、その結果を一時記憶部に格納する。
【0214】
【数19】
【0215】
判定の結果、mがαAAmaxより小さく、かつ、mがαBBmaxより小さい場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間には辺は不要であると判定し、その結果を一時記憶部に格納する。一方、判定の結果、mがαAAmax以上、または、mがαBBmax以上である場合には、一時記憶部に格納されたノード及びノード間の辺について、第1勝者ノード及び第2勝者ノード間に辺は必要であると判定し、その結果を一時記憶部に格納する。
【0216】
このように、第1勝者ノード及び第2勝者ノードの最小ノード密度mを、第1勝者ノード及び第2勝者ノードをそれぞれ含むサブクラスタの平均的なノード密度と比較することで、第1勝者ノード及び第2勝者ノードを含む領域におけるノード密度の凹凸の大きさを判定することができる。即ち、サブクラスタA及びサブクラスタBの間に存在する分布の谷間のノード密度mが、閾値αAAmax又はαBBmaxより大きな場合には、ノード密度の形状は小さな凹凸であると判定することができる。
【0217】
ここで、αA及びαBは一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。尚、αBについてもαAと同様にして算出することができるためここでは説明を省略する。
i) Amax/meanA−1≦1の場合には、αA=0.0とする。
ii) 1<Amax/meanA−1≦2の場合には、αA=0.5とする。
iii) 2<Amax/meanA−1の場合には、αA=1.0とする。
【0218】
Amax/meanAの値が1以下となるi)の場合には、AmaxとmeanAの値は同程度であり、密度の凹凸はノイズの影響によるものと判断する。そして、αの値を0.0とすることで、サブクラスタが統合されるようにする。また、Amax/meanAの値が2を超えるi i i)の場合には、AmaxはmeanAに比べて十分大きく、明らかな密度の凹凸が存在するものと判断する。そして、αの値を1.0とすることで、サブクラスタが分離されるようにする。
【0219】
そして、Amax/meanAの値が上述した場合以外となる i i)の場合には、αの値を0.5とすることで、密度の凹凸の大きさに応じてサブクラスタが統合又は分離されるようにする。尚、meanAはサブクラスタAに属すノードiのノード密度densityiの平均値を示し、NAをサブクラスタAに属するノードの数として、一時記憶部に格納される以下の式に基づいて算出し、その結果を一時記憶部に格納する。
【0220】
【数20】
【0221】
このように、サブクラスタへの分離を行う際に、サブクラスタに含まれるノード密度の凹凸の程度を判定し、ある基準を満たした2つのサブクラスタを1つに統合することで、分布の重なり領域の検出におけるサブクラスタの分けすぎによる不安定化を防止することができる。
【0222】
例えばノイズや学習サンプルが少ないことが原因で、密度の分布に多くの細かい凹凸が形成されることがある。このような場合に、第1勝者ノード及び第2勝者ノードがサブクラスタA及びBの間にある分布の重なり領域に位置する場合に、ノード間の接続を行う際にある基準を満たした2つのサブクラスタを1つに統合することで、密度の分布に多くの細かい凹凸が含まれる場合であっても密度の分布を平滑化することができる。
【0223】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードについて、ノード密度算出手段により算出されるノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。
【0224】
さらにノイズノード削除手段は、一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、注目するノードのノード密度を所定の閾値と比較するノード密度比較部と、注目するノードの隣接ノードの個数を算出する隣接ノード数算出部と、注目するノードをノイズノードとみなして削除するノイズノード削除部を有する。
【0225】
具体的には、例えば以下のようにして一時記憶部に格納されたノード、ノード密度、ノード間の辺、隣接ノードの個数について、ノード密度及び注目するノードの隣接ノードの個数に基づいて、注目するノードを削除し、その結果を一時記憶部に格納する。
【0226】
ノイズノード削除手段は、一時記憶部に格納されたノード、ノード間の辺、隣接ノードの個数について、注目するノードiについて、隣接ノード数算出部によりその隣接ノードの個数を算出し、その結果を一時記憶部に格納する。そして、一時記憶部に格納された隣接ノードの個数に応じて、以下の処理を実施する。
i)一時記憶部に格納された隣接ノード数が2の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【0227】
【数21】
【0228】
一時記憶部に格納された比較結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
ii)一時記憶部に格納された隣接ノード数が1の場合、ノード密度比較部はノードiのノード密度densityiを例えば一時記憶部に格納される以下の式に基づいて算出する閾値と比較し、その結果を一時記憶部に格納する。
【0229】
【数22】
【0230】
一時記憶部に格納された比較の結果について、ノード密度densityiが閾値より小さい場合には、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
iii)一時記憶部に格納された隣接ノード数について、隣接ノードを持たない場合、ノイズノード削除部は、一時記憶部に格納されたノードについて、ノードを削除し、その結果を一時記憶部に格納する。
【0231】
ここで、予め設定され一時記憶部に格納される所定のパラメータc1及びc2を調整することで、ノイズノード削除手段によるノイズノードの削除の振る舞いを調整することができる。
【0232】
なお、本発明は上述した実施の形態のみに限定されるものではなく、本発明の要旨を逸脱しない範囲において種々の変更が可能であることは勿論である。
【0233】
例えば、上述の実施の形態では、各ブロックの処理を、CPU(Central Processing Unit)にコンピュータプログラムを実行させることにより実現するソフトウェアとして説明したが、これに限定されるものではなく、任意の処理をハードウェアの構成とすることも可能である。また、ソフトウェアで行う場合、コンピュータプログラムは、記録媒体に記録して提供することも可能であり、また、インターネットその他の伝送媒体を介して伝送することにより提供することも可能である。
【0234】
さらに、本実施の形態においては、静止画像のラベリングについて説明したが動画像のラベリングとすることも可能である。この場合は、時系列情報、例えば存在している物体、その動きなどを考慮することになる。これにより現在の状態や動きから未来の動きを予測することができる。この場合、確率モデルは下記のように記載することができる。
【0235】
【数23】
hijは時系列情報を含めたモデルであり、l'jは前フレームの近傍ラベルを示す。時系列情報では、ラベルの位置は、ラベルは前フレームと同位置またはその近傍に存在する可能性が高い(連続性)とすることができ、ラベルの位置を推定することができる。また、車が動いた後には道路が出現するなどラベルの変化の仕方には特徴があり、ラベルの変化の仕方を推定することができる。さらに、車や歩行者を背景から分離するなど、移動している物体の検出が可能であり、動き情報を取得することができる。
【0236】
このような時系列情報を使用することで、過去から現在までのフレームとラベルの動きから未来の状態、例えば直進車の動きを予測したり、周囲の環境・状況から、例えば交差点で歩行者が出てくるなど、着目している対象の位置の推定・予測が可能となる。
【図面の簡単な説明】
【0237】
【図1】本発明の実施の形態にかかるラベリング装置を示すブロック図である。ラベリング装
【図2】入力画像を示す図である。
【図3】ラベリング結果を示す図である。
【図4】本発明の実施の形態にかかるラベリング装置のハードウェア構成の一例を示す図である。
【図5】本発明の実施の形態にかかる学習方法を示すフローチャートである。
【図6】(a)は、学習用画像であり、(b)は、第1の方法により、スーパーピクセルに分割した場合の画像を示している。
【図7】(a)は、学習用画像であり、(b)は、第1の方法により、スーパーピクセルに分割した場合の画像を示している。
【図8】本発明の実施の形態にかかるラベリング処理を示すフローチャートである。
【図9】(a)は入力画像、(b)は類似シーン画像を示す図である。
【図10】(a)乃至(c)は、類似シーン画像を基に、カテゴリ分布を推定した結果を示す図である。
【図11】(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図12】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図13】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図14】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図15】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図16】おなじく、(a)は入力画像(a)、(b)は正解ラベル、(c)は、第1の比較例、(d)は第2の比較例、(e)は実施例を示す図である。
【図17】本発明の実施例及び比較例の正答率を示す図である。
【図18】SOINNによる学習処理を説明するためのフローチャートである。
【図19】adjusted SOINNの処理方法を示すフローチャートである。
【図20】E−SOINNによる学習処理の処理概要を示すフローチャートである。
【図21】(a)及び(b)は、それぞれ入力画像及びCRFによるラベリング結果を示す図である。
【図22】同じく、(a)及び(b)は、それぞれ入力画像及びCRFによるラベリング結果を示す図である。
【符号の説明】
【0238】
10 学習部
11 スーパーピクセル生成部
12 特徴ベクトル算出部
20 確率演算部
21 局所単項ポテンシャル演算部
22 大域特徴算出部
23 類似画像抽出部
24 大域単項ポテンシャル演算部
25 整合性行列算出部
26 局所二項ポテンシャル演算部
27 大域二項ポテンシャル演算部
30 ラベリング部
31 初期ラベル設定部
100 コンピュータ
101 CPU
102 ROM
103 RAM
104 バス
105 入出力インターフェース
106 入力部
107 出力部
108 記憶部
109 通信部
111 磁気ディスク
112 光ディスク
113 フレキシブルディスク
114 半導体メモリ
【特許請求の範囲】
【請求項1】
入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置であって、
画像全体の特徴を大域特徴として算出する大域特徴算出部と、
予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出部と、
前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出部とを有するラベリング装置。
【請求項2】
前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出部と、
前記第1の整合性行列算出部が算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出部と、
前記第1の確率算出部が推定したラベルと前記第2の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有する
ことを特徴とする請求項1記載のラベリング装置。
【請求項3】
各画素毎の特徴を局所特徴として算出する局所特徴算出部と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出部と、
前記第1の確率算出部が推定したラベルと前記第3の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有する
ことを特徴とする請求項1記載のラベリング装置。
【請求項4】
各画素毎の特徴を局所特徴として算出する局所特徴算出部と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出部とを有し、
前記ラベル更新部は、第1乃至第3の確率算出部が推定したラベルに基づき出力ラベルを推定する
ことを特徴とする請求項2記載のラベリング装置。
【請求項5】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部と、
前記第1の確率算出部が推定したラベルと前記第4の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有する
ことを特徴とする請求項1記載のラベリング装置。
【請求項6】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部とを更に有し、
前記ラベル更新部は、第1、第2及び第4の確率算出部が推定したラベルに基づき出力ラベルを推定する
ことを特徴とする請求項2記載のラベリング装置。
【請求項7】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部とを更に有し
前記ラベル更新部は、第1乃至第4の確率算出部が推定したラベルに基づき出力ラベルを推定する
ことを特徴とする請求項4記載のラベリング装置。
【請求項8】
前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を更に有し、
ラベルの推定を前記スーパーピクセル単位で行なう
ことを特徴とする請求項1乃至8のいずれか1項記載のラベリング装置。
【請求項9】
前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を更に有し、
前記局所特徴算出部は、前記スーパーピクセル単位で前記局所特徴を算出する
ことを特徴とする請求項3、4、7、又は8のいずれか1項記載のラベリング装置。
【請求項10】
前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を有し、
前記第2の整合性行列算出部及び第4の確率算出部は、前記注目画素及び隣接画素をそれぞれ注目するスーパーピクセル及び隣接スーパーピクセルとして演算又は推定を行なう
ことを特徴とする請求項3、4、7、又は8のいずれか1項記載のラベリング装置。
【請求項11】
前記類似画像抽出部は、前記入力画像及び学習画像を2以上の領域に分割し、各領域毎の類似度に基づき前記類似画像を抽出する
ことを特徴とする請求項1乃至10のいずれか1項記載のラベリング装置。
【請求項12】
前記学習画像から予め得られる各カテゴリの特徴ベクトルは、各カテゴリを表す1又は複数の代表ベクトルである
ことを特徴とする請求項3、4、7、又は8のいずれか1項記載のラベリング装置。
【請求項13】
前記大域特徴算出部は、前記入力画像又は前記入力画像を複数に分割した分割領域毎に、RGBの3種類のヒストグラムを生成して前記大域特徴とする
ことを特徴とする請求項1記載のラベリング装置。
【請求項14】
前記大域特徴算出部は、M×M(Mは整数)画素の輝度値に基づき輝度値の勾配方向を求めたヒストグラムを生成して前記大域特徴とする
ことを特徴とする請求項1又は13記載のラベリング装置。
【請求項15】
前記大域特徴算出部は、前記入力画像にラプラシアンフィルタを施し得られたヒストグラムを前記大域特徴とする
ことを特徴とする請求項1、13又は14記載のラベリング装置。
【請求項16】
前記大域特徴算出部は、前記入力画像又は前記入力画像を縮小した縮小画像のCIE L*a*値を求め前記大域特徴とする
ことを特徴とする請求項1、13乃至15のいずれか1項記載のラベリング装置。
【請求項17】
前記第1の確率算出部は、Xを入力画像、iを画素、liをiのラベル、gi(li|X)を大域単項ポテンシャル関数、vGを大域特徴とするとき、
【数1】
で表される大域単項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項1記載のラベリング装置。
【請求項18】
前記第2の確率算出部は、Xを入力画像、i,jを画素、li,ljを、i,jのラベル、gij(li,lj|X)を大域二項ポテンシャル関数、ΘGを第1の整合性行列、vGを大域特徴とするとき、
【数2】
で表される大域二項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項2記載のラベリング装置。
【請求項19】
前記第3の確率算出部は、Xを入力画像、iを画素、liをiのラベル、fi(li|X)を局所単項ポテンシャル関数、vcolorを色の特徴から得られる色特徴ベクトル、vtextureを輝度値の特徴から得られるテクスチャ特徴ベクトルとするとき、
【数3】
で表される局所単項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項3記載のラベリング装置。
【請求項20】
前記第4の確率算出部は、Xを入力画像、i,jを画素、li,ljを、それぞれi,jのラベル、fij(li,lj|X)を局所二項ポテンシャル関数、wijを変数、ΘLを第2の整合性行列、kwをパラメータ、dcolor(i,j)2を色の特徴から得られる色特徴ベクトルのij間の距離、dtxture(i,j)2を輝度値の特徴から得られるテクスチャ特徴ベクトルのij間の距離、σcolor2、σtexture2をパラメータとするとき、
【数4】
で表される局所二項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項5記載のラベリング装置。
【請求項21】
入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング方法であって、
画像全体の特徴を示す大域特徴を算出する大域特徴算出工程と、
予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出工程と、
前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出工程とを有するラベリング方法。
【請求項22】
前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出工程と、
前記第1の整合性行列算出工程にて算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第2の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項21記載のラベリング方法。
【請求項23】
各画素毎の特徴を局所特徴として算出する局所特徴算出工程と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第3の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項21記載のラベリング方法。
【請求項24】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出工程と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第4の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項21記載のラベリング方法。
【請求項25】
入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング処理をコンピュータに実行させるためのプログラムであって、
画像全体の特徴を示す大域特徴を算出する大域特徴算出工程と、
予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出工程と、
前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出工程とを有するプログラム。
【請求項26】
前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出工程と、
前記第1の整合性行列算出工程にて算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第2の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項25記載のプログラム。
【請求項27】
各画素毎の特徴を局所特徴として算出する局所特徴算出工程と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第3の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項25記載のプログラム。
【請求項28】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出工程と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第4の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項25記載のプログラム。
【請求項1】
入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング装置であって、
画像全体の特徴を大域特徴として算出する大域特徴算出部と、
予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出部と、
前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出部とを有するラベリング装置。
【請求項2】
前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出部と、
前記第1の整合性行列算出部が算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出部と、
前記第1の確率算出部が推定したラベルと前記第2の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有する
ことを特徴とする請求項1記載のラベリング装置。
【請求項3】
各画素毎の特徴を局所特徴として算出する局所特徴算出部と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出部と、
前記第1の確率算出部が推定したラベルと前記第3の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有する
ことを特徴とする請求項1記載のラベリング装置。
【請求項4】
各画素毎の特徴を局所特徴として算出する局所特徴算出部と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出部とを有し、
前記ラベル更新部は、第1乃至第3の確率算出部が推定したラベルに基づき出力ラベルを推定する
ことを特徴とする請求項2記載のラベリング装置。
【請求項5】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部と、
前記第1の確率算出部が推定したラベルと前記第4の確率算出部が推定したラベルとに基づき出力ラベルを推定するラベル更新部とを更に有する
ことを特徴とする請求項1記載のラベリング装置。
【請求項6】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部とを更に有し、
前記ラベル更新部は、第1、第2及び第4の確率算出部が推定したラベルに基づき出力ラベルを推定する
ことを特徴とする請求項2記載のラベリング装置。
【請求項7】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出部と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出部とを更に有し
前記ラベル更新部は、第1乃至第4の確率算出部が推定したラベルに基づき出力ラベルを推定する
ことを特徴とする請求項4記載のラベリング装置。
【請求項8】
前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を更に有し、
ラベルの推定を前記スーパーピクセル単位で行なう
ことを特徴とする請求項1乃至8のいずれか1項記載のラベリング装置。
【請求項9】
前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を更に有し、
前記局所特徴算出部は、前記スーパーピクセル単位で前記局所特徴を算出する
ことを特徴とする請求項3、4、7、又は8のいずれか1項記載のラベリング装置。
【請求項10】
前記入力画像について複数の隣接する類似画素から構成されるスーパーピクセルを生成するスーパーピクセル生成部を有し、
前記第2の整合性行列算出部及び第4の確率算出部は、前記注目画素及び隣接画素をそれぞれ注目するスーパーピクセル及び隣接スーパーピクセルとして演算又は推定を行なう
ことを特徴とする請求項3、4、7、又は8のいずれか1項記載のラベリング装置。
【請求項11】
前記類似画像抽出部は、前記入力画像及び学習画像を2以上の領域に分割し、各領域毎の類似度に基づき前記類似画像を抽出する
ことを特徴とする請求項1乃至10のいずれか1項記載のラベリング装置。
【請求項12】
前記学習画像から予め得られる各カテゴリの特徴ベクトルは、各カテゴリを表す1又は複数の代表ベクトルである
ことを特徴とする請求項3、4、7、又は8のいずれか1項記載のラベリング装置。
【請求項13】
前記大域特徴算出部は、前記入力画像又は前記入力画像を複数に分割した分割領域毎に、RGBの3種類のヒストグラムを生成して前記大域特徴とする
ことを特徴とする請求項1記載のラベリング装置。
【請求項14】
前記大域特徴算出部は、M×M(Mは整数)画素の輝度値に基づき輝度値の勾配方向を求めたヒストグラムを生成して前記大域特徴とする
ことを特徴とする請求項1又は13記載のラベリング装置。
【請求項15】
前記大域特徴算出部は、前記入力画像にラプラシアンフィルタを施し得られたヒストグラムを前記大域特徴とする
ことを特徴とする請求項1、13又は14記載のラベリング装置。
【請求項16】
前記大域特徴算出部は、前記入力画像又は前記入力画像を縮小した縮小画像のCIE L*a*値を求め前記大域特徴とする
ことを特徴とする請求項1、13乃至15のいずれか1項記載のラベリング装置。
【請求項17】
前記第1の確率算出部は、Xを入力画像、iを画素、liをiのラベル、gi(li|X)を大域単項ポテンシャル関数、vGを大域特徴とするとき、
【数1】
で表される大域単項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項1記載のラベリング装置。
【請求項18】
前記第2の確率算出部は、Xを入力画像、i,jを画素、li,ljを、i,jのラベル、gij(li,lj|X)を大域二項ポテンシャル関数、ΘGを第1の整合性行列、vGを大域特徴とするとき、
【数2】
で表される大域二項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項2記載のラベリング装置。
【請求項19】
前記第3の確率算出部は、Xを入力画像、iを画素、liをiのラベル、fi(li|X)を局所単項ポテンシャル関数、vcolorを色の特徴から得られる色特徴ベクトル、vtextureを輝度値の特徴から得られるテクスチャ特徴ベクトルとするとき、
【数3】
で表される局所単項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項3記載のラベリング装置。
【請求項20】
前記第4の確率算出部は、Xを入力画像、i,jを画素、li,ljを、それぞれi,jのラベル、fij(li,lj|X)を局所二項ポテンシャル関数、wijを変数、ΘLを第2の整合性行列、kwをパラメータ、dcolor(i,j)2を色の特徴から得られる色特徴ベクトルのij間の距離、dtxture(i,j)2を輝度値の特徴から得られるテクスチャ特徴ベクトルのij間の距離、σcolor2、σtexture2をパラメータとするとき、
【数4】
で表される局所二項ポテンシャル関数に基づき入力画像のラベルを推定する
ことを特徴とする請求項5記載のラベリング装置。
【請求項21】
入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング方法であって、
画像全体の特徴を示す大域特徴を算出する大域特徴算出工程と、
予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出工程と、
前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出工程とを有するラベリング方法。
【請求項22】
前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出工程と、
前記第1の整合性行列算出工程にて算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第2の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項21記載のラベリング方法。
【請求項23】
各画素毎の特徴を局所特徴として算出する局所特徴算出工程と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第3の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項21記載のラベリング方法。
【請求項24】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出工程と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第4の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項21記載のラベリング方法。
【請求項25】
入力画像の各画素について、予め設定した複数のカテゴリラベルのいずれかを割り当てるラベリング処理をコンピュータに実行させるためのプログラムであって、
画像全体の特徴を示す大域特徴を算出する大域特徴算出工程と、
予めラベリングされた学習画像と入力画像における前記大域特徴の類似度に基づき前記学習画像の中から前記入力画像に類似する類似画像を抽出する類似画像抽出工程と、
前記類似画像の各画素における各ラベルの存在確率、及び前記類似画像と前記入力画像との類似度に基づき入力画像の各画素のラベルを推定する第1の確率算出工程とを有するプログラム。
【請求項26】
前記類似画像を使用して、前記入力画像に2つのカテゴリが存在する確率を示す第1の整合性行列を算出する第1の整合性行列算出工程と、
前記第1の整合性行列算出工程にて算出した第1の整合性行列に基づき入力画像の各画素のラベルを推定する第2の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第2の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項25記載のプログラム。
【請求項27】
各画素毎の特徴を局所特徴として算出する局所特徴算出工程と、
前記学習画像から予め得られる各カテゴリの特徴ベクトルと、前記局所特徴との距離に基づき前記入力画像の各画素のラベルを推定する第3の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第3の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項25記載のプログラム。
【請求項28】
前記類似画像を使用して注目画素及びこれに隣接する隣接画素のラベルの関係を示す第2の整合性行列を算出する第2の整合性行列算出工程と、
前記第2の整合性行列と、前記隣接画素の推定ラベルとに基づき前記入力画像の各画素のラベルを推定する第4の確率算出工程と、
前記第1の確率算出工程にて推定したラベルと前記第4の確率算出工程にて推定したラベルとに基づき出力ラベルを推定するラベル更新工程とを更に有する
ことを特徴とする請求項25記載のプログラム。
【図1】

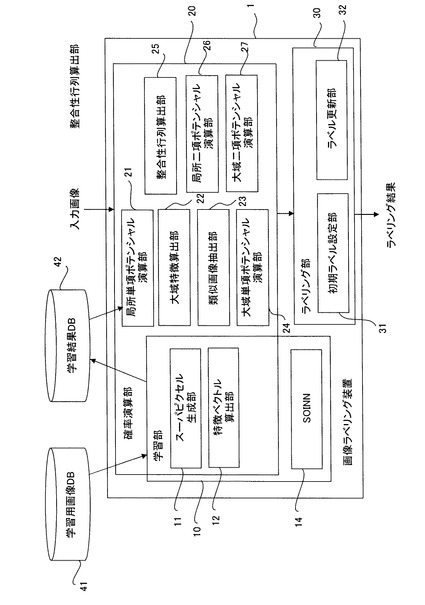
【図4】
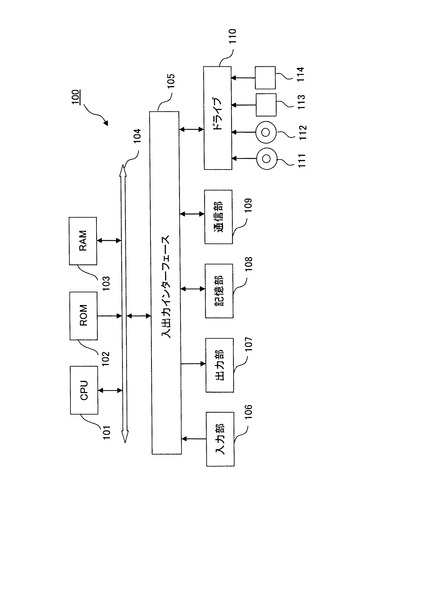
【図5】
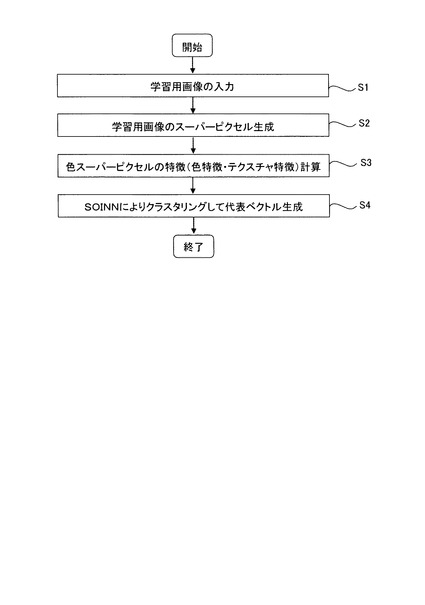
【図8】
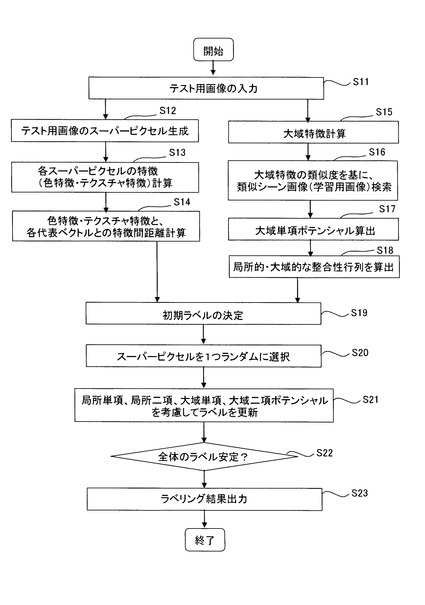
【図17】

【図18】
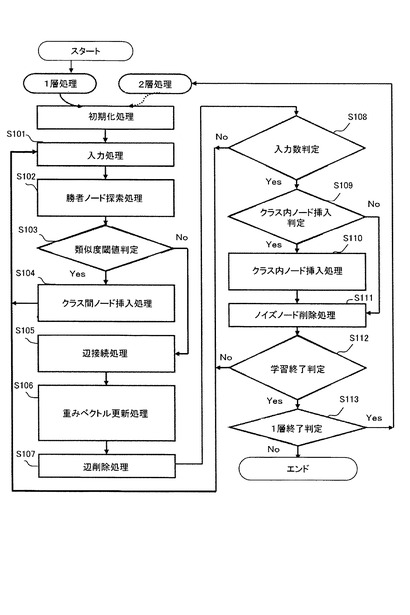
【図19】
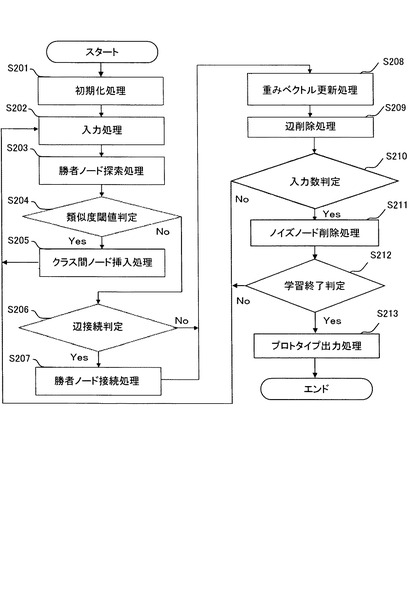
【図20】
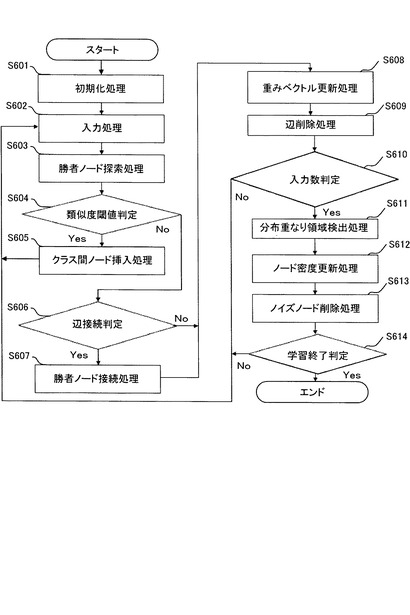
【図2】

【図3】

【図6】

【図7】

【図9】

【図10】
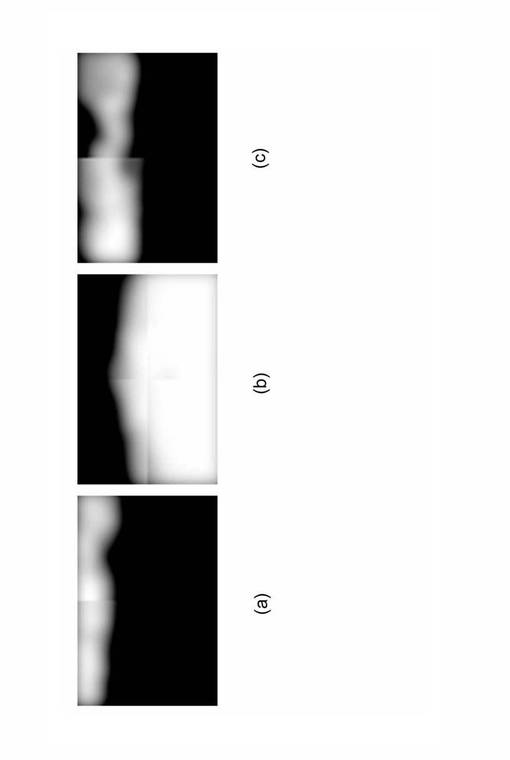
【図11】

【図12】

【図13】

【図14】

【図15】

【図16】

【図21】

【図22】
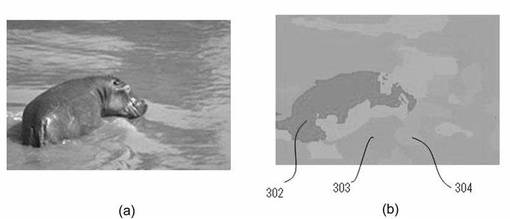
【図4】
【図5】
【図8】
【図17】
【図18】
【図19】
【図20】
【図2】
【図3】
【図6】
【図7】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図21】
【図22】
【公開番号】特開2008−217706(P2008−217706A)
【公開日】平成20年9月18日(2008.9.18)
【国際特許分類】
【出願番号】特願2007−57789(P2007−57789)
【出願日】平成19年3月7日(2007.3.7)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
【公開日】平成20年9月18日(2008.9.18)
【国際特許分類】
【出願日】平成19年3月7日(2007.3.7)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【Fターム(参考)】
[ Back to top ]