
レコメンド情報生成装置、レコメンド情報生成方法及びレコメンド情報生成プログラム
【課題】特徴辞書を更新した後のユーザ特徴ベクトルの計算にかかる負荷を軽減することを目的とする。
【解決手段】特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成装置であって、更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定手段と、更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定手段と、を有する、レコメンド情報生成装置を提供する。
【解決手段】特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成装置であって、更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定手段と、更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定手段と、を有する、レコメンド情報生成装置を提供する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、レコメンド情報生成装置、レコメンド情報生成方法及びレコメンド情報生成プログラムに関する。
【背景技術】
【0002】
レコメンデーション技術においては、ユーザが過去に利用したコンテンツをもとに、個人の嗜好性を学習し、当該ユーザに特徴が類似するコンテンツを推薦する。これを実現するための技術としては、非特許文献1にあるようにコンテンツフィルタリングという技術が用いられる。
【0003】
以下にコンテンツフィルタリングの方法について述べる。
【0004】
例として1日1回レコメンドを更新するような動画視聴サービスを想定する。また、ユーザが利用する端末(ユーザ端末)とレコメンド情報生成装置が互いに通信接続している形態で実現されているとする。このとき、ユーザ端末上でユーザが1つ以上の動画コンテンツを利用すると、ユーザ端末はそれらのコンテンツ利用履歴をレコメンド情報生成装置にアップロードする。その後、レコメンド情報生成装置は、非特許文献1にあるように次の3ステップで処理を行うことによりコンテンツフィルタリングを実現する。
(1)コンテンツを特徴付けるキーワード(特徴要素)を規定した特徴辞書を用いてコンテンツの特徴をコンテンツ特徴ベクトルとして表現する
(2)ユーザのコンテンツ利用履歴に基づき、各ユーザの嗜好性を示す、ユーザ特徴ベクトルを計算する
(3)コンテンツ特徴ベクトルとユーザ特徴ベクトルの類似度を計算し、類似度の高いコンテンツをレコメンド対象とする
【0005】
(1)においては、当該サービスで提供しているコンテンツそれぞれについてコンテンツ特徴ベクトルを計算することになる。コンテンツ特徴ベクトルにおけるベクトルの各要素は特徴要素で表される。特徴要素は、コンテンツを特徴付けると考えられるキーワードであり、どのようなキーワードを特徴要素とするかを規定したものが特徴辞書である。具体的には{野球、感動、空、・・・}などのキーワードの羅列がもっとも単純な特徴辞書の例である。
【0006】
ここで各コンテンツに付随するメタデータに対して、特徴辞書内のキーワードがどれだけ含まれているか、についてそれぞれ計算を行う。例えば、あるコンテンツのメタデータには「野球」という言葉が1つ入っており、「空」という言葉が1つ入っていれば、コンテンツ特徴ベクトルのそれぞれの特徴要素は{1,0,1,・・・}のように表すことができる。このように、コンテンツ特徴ベクトルの成分は、コンテンツ及び特徴要素に応じた値を有する。該ユーザが好むコンテンツ及び前記特徴要素に応じた値を有することとなる。この例では、どのキーワードについても1つ入っていたら、特徴要素の値を1としたが、これはもっとも単純な例であり、キーワードによってその値は可変であってもかまわない。この計算を当該サービスで提供しているコンテンツそれぞれについて実施すると次の(2)に処理が移る。
【0007】
次に(2)ではユーザ特徴ベクトルを計算する。
【0008】
全ユーザのうち、この処理で対象となるユーザは、通常、最後にレコメンド情報を生成した日時以降に、新たにコンテンツ利用履歴を送ってきたユーザとなる。なぜなら、新たにコンテンツ利用履歴を送ってきていないユーザは利用履歴に変化がないため、前回計算時からユーザ特徴ベクトルを更新する必要がないからである。
【0009】
ユーザのこれまでのコンテンツ利用履歴(新たに送ってきた分のみならず、過去の分も含む)に含まれるコンテンツのメタデータを先ほどの特徴辞書内のキーワードを以ってマッチングをかける。利用したコンテンツが複数あればその分マッチング対象となるメタデータも複数となる。例えばこれまでに10個のコンテンツのコンテンツ利用履歴をアップロードしたユーザの場合は、当該10個のコンテンツに付随するメタデータ全体に対して、キーワードをマッチングさせることになる。計算方法は(1)と同様に実現できる。この結果、ユーザのユーザ特徴ベクトルの成分は、該ユーザが好むコンテンツ及び特徴要素に応じた値を有することとなる。
【0010】
最後に(3)で全てのユーザ特徴ベクトルと、全てのコンテンツ特徴ベクトルの類似度を計算し、各ユーザについて類似度の近いコンテンツ特徴ベクトルを持つコンテンツのIDを記載したレコメンドリストを作成する。
【0011】
以上が、通常のレコメンド計算の概要である。
【0012】
ユーザの関心を推定するための特徴ベクトルの類似度を計算する例は、特許文献1又は特許文献2に開示されている。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開2009−74664号公報
【特許文献2】特開2004−348607号公報
【非特許文献】
【0014】
【非特許文献1】深澤,宮川,原,太田著「Ranking SVMを用いたコンテンツフィルタリングレコメンドシステムの開発」、人工知能学会論文誌12巻1号a,1997年
【発明の概要】
【発明が解決しようとする課題】
【0015】
ところが、例えば、新たな固有名詞を取り込むための特徴辞書の更新がなされた場合、全ユーザを対象にユーザ特徴ベクトルの更新を行う必要がある。特徴辞書の更新に伴う全ユーザのユーザ特徴ベクトルの更新には、通常時のユーザ特徴ベクトルの計算に比べて、一般に数倍の計算量が必要となる。ユーザレコメンド情報を随時提供するためには、一定の時間内にユーザ特徴ベクトル計算処理を完了しなければならないが、特徴辞書の更新時の計算量に合わせて計算リソースを準備するのは経済的に非効率である。
【0016】
本発明は、上記問題に鑑みてなされたものであり、特徴辞書を更新した後のユーザ特徴ベクトルの計算にかかる負荷を軽減することを目的とする。
【課題を解決するための手段】
【0017】
上述した課題を解決し目的を達成するため、本発明にかかるレコメンド情報生成装置は、特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成装置であって、更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定手段と、更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定手段と、を有する。
【発明の効果】
【0018】
本発明によれば、特徴辞書を更新した後のユーザ特徴ベクトルの計算にかかる負荷を軽減することができる。
【図面の簡単な説明】
【0019】
【図1】本発明の一実施形態におけるレコメンド情報生成装置の概要を表す図。
【図2】本発明の一実施形態におけるレコメンド情報生成装置のハードウェア構成例を表す図。
【図3】本発明の一実施形態によるレコメンド情報生成装置の機能ブロック図。
【図4】本発明の一実施形態によるレコメンド情報生成装置の処理のフローチャート。
【図5】既存の特徴辞書の例を表す図。
【図6】新たな特徴辞書の例を表す図。
【図7】特徴要素インデックス表の例を表す図。
【図8】特徴辞書が更新される前のユーザ特徴ベクトルの例を表す図。
【図9】ユーザのクラスタリングの例を表す図。
【図10】更新対象ユーザについてユーザ特徴ベクトルを計算した例を表す図。
【図11】更新待ちユーザ表の例を表す図。
【図12】更新待ちユーザの重複要素についてユーザ特徴ベクトルを推定した例を表す図。
【図13】更新待ちユーザの非重複要素についてユーザ特徴ベクトルを推定した例を表す図。
【図14】更新待ちユーザのクラスタリングの例を表す図。
【図15】更新対象ユーザについてユーザ特徴ベクトルを計算した例を表す図。
【図16】更新待ちユーザ表の更新の例を表す図。
【図17】更新待ちユーザについてユーザ特徴ベクトルを推定した例を表す図。
【発明を実施するための形態】
【0020】
以下、本発明の実施形態を図面に基づいて説明する。
【0021】
1.概要
2.ハードウェア構成
3.機能
4.処理フロー
4.1 特徴辞書更新直後の処理
4.2 2回目以降の処理
【0022】
(1.概要)
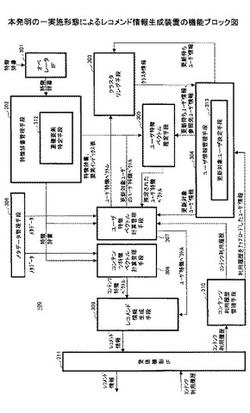
図1は、本発明の一実施形態におけるレコメンド情報生成装置100を含むシステム1の概要を表す。システム1は、レコメンド情報生成装置100と複数のユーザ端末101とを有する。
【0023】
レコメンド情報生成装置100は、特徴辞書を用いて、コンテンツ利用履歴を送信したユーザ端末101のユーザのユーザ特徴ベクトルを更新する。レコメンド情報生成装置100は、特徴辞書が更新された場合には、一部のユーザのユーザ特徴ベクトルのみを再計算する。一部のユーザとは、ユーザをクラスタリングして得られるクラスタの代表ユーザである。代表ユーザには、特徴辞書が更新された後、コンテンツ利用履歴を送信したユーザが含まれる。一方で、レコメンド情報生成装置100は、代表ユーザでない他のユーザのユーザ特徴ベクトルを、再計算された代表ユーザのユーザ特徴ベクトルに基づいて推定する。そして、得られた全ユーザのユーザ特徴ベクトルを用いてレコメンド情報を生成する。
【0024】
ユーザ端末101は、ユーザがコンテンツの利用に用いる端末であり、コンテンツを利用するたびに、又は一定の間隔ごとに、コンテンツ利用履歴をレコメンド情報生成装置100に対して送信する。コンテンツ利用履歴は、一般的にはインターネット等のネットワークを用いて送信される。
【0025】
このように、システム1に含まれるレコメンド情報生成装置100は、特徴辞書が更新された後に、一部のユーザのユーザ特徴ベクトルを推定してレコメンド情報を生成することで、処理負荷の急増を抑制することが可能となる。
【0026】
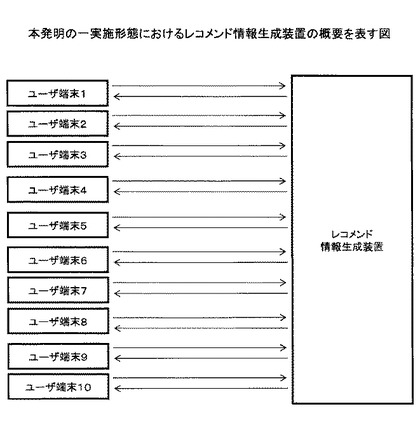
(2.ハードウェア構成)
図2は、本発明の一実施形態におけるレコメンド情報生成装置100のハードウェア構成例を表す。レコメンド情報生成装置100は、CPU200、ROM201、RAM202、HDD203、ネットワークコントーラ204、通信装置205、グラフィックスコントローラ206、表示装置207、入力コントローラ208、入力装置209、バス210を有する。
【0027】
CPU200は、本発明の一実施形態におけるレコメンド情報生成装置100で実行可能なレコメンド情報生成プログラムの動作制御を行う。ROM201は、CPU200が実行するレコメンド情報生成プログラムの動作に必要なOSやデータ等を記憶する。RAM202は、CPU200のワークエリア等を構成する。HDD203は、レコメンド情報生成プログラム本体や特徴辞書、ユーザ特徴ベクトル、コンテンツ特徴ベクトル、ユーザ情報、コンテンツのメタデータ等を記憶する。ネットワークコントローラ204は、通信装置205を介して、ネットワークに接続されるユーザ端末101と通信を行うための通信制御を行う。グラフィックスコントローラ206は、CRT又は液晶ディスプレイ等の表示装置207を介して、当該レコメンド情報生成装置100のオペレータに操作画面や情報を提供するための制御を行う。入力コントローラ208は、キーボード又はマウス等の入力装置209を介してオペレータから入力される信号を制御する。バス210は、当該レコメンド情報生成装置100を構成する上記装置を相互に接続し、データのやり取りを行うためのものである。
【0028】
上記構成により、本発明の一実施形態に係る当該レコメンド情報生成装置100は、特徴辞書が更新された後に、一部のユーザのユーザ特徴ベクトルを推定し、これを用いてレコメンド情報を生成することができる。
【0029】
なお、当該レコメンド情報生成装置100は、ユーザ端末101からアクセス可能なサーバ装置に統合されて提供されてもよい。このような場合には、レコメンド情報生成装置100は、ネットワーク上の他の通信端末から操作され得るため、表示装置207、入力装置209は備えなくてもよい。
【0030】
また、HDD203は、テーブドライブであってもよい。または、HDD203の有する機能が、ネットワーク上の、通信装置205を通じてアクセス可能な記憶装置に含まれていてもよい。
【0031】
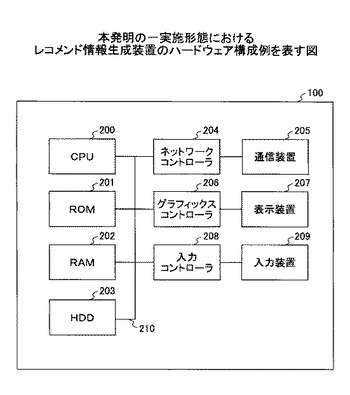
(3.機能)
図3は、本発明の一実施形態によるレコメンド情報生成装置100の機能ブロック図を表す。レコメンド情報生成装置100は、オペレータIF301、特徴辞書管理手段302、クラスタリング手段303、ユーザ情報管理手段304、ユーザ特徴ベクトル推定手段305、メタデータ管理手段306、ユーザ特徴ベクトル計算管理手段307、コンテンツ特徴ベクトル計算管理手段308、レコメンド情報生成手段309、コンテンツ利用履歴管理手段310、受信機側IF311を有する。
【0032】
オペレータIF301は、オペレータが入力した更新された特徴辞書を受け取り、特徴辞書管理手段302に渡す。
【0033】
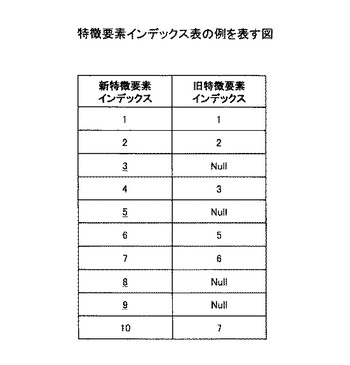
特徴辞書管理手段302は、重複要素特定手段312を有し、オペレータIF301から受け取った新たな特徴辞書と既存の特徴辞書とを管理する。また、特徴辞書管理手段302は、新たな特徴辞書に含まれるキーワードと、既存の特徴辞書に含まれるキーワードとを比較し、両方に含まれるキーワードを関連付けた特徴要素インデックス表を作成する。特徴要素インデックス表の具体例を図7に示す。以下、図7の例に基づいて情報要素インデックス表について説明する。
【0034】
例えば、図5に示されるような既存の特徴辞書と、図6に示されるような新たな特徴辞書とが管理されているとする(図6において新たに追加された特徴要素を下線で示す)。図5と図6の表は、それぞれ特徴要素インデックスと特徴要素の項目を有する。特徴要素インデックスとは、特徴辞書内の特徴要素を一意に特定するインデックス番号であり、特徴要素はコンテンツの特徴を表すためのキーワードである。特徴辞書管理手段302は、この二つの特徴辞書の特徴要素を比較し、重複要素特定手段312によって重複する特徴要素(以下、「重複要素」とする)を特定する。そして、図7に示すように、重複する特徴要素について、新しい特徴辞書の特徴要素インデックス(新特徴要素インデックス)と、既存の特徴辞書の特徴要素インデックス(旧特徴要素インデックス)とを関連付ける(新たに追加された特徴要素を下線で示す)。
【0035】
特徴辞書管理手段302は、ユーザ特徴ベクトルの推定を行うために、特徴辞書と特徴要素インデックス表とをユーザ特徴ベクトル推定手段305に渡す。また、特徴辞書管理手段302は、ユーザ特徴ベクトルとコンテンツ特徴ベクトルの計算のために、特徴辞書をユーザ特徴ベクトル計算管理手段307及びコンテンツ特徴ベクトル計算管理手段308に渡す。
【0036】
クラスタリング手段303は、計算済又は更新済のユーザ特徴ベクトルに基づいてユーザのクラスタリングを行う。クラスタリングは、ユーザ特徴ベクトルの間の類似度が近いもの同士でクラスタを形成するようにする。類似度が近いものを特定するために、例えば以下で表されるコサイン距離を用いられるが、その他の適切な方法で算出してもよい。
<x・y>/(|x||y|)
<x・y>:ベクトルxとベクトルyとの内積
|x|:ベクトルxのノルム
クラスタリング手法は、k-means法など如何なる適切な方法でよい。クラスタ数は、全ユーザ数以下の他の適切な数でもよい。計算結果となるクラスタ情報は、更新対象ユーザ決定手段313に渡される。
【0037】
ユーザ情報管理手段304は、更新対象ユーザ決定手段313を有し、更新された特徴辞書に関して、ユーザ特徴ベクトルを計算するユーザ(以下、「更新対象ユーザ」とする)と、推定により求めるユーザ(以下、「更新待ちユーザ」とする)とを管理する。
【0038】
更新対象ユーザ決定手段313は、受け取ったクラスタ情報に基づいて、更新対象ユーザを決定する。更新対象ユーザは、少なくとも1つのクラスタから1人の更新対象ユーザが決定されるように定められる。まず、前回レコメンド情報を生成した時以降にコンテンツ利用履歴の更新があったユーザを、更新対象ユーザとして決定する。次に、コンテンツ利用履歴を送信したユーザが存在しないクラスタ内から、例えばコンテンツの利用率の高い一人以上のユーザを更新対象ユーザに決定する。なお、更新対象ユーザの総数は、例えば当該レコメンド情報生成装置100に関連するユーザの数とその利用率との乗算によって定めることができる。利用率とは、例えば全ユーザにおけるアクティブユーザの割合などがある。この例において、ユーザの数が10人であり、アクティブユーザの割合が30%であるとすれば、更新対象ユーザの数は3人とすることができる。
【0039】
ここで、更新された特徴辞書に対し、一度も更新対象ユーザに選ばれていないユーザは、更新待ちユーザとして管理される。例えば、更新待ちユーザは、図11に例示されるように、更新待ちユーザ表を用いて管理される。更新待ちユーザ表に記載されるユーザが、一度更新対象ユーザとして選定されると、当該表からは削除される。
【0040】
ユーザ情報管理手段304は、更新対象ユーザ決定手段313が決定した更新対象ユーザの情報を、ユーザ特徴ベクトル計算管理手段307に渡す。また、ユーザ情報管理手段304は、更新待ちユーザ表に基づいて更新待ちユーザの情報をユーザ特徴ベクトル推定手段305に渡す。
【0041】
ユーザ情報管理手段304は、更新待ちユーザのユーザ特徴ベクトルの推定のために必要な、参照すべきユーザ(以下、「参照先ユーザ」とする)の情報も、ユーザ特徴ベクトル推定手段305に渡す。参照先ユーザは、同一クラスタ内の更新対象ユーザである。同一クラスタ内の更新対象ユーザの、計算されたユーザ特徴ベクトルが、更新待ちユーザのユーザ特徴ベクトルの推定のために用いられる。ここで、同一クラスタ内に複数の更新対象ユーザが存在する場合には、ユーザ特徴ベクトルの類似度が高い方を参照先ユーザとすることができる。
【0042】
ユーザ特徴ベクトル推定手段305は、更新された特徴辞書に基づいて、更新待ちユーザのユーザ特徴ベクトルを推定する。この時、ユーザ情報管理手段304から受け取った、参照先ユーザの情報を用いて、ユーザ特徴ベクトルを推定する。具体的な推定の処理は、後に実施例に基づき説明する。ユーザ特徴ベクトル推定手段305は、推定された更新待ちユーザのユーザ特徴ベクトルをユーザ特徴ベクトル計算管理手段307へと渡す。
【0043】
メタデータ管理手段306は、ユーザに提供されるコンテンツのメタデータを管理し、ユーザ特徴ベクトル計算管理手段307及びコンテンツ特徴ベクトル計算管理手段308へ渡す。メタデータには、特徴辞書内で指定されるようなキーワードが含まれ、ユーザ特徴ベクトル又はコンテンツ特徴ベクトルを計算するために用いられる。
【0044】
ユーザ特徴ベクトル計算管理手段307は全ユーザのユーザ特徴ベクトルを保持し、当該情報をクラスタリング手段303へと提供する。また、特徴辞書、コンテンツのメタデータ、コンテンツ利用履歴管理手段310から受け取ったコンテンツ利用履歴に基づいて、更新対象ユーザについてのユーザ特徴ベクトルを計算する。また、計算された更新対象ユーザのユーザ特徴ベクトルを、ユーザ特徴ベクトル推定手段305へと渡す。そして、更新された特徴辞書について計算された更新対象ユーザのユーザ特徴ベクトルと、更新待ちユーザの推定されたユーザ特徴ベクトルとからなる全ユーザのユーザ特徴ベクトルを管理する。ユーザ特徴ベクトル計算管理手段307は、レコメンド情報を生成するために、全ユーザのユーザ特徴ベクトルをレコメンド情報生成手段309へと渡す。
【0045】
コンテンツ特徴ベクトル計算管理308は、特徴辞書とコンテンツのメタデータに基づいて、各コンテンツのコンテンツ特徴ベクトルを計算して管理する。また、コンテンツ特徴ベクトル計算管理308は、計算されたコンテンツ特徴ベクトルをレコメンド情報生成手段309へ渡す。
【0046】
レコメンド情報生成手段309は、全ユーザのユーザ特徴ベクトルとコンテンツ特徴ベクトルとの類似度を計算し、各ユーザのためのレコメンド情報を作成する。レコメンド情報生成手段309は、レコメンド情報を受信機側IF111に渡す。
【0047】
コンテンツ利用履歴管理手段310は、受信機側IF311から受け取ったユーザのコンテンツ利用履歴情報を管理する。また、コンテンツ利用履歴管理手段310は、コンテンツ利用履歴をユーザ特徴ベクトル計算手段307に渡す。また、コンテンツ利用履歴管理手段310は、コンテンツ利用履歴の更新のあったユーザ情報をユーザ情報管理手段304に渡す。
【0048】
受信機側IF311は、レコメンド情報生成手段309から受け取ったレコメンド情報を受信機へ送り、ユーザ端末101へと送信させる。また、ユーザ端末101から送信され、受信機で受信されたコンテンツ利用履歴を受け取り、コンテンツ利用履歴管理手段310に渡す。
【0049】
以上の構成により、本発明の一実施形態に係る当該レコメンド情報生成装置100は、特徴辞書が更新された後、更新対象ユーザのユーザ特徴ベクトルを計算し、その結果を参照して更新待ちユーザのユーザ特徴ベクトルを推定することができる。また、計算された更新対象ユーザのユーザ特徴ベクトルと推定された更新待ちユーザのユーザ特徴ベクトルとを用いて、全ユーザのユーザ特徴ベクトルを更新することなく、レコメンド情報を生成することができる。
【0050】
(4.処理フロー)
以下に、本発明の一実施形態によるレコメンド情報生成装置100の処理フローについて、実施例に沿って説明する。
【0051】
(4.1 特徴辞書更新直後の処理)
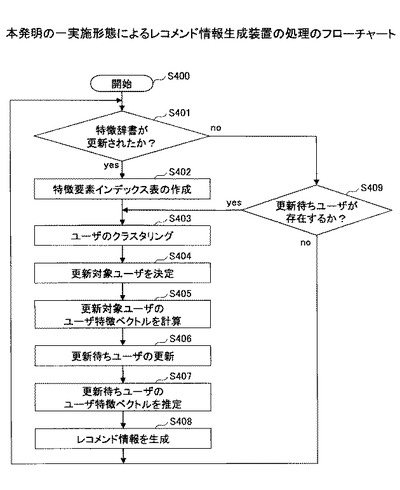
まず、図4乃至13を用いて、特徴辞書が更新された直後のレコメンド情報の生成に係る処理フローについて説明する。図4は、本発明の一実施形態によるレコメンド情報生成装置100がレコメンド情報の生成する処理のフローを表している。
【0052】
図4において、ステップS400から本発明の一実施形態によるレコメンド情報生成装置100の処理が開始される。
【0053】
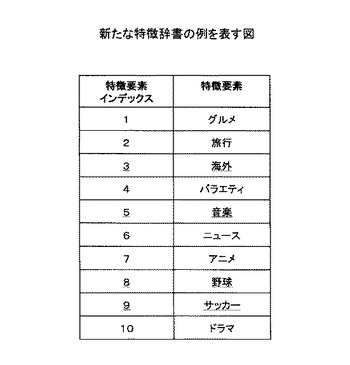
ステップS401において、特徴辞書管理手段302がオペレータIF301を通じて新たな特徴辞書を受け取った場合、すなわち特徴辞書が更新された場合にステップS402へと進む。そうでない場合にはステップS409へと進む(ステップS409の処理は次節で説明する)。本実施例では、図5に示した既存の特徴辞書を、図6に示した新たな特徴辞書で更新する例において説明を進める。
【0054】
ステップS402において、特徴辞書管理手段302は、新たな特徴辞書と既存の特徴辞書とを用いて、特徴要素インデックス表を作成する。本実施例においては、先述の通り、図7に示される特徴要素インデックス表が得られる。
【0055】
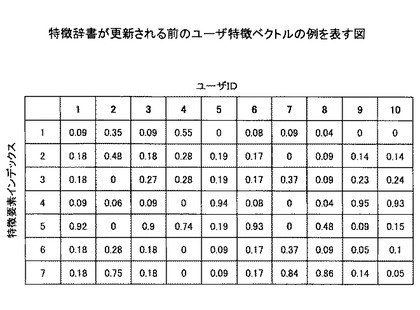
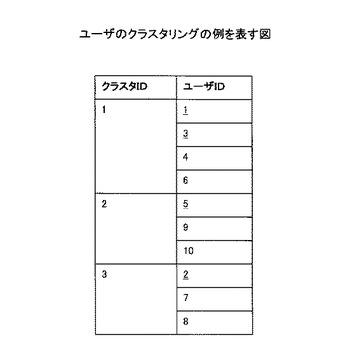
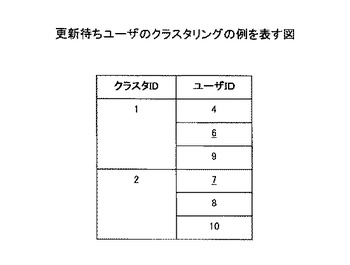
ステップS403において、クラスタリング手段303は、ユーザ特徴ベクトルを用いてユーザのクラスタリングを行う。本実施例においては、既存の特徴辞書についての全ユーザのユーザ特徴ベクトルが図8に示される通りであったとする。図8の表は、ユーザの識別子を表すユーザIDと、図5に対応する特徴要素インデックスとを有し、各ユーザの特徴要素ごとに、嗜好の強さを示す値を格納している。ここで、嗜好の強さを表す値は、0又は1以外の値で表され得る。図8のユーザ特徴ベクトルに基づいてクラスタリングを行った結果を図9に示す。図9の表は、クラスタの識別子を表すクラスタIDと、そのクラスタに属するユーザのユーザIDの項目を有し、図8で示されるユーザが3つのクラスタにクラスタリングされている。
【0056】
ステップS404において、更新対象ユーザ決定手段313は、クラスタごとに1人以上の更新対象ユーザを決定する。本実施例においては、前回レコメンド情報を生成された時以降に、新たにコンテンツ利用履歴をアップロードしたユーザのユーザIDが1、3、5のものであったとする。この時、更新対象ユーザ決定手段313は、ユーザIDが1、3、5のユーザを更新対象ユーザとして決定する。ここで、クラスタIDが3のクラスタについては、どのユーザもコンテンツ利用履歴をアップロードしていない。したがって、更新対象ユーザ決定手段313は、当該クラスタの中から、代表となるユーザ1名を更新対象ユーザとして決定する。ここでは、ユーザIDが2のユーザを更新対象ユーザとして決定する。以上の処理により、本実施例において、ユーザIDが1、3、5、2であるユーザが更新対象ユーザとして決定される(図9において更新対象ユーザを下線で示す)。
【0057】
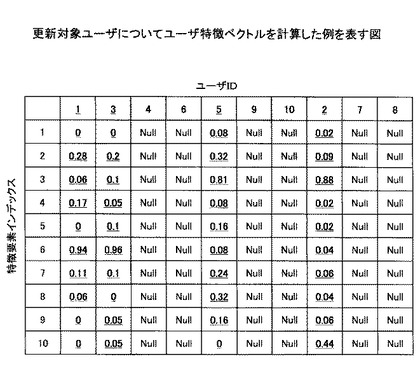
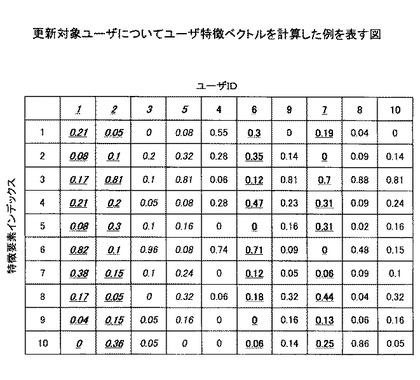
ステップS405において、ユーザ特徴ベクトル計算管理手段307は、更新対象ユーザのユーザ特徴ベクトルを、コンテンツ利用履歴、メタデータ、新たな特徴辞書に基づいて計算する。本実施例においては、ユーザIDが1、3、5、2のユーザに対してユーザ特徴ベクトルが計算され、それ以外のユーザについては計算されない。その結果の例を図10に示す(図10において計算された値を下線で示す)。
【0058】
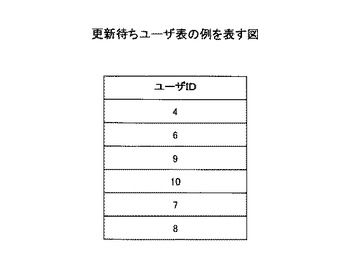
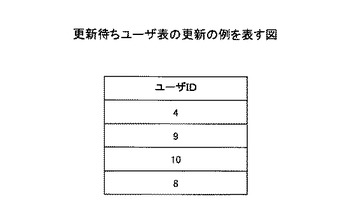
ステップS406において、ユーザ情報管理手段304は、ステップS405で更新対象ユーザとされなかったユーザを、更新待ちユーザとして管理する。本実施例においては、ユーザIDが4、6、9、10、7、8のユーザが更新待ちユーザとなる。ユーザ情報管理手段304は、例えば、図11に示される更新待ちユーザ表を用いて、更新待ちユーザを管理する。
【0059】
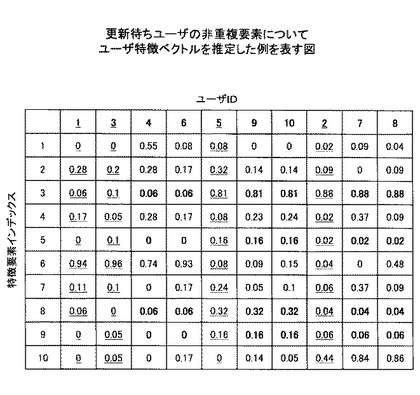
ステップS407において、ユーザ特徴ベクトル推定手段305は、更新待ちユーザのユーザ特徴ベクトルを推定する。ここで、更新待ちユーザのユーザ特徴ベクトルの推定方法を、図12、13を用いて実施例とともに説明する。
【0060】
まず、更新待ちユーザのユーザ特徴ベクトルのうち、重複要素特定手段312によって特定された新たな特徴辞書と既存の特徴辞書との重複要素について、既存の特徴辞書に対応するユーザ特徴ベクトルの値を、新たなユーザ特徴ベクトルへコピーする。ここで、コピーは図7の要素インデックス比較表をもとに、以下のように行われる。
a(n,i)=b(n,p(i))
ただし、b(n,null)=null
a:更新後の特徴辞書に則ったユーザ特徴ベクトル
b:更新前の特徴辞書に則ったユーザ特徴ベクトル
n:ユーザID
i:更新後の特徴辞書内の各特長要素(キーワード)の識別子
p(i):更新前の旧特徴要素インデックス(対応する特徴要素がない場合にはnullを示す)
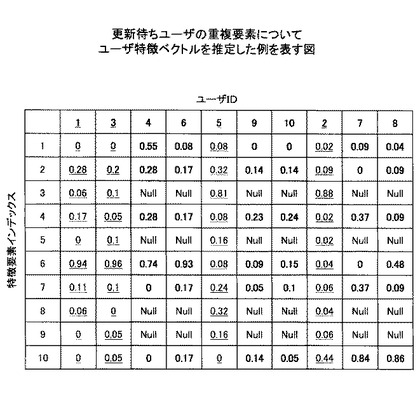
この処理により、更新待ちユーザのユーザ特徴ベクトルのうち、重複要素に対応する成分については該ユーザの更新前のユーザ特徴ベクトルと同じ値に設定される。この結果、図10の各ユーザ特徴ベクトルは図12のように更新される(図12においてコピーされた値を太字で示す)。
【0061】
図12の状態では、特徴ベクトル内に、値が入っていない(nullの)要素が存在する。これは新たな特徴辞書には存在するが、更新前の古い特徴辞書には規定されていなかったキーワードに対応する要素である。ここで、以下の処理を行う。
a(n,j)=a(m,j)
j:図7の旧特徴要素インデックスがnullとなるものに対応する新特徴要素のインデックス
m:ユーザnと同じクラスタに属するユーザであり、かつ、今回のユーザ特徴ベクトルで更新対象となったユーザの識別子(参照先ユーザ)
この処理により、更新待ちユーザのユーザ特徴ベクトルのうち、重複要素ではない非重複要素に対応する成分について、更新対象ユーザのユーザ特徴ベクトルと同じ値が設定される。これにより、更新待ちユーザのユーザ特徴ベクトルを、類似度の高い、すなわち嗜好性の近いユーザのユーザ特徴ベクトルから推定することによって得ることができる。なお、更新対象となったユーザがクラスタ内に複数存在する場合は、同一クラスタ内の任意のユーザ特徴ベクトルを参照してもよいし、最も類似度の高いユーザ特徴ベクトルを参照してもよい。また、更新対象となったユーザのユーザ特徴ベクトルの平均値を用いてもよい。
【0062】
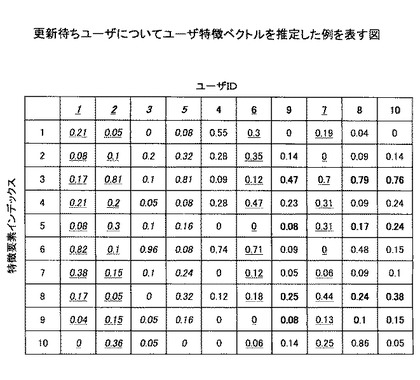
本実施例では、ユーザIDが4、6のユーザについては、同一クラスタ内のユーザIDが1のユーザを参照先ユーザとする。また、ユーザIDが9、10のユーザについては、同一クラスタ内のユーザIDが5のユーザを参照先ユーザとする。また、ユーザIDが7、8のユーザについては、同一クラスタ内のユーザIDが2のユーザを参照先ユーザとする。これにより、ユーザ特徴ベクトルは図13のようになる(図13において入力された値を太字で示す)。これによって全ユーザのユーザ特徴ベクトルが新たな特徴辞書に対応したことになる。
【0063】
図4のステップS408において、レコメンド情報生成手段309は、ユーザ特徴ベクトルに対する、各コンテンツ特徴ベクトルについて類似度を算出する。これによって、各ユーザ特徴ベクトルにおいて、類似度が大きいコンテンツ特徴ベクトルを割り出し、各ユーザに対して、レコメンド情報を生成する。
【0064】
以上の処理により、特徴辞書が更新された直後に、更新対象ユーザについてのみユーザ特徴ベクトルの再計算を行い、他のユーザについては、嗜好性の近い更新対象ユーザのユーザ特徴ベクトルに基づいて推定を行うことができる。これにより、特徴辞書が更新された直後のユーザ特徴ベクトルの更新にかかる負荷を軽減して、レコメンド情報を生成することができる。
【0065】
なお、ステップS406の更新待ちユーザの更新処理は、ステップS407において更新待ちユーザのユーザ特徴ベクトルの更新がなされるまでに完了していればよく、必ずしもステップS405の後に実行されなくてもよい。例えば、ステップ404において、更新対象ユーザが決定される際に同時に行われてもよい。
【0066】
(4.2 2回目以降の処理)
次に、図4、図14乃至16を用いて、前節における最初のユーザ特徴ベクトルの計算と推定が完了した後のレコメンド情報の生成に係る処理フローについて説明する。ここでは、上述の実施例における、図4のステップS400乃至S408が完了した後の、ステップS401からの処理について説明する。
【0067】
ステップS401において、前回のレコメンド情報生成S408以降に特徴辞書は更新されていないため、ステップS409へと進む。もしここで特徴辞書が更新されている場合には、上で説明した、特徴辞書が更新された直後の処理が、再度実行されることになる。
【0068】
ステップS409において、更新待ちユーザが存在する場合にはステップS403へと進む。更新待ちユーザが存在しない場合には、ステップS401へと進み、特徴辞書の更新を待つ。本実施例においては、図11の更新待ちユーザ表で管理される通り、更新待ちユーザが存在するため、ステップS403へと進む。
【0069】
ステップS403において、ユーザのクラスタリングを行う。本実施例においては、図11に示される、更新待ちユーザについてクラスタリングを行う。この時、先述のステップS405乃至S408で得たユーザ特徴ベクトルを用いる。クラスタリングの計算方法は、先に述べた方法と同様である。その結果は図14のようになる。ここでは、更新待ちユーザについてのみクラスタリングの対象とすることにより、特徴辞書の更新直後のクラスタリングと比較してユーザ数が減っているため、作成するクラスタの数を減らすことができ、クラスタリングの処理にかかる処理負荷を軽減することができる。なお、当該クラスタリングは、更新直後の処理と同様に、全ユーザを対象にクラスタリングしてもよい。
【0070】
ステップS404において、先に述べた方法と同様に、更新対象ユーザを決定する。本実施例では、前回のレコメンド情報生成時から本処理までの間に、コンテンツ利用履歴の更新があったユーザは、ユーザIDが1、2、6のユーザであったとする。この場合、更新対象ユーザは1、2、6となる。ここで、ユーザ1、2はクラスタリングの対象となっていないが、コンテンツ利用履歴が更新されているため、ユーザ特徴ベクトルが再計算される点に留意する。また、クラスタIDが2のクラスタは、どのユーザもコンテンツ利用履歴をアップロードしていないため、ここではユーザIDが7のユーザを更新対象ユーザに決定する。
【0071】
ステップS405において、更新対象ユーザのユーザ特徴ベクトルを計算する。本実施例においては、ユーザIDが1、2、6、7のユーザ特徴ベクトルを計算する。その結果、図15のようにユーザ特徴ベクトルは更新される(更新対象ユーザの更新されたユーザ特徴ベクトルは下線で示される。また、更新対象ユーザであるが、既に一度更新対象ユーザとして決定されていたため、今回クラスタリングの対象とされていないユーザ1、2については斜線で示される)。
【0072】
ステップS406において、ユーザ情報管理手段304は、新たに更新対象ユーザとして決定されたユーザを更新待ちユーザから外す。本実施例においては、ユーザIDが6、7のユーザを更新待ちユーザから外し、その結果、更新待ちユーザ表は図16のようになる。
【0073】
ステップS407において、更新待ちユーザである、ユーザIDが4,9、10,8であるユーザについて、ユーザ特徴ベクトルの推定を行う。上で述べた方法と同様に、図7の旧特徴要素インデックスがnullであるものについて、同一クラスタ内の更新対象ユーザのユーザ特徴ベクトルに基づいて値を推定する。
【0074】
ここで、推定方法は、上と同様に、参照先ユーザの値をそのままコピーしてもよいが、今回は、既に推定された値と今回参照する値とに基づいて算出してもよい。例えば、本実施例では以下のような方法を用いる。
【0075】
ユーザIDが4のユーザの特徴インデックス3について、同一クラスタ内の更新対象ユーザであるユーザIDが6のユーザのユーザ特徴ベクトルを元に推定する。現時点でのユーザIDが4のユーザの値は0.06であり、ユーザIDが6のユーザの値は0.12であるので、
(0.06+0.12)/2=0.09
とする。あるいは、重み付けの値として例えば0.7と0.3を用いて、
0.7×0.06+0.3×0.12=0.078
としてもよい。上記計算を残りのユーザに適用して、図17に示される全ユーザのユーザ特徴ベクトルが更新される(図17において、更新された値を太字で示す)。
【0076】
ステップS408において、先に述べたように、各ユーザ特徴ベクトルについてコンテンツ特徴ベクトルの類似度を計算することにより、各ユーザの嗜好性に基づいたレコメンド情報が生成される。
【0077】
以降、更新された特徴辞書に対して更新待ちユーザが存在しなくなるまで上記処理が繰り返され、最終的に全てのユーザ特徴ベクトルの更新が完了する。
【0078】
以上の処理により、特徴辞書が更新された後の、2回目以降のレコメンド情報生成においても、ユーザ特徴ベクトルの計算の負荷を軽減することができる。また、この時に、更新待ちユーザに嗜好性の近い複数のユーザのユーザ特徴ベクトルに基づきユーザ特徴ベクトルを推定することにより、精度を維持してレコメンド情報を生成することができる。
【符号の説明】
【0079】
100 レコメンド情報生成装置
301 オペレータIF
302 特徴辞書管理手段
303 クラスタリング手段
304 ユーザ情報管理手段
305 ユーザ特徴ベクトル推定手段
306 メタデータ管理手段
307 ユーザ特徴ベクトル計算管理手段
308 コンテンツ特徴ベクトル計算管理手段
309 レコメンド情報生成手段
310 コンテンツ利用履歴管理手段
311 受信機側IF
312 重複要素特定手段
313 更新対象ユーザ決定手段
【技術分野】
【0001】
本発明は、レコメンド情報生成装置、レコメンド情報生成方法及びレコメンド情報生成プログラムに関する。
【背景技術】
【0002】
レコメンデーション技術においては、ユーザが過去に利用したコンテンツをもとに、個人の嗜好性を学習し、当該ユーザに特徴が類似するコンテンツを推薦する。これを実現するための技術としては、非特許文献1にあるようにコンテンツフィルタリングという技術が用いられる。
【0003】
以下にコンテンツフィルタリングの方法について述べる。
【0004】
例として1日1回レコメンドを更新するような動画視聴サービスを想定する。また、ユーザが利用する端末(ユーザ端末)とレコメンド情報生成装置が互いに通信接続している形態で実現されているとする。このとき、ユーザ端末上でユーザが1つ以上の動画コンテンツを利用すると、ユーザ端末はそれらのコンテンツ利用履歴をレコメンド情報生成装置にアップロードする。その後、レコメンド情報生成装置は、非特許文献1にあるように次の3ステップで処理を行うことによりコンテンツフィルタリングを実現する。
(1)コンテンツを特徴付けるキーワード(特徴要素)を規定した特徴辞書を用いてコンテンツの特徴をコンテンツ特徴ベクトルとして表現する
(2)ユーザのコンテンツ利用履歴に基づき、各ユーザの嗜好性を示す、ユーザ特徴ベクトルを計算する
(3)コンテンツ特徴ベクトルとユーザ特徴ベクトルの類似度を計算し、類似度の高いコンテンツをレコメンド対象とする
【0005】
(1)においては、当該サービスで提供しているコンテンツそれぞれについてコンテンツ特徴ベクトルを計算することになる。コンテンツ特徴ベクトルにおけるベクトルの各要素は特徴要素で表される。特徴要素は、コンテンツを特徴付けると考えられるキーワードであり、どのようなキーワードを特徴要素とするかを規定したものが特徴辞書である。具体的には{野球、感動、空、・・・}などのキーワードの羅列がもっとも単純な特徴辞書の例である。
【0006】
ここで各コンテンツに付随するメタデータに対して、特徴辞書内のキーワードがどれだけ含まれているか、についてそれぞれ計算を行う。例えば、あるコンテンツのメタデータには「野球」という言葉が1つ入っており、「空」という言葉が1つ入っていれば、コンテンツ特徴ベクトルのそれぞれの特徴要素は{1,0,1,・・・}のように表すことができる。このように、コンテンツ特徴ベクトルの成分は、コンテンツ及び特徴要素に応じた値を有する。該ユーザが好むコンテンツ及び前記特徴要素に応じた値を有することとなる。この例では、どのキーワードについても1つ入っていたら、特徴要素の値を1としたが、これはもっとも単純な例であり、キーワードによってその値は可変であってもかまわない。この計算を当該サービスで提供しているコンテンツそれぞれについて実施すると次の(2)に処理が移る。
【0007】
次に(2)ではユーザ特徴ベクトルを計算する。
【0008】
全ユーザのうち、この処理で対象となるユーザは、通常、最後にレコメンド情報を生成した日時以降に、新たにコンテンツ利用履歴を送ってきたユーザとなる。なぜなら、新たにコンテンツ利用履歴を送ってきていないユーザは利用履歴に変化がないため、前回計算時からユーザ特徴ベクトルを更新する必要がないからである。
【0009】
ユーザのこれまでのコンテンツ利用履歴(新たに送ってきた分のみならず、過去の分も含む)に含まれるコンテンツのメタデータを先ほどの特徴辞書内のキーワードを以ってマッチングをかける。利用したコンテンツが複数あればその分マッチング対象となるメタデータも複数となる。例えばこれまでに10個のコンテンツのコンテンツ利用履歴をアップロードしたユーザの場合は、当該10個のコンテンツに付随するメタデータ全体に対して、キーワードをマッチングさせることになる。計算方法は(1)と同様に実現できる。この結果、ユーザのユーザ特徴ベクトルの成分は、該ユーザが好むコンテンツ及び特徴要素に応じた値を有することとなる。
【0010】
最後に(3)で全てのユーザ特徴ベクトルと、全てのコンテンツ特徴ベクトルの類似度を計算し、各ユーザについて類似度の近いコンテンツ特徴ベクトルを持つコンテンツのIDを記載したレコメンドリストを作成する。
【0011】
以上が、通常のレコメンド計算の概要である。
【0012】
ユーザの関心を推定するための特徴ベクトルの類似度を計算する例は、特許文献1又は特許文献2に開示されている。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開2009−74664号公報
【特許文献2】特開2004−348607号公報
【非特許文献】
【0014】
【非特許文献1】深澤,宮川,原,太田著「Ranking SVMを用いたコンテンツフィルタリングレコメンドシステムの開発」、人工知能学会論文誌12巻1号a,1997年
【発明の概要】
【発明が解決しようとする課題】
【0015】
ところが、例えば、新たな固有名詞を取り込むための特徴辞書の更新がなされた場合、全ユーザを対象にユーザ特徴ベクトルの更新を行う必要がある。特徴辞書の更新に伴う全ユーザのユーザ特徴ベクトルの更新には、通常時のユーザ特徴ベクトルの計算に比べて、一般に数倍の計算量が必要となる。ユーザレコメンド情報を随時提供するためには、一定の時間内にユーザ特徴ベクトル計算処理を完了しなければならないが、特徴辞書の更新時の計算量に合わせて計算リソースを準備するのは経済的に非効率である。
【0016】
本発明は、上記問題に鑑みてなされたものであり、特徴辞書を更新した後のユーザ特徴ベクトルの計算にかかる負荷を軽減することを目的とする。
【課題を解決するための手段】
【0017】
上述した課題を解決し目的を達成するため、本発明にかかるレコメンド情報生成装置は、特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成装置であって、更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定手段と、更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定手段と、を有する。
【発明の効果】
【0018】
本発明によれば、特徴辞書を更新した後のユーザ特徴ベクトルの計算にかかる負荷を軽減することができる。
【図面の簡単な説明】
【0019】
【図1】本発明の一実施形態におけるレコメンド情報生成装置の概要を表す図。
【図2】本発明の一実施形態におけるレコメンド情報生成装置のハードウェア構成例を表す図。
【図3】本発明の一実施形態によるレコメンド情報生成装置の機能ブロック図。
【図4】本発明の一実施形態によるレコメンド情報生成装置の処理のフローチャート。
【図5】既存の特徴辞書の例を表す図。
【図6】新たな特徴辞書の例を表す図。
【図7】特徴要素インデックス表の例を表す図。
【図8】特徴辞書が更新される前のユーザ特徴ベクトルの例を表す図。
【図9】ユーザのクラスタリングの例を表す図。
【図10】更新対象ユーザについてユーザ特徴ベクトルを計算した例を表す図。
【図11】更新待ちユーザ表の例を表す図。
【図12】更新待ちユーザの重複要素についてユーザ特徴ベクトルを推定した例を表す図。
【図13】更新待ちユーザの非重複要素についてユーザ特徴ベクトルを推定した例を表す図。
【図14】更新待ちユーザのクラスタリングの例を表す図。
【図15】更新対象ユーザについてユーザ特徴ベクトルを計算した例を表す図。
【図16】更新待ちユーザ表の更新の例を表す図。
【図17】更新待ちユーザについてユーザ特徴ベクトルを推定した例を表す図。
【発明を実施するための形態】
【0020】
以下、本発明の実施形態を図面に基づいて説明する。
【0021】
1.概要
2.ハードウェア構成
3.機能
4.処理フロー
4.1 特徴辞書更新直後の処理
4.2 2回目以降の処理
【0022】
(1.概要)
図1は、本発明の一実施形態におけるレコメンド情報生成装置100を含むシステム1の概要を表す。システム1は、レコメンド情報生成装置100と複数のユーザ端末101とを有する。
【0023】
レコメンド情報生成装置100は、特徴辞書を用いて、コンテンツ利用履歴を送信したユーザ端末101のユーザのユーザ特徴ベクトルを更新する。レコメンド情報生成装置100は、特徴辞書が更新された場合には、一部のユーザのユーザ特徴ベクトルのみを再計算する。一部のユーザとは、ユーザをクラスタリングして得られるクラスタの代表ユーザである。代表ユーザには、特徴辞書が更新された後、コンテンツ利用履歴を送信したユーザが含まれる。一方で、レコメンド情報生成装置100は、代表ユーザでない他のユーザのユーザ特徴ベクトルを、再計算された代表ユーザのユーザ特徴ベクトルに基づいて推定する。そして、得られた全ユーザのユーザ特徴ベクトルを用いてレコメンド情報を生成する。
【0024】
ユーザ端末101は、ユーザがコンテンツの利用に用いる端末であり、コンテンツを利用するたびに、又は一定の間隔ごとに、コンテンツ利用履歴をレコメンド情報生成装置100に対して送信する。コンテンツ利用履歴は、一般的にはインターネット等のネットワークを用いて送信される。
【0025】
このように、システム1に含まれるレコメンド情報生成装置100は、特徴辞書が更新された後に、一部のユーザのユーザ特徴ベクトルを推定してレコメンド情報を生成することで、処理負荷の急増を抑制することが可能となる。
【0026】
(2.ハードウェア構成)
図2は、本発明の一実施形態におけるレコメンド情報生成装置100のハードウェア構成例を表す。レコメンド情報生成装置100は、CPU200、ROM201、RAM202、HDD203、ネットワークコントーラ204、通信装置205、グラフィックスコントローラ206、表示装置207、入力コントローラ208、入力装置209、バス210を有する。
【0027】
CPU200は、本発明の一実施形態におけるレコメンド情報生成装置100で実行可能なレコメンド情報生成プログラムの動作制御を行う。ROM201は、CPU200が実行するレコメンド情報生成プログラムの動作に必要なOSやデータ等を記憶する。RAM202は、CPU200のワークエリア等を構成する。HDD203は、レコメンド情報生成プログラム本体や特徴辞書、ユーザ特徴ベクトル、コンテンツ特徴ベクトル、ユーザ情報、コンテンツのメタデータ等を記憶する。ネットワークコントローラ204は、通信装置205を介して、ネットワークに接続されるユーザ端末101と通信を行うための通信制御を行う。グラフィックスコントローラ206は、CRT又は液晶ディスプレイ等の表示装置207を介して、当該レコメンド情報生成装置100のオペレータに操作画面や情報を提供するための制御を行う。入力コントローラ208は、キーボード又はマウス等の入力装置209を介してオペレータから入力される信号を制御する。バス210は、当該レコメンド情報生成装置100を構成する上記装置を相互に接続し、データのやり取りを行うためのものである。
【0028】
上記構成により、本発明の一実施形態に係る当該レコメンド情報生成装置100は、特徴辞書が更新された後に、一部のユーザのユーザ特徴ベクトルを推定し、これを用いてレコメンド情報を生成することができる。
【0029】
なお、当該レコメンド情報生成装置100は、ユーザ端末101からアクセス可能なサーバ装置に統合されて提供されてもよい。このような場合には、レコメンド情報生成装置100は、ネットワーク上の他の通信端末から操作され得るため、表示装置207、入力装置209は備えなくてもよい。
【0030】
また、HDD203は、テーブドライブであってもよい。または、HDD203の有する機能が、ネットワーク上の、通信装置205を通じてアクセス可能な記憶装置に含まれていてもよい。
【0031】
(3.機能)
図3は、本発明の一実施形態によるレコメンド情報生成装置100の機能ブロック図を表す。レコメンド情報生成装置100は、オペレータIF301、特徴辞書管理手段302、クラスタリング手段303、ユーザ情報管理手段304、ユーザ特徴ベクトル推定手段305、メタデータ管理手段306、ユーザ特徴ベクトル計算管理手段307、コンテンツ特徴ベクトル計算管理手段308、レコメンド情報生成手段309、コンテンツ利用履歴管理手段310、受信機側IF311を有する。
【0032】
オペレータIF301は、オペレータが入力した更新された特徴辞書を受け取り、特徴辞書管理手段302に渡す。
【0033】
特徴辞書管理手段302は、重複要素特定手段312を有し、オペレータIF301から受け取った新たな特徴辞書と既存の特徴辞書とを管理する。また、特徴辞書管理手段302は、新たな特徴辞書に含まれるキーワードと、既存の特徴辞書に含まれるキーワードとを比較し、両方に含まれるキーワードを関連付けた特徴要素インデックス表を作成する。特徴要素インデックス表の具体例を図7に示す。以下、図7の例に基づいて情報要素インデックス表について説明する。
【0034】
例えば、図5に示されるような既存の特徴辞書と、図6に示されるような新たな特徴辞書とが管理されているとする(図6において新たに追加された特徴要素を下線で示す)。図5と図6の表は、それぞれ特徴要素インデックスと特徴要素の項目を有する。特徴要素インデックスとは、特徴辞書内の特徴要素を一意に特定するインデックス番号であり、特徴要素はコンテンツの特徴を表すためのキーワードである。特徴辞書管理手段302は、この二つの特徴辞書の特徴要素を比較し、重複要素特定手段312によって重複する特徴要素(以下、「重複要素」とする)を特定する。そして、図7に示すように、重複する特徴要素について、新しい特徴辞書の特徴要素インデックス(新特徴要素インデックス)と、既存の特徴辞書の特徴要素インデックス(旧特徴要素インデックス)とを関連付ける(新たに追加された特徴要素を下線で示す)。
【0035】
特徴辞書管理手段302は、ユーザ特徴ベクトルの推定を行うために、特徴辞書と特徴要素インデックス表とをユーザ特徴ベクトル推定手段305に渡す。また、特徴辞書管理手段302は、ユーザ特徴ベクトルとコンテンツ特徴ベクトルの計算のために、特徴辞書をユーザ特徴ベクトル計算管理手段307及びコンテンツ特徴ベクトル計算管理手段308に渡す。
【0036】
クラスタリング手段303は、計算済又は更新済のユーザ特徴ベクトルに基づいてユーザのクラスタリングを行う。クラスタリングは、ユーザ特徴ベクトルの間の類似度が近いもの同士でクラスタを形成するようにする。類似度が近いものを特定するために、例えば以下で表されるコサイン距離を用いられるが、その他の適切な方法で算出してもよい。
<x・y>/(|x||y|)
<x・y>:ベクトルxとベクトルyとの内積
|x|:ベクトルxのノルム
クラスタリング手法は、k-means法など如何なる適切な方法でよい。クラスタ数は、全ユーザ数以下の他の適切な数でもよい。計算結果となるクラスタ情報は、更新対象ユーザ決定手段313に渡される。
【0037】
ユーザ情報管理手段304は、更新対象ユーザ決定手段313を有し、更新された特徴辞書に関して、ユーザ特徴ベクトルを計算するユーザ(以下、「更新対象ユーザ」とする)と、推定により求めるユーザ(以下、「更新待ちユーザ」とする)とを管理する。
【0038】
更新対象ユーザ決定手段313は、受け取ったクラスタ情報に基づいて、更新対象ユーザを決定する。更新対象ユーザは、少なくとも1つのクラスタから1人の更新対象ユーザが決定されるように定められる。まず、前回レコメンド情報を生成した時以降にコンテンツ利用履歴の更新があったユーザを、更新対象ユーザとして決定する。次に、コンテンツ利用履歴を送信したユーザが存在しないクラスタ内から、例えばコンテンツの利用率の高い一人以上のユーザを更新対象ユーザに決定する。なお、更新対象ユーザの総数は、例えば当該レコメンド情報生成装置100に関連するユーザの数とその利用率との乗算によって定めることができる。利用率とは、例えば全ユーザにおけるアクティブユーザの割合などがある。この例において、ユーザの数が10人であり、アクティブユーザの割合が30%であるとすれば、更新対象ユーザの数は3人とすることができる。
【0039】
ここで、更新された特徴辞書に対し、一度も更新対象ユーザに選ばれていないユーザは、更新待ちユーザとして管理される。例えば、更新待ちユーザは、図11に例示されるように、更新待ちユーザ表を用いて管理される。更新待ちユーザ表に記載されるユーザが、一度更新対象ユーザとして選定されると、当該表からは削除される。
【0040】
ユーザ情報管理手段304は、更新対象ユーザ決定手段313が決定した更新対象ユーザの情報を、ユーザ特徴ベクトル計算管理手段307に渡す。また、ユーザ情報管理手段304は、更新待ちユーザ表に基づいて更新待ちユーザの情報をユーザ特徴ベクトル推定手段305に渡す。
【0041】
ユーザ情報管理手段304は、更新待ちユーザのユーザ特徴ベクトルの推定のために必要な、参照すべきユーザ(以下、「参照先ユーザ」とする)の情報も、ユーザ特徴ベクトル推定手段305に渡す。参照先ユーザは、同一クラスタ内の更新対象ユーザである。同一クラスタ内の更新対象ユーザの、計算されたユーザ特徴ベクトルが、更新待ちユーザのユーザ特徴ベクトルの推定のために用いられる。ここで、同一クラスタ内に複数の更新対象ユーザが存在する場合には、ユーザ特徴ベクトルの類似度が高い方を参照先ユーザとすることができる。
【0042】
ユーザ特徴ベクトル推定手段305は、更新された特徴辞書に基づいて、更新待ちユーザのユーザ特徴ベクトルを推定する。この時、ユーザ情報管理手段304から受け取った、参照先ユーザの情報を用いて、ユーザ特徴ベクトルを推定する。具体的な推定の処理は、後に実施例に基づき説明する。ユーザ特徴ベクトル推定手段305は、推定された更新待ちユーザのユーザ特徴ベクトルをユーザ特徴ベクトル計算管理手段307へと渡す。
【0043】
メタデータ管理手段306は、ユーザに提供されるコンテンツのメタデータを管理し、ユーザ特徴ベクトル計算管理手段307及びコンテンツ特徴ベクトル計算管理手段308へ渡す。メタデータには、特徴辞書内で指定されるようなキーワードが含まれ、ユーザ特徴ベクトル又はコンテンツ特徴ベクトルを計算するために用いられる。
【0044】
ユーザ特徴ベクトル計算管理手段307は全ユーザのユーザ特徴ベクトルを保持し、当該情報をクラスタリング手段303へと提供する。また、特徴辞書、コンテンツのメタデータ、コンテンツ利用履歴管理手段310から受け取ったコンテンツ利用履歴に基づいて、更新対象ユーザについてのユーザ特徴ベクトルを計算する。また、計算された更新対象ユーザのユーザ特徴ベクトルを、ユーザ特徴ベクトル推定手段305へと渡す。そして、更新された特徴辞書について計算された更新対象ユーザのユーザ特徴ベクトルと、更新待ちユーザの推定されたユーザ特徴ベクトルとからなる全ユーザのユーザ特徴ベクトルを管理する。ユーザ特徴ベクトル計算管理手段307は、レコメンド情報を生成するために、全ユーザのユーザ特徴ベクトルをレコメンド情報生成手段309へと渡す。
【0045】
コンテンツ特徴ベクトル計算管理308は、特徴辞書とコンテンツのメタデータに基づいて、各コンテンツのコンテンツ特徴ベクトルを計算して管理する。また、コンテンツ特徴ベクトル計算管理308は、計算されたコンテンツ特徴ベクトルをレコメンド情報生成手段309へ渡す。
【0046】
レコメンド情報生成手段309は、全ユーザのユーザ特徴ベクトルとコンテンツ特徴ベクトルとの類似度を計算し、各ユーザのためのレコメンド情報を作成する。レコメンド情報生成手段309は、レコメンド情報を受信機側IF111に渡す。
【0047】
コンテンツ利用履歴管理手段310は、受信機側IF311から受け取ったユーザのコンテンツ利用履歴情報を管理する。また、コンテンツ利用履歴管理手段310は、コンテンツ利用履歴をユーザ特徴ベクトル計算手段307に渡す。また、コンテンツ利用履歴管理手段310は、コンテンツ利用履歴の更新のあったユーザ情報をユーザ情報管理手段304に渡す。
【0048】
受信機側IF311は、レコメンド情報生成手段309から受け取ったレコメンド情報を受信機へ送り、ユーザ端末101へと送信させる。また、ユーザ端末101から送信され、受信機で受信されたコンテンツ利用履歴を受け取り、コンテンツ利用履歴管理手段310に渡す。
【0049】
以上の構成により、本発明の一実施形態に係る当該レコメンド情報生成装置100は、特徴辞書が更新された後、更新対象ユーザのユーザ特徴ベクトルを計算し、その結果を参照して更新待ちユーザのユーザ特徴ベクトルを推定することができる。また、計算された更新対象ユーザのユーザ特徴ベクトルと推定された更新待ちユーザのユーザ特徴ベクトルとを用いて、全ユーザのユーザ特徴ベクトルを更新することなく、レコメンド情報を生成することができる。
【0050】
(4.処理フロー)
以下に、本発明の一実施形態によるレコメンド情報生成装置100の処理フローについて、実施例に沿って説明する。
【0051】
(4.1 特徴辞書更新直後の処理)
まず、図4乃至13を用いて、特徴辞書が更新された直後のレコメンド情報の生成に係る処理フローについて説明する。図4は、本発明の一実施形態によるレコメンド情報生成装置100がレコメンド情報の生成する処理のフローを表している。
【0052】
図4において、ステップS400から本発明の一実施形態によるレコメンド情報生成装置100の処理が開始される。
【0053】
ステップS401において、特徴辞書管理手段302がオペレータIF301を通じて新たな特徴辞書を受け取った場合、すなわち特徴辞書が更新された場合にステップS402へと進む。そうでない場合にはステップS409へと進む(ステップS409の処理は次節で説明する)。本実施例では、図5に示した既存の特徴辞書を、図6に示した新たな特徴辞書で更新する例において説明を進める。
【0054】
ステップS402において、特徴辞書管理手段302は、新たな特徴辞書と既存の特徴辞書とを用いて、特徴要素インデックス表を作成する。本実施例においては、先述の通り、図7に示される特徴要素インデックス表が得られる。
【0055】
ステップS403において、クラスタリング手段303は、ユーザ特徴ベクトルを用いてユーザのクラスタリングを行う。本実施例においては、既存の特徴辞書についての全ユーザのユーザ特徴ベクトルが図8に示される通りであったとする。図8の表は、ユーザの識別子を表すユーザIDと、図5に対応する特徴要素インデックスとを有し、各ユーザの特徴要素ごとに、嗜好の強さを示す値を格納している。ここで、嗜好の強さを表す値は、0又は1以外の値で表され得る。図8のユーザ特徴ベクトルに基づいてクラスタリングを行った結果を図9に示す。図9の表は、クラスタの識別子を表すクラスタIDと、そのクラスタに属するユーザのユーザIDの項目を有し、図8で示されるユーザが3つのクラスタにクラスタリングされている。
【0056】
ステップS404において、更新対象ユーザ決定手段313は、クラスタごとに1人以上の更新対象ユーザを決定する。本実施例においては、前回レコメンド情報を生成された時以降に、新たにコンテンツ利用履歴をアップロードしたユーザのユーザIDが1、3、5のものであったとする。この時、更新対象ユーザ決定手段313は、ユーザIDが1、3、5のユーザを更新対象ユーザとして決定する。ここで、クラスタIDが3のクラスタについては、どのユーザもコンテンツ利用履歴をアップロードしていない。したがって、更新対象ユーザ決定手段313は、当該クラスタの中から、代表となるユーザ1名を更新対象ユーザとして決定する。ここでは、ユーザIDが2のユーザを更新対象ユーザとして決定する。以上の処理により、本実施例において、ユーザIDが1、3、5、2であるユーザが更新対象ユーザとして決定される(図9において更新対象ユーザを下線で示す)。
【0057】
ステップS405において、ユーザ特徴ベクトル計算管理手段307は、更新対象ユーザのユーザ特徴ベクトルを、コンテンツ利用履歴、メタデータ、新たな特徴辞書に基づいて計算する。本実施例においては、ユーザIDが1、3、5、2のユーザに対してユーザ特徴ベクトルが計算され、それ以外のユーザについては計算されない。その結果の例を図10に示す(図10において計算された値を下線で示す)。
【0058】
ステップS406において、ユーザ情報管理手段304は、ステップS405で更新対象ユーザとされなかったユーザを、更新待ちユーザとして管理する。本実施例においては、ユーザIDが4、6、9、10、7、8のユーザが更新待ちユーザとなる。ユーザ情報管理手段304は、例えば、図11に示される更新待ちユーザ表を用いて、更新待ちユーザを管理する。
【0059】
ステップS407において、ユーザ特徴ベクトル推定手段305は、更新待ちユーザのユーザ特徴ベクトルを推定する。ここで、更新待ちユーザのユーザ特徴ベクトルの推定方法を、図12、13を用いて実施例とともに説明する。
【0060】
まず、更新待ちユーザのユーザ特徴ベクトルのうち、重複要素特定手段312によって特定された新たな特徴辞書と既存の特徴辞書との重複要素について、既存の特徴辞書に対応するユーザ特徴ベクトルの値を、新たなユーザ特徴ベクトルへコピーする。ここで、コピーは図7の要素インデックス比較表をもとに、以下のように行われる。
a(n,i)=b(n,p(i))
ただし、b(n,null)=null
a:更新後の特徴辞書に則ったユーザ特徴ベクトル
b:更新前の特徴辞書に則ったユーザ特徴ベクトル
n:ユーザID
i:更新後の特徴辞書内の各特長要素(キーワード)の識別子
p(i):更新前の旧特徴要素インデックス(対応する特徴要素がない場合にはnullを示す)
この処理により、更新待ちユーザのユーザ特徴ベクトルのうち、重複要素に対応する成分については該ユーザの更新前のユーザ特徴ベクトルと同じ値に設定される。この結果、図10の各ユーザ特徴ベクトルは図12のように更新される(図12においてコピーされた値を太字で示す)。
【0061】
図12の状態では、特徴ベクトル内に、値が入っていない(nullの)要素が存在する。これは新たな特徴辞書には存在するが、更新前の古い特徴辞書には規定されていなかったキーワードに対応する要素である。ここで、以下の処理を行う。
a(n,j)=a(m,j)
j:図7の旧特徴要素インデックスがnullとなるものに対応する新特徴要素のインデックス
m:ユーザnと同じクラスタに属するユーザであり、かつ、今回のユーザ特徴ベクトルで更新対象となったユーザの識別子(参照先ユーザ)
この処理により、更新待ちユーザのユーザ特徴ベクトルのうち、重複要素ではない非重複要素に対応する成分について、更新対象ユーザのユーザ特徴ベクトルと同じ値が設定される。これにより、更新待ちユーザのユーザ特徴ベクトルを、類似度の高い、すなわち嗜好性の近いユーザのユーザ特徴ベクトルから推定することによって得ることができる。なお、更新対象となったユーザがクラスタ内に複数存在する場合は、同一クラスタ内の任意のユーザ特徴ベクトルを参照してもよいし、最も類似度の高いユーザ特徴ベクトルを参照してもよい。また、更新対象となったユーザのユーザ特徴ベクトルの平均値を用いてもよい。
【0062】
本実施例では、ユーザIDが4、6のユーザについては、同一クラスタ内のユーザIDが1のユーザを参照先ユーザとする。また、ユーザIDが9、10のユーザについては、同一クラスタ内のユーザIDが5のユーザを参照先ユーザとする。また、ユーザIDが7、8のユーザについては、同一クラスタ内のユーザIDが2のユーザを参照先ユーザとする。これにより、ユーザ特徴ベクトルは図13のようになる(図13において入力された値を太字で示す)。これによって全ユーザのユーザ特徴ベクトルが新たな特徴辞書に対応したことになる。
【0063】
図4のステップS408において、レコメンド情報生成手段309は、ユーザ特徴ベクトルに対する、各コンテンツ特徴ベクトルについて類似度を算出する。これによって、各ユーザ特徴ベクトルにおいて、類似度が大きいコンテンツ特徴ベクトルを割り出し、各ユーザに対して、レコメンド情報を生成する。
【0064】
以上の処理により、特徴辞書が更新された直後に、更新対象ユーザについてのみユーザ特徴ベクトルの再計算を行い、他のユーザについては、嗜好性の近い更新対象ユーザのユーザ特徴ベクトルに基づいて推定を行うことができる。これにより、特徴辞書が更新された直後のユーザ特徴ベクトルの更新にかかる負荷を軽減して、レコメンド情報を生成することができる。
【0065】
なお、ステップS406の更新待ちユーザの更新処理は、ステップS407において更新待ちユーザのユーザ特徴ベクトルの更新がなされるまでに完了していればよく、必ずしもステップS405の後に実行されなくてもよい。例えば、ステップ404において、更新対象ユーザが決定される際に同時に行われてもよい。
【0066】
(4.2 2回目以降の処理)
次に、図4、図14乃至16を用いて、前節における最初のユーザ特徴ベクトルの計算と推定が完了した後のレコメンド情報の生成に係る処理フローについて説明する。ここでは、上述の実施例における、図4のステップS400乃至S408が完了した後の、ステップS401からの処理について説明する。
【0067】
ステップS401において、前回のレコメンド情報生成S408以降に特徴辞書は更新されていないため、ステップS409へと進む。もしここで特徴辞書が更新されている場合には、上で説明した、特徴辞書が更新された直後の処理が、再度実行されることになる。
【0068】
ステップS409において、更新待ちユーザが存在する場合にはステップS403へと進む。更新待ちユーザが存在しない場合には、ステップS401へと進み、特徴辞書の更新を待つ。本実施例においては、図11の更新待ちユーザ表で管理される通り、更新待ちユーザが存在するため、ステップS403へと進む。
【0069】
ステップS403において、ユーザのクラスタリングを行う。本実施例においては、図11に示される、更新待ちユーザについてクラスタリングを行う。この時、先述のステップS405乃至S408で得たユーザ特徴ベクトルを用いる。クラスタリングの計算方法は、先に述べた方法と同様である。その結果は図14のようになる。ここでは、更新待ちユーザについてのみクラスタリングの対象とすることにより、特徴辞書の更新直後のクラスタリングと比較してユーザ数が減っているため、作成するクラスタの数を減らすことができ、クラスタリングの処理にかかる処理負荷を軽減することができる。なお、当該クラスタリングは、更新直後の処理と同様に、全ユーザを対象にクラスタリングしてもよい。
【0070】
ステップS404において、先に述べた方法と同様に、更新対象ユーザを決定する。本実施例では、前回のレコメンド情報生成時から本処理までの間に、コンテンツ利用履歴の更新があったユーザは、ユーザIDが1、2、6のユーザであったとする。この場合、更新対象ユーザは1、2、6となる。ここで、ユーザ1、2はクラスタリングの対象となっていないが、コンテンツ利用履歴が更新されているため、ユーザ特徴ベクトルが再計算される点に留意する。また、クラスタIDが2のクラスタは、どのユーザもコンテンツ利用履歴をアップロードしていないため、ここではユーザIDが7のユーザを更新対象ユーザに決定する。
【0071】
ステップS405において、更新対象ユーザのユーザ特徴ベクトルを計算する。本実施例においては、ユーザIDが1、2、6、7のユーザ特徴ベクトルを計算する。その結果、図15のようにユーザ特徴ベクトルは更新される(更新対象ユーザの更新されたユーザ特徴ベクトルは下線で示される。また、更新対象ユーザであるが、既に一度更新対象ユーザとして決定されていたため、今回クラスタリングの対象とされていないユーザ1、2については斜線で示される)。
【0072】
ステップS406において、ユーザ情報管理手段304は、新たに更新対象ユーザとして決定されたユーザを更新待ちユーザから外す。本実施例においては、ユーザIDが6、7のユーザを更新待ちユーザから外し、その結果、更新待ちユーザ表は図16のようになる。
【0073】
ステップS407において、更新待ちユーザである、ユーザIDが4,9、10,8であるユーザについて、ユーザ特徴ベクトルの推定を行う。上で述べた方法と同様に、図7の旧特徴要素インデックスがnullであるものについて、同一クラスタ内の更新対象ユーザのユーザ特徴ベクトルに基づいて値を推定する。
【0074】
ここで、推定方法は、上と同様に、参照先ユーザの値をそのままコピーしてもよいが、今回は、既に推定された値と今回参照する値とに基づいて算出してもよい。例えば、本実施例では以下のような方法を用いる。
【0075】
ユーザIDが4のユーザの特徴インデックス3について、同一クラスタ内の更新対象ユーザであるユーザIDが6のユーザのユーザ特徴ベクトルを元に推定する。現時点でのユーザIDが4のユーザの値は0.06であり、ユーザIDが6のユーザの値は0.12であるので、
(0.06+0.12)/2=0.09
とする。あるいは、重み付けの値として例えば0.7と0.3を用いて、
0.7×0.06+0.3×0.12=0.078
としてもよい。上記計算を残りのユーザに適用して、図17に示される全ユーザのユーザ特徴ベクトルが更新される(図17において、更新された値を太字で示す)。
【0076】
ステップS408において、先に述べたように、各ユーザ特徴ベクトルについてコンテンツ特徴ベクトルの類似度を計算することにより、各ユーザの嗜好性に基づいたレコメンド情報が生成される。
【0077】
以降、更新された特徴辞書に対して更新待ちユーザが存在しなくなるまで上記処理が繰り返され、最終的に全てのユーザ特徴ベクトルの更新が完了する。
【0078】
以上の処理により、特徴辞書が更新された後の、2回目以降のレコメンド情報生成においても、ユーザ特徴ベクトルの計算の負荷を軽減することができる。また、この時に、更新待ちユーザに嗜好性の近い複数のユーザのユーザ特徴ベクトルに基づきユーザ特徴ベクトルを推定することにより、精度を維持してレコメンド情報を生成することができる。
【符号の説明】
【0079】
100 レコメンド情報生成装置
301 オペレータIF
302 特徴辞書管理手段
303 クラスタリング手段
304 ユーザ情報管理手段
305 ユーザ特徴ベクトル推定手段
306 メタデータ管理手段
307 ユーザ特徴ベクトル計算管理手段
308 コンテンツ特徴ベクトル計算管理手段
309 レコメンド情報生成手段
310 コンテンツ利用履歴管理手段
311 受信機側IF
312 重複要素特定手段
313 更新対象ユーザ決定手段
【特許請求の範囲】
【請求項1】
特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成装置であって、
更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定手段と、
更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定手段と、
を有する、レコメンド情報生成装置。
【請求項2】
ユーザ特徴ベクトルを用いて複数のユーザを複数のクラスタにクラスタリングするクラスタリング手段と、
を有し、
前記更新対象ユーザ決定手段は、
前記複数のクラスタのうち、該クラスタに属するユーザであって、コンテンツの利用履歴をアップロードしたユーザが存在するクラスタ(第1のクラスタ)について、前記ユーザを前記第1のクラスタにおける更新対象ユーザとして決定し、
前記第1のクラスタ以外のクラスタ(第2のクラスタ)について、所定の選択基準に基づいて前記第2のクラスタに属するユーザのうち何れかのユーザを更新対象ユーザとして決定する、
請求項1に記載のレコメンド情報生成装置。
【請求項3】
前記更新された特徴辞書に対して、前記ユーザ特徴ベクトル推定手段によるユーザ特徴ベクトルの推定が1回以上なされている場合に、
前記クラスタリング手段は、前記更新対象ユーザと決定されたことのあるユーザ以外の複数のユーザをクラスタにクラスタリングし、
前記更新対象ユーザ決定手段は、該クラスタにおいて少なくとも1人以上のユーザを更新対象ユーザとして決定する、
請求項2に記載のレコメンド情報生成装置。
【請求項4】
前記ユーザ特徴ベクトル推定手段は、更新された該更新対象ユーザのユーザ特徴ベクトルと、前回の推定によって得られたユーザ特徴ベクトルとに基づいて、該更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定する、
請求項3に記載のレコメンド情報生成装置。
【請求項5】
前記更新された特徴辞書と更新前の特徴辞書とに重複して含まれる特徴要素である重複要素及びそれ以外の特徴要素である非重複要素を特定する重複要素特定手段と、
を有し、
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザ以外のユーザの更新後のユーザ特徴ベクトルの成分うち、
前記重複要素に対応する成分については該ユーザの更新前のユーザ特徴ベクトルと同じ値に設定し、
前記非重複要素に対応する成分については前記更新対象ユーザのユーザ特徴ベクトルと同じ値に設定する、
請求項1乃至3何れか一項記載のレコメンド情報生成装置。
【請求項6】
前記更新された特徴辞書と更新前の特徴辞書とに重複して含まれる特徴要素である重複要素及びそれ以外の特徴要素である非重複要素を特定する重複要素特定手段と、
を有し、
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザ以外のユーザの更新後のユーザ特徴ベクトルの成分うち、前記重複要素に対応する成分については該ユーザの更新前のユーザ特徴ベクトルと同じ値に設定し、
前記非重複要素に対応する成分については前記更新対象ユーザのユーザ特徴ベクトルと前回の推定によって得られたユーザ特徴ベクトルとに基づいて値を設定する、
請求項4に記載のレコメンド情報生成装置。
【請求項7】
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザが複数存在する場合、前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを、前記更新対象ユーザのユーザ特徴ベクトルのうち最も類似度の高い更新対象ユーザのユーザ特徴ベクトルを用いて推定する
請求項1乃至6何れか一項に記載のレコメンド情報生成装置。
【請求項8】
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザが複数存在する場合、前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを、前記複数の更新対象ユーザのユーザ特徴ベクトルの平均値を用いて推定する
請求項1乃至6何れか一項に記載のレコメンド情報生成装置。
【請求項9】
前記更新対象ユーザ決定手段は、更新対象ユーザの数が所定の閾値を超えないように該更新対象ユーザを決定し、
前記閾値は、全ユーザ数及びコンテンツの利用率との乗算によって決定する、
請求項1乃至8に記載のレコメンド情報生成装置。
【請求項10】
特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成方法であって、
更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定段階と、
更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定段階と、
を有する、レコメンド情報生成方法。
【請求項11】
特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成プログラムであって、コンピュータに、
更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定段階と、
更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定段階と、
を実行させる、レコメンド情報生成プログラム。
【請求項1】
特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成装置であって、
更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定手段と、
更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定手段と、
を有する、レコメンド情報生成装置。
【請求項2】
ユーザ特徴ベクトルを用いて複数のユーザを複数のクラスタにクラスタリングするクラスタリング手段と、
を有し、
前記更新対象ユーザ決定手段は、
前記複数のクラスタのうち、該クラスタに属するユーザであって、コンテンツの利用履歴をアップロードしたユーザが存在するクラスタ(第1のクラスタ)について、前記ユーザを前記第1のクラスタにおける更新対象ユーザとして決定し、
前記第1のクラスタ以外のクラスタ(第2のクラスタ)について、所定の選択基準に基づいて前記第2のクラスタに属するユーザのうち何れかのユーザを更新対象ユーザとして決定する、
請求項1に記載のレコメンド情報生成装置。
【請求項3】
前記更新された特徴辞書に対して、前記ユーザ特徴ベクトル推定手段によるユーザ特徴ベクトルの推定が1回以上なされている場合に、
前記クラスタリング手段は、前記更新対象ユーザと決定されたことのあるユーザ以外の複数のユーザをクラスタにクラスタリングし、
前記更新対象ユーザ決定手段は、該クラスタにおいて少なくとも1人以上のユーザを更新対象ユーザとして決定する、
請求項2に記載のレコメンド情報生成装置。
【請求項4】
前記ユーザ特徴ベクトル推定手段は、更新された該更新対象ユーザのユーザ特徴ベクトルと、前回の推定によって得られたユーザ特徴ベクトルとに基づいて、該更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定する、
請求項3に記載のレコメンド情報生成装置。
【請求項5】
前記更新された特徴辞書と更新前の特徴辞書とに重複して含まれる特徴要素である重複要素及びそれ以外の特徴要素である非重複要素を特定する重複要素特定手段と、
を有し、
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザ以外のユーザの更新後のユーザ特徴ベクトルの成分うち、
前記重複要素に対応する成分については該ユーザの更新前のユーザ特徴ベクトルと同じ値に設定し、
前記非重複要素に対応する成分については前記更新対象ユーザのユーザ特徴ベクトルと同じ値に設定する、
請求項1乃至3何れか一項記載のレコメンド情報生成装置。
【請求項6】
前記更新された特徴辞書と更新前の特徴辞書とに重複して含まれる特徴要素である重複要素及びそれ以外の特徴要素である非重複要素を特定する重複要素特定手段と、
を有し、
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザ以外のユーザの更新後のユーザ特徴ベクトルの成分うち、前記重複要素に対応する成分については該ユーザの更新前のユーザ特徴ベクトルと同じ値に設定し、
前記非重複要素に対応する成分については前記更新対象ユーザのユーザ特徴ベクトルと前回の推定によって得られたユーザ特徴ベクトルとに基づいて値を設定する、
請求項4に記載のレコメンド情報生成装置。
【請求項7】
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザが複数存在する場合、前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを、前記更新対象ユーザのユーザ特徴ベクトルのうち最も類似度の高い更新対象ユーザのユーザ特徴ベクトルを用いて推定する
請求項1乃至6何れか一項に記載のレコメンド情報生成装置。
【請求項8】
前記ユーザ特徴ベクトル推定手段は、前記更新対象ユーザが複数存在する場合、前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを、前記複数の更新対象ユーザのユーザ特徴ベクトルの平均値を用いて推定する
請求項1乃至6何れか一項に記載のレコメンド情報生成装置。
【請求項9】
前記更新対象ユーザ決定手段は、更新対象ユーザの数が所定の閾値を超えないように該更新対象ユーザを決定し、
前記閾値は、全ユーザ数及びコンテンツの利用率との乗算によって決定する、
請求項1乃至8に記載のレコメンド情報生成装置。
【請求項10】
特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成方法であって、
更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定段階と、
更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定段階と、
を有する、レコメンド情報生成方法。
【請求項11】
特徴辞書に含まれる特徴要素に基づいて作成される、コンテンツに対するユーザの嗜好を表すユーザ特徴ベクトルに基づいてレコメンド情報を生成するレコメンド情報生成プログラムであって、コンピュータに、
更新された特徴辞書に基づいて更新されるユーザ特徴ベクトルを有するユーザである更新対象ユーザを決定する更新対象ユーザ決定段階と、
更新された更新対象ユーザのユーザ特徴ベクトルに基づいて前記更新対象ユーザ以外のユーザのユーザ特徴ベクトルを推定するユーザ特徴ベクトル推定段階と、
を実行させる、レコメンド情報生成プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】

【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【公開番号】特開2013−105215(P2013−105215A)
【公開日】平成25年5月30日(2013.5.30)
【国際特許分類】
【出願番号】特願2011−246912(P2011−246912)
【出願日】平成23年11月10日(2011.11.10)
【出願人】(392026693)株式会社エヌ・ティ・ティ・ドコモ (5,876)
【公開日】平成25年5月30日(2013.5.30)
【国際特許分類】
【出願日】平成23年11月10日(2011.11.10)
【出願人】(392026693)株式会社エヌ・ティ・ティ・ドコモ (5,876)
[ Back to top ]