
並列コンピューティング・システムに使用されるネットワーク・インターフェース・カード
【課題】並列コンピューティングシステムに使用されるネットワークインターフェースカードを提供する。
【解決手段】ネットワークデバイスは、プライベートローカルメモリとパブリックローカルメモリに分けられるローカルメモリ、ローカルキャッシュ、ワーキングレジスタを含む複数のプロセッサを相互接続するネットワークを介して、データフローを管理するコントローラと、複数のプロセッサに転送されることになっているデータを受け取る、コントローラに結合された複数のキャッシュミラーレジスタとを備え、前記コントローラは、要求に応答して、プロセッサを中断させることなく、要求されたデータをじかにパブリックメモリに転送することと、要求されたデータを転送用の少なくとも1つのキャッシュミラーレジスタを介して、プロセッサローカルキャッシュと、プロセッサワーキングレジスタとに転送することとにより、データを受け取る。
【解決手段】ネットワークデバイスは、プライベートローカルメモリとパブリックローカルメモリに分けられるローカルメモリ、ローカルキャッシュ、ワーキングレジスタを含む複数のプロセッサを相互接続するネットワークを介して、データフローを管理するコントローラと、複数のプロセッサに転送されることになっているデータを受け取る、コントローラに結合された複数のキャッシュミラーレジスタとを備え、前記コントローラは、要求に応答して、プロセッサを中断させることなく、要求されたデータをじかにパブリックメモリに転送することと、要求されたデータを転送用の少なくとも1つのキャッシュミラーレジスタを介して、プロセッサローカルキャッシュと、プロセッサワーキングレジスタとに転送することとにより、データを受け取る。
【発明の詳細な説明】
【技術分野】
【0001】
(関連出願)
開示されるシステムおよび動作方法は、参照によって全体が本明細書中に組み入れられている以下の特許および特許出願に開示された主題に関するものである。
1.発明者としてCoke S.Reed氏の名前を挙げた「A Multiple Level Minimum Logic Network(マルチレベルの最小論理ネットワーク)」と称する米国特許第5,996,020号。
2.発明者としてJohn Hesse氏の名前を挙げた「A Scaleable Low Latency Switch for Usage in an Interconnect Structure(相互接続構造に使用される低レイテンシ(遅延時間)の短いスケーラブル・スイッチ)」と称する米国特許第6,289,021号。
3.発明者としてCoke Reed氏の名前を挙げた「Self−Regulating Interconnect Structure(相互接続構造の自己調整)」と称する2004年7月9日出願の米国特許出願第10/887,762号。
4.発明者としてCoke S.Reed氏とDavid Murphy氏の名前を挙げた「Highly Parallel Switching Systems Utilizing Error Correction(誤り訂正を利用する高度並列スイッチング・システム)」と称する米国特許出願第10/976,132号。
【0002】
並列コンピューティング・システムのノードは、ネットワークとネットワーク・インターフェース・コンポーネントとを含む相互接続サブシステム(interconnect subsystem)により接続される。
並列処理要素がノード(ときには、コンピューティング・ブレードと呼ばれることもある)内に位置づけられる場合には、これらのコンピューティング・ブレードは、ネットワーク・インターフェース・カード(ときには、このインターフェースが別のカード上にないこともある)を含む。
一部、このネットワークの特性に基づいて、オペレーティング・システムが選択される。
ネットワーク・インターフェース・カード(NIC)は、それらのプロセッサ、プロセッサ・インターフェース・プロトコル、ネットワーク、オペレーティング・システムの特性を前提として、最高の性能を達成するように設計されている。
【発明の概要】
【課題を解決するための手段】
【0003】
ネットワーク・デバイスの一実施形態により、コントローラは、複数のプロセッサを相互接続するネットワークを介して、データフローを管理する。
これらの複数のプロセッサは、プライベート・ローカル・メモリとパブリック・ローカル・メモリに分けられるローカル・メモリ、ローカル・キャッシュ、及びワーキング・レジスタを含む。
このネットワーク・デバイスはさらに、これらの複数のプロセッサに転送されることになっているデータを受け取る、上記コントローラに結合された複数のキャッシュ・ミラー・レジスタも含む。
上記コントローラは、要求に応答して、このプロセッサを中断させることなく、要求されたデータをじかにパブリック・メモリに転送することで、また、要求されたデータを転送用の少なくとも1つのキャッシュ・ミラー・レジスタを介して、プロセッサ・ローカル・キャッシュにも、プロセッサ・ワーキング・レジスタにも転送することで、データを受け取る。
【0004】
例示システム、および構造と動作方法の双方に関する関連技術の実施形態は、以下の説明および添付図面を参照すれば、もっともよく理解されるであろう。
【図面の簡単な説明】
【0005】
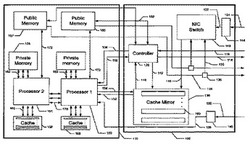
【図1A】処理ノードに、複数のネットワーク・インターフェース・カード(NIC)が接続されているのを示す略ブロック図である。
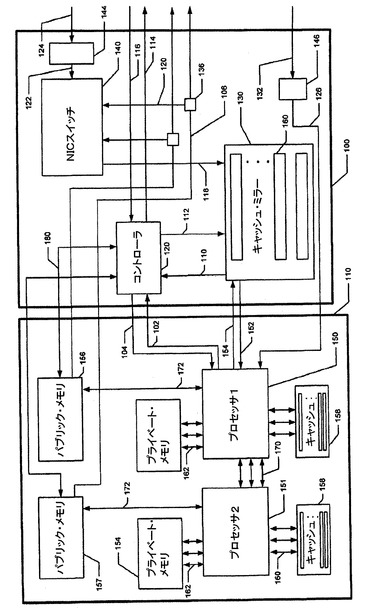
【図1B】パブリック・メモリに向けられたデータがプロセッサを通る処理ノードに、複数のネットワーク・インターフェース・カード(NIC)が接続されているのを示す略ブロック図である。
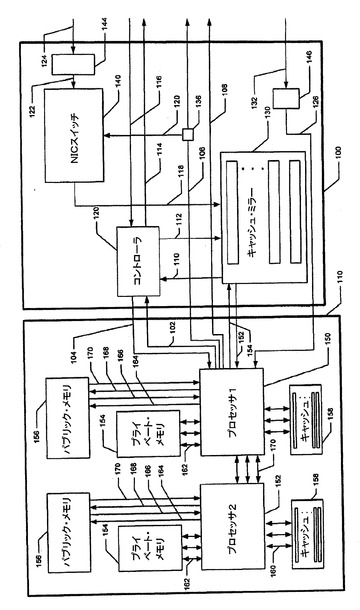
【図2】NICコントローラを示すブロック図である。
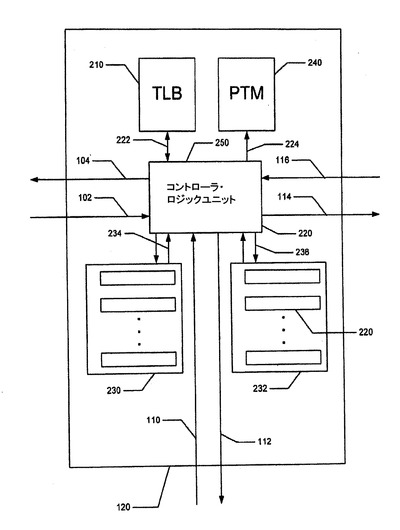
【図3】中央スイッチにより接続される処理ノード(ブレード)を含むシステムのブロック図である。
【図4】ギャザー・スキャッタ・レジスタのギャザー部分を示すブロック図である。
【図5】データをNICスイッチからギャザー・スキャッタ・レジスタのギャザー部分に運ぶためのツリー相互接続を示す略図である。
【図6】プロセッサとNICとの間で渡されるすべてのデータがギャザー・スキャッタ・レジスタを通る他の実施形態を示す略ブロック図である。さらに、プロセッサのメモリ・コントローラには連絡されないデータがギャザー・スキャッタ・レジスタを通る。
【図7】NIC上にData Vortex(登録商標)スイッチを使用し、さらに中央スイッチング・ハブ内にもData Vortex(登録商標)スイッチを使用する並列コンピュータのブロック図である。
【図8A】ただ1つのデータ行を含むただ1つのNICレジスタを示す略図である。
【図8B】2つのデータ行を含む複合NICギャザー・スキャッタ・レジスタを示すブロック図である。
【図9】それぞれのレジスタが8つのセルを含んでいるTギャザー・スキャッタ・レジスタ(T Gather-Scatter register)から成る集まりを示す略図である。
【発明を実施するための形態】
【0006】
クラスタ・コンピュータ用の現在のオペレーティング・システムは、レイテンシが大きく、かつ、短いパケットを効率的に運ぶことのできない利用可能ネットワークの特性に基づいて設計されている。
これらの欠点がData Vortex(登録商標)ネットワークにより除去されることを前提として、短いパケットに基づいて設計された新たなオペレーティング・システムが使用できる。
Data Vortex(登録商標)ネットワークおよび新たなオペレーティング・システムを用いて可能となる改良は、性能を最適化する新型のネットワーク・インターフェース・カードにより促進される。
本明細書中の開示内容は、これらの改良されたシステムへの使用に適した新規なネットワーク・インターフェース・カードを述べている。
本明細書中に述べられるNICのいくつかの実施形態の特徴は、NIC上のData Vortex(登録商標)により、短いパケットがレジスタに入れられることである。
これらのレジスタは、このシステムの全域からデータを集め、かつ、そのデータを、これらのプロセッサでいつでも使用できる状態にするのに役立つものである。
これらのレジスタは、そのキャッシュの一部のコピーをプロセッサに保存する(mirror)。一実施形態では、それぞれのレジスタには、複数のデータ入力項目(データエントリ)が入っている。
いくつかの実施形態では、これらのレジスタ、例えばキャッシュ・ミラー・レジスタ(CMR)と呼ばれるもの、あるいは、ギャザー・スキャッタ・レジスタと呼ばれるものにはそれぞれ、NIC上にキャッシュの一部を「コピー保存(mirrored)」するようにデータのキャシュ・ラインが入っている。
【0007】
いくつかの実施形態では、ネットワーク・インターフェース・カード(NIC)は、プロセッサと協働して、このシステムを通るデータの流れを管理するコントローラ(これは、スケジューラと呼ばれることもある)を含む。
別のNIC構成要素は、プロセッサに転送されることになっているデータを受け取るキャッシュ・ミラー・レジスタ(CMR)の集まりである。
データを、ローカル・メモリのプロセッサ・メモリ(プライベート・ローカル・メモリとパブリック・ローカル・メモリに分けられる)に受け取るように求めるプロセッサは、このような転送を処理する要求を上記コントローラに送る。
この転送がパブリック・メモリに行われる場合には、NICは、プロセッサを中断させることなく、このような転送を処理する。
この転送が、1)プロセッサのキャッシュ、2)プロセッサ・ワーキング・レジスタ、または、3)プロセッサで管理されるパブリック・メモリに行われる場合には、受取り側のコントローラは、データを受け取るもの(1つまたは複数)となるレジスタ内の記憶場所または記憶場所の集まりだけでなく、レジスタまたはレジスタの集まりも選択して、そのレジスタの識別子を受取り側のメモリ・マネージャに知らせる。
一実施形態では、このレジスタ識別子は、送り側のコントローラにも送られる。
送り側のコントローラは、受取り側のノード、および適切なノード上の受取り側のレジスタの識別子を、データパケット・ヘッダーに入れる。
1つまたは複数のパケットを含むメッセージを適正なCMRに送る。
レジスタには、単一の供給源からのパケット、または複数の供給源からのパケットが入っていることがある。
レジスタには、ノード・プロセッサに受け渡されることになっているキャッシュ・ラインが入っていることが多い。
異なる供給源からのパケットを同一レジスタに入れることは、データを集める効率的なやり方である。
すべてとは限らないが、いくつかの場合に、パケットをリモート・ノードに向けて送るプロセッサは、このターゲット・ノード・コントローラにパケットを送って、このような転送をスケジュールすることでデータを要求するようにリモート・ノードに指示する。
この例示開示内容は、これらの構成要素の物理的な相互接続を述べ、さらにデバイス間のデータの流れも述べている。
【0008】
CMRへの効率的なローディングは、短いパケットを処理できるスイッチによって処理される。
Data Vortex(登録商標)は、このタスクを処理するのに充分適したスイッチである。
【0009】
並列処理システムは、ネットワークにより相互接続された複数のノードを含む。
この例示開示内容は、それらの処理ノードをネットワーク・システムに接続する手段および方法を述べている。
有用なクラスのアプリケーションでは、ネットワーク・システム内の所与のプロセッサはたいてい、アイドル状態であり、処理ノードから処理ノードへとメッセージ・パケットが移動するのに費やされる時間により、少なくとも一部望ましくない状態がもたらされる。
移動時間は、レイテンシと呼ばれる。
レイテンシの一因となる第1のファクタは、メッセージ・パケットがネットワーク上で費やす時間である。
この時間は、上記の組み入れられた特許および特許出願に記載されているネットワーク・システムを用いることで、大幅に減らされる。
この時間の別の部分は、ネットワークとコンピューティング・ノードとの間のインターフェースにおいて、ハードウェアとソフトウェアのオーバーヘッドによるものである。
このシステムでは、インターフェース・レンテンシが大幅に減らされる。
この例示構造および例示システムはまた、プロセッサの中断が極力減らされるという利点もある。
この例示構造および例示システムの他の利点は、ギャザー動作とスキャッタ動作を効率的に処理することである。
【0010】
このシステムは複数のコンピューティング・ノードを含む。
それぞれのコンピューティング・ノードは、複数のスイッチ・チップを利用するネットワークにより接続された1つのNICを持っている。
例示実施形態では、それぞれのNICは1つまたは複数のData Vortex(登録商標)スイッチ・チップを含み、また、このネットワークは1つまたは複数のData Vortex(登録商標)スイッチ・チップを含む。
【0011】
図1Aを参照すると、コンピューティング・ノード110とNIC100から成る第1のシステム実施形態を略ブロック図が示している。
このコンピューティング・ノードは、1つまたは複数のマイクロプロセッサと、関連するメモリを含む。
さらに、このコンピューティング・ノードは、ディスク・ドライブと、おそらく他のハードウェアを含むことがある。
この例示設計は、2つの処理チップを持っている。
他の設計は、チップの数が異なる場合もある。
この例示プロセッサは、関連するオフチップ・キャッシュを持っている。
他の設計では、このプロセッサ・キャッシュのすべてがプロセッサ・チップ上にあることもある。
図1Aの例示設計では、プロセッサとNICとの間のやり取りのすべてが、プロセッサ1(150)により実行される。
他の設計では、NICは、プロセッサ1およびプロセッサ2とじかにやり取りできる。 NICは、プロセッサ1を介して、プロセッサ1のパブリック・メモリ156にアクセスする。
プロセッサ1からNICへのやり取りは、この例示開示内容では、メッセージ・パケットをNICに送ることとして述べられている。
実際は、プロセッサ1は、この動作を、メモリ・マップドI/O(MMIO)への格納を行うものと見なしている。
多くの場合に、パケットを送る用語は、実際は、記述の前後関係により、異なる解釈を持つことがある。
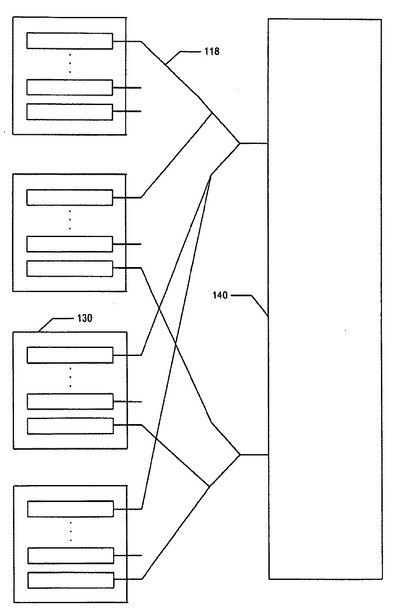
【0012】
NIC100は、処理ノード110に送られようとするデータを保持するために、3つの主要構成要素、すなわち、1)NICスイッチ140、2)コントローラ120、レジスタ130を含む。
これら3つの構成要素の動作は、このシステムを通してメッセージ・パケットを追跡する例により述べられる。
【0013】
例1は、プロセッサ2(152)がリモート・ノードにデータを要求するケースを扱っている。
プロセッサ2は、図2に示されるNICコントローラ120のコントローラ・ロジックユニット250内にあるメモリ・バッファ・スタック230中の要求メモリ・バッファ220にプロセッサ2で要求を書き込ませることで、その要求を、プロセッサ1を介してコントローラ120に送る。
このコントローラは、これらの要求が入っている要求バッファのスタックを含む。
この要求バッファがオーバーフローしないようにする一方法は、所与の時間に、限られた数の未完了要求(outstanding request)しか認めないことである。
この要求には、ターゲット・データを含むノードの識別子が入っており、さらに、このデータを格納する記憶場所の物理アドレスまたは仮想アドレスも入っている。
5つのケースが考察される。
【0014】
ケースI。
コンピューティング・ノード上のプロセッサPR(150または152)は、データをリモート・ノードのパブリック・メモリから、プロセッサPRのパブリック・メモリ空間内の記憶場所に転送するように求める。
現行例よりも興味深いケースでは、プロセッサPRは、この記憶場所の仮想アドレスを与える。
この要求は、コントローラ120に要求パケット(request packet)を送ることで、出される。
プロセッサPRがプロセッサ2(152)である場合には、この要求は、プロセッサ1(150)を通る。
この要求パケットは、ライン170とライン102上を進む。
この要求パケットには、要求番号(request number)を示すフィールド(図2に示されるバッファ230内の記憶場所)、この要求がリモート・ノードのローカル・パブリック・メモリ中のデータに対するものであることを示すフィールド、転送されるデータの量が入っているフィールド、転送されるデータの仮想アドレス(この仮想アドレスは、そのデータがリモート・ノード上にあることを示している)を示すフィールド、および、プロセッサPRがアクセスするメモリ上においてデータが格納される記憶場所の仮想アドレスを示すフィールド、が入っている。
コントローラ120は、この仮想アドレスを持つデータが格納されているリモート・ノードのラベル(標識)を含むテーブルを持っている。
図2を参照すると、コントローラ・ロジックユニット250は、その要求を、メッセージ番号で示されるバッファ230内の記憶場所に入れる。
プロセッサは、限られた数の未完了要求しか持つことができないために、バッファ230は決してオーバーフローしない。
一実施形態では、要求は、受け取られる順番に処理される。他の実施形態では、要求は、一部、サービス基準の品質に基づいて処理される。
データが適正な記憶場所にうまく受け渡されるまで、この要求は、要求バッファ(request buffer)230にとどまる。
コントローラ・ロジックユニット250は、要求バッファ230からの要求にアクセスし、また、例えばコンピューティング・ノードの物理的記憶場所を格納している物理的ページテーブル・マップ(PTM)240にアクセスすることで(ときには、アクセスされるメモリの仮想アドレスの先行ビットに基づいて)、転送されるデータを格納しているコンピューティング・ノードの物理的記憶場所を捜す。
次に、コントローラ・ロジックユニット250は、データに対する要求を、アクセスされるデータ(このデータは、送り側のプロセッサPSに関連する)を格納しているコンピューティング・ノードに関連するNICに送る。
この要求パケットには、バッファ230内の要求の物理的記憶場所である要求パケット番号を示すフィールドが入っている。
この要求は、スイッチング・システムを介して、ターゲットNICに渡される。
図3は、NIC100に接続され、かつスイッチング・システム300にも接続されたブレード110を示している。
例示実施形態では、スイッチング・システム300は、上記の組み入れられた特許および特許出願に記載されているタイプのData Vortex(登録商標)である。
【0015】
要求がリモート・ノードへ移動中であるとき、コントローラ・ロジックユニット250は、到着するパケット(1つまたは複数)が格納される仮想メモリ基準(virtual memory reference)の物理的記憶場所を保持しているTLB210にアクセスする。
この物理的記憶場所が決定されて、それがバッファ230内の要求パケットの追加フィールドに追加される。
この設計の一面は、TLB内の物理的記憶場所へのアクセスが、この要求パケットを送ることと同時に行われて、このような探索(ルックアップ)で、このプロセスへのレイテンシが増さないようにすることである。
NIC上のメモリ量は、TLB210がローカル・メモリの物理アドレスだけを保持するという事実により、また、PTM240が、ブレード上のメモリのアドレスではなく、ブレード・アドレスだけを保持するという事実により、減らされる。
公知の技術を使用して、ハッシング技法を実行し、かつ、最近アクセスされたアドレスを格納するための特定の記憶場所を含めるように、TLBとPTMを設計することもある。
シーケンスの構成要素(メンバ)を、このシーケンスの第1の構成要素からのオフセットに基づいて格納するのに用いられる技法は、Cなどの言語の特徴である。
この技法は、TLBのサイズを減らすのに有利に使用できる。
【0016】
要求は、リモート・ノード(データ送り側のノード)に到着して、コントローラ120のコントローラ・ロジックユニット250に入る。
コントローラ・ロジックユニット250は、この要求をバッファ232に入れる。
複数の様々な技法を使用して、バッファ232がオーバーフローしないようにすることもある。
一実施形態では、バッファ232は、このシステム内に、処理ノード(ブレード)の数のN倍の要求数の容量を持っている。
このシステムは、いかなるノードもN個よりも多くのデータパケットを個々のリモート・ノードには要求できないというルールで制約を受ける。
一実施形態では、バッファ232は、N個のセクションに分けられ、しかも、それぞれのブレード用に1つのセクションが確保される。
他の実施形態では、送り側のコントローラは、要求を送る許可を求める。
さらに他の実施形態では、バッファの調整がまったく行われず、また、フル・バッファ(全バッファ、full buffer)232を用いてのコントローラへの要求が拒否されて、ACKが戻される。
確実にバッファ232がオーバーフローしないようにするために、トークンの使用を含め、他の技法が使用されることもある。
超大型のシステムでは、バッファ232は、N個のセクションに分けられ、しかも、一群のブレード(例えば、キャビネット内のブレードのすべて)用に1つのセクションが確保される。
【0017】
コントローラ・ロジックユニット250は、TLBにアクセスして、コントローラ・ロジックユニット250のローカル・パブリック・メモリ空間内にデータを見出すことで、バッファ232からの要求を処理する。
次に、要求されたデータは、そのヘッダーに入っているユニット230内のパケット要求のアドレスとともに、要求側のコントローラ・ユニットに戻される。
コントローラ・ロジックユニット250は、その物理アドレスをバッファ230から得て、そのデータを、ローカル・パブリック・メモリ空間内の適正な物理アドレスに送る。
【0018】
データ要求に関連するデータ転送が複数のパケットを含む一実施形態では、要求されるパケットの数は、ユニット230に格納された要求パケットの中に示される。
これらのパケットがそれぞれ到着すると、コントローラ・ロジックユニット250は、特定された要求に関連する到着パケットの数の現在合計高を維持する。
したがって、転送が完了したときに、コントローラ・ロジックユニット250は通知がある。
完了時に、コントローラは、確認応答(ACK)をプロセッサPRとプロセッサPSに送る。
ACKに応答して、プロセッサPRは、別の要求で使用される要求パケット番号を解放する。
【0019】
コントローラはまた、データ要求側のプロセッサにACKパケットを送って、そのデータが所定の場所にあることを示す。
ACKに応答して、プロセッサは、データに対する未完了要求の数の記録を取るカウンタを減らす。
データがうまく転送された(いくつかの実施形態では、ACKにより表される)後で、コントローラ・ロジックユニット250は、別の要求に対して、バッファ230内の該当記憶場所を解放する。
いくつかの実施形態では、所与の要求に応答して受け渡されるパケットが、順番に到着する。他の実施形態では、所与の要求に関連するパケットは、コントローラによりパケットを順番に並べられるようにするパケット番号を、それらのパケットのヘッダーに含む。 中央スイッチ・ハブに複数のスイッチ・チップを使用するさらに他の実施形態では、複数のライン124は、この中央スイッチ・ハブからデータを受け渡す。
また、メッセージ内でのパケットの適正な配置は、そのパケットがどのラインに到着するかによって決まる。
ケースIの説明は、1つまたは複数のパケットをローカル・パブリック記憶素子に入れることのできるメモリ・コントローラを、コントローラ120が利用することを前提としている。
【0020】
ケースII。
プロセッサPRは、リモート・パブリック・メモリ内のデータを、プロセッサPRのキャッシュまたはワーキング・レジスタ内の記憶場所に格納するように求める。
プロセッサPRは、そのデータを、メモリ・バッファ130内に位置づけられたCMR160に格納するように求める。
それぞれのCMRレジスタはロックを含み、そのロックが解除されるまで、データがプロセッサPRに流れないようにしている。
プロセッサPRは、どのCMRユニットが使用してないか追跡する記憶場所を別にしておく。
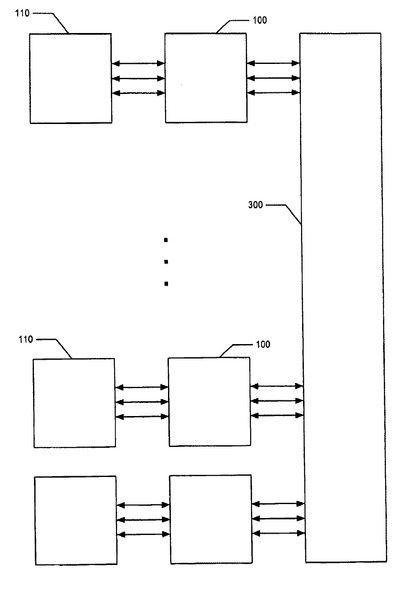
図4は、それぞれのCMRがN個のセル(記憶場所)を含んでいるM個のCMRユニットを含むバッファ130を示している。
データを要求するプロセッサは、関連するNIC上のコントローラ120に要求を送って、所与の仮想アドレスでのデータ項目を、バッファ130内のM・Nセルの1つまたは複数に送るように求める。
コントローラ・ロジックユニット250は、PTMを利用して、その要求されたデータが入っているノードの物理的記憶場所を突き止める。
要求パケットは、このデータを受け取るセル(1つまたは複数)のアドレスだけでなく、受取り側のノードの物理アドレスも含む。
この要求パケットはまた、その要求されたデータの仮想アドレスも含む。
この要求パケットは、データを含むノードにシステム・スイッチ300を介して進む。 ケースIの場合と同様に、受取り側のコントローラ・ロジックユニット250は、要求をバッファ(図示されてない)に入れて、要求を処理できるまで、その要求を保持する。 リモート・データを含むノードが要求を処理するときに、そのノードは、ローカルTLBにアクセスして、そのデータの物理アドレスを見出す。
そのデータを含むパケットは、ライン124上で、プロセッサPRに関連するNIC上のバッファ144に進む。
バッファ144にオーバーフローさせない方法は、バッファ232のオーバーフロー管理と同一の方法で処理される。
NICスイッチに到着したデータパケットは、データ・ライン118を介して、適正なCMRセルに送られる。
【0021】
図4は、それぞれのCMR160がN個のデータ・セル402を含んでいるM個のCMRを含むバッファ130を示している。
NICスイッチが512個の出力ポートを持ち、また、それぞれのCMR内のセルの数が8であって、かつNが64に等しい例では、それぞれのセルは、この場合、NICスイッチの一意の出力ポートに接続されることもある。
NICスイッチ140がData Vortex(登録商標)スイッチであり、また、これらのポートのそれぞれが2Gb/秒にて動作する場合には、CMRに入る最大バンド幅は1テラビット/秒を超える。
プロセッサはまた、ローカル・パブリック・メモリからの要求データをプロセッサNIC上のCMRに送るように求めることもある。
このデータは、データ・ライン106を通り、またスイッチ130によりライン120に切り替えられて、NICスイッチまで進む。
【0022】
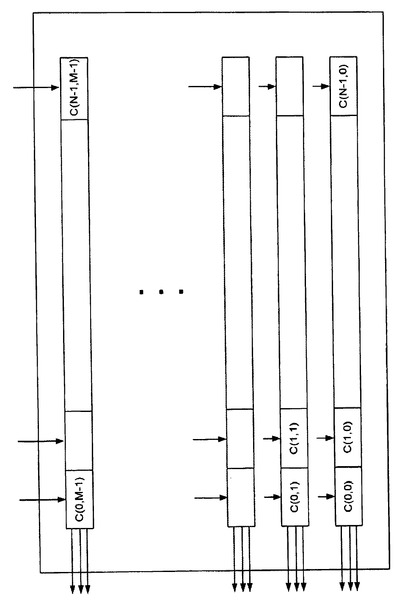
CMRセルの総数は、NICスイッチの出力ポートの数を越えることもある。
多数のCMRセルを可能にする一実施形態では、CMRは複数のバンクに分けられ、また、それぞれのバンクは、NICスイッチ内の出力ポートの数に等しい数のセルを持っている。
このデータ・ヘッダー内の上位のビットにより、このデータは、NICスイッチと、CMRのバンクとの間のツリーを通って分岐することができる。
CMRのバンクが4つある上記構成が図5に示されている。
データパケットをNICスイッチからCMRセルに運ぶラインの一部だけが図示されている。
【0023】
一実施形態では、プロセッサは、ただ1つの要求を出して、複数のデータ項目を関連するCMRに格納することもある。
例えば、プロセッサは、一連のデータ項目を、リモート記憶場所に連続的に格納して、プロセッサCMRバッファ内のセル行に入れるように求めるか、あるいは、一連のデータ項目を、プロセッサCMRバッファ内のセル列に格納するように求めることもある。
所与の要求に関連するパケットのそれぞれは、CMR内のセルのアドレスだけでなく、要求番号も含む。
異なる系列のデータ項目をセル列に格納すれば、プロセッサは、この例示構造および例示システムで可能となる強力で、かつ有用なコンピューティング・パラダイムで、複数のデータ・ストリームに同時にアクセスできる。
所与の要求に関連するパケットのすべてが、プロセッサPRに関連するNICで受け取られるときには、プロセッサPSにACKが戻される。
【0024】
データがCMRに転送されるときには、いつ所与のCMRラインがいっぱいとなって、プロセッサに転送できる状態になるのか決定する技法が使用される。
CMRライン情報を追跡する一方法は、コントローラ・ロジックユニット250内にある特定の組のM個のレジスタ(描かれてない)によって管理される。
これらのレジスタは、ここでは「CMRフル・ステータス・レジスタ」と呼ばれている。
プロセッサPRが複数の要求を出して、データをGSRの行Kに入れる前に、プロセッサPRは、行K中のどのセルがこのデータを受け取ることになっているのか突き止める。 プロセッサPRは、特定のパケットをコントローラ・ロジックユニット250に送って、その情報を示す。
プロセッサが、データをCMRレジスタのサブセットSに入れる要求を送る場合には、この要求に関連する「CMRフル・ステータス・レジスタ」のすべてが更新される。
データパケットが、プロセッサPRに関連するNICに戻ると、「CMRフル・ステータス・レジスタ」内のデータが変更される。行Kに予定されるパケットが到着すると、「CMRフル・ステータス・レジスタ」K内の値が減らされる。
「CMRフル・ステータス・レジスタ」の内容がゼロに減らされるときには、CMRの行Kに予定されるデータのすべてが到着しており、コントローラ・ロジックユニット250は、普通ならデータが行Kから、PRに関連するキャッシュに、あるいはPRのワーキング・レジスタに流れ込まないようにするロックを解除する。
いくつかの実施形態では、一定の時間後では、上記ロックが解除される前にデータがCMRレジスタから転送されて、CMRレジスタ内のデータが有効でないという指示が出される。
このCMR内のデータが有効であるかどうかを決定する一方法は、CMRレジスタ内の最左端の記憶場所にデータを送れないようにすることである。
他のデータ項目のすべてが到着しているときに、その最左端の記憶場所にコードワードを入れて、そのデータのすべてが到着していることを示す。
上記ロックが解除されるためではなく、タイムアウトのために、データが送られる場合には、その記憶場所にはコードワードを入れず、プロセッサは、そのデータが無効であると知らせることができよう。
【0025】
ケースIII。
プロセッサPは、リモート・プロセッサで追加CMR(図示されない)に書き込ませ、また、その追加CMRをローカル・プロセッサで読み取らせることで、短いメッセージをリモート・プロセッサに送る。
バッファがオーバーフローしないようにする方法は、バッファ232のオーバーフロー管理と同一のやり方で処理される。
送り側のプロセッサは、その短いメッセージを受取り側のコントローラに送り、そこで、ローカルで読み取って、リモートで書き込むことのできるCMRの中で、そのデータを管理する。
【0026】
ケースIV。
プロセッサPは、プロセッサPに対してローカルであるローカルNICコントローラにメッセージ・パケット(1つまたは複数)をプロセッサPで送らせ、また、このメッセージ・パケットをターゲット・コントローラに上記ローカルNICコントローラで送らせることで、短いメッセージをリモート・パブリック・メモリに送る。
ターゲット・コントローラ内の特定のバッファ空間が、これらのメッセージを保持する。
バッファがオーバーフローしないようにする方法は、バッファ232のオーバーフロー管理と同一のやり方で処理される。
これらの短いメッセージは、アトミックなメモリ操作物(atomic memory operation)と呼ばれている。これらの短いメッセージを使用すれば、分散形共用メモリ・マシン(distributed shared memory machine)内のメモリを制御できる。
プログラミング言語UPCでは、少数のアトミックなメモリ操作物は、分散形共用メモリ・マシン上でのプログラムの総体的な実行を容易ならしめる。
【0027】
ケースV。
プロセッサは、例えばライン172を介して、じかにメモリにアクセスすることで、データを、ローカル・パブリック・メモリ空間に送るか、あるいはローカル・パブリック・メモリ空間から受け取る。
このような操作は、競合状態を避けるために慎重に行われる。
プロセッサはまた、ライン180を介してローカル・パブリック・メモリに接続されたコントローラを経ることで、ローカル・パブリック・メモリにアクセスすることもある。
このコントローラを介してプロセッサがローカル・パブリック・メモリにアクセスする利点は、ローカル・パブリック・メモリにアクセスポイントをただ1つ持つことで、競合状態を避けている点である。
【0028】
図1Bに示される一実施形態では、データは、NICから、プロセッサを通って、パブリック・メモリ空間に渡されることもある。
動作の詳細は、プロセッサによって決まる。
いくつかのプロセッサ(「AMD Opteron」プロセッサを含む)では、メモリ・コントローラは、このプロセッサ内にあり、また、このNICでは、TLBを省略できる。
【0029】
中央スイッチ300内にData Vortex(登録商標)を使用する図3に示される分散形共用メモリシステムであって、図1Aまたは図1B中のNICスイッチ140用にData Vortex(登録商標)を用いるこの例示開示内容に述べられたネットワーク・インターフェースを使用する分散形共用メモリシステムのエンドツーエンド・レイテンシは、極めて低い。
このレイテンシは、NIC100の特徴の全部または大部分を単一のチップ上に取り入れることで、さらに減らされることもある。
【0030】
第1の実施形態では、NIC上のレジスタを使用して、データをこれらのプロセッサに転送した。
第2の実施形態では、これらのレジスタを使用して、データをプロセッサに転送するとともに、プロセッサから転送する。
第1の実施形態では、NICレジスタは、「キャッシュ・ミラー」と呼ばれた。
第2の実施形態では、NICレジスタは、「ギャザー・スキャッタ」レジスタと呼ばれる。
図6を参照すると、略ブロック図は、異なるやり方でアクセスする2つのタイプのメモリを含むかもしれない一実施形態を示している。
第1のタイプのメモリ644は、メモリ・コントローラを介して、プロセッサに接続される。「AMD Opteron」プロセッサの場合には、メモリ・コントローラは、コンピューティング・コア(1つまたは複数)と同一のシリコン・ダイ上にある。
第2のタイプのメモリ642は、メモリ・コントローラにより、ギャザー・スキャッタ・レジスタに接続される。
UPCなどのプログラミング言語(computing language)が使用される場合には、2つのタイプのメモリはそれぞれ、パブリック記憶領域とプライベート記憶領域に分けられることがある。
データ転送の要求は、これらのプロセッサから生じる。
図6では、このプロセッサは複数のユニット638を含み、また、それらのユニット638はそれぞれプロセッサ・コアと複数レベルのキャッシュを含む。
【0031】
プロセッサとメモリ・コントローラがデータをキャッシュ・ライン(64ビット・ワードを8つ含む)に移すケースに関して、「AMD Opteron」プロセッサに合致する模範的な説明が与えられる。
当業者であれば、ここに提示された例が、異なるサイズ・ブロックのデータを移す広範囲のプロセッサおよびメモリ・コントローラに対応するものと解釈できるであろう。
ここに記述される技法は、DRAM644から転送されるブロックが、DRAM642から転送されるブロックに等しくないようなケースに当てはめられる。
このシステムは、2つのケースを考慮に入れることで説明される。
【0032】
第1のケースでは、コンピューティング・ノード692上のプロセッサ690の処理コア638は、送り側の記憶場所から、プロセッサNIC(データ受取り側のNICはRNで表され、また、データ送り側のNICはSNで表される)のギャザー・スキャッタ・レジスタ内の一群の受取り側記憶場所に(しばしば、このような8つの記憶場所に)データが転送されるように求めている。
この要求の目的は、データを、ギャザー・スキャッタ・レジスタから、処理コア638内のローカル処理コア・ワーキング・レジスタ、処理コア638内のキャッシュまで、メモリ644まで、あるいは、RN上のメモリ642まで移せるようにすることである。
該当するケースでは、送り側の記憶場所は、リモート・メモリ644、メモリ642、またはリモート・ギャザー・スキャッタ・レジスタ630である。
処理コア638は、要求パケットを、ライン654を介してSNギャザー・スキャッタ・レジスタ630内の記憶場所に送ることで、要求を出す。
この要求は、RN上のプロセッサのローカル・ギャザー・スキャッタ・レジスタ内の8つの異なる記憶場所に8つの64ビット・ワードを受け渡すように、特定のリモート・ノードに求めることが多い。
このギャザー・スキャッタ・レジスタ内のロジックは、その要求パケットをRN内のNICコントローラに転送する。
RN内のNICコントローラは、その要求にラベルを割り当てて、NICコントローラ内で、その要求のラベルに設定された記憶場所の中でその要求のコピーを維持する。
単純な実施形態では、RN内の記憶場所は、SNのアドレス、すなわち、SNからのデータに対する特定の要求の識別子REQIDに設定される。
次に、RNは、その要求を、中央ハブ・スイッチを介して、SNで表されるリモート・データ送り側NICに送る。
SNコントローラは、記憶場所を割り当てて、その要求を格納する。
単純な実施形態では、SNは、その要求をアドレス(RN、REQIDのアドレス)に格納する。
この格納方式の有用な一面は、RNが、SN内でその要求を格納する場所に関する情報、SNが記憶場所を割り当て、かつ特定のパケットをRNに送って、その記憶場所をRNに知らせることによっても達成できる条件を持つことである。
様々な間接探索方式(lookup scheme)が実施されることもある。
【0033】
要求されたデータがSNのギャザー・スキャッタ・レジスタ内にはまだない場合には、SN上のNICコントローラは、そのデータを、メモリ634またはメモリ642から適正なギャザー・スキャッタ・レジスタに転送する。
8つの64ビット・ワードは、中央ハブ内の8つの異なるスイッチ・チップに転送され、次に、ノードRN上のNICスイッチ640に転送される。
これら8つのパケットのそれぞれは、要求されるデータ、RNのアドレス、要求ラベル、このデータを入れるギャザー・スキャッタ・レジスタ内のターゲット記憶場所、および、要求される8つのパケットのうちのどれを送ろうとするのか示す、整数(0、1、...7)から選ばれる一意のデータパケット識別子を含む。
パケットがうまく受け渡されると、受取り側のレジスタは、このデータパケット識別子を持つローカルACKを、その要求を格納しているRNコントローラ内の記憶場所に送る。
ACKを適正な記憶場所に受け渡す非常に効率的な方法は、Data Vortex(登録商標)スイッチ(描かれてない)をライン612上に、またはギャザー・スキャッタ・レジスタのハードウェア内に使用することである。
8つのローカルACKがすべて受け取られているときには、RNは、リモートACKを中央ハブ・スイッチを介してSN内のNICコントローラに送る。
ACKは、Data Vortex(登録商標)スイッチをRN上のNICコントローラに用いることで、その要求を保持する記憶場所に送られることもある。
ACKを受け取るときには、その要求パケットは廃棄され、また、その要求を保持する記憶場所は、別の要求パケットのために解放されることもある。
その要求に関連する8つのパケットのうちの1つが適正に受け取られない場合には、NACは、そのパケットを再送するように求める。
パケットのいっぱいのキャッシュ・ラインが受け取られているときには、そのキャッシュ・ラインは、その要求パケットで指定されるように、DRAM642、DRAM638内の正しい記憶場所、または処理コア638内のキャッシュに転送されることもある。
このキャッシュ・ラインがいっぱいであるかどうか決定する一方法は、第1の実施形態の記述の中で説明されている。
第1の実施形態の場合と同様に、タイミアウトによりデータを送ることも処理される。
【0034】
第2のケースでは、プロセッサは、例えば、SNがRNに要求を送って、RNにデータを要求するように求めることで、リモート記憶場所へのデータの送りを開始させる。
次に、このプロセスは、第1のケースの場合と同様に進行する。
【0035】
図7を参照すると、略ブロック図は、第3の実施形態を描いており、また、2つのプロセッサ750、メモリ706、NICチップ702を含むコンピューティング・ノード700を示し、さらに、中央ハブ・スイッチ・チップ750も示している。
図7は、この中央スイッチ・ハブに「AMD Opteron」プロセッサとData Vortex(登録商標)チップを使用する特定の並列コンピューティング・システムを示す図解例である。
この図解例の装置および動作方法は、他のプロセッサを用いる非常に広範なクラスの並列システムに当てはめられる。NICからデータを受け取る中央スイッチ・ハブ・チップのそれぞれに、ライン752により所与のコンピューティング・ノードが接続される。
NICにデータを送る中央スイッチ・ハブのそれぞれからデータを受け取るために、ライン754によりコンピューティング・ノードが接続される。
多くの有用な「1ホップ(one hop)」システムでは、データを、NICのすべてから受け取り、またNICのすべてに送るために、中央スイッチ・ハブ・チップのそれぞれが接続される。
例えば、中央スイッチ・ハブに、256のコンピューティング・ノードと40のData Vortex(登録商標)スイッチ・チップを含む「1ホップ」システムは、コンピューティング・ノード上の256のNIC出力リンク752(中央ハブ・スイッチ・チップのそれぞれに1つ)と、40のNIC入力リンク754(それぞれの中央ハブ・スイッチ・チップから1つ)を用いて構成されることもある。
【0036】
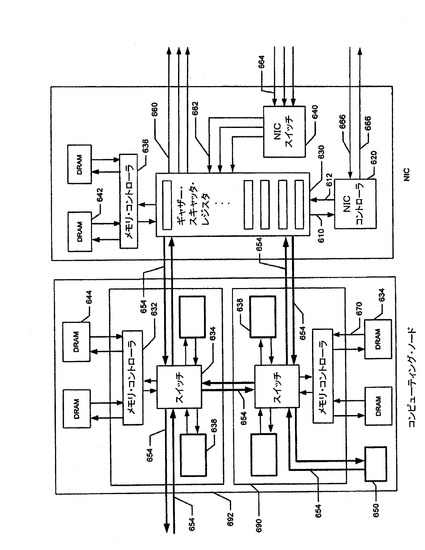
NICはレジスタの集まり710から成っている。
レジスタの集まり710は、単純レジスタ722を含み、さらに複合ギャザー・スキャッタ・レジスタ720も含む。
NICはまた、出力スイッチ740と入力スイッチ730も含む。
例示NICはまた、誤り訂正を実行して、ACKとNAKを送るEC−ACKユニット780も含む。
Data Vortex(登録商標)スイッチは、それらのスイッチとしての使用に充分適している。NIC上には、DRAMもメモリ・コントローラもまったく含まれない。 オンプロセッサ・メモリ・コントローラ774を介して、システム・メモリ706にアクセスする。コンピューティング・ノード間で転送されるすべてのデータは、ギャザー・スキャッタ・レジスタを使用する。
図7に示されているNICは、別個のNICコントローラを含まない。
図1A、図1B、図2、図6に示されるNICコントローラの機能は、「Opteron」プロセッサにより、さらに、ギャザー・スキャッタNICレジスタに組み入れられた計算ハードウェア(computational hardware)により実行される。
【0037】
図8Bとともに図8Aを参照すると、NICレジスタのそれぞれが複数のセルに分けられる。
セルの数は、まったく一般的なものである。
この図解例では、セルの数は8に設定され、また、セル内のビットの数は64に設定されている。
他の例は、それよりも多くのセル、またはそれよりも少ないセルを持つこともある。
最下部の単純NICレジスタにSNR(0)のラベルが付けられ、また、SNR(0)のすぐ上のレジスタにはSNR(1)のラベルが付けられるといった具合にNICレジスタに番号が付けられて、T+1の単純レジスタを持つシステムの場合には、SNR(0)、SNR(1)、SNR(2)、...、SNR(T)の順番列(シーケンス)を作り出すように、これらの単純レジスタにラベルが付けられる。
単純レジスタSR(D)内のセルにラベルを付けたものが、SR(D,0)、SR(D,1)、...、SR(D,7)である。
最初のt個の単純ノード・レジスタ、すなわちSNR(0)、SNR(1)、...、SNR(t−1)を使用して、残りの単純ノード・レジスタ、すなわちSNR(t)、SNR(t+1)、SNR(t+2)、...、SNR(T)のステータスをたどるように、整数t<Tが存在する。
U+1の複合レジスタを持つシステムでは、これらの複合レジスタには、CNR(0)、CNR(1)、...、CNR(U)のラベルが付けられる。
この複合レジスタCNRは、H(ヘッダー・レジスタ)とP(ペイロード・レジスタ)という2つのレジスタを含む。
図9は、複合レジスタ内のセルの一覧表を示している。
CNR(N)のK個のセル内のパケットは、H(N,K)にヘッダーを持ち、また、P(N,K)にペイロードを持っている。
複合NICレジスタの位置Kにある2つのセル内のパケットには、単にHKとPKとしてラベルが付けられる。
【0038】
データは、「Opteron」プロセッサ750からライン760を介して、またNIC入力スイッチ730からライン732を介して、NICレジスタ722のセルに転送され、またNICレジスタ720のセルに転送される。
ライン760およびライン732を介して入るデータは、図5に示される技法を用いて、あるいは、何か他の適切な手段により、広げられる(fanned out)ことがある。
図7は、広げる手段(ファンアウト)なしの構造を示している。
これらのNICレジスタの個々のセルは、個々にアドレス指定可能である。
それゆえ、所与のレジスタは、いくつかの異なるコンピューティング・ノードからデータを同時に受け取ることができる。
多数のセルがデータを受け取っている場合には、そのデータは、中央スイッチ・ハブ内の異なるスイッチ・チップ750から送られる。
同様に、所与のNICレジスタは、データを、複数のセルからライン760を介してプロセッサに、またライン742を介してNIC出力スイッチに同時に送ることができる。 NIC出力スイッチに到着したデータは、ライン734を介してNIC入力スイッチに送られて、NICが、プロセッサに受け渡されることになっているデータをもっとも有用な形式で再構成できるようにすることもある。
NIC出力スイッチに到着したデータはまた、ライン752を介して中央スイッチ・ハブに送られることもある。
所与の時間に単一NICレジスタから送られるデータは、このシステムの全域で、1つまたは複数のコンピューティング・ノード700上の他の多数のNICレジスタに分散されることもある。
【0039】
この図解例に示されるNICの動作は、「Opteron」プロセッサと「HyperTransportTM」技術のいくつかの特徴を利用している。
このプロセッサは、リモート・デバイスに書き込むことができる。
この例では、プロセッサは、NICレジスタに書き込むことで、メッセージ・パケットをリモート・ノードに送る。
このプロセッサは、ここではリモート・デバイス内の特定記憶場所への「send when ready(実行可能状態時に送る)」コマンドとして基準とされる1つまたは複数のコマンドを、リモート・デバイスに出すことができる。
制御に使用されるセル(セルH0またはセルP0)内の指定したビット(1つまたは複数)を、転送されるデータがリモート・デバイス内の特定記憶場所にあることを示すように設定する限り、「send when ready」コマンドは、リモート・デバイス上のハードウェア・インターフェースとともに、このプロセッサに64バイトのデータを転送させる。
プロセッサが、クラス「send when ready」のコマンドを出し、かつ、所定の設定時間間隔(「TIMEOUT」)が経過したときには、データのすべてが到着したとは限らない場合でも、リモート・デバイス上の記憶場所の内容が転送される。
TIMEOUT状態の結果としてプロセッサにデータを転送することがまれな事象であるように、数値TIMEOUTが設定される。
TIMEOUTが実際に発生する場合には、データは、HyperTransportTMを介してプロセッサに転送されるが、ただし、このプロセッサは、パケット内に適正なデータがないことを制御セル・ビットが示すことに留意している。
プロセッサが無効なパケットを受け取る場合には、プロセッサは、そのオペレーティング・システムで示されるやり方で応答する。
プロセッサは、クラス「send now(今、送る)」の1つまたは複数のコマンドを出す場合もある。
その場合、データを直ちに転送する。このコマンドは、そのデータが所定の場所にあることをプロセッサが確認したときだけ、使用されるべきである。
データが実行可能状態にあることをプロセッサに知らせる方法があるが、ただし、プロセッサは、通知を受け取るときは必ずレイテンシを増すために、上記コマンドは、実行するのにさらに多くの時間を要することがある。
このコマンドの利点は、転送されたデータ内のどんなフィールドも、制御情報用に確保する必要がないことである。
【0040】
いくつかのデータ転送例に示されるように、この例示システムおよび例示技法は、データ送り側のノードPSNDがPSNDコンピューティング・ノード上にあるデータをPREQコンピューティング・ノード上の記憶場所に転送するように求める要求側のプロセッサPREQにより、デバイス間でデータを転送する効率的な方法を可能にする。
この要求は、要求パケットをPSNDに送るプロセッサPREQにより出される。
この要求パケットは、ヘッダーとペイロードから成っている。
ペイロードは、その要求されたデータのアドレス(1つまたは複数)をノードPSND上に含み、さらに、データが送られることになっているノードPREQ上にも、その記憶場所を含む。
このデータは、ノードPREQ上の1つまたは複数の単純NICレジスタまたは複合NICレジスタに送られる。
他の例では、プロセッサPSNDは、PSNDのローカル・コンピューティング・ノード以外のコンピューティング・ノード上のレジスタにデータを送るように求めることもある。
PSNDノード上のデータの記憶場所の記述は、広範囲のフォーマットを用いて伝えられることもある。
このようなデータ記述の単純な例は、メモリ内の指定した記憶場所からスタートする所定の長さのストリング用のものである。
このデータの受取り側記憶場所は、単純NICレジスタまたは複合NICレジスタ内のセルのリストとして与えられている。
いくつかの転送例は以下の通りである。例1)は、その要求が、記憶場所Xからスタートする長さのデータ・ストリング(5・64)を、SNR(D,0)、SNR(D,1)、SNR(D,2)、SNR(D,3)、SNR(D,4)の単純レジスタ・セルに入れるものであるかもしれないわかりやすい例を示している。
受取り側記憶場所の記述のフォーマットは、広範囲のフォーマットで与えられることもある。
このデータは、5つのパケットでこのシステムの全域に送られることもある。
その場合、このストリングの最初の64ビットは、単純ノード・レジスタ・セルSNR(D,0)に送られ、このストリングの次の64ビットは、単純ノード・レジスタ・セルSNR(D,1)に送られるといった具合である。
この例では、ペイロードと、そのヘッダーには、PREQを含むコンピューティング・ノードのアドレスとSNR(D,1)のアドレスが、おそらく誤り訂正ビットを含む他の情報とともに入っているであろうから、1つのデータパケットは、このストリングの最初の64ビットを持っている。
例2)は、ネットワーク上のコーナーターン(corner turn)を示している。
同一のデータ・ストリングを、CNR(D,2)、CNR(D+1,2)、CNR(D+2,2)、CNR(D+3,2)、CNR(D+4,2)の複合レジスタ・セルに入れる要求が出される。
転送での第3のパケットは、ペイロード内に64ビットの第3のグループを持ち、またセルP(D,2)を持っている。
これらの転送用のアドレスを記述するのに、広範囲のフォーマットが用いられることもある。例3)は、一連の構造体(structure)からの指定した部分を含むデータを転送して、そのデータを、定められたストライドにて受取り側のNICレジスタに入れることを示している。
これらの転送用のアドレスを記述するのに、広範囲のフォーマットが用いられることもある。
【0041】
このシステムは、いくつかの動作を検査して述べられる。
検査される第1の動作は、リモート・ノードの仮想メモリ空間からのデータに対する要求である。
【0042】
「リモート・ノードI上のメモリからのデータに対する要求」動作は、「send when ready」コマンドを含むトランザクションにおいて役立つ。
データ要求側のプロセッサPREQは、リモート・データ送り側のプロセッサPSNDの仮想アドレス空間から、7つまでのデータ・セルを要求する。
このトランザクションは、このシステム内の様々な構成要素の機能を示している。
データ転送を行うために、PREQは、次の3つの機能を果たす。
1)このプロセッサは、データを受け取るNICレジスタの制御セルH0と制御セルP0の1つまたは複数にデータを送る。
2)このプロセッサは、この転送にTID(トランザクション識別子)を割り当てて、a)TID、b)TIDを用いて転送されようとするパケットの数、c)入ってくるパケットに誤り訂正を行い、かつACKとNAKを処理するEC−ACKユニット780へのプロセッサPSNDのアドレス、を送る。
3)プロセッサは、組RPSET(PSNDへの要求パケットREQを含む)内の複数の要求パケットを送る。
それゆえ、RPSETを送ることで、複数のコンピューティング・ノードから所定のコンピューティング・ノード上のNICレジスタにデータが集められることもある。
RPSETは、隣接する複合NICレジスタの集まりCNUMに対するデータを要求する。4)適切な時間(データが戻る最小時間)の後で、プロセッサPREQは、パケットの組RPSETを送る結果として、データを受け取る予定であるNICレジスタのすべてに、「send when ready」コマンドを送る。
【0043】
上記の機能1)に関して、プロセッサPREQは、要求パケットの組RPSETに応答してNICレジスタに転送されるパケットの数を、データを受け取るNICレジスタのそれぞれにあるP0内の適切なNUMPKフィールドに送ることで、その数を示す。この要求パケットの組により、J個の隣接する複合レジスタ(レジスタNR(S)、レジスタNR(S+1)、レジスタNR(S+J−1))内にデータが到着し、かつ、最下部の受取り側レジスタから最上部の受取りレジスタまで順番に、その受け取られたデータにアクセスする場合には、この整数Jも、最下部のターゲット・レジスタNR(S)のセルP0のフィールドORDERに入れられる。
他のターゲット・レジスタは、第2のフィールドに整数0を持っている。
第3のフィールドSENDはゼロに設定される。ただ1つのレジスタがデータを受け取ることになっているか、あるいは、プロセッサが、順序を顧慮せずにデータにアクセスすることになっている場合には、これらのフィールドのそれぞれに整数1を入れることもある。
制御セル内の情報の利用は、後の「注0」で説明される。
この情報を制御セルに転送する効率的な方法は、後の「注1」で説明される。
上記の機能2)に関して、EC−ACK管理ユニット780は、それぞれのTIDとともに、パケットをいくつ転送すべきか決定して、その適切なTIDに関連するACKまたはNAKを送る。
EC−ACK管理ユニット780の動作は、後の「注2」で説明される。
上記の機能3)に関して、処理ノード間のデータの処理は、データに対する要求パケットを送り、それらの要求パケットに応答してデータを送ることで、行われる。
プロセッサは、プロセッサのNICレジスタにデータを転送するように求め、次に、そのデータを、ローカルNICレジスタからプロセッサのローカル・メモリに移すことで、リモート・ノードからプロセッサ内のローカル・メモリにデータを移す。
【0044】
機能3)では、プロセッサPREQは、この要求されるデータが入っているノードの記憶場所を突き止める方法(多分、テーブルを利用して)を持っている。
これらのトランザクション・プロセスの第1の工程は、プロセッサPREQが要求パケットREQをPSNDに送るためのものである。
REQのペイロードには、1)データの転送元の記憶場所、2)受取り側のコンピューティング・ノードのアドレス、ターゲットNICレジスタ、並びに、このデータを受け取るNICレジスタ(720または722)内のセル(1つまたは複数)の記憶場所、3)トランザクション識別子(TID)の情報が入っている。
【0045】
プロセッサPREQは、要求パケットREQを送り出すのと同時に、いくつかのパケットを送り出すこともある。
一動作方式では、プロセッサPREQは、倍長NICレジスタ(double NIC register)720を利用して、所与の時間に1個〜7個のパケットを送り出す。
プロセッサPREQは、128バイトのペイロードを持つHyperTransportTMのダブル・ロード・パケット(double load packet)を形成する。
プロセッサPREQは、このパケットを倍長レジスタ720に送る。
このパケットを送る結果として、パケットREQと、おそらく他のパケットが、倍長レジスタに転送される。
パケットREQのペイロードは、この倍長レジスタ内の位置PKに転送され、また、パケットREQのヘッダーは、このレジスタ内の位置HKにある(ここで、0<K<8)。 HyperTransportTMのダブル・ロード・パケットはまた、特定のコードをH0およびP0に入れて、それぞれのセル(H1、H2、...、H7)内のフィールドを変更させ、NICレジスタ内のパケットのすべてが、NICレジスタからNIC出力スイッチにいつでも転送できる状態にあることを示す。
HyperTransportTMのダブル・ロード・パケットは、パケットの転送に役立つレジスタにロードされたパケットの数を含む他のコードを、H0セルおよびP0セルに入れることもある。
セルH0およびセルP0の用途は、まったく様々であり、これらのセルは、コンピュータのオペレーティング・システムで導かれる通りに使用されることになっている。
別法として、個々のHフィールドは、他の技法により変更されることもある。
このような技法の1つは、個々のヘッダーをHNに入らせて、送りビットを設定することであり、もっとも効果的には最後のビットをHNに入らせることである。
セルH0内のコードに応答して、転送ロジック(図示されてない)は、ライン742を介して、これらのパケットをNIC出力チップの個々の入力部に送る。
NIC出力スイッチの機能は、下記の「注3」で説明される。
これらのパケットは、ライン752を介して、個々の中央ハブ・スイッチ・チップ750に進む。
したがって、このレジスタから、1つまたは複数のパケットが同時に転送されることもある。
次に、これらのパケットは、パケット・ヘッダーにより、このシステム全体に分散される。
【0046】
プロセッサが、1つまたは複数の要求パケットから成る集まりを出してから適切な時間がたって、このプロセッサは、これらの要求パケットを送った結果としてデータを受け取る記憶場所に、1つまたは複数の「send when ready」コマンドを出すこともある。
【0047】
要求パケット(REQ)は、中央スイッチング・システム内のスイッチ・チップの1つを介して、PSNDに関連するNICに進む。要求パケットREQのヘッダーには、PSNDを含むコンピューティング・ノード上にあるNICのアドレスが入っている。
この中央スイッチ・ハブは、PSNDを含むコンピューティング・ノード上のNIC入力スイッチに、REQを受け渡す。
要求パケットREQのヘッダーは、形式REQの要求パケットを含むクラスのパケットを受け取るように指定されたいくつかの「サプライズ(意外な、surprise)」レジスタ722の1つに、要求パケットREQを受け渡す予定であることを示す。
レジスタ722は、要求されたデータ以外のパケットをプロセッサに受け渡すために、サプライズ・レジスタと呼ばれている。
ハードウェア(図示されてない)は、このサプライズ・レジスタSRにREQを入れる。要求パケットREQを含むサプライズ・レジスタにPSNDが出す「send now」コマンドまたは「send when ready」コマンドに応答して、SR内のデータがPSNDに転送される。
一実施形態では、要求パケットREQには、要求されるデータの仮想アドレスが入っている。プロセッサPSNDは、要求されるデータを得て、かつ、1つまたは複数のパケットを形成して、そのパケットを倍長レジスタREGSND720にロードする。
プロセッサPSNDは、ACK情報を利用して、これらのレジスタのどれが使用していないのか判定する。
ACK情報を利用して、どのレジスタが使用していないのか突き止める作業が、後の説明「注4」で説明される。
パケットRES(以下で追跡される任意のパケット)を含む応答パケットは、ペイロードが位置(P1,P2,...,P7)の一部または全部にあり、またヘッダーがH1,H2,...,H7内の対応する位置にあるようなレジスタREGSNDにロードされる。
これらのヘッダーには、1)プロセッサPREQを含むコンピューティング・ノードの記憶場所、2)プロセッサPREQを含むコンピューティング・ノード上のNICレジスタのアドレス、3)上記NICレジスタ内のターゲット・セルの記憶場所、4)TID、を含む様々な情報が入っている。
一対のレジスタ・セル[HK,PK]に入れられている最後のデータ・ビットは、ヘッダーHK内の特定のOUTPUTフィールドに入れられているコードである。
最後のビットが到着すると、データが、ヘッダーとペイロードのセル対から、ライン742を介して送られる。
H0のOUTPUTフィールドが送るように設定されていないために、セルP0とセルH0の内容は送られない。
【0048】
パケットRESは、ライン742を経てスイッチ740を通り、ライン752を経てスイッチ750を通り、ライン754を経てEC−ACKユニット780に送られる。
EC−ACKユニット780で実行される動作は、後の「注2」で説明される。
次に、パケットRESは、プロセッサPREQでパケットRESを受け取るように割り当てられたターゲットNICレジスタの適切なセルに受け渡される。
【0049】
(注0)。
図8Bを参照すると、パケットRESがターゲットNICレジスタに到着すると、そのペイロードは、プロセッサPREQで指定されたセルPKに入れられる。
パケットRESは、パケットの存在を示す先頭の1(leading one)を持っている。
RESのペイロード全体がセルPK内にあった後で(パケットRES内の先頭の1が到着してから適切な時間がたって)、RESの到着を示す信号が、セルPKからセルP0に送られる。
P0内のフィールドNUMPAKには、一組の要求パケットが送られた結果として、ターゲット・レジスタに向けて送られて、到着したパケットの総数があらかじめロードされる。
PKからP0への信号に応答して、フィールドNUMPAK内の数が1だけ減らされる。
これらのパケットのすべてが到着しているときには、まだ到着していないパケットの数を示す数値がデータ0に設定される。
フィールドNUMPAK内でのデータ0の存在は、NICレジスタのペイロード・フィールド内のデータをプロセッサPREQに転送するのに必要ではあるが、ただし不充分な条件である。
フィールドNUMPAK内に正の整数が位置づけられる場合には、まったく処置は講じられない。
フィールドNUMPAK内にデータ0が位置づけられ、データ0がフィールドORDER内にあり、また、データ0がフィールドSEND内にある場合には、まったく処置は講じられない。
フィールドNUMPAK内にデータ0が位置づけられ、かつ、正の整数がフィールドORDER内にある場合には、データ1は、フィールドSENDに入れられて、そのパケットがプロセッサPREQに送れる状態にあることを示す。
SENDフィールド内の1の値に応答し、かつ、プロセッサPREQの「send when ready」コマンドを受け取ると、HyperTransportTMラインにロードするハードウェアは、NICレジスタ内のペイロード・セルに入っているデータを、プロセッサPREQに送らせる。
NICレジスタNR(C)内のペイロード・データがプロセッサPREQに送られた後で、このレジスタ内のロジックは、フィールドORDER内の整数を減らして、フィールドORDER内の新たな数値を、ライン840を介して、NICレジスタNR(C+1)内のP0のフィールドORDERに送る。
次に、NR(C)内のロジックは、NR(C)のフィールドSEND、フィールドORDER、フィールドNUMPAKを、データ0に設定する。
ここに述べられるやり方で複合レジスタのP0のセルを用いれば、その要求されたデータを適正な順序で、プロセッサPREQに効率的に送ることができる。
【0050】
(注1)。
再び図8Bを参照すると、ロジックは、複合レジスタのヘッダー部分に関連するものであり、H0内の情報を利用して、セル(H1,H2,...,H7)の内容を完成する。 それゆえ、プロセッサPは、パケットをセルH0に送って、複合レジスタの下半分内のフィールドのすべてを満たすこともある。
このような定式(formulas)は、これらのセルに対してラベリング方式を使用する。 図9を参照すると、このような方式の1つは、セルに4−touple[T,U,V,W]でラベルを付ける。
ここで、[T,0,U,V]は、コンピューティング・ノードT上のセルA(U,V)を表し、また、[T,1,U,V]は、コンピューティング・ノードT上のセルB(U,V)を表す。
Tが、プロセッサPREQを含むコンピューティング・ノードのアドレスである場合には、0≦N≦7、HN=[T,1,C+N,0]の公式は、一組の要求パケットの結果として、隣接する7つの複合レジスタにデータを収めることを目標としたNICレジスタ内のP0値から成る7上位列を満たす。
【0051】
(注2)。
図7を参照すると、データを要求するプロセッサPREQは、いくつかの機能を果たす。
これらの機能の1つは、順序づけられた3つ組の整数[I,J,K]が入っているペイロードを持つパケットを送ることである。
ここで、Iは、この要求のTIDであり、また、Jは、この要求の結果として転送されるパケットの数であり、さらに、Kは、プロセッサPSNDを含むコンピューティング・ノードの記憶場所である。
TIDパケットは、プロセッサPREQにより、特定の組の単純NICレジスタを介してEC−ACKユニットに転送される。
これらのレジスタ内のデータは、NIC出力スイッチを通らない。定められた数のTID番号が許容される。
EC−ACKユニットは、このような組の許容されるTID番号をアドレスとして持つメモリを備えている。
ペイロード[I,J,K]を持つTIDパケットがEC−ACKユニットに到着すると、JとKの数値が記憶場所Iに格納される。TIDパケットは、コンピューティング・ノードのボード(computer node board)を決して離れないから、TIDパケットがEC−ACKユニットに到着すると、誤り訂正は不必要である。
【0052】
中央スイッチ・ハブからライン754を介して到着するデータパケットは、SerDesモジュール(図示されてない)を通ることがある。
次に、このパケットは、EC−ACKモジュールに入り、そこで、このパケットは誤りの検出および訂正を受ける。
誤り訂正は、EC−ACKユニット780で実行される。データの誤り訂正ができないが、ただし、TID、送り側ノード・アドレス、および提案される記憶セル・アドレスを突き止めることができる場合には、EC−ACKユニット780は、ライン782を介してNICレジスタにNAKを送って、そのNAKを送り側に送り戻すことができる。
EC−ACKユニット780がパケットを補正できず、また、その情報を復元してNAKを送ることができない場合には、このパケットを廃棄し、オペレーティング・システムは、タイムアウト状態のために、そのパケットに対する再要求を出す。
パケットがEC−ACKユニット780に到着し、誤りがまったく検出されないか、あるいは少なくとも1つの誤りが発生し、しかも、すべての誤りを訂正できるときには、このパケットのTIDを読み取って、記憶場所TID内の整数Jが減らされる。
記憶場所TID内の整数Jを減らした後で、その整数がデータ0である場合には、TIDに関連するデータパケットのすべてが到着していて、アドレスKを持つノードにACKを戻すことができる。
ノードKへのACKの転送は、EC−ACKモジュールにより達成されて、1つまたは複数のACKパケットが、複合NICレジスタ内のセル対に送られる。
【0053】
(注3)。
NIC出力スイッチは、1)欠陥ラインを、中央ハブ・スイッチ・チップに、または中央ハブ・スイッチ・チップからバイパスすることだけでなく、欠陥中央ハブ・スイッチ・チップをバイパスすることも、2)コンピュータ上で実行するジョブを分離すること、3)複数のホップを持つシステム内の中央スイッチ・ハブを通るパケットの平均レイテンシを下げること、を含むいくつかの機能を持っている。
3番目の機能は、複数のホップ・データ・ボーテックス・システム(hop data vortex system)に関して、ここに組み入れられた特許および特許出願に説明されている。
単純なホップ・システムでは、そのオペレーティング・システムは、このシステム内の欠陥ラインと中央スイッチの障害を示すデータを受け取り、また、その情報に基づいて、NIC出力スイッチは、これらの欠陥に基づいて道筋を定めることもある。
処理ノードの一部が所与の計算ジョブ(compute job)に割り当てられるときには、これらのノード間でデータを転送するために、いくつかの中央スイッチ・チップが用意される。
この例示技法を用いれば、厳密なシステム・セキュリティを維持できる。さらに、これらのジョブの1つが、単一のコンピューティング・ノードへの長い一連のパケットの流れを開始させ、かつ、その一連のパケットが、ネットワーク上でバックアップをもたらす場合でも、このバックアップは、他のジョブを妨げることはない。
このようなバックアップをもたらすプログラムは、このシステムの全域でデータパケットを引き出す要求側のプロセッサが過度の要求を行わないようにすることを規定したルールに違反している。
同様に、このシステム内のサプライズ・パケット(surprise packet)の数も制限される。
それゆえ、このシステムは、正確に使用されるときには、極度の効率で動作するように設計されている。
また、ユーザーが、このシステムを不正確に使用しても、このシステム上にある他のジョブに悪影響が及ぼされることはない。
【0054】
(注4)。
プロセッサPSNDは、その要求されたデータを1つまたは複数のNICレジスタに入れることで、プロセッサPREQからのデータパケットの要求に応答する。
パケットがNICレジスタから転送されるが、ただし、そのパケットがターゲット・レジスタに到着しない場合には、そのデータに対して別の要求が出される。
したがって、データは、そのデータに対するACKを受け取るまで、送り側のNICレジスタに残しておかれる。
ACKが受け取られると、プロセッサは、別のデータ転送に備えて、送り側のレジスタをプロセッサの有効リスト(available list)に復元することができる。
前節では、リモート記憶場所からのデータに対する要求が説明されている。
送り側のレジスタにACKがまったく戻されないためにデータを再送することで、リモート・ノードから、NICレジスタからのデータに対する要求がもたらされるが、これは、リモート・ノード上のNICレジスタに格納されるデータをプロセッサが要求して、得ることのできる理由のただ1つを表している。
リモートNICレジスタからデータを得る方法は、後でこの開示内容に説明される。
「リモート・ノードI上のメモリからのデータに対する要求」動作には、他のすべてのデータ転送が、このプロセスのわずかな簡略化または修正であるという性質がある。
【0055】
「リモート・ノードII上のメモリからのデータに対する要求」動作は、「send when requested」コマンドを含む有用なトランザクションである。
データを要求側のプロセッサPREQは、要求パケットREQをリモート・データ送り側のプロセッサPSNDに送って、単純レジスタSR(t+s)内の規定されたセルにデータを戻すようにプロセッサPSNDに指示することで、プロセッサPSNDの仮想アドレス空間から8つまでのデータ・セルを要求する。
要求パケットREQの受取りに応答して、プロセッサPSNDは、この要求されたデータを複合NICレジスタのペイロード・セルにロードし、さらに、ヘッダーを複合NICレジスタのヘッダー部分にロードして、これらのペイロード・パケットが、単純レジスタにおいて、要求パケットREQで規定される記憶場所に到着するようにしている。
8つのデータパケットを複合レジスタから送るときに、ヘッダーH0とペイロードP0を持つパケットは、例えば適正なビットをヘッダーH0のOUTPUTフィールドに入れることで、他の7つのパケットとともに送られる。前節において、要求側のプロセッサPREQが、数のNUMPAKを受取り側の複合NICレジスタ内のセルP0に入れるのと同様に、プロセッサPREQは、数のNUMPAKを補助セル850に入れる。
これらのパケットが単純NICレジスタ内に到着すると、信号がライン852を下って送られて、補助セル850内の数が減らされる。
この数が0に減らされると、プロセッサPREQは、1に設定された単一ビットを、単純レジスタSNR(r)内の規定された記憶場所にある1の適切なセルに入れる。
ここで、r<tである。
この1を入れるのに適した場所は、SNR(0)内で左から右に数え、引き続きSNR(1)内で左から右に数えるといった具合に数えることで、単純ノード・レジスタのs番目のセルである。
この記憶場所は、sを64で除算して、整数Iと剰余J(除法をなす)を得、その記憶場所を、SNR(I)内において、セルJにあるものとして特定すれば、見出すことができる。
プロセッサPREQは、SNR(0)、SNR(1)、...、SNR(t−1)のレジスタの内容を定期的にチェックして、どの単純ノード・レジスタが、要求されたデータのすべてを得ているのか突き止める。
【0056】
「複合リモートNICレジスタからのデータに対する要求」動作は、極めて単純である。
この要求側のプロセッサは、パケットを送って、H0の内容を変更する。
上記「注1」に説明されるように、H0を変更すると、NICレジスタの他のセル内のデータが適正に変更される。
あるいは、この要求側のプロセッサは、ライン732を介してパケットを送って、単一セル内のデータにアクセスすることもある。
【0057】
「単純NICレジスタ」から、データに対する要求が出されることもある。
要求側のプロセッサが単純NICレジスタからデータを得るために、このプロセッサは、送り側のプロセッサにサプライズ要求パケットを送って、その要求されたデータを複合レジスタにコピーするように送り側のプロセッサに求める。
【0058】
リモート・ノードからデータを要求するときに、機能3)の変更をリモート・ノード上のプロセッサに行わせれば、そのプロセッサにパケットを送ることができる。
異なるノードに8つのパケットを同時に送ることができ、それにより、それぞれのノードから8つのエッジを持つツリーを用いて、メッセージを極めて速くブロードキャストできる。
【0059】
いくつかの実施形態では、NICレジスタは、オフチップ・ストレージとして使用されることもある。
プロセッサのキャッシュ内のデータは、スワップ・アウトされる。
プロセッサは、スワップ・アウトされ得ないデータをキャッシュ・ラインに入れる都合の良いやり方として、ローカルNICレジスタを使用する。
【0060】
模範的な動作方法では、プロセッサがデータをローカル・レジスタ内であちこちに渡して、コンピュータを大型のシストリック・アレイとして使用できるようにすることで、このコンピュータの並列処理を実行することもある。
実際は、ノードX上のプロセッサが、データを、リモート・ノードY上のNICレジスタから、別のリモート・ノードZ上のNICレジスタに移動させる。
【0061】
中央ハブおよびNICのアーキテクチュアにおいてData Vortex(登録商標)チップを持つコンピュータを、この開示内容に基づいて効果的に使用するために、多くの技法が導入されることもある。
この例示システムおよび例示構造は、Opteronプロセッサへの特定の接続を利用しているが、リモート・デバイスへの他のインターフェースを持つ異なるプロセッサに、同様な技法が用いられることもある。
【符号の説明】
【0062】
100・・・NIC,
110、692、700・・・コンピューティング・ノード,
120・・・コントローラ,
130・・・キャッシュ・ミラー・レジスタ,
140、640・・・NICスイッチ,
144、230、232・・・バッファ,
150、151、690・・・プロセッサ,
154・・・プライベート・メモリ,
156、157・・・パブリック・メモリ,
158・・・キャッシュ,
160・・・CMR,
210・・・TLB,
220・・・メモリ・バッファ,
240・・・PTM,
250・・・コントローラ・ロックユニット,
300・・・スイッチング・システム,
620・・・NICコントローラ,
630・・・ギャザー・スキャッタ・レジスタ,
632、636・・・メモリ・コントローラ,
638・・・ユニット,
642、644・・・DRAM,
702・・・NICチップ,
706・・・メモリ,
720・・・複合ギャザー・スキャッタ・レジスタ,
730・・・入力スイッチ,
740・・・出力スイッチ,
774・・・オンプロセッサ・メモリ・コントローラ
【技術分野】
【0001】
(関連出願)
開示されるシステムおよび動作方法は、参照によって全体が本明細書中に組み入れられている以下の特許および特許出願に開示された主題に関するものである。
1.発明者としてCoke S.Reed氏の名前を挙げた「A Multiple Level Minimum Logic Network(マルチレベルの最小論理ネットワーク)」と称する米国特許第5,996,020号。
2.発明者としてJohn Hesse氏の名前を挙げた「A Scaleable Low Latency Switch for Usage in an Interconnect Structure(相互接続構造に使用される低レイテンシ(遅延時間)の短いスケーラブル・スイッチ)」と称する米国特許第6,289,021号。
3.発明者としてCoke Reed氏の名前を挙げた「Self−Regulating Interconnect Structure(相互接続構造の自己調整)」と称する2004年7月9日出願の米国特許出願第10/887,762号。
4.発明者としてCoke S.Reed氏とDavid Murphy氏の名前を挙げた「Highly Parallel Switching Systems Utilizing Error Correction(誤り訂正を利用する高度並列スイッチング・システム)」と称する米国特許出願第10/976,132号。
【0002】
並列コンピューティング・システムのノードは、ネットワークとネットワーク・インターフェース・コンポーネントとを含む相互接続サブシステム(interconnect subsystem)により接続される。
並列処理要素がノード(ときには、コンピューティング・ブレードと呼ばれることもある)内に位置づけられる場合には、これらのコンピューティング・ブレードは、ネットワーク・インターフェース・カード(ときには、このインターフェースが別のカード上にないこともある)を含む。
一部、このネットワークの特性に基づいて、オペレーティング・システムが選択される。
ネットワーク・インターフェース・カード(NIC)は、それらのプロセッサ、プロセッサ・インターフェース・プロトコル、ネットワーク、オペレーティング・システムの特性を前提として、最高の性能を達成するように設計されている。
【発明の概要】
【課題を解決するための手段】
【0003】
ネットワーク・デバイスの一実施形態により、コントローラは、複数のプロセッサを相互接続するネットワークを介して、データフローを管理する。
これらの複数のプロセッサは、プライベート・ローカル・メモリとパブリック・ローカル・メモリに分けられるローカル・メモリ、ローカル・キャッシュ、及びワーキング・レジスタを含む。
このネットワーク・デバイスはさらに、これらの複数のプロセッサに転送されることになっているデータを受け取る、上記コントローラに結合された複数のキャッシュ・ミラー・レジスタも含む。
上記コントローラは、要求に応答して、このプロセッサを中断させることなく、要求されたデータをじかにパブリック・メモリに転送することで、また、要求されたデータを転送用の少なくとも1つのキャッシュ・ミラー・レジスタを介して、プロセッサ・ローカル・キャッシュにも、プロセッサ・ワーキング・レジスタにも転送することで、データを受け取る。
【0004】
例示システム、および構造と動作方法の双方に関する関連技術の実施形態は、以下の説明および添付図面を参照すれば、もっともよく理解されるであろう。
【図面の簡単な説明】
【0005】
【図1A】処理ノードに、複数のネットワーク・インターフェース・カード(NIC)が接続されているのを示す略ブロック図である。
【図1B】パブリック・メモリに向けられたデータがプロセッサを通る処理ノードに、複数のネットワーク・インターフェース・カード(NIC)が接続されているのを示す略ブロック図である。
【図2】NICコントローラを示すブロック図である。
【図3】中央スイッチにより接続される処理ノード(ブレード)を含むシステムのブロック図である。
【図4】ギャザー・スキャッタ・レジスタのギャザー部分を示すブロック図である。
【図5】データをNICスイッチからギャザー・スキャッタ・レジスタのギャザー部分に運ぶためのツリー相互接続を示す略図である。
【図6】プロセッサとNICとの間で渡されるすべてのデータがギャザー・スキャッタ・レジスタを通る他の実施形態を示す略ブロック図である。さらに、プロセッサのメモリ・コントローラには連絡されないデータがギャザー・スキャッタ・レジスタを通る。
【図7】NIC上にData Vortex(登録商標)スイッチを使用し、さらに中央スイッチング・ハブ内にもData Vortex(登録商標)スイッチを使用する並列コンピュータのブロック図である。
【図8A】ただ1つのデータ行を含むただ1つのNICレジスタを示す略図である。
【図8B】2つのデータ行を含む複合NICギャザー・スキャッタ・レジスタを示すブロック図である。
【図9】それぞれのレジスタが8つのセルを含んでいるTギャザー・スキャッタ・レジスタ(T Gather-Scatter register)から成る集まりを示す略図である。
【発明を実施するための形態】
【0006】
クラスタ・コンピュータ用の現在のオペレーティング・システムは、レイテンシが大きく、かつ、短いパケットを効率的に運ぶことのできない利用可能ネットワークの特性に基づいて設計されている。
これらの欠点がData Vortex(登録商標)ネットワークにより除去されることを前提として、短いパケットに基づいて設計された新たなオペレーティング・システムが使用できる。
Data Vortex(登録商標)ネットワークおよび新たなオペレーティング・システムを用いて可能となる改良は、性能を最適化する新型のネットワーク・インターフェース・カードにより促進される。
本明細書中の開示内容は、これらの改良されたシステムへの使用に適した新規なネットワーク・インターフェース・カードを述べている。
本明細書中に述べられるNICのいくつかの実施形態の特徴は、NIC上のData Vortex(登録商標)により、短いパケットがレジスタに入れられることである。
これらのレジスタは、このシステムの全域からデータを集め、かつ、そのデータを、これらのプロセッサでいつでも使用できる状態にするのに役立つものである。
これらのレジスタは、そのキャッシュの一部のコピーをプロセッサに保存する(mirror)。一実施形態では、それぞれのレジスタには、複数のデータ入力項目(データエントリ)が入っている。
いくつかの実施形態では、これらのレジスタ、例えばキャッシュ・ミラー・レジスタ(CMR)と呼ばれるもの、あるいは、ギャザー・スキャッタ・レジスタと呼ばれるものにはそれぞれ、NIC上にキャッシュの一部を「コピー保存(mirrored)」するようにデータのキャシュ・ラインが入っている。
【0007】
いくつかの実施形態では、ネットワーク・インターフェース・カード(NIC)は、プロセッサと協働して、このシステムを通るデータの流れを管理するコントローラ(これは、スケジューラと呼ばれることもある)を含む。
別のNIC構成要素は、プロセッサに転送されることになっているデータを受け取るキャッシュ・ミラー・レジスタ(CMR)の集まりである。
データを、ローカル・メモリのプロセッサ・メモリ(プライベート・ローカル・メモリとパブリック・ローカル・メモリに分けられる)に受け取るように求めるプロセッサは、このような転送を処理する要求を上記コントローラに送る。
この転送がパブリック・メモリに行われる場合には、NICは、プロセッサを中断させることなく、このような転送を処理する。
この転送が、1)プロセッサのキャッシュ、2)プロセッサ・ワーキング・レジスタ、または、3)プロセッサで管理されるパブリック・メモリに行われる場合には、受取り側のコントローラは、データを受け取るもの(1つまたは複数)となるレジスタ内の記憶場所または記憶場所の集まりだけでなく、レジスタまたはレジスタの集まりも選択して、そのレジスタの識別子を受取り側のメモリ・マネージャに知らせる。
一実施形態では、このレジスタ識別子は、送り側のコントローラにも送られる。
送り側のコントローラは、受取り側のノード、および適切なノード上の受取り側のレジスタの識別子を、データパケット・ヘッダーに入れる。
1つまたは複数のパケットを含むメッセージを適正なCMRに送る。
レジスタには、単一の供給源からのパケット、または複数の供給源からのパケットが入っていることがある。
レジスタには、ノード・プロセッサに受け渡されることになっているキャッシュ・ラインが入っていることが多い。
異なる供給源からのパケットを同一レジスタに入れることは、データを集める効率的なやり方である。
すべてとは限らないが、いくつかの場合に、パケットをリモート・ノードに向けて送るプロセッサは、このターゲット・ノード・コントローラにパケットを送って、このような転送をスケジュールすることでデータを要求するようにリモート・ノードに指示する。
この例示開示内容は、これらの構成要素の物理的な相互接続を述べ、さらにデバイス間のデータの流れも述べている。
【0008】
CMRへの効率的なローディングは、短いパケットを処理できるスイッチによって処理される。
Data Vortex(登録商標)は、このタスクを処理するのに充分適したスイッチである。
【0009】
並列処理システムは、ネットワークにより相互接続された複数のノードを含む。
この例示開示内容は、それらの処理ノードをネットワーク・システムに接続する手段および方法を述べている。
有用なクラスのアプリケーションでは、ネットワーク・システム内の所与のプロセッサはたいてい、アイドル状態であり、処理ノードから処理ノードへとメッセージ・パケットが移動するのに費やされる時間により、少なくとも一部望ましくない状態がもたらされる。
移動時間は、レイテンシと呼ばれる。
レイテンシの一因となる第1のファクタは、メッセージ・パケットがネットワーク上で費やす時間である。
この時間は、上記の組み入れられた特許および特許出願に記載されているネットワーク・システムを用いることで、大幅に減らされる。
この時間の別の部分は、ネットワークとコンピューティング・ノードとの間のインターフェースにおいて、ハードウェアとソフトウェアのオーバーヘッドによるものである。
このシステムでは、インターフェース・レンテンシが大幅に減らされる。
この例示構造および例示システムはまた、プロセッサの中断が極力減らされるという利点もある。
この例示構造および例示システムの他の利点は、ギャザー動作とスキャッタ動作を効率的に処理することである。
【0010】
このシステムは複数のコンピューティング・ノードを含む。
それぞれのコンピューティング・ノードは、複数のスイッチ・チップを利用するネットワークにより接続された1つのNICを持っている。
例示実施形態では、それぞれのNICは1つまたは複数のData Vortex(登録商標)スイッチ・チップを含み、また、このネットワークは1つまたは複数のData Vortex(登録商標)スイッチ・チップを含む。
【0011】
図1Aを参照すると、コンピューティング・ノード110とNIC100から成る第1のシステム実施形態を略ブロック図が示している。
このコンピューティング・ノードは、1つまたは複数のマイクロプロセッサと、関連するメモリを含む。
さらに、このコンピューティング・ノードは、ディスク・ドライブと、おそらく他のハードウェアを含むことがある。
この例示設計は、2つの処理チップを持っている。
他の設計は、チップの数が異なる場合もある。
この例示プロセッサは、関連するオフチップ・キャッシュを持っている。
他の設計では、このプロセッサ・キャッシュのすべてがプロセッサ・チップ上にあることもある。
図1Aの例示設計では、プロセッサとNICとの間のやり取りのすべてが、プロセッサ1(150)により実行される。
他の設計では、NICは、プロセッサ1およびプロセッサ2とじかにやり取りできる。 NICは、プロセッサ1を介して、プロセッサ1のパブリック・メモリ156にアクセスする。
プロセッサ1からNICへのやり取りは、この例示開示内容では、メッセージ・パケットをNICに送ることとして述べられている。
実際は、プロセッサ1は、この動作を、メモリ・マップドI/O(MMIO)への格納を行うものと見なしている。
多くの場合に、パケットを送る用語は、実際は、記述の前後関係により、異なる解釈を持つことがある。
【0012】
NIC100は、処理ノード110に送られようとするデータを保持するために、3つの主要構成要素、すなわち、1)NICスイッチ140、2)コントローラ120、レジスタ130を含む。
これら3つの構成要素の動作は、このシステムを通してメッセージ・パケットを追跡する例により述べられる。
【0013】
例1は、プロセッサ2(152)がリモート・ノードにデータを要求するケースを扱っている。
プロセッサ2は、図2に示されるNICコントローラ120のコントローラ・ロジックユニット250内にあるメモリ・バッファ・スタック230中の要求メモリ・バッファ220にプロセッサ2で要求を書き込ませることで、その要求を、プロセッサ1を介してコントローラ120に送る。
このコントローラは、これらの要求が入っている要求バッファのスタックを含む。
この要求バッファがオーバーフローしないようにする一方法は、所与の時間に、限られた数の未完了要求(outstanding request)しか認めないことである。
この要求には、ターゲット・データを含むノードの識別子が入っており、さらに、このデータを格納する記憶場所の物理アドレスまたは仮想アドレスも入っている。
5つのケースが考察される。
【0014】
ケースI。
コンピューティング・ノード上のプロセッサPR(150または152)は、データをリモート・ノードのパブリック・メモリから、プロセッサPRのパブリック・メモリ空間内の記憶場所に転送するように求める。
現行例よりも興味深いケースでは、プロセッサPRは、この記憶場所の仮想アドレスを与える。
この要求は、コントローラ120に要求パケット(request packet)を送ることで、出される。
プロセッサPRがプロセッサ2(152)である場合には、この要求は、プロセッサ1(150)を通る。
この要求パケットは、ライン170とライン102上を進む。
この要求パケットには、要求番号(request number)を示すフィールド(図2に示されるバッファ230内の記憶場所)、この要求がリモート・ノードのローカル・パブリック・メモリ中のデータに対するものであることを示すフィールド、転送されるデータの量が入っているフィールド、転送されるデータの仮想アドレス(この仮想アドレスは、そのデータがリモート・ノード上にあることを示している)を示すフィールド、および、プロセッサPRがアクセスするメモリ上においてデータが格納される記憶場所の仮想アドレスを示すフィールド、が入っている。
コントローラ120は、この仮想アドレスを持つデータが格納されているリモート・ノードのラベル(標識)を含むテーブルを持っている。
図2を参照すると、コントローラ・ロジックユニット250は、その要求を、メッセージ番号で示されるバッファ230内の記憶場所に入れる。
プロセッサは、限られた数の未完了要求しか持つことができないために、バッファ230は決してオーバーフローしない。
一実施形態では、要求は、受け取られる順番に処理される。他の実施形態では、要求は、一部、サービス基準の品質に基づいて処理される。
データが適正な記憶場所にうまく受け渡されるまで、この要求は、要求バッファ(request buffer)230にとどまる。
コントローラ・ロジックユニット250は、要求バッファ230からの要求にアクセスし、また、例えばコンピューティング・ノードの物理的記憶場所を格納している物理的ページテーブル・マップ(PTM)240にアクセスすることで(ときには、アクセスされるメモリの仮想アドレスの先行ビットに基づいて)、転送されるデータを格納しているコンピューティング・ノードの物理的記憶場所を捜す。
次に、コントローラ・ロジックユニット250は、データに対する要求を、アクセスされるデータ(このデータは、送り側のプロセッサPSに関連する)を格納しているコンピューティング・ノードに関連するNICに送る。
この要求パケットには、バッファ230内の要求の物理的記憶場所である要求パケット番号を示すフィールドが入っている。
この要求は、スイッチング・システムを介して、ターゲットNICに渡される。
図3は、NIC100に接続され、かつスイッチング・システム300にも接続されたブレード110を示している。
例示実施形態では、スイッチング・システム300は、上記の組み入れられた特許および特許出願に記載されているタイプのData Vortex(登録商標)である。
【0015】
要求がリモート・ノードへ移動中であるとき、コントローラ・ロジックユニット250は、到着するパケット(1つまたは複数)が格納される仮想メモリ基準(virtual memory reference)の物理的記憶場所を保持しているTLB210にアクセスする。
この物理的記憶場所が決定されて、それがバッファ230内の要求パケットの追加フィールドに追加される。
この設計の一面は、TLB内の物理的記憶場所へのアクセスが、この要求パケットを送ることと同時に行われて、このような探索(ルックアップ)で、このプロセスへのレイテンシが増さないようにすることである。
NIC上のメモリ量は、TLB210がローカル・メモリの物理アドレスだけを保持するという事実により、また、PTM240が、ブレード上のメモリのアドレスではなく、ブレード・アドレスだけを保持するという事実により、減らされる。
公知の技術を使用して、ハッシング技法を実行し、かつ、最近アクセスされたアドレスを格納するための特定の記憶場所を含めるように、TLBとPTMを設計することもある。
シーケンスの構成要素(メンバ)を、このシーケンスの第1の構成要素からのオフセットに基づいて格納するのに用いられる技法は、Cなどの言語の特徴である。
この技法は、TLBのサイズを減らすのに有利に使用できる。
【0016】
要求は、リモート・ノード(データ送り側のノード)に到着して、コントローラ120のコントローラ・ロジックユニット250に入る。
コントローラ・ロジックユニット250は、この要求をバッファ232に入れる。
複数の様々な技法を使用して、バッファ232がオーバーフローしないようにすることもある。
一実施形態では、バッファ232は、このシステム内に、処理ノード(ブレード)の数のN倍の要求数の容量を持っている。
このシステムは、いかなるノードもN個よりも多くのデータパケットを個々のリモート・ノードには要求できないというルールで制約を受ける。
一実施形態では、バッファ232は、N個のセクションに分けられ、しかも、それぞれのブレード用に1つのセクションが確保される。
他の実施形態では、送り側のコントローラは、要求を送る許可を求める。
さらに他の実施形態では、バッファの調整がまったく行われず、また、フル・バッファ(全バッファ、full buffer)232を用いてのコントローラへの要求が拒否されて、ACKが戻される。
確実にバッファ232がオーバーフローしないようにするために、トークンの使用を含め、他の技法が使用されることもある。
超大型のシステムでは、バッファ232は、N個のセクションに分けられ、しかも、一群のブレード(例えば、キャビネット内のブレードのすべて)用に1つのセクションが確保される。
【0017】
コントローラ・ロジックユニット250は、TLBにアクセスして、コントローラ・ロジックユニット250のローカル・パブリック・メモリ空間内にデータを見出すことで、バッファ232からの要求を処理する。
次に、要求されたデータは、そのヘッダーに入っているユニット230内のパケット要求のアドレスとともに、要求側のコントローラ・ユニットに戻される。
コントローラ・ロジックユニット250は、その物理アドレスをバッファ230から得て、そのデータを、ローカル・パブリック・メモリ空間内の適正な物理アドレスに送る。
【0018】
データ要求に関連するデータ転送が複数のパケットを含む一実施形態では、要求されるパケットの数は、ユニット230に格納された要求パケットの中に示される。
これらのパケットがそれぞれ到着すると、コントローラ・ロジックユニット250は、特定された要求に関連する到着パケットの数の現在合計高を維持する。
したがって、転送が完了したときに、コントローラ・ロジックユニット250は通知がある。
完了時に、コントローラは、確認応答(ACK)をプロセッサPRとプロセッサPSに送る。
ACKに応答して、プロセッサPRは、別の要求で使用される要求パケット番号を解放する。
【0019】
コントローラはまた、データ要求側のプロセッサにACKパケットを送って、そのデータが所定の場所にあることを示す。
ACKに応答して、プロセッサは、データに対する未完了要求の数の記録を取るカウンタを減らす。
データがうまく転送された(いくつかの実施形態では、ACKにより表される)後で、コントローラ・ロジックユニット250は、別の要求に対して、バッファ230内の該当記憶場所を解放する。
いくつかの実施形態では、所与の要求に応答して受け渡されるパケットが、順番に到着する。他の実施形態では、所与の要求に関連するパケットは、コントローラによりパケットを順番に並べられるようにするパケット番号を、それらのパケットのヘッダーに含む。 中央スイッチ・ハブに複数のスイッチ・チップを使用するさらに他の実施形態では、複数のライン124は、この中央スイッチ・ハブからデータを受け渡す。
また、メッセージ内でのパケットの適正な配置は、そのパケットがどのラインに到着するかによって決まる。
ケースIの説明は、1つまたは複数のパケットをローカル・パブリック記憶素子に入れることのできるメモリ・コントローラを、コントローラ120が利用することを前提としている。
【0020】
ケースII。
プロセッサPRは、リモート・パブリック・メモリ内のデータを、プロセッサPRのキャッシュまたはワーキング・レジスタ内の記憶場所に格納するように求める。
プロセッサPRは、そのデータを、メモリ・バッファ130内に位置づけられたCMR160に格納するように求める。
それぞれのCMRレジスタはロックを含み、そのロックが解除されるまで、データがプロセッサPRに流れないようにしている。
プロセッサPRは、どのCMRユニットが使用してないか追跡する記憶場所を別にしておく。
図4は、それぞれのCMRがN個のセル(記憶場所)を含んでいるM個のCMRユニットを含むバッファ130を示している。
データを要求するプロセッサは、関連するNIC上のコントローラ120に要求を送って、所与の仮想アドレスでのデータ項目を、バッファ130内のM・Nセルの1つまたは複数に送るように求める。
コントローラ・ロジックユニット250は、PTMを利用して、その要求されたデータが入っているノードの物理的記憶場所を突き止める。
要求パケットは、このデータを受け取るセル(1つまたは複数)のアドレスだけでなく、受取り側のノードの物理アドレスも含む。
この要求パケットはまた、その要求されたデータの仮想アドレスも含む。
この要求パケットは、データを含むノードにシステム・スイッチ300を介して進む。 ケースIの場合と同様に、受取り側のコントローラ・ロジックユニット250は、要求をバッファ(図示されてない)に入れて、要求を処理できるまで、その要求を保持する。 リモート・データを含むノードが要求を処理するときに、そのノードは、ローカルTLBにアクセスして、そのデータの物理アドレスを見出す。
そのデータを含むパケットは、ライン124上で、プロセッサPRに関連するNIC上のバッファ144に進む。
バッファ144にオーバーフローさせない方法は、バッファ232のオーバーフロー管理と同一の方法で処理される。
NICスイッチに到着したデータパケットは、データ・ライン118を介して、適正なCMRセルに送られる。
【0021】
図4は、それぞれのCMR160がN個のデータ・セル402を含んでいるM個のCMRを含むバッファ130を示している。
NICスイッチが512個の出力ポートを持ち、また、それぞれのCMR内のセルの数が8であって、かつNが64に等しい例では、それぞれのセルは、この場合、NICスイッチの一意の出力ポートに接続されることもある。
NICスイッチ140がData Vortex(登録商標)スイッチであり、また、これらのポートのそれぞれが2Gb/秒にて動作する場合には、CMRに入る最大バンド幅は1テラビット/秒を超える。
プロセッサはまた、ローカル・パブリック・メモリからの要求データをプロセッサNIC上のCMRに送るように求めることもある。
このデータは、データ・ライン106を通り、またスイッチ130によりライン120に切り替えられて、NICスイッチまで進む。
【0022】
CMRセルの総数は、NICスイッチの出力ポートの数を越えることもある。
多数のCMRセルを可能にする一実施形態では、CMRは複数のバンクに分けられ、また、それぞれのバンクは、NICスイッチ内の出力ポートの数に等しい数のセルを持っている。
このデータ・ヘッダー内の上位のビットにより、このデータは、NICスイッチと、CMRのバンクとの間のツリーを通って分岐することができる。
CMRのバンクが4つある上記構成が図5に示されている。
データパケットをNICスイッチからCMRセルに運ぶラインの一部だけが図示されている。
【0023】
一実施形態では、プロセッサは、ただ1つの要求を出して、複数のデータ項目を関連するCMRに格納することもある。
例えば、プロセッサは、一連のデータ項目を、リモート記憶場所に連続的に格納して、プロセッサCMRバッファ内のセル行に入れるように求めるか、あるいは、一連のデータ項目を、プロセッサCMRバッファ内のセル列に格納するように求めることもある。
所与の要求に関連するパケットのそれぞれは、CMR内のセルのアドレスだけでなく、要求番号も含む。
異なる系列のデータ項目をセル列に格納すれば、プロセッサは、この例示構造および例示システムで可能となる強力で、かつ有用なコンピューティング・パラダイムで、複数のデータ・ストリームに同時にアクセスできる。
所与の要求に関連するパケットのすべてが、プロセッサPRに関連するNICで受け取られるときには、プロセッサPSにACKが戻される。
【0024】
データがCMRに転送されるときには、いつ所与のCMRラインがいっぱいとなって、プロセッサに転送できる状態になるのか決定する技法が使用される。
CMRライン情報を追跡する一方法は、コントローラ・ロジックユニット250内にある特定の組のM個のレジスタ(描かれてない)によって管理される。
これらのレジスタは、ここでは「CMRフル・ステータス・レジスタ」と呼ばれている。
プロセッサPRが複数の要求を出して、データをGSRの行Kに入れる前に、プロセッサPRは、行K中のどのセルがこのデータを受け取ることになっているのか突き止める。 プロセッサPRは、特定のパケットをコントローラ・ロジックユニット250に送って、その情報を示す。
プロセッサが、データをCMRレジスタのサブセットSに入れる要求を送る場合には、この要求に関連する「CMRフル・ステータス・レジスタ」のすべてが更新される。
データパケットが、プロセッサPRに関連するNICに戻ると、「CMRフル・ステータス・レジスタ」内のデータが変更される。行Kに予定されるパケットが到着すると、「CMRフル・ステータス・レジスタ」K内の値が減らされる。
「CMRフル・ステータス・レジスタ」の内容がゼロに減らされるときには、CMRの行Kに予定されるデータのすべてが到着しており、コントローラ・ロジックユニット250は、普通ならデータが行Kから、PRに関連するキャッシュに、あるいはPRのワーキング・レジスタに流れ込まないようにするロックを解除する。
いくつかの実施形態では、一定の時間後では、上記ロックが解除される前にデータがCMRレジスタから転送されて、CMRレジスタ内のデータが有効でないという指示が出される。
このCMR内のデータが有効であるかどうかを決定する一方法は、CMRレジスタ内の最左端の記憶場所にデータを送れないようにすることである。
他のデータ項目のすべてが到着しているときに、その最左端の記憶場所にコードワードを入れて、そのデータのすべてが到着していることを示す。
上記ロックが解除されるためではなく、タイムアウトのために、データが送られる場合には、その記憶場所にはコードワードを入れず、プロセッサは、そのデータが無効であると知らせることができよう。
【0025】
ケースIII。
プロセッサPは、リモート・プロセッサで追加CMR(図示されない)に書き込ませ、また、その追加CMRをローカル・プロセッサで読み取らせることで、短いメッセージをリモート・プロセッサに送る。
バッファがオーバーフローしないようにする方法は、バッファ232のオーバーフロー管理と同一のやり方で処理される。
送り側のプロセッサは、その短いメッセージを受取り側のコントローラに送り、そこで、ローカルで読み取って、リモートで書き込むことのできるCMRの中で、そのデータを管理する。
【0026】
ケースIV。
プロセッサPは、プロセッサPに対してローカルであるローカルNICコントローラにメッセージ・パケット(1つまたは複数)をプロセッサPで送らせ、また、このメッセージ・パケットをターゲット・コントローラに上記ローカルNICコントローラで送らせることで、短いメッセージをリモート・パブリック・メモリに送る。
ターゲット・コントローラ内の特定のバッファ空間が、これらのメッセージを保持する。
バッファがオーバーフローしないようにする方法は、バッファ232のオーバーフロー管理と同一のやり方で処理される。
これらの短いメッセージは、アトミックなメモリ操作物(atomic memory operation)と呼ばれている。これらの短いメッセージを使用すれば、分散形共用メモリ・マシン(distributed shared memory machine)内のメモリを制御できる。
プログラミング言語UPCでは、少数のアトミックなメモリ操作物は、分散形共用メモリ・マシン上でのプログラムの総体的な実行を容易ならしめる。
【0027】
ケースV。
プロセッサは、例えばライン172を介して、じかにメモリにアクセスすることで、データを、ローカル・パブリック・メモリ空間に送るか、あるいはローカル・パブリック・メモリ空間から受け取る。
このような操作は、競合状態を避けるために慎重に行われる。
プロセッサはまた、ライン180を介してローカル・パブリック・メモリに接続されたコントローラを経ることで、ローカル・パブリック・メモリにアクセスすることもある。
このコントローラを介してプロセッサがローカル・パブリック・メモリにアクセスする利点は、ローカル・パブリック・メモリにアクセスポイントをただ1つ持つことで、競合状態を避けている点である。
【0028】
図1Bに示される一実施形態では、データは、NICから、プロセッサを通って、パブリック・メモリ空間に渡されることもある。
動作の詳細は、プロセッサによって決まる。
いくつかのプロセッサ(「AMD Opteron」プロセッサを含む)では、メモリ・コントローラは、このプロセッサ内にあり、また、このNICでは、TLBを省略できる。
【0029】
中央スイッチ300内にData Vortex(登録商標)を使用する図3に示される分散形共用メモリシステムであって、図1Aまたは図1B中のNICスイッチ140用にData Vortex(登録商標)を用いるこの例示開示内容に述べられたネットワーク・インターフェースを使用する分散形共用メモリシステムのエンドツーエンド・レイテンシは、極めて低い。
このレイテンシは、NIC100の特徴の全部または大部分を単一のチップ上に取り入れることで、さらに減らされることもある。
【0030】
第1の実施形態では、NIC上のレジスタを使用して、データをこれらのプロセッサに転送した。
第2の実施形態では、これらのレジスタを使用して、データをプロセッサに転送するとともに、プロセッサから転送する。
第1の実施形態では、NICレジスタは、「キャッシュ・ミラー」と呼ばれた。
第2の実施形態では、NICレジスタは、「ギャザー・スキャッタ」レジスタと呼ばれる。
図6を参照すると、略ブロック図は、異なるやり方でアクセスする2つのタイプのメモリを含むかもしれない一実施形態を示している。
第1のタイプのメモリ644は、メモリ・コントローラを介して、プロセッサに接続される。「AMD Opteron」プロセッサの場合には、メモリ・コントローラは、コンピューティング・コア(1つまたは複数)と同一のシリコン・ダイ上にある。
第2のタイプのメモリ642は、メモリ・コントローラにより、ギャザー・スキャッタ・レジスタに接続される。
UPCなどのプログラミング言語(computing language)が使用される場合には、2つのタイプのメモリはそれぞれ、パブリック記憶領域とプライベート記憶領域に分けられることがある。
データ転送の要求は、これらのプロセッサから生じる。
図6では、このプロセッサは複数のユニット638を含み、また、それらのユニット638はそれぞれプロセッサ・コアと複数レベルのキャッシュを含む。
【0031】
プロセッサとメモリ・コントローラがデータをキャッシュ・ライン(64ビット・ワードを8つ含む)に移すケースに関して、「AMD Opteron」プロセッサに合致する模範的な説明が与えられる。
当業者であれば、ここに提示された例が、異なるサイズ・ブロックのデータを移す広範囲のプロセッサおよびメモリ・コントローラに対応するものと解釈できるであろう。
ここに記述される技法は、DRAM644から転送されるブロックが、DRAM642から転送されるブロックに等しくないようなケースに当てはめられる。
このシステムは、2つのケースを考慮に入れることで説明される。
【0032】
第1のケースでは、コンピューティング・ノード692上のプロセッサ690の処理コア638は、送り側の記憶場所から、プロセッサNIC(データ受取り側のNICはRNで表され、また、データ送り側のNICはSNで表される)のギャザー・スキャッタ・レジスタ内の一群の受取り側記憶場所に(しばしば、このような8つの記憶場所に)データが転送されるように求めている。
この要求の目的は、データを、ギャザー・スキャッタ・レジスタから、処理コア638内のローカル処理コア・ワーキング・レジスタ、処理コア638内のキャッシュまで、メモリ644まで、あるいは、RN上のメモリ642まで移せるようにすることである。
該当するケースでは、送り側の記憶場所は、リモート・メモリ644、メモリ642、またはリモート・ギャザー・スキャッタ・レジスタ630である。
処理コア638は、要求パケットを、ライン654を介してSNギャザー・スキャッタ・レジスタ630内の記憶場所に送ることで、要求を出す。
この要求は、RN上のプロセッサのローカル・ギャザー・スキャッタ・レジスタ内の8つの異なる記憶場所に8つの64ビット・ワードを受け渡すように、特定のリモート・ノードに求めることが多い。
このギャザー・スキャッタ・レジスタ内のロジックは、その要求パケットをRN内のNICコントローラに転送する。
RN内のNICコントローラは、その要求にラベルを割り当てて、NICコントローラ内で、その要求のラベルに設定された記憶場所の中でその要求のコピーを維持する。
単純な実施形態では、RN内の記憶場所は、SNのアドレス、すなわち、SNからのデータに対する特定の要求の識別子REQIDに設定される。
次に、RNは、その要求を、中央ハブ・スイッチを介して、SNで表されるリモート・データ送り側NICに送る。
SNコントローラは、記憶場所を割り当てて、その要求を格納する。
単純な実施形態では、SNは、その要求をアドレス(RN、REQIDのアドレス)に格納する。
この格納方式の有用な一面は、RNが、SN内でその要求を格納する場所に関する情報、SNが記憶場所を割り当て、かつ特定のパケットをRNに送って、その記憶場所をRNに知らせることによっても達成できる条件を持つことである。
様々な間接探索方式(lookup scheme)が実施されることもある。
【0033】
要求されたデータがSNのギャザー・スキャッタ・レジスタ内にはまだない場合には、SN上のNICコントローラは、そのデータを、メモリ634またはメモリ642から適正なギャザー・スキャッタ・レジスタに転送する。
8つの64ビット・ワードは、中央ハブ内の8つの異なるスイッチ・チップに転送され、次に、ノードRN上のNICスイッチ640に転送される。
これら8つのパケットのそれぞれは、要求されるデータ、RNのアドレス、要求ラベル、このデータを入れるギャザー・スキャッタ・レジスタ内のターゲット記憶場所、および、要求される8つのパケットのうちのどれを送ろうとするのか示す、整数(0、1、...7)から選ばれる一意のデータパケット識別子を含む。
パケットがうまく受け渡されると、受取り側のレジスタは、このデータパケット識別子を持つローカルACKを、その要求を格納しているRNコントローラ内の記憶場所に送る。
ACKを適正な記憶場所に受け渡す非常に効率的な方法は、Data Vortex(登録商標)スイッチ(描かれてない)をライン612上に、またはギャザー・スキャッタ・レジスタのハードウェア内に使用することである。
8つのローカルACKがすべて受け取られているときには、RNは、リモートACKを中央ハブ・スイッチを介してSN内のNICコントローラに送る。
ACKは、Data Vortex(登録商標)スイッチをRN上のNICコントローラに用いることで、その要求を保持する記憶場所に送られることもある。
ACKを受け取るときには、その要求パケットは廃棄され、また、その要求を保持する記憶場所は、別の要求パケットのために解放されることもある。
その要求に関連する8つのパケットのうちの1つが適正に受け取られない場合には、NACは、そのパケットを再送するように求める。
パケットのいっぱいのキャッシュ・ラインが受け取られているときには、そのキャッシュ・ラインは、その要求パケットで指定されるように、DRAM642、DRAM638内の正しい記憶場所、または処理コア638内のキャッシュに転送されることもある。
このキャッシュ・ラインがいっぱいであるかどうか決定する一方法は、第1の実施形態の記述の中で説明されている。
第1の実施形態の場合と同様に、タイミアウトによりデータを送ることも処理される。
【0034】
第2のケースでは、プロセッサは、例えば、SNがRNに要求を送って、RNにデータを要求するように求めることで、リモート記憶場所へのデータの送りを開始させる。
次に、このプロセスは、第1のケースの場合と同様に進行する。
【0035】
図7を参照すると、略ブロック図は、第3の実施形態を描いており、また、2つのプロセッサ750、メモリ706、NICチップ702を含むコンピューティング・ノード700を示し、さらに、中央ハブ・スイッチ・チップ750も示している。
図7は、この中央スイッチ・ハブに「AMD Opteron」プロセッサとData Vortex(登録商標)チップを使用する特定の並列コンピューティング・システムを示す図解例である。
この図解例の装置および動作方法は、他のプロセッサを用いる非常に広範なクラスの並列システムに当てはめられる。NICからデータを受け取る中央スイッチ・ハブ・チップのそれぞれに、ライン752により所与のコンピューティング・ノードが接続される。
NICにデータを送る中央スイッチ・ハブのそれぞれからデータを受け取るために、ライン754によりコンピューティング・ノードが接続される。
多くの有用な「1ホップ(one hop)」システムでは、データを、NICのすべてから受け取り、またNICのすべてに送るために、中央スイッチ・ハブ・チップのそれぞれが接続される。
例えば、中央スイッチ・ハブに、256のコンピューティング・ノードと40のData Vortex(登録商標)スイッチ・チップを含む「1ホップ」システムは、コンピューティング・ノード上の256のNIC出力リンク752(中央ハブ・スイッチ・チップのそれぞれに1つ)と、40のNIC入力リンク754(それぞれの中央ハブ・スイッチ・チップから1つ)を用いて構成されることもある。
【0036】
NICはレジスタの集まり710から成っている。
レジスタの集まり710は、単純レジスタ722を含み、さらに複合ギャザー・スキャッタ・レジスタ720も含む。
NICはまた、出力スイッチ740と入力スイッチ730も含む。
例示NICはまた、誤り訂正を実行して、ACKとNAKを送るEC−ACKユニット780も含む。
Data Vortex(登録商標)スイッチは、それらのスイッチとしての使用に充分適している。NIC上には、DRAMもメモリ・コントローラもまったく含まれない。 オンプロセッサ・メモリ・コントローラ774を介して、システム・メモリ706にアクセスする。コンピューティング・ノード間で転送されるすべてのデータは、ギャザー・スキャッタ・レジスタを使用する。
図7に示されているNICは、別個のNICコントローラを含まない。
図1A、図1B、図2、図6に示されるNICコントローラの機能は、「Opteron」プロセッサにより、さらに、ギャザー・スキャッタNICレジスタに組み入れられた計算ハードウェア(computational hardware)により実行される。
【0037】
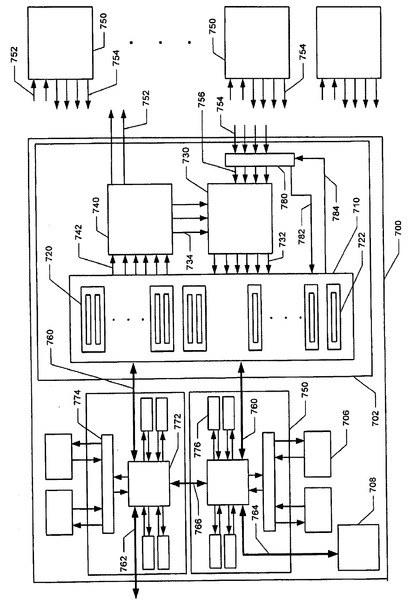
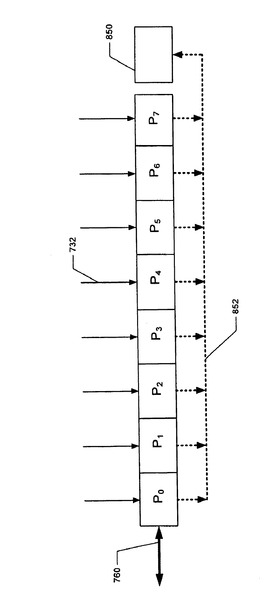
図8Bとともに図8Aを参照すると、NICレジスタのそれぞれが複数のセルに分けられる。
セルの数は、まったく一般的なものである。
この図解例では、セルの数は8に設定され、また、セル内のビットの数は64に設定されている。
他の例は、それよりも多くのセル、またはそれよりも少ないセルを持つこともある。
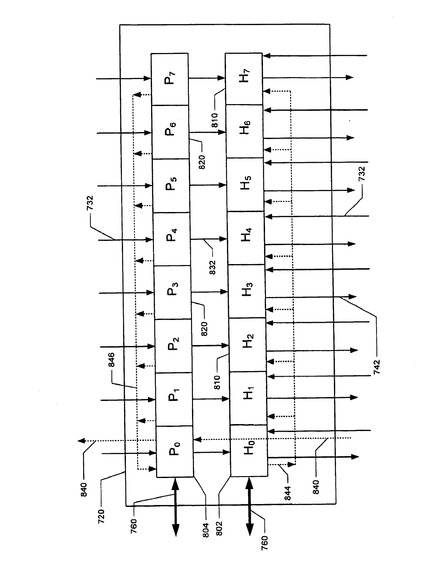
最下部の単純NICレジスタにSNR(0)のラベルが付けられ、また、SNR(0)のすぐ上のレジスタにはSNR(1)のラベルが付けられるといった具合にNICレジスタに番号が付けられて、T+1の単純レジスタを持つシステムの場合には、SNR(0)、SNR(1)、SNR(2)、...、SNR(T)の順番列(シーケンス)を作り出すように、これらの単純レジスタにラベルが付けられる。
単純レジスタSR(D)内のセルにラベルを付けたものが、SR(D,0)、SR(D,1)、...、SR(D,7)である。
最初のt個の単純ノード・レジスタ、すなわちSNR(0)、SNR(1)、...、SNR(t−1)を使用して、残りの単純ノード・レジスタ、すなわちSNR(t)、SNR(t+1)、SNR(t+2)、...、SNR(T)のステータスをたどるように、整数t<Tが存在する。
U+1の複合レジスタを持つシステムでは、これらの複合レジスタには、CNR(0)、CNR(1)、...、CNR(U)のラベルが付けられる。
この複合レジスタCNRは、H(ヘッダー・レジスタ)とP(ペイロード・レジスタ)という2つのレジスタを含む。
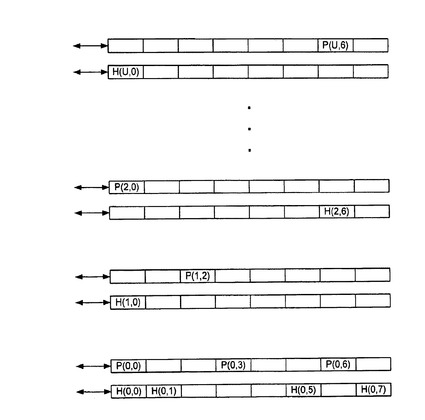
図9は、複合レジスタ内のセルの一覧表を示している。
CNR(N)のK個のセル内のパケットは、H(N,K)にヘッダーを持ち、また、P(N,K)にペイロードを持っている。
複合NICレジスタの位置Kにある2つのセル内のパケットには、単にHKとPKとしてラベルが付けられる。
【0038】
データは、「Opteron」プロセッサ750からライン760を介して、またNIC入力スイッチ730からライン732を介して、NICレジスタ722のセルに転送され、またNICレジスタ720のセルに転送される。
ライン760およびライン732を介して入るデータは、図5に示される技法を用いて、あるいは、何か他の適切な手段により、広げられる(fanned out)ことがある。
図7は、広げる手段(ファンアウト)なしの構造を示している。
これらのNICレジスタの個々のセルは、個々にアドレス指定可能である。
それゆえ、所与のレジスタは、いくつかの異なるコンピューティング・ノードからデータを同時に受け取ることができる。
多数のセルがデータを受け取っている場合には、そのデータは、中央スイッチ・ハブ内の異なるスイッチ・チップ750から送られる。
同様に、所与のNICレジスタは、データを、複数のセルからライン760を介してプロセッサに、またライン742を介してNIC出力スイッチに同時に送ることができる。 NIC出力スイッチに到着したデータは、ライン734を介してNIC入力スイッチに送られて、NICが、プロセッサに受け渡されることになっているデータをもっとも有用な形式で再構成できるようにすることもある。
NIC出力スイッチに到着したデータはまた、ライン752を介して中央スイッチ・ハブに送られることもある。
所与の時間に単一NICレジスタから送られるデータは、このシステムの全域で、1つまたは複数のコンピューティング・ノード700上の他の多数のNICレジスタに分散されることもある。
【0039】
この図解例に示されるNICの動作は、「Opteron」プロセッサと「HyperTransportTM」技術のいくつかの特徴を利用している。
このプロセッサは、リモート・デバイスに書き込むことができる。
この例では、プロセッサは、NICレジスタに書き込むことで、メッセージ・パケットをリモート・ノードに送る。
このプロセッサは、ここではリモート・デバイス内の特定記憶場所への「send when ready(実行可能状態時に送る)」コマンドとして基準とされる1つまたは複数のコマンドを、リモート・デバイスに出すことができる。
制御に使用されるセル(セルH0またはセルP0)内の指定したビット(1つまたは複数)を、転送されるデータがリモート・デバイス内の特定記憶場所にあることを示すように設定する限り、「send when ready」コマンドは、リモート・デバイス上のハードウェア・インターフェースとともに、このプロセッサに64バイトのデータを転送させる。
プロセッサが、クラス「send when ready」のコマンドを出し、かつ、所定の設定時間間隔(「TIMEOUT」)が経過したときには、データのすべてが到着したとは限らない場合でも、リモート・デバイス上の記憶場所の内容が転送される。
TIMEOUT状態の結果としてプロセッサにデータを転送することがまれな事象であるように、数値TIMEOUTが設定される。
TIMEOUTが実際に発生する場合には、データは、HyperTransportTMを介してプロセッサに転送されるが、ただし、このプロセッサは、パケット内に適正なデータがないことを制御セル・ビットが示すことに留意している。
プロセッサが無効なパケットを受け取る場合には、プロセッサは、そのオペレーティング・システムで示されるやり方で応答する。
プロセッサは、クラス「send now(今、送る)」の1つまたは複数のコマンドを出す場合もある。
その場合、データを直ちに転送する。このコマンドは、そのデータが所定の場所にあることをプロセッサが確認したときだけ、使用されるべきである。
データが実行可能状態にあることをプロセッサに知らせる方法があるが、ただし、プロセッサは、通知を受け取るときは必ずレイテンシを増すために、上記コマンドは、実行するのにさらに多くの時間を要することがある。
このコマンドの利点は、転送されたデータ内のどんなフィールドも、制御情報用に確保する必要がないことである。
【0040】
いくつかのデータ転送例に示されるように、この例示システムおよび例示技法は、データ送り側のノードPSNDがPSNDコンピューティング・ノード上にあるデータをPREQコンピューティング・ノード上の記憶場所に転送するように求める要求側のプロセッサPREQにより、デバイス間でデータを転送する効率的な方法を可能にする。
この要求は、要求パケットをPSNDに送るプロセッサPREQにより出される。
この要求パケットは、ヘッダーとペイロードから成っている。
ペイロードは、その要求されたデータのアドレス(1つまたは複数)をノードPSND上に含み、さらに、データが送られることになっているノードPREQ上にも、その記憶場所を含む。
このデータは、ノードPREQ上の1つまたは複数の単純NICレジスタまたは複合NICレジスタに送られる。
他の例では、プロセッサPSNDは、PSNDのローカル・コンピューティング・ノード以外のコンピューティング・ノード上のレジスタにデータを送るように求めることもある。
PSNDノード上のデータの記憶場所の記述は、広範囲のフォーマットを用いて伝えられることもある。
このようなデータ記述の単純な例は、メモリ内の指定した記憶場所からスタートする所定の長さのストリング用のものである。
このデータの受取り側記憶場所は、単純NICレジスタまたは複合NICレジスタ内のセルのリストとして与えられている。
いくつかの転送例は以下の通りである。例1)は、その要求が、記憶場所Xからスタートする長さのデータ・ストリング(5・64)を、SNR(D,0)、SNR(D,1)、SNR(D,2)、SNR(D,3)、SNR(D,4)の単純レジスタ・セルに入れるものであるかもしれないわかりやすい例を示している。
受取り側記憶場所の記述のフォーマットは、広範囲のフォーマットで与えられることもある。
このデータは、5つのパケットでこのシステムの全域に送られることもある。
その場合、このストリングの最初の64ビットは、単純ノード・レジスタ・セルSNR(D,0)に送られ、このストリングの次の64ビットは、単純ノード・レジスタ・セルSNR(D,1)に送られるといった具合である。
この例では、ペイロードと、そのヘッダーには、PREQを含むコンピューティング・ノードのアドレスとSNR(D,1)のアドレスが、おそらく誤り訂正ビットを含む他の情報とともに入っているであろうから、1つのデータパケットは、このストリングの最初の64ビットを持っている。
例2)は、ネットワーク上のコーナーターン(corner turn)を示している。
同一のデータ・ストリングを、CNR(D,2)、CNR(D+1,2)、CNR(D+2,2)、CNR(D+3,2)、CNR(D+4,2)の複合レジスタ・セルに入れる要求が出される。
転送での第3のパケットは、ペイロード内に64ビットの第3のグループを持ち、またセルP(D,2)を持っている。
これらの転送用のアドレスを記述するのに、広範囲のフォーマットが用いられることもある。例3)は、一連の構造体(structure)からの指定した部分を含むデータを転送して、そのデータを、定められたストライドにて受取り側のNICレジスタに入れることを示している。
これらの転送用のアドレスを記述するのに、広範囲のフォーマットが用いられることもある。
【0041】
このシステムは、いくつかの動作を検査して述べられる。
検査される第1の動作は、リモート・ノードの仮想メモリ空間からのデータに対する要求である。
【0042】
「リモート・ノードI上のメモリからのデータに対する要求」動作は、「send when ready」コマンドを含むトランザクションにおいて役立つ。
データ要求側のプロセッサPREQは、リモート・データ送り側のプロセッサPSNDの仮想アドレス空間から、7つまでのデータ・セルを要求する。
このトランザクションは、このシステム内の様々な構成要素の機能を示している。
データ転送を行うために、PREQは、次の3つの機能を果たす。
1)このプロセッサは、データを受け取るNICレジスタの制御セルH0と制御セルP0の1つまたは複数にデータを送る。
2)このプロセッサは、この転送にTID(トランザクション識別子)を割り当てて、a)TID、b)TIDを用いて転送されようとするパケットの数、c)入ってくるパケットに誤り訂正を行い、かつACKとNAKを処理するEC−ACKユニット780へのプロセッサPSNDのアドレス、を送る。
3)プロセッサは、組RPSET(PSNDへの要求パケットREQを含む)内の複数の要求パケットを送る。
それゆえ、RPSETを送ることで、複数のコンピューティング・ノードから所定のコンピューティング・ノード上のNICレジスタにデータが集められることもある。
RPSETは、隣接する複合NICレジスタの集まりCNUMに対するデータを要求する。4)適切な時間(データが戻る最小時間)の後で、プロセッサPREQは、パケットの組RPSETを送る結果として、データを受け取る予定であるNICレジスタのすべてに、「send when ready」コマンドを送る。
【0043】
上記の機能1)に関して、プロセッサPREQは、要求パケットの組RPSETに応答してNICレジスタに転送されるパケットの数を、データを受け取るNICレジスタのそれぞれにあるP0内の適切なNUMPKフィールドに送ることで、その数を示す。この要求パケットの組により、J個の隣接する複合レジスタ(レジスタNR(S)、レジスタNR(S+1)、レジスタNR(S+J−1))内にデータが到着し、かつ、最下部の受取り側レジスタから最上部の受取りレジスタまで順番に、その受け取られたデータにアクセスする場合には、この整数Jも、最下部のターゲット・レジスタNR(S)のセルP0のフィールドORDERに入れられる。
他のターゲット・レジスタは、第2のフィールドに整数0を持っている。
第3のフィールドSENDはゼロに設定される。ただ1つのレジスタがデータを受け取ることになっているか、あるいは、プロセッサが、順序を顧慮せずにデータにアクセスすることになっている場合には、これらのフィールドのそれぞれに整数1を入れることもある。
制御セル内の情報の利用は、後の「注0」で説明される。
この情報を制御セルに転送する効率的な方法は、後の「注1」で説明される。
上記の機能2)に関して、EC−ACK管理ユニット780は、それぞれのTIDとともに、パケットをいくつ転送すべきか決定して、その適切なTIDに関連するACKまたはNAKを送る。
EC−ACK管理ユニット780の動作は、後の「注2」で説明される。
上記の機能3)に関して、処理ノード間のデータの処理は、データに対する要求パケットを送り、それらの要求パケットに応答してデータを送ることで、行われる。
プロセッサは、プロセッサのNICレジスタにデータを転送するように求め、次に、そのデータを、ローカルNICレジスタからプロセッサのローカル・メモリに移すことで、リモート・ノードからプロセッサ内のローカル・メモリにデータを移す。
【0044】
機能3)では、プロセッサPREQは、この要求されるデータが入っているノードの記憶場所を突き止める方法(多分、テーブルを利用して)を持っている。
これらのトランザクション・プロセスの第1の工程は、プロセッサPREQが要求パケットREQをPSNDに送るためのものである。
REQのペイロードには、1)データの転送元の記憶場所、2)受取り側のコンピューティング・ノードのアドレス、ターゲットNICレジスタ、並びに、このデータを受け取るNICレジスタ(720または722)内のセル(1つまたは複数)の記憶場所、3)トランザクション識別子(TID)の情報が入っている。
【0045】
プロセッサPREQは、要求パケットREQを送り出すのと同時に、いくつかのパケットを送り出すこともある。
一動作方式では、プロセッサPREQは、倍長NICレジスタ(double NIC register)720を利用して、所与の時間に1個〜7個のパケットを送り出す。
プロセッサPREQは、128バイトのペイロードを持つHyperTransportTMのダブル・ロード・パケット(double load packet)を形成する。
プロセッサPREQは、このパケットを倍長レジスタ720に送る。
このパケットを送る結果として、パケットREQと、おそらく他のパケットが、倍長レジスタに転送される。
パケットREQのペイロードは、この倍長レジスタ内の位置PKに転送され、また、パケットREQのヘッダーは、このレジスタ内の位置HKにある(ここで、0<K<8)。 HyperTransportTMのダブル・ロード・パケットはまた、特定のコードをH0およびP0に入れて、それぞれのセル(H1、H2、...、H7)内のフィールドを変更させ、NICレジスタ内のパケットのすべてが、NICレジスタからNIC出力スイッチにいつでも転送できる状態にあることを示す。
HyperTransportTMのダブル・ロード・パケットは、パケットの転送に役立つレジスタにロードされたパケットの数を含む他のコードを、H0セルおよびP0セルに入れることもある。
セルH0およびセルP0の用途は、まったく様々であり、これらのセルは、コンピュータのオペレーティング・システムで導かれる通りに使用されることになっている。
別法として、個々のHフィールドは、他の技法により変更されることもある。
このような技法の1つは、個々のヘッダーをHNに入らせて、送りビットを設定することであり、もっとも効果的には最後のビットをHNに入らせることである。
セルH0内のコードに応答して、転送ロジック(図示されてない)は、ライン742を介して、これらのパケットをNIC出力チップの個々の入力部に送る。
NIC出力スイッチの機能は、下記の「注3」で説明される。
これらのパケットは、ライン752を介して、個々の中央ハブ・スイッチ・チップ750に進む。
したがって、このレジスタから、1つまたは複数のパケットが同時に転送されることもある。
次に、これらのパケットは、パケット・ヘッダーにより、このシステム全体に分散される。
【0046】
プロセッサが、1つまたは複数の要求パケットから成る集まりを出してから適切な時間がたって、このプロセッサは、これらの要求パケットを送った結果としてデータを受け取る記憶場所に、1つまたは複数の「send when ready」コマンドを出すこともある。
【0047】
要求パケット(REQ)は、中央スイッチング・システム内のスイッチ・チップの1つを介して、PSNDに関連するNICに進む。要求パケットREQのヘッダーには、PSNDを含むコンピューティング・ノード上にあるNICのアドレスが入っている。
この中央スイッチ・ハブは、PSNDを含むコンピューティング・ノード上のNIC入力スイッチに、REQを受け渡す。
要求パケットREQのヘッダーは、形式REQの要求パケットを含むクラスのパケットを受け取るように指定されたいくつかの「サプライズ(意外な、surprise)」レジスタ722の1つに、要求パケットREQを受け渡す予定であることを示す。
レジスタ722は、要求されたデータ以外のパケットをプロセッサに受け渡すために、サプライズ・レジスタと呼ばれている。
ハードウェア(図示されてない)は、このサプライズ・レジスタSRにREQを入れる。要求パケットREQを含むサプライズ・レジスタにPSNDが出す「send now」コマンドまたは「send when ready」コマンドに応答して、SR内のデータがPSNDに転送される。
一実施形態では、要求パケットREQには、要求されるデータの仮想アドレスが入っている。プロセッサPSNDは、要求されるデータを得て、かつ、1つまたは複数のパケットを形成して、そのパケットを倍長レジスタREGSND720にロードする。
プロセッサPSNDは、ACK情報を利用して、これらのレジスタのどれが使用していないのか判定する。
ACK情報を利用して、どのレジスタが使用していないのか突き止める作業が、後の説明「注4」で説明される。
パケットRES(以下で追跡される任意のパケット)を含む応答パケットは、ペイロードが位置(P1,P2,...,P7)の一部または全部にあり、またヘッダーがH1,H2,...,H7内の対応する位置にあるようなレジスタREGSNDにロードされる。
これらのヘッダーには、1)プロセッサPREQを含むコンピューティング・ノードの記憶場所、2)プロセッサPREQを含むコンピューティング・ノード上のNICレジスタのアドレス、3)上記NICレジスタ内のターゲット・セルの記憶場所、4)TID、を含む様々な情報が入っている。
一対のレジスタ・セル[HK,PK]に入れられている最後のデータ・ビットは、ヘッダーHK内の特定のOUTPUTフィールドに入れられているコードである。
最後のビットが到着すると、データが、ヘッダーとペイロードのセル対から、ライン742を介して送られる。
H0のOUTPUTフィールドが送るように設定されていないために、セルP0とセルH0の内容は送られない。
【0048】
パケットRESは、ライン742を経てスイッチ740を通り、ライン752を経てスイッチ750を通り、ライン754を経てEC−ACKユニット780に送られる。
EC−ACKユニット780で実行される動作は、後の「注2」で説明される。
次に、パケットRESは、プロセッサPREQでパケットRESを受け取るように割り当てられたターゲットNICレジスタの適切なセルに受け渡される。
【0049】
(注0)。
図8Bを参照すると、パケットRESがターゲットNICレジスタに到着すると、そのペイロードは、プロセッサPREQで指定されたセルPKに入れられる。
パケットRESは、パケットの存在を示す先頭の1(leading one)を持っている。
RESのペイロード全体がセルPK内にあった後で(パケットRES内の先頭の1が到着してから適切な時間がたって)、RESの到着を示す信号が、セルPKからセルP0に送られる。
P0内のフィールドNUMPAKには、一組の要求パケットが送られた結果として、ターゲット・レジスタに向けて送られて、到着したパケットの総数があらかじめロードされる。
PKからP0への信号に応答して、フィールドNUMPAK内の数が1だけ減らされる。
これらのパケットのすべてが到着しているときには、まだ到着していないパケットの数を示す数値がデータ0に設定される。
フィールドNUMPAK内でのデータ0の存在は、NICレジスタのペイロード・フィールド内のデータをプロセッサPREQに転送するのに必要ではあるが、ただし不充分な条件である。
フィールドNUMPAK内に正の整数が位置づけられる場合には、まったく処置は講じられない。
フィールドNUMPAK内にデータ0が位置づけられ、データ0がフィールドORDER内にあり、また、データ0がフィールドSEND内にある場合には、まったく処置は講じられない。
フィールドNUMPAK内にデータ0が位置づけられ、かつ、正の整数がフィールドORDER内にある場合には、データ1は、フィールドSENDに入れられて、そのパケットがプロセッサPREQに送れる状態にあることを示す。
SENDフィールド内の1の値に応答し、かつ、プロセッサPREQの「send when ready」コマンドを受け取ると、HyperTransportTMラインにロードするハードウェアは、NICレジスタ内のペイロード・セルに入っているデータを、プロセッサPREQに送らせる。
NICレジスタNR(C)内のペイロード・データがプロセッサPREQに送られた後で、このレジスタ内のロジックは、フィールドORDER内の整数を減らして、フィールドORDER内の新たな数値を、ライン840を介して、NICレジスタNR(C+1)内のP0のフィールドORDERに送る。
次に、NR(C)内のロジックは、NR(C)のフィールドSEND、フィールドORDER、フィールドNUMPAKを、データ0に設定する。
ここに述べられるやり方で複合レジスタのP0のセルを用いれば、その要求されたデータを適正な順序で、プロセッサPREQに効率的に送ることができる。
【0050】
(注1)。
再び図8Bを参照すると、ロジックは、複合レジスタのヘッダー部分に関連するものであり、H0内の情報を利用して、セル(H1,H2,...,H7)の内容を完成する。 それゆえ、プロセッサPは、パケットをセルH0に送って、複合レジスタの下半分内のフィールドのすべてを満たすこともある。
このような定式(formulas)は、これらのセルに対してラベリング方式を使用する。 図9を参照すると、このような方式の1つは、セルに4−touple[T,U,V,W]でラベルを付ける。
ここで、[T,0,U,V]は、コンピューティング・ノードT上のセルA(U,V)を表し、また、[T,1,U,V]は、コンピューティング・ノードT上のセルB(U,V)を表す。
Tが、プロセッサPREQを含むコンピューティング・ノードのアドレスである場合には、0≦N≦7、HN=[T,1,C+N,0]の公式は、一組の要求パケットの結果として、隣接する7つの複合レジスタにデータを収めることを目標としたNICレジスタ内のP0値から成る7上位列を満たす。
【0051】
(注2)。
図7を参照すると、データを要求するプロセッサPREQは、いくつかの機能を果たす。
これらの機能の1つは、順序づけられた3つ組の整数[I,J,K]が入っているペイロードを持つパケットを送ることである。
ここで、Iは、この要求のTIDであり、また、Jは、この要求の結果として転送されるパケットの数であり、さらに、Kは、プロセッサPSNDを含むコンピューティング・ノードの記憶場所である。
TIDパケットは、プロセッサPREQにより、特定の組の単純NICレジスタを介してEC−ACKユニットに転送される。
これらのレジスタ内のデータは、NIC出力スイッチを通らない。定められた数のTID番号が許容される。
EC−ACKユニットは、このような組の許容されるTID番号をアドレスとして持つメモリを備えている。
ペイロード[I,J,K]を持つTIDパケットがEC−ACKユニットに到着すると、JとKの数値が記憶場所Iに格納される。TIDパケットは、コンピューティング・ノードのボード(computer node board)を決して離れないから、TIDパケットがEC−ACKユニットに到着すると、誤り訂正は不必要である。
【0052】
中央スイッチ・ハブからライン754を介して到着するデータパケットは、SerDesモジュール(図示されてない)を通ることがある。
次に、このパケットは、EC−ACKモジュールに入り、そこで、このパケットは誤りの検出および訂正を受ける。
誤り訂正は、EC−ACKユニット780で実行される。データの誤り訂正ができないが、ただし、TID、送り側ノード・アドレス、および提案される記憶セル・アドレスを突き止めることができる場合には、EC−ACKユニット780は、ライン782を介してNICレジスタにNAKを送って、そのNAKを送り側に送り戻すことができる。
EC−ACKユニット780がパケットを補正できず、また、その情報を復元してNAKを送ることができない場合には、このパケットを廃棄し、オペレーティング・システムは、タイムアウト状態のために、そのパケットに対する再要求を出す。
パケットがEC−ACKユニット780に到着し、誤りがまったく検出されないか、あるいは少なくとも1つの誤りが発生し、しかも、すべての誤りを訂正できるときには、このパケットのTIDを読み取って、記憶場所TID内の整数Jが減らされる。
記憶場所TID内の整数Jを減らした後で、その整数がデータ0である場合には、TIDに関連するデータパケットのすべてが到着していて、アドレスKを持つノードにACKを戻すことができる。
ノードKへのACKの転送は、EC−ACKモジュールにより達成されて、1つまたは複数のACKパケットが、複合NICレジスタ内のセル対に送られる。
【0053】
(注3)。
NIC出力スイッチは、1)欠陥ラインを、中央ハブ・スイッチ・チップに、または中央ハブ・スイッチ・チップからバイパスすることだけでなく、欠陥中央ハブ・スイッチ・チップをバイパスすることも、2)コンピュータ上で実行するジョブを分離すること、3)複数のホップを持つシステム内の中央スイッチ・ハブを通るパケットの平均レイテンシを下げること、を含むいくつかの機能を持っている。
3番目の機能は、複数のホップ・データ・ボーテックス・システム(hop data vortex system)に関して、ここに組み入れられた特許および特許出願に説明されている。
単純なホップ・システムでは、そのオペレーティング・システムは、このシステム内の欠陥ラインと中央スイッチの障害を示すデータを受け取り、また、その情報に基づいて、NIC出力スイッチは、これらの欠陥に基づいて道筋を定めることもある。
処理ノードの一部が所与の計算ジョブ(compute job)に割り当てられるときには、これらのノード間でデータを転送するために、いくつかの中央スイッチ・チップが用意される。
この例示技法を用いれば、厳密なシステム・セキュリティを維持できる。さらに、これらのジョブの1つが、単一のコンピューティング・ノードへの長い一連のパケットの流れを開始させ、かつ、その一連のパケットが、ネットワーク上でバックアップをもたらす場合でも、このバックアップは、他のジョブを妨げることはない。
このようなバックアップをもたらすプログラムは、このシステムの全域でデータパケットを引き出す要求側のプロセッサが過度の要求を行わないようにすることを規定したルールに違反している。
同様に、このシステム内のサプライズ・パケット(surprise packet)の数も制限される。
それゆえ、このシステムは、正確に使用されるときには、極度の効率で動作するように設計されている。
また、ユーザーが、このシステムを不正確に使用しても、このシステム上にある他のジョブに悪影響が及ぼされることはない。
【0054】
(注4)。
プロセッサPSNDは、その要求されたデータを1つまたは複数のNICレジスタに入れることで、プロセッサPREQからのデータパケットの要求に応答する。
パケットがNICレジスタから転送されるが、ただし、そのパケットがターゲット・レジスタに到着しない場合には、そのデータに対して別の要求が出される。
したがって、データは、そのデータに対するACKを受け取るまで、送り側のNICレジスタに残しておかれる。
ACKが受け取られると、プロセッサは、別のデータ転送に備えて、送り側のレジスタをプロセッサの有効リスト(available list)に復元することができる。
前節では、リモート記憶場所からのデータに対する要求が説明されている。
送り側のレジスタにACKがまったく戻されないためにデータを再送することで、リモート・ノードから、NICレジスタからのデータに対する要求がもたらされるが、これは、リモート・ノード上のNICレジスタに格納されるデータをプロセッサが要求して、得ることのできる理由のただ1つを表している。
リモートNICレジスタからデータを得る方法は、後でこの開示内容に説明される。
「リモート・ノードI上のメモリからのデータに対する要求」動作には、他のすべてのデータ転送が、このプロセスのわずかな簡略化または修正であるという性質がある。
【0055】
「リモート・ノードII上のメモリからのデータに対する要求」動作は、「send when requested」コマンドを含む有用なトランザクションである。
データを要求側のプロセッサPREQは、要求パケットREQをリモート・データ送り側のプロセッサPSNDに送って、単純レジスタSR(t+s)内の規定されたセルにデータを戻すようにプロセッサPSNDに指示することで、プロセッサPSNDの仮想アドレス空間から8つまでのデータ・セルを要求する。
要求パケットREQの受取りに応答して、プロセッサPSNDは、この要求されたデータを複合NICレジスタのペイロード・セルにロードし、さらに、ヘッダーを複合NICレジスタのヘッダー部分にロードして、これらのペイロード・パケットが、単純レジスタにおいて、要求パケットREQで規定される記憶場所に到着するようにしている。
8つのデータパケットを複合レジスタから送るときに、ヘッダーH0とペイロードP0を持つパケットは、例えば適正なビットをヘッダーH0のOUTPUTフィールドに入れることで、他の7つのパケットとともに送られる。前節において、要求側のプロセッサPREQが、数のNUMPAKを受取り側の複合NICレジスタ内のセルP0に入れるのと同様に、プロセッサPREQは、数のNUMPAKを補助セル850に入れる。
これらのパケットが単純NICレジスタ内に到着すると、信号がライン852を下って送られて、補助セル850内の数が減らされる。
この数が0に減らされると、プロセッサPREQは、1に設定された単一ビットを、単純レジスタSNR(r)内の規定された記憶場所にある1の適切なセルに入れる。
ここで、r<tである。
この1を入れるのに適した場所は、SNR(0)内で左から右に数え、引き続きSNR(1)内で左から右に数えるといった具合に数えることで、単純ノード・レジスタのs番目のセルである。
この記憶場所は、sを64で除算して、整数Iと剰余J(除法をなす)を得、その記憶場所を、SNR(I)内において、セルJにあるものとして特定すれば、見出すことができる。
プロセッサPREQは、SNR(0)、SNR(1)、...、SNR(t−1)のレジスタの内容を定期的にチェックして、どの単純ノード・レジスタが、要求されたデータのすべてを得ているのか突き止める。
【0056】
「複合リモートNICレジスタからのデータに対する要求」動作は、極めて単純である。
この要求側のプロセッサは、パケットを送って、H0の内容を変更する。
上記「注1」に説明されるように、H0を変更すると、NICレジスタの他のセル内のデータが適正に変更される。
あるいは、この要求側のプロセッサは、ライン732を介してパケットを送って、単一セル内のデータにアクセスすることもある。
【0057】
「単純NICレジスタ」から、データに対する要求が出されることもある。
要求側のプロセッサが単純NICレジスタからデータを得るために、このプロセッサは、送り側のプロセッサにサプライズ要求パケットを送って、その要求されたデータを複合レジスタにコピーするように送り側のプロセッサに求める。
【0058】
リモート・ノードからデータを要求するときに、機能3)の変更をリモート・ノード上のプロセッサに行わせれば、そのプロセッサにパケットを送ることができる。
異なるノードに8つのパケットを同時に送ることができ、それにより、それぞれのノードから8つのエッジを持つツリーを用いて、メッセージを極めて速くブロードキャストできる。
【0059】
いくつかの実施形態では、NICレジスタは、オフチップ・ストレージとして使用されることもある。
プロセッサのキャッシュ内のデータは、スワップ・アウトされる。
プロセッサは、スワップ・アウトされ得ないデータをキャッシュ・ラインに入れる都合の良いやり方として、ローカルNICレジスタを使用する。
【0060】
模範的な動作方法では、プロセッサがデータをローカル・レジスタ内であちこちに渡して、コンピュータを大型のシストリック・アレイとして使用できるようにすることで、このコンピュータの並列処理を実行することもある。
実際は、ノードX上のプロセッサが、データを、リモート・ノードY上のNICレジスタから、別のリモート・ノードZ上のNICレジスタに移動させる。
【0061】
中央ハブおよびNICのアーキテクチュアにおいてData Vortex(登録商標)チップを持つコンピュータを、この開示内容に基づいて効果的に使用するために、多くの技法が導入されることもある。
この例示システムおよび例示構造は、Opteronプロセッサへの特定の接続を利用しているが、リモート・デバイスへの他のインターフェースを持つ異なるプロセッサに、同様な技法が用いられることもある。
【符号の説明】
【0062】
100・・・NIC,
110、692、700・・・コンピューティング・ノード,
120・・・コントローラ,
130・・・キャッシュ・ミラー・レジスタ,
140、640・・・NICスイッチ,
144、230、232・・・バッファ,
150、151、690・・・プロセッサ,
154・・・プライベート・メモリ,
156、157・・・パブリック・メモリ,
158・・・キャッシュ,
160・・・CMR,
210・・・TLB,
220・・・メモリ・バッファ,
240・・・PTM,
250・・・コントローラ・ロックユニット,
300・・・スイッチング・システム,
620・・・NICコントローラ,
630・・・ギャザー・スキャッタ・レジスタ,
632、636・・・メモリ・コントローラ,
638・・・ユニット,
642、644・・・DRAM,
702・・・NICチップ,
706・・・メモリ,
720・・・複合ギャザー・スキャッタ・レジスタ,
730・・・入力スイッチ,
740・・・出力スイッチ,
774・・・オンプロセッサ・メモリ・コントローラ
【特許請求の範囲】
【請求項1】
プライベート・ローカル・メモリとパブリック・ローカル・メモリに分けられるローカル・メモリ、ローカル・キャッシュ、および、ワーキング・レジスタを含む複数のプロセッサを相互接続するネットワークを介して、データフローを管理するコントローラと、
前記コントローラに結合された複数のキャッシュ・ミラー・レジスタであって、前記複数のプロセッサに転送されることになっているデータを受け取るキャッシュ・ミラー・レジスタと
を備え、
前記コントローラは、要求に応答して、前記複数のプロセッサを中断させることなく、要求されたデータをじかにパブリック・メモリに転送することと、要求されたデータを転送用の少なくとも1つのキャッシュ・ミラー・レジスタを介して、プロセッサ・ローカル・キャッシュと、プロセッサ・ワーキング・レジスタとに転送することとにより、データを受け取る
ネットワーク・デバイス。
【請求項2】
前記コントローラは、さらに、要求に応答して、少なくとも1つのキャッシュ・ミラー・レジスタを介して前記プロセッサで管理されるプロセッサ・パブリック・メモリにデータを受け入れる
請求項1に記載のネットワーク・デバイス。
【請求項3】
前記コントローラは、さらに、要求に応答して、少なくとも1つのキャッシュ・ミラー・レジスタを選択し、前記少なくとも1つのキャッシュ・ミラー・レジスタ内の少なくとも1つの記憶場所を選択してデータを受け取り、要求側のプロセッサのメモリ・マネージャに対して、前記選択された少なくとも1つのキャッシュ・ミラー・レジスタを特定する少なくとも1つのキャッシュ・ミラー・レジスタを介して前記データを受け取る
請求項1に記載のネットワーク・デバイス。
【請求項4】
並列コンピュータ内の複数のコンピューティング・ノードであって、それぞれがプロセッサと、複数のセルを含む複数のNICレジスタとを備えているコンピューティング・ノードと、
少なくとも1つのリモート・ノードからのデータを、プロセッサPREQに対してローカルである指定された複数のNICレジスタ内のセルに入れるように求め、その要求に応答して、要求されたデータを、前記指定されたNICレジスタ内のセルに転送するように構成されているプロセッサPREQと
を備えるネットワーク・デバイス。
【請求項1】
プライベート・ローカル・メモリとパブリック・ローカル・メモリに分けられるローカル・メモリ、ローカル・キャッシュ、および、ワーキング・レジスタを含む複数のプロセッサを相互接続するネットワークを介して、データフローを管理するコントローラと、
前記コントローラに結合された複数のキャッシュ・ミラー・レジスタであって、前記複数のプロセッサに転送されることになっているデータを受け取るキャッシュ・ミラー・レジスタと
を備え、
前記コントローラは、要求に応答して、前記複数のプロセッサを中断させることなく、要求されたデータをじかにパブリック・メモリに転送することと、要求されたデータを転送用の少なくとも1つのキャッシュ・ミラー・レジスタを介して、プロセッサ・ローカル・キャッシュと、プロセッサ・ワーキング・レジスタとに転送することとにより、データを受け取る
ネットワーク・デバイス。
【請求項2】
前記コントローラは、さらに、要求に応答して、少なくとも1つのキャッシュ・ミラー・レジスタを介して前記プロセッサで管理されるプロセッサ・パブリック・メモリにデータを受け入れる
請求項1に記載のネットワーク・デバイス。
【請求項3】
前記コントローラは、さらに、要求に応答して、少なくとも1つのキャッシュ・ミラー・レジスタを選択し、前記少なくとも1つのキャッシュ・ミラー・レジスタ内の少なくとも1つの記憶場所を選択してデータを受け取り、要求側のプロセッサのメモリ・マネージャに対して、前記選択された少なくとも1つのキャッシュ・ミラー・レジスタを特定する少なくとも1つのキャッシュ・ミラー・レジスタを介して前記データを受け取る
請求項1に記載のネットワーク・デバイス。
【請求項4】
並列コンピュータ内の複数のコンピューティング・ノードであって、それぞれがプロセッサと、複数のセルを含む複数のNICレジスタとを備えているコンピューティング・ノードと、
少なくとも1つのリモート・ノードからのデータを、プロセッサPREQに対してローカルである指定された複数のNICレジスタ内のセルに入れるように求め、その要求に応答して、要求されたデータを、前記指定されたNICレジスタ内のセルに転送するように構成されているプロセッサPREQと
を備えるネットワーク・デバイス。
【図1A】


【図1B】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8A】
【図8B】
【図9】
【図1B】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8A】
【図8B】
【図9】
【公表番号】特表2010−508591(P2010−508591A)
【公表日】平成22年3月18日(2010.3.18)
【国際特許分類】
【出願番号】特願2009−534899(P2009−534899)
【出願日】平成19年10月26日(2007.10.26)
【国際出願番号】PCT/US2007/082714
【国際公開番号】WO2008/052181
【国際公開日】平成20年5月2日(2008.5.2)
【出願人】(509117997)
【Fターム(参考)】
【公表日】平成22年3月18日(2010.3.18)
【国際特許分類】
【出願日】平成19年10月26日(2007.10.26)
【国際出願番号】PCT/US2007/082714
【国際公開番号】WO2008/052181
【国際公開日】平成20年5月2日(2008.5.2)
【出願人】(509117997)
【Fターム(参考)】
[ Back to top ]