
主題抽出装置、方法、及びプログラム
【課題】文書から主題を抽出する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、名詞句ペア作成部14で、名詞句ペアを作成する。名詞句頻度抽出部18で、名詞句各々の出現頻度、及び名詞句ペア各々の共起頻度を抽出し、出現確率勝敗算出部20で、名詞句各々の出現頻度及び名詞句ペアの共起頻度から求まる名詞句各々の出現確率を求め、名詞句ペアで出現確率に基づく勝敗を示す第1の素性を算出する。また、係り受け構造抽出部22で、名詞句ペアの係り受け構造毎の出現頻度を抽出し、係り受け関係勝敗算出部24で、名詞句ペアで係り先になり易さによる勝敗を示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書に含まれる名詞句の素性ベクトルを用いて学習された分類器に入力して、具体主題を示す名詞句を抽出する。
【解決手段】名詞句抽出部12で、具体主題の候補となる名詞句を抽出し、名詞句ペア作成部14で、名詞句ペアを作成する。名詞句頻度抽出部18で、名詞句各々の出現頻度、及び名詞句ペア各々の共起頻度を抽出し、出現確率勝敗算出部20で、名詞句各々の出現頻度及び名詞句ペアの共起頻度から求まる名詞句各々の出現確率を求め、名詞句ペアで出現確率に基づく勝敗を示す第1の素性を算出する。また、係り受け構造抽出部22で、名詞句ペアの係り受け構造毎の出現頻度を抽出し、係り受け関係勝敗算出部24で、名詞句ペアで係り先になり易さによる勝敗を示す第2の素性を算出する。素性ベクトル生成部26で、第1の素性及び第2の素性を並べた素性ベクトルを生成し、具体主題が既知の学習用文書に含まれる名詞句の素性ベクトルを用いて学習された分類器に入力して、具体主題を示す名詞句を抽出する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、主題抽出装置、方法、及びプログラムに係り、特に、テキストデータとして入力された文書から、その文書が何について書かれているかを示す主題を抽出する主題抽出装置、方法、及びプログラムに関する。
【背景技術】
【0002】
従来、テキスト内に出現する語の出現頻度、及び重要語が出現するテキスト数を用いて、文書内から重要語を抽出するシステムが提案されている(例えば、非特許文献1参照)。従来のシステムでは、文書中で出現頻度が高く、かつ特定の文書にのみ多く現れるような文字列を重要語として抽出している。
【0003】
従来のシステムでは、例えば、「A社の商品Zを買ってしまいました。月曜日に表参道に行ったらA社前がすごい人だかりで、ついふらふらと…。早速今日から使っていますが、使い勝手は上々。電車内でインターネットをしたり、マンガを見たりするのに使ってます。」という文書からは、出現頻度の高い「A社」が重要語として抽出される。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】高村大也、奥村学、「最大被覆問題とその変種による文書要約モデル」、人工知能学会論文誌、Vol.23、No.6、p.505−513、2008
【発明の概要】
【発明が解決しようとする課題】
【0005】
ここで、文書がXについて書かれている場合、Xを文書の「主題」と呼び、特に、主題が「固有表現」または「具体的な物」である場合、これを「具体主題」と呼ぶ。また、具体主題は、文書内において名詞句で表記される。主題は、文書の内容を最も含意し、端的に文書の内容を表すものである。よって、主題以外の名詞句よりも多くの情報を持ち、意味的な粒度が細かい名詞句が主題として抽出されることが望ましい。
【0006】
しかしながら、従来のシステムのように頻度の情報だけでは、粒度の大小を考慮することができないため、主題とは異なる名詞句が重要語として抽出される可能性がある、という問題がある。例えば、上記の例文は、「商品Z」について記述されており、主題は「商品Z」であるが、上記のように、従来のシステムでは、出現頻度の高い「A社」が重要語として抽出されてしまい、主題を抽出することができない。
【0007】
本発明は、上記問題点に鑑みてなされたものであり、文書から主題を抽出することができる主題抽出装置、方法、及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0008】
上記目的を達成するために、本発明の主題抽出装置は、入力された文書から名詞句を抽出する名詞句抽出手段と、多数の文書を含む大規模なテキストデータ中における、前記名詞句抽出手段により抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句からなる名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出する第1の素性算出手段と、多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出する第2の素性算出手段と、前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する主題抽出手段と、を含んで構成されている。
【0009】
本発明の主題抽出装置によれば、名詞句抽出手段が、入力された文書から名詞句を抽出する。文書の主題は名詞句であるため、名詞句抽出手段により抽出された名詞句が、文書の主題の候補となる。
【0010】
そして、第1の素性算出手段が、多数の文書を含む大規模なテキストデータ中における、名詞句抽出手段により抽出された名詞句各々の出現頻度、及び抽出された名詞句各々より選択された2つの名詞句からなる名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる名詞句各々の出現確率に基づいて、名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出する。主題としては、意味的な粒度が細かい名詞句が抽出されることが望ましい。第1の素性は、意味的な粒度が粗い名詞句に共起して意味的な粒度が細かい名詞句が出現する頻度よりも、意味的な粒度が細かい名詞句に共起して意味的な粒度が粗い名詞句が出現する頻度の方が高い傾向があることを考慮した素性である。
【0011】
また、第2の素性算出手段が、多数の文書を含む大規模なテキストデータ中における、名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出する。第2の素性は、主題が文書の内容を最も含意する言葉であり、より多くの情報を持つ語であるため、係り受け関係の係り先になり易い傾向があることを考慮した素性である。
【0012】
そして、主題抽出手段が、名詞句各々の第1の素性及び第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、抽出された名詞句各々から、入力された文書の主題となる名詞句を抽出する。
【0013】
このように、主題が備える性質を示す素性として、第1の素性及び第2の素性を用いるため、入力された文書から適切に主題を抽出することができる。
【0014】
また、前記名詞句抽出手段は、固有表現を含む名詞句、及び1つ以上名詞が連続して具体的な物を示す名詞句を抽出し、分類器は、固有表現または具体的な物を示す主題である具体主題が既知の学習用文書を用いて学習されたものを用いることができる。これにより、主題の中でも、特に、固有表現または具体的な物を示す具体主題を抽出することができる。
【0015】
また、前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句と他方の名詞句との共起頻度を該一方の名詞句の出現頻度で除して、該一方の名詞句の出現確率を求めることができる。上述の意味的な粒度を考慮した素性を算出するための出現確率の求め方の一例である。
【0016】
また、前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より出現確率が高い場合には勝ちを示す値、低い場合には負けを示す値、同じ場合または係り受け関係がない場合には引き分けを示す値を前記第1の素性として算出することができる。
【0017】
また、前記第2の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より係り先となる頻度が高い場合には、勝ちを示す値、低い場合には負けを示す値、同じ場合には引き分けを示す値を前記第2の素性として算出することができる。
【0018】
また、本発明の主題抽出方法は、入力された文書から名詞句を抽出し、多数の文書を含む大規模なテキストデータ中における、抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句を組み合わせた名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出し、多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出し、前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する方法である。
【0019】
また、本発明の主題抽出プログラムは、コンピュータを、上記主題抽出装置を構成する各手段として機能させるためのプログラムである。
【発明の効果】
【0020】
以上説明したように、本発明の主題抽出装置、方法、及びプログラムによれば、主題が備える性質を示す素性として、名詞句の意味的な粒度を反映した出現確率に基づく第1の素性、及び係り受け関係の係り先になり易いか否かを示す第2の素性を用いるため、入力された文書から、適切に主題を抽出することができる、という効果が得られる。
【図面の簡単な説明】
【0021】
【図1】本実施の形態の主題抽出装置の概略構成を示すブロック図である。
【図2】入力文書の一例を示す図である。
【図3】名詞句抽出部により抽出された名詞句の一例を示す図である。
【図4】名詞句ペア作成部により作成された名詞句ペアの一例を示す図である。
【図5】名詞句頻度抽出部により抽出された名詞句の出現頻度及び名詞句ペアの共起頻度の一例を示す図である。
【図6】出現確率勝敗算出部により算出された素性の一例を示す図である。
【図7】係り受け構造抽出部により抽出された係り受け構造の頻度の一例を示す図である。
【図8】係り受け関係勝敗算出部により算出された素性の一例を示す図である。
【図9】本実施の形態の主題抽出装置における主題抽出処理ルーチンの内容を示すフローチャートである。
【発明を実施するための形態】
【0022】
以下、図面を参照して本発明の実施の形態を詳細に説明する。
【0023】
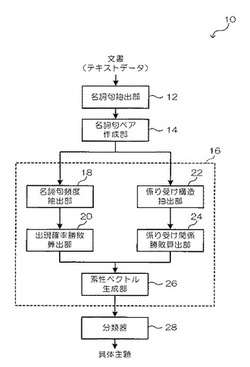
図1に示すように、本実施の形態の主題抽出装置10は、CPUと、RAMと、後述する主題抽出処理ルーチンを実行するためのプログラムや各種データを記憶したROMと、を含むコンピュータで構成することができる。このコンピュータは、機能的には、入力された文書(テキストデータ)から具体主題の候補となる名詞句を抽出する名詞句抽出部12と、抽出された名詞句から選択された2つの名詞句で名詞句ペアを作成する名詞句ペア作成部14と、名詞句各々の特徴である素性を抽出する素性抽出部16と、予め具体主題が既知の文書を用いて学習された分類器28と、を含んだ構成で表すことができる。
【0024】
素性抽出部16は、主題が備える性質を示す素性(特徴量)を抽出する。素性抽出部16は、名詞句の出現頻度及び名詞句ペアの共起頻度を抽出する名詞句頻度抽出部18と、名詞句の出現頻度及び名詞句ペアの共起頻度から求まる出現確率に基づく名詞句ペアの勝敗を示す第1の素性を算出する出現確率勝敗算出部20と、名詞句ペアの係り受け構造毎の出現頻度を抽出する係り受け構造抽出部22と、係り受け構造の出現頻度に基づく名詞句ペアの勝敗を示す第2の素性を算出する係り受け関係勝敗算出部24と、第1の素性及び第2の素性から素性ベクトルを生成する素性ベクトル生成部26と、を含んだ構成で表すことができる。
【0025】
なお、名詞句頻度抽出部18及び出現確率勝敗算出部20が本発明の第1の素性算出手段の一例であり、係り受け構造抽出部22及び係り受け関係勝敗算出部24が本発明の第2の素性算出手段の一例である。
【0026】
名詞句抽出部12は、入力された文書に対して形態素解析を行った上で、所定の名詞句を抽出する。主題は名詞句であるため、入力された文書に含まれる全ての名詞句が、抽出すべき主題の候補となる。ここでは、特に、具体主題を抽出することを目的として、固有表現を含む名詞句、及び1つ以上の名詞が連続して具体的な物を示す名詞句を、入力された文書の具体主題の候補として抽出する。
【0027】
固有表現を含む名詞句は、例えば、人名、地名、組織名などの固有物を表す表現であって、既存の固有表現抽出技術により抽出することができる。固有表現抽出技術としては、例えば、「今村賢治、斎藤邦子、浅野久子、「テキストからの知識抽出の基盤となる日本語基本解析技術」、NTT技術ジャーナル、社団法人電気通信協会、pp.20−23 (2008)」等に記載の技術を用いることができる。また、サ変名詞、動作名詞など、名詞の形態素情報も合わせて取得してもよい。
【0028】
また、1つ以上の名詞が連続して具体的な物を示す名詞句としては、例えば、「マンガ」及び「ビューア」という名詞が連続して、1つの具体的な物を示す名詞句「マンガビューア」等がある。「マンガ」及び「ビューア」も各々具体的な物を示す名詞であるため、この場合、1つ以上の名詞が連続して具体的な物を示す名詞句として、「マンガ」、「ビューア」及び「マンガビューア」が各々抽出される。
【0029】
図2に示すように、入力された文書(テキストA)が「A社の商品Zを買ってしまいました。月曜日に表参道に行ったらA社前がすごい人だかりで、ついふらふらと・・・。早速今日から使っていますが、使い勝手は上々。電車内でインターネットをしたり、マンガを見たりするのに使ってます。」であった場合には、名詞句抽出部12において、図3に示すように、「A社」、「商品Z」、「月曜日」、「表参道」、「今日」、「電車内」、「インターネット」及び「マンガ」が抽出される。
【0030】
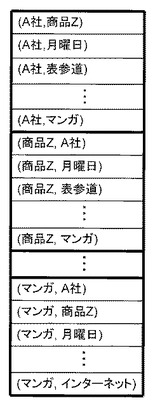
名詞句ペア作成部14は、名詞句抽出部12により抽出された名詞句から選択された2つの名詞句について、取り得る全ての順列で名詞句ペアを作成する。すなわち、名詞句がn個抽出された場合には、nP2個の名詞句ペアが作成される。図4に、名詞句ペア作成部14で作成された名詞句ペアの一例を示す。
【0031】
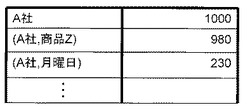
名詞句頻度抽出部18は、多数の文書を含む大規模なテキストデータを利用して、名詞句抽出部12により抽出された名詞句の出現頻度、及び名詞句ペア作成部14で作成された名詞句ペアの共起頻度を抽出する。大規模なテキストデータは、予め主題抽出装置の所定の記憶領域に記憶しておいてもよいし、ネットワークを介してWebから収集した文書集合などを用いてもよい。図5に、名詞句頻度抽出部18で抽出された名詞句の出現頻度、及び名詞句ペアの共起頻度の一例を示す。図5では、名詞句「A社」の出現頻度は「1000」、名詞句ペア「(A社,商品Z)」の共起頻度は「980」であることを表している。
【0032】
出現確率勝敗算出部20は、名詞句頻度抽出部18で抽出された名詞句の出現頻度、及び名詞句ペアの共起頻度に基づいて、出現確率を算出する。上述のように、意味的な粒度が細かい名詞句が主題として抽出されることが望ましい。ここで、意味的な粒度が粗い名詞句に共起して意味的な粒度が細かい名詞句が出現する頻度よりも、意味的な粒度が細かい名詞句に共起して意味的な粒度が粗い名詞句が出現する頻度の方が高い傾向がある。この傾向を利用して、主題が備える性質を示す素性として、名詞句ペアを構成する名詞句同士における出現確率に基づく勝敗を示す第1の素性を算出する。
【0033】
具体的には、名詞句A及び名詞句Bで構成された名詞句ペアについて、下記(1)式により名詞句Aの出現確率、下記(2)式により名詞句Bの出現確率を算出する。
【0034】
【数1】

【0035】
そして、下記(3)式に示すように、名詞句Aと名詞句Bとにおいて、出現確率が高い方が勝ち(win)、低い方が負け(lose)、同じ場合は引き分け(draw)とする。
【0036】
【数2】
【0037】
このように算出された勝敗を示す情報(win、lose、draw)を、素性として抽出する。
【0038】
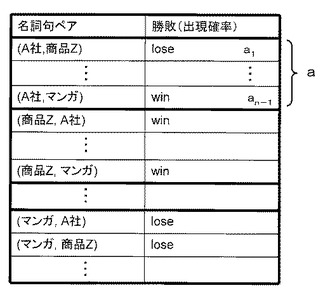
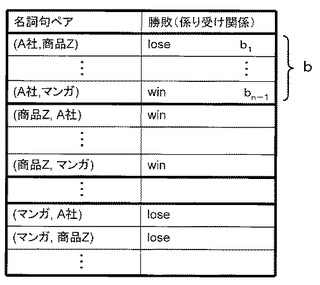
図6に、出現確率勝敗算出部20により算出された第1の素性の一例を示す。図6では、名詞句ペア(A,B)における前者(A)の勝敗を表している。例えば、名詞句ペア(A社、商品Z)では、名詞句「A社」の出現確率より名詞句「商品Z」の出現確率の方が高く、「A社」が負け(lose)であることを表している。一方、名詞句ペア(商品Z、A社)では、「商品Z」が勝ち(win)であることを表している。
【0039】
係り受け構造抽出部は22、多数の文書を含む大規模なテキストデータを利用して、名詞句ペア作成部14により作成された名詞句ペアの係り受け構造毎の出現頻度を抽出する。例えば、名詞句ペア(A,B)であれば、名詞句Aが係り元及び名詞句Bが係り先になる場合と、名詞句Bが係り元及び名詞句Aが係り先になる場合がある。前者の場合の係り受け構造、及び後者の場合の係り受け構造が大規模なテキストデータ内にどれだけ出現するかを抽出する。なお、本実施の形態では、名詞句ペア(A,B)と共に、名詞句ペア(B,A)も作成されているため、各名詞句ペアについて、前者を係り元及び後者を係り先とする係り受け構造、または後者を係り元及び前者を係り先とする係り受け構造の出現頻度のみを抽出するようにしてもよい。
【0040】
大規模なテキストデータは、予め主題抽出装置の所定の記憶領域に記憶しておいてもよいし、ネットワークを介してWebから収集した文書集合などを用いてもよい。大規模なテキストデータ内における出現頻度を抽出する際の係り受け構造の解析は、周知の係り受け解析技術を用いればよい。
【0041】
図7に、係り受け構造抽出部22で抽出された係り受け構造毎の出現頻度の一例を示す。
【0042】
係り受け関係勝敗算出部24は、係り受け構造抽出部22で抽出された名詞句ペアの係り受け構造毎の出現頻度に基づいた第2の素性を算出する。上述のように、主題は文書の内容を最も含意する言葉であり、より多くの情報を持つ語であるため、係り受け関係の係り先になり易い傾向がある。この傾向を利用して、主題が備える性質を示す素性として、名詞句ペアを構成する名詞句同士において、いずれが係り先になり易いかに基づく勝敗を示す第2の素性を算出する。
【0043】
具体的には、名詞句ペア(A,B)について、係り受け構造抽出部22で抽出された係り受け構造毎の出現頻度を参照して、名詞句Aと名詞句Bとにおいて、係り先になる頻度が高い方が勝ち(win)、低い方が負け(lose)、同じ場合または名詞句Aと名詞句Bとの間に係り受け関係がない場合は引き分け(draw)とする。
【0044】
図8に、係り受け関係勝敗算出部24により算出された第2の素性の一例を示す。図8では、名詞句ペア(A,B)における前者(A)の勝敗を表している。例えば、名詞句ペア(A社、商品Z)では、名詞句「A社」より名詞句「商品Z」の方が係り先になる頻度が高く、「A社」が負け(lose)であることを表している。一方、名詞句ペア(商品Z、A社)では、「商品Z」が勝ち(win)であることを表している。
【0045】
素性ベクトル生成部26は、出現確率勝敗算出部20で算出された第1の素性と、係り受け関係勝敗算出部24で算出された第2の素性とを並べた素性ベクトルを生成する。例えば、第1の素性が図6に示すように算出され、第2の素性が図8に示すように算出されたとする。この場合、名詞句Aの素性ベクトルは、図6のaで示される部分の素性a1〜an−1(nは名詞句抽出部12で抽出された名詞句の総数)、及び図8のbで示される部分の素性b1〜bn−1を並べたベクトル(a1,・・・,an−1,・・・,b1,・・・,bn−1)となる。なお、素性ベクトルの要素の並び順や構成等はこの例に限定されない。
【0046】
分類器28は、素性抽出部16で抽出した素性ベクトルを入力とし、機械学習により予め定められた分類ルールに基づいて、入力された素性ベクトルに対応する名詞句が具体主題となるか否かを判別する。分類ルールは、名詞句mの素性ベクトルα(m)を入力としたときに、名詞句mが具体主題となる可能性を示す値score(m)を返す関数のようなものであり、この関数をf( )とすると、
f(α(m))=score(m)
となる。
【0047】
この分類ルールf( )は、教師あり機械学習法を用いて予め学習しておく。例えば、テキスト集合中の名詞句に対して人手で具体主題であるか否かを示すラベルを付与するなどした、具体主題が既知の学習用文書について、素性抽出部16で抽出された素性ベクトルと、対応する名詞句に付されたラベルとを学習データとして利用し、分類ルールf( )を構成する関数のパラメタを学習する。例えば、「J. Lafferty, A. McCallum and F. Pereira, Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data, In Proc. of ICML-2001, Pages 282-289, 2001」等に記載された既知の機械学習により、素性が付与された具体主題の候補(抽出された全ての名詞句)の中から具体主題を示す名詞句を選択するための分類ルールを学習する。
【0048】
次に、図9を参照して、本実施の形態の主題抽出装置10において実行される主題抽出処理ルーチンについて説明する。本ルーチンは、予め学習データを用いて分類ルールを学習して分類器が生成された状態でスタートする。
【0049】
ステップ100で、文書(テキストデータ)が入力されると、次に、ステップ102で、入力された文書に対して形態素解析を行った上で、固有表現を含む名詞句、及び1つ以上の名詞が連続して具体的な物を示す名詞句を、入力された文書の具体主題の候補として抽出する。
【0050】
次に、ステップ104で、上記ステップ102で抽出された名詞句から選択された2つの名詞句について、取り得る全ての順列で名詞句ペアを作成する。
【0051】
次に、ステップ106で、多数の文書を含む大規模なテキストデータを利用して、上記ステップ102で抽出された名詞句の出現頻度、及び上記ステップ104で作成された名詞句ペアの共起頻度を抽出し、(1)式及び(2)式に従って、各名詞句の出現確率を求める。そして、名詞句ペアを構成する名詞句同士における出現確率に基づく勝敗を示す第1の素性を算出する。
【0052】
次に、ステップ108で、多数の文書を含む大規模なテキストデータを利用して、名詞句ペアの係り受け構造毎の出現頻度を抽出し、名詞句ペアを構成する名詞句同士において、いずれが係り先になり易いかに基づく勝敗を示す第2の素性を算出する。
【0053】
次に、ステップ110で、上記ステップ106で算出した第1の素性と、上記ステップ108で算出した第2の素性とを並べた素性ベクトルを生成する。
【0054】
次に、ステップ112で、上記ステップ110で生成した素性ベクトルを分類器に入力し、分類器の出力する値score(m)に基づいて、入力された素性ベクトルに対応する名詞句が具体主題となるか否かを判別し、具体主題となる名詞句を抽出し、抽出家かを出力して、処理を終了する。
【0055】
なお、本ルーチンでは、第1の素性を先に算出してから第2の素性を算出する処理としたが、第2の素性を先に算出してから第1の素性を算出してもよいし、第1の素性の算出と第2の素性の算出とを並行処理するようにしてもよい。
【0056】
以上説明したように、本実施の形態の主題抽出装置によれば、主題が備える性質を示す素性として、名詞句の意味的な粒度を反映した出現確率に基づく素性、及び係り受け関係の係り先になり易いか否かを示す素性を用いるため、入力された文書から、適切に主題を抽出することができる。
【0057】
また、上記の実施の形態では、主題の中でも、特に、固有表現または具体的な物を示す主題である具体主題を抽出する場合について説明したが、抽出する主題を具体主題に限定しない場合には、名詞句抽出部で、入力された文書から全ての名詞句を抽出するようにすればよい。また、分類器の分類ルールの学習において、具体主題に限定しない主題が既知の学習用文書を用いて学習すればよい。
【0058】
また、上記実施の形態で用いた第1の素性及び第2の素性に、各名詞句または名詞句に含まれる名詞の形態素情報を素性として加えてもよい。
【0059】
また、本発明は、上述した実施の形態に限定されるものではなく、この発明の要旨を逸脱しない範囲内で様々な変形や応用が可能である。
【0060】
また、本願明細書中において、プログラムが予めインストールされている実施の形態として説明したが、当該プログラムを、コンピュータ読み取り可能な記録媒体に格納して提供することも可能である。
【符号の説明】
【0061】
10 主題抽出装置
12 名詞句抽出部
14 名詞句ペア作成部
16 素性抽出部
18 名詞句頻度抽出部
20 出現確率勝敗算出部
22 係り受け構造抽出部
24 係り受け関係勝敗算出部
26 素性ベクトル生成部
28 分類器
【技術分野】
【0001】
本発明は、主題抽出装置、方法、及びプログラムに係り、特に、テキストデータとして入力された文書から、その文書が何について書かれているかを示す主題を抽出する主題抽出装置、方法、及びプログラムに関する。
【背景技術】
【0002】
従来、テキスト内に出現する語の出現頻度、及び重要語が出現するテキスト数を用いて、文書内から重要語を抽出するシステムが提案されている(例えば、非特許文献1参照)。従来のシステムでは、文書中で出現頻度が高く、かつ特定の文書にのみ多く現れるような文字列を重要語として抽出している。
【0003】
従来のシステムでは、例えば、「A社の商品Zを買ってしまいました。月曜日に表参道に行ったらA社前がすごい人だかりで、ついふらふらと…。早速今日から使っていますが、使い勝手は上々。電車内でインターネットをしたり、マンガを見たりするのに使ってます。」という文書からは、出現頻度の高い「A社」が重要語として抽出される。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】高村大也、奥村学、「最大被覆問題とその変種による文書要約モデル」、人工知能学会論文誌、Vol.23、No.6、p.505−513、2008
【発明の概要】
【発明が解決しようとする課題】
【0005】
ここで、文書がXについて書かれている場合、Xを文書の「主題」と呼び、特に、主題が「固有表現」または「具体的な物」である場合、これを「具体主題」と呼ぶ。また、具体主題は、文書内において名詞句で表記される。主題は、文書の内容を最も含意し、端的に文書の内容を表すものである。よって、主題以外の名詞句よりも多くの情報を持ち、意味的な粒度が細かい名詞句が主題として抽出されることが望ましい。
【0006】
しかしながら、従来のシステムのように頻度の情報だけでは、粒度の大小を考慮することができないため、主題とは異なる名詞句が重要語として抽出される可能性がある、という問題がある。例えば、上記の例文は、「商品Z」について記述されており、主題は「商品Z」であるが、上記のように、従来のシステムでは、出現頻度の高い「A社」が重要語として抽出されてしまい、主題を抽出することができない。
【0007】
本発明は、上記問題点に鑑みてなされたものであり、文書から主題を抽出することができる主題抽出装置、方法、及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0008】
上記目的を達成するために、本発明の主題抽出装置は、入力された文書から名詞句を抽出する名詞句抽出手段と、多数の文書を含む大規模なテキストデータ中における、前記名詞句抽出手段により抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句からなる名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出する第1の素性算出手段と、多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出する第2の素性算出手段と、前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する主題抽出手段と、を含んで構成されている。
【0009】
本発明の主題抽出装置によれば、名詞句抽出手段が、入力された文書から名詞句を抽出する。文書の主題は名詞句であるため、名詞句抽出手段により抽出された名詞句が、文書の主題の候補となる。
【0010】
そして、第1の素性算出手段が、多数の文書を含む大規模なテキストデータ中における、名詞句抽出手段により抽出された名詞句各々の出現頻度、及び抽出された名詞句各々より選択された2つの名詞句からなる名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる名詞句各々の出現確率に基づいて、名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出する。主題としては、意味的な粒度が細かい名詞句が抽出されることが望ましい。第1の素性は、意味的な粒度が粗い名詞句に共起して意味的な粒度が細かい名詞句が出現する頻度よりも、意味的な粒度が細かい名詞句に共起して意味的な粒度が粗い名詞句が出現する頻度の方が高い傾向があることを考慮した素性である。
【0011】
また、第2の素性算出手段が、多数の文書を含む大規模なテキストデータ中における、名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出する。第2の素性は、主題が文書の内容を最も含意する言葉であり、より多くの情報を持つ語であるため、係り受け関係の係り先になり易い傾向があることを考慮した素性である。
【0012】
そして、主題抽出手段が、名詞句各々の第1の素性及び第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、抽出された名詞句各々から、入力された文書の主題となる名詞句を抽出する。
【0013】
このように、主題が備える性質を示す素性として、第1の素性及び第2の素性を用いるため、入力された文書から適切に主題を抽出することができる。
【0014】
また、前記名詞句抽出手段は、固有表現を含む名詞句、及び1つ以上名詞が連続して具体的な物を示す名詞句を抽出し、分類器は、固有表現または具体的な物を示す主題である具体主題が既知の学習用文書を用いて学習されたものを用いることができる。これにより、主題の中でも、特に、固有表現または具体的な物を示す具体主題を抽出することができる。
【0015】
また、前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句と他方の名詞句との共起頻度を該一方の名詞句の出現頻度で除して、該一方の名詞句の出現確率を求めることができる。上述の意味的な粒度を考慮した素性を算出するための出現確率の求め方の一例である。
【0016】
また、前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より出現確率が高い場合には勝ちを示す値、低い場合には負けを示す値、同じ場合または係り受け関係がない場合には引き分けを示す値を前記第1の素性として算出することができる。
【0017】
また、前記第2の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より係り先となる頻度が高い場合には、勝ちを示す値、低い場合には負けを示す値、同じ場合には引き分けを示す値を前記第2の素性として算出することができる。
【0018】
また、本発明の主題抽出方法は、入力された文書から名詞句を抽出し、多数の文書を含む大規模なテキストデータ中における、抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句を組み合わせた名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出し、多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出し、前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する方法である。
【0019】
また、本発明の主題抽出プログラムは、コンピュータを、上記主題抽出装置を構成する各手段として機能させるためのプログラムである。
【発明の効果】
【0020】
以上説明したように、本発明の主題抽出装置、方法、及びプログラムによれば、主題が備える性質を示す素性として、名詞句の意味的な粒度を反映した出現確率に基づく第1の素性、及び係り受け関係の係り先になり易いか否かを示す第2の素性を用いるため、入力された文書から、適切に主題を抽出することができる、という効果が得られる。
【図面の簡単な説明】
【0021】
【図1】本実施の形態の主題抽出装置の概略構成を示すブロック図である。
【図2】入力文書の一例を示す図である。
【図3】名詞句抽出部により抽出された名詞句の一例を示す図である。
【図4】名詞句ペア作成部により作成された名詞句ペアの一例を示す図である。
【図5】名詞句頻度抽出部により抽出された名詞句の出現頻度及び名詞句ペアの共起頻度の一例を示す図である。
【図6】出現確率勝敗算出部により算出された素性の一例を示す図である。
【図7】係り受け構造抽出部により抽出された係り受け構造の頻度の一例を示す図である。
【図8】係り受け関係勝敗算出部により算出された素性の一例を示す図である。
【図9】本実施の形態の主題抽出装置における主題抽出処理ルーチンの内容を示すフローチャートである。
【発明を実施するための形態】
【0022】
以下、図面を参照して本発明の実施の形態を詳細に説明する。
【0023】
図1に示すように、本実施の形態の主題抽出装置10は、CPUと、RAMと、後述する主題抽出処理ルーチンを実行するためのプログラムや各種データを記憶したROMと、を含むコンピュータで構成することができる。このコンピュータは、機能的には、入力された文書(テキストデータ)から具体主題の候補となる名詞句を抽出する名詞句抽出部12と、抽出された名詞句から選択された2つの名詞句で名詞句ペアを作成する名詞句ペア作成部14と、名詞句各々の特徴である素性を抽出する素性抽出部16と、予め具体主題が既知の文書を用いて学習された分類器28と、を含んだ構成で表すことができる。
【0024】
素性抽出部16は、主題が備える性質を示す素性(特徴量)を抽出する。素性抽出部16は、名詞句の出現頻度及び名詞句ペアの共起頻度を抽出する名詞句頻度抽出部18と、名詞句の出現頻度及び名詞句ペアの共起頻度から求まる出現確率に基づく名詞句ペアの勝敗を示す第1の素性を算出する出現確率勝敗算出部20と、名詞句ペアの係り受け構造毎の出現頻度を抽出する係り受け構造抽出部22と、係り受け構造の出現頻度に基づく名詞句ペアの勝敗を示す第2の素性を算出する係り受け関係勝敗算出部24と、第1の素性及び第2の素性から素性ベクトルを生成する素性ベクトル生成部26と、を含んだ構成で表すことができる。
【0025】
なお、名詞句頻度抽出部18及び出現確率勝敗算出部20が本発明の第1の素性算出手段の一例であり、係り受け構造抽出部22及び係り受け関係勝敗算出部24が本発明の第2の素性算出手段の一例である。
【0026】
名詞句抽出部12は、入力された文書に対して形態素解析を行った上で、所定の名詞句を抽出する。主題は名詞句であるため、入力された文書に含まれる全ての名詞句が、抽出すべき主題の候補となる。ここでは、特に、具体主題を抽出することを目的として、固有表現を含む名詞句、及び1つ以上の名詞が連続して具体的な物を示す名詞句を、入力された文書の具体主題の候補として抽出する。
【0027】
固有表現を含む名詞句は、例えば、人名、地名、組織名などの固有物を表す表現であって、既存の固有表現抽出技術により抽出することができる。固有表現抽出技術としては、例えば、「今村賢治、斎藤邦子、浅野久子、「テキストからの知識抽出の基盤となる日本語基本解析技術」、NTT技術ジャーナル、社団法人電気通信協会、pp.20−23 (2008)」等に記載の技術を用いることができる。また、サ変名詞、動作名詞など、名詞の形態素情報も合わせて取得してもよい。
【0028】
また、1つ以上の名詞が連続して具体的な物を示す名詞句としては、例えば、「マンガ」及び「ビューア」という名詞が連続して、1つの具体的な物を示す名詞句「マンガビューア」等がある。「マンガ」及び「ビューア」も各々具体的な物を示す名詞であるため、この場合、1つ以上の名詞が連続して具体的な物を示す名詞句として、「マンガ」、「ビューア」及び「マンガビューア」が各々抽出される。
【0029】
図2に示すように、入力された文書(テキストA)が「A社の商品Zを買ってしまいました。月曜日に表参道に行ったらA社前がすごい人だかりで、ついふらふらと・・・。早速今日から使っていますが、使い勝手は上々。電車内でインターネットをしたり、マンガを見たりするのに使ってます。」であった場合には、名詞句抽出部12において、図3に示すように、「A社」、「商品Z」、「月曜日」、「表参道」、「今日」、「電車内」、「インターネット」及び「マンガ」が抽出される。
【0030】
名詞句ペア作成部14は、名詞句抽出部12により抽出された名詞句から選択された2つの名詞句について、取り得る全ての順列で名詞句ペアを作成する。すなわち、名詞句がn個抽出された場合には、nP2個の名詞句ペアが作成される。図4に、名詞句ペア作成部14で作成された名詞句ペアの一例を示す。
【0031】
名詞句頻度抽出部18は、多数の文書を含む大規模なテキストデータを利用して、名詞句抽出部12により抽出された名詞句の出現頻度、及び名詞句ペア作成部14で作成された名詞句ペアの共起頻度を抽出する。大規模なテキストデータは、予め主題抽出装置の所定の記憶領域に記憶しておいてもよいし、ネットワークを介してWebから収集した文書集合などを用いてもよい。図5に、名詞句頻度抽出部18で抽出された名詞句の出現頻度、及び名詞句ペアの共起頻度の一例を示す。図5では、名詞句「A社」の出現頻度は「1000」、名詞句ペア「(A社,商品Z)」の共起頻度は「980」であることを表している。
【0032】
出現確率勝敗算出部20は、名詞句頻度抽出部18で抽出された名詞句の出現頻度、及び名詞句ペアの共起頻度に基づいて、出現確率を算出する。上述のように、意味的な粒度が細かい名詞句が主題として抽出されることが望ましい。ここで、意味的な粒度が粗い名詞句に共起して意味的な粒度が細かい名詞句が出現する頻度よりも、意味的な粒度が細かい名詞句に共起して意味的な粒度が粗い名詞句が出現する頻度の方が高い傾向がある。この傾向を利用して、主題が備える性質を示す素性として、名詞句ペアを構成する名詞句同士における出現確率に基づく勝敗を示す第1の素性を算出する。
【0033】
具体的には、名詞句A及び名詞句Bで構成された名詞句ペアについて、下記(1)式により名詞句Aの出現確率、下記(2)式により名詞句Bの出現確率を算出する。
【0034】
【数1】
【0035】
そして、下記(3)式に示すように、名詞句Aと名詞句Bとにおいて、出現確率が高い方が勝ち(win)、低い方が負け(lose)、同じ場合は引き分け(draw)とする。
【0036】
【数2】
【0037】
このように算出された勝敗を示す情報(win、lose、draw)を、素性として抽出する。
【0038】
図6に、出現確率勝敗算出部20により算出された第1の素性の一例を示す。図6では、名詞句ペア(A,B)における前者(A)の勝敗を表している。例えば、名詞句ペア(A社、商品Z)では、名詞句「A社」の出現確率より名詞句「商品Z」の出現確率の方が高く、「A社」が負け(lose)であることを表している。一方、名詞句ペア(商品Z、A社)では、「商品Z」が勝ち(win)であることを表している。
【0039】
係り受け構造抽出部は22、多数の文書を含む大規模なテキストデータを利用して、名詞句ペア作成部14により作成された名詞句ペアの係り受け構造毎の出現頻度を抽出する。例えば、名詞句ペア(A,B)であれば、名詞句Aが係り元及び名詞句Bが係り先になる場合と、名詞句Bが係り元及び名詞句Aが係り先になる場合がある。前者の場合の係り受け構造、及び後者の場合の係り受け構造が大規模なテキストデータ内にどれだけ出現するかを抽出する。なお、本実施の形態では、名詞句ペア(A,B)と共に、名詞句ペア(B,A)も作成されているため、各名詞句ペアについて、前者を係り元及び後者を係り先とする係り受け構造、または後者を係り元及び前者を係り先とする係り受け構造の出現頻度のみを抽出するようにしてもよい。
【0040】
大規模なテキストデータは、予め主題抽出装置の所定の記憶領域に記憶しておいてもよいし、ネットワークを介してWebから収集した文書集合などを用いてもよい。大規模なテキストデータ内における出現頻度を抽出する際の係り受け構造の解析は、周知の係り受け解析技術を用いればよい。
【0041】
図7に、係り受け構造抽出部22で抽出された係り受け構造毎の出現頻度の一例を示す。
【0042】
係り受け関係勝敗算出部24は、係り受け構造抽出部22で抽出された名詞句ペアの係り受け構造毎の出現頻度に基づいた第2の素性を算出する。上述のように、主題は文書の内容を最も含意する言葉であり、より多くの情報を持つ語であるため、係り受け関係の係り先になり易い傾向がある。この傾向を利用して、主題が備える性質を示す素性として、名詞句ペアを構成する名詞句同士において、いずれが係り先になり易いかに基づく勝敗を示す第2の素性を算出する。
【0043】
具体的には、名詞句ペア(A,B)について、係り受け構造抽出部22で抽出された係り受け構造毎の出現頻度を参照して、名詞句Aと名詞句Bとにおいて、係り先になる頻度が高い方が勝ち(win)、低い方が負け(lose)、同じ場合または名詞句Aと名詞句Bとの間に係り受け関係がない場合は引き分け(draw)とする。
【0044】
図8に、係り受け関係勝敗算出部24により算出された第2の素性の一例を示す。図8では、名詞句ペア(A,B)における前者(A)の勝敗を表している。例えば、名詞句ペア(A社、商品Z)では、名詞句「A社」より名詞句「商品Z」の方が係り先になる頻度が高く、「A社」が負け(lose)であることを表している。一方、名詞句ペア(商品Z、A社)では、「商品Z」が勝ち(win)であることを表している。
【0045】
素性ベクトル生成部26は、出現確率勝敗算出部20で算出された第1の素性と、係り受け関係勝敗算出部24で算出された第2の素性とを並べた素性ベクトルを生成する。例えば、第1の素性が図6に示すように算出され、第2の素性が図8に示すように算出されたとする。この場合、名詞句Aの素性ベクトルは、図6のaで示される部分の素性a1〜an−1(nは名詞句抽出部12で抽出された名詞句の総数)、及び図8のbで示される部分の素性b1〜bn−1を並べたベクトル(a1,・・・,an−1,・・・,b1,・・・,bn−1)となる。なお、素性ベクトルの要素の並び順や構成等はこの例に限定されない。
【0046】
分類器28は、素性抽出部16で抽出した素性ベクトルを入力とし、機械学習により予め定められた分類ルールに基づいて、入力された素性ベクトルに対応する名詞句が具体主題となるか否かを判別する。分類ルールは、名詞句mの素性ベクトルα(m)を入力としたときに、名詞句mが具体主題となる可能性を示す値score(m)を返す関数のようなものであり、この関数をf( )とすると、
f(α(m))=score(m)
となる。
【0047】
この分類ルールf( )は、教師あり機械学習法を用いて予め学習しておく。例えば、テキスト集合中の名詞句に対して人手で具体主題であるか否かを示すラベルを付与するなどした、具体主題が既知の学習用文書について、素性抽出部16で抽出された素性ベクトルと、対応する名詞句に付されたラベルとを学習データとして利用し、分類ルールf( )を構成する関数のパラメタを学習する。例えば、「J. Lafferty, A. McCallum and F. Pereira, Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data, In Proc. of ICML-2001, Pages 282-289, 2001」等に記載された既知の機械学習により、素性が付与された具体主題の候補(抽出された全ての名詞句)の中から具体主題を示す名詞句を選択するための分類ルールを学習する。
【0048】
次に、図9を参照して、本実施の形態の主題抽出装置10において実行される主題抽出処理ルーチンについて説明する。本ルーチンは、予め学習データを用いて分類ルールを学習して分類器が生成された状態でスタートする。
【0049】
ステップ100で、文書(テキストデータ)が入力されると、次に、ステップ102で、入力された文書に対して形態素解析を行った上で、固有表現を含む名詞句、及び1つ以上の名詞が連続して具体的な物を示す名詞句を、入力された文書の具体主題の候補として抽出する。
【0050】
次に、ステップ104で、上記ステップ102で抽出された名詞句から選択された2つの名詞句について、取り得る全ての順列で名詞句ペアを作成する。
【0051】
次に、ステップ106で、多数の文書を含む大規模なテキストデータを利用して、上記ステップ102で抽出された名詞句の出現頻度、及び上記ステップ104で作成された名詞句ペアの共起頻度を抽出し、(1)式及び(2)式に従って、各名詞句の出現確率を求める。そして、名詞句ペアを構成する名詞句同士における出現確率に基づく勝敗を示す第1の素性を算出する。
【0052】
次に、ステップ108で、多数の文書を含む大規模なテキストデータを利用して、名詞句ペアの係り受け構造毎の出現頻度を抽出し、名詞句ペアを構成する名詞句同士において、いずれが係り先になり易いかに基づく勝敗を示す第2の素性を算出する。
【0053】
次に、ステップ110で、上記ステップ106で算出した第1の素性と、上記ステップ108で算出した第2の素性とを並べた素性ベクトルを生成する。
【0054】
次に、ステップ112で、上記ステップ110で生成した素性ベクトルを分類器に入力し、分類器の出力する値score(m)に基づいて、入力された素性ベクトルに対応する名詞句が具体主題となるか否かを判別し、具体主題となる名詞句を抽出し、抽出家かを出力して、処理を終了する。
【0055】
なお、本ルーチンでは、第1の素性を先に算出してから第2の素性を算出する処理としたが、第2の素性を先に算出してから第1の素性を算出してもよいし、第1の素性の算出と第2の素性の算出とを並行処理するようにしてもよい。
【0056】
以上説明したように、本実施の形態の主題抽出装置によれば、主題が備える性質を示す素性として、名詞句の意味的な粒度を反映した出現確率に基づく素性、及び係り受け関係の係り先になり易いか否かを示す素性を用いるため、入力された文書から、適切に主題を抽出することができる。
【0057】
また、上記の実施の形態では、主題の中でも、特に、固有表現または具体的な物を示す主題である具体主題を抽出する場合について説明したが、抽出する主題を具体主題に限定しない場合には、名詞句抽出部で、入力された文書から全ての名詞句を抽出するようにすればよい。また、分類器の分類ルールの学習において、具体主題に限定しない主題が既知の学習用文書を用いて学習すればよい。
【0058】
また、上記実施の形態で用いた第1の素性及び第2の素性に、各名詞句または名詞句に含まれる名詞の形態素情報を素性として加えてもよい。
【0059】
また、本発明は、上述した実施の形態に限定されるものではなく、この発明の要旨を逸脱しない範囲内で様々な変形や応用が可能である。
【0060】
また、本願明細書中において、プログラムが予めインストールされている実施の形態として説明したが、当該プログラムを、コンピュータ読み取り可能な記録媒体に格納して提供することも可能である。
【符号の説明】
【0061】
10 主題抽出装置
12 名詞句抽出部
14 名詞句ペア作成部
16 素性抽出部
18 名詞句頻度抽出部
20 出現確率勝敗算出部
22 係り受け構造抽出部
24 係り受け関係勝敗算出部
26 素性ベクトル生成部
28 分類器
【特許請求の範囲】
【請求項1】
入力された文書から名詞句を抽出する名詞句抽出手段と、
多数の文書を含む大規模なテキストデータ中における、前記名詞句抽出手段により抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句からなる名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出する第1の素性算出手段と、
多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出する第2の素性算出手段と、
前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する主題抽出手段と、
を含む主題抽出装置。
【請求項2】
前記名詞句抽出手段は、固有表現を含む名詞句、及び1つ以上の名詞が連続して具体的な物を示す名詞句を抽出し、
前記分類器は、固有表現または具体的な物を示す主題である具体主題が既知の学習用文書を用いて学習された
請求項1記載の主題抽出装置。
【請求項3】
前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句と他方の名詞句との共起頻度を該一方の名詞句の出現頻度で除して、該一方の名詞句の出現確率を求める請求項1または請求項2記載の主題抽出装置。
【請求項4】
前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より出現確率が高い場合には勝ちを示す値、低い場合には負けを示す値、同じ場合には引き分けを示す値を前記第1の素性として算出する請求項1〜請求項3のいずれか1項記載の主題抽出装置。
【請求項5】
前記第2の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より係り先となる頻度が高い場合には、勝ちを示す値、低い場合には負けを示す値、同じ場合または係り受け関係がない場合には引き分けを示す値を前記第2の素性として算出する請求項1〜請求項4のいずれか1項記載の主題抽出装置。
【請求項6】
入力された文書から名詞句を抽出し、
多数の文書を含む大規模なテキストデータ中における、抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句を組み合わせた名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出し、
多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出し、
前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する
主題抽出方法。
【請求項7】
コンピュータを、請求項1〜請求項5のいずれか1項記載の主題抽出装置を構成する各手段として機能させるための主題抽出プログラム。
【請求項1】
入力された文書から名詞句を抽出する名詞句抽出手段と、
多数の文書を含む大規模なテキストデータ中における、前記名詞句抽出手段により抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句からなる名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出する第1の素性算出手段と、
多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出する第2の素性算出手段と、
前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する主題抽出手段と、
を含む主題抽出装置。
【請求項2】
前記名詞句抽出手段は、固有表現を含む名詞句、及び1つ以上の名詞が連続して具体的な物を示す名詞句を抽出し、
前記分類器は、固有表現または具体的な物を示す主題である具体主題が既知の学習用文書を用いて学習された
請求項1記載の主題抽出装置。
【請求項3】
前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句と他方の名詞句との共起頻度を該一方の名詞句の出現頻度で除して、該一方の名詞句の出現確率を求める請求項1または請求項2記載の主題抽出装置。
【請求項4】
前記第1の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より出現確率が高い場合には勝ちを示す値、低い場合には負けを示す値、同じ場合には引き分けを示す値を前記第1の素性として算出する請求項1〜請求項3のいずれか1項記載の主題抽出装置。
【請求項5】
前記第2の素性算出手段は、前記名詞句ペアを構成する一方の名詞句について、該名詞句ペアを構成する他方の名詞句より係り先となる頻度が高い場合には、勝ちを示す値、低い場合には負けを示す値、同じ場合または係り受け関係がない場合には引き分けを示す値を前記第2の素性として算出する請求項1〜請求項4のいずれか1項記載の主題抽出装置。
【請求項6】
入力された文書から名詞句を抽出し、
多数の文書を含む大規模なテキストデータ中における、抽出された名詞句各々の出現頻度、及び前記抽出された名詞句各々より選択された2つの名詞句を組み合わせた名詞句ペア各々の共起頻度を求め、該名詞句各々の出現頻度及び該共起頻度から求まる前記名詞句各々の出現確率に基づいて、前記名詞句ペアを構成する名詞句のいずれの出現確率が高いかを示す第1の素性を算出し、
多数の文書を含む大規模なテキストデータ中における、前記名詞句ペアの係り受け構造毎の出現頻度に基づいて、該名詞句ペアを構成する名詞句のいずれが係り先になり易いかを示す第2の素性を算出し、
前記名詞句各々の前記第1の素性及び前記第2の素性を並べた素性列と、主題が既知の学習用文書に含まれる名詞句の素性列を用いて学習された分類器とに基づいて、前記抽出された名詞句各々から、前記入力された文書の主題となる名詞句を抽出する
主題抽出方法。
【請求項7】
コンピュータを、請求項1〜請求項5のいずれか1項記載の主題抽出装置を構成する各手段として機能させるための主題抽出プログラム。
【図1】


【図2】

【図3】

【図4】
【図5】
【図6】
【図7】

【図8】
【図9】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【公開番号】特開2012−173810(P2012−173810A)
【公開日】平成24年9月10日(2012.9.10)
【国際特許分類】
【出願番号】特願2011−32545(P2011−32545)
【出願日】平成23年2月17日(2011.2.17)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
【公開日】平成24年9月10日(2012.9.10)
【国際特許分類】
【出願日】平成23年2月17日(2011.2.17)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
[ Back to top ]