
住所データと地図データとのリンク処理方法およびリンク処理装置
【課題】 住所録や個人情報などから抽出した住所データAに、緯度経度情報を付加するために、比較的小さな処理負担で地図データへの正確なリンク処理を行う。
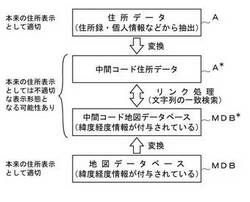
【解決手段】 本来の住所表示として適切な文字列からなる地図データMを多数収録した地図データベースMDBを用意する。住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定め、地図データベースMDB内の各データを、この変換ルールによって中間コードに変換し、中間コード地図データベースMDB*を用意する。与えられた住所データAを、上記変換ルールにより、中間コード住所データA*に変換し、A*について、MDB*内を検索して、文字列が一致する中間コード地図データM*へのリンク付けを行う。
【解決手段】 本来の住所表示として適切な文字列からなる地図データMを多数収録した地図データベースMDBを用意する。住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定め、地図データベースMDB内の各データを、この変換ルールによって中間コードに変換し、中間コード地図データベースMDB*を用意する。与えられた住所データAを、上記変換ルールにより、中間コード住所データA*に変換し、A*について、MDB*内を検索して、文字列が一致する中間コード地図データM*へのリンク付けを行う。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、住所録や個人情報などから抽出した住所を示す文字列に対して緯度経度情報を与えるために、当該文字列に対して、予め緯度経度情報が付与されている地図データをリンクさせる処理を行う技術に関する。
【背景技術】
【0002】
現在、インターネットのWebページ上などに地図画像を表示することは、ごく一般的に行われており、特定の場所の位置を、この地図画像上にプロットして示すことも広く行われている。しかしながら、住所録や個人情報などから抽出した住所を示す文字列(本願では、住所データと呼ぶ)には、通常、緯度経度情報は含まれていない。したがって、この住所データを構成する文字列のみを用いて、当該住所データが示す位置を地図画像上にプロットすることはできない。
【0003】
そこで、住所録や個人情報などから抽出した住所データに、緯度経度情報を付与するために、予め緯度経度情報が付与された住所を示す文字列(本願では、上記住所データと区別するために地図データと呼ぶ)を用意しておき、住所データと地図データとを対応づけるリンク処理が行われる。現在、地図データは、データベースとして国土地理院などから提供されており、北海道から沖縄に至るまで、日本全国の住所を示す文字列に、それぞれ所定の緯度経度情報が付与されている。このような地図データとのリンク付けを行うことができれば、住所録や個人情報などから抽出した任意の住所データに、緯度経度情報を付与することができる。
【0004】
たとえば、住所録から「東京都新宿区市谷加賀町一丁目2番3号」なる文字列からなる住所データが抽出された場合、上述した地図データのデータベースを検索して、同一の文字列を有する地図データに対するリンク付けを行うことができれば、リンク付けされた地図データに付与されていた緯度経度情報を、そのまま住所データに流用することができる。下記の特許文献1および2には、このようなリンク処理を効率的に行うための技術が開示されている。
【特許文献1】特開平10−154161号公報
【特許文献2】特開2003−223459号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
上述したとおり、特定の住所データを特定の地図データに対応づけるリンク処理は、基本的には、住所データを構成する文字列と地図データを構成する文字列との一致判定処理によって行われる。前述の例の場合、「東京都新宿区市谷加賀町一丁目2番3号」なる文字列からなる住所データに対応する地図データを探し出すには、北海道から沖縄に至るまで日本全国を網羅した地図データのデータベースを逐一検索し、同一の文字列をもった地図データを見つける処理を行うことになる。
【0006】
しかしながら、従来の手法では、この検索処理時の条件として、文字列の完全一致という条件設定を行うと、正しい検索を行うことができない場合がある。これは、国土地理院などから提供された地図データのデータベース上では、「東京都新宿区市谷加賀町一丁目2番3号」なる文字列として登録されていたとしても、住所録や個人情報などから抽出した住所データが、これと同一の文字列から構成されているとは限らないからである。住所録などに掲載する一般的な住所表記としては、たとえば、「市谷」の代わりに、「市ケ谷」,「市ヶ谷」,「市が谷」なる文字列が用いられることもあり、「一丁目2番3号」の代わりに、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」のような文字列が用いられることもある。
【0007】
このような書式の不統一という問題は、住所録や個人情報などから抽出した住所データ側だけの問題ではなく、地図データ側も同様の問題を抱えている。実際、国土地理院などから提供された地図データの書式も、日本全国完全に統一された書式にはなっていない。これは、国土地理院が、地図データの作成および緯度経度情報の測定を、個々の地方自治体に委ねており、各自治体によって、採用する書式が統一されていないためである。
【0008】
このような事情から、特定の住所データを特定の地図データに対応づけるリンク処理を正確に行おうとすればするほど、文字列相互の一致判定の条件設定が困難になり、一致判定のアルゴリズムは複雑化せざるを得ない。
【0009】
そこで、前述した特許文献1および2には、予め標準書式(正規表現)を定めておき、与えられた住所を示す文字列を、この標準書式に変換するための正規化処理を行い、正規化された状態で文字列の比較を行う手法が開示されている。しかしながら、様々な書式で記述された住所データや地図データを正規表現に変換するための正規化処理は、非常に複雑なアルゴリズムをもった負担の大きな処理にならざるを得ない。
【0010】
そこで本発明は、比較的小さな処理負担で、正確なリンク処理が可能になる住所データと地図データとのリンク処理方法およびリンク処理装置を提供することを目的とする。
【課題を解決するための手段】
【0011】
(1) 本発明の第1の態様は、与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う住所データと地図データとのリンク処理方法において、
住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定める変換ルール定義段階と、
データベースとして用意されている個々の地図データを、この変換ルールに基づいて中間コードに変換する処理を行い、中間コード地図データベースを作成する中間コード地図データベース作成段階と、
処理対象となる住所データを、この変換ルールに基づいて中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成段階と、
中間コード住所データに基づいて中間コード地図データベースを検索し、対応する中間コード地図データを特定し、処理対象となる住所データに特定の地図データを対応づけるデータ検索段階と、
を行うようにしたものである。
【0012】
(2) 本発明の第2の態様は、上述の第1の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを定めるようにしたものである。
【0013】
(3) 本発明の第3の態様は、上述の第1または第2の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めるようにしたものである。
【0014】
(4) 本発明の第4の態様は、上述の第1〜第3の態様に係る住所データと地図データとのリンク処理方法において、
中間コード地図データベース作成段階で、行政区画に応じて階層化された複数の階層データファイルによって構成される中間コード地図データベースを作成し、
データ検索段階で、中間コード地図データベースを上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索するようにしたものである。
【0015】
(5) 本発明の第5の態様は、上述の第4の態様に係る住所データと地図データとのリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加する作業を行い、
データ検索段階で、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定するようにしたものである。
【0016】
(6) 本発明の第6の態様は、上述の第5の態様に係る住所データと地図データとのリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内に、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データを、文字コードの大きい順にソートした状態で用意し、
データ検索段階で、中間コード住所データA*と、階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行するようにしたものである。
【0017】
(7) 本発明の第7の態様は、上述の第6の態様に係る住所データと地図データとのリンク処理方法において、
各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行するようにしたものである。
【0018】
(8) 本発明の第8の態様は、上述の第4〜第7の態様に係る住所データと地図データとのリンク処理方法において、
データ検索段階で、中間コード住所データA*に対応する中間コード地図データを検索することができなかった場合には、中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正処理を実行し、得られた修正住所データAA*を用いて、再度のデータ検索を行うようにしたものである。
【0019】
(9) 本発明の第9の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、全角数字および漢数字をすべて半角数字に置き換える処理もしくは半角数字および漢数字をすべて全角数字に置き換える処理を含む変換ルールを定めるようにしたものである。
【0020】
(10) 本発明の第10の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換える処理を含む変換ルールを定めるようにしたものである。
【0021】
(11) 本発明の第11の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換え、その後、数字もしくは数字群のうしろにこの特定文字がなければ、当該数字もしくは数字群のうしろにこの特定文字を付加する処理を含む変換ルールを定めるようにしたものである。
【0022】
(12) 本発明の第12の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
「ケ」,「ヶ」,「が」,「ツ」,「ッ」,「つ」,「大字」,「小字」,「字」なる文字をすべて削除する処理を含む変換ルールを定めるようにしたものである。
【0023】
(13) 本発明の第13の態様は、与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う住所データと地図データとのリンク処理装置において、
住所を示す文字列からなり、緯度経度情報が付与されている個々の地図データを、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための所定の変換ルールに基づいて変換することにより得られる中間コード地図データを、データベースの形式で格納した中間コード地図データベースと、
処理対象となる住所データを入力し、これを上記変換ルールに基づいて中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成手段と、
中間コード住所データに基づいて中間コード地図データベースを検索し、文字列が一致する中間コード地図データを特定するデータ検索手段と、
を設けるようにしたものである。
【0024】
(14) 本発明の第14の態様は、上述の第13の態様に係る住所データと地図データとのリンク処理装置において、
人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを用いるようにしたものである。
【0025】
(15) 本発明の第15の態様は、上述の第13または第14の態様に係る住所データと地図データとのリンク処理装置において、
互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めるようにしたものである。
【0026】
(16) 本発明の第16の態様は、上述の第13〜第15の態様に係る住所データと地図データとのリンク処理装置において、
中間コード地図データベースを、行政区画に応じて階層化された複数の階層データファイルによって構成し、
データ検索手段が、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索するようにしたものである。
【0027】
(17) 本発明の第17の態様は、上述の第16の態様に係る住所データと地図データとのリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加しておき、
データ検索手段が、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定するようにしたものである。
【0028】
(18) 本発明の第18の態様は、上述の第17の態様に係る住所データと地図データとのリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内に、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データを、文字コードの大きい順にソートされた状態で格納しておき、
データ検索手段が、中間コード住所データA*と、階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行うようにしたものである。
【0029】
(19) 本発明の第19の態様は、上述の第18の態様に係る住所データと地図データとのリンク処理装置において、
データ検索手段が、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行する処理を行うようにしたものである。
【0030】
(20) 本発明の第20の態様は、上述の第16〜第19の態様に係る住所データと地図データとのリンク処理装置において、
データ検索手段から、中間コード住所データA*に対応する中間コード地図データを検索することができなかった旨の報告を受けた場合に、当該中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正手段を更に設け、
データ検索手段が、この修正住所データAA*を用いて、再度のデータ検索を行うことができるようにしたものである。
【0031】
(21) 本発明の第21の態様は、上述の第13〜第20の態様に係る住所データと地図データとのリンク処理装置を、コンピュータに所定のプログラムを組み込むことにより構築するようにしたものである。
【発明の効果】
【0032】
以上のとおり、本発明に係る住所データと地図データとのリンク処理方法およびリンク処理装置によれば、本来の住所表示としては不適切な表示形態となる可能性のある中間コードを介して対応づけを行うようにしたため、比較的小さな処理負担で、正確なリンク処理が可能になる。
【発明を実施するための最良の形態】
【0033】
以下、本発明を図示する実施形態に基づいて説明する。
【0034】
<<< §1.一般的なリンク処理の手法 >>>
はじめに、説明の便宜上、住所データと地図データとについての一般的なリンク処理の手法を述べておく。図1は、一般的な住所データAと地図データMとのリンク処理の概念を示すブロック図である。既に述べたとおり、本願にいう「住所データA」とは、住所録や個人情報などから抽出した住所を示す文字列を意味し、経度緯度情報を有していないデータである。これに対して、本願にいう「地図データM」とは、本質的にはやはり住所を示す文字列からなるデータであるが、緯度経度情報が付与されたデータとなっている。住所データAと地図データMとのリンク処理の目的は、緯度経度情報が付されていない住所データAについて、対応する地図データMを探し出し、この対応する地図データMに付与されている経度緯度情報を、そのまま住所データAにも付与して利用できるようにすることにある。
【0035】
このように、任意の住所データAについて、特定の地図データMとのリンク処理を行い、緯度経度情報を付与できるようにするためには、予め、日本全国についての地図データMを集めた地図データベースMDBを用意しておけばよい。リンク処理の対象となる住所データAが与えられたら、地図データベースMDBを検索して、この住所データAを構成する文字列と一致する文字列をもった特定の地図データMを探して対応づければよい。
【0036】
地図データベースMDBとしては、国土地理院などから提供されているものを利用することができる。一般的に利用されている地図データベースMDBは、図2に示すように、行政区画に応じて階層化された複数の階層データファイルによって構成されている。すなわち、この例では、都道府県階層データファイルKEN、市区町村階層データファイルSHK、大字階層データファイルOAZ、字町階層データファイルAZC、街区階層データファイルGIK、地番階層データファイルTBN、枝番階層データファイルEBNなる7階層にわたった階層データファイルが用意されている。
【0037】
図3は、この地図データベースMDBを構成する各階層データファイルに収容されている個々の地図データMの一例を示すブロック図である(枝番階層データファイルEBNの図示は省略)。たとえば、都道府県階層データファイルKENには、「北海道」なる地図データから、「沖縄県」なる地図データに至るまで、都道府県の階層(最上位階層)に所属する地図データMが収容されている。同様に、市区町村階層データファイルSHKには、「北海道札幌市」なる地図データから、「沖縄県那覇市」なる地図データに至るまで、市区町村の階層(第2階層)に所属する地図データMが収容されている。
【0038】
この図3では、説明の便宜上、地図データ相互の上下関係を、隣接する階層間の一部に引いた直線で示している。たとえば、都道府県階層データファイルKENに所属する「東京都」から、市区町村階層データファイルSHKに所属する「東京都中央区」,「東京都新宿区」,「東京都千代田区」に対して直線が引かれているが、これは後者の地図データが前者の地図データに対応した下位階層データであることを、説明の便宜上、示すためのものである。
【0039】
同様に、「東京都新宿区」に対応した下位階層データが、大字階層データファイルOAZに所属する「東京都新宿区西早稲田」,「東京都新宿区市谷加賀町」,「東京都新宿区高田馬場」であることが示され、「東京都新宿区西早稲田」に対応した下位階層データが、字町階層データファイルAZCに所属する「東京都新宿区西早稲田一丁目」,「東京都新宿区西早稲田二丁目」,「東京都新宿区西早稲田三丁目」であることが示され、「東京都新宿区西早稲田二丁目」に対応した下位階層データが、街区階層データファイルGIKに所属する「東京都新宿区西早稲田二丁目1番」,「東京都新宿区西早稲田二丁目2番」,「東京都新宿区西早稲田二丁目3番」であることが示され、「東京都新宿区西早稲田二丁目3番」に対応した下位階層データが、地番階層データファイルTBNに所属する「東京都新宿区西早稲田二丁目3番1号」〜「東京都新宿区西早稲田二丁目3番29号」であることが示されている。
【0040】
図には示されていないが、これら各地図データには、それぞれ当該地図データによって示される地理的位置を代表する地点の緯度経度情報が付与されている。たとえば、都道府県階層データファイルKENに所属する「東京都」なる地図データには、東京都を代表する地点(たとえば、東京都の中心地点)の緯度経度情報が付与されており、市区町村階層データファイルSHKに所属する「東京都新宿区」なる地図データには、東京都新宿区を代表する地点(たとえば、新宿区の中心地点)の緯度経度情報が付与されている。同様に、地番階層データファイルTBNに所属する「東京都新宿区西早稲田二丁目3番29号」なる地図データには、当該番地を代表する地点の緯度経度情報が付与されている。
【0041】
このような構成をもった地図データベースMDBを予め用意しておけば、住所を示す任意の文字列からなる住所データAが与えられた場合、この地図データベースMDBを検索して、文字列の一致する地図データMを特定することにより、対応する緯度経度情報を得ることができる。たとえば、「東京都新宿区」という文字列からなる住所データAが与えられた場合、この地図データベースMDBを検索することにより、市区町村階層データファイルSHKに所属する「東京都新宿区」なる地図データMが文字列完全一致の地図データとしてヒットするので、当該地図データMに付与されていた緯度経度情報を、当該住所データAにそのまま付与することができる。
【0042】
地図データベースMDBに対する文字列の一致検索は、コンピュータを利用して行うことができるので、たとえば、10万人分の住所データAを含む個人情報ファイルが与えられたとしても、個々の住所データAを1件ずつ取り出して、地図データベースMDBに対する検索を行うことにより、この10万人分の住所データAのそれぞれに対して特定の地図データMを対応づけるリンク処理を行うことが可能であり、緯度経度情報を付与する処理が可能になる。
【0043】
<<< §2.本発明の基本的な発想 >>>
上述の§1では、リンク処理の基本的手法を述べたが、実際には、住所表記には様々な書式があるため、文字列の完全一致を条件とした検索処理では、対応する地図データを見つけることができない場合がある。そこで、前掲の特許文献1および2には、与えられた住所を示す文字列に対して正規化処理を行い、書式の標準化を図る技術が開示されている。
【0044】
たとえば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」などの表記についての正規表現や、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」などの表記についての正規表現を定めておき、様々な書式で記述されている住所を示す文字列を、すべてこの正規表現に改める正規化処理を行えば、文字列の完全一致を条件とした検索処理によって、正しいリンク処理が可能になる。
【0045】
しかしながら、現実的には、このような正規化処理は、非常に複雑なアルゴリズムをもった負担の大きな処理にならざるを得ない。たとえば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」なる表記についての正規表現を、「市ヶ谷」とする、と定めたとしても、「市谷」、「市ケ谷」,「市が谷」なる文字列があった場合に、これを機械的に「市ヶ谷」に置換する処理を行えばよいわけではない。そのような機械的な置換処理を行ってしまうと、たとえば、「春日部市谷原」のような文字列が、「春日部市ヶ谷原」のような誤った表記に変換されてしまう。また、「ケ」,「ヶ」,「が」なる文字の不統一が問題となるケースは、「市ヶ谷」だけでなく、「千駄ヶ谷」、「美ヶ原」など、他にもたくさん存在し、これら個々のケースにすべて対応可能な正規化処理は、非常に複雑なものにならざるを得ない。
【0046】
一方、住所を示す文字列において、表記の不統一が最も顕著な部分は、数字による住所記述部分(何条、何丁目、何番地、何番、何号といった表記部分)である。具体的には、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」などの表記形態は、いずれも一般的な住所録などでごく普通に用いられている。もちろん、人間が目視確認する作業を行えば、これらの表記はいずれも実質的に同一の住所表記である旨の判断を行うことができる。しかしながら、コンピュータを用いた文字列の一致検索では、全角数字と半角数字ですら、互いに異なる文字と判断されてしまう。
【0047】
しかも、このような数字による住所記述部分の不統一を解消するため、特定の書式を正規表現と定めたとしても、そのような正規表現に改める正規化処理は、やはり非常に複雑なものにならざるを得ない。たとえば、「数字による住所記述部分では、漢数字ではなく、全角アラビア数字を用いる」という正規表現を定めたとしても、住所を示す任意の文字列を、この正規表現に改める正規化処理は、それほど単純な処理にはならない。具体的には、「文字列中の漢数字をすべて全角アラビア数字に変更する」というアルゴリズムに基づいて、この正規化処理を実行しようとすると、「八丁目八番三号」という表記は、「8丁目8番3号」に置換されることになる。しかしながら、その副作用として、「青森県八戸市」という表記は、「青森県8戸市」に置換され、「東京都北区東十条」という表記は、「東京都北区東10条」に置換され、「東京都千代田区」という表記は、「東京都1000代田区」に置換されてしまうことになる。
【0048】
そこで従来は、このような様々な事例を考慮して、住所を示す任意の文字列について、できるだけ正確に標準書式に変換することが可能な正規化処理のアルゴリズムを案出することに苦心していた。
【0049】
これに対して、本発明の基本的な特徴は、共通の中間コードを介して、住所データと地図データとのリンクをとる、という点にある。ここで、「中間コード」とは、「住所を示す文字列」の一種ではあるが、本来の住所表示としては不適切な表示形態となる可能性のあるコードであり、この点において、従来の標準書式(正規表現)とは異なっている。たとえば、上述した「青森県8戸市」,「東京都北区東10条」,「東京都1000代田区」のような表記は、本来の住所表示としては不適切な表示形態であり、従来の標準書式(正規表現)にはなり得ない表記である。しかしながら、これらの表記は、本発明における中間コードとしては、認容できる表記ということになる。
【0050】
図4は、本発明に係る住所データと地図データとのリンク処理方法の基本概念を示すブロック図である。ここで、住所データAと地図データベースMDBは、図1のブロック図に示されているものと全く同じである。すなわち、住所データAは、住所録・個人情報などから抽出され、任意の書式で記述された住所を示す文字列であり、地図データベースMDBは、図2および図3に示す例のように、緯度経度情報が付与されている多数の地図データMの集合体である。図1に示す例では、住所データAを、地図データベースMDB内の特定の地図データMに直接リンク付けする処理を行ったが、本発明では、図4に示すとおり、住所データAを中間コード住所データA*に変換し、地図データベースMDBを中間コード地図データベースMDB*に変換し、中間コード住所データA*と中間コード地図データベースMDB*との間でのリンク処理(文字列の一致検索処理)が行われる。
【0051】
住所データAおよび地図データベースMDB(に含まれる地図データM)は、本来の住所表示として適切な文字列から構成されており、人間が目視した場合にも、正しい住所表記として認識される文字列であるが、中間コード住所データA*および中間コード地図データベースMDB*(に含まれる中間コード地図データM*)は、本来の住所表示としては不適切な表示形態となる可能性がある文字列である。本願では、「*」を含む符号で示すデータは、中間コードのデータであり、本来の住所表示としては不適切な表示形態となる可能性があるデータである。しかしながら、中間コード住所データA*および中間コード地図データベースMDB*は、相互のリンク処理、すなわち、文字列の一致検索処理にのみ利用され、本来の住所を提示するような用途に利用されることはないので、本来の住所表示としては不適切な表示形態となっていても何ら問題はないのである。
【0052】
このように、本発明では、中間コードの形式のデータは、リンク処理のためだけに利用されるので、本来の住所表示としては不適切な表示形態となっていても何ら問題はなく、それ故に、中間コードへの変換処理のアルゴリズムを非常に単純化することができる。図4に示す例の場合、住所データAを中間コード住所データA*に変換する変換ルールと、地図データベースMDBを中間コード地図データベースMDB*に変換する変換ルール(別言すれば、地図データMを中間コード地図データM*に変換する変換ルール)とは、同じルールが用いられ、しかも、この変換ルールは、前掲の従来技術における正規化処理のルールほど複雑なものにする必要はない。
【0053】
たとえば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」のような表記のバリエーションが生じるのは、「ケ」,「ヶ」,「が」なる文字の不統一に起因する問題であるが、このような問題を解決するため、本発明では、たとえば、文字列中に「ケ」,「ヶ」,「が」なる文字が含まれていたら、これらをすべて削除する、という変換ルールを定め、中間コードへの変換を行うことができる。このような変換ルールを適用すれば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」なる文字列は、いずれも「市谷」なる統一した形態の中間コードに変換されることになる。
【0054】
もっとも、上記変換ルールを適用すると、愛知県の「豊根村大字下黒川ケゴヤ」、京都府の「園部町口司カマカケ」などの住所表示が、それぞれ「豊根村大字下黒川ゴヤ」、京都府の「園部町口司カマカ」のように、本来の住所表示としては不適切な表示形態となる。従来の考え方であれば、正規化処理によって、このような不適切な表示形態が生じるのであれば、これを回避するために、何らかの手当を行う、という方針をとることになるが、本発明では、中間コード上にこのような不適切な表示形態が生じたとしても、何ら問題はないのである。
【0055】
すなわち、上記変換ルールによって、「豊根村大字下黒川ケゴヤ」が「豊根村大字下黒川ゴヤ」なる不適切な表示形態をもった中間コードに変換されたとしても、そのような不適切な表示形態への変換は、住所データAに基づく変換により得られた中間コード住所データA*と、地図データMに基づく変換により得られた中間コード地図データM*との双方において生じることになるので、「豊根村大字下黒川ゴヤ」なる不適切な表示形態をもった住所データA*と、同じく「豊根村大字下黒川ゴヤ」なる不適切な表示形態をもった地図データM*との間で、文字列の完全一致という形でリンク処理が可能になる。もちろん、「豊根村大字下黒川ゴヤ」なる文字列自体は、住所表示としては不適切であるが、このような文字列はリンク処理の目的にのみ利用されるので、実用上は何ら問題はない。
【0056】
同様に、数字による住所記述部分の不統一に起因する問題を解決するため、本発明では、たとえば、「文字列中の漢数字をすべて全角アラビア数字に変更する」という単純な変換ルールを適用することができる。この変換ルールを適用すれば、「八丁目八番三号」,「八丁目八番3号」,「八丁目8番3号」,「8丁目8番3号」という種々の形態の表記は、いずれも「8丁目8番3号」なる統一した表記をもった中間コードに置換されることになるし、「千五百二十六番地」や「壱千伍百弐拾六番地」は、「1526番地」なる統一した表記をもった中間コードに置換されることになる。
【0057】
ただし、上記変換ルールだけでは、前述したとおり、「青森県八戸市」が「青森県8戸市」に変換され、「東京都北区東十条」が「東京都北区東10条」に変換され、「東京都千代田区」が「東京都1000代田区」に変換されてしまうことになる。これらの変換によって得られる中間コードは、本来の住所表示としては不適切な表示形態である。従来の考え方であれば、このような不適切な表示形態は回避すべきものとされていたが、本発明では、中間コード上にこのような不適切な表示形態が生じたとしても、何ら問題はないのである。
【0058】
すなわち、上記変換ルールによって、中間コード住所データA*および中間コード地図データベースMDB*を得るようにすれば、「東京都1000代田区」なる中間コード住所データA*は、中間コード地図データベースMDB*内に収容されている「東京都1000代田区」なる同一文字列の中間コード地図データM*にリンク付けされることになる。もちろん、「東京都1000代田区」なる文字列自体は、住所表示としては不適切であるが、このような文字列はリンク処理の目的にのみ利用されるので、実用上は何ら問題はない。
【0059】
このように、本発明の基本的技術思想は、前掲の特許文献1および2に開示されている技術思想に対して、逆転の発想とも言うべきものである。すなわち、前掲の特許文献1および2に開示されている従来技術では、予め標準書式(正規表現)を定めておき、与えられた住所を示す文字列を、この標準書式に変換するための正規化処理を行い、正規化された状態で文字列の比較を行う、という手法をとることになる。ここで標準書式(正規表現)なるものは、あくまでも本来の住所表示として機能する書式を前提としているため、正規化処理によって、不適切な表示形態となるようなケースを避けるために、非常に複雑なアルゴリズムをもった正規化処理手順が必要になる。
【0060】
これに対して、本発明では、与えられた住所を示す文字列を、所定の変換ルールに基づいて中間コードに変換し、この中間コードの状態で文字列の比較を行う、という手法をとる。しかも、この中間コードなるものは、リンク処理を行う目的にのみ利用されるものであり、本来の住所表示としては不適切な表示形態となっても一向にかまわないのである。別言すれば、中間コード住所データA*側が不適切な表示形態となっていても、中間コード地図データM*側も同様に不適切な表示形態となっているので、文字列の一致という形式でリンク処理を行う上では、何ら支障は生じないのである。
【0061】
このように、本発明で用いる中間コードは、本来の住所表示として適切か否かは不問であるため、中間コードに変換するために用いる変換ルールは極めて単純なものですむ。かくして、本発明によれば、比較的小さな処理負担で、正確なリンク処理が可能になる住所データと地図データとのリンク処理方法を提供することが可能になる。
【0062】
<<< §3.本発明の基本的な実施形態に係るリンク処理方法 >>>
続いて、本発明の基本的な実施形態を説明する。図5は、本発明の基本的な実施形態に係るリンク処理方法の手順を示す流れ図である。このリンク処理は、処理対象となる住所データAを、緯度経度情報が付与されている特定の地図データMと対応づけることを目的としており、図示のとおり、4段階のステップから構成されている。
【0063】
まず、ステップS1は、住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定める変換ルール定義段階である。この変換は、複数通りのバリエーションをもった住所表記を、統一した表記に改めることを目的として行われるものであり、この目的に関しては、前掲の特許文献における正規化処理と同じである。したがって、ルールの内容としては、複数通りのバリエーションをもった住所表記を統一するために、複数通りの文字を1つの統一文字に置換したり、特定の文字を削除したりする取り決めがなされる。
【0064】
もっとも、既に§2で述べたとおり、この変換ルールは、従来技術における正規化処理のルールなどに比べると、極めて単純なルールですむ。これは、前述したとおり、本発明における中間コードは、本来の住所表示として適切か否かは不問であるためである。住所を示す文字列を、中間コードに「一義的に変換する」という意味は、「同一の文字列が与えられた場合、必ず同一の中間コードに変換される」という意味である。たとえば、文字列中に「ケ」,「ヶ」,「が」なる文字が含まれていたら、これらをすべて削除する、という変換ルールは、「一義的な変換」を行う変換ルールであり、「市ヶ谷」という文字列が与えられた場合、必ず、「市谷」という中間コードに変換されることになる。もっとも、その逆は必ずしも成り立たない。すなわち、変換により「市谷」という中間コードが得られたとしても、元の文字列は、必ずしも「市ヶ谷」であるとは限らない。
【0065】
図6は、このステップS1で定義する変換ルールの一例を示す図である。図示の例では、(1) 〜(4) の4つの変換ルールが定義されている。以下、これらの変換ルールを順に説明する。
【0066】
変換ルール(1) は、「全角数字および漢数字は、すべて半角数字に置き換える。」という規則である。なお、本願において、全角数字とは全角のアラビア数字を意味し、半角数字とは、当然、半角のアラビア数字を意味する。この変換ルールの目的は、数字の全角/半角の相違による不一致や、漢数字/アラビア数字の相違による不一致を排除することにある。図示の例のとおり、「1,2,3」といった全角数字は、「1,2,3」といった半角数字に変換され、「一,二,三」あるいは「壱,弐,参」といった漢数字も、「1,2,3」といった半角数字に変換される。また、「十(あるいは拾),百,千,万(あるいは萬)」といった位取りを有する漢数字も、「10,100,1000,10000」といった位取りを有する半角数字に変換される。
【0067】
この変換ルール(1) に従えば、「八丁目八番三号」,「八丁目八番3号」,「八丁目8番3号」,「8丁目8番3号」という種々の形態の表記は、いずれも「8丁目8番3号」なる中間コードに変換され、「千五百二十六番地」や「壱千伍百弐拾六番地」は、「1526番地」なる中間コードに変換される。もっとも、前述したとおり、「青森県八戸市」は「青森県8戸市」に変換され、「東京都北区東十条」は「東京都北区東10条」に変換され、「東京都千代田区」は「東京都1000代田区」に変換されることになり、本来の住所表示としては不適切な表示形態になることがある。
【0068】
変換ルール(2) は、「『条』,『の』,『丁目』,『番』,『番地』,『号』,全角ハイフンは、すべて半角ハイフンに置き換える。」という規則である。この変換ルールの目的は、数字による住所記述部分(何条、何丁目、何番地、何番、何号といった表記部分)内の数字以外の構成要素として用いられる可能性のある文字を、すべて半角ハイフンに置き換えて統一した表記にすることにある。たとえば、数字による住所記述部分として、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」のような様々な表記による文字列があったとしよう。これらの文字列に、上記変換ルール(1) を適用すると、それぞれ「1丁目2の3」,「1丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」のように、数字は半角数字に統一されたものの、数字以外の構成要素は統一されていない。そこで、続いて、この変換ルール(2) による変換を行うと、いずれも最終的に「1-2-3」なる統一した表記に変換されることになる。
【0069】
ここで、「条」,「の」,「丁目」,「番」,「番地」,「号」,全角ハイフンは、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字であり、このような文字をすべて半角ハイフンに置き換えることにより、数字による住所記述部分の書式を統一することができるのである。もっとも、この変換ルール(2) の適用対象は、数字による住所記述部分に限定されず、住所を示す文字列のすべてが適用対象となるので(それ故に、変換ルールは非常に単純になる)、たとえば、「松戸市牧の原」なる文字列は「松戸市牧-原」に変換され、「目黒区鷹番」なる文字列は「目黒区鷹-」に変換されてしまうことになる。このように、変換ルール(2) も、変換の結果、本来の住所表示としては不適切な表示形態となる可能性のある変換ルールである。
【0070】
変換ルール(3) は、「半角数字もしくは半角数字群のうしろに半角ハイフンがなければ、半角ハイフンを付加する」という規則である。この変換ルール(3) は、上述した変換ルール(1) および(2) による変換を行った後に実行すべきルールであり、変換ルール(1) および(2) と組み合わせることによって意味をもつルールである。変換ルール(1) および(2) を実行すると、漢数字/アラビア数字は、すべて半角数字に統一され、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字(すなわち、上述の例の場合、「条」,「の」,「丁目」,「番」,「番地」,「号」,全角ハイフン)は、すべて半角ハイフンに置き換えられる。その結果、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」のような様々な表記による文字列は、上述したとおり、すべて「1-2-3」なる統一した表記に変換されることになる。
【0071】
変換ルール(3) の目的は、こうして半角数字および半角ハイフンを用いて記述された数字による住所記述部分の末尾に、更に半角ハイフンを付加することにあり、別言すれば、すべての半角数字の末尾に半角ハイフンが付加された状態にすることにある。たとえば、数字による住所記述部分が、「1-2-3」なる文字列であった場合、この変換ルール(3) を適用することにより、この文字列は「1-2-3-」に変換されることになる。つまり、うしろに半角ハイフンがなかった「3」に、半角ハイフンが付加されたことになる。この変換ルール(3) における「半角数字もしくは半角数字群」の意味するところは、「1-23-456」のような文字列に対しては、「1-2-3-4-5-6-」のような変換を行うのではなく、「1-23-456-」のような変換を行うことを指している。つまり、半角数字が連続して並んでいる半角数字群があった場合は、当該半角数字群を構成する1つ1つの半角数字の末尾に半角ハイフンを付加するのではなく、当該半角数字群全体についての末尾に半角ハイフンを付加することになる。
【0072】
結局、この変換ルール(3) を適用した後は、すべての半角数字もしくは半角数字群のうしろに半角ハイフンが付加されることになる。このような変換処理を行う理由は、数字の桁の終了位置を明確にし、検索処理を円滑化するためである。たとえば、「東京都新宿区西早稲田二丁目三番の2」のような表記は、上述した変換ルール(1) ,(2) を適用することにより、「東京都新宿区西早稲田2-3-2」なる中間コードに変換されることになる。ここで、文字列の先頭から順に検索を行うことにすると、この検索処理のプロセスにおいて、「東京都新宿区西早稲田2-3-2」だけでなく、「東京都新宿区西早稲田2-3-21」,「東京都新宿区西早稲田2-3-22」,「東京都新宿区西早稲田2-3-23」なども候補としてヒットすることになる。もちろん、文字数までも含めた文字列の完全一致の判定を行えば、最終的には、「東京都新宿区西早稲田2-3-2」のみがヒットすることになるが、検索処理のプロセスにおいて、無関係な住所データが候補として挙がるのは好ましくない。
【0073】
変換ルール(3) を適用すれば、「東京都新宿区西早稲田二丁目三番の2」のような表記は、「東京都新宿区西早稲田2-3-2-」なる中間コードに変換されるので、「2-3-2-」なる表記のみがヒットすることになり、「2-3-21-」「2-3-22-」「2-3-23-」のような表記は、桁の途中で不一致が生じて候補から除外されることになる。もちろん、「東京都新宿区西早稲田2-3-2-」なる中間コードにおける末尾の半角ハイフンは、本来の住所表示としては不適切な表記ということになる。
【0074】
最後の変換ルール(4) は、「『ケ』,『ヶ』,『が』,『ツ』,『ッ』,『つ』,『大字』,『小字』,『字』なる文字をすべて削除する」という規則である。この変換ルールの目的は、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」のような表記のバリエーション、「美し丘」,「美しケ丘」,「美しヶ丘」,「美しが丘」のような表記のバリエーション、「四谷」,「四ツ谷」,「四ッ谷」,「四つ谷」のような表記のバリエーション、「大字」,「小字」,「字」のような表記のバリエーションを統一することにある。変換ルール(4) を適用すると、上記バリエーションは、それぞれ「市谷」、「美し丘」、「四谷」、「(字等を含まない表記)」に統一されることになる。もっとも、この変換ルール(4) を適用すると、「豊根村大字下黒川ケゴヤ」が「豊根村大字下黒川ゴヤ」に変換されてしまったり、「茨城県つくば市」が「茨城県くば市」に変換されてしまったりするので、やはり変換ルール(4) も、変換の結果、本来の住所表示としては不適切な表示形態となる可能性のある変換ルールということになる。
【0075】
図7は、図6に例示する変換ルール(1) 〜(4) を用いた中間コードへの具体的な変換例を示す図である。例1〜例4に示されている変換前の文字列は、いずれも実質的に同一地点の住所を示す文字列である。これらの文字列を図6に示すルールで中間コードに変換すると、変換後の中間コードは「東京都新宿区市谷3-5-6-」という完全に同一の文字列になる。例5は、「金山一条7番地」なる文字列が、「金山1-7-」に変換された例である。いずれも、変換後の中間コードは、末尾に半角ハイフンが付加された文字列となっており、本来の住所表示としては不適切な形態である。
【0076】
例6〜例8は、変換後に得られた中間コードが、本来の住所表示としては不適切な形態となっている点が、より顕著に表れた例である。たとえば、例6では、「東十条」なる文字列が「東10-条」となっている。これは、変換ルール(1) により、「十」なる漢数字が「10」なる半角数字に変換され、更に、変換ルール(3) により、「10」のうしろに半角ハイフンが付加されたためである。同様の理由により、例7では、「千代田区」が「1000-代田区」に変換されており、更に、変換ルール(3) を適用することにより、「一ツ橋」が「1-橋」に変換されている。また、例8では、「八戸市」が「8-戸市」に、「八幡」が「8-幡」に、それぞれ変換されている。
【0077】
このように、図7の変換後の欄に示されている中間コードは、いずれも本来の住所表示としては不適切な形態の文字列であるが、既に述べたとおり、本発明では、この中間コードはリンク処理の目的にのみ利用されるので、実用上は何ら問題はない。しかも、本発明では、「八丁目」や「八番地」なる文字列中の「八」は「8」に置き換えるが、「八戸市」や「八幡」なる文字列中の「八」はそのままにする、といった複雑な変換アルゴリズムは一切不要であり、変換ルール(1) では、文字列中のすべての「八」を例外なく「8」に置き換えればよいので、極めて単純な変換処理が可能になる。
【0078】
以上、図5の流れ図におけるステップS1の「変換ルール定義段階」で定義される変換ルールの一例を説明した。こうして、変換ルールの定義が完了すると、続いて、ステップS2において、中間コード地図データベース作成段階が行われる。これは、図3に示すようなデータベースとして用意されている個々の地図データM(国土地理院などから提供された緯度経度情報付のデータ)を、ステップS1で定義した変換ルールに基づいて、それぞれ中間コード地図データM*に変換する処理を行い、中間コード地図データベースMDB*を作成する処理である。
【0079】
たとえば、図3に示す地図データベースMDBに基づいて、図6に示す変換ルールを適用した変換処理を行うと、図8に示す中間コード地図データベースMDB*が得られる。図3に示されている個々の地図データMと図8に示されている個々の中間コード地図データM*とを比較すると、漢字からなる文字列の大部分は同一であるが、図8における数字による住所記述部分は、すべて半角数字+半角ハイフンという構成になっており、末尾には必ず半角ハイフンが付加された状態となっている。また、「東京都千代田区」のような文字列については、「東京都1000-代田区」のような不適切な形態への変換が行われている。なお、図8に示されている「Add1」などのデータの役割については、後述する§4で説明する。
【0080】
こうして、中間コード地図データベースMDB*が用意できたら、与えられた任意の住所データAに対して、当該データベースMDB*内の特定の地図データM*に対するリンク処理を行う準備が整ったことになる。そこで、まず、ステップS3において、中間コード住所データ作成段階を実行する。すなわち、与えられた処理対象となる住所データAを、ステップS1で定義した変換ルールに基づいて中間コードに変換する処理を行い、中間コード住所データA*を作成する処理が実行される。上述の例の場合、やはり図6に示す変換ルールに基づいて、住所データAを中間コードに変換する処理が行われることになる。たとえば、「東京都千代田区」という住所データAが与えられた場合、「東京都1000-代田区」という中間コード住所データA*に変換されることになる。
【0081】
最後のステップS4では、データ検索段階が行われる。すなわち、ステップS3で作成された中間コード住所データA*に基づいて、ステップS2で作成された中間コード地図データベースMDB*を検索し、対応する中間コード地図データM*を特定し、処理対象となる住所データAに特定の地図データMを対応づけるリンク処理が実行される。たとえば、「東京都千代田区」という住所データAに基づいて、ステップS3において「東京都1000-代田区」なる中間コード住所データA*が作成されたとすると、図8に示すような中間コード地図データベースMDB*に対して、「東京都1000-代田区」なる文字列に一致する中間コード地図データM*が検索されることになる。その結果、市区町村階層データファイル内の「東京都1000-代田区」なる中間コード地図データM*がヒットすることになるので、結局、「東京都千代田区」という住所データAが、「東京都千代田区」という地図データM(中間コード地図データM*の元になったデータ)にリンク付けされることになる。かくして、与えられた住所データAに対して、リンク付けされた地図データMの緯度経度情報を付与することができるようになる。
【0082】
なお、図6に示す変換ルールは、説明の便宜上、一例として示したものであり、本発明は、この特定の変換ルールのみに限定されるものではない。たとえば、図6に示す変換ルール(1) では、全角数字および漢数字をすべて半角数字に置き換え、数字の表記をすべて半角にする処理を行っているが、逆に、半角数字および漢数字をすべて全角数字に置き換え、数字の表記をすべて全角にする処理を行ってもかまわない。
【0083】
また、図6に示す変換ルール(2) では、「条」,「の」,「丁目」,「番」,「番地」,「号」,ハイフンといった、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を、すべて半角ハイフンに置き換える処理を行っているが、置換に用いる文字は、必ずしも半角ハイフンである必要はなく、予め定められた所定の特定文字であればよい。たとえば、半角ハイフンの代わりに「$」を用いれば、「2丁目3の2」のような表記は、「2$3$2」なる中間コードに変換され、半角ハイフンの代わりに「○」なる文字(本願での文字には、いわゆる記号も含まれる)を用いれば、「2丁目3の2」のような表記は、「2○3○2」なる中間コードに変換される。いずれも、本来の住所表示としては不適切な表示形態であるが、本発明で中間コードとして用いるには何ら支障はない。もちろん、半角ハイフンの代わりに「△×」のような複数の文字を用いれば、「2丁目3の2」のような表記は、「2△×3△×2」なる中間コードに変換されるが、これでも問題はない。要するに、変換ルール(2) は、一般論として定義すれば、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字(具体的には、「条」,「の」,「丁目」,「番」,「番地」,「号」,ハイフンなど)を、予め定められた所定の特定文字(複数の文字でもよい)に置き換える処理であれば十分である。
【0084】
図6に示す変換ルール(3) も同様である。前述したとおり、変換ルール(3) は、既に変換ルール(2) による変換が実行されていることを前提としたルールであり、一般論として定義すれば、変換ルール(2) によって、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字が所定の特定文字に置き換えられた場合、その後、数字もしくは数字群のうしろに当該特定文字がなければ、当該数字もしくは数字群のうしろに当該特定文字を付加する、というルールになる。したがって、変換ルール(2) において、特定文字として「$」を用いれば、「2丁目3の2」のような表記は、変換ルール(2) および(3) による変換によって、「2$3$2$」なる中間コードに変換されることになる。
【0085】
なお、本発明を実行する上で定義する変換ルールは、既に述べたとおり、住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するためのルールであれば、理論的にはどのような変換ルールであってもかまわないが、実用上は、次の2つの条件を満足するような変換ルールを定義するのが好ましい。
【0086】
第1の条件を満たす変換ルールは、「人間が目視したときに、住所表示として認識可能な中間コードが得られるようなルール」である。たとえば、図7の変換後の文字列は、いずれも本来の住所表示としては不適切な表示形態をもった文字列ではあるが、人間が目視した場合、いずれも何らかの住所表示であるという認識をもつことは可能である。したがって、図6に例示した変換ルールは、この第1の条件を満足する変換ルールであると言うことができる。
【0087】
この第1の条件を満足するような変換ルールを定義するメリットは、人間が中間コードを目視した場合、これを住所表示として認識できるため、リンク処理中に何らかのエラーが生じた場合であっても、柔軟な対応をとることができるという点である。たとえば、「北海道」なる文字列を「001」なるコードに置換し、「青森県」なる文字列を「002」なるコードに置換し、…というように、特定の文字列を特定の数字に置き換えてコード化する変換ルールを定義した場合、住所を示す文字列を、数字の羅列からなる中間コードに一義的に変換することが可能であり、当該中間コードは、もちろん、本来の住所表示としては不適切な表示形態となる。本発明の基本概念によれば、このように数字の羅列からなる中間コードへの変換が行われたとしても、この中間コードを媒介として、地図データと住所データとのリンク付けが行われれば支障は生じない。
【0088】
しかしながら、このような数字の羅列からなる中間コードの場合、人間が目視したとしても、でたらめな数字が並んでいるとしか見えず、もはや何らかの住所表示であるとの認識は得られない。したがって、リンク処理中に何らかのエラーが生じた場合であっても、どのような理由で不一致が生じているかを把握することが非常に困難になる。上述した第1の条件を満足する変換ルールを用いるようにすれば、得られる中間コードは、本来の住所表示としては不適切であったとしても、人間が目視した場合に何らかの住所表示としてとらえることができるので、不一致の原因を解析でき、柔軟な対応をとることができるようになるのである。
【0089】
一方、第2の条件を満たす変換ルールは、「互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないようなルール」である。別言すれば、「変換処理によって得られた中間コードにユニーク性が確保されるようなルール」と言うことができる。たとえば、異なる2通りの地図データに基づいて、全く同一の中間コードが得られるような変換ルールでは、中間コードにユニーク性が確保されないことになる。このように、ユニーク性が確保された中間コードが得られないとすると、所定の住所データに基づいて、対応する地図データを検索した結果、対応する地図データが複数組ヒットすることになり、1対1の対応関係を定義することができなくなる。
【0090】
もちろん、検索の結果、複数組の地図データがヒットしたような場合でも、これらを候補として提示して、最終的に人間の判断によって、正しい候補を選択する作業を行えば、本発明を実施することは可能である。しかしながら、上記第2の条件を満たす変換ルールを定めておけば、検索の結果、複数通りの候補が挙げられることを防ぐことができるので、実用上は、第2の条件を満たすルールを用いた方が好ましい。図6に例示した変換ルールは、この第2の条件も満足する変換ルールになっており、現存する住所表示に対して、この変換ルールを適用して得られる中間コードには、ユニーク性が確保されることになる。
【0091】
なお、図6に示す変換ルール(2) および(4) による変換を行うと、データ容量を減少させることができるという付加的な効果が得られる。一般に地図データベースMDBは膨大なデータ容量を必要とするが、図6に示す変換ルールによる変換で得られた中間コード地図データベースMDB*は、もとの地図データベースMDBに比べてデータ容量が減少するので、格納場所の記憶容量を削減できるという付加的なメリットが得られる。
【0092】
<<< §4.検索処理を円滑に行うための工夫 >>>
続いて、図5のステップS4として示されているデータ検索段階の処理を円滑に行うための工夫を述べる。ここでは、「東京都新宿区西早稲田二丁目3の29」という住所データAが与えられた場合に、図8に示すような中間コード地図データベースMDB*を検索する具体的な処理を例にとって説明を行うことにする。
【0093】
既に述べたとおり、図3に示す地図データベースMDBは、行政区画に応じて階層化された複数の階層データファイルによって構成されているため、これを所定の変換ルールに基づいて中間コードの形式に変換することによって得られる中間コード地図データベースMDB*(図8)も、行政区画に応じて階層化された複数の階層データファイルによって構成されることになる。しかも、第2階層以下の各階層データファイル内には、いずれも上位階層の地図データを構成する文字列を含んだ形式の地図データが格納されている。たとえば、図8の第2階層データファイルSHK内の「東京都新宿区」なる地図データには、第1階層データファイルKEN内の「東京都」なる文字列がそっくり含まれており、第3階層データファイルOAZ内の「東京都新宿区西早稲田」なる地図データには、第2階層データファイルSHK内の「東京都新宿区」なる文字列がそっくり含まれている。このような複数の階層データファイルによって構成されたデータベースに対しては、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索を行うようにすればよい。
【0094】
ここに示す実施形態では、このように、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索する便宜を考慮して、図8に示す中間コード地図データベースMDB*に、検索処理を円滑に行うための工夫を施している。すなわち、この中間コード地図データベースMDB*を作成する段階で、各階層データファイル内の各中間コード地図データM*に、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加する作業を行い、データ検索段階では、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定できるようにしている。
【0095】
図8に示す例の場合、たとえば、最上位階層のデータファイルKEN内の「東京都」なる中間コード地図データM*には、第2階層のデータファイルSHK内の対応する一連の中間コード地図データ「東京都中央区」,「東京都新宿区」,「東京都1000-代田区」,…の先頭アドレス「Add1」が付加されている。もちろん、データファイルKEN内の他の中間コード地図データM*にも、それぞれデータファイルSHK内の対応する一連の中間コード地図データの先頭アドレスが付加されている。また、このような関係は、別な階層間のデータファイルについても同様である。たとえば、第2階層のデータファイルSHK内の「東京都新宿区」なる中間コード地図データM*には、第3階層のデータファイルOAZ内の対応する一連の中間コード地図データ「東京都新宿区西早稲田」,「東京都新宿区市谷加賀町」,「東京都新宿区高田馬場」,…の先頭アドレス「Add2」が付加されている。以下の階層に関しても同様である。
【0096】
このように、個々の中間コード地図データM*に、それぞれ下位階層の対応する一連のデータの先頭アドレスを付加しておけば、非常に円滑な検索処理が可能になる。たとえば、「東京都新宿区西早稲田二丁目3の29」という住所データAが与えられた場合を考えてみよう。この場合、既に述べたとおり、この住所データAを、図6に示すような変換ルールに基づいて、「東京都新宿区西早稲田2-3-29-」のような中間コード住所データA*に変換する処理が行われる。そして、この中間コード住所データA*を構成する文字列の先頭部分と、図8に示す中間コード地図データベースMDB*の最上位階層のデータファイルKEN内の各中間コード地図データM*とが一致するか否かを調べる検索処理が実行される。この例の場合、データA*の先頭3文字の「東京都」なる文字列が、データファイルKEN内の「東京都」なるデータM*と一致することになる。
【0097】
そこで続いて、下位階層のデータファイルSHK内の検索が行われることになるが、このとき、データファイルKEN内の「東京都」なるデータM*に付加されていたアドレス「Add1」に基づいて、データファイルSHKのアドレス「Add1」から検索処理を開始すればよい。図示の例の場合、「東京都中央区」から検索が開始され、その次の「東京都新宿区」なるデータM*を検索した時点で、データA*の先頭の6文字との一致が確認されることになる。
【0098】
次に、第3階層のデータファイルOAZ内の検索が行われることになるが、このとき、データファイルSHK内の「東京都新宿区」なるデータM*に付加されていたアドレス「Add2」に基づいて、データファイルOAZのアドレス「Add2」から検索処理を開始すればよい。図示の例の場合、「東京都中央区西早稲田」から検索が開始され、その時点で直ちに、データA*の先頭の10文字との一致が確認されることになる。
【0099】
続いて、第4階層のデータファイルAZC内の検索が行われることになるが、このとき、データファイルOAZ内の「東京都新宿区西早稲田」なるデータM*に付加されていたアドレス「Add3」に基づいて、データファイルAZCのアドレス「Add3」から検索処理を開始すればよい。図示の例の場合、「東京都新宿区西早稲田1-」から検索が開始され、その次の「東京都新宿区西早稲田2-」なるデータM*を検索した時点で、データA*の先頭の12文字との一致が確認されることになる。
【0100】
更に、第5階層のデータファイルGIK内の検索が行われることになるが、このとき、データファイルAZC内の「東京都新宿区西早稲田2-」なるデータM*に付加されていたアドレス「Add4」に基づいて、データファイルGIKのアドレス「Add4」から検索処理を開始すればよい。図示の例の場合、「東京都新宿区西早稲田2-1-」から検索が開始され、次の次にある「東京都新宿区西早稲田2-3-」なるデータM*を検索した時点で、データA*の先頭の14文字との一致が確認されることになる。
【0101】
最後に、第6階層のデータファイルTBN内の検索が行われることになるが、このとき、データファイルGIK内の「東京都新宿区西早稲田2-3-」なるデータM*に付加されていたアドレス「Add5」に基づいて、データファイルTBNのアドレス「Add5」から検索処理を開始すればよい。図示の例の場合、「東京都新宿区西早稲田2-3-1-」から検索が開始され、やがて「東京都新宿区西早稲田2-3-29-」なるデータM*を検索した時点で、データA*の全文字との一致が確認されることになる。かくして、与えられた住所データAは、「東京都新宿区西早稲田2-3-29-」なるデータM*の変換前の地図データMに対応づけられる。
【0102】
なお、図8に示す中間コード地図データベースMDB*では、各階層データファイルにおける個々の中間コード地図データM*の並び順が、地理的な位置などに応じて決められているが(たとえば、最上位階層のデータファイルKENの場合は、北から南に向かう順)、円滑な検索処理を実行する上では、個々の中間コード地図データM*の並び順を、文字コードの大きい順にしておくのが好ましい。図9は、このような並び順を採った場合の最上位階層のデータファイルKENおよび第2階層のデータファイルSHKの内容を示すブロック図である。
【0103】
この図9に示す例では、たとえば、データファイルKENでは、各都道府県名の先頭文字のうち、最も文字コードが大きな「和」(シフトJISコード:9861)で始まる「和歌山県」が先頭に配置され、次に大きな「北」(シフトJISコード:966B)で始まる「北海道」が2番目に配置され、最も文字コードが小さな「愛」(シフトJISコード:88A4)で始まる「愛知県」が最後に配置されている。もちろん、第3階層以下のデータファイルについても、同様に、各データが文字コードの大きい順に配列されている。このように、文字コードの大きい順にデータが配列されたデータファイルを用意するには、中間コード地図データベース作成段階において、文字コードの大きい順にソートする処理を行った上で、各データを格納するようにすればよい。
【0104】
このように、各データを文字コードの大きい順に格納しておくと、コンピュータによる検索処理の手順は、大幅に効率化される。すなわち、データ検索段階では、中間コード住所データA*と、階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行えばよい。
【0105】
図10は、このような検索処理の手順を、具体例に即して説明するための図である。ここでは、前掲の例と同様に、「東京都新宿区西早稲田二丁目3の29」という住所データAが与えられ、これを図6に示す変換ルールで変換することにより、「東京都新宿区西早稲田2-3-29-」なる中間コード住所データA*に変換し、これに一致する中間コード地図データM*を検索する場合を考えてみる。
【0106】
まず、最上位階層であるデータファイルKENから検索処理が開始される(図10の1行目のステップ)。この検索処理作業における最初の比較対象は、中間コード住所データA*として与えられた「東京都新宿区西早稲田2-3-29-」なる文字列と、データファイルKENの最初に配置されたデータM*である「和歌山県」なる文字列である。文字列の大小比較は、通常、それぞれの文字列の先頭文字の文字コードの大小関係によって決定し、両者が同じ場合には、次の文字の文字コードの大小関係によって決定する、という手順を踏むことになる。したがって、上述の例の場合、「東京都新宿区西早稲田2-3-29-」なるデータA*の先頭文字「東」(シフトJISコード:938C)と、「和歌山県」なるデータM*の先頭文字「和」(シフトJISコード:9861)との大小関係の比較が行われる。その結果、A*<M*なる判定結果が得られる(2行目のステップ)。
【0107】
続いて、2番目のデータ「北海道」との比較が行われる。すなわち、M*=「北海道」の場合、先頭文字「北」のシフトJISコードは、「966B」であるから、やはりA*<M*なる判定結果が得られる(3行目のステップ)。やがて、データ「東京都」との比較が行われるが、M*=「東京都」の場合、先頭3文字までは「東京都」と同じになるため、4文字目の文字コードが比較される。すると、データA*の4文字目が「新」であるのに対し、データM*は4文字目が存在しないので、ここで初めてA*>M*と大小関係が逆転する。このように、ソート順に文字列の大小関係を比較してゆく処理を順次行い、初めてA*>M*となった場合には、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理が行われる。すなわち、「東京都」なるデータM*に付加されているアドレス「Add1」の位置から、次の階層SHKの検索が行われることになる(4行目のステップおよび図9)。
【0108】
こうして、データファイルSHK内に配置されている「東京都○○区」なる一連のデータについて、同様の検索が行われる。たとえば、M*=「東京都台東区」の場合、先頭3文字までは「東京都」と同じになるため、4文字目の文字コードが比較される。すると、データA*の4文字目が「新」(シフトJISコード:9056)であるのに対し、データM*の4文字目は「台」(シフトJISコード:91E4)であるため、まだA*<M*の状態である(5行目のステップ)。この階層SHK内の検索で、初めてA*>M*と大小関係が逆転するのは、M*=「東京都新宿区」の場合である。この時点で、次の階層OAZへの検索へと移行する処理が行われる(6行目のステップ)。もちろん、この場合の検索開始アドレス(ジャンプ先アドレス)は、「東京都新宿区」に付加されている先頭アドレスとなる。
【0109】
続いて、データファイルOAZ内の検索が行われる。たとえば、M*=「東京都新宿区北新宿」の場合、先頭6文字までは「東京都新宿区」と同じになるため、7文字目の文字コードが比較される。すると、データA*の7文字目が「西」(シフトJISコード:90BC)であるのに対し、データM*の7文字目は「北」(シフトJISコード:966B)であるため、まだA*<M*の状態である(7行目のステップ)。この階層OAZ内の検索で、初めてA*>M*と大小関係が逆転するのは、M*=「東京都新宿区西早稲田」の場合である。この時点で、次の階層AZCへの検索へと移行する処理が行われる(8行目のステップ)。もちろん、この場合の検索開始アドレス(ジャンプ先アドレス)は、「東京都新宿区西早稲田」に付加されている先頭アドレスとなる。
【0110】
こうして、データファイルAZC内の検索が行われる。たとえば、M*=「東京都新宿区西早稲田4-」の場合、先頭10文字までは「東京都新宿区西早稲田」と同じになるため、11文字目の文字コードが比較される。すると、データA*の11文字目が「2」(ASCIIコード:32)であるのに対し、データM*の11文字目は「4」(ASCIIコード:34)であるため、まだA*<M*の状態である(9行目のステップ)。M*=「東京都新宿区西早稲田3-」の場合も、同様に、A*<M*の状態が維持される(10行目のステップ)。この階層AZC内の検索で、初めてA*>M*と大小関係が逆転するのは、M*=「東京都新宿区西早稲田2-」の場合である。この時点で、次の階層GIKへの検索へと移行する処理が行われる(11行目のステップ)。もちろん、この場合の検索開始アドレス(ジャンプ先アドレス)は、「東京都新宿区西早稲田2-」に付加されている先頭アドレスとなる。
【0111】
同様の検索処理を繰り返してゆくと、最終的に、階層TBNでM*=「東京都新宿区西早稲田2-3-29-」の場合に、A*=M*となり、文字列の完全一致が得られる。かくして、中間コード住所データA*である「東京都新宿区西早稲田2-3-29-」は、中間コード地図データM*である「東京都新宿区西早稲田2-3-29-」にリンク付けされることになる。
【0112】
以上の検索手順は、コンピュータによる処理手順として極めて合理的である。すなわち、2つの文字コードの大小関係の判定は、機械語レベルの原始的な演算処理で行うことができ、A*<M*の状態から、初めてA*>M*と大小関係が逆転したことを判定する処理も、機械語レベルの原始的な演算処理で行うことができる。しかも、この大小関係が逆転したときの次の階層へのジャンプ先アドレスは、大小関係が逆転した位置のデータM*に付加されている先頭アドレスとして示されているので、ジャンプ先アドレスの取得処理も容易に行うことができる。
【0113】
図11は、上述した検索処理の基本手順を示す流れ図である。まず、ステップS11において、処理対象となる中間コード住所データA*を入力する。続いて、ステップS12において、パラメータiおよびjを初期値1に設定する。ここで、パラメータiは、検索対象となる階層を示すパラメータであり、パラメータjは、1つの階層内の着目中の地図データの番号を示すパラメータである。
【0114】
続いて、ステップS13において、中間コード地図データベースMDB*の第i階層の第j番目の地図データM*を比較対象として着目する。たとえば、iが初期値1,jが初期値1である場合、図9に示す第1階層KENの第1番目の中間コード地図データ「和歌山県」が比較対象の地図データM*として着目されることになる。
【0115】
次のステップS14では、ステップS11で入力した住所データA*と、着目した地図データM*と、の大小関係の比較が行われる。前述の具体例の場合、住所データA*「東京都新宿区西早稲田2-3-29-」と着目した地図データM*「和歌山県」との大小関係が比較されることになる。
【0116】
ここで、A*<M*の場合は、ステップS14からステップS15へと分岐し、パラメータjが最大値Jに到達したか否かが判定され、最大値Jに到達していなければ、ステップS16において、パラメータjが1だけ更新される。上述の例の場合、j=2となり、比較対象として着目される地図データM*は、「北海道」ということになる。こうして、パラメータjを1ずつ更新しながら、ステップS14の比較処理を繰り返してゆくと、やがてA*>M*と大小関係が逆転することになる。
【0117】
そこで、ステップS14の比較の結果、A*>M*の場合は、ステップS14からステップS19へと分岐し、更に、ステップS21へと進むことになる(ステップS19の処理については後述する)。このステップS21において、パラメータiが最大値Iに到達したか否かが判定され、最大値Iに到達していなければ、ステップS22において、パラメータiが1だけ更新され、パラメータjがkに設定される。ここで、kは、更新前の第i番目の階層の第j番目のデータM*に付与されていた先頭アドレスによって示される、更新後の第i番目の階層のデータM*の配置順を示す値である。要するに、このステップS22の処理は、次の階層(更新されたiで示される階層)の指定アドレス先へのジャンプ処理に相当する。
【0118】
図9に示す例の場合、パラメータi=1の状態では、第1階層のデータファイルKENに対する検索が行われ、パラメータj=1,2…と更新されるに従って、「和歌山県」,「北海道」,…なるデータM*と、データA*との大小関係が、ステップS14で比較されることになる。こうして、A*<M*なる判定結果が得られる限り、ステップS15,S16の処理が繰り返される。そして、jの更新により、「東京都」が比較対象として着目された時点で、ステップS14の比較結果が逆転し、ステップS19,S21を経て、ステップS22へと進むことになる。ここで、パラメータi=2となり、第2階層のデータファイルSHKに対する検索が行われる。このとき、パラメータjは1ではなく、j=kに設定されるが、これは図9に示す「東京都○○区」の先頭アドレス「Add1」へジャンプして、途中のデータから検索が開始されることを意味している。
【0119】
以上の処理を繰り返してゆくと、階層を示すパラメータiは、徐々に更新されてゆき、最終的に、i=6に更新されたときに、第6階層であるデータファイルTBNに対する検索が行われ、「東京都新宿区西早稲田2-3-29-」なる地図データM*が比較対象として着目された時点で、ステップS14における比較結果が「A*=M*」となる。この場合、ステップS18へと進み、データA*とデータM*とを対応づける処理が行われ、データ検索処理は終了する。
【0120】
ところで、この流れ図に示す処理手順は、エラー処理によって終了する場合もあり得る。たとえば、ステップS15において、j=Jに到達したと判断された場合は、ステップS17のエラー処理を経て、この処理手順は終了する。これは、当該階層のデータファイルに含まれているすべてのデータM*と比較を行ったにもかかわらず、A*<M*という大小関係が、逆転することがなかったことを意味する。このようなエラー処理によって手順が終了する原因は、ステップS11で入力した中間コード住所データA*が誤りであったためと考えられる。たとえば、住所データA*として、「哀知県○○○○」のような誤ったデータが入力された場合、「哀知県」<「愛知県」であるため、図9に示すデータファイルKEN内を最後まで検索しても、常にA*<M*なる比較結果が得られることになり、最終的に、ステップS15からステップS17のエラー処理に至ることになる。
【0121】
また、ステップS21において、i=Iに到達したと判断された場合は、ステップS23のエラー処理を経て、この処理手順は終了する。これは、最後の階層まで検索を行ったが、文字列の完全一致には至らなかったことを意味する。このようなエラー処理によって手順が終了する原因は、ステップS11で入力した中間コード住所データA*の末尾に余分な文字が含まれていたためと考えられる。たとえば、住所データA*として、「東京都新宿区西早稲田2-3-29-鈴木様方」のようなデータが入力された場合、「東京都新宿区西早稲田2-3-29-」<「東京都新宿区西早稲田2-3-29-鈴木様方」であるため、最終階層であるデータファイルTBN内の「東京都新宿区西早稲田2-3-29-」が比較対象として着目された時点で、A*>M*なる比較結果が得られることになり、最終的に、ステップS21からステップS23のエラー処理に至ることになる。
【0122】
もっとも、このステップS23のエラー処理は、必ずしも「検索失敗」としての取り扱いを行う必要はなく、ステップS23からステップS18へと移行して、通常の検索終了処理を行うようにしてもかまわない。たとえば、上述の例のように、住所データA*として、「東京都新宿区西早稲田2-3-29-鈴木様方」のようなデータが入力された場合、ステップS18へと移行して、「東京都新宿区西早稲田2-3-29-」なるデータM*に対応づけを行っても問題はない。
【0123】
最後に、ステップS19の判定処理およびステップS20のエラー処理について説明する。このステップS19の判定処理は、所定の階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれているか否かを判定するための処理である。ここで、そっくり含まれていると判定された場合にのみ、ステップS21およびS22の処理(下位階層の階層データファイル内の検索への移行処理)が行われることになり、そうでない場合には、ステップS20のエラー処理が行われることになる。
【0124】
このステップS19の判定処理を設けた理由は、次のような具体例を考えると容易に理解できよう。たとえば、ステップS11において、住所データA*として、「東橋都新宿区西早稲田2-3-29-」のようなデータが入力された場合を考えよう。この住所データA*は、「東京都」とするべきところを「東橋都」としており、明らかに誤ったデータである。しかしながら、このような住所データA*を用いて、第1階層のデータファイルKENを検索してゆくと、「東京都新宿区西早稲田2-3-29-」という正しい住所データA*を用いた検索と全く同様に、M*=「東京都」が比較対象として着目された時点で、A*>M*なる比較結果が得られてしまうことになる。これは、「橋」(シフトJISコード:8BB4)の文字コードが、「京」(シフトJISコード:8B9E)の文字コードよりも大きいため、「東橋都」>「東京都」なる大小関係になるためである。
【0125】
結局、M*=「東京都」が比較対象として着目された時点で、ステップS14からステップS19へと分岐することになる。このステップS19の処理は、要するに、住所データA*「東橋都新宿区西早稲田2-3-29-」の中に、地図データM*「東京都」なる文字列がそっくり含まれているか否かを判定する処理ということになる。この場合、住所データA*には、「東橋都」なる誤記があるため、「東京都」なる文字列がそっくり含まれている、という条件は満たさない。よって、ステップS19からステップS20へと進み、エラー処理が行われることになる。もちろん、住所データA*が、「東京都新宿区西早稲田2-3-29-」という正しい文字列であった場合には、「東京都」なる文字列がそっくり含まれているので、前述したとおり、ステップS21,S22の処理へと進むことになる。
【0126】
もちろん、ステップS11で入力する住所データA*に誤記がない、という前提であれば、ステップS19およびS20の手順は設ける必要はない。ただ、実用上は、そのような誤記の存在を予想して、ステップS19およびS20の手順を設けておくのが好ましい。
【0127】
なお、上述した実施形態では、各階層データファイル内に、中間コード地図データを、文字コードの大きい順にソートした状態で用意したが、逆に、文字コードの小さい順にソートした状態で用意しても、ほぼ同様の検索処理を実行することができる。すなわち、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*<M*となるまで検索を続けてゆけばよい。ただし、この場合、初めてA*<M*となるデータM*が見つかったら、その直前のデータM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する必要がある。このように、文字コードの小さい順にソートした階層データファイルを利用した検索を行う場合、A*とM*との大小関係が初めて逆転したときに、1つ手前のデータM*へと戻る処理を行わねばならなくなるので、あまり好ましくない。したがって、実用上は、上述したように、文字コードの大きい順にソートした階層データファイルを利用した検索を行うのが最も合理的である。
【0128】
<<< §5.検索に失敗した場合の修正処理 >>>
図11の流れ図に示す検索処理手順では、正しい検索結果が得られずに、エラー処理に至るケースがあることを述べた。ここでは、このような検索に失敗した場合でも、修正処理により正しい検索結果を得る可能性のある手法を説明する。
【0129】
ここで述べる修正処理が有効なのは、処理対象として与えられた住所データAが、本来の住所の一部を省略した形式のデータであった場合である。たとえば、図12に示す具体的な例を見てみよう。ここに示す例は、本来の住所表示が「東京都千代田区西神田1丁目1の1」であるべきところ、「東京都千代田区」の部分が省略され、「西神田1丁目1の1」なる文字列が住所データAとして与えられた場合である。この場合、変換により得られる中間コード住所データA*は、「西神田1-1-1-」なる文字列になる。このような文字列が、住所データA*として与えられても、図11の流れ図に示された手順では、正しい検索結果を得ることはできない。すなわち、「西神田」に一致する都道府県名は存在しないので、第1階層であるデータファイルKENの検索において、エラー処理が行われることになる。
【0130】
具体的には、「西神田」の先頭文字「西」(シフトJISコード:90BC)の文字コードは、「愛知県」の先頭文字「愛」(シフトJISコード:88A4)の文字コードよりも大きいので、第1階層であるデータファイルKENの検索途中のいずれかの時点で、A*>M*なる判断がなされ、ステップS19へと分岐するが、「西神田1-1-1-」なる文字列には、いずれの都道府県名も含まれていないので、ステップS20のエラー処理へと移行し、検索は失敗に終わることになる。
【0131】
このような場合、「西神田1-1-1-」なる文字列の先頭に、「東京都1000-代田区」なる文字列を補うような修正処理を施すことができれば、「東京都1000-代田区西神田1-1-1-」のような正しい住所データA*を得ることができ、この正しい住所データA*を用いて再度検索を行えば、リンク付けに成功する。以下に述べる手法は、このような修正処理を実現するためのものである。
【0132】
この修正処理を実行するために、ここに示す実施形態では、図13に示すような階層混合データファイルを用意している。この階層混合データファイルは、文字どおり、複数の階層データファイルに含まれているデータを混合したファイルである。具体的には、図8に示す各階層データファイルのうち、KEN,SHK,OAZの3つの階層データファイル内のデータを混合して収容したファイルになっている(図13には、説明の便宜上、個々のデータに、元の所属階層を括弧書きで示してある)。KEN,SHK,OAZの3つの階層データファイルが選ばれているのは、数字による住所記述部分を含まない上位n階層分(この例では、上位3階層分)の階層データファイルを混合対象としているためである。
【0133】
このような階層混合データファイルが用意できたら、図14の流れ図に示す手順により、住所データの修正処理を行うことができる。この修正処理は、上述したとおり、図11に示すデータ検索処理を実行したのに、中間コード住所データA*に対応する中間コード地図データM*を検索することができなかった場合に、中間コード住所データA*の文字列を修正する処理であり、この処理を行うことにより、修正後のデータを用いた再検索が可能になる。
【0134】
まず、図14のステップS31において、検索に失敗した中間コード住所データA*から、数字による住所記述部分を抜き取ることにより、部分一致検索用住所データB*を作成する処理を行う。たとえば、中間コード住所データA*=「西神田1-1-1-」の場合は、図15に示すように、数字による住所記述部分である「1-1-1-」を抜き取り、部分一致検索用住所データB*=「西神田」を作成する。本願において、「数字による住所記述部分」とは、既に述べたとおり、住所表示における何条、何丁目、何番地、何番、何号といった表記部分である。中間コード住所データA*中の「数字による住所記述部分」は、文字列の末尾側における「半角数字および半角ハイフンが連続して並んでいる部分」として認識することができる。
【0135】
次に、ステップS32において、階層混合データを検索し、部分一致検索用住所データB*を一部にでも含む地図データM*を抽出する。たとえば、上述の例の場合、部分一致検索用住所データB*=「西神田」であるから、図13に示す混合階層データファイルを検索して、「西神田」なる文字列を一部にでも含む地図データの検索を行う(部分一致検索)。ここでは、説明の便宜上、図16に示すような検索結果が得られたものとしよう。ここに示す地図データM*(1)〜M*(6)は、いずれも図13に示す階層混合データファイルに含まれていたデータであり、その一部に「西神田」なる文字列を含んでいる。図では、説明の便宜上、「西神田」の部分を矩形枠で囲って示してある。もちろん、これらの地図データM*(1)〜M*(6)は、文字列として「西神田」なる3文字を含んでいるためにヒットしたデータであり、必ずしも地名としての「西神田」を含んでいるわけではない。たとえば、地図データM*(1)の場合、地名としては「川西神田」が含まれていることになるが、「西神田」なる文字列が含まれているとしてヒットしたことになる。
【0136】
続いて、ステップS33において、ステップS32で抽出した各地図データM*に、ステップS31で抜き取った「数字による住所記述部分」を、部分一致検索用住所データB*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する。図16に示す地図データM*(1)〜M*(6)に対して、このステップS33の処理を実行した結果を図17に示す。すなわち、修正住所データAA*(1)〜AA*(6)は、それぞれ地図データM*(1)〜M*(6)に対して、ステップS31で抜き取った「1-1-1-」なる文字列を挿入して得られたデータである。このとき、挿入位置を、部分一致検索用住所データB*との位置関係が元の位置関係となるような位置とするので、図示の例の場合、「西神田」の直後に「1-1-1-」を挿入することになる。その結果、たとえば、データAA*(3)やAA*(6)では、「西神田1-1-1-町」のように、奇異な位置に「1-1-1-」なる文字列が挿入されている。
【0137】
いずれにしても、この図14の流れ図に示す住所データ修正処理を行うことにより、検索に失敗した「西神田1-1-1-」なる中間コード住所データA*に基づいて、6つの修正住所データAA*(1)〜AA*(6)が作成されたことになる。そこで、この6つの修正住所データAA*(1)〜AA*(6)のそれぞれを用いて、再度、図11の流れ図に示す検索処理を実行する。
【0138】
もちろん、6つの修正住所データAA*(1)〜AA*(6)は、必ずしも正しい住所データであるとは限らないので、再度の検索処理を行った場合も、エラー処理で終わる可能性もある。たとえば、データAA*(3)やAA*(6)には、「西神田1-1-1-町」のような奇異な表記が含まれているので、エラー処理が行われる。また、データAA*(1),AA*(4),AA*(5)に一致するような地図データは、実際には存在しないので、これらについてもエラー処理が行われることになる。結局、この例の場合、データAA*(2)のみが実際に存在する住所表示になっており、検索処理に成功し、所定の地図データに対するリンク付けが行われる。
【0139】
かくして、通常の検索方法では失敗した「西神田1-1-1-」なる不完全な中間コード住所データA*に基づいて、「東京都1000-代田区西神田1-1-1-」なる地図データM*がリンク付けされることになる。
【0140】
場合によっては、複数の修正住所データAA*が、再検索に成功する可能性がある。たとえば、上述の例の場合、「東京都千代田区西神田一丁目1番1号」という住所と、「愛知県江南市東野町西神田一丁目1番1号」という住所とが、いずれも実際に存在したとすると、図17の修正住所データAA*(2),AA*(4)の両方が検索処理に成功することになり、リンク付けの相手先候補が2通り見つかることになる。このように、リンク付けの相手先候補が複数見つかった場合、いずれか1つに絞り込むことは困難であるので、とりあえず複数通りの結果をすべて提示し、最終的に、人間による判断に委ねるようにする。もっとも、「西神田1-1-1-」なる表記が、東京都の西神田を指しているのか、愛知県の西神田を指しているのかを、これだけの情報から判断するのは、人間が行ったとしても困難である。実用上は、住所録などに含まれている電話番号などの情報なども参考にしながら、いずれが正しいかを判断することになろう。
【0141】
なお、上述の例では、図8に示す各階層データファイルとは別個に、図13に示すような階層混合データファイルを用意して、ステップS32の検索を行っているが、階層混合データファイルは必ずしも別個に用意する必要はない。すなわち、ステップS32では、数字による住所記述部分を含まない上位n階層分の階層データファイルの検索を行うことができればよいので、図13に示すような階層混合データファイル(上位3階層分の階層データファイルの混合ファイル)を用いる代わりに、図8に示す上位3階層分の階層データファイルKEN,SHK,OAZをそれぞれ検索するようにしてもかまわない。ただ、実用上は、検索処理の効率を向上させるために、図13に示すような階層混合データファイルを予め用意しておき、ステップS32の検索は、この階層混合データファイルに対して行うようにするのが好ましい。
【0142】
<<< §6.本発明の基本的な実施形態に係るリンク処理装置 >>>
最後に、これまで述べてきたリンク処理を実際に行うための処理装置の基本構成を、図18のブロック図を参照して説明する。この図18に示す装置は、与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う機能をもった装置であり、図示のとおり、中間コード地図データベース100、データ検索手段200、中間コード住所データ作成手段300,住所データ修正手段400なる構成要素からなる。
【0143】
中間コード地図データベース100は、中間コード地図データM*の集合から構成されるデータベースであり、図4に示すMDB*に相当する構成要素である。具体的には、行政区画に応じて階層化された複数の階層データファイルKEN,SHK,…によって構成されており、各データファイル内には、図8に示すように、多数の中間コード地図データM*が格納されており、各データM*には、緯度経度情報が付与されている。ここで、中間コード地図データM*は、本来の住所表示としては不適切な表示形態となる可能性のある中間コードとして記述されたデータであり、国土地理院などから提供された地図データMに対して、所定の変換ルール(たとえば、図6に示す変換ルール)に基づいて一義的変換を行うことにより得られたデータである。
【0144】
中間コード住所データ作成手段300は、処理対象となる住所データAを入力し、これを所定の変換ルール(中間コード地図データベース100を作成するときに用いたルールと同一のルール)に基づいて中間コードに変換する処理を行い、中間コード住所データA*を作成する機能をもった構成要素であり、図4おいて、住所データAから中間コード住所データA*への変換処理を行う構成要素ということになる。
【0145】
データ検索手段200は、中間コード住所データA*に基づいて中間コード地図データベース100を検索し、文字列が一致する中間コード地図データM*を特定する処理を行う構成要素であり、図4において、A*とMDB*との間のリンク処理を実行する構成要素ということになる。中間コード地図データベース100は、行政区画に応じて階層化された複数の階層データファイルKEN,SHK,…によって構成されているので、検索は、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に行われる。具体的な検索処理の手順は、たとえば、図11の流れ図に示したとおりである。このデータ検索手段200から得られる検索結果が、リンク処理の結果を示す情報ということになる。すなわち、この検索結果は、与えられた住所データAに対応付けられる地図データMを示すものであり、住所データAに付与する緯度経度情報を示すものになる。
【0146】
なお、中間コード地図データベース100を構成する複数の階層データファイルKEN,SHK,…に対する効率的な検索を可能にするためには、§4で述べたとおり、各階層データファイル内の各地図データに、下位階層の階層データファイル内の対応する一連の地図データの先頭アドレス(図8の「Add1」など)を付加しておき、データ検索手段200が、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定することができるようにしておけばよい。
【0147】
また、検索処理の効率を高めるためには、中間コード地図データベース100を構成する各階層データファイル内には、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データを、文字コードの大きい順にソートした状態で格納しておき、図11の流れ図に示す手順による検索処理が可能になるようにするのが好ましい。すなわち、データ検索手段200が、中間コード住所データA*と、1つの階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行うようにすればよい。
【0148】
このとき、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として(図11のステップS19の判断)、下位階層の階層データファイル内の検索へ移行する処理を行うようにすれば、中間コード住所データA*内に「東橋都」のような誤記が含まれていた場合に、エラー処理を行うことができる。
【0149】
一方、住所データ修正手段400は、§5で述べた検索に失敗した場合の修正処理を実行するための構成要素である。すなわち、データ検索手段200からの検索結果として、中間コード住所データA*に対応する中間コード地図データM*を検索することができなかった旨の報告(エラー処理が行われた旨の検索結果)を受けた場合に、次のような処理を実行する。まず、検索に失敗した中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成する(図14のステップS31)。続いて、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出する(図14のステップS32)。そして、抽出した地図データM*に、抜き取った数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する(図14のステップS33)。
【0150】
こうして、住所データ修正手段400によって、修正住所データAA*が作成されたら、これをデータ検索手段200へと与え、データ検索手段200により再度のデータ検索が行われるようにする。そうすることにより、「西神田1-1-1-」なる不完全な中間コード住所データA*に基づいて、「東京都1000-代田区西神田1-1-1-」なる地図データM*がリンク付けできるようになることは、既に§5で述べたとおりである。なお、データB*による部分一致検索を効率的に行うためには、中間コード地図データベース100内に、予め図13に示すような階層混合データファイルを用意しておくようにすればよい。
【0151】
以上、図18に示すブロック図を参照しながら、本発明の基本的な実施形態に係るリンク処理装置の構成および動作を説明したが、実用上は、このリンク処理装置は、コンピュータに専用のプログラムを組み込むことにより実現される装置である。すなわち、中間コード地図データベース100は、コンピュータの記憶装置内に格納されたデータベースとして構築されるものであり、データ検索手段200,中間コード住所データ作成手段300,住所データ修正手段400は、コンピュータに組み込まれたプログラムの作用として実現されるものである。もちろん、このようなプログラムは、コンピュータ読み取り可能な記録媒体に記録して配布したり、オンラインで配布したりすることが可能である。
【図面の簡単な説明】
【0152】
【図1】一般的な住所データと地図データとのリンク処理の概念を示すブロック図である。
【図2】行政区画に応じて階層化された複数の階層データファイルによって構成された地図データベースMDBの一例を示す図である。
【図3】図2に示す地図データベースMDBを構成する各階層データファイルに収容されている個々の地図データMの一例を示すブロック図である(枝番階層データファイルEBNの図示は省略)。
【図4】本発明に係る住所データと地図データとのリンク処理方法の基本概念を示すブロック図である。
【図5】本発明の基本的な実施形態に係るリンク処理方法の手順を示す流れ図である。
【図6】図5のステップS1で定義する変換ルールの一例を示す図である。
【図7】図6に例示する変換ルール(1) 〜(4) を用いた中間コードへの具体的な変換例を示す図である。
【図8】図3に示す地図データベースMDBに基づいて、図6に示す変換ルールを適用した変換処理を行うことにより得られる中間コード地図データベースMDB*の構成を示すブロック図である。
【図9】個々の中間コード地図データM*の並び順を、文字コードの大きい順にソートした場合の最上位階層のデータファイルKENおよび第2階層のデータファイルSHKの内容を示すブロック図である。
【図10】各データが文字コードの大きい順にソートされている場合の具体的な検索処理の手順を示す図である。
【図11】図10に示す検索処理の一般的な手順を示す流れ図である。
【図12】住所表示の一部が省略されているため、正しい検索が行われない例を示す図である。
【図13】検索に失敗した場合の修正処理を行うために用意された階層混合データファイルの一例を示す図である。
【図14】検索に失敗した場合の修正処理の手順を示す流れ図である。
【図15】図14のステップS31の具体的処理を示す図である。
【図16】図14のステップS32の処理結果の一例を示す図である。
【図17】図16に示す地図データM*(1)〜M*(6)に対して、図14のステップS33の処理を実行した結果を示す図である。
【図18】本発明の基本的な実施形態に係るリンク処理装置の基本構成を示すブロック図である。
【符号の説明】
【0153】
100…中間コード地図データベース
200…データ検索手段
300…中間コード住所データ作成手段
400…住所データ修正手段
A…住所データ
A*…中間コード住所データ
AA*,AA*(1)〜AA*(6)…修正住所データ
AZC…字町階層データファイル
Add1〜Add5…先頭アドレス
B*…部分一致検索用住所データ
EBN…枝番階層データファイル
GIK…街区階層データファイル
I…階層番号の最大値
i…階層番号を示すパラメータ
J…1つの階層データファイル内の総データ数
j…1つの階層データファイル内のデータ番号
KEN…都道府県階層データファイル
k…ジャンプ先のデータ番号
M…地図データ
M*,M*(1)〜M*(6)…中間コード住所データ
MDB…地図データベース
MDB*…中間コード地図データベース
OAZ…大字階層データファイル
S1〜S4,S11〜S22,S31〜S33…流れ図の各ステップ
SHK…市区町村階層データファイル
TBN…地番階層データファイル
【技術分野】
【0001】
本発明は、住所録や個人情報などから抽出した住所を示す文字列に対して緯度経度情報を与えるために、当該文字列に対して、予め緯度経度情報が付与されている地図データをリンクさせる処理を行う技術に関する。
【背景技術】
【0002】
現在、インターネットのWebページ上などに地図画像を表示することは、ごく一般的に行われており、特定の場所の位置を、この地図画像上にプロットして示すことも広く行われている。しかしながら、住所録や個人情報などから抽出した住所を示す文字列(本願では、住所データと呼ぶ)には、通常、緯度経度情報は含まれていない。したがって、この住所データを構成する文字列のみを用いて、当該住所データが示す位置を地図画像上にプロットすることはできない。
【0003】
そこで、住所録や個人情報などから抽出した住所データに、緯度経度情報を付与するために、予め緯度経度情報が付与された住所を示す文字列(本願では、上記住所データと区別するために地図データと呼ぶ)を用意しておき、住所データと地図データとを対応づけるリンク処理が行われる。現在、地図データは、データベースとして国土地理院などから提供されており、北海道から沖縄に至るまで、日本全国の住所を示す文字列に、それぞれ所定の緯度経度情報が付与されている。このような地図データとのリンク付けを行うことができれば、住所録や個人情報などから抽出した任意の住所データに、緯度経度情報を付与することができる。
【0004】
たとえば、住所録から「東京都新宿区市谷加賀町一丁目2番3号」なる文字列からなる住所データが抽出された場合、上述した地図データのデータベースを検索して、同一の文字列を有する地図データに対するリンク付けを行うことができれば、リンク付けされた地図データに付与されていた緯度経度情報を、そのまま住所データに流用することができる。下記の特許文献1および2には、このようなリンク処理を効率的に行うための技術が開示されている。
【特許文献1】特開平10−154161号公報
【特許文献2】特開2003−223459号公報
【発明の開示】
【発明が解決しようとする課題】
【0005】
上述したとおり、特定の住所データを特定の地図データに対応づけるリンク処理は、基本的には、住所データを構成する文字列と地図データを構成する文字列との一致判定処理によって行われる。前述の例の場合、「東京都新宿区市谷加賀町一丁目2番3号」なる文字列からなる住所データに対応する地図データを探し出すには、北海道から沖縄に至るまで日本全国を網羅した地図データのデータベースを逐一検索し、同一の文字列をもった地図データを見つける処理を行うことになる。
【0006】
しかしながら、従来の手法では、この検索処理時の条件として、文字列の完全一致という条件設定を行うと、正しい検索を行うことができない場合がある。これは、国土地理院などから提供された地図データのデータベース上では、「東京都新宿区市谷加賀町一丁目2番3号」なる文字列として登録されていたとしても、住所録や個人情報などから抽出した住所データが、これと同一の文字列から構成されているとは限らないからである。住所録などに掲載する一般的な住所表記としては、たとえば、「市谷」の代わりに、「市ケ谷」,「市ヶ谷」,「市が谷」なる文字列が用いられることもあり、「一丁目2番3号」の代わりに、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」のような文字列が用いられることもある。
【0007】
このような書式の不統一という問題は、住所録や個人情報などから抽出した住所データ側だけの問題ではなく、地図データ側も同様の問題を抱えている。実際、国土地理院などから提供された地図データの書式も、日本全国完全に統一された書式にはなっていない。これは、国土地理院が、地図データの作成および緯度経度情報の測定を、個々の地方自治体に委ねており、各自治体によって、採用する書式が統一されていないためである。
【0008】
このような事情から、特定の住所データを特定の地図データに対応づけるリンク処理を正確に行おうとすればするほど、文字列相互の一致判定の条件設定が困難になり、一致判定のアルゴリズムは複雑化せざるを得ない。
【0009】
そこで、前述した特許文献1および2には、予め標準書式(正規表現)を定めておき、与えられた住所を示す文字列を、この標準書式に変換するための正規化処理を行い、正規化された状態で文字列の比較を行う手法が開示されている。しかしながら、様々な書式で記述された住所データや地図データを正規表現に変換するための正規化処理は、非常に複雑なアルゴリズムをもった負担の大きな処理にならざるを得ない。
【0010】
そこで本発明は、比較的小さな処理負担で、正確なリンク処理が可能になる住所データと地図データとのリンク処理方法およびリンク処理装置を提供することを目的とする。
【課題を解決するための手段】
【0011】
(1) 本発明の第1の態様は、与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う住所データと地図データとのリンク処理方法において、
住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定める変換ルール定義段階と、
データベースとして用意されている個々の地図データを、この変換ルールに基づいて中間コードに変換する処理を行い、中間コード地図データベースを作成する中間コード地図データベース作成段階と、
処理対象となる住所データを、この変換ルールに基づいて中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成段階と、
中間コード住所データに基づいて中間コード地図データベースを検索し、対応する中間コード地図データを特定し、処理対象となる住所データに特定の地図データを対応づけるデータ検索段階と、
を行うようにしたものである。
【0012】
(2) 本発明の第2の態様は、上述の第1の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを定めるようにしたものである。
【0013】
(3) 本発明の第3の態様は、上述の第1または第2の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めるようにしたものである。
【0014】
(4) 本発明の第4の態様は、上述の第1〜第3の態様に係る住所データと地図データとのリンク処理方法において、
中間コード地図データベース作成段階で、行政区画に応じて階層化された複数の階層データファイルによって構成される中間コード地図データベースを作成し、
データ検索段階で、中間コード地図データベースを上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索するようにしたものである。
【0015】
(5) 本発明の第5の態様は、上述の第4の態様に係る住所データと地図データとのリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加する作業を行い、
データ検索段階で、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定するようにしたものである。
【0016】
(6) 本発明の第6の態様は、上述の第5の態様に係る住所データと地図データとのリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内に、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データを、文字コードの大きい順にソートした状態で用意し、
データ検索段階で、中間コード住所データA*と、階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行するようにしたものである。
【0017】
(7) 本発明の第7の態様は、上述の第6の態様に係る住所データと地図データとのリンク処理方法において、
各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行するようにしたものである。
【0018】
(8) 本発明の第8の態様は、上述の第4〜第7の態様に係る住所データと地図データとのリンク処理方法において、
データ検索段階で、中間コード住所データA*に対応する中間コード地図データを検索することができなかった場合には、中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正処理を実行し、得られた修正住所データAA*を用いて、再度のデータ検索を行うようにしたものである。
【0019】
(9) 本発明の第9の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、全角数字および漢数字をすべて半角数字に置き換える処理もしくは半角数字および漢数字をすべて全角数字に置き換える処理を含む変換ルールを定めるようにしたものである。
【0020】
(10) 本発明の第10の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換える処理を含む変換ルールを定めるようにしたものである。
【0021】
(11) 本発明の第11の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換え、その後、数字もしくは数字群のうしろにこの特定文字がなければ、当該数字もしくは数字群のうしろにこの特定文字を付加する処理を含む変換ルールを定めるようにしたものである。
【0022】
(12) 本発明の第12の態様は、上述の第1〜第8の態様に係る住所データと地図データとのリンク処理方法において、
「ケ」,「ヶ」,「が」,「ツ」,「ッ」,「つ」,「大字」,「小字」,「字」なる文字をすべて削除する処理を含む変換ルールを定めるようにしたものである。
【0023】
(13) 本発明の第13の態様は、与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う住所データと地図データとのリンク処理装置において、
住所を示す文字列からなり、緯度経度情報が付与されている個々の地図データを、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための所定の変換ルールに基づいて変換することにより得られる中間コード地図データを、データベースの形式で格納した中間コード地図データベースと、
処理対象となる住所データを入力し、これを上記変換ルールに基づいて中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成手段と、
中間コード住所データに基づいて中間コード地図データベースを検索し、文字列が一致する中間コード地図データを特定するデータ検索手段と、
を設けるようにしたものである。
【0024】
(14) 本発明の第14の態様は、上述の第13の態様に係る住所データと地図データとのリンク処理装置において、
人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを用いるようにしたものである。
【0025】
(15) 本発明の第15の態様は、上述の第13または第14の態様に係る住所データと地図データとのリンク処理装置において、
互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めるようにしたものである。
【0026】
(16) 本発明の第16の態様は、上述の第13〜第15の態様に係る住所データと地図データとのリンク処理装置において、
中間コード地図データベースを、行政区画に応じて階層化された複数の階層データファイルによって構成し、
データ検索手段が、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索するようにしたものである。
【0027】
(17) 本発明の第17の態様は、上述の第16の態様に係る住所データと地図データとのリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加しておき、
データ検索手段が、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定するようにしたものである。
【0028】
(18) 本発明の第18の態様は、上述の第17の態様に係る住所データと地図データとのリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内に、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データを、文字コードの大きい順にソートされた状態で格納しておき、
データ検索手段が、中間コード住所データA*と、階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行うようにしたものである。
【0029】
(19) 本発明の第19の態様は、上述の第18の態様に係る住所データと地図データとのリンク処理装置において、
データ検索手段が、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行する処理を行うようにしたものである。
【0030】
(20) 本発明の第20の態様は、上述の第16〜第19の態様に係る住所データと地図データとのリンク処理装置において、
データ検索手段から、中間コード住所データA*に対応する中間コード地図データを検索することができなかった旨の報告を受けた場合に、当該中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正手段を更に設け、
データ検索手段が、この修正住所データAA*を用いて、再度のデータ検索を行うことができるようにしたものである。
【0031】
(21) 本発明の第21の態様は、上述の第13〜第20の態様に係る住所データと地図データとのリンク処理装置を、コンピュータに所定のプログラムを組み込むことにより構築するようにしたものである。
【発明の効果】
【0032】
以上のとおり、本発明に係る住所データと地図データとのリンク処理方法およびリンク処理装置によれば、本来の住所表示としては不適切な表示形態となる可能性のある中間コードを介して対応づけを行うようにしたため、比較的小さな処理負担で、正確なリンク処理が可能になる。
【発明を実施するための最良の形態】
【0033】
以下、本発明を図示する実施形態に基づいて説明する。
【0034】
<<< §1.一般的なリンク処理の手法 >>>
はじめに、説明の便宜上、住所データと地図データとについての一般的なリンク処理の手法を述べておく。図1は、一般的な住所データAと地図データMとのリンク処理の概念を示すブロック図である。既に述べたとおり、本願にいう「住所データA」とは、住所録や個人情報などから抽出した住所を示す文字列を意味し、経度緯度情報を有していないデータである。これに対して、本願にいう「地図データM」とは、本質的にはやはり住所を示す文字列からなるデータであるが、緯度経度情報が付与されたデータとなっている。住所データAと地図データMとのリンク処理の目的は、緯度経度情報が付されていない住所データAについて、対応する地図データMを探し出し、この対応する地図データMに付与されている経度緯度情報を、そのまま住所データAにも付与して利用できるようにすることにある。
【0035】
このように、任意の住所データAについて、特定の地図データMとのリンク処理を行い、緯度経度情報を付与できるようにするためには、予め、日本全国についての地図データMを集めた地図データベースMDBを用意しておけばよい。リンク処理の対象となる住所データAが与えられたら、地図データベースMDBを検索して、この住所データAを構成する文字列と一致する文字列をもった特定の地図データMを探して対応づければよい。
【0036】
地図データベースMDBとしては、国土地理院などから提供されているものを利用することができる。一般的に利用されている地図データベースMDBは、図2に示すように、行政区画に応じて階層化された複数の階層データファイルによって構成されている。すなわち、この例では、都道府県階層データファイルKEN、市区町村階層データファイルSHK、大字階層データファイルOAZ、字町階層データファイルAZC、街区階層データファイルGIK、地番階層データファイルTBN、枝番階層データファイルEBNなる7階層にわたった階層データファイルが用意されている。
【0037】
図3は、この地図データベースMDBを構成する各階層データファイルに収容されている個々の地図データMの一例を示すブロック図である(枝番階層データファイルEBNの図示は省略)。たとえば、都道府県階層データファイルKENには、「北海道」なる地図データから、「沖縄県」なる地図データに至るまで、都道府県の階層(最上位階層)に所属する地図データMが収容されている。同様に、市区町村階層データファイルSHKには、「北海道札幌市」なる地図データから、「沖縄県那覇市」なる地図データに至るまで、市区町村の階層(第2階層)に所属する地図データMが収容されている。
【0038】
この図3では、説明の便宜上、地図データ相互の上下関係を、隣接する階層間の一部に引いた直線で示している。たとえば、都道府県階層データファイルKENに所属する「東京都」から、市区町村階層データファイルSHKに所属する「東京都中央区」,「東京都新宿区」,「東京都千代田区」に対して直線が引かれているが、これは後者の地図データが前者の地図データに対応した下位階層データであることを、説明の便宜上、示すためのものである。
【0039】
同様に、「東京都新宿区」に対応した下位階層データが、大字階層データファイルOAZに所属する「東京都新宿区西早稲田」,「東京都新宿区市谷加賀町」,「東京都新宿区高田馬場」であることが示され、「東京都新宿区西早稲田」に対応した下位階層データが、字町階層データファイルAZCに所属する「東京都新宿区西早稲田一丁目」,「東京都新宿区西早稲田二丁目」,「東京都新宿区西早稲田三丁目」であることが示され、「東京都新宿区西早稲田二丁目」に対応した下位階層データが、街区階層データファイルGIKに所属する「東京都新宿区西早稲田二丁目1番」,「東京都新宿区西早稲田二丁目2番」,「東京都新宿区西早稲田二丁目3番」であることが示され、「東京都新宿区西早稲田二丁目3番」に対応した下位階層データが、地番階層データファイルTBNに所属する「東京都新宿区西早稲田二丁目3番1号」〜「東京都新宿区西早稲田二丁目3番29号」であることが示されている。
【0040】
図には示されていないが、これら各地図データには、それぞれ当該地図データによって示される地理的位置を代表する地点の緯度経度情報が付与されている。たとえば、都道府県階層データファイルKENに所属する「東京都」なる地図データには、東京都を代表する地点(たとえば、東京都の中心地点)の緯度経度情報が付与されており、市区町村階層データファイルSHKに所属する「東京都新宿区」なる地図データには、東京都新宿区を代表する地点(たとえば、新宿区の中心地点)の緯度経度情報が付与されている。同様に、地番階層データファイルTBNに所属する「東京都新宿区西早稲田二丁目3番29号」なる地図データには、当該番地を代表する地点の緯度経度情報が付与されている。
【0041】
このような構成をもった地図データベースMDBを予め用意しておけば、住所を示す任意の文字列からなる住所データAが与えられた場合、この地図データベースMDBを検索して、文字列の一致する地図データMを特定することにより、対応する緯度経度情報を得ることができる。たとえば、「東京都新宿区」という文字列からなる住所データAが与えられた場合、この地図データベースMDBを検索することにより、市区町村階層データファイルSHKに所属する「東京都新宿区」なる地図データMが文字列完全一致の地図データとしてヒットするので、当該地図データMに付与されていた緯度経度情報を、当該住所データAにそのまま付与することができる。
【0042】
地図データベースMDBに対する文字列の一致検索は、コンピュータを利用して行うことができるので、たとえば、10万人分の住所データAを含む個人情報ファイルが与えられたとしても、個々の住所データAを1件ずつ取り出して、地図データベースMDBに対する検索を行うことにより、この10万人分の住所データAのそれぞれに対して特定の地図データMを対応づけるリンク処理を行うことが可能であり、緯度経度情報を付与する処理が可能になる。
【0043】
<<< §2.本発明の基本的な発想 >>>
上述の§1では、リンク処理の基本的手法を述べたが、実際には、住所表記には様々な書式があるため、文字列の完全一致を条件とした検索処理では、対応する地図データを見つけることができない場合がある。そこで、前掲の特許文献1および2には、与えられた住所を示す文字列に対して正規化処理を行い、書式の標準化を図る技術が開示されている。
【0044】
たとえば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」などの表記についての正規表現や、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」などの表記についての正規表現を定めておき、様々な書式で記述されている住所を示す文字列を、すべてこの正規表現に改める正規化処理を行えば、文字列の完全一致を条件とした検索処理によって、正しいリンク処理が可能になる。
【0045】
しかしながら、現実的には、このような正規化処理は、非常に複雑なアルゴリズムをもった負担の大きな処理にならざるを得ない。たとえば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」なる表記についての正規表現を、「市ヶ谷」とする、と定めたとしても、「市谷」、「市ケ谷」,「市が谷」なる文字列があった場合に、これを機械的に「市ヶ谷」に置換する処理を行えばよいわけではない。そのような機械的な置換処理を行ってしまうと、たとえば、「春日部市谷原」のような文字列が、「春日部市ヶ谷原」のような誤った表記に変換されてしまう。また、「ケ」,「ヶ」,「が」なる文字の不統一が問題となるケースは、「市ヶ谷」だけでなく、「千駄ヶ谷」、「美ヶ原」など、他にもたくさん存在し、これら個々のケースにすべて対応可能な正規化処理は、非常に複雑なものにならざるを得ない。
【0046】
一方、住所を示す文字列において、表記の不統一が最も顕著な部分は、数字による住所記述部分(何条、何丁目、何番地、何番、何号といった表記部分)である。具体的には、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」などの表記形態は、いずれも一般的な住所録などでごく普通に用いられている。もちろん、人間が目視確認する作業を行えば、これらの表記はいずれも実質的に同一の住所表記である旨の判断を行うことができる。しかしながら、コンピュータを用いた文字列の一致検索では、全角数字と半角数字ですら、互いに異なる文字と判断されてしまう。
【0047】
しかも、このような数字による住所記述部分の不統一を解消するため、特定の書式を正規表現と定めたとしても、そのような正規表現に改める正規化処理は、やはり非常に複雑なものにならざるを得ない。たとえば、「数字による住所記述部分では、漢数字ではなく、全角アラビア数字を用いる」という正規表現を定めたとしても、住所を示す任意の文字列を、この正規表現に改める正規化処理は、それほど単純な処理にはならない。具体的には、「文字列中の漢数字をすべて全角アラビア数字に変更する」というアルゴリズムに基づいて、この正規化処理を実行しようとすると、「八丁目八番三号」という表記は、「8丁目8番3号」に置換されることになる。しかしながら、その副作用として、「青森県八戸市」という表記は、「青森県8戸市」に置換され、「東京都北区東十条」という表記は、「東京都北区東10条」に置換され、「東京都千代田区」という表記は、「東京都1000代田区」に置換されてしまうことになる。
【0048】
そこで従来は、このような様々な事例を考慮して、住所を示す任意の文字列について、できるだけ正確に標準書式に変換することが可能な正規化処理のアルゴリズムを案出することに苦心していた。
【0049】
これに対して、本発明の基本的な特徴は、共通の中間コードを介して、住所データと地図データとのリンクをとる、という点にある。ここで、「中間コード」とは、「住所を示す文字列」の一種ではあるが、本来の住所表示としては不適切な表示形態となる可能性のあるコードであり、この点において、従来の標準書式(正規表現)とは異なっている。たとえば、上述した「青森県8戸市」,「東京都北区東10条」,「東京都1000代田区」のような表記は、本来の住所表示としては不適切な表示形態であり、従来の標準書式(正規表現)にはなり得ない表記である。しかしながら、これらの表記は、本発明における中間コードとしては、認容できる表記ということになる。
【0050】
図4は、本発明に係る住所データと地図データとのリンク処理方法の基本概念を示すブロック図である。ここで、住所データAと地図データベースMDBは、図1のブロック図に示されているものと全く同じである。すなわち、住所データAは、住所録・個人情報などから抽出され、任意の書式で記述された住所を示す文字列であり、地図データベースMDBは、図2および図3に示す例のように、緯度経度情報が付与されている多数の地図データMの集合体である。図1に示す例では、住所データAを、地図データベースMDB内の特定の地図データMに直接リンク付けする処理を行ったが、本発明では、図4に示すとおり、住所データAを中間コード住所データA*に変換し、地図データベースMDBを中間コード地図データベースMDB*に変換し、中間コード住所データA*と中間コード地図データベースMDB*との間でのリンク処理(文字列の一致検索処理)が行われる。
【0051】
住所データAおよび地図データベースMDB(に含まれる地図データM)は、本来の住所表示として適切な文字列から構成されており、人間が目視した場合にも、正しい住所表記として認識される文字列であるが、中間コード住所データA*および中間コード地図データベースMDB*(に含まれる中間コード地図データM*)は、本来の住所表示としては不適切な表示形態となる可能性がある文字列である。本願では、「*」を含む符号で示すデータは、中間コードのデータであり、本来の住所表示としては不適切な表示形態となる可能性があるデータである。しかしながら、中間コード住所データA*および中間コード地図データベースMDB*は、相互のリンク処理、すなわち、文字列の一致検索処理にのみ利用され、本来の住所を提示するような用途に利用されることはないので、本来の住所表示としては不適切な表示形態となっていても何ら問題はないのである。
【0052】
このように、本発明では、中間コードの形式のデータは、リンク処理のためだけに利用されるので、本来の住所表示としては不適切な表示形態となっていても何ら問題はなく、それ故に、中間コードへの変換処理のアルゴリズムを非常に単純化することができる。図4に示す例の場合、住所データAを中間コード住所データA*に変換する変換ルールと、地図データベースMDBを中間コード地図データベースMDB*に変換する変換ルール(別言すれば、地図データMを中間コード地図データM*に変換する変換ルール)とは、同じルールが用いられ、しかも、この変換ルールは、前掲の従来技術における正規化処理のルールほど複雑なものにする必要はない。
【0053】
たとえば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」のような表記のバリエーションが生じるのは、「ケ」,「ヶ」,「が」なる文字の不統一に起因する問題であるが、このような問題を解決するため、本発明では、たとえば、文字列中に「ケ」,「ヶ」,「が」なる文字が含まれていたら、これらをすべて削除する、という変換ルールを定め、中間コードへの変換を行うことができる。このような変換ルールを適用すれば、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」なる文字列は、いずれも「市谷」なる統一した形態の中間コードに変換されることになる。
【0054】
もっとも、上記変換ルールを適用すると、愛知県の「豊根村大字下黒川ケゴヤ」、京都府の「園部町口司カマカケ」などの住所表示が、それぞれ「豊根村大字下黒川ゴヤ」、京都府の「園部町口司カマカ」のように、本来の住所表示としては不適切な表示形態となる。従来の考え方であれば、正規化処理によって、このような不適切な表示形態が生じるのであれば、これを回避するために、何らかの手当を行う、という方針をとることになるが、本発明では、中間コード上にこのような不適切な表示形態が生じたとしても、何ら問題はないのである。
【0055】
すなわち、上記変換ルールによって、「豊根村大字下黒川ケゴヤ」が「豊根村大字下黒川ゴヤ」なる不適切な表示形態をもった中間コードに変換されたとしても、そのような不適切な表示形態への変換は、住所データAに基づく変換により得られた中間コード住所データA*と、地図データMに基づく変換により得られた中間コード地図データM*との双方において生じることになるので、「豊根村大字下黒川ゴヤ」なる不適切な表示形態をもった住所データA*と、同じく「豊根村大字下黒川ゴヤ」なる不適切な表示形態をもった地図データM*との間で、文字列の完全一致という形でリンク処理が可能になる。もちろん、「豊根村大字下黒川ゴヤ」なる文字列自体は、住所表示としては不適切であるが、このような文字列はリンク処理の目的にのみ利用されるので、実用上は何ら問題はない。
【0056】
同様に、数字による住所記述部分の不統一に起因する問題を解決するため、本発明では、たとえば、「文字列中の漢数字をすべて全角アラビア数字に変更する」という単純な変換ルールを適用することができる。この変換ルールを適用すれば、「八丁目八番三号」,「八丁目八番3号」,「八丁目8番3号」,「8丁目8番3号」という種々の形態の表記は、いずれも「8丁目8番3号」なる統一した表記をもった中間コードに置換されることになるし、「千五百二十六番地」や「壱千伍百弐拾六番地」は、「1526番地」なる統一した表記をもった中間コードに置換されることになる。
【0057】
ただし、上記変換ルールだけでは、前述したとおり、「青森県八戸市」が「青森県8戸市」に変換され、「東京都北区東十条」が「東京都北区東10条」に変換され、「東京都千代田区」が「東京都1000代田区」に変換されてしまうことになる。これらの変換によって得られる中間コードは、本来の住所表示としては不適切な表示形態である。従来の考え方であれば、このような不適切な表示形態は回避すべきものとされていたが、本発明では、中間コード上にこのような不適切な表示形態が生じたとしても、何ら問題はないのである。
【0058】
すなわち、上記変換ルールによって、中間コード住所データA*および中間コード地図データベースMDB*を得るようにすれば、「東京都1000代田区」なる中間コード住所データA*は、中間コード地図データベースMDB*内に収容されている「東京都1000代田区」なる同一文字列の中間コード地図データM*にリンク付けされることになる。もちろん、「東京都1000代田区」なる文字列自体は、住所表示としては不適切であるが、このような文字列はリンク処理の目的にのみ利用されるので、実用上は何ら問題はない。
【0059】
このように、本発明の基本的技術思想は、前掲の特許文献1および2に開示されている技術思想に対して、逆転の発想とも言うべきものである。すなわち、前掲の特許文献1および2に開示されている従来技術では、予め標準書式(正規表現)を定めておき、与えられた住所を示す文字列を、この標準書式に変換するための正規化処理を行い、正規化された状態で文字列の比較を行う、という手法をとることになる。ここで標準書式(正規表現)なるものは、あくまでも本来の住所表示として機能する書式を前提としているため、正規化処理によって、不適切な表示形態となるようなケースを避けるために、非常に複雑なアルゴリズムをもった正規化処理手順が必要になる。
【0060】
これに対して、本発明では、与えられた住所を示す文字列を、所定の変換ルールに基づいて中間コードに変換し、この中間コードの状態で文字列の比較を行う、という手法をとる。しかも、この中間コードなるものは、リンク処理を行う目的にのみ利用されるものであり、本来の住所表示としては不適切な表示形態となっても一向にかまわないのである。別言すれば、中間コード住所データA*側が不適切な表示形態となっていても、中間コード地図データM*側も同様に不適切な表示形態となっているので、文字列の一致という形式でリンク処理を行う上では、何ら支障は生じないのである。
【0061】
このように、本発明で用いる中間コードは、本来の住所表示として適切か否かは不問であるため、中間コードに変換するために用いる変換ルールは極めて単純なものですむ。かくして、本発明によれば、比較的小さな処理負担で、正確なリンク処理が可能になる住所データと地図データとのリンク処理方法を提供することが可能になる。
【0062】
<<< §3.本発明の基本的な実施形態に係るリンク処理方法 >>>
続いて、本発明の基本的な実施形態を説明する。図5は、本発明の基本的な実施形態に係るリンク処理方法の手順を示す流れ図である。このリンク処理は、処理対象となる住所データAを、緯度経度情報が付与されている特定の地図データMと対応づけることを目的としており、図示のとおり、4段階のステップから構成されている。
【0063】
まず、ステップS1は、住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定める変換ルール定義段階である。この変換は、複数通りのバリエーションをもった住所表記を、統一した表記に改めることを目的として行われるものであり、この目的に関しては、前掲の特許文献における正規化処理と同じである。したがって、ルールの内容としては、複数通りのバリエーションをもった住所表記を統一するために、複数通りの文字を1つの統一文字に置換したり、特定の文字を削除したりする取り決めがなされる。
【0064】
もっとも、既に§2で述べたとおり、この変換ルールは、従来技術における正規化処理のルールなどに比べると、極めて単純なルールですむ。これは、前述したとおり、本発明における中間コードは、本来の住所表示として適切か否かは不問であるためである。住所を示す文字列を、中間コードに「一義的に変換する」という意味は、「同一の文字列が与えられた場合、必ず同一の中間コードに変換される」という意味である。たとえば、文字列中に「ケ」,「ヶ」,「が」なる文字が含まれていたら、これらをすべて削除する、という変換ルールは、「一義的な変換」を行う変換ルールであり、「市ヶ谷」という文字列が与えられた場合、必ず、「市谷」という中間コードに変換されることになる。もっとも、その逆は必ずしも成り立たない。すなわち、変換により「市谷」という中間コードが得られたとしても、元の文字列は、必ずしも「市ヶ谷」であるとは限らない。
【0065】
図6は、このステップS1で定義する変換ルールの一例を示す図である。図示の例では、(1) 〜(4) の4つの変換ルールが定義されている。以下、これらの変換ルールを順に説明する。
【0066】
変換ルール(1) は、「全角数字および漢数字は、すべて半角数字に置き換える。」という規則である。なお、本願において、全角数字とは全角のアラビア数字を意味し、半角数字とは、当然、半角のアラビア数字を意味する。この変換ルールの目的は、数字の全角/半角の相違による不一致や、漢数字/アラビア数字の相違による不一致を排除することにある。図示の例のとおり、「1,2,3」といった全角数字は、「1,2,3」といった半角数字に変換され、「一,二,三」あるいは「壱,弐,参」といった漢数字も、「1,2,3」といった半角数字に変換される。また、「十(あるいは拾),百,千,万(あるいは萬)」といった位取りを有する漢数字も、「10,100,1000,10000」といった位取りを有する半角数字に変換される。
【0067】
この変換ルール(1) に従えば、「八丁目八番三号」,「八丁目八番3号」,「八丁目8番3号」,「8丁目8番3号」という種々の形態の表記は、いずれも「8丁目8番3号」なる中間コードに変換され、「千五百二十六番地」や「壱千伍百弐拾六番地」は、「1526番地」なる中間コードに変換される。もっとも、前述したとおり、「青森県八戸市」は「青森県8戸市」に変換され、「東京都北区東十条」は「東京都北区東10条」に変換され、「東京都千代田区」は「東京都1000代田区」に変換されることになり、本来の住所表示としては不適切な表示形態になることがある。
【0068】
変換ルール(2) は、「『条』,『の』,『丁目』,『番』,『番地』,『号』,全角ハイフンは、すべて半角ハイフンに置き換える。」という規則である。この変換ルールの目的は、数字による住所記述部分(何条、何丁目、何番地、何番、何号といった表記部分)内の数字以外の構成要素として用いられる可能性のある文字を、すべて半角ハイフンに置き換えて統一した表記にすることにある。たとえば、数字による住所記述部分として、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」のような様々な表記による文字列があったとしよう。これらの文字列に、上記変換ルール(1) を適用すると、それぞれ「1丁目2の3」,「1丁目2−3」,「1の2の3」,「1−2−3」,「1-2-3」のように、数字は半角数字に統一されたものの、数字以外の構成要素は統一されていない。そこで、続いて、この変換ルール(2) による変換を行うと、いずれも最終的に「1-2-3」なる統一した表記に変換されることになる。
【0069】
ここで、「条」,「の」,「丁目」,「番」,「番地」,「号」,全角ハイフンは、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字であり、このような文字をすべて半角ハイフンに置き換えることにより、数字による住所記述部分の書式を統一することができるのである。もっとも、この変換ルール(2) の適用対象は、数字による住所記述部分に限定されず、住所を示す文字列のすべてが適用対象となるので(それ故に、変換ルールは非常に単純になる)、たとえば、「松戸市牧の原」なる文字列は「松戸市牧-原」に変換され、「目黒区鷹番」なる文字列は「目黒区鷹-」に変換されてしまうことになる。このように、変換ルール(2) も、変換の結果、本来の住所表示としては不適切な表示形態となる可能性のある変換ルールである。
【0070】
変換ルール(3) は、「半角数字もしくは半角数字群のうしろに半角ハイフンがなければ、半角ハイフンを付加する」という規則である。この変換ルール(3) は、上述した変換ルール(1) および(2) による変換を行った後に実行すべきルールであり、変換ルール(1) および(2) と組み合わせることによって意味をもつルールである。変換ルール(1) および(2) を実行すると、漢数字/アラビア数字は、すべて半角数字に統一され、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字(すなわち、上述の例の場合、「条」,「の」,「丁目」,「番」,「番地」,「号」,全角ハイフン)は、すべて半角ハイフンに置き換えられる。その結果、「一丁目2番3号」、「一丁目2の3」,「一丁目2−3」,「1の2の3」,「1−2−3」のような様々な表記による文字列は、上述したとおり、すべて「1-2-3」なる統一した表記に変換されることになる。
【0071】
変換ルール(3) の目的は、こうして半角数字および半角ハイフンを用いて記述された数字による住所記述部分の末尾に、更に半角ハイフンを付加することにあり、別言すれば、すべての半角数字の末尾に半角ハイフンが付加された状態にすることにある。たとえば、数字による住所記述部分が、「1-2-3」なる文字列であった場合、この変換ルール(3) を適用することにより、この文字列は「1-2-3-」に変換されることになる。つまり、うしろに半角ハイフンがなかった「3」に、半角ハイフンが付加されたことになる。この変換ルール(3) における「半角数字もしくは半角数字群」の意味するところは、「1-23-456」のような文字列に対しては、「1-2-3-4-5-6-」のような変換を行うのではなく、「1-23-456-」のような変換を行うことを指している。つまり、半角数字が連続して並んでいる半角数字群があった場合は、当該半角数字群を構成する1つ1つの半角数字の末尾に半角ハイフンを付加するのではなく、当該半角数字群全体についての末尾に半角ハイフンを付加することになる。
【0072】
結局、この変換ルール(3) を適用した後は、すべての半角数字もしくは半角数字群のうしろに半角ハイフンが付加されることになる。このような変換処理を行う理由は、数字の桁の終了位置を明確にし、検索処理を円滑化するためである。たとえば、「東京都新宿区西早稲田二丁目三番の2」のような表記は、上述した変換ルール(1) ,(2) を適用することにより、「東京都新宿区西早稲田2-3-2」なる中間コードに変換されることになる。ここで、文字列の先頭から順に検索を行うことにすると、この検索処理のプロセスにおいて、「東京都新宿区西早稲田2-3-2」だけでなく、「東京都新宿区西早稲田2-3-21」,「東京都新宿区西早稲田2-3-22」,「東京都新宿区西早稲田2-3-23」なども候補としてヒットすることになる。もちろん、文字数までも含めた文字列の完全一致の判定を行えば、最終的には、「東京都新宿区西早稲田2-3-2」のみがヒットすることになるが、検索処理のプロセスにおいて、無関係な住所データが候補として挙がるのは好ましくない。
【0073】
変換ルール(3) を適用すれば、「東京都新宿区西早稲田二丁目三番の2」のような表記は、「東京都新宿区西早稲田2-3-2-」なる中間コードに変換されるので、「2-3-2-」なる表記のみがヒットすることになり、「2-3-21-」「2-3-22-」「2-3-23-」のような表記は、桁の途中で不一致が生じて候補から除外されることになる。もちろん、「東京都新宿区西早稲田2-3-2-」なる中間コードにおける末尾の半角ハイフンは、本来の住所表示としては不適切な表記ということになる。
【0074】
最後の変換ルール(4) は、「『ケ』,『ヶ』,『が』,『ツ』,『ッ』,『つ』,『大字』,『小字』,『字』なる文字をすべて削除する」という規則である。この変換ルールの目的は、「市谷」、「市ケ谷」,「市ヶ谷」,「市が谷」のような表記のバリエーション、「美し丘」,「美しケ丘」,「美しヶ丘」,「美しが丘」のような表記のバリエーション、「四谷」,「四ツ谷」,「四ッ谷」,「四つ谷」のような表記のバリエーション、「大字」,「小字」,「字」のような表記のバリエーションを統一することにある。変換ルール(4) を適用すると、上記バリエーションは、それぞれ「市谷」、「美し丘」、「四谷」、「(字等を含まない表記)」に統一されることになる。もっとも、この変換ルール(4) を適用すると、「豊根村大字下黒川ケゴヤ」が「豊根村大字下黒川ゴヤ」に変換されてしまったり、「茨城県つくば市」が「茨城県くば市」に変換されてしまったりするので、やはり変換ルール(4) も、変換の結果、本来の住所表示としては不適切な表示形態となる可能性のある変換ルールということになる。
【0075】
図7は、図6に例示する変換ルール(1) 〜(4) を用いた中間コードへの具体的な変換例を示す図である。例1〜例4に示されている変換前の文字列は、いずれも実質的に同一地点の住所を示す文字列である。これらの文字列を図6に示すルールで中間コードに変換すると、変換後の中間コードは「東京都新宿区市谷3-5-6-」という完全に同一の文字列になる。例5は、「金山一条7番地」なる文字列が、「金山1-7-」に変換された例である。いずれも、変換後の中間コードは、末尾に半角ハイフンが付加された文字列となっており、本来の住所表示としては不適切な形態である。
【0076】
例6〜例8は、変換後に得られた中間コードが、本来の住所表示としては不適切な形態となっている点が、より顕著に表れた例である。たとえば、例6では、「東十条」なる文字列が「東10-条」となっている。これは、変換ルール(1) により、「十」なる漢数字が「10」なる半角数字に変換され、更に、変換ルール(3) により、「10」のうしろに半角ハイフンが付加されたためである。同様の理由により、例7では、「千代田区」が「1000-代田区」に変換されており、更に、変換ルール(3) を適用することにより、「一ツ橋」が「1-橋」に変換されている。また、例8では、「八戸市」が「8-戸市」に、「八幡」が「8-幡」に、それぞれ変換されている。
【0077】
このように、図7の変換後の欄に示されている中間コードは、いずれも本来の住所表示としては不適切な形態の文字列であるが、既に述べたとおり、本発明では、この中間コードはリンク処理の目的にのみ利用されるので、実用上は何ら問題はない。しかも、本発明では、「八丁目」や「八番地」なる文字列中の「八」は「8」に置き換えるが、「八戸市」や「八幡」なる文字列中の「八」はそのままにする、といった複雑な変換アルゴリズムは一切不要であり、変換ルール(1) では、文字列中のすべての「八」を例外なく「8」に置き換えればよいので、極めて単純な変換処理が可能になる。
【0078】
以上、図5の流れ図におけるステップS1の「変換ルール定義段階」で定義される変換ルールの一例を説明した。こうして、変換ルールの定義が完了すると、続いて、ステップS2において、中間コード地図データベース作成段階が行われる。これは、図3に示すようなデータベースとして用意されている個々の地図データM(国土地理院などから提供された緯度経度情報付のデータ)を、ステップS1で定義した変換ルールに基づいて、それぞれ中間コード地図データM*に変換する処理を行い、中間コード地図データベースMDB*を作成する処理である。
【0079】
たとえば、図3に示す地図データベースMDBに基づいて、図6に示す変換ルールを適用した変換処理を行うと、図8に示す中間コード地図データベースMDB*が得られる。図3に示されている個々の地図データMと図8に示されている個々の中間コード地図データM*とを比較すると、漢字からなる文字列の大部分は同一であるが、図8における数字による住所記述部分は、すべて半角数字+半角ハイフンという構成になっており、末尾には必ず半角ハイフンが付加された状態となっている。また、「東京都千代田区」のような文字列については、「東京都1000-代田区」のような不適切な形態への変換が行われている。なお、図8に示されている「Add1」などのデータの役割については、後述する§4で説明する。
【0080】
こうして、中間コード地図データベースMDB*が用意できたら、与えられた任意の住所データAに対して、当該データベースMDB*内の特定の地図データM*に対するリンク処理を行う準備が整ったことになる。そこで、まず、ステップS3において、中間コード住所データ作成段階を実行する。すなわち、与えられた処理対象となる住所データAを、ステップS1で定義した変換ルールに基づいて中間コードに変換する処理を行い、中間コード住所データA*を作成する処理が実行される。上述の例の場合、やはり図6に示す変換ルールに基づいて、住所データAを中間コードに変換する処理が行われることになる。たとえば、「東京都千代田区」という住所データAが与えられた場合、「東京都1000-代田区」という中間コード住所データA*に変換されることになる。
【0081】
最後のステップS4では、データ検索段階が行われる。すなわち、ステップS3で作成された中間コード住所データA*に基づいて、ステップS2で作成された中間コード地図データベースMDB*を検索し、対応する中間コード地図データM*を特定し、処理対象となる住所データAに特定の地図データMを対応づけるリンク処理が実行される。たとえば、「東京都千代田区」という住所データAに基づいて、ステップS3において「東京都1000-代田区」なる中間コード住所データA*が作成されたとすると、図8に示すような中間コード地図データベースMDB*に対して、「東京都1000-代田区」なる文字列に一致する中間コード地図データM*が検索されることになる。その結果、市区町村階層データファイル内の「東京都1000-代田区」なる中間コード地図データM*がヒットすることになるので、結局、「東京都千代田区」という住所データAが、「東京都千代田区」という地図データM(中間コード地図データM*の元になったデータ)にリンク付けされることになる。かくして、与えられた住所データAに対して、リンク付けされた地図データMの緯度経度情報を付与することができるようになる。
【0082】
なお、図6に示す変換ルールは、説明の便宜上、一例として示したものであり、本発明は、この特定の変換ルールのみに限定されるものではない。たとえば、図6に示す変換ルール(1) では、全角数字および漢数字をすべて半角数字に置き換え、数字の表記をすべて半角にする処理を行っているが、逆に、半角数字および漢数字をすべて全角数字に置き換え、数字の表記をすべて全角にする処理を行ってもかまわない。
【0083】
また、図6に示す変換ルール(2) では、「条」,「の」,「丁目」,「番」,「番地」,「号」,ハイフンといった、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を、すべて半角ハイフンに置き換える処理を行っているが、置換に用いる文字は、必ずしも半角ハイフンである必要はなく、予め定められた所定の特定文字であればよい。たとえば、半角ハイフンの代わりに「$」を用いれば、「2丁目3の2」のような表記は、「2$3$2」なる中間コードに変換され、半角ハイフンの代わりに「○」なる文字(本願での文字には、いわゆる記号も含まれる)を用いれば、「2丁目3の2」のような表記は、「2○3○2」なる中間コードに変換される。いずれも、本来の住所表示としては不適切な表示形態であるが、本発明で中間コードとして用いるには何ら支障はない。もちろん、半角ハイフンの代わりに「△×」のような複数の文字を用いれば、「2丁目3の2」のような表記は、「2△×3△×2」なる中間コードに変換されるが、これでも問題はない。要するに、変換ルール(2) は、一般論として定義すれば、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字(具体的には、「条」,「の」,「丁目」,「番」,「番地」,「号」,ハイフンなど)を、予め定められた所定の特定文字(複数の文字でもよい)に置き換える処理であれば十分である。
【0084】
図6に示す変換ルール(3) も同様である。前述したとおり、変換ルール(3) は、既に変換ルール(2) による変換が実行されていることを前提としたルールであり、一般論として定義すれば、変換ルール(2) によって、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字が所定の特定文字に置き換えられた場合、その後、数字もしくは数字群のうしろに当該特定文字がなければ、当該数字もしくは数字群のうしろに当該特定文字を付加する、というルールになる。したがって、変換ルール(2) において、特定文字として「$」を用いれば、「2丁目3の2」のような表記は、変換ルール(2) および(3) による変換によって、「2$3$2$」なる中間コードに変換されることになる。
【0085】
なお、本発明を実行する上で定義する変換ルールは、既に述べたとおり、住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するためのルールであれば、理論的にはどのような変換ルールであってもかまわないが、実用上は、次の2つの条件を満足するような変換ルールを定義するのが好ましい。
【0086】
第1の条件を満たす変換ルールは、「人間が目視したときに、住所表示として認識可能な中間コードが得られるようなルール」である。たとえば、図7の変換後の文字列は、いずれも本来の住所表示としては不適切な表示形態をもった文字列ではあるが、人間が目視した場合、いずれも何らかの住所表示であるという認識をもつことは可能である。したがって、図6に例示した変換ルールは、この第1の条件を満足する変換ルールであると言うことができる。
【0087】
この第1の条件を満足するような変換ルールを定義するメリットは、人間が中間コードを目視した場合、これを住所表示として認識できるため、リンク処理中に何らかのエラーが生じた場合であっても、柔軟な対応をとることができるという点である。たとえば、「北海道」なる文字列を「001」なるコードに置換し、「青森県」なる文字列を「002」なるコードに置換し、…というように、特定の文字列を特定の数字に置き換えてコード化する変換ルールを定義した場合、住所を示す文字列を、数字の羅列からなる中間コードに一義的に変換することが可能であり、当該中間コードは、もちろん、本来の住所表示としては不適切な表示形態となる。本発明の基本概念によれば、このように数字の羅列からなる中間コードへの変換が行われたとしても、この中間コードを媒介として、地図データと住所データとのリンク付けが行われれば支障は生じない。
【0088】
しかしながら、このような数字の羅列からなる中間コードの場合、人間が目視したとしても、でたらめな数字が並んでいるとしか見えず、もはや何らかの住所表示であるとの認識は得られない。したがって、リンク処理中に何らかのエラーが生じた場合であっても、どのような理由で不一致が生じているかを把握することが非常に困難になる。上述した第1の条件を満足する変換ルールを用いるようにすれば、得られる中間コードは、本来の住所表示としては不適切であったとしても、人間が目視した場合に何らかの住所表示としてとらえることができるので、不一致の原因を解析でき、柔軟な対応をとることができるようになるのである。
【0089】
一方、第2の条件を満たす変換ルールは、「互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないようなルール」である。別言すれば、「変換処理によって得られた中間コードにユニーク性が確保されるようなルール」と言うことができる。たとえば、異なる2通りの地図データに基づいて、全く同一の中間コードが得られるような変換ルールでは、中間コードにユニーク性が確保されないことになる。このように、ユニーク性が確保された中間コードが得られないとすると、所定の住所データに基づいて、対応する地図データを検索した結果、対応する地図データが複数組ヒットすることになり、1対1の対応関係を定義することができなくなる。
【0090】
もちろん、検索の結果、複数組の地図データがヒットしたような場合でも、これらを候補として提示して、最終的に人間の判断によって、正しい候補を選択する作業を行えば、本発明を実施することは可能である。しかしながら、上記第2の条件を満たす変換ルールを定めておけば、検索の結果、複数通りの候補が挙げられることを防ぐことができるので、実用上は、第2の条件を満たすルールを用いた方が好ましい。図6に例示した変換ルールは、この第2の条件も満足する変換ルールになっており、現存する住所表示に対して、この変換ルールを適用して得られる中間コードには、ユニーク性が確保されることになる。
【0091】
なお、図6に示す変換ルール(2) および(4) による変換を行うと、データ容量を減少させることができるという付加的な効果が得られる。一般に地図データベースMDBは膨大なデータ容量を必要とするが、図6に示す変換ルールによる変換で得られた中間コード地図データベースMDB*は、もとの地図データベースMDBに比べてデータ容量が減少するので、格納場所の記憶容量を削減できるという付加的なメリットが得られる。
【0092】
<<< §4.検索処理を円滑に行うための工夫 >>>
続いて、図5のステップS4として示されているデータ検索段階の処理を円滑に行うための工夫を述べる。ここでは、「東京都新宿区西早稲田二丁目3の29」という住所データAが与えられた場合に、図8に示すような中間コード地図データベースMDB*を検索する具体的な処理を例にとって説明を行うことにする。
【0093】
既に述べたとおり、図3に示す地図データベースMDBは、行政区画に応じて階層化された複数の階層データファイルによって構成されているため、これを所定の変換ルールに基づいて中間コードの形式に変換することによって得られる中間コード地図データベースMDB*(図8)も、行政区画に応じて階層化された複数の階層データファイルによって構成されることになる。しかも、第2階層以下の各階層データファイル内には、いずれも上位階層の地図データを構成する文字列を含んだ形式の地図データが格納されている。たとえば、図8の第2階層データファイルSHK内の「東京都新宿区」なる地図データには、第1階層データファイルKEN内の「東京都」なる文字列がそっくり含まれており、第3階層データファイルOAZ内の「東京都新宿区西早稲田」なる地図データには、第2階層データファイルSHK内の「東京都新宿区」なる文字列がそっくり含まれている。このような複数の階層データファイルによって構成されたデータベースに対しては、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索を行うようにすればよい。
【0094】
ここに示す実施形態では、このように、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索する便宜を考慮して、図8に示す中間コード地図データベースMDB*に、検索処理を円滑に行うための工夫を施している。すなわち、この中間コード地図データベースMDB*を作成する段階で、各階層データファイル内の各中間コード地図データM*に、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加する作業を行い、データ検索段階では、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定できるようにしている。
【0095】
図8に示す例の場合、たとえば、最上位階層のデータファイルKEN内の「東京都」なる中間コード地図データM*には、第2階層のデータファイルSHK内の対応する一連の中間コード地図データ「東京都中央区」,「東京都新宿区」,「東京都1000-代田区」,…の先頭アドレス「Add1」が付加されている。もちろん、データファイルKEN内の他の中間コード地図データM*にも、それぞれデータファイルSHK内の対応する一連の中間コード地図データの先頭アドレスが付加されている。また、このような関係は、別な階層間のデータファイルについても同様である。たとえば、第2階層のデータファイルSHK内の「東京都新宿区」なる中間コード地図データM*には、第3階層のデータファイルOAZ内の対応する一連の中間コード地図データ「東京都新宿区西早稲田」,「東京都新宿区市谷加賀町」,「東京都新宿区高田馬場」,…の先頭アドレス「Add2」が付加されている。以下の階層に関しても同様である。
【0096】
このように、個々の中間コード地図データM*に、それぞれ下位階層の対応する一連のデータの先頭アドレスを付加しておけば、非常に円滑な検索処理が可能になる。たとえば、「東京都新宿区西早稲田二丁目3の29」という住所データAが与えられた場合を考えてみよう。この場合、既に述べたとおり、この住所データAを、図6に示すような変換ルールに基づいて、「東京都新宿区西早稲田2-3-29-」のような中間コード住所データA*に変換する処理が行われる。そして、この中間コード住所データA*を構成する文字列の先頭部分と、図8に示す中間コード地図データベースMDB*の最上位階層のデータファイルKEN内の各中間コード地図データM*とが一致するか否かを調べる検索処理が実行される。この例の場合、データA*の先頭3文字の「東京都」なる文字列が、データファイルKEN内の「東京都」なるデータM*と一致することになる。
【0097】
そこで続いて、下位階層のデータファイルSHK内の検索が行われることになるが、このとき、データファイルKEN内の「東京都」なるデータM*に付加されていたアドレス「Add1」に基づいて、データファイルSHKのアドレス「Add1」から検索処理を開始すればよい。図示の例の場合、「東京都中央区」から検索が開始され、その次の「東京都新宿区」なるデータM*を検索した時点で、データA*の先頭の6文字との一致が確認されることになる。
【0098】
次に、第3階層のデータファイルOAZ内の検索が行われることになるが、このとき、データファイルSHK内の「東京都新宿区」なるデータM*に付加されていたアドレス「Add2」に基づいて、データファイルOAZのアドレス「Add2」から検索処理を開始すればよい。図示の例の場合、「東京都中央区西早稲田」から検索が開始され、その時点で直ちに、データA*の先頭の10文字との一致が確認されることになる。
【0099】
続いて、第4階層のデータファイルAZC内の検索が行われることになるが、このとき、データファイルOAZ内の「東京都新宿区西早稲田」なるデータM*に付加されていたアドレス「Add3」に基づいて、データファイルAZCのアドレス「Add3」から検索処理を開始すればよい。図示の例の場合、「東京都新宿区西早稲田1-」から検索が開始され、その次の「東京都新宿区西早稲田2-」なるデータM*を検索した時点で、データA*の先頭の12文字との一致が確認されることになる。
【0100】
更に、第5階層のデータファイルGIK内の検索が行われることになるが、このとき、データファイルAZC内の「東京都新宿区西早稲田2-」なるデータM*に付加されていたアドレス「Add4」に基づいて、データファイルGIKのアドレス「Add4」から検索処理を開始すればよい。図示の例の場合、「東京都新宿区西早稲田2-1-」から検索が開始され、次の次にある「東京都新宿区西早稲田2-3-」なるデータM*を検索した時点で、データA*の先頭の14文字との一致が確認されることになる。
【0101】
最後に、第6階層のデータファイルTBN内の検索が行われることになるが、このとき、データファイルGIK内の「東京都新宿区西早稲田2-3-」なるデータM*に付加されていたアドレス「Add5」に基づいて、データファイルTBNのアドレス「Add5」から検索処理を開始すればよい。図示の例の場合、「東京都新宿区西早稲田2-3-1-」から検索が開始され、やがて「東京都新宿区西早稲田2-3-29-」なるデータM*を検索した時点で、データA*の全文字との一致が確認されることになる。かくして、与えられた住所データAは、「東京都新宿区西早稲田2-3-29-」なるデータM*の変換前の地図データMに対応づけられる。
【0102】
なお、図8に示す中間コード地図データベースMDB*では、各階層データファイルにおける個々の中間コード地図データM*の並び順が、地理的な位置などに応じて決められているが(たとえば、最上位階層のデータファイルKENの場合は、北から南に向かう順)、円滑な検索処理を実行する上では、個々の中間コード地図データM*の並び順を、文字コードの大きい順にしておくのが好ましい。図9は、このような並び順を採った場合の最上位階層のデータファイルKENおよび第2階層のデータファイルSHKの内容を示すブロック図である。
【0103】
この図9に示す例では、たとえば、データファイルKENでは、各都道府県名の先頭文字のうち、最も文字コードが大きな「和」(シフトJISコード:9861)で始まる「和歌山県」が先頭に配置され、次に大きな「北」(シフトJISコード:966B)で始まる「北海道」が2番目に配置され、最も文字コードが小さな「愛」(シフトJISコード:88A4)で始まる「愛知県」が最後に配置されている。もちろん、第3階層以下のデータファイルについても、同様に、各データが文字コードの大きい順に配列されている。このように、文字コードの大きい順にデータが配列されたデータファイルを用意するには、中間コード地図データベース作成段階において、文字コードの大きい順にソートする処理を行った上で、各データを格納するようにすればよい。
【0104】
このように、各データを文字コードの大きい順に格納しておくと、コンピュータによる検索処理の手順は、大幅に効率化される。すなわち、データ検索段階では、中間コード住所データA*と、階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行えばよい。
【0105】
図10は、このような検索処理の手順を、具体例に即して説明するための図である。ここでは、前掲の例と同様に、「東京都新宿区西早稲田二丁目3の29」という住所データAが与えられ、これを図6に示す変換ルールで変換することにより、「東京都新宿区西早稲田2-3-29-」なる中間コード住所データA*に変換し、これに一致する中間コード地図データM*を検索する場合を考えてみる。
【0106】
まず、最上位階層であるデータファイルKENから検索処理が開始される(図10の1行目のステップ)。この検索処理作業における最初の比較対象は、中間コード住所データA*として与えられた「東京都新宿区西早稲田2-3-29-」なる文字列と、データファイルKENの最初に配置されたデータM*である「和歌山県」なる文字列である。文字列の大小比較は、通常、それぞれの文字列の先頭文字の文字コードの大小関係によって決定し、両者が同じ場合には、次の文字の文字コードの大小関係によって決定する、という手順を踏むことになる。したがって、上述の例の場合、「東京都新宿区西早稲田2-3-29-」なるデータA*の先頭文字「東」(シフトJISコード:938C)と、「和歌山県」なるデータM*の先頭文字「和」(シフトJISコード:9861)との大小関係の比較が行われる。その結果、A*<M*なる判定結果が得られる(2行目のステップ)。
【0107】
続いて、2番目のデータ「北海道」との比較が行われる。すなわち、M*=「北海道」の場合、先頭文字「北」のシフトJISコードは、「966B」であるから、やはりA*<M*なる判定結果が得られる(3行目のステップ)。やがて、データ「東京都」との比較が行われるが、M*=「東京都」の場合、先頭3文字までは「東京都」と同じになるため、4文字目の文字コードが比較される。すると、データA*の4文字目が「新」であるのに対し、データM*は4文字目が存在しないので、ここで初めてA*>M*と大小関係が逆転する。このように、ソート順に文字列の大小関係を比較してゆく処理を順次行い、初めてA*>M*となった場合には、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理が行われる。すなわち、「東京都」なるデータM*に付加されているアドレス「Add1」の位置から、次の階層SHKの検索が行われることになる(4行目のステップおよび図9)。
【0108】
こうして、データファイルSHK内に配置されている「東京都○○区」なる一連のデータについて、同様の検索が行われる。たとえば、M*=「東京都台東区」の場合、先頭3文字までは「東京都」と同じになるため、4文字目の文字コードが比較される。すると、データA*の4文字目が「新」(シフトJISコード:9056)であるのに対し、データM*の4文字目は「台」(シフトJISコード:91E4)であるため、まだA*<M*の状態である(5行目のステップ)。この階層SHK内の検索で、初めてA*>M*と大小関係が逆転するのは、M*=「東京都新宿区」の場合である。この時点で、次の階層OAZへの検索へと移行する処理が行われる(6行目のステップ)。もちろん、この場合の検索開始アドレス(ジャンプ先アドレス)は、「東京都新宿区」に付加されている先頭アドレスとなる。
【0109】
続いて、データファイルOAZ内の検索が行われる。たとえば、M*=「東京都新宿区北新宿」の場合、先頭6文字までは「東京都新宿区」と同じになるため、7文字目の文字コードが比較される。すると、データA*の7文字目が「西」(シフトJISコード:90BC)であるのに対し、データM*の7文字目は「北」(シフトJISコード:966B)であるため、まだA*<M*の状態である(7行目のステップ)。この階層OAZ内の検索で、初めてA*>M*と大小関係が逆転するのは、M*=「東京都新宿区西早稲田」の場合である。この時点で、次の階層AZCへの検索へと移行する処理が行われる(8行目のステップ)。もちろん、この場合の検索開始アドレス(ジャンプ先アドレス)は、「東京都新宿区西早稲田」に付加されている先頭アドレスとなる。
【0110】
こうして、データファイルAZC内の検索が行われる。たとえば、M*=「東京都新宿区西早稲田4-」の場合、先頭10文字までは「東京都新宿区西早稲田」と同じになるため、11文字目の文字コードが比較される。すると、データA*の11文字目が「2」(ASCIIコード:32)であるのに対し、データM*の11文字目は「4」(ASCIIコード:34)であるため、まだA*<M*の状態である(9行目のステップ)。M*=「東京都新宿区西早稲田3-」の場合も、同様に、A*<M*の状態が維持される(10行目のステップ)。この階層AZC内の検索で、初めてA*>M*と大小関係が逆転するのは、M*=「東京都新宿区西早稲田2-」の場合である。この時点で、次の階層GIKへの検索へと移行する処理が行われる(11行目のステップ)。もちろん、この場合の検索開始アドレス(ジャンプ先アドレス)は、「東京都新宿区西早稲田2-」に付加されている先頭アドレスとなる。
【0111】
同様の検索処理を繰り返してゆくと、最終的に、階層TBNでM*=「東京都新宿区西早稲田2-3-29-」の場合に、A*=M*となり、文字列の完全一致が得られる。かくして、中間コード住所データA*である「東京都新宿区西早稲田2-3-29-」は、中間コード地図データM*である「東京都新宿区西早稲田2-3-29-」にリンク付けされることになる。
【0112】
以上の検索手順は、コンピュータによる処理手順として極めて合理的である。すなわち、2つの文字コードの大小関係の判定は、機械語レベルの原始的な演算処理で行うことができ、A*<M*の状態から、初めてA*>M*と大小関係が逆転したことを判定する処理も、機械語レベルの原始的な演算処理で行うことができる。しかも、この大小関係が逆転したときの次の階層へのジャンプ先アドレスは、大小関係が逆転した位置のデータM*に付加されている先頭アドレスとして示されているので、ジャンプ先アドレスの取得処理も容易に行うことができる。
【0113】
図11は、上述した検索処理の基本手順を示す流れ図である。まず、ステップS11において、処理対象となる中間コード住所データA*を入力する。続いて、ステップS12において、パラメータiおよびjを初期値1に設定する。ここで、パラメータiは、検索対象となる階層を示すパラメータであり、パラメータjは、1つの階層内の着目中の地図データの番号を示すパラメータである。
【0114】
続いて、ステップS13において、中間コード地図データベースMDB*の第i階層の第j番目の地図データM*を比較対象として着目する。たとえば、iが初期値1,jが初期値1である場合、図9に示す第1階層KENの第1番目の中間コード地図データ「和歌山県」が比較対象の地図データM*として着目されることになる。
【0115】
次のステップS14では、ステップS11で入力した住所データA*と、着目した地図データM*と、の大小関係の比較が行われる。前述の具体例の場合、住所データA*「東京都新宿区西早稲田2-3-29-」と着目した地図データM*「和歌山県」との大小関係が比較されることになる。
【0116】
ここで、A*<M*の場合は、ステップS14からステップS15へと分岐し、パラメータjが最大値Jに到達したか否かが判定され、最大値Jに到達していなければ、ステップS16において、パラメータjが1だけ更新される。上述の例の場合、j=2となり、比較対象として着目される地図データM*は、「北海道」ということになる。こうして、パラメータjを1ずつ更新しながら、ステップS14の比較処理を繰り返してゆくと、やがてA*>M*と大小関係が逆転することになる。
【0117】
そこで、ステップS14の比較の結果、A*>M*の場合は、ステップS14からステップS19へと分岐し、更に、ステップS21へと進むことになる(ステップS19の処理については後述する)。このステップS21において、パラメータiが最大値Iに到達したか否かが判定され、最大値Iに到達していなければ、ステップS22において、パラメータiが1だけ更新され、パラメータjがkに設定される。ここで、kは、更新前の第i番目の階層の第j番目のデータM*に付与されていた先頭アドレスによって示される、更新後の第i番目の階層のデータM*の配置順を示す値である。要するに、このステップS22の処理は、次の階層(更新されたiで示される階層)の指定アドレス先へのジャンプ処理に相当する。
【0118】
図9に示す例の場合、パラメータi=1の状態では、第1階層のデータファイルKENに対する検索が行われ、パラメータj=1,2…と更新されるに従って、「和歌山県」,「北海道」,…なるデータM*と、データA*との大小関係が、ステップS14で比較されることになる。こうして、A*<M*なる判定結果が得られる限り、ステップS15,S16の処理が繰り返される。そして、jの更新により、「東京都」が比較対象として着目された時点で、ステップS14の比較結果が逆転し、ステップS19,S21を経て、ステップS22へと進むことになる。ここで、パラメータi=2となり、第2階層のデータファイルSHKに対する検索が行われる。このとき、パラメータjは1ではなく、j=kに設定されるが、これは図9に示す「東京都○○区」の先頭アドレス「Add1」へジャンプして、途中のデータから検索が開始されることを意味している。
【0119】
以上の処理を繰り返してゆくと、階層を示すパラメータiは、徐々に更新されてゆき、最終的に、i=6に更新されたときに、第6階層であるデータファイルTBNに対する検索が行われ、「東京都新宿区西早稲田2-3-29-」なる地図データM*が比較対象として着目された時点で、ステップS14における比較結果が「A*=M*」となる。この場合、ステップS18へと進み、データA*とデータM*とを対応づける処理が行われ、データ検索処理は終了する。
【0120】
ところで、この流れ図に示す処理手順は、エラー処理によって終了する場合もあり得る。たとえば、ステップS15において、j=Jに到達したと判断された場合は、ステップS17のエラー処理を経て、この処理手順は終了する。これは、当該階層のデータファイルに含まれているすべてのデータM*と比較を行ったにもかかわらず、A*<M*という大小関係が、逆転することがなかったことを意味する。このようなエラー処理によって手順が終了する原因は、ステップS11で入力した中間コード住所データA*が誤りであったためと考えられる。たとえば、住所データA*として、「哀知県○○○○」のような誤ったデータが入力された場合、「哀知県」<「愛知県」であるため、図9に示すデータファイルKEN内を最後まで検索しても、常にA*<M*なる比較結果が得られることになり、最終的に、ステップS15からステップS17のエラー処理に至ることになる。
【0121】
また、ステップS21において、i=Iに到達したと判断された場合は、ステップS23のエラー処理を経て、この処理手順は終了する。これは、最後の階層まで検索を行ったが、文字列の完全一致には至らなかったことを意味する。このようなエラー処理によって手順が終了する原因は、ステップS11で入力した中間コード住所データA*の末尾に余分な文字が含まれていたためと考えられる。たとえば、住所データA*として、「東京都新宿区西早稲田2-3-29-鈴木様方」のようなデータが入力された場合、「東京都新宿区西早稲田2-3-29-」<「東京都新宿区西早稲田2-3-29-鈴木様方」であるため、最終階層であるデータファイルTBN内の「東京都新宿区西早稲田2-3-29-」が比較対象として着目された時点で、A*>M*なる比較結果が得られることになり、最終的に、ステップS21からステップS23のエラー処理に至ることになる。
【0122】
もっとも、このステップS23のエラー処理は、必ずしも「検索失敗」としての取り扱いを行う必要はなく、ステップS23からステップS18へと移行して、通常の検索終了処理を行うようにしてもかまわない。たとえば、上述の例のように、住所データA*として、「東京都新宿区西早稲田2-3-29-鈴木様方」のようなデータが入力された場合、ステップS18へと移行して、「東京都新宿区西早稲田2-3-29-」なるデータM*に対応づけを行っても問題はない。
【0123】
最後に、ステップS19の判定処理およびステップS20のエラー処理について説明する。このステップS19の判定処理は、所定の階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれているか否かを判定するための処理である。ここで、そっくり含まれていると判定された場合にのみ、ステップS21およびS22の処理(下位階層の階層データファイル内の検索への移行処理)が行われることになり、そうでない場合には、ステップS20のエラー処理が行われることになる。
【0124】
このステップS19の判定処理を設けた理由は、次のような具体例を考えると容易に理解できよう。たとえば、ステップS11において、住所データA*として、「東橋都新宿区西早稲田2-3-29-」のようなデータが入力された場合を考えよう。この住所データA*は、「東京都」とするべきところを「東橋都」としており、明らかに誤ったデータである。しかしながら、このような住所データA*を用いて、第1階層のデータファイルKENを検索してゆくと、「東京都新宿区西早稲田2-3-29-」という正しい住所データA*を用いた検索と全く同様に、M*=「東京都」が比較対象として着目された時点で、A*>M*なる比較結果が得られてしまうことになる。これは、「橋」(シフトJISコード:8BB4)の文字コードが、「京」(シフトJISコード:8B9E)の文字コードよりも大きいため、「東橋都」>「東京都」なる大小関係になるためである。
【0125】
結局、M*=「東京都」が比較対象として着目された時点で、ステップS14からステップS19へと分岐することになる。このステップS19の処理は、要するに、住所データA*「東橋都新宿区西早稲田2-3-29-」の中に、地図データM*「東京都」なる文字列がそっくり含まれているか否かを判定する処理ということになる。この場合、住所データA*には、「東橋都」なる誤記があるため、「東京都」なる文字列がそっくり含まれている、という条件は満たさない。よって、ステップS19からステップS20へと進み、エラー処理が行われることになる。もちろん、住所データA*が、「東京都新宿区西早稲田2-3-29-」という正しい文字列であった場合には、「東京都」なる文字列がそっくり含まれているので、前述したとおり、ステップS21,S22の処理へと進むことになる。
【0126】
もちろん、ステップS11で入力する住所データA*に誤記がない、という前提であれば、ステップS19およびS20の手順は設ける必要はない。ただ、実用上は、そのような誤記の存在を予想して、ステップS19およびS20の手順を設けておくのが好ましい。
【0127】
なお、上述した実施形態では、各階層データファイル内に、中間コード地図データを、文字コードの大きい順にソートした状態で用意したが、逆に、文字コードの小さい順にソートした状態で用意しても、ほぼ同様の検索処理を実行することができる。すなわち、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*<M*となるまで検索を続けてゆけばよい。ただし、この場合、初めてA*<M*となるデータM*が見つかったら、その直前のデータM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する必要がある。このように、文字コードの小さい順にソートした階層データファイルを利用した検索を行う場合、A*とM*との大小関係が初めて逆転したときに、1つ手前のデータM*へと戻る処理を行わねばならなくなるので、あまり好ましくない。したがって、実用上は、上述したように、文字コードの大きい順にソートした階層データファイルを利用した検索を行うのが最も合理的である。
【0128】
<<< §5.検索に失敗した場合の修正処理 >>>
図11の流れ図に示す検索処理手順では、正しい検索結果が得られずに、エラー処理に至るケースがあることを述べた。ここでは、このような検索に失敗した場合でも、修正処理により正しい検索結果を得る可能性のある手法を説明する。
【0129】
ここで述べる修正処理が有効なのは、処理対象として与えられた住所データAが、本来の住所の一部を省略した形式のデータであった場合である。たとえば、図12に示す具体的な例を見てみよう。ここに示す例は、本来の住所表示が「東京都千代田区西神田1丁目1の1」であるべきところ、「東京都千代田区」の部分が省略され、「西神田1丁目1の1」なる文字列が住所データAとして与えられた場合である。この場合、変換により得られる中間コード住所データA*は、「西神田1-1-1-」なる文字列になる。このような文字列が、住所データA*として与えられても、図11の流れ図に示された手順では、正しい検索結果を得ることはできない。すなわち、「西神田」に一致する都道府県名は存在しないので、第1階層であるデータファイルKENの検索において、エラー処理が行われることになる。
【0130】
具体的には、「西神田」の先頭文字「西」(シフトJISコード:90BC)の文字コードは、「愛知県」の先頭文字「愛」(シフトJISコード:88A4)の文字コードよりも大きいので、第1階層であるデータファイルKENの検索途中のいずれかの時点で、A*>M*なる判断がなされ、ステップS19へと分岐するが、「西神田1-1-1-」なる文字列には、いずれの都道府県名も含まれていないので、ステップS20のエラー処理へと移行し、検索は失敗に終わることになる。
【0131】
このような場合、「西神田1-1-1-」なる文字列の先頭に、「東京都1000-代田区」なる文字列を補うような修正処理を施すことができれば、「東京都1000-代田区西神田1-1-1-」のような正しい住所データA*を得ることができ、この正しい住所データA*を用いて再度検索を行えば、リンク付けに成功する。以下に述べる手法は、このような修正処理を実現するためのものである。
【0132】
この修正処理を実行するために、ここに示す実施形態では、図13に示すような階層混合データファイルを用意している。この階層混合データファイルは、文字どおり、複数の階層データファイルに含まれているデータを混合したファイルである。具体的には、図8に示す各階層データファイルのうち、KEN,SHK,OAZの3つの階層データファイル内のデータを混合して収容したファイルになっている(図13には、説明の便宜上、個々のデータに、元の所属階層を括弧書きで示してある)。KEN,SHK,OAZの3つの階層データファイルが選ばれているのは、数字による住所記述部分を含まない上位n階層分(この例では、上位3階層分)の階層データファイルを混合対象としているためである。
【0133】
このような階層混合データファイルが用意できたら、図14の流れ図に示す手順により、住所データの修正処理を行うことができる。この修正処理は、上述したとおり、図11に示すデータ検索処理を実行したのに、中間コード住所データA*に対応する中間コード地図データM*を検索することができなかった場合に、中間コード住所データA*の文字列を修正する処理であり、この処理を行うことにより、修正後のデータを用いた再検索が可能になる。
【0134】
まず、図14のステップS31において、検索に失敗した中間コード住所データA*から、数字による住所記述部分を抜き取ることにより、部分一致検索用住所データB*を作成する処理を行う。たとえば、中間コード住所データA*=「西神田1-1-1-」の場合は、図15に示すように、数字による住所記述部分である「1-1-1-」を抜き取り、部分一致検索用住所データB*=「西神田」を作成する。本願において、「数字による住所記述部分」とは、既に述べたとおり、住所表示における何条、何丁目、何番地、何番、何号といった表記部分である。中間コード住所データA*中の「数字による住所記述部分」は、文字列の末尾側における「半角数字および半角ハイフンが連続して並んでいる部分」として認識することができる。
【0135】
次に、ステップS32において、階層混合データを検索し、部分一致検索用住所データB*を一部にでも含む地図データM*を抽出する。たとえば、上述の例の場合、部分一致検索用住所データB*=「西神田」であるから、図13に示す混合階層データファイルを検索して、「西神田」なる文字列を一部にでも含む地図データの検索を行う(部分一致検索)。ここでは、説明の便宜上、図16に示すような検索結果が得られたものとしよう。ここに示す地図データM*(1)〜M*(6)は、いずれも図13に示す階層混合データファイルに含まれていたデータであり、その一部に「西神田」なる文字列を含んでいる。図では、説明の便宜上、「西神田」の部分を矩形枠で囲って示してある。もちろん、これらの地図データM*(1)〜M*(6)は、文字列として「西神田」なる3文字を含んでいるためにヒットしたデータであり、必ずしも地名としての「西神田」を含んでいるわけではない。たとえば、地図データM*(1)の場合、地名としては「川西神田」が含まれていることになるが、「西神田」なる文字列が含まれているとしてヒットしたことになる。
【0136】
続いて、ステップS33において、ステップS32で抽出した各地図データM*に、ステップS31で抜き取った「数字による住所記述部分」を、部分一致検索用住所データB*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する。図16に示す地図データM*(1)〜M*(6)に対して、このステップS33の処理を実行した結果を図17に示す。すなわち、修正住所データAA*(1)〜AA*(6)は、それぞれ地図データM*(1)〜M*(6)に対して、ステップS31で抜き取った「1-1-1-」なる文字列を挿入して得られたデータである。このとき、挿入位置を、部分一致検索用住所データB*との位置関係が元の位置関係となるような位置とするので、図示の例の場合、「西神田」の直後に「1-1-1-」を挿入することになる。その結果、たとえば、データAA*(3)やAA*(6)では、「西神田1-1-1-町」のように、奇異な位置に「1-1-1-」なる文字列が挿入されている。
【0137】
いずれにしても、この図14の流れ図に示す住所データ修正処理を行うことにより、検索に失敗した「西神田1-1-1-」なる中間コード住所データA*に基づいて、6つの修正住所データAA*(1)〜AA*(6)が作成されたことになる。そこで、この6つの修正住所データAA*(1)〜AA*(6)のそれぞれを用いて、再度、図11の流れ図に示す検索処理を実行する。
【0138】
もちろん、6つの修正住所データAA*(1)〜AA*(6)は、必ずしも正しい住所データであるとは限らないので、再度の検索処理を行った場合も、エラー処理で終わる可能性もある。たとえば、データAA*(3)やAA*(6)には、「西神田1-1-1-町」のような奇異な表記が含まれているので、エラー処理が行われる。また、データAA*(1),AA*(4),AA*(5)に一致するような地図データは、実際には存在しないので、これらについてもエラー処理が行われることになる。結局、この例の場合、データAA*(2)のみが実際に存在する住所表示になっており、検索処理に成功し、所定の地図データに対するリンク付けが行われる。
【0139】
かくして、通常の検索方法では失敗した「西神田1-1-1-」なる不完全な中間コード住所データA*に基づいて、「東京都1000-代田区西神田1-1-1-」なる地図データM*がリンク付けされることになる。
【0140】
場合によっては、複数の修正住所データAA*が、再検索に成功する可能性がある。たとえば、上述の例の場合、「東京都千代田区西神田一丁目1番1号」という住所と、「愛知県江南市東野町西神田一丁目1番1号」という住所とが、いずれも実際に存在したとすると、図17の修正住所データAA*(2),AA*(4)の両方が検索処理に成功することになり、リンク付けの相手先候補が2通り見つかることになる。このように、リンク付けの相手先候補が複数見つかった場合、いずれか1つに絞り込むことは困難であるので、とりあえず複数通りの結果をすべて提示し、最終的に、人間による判断に委ねるようにする。もっとも、「西神田1-1-1-」なる表記が、東京都の西神田を指しているのか、愛知県の西神田を指しているのかを、これだけの情報から判断するのは、人間が行ったとしても困難である。実用上は、住所録などに含まれている電話番号などの情報なども参考にしながら、いずれが正しいかを判断することになろう。
【0141】
なお、上述の例では、図8に示す各階層データファイルとは別個に、図13に示すような階層混合データファイルを用意して、ステップS32の検索を行っているが、階層混合データファイルは必ずしも別個に用意する必要はない。すなわち、ステップS32では、数字による住所記述部分を含まない上位n階層分の階層データファイルの検索を行うことができればよいので、図13に示すような階層混合データファイル(上位3階層分の階層データファイルの混合ファイル)を用いる代わりに、図8に示す上位3階層分の階層データファイルKEN,SHK,OAZをそれぞれ検索するようにしてもかまわない。ただ、実用上は、検索処理の効率を向上させるために、図13に示すような階層混合データファイルを予め用意しておき、ステップS32の検索は、この階層混合データファイルに対して行うようにするのが好ましい。
【0142】
<<< §6.本発明の基本的な実施形態に係るリンク処理装置 >>>
最後に、これまで述べてきたリンク処理を実際に行うための処理装置の基本構成を、図18のブロック図を参照して説明する。この図18に示す装置は、与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う機能をもった装置であり、図示のとおり、中間コード地図データベース100、データ検索手段200、中間コード住所データ作成手段300,住所データ修正手段400なる構成要素からなる。
【0143】
中間コード地図データベース100は、中間コード地図データM*の集合から構成されるデータベースであり、図4に示すMDB*に相当する構成要素である。具体的には、行政区画に応じて階層化された複数の階層データファイルKEN,SHK,…によって構成されており、各データファイル内には、図8に示すように、多数の中間コード地図データM*が格納されており、各データM*には、緯度経度情報が付与されている。ここで、中間コード地図データM*は、本来の住所表示としては不適切な表示形態となる可能性のある中間コードとして記述されたデータであり、国土地理院などから提供された地図データMに対して、所定の変換ルール(たとえば、図6に示す変換ルール)に基づいて一義的変換を行うことにより得られたデータである。
【0144】
中間コード住所データ作成手段300は、処理対象となる住所データAを入力し、これを所定の変換ルール(中間コード地図データベース100を作成するときに用いたルールと同一のルール)に基づいて中間コードに変換する処理を行い、中間コード住所データA*を作成する機能をもった構成要素であり、図4おいて、住所データAから中間コード住所データA*への変換処理を行う構成要素ということになる。
【0145】
データ検索手段200は、中間コード住所データA*に基づいて中間コード地図データベース100を検索し、文字列が一致する中間コード地図データM*を特定する処理を行う構成要素であり、図4において、A*とMDB*との間のリンク処理を実行する構成要素ということになる。中間コード地図データベース100は、行政区画に応じて階層化された複数の階層データファイルKEN,SHK,…によって構成されているので、検索は、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に行われる。具体的な検索処理の手順は、たとえば、図11の流れ図に示したとおりである。このデータ検索手段200から得られる検索結果が、リンク処理の結果を示す情報ということになる。すなわち、この検索結果は、与えられた住所データAに対応付けられる地図データMを示すものであり、住所データAに付与する緯度経度情報を示すものになる。
【0146】
なお、中間コード地図データベース100を構成する複数の階層データファイルKEN,SHK,…に対する効率的な検索を可能にするためには、§4で述べたとおり、各階層データファイル内の各地図データに、下位階層の階層データファイル内の対応する一連の地図データの先頭アドレス(図8の「Add1」など)を付加しておき、データ検索手段200が、この先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定することができるようにしておけばよい。
【0147】
また、検索処理の効率を高めるためには、中間コード地図データベース100を構成する各階層データファイル内には、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データを、文字コードの大きい順にソートした状態で格納しておき、図11の流れ図に示す手順による検索処理が可能になるようにするのが好ましい。すなわち、データ検索手段200が、中間コード住所データA*と、1つの階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行うようにすればよい。
【0148】
このとき、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として(図11のステップS19の判断)、下位階層の階層データファイル内の検索へ移行する処理を行うようにすれば、中間コード住所データA*内に「東橋都」のような誤記が含まれていた場合に、エラー処理を行うことができる。
【0149】
一方、住所データ修正手段400は、§5で述べた検索に失敗した場合の修正処理を実行するための構成要素である。すなわち、データ検索手段200からの検索結果として、中間コード住所データA*に対応する中間コード地図データM*を検索することができなかった旨の報告(エラー処理が行われた旨の検索結果)を受けた場合に、次のような処理を実行する。まず、検索に失敗した中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成する(図14のステップS31)。続いて、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出する(図14のステップS32)。そして、抽出した地図データM*に、抜き取った数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する(図14のステップS33)。
【0150】
こうして、住所データ修正手段400によって、修正住所データAA*が作成されたら、これをデータ検索手段200へと与え、データ検索手段200により再度のデータ検索が行われるようにする。そうすることにより、「西神田1-1-1-」なる不完全な中間コード住所データA*に基づいて、「東京都1000-代田区西神田1-1-1-」なる地図データM*がリンク付けできるようになることは、既に§5で述べたとおりである。なお、データB*による部分一致検索を効率的に行うためには、中間コード地図データベース100内に、予め図13に示すような階層混合データファイルを用意しておくようにすればよい。
【0151】
以上、図18に示すブロック図を参照しながら、本発明の基本的な実施形態に係るリンク処理装置の構成および動作を説明したが、実用上は、このリンク処理装置は、コンピュータに専用のプログラムを組み込むことにより実現される装置である。すなわち、中間コード地図データベース100は、コンピュータの記憶装置内に格納されたデータベースとして構築されるものであり、データ検索手段200,中間コード住所データ作成手段300,住所データ修正手段400は、コンピュータに組み込まれたプログラムの作用として実現されるものである。もちろん、このようなプログラムは、コンピュータ読み取り可能な記録媒体に記録して配布したり、オンラインで配布したりすることが可能である。
【図面の簡単な説明】
【0152】
【図1】一般的な住所データと地図データとのリンク処理の概念を示すブロック図である。
【図2】行政区画に応じて階層化された複数の階層データファイルによって構成された地図データベースMDBの一例を示す図である。
【図3】図2に示す地図データベースMDBを構成する各階層データファイルに収容されている個々の地図データMの一例を示すブロック図である(枝番階層データファイルEBNの図示は省略)。
【図4】本発明に係る住所データと地図データとのリンク処理方法の基本概念を示すブロック図である。
【図5】本発明の基本的な実施形態に係るリンク処理方法の手順を示す流れ図である。
【図6】図5のステップS1で定義する変換ルールの一例を示す図である。
【図7】図6に例示する変換ルール(1) 〜(4) を用いた中間コードへの具体的な変換例を示す図である。
【図8】図3に示す地図データベースMDBに基づいて、図6に示す変換ルールを適用した変換処理を行うことにより得られる中間コード地図データベースMDB*の構成を示すブロック図である。
【図9】個々の中間コード地図データM*の並び順を、文字コードの大きい順にソートした場合の最上位階層のデータファイルKENおよび第2階層のデータファイルSHKの内容を示すブロック図である。
【図10】各データが文字コードの大きい順にソートされている場合の具体的な検索処理の手順を示す図である。
【図11】図10に示す検索処理の一般的な手順を示す流れ図である。
【図12】住所表示の一部が省略されているため、正しい検索が行われない例を示す図である。
【図13】検索に失敗した場合の修正処理を行うために用意された階層混合データファイルの一例を示す図である。
【図14】検索に失敗した場合の修正処理の手順を示す流れ図である。
【図15】図14のステップS31の具体的処理を示す図である。
【図16】図14のステップS32の処理結果の一例を示す図である。
【図17】図16に示す地図データM*(1)〜M*(6)に対して、図14のステップS33の処理を実行した結果を示す図である。
【図18】本発明の基本的な実施形態に係るリンク処理装置の基本構成を示すブロック図である。
【符号の説明】
【0153】
100…中間コード地図データベース
200…データ検索手段
300…中間コード住所データ作成手段
400…住所データ修正手段
A…住所データ
A*…中間コード住所データ
AA*,AA*(1)〜AA*(6)…修正住所データ
AZC…字町階層データファイル
Add1〜Add5…先頭アドレス
B*…部分一致検索用住所データ
EBN…枝番階層データファイル
GIK…街区階層データファイル
I…階層番号の最大値
i…階層番号を示すパラメータ
J…1つの階層データファイル内の総データ数
j…1つの階層データファイル内のデータ番号
KEN…都道府県階層データファイル
k…ジャンプ先のデータ番号
M…地図データ
M*,M*(1)〜M*(6)…中間コード住所データ
MDB…地図データベース
MDB*…中間コード地図データベース
OAZ…大字階層データファイル
S1〜S4,S11〜S22,S31〜S33…流れ図の各ステップ
SHK…市区町村階層データファイル
TBN…地番階層データファイル
【特許請求の範囲】
【請求項1】
与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う方法であって、
住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定める変換ルール定義段階と、
データベースとして用意されている個々の地図データを、前記変換ルールに基づいて前記中間コードに変換する処理を行い、中間コード地図データベースを作成する中間コード地図データベース作成段階と、
処理対象となる住所データを、前記変換ルールに基づいて前記中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成段階と、
前記中間コード住所データに基づいて前記中間コード地図データベースを検索し、対応する中間コード地図データを特定し、前記処理対象となる住所データに特定の地図データを対応づけるデータ検索段階と、
を有することを特徴とする住所データと地図データとのリンク処理方法。
【請求項2】
請求項1に記載のリンク処理方法において、
変換ルール定義段階で、人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項3】
請求項1または2に記載のリンク処理方法において、
変換ルール定義段階で、互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項4】
請求項1〜3のいずれかに記載のリンク処理方法において、
中間コード地図データベース作成段階で、行政区画に応じて階層化された複数の階層データファイルによって構成される中間コード地図データベースを作成し、
データ検索段階で、前記中間コード地図データベースを上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索することを特徴とする住所データと地図データとのリンク処理方法。
【請求項5】
請求項4に記載のリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加する作業を行い、
データ検索段階で、前記先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定することを特徴とする住所データと地図データとのリンク処理方法。
【請求項6】
請求項5に記載のリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内には、上位階層の地図データを構成する文字列を含んだ形式の地図データを、文字コードの大きい順にソートした状態で用意し、
データ検索段階で、中間コード住所データA*と、前記階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行することを特徴とする住所データと地図データとのリンク処理方法。
【請求項7】
請求項6に記載のリンク処理方法において、
各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行することを特徴とする住所データと地図データとのリンク処理方法。
【請求項8】
請求項4〜7のいずれかに記載のリンク処理方法において、
データ検索段階で、中間コード住所データA*に対応する中間コード地図データを検索することができなかった場合には、前記中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った前記数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正処理を実行し、得られた修正住所データAA*を用いて、再度のデータ検索を行うことを特徴とする住所データと地図データとのリンク処理方法。
【請求項9】
請求項1〜8のいずれかに記載のリンク処理方法において、
変換ルール定義段階で、全角数字および漢数字をすべて半角数字に置き換える処理もしくは半角数字および漢数字をすべて全角数字に置き換える処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項10】
請求項1〜8のいずれかに記載のリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換える処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項11】
請求項1〜8のいずれかに記載のリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換え、その後、数字もしくは数字群のうしろに前記特定文字がなければ、当該数字もしくは数字群のうしろに前記特定文字を付加する処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項12】
請求項1〜8のいずれかに記載のリンク処理方法において、
「ケ」,「ヶ」,「が」,「ツ」,「ッ」,「つ」,「大字」,「小字」,「字」なる文字をすべて削除する処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項13】
与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う装置であって、
住所を示す文字列からなり、緯度経度情報が付与されている個々の地図データを、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための所定の変換ルールに基づいて変換することにより得られる中間コード地図データを、データベースの形式で格納した中間コード地図データベースと、
処理対象となる住所データを入力し、これを前記変換ルールに基づいて前記中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成手段と、
前記中間コード住所データに基づいて前記中間コード地図データベースを検索し、文字列が一致する中間コード地図データを特定するデータ検索手段と、
を備えることを特徴とする住所データと地図データとのリンク処理装置。
【請求項14】
請求項13に記載のリンク処理装置において、
人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを用いることを特徴とする住所データと地図データとのリンク処理装置。
【請求項15】
請求項13または14に記載のリンク処理装置において、
互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めることを特徴とする住所データと地図データとのリンク処理装置。
【請求項16】
請求項13〜15のいずれかに記載のリンク処理装置において、
中間コード地図データベースが、行政区画に応じて階層化された複数の階層データファイルによって構成されており、
データ検索手段が、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索することを特徴とする住所データと地図データとのリンク処理装置。
【請求項17】
請求項16に記載のリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスが付加されており、
データ検索手段が、前記先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定することを特徴とする住所データと地図データとのリンク処理装置。
【請求項18】
請求項17に記載のリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内には、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データが、文字コードの大きい順にソートされた状態で格納されており、
データ検索手段が、中間コード住所データA*と、前記階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行うことを特徴とする住所データと地図データとのリンク処理装置。
【請求項19】
請求項18に記載のリンク処理装置において、
データ検索手段が、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行する処理を行うことを特徴とする住所データと地図データとのリンク処理装置。
【請求項20】
請求項16〜19のいずれかに記載のリンク処理装置において、
データ検索手段から、中間コード住所データA*に対応する中間コード地図データを検索することができなかった旨の報告を受けた場合に、前記中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った前記数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正手段を更に設け、
データ検索手段が、前記修正住所データAA*を用いて、再度のデータ検索を行うことができるようにしたことを特徴とする住所データと地図データとのリンク処理装置。
【請求項21】
請求項13〜20のいずれかに記載のリンク処理装置としてコンピュータを機能させるためのプログラム。
【請求項1】
与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う方法であって、
住所を示す文字列を、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための変換ルールを定める変換ルール定義段階と、
データベースとして用意されている個々の地図データを、前記変換ルールに基づいて前記中間コードに変換する処理を行い、中間コード地図データベースを作成する中間コード地図データベース作成段階と、
処理対象となる住所データを、前記変換ルールに基づいて前記中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成段階と、
前記中間コード住所データに基づいて前記中間コード地図データベースを検索し、対応する中間コード地図データを特定し、前記処理対象となる住所データに特定の地図データを対応づけるデータ検索段階と、
を有することを特徴とする住所データと地図データとのリンク処理方法。
【請求項2】
請求項1に記載のリンク処理方法において、
変換ルール定義段階で、人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項3】
請求項1または2に記載のリンク処理方法において、
変換ルール定義段階で、互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項4】
請求項1〜3のいずれかに記載のリンク処理方法において、
中間コード地図データベース作成段階で、行政区画に応じて階層化された複数の階層データファイルによって構成される中間コード地図データベースを作成し、
データ検索段階で、前記中間コード地図データベースを上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索することを特徴とする住所データと地図データとのリンク処理方法。
【請求項5】
請求項4に記載のリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスを付加する作業を行い、
データ検索段階で、前記先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定することを特徴とする住所データと地図データとのリンク処理方法。
【請求項6】
請求項5に記載のリンク処理方法において、
中間コード地図データベース作成段階で、各階層データファイル内には、上位階層の地図データを構成する文字列を含んだ形式の地図データを、文字コードの大きい順にソートした状態で用意し、
データ検索段階で、中間コード住所データA*と、前記階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行することを特徴とする住所データと地図データとのリンク処理方法。
【請求項7】
請求項6に記載のリンク処理方法において、
各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行することを特徴とする住所データと地図データとのリンク処理方法。
【請求項8】
請求項4〜7のいずれかに記載のリンク処理方法において、
データ検索段階で、中間コード住所データA*に対応する中間コード地図データを検索することができなかった場合には、前記中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った前記数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正処理を実行し、得られた修正住所データAA*を用いて、再度のデータ検索を行うことを特徴とする住所データと地図データとのリンク処理方法。
【請求項9】
請求項1〜8のいずれかに記載のリンク処理方法において、
変換ルール定義段階で、全角数字および漢数字をすべて半角数字に置き換える処理もしくは半角数字および漢数字をすべて全角数字に置き換える処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項10】
請求項1〜8のいずれかに記載のリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換える処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項11】
請求項1〜8のいずれかに記載のリンク処理方法において、
変換ルール定義段階で、数字による住所記述部分内の数字以外の構成要素として用いられる可能性のある文字を所定の特定文字に置き換え、その後、数字もしくは数字群のうしろに前記特定文字がなければ、当該数字もしくは数字群のうしろに前記特定文字を付加する処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項12】
請求項1〜8のいずれかに記載のリンク処理方法において、
「ケ」,「ヶ」,「が」,「ツ」,「ッ」,「つ」,「大字」,「小字」,「字」なる文字をすべて削除する処理を含む変換ルールを定めることを特徴とする住所データと地図データとのリンク処理方法。
【請求項13】
与えられた住所データを、緯度経度情報が付与されている特定の地図データと対応づけるリンク処理を行う装置であって、
住所を示す文字列からなり、緯度経度情報が付与されている個々の地図データを、本来の住所表示としては不適切な表示形態となる可能性のある中間コードに一義的に変換するための所定の変換ルールに基づいて変換することにより得られる中間コード地図データを、データベースの形式で格納した中間コード地図データベースと、
処理対象となる住所データを入力し、これを前記変換ルールに基づいて前記中間コードに変換する処理を行い、中間コード住所データを作成する中間コード住所データ作成手段と、
前記中間コード住所データに基づいて前記中間コード地図データベースを検索し、文字列が一致する中間コード地図データを特定するデータ検索手段と、
を備えることを特徴とする住所データと地図データとのリンク処理装置。
【請求項14】
請求項13に記載のリンク処理装置において、
人間が目視したときに、住所表示として認識可能な中間コードが得られるような変換ルールを用いることを特徴とする住所データと地図データとのリンク処理装置。
【請求項15】
請求項13または14に記載のリンク処理装置において、
互いに異なる複数の地図データもしくは住所データが同一の中間コードに変換されることがないような変換ルールを定めることを特徴とする住所データと地図データとのリンク処理装置。
【請求項16】
請求項13〜15のいずれかに記載のリンク処理装置において、
中間コード地図データベースが、行政区画に応じて階層化された複数の階層データファイルによって構成されており、
データ検索手段が、上位階層側の階層データファイルから下位階層側の階層データファイルに向けて順に検索することを特徴とする住所データと地図データとのリンク処理装置。
【請求項17】
請求項16に記載のリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内の各中間コード地図データに、下位階層の階層データファイル内の対応する一連の中間コード地図データの先頭アドレスが付加されており、
データ検索手段が、前記先頭アドレスを利用して、下位階層側の階層データファイルの検索開始位置を決定することを特徴とする住所データと地図データとのリンク処理装置。
【請求項18】
請求項17に記載のリンク処理装置において、
中間コード地図データベースを構成する各階層データファイル内には、上位階層の地図データを構成する文字列をそっくり含んだ形式の地図データが、文字コードの大きい順にソートされた状態で格納されており、
データ検索手段が、中間コード住所データA*と、前記階層データファイル内の各地図データM*とについて、ソート順に文字列の大小関係を比較してゆく処理を順次行い、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*に付加されている先頭アドレスを利用して、下位階層の階層データファイル内の検索へ移行する処理を行うことを特徴とする住所データと地図データとのリンク処理装置。
【請求項19】
請求項18に記載のリンク処理装置において、
データ検索手段が、各階層データファイル内で初めてA*>M*となった場合に、当該地図データM*の文字列が、中間コード住所データA*内にそっくり含まれることを条件として、下位階層の階層データファイル内の検索へ移行する処理を行うことを特徴とする住所データと地図データとのリンク処理装置。
【請求項20】
請求項16〜19のいずれかに記載のリンク処理装置において、
データ検索手段から、中間コード住所データA*に対応する中間コード地図データを検索することができなかった旨の報告を受けた場合に、前記中間コード住所データA*から、数字による住所記述部分を抜き取ることにより部分一致検索用住所データB*を作成し、数字による住所記述部分を含まない上位n階層分の階層データファイルを検索し、B*を一部にでも含む地図データM*を抽出し、抽出した地図データM*に、抜き取った前記数字による住所記述部分を、B*との位置関係が元の位置関係となるように挿入して、修正住所データAA*を作成する住所データ修正手段を更に設け、
データ検索手段が、前記修正住所データAA*を用いて、再度のデータ検索を行うことができるようにしたことを特徴とする住所データと地図データとのリンク処理装置。
【請求項21】
請求項13〜20のいずれかに記載のリンク処理装置としてコンピュータを機能させるためのプログラム。
【図1】


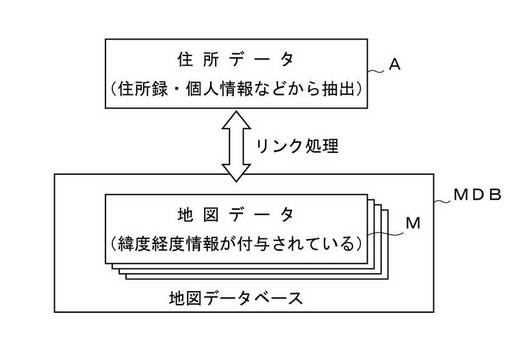
【図2】
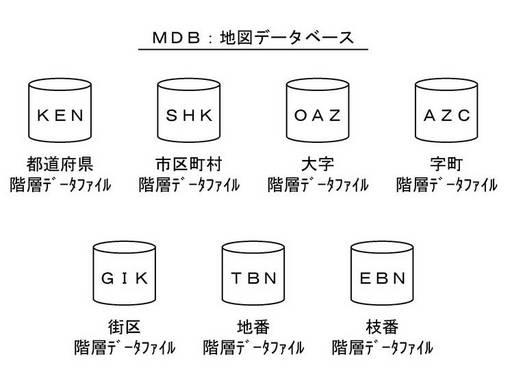
【図3】
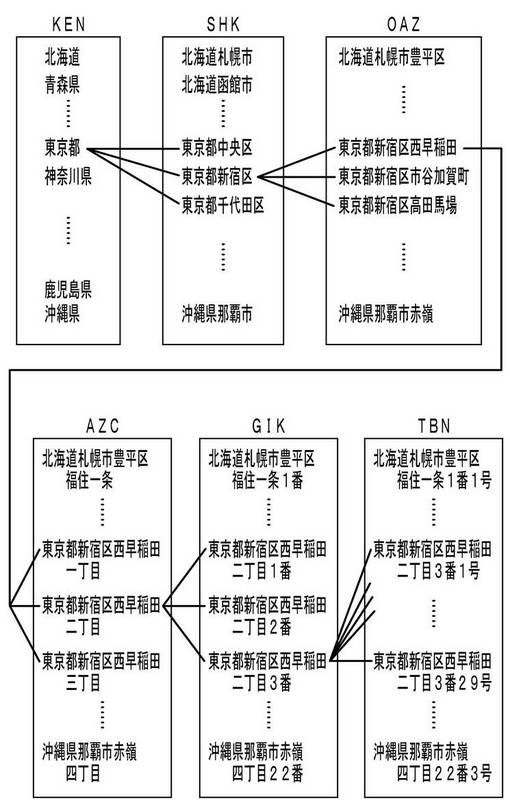
【図4】
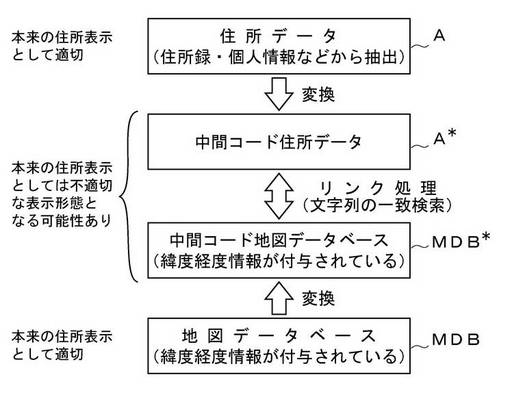
【図5】
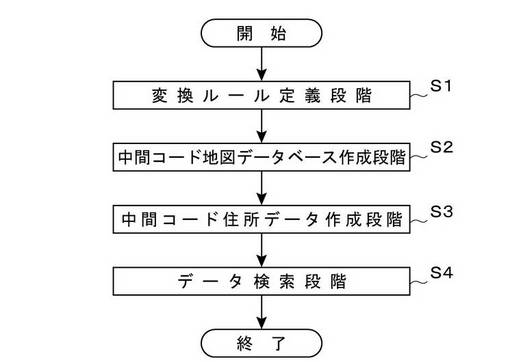
【図6】

【図7】

【図8】
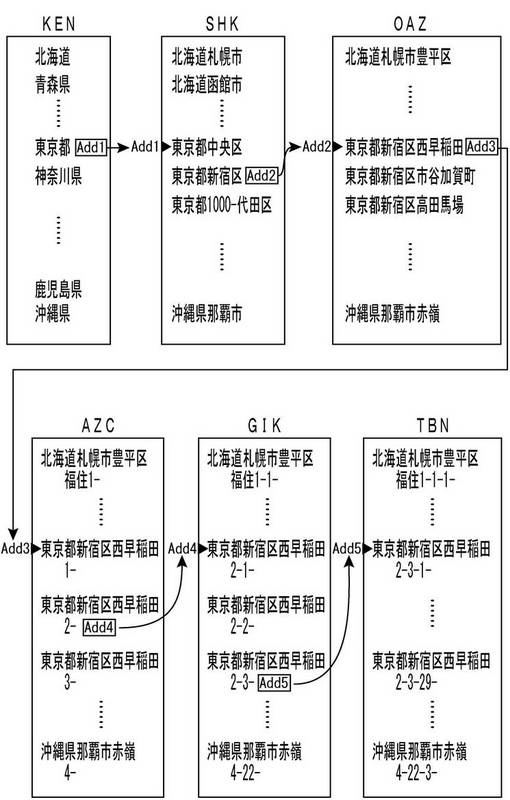
【図9】
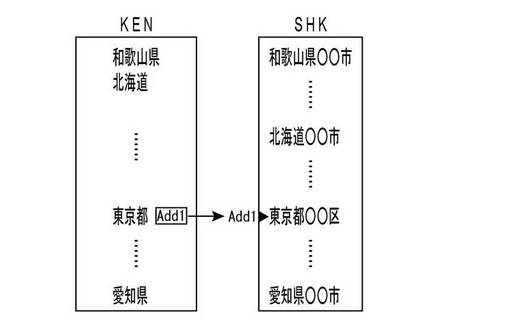
【図10】

【図11】
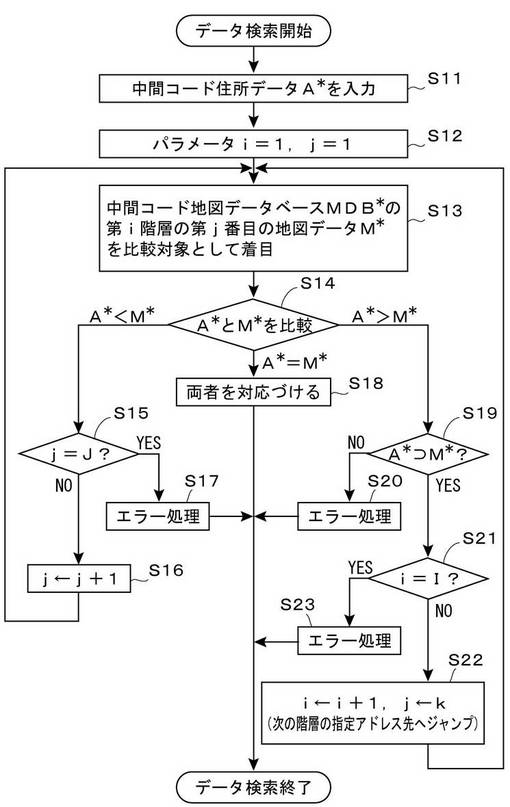
【図12】

【図13】
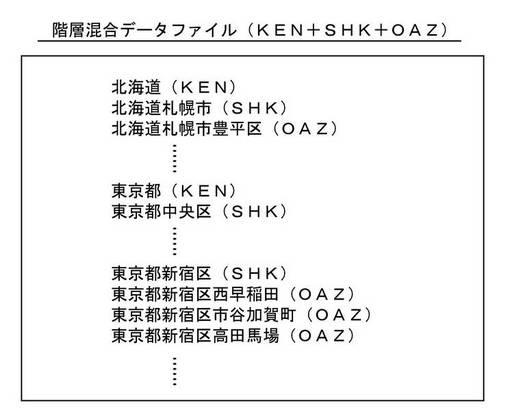
【図14】
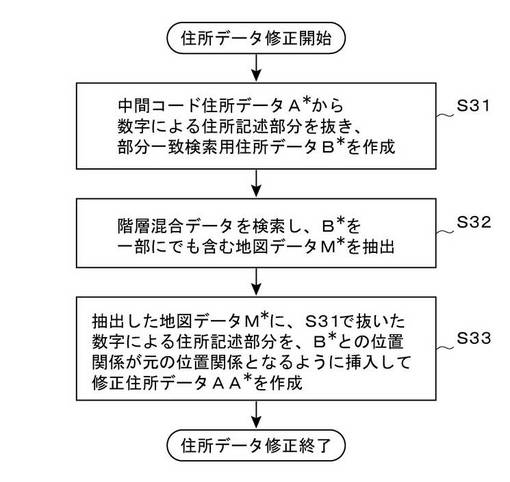
【図15】
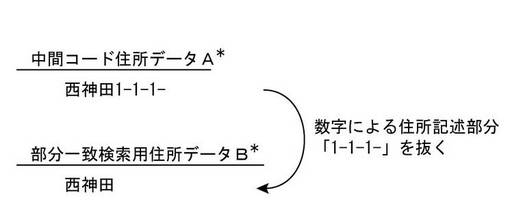
【図16】

【図17】

【図18】
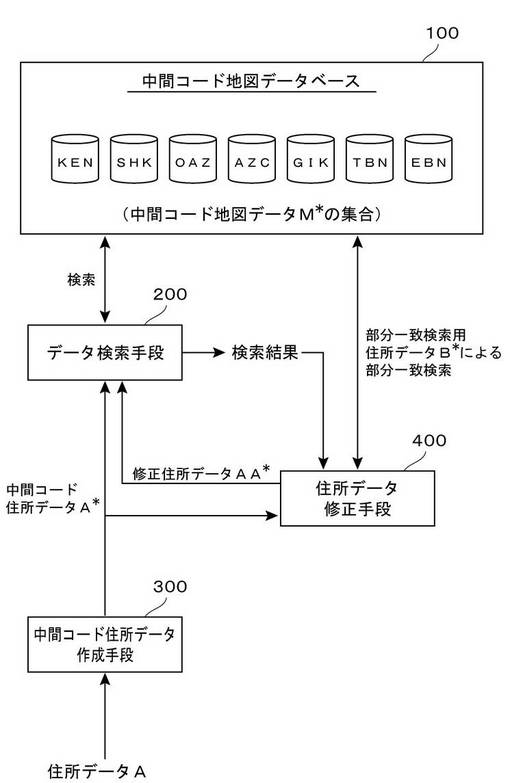
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【公開番号】特開2006−260365(P2006−260365A)
【公開日】平成18年9月28日(2006.9.28)
【国際特許分類】
【出願番号】特願2005−79092(P2005−79092)
【出願日】平成17年3月18日(2005.3.18)
【出願人】(500578216)株式会社ゼンリンデータコム (231)
【Fターム(参考)】
【公開日】平成18年9月28日(2006.9.28)
【国際特許分類】
【出願日】平成17年3月18日(2005.3.18)
【出願人】(500578216)株式会社ゼンリンデータコム (231)
【Fターム(参考)】
[ Back to top ]