
入力情報分析装置
【課題】入力情報の自動分類結果を容易に理解することができる表示技術を提供する。
【解決手段】入力情報解析手段10bは、複数の入力情報に含まれている単語情報と複数の入力情報それぞれとの対応関係を解析する。クラスタ帰属度判別手段10cおよびクラスタラベル語判別手段10dは、単語情報と入力情報との対応関係と、入力手段30から入力されたクラスタ数に基づいて、各入力情報が各分類に属する度合いを示す入力情報の帰属度および各クラスタの特徴を示すクラスタラベル語を判別する。クラスタシンボル座標情報算出手段10eは、各クラスタを示すクラスタシンボル情報を、2次元平面上の円または楕円に沿って配置するためのクラスタシンボル座標情報を算出する。入力シンボル座標情報算出手段10fは、各入力情報を示す入力シンボル情報を、クラスタを座標軸とする2次元平面上に配置するための入力シンボル座標情報を算出する。
【解決手段】入力情報解析手段10bは、複数の入力情報に含まれている単語情報と複数の入力情報それぞれとの対応関係を解析する。クラスタ帰属度判別手段10cおよびクラスタラベル語判別手段10dは、単語情報と入力情報との対応関係と、入力手段30から入力されたクラスタ数に基づいて、各入力情報が各分類に属する度合いを示す入力情報の帰属度および各クラスタの特徴を示すクラスタラベル語を判別する。クラスタシンボル座標情報算出手段10eは、各クラスタを示すクラスタシンボル情報を、2次元平面上の円または楕円に沿って配置するためのクラスタシンボル座標情報を算出する。入力シンボル座標情報算出手段10fは、各入力情報を示す入力シンボル情報を、クラスタを座標軸とする2次元平面上に配置するための入力シンボル座標情報を算出する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、入力情報分析技術に関し、特に、入力情報の自動分析結果を容易に理解することができるように表示する技術に関する。
【背景技術】
【0002】
これまで、アンケートや電話受付等のテキストを入力情報として様々な分析を行い、全体傾向の把握やデータ間の相関関係を見出す入力情報分析装置(テキストマイニング)の開発が行われている。
テキストマイニング技術の一つとして、予めカテゴリ(分類)を定めない文書分類技術(文書クラスタリング)が提案されている。例えば、特許文献1に記載されているような文書クラスタリングが知られている。この特許文献1に記載されている文書クラスタリングは、(1)分析対象のテキスト集合に応じて適切なクラスタ数(分類数)を推定する、(2)生成されたクラスタ(分類)に対し意味内容を示すクラスタラベル語を付与する、(3)文書データを階層構造に分類する階層化クラスタリング等を特徴としている。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2002−183171号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
一般に、クラスタリング技術を用いることによって、各種分類手法に応じた分類結果を得ることができるが、分類結果の解釈は難解であるため、分類結果の出力手法に工夫を要する。特許文献1においても、文書クラスタリング手法については開示されているが、クラスタリング結果の解釈を容易にするための出力手法については言及されていない。また、特許文献1には、生成されたクラスタの意味内容を示すクラスラベル語の抽出手法については言及されているが、クラスタラベル語の具体的な出力手法については言及されていない。
本発明は、このような点に鑑みて創案されたものであり、文書等の入力情報を分析する入力情報分析装置において、分析結果(クラスタリング結果)を容易に理解することができる技術を提供することを目的とする。
【課題を解決するための手段】
【0005】
本発明の入力情報分析装置は、メールで送られてくるデジタルの文書情報、電話で送られてくる音声情報、葉書に記入されているアナログの文書情報等を分析することができる。なお、好適には、音声情報やアナログの文書情報等は、デジタルの文書情報に変換されたものが用いられる。また、本発明の入力情報分析装置は、入力情報を所与のカテゴリに分類するものではなく、入力情報を、入力手段から入力された分類数(クラスタ数)に分類する手法(「クラスタリング」と呼ばれている)を用いている。分類数としては、適宜の正の整数を設定することができる。勿論、記憶手段に予め記憶されている分類数を用いることもできる。
本発明の入力情報分析装置は、入力手段、管理手段、入力情報解析手段、分類帰属度判別手段、分類特徴情報判別手段、分類シンボル座標情報算出手段、入力シンボル座標情報算出手段、出力手段を備えている。入力手段としては、テンキー、マウス、記憶媒体に記憶されている情報を読み取る読取手段等の種々の公知の入力手段が用いられる。出力手段としては、表示手段や印刷手段等の公知の種々の出力手段が用いられる。
入力情報解析手段は、入力手段から入力された複数の入力情報に含まれている複数の単語情報(変化形を考慮した、互いに異なる単語情報)を抽出し、抽出した各単語情報と各入力情報との対応関係を解析する。各単語情報と各入力情報との対応関係は、例えば、n行(n個の異なる単語情報)×m列(m個の入力情報)の単語・入力情報行列として判別することができる。
分類帰属度判別手段は、入力情報解析手段によって解析された、各単語情報と各入力情報との対応関係と分類数に基づいて、入力情報が分類に属する度合いを示す、入力情報の分類に対する帰属度を、各入力情報について、分類数の各分類に対して判別する。
分類特徴情報判別手段は、入力情報解析手段によって解析された、各単語情報と各入力情報との対応関係と分類数に基づいて、単語情報が分類に属する度合いを示す、単語情報の分類に対する帰属度を、各単語情報について、各分類に対して判別する。そして、判別した各単語情報の各分類に対する帰属度に基づいて、各分類に対して、複数の単語情報の中から、入力手段から入力された分類特徴情報数の単語情報を選択し、各分類の特徴を示す分類特徴情報として判別する。分類特徴情報数としては、適宜の正の整数を設定することができる。
分類帰属度判別手段により各入力情報の各分類に対する帰属度を判別する手法や、分類特徴情報判別手段により各単語情報の各分類に対する帰属度を判別する手法としては、公知の種々の手法を用いることができる。例えば、後述するNMF法を用いることができる。NMF法を用いる場合には、各入力情報の各分類に対する帰属度と各単語情報の各分類に対する帰属度を同時に判別することができる。
分類シンボル座標情報算出手段は、分類帰属度判別手段によって判別された、各入力情報の各分類に対する帰属度に基づいて、各分類を示す分類シンボル情報を、類似している分類を示す分類シンボル情報が隣接するように2次元平面上に配置するための分類シンボル座標情報を算出する。分類シンボル情報としては、記号や文字等の種々の情報を用いることができる。
入力シンボル座標情報算出手段は、各入力情報を示す入力シンボル情報を、分類シンボル情報が配置された、分類を座標軸とする2次元平面上に配置するための入力シンボル座標情報を算出する。入力シンボル情報としては、分類シンボル情報と識別可能な、記号や文字等の種々の情報を用いることができる。
管理手段は、分類シンボル座標情報算出手段によって算出された分類シンボル座標情報および入力シンボル座標情報算出手段によって算出された入力シンボル座標情報に基づいて、分類シンボル情報および入力シンボル情報を出力手段から出力する。
本発明では、類似している分類の分類シンボル情報が2次元平面上に配置されるため、類似している分類が存在するか否かを容易に把握することができる。また、どの分類に属する入力情報の数が多いかを容易に把握することができる。
【0006】
本発明の異なる形態では、分類シンボル座標情報算出手段は、分類シンボル情報が、2次元平面上の円または楕円に沿った位置に配置されるように分類シンボル座標情報を算出する。
円または楕円に沿った位置は、厳密に円または楕円の外周に沿っていなくてもよい。
なお、円又は楕円に沿って配置する場合には、円または楕円の外周線が閉じているため、隣接して配置されている分類シンボル情報で示される分類が類似していない箇所が存在することがある。例えば、類似している分類を示す分類シンボル情報を一方向に沿って順に配置する場合(第1番目の分類を示す第1番目の分類シンボル情報を配置し、第1番目の分類に類似している第2番目の分類を示す第2番目の分類シンボル情報を第1番目の分類シンボル情報に対して時計回り方向に配置する場合)には、最後の分類シンボル情報で示される分類と第1番目の分類シンボル情報で示される分類が類似していないことがある。本形態では、このような配置態様も、「類似している分類を示す分類シンボル情報が隣接するように2次元平面上に配置する」構成に包含される。
本形態では、閉じている線に沿って分類シンボル情報が配置されるため、類似している分類をより容易に把握することができる。
【0007】
本発明の他の異なる形態では、分類シンボル座標情報算出手段は、さらに、分類シンボル座標情報で示される位置を中心とする円または楕円に沿った位置に、当該分類シンボル座標位置に配置される分類シンボル情報で示される分類の分類特徴情報を配置するための分類特徴座標情報を算出する。そして、管理手段は、分類シンボル座標情報算出手段によって算出された分類特徴座標情報に基づいて、分類特徴情報を出力手段から出力する。
円または楕円に沿った位置は、厳密に円または楕円の外周に沿っていなくてもよい。
本形態では、2次元平面上に分類シンボル情報とともに、分類シンボル情報で示される分類の分類特徴情報も配置されるため、各分類の内容を容易に理解することができる。さらに、各分類の分類特徴情報が、各分類を示す分類シンボル情報の周りに配置されるため、各分類の内容をより容易に把握することができる。
【0008】
本発明のさらに他の異なる形態では、管理手段は、分類シンボル情報、入力シンボル情報および分類特徴情報を出力手段から出力している状態で、いずれかの分類特徴情報を指示する分類特徴指示信号が入力手段から入力されると、入力された分類特徴指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力する。
異なる出力態様としては、指示されている分類特徴情報を含む入力情報を示す入力シンボル情報と他の入力シンボル情報を識別可能な種々の出力態様を用いることができる。例えば、色、形、大きさ等が異なる出力態様が用いられる。
なお、分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報も出力可能に構成するのが好ましい。例えば、入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力するとともに、当該分類特徴情報を含む入力情報の一覧を出力するように構成する。あるいは、入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力し、この状態で、入力情報出力要求信号(例えば、入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報のいずれかを指示する入力情報出力要求信号)が入力手段から入力されると、当該分類特徴情報を含む入力情報の一覧を出力する。
本形態では、分類特徴情報と入力情報との対応関係、同じ分類特徴情報を含む入力情報の数や分布状態を容易に把握することができる。
【0009】
本発明の他の発明は、コンピュータに、前記した管理手段、入力情報解析手段、分類帰属度判別手段、分類特徴情報判別手段、分類シンボル座標情報算出手段、入力シンボル座標情報算出手段の処理を実行させるためのプログラムあるいはプログラムが記憶された記憶媒体である。
本発明のプログラムあるいは記憶媒体を用いることにより、前述した効果を得ることができる。
【発明の効果】
【0010】
本発明では、文書等の入力情報を分析する入力情報分析装置において、分析結果(クラスタリング結果)を容易に視覚によって把握することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の入力情報分析装置の一実施の形態の概略構成図である。
【図2】本発明の入力情報分析装置の一実施の形態の動作を説明する図である。
【図3】文書のクラスタ帰属度の1例を示す図である。
【図4】単語のクラスタ帰属度の1例を示す図である。
【図5】クラスタシンボル情報を対応分析により2次元平面上に算出(射影)した図の1例である。
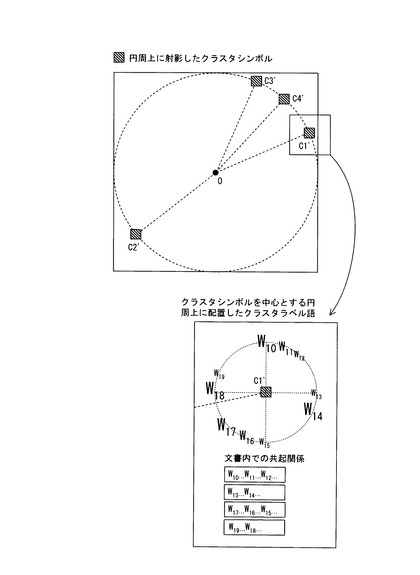
【図6】クラスタシンボル情報を円周上に射影した図の1例である。
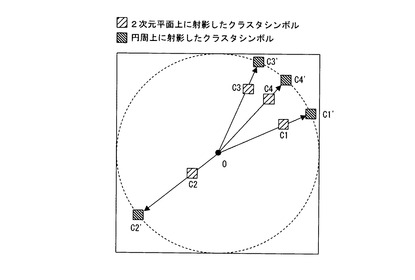
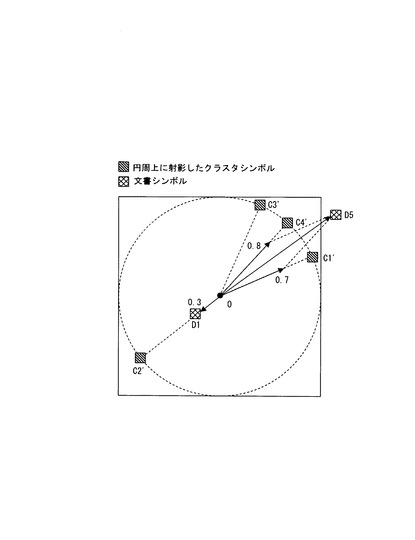
【図7】クラスタを座標軸とする2次元平面上に文書シンボル情報を配置した状態を示す図の1例である。
【図8】クラスタを座標軸とする2次元平面上にクラスタラベル語を配置した状態を示す図の1例である。
【図9】クラスタを座標軸とする2次元平面上にクラスタラベル語を配置した状態を示す図の他の例である。
【図10】階層状に出力する例を示す図である。
【図11】表示手段の表示画面の1例である。
【発明を実施するための形態】
【0012】
以下に本発明の実施の形態を、図面を参照して説明する。
本実施の形態の入力情報分析装置の概略構成が図1に示されている。
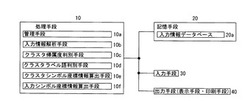
本実施の形態の入力情報分析装置は、処理手段10、記憶手段20、入力手段30、出力手段40等により構成される。
記憶手段20としては、ROMやRAM等の種々の記憶手段を用いることができる。記憶手段20は、入力された複数の入力情報が記憶される入力情報データベース20aを有している。記憶手段20の配設位置は、処理手段10がアクセス可能な範囲内で適宜設定可能である。
記憶手段20が本発明の「記憶手段」に対応する。
入力手段30としては、入力情報や各種の指示信号等を入力可能な、キーボード、表示手段の表示部に設けられているタッチパネル、マウス、記憶媒体に記憶されている情報を読み取る情報読取手段等の種々の入力手段を用いることができる。
入力手段30が本発明の「入力手段」に対応する。
出力手段40としては、表示手段や印刷手段等の出力情報を視覚で確認することができる出力手段を用いることができる。なお、遠方の端末装置と通信可能に構成される場合には、遠方の端末装置の入力手段や出力手段が、本発明の入力手段や出力手段に対応する。
出力手段40が本発明の「出力手段」に対応する。
【0013】
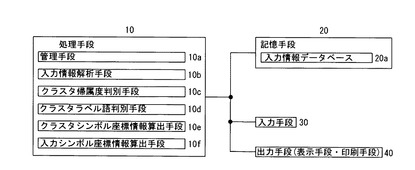
処理手段10は、管理手段10a、入力情報解析手段10b、クラスタ帰属度判別手段10c、クラスタラベル語判別手段10d、クラスタシンボル座標情報算出手段10e、入力シンボル座標情報算出手段10fを有している。処理手段10は、各手段10a〜10fの処理を実行する1つのCPUによって構成することもできるし、複数の処理手段の処理を実行する個別のCPUによって構成することもできる。
管理手段10aが本発明の「管理手段」に対応し、入力情報解析手段10bが本発明の「入力情報解析手段」に対応し、クラスタ帰属度判別手段10cが本発明の「分類帰属度判別手段」に対応し、クラスタラベル語判別手段10dが本発明の「分類特徴情報判別手段」に対応し、クラスタシンボル座標情報算出手段10eが本発明の「分類シンボル座標情報算出手段」に対応し、入力シンボル座標情報算出手段10fが本発明の「入力シンボル座標情報算出手段」に対応する。
【0014】
管理手段10aは、入力情報分析装置全体の処理を管理する。例えば、入力手段30からの入力情報や指示信号等の入力処理、クラスタシンボル情報、クラスタラベル語や入力シンボル情報の出力手段(表示手段や印刷手段)40への出力処理、各手段10b〜10fによる処理の実行等を管理する。なお、管理手段10aの処理を入力情報解析手段10b、クラスタ帰属度判別手段10c、クラスタラベル語判別手段10d、クラスタシンボル座標情報算出手段10e、入力シンボル座標情報算出手段10fにより実行するように構成することもできる。管理手段10aによる出力態様については後述する。
【0015】
入力情報解析手段10bは、入力手段30から入力されて記憶手段20の入力情報データベース20aに記憶されている入力情報を分割し、入力情報を構成している単語情報を抽出する。入力情報を構成している単語情報を抽出する手法としては、例えば、入力情報を形態素に分解する形態素解析手法が用いられる。形態素解析手法としては、種々の手法が知られている。例えば、最長一致法、分割数最小法等が知られている。なお、入力情報を形態素に分解する際に用いられる辞書が記憶手段20に記憶されている。
また、抽出した各単語情報(変化形を考慮した異なる単語情報)と各入力情報との対応関係を解析する。各単語情報と各入力情報との対応関係は、例えば、n個の単語情報×m個の入力情報から成る行列の形態で解析することができる。
入力情報データベース20aに記憶されている入力情報は、入力手段30から入力されて記憶される。したがって、入力情報データベース20aに記憶されている入力情報は、入力手段30から入力された入力情報に包含される。
【0016】
クラスタ帰属度判別手段10cは、入力情報解析手段10bにより解析された、各単語情報と各入力情報との対応関係と、入力手段30から入力されたクラスタ数(分類数)kに基づいて、入力情報がクラスタ(分類)に属する度合いを示す入力情報の帰属度を、各入力情報について、クラスタ数kの各クラスタに対して判別する。すなわち、各入力情報の各クラスタ(分類)に対する帰属度を判別する。
ここで、複数の入力情報をクラスタリングする(分類する)手法としては、種々の手法が知られている。
例えば、入力情報が属するクラスタ(分類)を一つに決定するハードクラスタリングが知られている。代表的なアルゴリズムとしては、例えば、k−means法、スペクトルクラスタリングが知られている。
また、入力情報が複数のクラスタ(分類)に属することを許容するソフトクラスタリングが知られている。代表的なアルゴリズムとしては、例えば、NMF(Non−negative Matrix Factorization:非負値行列因子分解)、pLSI、混合分布モデルが知られている。
NMFは、特異値分解と異なり、非負の行列に分解する次元縮約を利用したクラスタリング手法であり、文書以外にも画像、音声等のデータも取り扱うことができる。この手法により、文書データのクラスタリングと同時に、生成されたクラスタの特徴を表すクラスタラベル語(分類特徴語)を抽出することができる。
本実施の形態では、入力情報のクラスタリング手法としてNMFを用いている。
【0017】
NMFは、例えば、D.D.Lee and H.S.Seung“Algorithm for non−negative matrix factorization”(in Proc.NIPS,pp.556−562,2000)等に詳述されているが、要約すると以下のような手法である。
以下の[式1]に示すように、n×mの単語文書行列Xを、想定するクラスタ数kの次元に縮約するために、n×kの行列Uと、k×mの行列VTに分解する。VTは、Vの転置行列である。なお、nは、異なり単語数(入力された複数の文章中に出現する異なる単語の数)であり、mは、文書数であり、kは、クラスタ数(分類数)である。行列Xの要素としては、単語情報を用いることもできるし、[1]あるいは[0]を用いることもできるし、単語情報重要度評価値(TF−IDF)を用いることもできる。単語情報重要度評価値(TF−IDF)は、(TF−IDF)=TF×log(N/DF)によって求めることができる。ここで、TFは、文書毎の単語情報出現回数であり、Nは、文書の数であり、DFは、ある単語情報を含む文書の数である。
X=U×VT 〔式1〕
[式1]で分解された行列Uは、単語がクラスタに属する度合い(単語のクラスタに対する帰属度)を示し、行列Vは、文書がクラスタに属する度合い(文書のクラスタに対する帰属度)を示す。また、複数の単語のうち、クラスタに属する度合い(単語のクラスタに対する帰属度)の高い単語は、そのクラスタの特徴語(クラスタの内容を示すクラスタラベル語)として抽出することができる。
ここで、NMFは、縮約後の各軸をトピック(話題)と解釈することができ、その軸へ射影した値が関連度の大きさを表していると考える。NMFでは、縮約後の各軸は、LSI(潜在的意味インデキシング)のように直交していないが、縮約後の各軸を文書の構成要素であるトピックと捉えることによって、より意味的に適切なクラスタリングを行うことができる。
NMFを用いたクラスタリングでは、与えられた単語文書行列Xとクラスタ数kから、行列VとUを以下の[式2]の繰り返し計算から求める。
【数1】

[式2]
なお、UとVの初期値は適当な乱数が与えられる。
繰り返し計算によって||X−UVT||の値(分解の誤差)は単調に減少するが、解の最適性を保証するものではない(初期値に依存して局所最適解に収束)。
【0018】
クラスタラベル語判別手段10dは、入力情報解析手段10bにより解析された、各単語情報と各入力情報との対応関係と、入力手段30から入力されたクラスタ数(分類数)kに基づいて、単語情報がクラスタに属する度合いを示す単語情報の帰属度を、各単語情報について、クラスタ数kの各クラスタに対して判別する。すなわち、各単語情報の各クラスタ(分類)に対する帰属度を判別する。
そして、判別した各単語情報の各クラスタに対する帰属度に基づいて、各クラスタに対して、複数の単語情報の中からクラスタラベル数(分類特徴情報数)の単語情報を選択し、選択した単語情報を各クラスタのクラスタラベル語(分類特徴情報)として判別する。クラスタラベル数は、入力手段30から適宜入力することができる。勿論、記憶手段20に予め記憶されているクラスタラベル数を用いることもできる。また、各単語情報の各クラスタに対する帰属度に基づいて、クラスタラベル数の単語情報を選択する方法としては、例えば、各単語情報の該当クラスタに対する帰属度を比較し、該当クラスタに対する帰属度が高いクラスタラベル数の単語情報を選択する方法が用いられる。
【0019】
本実施の形態では、クラスタ帰属度判別手段10cによる、入力情報のクラスタに対する帰属度の判別、クラスタラベル語判別手段10dによる、単語情報のクラスタに対する帰属度の判別は、同時に行われる。すなわち、前述したように、NMFでは、n個の単語情報×m個の入力情報の単語文書行列Xを、単語情報のクラスタに対する帰属度を示す、n個の単語情報×k個のクラスタの行列Uと、入力情報のクラスタに対する帰属度を示す、k個のクラスタ×m個の入力情報の行列VTに分解し、行列UとVを同時に計算している。
なお、クラスタ帰属度判別手段10cによる、入力情報のクラスタに対する帰属度の判別方法や、クラスタラベル語判別手段10dによる、単語情報のクラスタに対する帰属度の判別方法はこれに限定されない。
【0020】
クラスタシンボル座標情報算出手段10eは、クラスタ帰属度判別手段10cによって判別された各入力情報の各クラスタに対する帰属度に基づいて、各クラスタを示すクラスタシンボル情報を2次元平面上に配置するためのクラスタシンボル座標情報を算出する。本実施の形態では、クラスタシンボル座標情報算出手段10eは、各入力情報の各クラスタに対する帰属度に基づいて、多変量解析の一手法である対応分析により、クラスタ間の相関を表す2次元座標情報を算出する。さらに、各クラスタシンボル情報を、類似しているクラスタを示すクラスタシンボル情報が隣接するように2次元平面上に配置するためのクラスタシンボル座標情報を算出する。クラスタが類似しているか否かは、例えば、クラスタに属する1つまたは複数の入力情報に同じ単語情報が含まれている度合い、クラスタに属する1つまたは複数の入力情報における同じ単語情報の出現回数等により判別することができる。
また、後述する入力情報を示す入力シンボル情報とクラスタシンボル情報との関係や入力情報の分布状態の判別を容易にするために、対応分析により算出した座標情報を、円(例えば、表示手段の表示エリアの内接円)または楕円に射影し、射影した位置を、クラスタシンボル情報を配置するクラスタシンボル座標情報として用いている。
クラスタシンボル情報を、円または楕円等の閉じている線に沿って、類似しているクラスタを示すクラスタシンボル情報が隣接するように配置する方法としては適宜の方法を用いることができる。例えば、一方向(時計回り方向あるいは反時計回り方向)に、類似しているクラスタが隣接するように各クラスタを示すクラスタシンボル情報を配置する方法を用いることができる。
クラスタシンボル情報を2次元平面上の円または楕円に沿って(閉じている線に沿って)配置することにより、類似したクラスタをより容易に把握することができる。勿論、クラスタシンボル情報の配置態様は、これに限定されず、適宜設定可能である。
【0021】
また、クラスタシンボル座標情報算出手段10cは、各クラスタのクラスタラベル語を、クラスタシンボル情報が配置された2次元平面上のクラスタシンボル情報が配置されている箇所の周り(例えば、クラスタシンボル情報が配置されている箇所を中心とする円または楕円に沿って)配置するためのクラスタラベル語座標情報を算出する。クラスタラベル語をクラスタシンボル情報の周りに配置する方法については後述する。
このように、クラスタシンボル情報の周りに、当該クラスタシンボル情報で示されるクラスタのクラスタラベル語が配置されていることにより、クラスタの内容を容易に把握することができる。
本実施の形態では、クラスタシンボル座標情報算出手段10eによってクラスタシンボル座標情報およびクラスタラベル語座標情報を算出したが、クラスタシンボル座標情報算出手段10eに代えて、クラスタシンボル座標情報算出手段とクラスタラベル語座標情報算出手段を設け、クラスタシンボル座標情報算出手段により、前述した方法でクラスタシンボル座標情報を算出し、クラスタラベル語座標情報算出手段により、前述した方法でクラスタラベル語座標情報を算出してもよい。
【0022】
入力シンボル座標情報算出手段10eは、入力情報を示す入力シンボル情報を、クラスタシンボル情報が配置された2次元平面上に配置するための入力シンボル座標情報を算出する。なお、クラスタシンボル情報が配置された2次元平面は、クラスタを座標軸とする2次元平面に対応する。
【0023】
管理手段10aは、クラスタシンボル座標情報算出手段10eで算出されたクラスタシンボル座標情報およびクラスタラベル語座標情報、入力シンボル座標情報算出手段10fで算出された入力シンボル座標情報に基づいて、クラスタシンボル情報およびクラスタラベル語、入力シンボル情報を出力手段(例えば、表示手段)40に出力する。
クラスタシンボル情報、入力シンボル情報としては、記号、文字や線等の種々の情報を用いることができる。また、クラスタラベル語としては、通常、文字情報が用いられる。
【0024】
次に、本実施の形態の動作を図2に示すフローチャートを用いて説明する。
図2に示されている処理は、例えば、入力情報分析処理の開始を指示する入力情報分析処理開始信号が入力手段30から入力されることによって開始される。
【0025】
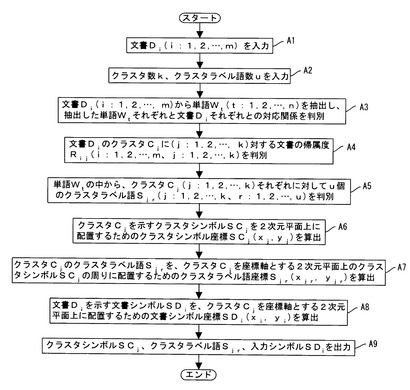
ステップA1では、入力手段30から入力されたm個の文書(入力情報)Di(i:1,2,…,m)を記憶手段20の入力情報データベース20aに記憶する。なお、文書(入力情報)Diは、予め入力情報データベース20aに記憶させておいてもよい。
ステップA2では、入力手段30からクラスタ数(分類数)k、クラスタラベル語数(分類特徴情報数)uが入力される。なお、クラスタ数kおよびクラスタラベル語数uは、予め入力し、記憶手段20に記憶させておいてもよい。
ステップA3では、入力されたm個の文書からn個の単語情報Wt(t:1,2,…,n)を抽出する。そして、抽出した各単語情報Wtと各文書Diとの対応関係を判別する。ステップA3の処理は、入力情報解析手段10bによって実行される。
【0026】
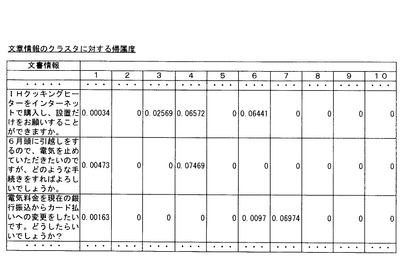
ステップA4では、ステップA3で判別した、各単語情報Wtと各文書Diとの対応関係と、ステップA2で入力されたクラスタ数kに基づいて、各文書Diの、クラスタ数kの各クラスタCj(j:1,2,…,k)に対する帰属度(文書の帰属度)Rij(i:1,2,…,m、j:1,2,…k)を判別する。ステップA4の処理は、クラスタ帰属度判別手段10cによって実行される。各文書Diの各クラスタCjに対する帰属度を判別した1例が、図3に示されている(図3では、クラスタ数kが10に設定されている)。
【0027】
ステップA5では、ステップA3で判別した、各単語情報Wtと各文書Diとの対応関係と、ステップA2で入力されたクラスタ数kに基づいて、各単語情報Wtの、クラスタ数kの各クラスタCj(j:1,2,…,k)に対する帰属度(単語情報の帰属度)を判別する。各単語情報Wtの各クラスタCjに対する帰属度を判別した1例が、図4に示されている(図4では、クラスタ数kが10に設定されている)。
そして、判別した、各単語情報Wtの各クラスタCjに対する帰属度に基づいて、各クラスタCjに対して、複数の単語情報Wtの中から、ステップA2で入力されたクラスタラベル語数uの単語情報を選択し、選択したクラスタラベル語数uの単語情報を各クラスタCjのクラスタラベル語Sjr(j:1,2,…,k、r:1,2,…,u)として判別する。ステップA5の処理は、クラスタラベル語判別手段10dによって実行される。
【0028】
ステップA6では、ステップA4で判別された、各文書Diの各クラスタCjに対する帰属度Rijに基づいて、各クラスタCjを示すクラスタシンボル情報SCjを2次元平面上に配置するためのクラスタシンボル座標情報SCj(xj,yj)を算出する。
本実施の形態では、まず、各文書Diの各クラスタCjに対する帰属度Rijに基づいて、対応分析により、図5に示されているように、クラスタCj間の相関を表す2次元座標情報を算出する。この時、類似しているクラスタCjを示すクラスタシンボル情報が隣接するように2次元座標情報が算出される。
そして、図6に示されているように、算出した2次元座標情報を、表示手段の表示画面に内接する円または楕円に射影した位置を示す2次元座標情報を、各クラスタCjを示すクラスタシンボル情報SCjのクラスタシンボル座標情報SCj(xj,yj)とする。ステップA6の処理は、クラスタシンボル座標情報算出手段10eによって実行される。
【0029】
ステップA7では、ステップA5で判別した、各クラスタCjのクラスタラベル語Sjrを、2次元平面上に配置するためのクラスタラベル語座標情報Sjr(xjr,yjr)を算出する。本実施の形態では、クラスタラベル語Sjrが、クラスタCjを示すクラスタシンボル情報SCjが配置される箇所を中心とする円または楕円に沿って配置されるようにクラスタラベル語座標情報Sjr(xjr,yjr)を算出する。
図8に、クラスタC1を示すクラスタシンボル情報が配置されている箇所を中心とする円に沿ってクラスタC1のクラスタラベル語W10〜W19が配置されている1例が示されている。クラスタラベル語W10〜W19は、クラスタシンボル情報の周りに同じ表示態様で配置されていてもよいが、クラスタラベル語の重要度等に応じて配置位置や表示態様を変えて配置するのが好ましい。
図8では、クラスタラベル語W10〜W19の文書内での共起関係に基づいてグループ分けし、グループ毎に配置している。文書内での共起関係は、例えば、クラスタラベル語が該当クラスタに分類された同一文書に出現しているか否かによって判別する方法等を用いることができる。図8の例では、クラスタラベル語W10、W11およびW12が同じ文書内に出現していることから共起関係がある(相関が高い)と見なされ、{W10、W11、W12}を含むグループができる。同様に、共起関係から、{W13、W14}、{W15、W16、W17}、{W18、W19}を含むグループができる。
クラスタラベル語座標情報の算出方法については、共起関係によりグループ化を行い、得られたグループ数を判別する。次に、クラスタシンボル情報が配置されている箇所を中心とする円周を前記判別したグループ数で等分し、クラスタラベル語の各グループを円周上に配置する起点となる座標を算出する。図8では、円周をグループ数4で等分した箇所を、各グループの起点として算出している。そして、算出したクラスタラベル語の各グループの起点となる座標から一方向(時計方向あるいは反時計方向)に各グループのクラスタラベル語を順に配置する。これにより、クラスタの内容を示す各クラスタラベル語の相関を容易に把握することができる。
なお、各グループのクラスタラベル語を配置する際の配置順序は、各クラスタラベル語の重要度の順等を用いることができる。クラスタラベル語の重要度は、各単語の単語情報重要度評価値(TF−IDF)や、各単語のクラスタに対する帰属度を用いて判別することができる。
また、図8では、各クラスタラベル語W10〜W19の重要度に応じて各クラスタラベル語W10〜W19のフォントサイズを変更している。これにより、各クラスタラベル語W10〜W19の重要度を容易に把握することができる。なお、各クラスタラベル語W10〜W19の重要度を識別可能に表示する方法としては、フォントサイズを変更する方法以外にも、例えば、色を変更する方法等を用いることもできる。
クラスタラベル語の配置方法や表示方法(フォントサイズ、色等)は、前述した方法に限定されず種々の方法を用いることができる。
また、ステップA7の処理は、クラスタシンボル座標情報算出手段10eによって実行される。
【0030】
ステップA8では、各文書Diを示す文書シンボル情報(入力シンボル情報)SDiを、クラスタシンボル情報SCjが配置された2次元平面上に配置するための文書シンボル座標情報(入力シンボル座標情報)SDi(xi,yi)を算出する。文書シンボル座標情報SDi(xi,yi)は、クラスタシンボル情報SCjのクラスタシンボル座標情報SCj(xj,yj)と、各文書Diの各クラスタCjに対する帰属度Rijにより一義的に定まる。
図7には、クラスタシンボル情報SCjと文書シンボル情報SDiが表示された1例が示されている。図7に示されている例は、文書D5のクラスタC1に対する帰属度が0.7、クラスタC4に対する帰属度が0.8、クラスタC2およびC3に対する帰属度が0の場合のものである。この場合、クラスタC1に対する帰属度0.7の長さを有するクラスタC1方向のベクトルと、クラスタC4に対する帰属度0.8の長さを有するクラスタC4方向のベクトルを合成した合成ベクトルが文書D5のベクトルを表している。これにより、文書D5を示す文書シンボル情報の文書シンボル座標情報が決定される。なお、各文書のベクトルの長さは、正規化することもできる。
ステップA8の処理は、入力シンボル座標情報算出手段10fによって実行される。
【0031】
ステップA9では、ステップA6で算出されたクラスタシンボル座標情報SCj(xj,yj)、ステップA7で算出されたクラスタラベル語座標情報Sjr(xjr.yjr)、ステップA8で算出された文書シンボル座標情報SDi(xi,yi)に基づいて、クラスタシンボル情報SCj、クラスタラベル語Sjr、文書シンボル情報SDiを出力手段40から出力する。
ステップA9の処理は、管理手段10aによって実行される。
【0032】
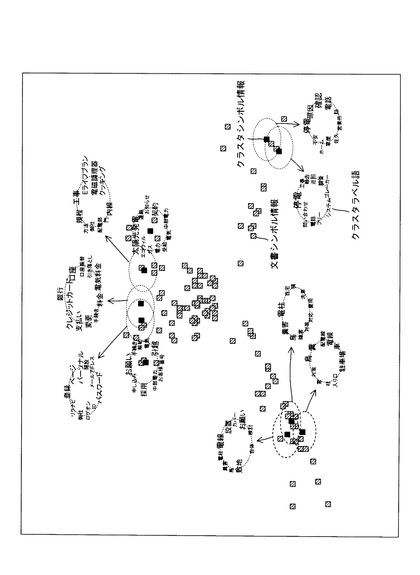
表示手段の表示画面にクラスタシンボル情報(分類シンボル情報)、クラスタラベル語(分類特徴情報)、文書シンボル情報(入力シンボル情報)が表示された1例が図11に示されている。
本実施の形態では、各クラスタを示すクラスタシンボル情報が、2次元平面上の円に沿って、類似しているクラスタ(分類)を示すクラスタシンボル情報が隣接するように配置されている。また、各クラスタの内容を示すクラスタラベル語が、クラスタシンボル情報を中心とする円に沿って、重要度や共起関係に基づいた配置位置や表示態様で配置されている。そして、文書シンボル情報が、各クラスタに対する帰属度に対応する位置に配置されている。
これにより、入力情報にどのような話題のグループ(クラスタ)があるかを把握することができる。また、類似しているクラスタを容易に把握することができる。また、クラスタラベル語により、クラスタの内容をある程度理解することができる。また、クラスタシンボル情報の位置と文書シンボル情報の位置によって、文書の話題間の相関をある程度把握することができる。
【0033】
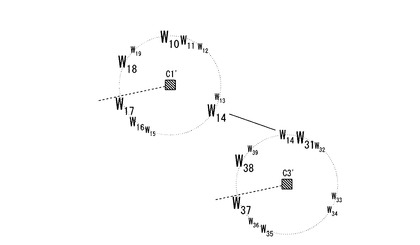
クラスタラベル語の表示方法として、前記した方法に限定されない。例えば、異なるクラスタのクラスタラベル語のうち、共通するクラスタラベル語を線で結ぶように表示することもできる。図9では、クラスタC1のクラスタラベル語とクラスタC3のクラスタラベル語のうち、共通するクラスタラベル語W14を線で結んでいる。これにより、クラスタラベル語を介して、クラスタ間の意味的な関連性を把握することができる。
【0034】
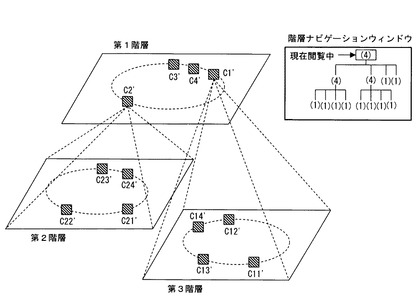
また、図10に示されているように、階層状にクラスタリングすることもできる。図10では、第1階層では、m個の文書を4個のクラスタC1〜C4でクラスタリングした状態が示されている。この状態で、クラスタC2を示すクラスタシンボル情報が指示されて、クラスタC2を指示するクラスタ指示信号(分類C2を指示する分類指示信号)が入力手段30から入力されると、m個の文書のうち、クラスタC2に分類された文書を更に4個のクラスタC21〜C24でクラスタリングした状態が示される。また、第1階層が表示されている状態で、クラスタC1を示すクラスタシンボル情報が指示されて、クラスタC1を指示するクラスタ指示信号(分類C1を指示する分類指示信号)が入力手段30から入力されると、m個の文書のうち、クラスタC1に分類された文書を更に4個のクラスタC11〜C14でクラスタリングした状態が示される。
なお、現在の表示状態がどの階層にあるかを把握することができるようにするために、階層状態を示す階層ナビゲーションを設けるのが好ましい。階層ナビゲーションウィンドウは、階層状にクラスタリングが可能なクラスタを指示するために使用することもできる。各階層のクラスタ数は、同じであってもよいし、入力手段30から異なるクラスタ数を設定することができるようにしてもよい。また、下位のクラスタリングが必要な場合に、クラスタ数を設定することができるようにしてもよい。
階層状のクラスタリングを可能とすることにより、より詳細に入力文書の分析を行うことができる。
【0035】
また、任意のクラスタラベル語を含む文書を表示させることもできる。
例えば、図11に示されているように、クラスタシンボル情報、クラスタラベル語、文書シンボル情報が表示画面に表示されている状態で、任意のクラスタラベル語(例えば、「太陽光発電」)が指示されて、クラスタラベル語を指示するクラスタラベル語指示信号(分類特徴情報を指示する分類特徴情報指示信号)が入力手段30から入力されると、クラスタラベル語指示信号で指示されているクラスタラベル語を含む文書(例えば、「太陽光発電」を含む文書)を示す文書シンボル情報が他の文書シンボル情報と識別可能な出力態様で出力される。他の文書シンボル情報と識別可能な出力態様としては、例えば、色、形、大きさ等が異なる出力態様を用いることができる。
なお、クラスタラベル語指示信号で指示されているクラスタラベル語を含む文書(入力情報)も出力可能に構成するのが好ましい。例えば、入力されたクラスタラベル語報指示信号で指示されているクラスタラベル語を含む文書を示す文書シンボル情報を、他の文書シンボル情報と異なる出力態様で出力するとともに、当該クラスタラベル語を含む文書の一覧を出力するように構成する。あるいは、入力されたクラスタラベル語指示信号で指示されているクラスタラベル語を含む文書を示す文書シンボル情報を、他の文書シンボル情報と異なる出力態様で出力し、この状態で、文書出力要求信号(入力情報出力要求信号)が入力手段30から入力されると、当該クラスタラベル語を含む入力情報の一覧を出力する。文書出力要求信号(入力情報出力要求信号)の入力方法としては、例えば、入力されたクラスタラベル語指示信号で指示されているクラスタラベル語を含む文書を示す文書シンボル情報(分類特徴情報を含む入力情報を示す入力シンボル情報)のいずれかを指示する方法等を用いることができる。
これにより、クラスタラベル語(分類特徴情報)と文書(入力情報)との対応関係、同じクラスタラベル語(分類特徴情報)を含む文書(入力情報)の数や分布状態を容易に把握することができる。
【0036】
本発明は、コンピュータに、前述した管理手段、入力情報解析手段、分類帰属度判別手段、分類特徴情報判別手段、分類シンボル座標情報算出手段と、入力シンボル座標情報算出手段の処理を実行させるためのプログラムあるいはプログラムが記憶された記憶媒体として構成することもできる。
【0037】
本発明は、実施の形態で説明した構成に限定されず、種々の変更、追加、削除が可能である。
例えば、クラスタシンボル情報(分類シンボル情報)を円または楕円に沿って配置したが、クラスタシンボル情報(分離シンボル情報)の配置態様は適宜変更可能である。また、クラスタシンボル情報(分類シンボル情報)の表示態様も適宜変更可能である。
クラスタラベル語(分類特徴情報)をクラスタシンボル情報(分類シンボル情報)を中心とする円または楕円に沿って配置したが、クラスタラベル語(分類特徴情報)の配置態様はこれに限定されない。また、クラスタラベル語(分類特徴情報)の出力は省略することもできる。
各文書(入力情報)の各クラスタ(分類)に対する帰属度や、各単語情報の各クラスタ(分類)に対する帰属度を判別する方法としては、NMF以外の種々の方法を用いることができる。
【符号の説明】
【0038】
10 処理手段
10a 管理手段
10b 入力情報解析手段
10c クラスタ帰属度判別手段(分類帰属度判別手段)
10d クラスタラベル語判別手段(分類特徴情報判別手段)
10e クラスタシンボル座標情報算出手段(分類シンボル座標情報算出手段)
10f 入力シンボル座標情報算出手段
20 記憶手段
20a 入力情報データベース
30 入力手段
40 出力手段
【技術分野】
【0001】
本発明は、入力情報分析技術に関し、特に、入力情報の自動分析結果を容易に理解することができるように表示する技術に関する。
【背景技術】
【0002】
これまで、アンケートや電話受付等のテキストを入力情報として様々な分析を行い、全体傾向の把握やデータ間の相関関係を見出す入力情報分析装置(テキストマイニング)の開発が行われている。
テキストマイニング技術の一つとして、予めカテゴリ(分類)を定めない文書分類技術(文書クラスタリング)が提案されている。例えば、特許文献1に記載されているような文書クラスタリングが知られている。この特許文献1に記載されている文書クラスタリングは、(1)分析対象のテキスト集合に応じて適切なクラスタ数(分類数)を推定する、(2)生成されたクラスタ(分類)に対し意味内容を示すクラスタラベル語を付与する、(3)文書データを階層構造に分類する階層化クラスタリング等を特徴としている。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2002−183171号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
一般に、クラスタリング技術を用いることによって、各種分類手法に応じた分類結果を得ることができるが、分類結果の解釈は難解であるため、分類結果の出力手法に工夫を要する。特許文献1においても、文書クラスタリング手法については開示されているが、クラスタリング結果の解釈を容易にするための出力手法については言及されていない。また、特許文献1には、生成されたクラスタの意味内容を示すクラスラベル語の抽出手法については言及されているが、クラスタラベル語の具体的な出力手法については言及されていない。
本発明は、このような点に鑑みて創案されたものであり、文書等の入力情報を分析する入力情報分析装置において、分析結果(クラスタリング結果)を容易に理解することができる技術を提供することを目的とする。
【課題を解決するための手段】
【0005】
本発明の入力情報分析装置は、メールで送られてくるデジタルの文書情報、電話で送られてくる音声情報、葉書に記入されているアナログの文書情報等を分析することができる。なお、好適には、音声情報やアナログの文書情報等は、デジタルの文書情報に変換されたものが用いられる。また、本発明の入力情報分析装置は、入力情報を所与のカテゴリに分類するものではなく、入力情報を、入力手段から入力された分類数(クラスタ数)に分類する手法(「クラスタリング」と呼ばれている)を用いている。分類数としては、適宜の正の整数を設定することができる。勿論、記憶手段に予め記憶されている分類数を用いることもできる。
本発明の入力情報分析装置は、入力手段、管理手段、入力情報解析手段、分類帰属度判別手段、分類特徴情報判別手段、分類シンボル座標情報算出手段、入力シンボル座標情報算出手段、出力手段を備えている。入力手段としては、テンキー、マウス、記憶媒体に記憶されている情報を読み取る読取手段等の種々の公知の入力手段が用いられる。出力手段としては、表示手段や印刷手段等の公知の種々の出力手段が用いられる。
入力情報解析手段は、入力手段から入力された複数の入力情報に含まれている複数の単語情報(変化形を考慮した、互いに異なる単語情報)を抽出し、抽出した各単語情報と各入力情報との対応関係を解析する。各単語情報と各入力情報との対応関係は、例えば、n行(n個の異なる単語情報)×m列(m個の入力情報)の単語・入力情報行列として判別することができる。
分類帰属度判別手段は、入力情報解析手段によって解析された、各単語情報と各入力情報との対応関係と分類数に基づいて、入力情報が分類に属する度合いを示す、入力情報の分類に対する帰属度を、各入力情報について、分類数の各分類に対して判別する。
分類特徴情報判別手段は、入力情報解析手段によって解析された、各単語情報と各入力情報との対応関係と分類数に基づいて、単語情報が分類に属する度合いを示す、単語情報の分類に対する帰属度を、各単語情報について、各分類に対して判別する。そして、判別した各単語情報の各分類に対する帰属度に基づいて、各分類に対して、複数の単語情報の中から、入力手段から入力された分類特徴情報数の単語情報を選択し、各分類の特徴を示す分類特徴情報として判別する。分類特徴情報数としては、適宜の正の整数を設定することができる。
分類帰属度判別手段により各入力情報の各分類に対する帰属度を判別する手法や、分類特徴情報判別手段により各単語情報の各分類に対する帰属度を判別する手法としては、公知の種々の手法を用いることができる。例えば、後述するNMF法を用いることができる。NMF法を用いる場合には、各入力情報の各分類に対する帰属度と各単語情報の各分類に対する帰属度を同時に判別することができる。
分類シンボル座標情報算出手段は、分類帰属度判別手段によって判別された、各入力情報の各分類に対する帰属度に基づいて、各分類を示す分類シンボル情報を、類似している分類を示す分類シンボル情報が隣接するように2次元平面上に配置するための分類シンボル座標情報を算出する。分類シンボル情報としては、記号や文字等の種々の情報を用いることができる。
入力シンボル座標情報算出手段は、各入力情報を示す入力シンボル情報を、分類シンボル情報が配置された、分類を座標軸とする2次元平面上に配置するための入力シンボル座標情報を算出する。入力シンボル情報としては、分類シンボル情報と識別可能な、記号や文字等の種々の情報を用いることができる。
管理手段は、分類シンボル座標情報算出手段によって算出された分類シンボル座標情報および入力シンボル座標情報算出手段によって算出された入力シンボル座標情報に基づいて、分類シンボル情報および入力シンボル情報を出力手段から出力する。
本発明では、類似している分類の分類シンボル情報が2次元平面上に配置されるため、類似している分類が存在するか否かを容易に把握することができる。また、どの分類に属する入力情報の数が多いかを容易に把握することができる。
【0006】
本発明の異なる形態では、分類シンボル座標情報算出手段は、分類シンボル情報が、2次元平面上の円または楕円に沿った位置に配置されるように分類シンボル座標情報を算出する。
円または楕円に沿った位置は、厳密に円または楕円の外周に沿っていなくてもよい。
なお、円又は楕円に沿って配置する場合には、円または楕円の外周線が閉じているため、隣接して配置されている分類シンボル情報で示される分類が類似していない箇所が存在することがある。例えば、類似している分類を示す分類シンボル情報を一方向に沿って順に配置する場合(第1番目の分類を示す第1番目の分類シンボル情報を配置し、第1番目の分類に類似している第2番目の分類を示す第2番目の分類シンボル情報を第1番目の分類シンボル情報に対して時計回り方向に配置する場合)には、最後の分類シンボル情報で示される分類と第1番目の分類シンボル情報で示される分類が類似していないことがある。本形態では、このような配置態様も、「類似している分類を示す分類シンボル情報が隣接するように2次元平面上に配置する」構成に包含される。
本形態では、閉じている線に沿って分類シンボル情報が配置されるため、類似している分類をより容易に把握することができる。
【0007】
本発明の他の異なる形態では、分類シンボル座標情報算出手段は、さらに、分類シンボル座標情報で示される位置を中心とする円または楕円に沿った位置に、当該分類シンボル座標位置に配置される分類シンボル情報で示される分類の分類特徴情報を配置するための分類特徴座標情報を算出する。そして、管理手段は、分類シンボル座標情報算出手段によって算出された分類特徴座標情報に基づいて、分類特徴情報を出力手段から出力する。
円または楕円に沿った位置は、厳密に円または楕円の外周に沿っていなくてもよい。
本形態では、2次元平面上に分類シンボル情報とともに、分類シンボル情報で示される分類の分類特徴情報も配置されるため、各分類の内容を容易に理解することができる。さらに、各分類の分類特徴情報が、各分類を示す分類シンボル情報の周りに配置されるため、各分類の内容をより容易に把握することができる。
【0008】
本発明のさらに他の異なる形態では、管理手段は、分類シンボル情報、入力シンボル情報および分類特徴情報を出力手段から出力している状態で、いずれかの分類特徴情報を指示する分類特徴指示信号が入力手段から入力されると、入力された分類特徴指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力する。
異なる出力態様としては、指示されている分類特徴情報を含む入力情報を示す入力シンボル情報と他の入力シンボル情報を識別可能な種々の出力態様を用いることができる。例えば、色、形、大きさ等が異なる出力態様が用いられる。
なお、分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報も出力可能に構成するのが好ましい。例えば、入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力するとともに、当該分類特徴情報を含む入力情報の一覧を出力するように構成する。あるいは、入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力し、この状態で、入力情報出力要求信号(例えば、入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報のいずれかを指示する入力情報出力要求信号)が入力手段から入力されると、当該分類特徴情報を含む入力情報の一覧を出力する。
本形態では、分類特徴情報と入力情報との対応関係、同じ分類特徴情報を含む入力情報の数や分布状態を容易に把握することができる。
【0009】
本発明の他の発明は、コンピュータに、前記した管理手段、入力情報解析手段、分類帰属度判別手段、分類特徴情報判別手段、分類シンボル座標情報算出手段、入力シンボル座標情報算出手段の処理を実行させるためのプログラムあるいはプログラムが記憶された記憶媒体である。
本発明のプログラムあるいは記憶媒体を用いることにより、前述した効果を得ることができる。
【発明の効果】
【0010】
本発明では、文書等の入力情報を分析する入力情報分析装置において、分析結果(クラスタリング結果)を容易に視覚によって把握することができる。
【図面の簡単な説明】
【0011】
【図1】本発明の入力情報分析装置の一実施の形態の概略構成図である。
【図2】本発明の入力情報分析装置の一実施の形態の動作を説明する図である。
【図3】文書のクラスタ帰属度の1例を示す図である。
【図4】単語のクラスタ帰属度の1例を示す図である。
【図5】クラスタシンボル情報を対応分析により2次元平面上に算出(射影)した図の1例である。
【図6】クラスタシンボル情報を円周上に射影した図の1例である。
【図7】クラスタを座標軸とする2次元平面上に文書シンボル情報を配置した状態を示す図の1例である。
【図8】クラスタを座標軸とする2次元平面上にクラスタラベル語を配置した状態を示す図の1例である。
【図9】クラスタを座標軸とする2次元平面上にクラスタラベル語を配置した状態を示す図の他の例である。
【図10】階層状に出力する例を示す図である。
【図11】表示手段の表示画面の1例である。
【発明を実施するための形態】
【0012】
以下に本発明の実施の形態を、図面を参照して説明する。
本実施の形態の入力情報分析装置の概略構成が図1に示されている。
本実施の形態の入力情報分析装置は、処理手段10、記憶手段20、入力手段30、出力手段40等により構成される。
記憶手段20としては、ROMやRAM等の種々の記憶手段を用いることができる。記憶手段20は、入力された複数の入力情報が記憶される入力情報データベース20aを有している。記憶手段20の配設位置は、処理手段10がアクセス可能な範囲内で適宜設定可能である。
記憶手段20が本発明の「記憶手段」に対応する。
入力手段30としては、入力情報や各種の指示信号等を入力可能な、キーボード、表示手段の表示部に設けられているタッチパネル、マウス、記憶媒体に記憶されている情報を読み取る情報読取手段等の種々の入力手段を用いることができる。
入力手段30が本発明の「入力手段」に対応する。
出力手段40としては、表示手段や印刷手段等の出力情報を視覚で確認することができる出力手段を用いることができる。なお、遠方の端末装置と通信可能に構成される場合には、遠方の端末装置の入力手段や出力手段が、本発明の入力手段や出力手段に対応する。
出力手段40が本発明の「出力手段」に対応する。
【0013】
処理手段10は、管理手段10a、入力情報解析手段10b、クラスタ帰属度判別手段10c、クラスタラベル語判別手段10d、クラスタシンボル座標情報算出手段10e、入力シンボル座標情報算出手段10fを有している。処理手段10は、各手段10a〜10fの処理を実行する1つのCPUによって構成することもできるし、複数の処理手段の処理を実行する個別のCPUによって構成することもできる。
管理手段10aが本発明の「管理手段」に対応し、入力情報解析手段10bが本発明の「入力情報解析手段」に対応し、クラスタ帰属度判別手段10cが本発明の「分類帰属度判別手段」に対応し、クラスタラベル語判別手段10dが本発明の「分類特徴情報判別手段」に対応し、クラスタシンボル座標情報算出手段10eが本発明の「分類シンボル座標情報算出手段」に対応し、入力シンボル座標情報算出手段10fが本発明の「入力シンボル座標情報算出手段」に対応する。
【0014】
管理手段10aは、入力情報分析装置全体の処理を管理する。例えば、入力手段30からの入力情報や指示信号等の入力処理、クラスタシンボル情報、クラスタラベル語や入力シンボル情報の出力手段(表示手段や印刷手段)40への出力処理、各手段10b〜10fによる処理の実行等を管理する。なお、管理手段10aの処理を入力情報解析手段10b、クラスタ帰属度判別手段10c、クラスタラベル語判別手段10d、クラスタシンボル座標情報算出手段10e、入力シンボル座標情報算出手段10fにより実行するように構成することもできる。管理手段10aによる出力態様については後述する。
【0015】
入力情報解析手段10bは、入力手段30から入力されて記憶手段20の入力情報データベース20aに記憶されている入力情報を分割し、入力情報を構成している単語情報を抽出する。入力情報を構成している単語情報を抽出する手法としては、例えば、入力情報を形態素に分解する形態素解析手法が用いられる。形態素解析手法としては、種々の手法が知られている。例えば、最長一致法、分割数最小法等が知られている。なお、入力情報を形態素に分解する際に用いられる辞書が記憶手段20に記憶されている。
また、抽出した各単語情報(変化形を考慮した異なる単語情報)と各入力情報との対応関係を解析する。各単語情報と各入力情報との対応関係は、例えば、n個の単語情報×m個の入力情報から成る行列の形態で解析することができる。
入力情報データベース20aに記憶されている入力情報は、入力手段30から入力されて記憶される。したがって、入力情報データベース20aに記憶されている入力情報は、入力手段30から入力された入力情報に包含される。
【0016】
クラスタ帰属度判別手段10cは、入力情報解析手段10bにより解析された、各単語情報と各入力情報との対応関係と、入力手段30から入力されたクラスタ数(分類数)kに基づいて、入力情報がクラスタ(分類)に属する度合いを示す入力情報の帰属度を、各入力情報について、クラスタ数kの各クラスタに対して判別する。すなわち、各入力情報の各クラスタ(分類)に対する帰属度を判別する。
ここで、複数の入力情報をクラスタリングする(分類する)手法としては、種々の手法が知られている。
例えば、入力情報が属するクラスタ(分類)を一つに決定するハードクラスタリングが知られている。代表的なアルゴリズムとしては、例えば、k−means法、スペクトルクラスタリングが知られている。
また、入力情報が複数のクラスタ(分類)に属することを許容するソフトクラスタリングが知られている。代表的なアルゴリズムとしては、例えば、NMF(Non−negative Matrix Factorization:非負値行列因子分解)、pLSI、混合分布モデルが知られている。
NMFは、特異値分解と異なり、非負の行列に分解する次元縮約を利用したクラスタリング手法であり、文書以外にも画像、音声等のデータも取り扱うことができる。この手法により、文書データのクラスタリングと同時に、生成されたクラスタの特徴を表すクラスタラベル語(分類特徴語)を抽出することができる。
本実施の形態では、入力情報のクラスタリング手法としてNMFを用いている。
【0017】
NMFは、例えば、D.D.Lee and H.S.Seung“Algorithm for non−negative matrix factorization”(in Proc.NIPS,pp.556−562,2000)等に詳述されているが、要約すると以下のような手法である。
以下の[式1]に示すように、n×mの単語文書行列Xを、想定するクラスタ数kの次元に縮約するために、n×kの行列Uと、k×mの行列VTに分解する。VTは、Vの転置行列である。なお、nは、異なり単語数(入力された複数の文章中に出現する異なる単語の数)であり、mは、文書数であり、kは、クラスタ数(分類数)である。行列Xの要素としては、単語情報を用いることもできるし、[1]あるいは[0]を用いることもできるし、単語情報重要度評価値(TF−IDF)を用いることもできる。単語情報重要度評価値(TF−IDF)は、(TF−IDF)=TF×log(N/DF)によって求めることができる。ここで、TFは、文書毎の単語情報出現回数であり、Nは、文書の数であり、DFは、ある単語情報を含む文書の数である。
X=U×VT 〔式1〕
[式1]で分解された行列Uは、単語がクラスタに属する度合い(単語のクラスタに対する帰属度)を示し、行列Vは、文書がクラスタに属する度合い(文書のクラスタに対する帰属度)を示す。また、複数の単語のうち、クラスタに属する度合い(単語のクラスタに対する帰属度)の高い単語は、そのクラスタの特徴語(クラスタの内容を示すクラスタラベル語)として抽出することができる。
ここで、NMFは、縮約後の各軸をトピック(話題)と解釈することができ、その軸へ射影した値が関連度の大きさを表していると考える。NMFでは、縮約後の各軸は、LSI(潜在的意味インデキシング)のように直交していないが、縮約後の各軸を文書の構成要素であるトピックと捉えることによって、より意味的に適切なクラスタリングを行うことができる。
NMFを用いたクラスタリングでは、与えられた単語文書行列Xとクラスタ数kから、行列VとUを以下の[式2]の繰り返し計算から求める。
【数1】
[式2]
なお、UとVの初期値は適当な乱数が与えられる。
繰り返し計算によって||X−UVT||の値(分解の誤差)は単調に減少するが、解の最適性を保証するものではない(初期値に依存して局所最適解に収束)。
【0018】
クラスタラベル語判別手段10dは、入力情報解析手段10bにより解析された、各単語情報と各入力情報との対応関係と、入力手段30から入力されたクラスタ数(分類数)kに基づいて、単語情報がクラスタに属する度合いを示す単語情報の帰属度を、各単語情報について、クラスタ数kの各クラスタに対して判別する。すなわち、各単語情報の各クラスタ(分類)に対する帰属度を判別する。
そして、判別した各単語情報の各クラスタに対する帰属度に基づいて、各クラスタに対して、複数の単語情報の中からクラスタラベル数(分類特徴情報数)の単語情報を選択し、選択した単語情報を各クラスタのクラスタラベル語(分類特徴情報)として判別する。クラスタラベル数は、入力手段30から適宜入力することができる。勿論、記憶手段20に予め記憶されているクラスタラベル数を用いることもできる。また、各単語情報の各クラスタに対する帰属度に基づいて、クラスタラベル数の単語情報を選択する方法としては、例えば、各単語情報の該当クラスタに対する帰属度を比較し、該当クラスタに対する帰属度が高いクラスタラベル数の単語情報を選択する方法が用いられる。
【0019】
本実施の形態では、クラスタ帰属度判別手段10cによる、入力情報のクラスタに対する帰属度の判別、クラスタラベル語判別手段10dによる、単語情報のクラスタに対する帰属度の判別は、同時に行われる。すなわち、前述したように、NMFでは、n個の単語情報×m個の入力情報の単語文書行列Xを、単語情報のクラスタに対する帰属度を示す、n個の単語情報×k個のクラスタの行列Uと、入力情報のクラスタに対する帰属度を示す、k個のクラスタ×m個の入力情報の行列VTに分解し、行列UとVを同時に計算している。
なお、クラスタ帰属度判別手段10cによる、入力情報のクラスタに対する帰属度の判別方法や、クラスタラベル語判別手段10dによる、単語情報のクラスタに対する帰属度の判別方法はこれに限定されない。
【0020】
クラスタシンボル座標情報算出手段10eは、クラスタ帰属度判別手段10cによって判別された各入力情報の各クラスタに対する帰属度に基づいて、各クラスタを示すクラスタシンボル情報を2次元平面上に配置するためのクラスタシンボル座標情報を算出する。本実施の形態では、クラスタシンボル座標情報算出手段10eは、各入力情報の各クラスタに対する帰属度に基づいて、多変量解析の一手法である対応分析により、クラスタ間の相関を表す2次元座標情報を算出する。さらに、各クラスタシンボル情報を、類似しているクラスタを示すクラスタシンボル情報が隣接するように2次元平面上に配置するためのクラスタシンボル座標情報を算出する。クラスタが類似しているか否かは、例えば、クラスタに属する1つまたは複数の入力情報に同じ単語情報が含まれている度合い、クラスタに属する1つまたは複数の入力情報における同じ単語情報の出現回数等により判別することができる。
また、後述する入力情報を示す入力シンボル情報とクラスタシンボル情報との関係や入力情報の分布状態の判別を容易にするために、対応分析により算出した座標情報を、円(例えば、表示手段の表示エリアの内接円)または楕円に射影し、射影した位置を、クラスタシンボル情報を配置するクラスタシンボル座標情報として用いている。
クラスタシンボル情報を、円または楕円等の閉じている線に沿って、類似しているクラスタを示すクラスタシンボル情報が隣接するように配置する方法としては適宜の方法を用いることができる。例えば、一方向(時計回り方向あるいは反時計回り方向)に、類似しているクラスタが隣接するように各クラスタを示すクラスタシンボル情報を配置する方法を用いることができる。
クラスタシンボル情報を2次元平面上の円または楕円に沿って(閉じている線に沿って)配置することにより、類似したクラスタをより容易に把握することができる。勿論、クラスタシンボル情報の配置態様は、これに限定されず、適宜設定可能である。
【0021】
また、クラスタシンボル座標情報算出手段10cは、各クラスタのクラスタラベル語を、クラスタシンボル情報が配置された2次元平面上のクラスタシンボル情報が配置されている箇所の周り(例えば、クラスタシンボル情報が配置されている箇所を中心とする円または楕円に沿って)配置するためのクラスタラベル語座標情報を算出する。クラスタラベル語をクラスタシンボル情報の周りに配置する方法については後述する。
このように、クラスタシンボル情報の周りに、当該クラスタシンボル情報で示されるクラスタのクラスタラベル語が配置されていることにより、クラスタの内容を容易に把握することができる。
本実施の形態では、クラスタシンボル座標情報算出手段10eによってクラスタシンボル座標情報およびクラスタラベル語座標情報を算出したが、クラスタシンボル座標情報算出手段10eに代えて、クラスタシンボル座標情報算出手段とクラスタラベル語座標情報算出手段を設け、クラスタシンボル座標情報算出手段により、前述した方法でクラスタシンボル座標情報を算出し、クラスタラベル語座標情報算出手段により、前述した方法でクラスタラベル語座標情報を算出してもよい。
【0022】
入力シンボル座標情報算出手段10eは、入力情報を示す入力シンボル情報を、クラスタシンボル情報が配置された2次元平面上に配置するための入力シンボル座標情報を算出する。なお、クラスタシンボル情報が配置された2次元平面は、クラスタを座標軸とする2次元平面に対応する。
【0023】
管理手段10aは、クラスタシンボル座標情報算出手段10eで算出されたクラスタシンボル座標情報およびクラスタラベル語座標情報、入力シンボル座標情報算出手段10fで算出された入力シンボル座標情報に基づいて、クラスタシンボル情報およびクラスタラベル語、入力シンボル情報を出力手段(例えば、表示手段)40に出力する。
クラスタシンボル情報、入力シンボル情報としては、記号、文字や線等の種々の情報を用いることができる。また、クラスタラベル語としては、通常、文字情報が用いられる。
【0024】
次に、本実施の形態の動作を図2に示すフローチャートを用いて説明する。
図2に示されている処理は、例えば、入力情報分析処理の開始を指示する入力情報分析処理開始信号が入力手段30から入力されることによって開始される。
【0025】
ステップA1では、入力手段30から入力されたm個の文書(入力情報)Di(i:1,2,…,m)を記憶手段20の入力情報データベース20aに記憶する。なお、文書(入力情報)Diは、予め入力情報データベース20aに記憶させておいてもよい。
ステップA2では、入力手段30からクラスタ数(分類数)k、クラスタラベル語数(分類特徴情報数)uが入力される。なお、クラスタ数kおよびクラスタラベル語数uは、予め入力し、記憶手段20に記憶させておいてもよい。
ステップA3では、入力されたm個の文書からn個の単語情報Wt(t:1,2,…,n)を抽出する。そして、抽出した各単語情報Wtと各文書Diとの対応関係を判別する。ステップA3の処理は、入力情報解析手段10bによって実行される。
【0026】
ステップA4では、ステップA3で判別した、各単語情報Wtと各文書Diとの対応関係と、ステップA2で入力されたクラスタ数kに基づいて、各文書Diの、クラスタ数kの各クラスタCj(j:1,2,…,k)に対する帰属度(文書の帰属度)Rij(i:1,2,…,m、j:1,2,…k)を判別する。ステップA4の処理は、クラスタ帰属度判別手段10cによって実行される。各文書Diの各クラスタCjに対する帰属度を判別した1例が、図3に示されている(図3では、クラスタ数kが10に設定されている)。
【0027】
ステップA5では、ステップA3で判別した、各単語情報Wtと各文書Diとの対応関係と、ステップA2で入力されたクラスタ数kに基づいて、各単語情報Wtの、クラスタ数kの各クラスタCj(j:1,2,…,k)に対する帰属度(単語情報の帰属度)を判別する。各単語情報Wtの各クラスタCjに対する帰属度を判別した1例が、図4に示されている(図4では、クラスタ数kが10に設定されている)。
そして、判別した、各単語情報Wtの各クラスタCjに対する帰属度に基づいて、各クラスタCjに対して、複数の単語情報Wtの中から、ステップA2で入力されたクラスタラベル語数uの単語情報を選択し、選択したクラスタラベル語数uの単語情報を各クラスタCjのクラスタラベル語Sjr(j:1,2,…,k、r:1,2,…,u)として判別する。ステップA5の処理は、クラスタラベル語判別手段10dによって実行される。
【0028】
ステップA6では、ステップA4で判別された、各文書Diの各クラスタCjに対する帰属度Rijに基づいて、各クラスタCjを示すクラスタシンボル情報SCjを2次元平面上に配置するためのクラスタシンボル座標情報SCj(xj,yj)を算出する。
本実施の形態では、まず、各文書Diの各クラスタCjに対する帰属度Rijに基づいて、対応分析により、図5に示されているように、クラスタCj間の相関を表す2次元座標情報を算出する。この時、類似しているクラスタCjを示すクラスタシンボル情報が隣接するように2次元座標情報が算出される。
そして、図6に示されているように、算出した2次元座標情報を、表示手段の表示画面に内接する円または楕円に射影した位置を示す2次元座標情報を、各クラスタCjを示すクラスタシンボル情報SCjのクラスタシンボル座標情報SCj(xj,yj)とする。ステップA6の処理は、クラスタシンボル座標情報算出手段10eによって実行される。
【0029】
ステップA7では、ステップA5で判別した、各クラスタCjのクラスタラベル語Sjrを、2次元平面上に配置するためのクラスタラベル語座標情報Sjr(xjr,yjr)を算出する。本実施の形態では、クラスタラベル語Sjrが、クラスタCjを示すクラスタシンボル情報SCjが配置される箇所を中心とする円または楕円に沿って配置されるようにクラスタラベル語座標情報Sjr(xjr,yjr)を算出する。
図8に、クラスタC1を示すクラスタシンボル情報が配置されている箇所を中心とする円に沿ってクラスタC1のクラスタラベル語W10〜W19が配置されている1例が示されている。クラスタラベル語W10〜W19は、クラスタシンボル情報の周りに同じ表示態様で配置されていてもよいが、クラスタラベル語の重要度等に応じて配置位置や表示態様を変えて配置するのが好ましい。
図8では、クラスタラベル語W10〜W19の文書内での共起関係に基づいてグループ分けし、グループ毎に配置している。文書内での共起関係は、例えば、クラスタラベル語が該当クラスタに分類された同一文書に出現しているか否かによって判別する方法等を用いることができる。図8の例では、クラスタラベル語W10、W11およびW12が同じ文書内に出現していることから共起関係がある(相関が高い)と見なされ、{W10、W11、W12}を含むグループができる。同様に、共起関係から、{W13、W14}、{W15、W16、W17}、{W18、W19}を含むグループができる。
クラスタラベル語座標情報の算出方法については、共起関係によりグループ化を行い、得られたグループ数を判別する。次に、クラスタシンボル情報が配置されている箇所を中心とする円周を前記判別したグループ数で等分し、クラスタラベル語の各グループを円周上に配置する起点となる座標を算出する。図8では、円周をグループ数4で等分した箇所を、各グループの起点として算出している。そして、算出したクラスタラベル語の各グループの起点となる座標から一方向(時計方向あるいは反時計方向)に各グループのクラスタラベル語を順に配置する。これにより、クラスタの内容を示す各クラスタラベル語の相関を容易に把握することができる。
なお、各グループのクラスタラベル語を配置する際の配置順序は、各クラスタラベル語の重要度の順等を用いることができる。クラスタラベル語の重要度は、各単語の単語情報重要度評価値(TF−IDF)や、各単語のクラスタに対する帰属度を用いて判別することができる。
また、図8では、各クラスタラベル語W10〜W19の重要度に応じて各クラスタラベル語W10〜W19のフォントサイズを変更している。これにより、各クラスタラベル語W10〜W19の重要度を容易に把握することができる。なお、各クラスタラベル語W10〜W19の重要度を識別可能に表示する方法としては、フォントサイズを変更する方法以外にも、例えば、色を変更する方法等を用いることもできる。
クラスタラベル語の配置方法や表示方法(フォントサイズ、色等)は、前述した方法に限定されず種々の方法を用いることができる。
また、ステップA7の処理は、クラスタシンボル座標情報算出手段10eによって実行される。
【0030】
ステップA8では、各文書Diを示す文書シンボル情報(入力シンボル情報)SDiを、クラスタシンボル情報SCjが配置された2次元平面上に配置するための文書シンボル座標情報(入力シンボル座標情報)SDi(xi,yi)を算出する。文書シンボル座標情報SDi(xi,yi)は、クラスタシンボル情報SCjのクラスタシンボル座標情報SCj(xj,yj)と、各文書Diの各クラスタCjに対する帰属度Rijにより一義的に定まる。
図7には、クラスタシンボル情報SCjと文書シンボル情報SDiが表示された1例が示されている。図7に示されている例は、文書D5のクラスタC1に対する帰属度が0.7、クラスタC4に対する帰属度が0.8、クラスタC2およびC3に対する帰属度が0の場合のものである。この場合、クラスタC1に対する帰属度0.7の長さを有するクラスタC1方向のベクトルと、クラスタC4に対する帰属度0.8の長さを有するクラスタC4方向のベクトルを合成した合成ベクトルが文書D5のベクトルを表している。これにより、文書D5を示す文書シンボル情報の文書シンボル座標情報が決定される。なお、各文書のベクトルの長さは、正規化することもできる。
ステップA8の処理は、入力シンボル座標情報算出手段10fによって実行される。
【0031】
ステップA9では、ステップA6で算出されたクラスタシンボル座標情報SCj(xj,yj)、ステップA7で算出されたクラスタラベル語座標情報Sjr(xjr.yjr)、ステップA8で算出された文書シンボル座標情報SDi(xi,yi)に基づいて、クラスタシンボル情報SCj、クラスタラベル語Sjr、文書シンボル情報SDiを出力手段40から出力する。
ステップA9の処理は、管理手段10aによって実行される。
【0032】
表示手段の表示画面にクラスタシンボル情報(分類シンボル情報)、クラスタラベル語(分類特徴情報)、文書シンボル情報(入力シンボル情報)が表示された1例が図11に示されている。
本実施の形態では、各クラスタを示すクラスタシンボル情報が、2次元平面上の円に沿って、類似しているクラスタ(分類)を示すクラスタシンボル情報が隣接するように配置されている。また、各クラスタの内容を示すクラスタラベル語が、クラスタシンボル情報を中心とする円に沿って、重要度や共起関係に基づいた配置位置や表示態様で配置されている。そして、文書シンボル情報が、各クラスタに対する帰属度に対応する位置に配置されている。
これにより、入力情報にどのような話題のグループ(クラスタ)があるかを把握することができる。また、類似しているクラスタを容易に把握することができる。また、クラスタラベル語により、クラスタの内容をある程度理解することができる。また、クラスタシンボル情報の位置と文書シンボル情報の位置によって、文書の話題間の相関をある程度把握することができる。
【0033】
クラスタラベル語の表示方法として、前記した方法に限定されない。例えば、異なるクラスタのクラスタラベル語のうち、共通するクラスタラベル語を線で結ぶように表示することもできる。図9では、クラスタC1のクラスタラベル語とクラスタC3のクラスタラベル語のうち、共通するクラスタラベル語W14を線で結んでいる。これにより、クラスタラベル語を介して、クラスタ間の意味的な関連性を把握することができる。
【0034】
また、図10に示されているように、階層状にクラスタリングすることもできる。図10では、第1階層では、m個の文書を4個のクラスタC1〜C4でクラスタリングした状態が示されている。この状態で、クラスタC2を示すクラスタシンボル情報が指示されて、クラスタC2を指示するクラスタ指示信号(分類C2を指示する分類指示信号)が入力手段30から入力されると、m個の文書のうち、クラスタC2に分類された文書を更に4個のクラスタC21〜C24でクラスタリングした状態が示される。また、第1階層が表示されている状態で、クラスタC1を示すクラスタシンボル情報が指示されて、クラスタC1を指示するクラスタ指示信号(分類C1を指示する分類指示信号)が入力手段30から入力されると、m個の文書のうち、クラスタC1に分類された文書を更に4個のクラスタC11〜C14でクラスタリングした状態が示される。
なお、現在の表示状態がどの階層にあるかを把握することができるようにするために、階層状態を示す階層ナビゲーションを設けるのが好ましい。階層ナビゲーションウィンドウは、階層状にクラスタリングが可能なクラスタを指示するために使用することもできる。各階層のクラスタ数は、同じであってもよいし、入力手段30から異なるクラスタ数を設定することができるようにしてもよい。また、下位のクラスタリングが必要な場合に、クラスタ数を設定することができるようにしてもよい。
階層状のクラスタリングを可能とすることにより、より詳細に入力文書の分析を行うことができる。
【0035】
また、任意のクラスタラベル語を含む文書を表示させることもできる。
例えば、図11に示されているように、クラスタシンボル情報、クラスタラベル語、文書シンボル情報が表示画面に表示されている状態で、任意のクラスタラベル語(例えば、「太陽光発電」)が指示されて、クラスタラベル語を指示するクラスタラベル語指示信号(分類特徴情報を指示する分類特徴情報指示信号)が入力手段30から入力されると、クラスタラベル語指示信号で指示されているクラスタラベル語を含む文書(例えば、「太陽光発電」を含む文書)を示す文書シンボル情報が他の文書シンボル情報と識別可能な出力態様で出力される。他の文書シンボル情報と識別可能な出力態様としては、例えば、色、形、大きさ等が異なる出力態様を用いることができる。
なお、クラスタラベル語指示信号で指示されているクラスタラベル語を含む文書(入力情報)も出力可能に構成するのが好ましい。例えば、入力されたクラスタラベル語報指示信号で指示されているクラスタラベル語を含む文書を示す文書シンボル情報を、他の文書シンボル情報と異なる出力態様で出力するとともに、当該クラスタラベル語を含む文書の一覧を出力するように構成する。あるいは、入力されたクラスタラベル語指示信号で指示されているクラスタラベル語を含む文書を示す文書シンボル情報を、他の文書シンボル情報と異なる出力態様で出力し、この状態で、文書出力要求信号(入力情報出力要求信号)が入力手段30から入力されると、当該クラスタラベル語を含む入力情報の一覧を出力する。文書出力要求信号(入力情報出力要求信号)の入力方法としては、例えば、入力されたクラスタラベル語指示信号で指示されているクラスタラベル語を含む文書を示す文書シンボル情報(分類特徴情報を含む入力情報を示す入力シンボル情報)のいずれかを指示する方法等を用いることができる。
これにより、クラスタラベル語(分類特徴情報)と文書(入力情報)との対応関係、同じクラスタラベル語(分類特徴情報)を含む文書(入力情報)の数や分布状態を容易に把握することができる。
【0036】
本発明は、コンピュータに、前述した管理手段、入力情報解析手段、分類帰属度判別手段、分類特徴情報判別手段、分類シンボル座標情報算出手段と、入力シンボル座標情報算出手段の処理を実行させるためのプログラムあるいはプログラムが記憶された記憶媒体として構成することもできる。
【0037】
本発明は、実施の形態で説明した構成に限定されず、種々の変更、追加、削除が可能である。
例えば、クラスタシンボル情報(分類シンボル情報)を円または楕円に沿って配置したが、クラスタシンボル情報(分離シンボル情報)の配置態様は適宜変更可能である。また、クラスタシンボル情報(分類シンボル情報)の表示態様も適宜変更可能である。
クラスタラベル語(分類特徴情報)をクラスタシンボル情報(分類シンボル情報)を中心とする円または楕円に沿って配置したが、クラスタラベル語(分類特徴情報)の配置態様はこれに限定されない。また、クラスタラベル語(分類特徴情報)の出力は省略することもできる。
各文書(入力情報)の各クラスタ(分類)に対する帰属度や、各単語情報の各クラスタ(分類)に対する帰属度を判別する方法としては、NMF以外の種々の方法を用いることができる。
【符号の説明】
【0038】
10 処理手段
10a 管理手段
10b 入力情報解析手段
10c クラスタ帰属度判別手段(分類帰属度判別手段)
10d クラスタラベル語判別手段(分類特徴情報判別手段)
10e クラスタシンボル座標情報算出手段(分類シンボル座標情報算出手段)
10f 入力シンボル座標情報算出手段
20 記憶手段
20a 入力情報データベース
30 入力手段
40 出力手段
【特許請求の範囲】
【請求項1】
入力情報を分析する入力情報分析装置であって、
入力手段と、管理手段と、入力情報解析手段と、分類帰属度判別手段と、分類特徴情報判別手段と、分類シンボル座標情報算出手段と、入力シンボル座標情報算出手段と、出力手段を備え、
前記入力情報解析手段は、前記入力手段から入力された複数の入力情報に含まれている複数の単語情報を抽出し、抽出した前記各単語情報と前記各入力情報との対応関係を解析し、
前記分類帰属度判別手段は、前記入力情報解析手段によって解析された、前記各単語情報と前記各入力情報との対応関係と、前記入力手段から入力された分類数に基づいて、入力情報が分類に属する度合いを示す入力情報の帰属度を、前記各入力情報について、前記分類数の各分類に対して判別し、
前記分類特徴情報判別手段は、
前記入力情報解析手段によって判別された、前記各単語情報と前記各入力情報との対応関係と、前記入力手段から入力された前記分類数に基づいて、単語情報が分類に属する度合いを示す単語情報の帰属度を、前記各単語情報について、前記各分類に対して判別し、
前記判別した各単語情報の帰属度に基づいて、前記各分類に対して、前記複数の単語情報の中から、前記入力手段から入力された分類特徴情報数の単語情報を選択し、前記各分類の特徴を示す分類特徴情報として判別し、
前記分類シンボル座標情報算出手段は、前記分類帰属度判別手段によって判別された前記各入力情報の帰属度に基づいて、前記各分類を示す分類シンボル情報を、類似している分類を示す分類シンボル情報が隣接するように2次元平面上に配置するための分類シンボル座標情報を算出し、
前記入力シンボル座標情報算出手段は、前記各入力情報を示す入力シンボル情報を、前記分類シンボル情報が配置された、前記分類を座標軸とする2次元平面上に配置するための入力シンボル座標情報を算出し、
前記管理手段は、前記分類シンボル座標情報算出手段によって算出された分類シンボル座標情報および前記入力シンボル座標情報算出手段によって算出された入力シンボル座標情報に基づいて、前記分類シンボル情報および前記入力シンボル情報を前記出力手段から出力することを特徴とする入力情報分析装置。
【請求項2】
請求項1に記載の入力情報分析装置であって、
前記分類シンボル座標情報算出手段は、前記分類シンボル情報が、2次元平面上の円または楕円に沿った位置に配置されるように、前記分類シンボル座標情報を算出することを特徴とする入力情報分析装置。
【請求項3】
請求項1または2に記載の入力情報分析装置であって、
前記分類シンボル座標情報算出手段は、さらに、前記算出した分類シンボル座標情報で示される位置を中心とする円または楕円に沿った位置に、当該分類シンボル座標位置に配置される分類シンボル情報で示される分類の分類特徴情報を配置するための分類特徴座標情報を算出し、
前記管理手段は、前記分類シンボル座標情報算出手段によって算出された分類特徴座標情報に基づいて、前記分類特徴情報を前記出力手段から出力することを特徴とする入力情報分析装置。
【請求項4】
請求項3に記載の入力情報分析装置であって、
前記管理手段は、前記分類シンボル情報、前記入力シンボル情報および前記分類特徴情報を前記出力手段から出力している状態で、いずれかの分類特徴情報を指示する分類特徴情報指示信号が前記入力手段から入力されると、前記入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力することを特徴とする入力情報分析装置。
【請求項5】
コンピュータに請求項1〜4のいずれかに記載の前記管理手段と、前記入力情報解析手段と、前記分類帰属度判別手段と、前記分類特徴情報判別手段と、前記分類シンボル座標情報算出手段と、前記入力シンボル座標情報算出手段の処理を実行させるためのプログラム。
【請求項6】
コンピュータに請求項1〜4のいずれかに記載の前記管理手段と、前記入力情報解析手段と、前記分類帰属度判別手段と、前記分類特徴情報判別手段と、前記分類シンボル座標情報算出手段と、前記入力シンボル座標情報算出手段の処理を実行させるためのプログラムが記録された記憶媒体。
【請求項1】
入力情報を分析する入力情報分析装置であって、
入力手段と、管理手段と、入力情報解析手段と、分類帰属度判別手段と、分類特徴情報判別手段と、分類シンボル座標情報算出手段と、入力シンボル座標情報算出手段と、出力手段を備え、
前記入力情報解析手段は、前記入力手段から入力された複数の入力情報に含まれている複数の単語情報を抽出し、抽出した前記各単語情報と前記各入力情報との対応関係を解析し、
前記分類帰属度判別手段は、前記入力情報解析手段によって解析された、前記各単語情報と前記各入力情報との対応関係と、前記入力手段から入力された分類数に基づいて、入力情報が分類に属する度合いを示す入力情報の帰属度を、前記各入力情報について、前記分類数の各分類に対して判別し、
前記分類特徴情報判別手段は、
前記入力情報解析手段によって判別された、前記各単語情報と前記各入力情報との対応関係と、前記入力手段から入力された前記分類数に基づいて、単語情報が分類に属する度合いを示す単語情報の帰属度を、前記各単語情報について、前記各分類に対して判別し、
前記判別した各単語情報の帰属度に基づいて、前記各分類に対して、前記複数の単語情報の中から、前記入力手段から入力された分類特徴情報数の単語情報を選択し、前記各分類の特徴を示す分類特徴情報として判別し、
前記分類シンボル座標情報算出手段は、前記分類帰属度判別手段によって判別された前記各入力情報の帰属度に基づいて、前記各分類を示す分類シンボル情報を、類似している分類を示す分類シンボル情報が隣接するように2次元平面上に配置するための分類シンボル座標情報を算出し、
前記入力シンボル座標情報算出手段は、前記各入力情報を示す入力シンボル情報を、前記分類シンボル情報が配置された、前記分類を座標軸とする2次元平面上に配置するための入力シンボル座標情報を算出し、
前記管理手段は、前記分類シンボル座標情報算出手段によって算出された分類シンボル座標情報および前記入力シンボル座標情報算出手段によって算出された入力シンボル座標情報に基づいて、前記分類シンボル情報および前記入力シンボル情報を前記出力手段から出力することを特徴とする入力情報分析装置。
【請求項2】
請求項1に記載の入力情報分析装置であって、
前記分類シンボル座標情報算出手段は、前記分類シンボル情報が、2次元平面上の円または楕円に沿った位置に配置されるように、前記分類シンボル座標情報を算出することを特徴とする入力情報分析装置。
【請求項3】
請求項1または2に記載の入力情報分析装置であって、
前記分類シンボル座標情報算出手段は、さらに、前記算出した分類シンボル座標情報で示される位置を中心とする円または楕円に沿った位置に、当該分類シンボル座標位置に配置される分類シンボル情報で示される分類の分類特徴情報を配置するための分類特徴座標情報を算出し、
前記管理手段は、前記分類シンボル座標情報算出手段によって算出された分類特徴座標情報に基づいて、前記分類特徴情報を前記出力手段から出力することを特徴とする入力情報分析装置。
【請求項4】
請求項3に記載の入力情報分析装置であって、
前記管理手段は、前記分類シンボル情報、前記入力シンボル情報および前記分類特徴情報を前記出力手段から出力している状態で、いずれかの分類特徴情報を指示する分類特徴情報指示信号が前記入力手段から入力されると、前記入力された分類特徴情報指示信号で指示されている分類特徴情報を含む入力情報を示す入力シンボル情報を、他の入力シンボル情報と異なる出力態様で出力することを特徴とする入力情報分析装置。
【請求項5】
コンピュータに請求項1〜4のいずれかに記載の前記管理手段と、前記入力情報解析手段と、前記分類帰属度判別手段と、前記分類特徴情報判別手段と、前記分類シンボル座標情報算出手段と、前記入力シンボル座標情報算出手段の処理を実行させるためのプログラム。
【請求項6】
コンピュータに請求項1〜4のいずれかに記載の前記管理手段と、前記入力情報解析手段と、前記分類帰属度判別手段と、前記分類特徴情報判別手段と、前記分類シンボル座標情報算出手段と、前記入力シンボル座標情報算出手段の処理を実行させるためのプログラムが記録された記憶媒体。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【公開番号】特開2012−88930(P2012−88930A)
【公開日】平成24年5月10日(2012.5.10)
【国際特許分類】
【出願番号】特願2010−234997(P2010−234997)
【出願日】平成22年10月19日(2010.10.19)
【出願人】(599105850)株式会社中電シーティーアイ (13)
【出願人】(000213297)中部電力株式会社 (811)
【Fターム(参考)】
【公開日】平成24年5月10日(2012.5.10)
【国際特許分類】
【出願日】平成22年10月19日(2010.10.19)
【出願人】(599105850)株式会社中電シーティーアイ (13)
【出願人】(000213297)中部電力株式会社 (811)
【Fターム(参考)】
[ Back to top ]