
処理装置、分散処理システム、及び処理プログラム
【課題】分散処理システムにおける性能・スケーラビリティを改善する。
【解決手段】Reduce処理部における集約キーの更新ができなくなるまで、Map処理部が複数のデータそれぞれが有するキーを、集約キー、未使用キー、及び使用済みキーとして関連付けてMapデータを生成する処理と、Reduce処理部が、集約キーを用いてMapデータを集約するとともに、集約後のMapデータのグループに含まれる各Mapデータの未使用キーを全て取得し、取得された未使用キーのうちの1つで、集約後のMapデータのグループに含まれる各Mapデータの集約キーを更新する(ステップS38)処理と、を繰り返す。これにより、関係データベースを用いなくとも、処理対象のデータを参照するのみで、複数のMapデータを集約することができる。
【解決手段】Reduce処理部における集約キーの更新ができなくなるまで、Map処理部が複数のデータそれぞれが有するキーを、集約キー、未使用キー、及び使用済みキーとして関連付けてMapデータを生成する処理と、Reduce処理部が、集約キーを用いてMapデータを集約するとともに、集約後のMapデータのグループに含まれる各Mapデータの未使用キーを全て取得し、取得された未使用キーのうちの1つで、集約後のMapデータのグループに含まれる各Mapデータの集約キーを更新する(ステップS38)処理と、を繰り返す。これにより、関係データベースを用いなくとも、処理対象のデータを参照するのみで、複数のMapデータを集約することができる。
【発明の詳細な説明】
【技術分野】
【0001】
本件は、処理装置、分散処理システム、及び処理プログラムに関する。
【背景技術】
【0002】
大量データを対象にした分析処理には、非常に長い処理時間を要する。これに対し、最近では、複数のマシンを用いて分散・並列処理を行うことで処理時間を短縮するアプローチがとられている。分散・並列処理としては、例えば、MapReduceアルゴリズムを用いた方法(例えば、非特許文献1参照)がある。また、MapReduceアルゴリズムのオープンソース実装として、Apache Hadoopが存在している。
【0003】
MapReduceは、主に元のデータを多数のキーと値のセットに分割する「Map処理」と、それらのキーと値のセットをあるルールによって集約する「Reduce処理」とによって構成される。Map処理及びReduce処理の各処理は、それぞれ複数並列に実行可能であるため、それらを複数の処理マシン(サーバなど)に割り当てることにより、複数マシンの処理性能を活用することができる。
【0004】
ただし、MapReduceによる分散・並列処理の効果を高めるには、それぞれのMap処理、Reduce処理の独立性を高くし、他の部分に依存せずに処理を行えるようにする必要がある。
【0005】
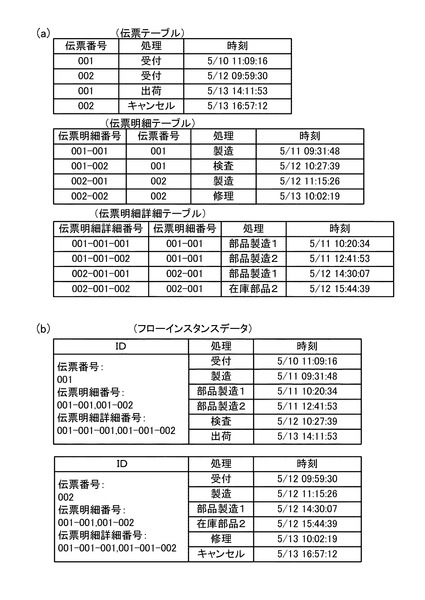
分析処理の一種として、大量のデータ群の中から、関係のあるデータをグルーピングするものがある。例えば、図33(a)に示すように、ある時期に行われた業務ログを、図33(b)に示すように、一連となっている業務フロー単位にグルーピングする場合などである。グルーピングの処理では、あるグループのデータ群を扱う際、別のグループのデータを考慮する必要が無いため、各グループの処理を複数サーバに分散させることにより、効率的に処理が行える。
【0006】
なお、図33(a)のように一連の業務フローが1つのキー種(図33(a)ではフローID)によって示されるデータをグルーピングする際には、MapReduceを用いることによってグルーピングは容易に達成される。MapReduceを行う処理マシンでは、あるキー値を持つデータ群を一箇所に集約する機能を標準で有しているためである。
【先行技術文献】
【非特許文献】
【0007】
【非特許文献1】Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters OSDI 2004
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかしながら、図34(a)のように、一連の業務フローを示すキーが複数(図34(a)では3種)存在する場合もあり得る。なお、図34(b)は、図34(a)のデータを集約した例を示している。このような場合には、単純にはグルーピングを行うことができない。複数のキー種を用いて関連のあるデータ群を集約する処理(以下、「複数キー集約処理」と呼ぶ)では、どのキーの組み合わせが一連のデータ群を示すのかが、データ全体を見ないと完全には確定しないからである。例えば、図34(a)の場合、伝票番号=001で集約しようとすると、伝票明細詳細テーブルのデータを集約できない。一方、伝票明細詳細番号=001-001-001で集約する場合、伝票テーブルのデータを集約できない。
【0009】
この場合、処理の進展に応じてキー値の組み合わせの情報を最新化しながら集約処理を進めるような工夫が必要であり、また、最新化する処理が不十分な場合には、データの集約漏れが発生する場合がある。
【0010】
これに対し、キー種間の関連を管理する表をRDB(関係データベース(Relational Database))などに作成することも考えられる。しかるに、分散・並列処理する各処理マシンが共通に参照・更新する箇所があると、分散処理の性能・スケーラビリティが劣化するおそれがある。
【0011】
そこで本件は上記の課題に鑑みてなされたものであり、性能・スケーラビリティの向上及びデータ集約漏れを防止することが可能な処理装置、分散処理システム、及び処理プログラムを提供することを目的とする。
【課題を解決するための手段】
【0012】
本明細書に記載の処理装置は、複数のキー種を用いて分類された複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を実行する処理装置であって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された、前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶する関連付け部と、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、該取得した未使用キーのうちの1つを次の集約キーとして決定し、前記取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する集約部と、を備え、前記集約キーの更新ができなくなるまで、前記関連付け部と前記集約部による処理を繰り返す処理装置である。
【0013】
本明細書に記載の分散処理システムは、本明細書に記載の処理装置を複数備え、複数の処理対象のデータを前記複数の処理装置に分散して、当該複数の処理装置において並行処理を実行する分散処理システムである。
【0014】
本明細書に記載の処理プログラムは、複数のキー種を用いて複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を、コンピュータに実行させる処理プログラムであって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと、未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶し、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、取得した前記未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを、前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを、取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、前記未使用キーの更新ができなくなるまで、コンピュータに繰り返し実行させる処理プログラムである。
【発明の効果】
【0015】
本明細書に記載の処理装置、分散処理システム、及び処理プログラムは、性能・スケーラビリティの向上、及びデータ集約漏れを防止することができるという効果を奏する。
【図面の簡単な説明】
【0016】
【図1】一実施形態に係る分散処理システムの構成を概略的に示す図である。
【図2】処理サーバのハードウェア構成を示す図である。
【図3】処理サーバの機能ブロック図である。
【図4】MapReduce処理の基本的な処理内容について説明するための図である。
【図5】MapReduce処理の一連の流れについて示すフローチャートである。
【図6】図6(a)は、Map処理における入力データの一例を示す図であり、図6(b)は、1つのMapデータのキー及び値の具体的な内容を示す図である。
【図7】集約対象のMapデータの一例を示す図である。
【図8】図8(a)〜図8(c)は、図7の最下層のテーブルについてMap処理を行った場合の例を説明するための図である。
【図9】ステップS14の具体的処理を示すフローチャート(その1)である。
【図10】ステップS14の具体的処理を示すフローチャート(その2)である。
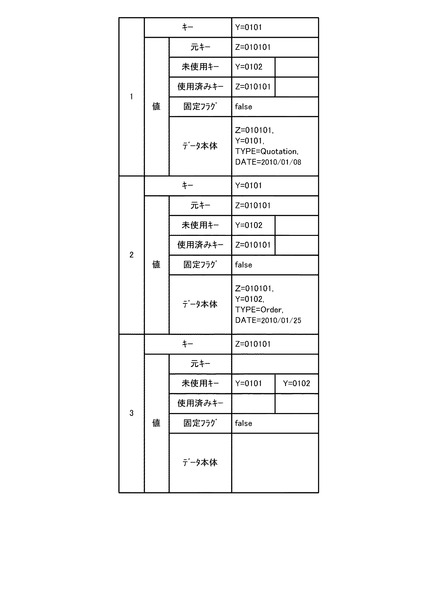
【図11】図11(a)は集約キーがZ=010101の集約グループを示す図であり、図11(b)は、図11(a)の集約グループのキー一覧リストであり、図11(c)は、図11(a)の集約グループのデータ一覧リストである。
【図12】図10のステップS38の処理を説明するための図である。
【図13】1回目の集約により、同階層で同一のキー値を持つデータ群が集約された様子を示した図である。
【図14】図14(a)〜図14(c)は、集約キーがY=0101のMapデータを集約する処理を説明するための図(リスト16,18)が示されている。
【図15】2回目の集約処理を行った後の状態を示す図である。
【図16】3回目の集約処理を行った後の状態を示す図である。
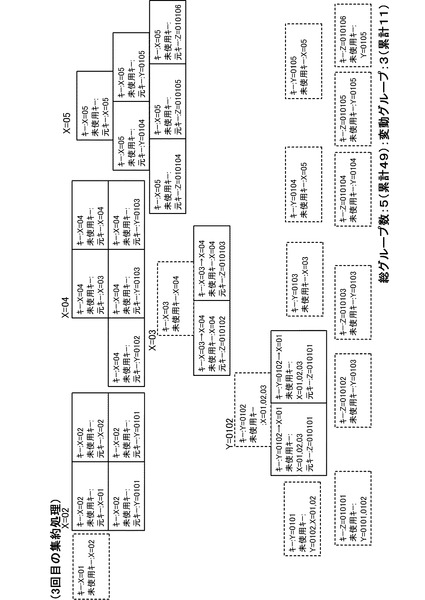
【図17】4回目の集約処理を行った後の状態を示す図である。
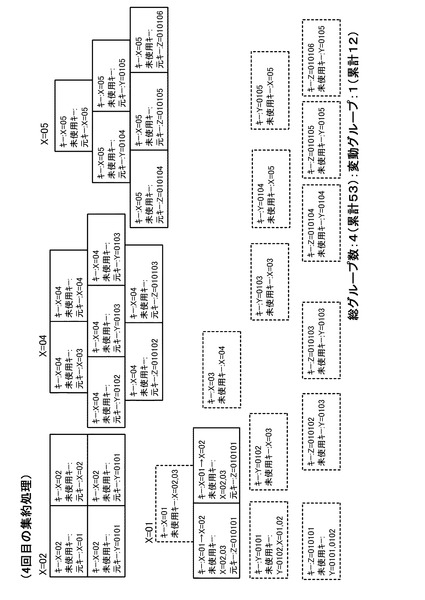
【図18】5回目の集約処理を行った後の状態を示す図である。
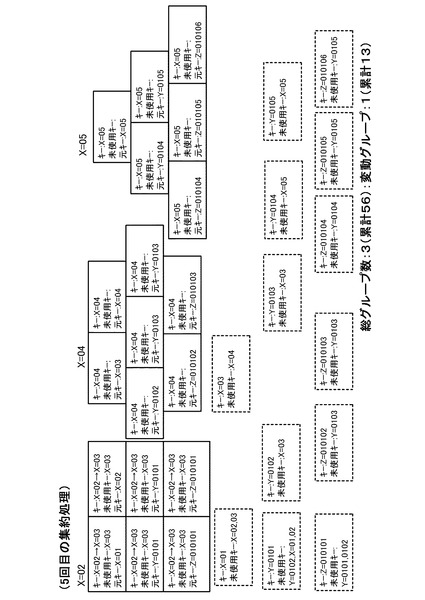
【図19】6回目の集約処理を行った後の状態を示す図である。
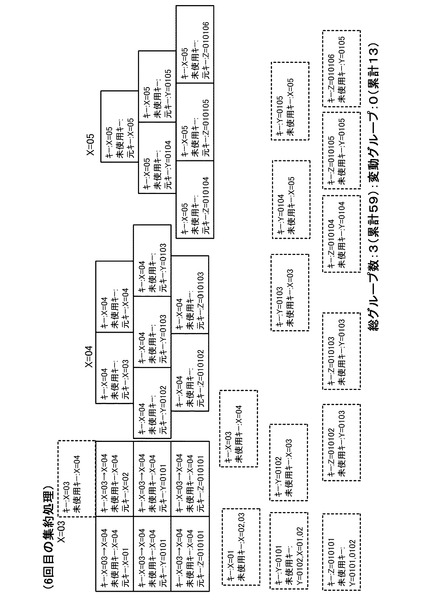
【図20】7回目の集約処理を行った後の状態を示す図である。
【図21】比較例において1回目の集約処理を行った後の状態を示す図である。
【図22】比較例において2回目の集約処理を行った後の状態を示す図である。
【図23】比較例において3回目の集約処理を行った後の状態を示す図である。
【図24】比較例において4回目の集約処理を行った後の状態を示す図である。
【図25】比較例において5回目の集約処理を行った後の状態を示す図である。
【図26】比較例において6回目の集約処理を行った後の状態を示す図である。
【図27】別例における図7に対応する図である。
【図28】別例において1回目の集約処理を行った後の状態を示す図である。
【図29】別例において2回目の集約処理を行った後の状態を示す図である。
【図30】別例において3回目の集約処理を行った後の状態を示す図である。
【図31】別例において4回目の集約処理を行った後の状態を示す図である。
【図32】別例において5回目の集約処理を行った後の状態を示す図である。
【図33】従来例を説明するための図(その1)である。
【図34】従来例を説明するための図(その2)である。
【発明を実施するための形態】
【0017】
以下、一実施形態について、図1〜図32に基づいて詳細に説明する。図1には、分散処理システム100の構成が概略的に示されている。本実施形態の分散処理システム100では、複数のキーが与えられたデータを集約する「複数キー集約処理」を行うこととし、当該処理では、MapReduceアルゴリズムを適用するものとする。ここで、集約とは、同一のキーのデータを取得することを意味する。
【0018】
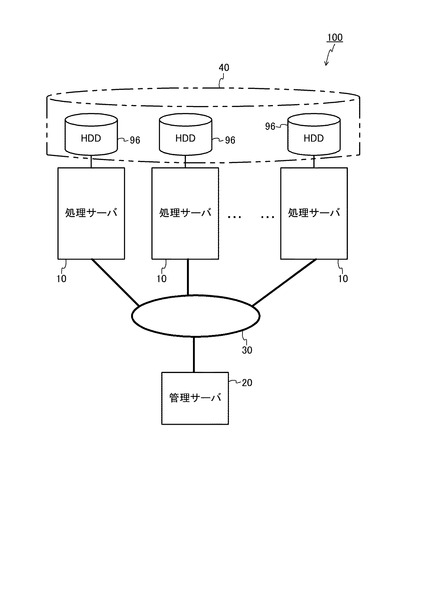
分散処理システム100は、図1に示すように、処理を実行するn台の処理装置としての処理サーバ10と、各処理サーバ10の処理を管理する管理サーバ20と、を備える。各処理サーバ10と管理サーバ20は、LAN(Local Area Network)、インターネットなどのネットワーク30に接続されている。
【0019】
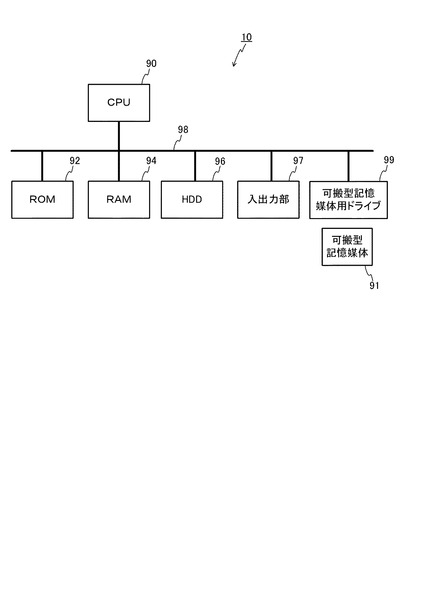
図2には、処理サーバ10のハードウェア構成が示されている。図2に示すように、処理サーバ10は、CPU90、ROM92、RAM94、記憶部(ここではHDD(Hard Disk Drive))96、入出力部97、可搬型記憶媒体用ドライブ99等を備えている。これら処理サーバ10の構成各部は、バス98に接続されている。処理サーバ10では、ROM92あるいはHDD96に格納されているプログラム(処理プログラム)、又は可搬型記憶媒体用ドライブ99が可搬型記憶媒体91から読み出したプログラム(処理プログラム)をCPU90が実行することにより、図3の各部の機能が実現される。
【0020】
図1に戻り、各処理サーバ10のディスク(HDD96)は、仮想的に1つのディスクに見える分散ファイルシステム40に組み込まれている。なお、図示の便宜上、図1では、HDD96を各処理サーバ10の外側に出して示している。なお、図1の構成図は、MapReduceのオープンソース実装であるHadoopを用いる場合の一例を示すものであり、管理サーバ20や分散ファイルシステム40は、分散処理システム100内に必ずしも設けなくてもよい。
【0021】
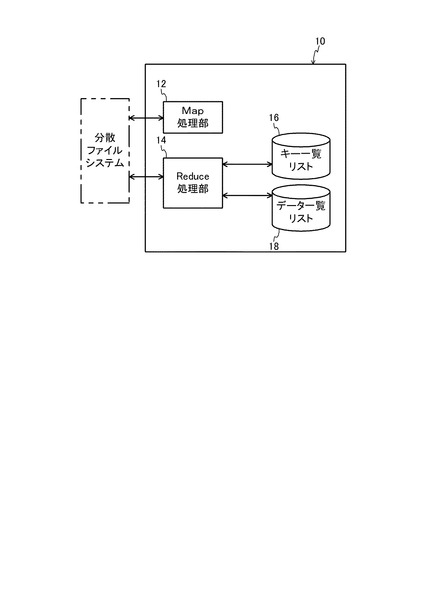
図3には、処理サーバ10の機能ブロック図が示されている。処理サーバ10は、図3に示すように、関連付け部としてのMap処理部12、及び集約部としてのReduce処理部14、としての機能を有する。また、HDD96により、キー一覧リスト16を格納する領域と、データ一覧リスト18を格納する領域とが用意されている。
【0022】
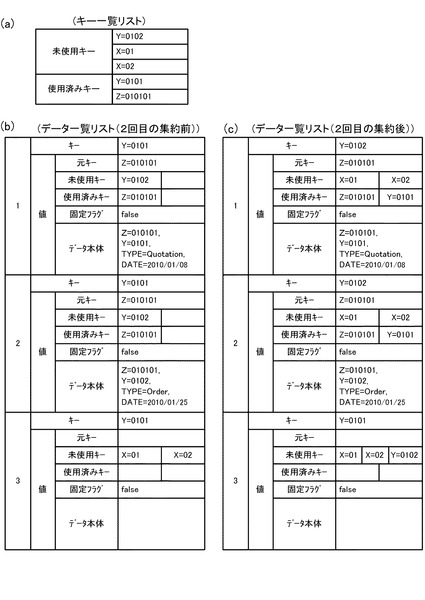
Map処理部12は、分散ファイルシステム40に格納されているデータを用いて、後述するMap処理を実行する。Reduce処理部14は、Map処理部12においてMap処理されたデータを用いて、後述するReduce処理を行う。キー一覧リスト16は、図11(b)に示すようなリストである。データ一覧リスト18は、図11(c)に示すようなリストである。
【0023】
次に、MapReduce処理の基本的な処理内容について、図4に基づいて、説明する。
【0024】
MapReduce処理では、分散ファイルシステム40上の処理対象のデータを、キーと値からなるMapデータに分割する処理(Map処理)と、キーの値に応じてMapデータを纏める処理(Reduce処理)とを、各処理サーバ10において分散・並列的に行う。
【0025】
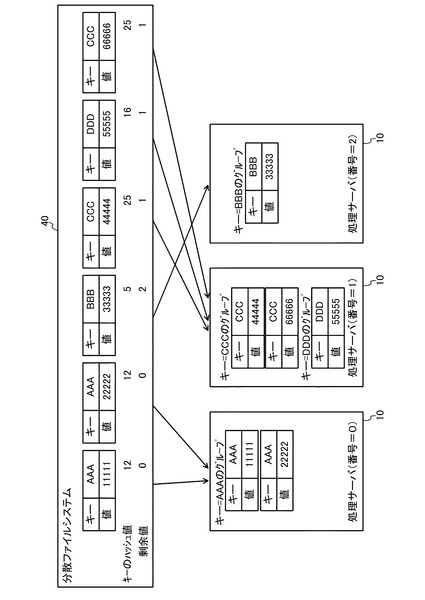
例えば、各処理サーバ10において分散・並列的に行われたMap処理によって、図4の上段に示すようなMapデータが生成されたとする。この場合、各処理サーバ10又は管理サーバ20は、各Mapデータのキーの値に対し、一意なハッシュ値を公知の計算方法により計算し、そのハッシュ値を処理サーバ数(図4では3)で割った剰余(0〜2)を求める。この場合、予め、各処理サーバ10に関し、対応する剰余値を、図4の下段に示す番号(0〜2)で決めておくことで、各Mapデータを処理する処理サーバ10を決定することができる。なお、同一の値のキーに対しては常に同一のハッシュ値が得られるため、同一のキー値を持ったMapデータ群は1つの処理サーバに集められる。また、ハッシュ値が偏りのない前提であれば、各Mapデータの処理を各サーバに偏りなく分散させることができる。なお、上述したハッシュ値から一意に処理サーバを決定する方法は、最も単純な例である。したがって、例えば、ハッシュ値に加えて、その時点の処理サーバの負荷を考慮に入れるなどして、より高度に処理サーバを決定することとしてもよい。
【0026】
各処理サーバ10(Reduce処理部14)は、集められたMapデータの集約キー(以下、単に「キー」とも呼ぶ)の値を参照する。そして、各処理サーバ10(Reduce処理部14)は、同一のキー値を持ったMapデータ(Mapデータ群)を1つのグループとし、そのグループに対してReduce処理を行う(図4の下段におけるキー=CCCのグループ参照)。なお、管理サーバ20は、各処理サーバ10の状態を把握しているため、各処理サーバ10におけるMap処理やReduce処理が完了したかどうかについても把握している。このため、管理サーバ20は、Reduce処理の結果を受けて、再度各処理サーバ10にMap処理を実行させるなどすることで、MapReduce処理を繰り返し行うことができる。
【0027】
次に、本実施形態の分散処理システム100における、複数キー集約処理の詳細について、説明する。
【0028】
なお、単一のキーでの集約であれば、上述したMapReduceの基本的な処理を行うことで実現できる(図33参照)。しかし、複数のキーを用いた集約の場合、MapReduce処理を複数回繰り返してデータを集約する必要がある。
【0029】
前述の通り、同じ集約キー(キー)を持ったMapデータは、同じサーバ・同じグループへ集約される。このため、本実施形態では、キー値を変更しながら、複数回のMapReduce処理を繰り返すことで、段階的にデータを集約するアプローチを採用する。なお、キー値を変更した場合には、ハッシュ値も変わるので、キー値変更後のデータは、別の処理サーバで処理される可能性もある。
【0030】
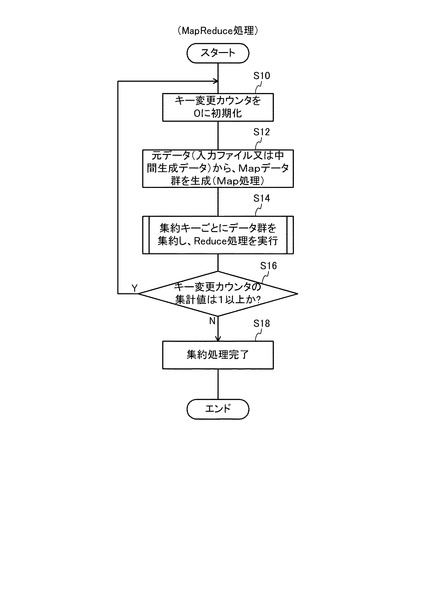
図5は、複数キー集約処理における具体的な処理の流れを示すフローチャートである。図5の複数キー集約処理では、Map処理とReduce処理とが必要回数繰り返される。
【0031】
図5の処理では、まず、ステップS10において、各処理サーバ10のReduce処理部14が、繰り返し制御用のカウンタとして、「キー変更カウンタ」を用意し、これを0に初期化する。なお、キー変更カウンタは、各処理サーバ10が更新することができる。各処理サーバ10では、Reduce処理が終わったことを契機にキー変更カウンタを更新する。
【0032】
次いで、ステップS12では、各処理サーバ10のMap処理部12が、Map処理を実行する。このステップS12では、Map処理部12が、分散ファイルシステム40上に存在する、入力データやReduce処理結果の中間生成データから、キー(集約キー)と値の組み合わせであるMapデータ群を生成し、分散ファイルシステム40に記憶する。
【0033】
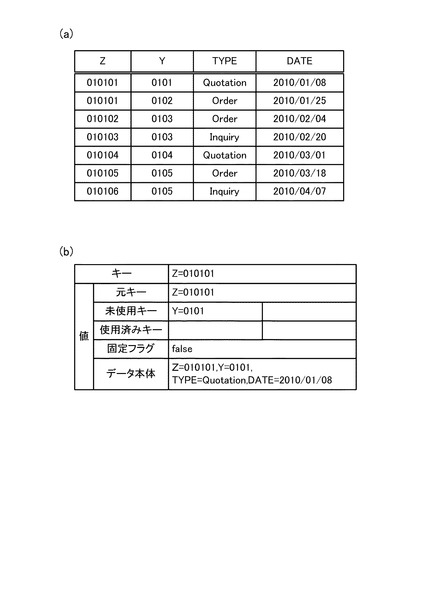
ここで、図5のステップS12を実行するのが1回目(初回)である場合には、Map処理部12は、入力データ(図6(a)に示すようなデータ)の各行の主キー値をキー(集約キー)とする(図6(b)参照)。なお、主キー値がどの値であるかは、あらかじめ定義しておくものとする。図6(a)では、主キー値は最左列の値である。また、Map処理部12は、図6(b)に示すように、値に、行全体の情報とキーの管理情報とを設定して、Mapデータを生成する。なお、Map処理は各行独立に実行可能であるため、行数を処理サーバ10の数で分割して、各処理サーバ10で分散して実行するものとする。ここで、Mapデータのキーの管理情報は、図6(b)に示すように、最初のキーを保存する「元キー」、未使用のキーを保存する「未使用キー」、過去に使用したキーを保存する「使用済みキー」、キー変更の必要が無いことを示す「固定フラグ」などである。
【0034】
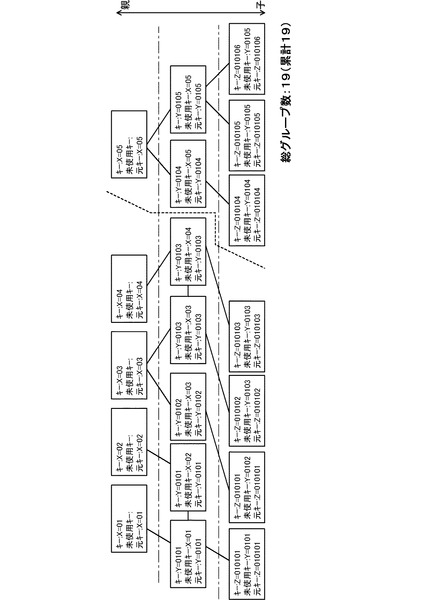
図7は、集約対象のMapデータの一例を示している。図7に示す例では、データは3階層に分類されており、19個のデータ実体が存在する。最上層ではXが主キーとなっており、01〜05までのキー値が存在する。2番目の層ではYが主キーとなっており、0101〜0105までのキー値が存在する。なお、2番目の層のデータは、関連キーとしてXも有しているため、最上層のデータと関連付けられている。また、最下層の主キーはZであり、010101〜010106までのキー値が存在する。なお、最下層のデータ(図6(a)のデータと同一)は、関連キーとしてYを有しているため、2番目の層のデータと関連付けられている。
【0035】
図7の例で特徴的なのは、関連の親子関係が複雑である点である。通常、このような構造のデータでは、一般には親と子の数の関係は1対多である。この点、図7の破線よりも右側のデータはそのような関係になっているが、図7の破線よりも左側では必ずしもそのような関係になっていない。例えばZ=010101のデータはY=0101にもY=0102にも関連している。親と子が常に1対多の関係であれば、下層のキーから順にZ→Y→Xと3回集約すればすべてのグループが正しく集約される。しかしながら、図7のようなケースではその方法では集約漏れするデータが生じるおそれがある。
【0036】
ここで、図7の最下層のデータ(Mapデータ)の生成方法(Map処理方法)について、図8(a)〜図8(c)に基づいて説明する。図8(a)は、最下層のデータのテーブル(元データ)である。図8(a)の元データは、管理サーバ20又はいずれかの処理サーバ10のMap処理部12によって、図8(b)に示すように、処理サーバ数(図8(b)では、処理サーバ数が2であるものとする)に分割される。そして、各処理サーバ10では、分割されたうちの1つのテーブルについて、Map処理を行い、図8(c)に示すように、Mapデータを生成する。このような処理により生成されるMapデータが、図7の最下層の7つのデータとなる。
【0037】
図5に戻り、次のステップS14では、各処理サーバ10のReduce処理部14が、Reduce処理を実行する。このReduce処理では、まず、管理サーバ20が、同一のキー値を持つMapデータ群を1つの処理サーバ10に集約する。そして、Reduce処理部14は、図9、図10のフローチャートに沿った処理を実行する。
【0038】
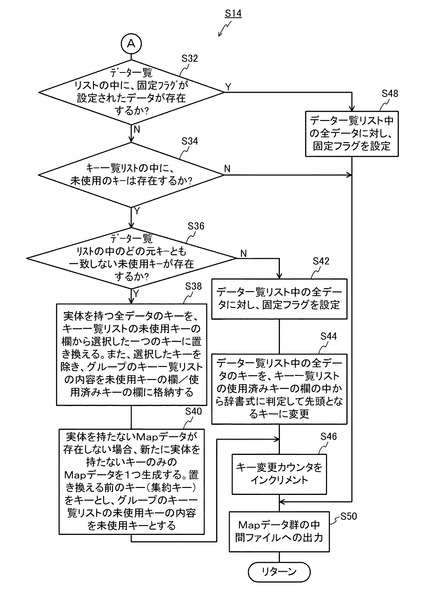
ここで、各処理サーバ10に対する入力は、図7で示される構造を有するMapデータの集合であり、キー値が同一のデータ群であるものとする。なお、キー値が同一のデータ群を、以下においては、「グループ」と呼ぶ。また、以下の説明では、図9、図10の処理の説明と併せて、図11(a)に示すMapデータ(特に、図11(a)において集約キーがZ=010101のデータ)のReduce処理を例にとり、説明する。
【0039】
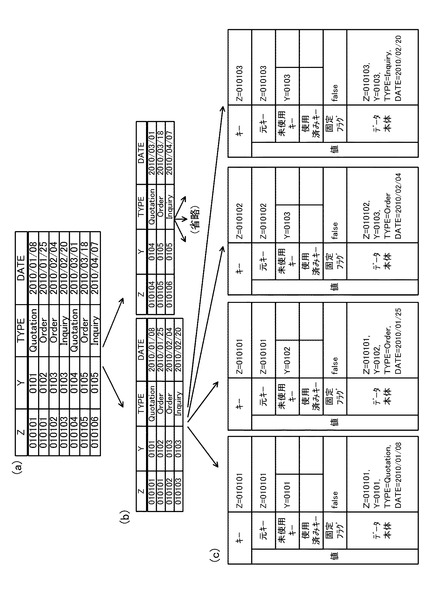
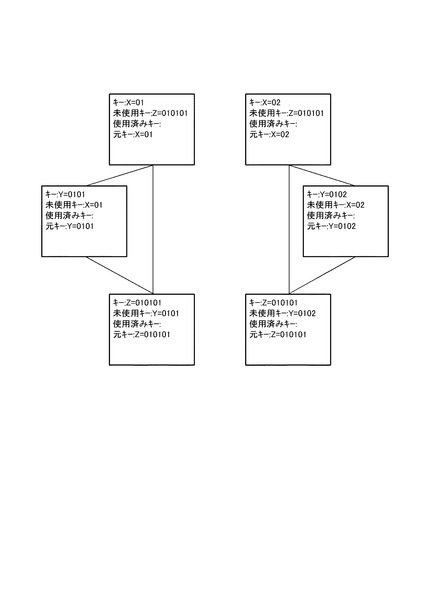
図9の処理では、まず、ステップS20において、各処理サーバ10のReduce処理部14が、グループのデータ一覧リスト18(図11(c)参照)、及びキー一覧リスト16(図11(b)参照)を初期化する。次いで、ステップS22では、Reduce処理部14が、グループの集約キーを使用済みキーとしてキー一覧リスト16へ追加する(図11(b)の最下段参照)。
【0040】
次いで、ステップS24では、Reduce処理部14が、処理対象のMapデータ(例えば、図11(a)の1番のデータ)を取得する。次いで、ステップS26では、Reduce処理部14が、Mapデータをグループのデータ一覧リスト18へコピーする(図11(c)の1番のデータ参照)。次いで、ステップS28では、Reduce処理部14が、ステップS26でコピーしたMapデータ中の未使用/使用済みキー値をグループのキー一覧リスト16へコピーする。なお、ここでは、図11(b)のキー一覧リスト16において、未使用キーの欄にY=0101がコピーされるが、使用済みキーは存在していないため、使用済みキーの欄には何もコピーされない。
【0041】
次いで、ステップS30では、Reduce処理部14が、未処理のMapデータが存在するか否かを判断する。ここでの判断が肯定された場合には、ステップS24に戻り、ステップS24〜S28の処理を繰り返す。その結果、ステップS30の判断が否定される段階では、図11(c)のデータ一覧リスト18に、2番のデータがコピーされるとともに、図11(b)のキー一覧リスト16に、未使用キーとして、Y=0102がコピーされる。このように、Reduce処理部14は、Mapデータ群から、各データを順次取得(1つずつ取得)して、データ一覧リスト18及びキー一覧リスト16にデータ、未使用キーや使用済みキーをコピーする。なお、キー一覧リスト16における、未使用キーの欄と使用済みキーの欄は排他的ではなく、未使用キーの欄と使用済みキーの欄に同じキーを格納することもできる。一方、未使用キーの欄の中で重複したキー、あるいは使用済みキーの欄の中で重複したキーがある場合には、1つのみ残して重複するキーを削除してもよい。
【0042】
以上のようにして、ステップS30の判断が否定された場合には、図10のステップS32に移行する。
【0043】
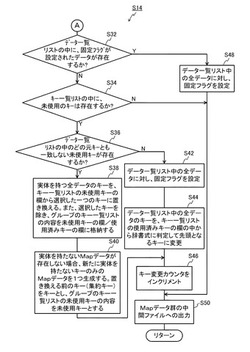
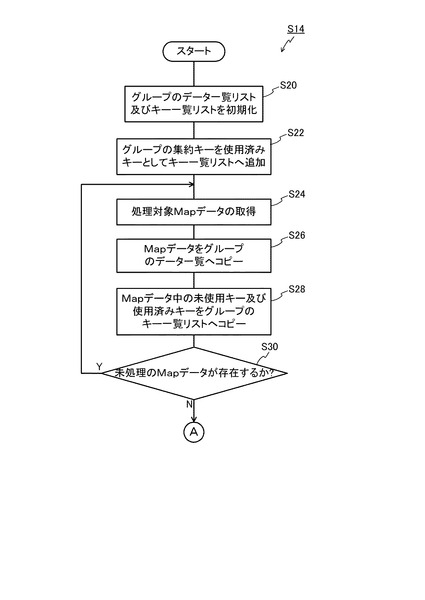
図10のステップS32では、Reduce処理部14が、データ一覧リスト18の中に固定フラグが設定されたデータが存在するか否かを判断する。ここでの判断が否定された場合には、ステップS34に移行する。なお、ステップS32の判断が肯定された場合には、ステップS48(このステップについては後述)に移行する。ここで、図11(c)の例では、データ一覧リスト18に、固定フラグが設定されたデータは存在していない(全てfalse)ので、ステップS32の判断は肯定されて、ステップS34に移行する。
【0044】
ステップS34に移行した場合、Reduce処理部14は、キー一覧リスト16の中に未使用のキーが存在するか否かを判断する。図11(b)の例では、キー一覧リスト16に、未使用のキーが存在しているので、ステップS34の判断は肯定され、ステップS36に移行する。
【0045】
ステップS36に移行した場合、Reduce処理部14は、データ一覧リスト18中のどの元キーとも一致しない未使用キーが存在するか否かを判断する。図11(b)の例では、キー一覧リスト16に、データ一覧リスト18中のどの元キーとも一致しない未使用キーが2つ存在しているので、ここでの判断は肯定され、ステップS38に移行する。
【0046】
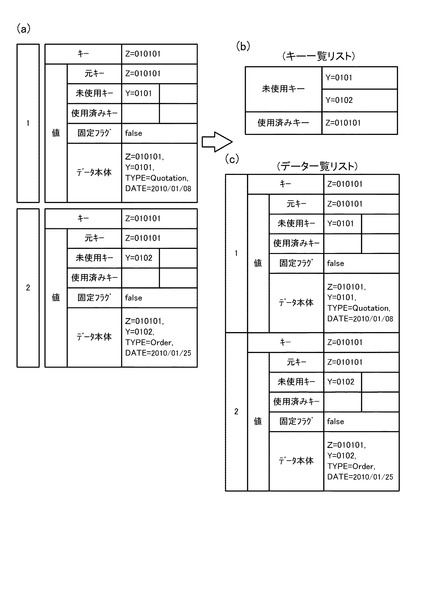
ステップS36の判断が肯定され、ステップS38に移行した場合、Reduce処理部14は、実体を持つ全データのキーを、未使用キーの欄から一つ選択したキーに書き換える。また、Reduce処理部14は、選択したキーを除き、グループのキー一覧リスト16の内容を未使用/使用済みキーに格納する。すなわち、ステップS38では、図12に示すように、Reduce処理部14は、データ一覧リスト18に含まれるMapデータの1番のデータのキーと2番のデータのキーをY=0101に書き換える。また、Reduce処理部14は、キー一覧リスト16の未使用キーからY=0101を除いた結果、すなわちY=0102を各データの未使用キーに格納する。また、キー一覧リスト16の使用済みキーであるZ=010101を各データの使用済みキーに格納する。
【0047】
次いで、ステップS40では、Reduce処理部14が、実体を持たないMapデータが存在しない場合、新たに実体を持たないキーのみのMapデータを1つ生成する。例えば、図12において3番のデータとして示すデータを生成する。この場合、書き換える前のキー(=集約キー)をキーとし、グループの未使用キー一覧の内容(図11(b))を未使用キーの欄に格納する。図12の3番のデータでは、キーとしてグループの集約キーであるZ=010101を設定し、未使用キーにはグループのキー一覧リスト16の未使用キーであるY=0101とY=0102を設定する。なお、使用済みキーの設定は必要なく、固定フラグは「false」とし、データ本体は空とする。
【0048】
次いで、ステップS46では、Reduce処理部14は、キー変更カウンタを1だけインクリメントする。次いで、ステップS50では、Reduce処理部14が、図1に示す分散ファイルシステム40上の、Mapデータ群の中間ファイルへの出力を行い、その後、図5のステップS16に移行する。なお、ステップS50で出力されるMapデータ群は、図12に示すデータである。
【0049】
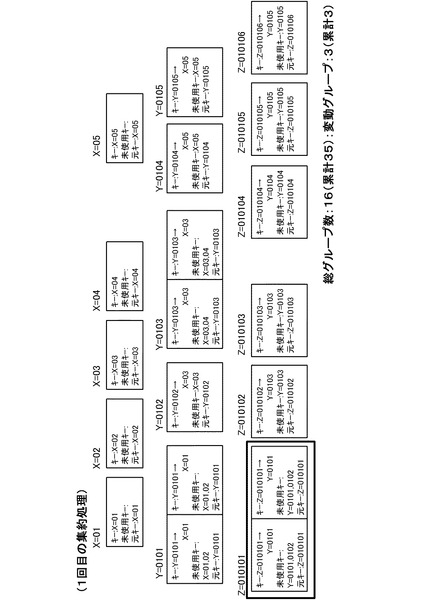
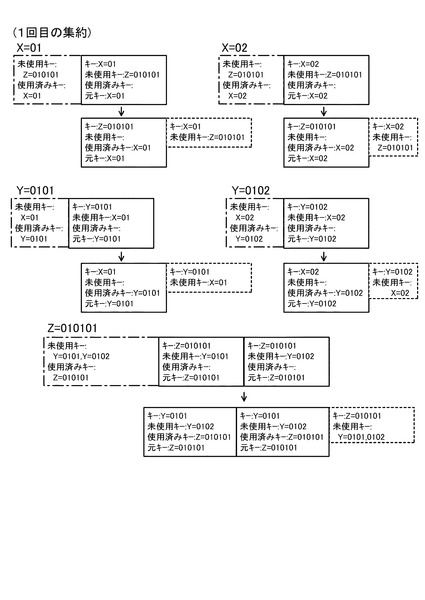
図13は、1回目の集約により、同階層で同一のキー値を持つデータ群(グループ)が集約された様子を示した図である。なお、図13に示すように、1回目の集約によって、Z=010101以外の2つのキー(Y=0101、Y=0103)のMapデータも集約されている。この図において、データを示す箱(矩形枠)の左上に示す値(Z=010101等)が、各集約グループを示しており、その値の下に隣接して配置された箱の一群がグループのデータを示している。また、箱の内部の「未使用キー」は、図11(b)におけるキー一覧リスト16の未使用キーの欄を示している。更に、箱の内部の「キー」の矢印の左側はその集約における集約キー、右側は未使用キーの中から一つ選択したキーで、次の集約において集約キーとなる値を示している。なお、図13では、図示及び説明の簡単のため、使用済みキーは表示していない。なお、図12のように、Reduce処理の終盤でキー情報のみのMapデータが生成されている(図12のデータ「3」)が、これは再集約(2回目以降の集約)が実施されたときにのみ意味を持つものなので、図13では図示していない。なお、図15において破線で示されている箱が、1回目の集約で生成されたキー情報のみのMapデータである。
【0050】
なお、図10の処理において、キー一覧リスト16の中に未使用のキーが存在していない場合(例えば、図13の最上段のデータ等の場合)には、ステップS34の判断が否定される。ステップS34の判断が否定された場合には、Reduce処理部14は、キー変更カウンタを0に維持したまま、ステップS50に移行し、Mapデータ群の中間ファイルへの出力を行った後、図5のステップS16に移行する。
【0051】
図5に戻り、次のステップS16に移行すると、管理サーバ20は、Reduce処理のキー変更カウンタの集計値が1以上か否かを判断する。上記例では、いずれかのグループで集約キーの変更が発生しており、図10のステップS46を経ている。したがって、キー変更カウンタの集計値は1以上となるため、ステップS16の判断は肯定され、ステップS10に戻る。そして、ステップS10〜S16の処理(再度のMapReduce処理)を繰り返す。
【0052】
なお、図10の処理において、データ一覧中のどの元キーとも一致しない未使用キーが存在しない場合には、ステップS36の判断が否定される。この場合、キー値の変更が一巡したとみなせるので、それ以上の変更は無意味となる。したがって、この場合には、ステップS42に移行し、Reduce処理部14が、データ一覧リスト18中の全データに対し、固定フラグを設定する。そして、ステップS44において、Reduce処理部14は、データ一覧中の全データのキーを、使用済みキー一覧の中から、辞書式に判定して先頭となるキー値を変更する。なお、これらステップS42、S44の具体的処理については、後述する。その後は、上記と同様、ステップS46、S50を経て、図5のステップS16に移行する。
【0053】
また、図10のステップS32において、データ一覧リスト18の中に固定フラグが設定されたデータが存在していた場合には、ステップS48に移行する。このステップS48では、Reduce処理部14が、データ一覧中の全データに対し、固定フラグを設定することで、その時点の集約キーをそのまま用いて再集約可能な状態にする。そして、ステップS50において、Mapデータ群の中間ファイルへの出力を行った後、図5のステップS16に移行する。
【0054】
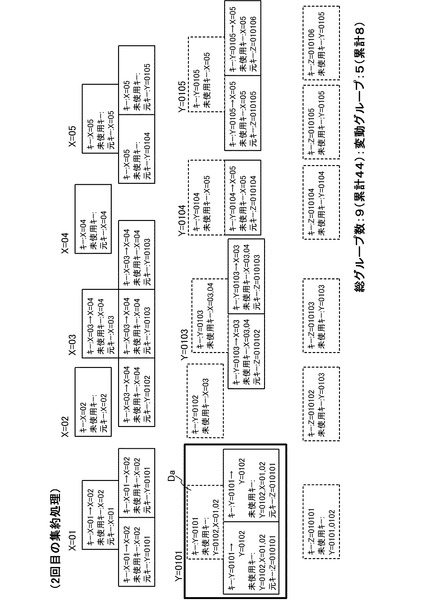
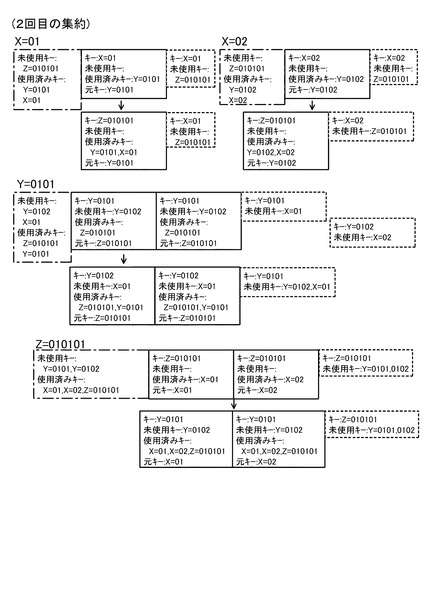
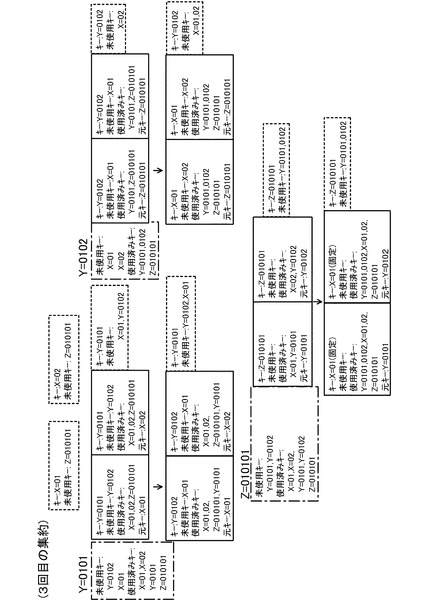
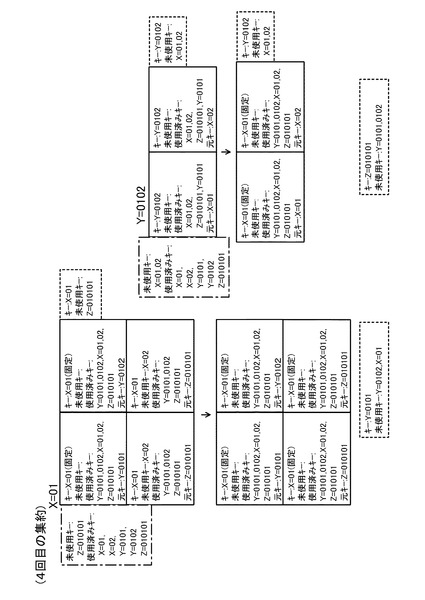
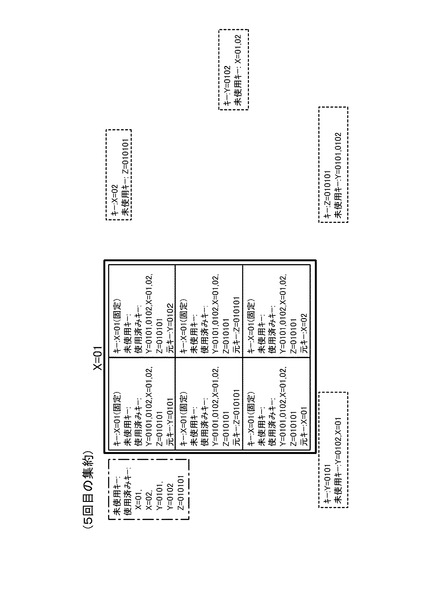
次に、2回目の集約処理について説明する。図14(a)〜図14(c)には、集約キーがY=0101のMapデータを集約する処理を説明するための図(リスト16,18)が示されている。図14(b)のデータ一覧リストのうち1、2番目のデータは、図12の1、2番目のデータと同一である。これに対し、3番目のデータは、図13のY=0101のグループを集約した際に生成されたデータ実体のないデータ(図15の符号Daで示す破線の箱参照)である。また、これら3つのデータからは、キー一覧リスト16として、図14(a)のようなリストが得られる。これら、図14(a)のキー一覧リスト及び図14(b)のデータ一覧リストを用いて図10の処理を行うと、図14(c)のような3つのデータを得ることができる。このような2回目の集約処理を行った後の状態が、図15に示されている。図15に示すように、2回目の集約処理の結果、集約キーがY=0101のMapデータ以外のMapデータも集約されていることが分かる。
【0055】
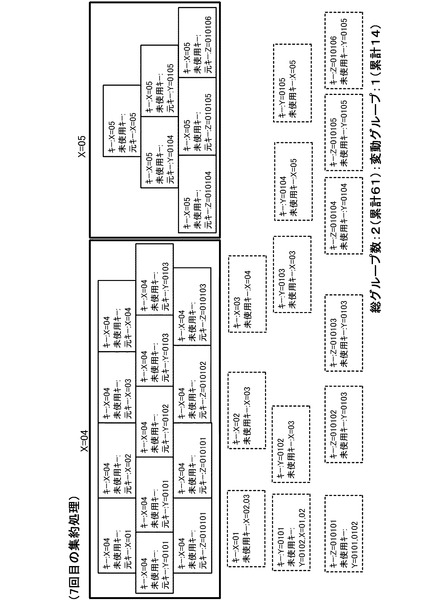
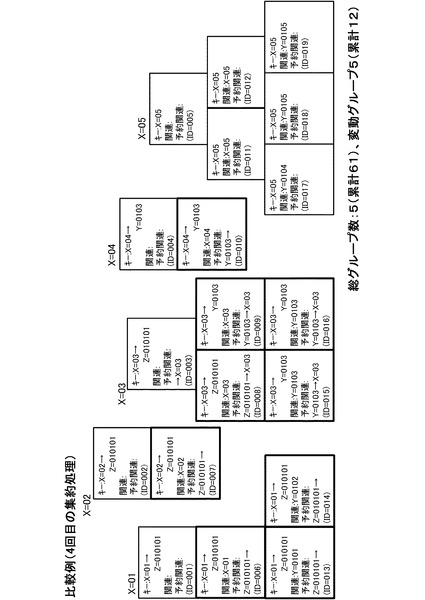
以下、同様に集約処理を繰り返すと、3回目の集約処理の結果は、図16のようになる。また、4回目の集約処理の結果は、図17のようになり、5回目の集約処理の結果は、図18のようになり、6回目の集約処理の結果は、図19のようになる。そして、7回目の集約処理の結果、図20のようになる。図20の状態では全グループに未使用キーが存在しなくなるため(全処理サーバ10においてステップS34が否定されるため)、キー変更カウンタは0のままとなる。この場合、図5のステップS16の判断が否定され、ステップS18に移行する。そして、管理サーバ20は、ステップS18において集約処理を完了する。
【0056】
本実施形態では、上記のようなMapReduce処理を行うことで、図20に示すように、X=04のグループとX=05の2グループとなる。これにより、複数のMapデータを、図7の状態から正確に(集約漏れなく)2つのグループに集約できたことになる。
【0057】
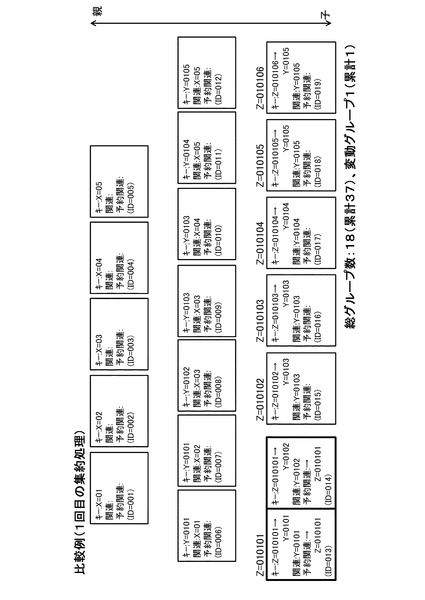
(比較例)
ここで、比較例(従来法を用いて、図7のデータを集約する場合)について説明する。なお、以下の処理は、各処理サーバ10が行うものとする。
【0058】
従来法としては、各データは変更可能なキー、不変の関連キーリスト(データにおいて定義されているキー)、再集約のフラグを兼ねる変更可能な予約関連キーを有することとする。また、上述した実施形態で用いたデータ実体を持たないキー値のみのデータは用いていない。従来法では、実体のないデータを用いないことを理由に、集約処理を全階層同時に行うことはできないため、キー値の種類毎に下層の方から順に集約する必要が生じる。
【0059】
図21には、元データの主キーをキー、関連キーを関連キーリストに格納し、最下層のキーであるZを集約キーとして1回目の集約を行った結果が示されている。なお、図21及びこれ以降の図面では、各データの識別のため、処理には使用しないIDを示している。図21では、Z=010101のグループのみ、複数の関連キーを含んでいる。このように、グループ内に複数の関連キーが存在する場合、そのグループのデータには予約関連キーが設定される。予約関連キーの値は、そのグループの集約キーとなる。従って、Z=010101のグループではZ=010101が予約関連キーとなる。また、1回目の集約が行われたデータ又はグループのキーは、関連キーに変更される。
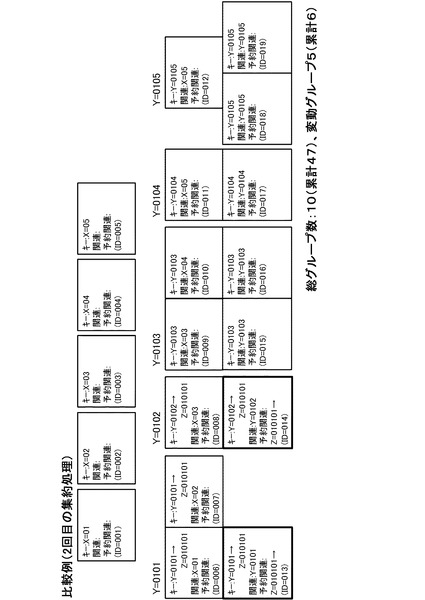
【0060】
次いで、2回目の集約では、2番目の層のキーであるYでの集約が行われる。その結果が図22に示されている。ここで、図22に示すように、Y=0101とY=0102のグループには、1回目の集約時に予約関連キーを設定したデータが含まれている。このため、次の3回目の集約では、最上層のキーではなく、予約関連キーで集約が行われる。一方、予約関連キーが設定されていないグループについては、2回目と同じキー値で再度集約が行われる。
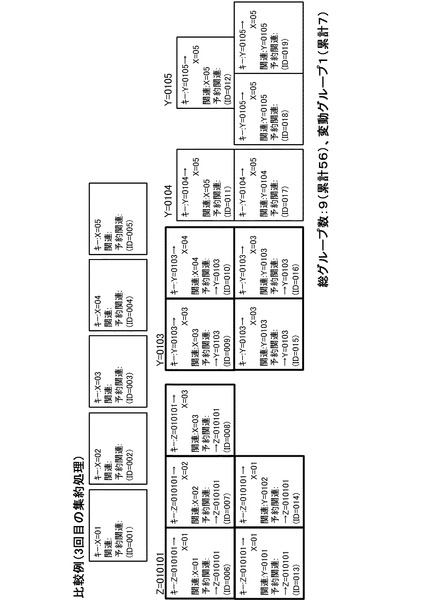
【0061】
3回目の集約結果が図23に示されている。予約関連キーでの集約を終えたので、次の集約は最上層のキーであるXでの集約となるが、Z=010101とY=0103のグループには複数のXのキー値が含まれるため、各データに予約関連キーが設定される。
【0062】
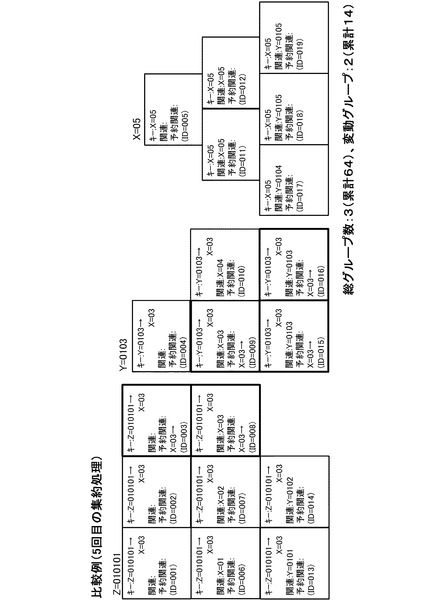
以下、上記と同様の処理が繰り返されることにより、4回目の集約処理の結果、図24のようになり、5回目の集約処理の結果、図25のようになり、6回目の集約処理の結果、図26のようになる。図26に示すように、6回目の集約処理が完了した段階では、上記実施形態と同様、データを2つのグループに集約することができる。
【0063】
ここで、複数キー集約処理全体の処理量の概算として、処理対象となるグループ数を用いると、初期状態から集約完了までの累計総グループ数は、本実施形態の場合、61グループ(図20参照)、比較例の場合、66グループ(図26参照)となる。すなわち、初期状態から集約完了までの累計総グループ数は、本実施形態のほうが少ないことが分かる。また、前の集約時から変動があったグループの累計は、本実施形態が14であり(図20参照)、比較例が15である(図26参照)ので、本実施形態のほうが少ないことが分かる。
【0064】
更に、本実施形態の場合、一度集約されたデータ群は、それ以降分断されることが無いのに対し、比較例では図21から図22へ遷移する際のID=013、014のように、一度集約されたデータ群が分断されることがある。このような点から、本実施形態の方が、グループ内での統計処理などを漸次的に計算するのに都合が良いことになる。
【0065】
(別例について)
以下、図7とは異なる例について、図27〜図32に基づいて説明する。なお、図28〜図32では、Mapデータの近傍に、集約処理に用いるキー一覧リスト16を併記するものとする(一点鎖線で示す箱)。
【0066】
図27には、図7の例と同様に3階層に分かれているものの、関連がループしており、親子関係が明確ではないデータの一例が示されている。なお、この例では2系統のループがあるが、Z=010101が共通して含まれているため、集約処理の結果、全てのデータが1グループに集約されるのが正しい集約結果である。
【0067】
図27のデータに対して本実施形態の処理を適用し、各処理サーバ10のReduce処理部14が、1回目の集約処理を行った結果が図28(矢印の下側のデータ)である。
【0068】
図28では、Reduce処理部14は、それぞれ元のデータの主キーで集約している。この場合、Z=010101のみ複数のデータが集約される。また、各グループに未使用のキーが存在するため、Reduce処理部14は、キーを未使用のキーのうちの1つに変更し、2回目の集約を行う。図29には、2回目の集約を行った結果(矢印の下側のデータ)が示されている。
【0069】
同様に、Reduce処理部14が3回目の集約を行うと図30の矢印の下側の状態となる。ここで、Z=010101のグループでは、各データの未使用のキーが無くなり、実体の無いデータの未使用キーはグループ内のデータの元キーと一致するものしかなくなる(図10のステップS36が否定される)。これにより、キー変更が一巡したことがわかるため、固定フラグを設定するとともに(ステップS42)、グループ内の使用済みキーの中から、辞書式に評価して先頭となるキー(ここでは、X=01)を見つけ、次の集約キーとする(ステップS44)。なお、辞書式に評価して先頭を見つける処理は、各キー種の関係から親子関係(階層構造)の最上位を見つける処理を意味する。
【0070】
同様にして、Reduce処理部14が4回目の集約を行うと、図31の状態となる。ここで、X=01に集約されたグループには、固定フラグが設定されたデータが含まれる(ステップS32が肯定される)。このため、Reduce処理部14は、固定フラグが設定されていなかったデータにも固定フラグを設定する(ステップS48)。
【0071】
また、Y=0102のグループでも、使用可能性のあるキーは元キーと一致するものしかなくなる(図10のステップS36が否定される)ため、キー変更一巡となる。このため、Reduce処理部14は、次の集約キーをX=01とし、固定フラグを設定する(ステップS42)。この結果、図32に示すように、Reduce処理部14が5回目の集約を行うと、すべてのデータが固定フラグ付きでX=01に集約され、集約が完了する。この場合、前述したように、1グループに正確に集約されることになる。以上のように、図27のようなデータの関係がループする場合であっても、本実施形態では、正確に、データを集約することが可能である。
【0072】
以上詳細に説明したように、本実施形態の処理サーバ10によると、Map処理部12が行う、複数のデータそれぞれが有するキーを、集約に用いる集約キー、集約において未だ用いていない未使用キー、及び既に集約に用いた使用済みキーのいずれかに分類して、Mapデータに関連付けて分散ファイルシステム40に記憶する処理(ステップS12)と、Reduce処理部14が行う、記憶された複数のデータのうち、同一の集約キーに関連付けられたMapデータを取得する(ステップS26)とともに、取得したMapデータ群に含まれる未使用キーを全て取得し(ステップS28)、取得した未使用キーのうちの1つを次の集約キーとして決定し、取得したデータに関連付けて記憶された集約キーを次の集約キーに更新し(ステップS38)、取得したデータに関連付けて記憶された未使用キーを取得した未使用キーから次の集約キーを除いた残りの未使用キーに更新する(ステップS40)処理を、Reduce処理部14における集約キーの更新ができなくなるまで繰り返す。これにより、RDB(関係データベース)を用いなくとも、処理対象のデータを参照するのみで、複数のMapデータを集約することができる。これにより、性能・スケーラビリティ改善効果を最大限に得ることが可能となる。また、Map処理部12とReduce処理部14とが処理を繰り返し行うことで、データに関連のある範囲のキーがデータ間を伝達していくので、データ集約の漏れをなくすことができる。
【0073】
また、本実施形態では、Reduce処理部14は、複数のMapデータを集約する際に、更新を行う前の集約キーを集約キーとし、集計された(取得された)未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たなMapデータとして生成するので(ステップS40)、親子関係(階層関係)にある全ての階層の集約処理を同時に行うことが可能となる。これにより、処理時間の短縮を図ることが可能となる。
【0074】
また、本実施形態では、Reduce処理部14は、集約キーを更新できなくなったデータの集約キーを、使用済みキーとしてMapデータに関連付けられているキーのうち、親子関係(階層関係)の最上位にあるキーで更新するとともに、Mapデータに、集約キーのそれ以上の更新を禁止するフラグ(固定フラグ)を設定する(データに対応付けて固定フラグを記憶する)(ステップS42、S44)。これにより、集約キーの更新が一巡したときには、それ以降、集約キーは更新されなくなるので、集約キーの更新が一巡したときに発生し得る、処理の永久ループを防止することが可能となる。
【0075】
また、本実施形態の分散処理システム100は、上記のような処理サーバ10を複数備えているので、複数のMapデータを、複数の処理サーバ10上で分散・並行的にMapReduce処理することが可能となる。
【0076】
なお、上記の処理機能は、コンピュータによって実現することができる。その場合、処理装置が有すべき機能の処理内容を記述したプログラムが提供される。そのプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。
【0077】
プログラムを流通させる場合には、例えば、そのプログラムが記録されたDVD(Digital Versatile Disc)、CD−ROM(Compact Disc Read Only Memory)などの可搬型記録媒体の形態で販売される。また、プログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することもできる。
【0078】
プログラムを実行するコンピュータは、例えば、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、自己の記憶装置に格納する。そして、コンピュータは、自己の記憶装置からプログラムを読み取り、プログラムに従った処理を実行する。なお、コンピュータは、可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することもできる。また、コンピュータは、サーバコンピュータからプログラムが転送されるごとに、逐次、受け取ったプログラムに従った処理を実行することもできる。
【0079】
上述した実施形態は本発明の好適な実施の例である。但し、これに限定されるものではなく、本発明の要旨を逸脱しない範囲内において種々変形実施可能である。
【0080】
なお、以上の説明に関して更に以下の付記を開示する。
(付記1) 複数のキー種を用いて分類された複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を実行する処理装置であって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された、前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶する関連付け部と、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、該取得した未使用キーのうちの1つを次の集約キーとして決定し、前記取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する集約部と、を備え、前記集約キーの更新ができなくなるまで、前記関連付け部と前記集約部による処理を繰り返すことを特徴とする処理装置。
(付記2) 前記集約部は、前記更新を行う前の前記集約キーを集約キーとし、取得した前記未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たな処理対象のデータとして生成して前記記憶部に記憶することを特徴とする付記1に記載の処理装置。
(付記3) 前記関連付け部は、前記処理対象のデータに、既に集約に用いた使用済みキーを関連付け、前記集約部は、前記集約キーの更新ができなくなったデータに対応付けて前記記憶部に記憶された集約キーを、前記データに前記使用済みキーとして関連付けられているキーのうち、親子関係の最上位にあるキー種のキーで更新し、当該データに対応付けて前記集約キーの更新を禁止する情報を前記記憶部に記憶し、前記記憶部に格納された前記複数のデータのうち、同一の集約キーに関連付けられ、且つ、前記集約キーの更新を禁止する情報が関連付けられていないデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、前記取得した未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに対応付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに対応付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新することを特徴とする付記1又は2に記載の処理装置。
(付記4) 付記1〜3のいずれかに記載の処理装置を複数備え、複数の処理対象のデータを前記複数の処理装置に分散して、当該複数の処理装置において並行処理を実行することを特徴とする分散処理システム。
(付記5) 複数のキー種を用いて複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を、コンピュータに実行させる処理プログラムであって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと、未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶し、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、取得した前記未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを、前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを、取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、前記未使用キーの更新ができなくなるまで、コンピュータに繰り返し実行させることを特徴とする処理プログラム。
(付記6) 前記集約する処理では、前記更新を行う前の前記集約キーを集約キーとし、取得した前記未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たな処理対象のデータとして生成して前記記憶部に記憶する処理をコンピュータに実行させることを特徴とする付記5に記載の処理プログラム。
(付記7) 前記関連付ける処理では、前記処理対象のデータに、既に集約に用いた使用済みキーを関連付ける処理をコンピュータに実行させ、前記集約する処理では、前記集約キーの更新ができなくなったデータに対応付けて前記記憶部に記憶された集約キーを、前記データに前記使用済みキーとして関連付けられているキーのうち、親子関係の最上位にあるキー種のキーで更新し、当該データに対応付けて前記集約キーの更新を禁止する情報を前記記憶部に記憶し、前記記憶部に格納された前記複数のデータのうち、同一の集約キーに関連付けられ、且つ、前記集約キーの更新を禁止する情報が関連付けられていないデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、前記取得した未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに対応付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに対応付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、コンピュータに実行させることを特徴とする付記5又は6に記載の処理プログラム。
【符号の説明】
【0081】
10 処理サーバ(処理装置)
12 Map処理部(関連付け部)
14 Reduce処理部(集約部)
90 CPU(コンピュータ)
96 HDD(記憶部)
100 分散処理システム
【技術分野】
【0001】
本件は、処理装置、分散処理システム、及び処理プログラムに関する。
【背景技術】
【0002】
大量データを対象にした分析処理には、非常に長い処理時間を要する。これに対し、最近では、複数のマシンを用いて分散・並列処理を行うことで処理時間を短縮するアプローチがとられている。分散・並列処理としては、例えば、MapReduceアルゴリズムを用いた方法(例えば、非特許文献1参照)がある。また、MapReduceアルゴリズムのオープンソース実装として、Apache Hadoopが存在している。
【0003】
MapReduceは、主に元のデータを多数のキーと値のセットに分割する「Map処理」と、それらのキーと値のセットをあるルールによって集約する「Reduce処理」とによって構成される。Map処理及びReduce処理の各処理は、それぞれ複数並列に実行可能であるため、それらを複数の処理マシン(サーバなど)に割り当てることにより、複数マシンの処理性能を活用することができる。
【0004】
ただし、MapReduceによる分散・並列処理の効果を高めるには、それぞれのMap処理、Reduce処理の独立性を高くし、他の部分に依存せずに処理を行えるようにする必要がある。
【0005】
分析処理の一種として、大量のデータ群の中から、関係のあるデータをグルーピングするものがある。例えば、図33(a)に示すように、ある時期に行われた業務ログを、図33(b)に示すように、一連となっている業務フロー単位にグルーピングする場合などである。グルーピングの処理では、あるグループのデータ群を扱う際、別のグループのデータを考慮する必要が無いため、各グループの処理を複数サーバに分散させることにより、効率的に処理が行える。
【0006】
なお、図33(a)のように一連の業務フローが1つのキー種(図33(a)ではフローID)によって示されるデータをグルーピングする際には、MapReduceを用いることによってグルーピングは容易に達成される。MapReduceを行う処理マシンでは、あるキー値を持つデータ群を一箇所に集約する機能を標準で有しているためである。
【先行技術文献】
【非特許文献】
【0007】
【非特許文献1】Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters OSDI 2004
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかしながら、図34(a)のように、一連の業務フローを示すキーが複数(図34(a)では3種)存在する場合もあり得る。なお、図34(b)は、図34(a)のデータを集約した例を示している。このような場合には、単純にはグルーピングを行うことができない。複数のキー種を用いて関連のあるデータ群を集約する処理(以下、「複数キー集約処理」と呼ぶ)では、どのキーの組み合わせが一連のデータ群を示すのかが、データ全体を見ないと完全には確定しないからである。例えば、図34(a)の場合、伝票番号=001で集約しようとすると、伝票明細詳細テーブルのデータを集約できない。一方、伝票明細詳細番号=001-001-001で集約する場合、伝票テーブルのデータを集約できない。
【0009】
この場合、処理の進展に応じてキー値の組み合わせの情報を最新化しながら集約処理を進めるような工夫が必要であり、また、最新化する処理が不十分な場合には、データの集約漏れが発生する場合がある。
【0010】
これに対し、キー種間の関連を管理する表をRDB(関係データベース(Relational Database))などに作成することも考えられる。しかるに、分散・並列処理する各処理マシンが共通に参照・更新する箇所があると、分散処理の性能・スケーラビリティが劣化するおそれがある。
【0011】
そこで本件は上記の課題に鑑みてなされたものであり、性能・スケーラビリティの向上及びデータ集約漏れを防止することが可能な処理装置、分散処理システム、及び処理プログラムを提供することを目的とする。
【課題を解決するための手段】
【0012】
本明細書に記載の処理装置は、複数のキー種を用いて分類された複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を実行する処理装置であって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された、前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶する関連付け部と、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、該取得した未使用キーのうちの1つを次の集約キーとして決定し、前記取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する集約部と、を備え、前記集約キーの更新ができなくなるまで、前記関連付け部と前記集約部による処理を繰り返す処理装置である。
【0013】
本明細書に記載の分散処理システムは、本明細書に記載の処理装置を複数備え、複数の処理対象のデータを前記複数の処理装置に分散して、当該複数の処理装置において並行処理を実行する分散処理システムである。
【0014】
本明細書に記載の処理プログラムは、複数のキー種を用いて複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を、コンピュータに実行させる処理プログラムであって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと、未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶し、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、取得した前記未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを、前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを、取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、前記未使用キーの更新ができなくなるまで、コンピュータに繰り返し実行させる処理プログラムである。
【発明の効果】
【0015】
本明細書に記載の処理装置、分散処理システム、及び処理プログラムは、性能・スケーラビリティの向上、及びデータ集約漏れを防止することができるという効果を奏する。
【図面の簡単な説明】
【0016】
【図1】一実施形態に係る分散処理システムの構成を概略的に示す図である。
【図2】処理サーバのハードウェア構成を示す図である。
【図3】処理サーバの機能ブロック図である。
【図4】MapReduce処理の基本的な処理内容について説明するための図である。
【図5】MapReduce処理の一連の流れについて示すフローチャートである。
【図6】図6(a)は、Map処理における入力データの一例を示す図であり、図6(b)は、1つのMapデータのキー及び値の具体的な内容を示す図である。
【図7】集約対象のMapデータの一例を示す図である。
【図8】図8(a)〜図8(c)は、図7の最下層のテーブルについてMap処理を行った場合の例を説明するための図である。
【図9】ステップS14の具体的処理を示すフローチャート(その1)である。
【図10】ステップS14の具体的処理を示すフローチャート(その2)である。
【図11】図11(a)は集約キーがZ=010101の集約グループを示す図であり、図11(b)は、図11(a)の集約グループのキー一覧リストであり、図11(c)は、図11(a)の集約グループのデータ一覧リストである。
【図12】図10のステップS38の処理を説明するための図である。
【図13】1回目の集約により、同階層で同一のキー値を持つデータ群が集約された様子を示した図である。
【図14】図14(a)〜図14(c)は、集約キーがY=0101のMapデータを集約する処理を説明するための図(リスト16,18)が示されている。
【図15】2回目の集約処理を行った後の状態を示す図である。
【図16】3回目の集約処理を行った後の状態を示す図である。
【図17】4回目の集約処理を行った後の状態を示す図である。
【図18】5回目の集約処理を行った後の状態を示す図である。
【図19】6回目の集約処理を行った後の状態を示す図である。
【図20】7回目の集約処理を行った後の状態を示す図である。
【図21】比較例において1回目の集約処理を行った後の状態を示す図である。
【図22】比較例において2回目の集約処理を行った後の状態を示す図である。
【図23】比較例において3回目の集約処理を行った後の状態を示す図である。
【図24】比較例において4回目の集約処理を行った後の状態を示す図である。
【図25】比較例において5回目の集約処理を行った後の状態を示す図である。
【図26】比較例において6回目の集約処理を行った後の状態を示す図である。
【図27】別例における図7に対応する図である。
【図28】別例において1回目の集約処理を行った後の状態を示す図である。
【図29】別例において2回目の集約処理を行った後の状態を示す図である。
【図30】別例において3回目の集約処理を行った後の状態を示す図である。
【図31】別例において4回目の集約処理を行った後の状態を示す図である。
【図32】別例において5回目の集約処理を行った後の状態を示す図である。
【図33】従来例を説明するための図(その1)である。
【図34】従来例を説明するための図(その2)である。
【発明を実施するための形態】
【0017】
以下、一実施形態について、図1〜図32に基づいて詳細に説明する。図1には、分散処理システム100の構成が概略的に示されている。本実施形態の分散処理システム100では、複数のキーが与えられたデータを集約する「複数キー集約処理」を行うこととし、当該処理では、MapReduceアルゴリズムを適用するものとする。ここで、集約とは、同一のキーのデータを取得することを意味する。
【0018】
分散処理システム100は、図1に示すように、処理を実行するn台の処理装置としての処理サーバ10と、各処理サーバ10の処理を管理する管理サーバ20と、を備える。各処理サーバ10と管理サーバ20は、LAN(Local Area Network)、インターネットなどのネットワーク30に接続されている。
【0019】
図2には、処理サーバ10のハードウェア構成が示されている。図2に示すように、処理サーバ10は、CPU90、ROM92、RAM94、記憶部(ここではHDD(Hard Disk Drive))96、入出力部97、可搬型記憶媒体用ドライブ99等を備えている。これら処理サーバ10の構成各部は、バス98に接続されている。処理サーバ10では、ROM92あるいはHDD96に格納されているプログラム(処理プログラム)、又は可搬型記憶媒体用ドライブ99が可搬型記憶媒体91から読み出したプログラム(処理プログラム)をCPU90が実行することにより、図3の各部の機能が実現される。
【0020】
図1に戻り、各処理サーバ10のディスク(HDD96)は、仮想的に1つのディスクに見える分散ファイルシステム40に組み込まれている。なお、図示の便宜上、図1では、HDD96を各処理サーバ10の外側に出して示している。なお、図1の構成図は、MapReduceのオープンソース実装であるHadoopを用いる場合の一例を示すものであり、管理サーバ20や分散ファイルシステム40は、分散処理システム100内に必ずしも設けなくてもよい。
【0021】
図3には、処理サーバ10の機能ブロック図が示されている。処理サーバ10は、図3に示すように、関連付け部としてのMap処理部12、及び集約部としてのReduce処理部14、としての機能を有する。また、HDD96により、キー一覧リスト16を格納する領域と、データ一覧リスト18を格納する領域とが用意されている。
【0022】
Map処理部12は、分散ファイルシステム40に格納されているデータを用いて、後述するMap処理を実行する。Reduce処理部14は、Map処理部12においてMap処理されたデータを用いて、後述するReduce処理を行う。キー一覧リスト16は、図11(b)に示すようなリストである。データ一覧リスト18は、図11(c)に示すようなリストである。
【0023】
次に、MapReduce処理の基本的な処理内容について、図4に基づいて、説明する。
【0024】
MapReduce処理では、分散ファイルシステム40上の処理対象のデータを、キーと値からなるMapデータに分割する処理(Map処理)と、キーの値に応じてMapデータを纏める処理(Reduce処理)とを、各処理サーバ10において分散・並列的に行う。
【0025】
例えば、各処理サーバ10において分散・並列的に行われたMap処理によって、図4の上段に示すようなMapデータが生成されたとする。この場合、各処理サーバ10又は管理サーバ20は、各Mapデータのキーの値に対し、一意なハッシュ値を公知の計算方法により計算し、そのハッシュ値を処理サーバ数(図4では3)で割った剰余(0〜2)を求める。この場合、予め、各処理サーバ10に関し、対応する剰余値を、図4の下段に示す番号(0〜2)で決めておくことで、各Mapデータを処理する処理サーバ10を決定することができる。なお、同一の値のキーに対しては常に同一のハッシュ値が得られるため、同一のキー値を持ったMapデータ群は1つの処理サーバに集められる。また、ハッシュ値が偏りのない前提であれば、各Mapデータの処理を各サーバに偏りなく分散させることができる。なお、上述したハッシュ値から一意に処理サーバを決定する方法は、最も単純な例である。したがって、例えば、ハッシュ値に加えて、その時点の処理サーバの負荷を考慮に入れるなどして、より高度に処理サーバを決定することとしてもよい。
【0026】
各処理サーバ10(Reduce処理部14)は、集められたMapデータの集約キー(以下、単に「キー」とも呼ぶ)の値を参照する。そして、各処理サーバ10(Reduce処理部14)は、同一のキー値を持ったMapデータ(Mapデータ群)を1つのグループとし、そのグループに対してReduce処理を行う(図4の下段におけるキー=CCCのグループ参照)。なお、管理サーバ20は、各処理サーバ10の状態を把握しているため、各処理サーバ10におけるMap処理やReduce処理が完了したかどうかについても把握している。このため、管理サーバ20は、Reduce処理の結果を受けて、再度各処理サーバ10にMap処理を実行させるなどすることで、MapReduce処理を繰り返し行うことができる。
【0027】
次に、本実施形態の分散処理システム100における、複数キー集約処理の詳細について、説明する。
【0028】
なお、単一のキーでの集約であれば、上述したMapReduceの基本的な処理を行うことで実現できる(図33参照)。しかし、複数のキーを用いた集約の場合、MapReduce処理を複数回繰り返してデータを集約する必要がある。
【0029】
前述の通り、同じ集約キー(キー)を持ったMapデータは、同じサーバ・同じグループへ集約される。このため、本実施形態では、キー値を変更しながら、複数回のMapReduce処理を繰り返すことで、段階的にデータを集約するアプローチを採用する。なお、キー値を変更した場合には、ハッシュ値も変わるので、キー値変更後のデータは、別の処理サーバで処理される可能性もある。
【0030】
図5は、複数キー集約処理における具体的な処理の流れを示すフローチャートである。図5の複数キー集約処理では、Map処理とReduce処理とが必要回数繰り返される。
【0031】
図5の処理では、まず、ステップS10において、各処理サーバ10のReduce処理部14が、繰り返し制御用のカウンタとして、「キー変更カウンタ」を用意し、これを0に初期化する。なお、キー変更カウンタは、各処理サーバ10が更新することができる。各処理サーバ10では、Reduce処理が終わったことを契機にキー変更カウンタを更新する。
【0032】
次いで、ステップS12では、各処理サーバ10のMap処理部12が、Map処理を実行する。このステップS12では、Map処理部12が、分散ファイルシステム40上に存在する、入力データやReduce処理結果の中間生成データから、キー(集約キー)と値の組み合わせであるMapデータ群を生成し、分散ファイルシステム40に記憶する。
【0033】
ここで、図5のステップS12を実行するのが1回目(初回)である場合には、Map処理部12は、入力データ(図6(a)に示すようなデータ)の各行の主キー値をキー(集約キー)とする(図6(b)参照)。なお、主キー値がどの値であるかは、あらかじめ定義しておくものとする。図6(a)では、主キー値は最左列の値である。また、Map処理部12は、図6(b)に示すように、値に、行全体の情報とキーの管理情報とを設定して、Mapデータを生成する。なお、Map処理は各行独立に実行可能であるため、行数を処理サーバ10の数で分割して、各処理サーバ10で分散して実行するものとする。ここで、Mapデータのキーの管理情報は、図6(b)に示すように、最初のキーを保存する「元キー」、未使用のキーを保存する「未使用キー」、過去に使用したキーを保存する「使用済みキー」、キー変更の必要が無いことを示す「固定フラグ」などである。
【0034】
図7は、集約対象のMapデータの一例を示している。図7に示す例では、データは3階層に分類されており、19個のデータ実体が存在する。最上層ではXが主キーとなっており、01〜05までのキー値が存在する。2番目の層ではYが主キーとなっており、0101〜0105までのキー値が存在する。なお、2番目の層のデータは、関連キーとしてXも有しているため、最上層のデータと関連付けられている。また、最下層の主キーはZであり、010101〜010106までのキー値が存在する。なお、最下層のデータ(図6(a)のデータと同一)は、関連キーとしてYを有しているため、2番目の層のデータと関連付けられている。
【0035】
図7の例で特徴的なのは、関連の親子関係が複雑である点である。通常、このような構造のデータでは、一般には親と子の数の関係は1対多である。この点、図7の破線よりも右側のデータはそのような関係になっているが、図7の破線よりも左側では必ずしもそのような関係になっていない。例えばZ=010101のデータはY=0101にもY=0102にも関連している。親と子が常に1対多の関係であれば、下層のキーから順にZ→Y→Xと3回集約すればすべてのグループが正しく集約される。しかしながら、図7のようなケースではその方法では集約漏れするデータが生じるおそれがある。
【0036】
ここで、図7の最下層のデータ(Mapデータ)の生成方法(Map処理方法)について、図8(a)〜図8(c)に基づいて説明する。図8(a)は、最下層のデータのテーブル(元データ)である。図8(a)の元データは、管理サーバ20又はいずれかの処理サーバ10のMap処理部12によって、図8(b)に示すように、処理サーバ数(図8(b)では、処理サーバ数が2であるものとする)に分割される。そして、各処理サーバ10では、分割されたうちの1つのテーブルについて、Map処理を行い、図8(c)に示すように、Mapデータを生成する。このような処理により生成されるMapデータが、図7の最下層の7つのデータとなる。
【0037】
図5に戻り、次のステップS14では、各処理サーバ10のReduce処理部14が、Reduce処理を実行する。このReduce処理では、まず、管理サーバ20が、同一のキー値を持つMapデータ群を1つの処理サーバ10に集約する。そして、Reduce処理部14は、図9、図10のフローチャートに沿った処理を実行する。
【0038】
ここで、各処理サーバ10に対する入力は、図7で示される構造を有するMapデータの集合であり、キー値が同一のデータ群であるものとする。なお、キー値が同一のデータ群を、以下においては、「グループ」と呼ぶ。また、以下の説明では、図9、図10の処理の説明と併せて、図11(a)に示すMapデータ(特に、図11(a)において集約キーがZ=010101のデータ)のReduce処理を例にとり、説明する。
【0039】
図9の処理では、まず、ステップS20において、各処理サーバ10のReduce処理部14が、グループのデータ一覧リスト18(図11(c)参照)、及びキー一覧リスト16(図11(b)参照)を初期化する。次いで、ステップS22では、Reduce処理部14が、グループの集約キーを使用済みキーとしてキー一覧リスト16へ追加する(図11(b)の最下段参照)。
【0040】
次いで、ステップS24では、Reduce処理部14が、処理対象のMapデータ(例えば、図11(a)の1番のデータ)を取得する。次いで、ステップS26では、Reduce処理部14が、Mapデータをグループのデータ一覧リスト18へコピーする(図11(c)の1番のデータ参照)。次いで、ステップS28では、Reduce処理部14が、ステップS26でコピーしたMapデータ中の未使用/使用済みキー値をグループのキー一覧リスト16へコピーする。なお、ここでは、図11(b)のキー一覧リスト16において、未使用キーの欄にY=0101がコピーされるが、使用済みキーは存在していないため、使用済みキーの欄には何もコピーされない。
【0041】
次いで、ステップS30では、Reduce処理部14が、未処理のMapデータが存在するか否かを判断する。ここでの判断が肯定された場合には、ステップS24に戻り、ステップS24〜S28の処理を繰り返す。その結果、ステップS30の判断が否定される段階では、図11(c)のデータ一覧リスト18に、2番のデータがコピーされるとともに、図11(b)のキー一覧リスト16に、未使用キーとして、Y=0102がコピーされる。このように、Reduce処理部14は、Mapデータ群から、各データを順次取得(1つずつ取得)して、データ一覧リスト18及びキー一覧リスト16にデータ、未使用キーや使用済みキーをコピーする。なお、キー一覧リスト16における、未使用キーの欄と使用済みキーの欄は排他的ではなく、未使用キーの欄と使用済みキーの欄に同じキーを格納することもできる。一方、未使用キーの欄の中で重複したキー、あるいは使用済みキーの欄の中で重複したキーがある場合には、1つのみ残して重複するキーを削除してもよい。
【0042】
以上のようにして、ステップS30の判断が否定された場合には、図10のステップS32に移行する。
【0043】
図10のステップS32では、Reduce処理部14が、データ一覧リスト18の中に固定フラグが設定されたデータが存在するか否かを判断する。ここでの判断が否定された場合には、ステップS34に移行する。なお、ステップS32の判断が肯定された場合には、ステップS48(このステップについては後述)に移行する。ここで、図11(c)の例では、データ一覧リスト18に、固定フラグが設定されたデータは存在していない(全てfalse)ので、ステップS32の判断は肯定されて、ステップS34に移行する。
【0044】
ステップS34に移行した場合、Reduce処理部14は、キー一覧リスト16の中に未使用のキーが存在するか否かを判断する。図11(b)の例では、キー一覧リスト16に、未使用のキーが存在しているので、ステップS34の判断は肯定され、ステップS36に移行する。
【0045】
ステップS36に移行した場合、Reduce処理部14は、データ一覧リスト18中のどの元キーとも一致しない未使用キーが存在するか否かを判断する。図11(b)の例では、キー一覧リスト16に、データ一覧リスト18中のどの元キーとも一致しない未使用キーが2つ存在しているので、ここでの判断は肯定され、ステップS38に移行する。
【0046】
ステップS36の判断が肯定され、ステップS38に移行した場合、Reduce処理部14は、実体を持つ全データのキーを、未使用キーの欄から一つ選択したキーに書き換える。また、Reduce処理部14は、選択したキーを除き、グループのキー一覧リスト16の内容を未使用/使用済みキーに格納する。すなわち、ステップS38では、図12に示すように、Reduce処理部14は、データ一覧リスト18に含まれるMapデータの1番のデータのキーと2番のデータのキーをY=0101に書き換える。また、Reduce処理部14は、キー一覧リスト16の未使用キーからY=0101を除いた結果、すなわちY=0102を各データの未使用キーに格納する。また、キー一覧リスト16の使用済みキーであるZ=010101を各データの使用済みキーに格納する。
【0047】
次いで、ステップS40では、Reduce処理部14が、実体を持たないMapデータが存在しない場合、新たに実体を持たないキーのみのMapデータを1つ生成する。例えば、図12において3番のデータとして示すデータを生成する。この場合、書き換える前のキー(=集約キー)をキーとし、グループの未使用キー一覧の内容(図11(b))を未使用キーの欄に格納する。図12の3番のデータでは、キーとしてグループの集約キーであるZ=010101を設定し、未使用キーにはグループのキー一覧リスト16の未使用キーであるY=0101とY=0102を設定する。なお、使用済みキーの設定は必要なく、固定フラグは「false」とし、データ本体は空とする。
【0048】
次いで、ステップS46では、Reduce処理部14は、キー変更カウンタを1だけインクリメントする。次いで、ステップS50では、Reduce処理部14が、図1に示す分散ファイルシステム40上の、Mapデータ群の中間ファイルへの出力を行い、その後、図5のステップS16に移行する。なお、ステップS50で出力されるMapデータ群は、図12に示すデータである。
【0049】
図13は、1回目の集約により、同階層で同一のキー値を持つデータ群(グループ)が集約された様子を示した図である。なお、図13に示すように、1回目の集約によって、Z=010101以外の2つのキー(Y=0101、Y=0103)のMapデータも集約されている。この図において、データを示す箱(矩形枠)の左上に示す値(Z=010101等)が、各集約グループを示しており、その値の下に隣接して配置された箱の一群がグループのデータを示している。また、箱の内部の「未使用キー」は、図11(b)におけるキー一覧リスト16の未使用キーの欄を示している。更に、箱の内部の「キー」の矢印の左側はその集約における集約キー、右側は未使用キーの中から一つ選択したキーで、次の集約において集約キーとなる値を示している。なお、図13では、図示及び説明の簡単のため、使用済みキーは表示していない。なお、図12のように、Reduce処理の終盤でキー情報のみのMapデータが生成されている(図12のデータ「3」)が、これは再集約(2回目以降の集約)が実施されたときにのみ意味を持つものなので、図13では図示していない。なお、図15において破線で示されている箱が、1回目の集約で生成されたキー情報のみのMapデータである。
【0050】
なお、図10の処理において、キー一覧リスト16の中に未使用のキーが存在していない場合(例えば、図13の最上段のデータ等の場合)には、ステップS34の判断が否定される。ステップS34の判断が否定された場合には、Reduce処理部14は、キー変更カウンタを0に維持したまま、ステップS50に移行し、Mapデータ群の中間ファイルへの出力を行った後、図5のステップS16に移行する。
【0051】
図5に戻り、次のステップS16に移行すると、管理サーバ20は、Reduce処理のキー変更カウンタの集計値が1以上か否かを判断する。上記例では、いずれかのグループで集約キーの変更が発生しており、図10のステップS46を経ている。したがって、キー変更カウンタの集計値は1以上となるため、ステップS16の判断は肯定され、ステップS10に戻る。そして、ステップS10〜S16の処理(再度のMapReduce処理)を繰り返す。
【0052】
なお、図10の処理において、データ一覧中のどの元キーとも一致しない未使用キーが存在しない場合には、ステップS36の判断が否定される。この場合、キー値の変更が一巡したとみなせるので、それ以上の変更は無意味となる。したがって、この場合には、ステップS42に移行し、Reduce処理部14が、データ一覧リスト18中の全データに対し、固定フラグを設定する。そして、ステップS44において、Reduce処理部14は、データ一覧中の全データのキーを、使用済みキー一覧の中から、辞書式に判定して先頭となるキー値を変更する。なお、これらステップS42、S44の具体的処理については、後述する。その後は、上記と同様、ステップS46、S50を経て、図5のステップS16に移行する。
【0053】
また、図10のステップS32において、データ一覧リスト18の中に固定フラグが設定されたデータが存在していた場合には、ステップS48に移行する。このステップS48では、Reduce処理部14が、データ一覧中の全データに対し、固定フラグを設定することで、その時点の集約キーをそのまま用いて再集約可能な状態にする。そして、ステップS50において、Mapデータ群の中間ファイルへの出力を行った後、図5のステップS16に移行する。
【0054】
次に、2回目の集約処理について説明する。図14(a)〜図14(c)には、集約キーがY=0101のMapデータを集約する処理を説明するための図(リスト16,18)が示されている。図14(b)のデータ一覧リストのうち1、2番目のデータは、図12の1、2番目のデータと同一である。これに対し、3番目のデータは、図13のY=0101のグループを集約した際に生成されたデータ実体のないデータ(図15の符号Daで示す破線の箱参照)である。また、これら3つのデータからは、キー一覧リスト16として、図14(a)のようなリストが得られる。これら、図14(a)のキー一覧リスト及び図14(b)のデータ一覧リストを用いて図10の処理を行うと、図14(c)のような3つのデータを得ることができる。このような2回目の集約処理を行った後の状態が、図15に示されている。図15に示すように、2回目の集約処理の結果、集約キーがY=0101のMapデータ以外のMapデータも集約されていることが分かる。
【0055】
以下、同様に集約処理を繰り返すと、3回目の集約処理の結果は、図16のようになる。また、4回目の集約処理の結果は、図17のようになり、5回目の集約処理の結果は、図18のようになり、6回目の集約処理の結果は、図19のようになる。そして、7回目の集約処理の結果、図20のようになる。図20の状態では全グループに未使用キーが存在しなくなるため(全処理サーバ10においてステップS34が否定されるため)、キー変更カウンタは0のままとなる。この場合、図5のステップS16の判断が否定され、ステップS18に移行する。そして、管理サーバ20は、ステップS18において集約処理を完了する。
【0056】
本実施形態では、上記のようなMapReduce処理を行うことで、図20に示すように、X=04のグループとX=05の2グループとなる。これにより、複数のMapデータを、図7の状態から正確に(集約漏れなく)2つのグループに集約できたことになる。
【0057】
(比較例)
ここで、比較例(従来法を用いて、図7のデータを集約する場合)について説明する。なお、以下の処理は、各処理サーバ10が行うものとする。
【0058】
従来法としては、各データは変更可能なキー、不変の関連キーリスト(データにおいて定義されているキー)、再集約のフラグを兼ねる変更可能な予約関連キーを有することとする。また、上述した実施形態で用いたデータ実体を持たないキー値のみのデータは用いていない。従来法では、実体のないデータを用いないことを理由に、集約処理を全階層同時に行うことはできないため、キー値の種類毎に下層の方から順に集約する必要が生じる。
【0059】
図21には、元データの主キーをキー、関連キーを関連キーリストに格納し、最下層のキーであるZを集約キーとして1回目の集約を行った結果が示されている。なお、図21及びこれ以降の図面では、各データの識別のため、処理には使用しないIDを示している。図21では、Z=010101のグループのみ、複数の関連キーを含んでいる。このように、グループ内に複数の関連キーが存在する場合、そのグループのデータには予約関連キーが設定される。予約関連キーの値は、そのグループの集約キーとなる。従って、Z=010101のグループではZ=010101が予約関連キーとなる。また、1回目の集約が行われたデータ又はグループのキーは、関連キーに変更される。
【0060】
次いで、2回目の集約では、2番目の層のキーであるYでの集約が行われる。その結果が図22に示されている。ここで、図22に示すように、Y=0101とY=0102のグループには、1回目の集約時に予約関連キーを設定したデータが含まれている。このため、次の3回目の集約では、最上層のキーではなく、予約関連キーで集約が行われる。一方、予約関連キーが設定されていないグループについては、2回目と同じキー値で再度集約が行われる。
【0061】
3回目の集約結果が図23に示されている。予約関連キーでの集約を終えたので、次の集約は最上層のキーであるXでの集約となるが、Z=010101とY=0103のグループには複数のXのキー値が含まれるため、各データに予約関連キーが設定される。
【0062】
以下、上記と同様の処理が繰り返されることにより、4回目の集約処理の結果、図24のようになり、5回目の集約処理の結果、図25のようになり、6回目の集約処理の結果、図26のようになる。図26に示すように、6回目の集約処理が完了した段階では、上記実施形態と同様、データを2つのグループに集約することができる。
【0063】
ここで、複数キー集約処理全体の処理量の概算として、処理対象となるグループ数を用いると、初期状態から集約完了までの累計総グループ数は、本実施形態の場合、61グループ(図20参照)、比較例の場合、66グループ(図26参照)となる。すなわち、初期状態から集約完了までの累計総グループ数は、本実施形態のほうが少ないことが分かる。また、前の集約時から変動があったグループの累計は、本実施形態が14であり(図20参照)、比較例が15である(図26参照)ので、本実施形態のほうが少ないことが分かる。
【0064】
更に、本実施形態の場合、一度集約されたデータ群は、それ以降分断されることが無いのに対し、比較例では図21から図22へ遷移する際のID=013、014のように、一度集約されたデータ群が分断されることがある。このような点から、本実施形態の方が、グループ内での統計処理などを漸次的に計算するのに都合が良いことになる。
【0065】
(別例について)
以下、図7とは異なる例について、図27〜図32に基づいて説明する。なお、図28〜図32では、Mapデータの近傍に、集約処理に用いるキー一覧リスト16を併記するものとする(一点鎖線で示す箱)。
【0066】
図27には、図7の例と同様に3階層に分かれているものの、関連がループしており、親子関係が明確ではないデータの一例が示されている。なお、この例では2系統のループがあるが、Z=010101が共通して含まれているため、集約処理の結果、全てのデータが1グループに集約されるのが正しい集約結果である。
【0067】
図27のデータに対して本実施形態の処理を適用し、各処理サーバ10のReduce処理部14が、1回目の集約処理を行った結果が図28(矢印の下側のデータ)である。
【0068】
図28では、Reduce処理部14は、それぞれ元のデータの主キーで集約している。この場合、Z=010101のみ複数のデータが集約される。また、各グループに未使用のキーが存在するため、Reduce処理部14は、キーを未使用のキーのうちの1つに変更し、2回目の集約を行う。図29には、2回目の集約を行った結果(矢印の下側のデータ)が示されている。
【0069】
同様に、Reduce処理部14が3回目の集約を行うと図30の矢印の下側の状態となる。ここで、Z=010101のグループでは、各データの未使用のキーが無くなり、実体の無いデータの未使用キーはグループ内のデータの元キーと一致するものしかなくなる(図10のステップS36が否定される)。これにより、キー変更が一巡したことがわかるため、固定フラグを設定するとともに(ステップS42)、グループ内の使用済みキーの中から、辞書式に評価して先頭となるキー(ここでは、X=01)を見つけ、次の集約キーとする(ステップS44)。なお、辞書式に評価して先頭を見つける処理は、各キー種の関係から親子関係(階層構造)の最上位を見つける処理を意味する。
【0070】
同様にして、Reduce処理部14が4回目の集約を行うと、図31の状態となる。ここで、X=01に集約されたグループには、固定フラグが設定されたデータが含まれる(ステップS32が肯定される)。このため、Reduce処理部14は、固定フラグが設定されていなかったデータにも固定フラグを設定する(ステップS48)。
【0071】
また、Y=0102のグループでも、使用可能性のあるキーは元キーと一致するものしかなくなる(図10のステップS36が否定される)ため、キー変更一巡となる。このため、Reduce処理部14は、次の集約キーをX=01とし、固定フラグを設定する(ステップS42)。この結果、図32に示すように、Reduce処理部14が5回目の集約を行うと、すべてのデータが固定フラグ付きでX=01に集約され、集約が完了する。この場合、前述したように、1グループに正確に集約されることになる。以上のように、図27のようなデータの関係がループする場合であっても、本実施形態では、正確に、データを集約することが可能である。
【0072】
以上詳細に説明したように、本実施形態の処理サーバ10によると、Map処理部12が行う、複数のデータそれぞれが有するキーを、集約に用いる集約キー、集約において未だ用いていない未使用キー、及び既に集約に用いた使用済みキーのいずれかに分類して、Mapデータに関連付けて分散ファイルシステム40に記憶する処理(ステップS12)と、Reduce処理部14が行う、記憶された複数のデータのうち、同一の集約キーに関連付けられたMapデータを取得する(ステップS26)とともに、取得したMapデータ群に含まれる未使用キーを全て取得し(ステップS28)、取得した未使用キーのうちの1つを次の集約キーとして決定し、取得したデータに関連付けて記憶された集約キーを次の集約キーに更新し(ステップS38)、取得したデータに関連付けて記憶された未使用キーを取得した未使用キーから次の集約キーを除いた残りの未使用キーに更新する(ステップS40)処理を、Reduce処理部14における集約キーの更新ができなくなるまで繰り返す。これにより、RDB(関係データベース)を用いなくとも、処理対象のデータを参照するのみで、複数のMapデータを集約することができる。これにより、性能・スケーラビリティ改善効果を最大限に得ることが可能となる。また、Map処理部12とReduce処理部14とが処理を繰り返し行うことで、データに関連のある範囲のキーがデータ間を伝達していくので、データ集約の漏れをなくすことができる。
【0073】
また、本実施形態では、Reduce処理部14は、複数のMapデータを集約する際に、更新を行う前の集約キーを集約キーとし、集計された(取得された)未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たなMapデータとして生成するので(ステップS40)、親子関係(階層関係)にある全ての階層の集約処理を同時に行うことが可能となる。これにより、処理時間の短縮を図ることが可能となる。
【0074】
また、本実施形態では、Reduce処理部14は、集約キーを更新できなくなったデータの集約キーを、使用済みキーとしてMapデータに関連付けられているキーのうち、親子関係(階層関係)の最上位にあるキーで更新するとともに、Mapデータに、集約キーのそれ以上の更新を禁止するフラグ(固定フラグ)を設定する(データに対応付けて固定フラグを記憶する)(ステップS42、S44)。これにより、集約キーの更新が一巡したときには、それ以降、集約キーは更新されなくなるので、集約キーの更新が一巡したときに発生し得る、処理の永久ループを防止することが可能となる。
【0075】
また、本実施形態の分散処理システム100は、上記のような処理サーバ10を複数備えているので、複数のMapデータを、複数の処理サーバ10上で分散・並行的にMapReduce処理することが可能となる。
【0076】
なお、上記の処理機能は、コンピュータによって実現することができる。その場合、処理装置が有すべき機能の処理内容を記述したプログラムが提供される。そのプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。
【0077】
プログラムを流通させる場合には、例えば、そのプログラムが記録されたDVD(Digital Versatile Disc)、CD−ROM(Compact Disc Read Only Memory)などの可搬型記録媒体の形態で販売される。また、プログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することもできる。
【0078】
プログラムを実行するコンピュータは、例えば、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、自己の記憶装置に格納する。そして、コンピュータは、自己の記憶装置からプログラムを読み取り、プログラムに従った処理を実行する。なお、コンピュータは、可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することもできる。また、コンピュータは、サーバコンピュータからプログラムが転送されるごとに、逐次、受け取ったプログラムに従った処理を実行することもできる。
【0079】
上述した実施形態は本発明の好適な実施の例である。但し、これに限定されるものではなく、本発明の要旨を逸脱しない範囲内において種々変形実施可能である。
【0080】
なお、以上の説明に関して更に以下の付記を開示する。
(付記1) 複数のキー種を用いて分類された複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を実行する処理装置であって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された、前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶する関連付け部と、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、該取得した未使用キーのうちの1つを次の集約キーとして決定し、前記取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する集約部と、を備え、前記集約キーの更新ができなくなるまで、前記関連付け部と前記集約部による処理を繰り返すことを特徴とする処理装置。
(付記2) 前記集約部は、前記更新を行う前の前記集約キーを集約キーとし、取得した前記未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たな処理対象のデータとして生成して前記記憶部に記憶することを特徴とする付記1に記載の処理装置。
(付記3) 前記関連付け部は、前記処理対象のデータに、既に集約に用いた使用済みキーを関連付け、前記集約部は、前記集約キーの更新ができなくなったデータに対応付けて前記記憶部に記憶された集約キーを、前記データに前記使用済みキーとして関連付けられているキーのうち、親子関係の最上位にあるキー種のキーで更新し、当該データに対応付けて前記集約キーの更新を禁止する情報を前記記憶部に記憶し、前記記憶部に格納された前記複数のデータのうち、同一の集約キーに関連付けられ、且つ、前記集約キーの更新を禁止する情報が関連付けられていないデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、前記取得した未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに対応付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに対応付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新することを特徴とする付記1又は2に記載の処理装置。
(付記4) 付記1〜3のいずれかに記載の処理装置を複数備え、複数の処理対象のデータを前記複数の処理装置に分散して、当該複数の処理装置において並行処理を実行することを特徴とする分散処理システム。
(付記5) 複数のキー種を用いて複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を、コンピュータに実行させる処理プログラムであって、前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと、未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶し、前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、取得した前記未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを、前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを、取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、前記未使用キーの更新ができなくなるまで、コンピュータに繰り返し実行させることを特徴とする処理プログラム。
(付記6) 前記集約する処理では、前記更新を行う前の前記集約キーを集約キーとし、取得した前記未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たな処理対象のデータとして生成して前記記憶部に記憶する処理をコンピュータに実行させることを特徴とする付記5に記載の処理プログラム。
(付記7) 前記関連付ける処理では、前記処理対象のデータに、既に集約に用いた使用済みキーを関連付ける処理をコンピュータに実行させ、前記集約する処理では、前記集約キーの更新ができなくなったデータに対応付けて前記記憶部に記憶された集約キーを、前記データに前記使用済みキーとして関連付けられているキーのうち、親子関係の最上位にあるキー種のキーで更新し、当該データに対応付けて前記集約キーの更新を禁止する情報を前記記憶部に記憶し、前記記憶部に格納された前記複数のデータのうち、同一の集約キーに関連付けられ、且つ、前記集約キーの更新を禁止する情報が関連付けられていないデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、前記取得した未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに対応付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに対応付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、コンピュータに実行させることを特徴とする付記5又は6に記載の処理プログラム。
【符号の説明】
【0081】
10 処理サーバ(処理装置)
12 Map処理部(関連付け部)
14 Reduce処理部(集約部)
90 CPU(コンピュータ)
96 HDD(記憶部)
100 分散処理システム
【特許請求の範囲】
【請求項1】
複数のキー種を用いて分類された複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を実行する処理装置であって、
前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された、前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶する関連付け部と、
前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、該取得した未使用キーのうちの1つを次の集約キーとして決定し、前記取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する集約部と、
を備え、
前記集約キーの更新ができなくなるまで、前記関連付け部と前記集約部による処理を繰り返すことを特徴とする処理装置。
【請求項2】
前記集約部は、前記更新を行う前の前記集約キーを集約キーとし、取得した前記未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たな処理対象のデータとして生成して前記記憶部に記憶することを特徴とする請求項1に記載の処理装置。
【請求項3】
前記関連付け部は、前記処理対象のデータに、既に集約に用いた使用済みキーを関連付け、
前記集約部は、前記集約キーの更新ができなくなったデータに対応付けて前記記憶部に記憶された集約キーを、前記データに前記使用済みキーとして関連付けられているキーのうち、親子関係の最上位にあるキー種のキーで更新し、当該データに対応付けて前記集約キーの更新を禁止する情報を前記記憶部に記憶し、前記記憶部に格納された前記複数のデータのうち、同一の集約キーに関連付けられ、且つ、前記集約キーの更新を禁止する情報が関連付けられていないデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、前記取得した未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに対応付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに対応付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新することを特徴とする請求項1又は2に記載の処理装置。
【請求項4】
請求項1〜3のいずれか一項に記載の処理装置を複数備え、
複数の処理対象のデータを前記複数の処理装置に分散して、当該複数の処理装置において並行処理を実行することを特徴とする分散処理システム。
【請求項5】
複数のキー種を用いて複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を、コンピュータに実行させる処理プログラムであって、
前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと、未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶し、
前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、
取得した前記データに含まれる未使用キーを全て取得し、
取得した前記未使用キーのうちの1つを次の集約キーとして決定し、
取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを、前記次の集約キーに更新し、
取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを、取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、
前記未使用キーの更新ができなくなるまで、コンピュータに繰り返し実行させることを特徴とする処理プログラム。
【請求項1】
複数のキー種を用いて分類された複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を実行する処理装置であって、
前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された、前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶する関連付け部と、
前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、該取得した未使用キーのうちの1つを次の集約キーとして決定し、前記取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する集約部と、
を備え、
前記集約キーの更新ができなくなるまで、前記関連付け部と前記集約部による処理を繰り返すことを特徴とする処理装置。
【請求項2】
前記集約部は、前記更新を行う前の前記集約キーを集約キーとし、取得した前記未使用キーのすべてを未使用キーとする、データとしての実体のないデータを新たな処理対象のデータとして生成して前記記憶部に記憶することを特徴とする請求項1に記載の処理装置。
【請求項3】
前記関連付け部は、前記処理対象のデータに、既に集約に用いた使用済みキーを関連付け、
前記集約部は、前記集約キーの更新ができなくなったデータに対応付けて前記記憶部に記憶された集約キーを、前記データに前記使用済みキーとして関連付けられているキーのうち、親子関係の最上位にあるキー種のキーで更新し、当該データに対応付けて前記集約キーの更新を禁止する情報を前記記憶部に記憶し、前記記憶部に格納された前記複数のデータのうち、同一の集約キーに関連付けられ、且つ、前記集約キーの更新を禁止する情報が関連付けられていないデータを取得し、取得した前記データに含まれる未使用キーを全て取得し、前記取得した未使用キーのうちの1つを次の集約キーとして決定し、取得した前記データに対応付けて前記記憶部に記憶された前記集約キーを前記次の集約キーに更新し、取得した前記データに対応付けて前記記憶部に記憶された前記未使用キーを取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新することを特徴とする請求項1又は2に記載の処理装置。
【請求項4】
請求項1〜3のいずれか一項に記載の処理装置を複数備え、
複数の処理対象のデータを前記複数の処理装置に分散して、当該複数の処理装置において並行処理を実行することを特徴とする分散処理システム。
【請求項5】
複数のキー種を用いて複数のデータの中から関連のあるデータを集約してデータ群を生成する処理を、コンピュータに実行させる処理プログラムであって、
前記複数のキー種を用いて分類された複数のデータを記憶する記憶部に記憶された前記複数のデータのそれぞれについて、該データが有する前記複数のキー種のキーを、前記集約に用いる集約キーと、未使用キーのいずれかに分類して、各データに関連付けて前記記憶部に記憶し、
前記記憶部に記憶された前記複数のデータのうち、同一の集約キーに関連付けられたデータを取得し、
取得した前記データに含まれる未使用キーを全て取得し、
取得した前記未使用キーのうちの1つを次の集約キーとして決定し、
取得した前記データに関連付けて前記記憶部に記憶された前記集約キーを、前記次の集約キーに更新し、
取得した前記データに関連付けて前記記憶部に記憶された前記未使用キーを、取得した前記未使用キーから前記次の集約キーを除いた残りの未使用キーに更新する処理を、
前記未使用キーの更新ができなくなるまで、コンピュータに繰り返し実行させることを特徴とする処理プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】

【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】

【図34】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【公開番号】特開2012−190078(P2012−190078A)
【公開日】平成24年10月4日(2012.10.4)
【国際特許分類】
【出願番号】特願2011−50745(P2011−50745)
【出願日】平成23年3月8日(2011.3.8)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
【公開日】平成24年10月4日(2012.10.4)
【国際特許分類】
【出願日】平成23年3月8日(2011.3.8)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
[ Back to top ]