
動作訓練装置、動作訓練システム、動作訓練装置の制御方法及びプログラム
【課題】動作訓練の効率を向上する動作訓練装置を提供する。
【解決手段】訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置であって、訓練者を撮影するための撮影手段と、基準画像をディスプレイを介して訓練者に提示する提示手段と、撮影手段で撮影した画像から抽出した訓練者の特徴情報に基づいて、提示手段で提示した基準画像のサイズ及び位置を正規化し、該正規化した画像と撮影画像とを合成する合成手段と、合成手段で合成した画像をディスプレイに表示する表示制御手段とを備える。
【解決手段】訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置であって、訓練者を撮影するための撮影手段と、基準画像をディスプレイを介して訓練者に提示する提示手段と、撮影手段で撮影した画像から抽出した訓練者の特徴情報に基づいて、提示手段で提示した基準画像のサイズ及び位置を正規化し、該正規化した画像と撮影画像とを合成する合成手段と、合成手段で合成した画像をディスプレイに表示する表示制御手段とを備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、特定の動作の訓練を行うための動作訓練装置、動作訓練システム及び動作訓練装置の制御方法及びプログラムに関する。
【背景技術】
【0002】
特定の動作の訓練を行うための動作訓練装置及び動作訓練システムとして、従来より種々の技術が提案されている。例えば、特許文献1に開示された発話練習システムでは、教師用の音声波形データと聾者や知的障害等の訓練者自身が発声する音声波形データを当該聾者が見るディスプレイに同時に表示することで、当該聾者が両方の波形データを比較しながら発声練習を実行できるようにしている。このシステムによれば、当該聾者のディスプレイに予め記憶されている教師用の映像とカメラが撮影した当該聾者の映像を同時に表示することにより、聾者の発話訓練を行うことができる。一方、非特許文献1に開示された言葉学習支援システムでは、知的障害児の発話訓練において、当該障害児が見るディスプレイに発話の手本となる教師の画像とWebカメラが撮影した当該障害児の顔のライブ画像を同一画面上に並べて表示し、障害児自身の口の動きを手本と比較して確認可能としている。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開平10−161518号公報
【非特許文献】
【0004】
【非特許文献1】知的障害児の「ことば」の学習支援コンテンツの開発(兵庫県立教育研修所,2003年):http://web3.cec.or.jp/jissenjirei/public/jyugyou_tenkai1/CEC01225_1.html
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、従来のこのような動作訓練装置は、訓練者が模範とすべき基準画像と自分の画像(例えば、顔画像)とを見比べながら訓練を行う必要があった。このため、その訓練者がどのような動作に矯正すべきかを認識することが困難であった。
【0006】
本発明は、上述の課題に鑑みてなされたものであり、動作訓練の効率を向上する動作訓練装置を提供するものである。
【課題を解決するための手段】
【0007】
上記課題を解決するため、本発明に係る動作訓練装置は、訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置であって、訓練者を撮影するための撮影手段と、前記基準画像をディスプレイを介して訓練者に提示する提示手段と、前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手段と、前記合成手段で合成した画像を前記ディスプレイに表示する表示制御手段と、を備える。
【発明の効果】
【0008】
本発明によれば、動作訓練の効率を向上する動作訓練装置を提供することができる。
【図面の簡単な説明】
【0009】
【図1】本発明の実施例1に係る発話訓練システムの全体構成を示す図。
【図2】実施例1、2、4に係る発話訓練システムの内部構成を示すブロック図。
【図3】実施例1に係る発話訓練システムの全体の処理の流れを示す図。
【図4】実施例1及び3に係る発話訓練システムの画像正規化合成処理の流れを示す図。
【図5】実施例1乃至3に係る発話訓練システムの画像表示部に表示した情報を示す図。
【図6】実施例2に係る発話訓練システムの全体の処理の流れを示す図。
【図7】実施例2に係る発話訓練システムの指導メッセージ生成処理の流れを示す図。
【図8】実施例2に係る発話訓練システムの訓練者2の画像及び基準口形画像における口のサイズと位置の情報を示す図。
【図9】実施例3に係る発話訓練システムの全体の処理の流れを示す図。
【図10】実施例4に係る発話訓練システムの全体の処理の流れを示す図。
【発明を実施するための形態】
【0010】
以下に、本発明の実施の形態について添付図面を参照して詳細に説明する。なお、以下に説明する実施の形態は、本発明の実現手段としての一例であり、本発明は、その趣旨を逸脱しない範囲で以下の実施形態を修正又は変形したものに適用可能である。
【0011】
<実施例1>
本実施例に係る動作訓練システムは、遠隔地に居る訓練者(聾者)と指導者との間にデジタル双方向回線を設定し、その端末間で映像・音声を介した発話訓練を行うための発話訓練システムを想定して説明する。
【0012】
[発話訓練システムの全体構成(図1)]
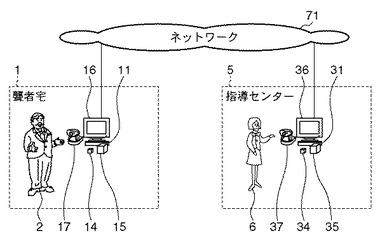
本実施例に係る発話訓練システムは、訓練者2が用いるための訓練者端末11(第1の情報処理装置)と、訓練者端末11とネットワーク71で接続された、指導者6が用いるための指導者端末31(第2の情報処理装置)とを備える。訓練者端末11及び指導者端末31は、本実施例では、地理的に離れた2つの地点1、5に設置されているものとする。地点1は、例えば、訓練者2である聾者の自宅であり、地点5は、例えば、指導者6が駐在する指導センター等の施設である。
【0013】
訓練者端末11は、訓練者2である聾者を撮影するためのカメラ等で構成される撮像部17(第1の撮影手段)と、発話訓練に必要な画像情報や各種の指示を聾者へ表示するためのディスプレイ等で構成される画像表示部16(以下、表示部16)と、訓練者2の音声を入力するためのマイク等で構成される音声入力部14と、通信相手である指導者6の音声データによる指示を発音するためのスピーカ等で構成される音声出力部15とを有する。
【0014】
一方の指導者端末31は、指導者6を撮影するためのカメラ等で構成される撮像部37(第2の撮影手段、取得手段)と、聾者の発話訓練に必要な各種情報を表示するためのディスプレイ等で構成される画像表示部36(以下、表示部36)と、音声を入力するためのマイク等で構成される音声入力部34と、通信相手である訓練者2の音声データを発音するためのスピーカ等で構成される音声出力部35とを有する。また、システム全体の制御もこの指導者端末31の全体制御部32が管理している。
【0015】
ここで、本実施例に係る発話訓練システムの全体の処理の概要を説明する。まず、発話訓練の予定時刻等に指導者6がマウス(不図示)等を用いて指導者端末31の表示部36に表示された「接続」ボタンを押下する。「接続」ボタンが押下されると、接続要求が訓練者端末11へと送信され、必要な接続開始処理がなされた後、訓練者端末11と指導者端末31との間の映像・音声のコネクションが確立する。
【0016】
次に、指導者6が表示部36で発話訓練を行う単語(例えば「いぬ」)を選択すると、その単語のテキストデータが訓練者端末11へ送信される。訓練者端末11で受信された単語のテキストデータは、表示部16に表示される。これにより、訓練者2はまず、発話訓練語が「いぬ」であることを確認することができる。次に、指導者6が表示部16の「発話練習開始」ボタンを押すと、まず、最初の単語「い」が発話対象文字として設定され、単語「い」の基準口形画像データが基準口形データベースから読み出されて訓練者端末11へ送信される。訓練者端末11で受信された基準口形画像データは、表示部16に表示される。聾者が単語「い」の基準口形画像とテロップ情報を参照しながら、音声入力部14に向かって「い」の音声を発声する。音声が発生されると、入力された音声データ及び撮像部17が撮影した訓練者2の顔画像が指導者端末31へ送信される。
【0017】
指導者端末31側では、まず、受信した訓練者2の顔画像データを分析し、聾者の顔の輪郭情報と口の中心位置を算出する。続いて、これらの抽出情報に基づいて、基準画像から抜き出した当該「い」の基本口形画像の表示サイズと表示位置(基準位置)とを正規化し、当該訓練者2の顔画像上に合成を施した後に訓練者端末11へ送信する。ただし、ここでいう「合成」とは、「重畳」という言葉と同等の意味であるものとする。
【0018】
訓練者端末11で受信された当該合成画像は表示部16に表示される。訓練者2は自分の顔画像上に適切な位置に合成された「い」の発音時の手本となる口形情報を確認し、正しい発音になるように自分の口の開き方を修正することができる。次に、指導者6がマウス等で表示部36に表示された「次の文字」ボタンを押下すると、発話対象文字として「ぬ」の文字が設定され、上述の手順を繰り返す。更に、次の単語の発話練習を行う場合は、指導者6が画面から単語を選び直した後に上記の手順を繰り返す。このようにして、訓練者2である聾者が様々な単語の発話練習を容易に実行することが可能となる。
【0019】
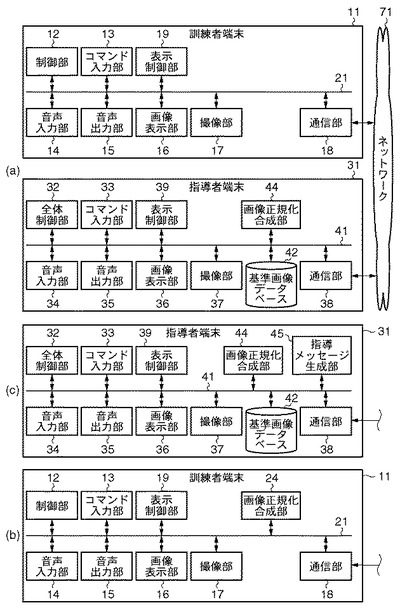
[発話訓練システムの内部構成(図2(a))]
訓練者端末11は、制御部12、コマンド入力部13、音声入力部14、音声出力部15、表示部16、撮像部17、通信部18(画像入力手段)、表示制御部19(第1の表示制御手段)、及びこれらの各要素を接続するためのバス21を備える。
【0020】
まず、コマンド入力部13は、ボタン等のインターフェイスからなり、訓練者2である聾者の各種指示をバス21を介して制御部12へと出力する。音声入力部14は、訓練者2の音声データを入力し、バス21を介して制御部12へ出力するためのものであり、例えば、エレクトリックコンデンサ式のマイクロフォンが用いられる。音声出力部15は、通信相手である指導者6の音声データや訓練者2に対する音声による指示を出力するためのものであり、例えば、一般的なダイナミック型スピーカが用いられる。
【0021】
表示部16は、表示制御部19が出力する画像データやテキストデータを表示するためのものであり、例えば液晶ディスプレイが用いられる。撮像部17は、訓練者2である聾者の様子を撮影するためのものであり、例えば、Pan、Tilt、Zoomカメラや、固定式のカメラ等が用いられる。
【0022】
通信部18は、訓練者端末11から出力するデータ及び訓練者端末11に外部から入力されるデータに対してプロトコルの変換等を行い、ネットワーク71を経由した指導者端末31とのデータ通信を可能としている。表示制御部19は、指導者端末31から受信した基準口形画像、合成画像及び訓練者の動作を矯正するための指導情報等のデータの表示出力制御を行うためのものである。制御部12は、RAM(不図示)に記憶されている訓練者端末11用のアプリケーションプログラムに基づいて自ら演算処理等を行い、或いは上述した各構成要素を制御し、訓練者端末11を機能させる。
【0023】
指導者端末31は、全体制御部32、コマンド入力部33、音声入力部34、音声出力部35、表示部36、撮像部37、基準画像データベース、通信部38、表示制御部39(第2の表示制御手段)、画像正規化合成部44(以下、合成部44)、及びこれらの各要素を接続するためのバス41を備える。
【0024】
コマンド入力部33は、押下ボタン等のインターフェイスからなり、指導者6の各種指示をバス41を介して全体制御部32へ出力する。音声入力部34は、指導者6の音声データを入力し、バス41を介して制御部12へ出力するためのものであり、例えば、エレクトリックコンデンサ式のマイクロフォンが用いられる。
【0025】
音声出力部35は、通信相手である訓練者2の音声データ等を出力するためのものであり、例えば、一般的なダイナミック型スピーカが用いられる。表示部36は、表示制御部39が出力する画像データやテキストデータを出力するためのものであり、例えば液晶ディスプレイが用いられる。
【0026】
表示制御部39は、訓練者2に提示するものと同等の情報、すなわち、基準口形画像、合成画像及び指導情報等のデータの表示出力制御を行うためのものである。撮像部37は、指導者6の様子を撮影するためのものであり、例えば、Pan、Tilt、Zoomカメラや、固定式のカメラ等が用いられる。
【0027】
通信部38は、指導者端末31から出力するデータ及び指導者端末31に入力するデータに対してプロトコルの変換等を行い、ネットワーク71を経由した訓練者端末11とのデータ通信を可能としている。基準画像データベース42は、日本語の50音やアルファベット等の各発話音の模範的な口形を撮影した基準口形画像データ(静止画)、及び発話訓練の対象となる単語や語句のリスト(テキストデータ)を記憶するものである。
【0028】
合成部44は、訓練者端末11から受信した訓練者2の顔画像データから抽出した特徴情報に基づいて、模範とすべき基準画像から抽出した口の部分画像の表示サイズと表示位置を正規化して当該撮影画像上に合成するためのものである。
【0029】
最後に、全体制御部32は、RAM(不図示)に記憶された発話訓練システム制御用のアプリケーションプログラムに基づいて自ら演算処理等を行い、或いは上述の各構成要素を制御し、訓練者端末11及び指導者端末31を機能させる。
【0030】
一方、71はネットワークを示している。このネットワーク71は、本実施例では、TCP/IPネットワークを用いる。このため、インターネットやLAN(Local Area Network)等のいずれも用いることが可能である。また、通信プロトコルはTCP/IPに依存する必要はなく、IPX/ISXやAppleTalkと言った同様の機能を果たすプロトコルを用いても良い。回線に関しても、これらのプロトコルを使用できるのであれば、有線や無線等のいかなる回線を用いても構わない。
【0031】
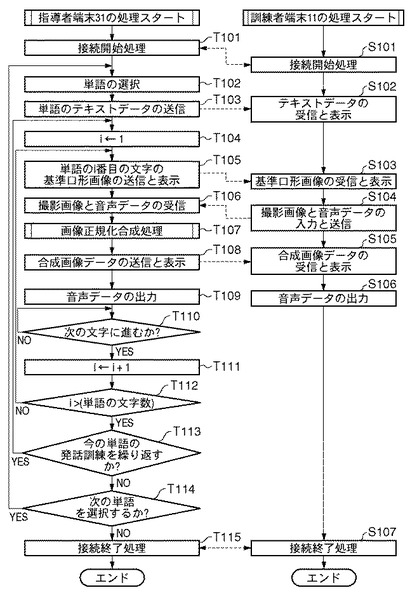
[発話訓練システムの全体的な処理手順(動作訓練手順)(図3)]
まず、指導者6が指導者端末31に処理開始の命令を与えると、全体制御部32が記憶装置(不図示)に格納された発話訓練システムのプログラムをRAM(不図示)で展開し、画面に必要な情報を表示させた後、所定の処理をスタートさせる。一方、訓練者2が訓練者端末11に対して処理開始の命令を与えると、制御部12が記憶装置(不図示)内の訓練者端末11用のプログラムをRAM(不図示)で展開し、画面に必要な情報を表示した後、所定の処理をスタートさせる。
【0032】
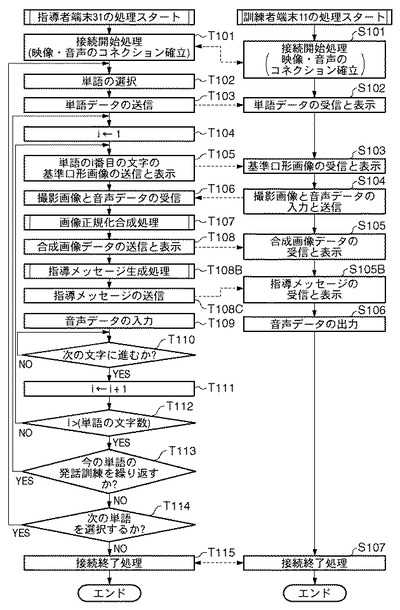
次に、指導者6が指導者端末31のコマンド入力部33であるマウスを用いて画面の「接続」ボタンを押下すると、全体制御部32は通信部を介して訓練者端末11に対して「接続開始要求」を送信する(T101)。訓練者端末11は、通信部18を介して当該要求を受信した後に「接続許可」の返信を行う(S101)。この結果、訓練者端末11及び指導者端末31の双方で接続開始に必要な処理が実行され、両端末間の映像・音声のコネクションが確立する。
【0033】
次に、全体制御部32は、基準画像データベース42内の単語・語句のリストを画面に表示する。指導者6がコマンド入力部33のマウスにより、表示された単語・語句の一覧の中から訓練者2に発声させる単語(例えば「いぬ」)を選択する(T102)。選択した単語「いぬ」は、発声対象語としてRAMに格納される。ただし、ここでは画面に表示した単語・語句の一覧の中から発声対象語を選択したが本発明はその限りでなく、キーボード等のデータ入力装置により当該発声対象語を直接入力するように構成してもよい。
【0034】
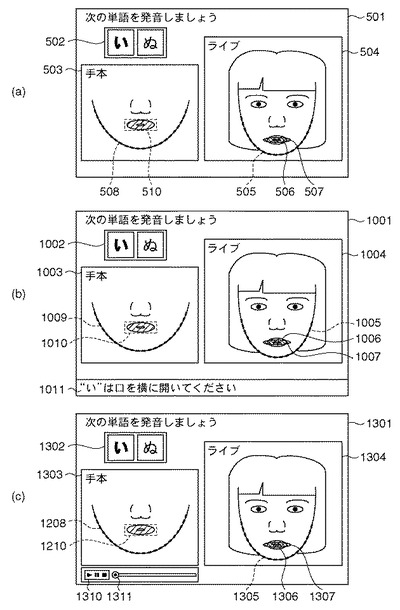
次に、全体制御部32は、RAMに格納された発声対象語のテキストデータを通信部38を介して訓練者端末11へ送信する(T103)。訓練者端末11において、通信部18が当該発声対象語のテキストデータを受信すると、表示制御部19は図5(a)の符号502のように当該テキストデータを画面501に表示する(S102)。
【0035】
次に、全体制御部32は、インデックスiを1で初期化する(T104)。次に、全体制御部32は、基準画像データベース42から発声対象語「いぬ」のi番目の発話音の基準口形画像データ(静止画)を読み出し、通信部38を介して訓練者端末11へ送信する(T105)。その後、表示制御部39が当該基準口形画像データを表示部36に表示する。
【0036】
一方、訓練者端末11において、通信部18が当該基準口形画像データを受信した後、表示制御部19が図5(a)の503のように当該基準口形画像データを表示部16に表示する(S103)。このように基準画像である基準口形画像データを訓練者に提示する提示手順を行う。同時に、表示制御部19は画面のテキストデータの現在の発話音を図5(a)の符号502のように強調表示するように制御する。
【0037】
続いて、撮像部17により訓練者を撮影する撮影手順を行う。そして、訓練者端末11の制御部12は、撮像部17が撮影した訓練者2の撮影画像データ、及び、音声入力部14から入力された訓練者2の音声データを通信部18を介して指導者端末31へ送信する(S104)。
【0038】
次に、指導者端末31は通信部38を介して訓練者2の撮影画像データと音声データのセットを受信し、RAMに格納する(T106)。続いて、全体制御部32の命令により合成部44は、当該訓練者2の撮影画像データと基準口形画像データに基づいて、次のような処理手順(図4(a)参照)により画像正規化合成処理を実行する(T107)。この画像正規化合成処理は、基準口形画像データと撮影画像データとをサイズ及び位置を合わせて合成する合成手順である。
【0039】
まず、合成部44は、当該撮影画像データをしかるべき顔抽出手法で解析して訓練者2の顎の輪郭情報505(図5(a)参照)を抽出し、RAMに格納する(M101)。次に、合成部44は、RAMに格納された現在の発話音の基本口形動画像データをしかるべき顔抽出手法で解析して基準口形の顎の輪郭情報508(図5(a)参照)を同様に抽出し、RAMに格納する(M102)。ただし、M101及びM102における顎の輪郭情報の算出手段としては、公知のいかなる顔抽出手法を用いてもよいものとして説明を省略する。
【0040】
次に、合成部44は、抽出した両輪郭情報505、508のサイズ比rを算出する(M103)。そして、合成部44は、当該訓練者2の画像データをしかるべき顔抽出手法で解析して訓練者2の口の中心座標506(xc、yc)を求め、RAMに格納する(M104)。ただし、この口の中心座標の算出手段としては、公知のいかなる顔抽出手法を用いてもよいものとし、説明を省略する。
【0041】
次に、合成部44は、当該基本口形画像データから口の領域をトリミングし、口の部分画像510を作成する。続いて、この口の部分画像510を上記顎のサイズ比rを用いて適切に拡大あるいは縮小した後、上記中心座標506(xc、yc)に基づいて口の中心位置を一致させて当該訓練者2の撮影画像上に合成する(図5(a)の符号507参照)(M105)。基本口形画像データの顎の方が撮影画像データよりも大きい場合は、口の部分画像510を縮小し、基本口形画像データの顎の方が撮影画像データよりも小さい場合は、口の部分画像510を拡大する。ただし、訓練者自身の口と基本口形との比較がしやすいように、アルファブレンディング等に代表される透過合成アルゴリズムを用いて画像を合成してもよい。合成画像504はRAMに格納される。また、逆に、基準口形画像データのサイズに合わせて、撮影画像データを拡大、縮小して、部分画像510を合成してもよい。この場合、部分画像510の拡大、縮小は不要である。
【0042】
このような画像正規化合成処理(T107)を実行した後、全体制御部32は、合成部44が生成した当該合成画像を通信部38を介して訓練者端末11へ送信する(T108)。その後、表示制御部39が、当該合成画像504(図5(a)参照)を指導者端末31の表示部36に表示する。
【0043】
一方、訓練者2の訓練者端末11では、通信部18が当該合成画像を受信した後、表示制御部19が当該合成画像を表示部16に表示する(S105)。この表示は合成画像を表示する表示制御手順である。次に、全体制御部32は、T106で受信した訓練者2の音声データを音声出力部35であるスピーカから出力する(T109)。一方、訓練者端末11においても、制御部12が、S104で入力された訓練者2自身の音声データを音声出力部15であるスピーカから出力する(S106)。
【0044】
なお、上述のT106〜T109、及びS103〜S106の処理は高速で実行が繰り返されるものとし、この結果、訓練者端末11の表示部16に表示された訓練者の撮影画像上には当該基準静止画データがほぼリアルタイムに表示される(図5(a)の507参照)。
【0045】
次に、全体制御部32は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して次の文字に進めるか否かの判断を促す(T110)。指導者6がコマンド入力部33であるマウスにより「はい」を選択した場合はT111へ進んでインデックスiを1インクリメントし(T111)、「いいえ」を選択した場合は本ステップの待ち状態を続ける。
【0046】
次に、制御部12は、インデックスiが発声対象語「いぬ」の文字数(=2)を超えたか否かを判断する。真ならばT113へ、偽ならばT105へ処理を進める(T112)。次に、制御部12は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して今の発声対象語の発話訓練を繰り返すか否かの判断を促す。指導者6がコマンド入力部33であるマウスにより「はい」を選択した場合はT104へ、「いいえ」を選択した場合はT114へ処理を進める(T113)。
【0047】
次に、制御部12は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して次の単語を選択するか、発話訓練を終了するかの判断を促す。指導者6がコマンド入力部33であるマウスにより前者を選択した場合はT102へ、後者を選択した場合はT115へ処理を進める(T112)。
【0048】
次に、全体制御部32は通信部38を介して訓練者端末11に対して「接続終了要求」を送信する(T115)。訓練者端末11は、通信部18を介して当該要求を受信した後に「切断許可」の返信を行う(S107)。その後、両端末において接続終了に必要な処理が実行され、両端末間の映像・音声のコネクションが切断される。以上が、基準口形画像として静止画データを用いた時の発話訓練実行時の処理の流れである。
【0049】
以上述べた通り、本実施例によれば、訓練者2は、自分自身の撮影画像上に正規化されて合成された基準動作形状を参照しながら容易に訓練を実行することができるため、動作訓練の効果を向上させることが可能となる。
【0050】
<実施例2>
本実施例の発話訓練システム全体の物理的構成は実施例1と同様である(図1参照)。本実施例の発話訓練システムの内部構成は、実施例1の内部構成に対して、指導者端末31に指導メッセージ生成部45が追加されている点が異なる(図2(b)参照)。
【0051】
指導メッセージ生成部45は、訓練者端末11から受信した訓練者の撮影画像データ及び基準画像データベース42に記憶された基準画像データにおける口の部分領域の差分に応じて、訓練者2向けの指導メッセージを適切に生成してバス41へと出力するためのものである。
【0052】
[発話訓練システムの全体的な処理手順(図6)]
本実施例では、実施例1の発話訓練システムのフローチャート(図3)に対して、T108B、T108C及びS105Bが追加される点が異なる。以下、この3ステップの処理内容について説明する。
【0053】
全体制御部32の命令により、指導メッセージ生成部45は後述する指導メッセージ生成処理を実行する(T108B)。続いて、全体制御部32は、当該生成された指導メッセージデータgmsgを、通信部18を介して訓練者端末11へ送信する(T108C)。一方、訓練者端末11の通信部18が当該指導メッセージデータを受信すると、表示制御部19は当該メッセージデータを図5(b)の符号1011のように表示部16に表示する(S105B)。このようにして、訓練者2の撮影画像と基準口形画像との差分に応じて指導メッセージを生成して、当該指導メッセージを訓練者2に提示する。
【0054】
[指導メッセージ生成部45の詳細な処理手順(図7)]
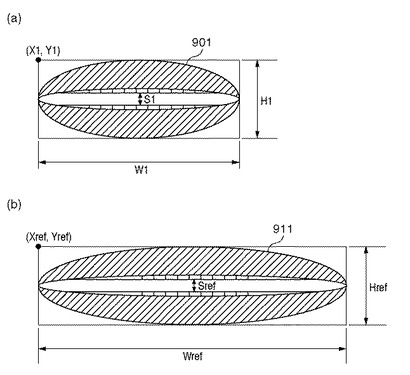
まず、指導メッセージ生成部45は、適切な顔抽出手法により訓練者端末11から受信した撮影画像データから口の部分画像901を抽出した後、当該撮影画像データにおける口のサイズ(H1,W1,S1)と位置(X1,Y1)を算出し(図8(a)参照)、RAMに格納する(G101)。
【0055】
次に、指導メッセージ生成部45は、適切な顔抽出手法により基準口形画像から基準口形の部分画像911を抽出した後、基準口形の部分画像911のサイズ(Href,Wref,Sref)と位置(Xref,Yref)を算出し(図8(b)参照)、RAMに格納する(G102)。
【0056】
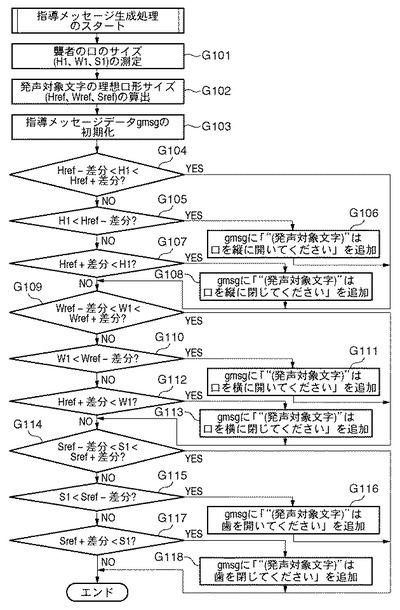
次に、指導メッセージ生成部45は、指導メッセージデータ(gmsgとする)を空文字列(“”)で初期化する(G103)。次に、指導メッセージ生成部45は、縦方向の口の開き具合が適切であるか否かの判断を次式を用いて行い、真ならばG109へ、偽ならばG105へ進む(G104)。
Href−差分<H1<Href+差分
次に、指導メッセージ生成部45は、縦方向の口の開き具合が基準よりも小さいか否かの判断を次式を用いて行う(G105)。
H1<Href−差分
G105で真である場合には、gmsgに次の文字列を追加する(G106)。
「“(発声対象文字)”は口を縦に開いてください」
ただし、“(発声対象文字)”の部分には発話対象語の“い”や“ぬ”の文字が挿入されるものとする。
【0057】
次に、指導メッセージ生成部45は、縦方向の口の開き具合が基準よりも大きいか否かの判断を次式を用いて行う(G107)。
Href+差分<H1
G107で真である場合には、gmsgに次の文字列を追加する(G108)。
「“(発声対象文字)”は口を縦に閉じてください」
ただし、“(発声対象文字)”の部分には発話対象語の“い”や“ぬ”の文字が挿入されるものとする。
【0058】
次に、指導メッセージ生成部45は、横方向の口の開き具合が適切であるか否かの判断を次式を用いて行う(G109)。
Wref−差分<W1<Wref+差分
G109で真である場合にはG114へ、偽である場合にはG110へ進む。
【0059】
次に、指導メッセージ生成部45は、横方向の口の開き具合が基準よりも小さいか否かの判断を次式を用いて行う(G110)。
W1<Wref−差分
G110で真である場合には、gmsgに次の文字列を追加する(G111)。
「“(発声対象文字)”は口を横に開いてください」
次に、指導メッセージ生成部45は、横方向の口の開き具合が基準よりも大きいか否かの判断を次式を用いて行う(G112)。
Wref+差分<W1
G112で真である場合には、gmsgに次の文字列を追加する(G113)。
「“(発声対象文字)”は口を横に閉じてください」
次に、指導メッセージ生成部45は、歯の間隔が適切であるか否かの判断を次式を用いて行い(G114)、真である場合にはG115へ進み、偽である場合には指導メッセージ生成処理を終了する。
Sref−差分<S1<Sref+差分
次に、指導メッセージ生成部45は、上歯と下歯との間隔が基準よりも小さいか否かの判断を次式を用いて行う(G115)。
S1<Sref−差分
G115で真である場合には、gmsgに次の文字列を追加する(G116)。
「“(発声対象文字)”は歯を開いてください」
次に、指導メッセージ生成部45は、歯の間隔が基準よりも大きいか否かの判断を次式を用いて行う(G117)。
Sref+差分<S1
G117で真である場合には、gmsgに次の文字列を追加し、偽である場合には、指導メッセージ生成処理を終了する(G118)。
「“(発声対象文字)”は歯を閉じてください」
このような指導メッセージ生成処理により、RAMのgmsgには訓練者2に提示する指導メッセージデータが格納される。
【0060】
以上述べた通り、本実施例によれば、訓練者2は自分自身の撮影画像上に合成された基準動作形状の情報に加えて適切な内容の指導メッセージを確認することで、自分の動作の修正方法を容易に確認することができるようになる。
【0061】
<実施例3>
本実施例では、基準口形画像データとして動画像データを利用する発話訓練システムの一態様について説明する。本実施例の発話訓練システムの全体の物理的構成は、実施例1と同様である(図1参照)。
【0062】
また、本実施例の内部構成は、実施例1と同様であるが(図2参照)、基準画像データベース42の機能が次のように変更される。基準画像データベース42は、発話訓練の際に用いる複数の単語や語句のテキストデータ、及びそれらの各々を発話する際の模範的な口の動きを含んだ基準口形動画像データを記憶するためのものである。
【0063】
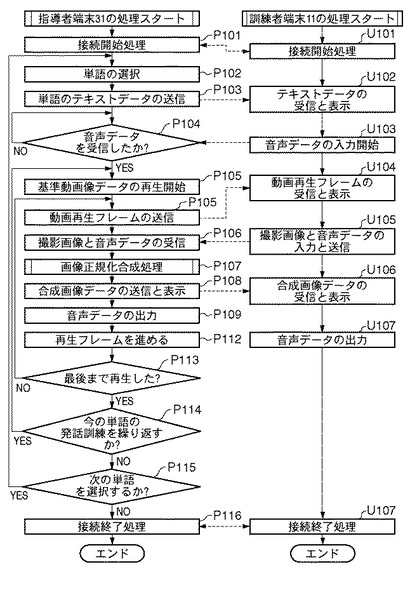
[発話訓練システムの全体的な処理手順(図9)]
P101〜P103及びU101〜U102は、それぞれ、実施例1のフローチャート(図3)におけるT101〜T103及びS101〜S102と同等なので説明を省略する。
【0064】
指導者6の指導者端末31の全体制御部32は、訓練者端末11からの音声入力開始の待ち状態となっている(P104)。ここで、訓練者2が訓練者端末11の音声入力部14から音声データの入力を開始すると、制御部12は通信部18を介して当該音声データを指導者端末31へ送信する(U103)。
【0065】
指導者端末31の全体制御部32は、通信部38を介して当該訓練者2の音声データを受信すると(P104)、基準画像データベース42内の現在の発話対象語「いぬ」に対応した基準動画像データをRAMにロードし、再生を開始する(P105)。
【0066】
次に、全体制御部32は、当該基準動画像データの現在の再生フレームを、通信部38を介して訓練者端末11へ送信する(P105)。一方、訓練者端末11の通信部18が当該動画再生フレームを受信すると、表示制御部19が当該再生フレームを図5(c)の1303のように表示部16に表示する(U104)。同時に、表示制御部19は、現在の動画再生フレームの再生位置を再生進捗バー1311に表示する。なお、同時に表示部16に配置された再生制御ボタン1310を用いて、訓練者2自身が当該基準口形動画データの再生・一時停止・終了を制御できるようにしてもよい。
【0067】
続いて、制御部12は、撮像部17が撮影した訓練者2の画像データ、及び音声入力部14から入力された訓練者2の音声データを通信部18を介して指導者端末31へ送信する(U105)。
【0068】
次に、指導者端末31は、通信部38を介して訓練者2の撮影画像データと音声データとのセットを受信し、RAMへ格納する(P106)。次に、全体制御部32の命令により合成部44は、受信した当該撮影画像データと基準口形動画像データに基づいて、図4(b)のフローチャートで示される画像正規化合成処理を実行する(P107)。なお、図4(b)のフローチャートの各ステップの内、N101、N103〜N105は、実施例1の画像正規化合成処理のフローチャート(図4(a))のM101、M103〜M105と夫々処理内容が同じであるので説明を省略する。
【0069】
ここでは、処理内容が異なるN102の処理内容について説明する。合成部44は、RAMの基本口形動画像データの現在の再生フレームにおける顎の輪郭情報1208(図5(c)参照)を抽出し、当該RAMに格納する(N102)。その後、N103〜N105において、基準口形が正規化されて構成された合成画像が生成され、RAMに格納される。以上が、実施例3における画像正規化合成処理の流れである。
【0070】
次に、全体制御部32は、合成部44が生成した合成画像504を通信部38を介して訓練者端末11へ送信する。続いて、表示制御部39が、当該合成画像504を表示部36に表示する(P108)。一方、訓練者2の訓練者端末11では、通信部18が当該合成画像を受信した後、表示制御部19が当該合成画像を図5(c)の符号1304で示すように表示部16に表示する(U106)。
【0071】
次に、全体制御部32は、T107で受信した訓練者2の音声データを音声出力部35であるスピーカから出力する(P109)。一方、訓練者端末11でも、制御部12が、U105で入力された訓練者2自身の音声データを音声出力部15であるスピーカから出力する(U107)。また、基準動画像データが基準音声データを有する場合、U104でこの基準音声データも含めて訓練者端末11で受信するようにして、当該訓練者2自身の音声データと合成して出力するようにしてもよい。
【0072】
続いて、訓練者端末11の全体制御部32は、現在の基本口形動画像データの再生フレームを1つ進める(P112)。なお、上述のP105〜P112及びU104〜U107の処理は高速で実行が繰り返されるものとし、この結果、訓練者端末11の表示部16に表示された訓練者2の撮影画像上には基準動画像データがほぼリアルタイムに重畳合成される(図5(c)の符号1307参照)。
【0073】
次に、訓練者端末11の全体制御部32は、現在の基本口形動画像データの再生が最終フレームまで到達したか否かを判断し、真ならば次のステップへ、偽ならばP105へ進む(P113)。
【0074】
次に、全体制御部32は、しかるべき選択メッセージを表示部36に表示し、訓練者2に対して今の発声対象語の動画像による発話訓練を繰り返すか否かの判断を促す。指導者6がコマンド入力部であるマウスにより「はい」を選択した場合はP105へ、「いいえ」を選択した場合はP115へ処理を進める(P114)。
【0075】
次に、全体制御部32は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して次の単語を選択するか発話訓練を終了するかの判断を促す。指導者6がコマンド入力部33であるマウスにより前者を選択した場合はP102へ、後者を選択した場合はP116へ処理を進める(P115)。
【0076】
続いて、P116及びU108において、夫々、実施例1のT115、S107と同様の接続終了処理が実行され、指導者端末31と訓練者端末11との間の映像・音声のコネクションが切断され、本発話訓練システムの処理が終了する。以上が、基準口形画像として動画像データを用いた時の発話訓練実行処理の流れである。
【0077】
以上述べた通り、本実施例によれば、訓練者2は、自分自身の撮影画像上に正規化されて合成された基準口形の動画像を参照しながら容易に訓練を実行することができるため、発話訓練の効果を向上させることが可能となる。
【0078】
<実施例4>
上述の実施例1〜3では、指導者端末31側に設けた合成部44(図2(a)参照)が訓練者端末11から受信した訓練者2の撮影画像へ正規化した基準画像を合成した後に訓練者端末11へ返信したが、本発明はその限りではない。本実施例では、訓練者端末11側に当該画像正規化合成部24(図2(c)参照)を設け、訓練者端末11の撮像部17が撮影画像を出力した直後に正規化した基準画像を合成し、当該合成画像を表示部16にリアルタイムに表示するように構成してもよい。
【0079】
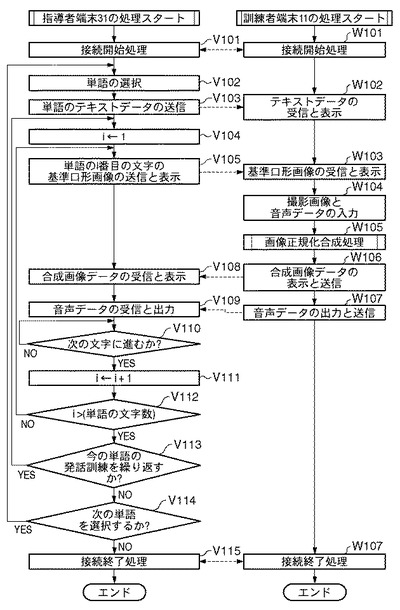
[発話訓練システムの全体的な処理手順(図10)]
V101〜V105及びW101〜W103は、それぞれ、実施例1のフローチャート(図3)におけるT101〜T105及びS101〜S103と同等なので説明を省略する。
【0080】
続いて、訓練者2の訓練者端末11の撮像部17は、撮影画像をバス21を介して制御部12へ出力する。一方、音声入力部14は、入力された音声データを当該制御部12へ出力する(W104)。
【0081】
次に、訓練者端末11の制御部12の命令により画像正規化合成部24は、画像正規化合成処理を実行する(W105)。ただし、この画像正規化合成処理のフローチャートは実施例1と同様であり(図4参照)、かつ、各ステップの処理内容も同等であるため説明を省略する。
【0082】
まず、制御部12の命令により表示制御部19は、画像正規化合成部24が出力した当該合成画像を表示部16に図5(a)の符号507のように出力する(W106)。このように、本実施例4における訓練者端末11の表示部16に表示される情報の内容は、実施例1の場合と全く同じであって図5(a)で示される。一方、当該制御部12は、通信部18を介して当該合成画像を訓練者端末11へ送信する。
【0083】
一方、指導者6の指導者端末31では、通信部38が当該合成画像を受信した後、表示制御部39が当該合成画像を表示部36に表示する(V108)。続いて、訓練者端末11の制御部12は、W104で入力された音声データを音声出力部35から出力する一方、通信部18を介して指導者端末31へ送信する(W107)。
【0084】
一方、指導者6の指導者端末31では、通信部38が当該音声データを受信すると、全体制御部32が当該音声データを音声出力部35から出力する(V109)。
【0085】
なお、V108〜V109及びW103〜W107の処理は高速でその実行が繰り返されるものとし、その結果、表示部16に表示された訓練者2の撮影画像上には基準口形画像がリアルタイムで重畳合成される(図5の符号507参照)。
【0086】
以降のV110〜V115、W109の処理は、実施例1の発話訓練システムのフローチャート(図3)におけるT110〜T115、S107と夫々処理内容が同じであるので説明を省略する。以上が、実施例4の発話訓練システムの処理の流れである。
【0087】
以上述べた通り、本実施例によれば、訓練者2は、自分自身の撮影画像上にリアルタイムで正規化されて合成された基準口形を確認しながら容易に訓練を実行することができるため、発話訓練の効果を向上させることが可能となる。
【0088】
<他の実施例>
上述の実施例1乃至4では、遠隔地にある訓練者端末11と指導者端末31とをネットワークで接続した動作訓練システムについて言及したが、本発明はその限りではない。例えば、両端末が同一地点内にあって近接している構成や1つの端末を訓練者と指導者が共有する構成にも適用することが可能である。更に、訓練者の端末のみが存在し、その中で実行される指導用のプログラムを用いて当該訓練者が単独で動作訓練をする構成にも適用できる。更に、訓練者が音声入力部で入力した音声データ及び基準画像に含まれる音声データ(基準口形動画像データに含まれる音声データ)のスペクトルを合成するスペクトル合成部を更に備え、表示制御部が、スペクトル合成部で合成したスペクトルを少なくとも訓練者2の画像表示部に同時に表示するようにしてもよい。
【0089】
また、上述の実施例1乃至4では、本発明を聾者の発話訓練に適用した場合の例について述べたが本発明はその限りでなく、例えば、身体障害者の手足等の動きのレッスンにも適用することも可能である。更に、ダンスやバレエのレッスンから各種スポーツ(ゴルフ、テニス、野球等)の練習等、様々なジャンルにおける動作の訓練にも適用できることは言うまでもない。
【0090】
また、本発明は、以下の処理を実行することによっても実現される。即ち、上述した実施形態の機能を実現するソフトウェア(プログラム)を、ネットワーク又は各種記憶媒体を介してシステム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)がプログラムを読み出して実行する処理である
【技術分野】
【0001】
本発明は、特定の動作の訓練を行うための動作訓練装置、動作訓練システム及び動作訓練装置の制御方法及びプログラムに関する。
【背景技術】
【0002】
特定の動作の訓練を行うための動作訓練装置及び動作訓練システムとして、従来より種々の技術が提案されている。例えば、特許文献1に開示された発話練習システムでは、教師用の音声波形データと聾者や知的障害等の訓練者自身が発声する音声波形データを当該聾者が見るディスプレイに同時に表示することで、当該聾者が両方の波形データを比較しながら発声練習を実行できるようにしている。このシステムによれば、当該聾者のディスプレイに予め記憶されている教師用の映像とカメラが撮影した当該聾者の映像を同時に表示することにより、聾者の発話訓練を行うことができる。一方、非特許文献1に開示された言葉学習支援システムでは、知的障害児の発話訓練において、当該障害児が見るディスプレイに発話の手本となる教師の画像とWebカメラが撮影した当該障害児の顔のライブ画像を同一画面上に並べて表示し、障害児自身の口の動きを手本と比較して確認可能としている。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開平10−161518号公報
【非特許文献】
【0004】
【非特許文献1】知的障害児の「ことば」の学習支援コンテンツの開発(兵庫県立教育研修所,2003年):http://web3.cec.or.jp/jissenjirei/public/jyugyou_tenkai1/CEC01225_1.html
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、従来のこのような動作訓練装置は、訓練者が模範とすべき基準画像と自分の画像(例えば、顔画像)とを見比べながら訓練を行う必要があった。このため、その訓練者がどのような動作に矯正すべきかを認識することが困難であった。
【0006】
本発明は、上述の課題に鑑みてなされたものであり、動作訓練の効率を向上する動作訓練装置を提供するものである。
【課題を解決するための手段】
【0007】
上記課題を解決するため、本発明に係る動作訓練装置は、訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置であって、訓練者を撮影するための撮影手段と、前記基準画像をディスプレイを介して訓練者に提示する提示手段と、前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手段と、前記合成手段で合成した画像を前記ディスプレイに表示する表示制御手段と、を備える。
【発明の効果】
【0008】
本発明によれば、動作訓練の効率を向上する動作訓練装置を提供することができる。
【図面の簡単な説明】
【0009】
【図1】本発明の実施例1に係る発話訓練システムの全体構成を示す図。
【図2】実施例1、2、4に係る発話訓練システムの内部構成を示すブロック図。
【図3】実施例1に係る発話訓練システムの全体の処理の流れを示す図。
【図4】実施例1及び3に係る発話訓練システムの画像正規化合成処理の流れを示す図。
【図5】実施例1乃至3に係る発話訓練システムの画像表示部に表示した情報を示す図。
【図6】実施例2に係る発話訓練システムの全体の処理の流れを示す図。
【図7】実施例2に係る発話訓練システムの指導メッセージ生成処理の流れを示す図。
【図8】実施例2に係る発話訓練システムの訓練者2の画像及び基準口形画像における口のサイズと位置の情報を示す図。
【図9】実施例3に係る発話訓練システムの全体の処理の流れを示す図。
【図10】実施例4に係る発話訓練システムの全体の処理の流れを示す図。
【発明を実施するための形態】
【0010】
以下に、本発明の実施の形態について添付図面を参照して詳細に説明する。なお、以下に説明する実施の形態は、本発明の実現手段としての一例であり、本発明は、その趣旨を逸脱しない範囲で以下の実施形態を修正又は変形したものに適用可能である。
【0011】
<実施例1>
本実施例に係る動作訓練システムは、遠隔地に居る訓練者(聾者)と指導者との間にデジタル双方向回線を設定し、その端末間で映像・音声を介した発話訓練を行うための発話訓練システムを想定して説明する。
【0012】
[発話訓練システムの全体構成(図1)]
本実施例に係る発話訓練システムは、訓練者2が用いるための訓練者端末11(第1の情報処理装置)と、訓練者端末11とネットワーク71で接続された、指導者6が用いるための指導者端末31(第2の情報処理装置)とを備える。訓練者端末11及び指導者端末31は、本実施例では、地理的に離れた2つの地点1、5に設置されているものとする。地点1は、例えば、訓練者2である聾者の自宅であり、地点5は、例えば、指導者6が駐在する指導センター等の施設である。
【0013】
訓練者端末11は、訓練者2である聾者を撮影するためのカメラ等で構成される撮像部17(第1の撮影手段)と、発話訓練に必要な画像情報や各種の指示を聾者へ表示するためのディスプレイ等で構成される画像表示部16(以下、表示部16)と、訓練者2の音声を入力するためのマイク等で構成される音声入力部14と、通信相手である指導者6の音声データによる指示を発音するためのスピーカ等で構成される音声出力部15とを有する。
【0014】
一方の指導者端末31は、指導者6を撮影するためのカメラ等で構成される撮像部37(第2の撮影手段、取得手段)と、聾者の発話訓練に必要な各種情報を表示するためのディスプレイ等で構成される画像表示部36(以下、表示部36)と、音声を入力するためのマイク等で構成される音声入力部34と、通信相手である訓練者2の音声データを発音するためのスピーカ等で構成される音声出力部35とを有する。また、システム全体の制御もこの指導者端末31の全体制御部32が管理している。
【0015】
ここで、本実施例に係る発話訓練システムの全体の処理の概要を説明する。まず、発話訓練の予定時刻等に指導者6がマウス(不図示)等を用いて指導者端末31の表示部36に表示された「接続」ボタンを押下する。「接続」ボタンが押下されると、接続要求が訓練者端末11へと送信され、必要な接続開始処理がなされた後、訓練者端末11と指導者端末31との間の映像・音声のコネクションが確立する。
【0016】
次に、指導者6が表示部36で発話訓練を行う単語(例えば「いぬ」)を選択すると、その単語のテキストデータが訓練者端末11へ送信される。訓練者端末11で受信された単語のテキストデータは、表示部16に表示される。これにより、訓練者2はまず、発話訓練語が「いぬ」であることを確認することができる。次に、指導者6が表示部16の「発話練習開始」ボタンを押すと、まず、最初の単語「い」が発話対象文字として設定され、単語「い」の基準口形画像データが基準口形データベースから読み出されて訓練者端末11へ送信される。訓練者端末11で受信された基準口形画像データは、表示部16に表示される。聾者が単語「い」の基準口形画像とテロップ情報を参照しながら、音声入力部14に向かって「い」の音声を発声する。音声が発生されると、入力された音声データ及び撮像部17が撮影した訓練者2の顔画像が指導者端末31へ送信される。
【0017】
指導者端末31側では、まず、受信した訓練者2の顔画像データを分析し、聾者の顔の輪郭情報と口の中心位置を算出する。続いて、これらの抽出情報に基づいて、基準画像から抜き出した当該「い」の基本口形画像の表示サイズと表示位置(基準位置)とを正規化し、当該訓練者2の顔画像上に合成を施した後に訓練者端末11へ送信する。ただし、ここでいう「合成」とは、「重畳」という言葉と同等の意味であるものとする。
【0018】
訓練者端末11で受信された当該合成画像は表示部16に表示される。訓練者2は自分の顔画像上に適切な位置に合成された「い」の発音時の手本となる口形情報を確認し、正しい発音になるように自分の口の開き方を修正することができる。次に、指導者6がマウス等で表示部36に表示された「次の文字」ボタンを押下すると、発話対象文字として「ぬ」の文字が設定され、上述の手順を繰り返す。更に、次の単語の発話練習を行う場合は、指導者6が画面から単語を選び直した後に上記の手順を繰り返す。このようにして、訓練者2である聾者が様々な単語の発話練習を容易に実行することが可能となる。
【0019】
[発話訓練システムの内部構成(図2(a))]
訓練者端末11は、制御部12、コマンド入力部13、音声入力部14、音声出力部15、表示部16、撮像部17、通信部18(画像入力手段)、表示制御部19(第1の表示制御手段)、及びこれらの各要素を接続するためのバス21を備える。
【0020】
まず、コマンド入力部13は、ボタン等のインターフェイスからなり、訓練者2である聾者の各種指示をバス21を介して制御部12へと出力する。音声入力部14は、訓練者2の音声データを入力し、バス21を介して制御部12へ出力するためのものであり、例えば、エレクトリックコンデンサ式のマイクロフォンが用いられる。音声出力部15は、通信相手である指導者6の音声データや訓練者2に対する音声による指示を出力するためのものであり、例えば、一般的なダイナミック型スピーカが用いられる。
【0021】
表示部16は、表示制御部19が出力する画像データやテキストデータを表示するためのものであり、例えば液晶ディスプレイが用いられる。撮像部17は、訓練者2である聾者の様子を撮影するためのものであり、例えば、Pan、Tilt、Zoomカメラや、固定式のカメラ等が用いられる。
【0022】
通信部18は、訓練者端末11から出力するデータ及び訓練者端末11に外部から入力されるデータに対してプロトコルの変換等を行い、ネットワーク71を経由した指導者端末31とのデータ通信を可能としている。表示制御部19は、指導者端末31から受信した基準口形画像、合成画像及び訓練者の動作を矯正するための指導情報等のデータの表示出力制御を行うためのものである。制御部12は、RAM(不図示)に記憶されている訓練者端末11用のアプリケーションプログラムに基づいて自ら演算処理等を行い、或いは上述した各構成要素を制御し、訓練者端末11を機能させる。
【0023】
指導者端末31は、全体制御部32、コマンド入力部33、音声入力部34、音声出力部35、表示部36、撮像部37、基準画像データベース、通信部38、表示制御部39(第2の表示制御手段)、画像正規化合成部44(以下、合成部44)、及びこれらの各要素を接続するためのバス41を備える。
【0024】
コマンド入力部33は、押下ボタン等のインターフェイスからなり、指導者6の各種指示をバス41を介して全体制御部32へ出力する。音声入力部34は、指導者6の音声データを入力し、バス41を介して制御部12へ出力するためのものであり、例えば、エレクトリックコンデンサ式のマイクロフォンが用いられる。
【0025】
音声出力部35は、通信相手である訓練者2の音声データ等を出力するためのものであり、例えば、一般的なダイナミック型スピーカが用いられる。表示部36は、表示制御部39が出力する画像データやテキストデータを出力するためのものであり、例えば液晶ディスプレイが用いられる。
【0026】
表示制御部39は、訓練者2に提示するものと同等の情報、すなわち、基準口形画像、合成画像及び指導情報等のデータの表示出力制御を行うためのものである。撮像部37は、指導者6の様子を撮影するためのものであり、例えば、Pan、Tilt、Zoomカメラや、固定式のカメラ等が用いられる。
【0027】
通信部38は、指導者端末31から出力するデータ及び指導者端末31に入力するデータに対してプロトコルの変換等を行い、ネットワーク71を経由した訓練者端末11とのデータ通信を可能としている。基準画像データベース42は、日本語の50音やアルファベット等の各発話音の模範的な口形を撮影した基準口形画像データ(静止画)、及び発話訓練の対象となる単語や語句のリスト(テキストデータ)を記憶するものである。
【0028】
合成部44は、訓練者端末11から受信した訓練者2の顔画像データから抽出した特徴情報に基づいて、模範とすべき基準画像から抽出した口の部分画像の表示サイズと表示位置を正規化して当該撮影画像上に合成するためのものである。
【0029】
最後に、全体制御部32は、RAM(不図示)に記憶された発話訓練システム制御用のアプリケーションプログラムに基づいて自ら演算処理等を行い、或いは上述の各構成要素を制御し、訓練者端末11及び指導者端末31を機能させる。
【0030】
一方、71はネットワークを示している。このネットワーク71は、本実施例では、TCP/IPネットワークを用いる。このため、インターネットやLAN(Local Area Network)等のいずれも用いることが可能である。また、通信プロトコルはTCP/IPに依存する必要はなく、IPX/ISXやAppleTalkと言った同様の機能を果たすプロトコルを用いても良い。回線に関しても、これらのプロトコルを使用できるのであれば、有線や無線等のいかなる回線を用いても構わない。
【0031】
[発話訓練システムの全体的な処理手順(動作訓練手順)(図3)]
まず、指導者6が指導者端末31に処理開始の命令を与えると、全体制御部32が記憶装置(不図示)に格納された発話訓練システムのプログラムをRAM(不図示)で展開し、画面に必要な情報を表示させた後、所定の処理をスタートさせる。一方、訓練者2が訓練者端末11に対して処理開始の命令を与えると、制御部12が記憶装置(不図示)内の訓練者端末11用のプログラムをRAM(不図示)で展開し、画面に必要な情報を表示した後、所定の処理をスタートさせる。
【0032】
次に、指導者6が指導者端末31のコマンド入力部33であるマウスを用いて画面の「接続」ボタンを押下すると、全体制御部32は通信部を介して訓練者端末11に対して「接続開始要求」を送信する(T101)。訓練者端末11は、通信部18を介して当該要求を受信した後に「接続許可」の返信を行う(S101)。この結果、訓練者端末11及び指導者端末31の双方で接続開始に必要な処理が実行され、両端末間の映像・音声のコネクションが確立する。
【0033】
次に、全体制御部32は、基準画像データベース42内の単語・語句のリストを画面に表示する。指導者6がコマンド入力部33のマウスにより、表示された単語・語句の一覧の中から訓練者2に発声させる単語(例えば「いぬ」)を選択する(T102)。選択した単語「いぬ」は、発声対象語としてRAMに格納される。ただし、ここでは画面に表示した単語・語句の一覧の中から発声対象語を選択したが本発明はその限りでなく、キーボード等のデータ入力装置により当該発声対象語を直接入力するように構成してもよい。
【0034】
次に、全体制御部32は、RAMに格納された発声対象語のテキストデータを通信部38を介して訓練者端末11へ送信する(T103)。訓練者端末11において、通信部18が当該発声対象語のテキストデータを受信すると、表示制御部19は図5(a)の符号502のように当該テキストデータを画面501に表示する(S102)。
【0035】
次に、全体制御部32は、インデックスiを1で初期化する(T104)。次に、全体制御部32は、基準画像データベース42から発声対象語「いぬ」のi番目の発話音の基準口形画像データ(静止画)を読み出し、通信部38を介して訓練者端末11へ送信する(T105)。その後、表示制御部39が当該基準口形画像データを表示部36に表示する。
【0036】
一方、訓練者端末11において、通信部18が当該基準口形画像データを受信した後、表示制御部19が図5(a)の503のように当該基準口形画像データを表示部16に表示する(S103)。このように基準画像である基準口形画像データを訓練者に提示する提示手順を行う。同時に、表示制御部19は画面のテキストデータの現在の発話音を図5(a)の符号502のように強調表示するように制御する。
【0037】
続いて、撮像部17により訓練者を撮影する撮影手順を行う。そして、訓練者端末11の制御部12は、撮像部17が撮影した訓練者2の撮影画像データ、及び、音声入力部14から入力された訓練者2の音声データを通信部18を介して指導者端末31へ送信する(S104)。
【0038】
次に、指導者端末31は通信部38を介して訓練者2の撮影画像データと音声データのセットを受信し、RAMに格納する(T106)。続いて、全体制御部32の命令により合成部44は、当該訓練者2の撮影画像データと基準口形画像データに基づいて、次のような処理手順(図4(a)参照)により画像正規化合成処理を実行する(T107)。この画像正規化合成処理は、基準口形画像データと撮影画像データとをサイズ及び位置を合わせて合成する合成手順である。
【0039】
まず、合成部44は、当該撮影画像データをしかるべき顔抽出手法で解析して訓練者2の顎の輪郭情報505(図5(a)参照)を抽出し、RAMに格納する(M101)。次に、合成部44は、RAMに格納された現在の発話音の基本口形動画像データをしかるべき顔抽出手法で解析して基準口形の顎の輪郭情報508(図5(a)参照)を同様に抽出し、RAMに格納する(M102)。ただし、M101及びM102における顎の輪郭情報の算出手段としては、公知のいかなる顔抽出手法を用いてもよいものとして説明を省略する。
【0040】
次に、合成部44は、抽出した両輪郭情報505、508のサイズ比rを算出する(M103)。そして、合成部44は、当該訓練者2の画像データをしかるべき顔抽出手法で解析して訓練者2の口の中心座標506(xc、yc)を求め、RAMに格納する(M104)。ただし、この口の中心座標の算出手段としては、公知のいかなる顔抽出手法を用いてもよいものとし、説明を省略する。
【0041】
次に、合成部44は、当該基本口形画像データから口の領域をトリミングし、口の部分画像510を作成する。続いて、この口の部分画像510を上記顎のサイズ比rを用いて適切に拡大あるいは縮小した後、上記中心座標506(xc、yc)に基づいて口の中心位置を一致させて当該訓練者2の撮影画像上に合成する(図5(a)の符号507参照)(M105)。基本口形画像データの顎の方が撮影画像データよりも大きい場合は、口の部分画像510を縮小し、基本口形画像データの顎の方が撮影画像データよりも小さい場合は、口の部分画像510を拡大する。ただし、訓練者自身の口と基本口形との比較がしやすいように、アルファブレンディング等に代表される透過合成アルゴリズムを用いて画像を合成してもよい。合成画像504はRAMに格納される。また、逆に、基準口形画像データのサイズに合わせて、撮影画像データを拡大、縮小して、部分画像510を合成してもよい。この場合、部分画像510の拡大、縮小は不要である。
【0042】
このような画像正規化合成処理(T107)を実行した後、全体制御部32は、合成部44が生成した当該合成画像を通信部38を介して訓練者端末11へ送信する(T108)。その後、表示制御部39が、当該合成画像504(図5(a)参照)を指導者端末31の表示部36に表示する。
【0043】
一方、訓練者2の訓練者端末11では、通信部18が当該合成画像を受信した後、表示制御部19が当該合成画像を表示部16に表示する(S105)。この表示は合成画像を表示する表示制御手順である。次に、全体制御部32は、T106で受信した訓練者2の音声データを音声出力部35であるスピーカから出力する(T109)。一方、訓練者端末11においても、制御部12が、S104で入力された訓練者2自身の音声データを音声出力部15であるスピーカから出力する(S106)。
【0044】
なお、上述のT106〜T109、及びS103〜S106の処理は高速で実行が繰り返されるものとし、この結果、訓練者端末11の表示部16に表示された訓練者の撮影画像上には当該基準静止画データがほぼリアルタイムに表示される(図5(a)の507参照)。
【0045】
次に、全体制御部32は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して次の文字に進めるか否かの判断を促す(T110)。指導者6がコマンド入力部33であるマウスにより「はい」を選択した場合はT111へ進んでインデックスiを1インクリメントし(T111)、「いいえ」を選択した場合は本ステップの待ち状態を続ける。
【0046】
次に、制御部12は、インデックスiが発声対象語「いぬ」の文字数(=2)を超えたか否かを判断する。真ならばT113へ、偽ならばT105へ処理を進める(T112)。次に、制御部12は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して今の発声対象語の発話訓練を繰り返すか否かの判断を促す。指導者6がコマンド入力部33であるマウスにより「はい」を選択した場合はT104へ、「いいえ」を選択した場合はT114へ処理を進める(T113)。
【0047】
次に、制御部12は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して次の単語を選択するか、発話訓練を終了するかの判断を促す。指導者6がコマンド入力部33であるマウスにより前者を選択した場合はT102へ、後者を選択した場合はT115へ処理を進める(T112)。
【0048】
次に、全体制御部32は通信部38を介して訓練者端末11に対して「接続終了要求」を送信する(T115)。訓練者端末11は、通信部18を介して当該要求を受信した後に「切断許可」の返信を行う(S107)。その後、両端末において接続終了に必要な処理が実行され、両端末間の映像・音声のコネクションが切断される。以上が、基準口形画像として静止画データを用いた時の発話訓練実行時の処理の流れである。
【0049】
以上述べた通り、本実施例によれば、訓練者2は、自分自身の撮影画像上に正規化されて合成された基準動作形状を参照しながら容易に訓練を実行することができるため、動作訓練の効果を向上させることが可能となる。
【0050】
<実施例2>
本実施例の発話訓練システム全体の物理的構成は実施例1と同様である(図1参照)。本実施例の発話訓練システムの内部構成は、実施例1の内部構成に対して、指導者端末31に指導メッセージ生成部45が追加されている点が異なる(図2(b)参照)。
【0051】
指導メッセージ生成部45は、訓練者端末11から受信した訓練者の撮影画像データ及び基準画像データベース42に記憶された基準画像データにおける口の部分領域の差分に応じて、訓練者2向けの指導メッセージを適切に生成してバス41へと出力するためのものである。
【0052】
[発話訓練システムの全体的な処理手順(図6)]
本実施例では、実施例1の発話訓練システムのフローチャート(図3)に対して、T108B、T108C及びS105Bが追加される点が異なる。以下、この3ステップの処理内容について説明する。
【0053】
全体制御部32の命令により、指導メッセージ生成部45は後述する指導メッセージ生成処理を実行する(T108B)。続いて、全体制御部32は、当該生成された指導メッセージデータgmsgを、通信部18を介して訓練者端末11へ送信する(T108C)。一方、訓練者端末11の通信部18が当該指導メッセージデータを受信すると、表示制御部19は当該メッセージデータを図5(b)の符号1011のように表示部16に表示する(S105B)。このようにして、訓練者2の撮影画像と基準口形画像との差分に応じて指導メッセージを生成して、当該指導メッセージを訓練者2に提示する。
【0054】
[指導メッセージ生成部45の詳細な処理手順(図7)]
まず、指導メッセージ生成部45は、適切な顔抽出手法により訓練者端末11から受信した撮影画像データから口の部分画像901を抽出した後、当該撮影画像データにおける口のサイズ(H1,W1,S1)と位置(X1,Y1)を算出し(図8(a)参照)、RAMに格納する(G101)。
【0055】
次に、指導メッセージ生成部45は、適切な顔抽出手法により基準口形画像から基準口形の部分画像911を抽出した後、基準口形の部分画像911のサイズ(Href,Wref,Sref)と位置(Xref,Yref)を算出し(図8(b)参照)、RAMに格納する(G102)。
【0056】
次に、指導メッセージ生成部45は、指導メッセージデータ(gmsgとする)を空文字列(“”)で初期化する(G103)。次に、指導メッセージ生成部45は、縦方向の口の開き具合が適切であるか否かの判断を次式を用いて行い、真ならばG109へ、偽ならばG105へ進む(G104)。
Href−差分<H1<Href+差分
次に、指導メッセージ生成部45は、縦方向の口の開き具合が基準よりも小さいか否かの判断を次式を用いて行う(G105)。
H1<Href−差分
G105で真である場合には、gmsgに次の文字列を追加する(G106)。
「“(発声対象文字)”は口を縦に開いてください」
ただし、“(発声対象文字)”の部分には発話対象語の“い”や“ぬ”の文字が挿入されるものとする。
【0057】
次に、指導メッセージ生成部45は、縦方向の口の開き具合が基準よりも大きいか否かの判断を次式を用いて行う(G107)。
Href+差分<H1
G107で真である場合には、gmsgに次の文字列を追加する(G108)。
「“(発声対象文字)”は口を縦に閉じてください」
ただし、“(発声対象文字)”の部分には発話対象語の“い”や“ぬ”の文字が挿入されるものとする。
【0058】
次に、指導メッセージ生成部45は、横方向の口の開き具合が適切であるか否かの判断を次式を用いて行う(G109)。
Wref−差分<W1<Wref+差分
G109で真である場合にはG114へ、偽である場合にはG110へ進む。
【0059】
次に、指導メッセージ生成部45は、横方向の口の開き具合が基準よりも小さいか否かの判断を次式を用いて行う(G110)。
W1<Wref−差分
G110で真である場合には、gmsgに次の文字列を追加する(G111)。
「“(発声対象文字)”は口を横に開いてください」
次に、指導メッセージ生成部45は、横方向の口の開き具合が基準よりも大きいか否かの判断を次式を用いて行う(G112)。
Wref+差分<W1
G112で真である場合には、gmsgに次の文字列を追加する(G113)。
「“(発声対象文字)”は口を横に閉じてください」
次に、指導メッセージ生成部45は、歯の間隔が適切であるか否かの判断を次式を用いて行い(G114)、真である場合にはG115へ進み、偽である場合には指導メッセージ生成処理を終了する。
Sref−差分<S1<Sref+差分
次に、指導メッセージ生成部45は、上歯と下歯との間隔が基準よりも小さいか否かの判断を次式を用いて行う(G115)。
S1<Sref−差分
G115で真である場合には、gmsgに次の文字列を追加する(G116)。
「“(発声対象文字)”は歯を開いてください」
次に、指導メッセージ生成部45は、歯の間隔が基準よりも大きいか否かの判断を次式を用いて行う(G117)。
Sref+差分<S1
G117で真である場合には、gmsgに次の文字列を追加し、偽である場合には、指導メッセージ生成処理を終了する(G118)。
「“(発声対象文字)”は歯を閉じてください」
このような指導メッセージ生成処理により、RAMのgmsgには訓練者2に提示する指導メッセージデータが格納される。
【0060】
以上述べた通り、本実施例によれば、訓練者2は自分自身の撮影画像上に合成された基準動作形状の情報に加えて適切な内容の指導メッセージを確認することで、自分の動作の修正方法を容易に確認することができるようになる。
【0061】
<実施例3>
本実施例では、基準口形画像データとして動画像データを利用する発話訓練システムの一態様について説明する。本実施例の発話訓練システムの全体の物理的構成は、実施例1と同様である(図1参照)。
【0062】
また、本実施例の内部構成は、実施例1と同様であるが(図2参照)、基準画像データベース42の機能が次のように変更される。基準画像データベース42は、発話訓練の際に用いる複数の単語や語句のテキストデータ、及びそれらの各々を発話する際の模範的な口の動きを含んだ基準口形動画像データを記憶するためのものである。
【0063】
[発話訓練システムの全体的な処理手順(図9)]
P101〜P103及びU101〜U102は、それぞれ、実施例1のフローチャート(図3)におけるT101〜T103及びS101〜S102と同等なので説明を省略する。
【0064】
指導者6の指導者端末31の全体制御部32は、訓練者端末11からの音声入力開始の待ち状態となっている(P104)。ここで、訓練者2が訓練者端末11の音声入力部14から音声データの入力を開始すると、制御部12は通信部18を介して当該音声データを指導者端末31へ送信する(U103)。
【0065】
指導者端末31の全体制御部32は、通信部38を介して当該訓練者2の音声データを受信すると(P104)、基準画像データベース42内の現在の発話対象語「いぬ」に対応した基準動画像データをRAMにロードし、再生を開始する(P105)。
【0066】
次に、全体制御部32は、当該基準動画像データの現在の再生フレームを、通信部38を介して訓練者端末11へ送信する(P105)。一方、訓練者端末11の通信部18が当該動画再生フレームを受信すると、表示制御部19が当該再生フレームを図5(c)の1303のように表示部16に表示する(U104)。同時に、表示制御部19は、現在の動画再生フレームの再生位置を再生進捗バー1311に表示する。なお、同時に表示部16に配置された再生制御ボタン1310を用いて、訓練者2自身が当該基準口形動画データの再生・一時停止・終了を制御できるようにしてもよい。
【0067】
続いて、制御部12は、撮像部17が撮影した訓練者2の画像データ、及び音声入力部14から入力された訓練者2の音声データを通信部18を介して指導者端末31へ送信する(U105)。
【0068】
次に、指導者端末31は、通信部38を介して訓練者2の撮影画像データと音声データとのセットを受信し、RAMへ格納する(P106)。次に、全体制御部32の命令により合成部44は、受信した当該撮影画像データと基準口形動画像データに基づいて、図4(b)のフローチャートで示される画像正規化合成処理を実行する(P107)。なお、図4(b)のフローチャートの各ステップの内、N101、N103〜N105は、実施例1の画像正規化合成処理のフローチャート(図4(a))のM101、M103〜M105と夫々処理内容が同じであるので説明を省略する。
【0069】
ここでは、処理内容が異なるN102の処理内容について説明する。合成部44は、RAMの基本口形動画像データの現在の再生フレームにおける顎の輪郭情報1208(図5(c)参照)を抽出し、当該RAMに格納する(N102)。その後、N103〜N105において、基準口形が正規化されて構成された合成画像が生成され、RAMに格納される。以上が、実施例3における画像正規化合成処理の流れである。
【0070】
次に、全体制御部32は、合成部44が生成した合成画像504を通信部38を介して訓練者端末11へ送信する。続いて、表示制御部39が、当該合成画像504を表示部36に表示する(P108)。一方、訓練者2の訓練者端末11では、通信部18が当該合成画像を受信した後、表示制御部19が当該合成画像を図5(c)の符号1304で示すように表示部16に表示する(U106)。
【0071】
次に、全体制御部32は、T107で受信した訓練者2の音声データを音声出力部35であるスピーカから出力する(P109)。一方、訓練者端末11でも、制御部12が、U105で入力された訓練者2自身の音声データを音声出力部15であるスピーカから出力する(U107)。また、基準動画像データが基準音声データを有する場合、U104でこの基準音声データも含めて訓練者端末11で受信するようにして、当該訓練者2自身の音声データと合成して出力するようにしてもよい。
【0072】
続いて、訓練者端末11の全体制御部32は、現在の基本口形動画像データの再生フレームを1つ進める(P112)。なお、上述のP105〜P112及びU104〜U107の処理は高速で実行が繰り返されるものとし、この結果、訓練者端末11の表示部16に表示された訓練者2の撮影画像上には基準動画像データがほぼリアルタイムに重畳合成される(図5(c)の符号1307参照)。
【0073】
次に、訓練者端末11の全体制御部32は、現在の基本口形動画像データの再生が最終フレームまで到達したか否かを判断し、真ならば次のステップへ、偽ならばP105へ進む(P113)。
【0074】
次に、全体制御部32は、しかるべき選択メッセージを表示部36に表示し、訓練者2に対して今の発声対象語の動画像による発話訓練を繰り返すか否かの判断を促す。指導者6がコマンド入力部であるマウスにより「はい」を選択した場合はP105へ、「いいえ」を選択した場合はP115へ処理を進める(P114)。
【0075】
次に、全体制御部32は、しかるべき選択メッセージを表示部36に表示し、指導者6に対して次の単語を選択するか発話訓練を終了するかの判断を促す。指導者6がコマンド入力部33であるマウスにより前者を選択した場合はP102へ、後者を選択した場合はP116へ処理を進める(P115)。
【0076】
続いて、P116及びU108において、夫々、実施例1のT115、S107と同様の接続終了処理が実行され、指導者端末31と訓練者端末11との間の映像・音声のコネクションが切断され、本発話訓練システムの処理が終了する。以上が、基準口形画像として動画像データを用いた時の発話訓練実行処理の流れである。
【0077】
以上述べた通り、本実施例によれば、訓練者2は、自分自身の撮影画像上に正規化されて合成された基準口形の動画像を参照しながら容易に訓練を実行することができるため、発話訓練の効果を向上させることが可能となる。
【0078】
<実施例4>
上述の実施例1〜3では、指導者端末31側に設けた合成部44(図2(a)参照)が訓練者端末11から受信した訓練者2の撮影画像へ正規化した基準画像を合成した後に訓練者端末11へ返信したが、本発明はその限りではない。本実施例では、訓練者端末11側に当該画像正規化合成部24(図2(c)参照)を設け、訓練者端末11の撮像部17が撮影画像を出力した直後に正規化した基準画像を合成し、当該合成画像を表示部16にリアルタイムに表示するように構成してもよい。
【0079】
[発話訓練システムの全体的な処理手順(図10)]
V101〜V105及びW101〜W103は、それぞれ、実施例1のフローチャート(図3)におけるT101〜T105及びS101〜S103と同等なので説明を省略する。
【0080】
続いて、訓練者2の訓練者端末11の撮像部17は、撮影画像をバス21を介して制御部12へ出力する。一方、音声入力部14は、入力された音声データを当該制御部12へ出力する(W104)。
【0081】
次に、訓練者端末11の制御部12の命令により画像正規化合成部24は、画像正規化合成処理を実行する(W105)。ただし、この画像正規化合成処理のフローチャートは実施例1と同様であり(図4参照)、かつ、各ステップの処理内容も同等であるため説明を省略する。
【0082】
まず、制御部12の命令により表示制御部19は、画像正規化合成部24が出力した当該合成画像を表示部16に図5(a)の符号507のように出力する(W106)。このように、本実施例4における訓練者端末11の表示部16に表示される情報の内容は、実施例1の場合と全く同じであって図5(a)で示される。一方、当該制御部12は、通信部18を介して当該合成画像を訓練者端末11へ送信する。
【0083】
一方、指導者6の指導者端末31では、通信部38が当該合成画像を受信した後、表示制御部39が当該合成画像を表示部36に表示する(V108)。続いて、訓練者端末11の制御部12は、W104で入力された音声データを音声出力部35から出力する一方、通信部18を介して指導者端末31へ送信する(W107)。
【0084】
一方、指導者6の指導者端末31では、通信部38が当該音声データを受信すると、全体制御部32が当該音声データを音声出力部35から出力する(V109)。
【0085】
なお、V108〜V109及びW103〜W107の処理は高速でその実行が繰り返されるものとし、その結果、表示部16に表示された訓練者2の撮影画像上には基準口形画像がリアルタイムで重畳合成される(図5の符号507参照)。
【0086】
以降のV110〜V115、W109の処理は、実施例1の発話訓練システムのフローチャート(図3)におけるT110〜T115、S107と夫々処理内容が同じであるので説明を省略する。以上が、実施例4の発話訓練システムの処理の流れである。
【0087】
以上述べた通り、本実施例によれば、訓練者2は、自分自身の撮影画像上にリアルタイムで正規化されて合成された基準口形を確認しながら容易に訓練を実行することができるため、発話訓練の効果を向上させることが可能となる。
【0088】
<他の実施例>
上述の実施例1乃至4では、遠隔地にある訓練者端末11と指導者端末31とをネットワークで接続した動作訓練システムについて言及したが、本発明はその限りではない。例えば、両端末が同一地点内にあって近接している構成や1つの端末を訓練者と指導者が共有する構成にも適用することが可能である。更に、訓練者の端末のみが存在し、その中で実行される指導用のプログラムを用いて当該訓練者が単独で動作訓練をする構成にも適用できる。更に、訓練者が音声入力部で入力した音声データ及び基準画像に含まれる音声データ(基準口形動画像データに含まれる音声データ)のスペクトルを合成するスペクトル合成部を更に備え、表示制御部が、スペクトル合成部で合成したスペクトルを少なくとも訓練者2の画像表示部に同時に表示するようにしてもよい。
【0089】
また、上述の実施例1乃至4では、本発明を聾者の発話訓練に適用した場合の例について述べたが本発明はその限りでなく、例えば、身体障害者の手足等の動きのレッスンにも適用することも可能である。更に、ダンスやバレエのレッスンから各種スポーツ(ゴルフ、テニス、野球等)の練習等、様々なジャンルにおける動作の訓練にも適用できることは言うまでもない。
【0090】
また、本発明は、以下の処理を実行することによっても実現される。即ち、上述した実施形態の機能を実現するソフトウェア(プログラム)を、ネットワーク又は各種記憶媒体を介してシステム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)がプログラムを読み出して実行する処理である
【特許請求の範囲】
【請求項1】
訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置であって、
訓練者を撮影するための撮影手段と、
前記基準画像をディスプレイを介して訓練者に提示する提示手段と、
前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手段と、
前記合成手段で合成した画像を前記ディスプレイに表示する表示制御手段と、
を備えることを特徴とする動作訓練装置。
【請求項2】
前記訓練者を指導する指導者の前記動作を撮影することにより前記基準画像を取得する取得手段を更に備えることを特徴とする請求項1に記載の動作訓練装置。
【請求項3】
前記基準画像を予め記憶する記憶手段を更に備えることを特徴とする請求項1に記載の動作訓練装置。
【請求項4】
前記基準画像を外部から入力するための画像入力手段を更に備えることを特徴とする請求項1に記載の動作訓練装置。
【請求項5】
前記基準画像における基準位置と、前記撮影画像における前記基準位置に対応する位置との差分を算出する算出手段と、
前記算出手段で算出した差分に基づいて、訓練者の動作を矯正するための指導情報を生成する生成手段と、を更に備え、
前記表示制御手段は、前記生成手段で生成した指導情報を前記ディスプレイに表示することを特徴とする請求項1に記載の動作訓練装置。
【請求項6】
訓練者の音声を入力するための音声入力手段を更に備え、
前記表示制御手段は、前記音声入力手段で訓練者の音声が入力された場合に、前記合成手段で合成した画像の表示を開始することを特徴とする請求項1に記載の動作訓練装置。
【請求項7】
訓練者の音声を入力するための音声入力手段と、
前記音声入力手段で入力した音声データ及び前記基準画像に含まれる音声データのスペクトルを合成するスペクトル合成手段と、を更に備え、
前記表示制御手段は、前記スペクトル合成手段で合成したスペクトルを前記ディスプレイに表示することを特徴とする請求項1に記載の動作訓練装置。
【請求項8】
第1の情報処理装置と、
前記第1の情報処理装置とネットワークで接続された第2の情報処理装置と、を備え、
前記第1の情報処理装置が、
第1の表示制御手段と、
訓練者を撮影するための第1の撮影手段と、
訓練者が模範とすべき予め定めた動作の基準画像をディスプレイを介して訓練者に提示する提示手段と、を備え、
前記第2の情報処理装置が、
第2の表示制御手段と、
前記訓練者を指導する指導者の前記動作を撮影することにより前記提示手段で提示するための基準画像を取得する第2の撮影手段と、
を備えた動作訓練システムであって、
前記第1、第2の情報処理装置のいずれかが、
前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手段を備え、
前記第1及び第2の表示制御手段が、前記合成手段で合成した画像をそれぞれのディスプレイに表示することを特徴とする動作訓練システム。
【請求項9】
訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置の制御方法であって、
撮影手段が、訓練者を撮影し、
提示手段が、前記基準画像をディスプレイを介して訓練者に提示し、
合成手段が、前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成し、
表示制御手段が、前記合成手段で合成した画像を前記ディスプレイに表示することを特徴とする制御方法。
【請求項10】
コンピュータを、訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置として機能させるプログラムであって、
訓練者を撮影する撮影手順と、
前記基準画像をディスプレイを介して訓練者に提示する提示手順と、
前記提示手順で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手順と、
前記合成手順で合成した画像を前記ディスプレイに表示する表示制御手順と、
を有することを特徴とするプログラム。
【請求項1】
訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置であって、
訓練者を撮影するための撮影手段と、
前記基準画像をディスプレイを介して訓練者に提示する提示手段と、
前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手段と、
前記合成手段で合成した画像を前記ディスプレイに表示する表示制御手段と、
を備えることを特徴とする動作訓練装置。
【請求項2】
前記訓練者を指導する指導者の前記動作を撮影することにより前記基準画像を取得する取得手段を更に備えることを特徴とする請求項1に記載の動作訓練装置。
【請求項3】
前記基準画像を予め記憶する記憶手段を更に備えることを特徴とする請求項1に記載の動作訓練装置。
【請求項4】
前記基準画像を外部から入力するための画像入力手段を更に備えることを特徴とする請求項1に記載の動作訓練装置。
【請求項5】
前記基準画像における基準位置と、前記撮影画像における前記基準位置に対応する位置との差分を算出する算出手段と、
前記算出手段で算出した差分に基づいて、訓練者の動作を矯正するための指導情報を生成する生成手段と、を更に備え、
前記表示制御手段は、前記生成手段で生成した指導情報を前記ディスプレイに表示することを特徴とする請求項1に記載の動作訓練装置。
【請求項6】
訓練者の音声を入力するための音声入力手段を更に備え、
前記表示制御手段は、前記音声入力手段で訓練者の音声が入力された場合に、前記合成手段で合成した画像の表示を開始することを特徴とする請求項1に記載の動作訓練装置。
【請求項7】
訓練者の音声を入力するための音声入力手段と、
前記音声入力手段で入力した音声データ及び前記基準画像に含まれる音声データのスペクトルを合成するスペクトル合成手段と、を更に備え、
前記表示制御手段は、前記スペクトル合成手段で合成したスペクトルを前記ディスプレイに表示することを特徴とする請求項1に記載の動作訓練装置。
【請求項8】
第1の情報処理装置と、
前記第1の情報処理装置とネットワークで接続された第2の情報処理装置と、を備え、
前記第1の情報処理装置が、
第1の表示制御手段と、
訓練者を撮影するための第1の撮影手段と、
訓練者が模範とすべき予め定めた動作の基準画像をディスプレイを介して訓練者に提示する提示手段と、を備え、
前記第2の情報処理装置が、
第2の表示制御手段と、
前記訓練者を指導する指導者の前記動作を撮影することにより前記提示手段で提示するための基準画像を取得する第2の撮影手段と、
を備えた動作訓練システムであって、
前記第1、第2の情報処理装置のいずれかが、
前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手段を備え、
前記第1及び第2の表示制御手段が、前記合成手段で合成した画像をそれぞれのディスプレイに表示することを特徴とする動作訓練システム。
【請求項9】
訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置の制御方法であって、
撮影手段が、訓練者を撮影し、
提示手段が、前記基準画像をディスプレイを介して訓練者に提示し、
合成手段が、前記提示手段で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成し、
表示制御手段が、前記合成手段で合成した画像を前記ディスプレイに表示することを特徴とする制御方法。
【請求項10】
コンピュータを、訓練者が模範とすべき予め定めた動作の基準画像を用いて、当該動作の訓練を行うための動作訓練装置として機能させるプログラムであって、
訓練者を撮影する撮影手順と、
前記基準画像をディスプレイを介して訓練者に提示する提示手順と、
前記提示手順で提示した基準画像と前記撮影画像とをサイズ及び位置を合わせて合成する合成手順と、
前記合成手順で合成した画像を前記ディスプレイに表示する表示制御手順と、
を有することを特徴とするプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2011−48096(P2011−48096A)
【公開日】平成23年3月10日(2011.3.10)
【国際特許分類】
【出願番号】特願2009−195824(P2009−195824)
【出願日】平成21年8月26日(2009.8.26)
【出願人】(000001007)キヤノン株式会社 (59,756)
【Fターム(参考)】
【公開日】平成23年3月10日(2011.3.10)
【国際特許分類】
【出願日】平成21年8月26日(2009.8.26)
【出願人】(000001007)キヤノン株式会社 (59,756)
【Fターム(参考)】
[ Back to top ]