
動的バイナリ・トランスレータに関するメモリ管理のための装置、方法、およびコンピュータ・プログラム
【課題】あるページ・サイズの第1のブロックを、他のページ・サイズの第2のブロックへと変換するための動的バイナリ・トランスレータ装置を提供する。
【解決手段】装置は、第1のメモリ506のメモリ・ページ特性に応じて、第1のメモリのアドレスを第2のメモリ512のアドレスにマッピングするためのリダイレクト・ページ・マッパ514と、第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算することを実行するように動作可能なメモリ障害挙動検出器516と、障害カウントがトリガしきい値に達したことに応じて、第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて第1のブロックを再変換済みブロックへと再変換することを実行するように動作可能な再生成コンポーネント518と、を備える。
【解決手段】装置は、第1のメモリ506のメモリ・ページ特性に応じて、第1のメモリのアドレスを第2のメモリ512のアドレスにマッピングするためのリダイレクト・ページ・マッパ514と、第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算することを実行するように動作可能なメモリ障害挙動検出器516と、障害カウントがトリガしきい値に達したことに応じて、第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて第1のブロックを再変換済みブロックへと再変換することを実行するように動作可能な再生成コンポーネント518と、を備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、動的バイナリ・トランスレータの分野に関し、より具体的には、動的バイナリ・トランスレータにおけるメモリ管理に関する。
【背景技術】
【0002】
動的バイナリ・トランスレータは、コンピューティングの技術分野で良く知られている。動的バイナリ・トランスレータは、通常は命令の基本ブロックの形の入力命令を受け入れ、それらをあるコンピューティング環境での実行に好適な対象プログラム・コード(subject program code)から、異なるコンピューティング環境での実行に好適な目標プログラム・コード(target program code)に変換するように動作する。この変換が最初の実行時に対象プログラム・コード上で実行されるため「動的」という用語が使用され、実行に先立って実施され、静的再コンパイルの形として特徴付けることができる静的変換と区別される。多くの動的バイナリ・トランスレータでは、最初の実行時に変換されたコードの基本ブロックが、その後の再実行時に使用するために保存される。
【0003】
あるコンピュータ・アーキテクチャおよびオペレーティング・システム(対象アーキテクチャ/対象OS)からのアプリケーション・コード(対象プログラム)を、第2の互換性のないコンピュータ・アーキテクチャおよびオペレーティング・システム(目標アーキテクチャ/目標OS)上で実行するために必要な動的バイナリ・トランスレータに関して直面する可能性のある問題の1つが、2つのプラットフォームによってメモリ管理に使用されるページ・サイズの相違である。これは特に、目標OSが、対象OSによって使用されるよりも大きなページ・サイズのみをサポートしている場合に問題となる。例示的なシナリオは、x86 Linux(R)プラットフォームがPower Linux上でエミュレートされている場合である。ここでは、対象OSは4kページを提供するが、目標OSは一般に64kページを提供するように構成されている。(Linuxは米国、他の諸外国、またはその両方における、Linus Torvaldsの登録商標である。)
【0004】
この状況では、次の2つの明確な問題が発生する。
【0005】
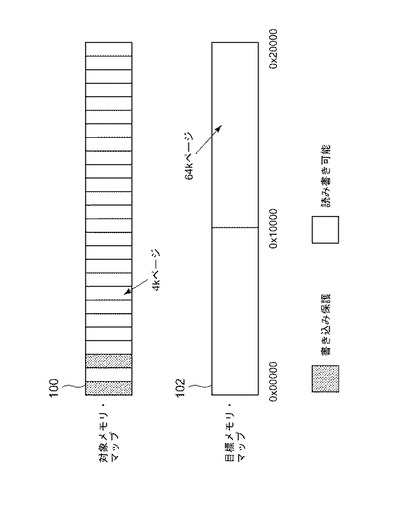
1)対象プログラムの動作(semantic)に適合させるために十分なほど小さい粒度でページ保護をすることが容易にできない。図1に示されるように、たとえば対象プログラムがメモリの隣接する3ページに異なる保護を割り振ろうとする場合、例示的な対象メモリ・マップ100は4kのページ・サイズを有し、例示的な目標メモリ・マップ102は64kのページ・サイズを有するため、目標OSは要求された割り振りを提供できない可能性がある。
【0006】
対象プログラムが、アドレス0および0x2000のページには書込み保護を適用するが、他のページには適用しない場合、動的バイナリ・トランスレータは(目標オペレーティング・システムを介して)0から0x10000までの領域のみを書込み保護することができ、書き込み可能ページおよび書き込み不可ページの両方に必要な保護制約を満たすことはできない。
【0007】
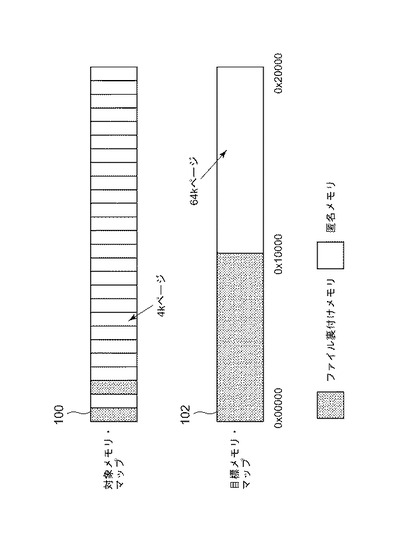
2)単一の目標ページ・サイズ領域内で異なるタイプのメモリを混合することができない。たとえばオペレーティング・システムは、匿名メモリ(anonymous memory)およびファイル裏付けメモリ(file-backed memory)のマッピングをサポートすることができる。ここで、匿名メモリは、それをマッピングする対象プログラムに対してのみ可視である。他方、ファイル裏付けメモリへの変更はストレージ内のファイルへ再コミットされるため、そのファイルの他のユーザも観察することができる。目標オペレーティング・システムは、それ独自のページ・サイズの倍数でのみマッピングを提供するため、トランスレータは単一のページ内で2つの異なるマッピングをサポートすることができない。
【0008】
図2に示される例では、対象プログラムはアドレス0および0x2000でファイルの2ページをマッピングしている。目標OSは、目標ページ・サイズ領域のみをマッピングできるため、ここではファイルの64kページ内でのマッピングを選択している。しかし、次に(対象が匿名メモリを要求した)0x1000でのメモリへの何らかの書き込みがファイルに再コミットされることになり、結果として不正な挙動が発生する。同様の問題が、2つのプロセスが匿名メモリの単一領域を共有する共有匿名マップ、および、オペレーティング・システムが異なるプロセス間で共有され任意の場所でプロセスのアドレス・スペースに接続可能なメモリ領域を割り振る従来の共有メモリなどの、他の種類のメモリ・マッピングにも当てはまる。
【0009】
この問題に緊密に関係するのが、ファイルのマッピング部分である。オペレーティング・システムは、一般に、ファイル全体ではなくファイルの特定部分をマッピングするための手段を提供し、ここではマッピングされる部分が、通常、ファイルへのページ位置合わせオフセットで開始および終了する。たとえば長さ0x40000のファイルの場合、アプリケーションは、開始+0x3000から開始+0xb000までの領域のみをマッピングするように選択してよい。目標オペレーティング・システムがページ・サイズ・オフセットのみをサポートする場合、マッピングに使用可能な最も小さい部分は、開始から開始+0x10000までとなり、これは対象プログラムの要求に十分緊密に対応するものではない。この問題は、マップ・タイプの混合と同じ手段で対処可能であるため、本開示の目的では2つの問題は同様であるとみなされるものとする。
【0010】
次に、ページ保護エミュレーションの基本的な問題に対する知られた手法について論じる。3つの既存の手法が知られている。第1の手法は、基礎となるハードウェアがサポートできる場合に、より低い粒度での保護を可能にするように目標オペレーティング・システムを修正することである。こうすることにより、大幅なランタイム・オーバヘッドなしに必要な保護が提供できるが、オペレーティング・システムの修正が必要であり、さらにハードウェアがより低い粒度でサポートできる必要があるため、必ずしも実行可能であるとは限らない。
【0011】
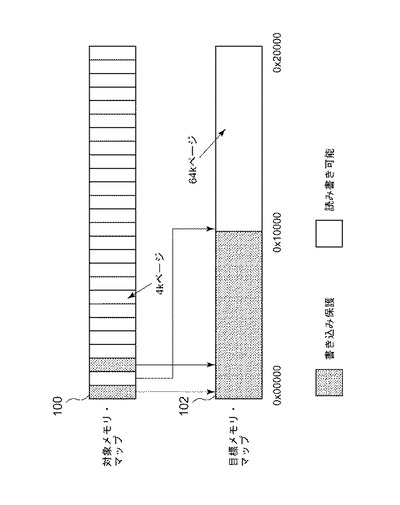
第2の手法は、動的バイナリ・トランスレータについて、対象アドレスと目標アドレスとの間に非線形マッピングを提供することである。その結果として、必要な領域よりも大きな領域をマッピングし、どの目標アドレスがあらゆる所与の対象アドレスに対するマッピングを含むかを記述したページ・テーブルを提供することにより、任意の必要なマッピングがサポート可能となる。この技法では、目標ページは任意のアドレスでトランスレータによってマッピング可能である。その結果として、必要な保護が提供可能となり、ランタイム時に対象アドレスが対応する目標マップに変換される。変換は、Intel IA−32アーキテクチャ・マニュアル、ボリューム3Aに記載されているように、従来のページ・テーブルで実行することができる。こうしたページ・テーブルはソフトウェアで容易に実装可能であるが、各アドレスについてアドレス変換を実行するコストは高く、受容可能な性能を達成するのは困難な可能性がある。この技法に従った例示的なマッピングが図3に示されている。
【0012】
第3の手法は、対象アドレスと目標アドレスとの間に線形マッピングを提供するが、保護のみをエミュレートするためのソフトウェアを使用する。こうした技法については、米国特許出願公開第2010/0030975A1号に詳細に記載されている。この技法の場合、すべてのページは読み取り可能および書き込み可能の両方としてマッピングされる。対象プログラムに代わって各メモリ・アクセス動作が実行される前に、テーブルから保護情報を抽出し、この情報をアクセスされる予定のアドレスに挿入する高速ルックアップが実行される。結果として対象プログラムによって要求された保護に従い、許可されるべきでないアクセスは失敗となる。これにより、何らかのランタイム・オーバヘッドがもたらされるが、各アクセスに対する全ページ・テーブル・ルックアップほどのコストはかからない。
【0013】
前述の第2の問題についても3つの既存の手法が知られており、これらはページ保護エミュレーションについて前述した手法と類似するものと考えることができる。
【0014】
第1の手法は、対象プログラムのマッピング要求を追加のエミュレーションなしに直接サポートできるようにするのに十分な低い粒度のマッピングをサポートするように目標オペレーティング・システムを修正することである。こうすることにより、最も小さなランタイム・オーバヘッドが実現されるが、実際には、オペレーティング・システムが全体にわたって異なるページ・サイズを認識していなければならないため、単により低い粒度のページ保護を与えるよりも困難であることが分かる。また、オペレーティング・システムが動的バイナリ・トランスレータ開発者の完全な制御の下にない場合、このオプションは非実用的であることが十分に分かる。
【0015】
ページ保護問題について説明した第2の手法は、単一の目標ページ内での異なるマップの混合の問題も解決する。対象アドレスから目標アドレスへの非線形変換を提供することによって、マップの任意の組み合わせが提供される。結果として対象プログラムは、実際にはたとえどこか他の場所にマッピングされている場合であっても、要求された場所に存在するように見える。しかし前述のように、この手法はかなりのランタイム・オーバヘッドをもたらすため、全体の性能が許容できないものとなる可能性がある。
【0016】
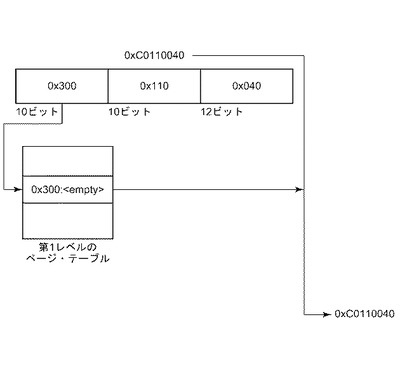
第3の手法は、対象プログラムによってアクセスできないように、(任意の使用可能な手段によって)要求された場所で直接マッピングできない領域を保護する。本手法は、米国特許出願公開第2010/0030975A1号でも説明がなされている。その後、要求されたマッピングはアドレス・スペース内のどこか他の場所で実行される。結果として対象プログラムは直接アクセスすることができない。対象プログラムがこれらの領域にアクセスした場合、障害が発生し、信号が動的バイナリ・トランスレータに送達される。動的バイナリ・トランスレータによるプログラム状態の検査によって、どのアドレスにアクセスされているかが決定され、この時点で信号ハンドラは要求されたアドレスを決定するためにアドレス変換を実行することができる。次に信号ハンドラ内でアクセスがエミュレートされ、動作が完了した対象プログラムに制御が戻される。図4は、アドレス0x4000でどのようにマップが保護されるか、および、信号ハンドラによって0xF00000000のマップの一部104へどのようにアクセスがリダイレクトできるのかを示す。
【0017】
この方法は、多くの場合良好な性能を提供するが、直接アクセスできない領域が非常に頻繁に使用される場合、多くの障害を処理するコストが非常に高くなる。
【先行技術文献】
【特許文献】
【0018】
【特許文献1】米国特許出願公開第2010/0030975A1号
【非特許文献】
【0019】
【非特許文献1】Intel IA−32アーキテクチャ・マニュアル、ボリューム3A、インテル・コーポレーション
【発明の概要】
【発明が解決しようとする課題】
【0020】
したがって、対象コンピューティング環境と目標コンピューティング環境との間でのメモリ管理における相違によって動的バイナリ・トランスレータに課せられる制約を克服する、改良された方法を有することが望ましい。
【課題を解決するための手段】
【0021】
したがって本発明は、第1の態様において、第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、第1のページ・サイズとは異なる第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための、動的バイナリ・トランスレータ装置を提供する。装置は、第1のメモリのメモリ・ページ特性に応じて、第1のメモリの少なくとも1つのアドレスを第2のメモリのアドレスにマッピングするためのリダイレクト・ページ・マッパと、第2のブロックの実行中にメモリ障害を検出し、障害カウントのトリガしきい値までの累算を実行するように動作可能なメモリ障害挙動検出器と、障害カウントがトリガしきい値に達したことに応じて当該第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて当該第1のブロックを再変換済みブロックへと再変換することを実行するように動作可能な再生成コンポーネントを備える。
【0022】
好ましくは、第1のメモリのメモリ・ページ特性はページ保護特性を備える。好ましくは、第1のメモリのメモリ・ページ特性はファイル裏付けメモリ特性を備える。好ましくは、さらに再生成コンポーネントは、第1のメモリの少なくとも1つのアドレスの第2のメモリのアドレスへの当該マッピングが、同じアドレスを戻す場合に、ページ・テーブル・ウォークをバイパスするように動作可能である。好ましくは、さらに再生成コンポーネントは、メモリ・アクセスが、再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、ページ・テーブル・ウォークをバイパスするように動作可能である。
【0023】
第2の態様では、第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータを操作する方法が提供される。第2のページ・サイズは第1のページ・サイズとは異なるものである。方法は、第1のメモリのメモリ・ページ特性に応じて、リダイレクト・ページ・マッパが、第1のメモリの少なくとも1つのアドレスを第2のメモリのアドレスにマッピングするステップと、メモリ障害挙動検出器が、第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算するステップと、障害カウントがトリガしきい値に達したことに応じて、再生成コンポーネントが、第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて当該第1のブロックを再変換済みブロックへと再変換するステップを含む。
【0024】
好ましくは、第1のメモリのメモリ・ページ特性はページ保護特性を備える。好ましくは、第1のメモリのメモリ・ページ特性はファイル裏付けメモリ特性を備える。好ましくは、さらに再生成コンポーネントは、当該第1のメモリの少なくとも1つのアドレスの当該第2のメモリのアドレスへの当該マッピングが、同じアドレスを戻す場合に、当該ページ・テーブル・ウォークをバイパスするように動作可能である。好ましくは、さらに再生成コンポーネントは、メモリ・アクセスが、再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、当該ページ・テーブル・ウォークをバイパスするように動作可能である。
【0025】
第3の態様では、コンピュータ・システムにロードされ、そこで実行された場合、第2の態様に従った方法の諸ステップを当該コンピュータ・システムに実行させるコンピュータ・プログラムが提供される。
【0026】
したがって、本発明の好ましい諸実施形態は、有利なことに、対象コンピューティング環境と目標コンピューティング環境との間でのメモリ管理における相違によって動的バイナリ・トランスレータに課せられる制約を克服する、改良された方法を提供する。
【0027】
次に、本発明の好ましい実施形態について、添付の図面を参照しながら単なる例示として説明する。
【図面の簡単な説明】
【0028】
【図1】従来技術に従った書き込み保護を有する対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図2】従来技術に従ったファイル裏付けおよび匿名メモリを有する対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図3】従来技術に従った書き込み保護を有する対象メモリおよび目標メモリの改良された配置構成を、簡略化された形で示す概略図である。
【図4】従来技術に従ったファイル裏付けおよび匿名メモリを有する対象メモリおよび目標メモリの改良された配置構成を、簡略化された形で示す概略図である。
【図5】本発明の好ましい実施形態に従った物理コンポーネントまたは論理コンポーネントの装置または配置構成を、簡略化された形で示す概略図である。
【図6】本発明の好ましい実施形態に従ったシステムの操作方法を示す、流れ図である。
【図7】本発明の好ましい実施形態の実装に好適な対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図8】本発明の好ましい実施形態に従った対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図9】本発明の好ましい実施形態に従った例示的ページ・マップ構造を、簡略化された形で示す概略図である。
【図10】本発明の好ましい実施形態に従った他の例示的ページ・マップ構造を、簡略化された形で示す概略図である。
【発明を実施するための形態】
【0029】
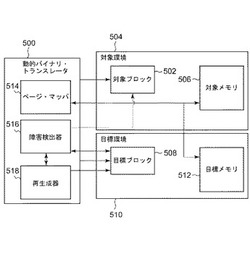
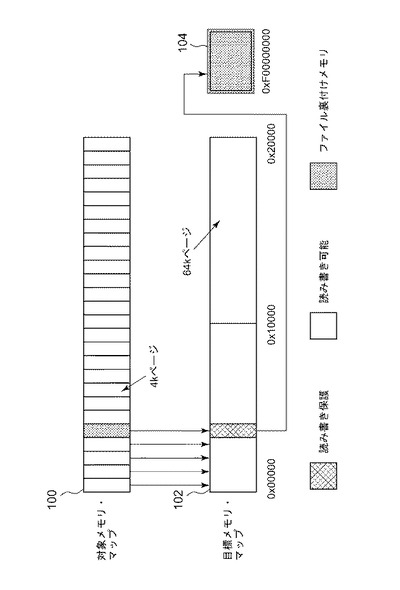
図5には、本発明の好ましい実施形態に従った物理コンポーネントまたは論理コンポーネントの装置または配置構成が簡略化された概略図の形で示されている。図5では、第1のページ・サイズの第1のメモリ506を有する対象実行環境504における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロック502を、第2のページ・サイズの第2のメモリ512を有する第2の実行環境510における実行のための少なくとも1つの第2のブロック508へと変換するための、動的バイナリ・トランスレータ装置500が示されている。第2のページ・サイズは第1のページ・サイズとは異なるものである。動的バイナリ・トランスレータ装置500は、第1のメモリ506のメモリ・ページ特性に応答して、第1のメモリ506の少なくとも1つのアドレスを第2のメモリ512のアドレスにマッピングするためのリダイレクト・ページ・マッパ514を備える。加えて、動的バイナリ・トランスレータ装置500は、第2のブロック508の実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算することを実行するように動作可能なメモリ障害挙動検出器516と、障害カウントがトリガしきい値に達したことに応じて、第2のブロック508を廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて第1のブロック502を第2のブロック508の再変換済みバージョンへと再変換することを実行するように動作可能な再生成コンポーネント518を備える。
【0030】
本発明の好ましい実施形態に従うシステムに関して見てきたが、次に、本発明の好ましい実施形態に従った動的バイナリ・トランスレータの操作方法をフローチャートの形式で示した図6に目を向けてみる。
【0031】
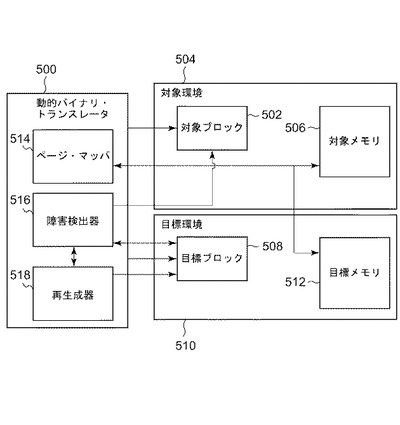
図6では、第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータ装置を操作する方法の諸ステップが示されている。第2のページ・サイズは当該第1のページ・サイズとは異なるものである。開始ステップ600で開始され、第1のメモリのメモリ・ページ特性を決定するステップ602と、リダイレクト・ページ・マッパによって、当該第1のメモリの少なくとも1つのアドレスを当該第2のメモリのアドレスにマッピングするステップ604とを含む。ステップ606では、メモリ障害挙動検出器が、第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算する。ステップ608では、障害カウントがトリガしきい値に達したことに応答して、動的バイナリ・トランスレータの再生成コンポーネントが第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて第1のブロックを第2のブロックの再変換済みバージョンへと再変換する。このプロセスは終了ステップ610で終了する。
【0032】
したがって提案された機構は、ハードウェア、ソフトウェア、またはハードウェアおよびソフトウェアの組み合わせのいずれで具体化されるかに関わらず、追加のオペレーティング・システムの修正を必要とすることなく、幅広い領域のアプリケーションの動作について良好な性能特性を提供する単一の目標ページ・サイズ領域内でのマップ・タイプの混合をサポートするための手段を提供する。
【0033】
対象プログラム・マッピング要求は、可能であれば要求された場所において提供される。すなわち、単一のマップ・タイプのみが要求され、満たされていない可能性のあるファイル・オフセット制約がない場合、マップは対象アクセス可能メモリ内に直接配置され、いかなる追加のアドレス変換も不要である。こうした直接マッピングが不可能な場合、マップは、動的バイナリ・トランスレータによってアクセス可能であるが対象プログラムによっては直接アクセス不可能なメモリの好適な領域内に配置される。次に、対象可視アドレス・スペースの対応部分がアクセス不可としてマーク付けされる。結果としてアクセスは障害(fault)となる。かかる領域へのアクセスが実行された場合、障害が処理されて正しいアクセスが信号ハンドラによって実行される。
【0034】
第1の好ましい実施形態では、観察されたアプリケーションの動作に基づく、障害処理からページ・テーブル・ルックアップへのモード切換え手段が提供される。短期間に多数の障害が見られた場合、トランスレータは自ら生成したすべての実行可能コードを破棄し、各アクセスについてページ・テーブル・ウォークを実行するコードの生成を開始する。これによって目標仮想アドレス・スペース内の適切な位置へとアドレスを変換することになる。障害処理機構は、必要であれば依然として有効であることに留意されたい。ページ・テーブルは、対象アドレスから適切な目標アドレスへのマッピングを提供するトランスレータによって生成される。
【0035】
他の好ましい実施形態では、ルックアップ・オーバヘッドを減らすために、ほぼ線形の対象アドレスから目標アドレスへのマッピングを用いた部分的なページ・テーブル・ウォークを使用するための手段が提供可能である。最適化の例として、ページ・テーブルは変換が必要なページについてのみ記入され、ページ・テーブル内の他のエントリはemptyとしてマーク付けされる。このようなエントリに遭遇した場合、ルックアップは早期に停止し、オリジナルの未変換アドレスが使用される。ページ・テーブル自体の使用は当技術分野で知られているが、ほとんどのアドレスが変換なしに直接マッピングし、ショートカット・パスが使用可能なページ・テーブルの使用は、既知の技術分野における有利な改良である。
【0036】
他の最適化として、アクセス・タイプの静的変換時評価に基づいた、ページ・ルックアップ・オーバヘッドからのアクセス除外のための手段が提供される。この最適化では、アドレス変換が必要な可能性が低いとみなされるアクセスは、ページ・テーブル・ルックアップなしに実行可能であり、たとえばスタックへのアクセスはコード変換時に容易に検出可能であり、ファイル裏付けマップまたは共有メモリへのアクセスが必要な可能性は低い。
【0037】
一代替実施形態では、アクセス・モードをアクセスごとに切り換えるための手段を提供する。この最適化では、すべてのコードはページ・テーブル・ルックアップなしに生成可能であり、コードの個々のブロックは、それらのアドレスで障害が観察された場合にルックアップを含めるように再生成することができる。
【0038】
他の代替実施形態は、アドレス・ルックアップが必要な時点を決定するために、低コスト・ランタイム・フィルタとしてのマスクされたアドレスの比較を提供する。この代替手法では、可変ビット・マスクを使用し、各アドレスにマスクを適用し、既知の値と比較して、ルックアップが必要であることがわかっている領域内にそのアドレスが存在するかどうかを決定することによって、アドレス変換が必要となるアクセスをフィルタリングすることが可能である。
【0039】
本発明の細部は、以下で詳細に説明するような、本明細書の図7および図8に示された作業例に最も良く表されている。説明のために、対象ページ・サイズは4k、目標ページ・サイズは64kであるものと仮定されている。ページ保護は、Power Linux上に提供されるsubpage_protシステムコールなどの機能を使用して、4k粒度で適用可能であることが想定されている。しかしこうした機能が使用できなかった場合、前述のような保護のソフトウェア実装を代わりに使用することができる。当業者であれば、本発明の諸実施形態による同様に有利な方法で、多くの他のページ・サイズ特性が取扱い可能であることは明らかであろう。
【0040】
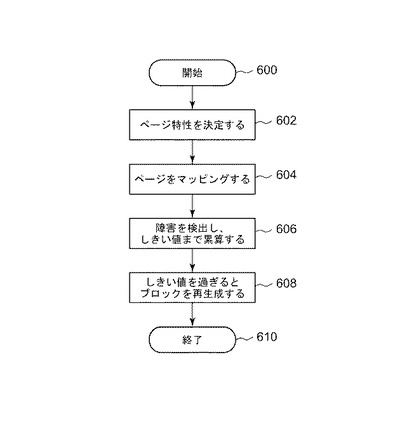
図7を見ると、例示的な対象ページ・マップ100および例示的な目標ページ・マップ102が示されている。まず初めに、対象プログラムのバイナリ700、動的リンカ702、スタック704、およびヒープ706がマッピングされる。動的バイナリ・トランスレータによってプログラムが実行されると、1つまたは複数のランタイム・ライブラリ708もマッピングされる。この例では、これらのマッピングはすべて直接実行可能であり、本発明の好ましい諸実施形態が提供する特別な機構は不要である。
【0041】
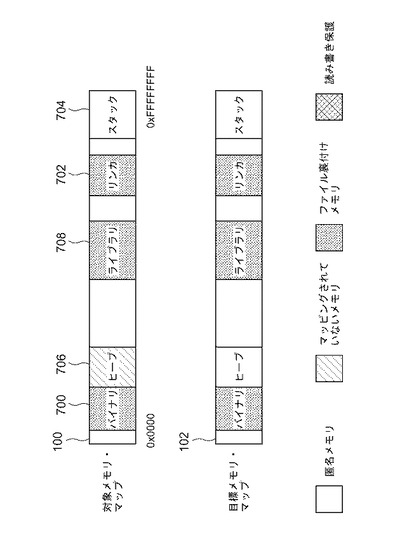
対象プログラムで遭遇する各命令に対して、トランスレータは目標アーキテクチャ上で実行可能な等価命令を生成し、ロードおよび格納のために特別なアドレス操作は一切実行されず、メモリには直接アクセスされる。次に、対象プログラムは0x10000000で匿名メモリのページにマッピングし、アドレス0x10001000のファイル裏付けメモリのページが後に続く。目標オペレーティング・システムはこのマッピングをサポートできないため、トランスレータはファイル裏付けメモリをアドレス・スペースの異なる部分に配置し、0x10001000のページをアクセス不可としてマーク付けしなければならない。この状況が図8に示されている。
【0042】
アドレス0x10001000のページにアクセスしようとすると障害が受信され、トランスレータはこれを受け取って、0xF00000000でのマッピング104内にアクセスするための正しいアドレスを計算し、そのアドレスでのアクセスを実行する。
【0043】
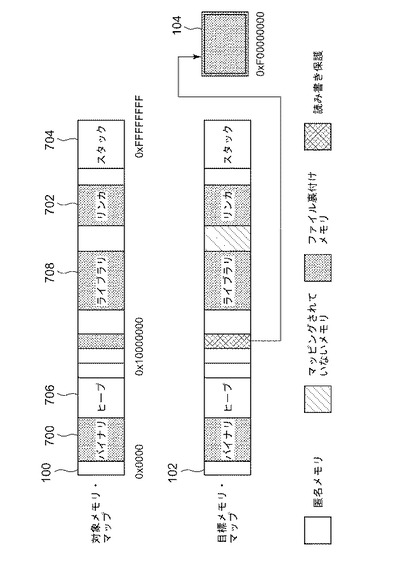
したがって第1の好ましい実施形態では、観察されたアプリケーションの動作に基づく、障害処理からページ・テーブル・ルックアップへの動的モード切り換えのための方法および装置が提供される。0x10001000のこのファイル裏付けマップに対して多くのアクセスが実行された場合、障害ハンドラにおけるこれらの障害の処理および適切なアドレス変換実行のコストが、アプリケーションの性能を支配することになる。このようにアクセスを実行するコストは、障害処理のコストを含め、メモリに直接アクセスするよりも2倍から3倍となる可能性があることに留意されたい。各障害を受信した時点で、トランスレータは障害の合計数を記録し、かなり多くの数が受信された場合、または所与の期間内にかなり高い率で障害が観察された場合、トランスレータは、障害のコストを避けるためにアドレス変換が各アクセスについてランタイム時に実行される、異なる動作モードに切り換えることができる。トランスレータは、対象アドレスを目標アドレスにマッピングするページ・テーブルを生成する。ほとんどのアドレスでは、ほとんどのマップが依然として等価の場所にマッピングされるように、ページ・テーブルは実際に対象アドレスを同じ目標アドレスへと再マッピングすることになる。しかし、問題のファイル・アクセスの場合、ページ・テーブルは0xF00000000に相対的な目標アドレスへとアドレスをマッピングすることになる。ページ・テーブルは、前述のマニュアルで説明されているような、Intel IA−32アーキテクチャによって使用されるページ・テーブルと同様に構築可能である。しかし、ページ保護は依然としてオペレーティング・システムの既存の機能を使用して処理できるため、このページ・テーブルはマップの保護に関する情報を記録する必要がない。アクセスされることになるアドレスが0x1000101Cの場合、ページ・テーブルの関連部分は図9に示されるようになる。
【0044】
ここではすべての生成されたコードが廃棄され、再生成されるが、各対象のロードまたは格納のための単純なロードまたは格納命令を生成する代わりに、正しいアドレスを計算するためのページ・テーブル・ルックアップが生成される。コードの例示的実施形態では、対象命令については以下のようなものとなる。
loadb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
そして結果として、以下のような目標命令シーケンスが生じる。
add r12,r2,r3 #2つのアドレス・レジスタを追加することによって対象アドレスを計算する
sr r13,r12,22 #アドレスの上位10ビットを取得する
sl r13,r12,3 #8倍することによってインデックスを第1レベルのテーブルに入れる(各エントリは8バイト・アドレスである)
ld r13,r13(r30) #第1レベルのページ・テーブルからアドレスをロードする(r30はここでは第1レベルのテーブルのアドレスを含む)
sr r14,r12,12 アドレスの上位20ビットを取得する
and r14,r14,0x3ff #アドレスの次の10ビットを取得し、インデックスを第2レベルのテーブルに入れる
sl r14,r14,3 #8倍することによってインデックスを第2レベルのテーブルに入れる
ld r15,r13,r14 #第2レベルのテーブルからページ・アドレスをロードする
and r16,r13,0xfff #対象アドレスからオフセットをページに入れる
lb r1,r15,r16 #新規ページ・アドレスからロードする+ページのオフセット
【0045】
必要な追加のチェック回数を減らすため、マッピングされていないページがあれば、それらのページ・テーブル・エントリをメモリの既知のマッピングされていない領域に向けて送ることが可能である。その結果として適切な障害が生成されることになる。ページ境界をまたがっているアドレスを処理するために、このシーケンスでは何らかの追加の命令が必要となる場合がある。
【0046】
一実施形態では、ルックアップ・オーバヘッドを減らすために、対象アドレスから目標アドレスへのほぼ線形のマッピングを利用した、部分的なページ・テーブル・ウォークが実装可能である。もちろん、対象から目標への完全なマッピングが提供される場合、前述のスキームを利用して目標マップを任意の位置に配置することが可能である。しかし、ほとんどの場合、要求された対象アドレスと同一の目標アドレスにアドレスをマッピングすることが可能であるものと考えると、ほとんどの場合、ルックアップは単に同じアドレスを戻すことになる。これにより、第1レベルのテーブルのみの即時チェックを優先して、全体ルックアップをバイパスできるようにする最適化が使用可能である。このスキームでは、第1レベルのページ・テーブル内の単一エントリによってカバーされているアドレスの全領域(前述のスキームでは4MBの領域)が、いかなる特別な処理も必要としない場合、第1レベルのテーブル内のエントリは、次のテーブルを示すポインタではなく特別なマーカ値を含むことができる。第1レベルのテーブルからのアドレスがロードされると、この値が見つかった場合、残りのルックアップは打ち切られ、代わりにオリジナル・アドレスが使用される。これに関する例示的なコード・シーケンスが以下に示される。
【0047】
例示的なコード例では、対象命令について以下のようなものとなる。
loadb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
そして結果として、以下のような目標命令シーケンスが生じる。
add r12,r2,r3 #2つのアドレス・レジスタを追加することによって対象アドレスを計算する
sr r13,r12,22 #アドレスの上位10ビットを取得する
sl r13,r12,3 #8倍することによってインデックスを第1レベルのテーブルに入れる(各エントリは8バイト・アドレスである)
ld r13,r13(r30) #第1レベルのページ・テーブルからアドレスをロードする(r30はここでは第1レベルのテーブルのアドレスを含む)
cmp r13,0 #ゼロと比較する(ゼロはここでは「empty」マーカ値として使用される)
beq normal #等しい場合、標準ロードへと分岐する
sr r14,r12,12 アドレスの上位20ビットを取得する
and r14,r14,0x3ff #アドレスの次の10ビットを取得し、インデックスを第2レベルのテーブルに入れる
sl r14,r14,3 #8倍することによってインデックスを第2レベルのテーブルに入れる
ld r15,r13,r14 #第2レベルのテーブルからページ・アドレスをロードする
and r16,r13,0xfff #対象アドレスからオフセットをページに入れる
lb r1,r15,r16 #新規ページ・アドレスからロードする+ページのオフセット
b end #標準ロードを過ぎて分岐する
normal:
lb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
end:
【0048】
共通パスで使用される命令には下線が付けられている。また、この最適化によって回避されるものはイタリック体で示されている。ここでは共通のケースでいくつかの命令が省略され、結果として大多数のアクセスがアドレス変換を必要としない場合、全体の性能が向上することになる。
【0049】
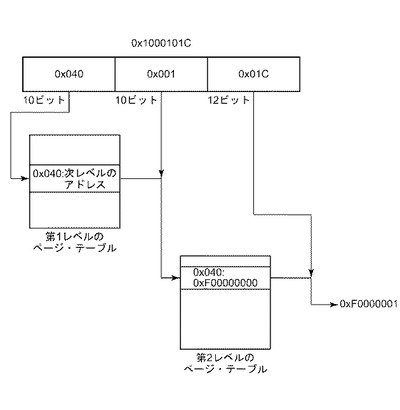
図10は、システムがアドレス0xc0110040にアクセスしている場合、ページ・テーブルがこの状況でどのようなものと見えるかの一例を示している。
【0050】
他の拡張機能では、アクセス・タイプの静的変換時評価に基づいた、ページ・ルックアップ・オーバヘッドからの一定のアクセス除外のための手段が提供可能である。
【0051】
いくつかの対象アーキテクチャでは、アーキテクチャ上の機能または共通の規則により、命令の静的検査に基づいて、メモリ・アクセスの予期される特性を識別することが可能となる。たとえばIA−32命令セットでは、プッシュ命令およびポップ命令を使用してスタックにアクセスすることができる。加えて、ESPレジスタは現行のスタック・ポインタとしてほぼ独占的に維持されるが、EBPはしばしば現行のスタック・フレームのトップを指示するために使用される。いくつかのオペレーティング・システムおよび環境では、これらのような特性を使用して、アドレス変換を必要とする可能性が低いとみなされるアクセスからアドレス変換を除去することができる。IA−32アプリケーションの変換の場合、スタックはファイルが裏付けされるかまたは他のプロセスと共用される可能性が低いため、さらにはスタックの正確な位置およびサイズはしばしばトランスレータ自体の制御下にあるため、スタック・アクセスがアドレス変換を必要とする可能性が非常に低い旨をアサートできる可能性がある。したがって、ESPまたはEBPに基づくアクセスに関してページ・テーブル・ルックアップを据え付けないことを選択することで、アドレス変換オーバヘッドの大幅な節減が達成可能である。他のアーキテクチャについても同様の規則が存在する。
【0052】
フェイルセーフとしてオリジナルの信号処理コードが保持され、ルックアップが生成されないいずれのアクセスも障害となり、ともかく正しく処理されることになる。
【0053】
いずれかのルックアップが据え付けられる前に障害となったトランスレータに各対象命令のアドレスを記録させることによって、他の改良を使用することができる。ルックアップが必要であることが決定された場合、障害となったことがわかっているアドレスに対してのみルックアップを据え付けることができる。実行が継続される場合、必要に応じて特定の命令シーケンスに対してコードを再生成することにより、障害が見られる命令にルックアップが追加される。これによって最小限のルックアップが生成されることが保証され、要求された位置にマッピングされていないメモリには決してアクセスしないコードについて高性能が保証される。アプリケーションの挙動は経時的に変化しやすいため、すべてのルックアップ・コードを定期的に除去し、プロファイリングを再始動することも有用な可能性があり、それによってもはやルックアップを必要としないコードが性能を犠牲にし続けることのないように保証される。
【0054】
代替のフィルタリング機構として、変換が必要な通常アクセスされるアドレスの範囲が狭く、隣接している場合、マスクおよび比較動作を使用することができる。前述の例では、単一のページのみがアドレス変換を要求した。こうした状況が存在する場合は必ず、単にアドレスをマスキングし、特定のビット値と比較することによって、より最適なアドレス・フィルタリング手法を採用することができる。現在使用されているマスクおよび値は、追加のロード命令の生成を避けるためにレジスタ内に維持することができる。この最適化に関する例示的なコード・シーケンスが、対象命令について以下のように示される。
loadb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
そして結果として、以下のような目標命令シーケンスが生じる。
add r12,r2,r3 #2つのアドレス・レジスタを追加することによって対象アドレスを計算する
and r13,r12,r29 #アドレスをr29の値(現在のアドレス・マスク値)でマスキングする
cmp r13,r28 #この結果をr28の値(現在んアドレス比較値)と比較する
bne normal #値が一致しない場合、変換は不要であるものと仮定する
sr r13,r12,22 #アドレスの上位10ビットを取得する
sl r13,r12,3 #8倍することによってインデックスを第1レベルのテーブルに入れる(各エントリは8バイト・アドレスである)
ld r13,r13(r30) #第1レベルのページ・テーブルからアドレスをロードする(r30はここでは第1レベルのテーブルのアドレスを含む)
sr r14,r12,12 アドレスの上位20ビットを取得する
and r14,r14,0x3ff #アドレスの次の10ビットを取得し、インデックスを第2レベルのテーブルに入れる
sl r14,r14,3 #8倍することによってインデックスを第2レベルのテーブルに入れる
ld r15,r13,r14 #第2レベルのテーブルからページ・アドレスをロードする
and r16,r13,0xfff #対象アドレスからオフセットをページに入れる
lb r1,r15,r16 #新規ページ・アドレスからロードする+ページのオフセット
b end #標準ロードを過ぎて分岐する
normal:
lb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
end:
【0055】
共通パスで使用される命令には下線が付けられている。また、この最適化によって回避されるものはイタリック体で示されている。ここでは共通のケースでいくつかの命令が省略され、結果として大多数のアクセスがアドレス変換を必要としない場合、全体の性能が向上することになる。
【0056】
実行が進行し、メモリ・マップが変更された場合、それに応じて現在のマスクおよびアドレス比較値も更新することができる。
【0057】
当業者であれば、本発明の好ましい諸実施形態の方法のすべてまたは一部が、方法の諸ステップを実行するように配置構成された論理要素を備える1つの論理装置または複数の論理装置内で好適かつ有用に具体化可能であること、および、こうした論理要素がハードウェア・コンポーネント、ファームウェア・コンポーネント、またはそれらの組み合わせを備えることが可能であることが明らかとなろう。
【0058】
当業者であれば、本発明の好ましい諸実施形態に従った論理配置構成のすべてまたは一部が、方法の諸ステップを実行するための論理要素を備える論理装置内で好適に具体化可能であること、および、こうした論理要素が、たとえばプログラム可能論理アレイまたは特定用途向け集積回路内の論理ゲートなどのコンポーネントを備えることが可能であることが、等しく明らかとなろう。さらにこうした論理配置構成は、たとえば固定または伝送可能なキャリア媒体を使用して格納および伝送可能な仮想ハードウェア記述子言語を使用するアレイまたは回路内などに、一時的または永続的に論理構造を確立するための実行可能要素内で具体化することができる。
【0059】
前述の方法および配置構成が、1つまたは複数のプロセッサ(図示せず)上で実行中のソフトウェア内で完全または部分的に好適に実施可能であること、および、ソフトウェアが、磁気または光ディスクなどの任意の好適なデータ・キャリア(同じく図示せず)上で搬送される1つまたは複数のコンピュータ・プログラム要素の形で提供可能であることを理解されよう。データ伝送のためのチャネルは、同様に、すべての記述のストレージ媒体ならびに有線または無線の信号搬送媒体などの信号搬送媒体を備えることができる。
【0060】
一般に、方法は、所望の結果を導く首尾一貫したステップ・シーケンスであるものと考えられる。これらのステップは、物理量の物理操作を必要とする。通常、これらの量は、格納、転送、結合、比較、およびその他の操作が実行されることが可能な電気信号または磁気信号の形を取るが、その限りではない。時には、主として一般的な用法の理由で、これらの信号をビット、値、パラメータ、アイテム、要素、オブジェクト、シンボル、文字、項、数などと言い表すことが便利である。しかし、これらのすべての用語および同様の用語は適切な物理量に関連付けられるものであり、これらの量に適用される単なる便利なラベルであることに留意されたい。
【0061】
さらに本発明は、コンピュータ・システムと共に使用するためのコンピュータ・プログラム製品としても好適に具体化することができる。こうした実装は、たとえばディスケット、CD−ROM、ROM、またはハード・ディスクのようなコンピュータ読み取り可能媒体などの有形媒体上に固定されるか、あるいは、光またはアナログの通信回線を含むがこれらに限定されない有形媒体を介して、または、マイクロ波、赤外線、または他の伝送技法を含むがこれらに限定されない無線技法を使用して無形に、モデムまたは他のインターフェース・デバイスを通じてコンピュータ・システムに伝送可能である、一連のコンピュータ読み取り可能命令を備えることができる。一連のコンピュータ読み取り可能命令は、本明細書で前述した機能のすべてまたは一部を具体化する。
【0062】
当業者であれば、こうしたコンピュータ読み取り可能命令が、多くのコンピュータ・アーキテクチャまたはオペレーティング・システムと共に使用するためのいくつかのプログラミング言語で作成可能であることを理解されよう。さらに、こうした命令は、半導体、磁気、または光を含むがこれらに限定されない、現行または将来の任意のメモリ技術を使用して格納すること、あるいは、光、赤外線、またはマイクロ波を含むがこれらに限定されない、現行または将来の任意の通信技術を使用して伝送することが、可能である。こうしたコンピュータ・プログラム製品は、たとえばパッケージ・ソフトウェアなどの印刷文書または電子文書が添付された取り外し可能媒体として配布されること、コンピュータ・システムのたとえばシステムROMまたは固定ディスク上に事前ロードされること、あるいは、たとえばインターネットまたはワールド・ワイド・ウェブなどのネットワークを介してサーバまたは電子掲示板から配布されることが、可能であることが企図される。
【0063】
他の代替実施形態では、本発明の好ましい実施形態は機能データをその上に有するデータ・キャリアの形で実現可能であり、当該機能データは、コンピュータ・システムにロードされ、コンピュータ・システムによって動作された場合、当該コンピュータ・システムが方法のすべてのステップを実行可能とするための機能コンピュータ・データ構造を備える。
【0064】
当業者であれば、本発明の範囲を逸脱することなく、前述の例示的実施形態に対する多くの改良および修正が実行可能であることが明らかとなろう。
【符号の説明】
【0065】
500 動的バイナリ・トランスレータ
502 対象ブロック
504 対象環境
506 対象メモリ
508 目標ブロック
510 目標環境
512 目標メモリ
514 ページ・マッパ
516 障害検出器
518 再生成器
【技術分野】
【0001】
本発明は、動的バイナリ・トランスレータの分野に関し、より具体的には、動的バイナリ・トランスレータにおけるメモリ管理に関する。
【背景技術】
【0002】
動的バイナリ・トランスレータは、コンピューティングの技術分野で良く知られている。動的バイナリ・トランスレータは、通常は命令の基本ブロックの形の入力命令を受け入れ、それらをあるコンピューティング環境での実行に好適な対象プログラム・コード(subject program code)から、異なるコンピューティング環境での実行に好適な目標プログラム・コード(target program code)に変換するように動作する。この変換が最初の実行時に対象プログラム・コード上で実行されるため「動的」という用語が使用され、実行に先立って実施され、静的再コンパイルの形として特徴付けることができる静的変換と区別される。多くの動的バイナリ・トランスレータでは、最初の実行時に変換されたコードの基本ブロックが、その後の再実行時に使用するために保存される。
【0003】
あるコンピュータ・アーキテクチャおよびオペレーティング・システム(対象アーキテクチャ/対象OS)からのアプリケーション・コード(対象プログラム)を、第2の互換性のないコンピュータ・アーキテクチャおよびオペレーティング・システム(目標アーキテクチャ/目標OS)上で実行するために必要な動的バイナリ・トランスレータに関して直面する可能性のある問題の1つが、2つのプラットフォームによってメモリ管理に使用されるページ・サイズの相違である。これは特に、目標OSが、対象OSによって使用されるよりも大きなページ・サイズのみをサポートしている場合に問題となる。例示的なシナリオは、x86 Linux(R)プラットフォームがPower Linux上でエミュレートされている場合である。ここでは、対象OSは4kページを提供するが、目標OSは一般に64kページを提供するように構成されている。(Linuxは米国、他の諸外国、またはその両方における、Linus Torvaldsの登録商標である。)
【0004】
この状況では、次の2つの明確な問題が発生する。
【0005】
1)対象プログラムの動作(semantic)に適合させるために十分なほど小さい粒度でページ保護をすることが容易にできない。図1に示されるように、たとえば対象プログラムがメモリの隣接する3ページに異なる保護を割り振ろうとする場合、例示的な対象メモリ・マップ100は4kのページ・サイズを有し、例示的な目標メモリ・マップ102は64kのページ・サイズを有するため、目標OSは要求された割り振りを提供できない可能性がある。
【0006】
対象プログラムが、アドレス0および0x2000のページには書込み保護を適用するが、他のページには適用しない場合、動的バイナリ・トランスレータは(目標オペレーティング・システムを介して)0から0x10000までの領域のみを書込み保護することができ、書き込み可能ページおよび書き込み不可ページの両方に必要な保護制約を満たすことはできない。
【0007】
2)単一の目標ページ・サイズ領域内で異なるタイプのメモリを混合することができない。たとえばオペレーティング・システムは、匿名メモリ(anonymous memory)およびファイル裏付けメモリ(file-backed memory)のマッピングをサポートすることができる。ここで、匿名メモリは、それをマッピングする対象プログラムに対してのみ可視である。他方、ファイル裏付けメモリへの変更はストレージ内のファイルへ再コミットされるため、そのファイルの他のユーザも観察することができる。目標オペレーティング・システムは、それ独自のページ・サイズの倍数でのみマッピングを提供するため、トランスレータは単一のページ内で2つの異なるマッピングをサポートすることができない。
【0008】
図2に示される例では、対象プログラムはアドレス0および0x2000でファイルの2ページをマッピングしている。目標OSは、目標ページ・サイズ領域のみをマッピングできるため、ここではファイルの64kページ内でのマッピングを選択している。しかし、次に(対象が匿名メモリを要求した)0x1000でのメモリへの何らかの書き込みがファイルに再コミットされることになり、結果として不正な挙動が発生する。同様の問題が、2つのプロセスが匿名メモリの単一領域を共有する共有匿名マップ、および、オペレーティング・システムが異なるプロセス間で共有され任意の場所でプロセスのアドレス・スペースに接続可能なメモリ領域を割り振る従来の共有メモリなどの、他の種類のメモリ・マッピングにも当てはまる。
【0009】
この問題に緊密に関係するのが、ファイルのマッピング部分である。オペレーティング・システムは、一般に、ファイル全体ではなくファイルの特定部分をマッピングするための手段を提供し、ここではマッピングされる部分が、通常、ファイルへのページ位置合わせオフセットで開始および終了する。たとえば長さ0x40000のファイルの場合、アプリケーションは、開始+0x3000から開始+0xb000までの領域のみをマッピングするように選択してよい。目標オペレーティング・システムがページ・サイズ・オフセットのみをサポートする場合、マッピングに使用可能な最も小さい部分は、開始から開始+0x10000までとなり、これは対象プログラムの要求に十分緊密に対応するものではない。この問題は、マップ・タイプの混合と同じ手段で対処可能であるため、本開示の目的では2つの問題は同様であるとみなされるものとする。
【0010】
次に、ページ保護エミュレーションの基本的な問題に対する知られた手法について論じる。3つの既存の手法が知られている。第1の手法は、基礎となるハードウェアがサポートできる場合に、より低い粒度での保護を可能にするように目標オペレーティング・システムを修正することである。こうすることにより、大幅なランタイム・オーバヘッドなしに必要な保護が提供できるが、オペレーティング・システムの修正が必要であり、さらにハードウェアがより低い粒度でサポートできる必要があるため、必ずしも実行可能であるとは限らない。
【0011】
第2の手法は、動的バイナリ・トランスレータについて、対象アドレスと目標アドレスとの間に非線形マッピングを提供することである。その結果として、必要な領域よりも大きな領域をマッピングし、どの目標アドレスがあらゆる所与の対象アドレスに対するマッピングを含むかを記述したページ・テーブルを提供することにより、任意の必要なマッピングがサポート可能となる。この技法では、目標ページは任意のアドレスでトランスレータによってマッピング可能である。その結果として、必要な保護が提供可能となり、ランタイム時に対象アドレスが対応する目標マップに変換される。変換は、Intel IA−32アーキテクチャ・マニュアル、ボリューム3Aに記載されているように、従来のページ・テーブルで実行することができる。こうしたページ・テーブルはソフトウェアで容易に実装可能であるが、各アドレスについてアドレス変換を実行するコストは高く、受容可能な性能を達成するのは困難な可能性がある。この技法に従った例示的なマッピングが図3に示されている。
【0012】
第3の手法は、対象アドレスと目標アドレスとの間に線形マッピングを提供するが、保護のみをエミュレートするためのソフトウェアを使用する。こうした技法については、米国特許出願公開第2010/0030975A1号に詳細に記載されている。この技法の場合、すべてのページは読み取り可能および書き込み可能の両方としてマッピングされる。対象プログラムに代わって各メモリ・アクセス動作が実行される前に、テーブルから保護情報を抽出し、この情報をアクセスされる予定のアドレスに挿入する高速ルックアップが実行される。結果として対象プログラムによって要求された保護に従い、許可されるべきでないアクセスは失敗となる。これにより、何らかのランタイム・オーバヘッドがもたらされるが、各アクセスに対する全ページ・テーブル・ルックアップほどのコストはかからない。
【0013】
前述の第2の問題についても3つの既存の手法が知られており、これらはページ保護エミュレーションについて前述した手法と類似するものと考えることができる。
【0014】
第1の手法は、対象プログラムのマッピング要求を追加のエミュレーションなしに直接サポートできるようにするのに十分な低い粒度のマッピングをサポートするように目標オペレーティング・システムを修正することである。こうすることにより、最も小さなランタイム・オーバヘッドが実現されるが、実際には、オペレーティング・システムが全体にわたって異なるページ・サイズを認識していなければならないため、単により低い粒度のページ保護を与えるよりも困難であることが分かる。また、オペレーティング・システムが動的バイナリ・トランスレータ開発者の完全な制御の下にない場合、このオプションは非実用的であることが十分に分かる。
【0015】
ページ保護問題について説明した第2の手法は、単一の目標ページ内での異なるマップの混合の問題も解決する。対象アドレスから目標アドレスへの非線形変換を提供することによって、マップの任意の組み合わせが提供される。結果として対象プログラムは、実際にはたとえどこか他の場所にマッピングされている場合であっても、要求された場所に存在するように見える。しかし前述のように、この手法はかなりのランタイム・オーバヘッドをもたらすため、全体の性能が許容できないものとなる可能性がある。
【0016】
第3の手法は、対象プログラムによってアクセスできないように、(任意の使用可能な手段によって)要求された場所で直接マッピングできない領域を保護する。本手法は、米国特許出願公開第2010/0030975A1号でも説明がなされている。その後、要求されたマッピングはアドレス・スペース内のどこか他の場所で実行される。結果として対象プログラムは直接アクセスすることができない。対象プログラムがこれらの領域にアクセスした場合、障害が発生し、信号が動的バイナリ・トランスレータに送達される。動的バイナリ・トランスレータによるプログラム状態の検査によって、どのアドレスにアクセスされているかが決定され、この時点で信号ハンドラは要求されたアドレスを決定するためにアドレス変換を実行することができる。次に信号ハンドラ内でアクセスがエミュレートされ、動作が完了した対象プログラムに制御が戻される。図4は、アドレス0x4000でどのようにマップが保護されるか、および、信号ハンドラによって0xF00000000のマップの一部104へどのようにアクセスがリダイレクトできるのかを示す。
【0017】
この方法は、多くの場合良好な性能を提供するが、直接アクセスできない領域が非常に頻繁に使用される場合、多くの障害を処理するコストが非常に高くなる。
【先行技術文献】
【特許文献】
【0018】
【特許文献1】米国特許出願公開第2010/0030975A1号
【非特許文献】
【0019】
【非特許文献1】Intel IA−32アーキテクチャ・マニュアル、ボリューム3A、インテル・コーポレーション
【発明の概要】
【発明が解決しようとする課題】
【0020】
したがって、対象コンピューティング環境と目標コンピューティング環境との間でのメモリ管理における相違によって動的バイナリ・トランスレータに課せられる制約を克服する、改良された方法を有することが望ましい。
【課題を解決するための手段】
【0021】
したがって本発明は、第1の態様において、第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、第1のページ・サイズとは異なる第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための、動的バイナリ・トランスレータ装置を提供する。装置は、第1のメモリのメモリ・ページ特性に応じて、第1のメモリの少なくとも1つのアドレスを第2のメモリのアドレスにマッピングするためのリダイレクト・ページ・マッパと、第2のブロックの実行中にメモリ障害を検出し、障害カウントのトリガしきい値までの累算を実行するように動作可能なメモリ障害挙動検出器と、障害カウントがトリガしきい値に達したことに応じて当該第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて当該第1のブロックを再変換済みブロックへと再変換することを実行するように動作可能な再生成コンポーネントを備える。
【0022】
好ましくは、第1のメモリのメモリ・ページ特性はページ保護特性を備える。好ましくは、第1のメモリのメモリ・ページ特性はファイル裏付けメモリ特性を備える。好ましくは、さらに再生成コンポーネントは、第1のメモリの少なくとも1つのアドレスの第2のメモリのアドレスへの当該マッピングが、同じアドレスを戻す場合に、ページ・テーブル・ウォークをバイパスするように動作可能である。好ましくは、さらに再生成コンポーネントは、メモリ・アクセスが、再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、ページ・テーブル・ウォークをバイパスするように動作可能である。
【0023】
第2の態様では、第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータを操作する方法が提供される。第2のページ・サイズは第1のページ・サイズとは異なるものである。方法は、第1のメモリのメモリ・ページ特性に応じて、リダイレクト・ページ・マッパが、第1のメモリの少なくとも1つのアドレスを第2のメモリのアドレスにマッピングするステップと、メモリ障害挙動検出器が、第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算するステップと、障害カウントがトリガしきい値に達したことに応じて、再生成コンポーネントが、第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて当該第1のブロックを再変換済みブロックへと再変換するステップを含む。
【0024】
好ましくは、第1のメモリのメモリ・ページ特性はページ保護特性を備える。好ましくは、第1のメモリのメモリ・ページ特性はファイル裏付けメモリ特性を備える。好ましくは、さらに再生成コンポーネントは、当該第1のメモリの少なくとも1つのアドレスの当該第2のメモリのアドレスへの当該マッピングが、同じアドレスを戻す場合に、当該ページ・テーブル・ウォークをバイパスするように動作可能である。好ましくは、さらに再生成コンポーネントは、メモリ・アクセスが、再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、当該ページ・テーブル・ウォークをバイパスするように動作可能である。
【0025】
第3の態様では、コンピュータ・システムにロードされ、そこで実行された場合、第2の態様に従った方法の諸ステップを当該コンピュータ・システムに実行させるコンピュータ・プログラムが提供される。
【0026】
したがって、本発明の好ましい諸実施形態は、有利なことに、対象コンピューティング環境と目標コンピューティング環境との間でのメモリ管理における相違によって動的バイナリ・トランスレータに課せられる制約を克服する、改良された方法を提供する。
【0027】
次に、本発明の好ましい実施形態について、添付の図面を参照しながら単なる例示として説明する。
【図面の簡単な説明】
【0028】
【図1】従来技術に従った書き込み保護を有する対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図2】従来技術に従ったファイル裏付けおよび匿名メモリを有する対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図3】従来技術に従った書き込み保護を有する対象メモリおよび目標メモリの改良された配置構成を、簡略化された形で示す概略図である。
【図4】従来技術に従ったファイル裏付けおよび匿名メモリを有する対象メモリおよび目標メモリの改良された配置構成を、簡略化された形で示す概略図である。
【図5】本発明の好ましい実施形態に従った物理コンポーネントまたは論理コンポーネントの装置または配置構成を、簡略化された形で示す概略図である。
【図6】本発明の好ましい実施形態に従ったシステムの操作方法を示す、流れ図である。
【図7】本発明の好ましい実施形態の実装に好適な対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図8】本発明の好ましい実施形態に従った対象メモリおよび目標メモリの配置構成を、簡略化された形で示す概略図である。
【図9】本発明の好ましい実施形態に従った例示的ページ・マップ構造を、簡略化された形で示す概略図である。
【図10】本発明の好ましい実施形態に従った他の例示的ページ・マップ構造を、簡略化された形で示す概略図である。
【発明を実施するための形態】
【0029】
図5には、本発明の好ましい実施形態に従った物理コンポーネントまたは論理コンポーネントの装置または配置構成が簡略化された概略図の形で示されている。図5では、第1のページ・サイズの第1のメモリ506を有する対象実行環境504における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロック502を、第2のページ・サイズの第2のメモリ512を有する第2の実行環境510における実行のための少なくとも1つの第2のブロック508へと変換するための、動的バイナリ・トランスレータ装置500が示されている。第2のページ・サイズは第1のページ・サイズとは異なるものである。動的バイナリ・トランスレータ装置500は、第1のメモリ506のメモリ・ページ特性に応答して、第1のメモリ506の少なくとも1つのアドレスを第2のメモリ512のアドレスにマッピングするためのリダイレクト・ページ・マッパ514を備える。加えて、動的バイナリ・トランスレータ装置500は、第2のブロック508の実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算することを実行するように動作可能なメモリ障害挙動検出器516と、障害カウントがトリガしきい値に達したことに応じて、第2のブロック508を廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて第1のブロック502を第2のブロック508の再変換済みバージョンへと再変換することを実行するように動作可能な再生成コンポーネント518を備える。
【0030】
本発明の好ましい実施形態に従うシステムに関して見てきたが、次に、本発明の好ましい実施形態に従った動的バイナリ・トランスレータの操作方法をフローチャートの形式で示した図6に目を向けてみる。
【0031】
図6では、第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータ装置を操作する方法の諸ステップが示されている。第2のページ・サイズは当該第1のページ・サイズとは異なるものである。開始ステップ600で開始され、第1のメモリのメモリ・ページ特性を決定するステップ602と、リダイレクト・ページ・マッパによって、当該第1のメモリの少なくとも1つのアドレスを当該第2のメモリのアドレスにマッピングするステップ604とを含む。ステップ606では、メモリ障害挙動検出器が、第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算する。ステップ608では、障害カウントがトリガしきい値に達したことに応答して、動的バイナリ・トランスレータの再生成コンポーネントが第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて第1のブロックを第2のブロックの再変換済みバージョンへと再変換する。このプロセスは終了ステップ610で終了する。
【0032】
したがって提案された機構は、ハードウェア、ソフトウェア、またはハードウェアおよびソフトウェアの組み合わせのいずれで具体化されるかに関わらず、追加のオペレーティング・システムの修正を必要とすることなく、幅広い領域のアプリケーションの動作について良好な性能特性を提供する単一の目標ページ・サイズ領域内でのマップ・タイプの混合をサポートするための手段を提供する。
【0033】
対象プログラム・マッピング要求は、可能であれば要求された場所において提供される。すなわち、単一のマップ・タイプのみが要求され、満たされていない可能性のあるファイル・オフセット制約がない場合、マップは対象アクセス可能メモリ内に直接配置され、いかなる追加のアドレス変換も不要である。こうした直接マッピングが不可能な場合、マップは、動的バイナリ・トランスレータによってアクセス可能であるが対象プログラムによっては直接アクセス不可能なメモリの好適な領域内に配置される。次に、対象可視アドレス・スペースの対応部分がアクセス不可としてマーク付けされる。結果としてアクセスは障害(fault)となる。かかる領域へのアクセスが実行された場合、障害が処理されて正しいアクセスが信号ハンドラによって実行される。
【0034】
第1の好ましい実施形態では、観察されたアプリケーションの動作に基づく、障害処理からページ・テーブル・ルックアップへのモード切換え手段が提供される。短期間に多数の障害が見られた場合、トランスレータは自ら生成したすべての実行可能コードを破棄し、各アクセスについてページ・テーブル・ウォークを実行するコードの生成を開始する。これによって目標仮想アドレス・スペース内の適切な位置へとアドレスを変換することになる。障害処理機構は、必要であれば依然として有効であることに留意されたい。ページ・テーブルは、対象アドレスから適切な目標アドレスへのマッピングを提供するトランスレータによって生成される。
【0035】
他の好ましい実施形態では、ルックアップ・オーバヘッドを減らすために、ほぼ線形の対象アドレスから目標アドレスへのマッピングを用いた部分的なページ・テーブル・ウォークを使用するための手段が提供可能である。最適化の例として、ページ・テーブルは変換が必要なページについてのみ記入され、ページ・テーブル内の他のエントリはemptyとしてマーク付けされる。このようなエントリに遭遇した場合、ルックアップは早期に停止し、オリジナルの未変換アドレスが使用される。ページ・テーブル自体の使用は当技術分野で知られているが、ほとんどのアドレスが変換なしに直接マッピングし、ショートカット・パスが使用可能なページ・テーブルの使用は、既知の技術分野における有利な改良である。
【0036】
他の最適化として、アクセス・タイプの静的変換時評価に基づいた、ページ・ルックアップ・オーバヘッドからのアクセス除外のための手段が提供される。この最適化では、アドレス変換が必要な可能性が低いとみなされるアクセスは、ページ・テーブル・ルックアップなしに実行可能であり、たとえばスタックへのアクセスはコード変換時に容易に検出可能であり、ファイル裏付けマップまたは共有メモリへのアクセスが必要な可能性は低い。
【0037】
一代替実施形態では、アクセス・モードをアクセスごとに切り換えるための手段を提供する。この最適化では、すべてのコードはページ・テーブル・ルックアップなしに生成可能であり、コードの個々のブロックは、それらのアドレスで障害が観察された場合にルックアップを含めるように再生成することができる。
【0038】
他の代替実施形態は、アドレス・ルックアップが必要な時点を決定するために、低コスト・ランタイム・フィルタとしてのマスクされたアドレスの比較を提供する。この代替手法では、可変ビット・マスクを使用し、各アドレスにマスクを適用し、既知の値と比較して、ルックアップが必要であることがわかっている領域内にそのアドレスが存在するかどうかを決定することによって、アドレス変換が必要となるアクセスをフィルタリングすることが可能である。
【0039】
本発明の細部は、以下で詳細に説明するような、本明細書の図7および図8に示された作業例に最も良く表されている。説明のために、対象ページ・サイズは4k、目標ページ・サイズは64kであるものと仮定されている。ページ保護は、Power Linux上に提供されるsubpage_protシステムコールなどの機能を使用して、4k粒度で適用可能であることが想定されている。しかしこうした機能が使用できなかった場合、前述のような保護のソフトウェア実装を代わりに使用することができる。当業者であれば、本発明の諸実施形態による同様に有利な方法で、多くの他のページ・サイズ特性が取扱い可能であることは明らかであろう。
【0040】
図7を見ると、例示的な対象ページ・マップ100および例示的な目標ページ・マップ102が示されている。まず初めに、対象プログラムのバイナリ700、動的リンカ702、スタック704、およびヒープ706がマッピングされる。動的バイナリ・トランスレータによってプログラムが実行されると、1つまたは複数のランタイム・ライブラリ708もマッピングされる。この例では、これらのマッピングはすべて直接実行可能であり、本発明の好ましい諸実施形態が提供する特別な機構は不要である。
【0041】
対象プログラムで遭遇する各命令に対して、トランスレータは目標アーキテクチャ上で実行可能な等価命令を生成し、ロードおよび格納のために特別なアドレス操作は一切実行されず、メモリには直接アクセスされる。次に、対象プログラムは0x10000000で匿名メモリのページにマッピングし、アドレス0x10001000のファイル裏付けメモリのページが後に続く。目標オペレーティング・システムはこのマッピングをサポートできないため、トランスレータはファイル裏付けメモリをアドレス・スペースの異なる部分に配置し、0x10001000のページをアクセス不可としてマーク付けしなければならない。この状況が図8に示されている。
【0042】
アドレス0x10001000のページにアクセスしようとすると障害が受信され、トランスレータはこれを受け取って、0xF00000000でのマッピング104内にアクセスするための正しいアドレスを計算し、そのアドレスでのアクセスを実行する。
【0043】
したがって第1の好ましい実施形態では、観察されたアプリケーションの動作に基づく、障害処理からページ・テーブル・ルックアップへの動的モード切り換えのための方法および装置が提供される。0x10001000のこのファイル裏付けマップに対して多くのアクセスが実行された場合、障害ハンドラにおけるこれらの障害の処理および適切なアドレス変換実行のコストが、アプリケーションの性能を支配することになる。このようにアクセスを実行するコストは、障害処理のコストを含め、メモリに直接アクセスするよりも2倍から3倍となる可能性があることに留意されたい。各障害を受信した時点で、トランスレータは障害の合計数を記録し、かなり多くの数が受信された場合、または所与の期間内にかなり高い率で障害が観察された場合、トランスレータは、障害のコストを避けるためにアドレス変換が各アクセスについてランタイム時に実行される、異なる動作モードに切り換えることができる。トランスレータは、対象アドレスを目標アドレスにマッピングするページ・テーブルを生成する。ほとんどのアドレスでは、ほとんどのマップが依然として等価の場所にマッピングされるように、ページ・テーブルは実際に対象アドレスを同じ目標アドレスへと再マッピングすることになる。しかし、問題のファイル・アクセスの場合、ページ・テーブルは0xF00000000に相対的な目標アドレスへとアドレスをマッピングすることになる。ページ・テーブルは、前述のマニュアルで説明されているような、Intel IA−32アーキテクチャによって使用されるページ・テーブルと同様に構築可能である。しかし、ページ保護は依然としてオペレーティング・システムの既存の機能を使用して処理できるため、このページ・テーブルはマップの保護に関する情報を記録する必要がない。アクセスされることになるアドレスが0x1000101Cの場合、ページ・テーブルの関連部分は図9に示されるようになる。
【0044】
ここではすべての生成されたコードが廃棄され、再生成されるが、各対象のロードまたは格納のための単純なロードまたは格納命令を生成する代わりに、正しいアドレスを計算するためのページ・テーブル・ルックアップが生成される。コードの例示的実施形態では、対象命令については以下のようなものとなる。
loadb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
そして結果として、以下のような目標命令シーケンスが生じる。
add r12,r2,r3 #2つのアドレス・レジスタを追加することによって対象アドレスを計算する
sr r13,r12,22 #アドレスの上位10ビットを取得する
sl r13,r12,3 #8倍することによってインデックスを第1レベルのテーブルに入れる(各エントリは8バイト・アドレスである)
ld r13,r13(r30) #第1レベルのページ・テーブルからアドレスをロードする(r30はここでは第1レベルのテーブルのアドレスを含む)
sr r14,r12,12 アドレスの上位20ビットを取得する
and r14,r14,0x3ff #アドレスの次の10ビットを取得し、インデックスを第2レベルのテーブルに入れる
sl r14,r14,3 #8倍することによってインデックスを第2レベルのテーブルに入れる
ld r15,r13,r14 #第2レベルのテーブルからページ・アドレスをロードする
and r16,r13,0xfff #対象アドレスからオフセットをページに入れる
lb r1,r15,r16 #新規ページ・アドレスからロードする+ページのオフセット
【0045】
必要な追加のチェック回数を減らすため、マッピングされていないページがあれば、それらのページ・テーブル・エントリをメモリの既知のマッピングされていない領域に向けて送ることが可能である。その結果として適切な障害が生成されることになる。ページ境界をまたがっているアドレスを処理するために、このシーケンスでは何らかの追加の命令が必要となる場合がある。
【0046】
一実施形態では、ルックアップ・オーバヘッドを減らすために、対象アドレスから目標アドレスへのほぼ線形のマッピングを利用した、部分的なページ・テーブル・ウォークが実装可能である。もちろん、対象から目標への完全なマッピングが提供される場合、前述のスキームを利用して目標マップを任意の位置に配置することが可能である。しかし、ほとんどの場合、要求された対象アドレスと同一の目標アドレスにアドレスをマッピングすることが可能であるものと考えると、ほとんどの場合、ルックアップは単に同じアドレスを戻すことになる。これにより、第1レベルのテーブルのみの即時チェックを優先して、全体ルックアップをバイパスできるようにする最適化が使用可能である。このスキームでは、第1レベルのページ・テーブル内の単一エントリによってカバーされているアドレスの全領域(前述のスキームでは4MBの領域)が、いかなる特別な処理も必要としない場合、第1レベルのテーブル内のエントリは、次のテーブルを示すポインタではなく特別なマーカ値を含むことができる。第1レベルのテーブルからのアドレスがロードされると、この値が見つかった場合、残りのルックアップは打ち切られ、代わりにオリジナル・アドレスが使用される。これに関する例示的なコード・シーケンスが以下に示される。
【0047】
例示的なコード例では、対象命令について以下のようなものとなる。
loadb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
そして結果として、以下のような目標命令シーケンスが生じる。
add r12,r2,r3 #2つのアドレス・レジスタを追加することによって対象アドレスを計算する
sr r13,r12,22 #アドレスの上位10ビットを取得する
sl r13,r12,3 #8倍することによってインデックスを第1レベルのテーブルに入れる(各エントリは8バイト・アドレスである)
ld r13,r13(r30) #第1レベルのページ・テーブルからアドレスをロードする(r30はここでは第1レベルのテーブルのアドレスを含む)
cmp r13,0 #ゼロと比較する(ゼロはここでは「empty」マーカ値として使用される)
beq normal #等しい場合、標準ロードへと分岐する
sr r14,r12,12 アドレスの上位20ビットを取得する
and r14,r14,0x3ff #アドレスの次の10ビットを取得し、インデックスを第2レベルのテーブルに入れる
sl r14,r14,3 #8倍することによってインデックスを第2レベルのテーブルに入れる
ld r15,r13,r14 #第2レベルのテーブルからページ・アドレスをロードする
and r16,r13,0xfff #対象アドレスからオフセットをページに入れる
lb r1,r15,r16 #新規ページ・アドレスからロードする+ページのオフセット
b end #標準ロードを過ぎて分岐する
normal:
lb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
end:
【0048】
共通パスで使用される命令には下線が付けられている。また、この最適化によって回避されるものはイタリック体で示されている。ここでは共通のケースでいくつかの命令が省略され、結果として大多数のアクセスがアドレス変換を必要としない場合、全体の性能が向上することになる。
【0049】
図10は、システムがアドレス0xc0110040にアクセスしている場合、ページ・テーブルがこの状況でどのようなものと見えるかの一例を示している。
【0050】
他の拡張機能では、アクセス・タイプの静的変換時評価に基づいた、ページ・ルックアップ・オーバヘッドからの一定のアクセス除外のための手段が提供可能である。
【0051】
いくつかの対象アーキテクチャでは、アーキテクチャ上の機能または共通の規則により、命令の静的検査に基づいて、メモリ・アクセスの予期される特性を識別することが可能となる。たとえばIA−32命令セットでは、プッシュ命令およびポップ命令を使用してスタックにアクセスすることができる。加えて、ESPレジスタは現行のスタック・ポインタとしてほぼ独占的に維持されるが、EBPはしばしば現行のスタック・フレームのトップを指示するために使用される。いくつかのオペレーティング・システムおよび環境では、これらのような特性を使用して、アドレス変換を必要とする可能性が低いとみなされるアクセスからアドレス変換を除去することができる。IA−32アプリケーションの変換の場合、スタックはファイルが裏付けされるかまたは他のプロセスと共用される可能性が低いため、さらにはスタックの正確な位置およびサイズはしばしばトランスレータ自体の制御下にあるため、スタック・アクセスがアドレス変換を必要とする可能性が非常に低い旨をアサートできる可能性がある。したがって、ESPまたはEBPに基づくアクセスに関してページ・テーブル・ルックアップを据え付けないことを選択することで、アドレス変換オーバヘッドの大幅な節減が達成可能である。他のアーキテクチャについても同様の規則が存在する。
【0052】
フェイルセーフとしてオリジナルの信号処理コードが保持され、ルックアップが生成されないいずれのアクセスも障害となり、ともかく正しく処理されることになる。
【0053】
いずれかのルックアップが据え付けられる前に障害となったトランスレータに各対象命令のアドレスを記録させることによって、他の改良を使用することができる。ルックアップが必要であることが決定された場合、障害となったことがわかっているアドレスに対してのみルックアップを据え付けることができる。実行が継続される場合、必要に応じて特定の命令シーケンスに対してコードを再生成することにより、障害が見られる命令にルックアップが追加される。これによって最小限のルックアップが生成されることが保証され、要求された位置にマッピングされていないメモリには決してアクセスしないコードについて高性能が保証される。アプリケーションの挙動は経時的に変化しやすいため、すべてのルックアップ・コードを定期的に除去し、プロファイリングを再始動することも有用な可能性があり、それによってもはやルックアップを必要としないコードが性能を犠牲にし続けることのないように保証される。
【0054】
代替のフィルタリング機構として、変換が必要な通常アクセスされるアドレスの範囲が狭く、隣接している場合、マスクおよび比較動作を使用することができる。前述の例では、単一のページのみがアドレス変換を要求した。こうした状況が存在する場合は必ず、単にアドレスをマスキングし、特定のビット値と比較することによって、より最適なアドレス・フィルタリング手法を採用することができる。現在使用されているマスクおよび値は、追加のロード命令の生成を避けるためにレジスタ内に維持することができる。この最適化に関する例示的なコード・シーケンスが、対象命令について以下のように示される。
loadb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
そして結果として、以下のような目標命令シーケンスが生じる。
add r12,r2,r3 #2つのアドレス・レジスタを追加することによって対象アドレスを計算する
and r13,r12,r29 #アドレスをr29の値(現在のアドレス・マスク値)でマスキングする
cmp r13,r28 #この結果をr28の値(現在んアドレス比較値)と比較する
bne normal #値が一致しない場合、変換は不要であるものと仮定する
sr r13,r12,22 #アドレスの上位10ビットを取得する
sl r13,r12,3 #8倍することによってインデックスを第1レベルのテーブルに入れる(各エントリは8バイト・アドレスである)
ld r13,r13(r30) #第1レベルのページ・テーブルからアドレスをロードする(r30はここでは第1レベルのテーブルのアドレスを含む)
sr r14,r12,12 アドレスの上位20ビットを取得する
and r14,r14,0x3ff #アドレスの次の10ビットを取得し、インデックスを第2レベルのテーブルに入れる
sl r14,r14,3 #8倍することによってインデックスを第2レベルのテーブルに入れる
ld r15,r13,r14 #第2レベルのテーブルからページ・アドレスをロードする
and r16,r13,0xfff #対象アドレスからオフセットをページに入れる
lb r1,r15,r16 #新規ページ・アドレスからロードする+ページのオフセット
b end #標準ロードを過ぎて分岐する
normal:
lb r1,r2(r3) #アドレス(r2+r3)からバイトをロードし、結果をr1内に配置する
end:
【0055】
共通パスで使用される命令には下線が付けられている。また、この最適化によって回避されるものはイタリック体で示されている。ここでは共通のケースでいくつかの命令が省略され、結果として大多数のアクセスがアドレス変換を必要としない場合、全体の性能が向上することになる。
【0056】
実行が進行し、メモリ・マップが変更された場合、それに応じて現在のマスクおよびアドレス比較値も更新することができる。
【0057】
当業者であれば、本発明の好ましい諸実施形態の方法のすべてまたは一部が、方法の諸ステップを実行するように配置構成された論理要素を備える1つの論理装置または複数の論理装置内で好適かつ有用に具体化可能であること、および、こうした論理要素がハードウェア・コンポーネント、ファームウェア・コンポーネント、またはそれらの組み合わせを備えることが可能であることが明らかとなろう。
【0058】
当業者であれば、本発明の好ましい諸実施形態に従った論理配置構成のすべてまたは一部が、方法の諸ステップを実行するための論理要素を備える論理装置内で好適に具体化可能であること、および、こうした論理要素が、たとえばプログラム可能論理アレイまたは特定用途向け集積回路内の論理ゲートなどのコンポーネントを備えることが可能であることが、等しく明らかとなろう。さらにこうした論理配置構成は、たとえば固定または伝送可能なキャリア媒体を使用して格納および伝送可能な仮想ハードウェア記述子言語を使用するアレイまたは回路内などに、一時的または永続的に論理構造を確立するための実行可能要素内で具体化することができる。
【0059】
前述の方法および配置構成が、1つまたは複数のプロセッサ(図示せず)上で実行中のソフトウェア内で完全または部分的に好適に実施可能であること、および、ソフトウェアが、磁気または光ディスクなどの任意の好適なデータ・キャリア(同じく図示せず)上で搬送される1つまたは複数のコンピュータ・プログラム要素の形で提供可能であることを理解されよう。データ伝送のためのチャネルは、同様に、すべての記述のストレージ媒体ならびに有線または無線の信号搬送媒体などの信号搬送媒体を備えることができる。
【0060】
一般に、方法は、所望の結果を導く首尾一貫したステップ・シーケンスであるものと考えられる。これらのステップは、物理量の物理操作を必要とする。通常、これらの量は、格納、転送、結合、比較、およびその他の操作が実行されることが可能な電気信号または磁気信号の形を取るが、その限りではない。時には、主として一般的な用法の理由で、これらの信号をビット、値、パラメータ、アイテム、要素、オブジェクト、シンボル、文字、項、数などと言い表すことが便利である。しかし、これらのすべての用語および同様の用語は適切な物理量に関連付けられるものであり、これらの量に適用される単なる便利なラベルであることに留意されたい。
【0061】
さらに本発明は、コンピュータ・システムと共に使用するためのコンピュータ・プログラム製品としても好適に具体化することができる。こうした実装は、たとえばディスケット、CD−ROM、ROM、またはハード・ディスクのようなコンピュータ読み取り可能媒体などの有形媒体上に固定されるか、あるいは、光またはアナログの通信回線を含むがこれらに限定されない有形媒体を介して、または、マイクロ波、赤外線、または他の伝送技法を含むがこれらに限定されない無線技法を使用して無形に、モデムまたは他のインターフェース・デバイスを通じてコンピュータ・システムに伝送可能である、一連のコンピュータ読み取り可能命令を備えることができる。一連のコンピュータ読み取り可能命令は、本明細書で前述した機能のすべてまたは一部を具体化する。
【0062】
当業者であれば、こうしたコンピュータ読み取り可能命令が、多くのコンピュータ・アーキテクチャまたはオペレーティング・システムと共に使用するためのいくつかのプログラミング言語で作成可能であることを理解されよう。さらに、こうした命令は、半導体、磁気、または光を含むがこれらに限定されない、現行または将来の任意のメモリ技術を使用して格納すること、あるいは、光、赤外線、またはマイクロ波を含むがこれらに限定されない、現行または将来の任意の通信技術を使用して伝送することが、可能である。こうしたコンピュータ・プログラム製品は、たとえばパッケージ・ソフトウェアなどの印刷文書または電子文書が添付された取り外し可能媒体として配布されること、コンピュータ・システムのたとえばシステムROMまたは固定ディスク上に事前ロードされること、あるいは、たとえばインターネットまたはワールド・ワイド・ウェブなどのネットワークを介してサーバまたは電子掲示板から配布されることが、可能であることが企図される。
【0063】
他の代替実施形態では、本発明の好ましい実施形態は機能データをその上に有するデータ・キャリアの形で実現可能であり、当該機能データは、コンピュータ・システムにロードされ、コンピュータ・システムによって動作された場合、当該コンピュータ・システムが方法のすべてのステップを実行可能とするための機能コンピュータ・データ構造を備える。
【0064】
当業者であれば、本発明の範囲を逸脱することなく、前述の例示的実施形態に対する多くの改良および修正が実行可能であることが明らかとなろう。
【符号の説明】
【0065】
500 動的バイナリ・トランスレータ
502 対象ブロック
504 対象環境
506 対象メモリ
508 目標ブロック
510 目標環境
512 目標メモリ
514 ページ・マッパ
516 障害検出器
518 再生成器
【特許請求の範囲】
【請求項1】
第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、前記第1のページ・サイズとは異なる第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータ装置であって、
前記第1のメモリのメモリ・ページ特性に応じて、前記第1のメモリの少なくとも1つのアドレスを前記第2のメモリのアドレスにマッピングするためのリダイレクト・ページ・マッパと、
前記第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算することを実行するように動作可能なメモリ障害挙動検出器と、
前記障害カウントが前記トリガしきい値に達したことに応じて、前記第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて前記第1のブロックを再変換済みブロックへと再変換することを実行するように動作可能な再生成コンポーネントと、
を備える、装置。
【請求項2】
前記第1のメモリの前記メモリ・ページ特性がページ保護特性を備える、請求項1に記載の装置。
【請求項3】
前記第1のメモリの前記メモリ・ページ特性がファイル裏付けメモリ特性を備える、請求項1または2に記載の装置。
【請求項4】
さらに前記再生成コンポーネントが、前記第1のメモリの少なくとも1つのアドレスの前記第2のメモリのアドレスへの前記マッピングが同じアドレスを戻す場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、前記請求項のいずれか一項に記載の装置。
【請求項5】
さらに前記再生成コンポーネントが、メモリ・アクセスが再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、前記請求項のいずれか一項に記載の装置。
【請求項6】
第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、前記第1のページ・サイズとは異なる第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータを操作する方法であって、
リダイレクト・ページ・マッパが、前記第1のメモリのメモリ・ページ特性に応じて、前記第1のメモリの少なくとも1つのアドレスを前記第2のメモリのアドレスにマッピングするステップと、
メモリ障害挙動検出器が、前記第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算するステップと、
再生成コンポーネントが、前記障害カウントが当該トリガしきい値に達したことに応じて、前記第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて前記第1のブロックを再変換済みブロックへと再変換するステップと、
を含む、方法。
【請求項7】
前記第1のメモリのメモリ・ページ特性がページ保護特性を備える、請求項6に記載の方法。
【請求項8】
前記第1のメモリのメモリ・ページ特性がファイル裏付けメモリ特性特徴を備える、請求項6または7に記載の方法。
【請求項9】
さらに前記再生成コンポーネントが、前記第1のメモリの少なくとも1つのアドレスの前記第2のメモリのアドレスへの前記マッピングが同じアドレスを戻す場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、請求項6から8のいずれか一項に記載の方法。
【請求項10】
さらに前記再生成コンポーネントが、メモリ・アクセスが再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、請求項6から9のいずれか一項に記載の方法。
【請求項11】
請求項6から10のいずれか一項に記載の方法のステップをコンピュータに実行させる、コンピュータ・プログラム。
【請求項1】
第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、前記第1のページ・サイズとは異なる第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータ装置であって、
前記第1のメモリのメモリ・ページ特性に応じて、前記第1のメモリの少なくとも1つのアドレスを前記第2のメモリのアドレスにマッピングするためのリダイレクト・ページ・マッパと、
前記第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算することを実行するように動作可能なメモリ障害挙動検出器と、
前記障害カウントが前記トリガしきい値に達したことに応じて、前記第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて前記第1のブロックを再変換済みブロックへと再変換することを実行するように動作可能な再生成コンポーネントと、
を備える、装置。
【請求項2】
前記第1のメモリの前記メモリ・ページ特性がページ保護特性を備える、請求項1に記載の装置。
【請求項3】
前記第1のメモリの前記メモリ・ページ特性がファイル裏付けメモリ特性を備える、請求項1または2に記載の装置。
【請求項4】
さらに前記再生成コンポーネントが、前記第1のメモリの少なくとも1つのアドレスの前記第2のメモリのアドレスへの前記マッピングが同じアドレスを戻す場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、前記請求項のいずれか一項に記載の装置。
【請求項5】
さらに前記再生成コンポーネントが、メモリ・アクセスが再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、前記請求項のいずれか一項に記載の装置。
【請求項6】
第1のページ・サイズの第1のメモリを有する対象実行環境における実行を目的としたバイナリ・コンピュータ・コードの少なくとも1つの第1のブロックを、前記第1のページ・サイズとは異なる第2のページ・サイズの第2のメモリを有する第2の実行環境における実行のための少なくとも1つの第2のブロックへと変換するための動的バイナリ・トランスレータを操作する方法であって、
リダイレクト・ページ・マッパが、前記第1のメモリのメモリ・ページ特性に応じて、前記第1のメモリの少なくとも1つのアドレスを前記第2のメモリのアドレスにマッピングするステップと、
メモリ障害挙動検出器が、前記第2のブロックの実行中にメモリ障害を検出し、障害カウントをトリガしきい値まで累算するステップと、
再生成コンポーネントが、前記障害カウントが当該トリガしきい値に達したことに応じて、前記第2のブロックを廃棄し、ページ・テーブル・ウォークにより再マッピングされたメモリ参照を用いて前記第1のブロックを再変換済みブロックへと再変換するステップと、
を含む、方法。
【請求項7】
前記第1のメモリのメモリ・ページ特性がページ保護特性を備える、請求項6に記載の方法。
【請求項8】
前記第1のメモリのメモリ・ページ特性がファイル裏付けメモリ特性特徴を備える、請求項6または7に記載の方法。
【請求項9】
さらに前記再生成コンポーネントが、前記第1のメモリの少なくとも1つのアドレスの前記第2のメモリのアドレスへの前記マッピングが同じアドレスを戻す場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、請求項6から8のいずれか一項に記載の方法。
【請求項10】
さらに前記再生成コンポーネントが、メモリ・アクセスが再マッピングを必要としないタイプのメモリへのメモリ・アクセスとして識別される場合に、前記ページ・テーブル・ウォークをバイパスするように動作可能である、請求項6から9のいずれか一項に記載の方法。
【請求項11】
請求項6から10のいずれか一項に記載の方法のステップをコンピュータに実行させる、コンピュータ・プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2012−104104(P2012−104104A)
【公開日】平成24年5月31日(2012.5.31)
【国際特許分類】
【出願番号】特願2011−217087(P2011−217087)
【出願日】平成23年9月30日(2011.9.30)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MASCHINES CORPORATION
【Fターム(参考)】
【公開日】平成24年5月31日(2012.5.31)
【国際特許分類】
【出願日】平成23年9月30日(2011.9.30)
【出願人】(390009531)インターナショナル・ビジネス・マシーンズ・コーポレーション (4,084)
【氏名又は名称原語表記】INTERNATIONAL BUSINESS MASCHINES CORPORATION
【Fターム(参考)】
[ Back to top ]