
医用同義語辞書作成装置および医用同義語辞書作成方法
【課題】読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成する医用同義語辞書作成装置を提供する。
【解決手段】同義語判定部120は、(i)読影レポートに基づいて、キーワード対が同義語であるか否かを判定し、(ii)各画像特徴量とキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、キーワード対を構成するキーワードの作成の基となった医用画像から算出した各画像特徴量に対して重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、キーワード対に対する2つの画像特徴量ベクトルを比較することにより、キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する。
【解決手段】同義語判定部120は、(i)読影レポートに基づいて、キーワード対が同義語であるか否かを判定し、(ii)各画像特徴量とキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、キーワード対を構成するキーワードの作成の基となった医用画像から算出した各画像特徴量に対して重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、キーワード対に対する2つの画像特徴量ベクトルを比較することにより、キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、読影レポートにおける医用同義語辞書を自動的に作成する医用同義語辞書作成装置および医用同義語辞書作成方法に関する。
【背景技術】
【0002】
近年、画像診断の分野では撮影画像および読影レポートのデジタル化が進み、医師が大量のデータを共有することが容易になっている。ここで、読影レポートとは、撮影画像に対して読影者が下した診断を示すテキスト情報のことである。つまり、読影レポートは、医用画像を読影した結果が記載された文書データである。また、画像を保管および通信するシステムであるPACS(Picture Archiving and Communication Systems)内に保管されている読影レポート同士は、共通のIDやキーワードで互いに紐付けされて管理されており、保管されている過去の読影レポートの有効な二次利用が求められている。
【0003】
読影レポートの有効な二次利用の一つとしては、レポートのテキスト検索が挙げられる。一般的なテキスト検索では、検索キーワードと同じキーワードを持つ読影レポートを検索結果として出力するが、同じ意味を持ちながら異なる表記がされているレポートについては検索結果から外れてしまうという問題が存在する。そのため、より汎用性の高いテキスト検索を実現するためには、同じ意味を持つキーワード同士を結びつける同義語辞書の作成が必須になる。
【0004】
このような同義語辞書を作成する従来技術として、特許文献1では、「人名に対応する顔画像は一意に決まる」ことを利用し、ウェブ上のドキュメントから様々な表記の人名と、その人名が付与された顔画像を抽出し、類似した顔画像に付与された人名を全て同義語(別名)として登録する方法が提案されている。この方法では画像の類似性に基づいた同義語処理を行っており、テキスト情報だけを用いた処理よりも、より精度の高い同義語辞書を作成することができる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2010−128926号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかし、特許文献1に記載の方法を画像診断分野における読影レポートに適用した場合、キーワードごとに関連する画像特徴量が異なるため、単純に画像の類似性を用いるだけでは、キーワード間の正しい同義語関係を判定できないという課題がある。
【0007】
例えば、肝腫瘤の画像に対して付与された「辺縁明瞭」というキーワードはエッジ等の形状に関する画像特徴量と関係しているが、濃度に関する画像特徴量とは関係しない。一方、「高吸収」というキーワードは濃度に関する画像特徴量と関係しているが、形状に関する画像特徴量とは関係しない。このため、「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する際、形状と濃度に関する画像特徴量の値をそのまま用いると、「辺縁明瞭」とは関係のない濃度に関する画像特徴量、また、「高吸収」とは関係のない形状に関する画像特徴量が、それぞれ画像の類似判定に含まれてしまう。よって、画像の類似性を正しく評価することができない。そのため、読影レポートにおいて画像を用いてキーワード間の同義語関係を判定するためには、画像特徴量の中からキーワードに関連する画像特徴量を適切に選択する必要がある。
【0008】
本発明は、上記課題を解決するためになされたものであり、キーワードに適合する画像特徴量を選択することにより、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成する医用同義語辞書作成装置および医用同義語辞書作成方法を提供することを目的とする。
【課題を解決するための手段】
【0009】
上記課題を解決するために、本発明のある局面に係る医用同義語辞書作成装置は、医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得部と、医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得部が取得した読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出部と、前記キーワード抽出部が抽出したキーワードからキーワード対を選択するキーワード対選択部と、前記キーワード対選択部が選択したキーワード対が同義語であるか否かを判定する同義語判定部と、前記同義語判定部が同義語であると判定したキーワード対を、医用同義語辞書に含まれる同義語として出力する出力部とを備え、前記同義語判定部は、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する。
【0010】
この構成によると、読影レポートに基づいた同義語判定と、医用画像から抽出される画像特徴量に基づいた同義語判定とを行っている。後者については、医用画像から抽出される各画像特徴量について、読影レポートに記載されているキーワードとの間の関連性が高いものほど大きな重みで重み付けを行った上で、重み付けされた画像特徴量同士を比較している。このため、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成することができる。
【0011】
なお、本発明は、このような特徴的な処理部を備える医用同義語辞書作成装置として実現することができるだけでなく、医用同義語辞書作成装置に含まれる特徴的な処理部が実行する処理をステップとする医用同義語辞書作成方法として実現することができる。また、医用同義語辞書作成装置が備える特徴的な処理部としてコンピュータを機能させるためのプログラムとして実現することもできる。また、医用同義語辞書作成方法に含まれる特徴的なステップをコンピュータに実行させるプログラムとして実現することもできる。そして、そのようなプログラムを、CD−ROM(Compact Disc−Read Only Memory)等のコンピュータ読取可能な不揮発性の記録媒体やインターネット等の通信ネットワークを介して流通させることができるのは、言うまでもない。
【発明の効果】
【0012】
本発明によると、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成することができる。
【図面の簡単な説明】
【0013】
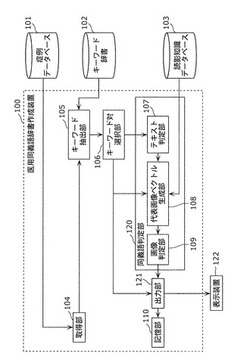
【図1】本発明の実施の形態1における、医用同義語辞書作成装置の特徴的な機能構成を示すブロック図
【図2】本発明の実施の形態1における、症例データベースに記憶されている症例データの一例を示す図
【図3】本発明の実施の形態1における、キーワード辞書の一例を示す図
【図4】本発明の実施の形態1における、読影知識作成の手順を示すフローチャート
【図5】本発明の実施の形態1における、画像特徴量抽出の手順を示すフローチャート
【図6】本発明の実施の形態1における、腹部CT検査の読影レポートの例を示す図
【図7】本発明の実施の形態1における、読影レポートから抽出された読影項目および疾病名を示す図
【図8】本発明の実施の形態1における、読影レポートから抽出された読影項目および疾病名、及び、読影項目と同時に抽出された位置と時相の情報を示す図
【図9】本発明の実施の形態1における、読影レポートから抽出された読影項目および疾病名、及び、文脈解釈を行って読影項目と同時に抽出された位置と時相の情報を示す図
【図10】本発明の実施の形態1における、読影知識抽出のために取得したデータ一式を示す図
【図11】本発明の実施の形態1における、読影項目と画像特徴量との間の相関関係(二値)の概念図
【図12】本発明の実施の形態1における、読影項目と画像特徴量との間の相関関係(多値)の概念図
【図13】本発明の実施の形態1における、疾病名と画像特徴量との間の相関関係(二値)の概念図
【図14】本発明の実施の形態1における、読影項目と疾病名との間の相関関係(二値)の概念図
【図15】本発明の実施の形態1における、読影知識として抽出した(画像特徴量−読影項目)間の相関関係の格納形式を示す図
【図16】本発明の実施の形態1における、読影知識として抽出した(画像特徴量−疾病名)間の相関関係の格納形式を示す図
【図17】本発明の実施の形態1における、読影知識として抽出した(読影項目−疾病名)間の相関関係の格納形式を示す図
【図18】本発明の実施の形態1における、医用同義語辞書作成装置が実行する全体的な処理の流れを示すフローチャート
【図19】本発明の実施の形態1における、キーワード抽出処理(図18のステップS302)の出力例を示す図
【図20】本発明の実施の形態1における、同義語判定処理(図18のステップS303)に用いるキーワードベクトルの概念図
【図21】本発明の実施の形態1における、代表画像ベクトル生成処理(図18のステップS305)の詳細な処理の流れの一例を示すフローチャート
【図22】本発明の実施の形態1における、代表画像ベクトル生成処理(図18のステップS305)の詳細な処理の流れの一例を示すフローチャート
【図23】本発明の実施の形態1の変形例に係る医用同義語辞書作成装置の特徴的な機能構成を示すブロック図
【図24】本発明の実施の形態2における、医用同義語辞書作成装置の特徴的な機能構成を示すブロック図
【図25】本発明の実施の形態2における、医用同義語辞書作成装置が実行する全体的な処理の流れを示すフローチャート
【図26】医用同義語辞書データベースを利用したシステムの構成を示す図
【発明を実施するための形態】
【0014】
以下、本発明の実施の形態について、図面を参照しながら説明する。なお、以下で説明する実施の形態は、いずれも本発明の好ましい一具体例を示すものである。以下の実施の形態で示される数値、構成要素、構成要素の接続形態、ステップ、ステップの順序などは、一例であり、本発明を限定する主旨ではない。本発明は、特許請求の範囲だけによって限定される。よって、以下の実施の形態における構成要素のうち、本発明の最上位概念を示す独立請求項に記載されていない構成要素については、本発明の課題を達成するのに必ずしも必要ではないが、より好ましい形態を構成するものとして説明される。
【0015】
本発明の実施の形態に係る医用同義語辞書作成装置は、超音波画像、CT(Computed Tomography)画像、または核磁気共鳴画像等の医用画像に対する読影レポートに記述されたキーワードに関する医用同義語辞書を作成する装置である。本明細書中では「画像データ」のことを単に「画像」と言う。
【0016】
本発明の一実施態様に係る医用同義語辞書作成装置は、医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得部と、医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得部が取得した読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出部と、前記キーワード抽出部が抽出したキーワードからキーワード対を選択するキーワード対選択部と、前記キーワード対選択部が選択したキーワード対が同義語であるか否かを判定する同義語判定部と、前記同義語判定部が同義語であると判定したキーワード対を、医用同義語辞書に含まれる同義語として出力する出力部とを備え、前記同義語判定部は、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する。
【0017】
この構成によると、読影レポートに基づいた同義語判定と、医用画像から抽出される画像特徴量に基づいた同義語判定とを行っている。後者については、医用画像から抽出される各画像特徴量について、読影レポートに記載されているキーワードとの間の関連性が高いものほど大きな重みで重み付けを行った上で、重み付けされた画像特徴量同士を比較している。このため、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成することができる。
【0018】
具体的には、前記同義語判定部は、前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部と、前記テキスト判定部で同義語であると判定された場合に、前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部とを含み、前記出力部は、前記画像判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力する。
【0019】
また、前記同義語判定部は、前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部と、前記画像判定部で同義語であると判定された場合に、前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部とを含み、前記出力部は、前記テキスト判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力するものであっても良い。
【0020】
また、前記テキスト判定部は、前記キーワード対を構成する各キーワードについて、前記読影レポート中の当該キーワードを含む文章中の当該キーワード以外のキーワードの出現頻度をベクトルの要素とするキーワードベクトルを作成し、作成したキーワードベクトル間の距離が第1閾値以下であれば、前記キーワード対が同義語であると判定するものであっても良い。
【0021】
また、前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成するものであっても良い。
【0022】
この構成によると、読影項目と関連性のある画像特徴量に大きな重みで重み付けを行うことができる。
【0023】
また、前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが疾病名である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する疾病名との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と疾病名である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成するものであっても良い。
【0024】
この構成によると、疾病名と関連性のある画像特徴量に大きな重みで重み付けを行うことができる。
【0025】
また、前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、(i)医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うとともに、(ii)前記読影レポートの中から当該キーワードと共起する疾病名を検出し、読影項目と疾病名との関連性を予め定めた二項間関係情報に基づいて、前記各画像特徴量を読影項目である当該キーワードと当該キーワードと共起する前記疾病名との間の関連性が高いほど大きな値の重みでさらに重み付けを行うことにより、重み付けされた各画像特徴量を要素とする当該キーワードの画像特徴量ベクトルを生成するものであっても良い。
【0026】
この構成によると、読影項目と関連性の低い症例の重みは小さくなるため、読影項目と関連性の低い症例を取り除いた画像特徴量ベクトルを生成することができる。これにより、画像の類似性をより正しく評価することができ、医用同義語辞書の精度を向上させることができる。
【0027】
好ましくは、前記キーワード対選択部は、読影項目同士または疾病名同士のキーワード対のみを選択する。
【0028】
疾病名は複数の診断項目の上位概念であるため、疾病名と診断項目とは直接同義語にはならない。そのため、疾病名と診断項目の対を選択しないことで、処理時間を低減することができる。
【0029】
また、上述の医用同義語辞書作成装置は、さらに、前記出力部が出力するキーワード対を、前記医用同義語辞書に含まれる同義語として記憶する記憶部を備えるものであっても良い。
【0030】
好ましくは、前記取得部は、医用画像と当該医用画像に対する読影レポートとの組である症例データが記憶されている症例データベースから、前記医用画像と前記読影レポートとを取得し、前記医用同義語辞書作成装置は、さらに、前記症例データベースに記憶されている症例データが更新されているか否かを判断し、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させ、前記医用同義語辞書に含まれる同義語を更新する更新制御部を備える。
【0031】
この構成によると、症例データベースに記憶されている症例データが更新された場合であっても、医用同義語辞書を自動的に更新することができるため、より汎用性の高い医用同義語辞書を用いた検索が可能になる。
【0032】
なお、前記更新制御部は、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、前記医用同義語辞書に含まれる全てのキーワードについて同義語を更新するものであっても良い。
【0033】
また、前記更新制御部は、(i)前記症例データベースに記憶されている前記症例データにおける各キーワードの出現頻度を算出し、(ii)前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、出現頻度が第2閾値以下のキーワードについてのみ同義語を更新するものであっても良い。
【0034】
高頻度のキーワードが新しく追加された場合は、仮に同義語か否かの判定をし直したとしても結果は変わらないため、医用同義語辞書の更新を行う必要性が低い。一方、出現頻度が少ないキーワードに対しては、同義語関係の不確実性が高いため、医用同義語辞書を更新する必要性が高い。このように、症例データベース内のキーワード頻度に応じて同義語辞書の更新の可否を判定することにより、更新時の計算量を低減できるため、更新時間を短縮することができる。
【0035】
本発明の他の実施態様に係る医用同義語辞書作成方法は、医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得ステップと、医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得ステップで取得された読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出ステップと、前記キーワード抽出ステップで抽出されたキーワードからキーワード対を選択するキーワード対選択ステップと、前記キーワード対選択ステップで選択されたキーワード対が同義語であるか否かを判定する同義語判定ステップと、前記同義語判定ステップで同義語であると判定されたキーワード対を、医用同義語辞書に含まれる同義語として出力する出力ステップとを含み、前記同義語判定ステップでは、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択ステップで選択されたキーワード対が同義語であると判定する。
【0036】
本発明のさらに他の実施態様に係るプログラムは、上述の医用同義語辞書作成方法に含まれる各ステップをコンピュータに実行させるためのプログラムである。
【0037】
(実施の形態1)
本実施の形態で用いる用語を説明する。
【0038】
「画像特徴量」とは、医用画像における臓器や病変部分の形状に関するもの、輝度分布に関するものなどを示す。画像特徴量として、例えば、非特許文献:「根本,清水,萩原,小畑,縄野,“多数の特徴量からの特徴選択による乳房X線像上の腫瘤影判別精度の改善と高速な特徴選択法の提案”,電子情報通信学会論文誌D−II,Vol.J88−D−II,No.2,pp.416−426,2005年2月」に490種類の特徴量を用いることが記載されている。本実施の形態においても、使用した医用画像撮影装置(モダリティ)、または対象臓器ごとに予め定めた数十〜数百種の画像特徴量を用いる。
【0039】
「キーワード」とは、以下に述べる「読影項目」と「疾病名」の何れかを示す。
【0040】
「読影項目」とは、本実施の形態では、「読影医が、読影対象の画像の特徴を言語化した文字列」と定義する。使用する医用画像撮影装置、対象臓器等で使用される用語はほぼ限定されるが、例えば、分葉状、棘状、不整形、境界明瞭、輪郭不明瞭、低/高濃度、低/高吸収、スリガラス状、石灰化、モザイク状、濃染、低/高エコー、毛羽立ち、等が挙げられる。
【0041】
「疾病名」とは、読影者が医用画像やその他の検査を基に診断した疾病名のことである。例えば、肝細胞癌、嚢胞、血管腫、等が挙げられる。
【0042】
(実施の形態1:構成の説明)
以下、本発明の実施の形態1に係る医用同義語辞書作成装置について、図面を用いて詳細に説明する。
【0043】
図1は、本発明の実施の形態1に係る医用同義語辞書作成装置の特徴的な機能構成を示すブロック図である。
【0044】
図1に示すように、医用同義語辞書作成装置100は、症例データベース101内に記憶されている読影レポートから抽出されるキーワードの同義語辞書である医用同義語辞書を作成する装置である。なお、本明細書中で同義語とは同一の意味の語に限定されず、類似の意味の語である類義語も含むものとする。つまり、本発明に係る医用同義語辞書作成装置は、医用類義語辞書作成装置としても利用可能である。
【0045】
医用同義語辞書作成装置100は、取得部104、キーワード抽出部105、キーワード対選択部106、同義語判定部120、出力部121、および記憶部110を備える。
【0046】
同義語判定部120は、テキスト判定部107、代表画像ベクトル生成部108、および画像判定部109を備える。
【0047】
医用同義語辞書作成装置100は、外部の症例データベース101、キーワード辞書102、読影知識データベース103、および表示装置122に接続される。
【0048】
以下、図1に示した、症例データベース101、キーワード辞書102、読影知識データベース103、および医用同義語辞書作成装置100の各構成要素の詳細について順に説明する。
【0049】
症例データベース101は、例えばハードディスク、メモリ等からなる記憶装置である。症例データベース101は、読影者に提示する読影対象の画像を示す医用画像と、その医用画像に対応する読影レポートとから構成される症例データを記憶しているデータベースである。ここで、医用画像とは、画像診断のために用いられる画像データであり、電子媒体に格納された画像データを示す。また、読影レポートとは、医用画像の読影結果に加え、画像診断後に行われる生検等の確定診断結果までを示す情報である。読影レポートは、文書データ(テキストデータ)である。生検とは、患部の一部を切り取って、顕微鏡などで調べる検査のことである。
【0050】
図2は、症例データベース101に記憶されている症例データを構成する、医用画像20としてのCT画像および読影レポート21の一例をそれぞれ示す図である。読影レポート21は、読影レポートID22、画像ID23、画像所見24および確定診断結果25を含む。1つの症例データは同一の患者から作成される。
【0051】
読影レポートID22は、読影レポート21を識別するための識別子であり、読影レポート21ごとに識別子が異なる。画像ID23は、医用画像20を識別するための識別子であり、医用画像20ごとに識別子が異なる。画像所見24は、画像ID23の医用画像20に対する読影者の診断結果を示す情報である。つまり、画像所見24は、疾病名を含む診断結果(読影結果)および診断理由(読影理由)を示す情報である。確定診断結果25は、医用画像20の患者の確定診断結果を示す。ここで確定診断結果とは、手術または生検で得られた試験体の顕微鏡による病理検査、またはその他様々な手段によって、対象の患者の真の状態が何であったのかを明らかにした診断結果である。
【0052】
キーワード辞書102は、例えばハードディスク、メモリ等からなる記憶装置である。
【0053】
キーワード辞書102は、読影レポート21からの抽出対象となるキーワード(キーワード辞書データ)を記憶しているデータベースである。図3は、キーワード辞書102に記憶されているキーワードの一例を示す図である。図3に示すように、キーワード辞書102には、キーワード名30とキーワード属性31とがリスト形式で記憶されている。ここで、キーワード属性31とは、キーワード名30のキーワードが読影項目か疾病名かを示すデータである。例えば、濃染というキーワードのキーワード属性は読影項目である。
【0054】
読影知識データベース103は、例えばハードディスク、メモリ等からなる記憶装置である。
【0055】
読影知識データベース103は、読影レポート21から抽出したキーワード間の相関関係(関連性)を示す二項間関係情報と、キーワードと医用画像20から抽出した画像特徴量との相関関係(関連性)を示す二項間関係情報とを記憶しているデータベースである。二項間関係情報は、症例データベース101のデータを用いて自動的に作成される。データベースの構成および作成方法については後述する。
【0056】
取得部104は、症例データベース101から、読影者が診断を行った医用画像20および読影レポート21を取得する。取得部104は、取得した医用画像20および読影レポート21を、キーワード抽出部105に出力する。
【0057】
キーワード抽出部105は、キーワード辞書102を参照することにより、取得部104が取得した読影レポート21の中からキーワード辞書102に登録されているキーワードを抽出し、抽出したキーワードをリスト化してキーワード対選択部106に出力する。具体的なキーワード抽出方法については後述する。
【0058】
キーワード対選択部106は、キーワード抽出部105が抽出したキーワードリストから未選択のキーワード対を選択し、選択したキーワード対を、テキスト判定部107、代表画像ベクトル生成部108、および出力部121に出力する。
【0059】
同義語判定部120は、キーワード対選択部106が選択したキーワード対が同義語であるか否かを判定する。
【0060】
つまり、テキスト判定部107は、読影レポート21に基づいて、キーワード対選択部106が選択したキーワード対に対して同義語判定を行い、同義語と判定した場合には、判定結果を代表画像ベクトル生成部108に出力する。具体的な同義語判定方法については後述する。
【0061】
代表画像ベクトル生成部108は、テキスト判定部107でキーワード対選択部106が選択したキーワード対が同義語であると判定された場合に、キーワード対選択部106から取得したキーワード対と、読影知識データベース103に記憶されている二項間関係情報と、症例データベース101に記憶されている医用画像20とを用いて、キーワード対選択部106が選択したキーワード対を構成する各キーワードに対する代表画像ベクトルを生成し、画像判定部109に出力する。ここで、代表画像ベクトルとは、各キーワードが付与されている医用画像群に対して算出された画像特徴量のベクトルであり、このベクトルには読影知識データベース103に記憶されているキーワード毎に算出された画像特徴量に対する重みが付加される。
【0062】
医用同義語辞書作成に代表画像ベクトルを用いる理由は以下の通りである。
【0063】
読影レポート21とは、医用画像20に対して医学的に統一された診断指針に基づいて記述されたテキストであるため、同義語関係にあるキーワードは同じ画像特徴を呈する。つまり、キーワード間の同義語関係は画像の類似性で評価することができる。すなわち、テキストだけを用いて作成された同義語関係を画像の類似性で再評価することにより、テキストだけを用いるよりも精度の高い医用同義語辞書を作成することができる。
【0064】
しかし、読影レポート21中のキーワードの同義語関係を評価するために、すべてのキーワードに対して同一の画像特徴量を用いて画像の類似性を評価することはできない。何故なら、それぞれのキーワードごとに、関連する画像特徴量が異なるからである。例えば、「辺縁明瞭」というキーワードはエッジ等の形状に関する画像特徴量と関係しているが、「高吸収」というキーワードは濃度に関する画像特徴量と関係している。「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する際、形状と濃度に関する画像特徴量の値をそのまま用いてしまうと、「辺縁明瞭」とは関係のない濃度に関する画像特徴量、そして、「高吸収」とは関係のない形状に関する画像特徴量が、それぞれ画像の類似判定に含まれてしまい、画像の類似性を正しく評価することができない。
【0065】
そこで、代表画像ベクトル生成部108は、各キーワードが付属する画像から算出された画像特徴量に対して、読影知識データベース103に記憶されている(キーワード−画像特徴量)間の関連性を示す値によって重み付けを行うことによって代表画像ベクトルを生成する。
【0066】
これにより、「辺縁明瞭」の画像に対しては形状情報の値に、「高吸収」の画像に対しては濃度情報の値に大きな重みを付けることができるため、画像の類似性を正しく評価することができ、画像の類似性に基づくキーワード間の同義語判定が可能になる。
【0067】
具体的な代表画像ベクトル生成方法は後述する。
【0068】
画像判定部109は、代表画像ベクトル生成部108が生成した代表画像ベクトルを用いて、キーワード対選択部106が選択したキーワード対が同義語であるか否かを再判定し、判定結果を出力部121に出力する。
【0069】
出力部121は、キーワード対選択部106から取得したキーワード対のうち、画像判定部109で同義語と判定されたキーワード対を、医用同義語辞書に含まれる同義語として記憶部110に書き込む、または、表示装置122に表示する。
【0070】
次に、読影知識データベース103の作成方法、および以上のように構成された医用同義語辞書作成装置100の動作について順に説明する。
【0071】
(実施の形態1:読影知識データベース103の事前作成)
医用同義語辞書作成を行うに当たり、事前に読影知識を得て、読影知識データベース103に格納しておく。読影知識は、医用画像とその医用画像を読影した結果である読影レポートとの対から構成される“症例”(症例データ)を複数集めたものから得られる。症例は、症例データベース101に格納されたものを用いてもよいし、他のデータベースに格納されたものを用いてもよい。必要な症例数は、種種のデータマイニングアルゴリズムを用いて何らかの法則性および知識を得るために十分となる数である。通常は数百〜数万個のデータが用いられる。本実施の形態では、読影知識として、(1)画像特徴量、(2)読影項目、(3)疾病名 の三項のうち二項間の相関関係を用いる。ここで、読影時の診断疾病名とその他の検査を経て確定診断した疾病名とは異なることがあるが、読影知識データベースを作成する際は、確定診断の結果を用いる。
【0072】
以下、図4のフローチャートを用いて読影知識作成の手順を説明する。本実施の形態で対象とする、つまり使用する医用画像撮影装置はマルチスライスCTとし、対象臓器および疾病は、それぞれ肝臓および肝腫瘤とする。
【0073】
ステップS101では、読影知識を得るための症例が格納されたデータベースから症例を1つ取得する。ここで読影知識を得るための症例の総数をC個とする。1つの症例は、医用画像とその医用画像を読影した結果である読影レポートとの対で構成されている。医用画像がマルチスライスCT装置により取得された場合、1つの症例は多数枚のスライス画像を含むことになる。また、通常、マルチスライスCT画像を医師が読影する場合、重要なスライス画像1〜数枚を、キー画像として読影レポートに添付する。以後、多数枚のスライス画像集合、あるいは、数枚のキー画像を単に「医用画像」、「画像」と呼ぶこともある。
【0074】
ステップS102では、医用画像から画像特徴量を抽出する。ステップS102の処理を、図5のフローチャートを用いて詳細に説明する。
【0075】
ステップS201では、対象臓器の領域を抽出する。本実施の形態では肝臓領域を抽出する。肝臓領域抽出法として、例えば、非特許文献:「田中,清水,小畑,“異常部位の濃度パターンを考慮した肝臓領域抽出手法の改良<第二報>”,電子情報通信学会技術研究報告,医用画像,104(580),pp.7−12,2005年1月」等の手法を用いることができる。
【0076】
ステップS202では、ステップS201で抽出された臓器領域から病変領域を抽出する。本実施の形態では肝臓領域から腫瘤領域を抽出する。肝腫瘤領域抽出法として、例えば、非特許文献「中川、清水,一杉,小畑,“3次元腹部CT像からの肝腫瘤影の自動抽出手法の開発<第二報>”,医用画像,102(575),pp.89−94,2003年1月」等の手法を用いることができる。ここで、i番目の症例における画像から抽出した腫瘤の数をMiとすると、腫瘤は(症例番号,腫瘤番号)の組(i,j)で特定できる。ここで、1≦i≦C,1≦j≦Miである。また本実施の形態では病変として肝腫瘤を対象としているため、“腫瘤番号”と呼んだが、本発明で共通の表現を用いて“病変番号”と呼ぶこともできる。
【0077】
ステップS203では、ステップS202で抽出された病変領域のうち、1つの領域を選択する。
【0078】
ステップS204では、ステップS203で選択された病変領域から画像特徴量を抽出する。本実施の形態では、画像特徴量として、非特許文献:「根本,清水,萩原,小畑,縄野,“多数の特徴量からの特徴選択による乳房X線像上の腫瘤影判別精度の改善と高速な特徴選択法の提案”,電子情報通信学会論文誌D−II,Vol.J88−D−II,No.2,pp.416−426,2005年2月」に記載された490種類の特徴量のうち、肝腫瘤にも適用可能な特徴量をいくつか選択して用いる。この特徴量数をNF個とする。本ステップで抽出された特徴量は、(症例番号,この症例(医用画像)から抽出された腫瘤番号,特徴量番号)の組(i,j,k)で特定できる。ここで、1≦i≦C,1≦j≦Mi,1≦k≦NFである。
【0079】
ステップS205では、ステップS202で抽出された病変領域のうち未選択の病変があるかどうかをチェックし、未選択の病変がある場合は、ステップS203に戻り未選択の病変領域を選択した後、ステップS204を再実行する。未選択の病変がない場合、すなわち、ステップS202で抽出された全ての病変領域に対し、ステップS204の特徴量選択を行った場合は図5のフローチャートの処理を終了し、図4のフローチャートに戻る。
【0080】
図4のステップS103では、読影レポートの解析処理を行う。具体的には読影レポートから読影項目及び疾病名を抽出する。本実施の形態では読影項目が格納された読影項目単語辞書、および疾病名が格納された疾病名単語辞書を用いた形態素解析及び構文解析を行う。これらの処理により、各単語辞書に格納された単語と一致する単語を抽出する。形態素解析技術としては、例えば、MeCab(http://mecab.sourceforge.net)やChaSen(http://chasen−legacy.sourceforge.jp)等が、構文解析技術としては、KNP(http://nlp.kuee.kyoto−u.ac.jp/nl−resource/knp.html)、CaboCha(http://chasen.org/〜taku/software/cabocha/)等が存在する。読影レポートは医師により読影レポート独特の表現で記述されることが多いので、読影レポートに特化した形態素解析技術、構文解析技術、各単語辞書を開発することが望ましい。
【0081】
図6は腹部CT検査の読影レポートの例であり、図7は図6の読影レポートから抽出された読影項目および疾病名を示す。読影項目は通常複数個、疾病名は1個抽出される。i番目の症例における読影レポートから抽出した読影項目の数をNiとすると、読影項目は(症例番号,読影項目番号)の組(i,j)で特定できる。ここで、1≦i≦C,1≦j≦Niである。
【0082】
また、図7では、読影項目および疾病名の単語のみを抽出しているが、読影レポートにおける病変の位置を表す文字列、時相を表す文字列を同時に抽出してもよい。ここで、時相について補足する。肝臓の病変の鑑別には、造影剤を急速静注して経時的に撮像する造影検査が有用とされている。肝臓の造影検査では一般に、肝動脈に造影剤が流入し多血性の腫瘍が濃染する動脈相、腸管や脾臓に分布した造影剤が門脈から肝臓に流入し肝実質が最も造影される門脈相、肝の血管内外の造影剤が平衡に達する平衡相、肝の間質に造影剤が貯留する晩期相などにおいて、肝臓が撮像される。読影レポートには病変の臓器における位置や、造影検査であれば着目した時相の情報が記述されていることが多い。このため、読影項目だけでなく位置や時相の情報も合わせて抽出することで、後で説明する読影知識の抽出に有効となる。図8に、読影項目と同時に位置と時相の情報を抽出した例を示す。例えば、図6の読影レポートを解析し、「肝S3区域に早期濃染を認め」という文節から「早期濃染」の位置属性として「肝S3区域」が抽出される。同様に、「後期相でwashoutされており」という文節から「washout」の時相属性として「後期相」が抽出される。
【0083】
図6の読影レポートを、単純に解釈すると、図8のように「早期濃染」に関する時相、washoutに関する位置の部分が空白になる。これに対し、読影項目「早期濃染」は早期相に対応した単語であるという事前知識を利用したり、「早期濃染」の状態を示す腫瘤と「後期相でwashout」される腫瘤が同一の腫瘤を指すという高度な文脈解釈を行ったりすることができれば、抽出される位置と時相の情報は図9のようになる。
【0084】
ステップS104では、読影知識を得るための症例が格納されたデータベースにおいて未取得の症例があるかどうかをチェックし、未取得の症例がある場合は、ステップS101に戻り未取得の症例を取得した後、ステップS102およびS103を実行する。未取得の症例がない場合、すなわち、全ての症例に対し、ステップS102の画像特徴抽出およびステップS103のレポート解析を実施済の場合は、ステップS105に進む。
【0085】
ステップS102とステップS103の結果は相互に依存しないため、実行順は逆でも構わない。
【0086】
ステップS105に到達した時点で、図10で表されるデータ一式が取得できたことになる。つまり、症例ごとに画像特徴量と読影項目と疾病名とが取得される。症例番号1の症例については、医用画像中にM1個の病変が含まれており、各病変から抽出される画像特徴量の個数はNF個である。また、読影レポート中の読影項目の数はN1個である。例えば、病変番号(1,1)で示される1つ目の病変のうち、1つ目の画像特徴量の値は0.851である。また、読影項目番号(1,1)で示される1つ目の読影項目の値は「早期濃染」である。
【0087】
ステップS105では、ステップS102で得られた画像特徴量、ステップS103で得られた読影項目および疾病名から、読影知識を抽出する。本実施の形態では、画像特徴量、読影項目、疾病名という三項のうちの二項の相関関係を、読影知識とする。
【0088】
以下では、画像特徴量、読影項目、疾病名という三項から得られる三組の二項の相関関係について説明する。
【0089】
(1)(画像特徴量−読影項目)間の相関関係
1対の(画像特徴量,読影項目)間の相関関係の求め方について説明する。相関関係の表現形態は複数あるが、ここでは相関比を用いる。相関比は、質的データと量的データとの間の相関関係を表す指標であり、(式1)で表される。
【0090】
【数1】

【0091】
読影レポート中に、ある読影項目を含む場合および含まない場合の2カテゴリを考え、これを質的データとする。医用画像から抽出した、ある画像特徴量の値そのものを量的データとする。例えば、読影知識を抽出するための症例データベースに含まれる全症例に対し、読影レポートを、ある読影項目を含むものまたは含まないものに区分する。ここでは、読影項目「早期濃染」と画像特徴量「早期相における腫瘤内部の輝度平均値」との相関比を求める方法について説明する。(式1)においては、カテゴリi=1を「早期濃染」を含むもの、カテゴリi=2を「早期濃染」を含まないものとする。読影レポートに「早期濃染」を含む症例から抽出した腫瘤画像の「早期相における腫瘤内部の輝度平均値」であるj番目の観測値をx1jとする。また、読影レポートに「早期濃染」を含まない症例から抽出した腫瘤画像の「早期相における腫瘤内部の輝度平均値」であるj番目の観測値をx2jとする。「早期濃染」とは造影早期相にてCT値が上昇することを表すため、この場合、相関比が大きく(1に近く)なることが予想される。また、早期濃染は腫瘤の種類に依存し、腫瘤の大きさには依存しないため、読影項目「早期濃染」と画像特徴量「腫瘤面積」との相関比は小さく(0に近く)なることが予想される。このようにして、全ての読影項目と全ての画像特徴量との間の相関比を計算する。
【0092】
図11に、読影項目と画像特徴量との間の相関関係(ここでは、相関比)の概念図を示す。左側には複数の読影項目、右側には複数の画像特徴量の名称が列挙されている。そして、相関比が閾値以上の読影項目と画像特徴量の間が実線で結ばれている。計算した相関比を最終的に閾値で二値化すると、図11のような情報が求められることになる。その一例について補足する。肝腫瘤の造影CT検査においては、殆どの腫瘤は造影剤使用前のCT画像(単純、単純CT、単純相などと呼ぶ)で低濃度に描出され、多くの場合、読影レポートに「低濃度」「LDA(Low Density Area)あり」などと記述される。そのため、「低輝度」や「LDA」といった読影項目と、造影剤使用前のCT画像における腫瘤内部の輝度平均(図11では「単純相 輝度平均」と略記載)との相関が大きくなる。
【0093】
また、図12に、読影項目と画像特徴量との間の相関関係(例えば、相関比)の別の概念図を示す。この図では、相関比を多値表現しており、読影項目と画像特徴量の間の実線の太さが相関比の大きさに相当している。例えば、造影早期相にてCT値が上昇する「早期濃染」と、早期動脈相(早期相、動脈相とも略される)における腫瘤内部の輝度平均(図12では「動脈相 輝度平均」と略記載)との相関が大きくなっている。
【0094】
相関比の値に着目することで、ある読影項目と相関の高い画像特徴量を特定することができる。実際には1つの症例には、複数の画像や複数の病変(腫瘤)を含む場合が多く、その場合は読影レポートには複数の病変に関する記載が含まれることになる。例えば、造影CT検査では、造影剤使用前や使用後の複数時刻におけるタイミングでCT撮影を行う。そのため、スライス画像の集合が複数得られ、スライス画像の1つの集合には複数の病変(腫瘤)が含まれ、1つの病変からは複数の画像特徴量が抽出される。そのため、(スライス画像集合数)×(1人の患者から検出された病変数)×(画像特徴量の種類数)の個数だけ画像特徴量が得られ、これら複数の画像特徴量と、1つの読影レポートから抽出された複数の読影項目や疾病名との相関関係を求める必要がある。もちろん大量の症例を用いることにより、対応が正しく得られる可能性があるが、図9のように病変位置と時相を用いる等して、読影レポートの記載と、対応する画像特徴量とをある程度事前に対応づけることができれば、より正確に相関関係を求めることができる。
【0095】
先の説明では、質的データが、ある読影項目を含むものおよび含まないものの2カテゴリである場合について説明したが、ある読影項目(例えば、「境界明瞭」)と、その対義語となる読影項目(例えば、「境界不明瞭」)との2カテゴリであってもよい。また、読影項目が「低濃度」、「中濃度」、「高濃度」などの序数尺度の場合は、それらの各々をカテゴリとして(この例では3カテゴリ)、相関比を計算してもよい。
【0096】
また、「低濃度」、「低輝度」、「低吸収」などの同義語については、予め医用同義語辞書を作成しておき、それらを同一の読影項目として扱う。
【0097】
(2)(画像特徴量−疾病名)間の相関関係
1対の(画像特徴量,疾病名)間の相関関係については、(画像特徴量,読影項目)間の場合と同じく相関比を用いることができる。図13に、疾病名と画像特徴量との間の相関関係(例えば、相関比)の概念図を示す。この図では図11と同じく相関関係を二値表現しているが、もちろん図12のような多値表現を行うことも可能である。
【0098】
(3)(読影項目−疾病名)間の相関関係
1対の(読影項目,疾病名)間の相関関係の求め方について説明する。相関関係の表現形態は複数あるが、ここでは支持度を用いる。支持度は、質的データ間の相関ルールを表す指標であり、(式2)で表される。
【0099】
【数2】
【0100】
この支持度は、全症例において読影項目Xと疾病名Yとが同時に出現する確率(共起確率)を意味する。支持度を用いることで、関連性の強い読影項目と疾病名との組合せを特定することができる。
【0101】
なお、支持度の代わりに、(式3)で示される確信度や、(式4)で示されるリフト値を用いても良い。
【0102】
【数3】
【0103】
【数4】
【0104】
確信度とは、条件部Xのアイテムの出現を条件としたときの結論部Yのアイテムが出現する確率である。リフト値とは、Xの出現を条件としないときのYの出現確率に対して、Xの出現を条件としたときのYの出現確率がどの程度上昇したかを示す指標である。その他、conviction,φ係数を用いても良い。conviction,φ係数については相関ルール分析に関する文献(例えば、非特許文献:「データマイニングとその応用」、加藤/羽室/矢田 共著、朝倉書店)に記載されている。
【0105】
図14に、読影項目と疾病名との間の相関関係(例えば、支持度)の概念図を示す。この図では図11と同じく相関関係を二値表現しているが、もちろん図12のような多値表現を行うことも可能である。
【0106】
以上の方法にて、ステップS105の処理を行うと、図15、図16、図17のような、(画像特徴量−読影項目)間の相関関係、(画像特徴量−疾病名)間の相関関係、(読影項目−疾病名)間の相関関係が、それぞれ得られる。なお表中の数値は、図15、図16では相関比、図17では支持度である。また、得られた相関関係は、図15、図16、図17の形式にて読影知識データベース103に格納される。
【0107】
以上、読影知識データベース103の作成方法について述べた。次に、医用同義語辞書作成装置100の動作について説明する。
【0108】
(実施の形態1:医用同義語辞書作成装置100の動作の説明)
図18は、医用同義語辞書作成装置100が実行する処理の全体的な流れを示すフローチャートである。以下、図18を用いて、医用同義語辞書作成装置100が実行する処理の全体的な流れについて説明する。
【0109】
まず、取得部104は、症例データベース101から、読影者が診断した医用画像20と読影レポート21を取得し、キーワード抽出部105に出力する(ステップS301)。医用画像20と読影レポート21は、例えば、1週間単位などの固定期間ごとに取得してもよいし、ユーザが指定する任意のタイミングで取得してもよい。
【0110】
次に、キーワード抽出部105は、キーワード辞書102を参照することにより、取得部104から取得した読影レポート21の中からキーワードを抽出し、抽出したキーワードと読影レポートID22をリスト化してキーワード対選択部106に出力する(ステップS302)。特に、キーワード抽出部105は、画像所見24と確定診断結果25とからキーワードを抽出する。
【0111】
抽出されたキーワードと読影レポートID22のリストの一例を図19に示す。キーワード抽出方法としては、例えば、読影レポート21の中から、キーワード辞書102に記憶されているキーワードと一致するキーワードを抽出すればよい。図19に示すリストより、例えば、キーワード「高吸収」を含む読影レポート21の読影レポートID22は、r_12およびr_14などであることが分かる。
【0112】
次に、キーワード対選択部106は、キーワード抽出部105から取得したキーワードリストから未選択のキーワード対を選択し、選択したキーワード対をテキスト判定部107、代表画像ベクトル生成部108、および出力部121に出力する(ステップS303)。
【0113】
なお、キーワード対選択部106は、キーワード対を選択する際に、疾病名の対、および診断項目の対のみを選択してもよい。疾病名は複数の診断項目の上位概念であるため、疾病名と診断項目とは直接同義語にはならない。そのため、疾病名と診断項目の対を選択しないことで、処理時間を低減することができる。
【0114】
次に、テキスト判定部107は、取得部104が取得した読影レポート21に基づいて、キーワード対選択部106が選択したキーワード対に対して同義語判定を行い、同義語と判定した場合には、判定結果を代表画像ベクトル生成部108に通知する。一方、同義語と判定しなかった場合は、ステップS303へ戻る(ステップS304)。具体的な同義語判定方法としては、例えば、判定対象となるキーワードの前後に出現するキーワード頻度の類似性に基づいて、キーワード対が類義語か否かを判定すればよい。以下、キーワード対選択部106で「辺縁明瞭」と「高吸収」の2つのキーワードが選択された場合を例に、テキスト判定部107の処理の一例を説明する。つまり、テキスト判定部107は、図19に示すキーワードと読影レポートID22のリストを参照し、「辺縁明瞭」が付与されている読影レポートID22を抽出する。テキスト判定部107は、抽出した読影レポートID22の読影レポート21の画像所見24および確定診断結果25に含まれるテキストデータを取得する。テキスト判定部107は、取得したテキストデータから「辺縁明瞭」を含む一文を選択する。テキスト判定部107は、選択した一文から「辺縁明瞭」以外のキーワードを抽出し、図20に示すようなキーワードベクトルを作成する。ここで、ti(i=1〜n)はキーワードiの出現頻度、nはキーワードの種類数であり、各キーワードの出現頻度がベクトルの要素である。次に、テキスト判定部107は、「高吸収」に対するキーワードベクトルを、「辺縁明瞭」の場合と同様の手法で作成する。最後に、テキスト判定部107は、作成された2つのキーワードベクトル間のコサイン距離を算出し、算出した距離が閾値以下であれば同義語であると判定し、閾値より大きければ同義語でないと判定する。このようなテキストに基づいた同義語判定の詳細なアルゴリズムは、非特許文献:「山本,梅村,“辞書を用いない関連語リストの構築方法”,情報処理学会研究報告,vol.2002(20),pp.81−88,2002−03−04」に開示されている。
【0115】
次に、代表画像ベクトル生成部108は、テキスト判定部107でキーワード対が同義語であると判定された場合に、キーワード対選択部106が選択したキーワード対と、読影知識データベース103に記憶されている二項間関係情報と、症例データベース101に記憶されている医用画像20とを用いて、キーワード対選択部106から取得したキーワードに対する代表画像ベクトルを生成し、画像判定部109に出力する(ステップS305)。
【0116】
図21にステップS305の処理の詳細なフローチャートの一例を示す。以下、図21を用いて具体的な代表画像ベクトル生成方法について説明する。
【0117】
まず初めに、代表画像ベクトル生成部108は、キーワード対選択部106から取得したキーワード対の中から1つのキーワードを選択する(ステップS401)。
【0118】
次に、代表画像ベクトル生成部108は、読影知識データベース103から、ステップS401で選択したキーワードに対する画像重みを取得する(ステップS402)。画像重みとは、画像特徴量に掛けられる重みのことである。キーワードが読影項目の場合には、図15に示す(画像特徴量−読影項目)間の相関関係より画像重みを取得する。例えば、キーワードが読影項目1の場合には、画像特徴量1に対する画像重みは0.808であり、画像特徴量2に対する画像重みは0.627である。また、キーワードが疾病名の場合には、図16に示す(画像特徴量−疾病名)間の相関関係より画像重みを取得する。例えば、キーワードが疾病名1の場合には、画像特徴量1に対する画像重みは0.671であり、画像特徴量2に対する画像重みは0.697である。
【0119】
次に、代表画像ベクトル生成部108は、ステップS401で選択したキーワードが付与された医用画像20に対して画像特徴量ベクトルを算出する(ステップS403)。キーワードが付与された医用画像20とは、キーワードを含む読影レポート21の作成の基となった医用画像20のことである。画像特徴量ベクトルとは、医用画像20から算出された画像特徴量をベクトル表現したものである。例えば、画像特徴量としてエッジ強度と輝度分散を算出する場合は、医用画像20から算出したエッジ強度の平均値sと輝度分散の平均値tを、画像特徴量ベクトル(s,t)として出力する。実際には、前述のように臓器および病変部分の形状および輝度分布に関する数十〜数百種の画像特徴量を用いるため、画像特徴量ベクトルは数十から数百次元のベクトルとなる。なお、個々の医用画像20に対して算出される画像特徴量は、予め症例データベース101に記憶しておき、症例データベース101を参照することで取得しても構わない。これにより、本ステップでの処理時間が低減できる。
【0120】
次に、代表画像ベクトル生成部108は、ステップS405から取得した画像重みを、ステップS406で算出した画像特徴量ベクトルに掛け合わせ、代表画像ベクトルとして出力する(ステップS404)。例えば、ステップS402で画像重み(エッジ強度の重みw1,輝度分散の重みw2)が取得され、ステップS403で画像特徴量ベクトル(例えばエッジ強度の平均値f1と輝度分散の平均値f2)が、(f1,f2)のベクトル形式で出力されたとする。この場合、ステップS404で、代表画像ベクトル生成部108は、代表画像ベクトルとして、画像特徴量ベクトルに画像重みを掛け合わせた(w1・f1,w2・f2)を出力する。
【0121】
なお、ステップS403では、画像特徴量ベクトルを、画像ID23と画像特徴量とを対応付けたリスト形式で出力してもよい。この場合、ステップS404では、画像ID23ごとに画像重みと画像特徴量ベクトルを掛け合わせ、最後に掛け合わせにより得られるベクトルの平均ベクトルを代表画像ベクトルとして出力すればよい。
【0122】
ステップS404で代表画像ベクトルを算出することにより、前述した「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する際、「辺縁明瞭」の画像に対しては形状情報、「高吸収」の画像に対しては濃度情報の画像特徴量に大きな重みを重みづけることができるため、画像の類似性に基づくキーワード間の同義語判定を正しく行うことが可能になる。
【0123】
最後に、代表画像ベクトル生成部108は、キーワード対選択部106から取得した全てのキーワードが、ステップS401において選択されたか否かを判定し、選択されてないキーワードがある場合はステップS401へ戻り、全てのキーワードが選択されている場合は処理を終了する(ステップS405)。
【0124】
以上のステップS401〜S405の処理を行うことにより、ステップS305において、ステップS303で選択したキーワードに対する代表画像ベクトルを生成することが可能になる。
【0125】
なお、ステップS401で選択したキーワードが読影項目の場合は、共起する疾病名による重みを付加した代表画像ベクトルを生成してもよい。
【0126】
図17に示すように、疾病名と読影項目の相関関係(支持度)は疾病名によって異なる。支持度の値は、疾病名に対する読影項目の寄与度を示す。医師が疾病名を決める際に典型的に利用される読影項目に対する支持度は高くなり、一方、S301で取得された症例が非典型な症例の場合、または、医用同義語辞書作成装置による読影項目の誤抽出があった場合には、疾病名に対する読影項目の支持度は低くなる。代表画像ベクトルは各読影項目に対する典型的な画像特徴量を示すベクトルであり、支持度の低い読影項目が付与された画像は、代表画像ベクトルを作成する際のノイズ要因の一つになる。例えば、「高吸収」という読影項目は、「肝細胞癌(疾病名)」の診断に典型的に用いられるため、「肝細胞癌」に対する「高吸収」の支持度は高い値となり、濃度に関する画像特徴量の重みが大きくなる。一方、「高吸収」は「嚢胞(疾病名)」の診断には殆ど用いられないため、「嚢胞」に対する「高吸収」の支持度の値は低くなり、濃度に関する画像特徴量の重みが小さくなる。よって、代表画像ベクトルを作成する際に、このような支持度の低い症例を取り除くことができれば、より正しく画像の類似性を評価することができ、医用同義語辞書の精度を向上させることができる。
【0127】
具体的なステップS305の処理のフローチャートを図22に示す。以下、図22を用いて、読影項目と共起する疾病名による重みを付加した代表画像ベクトル生成方法について説明する。なお、図21と同じ構成要素については同じ符号を付し、説明を繰り返さない。
【0128】
ステップS401〜S403の処理の実行後、代表画像ベクトル生成部108は、ステップS401で取得したキーワードのキーワード属性31が読影項目か否かを判定し、読影項目の場合はステップS502に進み、読影項目でなかった場合はステップS404に進む(ステップS501)。
【0129】
次に、代表画像ベクトル生成部108は、ステップS401で取得したキーワードと共起する疾病名を取得し、画像ID23と共にリスト化する(ステップS502)。具体的には、代表画像ベクトル生成部108は、取得したキーワードが含まれる画像所見24と同じ読影レポート21に含まれる確定診断結果25を、取得したキーワードとともに共起する疾病名として決定する。代表画像ベクトル生成部108は、確定診断結果25を、確定診断結果25と同じ読影レポート21に含まれる画像ID23と共にリスト化する。
【0130】
次に、代表画像ベクトル生成部108は、ステップS401で選択した読影項目と、ステップS502で取得した疾病名との間の相関関係(支持度)を、(読影項目−疾病名)の重みとして読影知識データベース103から取得し、画像ID23と共にリスト化する(ステップS503)。この画像ID23は、ステップS502で説明した画像ID23と同じである。
【0131】
次に、代表画像ベクトル生成部108は、ステップS405から取得したキーワード重みベクトルと、ステップS406で算出した画像特徴量ベクトルと、ステップS503から取得した(読影項目−疾病名)の重みを掛け合わせることにより、代表画像ベクトルを算出する(ステップS504)。例えば、ステップS401で読影項目Aが選択された時に、ステップS402で読影項目Aに対する画像重み(w1,w2)が取得されたとする。また、ステップS403で画像特徴量ベクトル(例えばエッジ強度の値f1と輝度分散の値f2)が、画像ID23ごとに(f1,f2)のベクトル形式で算出されたとする。また、ステップS503では(読影項目−疾病名)の重みαが画像ID23ごとに取得されたとする。このとき、ステップS504では、代表画像ベクトル生成部108は、画像特徴量ベクトル(f1,f2)に、画像重み(w1,w2)と(読影項目−疾病名)の重みαを掛け合わせた(α・w1・f1,α・w2・f2)を画像ID23ごとに算出し、これらの平均ベクトルを代表画像ベクトルとして出力する。
【0132】
ステップS504またはS404の処理後、ステップS405の処理が実行される。
【0133】
以上のステップS401〜S405およびステップS501〜S504の処理を行うことにより、ステップS305において、ステップS303で選択したキーワードが読影項目の場合に、共起する疾病名による重みを付加した代表画像ベクトルを生成することが可能になる。例えば、「高吸収」という読影項目に対する代表画像ベクトルを作成する場合では、肝細胞癌と共起して利用されている画像に対しては重みが大きく付与され、一方、嚢胞と共起して利用されている画像に対しては小さい重みが付与される。このため、実際には肝細胞癌の画像のみを用いて代表画像ベクトルを作成することができ、「高吸収」に対してより典型的な画像特徴量を表す画像ベクトルを作成することができる。
【0134】
ここで、図18に示した医用同義語辞書作成装置100の動作の説明に戻る。
【0135】
画像判定部109は、代表画像ベクトル生成部108から取得した代表画像ベクトルを用いて、キーワード対選択部106が選択したキーワード対の同義語関係を再判定し、判定結果を出力部121に通知する(ステップS306)。
【0136】
例えば、画像判定部109は、代表画像ベクトル間のユークリッド距離を算出し、算出した距離が閾値以下の場合に、選択したキーワード対が同義語であると判定し、算出した距離が閾値よりも大きい場合に、選択したキーワード対が同義語でないと判定する。これにより、複数の画像特徴量の中から、医師が着目した画像特徴量のみを用いて画像の類似性を評価することができる。
【0137】
次に、出力部121は、画像判定部109で同義語と判定された場合に、キーワード対選択部106から取得したキーワード対を、医用同義語辞書に含まれる同義語として記憶部110に書き込む(ステップS307)。これにより、記憶部110には複数の同義語を含む医用同義語辞書が記憶される。
【0138】
最後に、キーワード対選択部106は、ステップS303で全てのキーワード対を選択下か否かを判定し、選択されていないキーワード対がある場合にはステップS303に戻り、全てのキーワード対が選択されている場合には処理を終了する(ステップS308)。
【0139】
以上、図18に示すステップS301〜S308の処理を実行することにより、医用同義語辞書作成装置100は、キーワードに適合する画像特徴量を動的に選択することができ、読影レポート21に対して画像の類似性に基づく医用同義語辞書を作成することができる。
【0140】
(従来手法との比較)
例えば「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する場合、特許文献1の手法では、形状情報と濃度情報の両方を用いて画像の類似性を評価するため、キーワードとは関係の無い画像特徴量が類似評価に含まれてしまい、同義語であると間違って判定される可能性がある。しかし、本手法では「辺縁明瞭」の画像に対しては形状情報、「高吸収」の画像に対しては濃度情報の値に重みづけて画像の類似度を評価できるため、画像の類似度は低くなり、この2つのキーワードは同義語ではないと正しく判定することができる。
【0141】
以上のように、本実施の形態に係る医用同義語辞書作成装置100は、キーワードに適合する画像特徴量を動的に選択することにより、読影レポート21に対して画像の類似性に基づいた医用同義語辞書を作成することができる。
【0142】
なお、症例データベース101、キーワード辞書102、および読影知識データベース103は、医用同義語辞書作成装置100に備えられていてもよい。
【0143】
また、症例データベース101、キーワード辞書102、および読影知識データベース103は、医用同義語辞書作成装置100とネットワークを介して接続されたサーバ上に備えられてもよい。
【0144】
また、読影レポート21は、医用画像20内に付属データとして含まれていてもよい。
【0145】
(実施の形態1の変形例)
図1に示した実施の形態1に係る医用同義語辞書作成装置100の同義語判定部120は、テキスト判定部107、代表画像ベクトル生成部108、画像判定部109の順に処理を実行した。つまり、テキスト判定部107が、キーワード対選択部106が選択したキーワード対が同義語か否かを判定する。次に、代表画像ベクトル生成部108および画像判定部109が、テキスト判定部107が同義語であると判定したキーワード対について同義語か否かを再判定する。
【0146】
実施の形態1の変形例では、同義語判定部による同義語判定の順序が実施の形態1とは異なる。
【0147】
図23は、実施の形態1の変形例に係る医用同義語辞書作成装置の特徴的な機能構成を示すブロック図である。
【0148】
医用同義語辞書作成装置100Aは、図1に示した医用同義語辞書作成装置100の構成において、同義語判定部120の代わりに、同義語判定部120Aを用いている点が異なる。それ以外の構成は実施の形態1と同様であるため、その詳細な説明は繰り返さない。
【0149】
同義語判定部120Aは、代表画像ベクトル生成部108と、画像判定部109と、テキスト判定部107とを含む。各処理部は接続先が実施の形態1とは異なるが、処理は実施の形態1と同様である。
【0150】
つまり、代表画像ベクトル生成部108は、キーワード対選択部106が選択したキーワード対と、読影知識データベース103に記憶されている二項間関係情報と、症例データベース101に記憶されている医用画像20とを用いて、キーワード対選択部106が選択したキーワード対を構成する各キーワードに対する代表画像ベクトルを生成し、画像判定部109に出力する。
【0151】
画像判定部109は、代表画像ベクトル生成部108が生成した代表画像ベクトルを用いて、キーワード対選択部106が選択したキーワード対が同義語であるか否かを判定し、判定結果をテキスト判定部107に出力する。
【0152】
テキスト判定部107は、画像判定部109でキーワード対選択部106が選択したキーワード対が同義語であると判定された場合に、読影レポート21に基づいて、キーワード対選択部106が選択したキーワード対に対して同義語であるか否かの再判定を行い、同義語と判定した場合には、判定結果を出力部121に出力する。具体的な同義語判定方法については後述する。
【0153】
実施の形態1の変形例に係る医用同義語辞書作成装置100Aは、キーワードに適合する画像特徴量を動的に選択することにより、読影レポート21に対して画像の類似性に基づいた医用同義語辞書を作成することができる。
【0154】
(実施の形態2)
次に、本発明の実施の形態2に係る医用同義語辞書作成装置200について、図面を用いて詳細に説明する。
【0155】
本実施の形態の医用同義語辞書作成装置200は、症例データベース101に記憶されている症例データが更新された際に、医用同義語辞書を自動的に更新する特徴を有する。
【0156】
上述の実施の形態1に係る医用同義語辞書作成装置100は、症例データベース101が与えられた際に医用同義語辞書を自動的に算出する。ここで、症例データベース101には日々の診断の結果が蓄積され、逐次更新される特徴を持つ。医用同義語辞書に存在しないキーワードを含んだ読影レポート21が、症例データベース101に新しく追加された場合、新たに追加されたキーワードに対しては、そのキーワードと同義語となるキーワードが存在するか否かについて決定されていない。このため、この新たに追加されたキーワードを使った汎用性の高い検索を行うことができないという問題が生じる。
【0157】
そこで本実施の形態における医用同義語辞書作成装置200は、症例データベース101に記憶されている症例データの更新に応じて、キーワードに関する医用同義語辞書を新たに作成し、記憶部110に記憶する。
【0158】
これにより、症例データベース101に記憶されている症例データが更新された場合であっても、汎用性の高い検索が可能になる。
【0159】
以下、初めに図24を参照しながら、医用同義語辞書作成装置200の各構成について順に説明する。
【0160】
(実施の形態2:構成の説明)
図24は、本発明の実施の形態2に係る医用同義語辞書作成装置200の特徴的な機能構成を示すブロック図である。
【0161】
図24において、図1と同じ構成要素については同じ符号を付し、説明を繰り返さない。図24に示す医用同義語辞書作成装置200が図1に示す医用同義語辞書作成装置100と相違する点は、症例データベース101から取得した症例から、医用同義語辞書を更新するか否かを判定する更新制御部201を有する点である。
【0162】
更新制御部201は、症例データベース101から取得した医用画像20および読影レポート21を用いて、医用同義語辞書を更新するか否かを判定する。ここで、更新すると判定した場合は、更新制御部201は、取得部104、キーワード抽出部105、キーワード対選択部106、同義語判定部120および出力部121を動作させ、医用同義語辞書に含まれる同義語を更新する。一方、更新しないと判定した場合には、更新制御部201は、医用同義語辞書に含まれる同義語の更新を行わない。医用同義語辞書を更新するか否かの具体的な判定方法については後述する。
【0163】
次に、以上のように構成された医用同義語辞書作成装置200の動作について説明する。
【0164】
(実施の形態2:動作の説明)
図25は、医用同義語辞書作成装置200が実行する処理の全体的な流れを示すフローチャートである。図25において、図18と同じ構成要素については同じ符号を付し、説明を繰り返さない。
【0165】
更新制御部201は、症例データベース101から取得した症例データを用いて、医用同義語辞書を更新するか否かを判定する。ここで、医用同義語辞書を更新すると判定した場合は、ステップS301へ進む。一方、医用同義語辞書を更新しないと判定した場合には、処理を終了する(ステップS601)。
【0166】
具体的には、更新制御部201は、症例データベース101に記憶されている症例データが追加、削除または変更されることにより、症例データが更新された場合に、医用同義語辞書を更新すると判定し、症例データが更新されていない場合に、医用同義語辞書を更新しないと判定する。
【0167】
更新制御部201は、症例データが更新された場合に、全てのキーワードについて医用同義語辞書を更新しても良いし、症例データベース101に記憶されている全症例データにおける各キーワードの出現頻度をカウントし、出現頻度が閾値以下のキーワードに対してのみ、医用同義語辞書を更新してもよい。症例データベース101内に含まれるキーワードの出現頻度が十分に大きければ、既に十分な数のデータを用いて同義語関係が評価されたことになる。このような高頻度のキーワードが新しく追加された場合は、仮にキーワードベクトル間のコサイン距離および代表画像ベクトル間のユークリッド距離の再計算を行ったとしても値は大きく変化しないため、医用同義語辞書の更新を行う必要性が低い。一方、出現頻度が少ないキーワードに対しては、同義語関係の不確実性が高いため、医用同義語辞書を更新する必要性が高い。このように、症例データベース内のキーワード頻度に応じて同義語辞書の更新の可否を判定することにより、更新時の計算量を低減できるため、更新時間を短縮することができる。
【0168】
以上のように、本実施の形態に係る医用同義語辞書作成装置200は、症例データベース101に記憶されている症例データが更新された場合であっても、医用同義語辞書を自動的に更新することができるため、より汎用性の高い医用同義語辞書を用いた検索が可能になる。
【0169】
以上、本発明に係る医用同義語辞書作成装置について、実施の形態に基づいて説明したが、本発明は、これらの実施の形態に限定されるものではない。本発明の趣旨を逸脱しない限り、当業者が思いつく各種変形を本実施の形態に施したもの、異なる実施の形態における構成要素を組み合わせて構築される形態なども、本発明の範囲内に含まれる。
【0170】
例えば、実施の形態2に係る医用同義語辞書作成装置200の同義語判定部120の代わりに、実施の形態1の変形例で説明した同義語判定部120Aを用いても良い。
【0171】
また、実施の形態1または実施の形態2で作成され記憶部110に記憶された医用同義語辞書は、診断の支援に用いたり、医用情報の検索に用いたりすることができる。例えば、図26に示すように、医用同義語辞書データベース301と、診断支援装置302または検索装置303とをインターネット等のネットワーク304を介して接続しても良い。医用同義語辞書データベース301には、記憶部110に記憶されたのと同じ医用同義語辞書が記憶されている。診断支援装置302は、医用同義語辞書データベース301に記憶されている医用同義語辞書を参照することにより、読影項目または疾病名の同義語も含めて診断支援を行う。また、検索装置303は、医用同義語辞書データベース301に記憶されている医用同義語辞書を参照することにより、読影項目または疾病名の同義語も含めて類似症例の検索を行う。
【0172】
また、上記の医用同義語辞書作成装置は、具体的には、マイクロプロセッサ、ROM、RAM、ハードディスクドライブ、ディスプレイユニット、キーボード、マウスなどから構成されるコンピュータシステムとして構成されても良い。RAMまたはハードディスクドライブには、コンピュータプログラムが記憶されている。マイクロプロセッサが、コンピュータプログラムに従って動作することにより、医用同義語辞書作成装置は、その機能を達成する。ここでコンピュータプログラムは、所定の機能を達成するために、コンピュータに対する指令を示す命令コードが複数個組み合わされて構成されたものである。
【0173】
さらに、上記の医用同義語辞書作成装置を構成する構成要素の一部または全部は、1個のシステムLSI(Large Scale Integration:大規模集積回路)から構成されているとしても良い。システムLSIは、複数の構成部を1個のチップ上に集積して製造された超多機能LSIであり、具体的には、マイクロプロセッサ、ROM、RAMなどを含んで構成されるコンピュータシステムである。RAMには、コンピュータプログラムが記憶されている。マイクロプロセッサが、コンピュータプログラムに従って動作することにより、システムLSIは、その機能を達成する。
【0174】
さらにまた、上記の医用同義語辞書作成装置を構成する構成要素の一部または全部は、医用同義語辞書作成装置に脱着可能なICカードまたは単体のモジュールから構成されているとしても良い。ICカードまたはモジュールは、マイクロプロセッサ、ROM、RAMなどから構成されるコンピュータシステムである。ICカードまたはモジュールは、上記の超多機能LSIを含むとしても良い。マイクロプロセッサが、コンピュータプログラムに従って動作することにより、ICカードまたはモジュールは、その機能を達成する。このICカードまたはこのモジュールは、耐タンパ性を有するとしても良い。
【0175】
また、本発明は、上記に示す方法であるとしても良い。また、これらの方法をコンピュータにより実現するコンピュータプログラムであるとしても良いし、前記コンピュータプログラムからなるデジタル信号であるとしても良い。
【0176】
さらに、本発明は、上記コンピュータプログラムまたは上記デジタル信号をコンピュータ読み取り可能な非一時的な記録媒体、例えば、フレキシブルディスク、ハードディスク、CD−ROM、MO、DVD、DVD−ROM、DVD−RAM、BD(Blu−ray Disc(登録商標))、半導体メモリなどに記録したものとしても良い。また、これらの非一時的な記録媒体に記録されている上記デジタル信号であるとしても良い。
【0177】
また、本発明は、上記コンピュータプログラムまたは上記デジタル信号を、電気通信回線、無線または有線通信回線、インターネットを代表とするネットワーク、データ放送等を経由して伝送するものとしても良い。
【0178】
また、本発明は、マイクロプロセッサとメモリを備えたコンピュータシステムであって、上記メモリは、上記コンピュータプログラムを記憶しており、上記マイクロプロセッサは、上記コンピュータプログラムに従って動作するとしても良い。
【0179】
また、上記プログラムまたは上記デジタル信号を上記非一時的な記録媒体に記録して移送することにより、または上記プログラムまたは上記デジタル信号を上記ネットワーク等を経由して移送することにより、独立した他のコンピュータシステムにより実施するとしても良い。
【産業上の利用可能性】
【0180】
本発明は、画像診断分野の読影レポートにおける医用同義語辞書作成装置等として利用可能である。
【符号の説明】
【0181】
20 医用画像
21 読影レポート
22 読影レポートID
23 画像ID
24 画像所見
25 確定診断結果
30 キーワード名
31 キーワード属性
100、100A、200 医用同義語辞書作成装置
101 症例データベース
102 キーワード辞書
103 読影知識データベース
104 取得部
105 キーワード抽出部
106 キーワード対選択部
107 テキスト判定部
108 代表画像ベクトル生成部
109 画像判定部
110 記憶部
120、120A 同義語判定部
121 出力部
122 表示装置
201 更新制御部
301 医用同義語辞書データベース
302 診断支援装置
303 検索装置
304 ネットワーク
【技術分野】
【0001】
本発明は、読影レポートにおける医用同義語辞書を自動的に作成する医用同義語辞書作成装置および医用同義語辞書作成方法に関する。
【背景技術】
【0002】
近年、画像診断の分野では撮影画像および読影レポートのデジタル化が進み、医師が大量のデータを共有することが容易になっている。ここで、読影レポートとは、撮影画像に対して読影者が下した診断を示すテキスト情報のことである。つまり、読影レポートは、医用画像を読影した結果が記載された文書データである。また、画像を保管および通信するシステムであるPACS(Picture Archiving and Communication Systems)内に保管されている読影レポート同士は、共通のIDやキーワードで互いに紐付けされて管理されており、保管されている過去の読影レポートの有効な二次利用が求められている。
【0003】
読影レポートの有効な二次利用の一つとしては、レポートのテキスト検索が挙げられる。一般的なテキスト検索では、検索キーワードと同じキーワードを持つ読影レポートを検索結果として出力するが、同じ意味を持ちながら異なる表記がされているレポートについては検索結果から外れてしまうという問題が存在する。そのため、より汎用性の高いテキスト検索を実現するためには、同じ意味を持つキーワード同士を結びつける同義語辞書の作成が必須になる。
【0004】
このような同義語辞書を作成する従来技術として、特許文献1では、「人名に対応する顔画像は一意に決まる」ことを利用し、ウェブ上のドキュメントから様々な表記の人名と、その人名が付与された顔画像を抽出し、類似した顔画像に付与された人名を全て同義語(別名)として登録する方法が提案されている。この方法では画像の類似性に基づいた同義語処理を行っており、テキスト情報だけを用いた処理よりも、より精度の高い同義語辞書を作成することができる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2010−128926号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかし、特許文献1に記載の方法を画像診断分野における読影レポートに適用した場合、キーワードごとに関連する画像特徴量が異なるため、単純に画像の類似性を用いるだけでは、キーワード間の正しい同義語関係を判定できないという課題がある。
【0007】
例えば、肝腫瘤の画像に対して付与された「辺縁明瞭」というキーワードはエッジ等の形状に関する画像特徴量と関係しているが、濃度に関する画像特徴量とは関係しない。一方、「高吸収」というキーワードは濃度に関する画像特徴量と関係しているが、形状に関する画像特徴量とは関係しない。このため、「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する際、形状と濃度に関する画像特徴量の値をそのまま用いると、「辺縁明瞭」とは関係のない濃度に関する画像特徴量、また、「高吸収」とは関係のない形状に関する画像特徴量が、それぞれ画像の類似判定に含まれてしまう。よって、画像の類似性を正しく評価することができない。そのため、読影レポートにおいて画像を用いてキーワード間の同義語関係を判定するためには、画像特徴量の中からキーワードに関連する画像特徴量を適切に選択する必要がある。
【0008】
本発明は、上記課題を解決するためになされたものであり、キーワードに適合する画像特徴量を選択することにより、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成する医用同義語辞書作成装置および医用同義語辞書作成方法を提供することを目的とする。
【課題を解決するための手段】
【0009】
上記課題を解決するために、本発明のある局面に係る医用同義語辞書作成装置は、医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得部と、医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得部が取得した読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出部と、前記キーワード抽出部が抽出したキーワードからキーワード対を選択するキーワード対選択部と、前記キーワード対選択部が選択したキーワード対が同義語であるか否かを判定する同義語判定部と、前記同義語判定部が同義語であると判定したキーワード対を、医用同義語辞書に含まれる同義語として出力する出力部とを備え、前記同義語判定部は、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する。
【0010】
この構成によると、読影レポートに基づいた同義語判定と、医用画像から抽出される画像特徴量に基づいた同義語判定とを行っている。後者については、医用画像から抽出される各画像特徴量について、読影レポートに記載されているキーワードとの間の関連性が高いものほど大きな重みで重み付けを行った上で、重み付けされた画像特徴量同士を比較している。このため、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成することができる。
【0011】
なお、本発明は、このような特徴的な処理部を備える医用同義語辞書作成装置として実現することができるだけでなく、医用同義語辞書作成装置に含まれる特徴的な処理部が実行する処理をステップとする医用同義語辞書作成方法として実現することができる。また、医用同義語辞書作成装置が備える特徴的な処理部としてコンピュータを機能させるためのプログラムとして実現することもできる。また、医用同義語辞書作成方法に含まれる特徴的なステップをコンピュータに実行させるプログラムとして実現することもできる。そして、そのようなプログラムを、CD−ROM(Compact Disc−Read Only Memory)等のコンピュータ読取可能な不揮発性の記録媒体やインターネット等の通信ネットワークを介して流通させることができるのは、言うまでもない。
【発明の効果】
【0012】
本発明によると、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成することができる。
【図面の簡単な説明】
【0013】
【図1】本発明の実施の形態1における、医用同義語辞書作成装置の特徴的な機能構成を示すブロック図
【図2】本発明の実施の形態1における、症例データベースに記憶されている症例データの一例を示す図
【図3】本発明の実施の形態1における、キーワード辞書の一例を示す図
【図4】本発明の実施の形態1における、読影知識作成の手順を示すフローチャート
【図5】本発明の実施の形態1における、画像特徴量抽出の手順を示すフローチャート
【図6】本発明の実施の形態1における、腹部CT検査の読影レポートの例を示す図
【図7】本発明の実施の形態1における、読影レポートから抽出された読影項目および疾病名を示す図
【図8】本発明の実施の形態1における、読影レポートから抽出された読影項目および疾病名、及び、読影項目と同時に抽出された位置と時相の情報を示す図
【図9】本発明の実施の形態1における、読影レポートから抽出された読影項目および疾病名、及び、文脈解釈を行って読影項目と同時に抽出された位置と時相の情報を示す図
【図10】本発明の実施の形態1における、読影知識抽出のために取得したデータ一式を示す図
【図11】本発明の実施の形態1における、読影項目と画像特徴量との間の相関関係(二値)の概念図
【図12】本発明の実施の形態1における、読影項目と画像特徴量との間の相関関係(多値)の概念図
【図13】本発明の実施の形態1における、疾病名と画像特徴量との間の相関関係(二値)の概念図
【図14】本発明の実施の形態1における、読影項目と疾病名との間の相関関係(二値)の概念図
【図15】本発明の実施の形態1における、読影知識として抽出した(画像特徴量−読影項目)間の相関関係の格納形式を示す図
【図16】本発明の実施の形態1における、読影知識として抽出した(画像特徴量−疾病名)間の相関関係の格納形式を示す図
【図17】本発明の実施の形態1における、読影知識として抽出した(読影項目−疾病名)間の相関関係の格納形式を示す図
【図18】本発明の実施の形態1における、医用同義語辞書作成装置が実行する全体的な処理の流れを示すフローチャート
【図19】本発明の実施の形態1における、キーワード抽出処理(図18のステップS302)の出力例を示す図
【図20】本発明の実施の形態1における、同義語判定処理(図18のステップS303)に用いるキーワードベクトルの概念図
【図21】本発明の実施の形態1における、代表画像ベクトル生成処理(図18のステップS305)の詳細な処理の流れの一例を示すフローチャート
【図22】本発明の実施の形態1における、代表画像ベクトル生成処理(図18のステップS305)の詳細な処理の流れの一例を示すフローチャート
【図23】本発明の実施の形態1の変形例に係る医用同義語辞書作成装置の特徴的な機能構成を示すブロック図
【図24】本発明の実施の形態2における、医用同義語辞書作成装置の特徴的な機能構成を示すブロック図
【図25】本発明の実施の形態2における、医用同義語辞書作成装置が実行する全体的な処理の流れを示すフローチャート
【図26】医用同義語辞書データベースを利用したシステムの構成を示す図
【発明を実施するための形態】
【0014】
以下、本発明の実施の形態について、図面を参照しながら説明する。なお、以下で説明する実施の形態は、いずれも本発明の好ましい一具体例を示すものである。以下の実施の形態で示される数値、構成要素、構成要素の接続形態、ステップ、ステップの順序などは、一例であり、本発明を限定する主旨ではない。本発明は、特許請求の範囲だけによって限定される。よって、以下の実施の形態における構成要素のうち、本発明の最上位概念を示す独立請求項に記載されていない構成要素については、本発明の課題を達成するのに必ずしも必要ではないが、より好ましい形態を構成するものとして説明される。
【0015】
本発明の実施の形態に係る医用同義語辞書作成装置は、超音波画像、CT(Computed Tomography)画像、または核磁気共鳴画像等の医用画像に対する読影レポートに記述されたキーワードに関する医用同義語辞書を作成する装置である。本明細書中では「画像データ」のことを単に「画像」と言う。
【0016】
本発明の一実施態様に係る医用同義語辞書作成装置は、医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得部と、医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得部が取得した読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出部と、前記キーワード抽出部が抽出したキーワードからキーワード対を選択するキーワード対選択部と、前記キーワード対選択部が選択したキーワード対が同義語であるか否かを判定する同義語判定部と、前記同義語判定部が同義語であると判定したキーワード対を、医用同義語辞書に含まれる同義語として出力する出力部とを備え、前記同義語判定部は、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する。
【0017】
この構成によると、読影レポートに基づいた同義語判定と、医用画像から抽出される画像特徴量に基づいた同義語判定とを行っている。後者については、医用画像から抽出される各画像特徴量について、読影レポートに記載されているキーワードとの間の関連性が高いものほど大きな重みで重み付けを行った上で、重み付けされた画像特徴量同士を比較している。このため、読影レポートに対して画像の類似性を正しく評価した上で医用同義語辞書を作成することができる。
【0018】
具体的には、前記同義語判定部は、前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部と、前記テキスト判定部で同義語であると判定された場合に、前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部とを含み、前記出力部は、前記画像判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力する。
【0019】
また、前記同義語判定部は、前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部と、前記画像判定部で同義語であると判定された場合に、前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部とを含み、前記出力部は、前記テキスト判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力するものであっても良い。
【0020】
また、前記テキスト判定部は、前記キーワード対を構成する各キーワードについて、前記読影レポート中の当該キーワードを含む文章中の当該キーワード以外のキーワードの出現頻度をベクトルの要素とするキーワードベクトルを作成し、作成したキーワードベクトル間の距離が第1閾値以下であれば、前記キーワード対が同義語であると判定するものであっても良い。
【0021】
また、前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成するものであっても良い。
【0022】
この構成によると、読影項目と関連性のある画像特徴量に大きな重みで重み付けを行うことができる。
【0023】
また、前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが疾病名である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する疾病名との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と疾病名である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成するものであっても良い。
【0024】
この構成によると、疾病名と関連性のある画像特徴量に大きな重みで重み付けを行うことができる。
【0025】
また、前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、(i)医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うとともに、(ii)前記読影レポートの中から当該キーワードと共起する疾病名を検出し、読影項目と疾病名との関連性を予め定めた二項間関係情報に基づいて、前記各画像特徴量を読影項目である当該キーワードと当該キーワードと共起する前記疾病名との間の関連性が高いほど大きな値の重みでさらに重み付けを行うことにより、重み付けされた各画像特徴量を要素とする当該キーワードの画像特徴量ベクトルを生成するものであっても良い。
【0026】
この構成によると、読影項目と関連性の低い症例の重みは小さくなるため、読影項目と関連性の低い症例を取り除いた画像特徴量ベクトルを生成することができる。これにより、画像の類似性をより正しく評価することができ、医用同義語辞書の精度を向上させることができる。
【0027】
好ましくは、前記キーワード対選択部は、読影項目同士または疾病名同士のキーワード対のみを選択する。
【0028】
疾病名は複数の診断項目の上位概念であるため、疾病名と診断項目とは直接同義語にはならない。そのため、疾病名と診断項目の対を選択しないことで、処理時間を低減することができる。
【0029】
また、上述の医用同義語辞書作成装置は、さらに、前記出力部が出力するキーワード対を、前記医用同義語辞書に含まれる同義語として記憶する記憶部を備えるものであっても良い。
【0030】
好ましくは、前記取得部は、医用画像と当該医用画像に対する読影レポートとの組である症例データが記憶されている症例データベースから、前記医用画像と前記読影レポートとを取得し、前記医用同義語辞書作成装置は、さらに、前記症例データベースに記憶されている症例データが更新されているか否かを判断し、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させ、前記医用同義語辞書に含まれる同義語を更新する更新制御部を備える。
【0031】
この構成によると、症例データベースに記憶されている症例データが更新された場合であっても、医用同義語辞書を自動的に更新することができるため、より汎用性の高い医用同義語辞書を用いた検索が可能になる。
【0032】
なお、前記更新制御部は、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、前記医用同義語辞書に含まれる全てのキーワードについて同義語を更新するものであっても良い。
【0033】
また、前記更新制御部は、(i)前記症例データベースに記憶されている前記症例データにおける各キーワードの出現頻度を算出し、(ii)前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、出現頻度が第2閾値以下のキーワードについてのみ同義語を更新するものであっても良い。
【0034】
高頻度のキーワードが新しく追加された場合は、仮に同義語か否かの判定をし直したとしても結果は変わらないため、医用同義語辞書の更新を行う必要性が低い。一方、出現頻度が少ないキーワードに対しては、同義語関係の不確実性が高いため、医用同義語辞書を更新する必要性が高い。このように、症例データベース内のキーワード頻度に応じて同義語辞書の更新の可否を判定することにより、更新時の計算量を低減できるため、更新時間を短縮することができる。
【0035】
本発明の他の実施態様に係る医用同義語辞書作成方法は、医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得ステップと、医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得ステップで取得された読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出ステップと、前記キーワード抽出ステップで抽出されたキーワードからキーワード対を選択するキーワード対選択ステップと、前記キーワード対選択ステップで選択されたキーワード対が同義語であるか否かを判定する同義語判定ステップと、前記同義語判定ステップで同義語であると判定されたキーワード対を、医用同義語辞書に含まれる同義語として出力する出力ステップとを含み、前記同義語判定ステップでは、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択ステップで選択されたキーワード対が同義語であると判定する。
【0036】
本発明のさらに他の実施態様に係るプログラムは、上述の医用同義語辞書作成方法に含まれる各ステップをコンピュータに実行させるためのプログラムである。
【0037】
(実施の形態1)
本実施の形態で用いる用語を説明する。
【0038】
「画像特徴量」とは、医用画像における臓器や病変部分の形状に関するもの、輝度分布に関するものなどを示す。画像特徴量として、例えば、非特許文献:「根本,清水,萩原,小畑,縄野,“多数の特徴量からの特徴選択による乳房X線像上の腫瘤影判別精度の改善と高速な特徴選択法の提案”,電子情報通信学会論文誌D−II,Vol.J88−D−II,No.2,pp.416−426,2005年2月」に490種類の特徴量を用いることが記載されている。本実施の形態においても、使用した医用画像撮影装置(モダリティ)、または対象臓器ごとに予め定めた数十〜数百種の画像特徴量を用いる。
【0039】
「キーワード」とは、以下に述べる「読影項目」と「疾病名」の何れかを示す。
【0040】
「読影項目」とは、本実施の形態では、「読影医が、読影対象の画像の特徴を言語化した文字列」と定義する。使用する医用画像撮影装置、対象臓器等で使用される用語はほぼ限定されるが、例えば、分葉状、棘状、不整形、境界明瞭、輪郭不明瞭、低/高濃度、低/高吸収、スリガラス状、石灰化、モザイク状、濃染、低/高エコー、毛羽立ち、等が挙げられる。
【0041】
「疾病名」とは、読影者が医用画像やその他の検査を基に診断した疾病名のことである。例えば、肝細胞癌、嚢胞、血管腫、等が挙げられる。
【0042】
(実施の形態1:構成の説明)
以下、本発明の実施の形態1に係る医用同義語辞書作成装置について、図面を用いて詳細に説明する。
【0043】
図1は、本発明の実施の形態1に係る医用同義語辞書作成装置の特徴的な機能構成を示すブロック図である。
【0044】
図1に示すように、医用同義語辞書作成装置100は、症例データベース101内に記憶されている読影レポートから抽出されるキーワードの同義語辞書である医用同義語辞書を作成する装置である。なお、本明細書中で同義語とは同一の意味の語に限定されず、類似の意味の語である類義語も含むものとする。つまり、本発明に係る医用同義語辞書作成装置は、医用類義語辞書作成装置としても利用可能である。
【0045】
医用同義語辞書作成装置100は、取得部104、キーワード抽出部105、キーワード対選択部106、同義語判定部120、出力部121、および記憶部110を備える。
【0046】
同義語判定部120は、テキスト判定部107、代表画像ベクトル生成部108、および画像判定部109を備える。
【0047】
医用同義語辞書作成装置100は、外部の症例データベース101、キーワード辞書102、読影知識データベース103、および表示装置122に接続される。
【0048】
以下、図1に示した、症例データベース101、キーワード辞書102、読影知識データベース103、および医用同義語辞書作成装置100の各構成要素の詳細について順に説明する。
【0049】
症例データベース101は、例えばハードディスク、メモリ等からなる記憶装置である。症例データベース101は、読影者に提示する読影対象の画像を示す医用画像と、その医用画像に対応する読影レポートとから構成される症例データを記憶しているデータベースである。ここで、医用画像とは、画像診断のために用いられる画像データであり、電子媒体に格納された画像データを示す。また、読影レポートとは、医用画像の読影結果に加え、画像診断後に行われる生検等の確定診断結果までを示す情報である。読影レポートは、文書データ(テキストデータ)である。生検とは、患部の一部を切り取って、顕微鏡などで調べる検査のことである。
【0050】
図2は、症例データベース101に記憶されている症例データを構成する、医用画像20としてのCT画像および読影レポート21の一例をそれぞれ示す図である。読影レポート21は、読影レポートID22、画像ID23、画像所見24および確定診断結果25を含む。1つの症例データは同一の患者から作成される。
【0051】
読影レポートID22は、読影レポート21を識別するための識別子であり、読影レポート21ごとに識別子が異なる。画像ID23は、医用画像20を識別するための識別子であり、医用画像20ごとに識別子が異なる。画像所見24は、画像ID23の医用画像20に対する読影者の診断結果を示す情報である。つまり、画像所見24は、疾病名を含む診断結果(読影結果)および診断理由(読影理由)を示す情報である。確定診断結果25は、医用画像20の患者の確定診断結果を示す。ここで確定診断結果とは、手術または生検で得られた試験体の顕微鏡による病理検査、またはその他様々な手段によって、対象の患者の真の状態が何であったのかを明らかにした診断結果である。
【0052】
キーワード辞書102は、例えばハードディスク、メモリ等からなる記憶装置である。
【0053】
キーワード辞書102は、読影レポート21からの抽出対象となるキーワード(キーワード辞書データ)を記憶しているデータベースである。図3は、キーワード辞書102に記憶されているキーワードの一例を示す図である。図3に示すように、キーワード辞書102には、キーワード名30とキーワード属性31とがリスト形式で記憶されている。ここで、キーワード属性31とは、キーワード名30のキーワードが読影項目か疾病名かを示すデータである。例えば、濃染というキーワードのキーワード属性は読影項目である。
【0054】
読影知識データベース103は、例えばハードディスク、メモリ等からなる記憶装置である。
【0055】
読影知識データベース103は、読影レポート21から抽出したキーワード間の相関関係(関連性)を示す二項間関係情報と、キーワードと医用画像20から抽出した画像特徴量との相関関係(関連性)を示す二項間関係情報とを記憶しているデータベースである。二項間関係情報は、症例データベース101のデータを用いて自動的に作成される。データベースの構成および作成方法については後述する。
【0056】
取得部104は、症例データベース101から、読影者が診断を行った医用画像20および読影レポート21を取得する。取得部104は、取得した医用画像20および読影レポート21を、キーワード抽出部105に出力する。
【0057】
キーワード抽出部105は、キーワード辞書102を参照することにより、取得部104が取得した読影レポート21の中からキーワード辞書102に登録されているキーワードを抽出し、抽出したキーワードをリスト化してキーワード対選択部106に出力する。具体的なキーワード抽出方法については後述する。
【0058】
キーワード対選択部106は、キーワード抽出部105が抽出したキーワードリストから未選択のキーワード対を選択し、選択したキーワード対を、テキスト判定部107、代表画像ベクトル生成部108、および出力部121に出力する。
【0059】
同義語判定部120は、キーワード対選択部106が選択したキーワード対が同義語であるか否かを判定する。
【0060】
つまり、テキスト判定部107は、読影レポート21に基づいて、キーワード対選択部106が選択したキーワード対に対して同義語判定を行い、同義語と判定した場合には、判定結果を代表画像ベクトル生成部108に出力する。具体的な同義語判定方法については後述する。
【0061】
代表画像ベクトル生成部108は、テキスト判定部107でキーワード対選択部106が選択したキーワード対が同義語であると判定された場合に、キーワード対選択部106から取得したキーワード対と、読影知識データベース103に記憶されている二項間関係情報と、症例データベース101に記憶されている医用画像20とを用いて、キーワード対選択部106が選択したキーワード対を構成する各キーワードに対する代表画像ベクトルを生成し、画像判定部109に出力する。ここで、代表画像ベクトルとは、各キーワードが付与されている医用画像群に対して算出された画像特徴量のベクトルであり、このベクトルには読影知識データベース103に記憶されているキーワード毎に算出された画像特徴量に対する重みが付加される。
【0062】
医用同義語辞書作成に代表画像ベクトルを用いる理由は以下の通りである。
【0063】
読影レポート21とは、医用画像20に対して医学的に統一された診断指針に基づいて記述されたテキストであるため、同義語関係にあるキーワードは同じ画像特徴を呈する。つまり、キーワード間の同義語関係は画像の類似性で評価することができる。すなわち、テキストだけを用いて作成された同義語関係を画像の類似性で再評価することにより、テキストだけを用いるよりも精度の高い医用同義語辞書を作成することができる。
【0064】
しかし、読影レポート21中のキーワードの同義語関係を評価するために、すべてのキーワードに対して同一の画像特徴量を用いて画像の類似性を評価することはできない。何故なら、それぞれのキーワードごとに、関連する画像特徴量が異なるからである。例えば、「辺縁明瞭」というキーワードはエッジ等の形状に関する画像特徴量と関係しているが、「高吸収」というキーワードは濃度に関する画像特徴量と関係している。「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する際、形状と濃度に関する画像特徴量の値をそのまま用いてしまうと、「辺縁明瞭」とは関係のない濃度に関する画像特徴量、そして、「高吸収」とは関係のない形状に関する画像特徴量が、それぞれ画像の類似判定に含まれてしまい、画像の類似性を正しく評価することができない。
【0065】
そこで、代表画像ベクトル生成部108は、各キーワードが付属する画像から算出された画像特徴量に対して、読影知識データベース103に記憶されている(キーワード−画像特徴量)間の関連性を示す値によって重み付けを行うことによって代表画像ベクトルを生成する。
【0066】
これにより、「辺縁明瞭」の画像に対しては形状情報の値に、「高吸収」の画像に対しては濃度情報の値に大きな重みを付けることができるため、画像の類似性を正しく評価することができ、画像の類似性に基づくキーワード間の同義語判定が可能になる。
【0067】
具体的な代表画像ベクトル生成方法は後述する。
【0068】
画像判定部109は、代表画像ベクトル生成部108が生成した代表画像ベクトルを用いて、キーワード対選択部106が選択したキーワード対が同義語であるか否かを再判定し、判定結果を出力部121に出力する。
【0069】
出力部121は、キーワード対選択部106から取得したキーワード対のうち、画像判定部109で同義語と判定されたキーワード対を、医用同義語辞書に含まれる同義語として記憶部110に書き込む、または、表示装置122に表示する。
【0070】
次に、読影知識データベース103の作成方法、および以上のように構成された医用同義語辞書作成装置100の動作について順に説明する。
【0071】
(実施の形態1:読影知識データベース103の事前作成)
医用同義語辞書作成を行うに当たり、事前に読影知識を得て、読影知識データベース103に格納しておく。読影知識は、医用画像とその医用画像を読影した結果である読影レポートとの対から構成される“症例”(症例データ)を複数集めたものから得られる。症例は、症例データベース101に格納されたものを用いてもよいし、他のデータベースに格納されたものを用いてもよい。必要な症例数は、種種のデータマイニングアルゴリズムを用いて何らかの法則性および知識を得るために十分となる数である。通常は数百〜数万個のデータが用いられる。本実施の形態では、読影知識として、(1)画像特徴量、(2)読影項目、(3)疾病名 の三項のうち二項間の相関関係を用いる。ここで、読影時の診断疾病名とその他の検査を経て確定診断した疾病名とは異なることがあるが、読影知識データベースを作成する際は、確定診断の結果を用いる。
【0072】
以下、図4のフローチャートを用いて読影知識作成の手順を説明する。本実施の形態で対象とする、つまり使用する医用画像撮影装置はマルチスライスCTとし、対象臓器および疾病は、それぞれ肝臓および肝腫瘤とする。
【0073】
ステップS101では、読影知識を得るための症例が格納されたデータベースから症例を1つ取得する。ここで読影知識を得るための症例の総数をC個とする。1つの症例は、医用画像とその医用画像を読影した結果である読影レポートとの対で構成されている。医用画像がマルチスライスCT装置により取得された場合、1つの症例は多数枚のスライス画像を含むことになる。また、通常、マルチスライスCT画像を医師が読影する場合、重要なスライス画像1〜数枚を、キー画像として読影レポートに添付する。以後、多数枚のスライス画像集合、あるいは、数枚のキー画像を単に「医用画像」、「画像」と呼ぶこともある。
【0074】
ステップS102では、医用画像から画像特徴量を抽出する。ステップS102の処理を、図5のフローチャートを用いて詳細に説明する。
【0075】
ステップS201では、対象臓器の領域を抽出する。本実施の形態では肝臓領域を抽出する。肝臓領域抽出法として、例えば、非特許文献:「田中,清水,小畑,“異常部位の濃度パターンを考慮した肝臓領域抽出手法の改良<第二報>”,電子情報通信学会技術研究報告,医用画像,104(580),pp.7−12,2005年1月」等の手法を用いることができる。
【0076】
ステップS202では、ステップS201で抽出された臓器領域から病変領域を抽出する。本実施の形態では肝臓領域から腫瘤領域を抽出する。肝腫瘤領域抽出法として、例えば、非特許文献「中川、清水,一杉,小畑,“3次元腹部CT像からの肝腫瘤影の自動抽出手法の開発<第二報>”,医用画像,102(575),pp.89−94,2003年1月」等の手法を用いることができる。ここで、i番目の症例における画像から抽出した腫瘤の数をMiとすると、腫瘤は(症例番号,腫瘤番号)の組(i,j)で特定できる。ここで、1≦i≦C,1≦j≦Miである。また本実施の形態では病変として肝腫瘤を対象としているため、“腫瘤番号”と呼んだが、本発明で共通の表現を用いて“病変番号”と呼ぶこともできる。
【0077】
ステップS203では、ステップS202で抽出された病変領域のうち、1つの領域を選択する。
【0078】
ステップS204では、ステップS203で選択された病変領域から画像特徴量を抽出する。本実施の形態では、画像特徴量として、非特許文献:「根本,清水,萩原,小畑,縄野,“多数の特徴量からの特徴選択による乳房X線像上の腫瘤影判別精度の改善と高速な特徴選択法の提案”,電子情報通信学会論文誌D−II,Vol.J88−D−II,No.2,pp.416−426,2005年2月」に記載された490種類の特徴量のうち、肝腫瘤にも適用可能な特徴量をいくつか選択して用いる。この特徴量数をNF個とする。本ステップで抽出された特徴量は、(症例番号,この症例(医用画像)から抽出された腫瘤番号,特徴量番号)の組(i,j,k)で特定できる。ここで、1≦i≦C,1≦j≦Mi,1≦k≦NFである。
【0079】
ステップS205では、ステップS202で抽出された病変領域のうち未選択の病変があるかどうかをチェックし、未選択の病変がある場合は、ステップS203に戻り未選択の病変領域を選択した後、ステップS204を再実行する。未選択の病変がない場合、すなわち、ステップS202で抽出された全ての病変領域に対し、ステップS204の特徴量選択を行った場合は図5のフローチャートの処理を終了し、図4のフローチャートに戻る。
【0080】
図4のステップS103では、読影レポートの解析処理を行う。具体的には読影レポートから読影項目及び疾病名を抽出する。本実施の形態では読影項目が格納された読影項目単語辞書、および疾病名が格納された疾病名単語辞書を用いた形態素解析及び構文解析を行う。これらの処理により、各単語辞書に格納された単語と一致する単語を抽出する。形態素解析技術としては、例えば、MeCab(http://mecab.sourceforge.net)やChaSen(http://chasen−legacy.sourceforge.jp)等が、構文解析技術としては、KNP(http://nlp.kuee.kyoto−u.ac.jp/nl−resource/knp.html)、CaboCha(http://chasen.org/〜taku/software/cabocha/)等が存在する。読影レポートは医師により読影レポート独特の表現で記述されることが多いので、読影レポートに特化した形態素解析技術、構文解析技術、各単語辞書を開発することが望ましい。
【0081】
図6は腹部CT検査の読影レポートの例であり、図7は図6の読影レポートから抽出された読影項目および疾病名を示す。読影項目は通常複数個、疾病名は1個抽出される。i番目の症例における読影レポートから抽出した読影項目の数をNiとすると、読影項目は(症例番号,読影項目番号)の組(i,j)で特定できる。ここで、1≦i≦C,1≦j≦Niである。
【0082】
また、図7では、読影項目および疾病名の単語のみを抽出しているが、読影レポートにおける病変の位置を表す文字列、時相を表す文字列を同時に抽出してもよい。ここで、時相について補足する。肝臓の病変の鑑別には、造影剤を急速静注して経時的に撮像する造影検査が有用とされている。肝臓の造影検査では一般に、肝動脈に造影剤が流入し多血性の腫瘍が濃染する動脈相、腸管や脾臓に分布した造影剤が門脈から肝臓に流入し肝実質が最も造影される門脈相、肝の血管内外の造影剤が平衡に達する平衡相、肝の間質に造影剤が貯留する晩期相などにおいて、肝臓が撮像される。読影レポートには病変の臓器における位置や、造影検査であれば着目した時相の情報が記述されていることが多い。このため、読影項目だけでなく位置や時相の情報も合わせて抽出することで、後で説明する読影知識の抽出に有効となる。図8に、読影項目と同時に位置と時相の情報を抽出した例を示す。例えば、図6の読影レポートを解析し、「肝S3区域に早期濃染を認め」という文節から「早期濃染」の位置属性として「肝S3区域」が抽出される。同様に、「後期相でwashoutされており」という文節から「washout」の時相属性として「後期相」が抽出される。
【0083】
図6の読影レポートを、単純に解釈すると、図8のように「早期濃染」に関する時相、washoutに関する位置の部分が空白になる。これに対し、読影項目「早期濃染」は早期相に対応した単語であるという事前知識を利用したり、「早期濃染」の状態を示す腫瘤と「後期相でwashout」される腫瘤が同一の腫瘤を指すという高度な文脈解釈を行ったりすることができれば、抽出される位置と時相の情報は図9のようになる。
【0084】
ステップS104では、読影知識を得るための症例が格納されたデータベースにおいて未取得の症例があるかどうかをチェックし、未取得の症例がある場合は、ステップS101に戻り未取得の症例を取得した後、ステップS102およびS103を実行する。未取得の症例がない場合、すなわち、全ての症例に対し、ステップS102の画像特徴抽出およびステップS103のレポート解析を実施済の場合は、ステップS105に進む。
【0085】
ステップS102とステップS103の結果は相互に依存しないため、実行順は逆でも構わない。
【0086】
ステップS105に到達した時点で、図10で表されるデータ一式が取得できたことになる。つまり、症例ごとに画像特徴量と読影項目と疾病名とが取得される。症例番号1の症例については、医用画像中にM1個の病変が含まれており、各病変から抽出される画像特徴量の個数はNF個である。また、読影レポート中の読影項目の数はN1個である。例えば、病変番号(1,1)で示される1つ目の病変のうち、1つ目の画像特徴量の値は0.851である。また、読影項目番号(1,1)で示される1つ目の読影項目の値は「早期濃染」である。
【0087】
ステップS105では、ステップS102で得られた画像特徴量、ステップS103で得られた読影項目および疾病名から、読影知識を抽出する。本実施の形態では、画像特徴量、読影項目、疾病名という三項のうちの二項の相関関係を、読影知識とする。
【0088】
以下では、画像特徴量、読影項目、疾病名という三項から得られる三組の二項の相関関係について説明する。
【0089】
(1)(画像特徴量−読影項目)間の相関関係
1対の(画像特徴量,読影項目)間の相関関係の求め方について説明する。相関関係の表現形態は複数あるが、ここでは相関比を用いる。相関比は、質的データと量的データとの間の相関関係を表す指標であり、(式1)で表される。
【0090】
【数1】
【0091】
読影レポート中に、ある読影項目を含む場合および含まない場合の2カテゴリを考え、これを質的データとする。医用画像から抽出した、ある画像特徴量の値そのものを量的データとする。例えば、読影知識を抽出するための症例データベースに含まれる全症例に対し、読影レポートを、ある読影項目を含むものまたは含まないものに区分する。ここでは、読影項目「早期濃染」と画像特徴量「早期相における腫瘤内部の輝度平均値」との相関比を求める方法について説明する。(式1)においては、カテゴリi=1を「早期濃染」を含むもの、カテゴリi=2を「早期濃染」を含まないものとする。読影レポートに「早期濃染」を含む症例から抽出した腫瘤画像の「早期相における腫瘤内部の輝度平均値」であるj番目の観測値をx1jとする。また、読影レポートに「早期濃染」を含まない症例から抽出した腫瘤画像の「早期相における腫瘤内部の輝度平均値」であるj番目の観測値をx2jとする。「早期濃染」とは造影早期相にてCT値が上昇することを表すため、この場合、相関比が大きく(1に近く)なることが予想される。また、早期濃染は腫瘤の種類に依存し、腫瘤の大きさには依存しないため、読影項目「早期濃染」と画像特徴量「腫瘤面積」との相関比は小さく(0に近く)なることが予想される。このようにして、全ての読影項目と全ての画像特徴量との間の相関比を計算する。
【0092】
図11に、読影項目と画像特徴量との間の相関関係(ここでは、相関比)の概念図を示す。左側には複数の読影項目、右側には複数の画像特徴量の名称が列挙されている。そして、相関比が閾値以上の読影項目と画像特徴量の間が実線で結ばれている。計算した相関比を最終的に閾値で二値化すると、図11のような情報が求められることになる。その一例について補足する。肝腫瘤の造影CT検査においては、殆どの腫瘤は造影剤使用前のCT画像(単純、単純CT、単純相などと呼ぶ)で低濃度に描出され、多くの場合、読影レポートに「低濃度」「LDA(Low Density Area)あり」などと記述される。そのため、「低輝度」や「LDA」といった読影項目と、造影剤使用前のCT画像における腫瘤内部の輝度平均(図11では「単純相 輝度平均」と略記載)との相関が大きくなる。
【0093】
また、図12に、読影項目と画像特徴量との間の相関関係(例えば、相関比)の別の概念図を示す。この図では、相関比を多値表現しており、読影項目と画像特徴量の間の実線の太さが相関比の大きさに相当している。例えば、造影早期相にてCT値が上昇する「早期濃染」と、早期動脈相(早期相、動脈相とも略される)における腫瘤内部の輝度平均(図12では「動脈相 輝度平均」と略記載)との相関が大きくなっている。
【0094】
相関比の値に着目することで、ある読影項目と相関の高い画像特徴量を特定することができる。実際には1つの症例には、複数の画像や複数の病変(腫瘤)を含む場合が多く、その場合は読影レポートには複数の病変に関する記載が含まれることになる。例えば、造影CT検査では、造影剤使用前や使用後の複数時刻におけるタイミングでCT撮影を行う。そのため、スライス画像の集合が複数得られ、スライス画像の1つの集合には複数の病変(腫瘤)が含まれ、1つの病変からは複数の画像特徴量が抽出される。そのため、(スライス画像集合数)×(1人の患者から検出された病変数)×(画像特徴量の種類数)の個数だけ画像特徴量が得られ、これら複数の画像特徴量と、1つの読影レポートから抽出された複数の読影項目や疾病名との相関関係を求める必要がある。もちろん大量の症例を用いることにより、対応が正しく得られる可能性があるが、図9のように病変位置と時相を用いる等して、読影レポートの記載と、対応する画像特徴量とをある程度事前に対応づけることができれば、より正確に相関関係を求めることができる。
【0095】
先の説明では、質的データが、ある読影項目を含むものおよび含まないものの2カテゴリである場合について説明したが、ある読影項目(例えば、「境界明瞭」)と、その対義語となる読影項目(例えば、「境界不明瞭」)との2カテゴリであってもよい。また、読影項目が「低濃度」、「中濃度」、「高濃度」などの序数尺度の場合は、それらの各々をカテゴリとして(この例では3カテゴリ)、相関比を計算してもよい。
【0096】
また、「低濃度」、「低輝度」、「低吸収」などの同義語については、予め医用同義語辞書を作成しておき、それらを同一の読影項目として扱う。
【0097】
(2)(画像特徴量−疾病名)間の相関関係
1対の(画像特徴量,疾病名)間の相関関係については、(画像特徴量,読影項目)間の場合と同じく相関比を用いることができる。図13に、疾病名と画像特徴量との間の相関関係(例えば、相関比)の概念図を示す。この図では図11と同じく相関関係を二値表現しているが、もちろん図12のような多値表現を行うことも可能である。
【0098】
(3)(読影項目−疾病名)間の相関関係
1対の(読影項目,疾病名)間の相関関係の求め方について説明する。相関関係の表現形態は複数あるが、ここでは支持度を用いる。支持度は、質的データ間の相関ルールを表す指標であり、(式2)で表される。
【0099】
【数2】
【0100】
この支持度は、全症例において読影項目Xと疾病名Yとが同時に出現する確率(共起確率)を意味する。支持度を用いることで、関連性の強い読影項目と疾病名との組合せを特定することができる。
【0101】
なお、支持度の代わりに、(式3)で示される確信度や、(式4)で示されるリフト値を用いても良い。
【0102】
【数3】
【0103】
【数4】
【0104】
確信度とは、条件部Xのアイテムの出現を条件としたときの結論部Yのアイテムが出現する確率である。リフト値とは、Xの出現を条件としないときのYの出現確率に対して、Xの出現を条件としたときのYの出現確率がどの程度上昇したかを示す指標である。その他、conviction,φ係数を用いても良い。conviction,φ係数については相関ルール分析に関する文献(例えば、非特許文献:「データマイニングとその応用」、加藤/羽室/矢田 共著、朝倉書店)に記載されている。
【0105】
図14に、読影項目と疾病名との間の相関関係(例えば、支持度)の概念図を示す。この図では図11と同じく相関関係を二値表現しているが、もちろん図12のような多値表現を行うことも可能である。
【0106】
以上の方法にて、ステップS105の処理を行うと、図15、図16、図17のような、(画像特徴量−読影項目)間の相関関係、(画像特徴量−疾病名)間の相関関係、(読影項目−疾病名)間の相関関係が、それぞれ得られる。なお表中の数値は、図15、図16では相関比、図17では支持度である。また、得られた相関関係は、図15、図16、図17の形式にて読影知識データベース103に格納される。
【0107】
以上、読影知識データベース103の作成方法について述べた。次に、医用同義語辞書作成装置100の動作について説明する。
【0108】
(実施の形態1:医用同義語辞書作成装置100の動作の説明)
図18は、医用同義語辞書作成装置100が実行する処理の全体的な流れを示すフローチャートである。以下、図18を用いて、医用同義語辞書作成装置100が実行する処理の全体的な流れについて説明する。
【0109】
まず、取得部104は、症例データベース101から、読影者が診断した医用画像20と読影レポート21を取得し、キーワード抽出部105に出力する(ステップS301)。医用画像20と読影レポート21は、例えば、1週間単位などの固定期間ごとに取得してもよいし、ユーザが指定する任意のタイミングで取得してもよい。
【0110】
次に、キーワード抽出部105は、キーワード辞書102を参照することにより、取得部104から取得した読影レポート21の中からキーワードを抽出し、抽出したキーワードと読影レポートID22をリスト化してキーワード対選択部106に出力する(ステップS302)。特に、キーワード抽出部105は、画像所見24と確定診断結果25とからキーワードを抽出する。
【0111】
抽出されたキーワードと読影レポートID22のリストの一例を図19に示す。キーワード抽出方法としては、例えば、読影レポート21の中から、キーワード辞書102に記憶されているキーワードと一致するキーワードを抽出すればよい。図19に示すリストより、例えば、キーワード「高吸収」を含む読影レポート21の読影レポートID22は、r_12およびr_14などであることが分かる。
【0112】
次に、キーワード対選択部106は、キーワード抽出部105から取得したキーワードリストから未選択のキーワード対を選択し、選択したキーワード対をテキスト判定部107、代表画像ベクトル生成部108、および出力部121に出力する(ステップS303)。
【0113】
なお、キーワード対選択部106は、キーワード対を選択する際に、疾病名の対、および診断項目の対のみを選択してもよい。疾病名は複数の診断項目の上位概念であるため、疾病名と診断項目とは直接同義語にはならない。そのため、疾病名と診断項目の対を選択しないことで、処理時間を低減することができる。
【0114】
次に、テキスト判定部107は、取得部104が取得した読影レポート21に基づいて、キーワード対選択部106が選択したキーワード対に対して同義語判定を行い、同義語と判定した場合には、判定結果を代表画像ベクトル生成部108に通知する。一方、同義語と判定しなかった場合は、ステップS303へ戻る(ステップS304)。具体的な同義語判定方法としては、例えば、判定対象となるキーワードの前後に出現するキーワード頻度の類似性に基づいて、キーワード対が類義語か否かを判定すればよい。以下、キーワード対選択部106で「辺縁明瞭」と「高吸収」の2つのキーワードが選択された場合を例に、テキスト判定部107の処理の一例を説明する。つまり、テキスト判定部107は、図19に示すキーワードと読影レポートID22のリストを参照し、「辺縁明瞭」が付与されている読影レポートID22を抽出する。テキスト判定部107は、抽出した読影レポートID22の読影レポート21の画像所見24および確定診断結果25に含まれるテキストデータを取得する。テキスト判定部107は、取得したテキストデータから「辺縁明瞭」を含む一文を選択する。テキスト判定部107は、選択した一文から「辺縁明瞭」以外のキーワードを抽出し、図20に示すようなキーワードベクトルを作成する。ここで、ti(i=1〜n)はキーワードiの出現頻度、nはキーワードの種類数であり、各キーワードの出現頻度がベクトルの要素である。次に、テキスト判定部107は、「高吸収」に対するキーワードベクトルを、「辺縁明瞭」の場合と同様の手法で作成する。最後に、テキスト判定部107は、作成された2つのキーワードベクトル間のコサイン距離を算出し、算出した距離が閾値以下であれば同義語であると判定し、閾値より大きければ同義語でないと判定する。このようなテキストに基づいた同義語判定の詳細なアルゴリズムは、非特許文献:「山本,梅村,“辞書を用いない関連語リストの構築方法”,情報処理学会研究報告,vol.2002(20),pp.81−88,2002−03−04」に開示されている。
【0115】
次に、代表画像ベクトル生成部108は、テキスト判定部107でキーワード対が同義語であると判定された場合に、キーワード対選択部106が選択したキーワード対と、読影知識データベース103に記憶されている二項間関係情報と、症例データベース101に記憶されている医用画像20とを用いて、キーワード対選択部106から取得したキーワードに対する代表画像ベクトルを生成し、画像判定部109に出力する(ステップS305)。
【0116】
図21にステップS305の処理の詳細なフローチャートの一例を示す。以下、図21を用いて具体的な代表画像ベクトル生成方法について説明する。
【0117】
まず初めに、代表画像ベクトル生成部108は、キーワード対選択部106から取得したキーワード対の中から1つのキーワードを選択する(ステップS401)。
【0118】
次に、代表画像ベクトル生成部108は、読影知識データベース103から、ステップS401で選択したキーワードに対する画像重みを取得する(ステップS402)。画像重みとは、画像特徴量に掛けられる重みのことである。キーワードが読影項目の場合には、図15に示す(画像特徴量−読影項目)間の相関関係より画像重みを取得する。例えば、キーワードが読影項目1の場合には、画像特徴量1に対する画像重みは0.808であり、画像特徴量2に対する画像重みは0.627である。また、キーワードが疾病名の場合には、図16に示す(画像特徴量−疾病名)間の相関関係より画像重みを取得する。例えば、キーワードが疾病名1の場合には、画像特徴量1に対する画像重みは0.671であり、画像特徴量2に対する画像重みは0.697である。
【0119】
次に、代表画像ベクトル生成部108は、ステップS401で選択したキーワードが付与された医用画像20に対して画像特徴量ベクトルを算出する(ステップS403)。キーワードが付与された医用画像20とは、キーワードを含む読影レポート21の作成の基となった医用画像20のことである。画像特徴量ベクトルとは、医用画像20から算出された画像特徴量をベクトル表現したものである。例えば、画像特徴量としてエッジ強度と輝度分散を算出する場合は、医用画像20から算出したエッジ強度の平均値sと輝度分散の平均値tを、画像特徴量ベクトル(s,t)として出力する。実際には、前述のように臓器および病変部分の形状および輝度分布に関する数十〜数百種の画像特徴量を用いるため、画像特徴量ベクトルは数十から数百次元のベクトルとなる。なお、個々の医用画像20に対して算出される画像特徴量は、予め症例データベース101に記憶しておき、症例データベース101を参照することで取得しても構わない。これにより、本ステップでの処理時間が低減できる。
【0120】
次に、代表画像ベクトル生成部108は、ステップS405から取得した画像重みを、ステップS406で算出した画像特徴量ベクトルに掛け合わせ、代表画像ベクトルとして出力する(ステップS404)。例えば、ステップS402で画像重み(エッジ強度の重みw1,輝度分散の重みw2)が取得され、ステップS403で画像特徴量ベクトル(例えばエッジ強度の平均値f1と輝度分散の平均値f2)が、(f1,f2)のベクトル形式で出力されたとする。この場合、ステップS404で、代表画像ベクトル生成部108は、代表画像ベクトルとして、画像特徴量ベクトルに画像重みを掛け合わせた(w1・f1,w2・f2)を出力する。
【0121】
なお、ステップS403では、画像特徴量ベクトルを、画像ID23と画像特徴量とを対応付けたリスト形式で出力してもよい。この場合、ステップS404では、画像ID23ごとに画像重みと画像特徴量ベクトルを掛け合わせ、最後に掛け合わせにより得られるベクトルの平均ベクトルを代表画像ベクトルとして出力すればよい。
【0122】
ステップS404で代表画像ベクトルを算出することにより、前述した「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する際、「辺縁明瞭」の画像に対しては形状情報、「高吸収」の画像に対しては濃度情報の画像特徴量に大きな重みを重みづけることができるため、画像の類似性に基づくキーワード間の同義語判定を正しく行うことが可能になる。
【0123】
最後に、代表画像ベクトル生成部108は、キーワード対選択部106から取得した全てのキーワードが、ステップS401において選択されたか否かを判定し、選択されてないキーワードがある場合はステップS401へ戻り、全てのキーワードが選択されている場合は処理を終了する(ステップS405)。
【0124】
以上のステップS401〜S405の処理を行うことにより、ステップS305において、ステップS303で選択したキーワードに対する代表画像ベクトルを生成することが可能になる。
【0125】
なお、ステップS401で選択したキーワードが読影項目の場合は、共起する疾病名による重みを付加した代表画像ベクトルを生成してもよい。
【0126】
図17に示すように、疾病名と読影項目の相関関係(支持度)は疾病名によって異なる。支持度の値は、疾病名に対する読影項目の寄与度を示す。医師が疾病名を決める際に典型的に利用される読影項目に対する支持度は高くなり、一方、S301で取得された症例が非典型な症例の場合、または、医用同義語辞書作成装置による読影項目の誤抽出があった場合には、疾病名に対する読影項目の支持度は低くなる。代表画像ベクトルは各読影項目に対する典型的な画像特徴量を示すベクトルであり、支持度の低い読影項目が付与された画像は、代表画像ベクトルを作成する際のノイズ要因の一つになる。例えば、「高吸収」という読影項目は、「肝細胞癌(疾病名)」の診断に典型的に用いられるため、「肝細胞癌」に対する「高吸収」の支持度は高い値となり、濃度に関する画像特徴量の重みが大きくなる。一方、「高吸収」は「嚢胞(疾病名)」の診断には殆ど用いられないため、「嚢胞」に対する「高吸収」の支持度の値は低くなり、濃度に関する画像特徴量の重みが小さくなる。よって、代表画像ベクトルを作成する際に、このような支持度の低い症例を取り除くことができれば、より正しく画像の類似性を評価することができ、医用同義語辞書の精度を向上させることができる。
【0127】
具体的なステップS305の処理のフローチャートを図22に示す。以下、図22を用いて、読影項目と共起する疾病名による重みを付加した代表画像ベクトル生成方法について説明する。なお、図21と同じ構成要素については同じ符号を付し、説明を繰り返さない。
【0128】
ステップS401〜S403の処理の実行後、代表画像ベクトル生成部108は、ステップS401で取得したキーワードのキーワード属性31が読影項目か否かを判定し、読影項目の場合はステップS502に進み、読影項目でなかった場合はステップS404に進む(ステップS501)。
【0129】
次に、代表画像ベクトル生成部108は、ステップS401で取得したキーワードと共起する疾病名を取得し、画像ID23と共にリスト化する(ステップS502)。具体的には、代表画像ベクトル生成部108は、取得したキーワードが含まれる画像所見24と同じ読影レポート21に含まれる確定診断結果25を、取得したキーワードとともに共起する疾病名として決定する。代表画像ベクトル生成部108は、確定診断結果25を、確定診断結果25と同じ読影レポート21に含まれる画像ID23と共にリスト化する。
【0130】
次に、代表画像ベクトル生成部108は、ステップS401で選択した読影項目と、ステップS502で取得した疾病名との間の相関関係(支持度)を、(読影項目−疾病名)の重みとして読影知識データベース103から取得し、画像ID23と共にリスト化する(ステップS503)。この画像ID23は、ステップS502で説明した画像ID23と同じである。
【0131】
次に、代表画像ベクトル生成部108は、ステップS405から取得したキーワード重みベクトルと、ステップS406で算出した画像特徴量ベクトルと、ステップS503から取得した(読影項目−疾病名)の重みを掛け合わせることにより、代表画像ベクトルを算出する(ステップS504)。例えば、ステップS401で読影項目Aが選択された時に、ステップS402で読影項目Aに対する画像重み(w1,w2)が取得されたとする。また、ステップS403で画像特徴量ベクトル(例えばエッジ強度の値f1と輝度分散の値f2)が、画像ID23ごとに(f1,f2)のベクトル形式で算出されたとする。また、ステップS503では(読影項目−疾病名)の重みαが画像ID23ごとに取得されたとする。このとき、ステップS504では、代表画像ベクトル生成部108は、画像特徴量ベクトル(f1,f2)に、画像重み(w1,w2)と(読影項目−疾病名)の重みαを掛け合わせた(α・w1・f1,α・w2・f2)を画像ID23ごとに算出し、これらの平均ベクトルを代表画像ベクトルとして出力する。
【0132】
ステップS504またはS404の処理後、ステップS405の処理が実行される。
【0133】
以上のステップS401〜S405およびステップS501〜S504の処理を行うことにより、ステップS305において、ステップS303で選択したキーワードが読影項目の場合に、共起する疾病名による重みを付加した代表画像ベクトルを生成することが可能になる。例えば、「高吸収」という読影項目に対する代表画像ベクトルを作成する場合では、肝細胞癌と共起して利用されている画像に対しては重みが大きく付与され、一方、嚢胞と共起して利用されている画像に対しては小さい重みが付与される。このため、実際には肝細胞癌の画像のみを用いて代表画像ベクトルを作成することができ、「高吸収」に対してより典型的な画像特徴量を表す画像ベクトルを作成することができる。
【0134】
ここで、図18に示した医用同義語辞書作成装置100の動作の説明に戻る。
【0135】
画像判定部109は、代表画像ベクトル生成部108から取得した代表画像ベクトルを用いて、キーワード対選択部106が選択したキーワード対の同義語関係を再判定し、判定結果を出力部121に通知する(ステップS306)。
【0136】
例えば、画像判定部109は、代表画像ベクトル間のユークリッド距離を算出し、算出した距離が閾値以下の場合に、選択したキーワード対が同義語であると判定し、算出した距離が閾値よりも大きい場合に、選択したキーワード対が同義語でないと判定する。これにより、複数の画像特徴量の中から、医師が着目した画像特徴量のみを用いて画像の類似性を評価することができる。
【0137】
次に、出力部121は、画像判定部109で同義語と判定された場合に、キーワード対選択部106から取得したキーワード対を、医用同義語辞書に含まれる同義語として記憶部110に書き込む(ステップS307)。これにより、記憶部110には複数の同義語を含む医用同義語辞書が記憶される。
【0138】
最後に、キーワード対選択部106は、ステップS303で全てのキーワード対を選択下か否かを判定し、選択されていないキーワード対がある場合にはステップS303に戻り、全てのキーワード対が選択されている場合には処理を終了する(ステップS308)。
【0139】
以上、図18に示すステップS301〜S308の処理を実行することにより、医用同義語辞書作成装置100は、キーワードに適合する画像特徴量を動的に選択することができ、読影レポート21に対して画像の類似性に基づく医用同義語辞書を作成することができる。
【0140】
(従来手法との比較)
例えば「辺縁明瞭」と「高吸収」の同義語関係を画像の類似性を用いて評価する場合、特許文献1の手法では、形状情報と濃度情報の両方を用いて画像の類似性を評価するため、キーワードとは関係の無い画像特徴量が類似評価に含まれてしまい、同義語であると間違って判定される可能性がある。しかし、本手法では「辺縁明瞭」の画像に対しては形状情報、「高吸収」の画像に対しては濃度情報の値に重みづけて画像の類似度を評価できるため、画像の類似度は低くなり、この2つのキーワードは同義語ではないと正しく判定することができる。
【0141】
以上のように、本実施の形態に係る医用同義語辞書作成装置100は、キーワードに適合する画像特徴量を動的に選択することにより、読影レポート21に対して画像の類似性に基づいた医用同義語辞書を作成することができる。
【0142】
なお、症例データベース101、キーワード辞書102、および読影知識データベース103は、医用同義語辞書作成装置100に備えられていてもよい。
【0143】
また、症例データベース101、キーワード辞書102、および読影知識データベース103は、医用同義語辞書作成装置100とネットワークを介して接続されたサーバ上に備えられてもよい。
【0144】
また、読影レポート21は、医用画像20内に付属データとして含まれていてもよい。
【0145】
(実施の形態1の変形例)
図1に示した実施の形態1に係る医用同義語辞書作成装置100の同義語判定部120は、テキスト判定部107、代表画像ベクトル生成部108、画像判定部109の順に処理を実行した。つまり、テキスト判定部107が、キーワード対選択部106が選択したキーワード対が同義語か否かを判定する。次に、代表画像ベクトル生成部108および画像判定部109が、テキスト判定部107が同義語であると判定したキーワード対について同義語か否かを再判定する。
【0146】
実施の形態1の変形例では、同義語判定部による同義語判定の順序が実施の形態1とは異なる。
【0147】
図23は、実施の形態1の変形例に係る医用同義語辞書作成装置の特徴的な機能構成を示すブロック図である。
【0148】
医用同義語辞書作成装置100Aは、図1に示した医用同義語辞書作成装置100の構成において、同義語判定部120の代わりに、同義語判定部120Aを用いている点が異なる。それ以外の構成は実施の形態1と同様であるため、その詳細な説明は繰り返さない。
【0149】
同義語判定部120Aは、代表画像ベクトル生成部108と、画像判定部109と、テキスト判定部107とを含む。各処理部は接続先が実施の形態1とは異なるが、処理は実施の形態1と同様である。
【0150】
つまり、代表画像ベクトル生成部108は、キーワード対選択部106が選択したキーワード対と、読影知識データベース103に記憶されている二項間関係情報と、症例データベース101に記憶されている医用画像20とを用いて、キーワード対選択部106が選択したキーワード対を構成する各キーワードに対する代表画像ベクトルを生成し、画像判定部109に出力する。
【0151】
画像判定部109は、代表画像ベクトル生成部108が生成した代表画像ベクトルを用いて、キーワード対選択部106が選択したキーワード対が同義語であるか否かを判定し、判定結果をテキスト判定部107に出力する。
【0152】
テキスト判定部107は、画像判定部109でキーワード対選択部106が選択したキーワード対が同義語であると判定された場合に、読影レポート21に基づいて、キーワード対選択部106が選択したキーワード対に対して同義語であるか否かの再判定を行い、同義語と判定した場合には、判定結果を出力部121に出力する。具体的な同義語判定方法については後述する。
【0153】
実施の形態1の変形例に係る医用同義語辞書作成装置100Aは、キーワードに適合する画像特徴量を動的に選択することにより、読影レポート21に対して画像の類似性に基づいた医用同義語辞書を作成することができる。
【0154】
(実施の形態2)
次に、本発明の実施の形態2に係る医用同義語辞書作成装置200について、図面を用いて詳細に説明する。
【0155】
本実施の形態の医用同義語辞書作成装置200は、症例データベース101に記憶されている症例データが更新された際に、医用同義語辞書を自動的に更新する特徴を有する。
【0156】
上述の実施の形態1に係る医用同義語辞書作成装置100は、症例データベース101が与えられた際に医用同義語辞書を自動的に算出する。ここで、症例データベース101には日々の診断の結果が蓄積され、逐次更新される特徴を持つ。医用同義語辞書に存在しないキーワードを含んだ読影レポート21が、症例データベース101に新しく追加された場合、新たに追加されたキーワードに対しては、そのキーワードと同義語となるキーワードが存在するか否かについて決定されていない。このため、この新たに追加されたキーワードを使った汎用性の高い検索を行うことができないという問題が生じる。
【0157】
そこで本実施の形態における医用同義語辞書作成装置200は、症例データベース101に記憶されている症例データの更新に応じて、キーワードに関する医用同義語辞書を新たに作成し、記憶部110に記憶する。
【0158】
これにより、症例データベース101に記憶されている症例データが更新された場合であっても、汎用性の高い検索が可能になる。
【0159】
以下、初めに図24を参照しながら、医用同義語辞書作成装置200の各構成について順に説明する。
【0160】
(実施の形態2:構成の説明)
図24は、本発明の実施の形態2に係る医用同義語辞書作成装置200の特徴的な機能構成を示すブロック図である。
【0161】
図24において、図1と同じ構成要素については同じ符号を付し、説明を繰り返さない。図24に示す医用同義語辞書作成装置200が図1に示す医用同義語辞書作成装置100と相違する点は、症例データベース101から取得した症例から、医用同義語辞書を更新するか否かを判定する更新制御部201を有する点である。
【0162】
更新制御部201は、症例データベース101から取得した医用画像20および読影レポート21を用いて、医用同義語辞書を更新するか否かを判定する。ここで、更新すると判定した場合は、更新制御部201は、取得部104、キーワード抽出部105、キーワード対選択部106、同義語判定部120および出力部121を動作させ、医用同義語辞書に含まれる同義語を更新する。一方、更新しないと判定した場合には、更新制御部201は、医用同義語辞書に含まれる同義語の更新を行わない。医用同義語辞書を更新するか否かの具体的な判定方法については後述する。
【0163】
次に、以上のように構成された医用同義語辞書作成装置200の動作について説明する。
【0164】
(実施の形態2:動作の説明)
図25は、医用同義語辞書作成装置200が実行する処理の全体的な流れを示すフローチャートである。図25において、図18と同じ構成要素については同じ符号を付し、説明を繰り返さない。
【0165】
更新制御部201は、症例データベース101から取得した症例データを用いて、医用同義語辞書を更新するか否かを判定する。ここで、医用同義語辞書を更新すると判定した場合は、ステップS301へ進む。一方、医用同義語辞書を更新しないと判定した場合には、処理を終了する(ステップS601)。
【0166】
具体的には、更新制御部201は、症例データベース101に記憶されている症例データが追加、削除または変更されることにより、症例データが更新された場合に、医用同義語辞書を更新すると判定し、症例データが更新されていない場合に、医用同義語辞書を更新しないと判定する。
【0167】
更新制御部201は、症例データが更新された場合に、全てのキーワードについて医用同義語辞書を更新しても良いし、症例データベース101に記憶されている全症例データにおける各キーワードの出現頻度をカウントし、出現頻度が閾値以下のキーワードに対してのみ、医用同義語辞書を更新してもよい。症例データベース101内に含まれるキーワードの出現頻度が十分に大きければ、既に十分な数のデータを用いて同義語関係が評価されたことになる。このような高頻度のキーワードが新しく追加された場合は、仮にキーワードベクトル間のコサイン距離および代表画像ベクトル間のユークリッド距離の再計算を行ったとしても値は大きく変化しないため、医用同義語辞書の更新を行う必要性が低い。一方、出現頻度が少ないキーワードに対しては、同義語関係の不確実性が高いため、医用同義語辞書を更新する必要性が高い。このように、症例データベース内のキーワード頻度に応じて同義語辞書の更新の可否を判定することにより、更新時の計算量を低減できるため、更新時間を短縮することができる。
【0168】
以上のように、本実施の形態に係る医用同義語辞書作成装置200は、症例データベース101に記憶されている症例データが更新された場合であっても、医用同義語辞書を自動的に更新することができるため、より汎用性の高い医用同義語辞書を用いた検索が可能になる。
【0169】
以上、本発明に係る医用同義語辞書作成装置について、実施の形態に基づいて説明したが、本発明は、これらの実施の形態に限定されるものではない。本発明の趣旨を逸脱しない限り、当業者が思いつく各種変形を本実施の形態に施したもの、異なる実施の形態における構成要素を組み合わせて構築される形態なども、本発明の範囲内に含まれる。
【0170】
例えば、実施の形態2に係る医用同義語辞書作成装置200の同義語判定部120の代わりに、実施の形態1の変形例で説明した同義語判定部120Aを用いても良い。
【0171】
また、実施の形態1または実施の形態2で作成され記憶部110に記憶された医用同義語辞書は、診断の支援に用いたり、医用情報の検索に用いたりすることができる。例えば、図26に示すように、医用同義語辞書データベース301と、診断支援装置302または検索装置303とをインターネット等のネットワーク304を介して接続しても良い。医用同義語辞書データベース301には、記憶部110に記憶されたのと同じ医用同義語辞書が記憶されている。診断支援装置302は、医用同義語辞書データベース301に記憶されている医用同義語辞書を参照することにより、読影項目または疾病名の同義語も含めて診断支援を行う。また、検索装置303は、医用同義語辞書データベース301に記憶されている医用同義語辞書を参照することにより、読影項目または疾病名の同義語も含めて類似症例の検索を行う。
【0172】
また、上記の医用同義語辞書作成装置は、具体的には、マイクロプロセッサ、ROM、RAM、ハードディスクドライブ、ディスプレイユニット、キーボード、マウスなどから構成されるコンピュータシステムとして構成されても良い。RAMまたはハードディスクドライブには、コンピュータプログラムが記憶されている。マイクロプロセッサが、コンピュータプログラムに従って動作することにより、医用同義語辞書作成装置は、その機能を達成する。ここでコンピュータプログラムは、所定の機能を達成するために、コンピュータに対する指令を示す命令コードが複数個組み合わされて構成されたものである。
【0173】
さらに、上記の医用同義語辞書作成装置を構成する構成要素の一部または全部は、1個のシステムLSI(Large Scale Integration:大規模集積回路)から構成されているとしても良い。システムLSIは、複数の構成部を1個のチップ上に集積して製造された超多機能LSIであり、具体的には、マイクロプロセッサ、ROM、RAMなどを含んで構成されるコンピュータシステムである。RAMには、コンピュータプログラムが記憶されている。マイクロプロセッサが、コンピュータプログラムに従って動作することにより、システムLSIは、その機能を達成する。
【0174】
さらにまた、上記の医用同義語辞書作成装置を構成する構成要素の一部または全部は、医用同義語辞書作成装置に脱着可能なICカードまたは単体のモジュールから構成されているとしても良い。ICカードまたはモジュールは、マイクロプロセッサ、ROM、RAMなどから構成されるコンピュータシステムである。ICカードまたはモジュールは、上記の超多機能LSIを含むとしても良い。マイクロプロセッサが、コンピュータプログラムに従って動作することにより、ICカードまたはモジュールは、その機能を達成する。このICカードまたはこのモジュールは、耐タンパ性を有するとしても良い。
【0175】
また、本発明は、上記に示す方法であるとしても良い。また、これらの方法をコンピュータにより実現するコンピュータプログラムであるとしても良いし、前記コンピュータプログラムからなるデジタル信号であるとしても良い。
【0176】
さらに、本発明は、上記コンピュータプログラムまたは上記デジタル信号をコンピュータ読み取り可能な非一時的な記録媒体、例えば、フレキシブルディスク、ハードディスク、CD−ROM、MO、DVD、DVD−ROM、DVD−RAM、BD(Blu−ray Disc(登録商標))、半導体メモリなどに記録したものとしても良い。また、これらの非一時的な記録媒体に記録されている上記デジタル信号であるとしても良い。
【0177】
また、本発明は、上記コンピュータプログラムまたは上記デジタル信号を、電気通信回線、無線または有線通信回線、インターネットを代表とするネットワーク、データ放送等を経由して伝送するものとしても良い。
【0178】
また、本発明は、マイクロプロセッサとメモリを備えたコンピュータシステムであって、上記メモリは、上記コンピュータプログラムを記憶しており、上記マイクロプロセッサは、上記コンピュータプログラムに従って動作するとしても良い。
【0179】
また、上記プログラムまたは上記デジタル信号を上記非一時的な記録媒体に記録して移送することにより、または上記プログラムまたは上記デジタル信号を上記ネットワーク等を経由して移送することにより、独立した他のコンピュータシステムにより実施するとしても良い。
【産業上の利用可能性】
【0180】
本発明は、画像診断分野の読影レポートにおける医用同義語辞書作成装置等として利用可能である。
【符号の説明】
【0181】
20 医用画像
21 読影レポート
22 読影レポートID
23 画像ID
24 画像所見
25 確定診断結果
30 キーワード名
31 キーワード属性
100、100A、200 医用同義語辞書作成装置
101 症例データベース
102 キーワード辞書
103 読影知識データベース
104 取得部
105 キーワード抽出部
106 キーワード対選択部
107 テキスト判定部
108 代表画像ベクトル生成部
109 画像判定部
110 記憶部
120、120A 同義語判定部
121 出力部
122 表示装置
201 更新制御部
301 医用同義語辞書データベース
302 診断支援装置
303 検索装置
304 ネットワーク
【特許請求の範囲】
【請求項1】
医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得部と、
医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得部が取得した読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出部と、
前記キーワード抽出部が抽出したキーワードからキーワード対を選択するキーワード対選択部と、
前記キーワード対選択部が選択したキーワード対が同義語であるか否かを判定する同義語判定部と、
前記同義語判定部が同義語であると判定したキーワード対を、医用同義語辞書に含まれる同義語として出力する出力部と
を備え、
前記同義語判定部は、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する
医用同義語辞書作成装置。
【請求項2】
前記同義語判定部は、
前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部と、
前記テキスト判定部で同義語であると判定された場合に、前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、
前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部と
を含み、
前記出力部は、前記画像判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力する
請求項1記載の医用同義語辞書作成装置。
【請求項3】
前記同義語判定部は、
前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、
前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部と、
前記画像判定部で同義語であると判定された場合に、前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部と
を含み、
前記出力部は、前記テキスト判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力する
請求項1記載の医用同義語辞書作成装置。
【請求項4】
前記テキスト判定部は、前記キーワード対を構成する各キーワードについて、前記読影レポート中の当該キーワードを含む文章中の当該キーワード以外のキーワードの出現頻度をベクトルの要素とするキーワードベクトルを作成し、作成したキーワードベクトル間の距離が第1閾値以下であれば、前記キーワード対が同義語であると判定する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項5】
前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項6】
前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが疾病名である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する疾病名との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と疾病名である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項7】
前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、(i)医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うとともに、(ii)前記読影レポートの中から当該キーワードと共起する疾病名を検出し、読影項目と疾病名との関連性を予め定めた二項間関係情報に基づいて、前記各画像特徴量を読影項目である当該キーワードと当該キーワードと共起する前記疾病名との間の関連性が高いほど大きな値の重みでさらに重み付けを行うことにより、重み付けされた各画像特徴量を要素とする当該キーワードの画像特徴量ベクトルを生成する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項8】
前記キーワード対選択部は、読影項目同士または疾病名同士のキーワード対のみを選択する
請求項1〜7のいずれか1項に記載の医用同義語辞書作成装置。
【請求項9】
さらに、
前記出力部が出力するキーワード対を、前記医用同義語辞書に含まれる同義語として記憶する記憶部を備える
請求項1〜8のいずれか1項に記載の医用同義語辞書作成装置。
【請求項10】
前記取得部は、医用画像と当該医用画像に対する読影レポートとの組である症例データが記憶されている症例データベースから、前記医用画像と前記読影レポートとを取得し、
前記医用同義語辞書作成装置は、さらに、
前記症例データベースに記憶されている症例データが更新されているか否かを判断し、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させ、前記医用同義語辞書に含まれる同義語を更新する更新制御部を備える
請求項1〜9のいずれか1項に記載の医用同義語辞書作成装置。
【請求項11】
前記更新制御部は、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、前記医用同義語辞書に含まれる全てのキーワードについて同義語を更新する
請求項10に記載の医用同義語辞書作成装置。
【請求項12】
前記更新制御部は、(i)前記症例データベースに記憶されている前記症例データにおける各キーワードの出現頻度を算出し、(ii)前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、出現頻度が第2閾値以下のキーワードについてのみ同義語を更新する
請求項10に記載の医用同義語辞書作成装置。
【請求項13】
医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得ステップと、
医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得ステップで取得された読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出ステップと、
前記キーワード抽出ステップで抽出されたキーワードからキーワード対を選択するキーワード対選択ステップと、
前記キーワード対選択ステップで選択されたキーワード対が同義語であるか否かを判定する同義語判定ステップと、
前記同義語判定ステップで同義語であると判定されたキーワード対を、医用同義語辞書に含まれる同義語として出力する出力ステップと
を含み、
前記同義語判定ステップでは、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択ステップで選択されたキーワード対が同義語であると判定する
医用同義語辞書作成方法。
【請求項14】
請求項13に記載の医用同義語辞書作成方法に含まれる各ステップをコンピュータに実行させるためのプログラム。
【請求項1】
医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得部と、
医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得部が取得した読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出部と、
前記キーワード抽出部が抽出したキーワードからキーワード対を選択するキーワード対選択部と、
前記キーワード対選択部が選択したキーワード対が同義語であるか否かを判定する同義語判定部と、
前記同義語判定部が同義語であると判定したキーワード対を、医用同義語辞書に含まれる同義語として出力する出力部と
を備え、
前記同義語判定部は、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択部が選択したキーワード対が同義語であると判定する
医用同義語辞書作成装置。
【請求項2】
前記同義語判定部は、
前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部と、
前記テキスト判定部で同義語であると判定された場合に、前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、
前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部と
を含み、
前記出力部は、前記画像判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力する
請求項1記載の医用同義語辞書作成装置。
【請求項3】
前記同義語判定部は、
前記二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより各キーワードの画像特徴量ベクトルを生成する代表画像ベクトル生成部と、
前記代表画像ベクトル生成部が生成した前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定する画像判定部と、
前記画像判定部で同義語であると判定された場合に、前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定するテキスト判定部と
を含み、
前記出力部は、前記テキスト判定部が同義語であると判定したキーワード対を、前記医用同義語辞書に含まれる同義語として出力する
請求項1記載の医用同義語辞書作成装置。
【請求項4】
前記テキスト判定部は、前記キーワード対を構成する各キーワードについて、前記読影レポート中の当該キーワードを含む文章中の当該キーワード以外のキーワードの出現頻度をベクトルの要素とするキーワードベクトルを作成し、作成したキーワードベクトル間の距離が第1閾値以下であれば、前記キーワード対が同義語であると判定する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項5】
前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項6】
前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが疾病名である場合、医用画像から抽出される各画像特徴量と前記医用画像に対する疾病名との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と疾病名である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより当該キーワードの画像特徴量ベクトルを生成する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項7】
前記代表画像ベクトル生成部は、前記キーワード対を構成するキーワードが読影項目である場合、(i)医用画像から抽出される各画像特徴量と前記医用画像に対する読影項目との関連性を予め定めた二項間関係情報に基づいて、当該キーワードの作成の基となった医用画像から算出した各画像特徴量に当該画像特徴量と読影項目である当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うとともに、(ii)前記読影レポートの中から当該キーワードと共起する疾病名を検出し、読影項目と疾病名との関連性を予め定めた二項間関係情報に基づいて、前記各画像特徴量を読影項目である当該キーワードと当該キーワードと共起する前記疾病名との間の関連性が高いほど大きな値の重みでさらに重み付けを行うことにより、重み付けされた各画像特徴量を要素とする当該キーワードの画像特徴量ベクトルを生成する
請求項2または3に記載の医用同義語辞書作成装置。
【請求項8】
前記キーワード対選択部は、読影項目同士または疾病名同士のキーワード対のみを選択する
請求項1〜7のいずれか1項に記載の医用同義語辞書作成装置。
【請求項9】
さらに、
前記出力部が出力するキーワード対を、前記医用同義語辞書に含まれる同義語として記憶する記憶部を備える
請求項1〜8のいずれか1項に記載の医用同義語辞書作成装置。
【請求項10】
前記取得部は、医用画像と当該医用画像に対する読影レポートとの組である症例データが記憶されている症例データベースから、前記医用画像と前記読影レポートとを取得し、
前記医用同義語辞書作成装置は、さらに、
前記症例データベースに記憶されている症例データが更新されているか否かを判断し、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させ、前記医用同義語辞書に含まれる同義語を更新する更新制御部を備える
請求項1〜9のいずれか1項に記載の医用同義語辞書作成装置。
【請求項11】
前記更新制御部は、前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、前記医用同義語辞書に含まれる全てのキーワードについて同義語を更新する
請求項10に記載の医用同義語辞書作成装置。
【請求項12】
前記更新制御部は、(i)前記症例データベースに記憶されている前記症例データにおける各キーワードの出現頻度を算出し、(ii)前記症例データが更新されていると判断した場合に、前記取得部、前記キーワード抽出部、前記キーワード対選択部、前記同義語判定部および前記出力部を動作させることにより、出現頻度が第2閾値以下のキーワードについてのみ同義語を更新する
請求項10に記載の医用同義語辞書作成装置。
【請求項13】
医用画像と、当該医用画像を読影した結果が記載された文書データである読影レポートとを取得する取得ステップと、
医用画像の特徴を示す文字列の読影項目または医用画像の診断結果を示す文字列の疾病名であるキーワードが登録されているキーワード辞書データを参照して、前記取得ステップで取得された読影レポートから前記キーワード辞書データに登録されているキーワードを抽出するキーワード抽出ステップと、
前記キーワード抽出ステップで抽出されたキーワードからキーワード対を選択するキーワード対選択ステップと、
前記キーワード対選択ステップで選択されたキーワード対が同義語であるか否かを判定する同義語判定ステップと、
前記同義語判定ステップで同義語であると判定されたキーワード対を、医用同義語辞書に含まれる同義語として出力する出力ステップと
を含み、
前記同義語判定ステップでは、(i)前記読影レポートに基づいて、前記キーワード対が同義語であるか否かを判定し、(ii)医用画像から抽出される各画像特徴量と前記医用画像に対するキーワードとの間の関連性を予め定めた二項間関係情報に基づいて、前記キーワード対を構成するキーワードごとに当該キーワードの作成の基となった医用画像から算出した各画像特徴量に対して当該画像特徴量と当該キーワードとの間の関連性が高いほど大きな値の重み付けを行うことにより、重み付けされた各画像特徴量を要素とする各キーワードの画像特徴量ベクトルを作成し、前記キーワード対に対する2つの画像特徴量ベクトルを比較することにより、前記キーワード対が同義語であるか否かを判定し、(iii)2つの判定結果が共に同義語であることを示す場合に、前記キーワード対選択ステップで選択されたキーワード対が同義語であると判定する
医用同義語辞書作成方法。
【請求項14】
請求項13に記載の医用同義語辞書作成方法に含まれる各ステップをコンピュータに実行させるためのプログラム。
【図1】

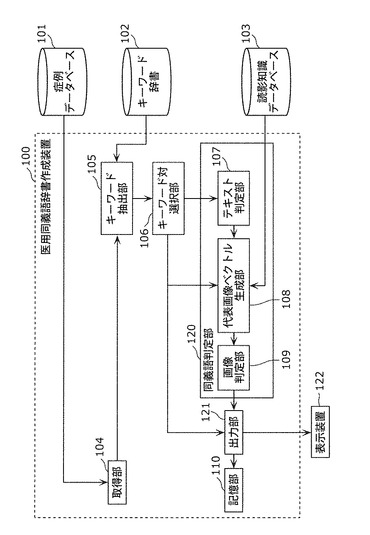
【図3】
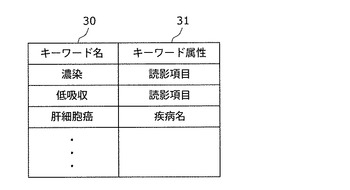
【図4】
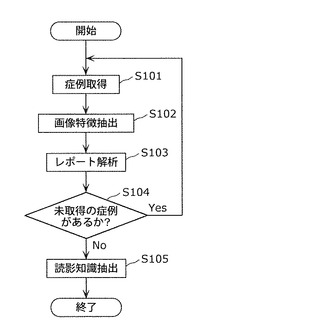
【図5】
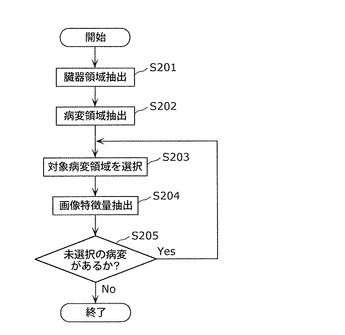
【図6】

【図7】
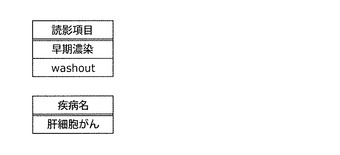
【図8】
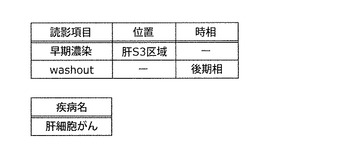
【図9】

【図10】
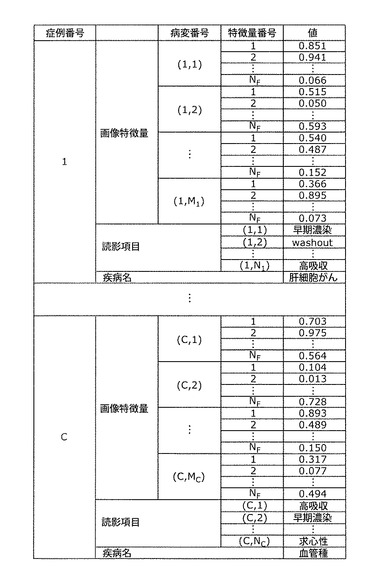
【図11】
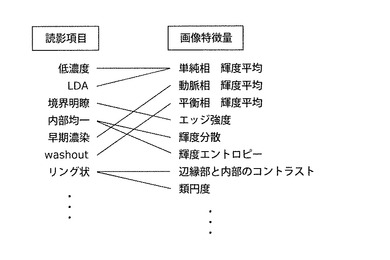
【図12】
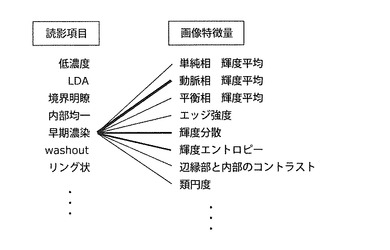
【図13】
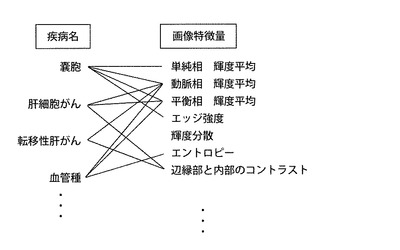
【図14】
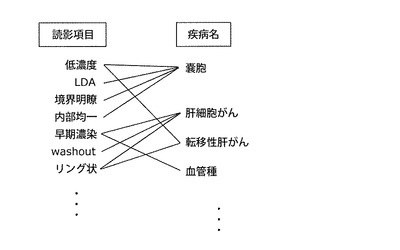
【図15】
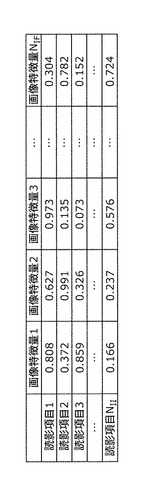
【図16】
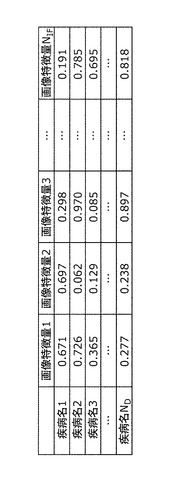
【図17】
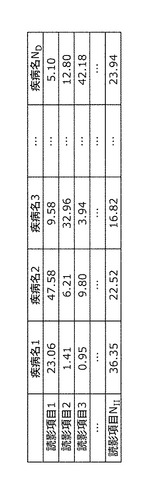
【図18】
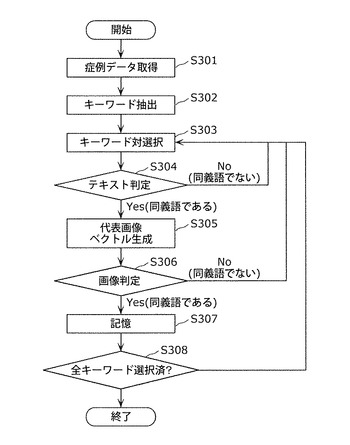
【図19】
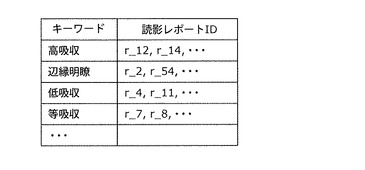
【図20】
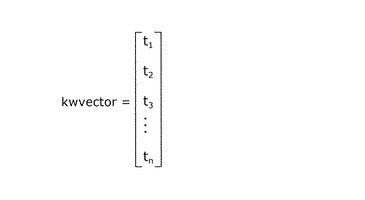
【図21】
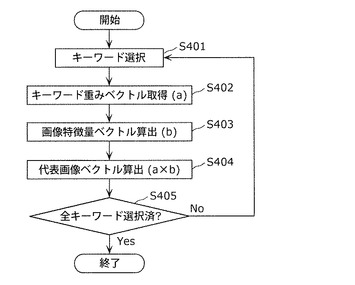
【図22】
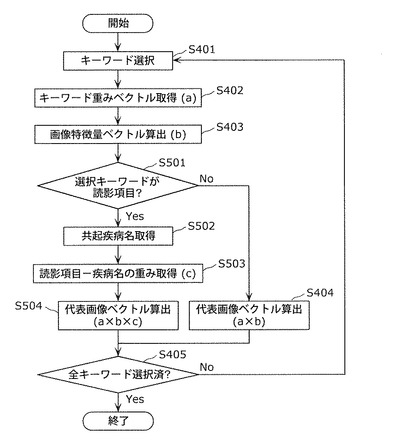
【図23】
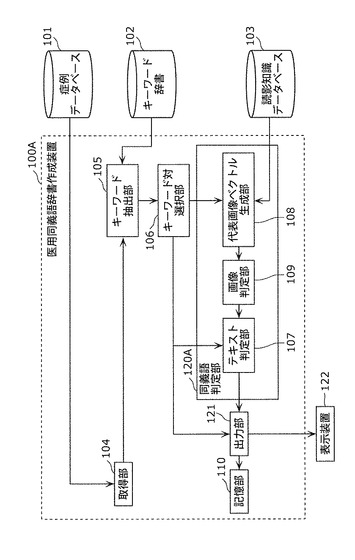
【図24】
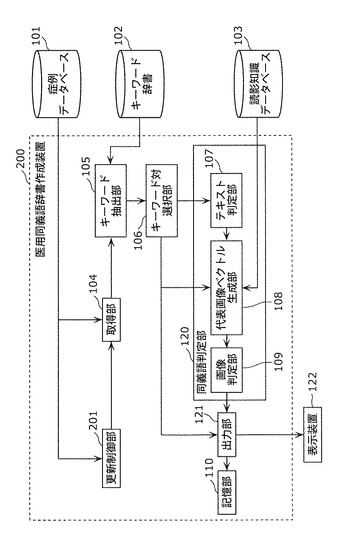
【図25】
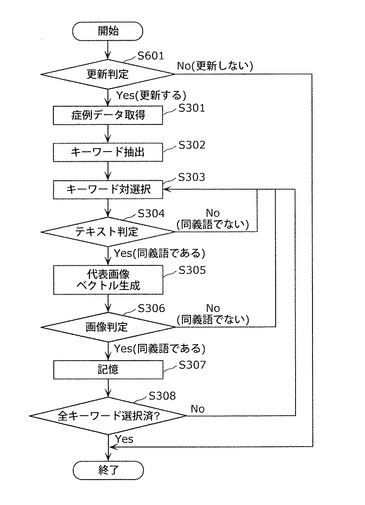
【図26】
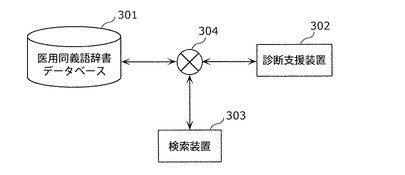
【図2】
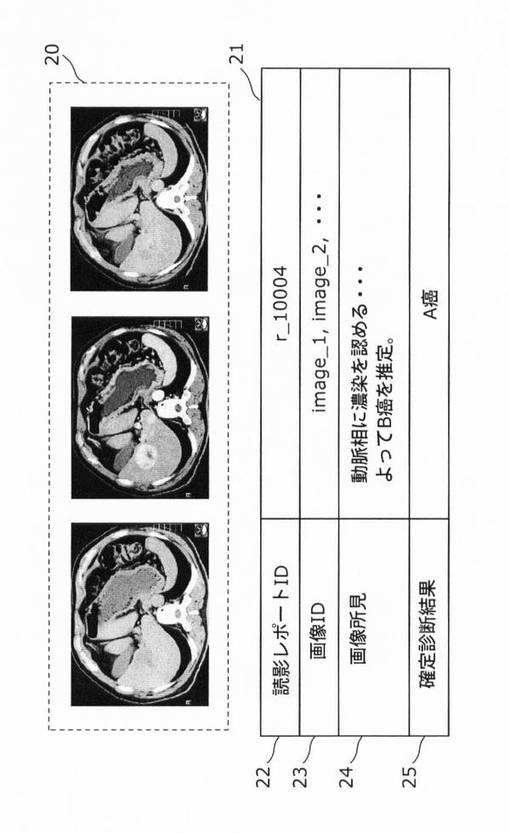
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図2】
【公開番号】特開2013−105465(P2013−105465A)
【公開日】平成25年5月30日(2013.5.30)
【国際特許分類】
【出願番号】特願2011−251137(P2011−251137)
【出願日】平成23年11月16日(2011.11.16)
【出願人】(000005821)パナソニック株式会社 (73,050)
【Fターム(参考)】
【公開日】平成25年5月30日(2013.5.30)
【国際特許分類】
【出願日】平成23年11月16日(2011.11.16)
【出願人】(000005821)パナソニック株式会社 (73,050)
【Fターム(参考)】
[ Back to top ]