
医療情報抽出装置、及び医療情報抽出プログラム
【課題】病名の階層構造を利用して個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる医療情報抽出装置及びプログラムを提供する。
【解決手段】
医療情報抽出装置1のCPU10は処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する。CPU10は、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを抽出する。CPU10は抽出したパッセージを含む対象文書集合を元にして、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する。
【解決手段】
医療情報抽出装置1のCPU10は処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する。CPU10は、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを抽出する。CPU10は抽出したパッセージを含む対象文書集合を元にして、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は医療情報抽出装置及び医療情報抽出プログラムに関する。特に、医師が診断などの際に電子カルテルシステムを用いたり、患者や患者の家族が病気についての情報をインターネットで調べたりする場合など、人間が医療に関わる情報を処理する場面において、コンピュータを用いて情報処理を支援する医療情報抽出装置、及び医療情報抽出プログラムに関する。
【背景技術】
【0002】
電子カルテルシステムなどの医療情報システムは、病院、診療所などの医療機関において、医師や看護士が診断や処置についての判断を行う際に、コンピュータを介して診断や処置を支援する情報システムである。このような情報システムで利用することが可能な医学的な知識を、自動的に抽出する装置が提案されている。抽出した医学的な知識は、前記医療機関において、利用することが可能だけではなく、患者や患者の家族が病気についての情報をインターネットで調べようとする際にも、利用可能である。
【0003】
こうした医療情報抽出方法についての従来技術としては特許文献1〜特許文献2、或いは、非特許文献1がある。
特許文献1は2単語間の類似度を計算する技術であり、単語間の相関をシソーラス辞書とコーパスを用いて算出するようにしている。特許文献2、特許文献3は、文書検索において、適切な検索を行うために単語間の概念階層を利用するものであり、検索キーに関連する文書の検索時の検索漏れや、不要文書を抽出するようなノイズを少なくするために、シソーラス辞書を用いる技術である。
【0004】
非特許文献1では、医療分野を例として、インターネット上のWeb文書から、ある話題に適合するパッセージ(文書の一部)を自動的に抽出する方法が提案されている。具体的には、まず、病名を検索キーとして、Web文書を自動的に収集し、タグの情報を用いて文書を細かく分割してパッセージの候補を抽出する。次に、症状を表わす表現を症状リストとして予め人手で用意しておき、この症状リストに適合するパッセージを候補の中から選択する。次に選択したパッセージの候補を類似度の大きなものから、順に出力するというものである。
【特許文献1】特開2005-38162号公報
【特許文献2】特開2003-22277号公報
【特許文献3】特開2003-345824号公報
【非特許文献1】「医療分野におけるWeb文書からの話題抽出方法」,人工知能学会全国大会(第19回)、1E1-01,2005
【発明の開示】
【発明が解決しようとする課題】
【0005】
ところで、病名と症状や、病名と薬品名、病名と検査項目などのような医学的知識は、その量が膨大であること、日々更新される知識であることなどの理由により、従来は、コンピュータによる支援には用いられていない。データマイニングを医療分野に適用しようとする試みは見られるものの、まだ、限定的な適用に留まっている。
【0006】
このような医学的知識を特定する上で、「病名」は、非常重要である。Webの検索において、必要とする知識を特定するために病名を用いることで、かなり、適切な限定を行うことができる。
【0007】
しかしながら、Webから得られる膨大な文書や、電子カルテ上の医療情報から、病名と症状のような医学的に知識を取り出すためには、個々の病名に関する情報を統計的に安定して推定することが難しいことや、個々の病名に関する情報がバラバラで関連付けられていないという問題があった。
【0008】
特許文献1は、2単語間の類似度をシソーラス上の階層の深さ、概念の階層及びパス上の概念に依存させて計算する技術である。しかし、階層構造の利用は、2単語間のみに対して適応され、類似度が算出されている。又、情報量の少ない単語や情報量のオーダーの異なる単語間に対しては、統計的に有効な類似度の算出が困難となる。
【0009】
特許文献2や、特許文献3に示されている従来技術は、文書検索における検索結果の質の向上を目的としたものであり、検索時に階層構造を表現した辞書から検索キーの上位概念単語、下位概念単語を抽出し、それらの単語を検索キーに追加して文書検索を行うものである。
【0010】
非特許文献1は、病名は検索のためのキーとして利用するだけなので、病名の間に存在する階層構造を利用していない。非特許文献1は、病名そのものを検索キーとして病名に関する症状パッセージを抽出する手法のため、Web上に蓄積されたテキスト量が少ない病名に関しては抽出できるパッセージが限定される。さらに、非特許文献1では、人手で用意した症状リストは、多様な表現を持つ症状を的確に表わすことが困難であり、症状を含むパッセージの抽出精度を左右する。又、非特許文献1の技術は、類似度の大きいパッセージそのものを出力する形式であることから、パッセージの質や大きさに依存した結果には一貫性がなく、さらに、同じ意味(症状)を表現したパッセージに対する処理は行われておらず、2次利用しにくいという問題があった。
【0011】
すなわち、上記の特許文献1〜3、非特許文献1の技術には、病名と症状との間の階層的な情報などによって医療情報を抽出するための装置及びプログラムについてや、或いは、文書と、病名に関する既存の知識を利用して抽出する装置及びプログラムに関しても開示されいない。又、上記各文献には検索後に、検索された文書集合を用いて統計的な情報を推定する装置及びプログラムについては開示されていない。
【0012】
そして、従来の医療情報の抽出は個々の病名から得られた文書を別々に使用していたため、病名に対応する文書の量が少なく、統計的な情報の推定が安定して行えない問題があった。
【0013】
本発明の目的は、病名の階層構造を利用して、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる医療情報抽出装置及び医療情報抽出プログラムを提供することを目的としている。
【課題を解決するための手段】
【0014】
上記問題点を解決するために本発明の医療情報抽出装置は、病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する医療情報抽出装置において、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段と、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段と、前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段とを備えたことを特徴とする。
【0015】
ここで、「病名と関連する関連項目」とは、病名と関連する症状、原因、処置、薬品名などをいい、その病名に関して関連して取り上げられている事項をいう。又、相関度は、項目と病名とが共に出現する度合のことである。 従来は、個々の病名から得られた文書を別々に使用していたため、個々の病名に対応する文書の量が少なく、統計的な情報の推定が安定して行えないという問題があった。それに対して、本発明によれば、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0016】
例えば、上位概念である病名には、階層構造が形成されているものがある。例えば「糖尿病」の中に階層構造を形成する「1型糖尿病」、「2型糖尿病」などが存在する。従って、それぞれの病名をキーとして検索して得られた文書は互いに関連しており、類似していることが期待できる。本発明では、こうした情報を利用するのである。
【0017】
前記医療情報抽出装置は、前記構成に加えて、前記パッセージ抽出手段が、前記パッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するようにしてもよい。
【0018】
このように構成されていることにより、対象文書から該処理対象病名と関連のあるパッセージが、適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0019】
又、前記医療情報抽出装置は、前記構成加えて、前記パッセージ抽出手段が、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるようにしてもよい。
【0020】
このように構成されていることにより、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、前記各出現頻度に応じたものとすることができる。
【0021】
さらには、医療情報抽出装置は、前記構成に加えて、前記処理対象病名と各関連病名に関してそれぞれ対象文書から共起語と該共起語の共起度を求める共起語取得手段を有し、前記パッセージ抽出手段が、各パッセージの適合度を求める際に、各病名の共起語の共起度と出現頻度とをさらに用いるようにしてもよい。
【0022】
ここで、共起語とは、項目の間において、共起する語のことであり、共起度は、共起する度合いのことである。
このように構成されていることにより、パッセージの適合度が、各病名の共起語の共起度と出現頻度に応じたものにすることができる。
【0023】
又、医療情報抽出装置は、前記構成に加えて、概念関係抽出手段が、処理対象病名と前記関連項目の項目リスト内の各項目との相関度(以下、第1相関度という)と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との相関度(以下、第2相関度という)を求め、さらに、前記第2相関度を、前記処理対象病名と各関連病名との関連度で重み付けしたものを前記第1相関度に加算することにより、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を算出するようにしてもよい。
【0024】
このように構成されていることにより、処理対象病名と前記関連項目の項目リスト内の各項目との相関度(第1相関度)と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との相関度(第2相関度)の両相関度が考慮され相関度を得ることができる。
【0025】
又、医療情報抽出装置は、前記構成に加えて、概念関係抽出手段が、処理対象病名が予め与えられている病名間の階層構造において複数のノードに分類されている場合には、それぞれのノードが前記関連項目のうちのどの観点により分類されているかに基づいて、観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いるようにしてもよい。
【0026】
すなわち、病名が複数のノードに分類されるとともに、あるノードがある項目(例えば「原因」)の観点で分類されている場合は、その観点が一致する項目リスト内の項目(「原因」)との相関度を算出する場合のみ、該同じノードに分類されている病名を関連病名として用いるようにする。
【0027】
このようにすることにより、病名のそれぞれの分類箇所が、「原因」による分類であるか、又は、「症状」による分類で有るかを利用して、他の病名から概念関係を抽出する際に利用できる。
【0028】
又、医療情報抽出装置は、前記構成に加えて、前記概念関係抽出手段が、複数のノードに分類されている病名を含むノードに対し、このノードに分類されている各病名について求めた関連項目の項目リスト内の各項目との相関度の内、どの項目リスト内の各項目との相関度が各病名間で最も似通っているかに基づいて、このノードが分類されている観点を推定するようにしてもよい。
【0029】
例えば、ノードが「原因」の観点による分類であるか、「症状」の観点による分類であるかは、各病名毎に抽出した原因リストや、症状リストがどの程度類似しているかに基づいて推定できる。このように概念関係抽出手段がノードが分類されている観点を推定することによって、請求項6の作用を容易に実現できる。
【0030】
又、本発明の医療情報抽出方法は、病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する医療情報抽出方法において、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する段階と、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出する段階と、前記抽出されたパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出して概念関係を抽出する段階と含むことを特徴とする。
【0031】
このように構成されていることにより、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる方法を提供できる。
【0032】
又、前記パッセージを抽出する段階が、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して該適合度に基づいて抽出するようにしてもよい。
【0033】
このように構成されていることにより、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる方法を提供できる。
【0034】
又、本発明のプログラムは、病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する際に、コンピュータに、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段、前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段として、機能させることを特徴とする。
【0035】
このように構成されていることにより、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができるプログラムを提供できる。
【0036】
又、前記プログラムにより、コンピュータが前記パッセージ抽出手段として機能する際に、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するようにしてもよい。
【0037】
このように構成されていることにより、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができるプログラムを提供できる。
【0038】
又、前記プログラムにより、コンピュータが前記パッセージ抽出手段として機能する際に、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるようにしてもよい。
【0039】
このように構成されていることにより、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、前記各出現頻度に応じたものとすることができるプログラムを提供できる。
【発明を実施するための最良の形態】
【0040】
以下、本発明を具体化した医療情報抽出装置、方法及びプログラムの一実施形態を図1〜5を参照して説明する。
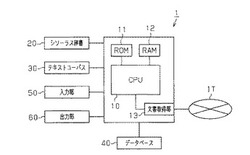
図1に示すように、医療情報抽出装置1はパーソナルコンピュータからなる。医療情報抽出装置1は互いにバスで接続されたCPU10、ROM11、RAM12、及び文書取得部13を備えるとともにシソーラスのデータを記憶するシソーラス辞書部20、コーパスのデータや、テキスト文のデータを記憶するテキストコーパス30、データベース40、入力部50、出力部60を備える。前記ROM11には、医療情報抽出プログラム等の各種プログラムが格納されている。RAM12は前記各種プログラムを実行する際に使用される作業用記憶領域や、バッファ領域を備えている。
【0041】
シソーラス辞書部20、テキストコーパス30、及びデータベース40は例えば、ハードデイスクからなるが、限定されるものではない。入力部50はキーボード、マウス、等からなる。又、出力部60は表示装置やプリンタ等からなる。文書取得部13は、インターネットITに接続されている。
【0042】
次に、医療情報抽出装置1による医療情報の抽出について説明する。
まず、医療情報を収集するためのキーワードリストである病名リストと、関連項目リストについて説明する。該病名リスト、及び関連項目リストはデータベース40に格納されている。ここで、関連項目リストは初期セットとなる。
【0043】
病名リストは、上位概念の階層構造を記した、例えば、MEDISのICD10の国際疾病分類第10版のデータを利用し、このMEDISに対し病名を検索クエリとして検索エンジンで検索し、検索ヒット数順に並べ替えたものを病名リストとして作成してもよい。
【0044】
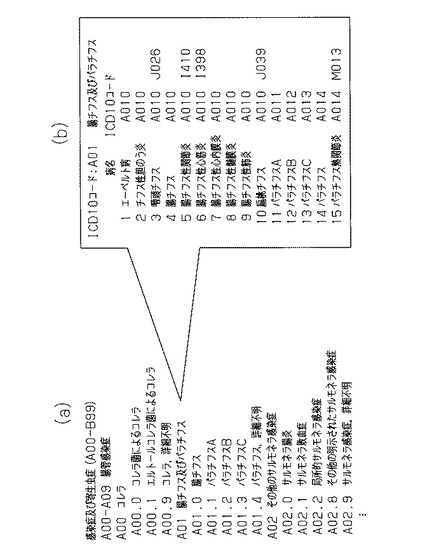
MEDISのICD10の国際疾病分類第10版の例を図4に例示する。図4(a)は、「感染症」に関するノードの部分であり、例えば、「A01 腸チフス及びパラチフス」では、A01.0〜A01.4まで分類されているが、さらには、A01の内には、図4(b)に示すように1〜15に亘って各種の病名に細分類されている。この場合、「腸チフス」を処理対象病名とした場合、これ以外の「A01」に挙げられている他の病名は関連病名となる。
【0045】
又、「病名」を上位概念としたとき、下位概念である「病名と関連する関連項目」は、病名と関連する「症状」、「原因」、「処置」、「薬品名」などがある。これには、「病名」と密接に関連する事項である。「症状」は当該病名の罹患患者が呈する状態を示し、「原因」は、当該病名の罹患原因となるものであり、「処置」は、当該病名の対応治療等を示し、「薬品名」は、当該病名に使用される治療薬等を示す。初期セットである関連項目リストとはこれらがそれぞれリストとして作成されたものである。例えば、「症状」に関しては、症状リストといい、「原因」に関しては、原因リストという。他の関連項目についても同様のリストが作成される。下位概念である「症状」、「原因」、「処置」、「薬品名」などは、各病名に対してリスト形式で提示されている。
【0046】
なお、両リストは、医学事典に記載されている主な症状、原因、薬品名を人手により抽出したものをそれぞれリストの項目として作成した上で、データベース40に格納するようにしてもよい。
【0047】
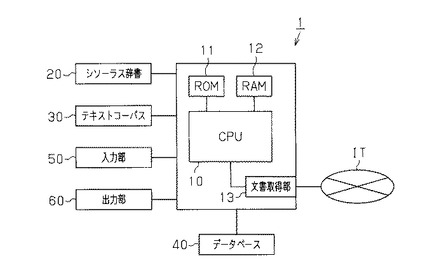
次に、医療情報抽出装置1のCPU10は、医療情報抽出プログラムを起動すると、図2に示すフローチャートを実行する。
(文書の収集処理)
S10では、CPU10は文書収集を行う。文書収集は、前記病名リストから病名(関連病名も含む)をキーワードとして用いて行われる。CPU10は、病名リストから病名(関連病名も含む)を順次読込みして、文書取得部13を介してインターネットITへ送出する。このとき、CPU10はインターネットIT上の自由書式の文書としてのWeb文書を検索するためには、ウェブブラウザの検索エンジンを使用してもよい。インターネットIT上で検索されたWeb文書は、文書取得部13を介してテキストコーパス30に収集される。ここでの機能によりCPU10は文書取得手段に相当する。
【0048】
(パッセージ抽出処理)
S20では、CPU10は、収集したWeb文書を元にパッセージ抽出を行う。Web文書は、1文書内に複数の話題が含まれていることがあり、不要部が存在する可能性がある。そのため、CPU10は分割情報に基づいてパッセージの抽出を行う。ここで、分割情報とは、Web文書がHTML文書の場合は、タグであり、Web文書が通常のテキスト文書の場合は、段落が相当する。この分割情報に基づいて、該文書の書き手の意図する分割点で文書を分割し、医療情報がない不要な部分を除去し、医療情報があるパッセージを抽出する。
【0049】
このとき、対象とするキーワードの上位階層及び下位階層の各病名の出現頻度に基づいてパッセージを抽出してもよく、又、上位階層と下位階層の病名間の関連度を重みとして利用してもよい。ここでの機能により、CPU10はパッセージ抽出手段に相当する。
【0050】
本実施形態では、パッセージの適合度を算出して、該適合度が閾値以上のパッセージを適合度が高いとして抽出する。又、適合度が閾値未満のパッセージは、パッセージの適合度が低いものとして抽出の対象から除外される。
【0051】
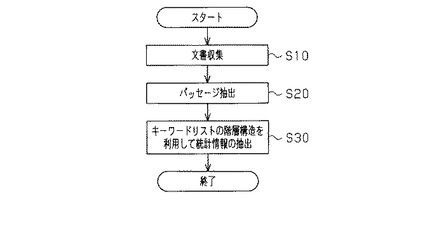
図3は、検索によって得られた対象文書集合を示し、各パッセージp1,p2、…pkが抽出された例が示されている。
(パッセージの適合度の算出方法)
ここで、上位概念である「病名」の階層構造を利用する場合のパッセージの適合度の算出方法を説明する。ここでは、処理対象病名dT=”腸チフス性関節炎”に対するパッセージpkの適合度の例を挙げる。
【0052】
下記に示すように処理対象病名dT=”腸チフス性関節炎”に対して、L個の関連病名{r1,r2,…,rL}とその関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}が与えられている。なお、関連度については、後述する。
【0053】
関連病名{r1,r2,…,rL}={"腸チフス","腸チフス性心筋炎",……}
関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}={0.4,0.15,……}
このとき、処理対象病名drに対するパッセージpkの適合度F(dT,pk)を次式(1)により算出する。
【0054】
【数1】

上記式中、P(ri,pk)はパッセージpkにおける関連病名riの出現確率であり、パッセージpkにおける関連病名riの出現回数f(ri,pk)からP(ri,pk)=f(ri,pk)/Qkとして算出する。
【0055】
(病名間の関連度の算出方法)
ある病名dと関連病名rとの関連度I(d,r)の算出方法について説明する。
病名dをキーワードとして検索して得られた文書集合をDd、関連病名rをキーワードとして検索して得られた文書集合をDrとする。
【0056】
文書集合Ddと文書集合Drの和集合D0=(Dd∪Dr)に含まれる単語の異なり数(語彙数)をVとし、文書集合DdとDrのそれぞれについて、各単語{t1,t2…tV}の出現回数を要素値とする
【0057】
【数2】
を生成する。
【0058】
【数3】
前記2つのベクトル間のコサイン類似度
【0059】
【数4】
は文書集合DdとDrがどの程度類似しているかを示している。これを病名dと関連病名rとの関連度I(d,r)として用いる。
【0060】
なお、この他、文書集合DdとDrの和集合D0=(Dd∪Dr)における病名dと関連病名rの相互情報量を関連度として用いてもよい。
【0061】
【数5】
(概念関係抽出処理、すなわち統計情報の抽出)
再び図2のフローチャートの説明に戻る。S30では、CPU10は、キーワードリストの階層構造を利用して統計情報の抽出を行う。すなわち、CPU10は、作成したリスト(例えば関連項目リストである症状リスト)の初期セットを利用してキーワードである病名と関連項目(例えば「ある症状」)の間の統計的な情報(以下、統計情報という)を抽出する。この統計情報の抽出が、概念関係抽出に相当する。ここでの機能により、CPU10は、概念関係抽出手段に相当する。
【0062】
ここで、統計情報としては、2つの単語が共起する頻度や、共起する頻度とそれぞれの生起確率を考慮した後述する相互情報量や、TF-IDFなどを用いることが可能である。この時、それぞれの情報量にパッセージ文書が属するドメインや検索ヒット数に対応した重みを掛けてもよい。このようにすることによりどのような症状が、どの程度の頻度で、生起するかの情報を得ることができる。
【0063】
本実施形態では、下記(1. 相関度R(dT,w)の算出)を行い、さらに、(2. 相関度R(ri,w)の算出及び相関度R'(dT,w)の算出)を行うことにより、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する。
【0064】
(相関度の算出)
ここで、概念関係抽出において、使用される相関度の算出、すなわち、関連項目の項目リスト内の各項目と前記処理対象病名との相関度の算出方法について説明する。
【0065】
なお、ここでは原因を表わす項目リストLC、症状を表わす項目リストLS、薬品を表わす項目リストLMが、下記のように与えられているとする。
LC={wc1,wc2,……wcNc}、
LS={ws1,ws2,……wsNs}、
LM={wm1,wm2,……wmNm}、
Nc、Ns、Nmは各リストの項目数である。
【0066】
(1. 相関度R(dT,w)の算出)
処理対象病名dT="腸チフス性関節炎"に対して、各項目リスト内の各項目wとの相関度R(dT,w)を算出し、病名dTにはどのような原因/症状/薬品がどの程度関連しているかを知識として抽出する。相関度R(dT,w)は第1相関度に相当する。この場合、相関度R(dT,w)は、統計的尺度により算出する。統計的尺度としては、下記のものを挙げることができ、いずれの統計的尺度を使用してもよい。
【0067】
1. 対象文書集合における処理対象病名dTと各項目wとの共起回数freq(dT,w)
共起回数freq(dT,w)は、同じパッセージの中に各項目wがどれだけあったかを示している。
【0068】
2. 対象文書集合における処理対象病名dTと相互情報量
【0069】
【数6】
3. 対象文書集合における各項目wのTF-IDF値
【0070】
【数7】
(2. 相関度R(ri,w)の算出及び相関度R'(dT,w)の算出)
次に、L個の関連病名riと各項目リスト内の各項目wとの相関度R(ri,w)の算出する。相関度R(ri,w)は第2相関度に相当する。
【0071】
前述したように、処理対象病名dT=”腸チフス性関節炎”に対して、L個の関連病名{r1,r2,…,rL}とその関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}が与えられている。
関連病名{r1,r2,…,rL}={"腸チフス","腸チフス性心筋炎",……}
関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}={0.4,0.15,……}
各関連病名{r1,r2,…,rL}に対しても、上記の統計的尺度により相関度R(dT,w)を求めたと同様に相関度R(ri,w)(なお、i=1,2,……Lである)を算出する。
【0072】
そして、得られた前記相関度R(ri,w))と各関連病名との関連度I(dT,ri)で重み付けしながら加算し、これを処理対象病名dTと項目wとの相関度R'(dT,w)とする。すなわち、
【0073】
【数8】
を処理対象病名dTと項目wとの相関度として用いる。
【0074】
(処理対象病名が複数のノードに分類されている場合)
ところで、処理対象病名が複数のノードに分類されている場合について説明する。
前述したように、図4(a)は、「感染症」に関するノードの部分であり、例えば、「A01 腸チフス及びパラチフス」について記載されている。
【0075】
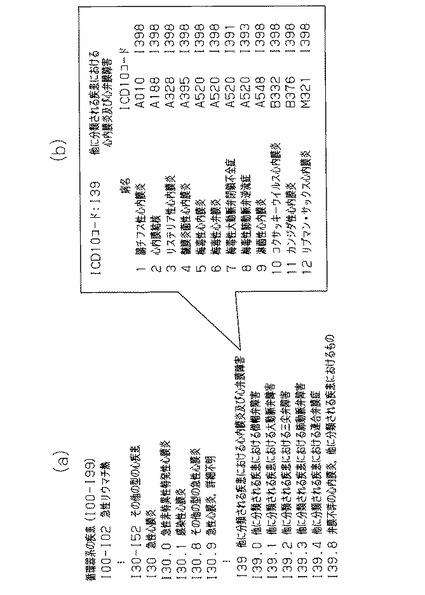
一方、図5(a)、(b)は、MEDISのICD10の国際疾病分類第10版において、「症状」が共通している観点での分類の例である。この場合、例えば、図4(b)、図5(b)に示すように「腸チフス性心内膜炎(ICD10コード=A010,1398)」は、階層的分類の中で複数に分類されていることが分かる。このように複数ノードに分類されている「病名」は、それぞれのノードに属する他の病名が関連病名となるが、ここでA01(腸チフス及びパラチフス)に属する病名は原因がチフス菌である点が共通であり、I39(……心内膜炎及び心弁膜障害)に属する病名は症状が心内膜炎・心弁膜障害である点が共通である。
【0076】
このようにある病名が複数箇所に分類されている場合、観点が異なってそれぞれ分類されていることになる。それぞれの分類箇所が、原因による分類であるか、又は、症状による分類であるかを利用して、他の病名から概念関係を抽出する際に利用する。
【0077】
すなわち、概念関係抽出手段であるCPU10は、観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いるようにする。
【0078】
このようにすることにより、同じノードに分類されていない病名については関連病名としては扱われずその相関度が算出されないため、同じノードに分類された処理対象病名と関連病名に関する相関度のみが算出され、概念関係抽出の際に同じノードに分類されていない病名の影響を受けることがない。
【0079】
なお、「原因」という観点での分類であるか、又は、「症状」という観点での分類かは、CPU10は、各病名毎に原因リストや症状リストに対して求めた相関度がどの程度類似しているかに基づいて推定できる。以下、分類の観点を推定する方法を具体的に説明する。
【0080】
あるノードAに分類されているM個の病名を{d1,d2,…,dM}とする。{d1,d2,…,dM}のうちいくつかの病名がノードAとは異なるノードにも分類されている場合、下記の手順でノードAの分類の観点を推定する。
【0081】
まず、各病名{d1,d2,…,dM}に対して、前述の方法により関連項目の項目リスト内の各項目wとの相関度R(di,w)を求める。原因を表わす項目リストLC、症状を現す項目リストLS、薬品を表わす項目リストLMに対応する病名diとの相関度のセットをそれぞれ以下のように表わす。
【0082】
RC(di,LC)={R(di,wc1), R(di,wc2), …,R(di,wcNc),}
Rs(di,Ls)={R(di,ws1), R(di,ws2), …,R(di,wsNs),}
RM(di,LM)={R(di,wm1), R(di,wm2), …,R(di,wmNm),}
ノードA内の各病名{d1,d2,…,dM}に対して得られた原因を表わす項目リストLCとの相関度のセットRC(di,LC) {i=1,2,…M}がどの程度似通っているかは、RC(di,LC)を次元数NCの相関度ベクトルと見なして、これらの分散を計算することにより評価できる。即ち、M個のベクトルRC(di,LC) {i=1,2,…M}の分散V(A,LC)を次式により求める。
【0083】
【数9】
ここで、μ(A,LC)はM個の相関度ベクトルRC(di,LC)の平均ベクトルであり、下記式で表わされる。
【0084】
【数10】
また、(RC(di,LC)−μ(A,LC))2はRC(di,LC)とμ(A,LC)とのユークリッド距離の2乗である。
【0085】
症状を表わす項目リストLS、薬品を表わす項目リストLMに対しても、同様の手順で相関度ベクトルRs(di,Ls)及びRM(di,LM)の分散V(A,LS)及びV(A,LM)を計算する。
ノードA内の各病名の原因が共通している場合、ノードA内の各病名と原因を表わす項目リストLC内の各項目との相関度が似通った傾向を示すため、M個の相関度ベクトルRC(di,LC)の分散V(A,LC)の値は小さくなる。又、原因が各病名間で異なっていれば分散V(A,LC)の値は大きくなる。従って、V(A,LC)、V(A,LS)及びV(A,LM)の値を比較して、これら3つの中でV(A,LC)が最も小さい場合に、ノードAの分類の観点が「原因」である、と判断する。又、V(A,LS)が最も小さければ「症状」、V(A,LM)が最も小さければ「薬品」であると判断する。
【0086】
以上のようにして、ノード内の各病名毎に求めた各項目リスト内の項目との相関度がどの程度類似しているかに基づいて、そのノードの分類の観点を推定することができる。なお、上記の説明で評価尺度として用いたM個の相関度ベクトルRC(di,LC)の分散の代わりに、M個の相関度ベクトルRC(di,LC)とこれらの平均ベクトルμ(A,LC)とのコサイン類似度の総和(又は平均値)を用いることも可能である(この場合、相関度ベクトルが似通っている評価尺度の値は大きくなる。)
なお、複数ノードに分類されている病名を含む全てのノードについて、予め人手で分類の観点(原因、症状、部位等)のコードを関連付けしておいてもよい。CPU10は、このコードを読みとることによりどの観点での分類かを判断することができる。
【0087】
このようにして、CPU10はS30の処理が終了すると、このプログラムの実行を終了する。
以上詳述した本実施の形態によれば、以下に記載する各効果を得ることができる。
【0088】
(1) 本実施形態の医療情報抽出装置1のCPU10は、文書取得手段として、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得するようにした。そして、CPU10は、パッセージ抽出手段として、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを抽出するようにした。さらに、CPU10は、抽出したパッセージを含む対象文書集合を元にして、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出するようにした。この結果、本実施形態によれば、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0089】
(2) 又、医療情報抽出装置1のCPU10は、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するようにした。この結果、対象文書から該処理対象病名と関連のあるパッセージが、適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0090】
(3) 又、医療情報抽出装置1のCPU10は、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるようにした。この結果、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、各出現頻度に応じたものとすることができる。
【0091】
(4) 又、本実施形態では、医療情報抽出装置1のCPU10は、処理対象病名と関連項目の項目リスト内の各項目との第1相関度(相関度R(dT,w))と、処理対象病名の関連病名と関連項目の項目リスト内の各項目との第2相関度(相関度R(ri,w))を求めるようにした。そして、CPU10は、さらに、第2相関度(相関度R(ri,w))を、前記処理対象病名と各関連病名との関連度で重み付けしたものを第1相関度(相関度R(dT,w))に加算することにより、関連項目の項目リスト内の各項目と処理対象病名との相関度を算出するようにした。この結果、処理対象病名と前記関連項目の項目リスト内の各項目との第1相関度と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との第2相関度の両相関度が考慮され相関度を得ることができる。
【0092】
(5) 本実施形態は、CPU10が処理対象病名が予め与えられている病名間の階層構造において複数のノードに分類されている場合、それぞれのノードが前記関連項目のうちのどの観点により分類されているかに基づき観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いる。この結果、病名のそれぞれの分類箇所が、「原因」による分類であるか、又は、「症状」による分類で有るかを利用して、他の病名から概念関係を抽出する際に利用できる。
【0093】
(6) 本実施形態の医療情報抽出装置1は、CPU10が複数のノードに分類されている病名を含むノードに対し、このノードに分類されている各病名について求めた関連項目の項目リストの内、どの項目リストが各病名間で最も似通っているかに基づいて、このノードが分類されている観点を推定するようにした。この結果、このように概念関係抽出手段がノードが分類されている観点を推定することによって、病名のそれぞれの分類箇所が、「原因」による分類であるか、又は、「症状」による分類で有るかを利用して、他の病名から概念関係を抽出する際に利用できる。
【0094】
(7) 本実施形態の医療情報抽出方法は、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得するし、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出する。そして、本実施形態の医療情報抽出方法は、前記抽出されたパッセージを含む対象文書集合を元にして、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出して概念関係を抽出する。この結果、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができる。又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0095】
(8) 又、本実施形態の医療情報抽出方法は、前記パッセージを抽出する段階が、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出する。この結果、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0096】
(9) 又、本実施形態の医療情報抽出プログラムは、パーソナルコンピュータのCPU10に、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段として機能させる。又、前記プログラムは、CPU10に処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段として機能させる。さらに、前記プログラムは、CPU10に、抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段として機能させる。この結果、このプログラムがCPU10に実行されることにより、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0097】
(10) 又、本実施形態の医療情報抽出プログラムは、CPU10に、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するように機能させる。この結果、このプログラムがCPU10に実行されることにより、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0098】
(11) 又、本実施形態の医療情報抽出プログラムは、CPU10に、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるように機能させる。この結果、このプログラムがCPU10に実行されることにより、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、前記各出現頻度に応じたものとすることができる。
【0099】
なお、本発明の実施形態は以下のように変更してもよい。
○ 前記実施形態で説明した「パッセージの適合度の算出方法」の代わりに下記のようにパッセージの適合度の算出を行ってもよい。
【0100】
すなわち、CPU10は、対象文書集合から、処理対象病名drに対してM個の共起語{c1(dT),c2(dT)……,cM(dT)}と共起度{C1(dT),C2(dT)……,CM(dT)}を予め求めておく。又、各関連病名{r1,r2,……,rL}に対しても同様にM個の共起語{c1(ri),c2(ri)……,cM(ri)}と共起度{C1(ri),C2(ri)……,CM(ri)}(i=1,……L)を、適合度の算出の前に予め求めておく。
【0101】
CPU10は、各病名について、パッセージにおける共起語の出現頻度を共起度で重みつけしながら加算することにより、個々の病名に対するパッセージの適合度が得られる。これらをさらに、処理対象病名と関連病名との関連度で重み付けしながら加算することにより、処理対象病名dTに対するパッセージの適合度とする(下記式(2)参照)。
【0102】
【数11】
なお、この式には処理対象病名dTの出現頻度P(dT,pk)と各関連病名riの出現頻度P(ri、pk)が直接含まれていないが、病名dの共起語リスト{c1(d),c2(d)……,cM(d)}の中にd自身が含まれることを許せば上記式(2)でのパッセージの適合度F(dT,pk)の定義を包含することになる。又、共起語リストに自陣を含めない場合には、F'(dT,pk)とF(dT,pk)の和をパッセージ適合度とすればよい。
【0103】
そして、CPU10はこの適合度が閾値以上のパッセージのみを抽出する。ここでは、CPU10は共起語取得手段に相当する。
このようにすると、パッセージの適合度が、各病名の共起語の共起度と出現頻度に応じたものにすることができる。
【図面の簡単な説明】
【0104】
【図1】医療情報抽出装置1の概略ブロック図。
【図2】CPU10が実行する医療情報抽出プログラムのフローチャート。
【図3】検索によって得られた対象文書集合の説明図。
【図4】(a)、(b)はMEDISのICD10の国際疾病分類第10版の分類例の説明図。
【図5】(a)、(b)はMEDISのICD10の国際疾病分類第10版の分類例の説明図。
【符号の説明】
【0105】
1…医療情報抽出装置、10…CPU(文書取得手段、パッセージ抽出手段、概念関係抽出手段、共起語取得手段)。
【技術分野】
【0001】
本発明は医療情報抽出装置及び医療情報抽出プログラムに関する。特に、医師が診断などの際に電子カルテルシステムを用いたり、患者や患者の家族が病気についての情報をインターネットで調べたりする場合など、人間が医療に関わる情報を処理する場面において、コンピュータを用いて情報処理を支援する医療情報抽出装置、及び医療情報抽出プログラムに関する。
【背景技術】
【0002】
電子カルテルシステムなどの医療情報システムは、病院、診療所などの医療機関において、医師や看護士が診断や処置についての判断を行う際に、コンピュータを介して診断や処置を支援する情報システムである。このような情報システムで利用することが可能な医学的な知識を、自動的に抽出する装置が提案されている。抽出した医学的な知識は、前記医療機関において、利用することが可能だけではなく、患者や患者の家族が病気についての情報をインターネットで調べようとする際にも、利用可能である。
【0003】
こうした医療情報抽出方法についての従来技術としては特許文献1〜特許文献2、或いは、非特許文献1がある。
特許文献1は2単語間の類似度を計算する技術であり、単語間の相関をシソーラス辞書とコーパスを用いて算出するようにしている。特許文献2、特許文献3は、文書検索において、適切な検索を行うために単語間の概念階層を利用するものであり、検索キーに関連する文書の検索時の検索漏れや、不要文書を抽出するようなノイズを少なくするために、シソーラス辞書を用いる技術である。
【0004】
非特許文献1では、医療分野を例として、インターネット上のWeb文書から、ある話題に適合するパッセージ(文書の一部)を自動的に抽出する方法が提案されている。具体的には、まず、病名を検索キーとして、Web文書を自動的に収集し、タグの情報を用いて文書を細かく分割してパッセージの候補を抽出する。次に、症状を表わす表現を症状リストとして予め人手で用意しておき、この症状リストに適合するパッセージを候補の中から選択する。次に選択したパッセージの候補を類似度の大きなものから、順に出力するというものである。
【特許文献1】特開2005-38162号公報
【特許文献2】特開2003-22277号公報
【特許文献3】特開2003-345824号公報
【非特許文献1】「医療分野におけるWeb文書からの話題抽出方法」,人工知能学会全国大会(第19回)、1E1-01,2005
【発明の開示】
【発明が解決しようとする課題】
【0005】
ところで、病名と症状や、病名と薬品名、病名と検査項目などのような医学的知識は、その量が膨大であること、日々更新される知識であることなどの理由により、従来は、コンピュータによる支援には用いられていない。データマイニングを医療分野に適用しようとする試みは見られるものの、まだ、限定的な適用に留まっている。
【0006】
このような医学的知識を特定する上で、「病名」は、非常重要である。Webの検索において、必要とする知識を特定するために病名を用いることで、かなり、適切な限定を行うことができる。
【0007】
しかしながら、Webから得られる膨大な文書や、電子カルテ上の医療情報から、病名と症状のような医学的に知識を取り出すためには、個々の病名に関する情報を統計的に安定して推定することが難しいことや、個々の病名に関する情報がバラバラで関連付けられていないという問題があった。
【0008】
特許文献1は、2単語間の類似度をシソーラス上の階層の深さ、概念の階層及びパス上の概念に依存させて計算する技術である。しかし、階層構造の利用は、2単語間のみに対して適応され、類似度が算出されている。又、情報量の少ない単語や情報量のオーダーの異なる単語間に対しては、統計的に有効な類似度の算出が困難となる。
【0009】
特許文献2や、特許文献3に示されている従来技術は、文書検索における検索結果の質の向上を目的としたものであり、検索時に階層構造を表現した辞書から検索キーの上位概念単語、下位概念単語を抽出し、それらの単語を検索キーに追加して文書検索を行うものである。
【0010】
非特許文献1は、病名は検索のためのキーとして利用するだけなので、病名の間に存在する階層構造を利用していない。非特許文献1は、病名そのものを検索キーとして病名に関する症状パッセージを抽出する手法のため、Web上に蓄積されたテキスト量が少ない病名に関しては抽出できるパッセージが限定される。さらに、非特許文献1では、人手で用意した症状リストは、多様な表現を持つ症状を的確に表わすことが困難であり、症状を含むパッセージの抽出精度を左右する。又、非特許文献1の技術は、類似度の大きいパッセージそのものを出力する形式であることから、パッセージの質や大きさに依存した結果には一貫性がなく、さらに、同じ意味(症状)を表現したパッセージに対する処理は行われておらず、2次利用しにくいという問題があった。
【0011】
すなわち、上記の特許文献1〜3、非特許文献1の技術には、病名と症状との間の階層的な情報などによって医療情報を抽出するための装置及びプログラムについてや、或いは、文書と、病名に関する既存の知識を利用して抽出する装置及びプログラムに関しても開示されいない。又、上記各文献には検索後に、検索された文書集合を用いて統計的な情報を推定する装置及びプログラムについては開示されていない。
【0012】
そして、従来の医療情報の抽出は個々の病名から得られた文書を別々に使用していたため、病名に対応する文書の量が少なく、統計的な情報の推定が安定して行えない問題があった。
【0013】
本発明の目的は、病名の階層構造を利用して、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる医療情報抽出装置及び医療情報抽出プログラムを提供することを目的としている。
【課題を解決するための手段】
【0014】
上記問題点を解決するために本発明の医療情報抽出装置は、病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する医療情報抽出装置において、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段と、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段と、前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段とを備えたことを特徴とする。
【0015】
ここで、「病名と関連する関連項目」とは、病名と関連する症状、原因、処置、薬品名などをいい、その病名に関して関連して取り上げられている事項をいう。又、相関度は、項目と病名とが共に出現する度合のことである。 従来は、個々の病名から得られた文書を別々に使用していたため、個々の病名に対応する文書の量が少なく、統計的な情報の推定が安定して行えないという問題があった。それに対して、本発明によれば、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0016】
例えば、上位概念である病名には、階層構造が形成されているものがある。例えば「糖尿病」の中に階層構造を形成する「1型糖尿病」、「2型糖尿病」などが存在する。従って、それぞれの病名をキーとして検索して得られた文書は互いに関連しており、類似していることが期待できる。本発明では、こうした情報を利用するのである。
【0017】
前記医療情報抽出装置は、前記構成に加えて、前記パッセージ抽出手段が、前記パッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するようにしてもよい。
【0018】
このように構成されていることにより、対象文書から該処理対象病名と関連のあるパッセージが、適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0019】
又、前記医療情報抽出装置は、前記構成加えて、前記パッセージ抽出手段が、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるようにしてもよい。
【0020】
このように構成されていることにより、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、前記各出現頻度に応じたものとすることができる。
【0021】
さらには、医療情報抽出装置は、前記構成に加えて、前記処理対象病名と各関連病名に関してそれぞれ対象文書から共起語と該共起語の共起度を求める共起語取得手段を有し、前記パッセージ抽出手段が、各パッセージの適合度を求める際に、各病名の共起語の共起度と出現頻度とをさらに用いるようにしてもよい。
【0022】
ここで、共起語とは、項目の間において、共起する語のことであり、共起度は、共起する度合いのことである。
このように構成されていることにより、パッセージの適合度が、各病名の共起語の共起度と出現頻度に応じたものにすることができる。
【0023】
又、医療情報抽出装置は、前記構成に加えて、概念関係抽出手段が、処理対象病名と前記関連項目の項目リスト内の各項目との相関度(以下、第1相関度という)と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との相関度(以下、第2相関度という)を求め、さらに、前記第2相関度を、前記処理対象病名と各関連病名との関連度で重み付けしたものを前記第1相関度に加算することにより、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を算出するようにしてもよい。
【0024】
このように構成されていることにより、処理対象病名と前記関連項目の項目リスト内の各項目との相関度(第1相関度)と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との相関度(第2相関度)の両相関度が考慮され相関度を得ることができる。
【0025】
又、医療情報抽出装置は、前記構成に加えて、概念関係抽出手段が、処理対象病名が予め与えられている病名間の階層構造において複数のノードに分類されている場合には、それぞれのノードが前記関連項目のうちのどの観点により分類されているかに基づいて、観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いるようにしてもよい。
【0026】
すなわち、病名が複数のノードに分類されるとともに、あるノードがある項目(例えば「原因」)の観点で分類されている場合は、その観点が一致する項目リスト内の項目(「原因」)との相関度を算出する場合のみ、該同じノードに分類されている病名を関連病名として用いるようにする。
【0027】
このようにすることにより、病名のそれぞれの分類箇所が、「原因」による分類であるか、又は、「症状」による分類で有るかを利用して、他の病名から概念関係を抽出する際に利用できる。
【0028】
又、医療情報抽出装置は、前記構成に加えて、前記概念関係抽出手段が、複数のノードに分類されている病名を含むノードに対し、このノードに分類されている各病名について求めた関連項目の項目リスト内の各項目との相関度の内、どの項目リスト内の各項目との相関度が各病名間で最も似通っているかに基づいて、このノードが分類されている観点を推定するようにしてもよい。
【0029】
例えば、ノードが「原因」の観点による分類であるか、「症状」の観点による分類であるかは、各病名毎に抽出した原因リストや、症状リストがどの程度類似しているかに基づいて推定できる。このように概念関係抽出手段がノードが分類されている観点を推定することによって、請求項6の作用を容易に実現できる。
【0030】
又、本発明の医療情報抽出方法は、病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する医療情報抽出方法において、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する段階と、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出する段階と、前記抽出されたパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出して概念関係を抽出する段階と含むことを特徴とする。
【0031】
このように構成されていることにより、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる方法を提供できる。
【0032】
又、前記パッセージを抽出する段階が、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して該適合度に基づいて抽出するようにしてもよい。
【0033】
このように構成されていることにより、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる方法を提供できる。
【0034】
又、本発明のプログラムは、病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する際に、コンピュータに、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段、前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段として、機能させることを特徴とする。
【0035】
このように構成されていることにより、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができるプログラムを提供できる。
【0036】
又、前記プログラムにより、コンピュータが前記パッセージ抽出手段として機能する際に、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するようにしてもよい。
【0037】
このように構成されていることにより、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができるプログラムを提供できる。
【0038】
又、前記プログラムにより、コンピュータが前記パッセージ抽出手段として機能する際に、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるようにしてもよい。
【0039】
このように構成されていることにより、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、前記各出現頻度に応じたものとすることができるプログラムを提供できる。
【発明を実施するための最良の形態】
【0040】
以下、本発明を具体化した医療情報抽出装置、方法及びプログラムの一実施形態を図1〜5を参照して説明する。
図1に示すように、医療情報抽出装置1はパーソナルコンピュータからなる。医療情報抽出装置1は互いにバスで接続されたCPU10、ROM11、RAM12、及び文書取得部13を備えるとともにシソーラスのデータを記憶するシソーラス辞書部20、コーパスのデータや、テキスト文のデータを記憶するテキストコーパス30、データベース40、入力部50、出力部60を備える。前記ROM11には、医療情報抽出プログラム等の各種プログラムが格納されている。RAM12は前記各種プログラムを実行する際に使用される作業用記憶領域や、バッファ領域を備えている。
【0041】
シソーラス辞書部20、テキストコーパス30、及びデータベース40は例えば、ハードデイスクからなるが、限定されるものではない。入力部50はキーボード、マウス、等からなる。又、出力部60は表示装置やプリンタ等からなる。文書取得部13は、インターネットITに接続されている。
【0042】
次に、医療情報抽出装置1による医療情報の抽出について説明する。
まず、医療情報を収集するためのキーワードリストである病名リストと、関連項目リストについて説明する。該病名リスト、及び関連項目リストはデータベース40に格納されている。ここで、関連項目リストは初期セットとなる。
【0043】
病名リストは、上位概念の階層構造を記した、例えば、MEDISのICD10の国際疾病分類第10版のデータを利用し、このMEDISに対し病名を検索クエリとして検索エンジンで検索し、検索ヒット数順に並べ替えたものを病名リストとして作成してもよい。
【0044】
MEDISのICD10の国際疾病分類第10版の例を図4に例示する。図4(a)は、「感染症」に関するノードの部分であり、例えば、「A01 腸チフス及びパラチフス」では、A01.0〜A01.4まで分類されているが、さらには、A01の内には、図4(b)に示すように1〜15に亘って各種の病名に細分類されている。この場合、「腸チフス」を処理対象病名とした場合、これ以外の「A01」に挙げられている他の病名は関連病名となる。
【0045】
又、「病名」を上位概念としたとき、下位概念である「病名と関連する関連項目」は、病名と関連する「症状」、「原因」、「処置」、「薬品名」などがある。これには、「病名」と密接に関連する事項である。「症状」は当該病名の罹患患者が呈する状態を示し、「原因」は、当該病名の罹患原因となるものであり、「処置」は、当該病名の対応治療等を示し、「薬品名」は、当該病名に使用される治療薬等を示す。初期セットである関連項目リストとはこれらがそれぞれリストとして作成されたものである。例えば、「症状」に関しては、症状リストといい、「原因」に関しては、原因リストという。他の関連項目についても同様のリストが作成される。下位概念である「症状」、「原因」、「処置」、「薬品名」などは、各病名に対してリスト形式で提示されている。
【0046】
なお、両リストは、医学事典に記載されている主な症状、原因、薬品名を人手により抽出したものをそれぞれリストの項目として作成した上で、データベース40に格納するようにしてもよい。
【0047】
次に、医療情報抽出装置1のCPU10は、医療情報抽出プログラムを起動すると、図2に示すフローチャートを実行する。
(文書の収集処理)
S10では、CPU10は文書収集を行う。文書収集は、前記病名リストから病名(関連病名も含む)をキーワードとして用いて行われる。CPU10は、病名リストから病名(関連病名も含む)を順次読込みして、文書取得部13を介してインターネットITへ送出する。このとき、CPU10はインターネットIT上の自由書式の文書としてのWeb文書を検索するためには、ウェブブラウザの検索エンジンを使用してもよい。インターネットIT上で検索されたWeb文書は、文書取得部13を介してテキストコーパス30に収集される。ここでの機能によりCPU10は文書取得手段に相当する。
【0048】
(パッセージ抽出処理)
S20では、CPU10は、収集したWeb文書を元にパッセージ抽出を行う。Web文書は、1文書内に複数の話題が含まれていることがあり、不要部が存在する可能性がある。そのため、CPU10は分割情報に基づいてパッセージの抽出を行う。ここで、分割情報とは、Web文書がHTML文書の場合は、タグであり、Web文書が通常のテキスト文書の場合は、段落が相当する。この分割情報に基づいて、該文書の書き手の意図する分割点で文書を分割し、医療情報がない不要な部分を除去し、医療情報があるパッセージを抽出する。
【0049】
このとき、対象とするキーワードの上位階層及び下位階層の各病名の出現頻度に基づいてパッセージを抽出してもよく、又、上位階層と下位階層の病名間の関連度を重みとして利用してもよい。ここでの機能により、CPU10はパッセージ抽出手段に相当する。
【0050】
本実施形態では、パッセージの適合度を算出して、該適合度が閾値以上のパッセージを適合度が高いとして抽出する。又、適合度が閾値未満のパッセージは、パッセージの適合度が低いものとして抽出の対象から除外される。
【0051】
図3は、検索によって得られた対象文書集合を示し、各パッセージp1,p2、…pkが抽出された例が示されている。
(パッセージの適合度の算出方法)
ここで、上位概念である「病名」の階層構造を利用する場合のパッセージの適合度の算出方法を説明する。ここでは、処理対象病名dT=”腸チフス性関節炎”に対するパッセージpkの適合度の例を挙げる。
【0052】
下記に示すように処理対象病名dT=”腸チフス性関節炎”に対して、L個の関連病名{r1,r2,…,rL}とその関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}が与えられている。なお、関連度については、後述する。
【0053】
関連病名{r1,r2,…,rL}={"腸チフス","腸チフス性心筋炎",……}
関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}={0.4,0.15,……}
このとき、処理対象病名drに対するパッセージpkの適合度F(dT,pk)を次式(1)により算出する。
【0054】
【数1】
上記式中、P(ri,pk)はパッセージpkにおける関連病名riの出現確率であり、パッセージpkにおける関連病名riの出現回数f(ri,pk)からP(ri,pk)=f(ri,pk)/Qkとして算出する。
【0055】
(病名間の関連度の算出方法)
ある病名dと関連病名rとの関連度I(d,r)の算出方法について説明する。
病名dをキーワードとして検索して得られた文書集合をDd、関連病名rをキーワードとして検索して得られた文書集合をDrとする。
【0056】
文書集合Ddと文書集合Drの和集合D0=(Dd∪Dr)に含まれる単語の異なり数(語彙数)をVとし、文書集合DdとDrのそれぞれについて、各単語{t1,t2…tV}の出現回数を要素値とする
【0057】
【数2】
を生成する。
【0058】
【数3】
前記2つのベクトル間のコサイン類似度
【0059】
【数4】
は文書集合DdとDrがどの程度類似しているかを示している。これを病名dと関連病名rとの関連度I(d,r)として用いる。
【0060】
なお、この他、文書集合DdとDrの和集合D0=(Dd∪Dr)における病名dと関連病名rの相互情報量を関連度として用いてもよい。
【0061】
【数5】
(概念関係抽出処理、すなわち統計情報の抽出)
再び図2のフローチャートの説明に戻る。S30では、CPU10は、キーワードリストの階層構造を利用して統計情報の抽出を行う。すなわち、CPU10は、作成したリスト(例えば関連項目リストである症状リスト)の初期セットを利用してキーワードである病名と関連項目(例えば「ある症状」)の間の統計的な情報(以下、統計情報という)を抽出する。この統計情報の抽出が、概念関係抽出に相当する。ここでの機能により、CPU10は、概念関係抽出手段に相当する。
【0062】
ここで、統計情報としては、2つの単語が共起する頻度や、共起する頻度とそれぞれの生起確率を考慮した後述する相互情報量や、TF-IDFなどを用いることが可能である。この時、それぞれの情報量にパッセージ文書が属するドメインや検索ヒット数に対応した重みを掛けてもよい。このようにすることによりどのような症状が、どの程度の頻度で、生起するかの情報を得ることができる。
【0063】
本実施形態では、下記(1. 相関度R(dT,w)の算出)を行い、さらに、(2. 相関度R(ri,w)の算出及び相関度R'(dT,w)の算出)を行うことにより、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する。
【0064】
(相関度の算出)
ここで、概念関係抽出において、使用される相関度の算出、すなわち、関連項目の項目リスト内の各項目と前記処理対象病名との相関度の算出方法について説明する。
【0065】
なお、ここでは原因を表わす項目リストLC、症状を表わす項目リストLS、薬品を表わす項目リストLMが、下記のように与えられているとする。
LC={wc1,wc2,……wcNc}、
LS={ws1,ws2,……wsNs}、
LM={wm1,wm2,……wmNm}、
Nc、Ns、Nmは各リストの項目数である。
【0066】
(1. 相関度R(dT,w)の算出)
処理対象病名dT="腸チフス性関節炎"に対して、各項目リスト内の各項目wとの相関度R(dT,w)を算出し、病名dTにはどのような原因/症状/薬品がどの程度関連しているかを知識として抽出する。相関度R(dT,w)は第1相関度に相当する。この場合、相関度R(dT,w)は、統計的尺度により算出する。統計的尺度としては、下記のものを挙げることができ、いずれの統計的尺度を使用してもよい。
【0067】
1. 対象文書集合における処理対象病名dTと各項目wとの共起回数freq(dT,w)
共起回数freq(dT,w)は、同じパッセージの中に各項目wがどれだけあったかを示している。
【0068】
2. 対象文書集合における処理対象病名dTと相互情報量
【0069】
【数6】
3. 対象文書集合における各項目wのTF-IDF値
【0070】
【数7】
(2. 相関度R(ri,w)の算出及び相関度R'(dT,w)の算出)
次に、L個の関連病名riと各項目リスト内の各項目wとの相関度R(ri,w)の算出する。相関度R(ri,w)は第2相関度に相当する。
【0071】
前述したように、処理対象病名dT=”腸チフス性関節炎”に対して、L個の関連病名{r1,r2,…,rL}とその関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}が与えられている。
関連病名{r1,r2,…,rL}={"腸チフス","腸チフス性心筋炎",……}
関連度{I(dT,r1),I(dT,r2),……,I(dT,rL)}={0.4,0.15,……}
各関連病名{r1,r2,…,rL}に対しても、上記の統計的尺度により相関度R(dT,w)を求めたと同様に相関度R(ri,w)(なお、i=1,2,……Lである)を算出する。
【0072】
そして、得られた前記相関度R(ri,w))と各関連病名との関連度I(dT,ri)で重み付けしながら加算し、これを処理対象病名dTと項目wとの相関度R'(dT,w)とする。すなわち、
【0073】
【数8】
を処理対象病名dTと項目wとの相関度として用いる。
【0074】
(処理対象病名が複数のノードに分類されている場合)
ところで、処理対象病名が複数のノードに分類されている場合について説明する。
前述したように、図4(a)は、「感染症」に関するノードの部分であり、例えば、「A01 腸チフス及びパラチフス」について記載されている。
【0075】
一方、図5(a)、(b)は、MEDISのICD10の国際疾病分類第10版において、「症状」が共通している観点での分類の例である。この場合、例えば、図4(b)、図5(b)に示すように「腸チフス性心内膜炎(ICD10コード=A010,1398)」は、階層的分類の中で複数に分類されていることが分かる。このように複数ノードに分類されている「病名」は、それぞれのノードに属する他の病名が関連病名となるが、ここでA01(腸チフス及びパラチフス)に属する病名は原因がチフス菌である点が共通であり、I39(……心内膜炎及び心弁膜障害)に属する病名は症状が心内膜炎・心弁膜障害である点が共通である。
【0076】
このようにある病名が複数箇所に分類されている場合、観点が異なってそれぞれ分類されていることになる。それぞれの分類箇所が、原因による分類であるか、又は、症状による分類であるかを利用して、他の病名から概念関係を抽出する際に利用する。
【0077】
すなわち、概念関係抽出手段であるCPU10は、観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いるようにする。
【0078】
このようにすることにより、同じノードに分類されていない病名については関連病名としては扱われずその相関度が算出されないため、同じノードに分類された処理対象病名と関連病名に関する相関度のみが算出され、概念関係抽出の際に同じノードに分類されていない病名の影響を受けることがない。
【0079】
なお、「原因」という観点での分類であるか、又は、「症状」という観点での分類かは、CPU10は、各病名毎に原因リストや症状リストに対して求めた相関度がどの程度類似しているかに基づいて推定できる。以下、分類の観点を推定する方法を具体的に説明する。
【0080】
あるノードAに分類されているM個の病名を{d1,d2,…,dM}とする。{d1,d2,…,dM}のうちいくつかの病名がノードAとは異なるノードにも分類されている場合、下記の手順でノードAの分類の観点を推定する。
【0081】
まず、各病名{d1,d2,…,dM}に対して、前述の方法により関連項目の項目リスト内の各項目wとの相関度R(di,w)を求める。原因を表わす項目リストLC、症状を現す項目リストLS、薬品を表わす項目リストLMに対応する病名diとの相関度のセットをそれぞれ以下のように表わす。
【0082】
RC(di,LC)={R(di,wc1), R(di,wc2), …,R(di,wcNc),}
Rs(di,Ls)={R(di,ws1), R(di,ws2), …,R(di,wsNs),}
RM(di,LM)={R(di,wm1), R(di,wm2), …,R(di,wmNm),}
ノードA内の各病名{d1,d2,…,dM}に対して得られた原因を表わす項目リストLCとの相関度のセットRC(di,LC) {i=1,2,…M}がどの程度似通っているかは、RC(di,LC)を次元数NCの相関度ベクトルと見なして、これらの分散を計算することにより評価できる。即ち、M個のベクトルRC(di,LC) {i=1,2,…M}の分散V(A,LC)を次式により求める。
【0083】
【数9】
ここで、μ(A,LC)はM個の相関度ベクトルRC(di,LC)の平均ベクトルであり、下記式で表わされる。
【0084】
【数10】
また、(RC(di,LC)−μ(A,LC))2はRC(di,LC)とμ(A,LC)とのユークリッド距離の2乗である。
【0085】
症状を表わす項目リストLS、薬品を表わす項目リストLMに対しても、同様の手順で相関度ベクトルRs(di,Ls)及びRM(di,LM)の分散V(A,LS)及びV(A,LM)を計算する。
ノードA内の各病名の原因が共通している場合、ノードA内の各病名と原因を表わす項目リストLC内の各項目との相関度が似通った傾向を示すため、M個の相関度ベクトルRC(di,LC)の分散V(A,LC)の値は小さくなる。又、原因が各病名間で異なっていれば分散V(A,LC)の値は大きくなる。従って、V(A,LC)、V(A,LS)及びV(A,LM)の値を比較して、これら3つの中でV(A,LC)が最も小さい場合に、ノードAの分類の観点が「原因」である、と判断する。又、V(A,LS)が最も小さければ「症状」、V(A,LM)が最も小さければ「薬品」であると判断する。
【0086】
以上のようにして、ノード内の各病名毎に求めた各項目リスト内の項目との相関度がどの程度類似しているかに基づいて、そのノードの分類の観点を推定することができる。なお、上記の説明で評価尺度として用いたM個の相関度ベクトルRC(di,LC)の分散の代わりに、M個の相関度ベクトルRC(di,LC)とこれらの平均ベクトルμ(A,LC)とのコサイン類似度の総和(又は平均値)を用いることも可能である(この場合、相関度ベクトルが似通っている評価尺度の値は大きくなる。)
なお、複数ノードに分類されている病名を含む全てのノードについて、予め人手で分類の観点(原因、症状、部位等)のコードを関連付けしておいてもよい。CPU10は、このコードを読みとることによりどの観点での分類かを判断することができる。
【0087】
このようにして、CPU10はS30の処理が終了すると、このプログラムの実行を終了する。
以上詳述した本実施の形態によれば、以下に記載する各効果を得ることができる。
【0088】
(1) 本実施形態の医療情報抽出装置1のCPU10は、文書取得手段として、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得するようにした。そして、CPU10は、パッセージ抽出手段として、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを抽出するようにした。さらに、CPU10は、抽出したパッセージを含む対象文書集合を元にして、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出するようにした。この結果、本実施形態によれば、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0089】
(2) 又、医療情報抽出装置1のCPU10は、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するようにした。この結果、対象文書から該処理対象病名と関連のあるパッセージが、適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0090】
(3) 又、医療情報抽出装置1のCPU10は、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるようにした。この結果、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、各出現頻度に応じたものとすることができる。
【0091】
(4) 又、本実施形態では、医療情報抽出装置1のCPU10は、処理対象病名と関連項目の項目リスト内の各項目との第1相関度(相関度R(dT,w))と、処理対象病名の関連病名と関連項目の項目リスト内の各項目との第2相関度(相関度R(ri,w))を求めるようにした。そして、CPU10は、さらに、第2相関度(相関度R(ri,w))を、前記処理対象病名と各関連病名との関連度で重み付けしたものを第1相関度(相関度R(dT,w))に加算することにより、関連項目の項目リスト内の各項目と処理対象病名との相関度を算出するようにした。この結果、処理対象病名と前記関連項目の項目リスト内の各項目との第1相関度と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との第2相関度の両相関度が考慮され相関度を得ることができる。
【0092】
(5) 本実施形態は、CPU10が処理対象病名が予め与えられている病名間の階層構造において複数のノードに分類されている場合、それぞれのノードが前記関連項目のうちのどの観点により分類されているかに基づき観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いる。この結果、病名のそれぞれの分類箇所が、「原因」による分類であるか、又は、「症状」による分類で有るかを利用して、他の病名から概念関係を抽出する際に利用できる。
【0093】
(6) 本実施形態の医療情報抽出装置1は、CPU10が複数のノードに分類されている病名を含むノードに対し、このノードに分類されている各病名について求めた関連項目の項目リストの内、どの項目リストが各病名間で最も似通っているかに基づいて、このノードが分類されている観点を推定するようにした。この結果、このように概念関係抽出手段がノードが分類されている観点を推定することによって、病名のそれぞれの分類箇所が、「原因」による分類であるか、又は、「症状」による分類で有るかを利用して、他の病名から概念関係を抽出する際に利用できる。
【0094】
(7) 本実施形態の医療情報抽出方法は、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得するし、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出する。そして、本実施形態の医療情報抽出方法は、前記抽出されたパッセージを含む対象文書集合を元にして、関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出して概念関係を抽出する。この結果、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができる。又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0095】
(8) 又、本実施形態の医療情報抽出方法は、前記パッセージを抽出する段階が、前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出する。この結果、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0096】
(9) 又、本実施形態の医療情報抽出プログラムは、パーソナルコンピュータのCPU10に、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段として機能させる。又、前記プログラムは、CPU10に処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段として機能させる。さらに、前記プログラムは、CPU10に、抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段として機能させる。この結果、このプログラムがCPU10に実行されることにより、病名の階層構造を利用して個々の病名に関する情報を統計的に安定して推定することができ、又、個々の病名に関しての文書だけでなく、関連した文書の情報を合わせて用いることが可能となり、統計的な情報の推定が、より安定的に行うことができる。
【0097】
(10) 又、本実施形態の医療情報抽出プログラムは、CPU10に、処理対象病名とその関連病名との間の関係を利用して対象文書から該処理対象病名と関連のあるパッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出するように機能させる。この結果、このプログラムがCPU10に実行されることにより、対象文書から該処理対象病名と関連のあるパッセージが、パッセージの適合度という客観的な数値に基づいて抽出できるため、的確に対象文書から該処理対象病名と関連のあるパッセージを抽出することができる。
【0098】
(11) 又、本実施形態の医療情報抽出プログラムは、CPU10に、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めるように機能させる。この結果、このプログラムがCPU10に実行されることにより、パッセージの適合度が、各パッセージの処理対象病名の出現頻度と、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものが加算されているため、前記各出現頻度に応じたものとすることができる。
【0099】
なお、本発明の実施形態は以下のように変更してもよい。
○ 前記実施形態で説明した「パッセージの適合度の算出方法」の代わりに下記のようにパッセージの適合度の算出を行ってもよい。
【0100】
すなわち、CPU10は、対象文書集合から、処理対象病名drに対してM個の共起語{c1(dT),c2(dT)……,cM(dT)}と共起度{C1(dT),C2(dT)……,CM(dT)}を予め求めておく。又、各関連病名{r1,r2,……,rL}に対しても同様にM個の共起語{c1(ri),c2(ri)……,cM(ri)}と共起度{C1(ri),C2(ri)……,CM(ri)}(i=1,……L)を、適合度の算出の前に予め求めておく。
【0101】
CPU10は、各病名について、パッセージにおける共起語の出現頻度を共起度で重みつけしながら加算することにより、個々の病名に対するパッセージの適合度が得られる。これらをさらに、処理対象病名と関連病名との関連度で重み付けしながら加算することにより、処理対象病名dTに対するパッセージの適合度とする(下記式(2)参照)。
【0102】
【数11】
なお、この式には処理対象病名dTの出現頻度P(dT,pk)と各関連病名riの出現頻度P(ri、pk)が直接含まれていないが、病名dの共起語リスト{c1(d),c2(d)……,cM(d)}の中にd自身が含まれることを許せば上記式(2)でのパッセージの適合度F(dT,pk)の定義を包含することになる。又、共起語リストに自陣を含めない場合には、F'(dT,pk)とF(dT,pk)の和をパッセージ適合度とすればよい。
【0103】
そして、CPU10はこの適合度が閾値以上のパッセージのみを抽出する。ここでは、CPU10は共起語取得手段に相当する。
このようにすると、パッセージの適合度が、各病名の共起語の共起度と出現頻度に応じたものにすることができる。
【図面の簡単な説明】
【0104】
【図1】医療情報抽出装置1の概略ブロック図。
【図2】CPU10が実行する医療情報抽出プログラムのフローチャート。
【図3】検索によって得られた対象文書集合の説明図。
【図4】(a)、(b)はMEDISのICD10の国際疾病分類第10版の分類例の説明図。
【図5】(a)、(b)はMEDISのICD10の国際疾病分類第10版の分類例の説明図。
【符号の説明】
【0105】
1…医療情報抽出装置、10…CPU(文書取得手段、パッセージ抽出手段、概念関係抽出手段、共起語取得手段)。
【特許請求の範囲】
【請求項1】
病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する医療情報抽出装置において、
処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段と、
前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段と、
前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段とを備えたことを特徴とする医療情報抽出装置。
【請求項2】
前記パッセージ抽出手段が、前記パッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出することを特徴とする請求項1に記載の医療情報抽出装置。
【請求項3】
前記パッセージ抽出手段が、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めることを特徴とする請求項2に記載の医療情報抽出装置。
【請求項4】
前記処理対象病名と各関連病名に関してそれぞれ対象文書から共起語と該共起語の共起度を求める共起語取得手段を有し、
前記パッセージ抽出手段が、各パッセージの適合度を求める際に、各病名の共起語の共起度と出現頻度とをさらに用いることを特徴とする請求項2又は請求項3に記載の医療情報抽出装置。
【請求項5】
前記概念関係抽出手段が、処理対象病名と前記関連項目の項目リスト内の各項目との相関度(以下、第1相関度という)と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との相関度(以下、第2相関度という)を求め、さらに、前記第2相関度を、前記処理対象病名と各関連病名との関連度で重み付けしたものを前記第1相関度に加算することにより、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を算出することを特徴とする請求項1乃至請求項4のうちいずれか1項に記載の医療情報抽出装置。
【請求項6】
前記概念関係抽出手段が、処理対象病名が予め与えられている病名間の階層構造において複数のノードに分類されている場合には、それぞれのノードが前記関連項目のうちのどの観点により分類されているかに基づいて、観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いることを特徴とする請求項1乃至請求項5のうちいずれか1項に記載の医療情報抽出装置。
【請求項7】
前記概念関係抽出手段が、複数のノードに分類されている病名を含むノードに対し、このノードに分類されている各病名について求めた関連項目の項目リスト内の各項目との相関度の内、どの項目リスト内の各項目との相関度が各病名間で最も似通っているかに基づいて、このノードが分類されている観点を推定することを特徴とする請求項6に記載の医療情報抽出装置。
【請求項8】
コンピュータに、
病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する際に、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段、
前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段、
前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段として、機能させるためのプログラム。
【請求項1】
病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する医療情報抽出装置において、
処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段と、
前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段と、
前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段とを備えたことを特徴とする医療情報抽出装置。
【請求項2】
前記パッセージ抽出手段が、前記パッセージを、処理対象病名に対するパッセージの適合度を算出して、該適合度に基づいて抽出することを特徴とする請求項1に記載の医療情報抽出装置。
【請求項3】
前記パッセージ抽出手段が、各パッセージの処理対象病名の出現頻度に対して、関連病名の出現頻度を処理対象病名と各関連病名との関連度で重み付けしたものを加算することによりパッセージの適合度を求めることを特徴とする請求項2に記載の医療情報抽出装置。
【請求項4】
前記処理対象病名と各関連病名に関してそれぞれ対象文書から共起語と該共起語の共起度を求める共起語取得手段を有し、
前記パッセージ抽出手段が、各パッセージの適合度を求める際に、各病名の共起語の共起度と出現頻度とをさらに用いることを特徴とする請求項2又は請求項3に記載の医療情報抽出装置。
【請求項5】
前記概念関係抽出手段が、処理対象病名と前記関連項目の項目リスト内の各項目との相関度(以下、第1相関度という)と、処理対象病名の関連病名と前記関連項目の項目リスト内の各項目との相関度(以下、第2相関度という)を求め、さらに、前記第2相関度を、前記処理対象病名と各関連病名との関連度で重み付けしたものを前記第1相関度に加算することにより、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を算出することを特徴とする請求項1乃至請求項4のうちいずれか1項に記載の医療情報抽出装置。
【請求項6】
前記概念関係抽出手段が、処理対象病名が予め与えられている病名間の階層構造において複数のノードに分類されている場合には、それぞれのノードが前記関連項目のうちのどの観点により分類されているかに基づいて、観点が一致する項目リスト内の各項目との相関度を算出する場合のみ、同じノードに分類されている病名を関連病名として用いることを特徴とする請求項1乃至請求項5のうちいずれか1項に記載の医療情報抽出装置。
【請求項7】
前記概念関係抽出手段が、複数のノードに分類されている病名を含むノードに対し、このノードに分類されている各病名について求めた関連項目の項目リスト内の各項目との相関度の内、どの項目リスト内の各項目との相関度が各病名間で最も似通っているかに基づいて、このノードが分類されている観点を推定することを特徴とする請求項6に記載の医療情報抽出装置。
【請求項8】
コンピュータに、
病名と、該病名と関連する関連項目との関係を自由書式の文書から抽出する際に、処理対象病名と、病名間の階層構造をなす関連病名とをキーワードとして検索が行われた対象文書を取得する文書取得手段、
前記処理対象病名とその関連病名との間の関係を利用して前記対象文書から該処理対象病名と関連のあるパッセージを抽出するパッセージ抽出手段、
前記パッセージ抽出手段が抽出したパッセージを含む対象文書集合を元にして、前記関連項目の項目リスト内の各項目と処理対象病名との相関度を、対象病名と関連病名との関係を利用して算出する概念関係抽出手段として、機能させるためのプログラム。
【図1】

【図2】
【図3】
【図4】
【図5】
【図2】
【図3】
【図4】
【図5】
【公開番号】特開2008−83928(P2008−83928A)
【公開日】平成20年4月10日(2008.4.10)
【国際特許分類】
【出願番号】特願2006−262359(P2006−262359)
【出願日】平成18年9月27日(2006.9.27)
【出願人】(304019399)国立大学法人岐阜大学 (289)
【出願人】(000001889)三洋電機株式会社 (18,308)
【Fターム(参考)】
【公開日】平成20年4月10日(2008.4.10)
【国際特許分類】
【出願日】平成18年9月27日(2006.9.27)
【出願人】(304019399)国立大学法人岐阜大学 (289)
【出願人】(000001889)三洋電機株式会社 (18,308)
【Fターム(参考)】
[ Back to top ]