
半導体装置
【課題】所望の論理回路を構成する記憶素子ブロックの総量を減らすことを図る。
【解決手段】N(Nは、2以上の整数)本のアドレス線と、N本のデータ線と、複数の記憶部であって、各記憶部は、前記N本のアドレス線から入力されるアドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、前記ワード線とデータ線に接続し、真理値表を構成するデータをそれぞれ記憶し、前記ワード線から入力される前記ワード選択信号により、前記データを前記データ線に入出力する複数の記憶素子を有する、複数の記憶部と、を備え、前記記憶部のN本のアドレス線は、前記記憶部の他のN個の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のN本のデータ線は、前記記憶部の他のN個の記憶部のアドレス線に、それぞれ接続する半導体装置が提供される。
【解決手段】N(Nは、2以上の整数)本のアドレス線と、N本のデータ線と、複数の記憶部であって、各記憶部は、前記N本のアドレス線から入力されるアドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、前記ワード線とデータ線に接続し、真理値表を構成するデータをそれぞれ記憶し、前記ワード線から入力される前記ワード選択信号により、前記データを前記データ線に入出力する複数の記憶素子を有する、複数の記憶部と、を備え、前記記憶部のN本のアドレス線は、前記記憶部の他のN個の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のN本のデータ線は、前記記憶部の他のN個の記憶部のアドレス線に、それぞれ接続する半導体装置が提供される。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、半導体装置に関する。
【背景技術】
【0002】
PLD(Programmable Logic Device)が知られている。PLDは、構成する論理回路を変更可能な半導体装置であり、複数の論理要素、及び複数の接続要素を有する。
【0003】
論理要素は、組合せ回路又は順序回路として動作する。論理要素は、例えば、真理値表を構成する複数の記憶素子からなる記憶素子ブロックである。複数の記憶素子は、例えば、SRAM(Static Random Access Memory)である。
【0004】
接続要素は、論理要素間の接続を切り替える。接続要素は、例えば、トランジスタスイッチング素子である。よって、PLDは、例えば、SRAMを書き換え、スイッチング素子のオン/オフで、構成する論理回路を書き換える。
【0005】
記憶素子ブロックを、接続要素として動作させる半導体装置が開示されている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2003−224468号公報
【特許文献2】特開2003−149300号公報
【特許文献3】国際公開第07/060763号パンフレット
【特許文献4】国際公開第09/001426号パンフレット
【特許文献5】国際公開第07/060738号パンフレット
【特許文献6】特開2009−194676号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
記憶素子ブロックを接続要素として動作させる半導体装置は、論理要素として動作する記憶素子の比率を上げることで、所望の論理回路を構成する記憶素子ブロックの総量を減らすことができる。
【課題を解決するための手段】
【0008】
1つの側面では、本発明は、所望の論理回路を構成する記憶素子ブロックの総量を減らすことを目的とする。
【0009】
上記の課題の解決を意図する実施形態は、下記の第1のセットに係る(1)〜(15)に記載のようなものである。
(1)N(Nは、2以上の整数)本のアドレス線と、
N本のデータ線と、
複数の記憶部であって、各記憶部は、
前記N本のアドレス線から入力されるアドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、
前記ワード線とデータ線に接続し、真理値表を構成するデータをそれぞれ記憶し、前記ワード線から入力される前記ワード選択信号により、前記データを前記データ線に入出力する複数の記憶素子を有する、複数の記憶部と、を備え、
前記記憶部のN本のアドレス線は、前記記憶部の他のN個の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のN本のデータ線は、前記記憶部の他のN個の記憶部のアドレス線に、それぞれ接続することを特徴とする半導体装置。
(2)前記N本のアドレス線と、前記N本のデータ線とはそれぞれ、1本のアドレス線と、1本のデータ線とにより対をなす(1)に記載の半導体装置。
(3)前記複数の記憶部を選択する記憶部デコーダをさらに有する(1)又は(2)に記載の半導体装置。
(4)順序回路を有し、
前記複数の記憶部は、前記N本のデータ線の中の少なくとも1本のデータ線を前記順序回路の信号入力線に接続するとともに、前記N本のアドレス線の中の少なくとも1本のアドレス線を前記順序回路の信号出力線に接続する(1)〜(3)の何れか1項に記載の半導体装置。
(5)前記Nは、6〜8の整数である(1)〜(4)の何れか1項に記載の半導体装置。
(6)前記複数の記憶部は、前記N本のデータ線の中の6本のデータ線を、隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続するとともに、前記N本のアドレス線の中の6本のアドレス線を、前記隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続する(1)〜(5)の何れか1項に記載の半導体装置。
(7)前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項(1)〜(6)の何れか1項に記載の半導体装置。
(8)前記複数の記憶部のうちの少なくとも1つの記憶部に隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から第1の方向に第1の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向に交差する第2の方向に第2の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向と前記第2の方向に交差する第3の方向に第3の距離を置いて配置され、
前記第1〜第3の距離は、第1の距離、第2の距離、第3の距離の順番で長くなる、(1)〜(7)の何れか1項に記載の半導体装置。
(9)前記第1の方向と、前記第2の方向とは、互いに直交している(1)〜(8)の何れか1項に記載の半導体装置。
(10)前記複数の記憶部の少なくとも1つの記憶部は、隣接する他の記憶部以外の記憶部のデータ線に、1本のアドレス線を接続する(1)〜(9)の何れか1項に記載の半導体装置。
(11)前記複数の記憶部の何れかは、前記複数の記憶部のうちの少なくとも1つの記憶部から前記第1〜第3の方向の何れかの方向に配置され、
前記複数の記憶部の少なくとも1つの記憶部は、前記第1〜第3の距離の何れか1つを5倍した位置に配置された記憶部のデータ線に、1本のアドレス線を接続する(6)〜(10)の何れか1項に記載の半導体装置。
(12)前記複数の記憶部は、再構成可能な論理要素及び/又は接続要素として使用される(1)〜(11)の何れか1項に記載の半導体装置。
(13)前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する(1)〜(12)の何れか1項に記載の半導体装置。
(14)前記真理値表を構成するデータを記憶する記憶装置をさらに有する(13)に記載の半導体装置。
(15)物理的な配線層数が4層以下である(1)〜(14)の何れか1項に記載の半導体装置。
【0010】
また、記憶素子ブロックを接続要素として動作させる半導体装置は、他の装置とデータの入出力が可能である。しかしながら、他の装置とのデータの入出力方式が決まらないと、上記半導体装置は、他の装置とデータの入出力を行うことができない。
【0011】
別な側面では、本発明は、半導体装置と演算処理装置とのデータの入出力を行うことを目的とする。
【0012】
上記の課題の解決を意図する実施形態は、下記の第2のセットに係る(1)〜(11)に記載のようなものである。
(1)それぞれが複数の記憶部を有する第1及び第2の論理部であって、各記憶部は、第1アドレス線から入力されるメモリ動作用アドレス、又は、第2アドレス線から入力される論理動作用アドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、前記ワード線とデータ線とに接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子と、を有する、第1及び第2の論理部と、
前記第1の論理部が有する記憶部の第1アドレス線及びデータ線と接続する第1の入出力部、前記第2の論理部が有する記憶部の第2アドレス線及びデータ線と接続する第2の入出力部、及び、前記第1の入出力部に対してメモリ動作用アドレス及びデータを出力する制御を行うとともに、前記第2の入出力部に対して論理動作用アドレスを出力し且つデータを受け取る制御を行う制御部、を有する演算処理部と、
を備えることを特徴とする半導体装置。
(2)第1の論理部又は第2の論理部に含まれる前記記憶部の論理動作用アドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部の論理動作用アドレス線に、それぞれ接続する(1)に記載の半導体装置。
(3)前記第1の論理部及び前記第2の論理部に含まれる前記複数の記憶部は、再構成可能である(1)又は(2)に記載の半導体装置。
(4)前記第1の論理部及び前記第2の論理部は、前記複数の記憶部を選択する記憶部デコーダをそれぞれ有する(1)〜(3)の何れか1項に記載の半導体装置。
(5)前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する(1)〜(4)の何れか1項に記載の半導体装置。
(6)前記真理値表を構成するデータを記憶する記憶装置をさらに有する(1)〜(5)の何れか1項に記載の半導体装置。
(7)物理的な配線層数が4層以下である(1)〜(6)の何れか1項に記載の半導体装置。
(8)前記第1の論理部が有する前記記憶部の数と、前記第2の論理部が有する前記記憶部の数とが同一である(1)〜(7)の何れか1項に記載の半導体装置。
(9)前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する(1)〜(8)の何れか1項に記載の半導体装置。
(10)演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、第1の論理部に、論理動作又は接続関係を規定する真理値表データを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第1の論理部の記憶部に、前記論理動作又は接続関係を規定する真理値表データを記憶するステップと、
前記演算処理部が、第2の論理部に、論理動作用アドレスを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第2の論理部の記憶部が、前記論理動作用アドレスにより特定される記憶素子からデータを出力するステップと、
前記演算処理装置は、前記第2の論理部からデータを受け取るステップと、を有する特徴とする制御方法。
(11)前記演算処理装置は前記半導体装置に含まれる、(10)に記載の制御方法。
【0013】
上記の課題の解決を意図する実施形態は、下記の第3のセットに係る(1)〜(11)に記載のようなものである。
(1)データを演算処理する演算処理部と、
複数の記憶部及び入出力部を有する論理部であって、
各記憶部は、アドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力するアドレスデコーダと、データ線とワード線に接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子とを有し、
前記入出力部は、前記演算処理部の少なくとも1つの出力信号線と前記アドレス線のすくなくとも1つとを接続すると共に、前記演算処理部の少なくとも1つの入力信号線と前記データ線の少なくとも1つとを接続する、演算処理部と、
を備えることを特徴とする半導体装置。
(2)前記記憶部のアドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部のアドレス線に、それぞれ接続する(1)に記載の半導体装置。
(3)前記複数の記憶部は、再構成可能である(1)又は(2)に記載の半導体装置。
(4)前記論理部は、前記複数の記憶部を選択する記憶部デコーダをさらに有する(1)〜(3)の何れかに記載の半導体装置。
(5)前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する(1)〜(4)の何れかに記載の半導体装置。
(6)前記真理値表を構成するデータを記憶する記憶装置をさらに有する(1)〜(5)の何れかに記載の半導体装置。
(7)物理的な配線層数が4層以下である(1)〜(6)の何れかに記載の半導体装置。
(8)前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する(1)〜(7)の何れか1項に記載の半導体装置。
(9)演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、前記演算処理部に含まれる論理部に、アドレスを出力するステップであって、前記論理部は複数の記憶素子を有し、各記憶素子は、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶する、ステップと、
前記論理部は、前記演算処理部の少なくとも1つの出力信号線と接続される少なくとも1つのアドレス線から、前記アドレスを受け取るステップと、
前記論理部は、前記アドレスにより特定される記憶素子からデータを出力するステップと、
前記論理部は、前記データを、前記演算処理部の少なくとも1つの入力信号線と接続される少なくとも1つのデータ線を介して、前記演算処理部に出力するステップと、
を有することを特徴とする制御方法。
(10)前記論理部は、前記読み出したデータを、前記論理部内の記憶部と繋がる少なくとも1つのデータ線から、前記演算処理部の少なくとも1つの入力信号線に出力する、(9)に記載の制御方法。
(11)前記演算処理装置は前記半導体装置に含まれる、(9)又は(10)に記載の制御方法。
【0014】
また、PLDの1つとしてMPLD(Memory−based Programmable Logic Device)がある。MPLDは、LUTベースのPLDと同様に、メモリセルユニットで回路構成を実現する。MPLDは、真理値表データが書き込まれるメモリセルユニットが、論理要素として機能する点で、上記したLUTベースのPLDと同じであるが、LUT同士の接続要素としても機能する点で、メモリセルユニット間の接続に専用の切り替え回路を有するLUTベースのPLDと異なる。しかし、MPLDは、メモリセルユニットを論理要素及び/又は論理要素間の接続を切り替える接続要素として使用するため、データパスを変えるためには、LUTベースのPLDと同様に、メモリセルに保持された真理値表データを書き換える必要がある。そのため、MPLDで、動的再構成を実行すると、メモリセルユニットへのデータの書き込み処理が生じるため、処理が遅延する。
【0015】
さらに別な側面では、本発明はMPLDを有する半導体装置の再構成時間を短縮化することができる。
【0016】
上記の課題の解決を意図する実施形態は、下記の第4のセットに係る(1)〜(5)に記載のようなものである。
【0017】
(1)各々が複数のメモリセルユニットを有し、且つ、前記メモリセルユニットに真理値表データを書き込むと、論理要素又は接続要素として動作する複数のプログラマブル論理部と、
各々が複数の前記真理値表データである複数の構成情報を保持するキャッシュ部と、
前記複数のプログラマブル論理部のうちの第1のプログラマブル論理部が、分岐論理を構成する第1の構成情報で再構成されている場合、前記分岐論理の実行前に、前記複数のプログラマブル論理部のうちの第2のプログラマブル論理部を、前記分岐論理の分岐先回路を構成する前記第2の構成情報で投機的に再構成する構成制御部と、
を備えることを特徴とする半導体装置。
(2)前記キャッシュ部は、演算器を示す真理値表データである演算器データと、状態遷移を示す真理値表データである制御データとを、分けて保持し、
前記構成制御部は、前記制御データと、前記制御データの状態遷移により示される演算器を含む前記演算器データを、前記キャッシュ部からそれぞれ読み込んで、前記プログラマブル論理部を再構成する、ことを特徴とする(1)に記載の半導体装置。
(3)前記キャッシュ部が保持する制御データを包含する記憶部をさらに有し、
前記構成制御部は、前記キャッシュ部が保持する制御データの次に、前記プログラマブル論理部を再構成するための制御データを、前記記憶部から読み出して、前記キャッシュ部に記憶する、ことを特徴とする(1)又は(2)に記載の半導体装置。
(4)前記記憶部に記憶される前記制御データの真理値表データは圧縮されており、
前記キャッシュ部は、圧縮した真理値表データを保持し、
前記構成制御部は、前記圧縮した真理値表データを解凍して、当該解凍した真理値表データで前記プログラマブル論理部を再構成する、ことを特徴とする(1)〜(3)の何れか1項に記載の半導体装置。
(5)前記第2の構成情報で構成された第2のプログラマブル論理部の演算結果が、前記第2の構成情報が前記第1の構成情報の分岐論理の分岐先回路ではないことを示す場合、前記構成制御部は、前記第2のプログラマブル論理部以外のプログラマブル論理部を、前記分岐論理の分岐先を含む第3の構成情報で再構成する、(1)〜(4)の何れか1項に記載の半導体装置。
【発明の効果】
【0018】
第1の側面では、本発明は、所望の論理回路を構成する記憶素子ブロックの総量を減らすことができる。
【0019】
第2の側面では、本発明は、半導体装置と演算処理装置とのデータの入出力を行うことができる。
【0020】
第3の側面では、本発明は、MPLDを有する半導体装置の再構成時間を短縮化することができる。
【図面の簡単な説明】
【0021】
【図1】MPLDの一例を示す図である。
【図2】MPLDのメモリ動作の一例を示す図である。
【図3】MLUTの論理動作の一例を示す図である。
【図4】MLUTの第1例を示す図である。
【図5】1ポート記憶素子の一例を示す図である。
【図6】論理要素として動作するMLUTの一例を示す図である。
【図7】論理回路として動作するMLUTの一例を示す図である。
【図8】図7に示す論理回路の真理値表を示す図である。
【図9】接続要素として動作するMLUTの一例を示す図である。
【図10】図9に示す接続要素の真理値表を示す図である。
【図11】4つのAD対を有するMLUTによって実現される接続要素の一例を示す図である。
【図12】1つのMLUTが、論理要素及び接続要素として動作する一例を示す図である。
【図13】図12に示す論理要素及び接続要素の真理値表を示す図である。
【図14】4つのAD対を有するMLUTによって実現される論理動作及び接続要素の一例を示す図である。
【図15】MLUTで構成される2ビット加算器の回路構成の一例を示す図である。
【図16】2ビット加算器動作の真理値表を示す図である
【図17】7つのAD対を有するMLUTの一例を示す図である。
【図18A】7個のAD対を有するMLUTの一例を示す図である。
【図18B】7個のAD対を有するMLUTの平面構造の一例を示す図である。
【図19】MLUTの第2例を示す図である。
【図20】2ポート記憶素子の一例を示す図である。
【図21】MLUTの第3例を示す図である。
【図22】MLUT配置の第1例を示す平面図である。
【図23】MLUTの配置の第2例を示す平面図である。
【図24】MLUT間の結線の一例を示す図である。
【図25】離間して配置されるMLUTを隣接MLUTを介して接続する例を示す図である。
【図26A】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図26B】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図26C】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図26D】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図27】最密充填配置構造と、非最密充填配置構造を示す図である。
【図28】最密充填配置構造におけるAD対の数の一例を示す図である。
【図29】MLUTのAD対の結線構造の1例を示す図である。
【図30】MLUTのAD対の結線構造の別な例を示す図である。
【図31】MLUTのAD対の結線構造の他の例を示す図である。
【図32】MLUTのAD対の結線構造の他の例を示す図である。
【図33】MLUTのAD対の結線構造の他の例を示す図である。
【図34】MLUTを有するMLUTブロックの一例を示す図である。
【図35】15行×30列のMLUTを有するMLUT領域における近距離配線パターンの配置の一例を示す図である。
【図36】15行×30列のMLUTを有するMLUT領域における第1の離間配線パターンの配置を示す図である。
【図37】15行×30列のMLUTを有するMLUT領域における第2の離間配線パターンの配置を示す図である。
【図38】15行×30列のMLUTを有するMLUT領域における第3の離間配線パターンの配置を示す図である。
【図39】15行×30列のMLUTを有するMLUT領域における第4の離間配線パターンの配置を示す図である。
【図40】15行×30列のMLUTを有するMLUT領域における第5の離間配線パターンの配置を示す図である。
【図41】MPLDを搭載した半導体装置の配置ブロックの一例を示す図である。
【図42】MPLDの配置・配線を実行する情報処理装置の1例を示す図である。
【図43】情報処理装置が、MPLDに配置・配線するためのビットストリームデータを生成するフローの1例を示す図である。
【図44】図41に示す半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。
【図45】8点離散フーリエ変換をバタフライ演算で行うときのアルゴリズムの一例を示す。
【図46】MPLDを搭載した半導体装置の一例を示す図である。
【図47】演算処理部と、MPLDとのデータの入出力を行う入出力部の一例を概略的に示す図である。
【図48】演算処理部と、MPLDとのデータの入出力を行う入出力部の別な例を示す図である。
【図49】論理動作とメモリ動作を同時に行うMPLD、及び演算処理部の一例を示す図である。
【図50】複数のMPLD、及び演算処理部の一例を示す図である。
【図51】MPLDを搭載した半導体装置の他の例における配置ブロックの一例を示す図である。
【図52】MPLDを搭載した半導体装置の他の例における配置構造の一例を示す図である。
【図53】動作合成の一例を示す図である。
【図54】論理回路x=(a+b)*(b+c)を構成するCDFGの例を示す図である。
【図55】図54に示すCDFGを、速度優先スケジューリングでスケジューリングした結果を示す図である。
【図56】図54に示すCDFGを、ハードウェア量優先スケジューリングでスケジューリングした結果を示す図である。
【図57】第1の論理ブロックと第2の論理ブロックとの2つの論理ブロックに面分割された論理回路を実行する1つの例を示す。
【図58】アロケーションのときに論理回路を面分割する1例を示す図である。
【図59】MLUTに論理回路情報などの情報を書き込む手順を示すフローチャートの一例である。
【図60】MPLDを搭載した半導体装置の他の例における配置構造を示す図である。
【図61】MPLDを搭載した半導体装置の他の例における配置構造を示す図である。
【図62】半導体装置の配線層の一例を示す断面図である。
【図63】半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。
【図64】DESの計算アルゴリズムのフローの一例を示す図である。
【図65】F関数のアルゴリズムのフローを示す図である。
【図66】図66は、半導体装置の一例を示すブロック図である
【図67】図67は、メインメモリのメモリマップの一例を示す図である。
【図68】図68は、構成制御部の詳細ブロック図である。
【図69】図69は、MPLDで構成されるデータパスブロック及びステートマシンの一例を示す図である。
【図70】図70は、半導体装置の投機実行に関する処理フローの一例を示す図である。
【図71】図71は、半導体装置のキャッシュ制御に関する処理フローである。
【発明を実施するための形態】
【0022】
以下、〔1〕MPLD、〔2〕MLUT、〔3〕MLUTの構造、〔4〕1つのMPLDを搭載した半導体装置、〔5〕1つのMPLDと、演算処理部とを搭載した半導体装置、〔6〕2つのMPLDと、演算処理部とを搭載した半導体装置、〔7〕動的再構成に適する半導体装置に分けて、順に実施例を説明する。以下に説明するMPLD〔1〕は、複数のMLUT〔2〕を有してなり、MPLD〔1〕は、演算処理部と組み合わされて、半導体装置〔4〕又は〔5〕又は〔6〕又は〔7〕を構成する。
【0023】
〔1〕MPLD
図1は、半導体装置の一例を示す図である。図1に示す20は、半導体装置としてのMPLD(Memory−based Programmable Logic Device)である。MPLD20は、記憶素子ブロックとしてのMLUT(Multi Look−Up−Table)30を複数有するとともに、MLUTデコーダ12を有する。また、後述するように、MPLD20は、演算処理装置と接続する論理部として動作する。
【0024】
MPLD20は、複数の記憶素子を含む。記憶素子には、真理値表を構成するデータがそれぞれ記憶されることで、MPLD20は、論理要素、又は、接続要素、又は、論理要素及び接続要素として動作する論理動作を行う。
【0025】
MPLD20はさらに、メモリ動作を行う。メモリ動作とは、MLUT30に含まれる記憶素子へのデータの書き込みや読み出しをいう。よって、MPLD20は、主記憶装置や、キャッシュメモリとして動作することができる。
【0026】
MLUT30へのデータの書き込みは、真理値表データの書き換えにもなるため、メモリ動作は、真理値表データの再構成を生じる。なお、再構成のうち、MPLD内の特定の1つ又は複数のMLUT、又はMLUTを構成する特定の1つ又は複数の記憶素子に記憶された真理値表データを書き換えることを「部分再構成」という。
【0027】
図1には、メモリ動作では、MPLDアドレス、メモリ動作用アドレスMA、書き込みデータWD、及び読み出しデータRDの何れかの信号を使用され、それらの信号と、それらの信号を通す結線とが図示される。また、論理動作では、論理動作用アドレスLA、及び論理動作用データLDが使用され、それらの信号と、それらの信号を通す結線とが図示される。なお、メモリ動作用アドレスMAとは、MPLD20に含まれる各MLUTに供給されるメモリ動作用のアドレスである。MPLDアドレスとは、MPLD20内に含まれる1つのMLUTを特定するアドレスであり、メモリ動作用アドレスMAを供給するMLUTを特定するアドレス信号である。
【0028】
〔1.1〕MPLDのメモリ動作
図2は、MPLDのメモリ動作の一例を示す図である。MPLD20は、メモリ動作で、実線で示されるメモリ動作用アドレス、MLUTアドレス、書き込みデータWD、及び読み出しデータRDの何れかの信号を使用し、破線で示される論理動作用アドレスLA、及び論理動作用データLDは使用しない。なお、メモリ動作用アドレス、MLUTアドレス、及び書き込みデータWDは、例えば、MPLD20の外部にある演算処理装置によって出力され、読み出しデータWDは、演算処理装置に出力される。
【0029】
メモリ動作では、MPLD20は、記憶素子を特定するアドレスとして、メモリ動作用アドレス及びMLUTアドレスを受け取るとともに、書き込みのときは書き込みデータWDを受け取り、読み出しのときは読み出しデータLDを出力する。
【0030】
MLUTアドレスとは、MPLD20内に含まれる1つのMLUTを特定するアドレスである。MLUTアドレスは、m本の信号線を介してMPLD20に出力される。なお、mとは、MLUTを特定する選択アドレス信号線の数である。m本の信号線で、2のm乗のMLUTを特定することができる。MLUTデコーダ12は、m本の信号線を介してMLUTアドレスを受け取るとともに、MLUTアドレスをデコードして、メモリ動作の対象となるMLUT30を選択し特定する。メモリ動作用アドレスは、n本の信号線を介して、図10を用いて後述するアドレスデコーダでデコードされて、メモリ動作の対象となるメモリセルを選択する。
【0031】
なお、MPLD20は、例えば、MLUTアドレス、書き込みデータWD及び読み出しデータLDは、全てn本の信号線を介して受け取る。なお、nとは、図4を用いて後述されるように、MLUTのメモリ動作用又は論理動作用の選択アドレス信号線の数である。MPLD20は、n本の信号線を介して、MLUTアドレス、書き込みデータ及び読み出しデータを各MLUTに供給する。なお、メモリ動作用アドレスMA、書き込みデータWD及び読み出しデータRDの詳細は、MLUTの例とともに、図4、図19、及び図21を用いて後述する。
【0032】
〔1.2〕MPLDの論理動作
図3は、MPLD20の論理動作の一例を示す図である。図3において、MPLD20の論理動作では、実線で示される論理動作用アドレスLA、及び論理動作用データLDを使用する。
【0033】
MPLD20の論理動作では、論理動作用アドレスLAは、外部装置から出力され、MLUT30の真理値表によって構成される論理回路の入力信号として使用される。そして、論理動作用データLDは、上記論理回路の出力信号であり、論理回路の出力信号として、外部装置に出力される。
【0034】
複数のMLUTのうち、MPLD20の外延に配置されるMLUTは、MPLD20の外部の装置と、論理動作用のデータである論理動作用アドレスLAを受け取り、論理動作用データLDを出力するMLUTとして動作する。例えば、例えば、図1に示すMLUT30a、30bは、半導体装置100の外部から論理動作用アドレスLAを受け取り、周囲にある他のMLUT30dに論理動作用データLDを出力する。また、図1に示すMLUT30e、30fは、他のMLUT30c、30dから論理動作用アドレスLAを受け取り、MPLD20の外部に論理動作用データLDを出力する。
【0035】
MLUTの論理動作用アドレスLAのアドレス線は、隣接するMLUTの論理動作用データLDのデータ線と接続しており、例えば、MLUT30cは、MLUT30aから出力された論理動作用データを、論理動作用アドレスとして受け取る。このように、MLUTの論理動作用アドレス又は論理動作用データは、周囲にあるMLUTとの入出力により得られる点で、各々のMLUTが独自に接続するMLUTアドレスと異なる。
【0036】
MPLD20の論理動作により実現される論理は、MLUT30に記憶される真理値表データにより実現される。いくつかのMLUT30は、AND回路、加算器などの組み合わせ回路としての論理要素として動作する。他のMLUTは、組み合わせ回路を実現するMLUT30間を接続する接続要素として動作する。論理要素、及び接続要素を実現するための真理値表データの書き換えは、上述のメモリ動作による再構成によりなされる。
【0037】
〔2〕MLUT
以下に、MLUTについて説明する。
〔2.1〕MLUTの第1例
図4は、MLUTの第1例を示す図である。図4に示すMLUT30は、アドレス切替回路10aと、アドレスデコーダ9と、記憶素子40と、出力データ切替回路10bとを有する。図10に示すMLUT30は、動作切替信号が論理動作を示す場合、論理動作用アドレスLAに従って、論理動作用データLDを出力するように動作する。また、MLUT30は、動作切替信号がメモリ動作を示す場合、メモリ動作用アドレスに従って、書き込みデータを受け入れ、又は、読み出しデータを出力するように動作する。
【0038】
アドレス切替回路10aは、メモリ動作用アドレスMAが入力されるn本のメモリ動作用アドレス信号線と、論理動作用アドレスLAが入力されるn本の論理動作用アドレス入力信号線と、動作切替信号が入力される動作切替信号線とを接続する。アドレス切替回路10aは、動作切替信号に基づいて、メモリ動作用アドレスMA、又は論理動作用アドレスLAのいずれかをn本の選択アドレス信号線に出力するように動作する。このように、アドレス切替回路10aが、アドレス信号線を選択するのは、記憶素子40が読み出し動作と書き込み動作の何れかを受け付ける1ポート型の記憶素子であるからである。
【0039】
図4に示すアドレスデコーダ9は、アドレス切替回路10aから供給されるn本のアドレス信号線から受け取った選択アドレス信号をデコードし、2のn乗本のワード線にデコード信号を出力する。
【0040】
n×2n個の記憶素子は、2のn乗本のワード線と、n本の書き込みデータ線と、n個の出力ビット線の接続部分に配置される。記憶素子の詳細例は、図5を用いて後述する。
【0041】
出力データ切り替え回路10bは、n本の出力ビット線から信号を受け取ると、入力される動作切替信号に従って、記憶素子から読み出したデータをn本の読み出しデータ信号線に出力し、又は、読み出しデータを論理動作用信号線に出力するように動作する。
【0042】
〔2.2〕MLUTの記憶素子
図5は、1ポート型の記憶素子の一例を示す図である。図5に示す1ポート型の記憶素子は、SRAMであり、図4に示す記憶素子として使用できる。図5に示す1ポートSRAM40は、第1及び第2のpMOS(positive channel Metal Oxide Semiconductor)トランジスタ161、162と、第1〜第4のnMOS(negative channel MOS)トランジスタ163〜166とを有する。
【0043】
第1のpMOSトランジスタ161のソースと、第2のpMOSトランジスタ162のソースとは、VDD(電源電圧端)に接続する。第1のpMOSトランジスタ161のドレーンは、第1のnMOSトランジスタ163のソースと、第2のpMOSトランジスタのゲート162と、第2のnMOSトランジスタのゲート504と、第3のnMOSトランジスタ505のソースとに接続する。第1のpMOSトランジスタ161のゲートは、第1のnMOSトランジスタ163のゲートと、第2のpMOSトランジスタ162のドレーンと、第2のnMOSトランジスタ504のドレーンと、第4のnMOSトランジスタ506のソースとに接続する。第1のnMOSトランジスタ163のドレーンと、第2のnMOSトランジスタ504のドレーンは、VSS(接地電圧端)に接続される。
【0044】
第3のnMOSトランジスタ165のドレーンは、第1のビット線BLに接続される。第3のnMOSトランジスタ165のゲートは、ワード線WLに接続される。第4のnMOSトランジスタ166のドレーンは、第2のビット線qBLに接続される。第4のnMOSトランジスタ166のゲートは、ワード線WLに接続される。
【0045】
上記構成により、書き込み動作では、1ポート記憶素子40は、ワード線WLの信号レベル「H」により、書込ビット線BL、及び、書込ビット線qBLの信号レベルを、保持する。
【0046】
〔2.3〕MLUTの論理動作
A.論理要素
図6は、論理要素として動作するMLUTの一例を示す図である。図6に示すMLUT30a、30bは、論理動作用アドレス線A0〜A3から論理動作用アドレスLAを受け取り、論理動作用データ線D0〜D3に論理動作用データLDを出力する。なお、MLUT30aの論理動作用アドレス線A2は、隣接するMLUT30bの論理動作用データ線D0と接続しており、MLUT30aは、MLUT30bから出力された論理動作用データLDを、論理動作用アドレスLAとして受け取る。また、MLUT30aの論理動作用データ線D2は、MLUT30bの論理動作用アドレス線A0と接続しており、MLUT30aが出力した論理動作用データLDは、MLUT30bで論理動作用アドレスLAとして受け取られる。このように、MPLD同士の連結は、1対のアドレス線とデータ線とを用いる。以下、MLUT30aの論理動作用アドレス線A2と、論理動作用データ線D2のように、MLUTの連結に使用されるアドレス線とデータ線の対を「AD対」という。
【0047】
なお、図6では、MLUT30a、30bが有するAD対は4であるが、AD対の数は、後述するように4に限定されない。
【0048】
図7は、論理回路として動作するMLUTの一例を示す図である。本例では、論理動作用アドレス線A0及びA1を2入力NOR回路701の入力とし、論理動作用アドレス線A2及びA3を2入力NAND回路702の入力とする。そして、2入力NOR回路の出力と、2入力NAND回路702の出力を、2入力NAND回路703に入力し、2入力NAND回路703の出力をデータ線D0に出力する論理回路を構成する。
【0049】
図8は、図7に示す論理回路の真理値表を示す図である。図7の論理回路は、4入力のため、入力A0〜A3の全ての入力を入力として使用する。一方、出力は、1つのみなので、出力D0のみを出力として使用する。真理値表の出力D1〜D3の欄には「*」が記載されている。これは、「0」又は「1」のいずれの値でもよいことを示す。しかしながら、実際に再構成のために真理値表データをMLUTに書き込むときには、これらの欄には、「0」又は「1」のいずれかの値を書き込む必要がある。
【0050】
B.接続要素の機能
図9は、接続要素として動作するMLUTの一例を示す図である。図9では、接続要素としてのMLUTは、アドレス線A0の信号をデータ線D1に出力し、アドレス線A1の信号をデータ線D2に出力し、論理動作用アドレス線A2の信号をデータ線D3に出力するように動作する。接続要素としてのMLUTはさらに、アドレス線A3の信号をデータ線D1に出力するように動作する。
【0051】
図10は、図9に示す接続要素の真理値表を示す図である。図9に示す接続要素は、4入力4出力である。したがって、入力A0〜A3の全ての入力と、出力D0〜D3の全ての出力が使用される。図10に示す真理値表によって、MLUTは、入力A0の信号を出力D1に出力し、入力A1の信号を出力D2に出力し、入力A2の信号を出力D3に出力し、入力A3の信号を出力D0に出力する接続要素として動作する。
【0052】
図11は、4つのAD対を有するMLUTによって実現される接続要素の一例を示す図である。図11において、1点鎖線は、AD対0に入力された信号がAD対1に出力される信号の流れを示す。2点鎖線は、第2のAD対ADAに入力された信号がAD対2に出力される信号の流れを示す。破線は、AD対2に入力された信号がAD対3に出力される信号の流れを示す。実線は、AD対3に入力された信号がAD対0に出力される信号の流れを示す。
【0053】
なお、図11では、MLUT30が有するAD対は4であるが、AD対の数は、後述するように4に限定されない。
【0054】
C.論理要素と接続要素の組合せ機能
図12は、1つのMLUTが、論理要素及び接続要素として動作する一例を示す図である。図12に示す例では、アドレス線A0及びA1を2入力NOR回路121の入力とし、2入力NOR回路121の出力と、論理動作用アドレス線A2とを2入力NAND回路122の入力とし、2入力NAND回路122の出力をデータ線D0に出力する論理回路を構成する。また同時に、アドレス線A3の信号をデータ線D2に出力する接続要素を構成する。
【0055】
図13に、図12に示す論理要素及び接続要素の真理値表を示す。図12の論理動作は、入力D0〜D3の3つの入力を使用し、1つの出力D0を出力として使用する。一方、図(a)の接続要素は、入力A3の信号を出力D2に出力する接続要素が構成される。
【0056】
図14は、4つのAD対を有するMLUTによって実現される論理動作及び接続要素の一例を示す図である。上述のように、MLUT30は、3入力1出力の論理動作と、1入力1出力の接続要素との2つの動作を1つのMLUT30で実現する。具体的には、論理動作は、AD対0のアドレス線と、AD対1のアドレス線と、AD対2のアドレス線とを入力として使用する。そして、AD対0のアドレス線を出力と使用する。また、接続要素は、破線で示すようにAD対3に入力された信号をAD対2に出力する。
【0057】
なお、N個のAD対を有するMLUTには、N個の入力を有し、N個の出力を有する任意の論理回路を構成することができる。さらにまた、N個のAD対を有するMLUTでは、合計で1〜Nの任意の数の入力数を有し、1〜Nの任意の数の出力数を有する任意の論理動作と、接続要素とを同時に構成することができる。
【0058】
〔2.4〕7つのAD対を有するMLUT
図15〜図17を用いて、7つのAD対を有するMLUT上に真理値表の動作を実現する1例を説明する。
【0059】
図15は、MLUTで構成される2ビット加算器の回路構成の一例を示す図である。2ビット加算器は、1ビット全加算器を2つ接続することにより構成される。図15において、2ビット加算器は、入力A0、B0、及びCinを入力として使用し、出力S0及び桁上がり出力として使用する第1の1ビット全加算器を有する。また、入力A1、B1、及び第1の1ビット全加算器の桁上がりを入力として使用し、出力S1及びCoutを出力として使用する第2の1ビット全加算器を有する。
【0060】
第1の1ビット全加算器は、入力A0及びB0を第1の2入力XOR回路4.401と、第1の2入力AND回路152の入力とする。第1の2入力XOR回路151の出力及び入力Cinを、第2の2入力XOR回路153と、第2の2入力AND回路154の入力とする。第1の2入力AND回路152の出力及び第2の2入力AND回路154の出力を第1の2入力OR回路155の入力とする。さらに、第2の2入力XOR回路153の出力を出力S0とし、第1の2入力OR回路155の出力を桁上がり出力とする。
【0061】
第2の1ビット全加算器は、入力A1及びB1を第3の2入力XOR回路156と、第3の2入力AND回路157の入力とする。第3の2入力XOR回路156の出力及び第1の2入力OR回路155の出力を、第4の2入力XOR158回路と、第4の2入力AND回路159の入力とする。第3の2入力AND回路157の出力及び第4の2入力AND回路159の出力を第2の2入力OR回路4.410の入力とする。さらに、第4の2入力XOR回路158の出力を出力S1とし、第2の2入力OR回路160の出力を出力Coutとする。
【0062】
図16は、図15の2ビット加算器動作の真理値表を示す図である。図15の2ビット加算器動作は、入力A0、A1、B0、B1、及びCinの5つの入力を使用する。そして、出力S0、S1、及びCoutの3つの出力を使用する。
【0063】
図17は、7つのAD対を有するMLUTの一例を示す図である。図15及び図16に記載される2ビット加算器を図17に示すMLUT30に真理値表として実現するためには、5つのAD対の論理制御用アドレス線を入力線として使用し、3つのAD対の論理制御用データ線を出力線として使用する必要がある。さらに、2つのAD対は、接続要素用に使用することができる。このため、7つのAD対を有するMLUT30では、2ビット加算器の論理動作を実現するとともに、2つの接続要素を実現することが可能になる。
【0064】
例えば、AD対0を入力A0及び出力S0に使用し、AD対1を入力A1及び出力S1に使用し、AD対2を入力Cin及び出力Coutに使用し、AD対3のアドレス線を入力B0に使用する。そして、第5のAD対AD4のアドレス線を入力B1に使用することができる。
【0065】
加算器は、四則演算などの演算回路を構成する場合に非常に多く使用される回路である。また、通常の演算処理では、2ビット以上のデータを処理される。従って、5入力3出力で構成される2ビット加算器を1つのMLUTで構成することによって、MPLDの配置・配線効率が向上することは、有利である。すなわち、2ビット加算器を1つのMLUTで構成することにより、同一数のMLUTを有するMPLDに搭載できる演算回路の数を増やすことができる。さらに、多ビット加算器、及び多ビット乗算器など配線パターンが決まっている論理回路を、2ビット加算器を有するモジュールとして用意することも可能である。
【0066】
また、7つのAD対を有するMLUTでは、2ビット加算器の論理動作を実現した上で、さらに2経路の接続要素を実現できることは、MPLDの配置・配線効率を考えると、さらに有利である。すなわち、配置・配線アルゴリズムを実行するときに、2ビット加算器を配置したMLUTに、さらに付加的に接続要素を有することができる。このため、MLUTに配置した真理値表をそれぞれ配線するときの自由度が向上する。なお、配置・配線とは、MLUTは、論理要素及び/又は接続要素として動作するので、MLUTへの真理値表データの書込は、論理動作の配置、及び/又は、MLUT間の配線を意味する。そのため、真理値表データの生成を「配置・配線」という。
【0067】
本例では、7つのAD対を有するMLUTで、2ビット加算器の論理動作と、接続要素とを同時に実現する実施形態について説明した。しかしながら、5つのAD対を有するMLUTでは、2ビット加算器の論理動作を実現することができる。また、6つのAD対を有するMLUTでは、2ビット加算器の論理動作と、1つの接続要素とを実現することができる。さらに、8つのAD対を有するMLUTでは、2ビット加算器の論理動作と、3つの接続要素とを実現することができる。
【0068】
また、9つのAD対を有するMLUTでは、4ビット加算器の論理動作を実現することができる。10個のAD対を有するMLUTでは、4ビット加算器の論理動作と、1つの接続要素とを実現することができる。このように、5〜10程度のAD対を有するMLUTでは、配置・配線効率を向上させる構成が可能になる。
【0069】
〔2.5〕MLUTの物理的な配置
図18Aは、7個のAD対を有するMLUTの一例を示す図である。図18Aに示すMLUT30は、アドレス行デコーダ9cと、アドレス列デコーダ9dと、記憶素子40cとを有する。図18Aに示すMLUT30には、それぞれが7つの信号からなる論理動作用アドレスLAと、書き込みデータWDとが入力され、それぞれが7つの信号からなる読み出しデータRDと、論理動作用データLDとが出力される。アドレス切替回路10aは、出力データ切り替え回路10bは、図4を用いて説明した回路と同じ動作をするため、説明を省略する。
【0070】
アドレス行デコーダ9cは、m本の信号入力である論理動作用アドレスLAをデコードして、2のm乗のワード線にワード選択信号を出力する。記憶素子40cは、2L個の記憶素子ブロック(40c−1、・・・、40c−2L)である。各記憶素子ブロックは、n×2m個の記憶素子を有し、2m本のワード線と、n本の書き込みデータ線と、n個の出力ビット線の接続部分に配置される。mは、N−Lの整数であり、Lはnより小さい整数である。「n、m、L」は、例えば、「7、5、2」、又は、「7、4、3」である。
【0071】
アドレス列デコーダ9dは、L本の信号入力である論理動作用アドレスLAをデコードして、2のL乗のブロック選択信号を生成して、ブロック選択信号により、上記した2L個の記憶素子ブロックのいずれかのn個の出力ビット線を選択する。例えば、L=2の場合、記憶素子ブロックは22=4個あり、各記憶素子ブロックは25=32本のワード線及び出力ビット線を有するため、アドレス列デコーダ9dは、ブロック選択信号により何れかの記憶素子ブロックの出力ビット線32本を選択する。また、L=3の場合、記憶素子ブロックは23=8個あり、各記憶素子ブロックは24=16本のワード線及び出力ビット線を有するため、アドレス列デコーダ9dは、ブロック選択信号により何れかの記憶素子ブロックの出力ビット線16本を選択する。
【0072】
アドレス列デコーダ9dを設けて、記憶素子を列方向に広げることで、出力ビット線の長さを短縮することが出来る。
【0073】
図18Bは、図18Aに示すMLUT30を2つ組み合わせたMLUTのフロアプランを示す図である。図18Bに示すMLUT30は、図18Aに示すMLUTが有する構成を含む。図18Bに示すMLUT30は、メモリ論理制御部10cと、アドレス行デコーダ9c−1及び9c−2と、アドレス列デコーダ9d−1及び9d−2と、記憶素子40c−1及び40c−2と、読み出し駆動部11a−1及び11a−2とを有する。
【0074】
アドレス行デコーダ9c−1及び9c−2、及び、アドレス行デコーダ9d−1及び9d−2には、メモリ論理制御部10cから出力される7つの選択アドレス信号を入力する7つの選択アドレス線がそれぞれ接続される。アドレス行デコーダ9c−1、及び、アドレス列デコーダ9d−1は、記憶素子40c−1に対してワード選択信号及びブロック選択信号をそれぞれ供給する。アドレス行デコーダ9c−2、及び、アドレス列デコーダ9d−2は、記憶素子40c−2に対してワード選択信号及びブロック選択信号をそれぞれ供給する。
【0075】
図18Bに示すMLUT30には、図示されないが、それぞれが7つの信号からなると、論理動作用アドレスLAと、書き込みデータWDとが入力され、それぞれが7つの信号からなる読み出しデータRDと、論理動作用データLDとが出力される。図18Bに示すMLUT30には、さらに、図示されないが、メモリ動作用アドレスMA、動作切替信号が入力される。
【0076】
メモリ論理制御部10cには、図18Aのアドレス切替回路10aと、出力データ切り替え回路10bとが配置される。メモリ動作用アドレスMAと、論理動作用アドレスLAと、書き込みデータWDと、読み出しデータRDと、論理動作用データLDとはそれぞれ、メモリ論理制御部10cを介して、MLUT30に入出力される。
【0077】
アドレス行デコーダ9c−1及び9c−2は、記憶素子領域40c−1と、記憶素子40c−2との間に配置される。
【0078】
第1及び第2の読み出し駆動部11a及び11bはそれぞれ、第1及び第2の記憶素子領域40c及び40dと、メモリ論理制御部10cとの間に配置される。第1及び第2の読み出し駆動部11a及び11bは、第1及び第2の記憶素子領域40c及び40dに配置される記憶素子40から読み出す7つのビット信号を増幅して、読み出し速度を高速化するように構成される。
【0079】
本例では、アドレス行アドレスに入力される選択アドレス信号の数を4つ、又は5つにしている。選択アドレス信号の数を5以下とすることで、ワード選択信号の数が、24=16本、又は、25=32本となり、出力ビット線の長さを短縮することが出来る。そのため、一般的なSRAM回路において必須の構成要素であるセンスアンプと、プリチャージ回路とが不要である回路構成が実現される。図18A又は図18Bに示すMLUT30は、一般的なSRAMと異なり、記憶素子数の数の大規模化はしなくてもよい。
【0080】
MLUTに含まれる記憶素子の数は、多くても10×210個程度である。これは、一般に数Mビット以上の大規模回路として構成される記憶装置としてのSRAMメモリと比較すると非常に小さな回路である。このため、一般的なSRAMメモリとして使用する記憶装置に搭載されるときには、微細化上で問題にならないセンスアンプ、プリチャージ回路、及びこれらの周辺回路の大きさが、MLUTの回路構成では、問題になる。一般的なSRAMメモリなどの記憶装置に配置されるセンスアンプ、及びプリチャージ回路は、配線層に生じる時定数τが大きくなり、信号の伝達遅延時間が大きくなることを防止するために配置される回路である。これは、アドレスデコーダと、記憶素子との間の配線長が長いためである。したがって、アドレスデコーダと、記憶素子との間の配線長に生じる時定数τを、MLUTの動作に影響を与えない程度に抑えることにより、センスアンプ、及びプリチャージ回路が不要な構成にできる。図18A及び図18Bに示す例では、アドレス行デコーダに入力される選択アドレス信号の数を5つ以下にすることにより、アドレス行デコーダと、記憶素子との間の配線長をMLUTの動作に影響を与えない程度に抑えることを可能にした。
【0081】
さらに本例では、アドレス行デコーダ9cは、第1の記憶素子領域40cと、第2の記憶素子領域40dとの間に配置される。一般的なSRAMメモリなどの記憶装置では、アドレス行デコーダは、記憶素子領域の一辺に接して配置される。このようにアドレス行デコーダを配置すると、アドレス行デコーダに隣接する記憶素子と、アドレス行デコーダから最も離隔する記憶素子とでは、配線距離が異なる。このため、配線層に生じる時定数τが異なるので、アドレス行デコーダからの信号伝達遅延時間が相違する。上述のように、本例では、センスアンプ、及びプリチャージ回路がない構成となるため、それぞれの記憶素子の間の信号伝達遅延時間の差を小さくする構成にすることが望ましい。そこで、本例では、記憶素子領域を、同一の大きさを有する第1の記憶素子領域40cと、第2の記憶素子領域40dとに分割し、その記憶素子領域の間にアドレス行デコーダ9cを配置した。これにより、それぞれの記憶素子の間の信号伝達遅延時間を抑えることが可能になった。
【0082】
本例では、アドレス行デコーダの選択アドレスの数が、5つであるが、アドレス行デコーダの選択アドレスの数は、6つ以下の任意の数とすることができる。しかしながら、アドレス行デコーダの数が適当な数でない場合には、アドレス列デコーダの配線長が増大し、適切な回路を構成できない可能性がある。7つのAD対を有するMLUTが説明されるが、AD対の数は、アドレス行デコーダ及びアドレス列デコーダに配線する選択アドレス数を調整することにより、5〜10の任意の数とすることができる。
【0083】
〔2.6〕MLUTの第2例
上記図4〜図18Bにおいて、1ポート型の記憶素子として用いるMLUTについて説明したが、以下に示す2ポート型の記憶素子として用いるMLUTについても適用可能である。
【0084】
図19は、MLUTの第2例を示す図である。図19に示すMLUT30は、データの書き込みと読み出しを同時に行うことができる。図19に示すMLUT30は、メモリ動作用のアドレスデコーダ9aと、論理動作用のアドレスデコーダ9bと、記憶素子40とを有する。図19に示すMLUTは、図4に示すMLUTと異なり、論理動作と、メモリ動作を同時に行うことができる。そのため、図19に示すMLUT30は、図4に示すMLUTと異なり、動作切替選択信号が不要であり、且つアドレス切替回路10a及び出力データ選択回路は有さない一方で、各々のアドレス用のアドレスデコーダ9a、9bを有する。その他、図4に示すMLUTと同じ構成を有する。なお、図18BのMLUT30に含まれる記憶素子は、データの書き込みと読み出しを可能にする2ポートの記憶素子である。
【0085】
〔2.7〕2ポートの記憶素子
図20は、2ポート記憶素子の一例を示す図である。図19に示す例では、2ポート記憶素子40Bは、SRAMであり、第1及び第2のpMOSトランジスタ501、502と、第3〜第8のnMOSランジスタ503〜508とを有する。
【0086】
図20に示すように、複数のMOSトランジスタから構成される2ポートSRAM40は、VDD、VSS、書込ワード線WWL、読出ワード線RWL、第1の書込ビット線WBL、第2の書込ビット線qWBL、第1の読出ビット線RBL、及び第2の読出ビット線qRBLに接続する。第1の書込ビット線WBLに印加される信号は、第2の書込ビット線qWBLに印加される信号の反転信号である。同様に、第1の読出ビット線RBLに印加される信号は、第2の読出ビット線qRBLに印加される信号の反転信号である。
【0087】
第1のpMOSトランジスタ501のソースと、第2のpMOSトランジスタ502のソースとは、VDDに接続される。第1のpMOSトランジスタ501のドレーンは、第1のnMOSトランジスタ503のソースと、第2のpMOSトランジスタのゲート502と、第2のnMOSトランジスタのゲート194と、第3のnMOSトランジスタ195のソースと、第4のnMOSトランジスタ506のソースとに接続される。
【0088】
第1のpMOSトランジスタ501のゲートは、第1のnMOSトランジスタ503のゲートと、第2のpMOSトランジスタ502のドレーンと、第2のnMOSトランジスタ194のドレーンと、第5のnMOSトランジスタ197のソースと、第6のnMOSトランジスタ198のソースとに接続される。第1のnMOSトランジスタ503のドレーンと、第2のnMOSトランジスタ194のドレーンは、VSSに接続される。
【0089】
第3のnMOSトランジスタ195のドレーンは、第1の書込ビット線WBLに接続される。第3のnMOSトランジスタ195のゲートは、書込ワード線WWLに接続される。第4のnMOSトランジスタ506のドレーンは、第1の読出ビット線RBLに接続される。第4のnMOSトランジスタ506のゲートは、読出ワード線RWLに接続される。
【0090】
第5のnMOSトランジスタ197のドレーンは、第2の書込ビット線qWBLに接続される。第5のnMOSトランジスタ197のゲートは、書込ワード線WWLに接続される。第6のnMOSトランジスタ198のドレーンは、第2の読出ビット線qRBLに接続される。第6のnMOSトランジスタ198のゲートは、読出ワード線RWLに接続される。
【0091】
上記構成により、書き込み動作では、2ポートSRAM40は、書込ワード線WWLの信号レベル「H」により、第1の書込ビット線WBL、及び、第2の書込ビット線qWBLの信号レベルを、保持する。
【0092】
上記構成により、読み出し動作では、2ポートSRAM40は、読出ワード線RWLの信号レベル「H」により、第1の読出ビット線RBL、及び、第2の読出ビット線qRBLに、2ポートSRAM40に保持した信号レベルにする。
【0093】
このように、メモリ動作用アドレスMA及び論理動作用アドレスLAは、記憶素子の1つのワード線を活性化することで、メモリ動作又は論理動作を、n×2n個の記憶素子の一部についてのみ行うことができる。また、メモリ動作用アドレスMA及び論理動作用アドレスLAは、MLUT30内の全ての記憶素子と繋がっているため、メモリ動作又は論理動作を、n×2n個の記憶素子の全ての記憶素子について行うことができる。なお、2ポート記憶素子を有するMLUTは、メモリ動作と論理動作を同時に行うことができる。
【0094】
〔2.8〕MLUTの第3例
図21は、MLUTの第3例を示す図である。図21に示すMLUT30は、アドレスデコーダ9aと、アドレスデコーダ9bと、第1の記憶素子40aと、第2の記憶素子40bと、NOT回路171とを有する。図21に示すMLUT30には、メモリ動作用アドレスMAと、論理動作用アドレスLAと、書き込みデータWDと、セレクト信号とが入力され、読み出しデータRDと、論理動作用データLDとが出力される。
【0095】
第3例に係るMLUTと、第2例に係るMLUTとの相違点は、セレクト信号により、第1の記憶素子40aと、第2の記憶素子40bが、それぞれ異なる動作をすることが可能になる点である。つまり、第1の記憶素子40aと、第2の記憶素子40bとは、一方が論理動作用として選択されるときに、他方をメモリ動作用として選択とするように構成できる。
【0096】
NOT回路171は、セレクト信号が入力される入力端子と、セレクト信号が反転した信号を出力する出力端子とを有する。
【0097】
n×2n個の第1及び第2の記憶素子40は、2n個のメモリ動作用ワード端子(図示せず)と、2n個の論理動作用ワード端子(図示せず)と、n個の書き込みデータ端子(図示せず)と、n個の読み出しデータ端子(図示せず)と、n個の論理動作用データ出力端子(図示せず)と、セレクト端子(図示せず)とを有する。メモリ動作用ワード端子に接続されるメモリ動作用ワード端子はそれぞれ、n個の記憶素子を選択するように構成される。同様に、論理動作用ワード端子に接続される論理動作用ワード端子はそれぞれ、n個の記憶素子を選択するように構成される。書き込みデータ端子には、書き込みデータWDが入力される。書き込みデータWDは、MLUTをメモリ動作させるとき、又はMLUTを再構成するときに使用される。しかしながら、MLUTに書き込まれた真理値表データを読み出すときには使用されない。すなわち、MLUTに書き込まれた真理値表データを読み出すときには、書き込みデータWDは、記憶素子には印加されず、高インピーダンス入力となるように構成される。読み出しデータ端子は、メモリ動作用ワード端子により選択されたn個の記憶素子に記憶されたデータを出力する。同様に、論理動作用データ出力端子は、論理動作用ワード端子により選択されたn個の記憶素子に記憶されたデータを出力する。
【0098】
第1の記憶素子のセレクト端子には、セレクト信号が入力される。第2の記憶素子のセレクト信号には、NOT回路の出力信号、すなわちセレクト信号が反転した信号が入力される。これにより、第1の記憶素子と、第2の記憶素子とは、一方が論理動作用として選択されるときに、他方をメモリ動作用として選択とするように構成される。このような構成にすることにより、動的再構成が可能になる。すなわち、一方の記憶素子が、論理動作をし、他方の記憶素子がメモリ動作をすることが可能になる。
【0099】
〔3〕MLUTの構造
MLUTの構造について説明する。まず、MLUT領域に配置されるそれぞれのMLUTの配置構造について説明し、次に、MLUTのAD対の結線構造について説明する。そして、最後にMLUT領域の構造の1つの実施形態について説明する。
【0100】
〔3.1〕MLUTの配置構造
ここでは、MLUT領域に配置されるそれぞれのMLUTの配置構造について説明する。まず、MLUTのマトリックス配置構造について説明し、次いで、MLUTの交互配置構造について説明する。
【0101】
〔3.1.1〕MLUTのマトリックス配置構造
図22は、MLUT配置の第1例を示す平面図である。図22を参照して、MLUT領域におけるMLUTの配置の第1例について説明する。図22において、MLUTは、説明のために円形状に示される。しかしながら、上述のように、本発明の通常の実施形態では、MLUTの平面形状は、長方形状、又は正方形状である。また、以下の説明において、MLUTは、円形状に示されることがあるが、それぞれのMLUTは、長方形状、又は正方形状であると解するべきである。
【0102】
図22では、MLUT30は、マトリックス状に配置される。MLUT領域8は、半導体装置においてMLUT30が配置される領域である。MLUT30は、MLUT領域8において、第1の方向に同一の距離間隔で配置されるとともに、第1の方向と直角を成す第2の方向に第1の方向の間隔と同一の間隔、又は異なる間隔で配置される。このようにMLUT30を配置することで、MLUT30を近距離配線するときに、規則的に結線できる。なお、近距離配線とは、隣接するMLUT間を繋ぐ配線である。
【0103】
〔3.1.2〕MLUTの交互配置構造
図23は、MLUTの配置の第2例を示す平面図である。図23を参照して、MLUT領域8におけるMLUTの配置の第2例について説明する。図23に示す第2例では、MLUT30は、第1の方向に同一の距離間隔で配置され、第1の方向と直角を成す第2の方向に同一の間隔で配置される。加えて、第1及び第2の方向とは異なる四方に同一間隔で配置されるMLUT30を有するように配置される。本明細書では、このような配置構造を交互配置構造と称する。なお、好適には、第1、又は第2の方向のMLUT間の距離と、四方に配置される他のMLUT30との間の距離は同一にすることができる。また、四方に配置されるMLUT30を、第1の方向に配置される2つのMLUT30と、第2の方向に配置される2つのMLUT30とから構成される長方形の対角線の交点に配置することができる。この場合、それぞれのMLUT30は、第1の方向、及び第1の方向と垂直を成す第2の方向にそれぞれ同一間隔で配置される。また、第1及び第2の方向とは異なる第3及び第4の方向にも同一間隔で配置することができる。
【0104】
〔3.2〕MLUT間のAD対結線構造
〔3.2.1〕AD対結線構造
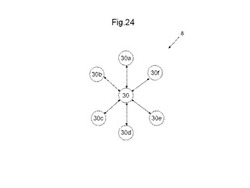
図24は、MLUT間の結線の一例を示す図である。ここで示されるAD対は、MLUTを真理値表として動作させるときに、MPLDの入出力信号線として使用するものである。MLUTはそれぞれ、MLUTをメモリ回路として使用するときに使用するメモリ動作用アドレス線、メモリ動作用データ線、及び制御信号線などの他の配線も有する。しかしながら、説明を簡明にするために、図24ではAD対以外の配線は省略する。図24を参照して、隣接するMLUT間の結線、すなわち近距離配線の結線について説明する。なお、離間配線は、近距離配線でないMLUT間を結線するAD対の配線をいう。図24には、6つのAD対を有するMLUT30と、MLUT30に隣接する第1のMLUT30aと、第2のMLUT30bと、第3のMLUT30cと、第4のMLUT30dと、第5のMLUT30eと、第6のMLUT30fとが交互配置に配置される。また、図24では、第1のMLUT30aと第4のMLUT30dとを結ぶ直線に平行な方向をMLUT30の縦方向と仮定し、第2のMLUT30bと第6のMLUT30fとを結ぶ直線に平行な方向をMLUT領域8の横方向と仮定する。
【0105】
本例では、MLUT30が有するそれぞれのAD対は、それぞれ異なるMLUTに隣接配線される。すなわち、第1のAD対は、隣接する第1のMLUT30aに結線される。第2のAD対は、隣接する第2のMLUT30bに結線される。第3のAD対は、隣接する第3のMLUT30cに結線される。第4のAD対は、隣接する第4のMLUT30dに結線される。第5のAD対は、隣接する第5のMLUT30eに結線される。第6のAD対は、隣接する第6のMLUT30fに結線される。
【0106】
図25は、隣接MLUTを介して距離を置いて配置された2つのMLUTの接続の一例を示す図である。この場合、MLUT30fは、MLUT30aとMLUT30との接続を行う接続要素として動作する。このように、MLUT30fを、距離を置いて配置されたMLUT30aとMLUT30とを接続する接続要素として使用する場合、MLUTfの真理値表の一部が、MLUT30と30aとの接続関係に使用されるため、MLUT30fにおける真理値表により実現可能な論理回路の規模が小さくなる。図25に示すように、隣接するMLUTを接続要素として利用して、距離を置いて配置されるMLUT30及び30aを接続すると、図24に示すMLUTと比して、所望の論理回路を構成するのに必要なMLUTの総量が増加することになる。
【0107】
図26A〜図26Dは、所望の論理回路を構成するために必要なMLUT数の一例を示す図である。図27は、隣接するMLUTにAD対で接続するMLUT構造である最密充填配置構造31Aと、離間配置されるMLUTとをAD対で接続するMLUT構造である非最密充填配置構造31Bを示す図である。所望の論理回路は、CLA加算器、RCA加算器、be加算器、及び8ルーレットLED回路などの回路を200〜1000程度の数のMLUTを有するMPLDに、自動配置配線ツールにより配置配線することにより行った。
【0108】
この結果、本比較に使用した全ての回路構成において、いずれの大きさのMPLDを使用した場合でも、最密充填配置構造31Aを有するMPLDが、非最密充填配置構造31Bを有するMPLDより、非配置・配線効率が高くなった。このため、最密充填配置構造31Aを有するMPLDは、非最密充填配置構造31Bを有するMPLDより、所望の論理回路を構成するMLUTの総量を減らすことができる。
【0109】
図28は、最密充填配置構造におけるAD対の数の一例を示す図である。図28では、32ビット乗算回路を手動構成した場合の必要メモリ容量とクリティカル・パス・セル数とを計算した。図示されるように、MLUTが備えるAD対の数は、6以上であると、クリティカルパルMLUT数が減少する。また、MLUTが備えるAD対の数は、6以上であると、必要メモリ容量が増加する。この結果は、AD対の数が少ない場合、所望の論理回路をMPLD20に配置配線するときに、それぞれ論理回路として動作するMLUT間の配線にスイッチング用に挿入されるMLUTの数が増加することを示す。AD対の数が少ないと、接続要素として機能できるMLUTの数が限定される。このため、接続要素として機能するMLUTを数多く通過しなければ、論理回路として動作するMLUT間を配線できない可能性がある。この結果、AD対の数が少ないと、論理回路を実現するために必要なMLUT数が増加する可能性がある。図28の例では、MLUTが有するN個のAD対のうち、5つのAD対は、論理回路として真理値表を構成するために使用することが望ましい。このため、MLUTが備えるAD対の数は、5以上であることが好ましい。
【0110】
一方、MLUTが備えるAD対の数を増やすと、配置・配線したときに実際に使用するMLUT当たりのAD対の数が減少することが予想される。そして、このために、配置・配線効率が低下する可能性がある。図28に示す、32ビット乗算回路を手動で配置・配線する場合に、AD対の数を8にすると、配置・配線に必要な領域は、AD対の数を6にするときの4倍に増加した。
【0111】
〔3.2.2〕マトリックス配置構造でのAD対結線構造
図29は、MLUTのAD対の結線構造の1例を示す図である。MLUT30は、マトリックス状に配置され、6つのAD対をそれぞれ有する。図29では、MLUT30とMLUT30aとを結ぶ直線に平行な方向をMLUT領域8の縦方向と仮定する。そして、MLUT30とMLUT30cとを結ぶ直線に平行な方向をMLUT領域8の横方向と仮定する。MLUT30は、縦方向に配置されるMLUT30a及び30bに近距離配線される第1及び第2のAD対と、横方向に配置されるMLUT30c及び30dに近距離配線される第3及び第4のAD対と、縦方向に位置するMLUT30の横方向に隣接する2つのMLUT30e及び30fにそれぞれ近距離配線される第5及び第6のAD対とを有する。
【0112】
このように、本例では、ある列に配置されるMLUT(例えば、MLUT30)の2つのAD対は、第1の列の方向に隣接するMLUTの横方向に隣接する2つのMLUTにそれぞれ近距離配線される。そして、その列に隣接する列に配置されるMLUT(例えば、MLUT30c及び30d)の2つのAD対は、第1の列の方向と反対の方向である第2の列の方向に隣接するMLUTの横方向に隣接する2つのMLUTにそれぞれ近距離配線される。このように近距離配線することで、隣接するMLUTを結線するAD対は、同一平面上で交差しない構造とすることができる。
【0113】
なお、この例では、全てのMLUTの第5及び第6のAD対は、縦方向に配置されるMLUTの横方向に隣接する2つのMLUTにそれぞれ近距離配線される。しかしながら、このAD対を横方向に配置されるMLUTの縦方向に隣接するMLUTに近距離配線する構造とすることもできる。例えば、MLUT30の第5及び第6のAD対は、横方向に配置されるMLUT30の縦方向に隣接する2つのMLUT30e及び30gにそれぞれ近距離配線できる。
【0114】
〔3.2.3〕交互配置構造でのAD対結線構造
図30は、MLUTのAD対の結線構造の別な例を示す図である。MLUT30はそれぞれ、交互配置構造で配置され、6つのAD対をそれぞれ有する。図30では、MLUT30とMLUT30aとを結ぶ直線に平行な方向をMLUT領域8の縦方向と仮定し、MLUT30bとMLUT30fとを結ぶ直線に平行な方向をMLUT領域8の横方向と仮定する。
【0115】
MLUT30は、縦方向に配置される2つのMLUT30a及び3dに結線される第1及び第2のAD対と、MLUT30が配置される列に隣接する列の双方の隣接する位置に配置される4つのMLUT30b、30c、30e、及び30fに近距離配線される第3、第4、第5、及び第6のAD対とを有する。
【0116】
本例では、MLUTを結線するAD対は、同一平面上で交差しない構造とすることができる。さらに、全てのMLUTのAD対の結線構造を同一な構造にすることができる。なお、この例では、全てのMLUTの2つのAD対は、縦方向に配置されるMLUTに結線されるが、このAD対を横方向に配置されるMLUTに結線する構造とすることもできる。すなわち、MLUT30の第1及び第2のAD対は、縦方向に配置される横方向に配置されるMLUT30a及び3dに近距離配線する代わりに、2つのMLUT30h及び30kに近距離配線することができる。
【0117】
〔3.2.4〕Dフリップフロップ結線を有するMLUTのAD対結線構造
図31は、MLUTのAD対の結線構造の他の例を示す図である。MLUTはそれぞれ、交互配置構造で配置され、7つのAD対をそれぞれ有する。また、MLUTはそれぞれ、Dフリップフロップ13を隣接して配置される。MLUTが有する7つのAD対の中で、6つのAD対は、隣接するそれぞれ6つのMLUTと近距離配線される。残りの1つのAD対は、隣接するDフリップフロップ13と結線される。近距離配線される6つのAD対は、図30に示す結線と同一の結線構造を有する近距離配線にすることができる。残りの1つのAD対は、アドレス線がDフリップフロップ13のD入力と結線され、データ線がQ出力と結線される。Dフリップフロップ13のCK入力は、全て結線され、全てのDフリップフロップ13を1つのクロック信号で動作させることができる。また、Dフリップフロップ13のCK入力を列ごとに結線し、列ごとに異なるクロック信号で動作させることができる。さらにまた、Dフリップフロップ13のCK入力を8個、又は16個など任意の数のグループごとに結線し、それぞれのグループで異なるクロック信号で動作させることができる。
【0118】
本例では、それぞれのMLUTの1つのAD対にDフリップフロップが結線されるので、MLUT領域に順序回路を形成することができる。真理値表を構成する機能のみを有するMLUTのみで構成されるMLUT領域では、組み合わせ回路を構成することは、可能であるが、順序回路を構成することは、難しい。そこで、本例では、それぞれのMLUTの1つのAD対にDフリップフロップを結線することで、順序回路を形成することを可能にする。
【0119】
なお、本例では、DフリップフロップがAD対に結線されるが、セット・リセット・フリッププロップ、Tフリップフロップ、又はJKフリップフロップなどの他のフリップフロップを結線できる。また、セット入力、リセット入力、又はQB出力などの入出力を有するDフリップフロップを結線できる。さらに、DフリップフロップのQ出力に結線されるMLUTのデータ線を、DフリップフロップのQB出力に結線できる。さらに、全てのMLUTがそれぞれ、Dフリップフロップと結線するAD対を有する必要はなく、MLUT領域を構成するMLUTの中で、所定の割合のMLUTのみがDフリップフロップと結線するAD対を有する構造にすることができる。また、以下の説明において、MLUTの1つのAD対をDフリップフロップに結線することを、Dフリップフロップ結線と称することがある。
【0120】
〔3.2.5〕離間配線を有する場合のMLUTのAD対結線構造
図32は、MLUTのAD対の結線構造の他の例を示す図である。MLUT30はそれぞれ、7つのAD対をそれぞれ有し、交互配置構造で配置される。MLUT30が有する7つのAD対の中で、6つのAD対は、隣接するそれぞれ6つのMLUT30と近距離配線される。残りの1つのAD対は、1列ごとに列を1つ変えたMLUT30と離間配線される。
【0121】
本例では、MLUT30はそれぞれ、1つの離間配線を有するので、離間配線は、MLUT30を接続要素として使用してMLUT間を接続するよりも、データの伝播遅延時間を減少させることができる。また、離間配線は、論理回路をMLUT領域8上に論理回路情報を配置・配線するときに、配線の柔軟性を高めることができる。なお、離間配線は、近距離配線ではないMLUT間の接続配線である。よって、隣接するMLUTではないMLUTと接続することで、上記の離間配線の効果が生じる。
【0122】
なお、本例では、全てのMLUTがそれぞれ、離間配線されるAD対を有するが、所定の割合のMLUTのみが離間配線するAD対を有する構造にしてもよい。例えば、ある割合のMLUTの1つのAD対を、離間配線として使用し、他のMLUTの1つのAD対を、Dフリップフロップ結線とすることができる。
【0123】
〔3.3〕MLUT領域の構造
〔3.3.1〕MLUT領域の全体的な構造
図33は、MLUTのAD対の結線構造の他の例を示す図である。図33を参照して、本例に係るMLUT領域の全体的な構造の一例を説明する。本例では、MLUT領域8は、15行×30列の交互配置構造で配置される450個のMLUT30を有する。MLUTはそれぞれ、7つのAD対を有し、6つのAD対を近距離配線として使用する。残りの1つのAD対は、離間配線、又はDフリップフロップ結線に使用する。図において、離間配線が結線されていないMLUTは、Dフリップフロップに結線される。
【0124】
本例では、15行×30列の交互配置構造で配置される7つのAD対を有するMLUTを用いて、MLUT領域が説明される。しかしながら、他の配置のMLUTを用いて、MLUT領域を構成できることは、当業者に明確に理解されるであろう。また、MLUT領域に配置されるMLUTの中で、離間配線が結線されるMLUTと、Dフリップフロップ結線されるMLUTの割合は、MPLDが使用される用途及び機能に基づいて任意に選択することができる。さらにまた、本例では、MLUTの配置構造は、交互配置構造であるが、マトリックス配置構造においても、本例と同様の結線構造を有することができる。すなわち、本例の配線構造を維持しながら、MLUTの配置構造を交互配置構造からマトリックス配置構造にトポロジカルに変換した構造とすることもできる(図29及び図30を参照のこと)。
【0125】
〔3.3.2〕MLUTブロックの構造
図34は、MLUTを有するMLUTブロックの一例を示す図である。本例では、MLUTブロックは、3行×6列のMLUTを1つのブロックとして構成する。各ブロック内のMLUTはそれぞれ、基本的には同一の配線規則に従って、離間配線、又はDフリップフロップ結線される。
【0126】
以下、基本的な結線規則を述べる。
【0127】
6つのAD対は、近距離配線に使用する。この規則は、MLUT領域8の端部に配置されるMLUT30でも同じである。このため、本例におけるMLUT領域8は、近距離配線として配置されるAD対を入出力線AD対として有し、これらのAD対により半導体装置100に配置される他の構成要素と結線することができる。
【0128】
1つのMLUTブロックに含まれる18個のMLUT30の中で6つのMLUTは、1つのAD対をDフリップフロップ結線する。このため、本例におけるMLUT領域は、3分の1の数のMLUTがDフリップフロップ結線されることになる。具体的には、図34において、「30F」の符号が付されたMLUT30である。すなわち、図34において、下の行の左から2列目及び3列目のMLUTと、中央の行の左から5列目及び6列目のMLUTと、上の行の左から3列目及び6列目のMLUTである。
【0129】
1つのMLUTブロックに含まれる残りの12個のMLUTには、離間配線が結線される。離間配線のうち、4本は縦方向に配置されるMLUT間で結線される第1の離間配線パターンで結線される。他の4本は左下から右上に整列するMLUT間で結線される第2の離間配線パターンで結線される。残りの4本は右下から左上に整列するMLUT間で結線される第3の離間配線パターンで結線される。
【0130】
第1の離間配線パターンで結線されるMLUTは、下の行の左から1列目及び4列目のMLUTと、中央の行の左から1列目のMLUTと、上の行の左から4列目のMLUTである。図34において、これらのMLUTはそれぞれ、「30C」の符号が付される。下の行の左から4列目のMLUTと、中央の行の左から1列目のMLUTとは、縦上方向に5つ離れたMLUTとそれぞれ離間配線が結線される。下の行の左から1列目のMLUTと、上の行の左から4列目のMLUTとは、縦下方向に5つ離れたMLUTとそれぞれ離間配線が結線される。
【0131】
第2の離間配線パターンで結線されるMLUTは、下の行の左から6列目のMLUTと、中央の行の左から2列目及び3行目のMLUTと、上の行の左から5列目のMLUTである。図34において、これらのMLUTはそれぞれ、「30L」の符号が付される。下の行の左から6列目のMLUTと、中央の行の左から3列目のMLUTとは、右上方向に5つ離れたMLUTとそれぞれ離間配線が結線される。中央の行の左から2列目のMLUTと、上の行の左から5列目のMLUTとは、左下方向に5つ離れたMLUTとそれぞれ離間配線が結線される。
【0132】
第3の離間配線パターンで結線されるMLUTは、下の行の左から5列目のMLUTと、中央の行の左から4行目のMLUTと、上の行の左から1行目及び2列目のMLUTである。図34において、これらのMLUTはそれぞれ、3Rの符号が付される。中央の行の左から4列目のMLUTと、上の行の左から1列目のMLUTとは、左上方向に5つ離れたMLUTとそれぞれ離間配線が結線される。下の行の左から5列目のMLUTと、上の行の左から2列目のMLUTとは、右下方向に5つ離れたMLUTとそれぞれ離間配線が結線される。
【0133】
図35は、15行×30列のMLUTを有するMLUT領域における近距離配線パターンの配置の一例を示す図である。図35において、円形の形状で示される450個のMLUTと、隣接する6つMLUT間をそれぞれ結線する近距離配線とが示される。MLUT領域8の端部に位置するMLUT30が有するいくつかのAD対は、未結線である。上述のように、これら未結線のAD対は、入出力回路部15、又は内部バス回路部などの半導体装置内の他の構成要素と結線することができる。
【0134】
図36〜図38に、本例におけるMLUT領域における第1〜第3の離間配線パターンの配置を示す。以下、それぞれの図を参照して、第1〜第3の離間配線パターンの配置の一例を説明する。
【0135】
〔3.3.3〕第1の離間配線パターンの配置構造
図36は、15行×30列のMLUTを有するMLUT領域における第1の離間配線パターンの配置を示す図である。図36において、円形の形状で示される450個のMLUT30と、隣接する6つMLUT間をそれぞれ結線する近距離配線と、縦方向に5つのMLUT30ごとに結線される第1の離間配線パターンとが示される。なお、第1の離間配線パターンで離間配線が結線されるべき位置に配置されるMLUTの中で、MLUT領域8の上端部及び下端部の近傍に位置するMLUT30のいくつかは、第1の離間配線パターンで離間配線が結線されていない。これらのMLUTは、第1の離間配線の規則に基づき結線すべきMLUTがMLUT領域8上に存在しない。このため、後述する第4及び第5の離間配線パターンで離間配線が結線される。
【0136】
〔3.3.4〕第2の離間配線パターンの配置構造
図37は、15行×30列のMLUTを有するMLUT領域における第2の離間配線パターンの配置を示す図である。図37において、円形の形状で示される450個のMLUT30と、隣接する6つMLUT間をそれぞれ結線する近距離配線と、左下から右上に整列するMLUT間で5つのMLUTごとに結線される第2の離間配線パターンとが示される。なお、第1の離間配線パターンと同様に、第2の離間配線パターンで離間配線が結線されるべき位置に配置されるMLUTの中で、MLUT領域8の端部の近傍に位置するMLUT30のいくつかは、後述する第4及び第5の離間配線パターンで離間配線が結線される。
【0137】
〔3.3.5〕第3の離間配線パターンの配置構造
図38は、15行×30列のMLUTを有するMLUT領域における第3の離間配線パターンの配置を示す図である。図において、円形の形状で示される450個のMLUT30と、隣接する6つMLUT間をそれぞれ結線する近距離配線と、右下から左上に整列するMLUT間で5つのMLUTごとに結線される第3の離間配線パターンとが示される。なお、第1及び第2の離間配線パターンと同様に、第3の離間配線パターンで離間配線が結線されるべき位置に配置されるMLUT30の中で、MLUT領域8の端部の近傍に位置するMLUT30のいくつかは、後述する第4及び第5の離間配線パターンで離間配線が結線される。
【0138】
〔3.3.6〕第4の離間配線パターンの配置構造
図39は、15行×30列のMLUTを有するMLUT領域における第4の離間配線パターンの配置を示す図である。上述のように、第4の離間配線パターンの配置は、図34に示すMLUTブロックにおいて規定される結線規則に基づくものではなく、MLUT領域8の端部の近傍に位置するMLUT30のいくつかを結線するものである。しかしながら、第1〜第3の離隔配線パターンの配置に類似する配置となるように、第4の離間配線パターンは、配置される。第4の配線パターンの規則を以下に示す。
【0139】
まず、第4の離間配線パターンは、第1〜第3の離間配線パターンと同様に、縦方向、左下から右上方向、又は右下から左上方向のいずれかのMLUTが整列した方向に平行に配置される。
【0140】
次に、第4の離間配線パターンは、いずれかの方向にMLUTを4つ離れたMLUTごとに配置される。この規則に則するために、本来は第1〜第3の離間配線パターンで結線されるべきMLUTのいくつかが、第4の離間配線パターンで結線される。例えば、図38において、上端の行の左端の列に配置されるMLUTは、第1の離間配線パターンで離間配線を結線されるべきMLUTであるが、第4の離間配線パターンで結線される。
【0141】
このように第4の離隔配線パターンは、第1〜第3の離隔配線パターンに類似した配線パターンを有するため、MLUT領域8上のそれぞれのMLUT30に論理回路情報を配置・配線するときに使用する配置・配線アルゴリズムに与える影響を低く抑えることができる。
【0142】
〔3.3.7〕第5の離間配線パターンの配置構造
図40は、15行×30列のMLUTを有するMLUT領域における第5の離間配線パターンの配置を示す図である。第5の離間配線パターンにより接続されるMLUTは、第1〜第4の離間配線パターンで結線することができず、かつ第4の離間配線パターンでも結線することができなかったMLUT30ある。本例におけるMLUT領域では、これらのMLUT30は、Dフリップフロップを介して結線することもできる。
【0143】
〔4〕1つのMPLDを搭載した半導体装置
ここでは、1つのMPLDを搭載した半導体装置の例について説明する。
【0144】
〔4.1〕1つのMPLDを搭載した半導体装置の配置構造
図41は、MPLDを搭載した半導体装置の配置ブロックの一例を示す図である。半導体装置100は、MPLD20と、入出力回路部15とを有する。入出力回路部15は、半導体装置100の外部の装置から信号を入力するための入力回路、半導体装置100の外部の装置から信号を出力するための出力回路、電源用セル、及びI/Oパッドを有する。
【0145】
入力回路はそれぞれ、MPLD20内に配置されるそれぞれのMLUT30を選択するアドレス線、それぞれのMLUT30を構成する記憶素子40を選択するアドレス線、それぞれのMLUT30を構成する記憶素子40にメモリ動作情報などを書き込むためのメモリ動作用データ線接続することができる。さらに入力回路は、MPLD20の端部に配置され他のMLUT30と結線されていないAD対の少なくとも1つの論理動作用アドレス線、及び制御信号などに接続することができる。出力回路はそれぞれ、メモリ動作用データ線、及びMPLD20の端部に配置され他のMLUT30と結線されていないAD対の少なくとも1つの論理動作用データ線などに接続することができる。入力回路及び出力回路と、MPLD20のそれぞれのAD対とは、直接接続することができる。また、入力回路及び出力回路と、MPLD20のAD対とは、バッファ回路を介して接続することもができる。バッファ回路を介することにより、信号伝送速度を向上させることができる。
【0146】
MPLDは、多入力多出力の論理回路を構成することができる。例えば図33を参照すると、30行×15列のMLUT領域8を有するMPLD20は、118個の未結線のAD対を有する。これらのAD対は、全て入出力信号線として使用できる。これは、このMLUT領域8を有するMPLD20は、118本の入力信号線、及び118本の出力信号線を有し、64ビットなどの多ビットの信号をパラレルに論理演算できることを意味する。したがって、MPLDは、高速、かつ多入力多出力な論理回路を実現できる。また、上述のように、MPLDは、規則的に配置されるMLUTを有するので、規則性がある回路、又は真理値表に使用することもできる。
【0147】
〔4.2〕MPLDへの配置・配線フロー
ここでは、半導体装置に搭載されるMPLDを配置・配線するフローの1つの例について説明する。
【0148】
図42は、MPLDの配置・配線を実行する情報処理装置の1例を示す図である。情報処理装置210は、演算処理部211と、入力部212と、出力部213と、記憶部214とを有する。演算処理部211は、入力部212に入力された配置・配線用のソフトウェア、RTL(Register Transfer Level)記述などの回路記述(以下、ネットリストとも称する)などの真理値表データを記憶部214に記憶する。また、演算処理部211は、記憶部214に記憶された配置・配線用のソフトウェアを用いて、記憶部214に記憶された回路記述に対して以下に示す配置・配線のフローを実行し、出力部213に出力する。出力部213には、半導体装置100(図示せず)を接続することができ、演算処理部211が実行した配置・配線情報を包含するビットストリームデータを、出力部213を介して半導体装置100に書き込むことができる。
【0149】
図43は、情報処理装置が、MPLDに配置・配線するためのビットストリームデータを生成するフローの1例を示す図である。まず、ネットリストをテクノロジー非依存論理最適化し(S201)、テクノロジーマッピングし(S202)、配置(S203)、配線する(S204)ことを有する。配置・配線されたビットストリームデータは、それぞれにMLUT30に書き込む論理回路情報に相当し、MPLD20のメモリ動作により、それぞれのMLUT30が備える記憶素子に書き込まれる。以下、それぞれのステップについて順に説明する。
【0150】
〔4.2.1〕テクノロジー非依存論理最適化
まず、ネットリストをテクノロジー非依存論理最適化するステップ(S201)について説明する。このステップでは、加算器、減算器、乗算器、及び除算器などの演算器部分と、他の論理回路部分とに分離して最適化することができる。
【0151】
RTL記述から、演算器部分と、他の論理回路部分とに分離するときに、RTL記述に記載される演算記号を抽出することにより、演算器部分を分離することができる。例えば、Verilog HDLによりRLT記述が記述される場合は、加算を意味する「+」、減算を意味する「−」、乗算を意味する「*」、除算を意味する「/」、及び剰余演算を意味する「%」などの演算子を抽出することにより、RTL記述から、演算器部分を分離することができる。C言語に類似する他の言語を使用する場合も、同様な方法で演算器部分を分離することができる。
【0152】
演算器部分は、全加算器、又は半加算器などを基本単位として最適化することができる。演算器部分を他の論理回路部分とともに最適化すると、NAND回路、XOR回路などの基本的なゲート回路を組み合わせることにより、演算器が構成されることになる。しかしながら、この場合は、論理合成するときに、様々なゲート回路に論理合成されるために、各種演算器が構成される回路が冗長になる可能性がある。そこで、演算器部分を他の論理回路部分と分離し、全加算器、又は半加算器別になどを基本単位としてモジュール合成することにより、演算器部分を効率的に最適化ができる。
【0153】
ここでモジュール合成とは、規則的な構造を有するメモリ、演算論理装置(ALU)、乗算器、及び加算器などのデータパス系モジュールなどを対象として、モジュールの機能と、ビット幅などの必要な情報とをパラメータとして与えて、モジュールのパターンを生成することをいう。
【0154】
例えば、5個以上のAD対を有するMLUTによりMPLDを構成する場合は、2ビット加算器を基本単位として、演算器部分をモジュール合成することができる。4ビット加算器は、2つのビット加算器で構成することができる。8ビット加算器は、4つのビット加算器で構成することができる。
【0155】
8ビット加算器などの基本的な演算回路は、2ビット加算器による配線情報を記憶部214に記憶することができる。このことにより、記憶される演算回路に関しては、後述の配線処理が必要でなくなり、処理の高速化が図れる。しかしながら、演算回路は、様々なビット数を有する。また、加算器においても、全加算器、半加算器に加えて、「キャリー先読み(キャリールックアヘッド:Carry look ahead)」と称されるものも存在する。このため、全てのパターンの演算回路を記憶部に記憶させることは、現実的ではない。そこで、2ビット加算器により演算回路を構成するための所定の配線規則ルを記憶部214に記憶し、その配線規則に基づいて演算回路を構成することができる。
【0156】
他の論理回路部分は、通常のLSI設計、又はFPGAの設計に使用される一般的な方法を使用する。例えば、ステートマシンの状態数の最小化、二段論理最適化、及び多段論理最適化などの処理を実行する。
【0157】
〔4.2.2〕テクノロジーマッピング
次に、情報処理装置210が、テクノロジー非依存論理最適化した後のネットリストを、MPLDを構成するMLUTに適当なネットリストとするように、テクノロジーマッピングするステップ(S202)について説明する。1つの例では、テクノロジーマッピングは、テクノロジー非依存論理最適化した後のネットリストを分解する第1のステップと、第1のステップで分解したネットリストをカバリングする第2のステップとを有する。
【0158】
第1のステップは、MLUTに構成される真理値表に1つの論理回路を包含できるように、論理回路の入力及び出力数K以下にするステップである。MLUTのAD対の数がNである場合、入力及び出力数Kは、AD対の数N以下でなければならない。第1のステップには、カーネルの括り出し、及びRoth−Karp decompositionなどを使用することができる。
【0159】
第2のステップは、MLUTに構成される真理値表の数を最適化するために、第1のステップで得られたネットリストのいくつかの節点をカバーするステップである。このステップでは、第1のステップで分解された真理値表の中で、2つ以上の真理値表を結合して1つのMLUTに包含できる真理値表を1つの真理値表にまとめる。これにより、MLUT30に構成される真理値表の数を最適化することができる。
【0160】
好適には、組み合わせ回路を最適化するときに、最適化後の組み合わせ回路が有する入力数及び出力数をMLUTが有するAD対の数よりも少なくすることができる。これにより、組み合わせ回路が配置されるMLUTを、同時に接続要素として使用することができる。なお、MPLDを構成するMLUTが6つ以上のAD対を有する場合には、入力線及び出力線の数を5つ以下になるように最適することができる。5つの入力線及び出力線を有することによって、1つのMLUTで2ビット加算器の真理値表を構成するためである。
〔4.2.3〕配置
次に情報処理装置210が、テクノロジーマッピングを実行した後のネットリストを、MPLD内のそれぞれのMLUTに配置するステップ(S203)について説明する。テクノロジーマッピングを実行した後のネットリストには、MLUTが有するAD対の数に応じて構成される論理回路部の真理値表と、それぞれのMLUTが有するAD対間の接続関係が記載される。本ステップでは、論理回路部の真理値表をそれぞれ、適当な位置のMLUTに配置する。具体的な配置手法としては、通常のLSI設計と同様に、初期配置に使用される構成的配置法(ランダム法、ペア・リンキング法、クラスタ成長法、及びミンカット法など)、及び配置改善に使用される繰り返し改善法(スタインバーグ法、ペア交換法、反復重心法、及びシミュレーテッド・アニーリング法など)などがある。
【0161】
〔4.2.4〕配線
最後にテクノロジーマッピングを実行した後のネットリストに基づいて、配置されたMLUT間を配線するステップ(S204)について説明する。テクノロジーマッピングを実行した後のネットリストに従って、論理回路として動作するMLUTが有するAD対間を、接続要素として機能するMLUTを用いて配線する。具体的な配置手法としては、通常のLSI設計と同様に、Leeのアルゴリズム、及びラインサーチアルゴリズムなどがある。この結果、所望の論理回路を実現するネットリストをMPLD上に配置・配線する真理値表データを構成するビットストリームデータが生成される。
【0162】
〔4.3〕1つのMPLDを搭載した半導体装置での再構成
これまで説明してきたように、MPLDは、再構成可能な論理回路を構成することができる複数の記憶素子を有する。MPLDのこの特性を利用して、MPLDを搭載した半導体装置では、MPLDに書き込まれる論理回路情報を再構成することができる。
【0163】
例えば、図41に記載されるMPLD20を搭載した半導体装置100での再構成は、図42に記載される情報処理装置210を使用して実現することができる。MPLD20に書き込むことができる論理回路情報を構成する複数のビットストリームデータを情報処理装置210の記憶部214に記憶する。そして、情報処理装置210の出力部213と接続された半導体装置100に情報処理装置210がビットストリームデータを書き込むことによって、MPLD20の再構成を実現できる。
【0164】
また、図41に記載されるMPLD20を搭載した半導体装置100での再構成は、半導体装置100と同一の基板に搭載されるマイクロプロセッサ(図示せず)と、記憶装置(図示せず)とを使用することによっても、実現することができる。
〔4.4〕1つのMPLDを搭載した半導体装置での部分再構成
〔4.4.1〕MPLDの部分再構成フロー
半導体装置に搭載されるMPLDを部分再構成するフローの1つの例について説明する。
【0165】
図44は、図41に示す半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。まず、ステップS211において、情報処理装置210が、MPLDに書き込まれている第1のビットストリームデータと、部分再構成実行後の第2のビットストリームデータとを比較する。比較は、それぞれのビットストリームデータに記載される同一のアドレスを有するMLUT間の内部に記載される真理値表を比較して行う。さらに、MLUTのぞれぞれのAD対に接続されるAD対の符号などを比較して行う。第1のビットストリームデータと、部分再構成実行後の第2のビットストリームデータとは、記憶装置に記憶できる。好適には、第2のビットストリームデータを生成するときに、第1のビットストリームデータと、第2のビットストリームデータとの間で同一の機能を有するMLUTに対して、第1のビットストリームデータと同一の符号を付することができる。次に、ステップS212において、第1のビットストリームデータと、第2のビットストリームデータの間で記載される真理値表データが異なるMLUTのアドレスを特定し、記憶装置に記憶する。MLUTのアドレスは、第1のビットストリームデータと、第2のビットストリームデータとの間で、MPLD上で同一の位置に位置するMLUTを同一のアドレスにすることができる。例えば、30行×15列のMLUT領域を有するMPLDにおいて、左上の頂点に位置するMLUTのアドレスを0番とし、そのMLUTの右側に位置するMLUTのアドレスを1番とし、以下同様に繰り返し、右下の頂点に位置するMLUTのアドレスを449番とすることができる。なお、第1のビットストリームデータと、第2のビットストリームデータとのそれぞれのMLUTのアドレスと物理的位置が対応しない場合には、両者の相関を明確にする手段を有することができる。例えば、相関関係を示したデータを記憶装置に記憶できる。次にステップS213において、情報処理装置210が、ステップS212で特定されたMLUTの1つのアドレスをMPLDに出力する。具体的には、MPLD20の行デコーダ12aと、列デコーダ12bとにアドレスを入力する。そしてステップS214において、情報処理装置210が、アドレスが指定されたMLUTの第2のビットストリームデータに記載される真理値表データを、MLUTに書き込む。MLUTにデータを書き込む方法については、既に述べているのでここでは詳細は省略する。
【0166】
第1のビットストリームデータと、第2のビットストリームデータの間で記載される真理値表データが異なるMLUTのアドレスが、さらに記憶装置に記憶されている場合は、ステップS213に戻る。第1のビットストリームデータと、第2のビットストリームデータの間で記載される論理回路情報が異なるMLUT30のアドレスが、他に記憶されていない場合には、部分再構成を終了する。
【0167】
〔4.4.2〕部分再構成の実施例
ここでは、部分再構成の利点を具体的な実施例に基づいて説明する。実施例は、高速フーリエ変換において一般に使用されるバタフライ演算に基づくものである。
【0168】
図45に、8点離散フーリエ変換をバタフライ演算で行うときのアルゴリズムの一例を示す。ここで、f(0)〜f(7)は、時間上の8個の点である。F(0)〜F(7)は、離散フーリエ変換後の8個の点である。W0〜W3は、回転因子である。図45において、矢印線の交点は、加算する点を示す。また、矢印線の交点に「−1」との記載がさらに付される場合は、減算する点を示す。さらに、矢印線上に回転因子W0〜W3が付される場合は、回転因子W0〜W3を乗算することを示す。したがって例えばステージS1において、f(0)は、f(4)にW0を乗じたものを加算されるとともに、f(4)にW0を乗じたものを減算される。このように、バタフライ演算では、各Stageにおいて、定数乗算がなされる。
【0169】
一般的に、定数乗算を論理回路で実現する場合、乗算回路を構成するよりも、シフト回路と加算演算とで定数乗算専用回路を構成することが多い。これは、単純に乗算回路を構成する場合に比べて、シフト回路と加算演算とで定数乗算専用回路を構成することにより、演算速度の高速化を図れるからである。さらにまた、シフト回路と加算演算を使用することにより、回路素子数を減らすことが可能であるため、チップ面積を削減できる効果を有する。例えば、定数「3」に変数「a」を乗ずる回路は、以下の式に示すようにシフト回路と加算演算とで構成できる。
3 * a = a*2 + a = (a<<1) + a
ここで、「*」は乗算を示し、「+」は加算を示し、「<」はシフト回路を示す。したがって、式「(a<<1) + a」は、変数aを2桁上位ビットにシフトし、その結果に変数aを加算することを意味する。
【0170】
一方、離散フーリエ変換の回転因子W0〜W3は、回路が使用される用途によって、様々な値をとり得る。したがって、同じ8点離散フーリエ変換をバタフライ演算で実現する回路を構成する場合でも、用途によって、種々の回路を構成する必要がある。例えば、回転因子W3が3である回路においては、回転因子W3を乗算する回路は、以下に示す式のように構成される。
3 * a = a*2 + a = (a<<1) + a
これに対し、回転因子W3が4である回路においては、回転因子W3を乗算する回路は、以下に示す式のように構成される。
4 * a = a*2 + a*2 = (a<<1) + (a<<1)
FPGAなど従来の再構成可能論理回路では、このように一部の回路のみが変更になった場合でも、再び配置・配線する必要があるか、又は論理回路情報を全て書き換える必要がある。しかしながら、MPLDは、論理回路情報が変更されたMLUTのアドレスを特定できるので、論理回路情報が変更されたMLUTのみを書き換えて、部分再構成することができる。この実施例では、「+ a」の論理回路を構成するMLUTを「+ (a<<1)」の論理回路を構成するMLUTに書き換えることにより部分再構成することができる。
【0171】
〔5〕1つのMPLDと、演算処理部とを搭載した半導体装置
ここでは、1つのMPLDと、演算処理部とを搭載した半導体装置の例について説明する。
【0172】
〔5.1〕MPLDと、演算処理部とを搭載した半導体装置
図46は、MPLDを搭載した半導体装置の一例を示す図である。半導体装置100は、MPLD20と、演算処理部220を有する。
【0173】
演算処理部220は、記憶部110、命令読出部120、レジスタ部130、及び命令実行部140を有する。演算処理部220は、MPLD20に記憶されたプログラムを実行することで、MPLD20とのデータの入出力を行い、MPLD20から受け取ったデータを演算する装置である。演算処理部220は、例えば、演算処理装置としてのMPU(Micro Processing Unit)である。MPLD20は、多入力多出力の論理演算を高速処理可能である。そのため、演算処理部220を、論理回路の一部の制御としての分岐命令等の例外処理や、MPLD20の状態制御としてのMPLD20の再構成、MPLD20内のSRAMを記憶領域としてデータアクセスする等の機能に限定することで、8ビット、16ビットなどのビット幅が狭い演算処理装置にすることができる。
【0174】
記憶部110は、命令又はデータを記憶する記憶装置である。記憶部110は、MPLD20が記憶するデータの一部を記憶する。記憶部110は、例えば、1次キャッシュメモリである。記憶部110は、例えば、SRAM(Static Random Access Memory)である。なお、以下の説明では、記憶部110は、MPLD20の上位キャッシュメモリとして説明するが、図52を用いて後述するように、一実施形態においては、演算処理部220は、記憶部26とデータ接続する。その場合は、下記のMPLD20のメモリ機能を利用する演算処理部220とのデータ入出力は、主記憶装置についても同じである。
【0175】
記憶部110は、演算処理部220の内部に設けられており、MPLD20より命令読出部120に近い位置にある。命令読出部120が、記憶部110に記憶されているデータにアクセスする場合(以下、「キャッシュヒット」という)、命令読出部120は短時間で対象データにアクセスすることが出来る。一方、命令読出部120が、キャッシュメモリに記憶されていないデータにアクセスする場合(以下、「キャッシュミス」という)、記憶部110の下位階層にあるMPLD20からデータを読み出すため、対象データへのアクセス時間は長くなる。そのため、キャッシュミスが生じないように、演算読出部120からのアクセス頻度が高いデータは記憶部110に保持される。
【0176】
命令読出部120は、記憶部110から命令を読み出し、読み出した命令を命令実行部140に出力する。
【0177】
命令実行部140は、命令読出部120から記憶部110から読み出した命令を受け取ると、命令により特定される処理を、レジスタ130に記憶されるデータに対して実行する。命令に応じた所定の命令処理とは、例えば、浮動小数点演算、整数演算、アドレス生成、分岐命令実行、レジスタ130に記憶されるデータを記憶部110へストアするストア動作、記憶部110に記憶されるデータをレジスタ130にロードするロード動作である。命令実行部140は、浮動小数点演算、整数演算、アドレス生成、分岐命令実行、及びストア又はロード動作を行う実行器を備えて、それらの実行器を用いて上記命令処理を実行する。命令実行部140は、入出力部150を介して、MPLD20に対してデータのストア又はロード動作を実行する。
【0178】
レジスタ130は、例えば、オペランド、又は、MPLD20へストア又はリード動作する際のアドレス、命令実行部140が実行対象とする命令が格納されているMPLD20のアドレスを記憶する。
【0179】
入出力部150は、MPLD20とのデータの入出力を行う。MPLD20は、図1〜図3を用いて説明した例と同じである。入出力部150は、MLUT30の論理動作用アドレスLAのアドレス線と、演算処理部220の出力端子D0からの1つの出力信号線とが接続すると共に、MLUT30の論理動作用データLDのデータ線と、演算処理部220の入力端子I0への入力信号線が接続する。このようにして、MPLD20の外延に配置されるMLUTの少なくとも一部は、演算処理部220との論理動作用アドレスLAを受け取り、又は、論理動作用データLDを出力する。
【0180】
入出力部150はさらに、図46に示されるように、MPLDアドレス、メモリ動作用アドレスMA、書込データWD、読出データRDの信号線と接続し、それらのデータの入出力により、MPLD20に対するメモリ動作を行う。
【0181】
上記構成から明らかなように、演算処理部220は、入出力部150を介して、メモリ動作用アドレスMA、MPLDアドレス、書込データWDをMPLD20に出力することで、MPLDのメモリ動作を生じさせるストア動作を実行し、入出力部150を介して、メモリ動作用アドレスMA、MPLDアドレスをMPLD20に出力することで、読出データRDを受け取る。このように、入出力部150のうち、メモリ動作用アドレスMA、MPLDアドレス、書込データWD、読出データRDの入出力を行う部分が、メモリ動作用の入出力部として動作する。
【0182】
また、上記構成から明らかなように、演算処理部220は、入出力部150を介して、論理動作用アドレスLAを出力し、論理動作用データLDを受け取ることでMPLDの論理動作の結果を受け取る。このように、入出力部150のうち、論理動作用アドレスLA、論理動作用データLDの入出力を行う部分が、論理動作用の入出力部として動作する。
【0183】
図47は、演算処理部と、MPLDとのデータの入出力を行う入出力部の一例を概略的に示す図である。MPLD20に含まれる入出力部21は、MLUT30のアドレス線と、演算処理部220の出力端子DOからの1つの出力信号線とが接続すると共に、MLUT30のデータ線と、演算処理部220の入力端子IOへの入力信号線が接続する。
【0184】
演算処理部220の論理動作用の入出力信号線と、MLUT30のアドレス又はデータ線との接続は、演算処理部220の入出力ビット数の数だけ用意される。例えば、演算処理部220が16ビットの出力ビット幅を有している場合、出力信号線及び入力信号線は、それぞれ16本となり、それらの信号線と接続するMLUTのアドレス線及びデータ線も16本となる。
【0185】
演算処理部220の入出力信号線と、MLUT30のアドレス又はデータ線との接続は、演算処理部220の入出力ビット数の数だけ用意される。例えば、演算処理部220が16ビットの出力ビット幅を有している場合、出力信号線及び入力信号線は、それぞれ16本となり、それらの信号線と接続するMLUTのアドレス線及びデータ線も16本となる。
【0186】
このように、演算処理部220の入出力信号線と、MLUT30のアドレス又はデータ線とをバス接続回路を介さずに直接接続することで、演算処理部220と、MPLD20が接続することができる。演算処理部220と、MPLD20の間の接続に、バス接続回路を介さないことにより、バスの調停回路によりマスタースレーブの設定が不要になる。この結果、演算処理部220と、MPLD20の間の信号の伝送速度の向上を図ることができる。またそれぞれの接続の間に、バッファ回路を挿入することができる。バッファ回路を挿入することにより、信号の伝達速度をさらなる向上を図ることができる。
【0187】
図48は、演算処理部と、MPLDとのデータの入出力を行う入出力部の別な例を示す図である。図48に示すように、演算処理部220は、MPLD20とのデータ入出力を行う入出力部230を有する。また、MPLD20も、演算処理部220とのデータ入出力を行う入出力部21を有する。入出力部21は、入出力部150は、例えば、MLUT30のAD対のアドレス線からアドレスを出力するポートA0〜A7、及び、MLUT30のAD対のデータ線からデータを入力するポートD0〜D7を有して、MPLD20の論理要素に対するデータ入出力を行うことができる。
【0188】
入出力部21はさらに、演算処理部220の入出力部230とデータ入出力を行うための所定のプロトコルに従う伝送制御を行う。所定のプロトコルに従う伝送制御とは、例えば、PCI Express等の高速シリアルバスや、パラレルバス等のバス制御である。このように、演算処理部220と、MPLD20とは、所定のバスによりデータ接続できる。
【0189】
なお、図48は、演算処理装置1つのMPLD20と接続しているが、入出力部230を介して他のMPLDとも接続できる。そして、演算処理部220は、入出力部230を介して、第1のMPLDが有するMLUTのアドレス線及びデータ線と、第2のMPLDが有するMLUTのアドレス線及びデータ線と接続し、第1のMPLDに対して論理動作のデータ入出力を行うとともに、第2のMPLDに対して再構成を含むメモリ動作を行うこともできる。よって、演算処理部220は、第1のMPLDの入出力部に対してアドレス及びデータを出力する制御を行うとともに、第2のMPLDの入出力部に対してアドレスを出力し且つデータを受け取る制御を行う。
【0190】
図49は、論理動作とメモリ動作を同時に行うMPLD、及び演算処理部の一例を示す図である。図49に示すMPLD20のMLUTは、図19に示すMLUTのように論理動作と、メモリ動作を同時に行うことができる。そのため、演算処理部220は、MPLD内のメモリ動作対象となる複数のMLUTから構成される第1論理部に対してメモリ動作を行うとともに、MPLD内の論理動作対象となる複数のMLUTから構成される第2論理部に対して論理動作を行う。
【0191】
図50は、複数のMPLD、及び演算処理部の一例を示す図である。図50に示すMPLD20A、20BのMLUTは、図4に示すMLUTのように論理動作と、メモリ動作を同時に行うことができない。そのため、演算処理部220は、メモリ動作象となる複数のMLUTを含む第1MPLD20Aに対してメモリ動作を行うとともに、論理動作対象となる複数のMLUTから構成される第2MPLD20Bに対して論理動作を行う。
【0192】
〔5.2〕MPLDと、演算処理部とを搭載した半導体装置の配置構造
図51は、MPLDを搭載した半導体装置の他の例における配置ブロックの一例を示す図である。半導体装置100は、MPLD20と、演算処理部220と、入出力回路部15とを有する。入出力回路部15は、図41を参照して説明した例と同様であるため、ここでは説明を省略する。演算処理部220は、図46を用いて説明したものである。
【0193】
本例では、MPLDアドレス信号線と、メモリ動作用アドレス信号線とは、演算処理部220に接続することができる。MPLD20の端部に配置され他のMLUT30と結線されていないAD対のいくつかは、演算処理部220に接続される。また、他のいくつかは、入出力回路部15に接続される。演算処理部220と、MPLDアドレス信号線と、メモリ動作用アドレス信号線とは、内部バス回路を介して接続でき、又は直接接続するもできる。演算処理部220と、MLUT30のAD対との接続は、内部バス回路を介して接続できる。また、演算処理部220と、MLUT30のAD対との接続は、直接接続することもできる。AD対を直接接続する場合は、内部バス回路を介して接続する場合と比較すると、高速動作が可能になる。これは、バス調停回路動作を必要としないためである。さらにまた、演算処理部220と、MPLD20のそれぞれのAD対とは、バッファ回路を介して接続することもできる。バッファ回路を介することにより、さらに信号伝送速度を向上させることができる。
【0194】
図52に、MPLDを搭載した半導体装置の他の例における配置構造の一例を示す図である。図52を参照すると、本例における半導体装置100は、マルチプレクサ22と、A/Dコンバータ24と、演算処理部220と、1つのMPLD20と、記憶部26と、MOSFET(Metal−Oxide−Semiconductor Field−Effect Transistor)ドライバ28とを有する。また、本例の半導体装置100の制御対象物の検出器出力からマルチプレクサ22に信号が入力され、制御対象物の制御入力にMOSFETドライバ28の出力が入力される。
【0195】
マルチプレクサ22は、32個、又は64個などの適当な数のアナログ信号が制御対象物の検出器から入力される。マルチプレクサ22は、入力された信号を時分割して、A/Dコンバータ24に出力する。A/Dコンバータ24は、時分割されたアナログ信号をデジタル信号に変換して、演算処理部220とMPLD20に出力する。A/Dコンバータ24からの信号を入力した演算処理部220は、外部の記憶装置に記憶されるソフトウェアの制御に基づいて、入力した信号の処理をMPLD20に命令する。このときに、MPLD20は、多入力多出力の演算処理、定型処理、及び背景処理などを行う。
【0196】
また、演算処理部220は、MPLD20に信号処理方法を命令するとともに、MPLD20からエラー信号、警報信号などが入力されたときの処理などの非定型処理を行う。演算処理部220は、MPLD20の論理回路情報を再構成することにより、種々の処理をMPLD20に実行させることができる。所定の処理が終了した後に、外部の記憶装置に記憶されるソフトウェアの制御に基づいて、演算処理部220は、MOSFETドライバ28を介して対象物にデータを制御対象物に出力する。これにより、制御対象物の検出器から本例における半導体装置100を介して制御対象物の制御器へのフィードバックループを形成することができる。したがって、多系統の制御を少ない部品で構成できる。
【0197】
本例における半導体装置100の応用例を、説明する。応用例として、半導体装置100は、自動車のドアミラーに付着した雨滴を除去する制御する。この場合、制御対象物の検出器は、自動車の運転手側のドアに設置されるドアミラー、助手席側のドアミラーに設置される及びフロントガラスなどに、それぞれ数個ずつ配置される雨滴検出器と、フロントガラス、又はボンネットなどに設置される雨量検出器などがある。また他の入力には、ドアミラー、フロントガラスなどに設置されるワイパの動作頻度、動作速度の信号などがある。これらの信号を入力される半導体装置100は、動作時間、動作周期、動作強度などを他の記憶装置に記憶されるソフトウェアに従って、決定する。そして、決定に基づき、MOSFETドライバ28の出力に接続されるワイパ駆動用モータに信号を出力し、ドアミラーのワイパを適当な時間、周期、強度で駆動する。また、何らかの故障が生じた場合は、MOSFETドライバ28の出力に接続されるLEDドライバに信号を入力して、運転手に警告を与えるために、LEDを駆動する。このとき、ワイパ駆動用モータに出力される信号の制御は、定型処理であり、かつ多ビット並列処理であるために、MPLD20により演算処理される。このとき、必要に応じてMPLD20の論理回路情報を再構成できる。一方、MOSFETドライバ28に出力される警告信号の制御は、非定型処理であるので、演算処理部220が処理する。
【0198】
〔5.3〕MPLDに書き込む論理回路情報の動作合成フロー
ここでは、半導体装置に搭載されたMPLDに書き込む論理回路情報を動作合成するフローについて説明する。
〔5.3.1〕動作合成について
【0199】
一般的に動作合成とは、設計対象の回路で処理したいアルゴリズム、すなわち動作記述から、その回路のRTLコードを生成することをいう。
【0200】
図53は、動作合成の一例を示す図である。図42に示す情報処理装置210が、動作合成を実行することができる。図53を参照すると、動作合成において、情報処理装置210は、ステップS221において、動作記述からCDFG(Control Data Flow Graph)を生成し、ステップS222において、CDFGをスケジューリングし、ステップS223において、スケジューリングしたCDFGをアロケーションし、ステップS224において、アロケーションしたCDFGからMPU命令コードを生成し、ステップS225において、RTL−CDFGとを生成する。なお、「MPU命令コード」とは、演算処理部220の命令コードである。
【0201】
動作記述には、デジタル回路設計用ハードウェア記述言語(HDL)の一種であるVHDL(VHSIC(Very High Speed Integrated Circuits)Hardware Description Language))を用いることができる。また、動作記述は、汎用性が高い、いわゆる高級言語(高水準言語とも称される)とすることもできる。ここで、高級言語は、プログラミング言語のうち、より自然語に近く、人間にとって理解しやすい構文や概念を持った言語の総称をいう。代表的な高級言語の種類としては、BASIC、FORTRAN、COBOL、C言語、C++、Java(登録商標)、Pascal、Lisp、Prolog、Smalltalkなどがある。
【0202】
MPU命令コードは、アセンブリ言語、又は機械語などの低級言語(低水準言語とも称される)であり、演算処理部が直接読み込む言語にすることができる。MPU命令コードは、ソフトウェアなどの形態で記憶装置などに記憶され、演算処理部が実行する処理の内容を規定する。MPU命令コードには、動作記述に記載される制御回路部分の一部などが含まれる。
【0203】
RTL−CDFGは、C言語の記述にレジスタ記述を追加したもの、又はverilog HDLなどのハードウェア記述言語(HDL)などにできる。RTL−CDFGは、図43に示す回路記述に相当するものである。図42に示す情報処理装置210は、図42及び図43を用いて説明した配置・配線フローにより、RTL−CDFGからビットストリームデータを生成することができる。
【0204】
以下、図53に示すそれぞれのステップについて、順に説明する。
【0205】
〔5.3.2〕CDFGを生成するステップ
図53に示すCDFGを生成するステップS221は、動作記述の実行の制御の流れと、データの流れとを解析し、プログラムのフローチャートに類似するCDFGに変換するステップとを有する。CDFG(Control Data Flow Graph)は、動作記述に現れたデータの流れ(データフロー)と各演算の実行順序の制御の流れ(コントロールフロー)を表し、節点、入力枝、出力枝、及び四則演算などの各種演算の種類を示す番号を有する。動作記述をCDFGに変換するときに、定数伝搬、共通演算除去などのコンパイラの最適化で行われる処理と同様な処理を行う。また併せて、動作記述に内在する並列性を引き出すように、フローグラフの構造を変換する処理なども実施してもよい。
【0206】
図54は、論理回路x=(a+b)*(b+c)を構成するCDFGの例を示す図である。この式は、「a」と「b」との論理和と、「b」と「c」との論理和との論理積「x」を求める式である。図54を参照すると、br1〜br7は、データ信号、又はコントロール信号を表す。節点br11〜br13は、演算を表す。節点br11及びbr12はそれぞれ、「a」と「b」との論理和と、「b」と「c」との論理和とを表す。節点br13は、節点br11の出力枝と、節点br12の出力枝との論理積を表す。
【0207】
〔5.3.3〕スケジューリングするステップ
図53に示すスケジューリングするステップS222は、全体のハードウェア量と、総制御ステップ数などの時間制約とを考慮して、動作記述中の各演算を実行する制御ステップを具体的に決定するステップである。すなわち、スケジューリングは、CDFGの節点に対応する演算をいつ実行するか、決定することである。言い換えると、どのクロックステップでCDFGの節点に対応する演算を実行するかを決定することである。この場合に、各演算の遅延時間を考慮して、全ての節点がクロック周期内に収まるようにスケジューリングする。スケジューリングは、速度優先スケジューリングと、ハードウェア量優先スケジューリングに分類される。速度優先スケジューリングは、全体の制御ステップ数を制約として与えて、その条件の下でハードウェア量が小さくなるようにスケジューリングを行なうものである。一方、ハードウェア量優先スケジューリングでは、使用可能なハードウェア量の制約を与えて、その条件の下で制御ステップ数が最小になるようにスケジューリングを行なうものである。
【0208】
図55は、図54に示すCDFGを、速度優先スケジューリングでスケジューリングした結果を示す図である。図55を参照すると、step 1において、図54に示すCDFGの節点c11で示される「a」と「b」との論理和と、節点c12で示される「b」と「c」との論理和と、節点c13で示される節点c11の出力枝と、節点c12の出力枝との論理積が全て実行される。このように、図55に示す速度優先スケジューリングでは、1つのステップで所与の論理回路を実行できる。しかしながら、節点c11で示される「a」と「b」との論理和と、節点c12で示される「b」と「c」との論理和とが同一のステップで実行されるため、2つの論理和回路を必要とされる。
【0209】
図56は、図54に示すCDFGを、ハードウェア量優先スケジューリングでスケジューリングした結果を示す図である。図56を参照すると、step 1において、図54に示すCDFGのうち、節点c11で示される「a」と「b」との論理和が実行される。そして、step 2において、節点c12で示される「b」と「c」との論理和と、節点c13で示される節点c11の出力枝と、節点c12の出力枝との論理積が実行される。このように、図55に示す速度優先スケジューリングが、1つのステップで所与の論理回路を実行するのに対し、ハードウェア量優先スケジューリングでは、2つのステップで所与の論理回路を実行する。このため、速度優先スケジューリングに比較して、ハードウェア量優先スケジューリングでは、処理時間が増加する。しかしながら、節点c11で示される「a」と「b」との論理和と、節点c12で示される「b」と「c」との論理和とが異なるステップで実行されるため、図55に示す速度優先スケジューリングが2つの論理和回路を必要とするのに対し、ハードウェア量優先スケジューリングでは、1つの論理和回路のみで2つの論理和演算を実行することができる。
【0210】
〔5.3.4〕アロケーションするステップ
アロケーションとは、スケジューリングの結果に基づいて、CDFGの演算節点に演算器を割り当て、データ選択のためのマルチプレクサと、データ記憶のためのレジスタとを生成すると共に、これらの演算器、レジスタ、およびマルチプレクサを制御するためのコントローラを生成し、それぞれを互いに接続することにより回路を合成することをいう。すなわち、アロケーションステップ(S223)では、CDFGの演算を表す各節点に対して、データの依存関係と与えられた制約とに基づき、制御ステップの割り当てが行われる。このときに、生成される論理回路において使用するMLUT数の見積もりを併せて行うことができる。
【0211】
アロケーションは、演算器部分と制御部分とに分離して実行することができる。以下、演算器部分と、制御部分とを順に説明する。
【0212】
演算器部分に含まれる回路には、3つの種類がある。第1の種類は、全加算器で構成することができるものである。これには、加算減算、乗算、カウンタ、比較演算などが含まれる。第2の種類は、マルチプレクサで構成することができるものである。これには、多ビットマルチプレクサ、及びバレルシフタなどが含まれる。第3の種類は、メモリ回路で構成することができるものである。これには、ルックアップテーブル、及びレジスタファイルなどが含まれる。いずれの種類の演算器においても、アロケーションするときには、ステップごとに、すなわちステートマシンのステートごとにレジスタ回路を挿入する。ここで、ステートマシンは、あらかじめ決められた複数の状態を、決められた条件に従って、決められた順番で遷移していくディジタル・デバイスである。ステートマシンのステートは、図56に示す「step 1」、又は「step 2」などのような、スケジューリングで規定される1つの制御ステップである。
【0213】
演算器部分のアロケーションは、演算器の種類とビット数とに基づいて実行する。ビット数は、C言語などの高級言語の型でビット数を決定することができる。これにより、C言語などの高級言語と互換性を有するCDFGを構成することができる。また、int、short、longなどの型ではビット幅が大きいと考えられる場合には、C言語の変数宣言の部分に拡張ディレクティブでビット数を規定しても良い。このように規定されるビット数に基づいて、それぞれの演算器に必要なMLUTの数を決定することができる。
【0214】
マルチプレクサで構成できる第1の種類の演算器では、ハードウェア量を優先するアロケーションと、速度を優先するアロケーションとのいずれかを選択して、アロケーションすることができる。例えば、多ビット加算器においては、ハードウェア量を優先するアロケーションでは、全加算器を多段に組み合わせることにより、多ビット加算器を構成できる。また、速度を優先するアロケーションでは、多段に組み合わせられる全加算器と、キャリー先読み論理回路とを有する多ビット加算器を構成することができる。
【0215】
5つ以上のAD対を有するMLUTにより構成されるMPLDにおいて、第1の種類の演算器を構成するMLUT数を見積もる場合は、2ビット加算器を1つのMLUTで構成することに基づいて、MLUT数を見積もることができる。例えば、4ビット加算器は、2つのビット加算器で構成されると見積もることができる。また、8ビット加算器は、4つのビット加算器で構成されると見積もることができる。この場合、各種の加算器に使用されるMLUT数の見積りは、容易になる。
【0216】
マルチプレクサで構成できる第2の種類の演算器は、ビット数に基づいてアロケーションすることができる。例えば、多ビットマルチプレクサでは、ビット数に応じたMLUTの数を記載したデータを記憶部214に有することにより、使用するMLUT数の見積りの簡易化が図れる。
【0217】
メモリ回路で構成できる第3の種類の演算器は、それぞれのMLUTをNビット×Nワードのメモリ回路と考えて、アロケーションすることができる。論理回路として動作するMPLDにおいて、一部のMLUTをメモリ回路として動作することが可能である場合には、MPLDの中で、第3の種類の演算器として動作するMLUTのみをメモリ回路として動作させることが可能になる。これにより、MPLD内部に論理回路とメモリ回路とを混載することができる。
【0218】
制御回路は、例えばC言語では、if文、case文、及び関数の呼び出し文などである。制御回路のアロケーションは、2入力NAND回路と、NOT回路とにより構成される回路により行うことができる。
【0219】
このように、演算回路と制御回路とを分離し、かつ演算回路を第1〜第3の種類に分離してアロケーションすることにより、それぞれの回路構成に適当なアロケーションを実行することができる。
【0220】
制御回路の見積りは、2入力NAND回路と、NOT回路とにより構成される回路を仮に論理合成し、その回路をテクノロジーマッピングすることによって行うことができる。例えば、if文は、2入力NAND回路と、NOT回路とを有する比較回路によって構成できる。
【0221】
〔5.3.5〕面分割
論理回路をアロケーションし、演算回路部分、及び制御回路部分のMLUT数の見積りをした結果、見積もられた論理回路が1つのMPLDに搭載できないと判断される場合がある。この場合には、論理回路を、1つのMPLDに搭載可能な複数の論理ブロックに面分割する必要が生じる。
【0222】
上述のように、MPLDは、再構成が可能な論理回路である。このため、論理回路を1つのMPLDに搭載できない場合には、論理回路を、1つのMPLDに搭載可能な複数の論理ブロックに分割し、分割した演算器ブロックごとに処理を順に実行することができる。本明細書では、演算器部分、及び制御部分などの論理回路を1つのMPLDに搭載できる大きさに分割することを「面分割」と称する。なお、面分割の説明に関して使用される用語「論理回路」は、アロケーションされたCDFGデータで示される論理回路であり、「論理ブロック」は、アロケーションされたCDFGデータで構成される論理回路を適当な大きさに分割したCDFGデータである。
【0223】
図57は、第1の論理ブロックと第2の論理ブロックとの2つの論理ブロックに面分割された論理回路を実行する1つの例を示す。本例では、MPLD20と演算処理部220とを搭載する半導体装置100と、記憶装置とによって、論理回路を実行することができる。また、MPLD20と演算処理部220とを搭載する半導体装置100にさらに記憶部26を搭載することによっても実行することができる。記憶装置、又は記憶部は、MPLD20の出力に接続され、第1の論理ブロックと第2の論理ブロックと、第1の論理ブロックの実行結果とを記憶する。
【0224】
ステップS231において、演算処理部は、MPLDに書き込まれた第1の論理ブロックを実行する。第1の論理ブロックは、1つ、又は複数のステートで構成することができる。ステップS232において、演算処理部は、ステップS231で実行された第1の論理ブロックの実行結果を記憶装置に記憶する。第1の論理ブロックの実行結果を記憶装置に記憶することにより、MPLDを第1の論理ブロックから第2の論理ブロックに再構成する間に、第1の論理ブロックの実行結果を保存して、第2の論理ブロックの入力として使用することができる。ステップS233において、演算処理部は、MPLDに書き込まれた第1の論理ブロックを第2の論理ブロックに再構成する。再構成するときに、MPLDの全てのMLUTを書き換えてもよく、第1及び第2の論理ブロックで使用されるMLUTのみを選択的に書き換えることもできる。また、一部のMLUTを書き換える部分再構成をしてもよい。ステップS234において、演算処理部は、ステップS232で記憶装置に記憶された第1の論理ブロックの実行結果を、第2の論理ブロックの入力信号として読み出す。ステップS235において、演算処理部は、ステップS234で読み出された第1の論理ブロックの実行結果を、第2の論理ブロックの入力信号としてMPLDの入力端子に入力して、第2の論理ブロックを実行する。
【0225】
本例では、論理回路は、2つの論理ブロックに面分割されるが、MPLDの大きさと、見積もった論理回路の大きさとの比較に基づいて、論理回路を適当な数の論理ブロックに面分割することができる。面分割は、図42に示す情報処理装置210が実行することができる。
【0226】
図58は、アロケーションのときに論理回路を面分割する1例を示す図である。図58を参照して、図42に示す情報処理装置210が、アロケーションのときに見積もった論理回路を、複数の論理ブロックに面分割するフローについて述べる。
【0227】
ステップS241において、情報処理装置210は、使用可能なMLUT数を決定する。情報処理装置210は、MPLDに搭載されるMLUTと、使用可能なMLUT数との関係を示すデータなどを記憶部に記憶することができる。このデータは、MPLDの配置・配線効率に基づき作成できる。使用可能なMLUT数は、このデータに基づいて決定することができる。ステップS242において、情報処理装置210は、ステートを搭載する面を生成する。ここで、面とは、CDFGのアロケーションにより、ステップごとのステートに分割された論理回路の1つ、又は複数のステートを搭載する論理ブロックをいう。ステップS243において、情報処理装置210は、ステートを面に搭載する。例えば、第1の面の最初のステップでは、アロケーションされた後の第1のステートを面に搭載し、第1のステートが搭載された後のステップでは、第2のステートを搭載する。ステップS244において、情報処理装置210は、面に搭載された全てのステートが使用するMLUT数を見積もる。見積りは、アロケーションされたそれぞれのステートのMLUT数を合計することにより行うことができる。
【0228】
ステップS245において、情報処理装置210は、さらにステートを面に搭載可能か否かを判定する。情報処理装置210は、面に搭載された全てのステートが使用するMLUT数の見積りと、MPLD20に搭載可能なMLUT数とに基づいて、さらにステートを面に搭載できるか否かを判定する。情報処理装置210が、さらにステートを面に搭載できると判断したときは、処理は、ステップS243に戻り、次のステートを面に搭載する。情報処理装置210が、さらにステートを面に搭載できないと判断したときは、処理は、ステップS246に進む。このとき、制御回路部のステートに関しては、情報処理装置210は、面に搭載するか、又は面に搭載せずにMPU命令コードとして生成するかを判断する必要がある。制御回路部のステートをMPU命令コードとして生成する場合は、情報処理装置210は、さらなるステートを面に搭載できないと判断し、そのステートは、面には搭載せずに、新たな面を生成する処理に移行する。また、情報処理装置210は、MPU命令コードとして生成するために、制御回路部のステートを記憶部に記憶する。
【0229】
ステップS246において、情報処理装置210は、未処理のステートの有無を判定する。未処理のステートがある場合は、処理は、ステップS243に戻り、ステートを搭載する面を新たに生成する。未処理のステートがない場合は、情報処理装置210は、処理を終了する。
【0230】
〔5.3.6〕MPU命令コードを生成するステップ
図53に示すMPU命令コードを生成するステップS224は、図58に示す面分割のときにステップS241において、MPU命令コードとして生成すると判断された制御回路部のステートから、MPU命令コードを生成するステップである。上述のように制御回路には、例えばC言語では、if文、case文、及び関数の呼び出し文などが含まれる。ステップS224では、情報処理装置210は、これらの関数を、演算処理部が読み出し可能な低級言語に変換する。
【0231】
ステップS224で生成されたMPU命令コードは、1つのMPLD20と、演算処理部220とともに半導体装置100に搭載される記憶部26に記憶することができる。また、半導体装置100とともに使用される記憶装置(図示せず)に記憶することもできる。
【0232】
〔5.3.7〕RTL−CDFGを生成するステップ
図53に示すRTL−CDFGを生成するステップS225は、CDFGをアロケーションするステップS223においてアロケーションされたCDFGからRTLレベルのCDFGを生成するステップである。CDFGをアロケーションするステップS223において、面分割がされた場合には、面分割された論理ブロックごとにRTLレベルのCDFGを生成する。
【0233】
ステップS225で生成されたRTL−CDFGは、図42及び図43を用いて説明した配置・配線フローにより、適当なビットストリームデータに変換することができる。面分割がされた場合には、面分割された論理ブロックごとにビットストリームデータを生成する。
【0234】
配置・配線された1つ、又は複数のビットストリームは、MPLDと、演算処理部とともに半導体装置に搭載される記憶部に記憶することができる。また、半導体装置とともに使用される記憶装置(図示せず)に記憶することもできる。面分割がされた場合には、演算処理部は、このビットストリームデータを使用して、複数の論理ブロックをMPLD上に再構成することができる。
【0235】
〔5.4〕1つのMPLDと演算処理部とを搭載した半導体装置での再構成
図51に記載される1つのMPLD20と演算処理部220とを搭載した半導体装置100においても、図41に記載される1つのMPLD20を搭載した半導体装置100と同様に、論理回路情報を再構成することができる。
【0236】
図59は、MLUTに論理回路情報などの情報を書き込む手順を示すフローチャートの一例である。ステップS247において、演算処理部220は、メモリ動作用アドレスMAにより、論理回路情報などの情報を書き込む記憶素子4を選択する。次いで、ステップ248において、演算処理部220は、記憶素子4に書き込むデータを出力する。ステップ249において、書き込む情報が他に存在するか否かを判定し、書き込む情報がある場合には、再度ステップS247に戻り、情報の書き込みを続ける。書き込む情報がない場合には、書き込み手順を終了する。情報の書き込みは、n×2n個の記憶素子の全ての記憶素子について行うことができ、またn×2n個の記憶素子の一部についてのみ行うことができる。
【0237】
上記のようにして、MPLD20の論理回路情報を再構成することができる。しかしながら、図51に記載される半導体装置100は、内部に演算処理部220を有するので、再構成に関する命令を演算処理部220が実行することができる。この場合には、図42に記載される情報処理装置210、又は半導体装置100が搭載される基板上のマイクロプロセッサを使用せずに、半導体装置100に搭載される演算処理部220が再構成を実行できる。このため、再構成のための情報処理装置210、又は基板上のマイクロプロセッサの入力部に半導体装置100を接続する必要がない。さらに、半導体装置100に搭載される演算処理部220がMPLD20に論理回路情報を書き込むため、高速動作が可能になる。したがって、図51に記載される半導体装置100では、高速かつ簡便な再構成が可能になる。
【0238】
〔5.5〕1つのMPLDと演算処理部とを搭載した半導体装置での部分再構成
図51に記載される1つのMPLD20と演算処理部とを搭載した半導体装置100においても、図41に記載される1つのMPLD20を搭載した半導体装置100と同様に、MPLD20の論理回路情報を部分再構成することができる。すなわち、図44を用いて説明したフローと同一のフローにより、MPLD20の論理回路情報を部分再構成することができる。しかしながら、図51に記載される半導体装置100は、内部に演算処理部220を有するので、上述の再構成の場合と同様に、情報処理装置210又は半導体装置100が搭載される基板上のマイクロプロセッサを使用せずに、半導体装置100に搭載される演算処理部220によって、部分再構成を実行することができる。
【0239】
〔6〕2つのMPLDと、演算処理部とを搭載した半導体装置
ここでは、2つのMPLDと、演算処理部とを搭載した半導体装置の例について説明する。
〔6.1〕2つのMPLDと、演算処理部とを搭載した半導体装置
図60は、MPLDを搭載した半導体装置の第1例における配置構造を示す図である。半導体装置100は、第1のMPLD20aと、第2のMPLD20bと、演算処理部220と、入出力回路部15とを有する。入出力回路部15、及び演算処理部220は、図41を参照して説明した例と同様であるため、ここでは説明を省略する。第1のMPLD20aと、第2のMPLD20bとは、それぞれ、別個に動作可能である。
【0240】
第1のMPLD20a、及び第2のMPLD20bと、演算処理部220との配線、及び入出力回路部15との配線については、図51及び図52などを用いて説明しているので、ここでは説明を省略する。
【0241】
第1のMPLD20aと、第2のMPLD20bとの間は、それぞれのMPLDを構成するMLUTが有するAD対で直接結線することができる。第1のMPLD20aと、第2のMPLD20bとをバス回路などを介さず直接接続することにより、2つのMPLD間の信号処理を高速化することができる。
【0242】
図61は、MPLDを搭載した半導体装置の第2例における配置構造を示す図である。図61を参照すると、本例における半導体装置100は、第1のMPLD20aと、第2のMPLD20bと、演算処理部220と、入出力回路部15と、記憶部26とを有する。
【0243】
記憶部26は、第1のMPLD20a、及び第2のMPLD20bにおいてそれぞれ実行される論理回路の実行結果を記憶するとともに、演算処理部220が実行するMPU命令コードを含むプログラムを格納する。半導体装置100に記憶部26を搭載することにより、以下に説明する動的再構成の処理が容易になる。記憶部26は、MPLDでの論理回路の実行結果を記憶するように、第1のMPLD20a、第2のMPLD20b、及び演算処理部220に結線される。
【0244】
図62は、半導体装置の配線層の一例を示す断面図である。半導体装置100は、MOSトランジスタなどの回路素子(図示せず)が形成される半導体基板160の上方に、配線層170を有する。配線層170は、それぞれの配線層に複数配置される配線を適当に接続することにより、回路基板上に形成される回路素子のそれぞれの端子(図示せず)を接続する。半導体装置100が有する回路素子のそれぞれの端子を適当に接続することにより、半導体装置100は、所望の動作を実現できる。
【0245】
配線層170は、第1の配線層172、第2の配線層174、第3の配線層176、及び第4の配線層178の4層の配線層を有する。半導体基板160、並びに第1〜第4の配線層172、174、176、及び178は、第1〜第4のビア接続部171、173、175、及び177を介して接続される。第1〜第4の配線層172、174、176、及び178、並びに第1〜第4のビア接続部171、173、175、及び177の層間は、斜線で示す絶縁層180が充填される。
【0246】
第1の配線層172は、図示されるように、断面において直線状となるように形成される。一部の第1の配線層172は、回路基板上に形成される回路素子の2つの端子間を接続するように、第1のビア接続部171を介して接続される。他の第1の配線層172は、回路基板上に形成される回路素子の端子と第1のビア接続部171を介して接続され、第2の配線層174と第2のビア接続部173を介して接続される。さらに他の第1の配線層172は、2つの異なる第2の配線層174間を接続するように、第2のビア接続部173を介して接続される。
【0247】
第2の配線層174は、回路素子が形成される半導体基板の表面を上方から見た場合に第1の配線層172と垂直を成す方向に略直線状となるように複数形成される。一部の第2の配線層174は、2つの異なる第1の配線層172間を接続するように、第2のビア接続部173を介して接続される。他の第2の配線層174は、第1の配線層172と第2のビア接続部173を介して接続され、第3の配線層176と第3のビア接続部175を介して接続される。さらに他の第2の配線層174は、2つの異なる第3の配線層176間を接続するように、第3のビア接続部175を介して接続される。
【0248】
第3の配線層176は、回路素子が形成される半導体基板の表面を上方から見た場合に第1の配線層172と平行になる方向に略直線状となるように複数形成される。一部の第3の配線層176は、2つの異なる第2の配線層174間を接続するように、第3のビア接続部175を介して接続される。他の第3の配線層176は、第2の配線層174と第3のビア接続部175を介して接続され、第4の配線層178と第4のビア接続部177を介して接続される。さらに他の第3の配線層176は、2つの異なる第4の配線層間を接続するように、第4のビア接続部177を介して接続される。一般的に第3の配線層176は、第1の配線層172、及び第2の配線層174と比較した場合に、大きな断面積を有するように形成される。
【0249】
第4の配線層178は、回路素子が形成される半導体基板の表面を上方から見た場合に第2の配線層174と平行になる方向に略直線状となるように複数形成される。第4の配線層178は、2つの異なる第3の配線層176間を接続するように、第4のビア接続部177を介して接続される。一般的に第4の配線層178は、第3の配線層176よりもさらに大きな断面積を有するように形成される。
【0250】
第1〜第4の配線層172、174、176、及び178は、アルミニウム、及びバリアメタルとして使用される銅などの導電性材料により形成される。第1〜第4のビア接続部171、173、175、及び177もまた、アルミニウムなどの導電性材料により形成される。絶縁層160は、二酸化ケイ素などの絶縁体材料により形成される。
【0251】
このように半導体装置においては、配線層は、半導体基板上に形成されるそれぞれの回路素子の端子間をそれぞれ接続するために形成される。システムオンチップ(以下、SOCと称する)と称される半導体装置では、半導体基板上に、演算処理部、記憶部、アナログ‐デジタル変換部、オペアンプなどのアナログ回路部、論理回路部などのデジタル回路部、及び入出力回路部などが搭載される。演算処理部が、高機能な処理を要求されない場合、例えば8ビット、16ビットなどの演算処理を行う演算処理部などの場合には、演算処理部は、一般に4層程度の配線層により、形成することができる。また、記憶部などのSOCに搭載される他の構成要素も一般に4層以下の配線層により、形成される。
【0252】
上述のように、MPLDは、CMOSトランジスタを有するSRAMと、CMOSトランジスタにより構成することができる論理回路とを有する。このため、MPLDは、SRAMなどのメモリ回路技術と、CMOS回路技術とを用いることで製造することができる。これらの技術は、一般的には半導体装置の集積度を考慮しても、3層、又は4層程度の配線層で形成することができる。また、MPLDは、MPLDをスイッチング機能として使用することができるので、FPGAのように接続チャネル領域を設ける必要が無い。このため、MPLDは、一般的なCMOS回路技術で製造される他の構成要素と同程度の集積度が期待できる。したがって、MPLDもまた、3層、又は4層程度の配線層で形成することができる。
【0253】
このように、MPLDの配線層は、SOCに搭載される他の構成要素と同様に、4層以下の配線層により、形成することができる。これは、半導体装置の製造面を考慮すると、MPLDがSOCと親和性を有することを意味する。すなわち、MPLDは、SOC半導体装置に搭載しやすいことを意味する。FPGAなどの他の再構成可能な論理回路は、一般的に、集積度を考慮すると8層から10層程度の多層の配線層を有する構造になる。このため、SOC回路部を多層配線する必要がない場合でも、FPGAなどの再構成可能な論理回路が多層配線を必要とするため、半導体装置が多層配線構造となる。これに対し、MPLDは、上述のように、3層、又は4層程度の配線層構造にすることができる。このため、SOC回路部の配線層構造に基づいて、半導体装置の配線層構造を決定することができる。例えば、半導体装置100は、物理的な配線層数が4層以下である。
【0254】
〔6.2〕2つのMPLDと、演算処理部とを搭載した半導体装置での動的再構成
〔6.2.1〕MPLDの動的再構成フロー
ここでは、半導体装置に搭載されるMPLDを動的再構成するフローの1つの例について説明する。
【0255】
図63は、図61に示す半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。ステップS251において、演算処理部220は、第1のMPLD20a、又は第2のMPLD20bの何れか一方、又は双方のMPLDに論理回路情報を書き込む。ここで書き込まれる論理回路情報は、一般的には、図42及び39を用いて説明されたビットストリームデータである。ビットストリームデータは、半導体装置に搭載される記憶部に記憶してもよく、半導体装置と接続される記憶装置に記憶してもよい。第1及び第2のMPLDの双方に論理回路情報を書き込む場合には、最初のサイクルでは、ステップS253は省略される。
【0256】
ステップS252において、演算処理部は、ステップS251で論理回路情報が書き込まれた一方のMPLDの論理回路情報を動作させる。演算処理部は、一方のMPLDに書き込まれた論理回路情報の動作結果を半導体装置に搭載される記憶部などの記憶手段に記憶する。これにより、記憶された動作結果を他方のMPLDの入力に使用できる。また、2つのMPLDのAD対が接続される場合には、動作が終了した後も一方のMPLDが動作結果を保持し、演算処理部からの指令により、その動作結果を他方のMPLDに入力信号として与えることができる。論理動作が終了したときに、演算処理部は、このMPLDから論理動作が終了したことを示すフラグを受信する。
【0257】
ステップS253において、演算処理部は、論理動作をしない他方のMPLDに論理回路情報を書き込む。書き込みが終了したときに、演算処理部は、このMPLDから書き込みが終了したことを示すフラグを受信する。上述のように、最初のサイクルでは、MPLDを論理動作させる前に、双方のMPLDに同時に論理回路情報を書き込むことができる。この場合も演算処理部は、書き込み終了時に書き込みが終了したことを示すフラグを受信する。
【0258】
ステップS254において、演算処理部は、一方のMPLDの論理動作が終了したことを示すフラグと、他方のMPLDの書き込みが終了したことを示すフラグを受信すると、書き込みが終了した他方のMPLDの論理動作を開始する。ステップS254で他方のMPLDの論理動作が開始されたのちに、ステップS255において、演算処理部は、他に書き込む論理回路情報があるか否かを判定する。他に書き込む論理回路情報がある場合には、処理は、ステップS253に戻る。そして、論理動作をしていないMPLDに論理回路情報への書き込みを開始する。他に書き込む論理回路情報がない場合には、演算処理部は、MPLDから論理動作が終了したことを示すフラグを受信した後に処理を終了する。
【0259】
ここで説明する動的再構成は、図53を用いて説明したMPU命令コードと、面分割されたRTL−CDFGから生成される複数のビットストリームとを用いて実現することができる。演算処理部は、演算処理部指令コードに従ってMPLDの再構成、論理動作開始指令、又はMPLDに搭載されなかった制御回路を実行する。また、MPLDの論理回路情報であるビットストリームデータは、面分割されたRTL−CDFGから生成されるビットストリームにすることができる。これにより、動作記述で記載されたデータ処理動作が、ハードウェアである半導体装置に搭載される演算処理部とMPLDとにより実現されることになる。このため、ソフトウェアである動作記述により演算処理部を動作させるよりも高速な動作が可能になる。
【0260】
〔6.2.2〕動的再構成の実施例
ここでは、動的再構成の利点を具体的な実施例に基づいて説明する。実施例は、共通鍵暗号方式の1つであるDES(Data Encryption Standard:データ暗号化標準)の暗号化に関するものである。ここでは、DESの暗号化計算について概略的に述べたのちに、本例における半導体装置によるDES計算の実行方法について説明する。
【0261】
〔6.2.2.1〕DESのアルゴリズム
図64は、DESの計算アルゴリズムのフローの一例を示す図である。DESは、固定ビット(例えば、64ビット)長の平文を入力とする。DESは56bit長の暗号化鍵を使い64bitの平文ブロックごとに暗号化するブロック暗号である。暗号化鍵は、64ビットだが、そのうち8ビットはパリティチェックに使うため、アルゴリズム上の実際の鍵の長さは56ビットである。DESの暗号化鍵は、共通鍵暗号方式であり、暗号化と復号に同一の鍵を用いる。また、DESでは、F(Feistel)関数という、置換と転置を行うラウンド関数を用いて、F関数を用いて繰り返し暗号化または復号化を行う暗号方式である。ステップS261において、初期転置を行う。初期転置は、ビット間の所定の転置を実行するものである。例えば、初期転置後の1ビット目のデータは、入力データの58ビット目のデータであり、初期転置後の2ビット目のデータは、入力データの50ビット目のデータである。このように、初期転置により、64ビットのそれぞれのデータの並び替えが行われる。
【0262】
ステップS262において、初期転置後の下位32ビットをF関数により処理する。F関数の処理は、図65に示すフローにより説明する。
【0263】
図65は、F関数のアルゴリズムのフローを示す図である。F関数には、初期転置処理がされたデータの下位32ビットが入力される。ステップS271において、入力された32ビットのデータは、拡張順列(expansion permutation)され、48ビットのデータが生成される。次いでステップS272において、拡張順列された48ビットのデータと、48ビットの巡回鍵との間で排他的論理和の処理がされる。
【0264】
ここで、巡回鍵について説明する。巡回鍵は、共通鍵を一定のアルゴリズムにより変換したものであり、1回のDES暗号化で16回行われるF関数処理ごとに異なる鍵になる。巡回鍵への変換アルゴリズムには、転置処理と、巡回シフト処理とが含まれる。
【0265】
Sボックス(substitution box)とは、mビットの入力をnビット出力に変換する関数であり、2mのルックアップテーブルである。ステップS273において、ステップS272で巡回鍵との間で排他的論理和の処理がされた48ビットのデータは、8個のSボックスによる変換により、6ビットのデータを4ビットのデータに変換する処理がされる。この結果、Sボックスにより処理される前は48ビットであったデータが、Sボックスの処理によって32ビットのデータに変換される。
【0266】
Sボックスは、S1〜S8のそれぞれ所定の値を有する真理値表により構成される。S1は、下位6ビットのデータを変換するSボックスであり、S2は、下位7ビットから12ビット目のデータを変換するSボックスである。以下同様に、S7は、36ビット目から42ビット目までのデータを変換するSボックスであり、S8は、43ビット目から48ビット目までのデータを変換するSボックスとなる。それぞれのSボックスは2行×4列の行列に対して、それぞれ4ビットずつのデータが割り当てられる。Sボックスの2ビットの行は、6ビットの入力データのMSB(最上位ビット、すわなち6ビット目)のデータと、LSB(最下位ビット、すわなち1ビット目)のデータにより構成される。Sボックスの4ビットの列は、6ビットの入力のMSBとLSBとを除いた中間の4ビット(2ビット目から5ビット目)のデータにより構成される。6ビットの入力データを、このような構成を有するSボックスに入力し、該当する真理値表の4ビットの値を出力することにより、6ビットの入力データを4ビットの出力データに変換することができる。表1にSボックスの例として、S1のSボックスを示す。
【0267】
【表1】

【0268】
S1では、例えば、6ビットの入力(100110)が与えられた場合、行は、MSBとLSBとにより(10)となり、列は、MSBとLSBとを除いた4ビットから(0011)となる。したがって、4ビットの出力データは、(1000)になる。
【0269】
ステップS274において、Sボックスによる変換が8回終了したか否かを判定する。Sボックスの処理が全て終了していない場合は、次のSボックスの処理を行う。また、Sボックスの処理が全て終了している場合は、処理は、ステップS275に進む。ステップS275において、S1〜S8の8個のSボックスで処理された4ビットのデータを全て並べて32ビットのデータを生成する。
【0270】
図64に示すステップS263において、Sボックスの処理により生成された32ビットのデータは、上位32ビットのデータとの間で排他的論理和の処理がされる。ステップS264において、64ビットの入力データの下位32ビットのデータを上位32ビットのデータとする。そして、ステップS263により生成される32ビットのデータを下位32ビットのデータとする。
【0271】
ステップS265において、F関数の処理を含む一連の処理が16回行われたか否かを判定する。処理が16回行われていない場合は、さらにF関数の処理からの一連の処理が行われる。このとき、巡回鍵は、処理ごとに異なる鍵になる。処理が16回行われた場合は、ステップS266において、64ビットのデータは、逆転置されて暗号化処理が完了する。
【0272】
〔6.2.2.2〕本例における半導体装置によるDES計算例
ここで、2つのMPLDと、演算処理部とを搭載した半導体装置によるDESアルゴリズムの計算例について、図64などを参照しながら説明する。MPLDを構成するMLUTは7個のAD対を有することとする。
【0273】
図64に示されるステップS261の初期転置と、ステップS266の逆転置とは1つのMLUTをメモリ回路として動作させて、転置先のビットを記憶させることができる。この処理は、MPLD内部の一部のMLUTのみをメモリ回路として動作させることが可能な場合に実現できる。MPLD内部の一部のMLUTのみをメモリ回路として動作させることができない場合は、外部の記憶装置、又は半導体装置に搭載される記憶部に転置先のビットを記憶させることができる。
【0274】
図64に示されるステップS263、及び図64に示されるステップS272における32ビット及び48ビットの排他的論理和の計算は、MPLDが計算する。MPLDは、多入力他出力の演算に適するからである。
【0275】
ステップS273のSボックスの処理を8回行う処理は、2つのMPLDを動的に再構成することにより、実現できる。例えば、1つのMLUTを真理値表として使用する。Sボックスの処理は6ビット入力に対して4ビット出力をするものであるので、7個のAD対を有するMLUTを使用する場合、6個のAD対の論理制御用アドレス線を6ビットの入力とし、4個のAD対の論理制御用データ線を4ビットの出力線とすることにより、Sボックスの真理値表を実現できる。そして、一方のMPLDでS1のSボックスの演算処理を行う間に、他方のMPLDにS2のSボックスの演算情報を書き込む。また、他方のMPLDでS2のSボックスの演算処理を行う間に、一方のMPLDにS3のSボックスの演算情報を書き込むなどして、動的に再構成しながらSボックスの演算処理を進めることができる。これにより、動的再構成を用いない場合と比較して、同一の演算処理を実現するための回路規模を大幅に少なくすることができる。
【0276】
ステップS272において使用される巡回鍵を生成するときにもMPLDを動的再構成して使用することができる。上述のように巡回鍵は、共通鍵に転置処理とシフト処理とを加えることにより生成され、F関数の動作ごとに異なる巡回鍵を使用する。そこで、2つのMPLDを動的再構成しながら使用することにより、一方のMPLDで巡回鍵を使用する演算処理を行う間に、他方のMPLDで次のサイクルで使用する巡回鍵を生成し、書き込む処理を行うことができる
【0277】
ここでは、2つのMPLDと、演算処理部とを搭載した半導体装置で実現される動的再構成について説明してきたが、1つのMPLDと、演算処理部とを搭載した半導体装置でも動的再構成を実現することができる。
【0278】
1つには、図19を用いて説明したMLUTを使用してMPLDを構成する場合には、動的再構成が可能になる。この型のMLUTは、セレクト信号により選択される2つの記憶素子群を有する。一方の記憶素子群で演算処理を行う間に他方の記憶素子群の論理回路情報を再構成することにより、動的再構成を実現することができる。
【0279】
また、物理的な構成では1つであるMPLDを、論理動作上は2つのMPLDであるとして扱うことにより、動的再構成が可能になる。例えば、1つのMPLDの半分の領域の第1のMPLD部として扱い、残りの半分の領域を第2のMPLD部として扱うことにより、物理的な構成では1つであるMPLDを、論理動作上は2つのMPLDであるとして扱うことができる。
【0280】
〔7〕動的再構成に適する半導体装置
【0281】
プログラマブルロジックデバイス(PLD)の動的再構成が知られている。動的再構成とは、PLD稼働中に、PLDの回路構成を切り替える技術である。動的再構成は、複数の小規模回路を、プログラムに従って短時間に頻繁に結線し直すことで、小規模回路で大規模回路の機能を実現することができる。
【0282】
PLDは、ハードウェアによる物理的な結線で命令を実行するワイヤードロジックを、ALU(Arithmetic Logical Unit)やLUT(Look up Table)で実現する回路である。ワイヤードロジックは、CISCプロセッサの演算対象であるマイクロコードによる処理の複数のステップを、1つの組み合わせ論理回路に展開して実現することができる。CISCプロセッサでは、1つの処理を実行するのに、複数のクロックが必要になるが、ワイヤードロジックでは、1つのクロックで実現することができ、データの流れを止めずに処理を高速に行うので、クロックあたりの処理能力が、CISCプロセッサと比して高い。そのため、ワイヤードロジックの回路構成は、複数の回路機能とともに、一連のデータの流れをも実現するため、「データパス」と呼ばれる。
【0283】
動的再構成可能なPLDは、機能ごとに固定された専用回路を切り替えるのではなく、小規模回路の再配置を行って専用回路を構成し、複数の小規模回路が協調してパイプライン処理を行う。なお、ここでいう「パイプライン」とは、連続動作処理を意味する。
【0284】
一般に、動的再構成可能なPLDは、ALUベース、又はLUTベースである。ALUは、加算器、シフタ、乗算器等を含む演算器セットであり、1つのALUで複数の機能を実現することができる。ALUベースの動的再構成可能なPLDは、ALUの機能を選択することで、動的再構成する。LUTは、複数のメモリセルからなるメモリセルユニットであるため、LUTベースの動的再構成可能なPLDは、再構成を行うとき、メモリセルユニットの書き換えが必要になる。また、LUTベースの動的再構成可能なPLDは、メモリセルユニット間の接続に、専用の切り替え回路を有しているので、動的再構成には、切り替え回路の再設定も必要になる。
【0285】
以下に示すプログラマブル論理部としてのMPLDを含む半導体装置は、少なくとも2つのMPLDを有し、MPLDの構成情報を保持するキャッシュ部と、キャッシュ部に保持された構成情報をMPLDに出力する構成制御部とを備える。構成制御部は、MPLDの1つが、分岐論理を構成する構成情報で再構成されている場合、前記分岐論理の実行前に、前記分岐論理の分岐先回路を構成する前記第2の構成情報で、前記複数のプログラマブル論理部のうちの第2のプログラマブル論理部を投機的に再構成する。このように、投機的にMPLDを再構成することで、分岐確定後にMPLDを再構成する必要が無いので、再構成時間を短縮化することができる。
【0286】
以下、〔7.1〕半導体装置、〔7.2〕MPLDの構成例、〔7.3〕半導体装置の動作フローの詳細例について順に説明する。なお、MPLD及びMLUTは、〔1〕、及び〔2〕においてそれぞれ説明したものが適用可能である。
【0287】
〔7.1〕半導体装置
図66は、半導体装置の一例を示すブロック図である。
図66に示す半導体装置100は、構成可能論理部としてのMPLD20A及び20B、変数保持部25、構成制御部300、キャッシュ部400A及び400Bを有する。半導体装置100は、演算処理部としてのMPU(Micro Processing Unit)220と接続し、及びメモリコントローラ550を介して、記憶部としてのメインメモリ500と接続する。半導体装置100は、MPU220、及び/又は、メモリコントローラ550及びメインメモリ500と一体化したIC(Integrated Circuit)チップとしてもよい。
【0288】
〔7.1.1〕MPLD
プログラマブル論理部としてのMPLD20A及び20Bは、複数のメモリセルユニットであるMLUT(Multi Look−Up−Table)を各々が有する。MLUTのメモリセルユニットは、SRAM(Static Random Access Memory)で構成してもよい。MLUTは、論理要素、又は、複数の論理要素間を接続する接続要素として機能する。
【0289】
MPLD20A及び20Bは、構成情報を書き込むことによって、再構成される。構成情報は、MPLD20A又は20Bを部分的に再構成するために、複数のMLUTを構成単位とする再構成単位毎に生成される。構成情報によって再構成単位毎に再構成される複数のMLUTを、以下「バンク」と言い、再構成単位を、以下「バンク単位」と言う。MPLD20A及び20Bは、データ信号を外部から受け取ると、構成情報で再構成された回路によって演算を行い、演算結果であるデータ信号を外部に出力する。なお、構成情報は、様々な演算器の真理値表から構成される演算器データ、及び、複数のステート、ステート変化のきっかけとなるイベント、これによって生じるステートの遷移を表す制御データから構成される。
【0290】
演算器データは、インバータ、AND演算、OR演算等の演算名称と各々が対応付けられる複数の真理値表データである。
【0291】
制御データは、演算器の種類と、演算器が割り当てられる複数のMLUT間のデータパスとを、ステート状態の遷移とともに規定した真理値表データである。制御データには、ステート識別情報、演算器、演算器の配置配線情報、ステートマシン(図67を用いて後述)を構成する真理値表データ、演算器の真理値表データを書き込むMLUTの識別情報、演算器リソースの配置配線情報を含む。
【0292】
〔7.1.2〕構成制御部
構成制御部300は、キャッシュ部400Aから構成情報(演算器データと制御データ)を読み出して、MPLD20A又は20Bに書き込む。また、キャッシュ部400Aに、書き込み対象となる構成情報(ここでは、制御データ)が無い場合、メモリコントローラにメモリアクセス命令を供給して、メインメモリ500に記憶される構成情報(制御データ)を読み出す。
【0293】
MPLD20A及び20Bの何れかが再構成された回路によって演算動作を行っているとき、演算動作を行っていないMPLDは、構成制御部300によって再構成される。なお、どの演算器データ及び制御データを、MPLDに書き込むかについては、後述するスケジュール情報でスケジュールされている。したがって、構成制御部300は、スケジュール情報を参照することで、スケジュールされたバンク単位の構成情報を、MPLDに書き込む。
【0294】
上記のように、構成制御部300は、構成情報で、MPLD20A又は20Bを再構成し、演算動作を実行するMPLDと、再構成するMPLDとを、スケジュール情報にしたがって適宜切り替て、連続的な演算動作を可能にする。
【0295】
〔7.1.3〕キャッシュ部
図66に示されるように、キャッシュ部400A及び400Bは、それぞれが異なるキャッシュメモリで構成される。キャッシュ部400A及び400Bは、それぞれ独立してデータの読み出し又は書き込み可能なキャッシュメモリであり、例えば、SRAMである。そのため、図66には図示しないが、キャッシュ部400A及び400Bは、データを保持するメモリセルアレイと、メモリセルアレイからデータを読み出し又は書き込むための行アドレスデコーダ、列アドレスデコーダ、及びアンプ等の周辺回路をそれぞれ備える。
【0296】
キャッシュ部400Aは、構成情報のうち演算器データを保持し、キャッシュ部400Bは、構成情報のうち制御データを保持する。演算器データは、半導体装置100の初期動作時に、メインメモリ500から読み出されて、キャッシュ部400Aに書き込まれる。演算器データは、MPLD30A又は30Bの再構成に際して、メインメモリ500から読み出されずに、キャッシュ部400Aから読み出される。メインメモリ500は、DRAM(Dynamic Random Access Memory)で構成されているため、データの読み出し速度が遅い。また、制御データは、データの遷移に係るMLUTの出力メモリセルを特定するのに対して、演算器データは、MLUTに書き込む真理値表データの大部分を構成するので、制御データよりもデータ量が大きい。そのため、MPLD20A又は20Bの再構成時には、メインメモリアクセス無しで、キャッシュ部400Aから、制御データ910よりもデータ量の大きい演算器データを読み出すことができるので、演算器データをキャッシュ部400Aに保持することで、MPLD20A又は20Bの再構成時間を短縮することができる。
【0297】
また、演算器データと制御データとを、MPLD20A又は20Bの再構成に合わせて同じデータではなく別個のデータとして、キャッシュ部400A及び400Bに別々に格納するので、制御データのキャッシュ部へのデータ書き込みとともに、演算器データをメインメモリ500から書き込む動作も不要となり、MPLD30A又は30Bの再構成時間を短縮することができる。
【0298】
さらに、キャッシュ部400Aは、半導体装置100の初期動作時に、演算器データ905が書き込まれ、その後は、読み出し動作となる。したがって、書き込みと読み出しを同時に実行する必要がないので、演算器データ905を保持するキャッシュ部400Aを構成するメモリは、ダブルポートではなくシングルポートのSRAMとすることができる。
〔7.1.4〕構成情報の詳細
上記のように、キャッシュ部400A及び400Bは、それぞれ、演算器データと、制御データとで構成される別個のキャッシュメモリである。以下に、演算器データと、制御データとの詳細例を説明する。
【0299】
演算器データは、以下のデータ構造を有する。
A.演算器データのデータ構造
ヘッダ部
演算器ID
演算器LUT数
データ部
演算器MLUT情報(圧縮データ)
【0300】
上記のように、演算器データは、ヘッダ部に、演算器を識別する「演算器ID」と、演算器を実装するのに必要なMLUTの数である「演算器MLUT数」とで定義される。また、データ部には、演算器に必要な演算器MLUT情報が、圧縮データで定義される。
【0301】
制御データは、以下のデータ構造を有する。
B.制御データのデータ構造
バンク番号:
演算器配置情報
演算器ID
行数情報
1行目のrow,col
2行目のrow,col
...
制御回路情報
ヘッダ部
制御回路LUT数
制御回路開始のrow, col
データ部
制御回路MLUT情報(圧縮データ)
【0302】
上記のように、制御データは、再構成するMLUTである「バンク」を識別する「バンク番号」と、そのバンクに配置する演算器IDと、演算器を「バンク」に配置するための演算器ID毎の行数情報を有する。さらに、制御データは、制御回路を構成するMLUTの数と、「バンク」において制御回路を開始する行列を「制御回路開始のrow, col」として規定する。また、制御回路に必要なMLUT情報が、圧縮データで定義される。
【0303】
構成制御部300は、制御データ内に含まれる演算器IDを参照して、対応する演算器データを読み出して、制御データの「行数情報」の行数に、対応する演算器データの演算器MLUT情報を書き込む。また、構成制御部300は、制御データ内に含まれる制御回路情報を参照して、「制御回路開始のrow, col」に、制御回路MLUT情報を書き込む。このようにして、構成制御部300は、バンク毎に「演算器MLUT情報」及び「制御回路MLUT情報」を書き込んで、MPLD20A又は20Bを再構成する。
【0304】
〔7.1.5〕メインメモリ
メインメモリ500は、構成情報としての演算器データ905、及び制御データ910−1〜910−N(Nは自然数)、プロファイル情報970、静的スケジュール情報975、プログラム980、及びコンパイルプログラム990を格納する。メインメモリ500は、DRAMである。メモリコントローラ550は、メインメモリ500のデータの読み出し、書き出し、DRAMのリフレッシュなどを行なう。
【0305】
図67は、メインメモリのメモリマップの一例を示す図である。
プログラム980は、MPLD20A及び20B、又は、MPU220に所定の処理を実行させるためのプログラムであり、C言語等のプログラム言語にコーディングされたプログラムである。MPU220は、コンパイルプログラム990を実行することで、プログラム980は、MPLD20A及び20Bの大きさの回路データに分割し、分割された複数の回路データのそれぞれから、演算器データ905及び制御データ910−1〜910−Nを生成する。
【0306】
〔1.6〕プロファイル情報
プロファイル情報970−1〜970−N(Nは自然数)は、演算器間の依存、依存データ更新、データフロー、データのライフタイム等のプロファイル(又は履歴)を分析したデータであり、コンパイル処理により、「バンク」毎に「投機的実行の優先」順位が判断されて、生成される。
【0307】
プロファイル情報は、メインメモリ500からキャッシュ部400A及び400Bへの構成情報のロードと、キャッシュ部400A及び400BとMPLD20A及び20B間のロードを、スケジュールするとともに、それらのロードを並列に実行するようにスケジュールされる。
【0308】
例えば、プロファイル情報は、制御データ910−1でMPLD20Aを再構成し、次に、制御データ910−2でMPLD20Bを再構成するというように、制御データ間の再構成順序を規定する。また、プロファイル情報は、制御データ910が分岐回路を規定している場合、分岐回路の実施により、どの制御データが実施されるべきかをスケジューリングする。
【0309】
プロファイル情報970−1〜970−Nは、構成制御部300(より詳細には、後述するスケジューラ)によって使用される。プロファイル情報のデータ構造は、以下の通りである。
【0310】
C.プロファイル情報のデータ構造
ヘッダ部
タイプ:静的か動的
個数 :動的分岐数、タイプが静的の場合は、0を設定
データ部
値 :スケジューラがチェック(エンコードされた値)
優先 :投機的実行の優先
バンク番号:実行バンク番号
【0311】
ヘッダ部の「タイプ」が「静的」である場合、プロファイル情報は、静的スケジュール情報975とも呼ばれる。静的スケジュール情報975は、システムリセット時のプロファイル情報と動作合成から生成される情報である。システムリスタート時に、構成制御部(スケジューラ)300、静的スケジュール情報としてのプロファイル情報を読み込むと、この情報を、構成制御部300で保持して、MPLDの投機的な再構成を行う。
【0312】
ヘッダ部の「動的分岐数」は、動的に分岐したときの分岐対象の「バンク」の個数を示す。データ部の「値」とは、条件分岐の値である。データ部の「優先」とは、投機的実行を優先して行う面を意味する。バンク番号とは、プロファイル情報に対応づけられるバンクの番号である。構成制御部(スケジューラ)300は、図69で後述するMPLDの一部に構成されるステートマシンが、構成制御部(スケジューラ)300によって予測した条件分岐の「値」と、MPLDによって実際に実行された条件分岐の「値」とが一致するか否かを判断する。ステートマシンが、判断結果を、構成制御部(スケジューラ)300に出力することで、構成制御部(スケジューラ)300は投機的実行の分岐失敗をチェックできる。
【0313】
構成制御部(スケジューラ)300は次の面を投機ロードする際、読み込んだプロファイル情報の「タイプ」が「静的」ならデータ部の値をチェックし、当該バンクをロードする。読み込んだプロファイル情報の「タイプ」が動的なら、データ部の「優先」の高い「バンク」をロードする。投機ロードの「バンク」が、再構成中のバンクとなった場合、そのバンクが動的分岐を生ずるバンクか否かを、データ部の「優先」値でチェックし、当該バンクが妥当かあるいは別のバンクをロードすべきか判断し、妥当なバンクを、メインメモリ500又は、キャッシュ部400A及び400Bからロードし実行する。このように、構成制御部(スケジューラ)300は、プロファイル情報の「優先」により、MPLDを投機的に再構成するように動作する。
【0314】
変数保持部25は、MPLD20A及び20B間を跨るライフタイムの長い変数を保持する記憶部である。変数保持部25が、ライフタイムの長い変数(例えば、グローバル変数等)を保持することで、MPLD20A及び20Bが変数を保持するMLUTを再構成する必要がなくなり、MLUTの有効活用が可能になる。
【0315】
図68は、構成制御部の詳細ブロック図である。構成制御部300は、キャッシュ制御310、システムリセット320、圧縮データ解凍330、スケジューラ340で示される機能を有する。これらの機能は、構成制御部300内部の回路や、構成制御部300がプログラムを実行することで実現される。以下、各機能について説明する。
【0316】
キャッシュ制御310は、構成制御部300によるキャッシュ部400A及び400B、メインメモリ500、MPLD20A及び20Bへのデータの入出力を行う機能である。
【0317】
システムリセット320は、構成制御部300が外部からシステムリセット(SR)信号を受け取ると、キャッシュ制御310に、初期動作を実行するように指示する機能である。初期動作とは、メインメモリ500からの演算器データ905及び制御データ910を読み出して、MPLD20A及び20Bへの書き込み、静的スケジュール情報975に従う演算器データ905及び制御データ910の読み出しである。
【0318】
圧縮データ解凍330は、キャッシュ部400A及び400Bに、演算器データ905及び制御データ910のMLUT情報は、圧縮されているので、圧縮された演算器データ905及び制御データ910のMLUT情報を解凍して、MPLD20A又は20Bに出力する機能である。
【0319】
演算器データ905及び制御データ910のMLUT情報は、コンパイルプログラム990により圧縮された形でメインメモリ500に記憶されうる。これは、メインメモリ500とキャッシュ部400A及び400Bとの間のデータ量の削減と、キャッシュ部400A及び400Bにおいて演算器データ905及び制御データ910を保持する記憶領域を削減するためである。
【0320】
MPLD20A及び20Bは、ALMマトリクス型のPLDと比べて、再構成するデータ量が多い。メインメモリ500をDRAMで構成した場合、メインメモリ500とキャッシュ部400A及び400Bとの間のデータ転送速度が、再構成時間の制約となりうる。そのため、構成情報である演算器データ905及び制御データ910のMLUT情報を圧縮してメインメモリに記憶し、キャッシュ部400A及び400Bに送信することで、MPLDによる再構成時間を短縮化することができる。また、MPLD20A及び20Bの構成情報の多くは演算器データ905である。演算器データ905を、キャッシュ部400Aに保持することでMPLDの再構成時間を短縮化できることはすでに述べたが、演算器データ905を圧縮してキャッシュ部400Aに保持することで、メインメモリ500と比して記憶容量の小さいキャッシュ部400Aで演算器データ905を保持可能になる。
【0321】
また、従来、プロセッサの技術分野において、データ圧縮とは、命令の圧縮には使用されていない。MLUT情報は、真理値表データで全て構成可能であるため、プログラム上の命令を演算器データに変換すると、データ圧縮が可能になる。
【0322】
圧縮及び解凍には、様々な技術が適用可能である。適用可能な圧縮及び解凍技術として、例えば、LZSSである。
【0323】
スケジューラ340は、プロファイル情報を順番に読み出して、MPLDを再構成するバンクの優先順位を判断し、MPLDに書き込む構成情報の順位を判断する。スケジューラ340は、プロファイル情報に規定される優先順位に従って、メインメモリ500から構成情報(制御データ)を読み出して、または、キャッシュ部400A及び400Bから構成情報(演算器データ及び制御データ)を読み出して、MPLDを再構成する。スケジューラ340は、プロファイル情報に従ってMPLDを再構成した結果、ステートマシンから投機実行の失敗出力を受けた場合、正しい分岐先となる制御データをキャッシュ部400A及び400B、又は、メインメモリ500から読み出す。なお、このように投機実行が失敗した場合であっても、読み出す制御データの真理値表データは圧縮されており、また、演算器データはキャッシュ部400Aに保持されているため、分岐先の制御データを読み出す時間を短くすることができるため、投機実行失敗時の再構成時間による遅延を短くすることができる。
【0324】
なお、ステートマシンは、MPLD上で構成情報により実現される。ステートマシーンは、少なくとも2つの機能を有する。1つは、MPU220のバス等のバスの制御や、図68には図示されていないが通信部から送信される通信パケット処理等の制御回路として動作するステートマシーンである。もう1つは、演算手順のデータフローの順番を制御する制御回路を動作させるステートマシーンである。なお、ステートマシーンは、静的スケジュール情報975により、システムリスタート時にMPLDに構成される。
【0325】
〔7.2〕MPLDの構成例
図69は、MPLDで構成されるデータパスブロック及びステートマシンの一例を示す図である。データパスブロック902は、演算器データ905に示される演算器が、MPLD20A又は20B内のMLUTに割り当てられることで実現される回路ブロックと、そのデータパスを示す。ステートは、各MPLDに構成可能なバンク単位の回路構成を識別する。ステートは、コンパイルプログラム990をMPU220が実行した際に、MPLD20A及び20Bの粒度に合わせて生成される。各ステートは、静的スケジュール情報975により順番付けされている。例えば、また、ステート1〜4は、MPLD20Aのバンク単位の記憶領域をそれぞれ特定する。また、ステート1は、MPLD20Aを構成し、ステート2は、MPLD20Bを構成し、ステート3は、MPLD20Aを構成し、ステート4は、MPLD20Bを構成するように、複数のMPLDを時系列毎に特定してもよい。このようにしてステート1からステート4へとMPLDの再構成が繰り替えられることで、段数の多いパイプラインを、小規模のMPLDで処理することが可能になる。
【0326】
ステートマシン915は、ステートの起動開始と、ステートのステータスを管理する。ステートマシン915は、データパス駆動信号をデータパスブロックに出力することで、ステートを起動し、ステータス信号を受け取ることで、ステートを管理する。
【0327】
S0ステートは外部からの実行トリガの監視と本処理の最後に本ステートに戻ることで、次に実行する制御データを設定する。これによりスケジューラ940は投機的実行の分岐失敗をチェックできる。
【0328】
〔7.3〕半導体装置の動作処理フロー
次に、半導体装置の動作処理フローについて説明する。
【0329】
図70は、半導体装置の投機実行に関する処理フローの一例を示す図である。まず、構成制御部300は、システムリセット信号が受信されたか否かを判断する(S1001)。システムリセット信号を受信した場合(S1001 Yes)、メインメモリ500から演算器データ905及び制御データ910を読み出して、キャッシュ部400A及び400Bにそれぞれ書き込む(S1002)。構成制御部300は、キャッシュ部400A及び400Bに保持された演算器データ905及び制御データ910を読み出して、演算器データ905及び制御データ910を解凍する(S1003)。構成制御部300は、解凍した演算器データ905及び制御データ910で、MPLD20A及び20Bをそれぞれ再構成する(S1004)。MPLD20A又は20Bは、ステートマシンのデータパス駆動信号に従い演算を開始する(S1005)。構成制御部300は、静的スケジュール情報975に従ってS1003〜S1005の処理を繰り返すとともに、投機実行が失敗したか否かを判断する(S1006)。投機実行の失敗は、ステートマシンから通知される。投機実行が失敗した場合(S1007 エラー)、投機実行の失敗を通知したステートマシンが動作するMPLDを、分岐先回路を含む演算器データ905及び制御データ910で再構成する(S1008)。
【0330】
投機実行が成功した場合(S1007 No)、投機実行により再構成されたMPLDの演算を開始する(S1009)。
【0331】
図71は、半導体装置のキャッシュ制御に関する処理フローである。構成制御部300は、静的スケジュール情報975に従って、キャッシュ部400Bに制御データ910があるかどうか判断する(S1101)。静的スケジュール情報975に特定される制御データ910が、キャッシュ部400Bに保持されるなら(S1101 Yes)、S1002〜S1008の処理を行う(S1102)。静的スケジュール情報975に特定される制御データ910が、キャッシュ部400Bに保持されていない場合(S1101 No)、構成制御部300は、メインメモリ500から制御データ910を読み出して(S1103)、読み出した制御データ910でMPLDを再構成する(S1104)。
【符号の説明】
【0332】
9 アドレスデコーダ
12 MLUTデコーダ
13 Dフリップフロップ
15 入出力回路部
20 MPLD
22 マルチプレクサ
24 A/Dコンバータ
25 変数保持部
26 記憶部
28 MOSFETドライバ
30 MLUT
40 記憶素子
100 半導体装置
150 入出力部
210 情報処理装置
211、220 演算処理部
300 構成制御部
310 キャッシュ制御
320 システムリセット
330 圧縮データ解凍
340 スケジューラ
400A キャッシュ部
400B キャッシュ部
500 メインメモリ
550 メモリコントローラ
902 データパスブロック
905 演算器データ
910 制御データ
915 ステートマシン
940 スケジューラ
970 プロファイル情報
975 静的スケジュール情報
980 プログラム
990 コンパイルプログラム
【技術分野】
【0001】
本発明は、半導体装置に関する。
【背景技術】
【0002】
PLD(Programmable Logic Device)が知られている。PLDは、構成する論理回路を変更可能な半導体装置であり、複数の論理要素、及び複数の接続要素を有する。
【0003】
論理要素は、組合せ回路又は順序回路として動作する。論理要素は、例えば、真理値表を構成する複数の記憶素子からなる記憶素子ブロックである。複数の記憶素子は、例えば、SRAM(Static Random Access Memory)である。
【0004】
接続要素は、論理要素間の接続を切り替える。接続要素は、例えば、トランジスタスイッチング素子である。よって、PLDは、例えば、SRAMを書き換え、スイッチング素子のオン/オフで、構成する論理回路を書き換える。
【0005】
記憶素子ブロックを、接続要素として動作させる半導体装置が開示されている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2003−224468号公報
【特許文献2】特開2003−149300号公報
【特許文献3】国際公開第07/060763号パンフレット
【特許文献4】国際公開第09/001426号パンフレット
【特許文献5】国際公開第07/060738号パンフレット
【特許文献6】特開2009−194676号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
記憶素子ブロックを接続要素として動作させる半導体装置は、論理要素として動作する記憶素子の比率を上げることで、所望の論理回路を構成する記憶素子ブロックの総量を減らすことができる。
【課題を解決するための手段】
【0008】
1つの側面では、本発明は、所望の論理回路を構成する記憶素子ブロックの総量を減らすことを目的とする。
【0009】
上記の課題の解決を意図する実施形態は、下記の第1のセットに係る(1)〜(15)に記載のようなものである。
(1)N(Nは、2以上の整数)本のアドレス線と、
N本のデータ線と、
複数の記憶部であって、各記憶部は、
前記N本のアドレス線から入力されるアドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、
前記ワード線とデータ線に接続し、真理値表を構成するデータをそれぞれ記憶し、前記ワード線から入力される前記ワード選択信号により、前記データを前記データ線に入出力する複数の記憶素子を有する、複数の記憶部と、を備え、
前記記憶部のN本のアドレス線は、前記記憶部の他のN個の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のN本のデータ線は、前記記憶部の他のN個の記憶部のアドレス線に、それぞれ接続することを特徴とする半導体装置。
(2)前記N本のアドレス線と、前記N本のデータ線とはそれぞれ、1本のアドレス線と、1本のデータ線とにより対をなす(1)に記載の半導体装置。
(3)前記複数の記憶部を選択する記憶部デコーダをさらに有する(1)又は(2)に記載の半導体装置。
(4)順序回路を有し、
前記複数の記憶部は、前記N本のデータ線の中の少なくとも1本のデータ線を前記順序回路の信号入力線に接続するとともに、前記N本のアドレス線の中の少なくとも1本のアドレス線を前記順序回路の信号出力線に接続する(1)〜(3)の何れか1項に記載の半導体装置。
(5)前記Nは、6〜8の整数である(1)〜(4)の何れか1項に記載の半導体装置。
(6)前記複数の記憶部は、前記N本のデータ線の中の6本のデータ線を、隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続するとともに、前記N本のアドレス線の中の6本のアドレス線を、前記隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続する(1)〜(5)の何れか1項に記載の半導体装置。
(7)前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項(1)〜(6)の何れか1項に記載の半導体装置。
(8)前記複数の記憶部のうちの少なくとも1つの記憶部に隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から第1の方向に第1の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向に交差する第2の方向に第2の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向と前記第2の方向に交差する第3の方向に第3の距離を置いて配置され、
前記第1〜第3の距離は、第1の距離、第2の距離、第3の距離の順番で長くなる、(1)〜(7)の何れか1項に記載の半導体装置。
(9)前記第1の方向と、前記第2の方向とは、互いに直交している(1)〜(8)の何れか1項に記載の半導体装置。
(10)前記複数の記憶部の少なくとも1つの記憶部は、隣接する他の記憶部以外の記憶部のデータ線に、1本のアドレス線を接続する(1)〜(9)の何れか1項に記載の半導体装置。
(11)前記複数の記憶部の何れかは、前記複数の記憶部のうちの少なくとも1つの記憶部から前記第1〜第3の方向の何れかの方向に配置され、
前記複数の記憶部の少なくとも1つの記憶部は、前記第1〜第3の距離の何れか1つを5倍した位置に配置された記憶部のデータ線に、1本のアドレス線を接続する(6)〜(10)の何れか1項に記載の半導体装置。
(12)前記複数の記憶部は、再構成可能な論理要素及び/又は接続要素として使用される(1)〜(11)の何れか1項に記載の半導体装置。
(13)前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する(1)〜(12)の何れか1項に記載の半導体装置。
(14)前記真理値表を構成するデータを記憶する記憶装置をさらに有する(13)に記載の半導体装置。
(15)物理的な配線層数が4層以下である(1)〜(14)の何れか1項に記載の半導体装置。
【0010】
また、記憶素子ブロックを接続要素として動作させる半導体装置は、他の装置とデータの入出力が可能である。しかしながら、他の装置とのデータの入出力方式が決まらないと、上記半導体装置は、他の装置とデータの入出力を行うことができない。
【0011】
別な側面では、本発明は、半導体装置と演算処理装置とのデータの入出力を行うことを目的とする。
【0012】
上記の課題の解決を意図する実施形態は、下記の第2のセットに係る(1)〜(11)に記載のようなものである。
(1)それぞれが複数の記憶部を有する第1及び第2の論理部であって、各記憶部は、第1アドレス線から入力されるメモリ動作用アドレス、又は、第2アドレス線から入力される論理動作用アドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、前記ワード線とデータ線とに接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子と、を有する、第1及び第2の論理部と、
前記第1の論理部が有する記憶部の第1アドレス線及びデータ線と接続する第1の入出力部、前記第2の論理部が有する記憶部の第2アドレス線及びデータ線と接続する第2の入出力部、及び、前記第1の入出力部に対してメモリ動作用アドレス及びデータを出力する制御を行うとともに、前記第2の入出力部に対して論理動作用アドレスを出力し且つデータを受け取る制御を行う制御部、を有する演算処理部と、
を備えることを特徴とする半導体装置。
(2)第1の論理部又は第2の論理部に含まれる前記記憶部の論理動作用アドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部の論理動作用アドレス線に、それぞれ接続する(1)に記載の半導体装置。
(3)前記第1の論理部及び前記第2の論理部に含まれる前記複数の記憶部は、再構成可能である(1)又は(2)に記載の半導体装置。
(4)前記第1の論理部及び前記第2の論理部は、前記複数の記憶部を選択する記憶部デコーダをそれぞれ有する(1)〜(3)の何れか1項に記載の半導体装置。
(5)前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する(1)〜(4)の何れか1項に記載の半導体装置。
(6)前記真理値表を構成するデータを記憶する記憶装置をさらに有する(1)〜(5)の何れか1項に記載の半導体装置。
(7)物理的な配線層数が4層以下である(1)〜(6)の何れか1項に記載の半導体装置。
(8)前記第1の論理部が有する前記記憶部の数と、前記第2の論理部が有する前記記憶部の数とが同一である(1)〜(7)の何れか1項に記載の半導体装置。
(9)前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する(1)〜(8)の何れか1項に記載の半導体装置。
(10)演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、第1の論理部に、論理動作又は接続関係を規定する真理値表データを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第1の論理部の記憶部に、前記論理動作又は接続関係を規定する真理値表データを記憶するステップと、
前記演算処理部が、第2の論理部に、論理動作用アドレスを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第2の論理部の記憶部が、前記論理動作用アドレスにより特定される記憶素子からデータを出力するステップと、
前記演算処理装置は、前記第2の論理部からデータを受け取るステップと、を有する特徴とする制御方法。
(11)前記演算処理装置は前記半導体装置に含まれる、(10)に記載の制御方法。
【0013】
上記の課題の解決を意図する実施形態は、下記の第3のセットに係る(1)〜(11)に記載のようなものである。
(1)データを演算処理する演算処理部と、
複数の記憶部及び入出力部を有する論理部であって、
各記憶部は、アドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力するアドレスデコーダと、データ線とワード線に接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子とを有し、
前記入出力部は、前記演算処理部の少なくとも1つの出力信号線と前記アドレス線のすくなくとも1つとを接続すると共に、前記演算処理部の少なくとも1つの入力信号線と前記データ線の少なくとも1つとを接続する、演算処理部と、
を備えることを特徴とする半導体装置。
(2)前記記憶部のアドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部のアドレス線に、それぞれ接続する(1)に記載の半導体装置。
(3)前記複数の記憶部は、再構成可能である(1)又は(2)に記載の半導体装置。
(4)前記論理部は、前記複数の記憶部を選択する記憶部デコーダをさらに有する(1)〜(3)の何れかに記載の半導体装置。
(5)前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する(1)〜(4)の何れかに記載の半導体装置。
(6)前記真理値表を構成するデータを記憶する記憶装置をさらに有する(1)〜(5)の何れかに記載の半導体装置。
(7)物理的な配線層数が4層以下である(1)〜(6)の何れかに記載の半導体装置。
(8)前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する(1)〜(7)の何れか1項に記載の半導体装置。
(9)演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、前記演算処理部に含まれる論理部に、アドレスを出力するステップであって、前記論理部は複数の記憶素子を有し、各記憶素子は、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶する、ステップと、
前記論理部は、前記演算処理部の少なくとも1つの出力信号線と接続される少なくとも1つのアドレス線から、前記アドレスを受け取るステップと、
前記論理部は、前記アドレスにより特定される記憶素子からデータを出力するステップと、
前記論理部は、前記データを、前記演算処理部の少なくとも1つの入力信号線と接続される少なくとも1つのデータ線を介して、前記演算処理部に出力するステップと、
を有することを特徴とする制御方法。
(10)前記論理部は、前記読み出したデータを、前記論理部内の記憶部と繋がる少なくとも1つのデータ線から、前記演算処理部の少なくとも1つの入力信号線に出力する、(9)に記載の制御方法。
(11)前記演算処理装置は前記半導体装置に含まれる、(9)又は(10)に記載の制御方法。
【0014】
また、PLDの1つとしてMPLD(Memory−based Programmable Logic Device)がある。MPLDは、LUTベースのPLDと同様に、メモリセルユニットで回路構成を実現する。MPLDは、真理値表データが書き込まれるメモリセルユニットが、論理要素として機能する点で、上記したLUTベースのPLDと同じであるが、LUT同士の接続要素としても機能する点で、メモリセルユニット間の接続に専用の切り替え回路を有するLUTベースのPLDと異なる。しかし、MPLDは、メモリセルユニットを論理要素及び/又は論理要素間の接続を切り替える接続要素として使用するため、データパスを変えるためには、LUTベースのPLDと同様に、メモリセルに保持された真理値表データを書き換える必要がある。そのため、MPLDで、動的再構成を実行すると、メモリセルユニットへのデータの書き込み処理が生じるため、処理が遅延する。
【0015】
さらに別な側面では、本発明はMPLDを有する半導体装置の再構成時間を短縮化することができる。
【0016】
上記の課題の解決を意図する実施形態は、下記の第4のセットに係る(1)〜(5)に記載のようなものである。
【0017】
(1)各々が複数のメモリセルユニットを有し、且つ、前記メモリセルユニットに真理値表データを書き込むと、論理要素又は接続要素として動作する複数のプログラマブル論理部と、
各々が複数の前記真理値表データである複数の構成情報を保持するキャッシュ部と、
前記複数のプログラマブル論理部のうちの第1のプログラマブル論理部が、分岐論理を構成する第1の構成情報で再構成されている場合、前記分岐論理の実行前に、前記複数のプログラマブル論理部のうちの第2のプログラマブル論理部を、前記分岐論理の分岐先回路を構成する前記第2の構成情報で投機的に再構成する構成制御部と、
を備えることを特徴とする半導体装置。
(2)前記キャッシュ部は、演算器を示す真理値表データである演算器データと、状態遷移を示す真理値表データである制御データとを、分けて保持し、
前記構成制御部は、前記制御データと、前記制御データの状態遷移により示される演算器を含む前記演算器データを、前記キャッシュ部からそれぞれ読み込んで、前記プログラマブル論理部を再構成する、ことを特徴とする(1)に記載の半導体装置。
(3)前記キャッシュ部が保持する制御データを包含する記憶部をさらに有し、
前記構成制御部は、前記キャッシュ部が保持する制御データの次に、前記プログラマブル論理部を再構成するための制御データを、前記記憶部から読み出して、前記キャッシュ部に記憶する、ことを特徴とする(1)又は(2)に記載の半導体装置。
(4)前記記憶部に記憶される前記制御データの真理値表データは圧縮されており、
前記キャッシュ部は、圧縮した真理値表データを保持し、
前記構成制御部は、前記圧縮した真理値表データを解凍して、当該解凍した真理値表データで前記プログラマブル論理部を再構成する、ことを特徴とする(1)〜(3)の何れか1項に記載の半導体装置。
(5)前記第2の構成情報で構成された第2のプログラマブル論理部の演算結果が、前記第2の構成情報が前記第1の構成情報の分岐論理の分岐先回路ではないことを示す場合、前記構成制御部は、前記第2のプログラマブル論理部以外のプログラマブル論理部を、前記分岐論理の分岐先を含む第3の構成情報で再構成する、(1)〜(4)の何れか1項に記載の半導体装置。
【発明の効果】
【0018】
第1の側面では、本発明は、所望の論理回路を構成する記憶素子ブロックの総量を減らすことができる。
【0019】
第2の側面では、本発明は、半導体装置と演算処理装置とのデータの入出力を行うことができる。
【0020】
第3の側面では、本発明は、MPLDを有する半導体装置の再構成時間を短縮化することができる。
【図面の簡単な説明】
【0021】
【図1】MPLDの一例を示す図である。
【図2】MPLDのメモリ動作の一例を示す図である。
【図3】MLUTの論理動作の一例を示す図である。
【図4】MLUTの第1例を示す図である。
【図5】1ポート記憶素子の一例を示す図である。
【図6】論理要素として動作するMLUTの一例を示す図である。
【図7】論理回路として動作するMLUTの一例を示す図である。
【図8】図7に示す論理回路の真理値表を示す図である。
【図9】接続要素として動作するMLUTの一例を示す図である。
【図10】図9に示す接続要素の真理値表を示す図である。
【図11】4つのAD対を有するMLUTによって実現される接続要素の一例を示す図である。
【図12】1つのMLUTが、論理要素及び接続要素として動作する一例を示す図である。
【図13】図12に示す論理要素及び接続要素の真理値表を示す図である。
【図14】4つのAD対を有するMLUTによって実現される論理動作及び接続要素の一例を示す図である。
【図15】MLUTで構成される2ビット加算器の回路構成の一例を示す図である。
【図16】2ビット加算器動作の真理値表を示す図である
【図17】7つのAD対を有するMLUTの一例を示す図である。
【図18A】7個のAD対を有するMLUTの一例を示す図である。
【図18B】7個のAD対を有するMLUTの平面構造の一例を示す図である。
【図19】MLUTの第2例を示す図である。
【図20】2ポート記憶素子の一例を示す図である。
【図21】MLUTの第3例を示す図である。
【図22】MLUT配置の第1例を示す平面図である。
【図23】MLUTの配置の第2例を示す平面図である。
【図24】MLUT間の結線の一例を示す図である。
【図25】離間して配置されるMLUTを隣接MLUTを介して接続する例を示す図である。
【図26A】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図26B】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図26C】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図26D】所望の論理回路を構成するために必要なMLUT数の一例を示す図である。
【図27】最密充填配置構造と、非最密充填配置構造を示す図である。
【図28】最密充填配置構造におけるAD対の数の一例を示す図である。
【図29】MLUTのAD対の結線構造の1例を示す図である。
【図30】MLUTのAD対の結線構造の別な例を示す図である。
【図31】MLUTのAD対の結線構造の他の例を示す図である。
【図32】MLUTのAD対の結線構造の他の例を示す図である。
【図33】MLUTのAD対の結線構造の他の例を示す図である。
【図34】MLUTを有するMLUTブロックの一例を示す図である。
【図35】15行×30列のMLUTを有するMLUT領域における近距離配線パターンの配置の一例を示す図である。
【図36】15行×30列のMLUTを有するMLUT領域における第1の離間配線パターンの配置を示す図である。
【図37】15行×30列のMLUTを有するMLUT領域における第2の離間配線パターンの配置を示す図である。
【図38】15行×30列のMLUTを有するMLUT領域における第3の離間配線パターンの配置を示す図である。
【図39】15行×30列のMLUTを有するMLUT領域における第4の離間配線パターンの配置を示す図である。
【図40】15行×30列のMLUTを有するMLUT領域における第5の離間配線パターンの配置を示す図である。
【図41】MPLDを搭載した半導体装置の配置ブロックの一例を示す図である。
【図42】MPLDの配置・配線を実行する情報処理装置の1例を示す図である。
【図43】情報処理装置が、MPLDに配置・配線するためのビットストリームデータを生成するフローの1例を示す図である。
【図44】図41に示す半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。
【図45】8点離散フーリエ変換をバタフライ演算で行うときのアルゴリズムの一例を示す。
【図46】MPLDを搭載した半導体装置の一例を示す図である。
【図47】演算処理部と、MPLDとのデータの入出力を行う入出力部の一例を概略的に示す図である。
【図48】演算処理部と、MPLDとのデータの入出力を行う入出力部の別な例を示す図である。
【図49】論理動作とメモリ動作を同時に行うMPLD、及び演算処理部の一例を示す図である。
【図50】複数のMPLD、及び演算処理部の一例を示す図である。
【図51】MPLDを搭載した半導体装置の他の例における配置ブロックの一例を示す図である。
【図52】MPLDを搭載した半導体装置の他の例における配置構造の一例を示す図である。
【図53】動作合成の一例を示す図である。
【図54】論理回路x=(a+b)*(b+c)を構成するCDFGの例を示す図である。
【図55】図54に示すCDFGを、速度優先スケジューリングでスケジューリングした結果を示す図である。
【図56】図54に示すCDFGを、ハードウェア量優先スケジューリングでスケジューリングした結果を示す図である。
【図57】第1の論理ブロックと第2の論理ブロックとの2つの論理ブロックに面分割された論理回路を実行する1つの例を示す。
【図58】アロケーションのときに論理回路を面分割する1例を示す図である。
【図59】MLUTに論理回路情報などの情報を書き込む手順を示すフローチャートの一例である。
【図60】MPLDを搭載した半導体装置の他の例における配置構造を示す図である。
【図61】MPLDを搭載した半導体装置の他の例における配置構造を示す図である。
【図62】半導体装置の配線層の一例を示す断面図である。
【図63】半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。
【図64】DESの計算アルゴリズムのフローの一例を示す図である。
【図65】F関数のアルゴリズムのフローを示す図である。
【図66】図66は、半導体装置の一例を示すブロック図である
【図67】図67は、メインメモリのメモリマップの一例を示す図である。
【図68】図68は、構成制御部の詳細ブロック図である。
【図69】図69は、MPLDで構成されるデータパスブロック及びステートマシンの一例を示す図である。
【図70】図70は、半導体装置の投機実行に関する処理フローの一例を示す図である。
【図71】図71は、半導体装置のキャッシュ制御に関する処理フローである。
【発明を実施するための形態】
【0022】
以下、〔1〕MPLD、〔2〕MLUT、〔3〕MLUTの構造、〔4〕1つのMPLDを搭載した半導体装置、〔5〕1つのMPLDと、演算処理部とを搭載した半導体装置、〔6〕2つのMPLDと、演算処理部とを搭載した半導体装置、〔7〕動的再構成に適する半導体装置に分けて、順に実施例を説明する。以下に説明するMPLD〔1〕は、複数のMLUT〔2〕を有してなり、MPLD〔1〕は、演算処理部と組み合わされて、半導体装置〔4〕又は〔5〕又は〔6〕又は〔7〕を構成する。
【0023】
〔1〕MPLD
図1は、半導体装置の一例を示す図である。図1に示す20は、半導体装置としてのMPLD(Memory−based Programmable Logic Device)である。MPLD20は、記憶素子ブロックとしてのMLUT(Multi Look−Up−Table)30を複数有するとともに、MLUTデコーダ12を有する。また、後述するように、MPLD20は、演算処理装置と接続する論理部として動作する。
【0024】
MPLD20は、複数の記憶素子を含む。記憶素子には、真理値表を構成するデータがそれぞれ記憶されることで、MPLD20は、論理要素、又は、接続要素、又は、論理要素及び接続要素として動作する論理動作を行う。
【0025】
MPLD20はさらに、メモリ動作を行う。メモリ動作とは、MLUT30に含まれる記憶素子へのデータの書き込みや読み出しをいう。よって、MPLD20は、主記憶装置や、キャッシュメモリとして動作することができる。
【0026】
MLUT30へのデータの書き込みは、真理値表データの書き換えにもなるため、メモリ動作は、真理値表データの再構成を生じる。なお、再構成のうち、MPLD内の特定の1つ又は複数のMLUT、又はMLUTを構成する特定の1つ又は複数の記憶素子に記憶された真理値表データを書き換えることを「部分再構成」という。
【0027】
図1には、メモリ動作では、MPLDアドレス、メモリ動作用アドレスMA、書き込みデータWD、及び読み出しデータRDの何れかの信号を使用され、それらの信号と、それらの信号を通す結線とが図示される。また、論理動作では、論理動作用アドレスLA、及び論理動作用データLDが使用され、それらの信号と、それらの信号を通す結線とが図示される。なお、メモリ動作用アドレスMAとは、MPLD20に含まれる各MLUTに供給されるメモリ動作用のアドレスである。MPLDアドレスとは、MPLD20内に含まれる1つのMLUTを特定するアドレスであり、メモリ動作用アドレスMAを供給するMLUTを特定するアドレス信号である。
【0028】
〔1.1〕MPLDのメモリ動作
図2は、MPLDのメモリ動作の一例を示す図である。MPLD20は、メモリ動作で、実線で示されるメモリ動作用アドレス、MLUTアドレス、書き込みデータWD、及び読み出しデータRDの何れかの信号を使用し、破線で示される論理動作用アドレスLA、及び論理動作用データLDは使用しない。なお、メモリ動作用アドレス、MLUTアドレス、及び書き込みデータWDは、例えば、MPLD20の外部にある演算処理装置によって出力され、読み出しデータWDは、演算処理装置に出力される。
【0029】
メモリ動作では、MPLD20は、記憶素子を特定するアドレスとして、メモリ動作用アドレス及びMLUTアドレスを受け取るとともに、書き込みのときは書き込みデータWDを受け取り、読み出しのときは読み出しデータLDを出力する。
【0030】
MLUTアドレスとは、MPLD20内に含まれる1つのMLUTを特定するアドレスである。MLUTアドレスは、m本の信号線を介してMPLD20に出力される。なお、mとは、MLUTを特定する選択アドレス信号線の数である。m本の信号線で、2のm乗のMLUTを特定することができる。MLUTデコーダ12は、m本の信号線を介してMLUTアドレスを受け取るとともに、MLUTアドレスをデコードして、メモリ動作の対象となるMLUT30を選択し特定する。メモリ動作用アドレスは、n本の信号線を介して、図10を用いて後述するアドレスデコーダでデコードされて、メモリ動作の対象となるメモリセルを選択する。
【0031】
なお、MPLD20は、例えば、MLUTアドレス、書き込みデータWD及び読み出しデータLDは、全てn本の信号線を介して受け取る。なお、nとは、図4を用いて後述されるように、MLUTのメモリ動作用又は論理動作用の選択アドレス信号線の数である。MPLD20は、n本の信号線を介して、MLUTアドレス、書き込みデータ及び読み出しデータを各MLUTに供給する。なお、メモリ動作用アドレスMA、書き込みデータWD及び読み出しデータRDの詳細は、MLUTの例とともに、図4、図19、及び図21を用いて後述する。
【0032】
〔1.2〕MPLDの論理動作
図3は、MPLD20の論理動作の一例を示す図である。図3において、MPLD20の論理動作では、実線で示される論理動作用アドレスLA、及び論理動作用データLDを使用する。
【0033】
MPLD20の論理動作では、論理動作用アドレスLAは、外部装置から出力され、MLUT30の真理値表によって構成される論理回路の入力信号として使用される。そして、論理動作用データLDは、上記論理回路の出力信号であり、論理回路の出力信号として、外部装置に出力される。
【0034】
複数のMLUTのうち、MPLD20の外延に配置されるMLUTは、MPLD20の外部の装置と、論理動作用のデータである論理動作用アドレスLAを受け取り、論理動作用データLDを出力するMLUTとして動作する。例えば、例えば、図1に示すMLUT30a、30bは、半導体装置100の外部から論理動作用アドレスLAを受け取り、周囲にある他のMLUT30dに論理動作用データLDを出力する。また、図1に示すMLUT30e、30fは、他のMLUT30c、30dから論理動作用アドレスLAを受け取り、MPLD20の外部に論理動作用データLDを出力する。
【0035】
MLUTの論理動作用アドレスLAのアドレス線は、隣接するMLUTの論理動作用データLDのデータ線と接続しており、例えば、MLUT30cは、MLUT30aから出力された論理動作用データを、論理動作用アドレスとして受け取る。このように、MLUTの論理動作用アドレス又は論理動作用データは、周囲にあるMLUTとの入出力により得られる点で、各々のMLUTが独自に接続するMLUTアドレスと異なる。
【0036】
MPLD20の論理動作により実現される論理は、MLUT30に記憶される真理値表データにより実現される。いくつかのMLUT30は、AND回路、加算器などの組み合わせ回路としての論理要素として動作する。他のMLUTは、組み合わせ回路を実現するMLUT30間を接続する接続要素として動作する。論理要素、及び接続要素を実現するための真理値表データの書き換えは、上述のメモリ動作による再構成によりなされる。
【0037】
〔2〕MLUT
以下に、MLUTについて説明する。
〔2.1〕MLUTの第1例
図4は、MLUTの第1例を示す図である。図4に示すMLUT30は、アドレス切替回路10aと、アドレスデコーダ9と、記憶素子40と、出力データ切替回路10bとを有する。図10に示すMLUT30は、動作切替信号が論理動作を示す場合、論理動作用アドレスLAに従って、論理動作用データLDを出力するように動作する。また、MLUT30は、動作切替信号がメモリ動作を示す場合、メモリ動作用アドレスに従って、書き込みデータを受け入れ、又は、読み出しデータを出力するように動作する。
【0038】
アドレス切替回路10aは、メモリ動作用アドレスMAが入力されるn本のメモリ動作用アドレス信号線と、論理動作用アドレスLAが入力されるn本の論理動作用アドレス入力信号線と、動作切替信号が入力される動作切替信号線とを接続する。アドレス切替回路10aは、動作切替信号に基づいて、メモリ動作用アドレスMA、又は論理動作用アドレスLAのいずれかをn本の選択アドレス信号線に出力するように動作する。このように、アドレス切替回路10aが、アドレス信号線を選択するのは、記憶素子40が読み出し動作と書き込み動作の何れかを受け付ける1ポート型の記憶素子であるからである。
【0039】
図4に示すアドレスデコーダ9は、アドレス切替回路10aから供給されるn本のアドレス信号線から受け取った選択アドレス信号をデコードし、2のn乗本のワード線にデコード信号を出力する。
【0040】
n×2n個の記憶素子は、2のn乗本のワード線と、n本の書き込みデータ線と、n個の出力ビット線の接続部分に配置される。記憶素子の詳細例は、図5を用いて後述する。
【0041】
出力データ切り替え回路10bは、n本の出力ビット線から信号を受け取ると、入力される動作切替信号に従って、記憶素子から読み出したデータをn本の読み出しデータ信号線に出力し、又は、読み出しデータを論理動作用信号線に出力するように動作する。
【0042】
〔2.2〕MLUTの記憶素子
図5は、1ポート型の記憶素子の一例を示す図である。図5に示す1ポート型の記憶素子は、SRAMであり、図4に示す記憶素子として使用できる。図5に示す1ポートSRAM40は、第1及び第2のpMOS(positive channel Metal Oxide Semiconductor)トランジスタ161、162と、第1〜第4のnMOS(negative channel MOS)トランジスタ163〜166とを有する。
【0043】
第1のpMOSトランジスタ161のソースと、第2のpMOSトランジスタ162のソースとは、VDD(電源電圧端)に接続する。第1のpMOSトランジスタ161のドレーンは、第1のnMOSトランジスタ163のソースと、第2のpMOSトランジスタのゲート162と、第2のnMOSトランジスタのゲート504と、第3のnMOSトランジスタ505のソースとに接続する。第1のpMOSトランジスタ161のゲートは、第1のnMOSトランジスタ163のゲートと、第2のpMOSトランジスタ162のドレーンと、第2のnMOSトランジスタ504のドレーンと、第4のnMOSトランジスタ506のソースとに接続する。第1のnMOSトランジスタ163のドレーンと、第2のnMOSトランジスタ504のドレーンは、VSS(接地電圧端)に接続される。
【0044】
第3のnMOSトランジスタ165のドレーンは、第1のビット線BLに接続される。第3のnMOSトランジスタ165のゲートは、ワード線WLに接続される。第4のnMOSトランジスタ166のドレーンは、第2のビット線qBLに接続される。第4のnMOSトランジスタ166のゲートは、ワード線WLに接続される。
【0045】
上記構成により、書き込み動作では、1ポート記憶素子40は、ワード線WLの信号レベル「H」により、書込ビット線BL、及び、書込ビット線qBLの信号レベルを、保持する。
【0046】
〔2.3〕MLUTの論理動作
A.論理要素
図6は、論理要素として動作するMLUTの一例を示す図である。図6に示すMLUT30a、30bは、論理動作用アドレス線A0〜A3から論理動作用アドレスLAを受け取り、論理動作用データ線D0〜D3に論理動作用データLDを出力する。なお、MLUT30aの論理動作用アドレス線A2は、隣接するMLUT30bの論理動作用データ線D0と接続しており、MLUT30aは、MLUT30bから出力された論理動作用データLDを、論理動作用アドレスLAとして受け取る。また、MLUT30aの論理動作用データ線D2は、MLUT30bの論理動作用アドレス線A0と接続しており、MLUT30aが出力した論理動作用データLDは、MLUT30bで論理動作用アドレスLAとして受け取られる。このように、MPLD同士の連結は、1対のアドレス線とデータ線とを用いる。以下、MLUT30aの論理動作用アドレス線A2と、論理動作用データ線D2のように、MLUTの連結に使用されるアドレス線とデータ線の対を「AD対」という。
【0047】
なお、図6では、MLUT30a、30bが有するAD対は4であるが、AD対の数は、後述するように4に限定されない。
【0048】
図7は、論理回路として動作するMLUTの一例を示す図である。本例では、論理動作用アドレス線A0及びA1を2入力NOR回路701の入力とし、論理動作用アドレス線A2及びA3を2入力NAND回路702の入力とする。そして、2入力NOR回路の出力と、2入力NAND回路702の出力を、2入力NAND回路703に入力し、2入力NAND回路703の出力をデータ線D0に出力する論理回路を構成する。
【0049】
図8は、図7に示す論理回路の真理値表を示す図である。図7の論理回路は、4入力のため、入力A0〜A3の全ての入力を入力として使用する。一方、出力は、1つのみなので、出力D0のみを出力として使用する。真理値表の出力D1〜D3の欄には「*」が記載されている。これは、「0」又は「1」のいずれの値でもよいことを示す。しかしながら、実際に再構成のために真理値表データをMLUTに書き込むときには、これらの欄には、「0」又は「1」のいずれかの値を書き込む必要がある。
【0050】
B.接続要素の機能
図9は、接続要素として動作するMLUTの一例を示す図である。図9では、接続要素としてのMLUTは、アドレス線A0の信号をデータ線D1に出力し、アドレス線A1の信号をデータ線D2に出力し、論理動作用アドレス線A2の信号をデータ線D3に出力するように動作する。接続要素としてのMLUTはさらに、アドレス線A3の信号をデータ線D1に出力するように動作する。
【0051】
図10は、図9に示す接続要素の真理値表を示す図である。図9に示す接続要素は、4入力4出力である。したがって、入力A0〜A3の全ての入力と、出力D0〜D3の全ての出力が使用される。図10に示す真理値表によって、MLUTは、入力A0の信号を出力D1に出力し、入力A1の信号を出力D2に出力し、入力A2の信号を出力D3に出力し、入力A3の信号を出力D0に出力する接続要素として動作する。
【0052】
図11は、4つのAD対を有するMLUTによって実現される接続要素の一例を示す図である。図11において、1点鎖線は、AD対0に入力された信号がAD対1に出力される信号の流れを示す。2点鎖線は、第2のAD対ADAに入力された信号がAD対2に出力される信号の流れを示す。破線は、AD対2に入力された信号がAD対3に出力される信号の流れを示す。実線は、AD対3に入力された信号がAD対0に出力される信号の流れを示す。
【0053】
なお、図11では、MLUT30が有するAD対は4であるが、AD対の数は、後述するように4に限定されない。
【0054】
C.論理要素と接続要素の組合せ機能
図12は、1つのMLUTが、論理要素及び接続要素として動作する一例を示す図である。図12に示す例では、アドレス線A0及びA1を2入力NOR回路121の入力とし、2入力NOR回路121の出力と、論理動作用アドレス線A2とを2入力NAND回路122の入力とし、2入力NAND回路122の出力をデータ線D0に出力する論理回路を構成する。また同時に、アドレス線A3の信号をデータ線D2に出力する接続要素を構成する。
【0055】
図13に、図12に示す論理要素及び接続要素の真理値表を示す。図12の論理動作は、入力D0〜D3の3つの入力を使用し、1つの出力D0を出力として使用する。一方、図(a)の接続要素は、入力A3の信号を出力D2に出力する接続要素が構成される。
【0056】
図14は、4つのAD対を有するMLUTによって実現される論理動作及び接続要素の一例を示す図である。上述のように、MLUT30は、3入力1出力の論理動作と、1入力1出力の接続要素との2つの動作を1つのMLUT30で実現する。具体的には、論理動作は、AD対0のアドレス線と、AD対1のアドレス線と、AD対2のアドレス線とを入力として使用する。そして、AD対0のアドレス線を出力と使用する。また、接続要素は、破線で示すようにAD対3に入力された信号をAD対2に出力する。
【0057】
なお、N個のAD対を有するMLUTには、N個の入力を有し、N個の出力を有する任意の論理回路を構成することができる。さらにまた、N個のAD対を有するMLUTでは、合計で1〜Nの任意の数の入力数を有し、1〜Nの任意の数の出力数を有する任意の論理動作と、接続要素とを同時に構成することができる。
【0058】
〔2.4〕7つのAD対を有するMLUT
図15〜図17を用いて、7つのAD対を有するMLUT上に真理値表の動作を実現する1例を説明する。
【0059】
図15は、MLUTで構成される2ビット加算器の回路構成の一例を示す図である。2ビット加算器は、1ビット全加算器を2つ接続することにより構成される。図15において、2ビット加算器は、入力A0、B0、及びCinを入力として使用し、出力S0及び桁上がり出力として使用する第1の1ビット全加算器を有する。また、入力A1、B1、及び第1の1ビット全加算器の桁上がりを入力として使用し、出力S1及びCoutを出力として使用する第2の1ビット全加算器を有する。
【0060】
第1の1ビット全加算器は、入力A0及びB0を第1の2入力XOR回路4.401と、第1の2入力AND回路152の入力とする。第1の2入力XOR回路151の出力及び入力Cinを、第2の2入力XOR回路153と、第2の2入力AND回路154の入力とする。第1の2入力AND回路152の出力及び第2の2入力AND回路154の出力を第1の2入力OR回路155の入力とする。さらに、第2の2入力XOR回路153の出力を出力S0とし、第1の2入力OR回路155の出力を桁上がり出力とする。
【0061】
第2の1ビット全加算器は、入力A1及びB1を第3の2入力XOR回路156と、第3の2入力AND回路157の入力とする。第3の2入力XOR回路156の出力及び第1の2入力OR回路155の出力を、第4の2入力XOR158回路と、第4の2入力AND回路159の入力とする。第3の2入力AND回路157の出力及び第4の2入力AND回路159の出力を第2の2入力OR回路4.410の入力とする。さらに、第4の2入力XOR回路158の出力を出力S1とし、第2の2入力OR回路160の出力を出力Coutとする。
【0062】
図16は、図15の2ビット加算器動作の真理値表を示す図である。図15の2ビット加算器動作は、入力A0、A1、B0、B1、及びCinの5つの入力を使用する。そして、出力S0、S1、及びCoutの3つの出力を使用する。
【0063】
図17は、7つのAD対を有するMLUTの一例を示す図である。図15及び図16に記載される2ビット加算器を図17に示すMLUT30に真理値表として実現するためには、5つのAD対の論理制御用アドレス線を入力線として使用し、3つのAD対の論理制御用データ線を出力線として使用する必要がある。さらに、2つのAD対は、接続要素用に使用することができる。このため、7つのAD対を有するMLUT30では、2ビット加算器の論理動作を実現するとともに、2つの接続要素を実現することが可能になる。
【0064】
例えば、AD対0を入力A0及び出力S0に使用し、AD対1を入力A1及び出力S1に使用し、AD対2を入力Cin及び出力Coutに使用し、AD対3のアドレス線を入力B0に使用する。そして、第5のAD対AD4のアドレス線を入力B1に使用することができる。
【0065】
加算器は、四則演算などの演算回路を構成する場合に非常に多く使用される回路である。また、通常の演算処理では、2ビット以上のデータを処理される。従って、5入力3出力で構成される2ビット加算器を1つのMLUTで構成することによって、MPLDの配置・配線効率が向上することは、有利である。すなわち、2ビット加算器を1つのMLUTで構成することにより、同一数のMLUTを有するMPLDに搭載できる演算回路の数を増やすことができる。さらに、多ビット加算器、及び多ビット乗算器など配線パターンが決まっている論理回路を、2ビット加算器を有するモジュールとして用意することも可能である。
【0066】
また、7つのAD対を有するMLUTでは、2ビット加算器の論理動作を実現した上で、さらに2経路の接続要素を実現できることは、MPLDの配置・配線効率を考えると、さらに有利である。すなわち、配置・配線アルゴリズムを実行するときに、2ビット加算器を配置したMLUTに、さらに付加的に接続要素を有することができる。このため、MLUTに配置した真理値表をそれぞれ配線するときの自由度が向上する。なお、配置・配線とは、MLUTは、論理要素及び/又は接続要素として動作するので、MLUTへの真理値表データの書込は、論理動作の配置、及び/又は、MLUT間の配線を意味する。そのため、真理値表データの生成を「配置・配線」という。
【0067】
本例では、7つのAD対を有するMLUTで、2ビット加算器の論理動作と、接続要素とを同時に実現する実施形態について説明した。しかしながら、5つのAD対を有するMLUTでは、2ビット加算器の論理動作を実現することができる。また、6つのAD対を有するMLUTでは、2ビット加算器の論理動作と、1つの接続要素とを実現することができる。さらに、8つのAD対を有するMLUTでは、2ビット加算器の論理動作と、3つの接続要素とを実現することができる。
【0068】
また、9つのAD対を有するMLUTでは、4ビット加算器の論理動作を実現することができる。10個のAD対を有するMLUTでは、4ビット加算器の論理動作と、1つの接続要素とを実現することができる。このように、5〜10程度のAD対を有するMLUTでは、配置・配線効率を向上させる構成が可能になる。
【0069】
〔2.5〕MLUTの物理的な配置
図18Aは、7個のAD対を有するMLUTの一例を示す図である。図18Aに示すMLUT30は、アドレス行デコーダ9cと、アドレス列デコーダ9dと、記憶素子40cとを有する。図18Aに示すMLUT30には、それぞれが7つの信号からなる論理動作用アドレスLAと、書き込みデータWDとが入力され、それぞれが7つの信号からなる読み出しデータRDと、論理動作用データLDとが出力される。アドレス切替回路10aは、出力データ切り替え回路10bは、図4を用いて説明した回路と同じ動作をするため、説明を省略する。
【0070】
アドレス行デコーダ9cは、m本の信号入力である論理動作用アドレスLAをデコードして、2のm乗のワード線にワード選択信号を出力する。記憶素子40cは、2L個の記憶素子ブロック(40c−1、・・・、40c−2L)である。各記憶素子ブロックは、n×2m個の記憶素子を有し、2m本のワード線と、n本の書き込みデータ線と、n個の出力ビット線の接続部分に配置される。mは、N−Lの整数であり、Lはnより小さい整数である。「n、m、L」は、例えば、「7、5、2」、又は、「7、4、3」である。
【0071】
アドレス列デコーダ9dは、L本の信号入力である論理動作用アドレスLAをデコードして、2のL乗のブロック選択信号を生成して、ブロック選択信号により、上記した2L個の記憶素子ブロックのいずれかのn個の出力ビット線を選択する。例えば、L=2の場合、記憶素子ブロックは22=4個あり、各記憶素子ブロックは25=32本のワード線及び出力ビット線を有するため、アドレス列デコーダ9dは、ブロック選択信号により何れかの記憶素子ブロックの出力ビット線32本を選択する。また、L=3の場合、記憶素子ブロックは23=8個あり、各記憶素子ブロックは24=16本のワード線及び出力ビット線を有するため、アドレス列デコーダ9dは、ブロック選択信号により何れかの記憶素子ブロックの出力ビット線16本を選択する。
【0072】
アドレス列デコーダ9dを設けて、記憶素子を列方向に広げることで、出力ビット線の長さを短縮することが出来る。
【0073】
図18Bは、図18Aに示すMLUT30を2つ組み合わせたMLUTのフロアプランを示す図である。図18Bに示すMLUT30は、図18Aに示すMLUTが有する構成を含む。図18Bに示すMLUT30は、メモリ論理制御部10cと、アドレス行デコーダ9c−1及び9c−2と、アドレス列デコーダ9d−1及び9d−2と、記憶素子40c−1及び40c−2と、読み出し駆動部11a−1及び11a−2とを有する。
【0074】
アドレス行デコーダ9c−1及び9c−2、及び、アドレス行デコーダ9d−1及び9d−2には、メモリ論理制御部10cから出力される7つの選択アドレス信号を入力する7つの選択アドレス線がそれぞれ接続される。アドレス行デコーダ9c−1、及び、アドレス列デコーダ9d−1は、記憶素子40c−1に対してワード選択信号及びブロック選択信号をそれぞれ供給する。アドレス行デコーダ9c−2、及び、アドレス列デコーダ9d−2は、記憶素子40c−2に対してワード選択信号及びブロック選択信号をそれぞれ供給する。
【0075】
図18Bに示すMLUT30には、図示されないが、それぞれが7つの信号からなると、論理動作用アドレスLAと、書き込みデータWDとが入力され、それぞれが7つの信号からなる読み出しデータRDと、論理動作用データLDとが出力される。図18Bに示すMLUT30には、さらに、図示されないが、メモリ動作用アドレスMA、動作切替信号が入力される。
【0076】
メモリ論理制御部10cには、図18Aのアドレス切替回路10aと、出力データ切り替え回路10bとが配置される。メモリ動作用アドレスMAと、論理動作用アドレスLAと、書き込みデータWDと、読み出しデータRDと、論理動作用データLDとはそれぞれ、メモリ論理制御部10cを介して、MLUT30に入出力される。
【0077】
アドレス行デコーダ9c−1及び9c−2は、記憶素子領域40c−1と、記憶素子40c−2との間に配置される。
【0078】
第1及び第2の読み出し駆動部11a及び11bはそれぞれ、第1及び第2の記憶素子領域40c及び40dと、メモリ論理制御部10cとの間に配置される。第1及び第2の読み出し駆動部11a及び11bは、第1及び第2の記憶素子領域40c及び40dに配置される記憶素子40から読み出す7つのビット信号を増幅して、読み出し速度を高速化するように構成される。
【0079】
本例では、アドレス行アドレスに入力される選択アドレス信号の数を4つ、又は5つにしている。選択アドレス信号の数を5以下とすることで、ワード選択信号の数が、24=16本、又は、25=32本となり、出力ビット線の長さを短縮することが出来る。そのため、一般的なSRAM回路において必須の構成要素であるセンスアンプと、プリチャージ回路とが不要である回路構成が実現される。図18A又は図18Bに示すMLUT30は、一般的なSRAMと異なり、記憶素子数の数の大規模化はしなくてもよい。
【0080】
MLUTに含まれる記憶素子の数は、多くても10×210個程度である。これは、一般に数Mビット以上の大規模回路として構成される記憶装置としてのSRAMメモリと比較すると非常に小さな回路である。このため、一般的なSRAMメモリとして使用する記憶装置に搭載されるときには、微細化上で問題にならないセンスアンプ、プリチャージ回路、及びこれらの周辺回路の大きさが、MLUTの回路構成では、問題になる。一般的なSRAMメモリなどの記憶装置に配置されるセンスアンプ、及びプリチャージ回路は、配線層に生じる時定数τが大きくなり、信号の伝達遅延時間が大きくなることを防止するために配置される回路である。これは、アドレスデコーダと、記憶素子との間の配線長が長いためである。したがって、アドレスデコーダと、記憶素子との間の配線長に生じる時定数τを、MLUTの動作に影響を与えない程度に抑えることにより、センスアンプ、及びプリチャージ回路が不要な構成にできる。図18A及び図18Bに示す例では、アドレス行デコーダに入力される選択アドレス信号の数を5つ以下にすることにより、アドレス行デコーダと、記憶素子との間の配線長をMLUTの動作に影響を与えない程度に抑えることを可能にした。
【0081】
さらに本例では、アドレス行デコーダ9cは、第1の記憶素子領域40cと、第2の記憶素子領域40dとの間に配置される。一般的なSRAMメモリなどの記憶装置では、アドレス行デコーダは、記憶素子領域の一辺に接して配置される。このようにアドレス行デコーダを配置すると、アドレス行デコーダに隣接する記憶素子と、アドレス行デコーダから最も離隔する記憶素子とでは、配線距離が異なる。このため、配線層に生じる時定数τが異なるので、アドレス行デコーダからの信号伝達遅延時間が相違する。上述のように、本例では、センスアンプ、及びプリチャージ回路がない構成となるため、それぞれの記憶素子の間の信号伝達遅延時間の差を小さくする構成にすることが望ましい。そこで、本例では、記憶素子領域を、同一の大きさを有する第1の記憶素子領域40cと、第2の記憶素子領域40dとに分割し、その記憶素子領域の間にアドレス行デコーダ9cを配置した。これにより、それぞれの記憶素子の間の信号伝達遅延時間を抑えることが可能になった。
【0082】
本例では、アドレス行デコーダの選択アドレスの数が、5つであるが、アドレス行デコーダの選択アドレスの数は、6つ以下の任意の数とすることができる。しかしながら、アドレス行デコーダの数が適当な数でない場合には、アドレス列デコーダの配線長が増大し、適切な回路を構成できない可能性がある。7つのAD対を有するMLUTが説明されるが、AD対の数は、アドレス行デコーダ及びアドレス列デコーダに配線する選択アドレス数を調整することにより、5〜10の任意の数とすることができる。
【0083】
〔2.6〕MLUTの第2例
上記図4〜図18Bにおいて、1ポート型の記憶素子として用いるMLUTについて説明したが、以下に示す2ポート型の記憶素子として用いるMLUTについても適用可能である。
【0084】
図19は、MLUTの第2例を示す図である。図19に示すMLUT30は、データの書き込みと読み出しを同時に行うことができる。図19に示すMLUT30は、メモリ動作用のアドレスデコーダ9aと、論理動作用のアドレスデコーダ9bと、記憶素子40とを有する。図19に示すMLUTは、図4に示すMLUTと異なり、論理動作と、メモリ動作を同時に行うことができる。そのため、図19に示すMLUT30は、図4に示すMLUTと異なり、動作切替選択信号が不要であり、且つアドレス切替回路10a及び出力データ選択回路は有さない一方で、各々のアドレス用のアドレスデコーダ9a、9bを有する。その他、図4に示すMLUTと同じ構成を有する。なお、図18BのMLUT30に含まれる記憶素子は、データの書き込みと読み出しを可能にする2ポートの記憶素子である。
【0085】
〔2.7〕2ポートの記憶素子
図20は、2ポート記憶素子の一例を示す図である。図19に示す例では、2ポート記憶素子40Bは、SRAMであり、第1及び第2のpMOSトランジスタ501、502と、第3〜第8のnMOSランジスタ503〜508とを有する。
【0086】
図20に示すように、複数のMOSトランジスタから構成される2ポートSRAM40は、VDD、VSS、書込ワード線WWL、読出ワード線RWL、第1の書込ビット線WBL、第2の書込ビット線qWBL、第1の読出ビット線RBL、及び第2の読出ビット線qRBLに接続する。第1の書込ビット線WBLに印加される信号は、第2の書込ビット線qWBLに印加される信号の反転信号である。同様に、第1の読出ビット線RBLに印加される信号は、第2の読出ビット線qRBLに印加される信号の反転信号である。
【0087】
第1のpMOSトランジスタ501のソースと、第2のpMOSトランジスタ502のソースとは、VDDに接続される。第1のpMOSトランジスタ501のドレーンは、第1のnMOSトランジスタ503のソースと、第2のpMOSトランジスタのゲート502と、第2のnMOSトランジスタのゲート194と、第3のnMOSトランジスタ195のソースと、第4のnMOSトランジスタ506のソースとに接続される。
【0088】
第1のpMOSトランジスタ501のゲートは、第1のnMOSトランジスタ503のゲートと、第2のpMOSトランジスタ502のドレーンと、第2のnMOSトランジスタ194のドレーンと、第5のnMOSトランジスタ197のソースと、第6のnMOSトランジスタ198のソースとに接続される。第1のnMOSトランジスタ503のドレーンと、第2のnMOSトランジスタ194のドレーンは、VSSに接続される。
【0089】
第3のnMOSトランジスタ195のドレーンは、第1の書込ビット線WBLに接続される。第3のnMOSトランジスタ195のゲートは、書込ワード線WWLに接続される。第4のnMOSトランジスタ506のドレーンは、第1の読出ビット線RBLに接続される。第4のnMOSトランジスタ506のゲートは、読出ワード線RWLに接続される。
【0090】
第5のnMOSトランジスタ197のドレーンは、第2の書込ビット線qWBLに接続される。第5のnMOSトランジスタ197のゲートは、書込ワード線WWLに接続される。第6のnMOSトランジスタ198のドレーンは、第2の読出ビット線qRBLに接続される。第6のnMOSトランジスタ198のゲートは、読出ワード線RWLに接続される。
【0091】
上記構成により、書き込み動作では、2ポートSRAM40は、書込ワード線WWLの信号レベル「H」により、第1の書込ビット線WBL、及び、第2の書込ビット線qWBLの信号レベルを、保持する。
【0092】
上記構成により、読み出し動作では、2ポートSRAM40は、読出ワード線RWLの信号レベル「H」により、第1の読出ビット線RBL、及び、第2の読出ビット線qRBLに、2ポートSRAM40に保持した信号レベルにする。
【0093】
このように、メモリ動作用アドレスMA及び論理動作用アドレスLAは、記憶素子の1つのワード線を活性化することで、メモリ動作又は論理動作を、n×2n個の記憶素子の一部についてのみ行うことができる。また、メモリ動作用アドレスMA及び論理動作用アドレスLAは、MLUT30内の全ての記憶素子と繋がっているため、メモリ動作又は論理動作を、n×2n個の記憶素子の全ての記憶素子について行うことができる。なお、2ポート記憶素子を有するMLUTは、メモリ動作と論理動作を同時に行うことができる。
【0094】
〔2.8〕MLUTの第3例
図21は、MLUTの第3例を示す図である。図21に示すMLUT30は、アドレスデコーダ9aと、アドレスデコーダ9bと、第1の記憶素子40aと、第2の記憶素子40bと、NOT回路171とを有する。図21に示すMLUT30には、メモリ動作用アドレスMAと、論理動作用アドレスLAと、書き込みデータWDと、セレクト信号とが入力され、読み出しデータRDと、論理動作用データLDとが出力される。
【0095】
第3例に係るMLUTと、第2例に係るMLUTとの相違点は、セレクト信号により、第1の記憶素子40aと、第2の記憶素子40bが、それぞれ異なる動作をすることが可能になる点である。つまり、第1の記憶素子40aと、第2の記憶素子40bとは、一方が論理動作用として選択されるときに、他方をメモリ動作用として選択とするように構成できる。
【0096】
NOT回路171は、セレクト信号が入力される入力端子と、セレクト信号が反転した信号を出力する出力端子とを有する。
【0097】
n×2n個の第1及び第2の記憶素子40は、2n個のメモリ動作用ワード端子(図示せず)と、2n個の論理動作用ワード端子(図示せず)と、n個の書き込みデータ端子(図示せず)と、n個の読み出しデータ端子(図示せず)と、n個の論理動作用データ出力端子(図示せず)と、セレクト端子(図示せず)とを有する。メモリ動作用ワード端子に接続されるメモリ動作用ワード端子はそれぞれ、n個の記憶素子を選択するように構成される。同様に、論理動作用ワード端子に接続される論理動作用ワード端子はそれぞれ、n個の記憶素子を選択するように構成される。書き込みデータ端子には、書き込みデータWDが入力される。書き込みデータWDは、MLUTをメモリ動作させるとき、又はMLUTを再構成するときに使用される。しかしながら、MLUTに書き込まれた真理値表データを読み出すときには使用されない。すなわち、MLUTに書き込まれた真理値表データを読み出すときには、書き込みデータWDは、記憶素子には印加されず、高インピーダンス入力となるように構成される。読み出しデータ端子は、メモリ動作用ワード端子により選択されたn個の記憶素子に記憶されたデータを出力する。同様に、論理動作用データ出力端子は、論理動作用ワード端子により選択されたn個の記憶素子に記憶されたデータを出力する。
【0098】
第1の記憶素子のセレクト端子には、セレクト信号が入力される。第2の記憶素子のセレクト信号には、NOT回路の出力信号、すなわちセレクト信号が反転した信号が入力される。これにより、第1の記憶素子と、第2の記憶素子とは、一方が論理動作用として選択されるときに、他方をメモリ動作用として選択とするように構成される。このような構成にすることにより、動的再構成が可能になる。すなわち、一方の記憶素子が、論理動作をし、他方の記憶素子がメモリ動作をすることが可能になる。
【0099】
〔3〕MLUTの構造
MLUTの構造について説明する。まず、MLUT領域に配置されるそれぞれのMLUTの配置構造について説明し、次に、MLUTのAD対の結線構造について説明する。そして、最後にMLUT領域の構造の1つの実施形態について説明する。
【0100】
〔3.1〕MLUTの配置構造
ここでは、MLUT領域に配置されるそれぞれのMLUTの配置構造について説明する。まず、MLUTのマトリックス配置構造について説明し、次いで、MLUTの交互配置構造について説明する。
【0101】
〔3.1.1〕MLUTのマトリックス配置構造
図22は、MLUT配置の第1例を示す平面図である。図22を参照して、MLUT領域におけるMLUTの配置の第1例について説明する。図22において、MLUTは、説明のために円形状に示される。しかしながら、上述のように、本発明の通常の実施形態では、MLUTの平面形状は、長方形状、又は正方形状である。また、以下の説明において、MLUTは、円形状に示されることがあるが、それぞれのMLUTは、長方形状、又は正方形状であると解するべきである。
【0102】
図22では、MLUT30は、マトリックス状に配置される。MLUT領域8は、半導体装置においてMLUT30が配置される領域である。MLUT30は、MLUT領域8において、第1の方向に同一の距離間隔で配置されるとともに、第1の方向と直角を成す第2の方向に第1の方向の間隔と同一の間隔、又は異なる間隔で配置される。このようにMLUT30を配置することで、MLUT30を近距離配線するときに、規則的に結線できる。なお、近距離配線とは、隣接するMLUT間を繋ぐ配線である。
【0103】
〔3.1.2〕MLUTの交互配置構造
図23は、MLUTの配置の第2例を示す平面図である。図23を参照して、MLUT領域8におけるMLUTの配置の第2例について説明する。図23に示す第2例では、MLUT30は、第1の方向に同一の距離間隔で配置され、第1の方向と直角を成す第2の方向に同一の間隔で配置される。加えて、第1及び第2の方向とは異なる四方に同一間隔で配置されるMLUT30を有するように配置される。本明細書では、このような配置構造を交互配置構造と称する。なお、好適には、第1、又は第2の方向のMLUT間の距離と、四方に配置される他のMLUT30との間の距離は同一にすることができる。また、四方に配置されるMLUT30を、第1の方向に配置される2つのMLUT30と、第2の方向に配置される2つのMLUT30とから構成される長方形の対角線の交点に配置することができる。この場合、それぞれのMLUT30は、第1の方向、及び第1の方向と垂直を成す第2の方向にそれぞれ同一間隔で配置される。また、第1及び第2の方向とは異なる第3及び第4の方向にも同一間隔で配置することができる。
【0104】
〔3.2〕MLUT間のAD対結線構造
〔3.2.1〕AD対結線構造
図24は、MLUT間の結線の一例を示す図である。ここで示されるAD対は、MLUTを真理値表として動作させるときに、MPLDの入出力信号線として使用するものである。MLUTはそれぞれ、MLUTをメモリ回路として使用するときに使用するメモリ動作用アドレス線、メモリ動作用データ線、及び制御信号線などの他の配線も有する。しかしながら、説明を簡明にするために、図24ではAD対以外の配線は省略する。図24を参照して、隣接するMLUT間の結線、すなわち近距離配線の結線について説明する。なお、離間配線は、近距離配線でないMLUT間を結線するAD対の配線をいう。図24には、6つのAD対を有するMLUT30と、MLUT30に隣接する第1のMLUT30aと、第2のMLUT30bと、第3のMLUT30cと、第4のMLUT30dと、第5のMLUT30eと、第6のMLUT30fとが交互配置に配置される。また、図24では、第1のMLUT30aと第4のMLUT30dとを結ぶ直線に平行な方向をMLUT30の縦方向と仮定し、第2のMLUT30bと第6のMLUT30fとを結ぶ直線に平行な方向をMLUT領域8の横方向と仮定する。
【0105】
本例では、MLUT30が有するそれぞれのAD対は、それぞれ異なるMLUTに隣接配線される。すなわち、第1のAD対は、隣接する第1のMLUT30aに結線される。第2のAD対は、隣接する第2のMLUT30bに結線される。第3のAD対は、隣接する第3のMLUT30cに結線される。第4のAD対は、隣接する第4のMLUT30dに結線される。第5のAD対は、隣接する第5のMLUT30eに結線される。第6のAD対は、隣接する第6のMLUT30fに結線される。
【0106】
図25は、隣接MLUTを介して距離を置いて配置された2つのMLUTの接続の一例を示す図である。この場合、MLUT30fは、MLUT30aとMLUT30との接続を行う接続要素として動作する。このように、MLUT30fを、距離を置いて配置されたMLUT30aとMLUT30とを接続する接続要素として使用する場合、MLUTfの真理値表の一部が、MLUT30と30aとの接続関係に使用されるため、MLUT30fにおける真理値表により実現可能な論理回路の規模が小さくなる。図25に示すように、隣接するMLUTを接続要素として利用して、距離を置いて配置されるMLUT30及び30aを接続すると、図24に示すMLUTと比して、所望の論理回路を構成するのに必要なMLUTの総量が増加することになる。
【0107】
図26A〜図26Dは、所望の論理回路を構成するために必要なMLUT数の一例を示す図である。図27は、隣接するMLUTにAD対で接続するMLUT構造である最密充填配置構造31Aと、離間配置されるMLUTとをAD対で接続するMLUT構造である非最密充填配置構造31Bを示す図である。所望の論理回路は、CLA加算器、RCA加算器、be加算器、及び8ルーレットLED回路などの回路を200〜1000程度の数のMLUTを有するMPLDに、自動配置配線ツールにより配置配線することにより行った。
【0108】
この結果、本比較に使用した全ての回路構成において、いずれの大きさのMPLDを使用した場合でも、最密充填配置構造31Aを有するMPLDが、非最密充填配置構造31Bを有するMPLDより、非配置・配線効率が高くなった。このため、最密充填配置構造31Aを有するMPLDは、非最密充填配置構造31Bを有するMPLDより、所望の論理回路を構成するMLUTの総量を減らすことができる。
【0109】
図28は、最密充填配置構造におけるAD対の数の一例を示す図である。図28では、32ビット乗算回路を手動構成した場合の必要メモリ容量とクリティカル・パス・セル数とを計算した。図示されるように、MLUTが備えるAD対の数は、6以上であると、クリティカルパルMLUT数が減少する。また、MLUTが備えるAD対の数は、6以上であると、必要メモリ容量が増加する。この結果は、AD対の数が少ない場合、所望の論理回路をMPLD20に配置配線するときに、それぞれ論理回路として動作するMLUT間の配線にスイッチング用に挿入されるMLUTの数が増加することを示す。AD対の数が少ないと、接続要素として機能できるMLUTの数が限定される。このため、接続要素として機能するMLUTを数多く通過しなければ、論理回路として動作するMLUT間を配線できない可能性がある。この結果、AD対の数が少ないと、論理回路を実現するために必要なMLUT数が増加する可能性がある。図28の例では、MLUTが有するN個のAD対のうち、5つのAD対は、論理回路として真理値表を構成するために使用することが望ましい。このため、MLUTが備えるAD対の数は、5以上であることが好ましい。
【0110】
一方、MLUTが備えるAD対の数を増やすと、配置・配線したときに実際に使用するMLUT当たりのAD対の数が減少することが予想される。そして、このために、配置・配線効率が低下する可能性がある。図28に示す、32ビット乗算回路を手動で配置・配線する場合に、AD対の数を8にすると、配置・配線に必要な領域は、AD対の数を6にするときの4倍に増加した。
【0111】
〔3.2.2〕マトリックス配置構造でのAD対結線構造
図29は、MLUTのAD対の結線構造の1例を示す図である。MLUT30は、マトリックス状に配置され、6つのAD対をそれぞれ有する。図29では、MLUT30とMLUT30aとを結ぶ直線に平行な方向をMLUT領域8の縦方向と仮定する。そして、MLUT30とMLUT30cとを結ぶ直線に平行な方向をMLUT領域8の横方向と仮定する。MLUT30は、縦方向に配置されるMLUT30a及び30bに近距離配線される第1及び第2のAD対と、横方向に配置されるMLUT30c及び30dに近距離配線される第3及び第4のAD対と、縦方向に位置するMLUT30の横方向に隣接する2つのMLUT30e及び30fにそれぞれ近距離配線される第5及び第6のAD対とを有する。
【0112】
このように、本例では、ある列に配置されるMLUT(例えば、MLUT30)の2つのAD対は、第1の列の方向に隣接するMLUTの横方向に隣接する2つのMLUTにそれぞれ近距離配線される。そして、その列に隣接する列に配置されるMLUT(例えば、MLUT30c及び30d)の2つのAD対は、第1の列の方向と反対の方向である第2の列の方向に隣接するMLUTの横方向に隣接する2つのMLUTにそれぞれ近距離配線される。このように近距離配線することで、隣接するMLUTを結線するAD対は、同一平面上で交差しない構造とすることができる。
【0113】
なお、この例では、全てのMLUTの第5及び第6のAD対は、縦方向に配置されるMLUTの横方向に隣接する2つのMLUTにそれぞれ近距離配線される。しかしながら、このAD対を横方向に配置されるMLUTの縦方向に隣接するMLUTに近距離配線する構造とすることもできる。例えば、MLUT30の第5及び第6のAD対は、横方向に配置されるMLUT30の縦方向に隣接する2つのMLUT30e及び30gにそれぞれ近距離配線できる。
【0114】
〔3.2.3〕交互配置構造でのAD対結線構造
図30は、MLUTのAD対の結線構造の別な例を示す図である。MLUT30はそれぞれ、交互配置構造で配置され、6つのAD対をそれぞれ有する。図30では、MLUT30とMLUT30aとを結ぶ直線に平行な方向をMLUT領域8の縦方向と仮定し、MLUT30bとMLUT30fとを結ぶ直線に平行な方向をMLUT領域8の横方向と仮定する。
【0115】
MLUT30は、縦方向に配置される2つのMLUT30a及び3dに結線される第1及び第2のAD対と、MLUT30が配置される列に隣接する列の双方の隣接する位置に配置される4つのMLUT30b、30c、30e、及び30fに近距離配線される第3、第4、第5、及び第6のAD対とを有する。
【0116】
本例では、MLUTを結線するAD対は、同一平面上で交差しない構造とすることができる。さらに、全てのMLUTのAD対の結線構造を同一な構造にすることができる。なお、この例では、全てのMLUTの2つのAD対は、縦方向に配置されるMLUTに結線されるが、このAD対を横方向に配置されるMLUTに結線する構造とすることもできる。すなわち、MLUT30の第1及び第2のAD対は、縦方向に配置される横方向に配置されるMLUT30a及び3dに近距離配線する代わりに、2つのMLUT30h及び30kに近距離配線することができる。
【0117】
〔3.2.4〕Dフリップフロップ結線を有するMLUTのAD対結線構造
図31は、MLUTのAD対の結線構造の他の例を示す図である。MLUTはそれぞれ、交互配置構造で配置され、7つのAD対をそれぞれ有する。また、MLUTはそれぞれ、Dフリップフロップ13を隣接して配置される。MLUTが有する7つのAD対の中で、6つのAD対は、隣接するそれぞれ6つのMLUTと近距離配線される。残りの1つのAD対は、隣接するDフリップフロップ13と結線される。近距離配線される6つのAD対は、図30に示す結線と同一の結線構造を有する近距離配線にすることができる。残りの1つのAD対は、アドレス線がDフリップフロップ13のD入力と結線され、データ線がQ出力と結線される。Dフリップフロップ13のCK入力は、全て結線され、全てのDフリップフロップ13を1つのクロック信号で動作させることができる。また、Dフリップフロップ13のCK入力を列ごとに結線し、列ごとに異なるクロック信号で動作させることができる。さらにまた、Dフリップフロップ13のCK入力を8個、又は16個など任意の数のグループごとに結線し、それぞれのグループで異なるクロック信号で動作させることができる。
【0118】
本例では、それぞれのMLUTの1つのAD対にDフリップフロップが結線されるので、MLUT領域に順序回路を形成することができる。真理値表を構成する機能のみを有するMLUTのみで構成されるMLUT領域では、組み合わせ回路を構成することは、可能であるが、順序回路を構成することは、難しい。そこで、本例では、それぞれのMLUTの1つのAD対にDフリップフロップを結線することで、順序回路を形成することを可能にする。
【0119】
なお、本例では、DフリップフロップがAD対に結線されるが、セット・リセット・フリッププロップ、Tフリップフロップ、又はJKフリップフロップなどの他のフリップフロップを結線できる。また、セット入力、リセット入力、又はQB出力などの入出力を有するDフリップフロップを結線できる。さらに、DフリップフロップのQ出力に結線されるMLUTのデータ線を、DフリップフロップのQB出力に結線できる。さらに、全てのMLUTがそれぞれ、Dフリップフロップと結線するAD対を有する必要はなく、MLUT領域を構成するMLUTの中で、所定の割合のMLUTのみがDフリップフロップと結線するAD対を有する構造にすることができる。また、以下の説明において、MLUTの1つのAD対をDフリップフロップに結線することを、Dフリップフロップ結線と称することがある。
【0120】
〔3.2.5〕離間配線を有する場合のMLUTのAD対結線構造
図32は、MLUTのAD対の結線構造の他の例を示す図である。MLUT30はそれぞれ、7つのAD対をそれぞれ有し、交互配置構造で配置される。MLUT30が有する7つのAD対の中で、6つのAD対は、隣接するそれぞれ6つのMLUT30と近距離配線される。残りの1つのAD対は、1列ごとに列を1つ変えたMLUT30と離間配線される。
【0121】
本例では、MLUT30はそれぞれ、1つの離間配線を有するので、離間配線は、MLUT30を接続要素として使用してMLUT間を接続するよりも、データの伝播遅延時間を減少させることができる。また、離間配線は、論理回路をMLUT領域8上に論理回路情報を配置・配線するときに、配線の柔軟性を高めることができる。なお、離間配線は、近距離配線ではないMLUT間の接続配線である。よって、隣接するMLUTではないMLUTと接続することで、上記の離間配線の効果が生じる。
【0122】
なお、本例では、全てのMLUTがそれぞれ、離間配線されるAD対を有するが、所定の割合のMLUTのみが離間配線するAD対を有する構造にしてもよい。例えば、ある割合のMLUTの1つのAD対を、離間配線として使用し、他のMLUTの1つのAD対を、Dフリップフロップ結線とすることができる。
【0123】
〔3.3〕MLUT領域の構造
〔3.3.1〕MLUT領域の全体的な構造
図33は、MLUTのAD対の結線構造の他の例を示す図である。図33を参照して、本例に係るMLUT領域の全体的な構造の一例を説明する。本例では、MLUT領域8は、15行×30列の交互配置構造で配置される450個のMLUT30を有する。MLUTはそれぞれ、7つのAD対を有し、6つのAD対を近距離配線として使用する。残りの1つのAD対は、離間配線、又はDフリップフロップ結線に使用する。図において、離間配線が結線されていないMLUTは、Dフリップフロップに結線される。
【0124】
本例では、15行×30列の交互配置構造で配置される7つのAD対を有するMLUTを用いて、MLUT領域が説明される。しかしながら、他の配置のMLUTを用いて、MLUT領域を構成できることは、当業者に明確に理解されるであろう。また、MLUT領域に配置されるMLUTの中で、離間配線が結線されるMLUTと、Dフリップフロップ結線されるMLUTの割合は、MPLDが使用される用途及び機能に基づいて任意に選択することができる。さらにまた、本例では、MLUTの配置構造は、交互配置構造であるが、マトリックス配置構造においても、本例と同様の結線構造を有することができる。すなわち、本例の配線構造を維持しながら、MLUTの配置構造を交互配置構造からマトリックス配置構造にトポロジカルに変換した構造とすることもできる(図29及び図30を参照のこと)。
【0125】
〔3.3.2〕MLUTブロックの構造
図34は、MLUTを有するMLUTブロックの一例を示す図である。本例では、MLUTブロックは、3行×6列のMLUTを1つのブロックとして構成する。各ブロック内のMLUTはそれぞれ、基本的には同一の配線規則に従って、離間配線、又はDフリップフロップ結線される。
【0126】
以下、基本的な結線規則を述べる。
【0127】
6つのAD対は、近距離配線に使用する。この規則は、MLUT領域8の端部に配置されるMLUT30でも同じである。このため、本例におけるMLUT領域8は、近距離配線として配置されるAD対を入出力線AD対として有し、これらのAD対により半導体装置100に配置される他の構成要素と結線することができる。
【0128】
1つのMLUTブロックに含まれる18個のMLUT30の中で6つのMLUTは、1つのAD対をDフリップフロップ結線する。このため、本例におけるMLUT領域は、3分の1の数のMLUTがDフリップフロップ結線されることになる。具体的には、図34において、「30F」の符号が付されたMLUT30である。すなわち、図34において、下の行の左から2列目及び3列目のMLUTと、中央の行の左から5列目及び6列目のMLUTと、上の行の左から3列目及び6列目のMLUTである。
【0129】
1つのMLUTブロックに含まれる残りの12個のMLUTには、離間配線が結線される。離間配線のうち、4本は縦方向に配置されるMLUT間で結線される第1の離間配線パターンで結線される。他の4本は左下から右上に整列するMLUT間で結線される第2の離間配線パターンで結線される。残りの4本は右下から左上に整列するMLUT間で結線される第3の離間配線パターンで結線される。
【0130】
第1の離間配線パターンで結線されるMLUTは、下の行の左から1列目及び4列目のMLUTと、中央の行の左から1列目のMLUTと、上の行の左から4列目のMLUTである。図34において、これらのMLUTはそれぞれ、「30C」の符号が付される。下の行の左から4列目のMLUTと、中央の行の左から1列目のMLUTとは、縦上方向に5つ離れたMLUTとそれぞれ離間配線が結線される。下の行の左から1列目のMLUTと、上の行の左から4列目のMLUTとは、縦下方向に5つ離れたMLUTとそれぞれ離間配線が結線される。
【0131】
第2の離間配線パターンで結線されるMLUTは、下の行の左から6列目のMLUTと、中央の行の左から2列目及び3行目のMLUTと、上の行の左から5列目のMLUTである。図34において、これらのMLUTはそれぞれ、「30L」の符号が付される。下の行の左から6列目のMLUTと、中央の行の左から3列目のMLUTとは、右上方向に5つ離れたMLUTとそれぞれ離間配線が結線される。中央の行の左から2列目のMLUTと、上の行の左から5列目のMLUTとは、左下方向に5つ離れたMLUTとそれぞれ離間配線が結線される。
【0132】
第3の離間配線パターンで結線されるMLUTは、下の行の左から5列目のMLUTと、中央の行の左から4行目のMLUTと、上の行の左から1行目及び2列目のMLUTである。図34において、これらのMLUTはそれぞれ、3Rの符号が付される。中央の行の左から4列目のMLUTと、上の行の左から1列目のMLUTとは、左上方向に5つ離れたMLUTとそれぞれ離間配線が結線される。下の行の左から5列目のMLUTと、上の行の左から2列目のMLUTとは、右下方向に5つ離れたMLUTとそれぞれ離間配線が結線される。
【0133】
図35は、15行×30列のMLUTを有するMLUT領域における近距離配線パターンの配置の一例を示す図である。図35において、円形の形状で示される450個のMLUTと、隣接する6つMLUT間をそれぞれ結線する近距離配線とが示される。MLUT領域8の端部に位置するMLUT30が有するいくつかのAD対は、未結線である。上述のように、これら未結線のAD対は、入出力回路部15、又は内部バス回路部などの半導体装置内の他の構成要素と結線することができる。
【0134】
図36〜図38に、本例におけるMLUT領域における第1〜第3の離間配線パターンの配置を示す。以下、それぞれの図を参照して、第1〜第3の離間配線パターンの配置の一例を説明する。
【0135】
〔3.3.3〕第1の離間配線パターンの配置構造
図36は、15行×30列のMLUTを有するMLUT領域における第1の離間配線パターンの配置を示す図である。図36において、円形の形状で示される450個のMLUT30と、隣接する6つMLUT間をそれぞれ結線する近距離配線と、縦方向に5つのMLUT30ごとに結線される第1の離間配線パターンとが示される。なお、第1の離間配線パターンで離間配線が結線されるべき位置に配置されるMLUTの中で、MLUT領域8の上端部及び下端部の近傍に位置するMLUT30のいくつかは、第1の離間配線パターンで離間配線が結線されていない。これらのMLUTは、第1の離間配線の規則に基づき結線すべきMLUTがMLUT領域8上に存在しない。このため、後述する第4及び第5の離間配線パターンで離間配線が結線される。
【0136】
〔3.3.4〕第2の離間配線パターンの配置構造
図37は、15行×30列のMLUTを有するMLUT領域における第2の離間配線パターンの配置を示す図である。図37において、円形の形状で示される450個のMLUT30と、隣接する6つMLUT間をそれぞれ結線する近距離配線と、左下から右上に整列するMLUT間で5つのMLUTごとに結線される第2の離間配線パターンとが示される。なお、第1の離間配線パターンと同様に、第2の離間配線パターンで離間配線が結線されるべき位置に配置されるMLUTの中で、MLUT領域8の端部の近傍に位置するMLUT30のいくつかは、後述する第4及び第5の離間配線パターンで離間配線が結線される。
【0137】
〔3.3.5〕第3の離間配線パターンの配置構造
図38は、15行×30列のMLUTを有するMLUT領域における第3の離間配線パターンの配置を示す図である。図において、円形の形状で示される450個のMLUT30と、隣接する6つMLUT間をそれぞれ結線する近距離配線と、右下から左上に整列するMLUT間で5つのMLUTごとに結線される第3の離間配線パターンとが示される。なお、第1及び第2の離間配線パターンと同様に、第3の離間配線パターンで離間配線が結線されるべき位置に配置されるMLUT30の中で、MLUT領域8の端部の近傍に位置するMLUT30のいくつかは、後述する第4及び第5の離間配線パターンで離間配線が結線される。
【0138】
〔3.3.6〕第4の離間配線パターンの配置構造
図39は、15行×30列のMLUTを有するMLUT領域における第4の離間配線パターンの配置を示す図である。上述のように、第4の離間配線パターンの配置は、図34に示すMLUTブロックにおいて規定される結線規則に基づくものではなく、MLUT領域8の端部の近傍に位置するMLUT30のいくつかを結線するものである。しかしながら、第1〜第3の離隔配線パターンの配置に類似する配置となるように、第4の離間配線パターンは、配置される。第4の配線パターンの規則を以下に示す。
【0139】
まず、第4の離間配線パターンは、第1〜第3の離間配線パターンと同様に、縦方向、左下から右上方向、又は右下から左上方向のいずれかのMLUTが整列した方向に平行に配置される。
【0140】
次に、第4の離間配線パターンは、いずれかの方向にMLUTを4つ離れたMLUTごとに配置される。この規則に則するために、本来は第1〜第3の離間配線パターンで結線されるべきMLUTのいくつかが、第4の離間配線パターンで結線される。例えば、図38において、上端の行の左端の列に配置されるMLUTは、第1の離間配線パターンで離間配線を結線されるべきMLUTであるが、第4の離間配線パターンで結線される。
【0141】
このように第4の離隔配線パターンは、第1〜第3の離隔配線パターンに類似した配線パターンを有するため、MLUT領域8上のそれぞれのMLUT30に論理回路情報を配置・配線するときに使用する配置・配線アルゴリズムに与える影響を低く抑えることができる。
【0142】
〔3.3.7〕第5の離間配線パターンの配置構造
図40は、15行×30列のMLUTを有するMLUT領域における第5の離間配線パターンの配置を示す図である。第5の離間配線パターンにより接続されるMLUTは、第1〜第4の離間配線パターンで結線することができず、かつ第4の離間配線パターンでも結線することができなかったMLUT30ある。本例におけるMLUT領域では、これらのMLUT30は、Dフリップフロップを介して結線することもできる。
【0143】
〔4〕1つのMPLDを搭載した半導体装置
ここでは、1つのMPLDを搭載した半導体装置の例について説明する。
【0144】
〔4.1〕1つのMPLDを搭載した半導体装置の配置構造
図41は、MPLDを搭載した半導体装置の配置ブロックの一例を示す図である。半導体装置100は、MPLD20と、入出力回路部15とを有する。入出力回路部15は、半導体装置100の外部の装置から信号を入力するための入力回路、半導体装置100の外部の装置から信号を出力するための出力回路、電源用セル、及びI/Oパッドを有する。
【0145】
入力回路はそれぞれ、MPLD20内に配置されるそれぞれのMLUT30を選択するアドレス線、それぞれのMLUT30を構成する記憶素子40を選択するアドレス線、それぞれのMLUT30を構成する記憶素子40にメモリ動作情報などを書き込むためのメモリ動作用データ線接続することができる。さらに入力回路は、MPLD20の端部に配置され他のMLUT30と結線されていないAD対の少なくとも1つの論理動作用アドレス線、及び制御信号などに接続することができる。出力回路はそれぞれ、メモリ動作用データ線、及びMPLD20の端部に配置され他のMLUT30と結線されていないAD対の少なくとも1つの論理動作用データ線などに接続することができる。入力回路及び出力回路と、MPLD20のそれぞれのAD対とは、直接接続することができる。また、入力回路及び出力回路と、MPLD20のAD対とは、バッファ回路を介して接続することもができる。バッファ回路を介することにより、信号伝送速度を向上させることができる。
【0146】
MPLDは、多入力多出力の論理回路を構成することができる。例えば図33を参照すると、30行×15列のMLUT領域8を有するMPLD20は、118個の未結線のAD対を有する。これらのAD対は、全て入出力信号線として使用できる。これは、このMLUT領域8を有するMPLD20は、118本の入力信号線、及び118本の出力信号線を有し、64ビットなどの多ビットの信号をパラレルに論理演算できることを意味する。したがって、MPLDは、高速、かつ多入力多出力な論理回路を実現できる。また、上述のように、MPLDは、規則的に配置されるMLUTを有するので、規則性がある回路、又は真理値表に使用することもできる。
【0147】
〔4.2〕MPLDへの配置・配線フロー
ここでは、半導体装置に搭載されるMPLDを配置・配線するフローの1つの例について説明する。
【0148】
図42は、MPLDの配置・配線を実行する情報処理装置の1例を示す図である。情報処理装置210は、演算処理部211と、入力部212と、出力部213と、記憶部214とを有する。演算処理部211は、入力部212に入力された配置・配線用のソフトウェア、RTL(Register Transfer Level)記述などの回路記述(以下、ネットリストとも称する)などの真理値表データを記憶部214に記憶する。また、演算処理部211は、記憶部214に記憶された配置・配線用のソフトウェアを用いて、記憶部214に記憶された回路記述に対して以下に示す配置・配線のフローを実行し、出力部213に出力する。出力部213には、半導体装置100(図示せず)を接続することができ、演算処理部211が実行した配置・配線情報を包含するビットストリームデータを、出力部213を介して半導体装置100に書き込むことができる。
【0149】
図43は、情報処理装置が、MPLDに配置・配線するためのビットストリームデータを生成するフローの1例を示す図である。まず、ネットリストをテクノロジー非依存論理最適化し(S201)、テクノロジーマッピングし(S202)、配置(S203)、配線する(S204)ことを有する。配置・配線されたビットストリームデータは、それぞれにMLUT30に書き込む論理回路情報に相当し、MPLD20のメモリ動作により、それぞれのMLUT30が備える記憶素子に書き込まれる。以下、それぞれのステップについて順に説明する。
【0150】
〔4.2.1〕テクノロジー非依存論理最適化
まず、ネットリストをテクノロジー非依存論理最適化するステップ(S201)について説明する。このステップでは、加算器、減算器、乗算器、及び除算器などの演算器部分と、他の論理回路部分とに分離して最適化することができる。
【0151】
RTL記述から、演算器部分と、他の論理回路部分とに分離するときに、RTL記述に記載される演算記号を抽出することにより、演算器部分を分離することができる。例えば、Verilog HDLによりRLT記述が記述される場合は、加算を意味する「+」、減算を意味する「−」、乗算を意味する「*」、除算を意味する「/」、及び剰余演算を意味する「%」などの演算子を抽出することにより、RTL記述から、演算器部分を分離することができる。C言語に類似する他の言語を使用する場合も、同様な方法で演算器部分を分離することができる。
【0152】
演算器部分は、全加算器、又は半加算器などを基本単位として最適化することができる。演算器部分を他の論理回路部分とともに最適化すると、NAND回路、XOR回路などの基本的なゲート回路を組み合わせることにより、演算器が構成されることになる。しかしながら、この場合は、論理合成するときに、様々なゲート回路に論理合成されるために、各種演算器が構成される回路が冗長になる可能性がある。そこで、演算器部分を他の論理回路部分と分離し、全加算器、又は半加算器別になどを基本単位としてモジュール合成することにより、演算器部分を効率的に最適化ができる。
【0153】
ここでモジュール合成とは、規則的な構造を有するメモリ、演算論理装置(ALU)、乗算器、及び加算器などのデータパス系モジュールなどを対象として、モジュールの機能と、ビット幅などの必要な情報とをパラメータとして与えて、モジュールのパターンを生成することをいう。
【0154】
例えば、5個以上のAD対を有するMLUTによりMPLDを構成する場合は、2ビット加算器を基本単位として、演算器部分をモジュール合成することができる。4ビット加算器は、2つのビット加算器で構成することができる。8ビット加算器は、4つのビット加算器で構成することができる。
【0155】
8ビット加算器などの基本的な演算回路は、2ビット加算器による配線情報を記憶部214に記憶することができる。このことにより、記憶される演算回路に関しては、後述の配線処理が必要でなくなり、処理の高速化が図れる。しかしながら、演算回路は、様々なビット数を有する。また、加算器においても、全加算器、半加算器に加えて、「キャリー先読み(キャリールックアヘッド:Carry look ahead)」と称されるものも存在する。このため、全てのパターンの演算回路を記憶部に記憶させることは、現実的ではない。そこで、2ビット加算器により演算回路を構成するための所定の配線規則ルを記憶部214に記憶し、その配線規則に基づいて演算回路を構成することができる。
【0156】
他の論理回路部分は、通常のLSI設計、又はFPGAの設計に使用される一般的な方法を使用する。例えば、ステートマシンの状態数の最小化、二段論理最適化、及び多段論理最適化などの処理を実行する。
【0157】
〔4.2.2〕テクノロジーマッピング
次に、情報処理装置210が、テクノロジー非依存論理最適化した後のネットリストを、MPLDを構成するMLUTに適当なネットリストとするように、テクノロジーマッピングするステップ(S202)について説明する。1つの例では、テクノロジーマッピングは、テクノロジー非依存論理最適化した後のネットリストを分解する第1のステップと、第1のステップで分解したネットリストをカバリングする第2のステップとを有する。
【0158】
第1のステップは、MLUTに構成される真理値表に1つの論理回路を包含できるように、論理回路の入力及び出力数K以下にするステップである。MLUTのAD対の数がNである場合、入力及び出力数Kは、AD対の数N以下でなければならない。第1のステップには、カーネルの括り出し、及びRoth−Karp decompositionなどを使用することができる。
【0159】
第2のステップは、MLUTに構成される真理値表の数を最適化するために、第1のステップで得られたネットリストのいくつかの節点をカバーするステップである。このステップでは、第1のステップで分解された真理値表の中で、2つ以上の真理値表を結合して1つのMLUTに包含できる真理値表を1つの真理値表にまとめる。これにより、MLUT30に構成される真理値表の数を最適化することができる。
【0160】
好適には、組み合わせ回路を最適化するときに、最適化後の組み合わせ回路が有する入力数及び出力数をMLUTが有するAD対の数よりも少なくすることができる。これにより、組み合わせ回路が配置されるMLUTを、同時に接続要素として使用することができる。なお、MPLDを構成するMLUTが6つ以上のAD対を有する場合には、入力線及び出力線の数を5つ以下になるように最適することができる。5つの入力線及び出力線を有することによって、1つのMLUTで2ビット加算器の真理値表を構成するためである。
〔4.2.3〕配置
次に情報処理装置210が、テクノロジーマッピングを実行した後のネットリストを、MPLD内のそれぞれのMLUTに配置するステップ(S203)について説明する。テクノロジーマッピングを実行した後のネットリストには、MLUTが有するAD対の数に応じて構成される論理回路部の真理値表と、それぞれのMLUTが有するAD対間の接続関係が記載される。本ステップでは、論理回路部の真理値表をそれぞれ、適当な位置のMLUTに配置する。具体的な配置手法としては、通常のLSI設計と同様に、初期配置に使用される構成的配置法(ランダム法、ペア・リンキング法、クラスタ成長法、及びミンカット法など)、及び配置改善に使用される繰り返し改善法(スタインバーグ法、ペア交換法、反復重心法、及びシミュレーテッド・アニーリング法など)などがある。
【0161】
〔4.2.4〕配線
最後にテクノロジーマッピングを実行した後のネットリストに基づいて、配置されたMLUT間を配線するステップ(S204)について説明する。テクノロジーマッピングを実行した後のネットリストに従って、論理回路として動作するMLUTが有するAD対間を、接続要素として機能するMLUTを用いて配線する。具体的な配置手法としては、通常のLSI設計と同様に、Leeのアルゴリズム、及びラインサーチアルゴリズムなどがある。この結果、所望の論理回路を実現するネットリストをMPLD上に配置・配線する真理値表データを構成するビットストリームデータが生成される。
【0162】
〔4.3〕1つのMPLDを搭載した半導体装置での再構成
これまで説明してきたように、MPLDは、再構成可能な論理回路を構成することができる複数の記憶素子を有する。MPLDのこの特性を利用して、MPLDを搭載した半導体装置では、MPLDに書き込まれる論理回路情報を再構成することができる。
【0163】
例えば、図41に記載されるMPLD20を搭載した半導体装置100での再構成は、図42に記載される情報処理装置210を使用して実現することができる。MPLD20に書き込むことができる論理回路情報を構成する複数のビットストリームデータを情報処理装置210の記憶部214に記憶する。そして、情報処理装置210の出力部213と接続された半導体装置100に情報処理装置210がビットストリームデータを書き込むことによって、MPLD20の再構成を実現できる。
【0164】
また、図41に記載されるMPLD20を搭載した半導体装置100での再構成は、半導体装置100と同一の基板に搭載されるマイクロプロセッサ(図示せず)と、記憶装置(図示せず)とを使用することによっても、実現することができる。
〔4.4〕1つのMPLDを搭載した半導体装置での部分再構成
〔4.4.1〕MPLDの部分再構成フロー
半導体装置に搭載されるMPLDを部分再構成するフローの1つの例について説明する。
【0165】
図44は、図41に示す半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。まず、ステップS211において、情報処理装置210が、MPLDに書き込まれている第1のビットストリームデータと、部分再構成実行後の第2のビットストリームデータとを比較する。比較は、それぞれのビットストリームデータに記載される同一のアドレスを有するMLUT間の内部に記載される真理値表を比較して行う。さらに、MLUTのぞれぞれのAD対に接続されるAD対の符号などを比較して行う。第1のビットストリームデータと、部分再構成実行後の第2のビットストリームデータとは、記憶装置に記憶できる。好適には、第2のビットストリームデータを生成するときに、第1のビットストリームデータと、第2のビットストリームデータとの間で同一の機能を有するMLUTに対して、第1のビットストリームデータと同一の符号を付することができる。次に、ステップS212において、第1のビットストリームデータと、第2のビットストリームデータの間で記載される真理値表データが異なるMLUTのアドレスを特定し、記憶装置に記憶する。MLUTのアドレスは、第1のビットストリームデータと、第2のビットストリームデータとの間で、MPLD上で同一の位置に位置するMLUTを同一のアドレスにすることができる。例えば、30行×15列のMLUT領域を有するMPLDにおいて、左上の頂点に位置するMLUTのアドレスを0番とし、そのMLUTの右側に位置するMLUTのアドレスを1番とし、以下同様に繰り返し、右下の頂点に位置するMLUTのアドレスを449番とすることができる。なお、第1のビットストリームデータと、第2のビットストリームデータとのそれぞれのMLUTのアドレスと物理的位置が対応しない場合には、両者の相関を明確にする手段を有することができる。例えば、相関関係を示したデータを記憶装置に記憶できる。次にステップS213において、情報処理装置210が、ステップS212で特定されたMLUTの1つのアドレスをMPLDに出力する。具体的には、MPLD20の行デコーダ12aと、列デコーダ12bとにアドレスを入力する。そしてステップS214において、情報処理装置210が、アドレスが指定されたMLUTの第2のビットストリームデータに記載される真理値表データを、MLUTに書き込む。MLUTにデータを書き込む方法については、既に述べているのでここでは詳細は省略する。
【0166】
第1のビットストリームデータと、第2のビットストリームデータの間で記載される真理値表データが異なるMLUTのアドレスが、さらに記憶装置に記憶されている場合は、ステップS213に戻る。第1のビットストリームデータと、第2のビットストリームデータの間で記載される論理回路情報が異なるMLUT30のアドレスが、他に記憶されていない場合には、部分再構成を終了する。
【0167】
〔4.4.2〕部分再構成の実施例
ここでは、部分再構成の利点を具体的な実施例に基づいて説明する。実施例は、高速フーリエ変換において一般に使用されるバタフライ演算に基づくものである。
【0168】
図45に、8点離散フーリエ変換をバタフライ演算で行うときのアルゴリズムの一例を示す。ここで、f(0)〜f(7)は、時間上の8個の点である。F(0)〜F(7)は、離散フーリエ変換後の8個の点である。W0〜W3は、回転因子である。図45において、矢印線の交点は、加算する点を示す。また、矢印線の交点に「−1」との記載がさらに付される場合は、減算する点を示す。さらに、矢印線上に回転因子W0〜W3が付される場合は、回転因子W0〜W3を乗算することを示す。したがって例えばステージS1において、f(0)は、f(4)にW0を乗じたものを加算されるとともに、f(4)にW0を乗じたものを減算される。このように、バタフライ演算では、各Stageにおいて、定数乗算がなされる。
【0169】
一般的に、定数乗算を論理回路で実現する場合、乗算回路を構成するよりも、シフト回路と加算演算とで定数乗算専用回路を構成することが多い。これは、単純に乗算回路を構成する場合に比べて、シフト回路と加算演算とで定数乗算専用回路を構成することにより、演算速度の高速化を図れるからである。さらにまた、シフト回路と加算演算を使用することにより、回路素子数を減らすことが可能であるため、チップ面積を削減できる効果を有する。例えば、定数「3」に変数「a」を乗ずる回路は、以下の式に示すようにシフト回路と加算演算とで構成できる。
3 * a = a*2 + a = (a<<1) + a
ここで、「*」は乗算を示し、「+」は加算を示し、「<」はシフト回路を示す。したがって、式「(a<<1) + a」は、変数aを2桁上位ビットにシフトし、その結果に変数aを加算することを意味する。
【0170】
一方、離散フーリエ変換の回転因子W0〜W3は、回路が使用される用途によって、様々な値をとり得る。したがって、同じ8点離散フーリエ変換をバタフライ演算で実現する回路を構成する場合でも、用途によって、種々の回路を構成する必要がある。例えば、回転因子W3が3である回路においては、回転因子W3を乗算する回路は、以下に示す式のように構成される。
3 * a = a*2 + a = (a<<1) + a
これに対し、回転因子W3が4である回路においては、回転因子W3を乗算する回路は、以下に示す式のように構成される。
4 * a = a*2 + a*2 = (a<<1) + (a<<1)
FPGAなど従来の再構成可能論理回路では、このように一部の回路のみが変更になった場合でも、再び配置・配線する必要があるか、又は論理回路情報を全て書き換える必要がある。しかしながら、MPLDは、論理回路情報が変更されたMLUTのアドレスを特定できるので、論理回路情報が変更されたMLUTのみを書き換えて、部分再構成することができる。この実施例では、「+ a」の論理回路を構成するMLUTを「+ (a<<1)」の論理回路を構成するMLUTに書き換えることにより部分再構成することができる。
【0171】
〔5〕1つのMPLDと、演算処理部とを搭載した半導体装置
ここでは、1つのMPLDと、演算処理部とを搭載した半導体装置の例について説明する。
【0172】
〔5.1〕MPLDと、演算処理部とを搭載した半導体装置
図46は、MPLDを搭載した半導体装置の一例を示す図である。半導体装置100は、MPLD20と、演算処理部220を有する。
【0173】
演算処理部220は、記憶部110、命令読出部120、レジスタ部130、及び命令実行部140を有する。演算処理部220は、MPLD20に記憶されたプログラムを実行することで、MPLD20とのデータの入出力を行い、MPLD20から受け取ったデータを演算する装置である。演算処理部220は、例えば、演算処理装置としてのMPU(Micro Processing Unit)である。MPLD20は、多入力多出力の論理演算を高速処理可能である。そのため、演算処理部220を、論理回路の一部の制御としての分岐命令等の例外処理や、MPLD20の状態制御としてのMPLD20の再構成、MPLD20内のSRAMを記憶領域としてデータアクセスする等の機能に限定することで、8ビット、16ビットなどのビット幅が狭い演算処理装置にすることができる。
【0174】
記憶部110は、命令又はデータを記憶する記憶装置である。記憶部110は、MPLD20が記憶するデータの一部を記憶する。記憶部110は、例えば、1次キャッシュメモリである。記憶部110は、例えば、SRAM(Static Random Access Memory)である。なお、以下の説明では、記憶部110は、MPLD20の上位キャッシュメモリとして説明するが、図52を用いて後述するように、一実施形態においては、演算処理部220は、記憶部26とデータ接続する。その場合は、下記のMPLD20のメモリ機能を利用する演算処理部220とのデータ入出力は、主記憶装置についても同じである。
【0175】
記憶部110は、演算処理部220の内部に設けられており、MPLD20より命令読出部120に近い位置にある。命令読出部120が、記憶部110に記憶されているデータにアクセスする場合(以下、「キャッシュヒット」という)、命令読出部120は短時間で対象データにアクセスすることが出来る。一方、命令読出部120が、キャッシュメモリに記憶されていないデータにアクセスする場合(以下、「キャッシュミス」という)、記憶部110の下位階層にあるMPLD20からデータを読み出すため、対象データへのアクセス時間は長くなる。そのため、キャッシュミスが生じないように、演算読出部120からのアクセス頻度が高いデータは記憶部110に保持される。
【0176】
命令読出部120は、記憶部110から命令を読み出し、読み出した命令を命令実行部140に出力する。
【0177】
命令実行部140は、命令読出部120から記憶部110から読み出した命令を受け取ると、命令により特定される処理を、レジスタ130に記憶されるデータに対して実行する。命令に応じた所定の命令処理とは、例えば、浮動小数点演算、整数演算、アドレス生成、分岐命令実行、レジスタ130に記憶されるデータを記憶部110へストアするストア動作、記憶部110に記憶されるデータをレジスタ130にロードするロード動作である。命令実行部140は、浮動小数点演算、整数演算、アドレス生成、分岐命令実行、及びストア又はロード動作を行う実行器を備えて、それらの実行器を用いて上記命令処理を実行する。命令実行部140は、入出力部150を介して、MPLD20に対してデータのストア又はロード動作を実行する。
【0178】
レジスタ130は、例えば、オペランド、又は、MPLD20へストア又はリード動作する際のアドレス、命令実行部140が実行対象とする命令が格納されているMPLD20のアドレスを記憶する。
【0179】
入出力部150は、MPLD20とのデータの入出力を行う。MPLD20は、図1〜図3を用いて説明した例と同じである。入出力部150は、MLUT30の論理動作用アドレスLAのアドレス線と、演算処理部220の出力端子D0からの1つの出力信号線とが接続すると共に、MLUT30の論理動作用データLDのデータ線と、演算処理部220の入力端子I0への入力信号線が接続する。このようにして、MPLD20の外延に配置されるMLUTの少なくとも一部は、演算処理部220との論理動作用アドレスLAを受け取り、又は、論理動作用データLDを出力する。
【0180】
入出力部150はさらに、図46に示されるように、MPLDアドレス、メモリ動作用アドレスMA、書込データWD、読出データRDの信号線と接続し、それらのデータの入出力により、MPLD20に対するメモリ動作を行う。
【0181】
上記構成から明らかなように、演算処理部220は、入出力部150を介して、メモリ動作用アドレスMA、MPLDアドレス、書込データWDをMPLD20に出力することで、MPLDのメモリ動作を生じさせるストア動作を実行し、入出力部150を介して、メモリ動作用アドレスMA、MPLDアドレスをMPLD20に出力することで、読出データRDを受け取る。このように、入出力部150のうち、メモリ動作用アドレスMA、MPLDアドレス、書込データWD、読出データRDの入出力を行う部分が、メモリ動作用の入出力部として動作する。
【0182】
また、上記構成から明らかなように、演算処理部220は、入出力部150を介して、論理動作用アドレスLAを出力し、論理動作用データLDを受け取ることでMPLDの論理動作の結果を受け取る。このように、入出力部150のうち、論理動作用アドレスLA、論理動作用データLDの入出力を行う部分が、論理動作用の入出力部として動作する。
【0183】
図47は、演算処理部と、MPLDとのデータの入出力を行う入出力部の一例を概略的に示す図である。MPLD20に含まれる入出力部21は、MLUT30のアドレス線と、演算処理部220の出力端子DOからの1つの出力信号線とが接続すると共に、MLUT30のデータ線と、演算処理部220の入力端子IOへの入力信号線が接続する。
【0184】
演算処理部220の論理動作用の入出力信号線と、MLUT30のアドレス又はデータ線との接続は、演算処理部220の入出力ビット数の数だけ用意される。例えば、演算処理部220が16ビットの出力ビット幅を有している場合、出力信号線及び入力信号線は、それぞれ16本となり、それらの信号線と接続するMLUTのアドレス線及びデータ線も16本となる。
【0185】
演算処理部220の入出力信号線と、MLUT30のアドレス又はデータ線との接続は、演算処理部220の入出力ビット数の数だけ用意される。例えば、演算処理部220が16ビットの出力ビット幅を有している場合、出力信号線及び入力信号線は、それぞれ16本となり、それらの信号線と接続するMLUTのアドレス線及びデータ線も16本となる。
【0186】
このように、演算処理部220の入出力信号線と、MLUT30のアドレス又はデータ線とをバス接続回路を介さずに直接接続することで、演算処理部220と、MPLD20が接続することができる。演算処理部220と、MPLD20の間の接続に、バス接続回路を介さないことにより、バスの調停回路によりマスタースレーブの設定が不要になる。この結果、演算処理部220と、MPLD20の間の信号の伝送速度の向上を図ることができる。またそれぞれの接続の間に、バッファ回路を挿入することができる。バッファ回路を挿入することにより、信号の伝達速度をさらなる向上を図ることができる。
【0187】
図48は、演算処理部と、MPLDとのデータの入出力を行う入出力部の別な例を示す図である。図48に示すように、演算処理部220は、MPLD20とのデータ入出力を行う入出力部230を有する。また、MPLD20も、演算処理部220とのデータ入出力を行う入出力部21を有する。入出力部21は、入出力部150は、例えば、MLUT30のAD対のアドレス線からアドレスを出力するポートA0〜A7、及び、MLUT30のAD対のデータ線からデータを入力するポートD0〜D7を有して、MPLD20の論理要素に対するデータ入出力を行うことができる。
【0188】
入出力部21はさらに、演算処理部220の入出力部230とデータ入出力を行うための所定のプロトコルに従う伝送制御を行う。所定のプロトコルに従う伝送制御とは、例えば、PCI Express等の高速シリアルバスや、パラレルバス等のバス制御である。このように、演算処理部220と、MPLD20とは、所定のバスによりデータ接続できる。
【0189】
なお、図48は、演算処理装置1つのMPLD20と接続しているが、入出力部230を介して他のMPLDとも接続できる。そして、演算処理部220は、入出力部230を介して、第1のMPLDが有するMLUTのアドレス線及びデータ線と、第2のMPLDが有するMLUTのアドレス線及びデータ線と接続し、第1のMPLDに対して論理動作のデータ入出力を行うとともに、第2のMPLDに対して再構成を含むメモリ動作を行うこともできる。よって、演算処理部220は、第1のMPLDの入出力部に対してアドレス及びデータを出力する制御を行うとともに、第2のMPLDの入出力部に対してアドレスを出力し且つデータを受け取る制御を行う。
【0190】
図49は、論理動作とメモリ動作を同時に行うMPLD、及び演算処理部の一例を示す図である。図49に示すMPLD20のMLUTは、図19に示すMLUTのように論理動作と、メモリ動作を同時に行うことができる。そのため、演算処理部220は、MPLD内のメモリ動作対象となる複数のMLUTから構成される第1論理部に対してメモリ動作を行うとともに、MPLD内の論理動作対象となる複数のMLUTから構成される第2論理部に対して論理動作を行う。
【0191】
図50は、複数のMPLD、及び演算処理部の一例を示す図である。図50に示すMPLD20A、20BのMLUTは、図4に示すMLUTのように論理動作と、メモリ動作を同時に行うことができない。そのため、演算処理部220は、メモリ動作象となる複数のMLUTを含む第1MPLD20Aに対してメモリ動作を行うとともに、論理動作対象となる複数のMLUTから構成される第2MPLD20Bに対して論理動作を行う。
【0192】
〔5.2〕MPLDと、演算処理部とを搭載した半導体装置の配置構造
図51は、MPLDを搭載した半導体装置の他の例における配置ブロックの一例を示す図である。半導体装置100は、MPLD20と、演算処理部220と、入出力回路部15とを有する。入出力回路部15は、図41を参照して説明した例と同様であるため、ここでは説明を省略する。演算処理部220は、図46を用いて説明したものである。
【0193】
本例では、MPLDアドレス信号線と、メモリ動作用アドレス信号線とは、演算処理部220に接続することができる。MPLD20の端部に配置され他のMLUT30と結線されていないAD対のいくつかは、演算処理部220に接続される。また、他のいくつかは、入出力回路部15に接続される。演算処理部220と、MPLDアドレス信号線と、メモリ動作用アドレス信号線とは、内部バス回路を介して接続でき、又は直接接続するもできる。演算処理部220と、MLUT30のAD対との接続は、内部バス回路を介して接続できる。また、演算処理部220と、MLUT30のAD対との接続は、直接接続することもできる。AD対を直接接続する場合は、内部バス回路を介して接続する場合と比較すると、高速動作が可能になる。これは、バス調停回路動作を必要としないためである。さらにまた、演算処理部220と、MPLD20のそれぞれのAD対とは、バッファ回路を介して接続することもできる。バッファ回路を介することにより、さらに信号伝送速度を向上させることができる。
【0194】
図52に、MPLDを搭載した半導体装置の他の例における配置構造の一例を示す図である。図52を参照すると、本例における半導体装置100は、マルチプレクサ22と、A/Dコンバータ24と、演算処理部220と、1つのMPLD20と、記憶部26と、MOSFET(Metal−Oxide−Semiconductor Field−Effect Transistor)ドライバ28とを有する。また、本例の半導体装置100の制御対象物の検出器出力からマルチプレクサ22に信号が入力され、制御対象物の制御入力にMOSFETドライバ28の出力が入力される。
【0195】
マルチプレクサ22は、32個、又は64個などの適当な数のアナログ信号が制御対象物の検出器から入力される。マルチプレクサ22は、入力された信号を時分割して、A/Dコンバータ24に出力する。A/Dコンバータ24は、時分割されたアナログ信号をデジタル信号に変換して、演算処理部220とMPLD20に出力する。A/Dコンバータ24からの信号を入力した演算処理部220は、外部の記憶装置に記憶されるソフトウェアの制御に基づいて、入力した信号の処理をMPLD20に命令する。このときに、MPLD20は、多入力多出力の演算処理、定型処理、及び背景処理などを行う。
【0196】
また、演算処理部220は、MPLD20に信号処理方法を命令するとともに、MPLD20からエラー信号、警報信号などが入力されたときの処理などの非定型処理を行う。演算処理部220は、MPLD20の論理回路情報を再構成することにより、種々の処理をMPLD20に実行させることができる。所定の処理が終了した後に、外部の記憶装置に記憶されるソフトウェアの制御に基づいて、演算処理部220は、MOSFETドライバ28を介して対象物にデータを制御対象物に出力する。これにより、制御対象物の検出器から本例における半導体装置100を介して制御対象物の制御器へのフィードバックループを形成することができる。したがって、多系統の制御を少ない部品で構成できる。
【0197】
本例における半導体装置100の応用例を、説明する。応用例として、半導体装置100は、自動車のドアミラーに付着した雨滴を除去する制御する。この場合、制御対象物の検出器は、自動車の運転手側のドアに設置されるドアミラー、助手席側のドアミラーに設置される及びフロントガラスなどに、それぞれ数個ずつ配置される雨滴検出器と、フロントガラス、又はボンネットなどに設置される雨量検出器などがある。また他の入力には、ドアミラー、フロントガラスなどに設置されるワイパの動作頻度、動作速度の信号などがある。これらの信号を入力される半導体装置100は、動作時間、動作周期、動作強度などを他の記憶装置に記憶されるソフトウェアに従って、決定する。そして、決定に基づき、MOSFETドライバ28の出力に接続されるワイパ駆動用モータに信号を出力し、ドアミラーのワイパを適当な時間、周期、強度で駆動する。また、何らかの故障が生じた場合は、MOSFETドライバ28の出力に接続されるLEDドライバに信号を入力して、運転手に警告を与えるために、LEDを駆動する。このとき、ワイパ駆動用モータに出力される信号の制御は、定型処理であり、かつ多ビット並列処理であるために、MPLD20により演算処理される。このとき、必要に応じてMPLD20の論理回路情報を再構成できる。一方、MOSFETドライバ28に出力される警告信号の制御は、非定型処理であるので、演算処理部220が処理する。
【0198】
〔5.3〕MPLDに書き込む論理回路情報の動作合成フロー
ここでは、半導体装置に搭載されたMPLDに書き込む論理回路情報を動作合成するフローについて説明する。
〔5.3.1〕動作合成について
【0199】
一般的に動作合成とは、設計対象の回路で処理したいアルゴリズム、すなわち動作記述から、その回路のRTLコードを生成することをいう。
【0200】
図53は、動作合成の一例を示す図である。図42に示す情報処理装置210が、動作合成を実行することができる。図53を参照すると、動作合成において、情報処理装置210は、ステップS221において、動作記述からCDFG(Control Data Flow Graph)を生成し、ステップS222において、CDFGをスケジューリングし、ステップS223において、スケジューリングしたCDFGをアロケーションし、ステップS224において、アロケーションしたCDFGからMPU命令コードを生成し、ステップS225において、RTL−CDFGとを生成する。なお、「MPU命令コード」とは、演算処理部220の命令コードである。
【0201】
動作記述には、デジタル回路設計用ハードウェア記述言語(HDL)の一種であるVHDL(VHSIC(Very High Speed Integrated Circuits)Hardware Description Language))を用いることができる。また、動作記述は、汎用性が高い、いわゆる高級言語(高水準言語とも称される)とすることもできる。ここで、高級言語は、プログラミング言語のうち、より自然語に近く、人間にとって理解しやすい構文や概念を持った言語の総称をいう。代表的な高級言語の種類としては、BASIC、FORTRAN、COBOL、C言語、C++、Java(登録商標)、Pascal、Lisp、Prolog、Smalltalkなどがある。
【0202】
MPU命令コードは、アセンブリ言語、又は機械語などの低級言語(低水準言語とも称される)であり、演算処理部が直接読み込む言語にすることができる。MPU命令コードは、ソフトウェアなどの形態で記憶装置などに記憶され、演算処理部が実行する処理の内容を規定する。MPU命令コードには、動作記述に記載される制御回路部分の一部などが含まれる。
【0203】
RTL−CDFGは、C言語の記述にレジスタ記述を追加したもの、又はverilog HDLなどのハードウェア記述言語(HDL)などにできる。RTL−CDFGは、図43に示す回路記述に相当するものである。図42に示す情報処理装置210は、図42及び図43を用いて説明した配置・配線フローにより、RTL−CDFGからビットストリームデータを生成することができる。
【0204】
以下、図53に示すそれぞれのステップについて、順に説明する。
【0205】
〔5.3.2〕CDFGを生成するステップ
図53に示すCDFGを生成するステップS221は、動作記述の実行の制御の流れと、データの流れとを解析し、プログラムのフローチャートに類似するCDFGに変換するステップとを有する。CDFG(Control Data Flow Graph)は、動作記述に現れたデータの流れ(データフロー)と各演算の実行順序の制御の流れ(コントロールフロー)を表し、節点、入力枝、出力枝、及び四則演算などの各種演算の種類を示す番号を有する。動作記述をCDFGに変換するときに、定数伝搬、共通演算除去などのコンパイラの最適化で行われる処理と同様な処理を行う。また併せて、動作記述に内在する並列性を引き出すように、フローグラフの構造を変換する処理なども実施してもよい。
【0206】
図54は、論理回路x=(a+b)*(b+c)を構成するCDFGの例を示す図である。この式は、「a」と「b」との論理和と、「b」と「c」との論理和との論理積「x」を求める式である。図54を参照すると、br1〜br7は、データ信号、又はコントロール信号を表す。節点br11〜br13は、演算を表す。節点br11及びbr12はそれぞれ、「a」と「b」との論理和と、「b」と「c」との論理和とを表す。節点br13は、節点br11の出力枝と、節点br12の出力枝との論理積を表す。
【0207】
〔5.3.3〕スケジューリングするステップ
図53に示すスケジューリングするステップS222は、全体のハードウェア量と、総制御ステップ数などの時間制約とを考慮して、動作記述中の各演算を実行する制御ステップを具体的に決定するステップである。すなわち、スケジューリングは、CDFGの節点に対応する演算をいつ実行するか、決定することである。言い換えると、どのクロックステップでCDFGの節点に対応する演算を実行するかを決定することである。この場合に、各演算の遅延時間を考慮して、全ての節点がクロック周期内に収まるようにスケジューリングする。スケジューリングは、速度優先スケジューリングと、ハードウェア量優先スケジューリングに分類される。速度優先スケジューリングは、全体の制御ステップ数を制約として与えて、その条件の下でハードウェア量が小さくなるようにスケジューリングを行なうものである。一方、ハードウェア量優先スケジューリングでは、使用可能なハードウェア量の制約を与えて、その条件の下で制御ステップ数が最小になるようにスケジューリングを行なうものである。
【0208】
図55は、図54に示すCDFGを、速度優先スケジューリングでスケジューリングした結果を示す図である。図55を参照すると、step 1において、図54に示すCDFGの節点c11で示される「a」と「b」との論理和と、節点c12で示される「b」と「c」との論理和と、節点c13で示される節点c11の出力枝と、節点c12の出力枝との論理積が全て実行される。このように、図55に示す速度優先スケジューリングでは、1つのステップで所与の論理回路を実行できる。しかしながら、節点c11で示される「a」と「b」との論理和と、節点c12で示される「b」と「c」との論理和とが同一のステップで実行されるため、2つの論理和回路を必要とされる。
【0209】
図56は、図54に示すCDFGを、ハードウェア量優先スケジューリングでスケジューリングした結果を示す図である。図56を参照すると、step 1において、図54に示すCDFGのうち、節点c11で示される「a」と「b」との論理和が実行される。そして、step 2において、節点c12で示される「b」と「c」との論理和と、節点c13で示される節点c11の出力枝と、節点c12の出力枝との論理積が実行される。このように、図55に示す速度優先スケジューリングが、1つのステップで所与の論理回路を実行するのに対し、ハードウェア量優先スケジューリングでは、2つのステップで所与の論理回路を実行する。このため、速度優先スケジューリングに比較して、ハードウェア量優先スケジューリングでは、処理時間が増加する。しかしながら、節点c11で示される「a」と「b」との論理和と、節点c12で示される「b」と「c」との論理和とが異なるステップで実行されるため、図55に示す速度優先スケジューリングが2つの論理和回路を必要とするのに対し、ハードウェア量優先スケジューリングでは、1つの論理和回路のみで2つの論理和演算を実行することができる。
【0210】
〔5.3.4〕アロケーションするステップ
アロケーションとは、スケジューリングの結果に基づいて、CDFGの演算節点に演算器を割り当て、データ選択のためのマルチプレクサと、データ記憶のためのレジスタとを生成すると共に、これらの演算器、レジスタ、およびマルチプレクサを制御するためのコントローラを生成し、それぞれを互いに接続することにより回路を合成することをいう。すなわち、アロケーションステップ(S223)では、CDFGの演算を表す各節点に対して、データの依存関係と与えられた制約とに基づき、制御ステップの割り当てが行われる。このときに、生成される論理回路において使用するMLUT数の見積もりを併せて行うことができる。
【0211】
アロケーションは、演算器部分と制御部分とに分離して実行することができる。以下、演算器部分と、制御部分とを順に説明する。
【0212】
演算器部分に含まれる回路には、3つの種類がある。第1の種類は、全加算器で構成することができるものである。これには、加算減算、乗算、カウンタ、比較演算などが含まれる。第2の種類は、マルチプレクサで構成することができるものである。これには、多ビットマルチプレクサ、及びバレルシフタなどが含まれる。第3の種類は、メモリ回路で構成することができるものである。これには、ルックアップテーブル、及びレジスタファイルなどが含まれる。いずれの種類の演算器においても、アロケーションするときには、ステップごとに、すなわちステートマシンのステートごとにレジスタ回路を挿入する。ここで、ステートマシンは、あらかじめ決められた複数の状態を、決められた条件に従って、決められた順番で遷移していくディジタル・デバイスである。ステートマシンのステートは、図56に示す「step 1」、又は「step 2」などのような、スケジューリングで規定される1つの制御ステップである。
【0213】
演算器部分のアロケーションは、演算器の種類とビット数とに基づいて実行する。ビット数は、C言語などの高級言語の型でビット数を決定することができる。これにより、C言語などの高級言語と互換性を有するCDFGを構成することができる。また、int、short、longなどの型ではビット幅が大きいと考えられる場合には、C言語の変数宣言の部分に拡張ディレクティブでビット数を規定しても良い。このように規定されるビット数に基づいて、それぞれの演算器に必要なMLUTの数を決定することができる。
【0214】
マルチプレクサで構成できる第1の種類の演算器では、ハードウェア量を優先するアロケーションと、速度を優先するアロケーションとのいずれかを選択して、アロケーションすることができる。例えば、多ビット加算器においては、ハードウェア量を優先するアロケーションでは、全加算器を多段に組み合わせることにより、多ビット加算器を構成できる。また、速度を優先するアロケーションでは、多段に組み合わせられる全加算器と、キャリー先読み論理回路とを有する多ビット加算器を構成することができる。
【0215】
5つ以上のAD対を有するMLUTにより構成されるMPLDにおいて、第1の種類の演算器を構成するMLUT数を見積もる場合は、2ビット加算器を1つのMLUTで構成することに基づいて、MLUT数を見積もることができる。例えば、4ビット加算器は、2つのビット加算器で構成されると見積もることができる。また、8ビット加算器は、4つのビット加算器で構成されると見積もることができる。この場合、各種の加算器に使用されるMLUT数の見積りは、容易になる。
【0216】
マルチプレクサで構成できる第2の種類の演算器は、ビット数に基づいてアロケーションすることができる。例えば、多ビットマルチプレクサでは、ビット数に応じたMLUTの数を記載したデータを記憶部214に有することにより、使用するMLUT数の見積りの簡易化が図れる。
【0217】
メモリ回路で構成できる第3の種類の演算器は、それぞれのMLUTをNビット×Nワードのメモリ回路と考えて、アロケーションすることができる。論理回路として動作するMPLDにおいて、一部のMLUTをメモリ回路として動作することが可能である場合には、MPLDの中で、第3の種類の演算器として動作するMLUTのみをメモリ回路として動作させることが可能になる。これにより、MPLD内部に論理回路とメモリ回路とを混載することができる。
【0218】
制御回路は、例えばC言語では、if文、case文、及び関数の呼び出し文などである。制御回路のアロケーションは、2入力NAND回路と、NOT回路とにより構成される回路により行うことができる。
【0219】
このように、演算回路と制御回路とを分離し、かつ演算回路を第1〜第3の種類に分離してアロケーションすることにより、それぞれの回路構成に適当なアロケーションを実行することができる。
【0220】
制御回路の見積りは、2入力NAND回路と、NOT回路とにより構成される回路を仮に論理合成し、その回路をテクノロジーマッピングすることによって行うことができる。例えば、if文は、2入力NAND回路と、NOT回路とを有する比較回路によって構成できる。
【0221】
〔5.3.5〕面分割
論理回路をアロケーションし、演算回路部分、及び制御回路部分のMLUT数の見積りをした結果、見積もられた論理回路が1つのMPLDに搭載できないと判断される場合がある。この場合には、論理回路を、1つのMPLDに搭載可能な複数の論理ブロックに面分割する必要が生じる。
【0222】
上述のように、MPLDは、再構成が可能な論理回路である。このため、論理回路を1つのMPLDに搭載できない場合には、論理回路を、1つのMPLDに搭載可能な複数の論理ブロックに分割し、分割した演算器ブロックごとに処理を順に実行することができる。本明細書では、演算器部分、及び制御部分などの論理回路を1つのMPLDに搭載できる大きさに分割することを「面分割」と称する。なお、面分割の説明に関して使用される用語「論理回路」は、アロケーションされたCDFGデータで示される論理回路であり、「論理ブロック」は、アロケーションされたCDFGデータで構成される論理回路を適当な大きさに分割したCDFGデータである。
【0223】
図57は、第1の論理ブロックと第2の論理ブロックとの2つの論理ブロックに面分割された論理回路を実行する1つの例を示す。本例では、MPLD20と演算処理部220とを搭載する半導体装置100と、記憶装置とによって、論理回路を実行することができる。また、MPLD20と演算処理部220とを搭載する半導体装置100にさらに記憶部26を搭載することによっても実行することができる。記憶装置、又は記憶部は、MPLD20の出力に接続され、第1の論理ブロックと第2の論理ブロックと、第1の論理ブロックの実行結果とを記憶する。
【0224】
ステップS231において、演算処理部は、MPLDに書き込まれた第1の論理ブロックを実行する。第1の論理ブロックは、1つ、又は複数のステートで構成することができる。ステップS232において、演算処理部は、ステップS231で実行された第1の論理ブロックの実行結果を記憶装置に記憶する。第1の論理ブロックの実行結果を記憶装置に記憶することにより、MPLDを第1の論理ブロックから第2の論理ブロックに再構成する間に、第1の論理ブロックの実行結果を保存して、第2の論理ブロックの入力として使用することができる。ステップS233において、演算処理部は、MPLDに書き込まれた第1の論理ブロックを第2の論理ブロックに再構成する。再構成するときに、MPLDの全てのMLUTを書き換えてもよく、第1及び第2の論理ブロックで使用されるMLUTのみを選択的に書き換えることもできる。また、一部のMLUTを書き換える部分再構成をしてもよい。ステップS234において、演算処理部は、ステップS232で記憶装置に記憶された第1の論理ブロックの実行結果を、第2の論理ブロックの入力信号として読み出す。ステップS235において、演算処理部は、ステップS234で読み出された第1の論理ブロックの実行結果を、第2の論理ブロックの入力信号としてMPLDの入力端子に入力して、第2の論理ブロックを実行する。
【0225】
本例では、論理回路は、2つの論理ブロックに面分割されるが、MPLDの大きさと、見積もった論理回路の大きさとの比較に基づいて、論理回路を適当な数の論理ブロックに面分割することができる。面分割は、図42に示す情報処理装置210が実行することができる。
【0226】
図58は、アロケーションのときに論理回路を面分割する1例を示す図である。図58を参照して、図42に示す情報処理装置210が、アロケーションのときに見積もった論理回路を、複数の論理ブロックに面分割するフローについて述べる。
【0227】
ステップS241において、情報処理装置210は、使用可能なMLUT数を決定する。情報処理装置210は、MPLDに搭載されるMLUTと、使用可能なMLUT数との関係を示すデータなどを記憶部に記憶することができる。このデータは、MPLDの配置・配線効率に基づき作成できる。使用可能なMLUT数は、このデータに基づいて決定することができる。ステップS242において、情報処理装置210は、ステートを搭載する面を生成する。ここで、面とは、CDFGのアロケーションにより、ステップごとのステートに分割された論理回路の1つ、又は複数のステートを搭載する論理ブロックをいう。ステップS243において、情報処理装置210は、ステートを面に搭載する。例えば、第1の面の最初のステップでは、アロケーションされた後の第1のステートを面に搭載し、第1のステートが搭載された後のステップでは、第2のステートを搭載する。ステップS244において、情報処理装置210は、面に搭載された全てのステートが使用するMLUT数を見積もる。見積りは、アロケーションされたそれぞれのステートのMLUT数を合計することにより行うことができる。
【0228】
ステップS245において、情報処理装置210は、さらにステートを面に搭載可能か否かを判定する。情報処理装置210は、面に搭載された全てのステートが使用するMLUT数の見積りと、MPLD20に搭載可能なMLUT数とに基づいて、さらにステートを面に搭載できるか否かを判定する。情報処理装置210が、さらにステートを面に搭載できると判断したときは、処理は、ステップS243に戻り、次のステートを面に搭載する。情報処理装置210が、さらにステートを面に搭載できないと判断したときは、処理は、ステップS246に進む。このとき、制御回路部のステートに関しては、情報処理装置210は、面に搭載するか、又は面に搭載せずにMPU命令コードとして生成するかを判断する必要がある。制御回路部のステートをMPU命令コードとして生成する場合は、情報処理装置210は、さらなるステートを面に搭載できないと判断し、そのステートは、面には搭載せずに、新たな面を生成する処理に移行する。また、情報処理装置210は、MPU命令コードとして生成するために、制御回路部のステートを記憶部に記憶する。
【0229】
ステップS246において、情報処理装置210は、未処理のステートの有無を判定する。未処理のステートがある場合は、処理は、ステップS243に戻り、ステートを搭載する面を新たに生成する。未処理のステートがない場合は、情報処理装置210は、処理を終了する。
【0230】
〔5.3.6〕MPU命令コードを生成するステップ
図53に示すMPU命令コードを生成するステップS224は、図58に示す面分割のときにステップS241において、MPU命令コードとして生成すると判断された制御回路部のステートから、MPU命令コードを生成するステップである。上述のように制御回路には、例えばC言語では、if文、case文、及び関数の呼び出し文などが含まれる。ステップS224では、情報処理装置210は、これらの関数を、演算処理部が読み出し可能な低級言語に変換する。
【0231】
ステップS224で生成されたMPU命令コードは、1つのMPLD20と、演算処理部220とともに半導体装置100に搭載される記憶部26に記憶することができる。また、半導体装置100とともに使用される記憶装置(図示せず)に記憶することもできる。
【0232】
〔5.3.7〕RTL−CDFGを生成するステップ
図53に示すRTL−CDFGを生成するステップS225は、CDFGをアロケーションするステップS223においてアロケーションされたCDFGからRTLレベルのCDFGを生成するステップである。CDFGをアロケーションするステップS223において、面分割がされた場合には、面分割された論理ブロックごとにRTLレベルのCDFGを生成する。
【0233】
ステップS225で生成されたRTL−CDFGは、図42及び図43を用いて説明した配置・配線フローにより、適当なビットストリームデータに変換することができる。面分割がされた場合には、面分割された論理ブロックごとにビットストリームデータを生成する。
【0234】
配置・配線された1つ、又は複数のビットストリームは、MPLDと、演算処理部とともに半導体装置に搭載される記憶部に記憶することができる。また、半導体装置とともに使用される記憶装置(図示せず)に記憶することもできる。面分割がされた場合には、演算処理部は、このビットストリームデータを使用して、複数の論理ブロックをMPLD上に再構成することができる。
【0235】
〔5.4〕1つのMPLDと演算処理部とを搭載した半導体装置での再構成
図51に記載される1つのMPLD20と演算処理部220とを搭載した半導体装置100においても、図41に記載される1つのMPLD20を搭載した半導体装置100と同様に、論理回路情報を再構成することができる。
【0236】
図59は、MLUTに論理回路情報などの情報を書き込む手順を示すフローチャートの一例である。ステップS247において、演算処理部220は、メモリ動作用アドレスMAにより、論理回路情報などの情報を書き込む記憶素子4を選択する。次いで、ステップ248において、演算処理部220は、記憶素子4に書き込むデータを出力する。ステップ249において、書き込む情報が他に存在するか否かを判定し、書き込む情報がある場合には、再度ステップS247に戻り、情報の書き込みを続ける。書き込む情報がない場合には、書き込み手順を終了する。情報の書き込みは、n×2n個の記憶素子の全ての記憶素子について行うことができ、またn×2n個の記憶素子の一部についてのみ行うことができる。
【0237】
上記のようにして、MPLD20の論理回路情報を再構成することができる。しかしながら、図51に記載される半導体装置100は、内部に演算処理部220を有するので、再構成に関する命令を演算処理部220が実行することができる。この場合には、図42に記載される情報処理装置210、又は半導体装置100が搭載される基板上のマイクロプロセッサを使用せずに、半導体装置100に搭載される演算処理部220が再構成を実行できる。このため、再構成のための情報処理装置210、又は基板上のマイクロプロセッサの入力部に半導体装置100を接続する必要がない。さらに、半導体装置100に搭載される演算処理部220がMPLD20に論理回路情報を書き込むため、高速動作が可能になる。したがって、図51に記載される半導体装置100では、高速かつ簡便な再構成が可能になる。
【0238】
〔5.5〕1つのMPLDと演算処理部とを搭載した半導体装置での部分再構成
図51に記載される1つのMPLD20と演算処理部とを搭載した半導体装置100においても、図41に記載される1つのMPLD20を搭載した半導体装置100と同様に、MPLD20の論理回路情報を部分再構成することができる。すなわち、図44を用いて説明したフローと同一のフローにより、MPLD20の論理回路情報を部分再構成することができる。しかしながら、図51に記載される半導体装置100は、内部に演算処理部220を有するので、上述の再構成の場合と同様に、情報処理装置210又は半導体装置100が搭載される基板上のマイクロプロセッサを使用せずに、半導体装置100に搭載される演算処理部220によって、部分再構成を実行することができる。
【0239】
〔6〕2つのMPLDと、演算処理部とを搭載した半導体装置
ここでは、2つのMPLDと、演算処理部とを搭載した半導体装置の例について説明する。
〔6.1〕2つのMPLDと、演算処理部とを搭載した半導体装置
図60は、MPLDを搭載した半導体装置の第1例における配置構造を示す図である。半導体装置100は、第1のMPLD20aと、第2のMPLD20bと、演算処理部220と、入出力回路部15とを有する。入出力回路部15、及び演算処理部220は、図41を参照して説明した例と同様であるため、ここでは説明を省略する。第1のMPLD20aと、第2のMPLD20bとは、それぞれ、別個に動作可能である。
【0240】
第1のMPLD20a、及び第2のMPLD20bと、演算処理部220との配線、及び入出力回路部15との配線については、図51及び図52などを用いて説明しているので、ここでは説明を省略する。
【0241】
第1のMPLD20aと、第2のMPLD20bとの間は、それぞれのMPLDを構成するMLUTが有するAD対で直接結線することができる。第1のMPLD20aと、第2のMPLD20bとをバス回路などを介さず直接接続することにより、2つのMPLD間の信号処理を高速化することができる。
【0242】
図61は、MPLDを搭載した半導体装置の第2例における配置構造を示す図である。図61を参照すると、本例における半導体装置100は、第1のMPLD20aと、第2のMPLD20bと、演算処理部220と、入出力回路部15と、記憶部26とを有する。
【0243】
記憶部26は、第1のMPLD20a、及び第2のMPLD20bにおいてそれぞれ実行される論理回路の実行結果を記憶するとともに、演算処理部220が実行するMPU命令コードを含むプログラムを格納する。半導体装置100に記憶部26を搭載することにより、以下に説明する動的再構成の処理が容易になる。記憶部26は、MPLDでの論理回路の実行結果を記憶するように、第1のMPLD20a、第2のMPLD20b、及び演算処理部220に結線される。
【0244】
図62は、半導体装置の配線層の一例を示す断面図である。半導体装置100は、MOSトランジスタなどの回路素子(図示せず)が形成される半導体基板160の上方に、配線層170を有する。配線層170は、それぞれの配線層に複数配置される配線を適当に接続することにより、回路基板上に形成される回路素子のそれぞれの端子(図示せず)を接続する。半導体装置100が有する回路素子のそれぞれの端子を適当に接続することにより、半導体装置100は、所望の動作を実現できる。
【0245】
配線層170は、第1の配線層172、第2の配線層174、第3の配線層176、及び第4の配線層178の4層の配線層を有する。半導体基板160、並びに第1〜第4の配線層172、174、176、及び178は、第1〜第4のビア接続部171、173、175、及び177を介して接続される。第1〜第4の配線層172、174、176、及び178、並びに第1〜第4のビア接続部171、173、175、及び177の層間は、斜線で示す絶縁層180が充填される。
【0246】
第1の配線層172は、図示されるように、断面において直線状となるように形成される。一部の第1の配線層172は、回路基板上に形成される回路素子の2つの端子間を接続するように、第1のビア接続部171を介して接続される。他の第1の配線層172は、回路基板上に形成される回路素子の端子と第1のビア接続部171を介して接続され、第2の配線層174と第2のビア接続部173を介して接続される。さらに他の第1の配線層172は、2つの異なる第2の配線層174間を接続するように、第2のビア接続部173を介して接続される。
【0247】
第2の配線層174は、回路素子が形成される半導体基板の表面を上方から見た場合に第1の配線層172と垂直を成す方向に略直線状となるように複数形成される。一部の第2の配線層174は、2つの異なる第1の配線層172間を接続するように、第2のビア接続部173を介して接続される。他の第2の配線層174は、第1の配線層172と第2のビア接続部173を介して接続され、第3の配線層176と第3のビア接続部175を介して接続される。さらに他の第2の配線層174は、2つの異なる第3の配線層176間を接続するように、第3のビア接続部175を介して接続される。
【0248】
第3の配線層176は、回路素子が形成される半導体基板の表面を上方から見た場合に第1の配線層172と平行になる方向に略直線状となるように複数形成される。一部の第3の配線層176は、2つの異なる第2の配線層174間を接続するように、第3のビア接続部175を介して接続される。他の第3の配線層176は、第2の配線層174と第3のビア接続部175を介して接続され、第4の配線層178と第4のビア接続部177を介して接続される。さらに他の第3の配線層176は、2つの異なる第4の配線層間を接続するように、第4のビア接続部177を介して接続される。一般的に第3の配線層176は、第1の配線層172、及び第2の配線層174と比較した場合に、大きな断面積を有するように形成される。
【0249】
第4の配線層178は、回路素子が形成される半導体基板の表面を上方から見た場合に第2の配線層174と平行になる方向に略直線状となるように複数形成される。第4の配線層178は、2つの異なる第3の配線層176間を接続するように、第4のビア接続部177を介して接続される。一般的に第4の配線層178は、第3の配線層176よりもさらに大きな断面積を有するように形成される。
【0250】
第1〜第4の配線層172、174、176、及び178は、アルミニウム、及びバリアメタルとして使用される銅などの導電性材料により形成される。第1〜第4のビア接続部171、173、175、及び177もまた、アルミニウムなどの導電性材料により形成される。絶縁層160は、二酸化ケイ素などの絶縁体材料により形成される。
【0251】
このように半導体装置においては、配線層は、半導体基板上に形成されるそれぞれの回路素子の端子間をそれぞれ接続するために形成される。システムオンチップ(以下、SOCと称する)と称される半導体装置では、半導体基板上に、演算処理部、記憶部、アナログ‐デジタル変換部、オペアンプなどのアナログ回路部、論理回路部などのデジタル回路部、及び入出力回路部などが搭載される。演算処理部が、高機能な処理を要求されない場合、例えば8ビット、16ビットなどの演算処理を行う演算処理部などの場合には、演算処理部は、一般に4層程度の配線層により、形成することができる。また、記憶部などのSOCに搭載される他の構成要素も一般に4層以下の配線層により、形成される。
【0252】
上述のように、MPLDは、CMOSトランジスタを有するSRAMと、CMOSトランジスタにより構成することができる論理回路とを有する。このため、MPLDは、SRAMなどのメモリ回路技術と、CMOS回路技術とを用いることで製造することができる。これらの技術は、一般的には半導体装置の集積度を考慮しても、3層、又は4層程度の配線層で形成することができる。また、MPLDは、MPLDをスイッチング機能として使用することができるので、FPGAのように接続チャネル領域を設ける必要が無い。このため、MPLDは、一般的なCMOS回路技術で製造される他の構成要素と同程度の集積度が期待できる。したがって、MPLDもまた、3層、又は4層程度の配線層で形成することができる。
【0253】
このように、MPLDの配線層は、SOCに搭載される他の構成要素と同様に、4層以下の配線層により、形成することができる。これは、半導体装置の製造面を考慮すると、MPLDがSOCと親和性を有することを意味する。すなわち、MPLDは、SOC半導体装置に搭載しやすいことを意味する。FPGAなどの他の再構成可能な論理回路は、一般的に、集積度を考慮すると8層から10層程度の多層の配線層を有する構造になる。このため、SOC回路部を多層配線する必要がない場合でも、FPGAなどの再構成可能な論理回路が多層配線を必要とするため、半導体装置が多層配線構造となる。これに対し、MPLDは、上述のように、3層、又は4層程度の配線層構造にすることができる。このため、SOC回路部の配線層構造に基づいて、半導体装置の配線層構造を決定することができる。例えば、半導体装置100は、物理的な配線層数が4層以下である。
【0254】
〔6.2〕2つのMPLDと、演算処理部とを搭載した半導体装置での動的再構成
〔6.2.1〕MPLDの動的再構成フロー
ここでは、半導体装置に搭載されるMPLDを動的再構成するフローの1つの例について説明する。
【0255】
図63は、図61に示す半導体装置に搭載されるMPLDを部分再構成するフローの一例を示す図である。ステップS251において、演算処理部220は、第1のMPLD20a、又は第2のMPLD20bの何れか一方、又は双方のMPLDに論理回路情報を書き込む。ここで書き込まれる論理回路情報は、一般的には、図42及び39を用いて説明されたビットストリームデータである。ビットストリームデータは、半導体装置に搭載される記憶部に記憶してもよく、半導体装置と接続される記憶装置に記憶してもよい。第1及び第2のMPLDの双方に論理回路情報を書き込む場合には、最初のサイクルでは、ステップS253は省略される。
【0256】
ステップS252において、演算処理部は、ステップS251で論理回路情報が書き込まれた一方のMPLDの論理回路情報を動作させる。演算処理部は、一方のMPLDに書き込まれた論理回路情報の動作結果を半導体装置に搭載される記憶部などの記憶手段に記憶する。これにより、記憶された動作結果を他方のMPLDの入力に使用できる。また、2つのMPLDのAD対が接続される場合には、動作が終了した後も一方のMPLDが動作結果を保持し、演算処理部からの指令により、その動作結果を他方のMPLDに入力信号として与えることができる。論理動作が終了したときに、演算処理部は、このMPLDから論理動作が終了したことを示すフラグを受信する。
【0257】
ステップS253において、演算処理部は、論理動作をしない他方のMPLDに論理回路情報を書き込む。書き込みが終了したときに、演算処理部は、このMPLDから書き込みが終了したことを示すフラグを受信する。上述のように、最初のサイクルでは、MPLDを論理動作させる前に、双方のMPLDに同時に論理回路情報を書き込むことができる。この場合も演算処理部は、書き込み終了時に書き込みが終了したことを示すフラグを受信する。
【0258】
ステップS254において、演算処理部は、一方のMPLDの論理動作が終了したことを示すフラグと、他方のMPLDの書き込みが終了したことを示すフラグを受信すると、書き込みが終了した他方のMPLDの論理動作を開始する。ステップS254で他方のMPLDの論理動作が開始されたのちに、ステップS255において、演算処理部は、他に書き込む論理回路情報があるか否かを判定する。他に書き込む論理回路情報がある場合には、処理は、ステップS253に戻る。そして、論理動作をしていないMPLDに論理回路情報への書き込みを開始する。他に書き込む論理回路情報がない場合には、演算処理部は、MPLDから論理動作が終了したことを示すフラグを受信した後に処理を終了する。
【0259】
ここで説明する動的再構成は、図53を用いて説明したMPU命令コードと、面分割されたRTL−CDFGから生成される複数のビットストリームとを用いて実現することができる。演算処理部は、演算処理部指令コードに従ってMPLDの再構成、論理動作開始指令、又はMPLDに搭載されなかった制御回路を実行する。また、MPLDの論理回路情報であるビットストリームデータは、面分割されたRTL−CDFGから生成されるビットストリームにすることができる。これにより、動作記述で記載されたデータ処理動作が、ハードウェアである半導体装置に搭載される演算処理部とMPLDとにより実現されることになる。このため、ソフトウェアである動作記述により演算処理部を動作させるよりも高速な動作が可能になる。
【0260】
〔6.2.2〕動的再構成の実施例
ここでは、動的再構成の利点を具体的な実施例に基づいて説明する。実施例は、共通鍵暗号方式の1つであるDES(Data Encryption Standard:データ暗号化標準)の暗号化に関するものである。ここでは、DESの暗号化計算について概略的に述べたのちに、本例における半導体装置によるDES計算の実行方法について説明する。
【0261】
〔6.2.2.1〕DESのアルゴリズム
図64は、DESの計算アルゴリズムのフローの一例を示す図である。DESは、固定ビット(例えば、64ビット)長の平文を入力とする。DESは56bit長の暗号化鍵を使い64bitの平文ブロックごとに暗号化するブロック暗号である。暗号化鍵は、64ビットだが、そのうち8ビットはパリティチェックに使うため、アルゴリズム上の実際の鍵の長さは56ビットである。DESの暗号化鍵は、共通鍵暗号方式であり、暗号化と復号に同一の鍵を用いる。また、DESでは、F(Feistel)関数という、置換と転置を行うラウンド関数を用いて、F関数を用いて繰り返し暗号化または復号化を行う暗号方式である。ステップS261において、初期転置を行う。初期転置は、ビット間の所定の転置を実行するものである。例えば、初期転置後の1ビット目のデータは、入力データの58ビット目のデータであり、初期転置後の2ビット目のデータは、入力データの50ビット目のデータである。このように、初期転置により、64ビットのそれぞれのデータの並び替えが行われる。
【0262】
ステップS262において、初期転置後の下位32ビットをF関数により処理する。F関数の処理は、図65に示すフローにより説明する。
【0263】
図65は、F関数のアルゴリズムのフローを示す図である。F関数には、初期転置処理がされたデータの下位32ビットが入力される。ステップS271において、入力された32ビットのデータは、拡張順列(expansion permutation)され、48ビットのデータが生成される。次いでステップS272において、拡張順列された48ビットのデータと、48ビットの巡回鍵との間で排他的論理和の処理がされる。
【0264】
ここで、巡回鍵について説明する。巡回鍵は、共通鍵を一定のアルゴリズムにより変換したものであり、1回のDES暗号化で16回行われるF関数処理ごとに異なる鍵になる。巡回鍵への変換アルゴリズムには、転置処理と、巡回シフト処理とが含まれる。
【0265】
Sボックス(substitution box)とは、mビットの入力をnビット出力に変換する関数であり、2mのルックアップテーブルである。ステップS273において、ステップS272で巡回鍵との間で排他的論理和の処理がされた48ビットのデータは、8個のSボックスによる変換により、6ビットのデータを4ビットのデータに変換する処理がされる。この結果、Sボックスにより処理される前は48ビットであったデータが、Sボックスの処理によって32ビットのデータに変換される。
【0266】
Sボックスは、S1〜S8のそれぞれ所定の値を有する真理値表により構成される。S1は、下位6ビットのデータを変換するSボックスであり、S2は、下位7ビットから12ビット目のデータを変換するSボックスである。以下同様に、S7は、36ビット目から42ビット目までのデータを変換するSボックスであり、S8は、43ビット目から48ビット目までのデータを変換するSボックスとなる。それぞれのSボックスは2行×4列の行列に対して、それぞれ4ビットずつのデータが割り当てられる。Sボックスの2ビットの行は、6ビットの入力データのMSB(最上位ビット、すわなち6ビット目)のデータと、LSB(最下位ビット、すわなち1ビット目)のデータにより構成される。Sボックスの4ビットの列は、6ビットの入力のMSBとLSBとを除いた中間の4ビット(2ビット目から5ビット目)のデータにより構成される。6ビットの入力データを、このような構成を有するSボックスに入力し、該当する真理値表の4ビットの値を出力することにより、6ビットの入力データを4ビットの出力データに変換することができる。表1にSボックスの例として、S1のSボックスを示す。
【0267】
【表1】
【0268】
S1では、例えば、6ビットの入力(100110)が与えられた場合、行は、MSBとLSBとにより(10)となり、列は、MSBとLSBとを除いた4ビットから(0011)となる。したがって、4ビットの出力データは、(1000)になる。
【0269】
ステップS274において、Sボックスによる変換が8回終了したか否かを判定する。Sボックスの処理が全て終了していない場合は、次のSボックスの処理を行う。また、Sボックスの処理が全て終了している場合は、処理は、ステップS275に進む。ステップS275において、S1〜S8の8個のSボックスで処理された4ビットのデータを全て並べて32ビットのデータを生成する。
【0270】
図64に示すステップS263において、Sボックスの処理により生成された32ビットのデータは、上位32ビットのデータとの間で排他的論理和の処理がされる。ステップS264において、64ビットの入力データの下位32ビットのデータを上位32ビットのデータとする。そして、ステップS263により生成される32ビットのデータを下位32ビットのデータとする。
【0271】
ステップS265において、F関数の処理を含む一連の処理が16回行われたか否かを判定する。処理が16回行われていない場合は、さらにF関数の処理からの一連の処理が行われる。このとき、巡回鍵は、処理ごとに異なる鍵になる。処理が16回行われた場合は、ステップS266において、64ビットのデータは、逆転置されて暗号化処理が完了する。
【0272】
〔6.2.2.2〕本例における半導体装置によるDES計算例
ここで、2つのMPLDと、演算処理部とを搭載した半導体装置によるDESアルゴリズムの計算例について、図64などを参照しながら説明する。MPLDを構成するMLUTは7個のAD対を有することとする。
【0273】
図64に示されるステップS261の初期転置と、ステップS266の逆転置とは1つのMLUTをメモリ回路として動作させて、転置先のビットを記憶させることができる。この処理は、MPLD内部の一部のMLUTのみをメモリ回路として動作させることが可能な場合に実現できる。MPLD内部の一部のMLUTのみをメモリ回路として動作させることができない場合は、外部の記憶装置、又は半導体装置に搭載される記憶部に転置先のビットを記憶させることができる。
【0274】
図64に示されるステップS263、及び図64に示されるステップS272における32ビット及び48ビットの排他的論理和の計算は、MPLDが計算する。MPLDは、多入力他出力の演算に適するからである。
【0275】
ステップS273のSボックスの処理を8回行う処理は、2つのMPLDを動的に再構成することにより、実現できる。例えば、1つのMLUTを真理値表として使用する。Sボックスの処理は6ビット入力に対して4ビット出力をするものであるので、7個のAD対を有するMLUTを使用する場合、6個のAD対の論理制御用アドレス線を6ビットの入力とし、4個のAD対の論理制御用データ線を4ビットの出力線とすることにより、Sボックスの真理値表を実現できる。そして、一方のMPLDでS1のSボックスの演算処理を行う間に、他方のMPLDにS2のSボックスの演算情報を書き込む。また、他方のMPLDでS2のSボックスの演算処理を行う間に、一方のMPLDにS3のSボックスの演算情報を書き込むなどして、動的に再構成しながらSボックスの演算処理を進めることができる。これにより、動的再構成を用いない場合と比較して、同一の演算処理を実現するための回路規模を大幅に少なくすることができる。
【0276】
ステップS272において使用される巡回鍵を生成するときにもMPLDを動的再構成して使用することができる。上述のように巡回鍵は、共通鍵に転置処理とシフト処理とを加えることにより生成され、F関数の動作ごとに異なる巡回鍵を使用する。そこで、2つのMPLDを動的再構成しながら使用することにより、一方のMPLDで巡回鍵を使用する演算処理を行う間に、他方のMPLDで次のサイクルで使用する巡回鍵を生成し、書き込む処理を行うことができる
【0277】
ここでは、2つのMPLDと、演算処理部とを搭載した半導体装置で実現される動的再構成について説明してきたが、1つのMPLDと、演算処理部とを搭載した半導体装置でも動的再構成を実現することができる。
【0278】
1つには、図19を用いて説明したMLUTを使用してMPLDを構成する場合には、動的再構成が可能になる。この型のMLUTは、セレクト信号により選択される2つの記憶素子群を有する。一方の記憶素子群で演算処理を行う間に他方の記憶素子群の論理回路情報を再構成することにより、動的再構成を実現することができる。
【0279】
また、物理的な構成では1つであるMPLDを、論理動作上は2つのMPLDであるとして扱うことにより、動的再構成が可能になる。例えば、1つのMPLDの半分の領域の第1のMPLD部として扱い、残りの半分の領域を第2のMPLD部として扱うことにより、物理的な構成では1つであるMPLDを、論理動作上は2つのMPLDであるとして扱うことができる。
【0280】
〔7〕動的再構成に適する半導体装置
【0281】
プログラマブルロジックデバイス(PLD)の動的再構成が知られている。動的再構成とは、PLD稼働中に、PLDの回路構成を切り替える技術である。動的再構成は、複数の小規模回路を、プログラムに従って短時間に頻繁に結線し直すことで、小規模回路で大規模回路の機能を実現することができる。
【0282】
PLDは、ハードウェアによる物理的な結線で命令を実行するワイヤードロジックを、ALU(Arithmetic Logical Unit)やLUT(Look up Table)で実現する回路である。ワイヤードロジックは、CISCプロセッサの演算対象であるマイクロコードによる処理の複数のステップを、1つの組み合わせ論理回路に展開して実現することができる。CISCプロセッサでは、1つの処理を実行するのに、複数のクロックが必要になるが、ワイヤードロジックでは、1つのクロックで実現することができ、データの流れを止めずに処理を高速に行うので、クロックあたりの処理能力が、CISCプロセッサと比して高い。そのため、ワイヤードロジックの回路構成は、複数の回路機能とともに、一連のデータの流れをも実現するため、「データパス」と呼ばれる。
【0283】
動的再構成可能なPLDは、機能ごとに固定された専用回路を切り替えるのではなく、小規模回路の再配置を行って専用回路を構成し、複数の小規模回路が協調してパイプライン処理を行う。なお、ここでいう「パイプライン」とは、連続動作処理を意味する。
【0284】
一般に、動的再構成可能なPLDは、ALUベース、又はLUTベースである。ALUは、加算器、シフタ、乗算器等を含む演算器セットであり、1つのALUで複数の機能を実現することができる。ALUベースの動的再構成可能なPLDは、ALUの機能を選択することで、動的再構成する。LUTは、複数のメモリセルからなるメモリセルユニットであるため、LUTベースの動的再構成可能なPLDは、再構成を行うとき、メモリセルユニットの書き換えが必要になる。また、LUTベースの動的再構成可能なPLDは、メモリセルユニット間の接続に、専用の切り替え回路を有しているので、動的再構成には、切り替え回路の再設定も必要になる。
【0285】
以下に示すプログラマブル論理部としてのMPLDを含む半導体装置は、少なくとも2つのMPLDを有し、MPLDの構成情報を保持するキャッシュ部と、キャッシュ部に保持された構成情報をMPLDに出力する構成制御部とを備える。構成制御部は、MPLDの1つが、分岐論理を構成する構成情報で再構成されている場合、前記分岐論理の実行前に、前記分岐論理の分岐先回路を構成する前記第2の構成情報で、前記複数のプログラマブル論理部のうちの第2のプログラマブル論理部を投機的に再構成する。このように、投機的にMPLDを再構成することで、分岐確定後にMPLDを再構成する必要が無いので、再構成時間を短縮化することができる。
【0286】
以下、〔7.1〕半導体装置、〔7.2〕MPLDの構成例、〔7.3〕半導体装置の動作フローの詳細例について順に説明する。なお、MPLD及びMLUTは、〔1〕、及び〔2〕においてそれぞれ説明したものが適用可能である。
【0287】
〔7.1〕半導体装置
図66は、半導体装置の一例を示すブロック図である。
図66に示す半導体装置100は、構成可能論理部としてのMPLD20A及び20B、変数保持部25、構成制御部300、キャッシュ部400A及び400Bを有する。半導体装置100は、演算処理部としてのMPU(Micro Processing Unit)220と接続し、及びメモリコントローラ550を介して、記憶部としてのメインメモリ500と接続する。半導体装置100は、MPU220、及び/又は、メモリコントローラ550及びメインメモリ500と一体化したIC(Integrated Circuit)チップとしてもよい。
【0288】
〔7.1.1〕MPLD
プログラマブル論理部としてのMPLD20A及び20Bは、複数のメモリセルユニットであるMLUT(Multi Look−Up−Table)を各々が有する。MLUTのメモリセルユニットは、SRAM(Static Random Access Memory)で構成してもよい。MLUTは、論理要素、又は、複数の論理要素間を接続する接続要素として機能する。
【0289】
MPLD20A及び20Bは、構成情報を書き込むことによって、再構成される。構成情報は、MPLD20A又は20Bを部分的に再構成するために、複数のMLUTを構成単位とする再構成単位毎に生成される。構成情報によって再構成単位毎に再構成される複数のMLUTを、以下「バンク」と言い、再構成単位を、以下「バンク単位」と言う。MPLD20A及び20Bは、データ信号を外部から受け取ると、構成情報で再構成された回路によって演算を行い、演算結果であるデータ信号を外部に出力する。なお、構成情報は、様々な演算器の真理値表から構成される演算器データ、及び、複数のステート、ステート変化のきっかけとなるイベント、これによって生じるステートの遷移を表す制御データから構成される。
【0290】
演算器データは、インバータ、AND演算、OR演算等の演算名称と各々が対応付けられる複数の真理値表データである。
【0291】
制御データは、演算器の種類と、演算器が割り当てられる複数のMLUT間のデータパスとを、ステート状態の遷移とともに規定した真理値表データである。制御データには、ステート識別情報、演算器、演算器の配置配線情報、ステートマシン(図67を用いて後述)を構成する真理値表データ、演算器の真理値表データを書き込むMLUTの識別情報、演算器リソースの配置配線情報を含む。
【0292】
〔7.1.2〕構成制御部
構成制御部300は、キャッシュ部400Aから構成情報(演算器データと制御データ)を読み出して、MPLD20A又は20Bに書き込む。また、キャッシュ部400Aに、書き込み対象となる構成情報(ここでは、制御データ)が無い場合、メモリコントローラにメモリアクセス命令を供給して、メインメモリ500に記憶される構成情報(制御データ)を読み出す。
【0293】
MPLD20A及び20Bの何れかが再構成された回路によって演算動作を行っているとき、演算動作を行っていないMPLDは、構成制御部300によって再構成される。なお、どの演算器データ及び制御データを、MPLDに書き込むかについては、後述するスケジュール情報でスケジュールされている。したがって、構成制御部300は、スケジュール情報を参照することで、スケジュールされたバンク単位の構成情報を、MPLDに書き込む。
【0294】
上記のように、構成制御部300は、構成情報で、MPLD20A又は20Bを再構成し、演算動作を実行するMPLDと、再構成するMPLDとを、スケジュール情報にしたがって適宜切り替て、連続的な演算動作を可能にする。
【0295】
〔7.1.3〕キャッシュ部
図66に示されるように、キャッシュ部400A及び400Bは、それぞれが異なるキャッシュメモリで構成される。キャッシュ部400A及び400Bは、それぞれ独立してデータの読み出し又は書き込み可能なキャッシュメモリであり、例えば、SRAMである。そのため、図66には図示しないが、キャッシュ部400A及び400Bは、データを保持するメモリセルアレイと、メモリセルアレイからデータを読み出し又は書き込むための行アドレスデコーダ、列アドレスデコーダ、及びアンプ等の周辺回路をそれぞれ備える。
【0296】
キャッシュ部400Aは、構成情報のうち演算器データを保持し、キャッシュ部400Bは、構成情報のうち制御データを保持する。演算器データは、半導体装置100の初期動作時に、メインメモリ500から読み出されて、キャッシュ部400Aに書き込まれる。演算器データは、MPLD30A又は30Bの再構成に際して、メインメモリ500から読み出されずに、キャッシュ部400Aから読み出される。メインメモリ500は、DRAM(Dynamic Random Access Memory)で構成されているため、データの読み出し速度が遅い。また、制御データは、データの遷移に係るMLUTの出力メモリセルを特定するのに対して、演算器データは、MLUTに書き込む真理値表データの大部分を構成するので、制御データよりもデータ量が大きい。そのため、MPLD20A又は20Bの再構成時には、メインメモリアクセス無しで、キャッシュ部400Aから、制御データ910よりもデータ量の大きい演算器データを読み出すことができるので、演算器データをキャッシュ部400Aに保持することで、MPLD20A又は20Bの再構成時間を短縮することができる。
【0297】
また、演算器データと制御データとを、MPLD20A又は20Bの再構成に合わせて同じデータではなく別個のデータとして、キャッシュ部400A及び400Bに別々に格納するので、制御データのキャッシュ部へのデータ書き込みとともに、演算器データをメインメモリ500から書き込む動作も不要となり、MPLD30A又は30Bの再構成時間を短縮することができる。
【0298】
さらに、キャッシュ部400Aは、半導体装置100の初期動作時に、演算器データ905が書き込まれ、その後は、読み出し動作となる。したがって、書き込みと読み出しを同時に実行する必要がないので、演算器データ905を保持するキャッシュ部400Aを構成するメモリは、ダブルポートではなくシングルポートのSRAMとすることができる。
〔7.1.4〕構成情報の詳細
上記のように、キャッシュ部400A及び400Bは、それぞれ、演算器データと、制御データとで構成される別個のキャッシュメモリである。以下に、演算器データと、制御データとの詳細例を説明する。
【0299】
演算器データは、以下のデータ構造を有する。
A.演算器データのデータ構造
ヘッダ部
演算器ID
演算器LUT数
データ部
演算器MLUT情報(圧縮データ)
【0300】
上記のように、演算器データは、ヘッダ部に、演算器を識別する「演算器ID」と、演算器を実装するのに必要なMLUTの数である「演算器MLUT数」とで定義される。また、データ部には、演算器に必要な演算器MLUT情報が、圧縮データで定義される。
【0301】
制御データは、以下のデータ構造を有する。
B.制御データのデータ構造
バンク番号:
演算器配置情報
演算器ID
行数情報
1行目のrow,col
2行目のrow,col
...
制御回路情報
ヘッダ部
制御回路LUT数
制御回路開始のrow, col
データ部
制御回路MLUT情報(圧縮データ)
【0302】
上記のように、制御データは、再構成するMLUTである「バンク」を識別する「バンク番号」と、そのバンクに配置する演算器IDと、演算器を「バンク」に配置するための演算器ID毎の行数情報を有する。さらに、制御データは、制御回路を構成するMLUTの数と、「バンク」において制御回路を開始する行列を「制御回路開始のrow, col」として規定する。また、制御回路に必要なMLUT情報が、圧縮データで定義される。
【0303】
構成制御部300は、制御データ内に含まれる演算器IDを参照して、対応する演算器データを読み出して、制御データの「行数情報」の行数に、対応する演算器データの演算器MLUT情報を書き込む。また、構成制御部300は、制御データ内に含まれる制御回路情報を参照して、「制御回路開始のrow, col」に、制御回路MLUT情報を書き込む。このようにして、構成制御部300は、バンク毎に「演算器MLUT情報」及び「制御回路MLUT情報」を書き込んで、MPLD20A又は20Bを再構成する。
【0304】
〔7.1.5〕メインメモリ
メインメモリ500は、構成情報としての演算器データ905、及び制御データ910−1〜910−N(Nは自然数)、プロファイル情報970、静的スケジュール情報975、プログラム980、及びコンパイルプログラム990を格納する。メインメモリ500は、DRAMである。メモリコントローラ550は、メインメモリ500のデータの読み出し、書き出し、DRAMのリフレッシュなどを行なう。
【0305】
図67は、メインメモリのメモリマップの一例を示す図である。
プログラム980は、MPLD20A及び20B、又は、MPU220に所定の処理を実行させるためのプログラムであり、C言語等のプログラム言語にコーディングされたプログラムである。MPU220は、コンパイルプログラム990を実行することで、プログラム980は、MPLD20A及び20Bの大きさの回路データに分割し、分割された複数の回路データのそれぞれから、演算器データ905及び制御データ910−1〜910−Nを生成する。
【0306】
〔1.6〕プロファイル情報
プロファイル情報970−1〜970−N(Nは自然数)は、演算器間の依存、依存データ更新、データフロー、データのライフタイム等のプロファイル(又は履歴)を分析したデータであり、コンパイル処理により、「バンク」毎に「投機的実行の優先」順位が判断されて、生成される。
【0307】
プロファイル情報は、メインメモリ500からキャッシュ部400A及び400Bへの構成情報のロードと、キャッシュ部400A及び400BとMPLD20A及び20B間のロードを、スケジュールするとともに、それらのロードを並列に実行するようにスケジュールされる。
【0308】
例えば、プロファイル情報は、制御データ910−1でMPLD20Aを再構成し、次に、制御データ910−2でMPLD20Bを再構成するというように、制御データ間の再構成順序を規定する。また、プロファイル情報は、制御データ910が分岐回路を規定している場合、分岐回路の実施により、どの制御データが実施されるべきかをスケジューリングする。
【0309】
プロファイル情報970−1〜970−Nは、構成制御部300(より詳細には、後述するスケジューラ)によって使用される。プロファイル情報のデータ構造は、以下の通りである。
【0310】
C.プロファイル情報のデータ構造
ヘッダ部
タイプ:静的か動的
個数 :動的分岐数、タイプが静的の場合は、0を設定
データ部
値 :スケジューラがチェック(エンコードされた値)
優先 :投機的実行の優先
バンク番号:実行バンク番号
【0311】
ヘッダ部の「タイプ」が「静的」である場合、プロファイル情報は、静的スケジュール情報975とも呼ばれる。静的スケジュール情報975は、システムリセット時のプロファイル情報と動作合成から生成される情報である。システムリスタート時に、構成制御部(スケジューラ)300、静的スケジュール情報としてのプロファイル情報を読み込むと、この情報を、構成制御部300で保持して、MPLDの投機的な再構成を行う。
【0312】
ヘッダ部の「動的分岐数」は、動的に分岐したときの分岐対象の「バンク」の個数を示す。データ部の「値」とは、条件分岐の値である。データ部の「優先」とは、投機的実行を優先して行う面を意味する。バンク番号とは、プロファイル情報に対応づけられるバンクの番号である。構成制御部(スケジューラ)300は、図69で後述するMPLDの一部に構成されるステートマシンが、構成制御部(スケジューラ)300によって予測した条件分岐の「値」と、MPLDによって実際に実行された条件分岐の「値」とが一致するか否かを判断する。ステートマシンが、判断結果を、構成制御部(スケジューラ)300に出力することで、構成制御部(スケジューラ)300は投機的実行の分岐失敗をチェックできる。
【0313】
構成制御部(スケジューラ)300は次の面を投機ロードする際、読み込んだプロファイル情報の「タイプ」が「静的」ならデータ部の値をチェックし、当該バンクをロードする。読み込んだプロファイル情報の「タイプ」が動的なら、データ部の「優先」の高い「バンク」をロードする。投機ロードの「バンク」が、再構成中のバンクとなった場合、そのバンクが動的分岐を生ずるバンクか否かを、データ部の「優先」値でチェックし、当該バンクが妥当かあるいは別のバンクをロードすべきか判断し、妥当なバンクを、メインメモリ500又は、キャッシュ部400A及び400Bからロードし実行する。このように、構成制御部(スケジューラ)300は、プロファイル情報の「優先」により、MPLDを投機的に再構成するように動作する。
【0314】
変数保持部25は、MPLD20A及び20B間を跨るライフタイムの長い変数を保持する記憶部である。変数保持部25が、ライフタイムの長い変数(例えば、グローバル変数等)を保持することで、MPLD20A及び20Bが変数を保持するMLUTを再構成する必要がなくなり、MLUTの有効活用が可能になる。
【0315】
図68は、構成制御部の詳細ブロック図である。構成制御部300は、キャッシュ制御310、システムリセット320、圧縮データ解凍330、スケジューラ340で示される機能を有する。これらの機能は、構成制御部300内部の回路や、構成制御部300がプログラムを実行することで実現される。以下、各機能について説明する。
【0316】
キャッシュ制御310は、構成制御部300によるキャッシュ部400A及び400B、メインメモリ500、MPLD20A及び20Bへのデータの入出力を行う機能である。
【0317】
システムリセット320は、構成制御部300が外部からシステムリセット(SR)信号を受け取ると、キャッシュ制御310に、初期動作を実行するように指示する機能である。初期動作とは、メインメモリ500からの演算器データ905及び制御データ910を読み出して、MPLD20A及び20Bへの書き込み、静的スケジュール情報975に従う演算器データ905及び制御データ910の読み出しである。
【0318】
圧縮データ解凍330は、キャッシュ部400A及び400Bに、演算器データ905及び制御データ910のMLUT情報は、圧縮されているので、圧縮された演算器データ905及び制御データ910のMLUT情報を解凍して、MPLD20A又は20Bに出力する機能である。
【0319】
演算器データ905及び制御データ910のMLUT情報は、コンパイルプログラム990により圧縮された形でメインメモリ500に記憶されうる。これは、メインメモリ500とキャッシュ部400A及び400Bとの間のデータ量の削減と、キャッシュ部400A及び400Bにおいて演算器データ905及び制御データ910を保持する記憶領域を削減するためである。
【0320】
MPLD20A及び20Bは、ALMマトリクス型のPLDと比べて、再構成するデータ量が多い。メインメモリ500をDRAMで構成した場合、メインメモリ500とキャッシュ部400A及び400Bとの間のデータ転送速度が、再構成時間の制約となりうる。そのため、構成情報である演算器データ905及び制御データ910のMLUT情報を圧縮してメインメモリに記憶し、キャッシュ部400A及び400Bに送信することで、MPLDによる再構成時間を短縮化することができる。また、MPLD20A及び20Bの構成情報の多くは演算器データ905である。演算器データ905を、キャッシュ部400Aに保持することでMPLDの再構成時間を短縮化できることはすでに述べたが、演算器データ905を圧縮してキャッシュ部400Aに保持することで、メインメモリ500と比して記憶容量の小さいキャッシュ部400Aで演算器データ905を保持可能になる。
【0321】
また、従来、プロセッサの技術分野において、データ圧縮とは、命令の圧縮には使用されていない。MLUT情報は、真理値表データで全て構成可能であるため、プログラム上の命令を演算器データに変換すると、データ圧縮が可能になる。
【0322】
圧縮及び解凍には、様々な技術が適用可能である。適用可能な圧縮及び解凍技術として、例えば、LZSSである。
【0323】
スケジューラ340は、プロファイル情報を順番に読み出して、MPLDを再構成するバンクの優先順位を判断し、MPLDに書き込む構成情報の順位を判断する。スケジューラ340は、プロファイル情報に規定される優先順位に従って、メインメモリ500から構成情報(制御データ)を読み出して、または、キャッシュ部400A及び400Bから構成情報(演算器データ及び制御データ)を読み出して、MPLDを再構成する。スケジューラ340は、プロファイル情報に従ってMPLDを再構成した結果、ステートマシンから投機実行の失敗出力を受けた場合、正しい分岐先となる制御データをキャッシュ部400A及び400B、又は、メインメモリ500から読み出す。なお、このように投機実行が失敗した場合であっても、読み出す制御データの真理値表データは圧縮されており、また、演算器データはキャッシュ部400Aに保持されているため、分岐先の制御データを読み出す時間を短くすることができるため、投機実行失敗時の再構成時間による遅延を短くすることができる。
【0324】
なお、ステートマシンは、MPLD上で構成情報により実現される。ステートマシーンは、少なくとも2つの機能を有する。1つは、MPU220のバス等のバスの制御や、図68には図示されていないが通信部から送信される通信パケット処理等の制御回路として動作するステートマシーンである。もう1つは、演算手順のデータフローの順番を制御する制御回路を動作させるステートマシーンである。なお、ステートマシーンは、静的スケジュール情報975により、システムリスタート時にMPLDに構成される。
【0325】
〔7.2〕MPLDの構成例
図69は、MPLDで構成されるデータパスブロック及びステートマシンの一例を示す図である。データパスブロック902は、演算器データ905に示される演算器が、MPLD20A又は20B内のMLUTに割り当てられることで実現される回路ブロックと、そのデータパスを示す。ステートは、各MPLDに構成可能なバンク単位の回路構成を識別する。ステートは、コンパイルプログラム990をMPU220が実行した際に、MPLD20A及び20Bの粒度に合わせて生成される。各ステートは、静的スケジュール情報975により順番付けされている。例えば、また、ステート1〜4は、MPLD20Aのバンク単位の記憶領域をそれぞれ特定する。また、ステート1は、MPLD20Aを構成し、ステート2は、MPLD20Bを構成し、ステート3は、MPLD20Aを構成し、ステート4は、MPLD20Bを構成するように、複数のMPLDを時系列毎に特定してもよい。このようにしてステート1からステート4へとMPLDの再構成が繰り替えられることで、段数の多いパイプラインを、小規模のMPLDで処理することが可能になる。
【0326】
ステートマシン915は、ステートの起動開始と、ステートのステータスを管理する。ステートマシン915は、データパス駆動信号をデータパスブロックに出力することで、ステートを起動し、ステータス信号を受け取ることで、ステートを管理する。
【0327】
S0ステートは外部からの実行トリガの監視と本処理の最後に本ステートに戻ることで、次に実行する制御データを設定する。これによりスケジューラ940は投機的実行の分岐失敗をチェックできる。
【0328】
〔7.3〕半導体装置の動作処理フロー
次に、半導体装置の動作処理フローについて説明する。
【0329】
図70は、半導体装置の投機実行に関する処理フローの一例を示す図である。まず、構成制御部300は、システムリセット信号が受信されたか否かを判断する(S1001)。システムリセット信号を受信した場合(S1001 Yes)、メインメモリ500から演算器データ905及び制御データ910を読み出して、キャッシュ部400A及び400Bにそれぞれ書き込む(S1002)。構成制御部300は、キャッシュ部400A及び400Bに保持された演算器データ905及び制御データ910を読み出して、演算器データ905及び制御データ910を解凍する(S1003)。構成制御部300は、解凍した演算器データ905及び制御データ910で、MPLD20A及び20Bをそれぞれ再構成する(S1004)。MPLD20A又は20Bは、ステートマシンのデータパス駆動信号に従い演算を開始する(S1005)。構成制御部300は、静的スケジュール情報975に従ってS1003〜S1005の処理を繰り返すとともに、投機実行が失敗したか否かを判断する(S1006)。投機実行の失敗は、ステートマシンから通知される。投機実行が失敗した場合(S1007 エラー)、投機実行の失敗を通知したステートマシンが動作するMPLDを、分岐先回路を含む演算器データ905及び制御データ910で再構成する(S1008)。
【0330】
投機実行が成功した場合(S1007 No)、投機実行により再構成されたMPLDの演算を開始する(S1009)。
【0331】
図71は、半導体装置のキャッシュ制御に関する処理フローである。構成制御部300は、静的スケジュール情報975に従って、キャッシュ部400Bに制御データ910があるかどうか判断する(S1101)。静的スケジュール情報975に特定される制御データ910が、キャッシュ部400Bに保持されるなら(S1101 Yes)、S1002〜S1008の処理を行う(S1102)。静的スケジュール情報975に特定される制御データ910が、キャッシュ部400Bに保持されていない場合(S1101 No)、構成制御部300は、メインメモリ500から制御データ910を読み出して(S1103)、読み出した制御データ910でMPLDを再構成する(S1104)。
【符号の説明】
【0332】
9 アドレスデコーダ
12 MLUTデコーダ
13 Dフリップフロップ
15 入出力回路部
20 MPLD
22 マルチプレクサ
24 A/Dコンバータ
25 変数保持部
26 記憶部
28 MOSFETドライバ
30 MLUT
40 記憶素子
100 半導体装置
150 入出力部
210 情報処理装置
211、220 演算処理部
300 構成制御部
310 キャッシュ制御
320 システムリセット
330 圧縮データ解凍
340 スケジューラ
400A キャッシュ部
400B キャッシュ部
500 メインメモリ
550 メモリコントローラ
902 データパスブロック
905 演算器データ
910 制御データ
915 ステートマシン
940 スケジューラ
970 プロファイル情報
975 静的スケジュール情報
980 プログラム
990 コンパイルプログラム
【特許請求の範囲】
【請求項1】
N(Nは、2以上の整数)本のアドレス線と、
N本のデータ線と、
複数の記憶部であって、各記憶部は、
前記N本のアドレス線から入力されるアドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、
前記ワード線とデータ線に接続し、真理値表を構成するデータをそれぞれ記憶し、前記ワード線から入力される前記ワード選択信号により、前記データを前記データ線に入出力する複数の記憶素子を有する、複数の記憶部と、を備え、
前記記憶部のN本のアドレス線は、前記記憶部の他のN個の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のN本のデータ線は、前記記憶部の他のN個の記憶部のアドレス線に、それぞれ接続することを特徴とする半導体装置。
【請求項2】
前記N本のアドレス線と、前記N本のデータ線とはそれぞれ、1本のアドレス線と、1本のデータ線とにより対をなす請求項1に記載の半導体装置。
【請求項3】
前記複数の記憶部を選択する記憶部デコーダをさらに有する請求項1又は2に記載の半導体装置。
【請求項4】
順序回路を有し、
前記複数の記憶部は、前記N本のデータ線の中の少なくとも1本のデータ線を前記順序回路の信号入力線に接続するとともに、前記N本のアドレス線の中の少なくとも1本のアドレス線を前記順序回路の信号出力線に接続する請求項1〜3の何れか1項に記載の半導体装置。
【請求項5】
前記Nは、6〜8の整数である請求項1〜4の何れか1項に記載の半導体装置。
【請求項6】
前記複数の記憶部は、前記N本のデータ線の中の6本のデータ線を、隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続するとともに、前記N本のアドレス線の中の6本のアドレス線を、前記隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続する請求項1〜5の何れか1項に記載の半導体装置。
【請求項7】
前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項1〜6の何れか1項に記載の半導体装置。
【請求項8】
前記複数の記憶部のうちの少なくとも1つの記憶部に隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から第1の方向に第1の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向に交差する第2の方向に第2の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向と前記第2の方向に交差する第3の方向に第3の距離を置いて配置され、
前記第1〜第3の距離は、第1の距離、第2の距離、第3の距離の順番で長くなる、請求項1〜7の何れか1項に記載の半導体装置。
【請求項9】
前記第1の方向と、前記第2の方向とは、互いに直交している請求項1〜8の何れか1項に記載の半導体装置。
【請求項10】
前記複数の記憶部の少なくとも1つの記憶部は、隣接する他の記憶部以外の記憶部のデータ線に、1本のアドレス線を接続する請求項1〜9の何れか1項に記載の半導体装置。
【請求項11】
前記複数の記憶部の何れかは、前記複数の記憶部のうちの少なくとも1つの記憶部から前記第1〜第3の方向の何れかの方向に配置され、
前記複数の記憶部の少なくとも1つの記憶部は、前記第1〜第3の距離の何れか1つを5倍した位置に配置された記憶部のデータ線に、1本のアドレス線を接続する請求項6〜10の何れか1項に記載の半導体装置。
【請求項12】
前記複数の記憶部は、再構成可能な論理要素及び/又は接続要素として使用される請求項1〜11の何れか1項に記載の半導体装置。
【請求項13】
前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する請求項1〜12の何れか1項に記載の半導体装置。
【請求項14】
前記真理値表を構成するデータを記憶する記憶装置をさらに有する請求項13に記載の半導体装置。
【請求項15】
物理的な配線層数が4層以下である請求項1〜14の何れか1項に記載の半導体装置。
【請求項16】
それぞれが複数の記憶部を有する第1及び第2の論理部であって、各記憶部は、第1アドレス線から入力されるメモリ動作用アドレス、又は、第2アドレス線から入力される論理動作用アドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、前記ワード線とデータ線とに接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子と、を有する、第1及び第2の論理部と、
前記第1の論理部が有する記憶部の第1アドレス線及びデータ線と接続する第1の入出力部、前記第2の論理部が有する記憶部の第2アドレス線及びデータ線と接続する第2の入出力部、及び、前記第1の入出力部に対してメモリ動作用アドレス及びデータを出力する制御を行うとともに、前記第2の入出力部に対して論理動作用アドレスを出力し且つデータを受け取る制御を行う制御部、を有する演算処理部と、
を備えることを特徴とする半導体装置。
【請求項17】
第1の論理部又は第2の論理部に含まれる前記記憶部の論理動作用アドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部の論理動作用アドレス線に、それぞれ接続する請求項16に記載の半導体装置。
【請求項18】
前記第1の論理部及び前記第2の論理部に含まれる前記複数の記憶部は、再構成可能である請求項16又は17に記載の半導体装置。
【請求項19】
前記第1の論理部及び前記第2の論理部は、前記複数の記憶部を選択する記憶部デコーダをそれぞれ有する請求項16〜18の何れか1項に記載の半導体装置。
【請求項20】
前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する請求項16〜19の何れか1項に記載の半導体装置。
【請求項21】
前記真理値表を構成するデータを記憶する記憶装置をさらに有する請求項16〜20の何れか1項に記載の半導体装置。
【請求項22】
物理的な配線層数が4層以下である請求項16〜21の何れか1項に記載の半導体装置。
【請求項23】
前記第1の論理部が有する前記記憶部の数と、前記第2の論理部が有する前記記憶部の数とが同一である請求項16〜22の何れか1項に記載の半導体装置。
【請求項24】
前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項16〜23の何れか1項に記載の半導体装置。
【請求項25】
演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、第1の論理部に、論理動作又は接続関係を規定する真理値表データを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第1の論理部の記憶部に、前記論理動作又は接続関係を規定する真理値表データを記憶するステップと、
前記演算処理部が、第2の論理部に、論理動作用アドレスを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第2の論理部の記憶部が、前記論理動作用アドレスにより特定される記憶素子からデータを出力するステップと、
前記演算処理装置は、前記第2の論理部からデータを受け取るステップと、を有する特徴とする制御方法。
【請求項26】
前記演算処理装置は前記半導体装置に含まれる、請求項25に記載の制御方法。
【請求項27】
データを演算処理する演算処理部と、
複数の記憶部及び入出力部を有する論理部であって、
各記憶部は、アドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力するアドレスデコーダと、データ線とワード線に接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子とを有し、
前記入出力部は、前記演算処理部の少なくとも1つの出力信号線と前記アドレス線のすくなくとも1つとを接続すると共に、前記演算処理部の少なくとも1つの入力信号線と前記データ線の少なくとも1つとを接続する、演算処理部と、
を備えることを特徴とする半導体装置。
【請求項28】
前記記憶部のアドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部のアドレス線に、それぞれ接続する請求項27に記載の半導体装置。
【請求項29】
前記複数の記憶部は、再構成可能である請求項26又は27に記載の半導体装置。
【請求項30】
前記論理部は、前記複数の記憶部を選択する記憶部デコーダをさらに有する請求項26〜29の何れか1項に記載の半導体装置。
【請求項31】
前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する請求項26〜30の何れか1項に記載の半導体装置。
【請求項32】
前記真理値表を構成するデータを記憶する記憶装置をさらに有する請求項26〜31の何れかに記載の半導体装置。
【請求項33】
物理的な配線層数が4層以下である請求項26〜32の何れかに記載の半導体装置。
【請求項34】
前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項26〜33の何れか1項に記載の半導体装置。
【請求項35】
演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、前記演算処理部に含まれる論理部に、アドレスを出力するステップであって、前記論理部は複数の記憶素子を有し、各記憶素子は、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶する、ステップと、
前記論理部は、前記演算処理部の少なくとも1つの出力信号線と接続される少なくとも1つのアドレス線から、前記アドレスを受け取るステップと、
前記論理部は、前記アドレスにより特定される記憶素子からデータを出力するステップと、
前記論理部は、前記データを、前記演算処理部の少なくとも1つの入力信号線と接続される少なくとも1つのデータ線を介して、前記演算処理部に出力するステップと、
を有することを特徴とする制御方法。
【請求項36】
前記論理部は、前記読み出したデータを、前記論理部内の記憶部と繋がる少なくとも1つのデータ線から、前記演算処理部の少なくとも1つの入力信号線に出力する、請求項35に記載の制御方法。
【請求項37】
前記演算処理装置は前記半導体装置に含まれる、請求項35又は36に記載の制御方法。
【請求項38】
各々が複数のメモリセルユニットを有し、且つ、前記メモリセルユニットに真理値表データを書き込むと、論理要素又は接続要素として動作する複数のプログラマブル論理部と、
各々が複数の前記真理値表データである複数の構成情報を保持するキャッシュ部と、
前記複数のプログラマブル論理部のうちの第1のプログラマブル論理部が、分岐論理を構成する第1の構成情報で再構成されている場合、前記分岐論理の分岐先回路を構成する前記第2の構成情報で、前記複数のプログラマブル論理部のうちの第2のプログラマブル論理部を再構成する構成制御部と、
を備えることを特徴とする半導体装置。
【請求項39】
前記キャッシュ部は、演算器を示す真理値表データである演算器データと、状態遷移を示す真理値表データである制御データとを、分けて保持し、
前記構成制御部は、前記制御データと、前記制御データの状態遷移により示される演算器を含む前記演算器データを、前記キャッシュ部からそれぞれ読み込んで、前記プログラマブル論理部を再構成する、ことを特徴とする請求項38に記載の半導体装置。
【請求項40】
前記キャッシュ部が保持する制御データを包含する記憶部をさらに有し、
前記構成制御部は、前記キャッシュ部が保持する制御データの次に、前記プログラマブル論理部を再構成するための制御データを、前記記憶部から読み出して、前記キャッシュ部に記憶する、ことを特徴とする請求項38又は39に記載の半導体装置。
【請求項41】
前記記憶部に記憶される前記制御データの真理値表データは圧縮されており、
前記キャッシュ部は、圧縮した真理値表データを保持し、
前記構成制御部は、前記圧縮した真理値表データを解凍して、当該解凍した真理値表データで前記プログラマブル論理部を再構成する、ことを特徴とする請求項38〜40の何れか1項に記載の半導体装置。
【請求項42】
前記構成制御部は、前記複数のプログラマブル論理部のうちの第1のプログラマブル論理部が、分岐論理を構成する第3の構成情報で再構成されており、前記第3の構成情報の分岐論理の分岐先回路と予測した第4の構成情報で構成された第2のプログラマブル論理部の演算結果によって、前記第4の構成情報が前記第3の構成情報の分岐論理の分岐先回路を構成しなかった場合、前記第2のプログラマブル論理部以外のプログラマブル論理部を、前記分岐論理の分岐先を含む第5の構成情報で再構成する、請求項1〜4の何れか1項に記載の半導体装置。
【請求項1】
N(Nは、2以上の整数)本のアドレス線と、
N本のデータ線と、
複数の記憶部であって、各記憶部は、
前記N本のアドレス線から入力されるアドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、
前記ワード線とデータ線に接続し、真理値表を構成するデータをそれぞれ記憶し、前記ワード線から入力される前記ワード選択信号により、前記データを前記データ線に入出力する複数の記憶素子を有する、複数の記憶部と、を備え、
前記記憶部のN本のアドレス線は、前記記憶部の他のN個の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のN本のデータ線は、前記記憶部の他のN個の記憶部のアドレス線に、それぞれ接続することを特徴とする半導体装置。
【請求項2】
前記N本のアドレス線と、前記N本のデータ線とはそれぞれ、1本のアドレス線と、1本のデータ線とにより対をなす請求項1に記載の半導体装置。
【請求項3】
前記複数の記憶部を選択する記憶部デコーダをさらに有する請求項1又は2に記載の半導体装置。
【請求項4】
順序回路を有し、
前記複数の記憶部は、前記N本のデータ線の中の少なくとも1本のデータ線を前記順序回路の信号入力線に接続するとともに、前記N本のアドレス線の中の少なくとも1本のアドレス線を前記順序回路の信号出力線に接続する請求項1〜3の何れか1項に記載の半導体装置。
【請求項5】
前記Nは、6〜8の整数である請求項1〜4の何れか1項に記載の半導体装置。
【請求項6】
前記複数の記憶部は、前記N本のデータ線の中の6本のデータ線を、隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続するとともに、前記N本のアドレス線の中の6本のアドレス線を、前記隣接する他の6個の記憶部の1本のデータ線にそれぞれ接続する請求項1〜5の何れか1項に記載の半導体装置。
【請求項7】
前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項1〜6の何れか1項に記載の半導体装置。
【請求項8】
前記複数の記憶部のうちの少なくとも1つの記憶部に隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から第1の方向に第1の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向に交差する第2の方向に第2の距離を置いて配置され、
前記隣接する他のN個の記憶部のうち2つの記憶部は、前記少なくとも1つの記憶部から前記第1の方向と前記第2の方向に交差する第3の方向に第3の距離を置いて配置され、
前記第1〜第3の距離は、第1の距離、第2の距離、第3の距離の順番で長くなる、請求項1〜7の何れか1項に記載の半導体装置。
【請求項9】
前記第1の方向と、前記第2の方向とは、互いに直交している請求項1〜8の何れか1項に記載の半導体装置。
【請求項10】
前記複数の記憶部の少なくとも1つの記憶部は、隣接する他の記憶部以外の記憶部のデータ線に、1本のアドレス線を接続する請求項1〜9の何れか1項に記載の半導体装置。
【請求項11】
前記複数の記憶部の何れかは、前記複数の記憶部のうちの少なくとも1つの記憶部から前記第1〜第3の方向の何れかの方向に配置され、
前記複数の記憶部の少なくとも1つの記憶部は、前記第1〜第3の距離の何れか1つを5倍した位置に配置された記憶部のデータ線に、1本のアドレス線を接続する請求項6〜10の何れか1項に記載の半導体装置。
【請求項12】
前記複数の記憶部は、再構成可能な論理要素及び/又は接続要素として使用される請求項1〜11の何れか1項に記載の半導体装置。
【請求項13】
前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する請求項1〜12の何れか1項に記載の半導体装置。
【請求項14】
前記真理値表を構成するデータを記憶する記憶装置をさらに有する請求項13に記載の半導体装置。
【請求項15】
物理的な配線層数が4層以下である請求項1〜14の何れか1項に記載の半導体装置。
【請求項16】
それぞれが複数の記憶部を有する第1及び第2の論理部であって、各記憶部は、第1アドレス線から入力されるメモリ動作用アドレス、又は、第2アドレス線から入力される論理動作用アドレスをデコードしてワード線にワード選択信号を出力するアドレスデコーダと、前記ワード線とデータ線とに接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子と、を有する、第1及び第2の論理部と、
前記第1の論理部が有する記憶部の第1アドレス線及びデータ線と接続する第1の入出力部、前記第2の論理部が有する記憶部の第2アドレス線及びデータ線と接続する第2の入出力部、及び、前記第1の入出力部に対してメモリ動作用アドレス及びデータを出力する制御を行うとともに、前記第2の入出力部に対して論理動作用アドレスを出力し且つデータを受け取る制御を行う制御部、を有する演算処理部と、
を備えることを特徴とする半導体装置。
【請求項17】
第1の論理部又は第2の論理部に含まれる前記記憶部の論理動作用アドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部の論理動作用アドレス線に、それぞれ接続する請求項16に記載の半導体装置。
【請求項18】
前記第1の論理部及び前記第2の論理部に含まれる前記複数の記憶部は、再構成可能である請求項16又は17に記載の半導体装置。
【請求項19】
前記第1の論理部及び前記第2の論理部は、前記複数の記憶部を選択する記憶部デコーダをそれぞれ有する請求項16〜18の何れか1項に記載の半導体装置。
【請求項20】
前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する請求項16〜19の何れか1項に記載の半導体装置。
【請求項21】
前記真理値表を構成するデータを記憶する記憶装置をさらに有する請求項16〜20の何れか1項に記載の半導体装置。
【請求項22】
物理的な配線層数が4層以下である請求項16〜21の何れか1項に記載の半導体装置。
【請求項23】
前記第1の論理部が有する前記記憶部の数と、前記第2の論理部が有する前記記憶部の数とが同一である請求項16〜22の何れか1項に記載の半導体装置。
【請求項24】
前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項16〜23の何れか1項に記載の半導体装置。
【請求項25】
演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、第1の論理部に、論理動作又は接続関係を規定する真理値表データを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第1の論理部の記憶部に、前記論理動作又は接続関係を規定する真理値表データを記憶するステップと、
前記演算処理部が、第2の論理部に、論理動作用アドレスを出力するステップであって、前記第1の論理部は複数の記憶部を有し、各記憶部は複数の記憶素子を有する、ステップと、
前記第2の論理部の記憶部が、前記論理動作用アドレスにより特定される記憶素子からデータを出力するステップと、
前記演算処理装置は、前記第2の論理部からデータを受け取るステップと、を有する特徴とする制御方法。
【請求項26】
前記演算処理装置は前記半導体装置に含まれる、請求項25に記載の制御方法。
【請求項27】
データを演算処理する演算処理部と、
複数の記憶部及び入出力部を有する論理部であって、
各記憶部は、アドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力するアドレスデコーダと、データ線とワード線に接続し、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶するとともに、前記ワード線から入力される前記ワード選択信号により、前記データを入出力するデータ線に接続される複数の記憶素子とを有し、
前記入出力部は、前記演算処理部の少なくとも1つの出力信号線と前記アドレス線のすくなくとも1つとを接続すると共に、前記演算処理部の少なくとも1つの入力信号線と前記データ線の少なくとも1つとを接続する、演算処理部と、
を備えることを特徴とする半導体装置。
【請求項28】
前記記憶部のアドレス線は、前記記憶部の他の記憶部のデータ線に、それぞれ接続するとともに、前記記憶部のデータ線は、前記記憶部の他の記憶部のアドレス線に、それぞれ接続する請求項27に記載の半導体装置。
【請求項29】
前記複数の記憶部は、再構成可能である請求項26又は27に記載の半導体装置。
【請求項30】
前記論理部は、前記複数の記憶部を選択する記憶部デコーダをさらに有する請求項26〜29の何れか1項に記載の半導体装置。
【請求項31】
前記真理値表を構成するデータを記憶する記憶装置に接続する入出力部をさらに有する請求項26〜30の何れか1項に記載の半導体装置。
【請求項32】
前記真理値表を構成するデータを記憶する記憶装置をさらに有する請求項26〜31の何れかに記載の半導体装置。
【請求項33】
物理的な配線層数が4層以下である請求項26〜32の何れかに記載の半導体装置。
【請求項34】
前記アドレスデコーダは、行デコーダと列デコーダに分かれており、
前記行デコーダは、M(Mは5以下の整数であり、LはN−5の整数)本のアドレス線から入力されるアドレスをデコードして前記ワード線にワード選択信号を出力し、
前記列デコーダは、L本のアドレス線から入力されるアドレスをデコードして、前記複数の記憶素子から出力されるN本のデータ線を選択するデータ選択信号を出力する請求項26〜33の何れか1項に記載の半導体装置。
【請求項35】
演算処理部を用いた半導体装置の制御方法であって、
前記演算処理部が、前記演算処理部に含まれる論理部に、アドレスを出力するステップであって、前記論理部は複数の記憶素子を有し、各記憶素子は、論理動作又は接続関係を規定する真理値表を構成するデータをそれぞれ記憶する、ステップと、
前記論理部は、前記演算処理部の少なくとも1つの出力信号線と接続される少なくとも1つのアドレス線から、前記アドレスを受け取るステップと、
前記論理部は、前記アドレスにより特定される記憶素子からデータを出力するステップと、
前記論理部は、前記データを、前記演算処理部の少なくとも1つの入力信号線と接続される少なくとも1つのデータ線を介して、前記演算処理部に出力するステップと、
を有することを特徴とする制御方法。
【請求項36】
前記論理部は、前記読み出したデータを、前記論理部内の記憶部と繋がる少なくとも1つのデータ線から、前記演算処理部の少なくとも1つの入力信号線に出力する、請求項35に記載の制御方法。
【請求項37】
前記演算処理装置は前記半導体装置に含まれる、請求項35又は36に記載の制御方法。
【請求項38】
各々が複数のメモリセルユニットを有し、且つ、前記メモリセルユニットに真理値表データを書き込むと、論理要素又は接続要素として動作する複数のプログラマブル論理部と、
各々が複数の前記真理値表データである複数の構成情報を保持するキャッシュ部と、
前記複数のプログラマブル論理部のうちの第1のプログラマブル論理部が、分岐論理を構成する第1の構成情報で再構成されている場合、前記分岐論理の分岐先回路を構成する前記第2の構成情報で、前記複数のプログラマブル論理部のうちの第2のプログラマブル論理部を再構成する構成制御部と、
を備えることを特徴とする半導体装置。
【請求項39】
前記キャッシュ部は、演算器を示す真理値表データである演算器データと、状態遷移を示す真理値表データである制御データとを、分けて保持し、
前記構成制御部は、前記制御データと、前記制御データの状態遷移により示される演算器を含む前記演算器データを、前記キャッシュ部からそれぞれ読み込んで、前記プログラマブル論理部を再構成する、ことを特徴とする請求項38に記載の半導体装置。
【請求項40】
前記キャッシュ部が保持する制御データを包含する記憶部をさらに有し、
前記構成制御部は、前記キャッシュ部が保持する制御データの次に、前記プログラマブル論理部を再構成するための制御データを、前記記憶部から読み出して、前記キャッシュ部に記憶する、ことを特徴とする請求項38又は39に記載の半導体装置。
【請求項41】
前記記憶部に記憶される前記制御データの真理値表データは圧縮されており、
前記キャッシュ部は、圧縮した真理値表データを保持し、
前記構成制御部は、前記圧縮した真理値表データを解凍して、当該解凍した真理値表データで前記プログラマブル論理部を再構成する、ことを特徴とする請求項38〜40の何れか1項に記載の半導体装置。
【請求項42】
前記構成制御部は、前記複数のプログラマブル論理部のうちの第1のプログラマブル論理部が、分岐論理を構成する第3の構成情報で再構成されており、前記第3の構成情報の分岐論理の分岐先回路と予測した第4の構成情報で構成された第2のプログラマブル論理部の演算結果によって、前記第4の構成情報が前記第3の構成情報の分岐論理の分岐先回路を構成しなかった場合、前記第2のプログラマブル論理部以外のプログラマブル論理部を、前記分岐論理の分岐先を含む第5の構成情報で再構成する、請求項1〜4の何れか1項に記載の半導体装置。
【図1】

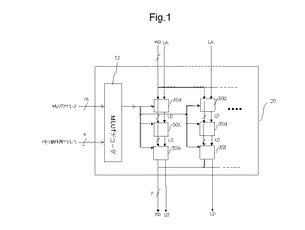
【図2】
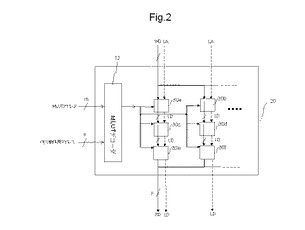
【図3】
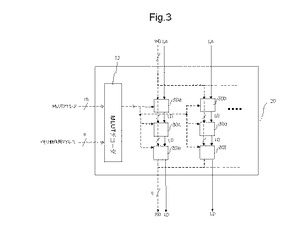
【図4】
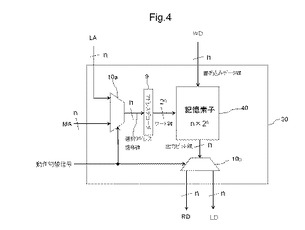
【図5】
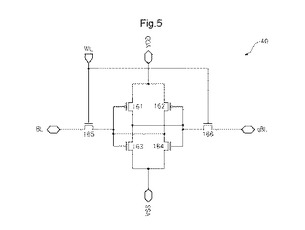
【図6】
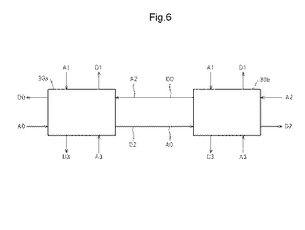
【図7】
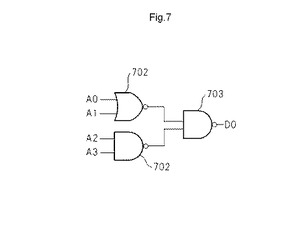
【図8】
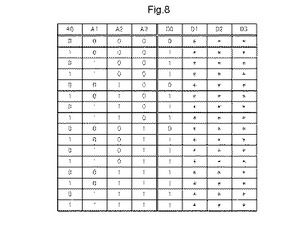
【図9】
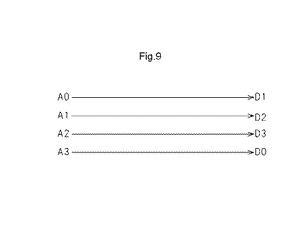
【図10】
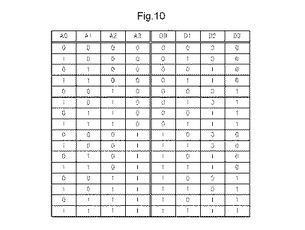
【図11】
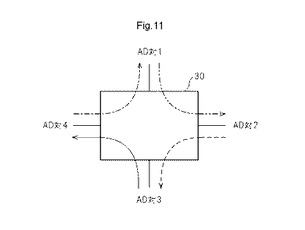
【図12】
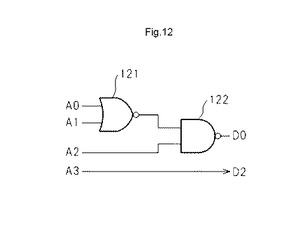
【図13】
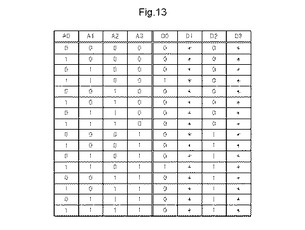
【図14】
【図15】
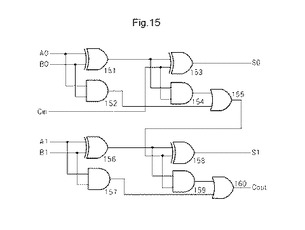
【図16】
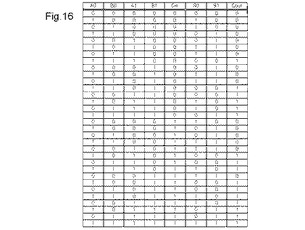
【図17】
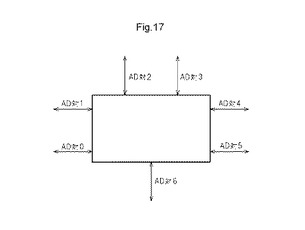
【図18A】
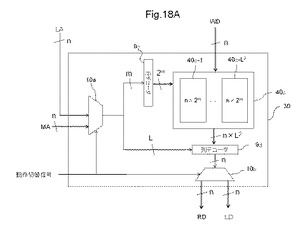
【図18B】
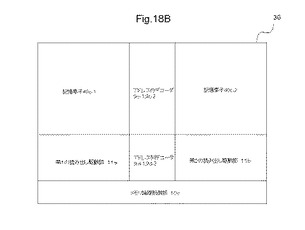
【図19】
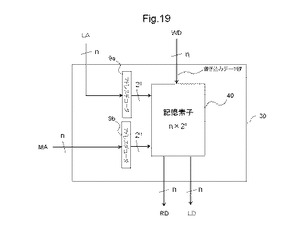
【図20】
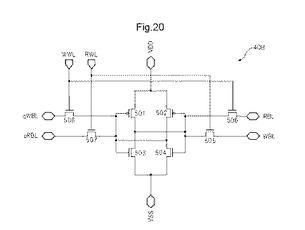
【図21】
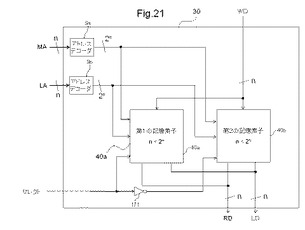
【図22】
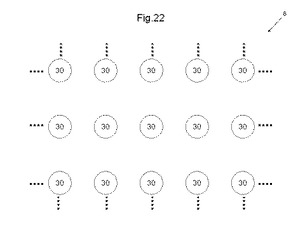
【図23】
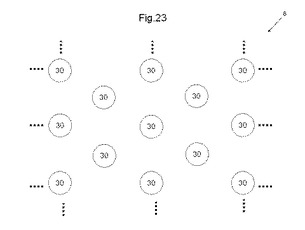
【図24】
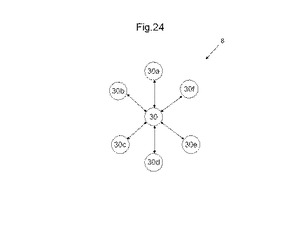
【図25】
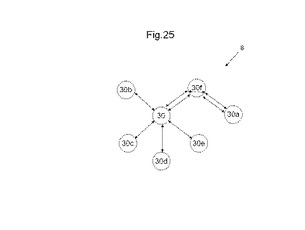
【図26A】
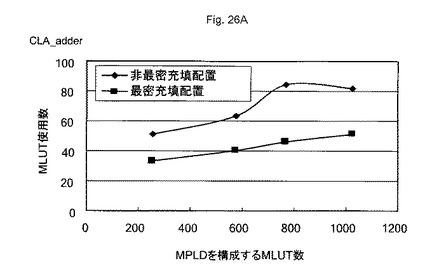
【図26B】
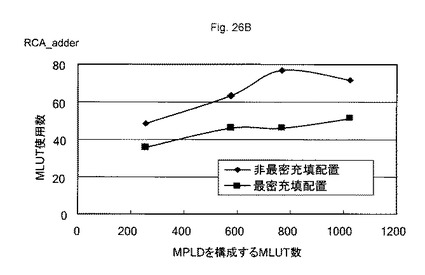
【図26C】
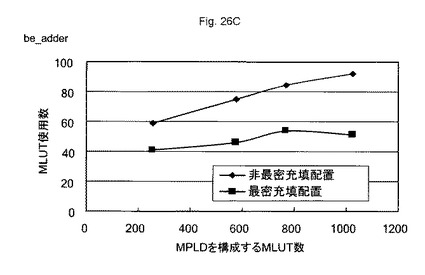
【図26D】
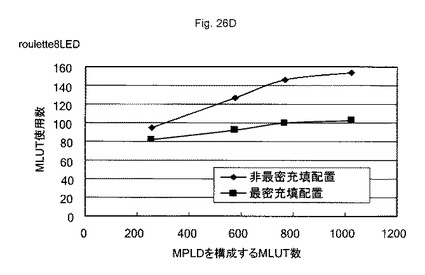
【図27】
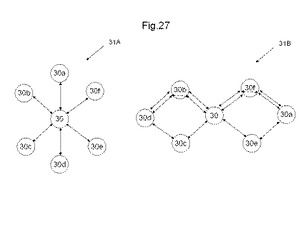
【図28】
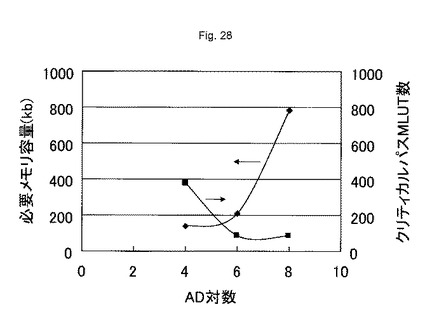
【図29】
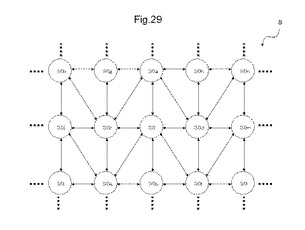
【図30】
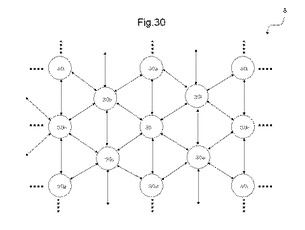
【図31】
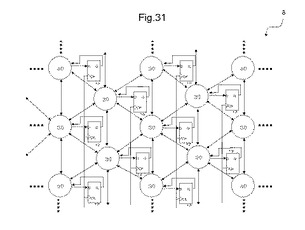
【図32】
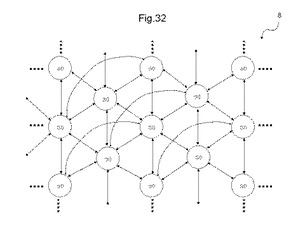
【図33】
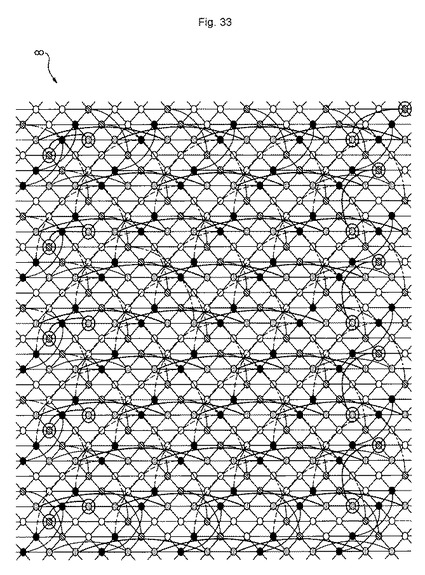
【図34】
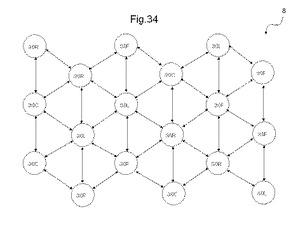
【図35】

【図36】

【図37】

【図38】

【図39】

【図40】

【図41】
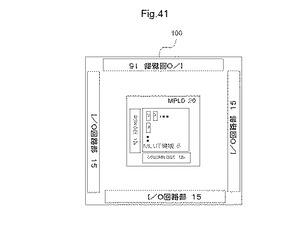
【図42】
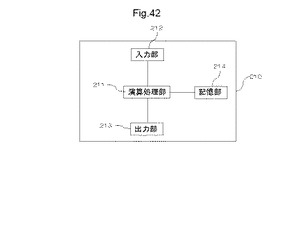
【図43】
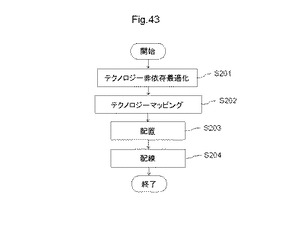
【図44】

【図45】
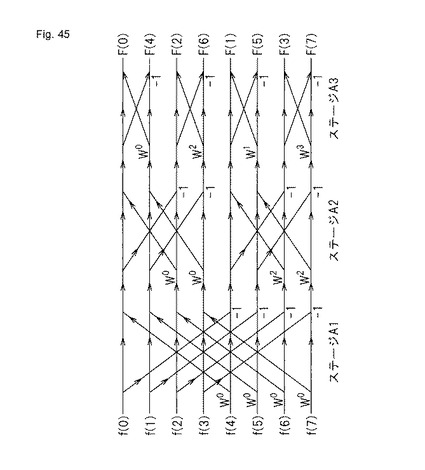
【図46】
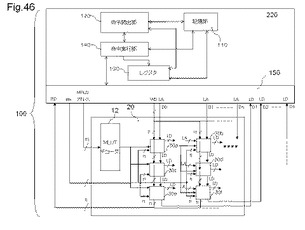
【図47】
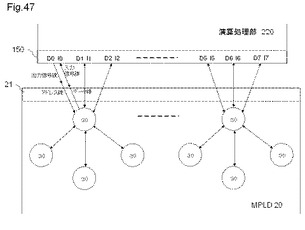
【図48】
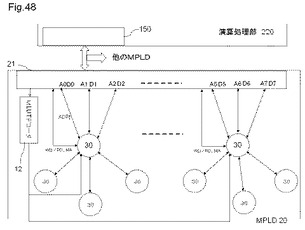
【図49】
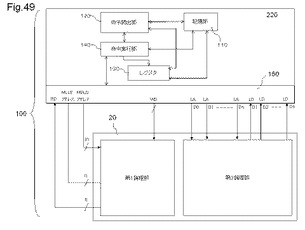
【図50】
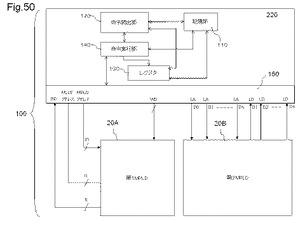
【図51】
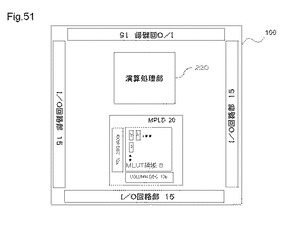
【図52】
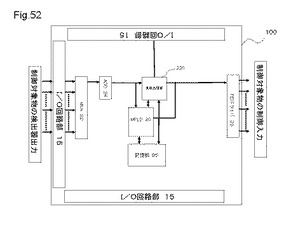
【図53】
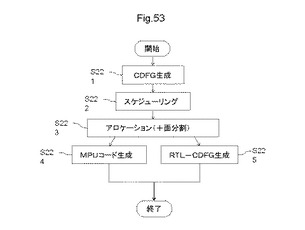
【図54】
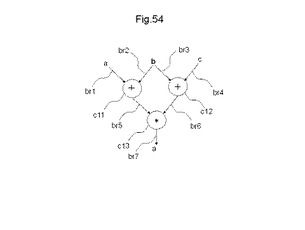
【図55】
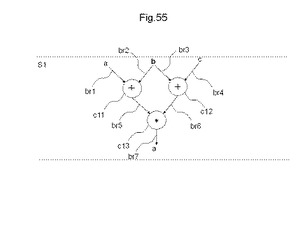
【図56】
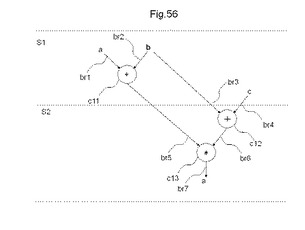
【図57】

【図58】
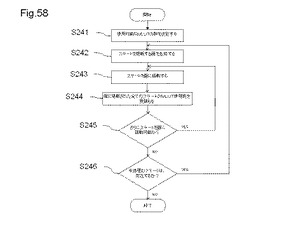
【図59】
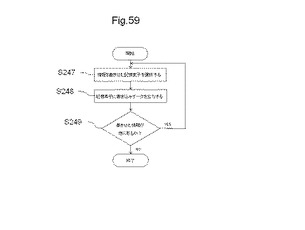
【図60】
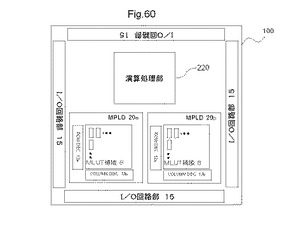
【図61】
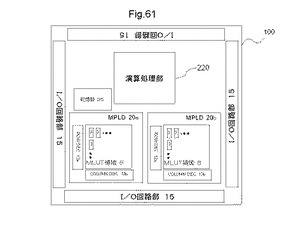
【図62】
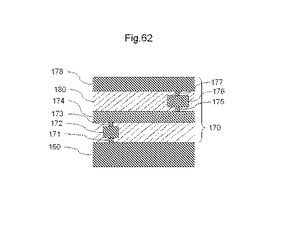
【図63】
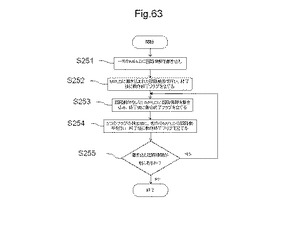
【図64】
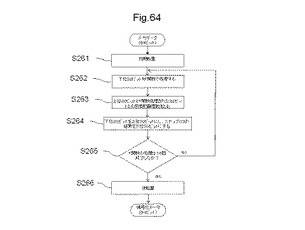
【図65】
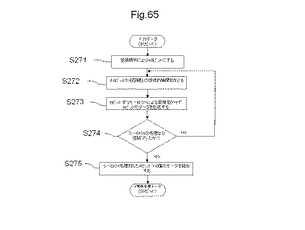
【図66】
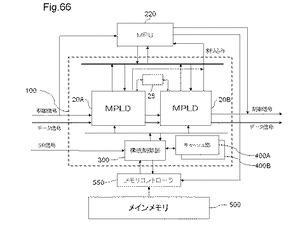
【図67】
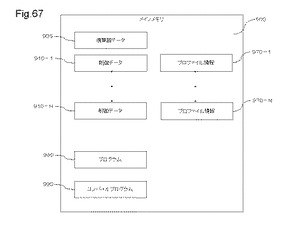
【図68】
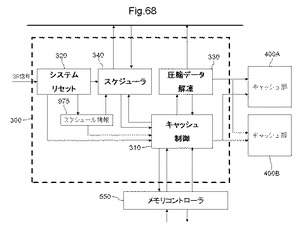
【図69】
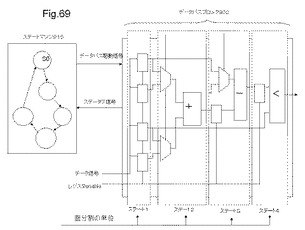
【図70】
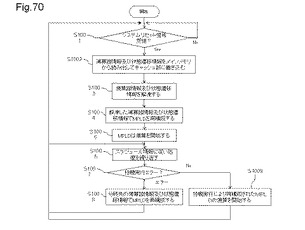
【図71】
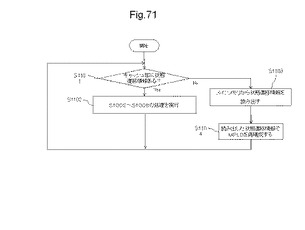
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18A】
【図18B】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26A】
【図26B】
【図26C】
【図26D】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【図40】
【図41】
【図42】
【図43】
【図44】
【図45】
【図46】
【図47】
【図48】
【図49】
【図50】
【図51】
【図52】
【図53】
【図54】
【図55】
【図56】
【図57】
【図58】
【図59】
【図60】
【図61】
【図62】
【図63】
【図64】
【図65】
【図66】
【図67】
【図68】
【図69】
【図70】
【図71】
【公開番号】特開2013−110730(P2013−110730A)
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願番号】特願2012−189334(P2012−189334)
【出願日】平成24年8月30日(2012.8.30)
【分割の表示】特願2012−521424(P2012−521424)の分割
【原出願日】平成23年6月13日(2011.6.13)
【出願人】(000204284)太陽誘電株式会社 (964)
【Fターム(参考)】
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願日】平成24年8月30日(2012.8.30)
【分割の表示】特願2012−521424(P2012−521424)の分割
【原出願日】平成23年6月13日(2011.6.13)
【出願人】(000204284)太陽誘電株式会社 (964)
【Fターム(参考)】
[ Back to top ]