
単語レベルの変換候補生成に基づく音声認識システム及び方法
【課題】単語レベルの変換候補生成に基づく音声認識システム及び方法が開示される。
【解決手段】音声認識システムは、音声認識の結果として、単語列及び単語列に含まれた単語のうち少なくとも1つの単語に対する変換候補単語が提供される場合、単語列及び変換候補単語を確認する音声認識結果確認部及び単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示する単語列表示部を備え、単語列表示部は区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示する。
【解決手段】音声認識システムは、音声認識の結果として、単語列及び単語列に含まれた単語のうち少なくとも1つの単語に対する変換候補単語が提供される場合、単語列及び変換候補単語を確認する音声認識結果確認部及び単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示する単語列表示部を備え、単語列表示部は区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は単語レベルの変換候補生成に基づく音声認識システム及び方法に関する。
【背景技術】
【0002】
音声認識によってディクテーション(dictation)しようとするとき、音声認識の後に出力された変換候補文章が極めて多い場合、ユーザに少しずつ異なるn個の文章を確認させて所望の文章を選択させることは難しい問題である。すなわち、モバイル端末のようなユーザ端末の場合、当該端末が小さいため一度に多くの文章を全て露出させることが難しく、ユーザの立場からはn個の文章を見たとき、どの文章が適切な文章であるかを一瞬で把握することができないという問題がある。
【0003】
本明細書では、音声認識によってより効果的にディクテーションを提供することのできる音声認識システム及び方法が提案される。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】韓国公開特許第2006−0098673号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
本発明の目的は、ユーザに音声認識の結果による文字列を表示して提供する際に、変換候補が存在する単語を文字列上の他の単語と区分して表示し、変換候補が存在する単語に対するユーザの選択に応じて当該単語を変換候補単語に変更して表示することで、一回の選択でユーザが音声認識の結果を単語ごとに修正することのできる音声認識システム及び音声認識方法を提供する。
【0006】
本発明の目的は、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列を選択し、選択された単語列に含まれる単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内で音声信号に対して認識された他の単語のうち、他の単語それぞれについて算出される信頼度を用いて選択される少なくとも1つの単語を候補単語に設定することで、より正確な単語ごとの結果を提供することのできる音声認識システム及び音声認識方法を提供する。
【0007】
本発明の目的は、表示された単語列の全てを一度に削除できるユーザインタフェースを提供することにあり、表示された単語列がとんでもない結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができる音声認識システム及び音声認識方法を提供する。
【0008】
本発明の目的は、音声認識によって作成される文章の単語列に対して、当該単語列が音声認識によって作成されたことを示す標識を単語列と共に表示しまたは送信することで、表示された単語列を確認するユーザ、またはこのような単語列をSMS、Eメールなどを介して受信したユーザが当該単語列が音声認識によって作成されたことを認識できる音声認識システム及び音声認識方法を提供する。
【課題を解決するための手段】
【0009】
音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、単語列及び変換候補単語を確認する音声認識結果確認部と、単語列を表示装置を介して表示する際に、変換候補単語が存在する少なくとも1つの単語を単語列の他の単語と区分して表示する単語列表示部とを備え、単語列表示部は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示することを特徴とする音声認識システムが提供される。
【0010】
本発明の一側面によると、音声認識システムは、表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部をさらに備え、単語列表示部は、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列を全て削除してもよい。
【0011】
本発明の他の側面によると、単語列が表示装置を介して表示される場合、または単語列が他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
【0012】
本発明の他の側面によると、音声認識システムは、入力装置を介して入力される音声信号を音声認識サーバに送信する音声信号送信部と、音声信号に対応する音声認識の結果を音声認識サーバを介して受信する音声認識結果受信部とをさらに備えてもよい。
【0013】
本発明の他の側面によると、音声認識システムは、入力装置を介して入力される音声信号に対応する音声認識の結果を生成する音声認識結果生成部をさらに備えてもよい。
【0014】
本発明の他の側面によると、単語列は、音声認識サーバでの音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列として選択されてもよい。
【0015】
本発明の他の側面によると、変換候補単語は、音声認識サーバで少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語として選択されてもよい。この場合、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよい。また、時間範囲は、認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0016】
音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する音声認識結果生成部と、ユーザ端末に音声認識の結果を提供する音声認識結果提供部と、を備え、端末の表示装置で単語列が表示され、変換候補が存在する少なくとも1つの単語が単語列の他の単語と区分して表示され、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が変換候補単語に変更されて表示されることを特徴とする音声認識システムが提供される。
【0017】
音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補が提供される場合、単語列及び変換候補単語を確認し、単語列を表示装置を介して表示する際に、変換候補が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示することを含み、表示することは、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を候補単語に変更して表示することを特徴とする音声認識方法が提供される。
【0018】
音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成し、ユーザ端末に音声認識の結果を提供することを含み、端末の表示装置で単語列が表示され、変換候補単語が存在する少なくとも1つの単語は単語列の他の単語と区分して表示され、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が候補単語に変更されて表示されることを特徴とする音声認識方法が提供される。
【発明の効果】
【0019】
本発明によると、ユーザに音声認識の結果による文字列を表示してユーザに提供する際に、変換候補が存在する単語を文字列上の他の単語と区分して表示し、変換候補が存在する単語に対するユーザの選択に応じて当該単語を変換候補単語に変更して表示することによって、一回の選択でユーザが音声認識の結果を単語ごとに修正することができる。
【0020】
本発明によると、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列を選択し、選択された単語列に含まれる単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内で音声信号に対して認識された他の単語のうち、他の単語それぞれに対して算出される信頼度を用いて選択される少なくとも1つの単語を変換候補単語として設定することで、より正確な単語ごとの結果を提供することができる。
【0021】
本発明によると、表示された単語列の全てを一度に削除できるユーザインタフェースを提供することができ、表示された単語列がとんでもない結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができる。
【0022】
本発明によると、音声認識によって作成される文章の単語列に対して、当該単語列が音声認識によって作成されたことを示す標識を単語列と共に表示しまたは送信することで、表示された単語列を確認するユーザ、またはこのような単語列をSMS、Eメールなどによって受信したユーザが当該単語列が音声認識によって作成されたことを認識することができる。
【図面の簡単な説明】
【0023】
【図1】本発明の一実施形態におけるユーザ端末及び音声認識サーバを示す図である。
【図2】本発明の一実施形態におけるユーザ端末のディスプレイ画面に単語列が表示された状態を示す一例である。
【図3】本発明の一実施形態におけるユーザ端末のディスプレイ画面でユーザの選択に応じて表示された単語を変換候補単語に変更して表示した状態を示す一例である。
【図4】本発明の一実施形態におけるユーザインタフェースを用いて表示された単語列を全て削除することを示す一例である。
【図5】本発明の一実施形態におけるユーザ端末において標識を表示する状態を示す一例である。
【図6】本発明の一実施形態における音声信号に対して検索された単語を示す図である。
【図7】本発明の一実施形態における音声認識システムの内部構成を説明するためのブロック図である。
【図8】本発明の一実施形態における音声認識方法を示すフローチャートである。
【図9】本発明の他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。
【図10】本発明の他の実施形態における音声認識方法を示すフローチャートである。
【図11】本発明の更に他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。
【図12】本発明の更に他の実施形態における音声認識方法を示すフローチャートである。
【図13】本発明の更に他の実施形態におけるユーザによって選択された単語の変換候補単語を表示した画面の一例である。
【発明を実施するための形態】
【0024】
以下、本発明の実施形態について添付の図面を参照しながら詳細に説明する。
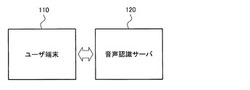
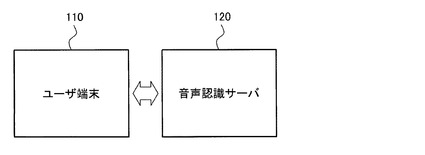
【0025】
図1は、本発明の一実施形態におけるユーザ端末及び音声認識サーバを示す図である。図1は、ユーザ端末110及び音声認識サーバ120を示している。
【0026】
ユーザ端末110には入力装置を介して音声信号が入力され、音声信号は音声認識サーバ120に送信されてもよい。ここで、音声認識サーバ120は、受信した音声信号に対応する音声認識の結果を生成してユーザ端末110に送信してもよい。
【0027】
ユーザ端末110は、音声認識サーバ120によって受信された音声認識の結果に含まれている単語列と、単語列に含まれる少なくとも1つの単語に対する変換候補単語を確認し、確認された単語列を表示装置を介して表示するところ、変換候補単語が存在する少なくとも1つの単語は単語列の残りの単語と区分されるように表示してもよい。
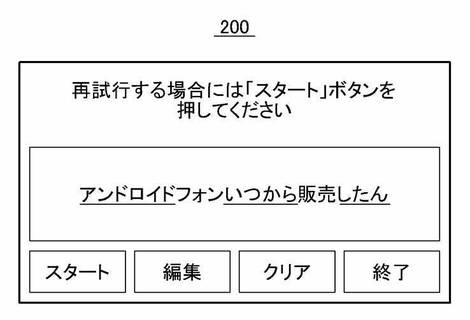
【0028】
図2は、本発明の一実施形態におけるユーザ端末のディスプレイ画面に単語列が表示された形状を示す一例である。図2に示すディスプレイ画面200は図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。ここで、ディスプレイ画面200には「アンドロイドフォンいつから販売したん」のように音声認識の結果を含む単語列が表示される。ここで、単語列に含まれる単語のうち、変換候補を有する単語は単語列に含まれる他の単語と区別されて表示される。すなわち、図2では変換候補が存在する単語「アンドロイド」、「いつから」、「したん」は,変換候補が存在しない単語「フォン」及び「販売」と区別されるようにアンダーラインで表示される。
【0029】
再び図1を参照すると、ユーザ端末110は区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示してもよい。ここで、単語がユーザによって選択されることはユーザ端末110が提供するユーザインタフェースを介して当該単語が選択されることを意味する。例えば、ユーザがタッチパッドを介して当該単語が表示された位置をタッチすることによって、当該単語がユーザによって選択される。
【0030】
図3は、本発明の一実施形態におけるユーザ端末のディスプレイ画面でユーザの選択に応じて表示された単語を変換候補単語に変更して表示した状態を示す一例である。図3に示すディスプレイ画面310から330はそれぞれ図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。
【0031】
まず、ディスプレイ画面310には「アンドロイドフォンいつから販売したん」のように最初の音声認識の結果を含む単語列が表示されている。ここで、ユーザが単語「したん」を選択する場合、ディスプレイ画面320のように単語「したん」が変換候補単語「した」のように変更して表示されてもよい。この場合、変更して表示された単語「した」も変換候補が存在しない他の単語と区分するためにアンダーラインで表示される。
【0032】
図3では単語を区分するためにアンダーラインを用いたが、アンダーラインは1つの例に過ぎず、字の大きさ、字の色、または模様などを異なるように表示する方法など、単語が区分される全ての方法のうち少なくとも1つの方法を用いてもよい。
【0033】
ユーザが単語「した」を再び選択した場合にはディスプレイ画面330のように単語「した」がその次の変換候補単語「したの」に変更されて表示されてもよい。
【0034】
もし、他の変換候補単語「したの」が存在しない場合には再びディスプレイ画面310のように本来の単語列に含まれている単語「したん」に変更されて表示されてもよい。
【0035】
このように、本実施形態では単語列に含まれる単語に対する変換候補のリストを提供する代わりに、ユーザの選択に応じて音声認識の変換候補単語を順次に変更可能であり、このような変換候補単語は音声認識による信頼度に応じて整列され、信頼度が高い順に表示される。ここで、大部分の場合、1,2回の変更によってユーザが意図した単語が表示される確率が極めて高いため、変換候補単語のリストを提供することで効率よくユーザに音声認識を通したディクテーション(dictation)を提供することができる。ここで、音声認識による単語の信頼度を算出する方法は公知の通りで、このように既に知らされた様々な方法の1つが単語の信頼度を算出するために用いられる。
【0036】
また、図3において、ユーザインタフェースの「編集」を用いてユーザが当該単語を直接編集できる機能を提供してもよい。
【0037】
再び図1を参照すると、ユーザ端末110は、表示された単語列を全て削除するためのユーザインタフェースを提供してもよい。すなわち、表示された単語列の全てを一度に削除することのできるユーザインタフェースを提供することによって、表示された単語列が全く違う結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができるようにする。
【0038】
図4は、本発明の一実施形態におけるユーザインタフェースを用いて表示された単語列を全て削除することを示す一例である。図4に示すディスプレイ画面410及び420はそれぞれ図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。
【0039】
ディスプレイ画面410は、音声認識の結果に含まれる単語列が表示された状態を示している。ここで、「クリア」411のような、ユーザ端末110が提供するユーザインタフェースを介してユーザがイベントを発生させる場合、ディスプレイ画面420のように表示された単語列を全て削除してもよい。すなわち、「好奇心の解消の消失30分到着」のようにユーザが意図した文章(単語列)と全く異なる文章が表示された場合、ユーザはこのような文章を編集することよってユーザ自身が文章を直接入力するか、または新たに音声認識の過程を行ってもよい。
【0040】
このような場合、本実施形態におけるユーザ端末110は「クリア」411のようなユーザインタフェースをユーザに提供し、ユーザが「クリア」411をタッチするなどのイベントが発生した場合、表示された文章の全体を削除することができる。
【0041】
再び図1を参照すると、ユーザ端末110は音声認識によって作成された文章(単語列)に音声認識に対する標識を含ませてもよい。ここで、音声認識に対する標識は当該文章が音声認識によって作成されたことを表す。例えば、ユーザが音声認識によって作成された文章をSMSやEメールなどを用いて他のユーザに提供する場合、他のユーザは当該文章に誤字またはエラーが存在しても、このような文章が音声認識によって作成されたことを直ちに確認することができる。
【0042】
図5は、本発明の一実施形態におけるユーザ端末で標識を提供する形状を示す一例である。図5に示すディスプレイ画面510は図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。
【0043】
ここで、ディスプレイ画面510は「アンドロイドフォンで映画を見ようとします。By Speech」のように単語列「アンドロイドフォンで映画を見ようとします。」だけではなく標識「By Speech」を共に表示している。すなわち、このような標識により,当該単語列が音声認識によって作成された文章であることをユーザが容易に把握することができる。
【0044】
再び図1を参照すると、音声認識サーバ120は、上述したようにユーザ端末110が受信した音声信号に対応する単語列及び変換候補単語を決定して音声認識の結果としてユーザ端末110に提供してもよい。ここで、音声認識サーバ120は、音声信号に対応してマッチングされ得る全ての単語列を探し、全ての単語列それぞれの確率のうち最も高い確率を有する単語列を音声認識の結果に含まれる単語列として選択する。また、音声認識サーバ120は、少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち、少なくとも1つの単語を音声認識の結果に含まれる変換候補単語として選択してもよい。この場合、他の単語のうち、少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度(confidence)に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0045】
図6は、本発明の一実施形態における音声信号に対して検索された単語を示す図である。図6において、矢印610は時間の流れを示し、四角形のボックスの長さは当該単語が認識された時間範囲を示す。ここで、互いに異なる時間範囲で認識される同一の単語、すなわち、図6において「イチゴ」(1)と「イチゴ」(2)、そして「ゴジュ」(1)と「ゴジュ」(2)とはスタート時刻は同一であるが、終了時間が互いに異なり、音声では確率的に当該時間帯において最も確率の高い単語を探したとき偶然に同じ単語になった場合である。
【0046】
まず、ユーザの発話内容が「イチゴジュース」と仮定する。すなわち、ユーザが「イチゴジュース」を発話して図1に示すユーザ端末110が入力装置を介して「イチゴジュース」が含まれた音声信号の入力を受けて音声認識サーバ120に送信すると、音声認識サーバ120は音声信号を分析して全ての含まれ得る単語列を確認し、最も高い確率を有する単語列を選択してもよい。ここで、図6では、最も高い確率を有する単語列として、単語「イチゴ」(1)と単語「ソース」が結合された「イチゴソース」が選択された場合を示している。
【0047】
この場合、音声認識サーバ120は、最も高い確率を有する単語列に含まれた単語「イチゴ」(1)と「ソース」とのそれぞれに対する変換候補単語を決定してもよい。すなわち、「イチゴ」(1)と「ソース」それぞれに対する当該時間範囲内に含まれる他の単語に対して各単語の信頼度を算出し、信頼度の高い順にn個の単語を変換候補単語として抽出してもよい。ここで、当該時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0048】
例えば、単語「ソース」に対する変換候補単語を求めるために、音声認識サーバ120は単語「ソース」に対して決定された時間範囲内に含まれる他の単語を確認する。ここで、時間範囲内に含まれる他の単語は単語「ソース」の認識が終了した時刻に予め選定された許容時間値を付与した時刻、そして「ソース」の認識がスタートした時刻の時間範囲内に含まれ,かつ、スタート時間が同一の単語を含んでもよい。ここで、許容時間値は30msのように音声認識サーバ120によって決定されてもよい。
【0049】
ここで、スタート時刻は同一であるが、終了した時間が「ソース」の認識が終了した時間よりも予め選定された許容時間値以上に短くて、当該時間範囲内にさらに他の単語が認識された場合には認識された各単語を結合して1つの変換候補単語として決定してもよい。
【0050】
すなわち、上述した一例として、単語「ゴジュ」(1)及び単語「ス」が結合して1つの単語「ゴジュス」として「ソース」の変換候補単語として選択される場合や、単語「ゴジュ」(1)及び単語「ュース」が結合して1つの単語「ゴージュュース」として「ソース」の変換候補単語として選択される場合を例にあげてもよい。また、単語「ゴジュ」(2)及び「シュース」そして「ジュス」が単語「ソース」の変換候補単語として選択されてもよい。すなわち、図6では単語「ゴジュ」(1)と単語「ズース」が結合された「ゴジュズース」だけが時間範囲から外れる関係により変換候補単語に選択されない一例を示している。もし、許容時間値を減らして時間範囲をさらに減せば、変換候補単語の選択のための範囲はさらに削減される。
【0051】
ここで、選択された変換候補単語が信頼度の高い順に「シュース」、「ジュス」、「ゴジュス」、「ゴジュュース」、及び「ゴジュ」(2)の順であれば、選択された変換候補単語は信頼度の高い順に応じて音声認識の結果に含まれてもよい。
【0052】
すなわち、図1及び図6を共に参照すると、ユーザ端末110は表示装置を介して「イチゴソース」を表示してもよい。この場合にも変換候補が存在する単語と変換候補が存在しない単語は互いに区分して表示されてもよい。ここで、単語「ソース」がユーザによって選択される場合、単語「ソース」は最初の順番に決定された単語「ジュース」に変更されて表示される。また、変更された単語「シュース」が再びユーザに選択される場合には単語「シュース」が二番目に決定された単語「ジュス」に変更されて表示される。これ以上変更する変換候補単語がない場合には、最初に表示された単語「ソース」がユーザに表示されたりユーザが直接に当該単語を編集可能な機能を提供したりしてもよい。
【0053】
このように、ユーザは変換候補単語全体のリストから所望する単語を検索することなく、選択によって次の変換候補単語を確認することができる。既に上述したように、信頼度に基づいて変換候補単語を選定すると、大部分の場合は1,2回の選択によってユーザが意図した単語が表示されることから、ユーザは変換候補単語全体を調べる必要がなく、単語列から特定単語を意図する単語に容易かつ素早く編集することができる。
【0054】
図7は、本発明の一実施形態における音声認識システムの内部構成を説明するためのブロック図である。このような音声認識システム700は、図7に示すように音声認識結果確認部730及び単語列表示部740を備えてもよく、必要に応じて選択的に音声信号送信部710及び音声認識結果受信部720を備えてもよい。ここで、音声認識システム700が音声信号送信部710及び音声認識結果受信部720を備える場合、音声認識システム700は図1に示すユーザ端末110に対応する。
【0055】
音声信号送信部710は、入力装置を介して入力される音声信号を音声認識サーバに送信する。例えば、ユーザの発話による音声信号がマイクのような入力装置を介して音声認識システム700から入力されてもよく、音声信号送信部710はこのような音声信号を音声認識サーバに送信してもよい。ここで、音声認識サーバは、図1を参照して説明した音声認識サーバ120に対応する。
【0056】
音声認識結果受信部720は音声信号に対応する音声認識の結果を音声認識サーバを介して受信する。ここで、単語列は音声認識サーバで音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列として選択される。また、変換候補単語は、音声認識サーバで少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語として選択されてもよい。ここで、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、及び認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0057】
音声認識結果確認部730は音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合に単語列及び変換候補単語を確認する。すなわち、音声認識サーバから音声認識の結果が受信されるなどの過程によって音声認識システム700に音声認識の結果が提供されると、音声認識システム700は音声認識結果確認部730を介して提供された音声認識の結果として単語列と変換候補単語を確認することができる。
【0058】
単語列表示部740は単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の他の単語と区分して表示する。ここで、単語列表示部740は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示する。もし、更に他の変換候補単語が存在し、変更された変換候補単語が再びユーザによって選択される場合、変更された変換候補単語は更に他の変換候補単語に変更されてもよい。
【0059】
また、音声認識システム700は、表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部(図示せず)をさらに備えてもよい。この場合、単語列表示部740はユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列を全て削除してもよい。
【0060】
また、単語列が表示装置を介して表示される場合、または単語列が他の機器に送信される場合、単語列が音声認識によって提供されたことを表す標識が単語列と共に表示されおよび送信されてもよい。
【0061】
図8は、本発明の一実施形態に係る音声認識方法を示すフローチャートである。本実施形態における音声認識方法は図7を参照して説明した音声認識システム700によって行われてもよい。図8では音声認識システム700によって各ステップが実施される過程を説明することによって、本実施形態における音声認識方法を説明する。この場合にもステップS810及びステップS820は必要に応じて選択的に音声認識システム700によって行われてもよい。
【0062】
ステップS810において、音声認識システム700は入力装置を介して入力される音声信号を音声認識サーバに送信する。例えば、ユーザの発話による音声信号がマイクのような入力装置を介して音声認識システム700から入力されてもよく、音声認識システム700はこのような音声信号を音声認識サーバに送信してもよい。ここで、音声認識サーバは図1を参照して説明した音声認識サーバ120に対応する。
【0063】
ステップS820において、音声認識システム700は音声信号に対応する音声認識の結果を音声認識サーバを介して受信する。ここで、単語列は、音声認識サーバで音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列として選択されてもよい。また、変換候補単語は、音声認識サーバで少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語として選択されてもよい。ここで、他の単語のうち少なくとも1つの単語は他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0064】
ステップS830において、音声認識システム700は音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、単語列及び変換候補単語を確認する。すなわち、音声認識サーバから音声認識の結果が受信されるなどの過程を介して音声認識システム700に音声認識の結果が提供されると、音声認識システム700はこのような提供された音声認識の結果として単語列と変換候補単語を確認する。
【0065】
ステップS840において、音声認識システム700は単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示する。ここで、音声認識システム700は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示する。もし、更に他の変換候補単語が存在し、変更された変換候補単語が再びユーザによって選択される場合、変更された変換候補単語は更に他の変換候補単語に変更されてもよい。
【0066】
また、音声認識システム700は、表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部(図示せず)をさらに備えてもよい。この場合、音声認識システム700は、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列の全てを削除する。
【0067】
また、単語列が表示装置を介して表示される場合、または単語列が他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
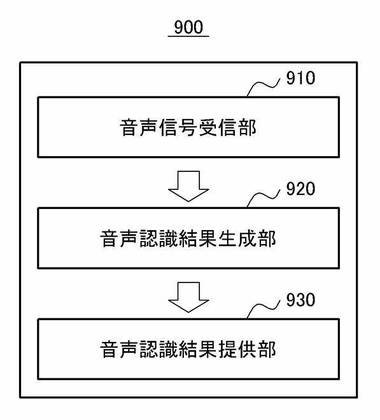
【0068】
図9は、本発明の他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。本実施形態に係る音声認識システム900は、図9に示すように音声認識結果生成部920及び音声認識結果提供部930を備えてもよく、必要に応じて選択的に音声信号受信部910を備えてもよい。ここで、音声認識システム900が音声信号受信部910を備える場合、音声認識システム900は図1で示した音声認識サーバ120に対応する。
【0069】
音声信号受信部910は端末の入力装置を介して入力された音声信号を端末を介して受信する。ここで、端末はユーザ端末として、図1を参照して説明したユーザ端末110に対応する。すなわち、ユーザ端末110の入力装置を介してユーザが発話した音声信号が入力されると、ユーザ端末110は入力された音声信号を音声認識システム900に送信してもよく、音声認識システム900は送信された音声信号を受信してもよい。
【0070】
音声認識結果生成部920は、音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する。ここで、音声認識結果生成部920は、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列を音声認識の結果に含まれる単語列として選択してもよい。また、音声認識結果生成部920は、少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語を音声認識の結果に含まれる変換候補単語として選択してもよい。ここで、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、及び認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0071】
音声認識結果提供部930はユーザ端末で音声認識の結果を提供する。ここで、提供された音声認識の結果に含まれる単語列は端末の表示装置を介して表示され、変換候補単語が存在する少なくとも1つの単語は単語列の他の単語と区分して表示される。また、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が変換候補単語に変更されて表示される。
【0072】
このような端末において、表示された単語列の全体を削除するのためのユーザインタフェースを提供してもよく、ここで、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列が全て削除されてもよい。
【0073】
また、単語列が表示装置を介して表示される場合、または単語列が端末から他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
【0074】
図10は、本発明の他の実施形態における音声認識方法を示すフローチャートである。本実施形態における音声認識方法については図9を参照して説明した音声認識システム900によって行われてもよい。図10では音声認識システム900によって各ステップが行われる過程を説明することで、本実施形態に係る音声認識方法を説明する。この場合にもステップS1010は必要に応じて選択的に音声認識システム700によって行われてもよい。
【0075】
ステップS1010において、音声認識システム900は端末の入力装置を介して入力された音声信号を端末で受信する。ここで、端末はユーザ端末として図1を参照して説明したユーザ端末110に対応する。すなわち、ユーザ端末110の入力装置を介してユーザが発話した音声信号が入力されると、ユーザ端末110は入力された音声信号を音声認識システム900に送信してもよく、音声認識システム900は送信された音声信号を受信してもよい。
【0076】
ステップS1020において、音声認識システム900は音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する。ここで、音声認識システム900は、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列を音声認識の結果に含まれる単語列として選択してもよい。また、音声認識システム900は、少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち、少なくとも1つの単語を音声認識の結果に含まれる変換候補単語として選択してもよい。ここで、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0077】
ステップS1030において、音声認識システム900はユーザ端末に音声認識の結果を提供する。ここで、提供された音声認識の結果に含まれる単語列は端末の表示装置を介して表示され、変換候補単語が存在する少なくとも1つの単語は単語列の残りの単語と区分して表示される。また、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が変換候補単語に変更されて表示される。
【0078】
このような端末において、表示された単語列の全体を削除するためのユーザインタフェースを提供してもよく、ここで、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列を全て削除してもよい。
【0079】
また、単語列が表示装置を介して表示される場合、または単語列が端末から他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
【0080】
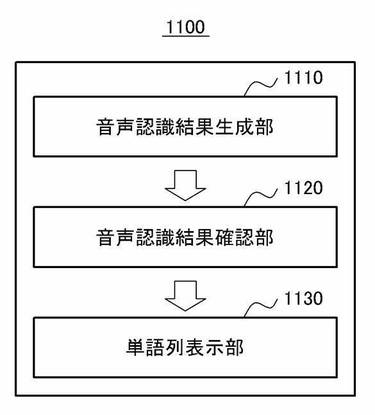
図11は、本発明の更に他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。本実施形態における音声認識システム1100は、図1で説明したユーザ端末110及び音声認識サーバ120とは異なり、1つのシステムで音声認識の結果の生成と表示が行われる。このような音声認識システム1100は、図11に示すように音声認識結果確認部1120及び単語列表示部1130を備え、必要に応じて選択的に音声認識結果生成部1110を備えてもよい。
【0081】
ここで、音声認識結果生成部1110を備えていない場合には、図7において音声認識システム700が音声信号送信部710及び音声認識結果受信部720を備えていない場合と同一であり、音声認識結果確認部1120及び単語列表示部1130は音声認識結果確認部730及び単語列表示部740と同一に動作するため、音声認識結果確認部1120及び単語列表示部1130に対する繰り返しの説明は省略する。
【0082】
音声認識結果生成部1110は入力装置を介して入力される音声信号に対応する音声認識の結果を生成する。ここで、音声認識の結果を生成する方法については既に詳しく説明したため繰り返しの説明は省略する。
【0083】
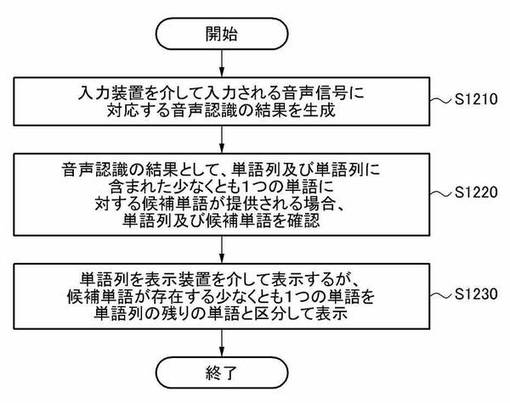
図12は、本発明の更に他の実施形態における音声認識方法を示すフローチャートである。本実施形態における音声認識方法は図11を参照して説明した音声認識システム1100によって行われてもよい。ここで、ステップS1210は必要に応じて音声認識システム1100によって行われてもよい。
【0084】
ここで、ステップS1210を行わない場合には、図8に示す音声認識システム700がステップS810及びステップS820を行わない場合と同一であり、ステップS1220及びステップS1230はステップS830及びステップS840と同一であるため、ステップS1220及びステップS1230に対する繰り返しの説明は省略する。
【0085】
ステップS1210において、音声認識システム1100は入力装置を介して入力される音声信号に対応する音声認識の結果を生成する。ここで、音声認識の結果を生成する方法については既に詳しく説明したため、その反復的な説明は省略する。
【0086】
図7から図12において省略された内容は図1から図6を参照されたい。
【0087】
本発明の更に他の実施形態に係る音声認識システム及び音声認識方法では、変換候補単語をリストの形式でユーザに提供してもよい。例えば、図1を参照して説明したユーザ端末110に対応する音声認識システムは入力装置を介して入力される音声信号を音声認識サーバに送信し、音声信号に対応する音声認識の結果を音声認識サーバを介して受信してもよい。ここで、音声認識システムは音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補が提供される場合、単語列および変換候補単語を確認して単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示してもよい。
【0088】
このとき、音声認識システムは、区分して表示された単語がユーザによって選択された場合、区分して表示された単語に対する変換候補単語をリストの形式で表示してもよい。一例として、図7に示す単語列表示部740は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語の変換候補のうち少なくとも1つの変換候補を含むリストを表示してもよい。この場合、単語列表示部740は区分して表示された単語を表示されたリストからユーザによって選択された変換候補単語に変更して表示してもよい。これは他の実施形態においても同様に適用されてもよい。
【0089】
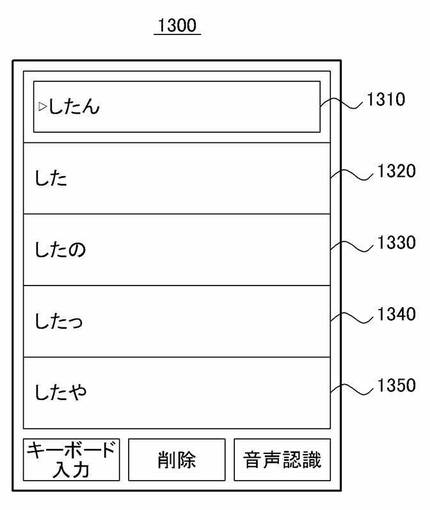
図13は、本発明の更に他の実施形態において、ユーザによって選択された単語の変換候補を表示した画面の一例である。ここで、ディスプレイ画面1300は、ユーザによって選択された単語「したん」1310と単語「したん」1310の変換候補単語1320から1350を示している。ユーザはこのように提示された変換候補単語1320から1350のうち単語「したん」1310を変換するための変換候補単語を選択してもよい。例えば、図13の一例として、ユーザは変換候補単語「した」1320を選択してもよく、この場合、音声認識システムは単語「したん」1310を変換候補単語「した」1320に変更して表示してもよい。
【0090】
このように、音声認識システムは、区分して表示された単語がユーザによって選択される場合、区分して表示された単語に対する変換候補単語をリストの形式で表示し、表示された変換候補単語のうちユーザによって選択された変換候補単語を、初めて区分して表示された単語のうちユーザによって選択された単語に変更して表示してもよい。
【0091】
本発明の実施形態によると、ユーザに音声認識の結果による文字列を表示してユーザに提供する際に、変換候補が存在する単語を文字列上の他の単語と区分して表示し、変換候補が存在する単語に対するユーザの選択に応じて当該単語を変換候補単語に変更して表示することによって、一回の選択でユーザが音声認識の結果を単語ごとに修正することができる。また、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列を選択し、選択された単語列に含まれる単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内で音声信号に対して認識された他の単語のうち、他の単語それぞれに対して算出される信頼度を用いて選択される少なくとも1つの単語を変換候補単語として設定することにより、より正確な単語ごとの結果を提供することができる。それだけではなく、表示された単語列の全てを一度に削除できるユーザインタフェースを提供することによって、表示された単語列がとんでもない結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができ、音声認識によって作成される文章の単語列に対して、当該単語列が音声認識によって作成されたことを表す標識を単語列と共に表示しまたは送信することで、表示された単語列を確認するユーザまたはこのような単語列をSMS、Eメールなどで受信したユーザが当該単語列が音声認識によって作成されたことを認識することができる。
【0092】
本発明の実施形態における方法は、多様なコンピュータ手段を介して様々な処理を実行することができるプログラム命令の形態で実現され、コンピュータ読取可能な記録媒体に記録されてもよい。コンピュータ読取可能な媒体は、プログラム命令、データファイル、データ構造などのうちの1つまたはその組合せを含んでもよい。媒体に記録されるプログラム命令は、本発明の目的のために特別に設計されて構成されたものでもよく、コンピュータソフトウェア分野の技術を有する当業者にとって公知のものであり、使用可能なものであってもよい。
【0093】
上述したように、本発明を限定された実施形態と図面によって説明したが、本発明は、上記の実施形態に限定されることなく、本発明が属する技術分野における通常の知識を有する者であれば、このような実施形態から多様な修正及び変形が可能である。
【0094】
したがって、本発明の範囲は、開示された実施形態に限定されるものではなく、特許請求の範囲だけではなく特許請求の範囲と均等なものなどによって定められる。
【符号の説明】
【0095】
110 ユーザ端末
120 音声認識サーバ
【技術分野】
【0001】
本発明は単語レベルの変換候補生成に基づく音声認識システム及び方法に関する。
【背景技術】
【0002】
音声認識によってディクテーション(dictation)しようとするとき、音声認識の後に出力された変換候補文章が極めて多い場合、ユーザに少しずつ異なるn個の文章を確認させて所望の文章を選択させることは難しい問題である。すなわち、モバイル端末のようなユーザ端末の場合、当該端末が小さいため一度に多くの文章を全て露出させることが難しく、ユーザの立場からはn個の文章を見たとき、どの文章が適切な文章であるかを一瞬で把握することができないという問題がある。
【0003】
本明細書では、音声認識によってより効果的にディクテーションを提供することのできる音声認識システム及び方法が提案される。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】韓国公開特許第2006−0098673号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
本発明の目的は、ユーザに音声認識の結果による文字列を表示して提供する際に、変換候補が存在する単語を文字列上の他の単語と区分して表示し、変換候補が存在する単語に対するユーザの選択に応じて当該単語を変換候補単語に変更して表示することで、一回の選択でユーザが音声認識の結果を単語ごとに修正することのできる音声認識システム及び音声認識方法を提供する。
【0006】
本発明の目的は、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列を選択し、選択された単語列に含まれる単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内で音声信号に対して認識された他の単語のうち、他の単語それぞれについて算出される信頼度を用いて選択される少なくとも1つの単語を候補単語に設定することで、より正確な単語ごとの結果を提供することのできる音声認識システム及び音声認識方法を提供する。
【0007】
本発明の目的は、表示された単語列の全てを一度に削除できるユーザインタフェースを提供することにあり、表示された単語列がとんでもない結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができる音声認識システム及び音声認識方法を提供する。
【0008】
本発明の目的は、音声認識によって作成される文章の単語列に対して、当該単語列が音声認識によって作成されたことを示す標識を単語列と共に表示しまたは送信することで、表示された単語列を確認するユーザ、またはこのような単語列をSMS、Eメールなどを介して受信したユーザが当該単語列が音声認識によって作成されたことを認識できる音声認識システム及び音声認識方法を提供する。
【課題を解決するための手段】
【0009】
音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、単語列及び変換候補単語を確認する音声認識結果確認部と、単語列を表示装置を介して表示する際に、変換候補単語が存在する少なくとも1つの単語を単語列の他の単語と区分して表示する単語列表示部とを備え、単語列表示部は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示することを特徴とする音声認識システムが提供される。
【0010】
本発明の一側面によると、音声認識システムは、表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部をさらに備え、単語列表示部は、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列を全て削除してもよい。
【0011】
本発明の他の側面によると、単語列が表示装置を介して表示される場合、または単語列が他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
【0012】
本発明の他の側面によると、音声認識システムは、入力装置を介して入力される音声信号を音声認識サーバに送信する音声信号送信部と、音声信号に対応する音声認識の結果を音声認識サーバを介して受信する音声認識結果受信部とをさらに備えてもよい。
【0013】
本発明の他の側面によると、音声認識システムは、入力装置を介して入力される音声信号に対応する音声認識の結果を生成する音声認識結果生成部をさらに備えてもよい。
【0014】
本発明の他の側面によると、単語列は、音声認識サーバでの音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列として選択されてもよい。
【0015】
本発明の他の側面によると、変換候補単語は、音声認識サーバで少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語として選択されてもよい。この場合、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよい。また、時間範囲は、認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0016】
音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する音声認識結果生成部と、ユーザ端末に音声認識の結果を提供する音声認識結果提供部と、を備え、端末の表示装置で単語列が表示され、変換候補が存在する少なくとも1つの単語が単語列の他の単語と区分して表示され、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が変換候補単語に変更されて表示されることを特徴とする音声認識システムが提供される。
【0017】
音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補が提供される場合、単語列及び変換候補単語を確認し、単語列を表示装置を介して表示する際に、変換候補が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示することを含み、表示することは、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を候補単語に変更して表示することを特徴とする音声認識方法が提供される。
【0018】
音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成し、ユーザ端末に音声認識の結果を提供することを含み、端末の表示装置で単語列が表示され、変換候補単語が存在する少なくとも1つの単語は単語列の他の単語と区分して表示され、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が候補単語に変更されて表示されることを特徴とする音声認識方法が提供される。
【発明の効果】
【0019】
本発明によると、ユーザに音声認識の結果による文字列を表示してユーザに提供する際に、変換候補が存在する単語を文字列上の他の単語と区分して表示し、変換候補が存在する単語に対するユーザの選択に応じて当該単語を変換候補単語に変更して表示することによって、一回の選択でユーザが音声認識の結果を単語ごとに修正することができる。
【0020】
本発明によると、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列を選択し、選択された単語列に含まれる単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内で音声信号に対して認識された他の単語のうち、他の単語それぞれに対して算出される信頼度を用いて選択される少なくとも1つの単語を変換候補単語として設定することで、より正確な単語ごとの結果を提供することができる。
【0021】
本発明によると、表示された単語列の全てを一度に削除できるユーザインタフェースを提供することができ、表示された単語列がとんでもない結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができる。
【0022】
本発明によると、音声認識によって作成される文章の単語列に対して、当該単語列が音声認識によって作成されたことを示す標識を単語列と共に表示しまたは送信することで、表示された単語列を確認するユーザ、またはこのような単語列をSMS、Eメールなどによって受信したユーザが当該単語列が音声認識によって作成されたことを認識することができる。
【図面の簡単な説明】
【0023】
【図1】本発明の一実施形態におけるユーザ端末及び音声認識サーバを示す図である。
【図2】本発明の一実施形態におけるユーザ端末のディスプレイ画面に単語列が表示された状態を示す一例である。
【図3】本発明の一実施形態におけるユーザ端末のディスプレイ画面でユーザの選択に応じて表示された単語を変換候補単語に変更して表示した状態を示す一例である。
【図4】本発明の一実施形態におけるユーザインタフェースを用いて表示された単語列を全て削除することを示す一例である。
【図5】本発明の一実施形態におけるユーザ端末において標識を表示する状態を示す一例である。
【図6】本発明の一実施形態における音声信号に対して検索された単語を示す図である。
【図7】本発明の一実施形態における音声認識システムの内部構成を説明するためのブロック図である。
【図8】本発明の一実施形態における音声認識方法を示すフローチャートである。
【図9】本発明の他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。
【図10】本発明の他の実施形態における音声認識方法を示すフローチャートである。
【図11】本発明の更に他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。
【図12】本発明の更に他の実施形態における音声認識方法を示すフローチャートである。
【図13】本発明の更に他の実施形態におけるユーザによって選択された単語の変換候補単語を表示した画面の一例である。
【発明を実施するための形態】
【0024】
以下、本発明の実施形態について添付の図面を参照しながら詳細に説明する。
【0025】
図1は、本発明の一実施形態におけるユーザ端末及び音声認識サーバを示す図である。図1は、ユーザ端末110及び音声認識サーバ120を示している。
【0026】
ユーザ端末110には入力装置を介して音声信号が入力され、音声信号は音声認識サーバ120に送信されてもよい。ここで、音声認識サーバ120は、受信した音声信号に対応する音声認識の結果を生成してユーザ端末110に送信してもよい。
【0027】
ユーザ端末110は、音声認識サーバ120によって受信された音声認識の結果に含まれている単語列と、単語列に含まれる少なくとも1つの単語に対する変換候補単語を確認し、確認された単語列を表示装置を介して表示するところ、変換候補単語が存在する少なくとも1つの単語は単語列の残りの単語と区分されるように表示してもよい。
【0028】
図2は、本発明の一実施形態におけるユーザ端末のディスプレイ画面に単語列が表示された形状を示す一例である。図2に示すディスプレイ画面200は図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。ここで、ディスプレイ画面200には「アンドロイドフォンいつから販売したん」のように音声認識の結果を含む単語列が表示される。ここで、単語列に含まれる単語のうち、変換候補を有する単語は単語列に含まれる他の単語と区別されて表示される。すなわち、図2では変換候補が存在する単語「アンドロイド」、「いつから」、「したん」は,変換候補が存在しない単語「フォン」及び「販売」と区別されるようにアンダーラインで表示される。
【0029】
再び図1を参照すると、ユーザ端末110は区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示してもよい。ここで、単語がユーザによって選択されることはユーザ端末110が提供するユーザインタフェースを介して当該単語が選択されることを意味する。例えば、ユーザがタッチパッドを介して当該単語が表示された位置をタッチすることによって、当該単語がユーザによって選択される。
【0030】
図3は、本発明の一実施形態におけるユーザ端末のディスプレイ画面でユーザの選択に応じて表示された単語を変換候補単語に変更して表示した状態を示す一例である。図3に示すディスプレイ画面310から330はそれぞれ図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。
【0031】
まず、ディスプレイ画面310には「アンドロイドフォンいつから販売したん」のように最初の音声認識の結果を含む単語列が表示されている。ここで、ユーザが単語「したん」を選択する場合、ディスプレイ画面320のように単語「したん」が変換候補単語「した」のように変更して表示されてもよい。この場合、変更して表示された単語「した」も変換候補が存在しない他の単語と区分するためにアンダーラインで表示される。
【0032】
図3では単語を区分するためにアンダーラインを用いたが、アンダーラインは1つの例に過ぎず、字の大きさ、字の色、または模様などを異なるように表示する方法など、単語が区分される全ての方法のうち少なくとも1つの方法を用いてもよい。
【0033】
ユーザが単語「した」を再び選択した場合にはディスプレイ画面330のように単語「した」がその次の変換候補単語「したの」に変更されて表示されてもよい。
【0034】
もし、他の変換候補単語「したの」が存在しない場合には再びディスプレイ画面310のように本来の単語列に含まれている単語「したん」に変更されて表示されてもよい。
【0035】
このように、本実施形態では単語列に含まれる単語に対する変換候補のリストを提供する代わりに、ユーザの選択に応じて音声認識の変換候補単語を順次に変更可能であり、このような変換候補単語は音声認識による信頼度に応じて整列され、信頼度が高い順に表示される。ここで、大部分の場合、1,2回の変更によってユーザが意図した単語が表示される確率が極めて高いため、変換候補単語のリストを提供することで効率よくユーザに音声認識を通したディクテーション(dictation)を提供することができる。ここで、音声認識による単語の信頼度を算出する方法は公知の通りで、このように既に知らされた様々な方法の1つが単語の信頼度を算出するために用いられる。
【0036】
また、図3において、ユーザインタフェースの「編集」を用いてユーザが当該単語を直接編集できる機能を提供してもよい。
【0037】
再び図1を参照すると、ユーザ端末110は、表示された単語列を全て削除するためのユーザインタフェースを提供してもよい。すなわち、表示された単語列の全てを一度に削除することのできるユーザインタフェースを提供することによって、表示された単語列が全く違う結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができるようにする。
【0038】
図4は、本発明の一実施形態におけるユーザインタフェースを用いて表示された単語列を全て削除することを示す一例である。図4に示すディスプレイ画面410及び420はそれぞれ図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。
【0039】
ディスプレイ画面410は、音声認識の結果に含まれる単語列が表示された状態を示している。ここで、「クリア」411のような、ユーザ端末110が提供するユーザインタフェースを介してユーザがイベントを発生させる場合、ディスプレイ画面420のように表示された単語列を全て削除してもよい。すなわち、「好奇心の解消の消失30分到着」のようにユーザが意図した文章(単語列)と全く異なる文章が表示された場合、ユーザはこのような文章を編集することよってユーザ自身が文章を直接入力するか、または新たに音声認識の過程を行ってもよい。
【0040】
このような場合、本実施形態におけるユーザ端末110は「クリア」411のようなユーザインタフェースをユーザに提供し、ユーザが「クリア」411をタッチするなどのイベントが発生した場合、表示された文章の全体を削除することができる。
【0041】
再び図1を参照すると、ユーザ端末110は音声認識によって作成された文章(単語列)に音声認識に対する標識を含ませてもよい。ここで、音声認識に対する標識は当該文章が音声認識によって作成されたことを表す。例えば、ユーザが音声認識によって作成された文章をSMSやEメールなどを用いて他のユーザに提供する場合、他のユーザは当該文章に誤字またはエラーが存在しても、このような文章が音声認識によって作成されたことを直ちに確認することができる。
【0042】
図5は、本発明の一実施形態におけるユーザ端末で標識を提供する形状を示す一例である。図5に示すディスプレイ画面510は図1を参照して説明したユーザ端末110のディスプレイ画面の一部に対応する。
【0043】
ここで、ディスプレイ画面510は「アンドロイドフォンで映画を見ようとします。By Speech」のように単語列「アンドロイドフォンで映画を見ようとします。」だけではなく標識「By Speech」を共に表示している。すなわち、このような標識により,当該単語列が音声認識によって作成された文章であることをユーザが容易に把握することができる。
【0044】
再び図1を参照すると、音声認識サーバ120は、上述したようにユーザ端末110が受信した音声信号に対応する単語列及び変換候補単語を決定して音声認識の結果としてユーザ端末110に提供してもよい。ここで、音声認識サーバ120は、音声信号に対応してマッチングされ得る全ての単語列を探し、全ての単語列それぞれの確率のうち最も高い確率を有する単語列を音声認識の結果に含まれる単語列として選択する。また、音声認識サーバ120は、少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち、少なくとも1つの単語を音声認識の結果に含まれる変換候補単語として選択してもよい。この場合、他の単語のうち、少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度(confidence)に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0045】
図6は、本発明の一実施形態における音声信号に対して検索された単語を示す図である。図6において、矢印610は時間の流れを示し、四角形のボックスの長さは当該単語が認識された時間範囲を示す。ここで、互いに異なる時間範囲で認識される同一の単語、すなわち、図6において「イチゴ」(1)と「イチゴ」(2)、そして「ゴジュ」(1)と「ゴジュ」(2)とはスタート時刻は同一であるが、終了時間が互いに異なり、音声では確率的に当該時間帯において最も確率の高い単語を探したとき偶然に同じ単語になった場合である。
【0046】
まず、ユーザの発話内容が「イチゴジュース」と仮定する。すなわち、ユーザが「イチゴジュース」を発話して図1に示すユーザ端末110が入力装置を介して「イチゴジュース」が含まれた音声信号の入力を受けて音声認識サーバ120に送信すると、音声認識サーバ120は音声信号を分析して全ての含まれ得る単語列を確認し、最も高い確率を有する単語列を選択してもよい。ここで、図6では、最も高い確率を有する単語列として、単語「イチゴ」(1)と単語「ソース」が結合された「イチゴソース」が選択された場合を示している。
【0047】
この場合、音声認識サーバ120は、最も高い確率を有する単語列に含まれた単語「イチゴ」(1)と「ソース」とのそれぞれに対する変換候補単語を決定してもよい。すなわち、「イチゴ」(1)と「ソース」それぞれに対する当該時間範囲内に含まれる他の単語に対して各単語の信頼度を算出し、信頼度の高い順にn個の単語を変換候補単語として抽出してもよい。ここで、当該時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0048】
例えば、単語「ソース」に対する変換候補単語を求めるために、音声認識サーバ120は単語「ソース」に対して決定された時間範囲内に含まれる他の単語を確認する。ここで、時間範囲内に含まれる他の単語は単語「ソース」の認識が終了した時刻に予め選定された許容時間値を付与した時刻、そして「ソース」の認識がスタートした時刻の時間範囲内に含まれ,かつ、スタート時間が同一の単語を含んでもよい。ここで、許容時間値は30msのように音声認識サーバ120によって決定されてもよい。
【0049】
ここで、スタート時刻は同一であるが、終了した時間が「ソース」の認識が終了した時間よりも予め選定された許容時間値以上に短くて、当該時間範囲内にさらに他の単語が認識された場合には認識された各単語を結合して1つの変換候補単語として決定してもよい。
【0050】
すなわち、上述した一例として、単語「ゴジュ」(1)及び単語「ス」が結合して1つの単語「ゴジュス」として「ソース」の変換候補単語として選択される場合や、単語「ゴジュ」(1)及び単語「ュース」が結合して1つの単語「ゴージュュース」として「ソース」の変換候補単語として選択される場合を例にあげてもよい。また、単語「ゴジュ」(2)及び「シュース」そして「ジュス」が単語「ソース」の変換候補単語として選択されてもよい。すなわち、図6では単語「ゴジュ」(1)と単語「ズース」が結合された「ゴジュズース」だけが時間範囲から外れる関係により変換候補単語に選択されない一例を示している。もし、許容時間値を減らして時間範囲をさらに減せば、変換候補単語の選択のための範囲はさらに削減される。
【0051】
ここで、選択された変換候補単語が信頼度の高い順に「シュース」、「ジュス」、「ゴジュス」、「ゴジュュース」、及び「ゴジュ」(2)の順であれば、選択された変換候補単語は信頼度の高い順に応じて音声認識の結果に含まれてもよい。
【0052】
すなわち、図1及び図6を共に参照すると、ユーザ端末110は表示装置を介して「イチゴソース」を表示してもよい。この場合にも変換候補が存在する単語と変換候補が存在しない単語は互いに区分して表示されてもよい。ここで、単語「ソース」がユーザによって選択される場合、単語「ソース」は最初の順番に決定された単語「ジュース」に変更されて表示される。また、変更された単語「シュース」が再びユーザに選択される場合には単語「シュース」が二番目に決定された単語「ジュス」に変更されて表示される。これ以上変更する変換候補単語がない場合には、最初に表示された単語「ソース」がユーザに表示されたりユーザが直接に当該単語を編集可能な機能を提供したりしてもよい。
【0053】
このように、ユーザは変換候補単語全体のリストから所望する単語を検索することなく、選択によって次の変換候補単語を確認することができる。既に上述したように、信頼度に基づいて変換候補単語を選定すると、大部分の場合は1,2回の選択によってユーザが意図した単語が表示されることから、ユーザは変換候補単語全体を調べる必要がなく、単語列から特定単語を意図する単語に容易かつ素早く編集することができる。
【0054】
図7は、本発明の一実施形態における音声認識システムの内部構成を説明するためのブロック図である。このような音声認識システム700は、図7に示すように音声認識結果確認部730及び単語列表示部740を備えてもよく、必要に応じて選択的に音声信号送信部710及び音声認識結果受信部720を備えてもよい。ここで、音声認識システム700が音声信号送信部710及び音声認識結果受信部720を備える場合、音声認識システム700は図1に示すユーザ端末110に対応する。
【0055】
音声信号送信部710は、入力装置を介して入力される音声信号を音声認識サーバに送信する。例えば、ユーザの発話による音声信号がマイクのような入力装置を介して音声認識システム700から入力されてもよく、音声信号送信部710はこのような音声信号を音声認識サーバに送信してもよい。ここで、音声認識サーバは、図1を参照して説明した音声認識サーバ120に対応する。
【0056】
音声認識結果受信部720は音声信号に対応する音声認識の結果を音声認識サーバを介して受信する。ここで、単語列は音声認識サーバで音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列として選択される。また、変換候補単語は、音声認識サーバで少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語として選択されてもよい。ここで、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、及び認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0057】
音声認識結果確認部730は音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合に単語列及び変換候補単語を確認する。すなわち、音声認識サーバから音声認識の結果が受信されるなどの過程によって音声認識システム700に音声認識の結果が提供されると、音声認識システム700は音声認識結果確認部730を介して提供された音声認識の結果として単語列と変換候補単語を確認することができる。
【0058】
単語列表示部740は単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の他の単語と区分して表示する。ここで、単語列表示部740は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示する。もし、更に他の変換候補単語が存在し、変更された変換候補単語が再びユーザによって選択される場合、変更された変換候補単語は更に他の変換候補単語に変更されてもよい。
【0059】
また、音声認識システム700は、表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部(図示せず)をさらに備えてもよい。この場合、単語列表示部740はユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列を全て削除してもよい。
【0060】
また、単語列が表示装置を介して表示される場合、または単語列が他の機器に送信される場合、単語列が音声認識によって提供されたことを表す標識が単語列と共に表示されおよび送信されてもよい。
【0061】
図8は、本発明の一実施形態に係る音声認識方法を示すフローチャートである。本実施形態における音声認識方法は図7を参照して説明した音声認識システム700によって行われてもよい。図8では音声認識システム700によって各ステップが実施される過程を説明することによって、本実施形態における音声認識方法を説明する。この場合にもステップS810及びステップS820は必要に応じて選択的に音声認識システム700によって行われてもよい。
【0062】
ステップS810において、音声認識システム700は入力装置を介して入力される音声信号を音声認識サーバに送信する。例えば、ユーザの発話による音声信号がマイクのような入力装置を介して音声認識システム700から入力されてもよく、音声認識システム700はこのような音声信号を音声認識サーバに送信してもよい。ここで、音声認識サーバは図1を参照して説明した音声認識サーバ120に対応する。
【0063】
ステップS820において、音声認識システム700は音声信号に対応する音声認識の結果を音声認識サーバを介して受信する。ここで、単語列は、音声認識サーバで音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列として選択されてもよい。また、変換候補単語は、音声認識サーバで少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語として選択されてもよい。ここで、他の単語のうち少なくとも1つの単語は他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0064】
ステップS830において、音声認識システム700は音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、単語列及び変換候補単語を確認する。すなわち、音声認識サーバから音声認識の結果が受信されるなどの過程を介して音声認識システム700に音声認識の結果が提供されると、音声認識システム700はこのような提供された音声認識の結果として単語列と変換候補単語を確認する。
【0065】
ステップS840において、音声認識システム700は単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示する。ここで、音声認識システム700は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語を変換候補単語に変更して表示する。もし、更に他の変換候補単語が存在し、変更された変換候補単語が再びユーザによって選択される場合、変更された変換候補単語は更に他の変換候補単語に変更されてもよい。
【0066】
また、音声認識システム700は、表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部(図示せず)をさらに備えてもよい。この場合、音声認識システム700は、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列の全てを削除する。
【0067】
また、単語列が表示装置を介して表示される場合、または単語列が他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
【0068】
図9は、本発明の他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。本実施形態に係る音声認識システム900は、図9に示すように音声認識結果生成部920及び音声認識結果提供部930を備えてもよく、必要に応じて選択的に音声信号受信部910を備えてもよい。ここで、音声認識システム900が音声信号受信部910を備える場合、音声認識システム900は図1で示した音声認識サーバ120に対応する。
【0069】
音声信号受信部910は端末の入力装置を介して入力された音声信号を端末を介して受信する。ここで、端末はユーザ端末として、図1を参照して説明したユーザ端末110に対応する。すなわち、ユーザ端末110の入力装置を介してユーザが発話した音声信号が入力されると、ユーザ端末110は入力された音声信号を音声認識システム900に送信してもよく、音声認識システム900は送信された音声信号を受信してもよい。
【0070】
音声認識結果生成部920は、音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する。ここで、音声認識結果生成部920は、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列を音声認識の結果に含まれる単語列として選択してもよい。また、音声認識結果生成部920は、少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち少なくとも1つの単語を音声認識の結果に含まれる変換候補単語として選択してもよい。ここで、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、及び認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0071】
音声認識結果提供部930はユーザ端末で音声認識の結果を提供する。ここで、提供された音声認識の結果に含まれる単語列は端末の表示装置を介して表示され、変換候補単語が存在する少なくとも1つの単語は単語列の他の単語と区分して表示される。また、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が変換候補単語に変更されて表示される。
【0072】
このような端末において、表示された単語列の全体を削除するのためのユーザインタフェースを提供してもよく、ここで、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列が全て削除されてもよい。
【0073】
また、単語列が表示装置を介して表示される場合、または単語列が端末から他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
【0074】
図10は、本発明の他の実施形態における音声認識方法を示すフローチャートである。本実施形態における音声認識方法については図9を参照して説明した音声認識システム900によって行われてもよい。図10では音声認識システム900によって各ステップが行われる過程を説明することで、本実施形態に係る音声認識方法を説明する。この場合にもステップS1010は必要に応じて選択的に音声認識システム700によって行われてもよい。
【0075】
ステップS1010において、音声認識システム900は端末の入力装置を介して入力された音声信号を端末で受信する。ここで、端末はユーザ端末として図1を参照して説明したユーザ端末110に対応する。すなわち、ユーザ端末110の入力装置を介してユーザが発話した音声信号が入力されると、ユーザ端末110は入力された音声信号を音声認識システム900に送信してもよく、音声認識システム900は送信された音声信号を受信してもよい。
【0076】
ステップS1020において、音声認識システム900は音声信号に対応する単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する。ここで、音声認識システム900は、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列を音声認識の結果に含まれる単語列として選択してもよい。また、音声認識システム900は、少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に音声信号によって認識された他の単語のうち、少なくとも1つの単語を音声認識の結果に含まれる変換候補単語として選択してもよい。ここで、他の単語のうち少なくとも1つの単語は、他の単語それぞれに対して算出される信頼度に基づいて選択されてもよく、時間範囲は認識がスタートした時刻及び認識が終了した時刻、そして認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されてもよい。
【0077】
ステップS1030において、音声認識システム900はユーザ端末に音声認識の結果を提供する。ここで、提供された音声認識の結果に含まれる単語列は端末の表示装置を介して表示され、変換候補単語が存在する少なくとも1つの単語は単語列の残りの単語と区分して表示される。また、区分して表示された単語が端末でユーザによって選択される場合、区分して表示された単語が変換候補単語に変更されて表示される。
【0078】
このような端末において、表示された単語列の全体を削除するためのユーザインタフェースを提供してもよく、ここで、ユーザインタフェースを介してユーザ入力が発生する場合、表示された単語列を全て削除してもよい。
【0079】
また、単語列が表示装置を介して表示される場合、または単語列が端末から他の機器に送信される場合、単語列が音声認識によって提供されたことを示す標識が単語列と共に表示されまたは送信されてもよい。
【0080】
図11は、本発明の更に他の実施形態における音声認識システムの内部構成を説明するためのブロック図である。本実施形態における音声認識システム1100は、図1で説明したユーザ端末110及び音声認識サーバ120とは異なり、1つのシステムで音声認識の結果の生成と表示が行われる。このような音声認識システム1100は、図11に示すように音声認識結果確認部1120及び単語列表示部1130を備え、必要に応じて選択的に音声認識結果生成部1110を備えてもよい。
【0081】
ここで、音声認識結果生成部1110を備えていない場合には、図7において音声認識システム700が音声信号送信部710及び音声認識結果受信部720を備えていない場合と同一であり、音声認識結果確認部1120及び単語列表示部1130は音声認識結果確認部730及び単語列表示部740と同一に動作するため、音声認識結果確認部1120及び単語列表示部1130に対する繰り返しの説明は省略する。
【0082】
音声認識結果生成部1110は入力装置を介して入力される音声信号に対応する音声認識の結果を生成する。ここで、音声認識の結果を生成する方法については既に詳しく説明したため繰り返しの説明は省略する。
【0083】
図12は、本発明の更に他の実施形態における音声認識方法を示すフローチャートである。本実施形態における音声認識方法は図11を参照して説明した音声認識システム1100によって行われてもよい。ここで、ステップS1210は必要に応じて音声認識システム1100によって行われてもよい。
【0084】
ここで、ステップS1210を行わない場合には、図8に示す音声認識システム700がステップS810及びステップS820を行わない場合と同一であり、ステップS1220及びステップS1230はステップS830及びステップS840と同一であるため、ステップS1220及びステップS1230に対する繰り返しの説明は省略する。
【0085】
ステップS1210において、音声認識システム1100は入力装置を介して入力される音声信号に対応する音声認識の結果を生成する。ここで、音声認識の結果を生成する方法については既に詳しく説明したため、その反復的な説明は省略する。
【0086】
図7から図12において省略された内容は図1から図6を参照されたい。
【0087】
本発明の更に他の実施形態に係る音声認識システム及び音声認識方法では、変換候補単語をリストの形式でユーザに提供してもよい。例えば、図1を参照して説明したユーザ端末110に対応する音声認識システムは入力装置を介して入力される音声信号を音声認識サーバに送信し、音声信号に対応する音声認識の結果を音声認識サーバを介して受信してもよい。ここで、音声認識システムは音声認識の結果として、単語列及び単語列に含まれる少なくとも1つの単語に対する変換候補が提供される場合、単語列および変換候補単語を確認して単語列を表示装置を介して表示するが、変換候補単語が存在する少なくとも1つの単語を単語列の残りの単語と区分して表示してもよい。
【0088】
このとき、音声認識システムは、区分して表示された単語がユーザによって選択された場合、区分して表示された単語に対する変換候補単語をリストの形式で表示してもよい。一例として、図7に示す単語列表示部740は、区分して表示された単語がユーザによって選択される場合、区分して表示された単語の変換候補のうち少なくとも1つの変換候補を含むリストを表示してもよい。この場合、単語列表示部740は区分して表示された単語を表示されたリストからユーザによって選択された変換候補単語に変更して表示してもよい。これは他の実施形態においても同様に適用されてもよい。
【0089】
図13は、本発明の更に他の実施形態において、ユーザによって選択された単語の変換候補を表示した画面の一例である。ここで、ディスプレイ画面1300は、ユーザによって選択された単語「したん」1310と単語「したん」1310の変換候補単語1320から1350を示している。ユーザはこのように提示された変換候補単語1320から1350のうち単語「したん」1310を変換するための変換候補単語を選択してもよい。例えば、図13の一例として、ユーザは変換候補単語「した」1320を選択してもよく、この場合、音声認識システムは単語「したん」1310を変換候補単語「した」1320に変更して表示してもよい。
【0090】
このように、音声認識システムは、区分して表示された単語がユーザによって選択される場合、区分して表示された単語に対する変換候補単語をリストの形式で表示し、表示された変換候補単語のうちユーザによって選択された変換候補単語を、初めて区分して表示された単語のうちユーザによって選択された単語に変更して表示してもよい。
【0091】
本発明の実施形態によると、ユーザに音声認識の結果による文字列を表示してユーザに提供する際に、変換候補が存在する単語を文字列上の他の単語と区分して表示し、変換候補が存在する単語に対するユーザの選択に応じて当該単語を変換候補単語に変更して表示することによって、一回の選択でユーザが音声認識の結果を単語ごとに修正することができる。また、音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち最も高い確率を有する単語列を選択し、選択された単語列に含まれる単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内で音声信号に対して認識された他の単語のうち、他の単語それぞれに対して算出される信頼度を用いて選択される少なくとも1つの単語を変換候補単語として設定することにより、より正確な単語ごとの結果を提供することができる。それだけではなく、表示された単語列の全てを一度に削除できるユーザインタフェースを提供することによって、表示された単語列がとんでもない結果である場合、ユーザが直接文章を入力したり、または再び音声認識の過程を行ったりすることができ、音声認識によって作成される文章の単語列に対して、当該単語列が音声認識によって作成されたことを表す標識を単語列と共に表示しまたは送信することで、表示された単語列を確認するユーザまたはこのような単語列をSMS、Eメールなどで受信したユーザが当該単語列が音声認識によって作成されたことを認識することができる。
【0092】
本発明の実施形態における方法は、多様なコンピュータ手段を介して様々な処理を実行することができるプログラム命令の形態で実現され、コンピュータ読取可能な記録媒体に記録されてもよい。コンピュータ読取可能な媒体は、プログラム命令、データファイル、データ構造などのうちの1つまたはその組合せを含んでもよい。媒体に記録されるプログラム命令は、本発明の目的のために特別に設計されて構成されたものでもよく、コンピュータソフトウェア分野の技術を有する当業者にとって公知のものであり、使用可能なものであってもよい。
【0093】
上述したように、本発明を限定された実施形態と図面によって説明したが、本発明は、上記の実施形態に限定されることなく、本発明が属する技術分野における通常の知識を有する者であれば、このような実施形態から多様な修正及び変形が可能である。
【0094】
したがって、本発明の範囲は、開示された実施形態に限定されるものではなく、特許請求の範囲だけではなく特許請求の範囲と均等なものなどによって定められる。
【符号の説明】
【0095】
110 ユーザ端末
120 音声認識サーバ
【特許請求の範囲】
【請求項1】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認する音声認識結果確認部と、
前記単語列を表示装置を介して表示する際に、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の他の単語と区分して表示する単語列表示部と、
を備え、
前記単語列表示部は、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語を前記変換候補単語に変更して表示することを特徴とする音声認識システム。
【請求項2】
前記表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部をさらに備え、
前記単語列表示部は、前記ユーザインタフェースを介してユーザ入力が発生する場合、前記表示された単語列を全て削除することを特徴とする請求項1に記載の音声認識システム。
【請求項3】
前記単語列が前記表示装置を介して表示される場合、または前記単語列が他の機器に送信される場合、前記単語列が音声認識によって提供されたことを示す標識が前記単語列と共に表示されまたは送信されることを特徴とする請求項1に記載の音声認識システム。
【請求項4】
入力装置を介して入力される音声信号を音声認識サーバに送信する音声信号送信部と、
前記音声信号に対応する前記音声認識の結果を前記音声認識サーバを介して受信する音声認識結果受信部と、
をさらに備えることを特徴とする請求項1に記載の音声認識システム。
【請求項5】
入力装置を介して入力される音声信号に対応する前記音声認識の結果を生成する音声認識結果生成部をさらに備えることを特徴とする請求項1に記載の音声認識システム。
【請求項6】
前記単語列は、前記音声認識サーバにおいて前記音声信号に対応してマッチングされ得る全ての単語列のうち、最も高い確率を有する単語列が選択されることを特徴とする請求項1に記載の音声認識システム。
【請求項7】
前記変換候補単語は、前記音声認識サーバにおいて前記少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内において前記音声信号によって認識される他の単語のうち少なくとも1つの単語が選択されることを特徴とする請求項1に記載の音声認識システム。
【請求項8】
前記他の単語のうち少なくとも1つの単語は、前記他の単語それぞれに対して算出される信頼度の高さに基づいて選択されることを特徴とする請求項7に記載の音声認識システム。
【請求項9】
前記時間範囲は、前記認識がスタートした時刻及び前記認識が終了した時刻、及び前記認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されることを特徴とする請求項7又は請求項8に記載の音声認識システム。
【請求項10】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する音声認識結果生成部と、
ユーザ端末に前記音声認識の結果を提供する音声認識結果提供部と、
を備え、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語が前記変換候補単語に変更されて表示されることを特徴とする音声認識システム。
【請求項11】
前記端末で前記表示された単語列の全体を削除するためのユーザインタフェースが提供され、
前記ユーザインタフェースを介してユーザ入力が発生する場合、前記表示された単語列が全て削除されることを特徴とする請求項10に記載の音声認識システム。
【請求項12】
前記単語列が前記表示装置を介して表示される場合、または前記単語列が前記端末から他の機器に送信される場合、前記単語列が音声認識によって提供されたことを表す標識が前記単語列と共に表示されまたは送信されることを特徴とする請求項10に記載の音声認識システム。
【請求項13】
前記端末の入力装置を介して入力された前記音声信号を前記端末を介して受信する音声信号受信部をさらに備えることを特徴とする請求項10に記載の音声認識システム。
【請求項14】
前記音声認識結果生成部は、前記音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列を前記音声認識の結果に含まれる単語列として選択することを特徴とする請求項10に記載の音声認識システム。
【請求項15】
前記音声認識結果生成部は、前記少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に前記の音声信号によって認識された他の単語のうち少なくとも1つの単語を前記音声認識の結果に含まれる変換候補単語として選択することを特徴とする請求項10に記載の音声認識システム。
【請求項16】
前記他の単語のうち少なくとも1つの単語は、前記他の単語それぞれに対して算出される信頼度に基づいて選択されることを特徴とする請求項15に記載の音声認識システム。
【請求項17】
前記時間範囲は、前記認識がスタートした時刻及び前記認識が終了した時刻、そして前記認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されることを特徴とする請求項15又は請求項16に記載の音声認識システム。
【請求項18】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認する音声認識結果確認部と、
前記単語列を表示装置を介して表示するが、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の他の単語と区分して表示する単語列表示部と、
を備え、
前記単語列表示部は、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストを表示することを特徴とする音声認識システム。
【請求項19】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する音声認識結果生成部と、
ユーザ端末で前記音声認識の結果を提供する音声認識結果提供部と、
を備え、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストが表示されることを特徴とする音声認識システム。
【請求項20】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認し、
前記単語列を表示装置を介して表示する際に、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の残りの単語と区分して表示することを含み、
前記表示することは、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語を前記変換候補単語に変更して表示することを特徴とする音声認識方法。
【請求項21】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成し、
ユーザ端末に前記音声認識の結果を提供するスことを含み、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語が前記変換候補単語に変更されて表示されることを特徴とする音声認識方法。
【請求項22】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認し、
前記単語列を表示装置を介して表示するが、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の残りの単語と区分して表示することを含み、
前記表示することは、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストを表示することを特徴とする音声認識方法。
【請求項23】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成し、
ユーザ端末に前記音声認識の結果を提供することとさせ、を含み、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストが表示されることを特徴とする音声認識方法。
【請求項24】
請求項20から請求項23のいずれか1項の方法を行うプログラムを記録したコンピュータで読み出し可能な記録媒体。
【請求項1】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認する音声認識結果確認部と、
前記単語列を表示装置を介して表示する際に、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の他の単語と区分して表示する単語列表示部と、
を備え、
前記単語列表示部は、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語を前記変換候補単語に変更して表示することを特徴とする音声認識システム。
【請求項2】
前記表示された単語列の全体を削除するためのユーザインタフェースを提供するユーザインタフェース部をさらに備え、
前記単語列表示部は、前記ユーザインタフェースを介してユーザ入力が発生する場合、前記表示された単語列を全て削除することを特徴とする請求項1に記載の音声認識システム。
【請求項3】
前記単語列が前記表示装置を介して表示される場合、または前記単語列が他の機器に送信される場合、前記単語列が音声認識によって提供されたことを示す標識が前記単語列と共に表示されまたは送信されることを特徴とする請求項1に記載の音声認識システム。
【請求項4】
入力装置を介して入力される音声信号を音声認識サーバに送信する音声信号送信部と、
前記音声信号に対応する前記音声認識の結果を前記音声認識サーバを介して受信する音声認識結果受信部と、
をさらに備えることを特徴とする請求項1に記載の音声認識システム。
【請求項5】
入力装置を介して入力される音声信号に対応する前記音声認識の結果を生成する音声認識結果生成部をさらに備えることを特徴とする請求項1に記載の音声認識システム。
【請求項6】
前記単語列は、前記音声認識サーバにおいて前記音声信号に対応してマッチングされ得る全ての単語列のうち、最も高い確率を有する単語列が選択されることを特徴とする請求項1に記載の音声認識システム。
【請求項7】
前記変換候補単語は、前記音声認識サーバにおいて前記少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内において前記音声信号によって認識される他の単語のうち少なくとも1つの単語が選択されることを特徴とする請求項1に記載の音声認識システム。
【請求項8】
前記他の単語のうち少なくとも1つの単語は、前記他の単語それぞれに対して算出される信頼度の高さに基づいて選択されることを特徴とする請求項7に記載の音声認識システム。
【請求項9】
前記時間範囲は、前記認識がスタートした時刻及び前記認識が終了した時刻、及び前記認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されることを特徴とする請求項7又は請求項8に記載の音声認識システム。
【請求項10】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する音声認識結果生成部と、
ユーザ端末に前記音声認識の結果を提供する音声認識結果提供部と、
を備え、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語が前記変換候補単語に変更されて表示されることを特徴とする音声認識システム。
【請求項11】
前記端末で前記表示された単語列の全体を削除するためのユーザインタフェースが提供され、
前記ユーザインタフェースを介してユーザ入力が発生する場合、前記表示された単語列が全て削除されることを特徴とする請求項10に記載の音声認識システム。
【請求項12】
前記単語列が前記表示装置を介して表示される場合、または前記単語列が前記端末から他の機器に送信される場合、前記単語列が音声認識によって提供されたことを表す標識が前記単語列と共に表示されまたは送信されることを特徴とする請求項10に記載の音声認識システム。
【請求項13】
前記端末の入力装置を介して入力された前記音声信号を前記端末を介して受信する音声信号受信部をさらに備えることを特徴とする請求項10に記載の音声認識システム。
【請求項14】
前記音声認識結果生成部は、前記音声信号に対応してマッチングされ得る全ての単語列それぞれの確率のうち、最も高い確率を有する単語列を前記音声認識の結果に含まれる単語列として選択することを特徴とする請求項10に記載の音声認識システム。
【請求項15】
前記音声認識結果生成部は、前記少なくとも1つの単語の認識がスタートした時刻及び認識が終了した時刻に基づいた時間範囲内に前記の音声信号によって認識された他の単語のうち少なくとも1つの単語を前記音声認識の結果に含まれる変換候補単語として選択することを特徴とする請求項10に記載の音声認識システム。
【請求項16】
前記他の単語のうち少なくとも1つの単語は、前記他の単語それぞれに対して算出される信頼度に基づいて選択されることを特徴とする請求項15に記載の音声認識システム。
【請求項17】
前記時間範囲は、前記認識がスタートした時刻及び前記認識が終了した時刻、そして前記認識が終了した時刻に付与される予め選定された許容時間値に応じて決定されることを特徴とする請求項15又は請求項16に記載の音声認識システム。
【請求項18】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認する音声認識結果確認部と、
前記単語列を表示装置を介して表示するが、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の他の単語と区分して表示する単語列表示部と、
を備え、
前記単語列表示部は、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストを表示することを特徴とする音声認識システム。
【請求項19】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成する音声認識結果生成部と、
ユーザ端末で前記音声認識の結果を提供する音声認識結果提供部と、
を備え、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストが表示されることを特徴とする音声認識システム。
【請求項20】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認し、
前記単語列を表示装置を介して表示する際に、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の残りの単語と区分して表示することを含み、
前記表示することは、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語を前記変換候補単語に変更して表示することを特徴とする音声認識方法。
【請求項21】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成し、
ユーザ端末に前記音声認識の結果を提供するスことを含み、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語が前記変換候補単語に変更されて表示されることを特徴とする音声認識方法。
【請求項22】
音声認識の結果として、単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語が提供される場合、前記単語列及び前記変換候補単語を確認し、
前記単語列を表示装置を介して表示するが、前記変換候補単語が存在する少なくとも1つの単語を前記単語列の残りの単語と区分して表示することを含み、
前記表示することは、前記区分して表示された単語がユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストを表示することを特徴とする音声認識方法。
【請求項23】
音声信号に対応する単語列及び前記単語列に含まれる少なくとも1つの単語に対する変換候補単語を決定して音声認識の結果として生成し、
ユーザ端末に前記音声認識の結果を提供することとさせ、を含み、
前記端末の表示装置で前記単語列が表示され、
前記変換候補単語が存在する少なくとも1つの単語は前記単語列の残りの単語と区分して表示され、
前記区分して表示された単語が前記端末で前記ユーザによって選択される場合、前記区分して表示された単語の変換候補単語のうち少なくとも1つの変換候補単語を含むリストが表示されることを特徴とする音声認識方法。
【請求項24】
請求項20から請求項23のいずれか1項の方法を行うプログラムを記録したコンピュータで読み出し可能な記録媒体。
【図1】


【図2】
【図3】

【図4】

【図5】

【図6】

【図7】

【図8】

【図9】
【図10】

【図11】
【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2012−237997(P2012−237997A)
【公開日】平成24年12月6日(2012.12.6)
【国際特許分類】
【出願番号】特願2012−106776(P2012−106776)
【出願日】平成24年5月8日(2012.5.8)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.アンドロイド
【出願人】(505205812)エヌエイチエヌ コーポレーション (408)
【公開日】平成24年12月6日(2012.12.6)
【国際特許分類】
【出願日】平成24年5月8日(2012.5.8)
【公序良俗違反の表示】
(特許庁注:以下のものは登録商標)
1.アンドロイド
【出願人】(505205812)エヌエイチエヌ コーポレーション (408)
[ Back to top ]